数值计算
一、数值稳定性
在计算机中执行数学运算需要使用有限的比特位来表达实数,这会引入近似误差。
近似误差可以在多步数值运算中传递、积累,从而导致理论上成功的算法失败。因此数值算法设计时要考虑将累计误差最小化。
当从头开始实现一个数值算法时,需要考虑数值稳定性。当使用现有的数值计算库(如
tensorflow)时,不需要考虑数值稳定性。
1.1 上溢出、下溢出
一种严重的误差是下溢出
underflow:当接近零的数字四舍五入为零时,发生下溢出。许多函数在参数为零和参数为一个非常小的正数时,行为是不同的。如:对数函数要求自变量大于零,除法中要求除数非零。
一种严重的误差是上溢出
overflow:当数值非常大,超过了计算机的表示范围时,发生上溢出。一个数值稳定性的例子是
softmax函数。设 ,则
softmax函数定义为:当所有的 都等于常数 时,
softmax函数的每个分量的理论值都为 。- 考虑 是一个非常大的负数(比如趋近负无穷),此时 下溢出。此时 分母为零,结果未定义。
- 考虑 是一个非常大的正数(比如趋近正无穷),此时 上溢出。 的结果未定义。
为了解决
softmax函数的数值稳定性问题,令 ,则有 的第 个分量为:- 当 的分量较小时, 的分量至少有一个为零,从而导致 的分母至少有一项为 1,从而解决了下溢出的问题。
- 当 的分量较大时, 相当于分子分母同时除以一个非常大的数 ,从而解决了上溢出。
当 的分量 较小时, 的计算结果可能为 0 。此时 趋向于负无穷,因此存在数值稳定性问题。
- 通常需要设计专门的函数来计算 ,而不是将 的结果传递给 函数。
- 函数应用非常广泛。通常将 函数的输出作为模型的输出。由于一般使用样本的交叉熵作为目标函数,因此需要用到 输出的对数。
softmax名字的来源是hardmax。hardmax把一个向量 映射成向量 。即: 最大元素的位置填充1,其它位置填充0。softmax会在这些位置填充0.0~1.0之间的值(如:某个概率值)。
1.2 Conditioning
Conditioning刻画了一个函数的如下特性:当函数的输入发生了微小的变化时,函数的输出的变化有多大。对于
Conditioning较大的函数,在数值计算中可能有问题。因为函数输入的舍入误差可能导致函数输出的较大变化。对于方阵 ,其条件数
condition number为:其中 为 的特征值。
- 方阵的条件数就是最大的特征值除以最小的特征值。
- 当方阵的条件数很大时,矩阵的求逆将对误差特别敏感(即: 的一个很小的扰动,将导致其逆矩阵一个非常明显的变化)。
- 条件数是矩阵本身的特性,它会放大那些包含矩阵求逆运算过程中的误差。
二、梯度下降法
梯度下降法是求解无约束最优化问题的一种常见方法,优点是实现简单。
对于函数: ,假设输入 ,则定义梯度:
函数的驻点满足: 。
沿着方向 的方向导数
directional derivative定义为:其中 为单位向量。
方向导数就是 。根据链式法则,它也等于 。
为了最小化 ,则寻找一个方向:沿着该方向,函数值减少的速度最快(换句话说,就是增加最慢)。即:
假设 与梯度的夹角为 ,则目标函数等于: 。
考虑到 ,以及梯度的大小与 无关,于是上述问题转化为:
于是: ,即 沿着梯度的相反的方向。即:梯度的方向是函数值增加最快的方向,梯度的相反方向是函数值减小的最快的方向。
因此:可以沿着负梯度的方向来降低 的值,这就是梯度下降法。
根据梯度下降法,为了寻找 的最小点,迭代过程为: 。其中: 为学习率,它是一个正数,决定了迭代的步长。
迭代结束条件为:梯度向量 的每个成分为零或者非常接近零。
选择学习率有多种方法:
一种方法是:选择 为一个小的、正的常数。
另一种方法是:给定多个 ,然后选择使得 最小的那个值作为本次迭代的学习率(即:选择一个使得目标函数下降最大的学习率)。
这种做法叫做线性搜索
line search。第三种方法是:求得使 取极小值的 ,即求解最优化问题:
这种方法也称作最速下降法。
在最速下降法中,假设相邻的三个迭代点分别为: ,可以证明: 。即相邻的两次搜索的方向是正交的!
证明:
根据最优化问题,有:
将 代入,有:
为求 极小值,则求解: 。
根据链式法则:
即: 。则有: 。
此时迭代的路线是锯齿形的,因此收敛速度较慢。
某些情况下如果梯度向量 的形式比较简单,则可以直接求解方程: 。
此时不用任何迭代,直接获得解析解。
梯度下降算法:
输入:
- 目标函数
- 梯度函数
- 计算精度
输出: 的极小点
算法步骤:
选取初始值 ,置 。
迭代,停止条件为:梯度收敛或者目标函数收敛。迭代步骤为:
计算目标函数 ,计算梯度 。
若梯度 ,则停止迭代, 。
若梯度 ,则令 ,求 : 。
通常这也是个最小化问题。但是可以给定一系列的的值,如:
[10,1,0.1,0.01,0.001,0.0001]。然后从中挑选使得目标函数最小的那个。令 ,计算 。
- 若 或者 时,停止迭代,此时 。
- 否则,令 ,计算梯度 继续迭代。
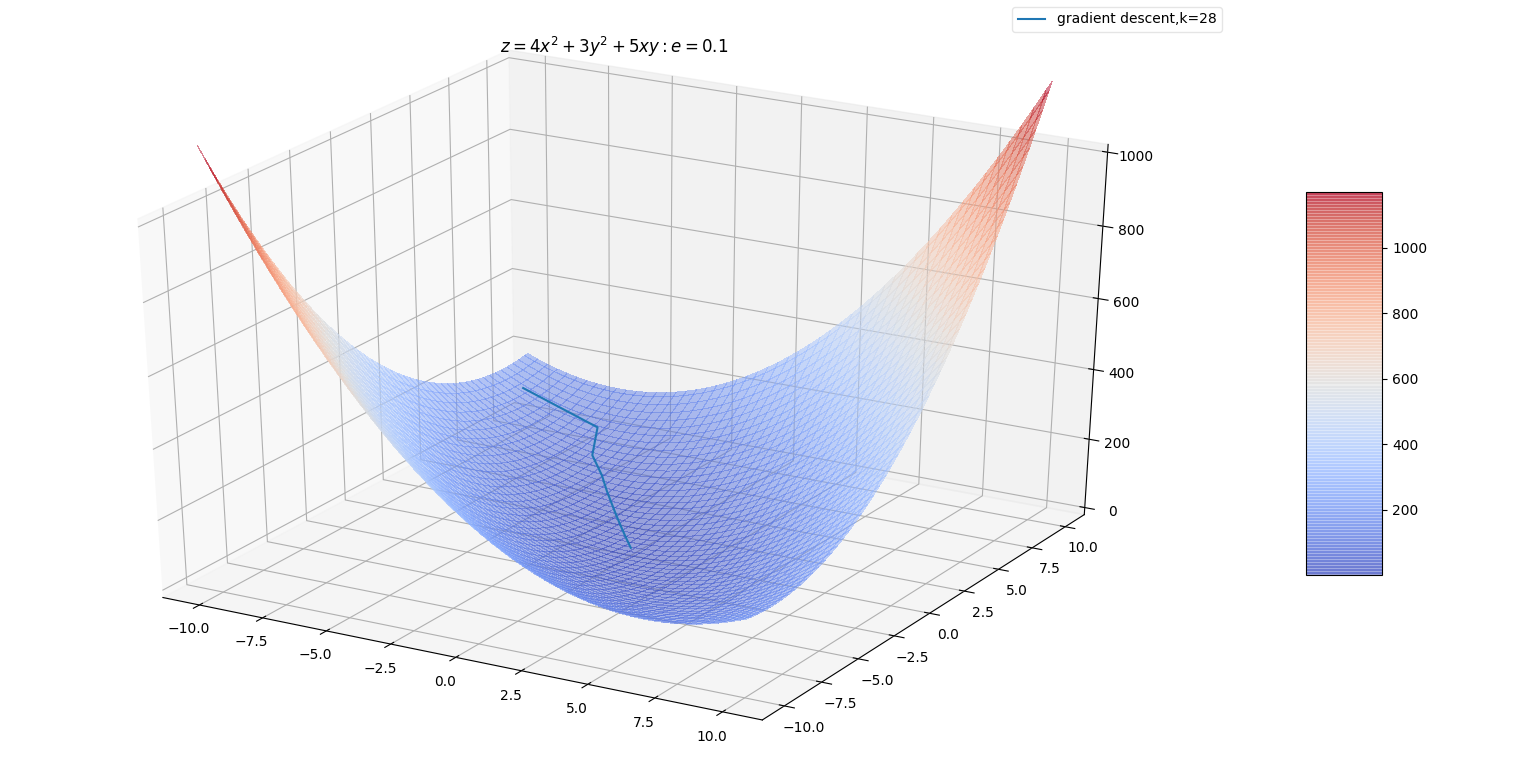
当目标函数是凸函数时,梯度下降法的解是全局最优的。通常情况下,梯度下降法的解不保证是全局最优的。
梯度下降法的收敛速度未必是最快的。
三、二阶导数与海森矩阵
3.1 海森矩阵
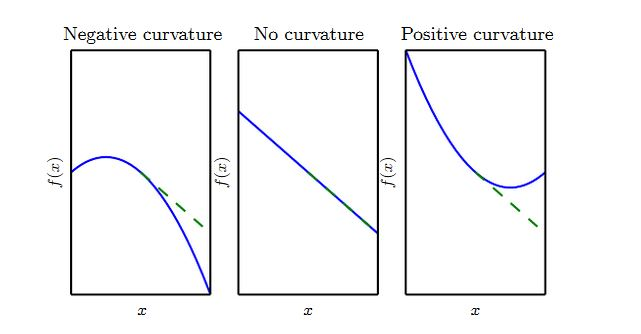
二阶导数 刻画了曲率。假设有一个二次函数(实际任务中,很多函数不是二次的,但是在局部可以近似为二次函数):
- 如果函数的二阶导数为零,则它是一条直线。如果梯度为 1,则当沿着负梯度的步长为 时,函数值减少 。
- 如果函数的二阶导数为负,则函数向下弯曲。如果梯度为1,则当沿着负梯度的步长为 时,函数值减少的量大于 。
- 如果函数的二阶导数为正,则函数向上弯曲。如果梯度为1,则当沿着负梯度的步长为 时,函数值减少的量少于 。
当函数输入为多维时,定义海森矩阵:
即海森矩阵的第 行 列元素为: 。
当二阶偏导是连续时,海森矩阵是对称阵,即有: 。
在深度学习中大多数海森矩阵都是对称阵。
对于特定方向 上的二阶导数为: 。
- 如果 是海森矩阵的特征向量,则该方向的二阶导数就是对应的特征值。
- 如果 不是海森矩阵的特征向量,则该方向的二阶导数就是所有特征值的加权平均,权重在
(0,1)之间。且与 夹角越小的特征向量对应的特征值具有更大的权重。 - 最大特征值确定了最大二阶导数,最小特征值确定最小二阶导数。
3.2 海森矩阵与学习率
将 在 处泰勒展开: 。其中: 为 处的梯度; 为 处的海森矩阵。
根据梯度下降法: 。
应用在点 ,有: 。
- 第一项代表函数在点 处的值。
- 第二项代表由于斜率的存在,导致函数值的变化。
- 第三项代表由于曲率的存在,对于函数值变化的矫正。
注意:如果 较大,则很有可能导致:沿着负梯度的方向,函数值反而增加!
如果 ,则无论 取多大的值, 可以保证函数值是减小的。
如果 , 则学习率 不能太大。若 太大则函数值增加。
根据 ,则需要满足: 。若 ,则会导致沿着负梯度的方向函数值在增加。
考虑最速下降法,选择使得 下降最快的 ,则有: 。求解 有: 。
根据 ,很明显有: 。
由于海森矩阵为实对称阵,因此它可以进行特征值分解。假设其特征值从大到小排列为: 。
海森矩阵的瑞利商为: 。可以证明:
根据 可知:海森矩阵决定了学习率的取值范围。最坏的情况下,梯度 与海森矩阵最大特征值 对应的特征向量平行,则此时最优学习率为 。
3.3 驻点与全局极小点
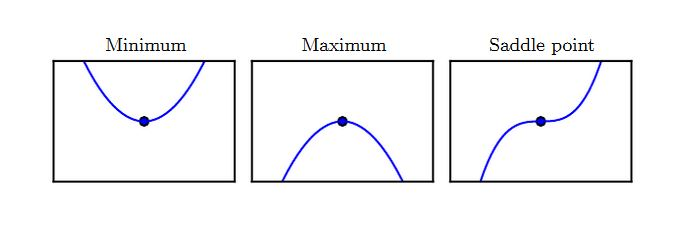
满足导数为零的点(即 )称作驻点。驻点可能为下面三种类型之一:
- 局部极小点:在 的一个邻域内,该点的值最小。
- 局部极大点:在 的一个邻域内,该点的值最大。
- 鞍点:既不是局部极小,也不是局部极大。
全局极小点:。
全局极小点可能有一个或者多个。
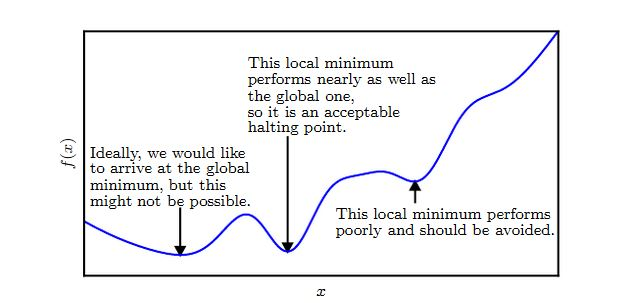
在深度学习中,目标函数很可能具有非常多的局部极小点,以及许多位于平坦区域的鞍点。这使得优化非常不利。
因此通常选取一个非常低的目标函数值,而不一定要是全局最小值。
二阶导数可以配合一阶导数来决定驻点的类型:
- 局部极小点: 。
- 局部极大点: 。
- :驻点的类型可能为任意三者之一。
对于多维的情况类似有:
局部极小点:,且海森矩阵为正定的(即所有的特征值都是正的)。
当海森矩阵为正定时,任意方向的二阶偏导数都是正的。
局部极大点:,且海森矩阵为负定的(即所有的特征值都是负的)。
当海森矩阵为负定时,任意方向的二阶偏导数都是负的。
,且海森矩阵的特征值中至少一个正值、至少一个负值时,为鞍点。
当海森矩阵非上述情况时,驻点类型无法判断。
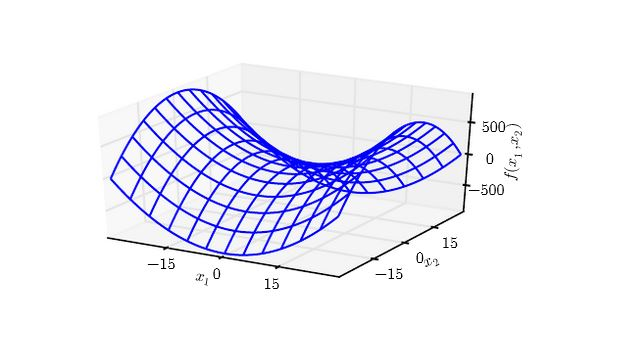
下图为 在原点附近的等值线。其海森矩阵为一正一负。
- 沿着 方向,曲线向上弯曲;沿着 方向,曲线向下弯曲。
- 鞍点就是在一个横截面内的局部极小值,另一个横截面内的局部极大值。
四、牛顿法
梯度下降法有个缺陷:它未能利用海森矩阵的信息。
当海森矩阵的条件数较大时,不同方向的梯度的变化差异很大。
在某些方向上,梯度变化很快;在有些方向上,梯度变化很慢。
梯度下降法未能利用海森矩阵,也就不知道应该优先搜索导数长期为负或者长期为正的方向。
本质上应该沿着负梯度方向搜索。但是沿着该方向的一段区间内,如果导数一直为正或者一直为负,则可以直接跨过该区间。前提是:必须保证该区间内,该方向导数不会发生正负改变。
当海森矩阵的条件数较大时,也难以选择合适的步长。
- 步长必须足够小,从而能够适应较强曲率的地方(对应着较大的二阶导数,即该区域比较陡峭)。
- 但是如果步长太小,对于曲率较小的地方(对应着较小的二阶导数,即该区域比较平缓)则推进太慢。
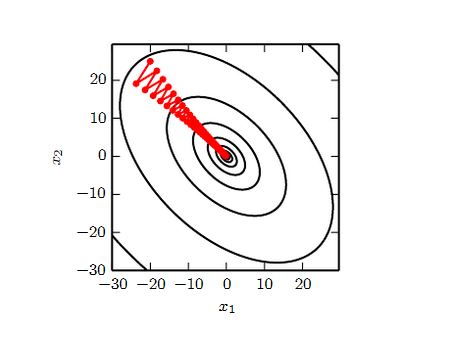
下图是利用梯度下降法寻找函数最小值的路径。该函数是二次函数,海森矩阵条件数为 5,表明最大曲率是最小曲率的5倍。红线为梯度下降的搜索路径。
它没有用最速下降法,而是用到线性搜索。如果是最速下降法,则相邻两次搜索的方向正交。
牛顿法结合了海森矩阵。
考虑泰勒展开式: 。其中 为 处的梯度; 为 处的海森矩阵。
如果 为极值点,则有: ,则有: 。
- 当 是个正定的二次型,则牛顿法直接一次就能到达最小值点。
- 当 不是正定的二次型,则可以在局部近似为正定的二次型,那么则采用多次牛顿法即可到达最小值点。
一维情况下,梯度下降法和牛顿法的原理展示:
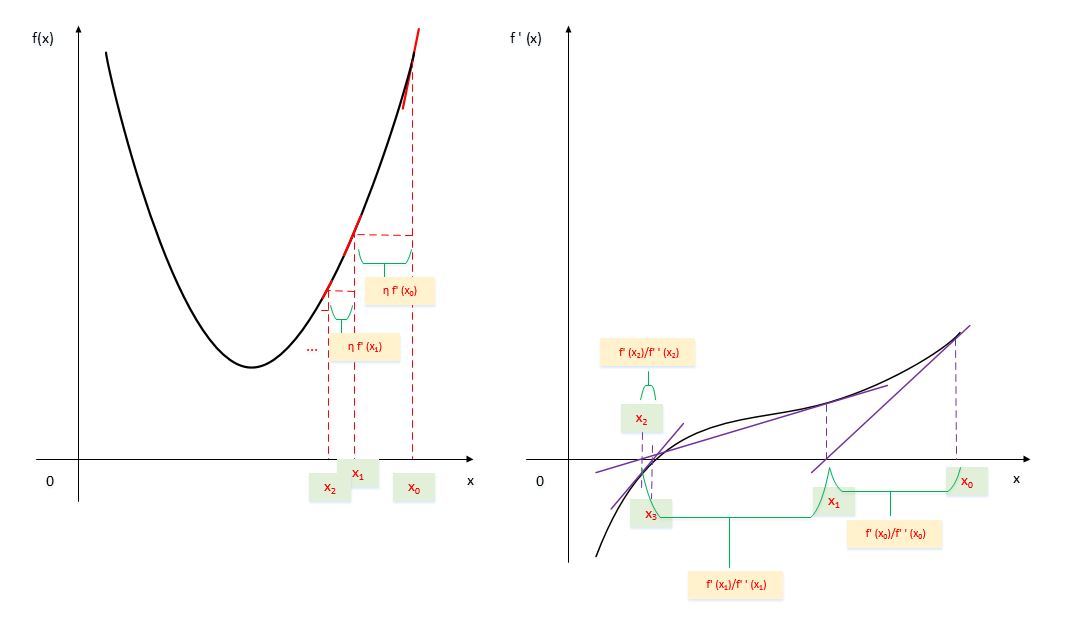
梯度下降法:下一次迭代的点 。
对于一维的情况,可以固定 。由于随着迭代的推进, 绝对值是减小的(直到0),因此越靠近极值点, 越小。
牛顿法:目标是 。
在一维情况下就是求解 。牛顿法的方法是:以 做 切线,该切线过点 。该切线在 轴上的交点就是: 。
推广到多维情况下就是: 。
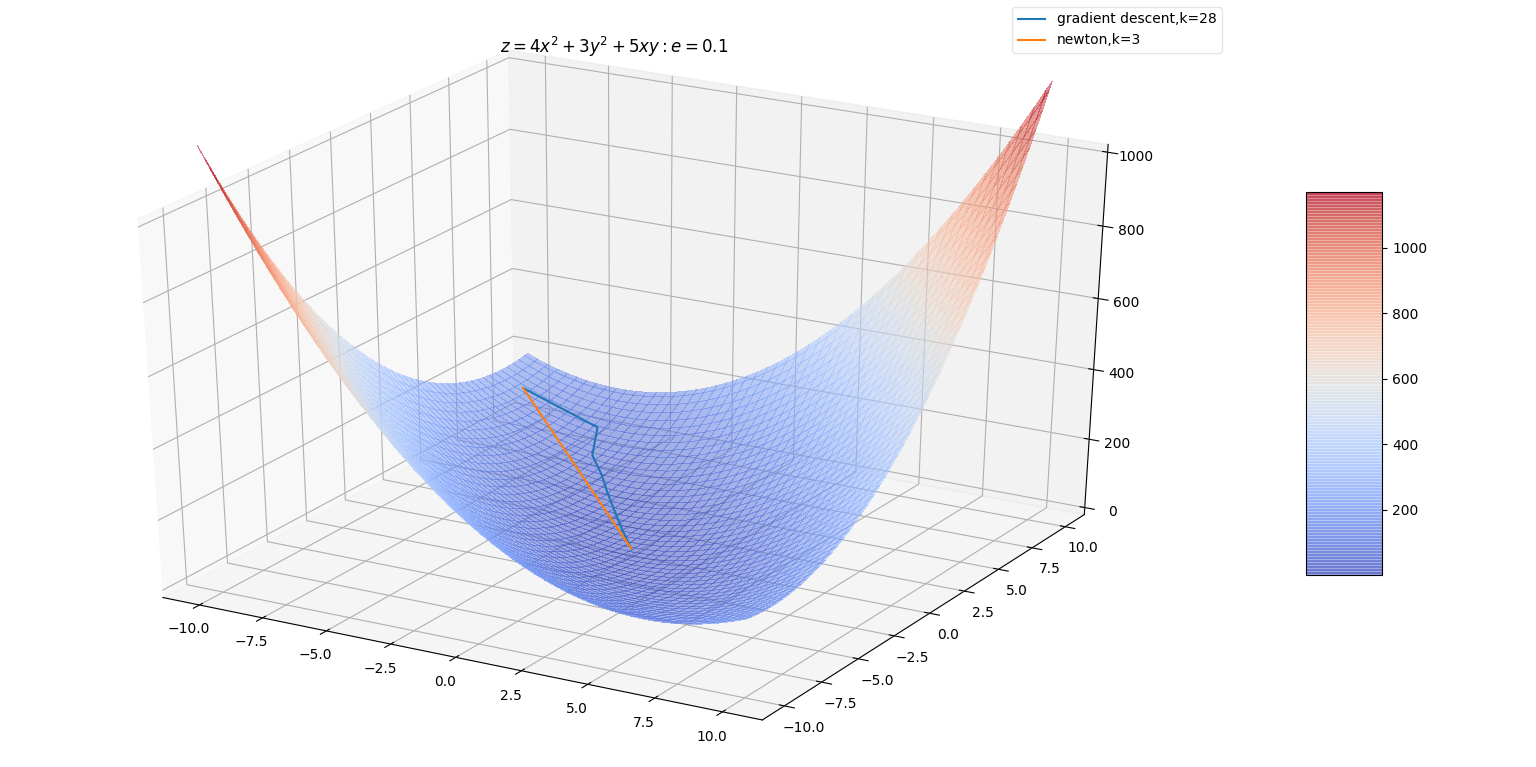
当位于一个极小值点附近时,牛顿法比梯度下降法能更快地到达极小值点。
如果在一个鞍点附近,牛顿法效果很差,因为牛顿法会主动跳入鞍点。而梯度下降法此时效果较好(除非负梯度的方向刚好指向了鞍点)。
仅仅利用了梯度的优化算法(如梯度下降法)称作一阶优化算法,同时利用了海森矩阵的优化算法(如牛顿法)称作二阶优化算法。
牛顿法算法:
输入:
- 目标函数
- 梯度
- 海森矩阵
- 精度要求
输出: 的极小值点
算法步骤:
选取初始值 , 置 。
迭代,停止条件为:梯度收敛。迭代步骤为:
计算 。
若 , 则停止计算,得到近似解 。
若 , 则:
- 计算 ,并求 ,使得: 。
- 置 。
- 置 ,继续迭代。
梯度下降法中,每一次 增加的方向一定是梯度相反的方向 。增加的幅度由 决定,若跨度过大容易引发震荡。
而牛顿法中,每一次 增加的方向是梯度增速最大的反方向 (它通常情况下与梯度不共线)。增加的幅度已经包含在 中(也可以乘以学习率作为幅度的系数)。
深度学习中的目标函数非常复杂,无法保证可以通过上述优化算法进行优化。因此有时会限定目标函数具有
Lipschitz连续,或者其导数Lipschitz连续。Lipschitz连续的定义:对于函数 ,存在一个Lipschitz常数 ,使得:
Lipschitz连续的意义是:输入的一个很小的变化,会引起输出的一个很小的变化。与之相反的是:输入的一个很小的变化,会引起输出的一个很大的变化
凸优化在某些特殊的领域取得了巨大的成功。但是在深度学习中,大多数优化问题都难以用凸优化来描述。
凸优化的重要性在深度学习中大大降低。凸优化仅仅作为一些深度学习算法的子程序。
五、拟牛顿法
5.1 原理
在牛顿法的迭代中,需要计算海森矩阵的逆矩阵 ,这一计算比较复杂。
可以考虑用一个 阶矩阵 来近似代替 。
先看海森矩阵满足的条件: 。
令 。则有:,或者 。
这称为拟牛顿条件。
根据牛顿法的迭代: ,将 在 的一阶泰勒展开:
当 是正定矩阵时,总有 ,因此每次都是沿着函数递减的方向迭代。
如果选择 作为 的近似时, 同样要满足两个条件:
必须是正定的。
满足拟牛顿条件: 。
因为 是给定的初始化条件,所以下标从 开始。
按照拟牛顿条件,在每次迭代中可以选择更新矩阵 。
正定矩阵定义:设 是 阶方阵,如果对任何非零向量 ,都有 ,就称 正定矩阵。
正定矩阵判定:
- 判定定理1:对称阵 为正定的充分必要条件是: 的特征值全为正。
- 判定定理2:对称阵 为正定的充分必要条件是: 的各阶顺序主子式都为正。
- 判定定理3:任意阵 为正定的充分必要条件是: 合同于单位阵。
正定矩阵的性质:
- 正定矩阵一定是非奇异的。奇异矩阵的定义:若 阶矩阵 为奇异阵,则其的行列式为零,即 。
- 正定矩阵的任一主子矩阵也是正定矩阵。
- 若 为 阶对称正定矩阵,则存在唯一的主对角线元素都是正数的下三角阵 ,使得 ,此分解式称为 正定矩阵的乔列斯基(
Cholesky)分解。 - 若 为 阶正定矩阵,则 为 阶可逆矩阵。
正定矩阵在某个合同变换下可化为标准型, 即对角矩阵。
所有特征值大于零的对称矩阵也是正定矩阵。
合同矩阵:两个实对称矩阵 和 是合同的,当且仅当存在一个可逆矩阵 ,使得
- 的合同变换:对某个可逆矩阵 ,对 执行 。
5.2 DFP 算法
DFP算法(Davidon-Fletcher-Powell) 选择 的方法是:假设每一步迭代中 是由 加上两个附加项构成:,其中 是待定矩阵。此时有:。
为了满足拟牛顿条件,可以取:。
这样的 不止一个。例如取 :
则迭代公式为:
可以证明:如果初始矩阵 是正定的,则迭代过程中每个矩阵 都是正定的。
DFP算法:输入:
- 目标函数
- 梯度
- 精度要求
输出: 的极小值点
算法步骤:
选取初始值 , 取 为正定对称矩阵,置 。
迭代,停止条件为:梯度收敛。迭代步骤为:
计算 。
若 , 则停止计算,得到近似解 。
若 , 则:
- 计算 。
- 一维搜索:求 : 。
- 设置 。
- 计算 。若 , 则停止计算,得到近似解 。
- 否则计算 ,置 ,继续迭代。
DFP算法中,每一次 增加的方向是 的方向。增加的幅度由 决定,若跨度过大容易引发震荡。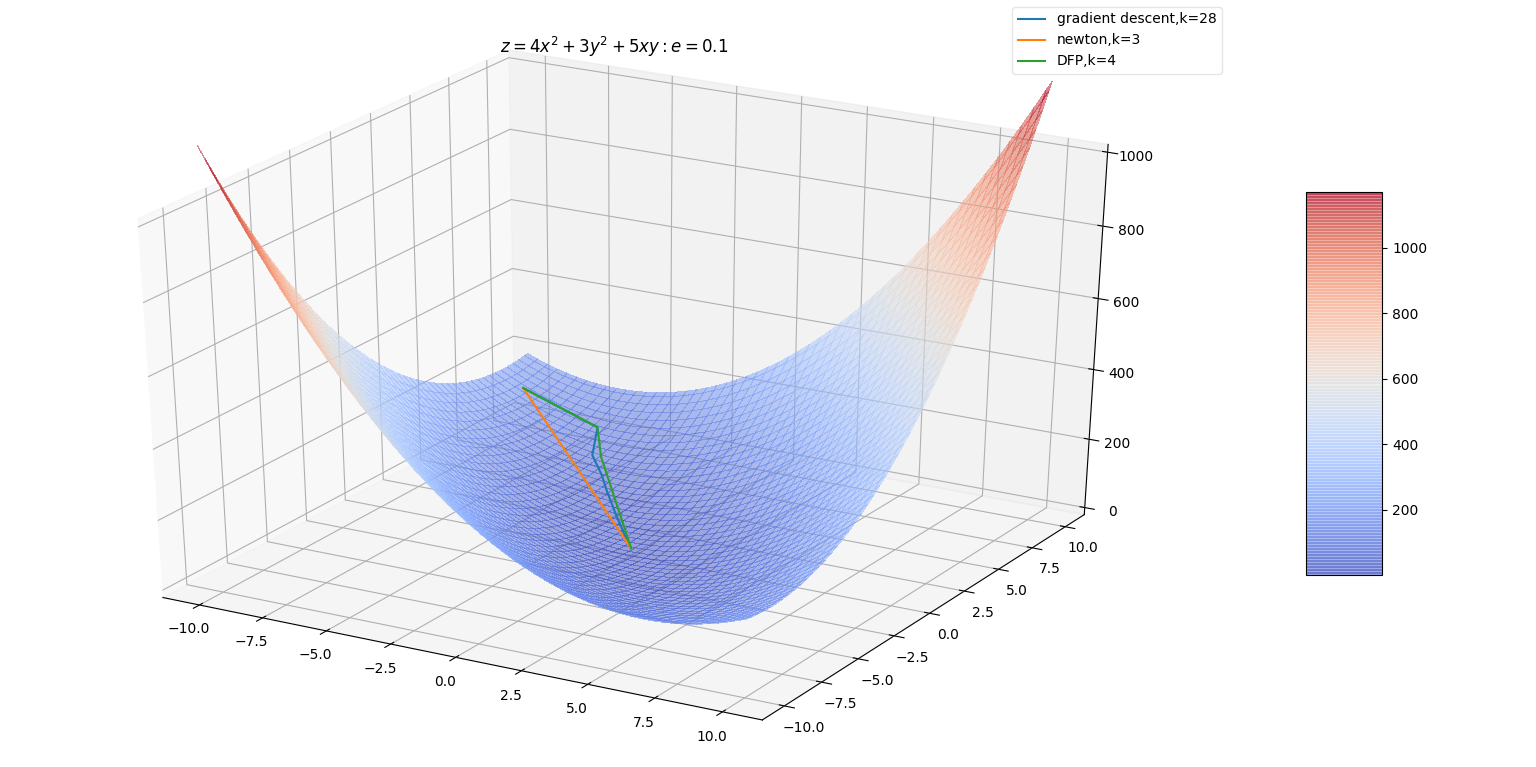
5.2 BFGS 算法
BFGS是最流行的拟牛顿算法。DFP算法中,用 逼近 。换个角度看,可以用矩阵 逼近海森矩阵 。此时对应的拟牛顿条件为: 。因为 是给定的初始化条件,所以下标从 开始。
令: ,有: 。
可以取 。寻找合适的 ,可以得到
BFGS算法矩阵的 的迭代公式:可以证明,若 是正定的,则迭代过程中每个矩阵 都是正定的。
BFGS算法:输入:
- 目标函数
- 梯度
- 精度要求
输出: 的极小值点
算法步骤:
选取初始值 , 取 为正定对称矩阵,置 。
迭代,停止条件为:梯度收敛。迭代步骤为:
计算 。
若 , 则停止计算,得到近似解 。
若 , 则:
由 求出 。
这里表面上看需要对矩阵求逆。但是实际上 有迭代公式。根据
Sherman-Morrison公式以及 的迭代公式,可以得到 的迭代公式。一维搜索:求 : 。
设置 。
计算 。若 , 则停止计算,得到近似解 。
否则计算 ,置 ,继续迭代。
BFPS算法中,每一次 增加的方向是 的方向。增加的幅度由 决定,若跨度过大容易引发震荡。
5.3 Broyden 类算法
若记 ,则对式子:
使用两次
Sherman-Morrison公式可得:令
DFP算法获得的 的迭代公式记作:由
BFGS算法获得的 的迭代公式记作 :他们都满足拟牛顿条件,所以他们的线性组合: 也满足拟牛顿条件,而且是正定的,其中 。
这样获得了一族拟牛顿法,称为
Broyden类算法。Sherman-Morrison公式:假设 是 阶可逆矩阵, 是 维列向量,且 也是可逆矩阵,则:.
六、 约束优化
在有的最优化问题中,希望输入 位于特定的集合 中,这称作约束优化问题。
集合 内的点 称作可行解。集合 也称作可行域。
约束优化的一个简单方法是:对梯度下降法进行修改,每次迭代后,将得到的新的 映射到集合 中。
如果使用线性搜索:则每次只搜索那些使得新的 位于集合 中的那些 。
- 另一个做法:将线性搜索得到的新的 映射到集合 中。
- 或者:在线性搜索之前,将梯度投影到可行域的切空间内。
在约束最优化问题中,常常利用拉格朗日对偶性将原始问题转换为对偶问题,通过求解对偶问题而得到原始问题的解。
约束最优化问题的原始问题:假设 是定义在 上的连续可微函数。考虑约束最优化问题:
可行域由等式和不等式确定: 。
6.1 原始问题
引入拉格朗日函数:
这里 是拉格朗日乘子, 。
是 的多元非线性函数。
定义函数:
其中下标 表示原始问题。则有:
若 满足原问题的约束,则很容易证明 ,等号在 时取到。
若 不满足原问题的约束:
- 若不满足 :设违反的为 ,则令 ,有: 。
- 若不满足 : 设违反的为 ,则令 ,有: 。
考虑极小化问题:
则该问题是与原始最优化问题是等价的,即他们有相同的问题。
- 称为广义拉格朗日函数的极大极小问题。
- 为了方便讨论,定义原始问题的最优值为: 。
6.2 对偶问题
定义 ,考虑极大化 ,即:
问题 称为广义拉格朗日函数的极大极小问题。它可以表示为约束最优化问题:
称为原始问题的对偶问题。
为了方便讨论,定义对偶问题的最优值为: 。
定理一:若原问题和对偶问题具有最优值,则:
推论一:设 为原始问题的可行解,且 的值为 ; 为对偶问题的可行解, 值为 。
如果有 ,则 分别为原始问题和对偶问题的最优解。
定理二:假设函数 和 为凸函数, 是仿射函数;并且假设不等式约束 是严格可行的,即存在 ,对于所有 有 。则存在 ,使得: 是原始问题 的解, 是对偶问题 的解,并且 。
定理三:假设函数 和 为凸函数, 是仿射函数;并且假设不等式约束 是严格可行的,即存在 ,对于所有 有 。则存在 ,使得 是原始问题 的解, 是对偶问题 的解的充要条件是: 满足下面的
Karush-kuhn-Tucker(KKT)条件:仿射函数:仿射函数即由
1阶多项式构成的函数。一般形式为 。这里: 是一个 矩阵, 是一个 维列向量, 是一个 维列向量。
它实际上反映了一种从 维到 维的空间线性映射关系。
凸函数:设 为定义在区间 上的函数,若对 上的任意两点 和任意的实数 ,总有 ,则 称为 上的凸函数 。