二十七、Prefix-Tuning[2021]
论文:
《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
微调是(
finetuning)使用大型pretrained语言模型执行下游任务(如摘要)的普遍范式,但它需要更新和存储语言模型的所有参数。因此,为了建立和部署依赖大型pretrained语言模型的NLP系统,目前需要为每个任务来存储语言模型参数的modified copy。考虑到当前语言模型的庞大规模,这可能是非常昂贵的,例如,GPT-2有774M参数、GPT-3有175B参数。解决这个问题的一个自然方法是
lightweight fine-tuning,它冻结了大部分pretrained parameters,并用小的可训练模块来augment模型。例如,adapter-tuning在pretrained语言模型的层之间插入额外的task-specific layers。adapter-tuning在自然语言理解和自然语言生成基准上有很好的表现,达到了与微调相当的性能,而只增加了大约2-4%的task-specific parameters。在另一个方面,
GPT-3可以在没有任何task-specific tuning的情况下部署。相反,用户将自然语言的任务指令(例如,TL;DR用于摘要任务)和一些样本添加到任务输入中,然后从语言模型中生成输出。这种方法被称为in-context learning或prompting。在本文中,我们提出了
prefix-tuning,这是一种轻量级的替代微调的方法用于自然语言生成任务,其灵感来自于prompting。考虑为数据表格生成文本描述的任务,如Figure 1所示,任务输入是一个线性化的表格(例如,"name: Starbucks | type: coffee shop"),输出是一个文本描述(例如,"Starbucks serves coffee.")。prefix-tuning将continuous task-specific vectors序列(我们称之为prefix,在Figure 1(bottom)中用红色块描述)前置到输入中。对于随后的tokens,Transformer可以关注prefix,就像它是一串"virtual tokens"一样,但与prompting不同的是,prefix完全由free parameters组成,不对应于real tokens。Figure 1 (top)中的微调会更新所有Transformer parameters,因此需要为每个任务存储模型的tuned copy。与微调相反,prefix-tuning只优化prefix。因此,我们只需要存储大型Transformer的一个副本、以及学到的一个task-specific prefix,为每个额外的任务产生一个非常小的开销(例如,250K参数用于table-to-text任务)。实际上是在模型的每一层
Layer(包括输入层)都添加了相同的一个prefix,而不同任务的prefix不同。
与微调相反,
prefix-tuning是模块化的:我们训练一个上游的prefix,这个上游的prefix引导下游的语言模型,而下游的语言模型保持unmodified。因此,单个语言模型可以一次同时支持许多任务。在任务对应不同用户的personalization的背景下,我们可以为每个用户准备一个单独的prefix,这个prefix只对该用户的数据进行训练从而避免数据交叉污染。此外,prefix-based的架构使我们甚至可以在一个batch中处理来自多个users/tasks的样本,这是其他轻量级微调方法所不能做到的。我们在使用
GPT-2在table-to-text generation任务上、以及使用BART在抽象摘要任务上评估prefix-tuning。在存储方面,prefix-tuning存储的参数比fine-tuning少1000倍。在对完整数据集进行训练时的性能方面,prefix-tuning和fine-tuning在table-to-text任务上不相上下,而prefix-tuning在摘要任务上会有小幅下降。在low-data setting中,prefix-tuning在这两项任务上的平均表现都优于微调。prefix-tuning还能更好地推断出有unseen主题的表格(在table-to-text任务)和文章(在摘要任务)。相关工作:
natural language generation: NLG的微调:目前SOTA的自然语言生成系统是基于fine-tuning pretrained LM。对于
table-to-text generation,《Text-to-text pre-training for data-to-text tasks》微调了一个sequence-to-sequence模型(T5)。对于抽取式摘要(
extractive summarization)和抽象式摘要(summarization),研究人员分别微调masked language model(如BERT)和encode-decoder model(如BART)。对于其他的
conditional NLG任务,如机器翻译和对话生成,微调也是普遍存在的范式。
在本文中,我们关注的是使用
GPT-2的table-to-text任务、以及使用BART的摘要任务,但prefix-tuning也可以应用于其他generation任务、以及其他pretrained模型。轻量级微调:轻量级微调冻结了大部分
pretrained parameters,并用小的可训练模块来修改pretrained model。关键的挑战是如何确定高性能的模块结构、以及要调优的pretrained parameters的子集。一条研究路线是考虑删除参数:通过在模型参数上训练一个
binary mask从而消除一些模型权重(《Masking as an efficient alternative to finetuning for pretrained language models》、《How fine can fine-tuning be? learning efficient language models》)。另一条研究路线考虑插入参数。例如:
《Side-tuning:A baseline for network adaptation via additive side networks》训练了一个"side"网络,该网络通过summation与pretrained model进行融合。adapter-tuning在pretrained LM的每一层之间插入task-specific layers(adapters)(《Parameter-efficient transfer learning for NLP》、《Exploring versatile generative languagemodel via parameter-efficient transfer learning》、《Learning multiple visual domains with residual adapters》、《Adapter-fusion: Non-destructive task composition for transfer learning》)。
这个研究方向调优了大约
3.6%的语言模型参数。与之相比,我们的方法在task-specific parameters方面进一步减少了30倍,只调优了0.1%的参数,同时保持了相当的性能。
Prompting:prompting是指在任务输入中前面添加指令和一些样本,并从语言模型中生成输出。GPT-3使用手动设计的prompts从而适配它的generation从而用于不同的任务,这个框架被称为in-context learning。然而,由于Transformers只能对有界长度的上下文进行条件生成(例如,GPT-3的2048 tokens),in-context learning无法完全利用长于上下文窗口的训练集。《Conditioned natural language generation using only unconditioned language model: An exploration》也通过关键词来提示从而控制generated sentence的情感或主题。在自然语言理解任务中,
prompt engineering已经在之前的工作中为BERT和RoBERTa等模型进行了探索。例如,AutoPrompt(《Autoprompt: Eliciting knowledge from language model swith automatically generated prompts》)搜索discrete trigger words的一个序列,并将其与每个输入拼接起来,从而引导被masked LM的情感或事实性知识。与AutoPrompt相比,我们的方法优化continuous prefixes,其表达能力更强。此外,我们专注于语言生成任务。
连续向量已经被用来引导语言模型;例如,
《Can unconditional language models recover arbitrary sentences?》表明,pretrained LSTM语言模型可以通过优化一个连续向量来重建任意的句子,使向量成为input-specific。相比之下,prefix-tuning优化了一个task-specific prefix,适用于该任务的所有实例。因此,与之前的工作(它的应用仅限于句子重建)不同的是,prefix-tuning可以应用于自然语言生成任务。可控的
generation:可控生成的目的是引导pretrained语言模型与句子层面的属性(例如,positive情感、或关于体育的话题)相匹配。这种控制可以在训练时发生:
《Ctrl: A conditional transformer language model for controllable generation》对语言模型(CTRL)进行预训练,从而对元数据(如关键词或URL)施加条件。此外,控制可以发生在解码期间,通过加权解码(
《GeDi: Generative Discriminator Guided Sequence Generation》)或迭代式地更新过去的activations(PPLM,《Plug and play language models: A simple approach to controlled text generation》)。
然而,目前还没有直接的方法来应用这些可控的生成技术来对所生成的内容进行细粒度的控制,如
table-to-text任务和摘要任务所要求的。
27.1 方法
考虑一个
conditional generation任务,输入是一个上下文tokens序列。我们关注两个任务,如Figure 2(right)所示:在
table-to-text任务中,在摘要任务中,
这里展示了
decoder-only模型、encoder-decoder模型。实际上encoder-only模型(如BERT)也可以采用类似的思路。
自回归语言模型:假设我们有一个基于
Transformer架构(如GPT-2)的自回归语言模型Figure 2(top)所示,令令
Transformer layer的激活;令时间步activation是activation layers的拼接。自回归Transformer模型将past activations的函数,如下所示:其中,最后一层的
next token的分布:其中:
pre-trained参数矩阵。token。Encoder-Decoder架构:我们也可以使用encoder-decoder架构(例如BART)来建模Figure 2(bottom)所示。所有Transformer encoder计算,所有微调:在微调框架中,我们用
pretrained parametersPrefix-Tuning的直觉:基于来自prompting的直觉,我们认为有一个适当的上下文可以引导语言模型而不改变其参数。例如,如果我们想让语言模型生成一个单词(如,“奥巴马”),我们可以在输入的签名添加它的常见搭配作为上下文(如,"巴拉克"),语言模型将为所需的单词分配更高的概率。将这一直觉延伸到生成单个单词或单个句子之外,我们想找到一个引导语言模型解决
NLG任务的上下文。直观地说,上下文可以通过指导从encoding;也可以通过指导next token的分布来影响"summarize the following table in one sentence")可能会指导专家标注员解决该任务,但对大多数pretrained LM来说是失败的。对离散的指令进行数据驱动的优化可能会有帮助,但discrete optimization在计算上具有挑战性。我们可以将指令作为
continuous word embeddings来优化,而不是对discrete tokens进行优化,其效果将向上传播到所有Transformer activation layers、并向右传播到后续的tokens。严格来说,这比discrete prompt更有表达能力,因为discrete prompt需要匹配一个真实的单词的embedding。同时,这比介入所有层的activations(即,微调)的表达能力要差,后者避免了长距离的依赖,并包括更多可调优的参数。因此,prefix-tuning优化了prefix的所有层。Prefix-Tuning的方法:prefix-tuning为自回归语言模型添加了一个前缀,得到Figure 2所示。这里,我们遵循方程
prefix是自由参数。prefix-tuning初始化一个尺寸为prefix parameters:训练目标为
prefix parameters是唯一可训练的参数。注意:这在每一层都添加了相同的
prefix,包括输入层。是否可以对不同的层采用不同的
prefix,使得表达能力更强?这就是P-Tuning V2的思想。这里,
当
当
prefix activations总是位于左侧的上下文中,因此会影响其右边的任何activations。
reparametrization parameters可以被放弃,只有前缀(这种重参数化为什么能提升效果?作者没有讲解原因。读者猜测是:原始的
这种重参数化技巧相当于对
27.2 实验
我们在三个标准的数据集上评估了
table-to-text generation任务:E2E, WebNLG, DART。E2E只有1个领域(即,餐厅评论),包含大约50K个样本,有8个不同的字段。对于一个source table,它包含多个test references,平均输出长度为22.9。我们使用官方的评估脚本,其中报告了BLEU, NIST, METEOR, ROOUGE-L, CIDEr。WebNLG有14个领域,包含22K个样本,输入(subject, property, object)三元组的序列。平均输出长度为22.5。在训练集和验证集,输入描述了来自9个不同的DBpedia类别的实体(例如,Monument)。测试集由两部分组成:前半部分包含训练数据中的DB类别,后半部分包含5个未见过的类别。这些未见过的类别被用来评估外推(extrapolation)。我们使用官方评估脚本,它报告BLEU, METEOR, TER。DART是开放领域,使用来自维基百科的open-domain tables。它的输入格式(entity-relation-entity)三元组与WebNLG相似。平均输出长度为21.6。它由来自WikiSQL, WikiTableQuestions, E2E, WebNLG的82K个样本组成,并应用了一些人工或自动转换。我们使用官方评估脚本并报告BLEU, METEOR, TER, Mover-Score, BERTScore, BLEURT。
对于摘要任务,我们使用
XSUM数据集,它是一个关于新闻文章的抽象摘要数据集,有225K个样本。文章的平均长度为431个单词,摘要的平均长度为23.3。我们报告了ROUGE-1, ROUGE-2, ROUGE-L。baseline:对于
table-to-text generation,我们将prefix-tuning与其他三种方法进行了比较:微调(FINETUNE)、仅对顶部2层进行微调(FT-TOP2)、adapter-tuning(ADAPTER)。我们还报告了目前在这些数据集上的
SOTA结果:在
E2E上,《Pragmatically informative text generation》使用了一个没有预训练的pragmatically informed model。在
WebNLG上,《Text-to-text pre-training for data-to-text tasks》对T5-large进行了微调。在
DART上,没有发布在这个数据集版本上训练的官方模型。
对于摘要,我们与微调
BART进行比较。
实验配置:
对于
table-to-text,我们使用GPT-2_MEDIUM和GPT-2_LARGE,source tables被线性化。对于摘要,我们使用BART_LARGE,源文章被截断为512个BPE tokens。我们的实现是基于
Hugging Face Transformer模型。在训练时,我们使用AdamW优化器和一个线性学习率调度器,正如Hugging Face默认设置所建议的。我们调优的超参数包括epoch数量、batch size、学习率、prefix长度。超参数的细节如下表所示。默认设置是训练10 epochs,使用batch size = 5,学习率prefix长度为10。table-to-text模型在TITAN Xp或GeForce GTX TITAN X机器上训练。在22K样本上,prefix-tuning每个epoch需要0.2小时,而微调则需要0.3小时。摘要模型在Tesla V100机器上训练,在XSUM数据集上每个epoch需要1.25小时。在解码时,对于三个
table-to-text数据集,我们使用beam size = 5的beam search。对于摘要,我们使用beam size = 6的beam search,以及0.8的长度归一化。对于table-to-text,每个句子的解码需要1.2秒(没有batching);对于摘要,每个batch的解码需要2.6秒(batch size = 10)。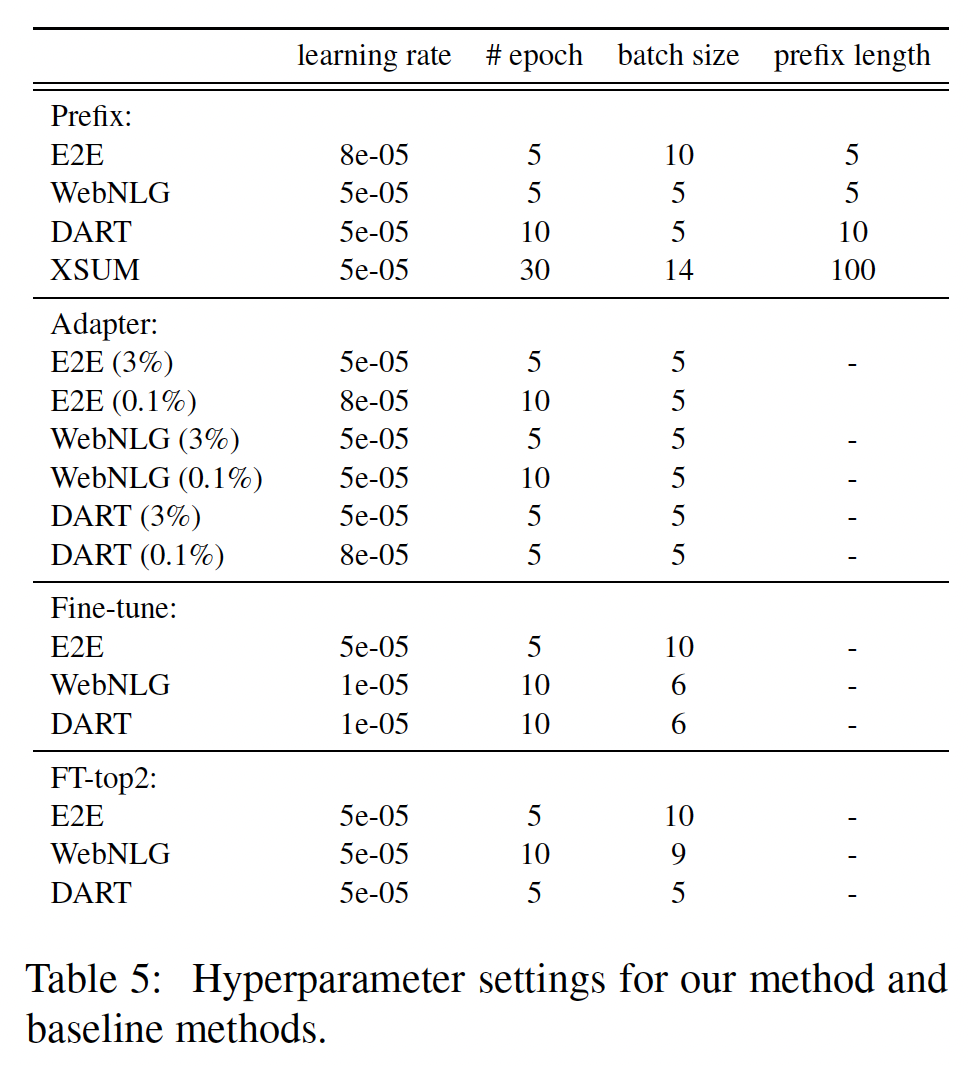
27.2.1 实验结果
Table-to-text Generation任务:我们发现,只添加0.1%的task-specific parameters,prefix-tuning在table-to-text generation中是有效的,超过了其他轻量级baseline(ADAPTER和FT-TOP2),并取得了与微调相当的性能。这一趋势在所有三个数据集上都是如此:E2E, WebNLG, DART。为了公平比较,我们将
prefix-tuning和adapter-tuning的参数数量匹配为0.1%。Table 1显示,prefix-tuning明显优于ADAPTER(0.1%),平均每个数据集获得4.1 BLEU的改善。即使我们与微调(
100%)和adapter-tuning(3.0%)相比(它们更新的参数数量要超过prefix-tuning),prefix-tuning仍然取得了相当或更好的结果。这表明prefix-tuning比adapter-tuning更具有帕累托效率:在提高生成质量的同时大大减少了参数。帕累托效率:效果好的同时参数量也少。
此外,在
DART上取得良好的性能表明,prefix-tuning可以泛化到具有不同领域和大量关系的table。我们将在后续实验深入研究外推性能(即泛化到对未见过的类别或主题)。总的来说,
prefix-tuning是一种有效的、节省空间的方法,可以使GPT-2适用于table-to-text generation。学到的prefix有足够的表达能力来引导GPT-2,以便正确地从非自然语言的格式中提取内容并生成文本描述。prefix-tuning也能很好地从GPT-2_MEDIUM扩展到GPT-2_LARGE,这表明它有可能扩展到具有类似架构的更大的模型,比如GPT-3。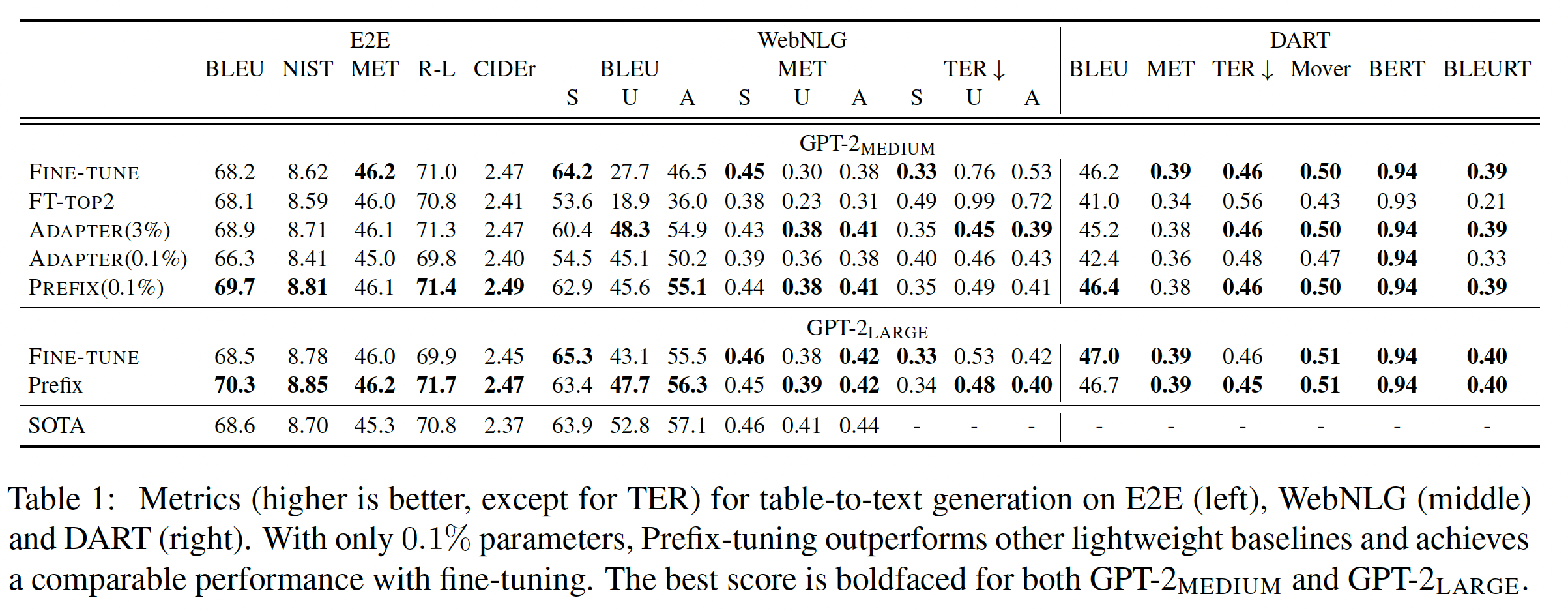
摘要任务:如
Table 2所示,在参数为2%的情况下,prefix-tuning获得的性能略低于微调(在ROUGE-L中为36.05 vs. 37.25)。在只有0.1%的参数下,prefix-tuning的性能低于full fine-tuning(35.05 vs. 37.25)。在
XSUM和table-to-text数据集之间有几个不同之处,可以解释为什么prefix-tuning在table-to-text中具有相对优势:XSUM包含的样本比三个table-to-text数据集平均多4倍。XSUM输入的文章比table-to-text数据集的线性化表格的输入平均长17倍。摘要任务可能比
table-to-text更复杂,因为它需要阅读理解、以及识别文章的关键内容。
Prefix(0.1%)和Prefix(2%)分别代表prefix length等于多少?论文并未说明。根据读者猜测,Prefix(0.1%)对应于prefix length = 5、Prefix(2%)对应于prefix = 100。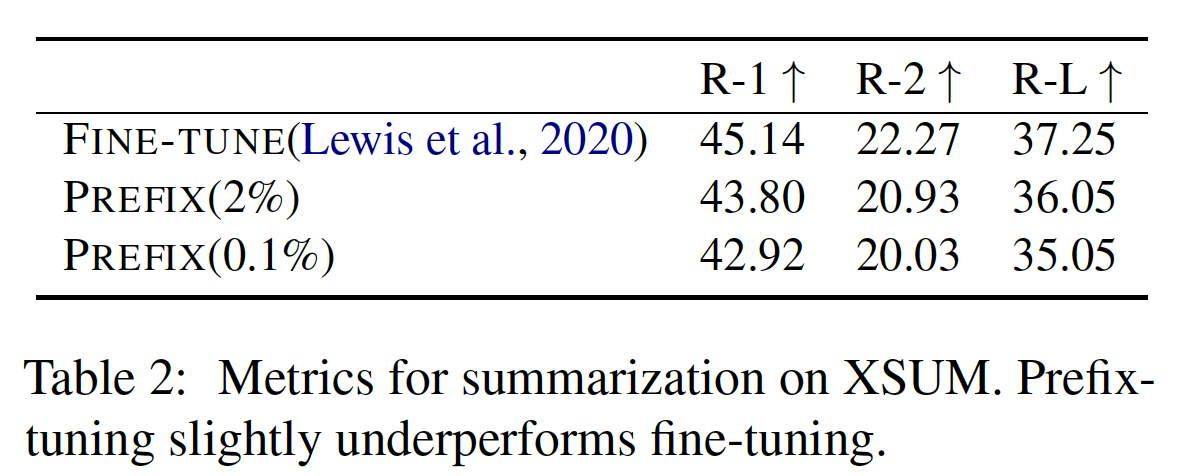
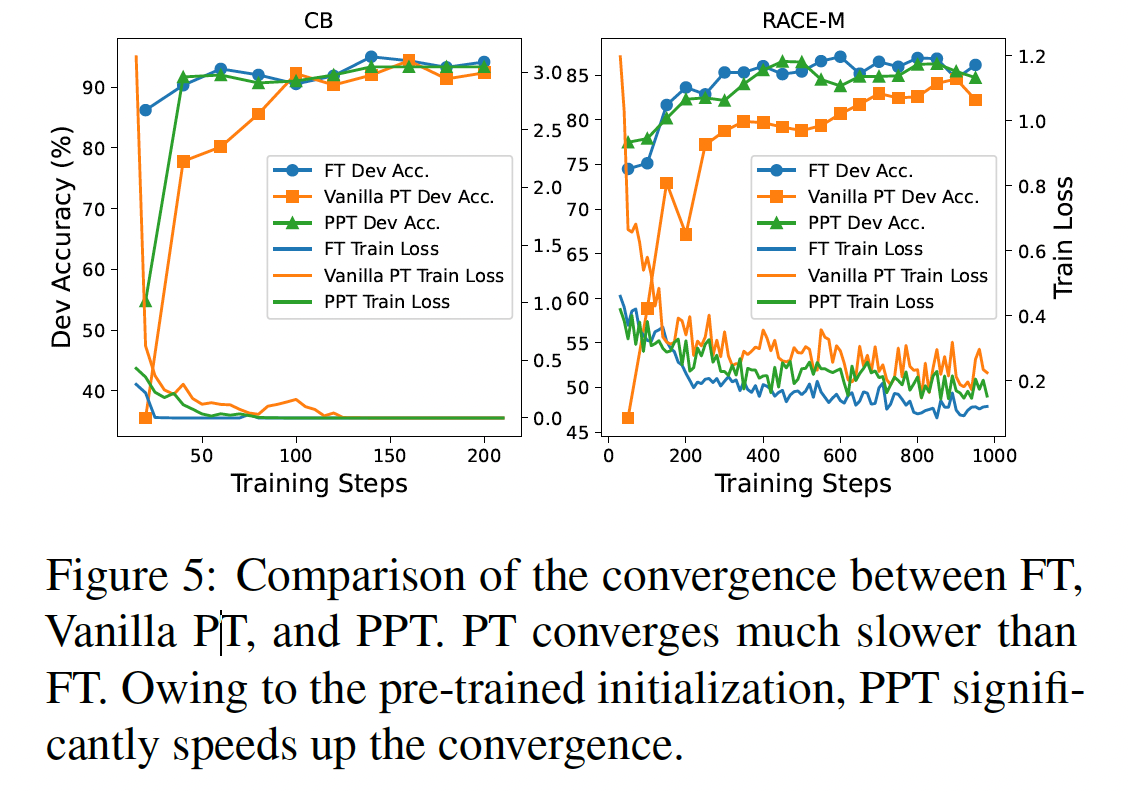
Low-data Setting:基于table-to-text任务和摘要任务的结果,我们观察到,当训练样本的数量较少时,prefix-tuning具有相对的优势。为了构建low-data settings,我们对完整的数据集(table-to-text的E2E、摘要任务的XSUM)进行降采样,得到大小为{50, 100, 200, 500}的小数据集。对于每个大小,我们采样五个不同的数据集,并训练两个training random seeds然后取平均。因此,我们对10个模型进行平均,以获得每个low-data setting的估计。Figure 3(right)显示,prefix-tuning在low-data setting下平均比微调多出2.9 BLEU,此外所需的参数也更少;但随着数据集规模的增加,差距也在缩小。从质量上看,
Figure 3(left)显示了由在不同数据量上训练的prefix-tuning model和fine-tuning model所产生的8个样本。虽然两种方法在low data区域下都倾向于生成不足(缺失表格内容),但prefix-tuning往往比微调更忠实。例如,微调(100, 200)错误地声称顾客的评价很低,而真实的评价是平均的;而prefix-tuning (100, 200)所生成的描述是忠实于表格的。
prefix-tuning和微调在low-data setting下的表现,更详细的曲线如Figure 6所示。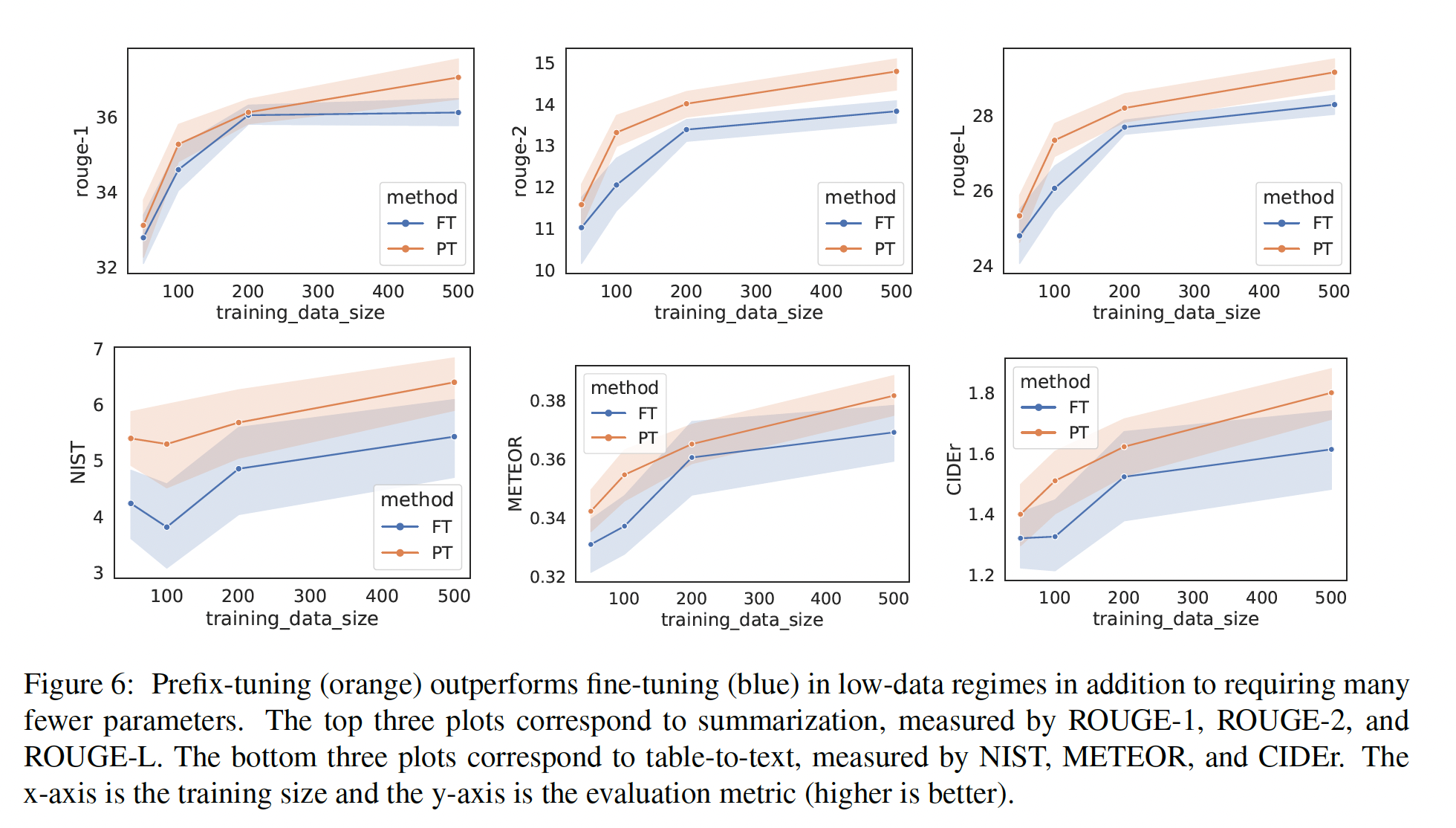
Extrapolation:我们现在研究了针对table-to-text和摘要任务对未见过的主题的推断性能。为了构建一个外推环境,我们对现有的数据集进行了拆分,使训练集和测试集涵盖不同的主题。对于
table-to-text,WebNLG数据集被table topics所标记。有9个类别在训练集和验证集中出现,表示为SEEN;5个类别只在测试集中出现,表示为UNSEEN。所以我们通过对SEEN类别的训练和对UNSEEN类别的测试来评估外推法。对于摘要,我们构建了两个外推数据子集:
在
news-to-sports中,我们对新闻文章进行训练,对体育文章进行测试。在
within-news中,我们对{world, UK, business}新闻进行训练,并对其余新闻类别(如健康、科技)进行测试。
如
Table 3和Table 1(中间)的"U"列所示,在table-to-text任务和摘要任务上,pre-fixtuning在所有指标下都比微调有更好的外推能力。我们还发现,
adapter-tuning取得了良好的外推性能,与pre-fixtuning相当,如Table 1所示。这种共同的趋势表明,保留语言模型参数确实对外推有积极影响。然而,这种收益的原因是一个开放的问题,我们将在后续章节进一步讨论。
27.2.2 消融分析
Prefix长度:较长的prefix意味着更多的可训练参数,因此有更强的表达能力。Figure 4显示,性能会随着prefix长度的增加而增加,直到一个阈值(摘要任务为200、table-to-text为10),然后性能会有轻微的下降。根据经验,较长的
prefix对推理速度的影响可以忽略不计,因为整个prefix的注意力计算在GPU上是并行的。
Full vs Embedding-only:如前文所述,我们讨论了优化"virtual tokens"的continuous embeddings。我们将这一想法实例化,并称之为embedding-only消融分析。word embeddings是自由参数,上层activation layers由Transformer计算。Table 4 (top)显示,性能明显下降,表明仅仅调优embedding layer并不具有足够的表达能力。embedding-only的消融分析给出了discrete prompt optimization的性能上限,因为discrete prompt限制了embedding layer要完全匹配真实单词的embedding。因此,我们有这样一个表达能力递增的链条:discrete prompting < embedding-only ablation < prefix-tuning。这里的结论是存疑的,因为
embedding-only的自由度降低。应该在采用embedding-only的时候,去掉参数化技巧(这就是P-Tuning的思想)。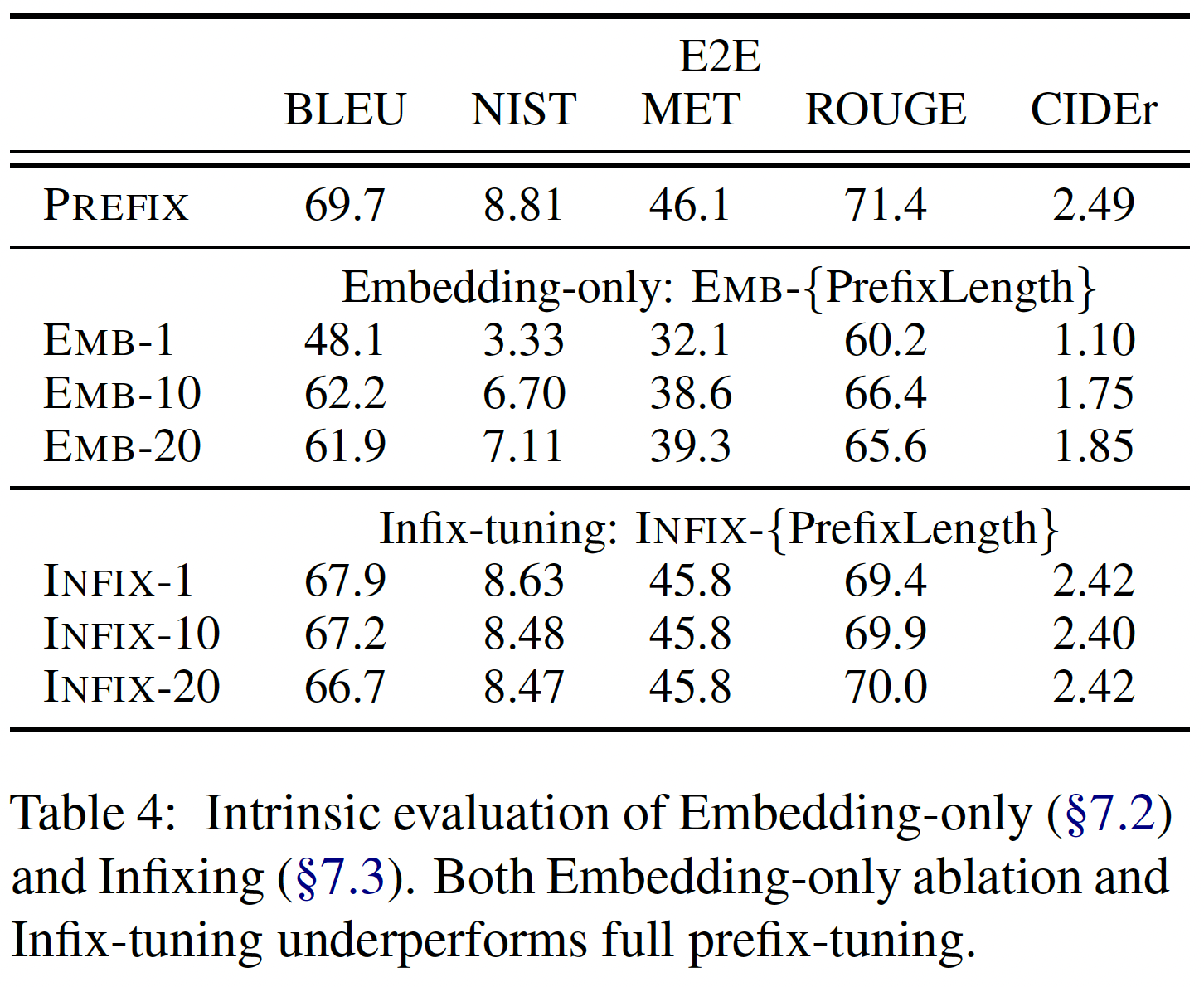
Prefixing vs Infixing:我们还研究了可训练的activations在序列中的位置如何影响表现。在prefix-tuning中,我们把它们放在开头activations放在infix-tuning。Table 4 (bottom)显示,infix-tuning的表现略逊于pre-tuning。我们认为这是因为prefix-tuning可以影响activations,而infix-tuning只能影响activations。初始化:我们发现,
prefix的初始化方式在low-data settings下有很大的影响。随机初始化会导致高方差的低性能。如Figure 5所示,用真实单词的activations来初始化prefix,可以明显改善generation。具体而言,用任务相关的单词如"summarization"和"table-to-text"来初始化所获得的性能,比用任务无关的单词如"elephant"和"divide"略好,但使用真实的单词仍然比随机要更好。由于我们用语言模型计算的真实单词的
activations来初始化前缀,这种初始化策略与尽可能地保留pretrained LM是一致的。注意:这里描述的是参数的初始化,而参数的梯度更新是采用参数化技巧。
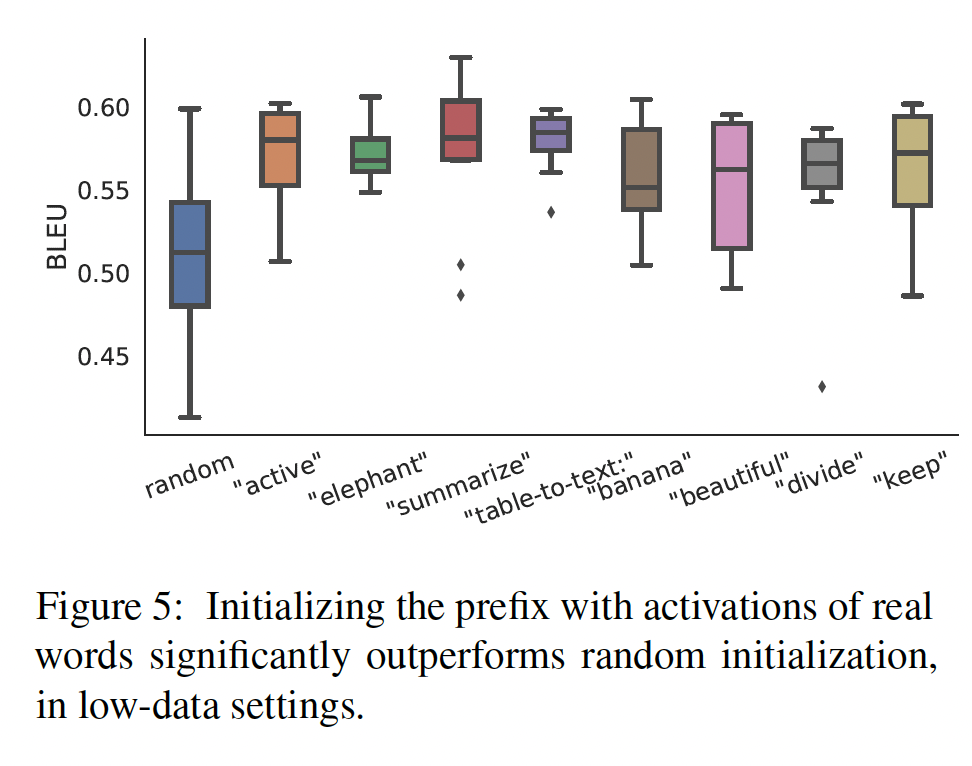
Figure 7给出了更多的关于初始化的指标。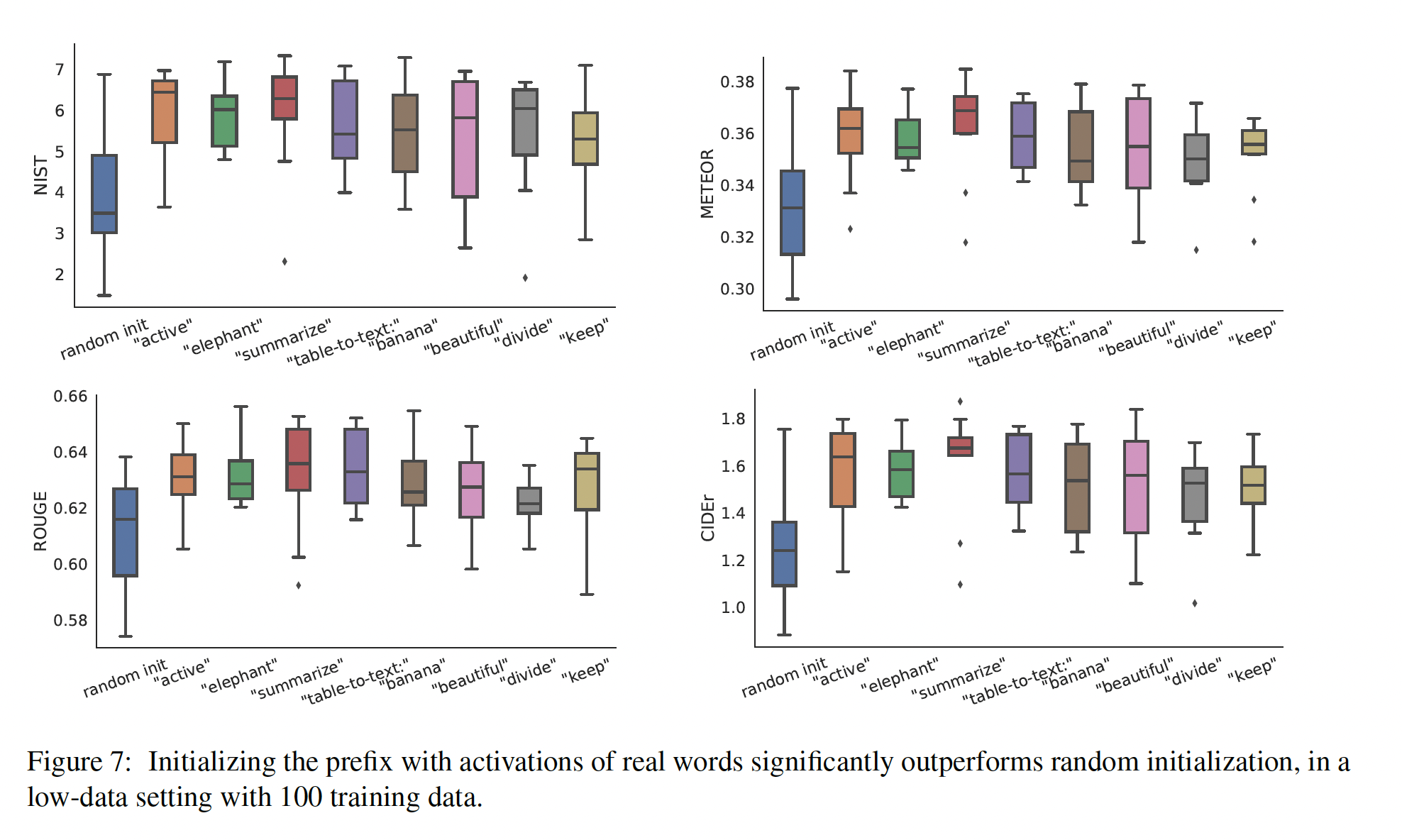
27.3 讨论
个性化(
Personalization):正如我们在前面章节中指出的,当有大量的任务需要独立训练时,prefix-tuning是有利的。一个实际的setting是用户隐私。为了保护用户隐私,每个用户的数据需要被分开,并且需要为每个用户独立训练一个个性化的模型。因此,每个用户可以被看作是一个独立的任务。如果有数以百万计的用户,prefix-tuning可以scale到这种setting,并保持模块化。通过增加或删除用户的prefix,可以灵活地增加或删除用户,而不会造成交叉污染。跨用户的
Batching:在personalization setting下,prefix-tuning允许对不同用户的query进行batching,即使这些query采用不同的prefix。当多个用户用他们的inputs来query云端GPU设备时,将这些用户放在同一batch是很有计算效率的。prefix-tuning可以保持共享的语言模型不变;因此,batching需要一个简单的步骤,即把personalized prefix添加到用户的输入之前,其余所有的计算都是不变的。相比之下,在adapter-tuning中,我们不能在不同的用户之间进行batching,因为adapter-tuning在共享的Transformer layers之间有personalized adapters。batch内不同样本的prefix不同,可以类似于word embedding的思路,认为每个用户一个id,prefix vector就是id embedding。Prefix-tuning的归纳偏置(Prefix-tuning):回顾一下,微调会更新所有的pretrained parameters,而prefix-tuning和adapter-tuning则会保留pretrained parameters。由于语言模型是在通用语料库上进行预训练的,保留语言模型参数可能有助于泛化到训练期间未见的领域。与这种直觉相一致的是,我们观察到prefix-tuning和adapter-tuning在extrapolation settings中都有明显的性能提升;然而,这种提升的原因是一个开放的问题。虽然
prefix-tuning和adapter-tuning都冻结了pretrained parameters,但它们调优不同的参数集合来影响Transformer的activations。回顾一下,prefix-tuning保持语言模型的完整,并使用prefix和pretrained attention blocks来影响后续的activations;adapter-tuning在语言模型的层之间插入可训练的模块,直接将residual vectors添加到activations中。此外,我们观察到,与adapter-tuning相比,prefix-tuning需要的参数要少得多,同时又能保持相当的性能。我们认为参数效率的提高是因为prefix-tuning尽可能地保持了pretrained LM的完整性,因此比adapter-tuning更能利用语言模型。《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》的同期工作使用intrinsic dimension表明,存在一个低维度的reparameterization,其微调效果与full parameter space一样。这解释了为什么只需更新少量的参数就能在下游任务上获得良好的准确率。我们的工作与这一发现相呼应,表明通过更新一个非常小的prefix就可以达到良好的generation性能。
二十八、P-Tuning[2021]
论文:
《GPT Understands, Too》
语言模型预训练是许多自然语言处理任务的成功方法。有证据表明,在预训练过程中,语言模型不仅学习了
contextualized text representation,还学习了语法、句法、常识、甚至世界知识。根据训练目标,预训练的语言模型可以分为三类:
用于自然语言生成(
natural language generation: NLG)的单向语言模型,如GPT。用于自然语言理解(
natural language understanding: NLU)的双向语言模型,如BERT。结合前两种范式的混合语言模型,如
XLNet、UniLM。
长期以来,研究人员观察到
GPT风格的模型在具有微调的NLU任务中表现不佳,因此认为它们天然地不适合语言理解。新兴的
GPT-3,以及它在具有手工制作的prompts的few-shot learning和zero-shot learning上的特殊表现,已经席卷机器学习界。它的成功表明,巨大的单向语言模型加上适当的manual prompt可能会对自然语言理解起作用。然而,手工制作一个表现最好的prompt就像在干草堆里找一根针,这往往需要不切实际的大型验证集。在许多情况下,prompt engineering实际上意味着对测试集的过拟合。此外,很容易创建adversarial prompts,导致性能大幅下降。鉴于这些问题,最近的工作集中在自动搜索离散的prompts(LPAQA、LM-BFF、Metaprompt),并证明其有效性。然而,由于神经网络本身是连续的,离散的prompts可能是次优的。在这项工作中,我们提出了一种新的方法
P-tuning,该方法在连续空间中自动搜索prompts,以弥补GPT和NLU applications之间的gap。P-tuning利用少数连续的free parameters作为prompts输入到pre-trained的语言模型中。然后,我们使用梯度下降法对continuous prompts进行优化,从而作为discrete prompt searching的一种替代。简单的
P-tuning方法为GPT带来了实质性的改进。我们在两个NLU基准上检验了基于P-tuning的GPT:LAMA knowledge probing和SuperGLUE。在
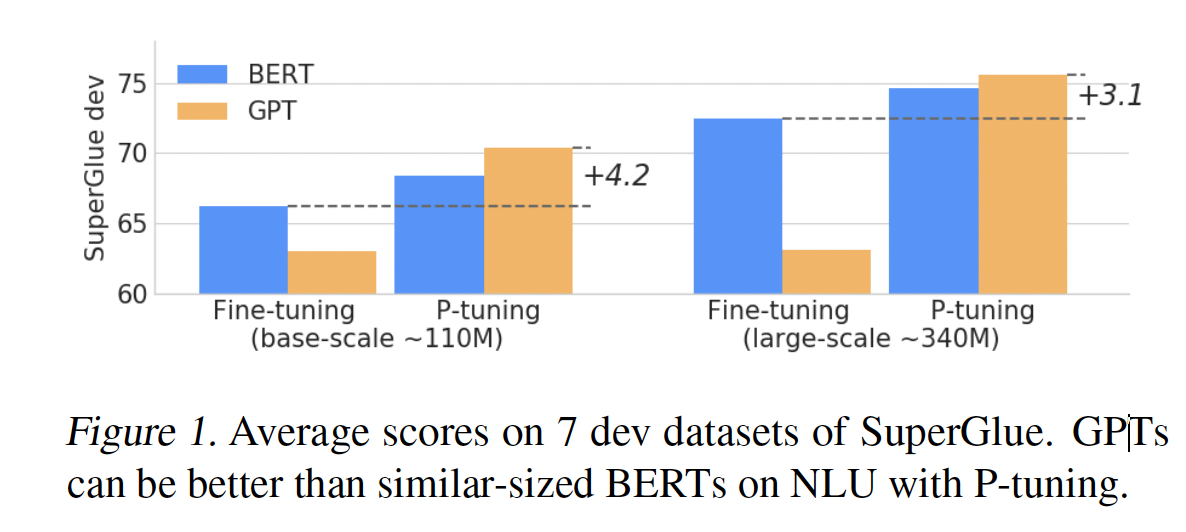
LAMA knowledge probing中,其中模型参数是fixed的,与原始手工的prompts相比,基于P-tuning的GPT在Precision@1中显示出26.2%-41.1%的绝对收益。最好的一个模型在LAMA中达到了64.2%,大大超过了SOTA的45.2%的prompt searching方法。在
SuperGlue中,我们在few-shot和完全监督的情况下联合应用P-tuning和微调。结果,GPT的性能与具有相同规模的BERT模型相比具有竞争力,对于某些数据集,GPT的性能甚至超过了BERT。进一步的实验表明,
BERT风格的模型也可以在一定程度上受益于P-tuning。我们表明,带有P-tuning的ALBERT大大超过了以前的方法,并在few-shot SuperGLUE基准上取得了新的SOTA。
我们的发现打破了
GPT只能generate而不能understand的刻板印象。它还表明,语言模型包含的世界知识、以及prior-task知识要比我们以前假设的多得多。P-tuning也可以作为一种通用的方法来调优pre-trained的语言模型,以获得最佳的下游任务性能。总而言之,我们做出了以下贡献:我们表明,在自然语言理解方面,
GPT可以和BERT一样具有竞争力(有时甚至更好),而P-tuning可以提高pre-trained语言模型的性能。这表明,GPT风格的架构在自然语言理解方面的潜力被低估了。我们表明,
P-tuning是一种通用的方法,可以在few-shot setting和fully-supervised setting下改善GPT和BERT。尤其地,通过P-tuning,我们的方法在LAMA knowledge probing和few-shot SuperGlue上的表现超过了SOTA的方法,这表明语言模型在预训练期间掌握了比我们之前想象的更多的世界知识和prior-task知识。
论文缺乏消融研究部分,一些关键设计只有结论没有实验的验证。
相关工作:
Pre-trained Language Model:最近,自监督预训练语言模型的突破,推动了自然语言处理的发展。GPT首次利用transformer架构对大规模web text进行预训练。BERT提出了masked language modeling,并创建了pre-train/finetuning范式。XLNet创新性地提出了permutation language modeling。RoBERTa进行了详细的实验,展示了与预训练有关的有用技术。BART, T5, UniLM,它们试图统一语言理解和语言生成。
作为知识库的语言模型:自语言模型诞生以来,研究人员观察到,语言模型不仅学习了
contextualized text representation,还学习了各种类型和数量的知识,包括语言知识和世界知识。《A structural probe for finding syntax in word representations》证明了语言模型产生的contextualized representation可以在embedding空间中形成解析树。《A multiscale visualization of attention in the transformer model》、《What does bert look at? an analysis of bert’s attention》研究了multi-head attention internal transformers,发现某些attention head可能对应于一些语法功能,包括共指关系(co-reference)和名词修饰。
另一个重要的方向是关于语言模型学习了多少世界知识或事实性知识。
LAMA提出利用从知识库中的fact三元组转化而来的完形填空测试来考察语言模型在记住fact的能力,其中答案是以单个token的形式给出的。在
《Language models are openk nowledge graphs》中,作者研究了attention矩阵,发现attention也会表明上下文中包含的知识三元组,从而开发了一个开放的知识图谱构建框架。《X-factr: Multilingual factual knowledge retrieval from pretrained language models》基于LAMA开发了一个multi-token的fact retrieval数据集。
Language Model Prompting:GPT-3的诞生、以及GPT-3在多任务和few-shot learning中的出色表现让人们感到震撼。然而,GPT-3并不是为微调而设计的,它在很大程度上依赖手工的prompts(或in-context learning)从而迁移到下游任务中。为了更好地将大型语言模型应用于自然语言理解,最近的工作集中在自动化搜索discrete prompts,通过挖掘训练语料(《How can we know what language models know?》)、token-based的梯度搜索(《Autoprompt: Eliciting knowledge from language models with automatically generated prompts》)、以及使用单独的模型(《Making pre-trained language models better few-shot learners》)如T5来生成prompts。然而,由于神经网络的连续性的特点,在离散空间中的搜索是具有挑战性的和次优的。最近,
《Prefix-tuning: Optimizing continuous prompts for generation》提出了用于自然语言生成任务的prefix-tuning,它采用了与我们的P-tuning类似的策略来训练continuous prompt。然而,它们在几个方面是不同的。首先,
prefix-tuning是为自然语言生成任务和GPT设计的,而P-tuning则针对自然语言理解任务和所有类型的语言模型。事实上,
prefix-tuning也可以用于所有类型的任务、所有类型的模型。第二,
prefix-tuning只允许在输入序列的开头添加prompt tokens,而P-tuning可以在任何地方插入tokens。第三,
prefix-tuning在transformer的每一层都侵入性地拼接了continuous prompt tokens,因为作者发现仅仅在输入中prompting并没有效果;相反,P-tuning非侵入性地只在输入中添加continuous prompts从而工作良好。最后,
P-tuning还介绍了如何使用anchor prompts来进一步改进。即,添加类似于
"?"这样的token在prompts中。
尽管存在差异,我们认为我们的
P-tuning和prefix-tuning都指出,学习continuous prompts是有用的,并且优于discrete prompt searching。
28.1 方法
动机:
GPT-3和DALLE的奇迹似乎表明,巨型模型总是不折不扣的提升机器智能的万能药。然而,在繁荣的背后,存在着不可忽视的挑战。一个致命的问题是,巨型模型的可迁移性很差。对于这些万亿规模的模型,在下游任务上的微调几乎很难进行。即使是对于many-shot finetuning setting,这些模型仍然太大,无法快速记忆fine-tuning samples(《Interventional few-shot learning》)。鉴于这一挑战,最近的工作集中在自动化搜索
discrete prompts,通过挖掘训练语料、token-based的梯度搜索、以及使用单独的模型来生成prompts。然而,我们深入研究了寻找continuous prompts的问题,其中continuous prompts可以通过微分来优化。接下来,我们介绍了
P-tuning的实现。与discrete prompts类似,P-tuning只对输入进行非侵入性的修改。尽管如此,P-tuning用它的differential output embeddings取代了pre-trained语言模型的input embedding。
28.1.1 架构
给定一个
pre-trained语言模型input tokens的序列pre-trained embedding layerinput embeddingstarget tokensoutput embeddings进行下游的处理。例如:在预训练中,
unmasked tokens,而[MASK] tokens。在句子分类中,
sentence tokens,而[CLS]。
prompttargetLAMA-TREx P36),一个模板可能是"The capital of Britain is [MASK]."(如下图所示),其中"The capital of ... is ... ."是prompt,"Britain"是上下文,"[MASK]"是target。prompts可以非常灵活,我们甚至可以将其插入上下文或target中。令
prompt token。为了简单起见,给定一个模板discrete prompts满足相反,
P-tuning将pseudo tokens,并将模板映射为:其中:
embedding张量,continuous prompts。最后,利用下游损失函数continuous prompt其中:
注意,这里的
prefix不一定要位于输入的开始,也可以位于输入的X和Y之间、甚至位于Y之后。关于
prefix的长度、位置,论文没有进行消融研究。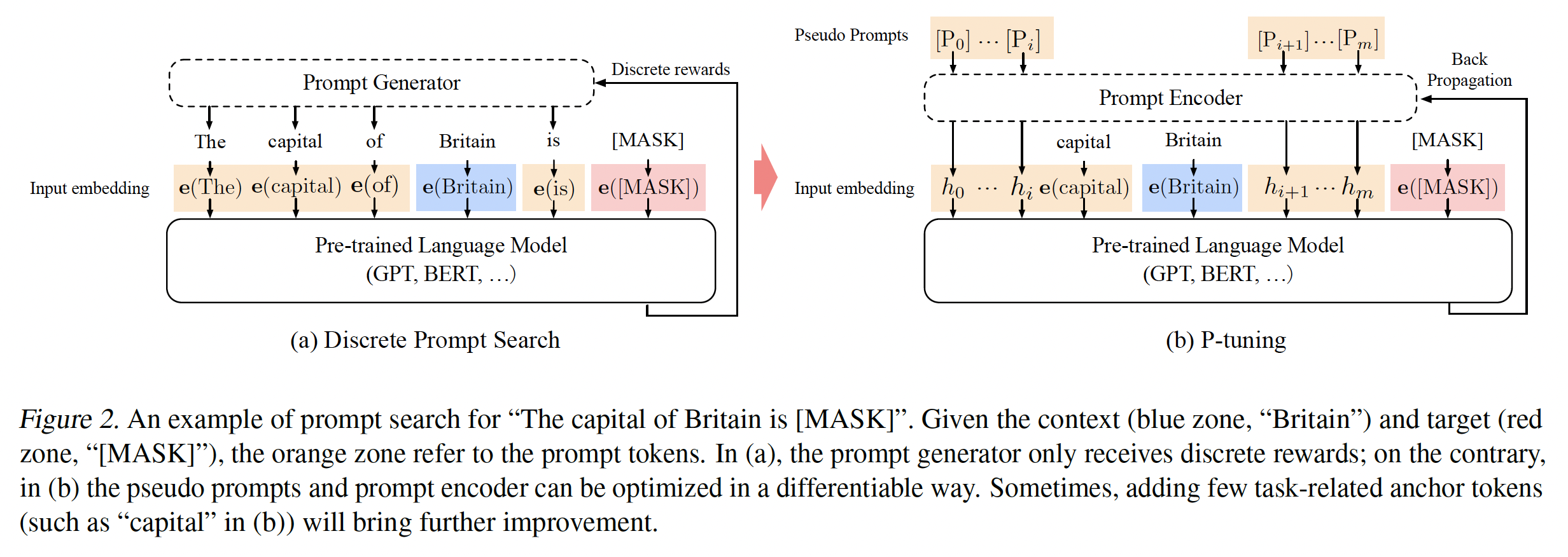
28.1.2 优化
虽然训练
continuous prompts的想法很直接,但在实践中,它面临着两个优化挑战:离散性:
word embedding《A convergence theory for deep learning via over-parameterization》),优化器将很容易陷入局部最小值。association:另一个担忧是,从直觉上讲,我们认为prompt embeddingsprompt embeddings相互关联起来。
鉴于这些挑战,在
P-tuning中,我们建议使用一个由非常简单的神经网络组成的prompt encoder将long-short term memory network: LSTM,具有ReLU激活的双层multilayer perceptron: MLP,从而鼓励离散性。正式地,语言模型input embeddings虽然
LSTM head的使用确实给continuous prompts的训练增加了一些参数,但LSTM head比pre-trained模型要小几个数量级。而且,在推理中,我们只需要输出embeddingLSTM head。Prefix-Tuning直接采用简单的MLP,那么它采用这里的LSTM + MLP是否也能提升效果?这种优化
Prefix-Tuning一样都是采用了参数化技巧。此外,为什么这里要用
LSTM?论文没有进行消融研究。此外,我们还发现,在
SuperGLUE基准测试中,添加一些anchor tokens有助于一些自然语言理解任务。例如,对于RTE任务,在prompt模板"[PRE][prompt tokens][HYP]?[prompt tokens][MASK]"中特别添加一个anchor token "?",对性能有很大的影响。通常情况下,这样的anchor words代表了每个组件的特性,在这个例子中,"?"表示"[HYP]"作为一个询问部分。缺乏消融研究。
28.2 实验
28.2.1 Knowledge Probing
知识探测,或被称为事实检索(
fact retrieval),评估语言模型从预训练中获得了多少现实世界的知识。LAMA数据集通过从知识库中选择的三元组创建的完形填空测试来评估它。例如,我们将把三元组(Dante, born-in, Florence)转化为一个带有人工的prompt(即,"Dante was born in [MASK].")的完形填空句子,然后我们要求语言模型推断出target。因为我们要评估从预训练中获得的知识,所以pre-trained语言模型的参数是固定的(即不进行微调)。数据集:
LAMA。LAMA强迫所有的答案都是single-token的格式。我们首先采用原始的LAMA-TREx数据集,其中包括41个Wikidata关系和总共34,039个测试三元组(即LAMA-34k,它涵盖了所有的BERT词表)。由于GPT和BERT的词表不同,我们建立了另一个版本的LAMA,它涵盖了GPT词表和BERT词表的交集。这个子集加起来大约有29k个测试三元组,我们把它命名为LAMA-29k。至于训练,所有的
prompt searching方法都需要一些额外的数据来训练或寻找prompts。我们遵循AutoPrompt(《Autoprompt: Eliciting knowledge from language models with automatically generated prompts》) 中的设置,作者从原始TRE-x数据集中构建了一个训练集。这个训练集与测试集类似,但答案分布略有不同。评估:最初,
LAMA为每个关系提供了如Table 1所示的人工prompt,这些prompt是有效的,但却是次优的。对于双向masked language model,我们只需要将"[X]"替换为主语实体、将"[Y]"替换为[MASK] token;对于GPT等单向语言模型,遵循LAMA最初在Transformer-XL上的设置,我们使用target position之前的模型输出。在进行P-tuning方面 ,我们对双向模型使用(3, sub, 3, obj, 3)模板,对单向模型使用(3, sub, 3, obj)模板,其中数字表示prompt tokens的数量。在这个知识探测任务中,我们不使用任何anchor tokens。在训练过程中,我们将学习率设置为1e-5,并使用Adam优化器。为什么要采用
(3, sub, 3, obj, 3)模板、(3, sub, 3, obj)模板?论文并未说明。
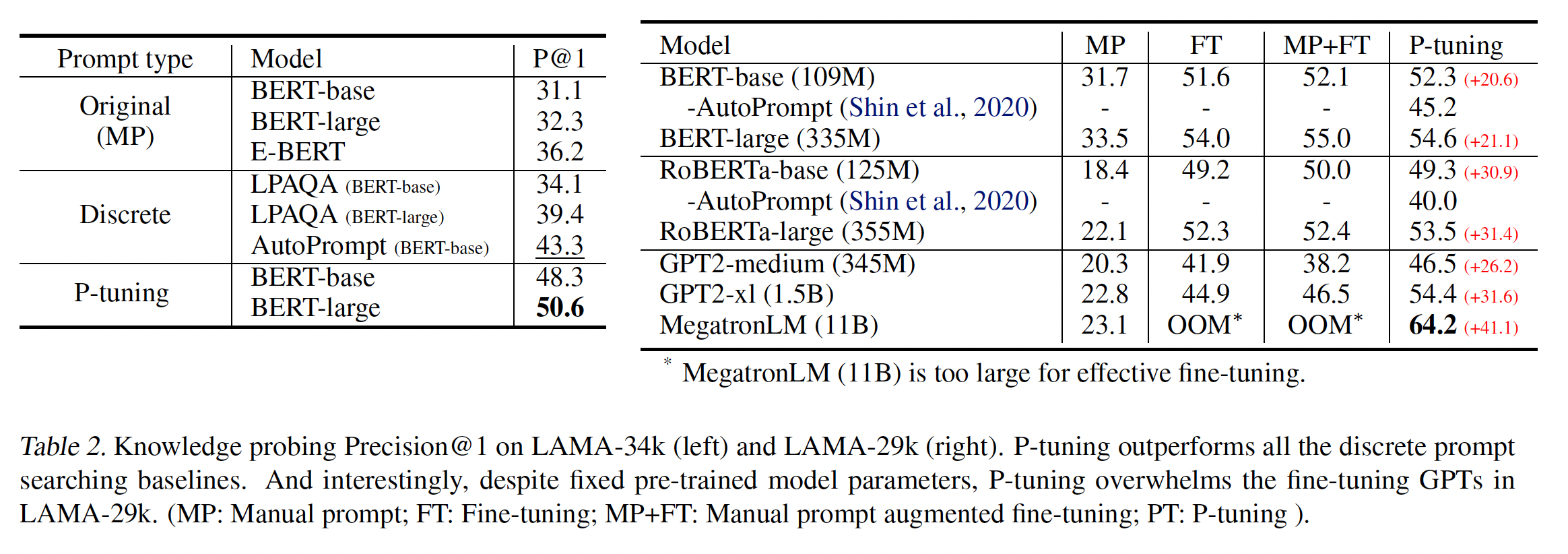
实验结果:结果如下表所示。可以看到:
P-tuning极大地推动了知识探测的效果,在LAMA-34k中从43.3%提升到50.6%,在LAMA-29k中从45.2%提升到最高64.2%。这一结果有力地表明,语言模型仅仅通过寻找更好的prompt,在没有微调的情况下捕获到的知识远比人们以前认为的要多。当
P-tuning与以前的discrete prompt searching方法如AutoPrompt、LPAQA在相同大小的模型上进行比较时,P-tuning仍然优于它们。AutoPrompt这一行代表什么含义?是AutoPrompt结合P-tuning,还是仅仅代表AutoPrompt?论文未说明。读者猜测是仅仅代表AutoPrompt。
P-tuning v.s. Fine-tuning:在传统的知识探测中,不允许通过微调来改变pre-trained模型的参数。我们试图评估语言模型在预训练期间学到了多少知识。然而,这项工作的基本内容是比较P-tuning和fine-tuning,特别是在GPT这样的单向性语言模型上。我们对以下问题特别感兴趣: 单向和双向语言模型是否从P-tuning中获得了相似的改进?为了对现有的
tuning方法进行全面回顾,我们包括以下方法:Manual Prompt: MP:使用LAMA的原始的人工prompts。Fine-tuning: FT:只呈现subject并微调模型以预测object。Manual Prompt with Fine-tuning: MP+FT:用人工prompts对语言模型进行微调。P-tuning:使用continuous prompts,同时固定语言模型的参数。
我们在
LAMA-29k中实现了这四种策略(见Table 2的右侧),我们发现P-tuning与fine-tuning-based方法相当或更好,这令人惊讶但也是合理的。令人惊讶的是,微调应该是更有潜力的,因为它调优了所有语言模型的参数,而
P-tuning则没有调优语言模型的参数。然而,这也是合理的,因为就知识探测而言,许多事实只能是hard-coded的,而不是由语言模型推断的。参数的微调可能会导致灾难性的遗忘。相反,P-tuning并不改变pre-trained模型的参数,而是通过寻找更好的continuous prompt来唤起所存储的知识。此外,有趣的是,看到
BERT在P-tuning的改善、和GPT在P-tuning的改善之间存在明显的差距。带有高质量人工prompts的微调(MP+FT)(PET-2、LM-BFF)已被证明是相当有效的,这在我们的实验中也被观察到。然而,令人惊讶的是,GPT从MP+FT中受益的程度不如从P-tuning中受益的程度,而BERT从MP+FP中收益程度与从P-tuning中收益程度相当。换句话说,P-tuning显示出与单向语言模型更好的亲和性。就更大的模型而言,如具有11B参数的MegatronLM,虽然微调几乎不工作,但P-tuning仍然适用,并在LAMA上达到了SOTA。
28.2.2 SuperGLUE
我们在
SuperGLUE基准上进行了实验从而评估P-tuning。总共有8个自然语言理解任务,我们专注于其中的7个任务,因为另一个任务ReCoRD没有采用prompts,因此没有P-tuning。这七个任务包括:问答 (BoolQ、MultiRC)、文本蕴含(CB、RTE)、共指解析(WiC)、因果推理(COPA)、以及词义消歧(WSC)。对于实验设置,我们考虑了
fully-supervised setting和few-shot setting。在
fully-supervised setting中,我们使用整个训练集(对于
few-shot setting,我们采用SuperGLUE的few-shot(也称为FewGlue)。FewGLUE是SuperGLUE的一个子集,每个任务由32个训练数据(400到20000)的未标记集(以前的工作(
PET finetuning)假定没有任何验证集,并根据经验选择采用固定的超参数(这基本上是过拟合于测试集)。与它不同的是,我们构建了适当的few-shot验证集(表示为LM-BFF),所以few-shot训练集
我们采用与
PET-2相同的评价指标。我们将自然语言理解任务重新表述为完形填空任务。与
PET finetuning使用带有人类手工制作的prompts的模式不同,P-tuning将initial prompt embeddings放在不同位置,然后与pretrained模型一起微调prompt embeddings。对于
fully-supervised settings,我们使用具有线性衰减学习率的AdamW optimizer。我们对超参数进行网格搜索,在{1e-5, 2e-5, 3e-5}的学习率、以及{16, 32}的batch size。对于小数据集(
COPA, WSC, CB, RTE),我们对pretrained模型微调20次。对于较大的数据集(WiC, BoolQ, MultiRC),我们将training epochs的数量减少到10个,因为模型会更早收敛。我们评估每个epoch的性能。我们使用早停来避免对训练数据的过拟合。对于
few-shot learning,我们使用与PET-2相同的超参数,只是将微调steps扩大到3500步(而不是该论文中的250步),因为prompt embeddings的微调需要更多步数。
P-tuning可以用于所有的单向模型和双向模型。我们选择总计算量相似的模型进行公平的比较,其中我们选择BERT-base与GPT2-base进行比较、BERT-large与GPT2-medium进行比较。像RoBERTa这样的模型具有类似的模型规模,但是是用更大的计算量来训练的,应该与更大规模的GPT进行比较。这将留给未来的工作。此外,对于
few-shot learning,我们也用albert-xxlarge-v2进行了实验,它在PET-2中被证明是在few-shot setting中表现最好的pretrained模型。对于每个pretrained模型,我们报告了standard finetuning(即使用[CLS] embedding进行分类)、PET finetuning、PET zero-shot和P-tuning的性能。Fully-supervised Learning:主要结果见Table 3和Table 4。首先,对于
bert-base-cased模型bert-large-cased模型,P-tuning在7个任务中的5个任务上优于所有其他bert-based模型。例外的是
WiC和MultiRC,P-tuning的表现比standard fine-tuning差一点。由于WiC和MultiRC都有相对较大的训练集,我们猜测这可能是由于standard fine-tuning可以从较大的数据集中获得比P-tuning更多的优势。相反,P-tuning在low-resource setting下似乎更有利。类似的观察也在后面的实验中显示。其次,对于
gpt2-base和gpt2-medium模型,P-tuning在所有gpt2-base模型中取得了最有前景的结果。
综上所述,我们可以得出结论,
P-tuning可以有效地提高bert-based模型和gpt-based模型的自然语言理解性能。此外:
在
base模型的规模下,带有P-tuning的gpt2-base在7个任务中的6个任务上超过了BERT-based模型的最佳结果,同时在WiC上取得了相差无几的结果。在
large模型的规模下,带有P-tuning的GPT2-medium在7个任务中的4个任务上显示出优势,而在RTE和WSC任务上则具有可比性。唯一的例外是WiC任务。我们注意到,在WiC任务中,标准微调在不同setting的模型上显示出最佳结果。我们推测,这是因为词义消歧任务不适合prompt-based MLM prediction。
最重要的是,我们得出结论,通过
P-tuning,GPT2实现了与BERT-based模型相当的甚至更好的性能。这一发现颠覆了我们的普遍看法,即双向模型(如BERT)在自然语言理解任务中总是比单向模型(如GPT2)更好。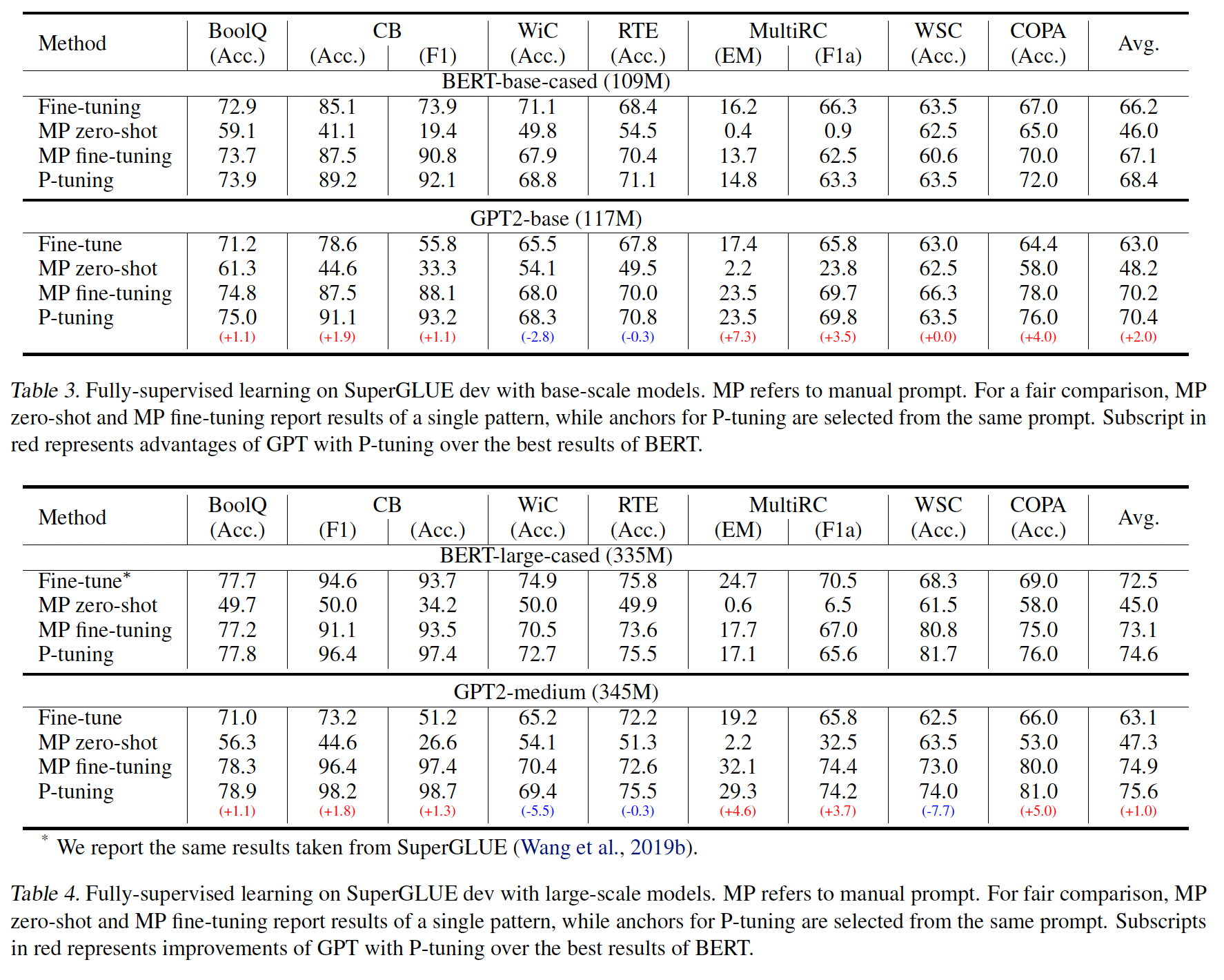
Few-shot learninng:次优的和敏感的
Manual Prompts:最初,PET/iPET在SuperGLUE的few-shot learning任务上,通过几个人工编写的prompts实现了SOTA,这些prompts是有效的但却是次优的,而且是劳动密集型的。为了全面了解
manual prompts,我们首先进行了比较实验。Table 6显示了使用不同manual prompts和P-tuning的结果。首先,结果显示,
few-shot的表现与prompts的语义、格式、语法没有明显的关联。人类认为合理的prompts对语言模型不一定有效。第二,
manual prompts的细微变化会导致大幅度的性能差异。pretrained语言模型对prompts的选择相当敏感。
我们可以得出结论,人工手写的
prompts比我们想象的要复杂。此外,Table 6还证明,使用manual prompts。这表明,在few-shot setting中挑选出最好的manual prompts也很有挑战性。相比之下,P-tuning在自动寻找更好的prompts方面似乎很有希望,而手工制作的prompts的希望要少得多。
SuperGLUE Few-shot Learning的新的SOTA:Table 5列出了通过P-tuning实现的Super-GLUE few-shot learning的最新结果。我们将其与几个baseline进行了比较,包括PET、GPT-3,其中GPT-3实现了以前的SuperGLUE Few-shot SOTA。值得注意的是,除了
manual prompt finetuning外,原始PET采用了多种额外的技术,包括数据增强、ensemble、以及知识蒸馏,以提高性能。此外,它通过过拟合测试集来进行模型选择和超参数调优。为了确保公平的比较,PET在我们的setting下进行了重新实验,去除所有的辅助技术(数据增强、ensemble、知识蒸馏)。考虑到PET提供了多个manual prompts,这里报告了平均的prompt性能和最佳的prompt性能。Table 5说明,P-tuning在所有任务上的表现一直优于具有manual prompts的PET(PET-best(7个任务中的5个任务上,解决方案对PET(multiple patterns的标准差,证明P-tuning可以搜索到远比manual prompts提示更好的prompts,并显著提高few-shot任务的性能。在包括CB, WiC, RTE, WSC的任务上,P-tuning甚至优于PET/iPET(ensemble、知识蒸馏)。与GPT-3相比,虽然GPT-3的规模比P-tuning大得多(albert-xxlargev2),P-tuning在7个任务中的6个任务中表现优异。结果证明了P-tuning在few-shot自然语言理解任务中的优势。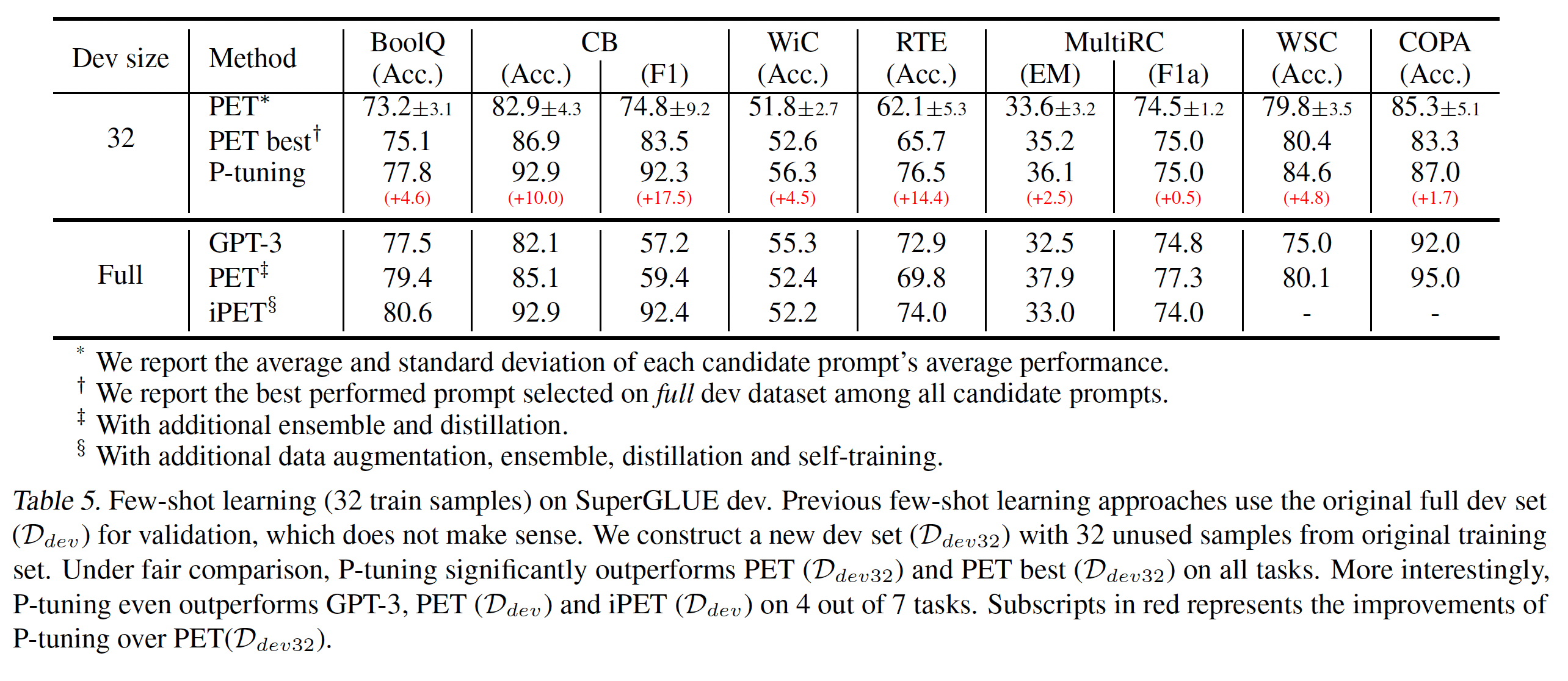
Finetuning v.s. MP finetuning v.s. P-tuning:Table 3和Table 4列出了三种tuning-based范式在提高自然语言理解的性能方面的结果。我们对这些tuning-based范式的不同表现特别感兴趣。总的来说,
P-tuning在BERT-based模型上平均比fine-tuning和MP fine-tuning高出2分左右,在GPT2-based模型上平均比fine-tuning和MP fine-tuning高出5分左右。具体来说,尽管
P-tuning在大多数任务上取得了最好的结果,但fine-tuning在那些难以制定成完形填空问题的任务(如WiC)上可以胜出。比较
P-tuning和MP fine-tuning,P-tuning一般比MP fine-tuning平均显示出更多的优势,因为MP fine-tuning要找到好的manual prompts是很困难的。相比之下,P-tuning总是能够自动搜索到更好的prompts。
作为调优
pretrained模型的新范式,P-tuning在调优pretrained模型的参数时,可以在广阔的prompt space中搜索。结果表明,它在prompting难以微调的larger-scale pre-trained模型方面具有竞争性的潜力。
二十九、P-Tuning V2[2021]
论文:
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
pretrained语言模型改善了各种自然语言理解任务的性能。一种广泛使用的方法,即微调,为target任务更新整个模型的参数集合。虽然微调获得了良好的性能,但它在训练过程中很耗费内存,因为必须存储所有参数的梯度和optimizer states。此外,在推理过程中为每个任务保留一份模型参数是不方便的,因为pre-trained模型通常很大。另一方面,
prompting冻结了pretrained模型的所有参数,并使用自然语言prompt来query语言模型(GPT-3)。例如,对于情感分析,我们可以将一个样本(例如,"Amazing movie!")与一个prompt"This movie is [MASK]"拼接起来,并要求pre-trained语言模型预测pre-trained是"good"和"bad"的概率,以决定该样本的标签。prompting完全不需要训练,只需存储一份模型参数。然而,与微调相比,discrete prompting(Autoprompt、LM-BFF)在许多情况下会导致次优的性能。prompt tuning是一种只调优continuous prompts的想法。具体来说,《Gpt understands, too》、《The power of scale for parameter-efficient prompt tuning》提出在input word embeddings的原始序列中添加可训练的continuous embeddings(也叫continuous prompts)。在训练期间,只有continuous prompts被更新。虽然在许多任务上,prompt tuning比prompting有所改进,但当模型规模不大,特别是小于10B参数时,它仍然不如微调的表现(《The power of scale for parameter-efficient prompt tuning》)。此外,正如我们的实验所显示的那样,与微调相比,prompt tuning在几个难的序列标注任务上的表现很差,如extractive的问答。我们在本文中的主要贡献是一个新的经验发现,即适当优化的
prompt tuning可以在不同的模型规模和自然语言理解任务中与微调相媲美。与之前工作中的观察相反,我们的发现揭示了prompt tuning在自然语言理解中的普遍性和潜力。从技术上讲,我们的方法
P-tuning v2在概念上并不新颖。它可以被看作是Deep Prompt Tuning(《Prefix-tuning: Optimizing continuous prompts for generation》、《Learning how to ask: Querying lms with mixtures of soft prompts》)的优化的和适配的实现,旨在generation和knowledge probing。最显著的改进来自于对pretrained模型的每一层(而不仅仅是输入层)应用continuous prompts。deep prompt tuning增加了continuous prompts的能力,并缩小了在各种setting下与微调的差距,特别是对于小模型和困难任务。此外,我们提出了一系列优化和实现的关键细节,以确保finetuning-comparable的性能。实验结果表明,
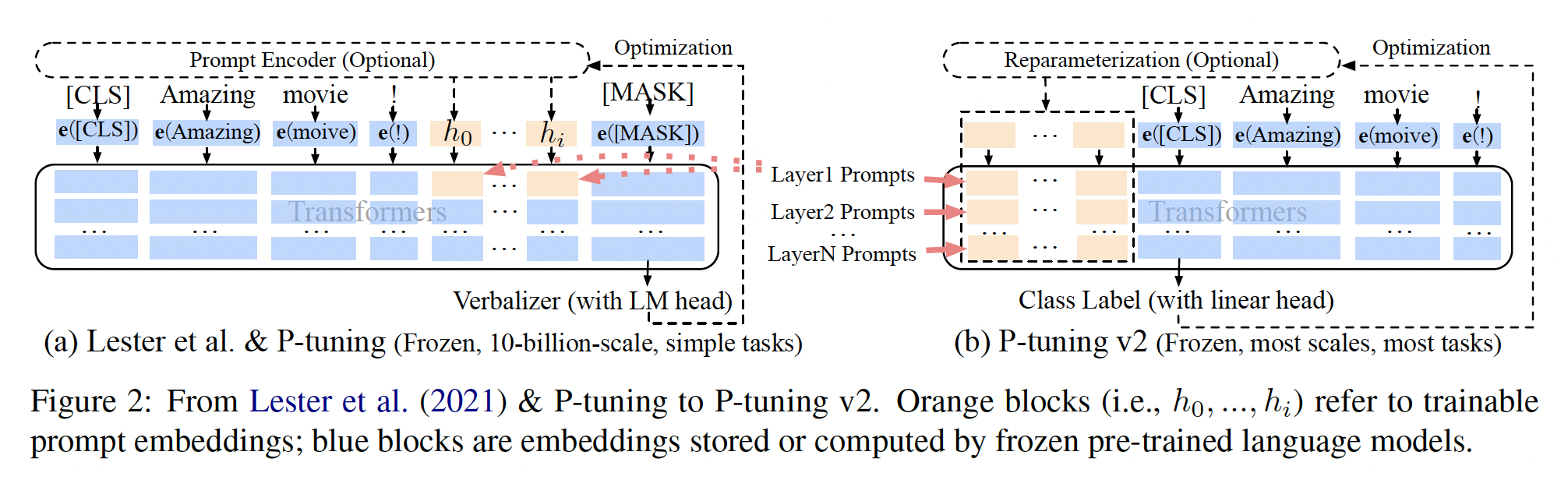
P-tuning v2在不同的模型规模(从300M到100B参数)和各种困难的序列标注任务(如抽取式问答、命名实体识别)上的性能与微调相媲美。与微调相比,P-tuning v2每个任务的可训练参数仅为微调时的0.1%到3%,这大大降低了训练时间成本、训练内存成本、以及每个任务的存储成本。P-tuning v2与P-tuning的核心变化是:P-tuning v2不仅在输入层插入continues prompts,而且在每个layer插入了continues prompts。这似乎就是Prefix-Tuning的思想?与
Prefix-Tuning的区别在于实现细节不同:P-Tuning v2直接采用Classification Head,这类似于BERT。P-Tuning v2发现某些任务上,重参数化技巧导致效果下降。
此外,论文实验部分聚焦于
fully-supervised setting,即有大量的标记数据用于训练。这主要是因为P-Tuning v2包含更多的trainable parameters,包括:每一层的trainable continues prompts、以及Linear Classification Head。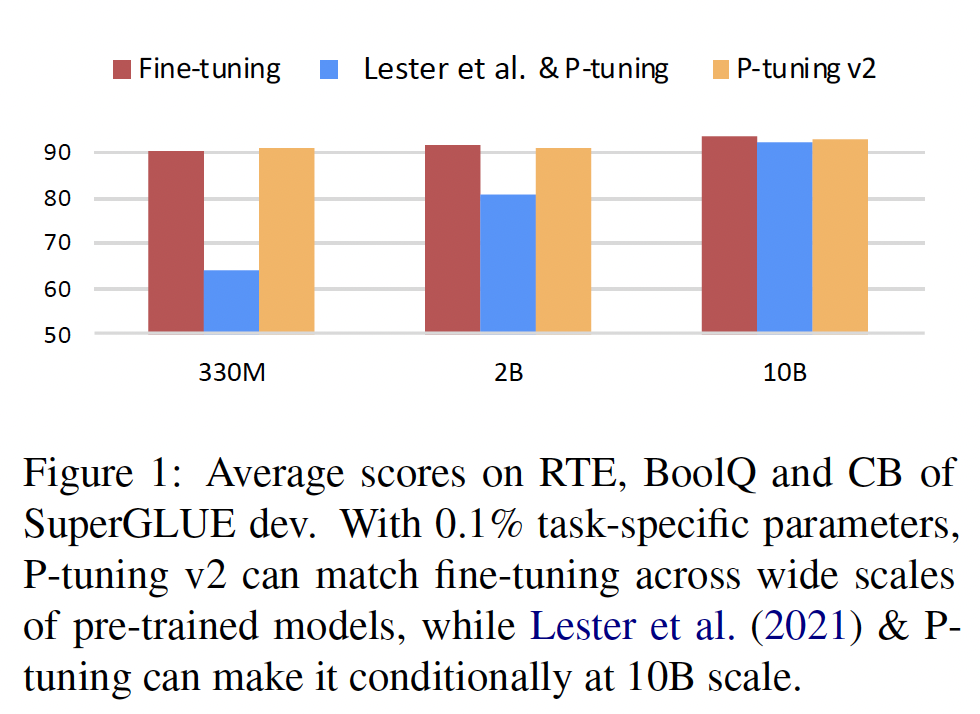
29.1 方法
自然语言理解任务:在这项工作中,我们将自然语言理解任务的挑战分为两个系列:简单的分类任务、困难的序列标注任务。
简单的分类任务涉及
label space上的分类。GLUE和SuperGLUE的大多数数据集都属于这个类别。困难的序列标注任务涉及对
tokens序列的分类,如命名实体识别、抽取式问答。
Prompt Tuning:令embedding layer。在discrete prompting(PET-2)的案例中 ,prompt tokensinput embedding sequence被表述为《The power of scale for parameter-efficient prompt tuning》和《Gpt understands, too》介绍了可训练的 ·continuous prompts,作为自然语言理解任务的自然语言prompts的替代,其中pretrained语言模型的参数被冻结。给定可训练的continuous embeddingsinput embedding sequence被写成prompt tuning与微调不相上下。注意,下图和
P-Tuning的原始论文有差异。在P-Tuning原始论文中:continues embeddings仅应用于输入层,但是这里应用到了Layer 1 Prompts。continues embeddings不仅仅在序列中间插入,而是可以在序列的头部插入一部分、在序列的中间插入一部分、甚至在序列的尾部插入一部分。
缺乏普遍性:
《The power of scale for parameter-efficient prompt tuning》、《Gpt understands, too》在许多NLP应用中被证明相当有效,但由于缺乏普遍性,在取代微调方面仍有不足,如下所述。缺少跨尺度的普遍性:
《The power of scale for parameter-efficient prompt tuning》表明,当模型规模超过10B参数时,prompt tuning可以与微调相媲美。然而,对于被广泛使用的中型模型(从100M到1B),prompt tuning的表现比微调差很多。缺少跨任务的普遍性:尽管
《The power of scale for parameter-efficient prompt tuning》、《Gpt understands, too》在一些自然语言理解基准上表现出了优越性,但prompt tuning在困难的序列标注任务上的有效性并没有得到验证。sequence tagging为每个input token来预测标签序列,这可能更难,而且与verbalizers不兼容(PET-2)。在我们的实验中,我们表明《The power of scale for parameter-efficient prompt tuning》、《Gpt understands, too》在典型的序列标注任务上的表现比微调差。
考虑到这些挑战,我们提出了
P-tuning v2,它将deep prompt tuning(《Prefix-tuning: Optimizing continuous prompts for generation》、《Learning how to ask: Querying lms with mixtures of soft prompts》)作为一个跨scales和跨自然语言理解任务的通用解决方案。Deep Prompt Tuning:在《The power of scale for parameter-efficient prompt tuning》、《Gpt understands, too》中,continuous prompts只被插入到input embedding sequence中(参照Figure 2(a))。这导致了两个挑战:首先,由于序列长度的限制,可调优的参数的数量是有限的。
第二,
input embeddings对模型预测有相对间接的影响。
为了解决这些挑战,
P-tuning v2采用了deep prompt tuning。如Figure 2所示,在不同的层中,prompts视为prefix tokens而被加入。一方面,
P-tuning v2有更多可调优的task-specific参数(从0.01%到0.1%-3%),从而允许更多的per-task容量,同时具有parameter-efficient。另一方面,被添加到更深的层的
prompts对模型预测有更加直接的影响(见附录B的分析)。
Optimization and Implementation:为实现最佳性能,有一些有用的优化和实施细节。Reparameterization:之前的工作通常利用reparameterization encoder(如MLP)(《Prefix-tuning:Optimizing continuous prompts for generation》、《Gpt understands, too.》)来转换trainable embeddings。然而,对于自然语言理解,我们发现其有用性取决于任务和数据集。对于一些数据集(如RTE, CoNLL04),MLP带来了持续的改进;对于其他数据集,MLP导致的结果影响很小,甚至是负面的(如BoolQ, CoNLL12)。更多分析见附录B。prompt长度:prompt长度在P-Tuning v2中起着关键作用。我们发现,不同的自然语言理解任务通常会在不同的prompt长度下达到最佳性能(参见附录B)。一般来说,简单的分类任务更喜欢较短的prompt(少于20 tokens);困难的序列标注任务更喜欢较长的prompt(大约100个)。多任务学习:在对单个任务进行微调之前,多任务学习用共享的
continuous prompts联合优化多个任务。多任务在P-Tuning v2中是可选的,但可以通过提供更好的初始化来进一步提高性能(《Ppt: Pre-trained prompt tuning for few-shot learning》)。Classification Head:使用language modeling head作为verbalizers(《It’s not just size that matters: Small language models are also few-shot learners》)一直是prompt tuning的核心(《Gpt understands, too》),但我们发现它在full-data setting中没有必要,而且与序列标注任务不兼容。P-tuning v2反而像BERT一样,在tokens之上应用了一个随机初始化的分类头(参考Figure 2)。
为了澄清
P-tuning v2的主要贡献,我们在Table 1中提出了与现有prompt tuning方法的概念性比较。
29.2 实验
我们在一组常用的
pre-trained模型、以及自然语言理解任务上进行了广泛的实验,以验证P-tuning v2的有效性。在这项工作中,除了微调,所有的方法都是在冻结的语言模型骨架上进行的,这与《The power of scale for parameter-efficient prompt tuning》的设置一致,但与《Gpt understands, too》的tuned setting有所不同。task-specific参数的比率(例如0.1%)是通过比较continuous prompts的参数和transformers的参数得出的。另外需要注意的是,我们的实验都是在fully-supervised setting下(而不是few-shot setting下)进行的。自然语言理解任务:首先,我们包括来自
SuperGLUE的数据集,以测试P-tuning v2的通用NLU能力。此外,我们还引入了一套序列标注任务,包括命名实体识别、抽取式问答、和语义角色标注。pre-trained模型:BERT-large, RoBERTa-large, DeBERTa-xlarge, GLMxlarge/xxlarge。它们都是为自然语言理解任务设计的双向模型,涵盖了从约300M到10B的广泛规模。多任务学习:对于多任务设置,我们结合每个任务类型的训练集(例如,结合语义角色标注任务的所有训练集)。我们对每个数据集使用单独的线性分类器,同时共享
continuous prompts。命名实体识别(
Name entity recognition: NER):给定一个句子,任务是预测某些类别的实体(如,地理名、人名、机构名)在句子中的span。我们采用了
CoNLL03, OntoNotes 5.0, CoNLL04数据集。所有的数据集都是以IOB2格式标记的。我们使用序列标注来解决NER任务,通过分配标签来标记某些类别实体的开始以及内部。语言模型为每个token生成一个representation,我们使用一个线性分类器来预测标签。我们使用官方脚本来评估结果。对于多任务设置,我们结合三个数据集的训练集进行预训练。我们对每个数据集使用不同的线性分类器,同时
continuous prompts。抽取式问答(
Extractive Question Answering):任务是从给定的上下文和问题中提取答案。我们使用SQuAD 1.1, SQuAD 2.0。遵循传统,我们将问题表述为序序列标注,为每个
token分配两个标签之一:"start"或"end",最后选择最有把握的(start, end) pair的span作为被提取的答案。如果最有把握的pair的概率低于阈值,该模型将假定该问题是不可回答的。对于
multitask setting,我们用于预训练的训练集结合了SQuAD 1.1和2.0的训练集。在预训练时,我们假设所有的问题,无论其来源如何,都可能是无法回答的。语义角色标注(
Semantic Role Labeling: SRL):任务是为句子中的单词或短语分配标签,表明它们在句子中的语义作用。我们在
CoNLL05, CoNLL12上评估P-tuning v2。由于一个句子可以有多个动词,我们在每个句子的末尾添加target verb token,从而帮助识别哪个动词用于预测。我们根据相应的语义角色representation,用线性分类器对每个词进行分类。对于
multitask setting,预训练训练集是CoNLL05、CoNLL12、propbank-release(用于训练语义角色标注的常见扩展数据)的训练集的组合。多任务训练策略与NER类似。
跨所有模型大小的结果:下表列出了
P-tuning v2在不同模型规模上的表现。在
SuperGLUE中,《The power of scale for parameter-efficient prompt tuning》和P-tuning在较小规模上的表现可能相当差。相反,P-tuning v2在较小规模的所有任务中都与微调的性能相媲美。P-tuning v2甚至在RTE上明显优于微调。就较大尺度(
2B到10B)的GLM而言,《The power of scale for parameter-efficient prompt tuning》、P-tuning与微调之间的差距逐渐缩小。在10B规模上,我们有一个与《The power of scale for parameter-efficient prompt tuning》报告类似的观察,即prompt tuning变得与微调相媲美。也就是说,
P-tuning v2在所有规模上都与微调相当,但与微调相比,只需要0.1%的task-specific参数。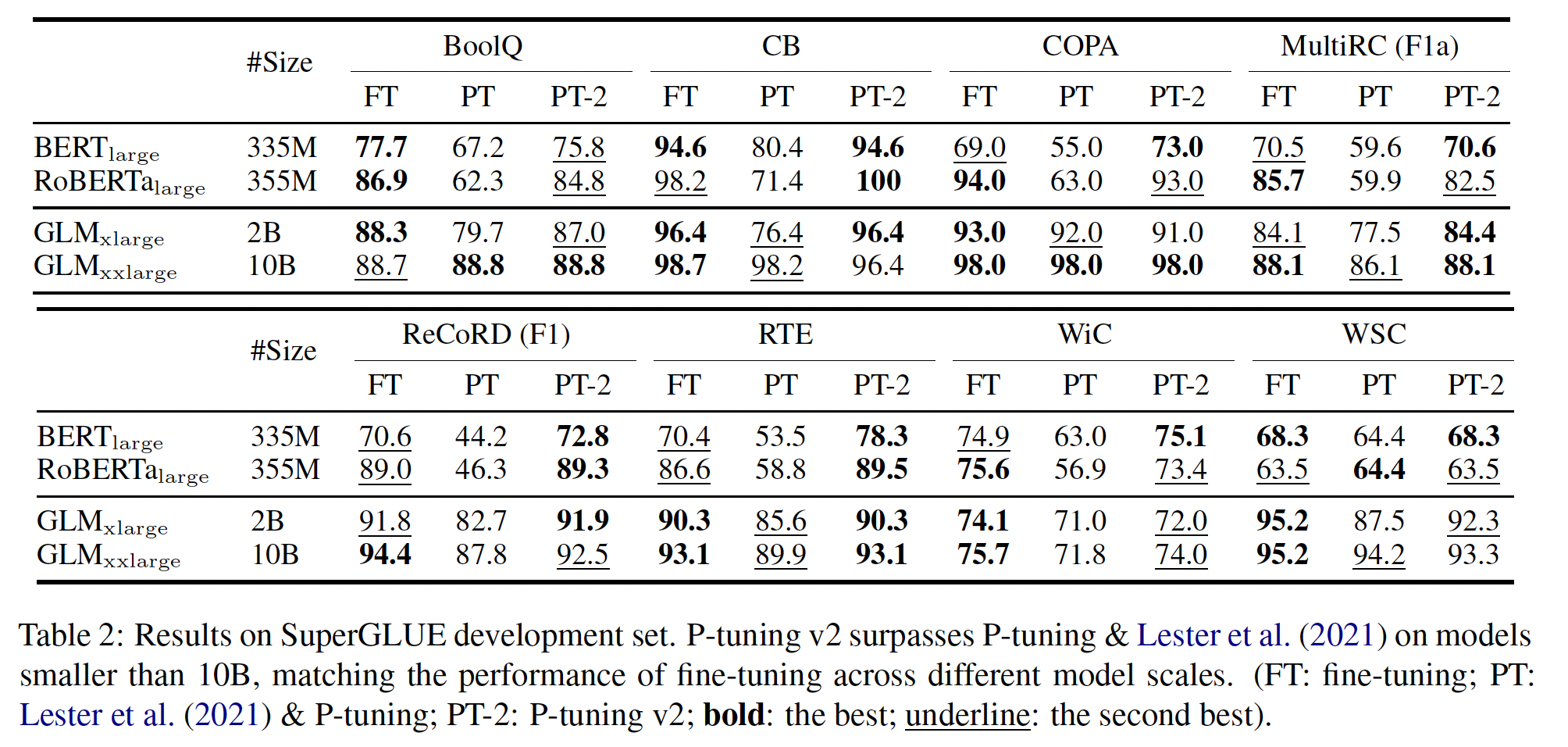
跨所有任务的结果:从下表可以看出,
P-tuning v2在所有任务上都可以与微调相媲美。P-tuning和《The power of scale for parameter-efficient prompt tuning》的表现要差得多,特别是在QA上,这可能是三个任务中最具挑战性的。我们还注意到,
《The power of scale for parameter-efficient prompt tuning》和P-tuning在SQuAD 2.0上有一些异常的结果。这可能是因为SQuAD 2.0包含不可回答的问题,这给single-layer prompt tuning带来了优化挑战。除了
QA之外,多任务学习一般会给P-Tuning v2的大多数任务带来明显的改进。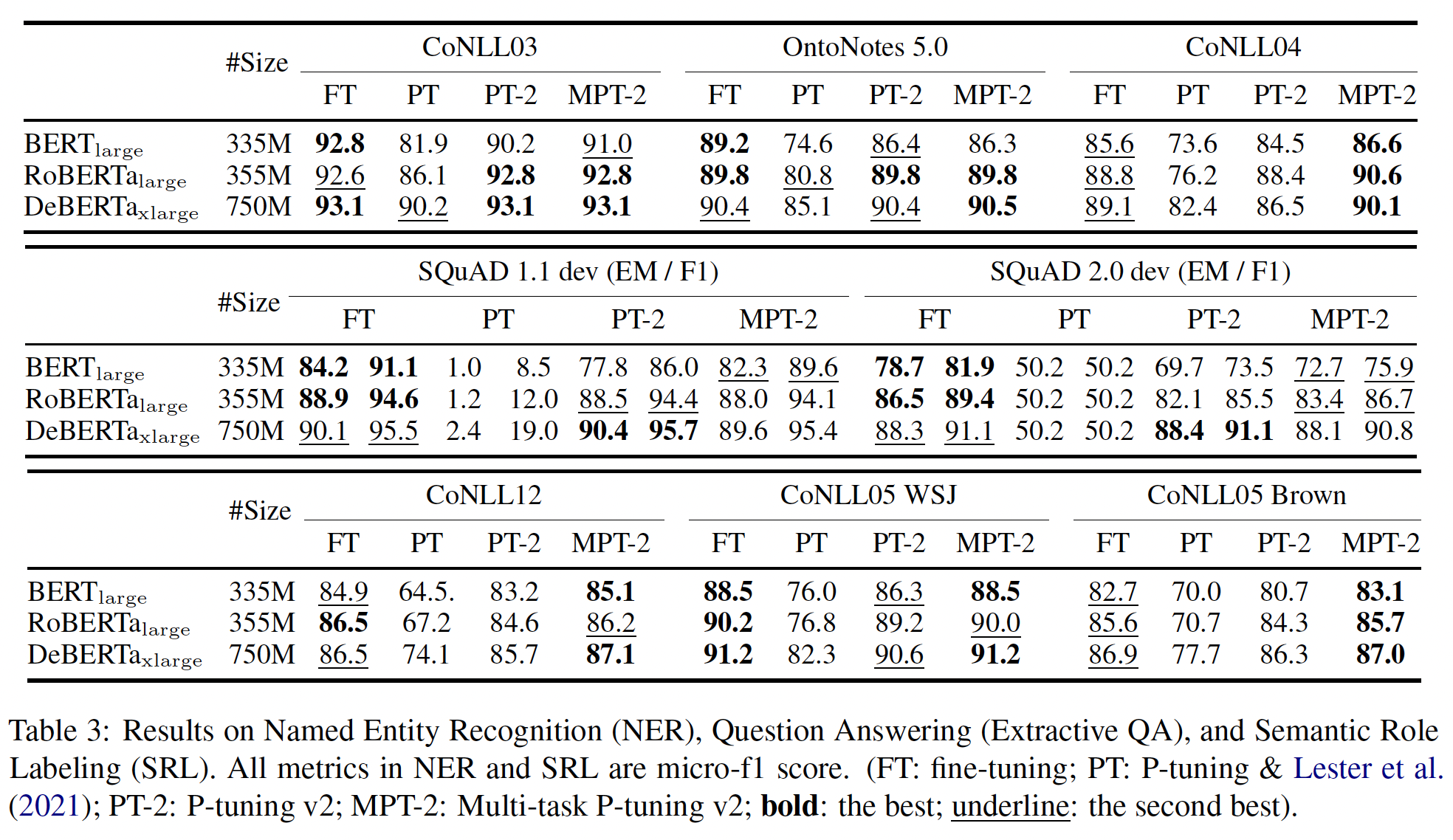
消融研究:
Verbalizer with LM head v.s. [CLS] label with linear head:Verbalizer with LM head一直是以前的prompt tuning方法的核心组成部分。然而,在supervised setting中,对于P-tuning v2,用大约几千个参数来调优一个linear head是可以承受的。我们在
Table 4中展示了我们的比较,其中我们保留了其他的超参数,只将[CLS] label的linear head改为verbalizer with LM head。在这里,为了简单起见,我们对SST-2, RTE, BoolQ使用"true"和"false"、对CB使用"true", "false", "neutral"。结果表明,verbalizer和[CLS]的表现没有明显区别。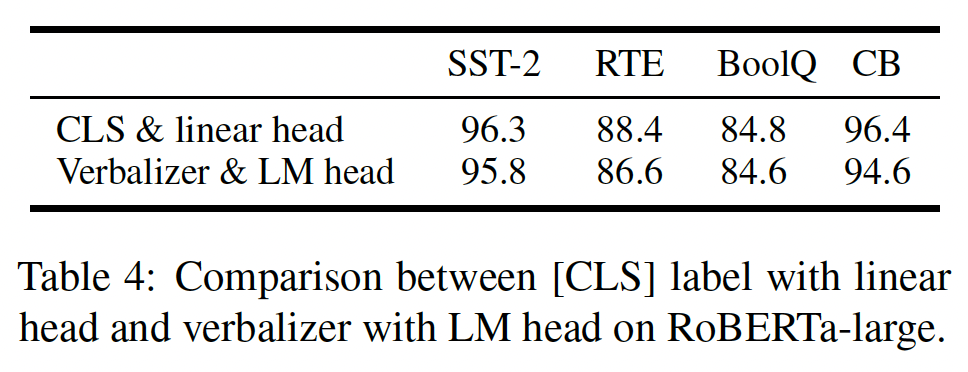
prompt depth:《The power of scale for parameter-efficient prompt tuning》、P-tuning和P-tuning v2的主要区别是multi-layer continuous prompts。为了验证它的确切影响,给定一定数量的prompts,我们按照升序和降序选择它们来添加prompts;对于其余的层,我们不作任何处理。如
Figure 3所示,在参数数量相同的情况下(即要添加prompts的transformer layers数量),按降序添加总是比按升序添加好。在RTE的情况下,只在第17-24层添加prompts可以产生与所有层添加prompts非常接近的性能。
Embedding v.s. MLP reparameterization:在prefix-tuning和P-tuning中,作者发现reparameterization在提高训练速度、鲁棒性和性能方面很有用。然而,我们进行的实验表明,reparameterization的效果在不同的NLU任务和数据集中是不一致的。如
Figure 4所示:在
RTE和CoNLL04中,MLP reparameterization通常表明在几乎所有的prompt长度上都比embedding的性能好。然而,在
BoolQ中,MLP和embedding的结果是相差无几的。在
CoNLL12中,embedding的结果一直优于MLP。
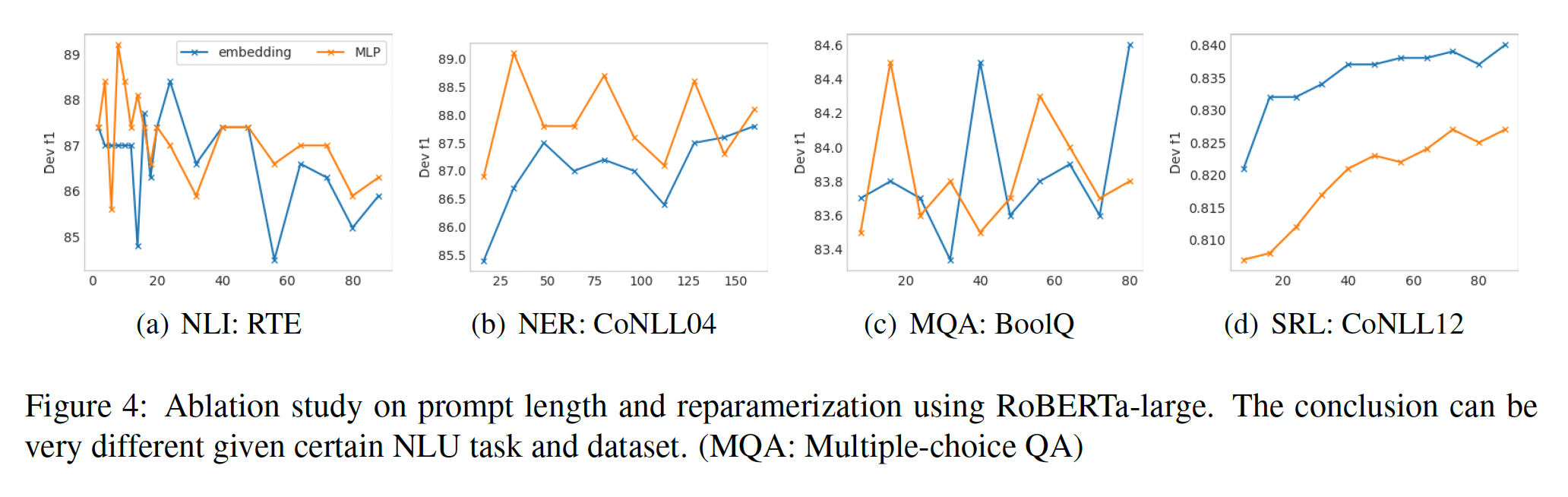
Prompt长度:prompt长度是P-tuning v2的另一个有影响力的超参数,其最佳值因任务而异。从Figure 4中我们观察到:对于简单的
NLU任务,通常情况下,较短的prompts就能获得最佳性能。对于困难的序列任务,通常情况下,长于
100的prompts会有帮助。
我们还发现,
reparameterization与最佳prompt长度有着密切的联系。例如,在RTE, CoNLL04, BoolQ中,MLP的reparameterization比embedding更早达到最佳结果。这一结论可能有助于对P-tuning的optimization属性进行一些思考。
三十、The Power of Scale for Parameter-Efficient Prompt Tuning[2021]
论文:
《The Power of Scale for Parameter-Efficient Prompt Tuning》
随着
pre-trained大型语言模型的广泛成功,出现了一系列的技术来适配这些通用模型的下游任务。ELMo提出冻结pre-trained模型并学习其每层表征的task-specific weighting。然而,自GPT和BERT以来,主流的adaptation技术是model tuning(也叫做"fine-tuning"),其中所有的模型参数在adaptation期间被调优,正如《Universal language model fine-tuning for text classification》所提出的。最近,
GPT-3表明,prompt design(也叫做"priming")在通过text prompts来调节frozen GPT-3 model的行为方面是惊人的有效。prompts通常由一个任务描述和/或几个典型的示例组成。这种回到 "冻结"pre-trained模型的做法很有吸引力,特别是在模型规模不断扩大的情况下。与其说每个下游任务都需要一个单独的模型副本,不如说一个通用模型可以同时为许多不同的任务服务。不幸的是,
prompt-based adaptation有几个关键的缺点。任务描述容易出错并需要人的参与,而且prompt的有效性受限于模型输入中能容纳多少conditioning text。因此,下游的任务质量仍然远远落后于tuned model。例如,尽管使用了16倍的参数,GPT-3 175B在SuperGLUE上的few-shot性能比fine-tuned T5-XXL低17.5分(71.8 vs. 89.3)。人们最近提出了一些
automate prompt design的努力。AutoPrompt提出了一种在单词的离散空间中的搜索算法,该算法被下游应用的训练数据所指导。虽然这种技术优于manual prompt design,但相对于model tuning来说仍有差距。《Prefix-tuning: Optimizing continuous prompts for generation》提出了"prefix tuning",并在生成式任务上显示了强大的结果。这种方法冻结了模型参数,并将tuning过程中的误差反向传播到prefix activations,这些prefix activations被放置在encoder stack中每一层(包括输入层)之前。《WARP: Word-level Adversarial ReProgramming》通过将可训练的参数限制在masked language model的输入子网和输出子网上,简化了这个配方,并在分类任务上显示了合理的结果。在本文中,我们提出了
prompt tuning作为适配语言模型的进一步简化。我们冻结了整个pre-trained模型,只允许每个下游任务有额外的tunable tokens被添加到input text之前。这种"soft prompt"是经过端到端训练的,可以浓缩来自完整的labeled数据集的信号,使我们的方法能够胜过few-shot prompts,并缩小与model tuning的质量差距(Figure 1)。同时,由于单个pre-trained模型用于所有下游任务,我们保留了frozen model的高效serving的优势(Figure 2)。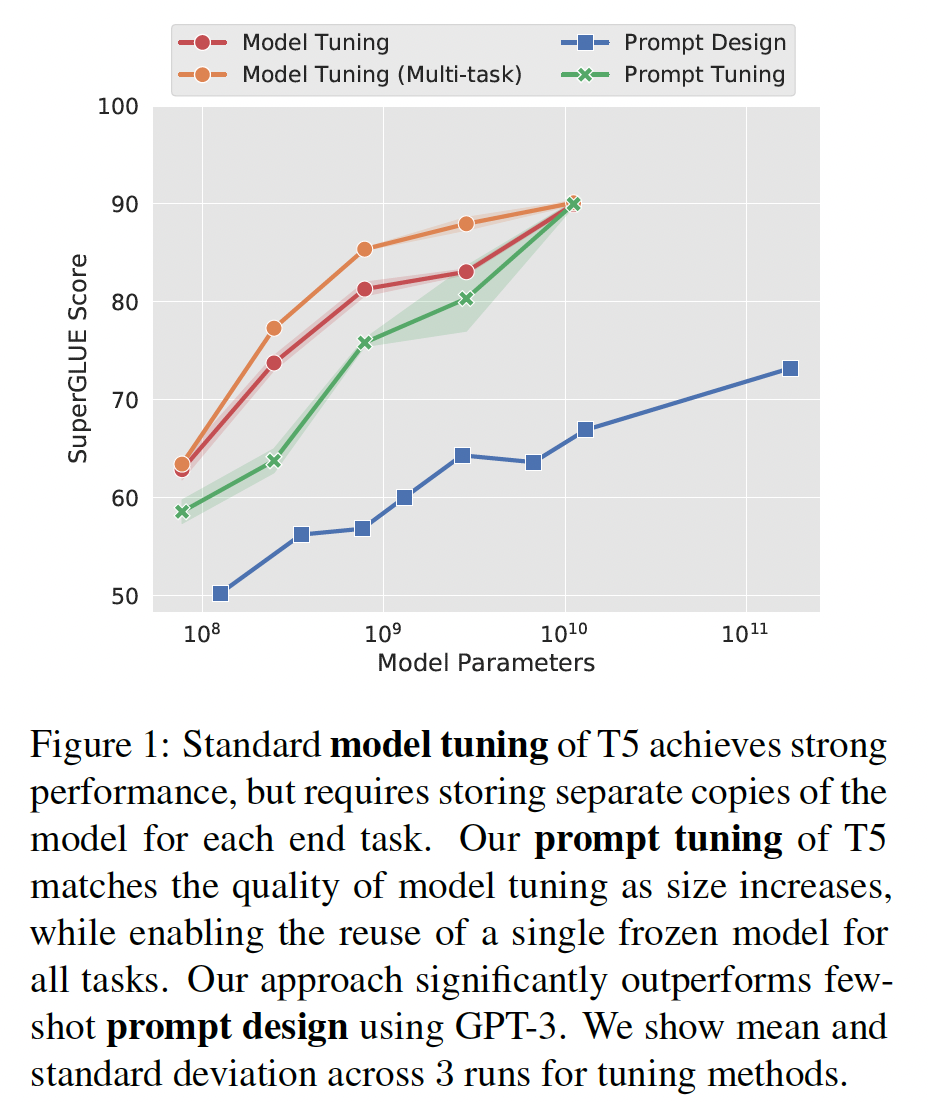
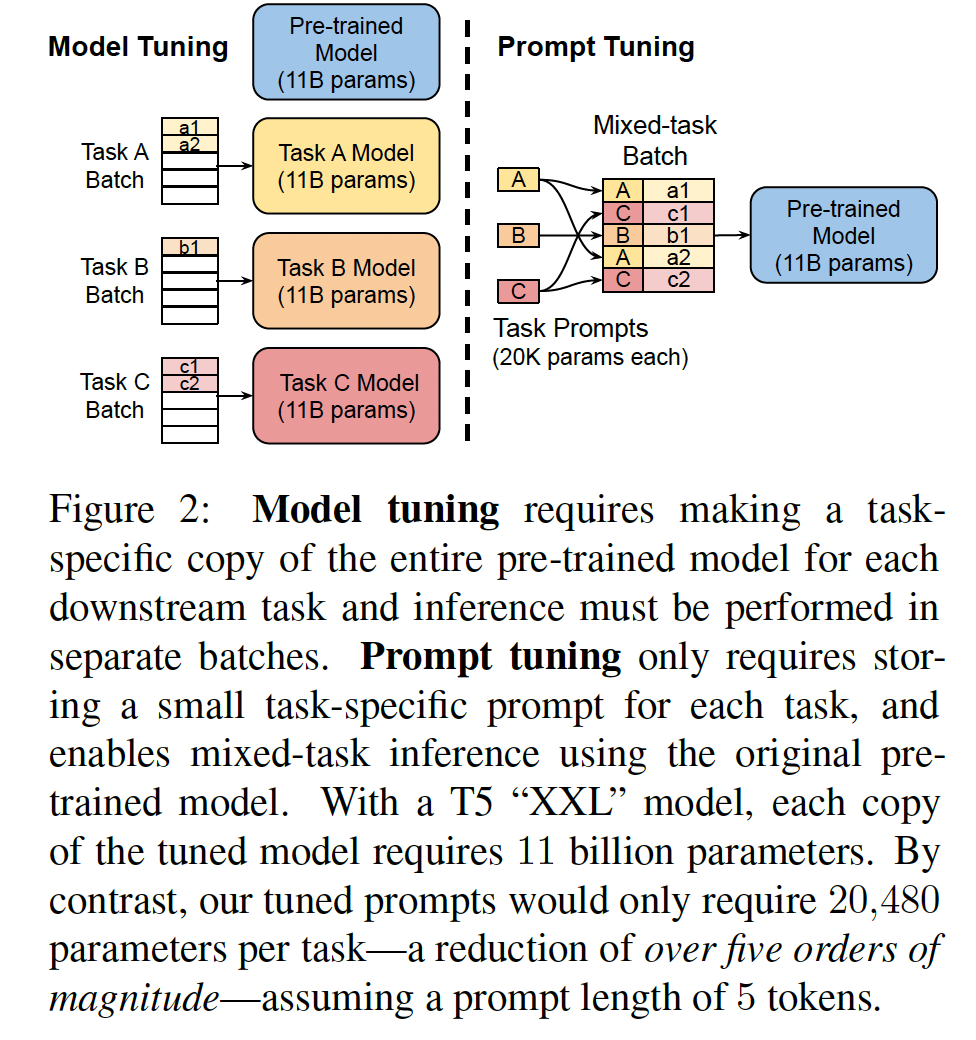
虽然我们与
《Prefix-tuning: Optimizing continuous prompts for generation》以及《WARP: Word-level Adversarial ReProgramming》同时开发了我们的方法,但我们是第一个表明单独的prompt tuning(没有中间层prefix或task-specific输出层)足以与model tuning竞争。通过详细实验,我们证明语言模型容量是这些方法成功的关键因素。如Figure 1所示,随着规模的扩大,prompt tuning变得更具竞争力。我们在实验中与类似的方法进行比较。明确地将
task-specific参数与一般语言理解所需的 "通用" 参数分开,有一系列额外的好处。我们在实验中表明,通过捕获在prompt中的任务定义,同时保持通用参数的固定,我们能够实现对domain shift的更好的适应性。此外,我们表明"prompt ensembling",即为同一任务来学习多个prompts,可以提高质量,并且比传统的model ensembling更有效率。最后,我们研究了我们学到的soft prompts的可解释性。本论文的方法是
full-data training的,而不是few-data training。总而言之,我们的主要贡献是:
提出了
prompt tuning,并展示了其在大型语言模型领域中与model tuning的竞争力。消除了许多设计的选择,并表明质量和鲁棒性随着模型规模的扩大而提高。
显示在
domain shift问题上,prompt tuning优于model tuning。提出
"prompt ensembling"并显示其有效性。
Prefix-Tuning和P-Tuning、P-Tuning v2都采用了重参数化技巧,这增加了训练的复杂性。Prefix-Tuning和P-Tuning v2对每一层添加了continues prompts,相比之下这里仅对输入层添加了continues prompts。P-Tuning也是仅对输入层添加了continues prompts,但是P-Tuning允许在输入的不同位置插入continues prompts。相比之下这里仅在输入的头部插入continues prompts。
30.1 Prompt Tuning
遵从
T5的"text-to-text"的方法,我们把所有的任务作为text generation。我们现在不是将分类任务建模为给定某个输入tokens的一个序列,class label;而是将分类任务建模为conditional generationclass label的tokens序列 。T5建模分类任务为transformer来建模,promptinng是在生成prompting是通过在输入tokens序列GPT-3中,prompt tokensrepresentation是模型的embedding table的一部分,通过被冻结的prompt需要选择prompt tokens,通过手动搜索、或非微分(non-differentiable)的搜索方法(《How can we know what language models know?》、《AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》)。prompt tuning消除了提示语prompt有自己的专用的、可以被更新的参数prompt design涉及从frozen embeddings的fixed vocabulary中选择prompt tokens,而prompt tuning可以被认为是使用special tokens的fixed prompt,其中只有这些prompt tokens的embedding可以被更新。我们新的conditional generation现在是具体而言,给定
tokens组成的序列T5做的第一件事是嵌入tokens,形成一个矩阵embedding空间的尺寸。我们的soft-prompts被表示为一个参数prompt的长度。然后,我们的prompt被拼接到embedded input,形成单个矩阵encoder-decoder。我们的模型被训练成最大化promp参数这是
Prefix-tuning在仅有输入被添加prefix的特殊情况,根据prefix-tuning的论文,这种情况的效果不佳。猜测原因是:Prefix-tuning中的模型规模不够大;Prefix-tuning采用了重参数化技巧的影响。
30.1.1 Design Decisions
有许多可能的方法来初始化
prompt representations。最简单的是从头开始训练,使用随机初始化。
一个更复杂的选择是将每个
prompt token初始化为一个从模型词表中提取的embedding。从概念上讲,我们的soft-prompt以与text preceding the input(即,普通的prompt)相同的方式来调节frozen network的行为,因此,word-like representation可能会成为一个好的初始化点。对于分类任务,第三个选择是用列举
output classes的embeddings来初始化prompt,类似于《Exploiting cloze-questions for few-shot text classification and natural language inference》的"verbalizers"。由于我们希望模型在输出中产生这些tokens,用valid target tokens的embedding来初始化prompt应该使模型将其输出限制在合法的输出类别中。
论文
《PPT: Pre-trained Prompt Tuning for Few-shot Learning》表明:在full-data training下更小模型上表现好的初始化方法,在few-shot training下更大模型中不一定有效。另一个设计考虑是
prompt长度。我们方法的参数成本是token embedding维度,prompt长度。prompt越短,必须被调优的新参数就越少,所以我们的目标是找到一个仍然表现良好的最小长度。
30.1.2 Unlearning Span Corruption
与
GPT-3等自回归语言模型不同,我们试验的T5模型使用encoder-decoder架构,并对span corruption objective进行预训练。具体来说,T5的任务是 "重建" 输入文本中的masked spans,这些spans被标记为独特的哨兵tokens。target output text由所有masked text组成,用哨兵tokens分开,再加上final sentinel token。例如,从文本"Thank you for inviting me to your party last week"中,我们可以构建一个预训练样本,输入是"Thank you <X> me to your party <Y> week",target输出是"<X> for inviting <Y> last <Z>"。虽然
《Exploring the limits of transfer learning with a unified text-to-text transformer》发现这种架构和pre-training objective比传统的语言建模更有效,但我们假设这种setting并不适合产生一个frozen model,其中这个frozen model可以随时通过prompt tuning来控制。具体而言,一个专门针对span corruption进行预训练的T5模型(如T5.1.1),从未见过真正自然的输入文本(不含哨兵tokens),也从未被要求预测真正自然的targets。事实上,由于T5的span corruption preprocessing的细节,每一个pre-training target都会以一个哨兵token开始。虽然这种输出哨兵的 "非自然" 倾向很容易通过微调来克服,但我们怀疑,由于解码器的先验无法被调整,仅通过prompt就很难覆盖这种倾向。考虑到这些问题,我们在三种情况下实验了
T5模型:"Span Corruption": 我们使用现成的pre-trained T5作为我们的frozen模型,并测试它为下游任务输出预期文本的能力。"Span Corruption + Sentinel": 我们使用相同的模型,但在所有的下游targets之前放置一个哨兵token,以便更接近于预训练中看到的targets。"LM Adaptation": 我们继续以少量的额外steps进行T5的自监督训练,但使用T5原始论文中的"LM" objective:给定一个自然文本前缀作为输入,模型必须产生自然文本的延续作为输出。至关重要的是,这种adaptation只发生一次,产生单个frozen模型,我们可以在任何数量的下游任务中作为prompt tuning来重复使用。通过
LM Adaptation,我们希望将T5"快速" 转变为一个与GPT-3更相似的模型,其中GPT-3总是输出真实的文本,并且作为一个"few-shot learner"对prompts做出良好的响应。与从头开始的预训练相比,这种后期转换的成功率并不明显,而且据我们所知,以前也没有人研究过这种情况。因此,我们对各种训练steps的adaptation进行了实验,最高可达100K步。
30.2 实验
实验配置:
模型:各种尺寸的
pre-trained T5 checkpoints(Small, Base, Large, XL, XXL)。我们利用公共的T5.1.1 checkpoitn,其中包括对原始T5.1的改进。默认配置为绿色的
x线,使用经过LM-adapted的T5版本(额外训练了100k步),使用class labels进行初始化,并使用100 tokens的prompt长度。虽然这比Prefix-tuning使用的默认的10-token prefix要长,但我们的方法仍然使用较少的task-specific参数,因为我们只调优了输入层,而不是覆盖所有网络层的激活。数据集:
SuperGLUE。我们的每个prompt都在单个的Super-GLUE任务上进行训练,没有多任务设置或跨任务来混合训练数据。我们使用
T5的标准交叉熵损失训练我们的prompts达30k步,学习率恒定为0.3,batch size = 32。checkpoint是通过验证集上的早停来选择的,其中停止的指标是数据集的默认指标,或者是用多个指标评估的数据集的平均指标。所有实验都在JAX中运行,使用Adafactor优化器,权重衰减1e-5,0.8,parameter scaling off。这些模型在Flax中实现。更多细节见附录A。
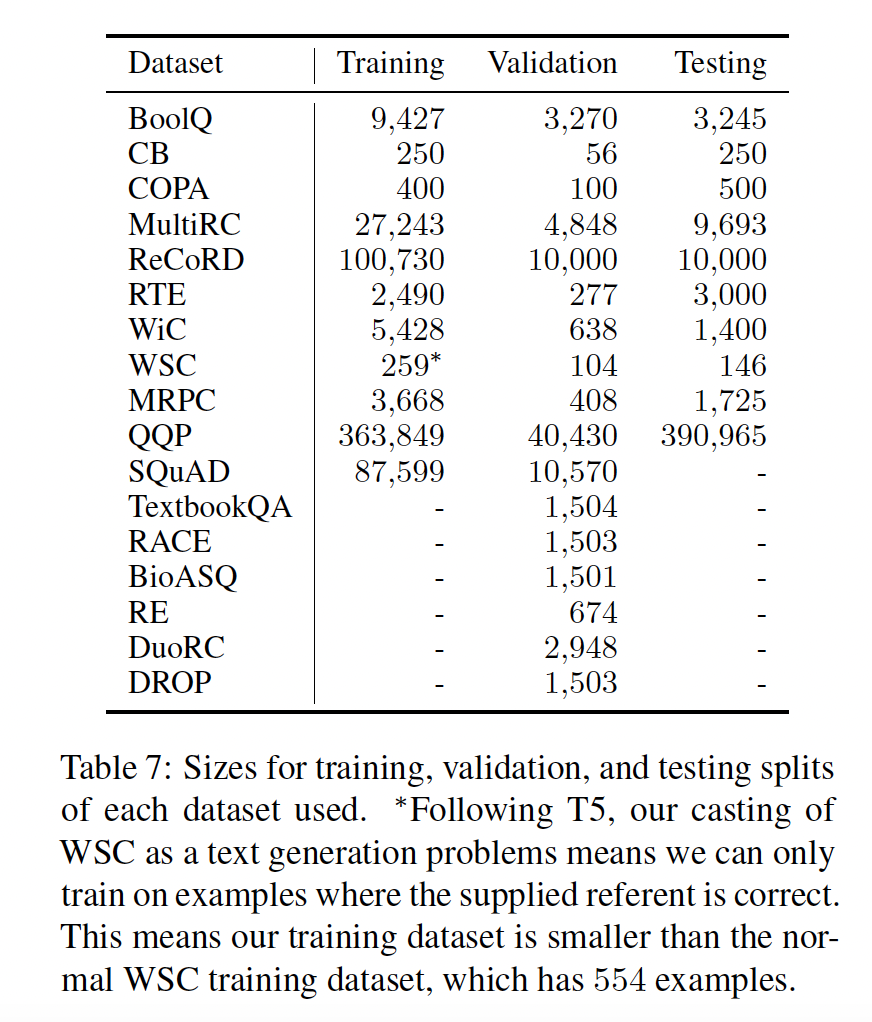
实验涉及到的数据的统计信息:
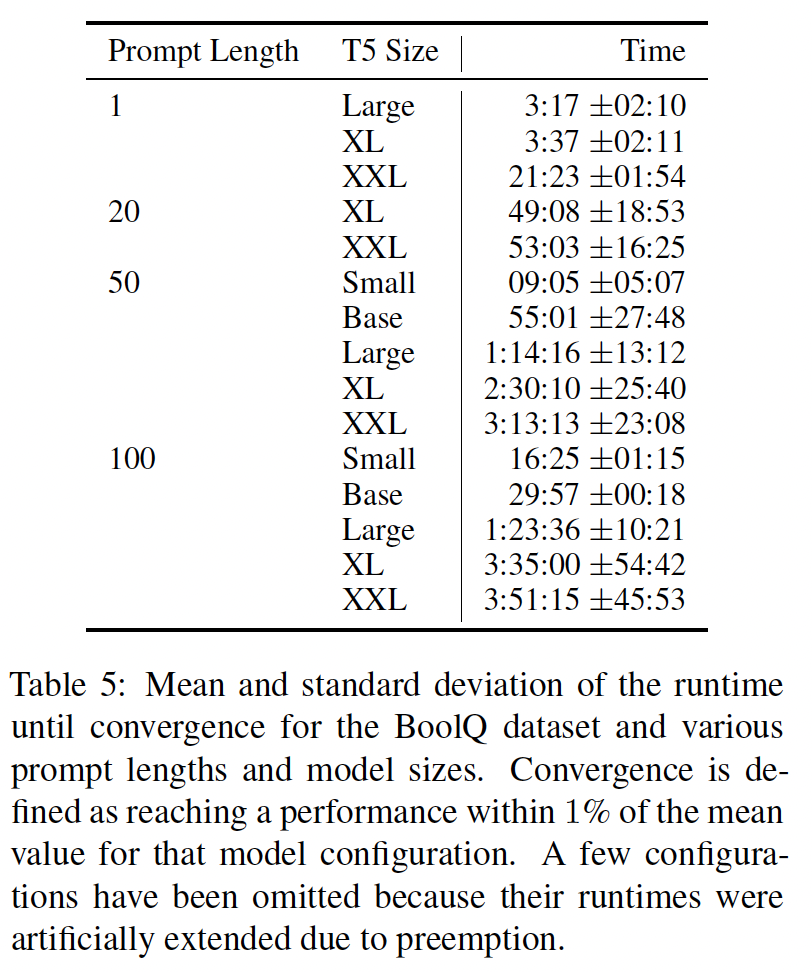
训练耗时:
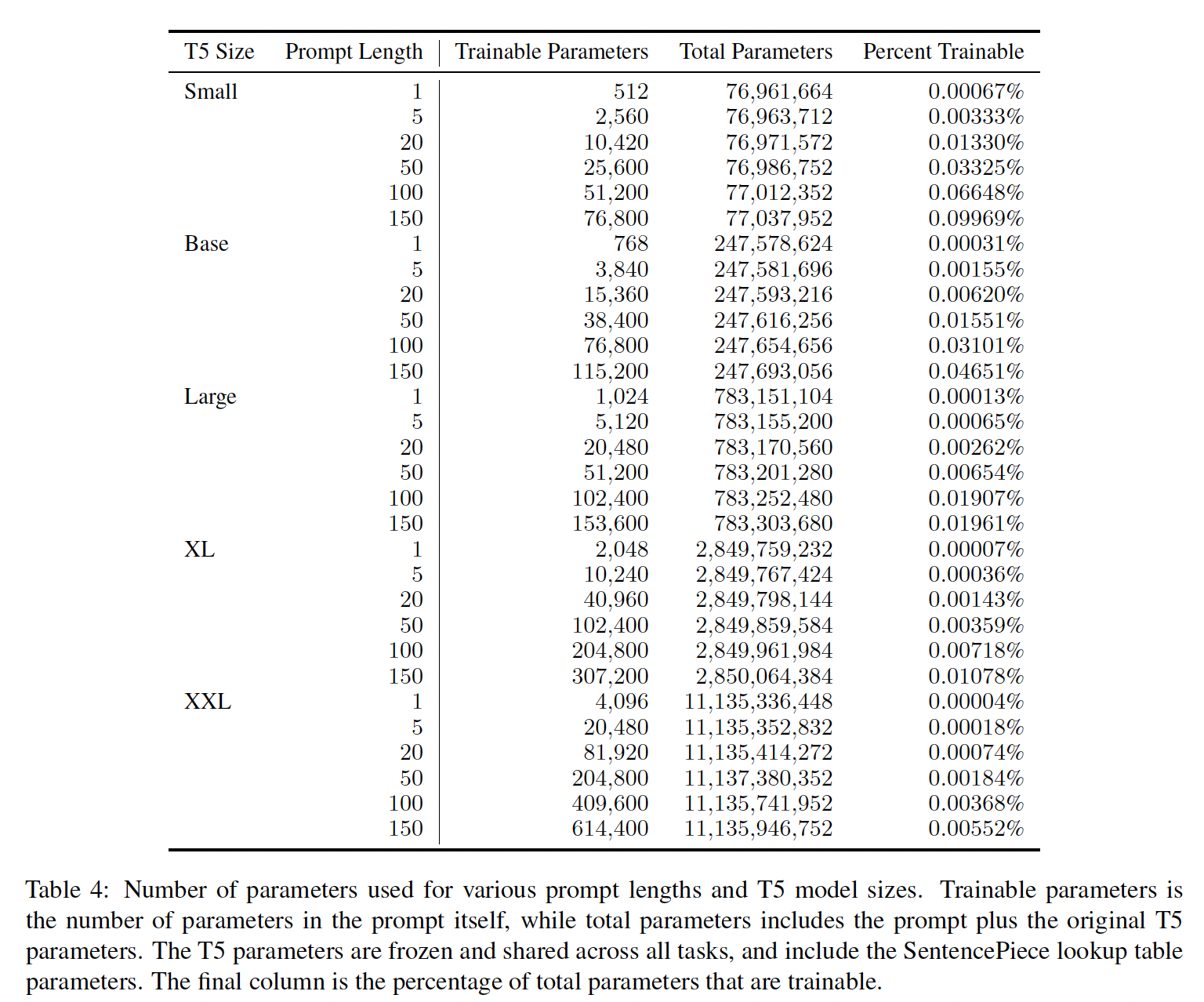
可训练参数的占比:
30.2.1 弥补差距
为了将我们的方法与标准
model tuning进行比较。我们考虑两个baseline:"Model Tuning":为了进行一对一的比较,我们对每个任务分别进行调优,就像我们的prompt tuning setup一样。"Model Tuning (Multitask)":我们使用T5的multi-task tuning setup来实现一个更具竞争力的baseline。在这种情况下,单个模型在所有的任务上被联合调优,用text prefix表示任务名称。
在下图中,我们看到,随着规模的增加,
prompt tuning与model tuning的竞争变得更加激烈。在XXL规模(11B参数)下,prompt tuning甚至与更强大的multi-task model tuning基线相匹配,尽管其task-specific参数少了20000倍。为了与
prompt design进行比较,我们将GPT-3 few-shot在SuperGLUE dev split上性能包括在内。下图显示,prompt tuning以很大的优势击败GPT-3 prompt design,prompt-tuned T5-Small与GPT-3 XL(参数规模超过16倍)相匹配,prompt-tuned T5-Large击败了GPT-3 175B(参数规模超过220倍)。
30.2.2 消融研究
Prompt Length(Figure 3(a)):对于大多数模型规模,增加prompt长度超过一个token是实现良好性能的关键。值得注意的是,XXL模型在single-token prompt下仍有很好的效果,这表明模型越大,实现目标行为所需的conditioning signal就越少。在所有的模型中,增加到20 tokens以上只能产生微弱的收益。tokens数量增加到150的时候,效果反而下降。这说明发生了过拟合。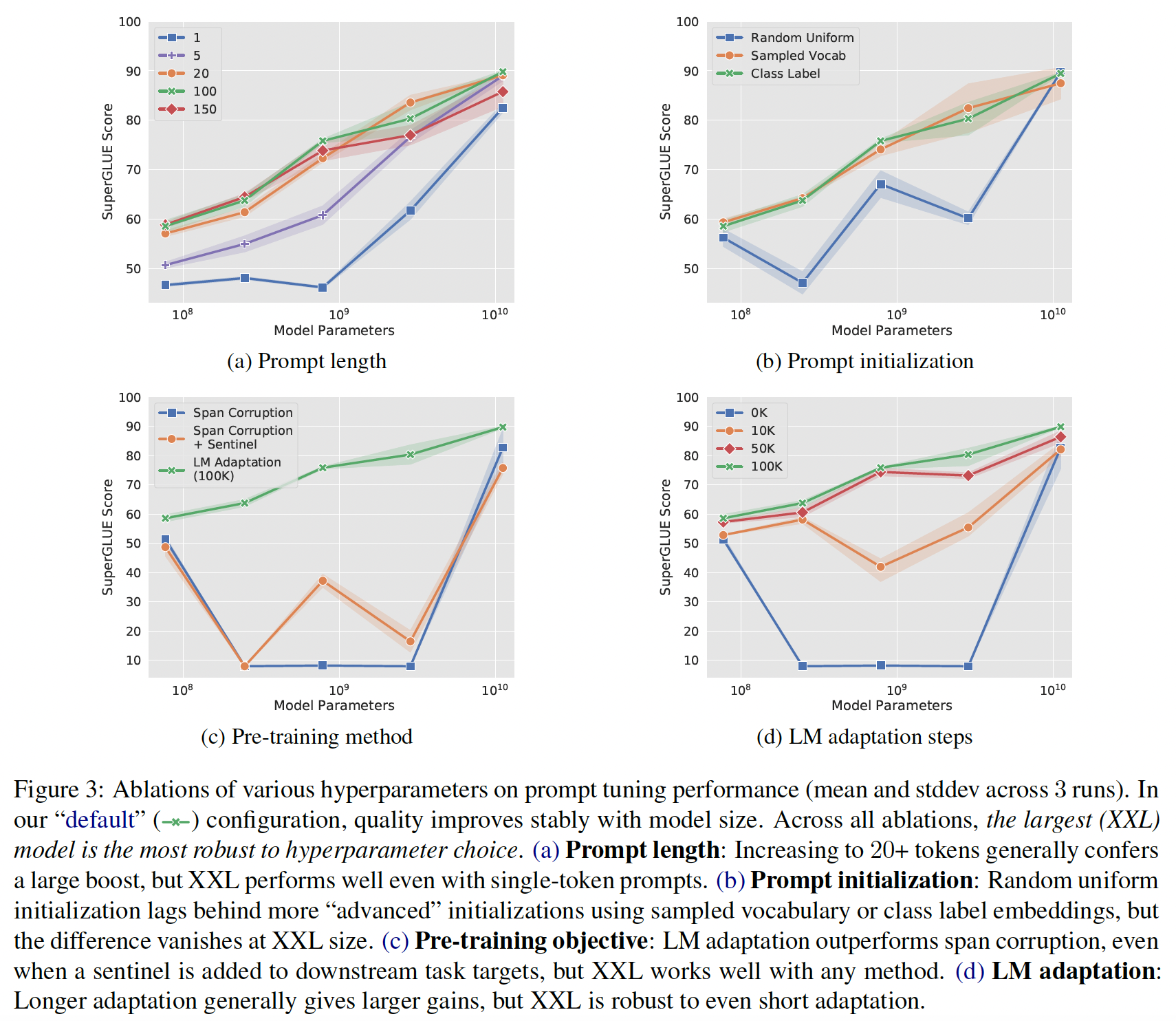
Prompt Initialization(Figure 3(b)):对于随机初始化,我们从
[-0.5, 0.5]范围内均匀采样。对于
sampled vocabulary初始化,我们从 在T5的Sentence-Piece词表中最 "常见" 的5000 tokens中随机采样,其中tokens按照在预训练语料库中的频次来排序。对于
class label初始化,我们采用下游任务每个类别的字符串对应的embedding来初始化prompt中的一个token。当一个class label是multi-token时,我们采用token embeddings的均值。对于较长的
prompt,通常在使用class label初始化之后,还剩下很多prompt tokens尚未初始化,此时我们采用sampled vocabulary初始化。
我们发现基于
class label的初始化表现最好。在较小的模型尺寸下,不同的初始化之间有很大的差距,但是一旦模型被放大到XXL规模,这些差异就会消失。Pre-training Objective(Figure 3(c)):pre-training objective对prompt tuning质量有明显的影响。T5默认的"span corruption" objective并不适合于训练frozen的模型从而用于后续的conditioned by prompts。即使是在下游目标中添加哨兵的 "变通方法" 也没有什么好处。
LM adaptation在所有的模型规模中都增加了效果。我们最大的
XXL模型是最宽容的,即使是span corruption objective也能给出强有力的结果。
adaption长度(Figure 3(d)):较长的adaption(最高可达100K步)提供了额外的收益。这表明,从span corruption到语言建模目标的 "过渡" 不是一个微不足道的变化,有效的过渡需要投入训练资源(原始T5预训练的10%的steps)。此外,我们观察到
XXL模型对非理想的配置也很稳健。在这种规模下,adaption的收益是相当小的。对于
non-optimal "span corruption" setting,我们观察到不同大小的模型的不稳定性:Small模型的表现优于较大的Base, Large, XL模型。经检查,我们发现对于许多任务,这些中型模型从未学会输出一个合法的类别标签,因此得分为0%。此外,这种糟糕的表现并不是由于"span corruption" setting的随机方差造成的,因为我们观察到每个大小的模型在3次运行中的方差很低。这些结果表明,使用用"sparn corruption" objective预训练的模型可能是不可靠的,5个模型中只有2个工作良好,而LM adapated版本在所有模型大小上都工作可靠。我们已经发布了
T5 1.1 checkpoint,使用LM objective对所有模型大小进行了100K步的适配。没有关于训练样本数量的消融研究?这方面的消融研究可以参考
PPT的实验部分。总体而言,样本数量越少,Prompt Tuning和Fine Tuning的差异越大。
30.2.3 与相似方法的比较
如下图所示,在具有可学习参数的方法中,
prompt tuning的参数效率最高,对于超过1B参数的模型,需要不到0.01%的task-specific参数。prefix tuning:学习prefix的一个序列,该序列添加到每个transformer layer的前面。相比之下,prompt tuning使用单个prompt representation,该prompt representation被添加到embedded input之前。prefix tuning还需要prefix的重参数化来稳定学习,这在训练过程中增加了大量的参数;而我们的配置不需要这种重新参数化。WARP:prompt parameters被添加到输入层。它限制模型产生单个输出,且限制为分类任务。prompt tuning没有这些限制。P-tuning:可学习的continuous prompts在embedded input中交错出现,使用基于human design的模式。我们的方法通过简单地将prompt添加到输入的开头,消除了这种复杂情况。为了达到强大的
SuperGLUE结果,P-tuning必须与model tuning结合使用,也就是说,模型联合更新prompt参数和main model parameters,而我们的方法保持原始语言模型是冻结的。P-tuning的原始论文中,原始语言模型也是冻结的。《Learning how to ask: Querying LMs with mixtures of soft prompts》:使用"soft words"来学习prompts,以便从pre-trained语言模型中提取知识。prompt与input的位置关系是基于手工设计的prommtp prototypes,每一层都包含一个学到的《Few-shot sequence learning with transformers》:使用一个可学习的prepended token来使transformer模型适应各种任务,但重点是小的合成数据集,旨在适应compositional task representation,而不是较大的真实世界数据集。更广泛地说,关于
task prompts的工作与关于"adapters"的工作密切相关,即在frozen pre-trained network layers之间插入小型bottleneck layers。adapters提供了另一种减少task-specific参数的手段。《Parameter-efficient transfer learning for NLP》在冻结BERT-Large并只增加2-4%的额外参数时,实现了接近full model tuning的GLUE性能。《MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer》在多语言背景下使用多个adapters,明确地将语言理解与任务规范分开,与我们的方法类似。
adapters和prompt tuning之间的一个核心区别是:这些方法如何改变模型行为。adapters通过允许重写任何给定层的activations来修改实际函数,该函数作用于input representation并由神经网络参数化。prompt tuning通过保持函数的固定、以及增加新的input representation来修改行为,这些new input representation会影响后续输入的处理方式。
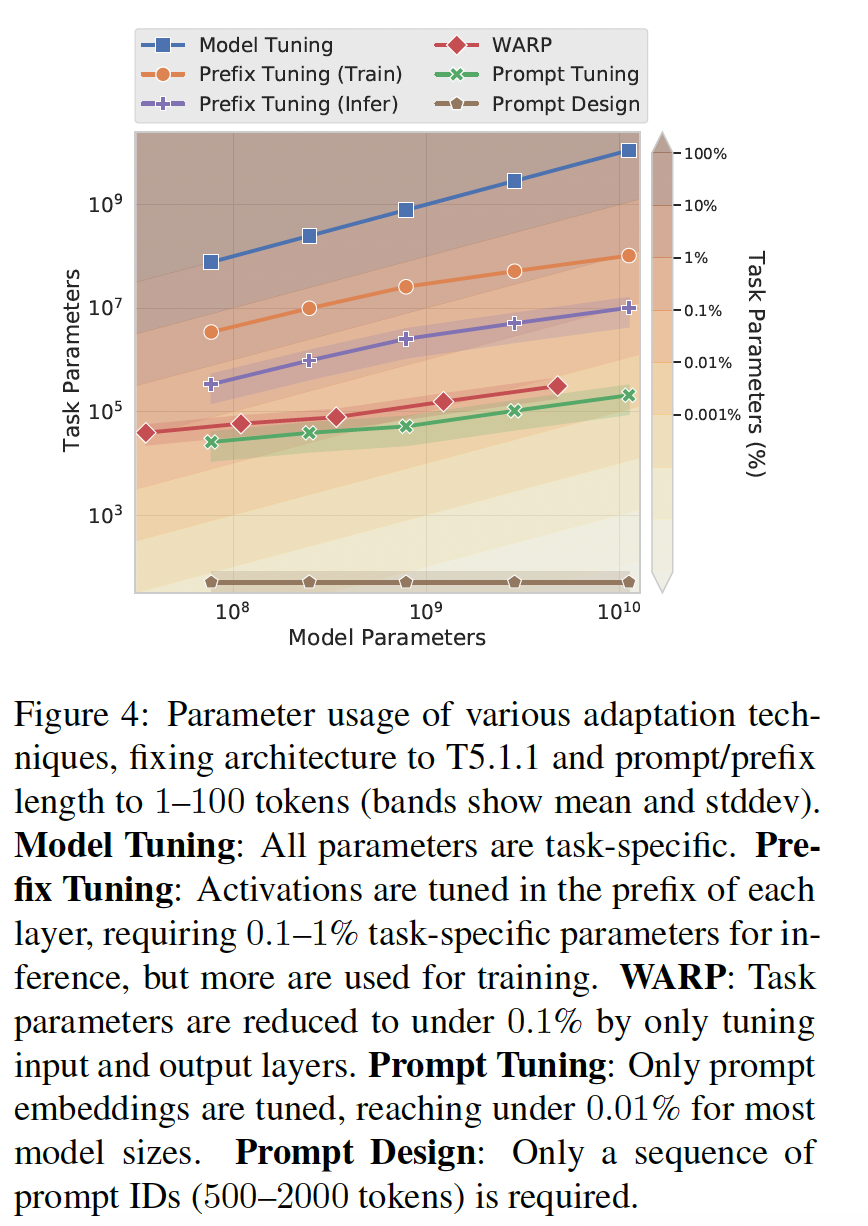
30.2.4 对 Domain Shift 的恢复能力
通过冻结
core language model parameters,prompt tuning防止模型修改模型对语言的通用理解。相反,prompt representations间接地调节了输入的representation。这减少了模型通过记忆特定的词汇线索、以及记忆虚假的相关关系来过拟合数据集的能力。这一限制表明,prompt tuning可能会提高对domain shift的鲁棒性,即输入的分布在训练和评估之间有所不同。我们在两个任务上研究
zero-shot domain transfer:问答、paraphrase detection。问答任务:
MRQA数据集作为in-domain数据集,然后我们在下表中的数据集(作为out-of-domain)上评估。prompt tuning大多数out-of-domain数据集上优于model tuning。在domain shifts较大的情况下(如BioASQ中的生物医学或TextbookQA中的数据集),prompt tuning的收益更大。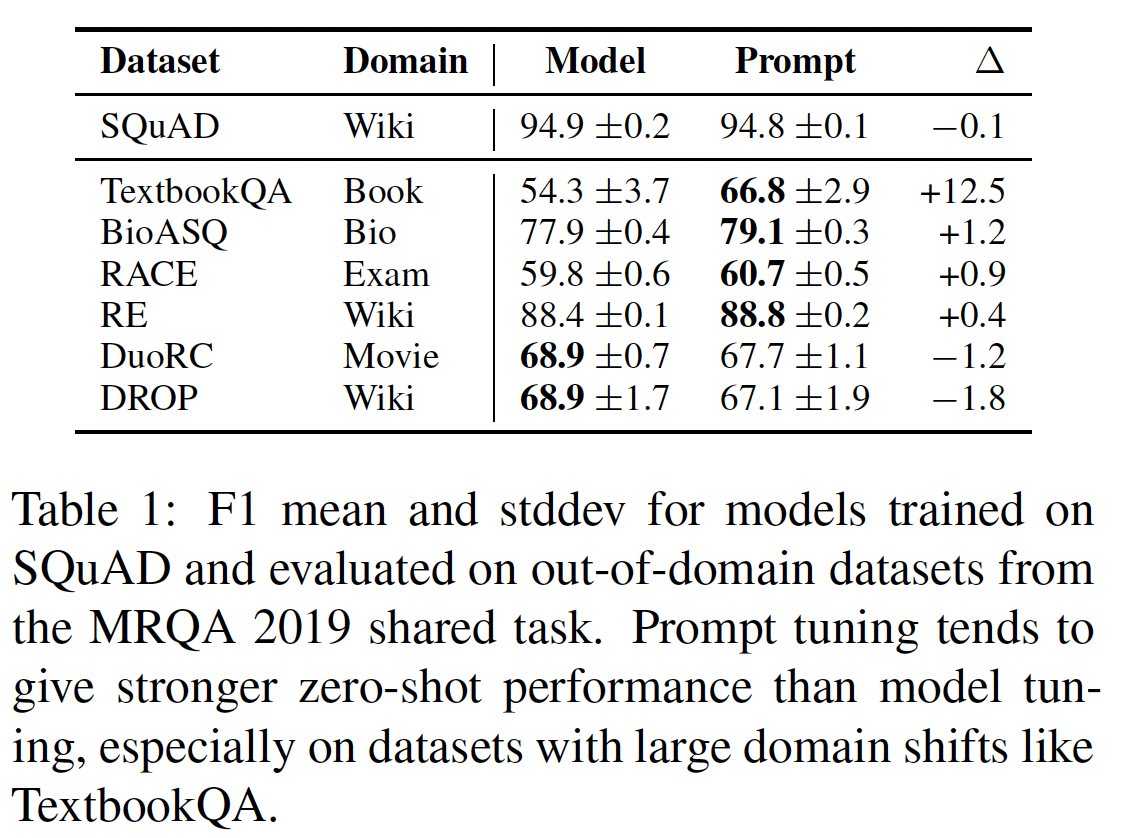
paraphrase detection:第一个任务是QQP,它询问社区问答网站Quora的两个问题是否是 "重复的"。第二个任务是MRPC,它询问的是来自新闻文章的两个句子是否是转述。和前面一样,我们在"in-domain"任务上进行训练,用in-domain验证集选择checkpoint,并在"out-of-domain"任务上进行out-of-domain评估。结果表明:在
QQP数据上训练一个轻量级的prompt并在MRPC上进行评估,比调优整个模型的性能好得多。在另一个方向上,结果要接近得多,prompt tuning显示了准确率的小幅提高和F1的小幅下降。这些结果支持这样的观点:
model tuning可能是过度参数化的,更容易过拟合训练任务,对不同领域的类似任务不利。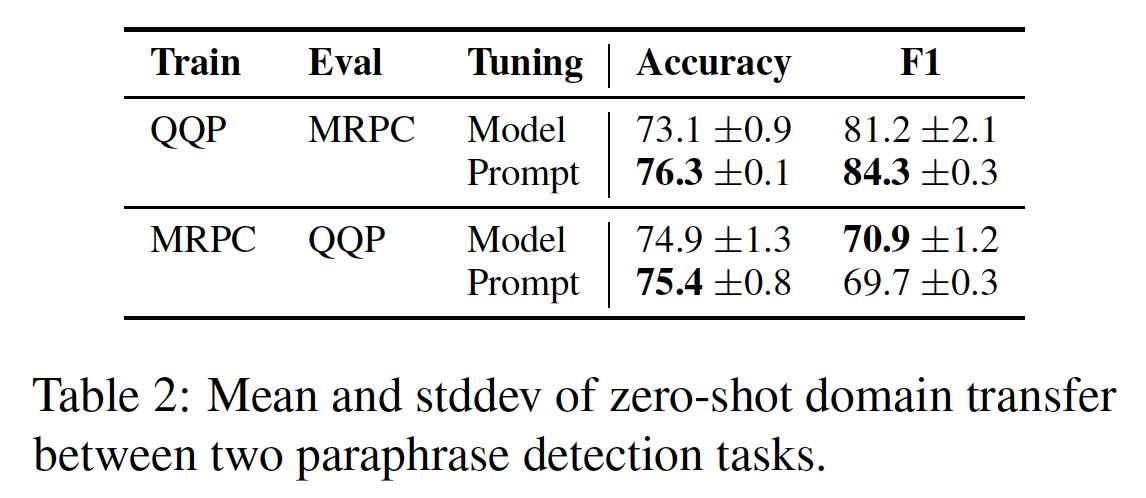
30.2.5 Prompt Ensembling
在相同数据上从不同的初始化而训练出来的一组神经模型,对这组模型的
ensembles被广泛观察到:改善了任务表现,并且对于估计模型的不确定性很有用。然而,随着模型规模的增加,ensembling可能变得不切实际。除了存储T5-XXL的每个副本需要42GiB),运行prompt tuning提供了一种更有效的方式来ensemblepre-trained语言模型的多个adaptations。通过在同一任务上训练prompts,我们为一个任务创建了core language modeling parameters。除了大幅降低存储成本外,prompt ensemble还使推断更有效率。为了处理一个样本,与其计算batch size = N的单次前向传播,在整个batch中复制该样本并改变prompt。这些节约反映了Figure 2中多任务处理的情况。为了证明
prompt ensembling的可行性,我们为每个SuperGLUE任务训练了五个prompts,使用一个frozen T5-XXL模型和我们默认的超参数。我们使用简单的多数投票来计算ensemble的预测结果。Table 3显示,在所有的任务中,ensemble都比单个prompt的均值要好,也比最好的单个prompt要好或与之匹配。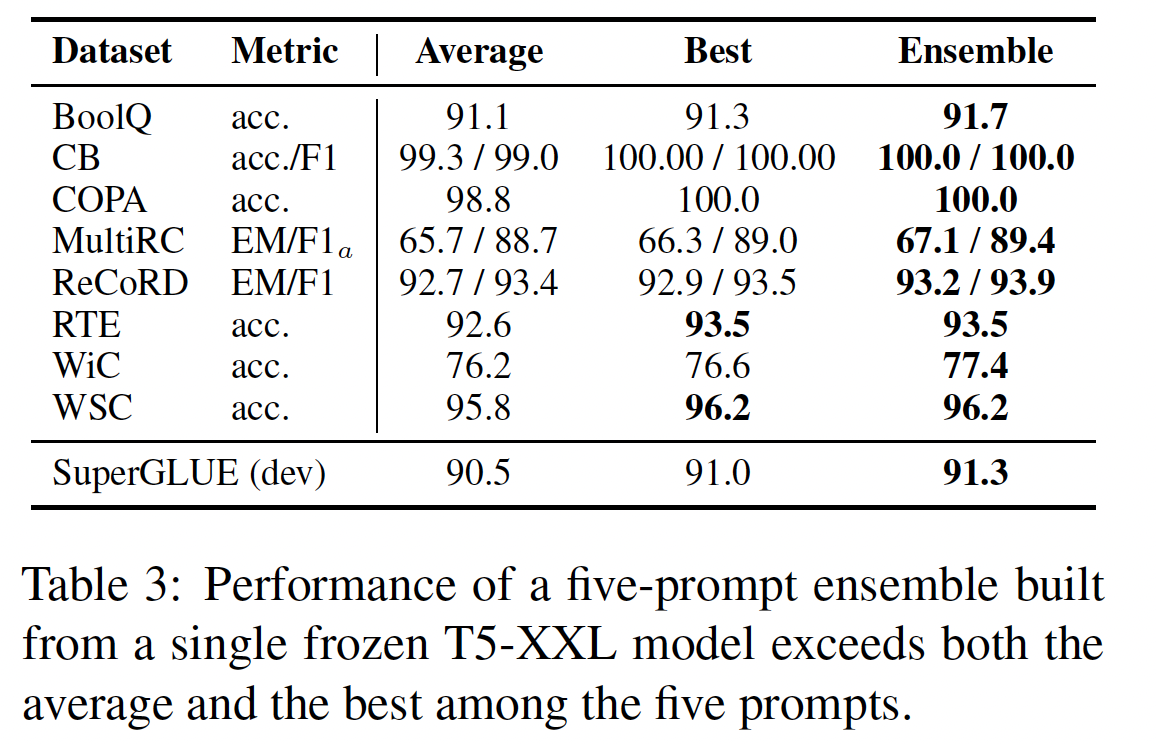
30.2.6 可解释性
一个理想的可解释的
prompt由自然语言组成,它清楚地描述了手头的任务,明确地要求模型做出一些结果或行动,并使人容易理解为什么prompt会从模型中引导这样的行为。由于
prompt tuning是在连续的embedding space而不是离散的token space中工作,解释prompt变得更加困难。为了测试我们学到的soft prompts的可解释性,我们从冻结的模型词表中计算出每个prompt token的最近邻(余弦相似度作为距离指标)。我们观察到,对于一个给定的
learned prompt token,top-5最近邻居成了紧密的语义簇。例如,我们看到词汇上相似的簇,如{ Technology / technology / Technologies/ technological / technologies },以及更多样化但仍然强烈相关的簇,如{ entirely / completely / totally / altogether/ 100% }。这些簇的性质表明,这些prompts实际上是在学习"word-like" representation。我们发现,从embedding space中抽取的随机向量并不显示这种语义聚类。当使用
"class label"策略初始化prompts时,我们经常发现class labels在训练中一直存在。具体来说,如果一个prompt token被初始化为一个给定的label,在调优之后,那么这个label往往是在learned token的近邻中。当用
"Random Uniform"或"Sampled Vocab"方法初始化时,class label也可以在prompts的最近邻中找到;但是它们往往作为多个prompt tokens的邻居出现。这表明,模型正在学习将预期的输出类别存储在
prompts中作为参考,而将prompt初始化为输出类别使之更容易、更集中化。这是否意味着:在
discrete prompts的设计过程中,我们可以将候选答案也加入到prompts中?比如:Options: postive, negative. Question: [X]. The sentiment is :。当检查较长的
prompts(如长度为100)时,我们经常发现有几个prompt具有相同的近邻。这表明,要么prompt中存在过剩的容量,要么prompt representation中缺乏序列结构使得模型难以将信息定位到特定的位置。正如
P-Tuning所述:从直觉上讲,他们认为prompt embeddings的值应该是相互依赖的,而不是相互独立的。如何很好地建模这种依赖性?这是一个挑战。虽然作为序列的
learned prompts显示出很少的可解释性,但我们确实观察到像science, technology, engineering这样的单词作为在BoolQ数据集上训练的prompt的最近邻的频率很高,大约20%的问题属于 "自然/科学" 类别。虽然还需要更多的调查,但这表明prompt的一个作用可能是引导模型解释特定领域或背景下的输入(例如 "科学")。
三十一、Querying LMs with Mixtures of Soft Prompts[2021]
论文:
《Learning How to Ask: Querying LMs with Mixtures of Soft Prompts》
pretrained语言模型(如ELMo、BERT、和BART)已被证明在其他自然语言处理任务中提供有用的representations。最近,《Language models as knowledge bases?》和《How can we know what language models know?》证明语言模型还包含可以通过prompt引发的事实知识和常识知识。例如,要查询莫扎特的出生日期,我们可以使用prompt“___ was born in ___”,其中我们将第一个空填入了 “莫扎特”,并要求一个完形填空语言模型(cloze language model)填写第二个空。《Language models as knowledge bases?》使用手动创建的prompts,而《How can we know what language models know?》使用基于挖掘(mining)和释义(paraphrasing)的方法来自动地扩充prompt集合。了解幼儿知道什么知识是困难的,因为他们对问题的形式非常敏感(
《Children’s Minds》)。民意调查也对问题设计敏感(《The assumptions and theory of public opinion polling》)。我们观察到,当我们查询一个语言模型而不是一个人时,我们有机会使用梯度下降来调优prompts,从而更好地引发所需类型的知识。神经语言模型将
prompt视为连续的单词向量的序列。我们在这个连续空间中进行调优,放宽了向量必须是实际英语单词的embedding的约束。允许使用"soft prompts"(由"soft words"组成)不仅方便优化,而且更加表达力强。soft prompts可以强调特定单词(通过增加它们的向量长度)或这些单词的特定维度。它们还可以调整那些具有误导性、模糊性的或过于具体的单词。考虑以下用于relation date-of-death的prompt:___x performed untile his death in __y这个
prompt可能适用于男歌手Cab Calloway,但如果我们希望它也适用于女画家Mary Cassatt,可能有助于软化"performed"和"his",以避免强调错误的职业和性别,并且可以将"until"软化为一个较弱的介词(因为事实上Cassatt在她最后的几年里失明无法继续绘画)。另一种将这些情况联系起来的方法是:一个
prompt使用"performed",另一个prompt使用"painted"。一般来说,可能有许多不同的词汇模式可以表明特定的relation,使用更多的模式将获得更好的覆盖率。因此,我们提出了学习mixture of soft prompts的方法。我们在几个完形填空语言模型上测试了这个想法,训练了用于补全三个数据集中的事实关系和常识关系的
prompts。通过对held-out样本进行比较,我们的方法显著优于先前的工作,即使是随机初始化的情况下也是如此。因此,当将其视为近似知识库时,语言模型知道的东西比我们意识到的要多。我们只是需要找到正确的提问方式。相关工作:
大多数先前的工作都是手动创建
prompts来从trained语言模型中提取答案。LM Prompt And Query Archive: LPAQA方法通过挖掘语料库、或paraphrasing现有prompts来搜索新的prompts。AutoPrompt通过使用梯度信号搜索improved prompts,然而其prompts仅限于实际(hard)的英语单词的序列,与我们的方法不同。
我们将我们的新型
soft prompts与所有这些系统进行比较。在我们于
2020年11月提交本文之后,arXiv上出现了两篇尚未发表的论文,它们也研究了soft prompts。《Prefix-tuning: Optimizing continuous prompts for generation》考虑了从pretrained语言模型(GPT-2或BART)以prompt为条件来生成文本。为了改进结果,他们在prompt之前添加了一些task-specific "soft tokens",并仅仅微调了这些tokens的embedding(在所有embedding layers上)。《GPT understands, too.》采用了与我们类似的策略,通过在连续空间中调优fill-in-the-blank prompts来对GPT-2和BERT模型进行测试,然而他们没有使用我们提出的增强方法。
与我们的工作类似,这两篇论文都取得了很大的进展。
在其他工作中:
《Inducing relational knowledge from BERT》从语料库中挖掘prompts,然后对整个语言模型进行微调,以使其更准确地补全prompts。PET、PET-2的方法类似,但是对于每个prompts,他们以不同的方式微调语言模型。
我们的方法通过调优
prompts本身来补充这些方法。询问语言模型对特定句子的了解程度的
probing system通常使用前馈网络而不是进一步的自然语言prompts。然而,AutoPrompt展示了如何使用自然语言prompts来询问特定句子。我们的方法可能适用于这些prompts,或者适用于包含input-output examples的few-shot learning(GPT-3)。
31.1 方法
给定一个固定的
pretrained语言模型、一个 特定的关系date-of-death)、一个由关系pairs组成的训练数据集held-outpairs上评估该系统。promptquery,我们用假设
word embedding的维度为soft prompt,即tokens可以为任意的embedding。然而,我们可以连续地调优这些向量。Deeply Perturbed Prompts:对于prompt中的每个tokenrepresentationprompt。我们通过添加一个小的扰动向量prompt,其中仅仅调优
layer 0等价于直接调优early stopping或其他形式的正则化技术从而保持很小。我们的直觉是:小的扰动将产生与LM所训练得到的activation patterns更加相似的activation patterns。和
Prefix-tuning的唯一区别在于:这里施加正则化技术使得每次的更新事实上,这可以在
Prefix-tuning中采用较小的学习率、以及梯度范数截断来实现。Mixture Modeling:给定关系soft promptsensemble predictive distribution:其中:
soft promtps
这就是
《How Can We Know What Language Models Know?》中采用的Prompt Ensembling策略。Data-Dependent Mixture Modeling:作为扩展,我们可以将neural softmax model来优化其中
需要两次推断:一次预测
Training Objective:给定soft promtpsmixture weights
31.2 实验
略。
本论文和
Prefix-Tuning非常类似,因此实验部分省略。
三十二、PPT[2021]
论文:
《PPT: Pre-trained Prompt Tuning for Few-shot Learning》
近年来,微调预训练语言模型(
pre-trained language model: PLM)取得了重大进展。通过调优整个模型的参数,可以将从大规模unlabeled语料库中获得的各种各样的知识适用于处理各种自然语言处理任务,并超越从头开始学习模型的方法(《Pre-trained models: Past, present and future》)。为简单起见,我们将这种完全模型的微调称为"FT"。如Figure 1 (b) and (c)所示,有两种主流的FT方法:第一种是
task-oriented fine-tuning,在PLM之上添加task-specific head,然后通过优化相应训练数据上的task-specific objectives来对整个模型进行微调。第二种是
prompt-oriented finetuning(《Exploiting cloze questions for few-shot text classification and natural language inference》),其灵感来自最近利用语言prompts来探索PLM中的知识的工作(LAMA、GPT-3)。在prompt-oriented finetuning中,数据样本被转换为包含prompt tokens的序列,并将下游任务形式化为语言建模问题。如FIgure 1(c)所示,通过在句子中添加prompt"It was <X>.",我们可以通过在mask position预测"great"或"terrible"来确定其情感极性。如Figure 1所示,与task-oriented fine-tuning相比,prompt-oriented finetuning更类似于pre-training objectives(masked language modeling),从而有助于更好地利用PLM中的知识,并经常获得更好的性能。
虽然
FT已经显示出有希望的结果,但随着模型规模的迅速增长,为每个下游任务进行整个大模型的微调和存储变得更加昂贵。为了解决这个挑战,《The power of scale for parameter-efficient prompt tuning》提出了prompt tuning: PT,以更低的成本将大型PLM适应于下游任务,如Figure 1(d)所示。具体而言,PT使用由continuous embeddings组成的soft prompts,而不是hard prompts(离散的语言短语)。这些continuous prompts通常是随机初始化并进行端到端学习。为了避免为每个下游任务存储整个模型,PT冻结所有PLM参数,仅微调soft prompts,而不添加任何中间层和task-specific组件。如果训练样本足够多,也可以把
Prompt Tuning中的Verbalizer替换为Task Head。在数据稀疏的条件下,Verbalizer的效果可能更好。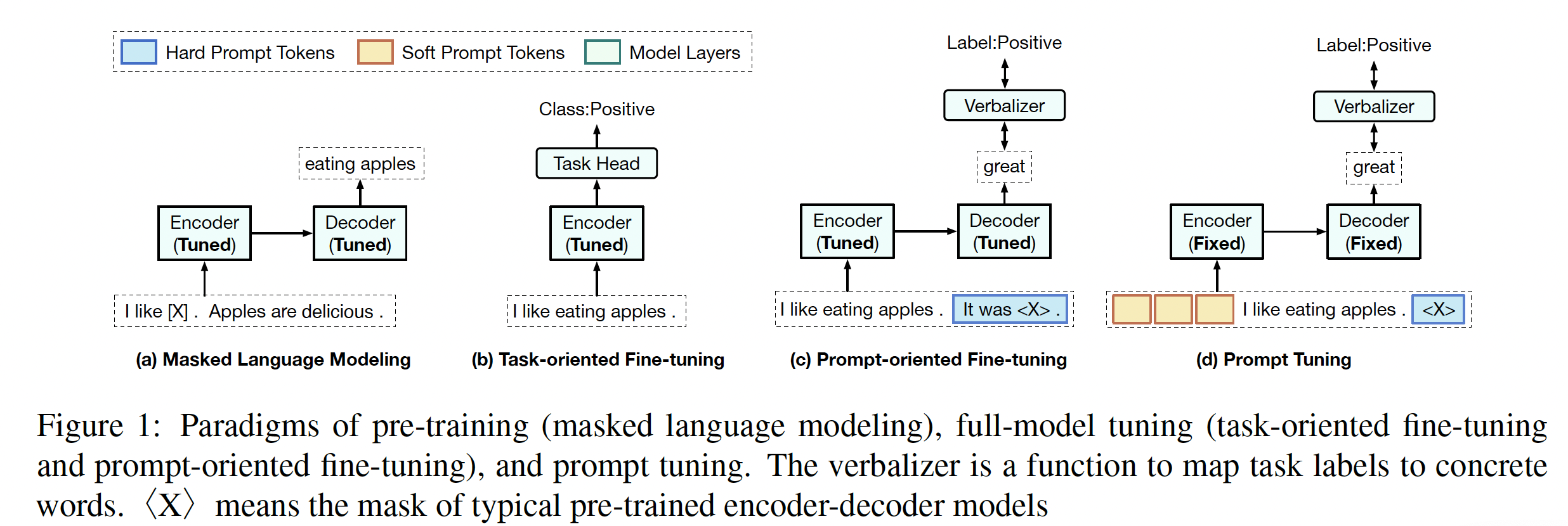
PT具有两个有前景的优势:首先,与
hard prompts相比,soft prompts可以进行端到端学习。其次,
PT是大规模PLM实际使用的一种高效而有效的范例,当下游数据足够时,与FT相媲美(Figure 2 (a))。
然而,如
Figure 2(b)所示,我们发现在few-shot settings下,PT的性能远远低于FT,这可能阻碍PT在各种低资源场景(low-resource scenarios)中的应用。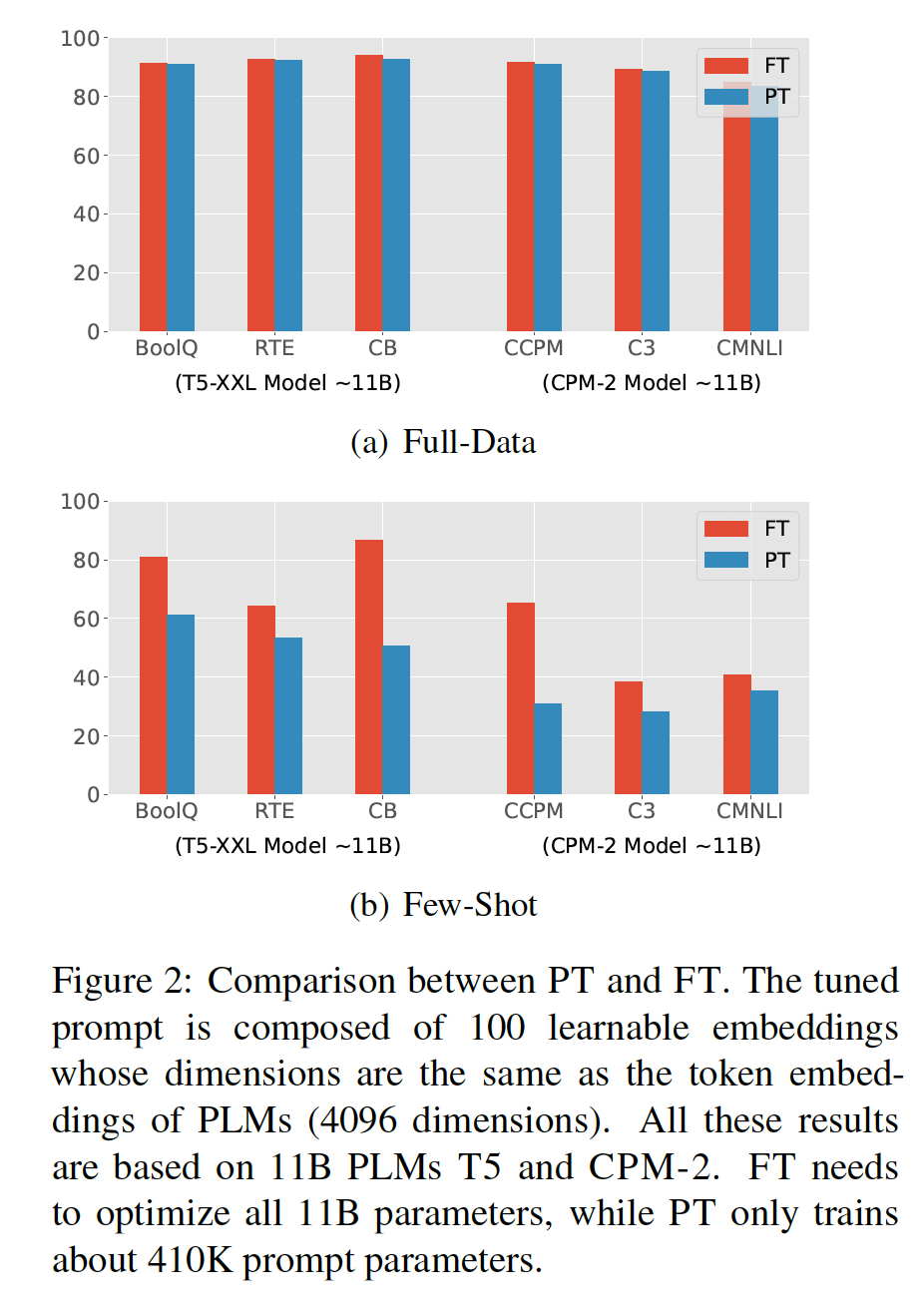
因此,在本文中,我们通过
PT探索如何以高效且有效的方式利用PLM进行few-shot learning。具体而言,我们进行了实证实验,以分析PT在PLM上的有效性,而这个方面在大多数现有研究中被忽视。我们的发现如下:选择合适的
verbalizer对性能有很大影响。简单地用
concrete word embeddings来初始化soft prompts无法改善性能。soft prompts和hard prompts的结合是有帮助的。所有这些方法都不能很好地处理
few-shot prompt tuning问题。
以上观察结果揭示了
PLM的prompt searching并不是一件简单的事情,仔细地初始化soft prompt tokens至关重要。为了帮助模型找到合适的
prompts,我们使用自监督任务在大规模unlabeled语料库上预训练soft prompt tokens。为了确保pre-trained prompts的泛化性,我们将典型的分类任务分为三种格式:sentence-pair classification、multiple-choice classification、single-text classification,每种格式对应一个自监督预训练任务。此外,我们发现multiple-choice classification在这些格式中更为通用,可以将所有分类任务统一到该格式中。我们将这个Pre-trained Prompt Tuning框架命名为"PPT"。我们在几个数据集上基于三个11B PLM(T5-XXL、mT5-XXL和CPM-2)上评估了PPT在few-shot场景下的性能。实验结果表明,PPT不仅可以大幅提升PT的性能,达到甚至超越FT方法,而且可以降低few-shot learning的方差。除了有效性外,PPT还保留了PT的parameter efficiency,这对于将来在大规模PLM上的应用是有价值的。本文的核心思想:
Prompt Tuning的自监督预训练,从而提升few-shot场景下的性能。注意:自监督的预训练非常消耗资源(算力成本、时间成本)。大多数用户没有足够的资源来支撑大模型的
PPT。相关工作:
PLM and Task-oriented Fine-tuning:最近,人们提出了各种强大的PLM,例如GPT、BERT、RoBERTa和T5。为了将这些PLM适应于下游NLP任务,究人员提出了task-oriented fine-tuning,其中使用PLM作为骨干并添加一些task-specific heads来优化task-specific objectives。然后,使用task-specific data对PLM和additional heads的所有参数进行微调。结果表明,task-oriented fine-tuning可以在一系列NLP任务上胜过从头开始训练的模型。Prompt-oriented Fine-tuning:大多数现有的PLM是使用language modeling objectives进行预训练的,然而下游任务的目标却有很大的差异。为了弥合预训练和下游任务之间的差距,人们引入了prompt-oriented fine-tuning。在prompt-oriented fine-tuning中,下游任务也被形式化为语言建模问题,通过插入language prompts,语言建模的结果可以对应到下游任务的solutions。knowledge probing(《Language models as knowledge bases?》、《A simple method for commonsense reasoning》、《Commonsense knowledge mining from pretrained models》)是激发prompts的发展的开创性工作。在knowledge probing中,语言triggers被广泛用于诱导PLM生成relational facts。这些开创性的工作表明,language prompts可以有效地引导PLM的知识。受此启发,由离散的单词所组成的人工设计的hard prompts首次用于prompt-oriented fine-tuning(PET、PET-2)。考虑到手动设计prompts既耗时又难以找到最佳选择,后来的研究(LM-BFF、LPAQA、AutoPrompt)提出了自动生成prompts的方法。然而,这些方法仍然将自动生成的prompts限制在离散空间中,而这通常不是最优的。为了克服离散空间的缺点,
Prefix-Tuning、P-Tuning、《PTR: prompt tuning with rules for text classification》、《WARP: Word-level adversarial reprogramming》和OptiPrompt探索了将hard prompt和soft prompts相结合。与使用concrete and discrete tokens的hard prompts不同,soft prompts由几个连续的可学习的embedding组成,这些embedding是随机初始化的。为了进一步发展,一些研究(《Prefix-tuning: Optimizing continuous prompts for generation》、《Learning how to ask: Querying lms with mixtures of soft prompts》、《The power of scale for parameter-efficient prompt tuning》)提出仅调优soft prompts并固定整个PLM参数。当模型足够大时,这种方法可以与full-model tuning相媲美。Few-shot Learning with PLM:由于长尾分布在实际应用中很常见,few-shot learning对于稳定有效地使用PLM非常有意义,因此近年来受到了广泛关注。除了GPT-3和PET展示了PLM在few-shot场景中的优势外,一些后续的工作《True few-shot learning with language models》、《FLEX: Unifying evaluation for few-shot nlp》也讨论了通过限制验证集的大小、以及提出统一框架来评估few-shot性能的合理的few-shot settings。也有一些工作《Cutting down on prompts and parameters: Simple few-shot learning with language models》指出PT在few-shot learning中的表现较差,但他们主要关注的是参数少于400M的PLM。本文研究了大型11B PLM的few-shot learning。
32.1 初步实验
本节中,我们展示了
few-shot learning的PT的初步实验。我们分析了三种策略,包括hybrid prompt tuning、verbalizer selection、以及real word initialization。我们遵循《The power of scale for parameter-efficient prompt tuning》的方法,使用T5-XXL(11B参数)进行PT,并使用了100个可调优的soft prompt tokens。我们按照
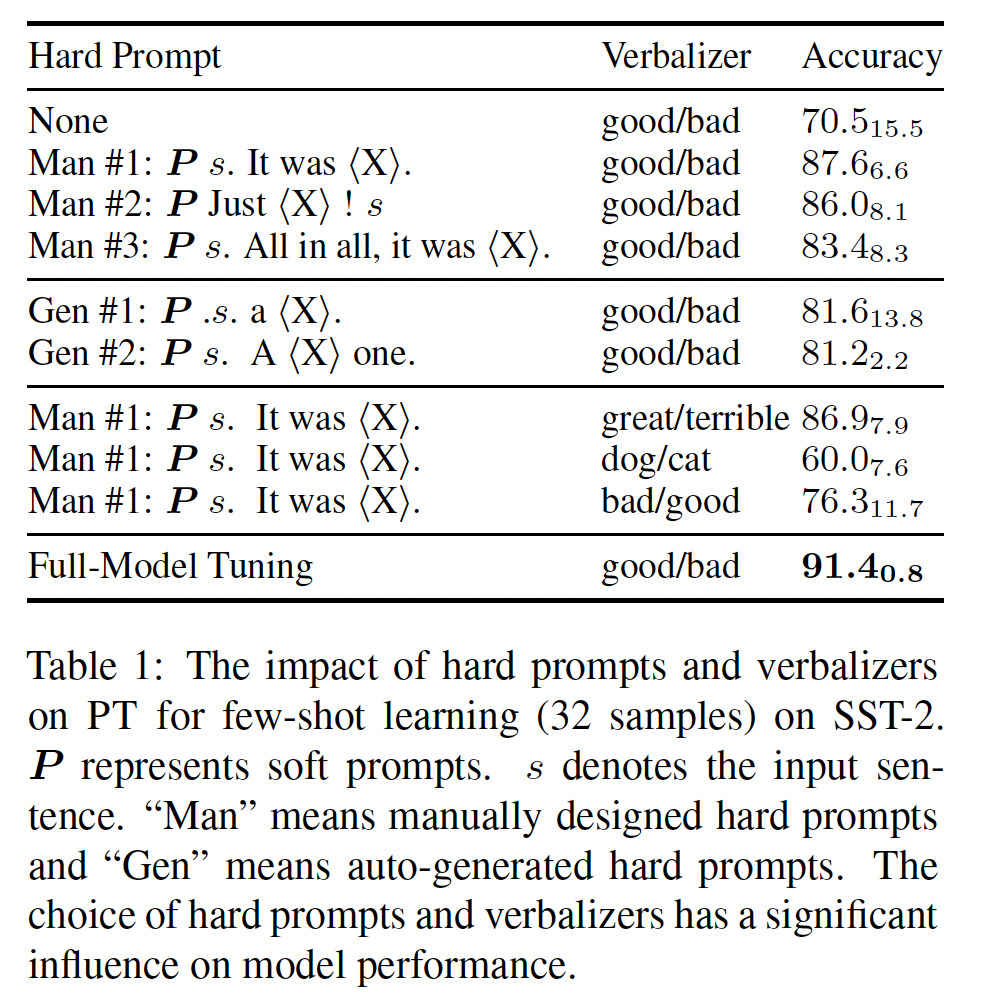
PET-2的方法,从原始训练数据中随机选择32个样本来构建训练集few-shot learning setting(《True few-shot learning with language models》)。我们按照《Revisiting few-sample bert fine-tuning》和《Making pre-trained language models better few-shot learners》的方法,使用原始验证集作为测试集Hybrid Prompt Tuning:在hybrid prompt tuning中,同时使用soft prompts和hard prompts(《GPT understands, too》、《PTR: prompt tuning with rules for text classification》)。然而,之前的工作是联合训练soft prompts和整个模型的。在只有prompt tokens可调优的PT中,hybrid prompts的有效性尚未得到充分探索。在Table 1中,我们展示了在情感分类任务上结合soft promptshard prompts、以及两个自动生成的hard prompts(《Making pre-trained language models better few-shot learners》)的结果。我们可以看到:hard prompts改善了PT,但仍然表现不如FT。此外,不同的
hard prompts对性能影响显著,因此需要进行大量的人力来进行prompt design和prompt selection。
Verbalizer Selection:verbalizer是将task-specific labels映射到具体的tokens。例如,在Figure 1(c) and (d)中,verbalizer将标签"Positive"映射到"great"。从Table 1中可以看出,verbalizer的选择对性能有显著影响。通常情况下,解释相应标签含义的common words效果较好。这也指导了我们对PPT的verbalizer selection。Real Word Initialization:在real word initialization中,我们使用concrete words的embedding来初始化soft prompt,并测试了四种初始化策略。先前的工作(《The power of scale for parameter-efficient prompt tuning》)已经验证了这种方法在小型PLM(少于3B参数)上的有效性。然而,从在SST-2和BoolQ上的实验结果(Table 2)中,我们发现对于11B模型,在few-shot场景下,real word initialization对性能几乎没有影响,甚至可能产生负面影响。这表明对小模型的观察不能直接应用于大模型,并且对soft prompts的良好初始化仍有待探索。注意:这里不仅是模型大小的差异,还有
full-data training和few-data training的差异。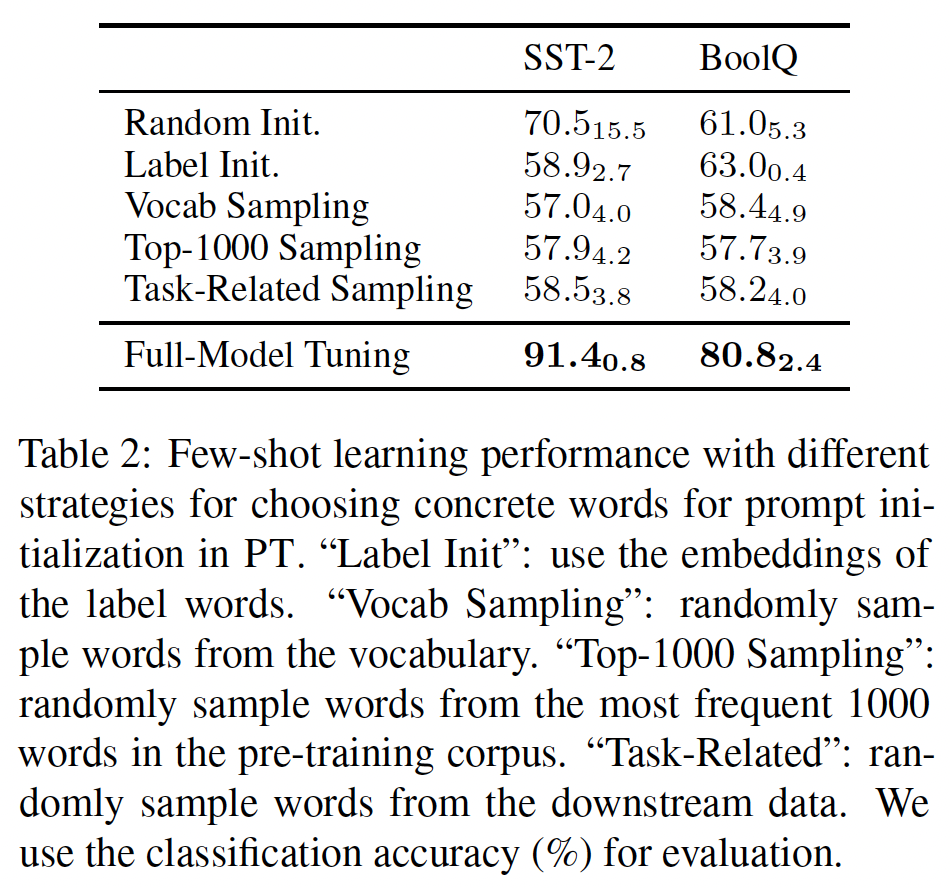
总之,尽管上述
enhancement策略不能使PT在few-shot settings下达到与FT相媲美的结果,但它们仍然是影响PT性能的关键因素。在接下来的章节中,我们将描述我们的PPT框架,并通过实验证明PPT不仅提供了良好的prompt initialization,而且充分利用了良好的verbalizer,并且与hybrid prompts互补。
33.2 Pre-trained Prompt Tuning (PPT)
在这一节中,我们将描述
PPT的整个框架,包括如何预训练prompts、以及如何将这些pre-trained prompts用于特定任务。
33.2.1 Overview
遵从
T5和《The power of scale for parameter-efficient prompt tuning》的方法,我们以text-to-text的格式解决所有下游任务。如Figure 1(c)所示,为了减少预训练和下游任务之间的objective gap,prompt-oriented fine-tuning将下游任务转换为完形填空风格的objective。以分类任务为例,给定一个输入句子labelpattern mappingnPLM的词表,prompt tokens作为提示,而且还保留了mask tokenPLM预测在masked positions的tokens。然后,一个verbalizerlabel tokenspattern-verbalizer pair其中:
tunable parameters,尤其是PLM的参数。为方便起见,我们用
"PVP"来表示这种pattern-verbalizer pair(《Exploiting cloze questions for few-shot text classification and natural language inference》)。在
PT(《The power of scale for parameter-efficient prompt tuning》)中,一组soft prompts由于大型
PLM的力量,上式被验证为在full-data settings下与这些FT方法相媲美。然而,我们发现很难学习到有效的soft prompts,这可能会导致在各种few-shot场景下的低性能。parameter initialization通常对模型训练和优化的难度有很大影响,我们的初步实验表明,现有的初始化策略对大型PLM的PT性能影响不大,甚至有负面影响。初步实验的更多细节在实验章节详述。最近,预训练已经被证明是一种有效的方法来寻找一个好的模型初始化。受此启发,我们建议对
soft prompts进行预训练。我们注意到,下游任务的一些groups与某些自我监督任务(这些自监督任务建立在unlabeled预训练语料上)有关。例如,一些sentence-pair classification形式的任务,如自然语言推理(natural language inference)、句子相似性,与预训练阶段使用的next sentence prediction: NSP任务相似。如Figure 3所示,这些任务都以两个句子为输入,并比较其语义。因此,由NSP所预训练的soft prompts可以成为这些sentence-pair任务的良好初始化。形式上,假设我们可以将下游任务分为
soft prompts之后,我们得到pre-trained promptssoft prompts initialization来优化公式这里对每一类任务(而不是每一个任务)来预训练一个
soft prompt。这里结合了
soft prompt(即,hard prompt(即,
33.2.2 Designing Pattern-Verbalizer Pairs for Pre-training
在本节中,我们以三个典型的分类任务为例,描述了用于
prompt pre-training的pattern-verbalizer pairSentence-Pair Classification:sentence-pair classification任务(如自然语言推理、句子相似性)以两个句子PVP,我们将BERT的next sentence prediction扩展为3-class分类作为预训练任务,label空间为label = 2)、相似的(label = 1)和不相关的(label = 0)。为了从unlabeled文档中构建信号,我们将彼此相邻的两个句子设为label = 2、将来自同一文档但非真正相邻的两个句子设为label = 1、将来自不同文档的两个句子设为label = 0。我们考虑标签集合sentence pair任务。则根据
input sentence pair代替。如果一个任务是二分类的,那么我们取
如果一个任务需要衡量两个句子之间的相似性,那么
Multiple-Choice Classification:许多任务可以被表述为multiple-choice classification,它需要一个query和几个候选答案作为输入。我们设计了一个next sentence selection任务来预训练prompt。给定一个句子作为queryquery不相邻的句子、以及来自其他文档的四个句子。对于大多数
multiple-choice tasks可以直接使用PVP。对于像阅读理解这样的任务,输入可能包含一个段落和一个问题。我们将它们拼接起来形成query。Single-Sentence Classification:对于single-sentence classification,我们为prompt pre-training创建伪标签。以情感分类为例,我们使用另一个小模型为预训练语料库中的句子标注情感标签,并过滤掉那些分类概率低的句子。在实践中,我们使用RoBERTa_BASE模型,并且该模型在我们评估的few-shot datasets之外的5-class情感分类数据集上被微调过。然后给定语料库中的一个句子对于有
5-class的情感分类任务,我们可以使用5-class的任务,我们从尽管上述方法提高了模型的性能,但我们不得不指出,它在推广到不同领域和不同
label集合大小的其他single-sentence classification任务上仍然是有限的。因此,我们提出了下一节所述的方法来解决这个问题。
32.2.3 Unifying Task Formats
上述用于预训练的
PVP可以统一为一种格式:multiple-choice classification。具体而言:对于
sentence-pair classification,query是两个句子的拼接,有三个选项:{no, maybe, yes}。对于
single-sentence classification,query是输入句子,选项是具体的标签。请注意,通过这种方式,pre-trained PVP可以用于任意领域的single text classification任务。
根据论文
《Finetuned Language Models Are Zero-Shot Learners》,在分类任务的prompts中添加options(即,task label space)是有益的。构建一个统一的
PVP类似于MultiQA和UnifiedQA的思想。最近,《Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections》使用一些hard prompts将几个任务统一为一个meta question answering任务。他们在一组QA数据集上用这个meta task来调优整个模型,然后迁移到low-resource settings下的其他分类任务。然而,我们的PPT侧重于在PLM主体被固定的情况下调优soft prompts,我们的预训练是在完全无监督的数据上进行的(而不是监督数据)。由于不同的任务可能有不同的候选数量和长度,我们构建的预训练样本的选项数量从
2到16不等,选项长度从50到20。我们使用PVP进行预训练,然后应用pre-trained soft prompts来解决上述的三个分类任务。
32.3 实验
配置:
同时考虑中文任务和英文任务(数据集如
Table 3所示)。对于少于5-class的任务,我们用原始训练数据中的32个样本构建TNews和YahooAnswer这样超过5-class的任务,很难用label-balanced的样本组成一个数据集。因此,我们为每种标签随机选择8个样本。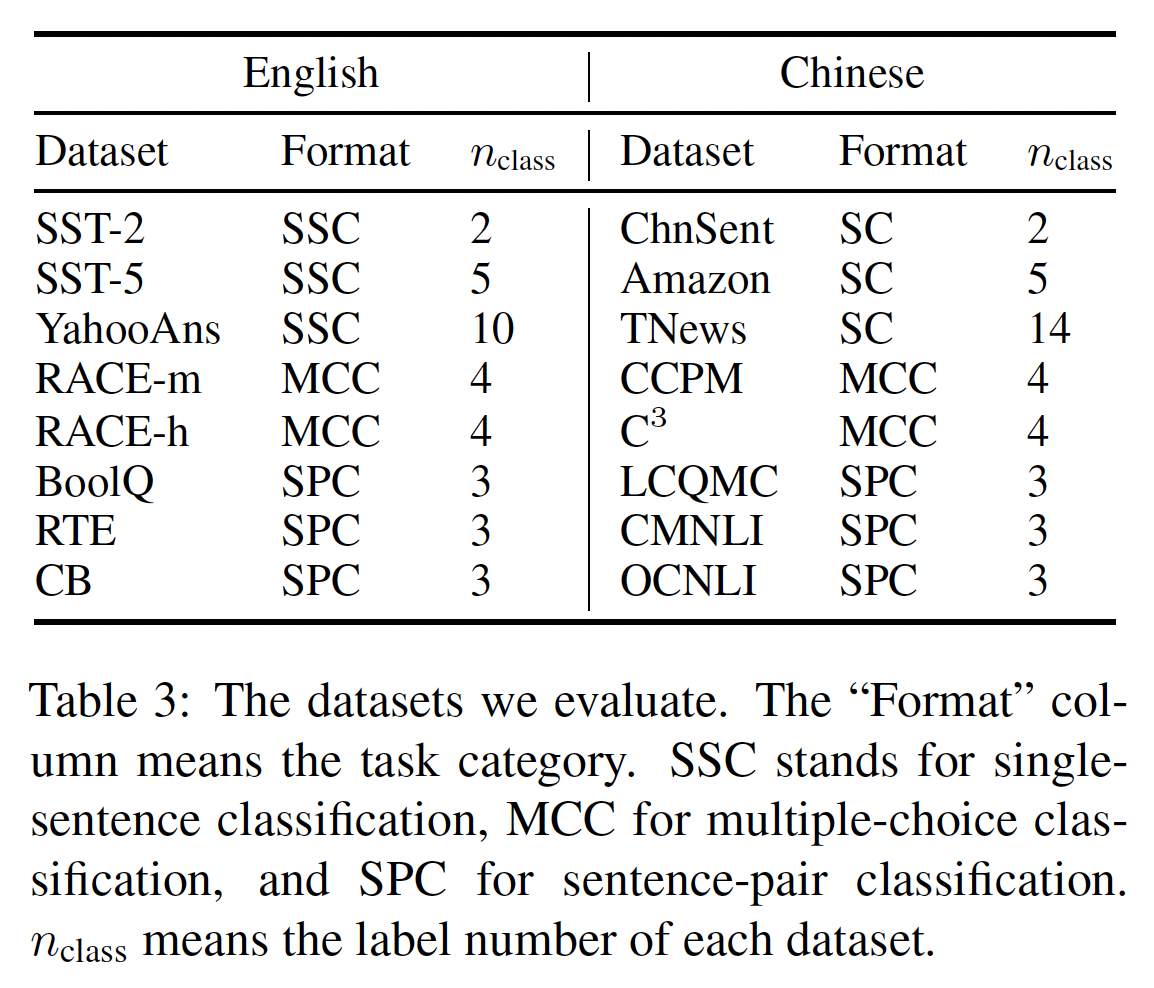
对于英语数据集,我们基于
11B参数的T5-XXL进行PT,因为之前的工作(《The power of scale for parameter-efficient prompt tuning》、《CPM-2: Large-scale cost-effective pretrained language models》)表明,T5-XXL在full-data setting下与FT相当。我们还在不同规模的T5上评估了FT,以验证更大的模型表现更好,因此基于T5-XXL来改进PT是有意义的。对于中文的数据集,我们基于
11B模型CPM-2进行PT。 由于CPM-2没有提供其他尺寸的模型,我们将其与不同尺寸的mT5进行比较。一致的是,我们对
PT使用100个soft tokens。因此,tunable parameters只有FT的11B(PT只需要为每个任务存储小3000倍的参数。对于
prompt pre-training,我们从OpenWebText数据集中为英语任务采样10GB数据, 从WuDaoCorpora数据集中为中文任务采样10GB数据。我们使用Yelp-5数据集来训练前文中提到的RoBERTa_BASE模型(生成情感分类伪标签从而用于Single-Sentence Classification)。
更多关于训练超参数的细节可以在附录
C中找到。英文和中文数据集的主要结果显示在
Table中。在FT block中,我们展示了T5模型在small尺寸到XXL尺寸的FT结果。在PT block中,我们展示了PPT和其他基线的结果:第一个基线是
Vanilla PT,其中soft prompts是从正态分布中随机初始化的。第二个基线是
Hybrid Prompt Tuning。我们还考虑了
《The power of scale for parameter-efficient prompt tuning》使用的LM Adaption,其中T5模型用语言建模目标进一步预训练了10K步,以减少预训练和PT之间的差距。我们测试了
PPT的两个变体:Hybrid PPT:精心设计的hard prompts与pre-trained soft prompt相结合。Unified PPT:所有任务都统一为multiple-choice classification格式。
从
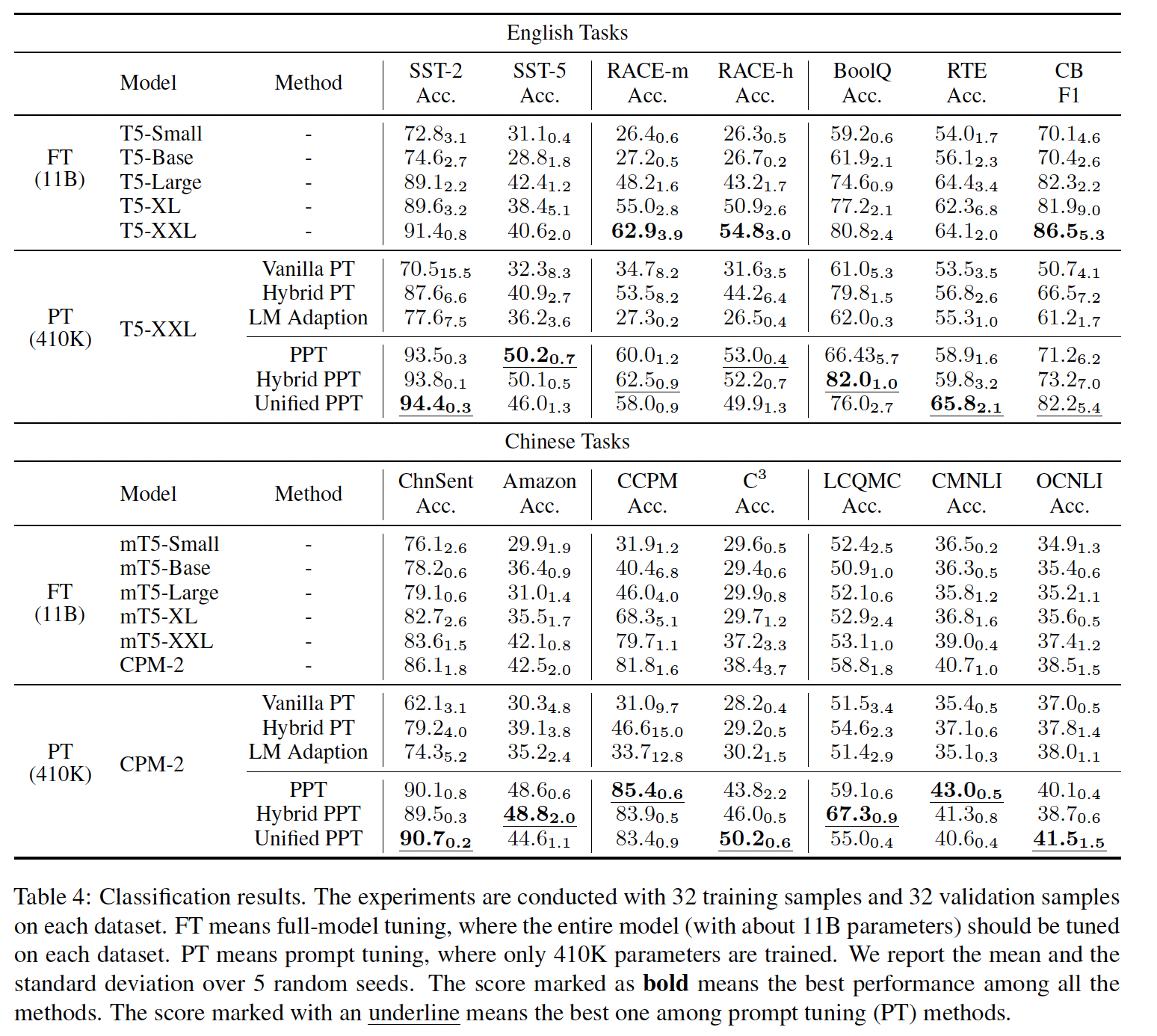
Table 4中我们可以看到四个观察结果:首先,较大的模型取得了较好的整体性能,这意味着增加模型的大小在
few-shot setting下仍然有帮助。因此,我们在大规模pre-trained的模型上研究PT。请注意,在中文的实验中,CPM-2和mT5-XXL共享相同的参数规模。由于CPM-2在所有的任务中都优于mT5-XXL,我们使用CPM-2作为base模型。其次,
PPT在大多数数据集上明显优于Vanilla PT和LM Adaption。虽然PPT在BoolQ上比Hybrid PT差,但结合PPT和hard prompts(Hybrid PPT)的表现优于所有基线。这意味着pre-training soft prompts和using hybrid prompts是互补的。在其他数据集如RACE-m、LCQMC和C3上也观察到类似的现象,在PPT中加入hard prompts会继续改善结果。第三,
PPT在所有中文数据集和大多数英文数据集上的表现都优于FT。这表明,在masked language modeling和下游任务之间仍然存在差距。prompt pre-training在一定程度上弥补了这个差距。基于这一观察,我们方法的一个直观扩展是用PT,我们将此作为未来工作。PPT没有根据下游任务来微调模型,而只有预训练任务第四,
PPT在大多数数据集上的方差较低。few-shot learning因其不稳定性而臭名昭著,这在Vanilla PT中变得非常明显。对于一些数据集,如SST-2,方差达到15.5,这意味着在一些随机种子下,模型的表现并不比随机猜测更好。结合hard prompt或进一步的语言建模预训练可以在一定程度上缓解这个问题。但是在一些数据集上,如CCPM,Hybrid PT增加了方差,LM Adaption不能保证平均性能。在预训练的帮助下,所有数据集的方差都保持在一个较低的水平。
Unified PPT:将所有格式统一为multiple-choice classification格式是PPT的另一个变体。在Table 4中,我们可以看到,Unified PPT达到了与PPT和Hybrid PPT相当的性能,仍然优于其他PT基线。然而,到目前为止,我们所考虑的数据集的标签规模不超过5个。对于有更大标签规模的任务,Unified PPT是一个不错的选择。在Table 5中,我们在超过5-class的数据集上测试Unified PPT。对于PT和FT,我们使用verbalizer将标签映射到直观选择的单词上。PT (MC)意味着我们以multiple-choice classification的形式解决任务,而不需要prompt pre-traini。我们不使用PPT进行single-sentence classification,因为很难找到其他合适的数据集来训练pseudo label annotator。然而,我们可以看到,Unified PPT仍然取得了最好的性能,甚至以很大的幅度超过了FT。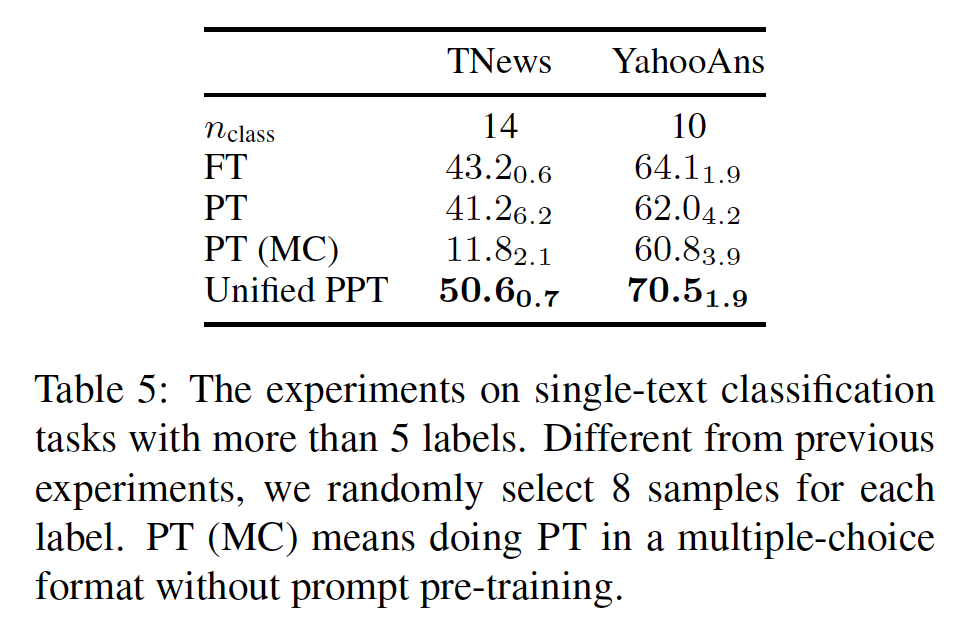
Sample Efficiency:我们讨论当训练样本数量增加时,FT, PT, PPT的性能如何变化。在Figure 4中,我们显示了这些方法在RACE-m和CB数据集上的趋势:对于
32到128个样本,PPT一直优于PT。当样本数量增长到
256时,三种方法的性能逐渐收敛。
我们还比较了给定完整训练数据的不同的
tuning方法。从Table 6中,我们可以看到:PPT和Unified PPT在大多数数据集上的表现仍然优于Vanilla PT。此外,我们观察到,尽管
PT在单个optimization step中比FT快,但它的收敛速度要慢得多,这导致了更长的训练时间。我们认为,PPT可以成为解决这一问题的有效方案。如Figure 5所示,有了pre-trained initialization,PPT在RACE-m和CB数据集上都加快了Vanilla PT的收敛速度。虽然
PPT可以加速Vanilla PT,但是预训练阶段很耗时间和资源。我们在附录
E中对训练消耗做了更详细的分析。由于PPT的收敛速度仍然比FT慢一些,如何进一步加快PT的收敛速度是值得在未来的工作中研究的。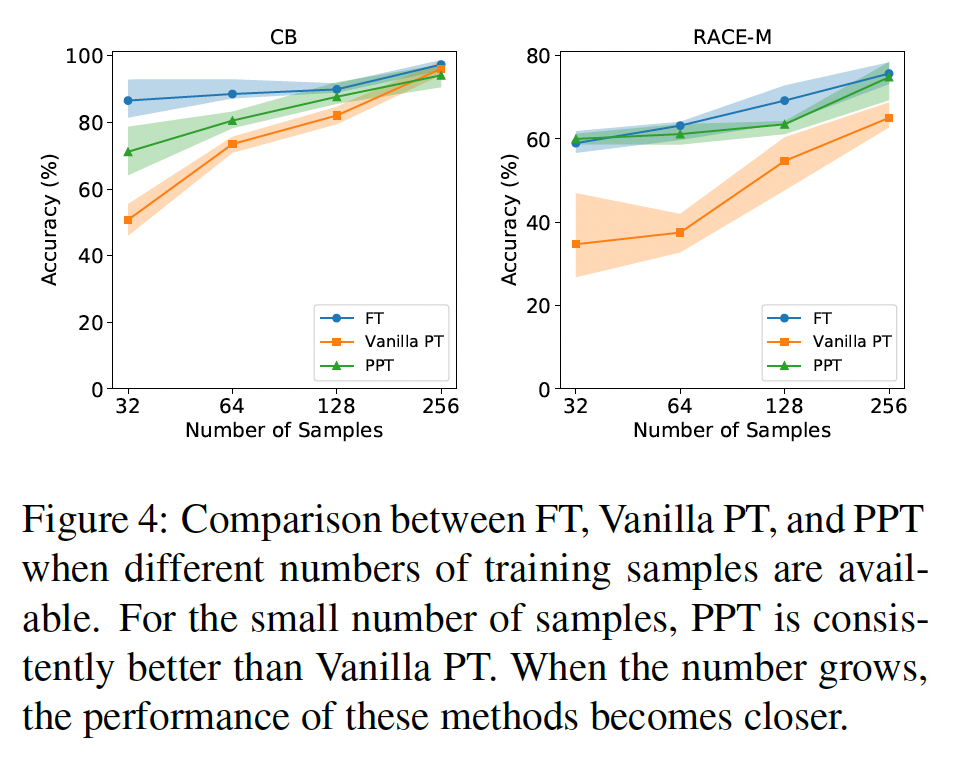

三十三、SPOT[2021]
论文:
《SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer》
过去几年,
pre-trained语言模型的规模不断扩大,多项研究表明增加模型规模是实现最佳性能的关键因素(BERT、T5、GPT-3)。尽管这一趋势不断推动自然语言处理各项benchmarks的发展,但模型规模的巨大也对其实际应用提出了挑战。对于超过100B参数的模型来说,为每个下游任务进行微调和部署单独的模型实例的成本将是难以承受的。为了克服微调的不可行性,GPT-3提出了Prompt Design,将每个下游任务都视为一项语言建模任务,并且在推理时通过提供manual text prompts并以manual text prompts为条件来指导frozen pre-trained模型执行不同的任务。他们展示了使用单个frozen GPT-3模型的出色的few-shot性能,然而其性能高度依赖于prompt的选择(《Calibrate before use: Improving few-shot performance of language models》),且仍然远落后于SOTA的微调结果。较新的研究探索了学习
soft prompts的方法,这可以看作是注入到语言模型中的额外的可学习参数。《The power of scale for parameter-efficient prompt tuning》提出了Prompt Tuning,这是一种简单的方法,通过在adaptation过程中为每个下游任务学习一个小的task-specific prompt(tunable tokens的一个序列,被添加到每个样本之前),以调节frozen的语言模型以执行该任务。引人注目的是,随着模型容量的增加,Prompt Tuning在性能上逐渐与Model Tuninng相媲美,而后者在每个下游任务上对整个模型进行微调。然而,在较小的模型规模(小于11B参数)下,Prompt Tuning与Model Tuninng之间仍存在较大差距。在本文中,我们提出了
SPOT: Soft Prompt Transfer,这是一种新颖的迁移学习方法,适用于Prompt Tuning。SPOT首先在一个或多个源任务上训练一个prompt,然后使用得到的prompt来初始化目标(下游)任务的prompt。我们的实验证明,SPOT在各种任务和模型规模上都显著改进了Prompt Tuning。例如,在SUPERGLUE基准测试中,使用T5 BASE(220M参数)和T5 XXL(11B参数)模型,我们分别获得了+10.1和+2.4的平均准确率的提升。更重要的是,SPOT在所有模型规模上与Model Tuninng相媲美甚至表现更好(见Figure 1)。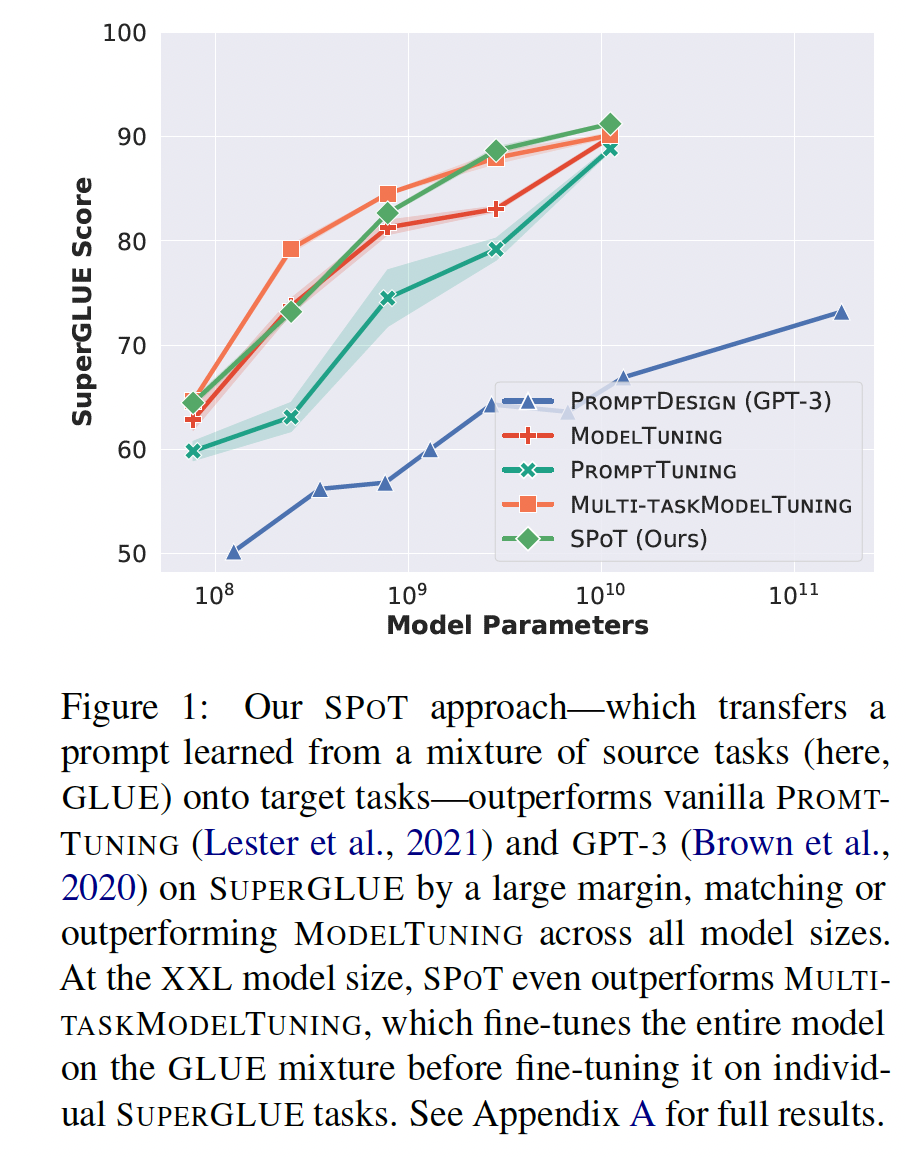
在这些结果的推动下,我们通过
soft task prompts的视角探究了任务之间的可迁移性。我们的目标是回答两个问题:(a):对于给定的目标任务,什么时候从源任务初始化prompt能够提升目标任务的性能?(b):我们能否利用task prompts高效地预测哪些源任务能够在新的目标任务上有效迁移?
为了回答问题
(a),我们对T5模型进行了系统性的研究,使用了26个自然语言处理任务,共计160种源任务和目标任务的组合。我们的结果表明,许多任务可以通过prompt transfer相互受益。为了回答问题(b),我们将learned task prompts解释为task embeddings,构建了一个针对任务的语义空间,并形式化了任务之间的相似性。我们设计了一种高效的检索算法来衡量task embedding的相似性,使从业者能够识别可能有positive transfer效果的源任务。基于预训练好的
soft prompt来进行初始化,这个思想已经在《PPT: Pre-trained Prompt Tuning for Few-shot Learning》中被采纳。区别在于:PPT是在大量的未标记语料库上针对soft prompt进行自监督的预训练,而SPOT是在大量的监督任务上进行多任务学习。总之,我们的主要贡献有:
我们提出了
SPOT,一种新颖的prompt-based的迁移学习方法,并展示了在不同规模下Prompt Tuning与Model Tuninng性能匹配的能力;在SUPERGLUE上,SPOT在所有模型规模上与Model Tuninng相媲美甚至更好。我们对任务的可迁移性进行了大规模的、系统的研究,展示了任务通过
prompt transfer相互受益的条件。我们提出了一种高效的检索方法,将
task prompts解释为task embeddings,构建了一个关于任务的语义空间,并通过测量task embedding的相似性来识别哪些任务可以相互受益。为了促进
prompt-based learning的未来研究,我们将发布我们的task prompts库和pretrained模型,并为NLP从业者提供实际的适用建议,网址为https://github.com/google-research/prompt-tuning/tree/main/prompt_tuning/spot。
相关工作:
parameter-efficient的迁移学习:大型pre-trained语言模型已经在许多自然语言处理任务中展现出卓越的性能。为了提高这些模型的实用性,早期的工作使用压缩技术获得轻量级模型。其他工作涉及仅更新模型的一小部分(《Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language models》)或task-specific模块,如适配器或低秩结构,同时保持模型的其余部分固定。最近,
GPT-3通过Prompt Design展示了令人印象深刻的few-shot性能,他们的模型在推断时通过manual text prompt来执行不同的任务。此后,一些工作专注于开发prompt-based learning方法,其中包括精心设计的prompt(PET-2)、prompt mining and paraphrasing(LPAQA)、gradient-based search用于改善prompts(AutoPrompt)和自动的prompt generation(LM-BFF)。然而,使用hard prompts被发现不够最优,并且对prompt的选择敏感(《Calibrate before use: Improving few-shot performance of language models》、《Gpt understands, too》)。因此,最近的研究开始转向学习soft prompts,它们可以看作是注入到模型中的可学习参数。对于prompt-based learning研究的最新综述,我们建议读者参考《Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing》的论文。在与之并行的工作中,
《PPT: Pre-trained prompt tuning for few-shot learning》也探索了prompt transfer的有效性。他们的方法使用手动设计的预训练任务,该预训练任务针对特定类型的下游任务进行了裁剪,因此在适用于新的下游任务方面可能扩展性较差。相比之下,我们使用现有的任务作为源任务,并展示了即使在源任务与目标任务之间存在不匹配(例如任务类型或输入/输出格式)时,prompt transfer仍然可以带来好处。任务的可迁移性:我们还建立在现有的任务可迁移性研究基础上。之前的工作表明,从数据丰富的源任务(
《Sentence encoders on stilts: Supplementary training on intermediate labeled-data tasks》)、需要复杂推理和推断的任务(《Intermediate-task transfer learning with pretrained language models: When and why does it work?》)、或与目标任务相似的任务(《Exploring and predicting transferability across NLP tasks》) 可以有效地进行迁移。也有工作在预测任务的可迁移性。《Exploring and predicting transferability across NLP tasks》使用从输入文本、或模型的diagonal Fisher information matrix导出的task embeddings,而《What to pre-train on? Efficient intermediate task selection》则探索了adapter-based的替代方法。在这里,我们使用相同的模型(没有
task-specific组件)和统一的text-to-text格式,可以更好地对任务空间进行建模。此外,相比较而言,prompt-based task embeddings的获取成本更低。
33.1 用 SPOT 改善 Prompt Tuning
为了改善
Prompt Tuning在目标任务上的性能,SPOT引入了source prompt tuning,这是在语言模型预训练和target prompt tuning之间的中间训练阶段(Figure 2 (left)),用于在一个或多个源任务上学习一个prompt(同时保持base模型冻结),然后将其用于初始化target task的prompt。我们的方法保留了
Prompt Tuning的所有计算优势:对于每个目标任务,它只需要存储一个小的task-specific prompt,从而使得单个frozen pretrained model可以在所有任务之间重复使用。在本节中,我们提供了一个通用的SPOT方法,其中单个可迁移的prompt被用于所有目标任务。在后面的正文中,我们探索了一种targeted方法,为不同的目标任务检索不同的source prompts。右图中,
Source Task Embeddings和Source Prompts有啥区别?二者不是一个概念吗?论文没有说明。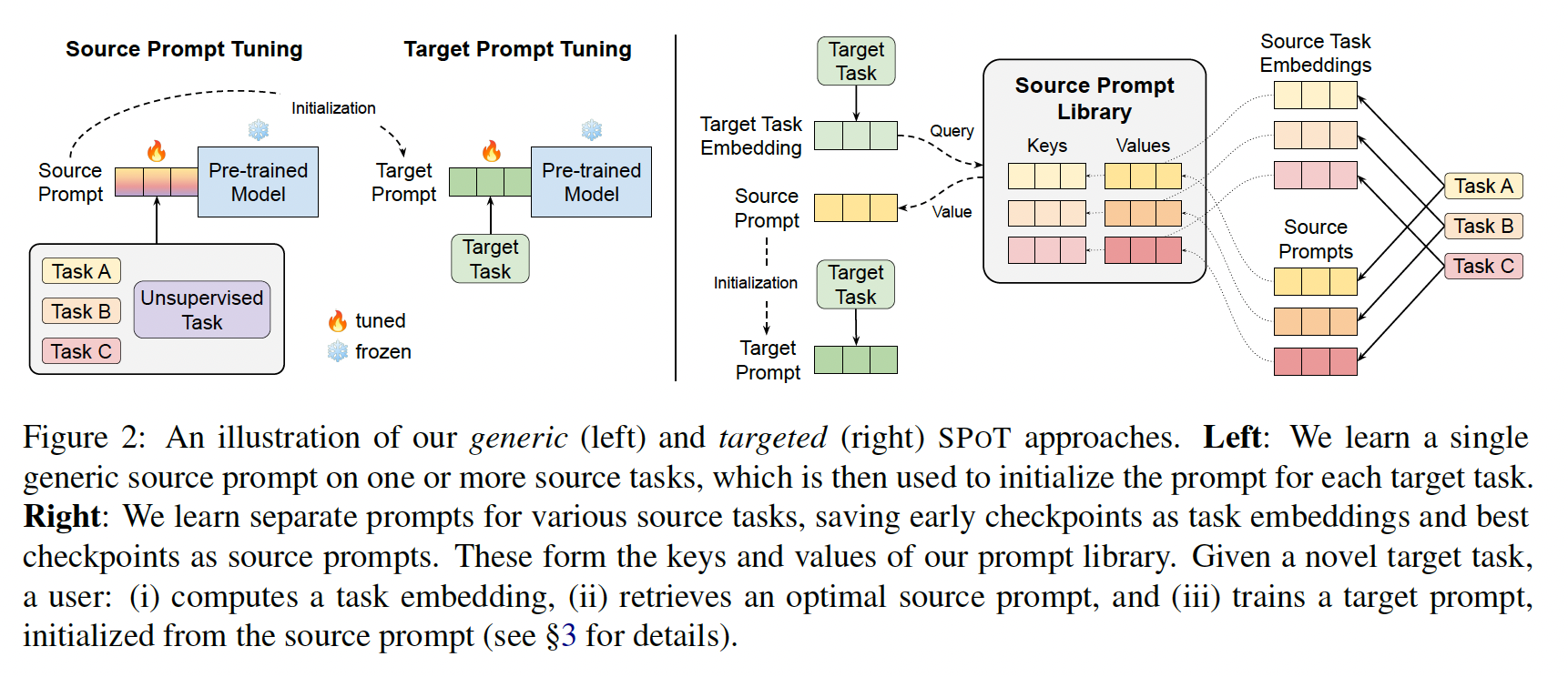
33.1.1 实验配置
我们的
frozen模型是建立在所有规模的pretrained T5 checkpoints上的:SMALL、BASE、LARGE、XL、XXL,分别具有60M、220M、770M、3B、11B参数。在我们使用SPOT进行实验时,我们利用了T5的LM adapted版本,《The power of scale for parameter-efficient prompt tuning》发现该版本对于Prompt Tuning来说更容易优化。Baselines:Prompt Tuning:《The power of scale for parameter-efficient prompt tuning》的原始prompt tuning方法,直接在每个目标任务上独立训练一个prompt。Model Tuning和Multi-Task Model Tuning:我们将prompt tuning方法与Model Tuning进行比较,Model Tuning是标准的微调方法(BERT、T5),其中所有模型参数在每个目标任务上单独进行微调。为了进行公平比较,我们还包括
Multi-Task Model Tuning作为一个更有竞争力的基线模型,它在对SPOT所使用的相同源任务的mixture上进行微调后,再对各个目标任务进行微调。
评估数据集:
GLUE和SUPERGLUE。我们进行固定步数的训练,并在与每个数据集相关联的验证集上报告结果。用于
source prompt tuning的数据:与语言模型预训练一样,训练数据的选择对于成功的prompt transfer至关重要。为了研究源训练数据对下游性能的影响,我们比较了多种不同的源任务。单个无监督学习任务:我们首先考虑使用
Colossal Clean Crawled Corpus: C4数据集的一部分来训练prompt,使用T5中讨论的prefix LM objective。尽管这个任务已经被用于预训练我们的frozen T5模型,但它仍然对学习通用的prompt有帮助。单个有监督学习任务:另一种选择是使用有监督任务来训练
prompt。我们使用MNLI或SQUAD作为单个源任务。MNLI在许多sentence-level分类任务中显示出帮助作用(《Sentence encoders on stilts: Supplementary training on intermediate labeled-data tasks》),而SQUAD被发现对于问答任务具有良好的泛化能力(《MultiQA: An empirical investigation of generalization and transfer in reading comprehension》)。多任务混合:到目前为止,我们一直使用单个源任务。另一种方法是多任务训练。在
T5的统一的text-to-text框架中,这简单地对应于将不同的数据集混合在一起。我们探索了来自不同NLP benchmarks或任务族的数据集混合,包括GLUE、SUPERGLUE、自然语言推理(NLI)、paraphrasing/semantic similarity、情感分析、MRQA上的问答、RAINBOW上的常识推理、机器翻译、摘要生成、以及GEM上的自然语言生成。我们从上述每个NLP benchmarks或任务族中创建源任务的mixture,以及一个包含所有数据集(C4 + 55个标记数据集)的mixture,使用T5中的examples-proportional混合策略,人工设定一个dataset size限制为读者猜测:这里不同的任务采用相同的
soft prompt,对应于Figure 2(Left)。
训练细节:我们严格按照
《The power of scale for parameter-efficient prompt tuning》的训练过程进行操作。具体来说,在source prompt tuning和target prompt tuning期间引入的唯一新参数是一个shared promptembedded的)输入序列的开头,其中prompt长度,embedding size。在所有情况下,我们设置tokens,并以固定的steps数量prompt。虽然《The power of scale for parameter-efficient prompt tuning》中将30K,但我们发现在大型数据集上进行额外的调优是有帮助的。因此,遵从T5,我们将Table 1中的消融实验("--longer tuning"的行)使用在
source prompt tuning期间,prompt token embeddings从sampled vocabulary中进行初始化(即5000 most common tokens)。在target prompt tuning期间,我们每500步保存一次checkpoint,并在具有最高validation性能的checkpoint上报告结果。附录C包含了Prompt Tuning和model tuning方法的训练细节。
33.1.2 SPOT 的效果
SPOT的效果:我们在Table 1和Figure 1中对比了SPOT和其他方法的结果。以下,我们详细总结和分析了我们的每一个发现。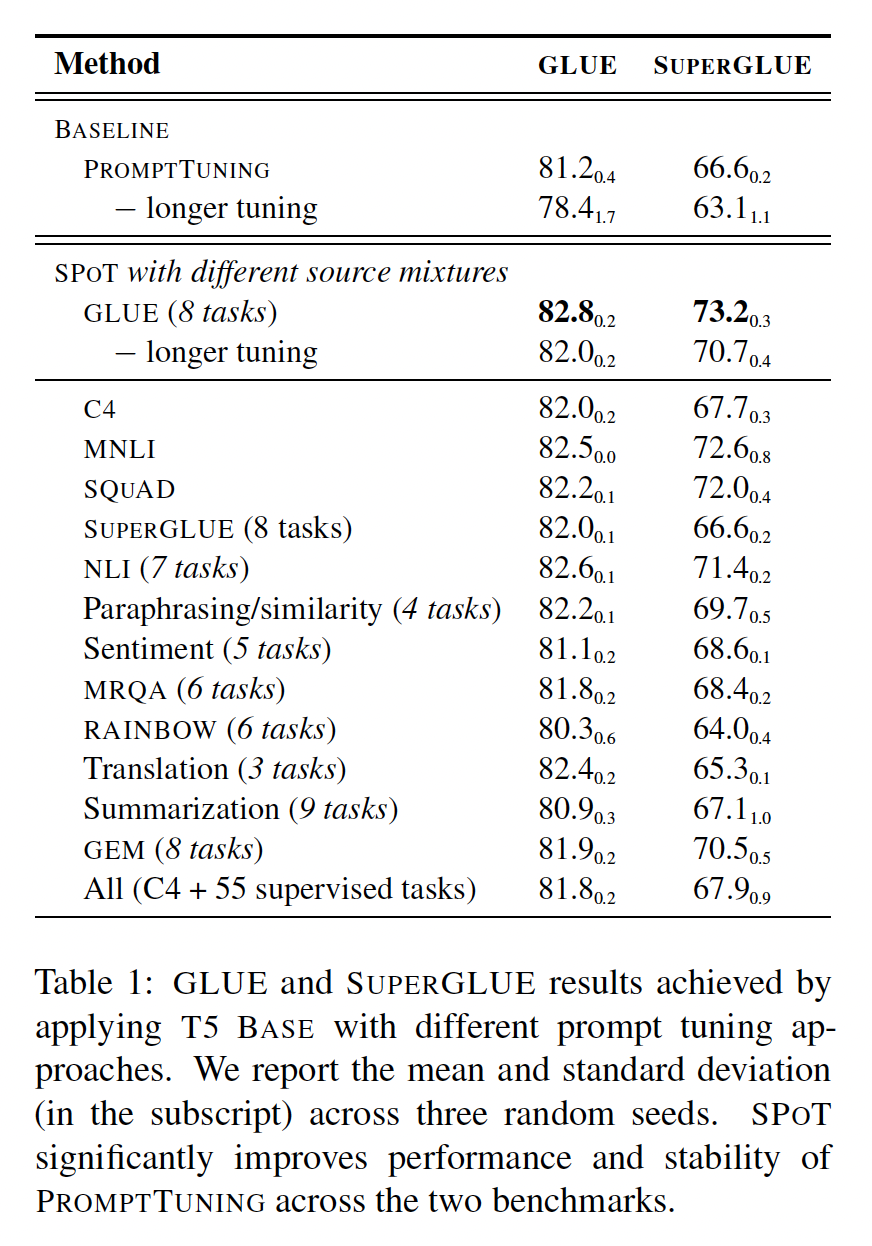
SPOT显著提高了Prompt Tuning的性能和稳定性:我们在T5 BASE上对GLUE和SUPERGLUE的benchmarks的结果(Table 1)表明,prompt transfer为Prompt Tuning提供了一种有效的改进性能的手段。例如,最佳的SPOT变体在GLUE和SUPERGLUE上的表现明显优于平凡的Prompt Tuning方法,分别获得+4.4和+10.1点的平均准确率提升。我们的消融研究表明,
longer tuning也是实现最佳性能的重要因素,并且与prompt transfer相辅相成。此外,当省略longer tuning时,我们观察到SPOT可以提高runs的稳定性。在
SPOT中,我们可以比较不同source mixtures的有效性(参见Table 1)。在
GLUE上进行的source prompt tuning在GLUE和SUPERGLUE上表现最好,分别获得82.8和73.2的平均分。有趣的是,对
C4进行的无监督的source prompt tuning(与我们的frozen模型的预训练使用的相同任务)仍然能够取得显著的改进,甚至在SUPERGLUE任务上超过使用SUPERGLUE数据集进行source prompt tuning的效果。使用
MNLI或SQUAD作为single source dataset在各个目标任务上也特别有帮助。其他
source mixtures可以带来显著的收益,其中一些任务类别(例如NLI和paraphrasing/semantic similarity)比其他任务类别获益更多。将所有数据集混合在一起并不能获得最佳结果,可能是由于任务干扰/负迁移问题,即在一个或多个
source tasks上取得良好的性能可能会对目标任务的性能产生负面影响。
SPOT有助于在所有模型规模上缩小与Model Tuning之间的差距:Figure 1显示了我们在不同模型规模下在SUPERGLUE上的结果(完整结果见附录A)。正如《The power of scale for parameter-efficient prompt tuning》所示,Prompt Tuning随着模型规模越大越有竞争力,并且在XXL规模上,它几乎与Model Tuning的性能相媲美。然而,在较小的模型规模下,两种方法之间仍然存在较大差距。我们展示了SPOT如何缩小这些差距,并在多个模型规模上大幅超过Model Tuning的性能,同时保留了Prompt Tuning所带来的所有计算优势。最后,在XXL规模上,SPOT取得了最好的平均分数91.2,比强大的Multi-Task Prompt Tuning baseline高1.1个点,尽管SPOT比multi-task source tuning和target tuning中使用的task-specific parameters要少27000倍。作为对
SPOT有效性的最终测试,我们将XXL模型的预测结果提交到SUPERGLUE排行榜,获得了89.2的分数。这远远超过了所有先前的使用parameter-efficient adaptation(例如GPT-3的71.8)的提交,并且几乎与fully fine-tuned T5 XXL(89.3)相匹配,尽管SPOT参数要少27000倍。据我们所知,SPOT是第一个在与调优十亿级参数的方法相媲美的parameter-efficient adaptation方法。详细信息请参见附录D。
33.2 预测 task transferability
到目前为止,我们已经看到
soft prompt transfer可以显著提升prompt tuning的性能,但选择正确的源任务进行迁移至关重要。例如,通过广泛的搜索,我们发现GLUE和MNLI提供了出色的源任务从而用于迁移至个别的GLUE和SUPERGLUE任务。但在资源受限的情况下,用户无法详尽搜索一组源任务时该怎么办?我们能否预测哪些任务最适合迁移到新的目标任务,而无需逐个测试这些源任务?为了调查这个问题,我们进行了一项大规模的实证研究,涉及
26个NLP任务。我们首先衡量所有任务组合之间的可迁移性。接下来,我们展示了通过将task prompts解释为task embeddings,我们可以构建一个关于任务的语义空间,其中相似的任务聚类在一起。基于这个观察,我们提出了一种检索算法,对于给定的新的目标任务,利用task embeddings的相似性来选择源任务(Figure 2(right))。我们提出的方法可以消除69%的源任务搜索空间,同时保持90%的best-case quality gain。
33.2.1 衡量可迁移性
我们研究了一组多样化的
16个源数据集和10个目标数据集(见Table 2)。我们考虑了所有160个可能的source-target pairs,并从每个源任务迁移到每个目标任务。所有源任务都是数据丰富的,或者已经在之前的研究中显示出正面的迁移效果。为了模拟真实情境,我们将低资源任务(训练样本少于10K)作为目标任务。为了限制计算成本,在我们的任务可迁移性实验中,我们使用了
T5 BASE模型。我们对每个源任务进行了262,144次prompt tuning steps。选择具有最高source task validation性能的prompt checkpoint来初始化different target tasks的prompts。由于目标数据集较小,我们只对每个目标任务进行了100,000次prompt tuning steps。我们使用不同的随机数种子重复每个实验三次。其他训练细节与 “实验配置 -- 训练细节” 相匹配。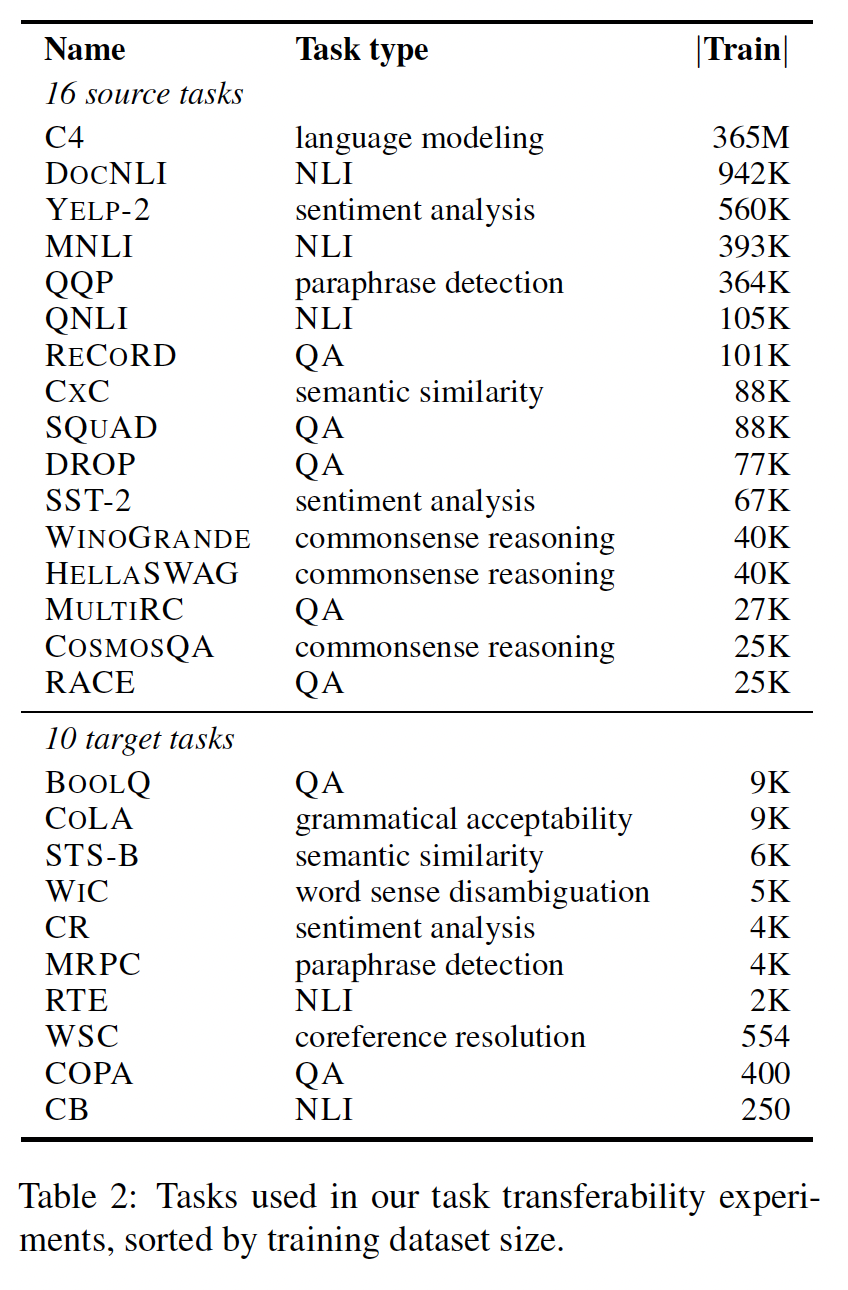
通过
prompt transfer,任务之间可以互相受益:Figure 3显示了我们的结果的热力图(完整结果见附录E)。在许多情况下,
prompt transfer对目标任务产生了显著的增益:MNLI --> CB的迁移导致relative error reduction最大,为58.9%,从平均分数92.7提高到97.0;其次是MNLI --> COPA(29.1%)和RECORD --> WSC(20.0%)。注意:它衡量的是错误率的下降,而不是正确率的上升。
对于每个目标任务使用最佳
source prompt(从48个中挑选)显著提高了10个目标任务的平均得分,从74.7提高到80.7。总体而言,从涉及句子之间语义关系的高级推理的大型源任务(例如
MNLI)进行有效迁移,或者当源任务和目标任务相似时(例如CXC --> STS-B),可以实现正面的迁移效果。有趣的是,相对不相似的任务之间也可以发生正面的迁移(例如RECORD --> WSC, SQUAD --> MRPC, CXC --> WIC)。
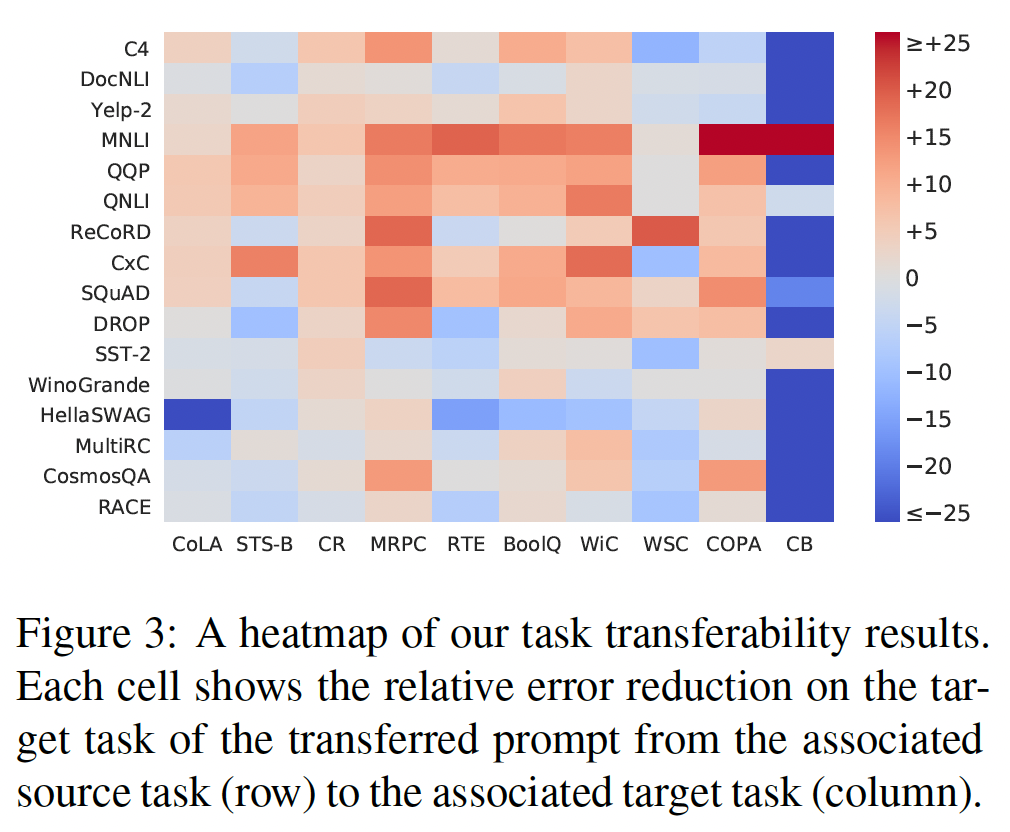
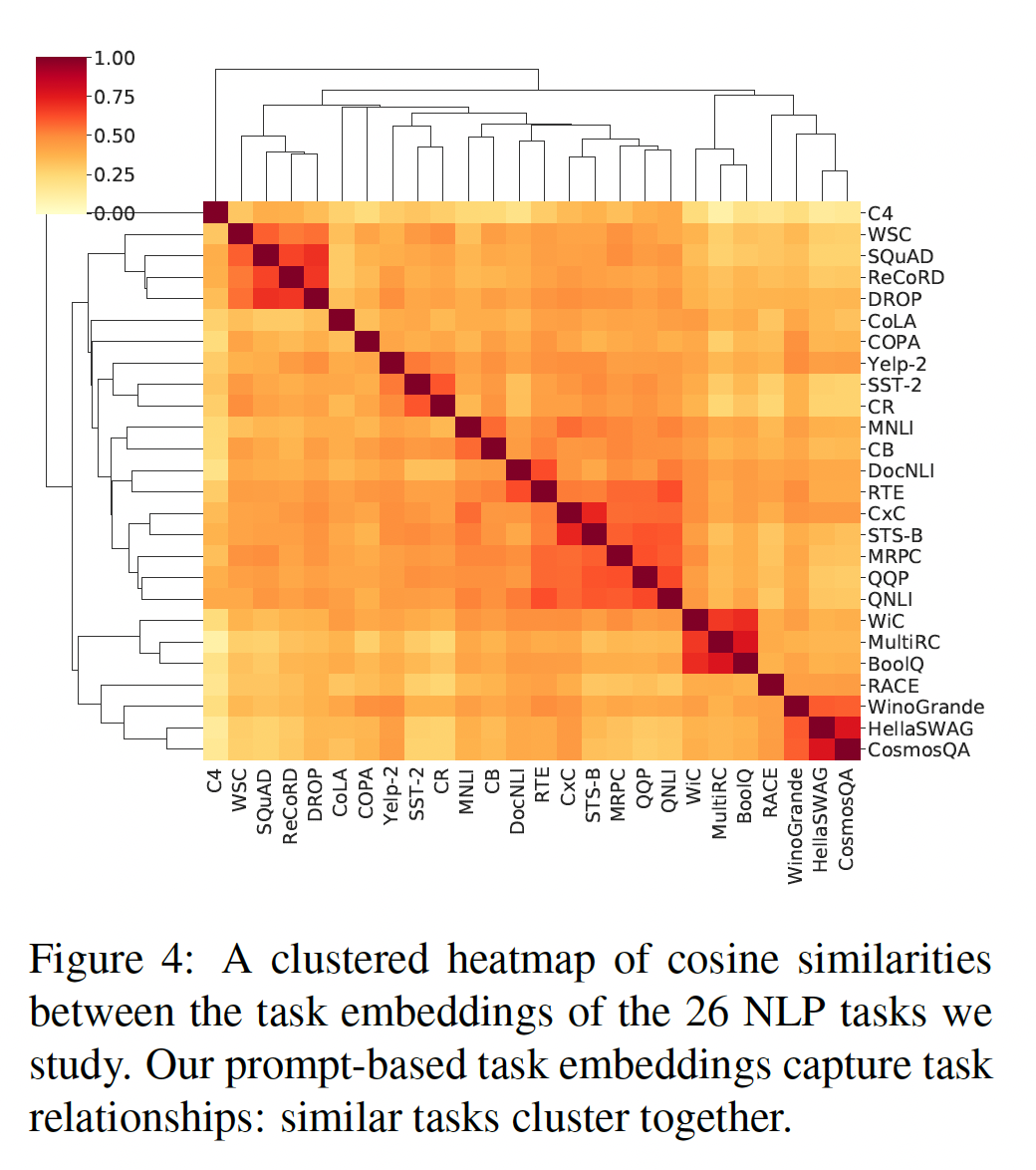
33.2.2 通过 prompts 定义 task similarity
由于在特定任务的
prompt tuning过程中仅更新prompt参数,所以learned prompts很可能包含了task-specific的知识。这表明它们可以用来推理任务的性质和任务之间的关系。为了验证这个想法,我们将task prompts解释为task embeddigns,并构建任务的语义空间。更具体地说,我们将task embeddigns定义为在该任务上训练了10,000 steps之后的prompt checkpoint。请注意,使用early checkpoints可以快速计算新目标任务的task embeddings。我们使用以下度量方法,通过测量两个任务
task embeddingsaverage tokens的余弦相似度:我们计算prompt tokens的average pooled representations之间的余弦相似度:其中
token、prompt token;per-token的平均余弦相似度:我们计算每个prompt token pair注意,根据前文描述,所有的
prompt的长度都是
task embeddings捕捉到任务之间的关系:Figure 4显示了使用average tokens的余弦相似度来计算的task embeddings之间的hierarchically-clustered热力图。我们观察到我们学到的task embeddings捕捉到了许多直观的任务关系。具体而言:相似的任务聚集在一起形成簇,包括问答任务(簇
SQUAD, RECORD,DROP,簇MULTIRC, BOOLQ)、情感分析(YELP-2, SST-2, CR)、自然语言推理(簇MNLI, CB,簇DOCNLI, RTE)、语义相似性(STS-B, CXC)、paraphrasing(MRPC, QQP)和常识推理(WINOGRANDE, HELLASWAG, COSMOSQA)。值得注意的是,由
SQUAD数据集构建的NLI任务QNLI与SQUAD不是密切相关的,这表明我们的task embeddings对于task type的敏感性高于domain similarity。有趣的是,它们还捕捉到了非直观的案例:
RECORD向WSC的可迁移性较高。此外,来自同一任务的
different prompts的task embeddings之间具有较高的相似性分数(请参见附录F)。
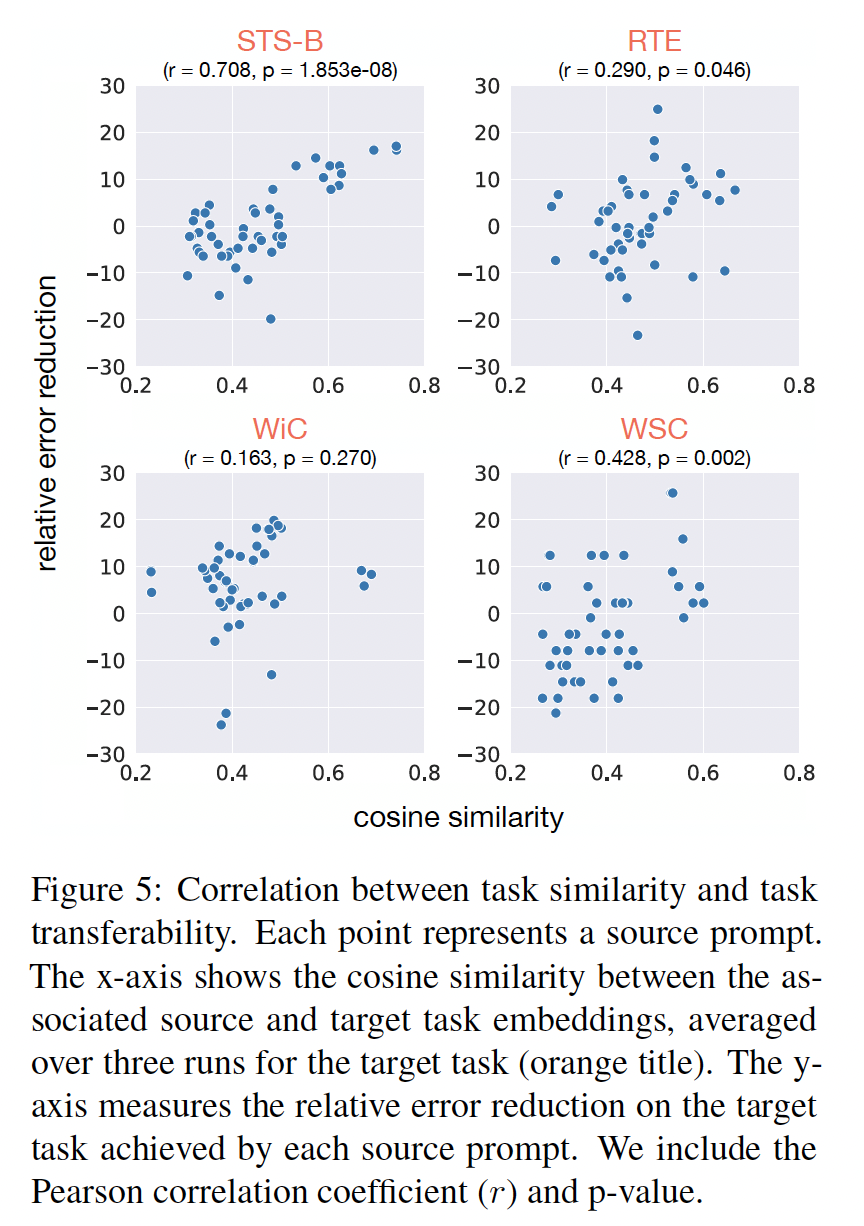
33.2.3 通过 similarity 来预测 transferability
我们利用
task embeddings来预测和利用任务的可迁移性。具体而言,我们探索了预测对于给定的目标任务最有利的源任务的方法,并利用它们的prompts来提高目标任务的性能。为了扩大我们的source prompts集合,我们使用每个源任务上三次不同的prompt tuning运行的prompts,,共得到48个source prompts。给定目标任务task embeddingsource promptsembeddingssource prompts列表记为ranked source prompts:这需要首先对每个任务(包括目标任务)进行预训练,然后才能得到
target prompt,并重新训练目标任务。因此,目标任务需要被训练两次。Best of Top-k:我们选择top-k source prompts,并将每个source prompt单独用于初始化target prompt。这个过程需要在目标任务prompt tuning。我们使用这prompt tuning中最好的结果来评估该方法的有效性。Top-k加权平均:我们用top-k source prompts的加权平均值target prompts,以便我们只需在目标任务prompt tuning。权重其中
task embedding。Top-k多任务混合:我们首先确定top-k prompts所对应的源任务,并将这些源任务的数据集和目标任务的数据集混合在一起,使用T5的examples-proportional混合策略。然后,我们在这个多任务mixture上进行prompt tuning,并使用final prompt checkpoint来初始化prompt从而用于target prompt tuning。
我们报告每种方法在所有目标任务上实现的平均分数。为了比较,我们测量相对于
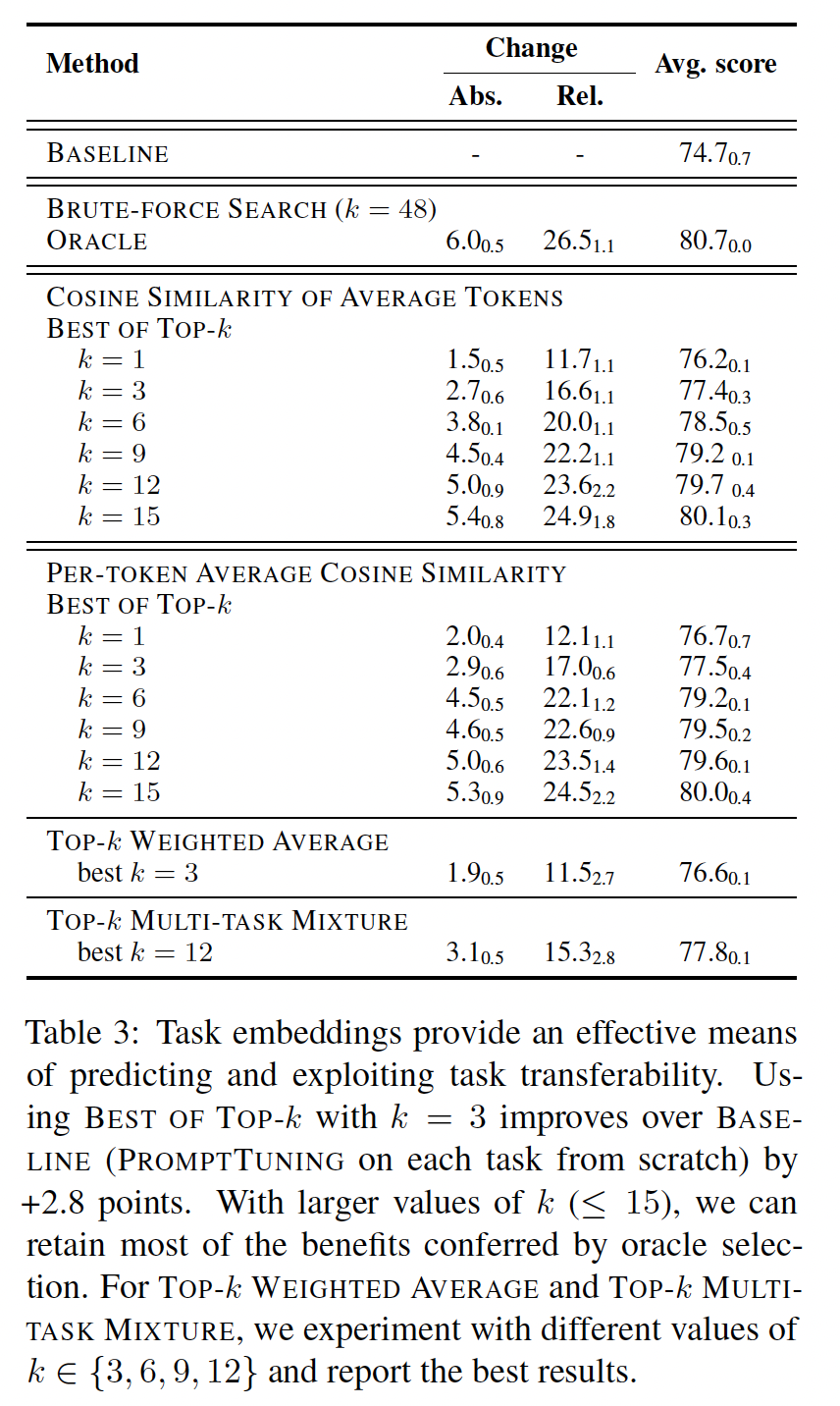
baseline(在每个目标任务上从头开始进行prompt tuning,即没有任何prompt transfer)的绝对改进和相对改进。此外,我们还包括了ORACLE结果,即通过暴力搜索确定每个目标任务的48 source prompts中最佳prompts所实现的结果。任务相似性与任务可迁移性之间的相关性:
Figure 5显示了在目标任务上relative error reduction随着source and target task embeddings之间的相似性变化的情况。总体而言,我们观察到在四个目标任务(一共
10个目标任务)上task embedding相似性和任务可迁移性之间存在显著的正相关性,其中包括:STS-B (p < 0.001), CB (p < 0.001), WSC (p < 0.01), RTE (p < 0.05);而在其他任务上相关性较弱。在某些情况下(例如在
BOOLQ上),尽管余弦相似度较低(0.4),我们观察到较大的relative error reduction(19.0%,通过MNLI的一个source prompt来实现的)。这表明除了任务相似性之外(数据大小、任务难度、领域相似性等),还可能有其他因素影响可迁移性的确定。
通过
task embeddings来检索targeted source tasks是有帮助的:Table 3比较了不同方法用于确定哪些source prompts对于给定的目标任务可能是有益的。总体而言,我们的结果显示
Best of Top-k的有效性:仅仅选择与目标任务具有最高
task embedding相似性的source prompt,使用每个per-token的余弦相似性,可以显著改善baseline结果(从74.7的平均分数提高到76.7,平均relative error reduction达12.1%)。对于每个目标任务,尝试所有的
top-3 source prompts(一共48个)会得到77.5的平均分数。
通过增加
oracle selection的大部分好处(80%增益,90%增益),同时消除了超过source prompts。Top-k加权平均与Best of Top-k(prompt tuning的情况下,这可能是Best of Top-k的一个有吸引力的替代方案。最后,
Top-k多任务混合也提供了一种方式,获得了平均分为77.8的较好的性能,甚至超过了Best of Top-k(
33.3 讨论
由于其他
parameter-efficient adaptation方法在特定情况下可能优于Prompt Tuning,测试类似于SPOT的方法是否可以成功地扩展到这些方法将是非常有趣的。与此同时,我们相信Prompt Tuning有其自身的优点。随着pre-trained语言模型变得越来越大,Prompt Tuning相对于其他方法的一些优势在于:在当前的可学习参数的方法中,
Prompt Tuning是参数效率最高的,在大多数模型规模下,只需要低于0.01%的task-specific parameters。Prompt Tuning比其他方法更简单,因为它不修改内部模型结构(参见Prefix Tuning方法,该方法在Transformer的encoder和decoder的每一层都添加了prefix);因此,Prompt Tuning允许mixed-task inference,并促进任务间的迁移学习。随着模型容量的增加,
Prompt Tuning与Model Tuning相媲美。据我们所知,其他方法尚未显示出这一点。Soft prompts可能被解释为自然语言指令。
此外,由于我们
prompt-based task embedding方法并没有捕捉到影响任务可迁移性的所有因素,因此我们将对其他task embedding方法的进一步探索留待未来工作中进行。
三十四、OptiPrompt[2021]
论文:
《Factual Probing Is [MASK]: Learning vs. Learning to Recall》
pretrained语言模型(如BERT)被优化用于预测internet语料库中的单词分布。自然而然地,这个分布编码了关于世界事实的信息。最近,研究人员对于衡量语言模型从预训练中获取多少事实信息产生了兴趣。《Language models as knowledge bases?》在LAMA基准测试中正式定义了这个project,该benchmark由(subject, relation, object)三元组以及人工编写的表达每种关系的模板组成。他们展示了BERT能够根据完形填空风格的prompt(例如,Dante was born in [MASK])预测objects,并将结果作为BERT所编码的事实信息量的下界。随后的工作尝试通过找到更好的prompts来缩紧这个下界。LPAQA使用文本挖掘和paraphrasing来找到一组候选prompts,并选择在训练集上准确率最高的prompts。AutoPrompt训练一个模型来自动生成prompts,通过搜索使得gold object label的期望似然最大化的tokens序列。
这两种方法都从
Wikidata中收集了额外的三元组来用于调优prompts。在本文中,我们在寻找更好的
promots方面迈出了下一步:不再限制搜索空间为离散的input tokens,而是直接在input embedding space中进行优化,找到最能引导事实的real-valued input vectors。我们还发现,使用manual prompts进行初始化可以为搜索过程提供更好的起点。我们的方法OptiPrompt简单而计算高效,在LAMA基准测试上将准确率从42.2%提高到48.6%,相比于以前的discrete方法有显著提升。在更困难的LAMA-UHN分组中,OptiPrompt将准确率从31.3%提高到38.4%。同时,我们观察到在训练数据上优化的
prompts可能会利用facts的底层分布中的一些规律。我们如何确保我们的prompts仅仅从语言模型中恢复信息?类似的问题最近在语言探究中得到了探索,其目标是探索在contextualized word representations中编码的语言属性。例如,通过观察从语言模型返回的representation,看看分类器是否可以预测"chef"是"made"的nominal subject(Figure 1)。最近的工作尝试将representation中所编码的信息与probe所学到的信息进行解耦。然而,这个问题在factual probing中尚未被探索,部分原因是因为假设仅仅通过观察其他实体的一组不重叠的事实,无法预测一个knowledge fact。例如,了解到但丁出生在佛罗伦萨,对于John Donne的出生地没有任何意义。
我们分析了我们的训练数据,并发现这个假设是不合理的。尽管训练数据是独立于
LAMA基准测试收集的,但在Wikidata关系的底层分布中存在足够的规律性,以至于一个简单的在训练数据上拟合的分类器,可以达到令人惊讶的良好性能。此外,我们的实验揭示了所有基于数据驱动的prompt-search方法(包括先前的方法和我们提出的OptiPrompt),都能够利用这些信息来提高预测准确性。在给定一些训练数据的情况下,一个良好的搜索算法可以利用简单的class统计和更高阶的词汇规律从而找到这样的propmts:该prompts从神经网络中恢复出一定数量的"facts"。这一发现使得解释知识探测任务上的相对准确率分数变得具有挑战性。我们展示了我们的对照实验如何让我们更详细地了解不同
probes的行为。例如,通过将测试集分成"easy"和"hard"两个子集,其中easy样本可以被random controls来预测,而hard样本则不行,我们可以得出一些关于哪些facts不太可能从训练数据中学到的结论。OptiPrompt在这两个子集中均优于先前的方法,表明它在从训练数据中学习、以及从语言模型中引导事实方面都更加优秀。我们最后提出了一些关于未来工作的建议,这些工作可能对训练数据的混淆效应(confounding effect)更不敏感。这就是
P-Tuning的核心思想。整篇论文讲的是:判断
pretrained LM的factual probing是来自于语言模型编码好的知识、还是来自于模型的学习能力?作者进行了一些实验,也没有得出什么有价值的结论。整体而言,没有多少实际价值,可以忽略不看。相关工作:
我们的工作延续了
《Language models as knowledge bases?》所开展的factual probing实验系列,他们引入了LAMA基准用于完形填空式factual probing。随后的LAMA相关工作介绍了用于优化prompts的数据驱动方法(LPAQA、AutoPrompt)。《BERT is not a knowledge base (yet): Factual knowledge vs. name-based reasoning in unsupervised qa》指出LAMA中的许多事实可以通过词汇线索进行预测,并引入了一个新的benchmark(LAMA-UHN),该benchmark对这些启发式方法不太敏感。我们的工作继承了这些项目,并引入了更有效的优化prompts技术:更有效的方法来优化prompts、更全面的方法来解释train/test overlap的作用。与我们同时进行的工作中,其他作者探索了
continuous prompt optimization:《BERTese: Learning to speak to BERT》使用编码器将手动编写的prompt映射为continuous vectors序列,然后用embedding空间中附近的离散tokens替换它们。《Prefix-tuning: Optimizing continuous prompts for generation》提出了Prefix-Tuning,用于对自回归语言模型中最左侧的hidden representations进行微调。《GPT understands, too》使用LSTM生成prompt vectors序列。
prompting也被广泛应用于通过语言模型实现"few-shot learning"。linguistic probing是一个广泛研究的领域,我们在此不尝试总结全部内容(有关概述,请参阅《A primer in bertology: What we know about how bert works》)。我们的工作与最近有关如何衡量probe是从representation中提取信息、还是学习从probe training data中predict annotation的方法相关。这些方法包括random baselines(《Designing and interpreting probes with control tasks》)和信息论度量(《Information theoretic probing with minimum description length》)。我们采用了《Information-theoretic probing for linguistic structure》的control functions的概念。我们的研究还与诊断
neural NLP models中的"shortcut learning"(《Shortcut learning in deep neural networks》)的更大范畴的工作相关。《Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference》发现BERT等模型往往是"right for the wrong reason",利用浅层启发式方法而非潜在的语言结构,类似的效果在许多其他任务中也被发现(《What makes reading comprehension questions easier?》、《Universal adversarial triggers for attacking and analyzing NLP》)。
34.1 方法
34.1.1 背景
LLAMA:factual probing setting是由LAMA benchmark引入的,旨在衡量pretrained语言模型中编码的事实信息量。在LAMA中,事实被定义为三元组subject(例如Dante)、place of birth)、object(例如Florence)。LAMA的事实来源于多个sources,包括Wikidata、ConceptNet、SQuAD。我们遵从最近的factual probing工作,这些工作专注于T-REx split,其中包含了41种Wikidata关系类型,每种类型最多1000个capital of这样的1-1关系、像place of birth这样的N-1关系、像shares border with这样的N-M关系。在
LAMA评估中,每种关系与一个人工编写的prompt相关联,该prompt包含一个[MASK] token,例如"[X] was born in [MASK]."。为了适应BERT等掩码语言模型(masked language models: MLM),LAMA仅限于object label是预定义的词表token。给定subjectrelation promptsubject占位符prompt template。如果gold objectLAMA是一个评估基准,因此没有训练数据。它的构建使得pretraiend语言模型可以在 “开箱即用” 的情况下进行评估,无需额外的微调。《Language models as knowledge bases?》指出,他们的基准只提供了pretrained语言模型中存储的事实信息量的一个下界估计,因为他们手动编写的prompts可能不是引发事实的最佳选择。因此,随后的工作重点是通过使用额外的训练数据找到更优的prompts来收紧这个下界。LPAQA:《How can we know what language models know?》使用一系列text-mining和paraphrasing技术为每个relation生成候选prompts集合。他们从Wikidata收集了一个训练数据集,确保与LAMA基准中的subject-object pairs没有重叠,并通过在该训练数据上测量准确率来选择prompts。他们考虑了一些selecting prompts的规则,包括基于top-K的基线方法、"optimized ensemble"方法(在训练数据上调优了每种关系的多个prompts的权重)。他们的prompt dataset(即,LPAQA)可以在线上获得。AutoPrompt:《AutoPrompt: Automatic prompt construction for masked language models》进一步推进了prompt optimization的发展,通过训练一个统计模型AutoPrompt从而在input tokens空间中搜索能够引发正确预测的prompts。他们为每种关系类型收集了1000个T-REx数据集、要么来自Wikidata,但不包含出现在LAMA基准中的三元组。他们为给定关系prompt,即subject后跟一定数量的"trigger" tokens:其中:
subject所替代。trigger token,该token可以是词表中的任何token。trigger tokens的数量。
这些
trigger tokens被初始化为[MASK] token,然后通过迭代式地更新,在每一步使用gradient-based搜索算法从而将其中一个trigger token替换为最大化在训练集上gold label概率的token。
34.1.2 OptiPrompt
我们的方法受到一种观点的启发,即将搜索限制在
vocabulary tokens空间内是一种次优且人为的约束。在AutoPrompt的情况下,在离散的子空间上优化也是低效的:在每一步中,我们必须枚举一组候选tokens,替换selected trigger token,并重新运行模型。Table 1中的示例也说明,即使由英语词表中的tokens组成,optimized textual prompts可能是难以理解的。这削弱了支持自然语言prompts的一个论点,即它们易于阅读,因此可能更容易解释。
在这种观点下,我们提出了
OptiPrompt,一种用于continuous prompt optimization的方法。OptiPrompt不局限于离散tokens的空间,而是直接搜索optimal prompts,使用embeddign空间中的任何向量来构成prompts。我们首先遵从AutoPrompt的方法,以如下形式来定义一个prompt:其中:
innput embeddingn维度(对于BERT-base为OptiPrompt更类似于P-Tuning:它们都是仅在输入上插入continous prompt;支持在输入的头部、中间、以及尾部插入continuous prompt。将
promtps视为稠密向量可以更高效地搜索optimal prompts。给定一些其中:
(subject, object ) pairs所构成的训练集。prompt template,其中占位符[X]被subject tokens
根据公式,该方法是监督学习,并且采用
zero-shot的模板形式(而不是few-shot)。在这种基本形式中,我们选择一个固定的
tokens。我们还考虑了一种更复杂的形式,使用manual prompts(我们使用LAMA基准测试中提供的prompts)来决定每种关系的tokens的数量manual prompts中的相应tokens使用pre-trained input embedding来初始化每个Table 1所示,我们可以将manual prompts"[X] is [MASK] citizen"转换为:并分别使用
is和citizen的embedding来初始化OptiPrompt支持个性化的prompt length,这在Prefix-Tuning、P-Tuning、Prompt-Tuning中都未试验过。设置:我们使用
AutoPrompt原始论文所收集的数据来训练OptiPrompt,该数据包含800个训练样本,其中有200个用于验证集。在我们的主要实验中,我们对BERT-base-cased模型进行probe,并在附录C中比较其他预训练语言模型。我们报告了top-1 micro-averaged accuracy:其中:
(subject, object)集合;更多实现细节参考附录的
B.1。LAMA结果:我们的结果在Table 2中呈现。总体而言,OptiPrompt在LAMA benchmark的准确率方面优于先前报告的结果与
AutoPrompt相比,我们的模型在LAMA上的表现提高了5.4%–6.4%,在更困难的LAMA-UHN benchmark上提高了6.2%–7.1%。这种改进在所有类别中都是一致的,除了
"1-1"类别,该类别包含两个关系,即capital和capital of(后者是前者的逆关系)。有趣的是,在这个类别中,产生最好结果的prompts是manual prompt,而LPAQA prompts和AutoPrompt prompts的表现逐渐变差。我们推测,很少有prompts能以高准确率引导这种关系;而且,即使有这种prompts,也难以通过随机的、非凸的optimization来找到。我们还发现,使用手动编写的
prompts来初始化prompt vectors可以持续改善性能。这验证了我们的直觉,即manual initialization为在非凸优化问题中找到一个好的解提供了很好的先验信息。结果按relation分类在附录的Table 8中进行了详细说明。
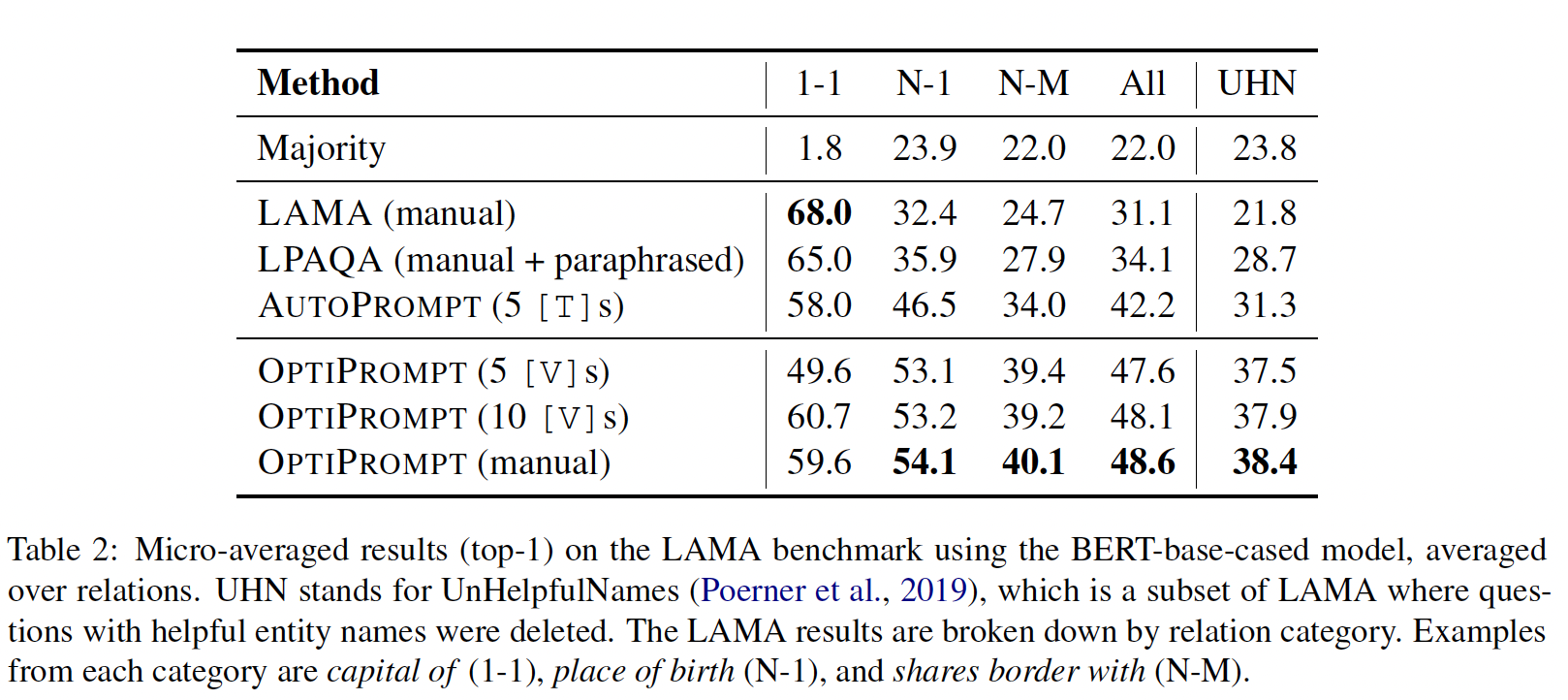
34.2 我们能否相信 Optimized Prompts
我们的实证探测结果证实了
OptiPrompt是一种有效的方法,在LAMA benchmark上的表现超过了先前最好的方法6.4%。然而,我们能否得出结论:BERT编码了比先前所知的更多的事实?我们的,就像LPAQA和AUTOPROMPT,是在in-distribution Wikidata relations上进行优化的,这可能意味着它们利用了底层fact distribution中的某些规律性。在本节中,我们旨在回答两个问题。首先,
Wikidata fact distribution中是否存在模式,其中统计模型理论上可以利用该模型来预测unseen facts?其次,
optimized prompts能否在实践中利用这些模式?
可以从训练数据中预测事实:我们首先研究是否可能仅通过查看训练数据来预测任何
facts。最简单的模式是class priorobject labels在关系subject实体如何,猜测它们都更容易。一种更复杂的模式是找到subject tokens和object labels之间的相关性,即估计subject名称的tokens。为了确定是否存在这样的模式,我们对
AutoPrompt原始论文收集的Wikidata训练集拟合了两个简单的概率模型:第一个模型总是预测
majority class,其中majority class的先验概率是从训练数据中学习的。第二个模型是一个朴素贝叶斯分类器(
bag-of-words),采用sdd-one smoothing(详见附录B.2中的详细信息)。
Table 3显示了这些模型在LAMA benchmark上的准确率,对relation进行了平均。majority class模型表现良好,因为在某些关系中,超过一半的样本属于多数类。朴素贝叶斯
baselien模型在所有类别中表现更好。
这个分析补充了
《BERT is not a knowledge base (yet): Factual knowledge vs. name-based reasoning in unsupervised qa》的观察,他们指出BERT可以利用cloze prompt中的表面信息 “猜测” 正确答案,例如预测具有典型意大利人名字的人可能出生在罗马。我们的结果表明,即使没有关于实体名称的先验信息,也有可能学习这些相关性,并且在Wikidata分布中可能存在其他更微妙的模式。
prompts可以利用训练数据:我们已经表明训练数据明显编码了某些规律性,简单的统计模型可以学习拟合训练数据。接下来,我们研究一个由pretrained语言模型构建的prompt optimization方法是否在实践中具有足够的表达能力来利用这些规律性。我们通过两个随机对照实验来试图回答这个问题,这些对照实验受到linguistic probing中类似提议的启发。在我们的随机模型(
Random Model: RM)基线中,我们优化prompts来引导具有与pretrained语言模型相同架构但参数随机初始化的神经网络中的facts。这类似于《Information-theoretic probing for linguistic structure》的control function,该函数从linguistic representation中删除信息。在这种setting下,任何成功的预测都必须是在训练数据上进行优化的结果。我们还考虑了随机嵌入(
Random Embedding: RE)基线,在这个基线中,我们仅重新初始化input embeddings。这类似于一个control task(《Designing and interpreting probes with control tasks》),是probing task的一种变体,其中单词类型与随机labels相关联。我们的动机是,Model setting更难优化,因此可能低估了prompt model从训练数据中利用信息的方式。
最后,我们直接在重新初始化的
BERT模型上进行微调,目标是更好地估计可以从训练数据中预测到的LAMA事实的数量。结果如
Figure 2所示(有关实现细节和更多结果,请参见附录B.1和Table 8)。在
RE setting下,AutoPrompt和OptiPropmt都能够找到引出一些正确预测的prompts。在
RM setting下,AutoPrompt的预测准确率为0%,可能是因为它更难优化;但是OptiPrompt仍然能够找到成功的prompts。大多数成功的预测是通过找到引出majority class labels的prompts来实现的,然而OptiPrompt也做出了一些正确的、不属于majority class labels的预测。我们的定性分析表明,这些prompts利用了类别统计信息、objects and subject tokens之间的相关性(附录A.2)。微调
BERT模型导致更高的准确率,表明存在一些prompts未能利用的模式。随机对照实验对于prompt optimization来说是一种具有挑战性的设置,可能在full pretrained的BERT模型下,prompts更好地利用了训练数据。我们通过计算每个prompt在LAMA数据集上引出training class majority label的频率来证明这一点,并将结果绘制在Figure 3中。AutoPrompt和OptiPrompt都容易过度预测majority class label。例如,尽管在RM setting中AutoPrompt的准确率为0%,但它在pretrained BERT模型上进行优化时,对于六个关系,它找到的prompt引出majority label的频率超过95%。LPAQA的prompts较少地预测majority class,可能是因为它们在拟合训练分布方面的效果较差。然而,显然LPAQA的prompts也编码了训练数据的分布。例如,LPAQA发现的最高排名的occupation prompts包括"[MASK] and actors [X]和"[MASK] and player [X]"等prompts,其中occupation prompts反映了Wikidata中最常见的几个职业。在附录A.2中,我们还讨论了一些例子,其中LPAQA发现:对prompt template进行细微修改会导致模型更频繁地预测majority label,相对于manual prompt和true test distribution。所有上述证据表明,optimized prompts在某种程度上可以学习到新的事实。


34.3 如何解释 Probing 结果
我们在前面的分析显示,
optimized prompts可以从训练数据中预测新的facts。在这个背景下,我们如何解释我们的factual probing结果呢?为了从另一个角度评估相对改进的情况,我们将LAMA数据集划分为easy子集和hard子集(每个子集的例子可以在Table 5中找到)。easy子集由这类facts组成:这些facts可以由三种模型之一来正确地预测,包括朴素贝叶斯模型、token embeddings重新初始化的fine-tuned BERT模型、所有参数重新初始化的fine-tuned BERT模型。easy子集可作为可以从训练数据中预测的facts的估计。hard子集包含剩余的事实。

Table 4显示了每个prompts在LAMA的这两个子集上的结果(每个relation的结果见Table 9)。首先,我们观察到所有的
probing方法在easy子集上的准确率都要高得多。使用更复杂的prompt optimization技术往往会在LAMA的easy子集上取得较大的改进,而在hard子集上的改进较小。OptiPrompt在easy子集上的改进比AutoPrompt高出7.4%;而在hard子集上,OptiPrompt也取得了较大的改进(+6.3%)。这表明OptiPrompt在从训练数据中学习和引导语言模型产生事实方面都表现更好。
为了进行更详细的定性分析,我们从每个子集中随机抽取了十个事实,仅保留那些至少有一个模型预测正确且不具有
majority class label的事实示例。这些示例在Table 5中展示,更好地展示了不同prompts引发的预测类型。例如,
AutoPrompt和OptiPrompt在某些情况下似乎在利用训练数据。在
easy子集中,它们在答案是subject name中的一个token时引发了更准确的预测。在
hard子集中,它们显示出对训练分布的过拟合迹象,错误地预测了最常见的object labels:如,洲(南极洲)、制造商(IBM)。
OptiPrompt在两个类别的某些事实中表现优于其他prompts。在一个容易的职业示例中,
AutoPrompt错误地预测了majority label(政治家),OptiPrompt(以及我们的朴素贝叶斯模型)明显编码了subject的某些方面与正确标签(演员)之间的词汇相关性。另一方面,在两个更困难的示例中,
OptiPrompt表现优于其他prompts:"Francis Hagerup used to work in Oslo."和"William Lyon Mackenzie King used to work in Ottawa."。在这两种情况下,LPAQA预测训练中的majority label(伦敦),AutoPrompt更接近地预测了地理位置(哥本哈根和蒙特利尔),而OptiPrompt预测了正确的城市。
我们注意到,我们不能得出结论说:没有办法从训练数据中预测这些
"had"的事实。这种分析的一个更普遍的限制是我们无法确定模型使用哪种策略来进行特定的预测。许多事实既可以通过学习class prior、学习subject tokens和object之间的词汇相关性、利用语言模型中的词汇信息来预测,也可能是因为语言模型真正编码了关于特定实体的信息。尽管如此,定性示例展示了prompt model行为中的有趣模式,这些模式无法从LAMA benchmark的summary accuracy结果中观察到,而通过查看一系列prompts的具体预测,我们可以更多地得到关于语言模型对特定事实编码的信息。
34.3 讨论
continuous vs. discrete prompts:我们发现continuous prompts和discrete prompts都能够找到利用训练数据的prompts。即使
prompts是离散的,也很少清楚为什么某个prompts会引发特定的预测。因此,我们认为continuous promtps更可取,因为它更容易、更高效地进行优化,并且能够做出更好的预测(无论是在easy子集还是hard子集上)。另一方面,
OptiPrompt(与AutoPrompt共享)的一个缺点是我们需要对语言模型进行白盒访问以计算梯度。在模型参数不可用的情况下,仍然需要discrete prompts,例如在通过API提供的大型语言模型的情况下。
learning vs. learning to recall:无论我们选择如何优化prompts,要解释模型为什么做出特定预测仍然很困难,无论这些预测是从训练数据中学到的还是在语言模型中编码的。未来的研究方向之一可能是考虑将预测归因于特定的训练样本的技术,目标是在预训练或prompt optimization过程中开发对facts获取方式的因果理解。更一般地说,我们的真正目标是理解预训练语言模型是如何学习和表示信息的。prompt-based probing可能会为这个问题提供一些见解,但我们希望未来的研究最终能够对神经网络行为提供更多机制性解释。例如,了解神经网络参数中的实体信息是如何组织的,并在input prompt的响应中被检索出来,将是一个有趣的研究方向。