三十五、T-Few[2022]
论文:
《Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning》
预训练语言模型已成为自然语言处理的基石,因为它们可以在感兴趣的任务上显著提高数据效率,即:使用预训练语言模型进行初始化通常会产生更好的结果,并且所需的标记数据更少。历史上常用的方法是在感兴趣的下游任务上使用梯度微调,以
pre-trained参数作为初始化。尽管微调产生了许多SOTA的结果(《Multitask prompted training enables zero-shot task generalization》),但它会导致模型专门针对单个任务采用全新的参数值集合,当在许多下游任务上进行微调时,这种方法可能变得不切实际。GPT-2, GPT-3提出的另一种替代方法是in-context learning: ICL,它通过输入prompted examples诱导模型执行下游任务。few-shot prompting将少量的input-target pair转换为(通常是)人类可以理解的指令和示例,同时包含一个需要进行预测的单个unlabeled example。值得注意的是,ICL不需要基于梯度的训练,因此允许单个模型立即执行各种任务。因此,ICL的执行完全依赖于模型在预训练期间学到的能力。这些特点导致了对ICL方法的最近广泛关注。尽管
ICL具有实际的优势,但它也有一些主要缺点:首先,每次模型进行预测时,处理所有
prompted的input-target pair都会带来重大的计算成本。假设
few-shot examples数量为其次,与微调相比,
ICL通常表现出较差的性能(GPT-3)。最后,
prompt的确切格式,包括措辞(《Do prompt-based models really understand the meaning of their prompts? 》)和示例排序(《Calibrate before use: Improving few-shot performance of language models》),对模型的性能产生重大且难以预测的影响,远超过微调的不同运行之间的差异。最近的研究还表明,即使提供错误的标签,ICL也能表现出良好的性能,这引发了关于实际学习程度的问题(《Rethinking the role of demonstrations: What makes in-context learning work?》)。
parameter-efficient fine-tuning: PEFT是一种额外的范式,它使模型能够通过仅更新一小部分新增的、或选择的参数来执行新任务。最近的方法在仅更新或新增全模型参数的一小部分(例如0.01%)的情况下,达到了与对整个模型进行微调相当的性能(《LoRA: Low-rank adaptation of large language models》、《The power of scale for parameter-efficient prompt tuning》)。此外,某些PEFT方法允许mixed-task batches,其中batch中的不同示例被以不同的方式处理(《The power of scale for parameter-efficient prompt tuning》),使得PEFT和ICL都适用于多任务模型。尽管
PEFT的优点解决了微调的一些缺点(与ICL相比),但在只有少量的标记数据可用时,对于PEFT方法是否能够良好运作,关注较少。本文的主要目标是通过提出一种配方,即:一个模型、一个PEFT方法、以及一组固定的超参数,在只更新模型的极小部分参数的情况下,在新的、未知的任务上实现强大的性能。具体而言,我们基于T0模型,这是T5模型在multitask mixture of prompted datasets上进行微调的一个变种。为了提高分类任务和多项选择任务的性能,我们添加了unlikelihood-based(《Improving and simplifying pattern exploiting training》、《Neural text generation with unlikelihood training》)和length normalization-based(GPT-3)的损失项。此外,我们开发了learned vectors的PEFT方法。10,000倍的参数的情况下,实现了比全模型微调更强的性能。最后,我们证明了在微调之前预训练《PPT: Pre-trained prompt tuning for few-shot learning》、《SPoT: Better frozen model adaptation through soft prompt transfer》)。我们的整体配方被称为T-Few,在RAFT这个真实世界的few-shot learning基准中,T-Few的性能显著优于ICL(甚至对比于16倍更大的模型),并且首次超越了人类,同时大大减少计算量,并允许在推理过程中进行mixed-task batches。为了方便在新问题上使用T-Few并进行有关PEFT的未来研究,我们发布了我们的代码。IA3的核心思想:将free vector以乘法的方式作用在activations上,而不是以加法的方式。相关工作:
目前,
prompt tuning是大型语言模型中最参数有效的方法之一(《Prefix-Tuning: Optimizing continuous prompts for generation》、《The power of scale for parameter-efficient prompt tuning》、《Learning how to ask: Querying LMs with mixtures of soft prompts》)。《P-Tuning v2:Prompt tuning can be comparable to fine-tuning universally across scales and tasks》提出了一些技巧来改善prompt tuning。《Input-Tuning: Adapting unfamiliar inputs to frozen pretrained models》通过调优prompts和input embeddings来提升性能《AdaPrompt: Adaptive model training for prompt-based NLP》通过持续的预训练来改进prompt embeddings。鉴于在训练
prompt embeddings时存在优化困难,《Black-box prompt learning for pre-trained language models》最近使用黑盒优化来训练prompt embeddings,无需梯度。有几项研究从可解释性的角度分析了
prompt tuning(《Prompt waywardness: The curious case of discretized interpretation of continuous prompts》)、以及与其他PEFT方法的相似性(《Towards a unified view of parameter-efficient transfer learning》)。
prompt tuning已经应用于包括continual learning、模型鲁棒性、摘要、机器翻译、co-training、探索语言模型、inverse prompting、以及迁移学习在内的各种自然语言处理应用中。《HyperPrompt: Prompt-based task-conditioning of transformers》最近提出使用hypernetwork来预测新任务的prompts(而不是通过梯度下降训练prompt parameters)。prompt tuning和其它PEFT方法也在语言模型之外的领域得到了探索(如视觉模型、vision-and-language模型)。另外,各种研究考虑了使用
discrete prompts进行few-shot full-model fine-tuning(《Exploiting cloze questions for few shot text classification and natural language inference》)。最近的研究分析了使用discrete prompts进行训练的情况:一些研究表明在训练不同数量的示例时,使用
prompting可以提高性能(《How many data points is a prompt worth?》)。另一些研究发现模型在
good prompts和bad prompts上训练时表现相似(《Do prompt-based models really understand the meaning of their prompts?》)。还有一些研究探索哪些
prompts对于few-shot setting和full-shot setting有效(《Do prompts solve NLP tasks using natural language?》)。
还有一些努力开发找到
discrete prompts的方法(《Auto-Prompt: Eliciting knowledge from language models with automatically generated prompts》、《Making pre-trained language models better few-shot learners》),并使用类似于prompt tuning的方法训练prompts(《Differentiable prompt makes pre-trained language models better few-shot learners》)。对于
ICL的改进也进行了大量的研究。《Meta-learning via language model in-context tuning》、《Metaicl: Learning to learn in context》使用ICL进行meta-learning,以在新任务上进行few-shot learning。《Can language models learn from explanations in context? 》表明,在提供解释的情况下,ICL可以得到改进,并且《Internet-augmented language models through few-shot prompting for open-domain question answering》使用从web检索到的文本进行开放域问答的ICL。与此同时,
《Rethinking the role of demonstrations: What makes in-context learning work?》分析了ICL的工作原理,并显示即使为in-context examples提供不正确的标签,ICL仍然可以表现良好。
随着百亿级参数语言模型的出现,近年来对于
PEFT方法及其在few-shot setting中的兼容性引起了广泛关注。《Compacter: Efficient low-rank hypercomplex adapter layers》发现在low-resource setting中PEFT优于标准微调。在同时进行的工作中,
《PERFECT: Prompt-free and efficient few-shot learning with language models》发现PEFT在few-shot fine-tuning中与discrete prompts(如PET)相比具有竞争力。同时,
《Adaptable adapters》提出了一个框架,引入了适应不同任务的adapters,展示了在few-shot settings中改进的结果。《PPT: Pre-trained prompt tuning for few-shot learning》和《SPoT: Better frozen model adaptation through soft prompt transfer》都探索了当有限标记数据可用时,pre-training prompt tuning parameters的改进。对于
few-shot learning,《Learning a universal template for few-shot dataset generalization》探索了学习通用的参数和数据集相关参数,以进行泛化。《Fast and flexible multi-task classification using conditional neural adaptive processes》使用条件神经自适应过程(conditional neural adaptive processes),《Universal representation learning from multiple domains for few-shot classification》利用多个特征提取器的蒸馏来学习few-shot learning中的新类别或领域。
35.1 背景知识
在本节中,我们重点介绍
ICL和PEFT,并描述进行prediction所需的计算成本、内存成本、以及存储成本。实际成本取决于实现和硬件,因此我们以FLOPs(浮点操作次数)来报告计算成本、以字节数来报告计算成本、内存成本。
35.1.1 Few-shot in-context learning (ICL)
In-Context Learning: ICL旨在通过馈入concatenated and prompted input-target examples(称为shots)以及一个未标记的query example,从而引导模型执行任务。以GPT-3的循环字母任务(cycled letter task)为例,一个4-shot的输入或上下文可能是"Please unscramble the letters into a word, and write that word: asinoc = casino, yfrogg = froggy, plesim = simple, iggestb = biggest, astedro =",期望的输出是"roasted"。ICL通过feeding in the context并从模型中采样,来引导自回归语言模型执行该任务。对于分类任务,每个标签与一个字符串相关联(例如,情感分析中的"positive"和"negative"),通过选择模型赋予最高概率的label string来分配标签。对于多项选择任务(例如,在问题的ICL的主要优势是它使得单个模型能够立即执行多个任务,无需进行微调。这也使得可以使用mixed-task batches,其中通过在输入中使用不同的上下文,数据batch中的不同示例对应于不同的任务。ICL通常仅使用有限数量的labeled examples进行操作,也就是所谓的少样本学习(few-shot learning),因此具有data-efficient的特点。尽管具有这些优势,
ICL也存在显著的实际缺点:首先,进行预测的计算成本大幅增加,因为模型需要处理所有的
in-context labeled examples。具体而言,忽略Transformer语言模型中自注意力操作的二次复杂度(与模型的其他部分相比通常较小,《Scaling laws for neural language models》),对于k-shot ICL,处理unlabeled example。其次,内存成本也以大约以
此外,对于给定任务,还需要一小部分磁盘存储空间来存储
in-context examples。例如,对于每个示例的prompted input and target长度为512 tokens的任务,存储32个示例在磁盘上大约需要66千字节的存储空间(32 examples °ø 512 tokens °ø 32 bits)。
实际上,推断成本相对于训练成本而言几乎可以忽略不计。大型语言模型的训练甚至微调都需要耗费巨大的显存、以及大量的时间。
除了上述成本之外,
ICL还表现出令人难以理解的行为。《Calibrate before use: Improving few-shot performance of language models》显示示例在上下文中的顺序会极大地影响模型的预测结果。《Rethinking the role of demonstrations: What makes in-context learning work?》表明,即使in-context example labels发生互换(即label变为不正确)的情况下,ICL仍然可以表现良好,这引发了关于ICL是否真正从labeled examples中 “学习” 的问题。已经提出了多种方法来缓解这些问题。降低计算成本的一种方法是缓存
in-context examples的键向量和值向量。这是可能的,因为decoder-only Transformer语言模型具有causal masking pattern,因此模型对context的激活不依赖于unlabeled example。在极端情况下,对于32-shot ICL,其中每个in-context example具有512 tokens,将导致GPT-3模型的键向量和值向量缓存超过144 GB(对于每个键向量和值向量,缓存规模为对于给定的任务,所有的
unlabeled example共享了相同的一组in-context examples,因此可以把这些in-context examples的activations缓存起来。另外,
《Noisy channel language model prompting for few-shot text classification》提出了ensemble ICL,其中不是使用concatenating the k training examples的输出概率,而是将模型在每个训练示例上的输出概率(即每个示例的1-shot ICL)相乘。这降低了non-parameter内存成本约为《Noisy channel language model prompting for few-shot text classification》发现ensemble ICL优于标准的拼接的变体。
35.1.2 Parameter-efficient fine-tuning
标准微调会更新
pre-trained模型的所有参数,但研究表明,可以只更新或添加相对较少的参数。早期的方法提出添加
adapters(《Learning multiple visual domains with residual adapters》、《Parameter-efficient transfer learning for NLP》、《Simple, scalable adaptation for neural machine translation》),这些adapters是插入到fixed pre-trained model的层之间的小型可训练前馈网络。此后,提出了各种复杂的
PEFT方法,包括选择稀疏参数子集来训练(《Parameter-efficient transfer learning with diff pruning》、《Training neural networks with fixed sparse masks》)、产生低秩更新(《LoRA: Low-rank adaptation of large language models》)、在较低维子空间中进行优化(《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》)、使用超复数乘法(hypercomplex multiplication)添加低秩适配器(《Compacter: Efficient low-rank hypercomplex adapter layers》)等等。相关地,
prompt tuning(《The power of scale for parameter-efficient prompt tuning》)和prefix tuning(《Prefix-Tuning: Optimizing continuous prompts for generation》)通过将learned continuous embeddings拼接到模型的输入或模型的激活中从而诱导模型执行任务;这可以看作是一种PEFT方法(《Towards a unified view of parameter-efficient transfer learning》)。
SOTA的PEFT方法可以在仅更新模型参数的极小比例(例如0.01%的比例)的情况下达到微调所有模型参数的性能。PEFT极大地减少了训练模型和保存模型所需的内存和存储空间。此外,某些PEFT方法直接支持mixed-task batches。例如,prompt tuning对于batch中的每个示例拼接不同的prompt embeddings,使单个模型能够执行多个任务(《The power of scale for parameter-efficient prompt tuning》)。另一方面,对模型进行重新参数化的PEFT(例如《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》、《LoRA: Low-rank adaptation of large language models》)对于mixed-task batches来说成本高或繁重。此外,不同的PEFT方法增加了执行推断所需的计算量和内存量的不同程度。例如,adapters实际上为模型添加了额外的(小型)层,从而导致计算成本和内存的小幅增加。PEFT还产生了额外的成本,即微调的成本,该成本必须执行一次,并且在模型用于推断时分摊。然而,我们将展示PEFT在考虑微调和推断时可以极大地提高计算效率,同时实现比ICL更好的准确性。
35.2 T-Few
鉴于
PEFT允许模型在相对较小的存储需求和计算成本下适应新任务,我们认为PEFT是ICL的一个有前景的替代方案。因此,我们的目标是开发一种配方,使模型能够在有限的labeled examples上实现高准确性,同时在推断期间允许mixed-task batches,并且计算和存储成本最小化。通过配方(配方指的是一种具体的模型和超参数设置),在任何新任务上都能提供强大的性能,无需手动调优或per-task adjustments。通过这种方式,我们可以确保我们的方法是在few-shot settings中的一个实际选项(realistic option),其中有限的标记数据可用于评估(《True few-shot learning with language models》、《Realistic evaluation of deep semi-supervised learning algorithms》)。
35.2.1 模型和数据集
作为第一步,我们必须选择一个
pre-trained模型。理想情况下,模型在有限数量的labeled examples上微调后应在新任务上达到高性能。在将PEFT方法应用于不同的pre-trained模型的初步实验中,我们发现T0的性能最佳。T0基于T5,T5是一种encoder-decoder Transformer模型,通过masked language modeling objective在大量未标记文本数据上进行了预训练。为了实现zero-shot泛化能力,即在没有任何额外基于梯度的训练的情况下执行任务的能力,T0是通过对T5在多任务混合数据集上进行微调而创建的。用于训练T0的数据集中的样本是通过应用来Public Pool of Prompts: P3的prompt templates来生成的,这些模板将每个数据集中的每个样本转换为prompted text-to-text format格式,其中每个标签对应于不同的字符串。为简洁起见,我们省略了对T0和T5的详细描述;有兴趣的读者可以参考论文《Multitask prompted training enables zero-shot task generalization》和《Exploring the limits of transfer learning with a unified text-to-text transformer》。T0发布了3B参数和11B参数的变体,分别称为"T0-3B"和"T0"。在本节中(我们的目标是通过大量实验设计T-Few配方),为了减少计算成本,我们使用T0-3B。对于所有的模型和实验,我们使用Hugging Face Transformers库。虽然
T0被设计用于zero-shot泛化,但我们将展示它在仅有少量标记示例进行微调后也能达到强大的性能。为了测试T0的泛化能力,《Multitask prompted training enables zero-shot task generalization》选择了一组任务(及相应的数据集),这组任务从multitask training mixture中hold out,具体来说,包括句子补全(COPA, H-SWAG, Story Cloze数据集)、自然语言推断(ANLI, CB, RTE数据集)、共指消解(WSC, Winogrande数据集)以及词义消歧(WiC数据集)等任务。通过在这些held-out数据集上测量性能,可以直接评估泛化能力。我们还将在后续正文中在RAFT基准测试中测试T-Few在未见过的"real-world" few-shot tasks上的能力,该基准测试没有验证集而只有一个held-out的测试集。为了便于比较,对于每个数据集我们使用与
GPT-3相同数量的few-shot training examples,数量从20到70不等。不幸的是,GPT-3使用的few-shot dataset的子集尚未公开披露。为了进行更鲁棒的比较,我们使用不同随机数种子进行抽样构建了五个few-shot datasets,并报告了中位数和四分位数范围。我们使用P3(《PromptSource: An integrated development environment and repository for natural language prompts》)prompt template为每个示例的每个步骤生成prompt。除非另有说明,我们将模型训练1K步,batch size = 8,并在训练结束时报告性能。在评估中,我们使用
"rank classification",即所有可能的标签字符串的对数概率进行排名,如果排名最高的选择是正确答案,则认为模型的预测是正确的。rank classification evaluation适用于分类任务和多选题任务。由于模型的性能可能根据使用的prompt template而有显著差异,我们报告了来自P3的所有prompt templates以及各个数据集的few-shot data subsets的中位数准确率。对于所有数据集,我们报告测试准确率、或者验证准确率(当测试标签不公开时,例如SuperGLUE数据集)。在本文中,我们报告了上述九个数据集的中位数准确率。每个数据集的详细结果在附录中提供。
35.2.2 Unlikelihood Training and Length Normalization
在研究
PEFT方法之前,我们首先探索了两个额外的损失项(few-shot fine-tuning性能。语言模型通常使用交叉熵损失target sequenceunlikelihood loss:在评估中,我们使用rank classification,它依赖于模型对正确选项和错误选项的概率。为了在训练过程中考虑这一点,我们添加了一个unlikelihood loss(《Improving and simplifying pattern exploiting training》、《Neural text generation with unlikelihood training》):其中,
target sequence,一共有target sequences。我们假设添加rank classification的结果,因为模型将被训练为将更低的概率分配给错误选项,从而提高正确选项为排名最高的选项的概率。例如,对于二分类任务,假设
label = 1(即,positive),那么模型可能在"positive"字符串上具有较高的logits、在"negative"字符串上具有较低的logits。然而,由于decoder的输出可以是任意字符串,它也可能输出{"positive", "negative"}之外的字符串,因此需要对这种情况进行抑制。这就是non-positive字符串,并计算它们的平均损失并使这个损失最小化。non-positive字符串的概率“ 最大化。长度归一化(
length normalization):对于给定的训练样本,可能的target sequences长度可以有显著差异,尤其是在多项选择任务中。基于概率对每个选项进行排名可能会 “偏向” 于较短的选项,因为模型分配给每个token的概率小于等于1.0。为了纠正这一点,我们考虑在执行rank classification时使用长度归一化(length normalization),即将模型对每个候选答案选项的分数除以该选项中的token数量(与GPT-3中使用的方法相同)。在评估期间使用长度归一化时,我们在训练过程中引入了一个额外的损失项使得更接近于长度归一化的评估:首先,我们计算给定输出序列的长度归一化的对数概率(
length-normalized log probability)然后,我们通过最小化
softmax交叉熵损失来最大化正确答案选项的长度归一化对数概率:
物理含义:
gold sequence的长度归一化的对数概率,要比incorrect sequence的长度归一化的对数概率要大得多。当使用
few-shot setting中调优超参数(这是一个问题,因为实际上具有合理大小的验证集非常小)。我们在附录
B中报告了在所有数据集上使用带有长度归一化和不带有长度归一化的T0-3B所有参数的微调结果。我们发现:添加
60.7%提高到62.71%。同时添加
63.3%。
由于这些损失项在不引入任何额外的超参数的情况下改善了性能,我们将它们包含在我们的方法中,并在后续的所有实验中使用它们。
35.2.3 PEFT With
为了能够与
few-shot ICL相比较,我们需要一个PEFT方法具备以下特点:首先,它必须添加或更新尽可能少的参数,以避免存储和内存成本。
其次,在新任务的
few-shot training后,它应该在这个新任务上获得较高的准确率。最后,它必须允许
mixed-task batches,因为这是ICL的一个能力。为了轻松实现mixed-task batches,PEFT方法理想情况下不应修改模型本身。否则,batch中的每个样本实际上需要由不同的模型或计算图进行处理。更方便的替代方法是直接修改模型的activations,因为可以根据样本对应的任务独立且廉价地对batch中的每个样本进行操作。
prompt tuning(《The power of scale for parameter-efficient prompt tuning》)和prefix tuning(《Prefix-Tuning: Optimizing continuous prompts for generation》)方法通过将learned vectors与activation or embedding sequences进行拼接来实现,因此它们是activation-modifying PEFT方法的例子从而允许mixed-task batches。然而,正如我们后面将讨论的,我们无法通过prompt tuning获得合理的准确率,并且发现更高性能的PEFT方法不允许mixed-task batches。因此,我们开发了一个满足我们要求的新的PEFT方法。作为替代方案,我们探索了模型
activations与一个learned vector的逐元素乘法(即rescaling)。具体而言,我们考虑形式为learned task-specific vector,activations序列。注意,这里进行了broadcasting,即运算期间将在初步实验中,我们发现在
Transformer模型的每组activations中引入一个learned rescaling vector是不必要的。相反,我们发现在自注意力机制、encoder-decoder注意力机制中的keys和values上引入rescaling vectors,以及position-wise feed-forward networks的中间激活上引入rescaling vectors,这就足够了。具体来说,使用Transformer的符号表示法,我们引入了三个learned vectors以及被引入到
position-wise feed-forward networks中:为什么引入这三个
learned vectors而不是更多或更少?论文并没有进行消融实验从而给出说明。我们在每个
Transformer层块中引入了单独的L-layer-block Transformer encoder增加了L-layer-block decoder增加了encoder-decoder注意力,所以因子为2),block数量。1进行初始化,以确保在添加它们时模型计算的整体函数不发生变化。我们将我们的方法称为"Infused Adapter by Inhibiting and Amplifying Inner Activations"。注意:
task-level的,即不同的任务采用不同的rescaling vector;相同的任务下,所有的样本共享相同的一组rescaling vector。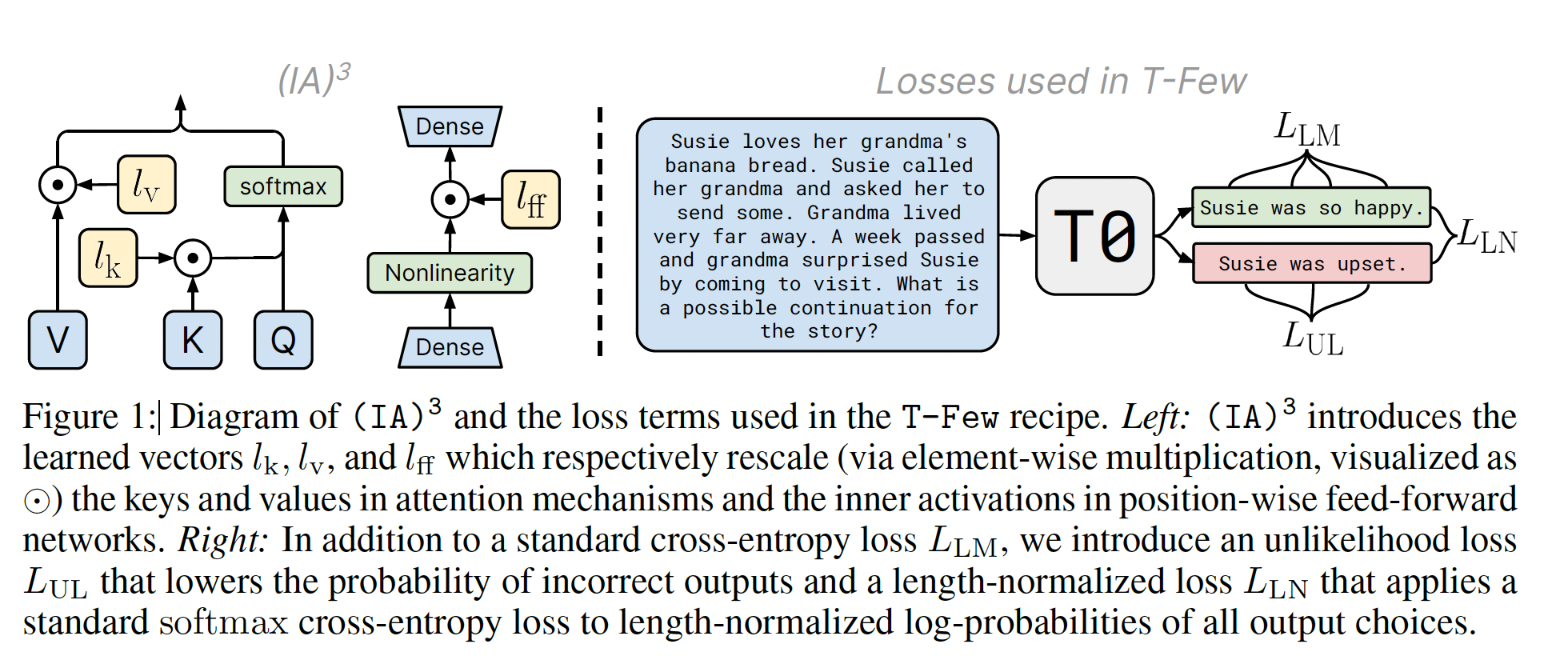
mixed-task batches成为可能,因为batch中的每个activations序列都可以与其对应的learned task vector进行独立且廉价的逐元素乘法。我们还注意到,如果模型只用于单个任务,在推断过程中可以固化。而在训练过程中还是需要单独处理,因为涉及到梯度更新。
为了验证
adaptation methods)进行了比较,我们的setting是在来自于held-out tasks的few-shot datasets上对T0-3B进行微调。具体而言,我们与9种强大的PEFT方法进行比较:BitFit(《BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models》)只更新bias参数。Adapters(《Parameter-efficient transfer learningfor NLP》)在自注意力和position-wise feed-forward networks之后引入了任务特定的层。Compacter和Compacter++(《Compacter: Efficient low-rank hypercomplex adapter layers》)通过使用低秩矩阵和超复数乘法 (hypercomplex multiplication)改进了Adapters。prompt tuning(《The power of scale for parameter-efficient prompt tuning》)学习了与任务相关的prompt embeddings,其中prompt embeddings与模型的输入进行连接;FISH Mask(《Training neural networks with fixed sparse masks》)根据近似Fisher信息选择要更新的参数子集。Intrinsic SAID(《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》)在低维子空间中执行优化。prefix-tuning(《Prefix-Tuning: Optimizing continuous prompts for generation》)学习了task-specific vectors,将其与模型的activations进行拼接。LoRA(《LoRA: Low-rank adaptation of large language models》)将低秩更新分配给参数矩阵。
此外,我们还包括完整模型微调(
fUll-model-fine-tuning)、以及仅更新layer normalization参数的基线方法。对于某些允许更改parameter efficiency的方法,我们报告了不同预算的结果:FISH Mask的0.2%和0.02%稀疏度、prompt tuning的10个和100个learned prompt vectors,以及Intrinsic SAID的20,000维或500,000维子空间。结果显示在
Figure 2中,详细的每个数据集结果在附录C中。我们发现,PEFT方法(如Intrinsic SAID和prompt tuning)更新或引入的参数较少,但我们的结果和
setting与一些我们进行比较的PEFT方法的过去研究有所不同:《Compacter: Efficient low-rank hypercomplex adapter layers 》报告Compacter和Compacter++在包括few-shot setting在内场景下,超越了全模型微调。《The power of scale for parameter-efficientprompt tuning》发现prompt tuning可以与全模型微调相媲美。并且在随后的研究中,《Finetuned language models are zero-shot learners》发现在few-shot setting下将prompt tuning应用于多任务微调模型时表现良好。
在这两种情况下,我们尝试了各种超参数选择来尝试匹配过去的结果。我们假设这种不一致可能是因为我们使用了不同的模型和数据集。特别是对于
prompt tuning,我们注意到验证集性能在训练过程中可能会大幅波动,这暗示可能存在优化问题。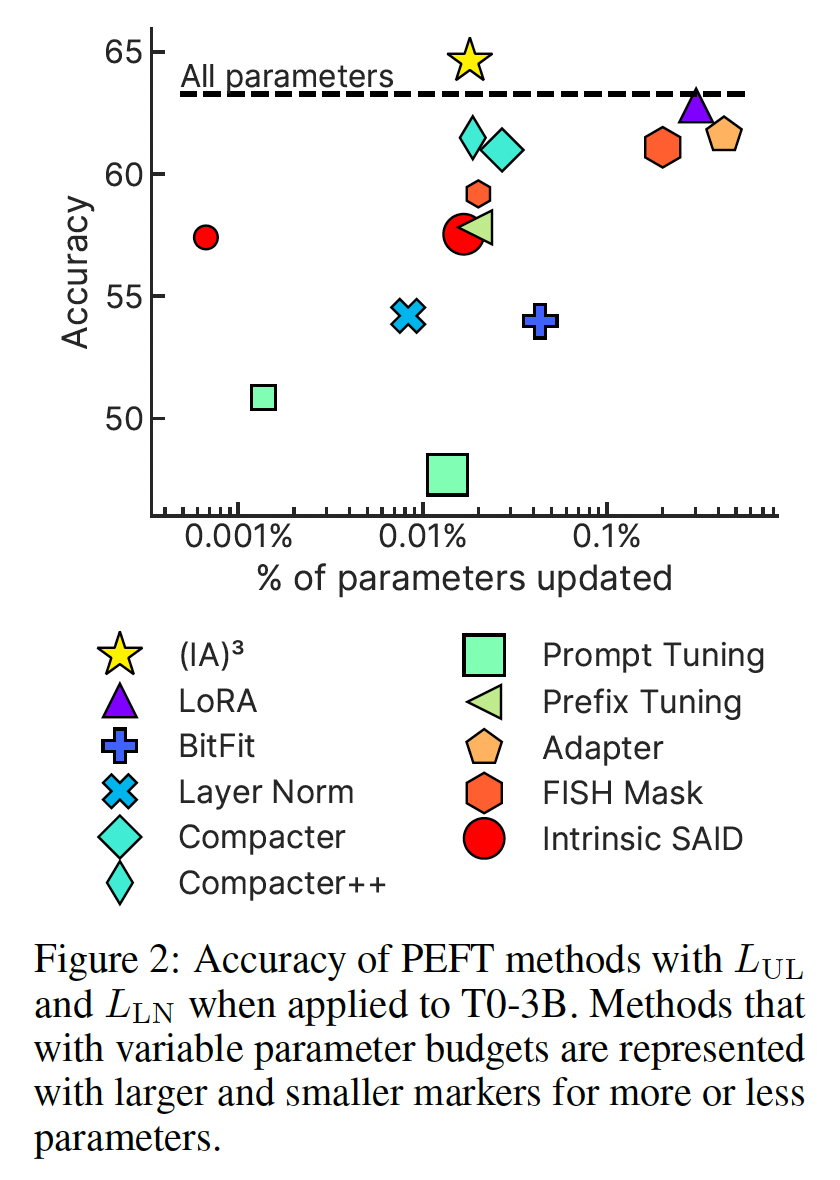
35.2.4 Pre-training
在最近的研究中,
《PPT: Pre-trained prompt tuning for few-shot learning》和《SPoT: Better frozen modeladaptation through soft prompt transfer 》表明,在对下游few-shot tasks进行微调时,对prompt tuning中的prompt embeddings进行预训练可以提高性能。在预训练中:《PPT: Pre-trained prompt tuning for few-shot learning》使用一组自监督任务应用于未标记文本数据。《SPoT: Better frozen modeladaptation through soft prompt transfer 》考虑使用来自单独任务或multitask mixture的embedding。
我们遵循
《SPoT: Better frozen modeladaptation through soft prompt transfer 》的方法,简单地在与训练T0时使用的相同multitask mixture上预训练batch size = 16进行100,000步的预训练。关于with/without pre-training (IA)3的准确率的完整比较,详见附录D。我们发现预训练将微调准确率从64.6提高到65.8,因此将预训练
35.2.5 组合在一起
总而言之,
T-Few的配方如下所述:我们使用
T0模型作为骨干。我们添加
multitask mixture上预训练的对于
objective,我们使用标准的语言模型损失unlikelihood loss我们使用
batch size = 8、学习率为Adafactor优化器进行1000步的训练,并使用线性衰减调度和60-step预热。我们在训练和推断过程中对下游数据集应用
prompt模板,将每个样本转换为指令性的text-to-text格式。
重要的是,我们以完全相同的方式将此配方应用于每个下游数据集,而不进行特定于数据集的超参数调优或修改。这使得该配方成为
few-shot learning settings(根据定义,此时的验证集非常非常小)中的一个实际可行选择。
35.3 实验
在
T0-3B上设计并建立了T-Few的配方后,我们现在将其应用于T0模型(拥有11B参数),并将性能与强的few-shot ICL基线进行比较。从这一点开始,我们在所有任务中使用完全相同的配方和超参数。在
T0任务上的性能:首先,我们评估T-Few在T0 held out数据集上的性能(这些held out数据集不在T0的training mixture中)。baseline方法为:T0的zero-shot learning(《Multitask prompted training enables zero-shot task generalization》),因为我们发现对于T0而言,few-shot ICL效果比zero-shot更差。使用
T5+LM的few-shot ICL方法(《The power of scale for parameter-efficient prompt tuning》)。使用
GPT-3的6.7B、13B、175B参数版本的few-shot ICL。
更多关于这些基线的详细信息请参见附录
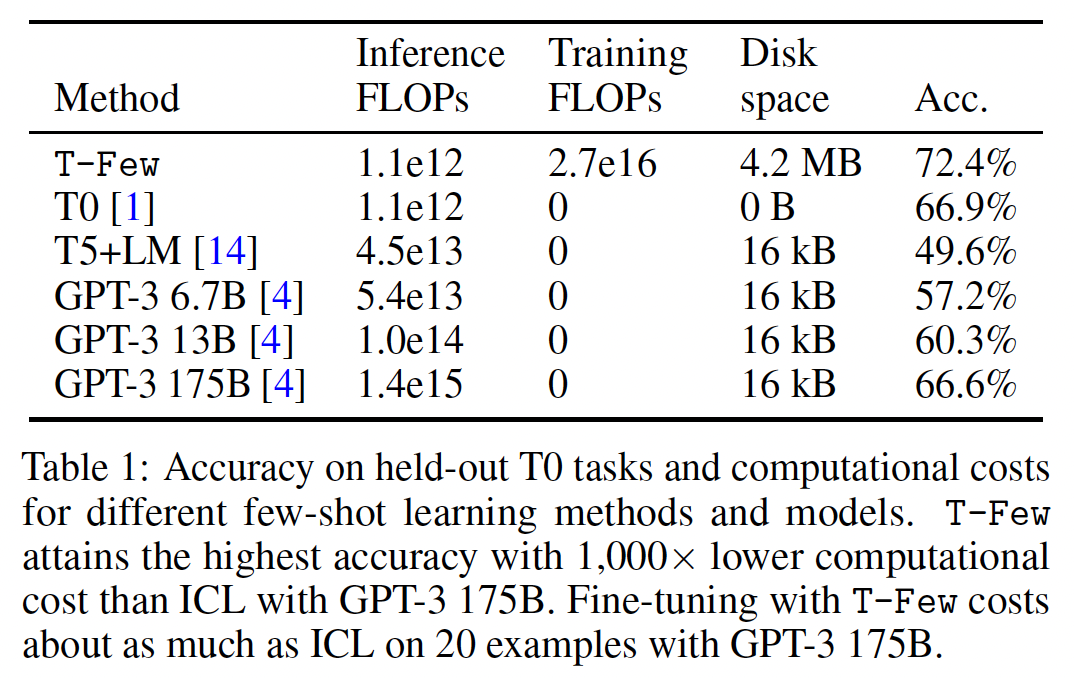
E。Table 1和Figure 3显示了在held-out T0数据集上的准确率,每个数据集的结果在附录E中报告。我们发现:T-Few在准确率上大大超过了所有其他方法。值得注意的是,尽管T-Few的规模约为GPT-3 175B的1/16,但其准确率比GPT-3 175B高出6%。T-Few的准确率也远高于使用较小的GPT-3版本的方法。T-Few的准确率还显著高于T0的zero-shot learning和T5+LM的few-shot ICL。
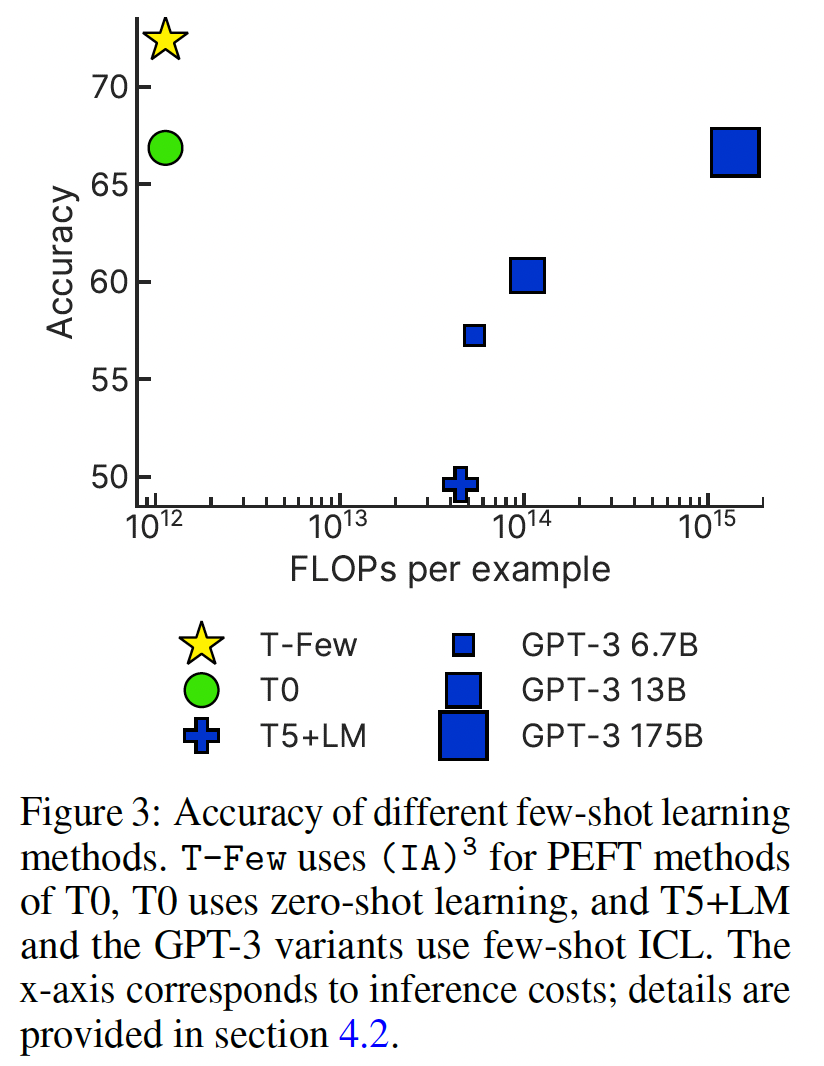
计算成本的比较:在确定了
T-Few明显优于ICL-based的模型之后,我们现在比较每种few-shot learning方法的相对成本。为简单起见,我们使用《Scaling laws for neural language models》引入的Transformer-based的语言模型的FLOPs-per-token估计值。具体而言,我们估计具有
decoder-only Transformer(例如GPT系列)在推理时每个token使用FLOPs,在训练时每个token使用FLOPs。像T0和T5这样的encoder-decoder模型(其中编码器和解码器具有相同数量的层和层大小)仅使用编码器或解码器处理每个标记(encoder和decoder的参数各自大约为完整模型的一半),因此每个token的FLOPs估计值减半,即FLOPs用于推理、FLOPs用于训练。我们注意到,
FLOPs不是真实世界计算成本的直接测量,因为延迟、功耗和其他成本可能因硬件和其他因素而有显著差异(《The efficiency misnomer》)。然而,我们关注FLOPs,因为它是一种与硬件无关的度量,与真实世界成本非常接近。我们在Table 1中总结了这些成本并进行了讨论。对于所有估计,我们使用我们考虑的数据集中的shots数量的中位数(41-shots)。rank evaluation和我们的unlikelihood loss都需要处理每个可能的输出选择以获得未标记样本的预测。我们考虑的数据集中输入和所有可能targets的combined tokenized sequence length的中位数组合长度为103。对于few-shot ICL中处理的上下文示例,仅需要正确的target,产生的序列长度的中位数为98。因此,假设缓存了key vectors和value vectors,使用ICL处理单个示例涉及处理41*98+103个tokens。我们在table 1中提供了我们的成本估计摘要。推理成本:除了提高准确性外,避免
few-shot ICL的主要优势是显著降低推理成本。使用T-Few处理single input and all target choices需要FLOPs,而使用GPT-3 175B的few-shot ICL则需要FLOPs——超过3个数量级。使用较小的GPT-3变体的ICL的推理成本也远高于T-Few的推理成本。如前所述,缓存
in-context examples的key and value vectors可以降低ICL的计算成本。然而,这只能导致大约41倍的减少,这远远不足以使任何GPT-3 ICL的成本与T-Few相当。训练成本:由于
T-Few是唯一涉及参数更新的方法,因此它是唯一产生训练成本的方法。对于一个具有11B参数的encoder-decoder模型进行1000步训练,其中batch size = 8、序列长度为103,大约需要FLOPs。虽然不容忽视,但这只是使用GPT-3 175B的few-shot ICL处理单个样本所需FLOPs的大约20倍。换句话说,训练T-Few的成本相当于使用GPT-3 175B来处理20个few-shot ICL的样本的成本。我们还发现,在单个数据集上使用T-Few对T0进行微调仅需要约半小时,在单个NVIDIA A100 GPU上进行。截至目前,这将花费约2美元的Microsoft Azure。存储成本:
T-Few还产生最大的存储成本。以单精度浮点数存储时,4.2 MB空间。相比之下,ICL方法只需要存储tokenized in-context examples(通常以32-bit整数来存储),导致较小的41*98*32 bits = 16 kB的磁盘空间需求。然而,我们注意到4.2 MB与model checkpoints本身的磁盘大小相比微不足道——存储10,000个任务的adaptation vectors所需的空间与T0 checkpoint(41.5 GB)大致相同。内存使用:在推理过程中,主要的内存成本是由模型的参数产生的。唯一比
T0(T-Few使用的模型)更小的模型是GPT-3 6.7B;否则,T-Few在推理过程中将产生更低的内存成本。训练T-Few时会产生额外的内存成本,因为需要缓存用于反向传播的intermediate activations、以及Adafactor中的gradient accumulator variables。然而,正如上面提到的,一个80GB的A100 GPU足以应对T-Few的需求。
Real-world Few-shot Tasks (RAFT)上的性能:到目前为止,我们在一系列并非专门设计用于benchmarking few-shot learning的数据集上进行了评估。为了更好地评估T-Few在现实世界中的表现,我们将我们的方法应用于RAFT benchmark。RAFT包括11个 “经济上有价值” 的任务,反映了真实世界的应用。重要的是,每个RAFT数据集只有50个训练示例,没有验证集,只有一个(更大的)没有公开标签的测试集,因此不可能通过在一个不切实际的大型验证集上进行调优或窥探测试集来 “作弊”。我们使用与数据集一起发布的标准prompts将T-Few应用于RAFT。当前五个最佳模型的准确率显示在Table 2中,详细信息请参见附录G。T-Few达到了75.8%的SOTA准确率,首次超过了人类基准(73.5%的准确率)。第二好的模型(来自
《True few-shot learning with prompts -- a real-world perspective》)的准确率低了6%,而GPT-3 175B仅达到62.7%。
这些结果验证了
T-Few可以直接应用于新的真实世界任务,并具有出色的性能。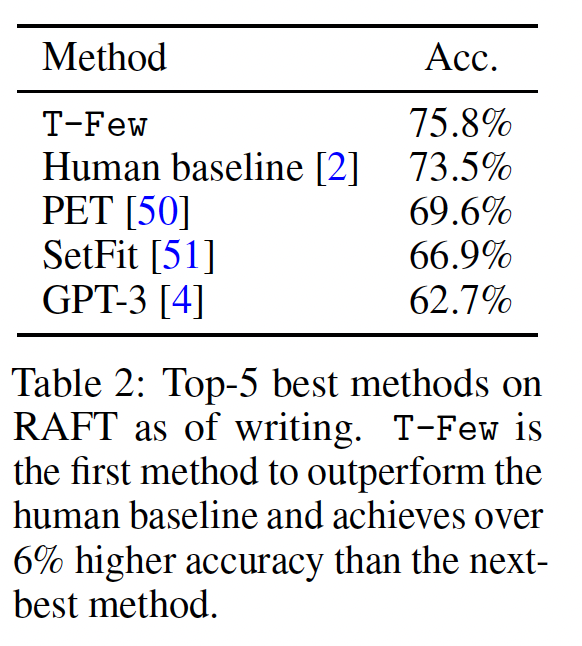
消融实验:鉴于我们的
T-Few设计实验是在T0-3B上进行的,我们对T0上的一些T-Few要素进行消融实验。结果显示在附录F中。尽管添加每个要素并不总是显著提高每个单独数据集的准确率,但每个要素在不同数据集之间一致提高了平均性能:去除预训练将准确率降低了1.6%、去除unlikelihood training损失和长度归一化损失将准确率降低了4.1%、同时去除预训练和其他额外损失项将准确率降低了2.5%。作者这里写反了?感觉正确的应该是:”去除预训练将准确率降低了
1.6%、去除unlikelihood training损失和长度归一化损失将准确率降低了2.5%、同时去除预训练和其他额外损失项将准确率降低了4.1%。“
三十六、MetaICL [ 2021]
论文:
《MetaICL: Learning to Learn In Context》
近年来,大型语言模型已经展示出能够进行
in-context learning(GPT-3)的能力,即它们通过:以少量训练样本为条件从而预测test input的补全的tokens。这种学习方式具有吸引力,因为模型仅通过推理就可以学习新任务,而无需进行任何参数更新。然而,in-context learning的性能明显落后于监督微调,而且结果往往具有很大的方差(《Calibrate before use: Improving few-shot performance of language models》、《True few-shot learning with language models》),并且很难设计模版从而将现有任务转化为这种格式。在本文中,我们通过引入
Meta-training for In-Context Learning: MetaICL来应对这些挑战。MetaICL在大量任务上对pretrained语言模型进行微调,以学习如何进行in-context learn,并在严格的全新任务上进行评估。每个meta-training example都匹配test setup,它包括来自一个任务的few-shot examples),这些样本将作为一个序列一起呈现给语言模型,并且第in-context learning,模型学会从给定样本中恢复任务的语义(对于测试期间新任务的in-context learning,这是必须要做到的)。这种方法与最近的一些工作相关,这些工作使用多任务学习来提高zero-shot性能。然而,MetaICL是独特的,因为它允许仅从task reformatting(例如,将所有内容简化为问答任务)或task-specific模板(例如,将不同任务转化为语言建模问题)。我们在取自
《Crossfit: A few-shot learning challenge for cross-task generalization in nlp》和《UnifiedQA: Crossing format boundaries with a single qa system》的大量不同任务上进行实验,包括142个文本分类、问答、自然语言推理、paraphrase detection数据集。我们报告了七种不同的设置,其中meta-training任务和目标任务之间没有重叠。据我们所知,这是目前所有相关工作中最多的目标任务数量,共有52个uninque的目标任务。核心就是
few-shot格式的模板的多任务微调。这和T0非常相似,T0是zero-shot格式的模板;而这里是few-shot格式的模板。实验结果表明,
MetaICL一致地超越了多个baselines,包括:没有
metatraining的各种LM in-context learning baselines(GPT-3、《Calibrate before use: Improving few-shot performance of language models》、《Surface form competition: Why the highest probability answer isn’t always right》、《Noisy channel languag emodel prompting for few-shot text classification》)。多任务学习后的
zero-shot transfer(《Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections》、《Finetuned language models are zero-shot learners》、《Multitask prompted training enables zero-shot task generalization》)。
当
meta-training任务和目标任务不相似时(例如任务格式、领域、或所需技能存在较大差异时),MetaICL对于multi-task zero-shot transfer的提升尤为显著。这表明MetaICL使得模型能够在推理过程中恢复任务的上下文语义,即使目标任务与meta-training任务没有相似之处。MetaICL通常接近(有时甚至超过)使用监督微调在目标数据集上训练的模型的性能,并且与参数增加8倍的模型的表现相当。我们还进行了大量实验分析,以确定MetaICL成功的关键因素,例如meta-training任务的数量和多样性。最后,我们展示了没有任何模板的
MetaICL比使用人工编写的自然语言指令的最新工作更好,同时结合两种方法可以获得最佳性能。代码和数据已公开发布在github.com/facebookresearch/MetaICL。相关工作:
In-context learning:GPT-3提出使用一个语言模型基于training examples拼接来进行few-shot learning,而无需参数更新。后续的研究(
《Calibrate before use: Improving few-shot performance of language models》、《Surface form competition: Why the highest probability answer isn’t always right》、《Noisy channel language model prompting for few-shot text classification》)进一步改进了该方法,在各种任务上展现出了有希望的结果。
然而,当目标任务与语言建模的性质非常不同、或语言模型的规模不够大时,语言模型进行
in-context learning的性能较差。此外,它可能具有较高的方差、以及较低的worst-case accuracy(《True few-shot learning with language models》、《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》)。我们的论文基于以训练样本为条件的
in-context learning的核心思想。我们展示了通过显式地训练in-context learning objective,MetaICL即使在较小的语言模型上也能取得显著改进。通过
multi-task learning的meta-training:我们的工作在很大程度上受到元学习(meta-learning)和多任务学习(multi-task learning)领域的大量研究的启发。先前的研究表明,在大量任务上进行多任务学习可以提高在新任务上的性能,无论是在zero-shot测试时,还是在进一步微调时(《Muppet: Massive multi-task representations with pre-finetuning》、《Crossfit: A few-shot learning challenge for cross-task generalization in nlp》)。特别是前者与我们的工作密切相关,因为它消除了对目标任务进行参数更新的需求。然而,这些zero-shot模型要么仅限于与训练任务共享相同格式的任务(例如,问答格式),要么严重依赖任务特定的模板,这些模板由于性能的高方差从而难以设计(《Reframing instructional prompts to gptk’s language》)。在本文中,我们提出了一种用于改进
few-shot性能的in-context learning的元训练(meta-training)方法。我们展示了它能够有效地学习新任务的语义,无需人工努力,并且明显优于zero-shot transfer方法。此外,虽然《Finetuned language models are zero-shot learners》表明元训练仅在模型具有68B或更多参数时才有效果,但我们的实验证明了即使在规模小得多的模型(770M)上也能取得改进。同时进行的研究工作
《Meta-learning via language model in-context tuning》提出了面向in-context learning的元训练方法。我们的方法在几个方面有所不同:我们消除了对人工编写模板或指令的要求,并包括了更多样的任务、更强的baseline模型、以及更大规模的广泛实验。
36.1 MetaICL
我们引入了
Meta-training for In-Context Learning: MetaICL。Table 1概述了这种方法。关键思想是使用多任务学习方案在meta-traning tasks的大型集合上进行训练,以使模型学习如何基于少量的训练样本进行条件学习,恢复任务的语义,并基于此进行输出预测。根据以前的文献(GPT-3),训练样本被拼接起来并作为单个输入提供给模型,这对于k-shot learning(例如,unseen target task上进行评估,推断过程直接遵循与元训练中相同的数据格式。这需要对每个下游任务都有大量的标记样本。

Meta-training:模型在我们称之为meta-training tasks的任务集合上进行元训练。对于每次迭代,随机选择一个meta-training task,并从所选任务的训练数据中采样negative log likelihood objective)来训练模型生成in-context learning,其中前如何拼接?参考实验部分:
[P][H]的方式。推断:对于一个新的目标任务,模型给出
Channel MetaICL:我们介绍了MetaICL的一种噪声通道变体(noisy channel variant),称为Channel MetaICL,参考了《Noisy channel language model prompting for few-shot text classification》的方法。在噪声channel models中,《Noisy channel language model prompting for few-shot text classification》的做法,使用具体而言,在元训练时,
36.2 实验
数据集:我们使用了从
CROSSFIT和UNIFIEDQA中获取的大量任务。总共有142个unique的任务,涵盖了各种问题,包括文本分类、问答、自然语言推理和paraphrase detection等任务。所有任务都是英文任务。我们在
Table 2中展示了七个不同的设置进行实验,其中meta-training tasks和目标任务之间没有重叠。总共有52个unique的目标任务,这比其他相关工作要大得多。每个目标任务都是分类任务或多项选择任务,其中给出了一组候选选项(Table 1中的HR --> LR(High resource to low resource):我们在一个设置中使用具有10,000个或更多训练样本的数据集作为元训练任务,其余数据集作为目标任务。我们认为将高资源数据集用于元训练,将低资源数据集用作目标任务是一种现实的和实用的few-shot learning设置。X --> X(X= {Classification, QA}):我们在两个设置中进行实验,其中元训练任务和目标任务共享任务格式(二者都是分类、或者都是问答),但是元训练任务和目标任务没有重叠。Non-X --> X(X = {Classification, QA, NLI, Paraphase}):最后,我们在四个设置中进行实验,其中元训练任务在任务格式上和所需能力上与目标任务不重叠。这些设置需要更具挑战性的泛化能力。
每个设置中都有一部分目标任务与任何元训练任务没有领域重叠(例如金融、诗歌、气候或医学)。我们报告了所有目标任务的结果,或者只报告没有领域重叠的目标任务的结果。
settings和数据集的详细信息及引文详见附录A。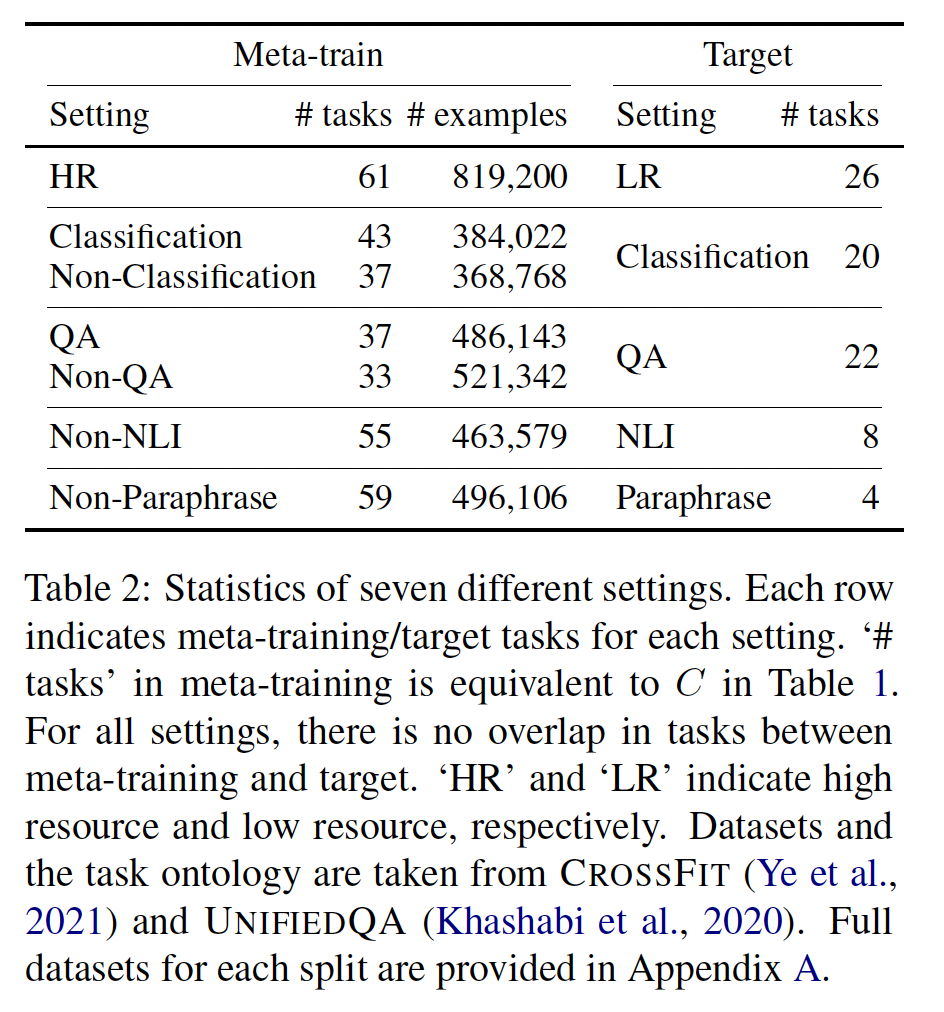
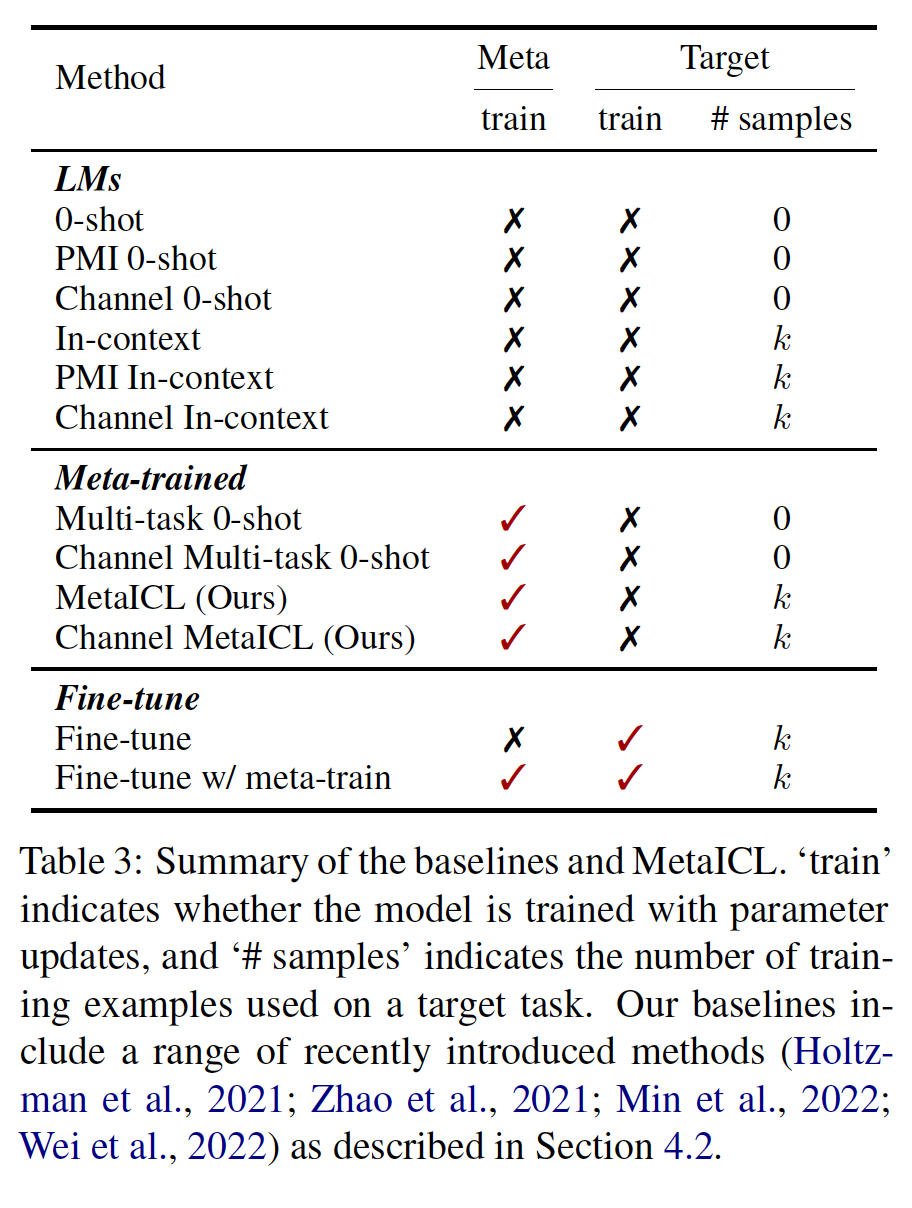
baseline:我们将MetaICL和Channel MetaICL与一系列baseline方法进行比较,如Table 3所总结的。注意:
In context learning方法没有梯度更新,通常而言它的效果要比有梯度更新的方法更差。0-shot:我们直接使用pretrained语言模型,并进行zero-shot推理,遵循GPT-3的方法。In-context:我们直接使用pretrained的语言模型,并通过在训练样本的拼接上进行in-context learning,遵循GPT-3的方法。PMI 0-shot, PMI In-context:我们使用 (《Surface form competition: Why the highest probability answer isn’t always right》)和《Calibrate before use: Improving few-shot performance of language models》的PMI方法进行0-shot learning和In-context learning。Channel 0-shot, Channel In-context:我们使用《Noisy channel language model prompting for few-shot text classification》的noisy channel模型进行0-shot learning和In-context learning。Multi-task 0-shot:我们在相同的元训练任务上训练语言模型,但没有in-context learning objective,即在没有其他zero-shot transfer。这相当于MetaICL。这是先前工作中的典型的多任务学习方法。当
prompt会更好?论文的实验证明,确实增加prompt会更好。Channel Multi-task 0-shot:我们有Multi-task 0-shot的channel变体。Fine-tune:我们在单个目标任务上对语言模型进行微调。由于需要为每个目标任务进行参数更新,因此无法直接与其他方法进行比较。Fine-tune w/ meta-train:我们首先在元训练任务上对语言模型进行训练,然后进一步在目标任务上进行微调。由于与Fine-tune相同的原因,这也无法直接与其他方法进行比较。
评估:我们使用
Macro-F1和Macro-Accuracy作为分类任务和非分类任务的评估指标。对于目标任务,我们使用
《Noisy channel language model prompting for few-shot text classification》的方法。由于已知in-context learning具有高方差性,我们使用了5组不同的k training examples。我们首先计算每个目标任务的平均性能和worst-case性能,然后报告所有目标任务的macro-average性能。实验细节:
作为基础的语言模型,我们使用了
GPT-2 Large,它由770M个参数组成。对于没有元训练的baseline(原始语言模型),我们还与GPT-J进行比较,它是目前最大的公开的因果语言模型,由6B个参数组成。模型不够大,因此实验结论不太可靠。众所周知,当模型规模足够大时,会发生能力的涌现。因此小模型上得出的结论无法推广到大模型。
模板的消除:先前的研究使用人工编写的模板将
input-output pair转换为自然语言句子。这些模板需要昂贵的人工工作(本文中的136个任务需要136个不同的模板),并且由于多种不同的写作方式,会导致模型性能不稳定(《Reframing instructional prompts to gptk’s language》)。我们消除了模板,使用原始数据集中提供的给定输入(如果有多个输入,则使用拼接)和label words。先前研究中的input-output方案与我们的方法的比较如Table 4所示。
训练细节:所有实现均使用
PyTorch和Transformers。对于元训练,我们每个任务使用最多16,384个训练样本。我们使用batch size = 8、学习率为1024。对于multi-task 0-shot基线(无in-context learning的基线),我们使用序列长度为256。我们训练模型30,000个steps。为了在元训练期间节省内存,我们使用Adam优化器的8-bit近似(《8-bit optimizers via block-wise quantization》)和混合精度训练(《Mixed precision training》)。训练使用了8块32GB的GPU,共计4.5小时。这比先前的研究效率大大提高,例如《Multitask prompted training enables zero-shot task generalization》中使用512GB的TPU训练了270小时。有关预处理和训练的更多细节,请参阅附录
B。
实验结果:
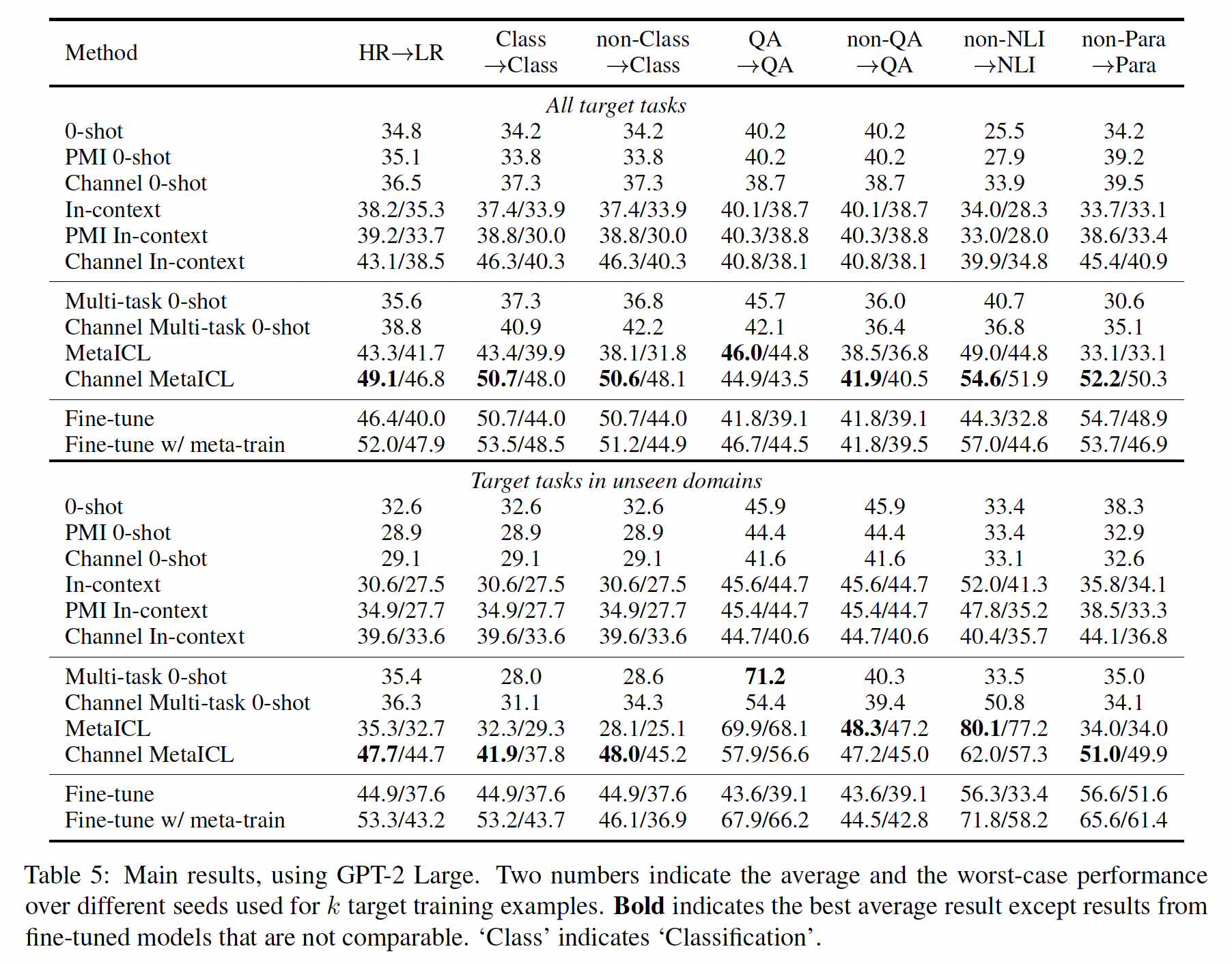
Table 5报告了使用GPT-2 Large的完整结果,我们计算了每个目标任务的平均性能和worst-case性能,并报告了它们的macro-average。顶部和底部分别评估了所有的目标任务、以及仅评估unseen domains的目标任务。我们的
baselines很强:首先讨论我们的baselines结果。在没有元训练的原始语言模型中(
Table 5的前六行),我们观察到channel in-context baselines是最有竞争力的,与《Noisy channel language model prompting for few-shot text classification》的研究结果一致。然后我们发现,在大多数设置中,
Multi-task 0-shot baselines并没有超过最佳的原始语言模型基线,尽管前者在大量元训练任务上进行了监督。这在一定程度上与《Finetuned language models are zero-shot learners》和《Multitask prompted training enables zero-shot task generalization》的发现相矛盾。这可能有两个原因:首先,我们的模型比他们的模型小得多(
770M vs. 11B–137B)。事实上,《Finetuned language models are zero-shot learners》报告了只有在模型大小为68B或更大时,Multi-task 0-shot才能优于原始语言模型。其次,我们与更强大的
channel baselines进行了比较,而他们没有这样做;Multi-task 0-shot优于non-channel LM baselines,但不优于channel LM baselines。
MetaICL优于baselines:MetaICL和Channel MetaICL在一系列strong baselines上始终表现优异。具体而言,在7个设置中,Channel MetaICL在6个设置中达到了最佳性能。在HR --> LR、non-NLI --> NLI和non-Para --> Para设置中,增益尤其显著(6-15%的绝对增益)。这值得注意,因为HR --> LR针对的是常见的低资源情况,新任务只有很少的标记样本;而另外两个设置代表了数据分布的巨大变化,测试任务与元训练任务相对而言不相似。这证明了即使没有密切相关的训练任务,MetaICL也能够在上下文中推断出新任务的语义。虽然
MetaICL在大多数设置中明显优于baselines,但在QA --> QA设置中,它只略微优于Multi-task 0-shot。这可能是因为元训练任务和目标任务相对而言相似,使得Multi-task 0-shot baseline能够达到非常强的性能。尽管如此,当模型在non-QA任务训练时,Multi-task 0-shot在QA上的性能显著下降,而MetaICL的性能下降要少得多。在
unseen domains上的增益要更大:在unseen domains上,MetaICL相对于Multi-task 0-shot的提升更为显著。具体而言,Multi-task 0-shot相对于原始语言模型baselines通常竞争力较弱,可能是因为它们需要更具挑战性的泛化能力。MetaICL在这个问题上受到的影响较小,在所有设置中始终优于或与原始语言模型baselines相媲美。与微调的比较:
MetaICL与没有元训练的微调模型相媲美,甚至有时表现更好。这是一个有前景的信号,因为以前的研究没有显示no parameter updates on the target的模型可以与或超过有监督模型。这里需要注意:
MetaICL也进行了参数更新,只是MetaICL在non-target任务上进行了参数更新(而不是target任务上)。这并不会降低训练代价,但是这大大降低了
target data的数据需求。然而,通过元训练的微调模型在性能上超过了
MetaICL和没有元训练的微调模型,因为元训练对于有监督学习和in-context learning都有帮助。这表明在允许learning without parameter updates的方法中仍有改进的空间。
与
GPT-J的比较:在Table 6中,我们将基于GPT-2 Large的模型与基于GPT-J的原始语言模型baselines进行比较,后者包含6B个参数。尽管MetaICL的规模较小(小8倍),但其在性能上优于或与GPT-J baselines相匹配。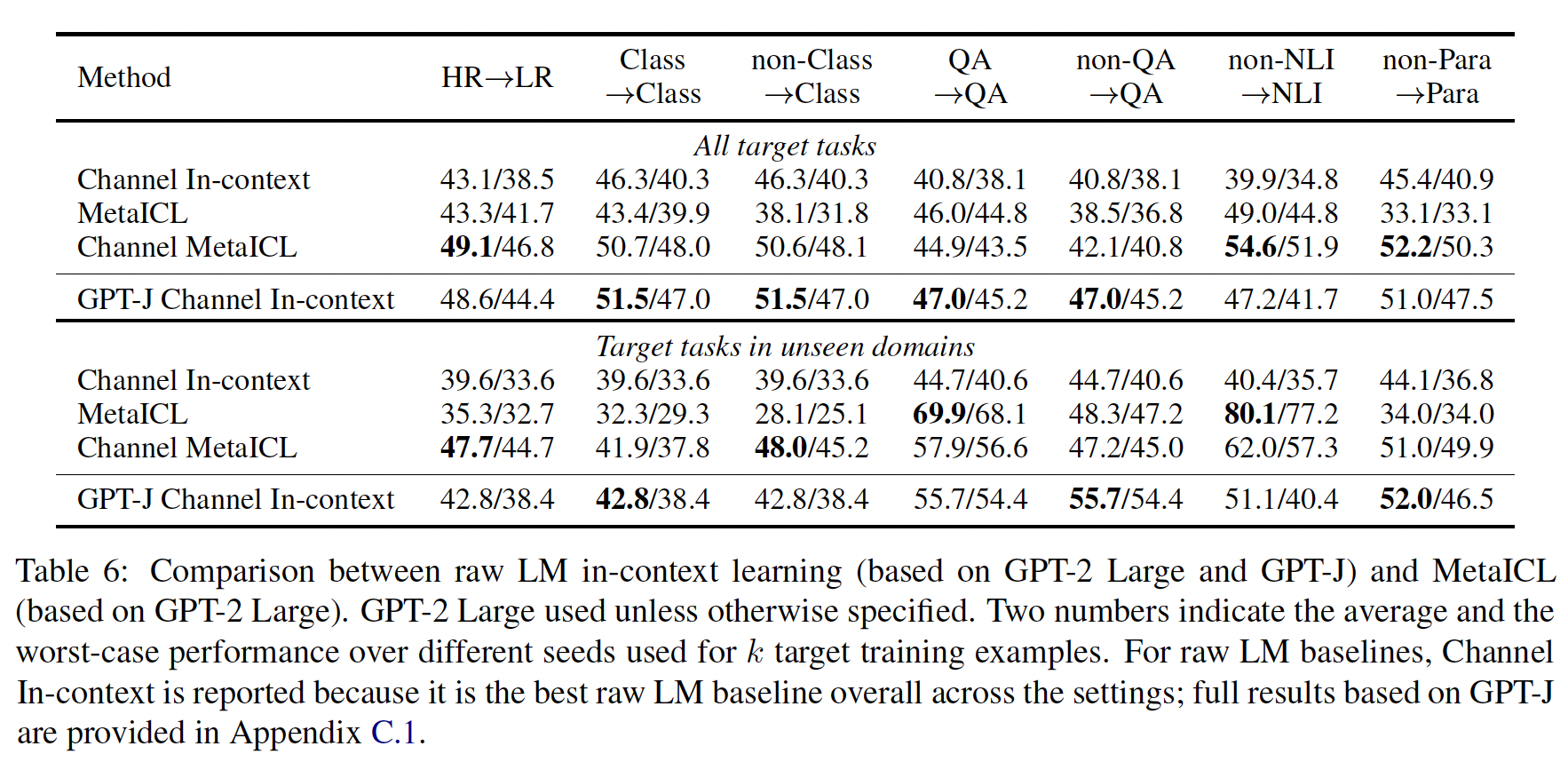
消融研究:
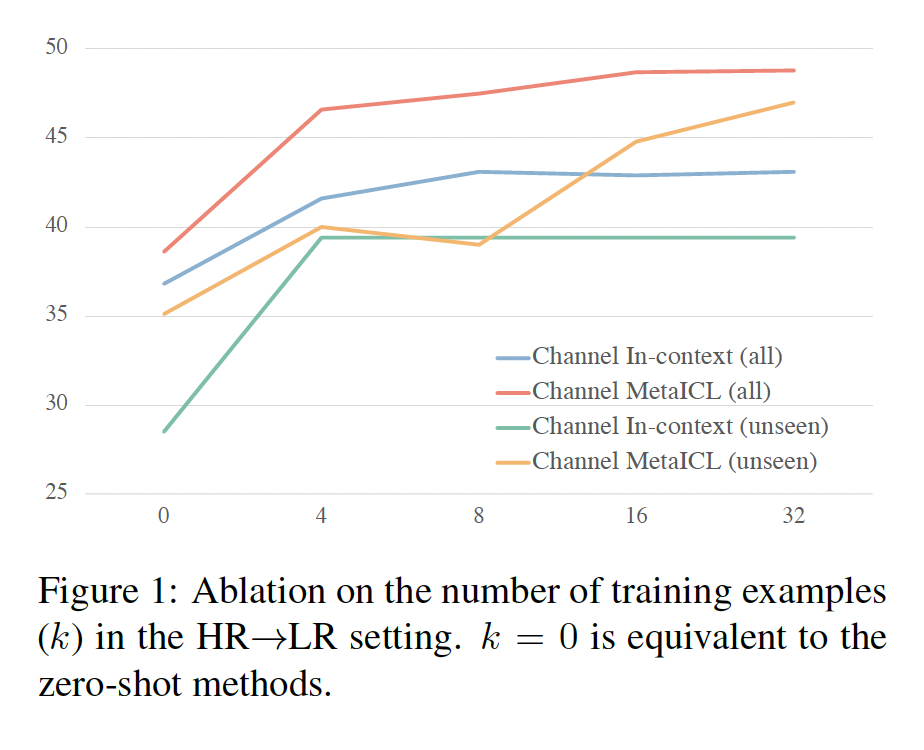
不同数量的训练样本:我们将训练样本的数量(
0、4、8、16变化到32。在in-context learning等同于zero-shot方法。结果如Figure 1所示。增加
Channel MetaICL优于原始的in-context learning。我们还发现,当
16时,性能往往趋于饱和,这可能是因为语言模型的序列长度限制,使得编码许多训练样本变得困难。
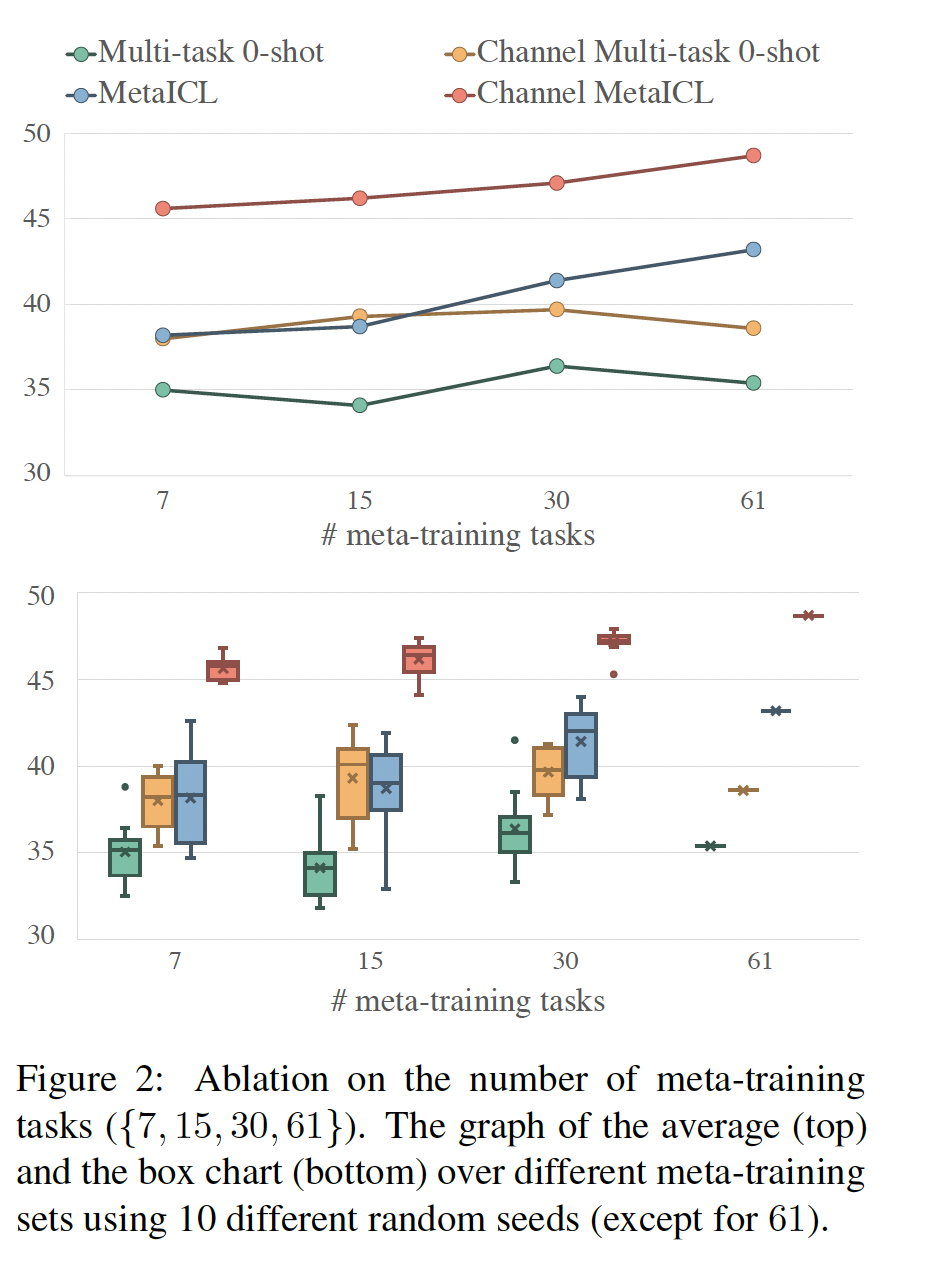
元训练任务的数量:为了观察元训练任务数量的影响,我们从
HR --> LR设置中的61个元训练任务中随机抽取{7, 15, 30}个任务。对于每个任务,我们使用十个不同的随机数种子从而额外地观察元训练任务选择的影响。Figure 2显示了结果。平均而言,性能随着元训练任务数量的增加而增加,这与
《Cross-task generalization via natural language crowdsourcing instructions》和《Finetuned language models are zero-shot learners》的结果一致。在不同数量的元训练任务中,
Channel MetaICL始终优于其他模型。然而,在不同的元训练任务的选择中存在着相当大的方差(
Figure 2底部),这表明元训练任务的选择对性能有重要影响。
元训练任务的多样性:我们假设元训练任务的多样性可能会影响
MetaICL的性能。为了验证这一假设,我们从HR --> LR设置的61个元训练数据集中随机选择13个数据集,并创建了两个设置:一个设置具有多样性的任务格式和所需能力,包括问答、自然语言推理、关系抽取、情感分析、主题分类、仇恨言论检测等。
另一个设置不太多样化,仅包括与情感分析、主题分类和仇恨言论检测相关的任务。
附录
A中报告了数据集的完整列表。使用这两个设置,我们比较了multi-task zero-shot transfer baseline和MetaICL的结果。结果如Table 7所示。我们发现,具有多样性元训练任务的MetaICL明显优于具有非多样性元训练任务的MetaICL。这表明元训练任务的多样性是MetaICL成功的一个重要因素之一。在附录
C.3中,我们提供了更多关于选择元训练任务的洞察,例如:高质量数据和多样化的领域往往有帮助(例如,
GLUE系列数据集)对抗性收集的数据往往没有帮助。
然而,还需要进行系统性的研究:关于如何选择最佳元训练任务、以及它们与特定的
target tasks的关系。这是我们留给未来的工作。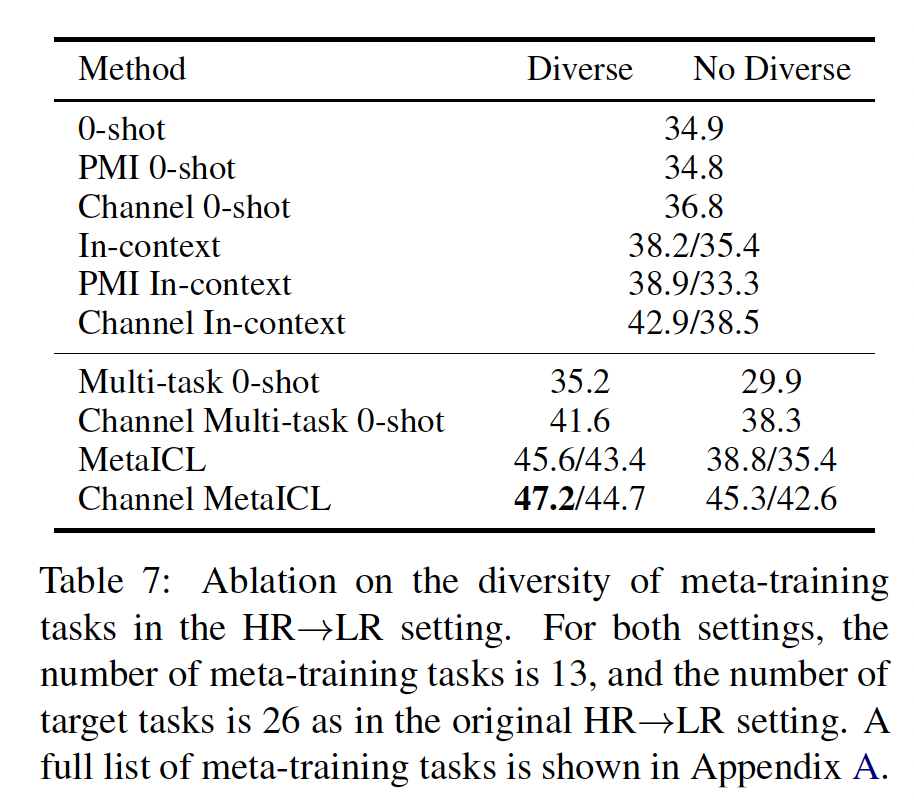
是否需要指令?最近的研究在
zero-shot learning或few-shot learning中使用了人工撰写的自然语言执行(《Cross-task generalization via natural language crowdsourcing instructions》、《Finetuned language models are zero-shot learners》、《Multitask prompted training enables zero-shot task generalization》)。虽然我们主张不使用指令来避免人工的工程和高方差,但我们也要问:在MetaICL中是否仍然有用?一方面,学习以为了回答这个问题,我们使用了
32个元训练任务和12个目标任务,这些任务来自于HR --> LR设置,其中《Multitask prompted training enables zero-shot task generalization》提供了人工撰写的指令。我们有两个变种:(a):每个元训练任务使用一条指令。(b):使用所有可用的指令,总共包括267条指令(每个元训练任务平均8.3条指令)。
《Multitask prompted training enables zero-shot task generalization》发现(b)比(a)更好。然后,我们将MetaICL和一系列with/without指令的baselines进行比较。结果如Table 8所示。与
《Finetuned language models are zero-shot learners》和《Multitask prompted training enables zero-shot task generalization》一样,Multi-task 0-shot优于raw-LM 0-shot baseline基线。然而,没有指令的
MetaICL优于具有指令的Multi-task 0-shot。此外,当
MetaICL联合使用指令时,MetaICL进一步提高了性能,显著优于所有baseline。实际上,当将每个任务的指令数量从0、1增加到8.3时,MetaICL的性能提升要远远超过Multi-task 0-shot does的性能提升。
总结如下:
(1):in-context learn(即,MetaICL)优于从指令中学习。(2):MetaICL和使用指令在很大程度上是互补的。(3):MetaICL实际上比Multi-task 0-shot更能从使用指令中获益。
值得注意的是,即便在可用任务和指令下进行训练的
Channel MetaICL的性能,仍然低于没有模板/指令的Channel MetaICL(根据Table 8的46.9与Table 5的49.1)。这可能是因为具有指令的模型训练过程中使用了更少的元训练任务,这是不可避免的,因为指令仅在61个元训练任务中的32个任务上可用。这支持我们之前选择不使用人工撰写的模板/指令的决策,因为为每个任务编写模板和指令需要大量的工作量。值得注意的是,由于存在许多变动的因素,例如语言模型的大小、类型(例如因果语言模型、掩码语言模型)、元训练任务与目标任务的划分等等,因此很难与
《Finetuned language models are zero-shot learners》和《Multitask prompted training enables zero-shot task generalization》直接进行比较。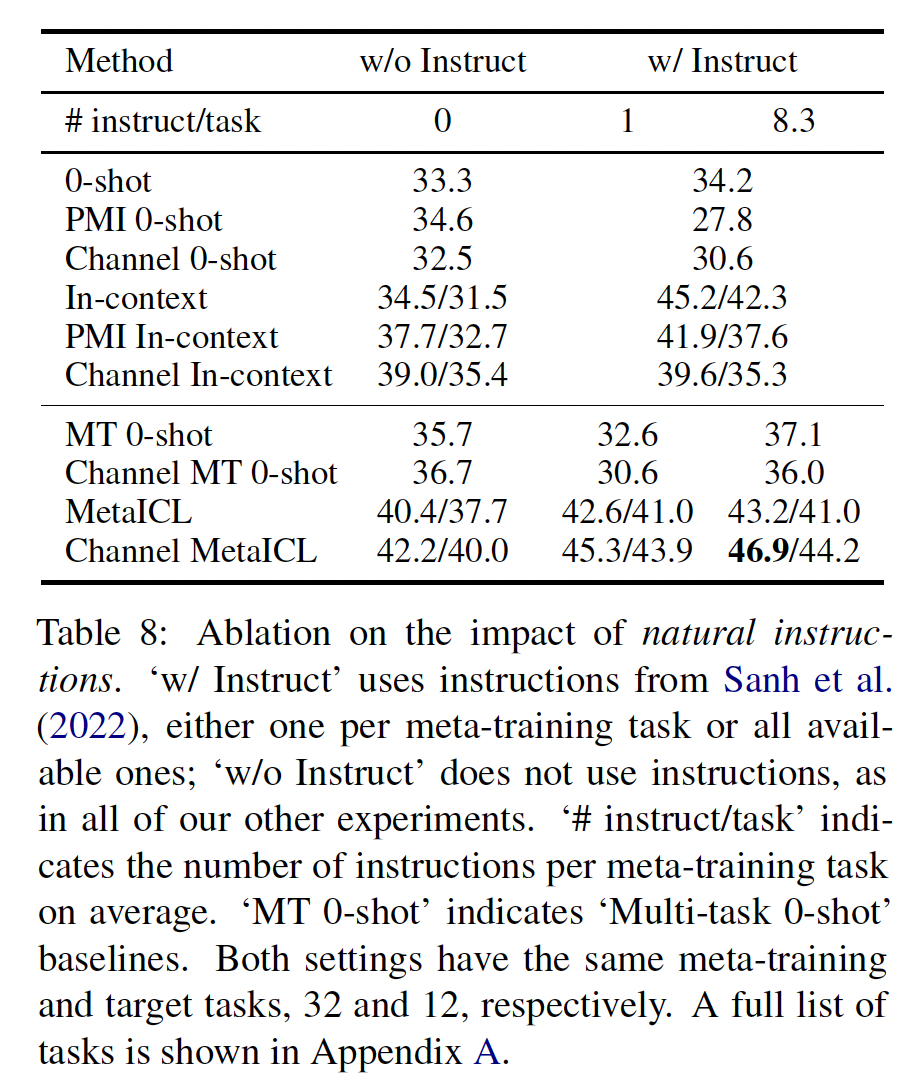
36.3 讨论
我们的工作在多个方面存在局限性。
首先,通常情况下,
in-context learning在元训练阶段和推理阶段都需要更长的上下文,因为需要将训练样本进行拼接,因此与不使用in-context learning的baseline方法相比,in-context learning方法的效率较低。其次,我们的工作使用了一个中等规模的因果语言模型(
GPT-2 Large,770M参数)进行实验。未来的工作可以探索将我们的方法扩展到掩码语言模型、以及更大的模型。第三,我们的实验侧重于具有候选选项集合的分类任务和多项选择任务。未来的工作可以研究将我们的方法应用于更广泛的任务范围,包括自由形式的生成。
其他未来工作的方向包括进一步改进
MetaICL以超越带有元训练的监督模型、确定哪些元训练任务对目标任务有帮助、以及如何更好地将MetaICL结合人工撰写的指令。