图的表达2
十七、PTE[2015]
学习有意义且有效的文本(例如
word、document)的representation,是许多机器学习任务(例如文本分类、文本聚类、文本检索)的关键前提条件。传统上,每个word都相互独立地表示,并且每个document都表示为bag-of-words。然而,这两种representation都存在数据稀疏、多义性polysemy、同义性synonymy等问题,因为在这两种representation中不同word之间的语义相关性semantic relatedness通常被忽略。word和document的分布式representation通过在低维空间中表达word和document,从而有效地解决了这个问题。在这个低维空间中,相似的word/document彼此紧密地嵌入。这些方法的基本思想来自于分布式假设distributional hypothesis:一个单词的意义是由它的使用环境所形成的 (you shall know a word by the company it keeps)。《Distributed representations of words and phrases and their compositionality》提出了一种简单而优雅的word embedding模型,称作SkipGram。SkipGram使用target word的embedding来预测局部窗口local window中每个单独的context word的embedding。《Distributed representations of sentences and documents》进一步扩展了这一思想,并提出了Paragraph Vector从而嵌入任意的文本片段,例如sentence和document。其基本思想是:使用sentence/document的embedding来预测sentence/document中word的embedding。和也利用word context的分布式相似性distributional similarity的其它经典方法(如布朗聚类Brown clustering、最近邻法)相比,这些text embedding方法已被证明是非常有效的,可以在单台机器上扩展到数百万个document。由于采用无监督学习,通过这些
text embedding模型学到的representation足够通用,可以应用于分类classification、聚类clustering、以及排序ranking等各种任务。然而,和端到端的复杂的深度学习方法(如卷积神经网络)相比时,text embedding的性能通常在特定任务上达不到要求。这毫不奇怪,因为深度神经网络在学习数据representation时充分利用了可用于任务的label信息。大多数text embedding方法在学习representation时都无法考虑label信息。只有在使用训练好的representation作为特征来训练分类器时,label才会被使用。换句话讲,无监督的text embedding对于不同的任务是可泛化generalizable的,但是对于特定任务的预测能力较弱。尽管存在这一缺陷,但是和深度神经网络相比,
text embedding方法仍有相当大的优势。- 首先,深度神经网络(尤其是卷积神经网络)的训练是计算密集型的,在处理大量数据的时候通常需要多个
GPU或CPU集群。 - 其次,卷积神经网络通常假设大量的标记样本可用,这在许多任务中是不现实的。对于容易获取的未标记数据,卷积神经网络通常使用预训练的方式来间接利用。
- 第三,卷积神经网络的训练需要多许多超参数进行详尽的调优,即使对于专家而言也是非常耗时的,而对于非专家而言是不可行的。
另一方面,像
SkipGram这样的text embedding方法效率更高、更容易调优、并且天然地适应于未标记数据。在论文
《PTE:Predictive Text Embedding through Large-scale Heterogeneous Text Networks》中,作者通过提出predictive text embedding: PTE来填补这一空白。PTE具有无监督text embedding的优点,但是在representation learning过程中自然地利用了标记信息。通过PTE,我们可以从有限的标记样本和大量的未标记样本中联合学习有效的低维representation。与无监督embedding相比,这种representation针对特定任务进行了优化,就像卷积神经网络所作的那样。即,PTE学到的representation对特定的分类任务具有很强的预测能力。PTE自然地扩展了作者之前的无监督信息网络embedding工作(《Line: Large-scale information network embedding》),并首先提出通过异质文本网络heterogeneous text networt学习word的低维embedding。该网络对word-word、word-document、word-label之间不同level的共现信息co-occurrence information进行编码。该网络被嵌入到一个低维向量空间中,该空间保留了网络中顶点之间的二阶邻近性second-order proximity。任意一段文本(例如sentence或document)的representation可以简单地推断为word representation的均值,结果证明这是非常有效的。整个优化过程仍然非常高效,在单台机器上可以扩展到数百万个document和数十亿个token。论文对现实世界的文本语料库进行了广泛的实验,包括
long document和short document。实验结果表明:PTE在各种文本分类任务中显著优于state-of-the-art的无监督embedding。与用于文本分类的端到端卷积神经网络相比,PTE在long document上表现更好、在short document上表现相当。与卷积神经网络相比,PTE具有各种优势,因为它更高效、有效地利用大规模未标记数据,并且对模型超参数不太敏感。作者相信PTE的探索指向了一个学习text embedding的方向,该方向可以在特定任务中与深度神经网络进行正面竞争。总而言之,论文的贡献如下:
- 论文提出以半监督的方式学习
predictive text embedding。未标记数据和标记信息被集成到一个异质文本网络中,该网络包含不同level的文本共现信息。 - 论文提出了一种高效的算法
PTE,它通过将异质文本网络嵌入到低维空间中来学习文本的分布式representation。该算法非常有效,几乎没有需要调优的超参数。 - 论文使用各种真实世界的数据集进行了广泛的实验,并将
PTE与无监督text embedding、卷积神经网络进行了比较。
- 首先,深度神经网络(尤其是卷积神经网络)的训练是计算密集型的,在处理大量数据的时候通常需要多个
相关工作:我们的工作主要涉及分布式文本
representation learning和信息网络embedding。Distributed Text Embedding:文本的分布式representation已被证明在许多自然语言处理任务中非常有效,例如单词类比word analogy、词性标注POS tagging、parsing、语言建模language modeling、以及情感分析sentiment analysis。现有的方法通常可以分为两类:无监督方法、监督方法。- 最近提出的无监督方法通常通过在局部上下文
local context(例如SkipGram)或者document级别(例如Paragraph Vector),利用word co-occurrence来学习word/document的embedding。这些方法非常有效,可以扩展到数百万个document。 - 监督方法通常基于深度神经网络架构,例如
recursive neural tensor network: RNTN、convolutional neural network: CNN。在RNTN中,每个word都嵌入到一个低维向量中,并且通过在parse tree中的子短语sub-phrase或者word上应用相同的、基于张量tensor-based的组合函数composition function来递归学习短语phrase的embedding。在CNN中,每个word也用一个向量来表示,并且在sentence的不同位置的上下文窗口上应用相同的卷积核,然后是一个最大池化层和一个全连接层。
这两类方法之间的主要区别在于它们如何在
representation learning阶段利用标记信息和未标记信息。无监督方法在representation learning时不包含标记信息,仅在将数据转换为学到的representation之后,才使用label来训练分类器。RNTN和CNN将label直接结合到representation learning中,因此学到的representation特别针对分类任务进行了调优。然而,为了融合未标记的样本,这些神经网络通常必须使用间接方法,例如使用无监督方法预训练word embedding。和这两类方法相比,PTE以半监督方式学习text embedding,representation learning算法直接利用标记信息和大量的未标记数据。与
predictive word embedding类似的另一项工作是《Learning word vectors for sentiment analysis》,该工作学习特别针对情感分析调优的word embedding。然而,他们的方法无法扩展到数百万个document,也无法推广到其它分类任务。- 最近提出的无监督方法通常通过在局部上下文
Information Network Embedding:我们的工作还与network/graph embedding问题有关,因为PTE的word representation是通过异质文本网络heterogeneous text network学到的。将
network/graph嵌入到低维空间,这在各种应用中非常有用,例如节点分类、链接预测。MDS、IsoMap、Laplacian eigenmap等经典graph embedding算法不适用于嵌入包含数百万个顶点、数十亿条边的大型网络。最近有一些工作试图嵌入非常大的现实世界网络。
《Deepwalk: Online learning of social representations》提出了一种叫做DeepWalk的network embedding模型,该模型在网络上使用截断的随机游走,并且仅适用于具有二元边的网络。我们先前的工作提出了一种新的大规模网络嵌入模型,称作LINE。LINE适用于任意类型的信息网络,无向或有向、二元边或者带权边。LINE模型优化了一个目标函数,该目标函数旨在保持局部网络结构local network structure和全局网络结构global network structure。DeepWalk和LINE都是无监督的,只能处理同质网络homogeneous network。PTE使用的network embedding算法扩展了LINE从而处理异质网络(网络中存在多种类型的顶点和边)。
17.1 模型
17.1.1 基本概念
让我们从正式定义
predictive text embedding问题(通过异质文本网络)来开始。与学习文本的通用语义representation的无监督text embedding方法(包括SkipGram和Paragraph Vector)相比,我们的目标是学习针对给定文本分类任务优化的文本representation。换句话讲,我们期待text embedding对给定任务的性能具有很强的预测能力。基本思想是:在学习text embedding时结合标记信息和未标记信息。为了实现这一点,首先需要有一个统一的representation对这两类信息(标记的和未标记的)进行编码。在本文中,我们提出了不同类型的网络来实现这一点,包括word-word co-occurrence network、word-document network、word-label network。word-word co-occurrence network:word-word共现网络表示为local context中的word共现信息。word的词表vocabulary,word之间的边的集合(共现关系)。wordword在给定窗口大小的上下文窗口中同时出现的次数。word-word网络捕获局部上下文中的word共现,这是现有word embedding方法(如SkipGram)使用的基本信息。除了局部上下文之外,document level的word共现也在经典的文本representation中被广泛探索,例如统计主题模型statistical topic model(如latent Dirichlet allocation: LDA)。为了捕获document level的word共现,我们引入了另一个网络,即word-document网络。word-document network:word-document网络表示为二部图document的集合,word的集合,word到document的链接构成的边集合。worddocumentworddocumentword-word网络和word-document网络对大规模语料库中的未标记信息进行编码,在局部上下文level和document level捕获word共现。为了对标记信息进行编码,我们引入了word-label网络,该网络在category-level捕获word共现。word-label network:word-label网络表示为二部图class的集合,word的集合,word到class的链接构成边的集合。category-level的word共现。wordclassdocumentworddocumentclass label。上述三种网络可以进一步融合为一个异质文本网络
heterogeneous text network(如下图所示)。Heterogeneous Text Network:异质文本网络是由标记文本数据和未标记文本数据共同构建的word-word网络、word-document网络、word-label网络的组合。它捕获不同level的word共现,并同时包含标记信息和未标记信息。注意,异质文本网络的定义可以推广到融合其它类型的网络,例如
word-sentence网络、word-paragraph网络、document-label网络等等。在这项工作中,我们使用三种类型的网络(word-word、word-document、word-label)作为说明性示例。我们特别关注word网络,以便首先将word表示为低维空间。然后可以通过聚合word representation来计算其它文本单元(如stentence或paragraph)的representation。子网的构建需要结合具体任务,并且对任务性能产生重大影响。但是论文并未给出子网构建的原则。可以借鉴的是:这里的
word-word捕获局部共现、word-document捕获全局共现。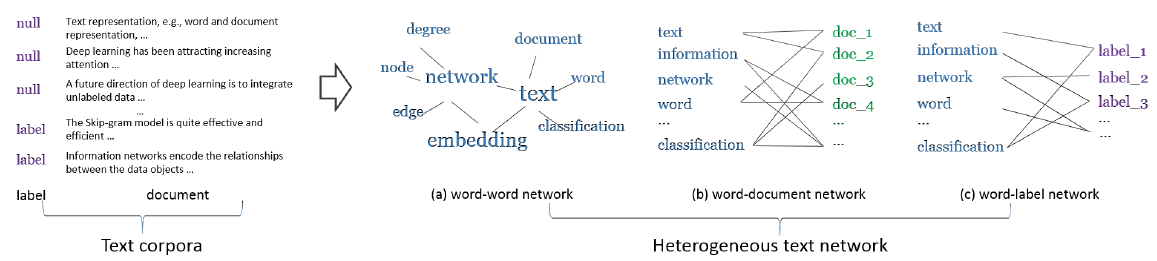
最后,我们正式定义
predictive text embedding问题如下:Predictive Text Embedding:给定具有标记信息和未标记信息的大量文本数据,predictive text embedding问题旨在通过将由文本数据构建的异质文本网络嵌入到低维向量空间中从而学习word的低维representation。接下来我们将介绍通过异质文本网络学习
predictive text embedding的方法。我们的方法首先将异质文本网络嵌入到低维空间来学习word的向量representation,然后根据学到的word embedding推断text embedding。由于异质文本网络由三个二部图组成,我们首先介绍一种嵌入单个二部图的方法。
17.1.2 二部图 Embedding
在我们之前的工作中,我们引入了
LINE模型来学习大规模信息网络的embedding。LINE主要是为同质网络而设计的,即具有相同类型节点的网络。LINE无法直接应用于异质网络,因为不同类型边的权重不具有可比性。在这里,我们首先将LINE模型用于嵌入二部图。基本思想是:利用顶点之间的二阶邻近性,假设具有相似邻域的顶点彼此相似,因此应该在低维空间中紧密地表示。对于二部图,假设顶点
给定一个二部图
其中:
embedding向量,embedding向量。对于
second-order proximity可以由它们的条件分布其中:
KL-divergence函数。degree:- 经验分布
忽略常数项,则上述目标函数重写为:
我们可以采用带边采样
edge sampling和负采样nagative sampling的随机梯度下降法来求解该最优化问题。在梯度下降的每一步:- 首先以正比于权重
binary edgeedge sampling。 - 然后通过
noise distributionnagative sampling。
采样过程解决了学习
network embedding中随机梯度下降的重大缺陷。详细的优化过程可以参考LINE的原始论文。word-word网络、word-document网络、word-label网络的embedding都可以通过上述模型来学习。注意,word-word网络本质上是一个二部图,可以将每条无向边视为两条有向边,并且将embedding。
17.1.2 异质文本网络 Embedding
异质文本网络由三个二部图组成:
word-word网络、word-document网络、word-label网络,其中word顶点在三个网络之间共享。为了学习异质文本网络的embedding,一种直观的方法是共同嵌入三个二部图,这可以通过最小化以下目标函数来实现:上述目标函数可以通过不同的方式进行优化,具体取决于如何使用标记信息(即
word-label网络)。- 一种解决方案是同时使用未标记数据(
word-word网络和word-document网络)和标记数据训练模型。我们称这种方法为联合训练joint training。 - 另一种解决方案是首先使用未标记数据来学习
embedding,然后使用word-label网络来微调embedding。这是受到深度学习文献中预训练和微调pre-training and fine-tuning思想的启发。
- 一种解决方案是同时使用未标记数据(
在联合训练中,所有三种类型的网络一起使用。优化目标
edge sampling(在每个step中对边进行采样从而进行模型更新,采样概率与边的权重成正比)。然而,当网络是异质的时候,不同类型顶点之间的边的权重是不可比的。更合理的解决方案是从三组边中交替采样。PTE联合训练算法:输入:
- 异质文本网络的三个子网
- 采样数量
- 负采样比例
- 异质文本网络的三个子网
输出:所有单词的
embedding算法步骤:
循环迭代,直到迭代了
step。迭代过程为:- 从
word embedding。 - 从
word embedding和document embedding。 - 从
word embedding和label embedding。
- 从
PTE预训练和微调算法:输入:
- 异质文本网络的三个子网
- 采样数量
- 负采样比例
- 异质文本网络的三个子网
输出:所有单词的
embedding算法步骤:
预训练阶段:循环迭代,直到迭代了
step。迭代过程为:- 从
word embedding。 - 从
word embedding和document embedding。
微调阶段:循环迭代,直到迭代了
step。迭代过程为:- 从
word embedding和label embedding。
- 从
Text Embedding:异质文本网络对不同level的word co-occurrence进行编码,这些编码是从未标记数据和特定分类任务的标记信息中提取的。因此,通过嵌入异质文本网络学习的word representation不仅更加鲁棒,而且针对该特定任务进行了优化。一旦学到了word vector,就可以通过简单地对这段文本中word的向量求均值来获得任意一段文本的representation。即,一段文本representation可以计算为:其中
wordembedding向量。事实上,
word embedding的均值是最小化以下目标函数的最优解:其中
word embedding和text embedding之间的、欧式距离的损失函数。与之相关的是
paragraph vector的推断过程,它的目标函数相同但是具有不同的损失函数:然而这个损失函数对应的目标函数没有闭式解
close form solution,因此必须通过梯度下降算法来优化。
17.2 实验
数据集:我们选择了长文
document、短document两种类型的数据集:长
document数据集:20newsgroup数据集:广泛使用的文本分类数据集,包含20个类别。wiki数据集:2010年4月的维基百科数据集,包含大约200万篇英文文章。我们仅保留2010年维基百科中出现的常见词汇。我们选择了七种不同类别,包括Art, History, Human, Mathematics, Nature, Technology, Sports。每种类别我们随机选择9000篇文章作为标记的document来训练。Imdb数据集:一个情感分类数据集。为避免训练数据和测试数据之间的分布偏差,我们随机混洗了训练数据和测试数据。RCV1数据集:一个大型文本分类基准语料库。我们从数据集中抽取了四个子集,包括Corporate, Economics, Government, Market。在RCV1数据集中,文档已经被处理为bag-of-word: BOW的格式,因此word的顺序已经被丢失。
短
document数据集:DBLP数据集:包含来自计算机科学领域论文的标题。我们选择了六个领域的论文,包括database, arti cial intelligence, hardware, system, programming languages, theory等。对于每个领域,我们选择该领域具有代表性的会议并收集该会议中发表的论文作为标记的document。
MR数据集:一个电影评论数据集,每条评论仅包含一个sentence。Twitter数据集:用于情感分类的Tweet语料库。我们从中随机抽取了120万Tweets然后拆分为训练集和测试集。
我们并没有在原始数据上执行进一步的文本归一化text normalization ,如删除停用词或者词干化。下表给出了数据集的详细统计信息。

baseline方法:我们将PTE算法和其它的文本数据representation learning算法进行比较,包括经典的BOW算法、state-of-the-art的无监督text embedding、以及state-of-the-art的监督text embedding方法。BOW:经典的BOW方法。每篇文档使用一个wordTFIDF值。SkipGram:根据SkipGram训练得到word embedding,然后我们使用word embedding的均值来作为document embedding。PVDBOW:一种paragraph embedding模型,其中document内word的顺序被忽略。PVDM:另一种paragraph embedding模型,其中document内word的顺序被考虑。LINE:我们之前的工作提出的大规模信息网络embedding模型。我们使用LINE模型分别学习word-word网络和word-dococument网络,分别记作word-word网络和word-document网络,记作CNN:基于卷积神经网络CNN模型来监督学习text embedding。尽管原始论文用于建模sentence,我们这里将其改编为适用于长文本在内的一般word序列。尽管CNN通常适用于完全标记的documnet,但是它也可以通过无监督的word embedding从而对模型进行预训练来利用未标记数据,这被记作CNN(pretrain)。PTE:我们提出的、学习predictive text embedding的方法。PTE有多种变体,它们使用word-word、word-document、word-label的不同组合。word-label的版本。word-word和word-label的版本。word-document和word-label的版本。word-word、word-document进行无监督训练,然后使用word-label来微调的版本。PTE(joint)为联合训练异质文本网络的版本。
实验配置:
SkipGram, PVDBOW, PVDM, PTE, PTE模型:- 随机梯度下降的
mini-batch size设为1。 - 学习率设为
T为总的迭代步数, - 负采样次数为
K=5。
- 随机梯度下降的
SkipGram, PVDBOW, PVDM, PTE模型:word-word网络共现窗口大小为5。CNN模型:我们使用《Convolutional neural networks for sentence classi cation》中的CNN结构。该结构使用一个卷积层,然后是最大池化层和全连接层。卷积层的窗口大小设为3,feature map数量设为100,随机选择训练集的1%作为验证集来执行早停。所有
embedding模型的词向量维度为100。
注意:对于
PTE模型,默认情况下在不同数据集上,超参数均按照上述设置。唯一需要调整的超参数的边采样中的样本数评估方式:一旦构建或学习了
document的向量representation,我们就会使用相同的训练数据集应用相同的分类过程。具体而言,训练集中的所有文档都用于representation learning阶段和classifier learning阶段。- 如果使用无监督
embedding方法,则在representation learning阶段不使用document的类别标签,仅在classifier learning阶段使用类别标签。 - 如果使用
predictive embedding方法,则同时在这两个阶段都使用类别标签。
对于测试数据集,我们在这两个阶段都留出
hold-out标签数据和document文本。注意:在
representation learning阶段保留所有测试数据,即这一阶段模型看不到测试数据的标签、也看不到测试数据的文本。在分类阶段,我们使用
LibLinear package中的one-vs-rest逻辑回归模型,并评估micro-F和macro-F1指标。每一种配置我们都执行十次,并报告指标的均值和方差。- 如果使用无监督
17.2.1 实验结果
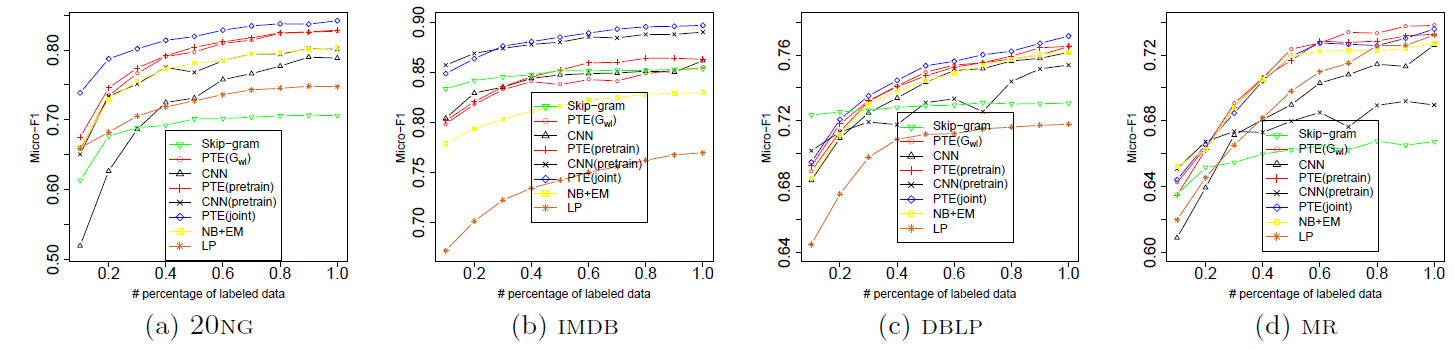
我们在
20NG,Wiki,IMDB数据集上的长文本效果对比如下。首先我们比较无监督
text embedding方法,可以看到:- 具有
document-level的word共现的embedding中表现最好。 PVDM性能不如PVDBOW,这和原始论文中的结论不同。不幸的是我们始终无法得出他们的结论。
然后我们比较
predictive embedding方法,可以看到:PTE(joint)效果最好。- 所有带
word-label网络PTE方法都超越了对应的无监督方法(即LINE模型),这表明了在监督学习下predictive text embedding的强大能力。 PTE(joint)超越了PTE(joint)也超越了PTE(pretrain),这表明联合训练未标记数据和标记数据,要比将它们分别独立训练并微调更有效。- 另外我们通过
embedding来对CNN进行预训练,然后使用label信息对其进行微调。出乎意料的是:预训练CNN在20NG和IMDB数据集上显著提高,并且在Wiki上几乎保持不变。这意味着训练良好的无监督embedding对CNN进行预训练非常有用。 - 但是,即使是预训练的
CNN,其性能仍然不如PTE(joint)。这可能的因为PTE模型可以联合训练标记数据和未标记数据,而CNN只能通过预训练和微调两阶段来各自独立的使用标记数据和未标记数据。 PTE(joint)也始终优于经典的BOW模型,尽管PTE(joint)的embedding向量维度远小于BOW的向量维度。
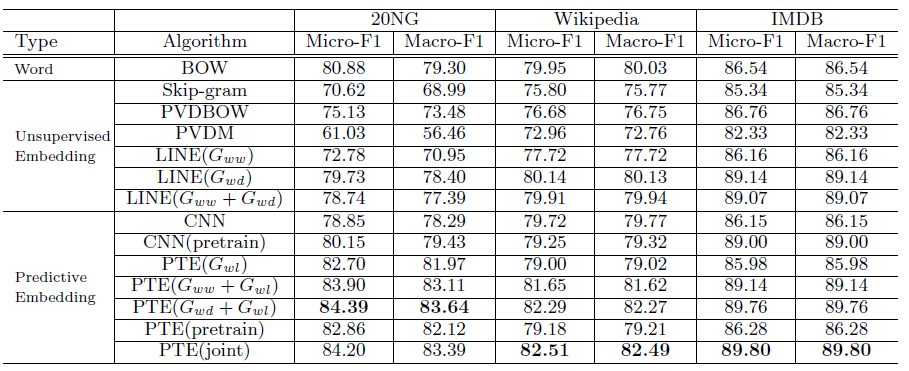
- 具有
我们在
RCV1数据集上的长文本效果对比如下。由于word之间的顺序丢失,因此要求保留word顺序信息的embedding方法不适用。这里我们观察到了类似的结论:predictive embedding方法超越了无监督embedding。PTE(joint)方法比PTE(pretrain)方法更有效。
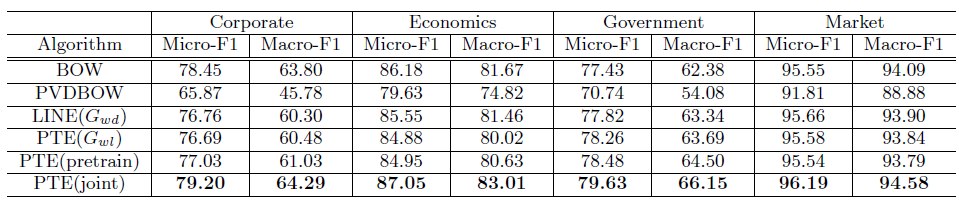
我们比较了
CNN和PTE(joint)在IMDB数据集上的训练实践。我们采用异步随机梯度下降算法,在1T内存、2.0G HZ的40核CPU上执行。平均而言PTE(joint)要比CNN快10倍以上。当使用pretrain时,CNN虽然训练速度加快,但是仍然比PTE(joint)慢 5倍以上。我们在短文本上比较了模型性能如下。
首先我们比较无监督
text embedding方法,可以看到:- 结合了
document-level和local-context level的word共现的 - 使用局部上下文级别
word共现的document级别word共现的document级别的word共现非常稀疏。我们在主题模型中也观察到了类似的结果。 PVDM性能仍然不如PVDBOW性能,这和长文本中结论一致。
然后我们比较
predictive embedding方法,可以看到:PTE在DBLP,MR数据集上性能最佳,CNN在Twitter数据集上性能最好。融合了
word-label网络的PTE方法超越了对应的无监督embedding方法(即LINE模型),这和长文本中结论一致。PTE(joint)超越了PTE(joint)超越了PTE(pretrain),这证明了对标记数据和未标记数据联合训练的优势。我们观察到
PTE(joint)并不能始终超越CNN。原因可能是单词歧义ambiguity问题,这类问题在短文本中更为严重。CNN通过在卷积核中使用局部上下文的word顺序来减少单词歧义问题,而PTE抛弃了word顺序。我们相信:如果利用了word顺序,则PTE还有很大提升空间。
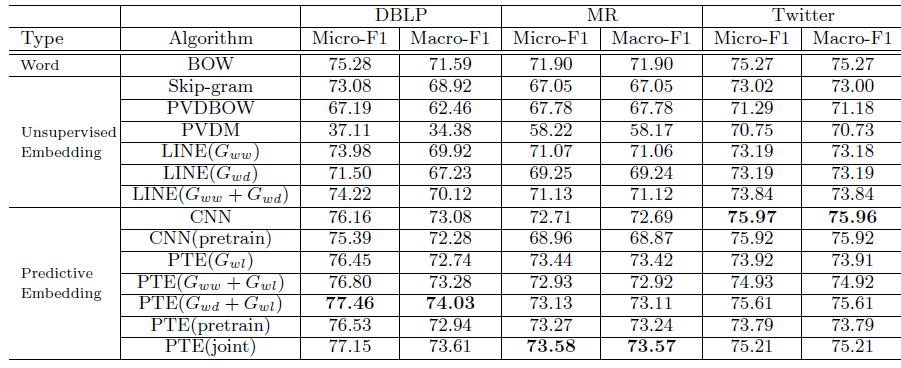
- 结合了
17.2.2 标记数据 & 未标记数据
我们考察标记样本规模的变化对
CNN和PTE的影响。我们考虑两种模式:- 监督学习:不包含未标记数据。如
CNN。 - 半监督学习:包含未标记数据。如
PTE(joint)、CNN等。
在半监督学习中,我们还比较了经典的半监督方法:带
EM的朴素贝叶斯NB+EM、标签传播算法label propagation:LP。可以看到:
CNN和PTE随着标记数据规模的增加,性能持续改善。- 在监督学习的
CNN和CNN或可与CNN媲美。 - 在半监督学习的
CNN(pretrain)和PTE(joint)之间,PTE(joint)始终优于CNN(pretrain)。 PTE(joint)还始终优于经典的NB+EM和LP方法。
另外我们还注意到:
- 当标记数据规模不足时,使用无监督
embedding的预训练CNN非常有效,尤其是在短文本上。当训练样本太少时,它甚至优于所有的PTE。 - 当标记数据规模增加时,预训练
CNN并不总是能够改善其性能,如DBLP和MR数据集。 - 对于
SkipGram模型,增加标记数据规模几乎不会进一步改善其性能。 - 在
DBLP数据集上,当标记样本太少时PTE性能甚至不如SkipGram。原因是当标记数据太少时,word-label网络的噪音太多。PTE将word-label网络与噪音较少的word-word, word-document网络同等对待。一种解决办法是:在标签数据不足时,调整word-label, word-word, word-document网络的采样概率。
- 监督学习:不包含未标记数据。如
我们考察未标记数据规模的变化对
CNN(pretrain)和PTE的影响。由于篇幅有限,这里我们仅给出20NG和DBLP数据集的效果。对于CNN,未标记数据可用于预训练。对于PTE,未标记数据可用于预训练或联合训练。在
20NG数据集上,我们使用10%文档作为标记数据,剩余文档作为未标记数据;在DBLP数据集上,我们随机抽取其它会议发表的20万篇论文的标题作为未标记数据。我们使用
CNN的预训练模型。可以看到:- 当未标记数据规模增加时,
CNN和PTE性能都有改善。 - 对于
PTE模型,未标记数据和标记数据联合训练的效果要优于“预训练和微调”的方式。
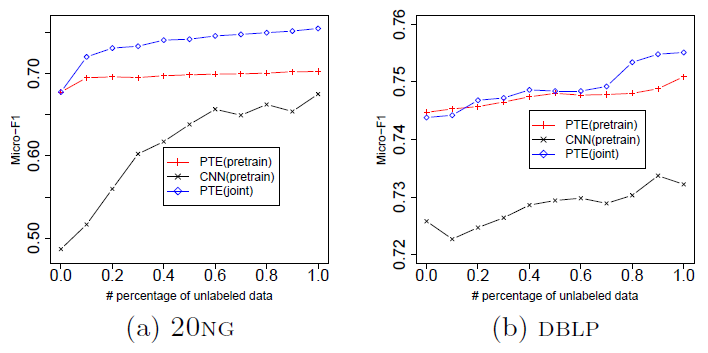
- 当未标记数据规模增加时,
17.2.3 参数敏感性与可视化
PTE模型除了训练步数T之外,大多数超参数对于不同训练集都是不敏感的(如学习率、batch size),所以可以使用默认配置。我们在
20NG和DBLP数据集上考察了PTE(joint)对于参数T的敏感性。可以看到:当T足够大时,PTE(joint)性能会收敛。实际应用中,我们可以将
T的数量设置称足够大。经验表明:T的合理范围是异质文本网络中所有边的数量的几倍。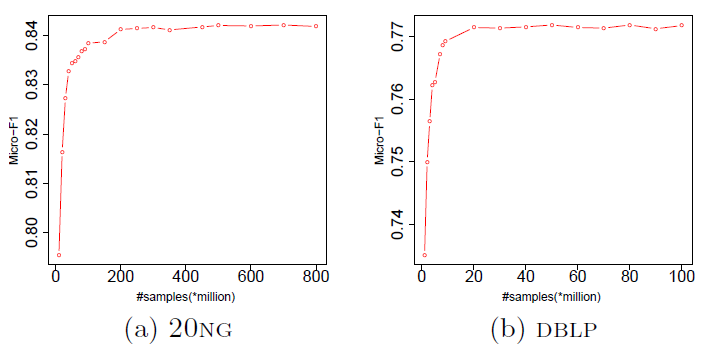
我们给出了无监督
embedding(以predictive embedding(以20NG数据集上采用tSNE可视化的结果。我们对训练集和测试集的文档均进行了可视化,其中
document embedding为document内所有word embedding的均值。可以看到:在训练集和测试集上,predictive embedding均比无监督embedding更好地区分了不同的类别。这直观表明了predictive embedding在文本分类任务中的强大能力。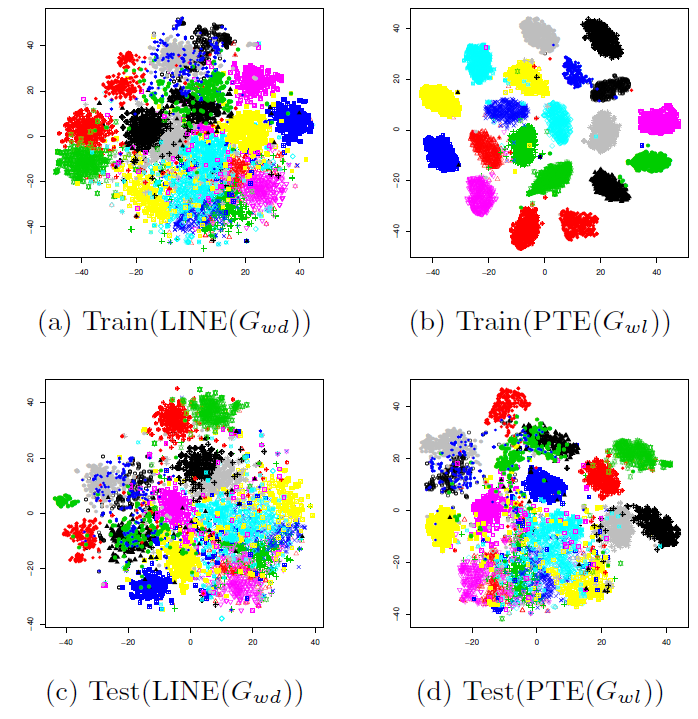
17.2.4 讨论
无监督
embedding使用的基本信息是局部上下文级别或者document级别的word共现。- 在长文本中,我们可以看到
document级别的word共现比局部上下文级别的word共现效果更好,并且二者的结合并不能进一步改善效果。 - 在短文本中,局部上下文级别的
word共现比document级别的word共现效果更好,并且二者的结合可以进一步改善效果。这是因为document级别的word共现受到文本长度太短的困扰,即文本太稀疏。
- 在长文本中,我们可以看到
predictive embedding中:与
PTE相比,CNN模型可以更有效地处理标记信息,尤其是在短文本上。这是因为CNN的模型结构比PTE复杂得多,尤其时CNN可以在局部上下文中利用词序从而解决word的歧义问题。因此,在标记数据非常稀疏的情况下,CNN可以超越PTE,尤其是在短文本上。但是这个优势是以大量的计算、详尽的超参数调优为代价的。与
CNN相比,PTE训练速度更快、超参数调整更容易(几乎没有需要调整的超参数)。当标记数据更为丰富时,PTE的性能至少和CNN一样好并且通常更好。PTE模型的一个明显优势是它可以联合训练标记数据和未标记数据。相比之下CNN只能通过预训练来间接利用未标记数据。当标记数据非常丰富时,这种预训练并不总是有帮助的。
实践指南:基于上述讨论,我们提供以下实践指南。
当没有标记数据时:
- 在长文本上使用
text embedding。 - 在短文本上使用
text embedding。
- 在长文本上使用
当只有少量标记数据时:
- 在长文本上使用
PTE来学习text embedding。 - 在短文本上使用
CNN(pretrain),其中预训练采用
- 在长文本上使用
当有大量标记数据时:
- 在长文本上使用
PTE(joint)来学习text embedding。 - 在短文本上从
PTE(joint)、CNN或者CNN(pretrain)三者之间选择,其中主要考虑训练效率和模型效果之间的平衡。
- 在长文本上使用
未来方向:
PTE中考虑word的词序。
十八、HNE[2015]
向量化的
data representation经常出现在许多数据挖掘application中。向量化的data representation更容易处理,因为每个数据都可以被视为驻留在欧式空间中的一个point。因此,可以通过一个合适的指标来直接衡量不同data point之间的相似性,从而解决分类、聚类、检索等传统任务。如《Data Classification: Algorithms and Applications》所示,学习良好的representation是数据挖掘和web搜索中的基本问题之一。与设计更复杂的模型相比,学习良好的representation对任务效果的影响通常更大。不幸的是,许多
network数据源(如Facebook, YouTube, Flickr, Twitter)无法自然地表示为向量化的输入。这些社交网络和社交媒体数据通常以图数据graph data和关系数据relational data二者组合的形式来表示。当前的研究集中在预定义pre-defined的特征向量、或者复杂的graph-based的算法来解决底层任务。人们在各种主题上完成了大量的研究,例如协同分类collective classification、社区检测community detection、链接预测link prediction、社交推荐social recommendation、定向广告targeted advertising等等。对于内容和链接而言,网络数据network data以embedding形式开发的unified representation非常重要。unified representation的基本假设是:一旦获得向量化的representation,网络挖掘任务就可以很容易地通过现有的机器学习算法来解决。然而,网络数据的
feature learning并不是一项简单的任务,因为网络数据具有许多特有的特性,例如网络的规模、动态性、噪声、以及异质性heterogeneity。首先,社交网站上的多媒体数据量呈指数级增长。到2011年年中,Facebook上的照片估计数量已达1000亿张,并且每天上传的新照片数量高达3.5亿张。其次,鉴于用户的不同背景background,社交媒体往往噪音很大。而且研究人员注意到,垃圾邮件发送者产生的数据比合法用户更多,这使得网络挖掘更加困难。最后,社交媒体数据包含多样diverse的、异质的信息。例如,当事件发生时,不同类型的媒体数据都会进行报道。如下图所示,当在谷歌中搜索 “马航MH17” 时,相关结果中不仅包含文本文档,还包含图像和视频。
此外,社交媒体数据不是孤立存在的,而是由各种类型的数据组合而成的。这些交互可以通过它们之间的链接显式或隐式地形成。例如,在同一网页中同时出现的图像和文本提供了它们之间的显式链接,而文本到文本的链接是通过不同
web document之间的超链接显式形成的。另一方面,用户的交互活动可以被视为隐式反馈,它链接了不同的社交媒体部分social media component。如果用户以相似的标签tag描述多张图像,那么一个合理的假设是:这些图像之间存在语义关系。很明显,如此庞大的数据量导致了复杂的异质网络,这给学习uniform representation带来了巨大的挑战。为了应对上述挑战,论文
《Heterogeneous Network Embedding via Deep Architectures》提出了一种关于network representation learning的新思想,称作Heterogeneous Network Embedding: HNE。HNE同时考虑了内容信息content information和关系信息relational information。HNE将不同的异质对象映射到一个统一unified的潜在空间中,以便可以直接比较来自不同空间的对象。与传统的线性
embedding模型不同,HNE将feature learning过程分解为深层的多个非线性层。HNE通过迭代求解关于feature learning和objective minimization的问题,从而协调并相互加强这两个部分。HNE同时建模了底层网络的全局链接结构global linkage structure和局部链接结构local linkage structure,这使得它在捕获网络链接方面比浅层embedding方案更强大,特别是当链接信息在揭示不同对象之间的语义相关性方面起关键作用时。沿着这个研究方向,论文利用网络链接来设计一个损失函数,从而迫使网络中存在链接的不同对象在embedding空间是相似的。network-preserved embedding的思想如下图所示。事实上根据
HNE的模型公式,HNE仅建模了局部链接结构(即,保留一阶邻域),并未建模全局链接结构。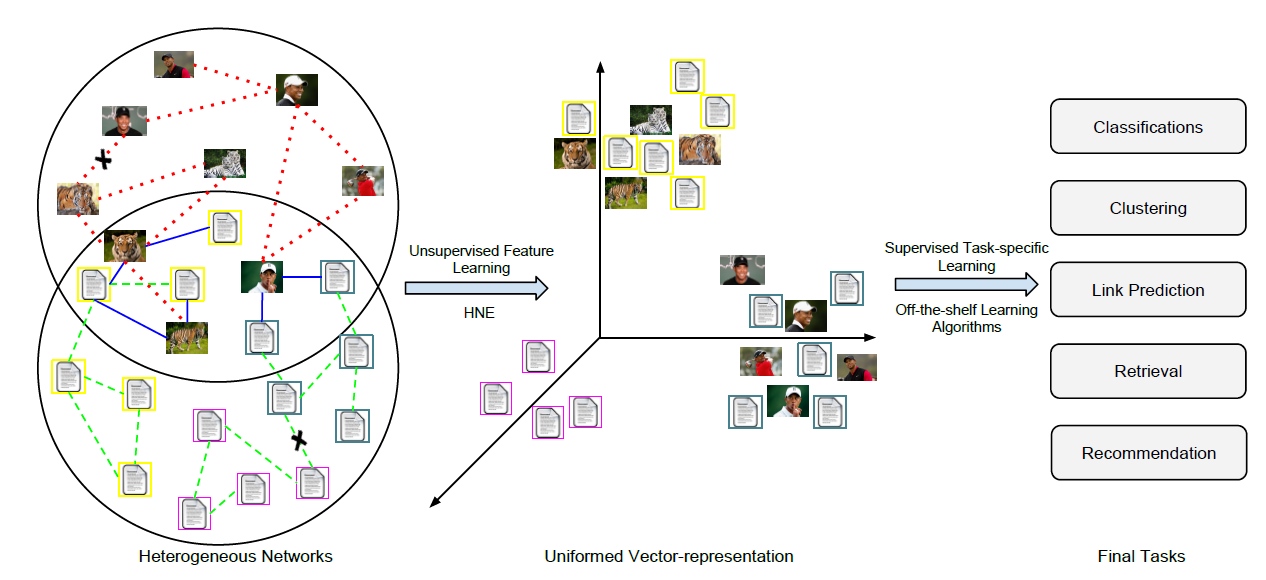
HNE框架的主要优点如下:- 鲁棒性:
HNE探索不同异质对象之间的全局一致性global consistency,从而学习由网络结构指导guide的unified feature representation。 - 无监督:
HNE是无监督并且独立于任务的,这使其适用于许多面向网络的数据挖掘application。 out-of-sample:HNE能够处理out-of-sample问题(即unseen顶点)。这解决了动态网络相关的挑战,其中随着时间的推移可能会在网络中添加新顶点。
- 鲁棒性:
相关工作:
Network Embedding:feature embedding的一个分支是由网络中的协同过滤和链接预测等application所推动的。这些application根据潜在属性对实体之间的关系进行建模。这些模型通常将问题迁移transfer为学习实体的embedding,这在数学上对应于对观察到的关系矩阵的矩阵分解问题。《Combining content and link for classification using matrix factorization》提出了一种在链接邻接矩阵linkage adjacency matrix和document-term frequency矩阵上联合分解的方法,从而用于网页分类。- 此外,
《Structure preserving embedding》提出了一种structure preserving的embedding框架,该框架将图嵌入到低维欧式空间中,并保持了全局拓扑属性。 - 此外,
DeepWalk从截断的随机游走中学习网络中顶点的潜在representation。
然而,这些模型仅关注单一关系
single relation,这无法应用于异质网络。而且这些模型中的大多数很难泛化到unseen sample(即训练期间未见过的顶点)。这些方法对异质网络的自然扩展是将多个关系矩阵堆叠在一起,然后应用传统的张量分解。这种
multi-relational embedding的缺点是不同term之间共享参数,这无法扩展到大型网络。《Latent feature learning in social media network》提出的非线性embedding模型使用Restricted Boltzmann Machine: RBM进行跨模型链接分析crossmodel link analysis。但是,它没有利用原始数据中的所有社交信息,这导致了次优的解决方案。此外,计算机视觉和语音方面的工作表明,与DNN和CNN相比,layer-wise的RBM训练对于大规模数据而言效率低下。深度学习:近年来,机器学习研究已经从基于人工制作的特征显著转向为基于原始数据学到的特征,这主要归功于深度学习的成功。深度学习模型在语音识别、图像识别/检测、以及最近的自然语言处理中变得越来越重要。深度学习技术是通用函数的逼近器
approximator。然而,从历史上来看,训练具有两层以上隐层的深度神经网络很难成功。困难在于高维的参数空间、以及高度非凸的目标函数,这使得基于梯度的方法受到局部极小值的困扰。深度学习的最新进展得益于多种因素的推动,例如大规模数据集的使用、算力的增长、以及无监督和监督训练算法的进步。
- 无监督深度学习(通常被称为预训练
pre-training),借助大量可用的未标记数据来提供鲁棒的初始化和正则化。例如,《Reducing the dimensionality of data with neural networks》首次使用RBM对深度神经网络进行layer-wise初始化。《Greedy layer-wise training of deep network》也提出了类似的方法,采用自编码器来进行权重初始化。 - 最近,多层神经网络的监督学习已经成为可能。
dropout的方法已经展示出特别的前景。《Imagenet classification with deep convolutional neural networks》提出的七层卷积神经网络在ImageNet大规模视觉识别挑战赛上取得了state-of-the-art的性能。该挑战赛是计算机视觉中最具挑战性的任务之一。来自这个七层卷积神经网络的中间层的特征,后来被证明是其它计算机视觉任务(如对象检测object detection)的良好的feature representation。
在深度学习架构的背景下,人们对利用来自多模态
multiple modalities的数据越来越感兴趣。自编码器和RBM等无监督深度学习方法被部署并联合重建(部分共享的网络partially shared network)音频和视频来执行feature learning,从而成功应用于多模态任务multimodal task。另一种方案,也有人努力学习具有多个任务的联合representation。对于图像和文本,一种特别有用的场景是通过将语义上有意义的embedding空间与图像label相结合,从而实现对unseen的label进行图像分类的zero-shot learning。据我们所知,之前很少有人尝试利用网络中的链接结构进行
representation learning。在《A deep learning approach to link prediction in dynamic network》中,它使用条件conditional的动态temporary的RBM对网络链接的动态性进行建模,主要任务是使用历史数据预测未来的链接。与我们最相似的工作是《Latent feature learning in social media network》,其中它在多媒体链接数据上训练一个content RBM。我们在几个方面与他们的工作不同:我们在无监督环境中使用监督学习的方案,我们的方法可以扩展到大规模数据集,我们执行多任务学习从而融合来自不同模态的形式。- 无监督深度学习(通常被称为预训练
18.1 模型
异质网络
heterogeneous network指的是具有不同类型对象、和/或具有不同类型链接的网络。从数学上讲,我们定义一个无向图此外,图
网络的异质性分别由集合
heterogeneous的。否则网络是异质heterogeneous的。下图说明了一个异质网络的示例,其中包含两种对象类型和三种链接类型。为了进一步便于理解,我们将假设对象类型为image: I、text: T。链接关系image-to-image(红色点虚线)、text-to-text(绿色短虚线)、image-to-text(蓝色实线),分别用RII, RTT, RIT表示。因此,在这种情况下,我们有因此,任何顶点
unique的内容信息。具体而言:- 对于每个图像顶点
- 对于每个文本顶点
例如,图像的内容是
RGB颜色空间中的原始像素格式,文本的内容是文档的Term Frequency - Inverse Document Frequency: TF-IDF得分。我们将链接关系表示为一个对称的邻接矩阵注意,这里的邻接矩阵元素取值为
{+1, -1},这和经典的{+1, 0}不同。这是为了后面的损失函数服务,给 “负边”(即,未链接的顶点对)一个非零值可以在损失函数中引入 “负边” 的信息。虽然这种邻接矩阵是完全稠密的矩阵,但是我们可以仅存储“正边”,从而仍然存储一个稀疏版本的邻接矩阵。- 对于每个图像顶点
接下来,我们首先引入一种新的损失函数来衡量跨网络的相关性,并以数学方式展示我们的
HNE框架。本质上,embedding过程为每个对象同时将异质内容和异质链接编码到一个representation中。然后我们提出了一种
linkage-guided的深度学习框架,从而同时对潜在空间embedding和feature learning进行联合建模。这可以通过使用反向传播技术有效地求解。最后,我们讨论了将
HNE算法直接扩展到多于两种对象类型的一般情况。
18.1.1 线性 HNE
异质
embedding任务的主要目标是学习映射函数,从而将不同模态的数据映射到公共空间,以便直接衡量对象之间的相似性。假设与图像顶点相关联的原始内容representationfeature machine。值得一提的是,我们使用两个线性变换矩阵
represetnation分别为尽管图像和文本可能在不同维度的空间中表示,但是变换矩阵
data point之间的相似性可以表示为投影空间中的内积,即:注意,由于嵌入到公共空间,不同类型对象(如文本和图像)之间也可以进行相似度计算,即:
这里
潜在
embedding与文献《Learning locally-adaptive decision functions for person verification》中已被广泛研究的相似性学习similarity learning和度量学习metric learning密切相关。即,两个顶点之间的相关性correlation可以通过投影矩阵application-specific的方式来建模异质关系的灵活性。对象之间的交互被表示为网络中的异质链接。我们假设:如果两个对象是连接的,则它们之间的相似性应该比孤立对象之间的相似性更大,从而反映这一事实(即,对象是连接的)。
注意,这里仅考虑一阶邻近性,即直接连接关系。
考虑两个图像
pairwise决策函数注意,要推断
in-sample。这意味着该方法具有泛化能力从而嵌入unseen顶点。这句话的意思是,
unseen的顶点,我们也可以计算对于所有顶点
bias值。则损失函数可以定义为:这可以视为由网络链接引导
guided的二元逻辑回归。text-text损失函数和image-text损失函数也是类似的,只需要将bias值。该损失函数仅捕获一阶邻近性(即局部网络结构),没有捕获高阶邻近性(既全局网络结构)。
该损失函数迫使相连的顶点之间的
embedding是相似的、不相连的顶点之间的embedding是不相似的。这就是为什么最终我们的目标函数如下:
其中:
image-image链接的数量,即text-text链接的数量,即image-text链接的数量,即F范数。bias值既可以从数据中学习得到,也可以设为固定值。为简单考虑,我们都设置为固定值。
该最优化问题可以通过坐标下降法
coordinate descent得到有效解决,每次固定一个变量从而求解另一个变量:首先固定参数
18.1.2 深度 HNE
目前为止,我们已经证明了我们的损失函数融合了网络结构,从而将不同异质成分
heterogeneous component映射到统一的潜在空间。然而,这种embedding函数仍然是线性的,可能缺乏建模复杂网络链接的能力。接下来我们引入深度学习框架。前面部分我们的解决方案可以分为两个步骤:
- 手动构造顶点的
feature representation:对于文本顶点使用其TF-IDF向量,对于图像顶点使用其原始RGB像素点拼接而成的向量。 - 将不同的
feature representation嵌入到公共的低维空间中。
这里我们通过深度学习将
feature representation的learning和embedding合并在一起。- 手动构造顶点的
feature representation learning:定义图像特征抽取的非线性函数为
CNN来抽取图像特征。下图为一个图像特征抽取模型,它由五个卷积层、两个全连接层组成。所有层都采用ReLU非线性激活函数。该模块称作deep image模块。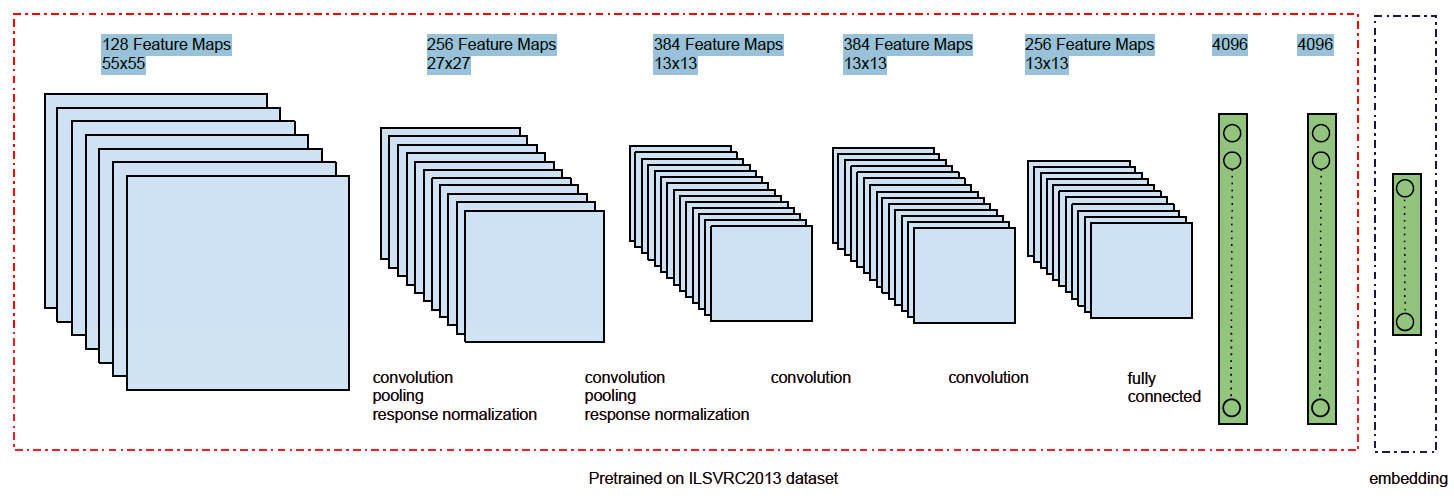
定义文本特征抽取的非线性函数为
FC对文本的TF-IDF输入来抽取特征。该模块称作deep text模块。
则我们的损失函数变为:
feature representation embedding:我们可以通过一个额外的线性embedding layer来级联deep image模块和deep text模块。定义
其中:
我们使用
dropout代替了我们使用新的损失函数:
与前面的
bias项。
该目标函数可以通过随机梯度下降
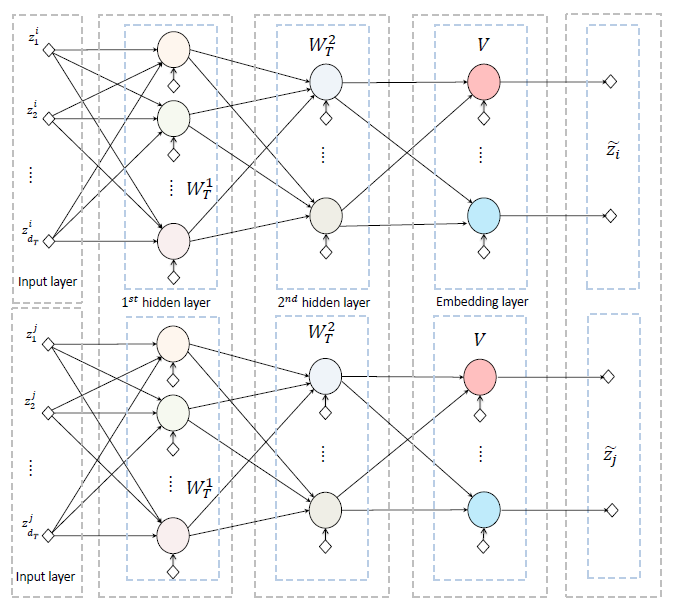
SGD来求解。为进行端到端的
HNE学习,我们将deep image模块和deep image模块连接起来。我们以text-text链接为例,另外两种类型的链接也是类似的。下图包含两个deep text模块,它们构成了pairwise的text-text模块。deep text模块包含两个FC全连接层,然后是一个线性embedding层。这里有些违反直觉。主流的
DNN模型都是先通过一个embedding层,然后再通过FC层。线性
embedding层的输出是公共潜在空间中的低维向量,该低维向量进一步送到预测层prediction layer来计算损失函数。text-text模块是对称的,下图中相同颜色的神经元共享相同的权重和偏差,箭头表示前向传播的方向。
HNE的整体架构如下图所示,图中展示了三个模块,从左到右依次为image-image模块、image-text模块、text-text模块。这些模块分别连接到prediction layer来计算损失函数。下图中,相同的颜色代表共享权重。箭头表示前向传播和反向传播的方向。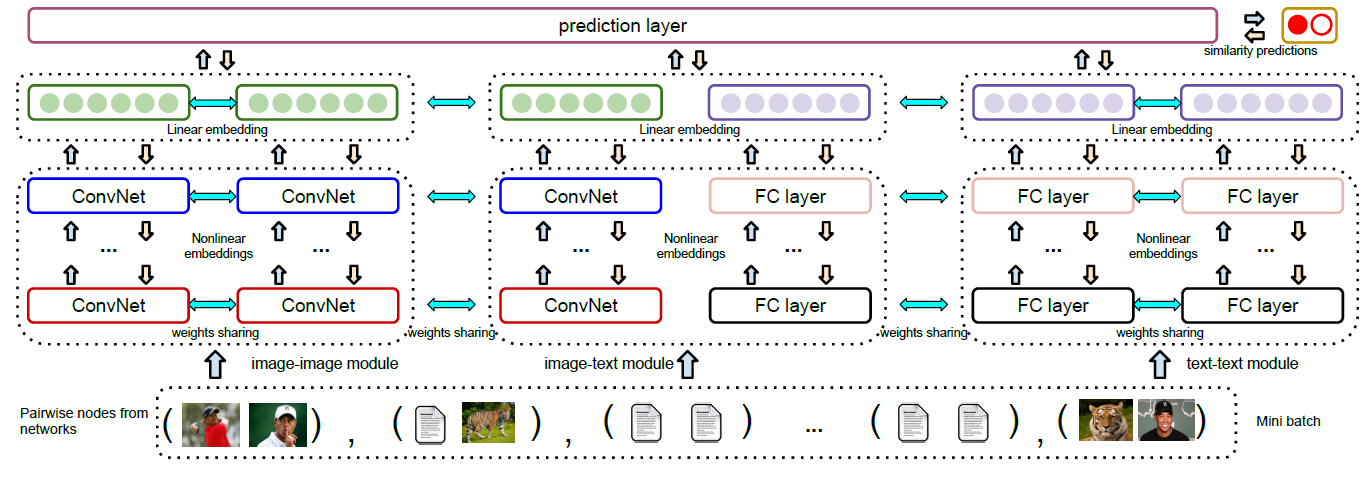
讨论:
- 目前为止我们仅展示了两种类型顶点的异质网络
embedding方法。事实上,我们的框架也支持多种类型顶点的异质网络embedding。 - 由于深度学习是高度非线性和非凸的,因为无法保证全局最优解。参数的初始化对模型性能至关重要。文献表明,即使最终任务与
pre-training任务不同,精心设计的pre-training也可以显著提高最终任务的表现。 - 值得一提的是,我们提出的方法是无监督学习方法,因此可以作为下游
fine-tuning微调阶段的预训练pretraining步骤来使用。换句话讲,如果我们想对网络顶点进行分类,那么我们可以从embedding layer获得最终特征并应用相应的机器学习算法。或者我们也可以将prediction layer替换为softmax层,然后进行微调为task-specific的端到端监督学习深度神经网络。
- 目前为止我们仅展示了两种类型顶点的异质网络
18.2 实验
数据集:我们使用来自现实世界社交网络的两个公开数据集。所有实验结果均在五次不同的运行中取均值。
BlogCatalog:一个社交博客网络,博主可以在预定义的类别下对其博客进行分类。这样的分类用于定义类标签,而following(即,关注)行为用于构建博主之间的链接。我们使用每个博主的所有博客内容的TF-IDF向量作为博主的内容特征。最终我们得到一个无向、同质图,每个顶点代表一个博主,顶点的特征为TF-IDF向量。最终该图包含5196个顶点、171743条边、类别数量6、内容向量维度8189,并且该数据集各类别是平衡的。NUS-WIDE:Flickr上的图像和文本数据,包含269648张关联有tag的图像,其中tag集合大小为5018。每一组image-tag标记有一个label,一共81个类别。由于原始数据中包含很多不属于任何类别的噪音样本,因此这些样本被删除。另外,我们将频次最高的
1000个tag作为文本并抽取其TF-IDF向量作为特征。我们进一步删除了不包含任何这1000个tag中单词的样本。最终我们分别随机抽样了53844和36352个样本进行训练和测试。我们将图像和文本分别视为独立的顶点来构建异质网络,训练网络包含
107688个顶点、测试网络包含72704个顶点。如果两个顶点共享至少一个概念concept,则构建它们之间的语义链接。我们对每个顶点最多随机采样30个链接,从而构建稀疏的邻接矩阵值得一提的是,我们以
out-of-sample方式来评估不同的算法。即,训练样本绝对不会出现在测试数据集中。
网络重建
Network Reconstruction:在分类、聚类或检索任务之前,我们首先对网络链接重建的质量进行基本的、直观的评估,从而验证我们的假设。我们从BlogCatalog数据集中随机选择500个顶点,然后可视化其链接,其中每个顶点的颜色代表其类别。可以看到:相对而言,社交“关注” 关系倾向于将具有相似属性的用户聚合在一起。
绝对而言,这种聚合之中存在大量噪音,其中
59.89%的链接连接到了不同类别的顶点。这是可以理解的,因为即使
HNE百分之百地重建了网络,但是原始网络本身就存在大量的、不同类别的顶点链接在一起的情况。
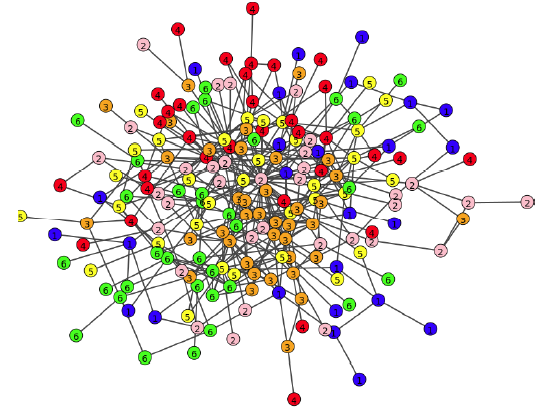
我们评估了算法学习
embedding过程中,训练集每个mini-batch的链接重建准确率 :预估正确的pair对的数量, 除以所有的pair对的数量。其中mini-batch = 128。结果如下图所示,其中横轴表示epoch,每个epoch包含500个step。红线表示每个epoch重建准确率的均值。可以看到:随着学习的推进,算法能够正确地重建80%以上的链接,而一开始的准确率只有55%。注意,这里是训练集的重建准确率,而不是测试集的。
18.2.1 BlogCatalog 数据集
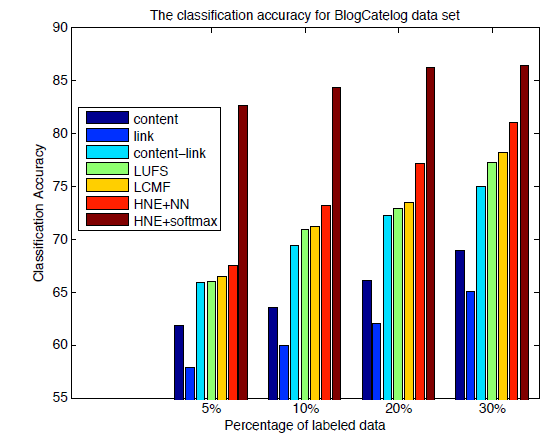
分类任务:在
BlogCatalog数据集上,我们将我们的feature learning方法和以下feature learning方法进行比较:Content:基于原始空间的内容特征,即用户所有博主的TF-IDF特征向量。Links:基于原始空间的链接特征,即用户的邻接关系作为特征。Link-Content:将内容和邻接关系都视为特征。LUFS:针对内容和链接的无监督特征抽取框架。LCMF:基于链接和内容的矩阵分解方法。HNE:我们提出的异质网络特征抽取方法。
对于这些抽取出来的特征,我们使用标准的
kNN分类器来评估特征的分类效果。为确保公平比较,所有方法的embedding维度固定为100。对于Content/Links/Link-Content方法抽取的特征,我们使用PCA算法投影到100维的空间。这些模型的分类准确率如下所示。可以看到:
- 在不同规模的训练集中,
HNE始终优于其它的baseline方法。这是因为网络链接可以编码很多有用的信息。 - 如果将
embedding视为预训练步骤,并通过将多类softmax替换掉predict layer来微调整个模型,则我们的效果会进一步提升。这表明了无监督的embedding学习对于有监督分类任务提供了很好的初始化,并能进一步提升性能。
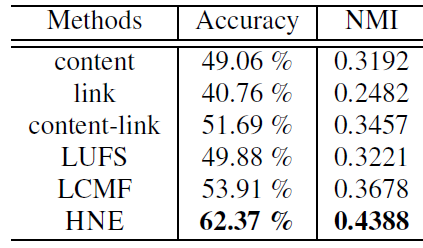
聚类任务:我们还比较了
BlogCatalog数据集上不同方法得到的embedding的聚类表现。与分类任务相比,聚类任务是完全无监督的,并很大程度上依赖于相似性度量函数。这里我们采用最常见的余弦相似度。我们根据聚类后的结果以及label信息,同时给出了准确率和互信息normalized mutual information :NMI作为评估指标。结果表明:
- 类似分类任务,仅使用链接会带来最差的结果。这可能是因为:在没有全局内容信息指导的条件下,相似性往往是局部的,并且对噪音非常敏感。
- 仅内容相似性不足以捕获关系信息。
- 通过链接和内容的简单组合,这可以提供与其它
baseline相当的性能。 - 我们的
HNE模型优于所有其它baseline模型并达到state-of-the-art的水平。
18.2.2 NUS-WIDE 数据集
与
BlogCatalog相比,NUS-WIDE数据集构成了一个包含图像、文本的异质网络。我们将在分类任务、跨模态检索cross-modal retrieval任务中评估HNE的性能。注意,跨模态检索任务在前一个数据集的同质场景中是不可行的。分类任务:鉴于
BlogCatalog的异质场景,我们将我们的方法和以下无监督的、能够处理多模态输入的baseline进行比较:Canonical Correlation Analysis: CCA:根据输入的多个数据源的关系将它们嵌入到共同的潜在空间。DT:一种迁移学习方法,通过潜在embedding来减少图像和文本之间的语义距离。LHNE:HNE的线性版本。
我们为所有其它
baseline方法抽取了4096维的特征,但是由于我们的HNE方法是端到端的,因此不需要为图像手动抽取特征。由于NUS-WIDE数据集是类别不平衡的,因此我们用平均精度average precsision:AP来评估每种可能的标签结果的分类性能。AP就是P-R曲线下的面积,mAP就是所有类别的AP的均值。事实上,AP就是把recall的取值根据11个水平(也可以划分更小的单位),然后取对应的Precision的平均值。在P-R曲线上这等价于曲线的线下面积。为了方便比较,所有方法的公共嵌入空间的维度为
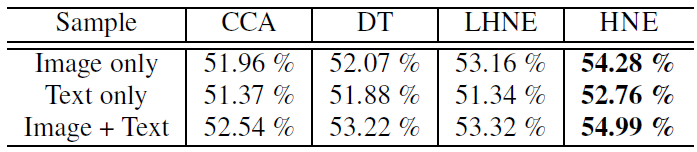
400维,并且使用线性支持向量机SVM来作为所有方法产出的embedding的通用分类器。之所以用SVM是因为计算AP需要预估一个概率值,而这不方便从深度神经网络分类器中取得。我们比较了三种配置:
image only:仅在图像顶点上学习embedding,然后训练SVM、执行分类测试。text only:仅在文本顶点上学习embedding,然后训练SVM、执行分类测试。image + text:同时使用图像顶点和文本顶点学习embedding,然后后训练SVM、执行分类测试。
可以看到:
- 对于所有方法,仅使用文本数据进行分类效果最差。这可能是由于:和图像输入相比,文本输入非常稀疏。
- 仅使用线性的
HNE,我们就可以获得与DT相当的结果,并且优于CCA。 - 非线性
HNE在所有三种配置中进一步提高性能,这表明使用非线性函数同时优化feature learning和潜在embedding的优势。
跨模态检索:为进一步验证
HNE的能力,我们在跨模态检索任务中将我们的方法和baseline进行比较。我们的目标是希望通过文本query来召回对应的图片。在所有81个label中,有75个出现在TF-IDF文本向量中。因此我们基于这75个label word来构建query向量:其中
query向量长度为1000, 除了第label对应的位置为1,其它所有位置为零。query向量一共有75个。根据学到的
embedding函数,我们将这些query向量都映射到公共潜在空间中,并通过欧式距离来检索测试集中的所有图像。我们报告了average precision at rank k: p@k(top k结果中的平均precision值) 的结果。 可以看到:HNE明显优于其它baseline。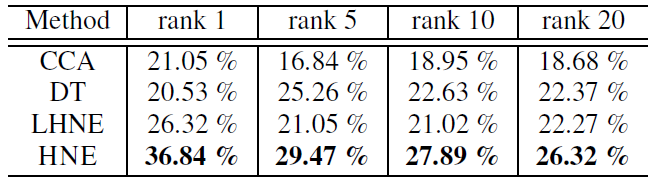
然后我们给出一些检索的案例。可以看到:
Mountain的第三个检索结果不正确,这可能是由于其它Mountain图像和带有牛的Mountain图像之间存在极大的视觉相似性。Cow的检索结果中包含三只鹿,这是因为这些图像具有多个tag,并通过“动物” 概念进行链接。由于我们的方法以及
ranking函数完全是无监督的,因此cow和deer等对象之间的联系会混淆我们的embedding学习。我们预期使用监督ranking可以提升性能。

18.2.3 其它
训练收敛性:我们展示了
HNE在BlogCatalog数据集上目标函数的变化,从而验证模型的收敛性。其中x轴代表epoch。可以看到:目标函数经过60个epoch的持续性降低之后趋向于平稳,这表明算法可以收敛到稳定结果。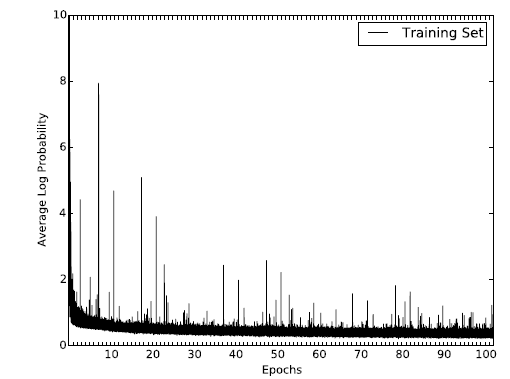
十九、AANE[2017]
网络分析已经成为许多实际应用中的有效工具,例如精准营销
targeted marketing和基因分析。识别有效特征对于这些任务至关重要,但是这涉及大量的人力和大规模的工程实验。作为替代方案,network embedding将每个节点的拓扑结构topological structure映射为低维的向量represetnation,从而可以很好地保留原始网络邻近性proximity。已有工作表明,network embedding可以使各种任务收益,例如节点分类、链接预测、网络聚类。虽然现有的
network embedding算法专注于纯网络pure network,但是现实世界网络中的节点通常关联一组丰富的特征或属性,这称作属性网络attributed network。像同质性homophily和社交影响social influence等社会科学理论表明:节点属性与网络结构高度相关,即一方的形成取决于并影响了另一方。例如,微博中用户帖子和“关注” 关系之间的强关联,论文主题和引用关系的高度相关性。在各种应用中,已有工作表明联合利用这两个信息源(即节点拓扑结构和节点属性)可以提高学习性能。受到这些的启发,论文《Accelerated Attributed Network Embedding》提出研究节点特征是否可能有助于学到更好的embedding representation。此外,现实世界的网络通常是大规模的,具有大量节点和高维特征。例如,截至
2016年,美国每月有超过6500万活跃的Twitter用户,每个用户可以发布数千条推文。这对embedding算法的可扩展性提出了更高的要求。属性网络embedding在以下三个方面具有挑战性:- 高的时间复杂度可能是限制算法在实践中应用的瓶颈。一些工作致力于利用网络结构和属性信息来寻找低秩
low-rank的潜在representation。它们要么在每次迭代中需要具有eigen-decomposition(其中 - 由于异质信息
heterogeneous information的各种组合,在网络和属性的联合空间中评估节点邻近性node proximity具有挑战性。另外,随着网络规模的扩大,节点属性邻近性node attribute proximity矩阵往往太大,无法存储在单机上,更不用说对它的操作了。因此,如果embedding算法也是可扩展的,那么将很有吸引力。 - 两个信息源都可能不完整
incomplete的且充满噪音noisy的,这进一步加剧了embedding representation learning问题。
因此,鉴于数据的独有特性,现有方法不能直接应用于可扩展的、属性网络的
embedding。为了应对上述挑战,论文研究了在属性网络上有效地学习embedding representation的问题。论文旨在回答以下问题:- 如何在网络结构和节点属性组成的联合空间中有效地建模节点邻近性?
- 如何使
vector representations learning过程具有可扩展性scalable和高效efficient?
通过调研这些问题,论文提出了一个称作
Accelerated Attributed Network Embedding: AANE的新框架。总之,本文贡献如下:- 正式定义属性网络
embeding问题。 - 提出一个可扩展的、高效的框架
AANE。AANE通过将节点属性邻近性纳入network embedding,从而学到有效的、统一的embedding representation。 - 提出一种分布式优化算法。该算法将复杂的建模和优化问题分解为许多低复杂度的子问题,使得
AANE能够高效地处理每个节点。 - 在三个真实数据集上验证了
AANE的效率和效果。
- 高的时间复杂度可能是限制算法在实践中应用的瓶颈。一些工作致力于利用网络结构和属性信息来寻找低秩
相关工作:
network embedding已经成为处理大规模网络的有效工具。人们已经从各个方面进行了努力。《Scalable learning of collective behavior based on sparse social dimensions》提出了一种edge-centric的聚类方案,从而提高学习效率并减轻内存需求。《Distributed large-scale natural graph factorization》提出了一种基于随机梯度下降的分布式矩阵分解算法来分解大规模图。《LINE: Large scale Information Network Embedding》通过将weighted edge展开unfolding为多个binary edge来提高随机梯度下降的效率。《Asymmetric transitivity preserving graph embedding》设计了一种Jacobi-Davidson类型的算法来近似和加速high-order proximity embedding中的奇异值分解。《Structural deep network embedding》涉及深度架构从而有效地嵌入节点的一阶邻近性和二阶邻近性。
人们已经研究并分析了各个领域中的属性网络,并表明:通过联合利用几何结构和节点属性来提高学习性能变得越来越有希望。
《What's in a hashtag? content based prediction of the spread of ideas in microblogging communities》通过利用内容和拓扑特征改善了对思想ideas传播的预测。《Exploring context and content links in social media: A latent space method》基于pairwise相似性对内容信息进行建模,并通过学习语义概念semantic concept之间的结构相关性structural correlation,从而将内容信息与上下文链接一起映射到语义潜在空间中。《Probabilistic latent document network embedding》通过为网络链接和文本内容找到一个联合的低维representation,从而为文档网络提出了一个基于概率的框架。《Heterogeneous network embedding via deep architectures》设计了一种深度学习方法,将丰富的链接信息和内容信息映射到潜在空间,同时捕获跨模态数据之间的相关性。
属性网络分析不同于多视图学习。属性网络的网络结构不止一个视图,其底层属性很复杂,包括连通性
connectivity、传递性transitivity、一阶和更高阶的邻近性等等。
19.1 模型
19.1.1 基本概念
设
每条边
定义节点
定义
attributed network embedding为:给定网络embedding向量embedding向量能够同时保留节点的结构邻近关系、节点的属性邻近关系。所有节点的embedding向量构成embedding矩阵
19.1.2 AANE
现实世界属性网络的理想
embedding方法需要满足以下三个要求:- 首先,它需要能够处理任意类型的边(如,无向/有向边、无权/带权边)。
- 其次,它需要同时在网络空间和属性空间中都很好地保持节点邻近性。
- 最后,可扩展性很重要,因为节点的数量
为此,我们开发了一个满足所有要求的、有效的、高效的框架
AANE。这里我们将描述AANE如何以有效的方式联合建模网络结构邻近性和属性邻近性。网络结构建模:为了保持
AANE提出两个假设:- 首先,假设基于图的映射
graph-based mapping在边上是平滑的,特别是对于节点密集的区域。这符合 “聚类假设”cluster hypothesis。 - 其次,具有更相似拓扑结构或由更高权重连接的一对节点更有可能具有相似的
embedding。
为了实现这些目标,我们提出以下损失函数来最小化相连节点之间的
embedding差异:其中
embedding representation,- 首先,假设基于图的映射
属性邻近性建模:节点的属性信息与网络拓扑结构紧密相关。网络空间中的节点邻近性应该与节点属性空间中的节点邻近性一致。为此,我们研究如何使得
embedding representation受对称矩阵分解
symmetric matrix factorization的启发,我们提出使用attribute affinity matrixembedding representation其中亲和矩阵可以通过节点属性相似性来计算,具体而言这里我们采用余弦相似度。假设节点
计算亲和矩阵的时间复杂度为
top k个节点,从而将时间复杂度和空间复杂度降低到Joint Embedding Representation Learning:现在我们有两个损失函数其中
- 当
embedding,。因此每个节点都可以是一个孤立的cluster。 - 当
embedding相同(即embedding空间中形成单个cluster。
因此我们可以通过调节
embedding空间中cluster的数量。AANE可以视为带正则化项的矩阵分解,其中将embedding空间中彼此靠近。AANE仅考虑网络结构的一阶邻近性,无法捕获网络结构的高阶邻近性。AANE仅捕获线性关系,未能捕获非线性关系。AANE分别独立地建模网络结构邻近性和节点属性邻近性,并未建模二者之间的交互。- 当
19.1.3 加速算法
AANE的目标函数不仅联合建模网络结构邻近性和节点属性亲和性,而且它还具有特殊的设计, 从而能够更有效地和分布式地优化:separable的,因此可以重新表述为双凸优化问题bi-convex optimization。如果我们添加一个副本
则目标函数重写为:
这表明
separable的。考虑到上式的每一项都是凸函数,因此这是一个双凸优化问题。因此我们可以将原始问题划分为但是, 对于这
Alternating Direction Method of Multipliers: ADMM的做法来加速优化过程:将学习过程转换为updating step和一个矩阵updating step。也可以用随机梯度下降法来求解。这里介绍的优化算法需要
现在我们介绍优化过程的细节。我们首先引入增强的拉格朗日函数:
其中
我们可以交替优化
step的更新为:根据偏导数为零,我们解得
这里我们使用
《Efficient and robust feature selection via joint-norms minimization》证明了这种更新规则的单调递减特性。由于每个子问题都是凸的,因此当由于原始问题是一个
bi-convex问题, 因此可以证明我们方法的收敛性,确保算法收敛到一个局部极小值点。这里有几点需要注意:在计算
计算
如果机器内存有限,则也可以不必存储亲和矩阵
其中
为了进行适当的初始化,我们在第一次迭代中将
AANE将优化过程分为updating step分配给worker。当原始残差整体而言,
AANE优化算法有几个不错的特性:- 首先,它使得
updating step彼此独立。因此,在每次迭代中,global coordination可以将任务并行分配给worker并从这些worker中收集结果,而无需考虑任务顺序。 - 其次,所有
updating step都具有低复杂度。 - 最后,该方法快速收敛到一个合适的解。
- 首先,它使得
AANE优化算法:输入:
- 图
- 节点属性矩阵
embedding维度- 收敛阈值
- 图
输出:所有节点的
embedding矩阵步骤:
从属性矩阵
初始化:
计算属性亲和矩阵
迭代,直到残差
- 计算
- 分配
worker, 然后更新:对于 - 计算
- 分配
worker, 然后更新:对于 - 计算
- 更新
- 计算
返回
下图说明了
AANE的基本思想:给定一个为了加速优化算法,我们提出了一种分布式优化算法,将原始问题分解为
worker。在最终输出中,节点1和节点3分别分配了相似的向量[0.54, 0.27]和[0.55, 0.28],这表明这两个节点在原始网络和属性的联合空间joint space中彼此相似。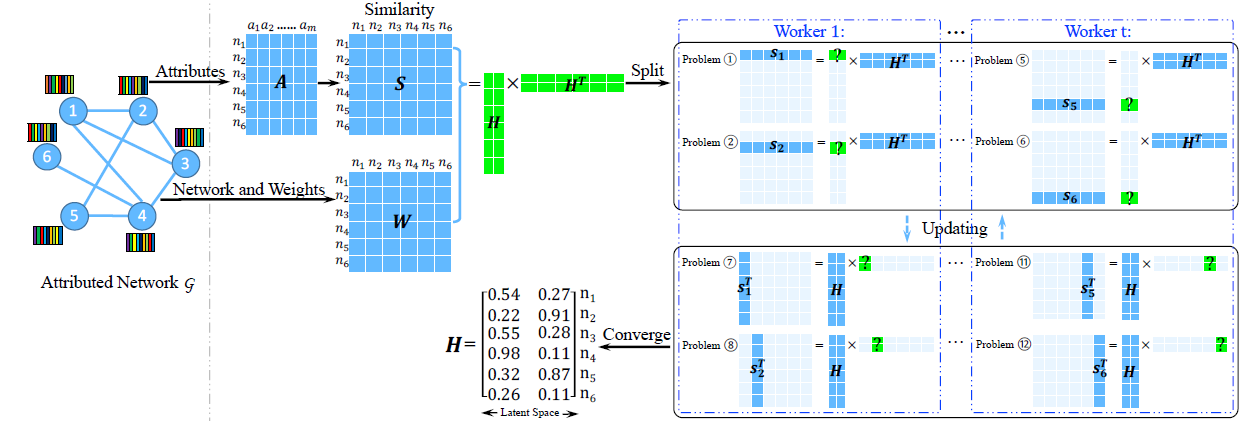
算法复杂度:由于
AANE的优化算法是一个典型的ADMM算法,因此训练算法在迭代很少的几个step之后就能收敛到很高的精度。在初始化步骤,由于需要计算奇异值向量,因此计算复杂度为
在每个子任务过程中,更新
另外,可以验证每个子任务的空间复杂度为
因此
AANE总的时间复杂度为worker数量。AANE的算法复杂度总体而言在
19.2 实验
数据集:
BlogCatalog数据集:一个博客社区,用户彼此关注从而构成一个网络。用户可以生成关键词来作为其博客的简短描述,我们将这些关键词作为节点(用户)的属性。用户也可以将其博客注册为指定的类别,我们将这些类别作为用户的label。没有关注或者没有指定类别的用户从网络中剔除。Flickr数据集:一个在线图片共享社区,用户彼此关注从而构成一个网络。用户可以为图片指定tag,我们将这些tag作为节点(用户)的属性。用于可以加入不同的组,我们将这些组作为用户的label。Yelp数据集:一个类似大众点评的本地生活评论网站。我们基于用户的社交关系来构成一个网络。我们从用户的评论中利用bag-of-word抽取文本信息来作为用户的属性信息。所有本地商家分为11个主要类别,如Active Life, Fast Food, Services...,我们将用户所点评的商家的类别作为用户的label。
这些数据集的统计信息如下所示。
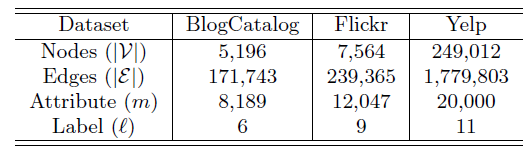
baseline模型:为评估节点属性的贡献,我们对比了DeepWalk,LINE,PCA等模型,这些baseline模型仅能处理网络结构或者节点属性,无法处理二者的融合;为了对比AANE的效率和效果,我们对比了其它的两种ANE模型LCMF, MultiSpec。DeepWalk:使用SkipGram学习基于图上的、截断的随机游走序列从而得到图的embedding。LINE:建模图的一阶邻近度和二阶邻近度从而得到图的embedding。PCA:经典的降维技术,它将属性矩阵top d个主成分作为图的embedding。LCMF:它通过对网络结构信息和顶点属性信息进行联合矩阵分解来学习图的embedding。MultiSpec:它将网络结构和顶点属性视为两个视图view,然后在两个视图之间执行co-regularizing spectral clustering来学习图的embedding。
实验配置:在所有实验中,我们首先在图上学习顶点的
embedding,然后根据学到的embedding向量作为特征,来训练一个SVM分类模型。分类模型在训练集上训练,然后在测试集上评估Macro-F1和Micro-F1指标。在训练
SVM时,我们使用五折交叉验证。所有的顶点被随机拆分为训练集、测试集,其中训练集和测试集之间的所有边都被移除。考虑到每个顶点可能属于多个类别,因此对每个类别我们训练一个二类SVM分类器。所有模型的
embedding维度设置为10并报告评估指标的均值。属性信息的影响:我们分别将分类训练集的规模设置为
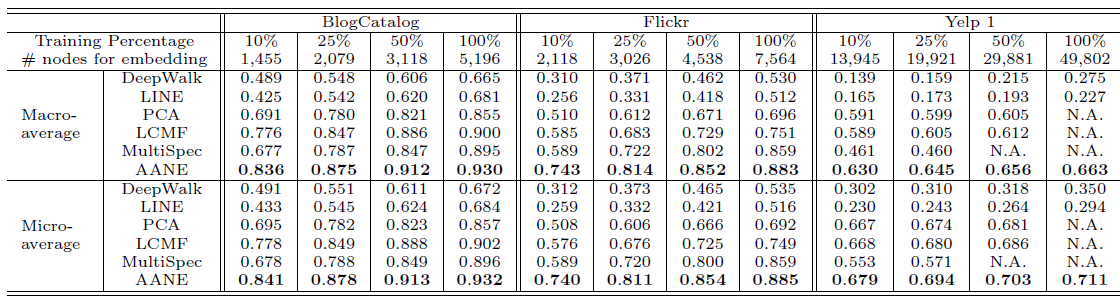
10%,25%,50%,100%。其中,由于Yelp数据集的规模太大,大多数ANE方法的复杂度太高而无法训练,因此我们随机抽取其20%的数据并设置为新的数据集,即Yelp1。所有模型的分类效果如下所示:
所有模型在完整的
Yelp数据集上的分类效果如下所示,其中PCA,LCMF,MultiSpec因为无法扩展到如此大的数据集,因此不参与比较: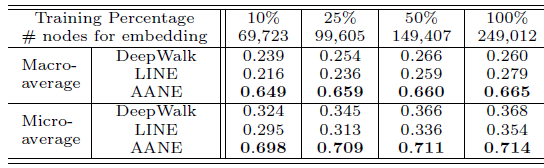
结论:
- 由于利用了顶点的属性信息,因此
LCMF,MultiSpec,AANE等属性网络embedding方法比DeepWalk,LINE等网络结构embedding方法效果更好。例如,在BlogCatalog数据集上,结合属性信息的AANE在Micro-average得分上比DeepWalk相对提升38.7%、比LINE提升36.3%。 - 我们提出的
AANE始终优于LCMF, MultiSpec方法。例如,在Flickr数据集上,AANE比LCMF相对提升18.2%。这可以解释为通过分解网络矩阵network matrix和属性矩阵attribute matrix学到的潜在特征是异质的,并且很难将它们直接结合起来。 LCMF,MultiSpec方法无法应用于大型数据集。
- 由于利用了顶点的属性信息,因此
效率评估:然后我们评估这些方法的训练效率。我们将
AANE和LCMF,MultiSpec这些属性网络embedding方法进行比较。下图给出了这些模型在不同数据集上、不同顶点规模的训练时间。结论:
AANE的训练时间始终比LCMF和MultiSpec更少。- 随着顶点规模的增加,训练效率之间的
gap也越来越大。 AANE可以在多线程环境下进一步提升训练效率。
这种比较意义不大,本质上
AANE是AANE的时间曲线是平行的,也就是相差常数时间。在算法中,相差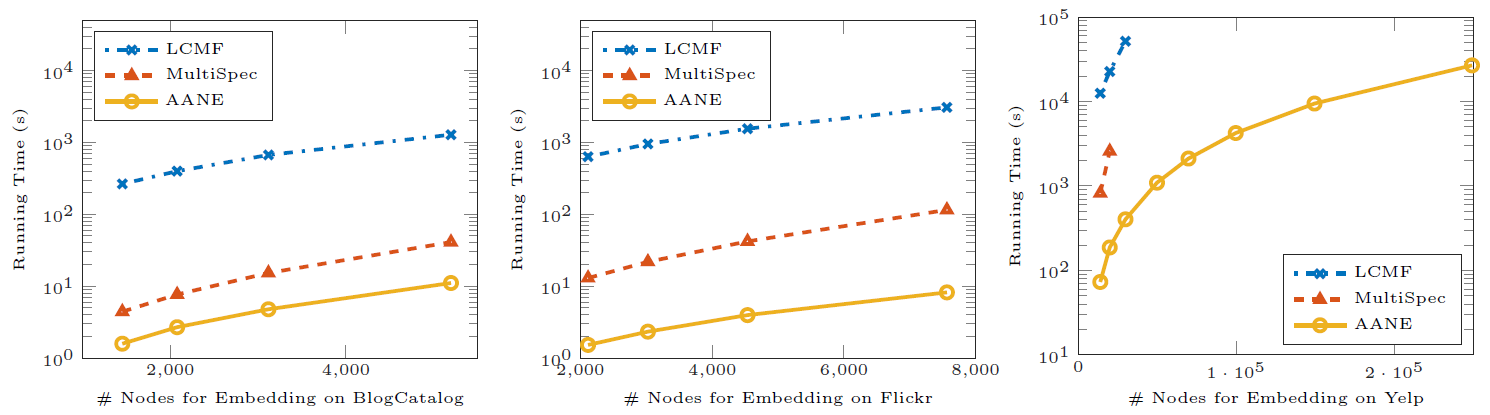
参数敏感性:这里我们研究参数
参数
Micro-F1效果如下所示。- 当
0时,模型未考虑网络结构信息,就好像所有节点都是孤立的。随着AANE开始根据拓扑结构对节点进行聚类,因此性能不断提升。 - 当
0.1时,模型在BlogCatalog和Flickr上的效果达到最佳。随着embedding。
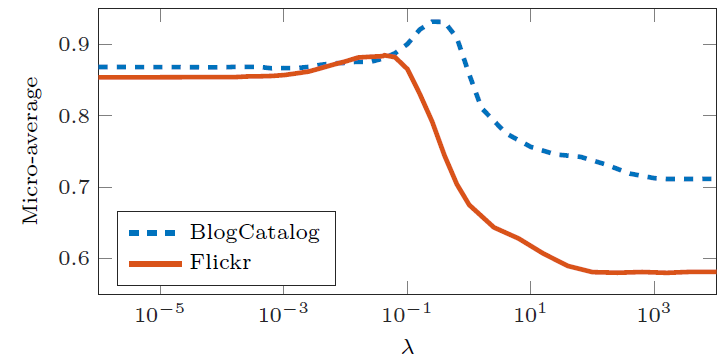
- 当
为研究
embedding维度20变化到180,对应的分类Micro-F1效果如下所示。我们仅给出Flickr数据集的结果,BlogCatalog和Yelp的结果也是类似的。可以看到:
- 无论
DeepWalk和LINE都不如属性网络embedding方法(AANE,LCMF,MultiSpec) - 无论
AANE的效果始终最佳。 - 当
embedding已经能够捕获大多数有意义的信息。
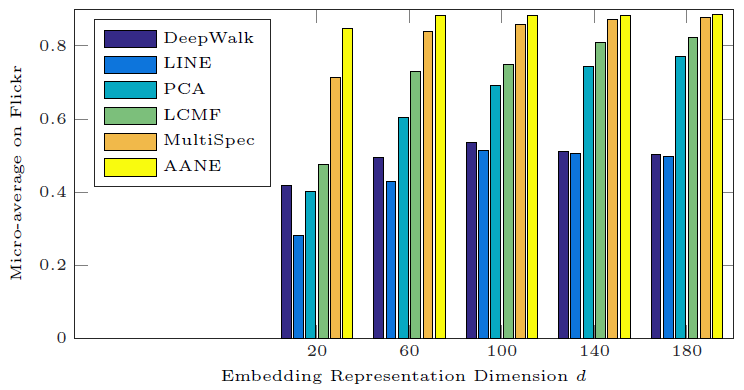
- 无论
二十、LANE[2017]
属性网络
attributed network在各种现实世界的信息系统中无处不在,例如学术网络、医疗保健系统。与仅观测节点之间交互和依赖关系的常规网络不同,属性网络中的每个节点通常关联一组丰富的特征。例如,随着社交网络服务的普及,人们不仅可以结识朋友从而形成在线社区,还可以积极分享意见、发表评论。在社会科学中,人们已经研究了社交影响理论social influence theory,即:个体的属性既可以反映、也可以影响他们的社区结构。此外,许多数据挖掘应用程序(如情感分析、信任预测)都可以受益于几何结构和节点属性之间的相关性。network embedding作为一种高效的图挖掘计算工具,旨在将网络中所有节点的拓扑邻近性topological proximity映射为连续的低维向量representation。学到的embedding representation有助于节点分类、链接预测、网络可视化等众多应用。虽然network embedding已被广泛研究,但是对Attributed Network Embedding: ANE的研究仍处于早期阶段。与从纯网络pure network学习的network embedding相比,ANE的目标是利用网络邻近性proximity和节点属性亲和性affinity。由于两种信息源的异质性,现有的network embedding算法很难直接应用于ANE。人们在各种现实世界的网络中收集了丰富的
label,如group或者社区类别。例如,在Facebook和Flickr等许多社交网络中,用户被允许加入一些预定义的分组。同组的用户倾向于分享类似主题的帖子或照片,并且组内用户之间也经常互动。引文网络是另一个例子。在同一个研究社区中发表的论文通常具有共同的主题,它们还大量引用来自同一社区的其它论文。这些事实可以用同质性假设homophily hypothesis来解释,即,具有相同label的个体通常具有相似的社交关系和相似的节点属性。label受到网络结构和属性信息的强烈影响,并与它们固有地相关。受到这一事实(即,label可能有助于学习更好的联合embedding representation)的启发,而现有方法关注于以无监督的方式学习embedding,论文《Label Informed Attributed Network Embedding》建议研究如何利用label信息并将其整合到ANE中。然而,在属性网络中建模和利用
label是一项困难的任务。有两个主要挑战:- 首先,属性网络和
label信息可能是稀疏sparse的、不完整incomplete的、噪音noisy的。例如,在社交网络中,单个用户的好友数量相比总用户量而言总是极少的,特定label的活跃用户的占比也可能很小。 - 其次,鉴于属性网络及其
label的异质性,学习统一的representation具有挑战性。与评论和帖子等属性不同,label将实例划分为不同的分组或社区。很难显式地建模所有这些多模态信息源之间的相关性correlation,并将它们共同嵌入到信息量丰富的embedding representation中。
因此,利用异质的、噪音的信息来相互补充从而获得有效的、鲁棒的
embedding representation是一项具有挑战性的任务。在论文
《Label Informed Attributed Network Embedding》中,作者研究了label informed attributed network embedding的问题,并提出了一个有效的框架LANE。具体而言,论文旨在回答以下问题:- 如何将
label建模且融合到ANE框架中? label对embedding representation learning的潜在影响是什么?LANE通过利用label对其它学习任务(如节点分类)做出多大贡献?
总之,论文的主要贡献如下:
- 正式定义
label informed attributed network embedding问题。 - 提出一个新的框架
LANE。LANE可以将label与属性网络关联,并通过建模它们的结构邻近性和相关性,将它们平滑地嵌入到低维representation中。 - 提出一种有效的交替算法来解决
LANE的优化问题。 - 实验评估和验证了
LANE在真实世界属性网络上的有效性。
- 首先,属性网络和
相关工作:
近年来,
network embedding越来越受欢迎。network embedding的开创性工作可以追溯到graph embedding问题,该问题由《On determining the genus of a graph in O(v^{O(g)}) steps》在1979年作为graph genus determining问题所引入。一系列更通用的
graph embedding方法是在2000年代左右开发的。他们的目标是生成可以对数据的非线性几何进行建模的低维流形low-dimensional manifold,包括Isomap、Laplacian Eigenmap、谱技术。到目前为止,由于网络数据的普遍性,人们已经实现了各种
network embedding算法。《Probabilistic latent semantic visualization: topic model for visualizing documents》将概率潜在语义分析probabilistic latent semantic analysis: pLSA应用于嵌入文档网络。《Community evolution in dynamic multi-mode networks》研究了利用时间信息分析动态多模式网络的优势。《Structure preserving embedding》利用半定程序semidefinite program来学习低维representation,从而很好地保留了全局拓扑结构。《Topic modeling with network regularization》设计了一种基于harmonic regularization的embedding框架来解决具有网络结构的主题建模问题。《Distributed large-scale natural graph factorization》提出了一种用于大规模图的异步分布式矩阵分解算法。《Learning social network embeddings for predicting information diffusion》将观察到的时间动态投影到潜在空间中,从而更好地建模网络中的信息扩散。《node2vec: Scalable feature learning for networks》通过增加邻域的灵活性,进一步推进了基于随机游走的embedding算法。- 为了嵌入异质网络,
《Learning latent representations of nodes for classifying in heterogeneous social networks》将transductive模型和深度学习技术扩展到该问题中。 《Revisiting semi-supervised learning with graph embeddings》利用概率模型以半监督方式进行network embedding。
最近,人们提出了几种基于深度学习的
embedding算法,从而进一步提高学习representation的性能。
在众多现实世界网络中,节点往往关联丰富的节点属性信息,因此人们提出了属性网络分析。在这些网络中,人们普遍认为几何结构和节点属性之间存在相关性。因此,同时利用这两者的算法可以提高整体的学习性能。例如,
《What's in a hashtag? content based prediction of the spread of ideas in microblogging communities》通过分析社交图的拓扑和内容,从而推进对思想ideas传播的预测。为了解决复杂的数据结构,人们致力于将两个信息源联合嵌入到一个统一的空间中。《Exploring context and content links in social media: A latent space method》探索了一种有效的算法,通过构建语义概念semantic concept的潜在空间,从而联合嵌入社交媒体中的链接和内容。《Probabilistic latent document network embedding》提出一个整体框架来同时处理文档链接和文本信息,并找到一个统一的低维representation。他们通过联合概率模型来实现这一目标。《Unsupervised streaming feature selection in social media》利用流式特征选择框架联合学习高维内容数据和链接信息中的潜在因子的概率。《Heterogeneous network embedding via deep architectures》将内容转换为另一个网络,并利用非线性多层embedding模型来学习构建的内容网络与原始网络之间的复杂交互。
在许多应用中,数据表现出多个方面
multiple facets,这些数据被称作多视图数据。多视图学习multi-view learning旨在从多个信息源中学习统计模型。人们已经提出了许多算法。《A reconstruction error based framework for multi-label and multi-view learning》研究了一种基于重构误差的框架,用于处理multi-label和multi-view学习。该框架可以显式量化多个label或视图的合并的性能。《Pre-trained multi-view word embedding using two-side neural network》应用了一个two-side多模态神经网络来嵌入基于多个数据源的word。
《A survey of multi-view machine learning》对多视图学习给出了更详细的回顾。我们的工作与多视图学习之间的主要区别在于:属性网络可以被视为一个特殊构建的数据源,而且ANE本身就是一个具有挑战性的问题。label也是具有特定形式的特殊数据源。
20.1 模型
20.1.1 基本概念
定义
除了网络结构和节点属性之外,每个节点还关联一组
label。节点的label矩阵为label种类。label向量,label,每个节点可以属于其中某一类label或者某几类label。我们定义
label informed attributed network embedding为:给定属性网络label信息representationlabel信息。我们提出了一种新颖的
informed attributed network embedding: LANE方法。LANE可以建模属性网络空间和label信息空间中的节点邻近性,并将它们联合嵌入到统一的低维representation中。下图说明了LANE的主要思想,图中有一个含有六个节点的属性网络,每个节点都有各自的label。LANE通过两个模块来学习节点的embedding:属性网络嵌入Attributed Network Embedding、标签信息嵌入Label Informed Embedding。- 首先,我们将网络结构邻近性和网络节点属性邻近性映射到两个潜在
representation - 其次,我们利用融合的
label信息,从而统一嵌入到另一个潜在空间 - 最后,我们将所有学到的潜在
representation映射到一个统一的representation
如下图所示,节点
1和节点3的embedding向量分别为[0.54, 0.27]和[0.55, 0.28],这意味着它们在原始空间中具有相似的属性。为了有效地学习节点embedding,我们设计了一种高效的交替优化算法。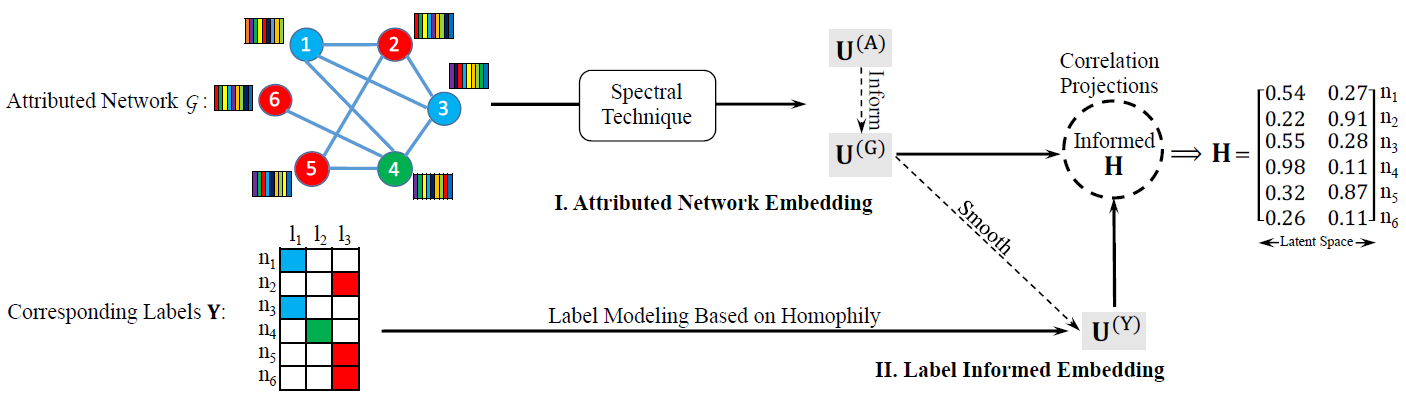
- 首先,我们将网络结构邻近性和网络节点属性邻近性映射到两个潜在
20.1.2 Attributed Network Embedding: ANE
Attributed Network Embedding模块的目标是寻找两个representation。首先考虑对网络结构进行建模。网络结构建模的核心思想是:如果节点
representation向量representation向量的相似性,其中AANE中采用边权重我们通过
- 当节点
- 当
该损失函数无法解决结构不相似但是
embedding都相等。因此论文增加了约束条件考虑所有节点,则我们得到总的不一致程度为:
定义图结构的
pair-wise结构相似性矩阵为这里采用这种归一化形式是为了得到拉普拉斯矩阵的矩阵形式。
则我们的目标函数为:
其中
representation矩阵,其第其中:
我们添加约束
- 当节点
与网络结构建模类似,我们对节点属性邻近性建模过程也是类似的。定义节点属性
pair-wise邻近性矩阵为representation矩阵为定义归一化拉普拉斯矩阵
为了将
这里是通过正则化的方式,迫使结构邻近性和节点属性邻近性产生高度的相关。
为了使得网络结构信息和节点属性信息互补,我们在模型中共同最大化
其中
ANE模块内部网络结构和节点属性的贡献。论文
《Accelerated Attributed Network Embedding》提出的AANE中,我们在
ANE模块基于pair-wise相似性来执行属性网络embedding。这种方法和谱聚类相一致,它有几个优点:- 对于输入没有很强的假设,即普适性较好,可以推广到很多实际问题。
- 目标函数可以使用很多图论来解释,如
ratio-cut partitioning、随机游走。 - 可以通过
eigen-decomposition特征值分解很容易求解问题。
20.1.3 Label Informed Embedding: LIE
label信息在确定每个节点内部结构方面起着至关重要的作用,它和网络结构、节点属性有着强烈的、固有的相关性。除了这些强相关性之外,label还可能被纳入前面提到的ANE模块中。然而,label通常是噪音noisy的、且不完整incomplete的。直接探索label可能会对最终的embedding产生负面影响。我们提出了一种对label进行建模的方法,并且使用两个步骤来强化embedding representation learning:label information modeling、correlation projection。Label Information Modeling:在这一步中,我们将label邻近性映射到潜在representationembedding来平滑label邻近性,使得当节点具有相同的label时,它们的网络结构、节点属性、以及最终的representation都趋近于相似。具体而言,我们根据
label将节点划分到对应的团clique中,对应的表示形式为label向量的内积。假设每个节点仅属于一个label类别:- 当节点
clique。 - 当节点
clique。
如果节点可以有多个
label类别,则我们根据
label邻近性来建模。令我们可以参考网络结构邻近性和节点属性邻近性建模,通过矩阵的特征值分解来求解
label信息的特殊结构:为解决该问题,我们利用学到的网络结构邻近性
smooth模型。我们定义以下目标函数使得相同label的节点具有相似的representation:这里假设结构相似的节点可能具有相同的
label。这里没有考虑属性邻近性,主要是为了将label融合到网络结构中。这里是否可以考虑引入一个平衡因子
label信息和属性网络embedding信息,即:embedding也是用网络结构邻近性smooth模型。这种方式有几个优点:
首先,矩阵
其次,联合的邻近性融合了更多的信息,这使得
label信息与网络结构、节点属性等信息相一致。另外第二项
label邻近性学习,因为label和节点结构、节点属性是高度相关的。最后,学到的潜在
representationlabel空间中大部分信息可被恢复。
因此,尽管
label信息可能是不完整的、且噪音的,但我们仍然能够捕获label空间中的节点邻近性。- 当节点
Correlation Projection:现在我们已经得到了属性网络embeddinglabel信息embeddingembedding我们将这些
embedding都投影到新的embedding空间则投影的目标函数定义为:
其中
embedding。这里通过相关性最大,从而从三个潜在
embedding中得到统一的embedding
20.1.4 联合学习
现在我们考虑所有的
embedding,以及所有的相关性。我们定义两个参数来平衡不同度量的重要性从而得到LANE的目标函数:其中:
ANE模块内部网络结构和节点属性的贡献,ANE模块和LIE模块的贡献。通过求解
embedding representation learning和correlation projection高度相关。通过这种方式,label邻近性,以及它们之间的相关性。优化算法:目标函数有四个矩阵变量需要优化,因此无法得到闭式解。这里我们采用一种交替优化算法来逼近最优解。基本思想是:每轮迭代时固定其中三个变量而求解另外一个变量的局部最优解。当固定其中三个变量时,目标函数就是剩下变量的凸函数。
考虑
其中
当
则
top类似地,最大化
top由于每个
updating step都是求解凸优化问题,因此可以保证收敛到局部最优解。我们从主要的信息源的
representationLANE训练算法:输入:
- 异质网络
label信息矩阵embedding维度- 收敛阈值
- 异质网络
输出:节点的
embedding矩阵步骤:
构建结构邻近度矩阵
label邻近度矩阵计算拉普拉斯矩阵
初始化:
迭代,直到
通过求解下式来更新
通过求解下式来更新
通过求解下式来更新
通过求解下式来更新
算法复杂度:
LANE框架在收敛之前只需要进行少量的迭代,在每轮迭代过程中都需要进行四个特征值分解。为计算top d个特征向量,类似于Lanczos方法的特征值分解方法最坏情况需要令
LANE的总的时间复杂度为spectral embedding的计算复杂度相同。由于LANE总的时间复杂度为另外,可以很容易得到
LANE的空间复杂度为这种复杂度对于大型网络而言是不可行的。
在某些网络中节点属性或者节点
label可能不可用。如,当移动通信公司希望分析客户网络以便提供更好的服务时,他们只能收集到通讯网络及其部分label信息,通讯内容、用户偏好之类的属性不可用。LANE也能够处理这类场景,其中节点属性或节点label之一发生缺失,或者二者全部缺失。我们以
label信息缺失为例,此时label信息建模)、label邻近性和其中
LANE的这种变体我们称作LANE_w/o_LABEL,其求解方法也类似于上述交替优化算法。
20.2 实验
数据集:
BlogCatalog数据集:一个博客社区,用户彼此关注从而构成一个网络。用户可以生成关键词来作为其博客的简短描述,我们将这些关键词作为节点(用户)的属性。用户也可以将其博客注册为指定的类别,我们将这些类别作为用户的label。Flickr数据集:一个在线图片共享社区,用户彼此关注从而构成一个网络。用户可以为图片指定tag,我们将这些tag作为节点(用户)的属性。用于可以加入不同的组,我们将这些组作为用户的label。

Baseline模型可以分为四类:- 首先,为评估
embedding的效果,我们使用原始特征作为baseline。 - 然后,为评估节点属性的贡献,我们考虑三种仅嵌入网络结构的方法,包括
DeepWalk,LINE, LANE_on_Net。 - 接着,为评估
label信息的贡献,我们考虑两种ANE方法,包括LCMF和LANE_w/o_Label。 - 最后,为评估
LANE的效果,我们考虑SpecComb和MultiView方法。
具体描述如下:
Original Features原始特征:将原始网络结构特征、原始节点属性特征直接拼接,从而作为节点特征。DeepWalk:使用SkipGram学习基于图上的、截断的随机游走序列从而得到图的embedding。LINE:建模图的一阶邻近度和二阶邻近度从而得到图的embedding。LCMF:它通过对网络结构信息和节点属性信息进行联合矩阵分解来学习图的embedding。SpecComb:将属性网络labelnormalized spectral embedding。最后选择top d的特征向量作为embedding。MultiView:将网络结构、节点属性、节点label视为三个视图,并在它们上共同应用正则化的谱聚类spectral clustering。LANE_on_NET和LANE_W/o_LABEL:是LANE的两个变种。LANE_on_NET仅对单纯的网络结构建模,LANE_W/o_LABEL对网络结构和节点属性建模(没有节点label信息)。
- 首先,为评估
实验配置:我们验证不同算法学到的
embedding对节点分类任务的有效性。我们使用五折交叉验证,并随机将数据集划分为训练集和测试集。其中,训练集不包含任何测试集的信息(训练期间测试节点是unseen的),但是测试集包含测试节点到任何其它节点的链接信息。我们首先在训练集上学到节点的
embedding,然后在训练集上训练一个SVM分类器,分类器的输入为节点的embedding、输出为节点的label类别。然后,为了得到测试集的embedding,我们首先构造两个线性映射函数embedding空间这相当于是根据
unseen节点的为简单起见这里我们使用线性映射,也可以使用其它非线性映射函数。我们并没有根据测试集来训练
embedding,因为这会泄露测试集的label信息embedding向量为:其中:
最后我们基于测试集的
embedding和训练集学到的SVM分类器来对测试集进行分类,并报告分类的F1指标。每种配置都随机执行10次并报告指标的均值。对于所有方法,
embedding维度为Baseline方法的其它超参数都使用原始论文中的超参数,LANE方法的超参数通过grid search搜索到合适的值。为证明
embedding的有效性,我们将LANE及其变体与原始特征进行比较。其中BlogCatalog数据集的原始特征为12346维、Flickr数据集的原始特征为18107维。实验中,我们将embedding维度从5增加到100。我们给出了Flickr数据集上不同BlogCatalog数据集,因为结果也类似。结论:
- 当
18107时,LANE_w/o_Label可以达到和原始特征相近的分类能力。 - 当
18107时,LANE可以达到和原始特征相近的分类能力。 LANE_on_Net比原始特征效果更差,这是因为它仅包含网络结构信息。
因此,通过利用
embedding representation learning,LANE实现了比原始特征更好的性能。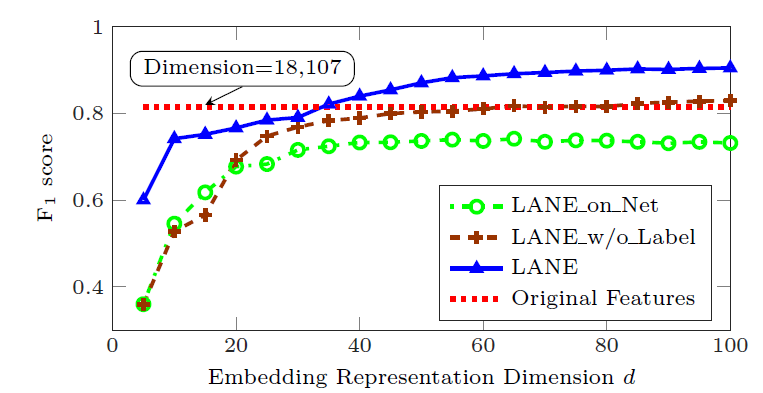
- 当
为研究
LANE的有效性,我们对比了所有的Baseline模型。我们固定结论:
- 所有情况下,
LANE总是优于Baseline模型。 - 当训练数据规模从
100%时,LANE的性能持续改善,但增长的幅度变小。
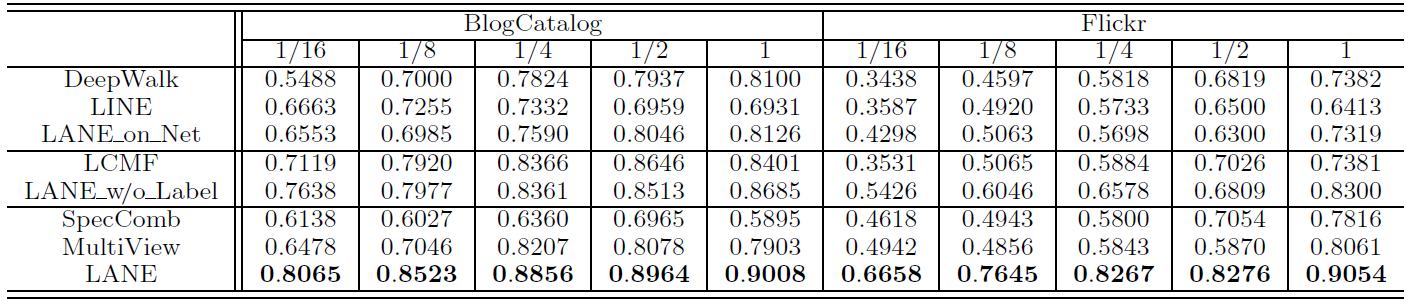
- 所有情况下,
为评估
label信息对于embedding的影响,我们分析上表中的数据。与单纯的网络结构
embedding方法(DeepWalk, LINE, LANE_on_Net) 相比,使用了节点属性信息的LANE_w/o_Label的效果更好。但是利用了label信息之后,LANE进一步超越了LANE_w/o_Label。这证明了将label信息融合到embedding中的优势。另外
LANE也超过了属性网络embedding方法LCMF,这进一步证明了label信息的优势。通过
LANE和SpecComb/MultiView的比较发现,SpecComb/MultiView的效果始终不如LANE,甚至比单纯的网络结构embedding方法(如DeepWalk)更差。这是因为:SpecComb没有明确考虑固有的相关性,并且直接拼接异质信息并不是组合异质信息的合适方法。MultiView会平等对待网络结构、节点属性、label信息,这也不是融合这些异质信息的好方法。
所有这些观察结果表明:
- 属性网络和
label之间确实存在很强的相关性。 label信息确实可以帮助我们获得更好的embedding representation。- 如何融合
label信息需要一种合适的方法。
LINE通过执行label informed embedding成功地实现了这一提升,并始终优于所有baseline方法。我们要强调的是:在节点分类任务中,所有方法都可以访问训练集中的label,并以不同的方式利用label信息。只有LANE, SpecComb, MultiView可以将这些label合并到embedding representation learning中。因此,LANE的优势不是拥有额外的信息源,而是执行label informed embedding的结果。超参数
label信息的贡献。我们同时将它们从0.01增加到100。Flickr数据集上的指标如下,BlogCatalog也有类似结果因此省略。结论:
当属性网络和
label信息都具有足够的贡献时,即LANE会实现相对较高的性能。当
当固定
0.01变化到100时,模型性能提升了42.7%;当固定0.01变化到100时,模型性能提升了16.07%。这表明label信息对于LANE的影响大于属性网络。因为在相同范围内取值时,模型性能随
label信息的影响更大。
总之,通过配置合理的参数,
LANE可以实现相对较高的性能。同时,label信息在embedding过程中非常重要。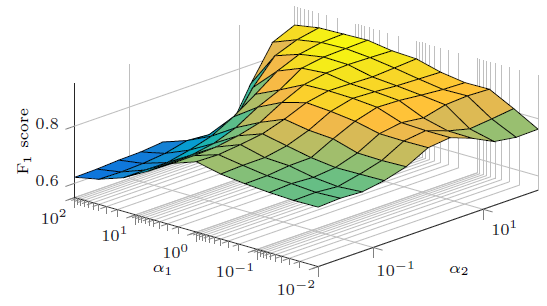
我们将
20变化到180来研究分类性能的影响。。在Flickr数据集上不同方法的效果和d的关系如下图,BlogCatalog也有类似结果因此省略。结论:
- 当
LANE始终比所有基准方法效果更好。 - 增加
LANE的分类性能首先提高,然后保持稳定。这在实际应用中很有吸引力,因为人们可以在大范围内安全地调整超参数
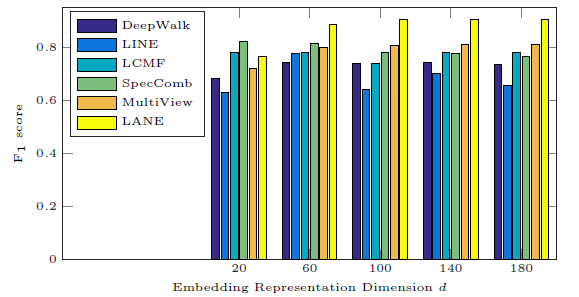
- 当
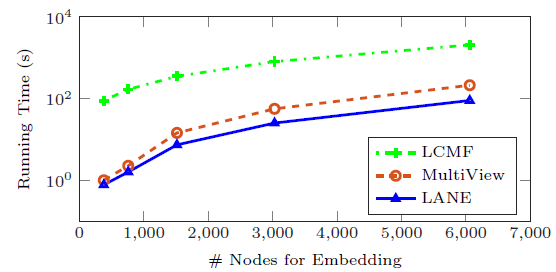
最后我们比较
LANE和两种属性网络ANE方法(LCMF和MultiView)的运行时间。我们在Flickr数据集上观察输入节点数量和训练时间(对数表示)的关系,BlogCatalog也有类似结果因此省略。结论:
LANE的运行时间最少。原因是:LCMF基于随机梯度下降来优化,这通常收敛速度很慢。MultiView具有和LANE相同的时间复杂度,但经验表明LANE可以在这两个数据集上仅使用几个迭代就能收敛。因此这证明了LANE的计算效率。
二十一、MVE[2017]
由于在现实世界中的广泛应用,挖掘和分析大规模信息网络(如社交网络、引文网络、航空网络)最近引起了很多关注。为了有效地、高效地挖掘此类网络,首要条件是找到有意义的
network representation。传统上,网络被表示为节点的邻接矩阵,这个矩阵既是高维的、又是稀疏的。最近,人们越来越关注将网络表示为低维空间(也称作network embedding),其中每个节点都用一个低维向量来表示。这样的向量能够保持节点之间的邻近性proximity,因此可被视为节点特征并有助于各种下游应用(如节点分类、链接预测、节点可视化)。尽管这些工作在许多网络中经验性地有效和高效,但是它们都假设网络中的节点之间仅存在一种类型的邻近性,而实际上网络中存在多种类型的邻近性。以科技文献中作者之间的网络为例,可以通过
co-authorship关系来得到邻近性,即两位作者是否曾经共同撰写过同一篇论文;也可以通过引用关系来得到邻近性,即一位作者是否引用另一位作者的论文。另一个例子是社交网站中用户之间的网络,其中存在多种类型的邻近性,例如由关注(following-followee)、回复、转发、引用等关系所产生的邻近性。每种邻近性定义了一个网络视图,多个邻近性产生了一个具有多视图multiple views的网络。每个单独的视图通常是稀疏sparse的、有偏biased的,因此现有方法学到的node representation可能不是那么全面。为了学到更鲁棒的node representation,一个自然的解决方案可能是利用来自多个视图的信息。这促使我们研究一个新的问题:学习多视图网络的
node representation,旨在通过考虑网络的多个视图来学习节点的robust representation。在文献中,人们已经提出了各种方法来从多个视图中学习数据representation,例如多视图聚类multi-view clustering方法、多视图矩阵分解multi-view matrix factorization方法。这些方法在许多application上表现良好,例如聚类任务、推荐任务。但是,当应用于我们的问题时,它们具有以下局限性:- 视图协同
collaboration不足。由于网络的每个单独的视图通常都是有偏biased的,因此学习节点的robust representation需要多个视图的协同。然而,大多数现有的多视图学习方法旨在找到跨不同视图的compatible representation,而不是促进不同视图的协同从而找到节点的robust representation。 - 缺乏权重学习
weight learning。为了学习节点的robust representation,需要整合来自多个视图的信息。在集成过程中,由于不同视图的重要性可能存在差异,因此需要仔细确定它们的权重。现有方法通常为所有视图分配相同的权重。换句话讲,不同的视图被同等对待,这对于大多数多视图网络而言是不合理的。
为了克服这些限制,我们正在寻求一种能够促进不同视图协同,并在集成过程中自动推断视图权重的方法。
在论文
《An Attention-based Collaboration Framework for Multi-View Network Representation Learning》中,作者提出了这种方法。作者首先引入一组view-specific的node representation,从而保持不同视图中节点的邻近性。然后作者组合view-specific的node representation从而用于投票出节点的robust representation。由于不同视图的信息量可能不同,因此理想的情况下,在投票过程中需要以不同的方式对待每个视图。换句话讲,每个视图的权重应该不同。受到最近神经机器翻译neural machine translation中注意力机制attention mechanism进展的启发,在论文中作者提出了一种基于注意力的方法来推断不同节点的各个视图权重。该方法利用一些标记数据。整个模型可以通过反向传播算法进行有效地训练,在优化view-specific node representation、以及投票出节点的robust representation(通过学习不同视图的权重)之间交替进行。作者对各种现实世界的多视图网络进行了广泛的实验。多标签节点分类任务、链接预测任务的实验结果表明:论文提出的方法优于用于学习单视图
node representation的最新方法、以及多视图的其它竞争性方法。总之,论文贡献如下:
- 论文建议研究
multi-view network representation learning,旨在通过利用来自多个视图的信息来学习node representation。 - 论文提出了一个新颖的协同框架,该框架促进了不同视图的协同
collaboration,以投票的方式得到节点的robust representation。论文引入了一种注意力机制,用于在投票期间学习不同视图的权重。 - 论文在几个多视图网络上进行了实验。两项任务的实验结果证明了所提出的方法在许多竞争性的
baseline上的效率和效果。
- 视图协同
相关工作:我们的工作与现有的、用于学习
network representation的scalable方法有关,包括DeepWalk, LINE, node2vec。这些方法使用不同的搜索策略来探索网络结构:深度优先搜索depth-first search: DFS、广度优先搜索breadth-first search: BFS、以及这两种搜索策略的组合。然而,所有这些方法都侧重于学习单视图网络single-view network的node representation,而我们研究多视图网络multiple-view network。另一类相关工作是多视图学习
multi-view learning,旨在利用来自多个视图的信息,并在分类、聚类、ranking、主题模型topic modeling等任务中显示出有效性。与我们最相似的工作是多视图聚类、以及多视图矩阵分解方法。例如:《Co-regularized multi-view spectral clustering》提出了一个谱聚类spectral clustering框架来正则化regularize不同视图的聚类假设clustering hypotheses。《Multiview spectral embedding》提出了一种多视图非负矩阵分解模型,旨在最小化每个视图的相关系数矩阵coefficient matrix和共性矩阵consensus matrix之间的距离。
我们的多视图
network representation方法与这些工作具有相似的直觉,旨在找到跨多个视图的、鲁棒的data representation。然而,主要区别在于现有方法为所有视图分配相同的权重,而我们的方法采用基于注意力的方法,从而为不同节点学习不同的视图投票权重。此外,我们的工作还与基于注意力的模型
attention based model有关。基于注意力的模型旨在推断训练数据不同部分的重要性,并让learning算法专注于信息量最大的部分。基于注意力的模型已经应用于各种任务,包括图像分类、机器翻译、语音识别。据我们所知,这是在multi-view network representation learning问题中首次尝试使用基于注意力的方法。
21.1 模型
21.1.1 基本概念
信息网络
Information Network定义:信息网络一个网络视图来自于节点之间的、单一类型的关系或邻近性
proximity,可以用一个边集合传统上,网络被表示为稀疏的、高维的邻接矩阵。最近,人们越来越关注学习网络的低维向量
representation(也称作network embedding)。Network Embedding定义:给定一个信息网络network embedding问题旨在为每个节点representationrepresentation保留节点之间的邻近性。最近人们已经提出了各种
network embedding方法。尽管它们已被证明在各种场景中有效果、高效率,但是它们都专注于具有单一类型关系的网络。然而,在现实中,我们经常观察到节点之间多种类型的关系。例如,对于社交网站(如Twitter)的用户,除了following(关注)关系之外,还存在其它关系,如转发retweet、引用mention等关系。每种类型的关系定义了节点之间的一个网络视图,而多种类型的关系产生了具有多个视图的网络。网络的不同视图之间通常互补,因此考虑多个视图可能有助于学习节点的robust representation。这促使我们研究学习多视图网络的node representation问题。Multi-view Network Embedding定义:给定带network embedding旨在为每个节点robust representationrepresentation在不同的视图中是一致consistent的。为了学习跨不同视图的、节点的
robust representation,我们需要设计一种方法来促进不同视图的协同、并投票来产生节点的robust representation。由于视图的质量不同,该方法还应该能够在投票期间对不同的视图进行不同的加权。这里我们介绍我们提出的、用于嵌入多视图网络的方法。大多数现有的多视图
network embedding方法,例如多视图聚类和多视图矩阵分解算法,都未能取得令人满意的结果。这是因为它们在训练过程中不能有效地促进不同视图的协同。此外,在组合多视图信息时,这些方法也无法为不同的视图分配合适的权重。为了解决这些挑战:
- 我们的方法首先挖掘了编码单个视图的邻近性的
node representation。在编码期间,我们提出了一个协同框架collaboration framework来促进不同视图的协同。 - 然后,我们通过投票
vote来进一步集成不同的视图,从而得到节点的robust representation。在投票过程中,我们通过基于注意力的机制来自动学习每个视图的投票权重。
我们的目标函数总结为:
其中:
robust representation。
注意:这里并没有引入超参数来平衡这两个目标函数。理论上可以引入超参数,比如
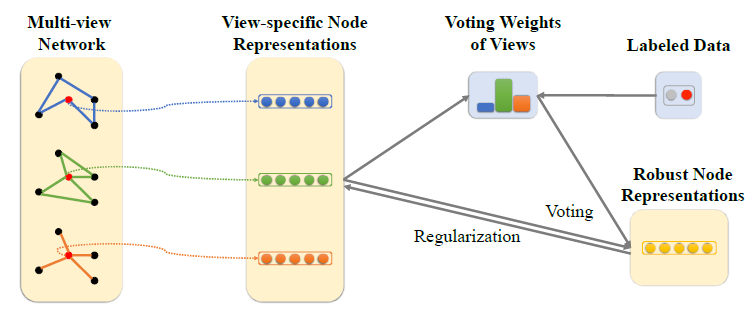
我们的方法如下所示,其中:黄色部分为协同框架,蓝色部分为基于注意力的权重学习,不同颜色的边代表不同的视图(共有三个视图),红色的节点为待分类的节点。
- 我们的方法首先挖掘了编码单个视图的邻近性的
12.1.2 协同框架
collaboration framework协同框架的目标是学习编码了单个视图节点邻近性的node representation,同时将它们集成起来通过投票产生节点的robust representation。对于每个节点view-specific representationrobust representation考虑视图
这意味着
其中
context representation。在我们的方法中,节点context representation在所有视图之间共享,这使得不同的view-specific representation将位于相同的语义空间中。我们还尝试了对不同视图采用不同的context representation,这作为我们方法的一个变种,并在试验中进行比较。context representation在所有视图之间共享,这使得节点的view-specific representation位于相同的语义空间中,这就是 “协同” 的含义。根据定义,概率分布
neighbor distribution。定义视图view-specific representation的目标是最小化邻居分布KL散度作为概率分布之间的距离的度量。我们将经验邻居分布定义为
out degree,即经过简化之后,视图
view-specific representation的目标函数为:该目标函数优化一阶邻近性(即直接邻域)。
直接优化视图
negative sampling技术,从而简化了条件概率的计算:其中
sigmoid函数,- 第一项用于最大化“正边”,即观察到的边
observed edge。 - 第二项用于最小化“负边”,即不存在的噪音边
noisy edge。其中
- 第一项用于最大化“正边”,即观察到的边
通过最小化
view-specific representation的目标函数,robust representation。在投票过程中由于各个视图的重要性可能不同,因此我们需要为每个视图分配不同的权重。考虑所有这些因素,我们引入正则化项:
其中:
该正则化使得最终的
robust representation与各view-specific representation保持一致。其物理意义为:一方面,要求节点的
robust representatioinview-specific representation的一致性consistency。另一方面,如果节点的
robust representation无法保留所有视图中的结构信息,则它保留较重要的那些视图的结构信息。即尽可能逼近如果采用相等的权重,那么
view-specific representation的均值。
直观而言,通过为每个节点
最终,不同的
view-specific representation基于以下方式投票从而产生robust representation:视图的权重作用在两个地方:投票产生
robust representation、不同视图的正则化系数。根据
很自然地,
robust representation被计算为view-specific representation的加权组合,加权系数为视图的投票权重,这非常直观。通过整合
view-specific representation学习阶段的目标、投票阶段的目标(即正则化项),则协同框架的最终目标为:其中
当
view-specific representation之间的一致性。
12.1.3 attention 机制
上述框架提出了一种灵活的方式让不同的视图相互协同。这里我们介绍一种基于
attention机制,用于在投票期间学习不同视图的权重。我们提出的方法非常通用,只需要提供少量标记数据就可以为specific-task学习不同节点的视图权重。基于
attention机制,我们使用softmax单元来定义节点其中:
view-specific representation的拼接向量feature vector,用于描述哪些特征的节点认为视图informative)。这里
这里使用拼接后的向量作为
query,而没有使用每个视图的representation向量作为query。后者使用局部的、单个视图的representation,前者使用全局的、所有视图的representation。
当
另外,每个节点的视图权重将由其
view-specific representation的拼接向量view-specific representation,因此视图权重也相似。这种性质是合理的,这使得我们能够利用view-specific representation中保留的邻近性更好地推断不同节点的注意力,即相似的representation有相似的attention。一旦学到视图的权重,则可以通过
robust representation。然后我们可以将该representation应用于不同的预测任务,并基于部分标记数据来使用反向传播算法来自动学习投票权重。以节点分类任务为例,我们基于视图的特征向量
其中:
robust representation;task-specific损失函数。我们根据梯度下降法来求解该最优化问题,其梯度为:
一旦求解出参数
总的目标函数为:
在本文中,我们研究两类预测任务:节点分类、链接预测。
在节点分类任务中,目标函数定义为:
其中:
one-hot向量;在链接预测任务中,目标函数定义为:
其中:
pair对;cos相似度。
12.1.4 优化
我们使用梯度下降法和反向传播算法来优化模型。具体地说,在每轮迭代中:
- 我们首先从网络中采样一组边,并优化节点的
view-specific representation - 然后我们使用标记数据来训练视图的参数向量
- 最后,基于学到的视图投票权重,我们集成节点的
view-specific representation来得到节点的robust representation。
算法本质上是一个半监督学习,以多任务的形式进行学习:无监督地优化节点邻近性损失、监督地优化节点分类损失。训练是以交替优化无监督损失、监督损失的方式进行。
- 我们首先从网络中采样一组边,并优化节点的
MVE算法:输入:
- 多视图网络
- 标记数据
- 更新
view-specific representation中采样的样本数 - 负采样比例
- 多视图网络
输出:节点的
robust representation算法步骤:
迭代直到算法收敛,迭代步骤为:
更新节点的
view-specific representation。 更新方式为:迭代直到本轮采样的“正边”数量大于- 随机选择一个视图,记作视图
- 从
- 求解
view-specific representation - 求解
context representation
- 随机选择一个视图,记作视图
更新顶点的投票权重。更新方式为:
- 求解
- 求解
通过
- 更新节点的
robust representation
- 更新节点的
MVE算法由三个过程组成:view-specific representation学习过程:该过程根据未标记数据、标记数据分别来学习节点的view-specific representation。根据之前的研究,这部分的计算复杂度为representation的维度,robust representation学习过程:该过程根据每个节点的view-specific representation投票得到最终的robust representation。这部分的计算复杂度为- 投票权重学习过程:这部分通过注意力机制来学习每个视图的投票权重。这部分的计算复杂度为
考虑到大多数网络有
21.2 实验
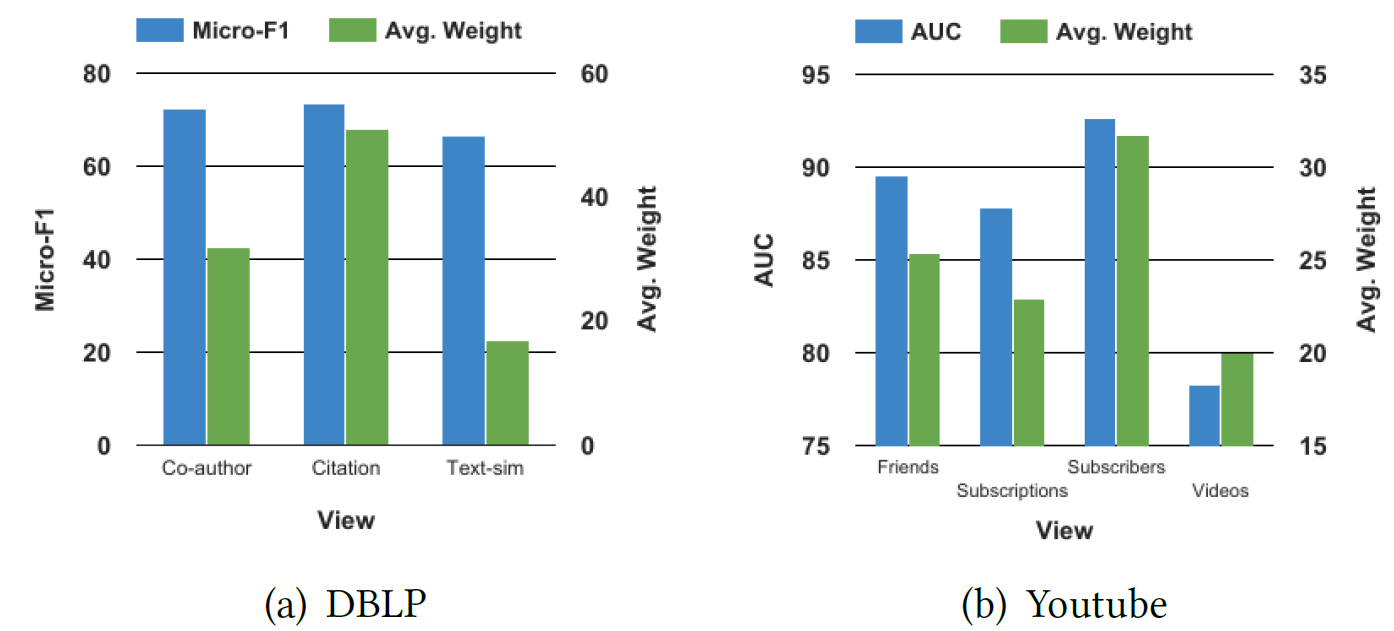
数据集:一共包含
5个数据集,其中前三个数据集用于节点分类任务,后两个数据集用于链接预测任务。DBLP:包含来自计算机科学领域论文的作者author。网络包含三种类型的视图:co-authorship视图:边的类型定义为作者之间共同发表论文的关系,边的权重为共同发表文章的数量。author-citation视图:边的类型定义为作者之间的论文引用关系,边的权重为作者text-similariry视图:边的类型定义为作者论文之间的相似度,边的权重为每个作者发表论文的标题、摘要计算得到的TF-IDF的cos相似度,每个顶点仅保留最相似的5个邻居顶点的链接及其权重。
我们选择
8个不同的研究领域作为label,包括machine learning, computational linguistics, programming language, data mining, database, system technology, hardware, theory。对于每个label我们选择该领域若干个具有代表性的会议,并且只有在这些会议中发表的论文才用于构建这三个视图。Flickr数据集:一个在线图片共享社区,用户彼此关注从而构成一个网络。用户可以为图片指定tag,我们将这些tag作为节点(用户)的属性。用于可以加入不同的组,我们将这些组作为用户的label。该网络包含两个视图:
friendship视图:边的类型定义为用户之间的关注,边的权重为0(没有关注)或1关注。tag-similarity视图:边的类型定义为用户所有图片tag之间的相似性,边的权重就是tag之间的相似度。每个节点仅保留最相似的100个邻居节点的链接及其权重。
PPI数据集:一个protein-protein interaction network,只考虑人类基因作为节点。我们根据coexpression, cooccurrance, database, experiments, fusion, neighborhood information构建了六个视图。Hallmark基因组提供的基因分组视为节点的类别。考虑到原始的网络非常稀疏,因此我们对每个视图通过添加邻居的邻居来扩展
degree小于1000的节点的邻居集合,直到扩展的邻居集合的规模达到1000。Youtube数据集:根据Youtube网络的用户社交数据构建的用户社交网络。我们构建了五个视图:common friends视图:边的类型定义为用户之间的共同好友,边的权重共同好友数量。common subscription视图:边的类型定义为共同订阅用户(站在subscriber的角度) ,边的权重为共同订阅用户数量。common subscriber视图:边的类型定义为共同订阅者(站在订阅用户的角度),边的权重为共同订阅者的数量。common favorite video视图:边的类型定义为共同喜爱的视频,边的权重为共同喜爱视频的数量。friendship视图:边的类型定义为是否好友关系,边的权重为0或1。
我们认为
friendship视图可以更好地反映用户之间的邻近性,因此我们使用前四个视图来训练,并预测第五个视图中的链接。Twitter数据集:根据Twitter网络的用户社交数据构建的用户社交网络。由于原始网络的稀疏性,我们将其视为无向图。我们根据回复reply、转发retweet、提及mention、好友friendship等关系定义了四个视图,其中前三个视图用于训练(以PPI数据集相同的形式重建),预测第四个视图中的链接。
Baseline模型:我们比较了两类方法:基于单视图single-view的方法、基于多视图multi-view的方法。LINE:一种用于单视图、可扩展的embedding方法。我们给出了它在所有单个视图的结果中,效果最好的那一个。node2vec:另一种用于单视图、可扩展的embedding方法。我们给出了它在所有单个视图的结果中,效果最好的那一个。node2vec-merge:node2vec的一个变种。为了融合多视图,我们合并了所有视图的边从而得到一个大的视图,然后通过node2vec来学习该视图的embedding。node2vec-concat:node2vec的另一个变种。为了融合多视图,我们首先从每个视图学到node embedding,然后将节点在每个视图的embedding拼接起来。CMSC:一个co-regularized多视图谱聚类模型。它可以应用于我们的任务,但是无法扩展到大规模的图。我们使用基于质心的变体,因为其效率更高并且质心的特征向量
eigen-vector可以视作节点的representation。MultiNMF:一个多视图的非负矩阵分解模型。它可以应用于我们的任务,但是无法扩展到大规模的图。MultiSPPMI:一个词向量模型,它通过分解单词的共现矩阵从而得到单词的embedding。这里我们通过联合分解不同视图的邻接矩阵,并在不同视图之间共享node representation,从而利用该模型来学习node representation。MVE:我们提出的方法,其中使用了协同框架和注意力机制。MVE-NoCollab:MVE的一个变体。我们针对不同的视图引入了不同的context node representation,因此节点的view-specific representation将位于不同的语义空间中。因此在训练期间,节点的view-specific representation无法协同。MVE-NoAttn:MVE的另一个变体。我们在投票期间为每个视图赋予相同的权重,因此没有采用注意力机制。
注意,我们并没有比较
DeepWalk模型,因为DeepWalk可以视为参数node2vec模型的特例。实验配置:
- 对于除了
node2vec-concat以外的其它所有方法,node representation维度设置为node2vec-concat方法,每个视图的representation维度为100,最终的维度为 - 对于
LINE和MVE,负采样系数为0.025。 - 对于
node2vec,窗口大小设为10、随机游走序列长度为40,超参数 - 对于
MVE,每轮迭代中的“正边”数量1000万,参数0.05。
- 对于除了
节点分类任务:我们将不同算法学到的
node reprsentation作为特征,并使用Lib-Linear软件包来训练one-vs-rest线性分类器。在分类器的训练过程中:- 对于
DBLP和PPI数据集,我们随机抽取10%的节点作为训练集,剩余90%作为测试集。 - 对于
Flickr数据集,我们随机选择100个节点作为训练集,以及10000个节点作为测试集。
为了学习视图权重,我们随机选择少量的标记样本来训练
MVE模型,这些标记样本不包含在测试集中,标记节点的数量参考数据集部分提供的图表。我们给出在测试集上的分类
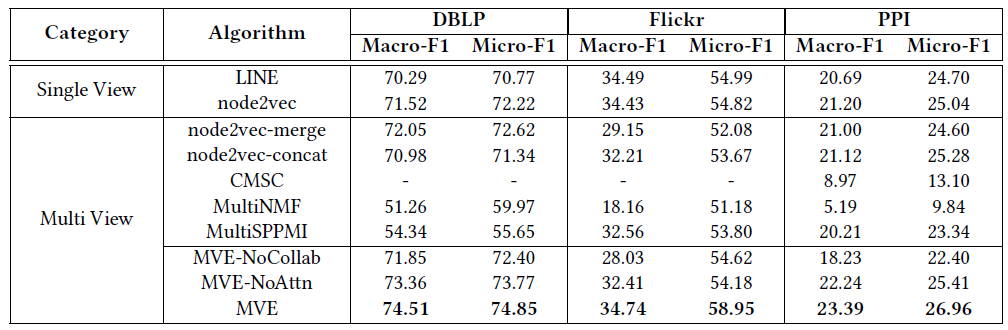
Micro-F1/Macro-F1值,每种配置随机执行10次并报告平均结果。由于CMSC无法扩展到非常大的网络,因此仅报告它在PPI网络上的结果。结论:
- 基于单视图的方法(
LINE和node2vec)分类效果都比较一般。 node2vec-merge通过合并不同视图的边来利用多视图信息。但是,不同视图的邻近性是无法直接比较的,简单地将它们融合在一起会破坏每个视图的网络结构。在Flickr数据集上,node2vec-merge方法的效果甚至还不如基于单视图的方法。node2vec-concat通过将学到的多个视图的view-specific representatioin进行拼接来利用多视图信息。但是,来自某些稀疏视图的representation可能会有严重有偏biased,这可能会破坏最终的representation。因此,即使该方法使用了更高的维度,node2vec-concat也不会显著优于其它的、基于单视图的方法。- 多视图聚类
CMSC和多视图矩阵分解(MultiNMF和MultiSPPMI) 的效果都较差,因为它们无法有效地实现不同视图的协同,也无法学习不同视图的权重。 - 我们提出的
MVE在不使用标签信息来学习视图权重的情况下,MVE-NoAttn超越了所有baseline方法。当使用注意力机制之后,MVE可以进一步提升效果。 - 如果
MVE去掉了不同视图的协同(即MVE-NoCollab),则会观察到较差的结果。这表明我们的协同框架确实可以通过促进视图的协同来提升性能。
- 对于
链接预测任务:链接预测任务旨在预测网络中最有可能形成的链接。由于节点规模巨大,因此预测全网的所有可能的链接是不现实的。因此我们为每个数据集构造一个核心节点集合,并且仅预测核心节点集合中的节点链接。
- 对于
Youtube数据集,核心节点集包含同时出现在所有四个视图中的所有节点,一共7654个节点。 - 对于
Twitter数据集,由于节点数量太多,我们随机采样了出现在所有三个视图中的5000个节点。
对核心节点集中的每对节点,我们用它们
robust representation向量的余弦相似度来作为形成链接的概率。另外,为了获得MVE模型中视图的投票权重,我们从每个数据集中随机抽取500条边作为标记数据,这些标记数据不包含在评估数据集中。我们通过核心数据集的
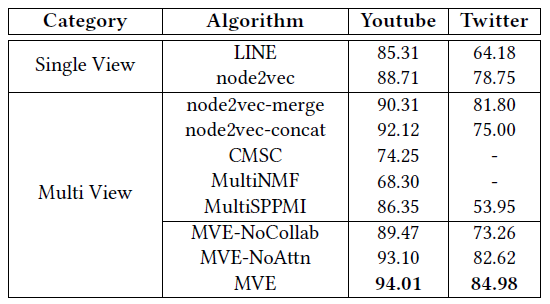
AUC来评估不同模型的链接预测能力。由于CMSC/MultiNMF无法扩展到非常大的网络,因此我们仅报告Youtube数据集上的结果。结论:
- 基于单视图的方法(
node2vec/LINE)效果都比较一般。 node2vec-merge通过合并不同视图的边来利用多视图信息。由于这两个数据集的不同视图具有可比性和互补性,因此node2vec-merge的效果得到改善。node2vec-concat通过将学到的多个视图的view-specific representatioin进行拼接来利用多视图信息。但是某些稀疏的视图(如Twitter数据集上的reply视图)可能会有严重的bias,这可能会破坏最终的representation。- 多视图聚类
CMSC和多视图矩阵分解(MultiNMF和MultiSPPMI) 的效果仍然都较差,因为它们无法有效地实现不同视图的协同,也无法学习不同视图的权重。 - 我们提出的
MVE方法让然优于所有的baseline方法。如果移除视图协同(MVE-NoCollab)或者移除注意力机制(MVE-NoAttn),则效果将下降。这表明我们协同框架的有效性和注意力机制的重要性。
- 对于
数据稀疏性:这里我们检查
MVE是否对稀疏数据也是鲁棒的。具体而言,我们研究MVE在不同degree节点上的性能,这对应于不同级别的数据稀疏性。每个节点的degree是所有视图的degree的总和。根据节点的degree,我们将DBLP数据集的所有节点划分为10个不同的分组、将Youtube数据集中所有节点划分为5个不同的分组。我们比较了
MVE, node2vec-merge和MVE-NoCollab在不同分组上的性能,效果如下图所示。图中组id越小则节点degree越大,组id越大则节点degree越小。因此越靠近右侧,数据越稀疏。结论如下:
对于
BDLP数据集,这三个模型在左侧的分组上效果均不理想。这是因为很多degree非常高的节点属于多个研究领域,因此难以正确分类。在右侧的分组中,
node2vec-merge和MVE-NoCollab的性能仍然很差,但是MVE明显优于它们。对于
Youtube数据集,也观察到类似的结果。这三个模型在左侧的分组上效果均不理想,但是在右侧的分组中MVE的效果优于node2vec-merge和MVE-NoCollab。
总之,
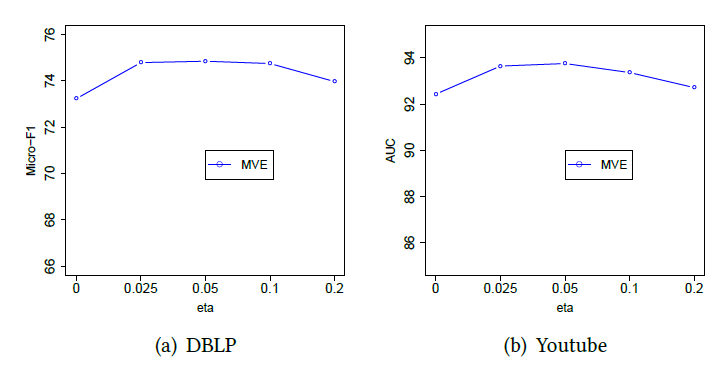
MVE在更稀疏的节点上取得了更好的效果,并且始终优于MVE-NoCollab和node2vec-merge。这表明我们的方法可以有效解决数据稀疏性问题,并帮助学到更鲁棒的node representation。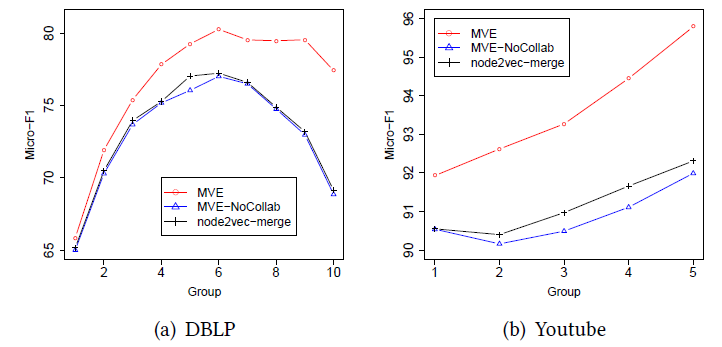
参数
view-specific representation保留的邻近性与view-specific representation的一致性。我们在节点分类任务和链接预测任务上比较了MVE随着不同结论:
- 当
MVE效果较差,因为不同视图无法通过正则化来彼此交流信息。 - 当
MVE效果持续改善。 - 当
MVE的效果比较稳定。 - 当
MVE效果持续下降。这是因为更大的view-specific representation趋同,从而忽略了视图之间的差异。
- 当
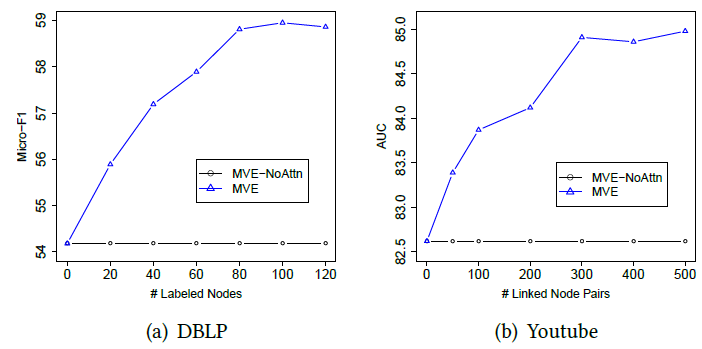
标记数据规模的敏感性:为了学习不同节点的视图投票权重,我们的框架需要一些标记数据。这里我们考察不同规模的标记数据对于效果的影响。我们观察随着标记数据规模的变化,
MVE和MVE-NoAttn的性能。结论:
- 通过利用标记数据来学习视图的投票权重,
MVE始终超越了其变体MVE-NoAttn - 在这两个数据集上,
MVE只需要很少的标记数据就可以使得预测性能收敛,这证明了我们基于注意力机制来学习投票权重的有效性。
- 通过利用标记数据来学习视图的投票权重,
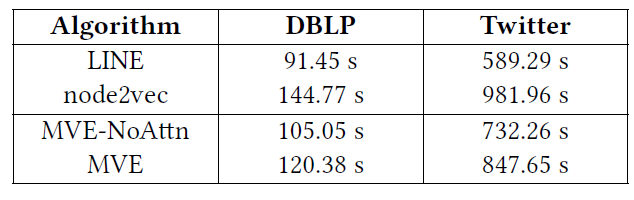
效率:我们在
DBLP和Twitter数据集上对比MVE和node2vec/LINE/MVE-NoAttn的训练时间。结论:
MVE和LINE/node2vec的运行时间都很接近。- 在拥有超过
30万顶点、1亿边的Twitter数据集上,MVE训练过程不超过15分钟,非常高效。 - 对比
MVE和MVE-NoAttn的训练时间,我们观察到MVE的权重学习过程在这两个数据集上花费的时间不到总训练时间的15%。这证明了我们基于注意力的权重学习方法具有很高的效率。
注意力权重分析:我们考察
MVE学到的注意力,以及这些注意力为什么能够改善性能。首先我们研究哪些视图会得到更高的注意力。我们以
DBLP和Youtube数据集为例。对每个视图,我们报告单独使用view-specific representation进行分类/链接预测的结果,以及每个视图所有节点的平均注意力得分。结论:单个视图的性能和它们分配的平均注意力正相关。即:我们的方法使每个节点关注于效果最好的视图。
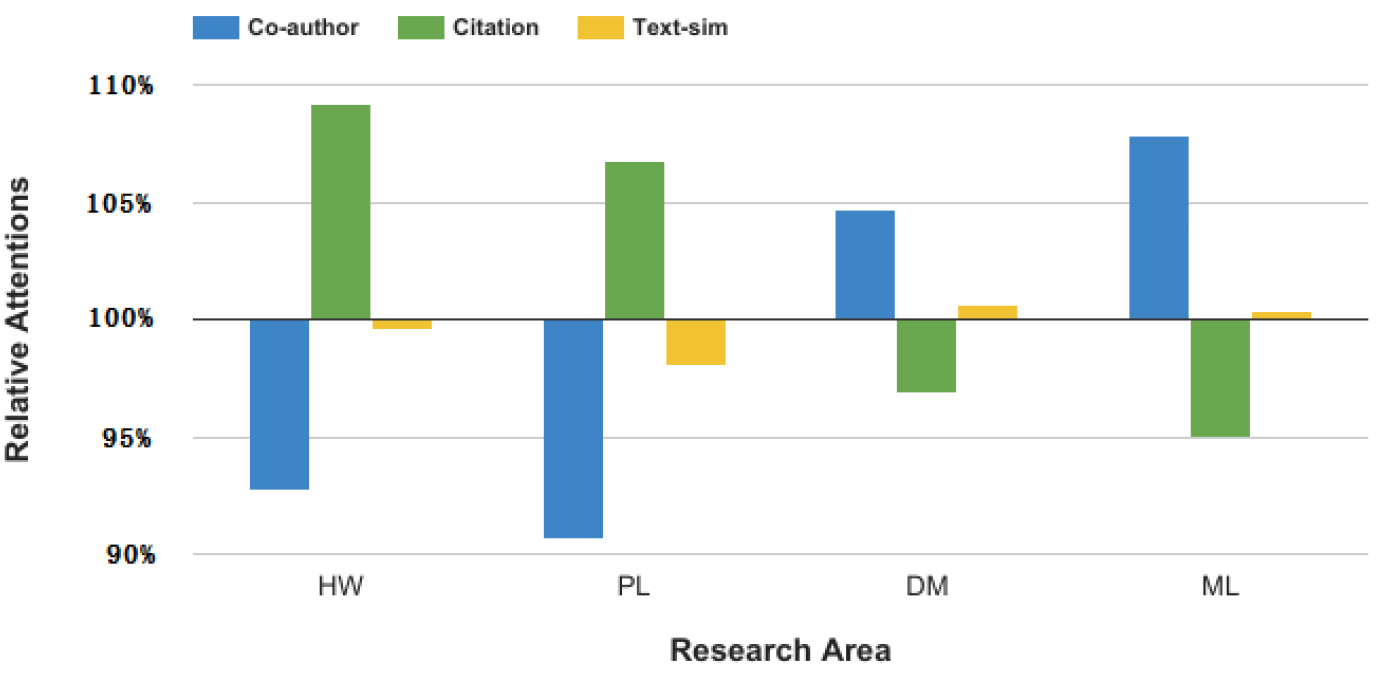
然后,我们比较不同
label中节点的注意力,从而在更细粒度进一步研究学到的注意力。我们以DBLP数据集为例,并研究四种label中的节点,包括hardware (HW), programming language (PL), data mining (DM) and machine learning (ML)。对每种label,我们计算属于该label的节点各视图平均分配的权重,并报告与其它label的节点各视图平均分配的权重的比值,以便了解哪些视图对于各label而言效果最好。结论:
- 对
HW/PL领域的节点而言,它们对citation视图的关注相对更多。 - 对
DM/ML邻域的节点而言,它们对co-author视图的关注相对更多。
这是因为我们的节点分类任务旨在预测不同作者的研究领域。为了提高预测的准确性,我们的注意力机制需要让节点关注于最能够与其它领域作者区分开的视图。
- 对于
HW和PL领域作者而言,与其它领域节点(每个节点就是一位作者)相比,这两个领域的作者可能会引用非常不同的论文,因此论文引用视图对它们的区分度最大。因此,HW/PL领域的节点对citation视图的注意力更大。 - 对于
DM/ML领域作者而言,他们更可能使用相似的术语并引用相似的论文,因此文本相似度视图、引文视图都无法将这些领域区分开来。因此,这些领域的节点很少关注文本相似性视图和引文视图,而更多地关注co-author视图。
总之,通过注意力机制学到的视图权重非常直观:迫使每个节点专注于信息量最高的视图。
- 对
case研究:最后我们提供一些case来展示view-specific representation和robust representation之间的差异。我们以DBLP数据集为例。 给定一个作者作为query,我们根据不同的embedding找出最相似的作者,相似度通过embedding向量的余弦相似度来衡量。结论:
view-specific representation可以很好地保留各个视图的结构邻近性,而robust representation则利用了来自所有不同视图的信息。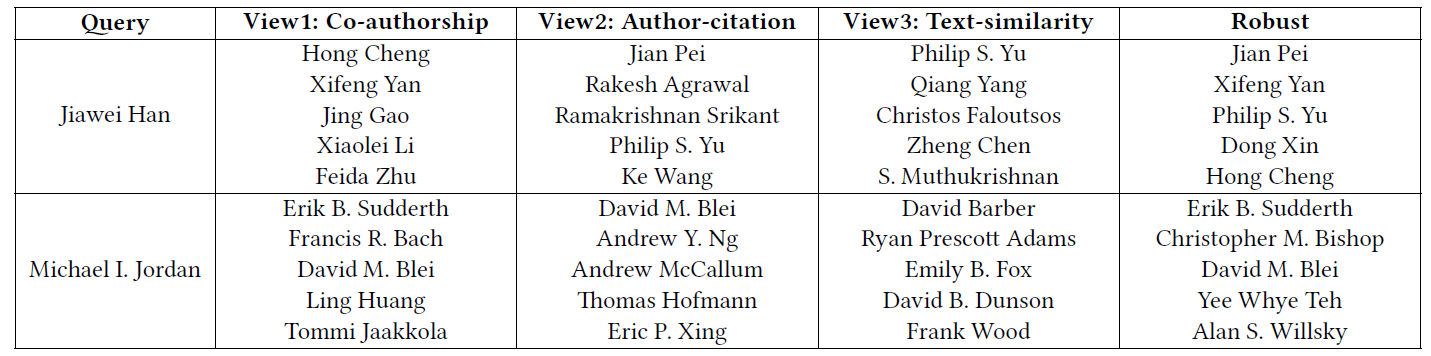
二十二、PMNE[2017]
随着大数据的兴起(尤其是社交网络),图挖掘已经成为分析对象之间的多样化关系、理解底层图的复杂结构的必要条件。分析如此复杂的系统对于了解社交网络的形成方式、或者预测未来的网络行为至关重要。
然而,图挖掘对网络的拓扑结构
topological structure非常敏感。例如,在社交网络分析中,图挖掘可以利用拓扑信息来识别网络中的社区,但是无法确定拓扑是否包含噪声(或其它错误)。避免这种情况的一种方法是使用多层网络multilayer network。多层网络是描述节点之间多种关系的一组网络,其中每个网络(一个网络代表一层 )代表一种特定类型的关系。多层网络也就是多视图网络。
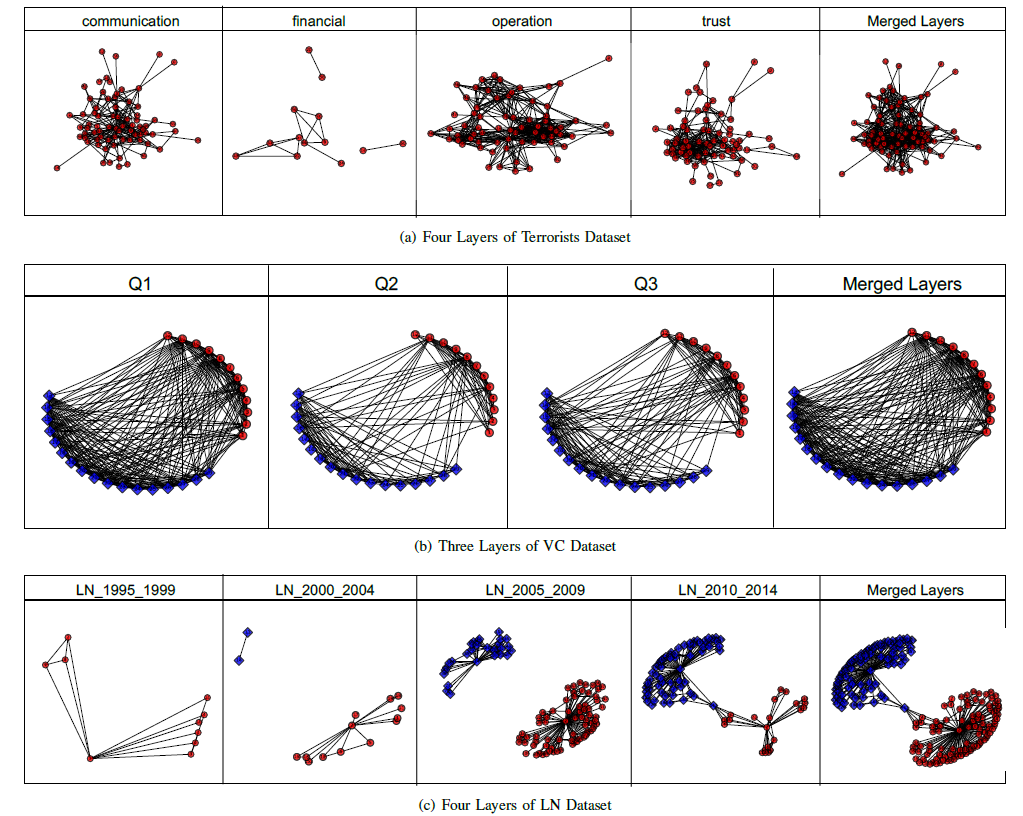
以
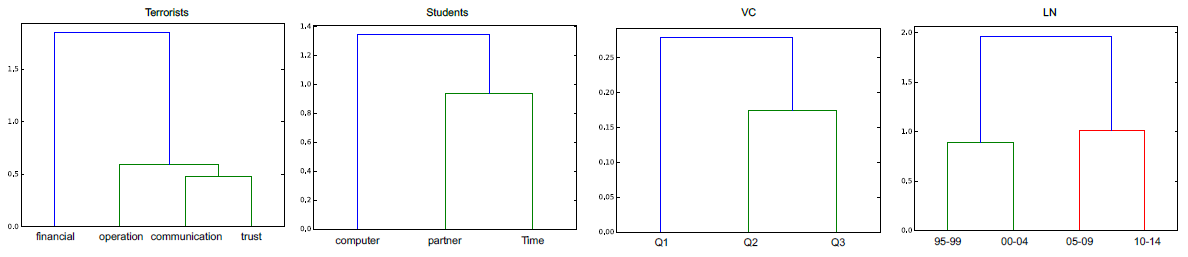
AUCS数据集为例。多个层代表大学院系61名员工之间的五种不同关系类型:共同工作、共进午餐、facebook好友、共度闲暇时光、共著学术论文。下图显示了这些不同层之间的距离(根据论文《Structural reducibility of multilayer networks》的方法),其中层之间的距离是包含双方的最小子树的根节点的distance value。从下图中,我们观察到一些关键的交互:例如,我们观察到 “共同工作”、“共进午餐” 密切相关,因为它们具有较小的layer distance;而 “共度闲暇时光” 和 “facebook好友” 也是密切相关的。一般而言,我们认为,多层网络通过考虑多种关系类型从而固有地反映了节点之间的基本交互essential interaction,并且对任何单个关系类型中的噪音都具有鲁棒性。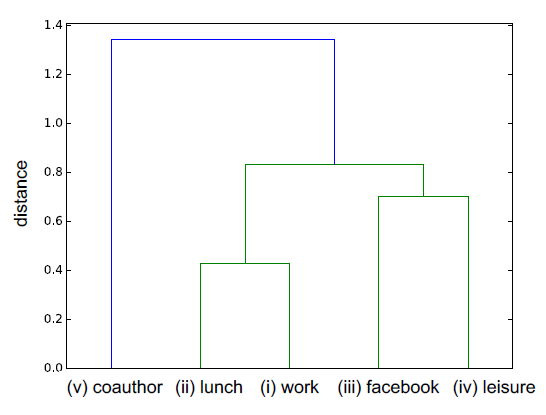
如今,多层网络上的图挖掘方法通常集中在不同的网络粒度,具体取决于任务。例如:
在节点粒度/边粒度上,
《Multiplex networks and interest group influence reputation: An exponential random graph model》和《Conditions for viral influence spreading through multiplex correlated social networks》专注于开发合适的中心性centrality指标,例如多层网络的cross-layer degree中心性。《Individual neighbourhood exploration in complex multi-layered social network》和《A method for group extraction in complex social networks》提出了多层局部聚类系数multilayered local clustering coefficient: MLCC和跨层聚类系数cross-layer clustering coefficient: CLCC来描述多层网络中节点的聚类系数。相比之下,
cluster级别通常用于社区检测,而layer级别通常用于分析不同层类型之间的交互。
在论文
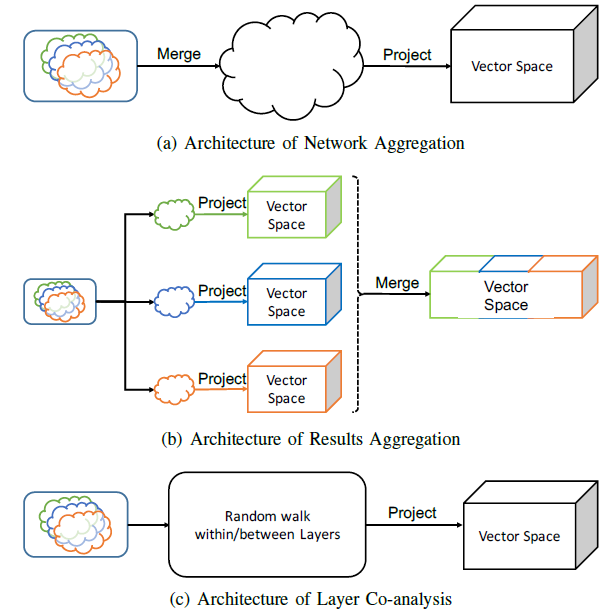
《Principled Multilayer Network Embedding》中,作者尝试通过结合所有粒度级别的分析,提出三种新颖的、多层网络的图挖掘方法。作者通过将多层网络的节点嵌入到向量空间来实现这一点。这个向量空间可以被解释为多层网络的隐式度量空间metric space,它自然地定义了节点之间的相似性概念,并捕获了原始多层网络的多个方面,最终促进了基于向量的representation来解决一系列任务。在标准的网络分析中,人们已经开发了许多这样的
network embedding方法,如DeepWalk, LINE, node2vec。这些方法都基于在输入图上生成随机游走的样本,随机游走的方式因方法而异。然而,这些方法是建立在单个图之上的,据作者所知,多层网络的graph embedding方法尚未得到严格的探索。因此,作者提出了一个通用的多层网络embedding框架,该框架适用于为单层网络开发的任何graph embedding方法。具体而言,作者介绍了将graph embedding扩展到多层网络的三种方法,即:网络聚合Network Aggregation、结果聚合Results Aggregation、网络协同Network Co-analysis。- 网络聚合:该方法的假设是来自不同层的所有边都是等价的。基于该假设,该方法将所有网络聚合为单个网络(如果不允许节点之间存在多条边,则聚合后为加权网络),然后应用现有的
graph embedding算法来分析合并的图。注意,这个合并的图不再区分关系类型。 - 结果聚合:该方法的假设是不同的层有完全不同的边,这意味着即使两个节点在不同的层中都有边,那么这些边是完全不同的、无法合并的。基于这个假设,该方法将
graph embedding方法分别应用于每一层,然后将向量空间合并在一起从而定义多层网络的向量空间。 - 网络协同:与前两种方法仅考虑
inter-layer边(network aggregation)或intra-layer边(results aggregation)不同,该方法利用不同层之间的交互来允许层之间的遍历,并保留每个层的结构。具体而言,论文引入了一种能够跨层遍历的、新的随机游走方法,从而编码节点和层之间的重要交互。
多层网络中的随机游走方法是单层
embedding方法的通用扩展。例如,node2vec和DeepWalk都是state-of-the-art的单层graph embedding方法。就像node2vec为DeepWalk添加了控制随机游走的同质性homophily和结构等价性structural equivalence的能力,论文使得随机游走能够遍历多个层。具体而言,论文添加论文没多大价值,典型的 ”水“ 文。
相关工作:这里我们回顾了标准的
network embedding的相关工作,即为单层网络提出的embedding方法。随着无监督
feature learning技术的发展,深度学习方法通过神经语言模型在自然语言处理任务中被证明是成功的。这些模型通过将word嵌入为向量来捕获人类语言的语义结构semantic structure和语法结构syntactic structure,甚至是捕获逻辑类比logical analogy。由于图可以被解释为一种语言(通过将随机游走视为等价的sentence),DeepWalk将此类方法引入网络分析,从而允许将网络节点投影到向量空间中。为了解决这类方法在应用于现实世界信息网络(通常包含数百万个节点)时的可扩展性问题,人们开发了LINE。LINE将DeepWalk的均匀随机游走扩展为一阶加权随机游走或二阶加权随机游走,从而可以在几个小时内将具有数百万节点、数十亿条边的网络投影到向量空间中。但是,这两种方法都有局限性。由于
DeepWalk使用均匀随机游走进行搜索,因此它无法控制所探索的邻域。相比之下,LINE提出了一种广度优先策略来采样节点,并在一阶邻域和二阶邻域上独立地优化似然性likelihood,但是它无法灵活地探索更深的节点。为了解决这两个限制,node2vec提供了一种灵活的、可控的策略,通过参数node2vec具有可扩展性,并且对扰动具有鲁棒性。当然,这些方法都无法处理多层网络的
layer之间的随机游走。因此,我们的网络协同方法是已有工作在随机游走能力方面的自然扩展。
22.1 模型
给定多层网络
layer集合,其中
layer多层网络嵌入任务是学习一个映射函数
我们提出了多层网络嵌入的三种架构如下图所示:
这篇论文是典型的 ”水”文,每什么价值。
22.1.1 网络聚合
网络聚合
network aggregation方法将多层网络的多个layer合并成单层网络,然后将常规的node2vec应用于合并后的单层网络。该方法的关键在于网络聚合函数:注意:这种方式将所有的层组合在一起,从而失去了每一层的细节信息,并且在学习映射
多层网络嵌入之网络聚合算法:
输入:
- 多层网络
node2vec的超参数
- 多层网络
输出:顶点的
embedding算法步骤:
初始化
网络聚合:
遍历每一对节点
遍历每一层
在
node2vec并返回每个节点的embedding
22.1.2 结果聚合
结果聚合
results aggregation方法将多层网络中的每一层视为一个独立的网络我们独立地学习每个网络
embedding,然后将节点在所有层的embedding拼接起来作为该节点的最终embedding。这种方法可以保持每一层的网络结构,但是无法利用层之间的交互信息。多层网络嵌入之结果聚合算法:
输入:
- 多层网络
node2vec的超参数
- 多层网络
输出:节点的
embedding算法步骤:
遍历每一层
- 初始化
- 遍历
- 在
node2vec得到顶点在第embedding
- 初始化
拼接节点在所有层的
embedding,得到节点的最终embedding
22.1.3 网络协同
为了克服网络聚合、结果聚合都无法利用层间交互的缺陷,我们采用网络协同
layer co-analysis来构建顶点embedding,该方法可以识别各层之间的交互,并保留各层的结构。考虑下图所示的多层网络随机游走,其中黑色点线代表每层顶点之间的对应关系,黑色粗线代表网络中的边。
- 如果在图
(a)中使用结果聚合,则节点A到节点C没有路径,因为结果聚合无法在层之间遍历。因此该方法无法学到节点A和C的关联。 - 如果在图
(b)中使用网络聚合,则会忽略节点
这使得我们我们寻求一种方法,该方法可以遍历从
A到C的跨层路径(图(a)的红色虚线表示),并可以保留多条边隐含的信息。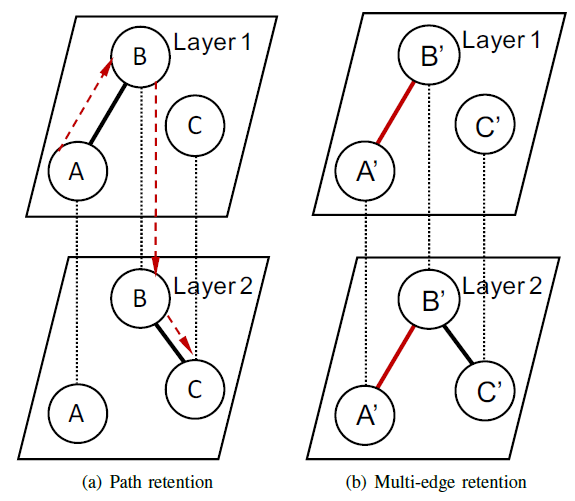
- 如果在图
node2vec在DeepWalk基础上引入了参数bias和全局bias,我们在node2vec基础上再引入参数令
其中
我们引入参数为
如果当前节点
node2vec在层其中
node2vec针对多层网络的修改:其中
如果当前节点
本文仅考虑二元边,也可以通过将遍历边的概率乘以归一化的边权重从而推广到加权的多层网络。
另外,我们将在未来探索如何通过分析多层网络的层距离来自动学习
多层网络嵌入之网络协同算法:
输入:
- 多层网络
- 随机游走序列数量
- 每条游走序列长度
- 超参数
- 多层网络
输出:节点的
embedding算法步骤:
初始化游走路径集合
迭代直到生成
随机选择一条边作为序列的起始边:
迭代直到第
- 以概率
next_layer - 以概率
next_layer中的下一个节点
- 以概率
对随机游走路径集合
node2vecSGD(基于node2vec对数似然目标函数的随机梯度下降)。
超参数
- 当
- 当
- 当
22.2 实验
数据集:
AUCS数据集:数据集为一个多层网络,代表大学部门的61位员工之间的五种不同关系:coworking, having lunch together, facebook friendship, onine friendship(having fun together), coauthorship。Terrorist数据集:数据集为一个多层网络,代表恐怖分子之间的不同关系:communication, financial, operation, trust。Student数据集:数据集为一个多层网络,代表Ben-Gurion University中185名学生之间的不同关系:Computer Network(学生在同一台机器上完成论文)、Partner’s Networt(学生共同完成论文)、Time Network(学生在同一时间提交论文)。Vickers Chan数据集VC:数据集为一个多层网络,代表七年级学生社交的不同互动关系:你在班上和谁打交道、谁是你班上最好的朋友、你最想和谁一起玩。Leskovec-Ng collaboration数据集LN:数据集为一个多层网络,代表从1995到2014不同年代Jure Leskovec和Andrew Ng的共同著作网络。我们将coauthorship网络按照5年一个layer,最终得到四层网络。在每层网络中,如果和这两个作者任意一个至少由一篇共同著作,则存在一条边。根据协作的频次,每位学者被标记为
Leskovec的协作者、或者Ng的协作者。
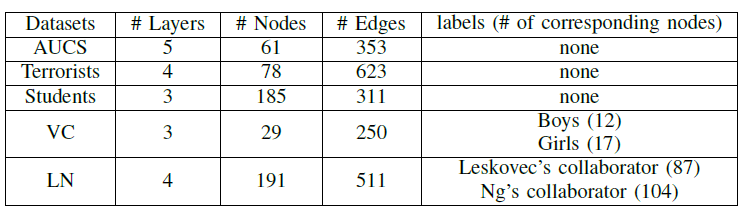
我们在这些多层网络数据集上执行链接预测任务,从而比较不同方法在链接预测任务上的性能。
我们将边
10%的边作为测试集。我们使用我们的
embedding方法在训练集embedding,然后计算10%预测为存在边,并将预测结果和准确率
acc为这个指标其实是召回率指标,而不是准确率。
F1得分为precision和recall的调和均值。这个指标预估每个层的边。
我们的方法中,超参数设置为:
10、每条随机游走序列的长度为80。baseline模型:我们在融合的网络中引入两个著名的链接预测算法:Common Neighbor Similarity:Jaccard Similarity:
这两种方法也是选择相似度最大的
top 10%来预测存在边。baseline没有graph embedding方法,垃圾。数据集太拉胯。不同方法在不同数据集上的评估结果如下表所示。可以看到,除了
LN数据集以外,我们的方法可以实现更高的准确率和F1得分。
不同数据集中各层之间的距离如下所示:
我们使用下图来给出三个多层网络每一层和相应的融合层的结构。由于
VC数据集和LN数据集带有标签信息,因此我们使用不同的形状和颜色来展示不同标签的顶点。在
Terrorists数据集中,多层网络显式了恐怖分子如何协作。显然,不同层之间的作用影响很大。这意味着如果我们需要预测两个顶点之间的链接,则需要考虑这两个顶点在不同层之间的交互。以图(a)为例,尽管financial层的顶点很少,但是四层之间的交互作用很强,而网络协同可以通过不同层的随机游走来恢复必要的信息。对于
AUCS/Students数据集,也是类似的结果。在
VC数据集中,不同question代表不同的关系,因此不同层之间的作用影响较弱。比如,“你在班上和谁打交道” (Q1)并不意味着你和她/他就是好朋友关系 (Q2)。由于第一个问题过于笼统,导致产生大量的噪音,因此无法指示这些顶点之间的真实关系。如果我们将这些层合并,或者更多地关注层交互上,那么网络聚合和网络协同都无法揭示真实的信息,反而会引入更多噪音。
在
LN数据集中,不同时间区间的layer没有任何交互。如,第一层没有蓝色顶点、第二层和第三层中两个簇自行扩展。这表明以下事实:层之间的交互作用并不是对应层中形成拓扑结构的关键。而且,各层之间的间隔为5年,因此层内的噪音使得我们的方法效果较差。相反,原始
Jaccard方法最好,因为它仅关心两个顶点的平均共享邻居数量,这种方法受噪音影响最小。
二十三、ANRL[2018]
网络是对现实世界中复杂系统进行探索和建模的通用数据结构,包括社交网络、学术网络、万维网等等。在大数据时代,网络已经成为一个重要媒介,用于有效地存储、访问交互实体的关系知识
relational knowledge。在网络中挖掘知识已经引起了学术界和工业界的持续关注,例如在线广告targeting、推荐系统。大多数的这些任务都需要精心设计的模型,并且需要大量专家努力进行特征工程,而representation learning是自动化的feature representation方案。采用representation learning之后,可以通过在低维向量空间中学习从而极大地提升网络中的知识挖掘任务,如聚类、链接预测、分类等任务。network representation learning中的相关工作可以追溯到基于图的降维方法,例如局部线性嵌入Locally Linear Embedding: LLE、Laplacian Eigenmap: LE。LLE和LE都通过构建最近邻图nearest neighbor graph来维护数据空间中的局部结构local structure。为了使相互连接的节点在representation空间中彼此更接近,人们计算亲和图affinity graph的相应eigenvector作为节点的representation。这些方法的一个主要问题是:由于计算eigenvector的计算复杂度太高,它们很难扩展到大型网络。受到
word2vec模型最近成功的启发,人们已经提出了许多基于网络结构的representation learning方法,并在各种application中显示出良好的性能。然而,节点属性信息没有受到太多关注,实际上这些节点属性信息可能在许多application中发挥重要作用。我们经常在现实世界的网络中观察到带各种属性的节点,这种网络被称作属性信息网络attributed information network。例如,在Facebook社交网络中,用户节点通常关联了个性化的用户画像,包括年龄、性别、教育、以及发帖内容。最近的一些努力通过整合网络拓扑信息和节点属性信息来探索属性信息网络,从而学到更好的representation。属性信息网络中的
representation learning仍然处于早期阶段,能力相当有限,原因是:- 网络拓扑和节点属性是两个异质的信息源,因此很难在公共向量空间中保存它们的属性。
- 观察到的网络数据往往是不完整
attributed information network的,甚至是噪音noisy的,这使得更加难以获取有信息量的representation。
为了解决上述挑战,论文
《ANRL: Attributed Network Representation Learning via Deep Neural Networks》提出了一个统一的框架,称作ANRL。该框架通过联合地集成网络结构信息和节点属性信息来学习属性信息网络中的、鲁棒的representation。更具体而言,论文利用深度神经网络的强大表达能力来捕获两个信息源的、复杂的相关性,这两个信息源由邻域增强自编码器neighbor enhancement autoencoder、以及属性感知attribute-aware的SkipGram模型组成。总而言之,论文的主要贡献如下:- 论文提出了一个统一的框架
ANRL,它将网络结构邻近性proximity和节点属性亲和性affinity无缝集成到低维representation空间中。更具体而言,论文设计了一个邻域增强自编码器,它可以在representation空间中更好地保持数据样本之间的相似性。论文还提出了一个属性感知的SkipGram模型来捕获结构相关性。这两个组件与一个共享的编码器相连,其中这个共享编码器捕获了节点属性信息以及网络结构信息。 - 论文通过两个任务(链接预测任务、节点分类任务)对六个数据集进行了广泛的实验,并通过实验证明了所提出模型的有效性。
相关工作:一些早期的工作和其它谱方法
spectral method旨在保留数据的局部几何结构,并在低维空间表达数据。这些方法是降维技术的一部分,可以被视为graph embedding的先驱。最近,
network representation learning在网络分析中越来越受欢迎。network representation learning专注于嵌入当前的网络而不是构建亲和图affinity graph。其中:DeepWalk执行截断的随机游走从而生成节点序列,并将节点序列视为sentence并输入到SkipGram模型从而学习representation。Node2vec通过采用广度优先breadth-first: BFS和深度优先depth-first: DFS的图搜索策略来探索不同的邻域,从而扩展了DeepWalk。LINE不是执行随机游走,而是优化一阶邻近性和二阶邻近性。GraRep提出为graph representation捕获k阶关系信息relational information。SDNE将图结构整合到深度自编码器deep autoencoder中,从而保持高度非线性的一阶邻近性和二阶邻近性。
属性信息网络在许多领域中无处不在。通过同时使用网络结构信息和节点属性信息来实现更好的
representation,这是很有前景的。一些现有的算法已经研究了将这两个信息源联合地嵌入到一个统一空间中的可能性。例如:TADW将DeepWalk和相关的文本特征整合到矩阵分解框架中。PTE利用label信息和不同level的单词共现信息来生成predictive text representation。TriDNR使用来自三方的信息(包括节点结构、节点内容、节点label)来联合学习node representation。
尽管上述方法确实将节点属性信息融合到
representation中,但它们是专门为文本数据设计的,不适用于许多其他类型的特征(如连续数值特征)。最近,人们已经提出了几种特征类型无关的
representation learning算法,以通过无监督或半监督的方式进一步提高性能。这些算法可以处理各种特征类型,并捕获结构邻近性structural proximity以及属性亲和性attribute affinity。AANE是一种分布式embedding方法,它通过分解属性亲和矩阵,并使用network lasso正则化来惩罚互相连接的节点之间的embedding difference,从而联合地学习node representation。Planetoid同时开发了transductive方法和inductive方法来联合预测图中的class label和邻域上下文。SNE通过利用端到端神经网络模型来捕获网络结构信息和节点属性信息之间复杂的相互关系,从而生成embedding。- 另一个半监督学习框架
SEANO采用输入样本属性、以及它平均邻域属性聚合的方式,从而缓解异常值在representation leraning过程中的负面影响。
也有一些工作在探索异质信息网络中的
representation learning。metapath2vec利用基于metapath的随机游走来生成异质节点序列,并采用异质SkipGram模型来学习node representation。《Attributed network embedding for learning in a dynamic environment》提出了一种模型,该模型可以在动态环境而不是静态网络中处理representation learning。《Attributed signed network embedding》研究了有符号信息网络中的representation learning问题。
我们将这些可能的扩展保留为未来的工作。
23.1 模型
令
属性信息网络的
representation learning任务的目标是:学习一个映射函数network structure proximity、节点属性邻近关系node attribute proximity。
23.1.1 邻域增强自编码器
为了编码节点的属性信息,我们设计了一个邻域增强自编码器模型。该自编码器由编码器和解码器组成,旨在重建目标节点的邻域而不是目标节点本身。值得注意的是,当我们的目标邻域是输入节点本身时,该自编码器退化为传统的自编码器。
具体而言,对于节点
target neighbor的聚合函数为定义每一层的隐向量为:
其中:
ReLU),我们的目标是最小化自编码器的损失:
其中:
函数
邻域加权平均
Weighted Average Neighbor:其中:
邻域的逐元素中位数
Elementwise Median Neighbor:其中
中位数指的是排序之后位于正中间的那个数。
与传统的自编码器相比,我们的邻域增强自编码器在保持节点之间的邻近性方面效果更好。因为邻域增强自编码器迫使节点重建相似的目标邻域,从而使得位置相近的节点具有相似的
representation。因此,它捕获了节点属性信息和局部网络结构信息。另外,重建的目标综合了多个邻域节点的信息,这比传统的重建单个节点(目标节点自身)更为鲁棒。因为单个节点的波动更大。
最后,我们提出的邻域增强自编码器是一个通用框架,可用于各种自编码器的变体,如降噪自编码器、变分自编码器。
23.1.2 属性感知 SkipGram 模型
属性感知
SkipGram模型将属性信息融合到SkipGram模型。具体而言,在SkipGram的目标函数中为随机游走上下文提供当前节点的属性信息:其中:
其中:
CNN编码器、针对序列数据的RNN编码器。这里我们使用邻域增强自编码器(见小面的小节)。representation。
因此,
直接优化
其中:
sigmoid函数。degree。
23.1.3 ANRL 模型
ARNL模型同时利用了网络结构和节点属性信息。如下图所示,ANRL模型由两个耦合的模块组成:邻域增强自编码器模块、属性感知SkipGram模块。编码器将输入的属性信息映射到低维向量空间,并扩展出两路输出:
- 左路输出为邻域增强自编码器的解码器部分。
- 右路输出用于预测属性感知
SkipGram的节点上下文。
邻域增强自编码器、属性感知
SkipGram共享网络的前几层(编码器部分),因此这两个模块相互耦合。通过这种方式,ARNL学到的节点representationANRL可以视为多任务模型,包括:基于邻域增强自编码器的邻域属性重建任务、基于属性感知SkipGram的上下文预测任务。二者共享节点的representation。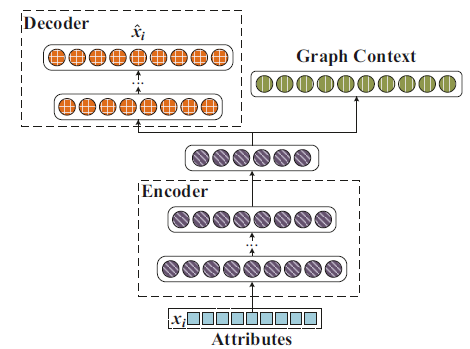
ANRL模型通过联合学习邻域增强自编码器模块、属性感知SkipGram模块两个模块,其目标函数为:其中:
representation。
通过这种方式,
ANRL将节点属性、局部网络结构、全局网络结构保留在一个统一的框架中。通过邻域增强自编码器模块捕获网络局部结构信息,通过属性感知的
SkipGram模块捕获网络全局结构信息,通过这两个模块同时捕获节点属性信息。值得注意的是:属性感知的
SkipGram模块的函数representation此外,为简单起见,我们使用单个非线性层来捕获图的上下文信息,并可以轻松地扩展到多个非线性层。
我们使用随机梯度算法来优化
ANRL训练算法:输入:
- 属性信息网络
- 每个节点开始的随机游走序列数量
- 随机游走序列长度
- 上下文窗口大小
embedding维度- 损失函数平衡系数
- 属性信息网络
输出:节点的
representation矩阵算法步骤:
对每个节点执行
从随机游走序列中构建每个节点的上下文集合
根据函数
随机初始化所有的参数
迭代直到模型收敛,迭代步骤为:
- 随机采样一个
mini-batch的节点及其上下文。 - 计算梯度
- 计算梯度
SkipGram模块的参数。
- 随机采样一个
返回
embedding矩阵。
23.2 实验
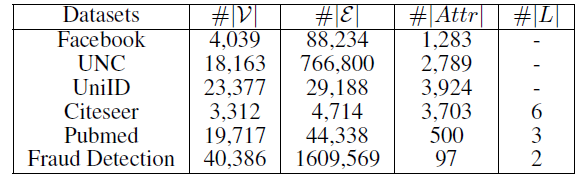
数据集:
社交网络数据集:
Facebook和UNC数据集是两个典型的社交网络数据集,节点代表用户,边代表用户的好友关系。引文网络数据集:
Citeseer和Pubmed是典型的引文网络数据集,节点代表论文或出版物,边代表它们之间的引用关系。Citeseer中的论文分为六种类别:Agents,AI,DB,IR,ML,HCI。Pubmed中的论文分别三种类别:Diabetes Mellitus Experimental、Diabetes Mellitus Type 1(I型糖尿病)、Diabetes Mellitus Type 2(II型糖尿病)。
用户行为网络数据集:
UniID和Fraud Detection是阿里巴巴提供的两个真实的用户行为数据集。UniID网络中的节点表示物理设备的ID,边表示在同一个用户的行为记录中观察到两个ID同时出现。Fraud Detection网络中存在两种类型的节点:cookie节点(代表买家)、seller节点(代表卖家)。cookie节点包含了带属性的cookie信息。为了获得同质
cookie网络,我们采用如下方法将二部图映射为仅包含cookie节点的图:当且仅当两个cookie之间存在至少五个共同的seller节点时,连接这两个cookie节点。我们的目标是鉴别哪些cookie是可疑的。
Baseline模型:我们将当前state-of-the-art的network representation learning方法划分为以下几组:- 仅属性的方法
Attribute-only:仅考虑节点属性信息。这里我们选择SVM和自编码器作为baseline模型。 - 仅结构的方法
Structure-only:仅考虑网络结构信息。这里我们选择DeepWalk, node2vec, LINE, SDNE作为baseline模型。 - 属性和结构的方法
Attribute + Structure:同时考虑节点属性信息和网络结构信息。这里我们选择AANE, SNE, Planetoid-T,TriDNR, SEANO作为baseline模型。
最后我们还给出
ANRL的几个变体:ANRL-WAN:使用Weighted Averate Neighbor来构造目标邻域。ANRL-EMN:使用Elementwise Media Neighbor来构造目标邻域。ANRL-OWN:采用传统的自编码器来重建节点自己,而不是重建目标邻域。
- 仅属性的方法
模型配置:
对于
baseline模型,我们使用原始作者发布的实现版本,并且baseline模型的参数已经调整为最优。在
Fraud Detection数据集中,我们选择将embedding维度设置为对于
LINE模型,我们将一阶representation和二阶representation拼接起来作为最终representation。对于
ANRL,我们选择随机游走序列长度为80、每个节点开始的随机游走序列数量为10、负采样比例为5、窗口大小为10。另外,
ANRL左路输出(包括了编码器和解码器)的层数和尺寸如下图所示,而右路输出仅使用单层神经网络。
链接预测任务:我们通过链接预测任务来评估各种算法学到的
embedding的链接预测能力。我们随机移除图中
50%的链接,然后在移除后的图上训练节点embedding。一旦获得了节点embedding,我们将被移除的链接作为正样本,然后随机选择相同数量的、并不存在的链接作为负样本,从而构造测试集。我们在测试集上评估embedding的链接预测能力,具体做法是:根据余弦相似度对正样本和负样本进行排序。我们采用AUC来评估排序的质量,较高的AUC表示更好的性能。在三个无标签的数据集(
Facebook,UNC,UniID)上进行链接预测任务的效果如下图所示。结论:ANRL在所有数据集上都显著超越了baseline。由于
DeepWalk,node2vec,LINE,SDNE仅利用网络结构信息,因此当网络极为稀疏时(如UniID数据集),它们的性能相对较差。有趣的是,在这一组四个模型中,
node2vec取得了最好的结果。主要是因为node2vec可以通过有偏的随机游走探索各种网络结构信息。与之前的研究结果一致:我们观察到结合节点属性和网络结构信息可以提高链接预测性能,这反映了属性信息的价值。
其中,
AANE,TriDNR仅利用一阶网络结构信息,它们无法捕获足够的信息来进行链接预测。而该组其余算法通过在网络上执行随机游走从而捕获更高阶的网络邻近信息从而获得更好的性能。ARNL同时利用了节点属性信息(通过邻域增强自编码器和属性感知SkipGram模型)、全局结构信息(通过属性感知SkipGram模型)、局部结构信息(通过邻域增强自编码器)。我们认为性能提升的主要原因之一是ANRL同时考虑了局部结构信息和全局结构信息。
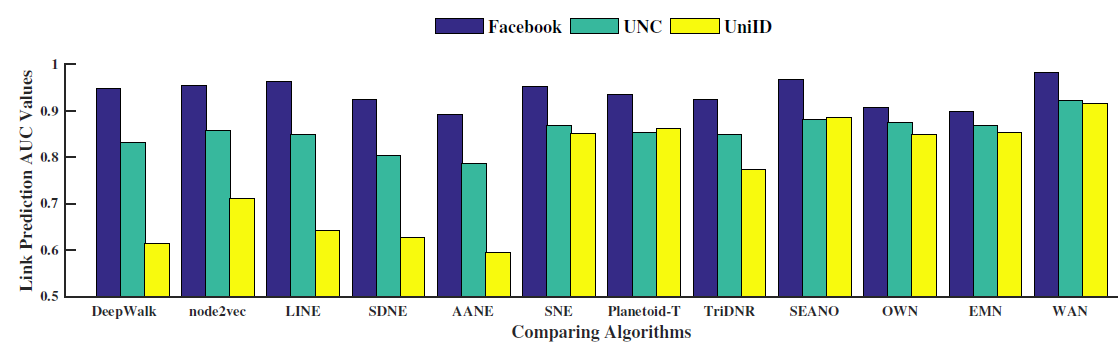
节点分类:我们通过分类预测任务来评估各种算法学到的
embedding的分类预测能力。我们从每个类别中随机选择
20个样本,并将它们作为标记数据(剩余所有节点在训练embedding过程中label信息不可用)来训练半监督baseline。在学到节点embedding之后,我们随机选择30%的节点来训练SVM分类器,剩余节点作为测试集用于评估性能。我们重复该过程10次,并报告测试集上的平均Macro-F1和平均Micro-F1。实验结果如下。结论:ANRL-WAN在所有数据集中超越了所有baseline方法,其它基于属性和结构的方法紧随其后,然后是基于结构的方法。这证明了属性信息的价值,对节点属性进行适当的建模可以带来更好的representation,并显著提高性能。attribute-only方法优于大多数structure-only方法。因为和节点属性相比,单纯的网络结构为分类任务提供的信息非常有限。另外,我们发现自编码器比
SVM稍差,这表明降维的过程中可能会丢失一部分有用的信息。SEANO通过在representation learning阶段聚合邻域的属性信息,超越了其它几种最新的Attribute + Structure方法。AANE在该组的表现不佳,原因是AANE涉及到亲和矩阵affinity matrix的分解操作。由于我们通常不知道每对节点之间的相似性,因此需要根据特定的相似性度量进行计算。这大大降低了AANE的性能。ANRL-WAN和ANRL-EMN的性能优于ANRL-OWN以及大多数其它baseline方法。ANRL-WAN明显优于ANRL-OWN,这证明了我们提出的邻域增强自编码器的有效性。此外,我们的属性感知SkipGram模块和邻域增强自编码器模块使得潜在representation更加平滑和鲁棒,这对于很多任务而言也是很重要的。
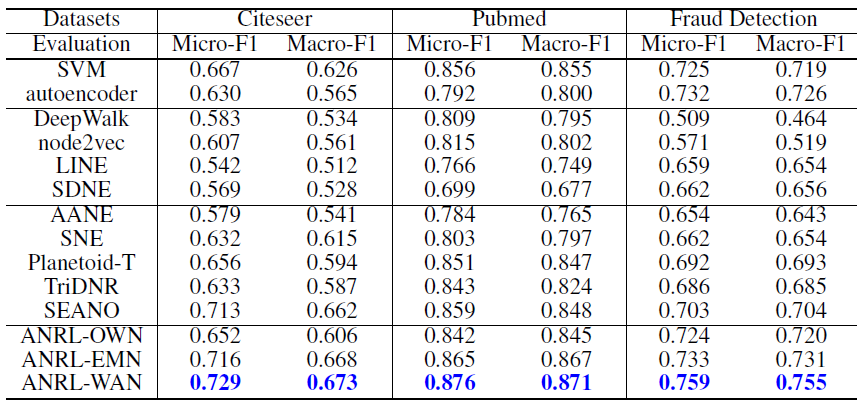
二十四、DANE[2018]
网络在现实世界中无处不在,例如社交网络、学术引用网络、通信网络。在各种网络中,属性网络
attributed network近年来备受关注。与仅有拓扑结构可用的普通网络plain network不同,属性网络的节点拥有丰富的属性信息,并有利于网络分析。例如,在学术引用网络中,不同文章之间的引用构成了一个网络,其中每个节点都是一篇文章,每个节点都有关于文章主题的、大量的文本信息。另一个例子是社交网络,用户之间可以相互联系,并且每个用户节点都有个性化的用户画像属性信息。此外,社会科学表明:节点的属性可以反映和影响其社区结构。因此,研究属性网络是必要且重要的。network embedding作为分析网络的基本工具,最近在数据挖掘和机器学习社区引起了极大的关注。network embedding在保持邻近性的同时为每个节点学习低维representation。然后,下游任务(如节点分类、链接预测、网络可视化)可以从学到的低维representation中获益。近年来,人们已经提出了各种network embedding方法,如DeepWalk, Node2Vec, LINE。然而,大多数现有的方法主要关注普通网络,忽略了节点的有用属性。例如,在Facebook或Twitter等社交网络中,每个用户都与其它用户连接,从而构成一个网络。大多数现有的方法在学习node representation时仅关注连接。但是每个节点的属性也可以提供有用的信息。一个很好的例子是用户画像。一名年轻用户可能与另一名年轻用户具有更多的相似性,而与年长用户不太相似。因此,在学习node representation时结合节点属性很重要。另外,网络的拓扑结构和节点属性是高度非线性的。因此,捕获高度非线性的特性从而发现底层模式
underlying pattern非常重要。然后,就可以在学到的node representation中更好地保留邻近性。然而,大多数现有的方法仅采用浅层模型,未能捕获到高度非线性的特性。此外,由于复杂的拓扑结构和节点属性,很难捕获这种高度非线性的特性。因此,捕获属性网络embedding的高度非线性特性是一项挑战。为解决上述问题,论文
《Deep Attributed Network Embedding》提出了一种用于属性网络的、新颖的deep attributed network embedding: DANE方法。具体而言,论文提出了一个深度模型来同时捕获网络拓扑结构和节点属性中底层的高度非线性。同时,所提出的模型可以迫使学到的node representation保持原始网络中的一阶邻近性和高阶邻近性。此外,为了从网络的拓扑结构和节点属性中学习一致consistent的和互补complementary的representation,论文提出了一种同时结合这两种信息的新策略。另外,为了获得鲁棒的node representation,论文提出了一种有效的 “最负采样” (most negative sampling)策略来使得损失函数更鲁棒。最后,论文进行了大量的实验来验证所提出方法的有效性。相关工作:
普通网络
embedding:network embedding可以追溯到graph embedding问题,如Laplacian Eigenmaps、LPP。这些方法在保持局部流形结构local manifold structure的同时学习数据embedding。然而,这些方法不适用于大型网络embedding,因为它们涉及耗时的eigen-decomposition操作,其时间复杂度为最近,随着大型网络的发展,很多
network embedding纷纷出现。例如:DeepWalk采用截断的随机游走和SkipGram来学习node representation。该方法基于以下观察:随机游走中节点的分布与自然语言中的单词分布很相似。LINE提出在学习节点representation时保持一阶邻近性和二阶邻近性。GraRep在LINE的基础上进一步提出保持高阶邻近性。Node2Vec提出通过一个有偏biased的随机游走来得到灵活的邻域概念。
然而,所有这些方法都仅利用了拓扑结构,而忽略了节点的有用属性。
属性网络
embedding:近年来,属性网络embedding引起了广泛的关注。人们已经为属性网络提出了各种各样的模型。TADW提出了一种inductive的矩阵分解方法来结合网络拓扑结构和节点属性。然而,它本质上是一个线性模型,对于复杂的属性网络而言是不够的。AANE和LANE采用图拉普拉斯graph Laplacian技术从网络拓扑结构和节点属性中学习联合embedding。《Semi-supervised classification with graph convolutional networks》提出了一种用于属性网络的图卷积神经网络模型。但是,这个模型仅是一种半监督方法,无法处理无监督的情况。《Tri-party deep network representation》提出将DeepWalk与神经网络结合起来用于network representation。尽管如此,DeepWalk部分仍然是一个浅层模型。- 最近,人们提出了两种无监督的深度属性网络
embedding方法:《Variational graph auto-encoders》、《Inductive representation learning on large graphs》。但是它们仅能隐式地探索拓扑结构。
因此,有必要以更有效的方式探索深度属性网络
embedding方法。
24.1 模型
24.1.1 基本概念
令
一阶邻近性定义:给定一个网络
first-order proximity为一阶邻近性表示:如果两个节点之间存在链接则它们是相似的,否则它们是不相似的。因此,可以将一阶邻近性视为局部邻近性
local proximity。高阶邻近性定义:给定一个网络
proximity matrix。
高阶邻近性刻画了节点之间的邻域相似性。具体来讲:如果两个节点共享相同的邻域则它们是相似的,否则是不相似的。因此,高阶邻近性
high-order proximity可以视为全局邻近性。语义邻近性定义:给定一个网络
semantic proximity为:属性网络
representation learning任务的目标是学习一个映射函数
24.1.2 DANE
属性网络
embedding面临三大挑战:- 高度非线性:网络拓扑结构和节点属性的底层结构都是高度非线性的,这种高度非线性很难捕获。
- 邻近性保持:属性网络的邻近性取决于网络拓扑结构和节点属性,如何挖掘和保持邻近性关系是一个难点。
- 信息的一致性
consistent和互补性complementary:网络拓扑结构和节点属性这两种信息源为每个节点提供了不同的视角,二者是是一致的(都能刻画节点之间的关系)、互补的(包含对方没有的信息)。因此,学到的节点embedding同时编码这两种信息的一致性、互补性非常重要。
为了解决这三个挑战,我们开发了一种新颖的
deep attributed network embedding: DANE方法。DANE利用深度神经网络分别捕获网络结构的非线性、节点属性的非线性来解决这些问题,整体架构如下。DANE有两个分支:- 第一个分支捕获高度非线性的网络结构,从而将输入
- 第二个分支捕获高度非线性的节点属性,从而将输入
这两路分支都采用深度非线性网络组成,从而捕获数据中的非线性关系。
模型的算法复杂度为
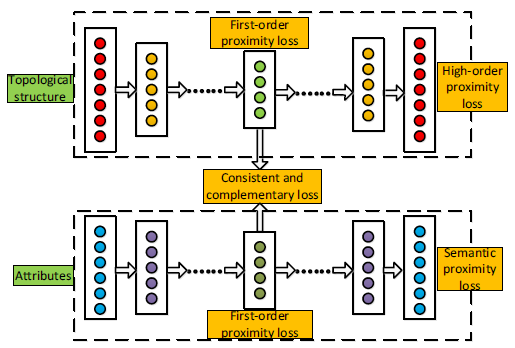
高度非线性:为捕获数据中的高度非线性,
DANE中的每一路分支都是一个自编码器。自编码器是用于feature learning的强大无监督深度模型。基本的自编码器包含三层,分别为输入层、隐层、输出层:其中:
hidden representation,自编码器的目标是最小化重构误差:
其中
为捕获网络拓扑结构和节点属性中的高度非线性,
DANE使用了其中编码器的第
embedding:在
DANE中:- 第一路分支的输入是高阶邻近矩阵
embedding记作 - 第二路分支的输入是节点属性矩阵
embedding记作
- 第一路分支的输入是高阶邻近矩阵
邻近性保持:属性网络中存在三种类型的邻近性,语义邻近性
semantic proximity、高阶邻近性high-order proximity,、一阶邻近性first-order proximity。为保持语义邻近性,我们最小化编码器输入
原因在
《Semantic hashing》中披露。具体而言,重建损失可以强迫神经网络平滑地捕获数据流形,从而可以保持样本之间的邻近性。因此,通过最小化重建损失,我们的方法可以保持节点属性中的语义邻近性。为了保持高阶邻近性,我们最小化编码器输入
具体而言,高阶邻近性
representation也将彼此相似。一阶邻近性捕获了局部结构,因此我们也需要捕获一阶邻近性。根据一阶邻近性的定义,如果两个节点之间存在边则它们是相似的。为保持这种邻近性,我们最大化对数似然:
注意,我们需要同时保留网络拓扑结构的一阶邻近性和节点属性的一阶邻近性,以便我们可以从这两种不同来源的信息中间取得一致的结果。
对于网络拓扑结构,节点
类似地,对于节点属性,节点
因此我们定义以下目标函数从而来同时保持网络拓扑结构的一阶邻近性和节点属性的一阶邻近性:
一致性、互补性的
embedding:网络拓扑结构和节点属性是同一个网络的两种不同模态的信息,因此我们应该确保从它们中学到的embedding是一致consistent的,即一致性。另一方面,这两种信息描述了同一个节点的不同方面,提供了互补的信息,因此学到的emedding应该是互补complementary的,即互补性。融合两种形式的
embeddingembedding。这种方式可以使得两种模式的embedding之间信息互补,但是无法确保它们之间是一致的。一致性指的是:
另一种融合的方式是:强制
DANE的两个分支采用共享的最高编码层,即embedding之间是一致的,但是丢失了大量的互补信息。因此,对于属性网络embedding,如何将网络拓扑结构和节点属性结合在一起是一个具有挑战性的问题。为了得到一致的、互补的
embedding,我们提出最大化以下似然估计:其中:
因此我们定义损失函数:
通过最小化该损失函数,我们可以强制
- 当它们来自于同一个节点时,尽可能地一致。但是它们又不完全相同,因此可以提供互补的信息。
- 当它们来自于不同节点时,尽可能推开。
但是上述损失函数的第二项过于严格。例如,如果两个节点
embedding推开。因此我们放松条件为:即:
- 当节点
- 当
为了保持节点之间的邻近性(三种类型的邻近性),并学习一致和互补的
embedding,DANE共同优化了目标函数:通过最小化该目标函数,我们获得了
representation,从而可以从网络拓扑结构和节点属性中保留一致、互补的信息。理论上可以利用超参数来平衡不同损失函数的重要性:
24.1.3 最负采样策略
考虑损失函数
实际应用中,很多链接由于各种原因未能观测到,所以邻接矩阵
embedding效果会较差。具体而言,假设当前节点为
因此参数
由于更新过程中
embedding效果越来越差。为缓解该问题,我们提出一个最负采样策略来获得更加鲁棒的
embedding。具体而言,在每次迭代过程中,我们首先计算然后对每个节点
most negative的负样本:然后基于这个最负样本,我们设置目标函数为:
采用这种最负采样策略,我们尽可能不违反潜在的相似节点,因此结果更加鲁棒。
“最负”样本本质上是最可能的“负样本”,这等价于为负样本赋予不同的置信度。
最负采样策略依赖于相似度矩阵
因此,最负采样策略并没有增加太大的额外开销。
24.3 实验
数据集:
- 论文引用数据集:我们采用
Cora, Citeseer, PubMed三个论文引用数据集,边代表论文之间的引用链接,节点的属性为论文的Bag-Of-Word表示。 Wiki数据集:维基百科数据集,边代表网页中的超链接,节点的属性为网页内容的Bag-Of-Word表示。
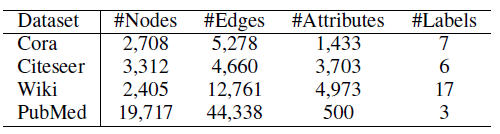
- 论文引用数据集:我们采用
Baseline方法:为评估DANE的性能,我们将它与其它几种baseline方法进行比较,包括4种普通网络的embedding方法、5种属性网络embedding方法。- 普通网络
embedding方法:DeepWalk,Node2vec,GraRep,LINE。 - 属性网络
embedding方法:TADW,ANE, 图自编码器Graph Auto-Encoder: GAE,变分图自编码器VGAE,SAGE。
- 普通网络
参数配置:
对于
DeepWalk, Node2Vec,我们将窗口大小设为10、随机游走序列长度为80、每个节点开始的随机游走序列数量为10。对于
GraRep,我们设定最大转移步长为5(即从一个节点最多经过5步转移到其它节点)。对于
LINE,我们将一阶embedding和二阶embedding拼接起来作为最终embedding。所有方法的
embedding维度为200(LINE的最终embedding维度为200 + 200 = 400)。对于所有其它
baseline方法,超参数配置都参考各自的原始论文。对于
DANE,为获得高阶邻近性矩阵Deep Walk获取随机游走序列,然后使用大小为10的滑动窗口来构造高阶邻近性矩阵对于
DANE,我们使用LeakyReLU作为激活函数。DANE在四个数据集上采用不同的体系结构,如下表所示。对于每个数据集,第一行对应于网络拓扑结构的体系结构,第二行对应于节点属性的体系结构。这里我们仅给出编码器的体系结构,解码器的体系结构为编码器结构的翻转。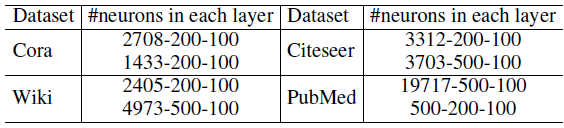
节点分类任务:我们首先使用不同的模型在数据集上通过无监督训练节点的
embedding,然后对学到的节点embedding进行节点分类任务。我们使用
{10%,30%,50%}的节点作为训练集,剩余节点作为测试集。对于随机选择的训练集,我们使用五折交叉验证来训练分类器,然后在测试集中评估分类性能,评估指标为Micro-F1和Macro-F1。不同
embedding方法的分类性能如下表所示,结论:- 与普通网络
embedding方法相比,DANE取得显著提升。 - 与属性网络
embedding方法相比,DANE大多数都效果更好。
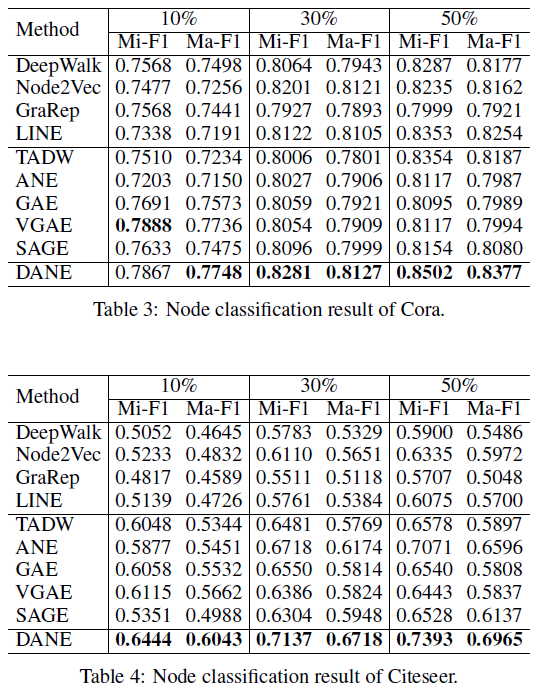
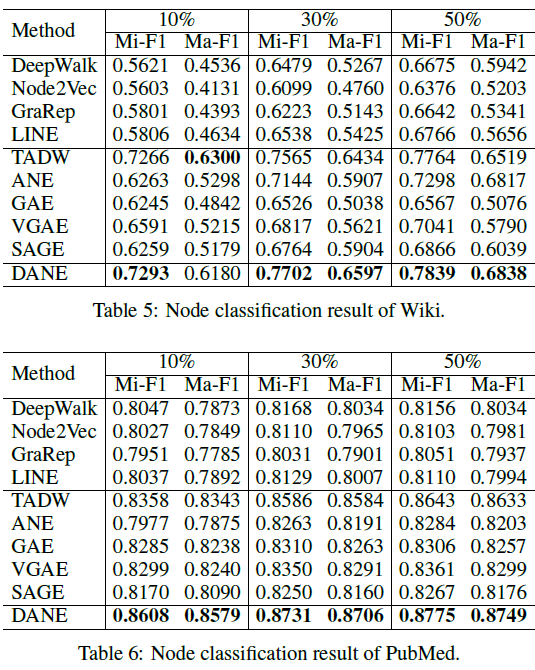
- 与普通网络
节点聚类任务:为展示
DANE在无监督任务上的性能,我们对学到的节点embedding进行聚类。这里我们采用k-means聚类方法,并使用聚类准确率(利用标签信息来评估)作为评估指标。评估结果如下。结论:大多数情况下,DANE具有更好的聚类效果。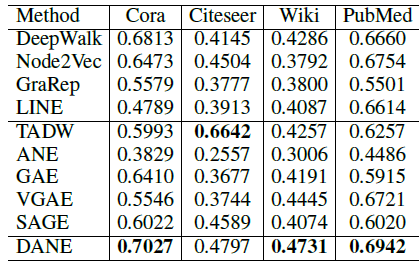
网络可视化:为进一步展示
DANE的效果,我们使用t-SNE可视化节点的embedding。我们仅给出Cora数据集的三种代表性baseline的结果。可以看到,和其它方法相比,DANE可以实现更紧凑、间隔更好的类簇。因此,我们的方法可以在有监督任务和无监督任务上实现更好的性能。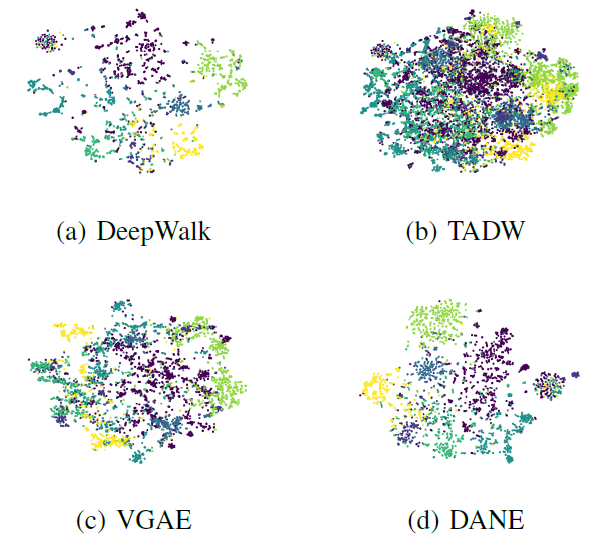
为评估采样策略的效果,我们将最负采样策略和其它两种替代方法进行比较:
第一种为随机采样策略
DANE-RS,此时负样本为随机采样得到。第二种为重要性采样策略
DANE-IS,此时负样本采样概率为:其中
直观而言,这种策略使得不相似的节点被采样为负样本的概率更大。
我们分别使用这两种采样策略来学习节点的
embedding,然后在Cora数据集上进行节点分类。结果如下所示。结论:DANE-RS性能最差,因为它无法区分不同的负样本。DANE-IS效果更好,但是比最负采样策略更差。因为最负采样策略始终可以找到最负的样本。
二十五、HERec[2018]
近年来,帮助用户从大量资源中发现感兴趣
item的推荐系统,已经在各种在线服务中发挥着越来越重要的作用。传统的推荐方法(如矩阵分解)主要旨在学习一个有效的预测函数来刻画user-item交互记录(即,user-item评分矩阵)。随着web服务的快速发展,各种辅助数据(即,辅助信息side information)在推荐系统中变得可用。尽管辅助数据可能包含对推荐有用的信息,但在推荐系统中很难建模和利用这些异质的、复杂的信息。此外,开发一种相对通用的方法来对不同系统或平台中的这些不同的数据进行建模更具挑战性。作为一个有前途的方向,人们提出了异质信息网络
heterogeneous information network: HIN来作为一种强大的信息建模方法。异质信息网络由多种类型的节点和链接组成,并在建模数据异质性方面具有灵活性,因此已在推荐系统中用于刻画丰富的辅助数据。如下图所示,我们展示了一个以HIN刻画的电影推荐的例子。我们可以看到:HIN包含由不同类型的关系链接的多种类型的实体。在HIN-based的representation下,推荐问题可被认为是HIN上的相似性搜索similarity search任务。这种推荐setting称为HIN-based的推荐,并在文献中受到了广泛关注。大多数现有的HIN-based推荐方法的基本思想是:利用path-based的、user-item之间的语义相关性semantic relatedness(如metapath-based相似性)而不是HIN,从而进行推荐。path-based相似性无法充分挖掘用户和item的潜在结构特征。
尽管
HIN-based方法在一定程度上实现了性能提升,但这些使用metapath-based相似性的方法存在两个主要问题。首先,
metapath-based相似性依赖于显式的路径可达path reachability,当路径稀疏或存在噪音时,推荐可能不可靠。HIN中的某些链接很可能是偶然形成的,它们没有表达有意义的语义。其次,
metapath-based相似性主要刻画在HIN上定义的语义关系,可能无法直接应用于推荐系统。在某些情况下,派生的path-based相似性可能对推荐系统没有显式的影响。现有方法主要学习线性加权机制来结合path-based相似性或潜在因子,无法学习HIN信息的、复杂的映射机制mapping mechanism进行推荐。metapath-based相似性,不一定意味着推荐有效性,即二者之间存在gap。
这两个问题本质上反映了
HIN-based推荐的两个基本问题,即HIN-based有效信息的提取extraction和利用exploitation。对于第一个问题,由于数据的异质性,开发一种方法来有效提取和表达
HIN的有用信息具有挑战性。与以前使用metapath-based相似性的研究不同,论文《Heterogeneous Information Network Embedding for Recommendation》的思想是:学习有效的异质网络representation,从而表达HIN重要的结构特征和属性。遵循DeepWalk和node2vec,论文用低维向量(即embedding)来刻画HIN中的节点。论文不想依赖显式的路径链接,而是希望使用潜在向量来编码HIN中的有用信息。与metapath-based相似性相比,学到的embedding具有更紧凑的形式,更易于使用和集成。此外,network embedding方法本身更能抵抗稀疏的、噪音的数据。然而,现有的大多数network embedding方法侧重于仅由单个类型的节点和链接组成的同质网络homogeneous network,无法直接处理由多种类型的节点和链接组成的异质网络heterogeneous network。因此,论文提出了一种新的异质网络embedding方法。考虑到metapath所反映的异质特性以及丰富的语义,所提出的方法首先使用由metapath派生的随机游走策略来生成节点序列。对于每个metapath,论文通过最大化根据给定metapath采样的节点序列中相邻节点的共现概率co-occurrence probability来学习节点的unique embedding representation。论文融合了节点关于不同metapath的多个embedding,从而作为HIN embedding的输出。在从
HIN获得embedding之后,论文研究如何从推荐系统中集成和利用这些信息。论文并未假设学到的embedding自然地适用于推荐系统。相反,论文提出并探索了三种融合函数fusion function,从而将一个节点的多个embedding集成到单个representation中来进行推荐。这三种融合函数包括:简单的线性融合、个性化的线性融合、个性化的非线性融合。这些融合函数提供了灵活的方法将HIN embedding变换为有用的推荐信息。特别地,论文强调个性化和非线性是该论文setting中信息变换information transformation需要考虑的两个关键点。最后,论文通过集成了fused HIN embedding来扩展经典的矩阵分解框架。预测模型prediction model和融合函数fusion function针对评分预测rating prediction任务而联合地优化。通过将上述两部分集成在一起,论文提出了一种新颖的、
HIN embedding based的推荐方法,称作HERec。HERec首先使用所提出的HIN embedding方法提取有用的、HIN-based的信息,然后使用所提取的信息利用扩展的矩阵分解模型进行推荐。下图展示了所提出方法的总体说明。对三个真实世界数据集的广泛实验证明了所提出方法的有效性。论文还验证了HERec缓解冷启动问题的能力,并检查了metapath对性能的影响。
总而言之,论文的主要贡献如下:
- 论文提出了一种由
metapath派生的异质网络embedding方法,从而揭示异质信息网络的语义信息和结构信息。此外,论文提出了一种通用的embedding融合方法,用于将基于不同metapath的不同embedding集成为单个representation。 - 论文提出了一种新颖的异质信息网络
embedding推荐模型,称作HERec。HERec可以有效地集成HIN中的各种embedding信息,从而提高推荐性能。此外,论文设计了一组三个灵活的融合函数fusioin function,从而有效地将HIN embedding变换为有用的推荐信息。 - 对三个真实世界的数据集的广泛实验验证了所提出模型的有效性。此外,论文还展示了所提出的模型对冷启动预测问题的能力,并揭示了来自
HIN的、变换后的embedding信息可以提高推荐性能。
相关工作:在这里,我们将从推荐系统、异质信息网络、
network embedding三个方面回顾相关的工作。推荐系统:在推荐系统的文献中,早期的工作主要采用协同过滤
collaborative filtering: CF方法来利用历史交互进行推荐。具体而言,矩阵分解matrix factorization: MF方法在许多application中展示了它的效果和效率。MF将user-item评分矩阵分解为两个低秩的user-specific矩阵和item-specific矩阵,然后利用分解后的矩阵做进一步的预测。由于
CF方法通常存在冷启动问题,许多工作尝试利用额外的信息来提高推荐性能。例如:《Recommender systems with social regularization》将社交关系集成到矩阵分解中用于推荐。《Ratings meet reviews, a combined approach to recommend》同时考虑了评分信息和评论信息,并提出了一个统一的模型来结合conten-based过滤和协同过滤,从而用于评分预测任务。《Exploiting geographical influence for collaborative point-of-interest recommendation》将用户偏好、社交影响力、地理影响力纳入推荐,并提出了统一的POI推荐框架。- 最近,
《Low-rank linear cold-start recommendation from social data》解释了三种流行的冷启动模型的缺点,并进一步提出了一种learning-based方法来解决冷启动问题,从而通过随机SVD来利用社交数据。
许多工作开始利用深度模型(例如卷积神经网络、自编码器)来利用文本信息、图像信息、以及网络结构信息来获得更好的推荐。此外,还有一些典型的框架聚焦于结合辅助信息进行推荐。
《Svdfeature: a toolkit for feature-based collaborative filtering》提出了一个典型的SVDFeature框架来有效地解决feature-based矩阵分解。《Factorization machines》提出了因子分解机factorization machine: FM,这是一种结合特征工程通用性generality的通用方法。
异质信息网络:作为一个新兴方向,异质信息网络可以自然地对推荐系统中的复杂对象及其丰富的关系进行建模,其中对象具有不同的类型、对象之间的链接代表不同的关系。人们已经提出了几种
path-based相似性度量来评估异质信息网络中对象的相似性。因此,一些研究人员开始意识到HIN-based推荐的重要性。《Incorporating heterogeneous information for personalized tag recommendation in social tagging systems》提出了OptRank方法,该方法通过利用社交标签系统social tagging system中包含的异质信息来缓解冷启动问题。此外,人们将
metapath的概念引入混合推荐系统hybrid recommender system。《Collaborative filtering with entity similarity regularization in heterogeneous information networks》利用metapath-based相似性作为矩阵分解框架中的正则化项。《Personalized entity recommendation: A heterogeneous information network approach》利用异质信息网络中不同类型的实体关系,提出了一种用于隐式反馈数据集的个性化推荐框架。《Hete-cf: Social-based collaborative filtering recommendation using heterogeneous relations》提出了一种使用异质关系的、基于协同过滤的社交推荐方法。- 最近,
《Semantic path based personalized recommendation on weighted heterogeneous information networks》提出了加权异质信息网络的概念,设计了一种metapath-based的协同过滤模型,灵活地集成异质信息从而进行个性化推荐。 - 在
《Integrating heterogeneous information via flexible regularization framework for recommendation》、《Recommendation in heterogeneous information network via dual similarity regularization》、《Dual similarity regularization for recommendation》中,用户相似性和item相似性都通过不同语义metapath下的、path-based相似性度量来评估,并提出了一种基于对偶正则化框架dual regularization framework的矩阵分解来进行评分预测。
大多数
HIN-based方法依赖于path-based相似性,这可能无法充分挖掘HIN上的用户潜在特征和item潜在特征从而进行推荐。network embedding:另一方面,network embedding在结构特征提取方面显示出它的潜力,并已成功应用于许多数据挖掘任务,如分类、聚类、推荐。Deepwalk结合了截断的随机游走和SkipGram来学习network representation。Node2Vec是一种基于有偏biased的随机游走过程的、更灵活的network embedding框架。- 此外,
LINE和SDNE刻画了二阶邻近性以及邻域关系。 GraRep模型可以捕获高阶邻近性用于学习network representation。
除了仅从网络拓扑结构中学习
network embedding之外,还有许多其他工作利用节点内容信息、以及其它可用的图信息graph information来学习鲁棒的representation。不幸的是,大多数network embedding方法都聚焦于同质网络,因此它们无法直接应用于异质网络。最近,一些工作试图通过
embedding方法分析异质网络。具体而言:《Heterogeneous network embedding via deep architectures》设计了一个深度embedding模型来捕获网络中异质数据之间的复杂交互。《Embedding of embedding (eoe): Joint embedding for coupled heterogeneous networks》提出了一种EOE方法来编码耦合异质网络的intra-network edges和inter-network edges。《metapath2vec: Scalable representation learning for heterogeneous networks》通过metapath定义节点的邻域,并通过带负采样的SkipGram来学习异质embedding。
尽管这些方法可以学习各种异质网络中的
network embedding,但它们的node representation和edge representation对于推荐而言可能不是最优的。因为这些
representation是基于无监督学到的,没有推荐任务的监督信息。
据我们所知,这是首次尝试采用
network embedding方法从异质信息网络中提取有用信息,并利用这些信息进行评分预测。该方法利用HIN的灵活性对复杂的异质上下文信息进行建模,同时借用network embedding的能力来学习有效的信息representation。最终的评分预测组件进一步集成了变换机制transformation mechanism,从而利用来自network embedding所学到的信息。
25.1 模型
25.1.1 基本概念
异质信息网络
heterogeneous information network: HIN定义:一个异质信息网络记作每个节点关联一个节点类型
异质信息网络的复杂性驱使我们提供
meta level的描述(如schema-level),以便更好地了解网络中节点类型和链接类型。因此,我们提出了网络模式network schema的概念,从而描述网络的meta结构。网络模式
network schema的定义: 定义网络模式为meta模板。如电影推荐的案例中:我们有多种类型的节点,包括用户
U、电影M、导演D,因此U-U)、用户对电影评分关系U-M、导演和电影的拍摄关系(D-M),因此网络模式
如下图所示,这是我们实验的三个数据集对应的网络模式。由于我们的任务重点关注用户和
item,因此用户和item类型用大的圆圈表示,其它类型用小圆圈表示。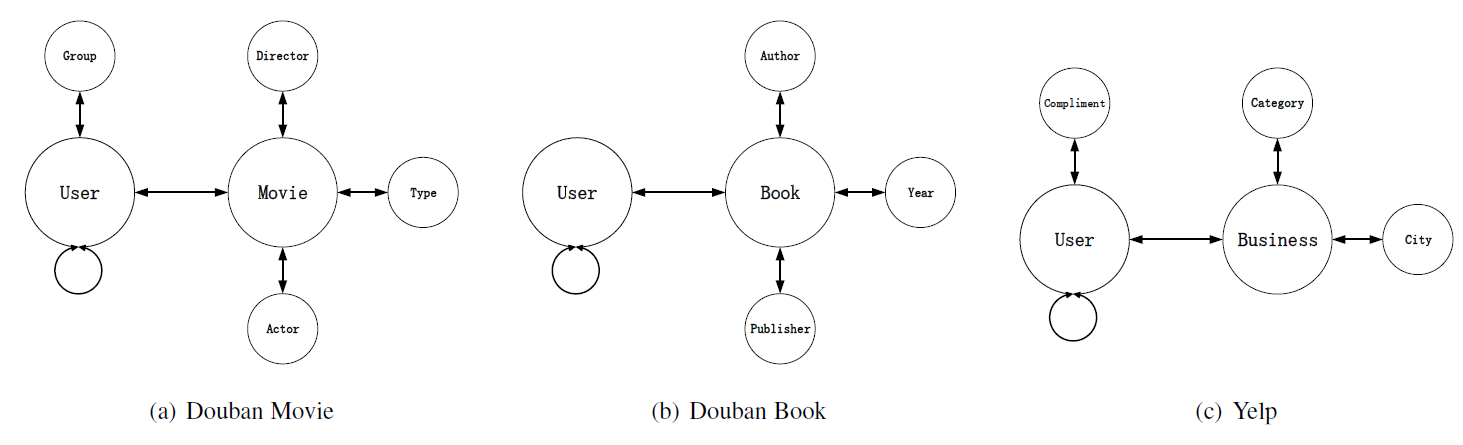
在
HIN中,两个节点可以通过不同的语义路径semantic path来链接,称作元路径metapath。metapath是定义在网络模式元路径
metapath定义:定义metapath简称
其中:
meta-path以电影推荐为例,两个节点之间可以通过多种
metapath相连,如:U-U、U-M-U、U-M-D-M-U。不同的metapath通常表示不同的语义。如:U-U:表示用户之间的好友关系。U-M-U:表示两个用户看过同一部电影。U-M-D-M-D:表示两个用户看过同一个导演的不同电影。
下表给出了实验中使用的
metapath信息。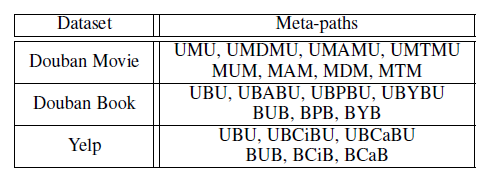
最近,
HIN已经成为建模各种复杂交互系统的主流方法。特别地,它已被用于描述复杂的、异质的推荐setting的推荐系统中。HIN based推荐的定义:在推荐系统中,各种类型的信息可以通过HINHIN中,我们仅关注两类节点(User节点、Item节点),以及它们之间的关系(即评分)。定义用户节点集合为item节点集合为itemHIN推荐的目标是:给定HINitem目前在
HIN based推荐上已有一些工作,但是它们大多数主要利用metapath-based相似性来增强推荐能力。我们提出一种新的HIN-based推荐方法HERec,该方法能够有效地利用HIN的信息。HERec主要分为两个部分:- 一种新的
HIN embedding方法,从而从HIN中学习user embedding和item embedding。 - 一组灵活的融合函数
fusion function,从而将学到的embedding集成到经典的矩阵分解框架中。
整体框架如下图所示:首先构建
HIN(图(a)),然后是HIN embedding(图(b)) 和Recomendation(图(c))。- 一种新的
25.1.2 HIN embedding
受
network embedding最新进展的启发,我们采用representation learning方法来提取和表达HIN的有用信息从而进行推荐。给定HINrepresentationemebdding向量高度概括了节点metapath-based相似性相比,学到的embedding更容易在后续过程中使用和集成。然而,现有的大多数
network embedding方法主要集中在同质图上,因此无法有效针对异质图进行建模。例如,开创性的工作deepwalk使用随机游走来生成节点序列,它无法区分不同类型的节点和边。因此,需要一种更通用的方式来遍历HIN并生成有意义的节点序列。metapath-based随机游走:要生成有意义的节点序列,关键是设计一种有效的游走策略,该策略能够捕获HIN中反映的复杂语义。在HIN的文献中,metapath是刻画HIN语义模式semantic pattern的重要概念。因此,我们建议使用metapath-based的随机游走方法来生成节点序列,然后利用SkipGram模型从节点序列中学到节点的embedding。给定异质网络
meta path其中:
随机游走序列将遵循
metapath以电影推荐为例:
给定一个
metapathUVM,从Tom开始我们可以生成两条随机游走序列:xxxxxxxxxxTom(User) --> The Terminator(Movie) --> Mary(User)Tom(User) --> Avater(Movie) --> bob(User) --> The Terminator(Movie) --> Mary(User)给定一个
metapathUMDMU,从Tom开始我们能够生成另外一条随机游走序列:xxxxxxxxxxTom(User) --> The Terminator(Movie) --> Cameron(Director) --> Avater(Movie) --> Mary(User)
可以直观看到这些
metapath生成的随机游走序列对应了不同的语义关系semantic relation。类型约束和过滤:我们的目标是提升推荐性能,因此重点是学习
user embedding和item embedding,其它类型节点(如Director)的embedding我们不太感兴趣。因此,我们仅选择从user类型节点或item类型节点开始的metapath。注意,这里进行的 ”开始节点“ 的过滤,仅保留 ”开始节点“ 类型为
user或item的序列。使用上述方法生成了随机游走序列之后,序列中可能包含不同类型的节点。我们进一步删除了序列中和起始节点类型不同的其它节点,最终得到的随机游走序列仅包含和起始类型相同的节点。
这时,随机游走序列要么都是
user节点、要么都是item节点。这种对随机游走序列的节点进行类型过滤有两个好处:
- 尽管随机游走序列是通过具有异质类型的
metapath构建的,但是最终的representation是在同质的邻域中学习的。同质邻域学习使得我们将相同类型的节点嵌入到相同的空间中。相对而言,将不同类型的节点嵌入到相同的空间的难度更大。 - 当窗口的长度固定时,类型过滤后的序列中,一个节点可以利用到更多的同质邻居。这些同质邻居可能比其它类型的异质邻居相关性更大。
如下图所示,为学习
user embedding和item embedding,我们仅考虑起始类型为用户类型或者item类型的metapath。我们可以衍生出一些metapath,如UMU, UMDMU,MUM等。以metapathUMU为例,我们可以根据概率一旦序列被生成,我们进一步删除与起始节点类型不同的其它节点,这样的到了一个同质的节点序列:
在这条同质节点序列中,节点之间的关系实际上是通过异质邻居节点(被删除的)构建的。
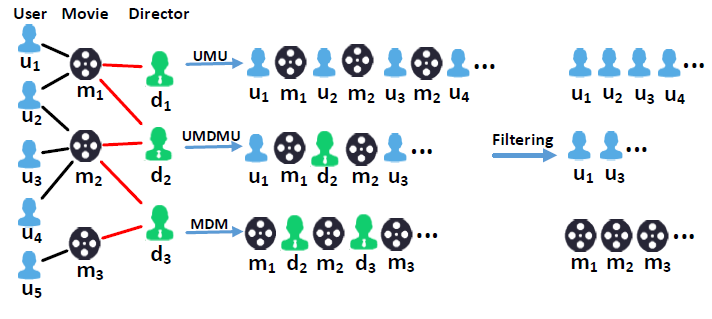
- 尽管随机游走序列是通过具有异质类型的
优化目标:现在我们聚焦于如何学习同质节点序列的
node embedding。给定过滤后的随机游走同质节点序列,对于每个节点node2vec一致,我们最大化以下目标函数:其中:
metapath下随机游走序列的同质邻域。
我们采用随机梯度下降
SGD来优化目标函数,从而学到embedding映射函数metapath-based的随机游走,并进行节点过滤来选择同质的邻居。这里是无监督的、同质的一阶邻近性保持。
单个
metapath的节点embedding算法:输入:
HINmetapath- 目标节点类型
embedding维度- 随机游走序列长度
- 上下文窗口大小
- 每个节点开始的随机游走序列数量
输出:每个节点
metapath下的embedding算法步骤:
通过标准正态分布来随机初始化
初始化随机游走路径集合为空:
对于每个类型为
- 初始化空路径:
- 从节点
path中。当path中节点数量为 - 将
path添加到paths中。
- 初始化空路径:
在
paths上,基于参数SkipGram的embedding学习算法。返回学到的节点
embedding
embedding融合Embedding Fusion:HIN embedding提供了从HIN抽取有效信息的通用方法。假设metapath的集合为metapath都能学到HIN的embedding,其中metapath的数量。换句话将,对于每个节点embeddingmetapath下学到的embedding转化为更合适的形式,从而有助于提高推荐性能。已有的研究通常采用线性加权的方式来融合
HIN中提取的信息,这可能无法获得对推荐任务有效的信息表示。因此我们建议采用更通用的函数item融合各metapath下学到的node embedding:其中
itemembedding。当前阶段我们并未指定
25.1.3 矩阵分解扩展
前面我们研究了如何从
HIN中提取和表达有效信息来进行推荐。通过HIN embedding,我们能够获得用户embeddingitem embeddingembedding进行推荐。评分预测器
Rating Predictor:我们基于经典的矩阵分解MF模型来构建predictor。在MF模型中,每个用户itemitem由于我们已经获得了用户
itemembedding,因此可以考虑将潜在因子向量和embedding向量集成在一起。集成后的predictor为:其中:
itemHIN embedding向量。itemitemHIN embedding配对的潜在因子向量。
对于该公式,我们需要注意两点:
首先,
embedding适用于MF。其次,我们并没有直接使用
HIN embedding刻画的是相同类型节点之间的相关性。因此,我们使用一组新的潜在因子这里很巧妙,它刻画了这样的事实:节点的相关性不同于推荐有效性。
这等价于:拼接
predictor的贡献。
融合函数
Fusion Function:前面我们假设融合函数HIN学到的节点embedding转化为对推荐系统有用的形式。这里我们仅讨论融合用户embedding的情况,item embedding融合也是类似的。我们建议使用三种类型的融合函数来融合
embedding:简单的线性融合。我们假设每个用户对每个
metapath都相同的偏好,因此我们为每个metapath分配统一的权重(即均值)。此外,我们还将embedding线性映射到目标空间:其中
metapath集合,metapath的线性映射参数。个性化线性融合。简单的线性融合无法建模用户对
metapath的个性化偏好,因此我们进一步为每个用户metapath上的偏好其中
metapath上的偏好权重。个性化非线性融合。线性融合在建模复杂数据关系时的表达能力有限,因此我们使用非线性函数来增强表达能力:
其中
sigmoid函数。尽管这里使用了两个非线性变换,也可以灵活地推广到多个非线性层,如多层感知机。
模型学习:我们将融合函数整合到矩阵分解框架中,联合学习融合函数和矩阵分解模型的参数。我们的目标函数为:
其中:
item融合的参数。
我们采用随机梯度下降
SGD来优化目标函数。这里一个难点是:梯度如何在矩阵分解模型、
HIN embedding模型之间传播。论文给出的方案是两阶段模型:- 首先通过
HIN embedding预训练,得到HIN embedding作为矩阵分解模型的输入特征。 - 然后通过随机梯度下降算法优化矩阵分解模型(包括融合函数)。
更好的做法是共同训练
HIN embedding模型和矩阵分解模型,使得监督信息能够输入给HIN embedding模型。此时,HIN embedding模型捕获矩阵分解模型的残差,从而构成boosting范式。HERec训练算法:输入:
HIN- 用户的
metapath集合item的metapath集合 embedding维度- 潜在因子向量的维度
- 随机游走序列长度
- 上下文窗口大小
- 每个节点开始的随机游走序列数量
user-item评分集合- 学习率
- 超参数
- 正则化系数
输出:
- 用户的潜在因子
item的潜在因子 - 和
HIN embedding配对的潜在因子 - 融合函数的参数
- 用户的潜在因子
算法步骤:
根据
HIN embedding算法获取每个用户metapathembedding,得到用户embedding根据
HIN embedding算法获取每个item metapathembedding,得到item embedding基于标准的正态分布来初始化参数
迭代直到收敛,迭代步骤为:
- 随机从
- 基于经典的矩阵分解模型来更新参数
- 对
- 计算梯度
- 对
- 计算梯度
- 随机从
返回
算法复杂度:
HERec包含两个阶段:HIN embedding阶段:这一阶段主要通过metapath based embedding算法得到每个节点在不同metapath下的embedding。由于DeepWalk的算法复杂度为embedding维度。因此每个metapath下,学习user embedding的算法复杂度为item embedding的算法复杂度为HIN embedding阶段的算法复杂度为值得注意的是:可以很容易地并行训练
HIN embedding。我们将使用多线程模式来实现HIN embedding,从而提高训练效率。矩阵分解
MF阶段:这一阶段通过联合学习融合函数和矩阵分解模型,从而得到最终的node representation。对于每个三元组
HERec对于的大型数据集的训练非常高效。另外,
SGD随机梯度下降在实践中表现很好,在我们的数据集中具有很快的收敛速度。
25.2 实验
数据集:
- 豆瓣电影数据集
Douban Movie:包含13367名用户在12677部电影上的1068278个评分。电影评分从1到5分。此外,数据集还包含用户和电影的社交信息和属性信息。 - 豆瓣读书数据集
Douban Book:包含13024名用户在22347本图书上的792026个评分。书籍评分从1到5分。数据集也包含用户和书籍的社交信息和属性信息。 Yelp数据集:包含16239名用户在14282个本地商家上的198397个评分。评分从1到5分。数据集包含用户和商家的社交关系和属性信息。
这三个数据集的详细说明如下。可以看到这三个书籍除了属于不同的领域之外,它们的数据稀疏性也不同:
Yelp数据集非常稀疏,Douban Movie数据集相对稠密。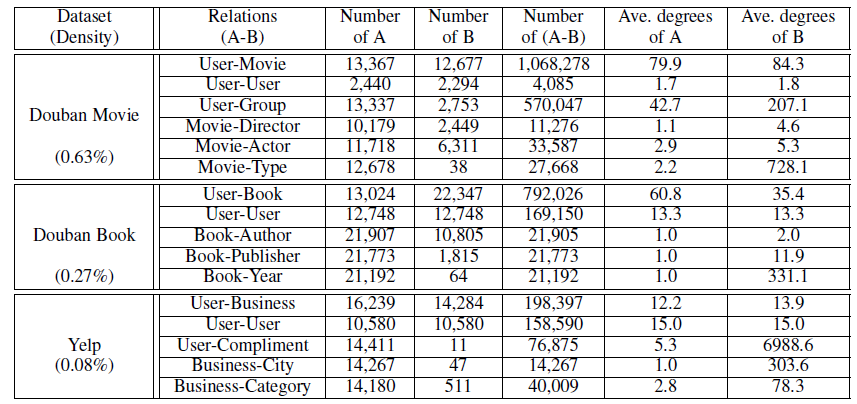
我们也给出这三个数据集用到的
meta-path集合:- 豆瓣电影数据集
评估指标:我们采用
mean absolute error: MAE和root mean square error: RMSE来评估推荐结果的质量。baseline方法:PMF:经典的概率矩阵分解模型,它将评分矩阵显式分解为两个低维矩阵。SoMF:引入社交网络信息的矩阵分解模型。社交关系通过正则化引入并集成到基本的矩阵分解模型中。FM-HIN:上下文感知的分解机模型,它能够利用各种辅助信息。在我们的实验中,我们抽取异质信息作为上下文特征,并将其集成到FM中。HeteMF:一种矩阵分解模型,它利用了HIN上metapath-based相似性。SemRec: 一种加权HIN上的协同过滤方法。它以相同的评分来连接用户和item。它通过加权的metapath以及加权的ensemble方法灵活地集成异质信息。DSR:一种具有双重相似度正则化的矩阵分解方法。该方法同时对用户和相似度较高的item、用户和相似度较低的item同时施加了约束。HERec-dw:HERec的一个变体,它采用了同质网络的DeepWalk而忽略了HIN中节点的异质性。HERec-mp:HERec的一个变体,它结合了metapath2vec ++的HIN embedding。这里它并没有执行随机游走序列的节点过滤,而是对包含异质节点的随机游走序列执行embedding。HERec:我们提出的HIN推荐模型。在有效性实验中,我们采用个性化的非线性融合函数。
我们的
baseline全面覆盖了现有的评分预测方法:PMF, SoMF为经典的MF预估方法;FM-HIN, HeteMF, SemRec, DSR为基于HIN的推荐,它们使用metapath-based相似性,代表了state-of-the-art的、基于的HIN方法。我们提出的方法包含一个
HIN embedding组件,它可以使用任何其它网络embedding方法取代。因此这里比较了两个变体:HERec-dw和HERec-mp。配置:
所有
MF模型的潜在因子维度为baseline配置要么使用原始论文的最佳配置,要么使用10%的验证集来择优。所有基于
HIN的方法都需要指定metapath。我们在下表中给出使用的metapath。我们选择比较短的metapath(最多4个step),因为长的metapath可能会引入语义噪音。基于
HERec的方法的配置为:embedding维度
有效性实验:对每个数据集,我们将原始的评分数据拆分为训练集和测试集。
- 对于豆瓣电影和豆瓣读书数据集,我们选择训练集的拆分比例分别为
{80%, 60%, 40%, 20%}。 - 对于
Yelp数据集,考虑到数据集非常稀疏,因此我们选择训练集的拆分比例为{90%, 80%, 70%, 60%}。
在每种拆分比例下,我们训练每个模型并报告各模型在测试集上评估结果。对每种拆分比例我们随机拆分
10次并评估10次,最终给出每个模型的评估均值。实验结果如下表所示。我们以PMF的结果作为基准,给出了其它方法相对于PMF的提升。结论:
所有
baseline方法中,基于HIN的方法(HeteMF,SemRec, FM-HIN, DSR)的性能优于传统MF方法(PMF,SoMF)。这证明了异质信息的有效性。值得注意的是:
FM-HIN模型在基于HIN的三个baseline中非常有效。一个直观解释是:在我们的数据集中,大多数原始特征是用户属性或item属性,这些属性信息可能包含了有效信息来改善推荐性能。我们的
HERec方法始终优于baseline。和其它HIN based方法相比,HERec采取了更有效的方式来利用HIN从而改进推荐系统。HERec在训练数据稀疏时的效果更为突出。如,在豆瓣图书数据集上使用20%的训练数据时,HERec相对于PMF的提升高达40%。这些结果表明了所提出方法的有效性,尤其是在稀疏数据集中。从
HERec的两个变体HERec-dw和HERec-mp可以看到:HERec-dw的效果要差得多。HERec-dw忽略数据的异质性,并将HIN视为同质网络。这表明异质信息的重要性。HERec-mp没有使用节点类型过滤,而是尝试使用异质序列将所有类型的节点都映射到相同的embedding空间中。相比较而言,HERec进行节点过滤,从而将同质节点映射到相同的embedding空间。虽然
metapath2vec更为通用,但是我们的方法在推荐任务中表现更好。我们的重点是学习user embedding和item embedding,而其它类型的对象仅用作构建同质邻域的桥梁。基于结果(HERec优于HERec-mp),我们认为执行task-specific HIN embedding有利于提高推荐性能。
- 对于豆瓣电影和豆瓣读书数据集,我们选择训练集的拆分比例分别为
不同融合函数:
HERec需要一种融合方法从而将节点的不同metapath下的embedding转换为合适的形式。这里我们讨论不同融合方法的效果。我们将线性融合函数的
HERec变体称作HERec-sl,将个性化线性融合函数的HERec变体称作HERec-pl, 将个性化非线性融合函数的HERec变体称作HERec-pnl。我们给出三个数据集上不同变体的性能比较,如下图所示。- 总体而言,这些变体的性能为:
HERec-pnl > HERec-pl > HERec-sl。 - 这三个变体中,简单的线性融合函数表现最差,因为它忽略了个性化和非线性。事实上,用户确实可能对
metapath有不同的偏好,因此应在metapath based方法中予以考虑。因此个性化融合函数显然可以提高性能。 HERec-pnl相对于HERec-pl的提升相对不大。一个可能的原因是:个性化的组合参数提高了线性模型的容量。尽管如此,通过考虑个性化和非线性变换,HERec-pnl仍然表现最好。
考虑到
HERec-pnl效果最好,因此后续的实验都将采取HERec-pnl。
- 总体而言,这些变体的性能为:
冷启动问题:
HIN有助于改善冷启动问题,因为虽然冷启动预测的评分记录较少,但是可以使用异质的上下文信息。我们以评分数量来衡量冷启动的严重程度。我们将测试集的用户根据他们的评分数量划分为三组:(0,5], (5,15], (15,30]。可以看到,第一组的预测最为困难,因为他们的评分数量最少。这里我们仅选择
HIN based baseline方法,包括SoMF,HeteMF,SemRec,DSR, FM-HIN。我们报告了它们相对于PMF的提升比例。- 总体而言,所有方法都优于
PMF。
- 总体而言,所有方法都优于
HERec在所有baseline方法中表现最好,并且在冷启动问题最严重(评分最稀疏)的组别中提升更大。结果表明:基于
HIN的信息可以有效提高推荐性能,并且HERec利用HIN信息的效果更好。
不同
metapath:为分析metapath数量对模型效果的影响,我们考虑不同的metapath依次添加到HERec中,并检查模型性能变化。可以看到:
- 用户节点开始的
metapath和item节点开始的metapath都有助于提升性能。 - 通常而言,随着更多
metapath的加入,性能通常会得到提高。但是,更多的metapath并不总是能够提升性能,而是略有波动。原因是某些metapath可能包含噪音,或者与现有的metapath存在信息冲突。 - 仅仅加入了几个
metapath,模型很快就实现了相对较好的性能。这证明了之前的发现:少量的高质量metapath就能带来较大性能改进。因此我们只需要选择少量的metapath就可以有效控制模型的复杂度。
- 用户节点开始的
参数敏感性:
HERec有几个关键的超参数。首先,对于基于矩阵分解的方法而言,最重要的超参数是潜在因子的维度
5从5增加到50,然后检查模型性能和
然后我们固定潜在因子数量
precitor中的不同信息。对(1,1)附近。这表明user HIN embedding和item HIM embedding都很重要。总体而言,模型性能随着
HERec对这两个参数不是很敏感。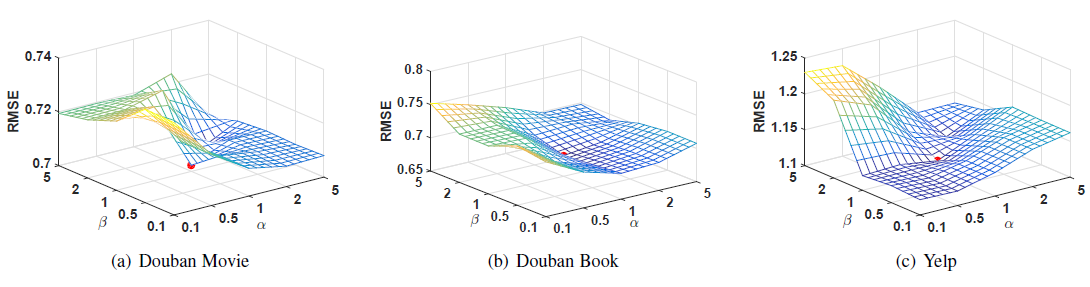
最后我们研究性能随迭代次数的变化。可以看到
HERec的收敛速度较快:对于稠密数据集(如豆瓣电影和豆瓣读书) 大约需要40到60次迭代;对于稀疏数据集(如Yelp),大约需要20次迭代。
二十六、GATNE[2019]
network embedding或network representation learning是一种很有前途的方法,可以将网络中的节点投影到低维连续的空间,同时保持网络结构和固有属性。由于network embedding推动了节点分类、链接预测、社区检测等下游network learning的重大进展,因此它最近引起了人们的极大关注。DeepWalk, LINE, node2vec是将深度学习技术引入网络分析从而学习node embedding的开创性工作。NetMF对不同network embedding算法的等价性equivalence进行了理论分析,而随后的NetSMF通过稀疏化给出了可扩展的解决方案。然而,它们被设计为仅处理具有单一类型节点和边的同质网络homogeneous network。最近,人们针对异质网络提出了
PTE, metapath2vec, HERec。然而,现实世界的网络应用(例如,电商)要复杂得多,不仅包含多种类型的节点和边,还包含一组丰富的属性。由于embedding learning的重要性和挑战性,已有大量工作尝试来研究复杂网络的embedding learning。根据网络拓扑(同质的或异质的)、属性(带属性或不带属性),论文《Representation Learning for Attributed Multiplex Heterogeneous Network》对六种不同类型的网络进行了分类,并在下表中总结了它们的相对进展。这六个类别包括:同质网络Homogeneous Network: HON、属性同质网络Attributed Homogeneous Network: AHON、异质网络Heterogeneous Network: HEN、属性异质网络Attributed Heterogeneous Network: AHEN、多重异质网络Multiplex Heterogeneous Network: MHEN、属性多重异质网络Attributed Multiplex Heterogeneous Network: AMHEN。可以看到,人们对AMHEN的研究最少。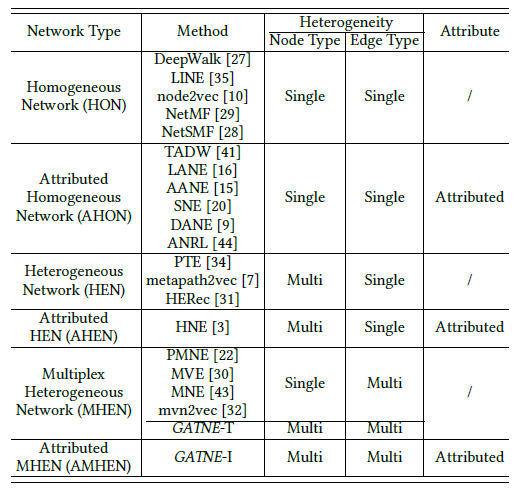
在论文
《Representation Learning for Attributed Multiplex Heterogeneous Network》中,作者专注于AMHEN的embedding learning,其中不同类型的节点可能与多种不同类型的边相连接,而且每个节点可能关联一组不同的属性。这在许多online application中很常见。例如,在论文使用的四个数据集中,Twitter有20.3%、YouTube有21.6%、Amazon有15.1%、Alibaba有16.3%的边具有不止一种类型。例如,在电商系统中,用户可能与item进行多种类型的交互,如点击click、转化conversion、加购物车add-to-cart、收藏add-to-preference。下图说明了这样的一个例子。显然,user和item具有本质上不同的属性,不应该一视同仁。此外,不同类型的user-item交互意味着不同程度的兴趣,应该区别对待。否则,系统无法准确捕获用户的行为模式behavioral pattern和偏好,因此无法满足实际使用的需求。下图中,左侧的用户和属性相关联,用户属性包括性别、年龄、地域;右侧的
item也和属性相关联,item属性包括价格、品牌等。user-item之间的边有四种类型:点击、加购物车、收藏、转化(即购买)。中间的三个子图代表三种建模方式,从上到下依次为HON, MHEN, AMHEN。最右侧给出了在阿里巴巴数据集上不同模型相对于DeepWalk性能的提升。可以看到,GATNE-I相比DeepWalk提升了28.23%。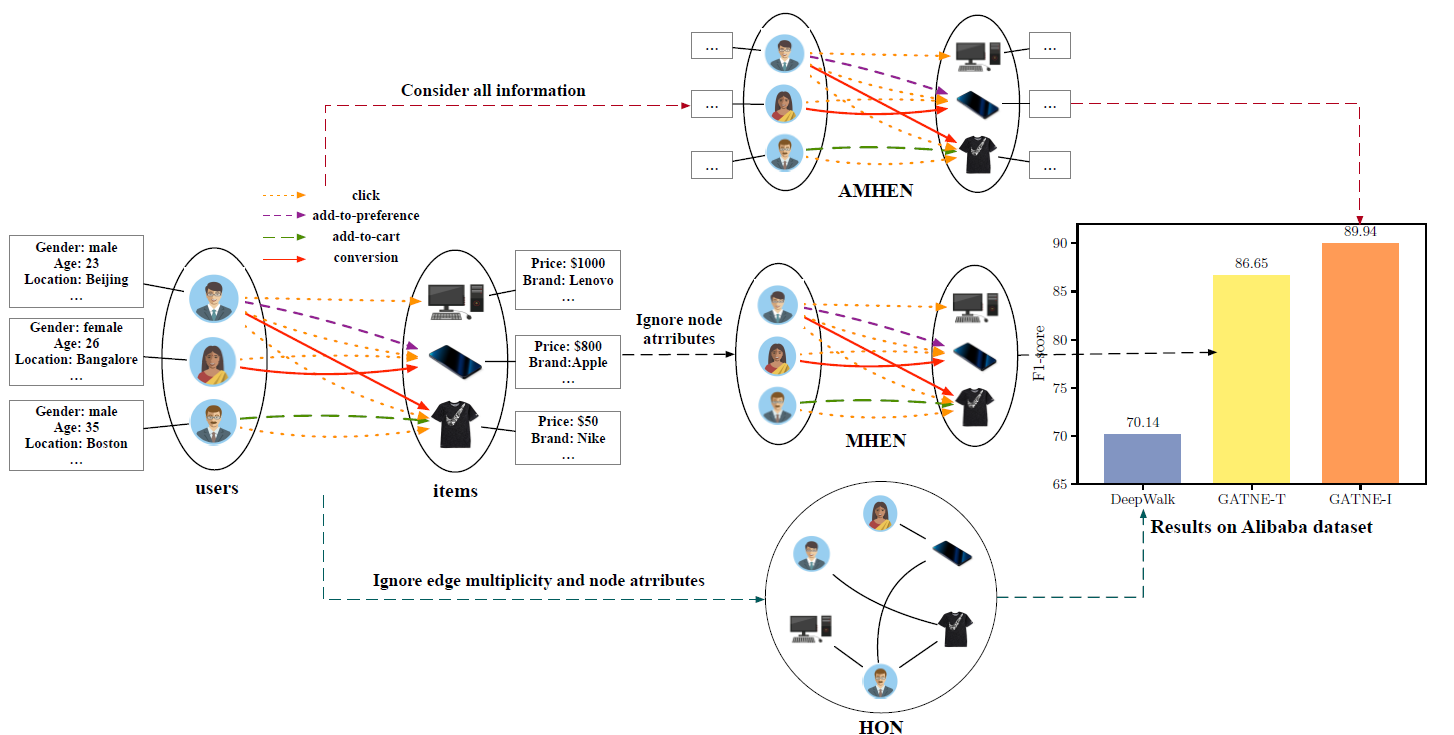
不仅因为异质性
heterogeneity和多重性multiplicity,在实践中处理AMHEN带来了几个独有的挑战:- 多重边
multiplex edge:每对节点pair对之间可以存在多种不同类型的关系,因此结合不同类型关系并学习统一的embedding非常重要。 - 部分观测
partial observation:真实网络的数据实际上只有部分被观测到。如,一个长尾用户可能只与某些商品产生很少的交互。现有的大部分network embedding方法仅关注于transductive场景,因此无法解决长尾或冷启动问题。 - 可扩展性
scalability:真实网络通常具有数十亿个节点、数百亿甚至千亿的边。因此模型的可扩展性非常重要。
为应对上述挑战,论文
《Representation Learning for Attributed Multiplex Heterogeneous Network》提出了一种新颖的方法来捕获丰富的属性信息,并利用来自不同节点类型的多重拓扑结构multiplex topological structure,即通用属性多重异质网络嵌入General Attributed Multiplex HeTerogeneous Network Embedding: GATNE。GATNE的主要特性如下:- 作者正式定义了
attributed multiplex heterogeneous network embedding问题,这是现实世界网络的更通用的representation。 GATNE同时支持attributed multiplex heterogeneous network的transductive embedding learning和inductive embedding learning。论文还给出了理论分析,从而证明所提出的transductive模型比现有模型(如MNE更通用)。- 论文为
GATNE开发了高效且可扩展的学习算法,从而能够有效地处理数亿个节点和数十亿条边。
论文进行了广泛的实验,从而在四种不同类型的数据集(
Amazon, YouTube, Twitter, Alibaba)上评估所提出的模型。实验结果表明:与state-of-the-art方法相比,论文的方法可以实现显著的提升。作者已经在阿里巴巴的分布式系统上部署了所提出的模型,并将该方法应用到了阿里巴巴的推荐引擎中。离线A/B test进一步证实了论文所提出方法的效果和效率。- 多重边
相关工作:这里我们回顾了
network embedding、heterogeneous network embedding、multiplex heterogeneous network embedding、attributed network embedding相关的state-of-the-art方法。Network Embedding:network embedding方面的工作主要包括两类,graph embedding: GE、graph neural network: GNN。GE的代表工作包括:DeepWalk方法通过随机游走在图上生成语料库,然后在语料库上训练SkipGram模型。LINE学习大型网络上的node representation,同时保持一阶邻近性和二阶邻近性。node2vec设计了一个有偏的随机游走程序来有效地探索不同类型的邻域。NetMF是一个统一的矩阵分解框架,用于从理论上理解和改进DeepWalk, LINE。
GNN中的热门工作包括:GCN(《Semi-Supervised Classification with Graph Convolutional Networks》) 使用卷积运算将邻域的feature representation融合到当前节点的feature representation中。GraphSAGE提供了一种将网络结构信息和节点特征相结合的inductive方法。GraphSAGE学习representation函数而不是每个节点的直接embedding,这有助于它可以应用到训练期间unseen的节点。
Heterogeneous Network Embedding:异质网络包含各种类型的节点和/或边。众所周知,由于异质内容和结构的各种组合,这类网络很难挖掘。目前人们在嵌入动态的、异质的大型网络方面所作的努力有限。HNE共同考虑网络中的内容和拓扑结构,将异质网络中的不同对象表示为统一的向量representation。PTE从label信息和不同级别的word co-occurrence信息中构建大型异质文本网络,然后将其嵌入到低维空间中。metapath2vec通过metapath-based随机游走来构建节点的异质邻域,然后利用异质SkipGram模型来执行node embedding。HERec使用metapath-based随机游走策略来生成有意义的节点序列从而学习network embedding。这些embedding首先通过一组融合函数进行变换,然后集成到扩展的矩阵分解模型中。
Multiplex Heterogeneous Network Embedding:现有方法通常研究节点之间具有单一类型邻近关系proximity的网络,它仅捕获网络的单个视图。然而,在现实世界中,节点之间通常存在多种类型的临近关系,产生具有多个视图的网络。PMNE提出了三种将多重网络投影到连续向量空间的方法。MVE使用注意力机制将多视图网络嵌入到单个协同的embedding中。MNE对每个节点使用一个common embedding以及若干个additional embedding,其中每种类型的边对应一个additional embedding。这些embedding由一个统一的network embedding模型来共同学习。mvn2vec探索了通过同时建模preservation和collaboration以分别表示不同视图中边语义edge semantic meaning从而实现更好的embedding结果的可行性。
Attributed Network Embedding:属性网络旨在为网络中的节点寻找低维向量representation,以便在representation中同时保持原始网络拓扑结构和节点属性邻近性。TADW在矩阵分解框架下,将节点的文本特征融入network representation learning中。LANE将label信息平滑地融合到属性网络embedding中,同时保持节点的相关性。AANE能够以分布式方式完成联合学习过程,从而加速属性网络embedding。SNE提出了一个通用框架,通过捕获结构邻近性和属性邻近性来嵌入社交网络。DANE可以捕获高度非线性并保持拓扑结构和节点属性中的各种邻近性。ANRL使用邻域增强自编码器对节点属性信息进行建模,并使用基于属性编码器和属性感知SkipGram模型来捕获网络结构。
26.1 模型
26.1.1 基本概念
给定图
异质网络
Heterogeneous Network定义:一个异质网络heterogeneous,否则是同质的homogeneous。对于异质网络,考虑到节点
属性网络
Attributed Network定义:一个属性网络属性多重异质网络
Attributed Multiplex Heterogeneous Network: AMHEN定义:一个属性多重异质网络AMHEN Embedding问题:给定一个AMHEN网络embedding。即,对每种边类型对节点
embedding,而不是所有视图共享一个embedding。这有两个好处:- 首先,可以通过各个视图的
embedding来聚合得到一个所有视图共享的embedding。 - 其次,各个视图的
embedding保持了各个视图的语义,因此可以用于view-level的任务,例如某个视图下的链接预测。
- 首先,可以通过各个视图的
我们首先在
transductive上下文中提出GATNE框架,对应的模型称作GATNE-T。我们还将GATNE-T与新的流行模型(如MNE)之间的联系进行了讨论。为解决部分观测
partial observation问题,我们进一步将模型扩展到inductive上下文中,并提出了GATNE-I模型。针对这两个模型,我们还提出了有效的优化算法。
26.1.2 GATNE-T
在
transductive环境中,我们将给定节点overall embedding拆分为两个部分,如下图所示:base embedding:节点base embedding在节点的不同边类型之间共享。edge embedding:节点embedding。
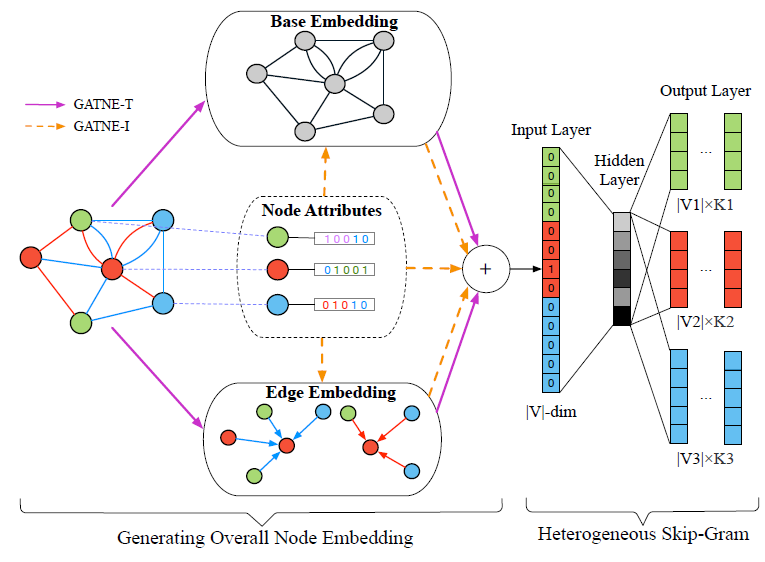
现在考虑
edge embedding。类似于GraphSage,我们假设节点embedding一共有embedding为:其中:
agg为一个聚合函数。类似于GraphSAGE,它可以为均值聚合:也可以为池化聚合,如最大池化:
其中
transductive模型中通过随机初始化。
第
K层embeddingembeddingembedding得到节点embedding矩阵:其中
edge embedding的维度,进一步地,我们使用
self-attention机制来计算加权系数edge embedding:其中:
edge embedding。
注意,这里在每种节点类型上都计算一个
self-attention,而并不是所有节点类型共享同一个self-attention。假设节点
base embedding为embedding为overall embedding为:其中:
edge embedding映射到和base embedding的同一空间。base embedding和edge embedding的重要性。令
另外,这里
embedding训练的目标是什么?要保持什么属性?论文都未提及。根据论文的示意图,猜测是用异质SoftMax保持一阶邻近性。
26.1.2 GATNE vs MNE
这里我们讨论
GATNE-T和MNE的关系。在GATNE-T中,我们使用attention机制来捕获不同边类型之间的影响因子。我们从理论上证明,GATNE-T是MNE的更为泛化的形式,可以提高模型的表达能力。在
MNE模型中,节点overall embedding为:其中
相比之下,
GATNE-T中,节点overall embedding为:其中
定理:对于任意
证明见原始论文。
因此,
GATNE-T的模型空间几乎包含了MNE的模型空间。
26.1.3 GATNE-I
GATNE-T的局限性在于它无法处理未观测数据。实际很多应用中,我们获得的数据只是部分观测的。这里我们将模型扩展到inductive环境中,并提出了GATNE-I。我们将节点
base embedding其中
即,不同类型的节点采用不同类型的映射函数。
注意:不同类型的节点可能具有不同维度的属性
类似地,节点
edge embedding其中
edge embedding,其中进一步地,在
inductive环境下,我们为最终的overall embedding添加了一个额外的属性项:其中
GATNE-T仅使用网络结构信息,而GATNE-I考虑了网络结构信息和节点属性信息。我们采用异质SkipGram算法,它的输出层给出了一组多项式分布,每个分布对应于输入节点如下图所示,这里有三种类型的节点(红色、绿色、蓝色)、两种类型的边(蓝色、橙色)。节点集合
GATNE-T和GATNE-I的区别主要在于base embeddingedge embedding- 在
transductive的GATNE-T中,每个节点的base embeddingedge embeddingGATNE-T无法处理训练期间未曾见过的节点。 - 在
inductive的GATNE-I中,每个节点的base embeddingedge embeddingbase embeddingedge embedding
- 在
26.1.4 模型学习
下面我们讨论如何学习
GATNE-T和GATNE-I。我们使用随机游走来生成节点序列,然后使用SkipGram来学习节点embedding。由于输入网络的每个视图都是异质的,因此我们使用metapath-based随机游走。给定网络在边类型
metapath schemaschema的长度。则在随机游走的第其中
基于
metapath的随机游走策略可以确保不同类型节点之间的语义关系能够适当地融合到SkipGram模型中。假设随机游走在视图
给定节点
其中
和
metapath2vec一样,我们也使用heterogeneous softmax函数,该函数针对节点其中
context embedding向量,overall embedding向量。这里分母仅考虑节点
metapath给出。最后,我们使用异质负采样
heterogeneous negative sampling来近似每对其中:
sigmoid函数,noise distribution。GATNE算法:输入:
- 网络
- 网络
overall embedding维度edge embedding维度- 学习率
- 一组
metapath schema - 负采样系数
- 随机游走序列长度
- 上下文窗口大小
- 平衡系数
- 模型深度
输出:每个节点
overall embedding算法步骤:
初始化模型所有的参数
对于每个边类型
metapath schema生成随机游走序列对每个边类型
迭代直到收敛。迭代步骤为:
节点
pair对在每个边类型上迭代(即- 根据
GATNE-T) 或者GATNE-I) 计算 - 采样
- 更新模型参数:
- 根据
GATNE算法中,基于随机游走算法的时间复杂度为overall embedding维度,空间复杂度为
edge embedding维度。
26.2 实验
这里我们首先介绍四个评估数据集和
baseline算法的细节。我们聚焦于链接预测任务,从而对比我们的方法与其它state-of-the-art方法。然后我们讨论参数敏感性、收敛性、可扩展性。最后我们在阿里巴巴推荐系统上报告了我们方法的离线A/B test结果。数据集:
Amazon Product Dataset:它是来自Amazon的商品评论和商品metadata的数据集。在我们的实验中,我们仅使用商品metadata,包含商品属性以及商品之间的共同浏览co-viewing, 共同购买co-purchasing关系。商品属性包括:价格、销售排名、品牌、类目。数据集的节点类型集合为
category。如果考虑所有商品则规模庞大,因此我们选择“电子”类目的商品进行试验。但是对很多baseline算法来讲,电子类目的商品数量仍然过于庞大,因此我们从整个图中提取了一个连通子图connected subgraph。YouTube Dataset:由15088个用户的各种互动行为组成的多重网络。一共包含5种互动类型,包括: 联系contact,共享好友shared friends,共享的订阅shared subscription, 共享的订阅者shared subscriber,共享的收藏视频shared favorite vieoes。因此在该数据集中,Twitter Dataset:包含2012-07-01到2012-07-07之间与希格斯玻色子Higgs boson的发现相关的推文。它由450000名Twitter用户之间的四种关系组成,包括:转发re-tweet,回复reply,提及mention,好友/关注者friendship/follower。 因此在该数据集中,Alibaba Dataset:包含user和item两种类型的节点,并且user-item之间存在四种交互类型。交互包括:点击click、添加到收藏add-to-preference、加到购物车add-to-cart、以及转化conversion(即购买)。因此,整个数据集太大无法在单台机器上评估不同方法的性能,因此我们在采样后的数据集上评估模型性能。 采样的阿里巴巴数据集称作
Alibaba-S。另外,我们也在阿里巴巴分布式云平台上对完全的数据集进行评估,完整的数据集称作Alibaba。
下表给出了这些数据集的统计信息,其中
n-types和e-types分别表示顶点类型和边类型的数量。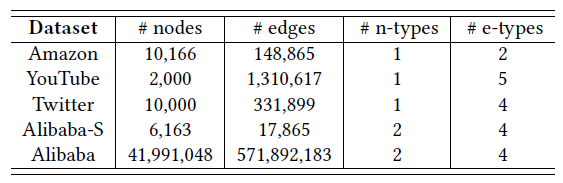
另外,由于单台机器的限制,我们用到的公共数据集是从原始公共数据集中采样的子图。下表给出了原始公共数据集的统计信息。
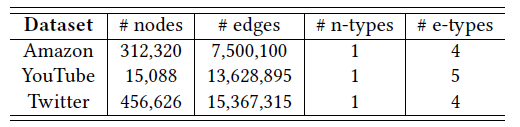
baseline:我们对比了以下几组baseline:Network Embedding Method:包括DeepWalk,LINE,noe2vec。由于这些方法只能处理同质图,因此我们向它们提供具有不同类型边的独立视图,并为每个视图获取node embedding。Heterogeneous Network Embedding Method:使用metapath2vec。当网络只有一种类型的节点时,它退化为DeepWalk。Multiplex Heterogeneous Network Embedding Method:比较的方法包括PMNE,MVE,MNE。我们将
PMNE的三种方法分别表示为PMNE(n),PMNE(r),PMNE(c)。MVE使用collaborated context embedding并将注意力机制应用于view-specific embedding。MNE对每种边类型使用一个comment embedding和一个additional embedding,这些embedding由统一的network embedding共同学习。Attributed Network Embedding Method:我们使用ANRL。ANRL使用邻域增强自编码器对节点属性信息进行建模,并使用基于属性编码器的属性感知SkipGram模型来捕获网络结构。Attributed Multiplex Heterogeneous Network Embedding Method:使用我们提出的GATNE。
另外,由于阿里巴巴数据集超过
4000万顶点、5亿条边,规模太大。考虑其它baseline的scalability,我们仅在该数据集上比较GATNE, DeepWalk, MVE, MNE等模型。对于一些没有节点属性的数据集,我们为它们生成节点特征。
运行环境:我们的运行环境分为两个部分:
- 一个是单台
Linux服务器,其配置为4 Xeon Platinum 8163 CPU @2.50GHz,512G Ram,8 NVIDIA Tesla V100-SXM2-16GB。该服务器用于训练四个较小的数据集。 - 另一个是分布式云平台,包含数千个
worker,每两个worker共享一个NVIDIA Tesla P100 GPU(16GB显存) 。该平台用于训练最大的完整的阿里巴巴数据集。
单机版可以分为三个部分:随机游走、模型训练和模型评估。随机游走部分参考
DeepWalk和metapath2vec的相应部分来实现。模型训练部分参考tensorflow的word2vec教程来实现。模型评估部分使用了scikit-learn中的一些标准评估函数。模型参数通过使用Adam的随机梯度下降进行更新和优化。分布式版根据阿里巴巴分布式云平台的编程规范来实现,以最大化分布式效率。
- 一个是单台
参数配置:
所有方法的
base/overall embedding维度均为edge embedding维度为每个节点开始的随机游走序列数量为
10,随机游走序列长度为10,上下文窗口大小为5,负采样系数为5,用于训练SkipGram模型的迭代数量为100。对于阿里巴巴数据集,
metapath schema设置为U-I-U和I-U-I。其中U表示用户顶点,I表示item顶点。(metapath2vec和GATNE都采用这种schema)DeepWalk:对于小数据集(公开数据集和Alibaba-S数据集),我们使用原作者的Github代码。对于阿里巴巴数据集,我们在阿里云平台上重新实现了DeepWalk。LINE:我们使用原作者的Github代码。我们使用LINE(1st+2nd)作为overall embedding。一阶embedding和二阶embedding大小均为100。样本量设为10亿。node2vec:我们使用原作者的Github代码,其中超参数metapath2vec:作者提供的代码仅适用于特定的数据集,无法推广到其它数据集。我们基于原始C++代码,用python重新开发从而为任意顶点类型的网络重新实现了metapath2vec。对于三个公共数据集,由于节点类型只有一种,因此
metapath2vec退化为DeepWalk。对于阿里巴巴数据集,metapath schema设置为U-I-U和I-U-I。PMNE:我们使用原作者的Github代码,其中PMNE(c)的层级转移概率为0.5。MVE:我们通过email从原作者取到代码。每个视图的embedding维度为200,每个epoch训练样本为1亿,一共训练10个epoch。对于阿里巴巴数据集,我们在阿里云平台上重新实现了该方法。
MNE:我们使用原作者的Github代码。对于阿里巴巴数据集,我们在阿里云平台上重新实现了该方法。我们将
additional embedding维度设为10。ANRL:我们适用来自阿里巴巴的Github代码。由于
YouTube和Twitter数据集没有节点属性,因此我们为它们生成节点属性。具体而言,我们将顶点经过DeepWalk学到的200维embedding视为节点属性。对于
Alibba-S和Amazon数据集,我们使用原始特征作为属性。GATNE:- 最大的
epoch设为50。如果ROC-AUC指标在验证集上有1个训练epoch未能改善,则我们执行早停。 - 对于每个边类型
1。 - 我们使用
tensorflow的Adam优化器,并使用默认配置,学习率设为0.001。 - 对于
A/B test试验,我们设置top N命中率)。 GATNE可以采用不同的聚合函数,如均值聚合或池化聚合都达到了相似的性能。最终我们在这里使用了均值聚合。- 在
GATNE-I中,我们采用
- 最大的
我们通过链接预测任务来比较不同模型的效果。对于每个原始图,我们分别创建了一个验证集和测试集。
- 验证集包含
5%随机选择的postive边、5%随机选择的negative边,它用于超参数选择和早停。 - 测试集包含
10%随机选择的postive边、10%随机选择的negative边,它用于评估模型,并且仅在调优好的超参数下运行一次。我们使用ROC曲线 (ROC-AUC)、PR曲线(PR-AUC)以及F1指标来评估。所有这些指标都在所选择的边类型之间取均值。
我们将剔除这些
postive边剩下的图作为训练集来训练embedding以及分类器。下图给出了三个公共数据集和Alibba-S的试验结果。可以看到:
GATNE在所有数据集上优于各种baseline。由于节点属性比较少,所以
GATNE-T在Amazon数据集上性能优于GATNE-I。而阿里巴巴数据集的节点属性丰富,所以GATNE-I的性能最优。ANRL对于节点属性比较敏感,由于Amazon数据集的节点属性太少,因此其效果相对其它baseline最差。另外,阿里巴巴数据集中
User和Item的节点属性位于不同的空间,因此ANRL在Alibaba-S数据集上效果也很差。在
Youtube和Twitter数据集上,GATNE-I性能类似于GATNE-T,因为这两个数据集的节点属性是Deepwalk得到的顶点embedding,它是通过网络结构来生成的。
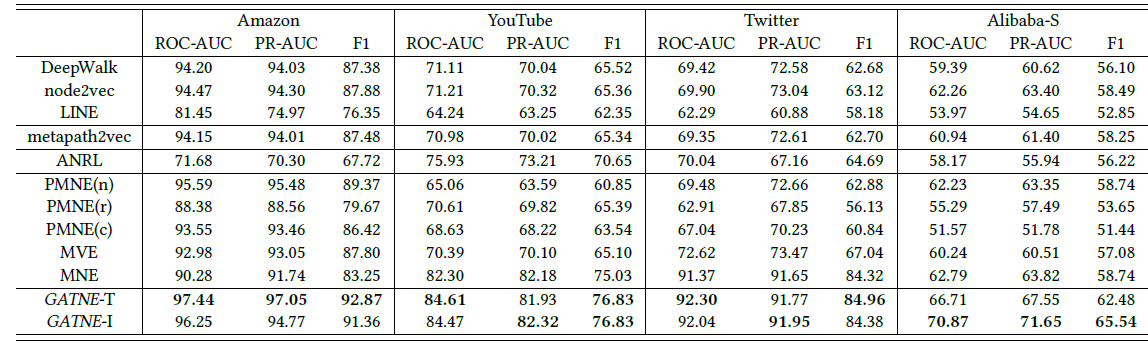
进一步地,我们给出阿里巴巴数据集的实验结果。
GATNE可以很好地扩展到阿里巴巴数据集上,并实现最佳效果。与之前的state-of-the-art算法相比,PR-AUC提高2.18%、ROC-AUC提高5.78%、F1得分提高5.99%。- 在大规模数据集中,
GATNE-I的性能超越了GATNE-T,这表明inductive方法在AMHEN中效果更好。
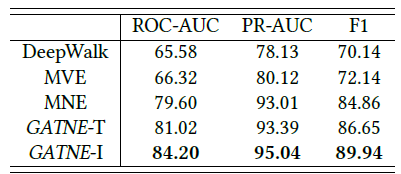
- 验证集包含
收敛性分析:我们在阿里巴巴数据集上分析了
GATNE的收敛性,如下图所示。可以看到:在大规模真实数据集上,GATNE-I的收敛速度更快、性能更好。
可扩展性分析:我们研究了
GATNE的scalability。如下图所示,我们给出了阿里巴巴数据集中,不同worker数量的加速比。可以看到:GATNE在分布式平台上具有很好的可扩展性,当增加worker数量时训练时间显著降低。
超参数敏感性:我们研究了不同超参数的敏感性,包括
overall embedding维度edge embedding维度GATNE的性能。可以看到:GATNE的性能在较大范围的d或s时相对稳定,当d或s太大或太小时性能会有降低。
我们在阿里云分布式平台上为我们的推荐系统部署了
GATNE-I。训练数据集包含1亿用户和1000万item, 每天有100亿次交互。我们用该模型为用户和商品生成embedding向量。对于每个用户,我们使用kNN和欧式距离来计算用户最有可能点击的top N item。我们的目标是最大化top N的命中率。推荐的
topN列表中包含用户点击的商品,则认为是命中。命中的推荐列表占所有推荐列表的比例,则为命中率。在
A/B test框架下,我们对GATNE-I, MNE, DeepWalk进行离线测试。结果表明:与GATNE-I的命中率比MNE提高3.25%、比DeepWalk提高24.26%。这一对比没有多大实际意义,因为阿里巴巴在线推荐框架不太可能是
MNE或者DeepWalk这种简单的模型。目前已有的一些公共数据集,并没有公开的训练集、验证集、测试集拆分方式。这导致在同一个数据集上进行随机拆分,最终评估的结果会不同。因此,我们无法使用先前论文中的结果。研究人员必须重新实现并运行所有的
baseline模型,从而减少了他们对于改进自己提出的模型的关注。这里我们呼吁所有的研究人员提供标准化的数据集,其中包含标准化的训练集、验证集、测试集拆分。研究人员可以在标准环境下评估他们的方法,并直接比较各论文的结果。这也有助于提高研究的可重复性
reproducibility。除了网络的异质性之外,网络的动态性对于网络表示学习也至关重要。捕获网络动态信息的方法有三种:
- 可以将动态信息添加到节点属性中。如我们可以用
LSTM之类的方法来捕获用户的动态行为。 - 动态信息(如每次交互的时间戳)可以视为边的属性。
- 可以考虑代表网络动态演化的几个快照。
我们将动态属性的多重异质网络的
representation learning作为未来的工作。- 可以将动态信息添加到节点属性中。如我们可以用
二十七、MNE[2018]
network embedding(也称作graph embedding)使用稠密向量来表达节点,并且已被很好地研究了多年。最近,受循环神经网络RNN的启发,人们基于图上的随机游走和随机梯度下降优化从而对network embedding进行了重新研究和开发,并可以应用于非常大的图。节点的embedding向量可用于编码网络的一些拓扑结构,然后可以作为下游模型的特征。network embedding已被证明有助于网络分析任务,包括链接预测、节点分类、社区检测。有些网络呈现多重性
multiplexity的特点,尤其是对于社交网络。在社交网络分析中,多重性是指两个人之间的多方面关系。如果我们把这个思想推广到各种网络,多重网络multiplex network是指网络中包含多种类型的关系,其中每一种关系都可以构成网络的一个子网(也称作一层layer或子图)。以社交网络为例。在Facebook等社交网络中,用户之间存在不同类型的交互,如好友关系、转发文章关系、聊天关系、转账关系。每种关系都将在所有用户之间创建一个子网。如果我们将所有关系视为一个统一的整体,那么我们将得到一个巨大的多重网络。虽然网络的每个子网仅能代表用户之间的一种交互,但是为了更好地理解多重网络整体,最好把来自这些子网的不同类型的信息集成在一起,而不牺牲各种类型信息的特有属性。考虑到网络可能很大的事实,在论文
《Scalable Multiplex Network Embedding》中,作者提出了一种可扩展的多重网络embedding模型,从而有效地将多类型关系multi-type relation的信息存储和学习到统一的embedding空间中。- 对于每个节点,论文提出一个高维的
common embedding向量,该向量在多重网络的所有子网中共享。论文通过common embedding向量在网络的不同子网之间建立桥梁。 - 对于每个节点,为了在不同子网上以较低内存需求的方式学习各子网的独有属性,论文还为每种类型的关系提出了一个低维的
additional embedding。
论文的贡献仅仅是这一个点,总体而言没有什么大的创新点,不够深入,一篇“水文”。
为了将这些不同维度(有高维的、有低维的)的
embedding对齐,论文为网络的每个子网引入了一个全局变换矩阵global transformation matrix。遵从DeepWalk,论文使用随机梯度下降来优化所提出的模型。由于全局变换矩阵的更新次数要比节点向量的更新次数多得多,因此论文添加了一个额外的正则化项来约束全局变换矩阵的范数。总而言之,本文贡献如下:
- 论文正式定义了多重网络
embedding问题,以及处理网络的多重属性multiplexity property。 - 论文提出了一种可扩展的多重网络
embedding模型,该模型将来自多类型关系multi-type relation的信息表达到统一的embedding空间中。 - 论文在链接预测、节点分类这两个网络分析任务上评估了所提出的
embedding算法。和当前的state-of-the-art模型相比,所提出的模型实现了更好或相当的性能,并且内存占用更少。
- 对于每个节点,论文提出一个高维的
相关工作:
多重网络分析:传统上,在社会科学中,多重性
multiplexity被用于描述用户之间社交关系的多个方面。多重性的思想可以推广到各种网络。在数据挖掘社区中,人们有时也使用 “多关系网络”multi-relational network这个术语来表达社交网络中的多类型关系multi-type relation,并验证在社交网络中考虑多类型关系可以帮助进行社区挖掘或链接预测等数据挖掘任务。此外,在生物信息学社区中,人们已经表明通过集成多个网络,可以改善node representation从而帮助基因功能分析。如今,多重网络上的图挖掘方法主要针对特定任务。对于链接预测,可以将传统方法应用于多重网络,而无需考虑边的类型信息。对于社区检测,
《A degree centrality in multi-layered social network》提出了跨子网的中心度centrality度量从而捕获多重网络中节点的中心度。除此之外,人们还提出了多子网局部聚类系数multilayered local clustering coefficient: MLCC和跨子网聚类系数cross-layer clustering coefficient: CLCC来描述多重网络中节点的聚类系数。在本文中,我们从
network embedding的角度提出了多重网络分析的通用解决方案。network embedding:network embedding(也称作graph embedding)已被很好地研究了很多年。network embedding也与流形学习manifold learning有关,而流形学习通常应用于高维数据的降维。network embedding侧重于为真实网络生成节点的向量representation,从而促进对网络的进一步分析。传统的network embedding方法通常涉及耗时的计算,例如用于分析图的谱属性spectral property的特征值分解eigenvalue decomposition。然而,由于真实世界的网络规模可能很大,这类方法算法复杂度太高从而不可行。最近,受到循环神经网络
RNN发展的启发,尤其是高效的word embedding方法,人们已经提出了许多network embedding方法来处理大型社交网络。例如,DeepWalk提出在网络上执行随机游走从而生成节点序列,然后对这些序列执行SkipGram算法从而生成节点embedding。在DeepWalk之上,Node2Vec增加了两个超参数来控制随机游走过程从而实现有偏biased的随机游走。其它的一些embedding模型专注于网络中特定类型的结构。例如,LINE尝试使用embedding来逼近网络的一阶邻近性和二阶邻近性。上述所有模型都已被证明对单一网络
single network的分析有用,但它们都没有考虑多重性。最近,《Principled multilayer network embedding》提出了三种方法来从多重网络中学习一个整体embedding。与该方法不同,我们提出一个高维的common embedding、以及每种类型的关系一个低维的additional embedding。最近的一项工作《Multi-layered network embedding》本质上是一个异质的信息网络,因为在该论文中,不同的子网有不同类型的节点。
27.1 模型
给定多重网络
multiplex network对于每个节点
common embedding向量common embedding向量作为跨不同关系类型传输信息的桥梁。为捕获不同关系类型的特点,对于每个节点我们在每个子网
additional embedding向量为了将
additional embedding空间映射到common embedding空间,我们引入变换矩阵embedding向量为:其中
这里变换矩阵是节点无关的,它在所有节点
对于多重网络
SkipGram算法学习node embedding。对于
SkipGram的目标函数为:我们定义
其中:
embedding。context embedding,它在所有子网中共享。不仅
common embedding向量context embedding此外,假设两个节点在不同子网中共享相同的邻域节点,那么这两个节点之间是相似的,即使它们位于不同的子网。这确保了相似性的跨子网的一致性。
为加速训练,我们采用负采样技术:
其中:
logistic函数。我们根据随机梯度下降
SGD来优化该目标函数。我们初始化所有的由于子网
MNE算法:输入:
- 多重网络
common embedding维度additional embedding维度- 学习率
- 随机游走序列长度
- 从每个顶点开始的随机游走序列数量
- 上下文窗口大小
- 负采样比例
- 转换矩阵的正则化参数
- 关系类型的全局重要性
- 多重网络
输出:每个节点
embedding算法步骤:
初始化
对每子网
生成随机游走序列集合
对于每个节点
对于节点
随机采样
计算
对正样本
如果
最终输出每个节点
embedding
我们的算法基于随机游走策略。假设有
27.2 实验
数据集:
我们选择了
Manlio De Domenico项目公开的四个多重网络,选择标准是:节点数量不能太少,且边不能太稀疏。这意味着每种关系类型的每个节点至少具有一条边。Vickers:对澳大利亚维多利亚州一所学校初一年级29名学生问卷调查得到的数据。问卷调查分三个问题,每个问题创建了网络中的一种关系。CKM:由伊利诺伊州、布卢明顿市、昆西市、加勒斯堡市四个镇的医师收集的数据。医师们提出了三个问题,每个问题都创建了网络中的一种关系。LAZEGA:多重社交网络,包含企业中的三种关系(工友co-work、好友、咨询advice)。C.ELEGANS:神经元多重网络,神经元不同的突触连接创建了网络中的不同关系。连接类型包括:ElectrJ、MonoSyn、PolySyn。
另外,由于上述多重网络的规模相对较小,为了测试我们模型的可扩展性和效果,我们还选择了两个真实的大型社交网络。
Twitter:包含一周内关于“希格斯玻色子发现”的所有推文。我们选择最大的两种关系(跟帖following和转发retweet)来构建多重网络。Private:一个在线社交网络。在该网络中,用户可以建立好友关系并将自己的文章发送给好友。我们随机选择40000名用户,这些用户都有毕业大学的信息,然后我们记录了这些用户一个月内所有文章的转发活动。我们在文章内容上应用了主题模型
topic model,然后将文章根据主题来分类。最终我们得到了16个主题,每个主题都创建了多重关系网络中的一种关系。如果再加上好友关系,则一共有17种关系。
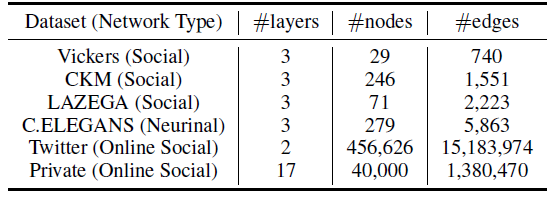
baseline方法:DeepWalk:通过随机游走策略构建节点序列,然后在节点序列上应用SkipGram算法来生成node embedding。LINE:保持图的一阶邻近度和二阶邻近度从而得到node embedding。Node2vec:基于有偏的随机游走得到节点序列,然后在节点序列上应用SkipGram算法来生成node embedding。PMNE:提出三种不同的模型将多重网络聚合,并为每个节点点生成一个overall embedding。这三种模型分别为PMNE(n)、PMNE(r)、PMNE(c)。
除了
embedding based之外,我们还比较了structure based方法,包括:Common neighbor:CN:每对节点pair对,它们的公共邻居节点越多,则存在链接的可能性越大。Jaccard Coefficient:JC:每对节点pair对,使用它们的邻居总数对公共邻居数量进行归一化。Adamic/Adar:AA:类似于JC,但是AA给那些邻居更少的节点更大的权重。
评估指标:
- 对于链接预测任务,我们使用
ROC-AUC作为评估指标。 - 对于节点分类任务,我们对学到的
embedding采用accuracy。
- 对于链接预测任务,我们使用
参数配置:
所有
embedding方法的embedding维度为200。由于
LINE有一阶embedding和二阶embedding,因此它们的维度都是100,最终拼接后的维度是200。对于所有基于随机游走的方法,我们将上下文窗口设为
10,负采样比例为5。对于
node2vec,我们根据实验使用最佳超参数,即对于
PMNE模型,我们使用原始论文给出的超参数。对于
MNE,我们将additional embedding的维度设为
链接预测任务:对每对节点我们计算其
embedding的余弦相似度,相似度越大则它们之间越可能存在链接。- 对于简单网络模型(如
DeepWalk,LINE,Node2Vec),我们将为每个子网训练一个单独的embedding,并使用该embedding来预估对应关系上的链接。这意味着这些embedding没有来自网络其它类型的信息。 - 对于多重网络模型,我们得到的
node embedding可以融合网络其它类型的信息。
我们在网络的每个子网上计算
AUC,并取所有子网的AUC均值作为最终结果。我们使用五折交叉验证,并报告了结果的均值和标准差。注意:
Twitter和Private数据集中,following关系和friendship关系是其它关系类型的基础。如,我们只能将文章发送给好友。因此在选择子网负边时,我们需要确保选择的是满足基础关系(如following/friendship关系)的负边。并且我们不会评估基础网络(即following/friendship网络)。结论:
- 对于几乎所有网络,联合考虑网络的不同关系类型都是有帮助的。这与我们假设一致,即来自任何单个子网的信息不足,并且不同子网的信息可以互补。
baseline方法的性能因为不同网络拓扑结构差异很大。如LAZEGA或C.ELEGANS这样的稠密网络,传统简单方法的性能就足够好,有时甚至比embedding方法还要好。但是当网络相对稀疏时,embedding based方法更好。- 我们的方法和
PMNE区别在于:PMNE为一个节点生成一个overall embedding,而我们的方法生成一组embedding用于捕获每种关系类型的不同信息。实验结果表明,这些信息可能非常重要。
总而言之,我们的方法稳定地超越了其它所有
baseline,或达到baseline相当的性能。我们的理解是:模型的common embedding会合并来自不同关系类型的信息,而additional embedding会保留每种关系类型特有的信息。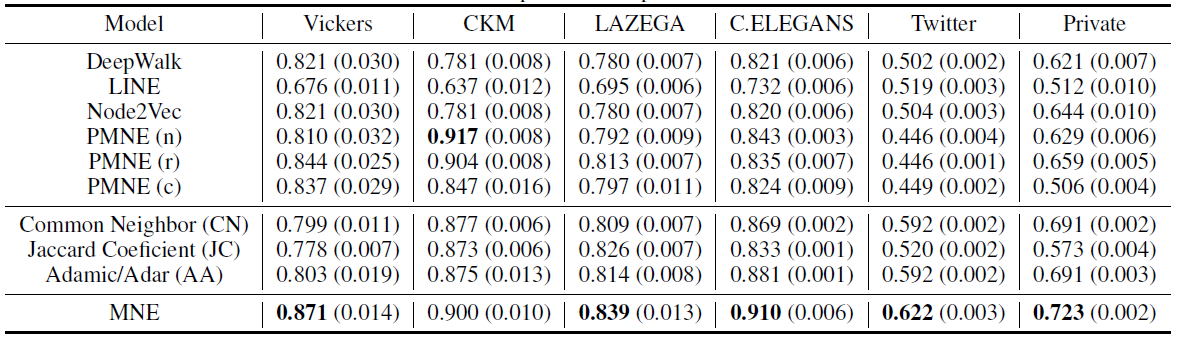
- 对于简单网络模型(如
参数敏感性:我们的方法有三个超参数:低维
additional embedding的维度addtional embedding的权重- 如图
(a)所示,当增加common embedding的帮助下,我们可以使用非常低的维度(约为common embedding维度的十分之一)来表达多重网络的每种关系类型。 - 如图
(b)所示,当增加1.0之后性能略有下降。 - 如图
(c)所示,如果将
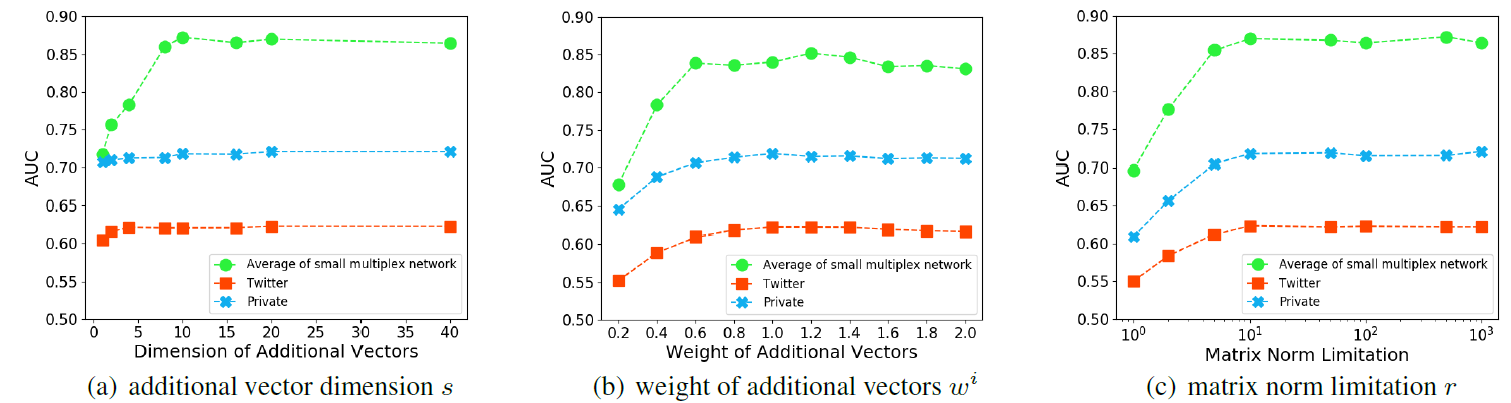
- 如图
节点分类:我们进行节点分类任务来评估
embedding质量。CKM社交网络是唯一提供分类标签的多重网络,因此我们将其作为实验数据集,label为researcher的原始公司。考虑数据集的大小,我们使用两折交叉验证。对于
DeepWalk/LINE/Node2Vec,由于它们是为简单网络设计的,因此我们为每个子图单独训练一个embedding,然后取所有子图的embedding均值作为最终embedding。对于我们的方法,我们将所有类型的权重1.0,然后所有子图embedding取平均作为最终embedding。如下图所示,我们的方法在所有
embedding方法中性能最好。可以看到即使是最简单的embedding取平均,我们的模型也可以得到高质量的overall embedding。数据集太小太简单,结论没有多大的说服力。
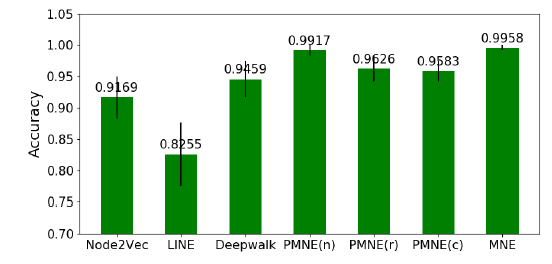
可扩展性:最后我们研究模型的可扩展性。由于现实世界的社交网络可能非常庞大,因此如果我们学习所有子图的
embedding,这些模型的训练和存储可能是一个巨大挑战。因此,我们提出了小维度的addtional embedding和变换矩阵的结构,试图在不牺牲整体性能的条件下减小整体模型的大小。如下所示,我们的方法使用的内存几乎和网络大小成线性关系。
- 与
Node2Vec和LINE相比,我们的模型在不牺牲性能的情况下仅使用十分之一的内存空间。DeepWalk/Line的空间复杂度为 - 对于
PMNE,由于它们将多重网络合并到单个网络中,因此它们的模型最小。但是它们的模型也丢失了各种类型关系特有的信息,这些信息在之前的实验中被证明很重要。
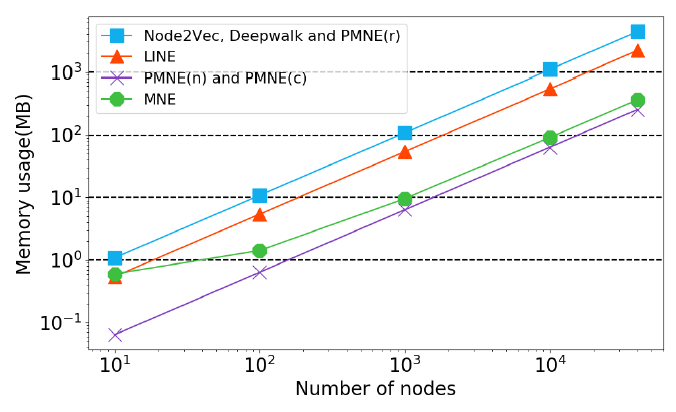
- 与
二十八、MVN2VEC[2018]
在实际
application中,对象可以通过不同类型的关系来连接。这些对象及其关系可以自然地由多视图网络multi-view network来表达,即多重网络multiplex network或multi-view graph。下图给出了一个示例性的多视图网络,其中每个视图对应于一种类型的边,并且所有视图共享同一组节点。作为一个更具体的例子,关于用户节点的四视图网络可用于描述社交网络服务,其中包括好友friendship、关注following、互发信息message exchange、帖子查看post viewing等关系。随着多视图网络的广泛应用,挖掘多视图网络是有意义的。
与此同时,
network embedding已成为一种用于网络数据的、可扩展的representation learning方法。具体而言,network embedding将网络的节点投影到embedding空间中。通过编码每个节点的语义信息,学到的embedding可以直接作为各种下游应用的特征。受到network embedding在同质网络中的成功的激励,论文《MVN2VEC: Preservation and Collaboration in Multi-View Network Embedding》认为更好地理解多视图网络embedding很重要。要设计多视图网络的
embedding方法,主要挑战在于如何使用来自不同视图的边的类型信息。因此,我们的兴趣集中在以下两个问题:当有多种类型的边可用时,对于多视图网络
embedding而言,特定specific的、重要important的目标是什么?即,多视图网络
embedding要优化的是什么目标?我们可以通过联合建模这些目标来实现更好的
embedding质量吗?
为了回答第一个问题,我们从嵌入真实世界多视图网络的实践中确定了两个这样的目标:保持
preservation和协同collaboration。collaboration:在某些数据集中,由于共享的潜在原因,可能观察到同一对节点pair对之间在不同视图中都存在边。例如,在社交网络中,如果我们在message exchange或post viewing视图中观察到用户pair对之间存在边,那么这两个用户很可能乐意彼此成为好友。在这种情况下,这些视图可能会互补,并且联合嵌入它们可能会比单独嵌入它们产生更好的结果。在联合嵌入多视图过程中,我们将这种协同效应synergetic effect称作collaboration。collaboration也是大多数现有多视图网络算法背后的主要直觉。preservation:另一方面,不同的网络视图可能具有不同的语义。也可能一部分节点在不同视图中具有完全不一致的边,因为不同视图中的边是由不相关的潜在原因unrelated latent reason而形成的。例如,职场关系
professional relationship可能并不总是与好友关系friendship保持一致。如果我们将图(b)中的职场关系视图和友谊关系视图嵌入到同一个embedding空间中,那么Gary的embedding将靠近Tilde和Elton。因此,由于传递性,Tilde的embedding也不会离Elton太远。然而,这并不是一个理想的结果,因为根据原始的多视图网络,Tilde和Elton在职场关系或好友关系方面都没有密切关联。换句话讲,以这种方式的embedding无法保持不同网络视图所携带的、独有unique的信息。我们将保持不同视图所携带的unique信息的这种需求need称作保持preservation。在论文中,我们将详细讨论preservation和collaboration的有效性和重要性。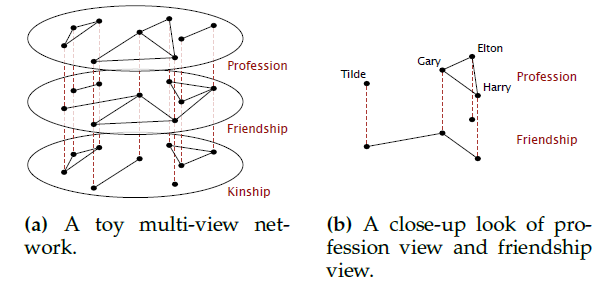
此外,
preservation和collaboration的需求可能在同一个多视图网络中共存。有两种场景会导致这种情况:- 一对视图是由非常相似的潜在原因产生的,而另一对视图是由完全不同的潜在原因产生的。。
- 在同一对视图中,一部分节点在不同视图中具有一致的边,而另一部分节点在不同视图中具有完全不一致的边。例如,在某些国家,职场关系和好友关系并不一致;而在另一些国家,同事之间经常成为好友。
因此,我们也有兴趣通过同时建模
preservation和collaboration来探索实现更好embedding质量的可行性。我们将在论文中详细介绍这一点。我们注意到,与其提出一个超越很多
baseline方法的、复杂的模型,不如将重点放在多视图网络embedding的collaboration和preservation目标上。在实验中,我们在不同场景中比较了侧重于不同目标的方法。出于同样的原因,本文排除了可以使用监督信息的场景,而从无监督场景学到的经验教训也可以应用于有监督的多视图网络embedding算法。此外,通过无监督方法学到的node embedding可以直接应用于不同的下游任务,而监督算法产生的embedding专有地适合监督信息所在的任务。总而言之,我们的贡献如下:
- 我们研究了对多视图网络
embedding而言特定specific的、重要important的目标,并且从嵌入现实世界的多视图网络的实践中,确定了preservation和collaboration这两个目标。 - 我们探索通过同时建模
preservation和collaboration来获得更好embedding的可行性,并提出了两种多视图网络embedding方法:MVN2VEC-CON、MVN2VEC-REG。 - 我们在四个数据集上对各种下游
application进行了实验。这些实验证实了preservation和collaboration的有效性和重要性,并证明了所提出方法的有效性。
相关工作:
network embedding:network embedding已成为学习分布式node representation的一种高效的、有效的方法。传统的无监督feature learning方法利用了常见的、网络的谱属性spectral property。与传统方法相反,大多数network embedding方法都是根据网络的局部属性local property来设计的,这些局部属性涉及节点之间的链接和邻近性。这种聚焦于局部属性的方法已被证明更具有可扩展性。许多最近的
network embedding算法的设计都是基于网络的局部属性,并且可以追溯到SkipGram模型,其中SkipGram模型被证明具有可扩展性和广泛的适用性。为了利用SkipGram模型,人们已经提出了各种策略来定义网络场景中的节点上下文。除了SkipGram模型之外,在文献中还可以找到保持某些其它网络属性的embedding方法。多视图网络:大多数现有的多视图网络方法旨在提高传统任务的性能,如聚类
clustering、分类classification、稠密子图挖掘dense subgraph mining等任务。另一个研究方向侧重于衡量和分析多视图网络中的交叉视图交互关系
cross-view interrelation。但是他们没有讨论嵌入多视图网络的目标,也没有研究他们所提出的度量和分析如何与多视图网络的embedding learning相关联。多视图网络
embedding:最近,《An attention-based collaboration framework for multi-view network representation learning》提出了一种基于注意力的协同框架,从而用于多视图网络embedding。这项工作的setting与我们不同,因为该工作需要监督信号从而用于注意力机制。此外,该方法并不直接建模preservation(该方法重点关注协同),而我们认为preservation是对多视图网络embedding很重要的目标之一。在该框架中,final embedding通过线性组合得到,因此是所有视图的representation之间的权衡trade-off。《Co-regularized deep multi-network embedding》还提出了一种用于嵌入multi-network的深度学习架构,其中multi-network是比多视图网络更通用的概念,并且允许跨网络进行多对多的对应correspondence。虽然所提出的模型可以应用于更具体的多视图网络,但是它并不聚焦于多视图网络embedding目标的研究。另一组相关工作研究了使用潜在空间模型联合建模多个网络视图的问题。这些工作再次没有建模
preservation。还有一些研究涉及多视图网络embedding,但是它们即不建模preservation和collaboration,也不旨在提供对这些目标的深入研究。此外,多视图矩阵分解问题也与多视图网络
embedding有关。《Multi-view clustering via joint nonnegative matrix factorization》提出了一种多视图非负矩阵分解模型,旨在最小化每个视图的邻接矩阵与共识矩阵consensus matrix之间的距离。虽然这些方法可以为每个节点生成一个向量,但是这些向量被建模以适应某些具体任务(如矩阵补全或聚类任务),而不是可用于不同下游application的、节点的分布式representation。其它类型网络的
embedding技术:在更大的范围内,人们最近在嵌入更通用的网络方面进行了一些研究,如异质信息网络heterogeneous information network: HIN。有些工作在metapath之上构建算法,但是相比于多视图网络,metapath对于具有多种类型节点的HIN而言更有意义。另一些工作是为具有额外辅助信息或特定结构的网络而设计的,这些网络不适用于多视图网络。最重要的是,这些方法是为它们想要嵌入的网络而设计的,因此并不专注于研究多视图网络embedding的特定需求和目标。多关系
multi-relational网络embedding(或知识图谱embedding):多关系网络embedding体现了与多视图网络embedding相关的另一个研究方向。这个方向的研究重点与多视图网络embedding有所不同,并不直接适用于我们的场景,因为这些网络中涉及的关系通常是有向的。此类方法中的一族流行方法是基于翻译的,其中有向边的head entitytail entityembedding满足:
28.1 模型
28.1.1 基本概念
- 多视图网络定义:多视图网络
- 多视图网络
embedding的目标是为每个节点center embedding向量center embedding向量之外,一系列流行的算法还为每个节点context embeddingembedding用作下游任务的特征向量时,我们遵从常见的做法,将center embedding作为特征。
28.1.2 朴素方法
可以通过把简单网络
embedding方法推广到多视图,从而得到多视图网络embedding的两种简单直接的方法:独立模型independent model、单空间模型one-space model。定义节点
embedding为embedding维度。独立模型分别独立嵌入每个视图,然后将所有视图的
embedding拼接从而得到final embedding:其中
这种方法得到的
node embedding保持了每个视图的信息,但是无法跨不同视图进行协同collaboration。单空间模型:单空间模型假设每个视图共享相同的参数,
final embedding为:其中
在单空间模型中所有视图的
embedding都相同,它们就是final embedding。因此final embedding和所有视图有关。这种方法得到的
node embedding鼓励不同视图进行协同,但是没有保持每个视图独有的信息。
我们通过
YouTube, Twitter这两个多视图网络来评估独立模型、单空间模型的效果。在这两个网络中,每个节点代表一个用户。
YouTube网络有三个视图,分别代表共同观看视频cmn-vid、共同订阅者cmnsub、共同好友cmn-fnd。Twitter有两个视图,分别表示回复reply、提及mention。下游任务是评估两个用户是否好友关系。评估结果如下表所示。可以看到并没有哪个模型的效果始终比另外一个更好。
- 在
YouTube数据集上,独立模型的效果优于单空间模型。 - 在
Twitter数据集上,单空间模型的效果优于独立模型。
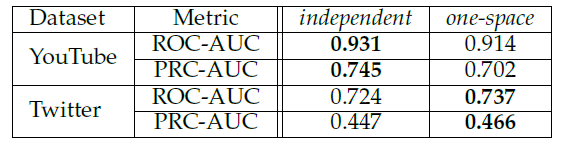
- 在
我们认为:不同网络的
network embedding对建模preservation和建模collaboration的需求不同,这使得采用独立模型、单空间模型的效果不同。具体而言:独立模型仅捕获perservation,单空间模型仅捕获collaboration。因此:- 如果某个数据集更需要建模
preservation,那么独立模型的效果将优于单空间模型。 - 如果某个数据集更需要建模
collaboration,那么单空间模型的效果将优于独立模型。
为证明我们的观点,我们检查了数据集中不同网络视图之间信息的一致性。给定两个集合,我们通过
Jaccard系数来衡量两个集合之间的相似性:给定多视图网络中的一对视图
对于每对视图,我们检查所有节点在它们之间的一致性,并给出一致性大于
0.5的节点占所有节点的比例。该比例定义为视图之间信息的一致性,即:其中
在
YouTube, Twitter数据集上不同视图的信息一致性结果如下图所示:YouTube数据集中每对视图之间几乎没有一致性。因此,该数据集最需要的是建模perservation,而不是collaboration。因此在该数据集上独立模型优于单空间模型。Twitter数据集中每对视图之间一致性较高,因此对该数据集建模collaboration可以带来效果的提升。因此该数据集上单空间模型优于独立模型。
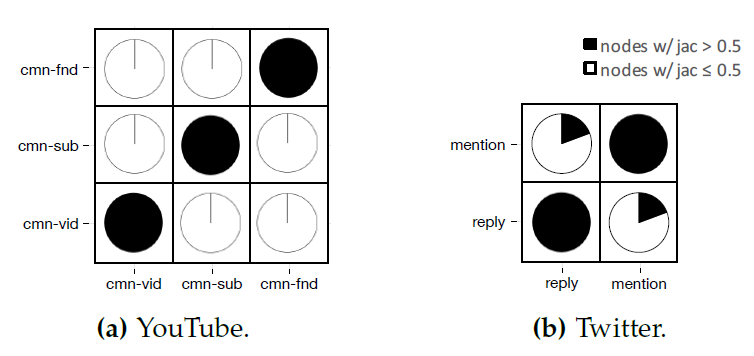
- 如果某个数据集更需要建模
28.1.3 MVN2VEC 模型
我们将
preservation和collaboration定义为多视图网络embedding中的重要目标。- 一种极端情况是,每个视图都具有独特的语义。此时仅需要建模
preservation,因此独立模型就可以产生比较好的结果。 - 另一种极端情况是,每个视图都具有相同的语义。此时仅需要建模
collaboration,因此单空间模型就能得到令人满意的结果。
但是,通常多视图网络介于两者之间,因此需要同时建模
preservation和collaboration。为此,我们提出两种方法MVN2VEC-CON和MVN2VEC-REG,它们都可以同时捕获这两个目标。其中MVN2VEC表示multi-view network to vector,CON表示constrained,REG表示regularized。- 一种极端情况是,每个视图都具有独特的语义。此时仅需要建模
根据之前的定义,节点
embedding为context embedding为给定视图
intra-view loss来衡量当前embedding来表达视图我们这里先不给出损失函数
MVN2VEC-CON:MVN2VEC-CON方法同时建模collaboration和preservation。首先,该方法不对
preservation。然后,该方法对context embedding施加约束:要求不同视图中的context embedding共享。具体做法为:其中
parameter共享比例的超参数,取值越大则参数共享比例越高,从而更多地建模collaboration。最终,
MVN2VEC-CON模型需要求解以下最优化问题:当模型完成训练之后,每个节点
final embedding为:其中
MVN2VEC-CON模型退化为独立模型。注意,这里用向量拼接而没有用均值聚合或
sum聚合。拼接操作能够保持每个视图的语义,即preservation。进一步地,为区分不同视图我们将
view-specific参数MVN2VEC-REG:MVN2VEC-REG方法也同时建模collaboration和preservation。该方法并未要求不同视图之间的参数共享,而是对不同视图的embedding施加正则化。MVN2VEC-REG的目标函数为:其中
- 一方面,
MVN2VEC-REG通过让view-specific的embedding子空间中,从而建模preservation。 - 另一方面,
MVN2VEC-REG通过跨视图的正则化来建模collaboration。
类似于
MVN2VEC-CON模型,在MVN2VEC-REG模型中超参数collaboration。当MVN2VEC-REG模型退化为独立模型。进一步地,为区分不同视图我们将
其中超参数
- 一方面,
视图内损失函数
intra-view loss:视图内损失函数SkipGram模型。具体而言,对于每个视图其中:
这个损失函数旨在保持视图内的一阶邻近性。
模型推断:为了优化
MVN2VEC-CON和MVN2VEC-REG的目标函数,我们选择异步随机梯度下降asynchronous stochastic gradient descent: ASGD。此外,我们也采用负采样技术来近似其中:
sigmoid函数,degree,或者也可以选择当使用负采样之后:
MVN2VEC-CON的目标函数为:MVN2VEC-REG的目标函数为:
.
随机游走
pair生成:在缺乏额外监督信息的情况下,我们假设不同网络视图的重要性相同,并从每个视图中采样相同数量的给定网络视图
pair对,其中节点的转移概率与所有outgoing edge的权重成正比。复杂度分析:对于每个网络视图,随机游走都是根据现有方法独立生成的。
《node2vec: Scalable feature learning for networks》的分析表明,整体复杂度为对于模型推断,
ASGD的迭代步数和(node, context) pair对的数量成线性关系,而这个数量正比于ASGD每步迭代的梯度计算正比于ASGD的计算复杂度是MVN2VEC训练算法:输入:
- 多视图网络
- 每个节点开始的随机游走序列数量
- 随机游走序列长度
- 上下文窗口大小
- 负采样比例
- 超参数
- 多视图网络
输出:每个节点的
embedding算法步骤:
从每个视图
对每个节点
对每个节点
迭代(下面的迭代步骤可以并行进行):
对于每个节点
28.2 实验
28.2.1 人工合成数据集
为直接研究不同模型在具有不同程度的
preservation和collaboration网络上的性能,我们设计了一组人工合成网络,并执行多类分类任务。这些人工合成网络记作intrusion probability。我们首先描述如何生成- 在带有标签
A或B的所有节点上生成一个随机网络,并在带有标签C或D的所有节点上生成另一个随机网络。将这两个随机网络的所有边放入视图
- 在带有标签
在带有标签
A或C的所有节点上生成一个随机网络,并在带有标签B或D的所有节点上生成另一个随机网络。将这两个随机网络的所有边放入视图为了生成上述四个随机网络,我们采用广泛被使用的优先连接过程
preferential attachment process,该过程用一条边将新节点连接到现有节点,并且是广泛使用的、可以生成幂律分布网络的方法 。通过这种方式,在视图A或B的节点应该和标签为C或D的节点有区分性;在视图A或C的节点应该和标签为B或D的节点有区分性。更一般地,
collaboration,较小的preservation。在network embedding过程只需要collaboration,因为每条边都有相同的概率落入我们人工合成网络
4000个节点、2个视图。每个节点关联一个label,label的取值集合为{A,B,C,D},并且每种类型的label有1000个节点。
对于每个
independent, one-space, MVN2VEC-CON, MVN2VEC-REG等方法学习node embedding,然后使用逻辑回归来执行分类任务来评估生成的embedding质量。我们从
4000个样本中采样得到验证集,通过验证集来调优超参数。同时我们随机抽取一部分节点作为测试集,并给出不同方法生成的embedding在测试集上的分类准确性和交叉熵。结论:
- 当
independent模型优于one-space模型,此时preservation占据统治地位。 - 当
one space模型优于independent模型,此时collaboration占据统治地位, - 大多数情况下(除了
0.5之外),我们提出的MVN2VEC性能优于independent/one-space模型。这意味着MVN2VEC有可能通过同时建模preservation和collaboration来实现更好的性能。 - 当
0.5时,one-space效果更好。这是可以预期的,因为在preservation。并且,任何针对preservatinon的额外建模都不会提高性能。
- 当
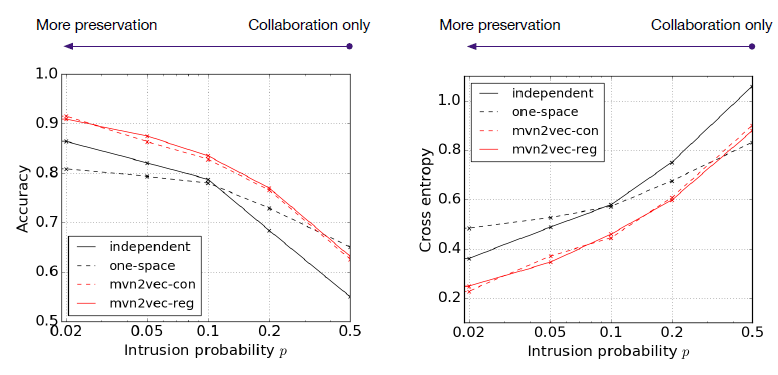
28.2.2 真实数据集
数据集:
Youtube数据集:一个视频分享网站。我们使用该数据集构建了一个三视图网络,其中核心用户core user为节点,三个视图分别为:共同好友关系、共同订阅者关系、共同爱好关系(都喜欢某个视频)。注意,core user为数据集作者通过爬虫爬取到的那些用户,而他们的好友可能不属于core user。由于没有类别标签,因此我们在该数据集上执行链接预测任务,目标是预测两个
core user之间是否是好友关系。由于原始数据集只有正样本(好友关系),因此对于每个core user的好友关系,我们随机选择5个非好友的core user来构造负样本。我们将数据集拆分为训练集、验证集、测试集。Twitter数据集:在线新闻和社交网站。我们使用该数据集构建了一个两视图网络,其中用户为节点,两个视图分别为:reply关系、mention关系。同样地,我们也在该数据集上执行链接预测任务,预测两个用户是否是好友。我们也采用相同的方式构造负样本。训练集、验证集、测试集的拆分方法与
Youtube数据集中的拆分方法相同。Snapchat数据集:一个多媒体社交网络。我们使用该数据集构建一个三视图网络,其中用户为节点,三个视图分别为:好友关系、聊天关系、故事阅读关系。我们收集了2017年春季连续两周的数据作为构建网络的数据,下游评估任务的数据是接下来一周(第三周)收集的数据。我们在
Snapchat数据集上采用不同模型学到node embedding,然后将node embedding作为输入从而执行下游的标签分类任务、链接预测任务。在分类任务中,我们根据第三周用户观看的历史记录,对用户是否观看了
10个最热门的发现频道discover channel进行分类。对于每个频道,观看过该频道的用户都被标记为正样本。我们随机选择未观看该频道的5倍用户(正样本的5倍)作为负样本。这是一个多标签分类问题,旨在推断用户对不同发现频道的偏好,从而指导内容服务中的产品设计。然后,我们将这些用户随机拆分为训练集、验证集、测试集,拆分比例为
80%:10%:10%。在连接预测任务中,我们预测两个用户是否会在第三周阅读彼此发布的
story。 正样本是一对好友,他们阅读了对方发布的story;负样本是一对好友,他们未阅读对方发布的story。注意:这种方式产生的正样本比负样本更多,这也是在实验中观察到较高PRC-AUC的原因。数据被随机分为训练集、验证集、测试集,约束条件是用户最多只能在三个子集中的一个子集中显示为阅读者
viewer。该任务旨在估计朋友之间阅读故事的可能性,以便application可以相应地对故事就那些排名。
我们提供了
Snapchat视图的一致性结果,可以看到在Snapchat网络中,视图一致性介于YouTube和Twitter之间。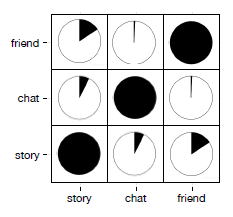
数据处理:
- 如果节点在多视图中至少一个视图中是孤立节点(在该视图中不与其它任何节点相连),则该节点将从评估中排除。这种处理方式可以确保仅嵌入单个视图时,每个节点都具有有效的
embedding。 - 对于所有三个网络上的每个任务,训练集、验证集、测试集的拆分比例为
80%:10%:10%。我们重复20次随机拆分数据集并执行评估,最终报告每个评估指标的均值和标准差。
- 如果节点在多视图中至少一个视图中是孤立节点(在该视图中不与其它任何节点相连),则该节点将从评估中排除。这种处理方式可以确保仅嵌入单个视图时,每个节点都具有有效的
baseline方法:independent模型:等价于MVN2VEC-CON,以及MVN2VEC-REG方法。它保留了每个视图独有的信息,但是不允许嵌入过程中跨视图的协同。one-space模型:它使得不同的视图可以协同学习统一的embedding,但不会保留每个视图特有的信息。view-merging模型:它首先将所有视图合并为一个统一的视图,然后学习该统一视图的embedding。为满足所有视图重要性都相同的假设,我们将统一视图中边的权重调整为所有视图中该边的权重之和。这种方法是
one-space的一个替代方法,而且区别在于:随机游走是否能够穿越不同的视图。就像one-space一样,view-merging方法也不会建模perservation。single-view模型:它仅从某一个视图中学习embedding,目的是为了验证引入更多的视图是否能够带来效果的提升。它等价于使用DeepWalk来嵌入多视图网络中的某一个视图。
我们还尝试了两个用于多视图网络
embedding的其它方法,包括:MVE:一种基于注意力机制的多视图网络embedding的半监督方法。为了公平地比较,在我们的无监督链接预测实验中,我们将相同的dummy class label分配给1%随机选择的节点。我们观察到,随机选择节点的比例并不会显著影实验中的评估结果。DMNE:一种基于深度学习体系结构的多视图网络embedding方法。
由于可扩展性的原因,我们在较小的
YouTube和Twitter数据集上比较了这两个baseline。评估方式:为公平起见,我们使用相同的、带有
根据
《Line:L arge-scale information network embedding》,每个embedding向量通过投影到单位球上从而进行后处理。在多标签分类任务中,节点特征仅仅是节点的
embedding,并且为每个label训练一个独立的逻辑回归模型。在链接预测任务中,节点pair对的特征是两个节点embedding向量的Hadamard product,正如《node2vec: Scalable feature learning for networks》所建议的。超参数配置:
对于
independent, MVN2VEC-CON, MVN2VEC-REG,我们设置embedding维度为embedding维度对于
single-view,我们设置对于随机游走序列,我们设置每个序列长度为
Snapchat数据集,每个节点开始的随机游走序列数量我们
SkipGram负采样比例为每个模型仅训练一个
epoch。MVN2VEC模型的
评估指标:
- 对于链接预测任务,我们使用
ROC-AUC和PRC-AUC这两个指标。 - 对于多标签分类任务,我们先计算每种标签的
ROC-AUC以及PRC-AUC,然后报告所有标签在这些指标上的均值。
- 对于链接预测任务,我们使用
实验结果:
所有利用多视图的模型都优于仅使用单视图的模型,这证明了利用多视图的必要性。
one-space方法和view-merging方法在所有数据集上的性能都差不多。这是可以预期的,因为它们都仅对collaboration进行建模,并且彼此之间的区别仅在于随机游走是否跨网络视图。在
YouTube上,我们提出的MVN2VEC模型表现不错,但是没有明显的超越independent模型。这是由于YouTube网络中,对preservation建模的需求占主导地位。在这种极端情况下,对collaboration额外的建模并不会带来显著的效果提升。在
Twitter上,collaboration比preservation更为重要,因此one-space方法要比independent方法更好。此外,
MVN2VEC-REG优于所有的baseline,而MVN2VEC-CON超越了independent但是比one-space更差。这一现象的原因可以解释为:尽管我们通过配置超参数context embeddingMVN2VEC-CON中每个视图的collaboration的能力受到限制。就
preservation和collaboration目标而言,Snapchat网络位于YouTube和Twitter之间。在Snapchat网络上,我们提出的MVN2VEC在所有指标上都优于所有baseline。这证明了通过同时建模preservation和collaboratioin来提升模型性能的可行性,并且不会使得模型过度复杂化、也不需要监督信息。MVN在YouTube上的表现不如MVN2VEC,我们认为MVE是一个collaboration框架,它并未显式地建模preservation。而preservation目标又是Youtube数据集必须的。同时,
MVE并未从其注意力机制中获得性能提升,因为在我们的实验设置中,并未为它提供所需要的监督信息。DMNE在YouTube上性能较差,原因是我们采用原始论文的超参数。另外,DMNE是为更通用的多网络multi-network而设计,并不是专门针对多视图网络而设计。
这些观察结果共同证明了通过同时建模
preservation和collaboration来提高性能的可行性,而不会使得模型过度复杂化,也不需要监督信息。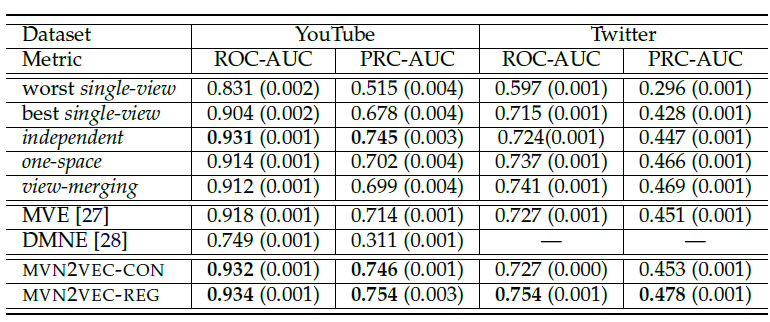
最后我们研究超参数的影响。
首先评估
embedding维度preservation进行建模。结论:
one-space方法在independent效果更差。不能期望one-space方法采用更大维度的embedding空间来保持多视图中不同视图携带的信息。independent方法在- 所有四种方法的最佳性能都集中在
one-space在四种方法之间,到达峰值性能的one-space不会划分embedding空间从而适应多个视图。
然后我们评估
我们首先关注
snapchat网络。- 对于
MVN2VEC-REG,当preservation;随着collaboration,可以看到对应地模型性能逐步改善。模型的性能峰值在 - 对于
MVN2VEC-CON,当preservation;随着collaboration。注意:当MVN2VEC-CON虽然context embedding的参数MVN2VEC-CON来建模更多的collaboration。
在
YouTube网络上,无论MVN2VEC都不会明显优于independent,因为YouTube网络被preservation统治。在
Twitter网络上,当MVN2VEC-REG超越了one-space;而无论MVN2VEC-CON都无法超越one-space,因为Twitter网络更多地需要建模collaboration,而MVN2VEC-CON的设计阻止了它建模更多的collaboration。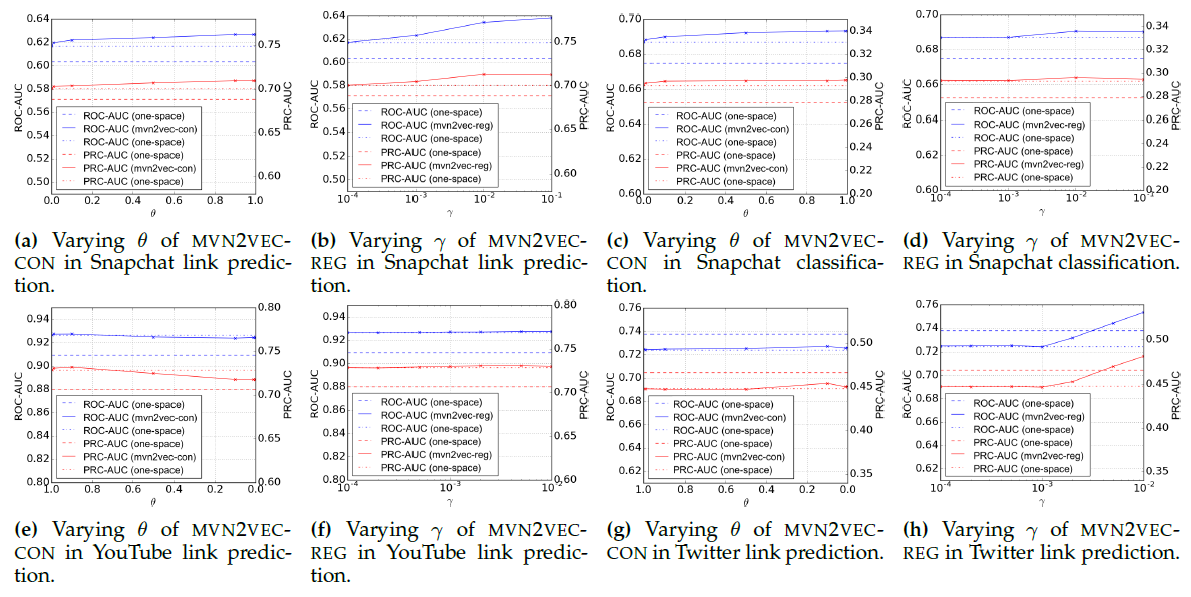
- 对于
二十九、SNE[2018]
社交网络是一类重要的网络,涵盖各种媒体,包括
Facebook和Twitter等社交网站、学术论文的引文网络、移动通信的caller–callee网络等等。许多application需要从社交网络中挖掘有用的信息。例如,内容供应商content provider需要将用户分组从而用于定向广告投放targeted advertising,推荐系统需要估计用户对item的偏好从而进行个性化推荐。为了将通用机器学习技术应用于网络结构化数据,学习有信息量informative的node representation是有必要的。最近,人们对
representation learning的研究兴趣已经从自然语言扩展到网络数据。人们已经提出了许多network embedding方法,并在各种application中展示出有前景的性能。然而,现有的方法主要集中在通用网络上,并且仅利用结构信息。对于社交网络,论文《Attributed Social Network Embeddin》指出:除了链接结构之外,几乎总是存在关于社交参与者social actor的丰富信息。例如,社交网站上的用户可能拥有年龄、性别、文本评论等画像信息。我们将所有此类辅助信息称为属性attribute,这些辅助信息不仅包含人口统计学数据,还包括其它信息如附属文本、可能存在的标签等等。社交参与者的这些丰富的属性信息揭示了同质效应homophily effect,该效应对社交网络的形成产生了巨大的影响。本质上,属性对社交网络的组织产生巨大的影响。许多研究证明了属性的重要性,从客观的人口统计学数据,到主观的政治取向和个人兴趣等偏好数据。为了说明这一点,我们从三个视图绘制了
Facebook数据集的user-user友谊矩阵。每一行或每一列代表一个用户,一个彩色点表示对应的用户是好友关系。每个视图是用户按照“年级”class year、“专业”major、“宿舍”dormitory等特定属性重新排序的结果。例如,图(a)首先按照 “年级” 属性对用户进行分组,然后按照时间顺序对 “年级” 进行排序。可以看到,每个视图中都存在清晰的块状结构block structure,其中块内的用户的连接更紧密。每个块结构实际上都指向相同属性的用户,例如,图(a)的右下角对应于2009年毕业的用户。这个现实世界的例子支持了属性同质性attribute homophily的重要性。通过共同考虑属性同质性和网络结构,我们相信可以学到更有信息量的node representation。此外,通过利用辅助的属性信息,可以很大程度上缓解链接稀疏link sparsity和冷启动cold-start问题。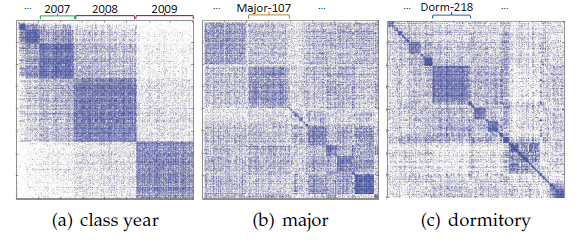
在论文
《Attributed Social Network Embedding》中,作者提出了一个叫做SNE的神经网络框架,用于从社交网络数据中学习node representation。SNE是使用实值特征向量的通用machine learner,其中每个特征表示节点的ID(用于学习网络结构)或一个属性。通过这种方式,我们可以轻松地集成任何类型和数量的属性。在论文的SNE框架下,每个特征都关联一个embedding,节点的final embedding是从节点的ID embedding(保持结构邻近性structural proximity))和属性embedding(保持属性邻近性attribute proximity)聚合而成。为了捕获特征之间的复杂交互,论文采用多层神经网络来利用深度学习的强大的representation和generalization能力。总之,论文贡献如下:
- 论文证明了集成网络结构和属性对于学习更有信息量的社交网络
node representation的重要性。 - 论文提出了一个通用框架
SNE,该框架通过保持社交网络的结构邻近性和属性邻近性来执行社交网络embedding。 - 论文对四个数据集进行了广泛的实验,其中包括链接预测、节点分类这两个任务。实验结果和案例研究证明了
SNE的效果和合理性。
- 论文证明了集成网络结构和属性对于学习更有信息量的社交网络
相关工作:这里我们简要总结了关于属性同质性
attribute homophily的研究,然后我们讨论与我们的工作密切相关的network embedding方法。社交网络中的属性同质性:社交网络属于一类特殊的网络,其中社交关系的形成不仅涉及自组织的网络过程
self-organizing network process,还涉及基于属性的过程attribute-based process。在embedding过程中考虑属性邻近性的动机源自属性同质性的巨大影响,其中属性邻近性在基于属性的过程中起着重要作用。因此,我们在这里对同质性研究进行简要概述。一般而言,“同质性原则”
homophily principle(即,“物以类聚,人以群分”)是社交生活中最引人注目和最强大的经验规律之一。- 相似的人倾向于成为好友的假设至少可以追溯到上世纪
70年代。在社会科学中,人们普遍预期:个体与大约同龄的其他人建立好友关系(《“Friendships and friendly relations》)。 - 在
《Homophily in voluntary organizations: Status distance and the composition of face-to-face groups》中,作者研究了群体的同质构成homogeneous composition和同质性出现the emergence of homophily的相互联系。 - 在
《Homophily in online dating: when do you like someone like yourself?》中,作者试图找出同质性在用户做出的在线约会选择中的作用。他们发现,在线约会系统的在线用户寻找像他们一样的人的频率要比系统预测的要高得多,就像在离线世界中一样。 - 近年来,
《Origins of homophily in an evolving social network》调查了大型大学社区中同质性的起源,该论文记录了随着时间推移的交互interaction、属性attribute、以及附属关系affiliation。
毫不奇怪,人们已经得出结论,除了结构邻近性之外,属性相似性的偏好也为社交网络的形成过程提供了一个重要因素。因此,为了获得更多关于社交网络的、有信息量的
representation,我们应该考虑属性信息。- 相似的人倾向于成为好友的假设至少可以追溯到上世纪
network embedding:一些早期的工作,例如局部线性嵌入Local Linear Embedding: LLE、IsoMap、Laplacian Eigenmap首先将数据转换为基于节点的特征向量的亲和图affinity graph(例如节点的k近邻),然后通过求解亲和矩阵affinity matrix的top-n的eigenvector来嵌入graph。最近的工作更侧重于将现有网络嵌入到低维向量空间中,从而帮助进一步的网络分析并实现比早期工作更好的性能。
- 在
《Deepwalk: Online learning of social representations》中,作者在网络上部署了截断的随机游走来生成节点序列。生成的节点序列在语言模型中被视为句子,并馈送到SkipGram模型来学习node mebdding。 - 在
《node2vec: Scalable feature learning for networks》中,作者通过平衡广度优先采样和深度优先采样,从而改变了生成节点序列的方式,最终实现了性能的提升。 《Line: Large-scale information network embedding》没有在网络上随机游走,而是提出了显式的目标函数来保持节点的一阶邻近性和二阶邻近性。《Structural deep network embedding》也没有在网络上随机游走,并且引入了具有多层非线性函数的深度模型来捕获高度非线性的网络结构。
然而,所有这些方法都只利用了网络结构。在社交网络中,存在大量的属性信息。单纯基于结构的方法无法捕获这些有价值的信息,因此可能会导致信息量少的
embedding。此外,当发生链接稀疏问题时,这些方法很容易受到影响。最近的一些工作探索了集成内容从而学习更好的representation的可能性。例如,
TADW提出了关联文本的DeepWalk,从而将文本特征融合到矩阵分解框架中。但是,TADW仅能处理文本属性。面对同样的问题,
TriDNR提出从基于结构的DeepWalk和label-fused的Doc2Vec模型中分别学习embedding,学到的embedding以iterative的方式线性组合在一起。在这样的方案下,两个独立模型之间的知识交互knowledge interaction只经过一系列的加权和运算,并且缺乏进一步的收敛约束convergence constrain。相比之下,我们的方法以端到端的方式同时建模结构邻近性和属性邻近性,并且没有这些限制。此外,通过早期融合结构模型和属性模型,这两部分将相互补充从而产生足够好的知识交互。
也有工作致力于探索用于
network embedding的半监督学习。《Deep learning via semi-supervised embedding》将基于embedding的正则化器与监督学习器结合起来,从而集成了标签信息。《Revisiting semi-supervised learning with graph embeddings》没有强迫正则化,而是使用embedding来预测graph中的context,并利用标签信息来构建transductive公式和inductive公式。在我们的框架中,标签信息可用的时候可以通过类似的方式融合。我们将这种扩展作为未来的工作,因为我们的工作聚焦于network embedding的属性建模。
- 在
29.1 模型
29.1.1 基本概念
定义社交网络
每条边
社交网络
embedding的目的是将节点映射到低维向量空间中。由于网络结构和节点属性提供了不同的信息源,因此关键是要同时捕获这两者。如下图所示,数字代表节点编号,相同的颜色代表相同的属性。基于网络结构
embedding的方法通常假设连接紧密的节点在embedding空间中彼此靠近。如,computer science。尽管要学到用户的更有信息量的
representation,必须捕获属性信息。在这项工作中,我们努力开发embedding方法从而同时保持社交网络的结构邻近性和属性邻近性。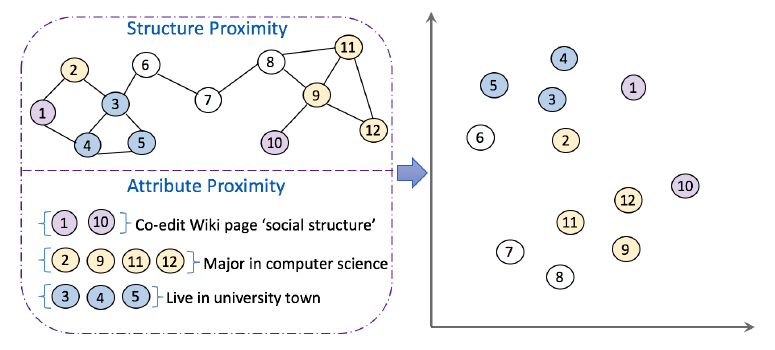
我们首先定义结构邻近性和属性邻近性:
结构邻近性
Structural Proximity:以网络链接关系表示的节点邻近性。对于节点node2vec的随机游走策略。属性邻近性
Attribute Proximity:以属性表示的节点邻近性。对于节点embedding空间中彼此靠近。这里假设用户属性特征都是离散型的(如果有连续型属性则可以离散化)。
29.1.2 SNE 模型
结构建模
Structure Modeling:根据结构邻近性的定义,网络结构建模的关键在于定义节点的pairwise邻近性。令
令节点
通过最大化所有节点上的这种条件概率,我们可以实现保持网络结构邻近性的目标。具体而言,我们建模全局网络结构的目标函数为:
建立了学习的目标函数之后,现在我们需要设计一个
embedding模型来估计pairwise邻近性函数embedding向量的内积。但是,众所周知,简单地将embedding向量内积会限制模型的表达能力,并导致较大的ranking loss。为了捕获现实世界网络的复杂非线性,我们建议采用一种深度架构来对节点的pairwise邻近性建模:其中:
embedding向量。context embedding向量。
注意:在我们的方案中,每个节点
embedding表示形式:节点embeddingcontext embeddingembedding,从而作为节点embedding。根据经验,这种方式效果更好。浅层
embedding模型到深层embedding模型是一种很自然的想法。属性编码
Encoding Attributes:很多现实世界的社交网络包含丰富的属性信息,这些属性信息可能是异质并且多样化的。为了避免人工特征工程,我们将所有属性转化为通用的feature vector的形式,从而有助于设计一种从属性数据中学习的通用方法。无论属性的语义如何,我们都可以将属性分为两类:- 离散属性:我们通过
one-hot encoding将离散属性转换为一组binary feature。如:性别属性的取值集合为{male, female},那么对于一位女性用户,我们用female。 - 连续属性:社交网络上自然地存在连续属性,如图像原始特征和音频原始特征。或者也可以通过离散变量人为地转换生成连续属性,如通过
TF-IDF将文档的bag-of-words representation转换为实值向量。另一个例子是历史特征,如用户购买item历史行为特征、用户checkin地点的历史行为特征,它们总是被归一化为实值向量从而减少可变长度的影响。
假设属性特征向量
embedding向量所示。然后我们聚合用户所有的属性特征
embedding:这里没有进行连续特征离散化,而是将连续特征直接嵌入并乘以特征取值。此外,这里直接均值聚合,可以结合
attention机制进行聚合。类似于网络结构建模,节点属性建模的目标是采用深度模型来近似属性之间的复杂的相互作用,从而对属性邻近性建模:
其中
context embedding向量。pair-wise属性邻近性建模从直觉上需要馈入两个节点的内容,但是这里只有一个节点内容和另一个节点的context embedding?
- 离散属性:我们通过
SNE模型:为了结合网络结构建模和节点属性建模,一种直观的方法是:将各自模型学到的embedding拼接起来,即后期融合late fusion方案。这种方法的主要缺点是:各个模型在彼此不知道对方的情况下单独训练,训练之后简单地组合各模型的embedding从而得到结果。相反,早期融合early fusion方案允许同时优化所有参数,因此属性建模和结构建模相互补充,使得两个部分密切交互。从本质上讲,早期融合方案在端到端深度学习方法中更为可取,因此,我们提出了如下所示的通用社交网络嵌入框架SNE,它通过在输入层之后进行早期融合来集成网络结构建模和节点属性建模。输入层:
- 网络结构建模的输入层为节点的
one-hot。 - 节点属性建模的输入层为节点的属性特征向量
- 网络结构建模的输入层为节点的
embedding层:- 网络结构建模的
embedding层将one-hot映射到捕获了网络结构信息的稠密向量 - 节点属性建模的
embedding层对属性特征向量进行编码,并生成聚合了属性信息的稠密向量
- 网络结构建模的
隐层:我们选择了
embedding向量。注意:一种常见的网络架构设计是使用塔式结构,即每层的神经元数量从底部到顶部依次减少。我们也遵循该设计原则,如下图所示。
输出层:定义邻居
context embedding为context embedding中缺乏节点的属性信息。因此节点
输出层将最后一层隐层
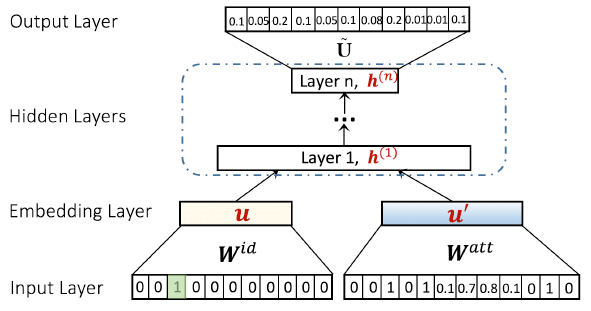
优化
Optimization:为求解模型参数,我们需要选择一个目标函数来进行优化。我们的目标函数是:使得所有节点上的条件链接概率最大化。即:其中:
这个目标函数有两个效果:强化
- 两个用户之间没有链接,并不意味着他们是不相似的。如,社交网络中很多用户之间没有链接,不是因为他们不相似,而是因为他们没有彼此认识的机会。因此,迫使
- 目标函数中,为了计算单个概率
为避免这些问题,我们使用负采样,从整个社交网络中采样一小部分负样本。主要思想是在梯度计算过程中进行近似,即:
其中:
注意,给定用户
为优化上述框架,我们使用了
Adam优化算法。此外,我们还使用了batch normalization。在embedding layer和每个隐层中,我们还使用了dropout。最终我们使用final embedding。- 两个用户之间没有链接,并不意味着他们是不相似的。如,社交网络中很多用户之间没有链接,不是因为他们不相似,而是因为他们没有彼此认识的机会。因此,迫使
29.1.3 与其它模型关联
这里我们讨论
SNE框架与其它相关模型的联系。我们展示了SNE包含了state-of-the-art的network embedding方法node2vec,也包含了线性潜在因子模型SVD++。具体而言,这两个模型可以视为浅层SNE的一个特例。为便于进一步讨论,我们首先给出单层SNE的预测模型为:当选择:
此时
SNE退化为node2vec。当选择:
此时
SNE退化为SVD++。
通过
SNE与一系列浅层模型的联系,我们可以看到我们设计SNE背后的合理性。具体而言,SNE加深了浅层模型,从而捕获网络结构和属性之间的底层交互。在建模可能具有复杂的、非线性固有结构的真实世界数据时,我们的SNE更有表达能力,并且可以更好地拟合真实世界数据。
29.2 实验
这里我们对四个可公开访问的社交网络数据集进行实验,旨在回答以下研究问题。
- 与
state-of-the-art的network embedding相比,SNE能否学到更好的node representation? - 导致
SNE学到更好representation的关键原因是什么? - 更深的隐层是否有助于学到更好的社交网络
embedding?
- 与
数据集:
- 社交网络:我们使用
Facebook的两个网络,分别包含来自两所美国大学的学生:University of Oklahoma(OKLAHOMA)、University of North Carolina at Chapel Hill(UNC) 。除了用户ID之外,还有七个用户属性:状态、性别、专业、第二专业、宿舍、高中、入学年份。注意,并非所有学生都有这七个属性,如在UNC数据集中的18163个学生中只有4018个学生包含所有属性。 - 引文网络:我们使用
DBLP和CITESEER数据集,每个节点代表一篇论文。属性为去除停用词以及词干化之后每篇论文的标题和内容。DBLP数据集由计算机科学四个研究方向的会议论文组成。CITESEER数据集由来自十个不同研究领域的科学出版物组成。这些研究方向或研究领域在节点分类任务中被视为标签。
- 社交网络:我们使用
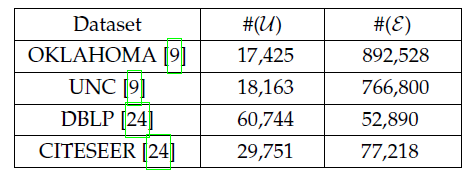
评估方式:我们采用了链接预测和节点分类任务。链接预测任务评估
node representation在重建网络结构中的能力,节点分类评估node representation是否包含足够的信息用于下游应用。链接预测任务:我们随机将
10%的链接作验证集来调整超参数,随机将10%的链接作为测试集,剩下80%的链接作为训练集来训练SNE。由于测试集/验证集仅包含正样本,因此我们随机选择数量相等、不存在的边作为负样本。我们使用AUROC作为评估指标(ROC曲线的面积),该指标越大越好。节点分类任务:我们首先在训练集上训练模型(包含所有节点、所有边、所有属性,但是没有节点
label),从而获得node embedding。其中模型的超参数通过链接预测任务来选取。然后我们将node embedding输入到LIBLINEAR分类器进行节点分类。我们随机选择根据链接预测任务获取节点分类任务的超参数,这种做法可能不是最佳的,应该根据节点分类任务来得到模型超参数。但是这里是两阶段的,因此如何根据第二阶段的标签信息来得到第一阶段的模型超参数,这是一个问题。
我们重复该过程十次并报告平均的
Macro-F1和Micro-F1得分。注意:由于只有DBLP和CITESEER数据集包含节点的类别标签,因此仅针对这两个数据集执行节点分类任务。
baseline方法:这里我们将SNE和若干个state-of-the-art的network embedding方法进行比较。node2vec:基于有偏的随机游走产生节点序列,然后对节点序列应用SkipGram模型来学习node embedding。有两个关键的超参数1.0时,node2vec降级为DeepWalk。LINE:分别通过保持网络的一阶邻近性和二阶邻近性来为每个节点学习一阶邻近性embedding和 二阶邻近性embedding。节点的final embedding为二者的拼接。TriDNR:通过耦合多个神经网络来联合建模网络结构、node-content相关性、label-content相关性,从而学习node embedding。我们搜索文本权重超参数
所有的
baseline都采用原始作者发布的实现。注意,node2vec/LINE都是仅考虑结构信息,为了和利用属性信息的SNE进行公平的比较,我们将它们学到的node embedding和属性向量拼接起来,从而扩展为包括属性的形式。我们称这类变体为node2vec+attr和LINE+attr。此外,我们了解到最近的network embedding工作《Label informed attributed network embedding》也考虑了属性信息,但是由于他们的代码不可用,因此我们没有进一步比较它。SNE参数配置:- 和
node2vec/LINE方法一致,我们选择embedding维度p/q和node2vec相同。 - 我们的实现基于
tensorflow,选择mini-batch的Adam优化器,搜索的batch size范围从[8,16,32,64,128,256],搜索的学习率从[0.1,0.01,0.001,0.0001]。 - 我们搜索超参数
SNE退化为仅考虑网络结构。 - 我们使用
softsign函数作为隐层激活函数。我们尝试了多种激活函数,最终发现softsign的效果最好。 - 我们使用均值
0.0、标准差0.01的高斯分布来随机初始化模型参数。 - 如无特殊说明,我们选择两个隐层,即
下表给出了通过验证集择优的每种方法的最佳超参数。
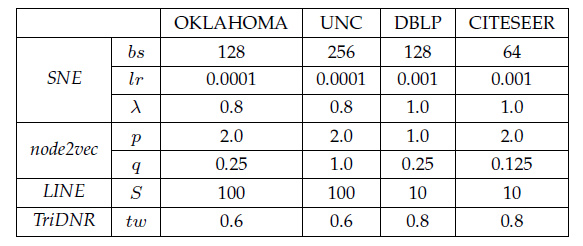
- 和
不同方法在四个数据集上链接预测任务的效果如下图所示。为探索不同网络稀疏性条件下各方法的鲁棒性,我们改变了训练链接的比例并研究了性能的变化。
结论:
SNE在所有方法中效果最佳。值得注意的是:和单纯的基于网络结构的node2vec/LINE相比,SNE在使用一半链接的条件下,性能更好。这证明了节点属性在链接预测方面的有效性,以及SNE通过节点属性学到更好的node embedding的合理性。此外,我们观察到
node2vec/LINE在DBLP和CITESEER上的性能随着训练比例越低,性能下降的更为明显。原因是DBLP/CITESEER数据集本身的链接就很少,因此当训练链接的比例降低时,链接的稀疏问题变得更加严重。相反,当我们使用更少的链接进行训练时,我们的SNE表现出更高的稳定性。这证明了对属性建模是有效的。聚焦于带属性的方法,我们发现集成属性的方式对于性能起着关键作用。
- 带属性的
node2vec+attr/LINE+attr相比node2vec/LINE略有改进,但是改进的幅度不大。这表明简单地将节点属性和embedding向量进行拼接的方式,无法充分利用属性中丰富的信号。这说明了将节点属性融合到网络embedding过程中的必要性。 SNE始终优于TriDNR。尽管TriDNR也是联合训练节点属性,但是我们的方法是在模型早期(输入层之后)就无缝地融合了属性信息,使得随后的非线性隐层可以捕获复杂的 ”网络结构-节点属性“ 交互信息,并学习更有效的node embedding。
- 带属性的
在基于结构的
embedding方法中,我们观察到node2vec在四个数据集中都优于LINE。一个合理的原因是:通过在社交网络上执行随机游走,node2vec可以捕获更高阶的邻近信息。相比之下,LINE仅对一阶邻近性和二阶邻近性建模,无法为链接预测捕获足够的信息。为验证这一点,我们进一步探索了一个额外的baseline:在随机游走时,选择和当前节点共享最多邻居的节点,从而直接利用二阶邻近性(即选择二阶邻近性最大的节点来游走)。不出所料,该baseline在所有数据集上的表现都很差(低于每个子图的底线)。这再次表明需要建模网络的高阶邻近性。由于
SNE使用和node2vec相同的随机游走过程,因此它可以从高阶邻近性中学习,并通过属性信息得到进一步补充。
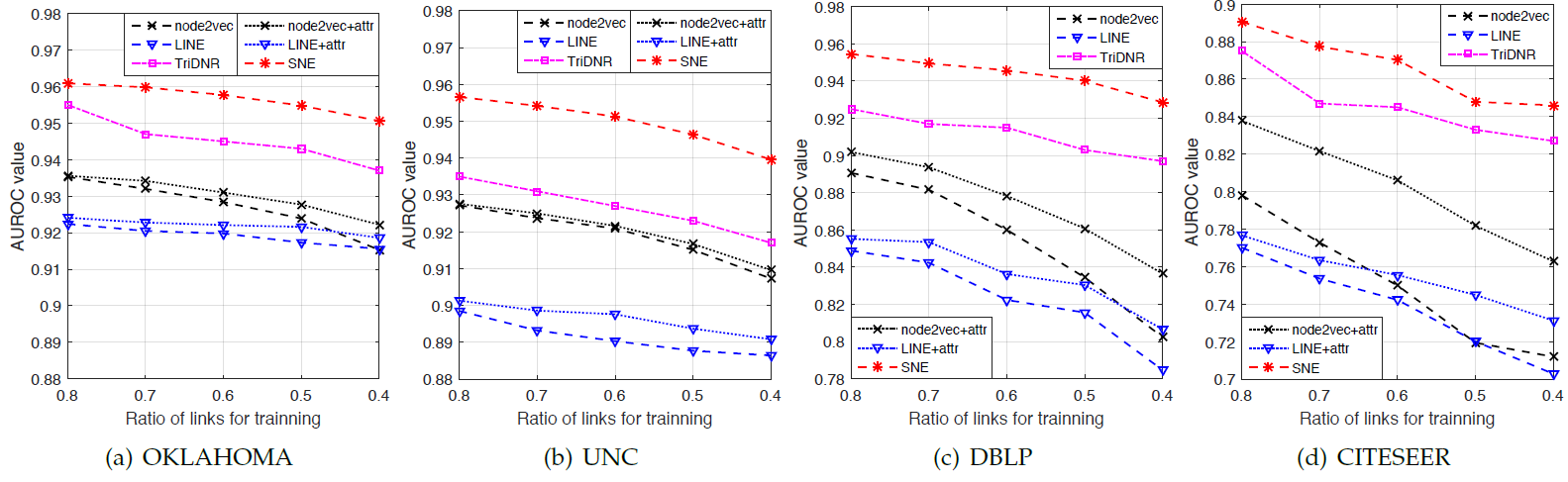
不同方法在两个数据集上的节点分类任务效果如下表所示。性能趋势和链接预测任务中的趋势一致。
- 在所有情况下,
SNE方法均超越了所有baseline。 - 仅使用网络结构的
node2vec和LINE表现最差,这进一步证明了社交网络上建模节点属性的有效性,并且正确建模属性信息可以导致更好的representation learning并有利于下游application。
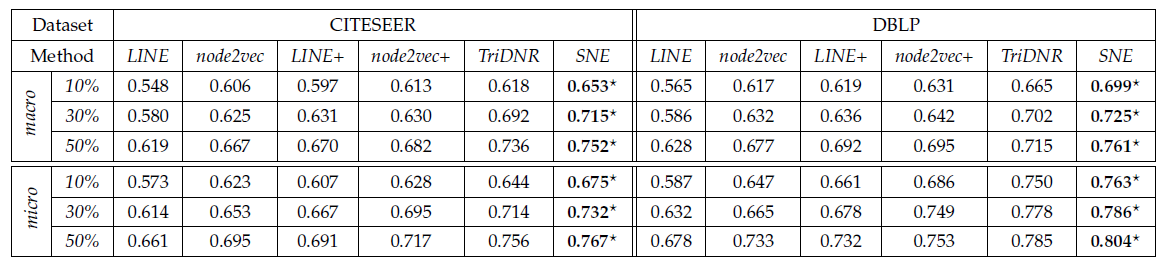
- 在所有情况下,
超参数
SNE模型的效果。我们以相同的方式来评估链接预测任务、节点分类任务,其中链接预测任务采用80%的链接作为训练集,节点分类任务采用50%的标记节点作为训练集。注意:当
- 最佳结果通常在
0.2。 - 通常属性信息在
SNE中起着重要作用,这一点可以通过SNE性能得到提升得以证明。当0.0 增加到0.2时,我们观察到CITESEER的性能显著提高。由于该数据集的链接较少,因此性能的提升表明属性有助于缓解链接稀疏问题。 - 当
SNE的效果优于node2vec。由于我们使用和node2vec相同的游走过程以及超参数
- 最佳结果通常在
为了解
SNE为什么要比其它方法效果好,这里我们对DBLP数据集进行研究。我们首先用每种方法学习每个节点的embedding,然后给定query paper我们利用node embedding检索最相似的三篇论文。其中,相似性是通过embedding的余弦相似度来衡量。为了和基于结构的方法进行公平比较,我们选择了
KDD 2006的一篇热门论文Group formation in large social networks: membership, growth, and evolution,该论文引用量达到1510。根据这篇论文的内容,我们预期相关结果应该是关于社交网络中群体或社区的结构演变。不同embedding方法检索到的最相关论文如下表。结论:
SNE返回了非常相关的结果:三篇论文都是关于动态社交网络分析和社区结构的。- 仅利用结构信息,
node2vec返回的结果似乎与query不太相似。node2vec似乎倾向于找到相关性较低、但是引用率较高的论文。这是因为随机游走过程可能容易偏向于具有更多链接的热门节点。尽管SNE也依赖于随机游走,但是SNE可以通过利用属性信息在一定程度上纠正这种偏差。 LINE也返回了和query不太相似的结果。这可能是由于仅建模一阶邻近性和二阶邻近性,忽略了丰富的属性信息。
通过以上定性分析我们得出结论:使用网络结构和节点属性都有利于检索相似节点。和单纯的基于结构的
embedding方法相比,SNE返回的结果与query更为相关。值得注意的是,对于本次研究,我们特意选择了一个热门的节点来缓解稀疏性问题,这实际上有利于基于结构的方法。即便如此,基于结构的方法也无法识别相关的结果。这揭示了仅依赖网络结构进行社交网络embedding的局限性,也证明了对节点属性进行建模的重要性。
最后我们探索隐层对于
SNE的影响。众所周知,增加神经网络的深度可以提高模型的泛化能力,但是由于优化困难这也可能降低模型性能。因此我们迫切想知道:使用更深层的网络是否可以提升SNE的性能。我们在DBLP上验证了SNE模型不同数量的隐层对应的链接预测、节点分类任务的性能。在其它数据集上的结论也是类似的,因此我们仅以DBLP为例。由于最后一层隐层的大小决定了SNE模型的表达能力,因此我们将所有模型的最后一层隐层都设为128维从而公平地比较。对每个比较的模型,我们都重新调优超参数从而充分发挥模型的能力。结论:
可以看到一个趋势:隐层越多模型性能越好。这表明在
SNE中使用更深的网络效果更好。但是,其代价是更多的训练时间。在普通的商用服务器上(2.4GHz的Intel Xeon CPU),单层SNE耗时25.6秒/epoch、三层SNE耗时81.9秒/epoch。我们停止探索更深层的模型,因为当前的
SNE使用全连接层,而深层的全连接层很难优化。并且很容易随着层的加深出现过拟合over-fitting和退化degrading。表中效果提升的衰减也暗示了这一点。为了解决该问题,我们建议采用现代的神经网络设计方法,如残差单元
residual unit或highway network。我们将该工作留给未来的工作。值得注意的是:当没有隐层时
SNE的性能会很差,与TriDNR处于同一水平。当增加了一层隐层时,模型效果大幅提升。这证明了以非线性方式学习 “网络结构 -- 节点属性” 交互的有效性。为证明这一点,我们进一步尝试在隐层使用恒等函数identity替代softsign激活函数,最终效果要比非线性softsign激活函数差得多。

三十、ProNE[2019]
在过去的几年里,
representation learning为网络挖掘和分析提供了一种新的范式。representation learning的目标是将网络结构投影到一个连续的embedding空间,同时保持网络的某些属性。广泛的研究表明,学到的embedding可以使得众多的数据挖掘任务受益。network embedding的最新进展大致可以分为三类:基于矩阵分解的方法,如SocDim, GraRep, HOPE, NetMF;基于SkipGram的模型,如DeepWalk, LINE, node2vec;基于图神经网络graph neural network: GNN的方法,如Graph Convolution, GraphSage, Graph Attention。通常,前两种方法预训练的embedding被输入到下游任务的学习模型中。因此,高效地生成有效的network embedding从而服务于大型网络application至关重要。然而,大多数现有模型都聚焦于提高embedding的效果effectiveness,使得模型的效率efficiency和可扩展性scalability受到限制。例如,在基于分解的模型中,GraRep的时间复杂度为SkipGram的模型中,当使用默认超参数时,在现代服务器上使用20个线程来学习一亿个节点、五亿条边的网络的embedding,LINE将花费数周时间,DeepWalk/node2vec将花费数月时间。为了解决当前工作的效率和可扩展性的限制,论文
《ProNE: Fast and Scalable Network Representation Learning》提出了一种高效的、且可扩展的network embedding算法ProNE。ProNE的总体思想是:首先以有效的方式初始化network embedding,然后增强这些embedding的表达能力。受大多数真实网络的长尾分布及其产生的网络稀疏性network sparsity的启发,第一步是通过将network embedding形式化为稀疏矩阵分解来实现。第二步是利用高阶Cheeger不等式对初始化的embedding进行谱域传播,目标是捕获网络的局部平滑localized smoothing信息和全局聚类global clustering信息。这种设计使得
ProNE成为一个速度极快的embedding模型,同时保持效果上的优势。论文在五个真实世界网络和一组随机网络上进行了实验。大量实验表明,单线程ProNE模型要比具有20个线程的、流行的network embedding benchmark(包括DeepWalk, LINE, node2vec)快大约10 ~ 400倍,如下图所示。论文的可扩展性分析表明,ProNE的时间成本与network volume和network density呈线性相关,使得ProNE可以扩展到数十亿规模的网络。事实上,通过仅使用一个线程,ProNE只需要29个小时来学习上述一亿个节点的网络的embedding。注意,ProNE也很容易并行化。
除了效率和可扩展性优势之外,
ProNE在多标签节点分类任务的所有数据集中也始终优于所有baseline。更重要的是,ProNE中的第二步(即,谱域传播spectral propagation)是增强network embedding的通用框架。通过将DeepWalk, LINE, node2vec, GraRep, HOPE生成的embedding作为输入,论文的谱域传播策略在一秒钟内为所有这些embedding进行了增强,并带来了平均+10%的相对提升。这篇论文的基本思想是:首先训练一个
initial embedding,然后通过消息传递机制在network上传播这个initial embedding从而refine。它复用了标签传播的思想,并没有太大的创新。至于initial embedding方法可以有多种选择,不一定必须采用论文中提到的方法。相关工作:最近出现的
network embedding很大程度上是由SkipGram在自然语言和网络挖掘中的应用所引发的。network embedding的历史可以追溯到谱聚类spectral clustering和社交维度学习social dimension learning。在network embedding的发展过程中,大多数方法旨在隐式地或显式地建模节点之间分布式distributional的相似性。受
word2vec模型的启发,人们已经提出了一系列基于SkipGram的embedding模型,用于将网络结构编码为连续空间,如DeepWalk, LINE, node2vec。最近的一项研究《Neural word embedding as implicit matrix factorization》表明,基于SkipGram的network embedding可以理解为隐式矩阵分解。此外,受到该研究的启发,《Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec》提出了NetMF模型来执行显式矩阵分解从而学习network embedding。NetMF与我们模型的区别在于:NetMF要分解的矩阵是稠密矩阵,其构造和分解涉及到ProNE模型将network embedding形式化为其它一些近期的、基于矩阵分解的
network embedding模型包括GraRep和HOPE。谱域的network emebdding与谱域降维方法有关,例如Isomap、Laplacian Eigenmap、spectral clustering。这些基于矩阵分解的方法通常需要昂贵的计算、以及过多的内存消耗,因为它们的时间复杂度和空间复杂度都很高。另一个重要的工作方向是将图谱
graph spectral推广到监督的graph learning中,如图卷积网络graph convolution network: GCN。在GCN中,卷积操作是在谱空间中定义的,参数化的filter是通过反向传播来学习的。与它们不同的是,我们的ProNE模型具有一个带通滤波器band-pass filter(该滤波器的参数是人为设定的,因此不需要学习),该滤波器同时结合了空间局部平滑spatial locality smoothing和全局聚类global clustering两个特点。此外,ProNE是一种无监督且任务无关的模型,旨在预训练通用的embedding,而大多数GCN是以辅助特征side feature(例如由ProNE学到的network embedding)作为输入的监督学习。
30.1 模型
定义图
degree matrix为对角矩阵给定网络
network embedding的目标是学习一个映射函数node representation可以使得各种下游的图挖掘任务受益。然而,目前的一个主要挑战是:大多数network embedding模型处理大规模网络在计算上不可行。例如,即使使用20个线程,DeepWalk学习一个包含一亿节点的稀疏图的embedding需要耗时几个月。我们提出的
ProNE是一种用于大规模网络的embedding的非常快速且可扩展的模型,它由两个步骤组成,如下图所示:- 首先
ProNE将network embedding建模为稀疏矩阵分解,从而获得节点的有效初始embedding。 - 然后
ProNE利用高阶Cheeger不等式来调制modulate谱域空间,并在调制后的谱域空间传播学到的embedding,从而集成了局部平滑信息和全局聚类信息。
- 首先
30.1.1 稀疏矩阵分解
分布式假设
distributional hypothesis启发了最近出现的word embedding和network embedding。这里我们展示了如何将基于分布式相似性distributional similarity-based的network embedding形式化为矩阵分解。network embedding作为稀疏矩阵分解:通常我们利用结构上下文structural context来建模节点相似性。我们建议利用最简单的结构,即edge,来表示node-context的pair对。然后我们得到了node-context集合contextsigmoid函数,context embedding;embedding。这里我们的上下文只考虑直接相连的节点(即,随机游走序列中的上下文窗口大小为
1)。考虑所有的边,则损失函数为
degree不同,因此我们对损失函数进行加权:其中
上述目标函数存在一个平凡解:对于任意
假设负采样比例为
其中
根据偏导数为零
定义邻近性矩阵
proximity matrix因此基于分布式相似性的
network embedding的目标函数等价于对truncated Singular Value Decomposition:tSVD,来求解,即:其中:
top d个奇异值组成的对角矩阵;d列。最终
embedding矩阵,第embedding向量。可以看到,由于
用于快速
embedding的稀疏化随机tSVD:虽然可以通过矩阵分解来求解network embedding,但是在大规模矩阵上执行tSVD的时间复杂度、空间复杂度仍然非常高。为了实现快速的network emebdding,我们建议使用随机tSVD。根据随机矩阵理论,该方法可以大大加快tSVD的速度,并具有理论的近似保证。- 首先寻找一个矩阵
- 假设找到这样的矩阵
SVD进行高效地分解。 - 假设已经得到分解
embedding矩阵为
随机矩阵理论使我们能够有效地找到
- 首先生成一个
- 然后定义矩阵
QR分解:
已有工作证明,基于
SkipGram的network embedding模型等价于隐式的矩阵分解,但是分解的是一个稠密矩阵,其计算复杂度为- 首先寻找一个矩阵
30.1.2 embedding 谱域传播
与
DeepWalk,LINE等其它流行方法类似,通过稀疏矩阵分解得到的embedding仅捕获局部结构信息。为了进一步集成全局网络属性(如社区结构),我们提出在谱域中传播embedding。注意,该策略是通用的,也可用于提升现有的embedding模型。network embedding与graph spectrum和graph partition的关联:高阶Cheeger不等式表明,graph spectral中的特征值与网络的空间局部平滑spatial locality smoothing、全局聚类global clustering密切相关。 我们首先介绍公式,然后展示如何帮助增强network embedding。在图论中,归一化的图拉普拉斯矩阵定义为:
给定信号
图上的信号传播
给定图
Cheeger常数来衡量图的划分效果:其中:
degree之和。Cheeger常数的物理意义为:随机选择给定图
k-way划分:定义
k阶Cheeger常数为Cheeger不等式给出了graph partition和graph spectrum之间的联系:可以看出:
无向图中连通分量的数量,等于拉普拉斯矩阵中取值为零的特征值数量。这可以通过设置
小特征值通过将网络划分为几个大的部分,从而控制网络的全局聚类效果;大特征值通过将网络划分为很多小部分,从而控制网络的局部平滑效果。
这启发我们通过在划分后的(或者说调制后的)网络的谱域中传播
embedding,从而将全局信息和局部信息集成到network embedding中。
假设
node embedding矩阵为embedding为:其中:
modulated调制的拉普拉斯矩阵,spectral modulator。
为同时考虑全局结构信息和局部结构信息,我们选择谱域调制器为:
其中
top最大和top最小的特征值进行衰减,分别导致放大局部网络信息和全局网络信息。调制的拉普拉斯矩阵为:为什么选择这种结构的谱域调制器,作者并未说明原因。另外,是否可以考虑简单地邻域聚合方式来
refine embedding。注意:
- 带通滤波器是通用的谱域网络调制器,也可以使用其它类型的滤波器。
- 可以利用截断的切比雪夫多项式来避免求解
- 为了保持由稀疏
tSVD实现的原始embedding空间的正交性,我们再次在SVD。
算法复杂度:
- 对
SVD分解的算法复杂度为QR分解的算法复杂度为 - 由于
因此第一步稀疏矩阵分解的算法复杂度为
embedding谱域传播的计算复杂度为ProNE的计算复杂度为ProNE的空间复杂度为- 对
并行性:
ProNE计算的主要时间消耗在稀疏矩阵乘法上,用单线程来处理足够高效,因此ProNE主要是单线程的。另外,目前稀疏矩阵乘法的并行化已经取得了一些进展,我们预期将来可以通过多线程的稀疏矩阵乘法进一步提升ProNE的训练效率。
30.2 实验
数据集:我们使用五个广泛使用的数据集来证明
ProNE的有效性,另外我们还使用一组人工合成网络来评估其效率和可扩展性。BlogCatalog数据集:一个社交博客网络,其中博主的兴趣作为label。Wiki数据集:Wikipedia dump文件前一百万个字节中的单词共现网络,其中节点标签是单词的的词性tag。PPI数据集:一个PPI网络的子集,其中节点标签是从基因组中提取的,代表生物学状态。DBLP数据集:一个学术引文网络,节点代表作者,会议conference为标签。YouTube数据集:一个YouTube用户之间的社交网络,其中节点标签代表基于所喜欢视频类型的用户分组。
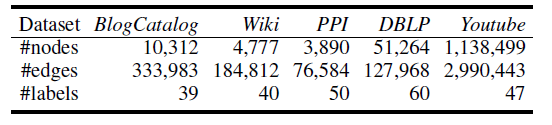
baseline方法:我们将ProNE和流行的baseline比较,其中包括基于SkipGram的 方法(DeepWalk, LINE, node2vec),以及基于矩阵分解的方法(GraRep, HOPE)。我们并未考虑基于卷积的方法,因为大多数基于卷积的方法都是监督的或半监督的,这要求额外的标签信息。
配置:
- 为进行公平比较,所有方法的
embedding维度为 - 对于
DeepWalk,node2vec,我们选择窗口大小为10,每个节点开始的随机游走序列的数量为10, 随机游走序列长度为40。 node2vec中的参数{0.25,0.50,1,2,4}。- 对于
LINE,负采样系数为 - 对于
GraRep,为公平起见,拼接的embedding维度为 - 对于
HOPE,(0,1)之间搜索最佳的值。 - 对于
ProNE,切比雪夫展开项的数量
运行配置:在
Intel Xeno(R) CPU E5-4650(2.70GHz),以及1T RAM的Red Hat server上运行。- 为进行公平比较,所有方法的
评估方式:我们随机抽取不同比例的标记节点从而训练
liblinear分类器,并将剩余的标记节点用于测试。我们重复训练和预测十次,报告平均的Micro-F1。Macro-F1的结果也类似,但是由于篇幅有限我们并未显示。我们根据
wall-clock时间来评估算法效率,并通过多种规模的网络中的学习时间来分析ProNE的可扩展性。效率:我们比较了不同方法的训练时间,并展示了
ProNE的可扩展性,如下图所示(单位为秒)。我们仅给出最快的三个baseline方法,因为矩阵分解的baseline方法GraRep, HOPE比它们要慢得多。注意:所有
baseline都使用了20个线程,而ProNE仅使用单个线程。结论:单线程
ProNE模型比20线程的LINE, DeepWalk, node2vec模型快10~400倍,也远远超越了其它矩阵分解方法。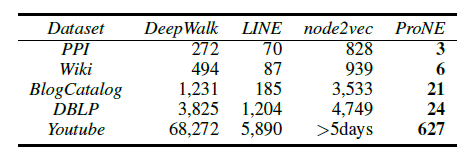
可扩展性:我们通过人工合成网络来评估
ProNE的可扩展性。首先我们生成节点degree固定为10的随机图,节点规模从1000到1亿。图
(a)给出不同大小随机图上ProNE的学习时间,这表明ProNE的时间代价随着网络规模的增加而线性增加。我们在图上也标注出
ProNE在五个真实数据集上的学习时间,其趋势也是和网络规模呈线性。另外,蓝色曲线表示ProNE的稀疏矩阵分解sparse matrix factorization:SMF的时间代价。图
(b)给出了ProNE在固定大小的1万个节点上,且节点degree从100到1000之间变化的随机图上的学习时间。可以看到:ProNE的学习效率和网络密度线性相关。
结论:
ProNE是一种可扩展的network embedding方法,它可以处理大规模、稠密的网络。
效果:我们在下表给出了不同模型预测的效果(给出了
Micro-F1的均值和标准差)。除了ProNE,我们还报告了ProNE中由稀疏矩阵分解SMF步骤生成的初始embedding结果。另外对于YouTube,node2vec在五天内无法完成,而HOPE,GraRep由于内存消耗太多而无法处理。结论:
ProNE在五个数据集中始终比baseline效果更好,这证明了其有效性。ProNE中第一步使用的简单稀疏矩阵分解SMF的效果与baseline相比相差无几甚至更好。随着谱域传播技术的进一步结合,由于有效地建模了局部结构平滑信息和全局聚类信息,ProNE在所有baseline中产生了最佳性能。
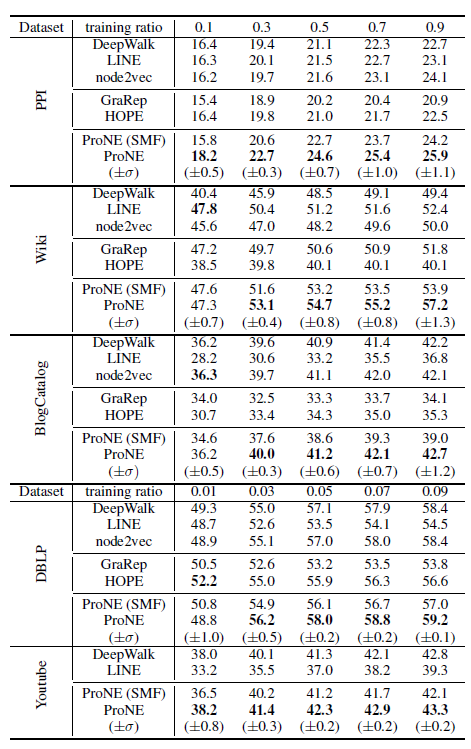
用于
embedding增强的谱域传播:最后我们将DeepWalk, LINE, node2vec, GraRep, HOPE学到的embedding输入到ProNE的谱域传播步骤中。下图显示了Wiki上的原始结果和增强结果(称作ProBaseline),说明了Pro版本对所有五个baseline的显著改进。平均而言,我们的谱域传播策略可以为所有方法提供+10%的相对提升,例如HOPE的改善为25%。另外,所有增强实验都在1秒钟内完成。结论:
ProNE的谱域传播是有效的,并且是改善network embedding的通用且高效策略。