Xgboost使用
一、安装
安装步骤:
下载源码,编译
libxgboost.so(对于windows则是libxgboost.dll)git clone --recursive https://github.com/dmlc/xgboost# 对于 windows 用户,需要执行:# git submodule init# git submodule updatecd xgboostmake -j4如果需要支持
GPU,则执行下面的编译步骤:xxxxxxxxxxcd xgboostmkdir buildcd buildcmake .. -DUSE_CUDA=ONcd ..make -j4安装
python支持xxxxxxxxxxcd python-packagesudo python setup.py install
二、调参
2.1 调参指导
当出现过拟合时,有两类参数可以缓解:
- 第一类参数:用于直接控制模型的复杂度。包括
max_depth,min_child_weight,gamma等参数 - 第二类参数:用于增加随机性,从而使得模型在训练时对于噪音不敏感。包括
subsample,colsample_bytree
你也可以直接减少步长
eta,但是此时需要增加num_round参数。- 第一类参数:用于直接控制模型的复杂度。包括
当遇到数据不平衡时(如广告点击率预测任务),有两种方式提高模型的预测性能:
如果你关心的是预测的
AUC:- 你可以通过
scale_pos_weight参数来平衡正负样本的权重 - 使用
AUC来评估
- 你可以通过
如果你关心的是预测的正确率:
- 你不能重新平衡正负样本
- 设置
max_delta_step为一个有限的值(如 1),从而有助于收敛
2.2 参数
2.2.1. 通用参数
booster: 指定了使用那一种booster。可选的值为:'gbtree': 表示采用xgboost(默认值)'gblinear': 表示采用线性模型。'gblinear'使用带l1,l2正则化的线性回归模型作为基学习器。因为boost算法是一个线性叠加的过程,而线性回归模型也是一个线性叠加的过程。因此叠加的最终结果就是一个整体的线性模型,xgboost最后会获得这个线性模型的系数。'dart': 表示采用dart booster
silent: 如果为 0(默认值),则表示打印运行时的信息;如果为 1, 则表示silent mode( 不打印这些信息)nthread: 指定了运行时的并行线程的数量。如果未设定该参数,则默认值为可用的最大线程数。num_pbuffer: 指定了prediction buffer的大小。通常设定为训练样本的数量。该参数由xgboost自动设定,无需用户指定。该
buffer用于保存上一轮boostring step的预测结果。num_feature: 样本的特征数量。通常设定为特征的最大维数。该参数由xgboost自动设定,无需用户指定。
2.2.2 tree booster 参数
针对tree booster 的参数(适用于booster=gbtree,dart) :
eta: 也称作学习率。默认为 0.3 。范围为[0,1]gamma: 也称作最小划分损失min_split_loss。 它刻画的是:对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。- 如果大于该阈值,则该叶子节点值得继续划分
- 如果小于该阈值,则该叶子节点不值得继续划分
该值越大,则算法越保守(尽可能的少划分)。默认值为 0
max_depth: 每棵子树的最大深度。其取值范围为 , 0 表示没有限制,默认值为6。该值越大,则子树越复杂;值越小,则子树越简单。
min_child_weight: 子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。- 如果它的所有子节点的权重之和大于该阈值,则该叶子节点值得继续划分
- 如果它的所有子节点的权重之和小于该阈值,则该叶子节点不值得继续划分
所谓的权重:
- 对于线性模型(
booster=gblinear),权重就是:叶子节点包含的样本数量。 因此该参数就是每个节点包含的最少样本数量。 - 对于树模型(
booster=gbtree,dart),权重就是:叶子节点包含样本的所有二阶偏导数之和。
该值越大,则算法越保守(尽可能的少划分)。默认值为 1
max_delta_step: 每棵树的权重估计时的最大delta step。取值范围为 ,0 表示没有限制,默认值为 0 。通常该参数不需要设置,但是在逻辑回归中,如果类别比例非常不平衡时,该参数可能有帮助。
subsample: 对训练样本的采样比例。取值范围为(0,1],默认值为 1 。如果为
0.5, 表示随机使用一半的训练样本来训练子树。它有助于缓解过拟合。colsample_bytree: 构建子树时,对特征的采样比例。取值范围为(0,1], 默认值为 1。如果为
0.5, 表示随机使用一半的特征来训练子树。它有助于缓解过拟合。colsample_bylevel: 寻找划分点时,对特征的采样比例。取值范围为(0,1], 默认值为 1。如果为
0.5, 表示随机使用一半的特征来寻找最佳划分点。它有助于缓解过拟合。lambda:L2正则化系数(基于weights的正则化),默认为 1。 该值越大则模型越简单alpha:L1正则化系数(基于weights的正则化),默认为 0。 该值越大则模型越简单tree_method: 指定了构建树的算法,可以为下列的值:(默认为'auto')'auto': 使用启发式算法来选择一个更快的tree_method:- 对于小的和中等的训练集,使用
exact greedy算法分裂节点 - 对于非常大的训练集,使用近似算法分裂节点
- 旧版本在单机上总是使用
exact greedy分裂节点
- 对于小的和中等的训练集,使用
'exact': 使用exact greedy算法分裂节点'approx': 使用近似算法分裂节点'hist': 使用histogram优化的近似算法分裂节点(比如使用了bin cacheing优化)'gpu_exact': 基于GPU的exact greedy算法分裂节点'gpu_hist': 基于GPU的histogram算法分裂节点
注意:分布式,以及外存版本的算法只支持
'approx','hist','gpu_hist'等近似算法sketch_eps: 指定了分桶的步长。其取值范围为(0,1), 默认值为 0.03 。它仅仅用于
tree_medhod='approx'。它会产生大约 个分桶。它并不会显示的分桶,而是会每隔
sketch_pes个单位(一个单位表示最大值减去最小值的区间)统计一次。用户通常不需要调整该参数。
scale_pos_weight: 用于调整正负样本的权重,常用于类别不平衡的分类问题。默认为 1。一个典型的参数值为:
负样本数量/正样本数量updater: 它是一个逗号分隔的字符串,指定了一组需要运行的tree updaters,用于构建和修正决策树。默认为'grow_colmaker,prune'。该参数通常是自动设定的,无需用户指定。但是用户也可以显式的指定。
refresh_leaf: 它是一个updater plugin。 如果为true,则树节点的统计数据和树的叶节点数据都被更新;否则只有树节点的统计数据被更新。默认为 1process_type: 指定要执行的处理过程(如:创建子树、更新子树)。该参数通常是自动设定的,无需用户指定。grow_policy: 用于指定子树的生长策略。仅仅支持tree_method='hist'。 有两种策略:'depthwise': 优先拆分那些靠近根部的子节点。默认为'depthwise''lossguide': 优先拆分导致损失函数降低最快的子节点
max_leaves: 最多的叶子节点。如果为0,则没有限制。默认值为 0 。该参数仅仅和
grow_policy='lossguide'关系较大。max_bin: 指定了最大的分桶数量。默认值为 256 。该参数仅仅当
tree_method='hist','gpu_hist'时有效。predictor: 指定预测器的算法,默认为'cpu_predictor'。可以为:'cpu_predictor': 使用CPU来预测'gpu_predictor': 使用GPU来预测。对于tree_method='gpu_exact,gpu_hist','gpu_redictor'是默认值。
2.2.3 dart booster 参数
sample_type: 它指定了丢弃时的策略:'uniform': 随机丢弃子树(默认值)'weighted': 根据权重的比例来丢弃子树
normaliz_type:它指定了归一化策略:'tree': 新的子树将被缩放为: ; 被丢弃的子树被缩放为 。其中 为学习率, 为被丢弃的子树的数量'forest':新的子树将被缩放为: ; 被丢弃的子树被缩放为 。其中 为学习率
rate_drop:dropout rate,指定了当前要丢弃的子树占当前所有子树的比例。范围为[0.0,1.0], 默认为0.0。one_drop: 如果该参数为true,则在dropout期间,至少有一个子树总是被丢弃。默认为 0 。skip_drop: 它指定了不执行dropout的概率,其范围是[0.0,1.0], 默认为 0.0 。如果跳过了
dropout,则新的子树直接加入到模型中(和xgboost相同的方式)
2.2.4 linear booster 参数
lambda:L2正则化系数(基于weights的正则化),默认为 0。 该值越大则模型越简单alpha:L1正则化系数(基于weights的正则化),默认为 0。 该值越大则模型越简单lambda_bias:L2正则化系数( 基于bias的正则化),默认为 0.没有基于
bias的L1正则化,因为它不重要。
2.4.5 tweedie regression 参数:
weedie_variance_power: 指定了tweedie分布的方差。取值范围为(1,2),默认为 1.5 。越接近1,则越接近泊松分布;越接近2,则越接近
gamma分布。
2.4.6 学习任务参数
objective:指定任务类型,默认为'reg:linear'。'reg:linear': 线性回归模型。它的模型输出是连续值'reg:logistic': 逻辑回归模型。它的模型输出是连续值,位于区间[0,1]。'binary:logistic': 二分类的逻辑回归模型,它的模型输出是连续值,位于区间[0,1],表示取正负类别的概率。它和
'reg:logistic'几乎完全相同,除了有一点不同:'reg:logistic'的默认evaluation metric是rmse。'binary:logistic'的默认evaluation metric是error
'binary:logitraw': 二分类的逻辑回归模型,输出为分数值(在logistic转换之前的值)'count:poisson': 对count data的poisson regression, 输出为泊松分布的均值。'multi:softmax': 基于softmax的多分类模型。此时你需要设定num_class参数来指定类别数量。'multi:softprob': 基于softmax的多分类模型,但是它的输出是一个矩阵:ndata*nclass,给出了每个样本属于每个类别的概率。'rank:pairwise': 排序模型(优化目标为最小化pairwise loss)'reg:gamma':gamma regression, 输出为伽马分布的均值。'reg:tweedie':'tweedie regression'。
base_score: 所有样本的初始预测分,它用于设定一个初始的、全局的bias。 默认为 0.5 。- 当迭代的数量足够大时,该参数没有什么影响
eval_metric: 用于验证集的评估指标。其默认值和objective参数高度相关。回归问题的默认值是
rmse; 分类问题的默认值是error; 排序问题的默认值是mean average precision。你可以指定多个
evaluation metrics。如果有多个验证集,以及多个评估指标.则: 使用最后一个验证集的最后一个评估指标来做早停。但是还是会计算出所有的验证集的所有评估指标。
'rmse': 均方误差。'mae': 绝对值平均误差'logloss': 负的对数似然函数'error': 二分类的错误率。它计算的是:预测错误的样本数/所有样本数所谓的预测是:正类概率大于0.5的样本预测为正类;否则为负类(即阈值为 0.5 )
'error@t': 二分类的错误率。但是它的阈值不再是 0.5, 而是由字符串t给出(它是一个数值转换的字符串)'merror': 多类分类的错误率。它计算的是:预测错误的样本数/所有样本数'mlogloss': 多类分类的负对数似然函数'auc':AUC得分'ndcg':Normalized Discounted Cumulative Gain得分'map':Mean average precision得分'ndcg@n','map@n':n为一个整数,用于切分验证集的top样本来求值。'ndcg-','map-','ndcg@n-','map@n-': NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions. training repeatedlypoisson-nloglik: 对于泊松回归,使用负的对数似然gamma-nloglik: 对于伽马回归,使用负的对数似然gamma-deviance: 对于伽马回归,使用残差的方差tweedie-nloglik: 对于tweedie回归,使用负的对数似然
seed: 随机数种子,默认为 0 。
三、外存计算
对于
external-memory和in-memory计算,二者几乎没有区别。除了在文件名上有所不同。in-memory的文件名为:filenameexternal-memory的文件名为:filename#cacheprefix。其中:filename:是你想加载的数据集 (libsvm文件 ) 的路径名当前只支持导入
libsvm格式的文件cacheprefix: 指定的cache文件的路径名。xgboost将使用它来做external memory cache。
如:
xxxxxxxxxxdtrain = xgb.DMatrix('../data/my_data.txt.train#train_cache.cache')此时你会发现在
my_data.txt所在的位置会由xgboost创建一个my_cache.cache文件。
推荐将
nthread设置为真实CPU的数量。- 现代的
CPU都支持超线程,如4核8线程。此时nthread设置为4而不是8
- 现代的
对于分布式计算,外存计算时文件名的设定方法也相同:
xxxxxxxxxxdata = "hdfs:///path-to-data/my_data.txt.train#train_cache.cache"
四、 GPU计算
xgboost支持使用gpu计算,前提是安装时开启了GPU支持要想使用
GPU训练,需要指定tree_method参数为下列的值:'gpu_exact': 标准的xgboost算法。它会对每个分裂点进行精确的搜索。相对于'gpu_hist',它的训练速度更慢,占用更多内存'gpu_hist':使用xgboost histogram近似算法。它的训练速度更快,占用更少内存
当
tree_method为'gpu_exact','gpu_hist'时,模型的predict默认采用GPU加速。你可以通过设置
predictor参数来指定predict时的计算设备:'cpu_predictor': 使用CPU来执行模型预测'gpu_predictor': 使用GPU来执行模型预测
多
GPU可以通过grow_gpu_hist参数和n_gpus参数配合使用。- 可以通过
gpu_id参数来选择设备,默认为 0 。如果非0,则GPU的编号规则为mod(gpu_id + i) % n_visible_devices for i in 0~n_gpus-1 - 如果
n_gpus设置为-1,则所有的GPU都被使用。它默认为 1 。
- 可以通过
多
GPU不一定比单个GPU更快,因为PCI总线的带宽限制,数据传输速度可能成为瓶颈。GPU 计算支持的参数:
parameter gpu_exact gpu_hist subsample ✘ ✔ colsample_bytree ✘ ✔ colsample_bylevel ✘ ✔ max_bin ✘ ✔ gpu_id ✔ ✔ n_gpus ✘ ✔ predictor ✔ ✔ grow_policy ✘ ✔ monotone_constraints ✘ ✔
五、单调约束
在模型中可能会有一些单调的约束:当 时:
- 若 ,则称该约束为单调递增约束
- 若 ,则称该约束为单调递减约束
如果想在
xgboost中添加单调约束,则可以设置monotone_constraints参数。假设样本有 2 个特征,则:
params['monotone_constraints'] = "(1,-1)":表示第一个特征是单调递增;第二个特征是单调递减params['monotone_constraints'] = "(1,0)":表示第一个特征是单调递增;第二个特征没有约束params['monotone_constraints'] = "(1,1)":表示第一个特征是单调递增;第二个特征是单调递增
右侧的
1表示单调递增约束;0表示无约束;-1表示单调递减约束。 有多少个特征,就对应多少个数值。
六、 DART booster
在
GBDT中,越早期加入的子树越重要;越后期加入的子树越不重要。DART booster原理:为了缓解过拟合,采用dropout技术,随机丢弃一些树。由于引入了随机性,因此
dart和gbtree有以下的不同:- 训练速度更慢
- 早停不稳定
DART booster也是使用与提升树相同的前向分步算法第 步,假设随机丢弃 棵,被丢弃的树的下标为集合 。
令 ,第 棵树为 。则目标函数为: 。
由于
dropout在设定目标函数时引入了随机丢弃,因此如果直接引入 ,则会引起超调。因此引入缩放因子,这称作为归一化: 。其中 为新的子树与丢弃的子树的权重之比, 为修正因子。
令 。采用归一化的原因是: 试图缩小 到目标之间的
gap; 而 也会试图缩小 到目标之间的gap。如果同时引入随机丢弃的子树集合 ,以及新的子树 ,则会引起超调。
有两种归一化策略:
'tree': 新加入的子树具有和每个丢弃的子树一样的权重,假设都是都是 。此时 ,则有:
要想缓解超调,则应该使得 ,则有: 。
'forest':新加入的子树的权重等于丢弃的子树的权重之和。假设被丢弃的子树权重都是 , 则此时 ,则有:要想缓解超调,则应该使得 ,则有: 。
七、Python API
7.1 数据接口
7.1.1 数据格式
xgboost的数据存储在DMatrix对象中xgboost支持直接从下列格式的文件中加载数据:libsvm文本格式的文件。其格式为:xxxxxxxxxx[label] [index1]:[value1] [index2]:[value2] ...[label] [index1]:[value1] [index2]:[value2] ......xgboost binary buffer文件
xxxxxxxxxxdtrain = xgb.DMatrix('train.svm.txt') #libsvm 格式dtest = xgb.DMatrix('test.svm.buffer') # xgboost binary buffer 文件xgboost也支持从二维的numpy array中加载数据xxxxxxxxxxdata = np.random.rand(5, 10)label = np.random.randint(2, size=5)dtrain = xgb.DMatrix(data, label=label)#从 numpy array 中加载你也可以从
scipy.sparse array中加载数据xxxxxxxxxxcsr = scipy.sparse.csr_matrix((dat, (row, col)))dtrain = xgb.DMatrix(csr)
7.1.2 DMatrix
DMatrix: 由xgboost内部使用的数据结构,它存储了数据集,并且针对了内存消耗和训练速度进行了优化。xxxxxxxxxxxgboost.DMatrix(data, label=None, missing=None, weight=None, silent=False,feature_names=None, feature_types=None, nthread=None)参数:
data:表示数据集。可以为:- 一个字符串,表示文件名。数据从该文件中加载
- 一个二维的
numpy array, 表示数据集。
label:一个序列,表示样本标记。missing: 一个值,它是缺失值的默认值。weight:一个序列,给出了数据集中每个样本的权重。silent: 一个布尔值。如果为True,则不输出中间信息。feature_names: 一个字符串序列,给出了每一个特征的名字feature_types: 一个字符串序列,给出了每个特征的数据类型nthread:
属性:
feature_names: 返回每个特征的名字feature_types: 返回每个特征的数据类型
方法:
.get_base_margin(): 返回一个浮点数,表示DMatrix的base margin。.set_base_margin(margin): 设置DMatrix的base margin- 参数:
margin: t一个序列,给出了每个样本的prediction margin
- 参数:
.get_float_info(field): 返回一个numpy array, 表示DMatrix的float property。.set_float_info(field,data): 设置DMatrix的float property。.set_float_info_npy2d(field,data): 设置DMatrix的float property。这里的data是二维的numpy array参数:
field: 一个字符串,给出了information的字段名。注:意义未知。data: 一个numpy array,给出了数据集每一个点的float information
.get_uint_info(field): 返回DMatrix的unsigned integer property。.set_unit_info(field,data): 设置DMatrix的unsigned integer property。参数:
field: 一个字符串,给出了information的字段名。注:意义未知。data: 一个numpy array, 给出了数据集每个点的uint information
返回值:一个
numpy array,表示数据集的unsigned integer information
.get_label(): 返回一个numpy array,表示DMatrix的label。.set_label(label): 设置样本标记。.set_label_npy2d(label): 设置样本标记。这里的label为二维的numpy array- 参数:
label: 一个序列,表示样本标记
- 参数:
.get_weight(): 一个numpy array,返回DMatrix的样本权重。.set_weight(weight): 设置样本权重。.set_weight_npy2d(weight): 设置样本权重。这里的weight为二维的numpy array- 参数:
weight:一个序列,表示样本权重
- 参数:
.num_col(): 返回DMatrix的列数- 返回值:一个整数,表示特征的数量
.num_row(): 返回DMatrix的行数- 返回值:一个整数,表示样本的数量
save_binary(fname,silent=True): 保存DMatrix到一个xgboost buffer文件中参数:
fname: 一个字符串,表示输出的文件名silent: 一个布尔值。如果为True,则不输出中间信息。
.set_group(group): 设置DMatrix每个组的大小(用于排序任务)- 参数:
group: 一个序列,给出了每个组的大小
- 参数:
slice(rindex): 切分DMaxtrix,返回一个新的DMatrix。 该新的DMatrix仅仅包含rindex- 参数:
rindex: 一个列表,给出了要保留的index - 返回值:一个新的
DMatrix对象
- 参数:
示例:
data/train.svm.txt的内容:xxxxxxxxxx1 1:1 2:21 1:2 2:31 1:3 2:41 1:4 2:50 1:5 2:60 1:6 2:70 1:7 2:80 1:8 2:9测试代码:
ximport xgboost as xgtimport numpy as npclass MatrixTest:'''测试 DMatrix'''def __init__(self):self._matrix1 = xgt.DMatrix('data/train.svm.txt')self._matrix2 = xgt.DMatrix(data=np.arange(0, 12).reshape((4, 3)),label=[1, 2, 3, 4], weight=[0.5, 0.4, 0.3, 0.2],silent=False, feature_names=['a', 'b', 'c'],feature_types=['int','int','float'], nthread=2)def print(self,matrix):print('feature_names:%s'%matrix.feature_names)print('feature_types:%s' % matrix.feature_types)def run_get(self,matrix):print('get_base_margin():', matrix.get_base_margin())print('get_label():', matrix.get_label())print('get_weight():', matrix.get_weight())print('num_col():', matrix.num_col())print('num_row():', matrix.num_row())def test(self):print('查看 matrix1 :')self.print(self._matrix1)# feature_names:['f0', 'f1', 'f2']# feature_types:Noneprint('\n查看 matrix2 :')self.print(self._matrix2)# feature_names:['a', 'b', 'c']# feature_types:['int', 'int', 'float']print('\n查看 matrix1 get:')self.run_get(self._matrix1)# get_base_margin(): []# get_label(): [1. 1. 1. 1. 0. 0. 0. 0.]# get_weight(): []# num_col(): 3# num_row(): 8print('\n查看 matrix2 get:')self.run_get(self._matrix2)# get_base_margin(): []# get_label(): [1. 2. 3. 4.]# get_weight(): [0.5 0.4 0.3 0.2]# num_col(): 3# num_row(): 4print(self._matrix2.slice([0,1]).get_label())# [1. 2.]
7.2 模型接口
7.2.1 Booster
Booster是xgboost的模型,它包含了训练、预测、评估等任务的底层实现。xxxxxxxxxxxbgoost.Booster(params=None,cache=(),model_file=None)参数:
params: 一个字典,给出了模型的参数。该
Booster将调用self.set_param(params)方法来设置模型的参数。cache:一个列表,给出了缓存的项。其元素是DMatrix的对象。模型从这些DMatrix对象中读取特征名字和特征类型(要求这些DMatrix对象具有相同的特征名字和特征类型)model_file: 一个字符串,给出了模型文件的位置。如果给出了
model_file,则调用self.load_model(model_file)来加载模型。
属性:
通过方法来存取、设置属性。
方法:
.attr(key): 获取booster的属性。如果该属性不存在,则返回None参数:
key: 一个字符串,表示要获取的属性的名字
.set_attr(**kwargs): 设置booster的属性参数:
kwargs: 关键字参数。注意:参数的值目前只支持字符串。如果参数的值为
None,则表示删除该参数
.attributes(): 以字典的形式返回booster的属性.set_param(params,value=None): 设置booster的参数参数:
params: 一个列表(元素为键值对)、一个字典、或者一个字符串。表示待设置的参数value: 如果params为字符串,那么params就是键,而value就是参数值。
.boost(dtrain,grad,hess): 执行一次训练迭代参数:
dtrain: 一个DMatrix对象,表示训练集grad: 一个列表,表示一阶的梯度hess: 一个列表,表示二阶的偏导数
.update(dtrain,iteration,fobj=None): 对一次迭代进行更新参数:
dtrain: 一个DMatrix对象,表示训练集iteration: 一个整数,表示当前的迭代步数编号fobj: 一个函数,表示自定义的目标函数
由于
Booster没有.train()方法,因此需要用下面的策略进行迭代:xxxxxxxxxxfor i in range(0,100):booster.update(train_matrix,iteration=i).copy(): 拷贝当前的booster,并返回一个新的Booster对象.dump_model(fout,fmap='',with_stats=False):dump模型到一个文本文件中。参数:
fout: 一个字符串,表示输出文件的文件名fmap: 一个字符串,表示存储feature map的文件的文件名。booster需要从它里面读取特征的信息。该文件每一行依次代表一个特征。每一行的格式为:
feature name:feature type。 其中feature type为int、float等表示数据类型的字符串。with_stats: 一个布尔值。如果为True,则输出split的统计信息
.get_dump(fmap='',with_stats=False,dump_format='text'):dump模型为字符的列表(而不是存到文件中)。参数:
fmap: 一个字符串,表示存储feature map的文件的文件名。booster需要从它里面读取特征的信息。with_stats: 一个布尔值。如果为True,则输出split的统计信息dump_format: 一个字符串,给出了输出的格式
返回值:一个字符串的列表。每个字符串描述了一棵子树。
.eval(data,name='eval',iteration=0): 对模型进行评估参数:
data: 一个DMatrix对象,表示数据集name: 一个字符串,表示数据集的名字iteration: 一个整数,表示当前的迭代编号
返回值:一个字符串,表示评估结果
.eval_set(evals,iteration=0,feval=None): 评估一系列的数据集参数:
evals: 一个列表,列表元素为元组(DMatrix,string), 它给出了待评估的数据集iteration: 一个整数,表示当前的迭代编号feval: 一个函数,给出了自定义的评估函数
返回值:一个字符串,表示评估结果
.get_fscore(fmap=''): 返回每个特征的重要性参数:
fmap: 一个字符串,给出了feature map文件的文件名。booster需要从它里面读取特征的信息。
返回值:一个字典,给出了每个特征的重要性
.get_score(fmap='',importance_type='weight'): 返回每个特征的重要性参数:
fmap: 一个字符串,给出了feature map文件的文件名。booster需要从它里面读取特征的信息。importance_type: 一个字符串,给出了特征的衡量指标。可以为:'weight': 此时特征重要性衡量标准为:该特征在所有的树中,被用于划分数据集的总次数。'gain': 此时特征重要性衡量标准为:该特征在树的'cover'中,获取的平均增益。
返回值:一个字典,给出了每个特征的重要性
.get_split_value_histogram(feature,fmap='',bins=None,as_pandas=True): 获取一个特征的划分value histogram。参数:
feature: 一个字符串,给出了划分特征的名字fmap: 一个字符串,给出了feature map文件的文件名。booster需要从它里面读取特征的信息。bins: 最大的分桶的数量。如果bins=None或者bins>n_unique,则分桶的数量实际上等于n_unique。 其中n_unique是划分点的值的uniqueas_pandas:一个布尔值。如果为True,则返回一个pandas.DataFrame; 否则返回一个numpy ndarray。
返回值:以一个
numpy ndarray或者pandas.DataFrame形式返回的、代表拆分点的histogram的结果。
.load_model(fname): 从文件中加载模型。- 参数:
fname: 一个文件或者一个内存buffer,xgboost从它加载模型
- 参数:
.save_model(fname): 保存模型到文件中- 参数:
fname: 一个字符串,表示文件名
- 参数:
save_raw(): 将模型保存成内存buffer- 返回值:一个内存
buffer,代表该模型
- 返回值:一个内存
.load_rabit_checkpoint(): 从rabit checkpoint中初始化模型。- 返回值:一个整数,表示模型的版本号
.predict(data,output_margin=False,ntree_limit=0,pred_leaf=False,pred_contribs=False,approx_contribs=False): 执行预测该方法不是线程安全的。对于每个
booster来讲,你只能在某个线程中调用它的.predict方法。如果你在多个线程中调用.predict方法,则可能会有问题。要想解决该问题,你必须在每个线程中调用
booster.copy()来拷贝该booster到每个线程中参数:
data: 一个DMatrix对象,表示测试集output_margin: 一个布尔值。表示是否输出原始的、未经过转换的margin valuentree_limit: 一个整数。表示使用多少棵子树来预测。默认值为0,表示使用所有的子树。如果训练的时候发生了早停,则你可以使用
booster.best_ntree_limit。pred_leaf: 一个布尔值。如果为True,则会输出每个样本在每个子树的哪个叶子上。它是一个nsample x ntrees的矩阵。每个子树的叶节点都是从
1开始编号的。pred_contribs: 一个布尔值。如果为True, 则输出每个特征对每个样本预测结果的贡献程度。它是一个nsample x ( nfeature+1)的矩阵。之所以加1,是因为有
bias的因素。它位于最后一列。其中样本所有的贡献程度相加,就是该样本最终的预测的结果。
approx_contribs: 一个布尔值。如果为True,则大致估算出每个特征的贡献程度。
返回值:一个
ndarray,表示预测结果
Booster没有train方法。因此有两种策略来获得训练好的Booster- 从训练好的模型的文件中
.load_model()来获取 - 多次调用
.update()方法
- 从训练好的模型的文件中
示例:
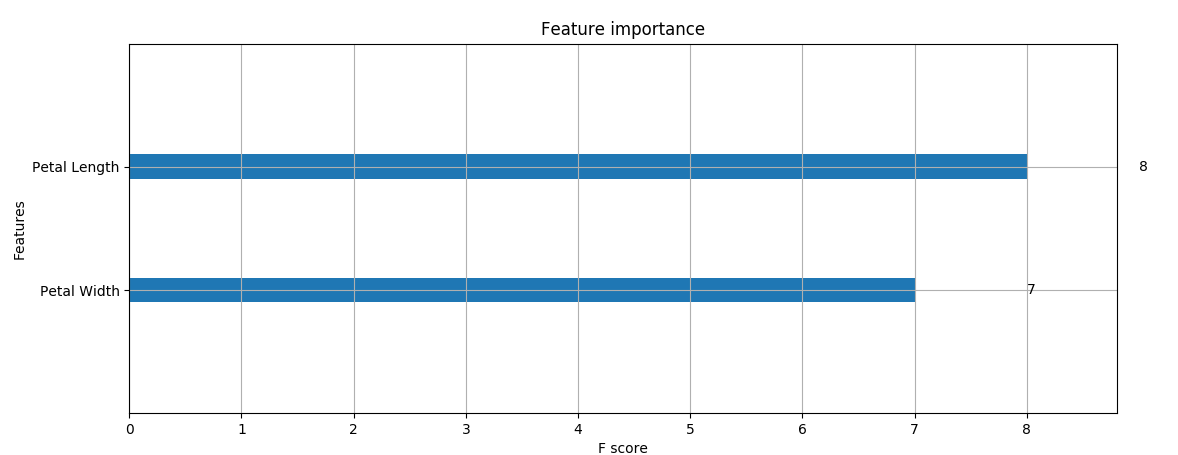
xxxxxxxxxximport xgboost as xgtimport numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_split_label_map={# 'Iris-setosa':0, #经过裁剪的,去掉了 iris 中的 setosa 类'Iris-versicolor':0,'Iris-virginica':1}class BoosterTest:'''测试 Booster'''def __init__(self):df=pd.read_csv('./data/iris.csv')_feature_names=['Sepal Length','Sepal Width','Petal Length','Petal Width']x=df[_feature_names]y=df['Class'].map(lambda x:_label_map[x])train_X,test_X,train_Y,test_Y=train_test_split(x,y,test_size=0.3,stratify=y,shuffle=True,random_state=1)self._train_matrix=xgt.DMatrix(data=train_X,label=train_Y,eature_names=_feature_names,feature_types=['float','float','float','float'])self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,feature_names=_feature_names,feature_types=['float', 'float', 'float', 'float'])self._booster=xgt.Booster(params={'booster':'gbtree','silent':0,#打印消息'eta':0.1, #学习率'max_depth':5,'tree_method':'exact','objective':'binary:logistic','eval_metric':'auc','seed':321},cache=[self._train_matrix,self._validate_matrix])def test_attribute(self):'''测试属性的设置和获取:return:'''self._booster.set_attr(key1= '1')print('attr:key1 -> ',self._booster.attr('key1'))print('attr:key2 -> ',self._booster.attr('key2'))print('attributes -> ',self._booster.attributes())def test_dump_model(self):'''测试 dump 模型:return:'''_dump_str=self._booster.get_dump(fmap='model/booster.feature',with_stats=True,dump_format='text')print('dump:',_dump_str[0][:20]+'...' if _dump_str else [])self._booster.dump_model('model/booster.model',fmap='model/booster.feature',with_stats=True)def test_train(self):'''训练:return:'''for i in range(0,100):self._booster.update(self._train_matrix,iteration=i)print(self._booster.eval(self._train_matrix, name='train', iteration=i))print(self._booster.eval(self._validate_matrix,name='eval',iteration=i))def test_importance(self):'''测试特征重要性:return:'''print('fscore:',self._booster.get_fscore('model/booster.feature'))print('score.weight:', self._booster.get_score(importance_type='weight'))print('score.gain:', self._booster.get_score(importance_type='gain'))def test(self):self.test_attribute()# attr:key1 -> 1# attr:key2 -> None# attributes -> {'key1': '1'}self.test_dump_model()# dump: []self.test_train()# [0] train-auc:0.980816# [0] eval-auc:0.933333# ...# [99] train-auc:0.998367# [99] eval-auc:0.995556self.test_dump_model()# dump: 0:[f2<4.85] yes=1,no...self.test_importance()# score: {'f2': 80, 'f3': 72, 'f0': 6, 'f1': 5}# score.weight: {'Petal Length': 80, 'Petal Width': 72, 'Sepal Length': 6, 'Sepal Width': 5}# score.gain: {'Petal Length': 3.6525380337500004, 'Petal Width': 2.2072901486111114, 'Sepal Length': 0.06247816666666667, 'Sepal Width': 0.09243024}if __name__ == '__main__':BoosterTest().test()
7.2.2 直接学习
xgboost.train(): 使用给定的参数来训练一个boosterxxxxxxxxxxxgboost.train(params, dtrain, num_boost_round=10, evals=(), obj=None, feval=None,maximize=False, early_stopping_rounds=None, evals_result=None, verbose_eval=True,xgb_model=None, callbacks=None, learning_rates=None)参数:
params: 一个列表(元素为键值对)、一个字典,表示训练的参数dtrain:一个DMatrix对象,表示训练集num_boost_round: 一个整数,表示boosting迭代数量evals: 一个列表,元素为(DMatrix,string)。 它给出了训练期间的验证集,以及验证集的名字(从而区分验证集的评估结果)。obj:一个函数,它表示自定义的目标函数feval: 一个函数,它表示自定义的evaluation函数maximize: 一个布尔值。如果为True,则表示是对feval求最大值;否则为求最小值early_stopping_rounds:一个整数,表示早停参数。如果在
early_stopping_rounds个迭代步内,验证集的验证误差没有下降,则训练停止。该参数要求
evals参数至少包含一个验证集。如果evals参数包含了多个验证集,则使用最后的一个。返回的模型是最后一次迭代的模型(而不是最佳的模型)。
如果早停发生,则模型拥有三个额外的字段:
.best_score: 最佳的分数.best_iteration: 最佳的迭代步数.best_ntree_limit: 最佳的子模型数量
evals_result: 一个字典,它给出了对测试集要进行评估的指标。verbose_eval: 一个布尔值或者整数。- 如果为
True,则evalutation metric将在每个boosting stage打印出来 - 如果为一个整数,则
evalutation metric将在每隔verbose_eval个boosting stage打印出来。另外最后一个boosting stage,以及早停的boosting stage的evalutation metric也会被打印
- 如果为
learning_rates: 一个列表,给出了每个迭代步的学习率。- 你可以让学习率进行衰减
xgb_model: 一个Booster实例,或者一个存储了xgboost模型的文件的文件名。它给出了待训练的模型。这种做法允许连续训练。
callbacks: 一个回调函数的列表,它给出了在每个迭代步结束之后需要调用的那些函数。你可以使用
xgboost中预定义的一些回调函数(位于xgboost.callback模块) 。如:xgboost.reset_learning_rate(custom_rates)
返回值:一个
Booster对象,表示训练好的模型
xgboost.cv(): 使用给定的参数执行交叉验证 。它常用作参数搜索 。xxxxxxxxxxxgboost.cv(params, dtrain, num_boost_round=10, nfold=3, stratified=False, folds=None,metrics=(), obj=None, feval=None, maximize=False, early_stopping_rounds=None,fpreproc=None, as_pandas=True, verbose_eval=None, show_stdv=True, seed=0,callbacks=None, shuffle=True)参数:
params: 一个列表(元素为键值对)、一个字典,表示训练的参数dtrain:一个DMatrix对象,表示训练集num_boost_round: 一个整数,表示boosting迭代数量nfold: 一个整数,表示交叉验证的fold的数量stratified: 一个布尔值。如果为True,则执行分层采样folds: 一个scikit-learn的KFold实例或者StratifiedKFold实例。metrics:一个字符串或者一个字符串的列表,指定了交叉验证时的evaluation metrics如果同时在
params里指定了eval_metric,则metrics参数优先。obj:一个函数,它表示自定义的目标函数feval: 一个函数,它表示自定义的evaluation函数maximize: 一个布尔值。如果为True,则表示是对feval求最大值;否则为求最小值early_stopping_rounds:一个整数,表示早停参数。如果在
early_stopping_rounds个迭代步内,验证集的验证误差没有下降,则训练停止。- 返回
evaluation history结果中的最后一项是最佳的迭代步的评估结果
- 返回
fpreproc: 一个函数。它是预处理函数,其参数为(dtrain,dtest,param), 返回值是经过了变换之后的(dtrain,dtest,param)as_pandas: 一个布尔值。如果为True,则返回一个pandas.DataFrame;否则返回一个numpy.ndarrayverbose_eval: 参考xgboost.train()show_stdv: 一个布尔值。是否verbose中打印标准差。它对返回结果没有影响。返回结果始终包含标准差。
seed: 一个整数,表示随机数种子callbacks: 参考xgboost.train()shuffle: 一个布尔值。如果为True,则创建folds之前先混洗数据。
返回值:一个字符串的列表,给出了
evaluation history。它给的是早停时刻的history(此时对应着最优模型),早停之后的结果被抛弃。
示例:
xxxxxxxxxxclass TrainTest:def __init__(self):df = pd.read_csv('./data/iris.csv')_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']x = df[_feature_names]y = df['Class'].map(lambda x: _label_map[x])train_X, test_X, train_Y, test_Y = train_test_split(x, y, test_size=0.3,stratify=y, shuffle=True, random_state=1)self._train_matrix = xgt.DMatrix(data=train_X, label=train_Y,feature_names=_feature_names,feature_types=['float', 'float', 'float', 'float'])self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,feature_names=_feature_names,feature_types=['float', 'float', 'float', 'float'])def train_test(self):params={'booster':'gbtree','eta':0.01,'max_depth':5,'tree_method':'exact','objective':'binary:logistic','eval_metric':['logloss','error','auc']}eval_rst={}booster=xgt.train(params,self._train_matrix,num_boost_round=20,evals=([(self._train_matrix,'valid1'),(self._validate_matrix,'valid2')]),early_stopping_rounds=5,evals_result=eval_rst,verbose_eval=True)## 训练输出# Multiple eval metrics have been passed: 'valid2-auc' will be used for early stopping.# Will train until valid2-auc hasn't improved in 5 rounds.# [0] valid1-logloss:0.685684 valid1-error:0.042857 valid1-auc:0.980816 valid2-logloss:0.685749 valid2-error:0.066667 valid2-auc:0.933333# ...# Stopping. Best iteration:# [1] valid1-logloss:0.678149 valid1-error:0.042857 valid1-auc:0.99551 valid2-logloss:0.677882 valid2-error:0.066667 valid2-auc:0.966667print('booster attributes:',booster.attributes())# booster attributes: {'best_iteration': '1', 'best_msg': '[1]\tvalid1-logloss:0.678149\tvalid1-error:0.042857\tvalid1-auc:0.99551\tvalid2-logloss:0.677882\tvalid2-error:0.066667\tvalid2-auc:0.966667', 'best_score': '0.966667'}print('fscore:', booster.get_fscore())# fscore: {'Petal Length': 8, 'Petal Width': 7}print('eval_rst:',eval_rst)# eval_rst: {'valid1': {'logloss': [0.685684, 0.678149, 0.671075, 0.663787, 0.656948, 0.649895], 'error': [0.042857, 0.042857, 0.042857, 0.042857, 0.042857, 0.042857], 'auc': [0.980816, 0.99551, 0.99551, 0.99551, 0.99551, 0.99551]}, 'valid2': {'logloss': [0.685749, 0.677882, 0.670747, 0.663147, 0.656263, 0.648916], 'error': [0.066667, 0.066667, 0.066667, 0.066667, 0.066667, 0.066667], 'auc': [0.933333, 0.966667, 0.966667, 0.966667, 0.966667, 0.966667]}}def cv_test(self):params = {'booster': 'gbtree','eta': 0.01,'max_depth': 5,'tree_method': 'exact','objective': 'binary:logistic','eval_metric': ['logloss', 'error', 'auc']}eval_history = xgt.cv(params, self._train_matrix,num_boost_round=20,nfold=3,stratified=True,metrics=['error', 'auc'],early_stopping_rounds=5,verbose_eval=True,shuffle=True)## 训练输出# [0] train-auc:0.974306+0.00309697 train-error:0.0428743+0.0177703 test-auc:0.887626+0.0695933 test-error:0.112374+0.0695933#....print('eval_history:', eval_history)# eval_history: test-auc-mean test-auc-std test-error-mean test-error-std \# 0 0.887626 0.069593 0.112374 0.069593# 1 0.925821 0.020752 0.112374 0.069593# 2 0.925821 0.020752 0.098485 0.050631# train-auc-mean train-auc-std train-error-mean train-error-std# 0 0.974306 0.003097 0.042874 0.01777# 1 0.987893 0.012337 0.042874 0.01777# 2 0.986735 0.011871 0.042874 0.01777
7.2.3 Scikit-Learn API
xgboost给出了针对scikit-learn接口的APIxgboost.XGBRegressor: 它实现了scikit-learn的回归模型APIxxxxxxxxxxclass xgboost.XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100,silent=True, objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None,gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1,colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)参数:
max_depth: 一个整数,表示子树的最大深度learning_rate: 一个浮点数,表示学习率n_estimators:一个整数,表示预期需要学习的子树的数量silent: 一个布尔值。如果为False,则打印中间信息objective: 一个字符串或者可调用对象,指定了目标函数。其函数签名为:objective(y_true,y_pred) -> gra,hess。 其中:y_true: 一个形状为[n_sample]的序列,表示真实的标签值y_pred: 一个形状为[n_sample]的序列,表示预测的标签值grad: 一个形状为[n_sample]的序列,表示每个样本处的梯度hess: 一个形状为[n_sample]的序列,表示每个样本处的二阶偏导数
booster: 一个字符串。指定了用哪一种基模型。可以为:'gbtree','gblinear','dart'n_jobs: 一个整数,指定了并行度,即开启多少个线程来训练。如果为-1,则使用所有的CPUgamma: 一个浮点数,也称作最小划分损失min_split_loss。 它刻画的是:对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。- 如果大于该阈值,则该叶子节点值得继续划分
- 如果小于该阈值,则该叶子节点不值得继续划分
min_child_weight: 一个整数,子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。- 如果它的所有子节点的权重之和大于该阈值,则该叶子节点值得继续划分
- 如果它的所有子节点的权重之和小于该阈值,则该叶子节点不值得继续划分
所谓的权重:
- 对于线性模型(
booster=gblinear),权重就是:叶子节点包含的样本数量。 因此该参数就是每个节点包含的最少样本数量。 - 对于树模型(
booster=gbtree,dart),权重就是:叶子节点包含样本的所有二阶偏导数之和。
max_delta_step: 一个整数,每棵树的权重估计时的最大delta step。取值范围为 ,0 表示没有限制,默认值为 0 。subsample:一个浮点数,对训练样本的采样比例。取值范围为(0,1],默认值为 1 。如果为
0.5, 表示随机使用一半的训练样本来训练子树。它有助于缓解过拟合。colsample_bytree: 一个浮点数,构建子树时,对特征的采样比例。取值范围为(0,1], 默认值为 1。如果为
0.5, 表示随机使用一半的特征来训练子树。它有助于缓解过拟合。colsample_bylevel: 一个浮点数,寻找划分点时,对特征的采样比例。取值范围为(0,1], 默认值为 1。如果为
0.5, 表示随机使用一半的特征来寻找最佳划分点。它有助于缓解过拟合。reg_alpha: 一个浮点数,是L1正则化系数。它是xgb的alpha参数reg_lambda: 一个浮点数,是L2正则化系数。它是xgb的lambda参数scale_pos_weight: 一个浮点数,用于调整正负样本的权重,常用于类别不平衡的分类问题。默认为 1。一个典型的参数值为:
负样本数量/正样本数量base_score:一个浮点数, 给所有样本的一个初始的预测得分。它引入了全局的biasrandom_state: 一个整数,表示随机数种子。missing: 一个浮点数,它的值代表发生了数据缺失。默认为np.nankwargs: 一个字典,给出了关键字参数。它用于设置Booster对象
xgboost.XGBClassifier:它实现了scikit-learn的分类模型APIxxxxxxxxxxclass xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100,silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1,nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,scale_pos_weight=1, base_score=0.5, random_state=0, seed=None,missing=None, **kwargs)参数参考
xgboost.XGBRegressorxgboost.XGBClassifier和xgboost.XGBRegressor的方法:.fit(): 训练模型xxxxxxxxxxfit(X, y, sample_weight=None, eval_set=None, eval_metric=None,early_stopping_rounds=None,verbose=True, xgb_model=None)参数:
X: 一个array-like,表示训练集y: 一个序列,表示标记sample_weight: 一个序列,给出了每个样本的权重eval_set: 一个列表,元素为(X,y),给出了验证集及其标签。它们用于早停。如果有多个验证集,则使用最后一个
eval_metric: 一个字符串或者可调用对象,用于evaluation metric- 如果为字符串,则是内置的度量函数的名字
- 如果为可调用对象,则它的签名为
(y_pred,y_true)==>(str,value)
early_stopping_rounds: 指定早停的次数。参考xgboost.train()verbose: 一个布尔值。如果为True,则打印验证集的评估结果。xgb_model:一个Booster实例,或者一个存储了xgboost模型的文件的文件名。它给出了待训练的模型。这种做法允许连续训练。
.predict():执行预测xxxxxxxxxxpredict(data, output_margin=False, ntree_limit=0)参数:
data: 一个DMatrix对象,表示测试集output_margin: 一个布尔值。表示是否输出原始的、未经过转换的margin valuentree_limit: 一个整数。表示使用多少棵子树来预测。默认值为0,表示使用所有的子树。如果训练的时候发生了早停,则你可以使用
booster.best_ntree_limit。
返回值:一个
ndarray,表示预测结果- 对于回归问题,返回的就是原始的预测结果
- 对于分类问题,返回的就是预测类别(阈值为 0.5 )
.predict_proba(data, output_margin=False, ntree_limit=0): 执行预测,预测的是各类别的概率参数:参考
.predict()返回值:一个
ndarray,表示预测结果它只用于分类问题,返回的是预测各类别的概率
.evals_result(): 返回一个字典,给出了各个验证集在各个验证参数上的历史值它不同于
cv()函数的返回值。cv()函数返回evaluation history是早停时刻的。而这里返回的是所有的历史值
示例:
xxxxxxxxxxclass SKLTest:def __init__(self):df = pd.read_csv('./data/iris.csv')_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']x = df[_feature_names]y = df['Class'].map(lambda x: _label_map[x])self.train_X, self.test_X, self.train_Y, self.test_Y = \train_test_split(x, y, test_size=0.3, stratify=y, shuffle=True, random_state=1)def train_test(self):clf=xgt.XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=100)clf.fit(self.train_X,self.train_Y,eval_metric='auc',eval_set=[( self.test_X,self.test_Y),],early_stopping_rounds=3)# 训练输出:# Will train until validation_0-auc hasn't improved in 3 rounds.# [0] validation_0-auc:0.933333# ...# Stopping. Best iteration:# [2] validation_0-auc:0.997778print('evals_result:',clf.evals_result())# evals_result: {'validation_0': {'auc': [0.933333, 0.966667, 0.997778, 0.997778, 0.997778]}}print('predict:',clf.predict(self.test_X))# predict: [1 1 0 0 0 1 1 1 0 0 0 1 1 0 1 1 0 1 0 0 0 0 0 1 1 0 0 1 1 0]
7.3 绘图API
xgboost.plot_importance():绘制特征重要性xxxxxxxxxxxgboost.plot_importance(booster, ax=None, height=0.2, xlim=None, ylim=None,title='Feature importance', xlabel='F score', ylabel='Features',importance_type='weight', max_num_features=None, grid=True,show_values=True, **kwargs)参数:
booster: 一个Booster对象, 一个XGBModel对象,或者由Booster.get_fscore()返回的字典ax: 一个matplotlib Axes对象。特征重要性将绘制在它上面。如果为
None,则新建一个Axesgrid: 一个布尔值。如果为True,则开启axes gridimportance_type: 一个字符串,指定了特征重要性的类别。参考Booster.get_fscore()max_num_features: 一个整数,指定展示的特征的最大数量。如果为None,则展示所有的特征height: 一个浮点数,指定bar的高度。它传递给ax.barh()xlim: 一个元组,传递给axes.xlim()ylim: 一个元组,传递给axes.ylim()title: 一个字符串,设置Axes的标题。默认为"Feature importance"。 如果为None,则没有标题xlabel: 一个字符串,设置Axes的X轴标题。默认为"F score"。 如果为None,则X轴没有标题ylabel:一个字符串,设置Axes的Y轴标题。默认为"Features"。 如果为None,则Y轴没有标题show_values: 一个布尔值。如果为True,则在绘图上展示具体的值。kwargs: 关键字参数,用于传递给ax.barh()
返回
ax(一个matplotlib Axes对象)xgboost.plot_tree(): 绘制指定的子树。xxxxxxxxxxxgboost.plot_tree(booster, fmap='', num_trees=0, rankdir='UT', ax=None, **kwargs)参数:
booster: 一个Booster对象, 一个XGBModel对象fmap: 一个字符串,给出了feature map文件的文件名num_trees: 一个整数,制定了要绘制的子数的编号。默认为 0rankdir: 一个字符串,它传递给graphviz的graph_attrax: 一个matplotlib Axes对象。特征重要性将绘制在它上面。如果为
None,则新建一个Axeskwargs: 关键字参数,用于传递给graphviz的graph_attr
返回
ax(一个matplotlib Axes对象)xgboost.tp_graphviz(): 转换指定的子树成一个graphviz实例。在
IPython中,可以自动绘制graphviz实例;否则你需要手动调用graphviz对象的.render()方法来绘制。xxxxxxxxxxxgboost.to_graphviz(booster, fmap='', num_trees=0, rankdir='UT', yes_color='#0000FF',no_color='#FF0000', **kwargs)参数:
yes_color: 一个字符串,给出了满足node condition的边的颜色no_color: 一个字符串,给出了不满足node condition的边的颜色- 其它参数参考
xgboost.plot_tree()
返回
ax(一个matplotlib Axes对象)示例:
xxxxxxxxxxclass PlotTest:def __init__(self):df = pd.read_csv('./data/iris.csv')_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']x = df[_feature_names]y = df['Class'].map(lambda x: _label_map[x])train_X, test_X, train_Y, test_Y = train_test_split(x, y,test_size=0.3, stratify=y, shuffle=True, random_state=1)self._train_matrix = xgt.DMatrix(data=train_X, label=train_Y,feature_names=_feature_names,feature_types=['float', 'float', 'float', 'float'])self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,feature_names=_feature_names,feature_types=['float', 'float', 'float', 'float'])def plot_test(self):params = {'booster': 'gbtree','eta': 0.01,'max_depth': 5,'tree_method': 'exact','objective': 'binary:logistic','eval_metric': ['logloss', 'error', 'auc']}eval_rst = {}booster = xgt.train(params, self._train_matrix,num_boost_round=20, evals=([(self._train_matrix, 'valid1'),(self._validate_matrix, 'valid2')]),early_stopping_rounds=5, evals_result=eval_rst, verbose_eval=True)xgt.plot_importance(booster)plt.show()