八、Compacter[2021]
论文:
《Compacter: Efficient Low-Rank Hypercomplex Adapter Layers》
SOTA的预训练语言模型(pretrained language models: PLMs)在自然语言处理中使用了高度过参数化的表示(over-parameterized representations),包含数以亿计的参数,从而在广泛的NLP benchmarks中获得成功。这些模型通常通过微调来应用于下游任务,这需要更新所有参数并为每个任务存储一个fine-tuned model的副本。这会导致巨大的存储成本和部署成本,并阻碍大规模PLM应用于实际应用。此外,已经证明over-parameterized models在低资源数据集上的微调会出现不稳定性,可能导致较差的性能。受
John von Neumann的名人名言的启发,我们问,既然我们已经通过PLM学到了通用的language representations,那么我们需要多少参数才能在标准NLP任务上达到SOTA的性能水平。具体来说,我们的目标是开发出实用的、内存高效的方法,在训练最小的参数集合的同时,达到与full fine-tuning相当或更好的性能。最近的文献已经引入了
parameter-efficient fine-tuning方法。这些方法通常固定pretrained model的参数,并为每个任务引入一组可训练的参数,在可训练参数数量以及任务性能之间进行权衡。在另一个研究方向中,prompts(即,任务的自然语言描述)和demonstrations一起,已被用来在某些benchmarks上达到合理的性能,而无需任何参数更新(《Language models are few-shot learners》),但它们的性能通常落后于fine-tuned的模型。它们还需要巨大的模型才能正常工作,但随着模型规模的增大,选择好的prompts变得更加困难(《True Few-Shot Learning with Language Models》)。soft prompt方法将prompts视为可训练的连续参数,这些参数被添加到input layer或intermediate layers的输入中(《Prefix-tuning: Optimizing continuous prompts for generation》、《Warp: Word-level adversarial reprogramming》、《The power of scale for parameter-efficient prompt tuning》)。 然而,这种方法通常需要大型模型才能取得良好的性能,并且对初始化非常敏感,在训练过程中不稳定。具有理论基础的低秩方法(
low-rank methods)使用随机投影训练位于低维子空间中的少量参数(《Measuring the intrinsic dimension of objective landscapes》、《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》)。然而,存储随机投影矩阵(random projection matrix)会造成大量内存开销,并导致训练时间缓慢。在另一个研究方向,adapter方法(《Parameter-efficient transfer learning for nlp》、《Efficient parametrization of multi-domain deep neural network》)在pretrained模型的不同层中插入可训练的transformations,需要比上述方法更多的参数,但更加内存高效,并获得与full fine-tuning相当的性能(《Parameter-efficient transfer learning for nlp》、《Exploring versatile generative language model via parameter-efficient transfer learning》)。在本文中,我们提出了
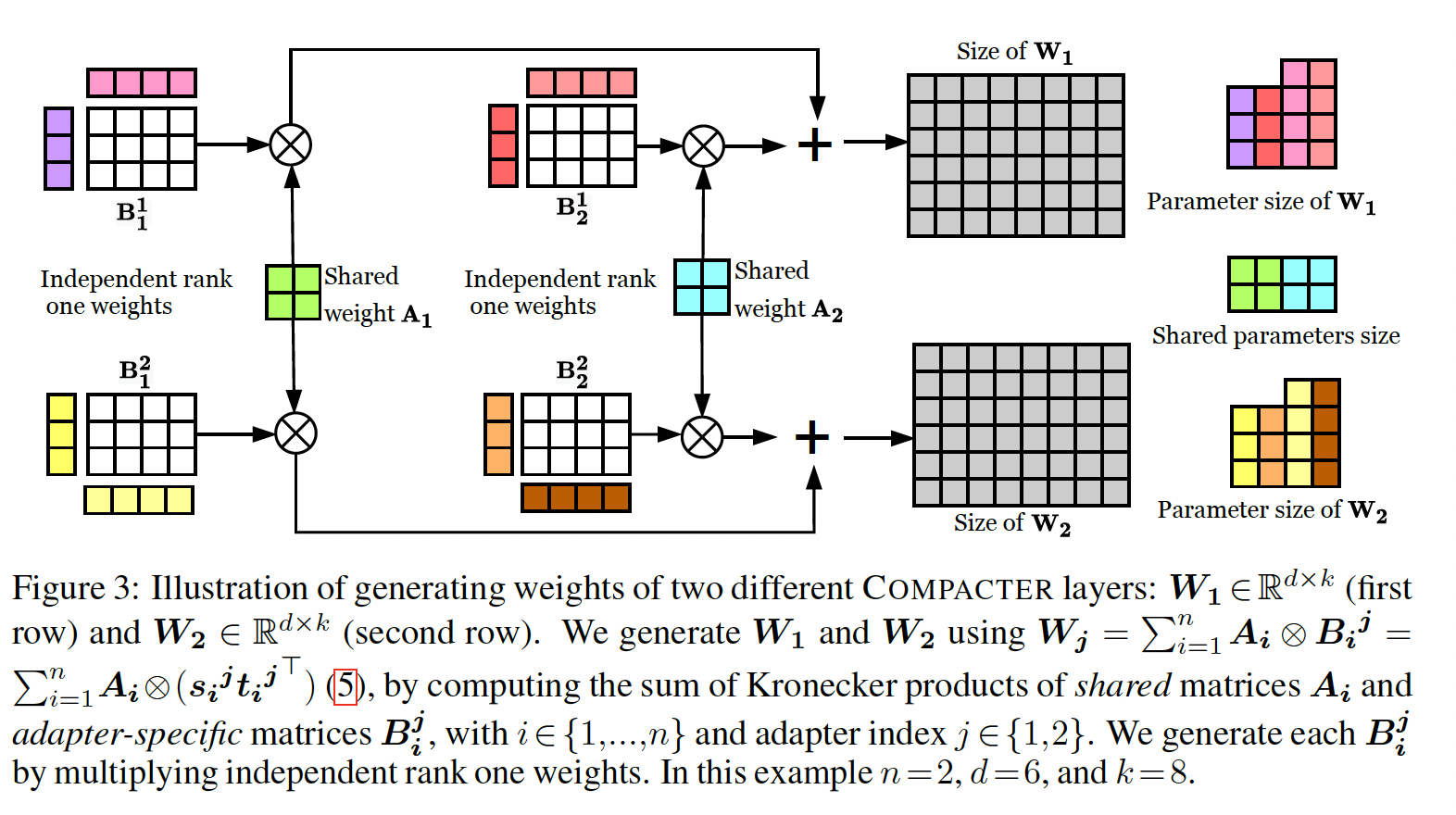
Compacter,一种对大规模语言模型进行微调的方法,与现有方法相比,在可训练参数数量、任务性能和内存占用之间取得了出色的平衡(参考Figure 1)。Compacter建立在adapters(《Parameter-efficient transfer learning for nlp》)、低秩方法(《Measuring the intrinsic dimension of objective landscapes》)、以及最近的超复杂乘法层(《Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications with 1/n parameters》)的概念之上。与adapters类似,Compacter在pretrained模型的权重中插入task-specific的权重矩阵。每个Compacter权重矩阵计算为:shared "slow" weights和"fast" rank-one matrices的Kronecker乘积之和,其中这个"slow" weights和"fast" matrices在每个Compacter layers上定义(见Figure 3)。因此,与常规adapters的Compacter实现了adapters的尺寸为Compacter训练了PLM参数的0.047%。在标准GLUE and SuperGLUE benchmarks中,Compacter优于其他parameter-efficient fine-tuning方法,并获得与full fine-tuning相当或更好的性能。在低资源环境中,Compacter优于标准微调。Compacter还是adapters的变体,但是它有两个优化:首先,通过两个向量的
Kronecker Product来获得矩阵1的矩阵分解),这降低了参数的数量。其次,通过在多个
adapter之间来共享
注意:这里并没有跨任务共享
adapter,只是在单个任务内部跨adapters共享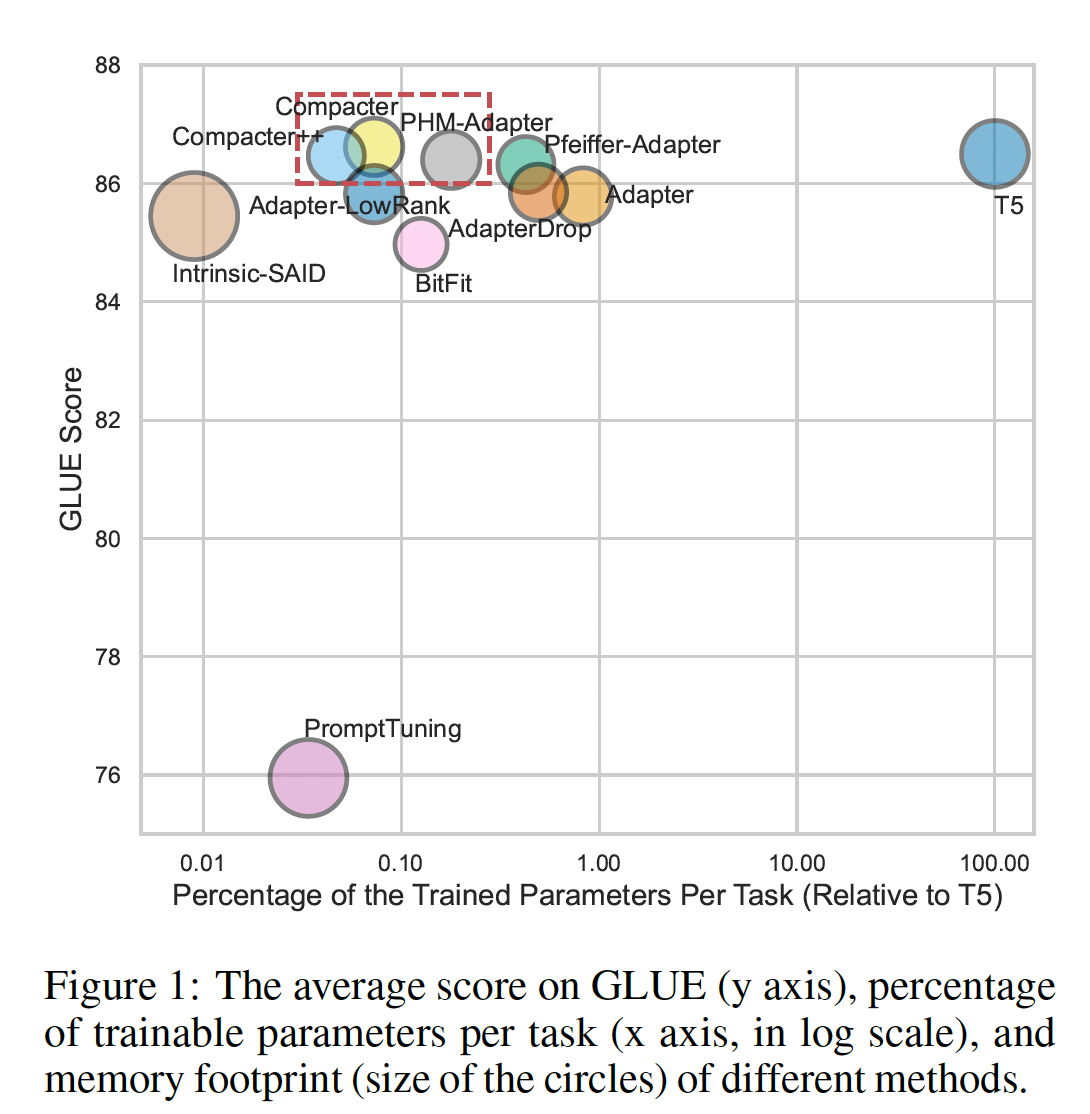
总结一下,我们的贡献如下:
1):我们提出了Compacter(Compact Adapter))layers,一种参数高效的方法来适配大型语言模型。2):我们证明Compacter在GLUE和SuperGLUE上获得了强大的经验性能。3):我们证明Compacter在低资源环境(low-resource settings)中优于微调。4):我们提供了Compacter的参数复杂度分析,显示它需要远少于adapters和fine-tuning的参数。5):我们系统地评估了最近的parameter-efficient fine-tuning方法,关于在训练时间和内存消耗方面的性能。
我们发布了我们的代码以促进未来的工作。
相关工作:
Adapters:最近兴起
adapters作为微调pretrained语言模型的新范式(《Parameter-efficient transfer learning for nlp》)。在另一条研究方向中,
《Udapter: Language adaptation for truly universal dependency parsing》根据adapters和contextual parameter generator网络(《Contextual parameter generation for universal neural machine translation》),提出了一种多语言依存解析(dependency parsing)方法,其中他们根据trained input language embeddings来生成adapter parameters。然而,与base model相比,这导致大幅增加的参数数量。同时,
《Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks》使用单个紧凑的超网络(hypernetwork),允许根据多个任务、以及transformer model的多个layers来高效地生成adapter weights。《Conditionally adaptive multi-task learning: Improving transfer learning in NLP using fewer parameters & less data》还为多任务学习提出了一种task-conditioned transformer,参数效率较低。
上述工作与
Compacter互补,可以潜在地将Compacter与contextual parameter generation相结合,从而生成adapter模块。与《Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks》相比,Compacter++将参数降低了6.2倍。Hypercomplex representations:在hypercomplex领域的深度学习进展还处于初级阶段,大多数工作都是近期的工作。用Hamilton乘法替换标准网络中的矩阵乘法,具有更少的自由度,在单次乘法操作中可以节省多达4倍的参数(《Quaternion recurrent neural networks》、《Lightweight and efficient neural natural language processing with quaternion networks》)。最近,
《Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications wit h1/n parameters》以一种方式扩展了这样的方法,在一个温和条件下,可以将全连接层的参数降低到hypercomplex space进行大型语言模型的efficient fine-tuning。其它
parameter-efficient方法:《Measuring the intrinsic dimension of objective landscapes》和《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》研究了在low-dimensional randomly oriented subspace中(而不是原始参数空间中)训练模型。另一条最近的研究线表明,像
BERT这样的pretrained模型在其能力上是冗余的,允许显著稀疏化而终端指标几乎不降低(《The lottery ticket hypothesis for pre-trained bert networks》、《When BERT Plays the Lottery, All Tickets Are Winning》、《Evaluating lottery tickets under distributional shifts》)。然而,这样的方法目前硬件支持不好,性能通常比专用的高效架构更差(《What is the state of neural network pruning?》)。
8.1 背景知识
我们首先介绍
Kronecker product和adapter layers所需的背景知识(《Parameter-efficient transfer learning for nlp》、《Efficient parametrization of multi-domain deep neural networks》)。Kronecker Product:矩阵Kronecker Product记做其中
即,将
Adapter Layers:最近的工作表明,微调语言模型的所有参数可能导致次优解,特别是对于low-resource datasets(《To tune or not to tune? adapting pretrained representations to diverse tasks》)。作为替代方法,《Efficient parametrization of multi-domain deep neural networks》和《Parameter-efficient transfer learningfor nlp》提出了在pretrained模型的layers中插入小的task-specific模块(称adapter layers),从而将模型迁移到新任务,如Figure 2所示。然后他们只训练adapters和layer normalizations,而pretrained模型的其余参数保持固定。这种方法允许pretrained语言模型高效地适应新的任务。transformer模型的每一层主要由两个模块组成:一个attention block、一个feed-forward block。这两个模块之后都有一个skip connection。如Figure 2所示,《Parameter-efficient transfer learningfor nlp》建议在skip connection之前、在每个block之后插入一个adapter layer。adapters是bottleneck架构。通过保持output dimension与input dimension相同,它们不会改变原始模型的结构或参数。第adapter layerdown-projectionGeLU非线性函数(《Gaussian error linear units (gelus)》)、以及up-projectionadapter layer的bottleneck维度。adapters定义为:其中
input hidden state。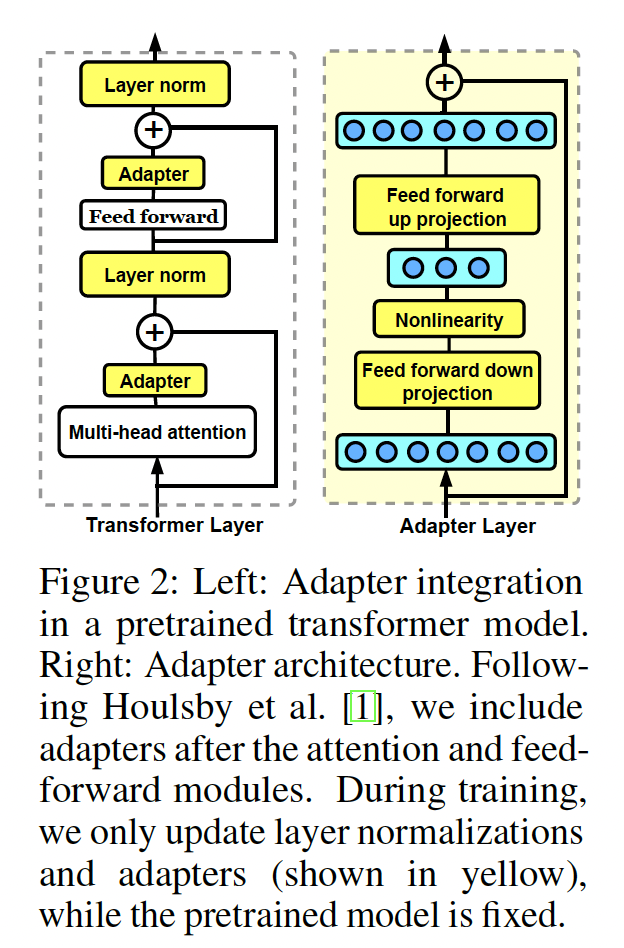
8.2 方法
在本节中,我们提出
Compacter,一种紧凑的和高效的方法来适配大型PLMs。问题形式化:我们考虑微调大规模语言模型的一般问题,其中给定包含
pretrained语言模型
8.2.1 Compact and Efficient Adapter Layers
在本节中,我们基于最近的
parameterized hypercomplex multiplication layers: PHM(《Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications with 1/n parameters》)的进展,引入adapter layers的一个高效版本。据我们所知,我们是第一个利用PHM layer来为大型transformer模型进行efficient fine-tuning的。PHM layer与全连接层具有相似的形式,将输入其中:
bias向量。关键区别在于:在
PHM layer中,Kronecker product的和。假设Kronecker products之和:其中:
PHM layer的参数复杂度为《Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications with 1/n parameters》)。这就是推荐算法中常用的矩阵分解方法。
8.2.2 Beyond Hypercomplex Adapters
先前的工作表明,
pretrained模型中捕获的一些信息可以被忽略从而用于迁移(《Revisiting Few-sample BERT Fine-tuning》、《Rethinking Embedding Coupling in Pre-trained Language Models》)。类似地,也观察到adapters中捕获的信息中存在冗余,lower layers中adapters的重要性较低(《Parameter-efficient transfer learningfor nlp》)。此外,在某些任务上,跨layers共享adapters仅导致性能上较小的降低(《AdapterDrop: On the Efficiency of Adapters in Transformers》)。受这些见解的启发,我们提出以下两点扩展,从而使hypercomplex adapters更高效:Sharing information across adapters:在所有层之间共享所有adapter parameters的限制性总体上太强,不能与微调或使用常规adapters的性能相媲美(《AdapterDrop: On the Efficiency of Adapters in Transformers》)。但是,我们如adapters分解为因此,我们将
adaptation weights分为:shared parameters:捕获对适配目标任务有用的通用信息。adapter-specific parameters:聚焦于捕获那些适配每个individual layer的相关信息。
具体来说,我们将
adapter layers之间shared parameters,而adapter-specific parameters。Low-rank parameterization:低秩方法(《Measuring the intrinsic dimension of objective landscapes》、《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》)表明,通过在低秩子空间中优化任务可以实现强大的性能。类似地,我们假设也可以通过在低秩子空间中学习transformations从而有效地适配模型。为此,我们提出将low-rank parameterized hypercomplex multiplication layer(LPHM):通常,我们设置
1的矩阵。根据目标任务的复杂性,可以将Figure 3说明了我们的方法。总体而言,LPHM layer将复杂度进一步降低到LPHM layer也可以看作利用跨adapters共享的"slow" weightsindividual layer的adapter-specific information的"fast" weights
Compacter:基于上述公式,我们引入Compacter layer,它将adapters中的down-projection layers和up-projection layers替换如下:其中:
up-projection权重down-projection权重
虽然
transformer中每层的两个adapters都有自己的、秩为1的adapter layers上共享是否可以将
8.3 参数效率
在本节中,我们比较
Compacter与adapters的参数数量。Adapters parameters:在标准设置中,transformer模型的每一层添加两个adapters(《Parameter-efficient transfer learningfor nlp》)。每个adapter layer包含down-projection矩阵up-projection矩阵adapter的bottleneck维度。因此,具有encoder-decoder transformer模型中,adapters总参数数量为encoder中包含decoder中包含PHM-Adapter parameters:在常规PHM layer中(《Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications with 1/n parameters》),如公式PHM layer的总参数量为adapters、PHM layer、以及大型PLM(如T5-large)的典型取值成立,其中hidden sizeadapter hidden sizePHM layer降低参数规模到标准全连接层参数数量的几乎类似地,使用
PHM layer建模down-projection矩阵和up-projection矩阵可以提供参数规模降低到近乎adapter with a PHM layer总共有encoder-decoder transformer模型,PHM-Adapter的参数总数为Compacter参数:Compacter在所有层之间共享权重矩阵Compacter对每个adapter也有两个秩为1的权重矩阵down-projection权重和up-projection权重的总参数数量为encoder-decoder transformer中,Compacter的总参数数量为在大量层的设置中,统治项为
Compacter的复杂度为adapters的PHM-Adapter的在
Compacter中保持恒定,总共PHM和adapter layers,222M参数的T5_BASE模型中,Compacter仅学习了0.047%的参数,同时保持与full fine-tuning相当的性能。
8.4 实验
数据集:遵循
T5,我们在GLUE和SUPERGLUE等benchmarks上评估各种方法的性能。这些benchmarks涵盖paraphrase detection(MRPC,QQP)、情感分类(SST-2)、自然语言推理(MNLI,RTE,QNLI,CB)、linguistic acceptability(CoLA)、问答(MultiRC,ReCoRD,BoolQ)、词义消歧(WiC)和句子补全(COPA)等多个任务。由于原始测试集不公开,我们遵循《Revisiting few-sample bert fine-tuning》的做法,从训练集中划分出1k个样本用作验证集,而使用原始验证数据作为测试集。对于样本数少于10k的数据集(RTE,MRPC,STS-B,CoLA,COPA,WiC,CB,BoolQ,MultiRC),我们将原始验证集等分为两半:一半用于验证、另一半用于测试。实验详细信息:我们在所有实验中使用当前最
SOTA的encoder-decoder T5 model作为所有方法的底层模型。为了计算效率,我们在T5_BASE模型上报告所有结果(112 encoder and decoder layers,共有222M个参数)。我们使用T5_BASE的HuggingFace PyTorch实现。我们在大型数据集上微调所有方法3 epochs,在GLUE的低资源数据集(MRPC,CoLA,STS-B,RTE,BoolQ,CB,COPA,WiC)上微调20 epochs从而使模型收敛(《Revisiting few-sample bert fine-tuning》)。对于所有adapter-based的方法,我们实验adapters的bottleneck size为{96,48,24}。我们为所有模型保存每个epoch的checkpoint,并报告最佳超参数的结果(最佳超参数通过每个任务的验证集上的表现来筛选)。对于PHM layer,我们使用《Parameterized hypercomplex graph neural networks for graph classification》的PyTorch实现。我们在附录A中包括low-level的详细信息。对于我们的方法,我们实验B中包括所有遵循
《Parameter efficientmulti-task fine-tuning for transformers via shared hypernetworks》在所有任务上、所有方法中,我们冻结pretrained模型的output layer。我们在附录C中显示了微调output layer的结果。一般而言,需要微调
output layer(即,prediction head)。因为这是与具体的任务密切相关的。实验结果表明,冻结pretrained模型的output layer,会大大损害下游任务的性能。遵循
《Parameter-efficient transfer learning for nlp》,我们在适用的情况下更新所有方法的layer normalization参数。baselines:我们与几种最近提出的parameter-efficient fine-tuning方法进行比较:T5_BASE:我们将我们的方法与标准的T5微调进行比较,其中我们对每个任务微调模型的所有参数。ADAPTER:我们与强大的adapter baseline(《Parameter-efficient transfer learning for nlp》)进行比较,它为每个任务在T5的每个transformer block的前馈模块之后、以及注意力模块之后添加adapters。PFEIFFER-ADAPTER:《AdapterFusion: Non-destructive task composition for transfer learning》提出的一种更高效的adapter变体,其中每层只保留一个adapter以获得更好的训练效率。我们实验了保留每层的两个adapters中的任何一个adapter,发现保留自注意力模块后的adapter表现最好。注意,
AdapterFusion原始论文中保留的是feed-forward layer之后的adapter。ADAPTER-LOWRANK:我们将每个adapter的权重参数化为两个秩为1的权重矩阵的乘积。PROMPT TUNING:prompt tuning(《The power of scale for parameter-efficient prompt tuning》)是《Prefix-tuning: Optimizing continuous prompts for generation》的后续变体,在输入前面添加随机初始化的continuous prompt(PROMPT TUNING-R)。我们还比较了一种变体,它使用
pretrained语言模型词表的token embeddings来初始化prompts(PROMPT TUNING-T)(《The power of scale for parameter-efficientprompt tuning》)。INTRINSIC-SAID:Structure Aware Intrinsic Dimension(《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》)通过在较低维子空间参数
pretrained模型的参数。Fastfood变换(《Fastfood-approximating kernel expansions in loglinear time》)的随机线性投影。
然后,他们考虑
PLM中的权重矩阵总数ADAPTERDROP:我们将《AdapterDrop: On the Efficiency of Adapters in Transformers》的方法应用于T5和ADAPTER,该方法通过删除lower transformer layers中的adapters来提高训练效率。因此,我们删除T5_BASE中both the encoder and the decoder的前五层中的adapters。BITFIT:《Tinytl: Reduce memory, not parametersfor efficient on-device learning》提出只训练bias而不训练权重。通过不存储intermediate activations,该方法实现了可观的内存节省。《Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language models》研究了一种类似的只微调bias和final output layer的方法。
我们的方法:
PHM-Adapter:我们如式PHM layer学习adapters的权重。据我们所知,我们是第一个利用PHM思想进行大型语言模型的高效微调的。Compacter:我们如LPHM layers学习adapters的权重。我们还探索了一个变体,其中我们在每个
transformer block中只保留feed-forward layer之后后的Compacter layer(COMPACTER++)。
GLUE Benchmark的结果:Table 1显示了T5_BASE在GLUE上的结果(T5_SMALL的结果见附录E)。Compacter和Compacter++优于所有以前的parameter-efficient方法,并与full fine-tuning的性能相当,而仅训练0.07%(Compacter)和0.047%(Compacter++)的参数。我们现在详细讨论不同的方法。Adapter-based methods:对于
Adapter,not fine-tuning the classifier会大大损害性能(85.78 vs 86.48, 参见附录C)。只在
self-attention模块之后添加adapters的PFEIFFER-ADAPTER优于标准的ADAPTER,而且参数更高效。ADAPTERDROP的性能低于微调,表明encoder-decoder T5 model中适配lower layers对其性能很重要。另外,
ADAPTER-LOWRANK的表达能力不足以在这个benchmark中表现良好。ADAPTER-LOWRANK的性能比Adapter更好,而且参数少得多,因此性价比更高。
Prompt tuning and BitFit:对于
PROMPT TUNING,我们观察到高度依赖初始化和学习率,这也在《Prefix-tuning: Optimizing continuous prompts for generation》中得到确认。我们使用多个随机种子进行了实验,但性能明显落后于微调,尤其是在低资源数据集上。这可以用这些方法的灵活性有限来解释,因为所有信息都需要包含在prefixes中。因此,该方法只允许与模型的其余部分有限的交互,良好的性能需要非常大的模型(《The power of scale for parameter-efficient prompt tuning》)。此外,序列长度的增加会导致内存开销,prompt tokens的数量受模型最大输入长度的限制,这使得这种方法缺乏灵活性,不适合处理大上下文。类似地,
BITFIT的表现也比微调差,尤其是在低资源数据集上。
Intrinsic-SAID:有趣的是,只微调模型参数的0.009%的INTRINSIC-SAID的平均性能仅比fine-tuning baseline低1.05分。但是,该方法有两个实际缺点:存储随机投影矩阵会导致可观的内存开销、训练非常缓慢。尽管如此,
INTRINSIC-SAID提供了关于pretrained语言模型的低秩优化有效性的见解(《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》),这推动了Compacter等parameter-efficient方法的发展。Compacter:对于我们提出的方法,我们观察到对PHM-ADAPTER和COMPACTER++微调输出层没有太大的性能差异(见附录C)。PHM-ADAPTER将ADAPTER的参数从0.83%降低到0.179%(n=12),4.64倍更高的参数效率。COMPACTER将参数数量降低到了显著的0.073%,同时获得了与full fine-tuning相当的结果。通过删除自注意力之后的
COMPACTER layer,COMPACTER++获得了类似的性能,同时将参数降低到0.047%。
不更新
layer normalization的适配可能是一个进一步减少参数的有前途的方向,例如,基于最近的normalization-free models的进展(《High-performance large-scale image recognition without normalization》),我们留待未来工作。
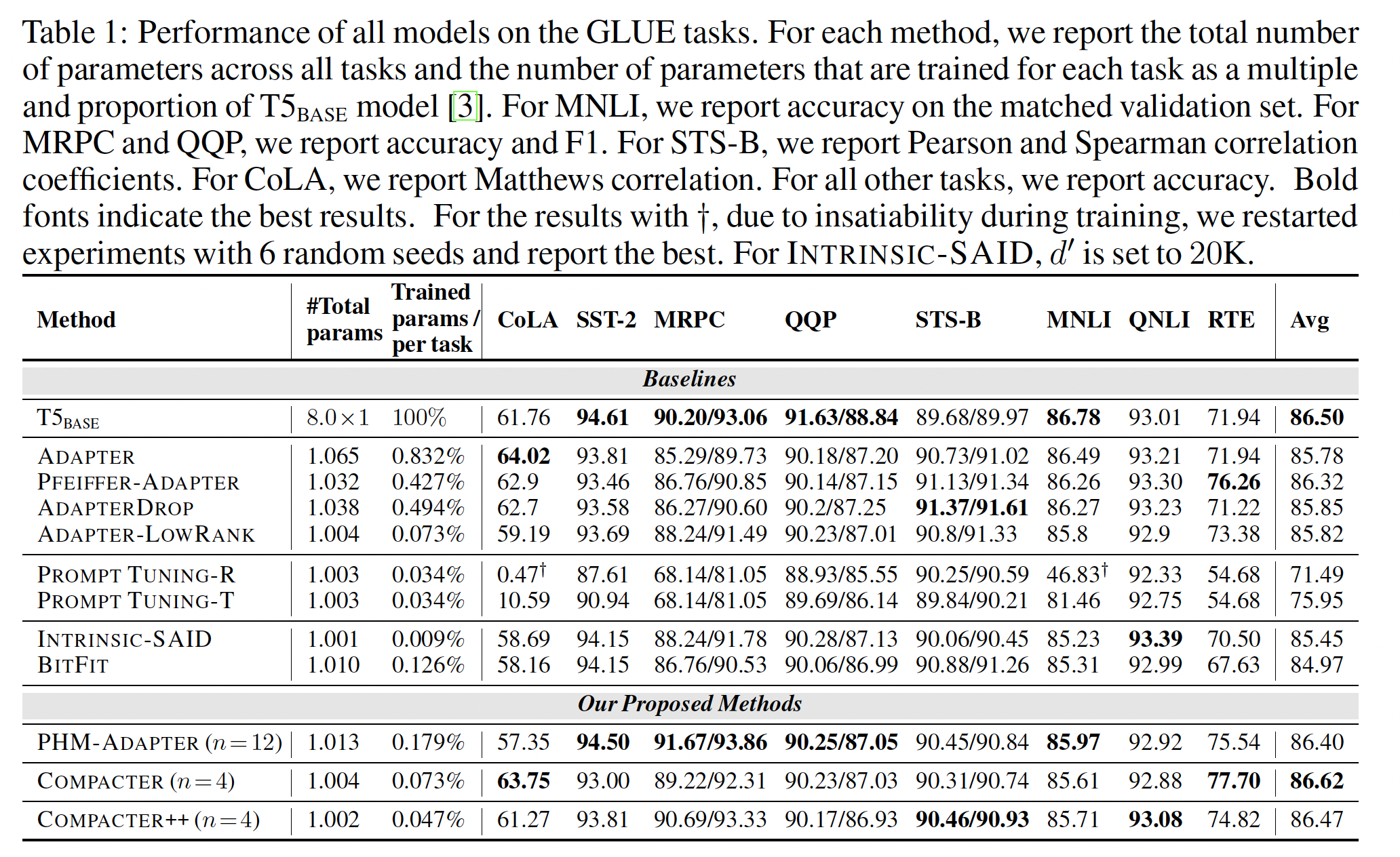
SUPERGLUE Benchmark的结果:Table 2显示了这些方法在SUPERGLUE上的性能。我们在附录D中包括所有Table 1中的GLUE相似的模式。COMPACTER和COMPACTER++相比其他parameter-efficient fine-tuning方法的性能明显更好,甚至优于full fine-tuning,同时只训练0.073%和0.048%的参数。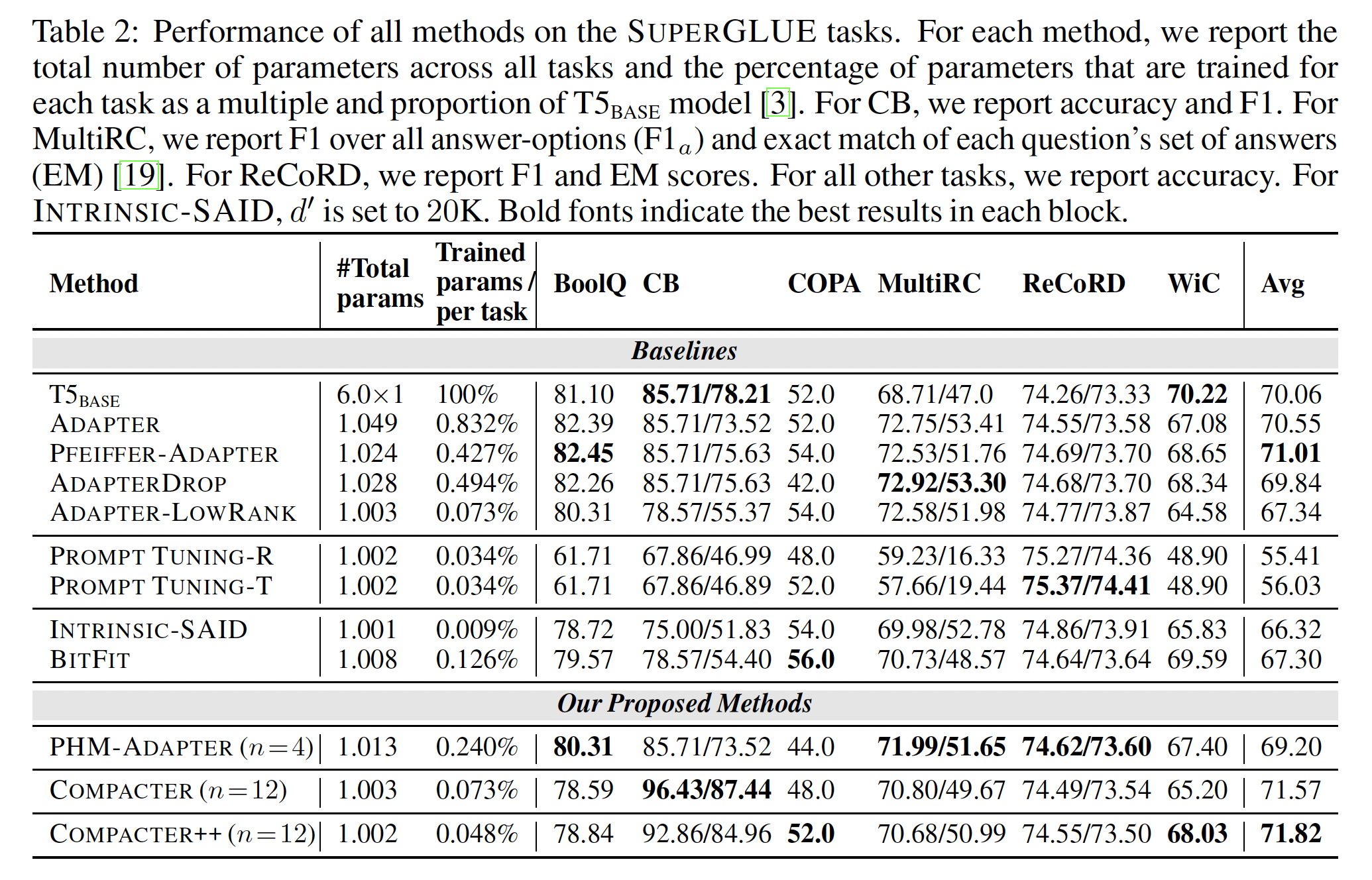
Efficiency Evaluation:在本节中,我们在相同的计算预算下比较我们提出的方法,与各种最近提出的parameter-compact fine-tuning方法的效率。为此,我们在MNLI数据集上对所有方法训练1 epoch。对于每个方法,我们选择最大的
batch size从而适合固定的GPU内存预算(24 GB)。对于所有
adapter-based方法,我们将bottleneck size固定为24。对于
PROMPT TUNING,我们将prefix tokens数量设置为100。对于
INTRINSIC-SAID,我们设置最后,对于
COMPACTER及其变体,我们设置
在
Table 3中,我们报告每个任务的trained parameters的百分比、每个epoch的训练时间、以及每个方法的内存使用情况。 此外,Figure 1显示了定量性能、trained parameters百分比、以及内存占用之间的权衡。我们的方法具有几个有吸引力的属性:
根据
Table 1中的分析,COMPACTER和COMPACTER++获得了高GLUE分数(平均跨所有任务)与明显更少的参数规模(分别为0.073%和0.047%)的最佳组合。除了
COMPACTER++的表现良好之外,COMPACTER++的内存需求是所有方法中第二低的,相比T5_BASE减少了41.94%的内存使用。COMPACTER和COMPACTER++也明显加速了训练,相对于T5_BASE分别减少了13.41%和26.51%的训练时间。另一方面,
BITFIT通过不存储intermediate activations,具有最低的内存需求(相对于T5_BASE减少64.2%),并且是最快的(相对于T5_BASE减少35.06%的训练时间),代价是定量性能更差(低1.53分,参见Table 1)。
除此之外我们还可以看到:
依靠
pruning adapters的方法,即PFEIFFER-ADAPTER和ADAPTERDROP减少了内存开销并改进了训练时间。然而,与COMPACTER++相比,它们的参数数目几乎高出一个数量级,分别多出9.1倍和10.5倍的参数。此外,
PFEIFFER-ADAPTER的性能与full fine-tuning相当(略有下降,参考Table 1),ADAPTERDROP获得了更低的性能(跨所有任务平均降低0.65)。我们注意到,从transformer layers中删除adapters是一种通用技术,可以进一步提高COMPACTER的效率,我们留待未来工作。类似地,尽管
ADAPTER-LOWRANK减少了内存开销并提高了训练时间,但它的性能更差(Table 1,跨所有任务平均降低0.68分)。
在另一个方面,
INTRINSIC-SAID和PROMPT TUNING方法的参数最少。但是,它们都带来很高的内存开销(分别相对于full fine-tuning高出41.14%和24.42%),训练最慢,其性能明显落后于full fine-tuning(见Table 1)。对于
PROMPT TUNING,高内存成本是因为self-attention需要存储完整的注意力矩阵以进行梯度计算,其计算复杂度与序列长度呈二次方关系。
对于
INTRINSIC-SAID,高内存需求是由于存储大的随机投影矩阵,这限制了INTRINSIC-SAID在微调大型PLM上的应用。此外,尽管理论上可以在FastFood transform进行投影计算,但即使使用CUDA实现,实践中也非常缓慢。对于具有大量参数的pretrained语言模型,为完整参数空间分配随机投影是不可行的。虽然Fastfood transform通过将内存使用从
总体而言,鉴于大型
transformer模型具有数百万甚至数十亿个参数,如T5,efficient memory usage对实际应用至关重要。COMPACTER和COMPACTER++在性能、内存使用、以及训练时间方面提供了很好的权衡。我们发现只需要相对较少的额外参数即可进行PLM的实用的和高效的适配。
Low-resource Fine-tuning:与T5_BASE相比,COMPACTER++的参数明显更少。在本节中,我们研究这是否可以帮助COMPACTER++在资源有限的设置中取得更好的泛化。我们对GLUE中的每个数据集进行降采样,样本量范围为{100,500,1000,2000,4000}。Figure 4显示了结果。COMPACTER++在低资源设置中明显改进了结果,表明它在这种情况下的微调更有效。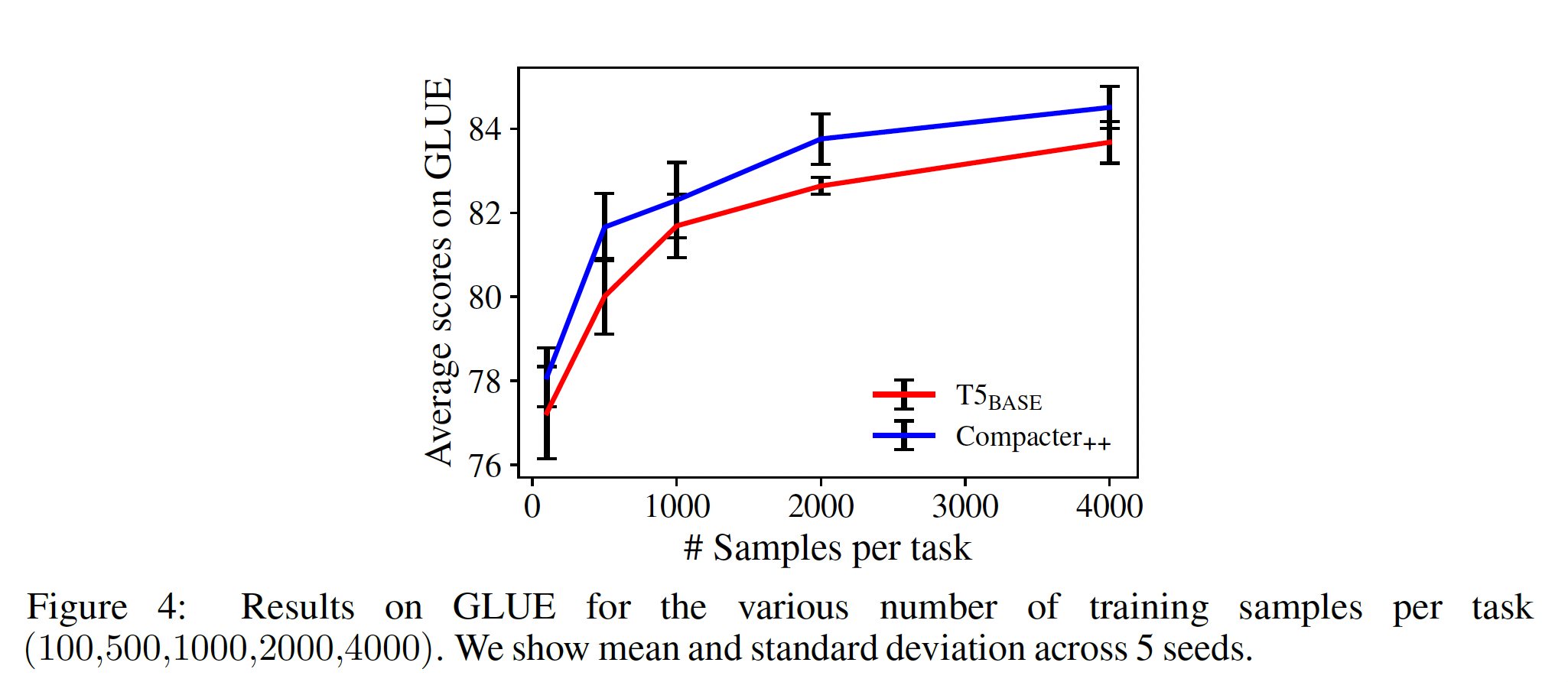
九、BitFit[2021]
论文:
《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》
大型
pre-trained transformer based语言模型,特别是来自BERT系列的bidirectional masked language models(BERT、Roberta、Spanbert),为许多NLP任务带来了显著改进。在常用范式下,模型在大型的、标注的语料上用LM objective被预训练,然后在task-specific的监督数据上微调。这些模型的large size使它们的训练和(更重要的是)部署变得昂贵。 加上对微调必须在何种程度上改变原始模型的理论疑问,已促使研究人员考虑finetuning variants,其中识别出模型参数的一个小的子集,这个参数子集需要为下游任务的良好性能而进行参数更新,同时保持所有其他参数不变。我们提出了一种简单有效的微调方法,其具有以下优点:
每个被微调的任务只改变很少的参数。
为每个任务改变相同的参数集合(
task-invariance)。被改变的参数在整个参数空间中都是隔离(
isolated)的且局部化(localized)的。对于小数据集到中型数据集,仅改变这些参数达到与
full fine-tuning相同的任务准确率,有时甚至能改善结果。
注意:对于大型数据集,
BitFit的效果较差。具体而言,我们展示
fine-tuning only the bias-terms而冻结网络的大部分是非常有效的。此外,如果我们允许任务在性能上稍微下降,我们可以只微调两个bias部分("query" bias、以及"middle-of-MLP" bias),这占模型的bias参数的一半,且仅占所有模型参数的0.04%。这一结果在内存受限环境中部署
multi-task fine-tuned models、以及在大多数参数固定的情况下启用trainable hardware implementations方面具有很大实用价值。 此外,它也开辟了一系列关于pre-trained networks中bias项的作用、以及微调过程的dynamics的研究方向。相关工作:识别最小的参数集合从而微调该参数集合从而在最终任务中取得良好性能,这个问题与模型压缩的实际问题相关,也与预训练和微调过程本质、预训练过程和微调过程诱导的 “语言知识” 、以及它们泛化到不同任务的程度等更基本问题都相关。
Over-parameterization:大型语言模型被证明是过参数化的:它们包含的参数多于推理所需的参数。《Compressing BERT: studying the effects of weight pruning on transfer learning》已经证明,可以在微调中利用过参数化(overparmeterization):裁剪后的网络在transfer setting中表现良好。我们的工作设置与之互补,其中整个模型都保留下来,但只更新某些参数。这些工作的显著成功引发了对 “彩票假设” (
lottery-ticket hypothesis)的兴趣(《The lottery ticket hypothesis: Finding sparse, trainable neural networks》、《The lottery ticket hypothesis for pretrained BERT networks》、《When BERT plays the lottery, all tickets are winning》):大模型在预训练中只需要诱导(以高的概率)已存在的子网络(这个子网络被具有正确inductive bias所初始化),并发现这些稀疏网络通常能很好地迁移到不同的任务。Bias terms:文献中很少讨论bias项及其重要性。《Masking as an efficient alternative to finetuning for pretrained language models》描述了一种masking-based的微调方法,明确提到忽略bias项,因为处理它们 “没有观察到对性能的积极影响”。一个例外是
《Bias also matters: Bias attribution for deep neural network explanation》的工作,他们从attribution方法的角度分析了bias项。他们证明了last layer bias values负责predicted class,并提出了反向传播其重要性的方法。《Extreme adaptation for personalized neural machine translation》微调了NMT systems的output softmax的bias,从而个性化output vocabulary。《Training batchnorm and only batchnorm: On the expressive power of random features in cnns》证明了仅通过训练batch-norm layers可以使随机初始化的CNN达到合理的准确率。最后,最接近我们工作的是,
《Tiny transfer learning: Towards memory-efficient on-device learning》证明了类似于我们的bias-only fine-tuning对pre-trained computer vision models的适配也是有效的。
我们的工作从经验上展示了
bias parameters改变网络行为的重要性和力量,呼吁我们进一步分析和关注bias项。
9.1 背景:fine-tuning 和 parameter-efficient fine-tuning
在通过模型微调的迁移学习中,
input被馈入pre-trained encoder network并生成contextualized representations。 然后,在encoder顶部添加task-specific classification layer(这里我们考虑线性分类器),并将整个网络(encoder + task-specific classifiers)端到端地训练从而最小化任务损失。理想的属性:尽管
fine-tuning per-task非常有效,但它也会导致每个pre-trained task都有一个唯一的、大型的模型,这使得很难推断微调过程中发生了什么改变;并且随着任务数量的增加,部署也变得困难。理想情况下,我们希望微调方法:(1):与fully fine-tuned model的结果相媲美。(2):仅改变模型参数的一小部分。(3):允许任务以流式的形式到达,而不是需要同时访问所有数据集。(4):对于高效的hardware based的部署,如果满足以下条件那就更好:跨不同任务之间,需要改变取值的参数集合是相同的。
Learning vs. Exposing:是否可以满足上述要求取决于有关大型pre-trained LM的微调过程本质的一个基本问题:微调过程诱导了学习新能力的程度有多大、以及暴露在预训练过程中学到的已有能力的程度。现有方法:两项最近的工作已经证明,通过仅改变参数的一个小的子集就可以适应各种最终任务。
第一项工作,
《Parameter-efficient transfer learning for NLP》通过在pre-trained model的层之间注入小的、可训练的task-specific "adapter" modules来实现这一目标,其中原始参数在任务之间共享。第二项工作,
《Parameter-efficient transfer learning with diff pruning》的"Diff-Pruning",通过将稀疏的、task-specific difference-vector添加到原始参数来实现相同的目标,其中原始参数保持固定并在任务之间共享。difference-vector经过正则化从而是稀疏的。
两种方法都仅为每个任务添加很少的可训练参数(准则
(2)),并且每个任务都可以在不重新访问前面的任务的情况下被添加(准则(3))。它们也部分满足准则(1),与full fine-tuning相比性能只有轻微的下降。adapter method还支持准则(4),但是Diff-Pruning不支持准则(4)。 然而,与Adapter方法相比,Diff-Pruning的参数效率更高(特别是它不添加新参数),并且也取得了更好的任务分数。在实验部分,我们将我们的方法与Diff-Pruning和Adapters进行了比较,结果表明我们在满足标准(4)的同时,在许多任务上表现更佳。Diff-Pruning的思想比较简单:固定pretrained parametersdiff vectortask-specific parameter为:其中:
因为
L0正则化难以优化,因此作者采用一个binary mask vector其中
dense vector参数。可以进一步松弛
0 ~ 1上的均匀分布的随机变量。0 ~1上的连续变量。其中Bernoulli分布的参数。
此时,作者优化
L0正则化项的期望:最终的目标函数为:
9.2 BitFit
我们提出了一种称为
BIas-Term FIne-Tuning: BitFit的方法,在该方法中,我们冻结了transformer-encoder的大多数参数,仅训练bias-terms和task-specific classification layer。BitFit具有三个关键特性:(1):匹配fully fine-tuned model的结果。(2):允许任务以流式的形式到达,因此不需要同时访问所有数据集。(3):仅微调模型参数的一小部分。
该方法是
parameter-efficient的:每个新任务仅需要存储bias terms parameter向量(占总参数规模的不到0.1%),以及task-specific final linear classifier layer。具体而言,
BERT encoder由self-attention heads开始(即,多头自注意力,key encoder, query encoder, value encoder,每个encoder的形式都是线性层,其中,
encoder layer的输出(对于第一个encoder layer,embedding layer的输出)。 然后,这些结果使用注意力机制(不涉及新参数)来组合:得到的结果然后被馈入带有
layer-norm (LN)的一个MLP:其中,所有的
bias项。结构为:
----------------------------skip connection-----
/ \
x -> attention - > h1 -> linear with dropout -> + -> LN -> linear with Gelu -> linear with dropout -> + -> LN -> output
\ /
----------------skip connection-----------------
bias项是加性(additive)的,且对应网络的很小一部分;在BERT_BASE和BERT_LARGE中,bias参数分别占每个模型总参数数的0.09%和0.08%。我们展示通过冻结除了
bias项以外的所有参数,并仅仅微调bias项bias参数的一个子集,即与query的bias、第二个MLP的bias(full-model fine-tuning相媲美的准确率。
9.3 实验
数据集:
GLUE benchmark。与以前的工作一致(
《Parameter-efficient transfer learning for NLP》、《Parameter-efficient transfer learning with diff pruning》),我们排除了WNLI任务,在该任务上BERT模型并未优于the majority baseline。模型和优化:我们使用公开可用的
pre-trained BERT_BASE, BERT_LARGE和pre-trained RoBERTa_BASE模型,使用HuggingFace接口和实现。附录§A.2列出了optimization的详细信息。与
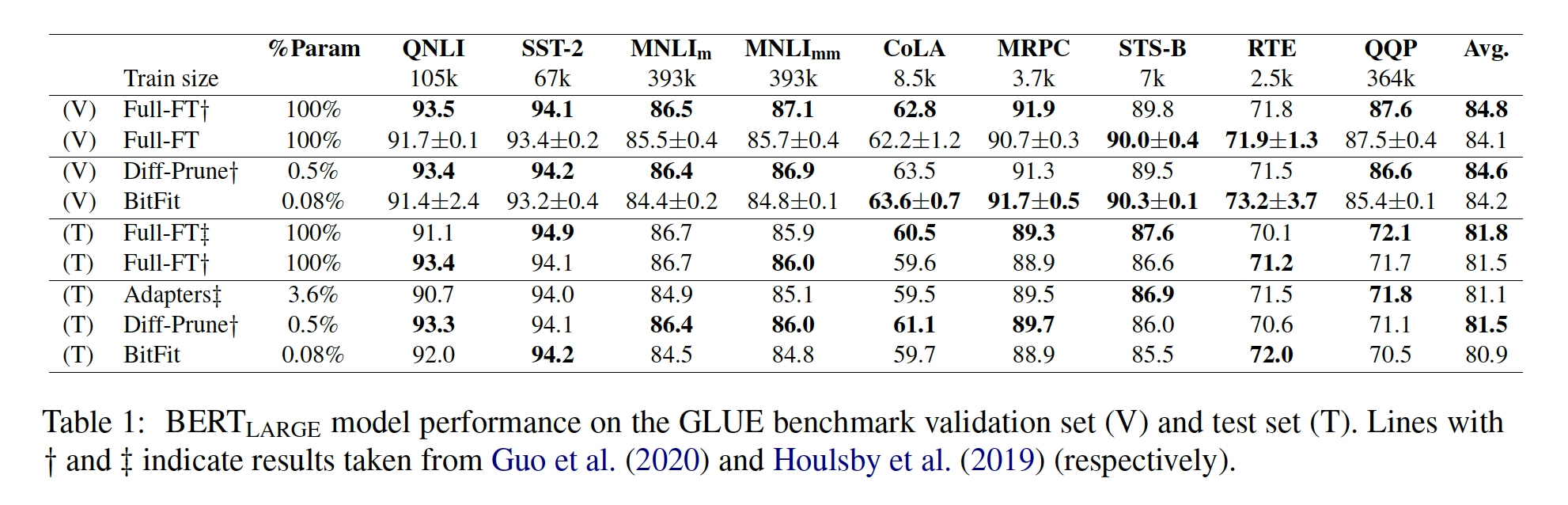
Diff-Pruning和Adapters的比较:在第一个实验中,我们将Bit-Fit与Diff-Pruning方法和Adapters方法进行了比较,当使用更少的参数时。Table 1报告了与《Parameter-efficient transfer learning for NLP》、《Parameter-efficient transfer learning with diff pruning》等报告的Adapter结果、Diff-Pruning结果相比的验证集和测试集性能。该实验使用BERT_LARGE模型。在验证集上,
BitFit与Diff-Pruning相比,在9个任务中的4个上表现更好,而使用的可训练参数少6倍。在测试集上,
BitFit与Diff-Pruning相比有2个明显的胜利,与Adapters相比有4个明显的胜利,同时使用的参数比Adapters少45倍。
不同的
Base-models:我们在不同的base模型(较小的BERT_BASE、以及表现更好的RoBERTa_BASE)上重复实验。Table 2中的结果表明趋势与Table 1保持一致。
bias参数特殊吗:bias参数特殊,还是任何随机的参数子集都可以?我们从整个模型中随机采样了与BitFit中一样多的参数,仅对它们进行了微调(Table 3中的"rand uniform"行)。结果在所有任务上都显著更差。如果我们随机采样参数矩阵中的完整行或完整列,结果也是类似的(Table 3中的"rand row/col"行)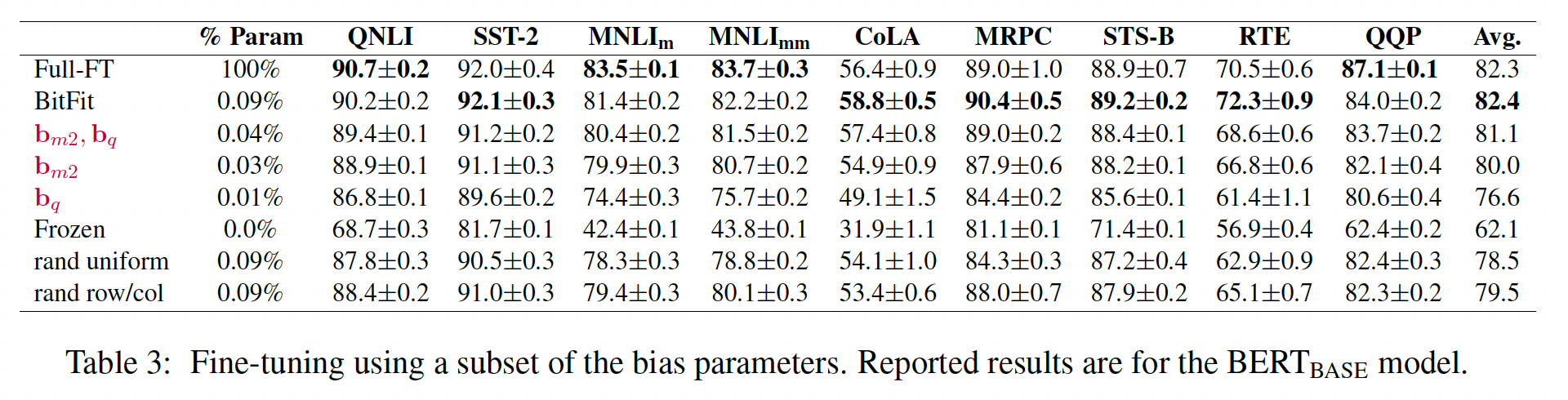
更少的
bias参数:我们可以仅微调bias参数的一个子集吗?我们将
bias向量LM上的初始值Figure 1显示了每一层每个bias项的变化量,针对RTE任务(其他任务看起来非常相似,见附录§A.4)。"key" bias《Multi-head attention: Collaborate instead of concatenate》的理论观察一致。相比之下,
"query" biasMLP层的bias768维映射到3072维)的变化最大。
Table 3报告了仅微调BERT_BASE模型的bias参数的结果只有轻微的下降。仅微调bias类型都是必要的。如预期的那样,使用frozen BERT_BASE模型会产生更差的结果。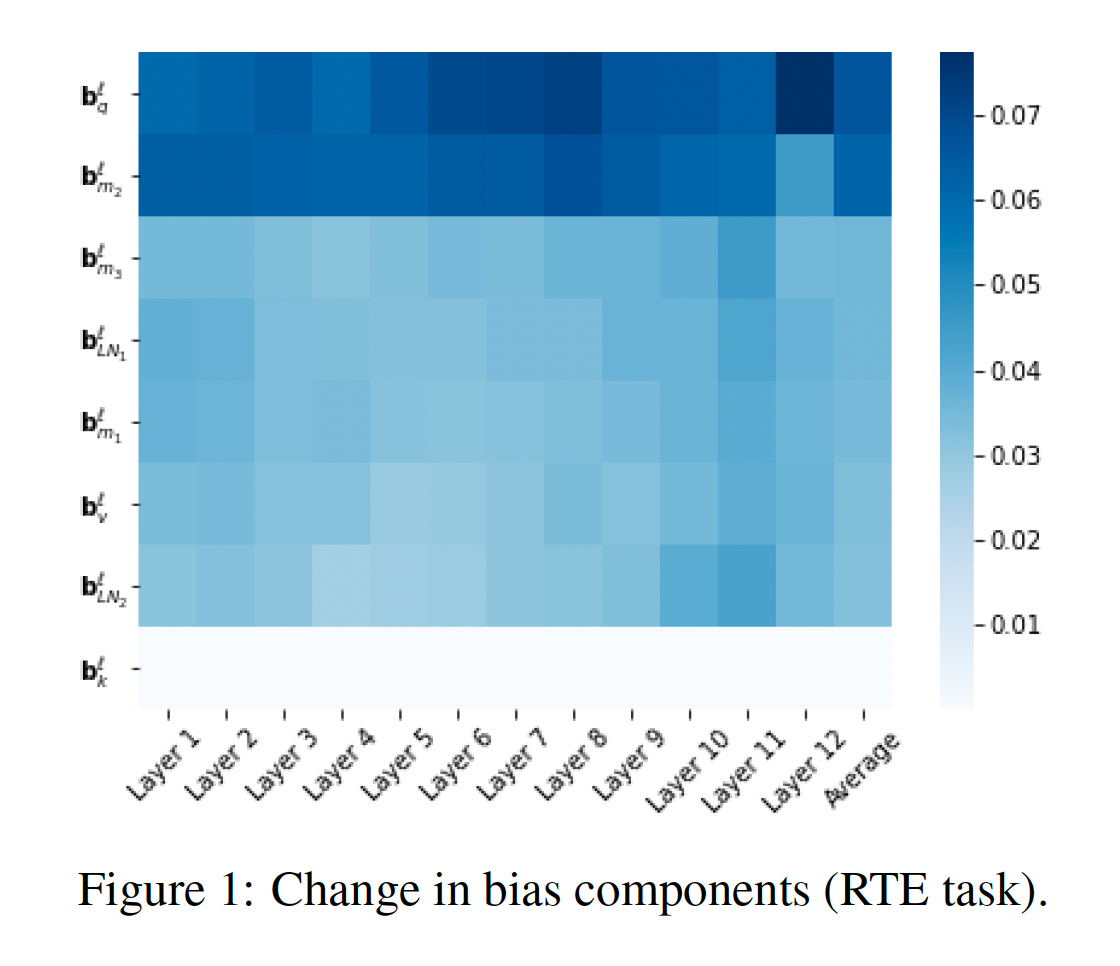
Generalization gap:尽管在大多数情况下,full fine-tuning几乎达到100%的训练准确率,但我们发现BitFit模型的generalization gap(训练误差与测试误差之间的差异)要明显更小。Token-level tasks:GLUE任务都是sentence level的。 我们还对PTB POS-tagging进行了token-level实验。BERT_BASE、BERT_LARGE和RoBERTa_BASE的full fine-tuning结果分别为97.2、97.4、97.2,而BitFit结果分别为97.2、97.4、97.1。训练数据的规模:
GLUE结果表明,BitFit达到full fine-tuning性能的能力与训练数据集大小之间存在反相关。为了测试这一点(并验证另一个
token-level task),我们在SQuAD v1.0的不同大小子集上进行了训练。Figure 2中的结果显示了一个明确的趋势:在较小的数据集上,
BitFit明显优于full fine-tuning。而当有更多可用的训练数据时,则
full fine-tuning优于BitFit。
我们得出结论:在中小数据集的情况下,
BitFit是一种值得考虑的targetted finetuning method。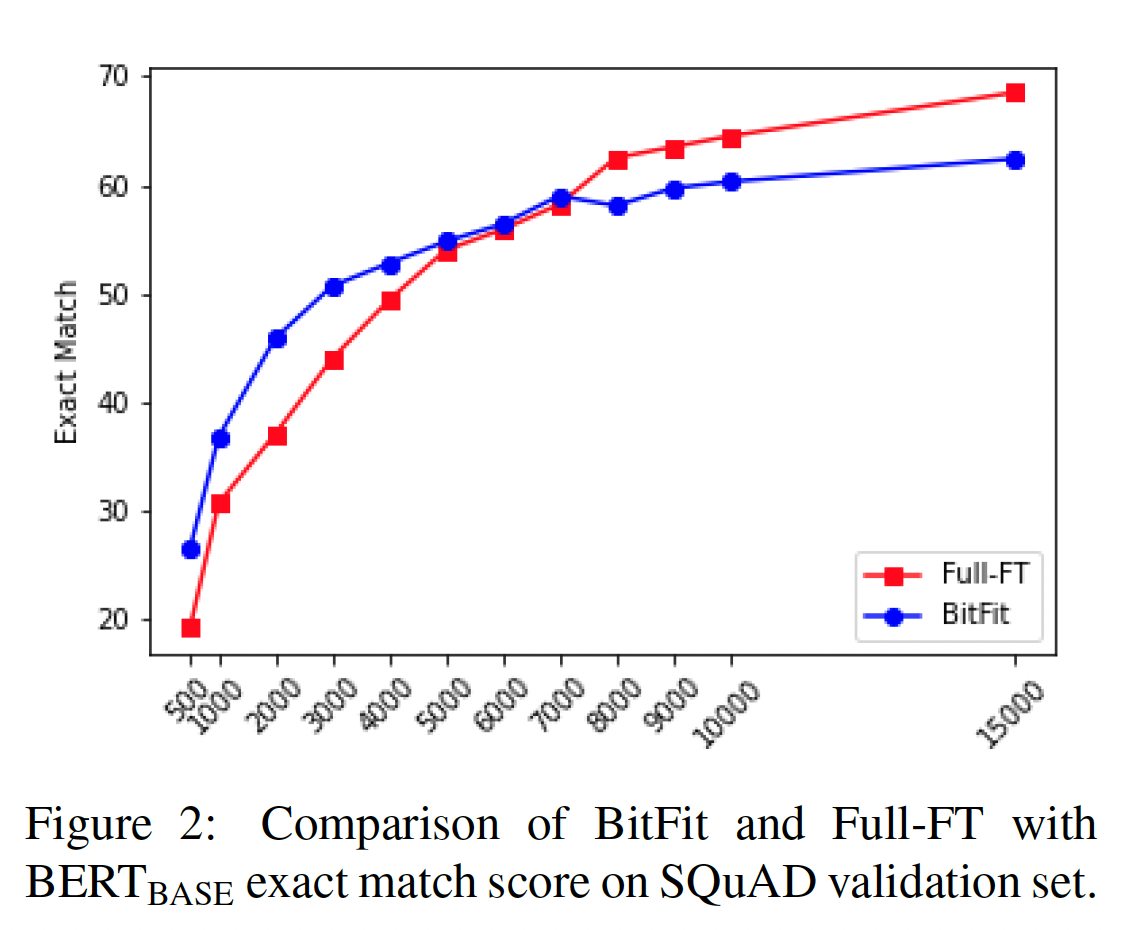
十、Towards a Unified View of Parameter-Efficient Transfer Learning
论文:
《Towards a Unified View of Parameter-Efficient Transfer Learning》
从
pre-trained language models: PLMs进行迁移学习现已成为自然语言处理的主流范式,在许多任务上都能取得强大的性能。将通用的PLM适配到下游任务的最常见方式是:微调所有的模型参数(full fine-tuning)。然而,这会为每个任务生成一份fine-tuned model parameters的副本,当应用于大量任务时,代价昂贵。随着PLM规模不断增大,从数亿(GPT-2、BART)到数百亿(GPT-3)乃至万亿参数(《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》),这个问题尤为突出。为缓解这个问题,一些轻量化的替代方法被提出,只更新少量额外参数而让大多数
pretrained parameters冻结。例如:adapter tuning(《Parameter-efficient transfer learning for nlp》)在pretrained network的每一层插入小的neural modules(称为adapters),在微调期间仅仅训练这些adapters。受
prompting方法成功启发(prompting方法通过textual prompts来控制PLMs,参考GPT-3、《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》),prefix tuning(《Prefix-tuning: Optimizing continuous prompts for generation》)和prompt tuning(《The power of scale for parameter-efficient prompt tuning》)在input layers或hidden layers之前追加额外的tunable prefix tokens,在微调下游任务时仅仅训练这些soft prompts。最近,
《LORA: Low-rank adaptation of large language models》学习低秩矩阵来逼近parameter updates。
我们在
Figure 1中给出这些方法的示意图。人们报告这些方法在不同任务集上都展示了与full fine-tuning相媲美的性能,而且通常所需更新的参数数量仅仅是原始模型参数数量的1%以下。除了参数节省,parameter-efficient tuning使得快速适配新任务时不会造成灾难性遗忘(《Adapter-Fusion: Non-destructive task composition for transfer learning》),并且通常在out-of-distribution evaluation中表现出更强的稳健性(《Prefix-tuning: Optimizing continuous prompts for generation》)。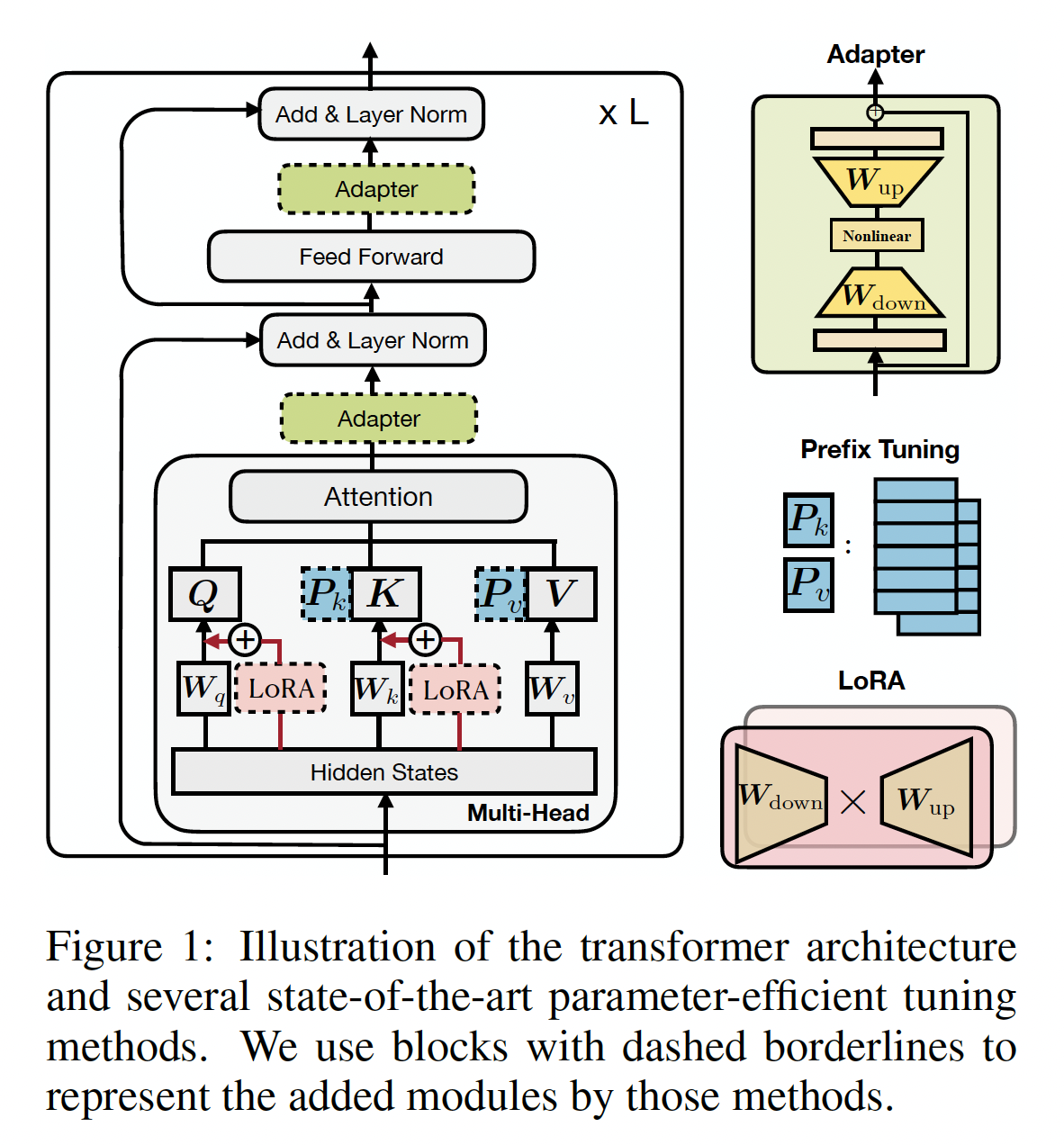
然而,我们认为这些
parameter-efficient tuning方法成功的重要因素理解不足,它们之间的联系仍不清晰。本文旨在回答三个问题:(1):这些方法之间如何关联?(2):这些方法是否共享某些设计元素,而这些设计元素对它们的有效性是必不可少的?如果答案是yes,那么这些设计元素是什么?(3)每个方法的有效因素能否迁移到其他方法中从而产生更有效的变体?
为回答这些问题,我们首先导出
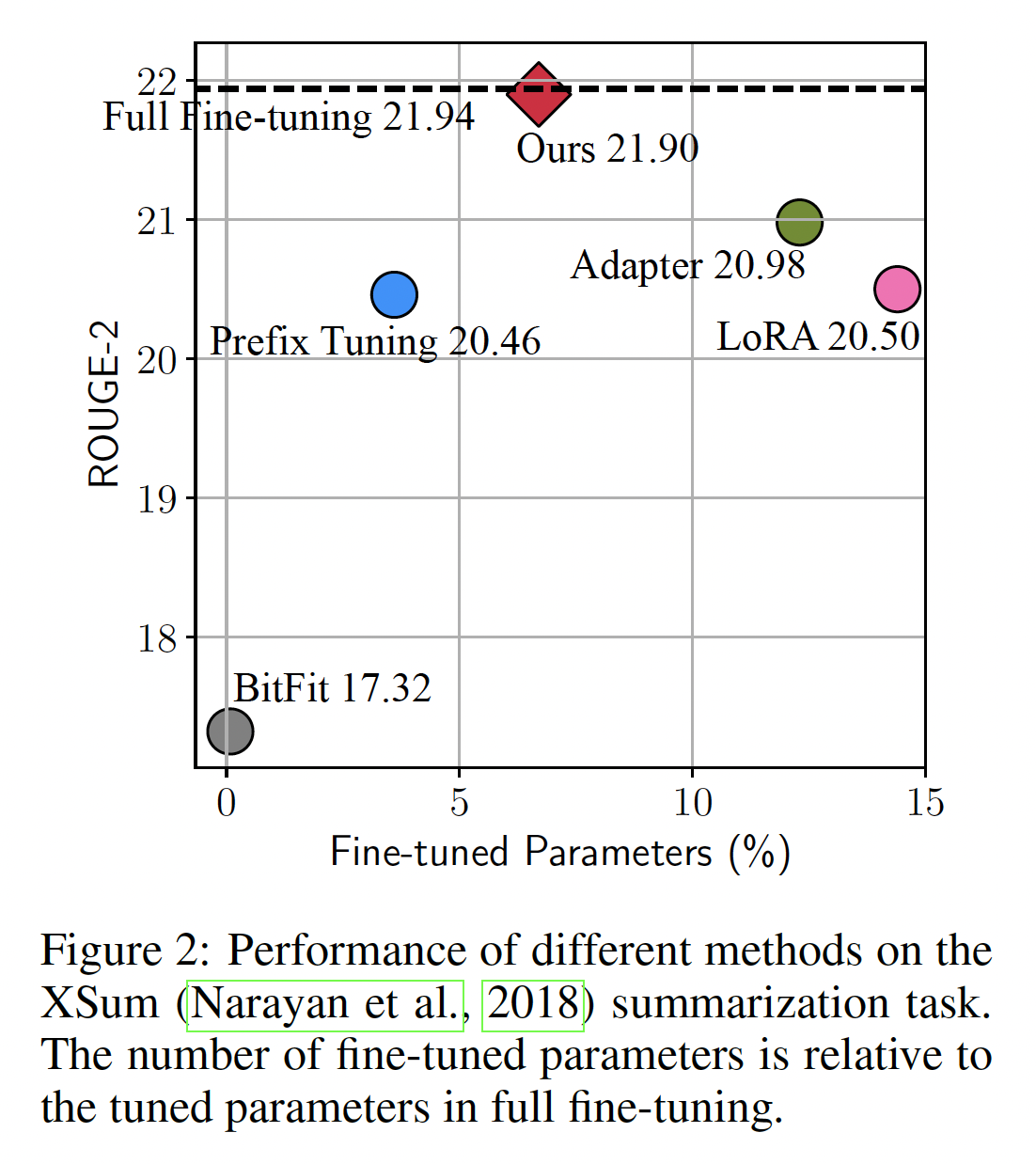
prefix tuning的另一形式,揭示prefix tuning与adapters的紧密联系。基于此,我们然后构想一个统一的框架,将上述方法表述为不同的、修改frozen PLMs的hidden representations的方式。我们的统一框架沿一组共享的设计维度分解之前的方法,如执行modification的函数、施加修改的位置、以及如何整合修改。这个框架使我们能够在方法之间传递design choices从而提出新的变体,如具有多个heads的adapters。在实验中,我们首先展示现有的parameter-efficient tuning方法在higher-resource和具挑战性的任务上仍落后于full fine-tuning,如Figure 2所示。然后我们利用统一框架识别关键的设计选择,并经验性地验证所提出的变体。我们在涵盖文本摘要、机器翻译、文本分类、以及通用语言理解的四个NLP benchmarks上的实验表明,所提出的变体使用的参数比现有方法更少,但效果更好,在所有四项任务上媲美了full fine-tuning的结果。作者提出的
MAM Adapter结合了prefix tuning和adapter:在
attention sub-layer上应用prefix tuning。在
ffn sub-layer上应用scaled parallel adapter。
10.1 基本概念
对
Transformer架构的回顾:Transformer模型现已成为支撑大多数SOTA的PLMs的主要架构。本节为完整起见,我们回顾这个模型的公式。Transformer模型由blocks组成,每个block(Figure 1)包含两类子层:多头自注意力层(multi-head self-attention)、全连接的前馈网络(feed-forward network: FFN)。注意力函数将
querykey-value pairs其中:
query的数量,key-value pairs的数量,多头注意力在
queries, keys, values。给定要执行注意力的序列query向量multi-head attention: MHA)在每个头上计算输出并将结果拼接起来:其中:
MHA中另一个重要的子层是全连接的前馈网络,它由两个线性变换组成,中间添加非线性激活函数
ReLU:其中:
FFN的中间层的维度,Transformer通常使用较大的
最后,对于这两种类型的子层,都应用了残差连接(
residual connection),并在残差连接之后馈入layer normalization。之前的
Parameter-Efficient Tuning方法概览:下面及Figure 1中,我们介绍几种SOTA的parameter-efficient tuning方法。除非特别说明,它们只调优被添加的参数而保持PLM的参数冻结。Adapters(《Parameter-efficient transfer learning for nlp》):Adapters方法在transformer层之间插入小的模块(adapter)。adapter layer一般使用down-projectionbottleneck维度up-projectionadapters被残差连接(residual connection)所包围。因此,包含adapter layer的公式为:《Parameter-efficient transfer learning for nlp》在transformer层内串行地放置两个adapters,一个在multi-head attention后面、一个在FFN子层后面。《Adapter-Fusion: Non-destructive task composition for transfer learning》提出了一种更高效的adapter变体,只在FFN的"add & layer norm"子层后插入adapter。Prefix Tuning(《Prefix-tuning: Optimizing continuous prompts for generation》):受textual prompting方法成功的启发(《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》),prefix tuning在每层的multi-head attention前追加tunable prefix vectors到keys和values。具体而言,两组prefix向量keysvaluesprefixed keys和prefix values上执行多头注意力。因此,多头注意力变为:head vectors,head的prerfix向量。prompt-tuning(《The power of scale for parameter-efficient prompt tuning》)简化了prefix-tuning,只在第一层的input word embeddings之前添加prefix向量。类似工作还包括P-tuninng(《GPT understands, too》)。LORA(《LORA: Low-rank adaptation of large language models》):LORA向transformer层内注入可训练的低秩矩阵,从而逼近weight updates。对于pre-trained weight matrixLORA用低秩分解来表示权重矩阵的update:其中
Figure 1所示,LORA将这个update应用于多头注意力中query projection matrix和value projection matrix对于多头注意力中线性投影的特定输入
LORA修改投影输出其中
第二项
LORA增加的模块。其他:其他
parameter-efficient tuning方法还包括:BitFit(《Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models》),只微调pretrained模型中的bias向量。diff-pruning(《Parameter-efficient transfer learning with diff pruning》),学习一个稀疏的parameter update vector。
10.2 统一的视角
我们首先推导
prefix tuning的等价形式,以建立其与adapters之间的联系。然后,我们提出了一个统一框架用于parameter-efficient tuning,该框架将几种前沿方法作为其实例。
10.2.1 更深入地看前 Prefix Tuning
方程
prefix tuning的机制,通过在原始的注意力keys和values前追加learnable vectors来改变注意力模块。这里,我们推导出该公式的等价形式,并提供prefix tuning的另一种视角。为了描述方便,我们忽略了上标和下标其中:
prefix上的归一化的注意力权重之和:注意,在这个视角的
prefix tuning中:第一项
prefix的注意力。而第二项
position-wise修改。
该给出了
prefix-tuning的另一种视角:本质上是通过线性插值对原始的head attention outputposition-wise修改:与
Adapters的联系:我们定义这与
adapter function形式非常相似,除了prefix tuning执行加权求和而adapter没有加权。Figure 3b展示了从这个视角的prefix tuning的计算图,允许我们像抽象adapter一样将prefix tuning抽象为插件模块(plug-in module)。此外,我们注意到当adapters中的这个视角还表明,
prefix向量的数量adapters中的bottleneck维度modification vectorrank limitation。因此我们也将bottleneck维度。直观而言,秩限制(rank limitation)意味着对任意输入basis vectors)的线性组合。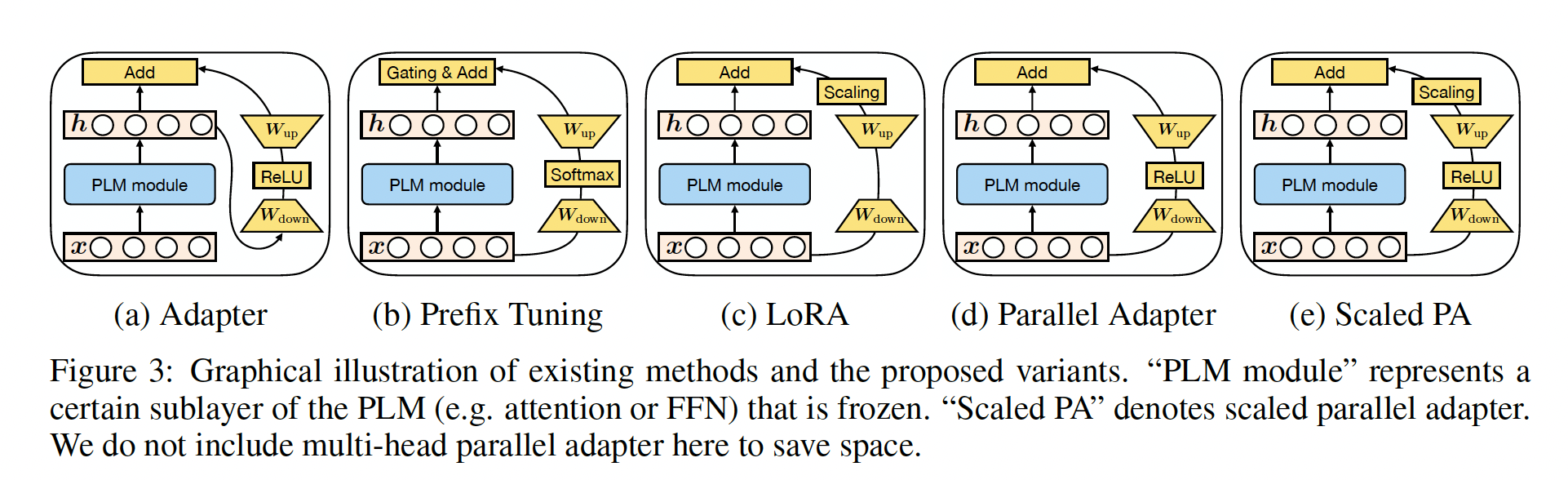
与
Adapters的不同之处:除了门控变量prefix tuning与adapters之间的三个不同之处。(1):如Figure 3所示,prefix tuning使用PLM layer的输入)来计算adapters使用PLM layer的输出)。因此,prefix tuning可以看作是对PLM layer的 “并行”计算,而典型的adapters是 “串行”计算。(2):相比prefix tuning,adapters在插入位置上更加灵活:adapters通常修改attention output或FFN output,而prefix tuning只修改每个head的attention output。经验上,这产生很大差异,我们将在实验章节中展示。(3):方程attention head,而adapters总是单头的,这使得prefix tuning更具表达能力:对于
prefix tuning,head attention的维度为head attention都有full rank updates。但对整个
attention output,只有在adapters才有full-rank updates。
值得注意的是,当
prefix tuning没有比adapters增加更多参数。我们在实验章节经验地验证这样的multi-head的影响。full rank updates指的是:update matrix
10.2.2 统一框架
受
prefix tuning与adapters之间联系的启发,我们提出一个通用框架,旨在统一几种SOTA的parameter-efficient tuning方法。具体而言,我们将它们建模为学习一个modification vectorhidden representations。正式地,我们将直接被修改的hidden representation表示为PLM sub-module的直接输入为attention output和attention input。为描述这个
modification过程,我们定义一组设计维度,不同方法可通过这些维度上的取值而实例化。我们下面详述这些设计维度,并展示adapters、prefix tuning、LORA在这些维度上的取值,如Table 1所示:Functional Form:是计算adapters、prefix tuning、以及LORA的函数形式。这些方法的函数形式类似,都有一个proj_down --> nonlinear --> proj_up的架构,而在LORA中"nonlinear "退化为恒等函数。Modified Representation:是直接被修改的hidden representation。Insertion Form:指被添加的模块如何插入到网络中。如前所述:传统的
adapters以串行的方式插入特定位置,input和output都是prefix tuning和LORA等价于将
Composition Function:指向量hidden representationhidden representation。例如,adapters执行简单的加法组合,prefix tuning使用门控的加法组合,LORA按常数因子缩放hidden representation上。
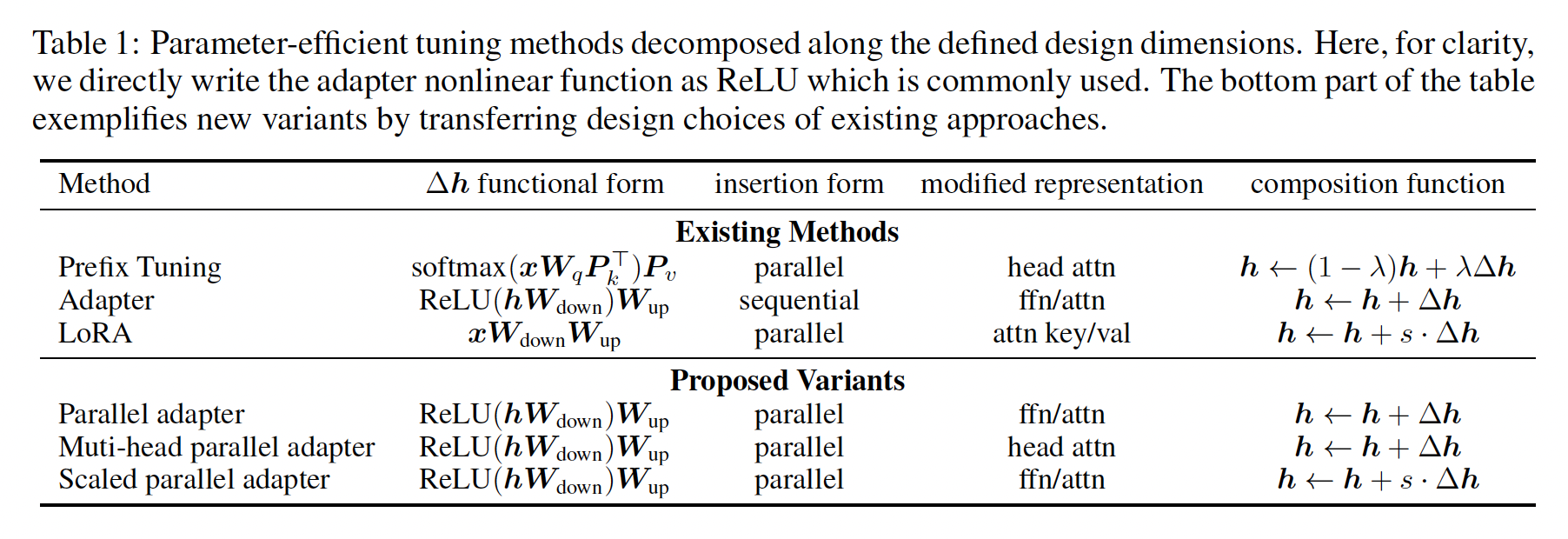
我们注意到,
Table 1之外许多其他方法也适合这个框架。例如:prompt tuning以类似prefix tuning的方式修改第一层的head attention。各种
adapter变体(《Adapter-Fusion: Non-destructive task composition for transfer learning》、《Compacter: Efficient low-rank hypercomplex adapter layers》)也可以类似adapter进行表示。
关键的是,这个统一框架允许我们沿这些设计维度研究
parameter-efficient tuning方法,识别关键的设计选择,并在方法间迁移设计元素,如下节所示。
10.2.3 迁移 Design Elements
在这里和
Figure 3中,我们描述一些新方法,这些新方法通过上述统一视角来推导,并通过在方法之间迁移设计元素::Parallel Adapter:一种变体,它将prefix tuning的parallel insertion迁移到adapters。有趣的是,我们由于其与prefix tuning的相似性而提出parallel adapter,而同期工作(《Serial or parallel? plugable adapter for multilingual machine translation》)也独立地提出并经验研究了这个变体;Multi-head Parallel Adapter:是进一步使adapters更类似prefix tuning。像prefix tuning一样,我们将parallel adapter应用了modify head attention。通过这种方式,这个变体不费力气地利用了multi-head projections提高了模型容量。Scaled Parallel Adapter:该变体将LORA的组合形式和插入形式迁移到Adapter,如Figure 3e所示。
到目前为止,我们的讨论和公式抛出了几个问题:
改变上述设计元素的方法是否展现不同特性?
哪些设计维度特别重要?
上述描述的新方法是否产生更好的性能?
我们在下节回答这些问题。
10.3 实验
数据集:
XSum:是一个英文摘要数据集,模型根据新闻文章来预测摘要。WMT 2016 en-ro数据集:英语到罗马尼亚语翻译。MNLI:是一个英语自然语言推理数据集,模型预测一个句子与另一个句子的关系是否蕴含、矛盾或中性。SST2:是一个英语情感分类benchmark,模型预测一个句子的情感是积极还是消极。
配置:
我们分别使用
BART_LARGE和其多语言版本mBART_LARGE作为XSum和en-ro翻译的pretrained模型,对于MNLI和SST2使用RoBERTa_BASE。如果需要,我们在
{1,30,200,512,1024}中变化bottleneck维。我们主要研究
adapters、prefix tuning(prefix)和LORA,在我们的实验中它们远超bitfit和prompt tuning。在分析部分,我们在
attention layers或FFN layers插入adapters以方便分析,但在最终比较中包括在两处同时插入adapters的结果。我们根据各自模型的公开代码重新实现这些方法。实现使用
huggingface transformers库。完整设置细节见附录A。
评估:我们在
XSum测试集上报告ROUGE 1/2/L分数,在en-ro测试集上报告BLEU分数,在MNLI和SST2开发集上报告准确率。对于MNLI和SST2,我们取5次随机运行的中位数。我们还报告每个parameter-efficient tuning方法相对于full fine-tuning的参数数量(#params)。Tunable Parameters的数量:BART和mBART有encoder-decoder结构,有三种注意力:encoder self-attention、decoder self-attention、decoder cross-attention。RoBERTa只有encoder self-attention。对于每个注意力子层,各方法使用的参数数量是:prefix tuning在keys和values前追加adapter有adapter)。如果
adapter作用在ffn上(而不是在attention上),则它使用attention上的adapter相同。LORA对query projection和value projection各自使用了一对
因此,对于特定的
prefix tuning与adapter使用相同数量的参数,而LORA使用更多参数。更多细节见附录B。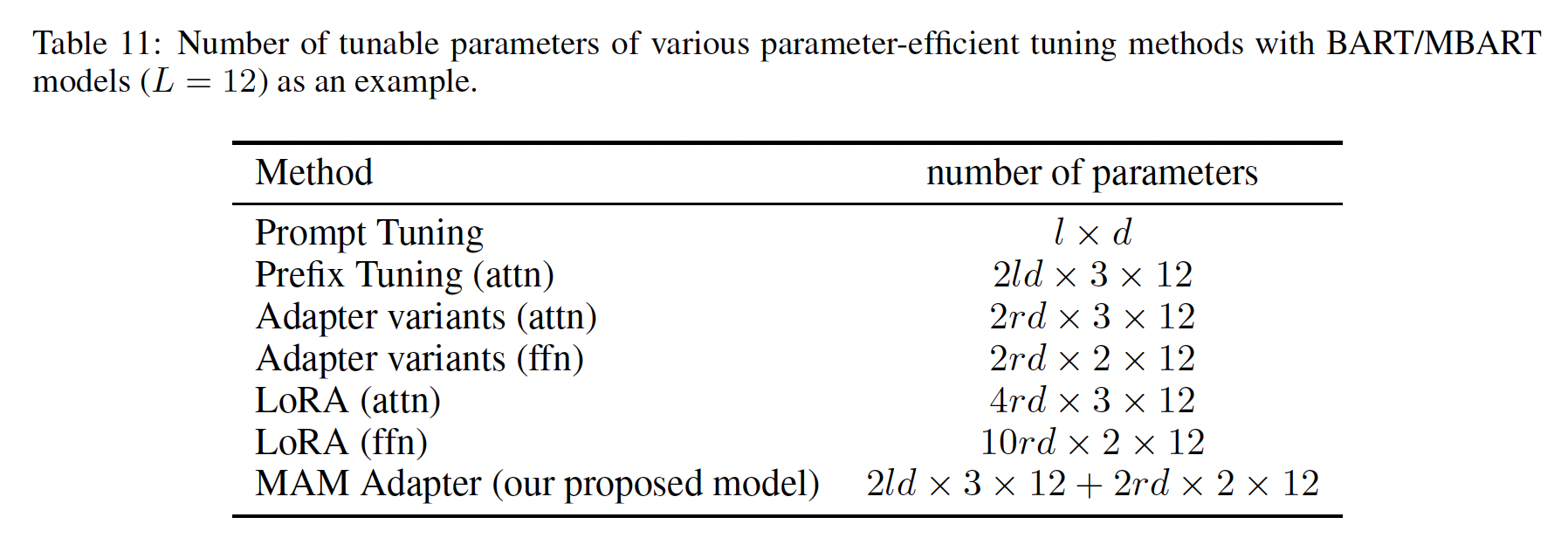
现有方法的结果:我们首先概述四个任务上现有方法的结果。如
Figure 4和Table 2所示,虽然现有方法在MNLI和SST2上通过调优少于1%的参数就能达到与full fine-tuning相媲美的性能,但在XSum和en-ro任务上如果我们调优5%的参数,仍与full fine-tuning存在较大差距。即使我们将相对参数大小增加到>10%,差距仍然显著。T5在high-resource翻译任务上观察到了更大的差距。这表明,许多声称在GLUE benchmark上用encoder-only模型与full fine-tuning达到可比结果的方法(《Parameter-efficient transfer learning with diff pruning》、bitfit、《Compacter: Efficient low-rank hypercomplex adapter layers》),或在相对简单的generation benchmarks(如,E2E)上用encoder-decoder模型与full fine-tuning达到可比结果的方法(prefix-tuning)可能无法很好地泛化到其他standard benchmarks。影响因素可能复杂,包括训练样本数量、任务复杂度、或者模型架构。因此,我们倡导未来这方面的研究在更多样的
benchmarks上报告结果,以展示更完整的性能概况。下面,我们的分析主要聚焦在XSum和en-ro数据集上,以更好区分不同的设计选择。我们注意到,这两个benchmarks是相对high-resource的,并且采用encoder-decoder model(即,BART)。MAM Adapter是本文提出的方法。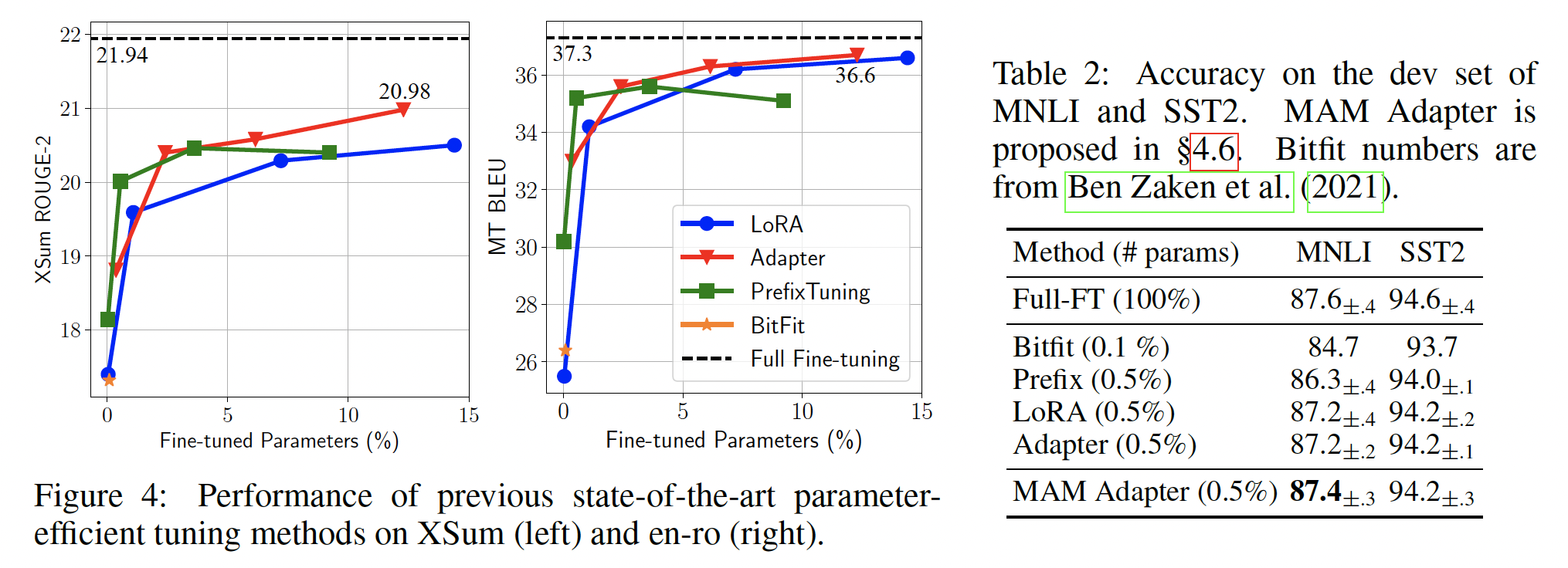
哪种插入形式更好,串行或并行?
我们首先研究插入形式这个设计维度,比较所提出的
parallel adapter: PA变体与传统的sequential adapter: SA,进行attention modification或者FFN modification。我们还以prefix tuning为参考。如Table 3所示:prefix tuning(它使用并行插入)优于attention sequential adapters。此外,
parallel adapter在所有情况下都优于sequential adapter,其中PA(ffn)在XSum上分别超过SA(ffn)1.7 R-2分,在en-ro上超过0.8 BLEU分。
鉴于
parallel adapter优于sequential adapter,我们在后续部分聚焦parallel adapter结果。这里没有比较这种情况:同时在
attn和ffn之后插入adapter。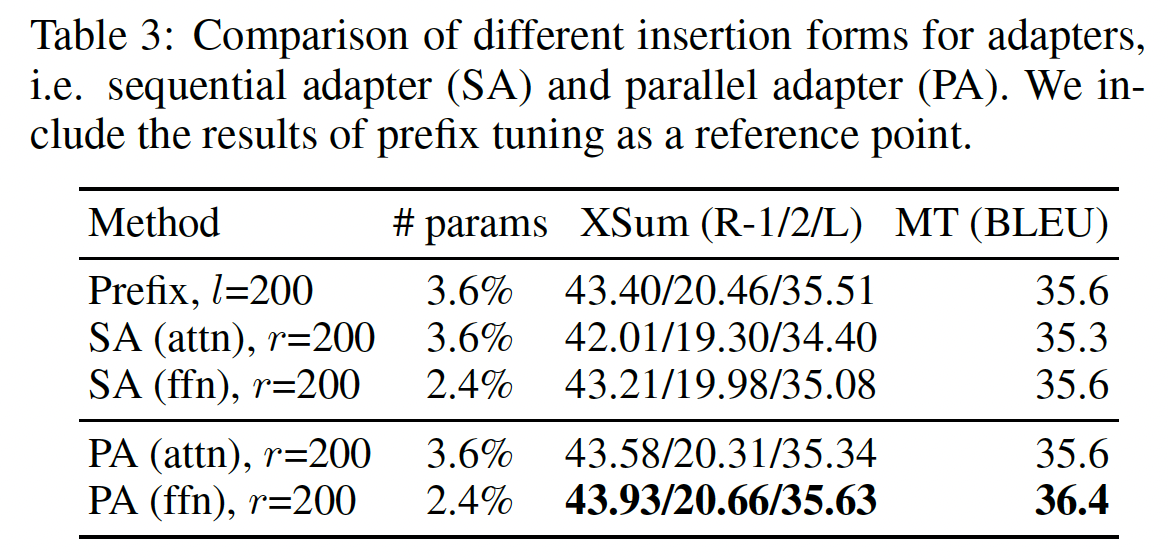
修改
attention representation还是ffn representation更好?我们现在研究修改不同
representation的效果。我们主要比较attention modification和FFN modification。为了更容易分析,我们将修改attention sub-layer中的任何hidden representations(如head output、query等)的方法归类为modifying attention模块。我们比较parallel adapters at attention和parallel adapters at FFN、以及prefix tuning上的结果。我们还将
FFN modification迁移到LORA,从而得到一个LORA(ffn)变体从而获得完整比较。具体而言,我们使用LORA来逼近FFN权重parameter updates。在这种情况下,LORA中用于LORA(ffn)使用比其他方法更小的结果如
Figure 5所示:首先,任何具有
FFN modification的方法在所有情况下都优于所有具有attention modification的方法(红色标记通常高于所有蓝色标记,唯一的例外是具有2.4%参数的ffn-PA)。其次,同一方法应用于
FFN modification总是优于其attention modification。例如,LORA(ffn)在XSum上优于LORA(attn)1 R-2分。我们还强调,
prefix tuning在我们进一步增加容量时并未持续改进,这在《Prefix-tuning: Optimizing continuous prompts for generation》中也有观察到。
这些结果表明,无论函数形式或组合函数如何,
FFN modification可以比attention modification更有效地利用所添加的参数。我们推测这是因为FFN学习task-specific textual patterns(《Transformer feed-forward layers are key-value memories》),而attention学习pairwise positional interactions,不需要大容量来适应新的任务。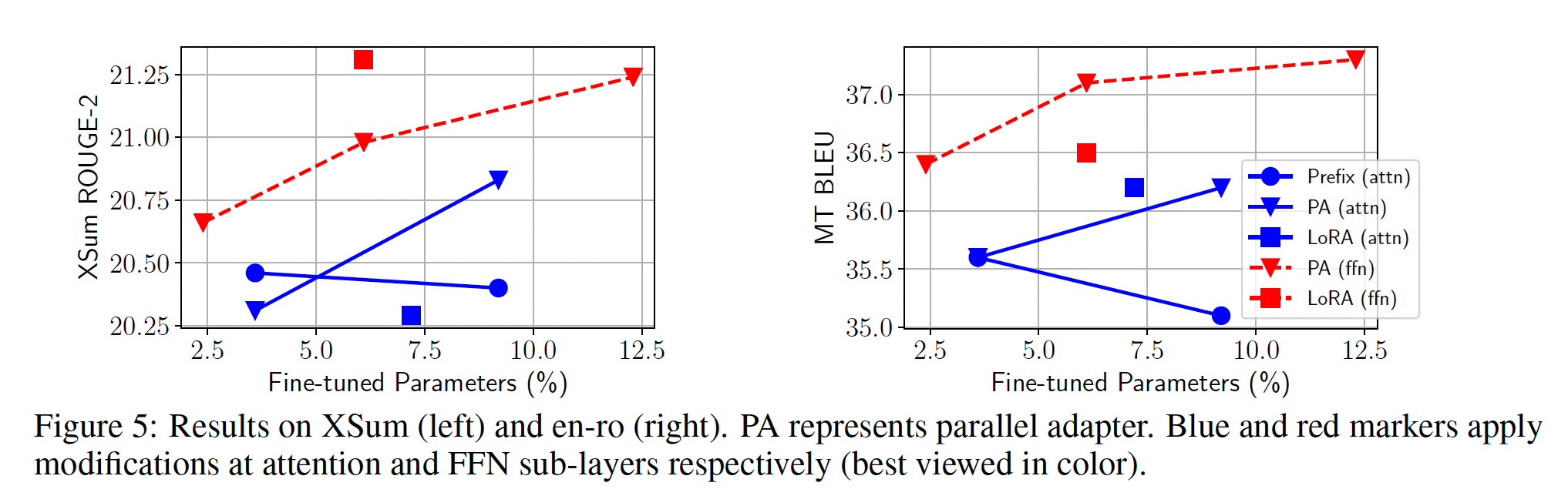
当我们只使用
0.1%的参数时,情形是否不同?在前文中,我们推断
prefix tuning比adapter(attn)更具表达力,但这在Figure 5中并未反映出来。我们推测这是因为multi-head attention仅在参数预算非常小时才具有优势。为验证这一假设,针对添加0.1%的pretrained parameters,我们比较prefix tuning和parallel adapters。为了消除组合函数(composition function)的影响,我们还报告了移除prefix tuning的门控的结果,即multi-head parallel adapter: MH PA变体的结果。结果如Table 4所示。在使用
0.1%参数时,多头方法(即,prefix tuning和MH PA(attn)优于所有其他方法至少1.6 BLEU分。令人惊讶的是,将
200减少到30仅导致prefix tuning0.4 BLEU的损失,而PA(attn)损失1.9 BLEU。prefix tuning中的gating composition function稍微提升了0.3 BLEU。我们强调,
MH parallel adapter相比单头版本提高了1.6 BLEU,这再次验证了multi-head formulation的有效性。
综合
Figure 5和Table 4的结果,我们得出结论:当参数预算非常小时,modifying head attention显示了最佳结果;而当参数预算更大时,modifying FFN效果更好。这表明,与《Parameter-efficient transfer learning for nlp》中平等地对待attention和FFN不同,将更大的参数预算分配给FFN modification可能更有效。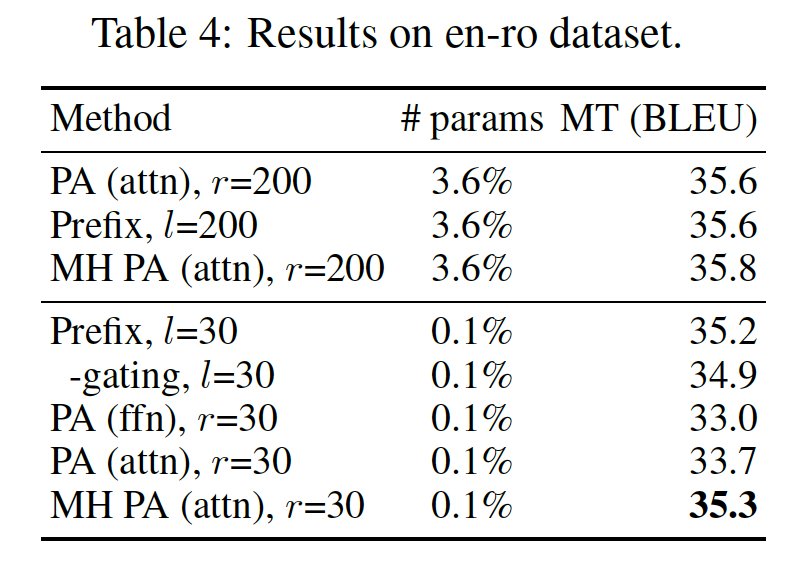
哪种组合函数(
Composition Function)更好?我们在前文中介绍了三种组合函数:简单相加(
adapter)、门控相加(prefix tuning)、以及缩放后再相加(LORA)。对于不使用softmax的函数形式,如果采用精确的门控相加显得不自然,我们通过在LORA上消融、以及比较提出的scaled parallel adapter: Scaled PA来检查另外两种形式。我们将modified representation约束为FFN,因为前面的实验表明:FFN modification通常更有效。Table 5报告了在XSum上的结果。我们将adapter的512、LORA的102,以使它们的tuned parameters数量相同。我们根据开发集的R-2 score选择LORA(s=4)优于parallel adapter。但是,如果我们通过设置LORA的组合函数插入到parallel adapter,产生的Scaled PA相比原始parallel adapter提高了0.56 ROUGE-2分。我们也尝试了可学习的标量,但没有更好的结果。因此,我们得出结论:scaling composition function优于普通的additive composition function,而且易于应用。
通过迁移有利的设计元素进行有效的集成:我们首先强调前面部分的三个发现:
(1):scaled parallel adapter是modify FFN的最佳变体。(2):FFN在更大容量下可以更好地利用modification。即,更大的参数预算下,
FFN modification要比attention modification更好。(3):像prefix tuning这样修改head attentions的方法可以只用0.1%的参数达到很强的表现。
受其启发,我们组合这些有利的设计。具体而言,我们在
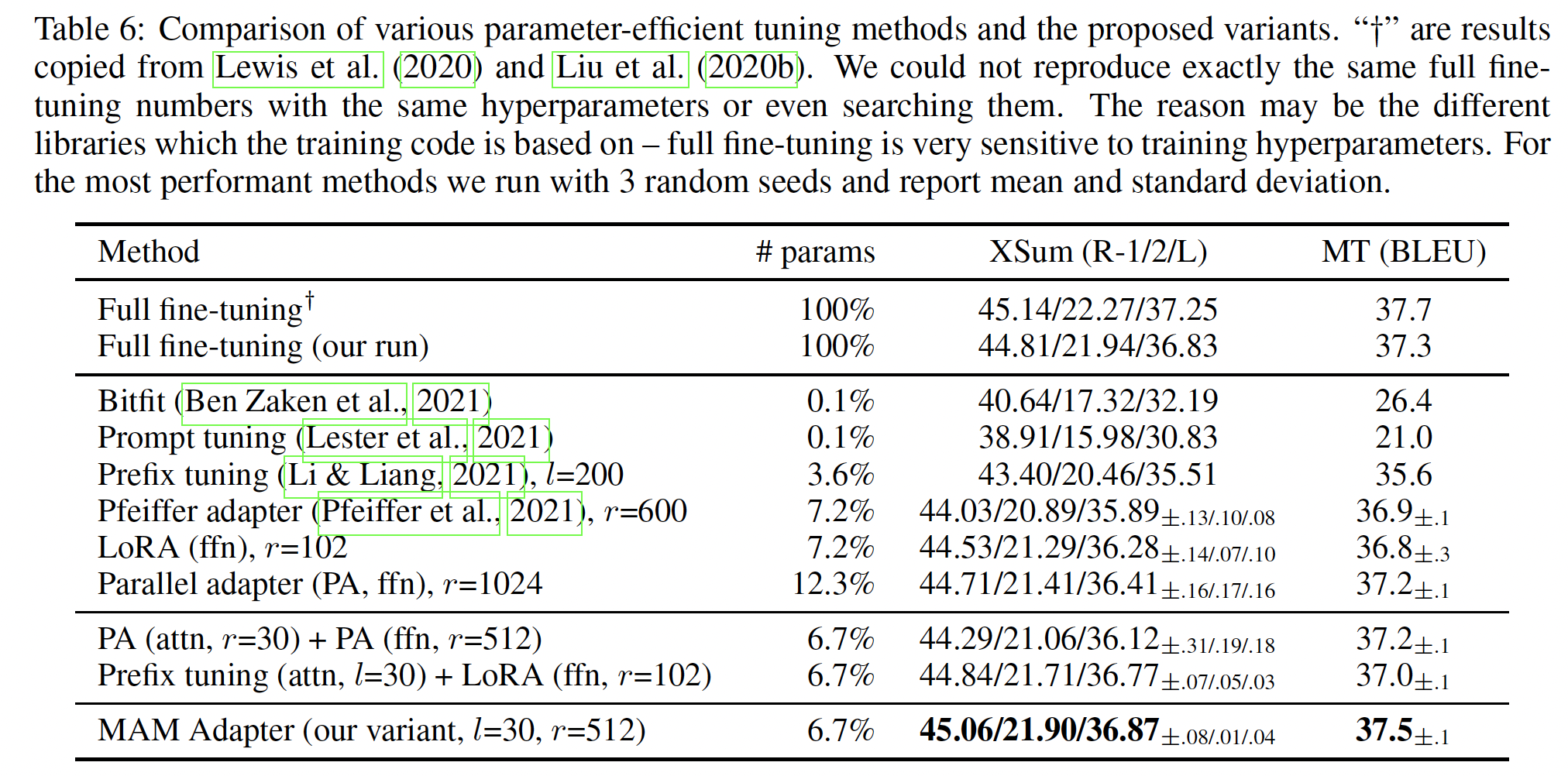
attention sub-layers使用具有small bottleneck dimensionprefix tuning,并分配更多参数预算使用scaled parallel adapter(FFN representation。由于prefix tuning在我们的统一框架中可以看作是adapter的一种形式,我们将这个变体称为Mix-And-Match adapter: MAM Adapter。在Table 6中,我们将MAM adapter与各种parameter-efficient tuning方法进行比较。MAM Adapter结合了prefix tuning和adapter:在
attention sub-layer上应用prefix tuning。在
ffn sub-layer上应用scaled parallel adapter。
为完整起见,
Table 6中还呈现了其他组合版本的结果:同时在attention layers和FFN layers使用parallel adapters、以及把prefix tuning(attn)和LORA(ffn)组合起来。这两个组合版本都能改进它们各自的原型。然而,MAM Adapter在两个任务上都达到了SOTA,只更新pre-trained parameters的6.7%就能匹配我们的full fine-tuning结果。在Table 2中,我们也呈现了MAM Adapter在MNLI和SST2上的结果,其中MAM Adapter通过添加0.5%的pretrained parameters达到了与full fine-tuning媲美的结果。