十、Calibrate Before Use[2021]
论文:
《Calibrate Before Use: Improving Few-Shot Performance of Language Models》
few-shot learning(用有限的样本来学习任务的能力)是智力的一个重要方面。最近的工作表明,大型神经语言模型可以在不进行微调的情况下进行few-shot learning。具体来说,当被提供以自然语言prompt描述的几个样本时,GPT-3可以执行许多任务。例如,为了进行情感分析,人们可以将GPT-3以一个prompt为条件,如:Input: Subpar acting. Sentiment: NegativeInput: Beautiful film. Sentiment: PositiveInput: Amazing. Sentiment:其中前两行对应两个
prompted examples,最后一行是一个测试样本。为了进行预测,该模型预测的后续token更有可能是单词"Positive"或"Negative"。这种
few-shot "in-context" learning的方式很有趣,因为它表明模型可以在没有参数更新的情况下学习。而且,更重要的是,与现在标准的微调方法相比,它有许多实际的优势:首先,它允许从业者 "快速制作"
NLP模型的原型:改变prompt会立即导致一个新的模型。其次,它为机器学习模型提供了一个百分之百自然语言的接口,这使得用户(甚至那些不是技术专家的人)可以创建
NLP系统。最后,由于
in-context learning在每个任务中都重复使用相同的模型,它在为许多不同的任务在serving时减少了内存需求和系统复杂性。
然而,尽管有这些承诺,我们表明,
GPT-3的准确率在不同的prompts中可能非常不稳定的。一个prompt包含三个部分:prompt格式、一组prompted examples、以及这些样本的排列组合(ordering)。我们表明,对这些因素的不同选择会导致高度不同的准确率。例如,在情感分析prompt中改变prompted examples的排列方式会使准确率从接近随机(54%)变为接近SOTA(93%)。这种不稳定性意味着GPT-3的用户(这些用户通常是手动设计prompts),不能期望持续获得良好的准确率。我们接下来分析一下造成这种不稳定性的原因。我们确定了语言模型的三个缺陷,这些缺陷导致它们在
few-shot learning期间偏向于某些答案。具体而言,它们受到majority label bias、recency bias、以及common token bias的影响。majority label bias和recency bias导致模型会预测在prompt中经常出现、或接近prompt末尾的training answer。例如,一个以negative training example结束的prompt可能会偏向于negative class。另一方面,
common token bias导致模型更倾向于在模型的预训练数据中经常出现的答案,例如,它更倾向于"United States"而不是"Saint Lucia"。这对于目标任务来说可能是次优的。
我们发现,这些
bias通常会导致模型的输出分布发生偏移。因此,我们可以通过 "校准" 输出分布来抵消这些bias。具体来说,我们通过输入一个content-free的dummy test input来估计模型对某些答案的bias。例如,在上面的prompt中,如果我们用"N/A"字符串替换"Amazing.",模型就会预测出62% Positive。然后我们拟合calibration parameters,使content-free input对每个答案都有统一的分数。这个contextual calibration程序提供了一个良好的calibration parameters setting,而不需要额外的训练数据。将噪音输入的
prediction分布作为校正参数,对test input的prediction分布进行校正。我们在一系列的任务上测试了
contextual calibration的有效性。在不同的prompt format和样本的选择中,contextual calibration一致地提高了GPT-3和GPT-2的准确率(绝对提升高达30.0%)(如下图所示)。它还使准确率在不同的prompt中更加稳定,从而减轻了对prompt engineering的需求。总的来说,contextual calibration是一种简单的方法,它使语言模型成为更好的few-shot learners:它使终端用户能够以相当少的努力获得更高的准确率。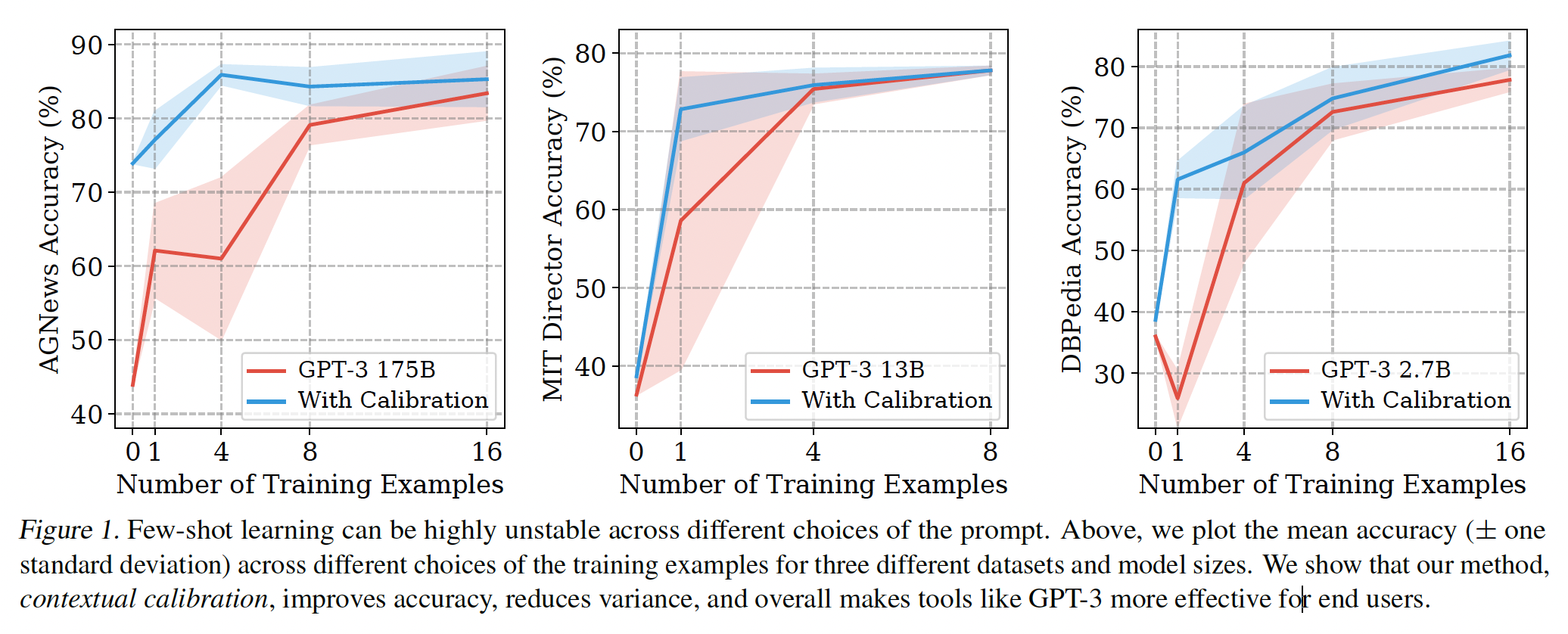
相关工作:
Few-shot Learning with Language Model:最近的工作使用语言模型来解决NLP任务,例如,story cloze prediction、knowledge base completion、和Winograd schema。GPT-2和GPT-3表明,大型语言模型可以通过in-context learning从而以few-shot的方式解决无数的任务。我们的论文对他们的setting提供了一个简单的修改从而提高性能。要求语言模型补全natural language prompt也作为一种方法从而"probe" language model,例如,分析事实性的知识或常识性知识。我们的结果表明,这些probing方法可能低估了模型的准确率,我们建议未来的工作利用contextual calibration的优势。NLP中Few-shot Learning的波动性:最近的工作表明,当使用masked language model(如BERT)进行zero-shot learning时,prompt的格式会影响准确率。独立且同时进行的工作也表明,当在few examples上微调masked language model时,prompted examples的选择会影响结果。我们表明,类似的不稳定性发生在left-to-right language model的in-context learning(即,没有微调)中。我们还显示了一个与example ordering有关的令人惊讶的不稳定性。此外,与过去的工作不同,我们分析了这些不稳定性发生的原因,并利用这一分析的见解来缓解这些问题。语言模型的失败:当语言模型被用于
in-context learning时,我们发现了失败的情况(例如,recency bias)。过去的工作发现,当语言模型被用于文本生成时也有类似的失败。例如,神经语言模型经常重复自己(《The curious case of neural text degeneration》)、遭受过度自信、遭受recency bias、喜欢通用的response而不是稀有文本。过去的工作通过修改模型的输出概率或生成方案来缓解这些退化,例如,显式地地防止重复(《A deep reinforced model for abstractive summarization》)、或使用采样而不是贪婪解码(《The curious case of neural text degeneration》)。
10.1 背景和实验设置
神经自回归语言模型将
tokens的一个序列作为输入,并输出next token的概率分布。大型神经语言模型可以使用in-context learning以zero-shot/few-shot的方式执行任务(GPT-2, GPT-3)。为此,一个自然语言的prompt被馈入模型。这个prompt包含三个部分:format格式、一组prompted examples、prompted examples的排列顺序(ordering)。Prompt Format:prompt format是一个模板,由占位符(针对prompted examples和测试样本)和任务的自然语言描述(这个描述也可能不存在)组成。例如,前面章节中的prompt format是一个具有以下风格的模板:"Input:" input "Sentiment:" label。还有许多其他的格式,例如,我们可以把任务设定为问答任务。Prompt Training Examples:prompted examples是用来教导语言模型如何解决手头的任务。前面章节中的prompt由两个prompted examples组成;我们把这称为"two-shot" learning。我们也考虑"zero-shot" learning,即不存在任何prompted examples。Training Example Permutation:当prompted examples被使用时,prompted examples之间有一个特定的排列方式,例如,在前面章节的prompt中,"Subpar acting"的样本排在第一位。这种排列方式很重要,因为神经语言模型是以从左到右的方式更新其hidden states。
为了对一个输入进行预测,我们把它放入
test placeholder中,并从语言模型中生成。例如,请看前面章节的prompt中的"Amazing."测试样本。对于
generation任务,我们从语言模型中贪婪地生成,直到它产生一个换行符。对于分类任务,每个类别的概率是由分配给该类别的
label name的概率给出的,例如,情感分类中的"Negative"和"Positive"。
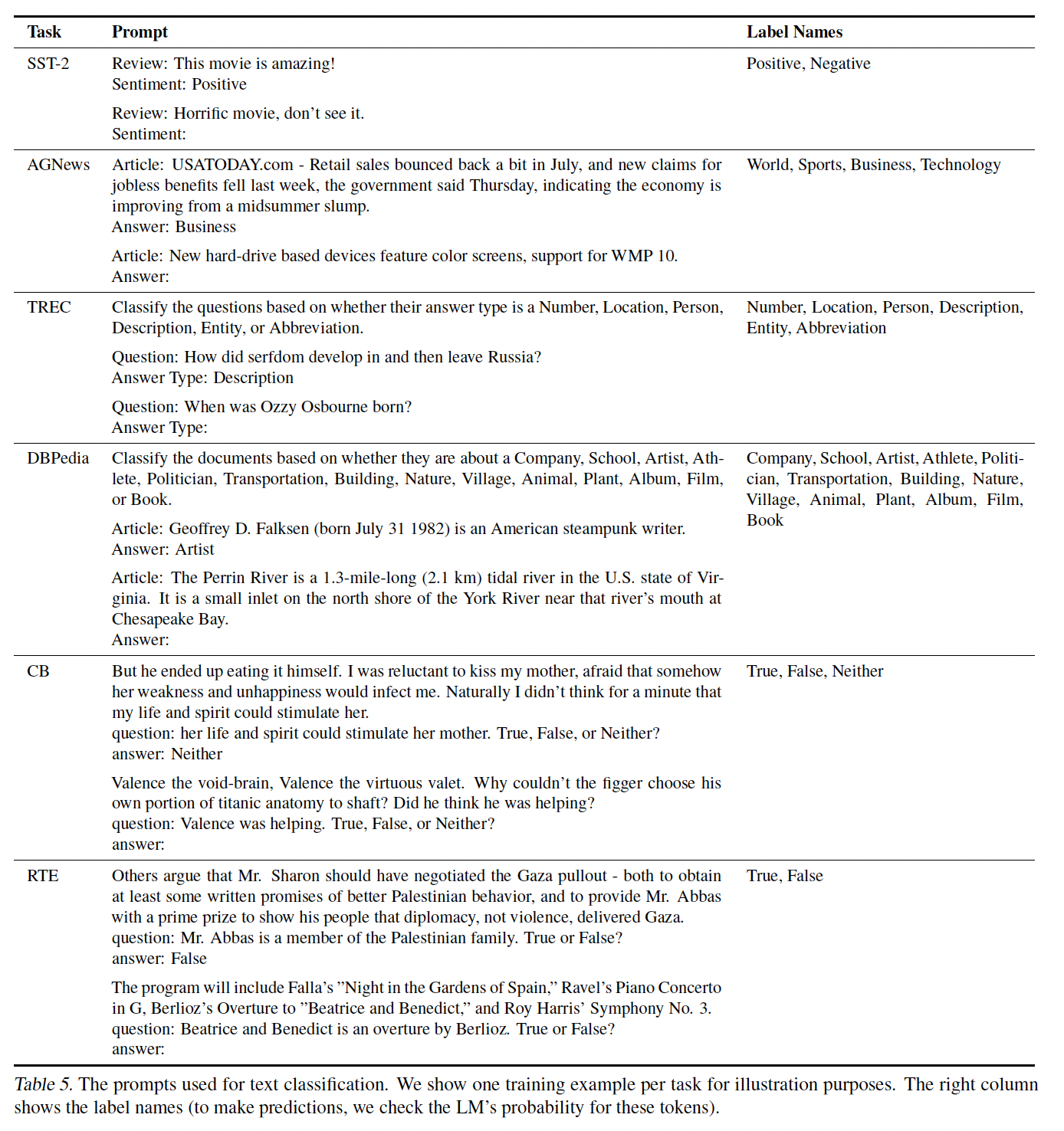
数据集和
prompt format:我们将数据集用于三个任务:文本分类、事实检索、信息提取。除非另有说明,我们对每个数据集都使用固定的prompt format,这些格式如下表所示。文本分类数据集:用于情感分析的
SST-2、用于问题分类的TREC、用于textual entailment的CB、来自SuperGLUE的RTE、用于话题分类的AGNews和DBPedia。事实检索数据集:
LAMA数据集。该数据集由knowledge base三元组(subject, relation, object)组成,这些三元组被放置在带有缺失object的模板中,例如"Obama was born in"。我们使用这些模板作为我们的prompt,并删除missing answer不在模板末端的样本(left-to-right的语言模型只能解决missing answer在模版末尾的问题)。答案总是single token,我们报告了所有三元组的平均准确率。信息提取数据集:两个
slot filling数据集,即ATIS、MIT Movies trivia10k13。我们为每个数据集使用两个随机槽,ATIS使用airline和出发日期、而MIT Movies使用导演姓名和电影类型。两个数据集的答案都是输入文本的span,例如,ATIS airline task是在给出"list a flight on american airlines from toronto to san diego"的句子时预测"american airlines"。我们使用模型所生成的输出和ground-truth span之间的Exact Match作为我们的评估指标。


模型细节:我们在三种规模的
GPT-3(2.7B/13B/175B参数)以及GPT-2(1.5B参数)上运行我们的实验。我们使用OpenAI的API访问GPT-3。我们发布代码来复制我们的实验。
10.2 准确率在不同的 Prompts 之间差异很大
这里研究
GPT-3的准确率如何随着我们对prompt的各个方面(prompted examples、排列组合、格式)的改变而改变。我们专注于数据集的一个子集,以简化我们的分析。在后续章节中,我们表明我们的发现在我们研究的所有数据集中都是成立的。GPT-3的准确率在很大程度上取决于prompted examples选择和prompted examples排列组合。具体来说,我们使用一个固定的prompt format并选择不同的随机的prompted examples集合。对于每一组prompted examples,我们评估所有可能的排列组合的准确率。下图显示了
SST-2(4-shot, GPT-3 2.7B)的结果。令人惊讶的是,改变排列组合可能与选择何种prompted examples一样重要,甚至更重要。例如,改变prompted examples的排列组合可以使准确率从接近机会(54.3%)上升到接近SOTA(93.4%)。关于对排列组合的敏感性的定性的示例,参考Table 2。这种对样本顺序的高度重要性与标准机器学习形成了鲜明的对比,在标准机器学习中,训练期间的样本顺序通常是不太重要的。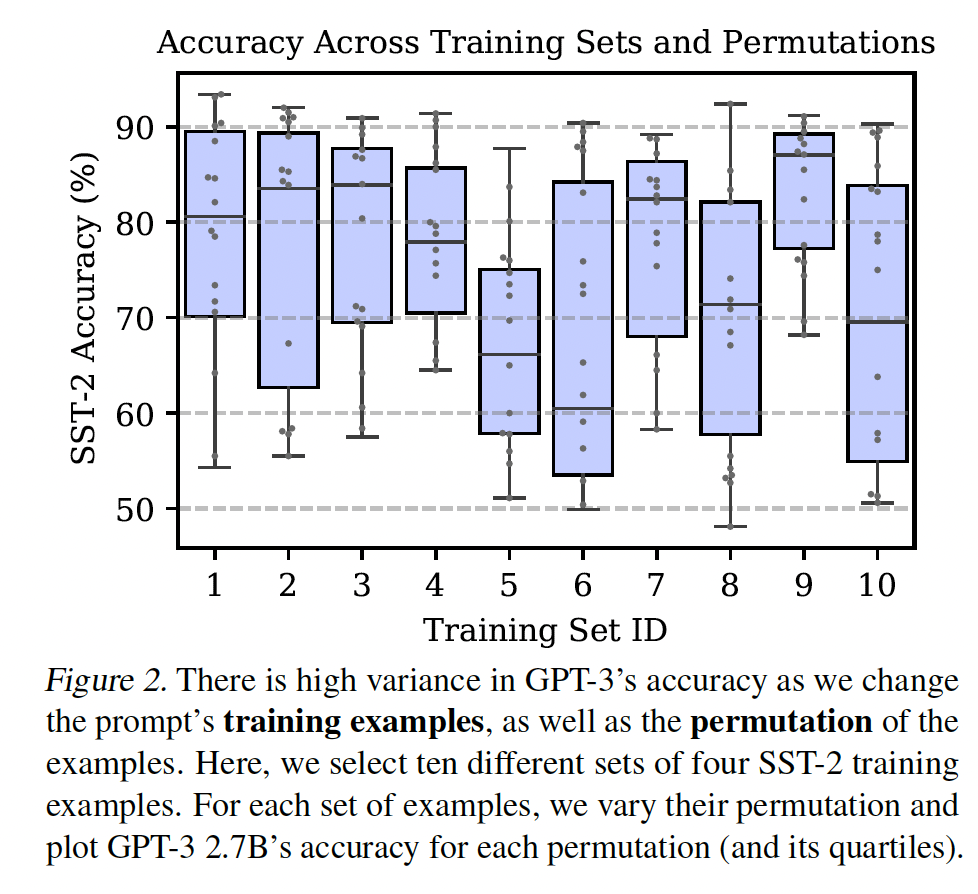

这种方差在更多的数据和更大的模型中持续存在:在
prompt中添加更多的prompted examples并不一定能减少准确率的方差。我们在下图中对三个不同的数据集扫描了不同数量的prompted examples(红色曲线)。即使我们使用16个prompted examples,方差仍然很高。此外,增加更多的prompted examples有时会伤害准确率(例如,DBPedia的0-shot到1-shot的平均准确率从36.0%下降到25.9%)。在使用较大的模型时,准确率的方差也会保持很高。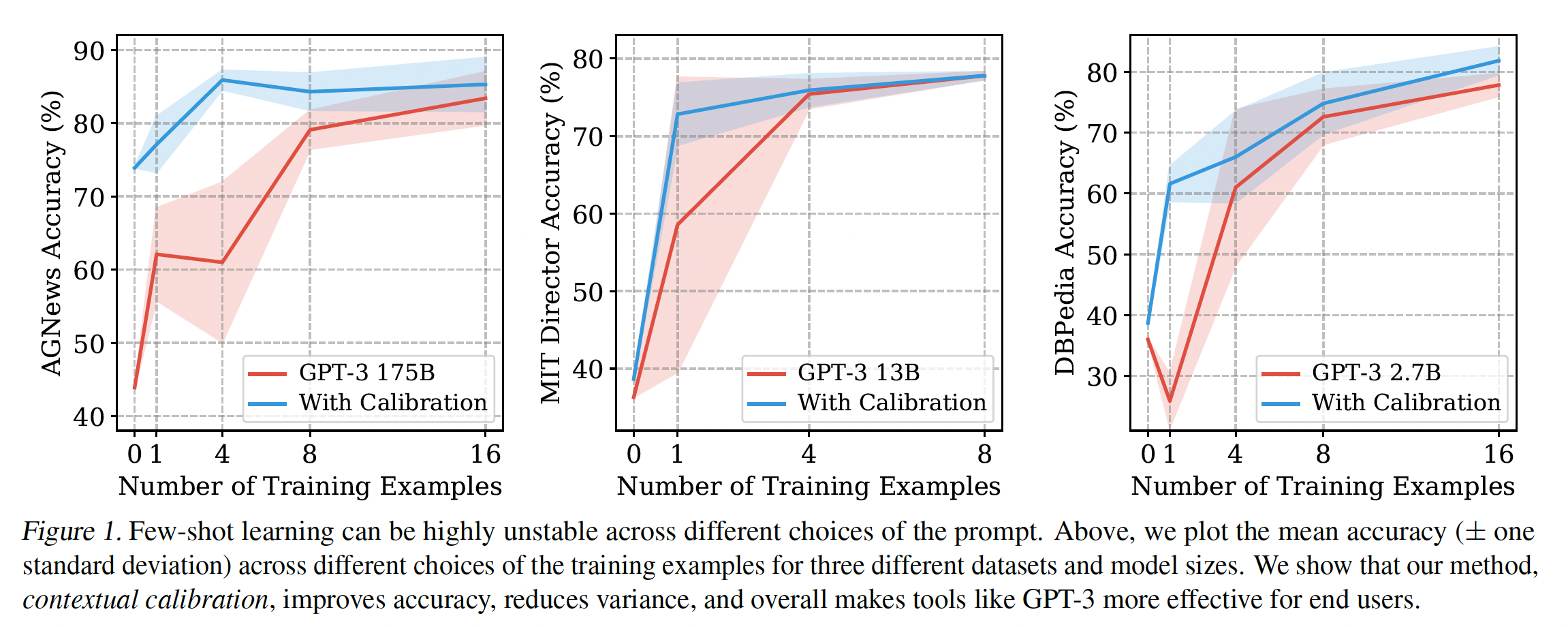
GPT-3的准确率高度依赖于prompt format:接下来我们保持固定的prompted examples和固定的排列组合,但改变prompt format。我们专注于SST-2,并手动设计了另外14种prompt format。这些格式包括question-answer模板、对话式模板、类似网页的prompts、以及label names的变化(所有格式如Table 7所示)。下图显示了其中10种格式的准确率。我们发现,有些格式平均来说比其他格式要好。然而,所有的格式在不同的训练集中仍然存在着高方差。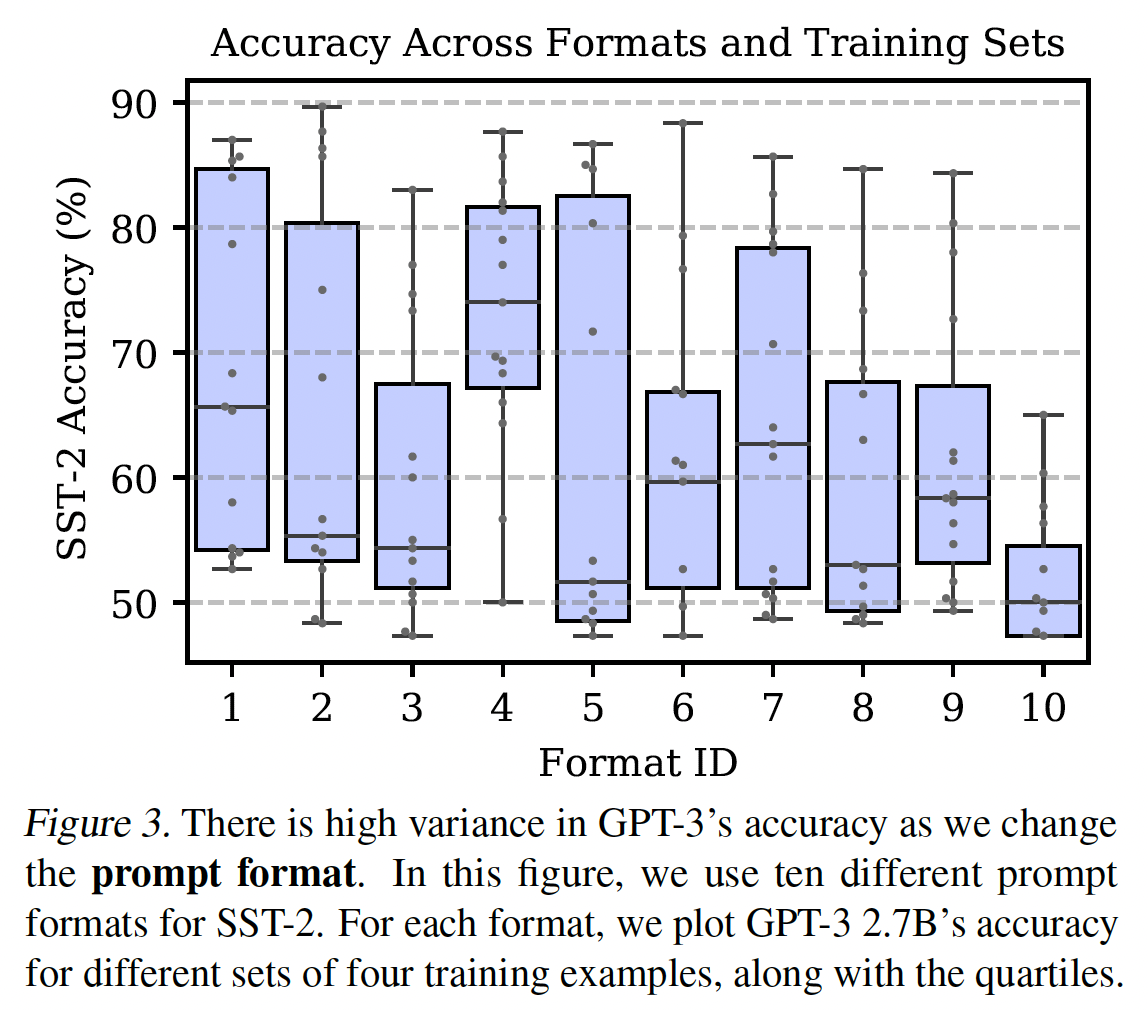
10.3 是什么导致了高方差?
接下来,我们分析了为什么
GPT-3的准确率在不同的prompted examples、排列组合、以及prompt format中会有所不同。具体而言,我们表明,方差的产生是因为语言模型偏向于输出以下答案:(1):在prompt format中频繁出现的答案(majority label bias)。(2):在prompt尾部出现的答案(recency bias)。(3):在预训练数据中常见的答案(common token bias)。
Majority Label Bias:我们发现GPT-3偏向于prompt中经常出现的答案。一个常见的情况是,当一个text classification prompt存在类别不平衡时,例如,在情感分类样本中更多的Positive样本。这表现在下图的"unbalanced"区域:当一个类别更高频时,GPT-3 2.7B严重偏向于预测该类别。由于SST-2情感分类数据集是平衡的,这种bias会导致很大的准确率下降。majority label bias也解释了为什么我们经常观察到从0-shot到1-shot的准确率下降:我们发现下降的原因是模型经常重复这个one training example的类别。majority label bias也发生在generation任务中。在使用GPT-3 2.7B的4-shot LAMA的验证集上,50.2%的模型预测是四个训练答案之一的重复(ground truth的重复率只有24.7%)。总的来说,majority label bias有助于解释为什么对prompted examples的不同选择会严重影响GPT-3的准确率:它改变了model prediction的分布。下图的含义:
4-shot SST-2中,选择不同的class组合导致不同的positive prediction概率(纵轴)。
Recency Bias:模型的majority label bias因其recency bias而加剧:倾向于重复那些出现在prompt尾部的答案。Figure 4的"balanced"区域表明了这一点。例如,当两个Negative样本出现在最后时(即,"PPNN"),该模型将严重倾向于Negative类别。此外,recency bias可以超过majority label bias,例如,"PPPN"训练集导致近90%的预测是Negative的,尽管prompted examples是Positive的。recency bias也会影响generation任务。对于4-shot LAMA,更接近prompt尾部的答案更有可能被模型重复。具体来说,模型对第一个、第二个、第三个和第四个prompted examples的答案分别 "过度预测"了8.5%、8.3%、14.3%和16.1%。总的来说,recency bias有助于解释为什么prompted examples的排列顺序很重要:样本的排序严重影响了model prediction的分布。Common Token Bias:最后,我们发现GPT-3偏向于输出其预训练分布中常见的tokens,这对于下游任务的答案分布来说可能是次优的。这种情况的一个简单案例发生在LAMA事实检索数据集上,其中模型经常预测常见的实体(如"America"),而ground-truth answer却是一个罕见的实体。在文本分类中,出现了一个更细微的
common token bias的案例。回顾一下,该模型是通过生成与每个类别相关的label name来进行预测的。因为某些label name称在预训练数据中出现的频率较高,所以模型会对预测某些类别有固有的bias。例如,在DBPedia(一个平衡的14-way主题分类数据集)上,GPT-3预测"book"类别的频率比"artist"类别高11倍。事实上,DBPedia label name的频率与GPT-3预测其类别的概率之间存在适度的相关性(common token bias有助于解释为什么label names的选择是重要的,以及为什么模型在罕见的答案上陷入困境。bias对模型预测的影响:我们发现,上述三种bias的最终结果通常是模型输出分布的simple shift。例如,下图直观地显示了SST-2 sentiment prompt的这种偏移。下图中使用的prompt和模型的固有bias导致模型对于Positive类别经常预测出高的信心。由于默认的50%阈值被用来进行预测,这导致了频繁的假阳性(false positive)。重要的是,请注意,如果我们能够最佳地设置分类阈值(在这个案例中,94%)。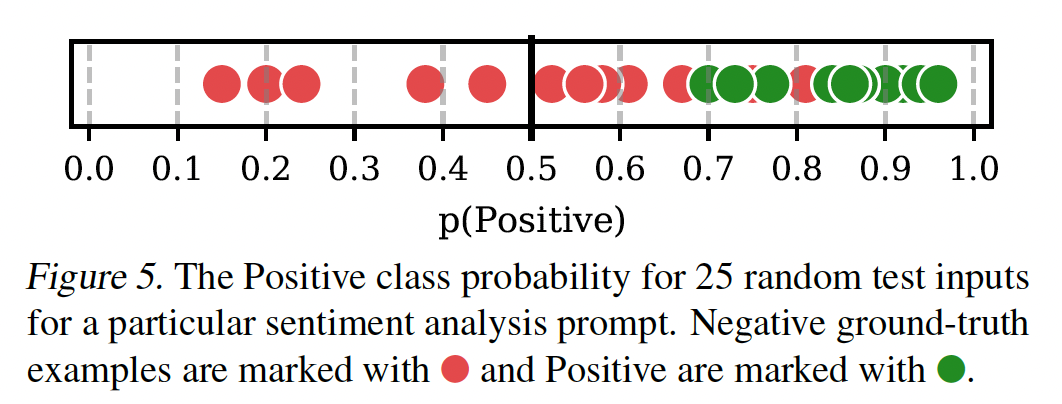
10.4 Contextual Calibration
到目前为止,我们已经表明,由于
prompt bias和模型的固有bias,GPT-3偏向于某些答案。这里,我们希望通过 "校准" 模型的输出概率来纠正这一点。调整输出概率的常见技术是应用仿射变换:其中:
对于分类任务,
label name相关联的概率的集合,重新归一化为1.0。对于生成任务,
first token的在整个候选集合上的概率集合。注意,这里是
generation的first token上进行调整。
在本文中,我们限制矩阵
vector scaling,从而防止参数在size上(对于生成任务,这个size大约是50k)呈二次方的增长。在
zero-shot/few-shot setting下,主要挑战是我们没有数据来学习data-free程序来推断这些参数的一个good setting。关键的想法是,模型对某些答案的bias可以通过输入一个content-free input来估计,比如 字符串"N/A"。例如,考虑two-shot prompt:xxxxxxxxxxInput: Subpar acting. Sentiment: NegativeInput: Beautiful film. Sentiment: PositiveInput: N/A Sentiment:其中
"N/A"作为test input。理想情况下,GPT-3会对这个测试输入进行评分,即50%为Positive、50%为Negative。然而,模型的bias导致模型把这个输入打分为61.8%的Positive。请注意,这个错误是contextual的:对prompted examples、排列组合、prompt格式的不同选择将导致对content-free input的不同预测。我们可以通过设置
content-free input的class scores统一。我们首先得到content-free input的test prediction,我们计算argmax。为什么选择这种
test input就是content-free input,那么content-free input调整为均匀分布的输出。实现细节:这个
contextual calibration程序增加了微不足道的计算开销,只需几行代码就能实现(计算和保存content-free input,存在许多好的选择,包括"N/A"字符串、空字符串、以及一些杂乱的tokens。在我们所有的实验中,我们对三种content-free的概率进行平均:"N/A"、"[MASK]"、以及空字符串。我们还可以以一种task-specific的方式制作content-free input。我们对LAMA进行了探索,我们用content-free input来代替subject,例如,我们用"N/A was born in"作为输入。Contextual Calibration的结果:在这里,我们评估了contextual calibration在我们所有的数据集和语言模型中的有效性。我们首先使用一个固定的prompt format,并选择prompted examples的五个不同的随机的集合,将它们以任意的顺序放在prompt中。我们没有人为地平衡分类任务中prompted examples的类别比例。我们在基线(无calibration的标准解码)和contextual calibration中使用相同的prompted examples集合。我们使用0-8个样本的labeling budget,因为使用超过8- shot会导致查询OpenAI API的成本变得过于昂贵。结果如下表所示。
Figure 1对于一部分任务绘制了下表中的数据。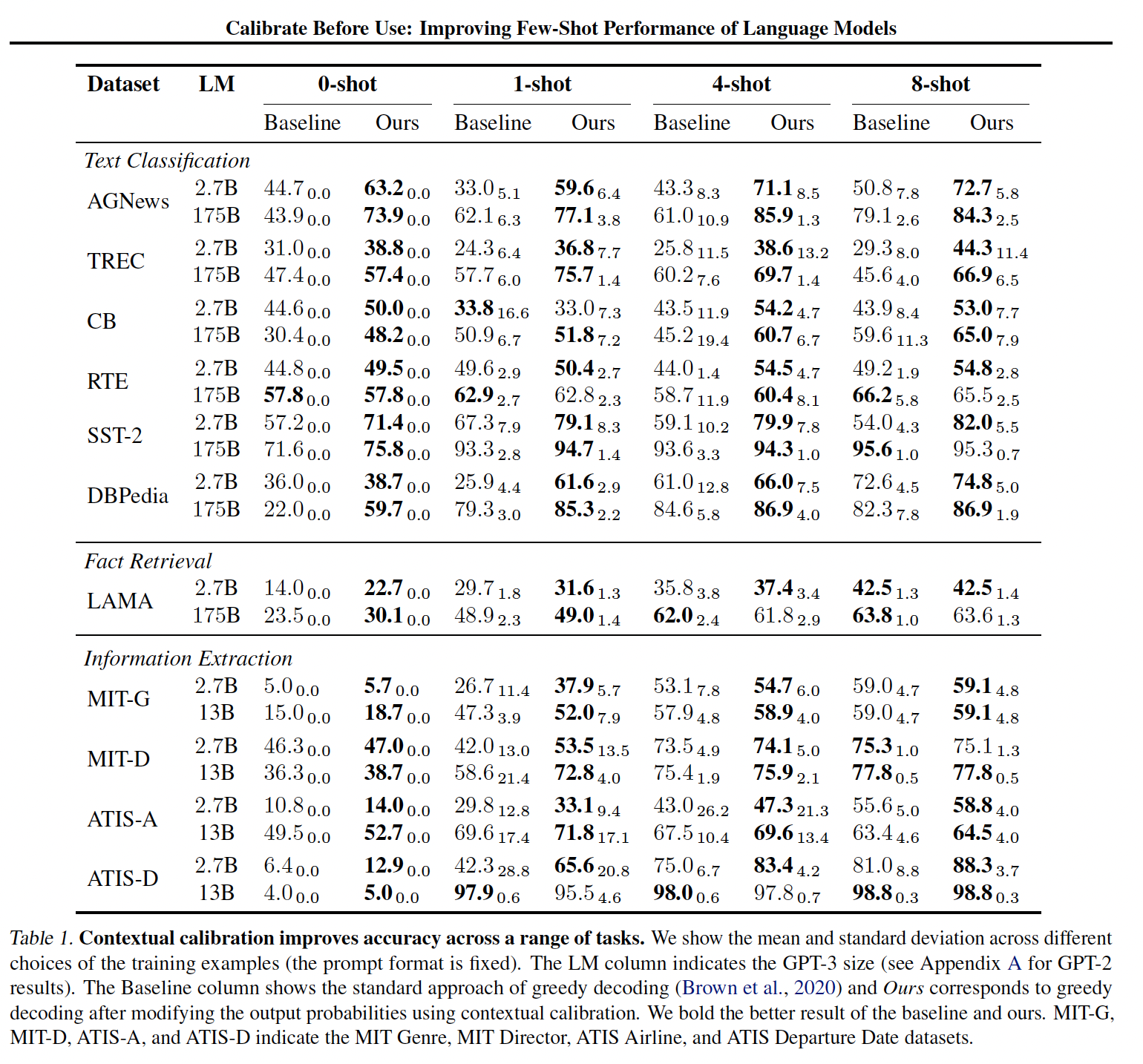
提高了平均准确率、以及
worst-case准确率:contextual calibration极大地提高了GPT-3的平均准确率、以及worst-case准确率,提升幅度(绝对值)高达30.0%。这些提高对分类任务和生成任务都适用。contextual calibration有时还允许GPT-3 2.7B的性能优于GPT-3 175B baseline高达19.3%,尽管前者的体积比后者小了50多倍。可以减少整个训练集的方差:
Figure 6显示了Table 1中所有任务的baseline和contextual calibration之间的标准差的差异。在大多数情况下,contextual calibration大大减少了方差;在其余情况下,contextual calibration并没有大大增加方差。
减少了从
0-shot到1-shot的drop:对于baseline,有四个案例在从0-shot到1-shot的过程中出现了准确率的下降(TREC, AGNews, DBpedia, SST-2)。我们把这种下降归因于majority label bias。contextual calibration在四种情况中的三种情况下消除了这种下降。改善
GPT-2:我们还测试了GPT-2 1.5B(参考Table 4)。我们发现,与GPT-3一样,GPT-2的准确率在不同的prompt中也有很大的差异。这表明,我们观察到的few-shot in-context learning的方差是语言模型的一个普遍问题。其次,contextual calibration对GPT-2来说是开箱即用的,它提高了大多数任务的平均准确率并减少了方差。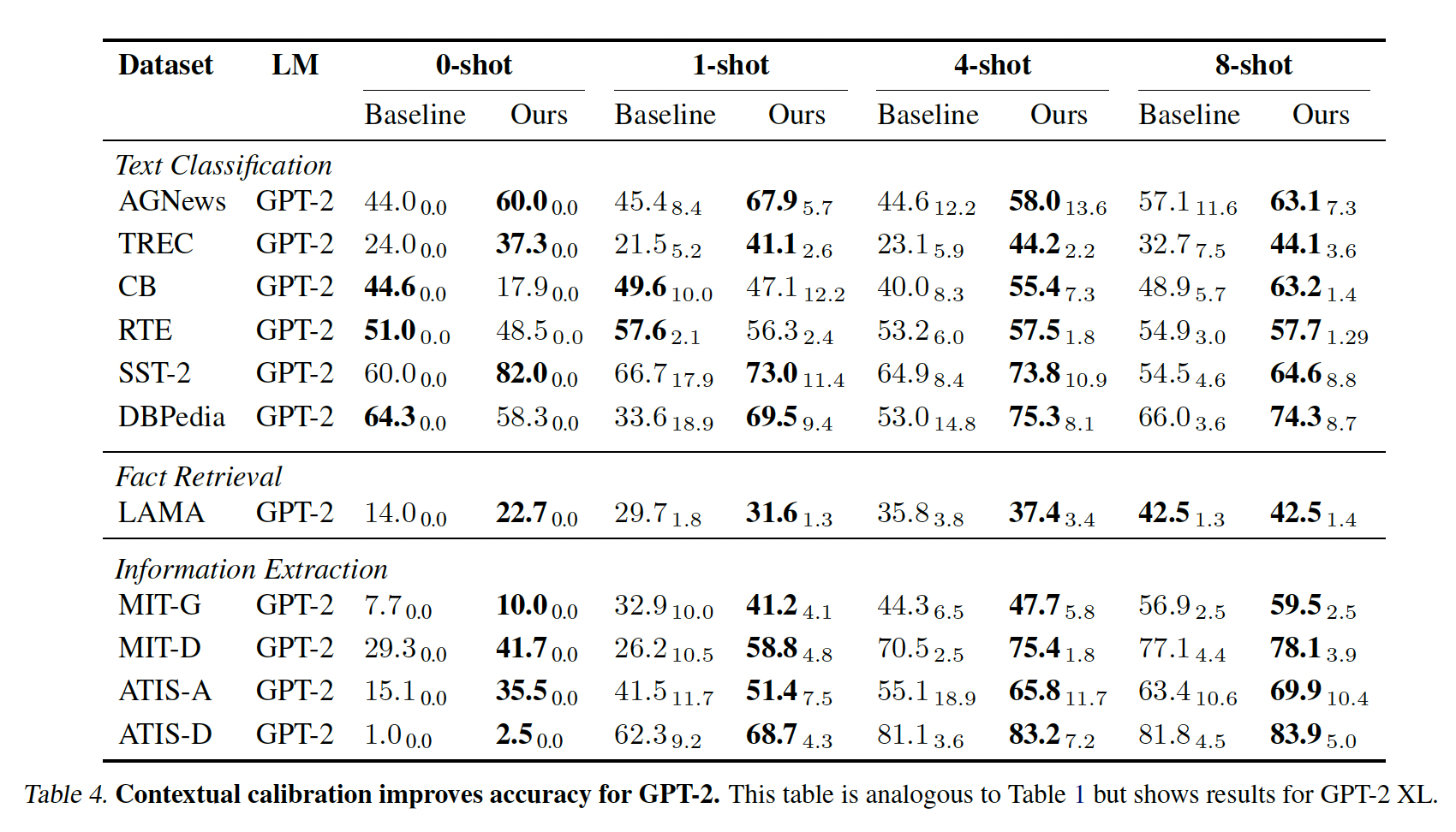
提高不同格式的准确率:在我们的下一组实验中,我们使用固定的
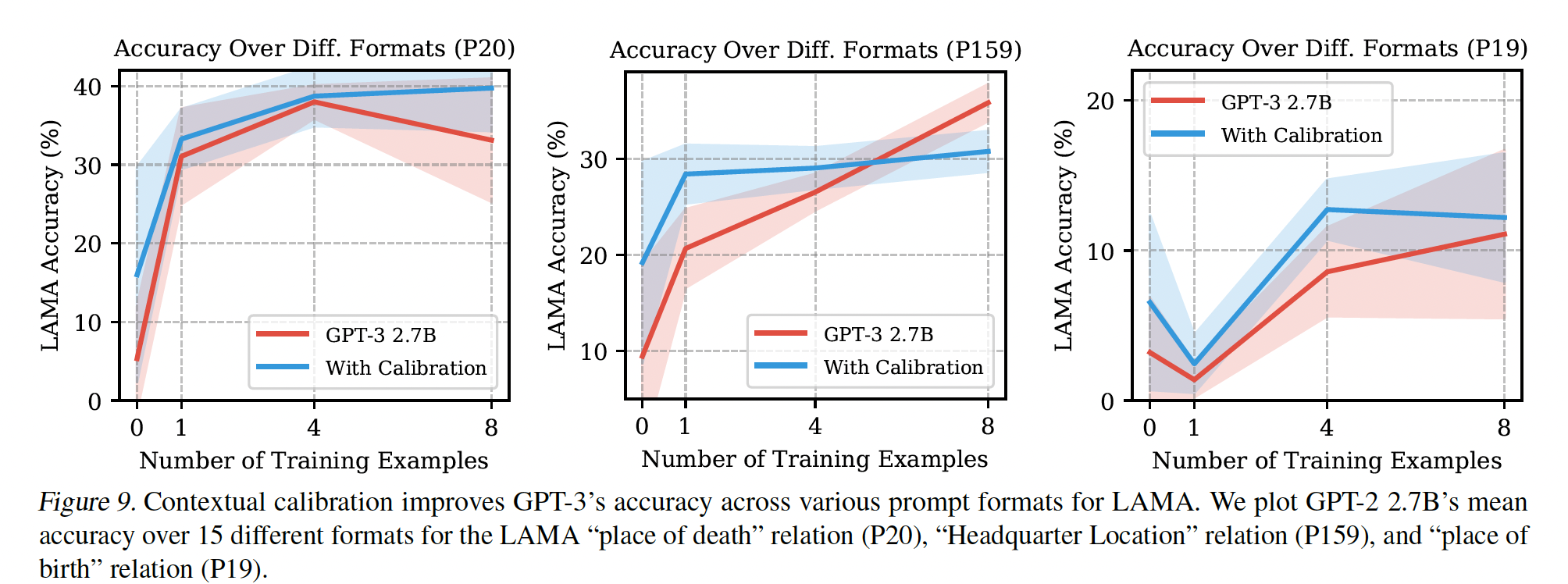
prompted examples集并改变prompt format。我们使用前面讨论的SST-2的15种prompt format。我们还通过使用AutoPrompt生成的original LAMA templates的转述,为LAMA中的三个随机关系(P20, P159, P19)各创建了15种prompt format。Figure 7是SST-2校准前后的结果,Figure 9是LAMA的结果。contextual calibration提高了两个数据集的平均准确率和worst-case准确率,并降低了SST-2的方差。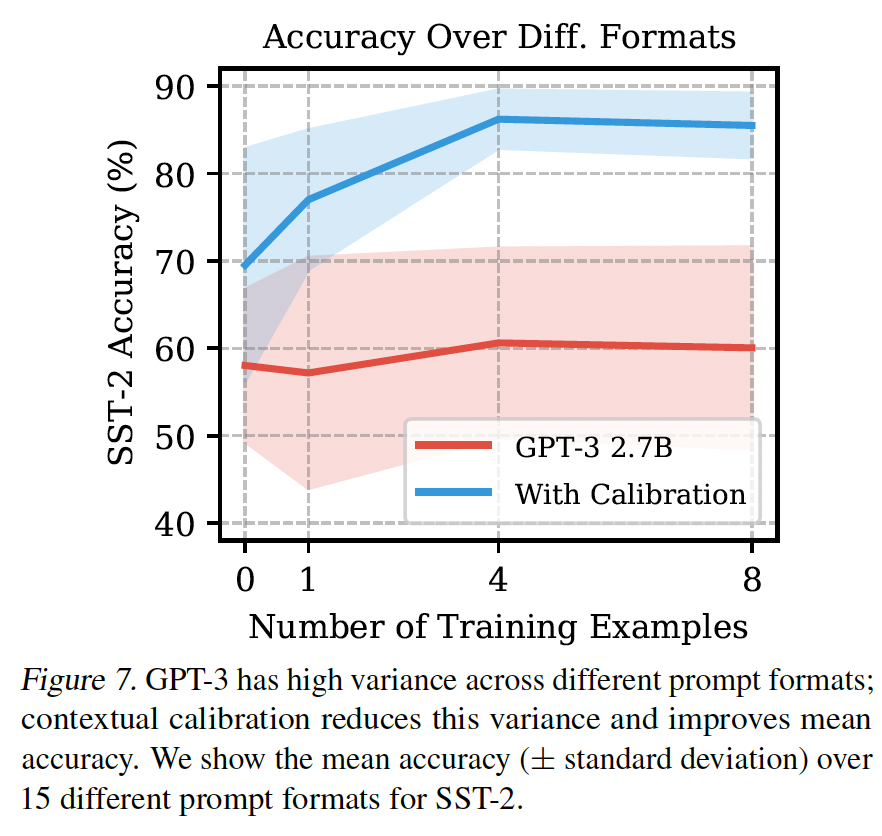
Contextual Calibration消融研究:最后,我们对contextual calibration进行了两项分析。我们首先分析了
contextual calibration在推断setting方面的有效性。为此,我们将其准确率与"oracle calibration"方法进行比较,后者使用验证集来寻找最佳的对角矩阵AGNews上评估了这个oracle calibration,发现contextual calibration与它惊人地接近(Figure 8)。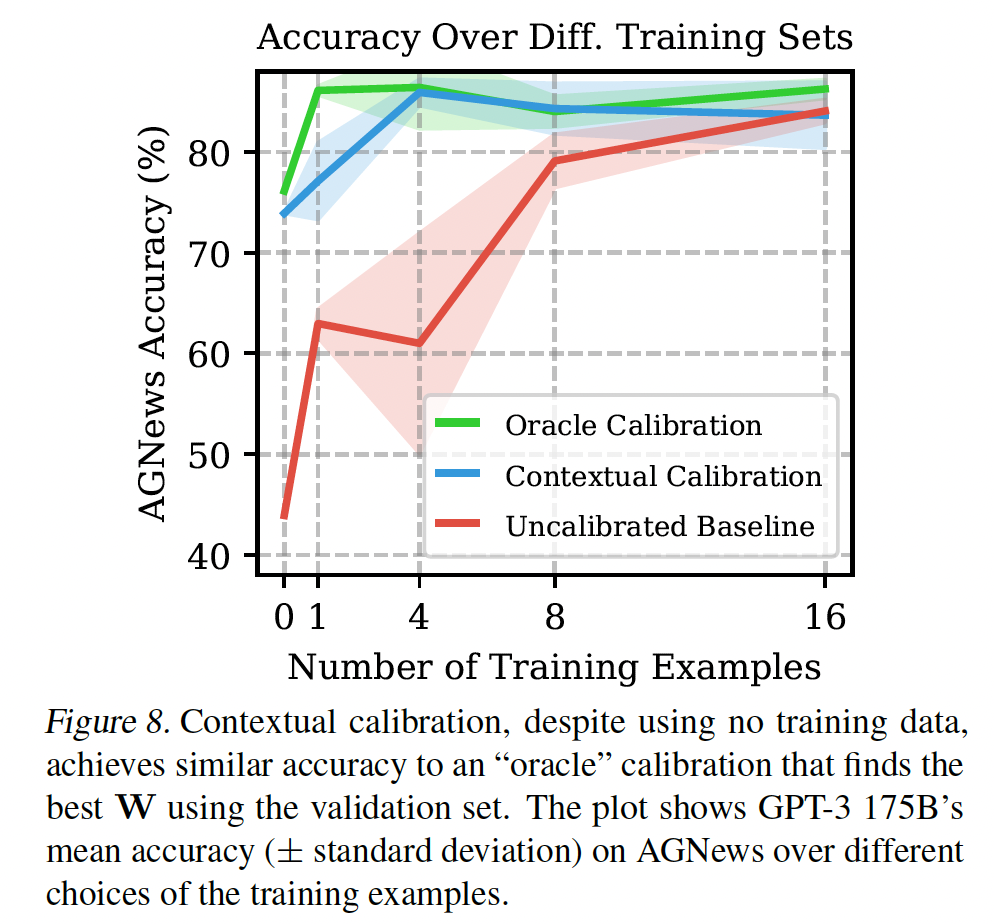
我们还研究了
content-free input的选择如何影响准确率。在Table 3中,我们显示了SST-2和AGNews对content-free input的不同选择的准确率。content-free input的选择很重要,然而,存在许多好的选择。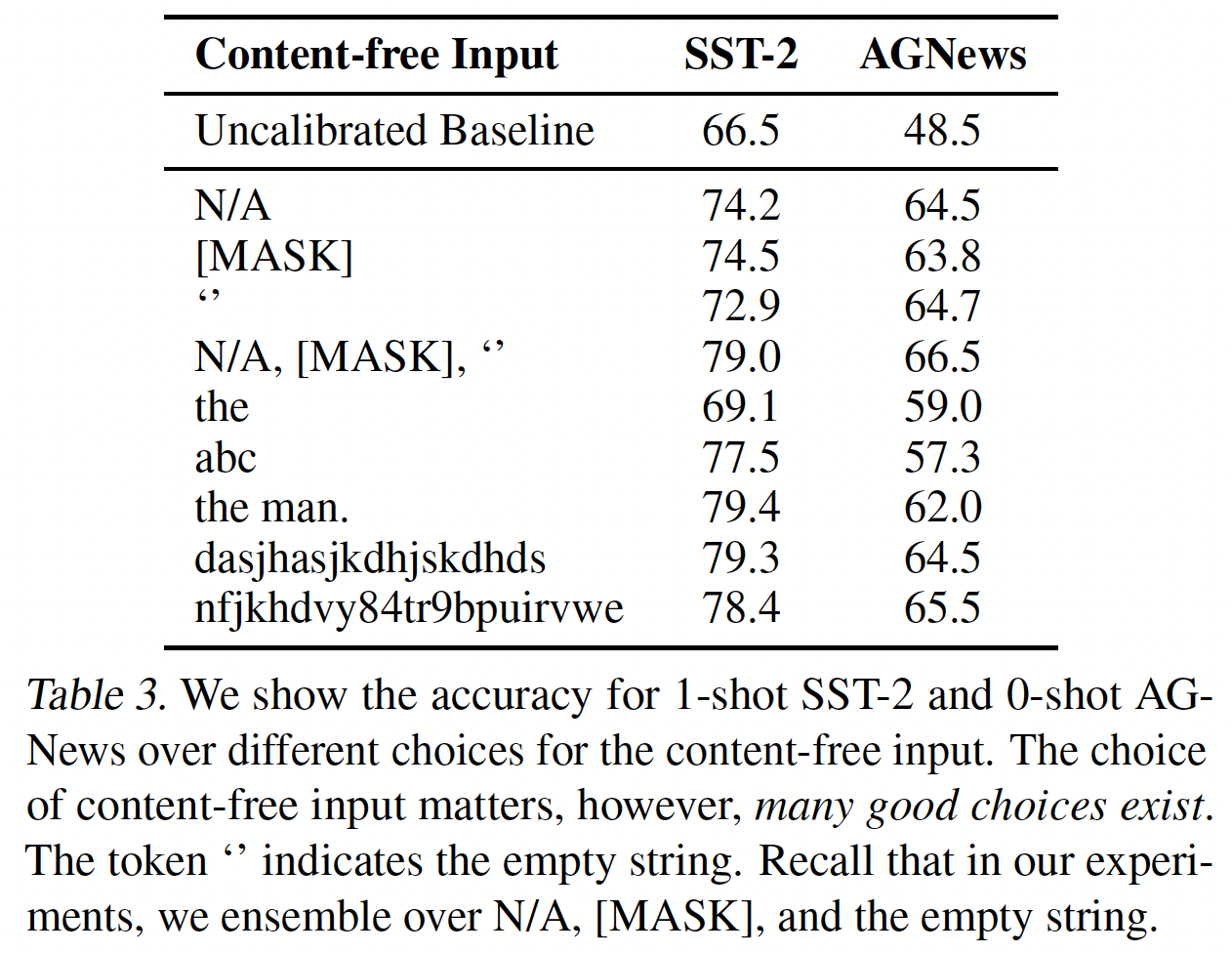
10.5 讨论
校准是否消除了对
Engineer Prompt的需要?"prompt engineering"背后的动机是,并非所有的prompts都能导致同样的准确率。因此,我们应该调整prompt的格式和样例,以达到最佳的性能。contextual calibration并不能消除对engineer prompts的需要,然而,它确实减轻了这种需要:contextual calibration使最佳prompts的准确率、平均prompts的准确率、以及worst case prompts的准确率更加相似(以及更高)。你应该在
Few-shot Setting中进行微调吗?我们使用一个固定的语言模型,没有微调。如前文所述,有许多理由不进行微调:它可以实现快速的原型设计;提供一个百分之百自然语言的接口;并且在为许多不同的任务serving时,在内存需求和系统复杂性方面更有效率。此外,就像没有
contextual calibration的in-context learning一样,微调在few-shot setting中可能是不稳定的(PET)。然而,如果这些缺点是可以接受或可以避免的,那么在某些情况下,微调可以比in-context learning提高准确率。未来工作的一个有趣的方向是研究contextual calibration和微调之间的相互作用,例如,contextual calibration是否缓解了微调的需要,或者反之亦然?从大的方面来看,我们的结果启发了
NLP的few-shot learning的两个未来研究方向。首先,在方法方面,我们表明,
good few-shot learning需要关注细节:诸如calibration等微小但重要的决定会极大地影响结果。这使得我们很难正确地开发和比较新的方法(如预训练方案或模型架构)。因此,我们希望使其他的few-shot learning方法更加稳健,也希望扩大我们的技术以涵盖更广泛的任务(例如,开放式generation的校准)。第二,在分析方面,我们的结果强调了了解
GPT-3从prompt中学到什么的必要性。该模型具有令人印象深刻的能力,可以通过更多的训练实例来提高。然而,我们表明该模型学习了一些表面的模式,如重复常见的答案。我们希望在未来的工作中能更好地理解和分析in-context learning的dynamics。
十一、KATE [2021]
论文:
《What Makes Good In-Context Examples for GPT-3?》
尽管
GPT-3具有强大而通用的in-context learning能力,但它也有一些实际的挑战/模糊之处。GPT-3利用从训练集中随机采样的task-relevant样本来构建上下文。在实践中,我们观察到,GPT-3的性能往往会随着in-context examples的不同选择而波动。如下表所示,在不同的in-context examples,经验结果的差异可能是很大的。这些结果对样本高度敏感。我们的工作旨在仔细研究这个问题,以便更深入地了解如何更好地选择in-context examples,以释放GPT-3的few-shot能力并进一步提高其性能。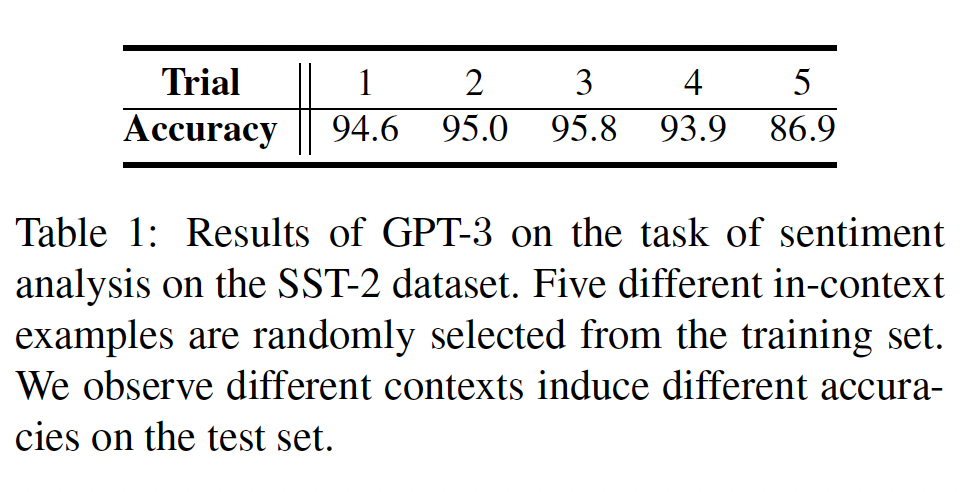
一个粗暴的方法是在整个数据集上进行
combinatorial search。不幸的是,这种策略在计算上是昂贵的,因此在许多情况下是不切实际的。为此,我们研究了采用不同的in-context examples对经验结果的影响。有趣的是,我们发现,在embedding空间中更接近测试样本的in-context examples始终能产生更强的性能(相对于更远的in-context examples)。受这一观察和最近retrieval-augmented model的成功启发,我们建议利用给定测试样本的最近邻(在所有可用的training instances中)作为相应的in-context examples。被检索到的样本与测试样本一起被提供给GPT-3进行最终预测。核心思想:
few-shot examples不是随机选择的,而是选择和test input最相似的。根据
《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》的结论,即使用随机的out of distribution输入和随机的标签的组合(这种组合甚至不是一个有效的样本)作为context,效果也比no demostrations要好。这个结论和本文不冲突,因为本文重点在说明:选择与test input最相似的训练样本,要比选择随机的训练样本,在few-shot learning中效果更好。为了验证所提出的方法的有效性,我们在几个自然语言理解任务和自然语言生成任务上对其进行了评估,包括情感分析、
table-to-text的生成、以及开放域的问答。我们观察到,retrieval-based in-context examples比随机采样的baseline更有效地释放了GPT-3的few-shot。即使in-context examples的数量较少,所提出的策略也能使GPT-3获得更强的性能。此外,我们发现,在检索过程中所采用的特定的sentence encoders起着关键作用。因此,我们对不同的pre-trained encoders进行了广泛的探索,结果表明,在natural language matching任务中微调的编码器在QA任务中作为更有效的in-context examples selector。详细的分析和案例研究进一步验证了所提方法的有效性。综上所述,我们在本文中的贡献如下:据我们所知,我们迈出了第一步,了解了
GPT-3针对不同的in-context examples选择的few-shot能力。为了缓解敏感性问题,引入了一个额外的检索模块来寻找与测试实例的语义相似的
in-context examples,以构建其相应的输入,这大大超过了基于random sampled examples的baseline的表现。在与任务相关的数据集上对
retrieval model进行微调,使GPT-3的经验结果更加强大。GPT-3的性能随着可供检索的样本数量的增加而提高。
相关工作:
Pre-trained Language Models:对于文本分类任务,引人注目的模型包括BERT, RoBERTa, XLNet;对于文本生成任务,值得注意的模型包括BART, T5, mT5, XLM, GPT, GPT-2。这些模型可以通过微调来适应许多不同的任务。然而,
GPT-3可以适应许多下游任务,而不需要进行微调。只需给定几个in-context examples,GPT-3就能迅速掌握模式,并在答案风格和内容上产生类似的答案。因此,GPT-3可以被认为是一个模式识别器来进行in-context learning。人们刚刚开始尝试从不同的角度来理解GPT-3。正如引言部分提到的,《Measuring massive multitask language understanding》研究GPT-3更能够回答哪些类别的问题。我们的工作重点是如何选择好的in-context examples。基于检索的文本生成:其中心思想是将检索到的样本作为典范/原型,并对其进行一些编辑。
GPT-3在一个角度上可以被自然地视为一个通用的编辑器,适应于广泛的任务。我们的工作独特地研究了如何在不进行微调的情况下最大限度地发挥GPT-3的优势。例如,我们为GPT-3提供的context的语义相似度越高,该模型能产生的结果就越好。其他编辑器或生成器则没有这种能力。用
kNN改进NLP系统:最近的一个工作方向是试图结合
nonparametric方法来提高一个给定模型的性能。这些方法首先访问测试样本的hidden representation,并在数据库中寻找该测试样本的最近邻。一旦找到最近邻,最近邻的标签就被用来增强模型的预测。例如,新引入的kNN-LM, kNN-MT, BERT-kNN通过从data-store中检索最近的next token。另一项相关工作是
kNN分类模型,他们在fine-tuned classification model的信心较低时使用kNN作为backoff。
我们的工作与其他方法有两个关键区别:
首先,其他方法使用最近的
next token distribution。然而,我们只使用最近的第二,其他方法可以访问模型的参数和
embedding,而我们无法访问。相反,我们使用其他一些独立预训练好的模型来获得sentence embedding,以检索最近的
11.1 方法
11.1.1 GPT-3 用于 In-Context Learning
GPT-3的in-context learning场景可以被看作是一个条件文本生成问题。具体来说,生成目标其中:
LM表示语言模型的参数;GPT-3中,training instances和它们相应的标签拼接起来而创建的。如下图所示,GPT-3被要求根据输入的三个样本从而将"mountain"翻译成德语版本。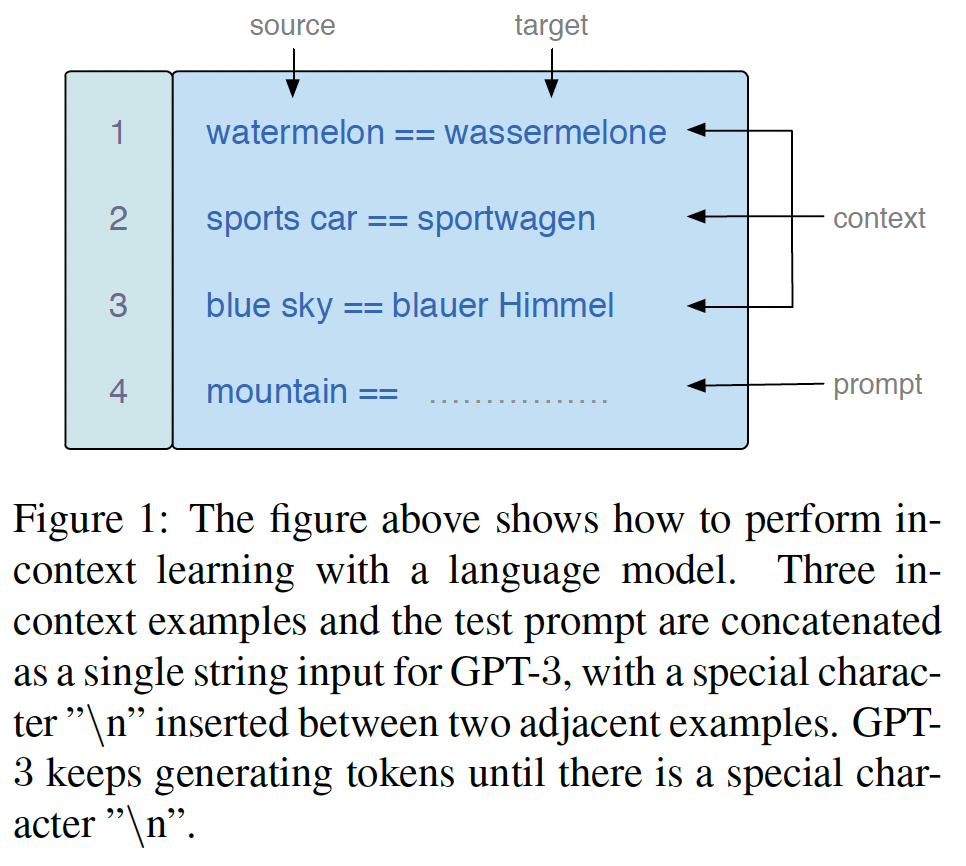
对于
GPT-3,这个生成过程是通过一个巨大的transformer-based的模型架构实现的。鉴于GPT-3模型的巨大规模,在task-specific samples上对其进行微调将是计算量巨大。因此,GPT-3通常是以上述的in-context learning方式来利用的。事实证明,GPT-3具有强大的few-shot能力,只需提供少量的demonstrations就可以表现得相当好。不幸的是,如Table 1所示,GPT的结果往往会随着选择不同的in-context examples而出现明显的波动。在这里,我们旨在通过明智地选择in-context examples来缓解这个问题。
11.1.2 In-Context Examples 的影响
鉴于观察到
GPT-3的实证结果对所选择的in-context examples很敏感,我们从实证的角度来看看in-context examples的作用。以前的retrieve-and-edit文献通常会检索出在某些embedding空间中与test sourcetest sourceGPT-3选择in-context examples。为此,我们研究了
in-context example和测试样本之间的距离对GPT-3的性能的影响。具体来说,我们在Natural Questions: NQ数据集上对两种in-context example选择策略进行了比较。对于每个测试样本,第一种方法利用最远的10个训练实例来构建上下文从而馈入GPT-3,而第二种方法则采用最近的10个邻居来构建上下文。我们使用pre-trained RoBERTa-large模型的CLS embedding作为sentence representation来衡量两个句子的临近程度(使用欧氏距离)。我们随机抽取了
100道测试题来进行评估,下表中报告了两种不同策略的平均Exact Match: EM得分。可以看出,最近邻作为in-context examples,相对于最远的训练样本,产生了更好的结果。此外,pre-trained RoBERTa模型作为有效的sentence embedding,用于检索程序。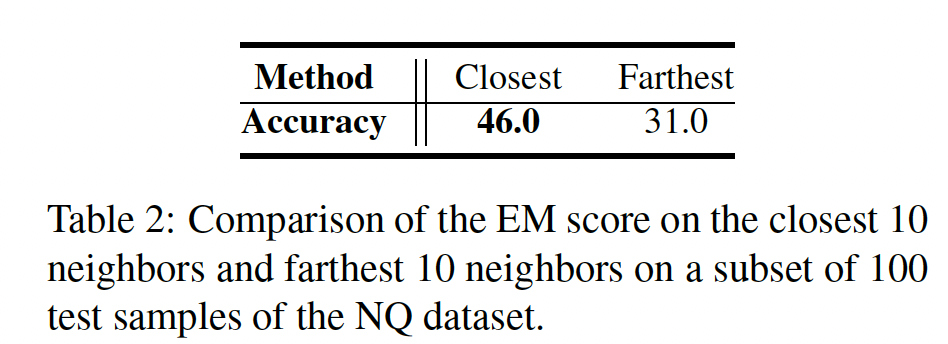
11.1.3 kNN-augmented In-Context Example Selection
基于上述发现,我们提出了
Knn-Augmented in-conText Example selection: KATE,一种为in-context learning选择good in-context examples的策略。这个过程在下图中得到了可视化。具体来说,我们首先使用某个
sentence encoder将训练集和测试集中的sources转换为vector representations。然后,对于每个test sourcesentence encoder的embedding空间中的距离)。给定一些预定义的相似性度量即,距离从近到远的排序。
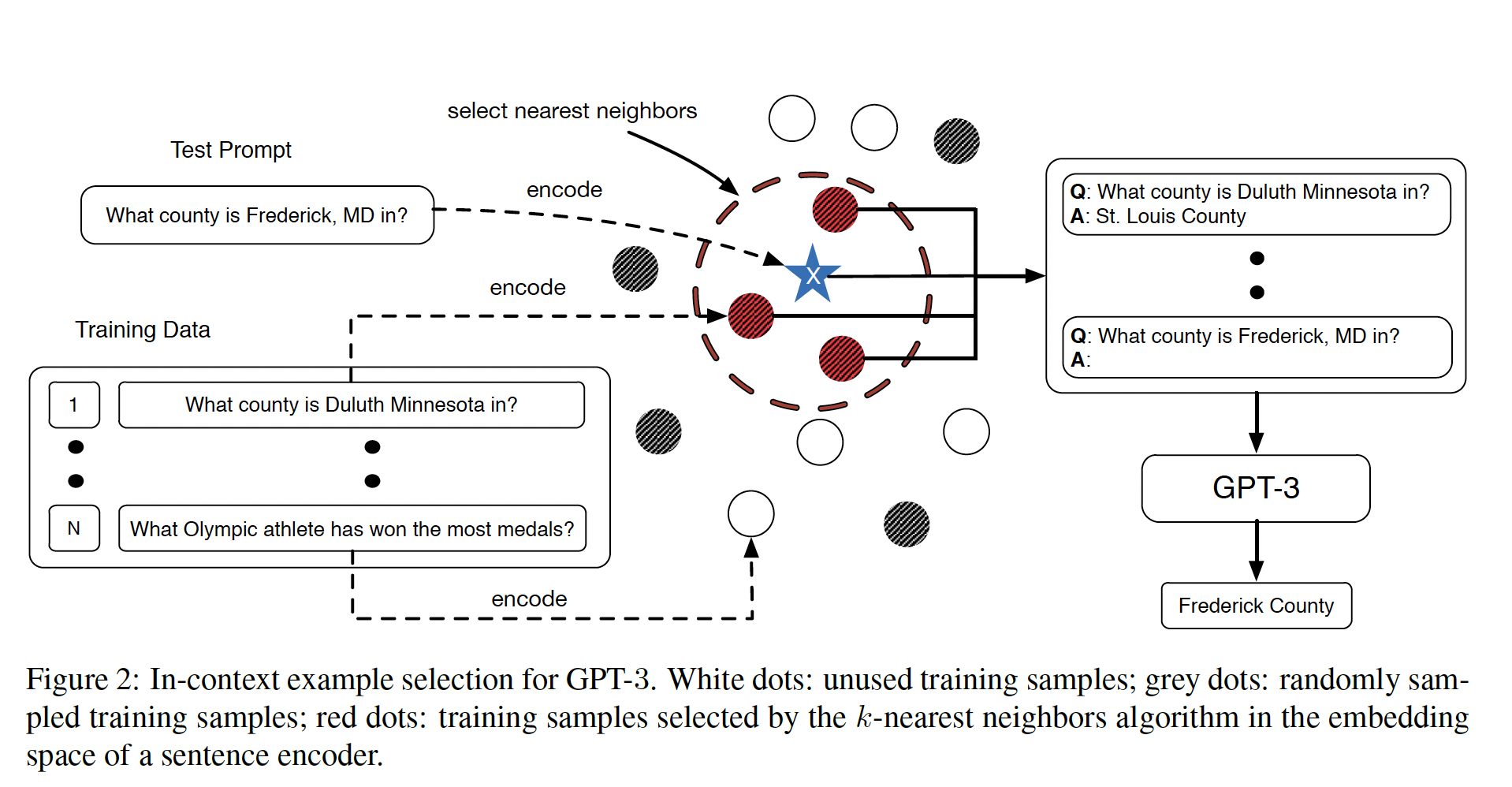
之后,将
sources与它们相应的label拼接起来,形成上下文test sourceGPT-3。算法图见Alogorithm 1。请注意,这里可以采用不同数量的in-context examples,我们在后面的章节中对其影响进行消融研究。
Retrieval Module的选择:我们的context selection方法的一个核心步骤是将句子映射到潜在语义空间中,这就留下了一个问题,即我们应该选择什么样的sentence encoder。我们在现有的pre-trained text encoder中进行了比较,发现它们足以检索出语义相似的句子。这些sentence encoder可以分为两类。第一类包括最通用的
pretrained sentence encoder,如pre-trained BERT, RoBERTa, or XLNet模型。这些模型已经在大量的无监督任务中进行了训练,并在许多自然语言任务中取得了良好的表现。相应的embedding包含来自原始句子的丰富语义信息。第二类包括在特定任务或数据集上微调后的
sentence encoder。例如,在STS基准数据集上训练好的sentence encoder应该能够比通用的pre-trained sentence encoder更好地评估不同问题之间的相似性。SentenceBert已经表明,这些经过微调的编码器在句子聚类、paraphrase mining、以及信息检索等任务上取得了很好的性能。
11.2 实验
任务:情感分类、
table-to-text generation、问答。数据集和data split如下表所示。就GPT-3 API中的超参数而言,我们将温度设置为0。我们让GPT-3继续生成tokens,直到出现一个特殊的换行符"\n"。温度为零使得
generation结果的随机性更小。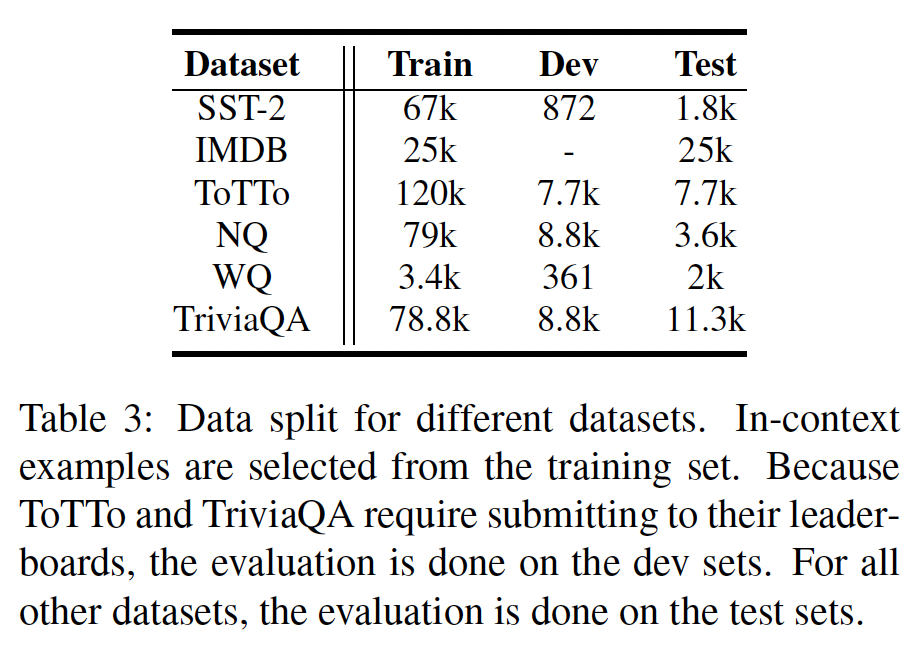
用于检索的
Sentence Embedding:为了检索语义相似的training instances,我们考虑如下两类的sentence embedding:原始的
pre-trained RoBERTa-large模型,记做在任务相关的数据上微调的
RoBERTa-large模型:在
SNLI和MultiNLI上微调的模型,记做先在
SNLI和MultiNLI上微调、然后再在STS-B上微调的模型,记做
值得注意的是,所有的
sentence encoder都有相同的结构(RoBERTa-large),唯一不同的是用于微调的具体数据集。Sentiment Analysis:对于情感分类,我们在transfer setting下选择in-context examples,其中一个数据集被视为训练集,评估是在另一个数据集上进行的。这种transfer setting是为了模拟现实世界中的情景,即我们想利用现有的labeled dataset来用于一个unlabeled dataset(一个类似的任务)。具体来说,我们从
SST-2训练集中选择in-context examples,要求GPT-3对IMDB测试集进行预测。为了探索在类似任务上微调好的sentence encoder是否会有利于KATE的性能,我们还采用了在SST-2训练集上微调好的pre-trained RoBERTa-large模型(被称为IMDB测试集的准确率来衡量的。由于增加更多的样本并不能进一步提高性能,所以in-context examples的数量被选为3。Table-to-Text Generation:给定一个Wikipedia table和一组highlighted cells,这项任务的重点是产生人类可读的文本描述。由于ToTTo的流行,我们利用它进行评估。我们使用BLEU和PARENT指标进行评价。ToTTo代码库包含评估和预处理脚本。由于GPT-3的输入长度限制(目前token数量限制为2048个),我们增加了一个额外的预处理步骤,即删除</cell>和</table>等closing角括号以节省一些空间。in-context examples的数量被设定为2。Question Answering:给定一个事实性的问题,问答任务要求模型生成正确的答案。根据先前的研究,我们使用Exact Match: EM得分来衡量GPT-3在开放领域的问答任务中的表现。EM得分被定义为predicted answers与ground-truth answer(如果有多个ground-truth answer,则只需要匹配其中之一即可)完全相同的比例。匹配是在字符串规范化之后进行的,其中包括去除上下文(仅保留答案部分)和标点符号。我们在三个开放领域的QA基准上进行了实验:Natural Questions: NQ、Web Questions: WQ、Trivia Question Answering: TriviaQA。对于这项任务,我们为
NQ和WQ挑选了最近的64个邻居作为in-context examples,为TriviaQA挑选了最近的10个邻居。对于TriviaQA,如果采用64个in-context examples,则超过了2048个tokens的限制。为了公平比较,我们将TriviaQA的基线和KATE方法的in-context examples数量设定为10个。评估是在NQ和WQ的测试集、以及TriviaQA的验证集上进行的。
baseline方法:随机采样:对于每个测试句子,我们从训练集中随机选择
in-context examples。我们在实验结果中称这种方法为Random。为了与KATE进行公平的比较,这个random baseline中的in-context examples的数量与KATE相同,以确保公平的比较。在测试集上,random baseline被重复五次,以获得平均分和相应的标准差。k-Nearest Neighbor: kNN:此外,为了研究retrieval module是否与GPT-3的few-shot learning互补,我们进一步考虑k-nearest neighbor baseline。具体来说:对于文本生成任务,与第一个
retrieved example相关联的targetpredicted target。对于情感分析和问答任务,利用
top k retrieved examples的targetfinal prediction是由target的多数投票决定的。如果出现平局的情况,我们取与测试句子最相似的例子的target作为预测。
为了确保公平的比较,我们在
pre-trained RoBERTa-large模型的相同embedding空间下比较baseline kNN和KATE。这个基线被缩写为
11.2.1 实验结果
情感分析:我们首先在情感分析任务上评估
KATE。结果显示在下表中。可以看出:相对于
random selection baseline,KATE始终产生更好的性能。值得注意的是,由于采用的是同一组
retrieved in-context examples,所以获得的结果没有方差。对于
KATE方法,当在NLI或NLI+STSB数据集上对pre-trained sentence encoder进行微调时,性能略有下降。由于IMDB数据集和NLI+STS-B数据集的目标不同,这表明在不同的任务上进行微调会损害KATE的性能。此外,
sentence encoder在STS-B数据集上被进一步微调了。 相比之下,KATE的性能受益。为了验证收益不仅仅来自于检索步骤,我们进一步比较了
值得注意的是,在
SST-2数据集上对RoBERTa-large模型的embedding进行微调后,92.46,低于既然
92.46,是否意味着用一个优秀的pretrained sentence encoder执行kNN就足够了?
这些结果表明,
GPT-3模型对最终结果至关重要,而检索模块是对GPT-3的few-shot能力的补充。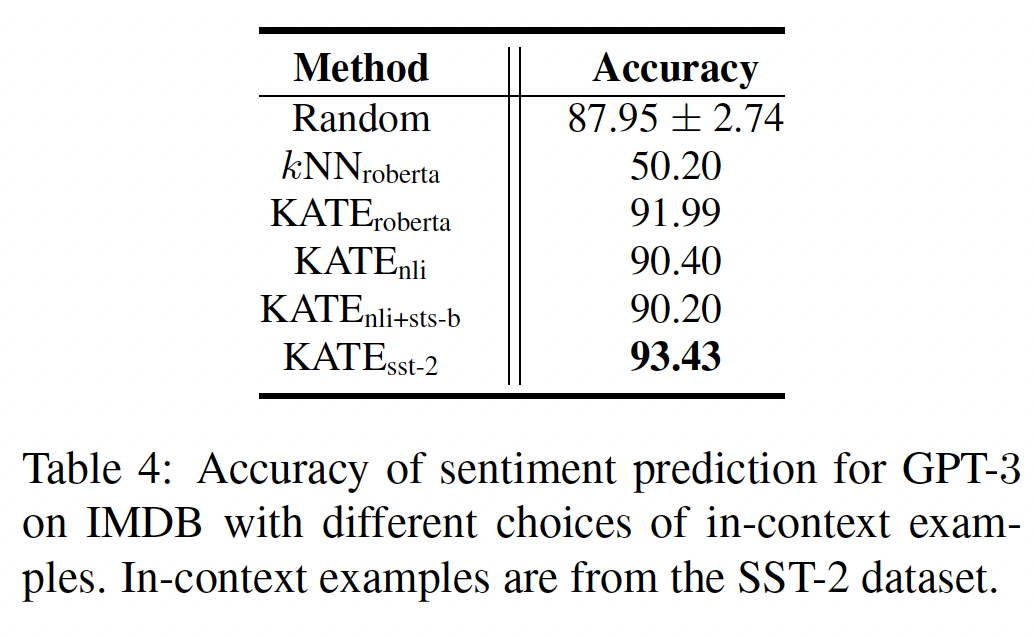
Table-to-Text Generation:我们利用ToTTo数据集来评估KATE的table-to-text generation任务。结果如下表所示。根据BLEU和PARENT分数,KATE方法比random baseline有了相当大的提高。在更细的
scale内,可以对overlap子集和non-overlap子集进行评估。overlap验证子集与训练集共享大量的标题名称,而non-overlap验证子集则不共享任何标题名称。可以看出,KATE方法改善了overlap子集和non-overlap子集的结果,这意味着检索模块对于如下的两种情形都有帮助:测试集遵循训练集的分布、测试集不遵循训练集的分布。与情感分析类似,从
ToTTo数据集和NLI+STS-B数据集的目标不同。从KATE的性能。对于kNN baseline,它的表现比random selection方法和KATE方法差得多,这再次表明检索过程和GPT-3协同工作从而取得更好的结果。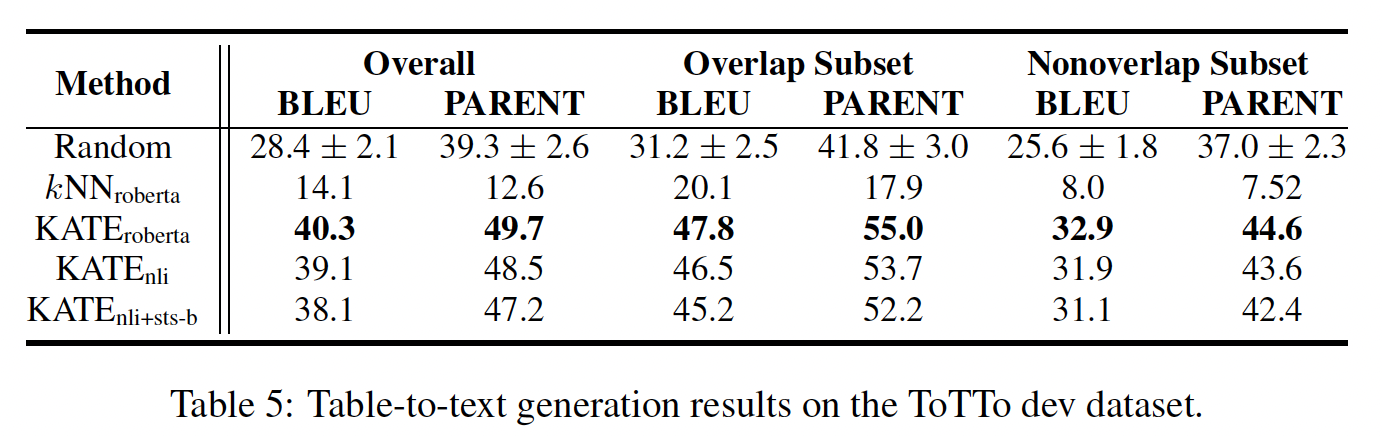
为了了解检索机制如何帮助
GPT-3的预测,我们对retrieved examples进行了一个案例研究(见Table 6)。通过从训练集中检索相关的样本,KATE提供了有用的关于table的详细信息(例如,得分、篮板、以及助攻的数量),从而给GPT-3以更准确的描述。另一方面,random selection方法有幻觉的问题,所生成的序列包含了表格中不存在的信息(例如,"senior year"和"University of Texas")。
Questing Answering:我们还在开放领域的问答任务上评估了KATE,如下表所示。对于问答任务,我们与一些SOTA的方法进行了比较,如RAG和T5。这两种方法都需要在特定的数据集上进行微调。KATE方法再次提高了GPT-3在各种基准中的few-shot prediction的准确率。值得注意的是,fine-tuned transformer模型作为更好的sentence encoder用于检索目的(与没有经过微调的RoBERTa_large模型相比)。NLI或STS-B数据集的微调有助于从问答数据集中检索出语义相似的问题。此外,在NQ和TriviaQA数据集上,对STS-B数据集的进一步微调提高了KATE的结果。我们还尝试减少random方法和KATE方法的in-context examples的数量,使其减少到5个,其中KATE的表现也优于baseline。因此,KATE相对于random baseline的优势在少量和大量的in-context examples都是成立的。更多的细节可以在消融研究部分找到。我们通过使用
top-1最近邻来评估其他基线64个最近邻(TriviaQA为10个最近邻)来确定答案(通过多数投票)。EM的得分趋向于与检索top-1最近邻相似。这些kNN baseline结果再次表明,检索模块和GPT-3一起工作可以获得更好的性能。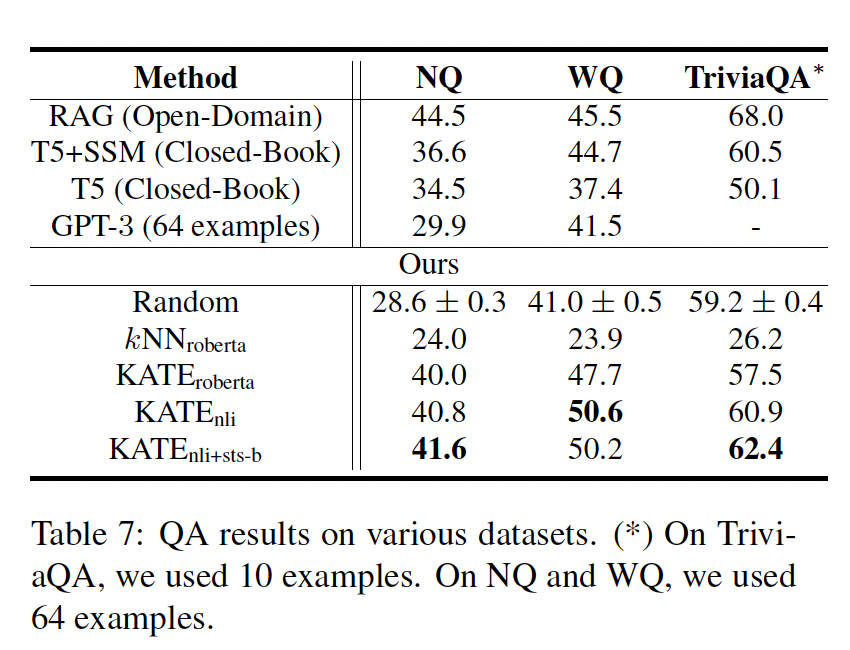
为了研究为什么
retrieval examples有帮助,我们进一步提出一个案例研究。具体来说,从NQ数据集中检索到的in-context examples如Table 8所示。对于第一个和第二个案例,random baseline提供了错误的答案,因为GPT-3无法recall确切的细节。然而,KATE选择的in-context examples包含正确的细节,这有利于GPT-3回答问题。对于第三个测试问题,random baseline导致GPT-3错误地将问题解释为要求一个specific location。与此相反,KATE选择了相似的问题,问的是对象的起源。利用这些specific location,GPT-3能够正确地解释和回答问题。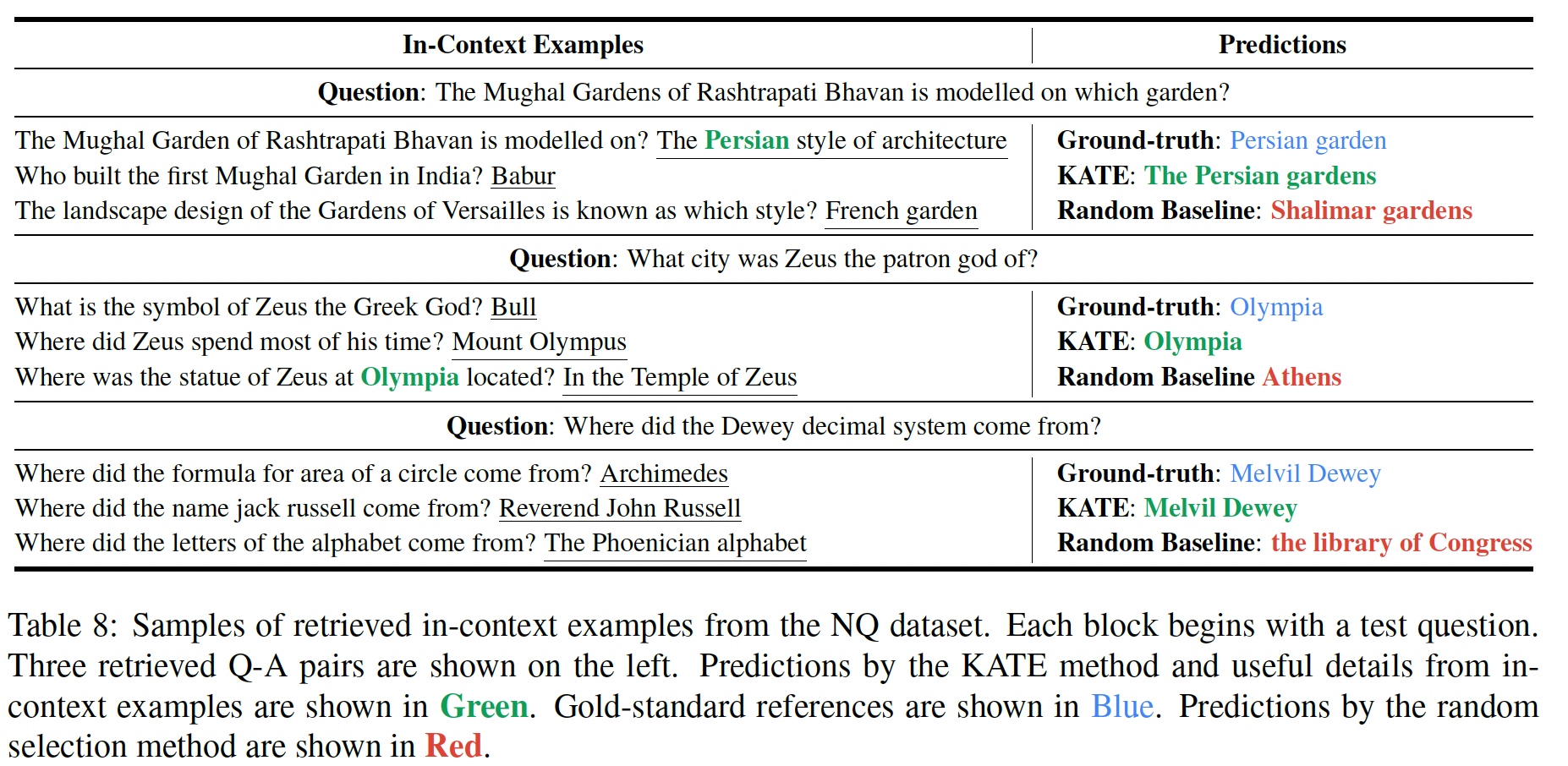
11.2.2 分析和消融研究
In-context Examples数量:我们首先研究了in-context examples的数量对KATE性能的影响。具体来说,在NQ数据集上,我们选择了5/10/20/35/64个in-context examples,在不同的设置下,将random baseline和如
Figure 3左图所示,KATE和random baseline都从利用更多的in-context examples中受益。然而,KATE始终优于random selection方法,即使in-context examples数量少到5个。这个结果很有意思,因为在实践中,采用较少的in-context examples会使GPT-3的推理效率更高。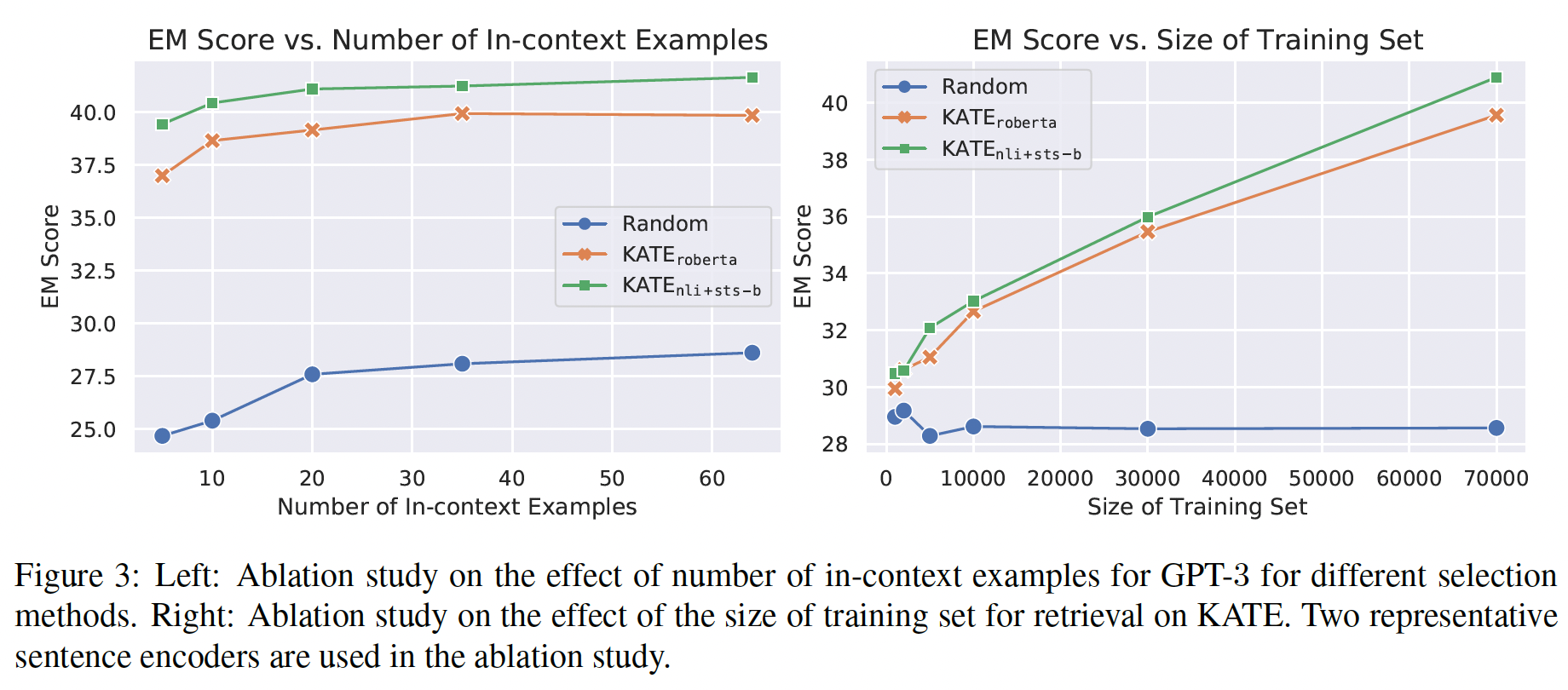
用于检索的训练集的大小:我们进一步研究训练集的大小如何影响
KATE方法。在NQ数据集上,我们从原始训练集中创建了新的子集,其大小分别为1k/2k/5k/10k/30k/70k。从这些子集(而不是原始的训练集)中检索in-context examples。近邻的数量被设置为64。我们将random selection方法和Figure 3的右图。对于EM分数也在增加。相比之下,random sampling baseline的结果变化不大。直观地说,随着训练集规模变大,
KATE更有可能检索到相关的in-context examples来帮助GPT-3正确地回答问题。正如我们之前在Table 8中显示的,retrieved in-context examples可以为GPT-3提供关键的详细信息,从而帮助GPT-3更好地回答问题。In-context Examples的顺序:此外,我们还探讨了in-context examples的顺序如何影响KATE的结果。如前所述,在标准设置下,retrieved in-context examples都是有序的,其中当NQ数据集中in-context examples的顺序,并实验了三个不同的顺序。此外,我们还探索了逆序,即当在这个特定的
NQ数据集上,逆序表现得最好。一个可能的解释是,由于彼此相邻的token具有相似的positional embedding,将最相似的句子放在靠近测试样本的地方,可能有助于GPT-3利用相应信息。然而,我们也在
WQ和TriviaQA上做了实验,发现默认顺序比逆序的表现略好。因此,顺序的选择是取决于数据的。另外,可以观察到,NQ结果之间的变化趋于相当小(与random baseline和KATE之间的差异相比),这表明in-context examples的顺序对KATE的性能没有重大影响。
十二、LM-BFF[2021]
论文:
《Making Pre-trained Language Models Better Few-shot Learners》
GPT-3模型在NLP界掀起了狂澜,它在无数的语言理解任务上展示了令人震惊的few-shot能力。只需给出一个自然语言prompt和一些任务demonstrations,GPT-3就能做出准确的预测,而无需更新其底层语言模型的任何权重。然而,虽然引人注目,GPT-3由175B个参数组成,这使得它在大多数实际应用中具有挑战性。在这项工作中,我们研究了一个更实际的场景,即我们只假设能够获得一个中等规模的语言模型,如
BERT或RoBERTa,以及少量的样本(即few-shot setting),我们可以用它来微调语言模型的权重。这种setting很有吸引力,因为:(1):这种模型可以在典型的research hardware上进行训练。(2):few-shot settings是现实的,因为通常既容易获得一些标注(如32个样本),又能有效地进行训练。(3):参数更新通常会导致更好的性能。
受
GPT-3研究结果的启发,我们提出了几个新的策略,将其few-shot learning能力扩展到我们的setting中,同时考虑分类问题、以及回归问题。首先,我们遵循
prompt-based prediction的路线。其中,prompt-based prediction首先由GPT系列研发从而用于zero-shot prediction,最近由PET(PET、PET-2)研究从而用于微调。prompt-based prediction将下游任务视为一个language modeling / masked language modeling问题,其中模型针对给定的prompt(通过一个task-specific模板来定义)直接生成文本式的响应(见Figure 1 (c))。然而,寻找正确的prompts是一门艺术:需要领域的专业知识、以及对语言模型内部工作原理的理解。即使投入了大量的精力,手动的prompts也可能是次优的。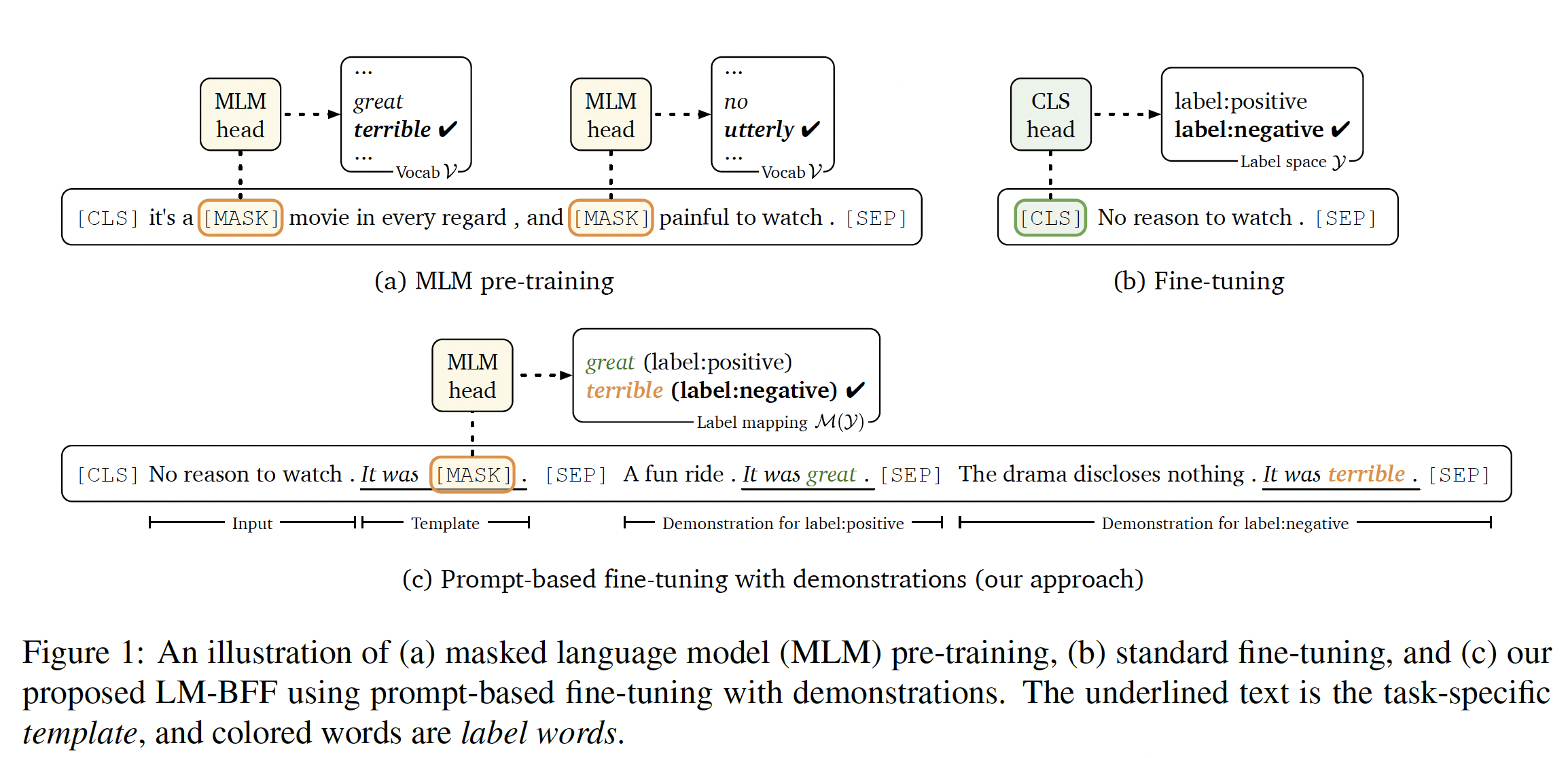
我们通过引入
automatic prompt generation来解决这个问题,包括一个pruned brute-force search来识别最佳的working label words、以及一个新的解码目标从而使用生成式T5模型自动生成模板。所有这些都只需要few-shot训练数据。这使我们能够低成本地获得有效的prompts,这些prompts媲美甚至超越于我们手动选择的prompts。即,用语言模型来生成
prompt的模板、verbalizer。第二,我们采用了将
demonstrations作为additional context的想法。GPT-3的朴素的"in-context learning"范式最多挑选了32个随机采样的样本,并将它们与input拼接起来。这种方法不能保证优先考虑most informative demonstrations,而且将不同类别的随机样本混合在一起会产生很长的上下文,很难从这个很长的上下文中学习。此外,可用demonstrations的数量被模型的最大输入长度所限制。我们开发了一个更精细的策略,对于每一个输入,我们每次从每个类别中随机采样一个样本,以创建多个
minimal的demonstration集合。我们还设计了一种新的采样策略,将inputs与相似的样本来配对,从而为模型提供更加discriminative的comparisons。即,更好地挑选
few-shot examples。
我们提出了一个系统性的评估,用于在
8 single-sentence和7 sentence-pair的NLP任务上分析few-shot性能。我们观察到,在给定少量训练样本的情况下:(1):prompt-based fine-tuning在很大程度上优于标准微调。(2):我们的automatic prompt search方法媲美甚至超越了人工prompts。(3):引入demonstrations对微调是有效的,并能提高few-shot性能。
这些简单而有效的方法加在一起,使我们在所评估的任务中获得了巨大的改善,与标准微调相比,我们获得了高达
30%的绝对改善(平均改善为11%)。例如,我们发现RoBERTa-large模型在大多数二元句子分类任务中取得了约90%的准确率,而只依赖于32个训练样本。我们把我们的方法称为better few-shot fine-tuning of language models: LM-BFF:一种强大的、与任务无关的few-shot learning方法。LM-BFF是一种基于微调的方法,它需要微调模型从而适配给定的模版,模板是由另一个pretrained LM来自动生成的。相关工作:
language model prompting:GPT系列推动了prompt-based learning的发展,我们遵循其许多核心概念。最近的
PET工作(PET、PET-2)也给了我们很大的启发,尽管他们主要关注的是semi-supervised setting,其中提供了大量的未标记样本。我们只使用少量的标记样本作为监督,并且还探索了automatically generated prompts和fine-tuning with demonstrations。此外,我们通过提供一个更加严格的框架从而偏离了他们的evaluation,我们将在正文部分讨论。最后,有大量关于
prompting的工作用于从pre-trained models中挖掘知识。与这些工作不同,我们专注于利用prompting从而用于对下游任务进行微调。
automatic prompt search:PET以及《Automatically identifying words that can serve as labels for few-shot text classification》探索了自动识别label words的方法。然而,与手工挑选的label words相比,这些结果都没有导致更好的性能。相比之下,我们的方法对模板和label words都进行了搜索,并且能够媲美甚至超越我们的人工prompts。此外,还有其他一些尝试。然而这些方法要么是在有限的领域内操作,如寻找表达特定关系的模式(
LPAQA),要么需要大量的样本来进行gradient-guided搜索(AutoPrompt、《Factual probing is [MASK]: Learning vs. learning to recall》)。我们的方法旨在开发只依赖少量annotations的通用搜索方法。
语言模型的微调:最近的一些研究关注于更好的语言模型微调方法(
《Universal language model fine-tuning for text classification》、《Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping》、《Mixout: Effective regularization to finetune large-scale pretrained language models》、《Revisiting few sample BERT fine-tuning》)。这些工作主要集中在优化和正则化技术上,以稳定微调工作。在这里,我们使用了标准的优化技术,而主要是将我们的努力聚焦在更极端的few-shot setting中更好的prompt-based fine-tuning方面。我们预计,这些研究的结果在很大程度上是对我们的补充。few-shot learning:广义上讲,我们的setting也与NLP中的其他few-shot learning范式有关,包括:半监督学习(给出一组未标记样本)、元学习(给出了一组辅助任务)、few-shot learning(给出了一个相关的中间任务)。我们偏离了这些setting,对可用的资源做了最小的假设:我们只假设有几个标注样本、以及一个pre-trained language model。我们的重点是了解在没有任何其他优势的情况下,我们能推动多远。
12.1 Problem Setup
任务描述:在这项工作中,我们假设可以获得一个
pre-trained language modellabel space为unseen的测试集对于模型选择和超参数调优,我们假设验证集
few-shot训练集相同,即在以下所有的实验中(除非另有说明),我们采取
Evaluation数据集:来自GLUE benchmark, SNLI, SST-5, MR, CR, MPQA, Subj, TREC等数据集中的8个single-sentence英语任务、7个sentence-pair英语任务。具体细节如下表所示。对于
single-sentence任务,目标是根据输入句子positive的。对于
sentence-pair任务,目标是给定一对输入句子
我们也可以交替使用
<S1>或(<S1>, <S2>)来指称输入。请注意,我们主要使用SST-2和SNLI进行实验和模型开发,使其接近于真正的few-shot setting,至少对于我们评估的所有其他数据集而言。
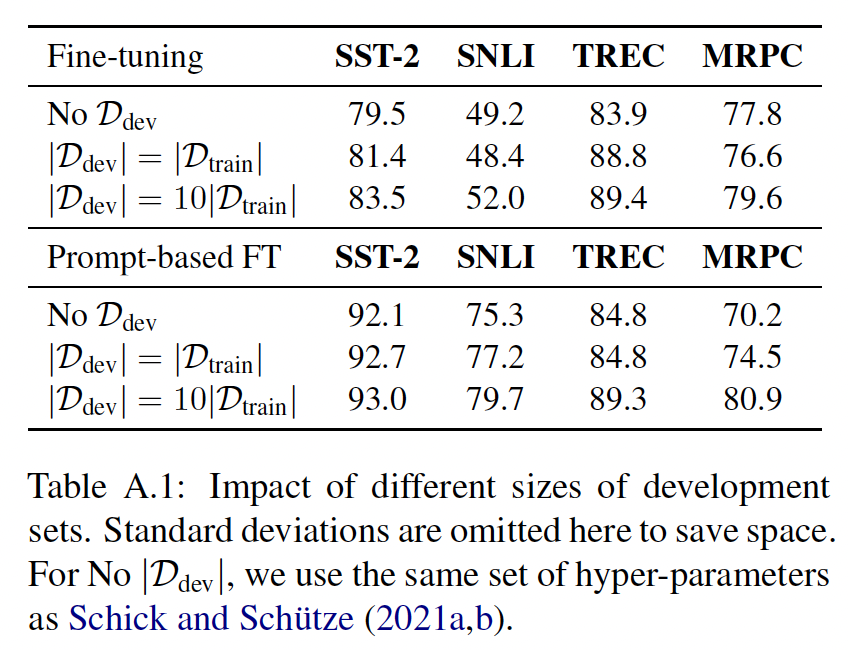
评估方式:系统地评估
few-shot的性能可能是很棘手的。众所周知,在小数据集上的微调可能存在不稳定性:在数据的新的split下,结果可能发生巨大变化。为了说明这一点,我们测量了5个不同的随机采样的split的平均性能。这个问题在PET-2中也有讨论:他们建议使用固定的训练集。我们认为,采样多个splits可以提供一个更鲁棒的性能度量,以及对方差的更好估计。我们还观察到,超参数可以产生很大的差异,因此我们为每个
data sample扫过多个超参数,并采取在该data sample在setting设置。超参数扫描空间为:学习率batch size1000步,每隔100步在验证集上评估并选择最佳的checkpoint。
12.2 Prompt-based 微调
给定一个
masked language modeltoken sequencehidden vectors的序列label spacecorrect label的对数概率来训练task-specific head:其中:
[CLS]的隐向量 。
同样地,对于回归任务,我们可以引入
gold label之间的mean squared error: MSE。在任何一种情况下,新参数的数量都是巨大的,例如,一个简单的二分类任务将为RoBERTa-large模型引入2048个新参数,这使得从少量的标注数据(例如,32个样本)中学习具有挑战性。解决这个问题的另一种方法是
prompt-based的微调,其中"auto-completing"自然语言prompts的任务。例如,我们可以用包含输入prompt(例如,"No reason to watch it .")来制定一个二元情感分类任务:并让
[MASK]中填写"great"(positive)还是"terrible"(negative)更合适。现在我们将这种方法正式用于分类任务和回归任务,并讨论prompt selection的重要性。分类任务:令
task label space到masked language modeling: MLP输入,其中[MASK] token,MLM,并且预测类别其中:
[MASK]的hidden vector,pre-softmax vector,labeltoken。当有标记样本集合
pre-trained weightspre-training和fine-tuning之间的gap,使其在few-shot场景下更加有效。虽然没有引入新的参数,但是这里需要对
initialization(而不是随机初始化为零)。回归任务:回归任务的配置和分类任务相同,但是回归任务将
label space《Hyperspherical prototype networks》的启发,我们将回归问题建模为两个点其中:
然后我们定义
我们微调
KL散度。这里对回归任务做了太强的假设:
首先,回归任务是有界的。对于 “房价预测” 这种取值空间理论上无界的问题,无法解决。
其次,要求
好的和坏的
Manual prompts:关键的挑战是构建模板label wordspromptPET、PET-2)都是手工制作模板和label words,这通常需要领域专业知识和反复试错。Table 1总结了我们实验中为每个数据集选择的手工模板和label words。这些模板和label words是通过直觉和考虑以前文献中使用的格式来设计的。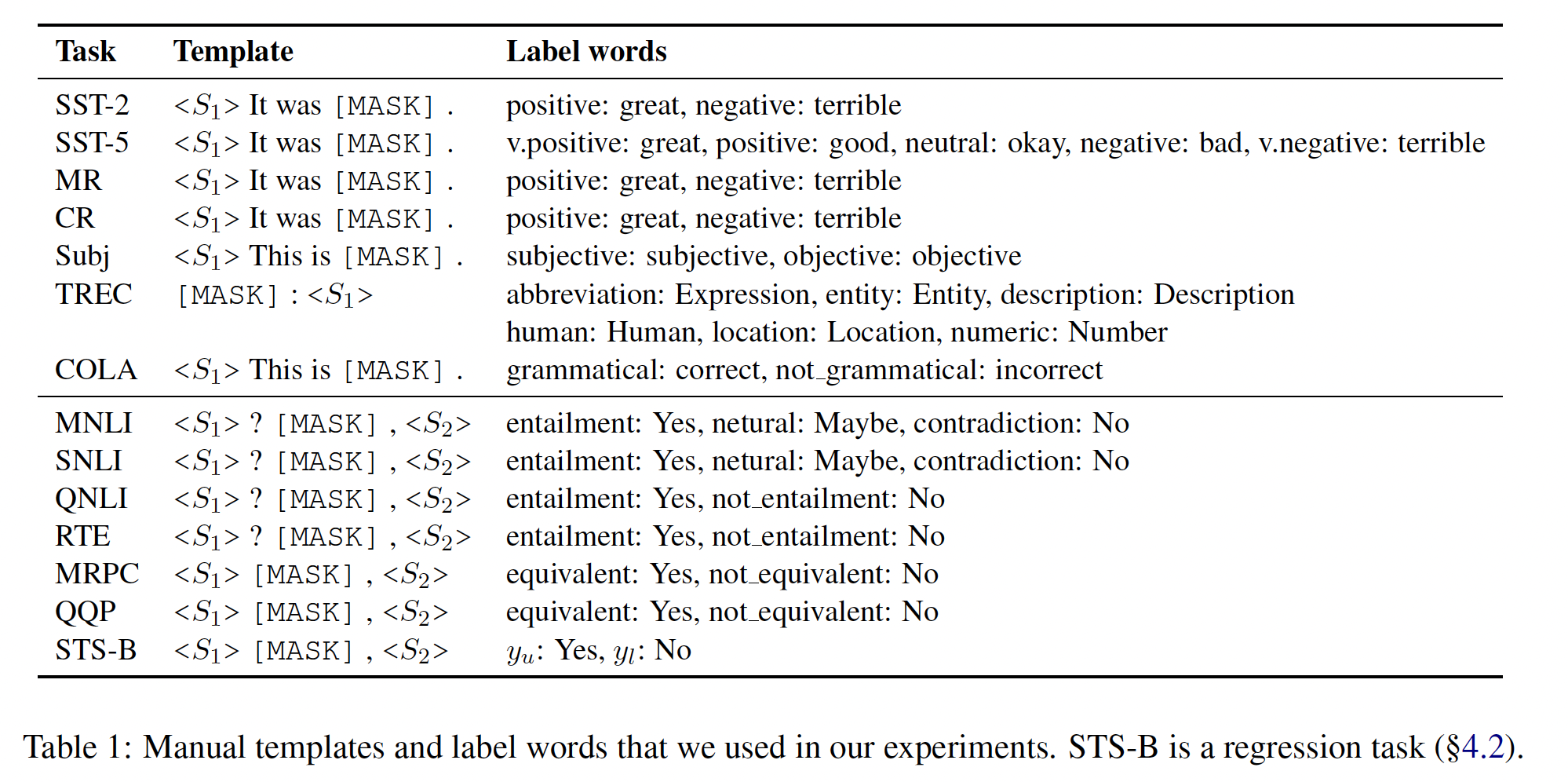
为了更好地了解什么是好的模板或好的
label word,我们对SST-2和SNLI进行了试点研究。Table 2显示,不同的prompts会导致最终准确率的巨大差异。具体而言:当模板固定时,
label words与 "语义类别" 的匹配度越高,最终准确率就越高(great/terrible > good/bad > cat/dog)。在极端的情况下,如果我们交换似是而非的label words(例如,great/terrible),我们会取得最差的整体表现。此外,对于同一组
label words,即使模板的一个小变化也会产生差异。例如,对于SNLI,如果我们把[MASK]放在最后,或者交换句子的顺序,我们观察到准确率的下降幅度超过10%。
上述证据清楚地强调了选择好的模板和好的
label words的重要性。然而,搜索prompts是很难的,因为搜索空间可能非常大,特别是对模板而言。更糟糕的是,我们只有少量样本可以用来指导我们的搜索,这很容易造成过拟合。我们接下来将解决这些问题。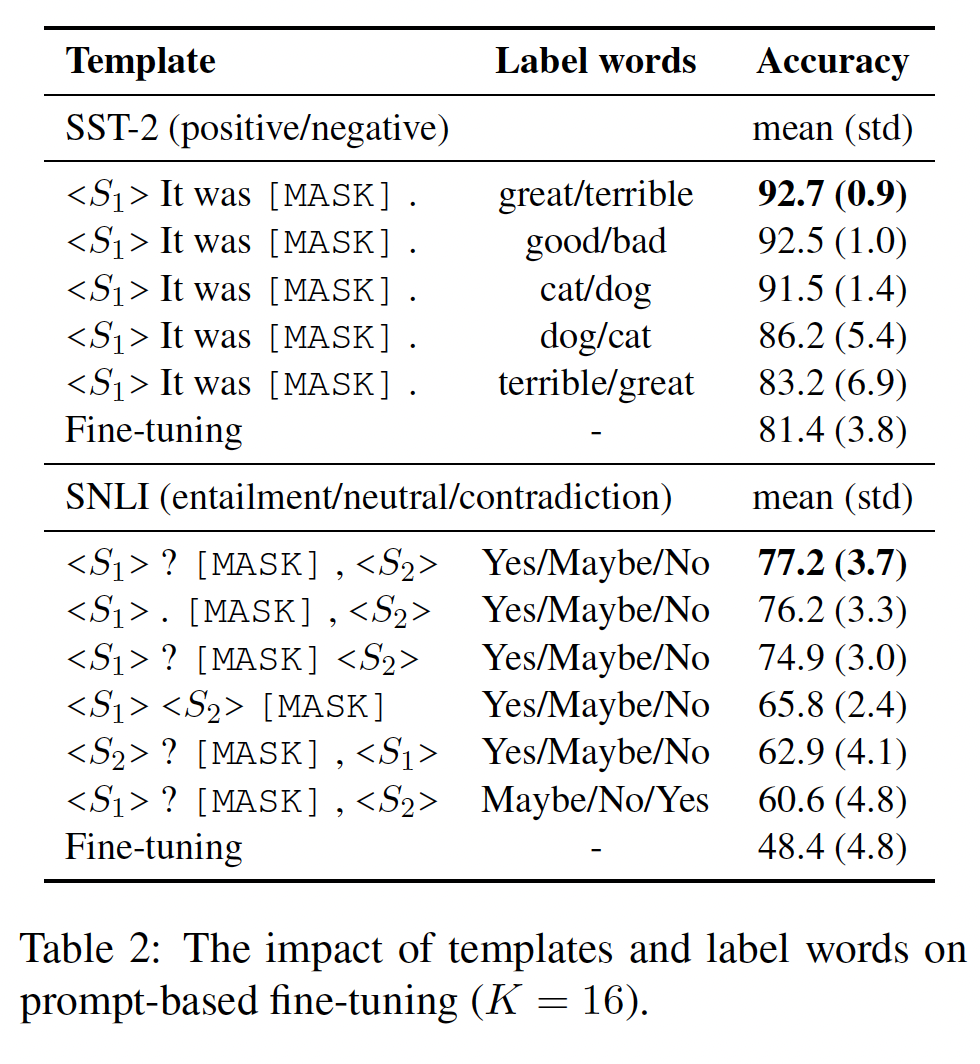
12.3 Automatic Prompt Generation
我们的目标是减少设计
prompts,所需的人类参与,并找到比我们手动选择的更理想的设置。在这里,我们假设是一个分类任务,但回归的过程是类似的。label words的自动选择:我们首先研究如何在给定一个固定的模板label word mapping首先,一般来说是难以实现的,因为搜索空间是类别数量的指数级。
其次,容易过拟合,因为在给定少量标注样本的情况下,我们将倾向于发现虚假的相关性。
作为一个简单的解决方案,对于每一个类别
top k的单词集合,这些单词构建了裁剪后的词表其中:
物理含义:针对训练集中类别为
label words。为了进一步缩小搜索空间,我们并没有在
top k,而是在裁剪后的空间中去检索。裁剪方式为:选择使得使zero-shot accuracy最大化的tokens,即top n assignments。C.2。然后,我们微调所有的top n assignments,并使用rerank以找到最佳的assignment。这种方法类似于PET、PET-2中的automatic verbalizer search方法,只是我们使用了一个简单得多的搜索过程(暴力搜索),并且还应用了re-ranking:我们发现re-ranking对我们很有帮助。rerank即利用验证集来挑选最佳的assignment。实验部分表明:
label words的自动选择上,效果不佳。因此这个算法的意义何在?模板的自动生成:接下来,我们研究如何从一组固定的
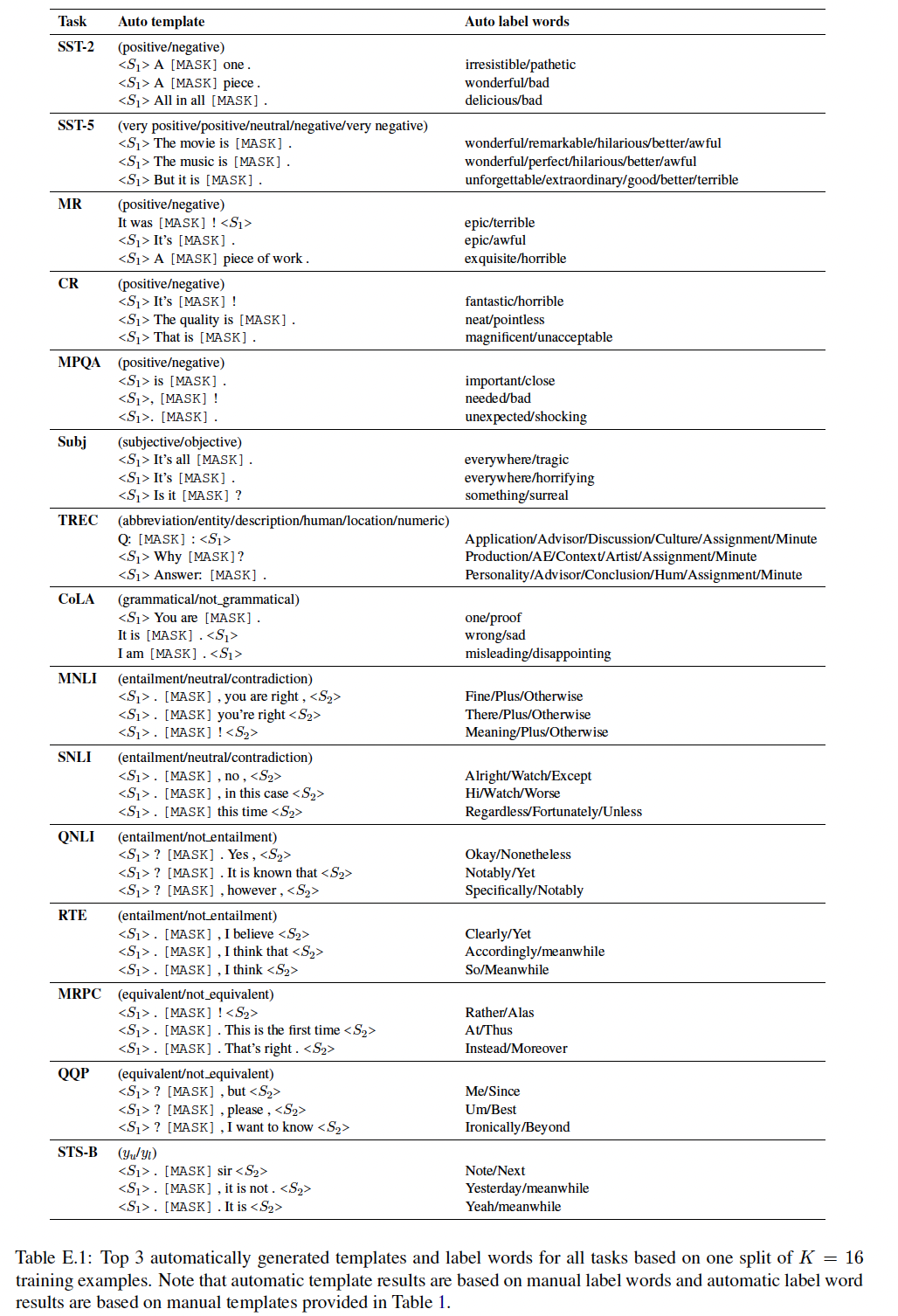
label wordsT5模型,一个大型的pre-trained text-to-text Transformer。T5经过预训练,可以在其输入中补全missing spans(由T5 mask tokens取代,例如<X>或<Y>)。例如,给定输入"Thank you <X> me to your party <Y> week",T5被训练从而生成"<X> for inviting <Y> last <Z>",这意味着"for inviting"是<X>的替换,"last"是<Y>的替换。这很适合于prompt generation:我们可以简单地从T5模型构建模板tokens数量。这里利用语言模型来生成模板,因此这里依赖于预训练好的语言模型(如
T5)。给定一个输入样本
T5模型的输入:prompt的开始、第二行以训练样本作为prompt的开始。如下图所示,我们依靠
T5模型来填充占位符。在解码时,我们的目标是找到一个能对T5的输出概率分布。它可以分解为:其中:
template tokens。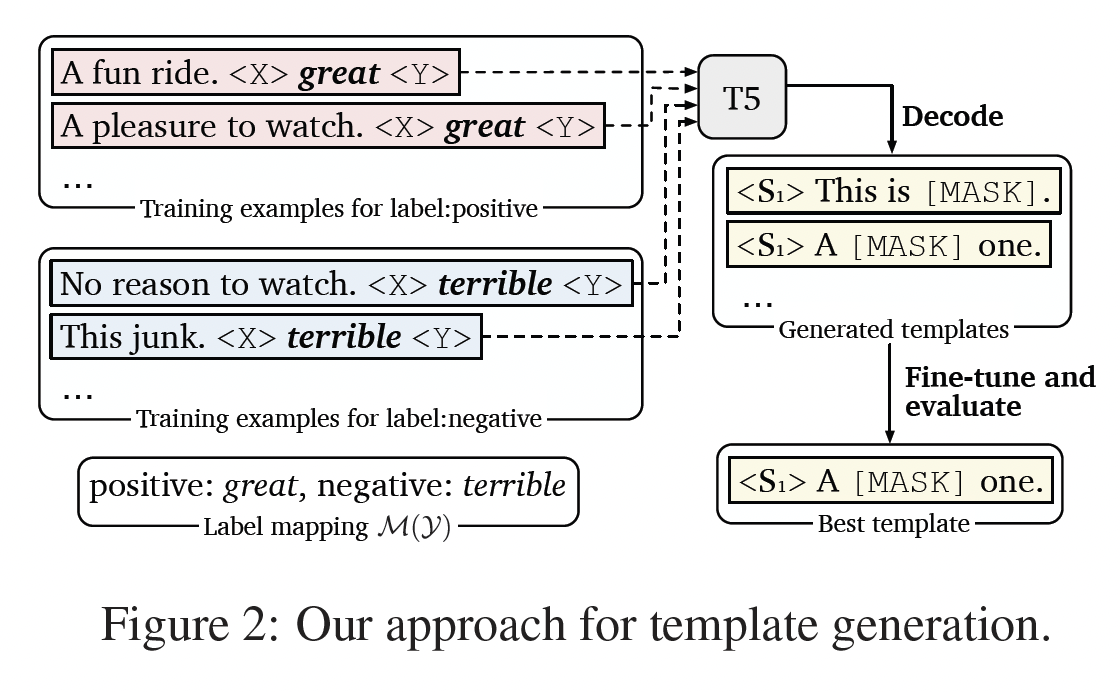
我们使用
beam search来解码多个模板候选。具体而言,我们使用一个wide beam width(例如,beam width = 100)来低成本地获得一大批多样化的模板。然后,我们在Table 3所示),或者挑选出top-k模板作为ensemble使用(table 4)。尽管在每个模板上微调模型可能显得很昂贵,但由于prompts相比,它很容易使用。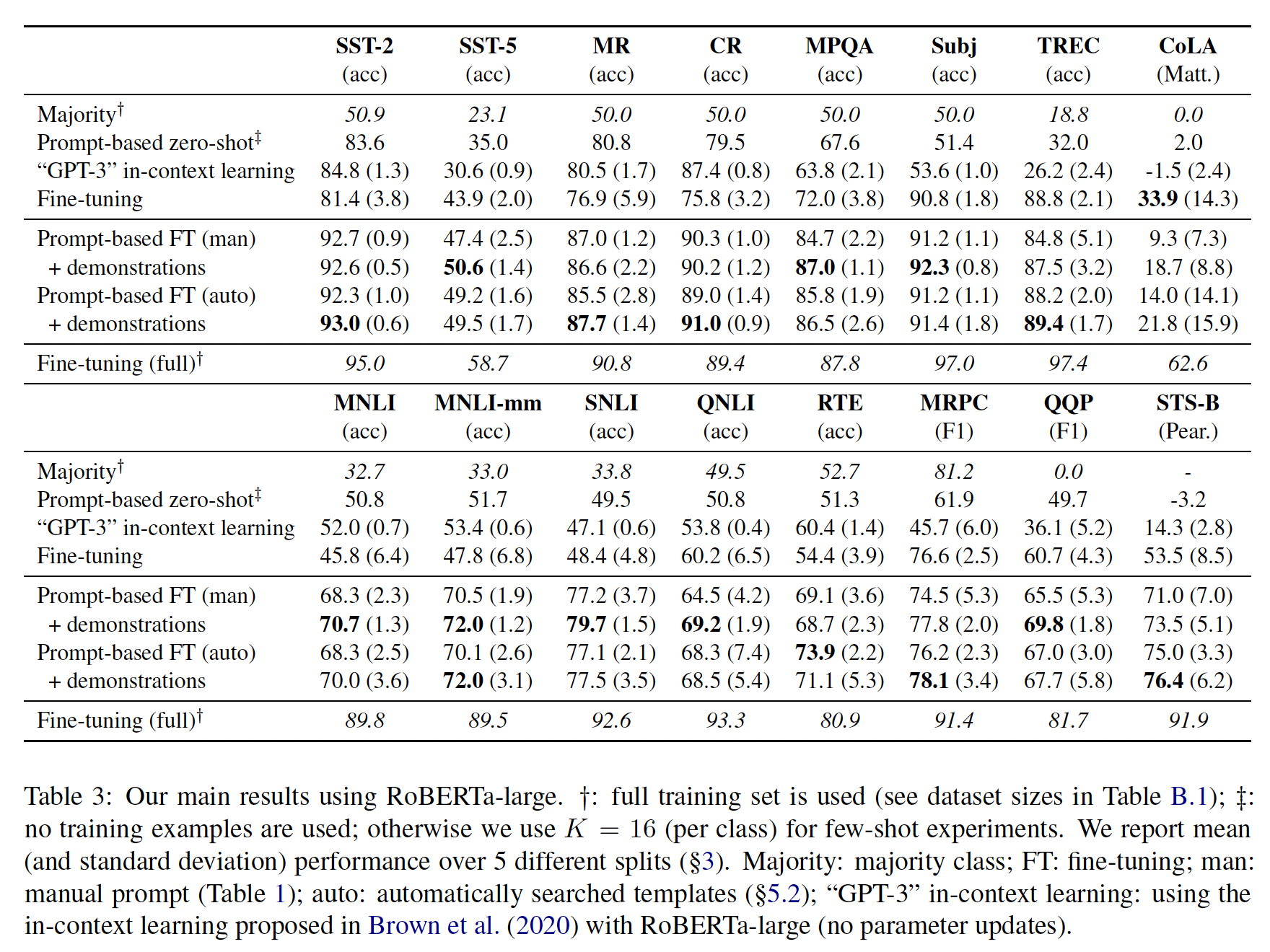

12.4 用 Demonstrations 进行微调
注意:这一节仅说明如何挑选
demonstrations,并没有说如何利用demonstrations来微调。
这里我们研究:当我们微调中等规模的语言模型时,我们是否能够利用
demonstrations,并找到更好的方法来利用demonstrations。训练样本作为
demonstrations:GPT-3对in-context learning的朴素做法只是将输入与从训练集中随机采样的多达32个样本连接起来。这种方法是次优的,因为:(1):可用的demonstrations数量受模型的最大输入长度限制。(2):将来自不同类别的众多随机样本混合在一起,会产生极长的、难以利用的上下文,特别是对于较小的模型。
为了解决这些问题,我们提出了一个更简单的解决方案:在每个
training step中,我们从每个类别中随机采样一个样本[MASK],记做Figure 1(c)):这里
在训练和推理过程中,我们为每个
demonstration集合。请注意,在训练期间,demonstratio样本都是从同一个集合demonstration集合,并在所有的demonstration集合中ensemble预测结果。采样相似的
demonstrations:我们观察到,控制demonstration样本contrastive demonstrationsquery具体而言,我们使用
pre-trained SBERT模型来获得所有输入句子的embedding(对于sentence-pair任务,我们使用两个句子的拼接)。在这里,我们只是将不带模板的原始句子馈入SBERT。对于每个queryquery的相似度得分top r = 50%的实例中采样从而作为demonstrations使用。类似于
KATE思路:对于测试样本,选择最相似的训练样本作为few-shot examples。这里依赖于外部的、预训练好的
sentence encoder。
12.5 实验
超参数调优:
对于网格搜索,我们选择学习率为
{1e-5, 2e-5, 5e-5}、batch size为{2, 4, 8}。我们使用早停来避免过拟合。
每次实验,我们训练模型
1000 steps,每隔100 steps验证一次验证集,然后选择最佳的checkpoint。
Prompt-based fine-tuning的实现细节:Table 1显示了我们在实验中使用的所有人工模板和label words。对于自动的模板生成,我们采用了
T5-3B模型,这是在单个GPU上能适应的最大的公开可用模型。对于自动搜索
label words,除了SST-5和TREC,我们将所有任务的100。对于
SST-5,我们设置了一个较小的对于
TREC,我们观察到仅仅使用条件似然来过滤manual label words的最近邻来重排top 30。
在所有的实验中,我们将
100。由于自动搜索中的大量试验,我们在这部分采取了一组固定的超参数:
batch size = 8,学习率为1e-5。由于
prompt-based微调的想法是使输入和输出的分布接近于预训练,所以实施细节是至关重要的。对于模板,如果句子不是在输入的开头,我们会在句子前加上额外的空格。
另外,如果句子与前缀(如
Table 1中的<S2>)拼接,我们会小写句子的第一个字母。另外,如果一个句子附加了任何标点符号(如
Table 1中的<S1>),那么原句的最后一个字符将被丢弃。最后,我们为
label words前置了一个空格。例如,在RoBERTa词表中,我们用" great "代替"great",其中" "代表空格。
Fine-tuning with demonstrations的实现细节:当使用demonstrations时,我们对每个输入采样demonstrations的16个不同的集合,并在推理过程中对每个类别的预测对数概率进行平均。我们发现,进一步增加样本的数量并没有带来实质性的改善。此外,我们还尝试了不同的聚合方法,如取最大置信度的结果,但我们没有发现有意义的改进。为了选择
demonstrations,我们将SBERT的roberta-large-nli-stsb mean-tokens作为我们的sentence embedding模型。
12.5.1 实验结果
我们在实验中使用
RoBERTa-large模型,并设置RoBERTa与BERT的比较可以在附录D中找到(见Table D.1)。对于automatic prompt search,在我们的主要结果中,我们只报告了automatic template search(它一直表现得最好,见Table 5)。为了正确看待我们的结果,我们与一些baseline进行了比较,即:在我们的
few-shot setting中的标准微调。使用完整训练集的标准微调。
简单地采取最高频的类(在完整的训练集上测量)。
prompt-based zero-shot prediction,我们采用我们的手动prompts并使用"GPT-3" in-context learning,我们使用相同的prompt-based zero-shot setting,,但用随机采样的32 demonstrations来augment上下文(仍然使用RoBERTa-large,而不是GPT-3)。
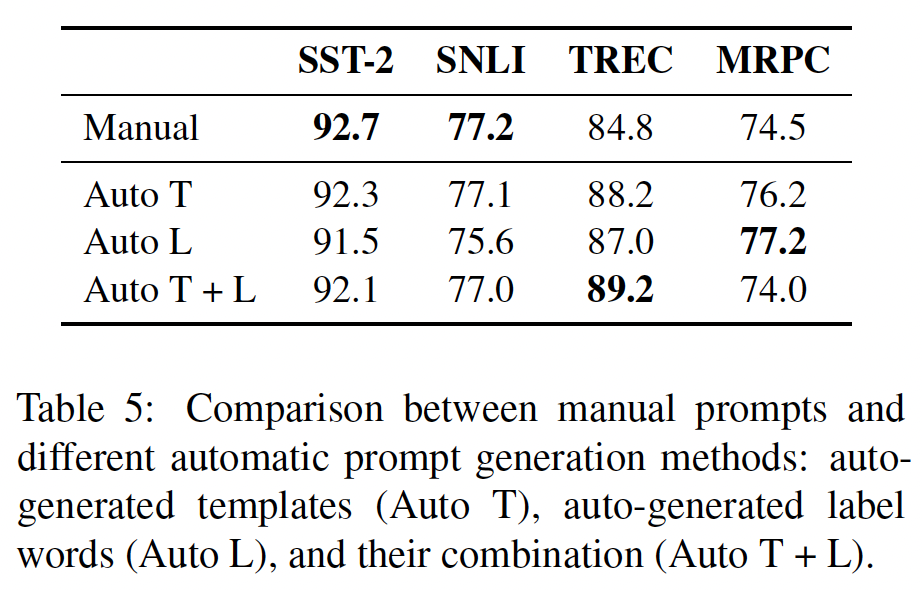
Pretrained BERT为输入的不同部分提供了两个segment embeddings (A/B)。在对BERT进行微调时,通常的做法是,在单句任务中只使用segment A,而在sentence-pair任务中使用segment A/B来处理两个句子。然而,在我们纳入demonstrations的案例中,我们有两个以上的句子。因此,我们探索了以下不同的segments策略:对所有句子使用
segment A(1-seg)。对原始输入使用
segment A、对demonstrations使用segment B(2-seg)。对每个句子使用不同的
segment embedding(n-seg),这就引入了新的segment embedding(在微调期间随机初始化和学习),因为pre-trained BERT只有两个segment embedding。
single-prompt的结果:Table 3显示了我们使用单一prompt的主要结果,无论是从我们手动设计的prompt,还是从最佳生成的prompt。首先,
prompt-based zero-shot prediction取得了比majority class好得多的性能,显示了RoBERTa的pre-encoded knowledge。另外,"GPT-3" in-context learning并不总是比zero-shot prediction好,可能是因为较小的语言模型没有足够的表达能力,不能像GPT-3那样开箱即用。第二,
prompt-based微调可以大大超过标准的微调,无论是在使用手动prompt还是生成的prompt时。CoLA是一个有趣的例外,因为输入可能是一个不符合TREC,QNLI和MRPC)。最后,在大多数任务中,在上下文中使用
demonstrations会带来一致的收益。
总之,我们的综合解决方案(用自动搜索的模板和采样的
demonstration集合进行微调)与标准微调相比,在SNLI上实现了30%的收益,平均收益为11%。ensemble-prompt的结果:automatic prompt search的一个优点是,我们可以生成我们想要的prompts,训练单个模型,并创建大型ensembles。PET也对用人工prompts训练的多个模型进行了ensemble。在Table 4中,我们对我们searched prompts和PET’s manual prompts,在MNLI和RTE(我们共同评估的两个数据集)上进行了直接比较。如结果所示,具有多个模板的
ensemble总是能提高性能。由相同数量的自动模板组成的ensemble取得了与PET’s manual prompts的ensemble相当或更好的性能。增加自动模板的数量会带来进一步的收益。如何
ensemble多个模板?作者这里未说明。读者猜测:采用PET相同的方式,对每个模板微调得到一个finetuned model,然后所有finetuned model的ensemble给测试集打上soft label。
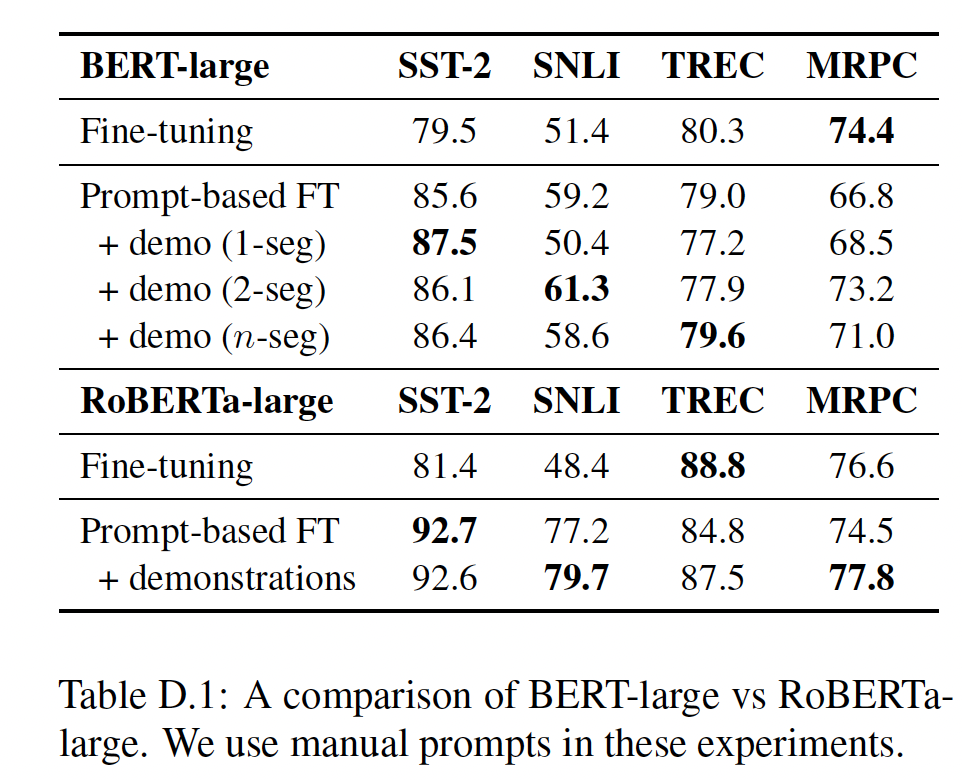
12.5.2 generated prompts 的分析
Table 5给出了使用manual prompts与automatic prompts的结果。对于automatic prompts,我们比较了模板搜索(Auto T)、label word搜索(Auto L)、以及联合搜索(Auto T + L)。在Auto T + L中,我们从manual label words开始,应用Auto T,然后是Auto L。在大多数情况下,
Auto T取得了与manual prompts相当或更高的性能,并且一直表现最佳。Auto L在TREC和MRPC上的表现优于manual prompts,但在SNLI上的表现却差很多。
Table 6显示了Auto T和Auto L的例子(完整列表见Table E.1)。Auto T模板一般都能很好地适应上下文和label words,但也可能包含有偏见的怪癖(例如,SNLI中的"{Yes/No}, no")。对于
Auto L的单词来说,情况是复杂的:虽然大多数看起来直观合理,但也有一些神秘的异常情况(例如,SNLI中"entailment"类的"Hi")。

12.5.3 demonstration sampling 的分析
Table 7比较了使用均匀采样、以及SBERT的选择性采样的demonstrations的性能。我们承认SBERT是在SNLI和MNLI数据集上训练的,因此我们也尝试了一个简单的sentence encoder,使用RoBERTa-large的hidden representations的均值池化。我们发现,无论在哪种情况下,使用选择性采样都优于均匀抽样,这突出了采样相似的样本对于纳入上下文中的demonstrations的重要性。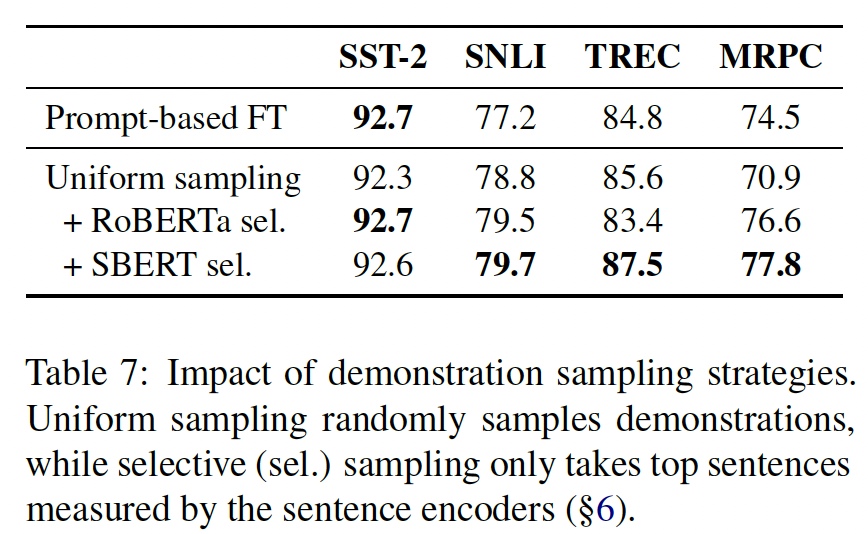
12.5.4 样本效率
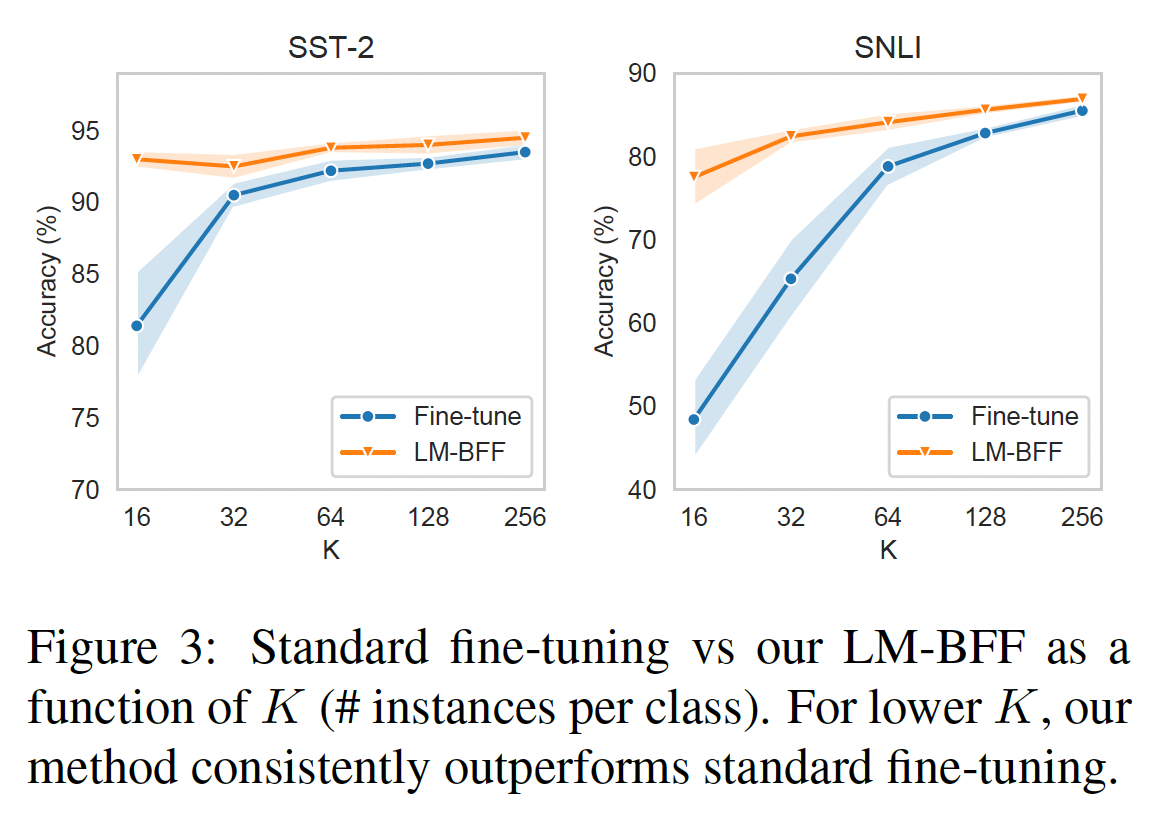
Figure 3说明了随着LM-BFF比较的结果如何。对于像
SST-2这样的简单任务(也见Table 3中的MR, CR, MPQA),尽管总共只用了32个样本,LMBFF的性能已经接近饱和,在整个数据集上与标准微调相媲美。在更难的
SNLI任务上,LMBFF随着
12.6 讨论
将
NLP任务重新表述为MLM,对few-shot learning有令人兴奋的意义,但也有局限性。首先,虽然
LM-BFF大大超过了标准的微调,但Table 3显示,总体而言,其性能仍然大大落后于有数千个样本的微调,特别是对于较难的任务。此外,就像标准微调一样,
LM-BFF的结果也受到高方差的影响。正如相关工作中所述,最近有几项研究试图解决few-shot fine-tuning的不稳定性,我们希望这些方法在这里也能有所帮助。关于
automatic prompt generation,尽管它很有效,但我们仍然发现:扩大搜索空间、或者在只有大约32个样本的基础上很好地泛化,这实际上是一个挑战。这部分地是由于我们对一些manual design的依赖,无论是manual templates(用于label word search)还是manual label words(用于模板搜索),这使我们的搜索得以启动,但也使它偏向于我们可能已经想象过的搜索空间的区域。最后,必须澄清的是,
LM-BFF倾向于某些任务:(1):可以自然地被视作"fill-in-the-blank"的问题。(2):有相对较短的输入序列。(3):不包含多个输出类别。
问题
(2)和(3)可以通过更长上下文的语言模型得到改善(例如Longformer)。对于无法在prompting中直接形式化的任务,如structured prediction,问题(1)是更基本的。我们把它作为一个开放的问题留给未来的工作。
十三、EPR[2021]
论文:
《Learning To Retrieve Prompts for In-Context Learning》
大型预训练语言模型中蕴含的出色语言技能和世界知识最近引发了自然语言理解中的新范式:
in-context learning。在这种范式下,语言模型接收一个prompt作为输入,该prompt通常包含几个训练样本,以及一个测试样本,并直接为测试样本生成输出而不对模型参数进行任何更新。这种方法首先在GPT-3中引入,但很快传播到其他语言模型中。in-context learning的一个吸引人的特点是它为多种语言理解任务提供了单个模型。然而,KATE表明,下游性能可以根据in-context examples的选择而大相径庭。这引发了对prompt retrieval的兴趣(参见Figure 1),在其中根据某些相似性度量选择训练样本作为prompts。最近的研究要么使用现成的无监督相似性度量,要么训练一个prompt retriever根据表面相似性(surface similarity)来选择样本(《Case-based reasoning for natural language queries over knowledge bases》)。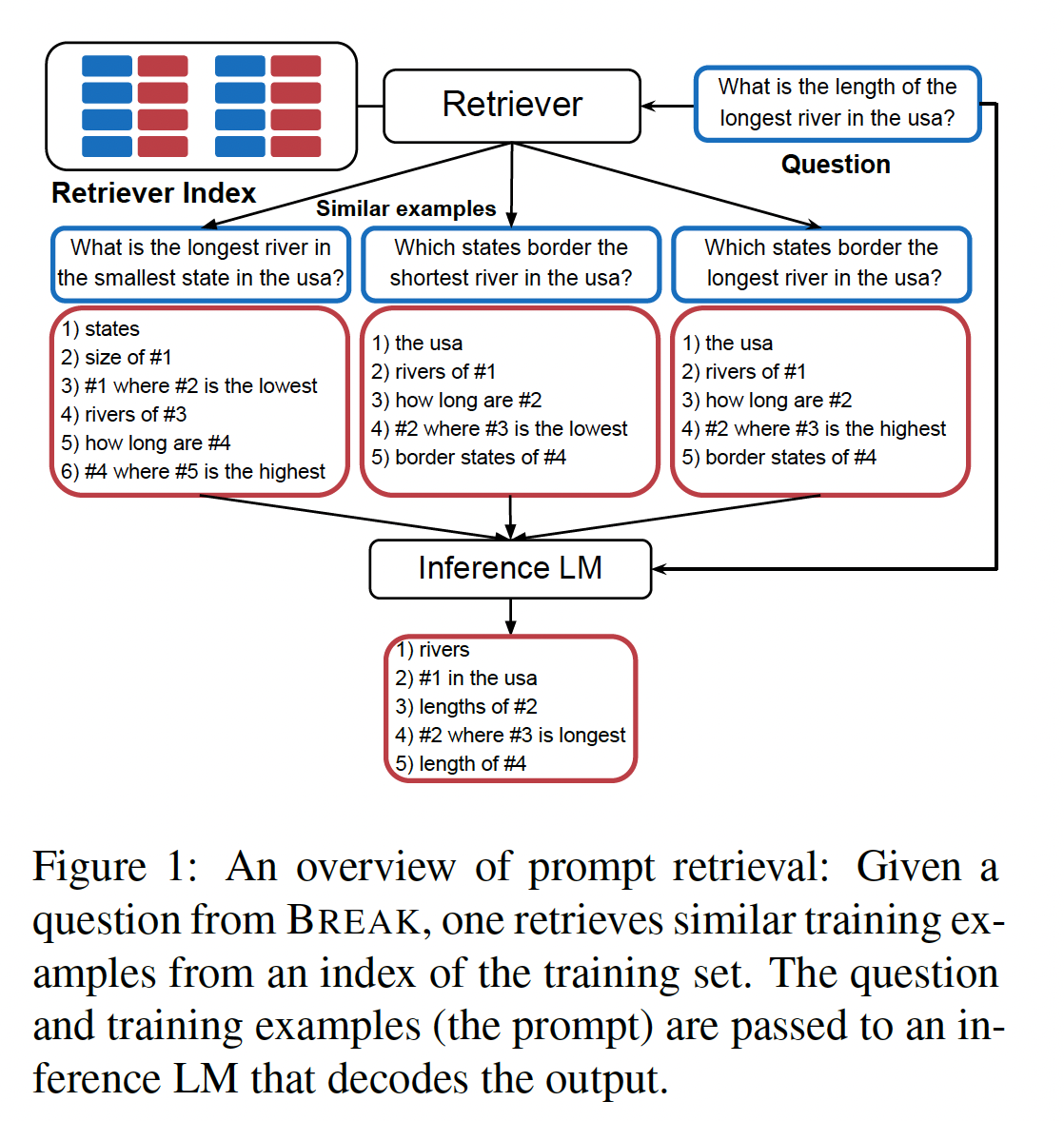
在这项工作中,我们建议使用语言模型本身来标注那些可以作为良好
prompts的样本,并从中训练一个prompt retriever。为了训练retriever(参见Figure 2),我们假设可以访问input-output pairs的训练集和一个scoring LM(一个用于对prompts进行评分的语言模型)。对于每个训练样本scoring LM估计在给定prompts的条件下,prompt retriever。我们认为,与先前提出的表面相似性启发式方法相比,使用LM对样本进行标记更好地代表了训练retriever的过程。重要的是,在创建训练数据时,我们可以访问gold labelprompts集合。这会产生良好的正样本和hard negative样本,有助于使用contrastive objective进行训练。
在训练一个高效的
retriever时使用scoring LM,在测试期间该retriever可能用不同的inference LM,有两种情况下是有益的:首先,当
scoring LM比inference LM更小并作为其代理时。这导致retriever的数据生成是廉价的、高效的,适用于广泛的研究人员。其次,即使
scoring LM和inference LM相同(例如,都是GPT-3),我们的方法也可以使用。
当我们无法访问模型参数,只能将其作为一个
service来使用时,这是有益的,而这种情况越来越普遍。在这种情况下,我们使用LM训练一个轻量级的retriever,该retriever只负责学习相似性函数。更一般地说,考虑到LM的规模在可预见的未来可能会继续增加,我们可以将我们的Efficient Prompt Retrieval: RPR方法视为一种与大型语言模型进行接口和交互学习的方法。我们在三个结构化的
sequence-to-sequence任务上对EPR进行了实证测试,这些任务涉及将输入的自然语言话语映射到语义表示:MTOP和SMCALFLOW专注于面向任务的对话、而BREAK则是一个将问题映射到基于语言的语义表示的benchmark。我们观察到,与先前的prompt retrieval方法相比,EPR在性能上有显著提升:当
scoring LM和inference LM相同(使用GPT-NEO)时,与最佳baseline相比,在BREAK任务上的性能从26%提高到31.9%、在MTOP任务上从57%提高到64.2%、在SMCALFLOW任务上从51.4%提高到54.3%。当将
GPT-NEO作为更大的语言模型(GPT-J, GPT-3, CODEX)的代理时,我们观察到类似的收益,在所有情况下性能都有显著提高。
总之,我们提出了一种在大型语言模型中检索用于
in-context learning的训练样本的方法,并展示了它在性能上显著优于先前的方法。鉴于最近在scaling语言模型方面的发展,设计与语言模型交互的高效方法是未来研究的重要方向。我们的代码和数据公开于https://github.com/OhadRubin/EPR。这里面包含四个模型:
一个无监督模型,用于检索候选训练样本集合(即,图中的
一个评分模型,用于为候选训练样本集合打分(即,图中的
一个对比学习模型(基于
BERT的模型),用于学习一个相似性度量。一个
inference模型,用于执行推断。
训练期间最终得到的是这个对比学习模型。在推断期间使用对比学习模型、
inference模型。无监督模型、评分模型主要用于生成label从而用于训练期间的对比学习。核心思想是:如何判断样本之间的相似性。可以基于无监督的
sentence embedding来得到。也可以通过监督学习来得到。对于监督学习,最重要的是如何得到针对相似性的标签。相关工作:
In-context learning:最近,incontext learning的工作显著增长。《A mathematical exploration of why language models help solve down stream tasks》指出,通过以prompt为条件,预测next word的任务接近线性可分性。《An explanation of in-context learning as implicit bayesian inference》提出,在in-context learning中,模型推断出prompt中样本之间的共享潜在概念(shared latent concept)。《Rethinking pretraining example design》提出了一种理论上基于in-context learning的bias的预训练方案,取得了显著的改进。最近,
《Rethinking the role of demonstrations: What makes in-context learning work?》表明,模型并不像之前认为的那样严重依赖于示范中提供的ground truth input-label mapping。
Retrieval:近期对训练dense retrievers的研究大幅增加,这得益于对开放域问答的兴趣。基于检索的方法的研究也在其他知识密集型任务中得到广泛应用(《Retrieval-augmented generation for knowledge-intensive NLP tasks》),例如fact verification(《Improving evidence retrieval for automated explainable fact-checking》)。类似于我们,
《Controllable semantic parsing via retrieval augmentation》提出在semantic parsing中使用检索。然而,他们侧重于控制模型所生成的输出。检索方法也在语言建模和机器翻译(《Nearest Neighbor Machine Translation》)中取得了成功应用。Prompts:开发用于语言模型的交互以及提取期望行为的方法已经引起了广泛关注,这些方法统称为prompting。在这项工作中,prompts是一组in-context training examples,但也有相当多的工作致力于通过用自然语言表述目标任务从而将自然语言任务转化为语言建模的形式(参见《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》)。这些方法包括通过manual patterns、decoding methods、以及自动提取hard prompts或soft prompts的方法进行prompt engineering。用于监督模型的
prompt retrieval:与此工作并行进行的是,对于监督模型而言,添加训练样本作为额外输入也被证明是有用的。《Training data is more valuable than you think: A simple and effective method by retrieving from training data》和《Human parity on commonsense qa: Augmenting self-attention with external attention》使用BM25并利用来自训练集的相似样本来检索和augmentinput。使用额外inputs对模型进行微调可以提高摘要和问答等任务的性能。这样的方法也有可能从更强的retriever中受益。
13.1 方法
Prompt Retrieval:问题介绍:给定一个由
input-output序列组成的训练集retrieverretriever能够检索一组训练样本prompt。给定
inference LMprompt应该在将测试样本prompttarget output sequence。具体而言,从LMsemantic parsing),其中meaning representation)。先前工作:
KATE研究了不同prompts对GPT-3性能的影响,并证明了in-context examples的选择对下游性能有很大影响。他们使用了一个无监督的sentence encoder对训练样本进行编码,并为每个测试样本检索了其最近邻。《Case-based reasoning for natural language queries over knowledge bases》针对知识库问答训练了一个监督的prompt retriever。该retriever通过监督信号来训练,这个监督信号针对知识库query来定制并依赖于query之间的表面相似性(surface similarity)。相反,我们的方法利用了生成式语言模型本身,因此更加通用。《Constrained language models yield few-shot semantic parsers》使用GPT-3为few-shot semantic parsing选择prompt的样本。然而,他们并没有训练一个retriever,,而是随机从训练集中抽取大量的utterance-program pairs,并根据GPT-3来选择与target instance question相似的pair。这导致了一个昂贵的推理过程,对于每个测试样本,需要运行数百次GPT-3,而不像我们的方法,它基于一个轻量级的亚线性retriever。
我们现在描述一种用于训练
EPR的方法,即一种用于in-context learning的efficient prompt retriever。首先,我们描述如何生成带标签的训练数据,然后介绍如何使用训练数据进行训练和推理。Figure 2概述了训练过程。这个
retriever的核心是如何对训练样本进行编码。
13.1.1 生成训练数据
我们的方法依赖于找到哪些训练样本可以作为其他训练样本的
good prompts。对所有training examples的pairs进行打分的计算复杂度是target序列input在输出序列方面相似的样本,这可以通过简单的检索方法来实现。为了生成高质量的候选训练样本集合,我们利用了一个无监督
retriever,即retriever的选择,我们尝试了基于表面文本相似性的sparse retrieverBM25、以及SBERT,并发现使用对候选集合打分:一旦对于训练样本
scoring LMinference LMcandidate prompt的得分为:其中:
LMpromptprompt在解码目标时的帮助程度(独立于其他候选prompt)。我们认为这个评分相比先前的方法更好地代表了训练样本在inference时的效用。我们将这个评分函数应用于所有的训练样本,并为每个训练样本定义了一组正样本
top-k个候选样本;以及一组负样本bottom-k个候选样本。这样做应该会得到relevant positive examples,假设候选集good prompt candidates和hard negatives,因为根据positive examples和negative examples,我们现在可以应用对比学习,接下来我们将描述这个过程。
13.1.2 Training and Inference
训练:我们的训练过程与
DPR(《Dense passage retrieval for open-domain question answering》) 中的对比学习过程完全相同。该过程得到一个接收input tokens序列input encodercondidate prompt的prompt encoderBERT-base进行初始化,并且通常情况下,输出向量表示由CLS token给出。训练的目标是学习一个相似度度量,使得对于给定的测试样本我们的训练样本的形式为
hard negative、同一个mini-batch中其他样本的hard negative所组成。我们将input和input-output pair之间的相似度得分定义为内积contrastive learning objective,并对每个样本最小化positive exam的负对数似然:这种方法的一个优点是,在
batch-size = B的情况下,利用in-batch negatives技巧 (《Efficient natural language response suggestion for smartreply》),有效batch size的数量级为Inference:训练input encoder和prompt encoder之后,我们使用FAISS在预处理步骤中对整个训练样本集进行编码。在测试时,给定输入序列final promptinference LM最相似的训练样本距离
需要注意的是,在训练时,我们独立地对每个训练样本进行评分;而在测试时,我们使用训练样本的集合。关于不同训练样之间的依赖关系建模留待将来研究。
13.2 实验
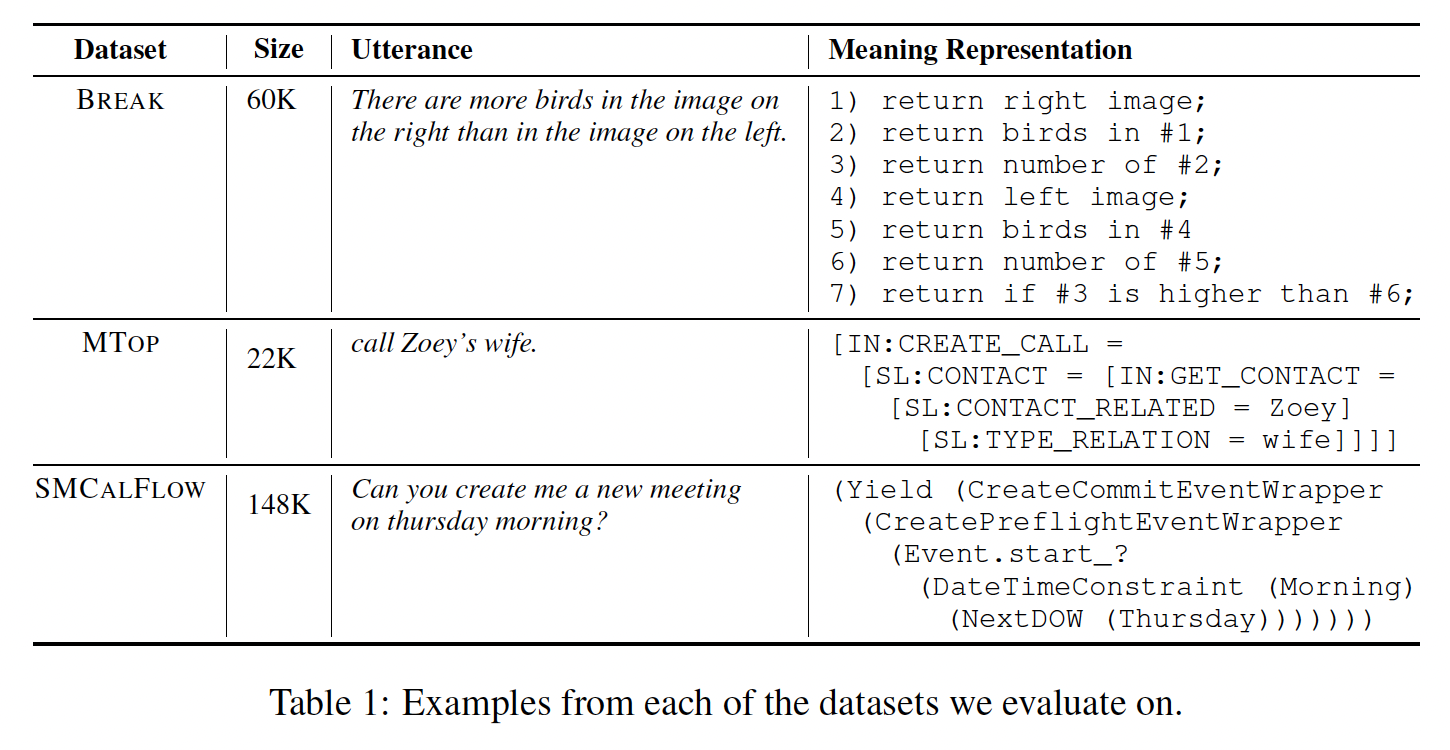
数据集:我们专注于将言语(
utterances)映射到meaning representations的任务,其中in-context examples可用于学习从输入到输出的映射。每个数据集的样本数量如Table 1所示。BREAK:这是一个将复杂自然语言问题映射为基于语言的meaning representation的数据集,其中问题被分解为有序的原子步骤的列表。我们使用low-level BREAK subset,其中training/development/test集合分别包含44K/7K/8K个样本。MTOP:这是一个语义解析数据集,专注于面向任务的对话,将命令映射为跨越11个领域的复杂嵌套query。我们使用MTOP的英语子集,其中training/development/test集合分别包含16K/2K/4K个样本。SMCALFLOW:这是一个涵盖日历、天气、地点和人物等任务的大型英文的面向任务数据集。其meaning representation是一个数据流程序,包含API调用、函数组合、以及复杂约束。SMCALFLOW包括15K个development集合的样本、134K个训练样本,我们从训练集中随机抽取了44K个样本用于训练。
baseline:首先我们考虑无监督的
baseline,它们都仅在测试期间使用:RANDOM:我们从训练集SBERT:我们使用SentenceTransformers库提供的BERT-based sentence embeddinngs。具体地,我们使用paraphrase-mpnet-base-v2,一个包含110M参数的模型,来编码测试语句in-context examples。这就是
KATE的思想。BM25:我们使用经典的sparse retrieval方法BM25,它是TF-IDF的一种扩展,用于检索与每个测试语句BRUTEFORCE:我们应用了《Constrained language models yield few-shot semantic parsers》提出的用于few-shot semantic parsing的prompt selection方法。给定一个测试样本200个训练样本。对于每个训练样本prompt。与我们类似,这种方法使用inference LM来选择prompts。然而,它是在测试时进行的,这导致推理速度较慢。
接下来,我们描述使用训练集
prompt retriever的基线方法。所有监督方法都共享以下模板。首先,使用
unsupervised retrieverBM25作为unsupervised retriever,因为它在性能上优于SBERT(参见后面的实验部分)。然后,对每个候选prompttop-k prompts标记为positive examples,bottom-k examples作为负例(DR-BM25:我们使用原始的BM25分数对正例和负例进行标记,并训练一个dense retriever。CASE-BASED REASONING (CBR):我们改编了《Case-based reasoning for natural language queries over knowledge bases》的评分函数,他们专注于知识库问答。他们定义了关于两个逻辑形式的权重,该权重是这两个逻辑形式中出现的关系集合之间的F1分数,并使用该权重对数据进行软标记。由于在我们的设置中,我们不假设逻辑形式,所以我们将输出序列tokens集合之间的F1分数,忽略停用词。EFFICIENT PROMPT RETRIEVAL (EPR):我们提出的完整方法。
最后,我们考虑两个
oracle模型:BM25-ORACLE:我们使用gold output sequenceDR-BM25能够学习到的上限。EPR有可能胜过这个oracle模型,因为它的训练信号超出了表面文本相似性。LM-ORACLE:我们在测试时使用针对训练数据标记的过程。给定一个测试样本scoring LMprompts的情况下生成EPR提供了一个上限,因为EPR的训练目标是模仿这种行为。
实验细节:
语言模型:在这项工作中,我们只训练了一个
dense retriever,但使用了scoring LM和inference LM。对于scoring LMGPT-NEO,一个在The Pile(由各种高质量资源构建而成的825 GB英文文本语料库)上训练的2.7B参数的语言模型。此外,我们考虑了以下
inference LM:GPT-J(600M参数)、GPT-3(175B参数)、CODEX(在GitHub的代码上进行微调的GPT-3 175B参数模型)。由于我们的任务涉及从话语到程序或meaning representations的映射,CODEX在in-context learning方面可能表现出色。对于所有语言模型,我们使用最大上下文大小
tokens。注意:还有两个模型也很重要:
unsupervised retrieverBERT的模型)。评估:
在
BREAK上,我们使用LF-EM(《Question decomposition with dependency graphs》)在开发集上评估性能。LF-EM是一种比官方指标Normalized Exact Match: NEM更好的指标,因为它衡量两个meaning representations是否在语义上等价。在测试集上,我们使用NEM进行评估。在
MTOP和SMCALFLOW上,我们使用Exact Match: EM进行评估,即inference LM生成的字符串是否与reference字符串完全相同。
我们在两种设置下评估
EPR:LM-as-a-service、和LM-as-a-proxy。LM-as-a-service:我们将GPT-NEO用作scoring LM和inference-LM。在此设置中,我们在BREAK、MTOP、SMCALFLOW的完整开发集上进行评估。LM-as-a-proxy:由于我们通过付费API访问GPT-3和CODEX,我们从每个数据集中随机抽取1000个开发集样本的子集,并对每个模型在此子集上进行一次评估。
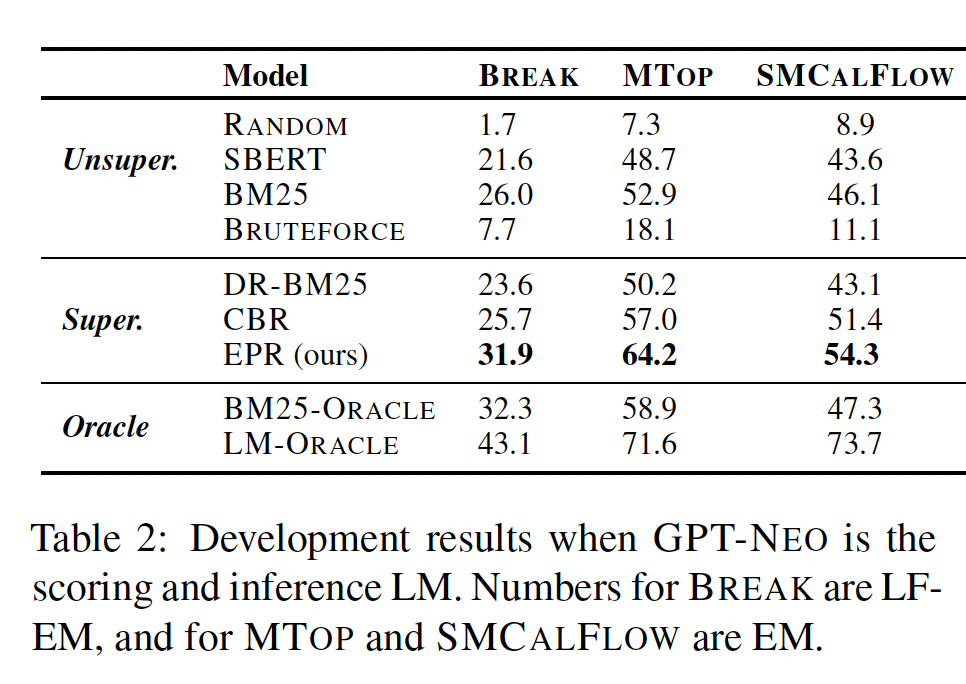
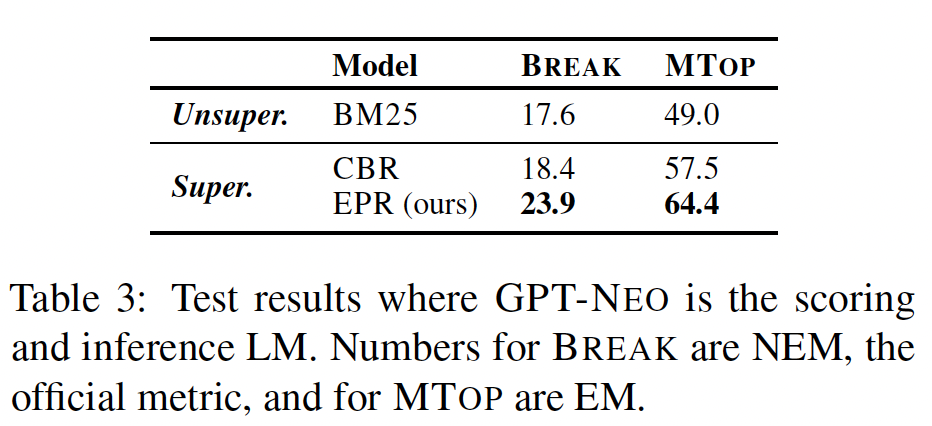
LM-as-a-service:Table 2报告了在开发集上,scoring LM和inference LM相同的结果。EPR在所有其他基线方法中表现出色。具体而言,与最佳基线相比,它将BREAK上的性能从26.0提高到31.9,将MTOP上的性能从57.0提高到64.2,将SMCALFLOW上的性能从51.4提高到54.3。这表明使用LM本身来标注样本是获得强大的prompt retriever的有效方法。Table 3显示了BREAK和MTOP上的测试集结果,证实EPR相对于BM25和CBR显著提高了性能。对于无监督方法:
RANDOM基线表明随机抽样训练样本导致性能较差。BM25在prompt retrieval中优于SBERT,因此我们在所有监督方法中使用BM25来检索候选集合最后,
BRUTEFORCE的性能不如BM25。我们认为这是因为训练集很大(约14K-120K个样本),抽取200个样本无法涵盖对GPT-NEO有用的样本。
有趣的是,
EPR在MTOP和SMCALFLOW上优于BM25-ORACLE,在BREAK上与BM25-ORACLE相当。这令人惊讶,因为BM25-ORACLE在测试时可以访问输出序列scoring LM提供的训练信号超出了表面文本相似性。LM-ORACLE的性能远高于EPR,表明scoring LM提供的监督很强,通过从该信号中训练更好的retriever可以显著提高性能。
我们进一步在
one-shot setup中评估我们的模型,即当提供给inference LM的prompts仅包含最高得分的样本时。在这种设置下,inference LM的应用方式与生成labeled data时相同,其中我们独立地处理每个prompt候选。由于训练时和测试时更加一致,我们可以预期EPR的优势更加明显。Table 4显示了结果。确实,EPR的性能优于最佳基线8.5%、优于BM25-ORACLE 5%。此外,我们还研究了ANYCORRECT-ORACLE,它测试由BM25返回的任何候选是否导致正确输出。ANYCORRECT-ORACLE达到了53.6%,比LM-ORACLE高20个百分点。这表明BM25提供的候选样本的高质量,因为只需单个prompt就可以达到超过50%的LF-EM。此外,这也暗示一个更好的评分函数有可能进一步提高性能。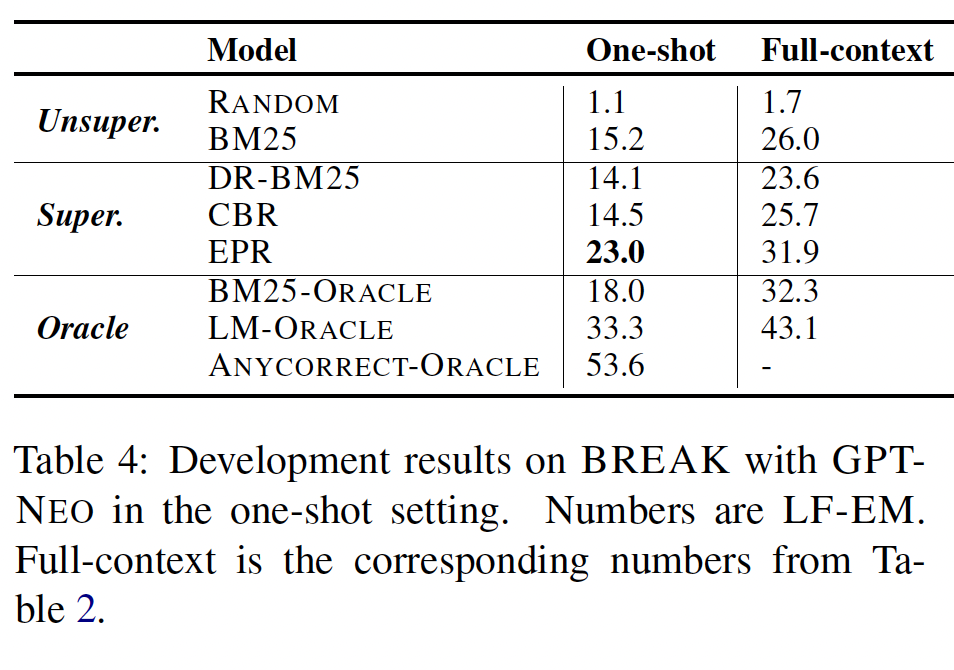
LM-as-a-proxy:Table 5显示了当scoring LM为GPT-NEO、而inference LM为更大的语言模型时的结果。首先,趋势与
LM-as-a-service设置相似,即EPR在所有数据集和预训练模型上均比先前的基线(包括最佳无监督基线BM25和最佳有监督基线CBR)提高了2-8个百分点。因此,GPT-NEO时选择训练样本的良好代理。为了进一步验证这一发现,我们评估了
GPT-J在BREAK上的性能,其中GPT-NEO作为scoring LM,与使用GPT-J本身作为scoring LM进行比较。我们发现性能略有改善,从31.5提高到33.6。类似地,当使用CODEX作为scoring LM和inference LM时,性能基本保持不变:29.5 -> 29.3。因此,使用较小的语言模型(GPT-NEO)是训练一个将应用于其他语言模型的retriever的有效策略。在不同的inference LM中,由于GPT-J是使用与GPT-NEO相同的数据和相同的过程进行训练的,因此在所有方面表现略好于GPT-NEO。CODEX优于GPT-3的原因可能是它是使用代码进行训练的,而我们的数据集涉及到将输入映射到程序或meaning representations。令人惊讶的是,尽管体积较小30倍,GPT-J在除MTOP以外的所有数据集上都优于CODEX和GPT-3。这可能可以解释为GPT-J是在不同的数据集(The Pile)上进行训练的。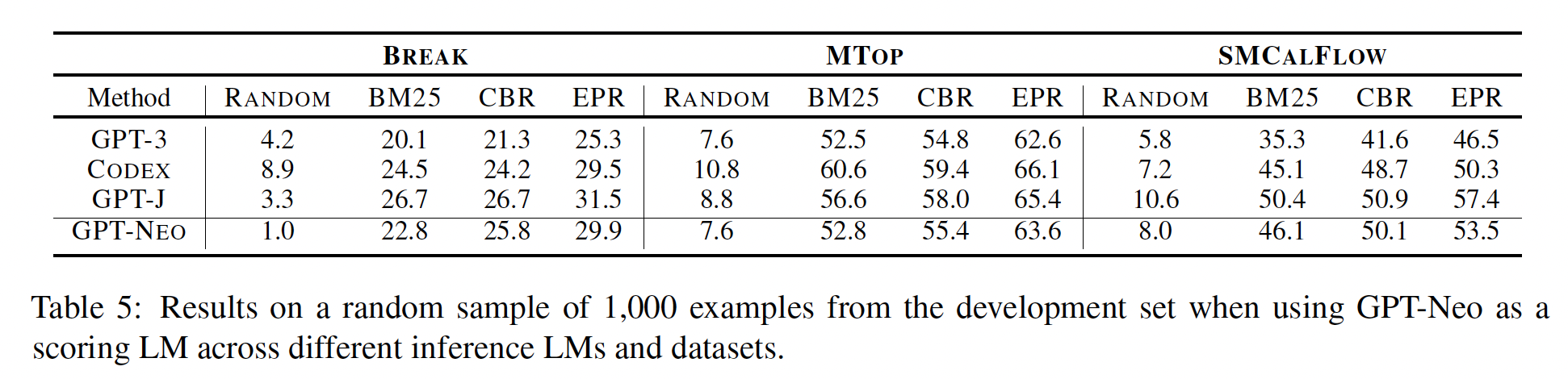
分析:
Table 6显示了来自BREAK的一个样本,其中EPR解码出了正确的输出,而CBR没有。EPR检索到的所有训练样本都执行了argmax(原始utterance中的argmin),并在最后一步返回"a code",而CBR检索到的第三个样本既没有执行argmax或argmin,也没有涉及"a code"。我们在附录A中提供了其他例子。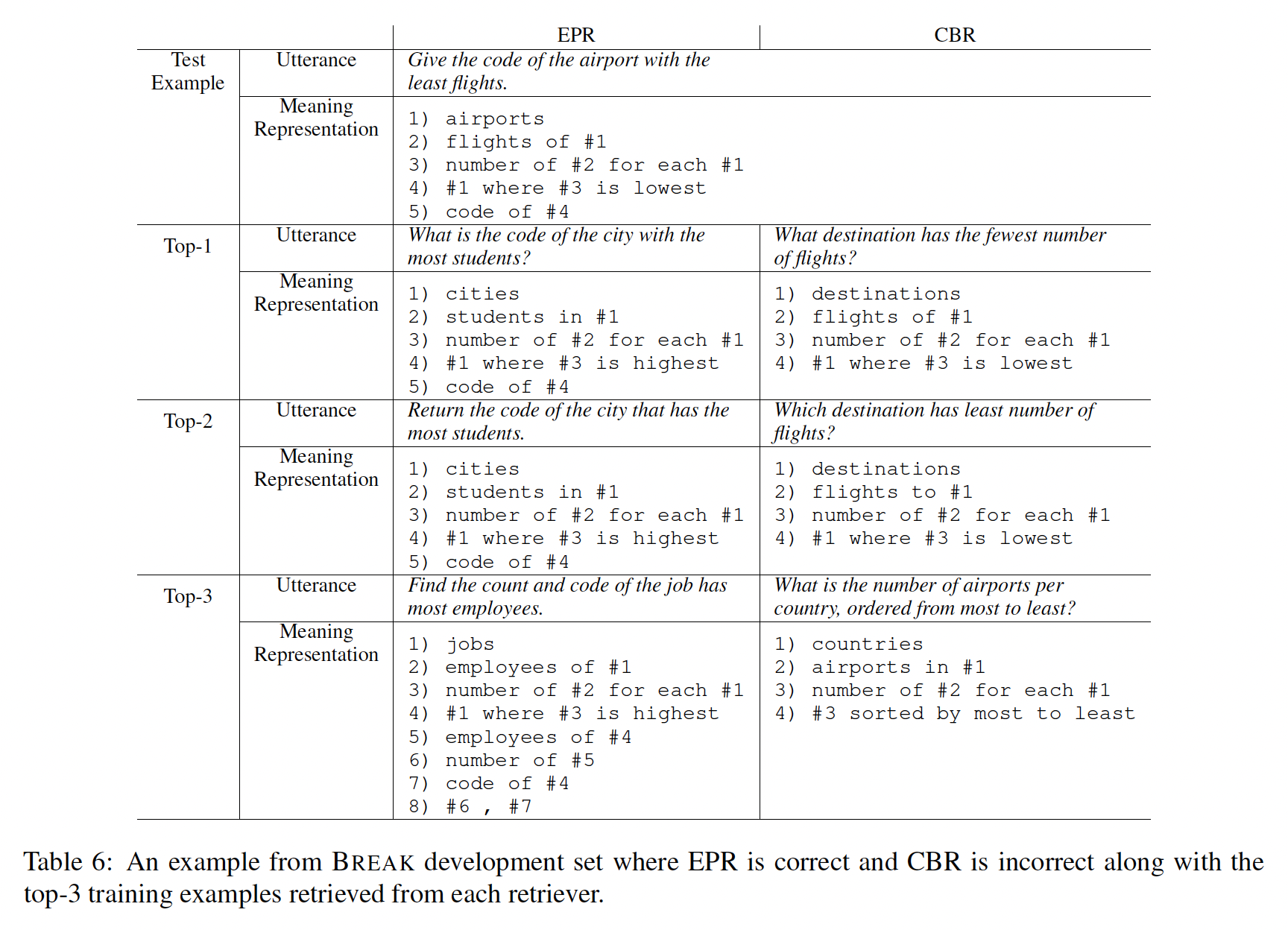
Figure 3显示了EPR学到的BREAK训练样本的embedding的t-SNE投影(其网页交互版本参考网址https://anonymous.4open.science/w/Learning-to-retrieve-prompts-for-in-context-learning-1C4F/),我们在其中应用了OPTICS聚类算法。检查聚类显示EPR捕捉到了词汇相似性和结构相似性。附录A中还提供了一些聚类的例子。
Prompt copying:我们分析语言模型如何利用in-context prompts。具体而言,我们想知道target output是直接从prompts中复制的还是由不同prompt片段组合而成,从而实现对新结构的泛化。为了实现这一点,我们定义了两种类型的复制行为:
精确复制:用于衡量生成的输出是否与
prompt中的任何样本完全匹配。抽象复制:用于量化生成的输出结构是否与
prompt中的任何结构相匹配。具体而言,我们消除了逻辑形式中的非结构元素(如实体和函数参数)的影响。我们将输入中出现的每个单词序列替换为字符串
[MASKED],包括target utterance和in-context examples。如果语言模型解码的掩码逻辑形式(masked logical form)出现在prompt定义的掩码样本集合中,我们就说语言模型复制了该抽象模式。
Table 7展示了我们在验证集上对三个数据集的结果,以及每个子集上的准确率。我们观察到,在MTOP和SMCALFLOW中,复制的率要高得多,抽象复制达到80%以上。此外,在发生复制的样本中,准确率要比未发生复制的样本高得多。例如,在MTOP上,有84.5%的样本进行了抽象复制,在这些样本中,EPR的EM为71.6%,而在整个验证集上的EM为64.2%。然而,即使在没有发生复制的情况下,准确率也不可忽视(23.4%),这表明模型在对新结构进行某种形式的泛化。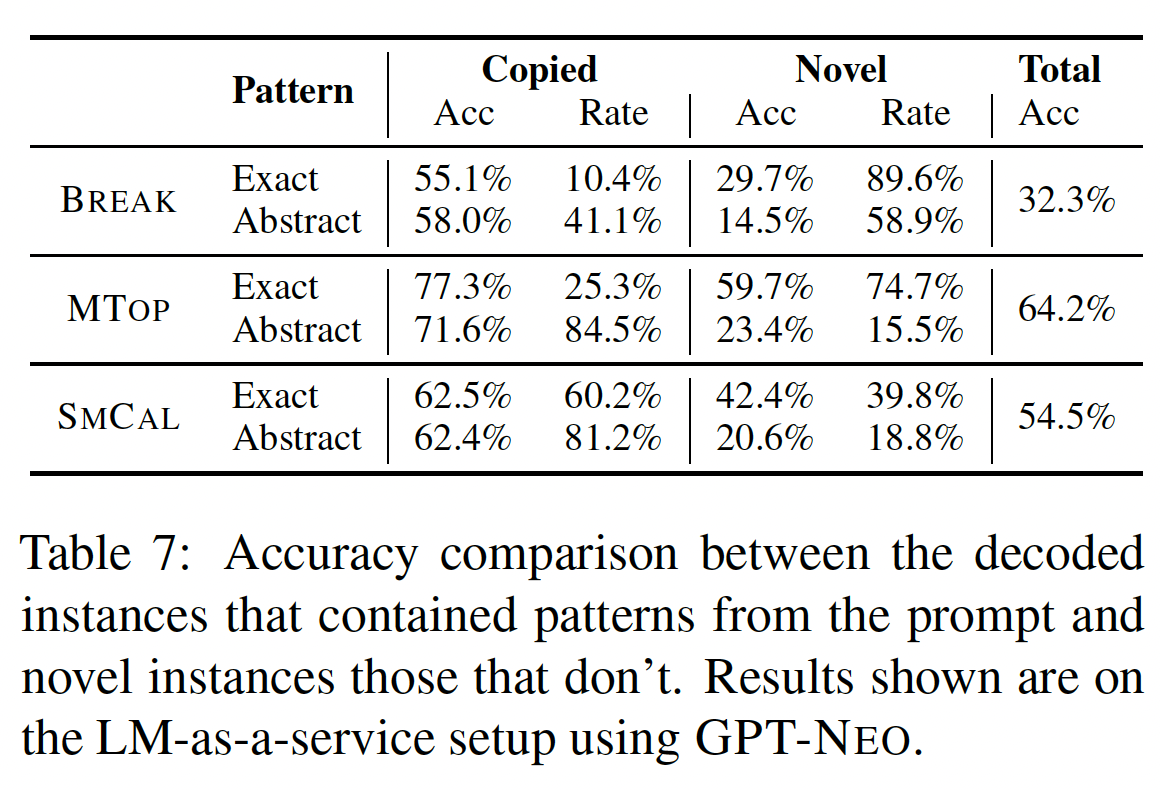
另一个后续的问题是模型是否均匀地从
prompts中复制模式,还是主要关注检索分数较高的prompts。为了回答这个问题,我们观察发生复制的样本子集。然后,我们为每个样本确定被复制的排名最高的prompt,并定义该prompt的distance指标为:该排名除以拟合该样本的prompts数目。Figure 4显示了BREAK数据集上的distance分布情况。我们观察到,复制主要来自排名较高的prompts。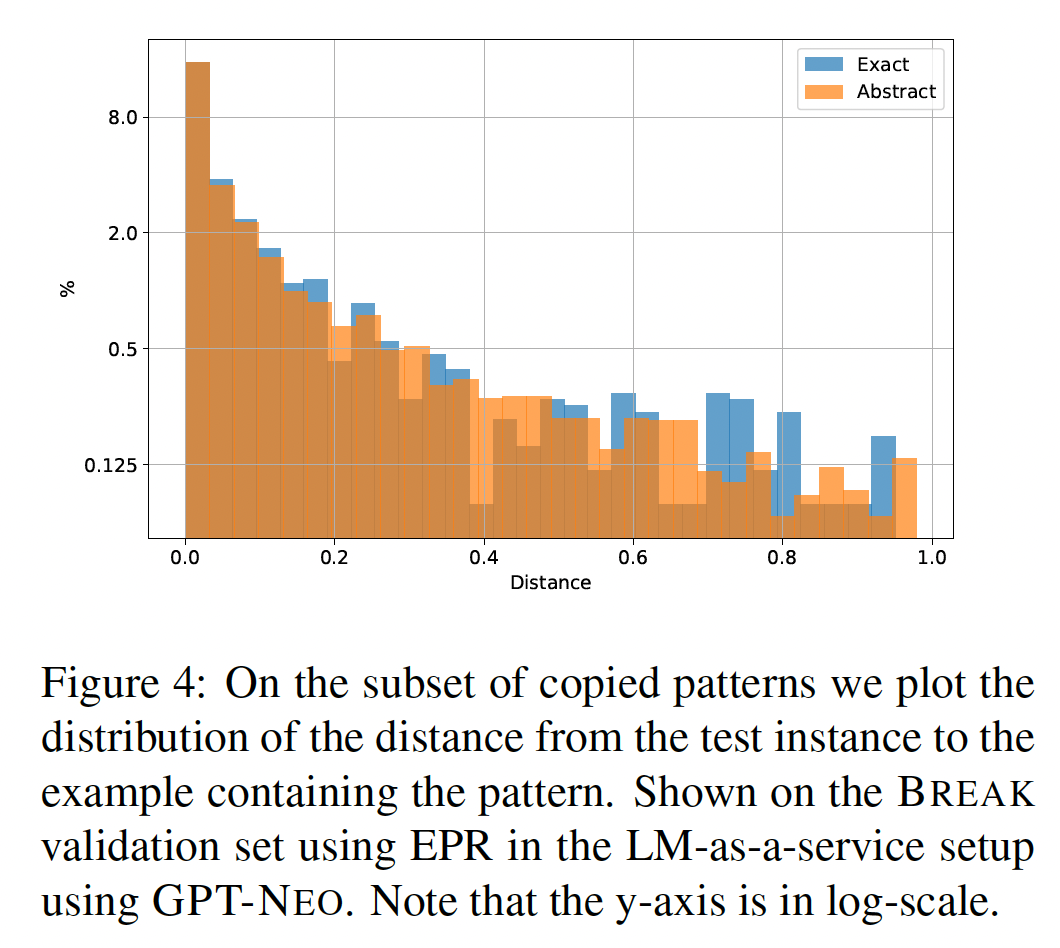
十四、ADAPET[2021]
论文
《Improving and Simplifying Pattern Exploiting Training》。
近年来,
pretrained语言模型在各种自然语言处理任务上显示出显著的进步(BERT、GPT、T5)。这些进步的大部分是通过在特定任务的标记数据上微调语言模型获得的。然而,当下游任务的标记数据非常有限时,性能可能会受到影响(《Unsupervised data augmentation for consistency training》、《Mix-Text: Linguistically-informed interpolation of hidden space for semi-supervised text classification》)。最近,
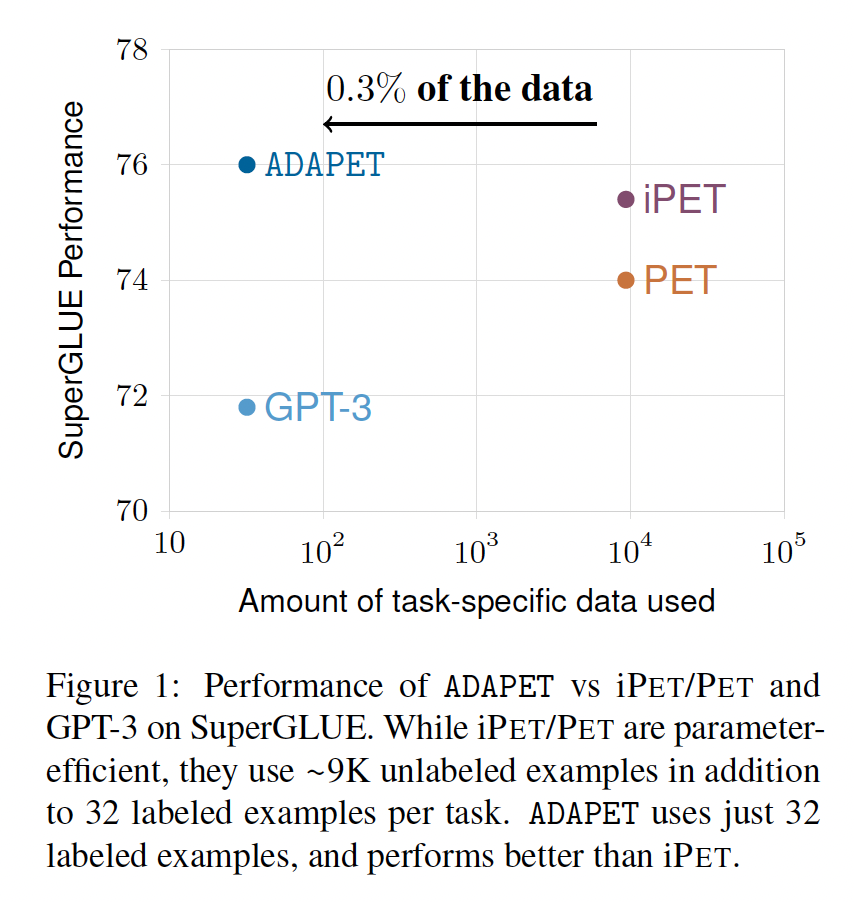
GPT-3展示了当语言模型扩展到千亿级参数时,它们可以在仅用少量标记样本来prompted的情况下学习得很好。然而,GPT-3(175B参数)的规模使其难以研究。因此,需要开发更小的语言模型,这些模型即使在标记数据有限的情况下也能同样好地工作。Pattern-Exploiting Training: PET(PET、PET-2)将自然语言理解任务重新表述为完形填空风格的问题,并进行gradient-based fine-tuning。通过这种方式,PET使用仅少量标记样本的ALBERT就优于GPT-3。然而,PET使用额外的task-specific的未标记数据。我们提出了
A Densely-supervised Approach to Pattern Exploiting Training: ADAPET,它通过解耦label tokens的损失、以及作用在整个原始输入的label-conditioned masked language modeling objective来提供更多的监督。 在SuperGLUE上,每个任务有32个标记样本,ADAPET优于iPET,并且没有任何未标记数据。核心思想:更多的掩码、更多的损失项。
当拼接正确的
label时,可以掩码label使得最大化correct label的概率、掩码input token使得最大化input token的概率。当拼接错误的
label时,可以掩码label使得最小化incorrect label的概率、掩码input token使得最小化input token的概率。
14.1 背景知识
完形填空风格的问题和
MLM:完形填空任务是一种问题,其中,文本中的某些部分被删除,而任务的目标是根据上下文填补缺失的部分。这里,被删除了某些部分的文本被认为是一个完形填空风格的问题。受完形填空任务的启发,BERT引入了MLM objective,该objective试图预测完形填空问题中masked position的原始单词。符号:令
masked locationtokenmasked locationlogit值。Unlabeled Data Access:PET、PET-2假设可以访问task-specific的未标记数据。对于某些应用程序(如情感分析),未标记数据可以便宜地获取。 但对于SuperGLUE,其中样本是带标签的text pairs,其中样本是被构建用来测试模型的自然语言理解能力,则获取未标记数据可能更昂贵。 例如,BoolQ的构建要求标注员在分配标签之前过滤good question-article pairs。 因此,在我们的设置中,我们不假设可以访问task-specific的未标记数据,这与GPT-3的设置一致。PET:我们的工作主要建立在PET(PET、PET-2)的基础上。PET将样本转换为完形填空风格的问题,类似于预训练期间使用的输入格式。PET中的query格式由Pattern-Verbalizer Pair: PVP来定义。每个PVP由以下两部分组成:一个
pattern:描述如何将输入转换为带有masked tokens的完形填空风格的问题。我们在Figure 2(a)中为entailment任务进行了说明。这里,我们使用模式<premise>? <mask>, <hypothesis>将前提"Oil prices fall back"和假设"Oil prices rise"转换为完形填空风格的问题。一个
verbalizer:描述如何将classes转换为tokens的输出空间。在Figure 2(a)中,verbalizer将"Not Entailment/Entailment"映射到"No/Yes"。
在为给定任务设计
PVP之后,PET从模型logit(在single-token label的情况下)。给定output tokens的空间Figure 2(a)中为{"Yes", "No"}),PET在logit来计算softmax。final loss如下所示:其中:
ground-truth,CE为交叉熵损失函数。PET还从不同模型的ensemble中蒸馏知识,这些模型从具有不同模式的标记数据和未标记数据上训练而来。iPET是PET的迭代式变体,它在迭代中训练模型:根据前一轮迭代的标签,每次迭代的训练集规模逐渐增大。 有关跨任务使用的不同patterns的描述,请参阅附录A.1。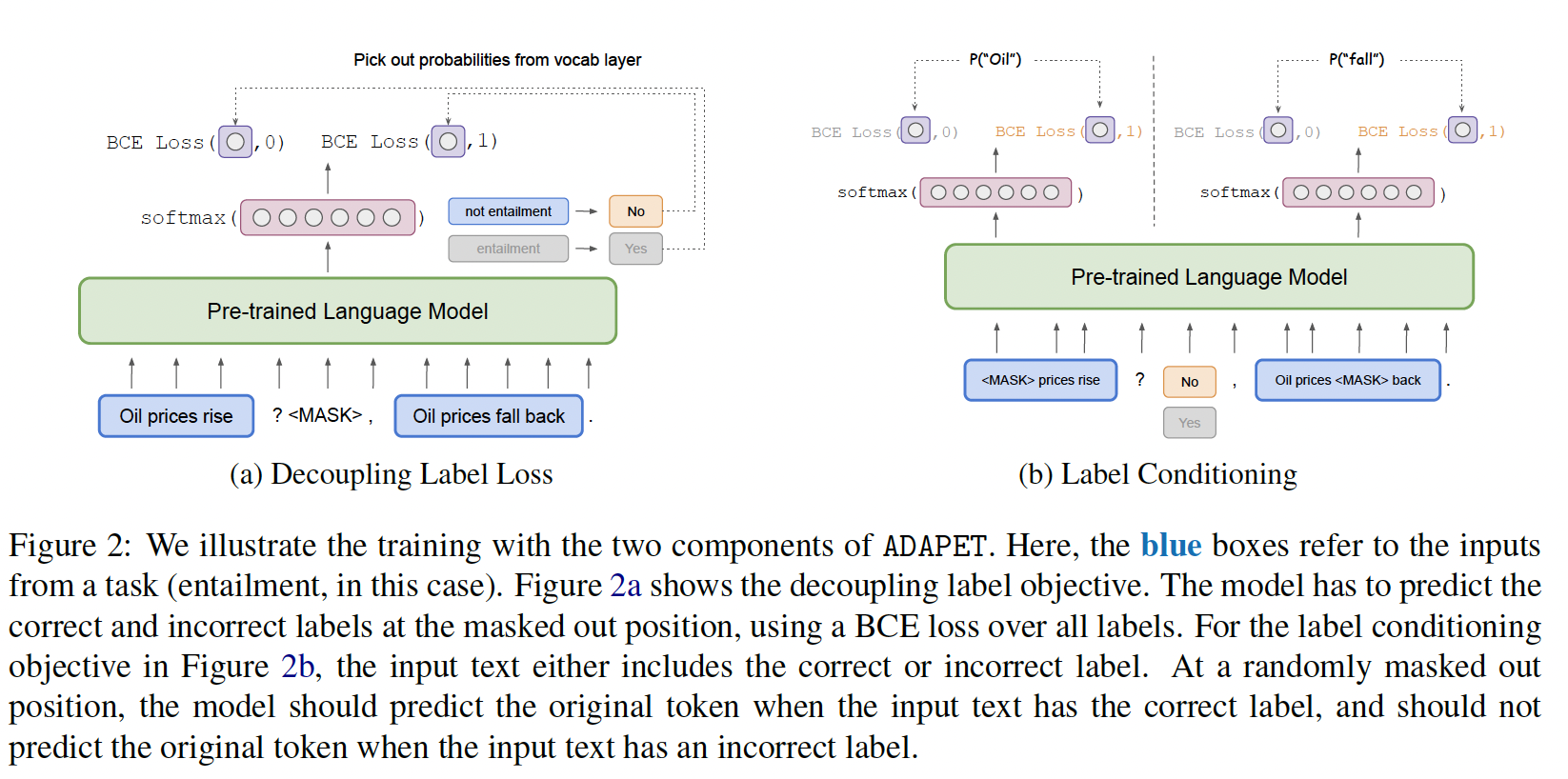
14.2 方法
我们提出的方法称为
ADAPET,它修改了PET的objective,以便在没有task-specific的未标记数据的情况下提供更多的监督并且学习。解耦
Label Losses:PET为specific task使用labels相对应的logits来计算class概率。这丢弃了词表中的所有其他与label无关的logits的信息。例如,在Figure 2(a)中,"oil"不是一个class token,所以LM head应该赋予"oil"一个低概率。但是,因为PET只提取与labels对应的token logits,所以non-label tokens永远不会有任何梯度信号。一个解决方案是将
objective改为常规的MLM objective。在这种情况下,incorrect classes对应的tokens与词表中的任何其他tokens之间没有区别。例如,在Figure 2(a)中,模型将被训练为把"Yes"(incorrect token)与其它任何tokens(如"oil")同等对待。虽然我们希望模型抑制"oil",但training objective仍应更加抑制"Yes"。在
ADAPET中,我们惩罚incorrect class tokens并鼓励correct class tokens。具体而言,模型在所有tokens上计算每个token的概率(归一化的softmax),以便每个概率都受到词表中所有tokens的logit的影响。然后,我们最大化correct class tokens的概率、最小化incorrect class tokens的概率。这相当于二元交叉熵,如Figure 2(a)所示。正式地,如果
该损失函数可以重写为使用二元交叉熵:
softmax交叉熵的近似。为不同任务统一损失函数:对于标签正好是
one token的常规任务,PET使用公式WSC,它没有incorrect class labels,PET使用原始的MLM objective而不是ADAPET中等效于没有第二项的对于其他具有
multi-token labels的任务(COPA, ReCoRD),PET将类别概率计算为单个token的对数概率之和。但是,如何将这些label概率转换为有效的概率分布,这还不是很清晰。PET没有归一化概率,而是使用hinge loss来确保correct label和incorrect labels之间有间隔。在
ADAPET中,对于标签中的每个token,correct tokens与每个其他tokens区分开来,这是通过以下损失:这个目标函数将
single loss based on multiple tokens拆分为multiple losses over single tokens。因此,我们不需要将单个tokens的概率相乘,也就不会遇到归一化问题。类似于
bag-of-words,这里认为多个tokens之间是独立的。Label Conditioning:PET objective包含问题:"Given the input, what is the right label?"。但是,由于输入空间和输出空间都由tokens组成,我们也可以问逆问题:"Given the answer, what is the correct context?"。模型被训练来预测给定标签的输入。正式地,设
tokens而来,tokens。在label conditioning objective中,我们关注量label的条件下预测输入中的masked tokens。在训练期间,如果标签是正确的,模型必须预测
original token,如Figure 2(b)所示。另外,如果标签是错误的,模型会被迫不预测original token。我们最大化decoupling label losses方法相同,只是输入和输出不同:ADAPET的final loss是decoupled label loss和label-conditioned MLM loss的总和。Label Conditioning和Label Losses可以统一起来:首先将输入和
correct label拼接起来:掩码label并预测label token、掩码输入并预测输入,最大化这两个概率。然后将输入和
incorrect label拼接起来:掩码label并预测non-label token、掩码输入并预测输入,最小化这两个概率。
注意:在训练的时候考虑
14.3 实验
我们在
SuperGLUE上运行实验,遵循PET-2的相同data split,其中每个任务包含32个标记样本。我们的代码使用
Pytorch在HuggingFace上的实现。 我们使用与PET相同的预训练模型和超参数,但将training batches的数量增加到1k,并在开发集上选择最佳checkpoint,因为训练steps数量更长的效果更好,即使是少量样本(《Revisiting few sample BERT fine-tuning》)。 对于所有消融实验,我们仅使用first pattern训练250个batches。 更多详细信息请参阅附录B。由于我们不假设可以访问未标记数据,我们不对
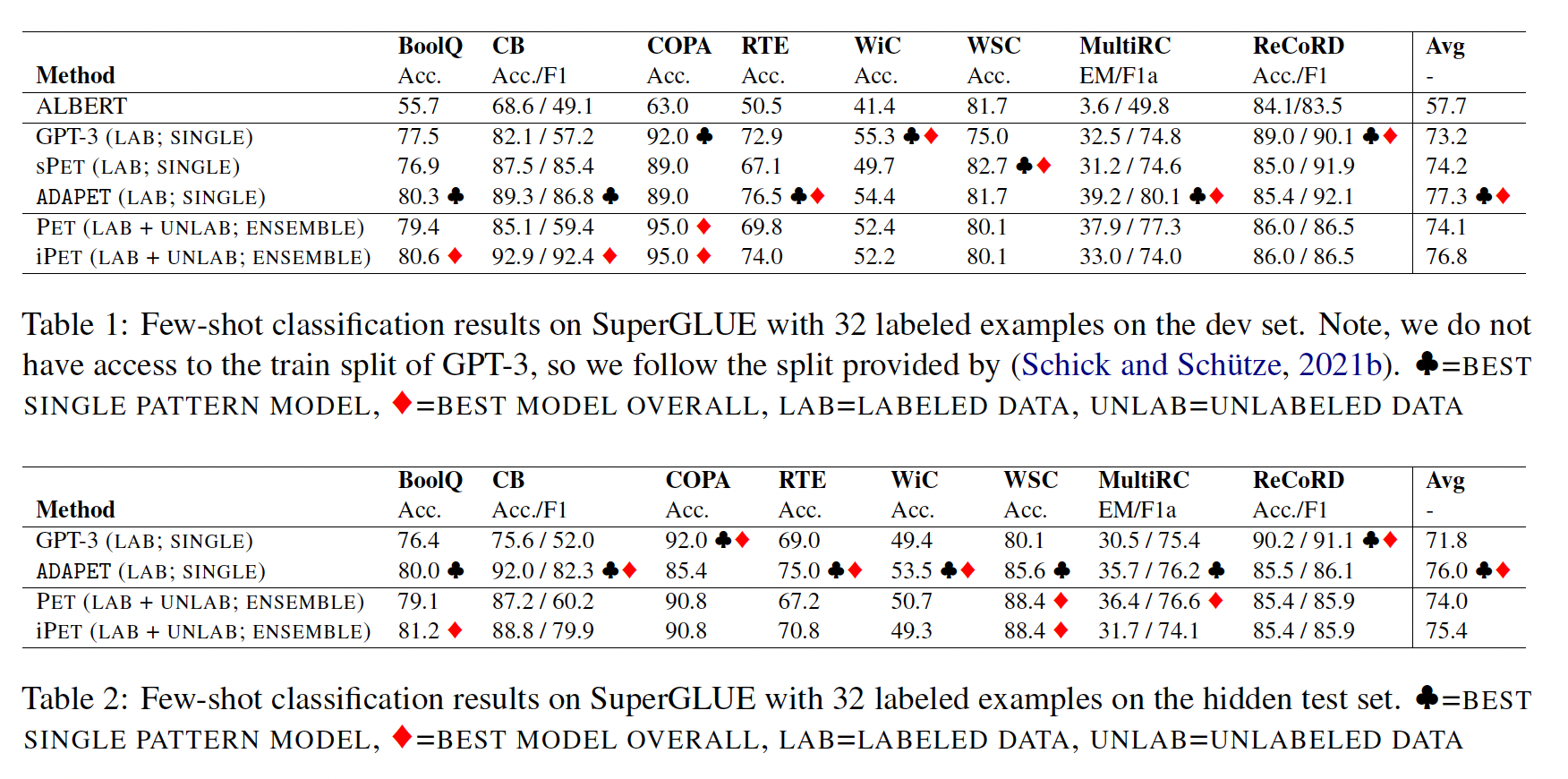
ADAPET应用PET和iPET的three-step训练过程。我们仍然假设可以访问完整的开发集来选择最佳掩码比例、以及最佳checkpoint,因为PET可能使用完整的开发集来选择超参数(我们直接复用它的超参数)。Table 1和Table 2显示了我们在验证集和测试集上的结果。我们与GPT-3和PET/iPET进行了比较。请注意,PET/iPET使用未标记数据和three-step训练过程。为了公平比较,我们训练PET with a single pattern: sPET共计1k个batches,并报告验证集上表现最好的模式的分数。我们在附录A.2中进一步分析了模型在每个模式下的表现。在开发集上,
ADAPET优于所有不使用未标记数据的模型,甚至优于PET的迭代式变体iPET达0.5分(绝对提升)。令人惊讶的是,sPET优于PET,但仍以2.6分落后于iPET。但是,这与PET-2的消融结果一致,该结果显示仅使用标记数据训练sPET模型的ensembling优于PET。此外,LM-BFF表明,具有最佳性能模式的模型优于ensembling sPET模型。在测试集上,
ADAPET优于所有其他模型,包括iPET,这是在没有未标记样本(每个任务平均9k)的情况下实现的,并在SuperGLUE上的few-shot learning中取得了SOTA结果。
损失消融实验:
Table 3显示了我们在本文中引入的损失函数的消融分析。从结果中可以看出:label conditioning: LC对ADAPET非常有利,尤其是在CB上。将我们修改的
decoupled label objective(ADAPET W/O LC)与sPET进行比较,我们看到它在CB上的F1得分较差,但在RTE和MultiRC上的表现要好得多。接下来,我们与仅在
correct label上条件化的LC进行比较。我们看到这在BoolQ上有下降,但在CB上有帮助。
我们在附录
C中对模型选择进行了消融实验。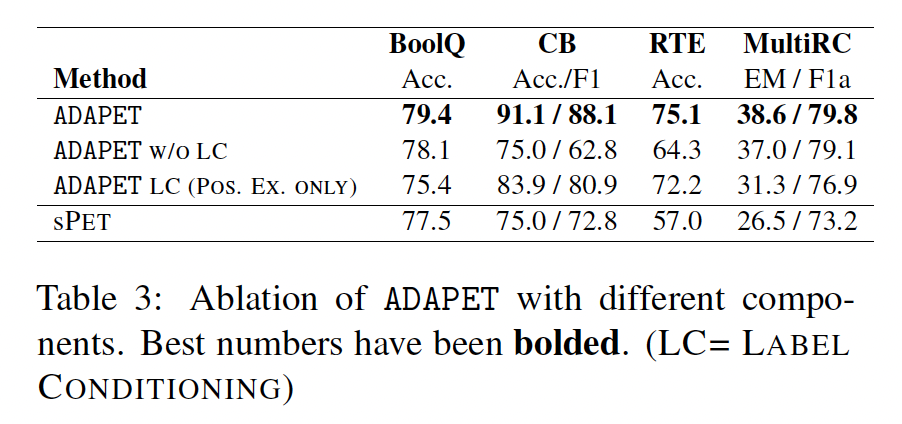
十五、Noisy Channel Prompt Tuning [2021]
论文:
《Noisy Channel Language Model Prompting for Few-Shot Text Classification》。
在
few-shot learning中,通过在输入前添加自然语言文本或连续向量(称作prompts)来引导大型语言模型,已经显示出很大的潜力(GPT-3)。先前的研究提出了寻找更好prompt的方法(AutoPrompt、Prefix-Tuning、《The power of scale for parameter-efficient prompt tuning》),或者对模型输出进行更好评分的方法(《Calibrate before use: Improving few-shot performance of language models》、《Surface form competition: Why the highest probability answer isn’t always right》)。这些研究直接预测target tokens以确定终端任务的预测结果。尽管结果看起来很有希望,但是在不同的verbalizers(用于表示label的文本表达)和种子之间,它们可能不稳定且方差很大,worst-case性能通常接近于随机(《True few-shot learning with language models》、《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》)。在本文中,我们介绍了一种针对大型语言模型的
prompted few-shot text classification的另一种channel模型,受到机器翻译中的noisy channel模型以及它们对其他任务的扩展的启发。与直接建模给定输入的label token的条件概率不同,channel模型计算给定输出的输入的条件概率(Figure 1)。直观地说,channel模型需要解释输入中的每个单词,从而在低数据情况下可能增强训练信号。我们研究了channel模型对语言模型prompting的影响,其中语言模型的参数被冻结。具体而言,我们在以下方法中比较了channel模型和其direct counterparts:用于
demonstration方法,无论是基于拼接的方法(GPT-3),还是我们提出的ensemble-based方法。用于
prompt tuning。

我们在十一个文本分类数据集上的实验结果表明,
channel模型的性能显著优于其direct counterparts。我们将channel模型的强大性能归因于其稳定性:在不同的verbalizers和随机数种子下,channel模型相比较于其direct counterparts,具有更低的方差、显著更高的worst-case accuracy。此外,我们还发现direct model with head tuning(即,在固定其他参数的同时调优语言模型的head参数),效果出奇地好,通常优于其他形式调优的direct model。虽然在不同的条件下可以选择不同的方法,但是在训练数据不平衡、或需要泛化到unseen labels时,具有prompt tuning的channel模型(称为channel prompt tuning)明显优于所有的direct baselines。总结起来,我们的贡献有三个方面:
我们引入了一种
noisy channel方法来进行language model prompting在few-shot text classification中的应用,表明它们在demonstration方法和prompt tuning方面明显优于其direct counterparts。我们发现在训练数据不平衡、或需要泛化到
unseen labels时,channel模型相较于direct models表现出特别强的性能。基于大量的消融实验,我们根据给定的条件(如目标任务、训练数据的大小、类别的数量、训练数据中标签的平衡性、以及是否需要泛化到
unseen labels),提供了在不同模型(direct vs. channel ; prompt tuning vs. head tuning)之间的选择建议。head tuning就是微调,prompt tuning就是continus prompt tuning,demonstration就是传统的prompts方法。
相关工作:
Channel Model:设direct models,计算noisy channel models最大化noisy channel方法在机器翻译领域取得了最大的成功,但它也在更一般的自然语言处理任务中进行了研究。先前的研究提供了channel模型比它们的direct counterparts更快地接近其渐近误差的理论分析 (《On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes》),并通过实验证明在文本分类、问答以及few-shot设置中,channel模型对distribution shift更具鲁棒性。本文使用大型语言模型在广泛的文本分类任务中探索
channel模型,重点是prompt-based few-shot learning。Few-shot Learning:在few-shot learning中,先前的研究采用了不同的方法,包括具有数据增强或一致性训练的半监督学习、以及元学习。最近的工作引入了对大型语言模型的prompting(或priming))。例如,GPT-3提出使用训练样本的拼接作为demonstration,这样当其被放到输入之前并馈入模型时,模型将按照训练样本中的模式返回输出。这种方法特别有吸引力,因为它消除了更新语言模型参数的需要,而更新参数通常是昂贵的和不切实际的。随后的研究提出了通过更好的model calibration来scoring labels的替代方法 (《Calibrate before use: Improving few-shot performance of language models》、《Surface form competition: Why the highest probability answer isn’t always right》),或者学习更好的prompts,,无论是在离散空间还是连续空间。几乎所有这些方法都是direct models,计算在给定具有prompts的输入我们的工作与两篇最近的论文密切相关:
《Improving and simplifying pattern exploiting training》(即,ADAPET)研究了面向masked language models的label-conditioning objective;虽然这不是严格的generative channel model,但是以输出discriminative objective,并且在测试时的推理与direct model相同。《Surface form competition: Why the highest probability answer isn’t always right》探索了一种zero-shot模型,该模型基于Pointwise Mutual Information来计算给定
据我们所知,我们的工作是第一个使用
noisy channel model从而在分类任务中用于语言模型prompting,并且首次将其与noisy channel文献联系起来。
15.1 方法
我们聚焦于文本分类任务。我们的目标是学习一个
task functionDirect:直接计算在给定输入Direct++:更强的direct model,遵从《Surface form competition: Why the highest probability answer isn’t always right》和《Calibrate before use: Improving few-shot performance of language models》,它计算这种方法的动机是:语言模型可能存在校准不佳的问题,并且在具有相同含义的不同字符串之间存在竞争。这种方法被用于本文稍后的
demonstration方法中。这里
NULL表示无效的输入,如空字符串、"NULL"字符串、或者任何其它的随机字符串。Channel:使用贝叶斯公式来重新参数化是否可以让
我们使用因果语言模型(
causal language model)direct model和channel model,其中因果语言模型给出了在给定文本在学习
task functionverbalizer"A three-hour cinema master class",而一个verbalizer"It was great"、和"It was terrible"。在few-shot设置中,我们还给定了一组我们感兴趣的是这样的方法:没有可训练参数、或者可训练参数的数量非常小(通常小于总参数量的
0.01%)。这是根据之前的观察结果得出的,即为每个任务更新和保存大量参数是昂贵且常常不可行的。Demonstration方法:在demonstration方法中,没有可训练参数。我们探索了三种预测方式,如Table 1所总结的。zero-shot:我们遵循GPT-3的方法,计算"A three-hour cinema master class":direct model计算"A three-hour cinema master class"之后分别跟随"It was great"的概率、以及"It was terrible"的概率。channel model计算"It was great"之前是"A three-hour cinema master class"的概率,以及"It was terrible"之前是"A three-hour cinema master class"的概率。
concat-based demonstrations:我们遵循GPT-3的few-shot learning方法。关键思想是将task setup。最初的方法是用于direct model,但可以自然地扩展为channel model。具体而言:direct model中的channel model中的
ensemble-based demonstrations:我们提出了一种新的方法作为concat-based demonstrations的替代方案,我们发现这个新方法是一个更强大的direct model。与将具体而言:
direct model中的channel model中的
这种方法还降低了内存消耗:基于拼接的方法的内存复杂度为
《Calibrate before use: Improving few-shot performance of language models》、《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》)。

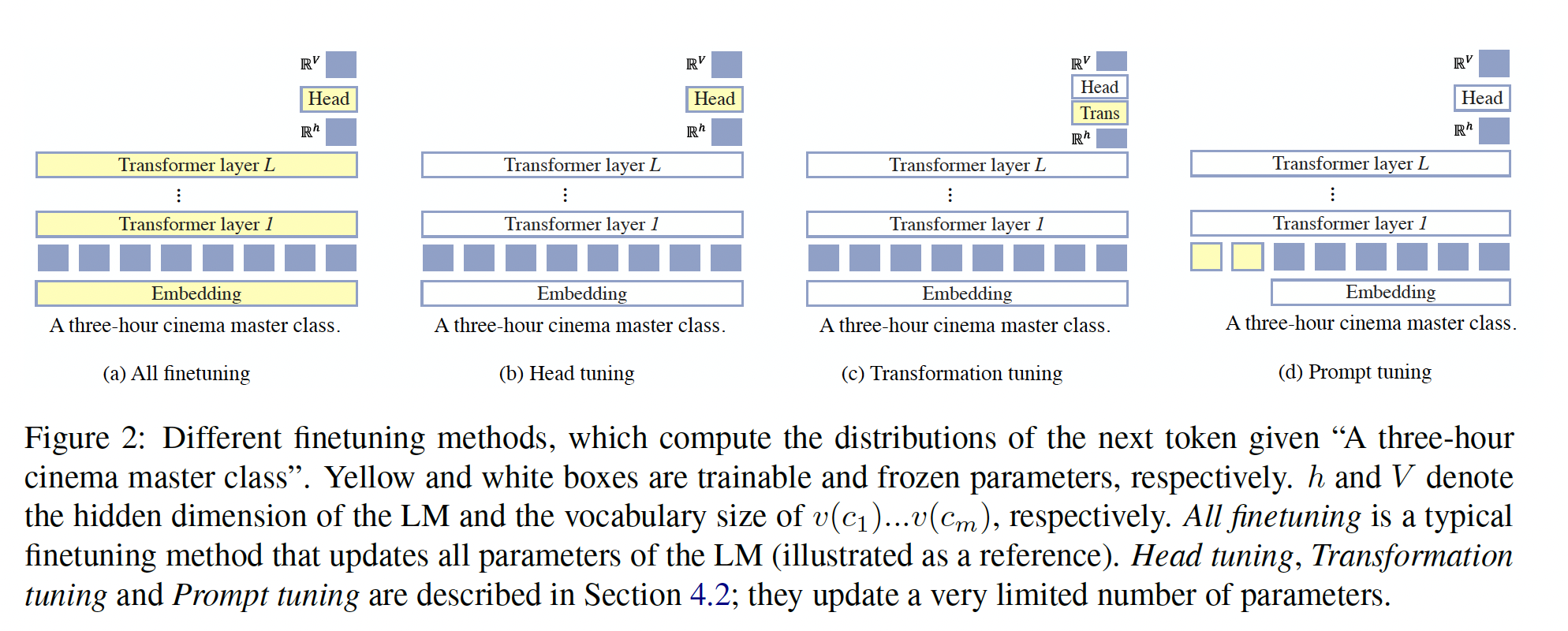
Tuning方法:我们还探索了仅调优少量模型参数的方法,如Figure 2所总结的。我们研究了direct models的head tuning和变transformation tuning。我们还考虑了针对direct models和channel models的prompt tuning方法,分别称为direct prompt tuning和channel prompt tuning。在训练和推理过程中,所有模型与Table 1中的zero-shot setup共享相同的input-output接口。head tuning:head tuning是对head进行微调的过程,head是语言模型的一个矩阵,该矩阵将最后一个Transformer layer的hidden representation转换为logit values。设head矩阵,Transformer layer的hidden representation。对于tokenembedding矩阵相绑定,但在head tuning过程中我们将它们独立开来。transformation tuning:作为head tuning的替代方法,我们使用一个新的变换矩阵tokenprompt tuning:prompt tuning是最近引起了广泛关注的方法。其核心思想是将语言模型视为一个黑盒模型,然后学习continuous prompt embeddings。我们遵循《The power of scale for parameter-efficient prompt tuning》的方法,将prompt tokensembedding。换句话说:direct models计算channel models计算
在语言模型中的参数除了
embedding之外都被冻结。这里是
zero-shot的格式。是否可以引入few-shot?
15.2 实验
数据集:十一个文本分类数据集,包括
SST-2、SST-5、MR、CR、Amazon、Yelp、TREC、AGNews、Yahoo、DBPedia、Subj。这些数据集每个任务包含不同数量的类别,从2个类别到14个类别。数据集的统计如Table 2所示。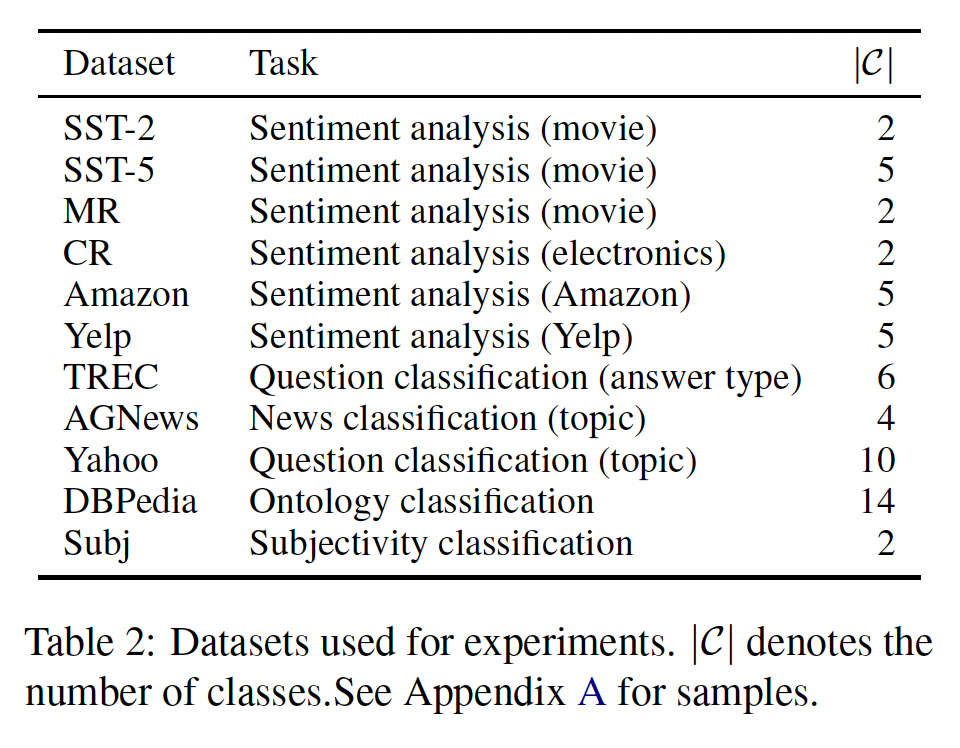
训练数据:对于
few-shot learning,我们主要使用训练集大小《Making pre-trained language models better few-shot learners》、《Cutting down on prompts and parameters: Simple few-shot learning with language models》),以进行更真实的和具有挑战性的评估。我们遵循之前工作中的所有超参数和细节(附录
B),这样就不需要held-out validation set。非常有限的数据更适合用于训练而不是验证,当验证集非常小的时候,交叉验证的效果较差(《True few-shot learning with language models》)。语言模型:我们使用
GPT-2作为语言模型。我们主要使用GPT-2 Large,但在附录C的消融实验中还尝试了不同大小(Small, Medium, Large, XLarge)。虽然我们只在GPT-2上进行了实验,但我们的实验很容易扩展到其他因果语言模型上。评估:我们使用准确率作为所有数据集的评估指标。
我们尝试了
4种不同的verbalizers(取自《Making pre-trained language models better few-shot learners》;完整列表请参见附录A),使用5个不同的随机种子进行训练数据采样,并使用4个不同的随机种子进行训练。然后我们报告平均准确率和worst-case准确率。鉴于few-shot learning模型的显着高方差(如前期工作所示),worst-case准确率与平均准确率同样重要。在高风险应用中,worst-case准确率可能更受关注。其他实现细节请参见附录
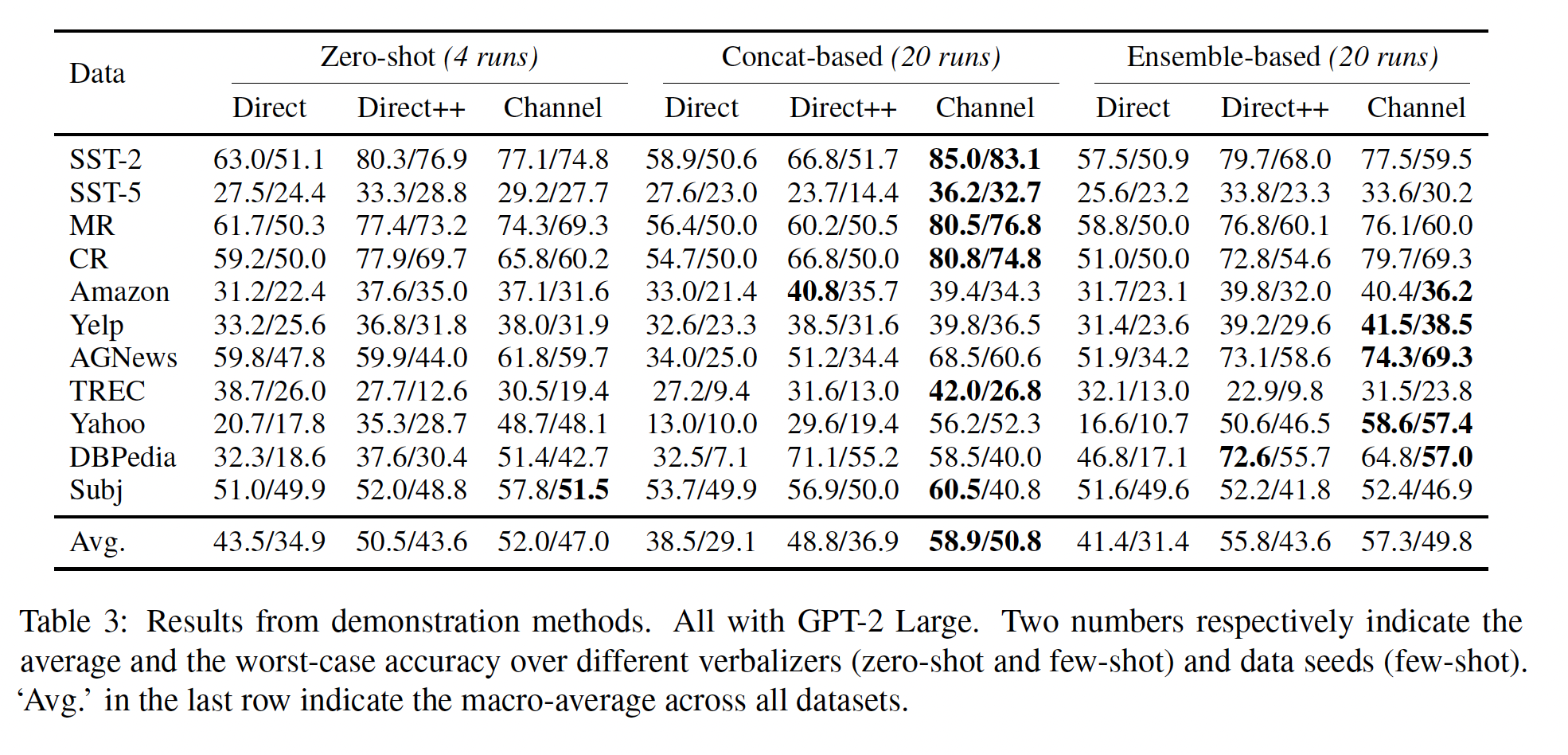
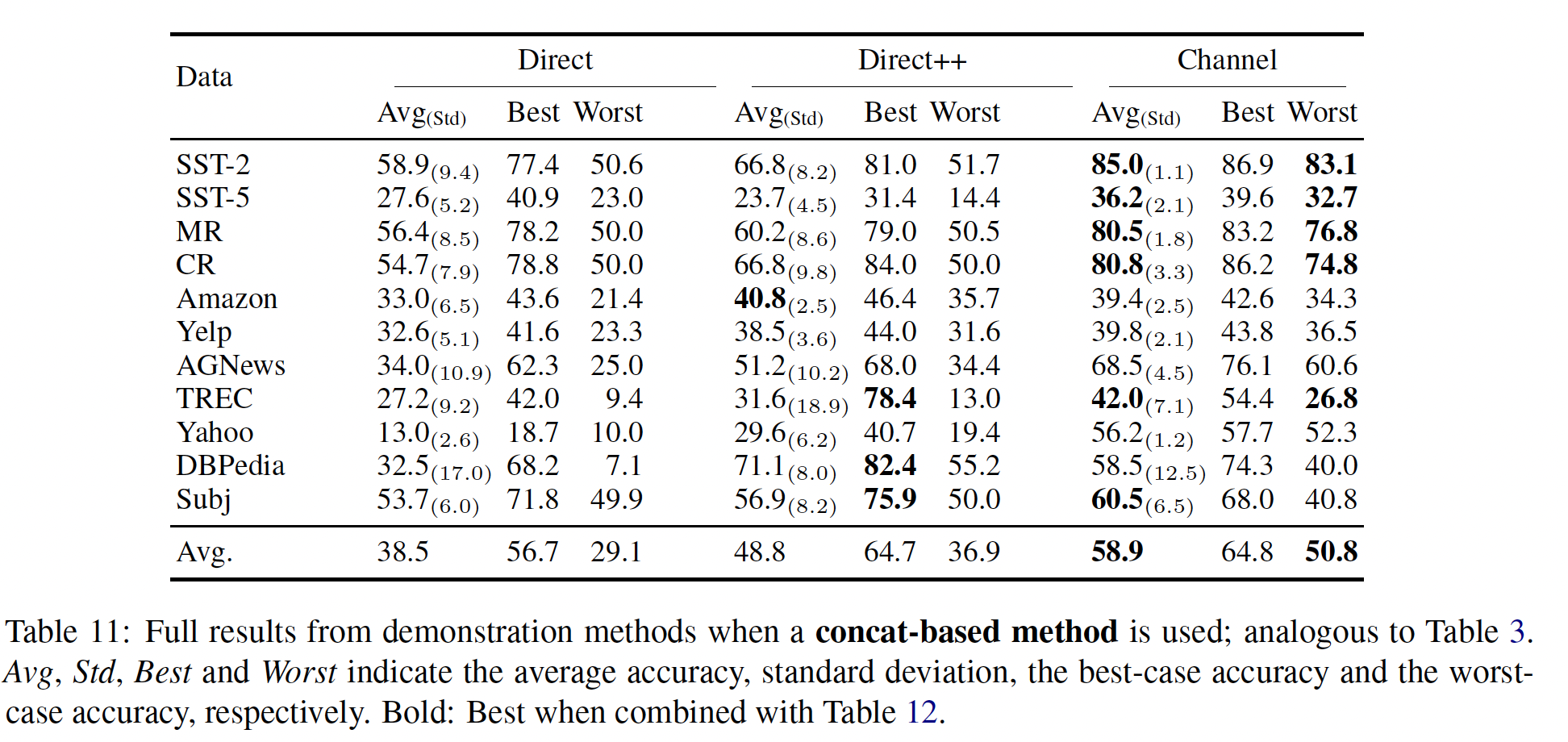
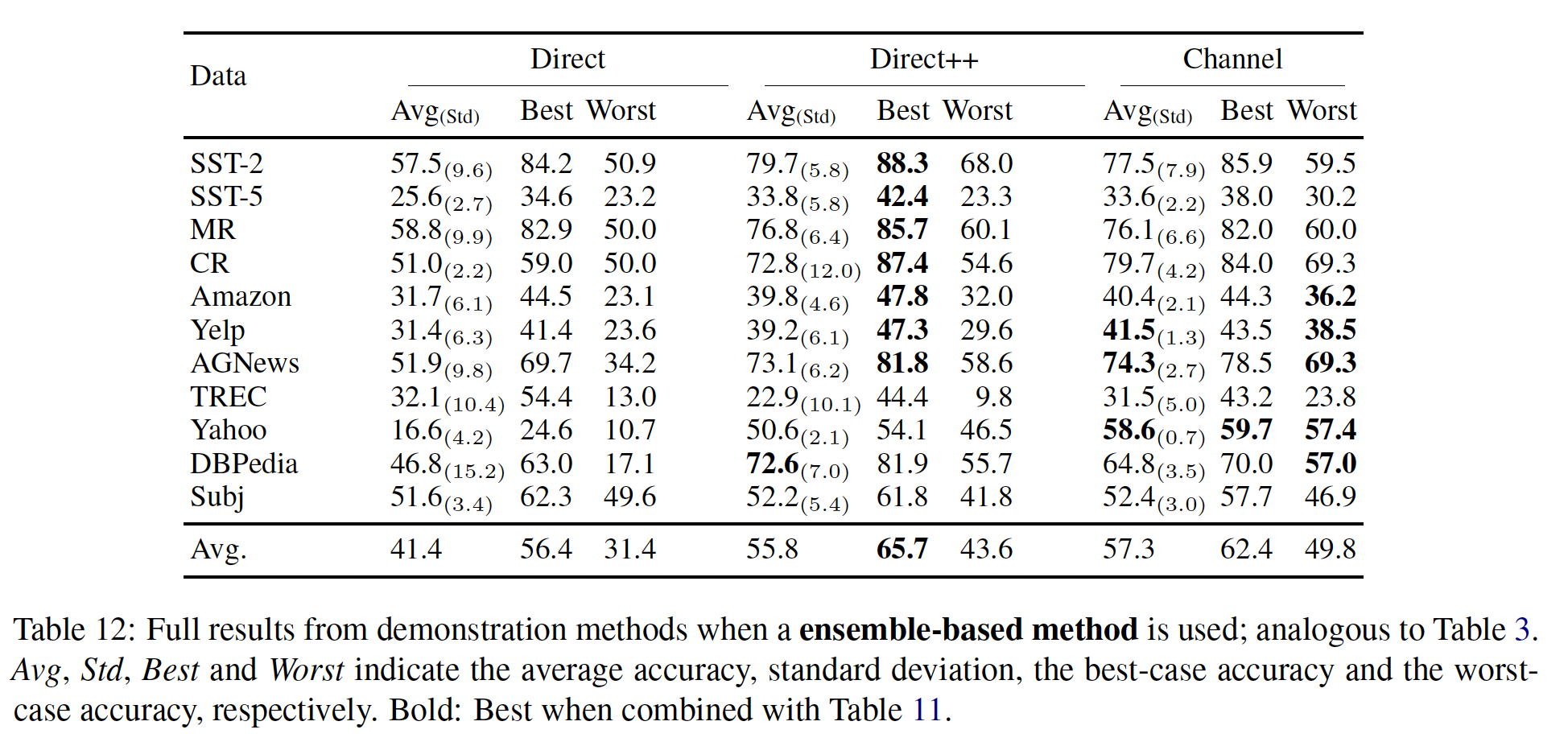
B。所有实验都可以从github.com/shmsw25/Channel-LM-Prompting进行复现。Demonstration Methods的实验结果:Table 3显示了demonstration方法的性能。Direct vs. Direct++:在所有设置中,Direct++明显优于朴素的direct model,这表明使用《Surface form competition: Why the highest probability answer isn’t always right》和《Calibrate before use: Improving few-shot performance of language models》所声称的那样。Concat vs. Ensemble:我们提出的ensemble-based方法在direct model中优于concat-based的方法,平均准确率和worst-case准确率分别提高了7%绝对值,这是在所有数据集上进行macro-averaged的结果。相反,在
channel models中,ensemble-based方法并不总是更好;它只在输入较长的数据集上表现更好。我们推测,ensemble-based方法在训练数据中的标签不平衡时可能会受到影响,而Direct++则明确考虑了这一点,正如《Calibrate before use: Improving few-shot performance of language models》所描述的那样。Direct++ vs. Channel:在few-shot setting中,channel models在几乎所有情况下优于direct models。最强的channel models相对于最强的direct models,平均准确率和worst-case准确率分别提高了3.1%和7.2%绝对值。标准差和
best-case准确率在Table 11和Table 12中报告。它们表明channel models的强大性能可以归因于其低方差。大多数数据集上Direct++实现了最高的best-case准确率,但它具有更高的方差,平均准确率和worst-case准确率低于channel models。Zero-shot vs. Few-shot:direct models在few-shot设置中的性能有时会下降,这也是之前的研究所观察到的(《Calibrate before use: Improving few-shot performance of language models》)。这可能是因为训练数据提供的demonstrations.导致模型校准错误,并容易受到demonstrations选择的偏见。然而,channel models在所有数据集上实现了明显优于zero-shot方法的few-shot性能。
Tuning Methods的实验结果:Table 4显示了tuning方法的性能。prompt tuning的比较:在使用prompt tuning时,channel models在所有数据集上始终以较大的优势优于direct models。平均准确率和worst-case准确率的改进分别为13.3%和23.5%的绝对值。标准差和
best-case准确率在Table 13中报告。与前面的发现一致,channel prompt tuning的强大性能可以通过其低方差来解释:direct prompt tuning通常可以实现更高的best-case准确率;然而,由于其高方差,其整体准确率较低,worst-case准确率显著降低。head tuning vs. prompt tuning:我们发现,head tuning是一种非常强大的方法,尽管在以前的工作中通常被忽略从而未被作为一个基准。它在所有情况下明显优于direct prompt tuning。它在一些数据集上也优于channel prompt tuning,特别是在TREC和Subj数据集上显著优于channel prompt tuning。对于这些数据集,任务(如,找到问题的答案类型、或识别陈述句subjectivity)与语言建模本质上不同,可能受益于直接更新语言模型的参数,而不是将语言模型作为黑盒使用。然而,
channel prompt tuning在大多数数据集上优于direct head tuning。最大的收益出现在Yahoo和DBPedia数据集上。事实上,在这些数据集上,channel prompt tuning甚至优于all funetuning(对语言模型的所有参数进行微调),在Yahoo上达到48.9/43.8,在DBPedia上达到66.3/50.4。我们推测,在这些数据集上使用unseen labels进行泛化,因为类别数目较大(10和14),在这些情况下,channel prompt tuning在显著优于direct models。
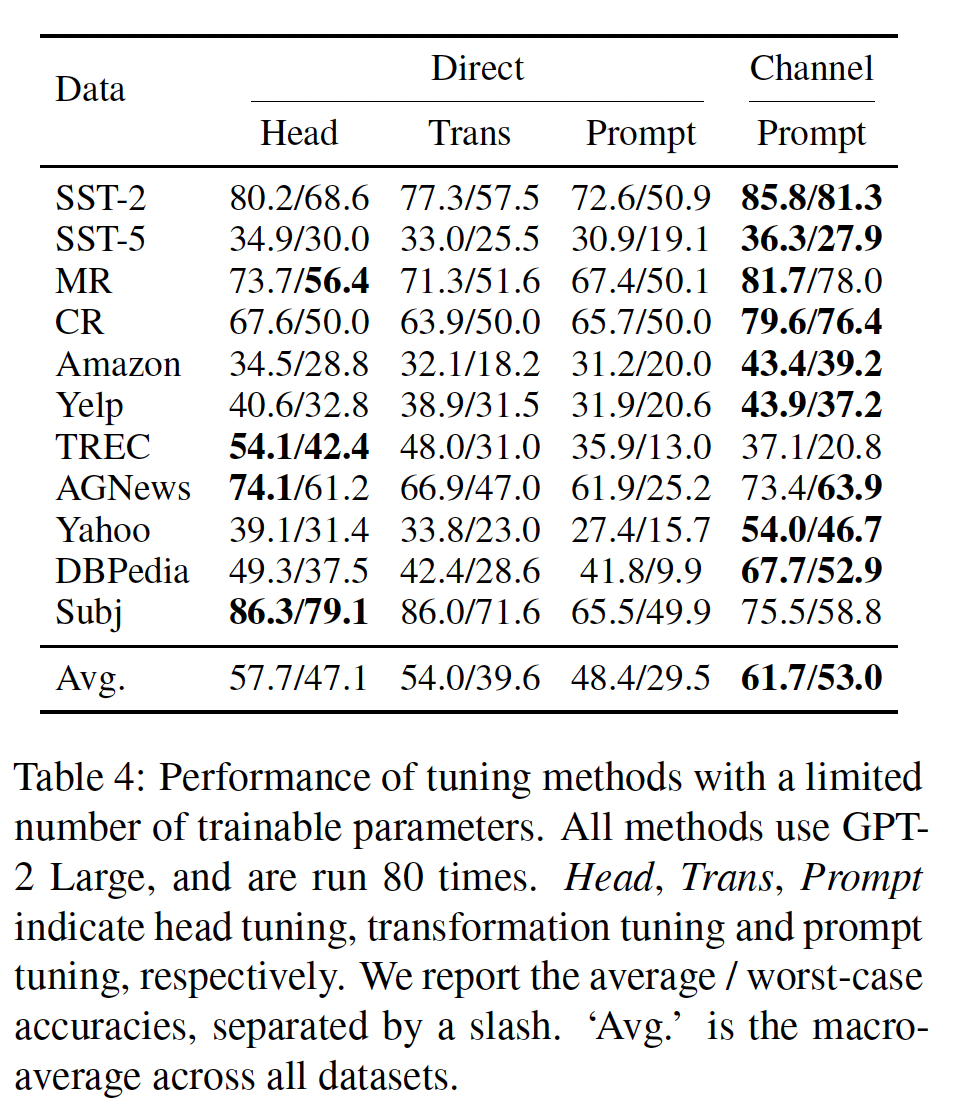
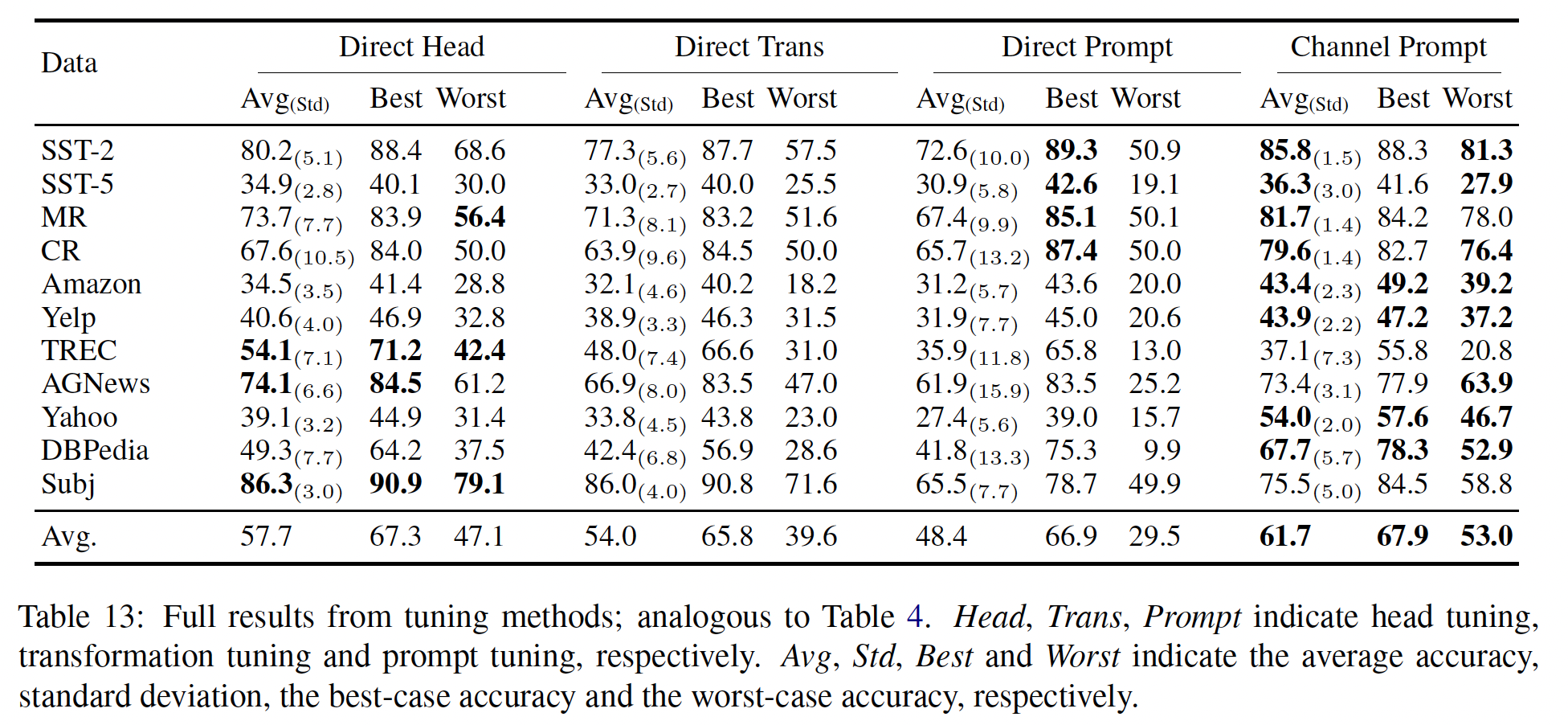
消融研究:对于消融实验,我们在
SST-2、MR、TREC和AGNews数据集上报告了实验结果,使用一个训练种子(而不是四个)、四个verbalizers、和五个数据种子(与main experiments相同)。改变训练样本数量:我们改变训练样本数量(
Figure 3所示。所有方法中,随着我们确认了
channel prompt tuning在head tuning的性能优于channel head tuning。当
direct prompt tuning和direct head tuning都优于channel prompt tuning。我们认为这是因为:首先,
channel models放大的训练信号(《Generative question answering: Learning to answer the whole question》)在其次,
channel models在标签分布不平衡时对结果更有裨益(在下一个消融实验中得到证实),这在较小的
值得注意的是,我们的
《The power of scale for parameter-efficient prompt tuning》的发现,即direct prompt tuning的性能与all finetuning(对语言模型的所有参数进行微调)相媲美,而参数效率更高。这只有在few-shot setup中,all finetuning明显优于其他方法。这与传统分析相矛盾,传统分析认为当训练数据稀少时,可训练参数更少的表现会更好(《On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes》)。这可能是因为这样的分析没有考虑到语言模型预训练,其中预训练为模型提供了监督,但不是终端任务的训练数据。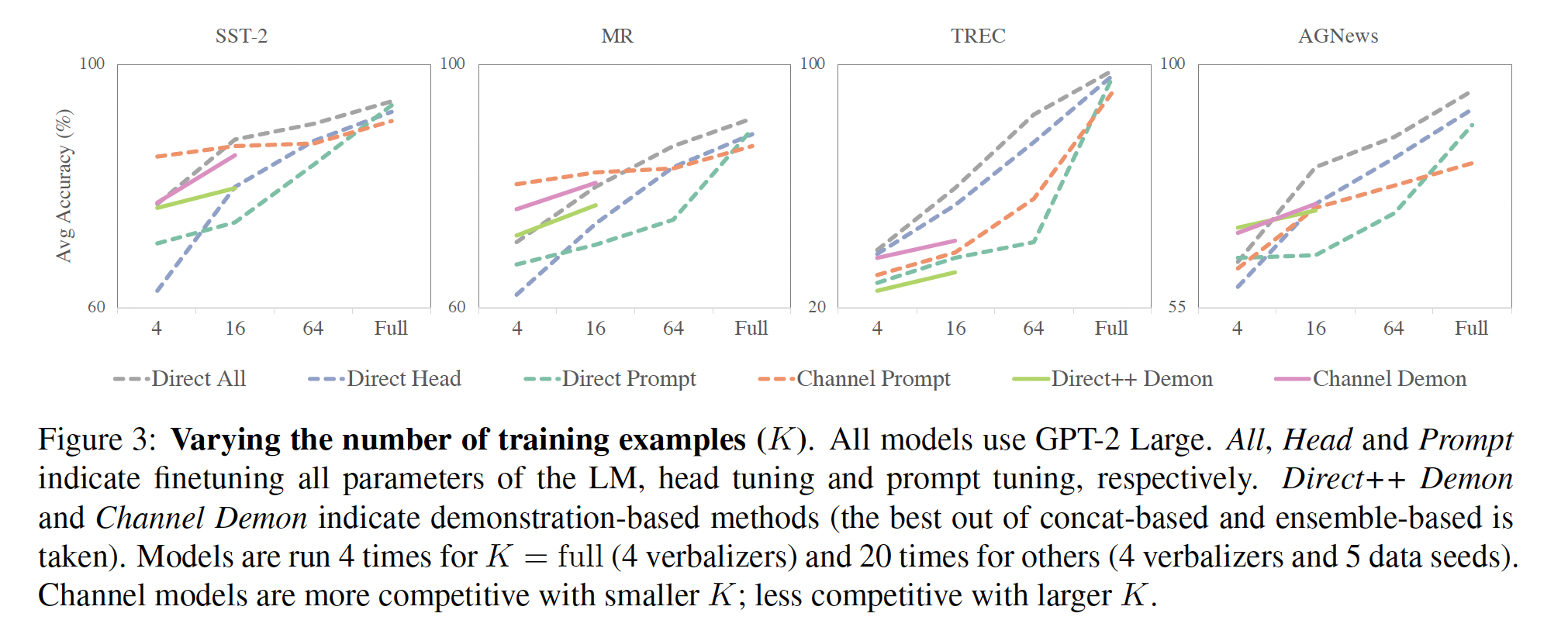
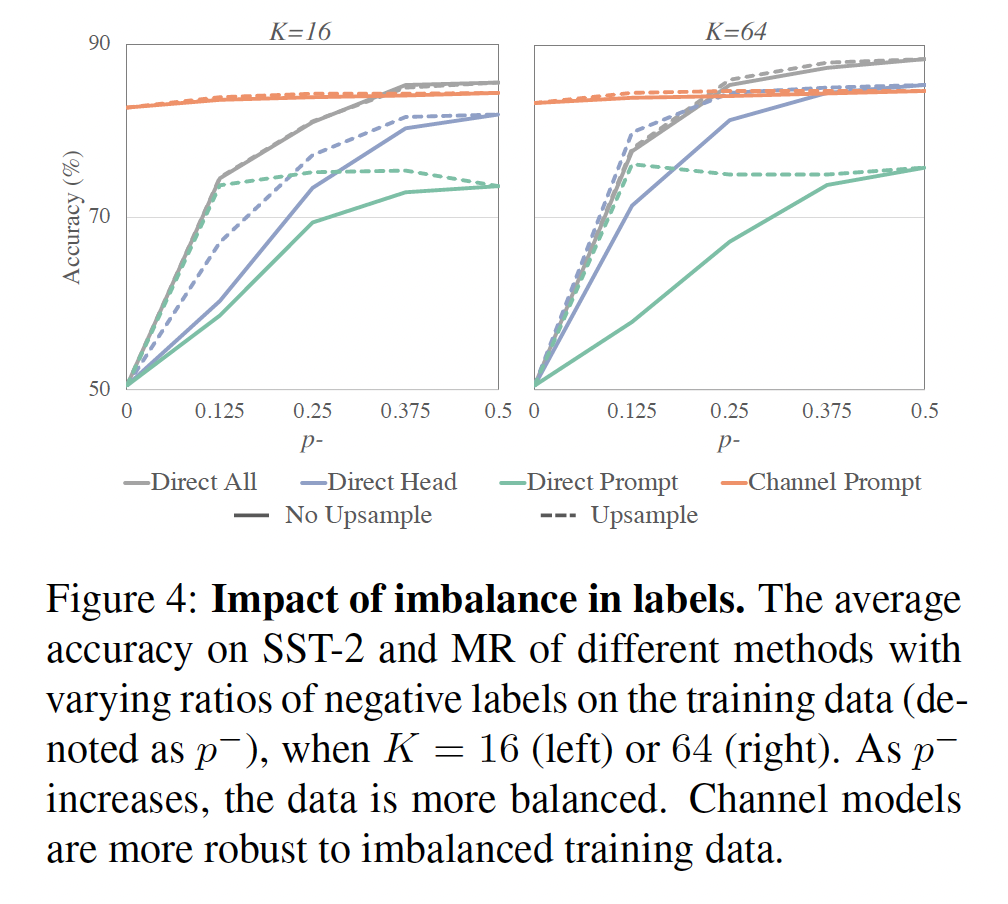
标签不平衡的影响:在二分类数据集(
SST-2和MR)上,我们用upsampling baselines进行了比较,其中我们对infrequent标签的训练样本进行上采样,以便模型在训练期间看到每个标签的训练样本数相等。结果在Figure 4中报告。所有
direct models对训练数据的不平衡都很敏感,即使在channel prompt tuning对不平衡不敏感,在direct models;当all finetuning。当
0.5时,direct head tuning与channel prompt tuning相当或优于后者。值得注意的是,在
direct prompt tuning与all finetuning和head tuning相当或优于后者。
泛化到
unseen labels:我们在一个具有挑战性的场景下进行实验,其中模型必须泛化到未见的标签。尽管这可能看起来是一个极端的场景,但这通常是一个实际的设置,例如,问题是用一组标签定义的,但以后可能需要添加新标签。首先,我们像
main experiments一样采样Table 5报告了结果。所有
direct models都无法预测在训练时未见的标签。然而,
channel prompt tuning可以预测未见的标签,并且其性能明显优于zero-shot。它在二分类数据集上优于all finetuning,在五个数据集上优于head tuning(除了在TREC数据集上head tuning对见过的标签取得了非常强的性能)。
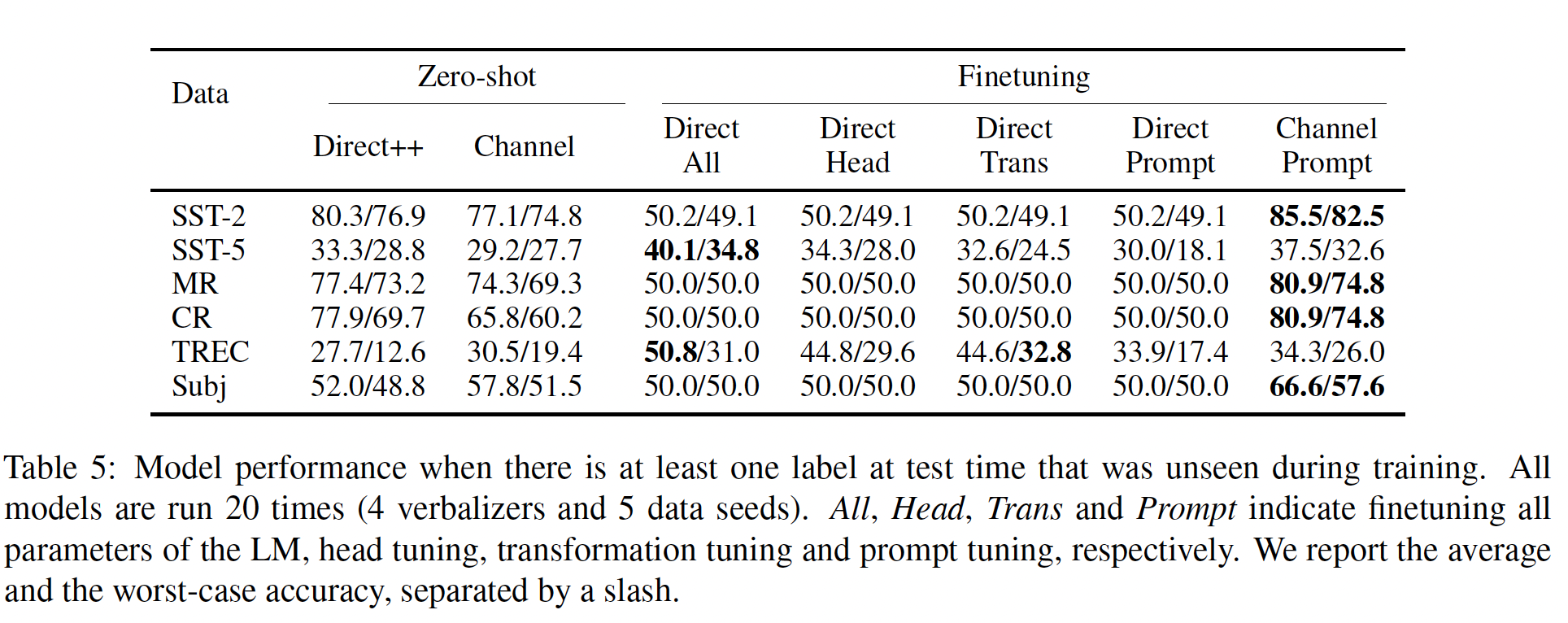
接下来,我们进行
zero-shot transfer learning,其中模型在一个数据集上训练,并在另一个数据集上测试。在这里,当标签在两个数据集之间不共享时,head tuning不适用。Figure 5显示了结果。channel prompt tuning在除了TREC的所有数据集上优于所有direct models,包括all finetuning。当任务本质上相似时,
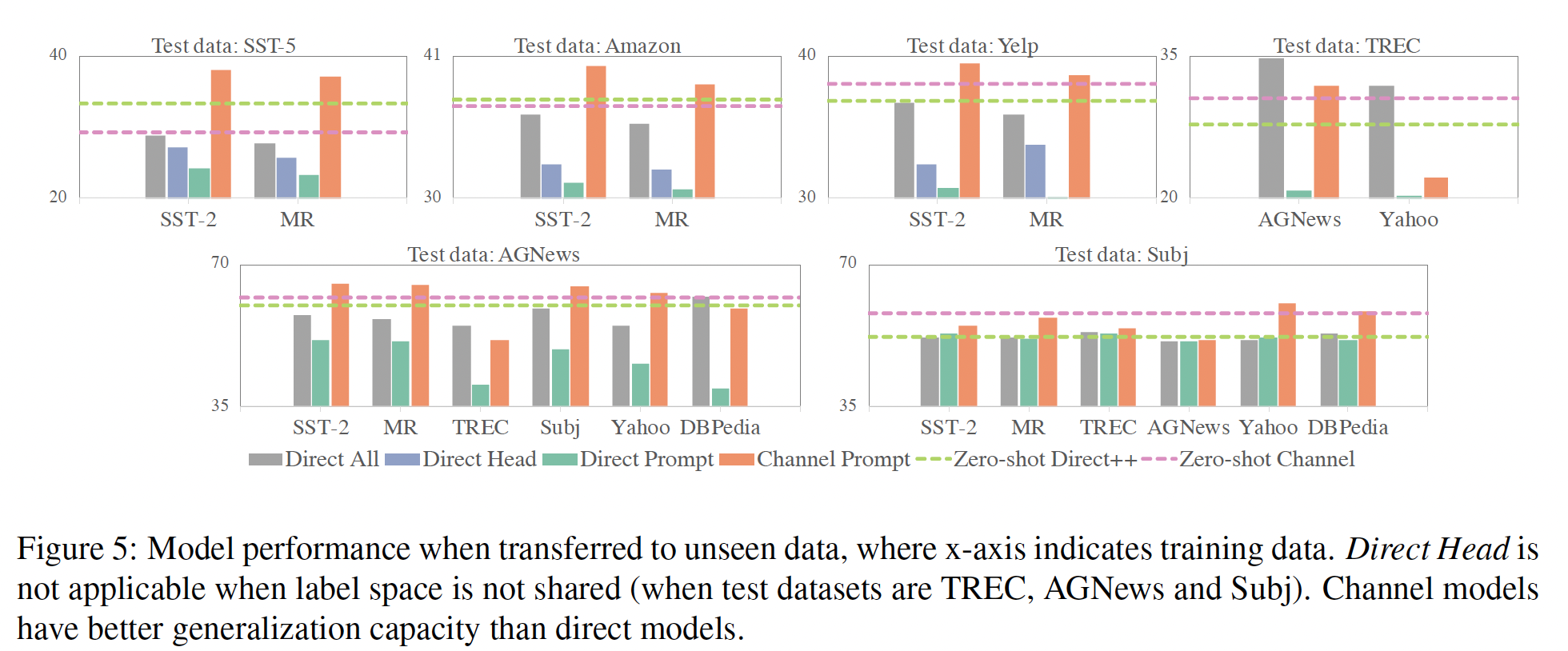
channel prompt tuning特别具有竞争力,例如,在Figure 5中的前三个图中,在二分类情感分析和五分类情感分析之间的迁移。实际上,在这种情况下,性能接近在in-domain数据上训练的模型。当任务本质上不同时,例如
Figure 5中的其余图,性能相对于zero-shot的增益较小。
我们认为需要做更多工作,使跨任务迁移更好,并发现何时可能进行跨任务迁移。
15.3 讨论
我们在
11个数据集上的实验表明,channel models明显优于它们的direct counterparts,主要是因为channel models的稳定性,即较低的方差和较好的worst-case准确率。我们还发现direct head tuning比以前工作认为的更具竞争力,并且不同的情况下倾向于选择不同的方法。具体来说,在以下方面首选channel prompt tuning:channel prompt tuning更具竞争力。我们推测有两个原因:首先,
channel models更稳定(即,实现低方差和高worst-case准确率),而direct models在其次,
channel models通过要求模型逐字解释输入来提供更多信号(《Generative question answering: Learning to answer the whole question》的说法),这在低数据的情况下是有利的。
数据不平衡或
direct models没有竞争力。我们认为这是因为LM head过于依赖标签的unconditional distributions。训练数据的标签不平衡是一个现实世界的问题,特别是当需要泛化到
unseen标签:所有direct models都无法预测在训练期间unseen标签,这表明它们在标签空间中过拟合。相比之下,channel models可以预测unseen标签,可能是因为标签空间是被间接建模的。这与先前的工作一致,该工作表明channel models在distribution shift下更具竞争力 (《Generative and discriminative text classification with recurrent neural networks》、《Generative question answering: Learning to answer the whole question》)。任务更接近语言建模:即使采用仔细选择的
verbalizer,如果任务与语言建模也差异太大(例如,TREC和Subj),head tuning优于prompt tuning。这可能是因为head tuning受益于直接更新语言模型的参数。这可能意味着因果语言模型不适合所有任务,或者我们需要更复杂的方法在不更新语言模型参数的情况下,来应用因果语言模型进行此类任务。
局限性和未来工作:虽然我们表明
channel models在few-shot文本分类中具有竞争力,但仍有一些局限性。首先,将
channel models用于非分类任务并不那么简单,因为建模先验分布是困难的。我们认为未来的工作可以通过一个单独的模型获得先验分布,并将其融入conditional LM,就像《Generative question answering: Learning to answer the whole question》那样做的,可能与beam search decoding相结合(如,《The neural noisy channel》、《Simple and effective noisy channel modeling for neural machine translation》)。其次,虽然本文重点介绍了因果语言模型,但如何与
masked LM一起使用channel models是一个开放性问题。虽然我们认为channel model与causal LM没有固有的限制,但现有的masked LM的特定预训练方式使其难以在不更新语言模型的参数的情况下使用channel models,例如,masked LM没有被训练用于生成长句子。最近的一种方法(ADAPET) 使用label-conditioning objective作为巧妙的方式将channel-like model引入现有的masked LM。扩展和进一步整合这些不同的方法对于在更广泛的场景中使用channel models非常重要。
十六、True Few-Shot Learning with Language Models【2021】
论文:
《True Few-Shot Learning with Language Models》
语言模型预训练的主要进展导致了语言模型可以只用少量的样本来学习一个新的任务,也就是
few-shot learning。few-shot learning克服了数据丰富的监督学习的许多挑战:收集标记的数据是昂贵的、往往需要专家、而且关于任务数量的scale很差。然而,语言模型的few-shot对文本任务的描述(即,"prompt")、训练样本的顺序、解码策略、其他超参数、以及学习算法本身非常敏感。因此,有效的模型选择(model selection)对于获得良好的few-shot性能至关重要。然而,最近的工作在
few-shot learning的模型选择方面存在一些问题。之前的工作使用了大量的训练样本或held-out examples来选择prompts(GPT-3、ADAPET、《Learning transferable visual models from natural language supervision》)和超参数(《Improving and simplifying pattern exploiting training》)。其他工作声称没有使用验证集来选择超参数(ADAPET、《Few-shot text generation with pattern-exploiting training》、《Entailment as few-shot learner》),但没有描述他们如何设计学习算法的其他方面(如training objectives)。考虑到所提出的算法的复杂性质,不太可能不使用验证集。在这项工作中,我们研究了当只使用所提供的样本进行模型选择时,先前的few-shot learning方法是否仍然表现良好,我们称这种设置为true few-shot learning。我们发现,
true few-shot model selection产生的prompts略微优于随机选择,而大大低于基于held-out examples的选择。我们的结果表明,之前的工作可能大大高估了语言模型的few-shot。换句话说,prompts如此有效的一个原因是它们经常使用许多样本进行调优(《How many data points is a prompt worth?》)。我们评估了两个标准的模型选择准则:交叉验证(cross-validation: CV)和最小描述长度(minimum description length :MDL)。我们发现这两个准则与随机选择相比只获得了有限的改进,而且比使用held-out examples进行模型选择要差很多。对于prompt selection,我们的观察结果对9个语言模型(模型规模横跨3个数量级)在3个分类任务和LAMA基准的41个任务中都是成立的。对于选择超参数来说,true few-shot selection会导致ADAPET(一种SOTA的few-shot方法)在8个任务中的性能下降2-10%。此外,true few-shot模型选择在性能上有很高的方差;所选择的模型往往比随机选择的模型差很多。我们发现在改变所使用的样本数量、计算量和我们的选择准则的保守性(conservativeness)时也有类似的结果。总的来说,我们的结果表明,模型选择是true few-shot learning的一个基本障碍。结合这篇论文的观点,一个自然的想法是:既然验证集那么重要,那么是否可以始终拆分一部分样本作为验证集?
进一步的思考是:对于不同的算法,应该在相同数据量(训练集 + 验证集)的条件下进行比较。
16.1 Can We Do Model Selection in Few-Shot Learning?
我们把
few-shot learning分为三种不同的情况,每一种情况都假定了对不同数据的访问。在此,我们对这些环境进行了正式的区分,以帮助未来的工作避免无意中比较在不同settings下执行的few-shot方法。考虑到监督学习的情况,我们有一个由输入
learning算法prompts。data-rich supervised learning:在data-rich supervised learning setting下,train-validatin splitmulti-distribution few-shot learning:由于大的few-shot setting用许多小的setting为multi-distribution few-shot learning。tuned few-shot learning:最近的工作并不假定可以从其他分布中获取数据,只使用单个分布中的几个样本来更新pretrained LM(GPT-3、ADAPET)从而进行few-shot learning。这些论文使用一个大的验证集learning算法tuned few-shot learning。例如,
GPT-3尝试用不同的措辞和训练样例数量来提高GPT-3的验证准确率。ADAPET根据验证结果选择early stopping iteration、prompt和其他特定模型的超参数。tuned few-shot learning依赖于许多标记样本,所以我们认为tuned few-shot learning并不符合few-shot learning的要求。如果有许多验证样本,它们可以被纳入训练集,并使用data-rich supervised learning进行训练。tuned few-shot learning算法应该与使用相同数量的总数据data-rich supervised learning算法进行比较。
在这项工作中,我们评估了在没有大的
tuned few-shot learning方法的成功,我们称之为true few-shot learning。从形式上看,我们的目标是选择一种具有低的期望损失有几篇论文声称,通过选择基于有根据的猜测的超参数,可以避免评估
PET、PET-2、《Entailment as few-shot learner》)。然而,所提出的学习算法本身是相当复杂的,如果不是通过使用validation性能,还不清楚它们是如何设计的。其他的工作是先用一个或多个其他数据集来选择学习算法和超参数,然后再对目标数据集进行评估(
LM-BFF、《Few-shot text generation with pattern-exploiting training》)。这类方法属于multi-distribution few-shot learning,不能直接与试图进行true few-shot learning的方法进行比较,尽管之前的工作已经进行了这种比较(《Entailment as few-shot learner》)。接下来,我们将描述两个模型选择准则:交叉验证、最小描述长度。我们用这两个准则来评估
true few-shot setting中的tuned few-shot方法。Cross-validation: CV:交叉验证是估计泛化损失的最广泛使用的方法之一。交叉验证也被用于先前的multi-distribution few-shot learning的工作中。交叉验证将
foldsfoldfolds其中
1到K之间的均匀分布。这样一来,交叉验证从标记样本集合中形成了
train-validation splits。 每个fold刚好只有有一个样本的CV通常被称为leave-one-out CV: LOOCV。Minimum description length: MDL:MDL可以通过评估在前面的foldsfold这个过程被称为 "在线编码" (
《Universal coding, information, prediction, and estimation》、《Present position and potential developments: Some personal views: Statistical theory: The prequential approach》),因为它评估了算法的泛化损失,因为它从越来越多的数据中 "在线"学习。我们使用在线编码,因为它已经被证明是估计MDL的有效方法,特别是对于深度学习方法(《The description length of deep learning models》)。MDL衡量泛化,因为它评估了一个学习算法在输入《Occam’s razor》)。最近的工作使用MDL来确定哪些学习算法在解释给定数据方面最为有效。方差问题:我们评估
CV(或者MDL)所选择的算法的泛化损失:folds拆分、以及所有可能的随机性之后,使得平均验证集最小的那个模型。通俗地讲,final model。注意:
该损失的期望应该是低的,其中期望跨不同的数据
splits
该损失的方差也应该是低的:
低方差意味着
CV/MDL可以可靠地选择一种算法:当用给定的我们还尝试在模型选择过程中显式地考虑算法的方差,选择
CV的保守估计,即其中:
物理含义:选择模型时,不是选择
dev损失最小的,而是选择dev损失加上具体而言,如果当采样
Watanabe Akaike Information(《Asymptotic equivalence of bayes cross validation and widely applicable information criterion in singular learning theory》) ,它将模型(用超参数
其它的
model selection准则:之前的工作已经开发了其他的model selection准则,如:Akaike Information Criterion: AIC、Watanabe-Akaike Information Criterion: WAIC、以及Mallows’ Cp。 这些方法往往依赖于深度学习中没有的假设或数值(AIC, Mallows' Cp),或者是LOOCV的近似值(WAIC)。由于SOTA的few-shot learning方法往往是基于深度学习的,我们专注于CV和MDL作为我们的model selection准则。在附录B中,我们还测试了其他几个适用于深度学习方法的准则。selection准则可以自动优化,例如用贝叶斯优化、进化方法、强化学习、或梯度下降。这类方法的目的是与穷举搜索的性能相匹配,这是最佳方法(在我们的工作中使用)。
16.2 True Few-Shot Prompt Selection
下面,我们对
LAMA进行测试。LAMA是一个用语言模型来检索事实的benchmark,之前的工作已经为其开发了许多designing prompts的策略。我们使用"TREx" split,其中包括41种关系,每种关系最多有1k个样本。我们只使用LAMA-UnHelpfulNames子集中的样本,该子集过滤掉了容易猜测的样本(例如,"The Apple Watch was created by _",答案是苹果)。我们测试了
9个不同规模的热门语言模型的5-shot accuracy:GPT-3(175B, 13B, 6.7B, 2.7B参数)、GPT-2(1.5B, 782M, 345M, 117M参数)、以及DistilGPT-2(GPT-2 117M的知识蒸馏版本,包含82M参数)。Prompts:为了形成我们的候选prompts集合LAMA以及LM Prompt And Query Archive: LPAQA。对于每种关系,我们使用来自LAMA的手工写的prompts,再加上LPAQA的prompts。LPAQA的prompts来自于:用back-translation的方式paraphrasing manual prompt、从Wikipedia中挖掘、从top mined prompt中paraphrasing。对于每种关系,我们最多使用
16个prompts,平均为12个prompts(关于我们使用的prompts的细节,见附录E.1)。计算
CV和MDL:我们在所有held-out样本上计算负对数似然从而作为损失函数我们使用
边际化(
marginalizing)样本顺序:训练样本的顺序影响到语言模型的泛化(《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》),因此我们将样本顺序视为一个随机因子prompt我们通过对所有
为了进行比较,我们展示了各种情况下的
test accuracy:总是选择最好的
prompts,像以前的工作一样使用held-out accuracy来选择。最差的
prompt作为一个下限。随机
prompts(我们展示了所有prompts的平均准确率)。
在
true few-shot learning中,prompt selection的表现如何:Figure 1(left)显示了结果:在不同的模型规模下(横跨三个数量级),
prompt selection比random selection获得了marginal improvement。通过
CV和MDL选择的prompts平均比best prompt(根据held-out数据来选择的)在绝对值上少5-7%。事实上,根据held-out performance选择的prompts往往优于那些以true few-shot选择prompts的大型模型。如Figure 1(right)所示,CV和MDL确实倾向于选择比平均水平更好的prompts,但只能将平均水平和best prompts之间的差距缩小20-40%。我们发现其他几个任务(参考后面的实验章节)和选择准则(参考附录B)也有类似结果。
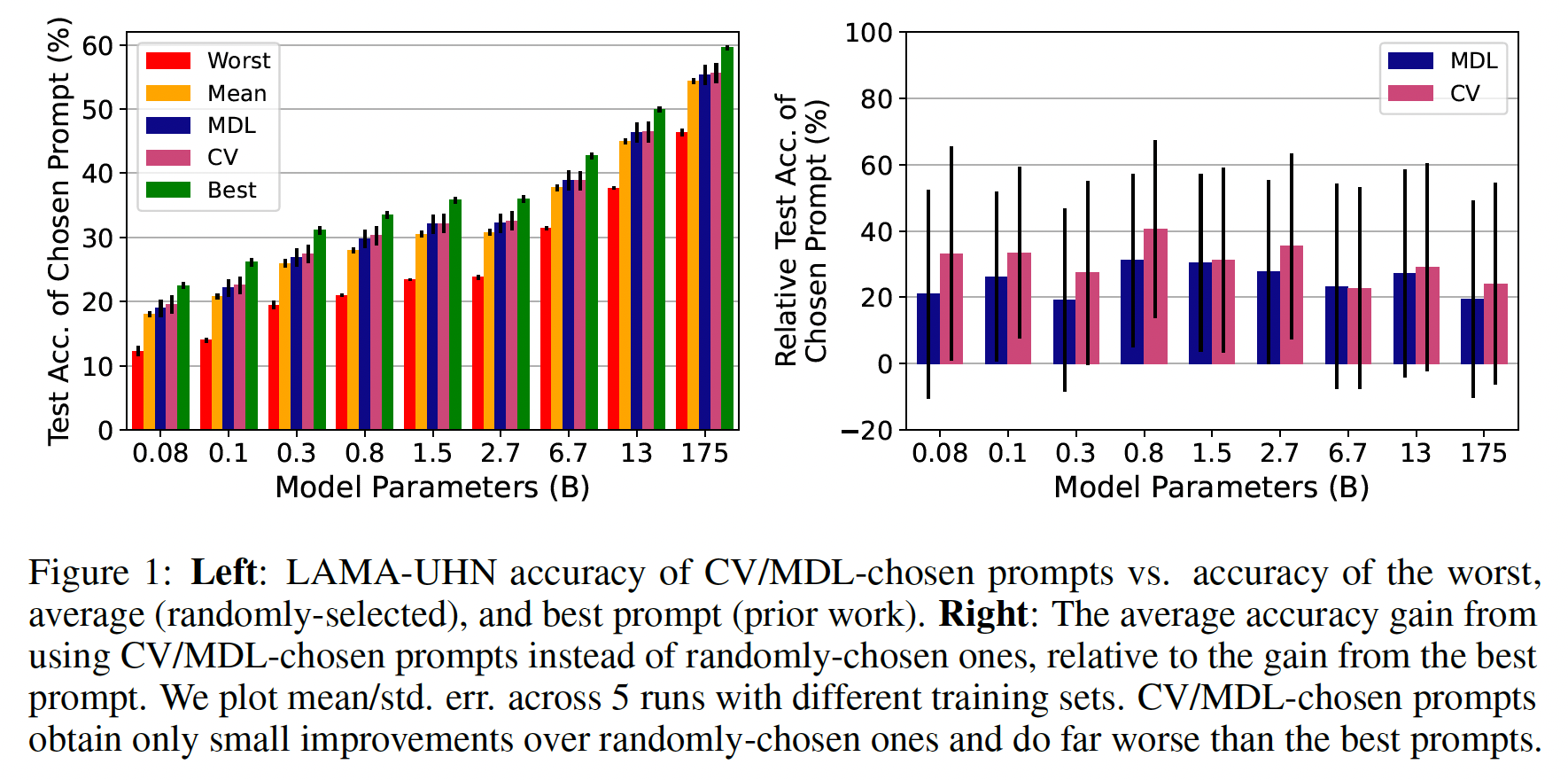
Figure 2(left)显示,CV/MDL在选择具有最高test accuracy的prompts时很费劲。对于像GPT-3 175B这样的大型模型来说,糟糕的top-prompt selection尤其普遍,这些模型激发了人们对prompt design的兴趣(CV只有21%的准确率,而随机选择只有9%的准确率)。在附录A中,我们表明,CV/MDL选择的prompts不仅在准确率上与best prompts不同,而且在它们如何有效地迁移到不同大小的模型上也不同。总的来说,我们的研究结果表明,在true few-shot setting中,optimal prompt selection是困难的,而且以前的工作通过使用held-out examples来进行prompt selection高估了语言模型的能力。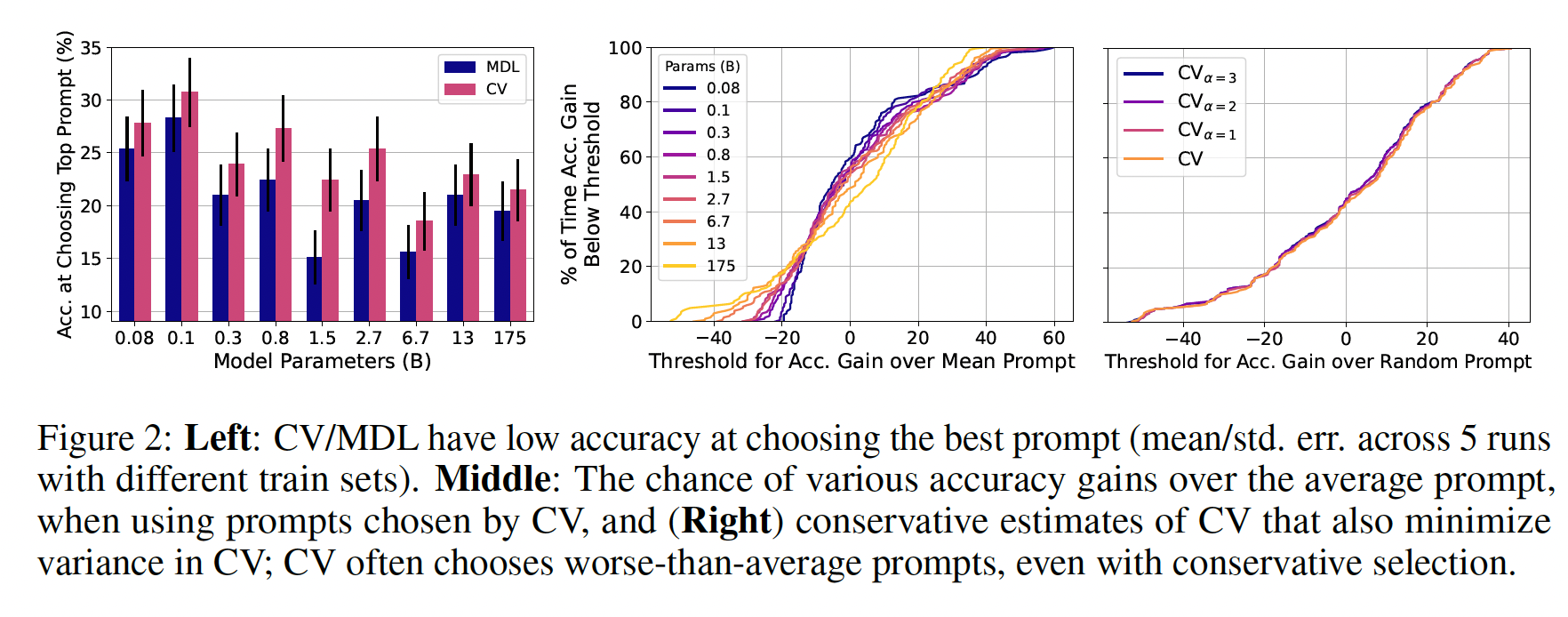
prompt selection比average prompt有多大的可靠改进:如果prompt selection的平均改进很小,那么对于一个给定的任务和训练集,我们至少能以高概率获得改进吗?Figure 1(left)显示,最差的prompts比平均水平差得多,因此,如果prompt selection有助于避免最差的prompts,那将是非常有用的。我们研究了prompt selection比average prompt获得各种accuracy gains的概率,并在Figur2 (middle)中显示了CV的结果(在附录C中显示了MDL的类似结果)。相对于
average prompt,CV/MDL所选择的prompts在test accuracy方面显示出很高的方差。对于大多数模型的大小(
0.1B-6.7B),CV和MDL比平均的、随机选择的prompt提高的机会只有大约56%,MDL只有大约55%。prompt selection的性能形成了一个长尾分布:对于所有的模型大小和CV/MDL,有大约27%的机会使得prompt selection导致~ 13%的accuracy drop。此外,随着模型大小的增加,尾巴也越来越重。对于最大的模型(
GPT-3 175B),CV/MDL选择的prompts有时比平均水平差得多,例如,有5%的时间差40%。
我们的结果表明了一个令人不安的趋势:随着模型越来越大,泛化性越来越好,我们可靠地选择
good prompts的能力就会下降。一个可能的解释是,更大的模型有能力画出更复杂的决策边界,需要更多的样本来估计unseen examples的true expected loss;我们可能需要随着模型的大小的增加来扩展验证集。在后续内容中,我们展示了其他几个任务的类似结果。总的来说,在true few-shot setting中,不能以任何合理的信心预期来自prompt selection的有限的average-case gains,这个问题只会随着更大的模型而变得更糟。我们能不能提高
prompt selection带来的性能改善的概率: 正如我们所表明的,CV和MDL并不能可靠地选择比平均水平更好的prompts。在此,我们探讨了通过明确地倾向于低方差的prompts,我们可以在多大程度上减少generalization loss的方差。对于最大的模型(GPT-3 175B),我们根据generalization loss的保守估计prompts。我们展示了以不同的置信度CV(prompts的test accuracy。如
Figure 2(right)所示,所有的CV相似的性能增益分布。例如,CV在50%的时间内优于average prompt,而51%的时间内优于average prompt。这些结果表明,当明确地将generalization loss的方差降到最低时,选择可靠地表现得比随机选择更好的prompts也是有意义的。prompt selection是否随着更多的标记样本而改善:prompt selection的不良表现可能是由于使用了如此少数量的标记样本。随着标记样本的数量的增加,我们期望prompt selection能够得到改善。因此,true few-shot prompt selection可能会在几十个样本中实现(尽管由于GPT等语言模型的输入长度限制,并不总是能够使用更多的样本)。因此,当我们使用越来越多的标记样本CV/MDL选择的prompts的test accuracy。对于
120种排列组合(以匹配held-out CV fold的次数相同)。我们对6.7B的参数模型进行实验,因为通过OpenAI API运行更大的模型,成本太高。如
Figure 3所示,无论是从任务表现(左图)还是从highest accuracy prompt(右图)来看,prompt selection的表现没有一致的趋势。即使在更高的数据区域(
40个样本),CV/MDL也很难选择有效的prompts;而且在不同的模型规模下,也没有一致的表现,比基于5个样本的选择更好。我们的发现是令人惊讶的,因为由于训练数据的稀缺性,true-few shot setting是prompt design被认为最有希望的地方(《How many data points is a prompt worth?》)。然而,true few-shot setting也是prompt selection最困难的地方,大大削弱了prompts的潜在价值。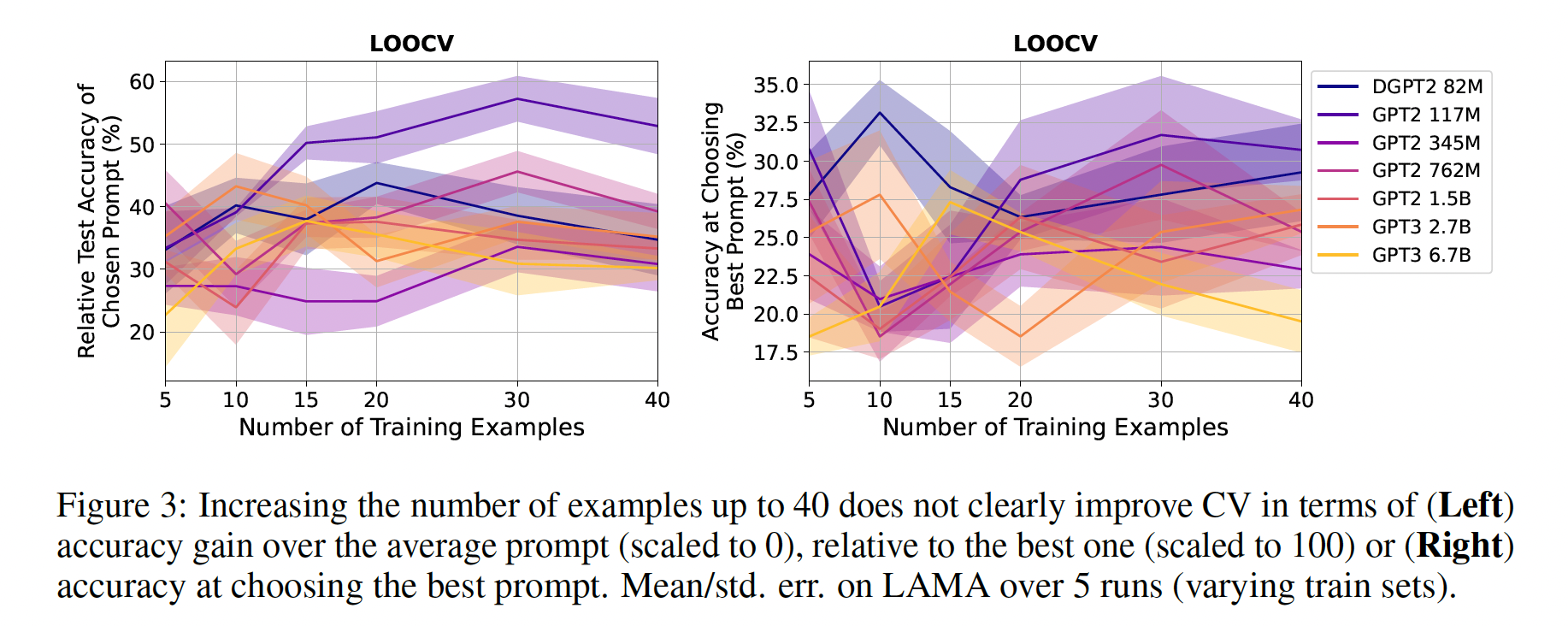
prompt selection是否随着更多的计算而改善:在前面的章节中,我们使用固定数量的prompt selection,但代价是增加计算量?为了回答这个问题,我们改变了用于计算上述期望值的LM的forward passes),并选择prompts。为了用单次forward pass来估计CV,我们采样单个foldfolds上为条件的LM时,foldFigure 4显示了在GPT-3 6.7B的结果。计算并不是
prompt selection的瓶颈,因为MDL的test accuracy在一次forward pass后大致趋于平稳,CV的test accuracy在forward pass后也是如此。这一观察结果在所有的6.7B参数的模型都成立(因篇幅关系省略)。我们的结果表明,true few-shot prompt selection从根本上受到可用样本数量的限制。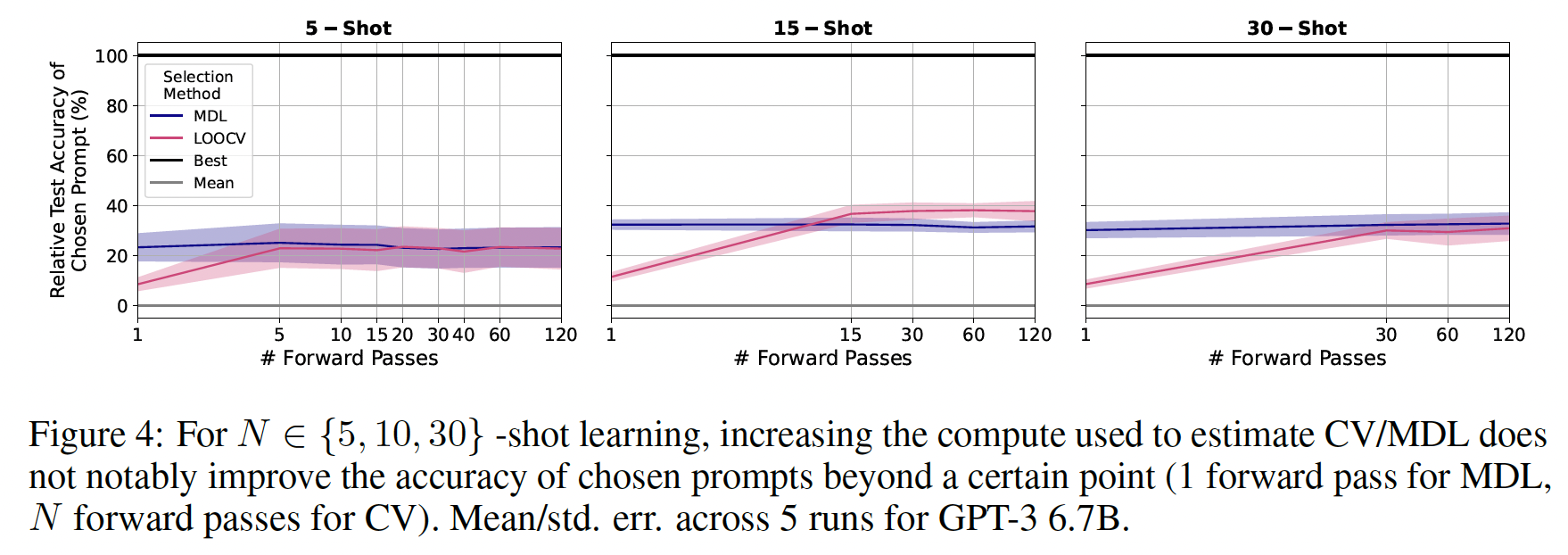
Prompt Selection在其他任务中是否具有挑战性:我们现在研究我们在LAMA任务上的结果在其他类型的NLP任务上的适用程度。我们研究了三个分类任务,之前的工作已经为其设计了各种prompts:Recognizing Textual Entailment: RTE、CommitmentBank: CB、Word-in-Context: WiC。RTE和CB涉及检测一个句子是否蕴含或矛盾另一个句子,而WiC涉及确定一个多义词是否在两个句子中使用相同的意义(例如,"Room and board"和"He nailed boards across the windows"中的"board")。进一步的任务细节见附录E.2。当使用由
CV、MDL、test accuracy选择的prompts时,我们评估GPT模型的准确率,正如我们对LAMA所做的那样。对于每个任务,我们在使用从任务训练集随机采样的5个训练样本时,使用完整的验证集来评估hold-out accuracy,同时确保每个类别至少包括一个样本。我们评估了5个训练集的误差均值和方差。作为我们的prompts集合,我们使用来自GPT-3原始论文和PET-2的手动编写的prompts:RTE/CB的3个prompts、WiC的4个prompts。PET-2为双向语言模型设计了prompts,因此在必要时,我们将他们的prompts修改为适合从左到右的语言模型(见附录E.2的prompts)。Figure 5显示了在每个任务中所选择的prompts的准确率。我们观察到与之前类似的趋势,即在不同的任务和模型大小中,
CV/MDL所选择的prompts几乎总是获得比根据test accuracy选择更低的平均准确率。即使在更少的prompts中进行选择(这里是3 ~ 4个),这一趋势也保持不变。CV/MDL所选择的prompts在不同的任务和模型大小中的test accuracy差异很大,经常选择比平均水平差的prompts(例如,在CB上)。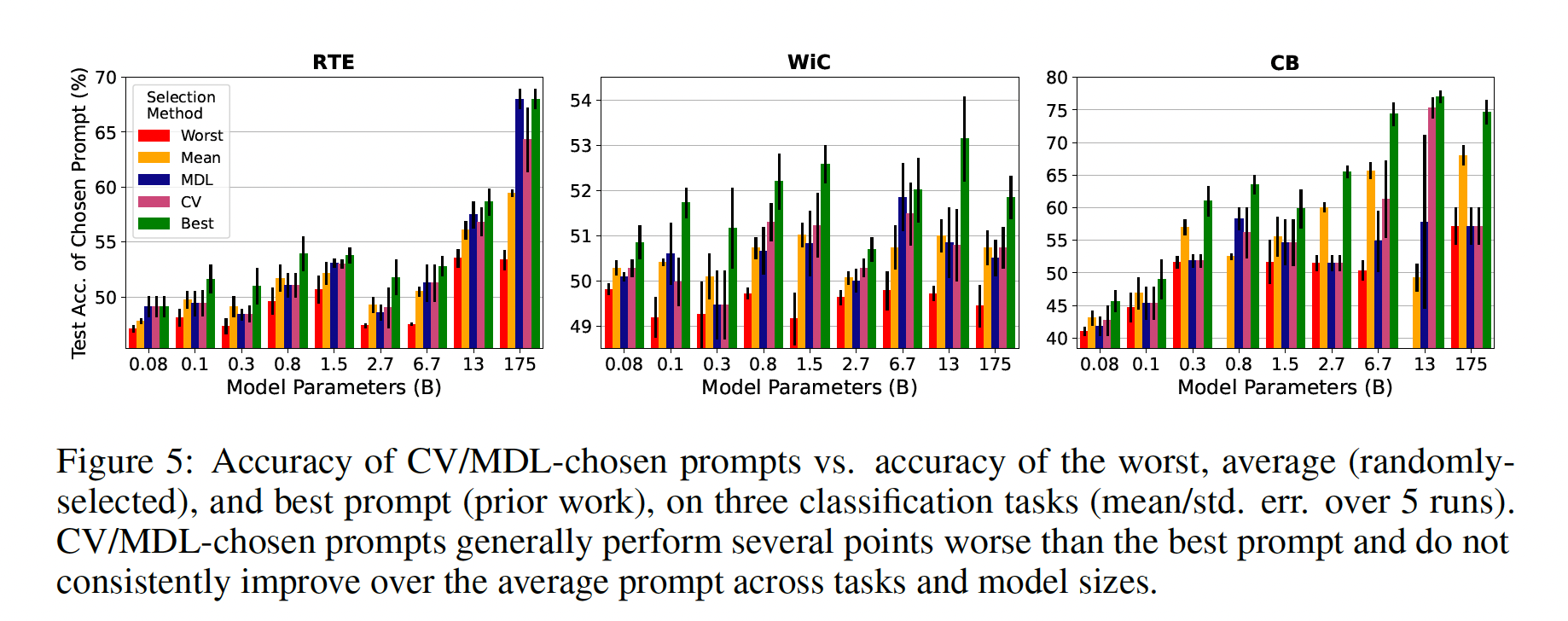
通过显示
prompt selection获得比average prompt更多的各种accuracy gains的概率,我们更详细地检查所选prompt的准确率的差异。在这里,我们选择了使用forward passes的CV的prompts(每个fold评估一次),因为它代表了计算和准确率之间的一个很好的权衡,很可能会在实践中使用。如Figure 6所示,forward passes又是高度分散的,往往是负面的,而且没有持续地实现提高。对于CB,GPT-3 175B有20%的机会使得准确率下降15%。模型大小在CV选择的prompts导致改善的机会上有很大的不同,例如,对于WiC来说,从38-82%,对于CB来说,从1-83%。总的来说,我们先前的发现可以延续到其他类型的任务中,这表明
prompt selection在总体上是具有挑战性的。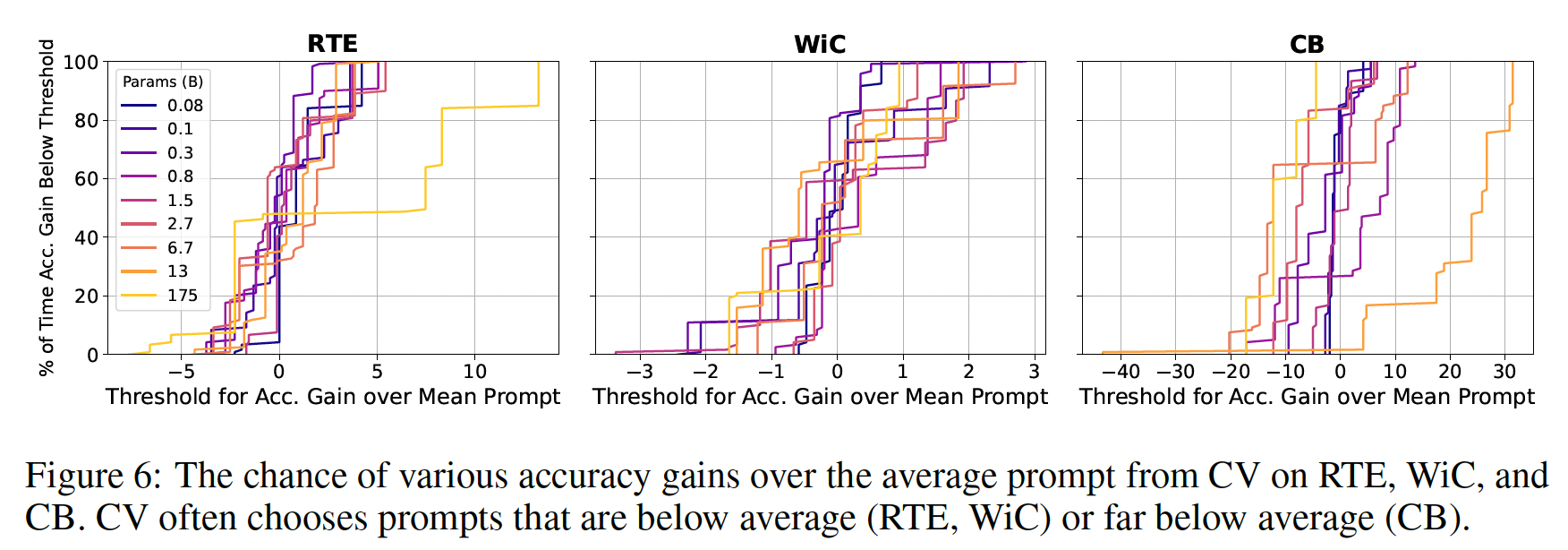
16.3 True Few-Shot Hyperparameter Selection
在证明了
true few-shot prompt selection是困难的之后,我们现在更普遍地研究在hyperparameter selection背景下的模型选择的有效性。我们研究了ADAPET模型(《Improving and simplifying pattern exploiting training》),因为它是开源的,而且根据SuperGLUE,它是目前表现最好的few-shot模型。ADAPET对预训练的pretrained ALBERT_xxlarge-v2 LM进行了微调,从而:在给定的
input条件下,将每个label分类为correct/incorrect。在给定
label和unmasked input tokens,预测被随机掩码的input tokens,类似于Masked LM(《BERT: Pre-training of deep bidirectional transformers for language understanding》)。
ADAPET是在tuned few-shot learning的背景下开发的,因为ADAPET的超参数是用validation examples来选择的。我们研究了ADAPET在true few-shot setting中的表现。我们以
true few-shot的方式选择了两个超参数:early stopping checkpoint、用于masked LM objective的被掩码的单词的比例。ADAPET在batch size = 16上执行T = 1000个梯度更新,并在validation accuracy的checkpoint。ADAPET还选择了最佳掩码比例ADAPET,我们对SuperGLUE进行了评估。SuperGLUE包括四个问答任务(BoolQ、COPA、MultiRC、ReCoRD)、一个共指解析任务(WSC)、两个蕴含性检测任务(RTE、CV)和一个常识性推理任务(WiC);任务细节见附录E.2。我们使用
CV/MDL来选择16种组合),然后用所选的FewGLUE,这是SuperGLUE的32-example子集,在之前的工作中用于few-shot learning。我们还使用了另外3个从SuperGLUE中随机采样的32-example子集,以估计不同训练集的性能方差。ADAPET在微调过程中使用了一个prompt,这是根据validation examples来选择的prompt。为了避免使用validation-tuned prompts,我们对每个任务使用第一个prompt,就像作者对消融研究所做的那样。由于训练ADAPET是昂贵的,我们用fold来评估CV/MDL。我们在Table 1中显示了结果。可以看到:在所有的
SuperGLUE任务中,CV/MDL的hyperparameter selection的表现与平均(随机选择的)超参数相似或更差,比最佳超参数差几个点。在
true few-shot setting中,ADAPET的平均SuperGLUE性能低于早期的方法(PET和iPET),突出了使用validation examples如何在few-shot learning中给人以进步的假象。在
MultiRC上,CV/MDL选择的超参数与最差的超参数有相似的性能,这也说明model selection方法在true few-shot setting中并不能始终如一地防止最差情况的发生。附录
D的初步分析表明,选择优于平均水平的超参数需要几千个样本。
总的来说,我们的结果表明,在数据量非常少的情况下,不仅是
prompt selection,而且是一般的model selection,都具有挑战性。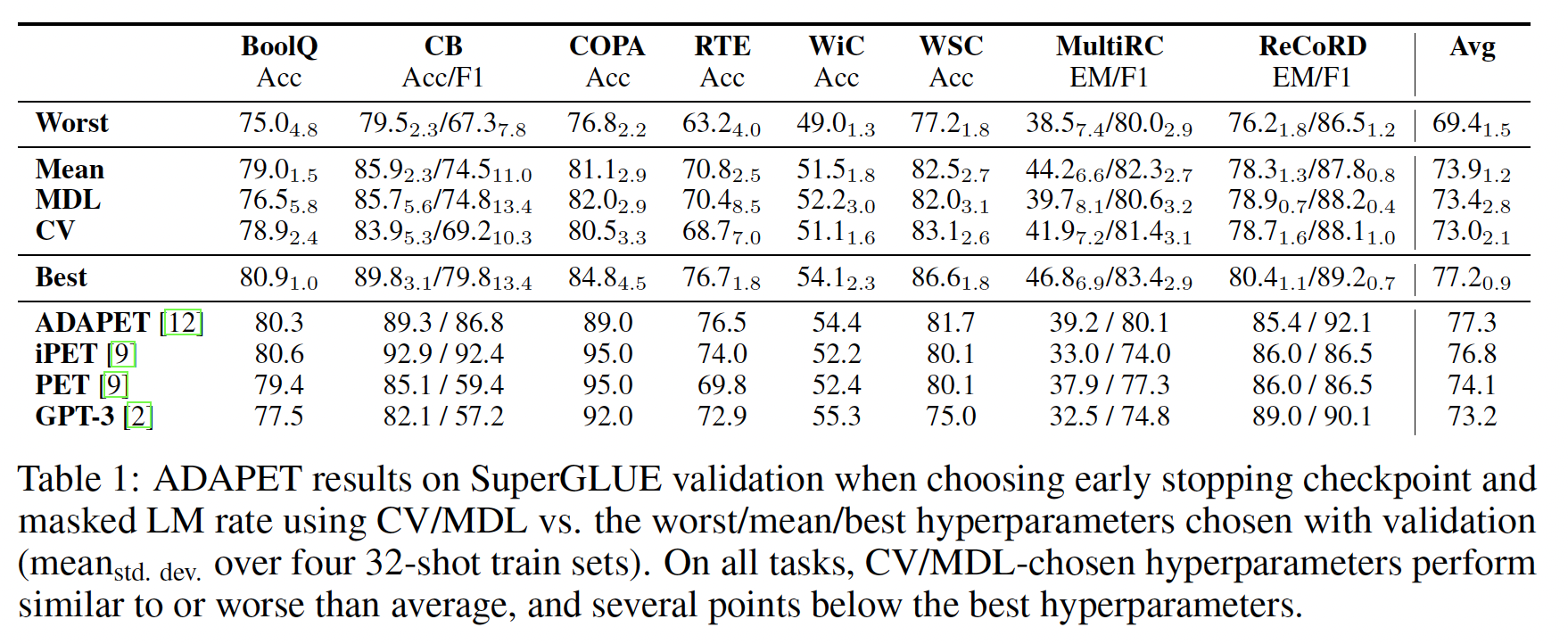
16.4 结论和未来工作
我们的工作表明,只用几个标记样本来对
few-shot learning算法做出最基本的决定也是有难度的。相反,做出额外的假设可能更有希望。meta-learning setting假定可以从许多其他任务中获取数据,以便进行learning selection和model selection。迁移学习和多任务学习假设能够获得与任务直接相关的有限数据。
数据增强技术假定有一种可行的方法可以从有限的数据中创造更多的数据。
其他的方法是假设没有标记的数据,并开发无监督的
model selection技术。
当标记的数据很便宜时,最简单的方法是假设有更多的样本用于验证。在这种情况下,我们可能更好地在额外的样本上进行训练。除非我们明确提出这样的假设,否则我们无法在
few-shot learning算法之间进行有意义的比较。考虑到model selection的挑战,我们发现上述途径是比true few-shot learning更有希望的未来方向。受先前工作的启发,我们对未来
true few-shot learning工作提出了建议:报告所有考虑的超参数(
prompts)和超参数选择的准则。将
validation examples包括在few-shot learning算法所使用的样本数量中。validation examples包括所有的样本用于决定学习的任何方面:超参数、prompts、训练目标、解码策略、模型结构等。一旦你决定了
learning算法,就直接提交你的模型进行测试评估,而不用先在validation数据上进行评估。汇报所进行的测试评估的总数量(理想情况下,只需一次)。只有在测试评估之后才使用验证集来报告任何消融实验,以避免用验证集对你的算法做出决定。不要依赖以前的工作中的超参数,这些超参数是用同一
benchmark(例如,SuperGLUE)的validation examples来调优的,以避免间接受益于validation examples。相反,只用给定的few-shot examples来重新调优这种超参数。
上述协议是严格的,但却模仿了
true few-shot learning算法在真实的、低数据环境中的使用方式。为了确保研究人员遵守这种严格的协议,未来的基准可能需要保持大型测试集的私密性,而只公布少量的标记的样本。考虑到我们在
true few-shot learning方面的负面结果,一个主要的问题仍然存在:在true zero-shot setting下,是否有可能选择模型?之前的工作是通过选择一个任意的
prompt(《Language models as knowledge bases?》、《Lessons from a new suite of psycholinguistic diagnosticsfor language models》)将语言模型用于zero-shot learning,这不需要数据,但却是次优的(《How can we know what language models know? 》)。其他工作尝试多个prompts,并通过试错和人工评估从而在它们之间进行选择(《Language models are unsupervised multitask learners》),有效地利用了人类监督。正如我们从开源代码中注意到的,
CLIP在使用ImageNet的训练集(1.28M个样本)广泛地调优prompts和标签名称后,在ImageNet上实现了高的zero-shot accuracy。作者报告说,仅通过调优prompts就获得了5% accuracy gain,但是用于调优的训练样本在true zero-shot learning中是不可用的。在没有任何标记数据的情况下,
model selection的问题甚至比真正的true few-shot更具挑战性。总的来说,我们的工作通过澄清true few-shot setting的假设,为未来的few-shot learning工作提供了指导,并从经验上证明了model selection是true few-shot learning的一个主要障碍。