八、BERT[2018]
语言模型预训练已被证明对改善许多自然语言处理任务是有效的。这些任务包括:
sentence-level的任务,如自然语言推理natural language inference和转述paraphrasing,其目的是通过整体分析来预测句子之间的关系。token-level的任务,如命名实体识别named entity recognition: NER和SQuAD问答question answering: QA,其中模型需要在token-level产生细粒度的输出。
目前有两种策略将预训练的
language representation应用于下游任务:feature-based和fine-tuning:feature-based方法(如ELMo)使用tasks-specific架构,其中使用预训练的representation作为额外的特征。fine-tuning方法(如GPT),引入了最小的task-specific参数,并通过简单地微调pretrained parameter从而对下游任务进行训练。
在之前的工作中,这两种方法在
pre-training期间共享相同的目标函数,其中它们使用单向语言模型来学习通用的language representation。即,
feature-based方法和fine-tuning方法采用相同的预训练方式,但是在应用到下游任务阶段才有所差异。论文
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》认为:目前的技术严重限制了pre-trained representation的能力,特别是对于微调fine-tuning方法。主要的限制是:标准的语言模型是单向的,这就限制了在预训练中可以使用的架构。例如,在GPT中,作者使用了一个从左到右的架构,其中在Transformer的self-attention layer中每个token只能关注前面的token。- 对于
sentence-level的任务,这样的限制是次优的。 - 对于
token-level的任务(如SQuAD问答任务),当应用基于微调的方法时,这样的限制可能是毁灭性的。因为在这种情况下,从两个方向融合上下文是至关重要的(因为可能需要关注后面的token而不是前面的,从而找到问题的答案)。
在论文
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中,作者通过从Transfromer中提出Bidirectional Encoder Representation: BERT来改善基于微调的方法。BERT通过提出一个新的预训练目标来解决前面提到的单向约束:masked language model: MLM任务,其灵感来自Cloze任务(即,完形填空任务)。MLM从输入中随机掩码一些token,任务的目标是仅根据上下文来预测被掩码单词的原始vocabulary id。与从左到右的语言模型预训练不同的是,MLM目标允许representation同时融合左侧和右侧的上下文,这使得我们可以预训练一个深度的双向Transformer。除了MLM,论文还引入了一个next sentence prediction: NSP任务来联合预训练text-pair representation。论文贡献如下:
- 作者证明了双向预训练对
language representation的重要性。与《Improving language understanding with unsupervised learning》使用单向语言模型进行预训练不同,BERT使用MLM来实现pre-trained deep bidirectional representation。这也与ELMo相反,后者使用独立训练的从左到右和从右到左的语言模型的浅层拼接shallow concatenation。 - 作者表明,预训练的
representation消除了许多严重工程化的task-specific架构的需要。BERT是第一个基于微调的representation model,它在大量的sentence-level和token-level任务上取得了SOTA的性能,超过了许多具有task-specific架构的系统。 BERT推动了11项NLP任务的state-of-the-art。作者还报告了BERT的大量消融实验,表明BERT模型的双向特性是唯一最重要的新贡献。
相关工作:
feature-based方法:几十年来,学习广泛适用的word representation一直是一个活跃的研究领域,包括非神经方法和神经方法。预训练的word embeddin被认为是现代NLP系统的一个组成部分,与从头开始学习的embedding相比,有很大的改进。这些方法已被推广到更粗的粒度,如
sentence embedding或paragraph embedding。与传统的word embedding一样,这些学到的representation通常也被用作下游模型的特征。ELMo沿着不同的维度推广了传统的word embedding研究。他们提出从语言模型中提取context-sensitive的特征。当将contextual word embedding与现有的task-specific架构相结合时,ELMo推进了几个主要NLP benchmark的SOTA,包括SQuAD上的问答、情感分析sentiment analysis和命名实体识别named entity recognition。fine-tuning方法:最近从语言模型中进行迁移学习的一个趋势是,在为下游监督任务微调同一模型之前,在语言模型目标上预训练该模型架构。这些方法的优点是,只需要从头开始学习非常少的参数。至少部分由于这一优势,GPT在GLUE benchmark的许多sentence-level任务上取得了当时SOTA的结果。从监督数据
supervised data迁移学习:虽然无监督预训练的优势在于几乎有不限量的数据可用,但也有工作表明,可以从具有大型数据集的监督任务中有效地迁移学习,如自然语言推理和机器翻译machine translation。在NLP之外,计算机视觉领域的研究也证明了从大型预训练模型进行迁移学习的重要性,其中一个有效的秘方是:对基于ImageNet预训练的模型进行微调。
8.1 模型
8.1.1 模型架构
BERT的模型架构是一个多层的、双向的Transformer encoder,基于《Attention is allyou need》描述的原始实现。由于最近Transformer的使用已经变得无处不在,而且我们的实现实际上与原版相同,因此我们将省略对模型架构的详细描述,请读者参考《Attention is allyou need》以及《The Annotated Transformer》等优秀出版物。在这项工作中,我们将层数(即
Transformer block)记做hidden size记做self-attention head数记做feed-forward/filter size设为4096。我们主要报告两种模型尺寸的结果:BERT_BASE:110M。BERT_LARGE:340M。
前馈神经网络是一个双层的全连接网络,输入维度为
BERT_BASE被选择为具有与GPT相同的模型大小,以便于比较。然而,关键的是,BERT Transformer使用的是双向自注意力,而GPT Transformer使用的是受约束的自注意力(每个token只能关注其左侧的上下文)。我们注意到,在文献中,双向Transformer通常被称为Transformer encoder,而只关注左侧上下文的Transformer被称为Transformer decoder(因为它可以用于文本生成)。BERT、GPT和ELMo之间的比较如下图所示。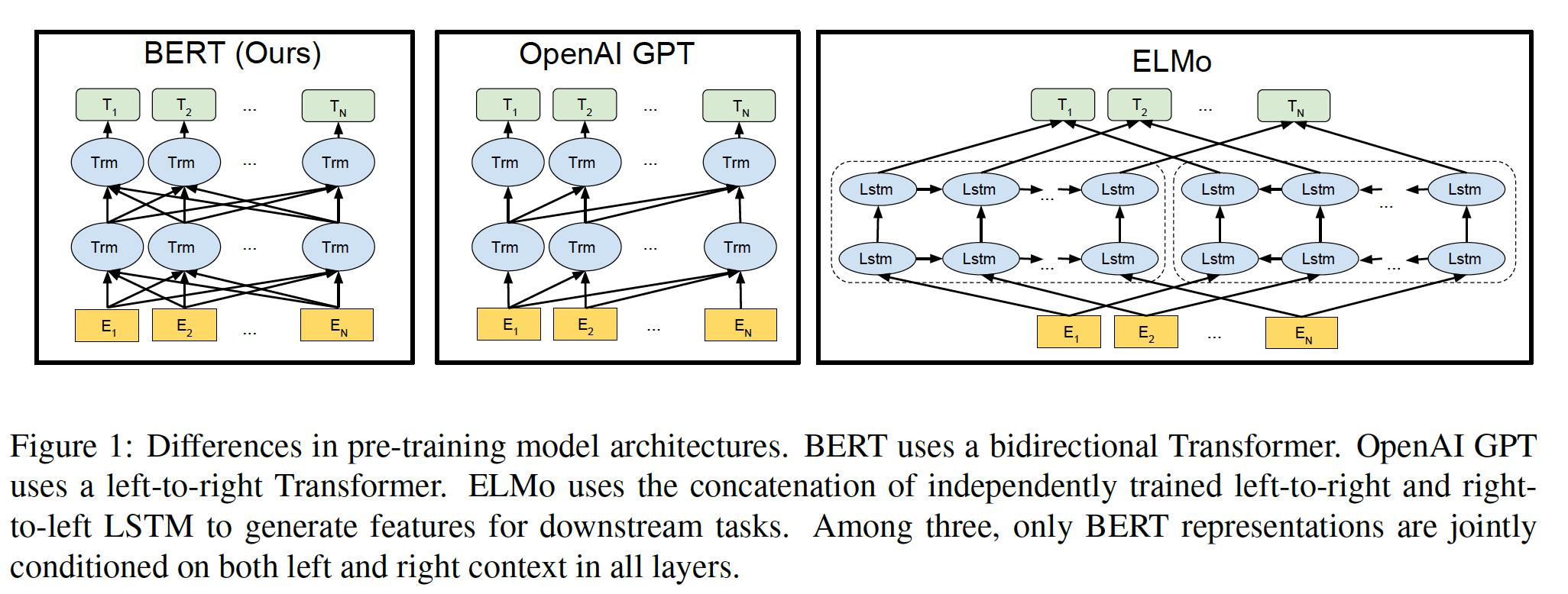
8.1.2 Input Representation
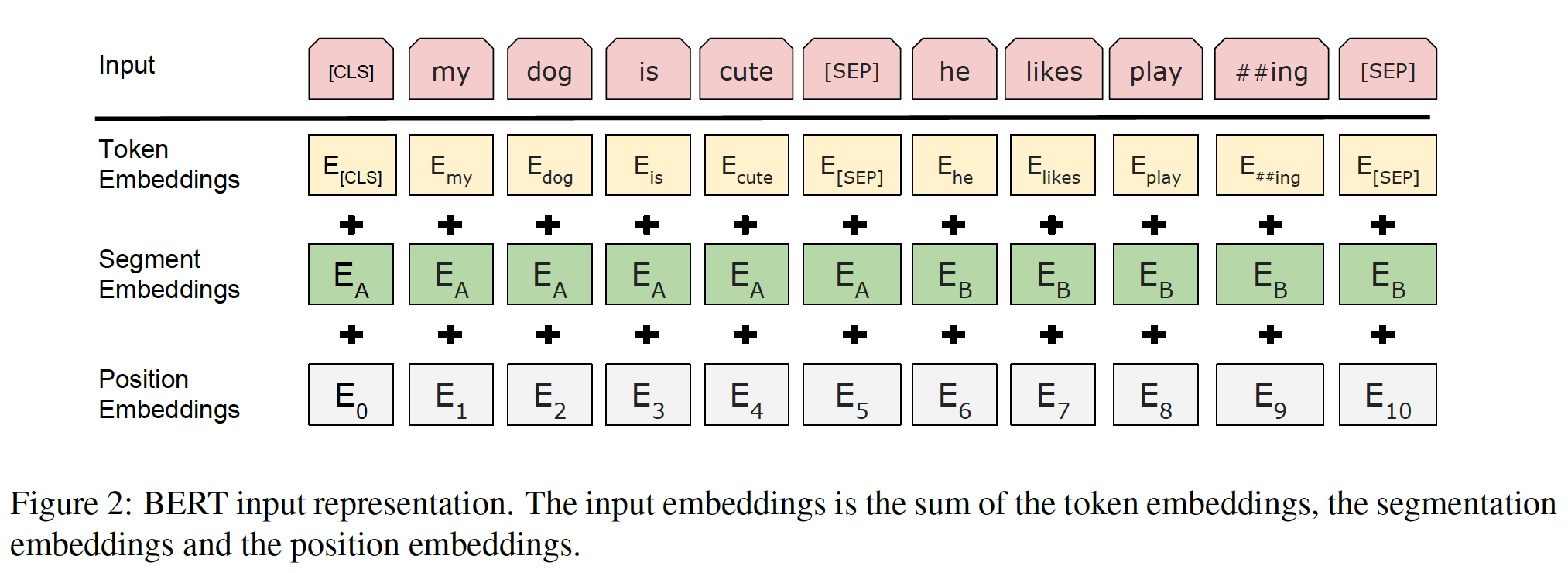
我们的
input representation能够在一个token序列中明确地表示单个文本句子或一对文本句子(如,[Question, Answer])。对于一个给定的token,它的input representation是由相应的token embedding、segment emebdding和position embedding相加而成的。下图给出了我们的input representation的直观表示。具体而言:
我们使用具有
30k个token的vocabulary的WordPiece embedding(《Google’s neural machine translation system: Bridging the gap between human and machine translation》)。我们用##指示被拆分的word piece。我们使用学到的
positional embedding,最大可以支持长度为512个token的序列。每个序列的第一个
token总是特殊的classification embedding,即[CLS]。与这个token相对应的final hidden state(即Transformer的输出)被用作分类任务的aggregate sequence representation。对于非分类任务,这个向量被忽略。sentence pair被打包成一个单一的序列。我们以两种方式区分这些句子。首先,我们用一个特殊的
token(即,[SEP])将这两个句子分开。(注意,每个句子的结尾都有一个[SEP])其次,我们在第一句的每个
token上添加一个学到的segment A Embedding,在第二句的每个token上添加一个学到的segment B Embedding。假设
segment编号为1和2,那么segment A embedding就是segment=1对应的embedding,segment B embedding就是segment=2对应的embedding。
对于单个句子的输入,我们只使用
segment A Embedding。注意,segment A也称作sentence A,因为这里一个句子就是一个segment。进一步地,我们是否可以对句子内部的子句、或者短语也作为更细粒度的
segment来提供embedding?
8.1.3 预训练任务
- 与
ELMo和GPT不同,我们没有使用传统的从左到右、或从右到左的语言模型来预训练BERT。相反,我们使用两个新颖的无监督预训练任务对BERT进行预训练。
a. Task1: Maksed LM
直观而言,我们有理由相信:深度双向模型严格来说比
left-to-right的模型、或浅层拼接了left-to-right and right-to-left的模型更强大。不幸的是,标准的conditional language model只能从左到右或从右到左进行训练,因为双向条件会让每个词在multi-layered context中间接地 "看到自己" 。为了训练深度双向
representation,我们采取了一种直接的方法,即随机掩码一定比例的input token,然后只预测那些被掩码的token。我们把这个过程称为 "masked LM"(MLM),尽管它在文献中经常被称为Cloze task。在这种情况下,对应于mask token的final hidden vector被馈入output softmax(输出空间为整个vocabulary),就像在标准语言模型中一样。在我们所有的实验中,对于每个序列我们随机掩码15%的WordPiece token。与降噪自编码器不同的是,我们只预测被掩码的单词,而不是重建整个输入。
被掩码的
token填充以[MASK]。尽管这确实允许我们获得一个双向的预训练模型,但这种方法有两个缺点:
首先,我们在预训练和微调之间产生了不匹配
mismatch,因为在微调过程中从来没有看到[MASK]这个token。为了缓解这一问题,我们并不总是用实际的
[MASK] token来替换被掩码的token。相反,训练数据生成器随机选择15%的token(例如,在句子"my dog is hairy"中它选择了hairy),然后它将执行以下程序:80%的情况下用[MASK] token替换该词,例如,"my dog is hairy" --> "my dog is [MASK]"。10%的情况下用一个随机的词来替换这个词,例如,"my dog is hairy" --> "my dog is apple"。10%的情况下保持该词不变,例如,"my dog is hairy" --> "my dog is hairy"。这样做的目的是为了使representation偏向于实际观察到的单词。
Transformer encoder不知道哪些单词会被要求预测、哪些单词已经被随机词所取代,所以它被迫保持每个input token的distributional contextual representation。此外,由于随机替换只发生在所有token的1.5%(即15%的10%),这似乎并不损害模型的语言理解能力。似乎论文并没有实验来验证这一点。
其次,每个
batch中只有15%的token被预测,这表明可能需要更多的pre-training step来使模型收敛。在实验部分,我们证明了MLM的收敛速度确实比left-to-right的模型(预测每个token)稍慢,但是MLM模型的经验改进empirical improvement远远超过了增加的训练成本。
b. Task2: Next Sentence Prediction
许多重要的下游任务,如
Question Answering: QA和Natural Language Inference: NLI,都是基于对两个文本句子之间关系的理解,而语言建模并没有直接捕获到这一点。为了训练一个能够理解句子关系的模型,我们预训练了一个二元化的next sentence prediction task,该任务可以从任何单语种的语料库中简单地生成。具体而言,在为每个预训练样本选择句子
A和句子B时:50%的情况下句子B是紧随句子A的实际的下一句。50%的情况下句子B是语料库中的一个随机句子。
例如:
xInput = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]Label = IsNextInput = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]Label = NotNext我们完全随机地选择
NotNext句子,最终的预训练模型在这个任务中达到了97% ~ 98%的准确率。尽管该任务很简单,但我们在实验中证明,针对这个任务的预训练对QA和NLI都非常有利。实际上后续的论文表明:
NSP预训练任务是没什么作用甚至是有害的。
8.1.4 预训练程序
预训练程序主要遵循现有的关于语言模型预训练的文献。对于预训练语料库,我们使用
BooksCorpus(800M单词)和English Wikipedia(2500M单词)的组合。对于Wikipedia,我们只提取文本段落,忽略了list、table、和header。至关重要的是,我们使用document-level语料库而不是混洗过的sentence-level语料库(如Billion Word Benchmark)从而提取长的连续文本序列。为了生成每个训练输入序列,我们从语料库中采样两个区间
span的文本,我们称之为 "句子",尽管它们通常比单个句长得多(但也可能更短)。- 第一个句子接受
Segment A Embedding,第二个句子接受Segment B Embedding。 50%的情况下句子B是紧随句子A之后的实际的下一句,50%的情况下句子B是一个随机的句子。这是用于next sentence prediction任务。- 这两个句子被采样,使得合并后的长度小于等于
512个token。
语言模型的
masking是在WordPiece tokenization之后进行的,其中使用15%的均匀的掩码率masking rate,并没有对部分word piece给予特殊考虑。- 第一个句子接受
我们用
batch size = 256来训练一百万个step,每个mini-batch有256 * 512 = 128000个token(这里是近似值,精确值为131072),因此相当于在0.33B单词的语料库上训练40个epoch。- 我们使用
Adam优化器,学习率为L2权重衰减为0.01。学习率在前10000步进行warmup,学习率线性衰减。 - 我们在所有
layer上使用0.1的dropout rate。 - 遵循
GPT,我们使用gelu激活函数不是标准的relu。 training loss是mean masked LM likelihood和mean next sentence prediction likelihood之和。
- 我们使用
BERT_BASE的训练在Pod configuration的4 Cloud TPUs上进行(共16个TPU芯片)。BERT_LARGE的训练在16 Cloud TPUs上进行(共64个TPU芯片)。BERT_BASE和BERT_LARGE的预训练都需要4天的时间来完成。
8.1.5 微调程序
对于
sequence-level分类任务,BERT的微调是直接的。为了获得输入序列的固定维度的、被池化的representation,我们采用输入的第一个token的final hidden state,这对应于特殊的[CLS]对应的word embedding。我们把这个向量表示为softmax计算的,即BERT和ground-truth标签的对数概率最大化。对于
span-level和token-level的预测任务,上述过程必须以task-specific的方式稍作修改。细节在实验部分给出。对于微调,模型的大部分超参数与预训练时相同,除了
batch size、learning rate和训练epoch的数量。dropout rate始终保持在0.1。最佳的超参数值是task-specific的,但我们发现以下数值范围在所有任务中都能很好地发挥作用:Batch size为16 、32;Learning rate (Adam)为5e-5、3e-5、2e-5;epoch数量为3、4。微调采用更小的
batch size、更小的学习率、更少的epoch。我们还观察到:大数据集(例如,
100k+带标记的训练样本)对超参数选择的敏感性远低于小数据集。微调通常是非常快的,所以简单地对上述超参数进行暴力搜索并选择在验证集上表现最好的模型是合理的。
8.1.6 BERT 和 GPT 的对比
与
BERT最具可比性的、现有的预训练方法是OpenAI GPT,它在一个大型文本语料库上训练了一个left-to-right的Transformer语言模型。事实上,BERT中的许多设计决定都是有意选择的,以尽可能地接近GPT,从而使这两种方法能够得到最低限度的比较。我们工作的核心论点是:我们提出的两个新颖的预训练任务占了经验改进的大部分,但我们确实注意到BERT和GPT的训练方式还有几个不同之处:GPT是在BooksCorpus(800M单词)上训练的,而BERT是在BooksCorpus和Wikipedia(2500M单词)上训练的。通常而言,更大的预训练语料库会带来更好的微调效果。
GPT使用句子分隔符sentence separator([SEP])和classifier token([CLS]),它们仅在微调期间引入;而BERT在预训练期间学习[SEP]、[CLS]和segment A/B embedding。GPT被训练了1M个step,batch size为32000个单词;BERT被训练了1M个step,batch size为128000个词。GPT在所有微调实验中使用相同的学习率5e-5;BERT选择了task-specific的、用于微调的学习率,这个学习率在验证集上表现最好。
为了隔绝
isolate这些差异的影响,我们在实验部分进行了大量消融实验,证明大部分的改进实际上来自新颖的预训练任务。
8.2 实验
8.2.1 GLUE 数据集
General Language Understanding Evaluation: GLUE基准是各种自然语言理解natural language understanding任务的集合。大多数GLUE数据集已经存在多年,但GLUE的目的是:- 首先,对这些数据集进行规范的
Train/Dev/Test的拆分。 - 其次,建立一个
evaluation server从而缓解评估不一致和测试集过拟合的问题。GLUE并未提供测试集的标签,用户必须将他们的预测上传到GLUE server进行评估,并对提交的次数有所限制。
- 首先,对这些数据集进行规范的
GLUE benchmark包括以下数据集:Multi-Genre Natural Language Inference: MNLI:是一个大规模、众包式的蕴含分类entailment classification任务。给定一对句子,任务的目标是:预测第二个句子相对于第一个句子是蕴含关系entailment、矛盾关系contradiction还是中性关系neutral。Quora Question Pairs: QQP:是一个二元分类任务,任务的目标是确定在Quora上提出的两个问题是否在语义上等价semantically equivalent。Question Natural Language Inference: QNLI:是Stanford Question Answering Dataset的一个版本,它被转换为一个二元分类任务。正样本是sentence确实包含正确答案的(question, sentence) pair,负样本是sentence中不包含答案的(question, sentence) pair。Stanford Sentiment Treebank: SST-2:是一个二元单句分类任务,由从电影评论中提取的句子组成,并具有人类对这些评论的情感的注释annotation。Corpus of Linguistic Acceptability: CoLA:是一个二元单句分类任务,任务的目标是预测一个英语句子是否在语言上 "acceptable"。Semantic Textual Similarity Benchmark: STS-B:是一个从新闻headlines和其他来源抽取的sentence pair的集合。它们被标记为1 ~ 5分,表示这两个句子在语义上的相似程度。Microsoft Research Paraphrase Corpus: MRPC:从在线新闻来源中自动提取的sentence pair组成,并由人类注释该sentence pair是否具有语义上的等价性。Recognizing Textual Entailment: RTE:是一个类似于MNLI的二元蕴含任务,但训练数据少得多。Winograd NLI: WNLI:是一个小型自然语言推理natural language inference数据集,源于《The winograd schema challenge》。GLUE的网页指出:这个数据集的构建存在问题,而且每一个提交给GLUE的训练好的系统的表现都比一个简单的baseline更差。这个简单的baseline直接预测majority class,并达到65.1的准确率。因此,出于对OpenAI GPT的公平比较,我们排除了这个数据集。对于我们的GLUE submission,我们总是预测majority class。即,对于每一个测试样本,预测它的类别为训练集中出现概率最高的那个类别(即
majority class)。
为了在
GLUE上进行微调,我们根据前文所述来表示输入序列或sequence pair,并使用对应于第一个输入token([CLS])的final hidden vectoraggregate representation。这在下图(a)和(b)中得到了直观的证明。在微调过程中引入的唯一新参数是一个分类层因为
GLUE数据集都是文本分类任务。对于所有的
GLUE任务,我们使用batch size = 32以及3个epoch。对于每个任务,我们用
5e-5、4e-5、3e-5、2e-5的学习率进行微调,并选择在验证集上表现最好的一个。此外,对于
BERT_LARGE,我们发现微调在小数据集上有时是不稳定的(也就是说,一些runs会产生退化degenerate的结果),所以我们运行了几个随机重启random restart,并选择了在验证集上表现最好的模型。通过随机重启,我们使用相同的
pre-trained checkpoint,但在微调期间进行不同的数据混洗和classifier layer初始化 。我们注意到,
GLUE数据集不包括测试集的标签,我们只为每个BERT_BASE和BERT_LARGE做一次evaluation server submission。
从图
(a)中看到,在微调期间只有一个[SEP]符号,这与预训练阶段不一致。在预训练阶段每个句子的末尾都添加一个[SEP]。这种不一致是否影响效果?可以通过实验来评估。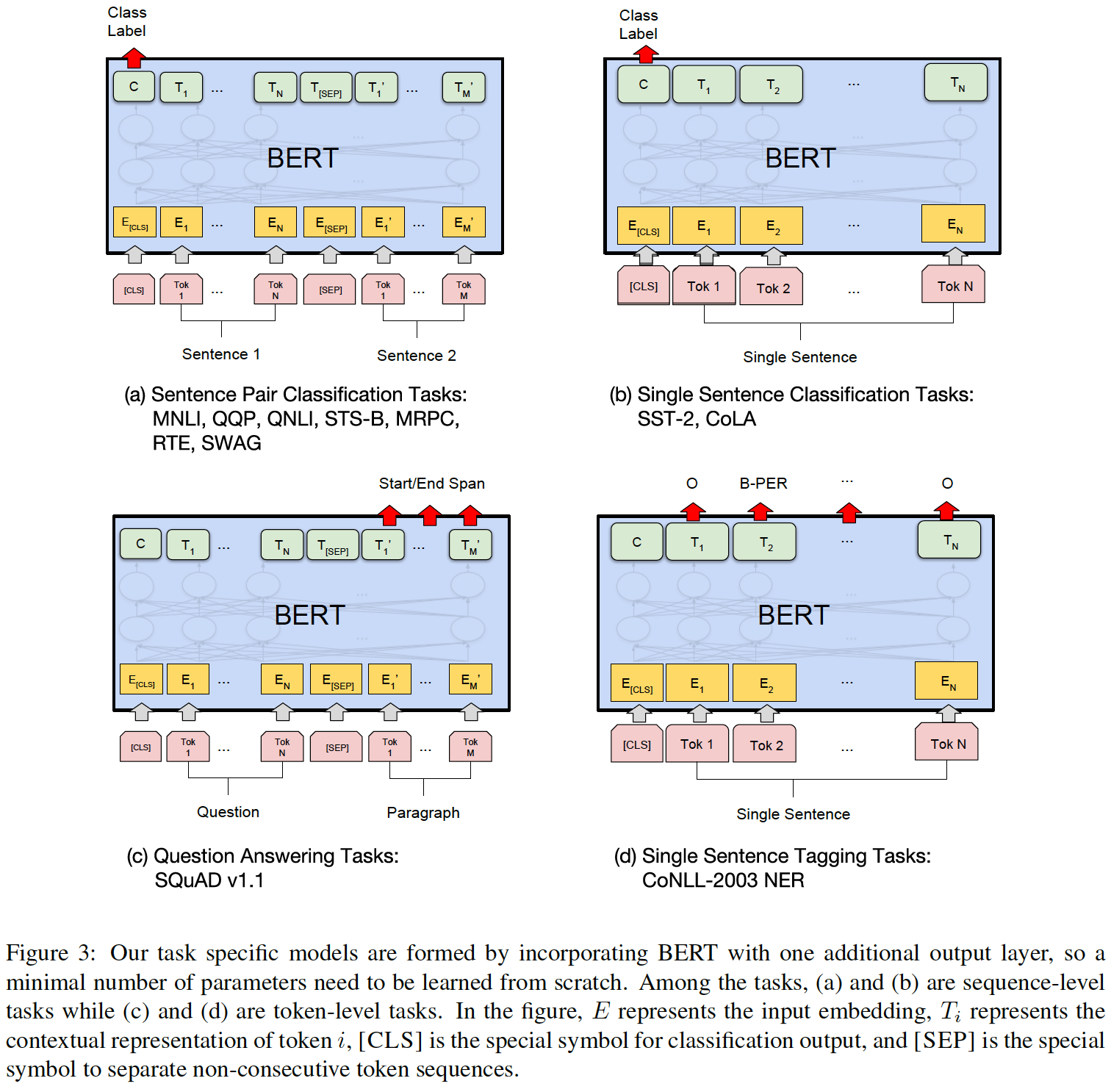
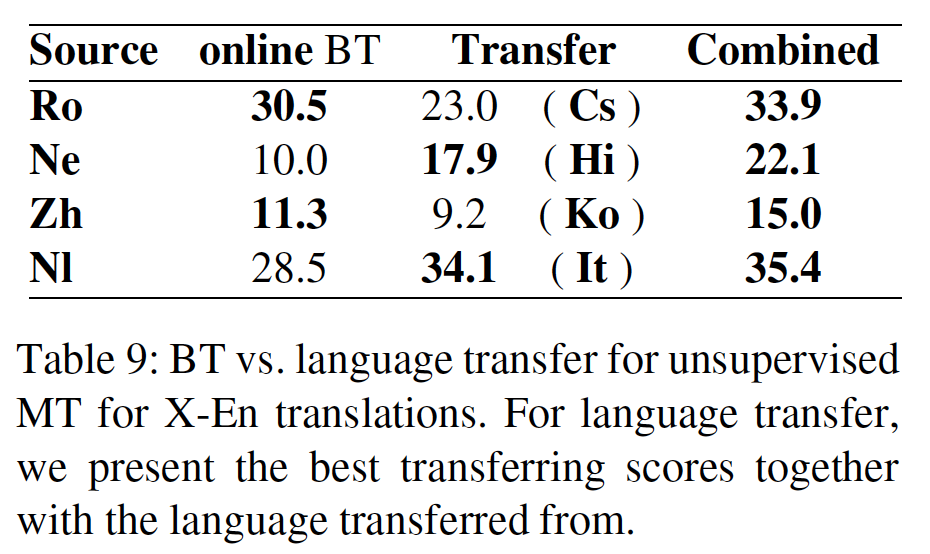
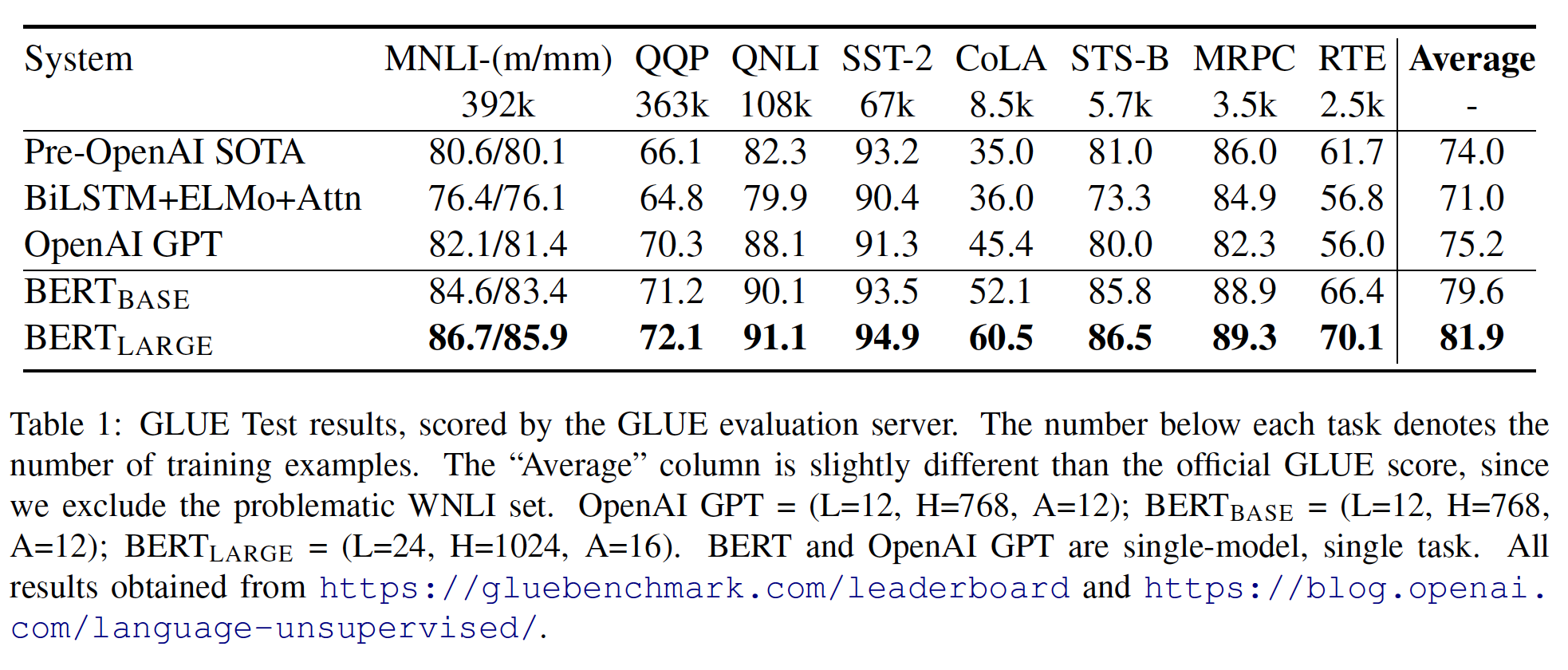
实验结果如下表所示:
BERT_BASE和BERT_LARGE在所有任务上的表现都大大超过了现有的系统,分别比SOTA的系统获得了4.4%和6.7%的平均精确度提升。请注意,BERT_BASE和OpenAI GPT在attention masking之外的模型架构方面几乎是相同的。对于最大和最广泛报道的
GLUE任务MNLI,BERT(这里是BERT_LARGE)相比SOTA获得了4.7%的绝对提升。在
GLUE的官方排行榜上,BERT_LARGE获得了80.4分;相比之下,排在榜首的系统(即OpenAI GPT)截至本文撰写之日获得了72.8分。下图中的
Average稍有差异,因为这里我们排除了有问题的WNLI数据集。值得注意的是,
BERT_LARGE在所有任务中都显著优于BERT_BASE,即使是那些训练数据非常少的任务。BERT模型大小的影响将在下面的实验中进行更深入的探讨。
8.2.2 SQuAD v1.1
Standford Question Answering Dataset: SQuAD是一个由10万个众包的(question, answer) pair组成的集合。给定一个问题和来自维基百科中包含答案的段落,任务的目标是预测该段落中的答案文本的区间answer text span。例如:xxxxxxxxxxInput Question: Where do water droplets collide with ice crystals to form precipitation?Input Paragraph:... Precipitation forms as smaller droplets coalesce via collision with other rain drops or ice crystals within a cloud. ...Output Answer: within a cloud这种类型的区间预测任务
span prediction task与GLUE的序列分类任务截然不同,但我们能够以一种直接的方式使BERT在SQuAD上运行。就像
GLUE一样,我们将输入的问题和段落表示为一个single packed sequence,其中question使用segment A embedding,段落使用segment B embedding。在微调过程中学习到的唯一的新参数是一个start vectorend vectorinput token在BERT中的的final hidden vector表示为Figure 3(c)所示。然后,单词answer span的起点start的概率被计算为softmax:其中
同样的公式用于
answer span的终点end,最大得分的span被用作预测。训练目标是正确的起点位置和终点位置的对数可能性。这里假设起点和终点之间是相互独立的。实际上这种假设通常不成立,终点和起点之间存在关联,如终点的位置大于等于起点。
我们用
5e-5的学习率和batch size = 32训练了3个epoch。在推理时,由于终点预测并没有考虑以起点为条件,我们增加了终点必须在起点之后的约束条件,但没有使用其他启发式方法。tokenized labeled span被调整回原始的untokenized input以进行评估。因为经过了
tonenization之后,原始的单词被拆分为word piece,这将影响span的位置。结果如下表所示。
SQuAD采用了高度严格的测试程序,提交者必须手动联系SQuAD的组织者,在一个隐藏的测试集上运行他们的系统,所以我们只提交了我们最好的系统进行测试。下表中显示的结果是我们第一次也是唯一一次向SQuAD提交的测试结果。我们注意到:
SQuAD排行榜上的榜首结果没有最新的公开的系统描述,而且在训练他们的系统时允许使用任何公共数据。因此,我们在提交的系统中使用了非常适度的数据增强:在SQuAD和TriviaQA上联合训练。我们表现最好的系统相比排行榜上榜首的系统高出
+1.5 F1(以ensembling系统的方式 )和+1.7 F1(以single系统的方式)。事实上,我们的单一BERT模型在F1得分方面优于top ensemble system。如果我们只对SQuAD进行微调(不包括TriviaQA),我们会损失0.1-0.4 F1,但仍然以很大的优势胜过所有现有系统。BERT ensemble使用了7个模型,它们分别使用不同的预训练checkpoint和fine-tuning seed。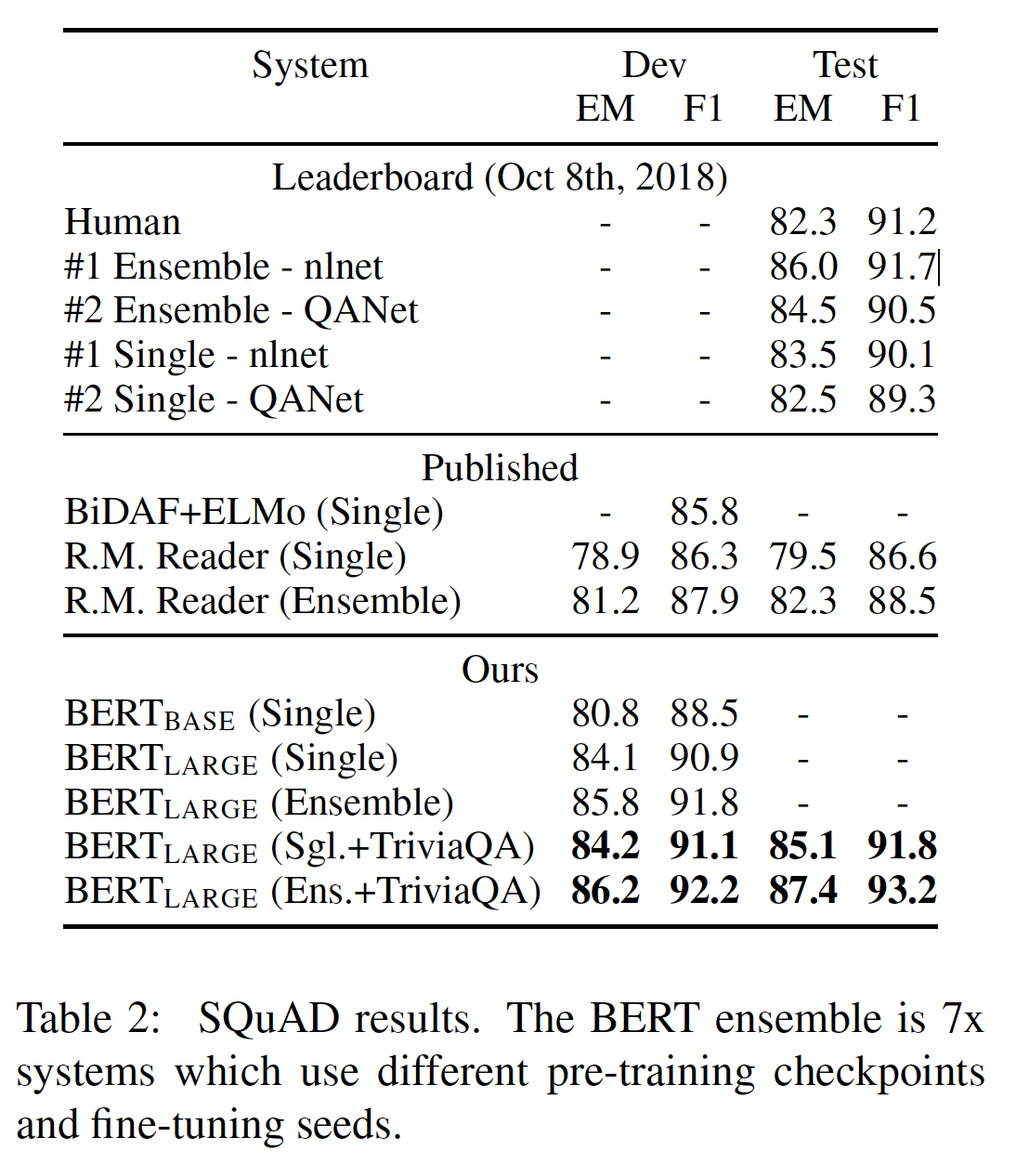
8.2.3 Named Entity Recognition
为了评估
token tagging任务的性能,我们在CoNLL 2003命名实体识别(NER)数据集上对BERT进行了微调。这个数据集由20万个训练单词组成,这些单词被标注为人物Person、组织Organization、位置Location、杂项Miscellaneous、或其他Other(非命名实体)。为了进行微调,我们将每个
tokenfinal hidden representationnon-autoregressive和no CRF)。为了与
WordPiece tokenization兼容,我们将每个CoNLL-tokenized input word馈入我们的WordPiece tokenizer,并使用与第一个sub-token对应的hidden state作为分类器的输入。例如:xxxxxxxxxxJim Hen ##son was a puppet ##eerI-PER I-PER X O O O X其中
X没有预测。Figure 3(d)中也给出了一个直观的表示。在NER中使用了cased WordPiece model(即,保留字母的大小写) ,而在所有其他任务中则使用了uncased model(即,所有字母转化为小写)。
结果如下表所示。
BERT_LARGE在CoNLL-2003 NER Test中优于现有的SOTA(Cross-View Training with multi-task learning)达到+0.2的改进。如果在
BERT的final hidden representation之上再接入自回归或CRF,预期将得到更好的效果。
8.2.4 SWAG
Situations With Adversarial Generations: SWAG数据集包含11.3万个sentence-pair completion的样本,评估了grounded commonsense inference。给定视频字幕数据集中的一个句子,任务是在四个选项中决定最合理的延续
concatenation。例如:xxxxxxxxxxA girl is going across a set of monkey bars. She(i) jumps up across the monkey bars.(ii) struggles onto the bars to grab her head.(iii) gets to the end and stands on a wooden plank.(iv) jumps up and does a back flip.将
BERT应用于SWAG数据集类似于GLUE。对于每个样本,我们构建四个输入序列,每个序列都包含给定句子(句子A)和一个可能的延续(句子B)的拼接。我们引入的唯一task-specific参数是一个向量final aggregate representationsoftmax:我们用
2e-5的学习率和batch size = 16对模型进行了3个epoch的微调。结果如下表所示。BERT_LARGE比作者的baseline(即,ESIM+ELMo系统)要提高27.1%。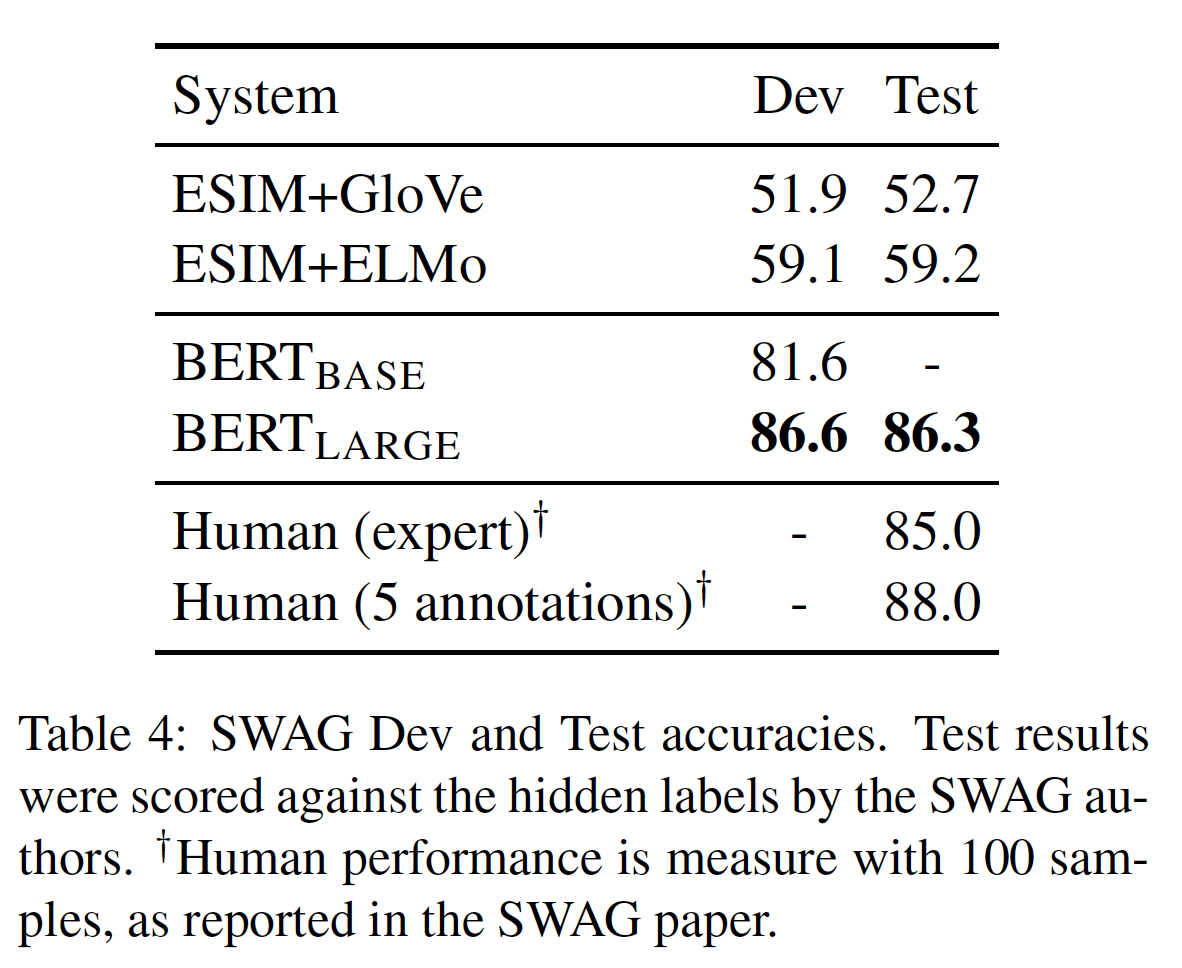
8.2.5 消融研究
- 尽管我们已经展示了极其强大的经验结果,但迄今为止所提出的结果并没有将
BERT框架的每个方面aspect的具体贡献分离出来。这里我们对BERT的一些方面进行了消融实验,以便更好地了解其相对重要性。
a. 预训练任务的效果
我们的核心主张
claim之一是BERT的深度双向性deep bidirectionality,这是由masked LM pre-training实现的并且是BERT与以前的工作相比最重要的一个改进。为了证明这一主张,我们评估了两个新模型,它们使用了与BERT_BASE完全相同的预训练数据、微调方案、以及Transformer超参数。No NSP:该模型使用MLM任务预训练,但是没有NSP任务。LTR & No NSP:该模型使用Left-to-Right: LTR的语言模型来训练,而不是使用MLM来训练 。在这种情况下,我们预测每一个input word,不应用任何masking。在微调时也应用了left-only约束,因为我们发现:用left-only-context进行预训练然后用bidirectional context进行微调总是更糟糕。此外,这个模型没有使用NSP任务进行预训练。这与
OpenAI GPT有直接的可比性,但使用了我们更大的训练数据集、我们的input representation、以及我们的微调方案。BERT在预训练期间学习[SEP]、[CLS]和segment A/B embedding,而GPT仅在微调期间学习这些input representation。
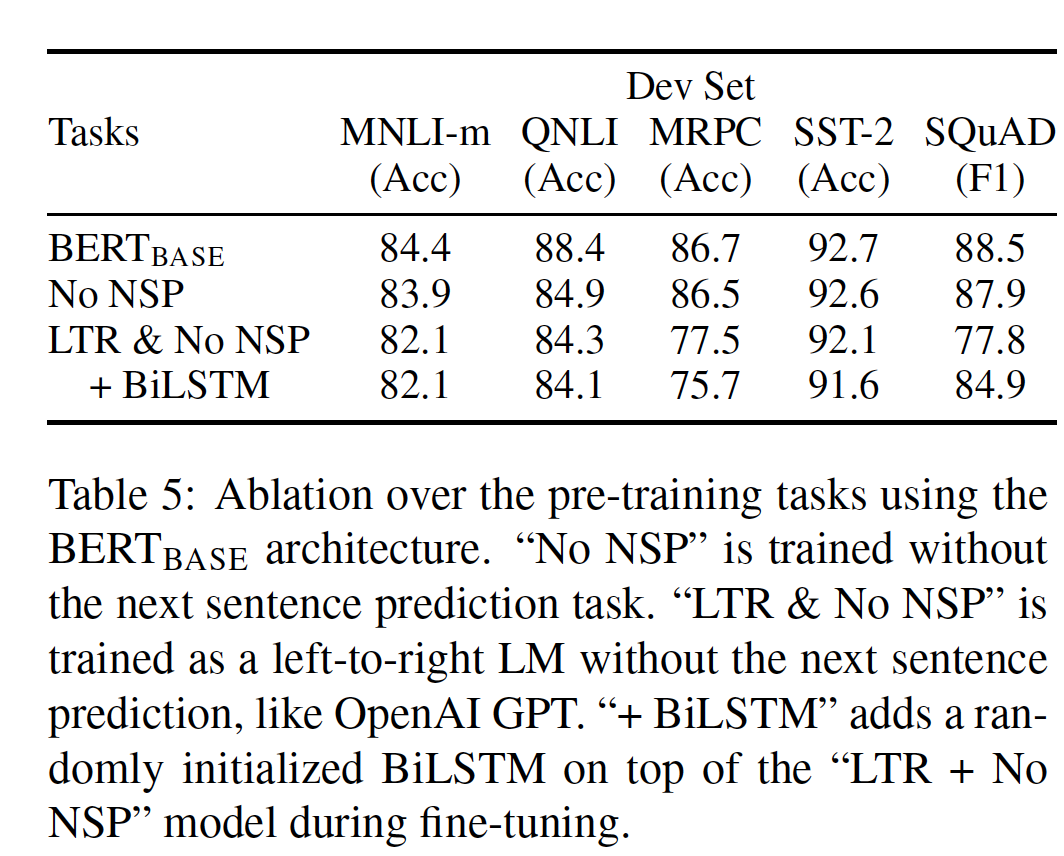
结果如下表所示。
我们首先检查了
NSP任务带来的影响。可以看到:去掉NSP对QNLI、MNLI和SQuAD的性能有很大的伤害。这些结果表明,我们的预训练方法对于获得前面介绍的强大的经验结果至关重要。后续的
XLNet和RoBERTa都表明:NSP任务不重要。而且RoBERTa的作者认为:BERT得出NSP任务重要的原因是,BERT的输入是两个句子的拼接,因此如果此时没有NSP任务则效果较差。在RoBERTa中,由于没有NSP任务,因此预训练样本就是一个完整的、来自单个文件的文档块。接下来,我们通过比较 "
No NSP"和 "LTR & No NSP"来评估训练bidirectional representation的影响。LTR模型在所有任务上的表现都比MLM模型更差,在MRPC和SQuAD上的下降幅度非常大。- 对于
SQuAD,直观而言,LTR模型在span预测和token预测方面的表现非常差,因为token-level hidden state没有右侧的上下文。 - 对于
MRPC而言,不清楚这种糟糕的表现是由于数据量小还是由于任务的性质,但是我们发现这种糟糕的表现在多次随机重启的full超参数扫描中是一致的。
- 对于
为了加强
LTR系统,我们尝试在它上面添加一个随机初始化的BiLSTM进行微调。这确实大大改善了SQuAD的结果,但结果仍然比预训练的双向模型差得多。它还损害了其它所有四个GLUE任务的性能。我们认识到:也可以像
ELMo那样,单独训练LTR和RTL模型,并将每个token表示为两个模型的拼接。然而:- 首先,这种方法比单一的双向模型要贵两倍。
- 其次,这种方法对像
QA这样的任务来说是不直观的,因为RTL模型不能以答案作为条件来回答问题(即,条件概率 - 最后,这种方法严格来说不如深度双向模型
deep bidirectional model强大,因为深度双向模型可以选择使用left context或right context。
b. Model Size 的效果
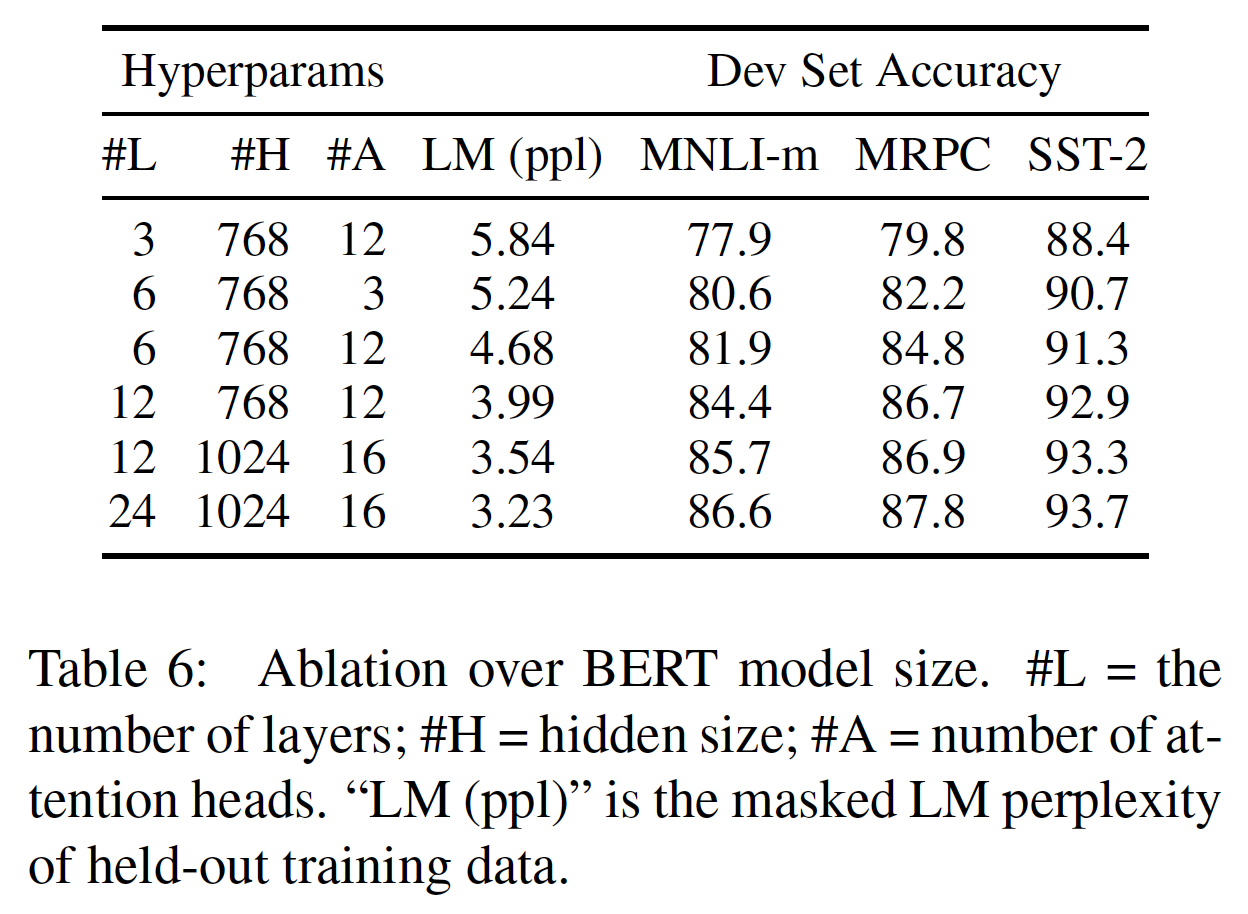
这里我们探讨了模型大小对微调任务准确性的影响。我们训练了一些具有不同层数、隐单元、以及注意力头的
BERT模型。除此之外,我们还使用了与前面所述相同的超参数和训练程序。选定的
GLUE任务的结果如下表所示。在这个表中,我们报告了5次随机重启微调的平均验证准确率。可以看到:更大的模型在所有四个数据集上都导致了一致的准确性提高,即使是只有
3600个标记的训练样本的MRPC。同样令人惊讶的是,我们能够在相对于现有文献已经相当大的模型之上实现如此显著的改进。例如:
《Attention is all you need》探索的最大的Transformer是(L=6,H=1024,A=16),编码器的参数为100M。- 而我们在文献中发现的最大的
Transformer是(L=64,H=512,A=2),参数为235M(《Character-level language modeling with deeper self-attention》)。 - 相比之下,
BERT_BASE包含110M参数,BERT_LARGE包含340M参数。
多年以来人们都知道,增加模型规模将导致大型任务(如机器翻译、语言建模)的持续改进,这可以通过下表所示的
held-out训练数据的LM perplexity来证明。然而,我们认为这是第一项工作,证明了扩展到极端的model size也会导致在非常小型的任务上有很大的改进,只要模型已经被充分地预训练过。即,增加模型规模不仅对大型任务有效,对小型任务也有效(模型需要被预训练)。
c. 训练步数的效果
下图展示了从一个已经预训练了
step的checkpoint进行微调后的MNLI验证准确性。这使我们能够回答以下问题。问题:
BERT是否真的需要如此大量的预训练(128,000 words/batch * 1,000,000 steps)来实现高的微调准确率?答案:是的。
BERT_BASE预训练一百万步时,与五十万步相比,在MNLI上实现了接近1.0%的微调准确率提升。问题:
MLM预训练的收敛速度是否比LTR预训练慢,因为每个batch中只有15%(而不是100%)的单词被预测?答案:是的,
MLM模型的收敛速度比LTR稍慢。然而,就绝对准确率而言,MLM模型几乎从一开始就超过了LTR模型。

d. Feature-based Approach with BERT
迄今为止,所有的
BERT结果都采用了微调方法,即在预训练的模型中加入一个简单的分类层,并在下游任务中联合微调所有的参数。然而,feature-based的方法,即从预训练的模型中抽取固定的特征,具有一定的优势:- 首先,并不是所有的
NLP任务都可以很容易地用Transformer编码器架构来表示,因此需要增加一个task-specific的模型架构。 - 其次,如果能够一次性地预先计算好训练数据的
expensive representation,然后在这个representation的基础上用不太昂贵的模型进行许多实验,这有很大的计算优势。
这里我们通过在
CoNLL-2003 NER任务上生成类似于ELMo的pre-trained contextual representation来评估BERT在feature-based的方法中的表现如何。为了做到这一点,我们使用与本文在Named Entity Recognition章节中相同的input representation,但是使用BERT的一个或多个层的激活值而没有微调任何参数。这些contextual embedding被用作一个双层BiLSTM的输入,这个双层BiLSTM具有768维并且是随机初始化的,并且这个双层BiLSTM位于最终的分类层之前。结果如下表所示。表现最好的方法是将预训练的
Transformer的最后四个隐层的token representation拼接起来,这比微调整个模型仅相差0.3 F1。这表明:BERT对微调方法和feature-based方法都是有效的。
- 首先,并不是所有的
九、XLNet[2019]
无监督表示学习
unsupervised representation learning在自然语言处理领域取得了巨大的成功。通常情况下,这些方法首先在大规模的无标签文本语料库中预训练神经网络,然后在下游任务中对模型或representation进行微调。在这个共同的high-level思想下,人们在各种文献中探讨了不同的无监督预训练目标unsupervised pretraining objective。其中,自回归autoregressive: AR语言建模language modeling和自编码autoencoding: AE是两个最成功的预训练目标。自回归语言建模旨在用自回归模型估计文本语料的概率分布。具体而言,给定一个文本序列
likelihood分解为前向乘积forward productbackward productdeep bidirectional context。相反,下游的语言理解任务往往需要双向的上下文信息。这就造成了自回归语言建模和有效的预训练之间的gap。相比之下,基于自编码的预训练并不进行显式的密度估计
density estimation(BERT,它一直是SOTA的预训练方法。给定输入的token序列,其中输入的某一部分token被一个特殊的符号[MASK]所取代,模型被训练为从破坏的版本中恢复原始token。由于任务目标不包含密度估计,所以BERT可以利用双向上下文来重建原始数据。作为一个直接的好处,这弥补了上述自回归语言建模中的bidirectional information gap,导致了性能的提高。然而:BERT在预训练时使用的[MASK]等人造符号在微调时不存在于真实数据中,从而导致了pretrain-finetune的不一致。- 此外,由于
predicted token在输入中被masked了,BERT不能像自回归语言建模那样使用乘积规则product rule建立联合概率模型。换句话说,BERT假设在给定unmasked token的条件下,predicted token之间是相互独立的。这是过于简化的,因为在自然语言中普遍存在着高阶的、长程的依赖性。
面对现有语言预训练目标的优点和缺点,在论文
《XLNet: Generalized Autoregressive Pretraining for Language Understanding》工作中,作者提出了一种广义的自回归方法,即XLNet。XLNet同时利用了自回归语言建模和自编码的优点,并避免了它们的局限。- 首先,
XLNet不是像传统的自回归模型那样使用固定的前向分解顺序forward factorization order或后向分解顺序backword factorization order,而是最大化关于分解顺序的所有可能的排列组合中,序列的期望对数似然expected log likelihood。由于排列操作permutation operation,每个位置的上下文可以同时由左右两侧的token组成。在预期中,每个位置学会利用来自所有位置的上下文信息,即捕获双向的上下文。 - 其次,作为一个广义的自回归语言模型,
XLNet不依赖于数据破坏data corruption。因此,XLNet不会受到BERT所带来的pretrain-finetune discrepancy的影响。同时,自回归目标还提供了一种自然的方法,可以使用乘积法则对predicted token的联合概率进行分解,消除了BERT中的独立性假设independence assumption。
除了新颖的预训练目标外,
XLNet还改进了预训练的架构设计。- 受自回归语言建模最新进展的启发,
XLNet将Transformer-XL的segment递归机制和相对编码方案relative encoding scheme融合到预训练中。根据经验,特别是在涉及较长文本序列的任务中,这会提高下游任务的性能。 - 简单直接地将
Transformer(-XL)架构应用于permutation-based的语言建模是行不通的,因为分解顺序是任意的、目标是模糊ambiguous的。作为一个解决方案,作者建议重新参数化reparameterizeTransformer(-XL)网络从而消除模糊性ambiguity。
根据经验,
XLNet在18个任务上取得了SOTA的结果,即:7个GLUE语言理解任务,3个阅读理解任务(包括SQuAD和RACE)、7个文本分类任务(包括Yelp和IMDB)、以及ClueWeb09-B文档排序任务。在一组公平的比较实验下,XLNet在多个benchmark上一直优于BERT。相关工作:
permutation-based的自回归建模的思想已经在《Neural autoregressive distribution estimation》和《Made: Masked autoencoder for distribution estimation》中进行了探讨,但有几个关键的区别。以前的模型是无序orderless的,而XLNet基本上是顺序感知order-aware的(带positional encoding)。这对语言理解language understanding很重要,因为无序模型会退化为bag-of-word,缺乏基本的表达能力。上述差异源于动机
motivation的根本差异:以前的模型旨在通过在模型中加入 "无序" 的归纳偏置inductive bias来改善密度估计,而XLNet的动机是使自回归语言模型学习双向上下文。
9.1 模型
9.1.1 背景
这里我们首先针对语言预训练
language pretraining来回顾并比较传统的自回归语言建模和BERT。给定一个文本序列
forward autoregressive factorization下的对数似然likelihood来进行预训练:其中:
RNN或Transformer)产生的context representation,embedding。vocabulary。
相比之下,
BERT是基于降噪自编码denoising auto-encoding的。具体来说,对于一个文本序列BERT首先通过随机设置15%)的token为特殊符号[MASK]从而构建一个破坏的版本masked token记做其中:
masked。Transformer,它将一个长度为T的文本序列hidden vector序列:Transformer的参数,hidden vector。
可以看到:在自回归语言建模中,
context representation为token(即,BERT中,context representation为token(即,两种预训练目标的优点和缺点比较如下:
独立性假设
Independence Assumption:正如BERT基于独立性假设来分解联合条件概率mask token相比之下,自回归语言建模目标使用普遍适用的乘积规则对
输入噪声
Input Noise:BERT的输入包含像[MASK]这样的人工符号,而这些符号在下游任务中从未出现过,这就造成了pretrain-finetune discrepancy。像BERT论文中那样用原始token替换[MASK]并不能解决问题,因为原始token只能以很小的概率被使用,否则相比之下,自回归语言建模并不依赖于任何输入破坏
input corruption,因此不会受到这个问题的影响。上下文不一致
Context Dependency:自回归representationtoken作为条件(即,左侧的token)。相比之下,
BERT representationBERT目标允许对模型进行预训练以更好地捕捉双向的上下文。
9.1.2 目标:排列语言建模
根据上面的比较,自回归语言模型和
BERT拥有各自独特的优势。一个自然的问题是:是否存在一种预训练目标,既能带来两者的优点又能避免它们的缺点?借用
orderless NADE(《Neural autoregressive distribution estimation》)的思路,我们提出了排列语言建模permutation language modeling目标,它不仅保留了自回归模型的优点,而且还允许模型捕获双向上下文。具体而言,对于一个长度为
autoregressive factorization。直观地说,如果模型参数在所有分解顺序中都是共享的,那么在预期中,模型将学会从两侧的所有位置收集信息。为了形式化这个思想,令
基本上,对于一个文本序列
likelihoodpretrain-finetune discrepancy。前向自回归分解和后向自回归分解分别采用了两种特殊的分解顺序:
Permutation的备注:所提出的目标只是排列分解顺序factorization order,而不是序列顺序sequence order。换句话说,我们保持原始的序列顺序,使用对应于原始序列的positional encoding,并依靠Transformer中恰当的attention mask来实现分解顺序的排列。请注意,这种选择是必要的,因为模型在微调期间只会遇到具有自然顺序的文本序列。XLNet在实现过程中并未采样attention mask来达到采样为了提供一个总体概览,我们在下图中展示了一个例子:给定相同的输入序列
tokenmem表示Transformer-XL的memory机制。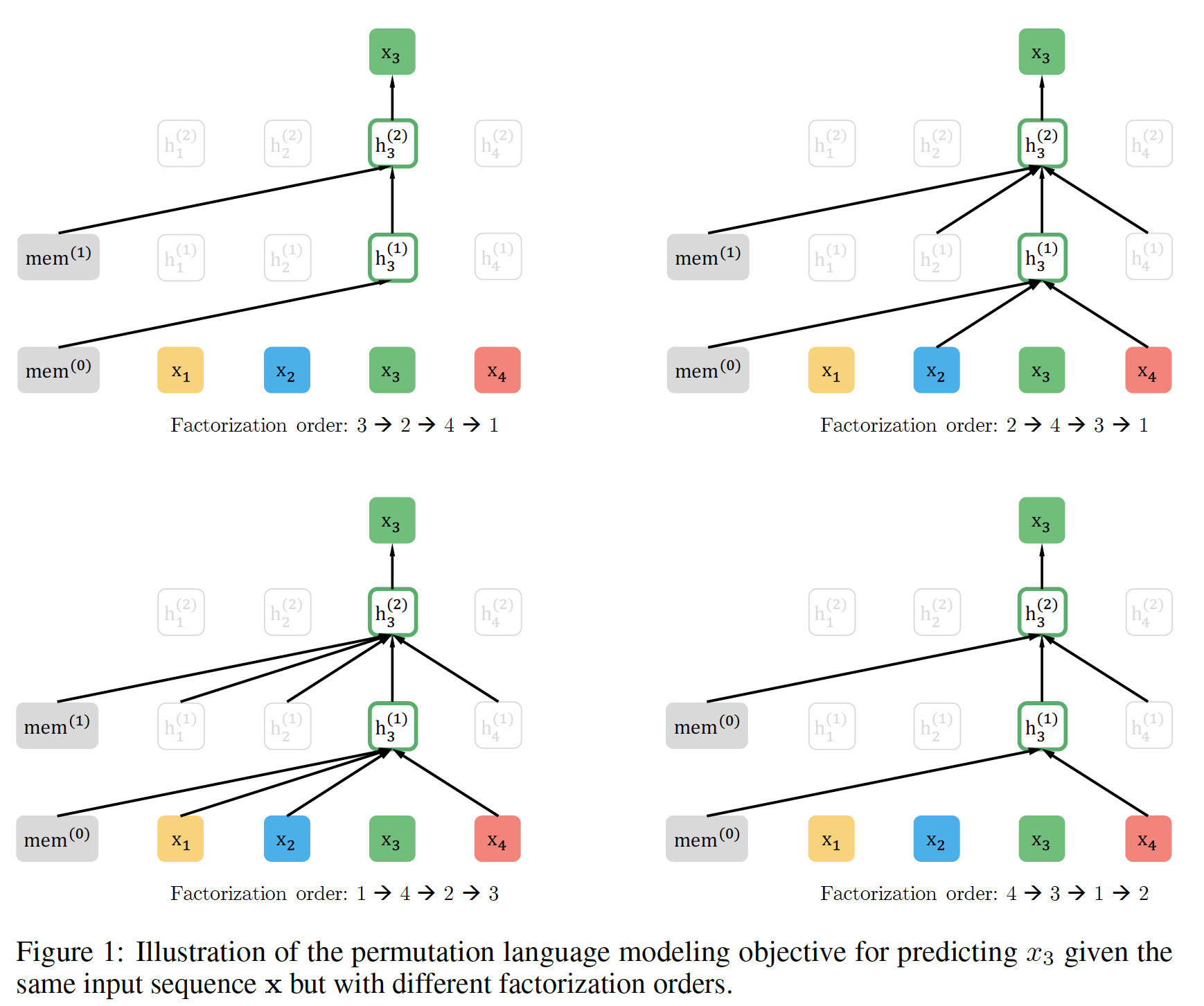
9.1.3 架构:双流自注意力
虽然排列语言建模目标具有理想的属性,但是标准
Transformer的朴素实现naive implementation可能无法工作。为了说明这个问题,假设我们使用标准的softmax公式对next-token分布parameterize,即:其中
Transformer网络生成的hidden representation(通过适当的掩码得到)。现在注意到:
representationrepresentation。为了避免这个问题,我们建议重新参数化next-token分布,使其感知到目标位置:其中
representation类型,它还将目标位置原始的
Transformer没有这个问题,因为Transformer输入序列的分解顺序是固定的(token就是位于序列中的位置但是,在排列语言建模目标,由于分解顺序是随机的,因此第
token的位置不确定(可能是原始序列中第一个位置、也可能是原始序列中最后一个位置)。标准的语言模型参数化失败的例子:考虑两个不同的排列
如果采用标准
Transformer的朴素实现,则有:从效果上看,两个不同的目标位置
ground-truth分布应当是不同的。双流自注意力
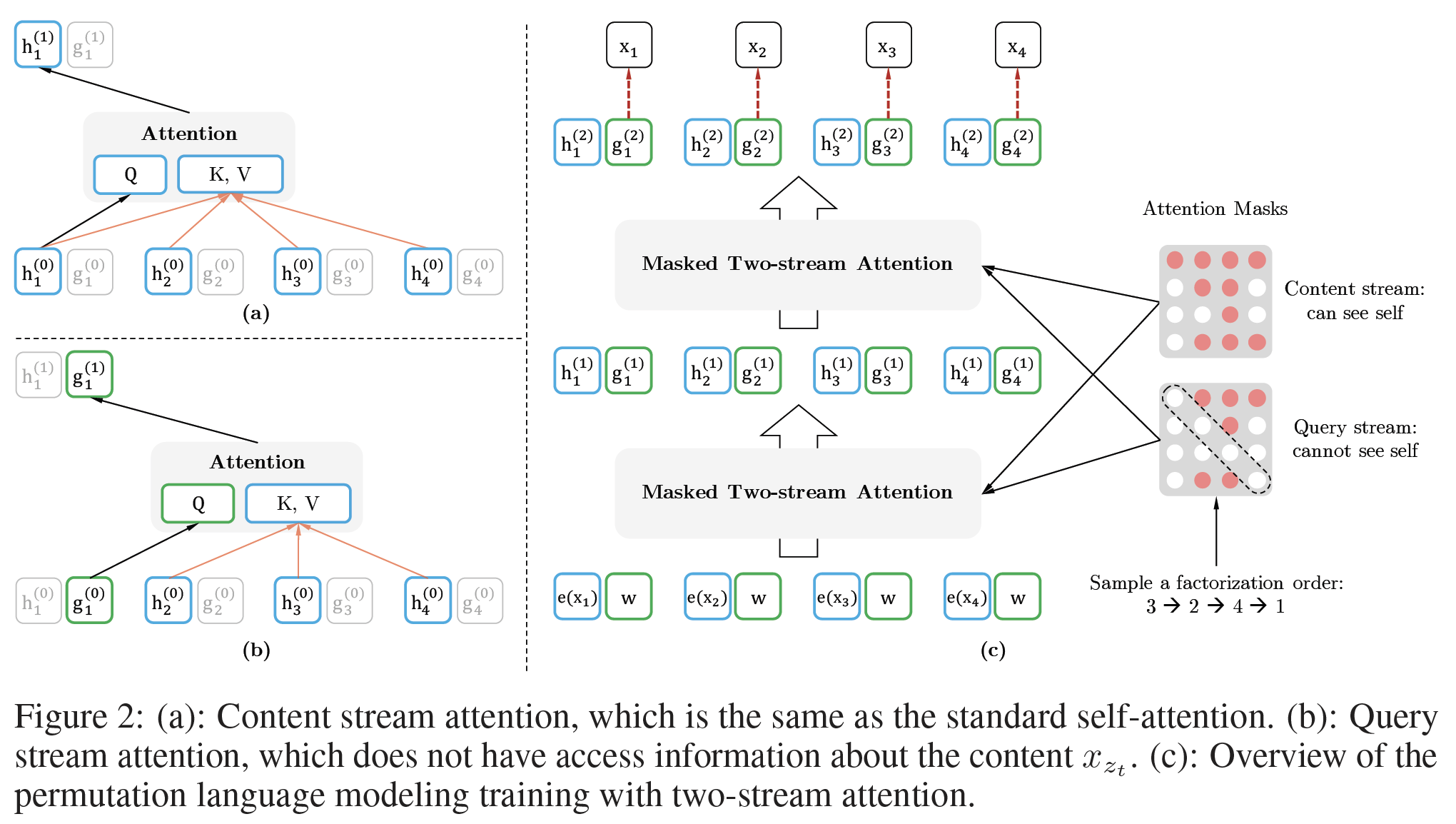
Two-Stream Self-Attention:虽然target-aware representation的思想消除了target prediction中的模糊性ambiguity,但如何形式化目标位置
token位于原始序列中的位置(而不是排列之后的位置,排列之后的位置就是为了使这个参数化
parameterization发挥作用,有两个要求在标准的Transformer架构中是矛盾的:- 为了预测
token - 为了预测
token
为了解决这样的矛盾,我们建议使用两组
hidden representation而不是一组:content representationTransformer中的标准hidden state类似。这个representation同时编码了上下文和注意,这里是小于等于号:
query representation
在计算上:
- 第一层查询流
query stream以trainable vector来初始化(即, - 而第一层内容流
content stream被设置为相应的word embedding(即,
对于每个自注意力层
representation stream用一组共享的参数进行更新:其中:
query, key, value。注意:
query stream中的key, value使用content stream中的key, value使用content representation的更新规则与标准的自注意力完全相同,因此在微调过程中,我们可以简单地放弃query stream,将content stream作为普通的Transformer(-XL)。最后,我们可以使用最后一层的
query representation因为
query representation包含了位置content representation不包含query representation来计算query representation会利用content representation来计算,而content representation就是传统的自注意力机制而不会用到query representation。- 为了预测
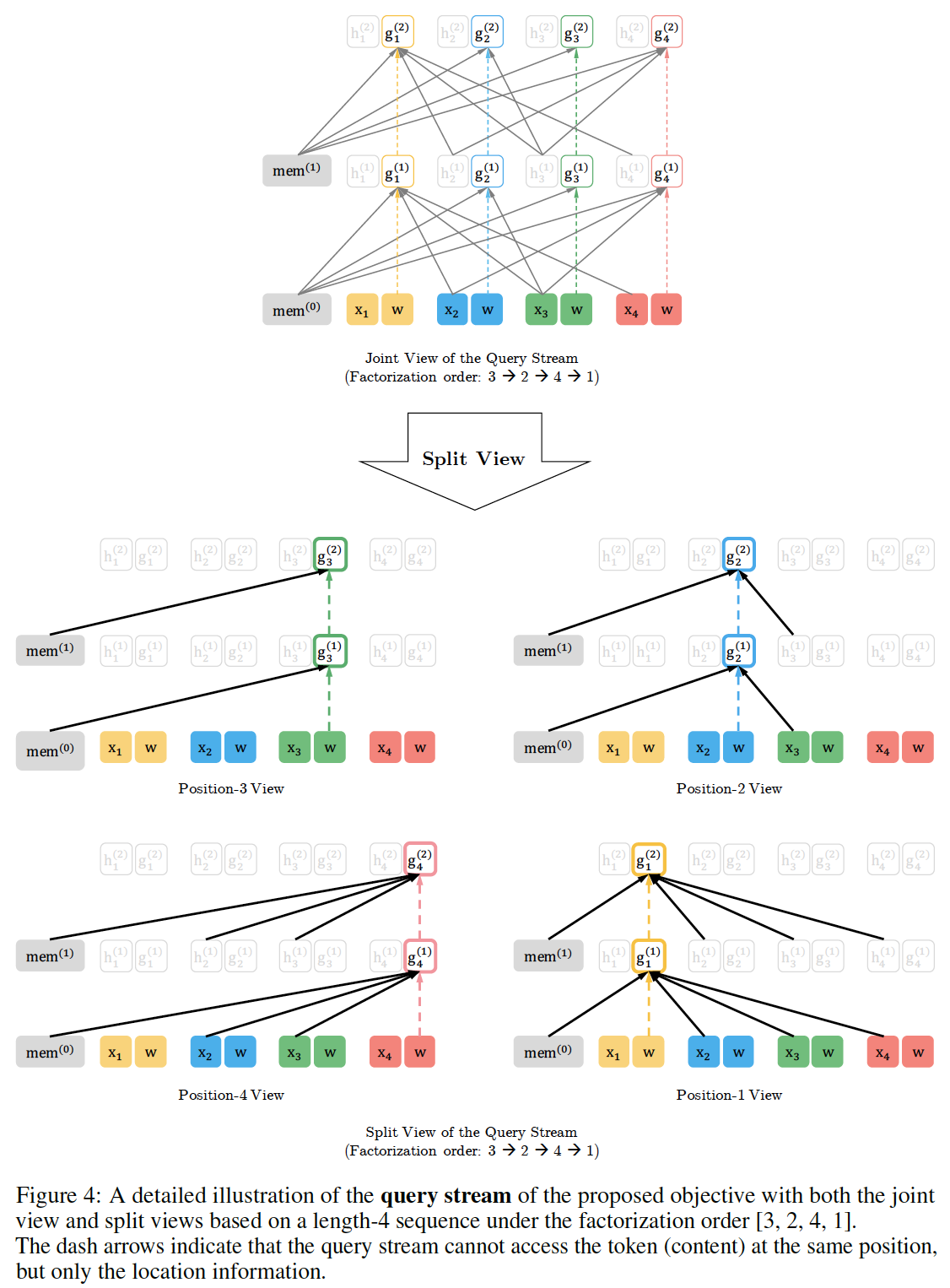
双流自注意力的示意图如下图所示,其中分解顺序为
3 -> 2 -> 4 -> 1而当位置图
(a):content stream,query,key/value。图
(b):query stream,query,key/value。图
(c):在attention mask中,第mask,白色代表不可见(掩码)、红色代表可见。query stream无法看到当前位置的内容,因此相比conent stream的attention mask,query stream的attention mask掩码了对角线。这就是通过生成合适的
attention mask来达到采样例如,
attention mask的第一行):- 由于
content stream中它可以看到所有位置(包括它自己),因此attention mask第一行全部是红色(可见)。 - 由于
query stream中它可以看到除了自己之外的所有其它位置,因此attention mask第一行除了第一个位置之外全部是红色。
- 由于
部分预测
Partial Prediction:虽然排列语言建模目标有几个好处,但由于排列组合,它是一个更具挑战性的优化问题,并在实验中导致收敛缓慢。为了降低优化难度,我们选择仅预测分解顺序中的最后一批token。正式地,我们把
non-target子序列target子序列non-target子序列的条件下最大化target子序列的对数似然log-likelihood,即:注意:
我们使用一个超参数
token被选中从而用于预测,即token,它们的query representation不需要计算,这就节省了速度和内存。这里假设序列的长度为
这里我们对所提出的排列语言建模目标进行了详细的可视化,包括
reusing memory机制(又称递归机制)、如何使用注意力掩码来排列分解顺序、以及两个注意力流的区别。如Figure 3和Figure 4所示,给定当前位置token此外,比较
Figure 3和Figure 4,我们可以看到query stream和content stream是如何通过attention mask在特定排列中工作的。主要的区别是:query stream不能做自注意力、不能访问当前位置上的token,而content stream则执行正常的自注意力。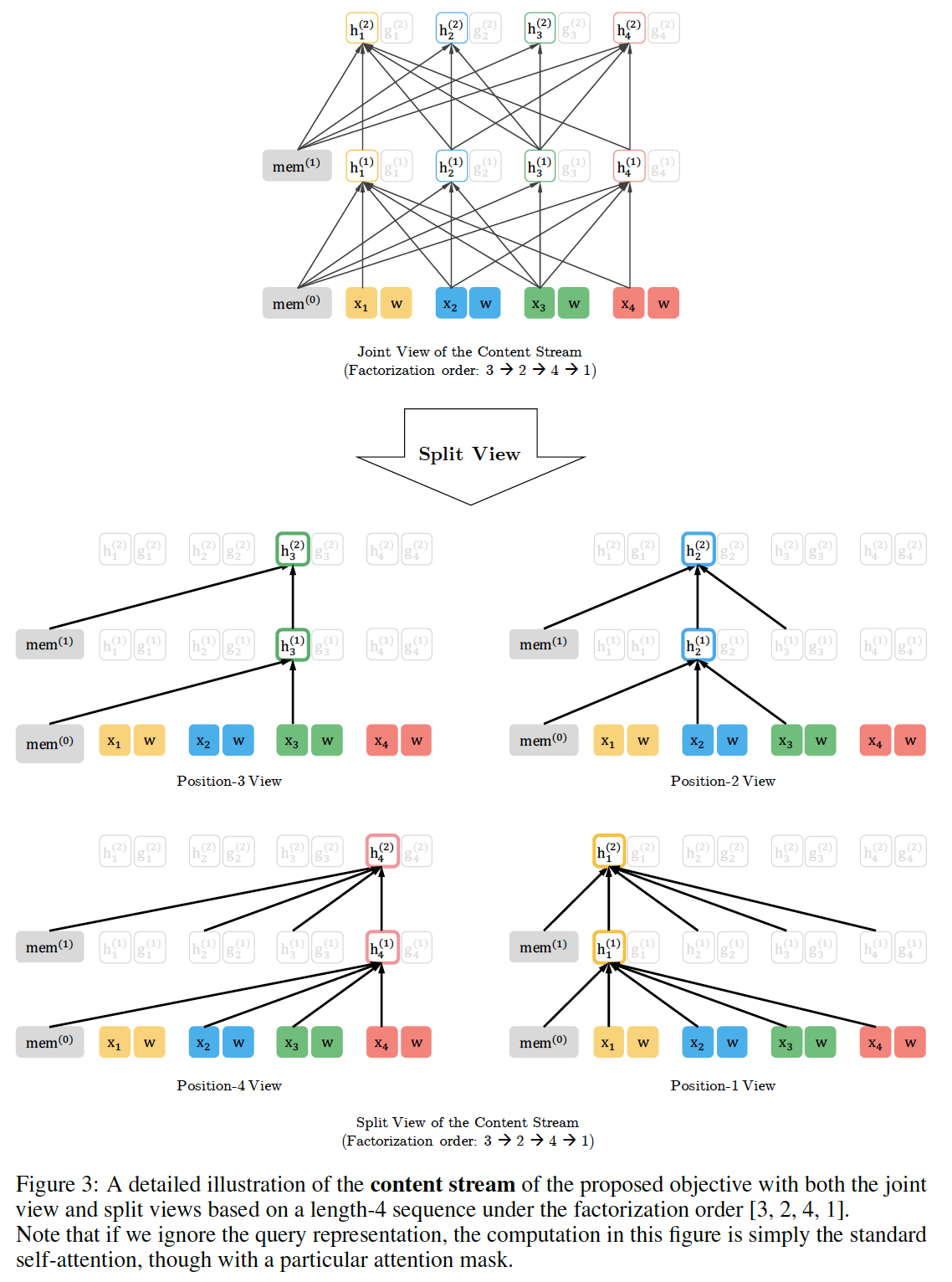
9.1.4 融合 Transformer-XL 的思想
由于我们的目标函数符合自回归框架,我们将
SOTA的自回归语言模型Transformer-XL纳入我们的预训练框架,并以它命名我们的方法(即,XLNet)。我们融合了Transformer-XL中的两项重要技术,即相对位置编码方案relative positional encoding scheme、段递归机制segment recurrence mechanism。如前所述,我们基于原始序列应用相对位置编码,这很直接。现在我们讨论如何将递归机制融合到所提出的
permutation setting中,并使模型能够重用previous segments的hidden state。在不失一般性的情况下,假设我们有来自长序列segment,即segment,然后为每个层content representationsegmentmemory的注意力机制可以写成:其中
注意,这里不用缓存
query representation,因为只有content representation才会被用来作为key和value。注意:
positional encoding只取决于原始序列中的实际位置。因此,一旦得到representationsegment的分解顺序的情况下缓存和复用memory。在预期中,该模型学习利用上一个segment的所有分解顺序的memory。不管前一个
segment的分解顺序如何,它始终位于当前segment之前,因此当前segment的任何位置都能看到所有的query stream也可以用同样的方法计算(只需要注意力机制中的修改key和value即可。)。最后,
Figure 2 (c)展示了所提出的具有双流注意力的排列语言建模的概况。更详细的介绍参考Figure 3和Figure 4。
9.1.5 建模多个 Segment
许多下游任务都有多个
input segment,例如,问答question answering: QA中包含一个问题和一个上下文段落。我们现在讨论一下我们如何预训练XLNet以便在自回归框架中对多个segment进行建模。在预训练阶段,遵从BERT,我们随机抽取两个segment(可以来自同一上下文,也可以来自不同的上下文),并将两个segment的拼接视为一个序列,以进行排列语言建模。我们仅复用属于同一上下文的memory。具体而言,我们模型的输入与
BERT类似:[A, SEP, B, SEP, CLS],其中"SEP"和"CLS"是两个特殊符号,"A"和"B"是两个segment。尽管我们遵循two-segment的数据格式,XLNet-Large没有使用next sentence prediction的目标,因为它在我们的消融研究中没有显示出一致的改进。注意,这里用于下游任务,即微调阶段。在预训练阶段,是没有多个
input segment的,因为预训练没有next sentence prediction目标。相对段编码
Relative Segment Encoding:从结构上看,与BERT在每个位置的word embedding中增加一个绝对段嵌入absolute segment embedding不同,我们从Transformer-XL中扩展了relative encoding的思想,也对segment进行相对编码。注意,这里也是用于下游任务,即微调阶段。
给定序列中的一对位置
segment,我们使用segment encodingsegment,则attention head的可学习模型参数。换句话说,我们仅考虑这两个位置是否在同一segment内,而不是考虑它们来自哪个具体的segment。这与relative encoding的核心思想是一致的,即,只对位置之间的关系进行建模。理论上讲,对于
input segment数量为2的输入,relative encoding和absolute encoding的模型容量是相同的,都是两个待学习的embedding参数。但是:- 二者的语义不同:
relative encoding的embedding空间编码了是否来自于同一个segment;absolute encoding的embedding空间编码了每个绝对segment id。 - 二者的用法不同:
relative encoding用于计算relative注意力系数,然后将这个系数添加到正常的注意力权重中;absolute encoding直接添加到word embedding从而直接计算注意力权重。
当位置
attend位置segment encodingquery向量,head-specific的偏置向量bias vector。最后,这个值使用
relative segment encoding有两个好处:首先,
relative encoding的归纳偏置inductive bias可以改善泛化性。其次,
relative encoding为那些有两个以上input segment的任务中进行微调提供了可能,而这是使用absolute segment encoding所不能做到的。因为
absolute segment encoding仅能编码训练期间看到的segment id(即,segment id = A、segment id = B,这两个id)。
- 二者的语义不同:
9.1.6 讨论和分析
a. 和 BERT 的比较
比较公式
BERT和XLNet都进行了部分预测,即仅预测序列中token的一个子集。- 这对
BERT来说是一个必须的选择,因为如果所有的token都被maksed了,就不可能做出任何有意义的预测。 - 此外,对于
BERT和XLNet来说,部分预测仅预测具有足够上下文的token,起到了降低优化难度的作用。 - 然而,前面内容讨论的独立性假设使得
BERT无法建模预测目标之间的依赖性。
- 这对
为了更好地理解这种差异,让我们考虑一个具体的例子:
[New, York, is, a, city]。假设BERT和XLNet都选择[New, York]这两个token作为预测目标,并最大化XLNet采样到了分解顺序[is, a, city, New, York]。在这种情况下,BERT和XLNet分别简化为以下目标:注意,
XLNet能够捕捉到一对目标(New, York)之间的依赖关系,而这个依赖关系被BERT忽略了。尽管在这个例子中,BERT学到了一些依赖关系,如(New, city)和(York, city)。但是很明显,在相同的目标下,XLNet总是能学到更多的依赖关系,并且包含 "denser" 的有效训练信号(即,上下文更长)。为了证明超一般性观点(而不是单个例子),我们现在转向更正式的表达。受之前工作的启发(
《Breaking the softmax bottleneck: A high-rank rnn language model》),给定一个序列target-context pair:token从而构成loss项pair注意:
ground-truth。无论给定一组
target tokennon-target tokenBERT和XLNet都能最大化其中:
token集合。这两个目标都由
loss项组成,其中target-context pairloss项target-context pair给定这个定义,我们考虑两种情况:
- 如果
BERT和XLNet所覆盖。 - 如果
XLNet所覆盖,而无法被BERT所覆盖。因此,XLNet能够比BERT覆盖更多的依赖关系。换句话说,XLNet目标包含更有效的训练信号,这将经验empirically地带来更好的性能。
- 如果
b. 和语言建模的比较
像
GPT这样的标准自回归语言模型只能覆盖依赖关系XLNet则能够在所有分解顺序的期望中覆盖这两种情况。标准自回归语言建模的这种限制在现实世界的应用中可能是至关重要的。例如,考虑一个
span extraction的问答任务,其中上下文是"Thom Yorke is the singer of Radiohead",问题是"Who is the singer of Radiohead"。在自回归语言建模中,"Thom Yorke"的representation不依赖于"Radiohead",因此"Thom Yorke"不会被标准方法(即,在上下文中所有的token representation上应用softmax)选为答案。更正式地说,考虑一个
context-target pair- 如果
token,那么自回归语言建模无法覆盖该依赖关系。 - 相比之下,
XLNet能够覆盖期望中的所有依赖关系。
- 如果
像
ELMo这样的方法以浅层的方式将前向语言模型和后向语言模型拼接起来,这不足以对两个方向之间的深层交互进行建模。
c. 弥合语言建模和预训练之间的 gap
由于缺乏双向上下文建模的能力,语言建模和预训练之间一直存在着
gap,正如前面内容所分析的。一些机器学习从业者甚至质疑:如果语言建模不能直接改善下游任务,那么它是否有意义。XLNet推广了语言建模并弥补了这个gap。因此,它进一步 "证实" 了语言建模的研究。此外,针对预训练而利用语言建模研究的快速进展也成为可能。作为一个例子,我们将Transformer-XL融合到XLNet中,从而证明最新的语言建模进展的有用性。
9.2 实验
9.2.1 预训练和实现
遵从
BERT,我们使用BooksCorpus和English Wikipedia作为我们预训练数据的一部分,它们合并起来有13GB的纯文本。此外,我们还包括Giga5(16GB文本)、ClueWeb 2012-B和Common Crawl进行预训练。我们使用启发式方法激进地过滤掉ClueWeb 2012-B和Common Crawl中短的或低质量的文章,结果分别得到19GB和78GB的文本。在使用
SentencePiece(《Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing》)进行tokenization后,我们为Wikipedia、BooksCorpus、Giga5、ClueWeb和Common Crawl分别得到27.8B、1.09B、4.75B、4.30B和19.97B个subword piece,共计32.89B个subword piece。我们最大的模型
XLNet-Large具有与BERT-Large相同的架构超参数,这导致了相似的模型大小。序列长度和memory长度分别被设置为512和384。我们在
512个TPU v3芯片上对XLNet-Large进行了500K步的训练,使用Adam优化器,线性学习率衰减,batch size = 2048,这大约需要2.5天。据观察,模型在训练结束时仍然对数据欠拟合,但继续预训练对下游任务没有帮助,这表明给定优化算法,模型没有足够的容量来充分利用数据规模。然而,在这项工作中,我们避免训练一个更大的模型,因为它在微调方面的实际用途可能是有限的。此外,类似于
BERT-Base,我们考虑只在BooksCorpus + Wikipedia上训练一个XLNet-Base,用于消融研究、以及和BERT的公平比较。由于引入了递归机制,我们使用了一个双向的
data input pipeline,其中前向和后向各占batch size的一半。双向的
data input pipeline意思是:在batch中,既有正序(相对于原始序列顺序)的输入、又有逆序(相对于原始序列顺序)的输入。这是为了配合span-based预测。因为
span-based预测直接将原始序列中连续token作为预测目标,顺序不变(如,从I like New York, because ...中截取(New, York))。如果只有正序输入,那么这些预测目标之间只能捕获前向的依赖性(如,p(York | New))。增加了逆序输入之后,这些预测目标之间就可以捕获后向的依赖性(如,p(New | York))。注意,这里影响的是预测目标之间的依赖性,而不是预测目标和上下文之间的依赖性。为了训练
XLNet-Large,我们将部分预测常数6。我们的微调程序遵循BERT,除非另有说明。我们采用了一种span-based预测的思想,首先采样一个长度token的上下文中随机选择连续的、跨度为token作为预测目标。假设随机选择的位置为
这种
span-based的方法易于实现,但是它强迫预测目标是连续的,且预测目标之间保持原始序列的顺序不变。预训练
XLNet的超参数如下表所示。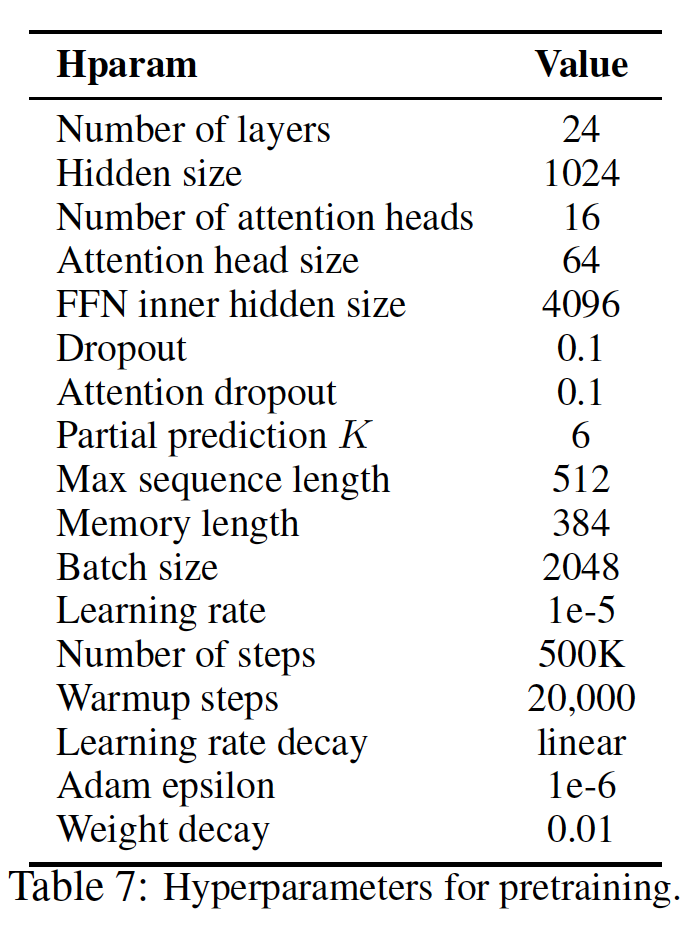
微调
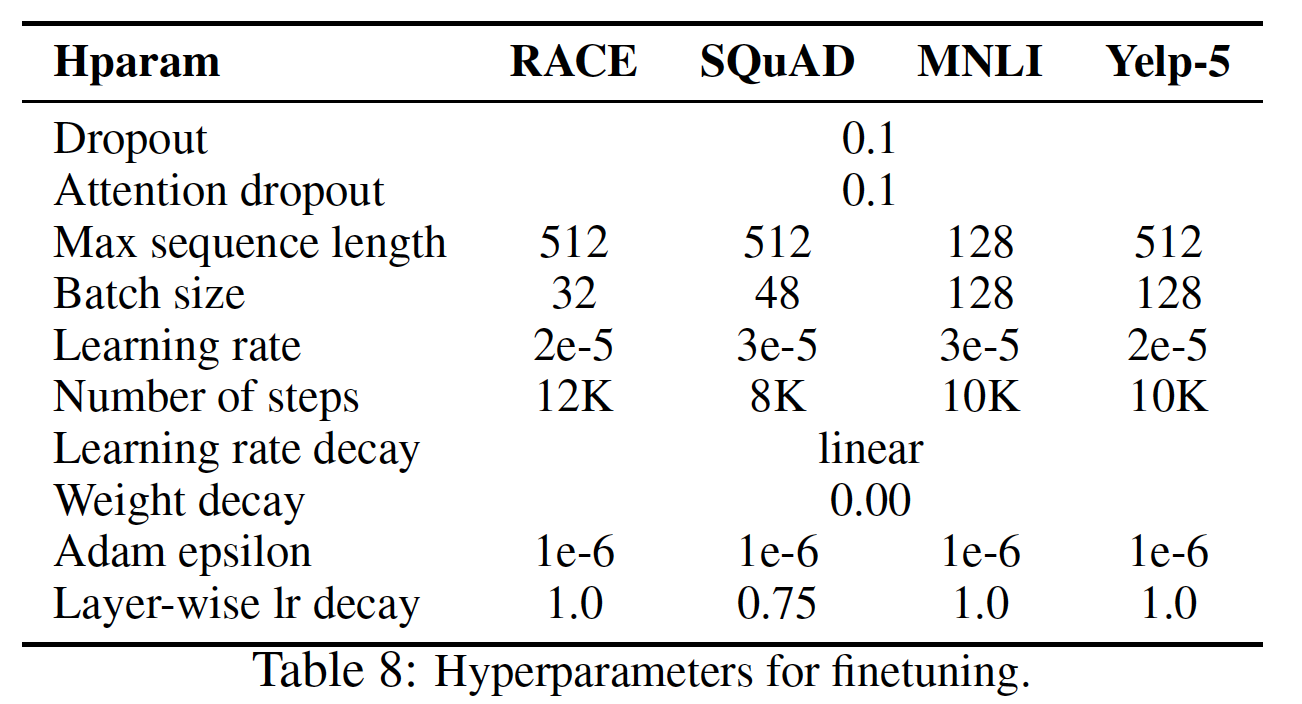
XLNet的超参数如下表所示。Layer-wise decay是指以自上而下的方式对各个层的学习率进行指数衰减。例如,假设第24层使用的学习率为Layer-wise衰减率为这意味着从上到下,更新的步幅越来越小。这隐含了一个约束:底层的更新更小而顶层的更新越大。
9.2.2 RACE 数据集
RACE数据集包含了近10万个问题,这些问题来自于12到18岁之间的中国初高中学生的英语考试,答案由人类专家生成。这是最难的阅读理解数据集之一,涉及到具有挑战性的推理问题。此外,RACE中段落的平均长度超过300,这比其他流行的阅读理解数据集如SQuAD长很多。因此,这个数据集可以作为长文本理解的一个挑战性的benchmark。在微调过程中,我们使用的序列长度为
640。如下表所示:- 单一模型
XLNet的准确率比最佳ensemble高出7.6分。 - 同样明显的是,
XLNet大大超过了其他预训练的模型,如BERT和GPT。
由于
RACE包含相对较长的段落,我们认为XLNet在这个数据集上获得巨大收益的原因之一是:除了自回归目标之外,XLNet融合了Transformer-XL架构从而提高了对长文本建模的能力。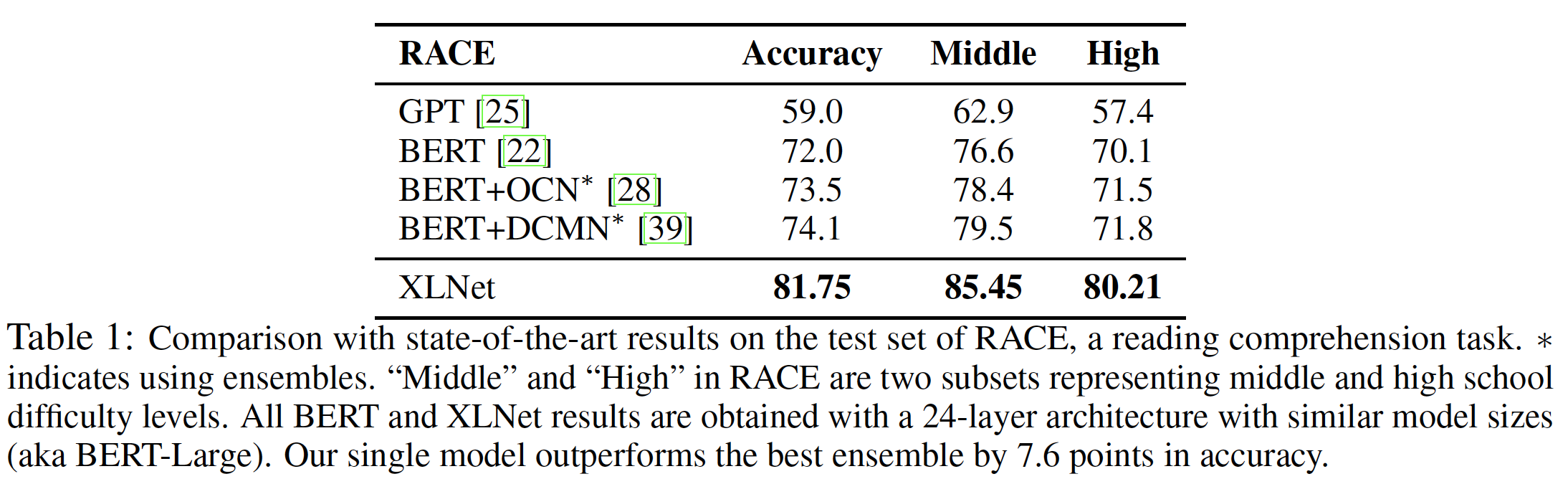
- 单一模型
9.2.3 SQuAD 数据集
SQuAD是一个具有两个任务的大规模阅读理解数据集。SQuAD1.1包含了在给定段落中总是有相应答案的问题,而SQuAD2.0则引入了不可回答的问题(即,给定段落中不存在答案)。为了在
SQuAD2.0上对XLNet进行微调,我们联合应用了类似于分类任务的逻辑回归损失(表明任务是否有答案)、和问答任务的标准span extraction损失。由于v1.1和v2.0在训练集中共享相同的可回答的问题,我们只需在v2.0上微调的模型中删除answerability prediction部分(即,任务是否有答案的部分),即可对v1.1进行评估。由于排行榜头部的方法都采用了某种形式的数据增强,我们在SQuAD2.0和NewsQA上联合训练了一个XLNet从而用于我们的排行榜submission。如下表所示:
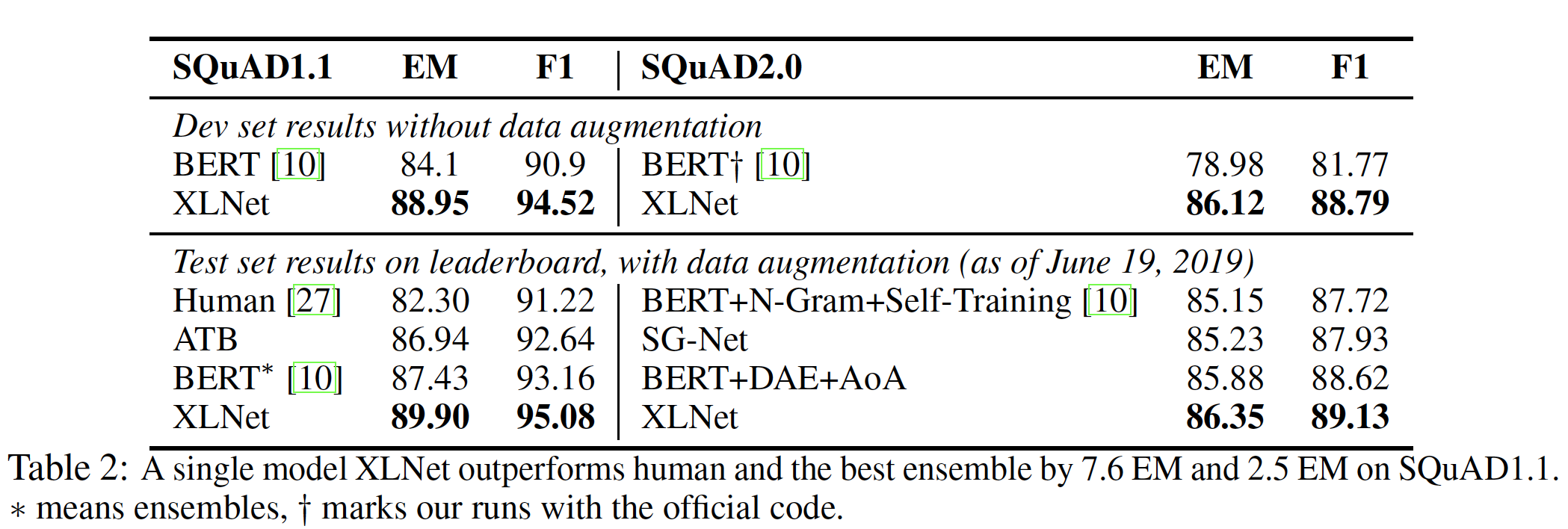
XLNet在排行榜上获得了SOTA的单一模型结果,超过了一系列基于BERT的方法。- 值得注意的是,在
v1.1中,XLNet的单一模型在EM指标上的表现比人类和最佳ensemble分别高出7.6分和2.5分。 - 最后,为了与
BERT直接比较从而消除排行榜submission上的额外技巧的影响,我们在验证集上将XLNet与BERT进行了比较。XLNet在v1.1和v2.0的F1指标中大大超过了BERT,分别超出3.6分和7.0分。
9.2.4 文本分类
遵从以前的文本分类工作(
《Character-level convolutional networks for text classification》、《Adversarial training methods for semi-supervised text classification》),我们在以下benchmark上评估了XLNet:IMDB、Yelp-2、Yelp-5、DBpedia、AG、Amazon-2和Amazon-5。如下表所示,
XLNet在所有给定的数据集上取得了新的SOTA结果,与BERT相比,在IMDB、Yelp-2、Yelp-5、Amazon-2和Amazon-5上的错误率分别降低了16%、18%、5%、9%和5%。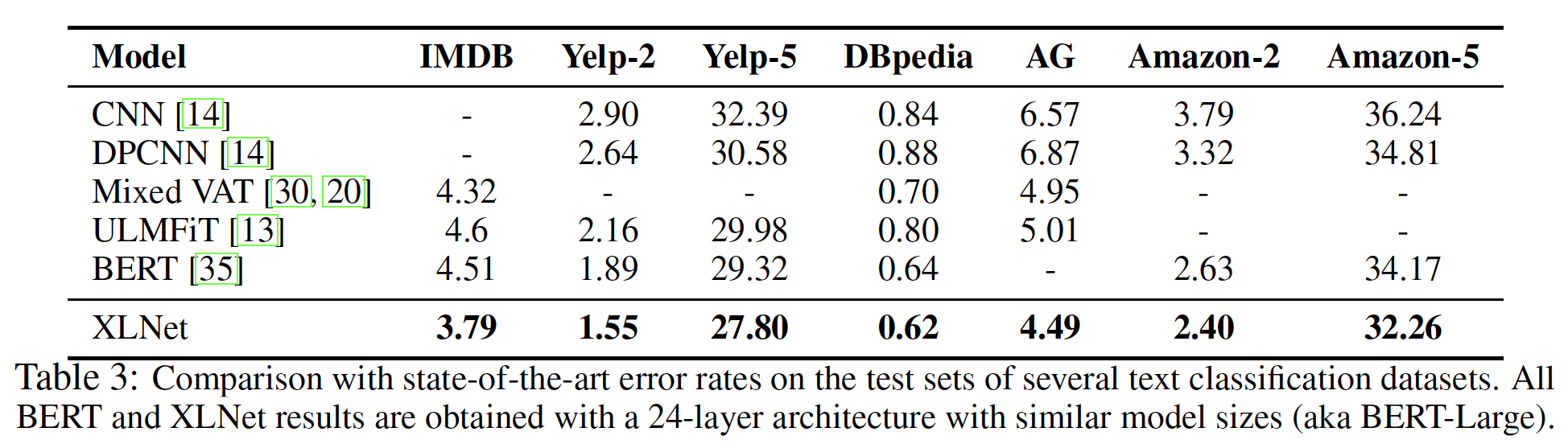
9.2.5 GLUE 数据集
GLUE数据集是一个包含9个自然语言理解任务的集合。测试集标签在公开发布的版本中被删除,所有用户必须在evaluation server上提交他们的预测,以获得测试集结果。在下表中,我们展示了多种
setting的结果,包括单任务和多任务、以及单一模型和ensemble。在多任务
setting中,我们在四个最大的数据集(即,NLI、SST-2、QNLI和QQP)上联合训练XLNet,并在其他数据集上微调网络。对于这四个大型数据集,我们只采用了单任务训练。
即,多任务训练仅用于其他的数据集。
对于
QNLI,我们在提交测试集时采用了《Multi-task deep neural networks for natural language understanding》中的pairwise relevance ranking方案。然而,为了与BERT进行公平的比较,我们对QNLI验证集的结果是基于标准的分类范式classification paradigm的。对于
WNLI,我们使用《A surprisingly robust trick for winograd schema challenge》中描述的损失。
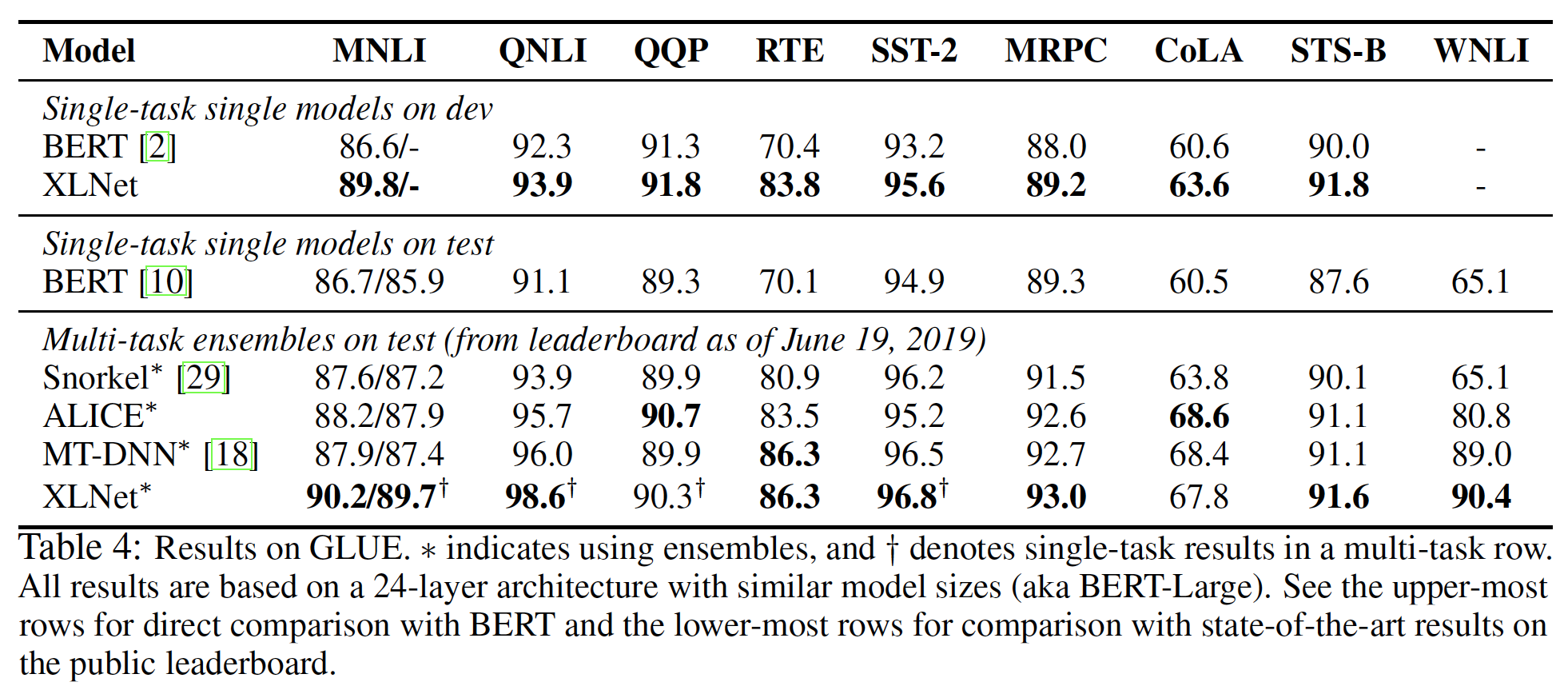
可以看到:
多任务
ensemble的XLNet在公共排行榜的9个任务中的7个任务上取得了SOTA的结果。在最广泛的基准任务MNLI上,XLNet将 "匹配" 和 "不匹配" 的setting分别提高了2.0分和1.8分。注意,排行榜上的竞争者采用了比
BERT更好的技术,如蒸馏、修改的多任务损失、或元学习meta learning,但仍然低于XLNet的表现。而XLNet除了使用标准的多任务学习方法外,没有采用额外的技巧。由于排行榜的目的不是为了消融研究或超参数调优,我们只在测试集上评估了我们最好的多任务模型。为了获得与
BERT的直接比较,我们在验证集上运行一个单任务XLNet。如下表的最上面几行所示,XLNet一直优于BERT,在RTE、MNLI、CoLA、SST-2和STS-B上分别提高了13.4分、3.2分、3.0分、2.4分 和1.8分。
9.2.6 ClueWeb09-B 数据集
遵从
《Convolutional neural networks for soft-matching n-grams in ad-hoc search》的setting,我们使用ClueWeb09-B数据集来评估文档排序document ranking的性能。这些query是由TREC 2009-2012Web Tracks基于50M个文档创建的,任务是对使用标准检索方法检索到的前100个文档进行rerank。由于document ranking或ad-hoc retrieval主要涉及low-level representation,而不是high-level的语义,这个数据集可以作为评估word embedding质量的测试平台。我们使用预训练好的
XLNet来抽取文档和query的word embedding而不进行微调,并采用kernel pooling network(《End-to-end neural ad-hoc ranking with kernel pooling》)对文档进行排序。结果如下表所示:
XLNet大大超过了其他方法,包括使用与我们相同训练程序的BERT模型。这说明XLNet比BERT能更好地学习low-level的word embedding。注意,为了公平比较,我们排除了
《Word-entity duet representations for document ranking》中的结果(ERR@20为19.55,略差于我们),因为它使用了额外的实体相关数据。DCG@k指标:item是否命中真实的目标item,取值为1或0。NDCG@k指标:对DCG@k的归一化,归一化分母为item数量(小于等于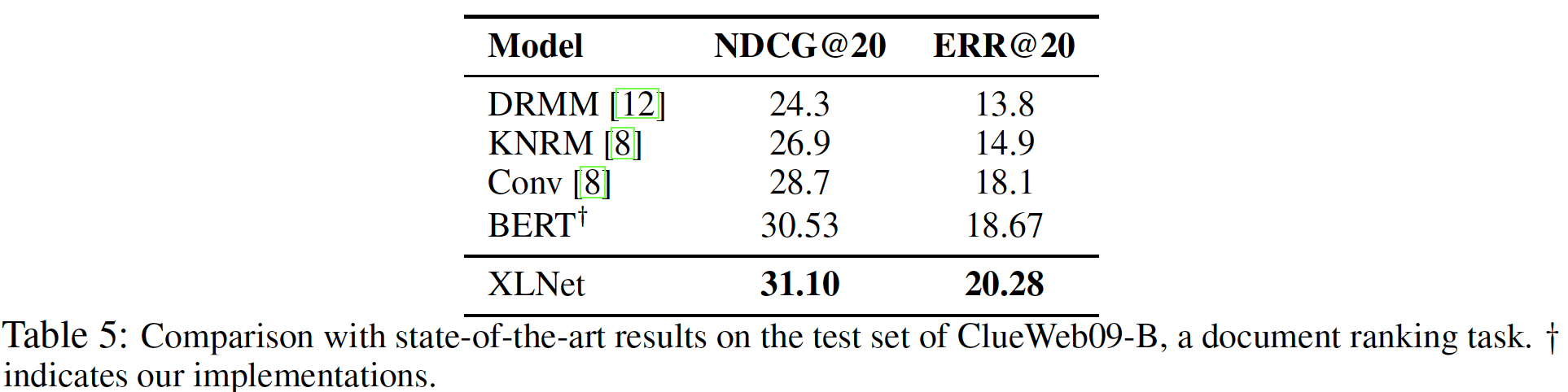
9.2.7 消融研究
基于四个具有不同特点的数据集,我们进行了一项消融研究从而了解每个设计选择的重要性。具体来说,我们希望研究的主要有三个方面:
- 排列语言建模目标的有效性,具体而言,是与
BERT使用的降噪自编码目标相比。 - 使用
Transformer-XL作为backbone神经架构、以及采用segment-level递归(即,使用memory)的重要性。 - 一些实施细节的必要性,包括
span-based的预测、双向input pipeline和next-sentence prediction。
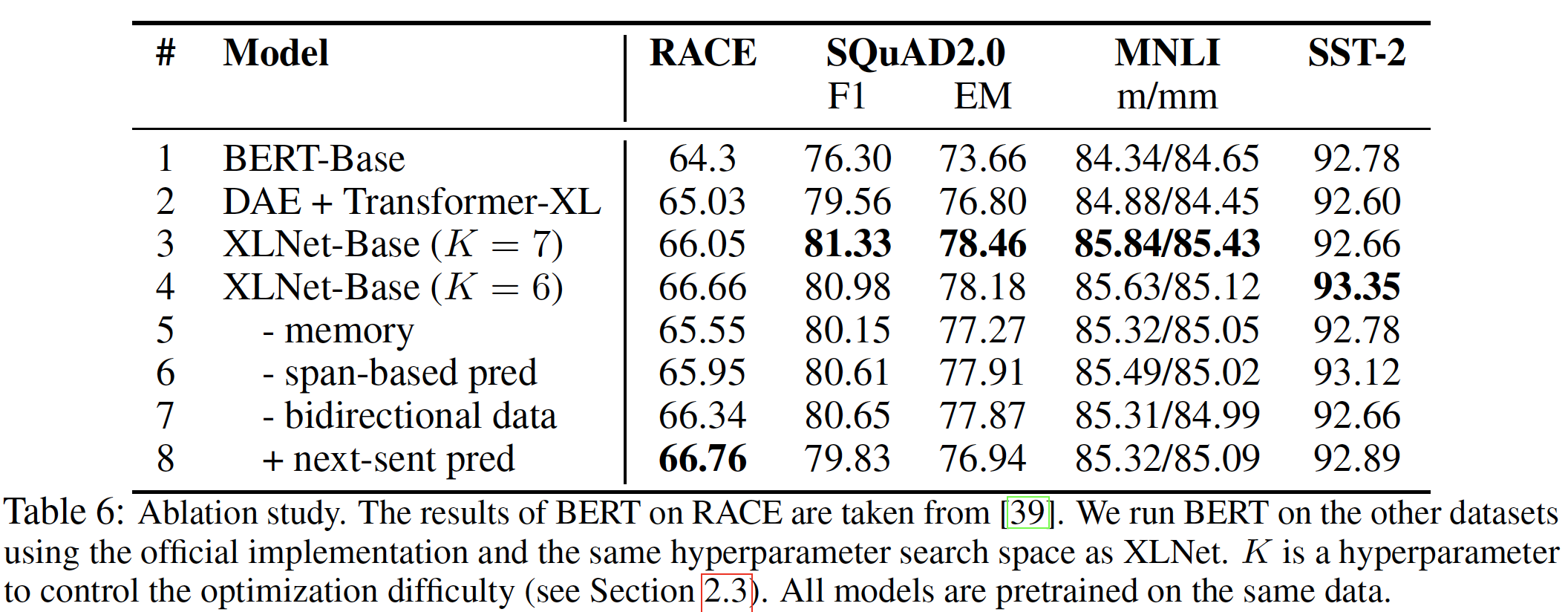
考虑到这些目的,在下表中,我们比较了具有不同实施细节的
6个XLNet-Base变体(第3 ~ 8行)、原始的BERT-Base模型(第1行),以及一个额外的Transformer-XL baseline(第2行)。这个Transformer-XL baseline用BERT中使用的降噪自编码enoising auto-encoding: DAE目标训练,但具有双向input pipeline。为了进行公平的比较,所有的模型都是基于一个12层的架构,具有与BERT-Base相同的模型超参数,并且只对Wikipedia + BooksCorpus进行训练。所有报告的结果都是5次运行的中位数。检查结果的第
1 ~ 4行,我们看到用不同的full XLNet-Base模型在各任务中的表现明显优于BERT、以及DAE训练的Transformer-XL,这显示了排列语言建模目标的优越性。同时,有趣的是,
DAE训练的Transformer-XL在RACE和SQuAD等长文本的任务中取得了比BERT更好的表现,这表明Transformer-XL在语言建模方面的卓越表现。DAE + Transformer-XL与BERT不同的地方在于:相对位置编码、以及segment-level递归。接下来,如果我们去掉
memory缓存机制(第5行),则性能明显下降,特别是对于涉及4个任务中最长上下文的RACE。此外,第
6 ~ 7行显示,span-based预测和双向input pipeline在XLNet中都发挥了重要作用。最后,我们意外地发现,在最初的
BERT中提出的next-sentence prediction目标在我们的setting中不一定能带来改进。相反,除了RACE数据集,next-sentence prediction往往会损害性能。因此,当我们训练XLNet-Large时,我们排除了next-sentence prediction目标。
- 排列语言建模目标的有效性,具体而言,是与
十、RoBERTa[2019]
ELMo、GPT、BERT、XLM和XLNet等自训练self-training方法带来了显著的性能提升,但要确定这些方法的哪些方面贡献最大,可能是一个挑战。训练的计算成本很高,限制了可以进行tuning的数量,而且通常是用不同规模的private training data进行的,这限制了我们衡量模型先进性的能力。论文
《RoBERTa: A Robustly Optimized BERT Pretraining Approach》提出了一项关于BERT预训练的复制研究replication study,其中包括对超参数调优和训练集规模的影响的仔细评估。论文发现BERT的训练明显不足。然后论文提出了一个改进的配方recipe用于训练BERT模型,作者称之为RoBERTa。RoBERTa可以匹配或超过所有的post-BERT方法的性能。作者的修改很简单,包括:- 在更多的数据上用更大的
batch来训练模型。 - 移除
next sentence prediction目标。 - 在更长的序列上进行训练。
- 动态地改变应用于训练数据的
masking pattern。
论文还收集了一个新的大型数据集(
CC-NEWS),其规模与其他privately used datasets相当,以更好地控制训练集的规模效应。当控制训练数据时,
RoBERTa改进的训练程序改善了GLUE和SQuAD上公布的BERT结果。当对额外的数据进行更长时间的训练时,RoBERTa在公共GLUE排行榜上取得了88.5分,与XLNet报告的88.4分相匹配。RoBERTa在GLUE任务中的4/9个任务上实现了SOTA,包括:MNLI、QNLI、RTE和STS-B四个任务。RoBERTa还在SQuAD和RACE上取得了SOTA的结果。总的来说,论文重新确立了BERT的masked language model训练目标相比最近提出的其他训练目标(如XLNet的排列自回归语言模型)具有竞争力。综上所述,本文的贡献在于:
- 论文提出了一套重要的
BERT设计选择和训练策略,并介绍了导致更好的下游任务性能的替代品alternatives。 - 论文使用了一个新的数据集
CCNEWS,并确认使用更多的数据进行预训练能够进一步提高了下游任务的性能。 - 论文的训练改进
improvement表明,在正确的设计选择下,masked language model预训练相比所有其他最近发表的方法具有竞争力。
论文发布了用
PyTorch实现的模型、预训练和微调代码。- 在更多的数据上用更大的
相关工作:人们为预训练方法设计了不同的训练目标,包括语言建模
language modeling、机器翻译machine translation和掩码语言模型masked language modeling。最近的许多论文都采用了为每个下游任务微调模型的基本配方basic recipe,并以某种变体的掩码语言模型目标进行预训练。然而,较新的方法通过多任务微调(UNILM)、融合实体嵌入(ERNIE)、跨度预测span prediction(SpanBERT)和自回归预训练(XLNet)的多种变体来改善性能。通过在更多的数据上训练更大的模型,通常也能提高性能。我们的目标是复制、简化和更好地微调
BERT的训练,作为一个参考,以更好地了解所有这些方法的相对性能。
10.1 分析
10.1.1 背景
这里我们简要介绍了
BERT的预训练方法和一些训练选择,我们将在下一节进行实验研究。Setup:BERT将两个segment(token的序列)的拼接作为输入,即segment Asegment Bsegment通常由一个以上的自然句子组成。这两个segment拼接之后作为单个输入序列馈入BERT,并以特殊的token来分隔它们:根据
BERT的原始论文,应该是该模型首先在一个大型的无标记文本语料库中进行预训练,随后使用下游任务的标记数据进行微调。
架构:
BERT使用著名的Transformer架构,我们将不详细回顾。我们使用一个具有Transformer架构。每个block使用这里的
block,每个block具有多个子层。训练目标:在预训练期间,
BERT使用两个目标:掩码语言模型和下一个句子预测next sentence prediction。Masked Language Model: MLM:在输入序列中随机选择一个token,并用特殊的token(即,[MASK])来代替。MLM的目标是masked token预测结果的交叉熵损失。BERT均匀随机地选择15%的input token,然后在所选的token中:80%被替换为[MASK]、10%保持不变、10%被替换为另一个被随机选择的vocabulary token。在最初的实现中,
random masking和random replacement在开始时进行一次,并在训练期间save起来(即固定下来)。尽管在实践中,数据是不断重复的(即,每个epoch都会重复遍历一轮所有样本),所以每个训练句子在不同epoch之间的mask并不总是相同的。即,这里的
random masking和random replacement是在所有样本的所有epoch上进行的,这必然需要对数据集存储多份,每一份对应于一个epoch。Next Sentence Prediction: NSP:NSP是一种二元分类损失,用于预测两个segment是否在原始文本中是相互紧跟着。正样本是通过从文本语料库中抽取前后连续的句子来创建的。负样本是通过将不同文件中的segment配对来创建的。正样本和负样本是以相同的概率采样的。NSP目标的设计是为了提高下游任务的性能,例如自然语言推理Natural Language Inference: NLI,这需要推理句子对sentence pair之间的关系。
Optimization:BERT用Adam优化,超参数为BERT训练时,所有层和注意力权重的dropout rate为GELU激活函数。- 模型被预训练一百万个
step(即,batch size为token。
数据:
BERT是在BOOKCORPUS和English WIKIPEDIA这两个数据集的联合上进行训练的,总共包含16GB的未压缩文本。
10.1.2 实验配置
实现:我们在
FAIRSEQ中重新实现了BERT。- 我们主要遵循前面给出的原始
BERT超参数,除了峰值学习率和预热step的数量(这两个超参数是针对每个setting单独调优的)。 - 我们另外发现训练对
Adambatch size训练时提高稳定性。 - 我们用最长为
token的序列进行预训练。 - 与原始
BERT不同,我们不随机注入短序列,也不在前90%的更新中使用缩短的序列长度进行训练。我们只用full-length的序列进行训练。 - 我们在
DGX-1机器上用混合精度浮点运算进行训练,每台机器有8个32GB Nvidia V100 GPU,通过Infiniband互连。
- 我们主要遵循前面给出的原始
数据:
BERT风格的预训练依赖于大量的文本。《Cloze-driven pretraining of self-attention networks》证明,增加数据规模可以提高最终任务的性能。有几项工作在比原始BERT更大、更多样化的数据集上进行了训练。不幸的是,并非所有的额外数据集都可以公开发布。对于我们的研究,我们专注于收集尽可能多的数据进行实验,使我们能够根据每个比较对象来匹配数据的整体质量和数量。我们考虑了五个不同规模和领域的英语语料库,总计超过
160GB的未压缩文本。我们使用了以下的文本语料库:BOOKCORPUS plus English WIKIPEDIA:这是用于训练BERT的原始数据(16GB)。CC-NEWS:我们从CommonCrawl News dataset的英文部分收集得到。该数据包含2016年9月至2019年2月间爬取的6300万篇英文新闻文章(过滤后为76GB)。OPENWEBTEXT:是GPT-2中描述的WebText语料库的开源复现。该文本是从Reddit上分享的URL中提取的web内容,至少有3个以上的点赞 (38GB)。STORIES:《A simple method for commonsense reasoning》介绍的数据集,包含CommonCrawl数据的一个子集,经过过滤以符合Winograd模式的故事式风格(31GB)。、
评估:遵从前面的工作,我们评估了预训练模型在以下三个
benchmark的下游任务的性能。GLUE:General Language Understanding Evaluation: GLUE benchmark是一个包含9个数据集的集合,用于评估自然语言理解系统。GLUE组织者提供了训练集和验证集的拆分,以及submission server和排行榜从而允许参与者在private held-out的测试集上评估和比较参与者的系统。对于
replication study,我们报告了在相应的单任务训练数据上对预训练模型进行微调后的验证集结果(即,没有multi-task training或ensembling)。我们的微调程序遵循原始的BERT论文。我们额外报告了从公共排行榜上获得的测试集结果。这些结果取决于一些
task-specific的修改,我们在后文中描述了这些修改。SQuAD:Stanford Question Answering Dataset: SQuAD提供了一段上下文和一个问题。任务是通过从上下文中提取相关的span来回答问题。我们对两个版本的SQuAD进行评估:V1.1和V2.0。- 在
V1.1中,上下文总是包含一个答案。此时 ,我们采用与BERT相同的span prediction方法。 - 而在
V2.0中,一些问题在给定的上下文中没有答案,使任务更具挑战性。此时,我们增加了一个额外的二分类器来预测问题是否可以回答。我们通过将分类损失和跨度损失span loss相加来联合训练。在评估过程中,我们只预测那些被分类为可回答的(context, question)的span index。
- 在
RACE:ReAding Comprehension from Examinations: RACE任务是一个大规模的阅读理解数据集reading comprehension dataset,包括28,000多个段落和近100K个问题。该数据集收集自中国的英语考试,这些考试是为初中和高中学生设计的。在RACE中,每个段落都与多个问题有关。对于每个问题,任务是从四个选项中选择一个正确的答案。与其他流行的阅读理解数据集相比,RACE的上下文明显较长,需要进行推理的question的占比很高。
10.1.3 训练过程分析
本节讨论并量化了哪些选择对成功预训练
BERT模型是重要的。具体而言,我们首先用与BERT_BASE相同的配置来训练BERT模型(110M参数)。静态掩码和动态掩码:正如前面所讨论的,
BERT依赖于随机掩码token并预测这个被掩码的token。原始的BERT实现在数据预处理过程中进行了一次掩码,导致了单一的静态掩码static mask。为了避免对每个训练样本在不同的epoch中使用相同的掩码,训练数据被重复了10次,因此在40个epoch的训练中,每个样本以10种不同的方式被掩码。因此,在训练期间,每个训练样本都被以相同的掩码而看过四次。我们将这一策略与动态掩码
dynamic masking进行比较。在动态掩蔽中,我们每次向模型馈入序列时都会生成masking pattern。在以更多的step或更大的数据集进行预训练时,这一点变得至关重要。如果是静态掩码,那么需要数据集拷贝多份,假如大型数据集是
1TB,拷贝100份那么就是100TB下表比较了
BERT原始论文公布的BERT_BASE结果和我们用静态掩码或动态掩码的重新实现。我们发现,我们对静态掩码的重新实现与原始BERT模型的表现相似,而动态掩码与静态掩码相当或略好。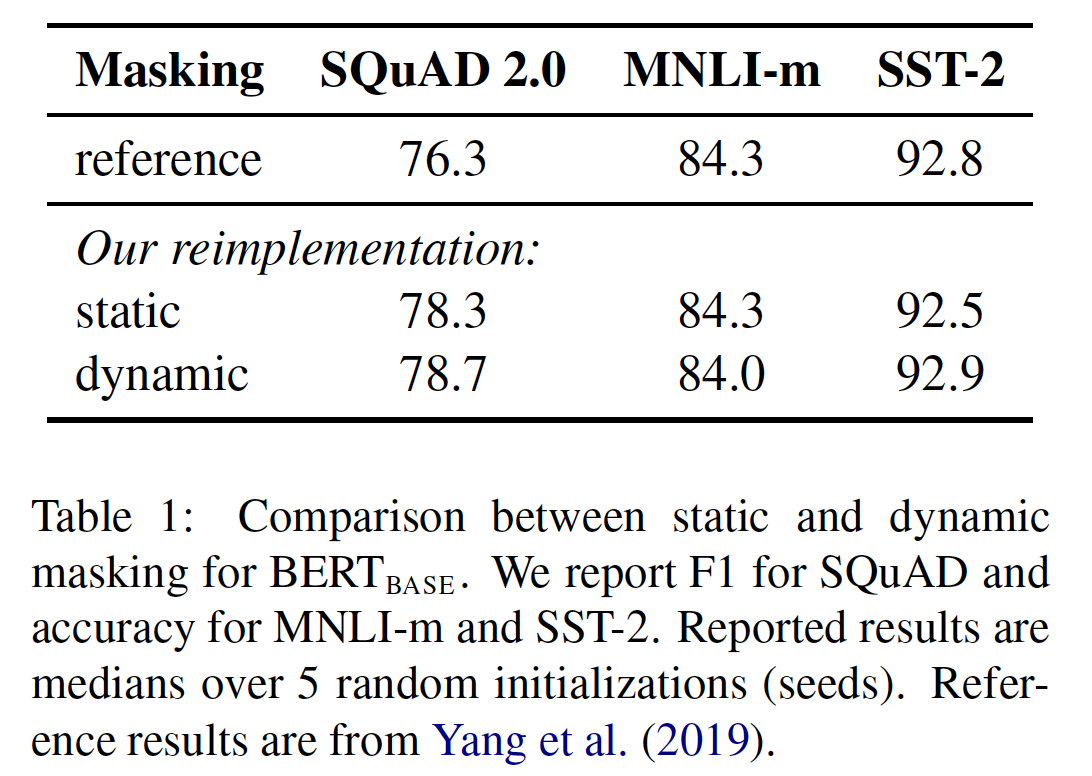
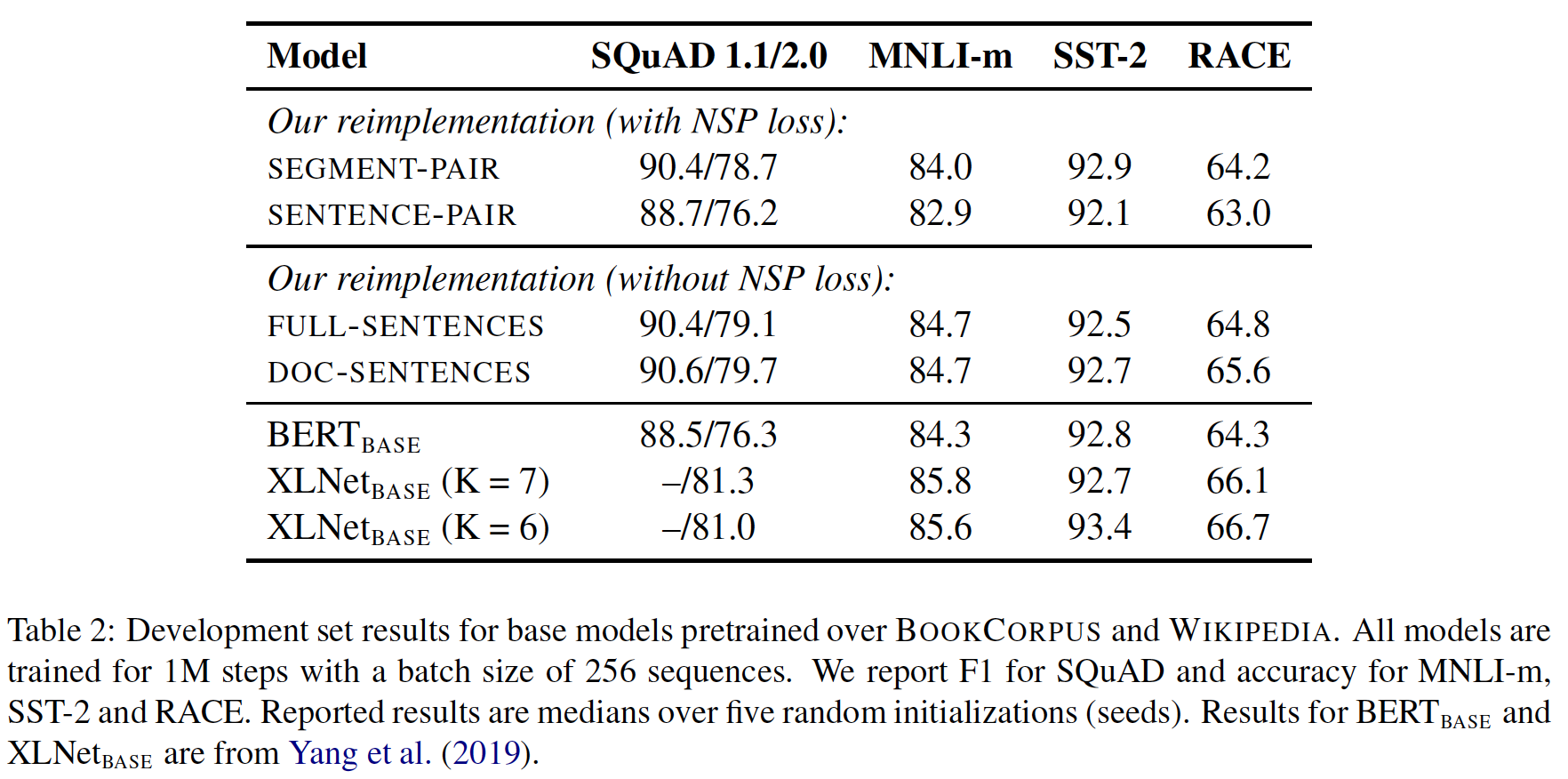
模型输入格式和
NSP:在最初的BERT预训练程序中,除了MLM目标之外模型还有一个Next Sentence Prediction: NSP目标。NSP目标被认为是训练原始BERT模型的一个重要因素。BERT原始论文观察到:移除NSP目标会损害性能,在QNLI、MNLI和SQuAD 1.1上的性能明显下降。然而,最近的一些工作质疑了NSP目标的必要性。为了更好地理解这种不一致,我们比较了几种替代的训练格式:
SEGMENT-PAIR+NSP:这遵循了BERT中使用的原始输入格式,以及NSP损失。每个输入有一对segment,每个segment可以包含多个自然句子,但总的拼接长度必须小于512个token。SENTENCE-PAIR+NSP:每个输入包含一对自然句子,可以从一个文档的连续部分采样,也可以从不同的文档分别采样。由于这些输入长度明显小于512个token,我们增加了batch size,使token的总数保持与SEGMENT-PAIR+NSP相似。我们保留了NSP损失。区别在于
segment pair还是sentence pair。FULL-SENTENCES:每个输入都是由从一个或多个文档中连续采样的完整句子打包而成,其中总长度最多为512个token。输入可能会跨文档的边界。当我们到达一个文档的末尾时,我们开始从下一个文档中采样句子,并在文档之间增加一个额外的分隔符。我们移除了NSP损失。DOC-SENTENCES:输入的构造与FULL-SENTENCES类似,只是它们不能跨越文档的边界。在文档结尾处采样的输入可能短于512个token,所以我们在这些情况下动态地增加batch size,以达到与FULL-SENTENCES相似的总token数量。我们移除了NSP损失。
下表展示了四个不同
setting的结果。- 我们首先比较了
BERT的原始SEGMENT-PAIR输入格式和SENTENCE-PAIR格式。这两种格式都保留了NSP损失,但后者使用了单个句子。我们发现:使用单个句子(而不是segment)会损害下游任务的性能,我们假设这是因为模型无法学习长距离的依赖关系。 - 我们接下来比较了单个文档的文本块(
DOC-SENTENCES)且没有NSP损失的训练。我们发现,这种setting优于最初公布的BERT_BASE结果(下表的倒数第三行),并且相比于该结果,这里移除NSP损失后下游任务性能相匹配或略有改善。有可能最初的BERT实现中针对移除NSP进行评估时,可能只是移除了损失项,而仍然保留了SEGMENT-PAIR的输入格式。 - 最后我们发现,限制序列来自单个文件(
DOC-SENTENCES)的表现要比打包来自多个文件(FULL-SENTENCES)的序列略好。然而,由于DOC-SENTENCES格式导致batch size大小不一,我们在剩下的实验中使用FULL-SENTENCES以便于与相关工作进行比较。
更大的
batch size来训练:过去在神经机器翻译方面的工作表明,在适当提高学习率的情况下,用非常大的mini-batch训练既可以提高训练速度、也可以提高end-task性能(《Scaling neural machine translation》)。最近的工作表明,BERT也适用于大batch的训练《Reducing bert pre-training time from 3 days to 76 minutes》。BERT原始论文最初对BERT_BASE进行了一百万步的训练,batch size = 256。通过梯度积累gradient accumulation,这在计算成本上相当于以batch size = 2K训练125K步,或以batch size = 8K训练31K步。在下表中,我们比较了当增加
batch size时(控制了每个训练样本被访问的次数,即相应地减少迭代步数),BERT_BASE的困惑性perplexity和下游任务性能。我们观察到:用大batch size的训练改善了MLM目标的困惑度、以及下游任务的准确率。大batch size的训练也更容易通过分布式数据并行训练来实现(因为DDP数据并行等价于扩大batch size),在后面的实验中,我们用batch size = 8K来训练。注意,在增加
batch size的时候也需要相应地增加学习率。值得注意的是,
《Reducing bert pre-training time from 3 days to 76 minutes》用更大的batch size来训练BERT,最高可达batch size = 32K。我们把对大batch训练的极限的进一步探索留给未来的工作。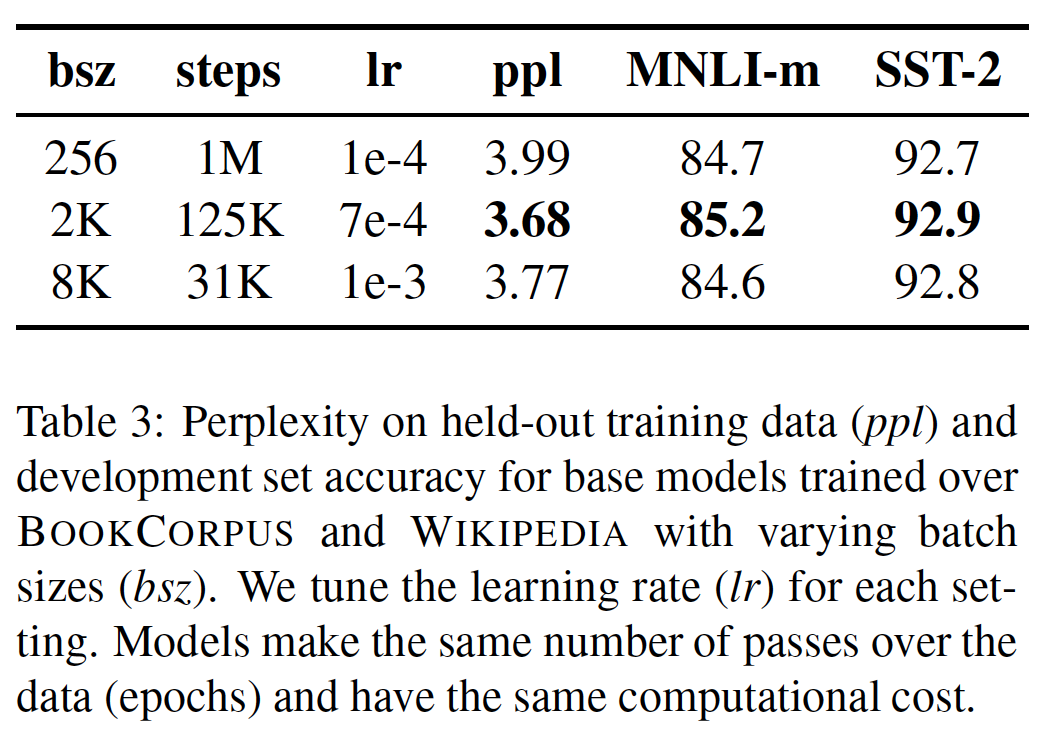
文本编码:
Byte-Pair Encoding: BPE(《Neural machine translation of rare words with subword units》)是character-level representation和word-level representation的混合体,可以处理自然语言语料库中常见的large vocabulary。BPE依赖于子词单元subwords unit,而不是全词full word,子词单元是通过对训练语料库进行统计分析而抽取的。BPE vocabulary size通常在10K-100K个子词单元之间。然而,在对大型和多样化的语料库进行建模时(例如在本文所考虑的语料库),unicode character可以占到这个vocabulary的相当大的一部分。GPT-2介绍了BPE的一个巧妙实现,使用字节byte而不是unicode character作为基本的子词单元。使用字节使得学习一个规模不大的subword vocabulary(50K个单元)成为可能,该vocabulary仍然可以对任何输入文本进行编码,而不会引入任何 "unknown"的标记。unicode character是2个字节,编码空间大小是65536。相比之下,byte是1个字节,编码空间大小是256。原始的
BERT实现使用大小为30K的character-level BPE vocabulary,这是在用启发式tokenization规则对输入进行预处理后学习的。按照GPT-2的做法,我们转而考虑用一个更大的byte-level BPE vocabulary来训练BERT,其中包含50K个子词单元,不需要对输入进行任何额外的预处理或tokenization。这为BERT_BASE和BERT_LARGE分别增加了约15M和20M的额外参数。早期的实验显示,这些编码之间只有轻微的差异,
GPT-2的BPE在一些任务上取得了略差的end-task性能。尽管如此,我们认为通用编码方案的优势超过了性能的轻微下降,并在我们其余的实验中使用这种编码。对这些编码的更详细的比较将留给未来的工作。
10.2 RoBERTa
在前文中,我们提出了对
BERT预训练程序的修改,以提高下游任务的性能。现在我们汇总这些改进并评估其综合影响。我们称这种配置为RoBERTa,即Robustly optimized BERT approach。具体而言,RoBERTa采用动态掩码、无NSP损失的FULL-SENTENCES、大型的mini-batch、较大的byte-level BPE进行训练。此外,我们还调研了在以前的工作中没有得到重视的其他两个重要因素:用于预训练的数据、以及训练
epoch数。例如,最近提出的XLNet架构使用比原始BERT多了近10倍的数据进行预训练。此外,XLNet也是以8倍的batch size、一半的训练step来进行训练,因此XLNet与BERT相比在训练期间看到了4倍的样本 。为了帮助将这些因素的重要性与其他建模选择(如,预训练目标)分开,我们首先按照
BERT_LARGE架构(RoBERTa。我们在可比的BOOKCORPUS加WIKIPEDIA数据集上进行了100K步的预训练,正如BERT原始论文所使用的那样。我们使用1024个V100 GPU对我们的模型进行了大约一天的预训练。BERT预训练进行了一百万步,而这里才预训练十万步?这是因为RoBERTa使用了更大的batch size(batch size = 8K),而原始BERT仅使用batch size = 256。实验结果如下表所示。
当控制训练数据时(第一行结果),我们观察到
RoBERTa比最初报告的BERT_LARGE结果有了很大的改进,再次证实了我们在前文中探讨的设计选择的重要性。RoBERTa训练期间处理的总数据量为8K * 100K,要远大于BERT(0.256K * 1000 K),为后者的3.125倍。所以效果好可能是因为训练的总数据量更大?接下来,我们将这些数据与前文描述的另外三个数据集(
CC-NEWS、OPENWEBTEXT、STORIES)结合起来(数据规模扩大十倍,160GB vs 16GB)。我们在合并的数据集上训练RoBERTa,训练的步数与之前相同(100K)。总体而言,我们对160GB的文本进行了预训练。我们观察到所有下游任务的性能都有进一步的改善,验证了预训练中数据大小和多样性的重要性。最后,我们对
RoBERTa的预训练时间明显延长,将预训练的步数从100K增加到300K甚至500K。我们再次观察到下游任务性能的显著提高,300K和500K训练步数的模型在大多数任务中的表现都超过了XLNet_LARGE。我们注意到,即使是我们训练时间最长的模型,似乎也没有过拟合我们的预训练数据,很可能会从additional training中受益。这里面引出一个话题:要想评估两个模型架构的相对好坏,需要在相同的数据集上训练相同的
epoch。
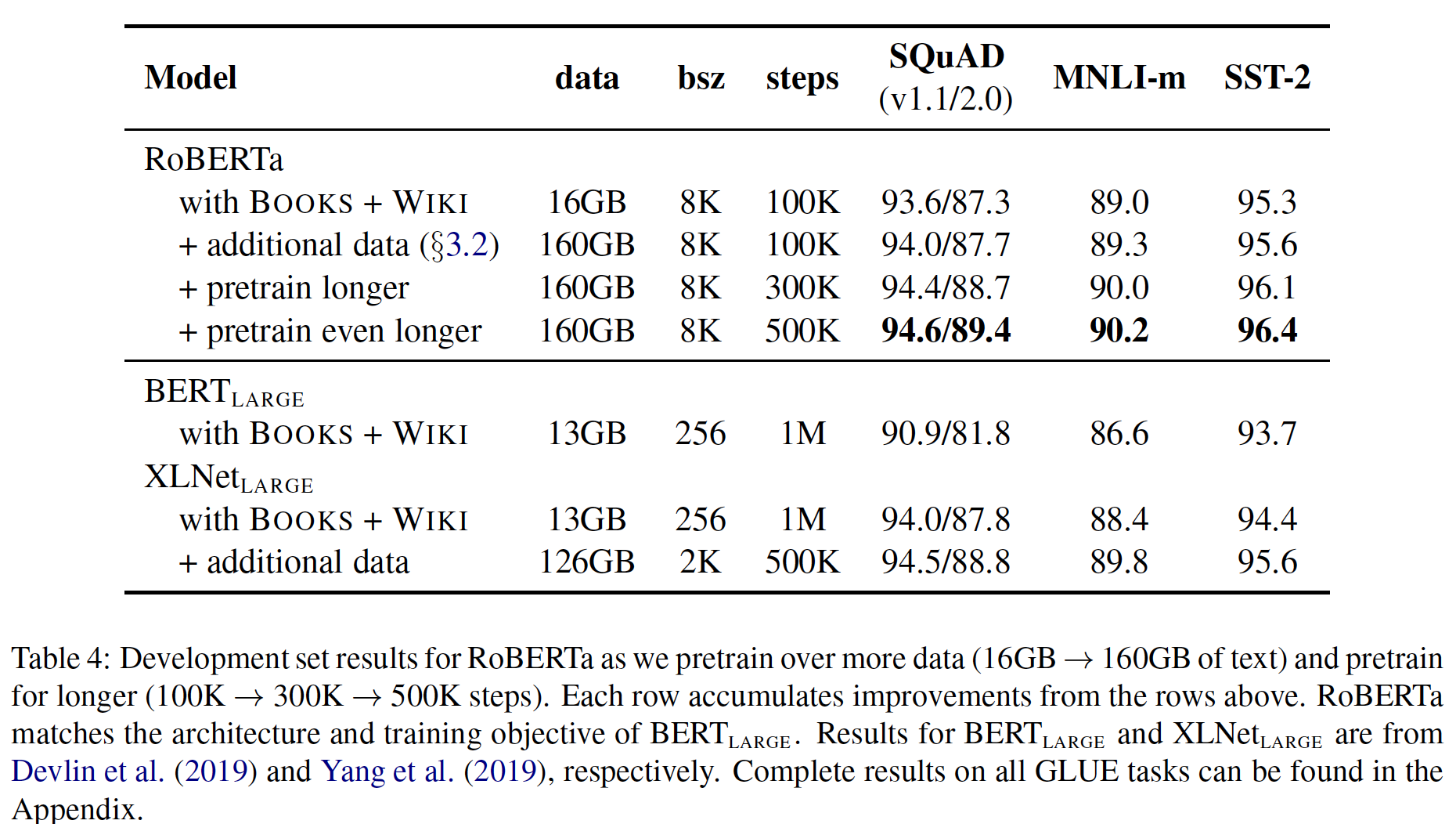
接下来我们在三个不同的
benchmark(即,GLUE、SQuaD、RACE)上评估我们最好的RoBERTa模型。具体而言,我们考虑在所有五个数据集(即BOOKCORPUS、English WIKIPEDIA、CC-NEWS、OPENWEBTEXT、STORIES)上训练500K步的RoBERTa。
10.2.1 GLUE 结果
对于
GLUE,我们考虑两种微调setting:在第一种
setting中(single-task,dev),我们为每个GLUE任务单独微调RoBERTa,只使用相应任务的训练数据。我们考虑对每个任务进行有限的超参数调优,其中6%的step中进行线性预热然后线性衰减到0。我们微调10个epoch,并根据每个任务的评价指标对验证集进行早停early stopping。其余的超参数与预训练时保持一致。在这种
setting下,我们报告了每个任务在五个随机初始化中的验证集指标,没有model ensembling。在第二种
setting中(ensembles,test),我们通过GLUE排行榜将RoBERTa与其它方法比较测试集上的评估结果。虽然许多提交给GLUE排行榜的方法都依赖于多任务微调multi-task finetuning,但我们的方法只依赖于单任务微调single-task finetuning。对于RTE、STS和MRPC,我们发现从MNLI单任务模型开始微调是有帮助的,而不是从baseline预训练的RoBERTa开始。我们探索了一个更大的超参数空间(如下表所述),每个任务采用5 ~ 7个模型的集成ensemble(不同的checkpoint)。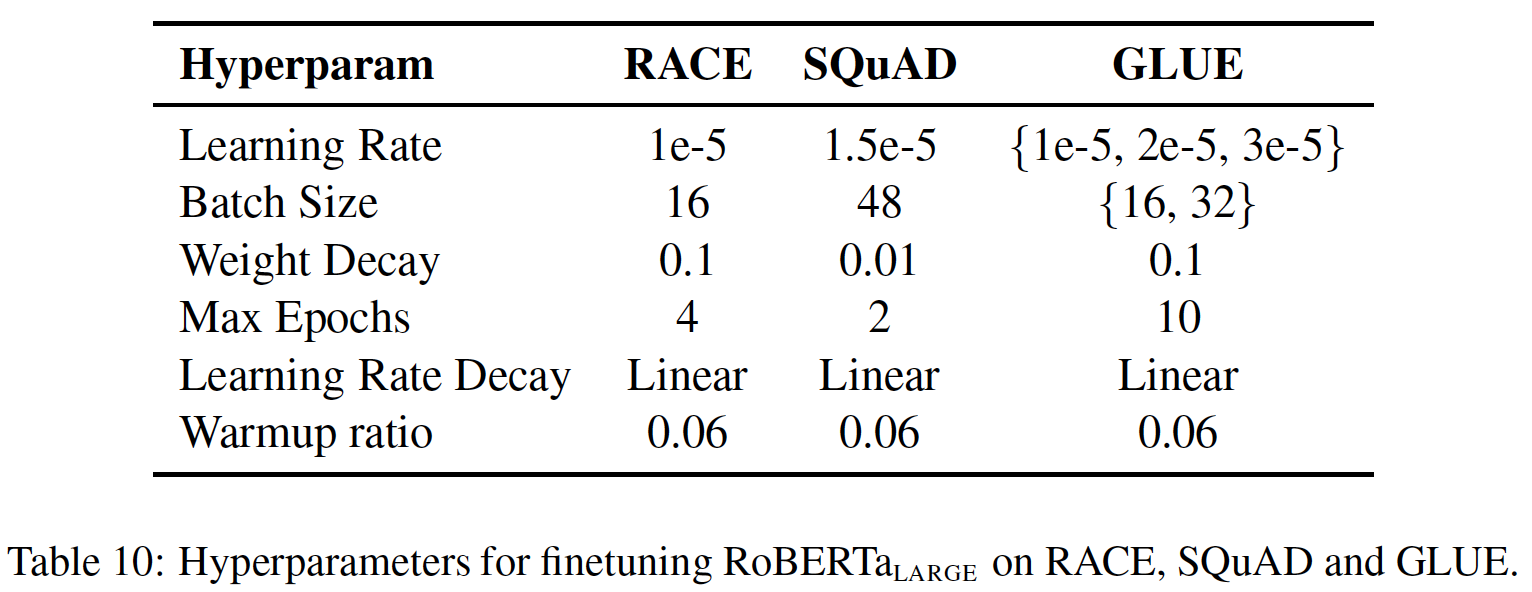
task-specific修改:GLUE的两项任务需要task-specific的微调方法,以获得有竞争力的排行榜结果:QNLI: 最近在GLUE排行榜上提交的结果对QNLI任务采用了pairwise ranking,即从训练集中挖掘出候选答案并相互比较,然后将其中一个(question, candidate)判定为正类positive。这种形式大大简化了任务,但与BERT没有直接可比性。遵从最近的工作,我们在test submission中采用了ranking方法,但为了与BERT直接比较,我们报告了基于pure classification方法的验证集结果。WNLI:我们发现提供的NLI格式的数据具有挑战性。相反,我们使用了来自SuperGLUE的重新格式化的WNLI数据,该数据指示了query代词和参考词referent的跨度span。我们使用《A surprisingly robust trick for winograd schema challenge》的margin ranking loss来微调RoBERTa。对于一个给定的输入句子,我们使用spaCy从句子中提取额外的候选名词短语(作为负样本),并对我们的模型进行微调,使其对positive referent phrase的评分高于任何生成的negative candidate phrase的评分。这种形式的一个不幸的后果是,我们只能利用positive的训练样本,这就排除了一半以上的训练样本。
实验结果如下表所示。
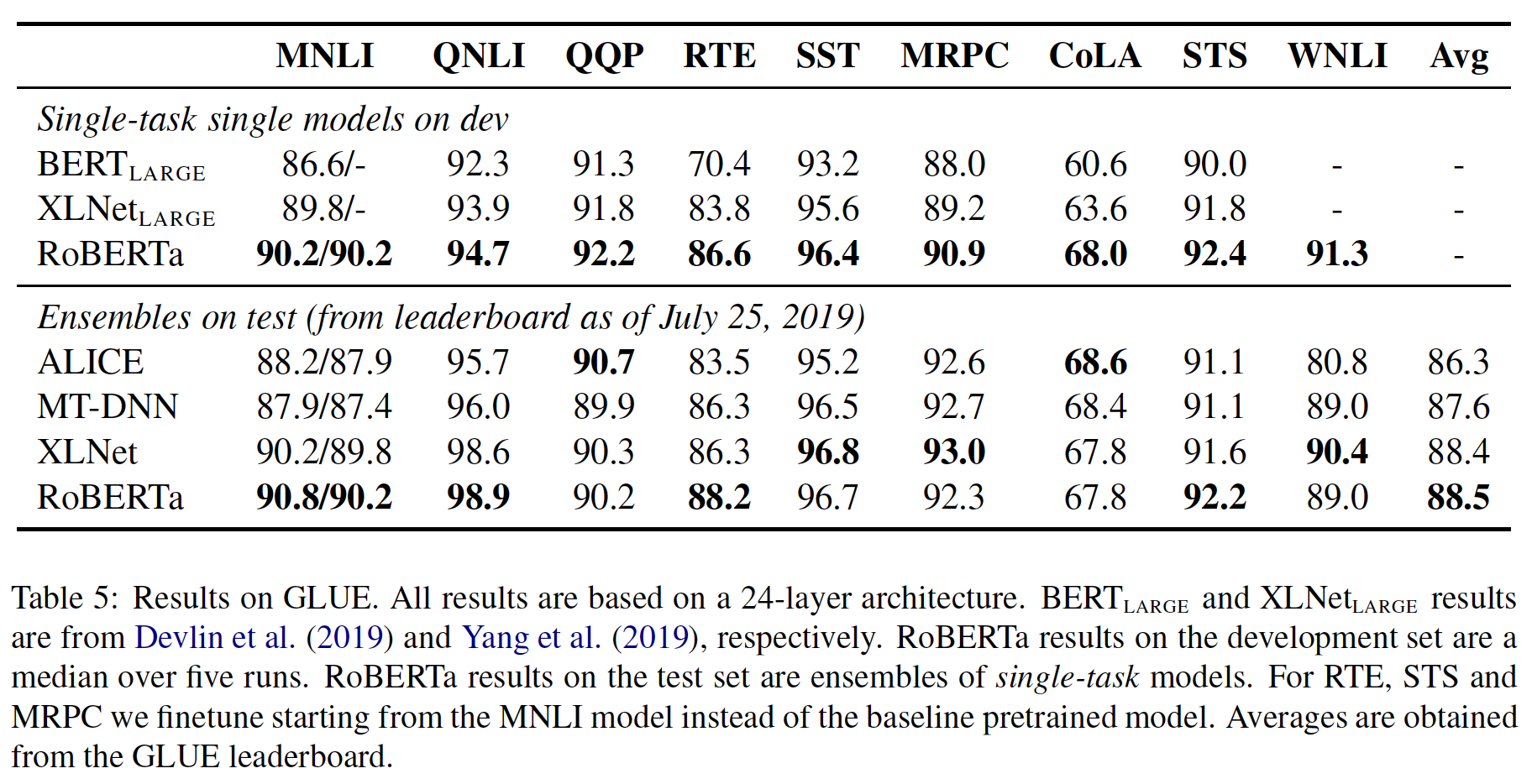
- 在第一个
setting(single-task,dev)中,RoBERTa在所有9个GLUE任务的验证集上都取得了SOTA的结果。最重要的是,RoBERTa使用了与BERT_LARGE相同的MLM预训练目标和架构,但却一致性地优于BERT_LARGE和XLNet_LARGE。这就提出了模型架构和预训练目标的相对重要性的问题,相比于我们在这项工作中探讨的数据集大小和训练时间等更普通的细节。 - 在第二个
setting(ensembles,test)中,我们将RoBERTa提交到GLUE排行榜,并在9个任务中的4个任务中取得了SOTA的结果,并且是迄今为止最高的平均得分。这特别令人振奋,因为RoBERTa不依赖于多任务微调,与其他大多数top submission不同。我们希望未来的工作可以通过纳入更复杂的多任务微调程序来进一步改善这些结果。
- 在第一个
10.2.2 SQuAD 结果
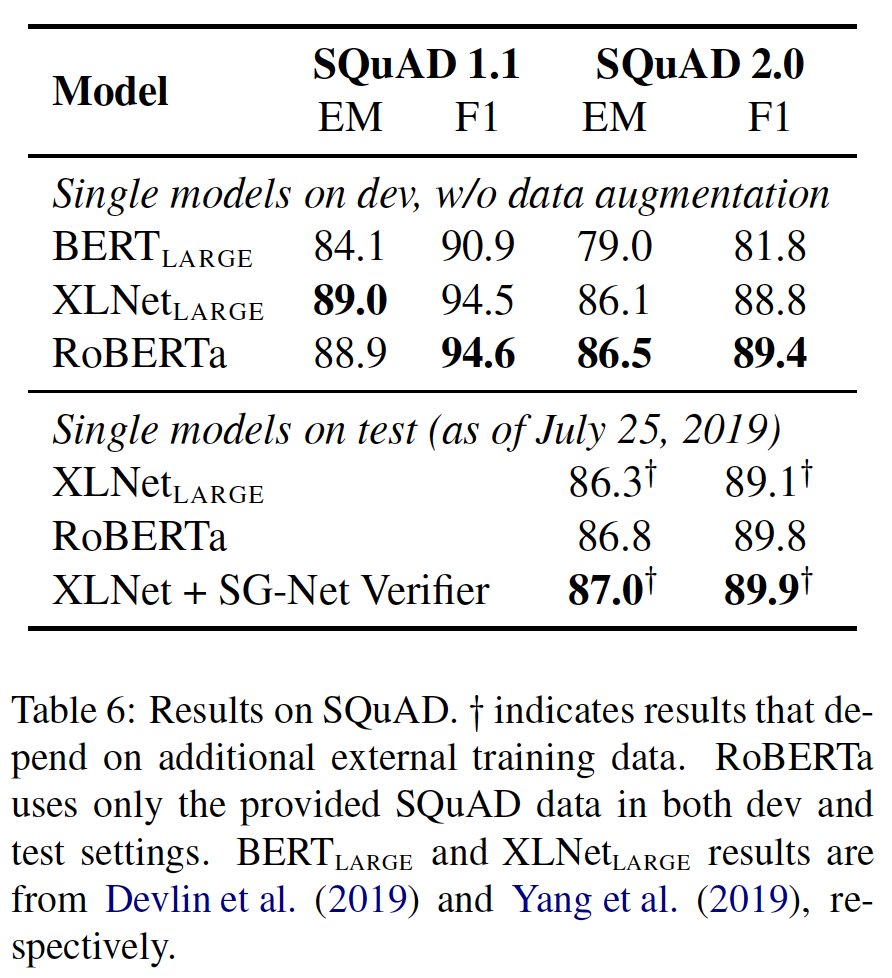
与过去的工作相比,我们对
SQuAD采取了更简单的方法。具体而言,虽然BERT和XLNet都用额外的QA数据集来增强他们的训练数据,但我们只用所提供的SQuAD训练数据来微调RoBERTa。XLNet原始论文还采用了一个自定义的layer-wise学习率调度来微调XLNet,而我们对所有层使用相同的学习率。- 对于
SQuAD v1.1,我们遵循与BERT相同的微调程序。 - 对于
SQuAD v2.0,我们还对一个给定的问题是否可以回答进行了分类。我们通过对分类损失和span loss进行求和,将这个分类器与span predictor联合训练。
- 对于
结果如下表所示。
在
SQuAD v1.1验证集上,RoBERTa与XLNet相匹配。在SQuAD v2.0验证集上,RoBERTa创造了新的SOTA,比XLNet提高了0.4个点(EM)和0.6个点(F1)。我们还将
RoBERTa提交到公共的SQuAD 2.0排行榜,并评估其相对于其他系统的性能。大多数top系统都建立在BERT或XLNet的基础上,这两个系统都依赖于额外的外部训练数据。相比之下,我们的submission没有使用任何额外的数据。我们的单个
RoBERTa模型优于所有单一模型的submission,并且是那些不依赖数据增强的系统中得分最高的。
10.2.3 RACE 结果
在
RACE中,系统被提供了一段文字、一个相关的问题和四个候选答案。系统需要回答这四个候选答案中哪一个是正确的。我们为这项任务修改了
RoBERTa:- 首先,将每个候选答案与相应的问题和段落拼接起来,形成单个序列。(因为有四个候选答案,因此得到四个序列)。
- 然后,我们对这四个序列中的每一个进行编码,并将得到的
[CLS] representation通过一个全连接层,用来预测正确的答案。
我们截断超过
128个token的question-answer,如果需要的话也截断段落,使序列的总长度最多为512个token。下表列出了
RACE测试集的结果。RoBERTa在初中setting和高中setting上都取得了SOTA的结果。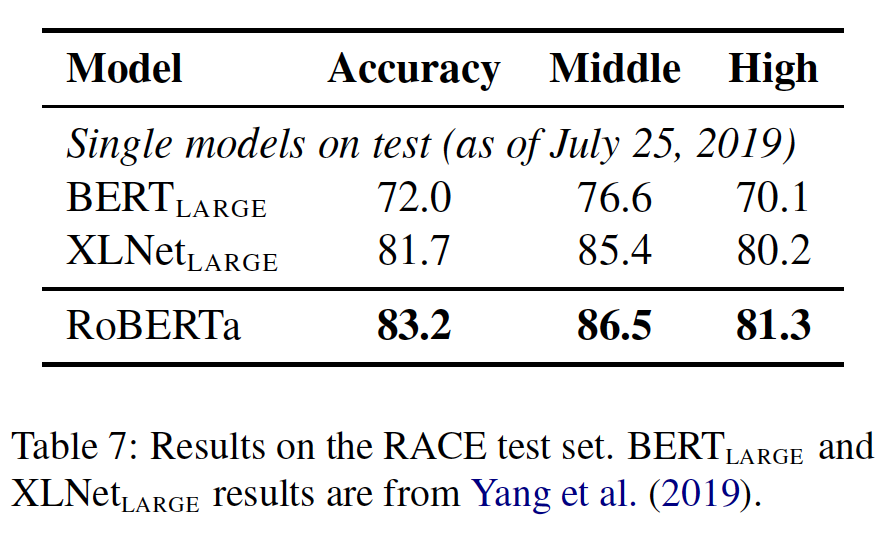
10.2.4 结论
在对
BERT模型进行预训练时,我们仔细评估了一些设计决策。我们发现以下决策可以大大改善BERT在下游任务上的性能:- 对模型进行更长时间的训练(即更多的
epoch)。 - 在更多的数据上进行更大
batch的训练(需要增大学习率)。 - 取消
next sentence prediction: NSP的目标。 - 在更长的序列上进行训练(即更长的上下文)。
- 动态改变应用于训练数据的
masking pattern(即dynamic masking)。
我们改进后的预训练程序被称作
RoBERTa。- 对模型进行更长时间的训练(即更多的
十一、ERNIE1.0 [2019]
language representation pre-training已被证明对改善许多自然语言处理任务很有效,如命名实体识别named entity recognition: NER、情感分析sentiment analysis: SA、问答question answering: QA。为了得到可靠的word representation,神经语言模型neural language model被设计为学习单词共现word cooccurrence,然后用无监督学习获得word embedding。Word2Vec和Glove中的方法将单词表示为向量,其中相似的单词具有相似的word representation。这些word representation为其他深度学习模型中的word vector提供了一个初始化。最近,很多工作,如Cove、Elmo、GPT和BERT通过不同的策略改进了word vector,这些改进被证明对下游自然语言处理任务更加有效。这些研究中,绝大多数都是只通过上下文预测缺失的单词来建模
representation。这些工作没有考虑句子中的先验知识prior knowledge。例如,在"Harry Potter is a series of fantasy novels written by J. K. Rowling"这句话中。"Harry Potter"是一个小说的名字,"J. K. Rowling"是作者。该模型很容易通过实体(即,小说名字"Harry Potter")内部的单词搭配来预测实体"Harry Potter"的缺失词(如,"[MASK] Potter"),而不需要长的上下文的帮助。该模型不能根据"Harry Potter "和"J. K. Rowling"之间的关系来预测"Harry Potter"(即,预测[MASK][MASK] is a series of fantasy novels written by J. K. Rowling)。直观而言,如果模型学习了更多的先验知识,模型就能获得更可靠的language representation。在论文
《ERNIE: Enhanced Representation through Knowledge Integration》中,作者提出了一个叫做ERNIE(enhanced representation through knowledge integration)的模型。ERNIE通过使用知识掩码knowledge masking的策略。除了基础的掩码
basic masking策略外,ERNIE还使用了两种知识策略:短语级phrase-level策略和实体级entity-level策略。ERNIE把一个短语或一个实体作为一个单元unit,每个单元通常由几个单词组成。在word representation训练中,同一单元中的所有单词都被掩码,而不是只有一个单词或字符被掩码。这样一来,短语和实体的先验知识就在训练过程中被隐式地学到了。ERNIE没有直接加入知识嵌入knowledge embedding,而是隐式地学习了知识和更长的语义依赖性,如实体之间的关系、实体的属性和事件的类型,从而指导word embedding的学习。这可以使模型具有更好的泛化能力和适应性。为了降低模型的训练成本,
ERNIE在异质的中文数据上进行了预训练,然后应用于5个中文NLP任务。ERNIE在所有这些任务中都取得了SOTA的结果。另外,在cloze test中的实验表明,ERNIE比其他strong baseline方法具有更好的知识推断knowledge inference能力。论文贡献如下:
- 论文引入了一种新的语言模型学习的处理方法,该方法掩码了短语和实体等单元,以便隐式地从这些单元中学习句法
syntactic information信息和语义信息semantic information。 ERNIE在各种中文自然语言处理任务上的表现显著优于之前的SOTA方法。- 论文发布了
ERNIE和预训练模型的代码,位于https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE。
论文还介绍了对话语言模型
Dialogue Language Model: DLM,它是在实验部分介绍的(而不是正文部分)。- 论文引入了一种新的语言模型学习的处理方法,该方法掩码了短语和实体等单元,以便隐式地从这些单元中学习句法
相关工作:
Context-independent Representation:将单词表示为连续向量的做法由来已久。《A neural probabilistic language model》提出了一个非常流行模型架构用于估计神经网络语言模型neural network language model: NNLM,其中一个带有线性投影层和一个非线性隐藏层的前馈神经网络被用来学习word vector representation。通过使用大量的无标签数据来预训练语言模型,可以有效地学习
general language representation。传统的方法侧重于与上下文无关的word embedding。诸如Word2Vec和Glove等方法将大型的文本语料库作为输入,并产生word vector(通常有几百个维度)。它们为词表vocabulary中的每个单词生成单个的word embedding representation。Context-aware Representation:然而,一个词在不同的上下文中可以有完全不同的含义。
Skip-thought提出了一种无监督学习方法,用于学习通用的分布式的sentence encoder。Cove表明,在各种常见的NLP任务上,添加这些context vector比只使用无监督的word vector和character vector提高了性能。ULMFit提出了一种有效的迁移学习方法,可以应用于NLP的任何任务。ELMo沿着不同的维度推广了传统的word embedding研究。他们提出从语言模型中抽取context-sensitive feature。GPT通过适配Transformer从而增强了context-sensitive embedding。
BERT使用两种不同的预训练任务进行语言建模:BERT随机掩码句子中一定比例的单词,并学习预测这些被掩码的单词。- 此外,
BERT学习预测两个句子是否相邻。该任务试图对两个句子之间的关系进行建模,而这是传统的语言模型无法捕获到的。
因此,这种特殊的预训练方案有助于
BERT在各种关键的NLP数据集上(如GLUE和SQUAD等)以较大的幅度超越SOTA的技术。还有一些研究人员试图在这些模型的基础上增加更多信息。
MT-DNN结合预训练学习和多任务学习来提高GLUE中几个不同任务的表现。GPT-2在预训练过程中加入了任务信息,并使他们的模型适应于zero-shot任务。XLM将language embedding添加到预训练过程中,在跨语言任务中取得了更好的结果。
异质数据
heterogeneous data:在异质无监督数据上预训练的语义编码器semantic encoder可以提高迁移学习性能。- 通用句子编码器(
《Universal sentence encoder》)采用了来自Wikipedia, web news, web QA pages, discussion forum的异质训练数据。 - 基于
response prediction的句子编码器(《Learning semantic textual similarity from conversations》)得益于来自Reddit对话的query-response pair data。 XLM将平行语料库parallel corpus引入BERT,与掩码语言模型masked language model: MLM任务联合训练。通过在异质数据上预训练的transformer模型,XLM在监督/无监督的机器翻译任务和分类任务上显示出巨大的性能增益。
- 通用句子编码器(
11.1 模型
我们在本节中介绍了
ERNIE及其详细实现。BERT和ERNIE之间的比较直观地显示在下图中。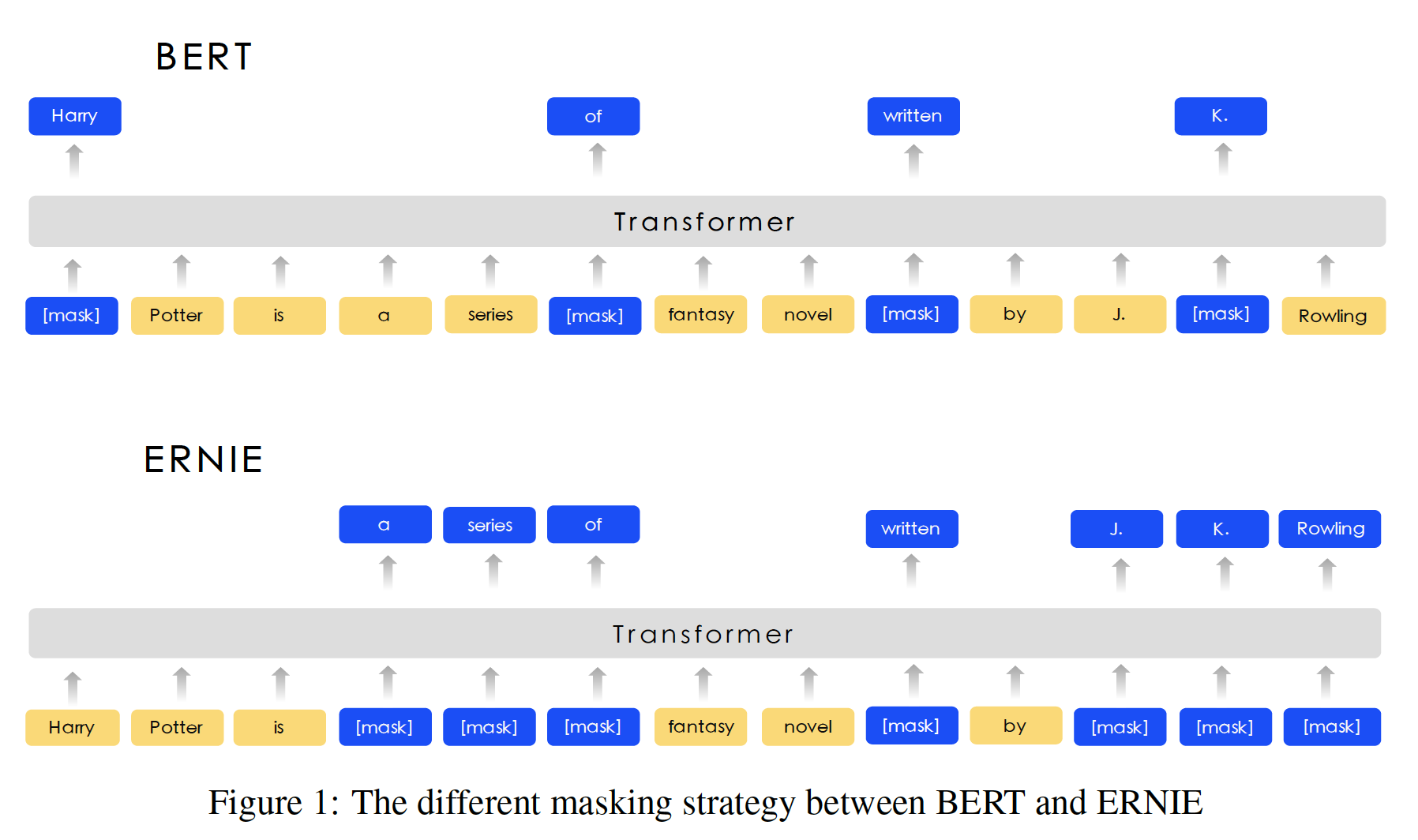
Transformer Encoder:就像之前的预训练模型(如,GPT, BERT, XLM)一样,ERNIE使用多层Transformer作为basic encoder。Transformer可以通过自注意力self-attention来捕获句子中每个token的上下文信息,并生成contextual embedding的序列。对于中文语料,我们在
CJK Unicode区间内的每个字符周围添加空格,并使用WordPiece来tokenize中文句子。对于一个给定的token,它的input representation是由相应的token embedding、segment embedding、以及position embedding相加而成的。每个序列的第一个token是特殊的classification embedding(即,[CLS])。“在
CJK Unicode区间内的每个字符周围添加空格” 意味着作者没有采用传统的中文分词工具,而是用字符粒度的分词。Knowledge Integration:我们使用先验知识prior knowledge来enhance我们的预训练语言模型。我们没有直接添加knowledge embedding,而是提出了一个多阶段的knowledge masking strategy,将phrase-level和entity-level的知识集成到language representation中。下图描述了一个句子的不同masking level。Basic-Level Masking:第一个learning stage是使用basic-level masking,它把一个句子当作一个基本语言单元language unit的序列。对于英语来说,基本语言单元是单词;对于汉语来说,基本语言单元是汉字。在训练过程中,我们随机掩码
15%的基本语言单元,并使用句子中的其他基本语言单元作为输入,然后训练一个transformer来预测被掩码的单元。基于basic level mask,我们可以得到一个basic word representation。因为它是在基本语义单元basic semantic unit的随机掩码上训练的,所以high level的语义知识很难被完全建模。Phrase-Level Masking:第二个learning stage是使用phrase-level masking。短语phrase是一组单词或字符一起作为一个概念单元conceptual unit。对于英语,我们使用词法分析lexical analysis和分块工具来获得句子中短语的边界,并使用一些与语言相关的分词工具segmentation tool来获得其他语言(如中文)的词/短语信息。在
phrase-level masking阶段,我们也使用基本语言单元作为训练输入,与basic-level masking不同的是,这次我们在句子中随机选择几个短语,同一短语中的所有基本单元同时被掩码并被预测。在这个阶段,短语信息被编码到word embedding中。注意:对于中文来讲,
phrase其实就是 “词” ;word就是 “字”、character就是“偏旁部首”。注意:这里的输入仍然是 “汉字” 粒度,但是掩码是短语粒度。
注意:这里需要第三方的中文分词工具,而且分词工具的好坏会影响
ERNIE模型的效果。Entity-Level Masking:第三个learning stage是使用entity-level masking。命名实体name entity包含人、地点、组织、产品等,可以用专有名词来表示。通常情况下,命名实体包含了句子中的重要信息。与
phrase-level masking阶段一样,我们首先分析句子中的命名实体,相同实体中的所有基本单元同时被掩码并被预测。注意:这里需要有第三方的
NER工具,而且识别的好坏会影响ERNIE模型的效果。
经过三个阶段的学习,我们得到了一个由更丰富的语义信息增强的
word representation。论文采用什么中文分词工具、什么中文
NER工具?作者并未说明。根据论文的描述,读者猜测这三个阶段是依次进行的:前
epoch使用basic-level masking、接下来epoch使用phrase-level masking、最后epoch使用entity-level masking。但是,
11.2 实验
ERNIE被选择为与BERT-BASE具有相同的模型尺寸以便于比较:ERNIE使用12个encoder layer,768个隐单元、12个注意力头。异质语料库预训练:
ERNIE采用异质语料进行预训练。遵从《Universal sentence encoder》,我们从混合语料库(中文维基百科Chinese Wikepedia、百度百科Baidu Baike、百度新闻Baidu news和百度贴吧Baidu Tieba)中抽取句子,抽取句子的数量分别为21M、51M、47M、54M。其中:- 百度百科:包含了用正式语言
formal language编写的百科全书文章,这被用作语言建模的strong basis。 - 百度新闻:提供有关电影名称、演员名称、足球队名称等最新信息。
- 百度贴吧:是一个类似于
Reddits的开放式讨论区,每个帖子都可以被视为一个dialogue thread。贴吧语料库被用于我们的Dialogue Language Model: DLM任务,这将在下一节讨论。
我们对汉字进行繁体到简体的转换,并对英文字母进行大写到小写的转换。我们的模型使用了
17964个unicode字符的vocabulary。- 百度百科:包含了用正式语言
Dialogue Language Model: DLM:对话数据对semantic representation很重要,因为相同答复所对应的query semantic往往是相似的。ERNIE在DLM任务上建模Query-Response对话结构。如下图所示,我们的方法引入了
dialogue embedding来识别对话中的角色,这与universal sentence encoder不同(《Universal sentence encoder》)。ERNIE的dialogue embedding与BERT中的token type embedding(即,segment embedding)起到相同的作用,只是ERNIE还可以表示多轮对话(例如QRQ、QRR、QQR,其中Q和R分别代表"Query"和"Response")。在
DLM任务中,不需要segment embedding,因为segment embedding是用于next sentence prediction任务。与
BERT中的MLM一样,我们应用掩码从而强制模型预测同时以query和response为条件的missing word。更重要的是,我们通过用一个随机选择的句子替换query或response来生成假的样本。该模型被设计用来判断多轮对话是真的还是假的。DLM任务帮助ERNIE学习对话中的隐式关系,这也增强了模型学习semantic representation的能力。DLM任务的模型结构与MLM任务的结构兼容,因此它与MLM任务交替进行预训练。DLM和MLM如何进行交替?是否可以联合训练,即BERT就是按照这种多任务的方式训练的)?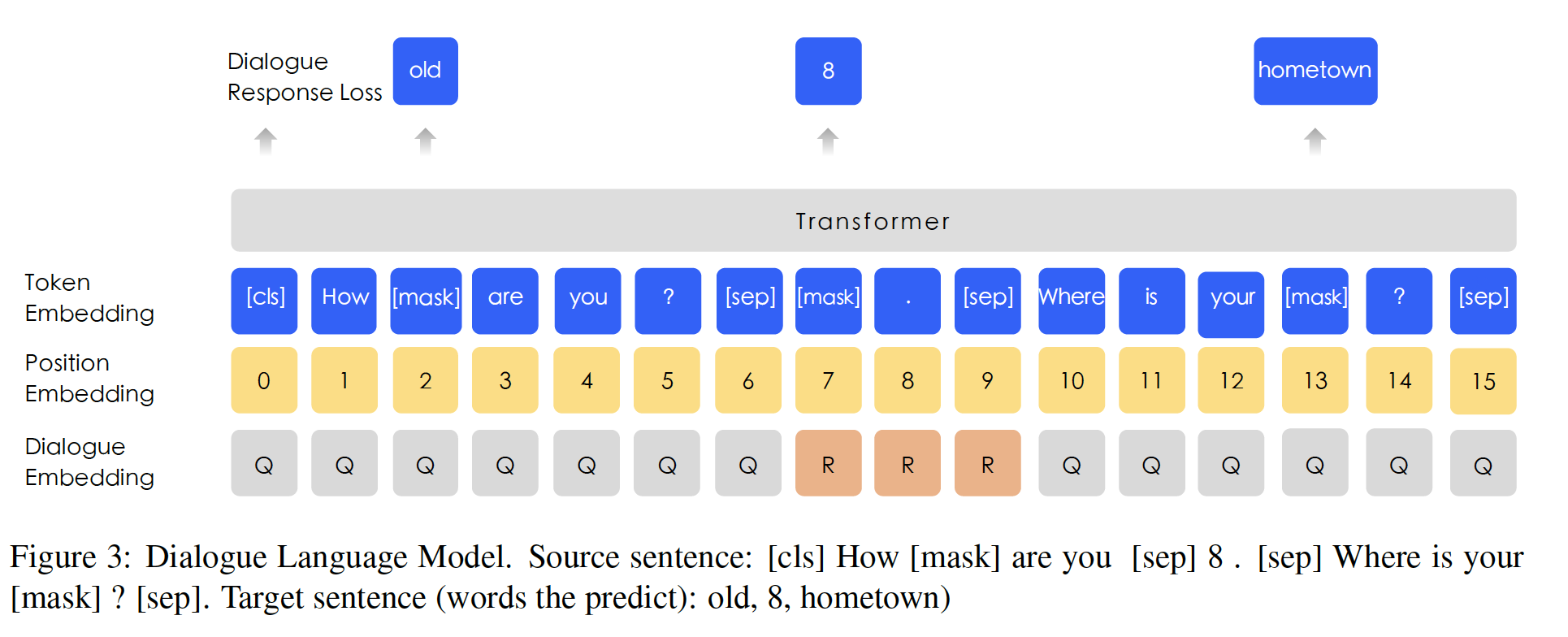
中文
NLP任务:ERNIE被应用于5项中文NLP任务,包括自然语言推理natural language inference、语义相似性semantic similarity、命名实体识别named entity recognition、情感分析sentiment analysis和问答question answering。自然语言推理:
Cross-lingual Natural Language Inference: XNLI语料库是MultiNLI语料库的一个众包集合。这些sentence pair都被人工标注为文本蕴含关系textual entailment,并被翻译成包括中文在内的14种语言。标签包含矛盾contradiction、中性neutral、以及蕴含entailment。我们遵循BERT中的中文实验。语义相似性:
Large-scale Chinese Question Matching Corpus: LCQMC旨在识别两个句子是否具有相同的意图。数据集中的每一对句子都与一个二元标签相关联,表明这两个句子是否具有相同的意图。命名实体识别:
MSRA-NER数据集是为命名实体识别而设计的,它由微软亚洲研究院发布。实体包含几种类型,包括人名、地名、组织名称等。这个任务可以被看作是一个序列标注任务。情感分析:
ChnSentiCorp: Song-bo是一个数据集,旨在判断一个句子的情感。它包括几个领域的评论,如酒店、书籍和电子计算机。这项任务的目标是判断该句子是正面positive的还是负面negative的。问答:
NLPCC-DBQA数据集的目标是选择相应问题的答案。这个数据集的评价方法包括MRR和F1得分。Mean Reciprocal Rank: MRR:ground-truth答案的位置(ground-truth的位置越靠前越好)。如果ground-truth答案不在预测答案集合
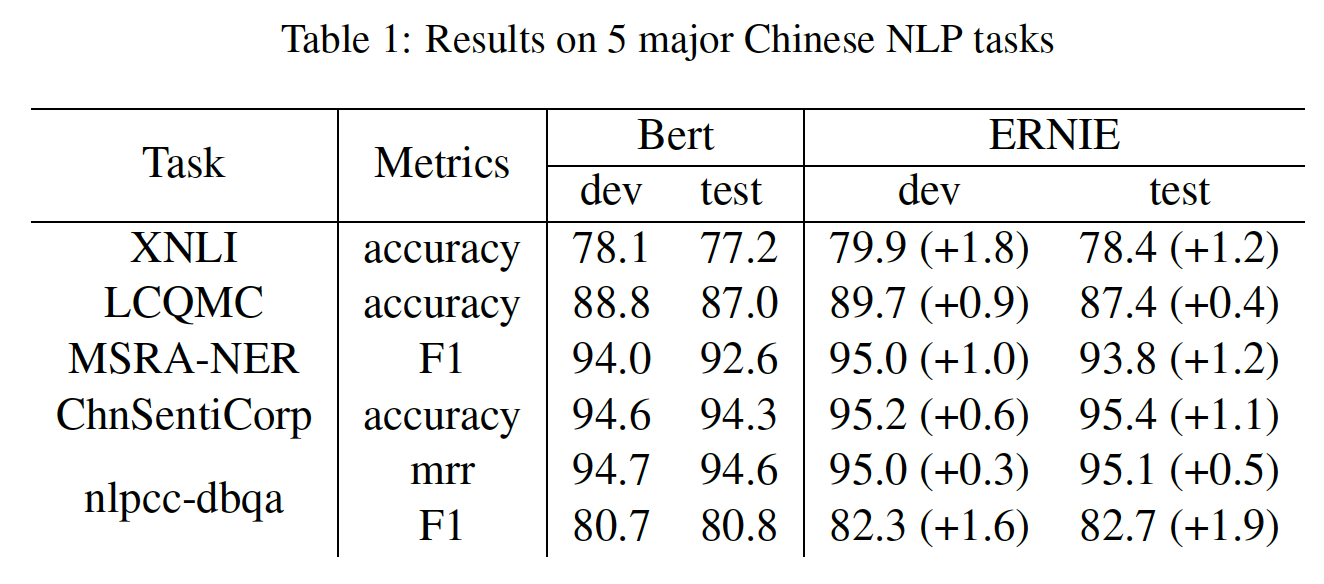
下表列出了
5个中文NLP任务的测试结果。可以看出:ERNIE在所有任务上都优于BERT,在这些中文NLP任务上创造了新的SOTA结果。- 对于
XNLI、MSRA-NER、ChnSentiCorp和NLPCC-DBQA任务,ERNIE比BERT获得了超过1%的绝对准确率的改进。
ERNIE的收益归功于其knowledge integration策略。论文仅仅介绍这个策略,但是究竟用到了哪些知识?以及如何对预训练语料库的中文句子进行分词、命名实体识别,都未提到。
消融研究:
Knowledge Masking策略的效果:我们从整个语料库中抽取10%的训练数据来验证knowledge masking策略的有效性(在XNLI数据集上评估)。结果如下表所示。可以看到:
- 在
baseline的word-level mask的基础上增加phrase-level mask可以提高模型的性能。 - 在此基础上,继续增加
entity-level mask策略,模型的性能得到进一步提高。 - 此外,在预训练数据集规模大
10倍的情况下,在XNLI测试集上实现了0.8%的性能提升。

- 在
DLM的效果:我们从整个语料库中抽取10%的训练数据来验证DLM任务的贡献(在XNLI数据集上评估)。我们从头开始预训练ERNIE,并报告XNLI任务中5次随机重启微调的平均结果。注意:这里我们并不是均匀抽取,而是对不同的预训练数据集抽取不同的比例。详细的实验设置和结果如下表所示。可以看到:纳入
DLM任务之后,验证集/测试集准确率分别提高了0.7%/1.0%。注意:因为
DLM是预训练任务,同时也是预训练数据集。如果with DLM和without DLM进行对比,那么预训练数据的规模就发生了变化。更好的做法是:
10% of all,同时对without DLM用MLM来代替DLM(而不是直接丢弃MLM的预训练数据)。否则这里的数据分布都变化了,实验结果难以直接对比。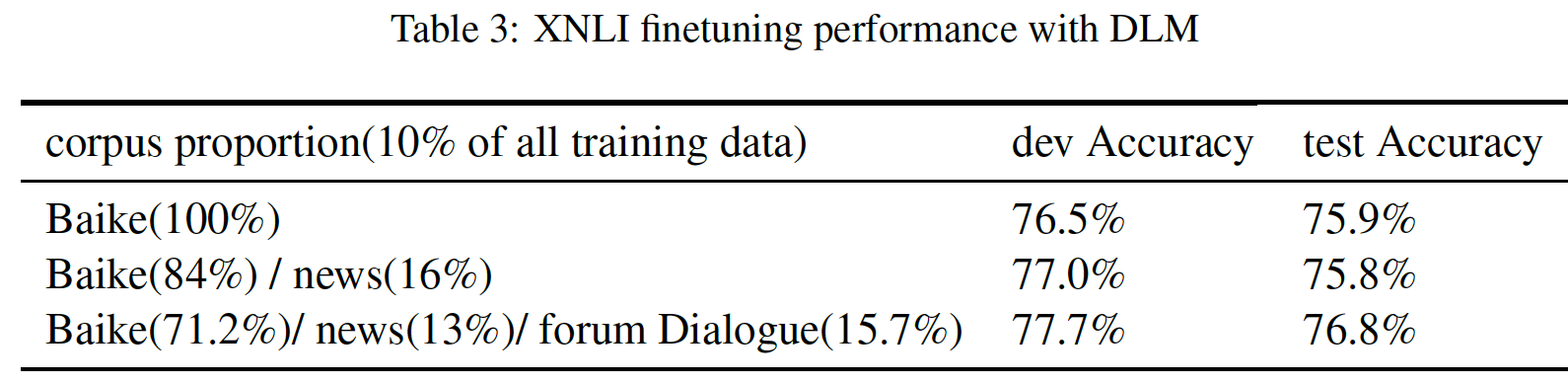
Cloze Test:为了验证ERNIE的知识学习能力,我们使用了几个Cloze test样本来检验模型。在实验中,我们从段落中删除命名实体,模型需要推断出被删除的命名实体是什么。下图给出了一些case。我们比较了BERT和ERNIE的预测结果。英文部分只是翻译,因为整篇论文是英文撰写并发表在国外,所以如果没有英文翻译部分,外国读者可能看不懂。
- 在
case 1中,BERT试图复制上下文中出现的名字,而ERNIE记住了文章中提到的relation的知识。 - 在
case 2和case 5中,BERT可以成功地根据上下文学习正确的pattern,因此正确地预测了命名实体的类型,但未能得到正确的实体。相反,ERNIE可以得到正确的实体。 - 在
case 3、4、6中,BERT得到与句子有关的几个字符,但很难预测semantic concept。 - 除了
case 4之外,ERNIE预测了所有正确的实体。虽然ERNIE在case 4中预测了错误的实体,但它能正确地预测语义类型,并得到另一个澳大利亚城市。
综上所述,这些案例表明
ERNIE在context-based的知识推理中表现得更好。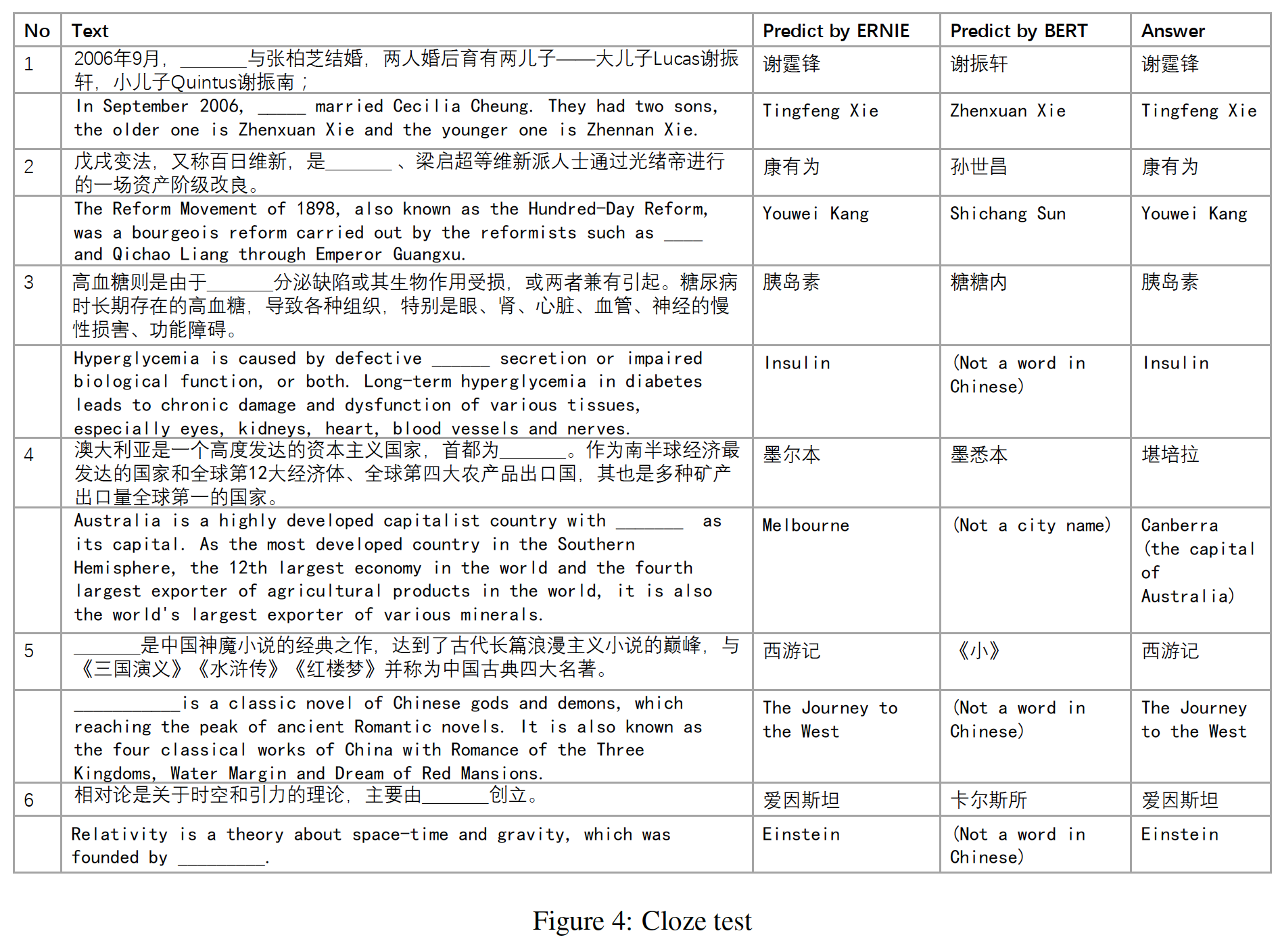
- 在
十二、ERNIE2.0 [2019]
预训练的
language representation,如ELMo、OpenAI GPT、BERT、ERNIE 1.0和XLNet,已经被证明可以有效地提高各种自然语言理解任务的性能,包括情感分类、自然语言推理、命名实体识别等等。一般而言,模型的预训练往往是根据
word和sentence的共现性co-occurrence来训练模型。而事实上,在训练语料库中,除了共现性之外,还有其他值得研究的词法lexical、句法syntactic和语义semantic信息。例如,像人名、地名、组织名称这样的命名实体,可能包含概念性的信息conceptual information。例如:- 句子顺序
sentence order和句子之间的邻近性proximity这样的信息使模型能够学习structure-aware representation。 - 而
document level的语义相似性、或句子间的篇章关系discourse relation使模型能够学习semantic-aware representation。
为了发现训练语料中所有有价值的信息(无论是
lexical、syntactic、 还是semantic的representation),论文《ERNIE 2.0: A CONTINUAL PRE-TRAINING FRAMEWORK FOR LANGUAGE UNDERSTANDING》提出了一个continual pre-training framework,名为ERNIE 2.0,它可以通过不断的多任务学习multi-task learning来增量地构建和训练大量的预训练任务。论文的
ERNIE 2.0框架支持在任何时候引入各种定制化的任务。这些任务共享相同的encoding network并通过多任务学习进行训练。这种方法使词法信息、句法信息和语义信息的encoding跨不同任务成为可能。此外,当给定一个新的任务时,ERNIE 2.0框架可以根据它所掌握的先前的训练参数来增量地训练distributed representation。总之,论文的贡献如下:
- 作者提出了一个
continual pre-training framework,即ERNIE 2.0,它以增量的方式支持定制化的训练任务和多任务预训练。 - 论文构建了几个无监督的语言处理任务来验证所提出的框架的有效性。实验结果表明,
ERNIE 2.0在16个任务上比BERT和XLNet取得了显著的改进,包括英文的GLUE benchmark和几个中文任务。 ERNIE 2.0的微调代码、以及在英文语料上预训练的模型可在https://github.com/PaddlePaddle/ERNIE上找到。
相比较于
ERNIE 1.0,ERNIE 2.0的改进在于预训练阶段的多任务学习。- 句子顺序
相关工作:
用于
language representation的无监督迁移学习:通过用大量的未标记数据来预训练语言模型从而学习general language representation是很有效的。传统的方法通常专注于与上下文无关的
word embedding。诸如Word2Vec和GloVe等方法通过在大型语料库上的word co-occurrence来学习fixed word embedding。最近,一些以
contextualized language representation为中心的研究被提出来,上下文相关的language representation在各种自然语言处理任务中显示出SOTA的结果。ELMo提出从语言模型中提取context-sensitive feature。OpenAI GPT通过调整Transformer从而加强了context-sensitive embedding。BERT采用了一个masked language model: MLM,同时在预训练中加入了next sentence prediction任务。XLM融合了两种方法来学习跨语言的语言模型,即仅依赖单语数据的无监督方法、以及利用平行双语数据的监督方法。MT-DNN通过在预训练模型的基础上共同学习GLUE中的几个监督任务,最终导致在其它监督任务(这些监督任务未在多任务微调阶段进行学习)中取得改进。XLNet使用Transformer-XL,并提出了一种推广的自回归预训练方法,即:通过对分解顺序的所有排列组合的期望似然expected likelihood最大化来学习双向上下文。
持续学习
Continual Learning:持续学习的目的是用几个任务依次训练模型,使模型在学习新的任务时能记住以前学过的知识。这种方法受到人类学习过程的启发,因为人类能够不断积累通过学习或经验获得的信息来有效地发展新的技能。通过持续学习,模型应该能够在新的任务中表现良好,这要归功于在以前的训练中获得的知识。
12.1 模型
12.1.1 ERNIE 2.0 Framework
如下图所示,
ERNIE 2.0框架是基于最近在自然语言处理中日益流行的预训练和微调的架构而建立的。ERNIE 2.0与传统的预训练方法不同,它不是用少量的预训练目标进行训练,而是可以不断引入大量的预训练任务,从而帮助模型有效地学习lexical、syntactic、 以及semantic的representation。在此基础上,ERNIE 2.0框架通过多任务学习不断更新预训练的模型。在微调过程中,ERNIE模型首先用预训练的参数进行初始化,然后用特定任务的数据进行微调。有两种形式的多任务:预训练阶段的多任务、微调阶段的多任务。这里指的是预训练阶段的多任务。
从下图右下角可以看到:预训练阶段的多任务共享相同的
bottom network。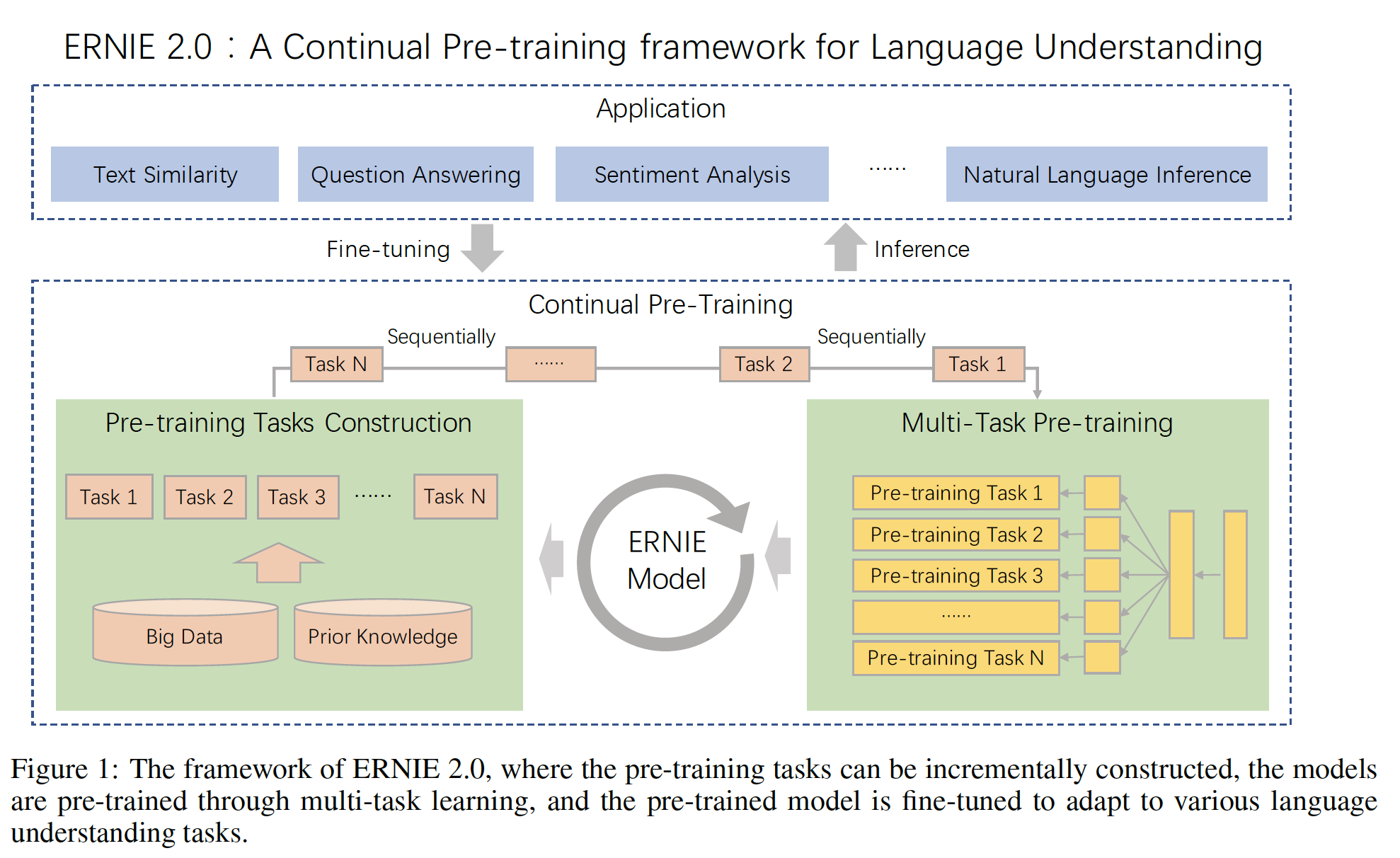
Continual Pre-training:continual pre-training的过程包含两个步骤:首先,我们不断地构建具有大数据和先验知识参与的无监督预训练任务。
对于预训练任务的构建,我们构建了不同类型的任务,包括
word-aware任务、structure-aware任务和semantic-aware任务。所有这些预训练任务都依赖于自监督信号或弱监督信号,这些信号可以从海量数据中获得,不需要人工标注。其次,我们通过多任务学习逐步更新
ERNIE模型。对于多任务预训练,
ERNIE 2.0框架以continuous learning的范式训练所有这些任务。具体而言,我们会先用一个简单的任务训练一个初始模型,然后不断引入新的预训练任务来更新模型。当增加一个新任务时,我们会以前一个任务来初始化parameters。每当引入一个新任务时,都会用前面的任务进行训练(这里采用联合训练),以确保模型不会忘记它所学的知识。这样一来,ERNIE框架就能不断学习和积累continuous learning过程中获得的知识,而知识的积累将使模型在新任务中表现更好。每次引入一个新任务都需要重新训练前面所有的旧任务,此时不是依次训练,而是联合训练(损失函数相加)。
另外,这些任务的学习顺序是否会影响最终效果?更近一步地,哪个任务是第一个学习的、哪个任务是最后一个学习的,是否会影响效果?
如下图所示,
continual pre-training的架构包含一系列共享的text encoding layer来编码上下文信息。这些text encoding layer可以通过使用RNN或deep Transformer来定制化。编码器的参数可以在所有预训练任务中更新。在我们的框架中,有两种损失函数:一种是
sequence-level损失,另一种是token-level损失,它们与BERT的损失函数类似。每个预训练任务都有自己的损失函数。在预训练期间,一个或多个sentence-level的损失函数可以与多个token-level的损失函数相结合从而持续地更新模型。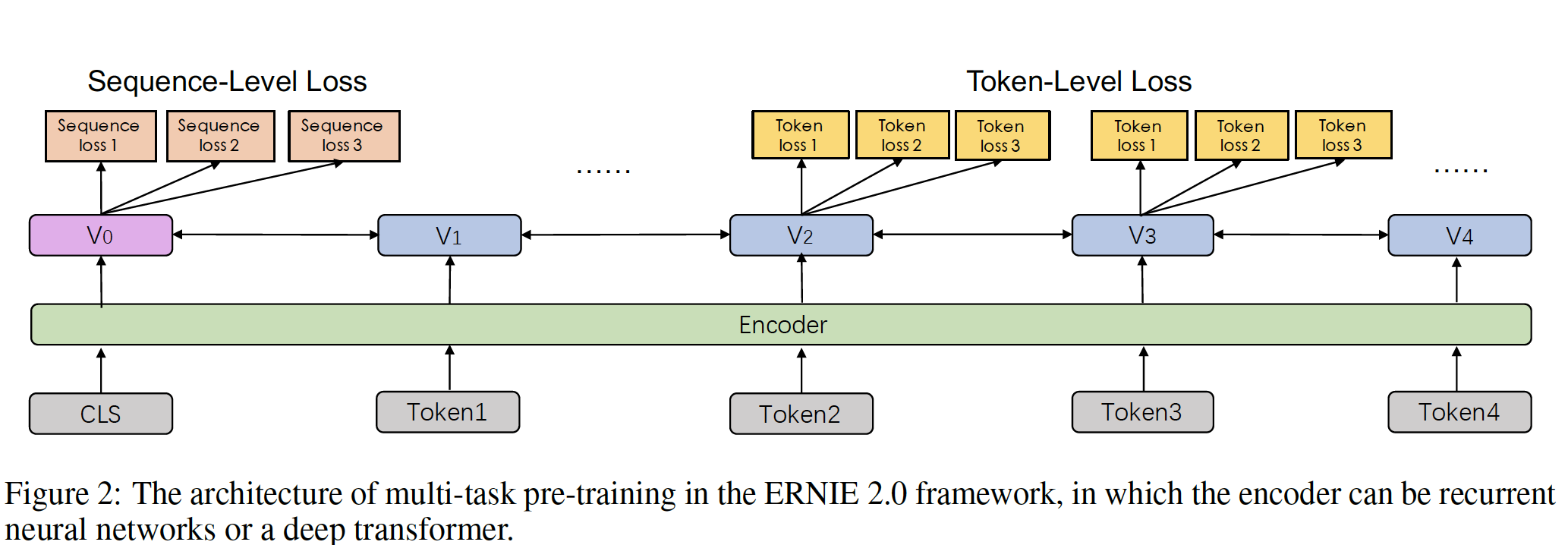
为
Application Task执行微调:凭借对task-specific监督数据的微调,预训练模型可以适配adapt不同的语言理解任务,如问答、自然语言推理、以及语义相似性。每个下游任务在被微调后都有自己的fine-tuned model。
12.1.2 ERNIE 2.0 Model
为了验证该框架的有效性,我们构建了几个无监督的语言处理任务,并开发了一个预训练模型,称为
ERNIE 2.0模型。在这一节中,我们介绍了该模型在上述框架中的实现。模型架构:
Transformer Encoder:ERNIE 2.0像其他预训练模型(如GPT、BERT、以及XLM)一样,使用multi-layer Transformer作为basic encoder。transformer可以通过自注意力来捕获序列中每个token的上下文信息,并生成contextual embedding的序列。给定一个序列,特殊的classification embedding(即,[CLS])被添加到该序列的第一个位置。此外,对于multiple input segment的任务,符号[SEP]被添加到segment之间作为分隔符。注意,
[SEP]被添加到每个segment的结尾,而不仅仅是两个segment之间。Task Embedding:ERNIE 2.0通过task embedding来调制modulate不同任务的特性。我们用一个从0到N的ID来表示不同的任务,每个task ID被分配给一个唯一的task embedding。相应的token embedding、segment embedding、position embedding、以及task embedding被作为模型的输入。在微调过程中,我们可以使用任何task ID来初始化我们的模型。ERNIE 2.0的结构如下图所示。因为微调期间是一个新的任务(即使是相同的任务类型,但是数据集不相同),与预训练的
task ID都不相同,所以选择任何一个task ID。
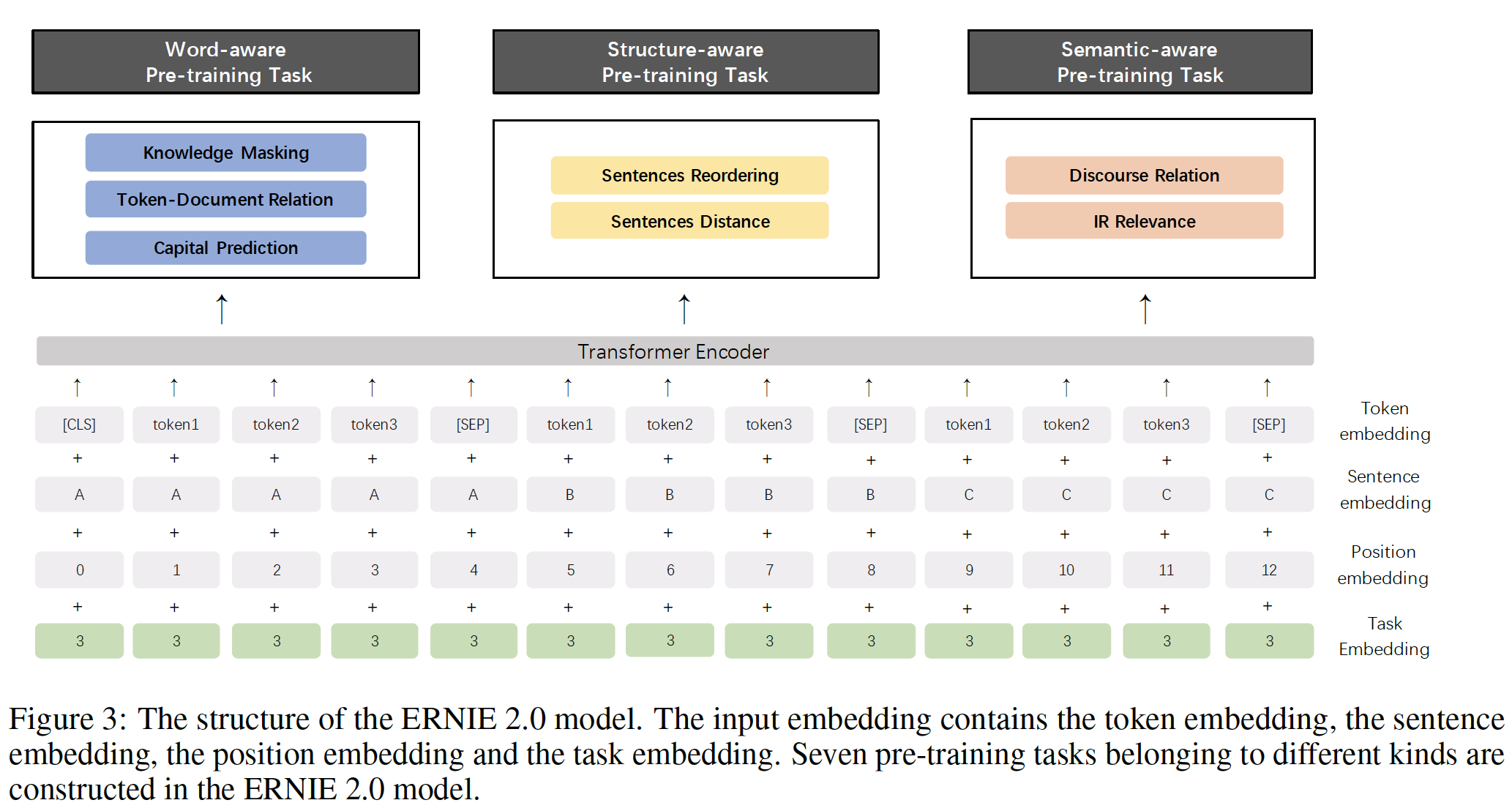
预训练任务:我们构建了几个任务来捕获训练语料中的不同方面的信息:
word-aware预训练任务:教模型捕获词法信息lexical information。Knowledge Masking Task:ERNIE 1.0提出了一个有效的策略,通过knowledge integration来增强representation。它引入了phrase masking和named entity masking,并预测whole masked phrase和whole masked named entity,从而帮助模型同时学习局部上下文和全局上下文中的依赖性。我们用这个任务来训练一个初始版本的模型。Capitalization Prediction Task:与句子中的其他词相比,大写的词capitalized word通常具有某些特定的语义价值semantic value。cased model(即,考虑字母大小写的模型)在命名实体识别等任务中具有一些优势,而uncased model(即,不考虑字母大小写的模型)则更适合于其他一些任务。为了结合两种模型的优势,我们增加了一个任务来预测单词是否被大写。这意味着
ERNIE 2.0不能在预处理阶段把所有文本转化为小写。Token-Document Relation Prediction Task: 我们增加了一个任务来预测一个segment中的token是否出现在原始文档的其他segment中。根据经验,出现在文档许多部分的词通常是常用的词或与文档的main topic有关。因此,通过识别出现在segment中的、文档的关键词,该任务可以使模型在一定程度上捕获到文档的关键词。这里无法区分文档关键词和常用词。那么是否可以分成三类:仅出现在当前
segment、出现在当前segment和当前文档的其它segment但是未出现在其它文档(即,文档关键词)、出现在当前segment以及其它文档的其它segment(即,常用词)。
structure-aware预训练任务:教模型捕获语料的句法信息syntactic information。Sentence Reordering Task:我们增加了一个sentence reordering任务来学习句子之间的关系。在这个任务的预训练过程中,一个给定的段落被随机拆分成segment,然后这些segment被随机混洗。我们让预训练模型来重新排序这些被打乱的segment。模型是一个sentences reordering任务可以使预训练的模型学习文档中句子之间的关系。通常
Sentence Distance Task:我们还构建了一个预训练任务,利用document-level信息学习句子距离。该任务被建模为一个三类分类问题:0代表两个句子在同一个文档中是相邻的、1代表两个句子在同一个文档中但是不相邻、2代表两个句子来自两个不同的文档。
semantic-aware预训练任务:教模型捕获语义信号semantic signal。Discourse Relation Task:除了上面提到的Sentence Distance Task,我们还引入了一个预测两个句子之间的语义或修辞关系的任务。我们使用《Mining discourse markers for unsupervised sentence representation learning》建立的数据来为英文任务训练一个预训练模型。遵从该论文的方法,我们还自动构建了一个中文数据集从而用于预训练。篇章关系有
174个类别标签,典型的例子如下:sentence 1 sentence 2 y 比赛的动机大不相同,但是“旋转瓶子”设法满足了所有玩家的需求。 这是一款精心制作的游戏。 truly 预谋多年之后,伯纳德没什么比嘲笑法律更好的了。 距基尔万农场不到一英里的沼泽地上的工人们挖出了一个人体躯干。 eventually 考虑某个垂直市场或有关多地点独特需求的知识。 欧内斯特(Ernest)的实力在于多地点竞技场,使伯奇(Birch)具有了新的能力。 indeed @ Sklivvz:但是你自己暗中使用了这样一种解释。 告诉你除了测量以外的任何问题都是不实际的。 namely 与来自B或C的类似能力的船只相比,Jeanneau的价格可能是便宜的。 在西雅图,36号和39号的价格下降了约20G,现在39号的价格比36号高出一些。 locally IR Relevance Task:我们建立了一个预训练任务来学习信息检索information retrieval: IR中的短文本相关性short text relevance。它是一个三类分类任务,预测query和title之间的关系。我们把query作为第一个句子,把title作为第二个句子。百度搜索引擎的搜索日志数据被用来作为我们的预训练数据。在这个任务中,有三种标签:0表示query和title之间具有强相关性,这意味着title在用户输入query后被点击。1表示query和title之间具有弱相关性,这意味着当用户输入query时,这些title出现在搜索结果中,但未能被用户点击。2表示query和title之间在语义信息上完全不相关,是随机的。
IR Relevance Task任务强烈依赖于百度的私有数据。
12.2 实验
我们将
ERNIE 2.0的性能与SOTA的预训练模型进行比较。- 对于英文任务,我们将
ERNIE 2.0与BERT, XLNet在GLUE上进行比较。 - 对于中文任务,我们
ERNIE 2.0与BERT, ERNIE 1.0在几个中文数据集上进行比较。
- 对于英文任务,我们将
12.2.1 预训练和实现
预训练数据:
- 与
BERT类似,英文语料库中的一些数据是从Wikipedia和BookCorpus爬取的。除此之外,我们还从Reddit上收集了一些。我们还使用Discovery数据作为我们的篇章关系discourse relation数据。 - 对于中文语料库,我们收集了各种数据,如百科全书、新闻、对话、信息检索、以及百度搜索引擎的
discourse relation数据。
预训练数据的细节如下表所示。
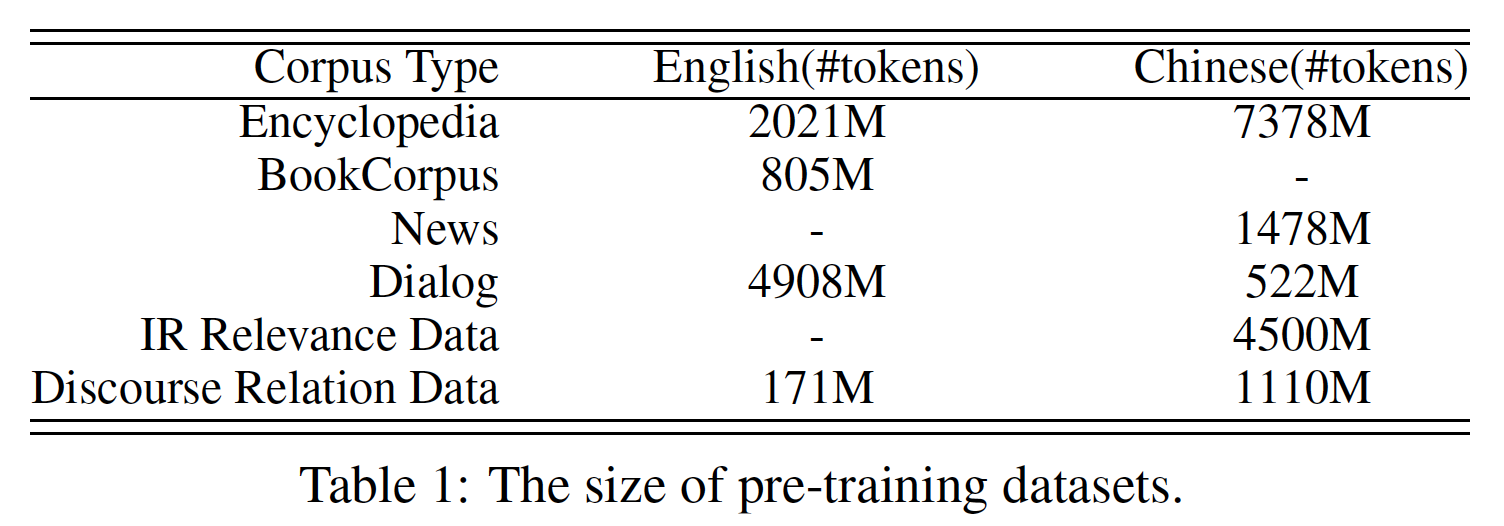
- 与
预训练
setting:为了与BERT进行比较,我们使用与BERT相同的transformer setting。base model包含12层、12个自注意力头、768维的hidden size,而large model包含24层、16个自注意力头、1024维的hidden size。XLNet的模型设置与BERT相同。对于英文语料和中文语料,
ERNIE 2.0的base model在48块NVidia v100 GPU上训练,large model在64块NVidia v100 GPU上训练。ERNIE 2.0框架是在PaddlePaddle上实现的,这是一个由百度开发的端到端开源深度学习平台。我们使用
Adam优化器,其参数固定为batch size为393216个token。英文模型的学习率被设定为5e-5,中文模型的学习率为1.28e-4。学习率由衰减方案noam来调度的,在每个预训练任务的前4000步进行warmup。通过float16操作,我们设法加速训练并减少模型的内存使用。每个预训练任务都被训练,直到预训练任务的指标收敛。每个预训练任务训练多少个
epoch?根据这里的说法,每个任务需要被训练到指标收敛。
12.2.2 微调任务
a. 英文任务
我们在
General Language Understanding Evaluation: GLUE上测试ERNIE 2.0的性能。具体而言,GLUE涵盖了多种多样的NLP数据集,包括:Corpus of Linguistic Acceptability: CoLA:CoLA由23种语言的10657个句子组成,由其原作者对acceptability(语法上可接受)进行标注。CoLA通常被用于这样的任务中:判断一个句子是否符合语法规范syntax specification。Stanford Sentiment Treebank: SST-2:SST-2由9645条电影评论组成,并针对情感分析进行了人工标注。Multi-genre Natural Language Inference: MNLI:MNLI是一个众包的集合,包括433K个sentence pair,并针对文本蕴含textual entailment进行了人工标注,通常用于文本推理任务。Recognizing Textual Entailment: RTE:RTE是一个与MNLI类似的语料库,通常用于自然语言推理任务。Winograd Natural Language Inference: WNLI:WNLI是一个捕获两个段落之间共指信息coreference information的语料库。Quora Question Pairs: QQP:QQP由40多万个sentence pair组成,数据提取自Quora QA社区,通常用于判断两个问题是否重复。Microsoft Research Paraphrase Corpus: MRPC:MRPC包含5800对从互联网上的新闻中提取的句子,并对其进行标注,以捕获一对句子之间的语义相等性semantic equivalence。MRPC通常被用于与QQP类似的任务。Semantic Textual Similarity Benchmark: STS-B:STS-B包含一个精选的英文数据集。这些数据集包含来自图像标题、新闻标题、以及用户论坛的文本。Question Natural Language Inference: QNLI:QNLI是一个语料库,会告诉人们一对给定文本之间的关系是否是question-answer。AX:AX是一个辅助性的手工制作的诊断测试套件,能够对模型进行详细的语言分析linguistic analysis。
下表是
GLUE中数据集的详细信息。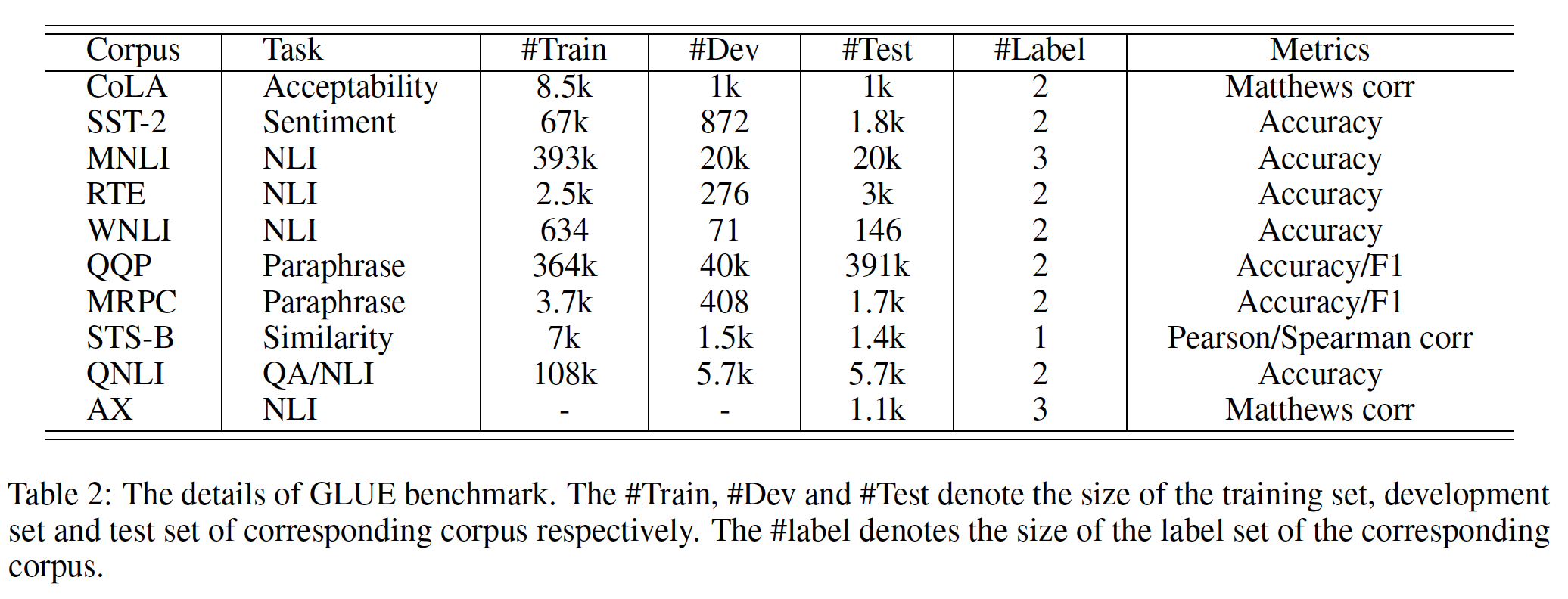
b. 中文任务
我们对
9个中文NLP任务进行了广泛的实验,包括机器阅读理解、命名实体识别、自然语言推理、语义相似性、情感分析、以及问答。具体而言,我们选择了以下中文数据集来评估ERNIE 2.0在中文任务上的表现。- 机器阅读理解
Machine Reading Comprehension: MRC:CMRC 2018、DRCD、DuReader。 - 命名实体识别
Named Entity Recognition: NER:MSRA-NER。 - 自然语言推理
Natural Language Inference: NLI:XNLI。 - 情感分析
Sentiment Analysis: SA:ChnSentiCorp。 - 语义相似度
Semantic Similarity: SS:LCQMC,BQ Corpus。 - 问答
Question Answering: QA:NLPCC-DBQA。
这些数据集的详细情况如下表所示。
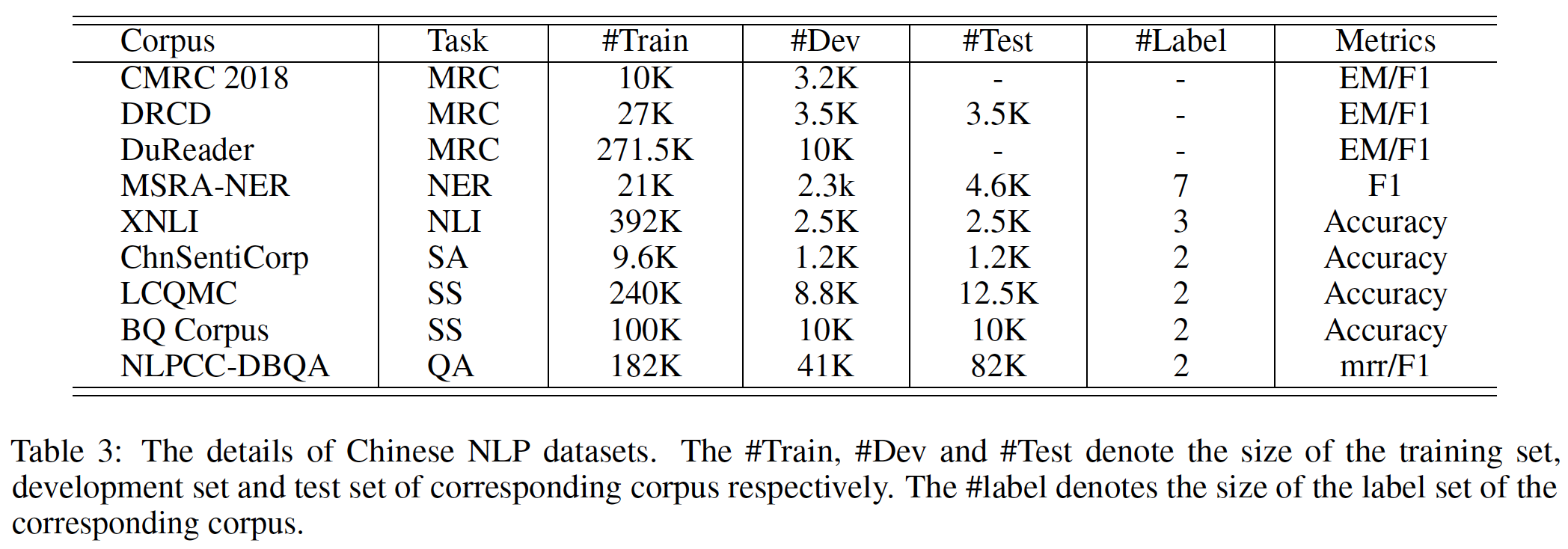
- 机器阅读理解
机器阅读理解
MCR:机器阅读理解是一个有代表性的document-level建模任务,其目的是从给定文本中提取连续的segment来回答问题。对于机器阅读理解任务,CMRC 2018、DRCD、DuReader被作为测试数据集。Chinese Machine Reading Comprehension 2018: CMRC 2018:CMRC 2018是一个用于机器阅读理解的抽取式阅读理解数据集,它由中国中文信息处理学会、IFLYTEK和哈尔滨工业大学发布。Delta Reading Comprehension Dataset: DRCD:DRCD也是一个抽取式阅读理解数据集,由Delta Research Institute发布。值得注意的是,DRCD是一个繁体中文数据集,所以我们使用一个已发布的工具将其预转换为简体中文。DuReader:DuReader是一个用于机器阅读理解和问答的大规模真实世界中文数据集,由百度在ACL 2018上发布。数据集中的所有问题都是从真实的匿名用户query中采样的,问题的答案是手动生成的。实验是在DuReader针对机器阅读理解的子集上进行的。
命名实体识别
NER:命名实体识别旨在识别各种实体,包括人名、地名、以及组织名称等。它可以被看作是一个序列标注任务。对于命名实体识别任务,我们选择了由微软亚洲研究院发布的MSRA-NER (SIGHAN 2006)数据集。自然语言推理
NLI:自然语言推理旨在确定两个句子或两个词之间的语义关系(蕴含entailment、矛盾contradiction、中性neutral)。对于自然语言推理任务,我们选择了流行的XNLI数据集。XNLI是MultiNLI语料库的一个众包集合,数据集中的pair都标注以文本蕴含标签,并翻译成包括中文在内的14种语言。情感分析
SA:情感分析旨在分析一个句子的情感是正面的还是负面的。情感分析可以被简单地认为是二分类任务。对于情感分析任务,我们使用ChnSentiCorp数据集,其中包括几个领域的评论,如酒店、书籍、以及电子计算机。语义相似性
SS:语义相似性旨在根据两个句子的语义内容的相似性来识别它们是否具有相同的意图。对于语义相似性任务,我们使用LCQMC和BQ Corpus数据集。LCQMC是由哈尔滨工业大学在COLTING 2018上发布的。BQ Corpus由哈尔滨工业大学和WeBank在EMNLP 2018上联合发布。这两个数据集中的每一对句子都与一个二元标签相关联,表明这两个句子是否具有相同的意图。问答
QA:问答旨在为相应的问题选择答案。对于问答任务,我们使用NLPCC-DBQA数据集,该数据集于2016年在NLPCC发布。
c. 实现细节
微调实验的配置如下表所示,分别为英文任务和中文任务的配置。
d. 实验结果
英文任务实验结果:为了保证实验的完整性,我们对每种方法的
base模型和large模型在GLUE上的表现进行了评估。值得注意的是,XLNet仅报告了单模型在验证集上的结果,因此我们只能比较ERNIE 2.0和XLNet在验证集上(而不是测试集上)的性能。为了获得与BERT和XLNet的公平比较,我们在验证集上运行了单任务和单模型的ERNIE 2.0。下表描述了关于GLUE的详细结果。这里的单任务指的是微调阶段的单任务(而不是预训阶段的单任务)。
可以看到:
- 根据
base模型的比较,ERNIE 2.0 BASE在所有10个任务上都优于BERT BASE,获得了80.6分。 - 根据
large模型在验证集上的比较,ERNIE 2.0 LARGE在除MNLI-m之外的所有8个任务上都一致性地优于BERT LARGE和XLNet LARGE。 - 根据
large模型在测试集上的比较,ERNIE 2.0 LARGE在所有10个任务中都优于BERT LARGE。最终,ERNIE 2.0 LARGE在GLUE测试集上得到了83.6分,比之前的SOTA预训练模型BERT LARGE实现了3.1%的改进。
- 根据
中文任务实验结果: 下表显示了在
9个经典的中文NLP任务上的表现。可以看出:ERNIE 1.0 BASE在XNLI、MSRA-NER、ChnSentiCorp、LCQMC和NLPCC-DBQA任务上的表现优于BERT BASE,但在其他任务上的表现则不太理想,这是由于两种方法的预训练不同造成的。具体而言,ERNIE 1.0 BASE的预训练数据不包含长度超过128的实例,但BERT BASE是用长度为512的实例预训练的。所提出的
ERNIE 2.0取得了进一步的进展,在所有9个任务上都明显优于BERT BASE。ERNIE 2.0 LARGE在这些中文NLP任务上取得了最好的性能,创造了新的SOTA结果。用
ERNIE 2.0 LARGE和别的模型的BASE版本比较,这是不公平的比较。应该LARGE对比LARGE。
没有消融研究?比如预训练任务的重要性、持续学习的方式等等。
十三、ERNIE3.0 [2021]
预训练的语言模型(如
ELMo、GPT、BERT和ERNIE),已被证明能有效提高各种自然语言处理任务的性能,包括情感分类、自然语言推理、文本摘要、命名实体识别等。一般而言,预训练的语言模型是以自监督的方式在大量的文本数据上学习的,然后在下游任务上进行微调,或者通过zero-shot/few-shot learning直接部署而无需针对具体任务进行微调。这种预训练语言模型已经成为自然语言处理任务的新范式。在过去的一两年中,预训练语言模型的一个重要趋势是它们的模型规模越来越大,这导致了预训练中更低的
perplexity,以及在下游任务中表现更好。- 人们提出了具有
10亿个参数的Megatron-LM用于语言理解,Megatron-LM使用简单但高效的层内模型并行intra-layer model parallel的方法,在几个数据集上取得了SOTA的结果。 100亿个参数的T5探索了预训练模型的极限,但很快这个记录就被拥有1750亿个参数的GPT-3模型所打破。GPT-3模型在few-shot甚至zero-shot的setting下具有良好的性能。- 不久之后,
Switch-Transformer作为世界上第一个万亿参数的预训练语言模型被提出。
然而,这些拥有数千亿参数的大型预训练语言模型是在纯文本上训练的。例如,
1750亿参数的GPT-3是在具有570GB过滤后的文本(这些文本来自Common Crawl)的语料库中训练的。这样的原始文本缺乏对语言知识linguistic knowledge和世界知识world knowledge等知识的explicit representation。此外,大多数大型模型是以自回归的方式进行训练的,但BERT原始论文显示,这类模型在适配下游语言理解任务时表现出较差的微调性能。在论文
《ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION》中,为了解决单一的自回归框架带来的问题,并探索知识增强knowledge enhanced的大型预训练模型的性能,作者提出了一个名为ERNIE 3.0的统一框架。ERNIE 3.0融合自回归网络auto-regressive network和自编码网络auto-encoding network,在一个由纯文本和大型知识图谱组成的4TB语料库上训练大型的知识增强模型。ERNIE 3.0可以通过zero-shot learning、few-shot learning或fine-tuning来同时处理自然语言理解任务和自然语言生成任务。此外,ERNIE 3.0支持在任何时候引入各种定制化的任务。这些定制化的任务共享相同的编码网络,并通过多任务学习进行训练。这种方法使词法信息、句法信息和语义信息的encoding跨不同任务成为可能。此外,当给定一个新的任务时,ERNIE 3.0框架可以根据它所掌握的先前的训练参数来增量地训练distributed representation。总而言之,论文贡献如下:
- 作者提出了一个统一的框架
ERNIE 3.0,它结合了自回归网络和自编码网络,这样训练出来的模型就可以通过zero-shot learning、few-shot learning或fine-tuning来同时处理自然语言理解任务和自然语言生成任务。 - 作者用
100亿个参数对大型知识增强模型进行预训练,并在自然语言理解和自然语言生成任务上进行了一系列的实验评估。实验结果表明,ERNIE 3.0在54项benchmark中始终以较大的优势胜过SOTA的模型,并在SuperGLUE benchmark中取得了第一名的成绩。
相比较于
ERNIE1.0和ERNIE2.0,ERNIE3.0使用了更大的模型、更大的预训练数据集、以及更多样化的预训练任务。此外,ERNIE 3.0使用了渐进式学习,并且修改了模型架构:不同的task具有task-specific network并共享相同的backbone network。- 人们提出了具有
相关工作:
大型预训练模型:自从
BERT被提出后,预训练的语言模型引起了越来越多的关注。研究趋势之一是增加模型规模从而导致更低的perplexity和更好的下游任务性能。因此,在过去的两年中,许多大型预训练模型被提出。T5模型有110亿个参数。T5模型通过一个统一的框架将所有基于文本的语言任务转换为text-to-text的格式,并充分探讨了预训练目标、架构、无标记数据集、迁移方法、以及其他因素的有效性。GPT-3在T5模型之后被提出,其中包括1750亿个参数,在few-shot/zero-shot setting下在各种任务上取得了惊人的表现。具体而言,GPT-3是一个自回归的语言模型,比其前身GPT-2的规模大10倍。然而,GPT-3在测试中显示出缺乏常识,存在偏见bias和隐私问题。《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》提出了一个名为Switch Transformer的1万亿参数模型,采用简化的MoE路由算法,以较少的通信和计算成本改进模型。该论文还提出了一个大规模的分布式训练方案来解决训练复杂性、通信成本和训练不稳定性的问题。
除了上面提到的模型,最近还提出了更多的非英语的大型模型。
《Cpm: A large-scale generative chinese pre-trained language model》发布了一个26亿参数的中文预训练语言模型Chinese Pre-trained Language Model: CPM。CPM在大规模中文训练数据上进行了生成式预训练,模型结构受到了GPT-3的启发。《Cpm-2: Large-scale cost-effective pre-trained language models》发布了110亿参数的模型CPM-2。《M6: A chinese multimodal pretrainer》提出了一种名为M6(Multi-Modality to Multi-Modality Multitask Mega-Transformer)的跨模态预训练方法,包括1000亿个参数用于多模态数据的统一预训练。《Pangu-alpha: Large-scale autoregressive pretrained chinese language models with auto-parallel computation》提出了一个名为PangGu-α的2000亿参数自回归语言模型。该模型在一个由2048个Ascend 910人工智能处理器组成的集群上进行训练,其分布式训练技术包括数据并行、op-level模型并行、pipeline模型并行、优化器模型并行和re-materialization。- 除了这些中文的大规模模型,人们还提出了一个名为
HyperCLOVA的韩语2040亿参数语言模型,其韩语的机器学习数据量是GPT-3的6500倍。
从上面讨论的内容来看,现在的观察表明,大规模预训练模型已经吸引了工业界和学术界越来越多的关注。
知识增强的模型:预训练的语言模型从大规模语料库中获取句法知识
syntactical knowledge和语义知识semantic knowledge,但缺乏世界知识world knowledge。最近,一些工作试图将世界知识纳入预训练的语言模型中。- 世界知识的典型形式是一个知识图谱
knowledge graph。许多工作将知识图谱中的entity embedding和relation embedding集成到预训练的语言模型中。 WKLM(《Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model》)用同类型的其他实体的名称替换原始文档中提到的实体,并训练模型将正确的实体与随机选择的实体区分开来。KEPLER(《Kepler: Aunified model for knowledge embedding and pre-trained language representation》)通过knowledge embedding和掩码语言模型目标来优化模型,将世界知识和language representation统一到同一语义空间。CoLAKE(《Colake: Contextualized language and knowledge embedding》)将语言上下文和知识上下文集成在一个word-knowledge graph中,并通过扩展的掩码语言模型目标共同为语言和知识来学习contextualized representation。
另一种现有的世界知识形式是大规模数据的额外标注。
ERNIE 1.0引入了phrase masking和named entity masking,并预测了whole masked phrase和whole masked named entity,以帮助模型学习局部上下文和全局上下文中的依赖信息。CALM(《Pretraining text-to-text transformers for concept-centric common sense》)通过两种自监督的预训练任务,教导模型检测和校正incorrect ordering of concept的、被破坏的句子,并将ground-truth句子与虚假的句子区分开来。K-Adapter(《K-adapter: Infusing knowledge into pre-trained models with adapters》)利用适配器adapter来区分知识来自哪里,其中适配器在具有额外标注信息的不同知识源上被训练得到。
- 世界知识的典型形式是一个知识图谱
13.1 模型
- 为了探索知识增强的大型预训练模型的有效性,我们提出了
ERNIE 3.0框架,对包括纯文本和知识图谱在内的大规模无监督语料进行预训练模型。此外,我们采用各种类型的预训练任务,使模型能够更有效地学习由词汇信息、句法信息和语义信息组成的不同level的知识,其中预训练任务分布在三个任务范式中,即自然语言理解、自然语言生成、和知识提取。因此,ERNIE 3.0创新性地设计了一个Continual Multi-Paradigms Unified Pre-training Framework,以实现多任务范式间的协同预训练collaborative pre-training。
13.1.1 总体框架
ERNIE 3.0的框架如下图所示,它可以广泛用于pre-training、fine-tuning和zero-shot/few-shot learning。流行的
unified pre-training strategy针对不同的well-designed cloze task共享一个Transformer network,然后应用specific self-attention mask来控制以何种上下文为条件来得到prediction。与普遍的统一预训练策略不同,ERNIE 3.0设计了一个新的Continual Multi-Paradigms Unified Pre-training Framework。我们认为:自然语言处理的不同任务范式对相同的底层抽象特征的依赖是一致的,如词汇信息和句法信息;但对
top-level具体特征的要求是不一致的,其中自然语言理解任务有学习语义连贯性semantic coherence的要求,而自然语言生成任务则期望进一步的上下文信息。因此,受多任务学习的经典模型架构的启发,即下层是所有任务共享的,而上层是特定任务的,我们提出了ERNIE 3.0,使不同的任务范式能够共享在一个shared network中学到的底层抽象特征,并分别利用在task-specific network中学到的、top-level的具体特征。此外,为了帮助模型有效地学习
lexical representation、syntactic representation和semantic representation,ERNIE 3.0利用了ERNIE 2.0中引入的continual multi-task learning framework。对不同类型的下游任务,我们首先用预训练好的shared network和相应的task-specific network的参数组合来初始化ERNIE 3.0,然后利用具体任务的数据执行相应的后续程序。ERNIE 1.0没有多任务结构。ERNIE 2.0虽然采用了多任务,但是这些任务共享相同的底层结构和top-level结构,并依次训练每个任务。最终只有一个task-specific network,该network学习到所有任务的信息。ERNIE 3.0也采用了多任务,但是不同的任务共享相同的底层结构、以及不同的top-level结构。最终有多个task-specific network,不同network学到不同任务的信息。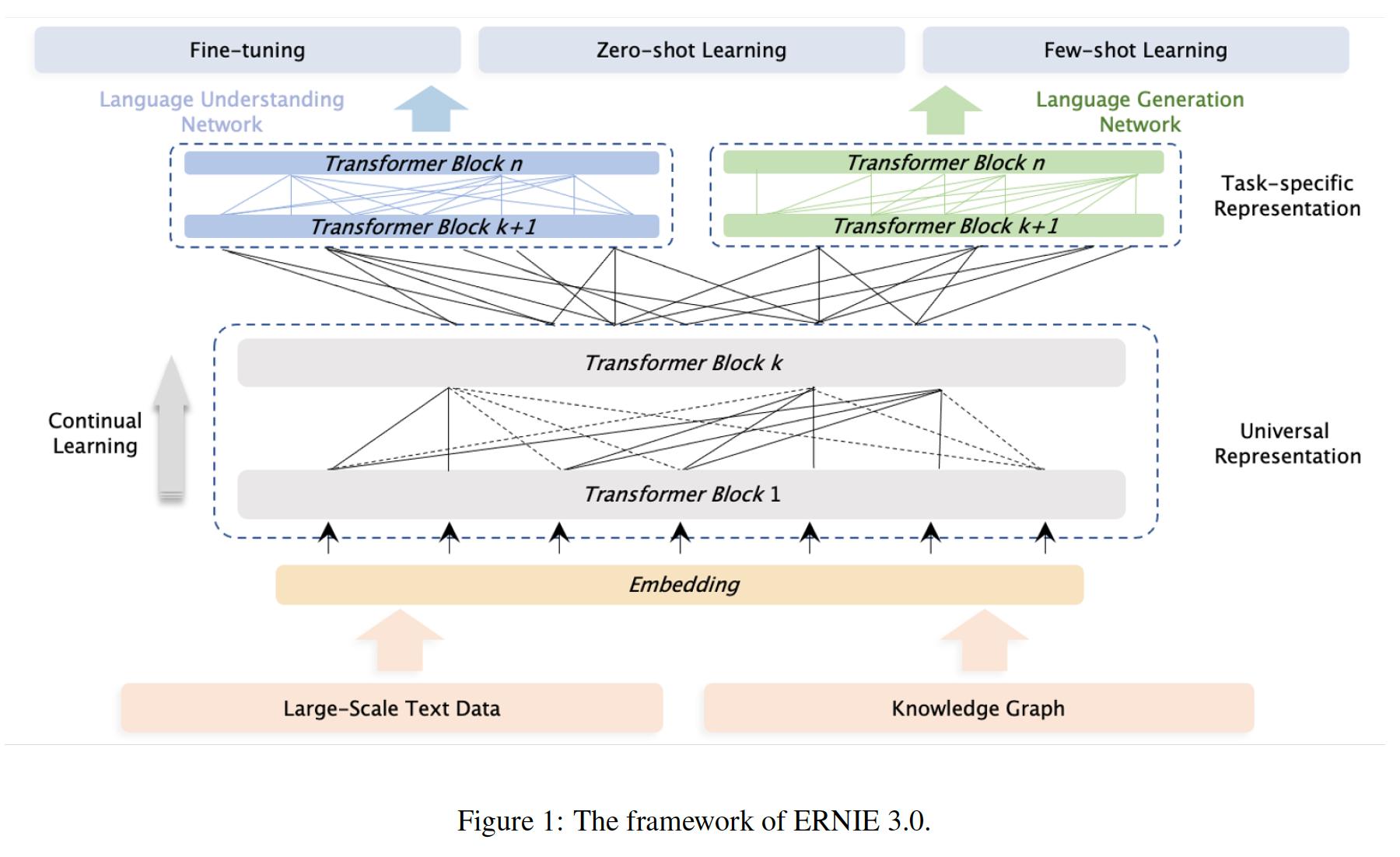
在
ERNIE 3.0中,我们把backbone shared network称作Universal Representation Module、把task-specific network称作Task-specific Representation Module。具体而言,
universal representation network扮演着通用语义特征提取器的角色,其中的参数在各种任务范式中都是共享的,包括自然语言理解、自然语言生成等等。而task-specific representation network承担着提取task-specific语义特征的功能,其中的参数是由task-specific目标学到的。ERNIE 3.0不仅使模型能够区分不同任务范式的task-specific语义信息,而且缓解了大型预训练模型在有限的时间和硬件资源下难以实现的困境,其中ERNIE 3.0允许模型只在微调阶段更新task-specific representation network的参数。具体而言,
ERNIE 3.0采用了一个Universal Representation Module和两个Task-specific Representation Module的协同架构。这两个Task-specific Representation Module为:natural language understanding specific representation module和natural language generation specific representation module。Universal Representation Module:ERNIE 3.0使用多层Transformer-XL作为backbone network。显然,Transformer模型的规模越大,其捕获和存储各种不同level的语义信息的能力就越强。因此,ERNIE 3.0设置了规模较大的universal representation module。而需要特别注意的是,memory module只对自然语言生成任务有效,同时控制attention mask矩阵。memory module对自然语言理解任务也有好处,为什么仅在自然语言生成任务中考虑memory module?作者未解释。ERNIE 3.0使用Transformer-XL作为backbone network,相比较而言,ERNIE 1.0和ERNIE 2.0使用BERT_BASE。Task-specific Representation Module:task-specific representation module也是一个多层Transformer-XL。ERNIE 3.0将task-specific representation module设置为manageable size,相比shared network的规模更小(根据论文的实现,仅占shared network参数规模的不到1%)。ERNIE 3.0构建了两个task-specific representation module,即NLU-specific representation module和NLG-specific representation module,其中前者是一个双向建模网络(自然语言理解),而后者是一个单向建模网络(自然语言生成)。
13.1.2 预训练任务
我们为各种任务范式构建了几个任务从而捕捉训练语料中不同方面的信息,并使预训练的模型具有理解、生成和推理的能力。
word-aware预训练任务:Knowledge Masked Language Modeling:ERNIE 1.0提出了一个有效的策略,通过knowledge integration来增强representation,即Knowledge Integrated Masked Language Modeling任务。它引入了phrase masking和named entity masking,预测whole masked phrase和whole masked named entity,帮助模型学习局部上下文和全局上下文中的依赖信息。Document Language Modeling:生成式预训练模型通常利用传统的语言模型(如GPT、GPT-2)或sequence-to-sequence的语言模型(如BART、T5、ERNIE-GEN)作为预训练任务。ERNIE 3.0选择了传统的语言模型作为预训练任务,以降低网络的复杂性,提高unified pre-training的效果。此外,为了使ERNIE 3.0的NLG network能够对较长的文本进行建模,我们引入了ERNIE-Doc中提出的Enhanced Recurrence Memory Mechanism,该机制通过将shifting-one-layer-downwards recurrence改为同层递归,可以对比传统recurrence Transformer建模更大的有效上下文长度。ERNIE-Doc的更新公式,和传统
recurrence Transformer的区别在于:传统recurrence Transformer使用SG(.)表示stop-gradient操作。但是,这种同层依赖(类似于
LSTM)打破了Transformer的并行性,可能不利于训练。
structure-aware预训练任务:Sentence Reordering:遵从ERNIE2.0,我们增加了一个sentence reordering任务来学习句子之间的关系。在这个任务的预训练过程中,一个给定的段落被随机拆分成segment,然后这些segment被随机混洗。我们让预训练模型来重新排序这些被打乱的segment(作为一个Sentence Distance:遵从ERNIE2.0,该任务被建模为一个三类分类问题:0代表两个句子在同一个文档中是相邻的、1代表两个句子在同一个文档中但是不相邻、2代表两个句子来自两个不同的文档。
knowledge-aware预训练任务:Universal Knowledge-Text Prediction: UKTP:UKTP任务是knowledge masked language modeling的扩展。knowledge masked language modeling只需要非结构化文本,而UKTP任务则同时需要非结构化文本和知识图谱。UKTP任务如下图所示。 给出知识图谱中的三元组和百科全书中的相应句子,我们随机掩码三元组中的关系relation或句子中的单词。为了预测三元组中的关系,模型需要检测
head entity和tail entity,并确定它们在相应句子中的语义关系。这个过程的本质与关系抽取任务中的
distant supervision algorithm相似(《Distant supervision for relation extraction without labeled data》)。distant supervision algorithm认为:如果两个实体参与了某种关系,任何包含这两个实体的句子都可能表达这种关系。为了预测相应句子中的单词,模型不仅考虑了句子中的依赖信息,还考虑了三元组中的逻辑关系。
具体来说,获得一个三元组和这个对应句子的程序如下:给定百科全书中的一篇文档,我们首先从知识图谱中找到
head entity或tail entity是文档标题的候选三元组,然后从候选三元组中head entity和tail entity同时在该文档的同一句子中被提及的三元组。注意,这里只需要
head entity和tail entity同时位于同一个句子即可,不需要relation也位于该句子中。注意,
input将知识图谱三元组和对应的文档句子拼接起来,这里把三元组也视为一个句子。注意,如果文档中的一个句子对应多个三元组怎么处理?作者未说明,读者猜测把每个三元组视为一个句子,然后与文档句子拼接起来。
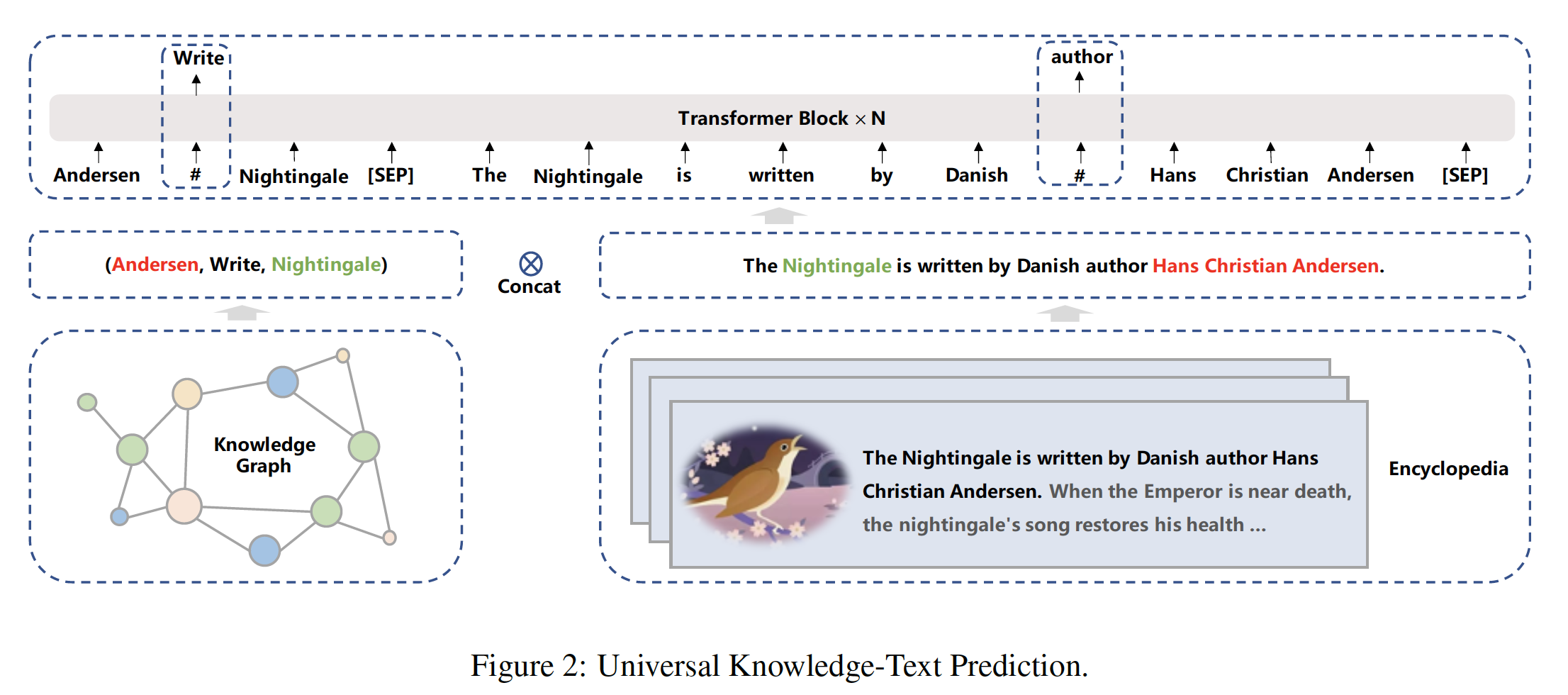
13.1.3 预训练过程
预训练算法:渐进式训练
progressive training最初是为了提高稳定性而提出的,它从一个高效的小模型开始并逐渐增加模型容量。最近的研究利用这一范式来加速模型训练。随着大型预训练的不断推进,其巨大的计算消耗成为进一步开发更强大模型的主要负担。渐进式训练的初步应用已经在transformer预训练中得到了体现。BERT设计了一个两阶段的训练,在前90%的更新中减少序列长度。GPT-2也线性地逐渐增加batch size,从一个小的值到full value。Efficientnet-v2也注意到,阶段性地改变regularization factor可以加快训练网络的速度。
为了进一步提高训练过程的收敛速度,我们建议通过逐步同时增加包括输入序列长度、
batch size、学习率、dropout rate在内的training factor,从而来更全面、更平稳的方式调整training regularization factor。事实上,Transformer模型采用learning rate warm-up策略来提高训练稳定性是很常见的,我们改进的渐进式学习策略与现有策略是兼容的。预训练数据:我们构建了一个大规模、多种类、高质量的中文文本语料库,存储量达
4TB,分11个不同的类别。据我们所知,与CLUECorpus2020(100GB)、中文多模态预训练数据(300GB)、CPM-2使用的WuDaoCorpus2.0(2.3TB中文数据和300GB英文数据)和PanGu Corpus(1.1TB)相比,这是目前最大的中文预训练语料。具体而言,我们为
ERNIE 3.0建立的语料库来自ERNIE 2.0(包括百度百科、维基百科、feed等等)、百度搜索(包括百家号、知乎、百度贴吧、百度经验)、Web text、QA-long、QA-short、Poetry 2&Couplet,以及来自医疗、法律和金融等领域的特定数据,以及拥有超过5000万条事实的百度知识图谱。为了提高数据质量,我们采取了以下预处理策略:
数据去重:数据去重是在不同的粒度上进行的,包括字符级、段落级和文档级。
- 在字符级,我们用单个字符替换连续的相同字符(即空格、制表符、感叹号、问号等)。
- 在段落级,我们用单个段落替换两个相同的连续段落,其中每个段落的句子长度为
- 在文档级,我们采用
Message Digest Algorithm5: MD5,通过比较每个文档中最长的前三个句子的MD5之和来过滤重复的文档。
字符级和段落级去重对于
ERNIE 3.0生成不重复的内容至关重要。少于
10个单词的句子被过滤掉,因为它们可能是有问题的或不完整的句子,包含的语义信息有限,无法用于模型预训练。我们进一步使用正则表达式进行句子分割,并基于百度的分词工具进行分词。这有助于
ERNIE 3.0在预训练中学习更好的句子边界和命名实体知识。
然后,每个数据集都乘以一个用户定义的乘数
user-defined multiplier number,从而为NLU-network预训练来增加数据的多样性。这个乘数代表了数据集的重要性,即:更高质量的数据集被更多地使用、更低质量的数据集被更少地使用。
百度分词工具、百度知识图谱、以及这个数据集都是私有的,没有这些工具和数据我们难以复现论文结果。
预训练
setting:ERNIE 3.0的universal representation module和task-specific representation module都使用Transformer-XL架构作为backbone。universal representation module具有48层、4096个隐单元、64个头,task-specific representation module具有12层、768个隐单元、12个头。universal representation module和task-specific representation module的总参数规模为100亿。可以看到,
task-specific representation module的规模远小于universal representation module。激活函数是
GeLU。上下文的最大序列长度为512,语言生成的memory长度为128。所有预训练任务的total batch size为6144。我们使用Adam优化器,学习率为1e-4,L2权重衰减为0.01,学习率在前一万步中进行预热,学习率线性衰减。在前一万步中,我们也使用渐进式学习来加速预训练初始阶段的收敛。模型用
384块NVDIA v100 GPU卡上训练了总共3750亿个token,并在PaddlePaddle框架上实现。凭借在《Zero: Memory optimizations toward training trillion parameter models》和《Zero-shot text-to-image generation》中使用的参数分片,我们设法减少了我们模型的内存占用,并解决了模型的总参数超过单个GPU卡的内存的问题。
13.2 实验
我们将
ERNIE 3.0与SOTA预训练模型,通过微调,在自然语言理解任务、自然语言生成任务、以及zero-shot learning上进行比较。评估任务:共
54个NLP任务:自然语言理解任务
Natural Language Understanding Task:14种自然语言理解任务,覆盖45个数据集。- 情感分析
Sentiment Analysis:NLPCC2014-SC, SE-ABSA16_PHNS, SE-ABSA16_CAME, BDCI2019。 - 观点抽取
Opinion extraction:COTE-BD, COTE-DP, COTE-MFW。 - 自然语言推理
Natural Language Inference:XNLI, OCNLI, CMNLI。 Winograd Schema Challenge:CLUEWSC2020。- 关系抽取
Relation Extraction:FinRE, SanWen。 - 事件抽
Event Extraction:CCKS2020。 - 语义相似度
Semantic Similarity:AFQMC, LCQMC, CSL, PAWS-X, BQ Corpus。 - 中文新闻分类
Chinese News Classification:TNEWS, IFLYTEK, THUCNEWS, CNSE, CNSS。 - 闭卷问答
Closed-Book Question Answering:NLPCC-DBQA, CHIP2019, cMedQA, cMedQA2, CKBQA, WebQA。 - 命名实体识别
Named Entity Recognition:CLUENER, Weibo, OntoNotes, CCKS2019。 - 机器阅读理解
Machine Reading Comprehension:CMRC 2018, CMRC2019, DRCD, DuReader, Dureader_robust, Dureader_checklist, Dureader_yesno, C^3, CHID。 - 法律文件分析
Legal Documents Analysis:CAIL2018-Task1, CAIL2018-Task2。 Cant Understanding:DogWhistle Insider, DogWhistle Outsider。- 文档检索
Document Retrieval:Sogou-log。
- 情感分析
自然语言生成任务
Natural Language Generation Task:7种自然语言理解任务,覆盖9个数据集。- 文本摘要
Text Summarization:LCSTS。 - 问题生成
Question Generation:KBQG, DuReader-QG, DuReader_robust-QG。 - 数学
Math:Math23K。 - 对抗生成
Advertisement Generation:AdGen。 - 翻译
Translation:WMT20-enzh。 - 对话生成
Dialogue Generation:KdConv。
- 文本摘要
自然语言理解任务上的微调结果:
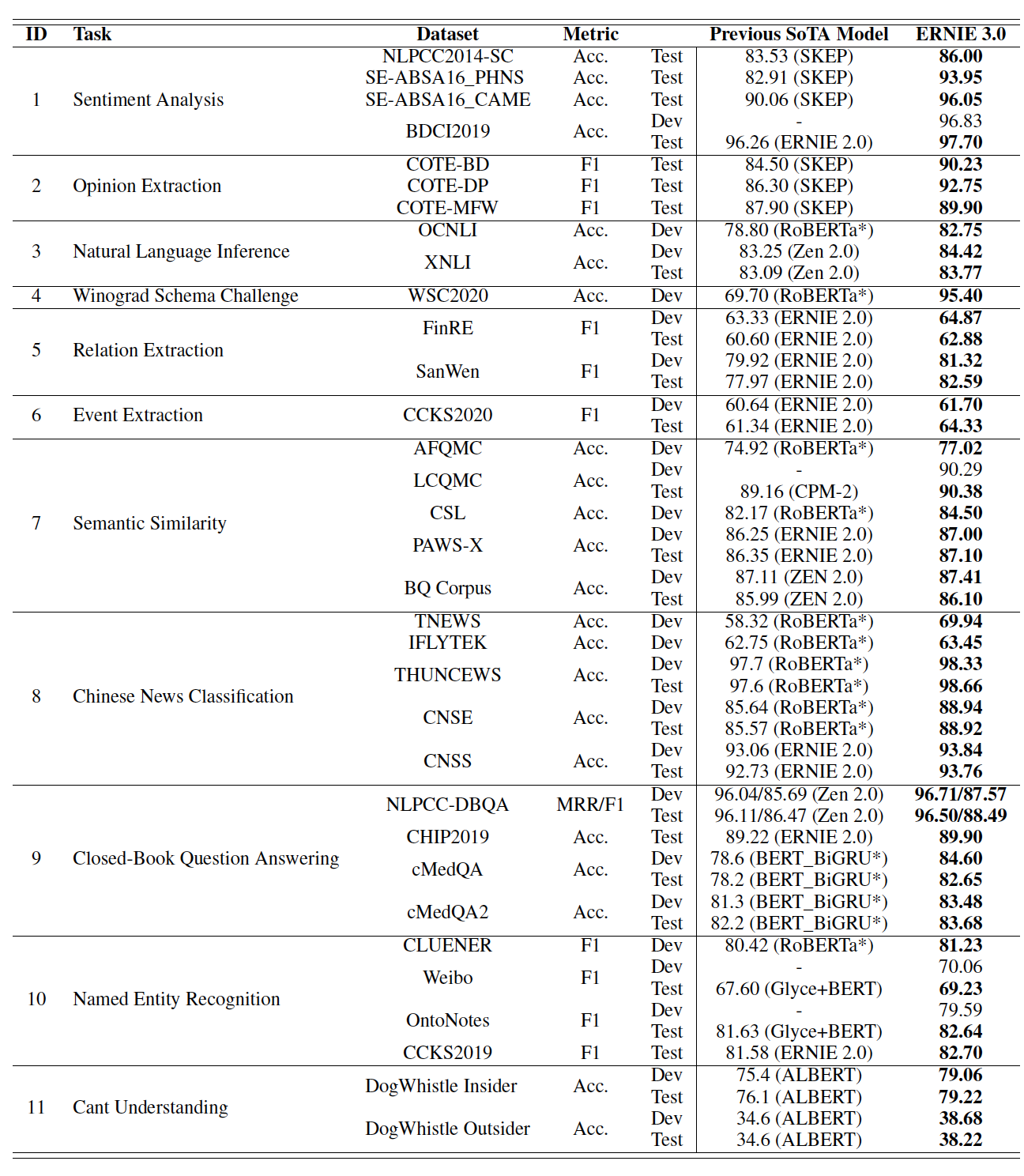
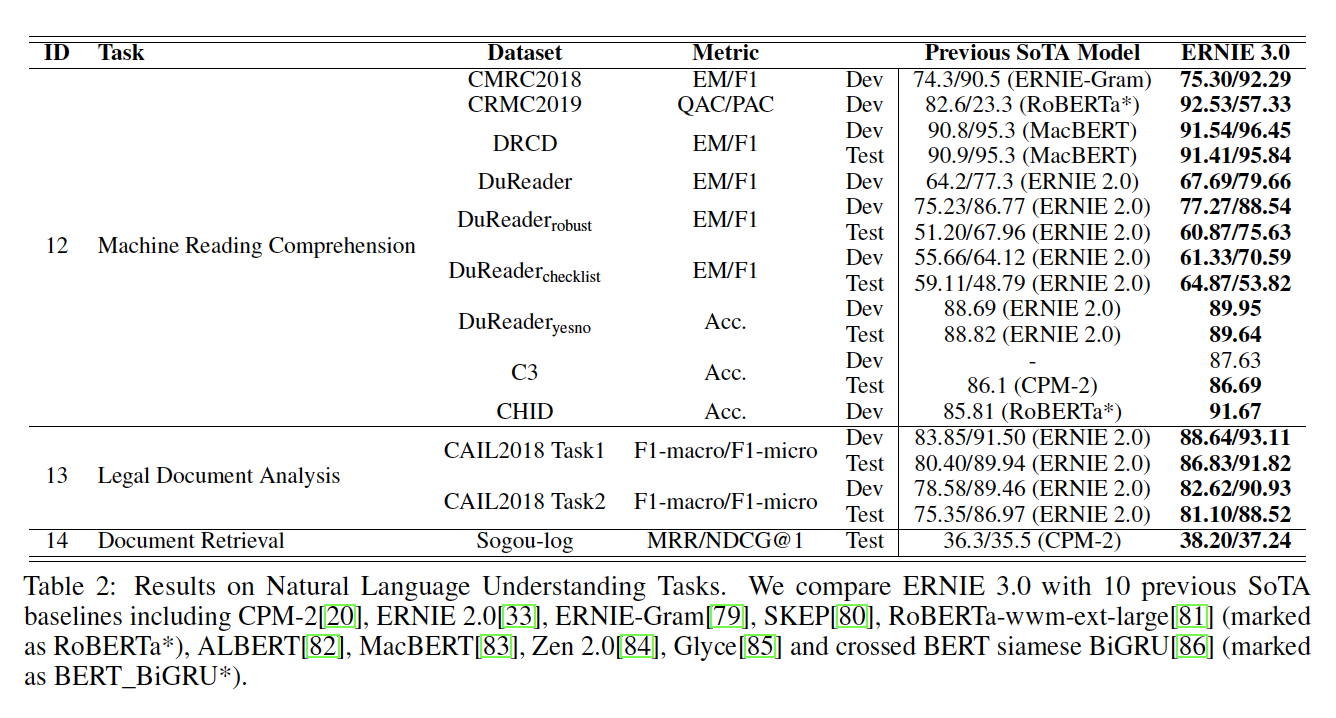
自然语言生成任务上的微调结果:
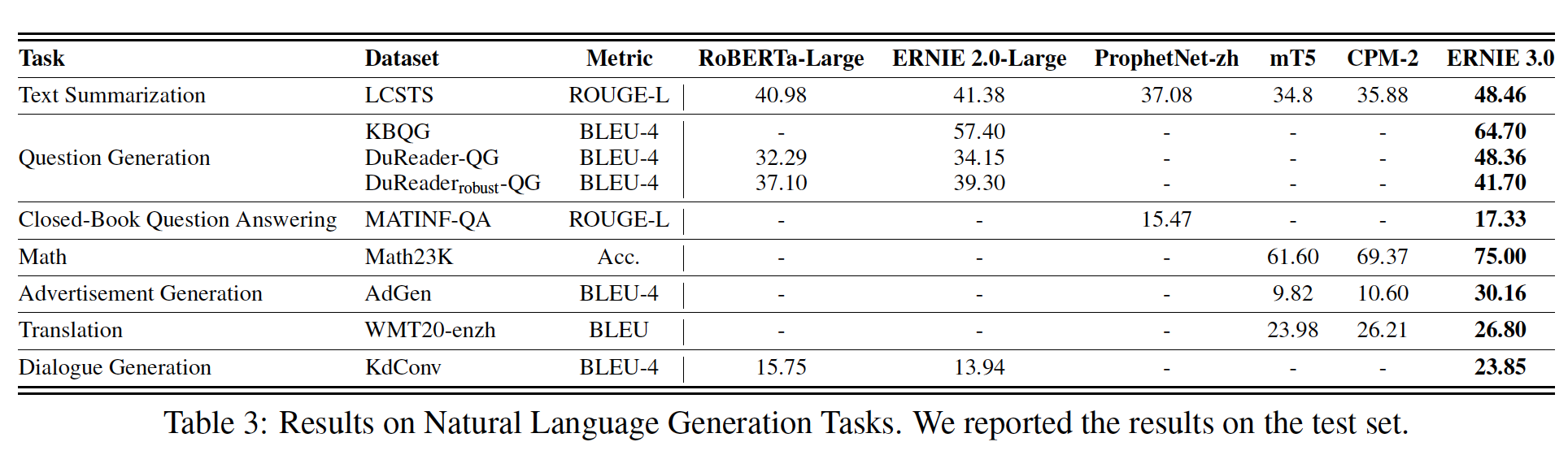
LUGE benchmark:我们在Language Understanding and Generation Evaluation: LUGE上的六个代表性任务上评估了ERNIE 3.0和其它方法。ERNIE 3.0比ERNIE 2.0和RoBERTa等领先的预训练模型平均提高5.36%。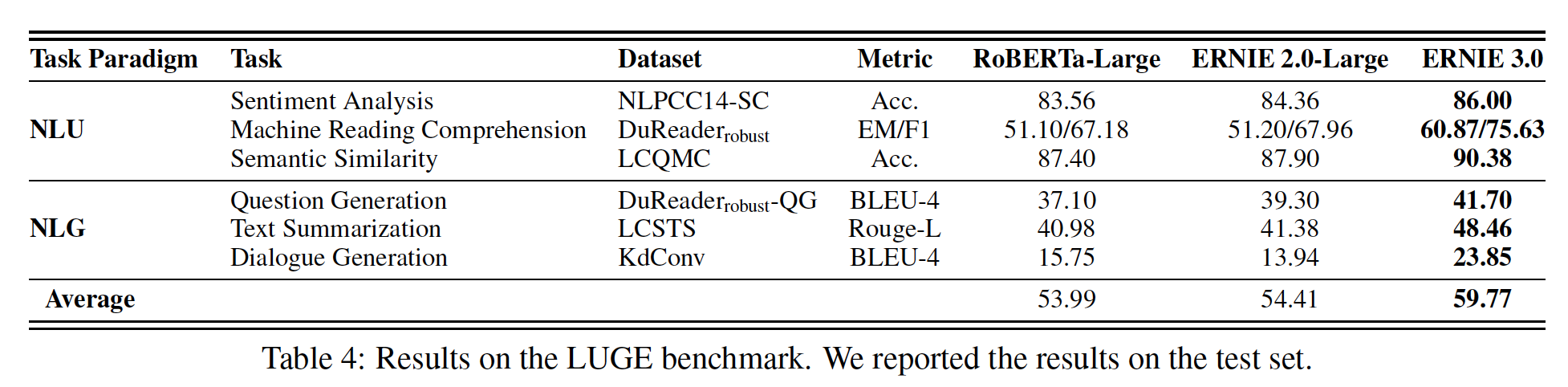
Zero-shot Learning评估:我们已经证明,ERNIE 3.0在pretraining-then-finetuning的范式下,在NLU和NLG任务上都优于以前的SOTA方法。这里我们评估ERNIE 3.0在zero-shot setting下的性能,此时模型没有执行任何梯度更新或微调。结果表明:与最近提出的大型语言模型如CPM-1(2.6B)、PanGu-α-2.6B和PanGu-α-13B相比,ERNIE 3.0在大多数下游任务上取得了强大的性能。 并且ERNIE 3.0可以产生更连贯、更自然和更准确的response(这是在我们人工收集的、跨越13个不同任务的450个案例中评定的)。评估方法:
Perplexity-based Method:在从多选答案中选择一个正确答案的任务中(如CHID和CMRC2017),我们比较了将每个答案填入上下文空白处时的per-token perplexity分,得分最低的那个将被预测为正确答案。在需要二分类或多分类的任务中,我们给每个
label分配一个更有语义的名字,并使用一个prompt将上下文和label形式化为人类可读的文本。然后,这类任务可以被视为多选任务。我们使用的prompt与CPM-1和PanGu-α中的prompt相似。Generation-based Method:在自由形式补全free-form completion的任务上(如闭卷问答),我们使用beam search,其中beam width为8并且没有长度惩罚。completion的最大生成长度由预定义数字来限制,这个数字基于数据集上答案长度的95%百分点来获得。我们使用exact match: EM、F1、Rouge-1等指标。ROUGE-N(其中N可以为1/2/...)为N-gram召回率:exact match为预测结果与ground-truth完全相同的测试样本占比。在
restrained completion的任务上(如抽取式机器阅读理解),我们使用restrained beam search,参数与自由形式补全任务相同。为每个样本构建一个Trie-Tree,以有效地限制生成空间,所生成的completion仅出现在给定的文本中。
结果:
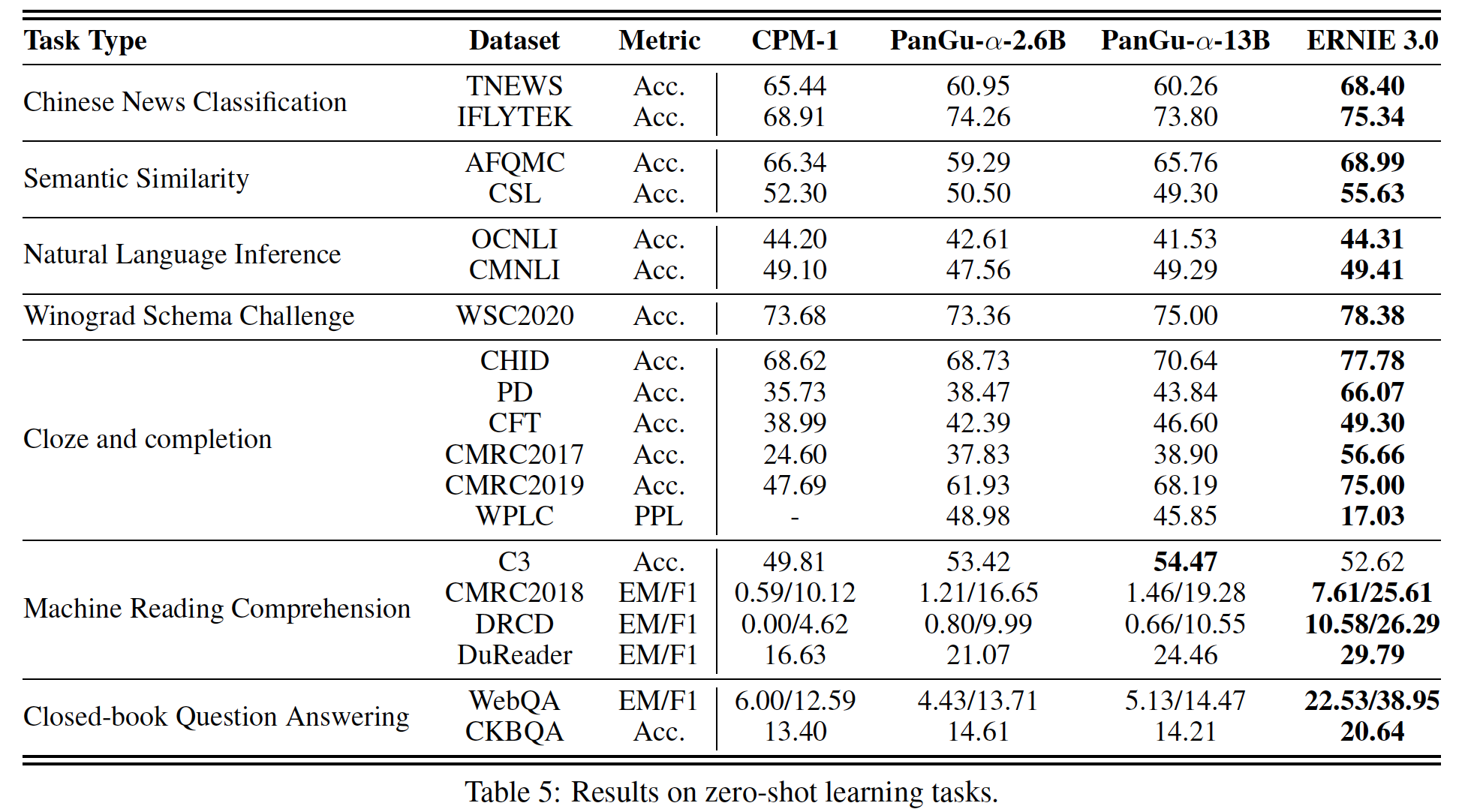
案例研究:我们人工收集了
450个案例,以评估当前大型预训练模型在5种不同类型的13个任务上的zero-shot generation能力,包括问答Question Answering、解释Interpretation、对话Dialogue、文本生成Text Generation和摘要Summarization。在人类评估中,标注者被要求对生成质量进行评分,评分标准为[0, 1, 2]。我们在Table 6中报告了连贯性coherence,、流畅性fluency和准确性accuracy的平均得分。并在Table 7中展示了ERNIE 3.0的一些zero-shot生成。与CPM-1、PLUG、PanGu-α相比,ERNIE 3.0平均能生成最连贯、最流畅和最准确的文本。三个评分指标的介绍如下,评分细节如Table 8所示。- 连贯性
coherence:衡量生成的内容是否与上下文相关并一致。 - 流畅性
fluency:评价生成的文本是否自然或可读。一个流畅的文本应该在生成的文本中没有语义上的矛盾。 - 准确性:评价生成的文本是否与
ground truth相同。
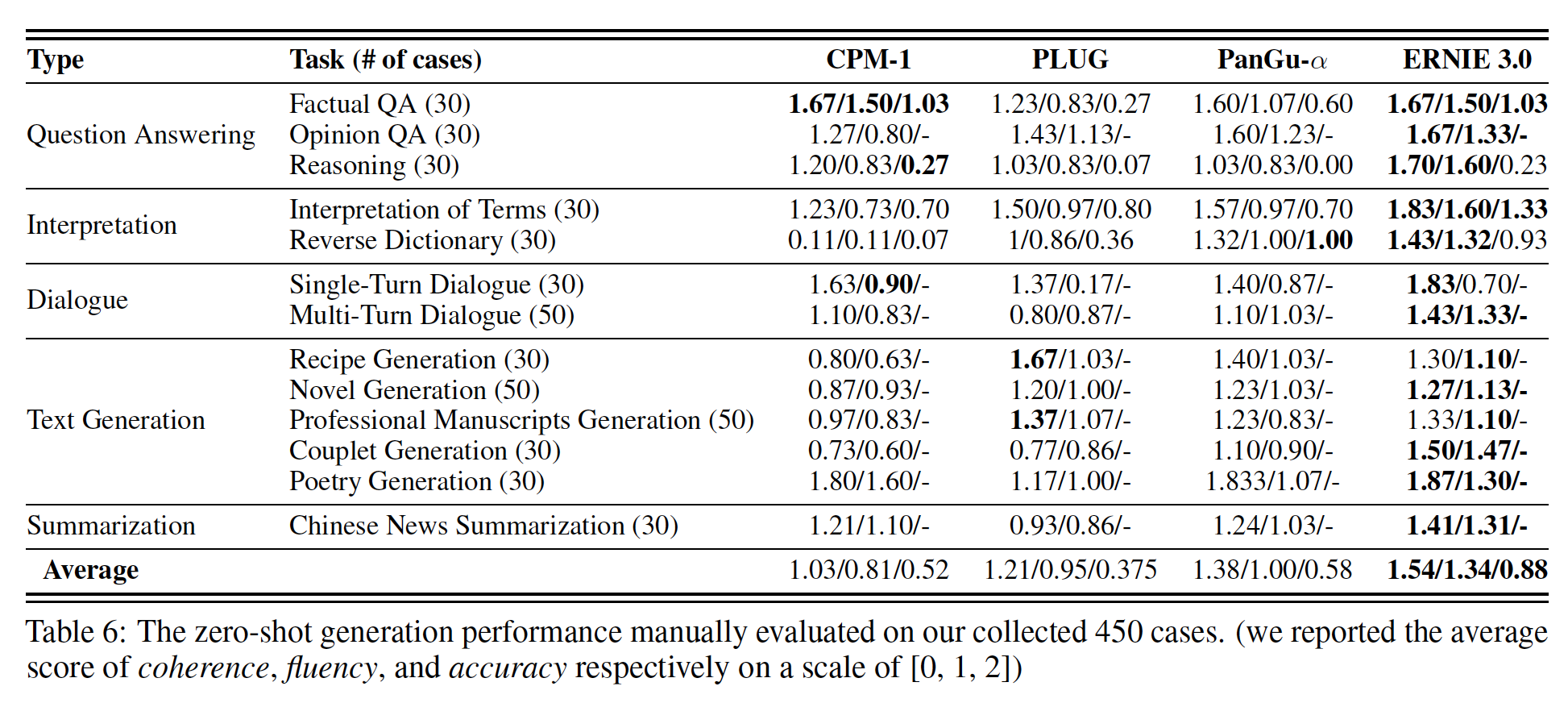

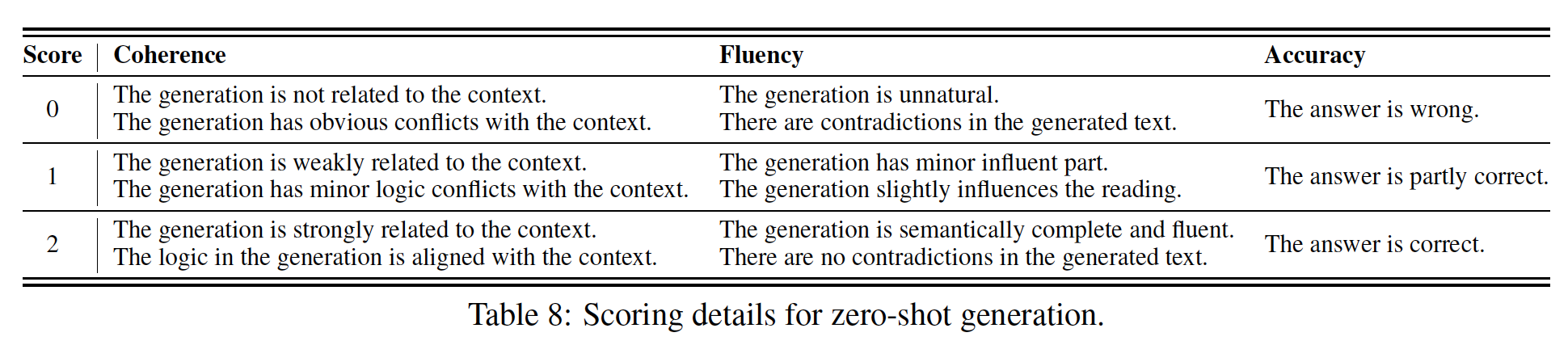
- 连贯性
SuperGLUE上的实验:SuperGLUE是一个针对自然语言理解的多任务benchmark。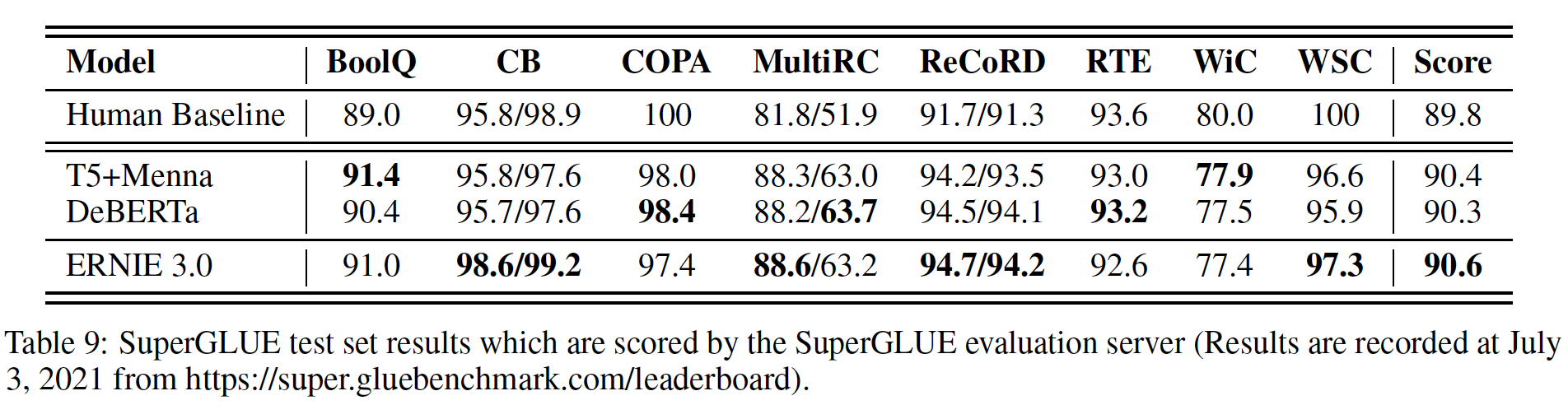
分析:
Task-specific Representation Module的有效性:为了验证task-specific network的有效性,我们将我们提出的结构与那些在各种预训练任务下共享参数的网络进行比较。对于消融测试,我们选择自然语言理解和自然语言生成作为两种不同的训练范式,并利用前面提到的相应任务。
unified network遵循base model setting(12层,768维,12个注意力头),每个任务范式的task-specific network被设置为3层、256维、4个注意力头。在对比模型,task-specific network在不同的任务范式中是共享的。下图说明了预训练过程中自然语言生成任务的perplexity变化。可以看到:- 在不同任务拥有自己的
task-specific network的模型达到了较高的收敛速度。 - 随着训练的进行,与具有
shared task-specific network的模型相比,性能优势变得更大。
实验结果显示了所提出的
task-specific network的有效性,并证明了区分不同任务的必要性。
- 在不同任务拥有自己的
Universal Knowledge-Text Prediction:为了universal knowledge-text prediction任务的性能,我们进行了一组消融实验。关系抽取任务是一个典型的
knowledge-driven任务,旨在预测给定句子中提到的两个实体之间的关系。具体来说,我们增加了四个special token,[HD], [/HD], [TL], [/TL],分别用来识别提到的头部实体和尾部实体,然后根据上述四个special token的final representation之和进行关系分类。我们在SanWen和FinRE数据集上构建了实验,如下表所示,knowledge enhancement策略在关系抽取任务上取得了卓越的经验性能。输入为
"[HD]实体A[\HD] .... [TL]实体B[\HD]...."。这里的前提是,一个句子中只有两个实体。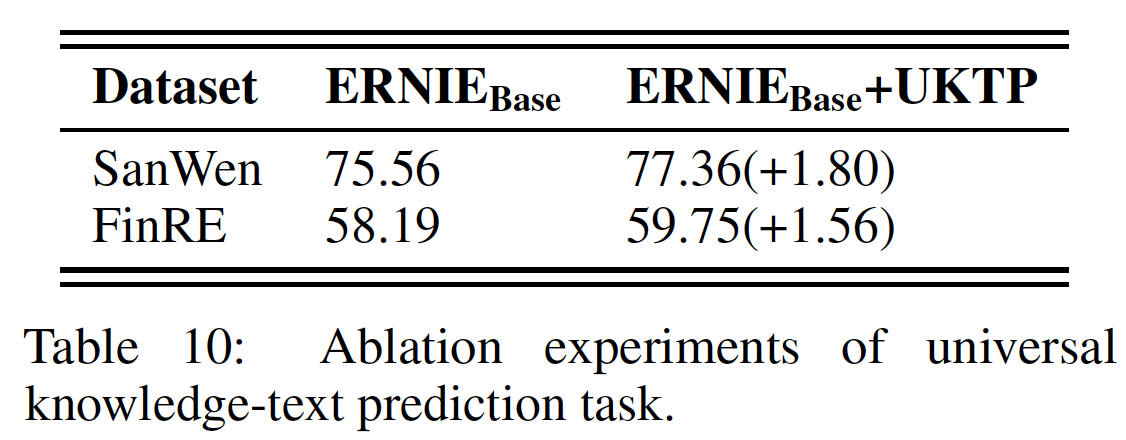
此外,在
CKBQA上进行的zero-shot generation实验也证实了universal knowledge-text prediction任务的有效性。具体来说,基于知识的问答任务需要一个模型基于知识图谱来搜索和推理出正确答案。用KBQA任务来衡量预训练语言模型的知识学习能力是合适的。我们使用"QUESTION: $QUESTION? ANSWER:"作为zero-shot learning的prompt,然后在CKBQA数据集上比较我们提出的模型和几个SOTA的预训练语言模型的性能。如Table 5所示,ERNIE 3.0在CKBQA数据集中的表现明显优于PanGu-α和CPM-1,这表明ERNIE 3.0具有记忆和学习更多知识的能力。Progressive Learning to Speed up Convergence:我们记录了两种架构配置的训练收敛速度,包括ERNIE_Base和ERNIE_1.5B。其中,ERNIE_Base的架构设置遵循《Ernie: Enhanced representation through knowledge integration》,ERNIE_1.5B模型的配置为48层、1536维、24个注意力头。如下表所示,我们记录了模型的
loss值收敛到与ERNIE3.0相同的训练时间。对于
ERNIE_Base模型,渐进式学习的收敛时间减少了65.21%,从11小时减少到4小时。在渐进式预热阶段,对于
ERNIE_Base,我们将batch size从8增加到2048,序列长度从128增加到512,学习率从0线性增加到1e-4,dropout rate保持0。对于
ERNIE_1.5B模型,渐进式学习的收敛时间减少了48%。在渐进式预热阶段,对于
ERNIE_1.5B,我们将batch size从8增加到8192,学习率从0线性增加到6e-4,dropout rate保持0。
对于这两种配置,我们在
8个NVIDIA Tesla V100 GPU上进行了预训练。其余实验设置与《Ernie: Enhanced representation through knowledge integration》相同。对于ERNIE_1.5B,为了在GPU内存的约束下达到峰值batch size,在预训练中使用梯度累积策略。梯度累积策略相当于增大
batch size。假设有batchbatch的梯度更新为:其中
梯度累积策略对于这
batch执行一次梯度更新,而不是batch的梯度,然后一次性更新。
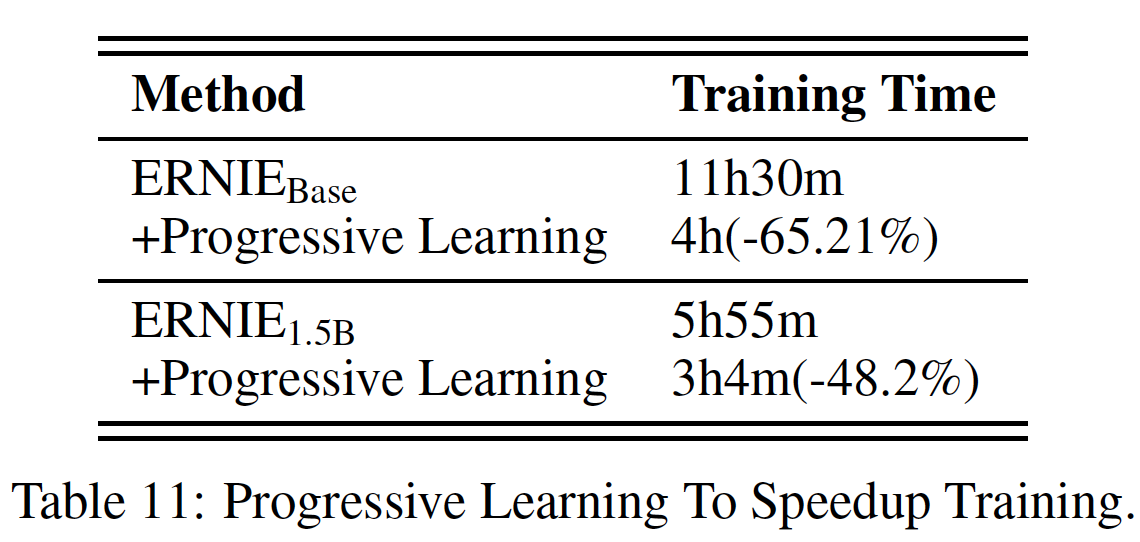
十四、ERNIE-Huawei [2019]
预训练的
language representation model,包括基于特征的方法和微调的方法,可以从文本中捕捉丰富的语言信息,从而使许多NLP应用受益。BERT作为最近提出的模型之一,通过简单的微调在各种NLP应用中获得了SOTA的结果,这些任务包括命名实体识别、问答、自然语言推理和文本分类。尽管预训练的
language representation model已经取得了可喜的成果,但它们忽略了为语言理解纳入知识信息。如下图所示,在不知道"Blowin’ in the Wind"是一首歌、以及"Chronicles: Volume One"是一本书的情况下,在entity typing任务(即,实体分类)中很难识别Bob Dylan的两个职业(即"songwriter"和"writer")。此外,在关系分类relation classification任务中,几乎不可能提取细粒度的关系,如composer作曲家和author作者。 对于现有的预训练的language representation model来说,下图例子中的两个句子在语法上是模糊ambiguous的,比如"UNK wrote UNK in UNK"。因此,考虑丰富的知识信息可以导致更好的语言理解,并相应地有利于各种knowledge-driven的应用,例如entity typing和relation classification。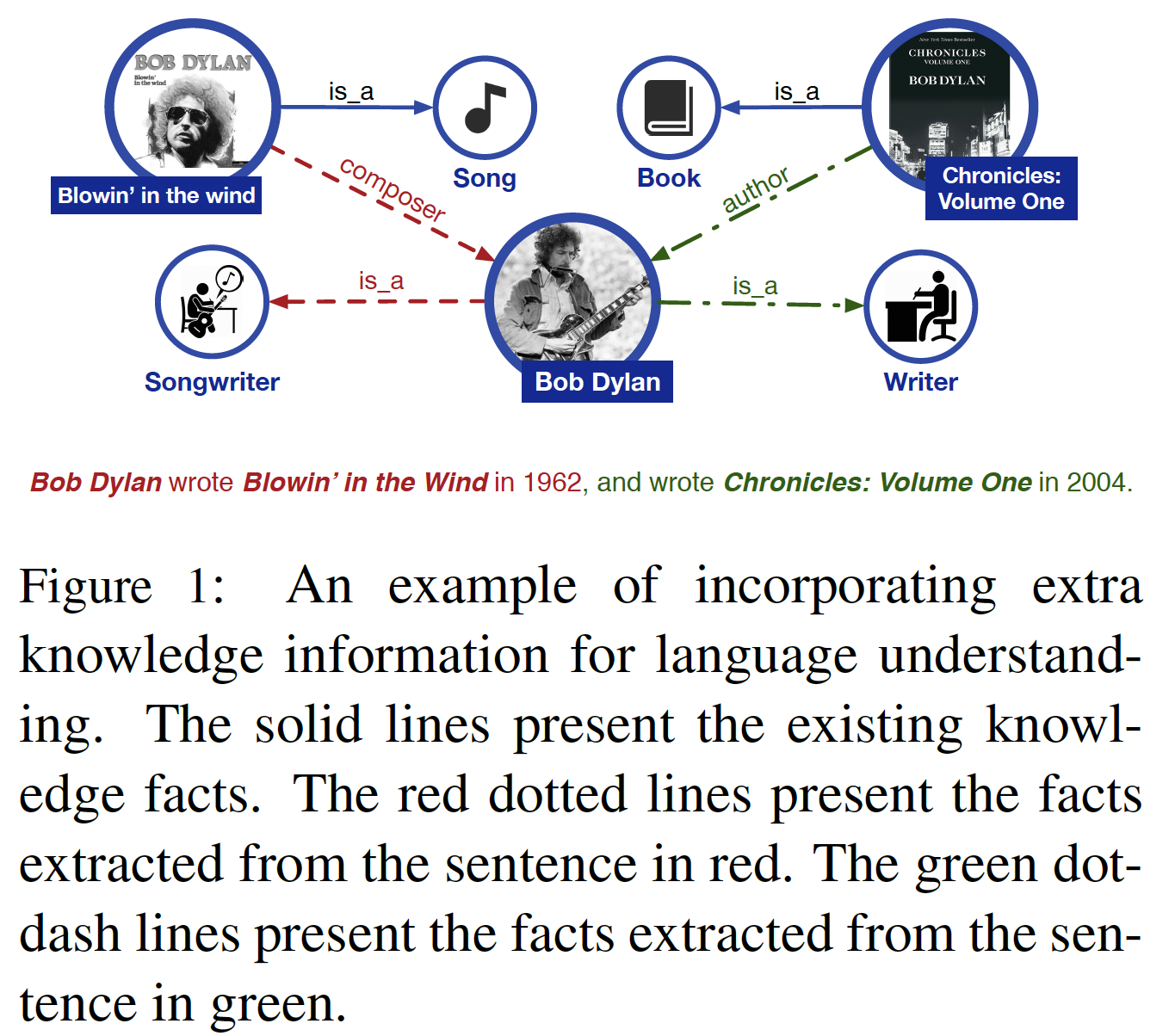
将外部知识纳入
language representation model有两个主要挑战:Structured Knowledge Encoding:对于给定的文本,如何为language representation model有效地在知识图谱中抽取和编码该文本相关的informative fact,这是一个重要的问题。Heterogeneous Information Fusion:针对language representation的预训练程序与knowledge representation程序截然不同,这导致了两个独立的向量空间。如何设计一个特殊的预训练目标来融合词法lexical的、句法syntactic的和知识knowledge的信息是另一个挑战。
为了克服上述挑战,论文
《ERNIE: Enhanced Language Representation with Informative Entities》提出了Enhanced Language RepresentatioN with Informative Entities: ERNIE,它同时在大规模文本语料和知识图谱上预训练language representation model。- 为了抽取和编码
knowledge information,ERNIE首先识别文本中提到的命名实体,然后将这些提到的实体与知识图谱中的相应实体对齐。ERNIE不直接使用知识图谱中的graph-based facts,而是用TransE等knowledge embedding算法对知识图谱的图结构进行编码,然后将informative entity embedding作为ERNIE的输入。基于文本和知识图谱之间的对齐alignments,ERNIE将knowledge module中的entity representation集成到semantic module的underlying layer。 - 与
BERT类似,ERNIE采用masked language model和next sentence prediction作为预训练目标。此外,为了更好地融合textual feature和knowledge feature,论文设计了一个新的预训练目标,即随机掩码输入文本中的一些token-entity alignment,要求模型从知识图谱中选择合适的实体来完成对齐alignment。与现有的预训练language representation model只利用局部上下文来预测token不同,ERNIE的目标要求模型同时聚合上下文和knowledge fact来同时预测token和实体,并导致一个knowledgeable language representation model。 - 论文对两个
knowledge-driven的NLP任务进行了实验,即entity typing和relation classification。实验结果表明:通过充分利用词法lexical的、句法syntactic的和知识knowledge的信息,ERNIE在这些knowledge-driven的任务上明显优于BERT。论文还在其他常见的NLP任务上评估了ERNIE,ERNIE仍然取得了可比comparable的结果。
预训练语料库容易获得,但是知识图谱一般比较难以获得。
本文中提到的
ERNIE指的是《ERNIE: Enhanced Language Representation with Informative Entities》,而不是Ernie: Enhanced representation through knowledge integration》。相关工作:预训练方法可以分为两类,即
feature-based的方法和finetuning方法。- 早期的工作主要是采用
feature-based的方法,将单词转化为distributed representation。由于这些预训练的word representation捕捉了文本语料中的句法信息syntactic information和语义信息semantic information,它们经常被用作各种NLP模型的input embedding和初始化参数,并且比随机初始化参数有显著的改进。由于这些word-level模型经常受到单词多义性的影响,ELMo进一步采用sequence-level模型来捕捉不同语言上下文下的复杂的word feature,并使用ELMo来生成context-aware word embedding。 - 与上述
feature-based的方法只使用pretrained language representation作为input feature不同,《Semi-supervised sequence learning》在未标记的文本上训练自编码器,然后将预训练的模型架构和参数作为其他specific NLP model的起点。受该论文的启发,人们提出了更多用于微调的预训练language representation model,如GPT、BERT。
虽然
feature-based的和finetuning的language representation model都取得了巨大的成功,但它们忽略了纳入知识信息。 正如最近的工作所证明的那样,注入额外的知识信息可以大大增强原始模型。因此,我们认为,额外的知识信息可以有效地有助于现有的预训练模型。事实上,一些工作已经尝试对单词和实体进行联合的representation learning,以有效利用外部知识图谱,并取得了可喜的成果。《Ernie: Enhanced representation through knowledge integration》提出了knowledge masking策略用于masked language model从而通过知识来增强language representation。在本文中,我们进一步利用语料库和知识图谱来训练BERT-based的enhanced language representation。- 早期的工作主要是采用
14.1 模型
我们记一个
token序列为token序列的长度。同时, 我们用token序列的实体序列entity sequence,其中token都能对齐一个实体。此外,我们把包含所有token的整个词表vocabulary表示为entity list表示为tokentoken和entity之间的对齐alignment定义为:named entity phrase中的第一个token对齐。实体有两种位置:第一种位置是位于知识图谱中的实体,第二种位置是位于文本句子中的实体。除了特别说明之外,本文中的实体都指的是位于文本句子中的实体。
这篇文章价值不大,实验部分参考意义也不大(用了预训练好的
BERT参数来初始化,这导致不公平的比较,而且效果反而不如BERT)。浪费时间。
14.1.1 模型架构
如下图所示,
ERNIE的整个模型架构由两个堆叠的模块组成:T-Encoder:底层的文本编码器textual encoder负责从input token中获取基本的词法信息和句法信息。K-Encoder:上层的知识编码器knowledgeable encoder负责将额外的token-oriented knowledge information集成到底层的文本信息中,这样我们就可以将token和实体的异质信息heterogeneous information表示为一个统一的特征空间feature space。
此外,
T-Encoder的层数记做K-Encoder的层数记做这里的
Entity Input是实体经过TransE算法之后得到的entity embedding。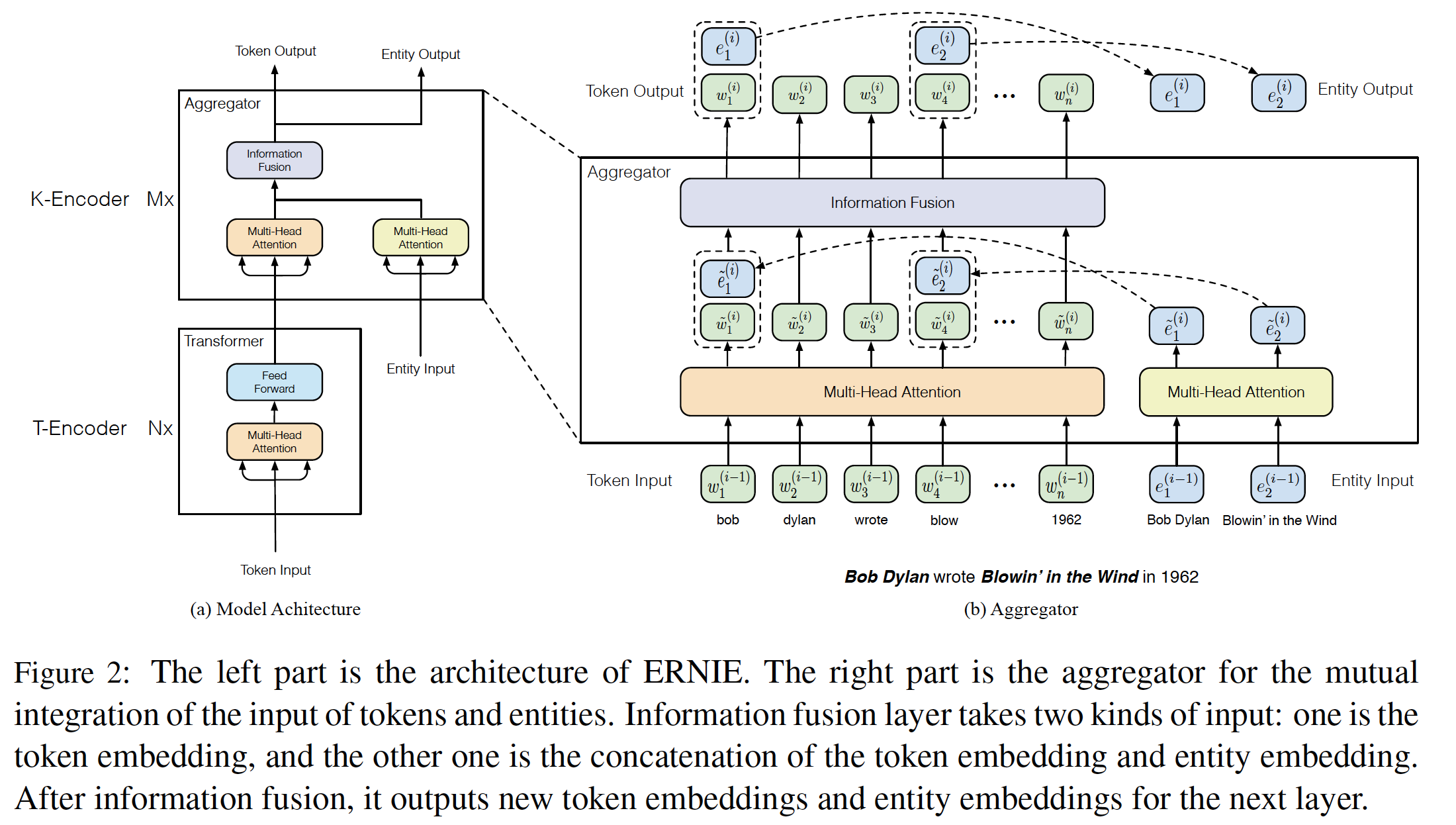
具体而言,给定一个
token序列token的token embedding、segment embedding、positional embedding相加从而计算其input embedding,然后计算词法特征lexical feature和syntactic feature其中
Transformer encoder。由于BERT中的实现相同,而且BERT很流行,我们不再对这个模块进行详述。在计算完
ERNIE采用knowledgeable encoder(K-Encoder)将知识信息注入language representation中。具体而言,我们用entity embeddingknowledge embedding模型TransE预训练的。然后,K-Encoder,从而融合异质信息并计算final output embedding。
14.1.2 Knowledgeable Encoder
如
Figure 2所示,K-Encoder由堆叠的aggregator组成,这些aggregator被设计用来对token和实体进行编码,并融合它们的异质特征heterogeneous feature。在第aggregator中,来自前一个aggregator的输出被作为input token embeddingentity embeddingmulti-head self-attention: MH-ATT:然后,第
aggregator采用信息融合层information fusion layer对token序列和实体序列进行相互集成mutual integration,并计算出每个token和实体的output embedding。对于一个token其中:
token信息和实体信息的inner hidden state。GELU函数。
information fusion layer其实就是单层前馈神经网络。对于没有相应实体的
token,information fusion layer计算output embedding而不进行集成,如下所示:为简单起见,第
aggregator的操作表示如下:最顶部
aggregator计算的、token和实体的output embedding将被用作K-Encoder的final output embedding。
14.1.3 Pre-training for Injecting Knowledge
为了通过
informative entity向language representation注入知识,我们为ERNIE提出了一个新的预训练任务,即随机掩码一些token-entity alignment,然后要求系统根据aligned token来预测所有相应的实体。由于我们的任务类似于训练降噪自编码器denoising auto-encoder,我们把这个过程称为denoising entity auto-encoder: dEA。考虑到softmax层来说是相当大的,因此我们仅要求系统根据给定的实体序列而不是知识图谱中的所有实体来预测。这里把候选的实体集合从
token序列所对应的实体集合中。由于当前token序列所对应的实体集合存在一定的相关性,因此这些负样本和ground-truth实体之间是相关的,因此是hard负样本。因此,建议随机从知识图谱中采样easy负样本。给定
token序列tokenaligned entity distribution为:其中:
token embedding空间映射到entity embedding空间)。tokenfinal output embedding。entityentity embedding。
entity embedding没有采用final output的,因为候选的entity可能没有馈入模型(如,某些entity被masked了)。然后我们根据
dEA的交叉熵损失函数。如何进行掩码?作者并未详细说明。读者猜测:以第一个实体为例,假设第一个实体对应
tokeninput变成:token序列但是根据
Figure 2,感觉作者是把token序列entity embedding序列考虑到在
token-entity alignment中存在一些错误,我们对dEA进行了以下操作:- 在
5%的时间里,对于一个给定的token-entity alignment,我们用另一个随机的实体替换该实体,这旨在训练我们的模型来纠正如下错误:token被aligned以一个wrong entity。 - 在
15%的时间里,我们掩码了token-entity alignment,这旨在训练我们的模型来纠正如下错误:entity alignment system没有抽取所有现有的alignment。 - 在其余的时间里,我们保持
token-entity alignment不变,这旨在鼓励我们的模型将实体信息集成到token representation中,以便更好地理解语言。
- 在
与
BERT类似,ERNIE也采用了masked language model: MLM和next sentence prediction: NSP作为预训练任务,以便ERNIE能够从文本中的token中获取词法信息lexical information和句法信息syntactic information。总体的预训练损失是dEA、MLM和NSP损失之和。
14.1.4 Fine-tuning for Specific Tasks
如下图所示,对于各种常见的
NLP任务,ERNIE可以采用类似于BERT的微调程序。我们可以把第一个token的final output embedding(这对应于特殊的[CLS] token)作为具体任务的输入序列的representation。对于一些
knowledge-driven的任务(例如,relation classification和entity typing),我们设计了特殊的微调程序。- 对于
relation classification:该任务要求系统基于上下文对给定entity pair的relation label进行分类。对relation classification进行微调的最直接的方法是:将池化层应用于给定实体的final output embedding,并用它们的entity embedding的拼接来表示给定的entity pair从而用于分类。在本文中,我们设计了另一种方法,它通过添加两个mark token来修改input token sequence从而以突出entity。这些额外的mark token起到了类似于relation classification模型中position embedding的作用。然后,我们也采用[CLS] token embedding来进行分类。注意,我们为head entity和tail entity分别设计了不同的token,即[HD]和[TL]。 - 对于
entity typing:该任务是relation classification的简化版。由于之前的entity typing模型充分利用了context embedding和entity embedding,我们认为:带有mark token [ENT]的被修改的输入序列可以引导ERNIE结合上下文信息和实体信息。

- 对于
14.2 实验
预训练数据集:对于从头开始训练
ERNIE的巨大成本,我们采用谷歌发布的BERT的参数来初始化Transformer block从而用于 编码token。由于预训练是一个由NSP、MLM和dEA组成的多任务程序,我们使用English Wikipedia作为预训练的语料库,并将文本与Wikidata对齐。在将语料库转换为预训练的格式化数据后,input有近45亿个subword和1.4亿个实体,并抛弃了少于3个实体的句子。采用
BERT的参数来初始化ERNIE,这并不是一个公平的比较。在对
ERNIE进行预训练之前,我们采用TransE在Wikidata上训练的knowledge embedding作为实体的input embedding。具体来说,我们从Wikidata中抽取部分样本,其中包含5,040,986个实体和24,267,796个fact三元组。entity embedding在训练期间是固定的,entity encoding module的参数都是随机初始化的。超参数配置和训练细节:我们将
token embedding和entity embedding的隐层维度分别表示为model size:114M。BERT_BASE的参数总量约为110M,这意味着ERNIE的knowledgeable module要比language module小得多,对运行时性能的影响很小。而且,我们只在有标注的语料库上对ERNIE进行了一个epoch的预训练。为了加速训练过程,我们将最大序列长度从512减少到256,因为自注意力的计算复杂度是序列长度的二次函数。为了保持一个batch中的token数量与BERT相同,我们将batch size加倍到512。除了将学习率设置为BERT中使用的预训练超参数。对于微调,大多数超参数与预训练相同,除了
batch size、学习率和训练epoch数量。我们发现以下可能的数值范围的效果较好:batch size = 32,学习率(Adam优化器)为epoch数量从3到10。我们还在
distantly supervised dataset(即FIGER)上评估ERNIE。由于深度堆叠的Transformer block的强大表达能力,我们发现小的batch size会导致模型对训练数据的过拟合。因此,我们使用较大的batch size和较少的训练epoch来避免过拟合,并保持学习率的范围不变,即批batch size = 2048、历时数为由于大多数数据集没有实体标注,我们使用
TAGME来抽取句子中提到的实体,并将它们与知识图谱中的相应实体联系起来。Entity Typing:给定实体及其上下文,entity typing要求系统为实体标注其各自的语义类型semantic type。为了评估这一任务的性能,我们在两个成熟的数据集FIGER和Open Entity上对ERNIE进行了微调。FIGER的训练集是用distant supervision进行标注的,其测试集是由人类进行标注的。Open Entity是一个完全由人工标注的数据集。这两个数据集的统计数据如下表所示。我们将我们的模型与以下entity typing的baseline模型进行比较:NFGEC、UFET。此外,我们还考虑了对BERT进行微调的结果,以便进行公平的比较。远程监督
distant supervision:对于一个给定的知识图谱中的一个三元组(由一对实体和一个关系构成),假设外部文档库中任何包含这对实体的句子,在一定程度上都反映了这种关系。因此可以利用知识图谱为外部文档库的句子标注relation。
在
FIGER上的结果如下表所示。可以看到,ERNIE在所有指标上超越了所有的baseline。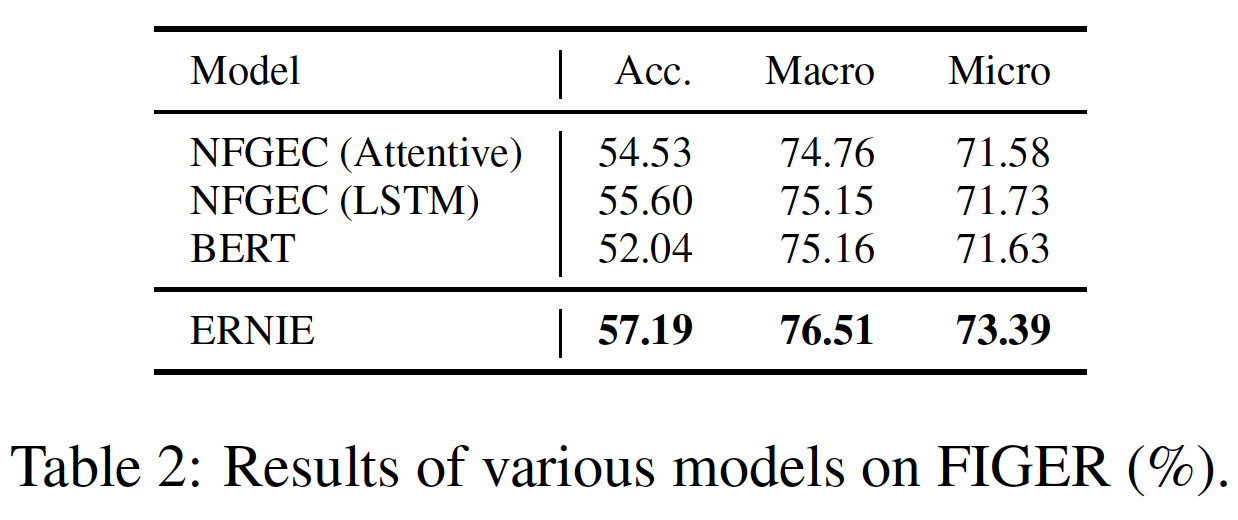
在
Open Entity上的结果如下表所示。可以看到,ERNIE在所有指标上超越了所有的baseline。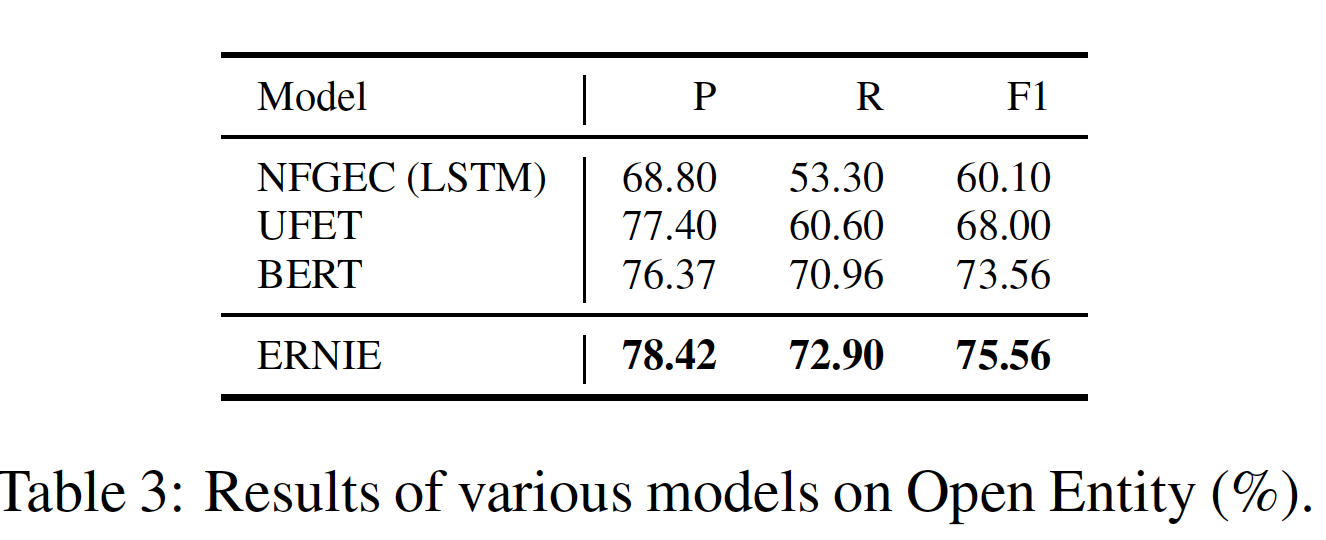
Relation Classification:关系分类旨在确定给定句子中两个实体之间的正确关系,这是一项重要的knowledge-driven的NLP任务。为了评估这项任务的性能,我们在两个成熟的数据集FewRel和TACRED上对ERNIE进行了微调。这两个数据集的统计数据见下表。由于FewRel的原始实验设置是few-shot learning,我们重新安排了FewRel数据集从而用于通用的关系分类。具体来说,我们从每个类中抽取100个实例作为训练集,并从每个类中分别抽取200个实例作为验证集和测试集。FewRel中有80个类,而TACRED中有42个类(包括一个特殊的关系"no relation")。
我们将我们的模型与下列关系分类的基线模型进行比较:
CNN、PA-LSTM、Contextualized GCN: C-GCN。此外,我们还考虑了对BERT进行微调的结果,以便进行公平的比较。FewRel和TACRED的实验结果如下表所示。可以看到,ERNIE在所有指标上超越了所有的baseline。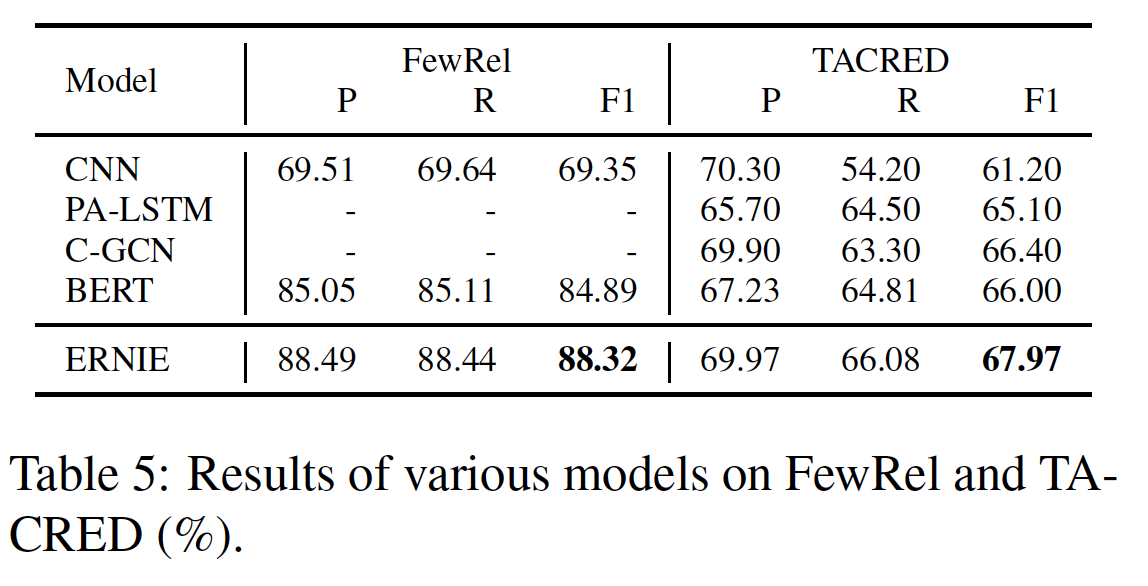
GLUE:General Language Understanding Evaluation: GLUE基准是一个多样化自然语言理解任务的集合。我们在GLUE的8个数据集上评估了ERNIE,并与BERT进行了比较。在下表中,我们报告了我们提交的评估结果和来自排行榜的
BERT的结果。我们注意到:- 在
MNLI、QQP、QNLI和SST-2等大数据集上,ERNIE与BERT_BASE一致。 - 在小数据集上,结果变得更加不稳定,即,
ERNIE在CoLA和RTE上更好,但在STS-B和MRPC上更糟。
ERNIE采用了BERT_BASE权重初始化,并且模型容量更大,结果反而效果更差?这意味着ERNIE没有什么价值,或者ERNIE没有被充分训练?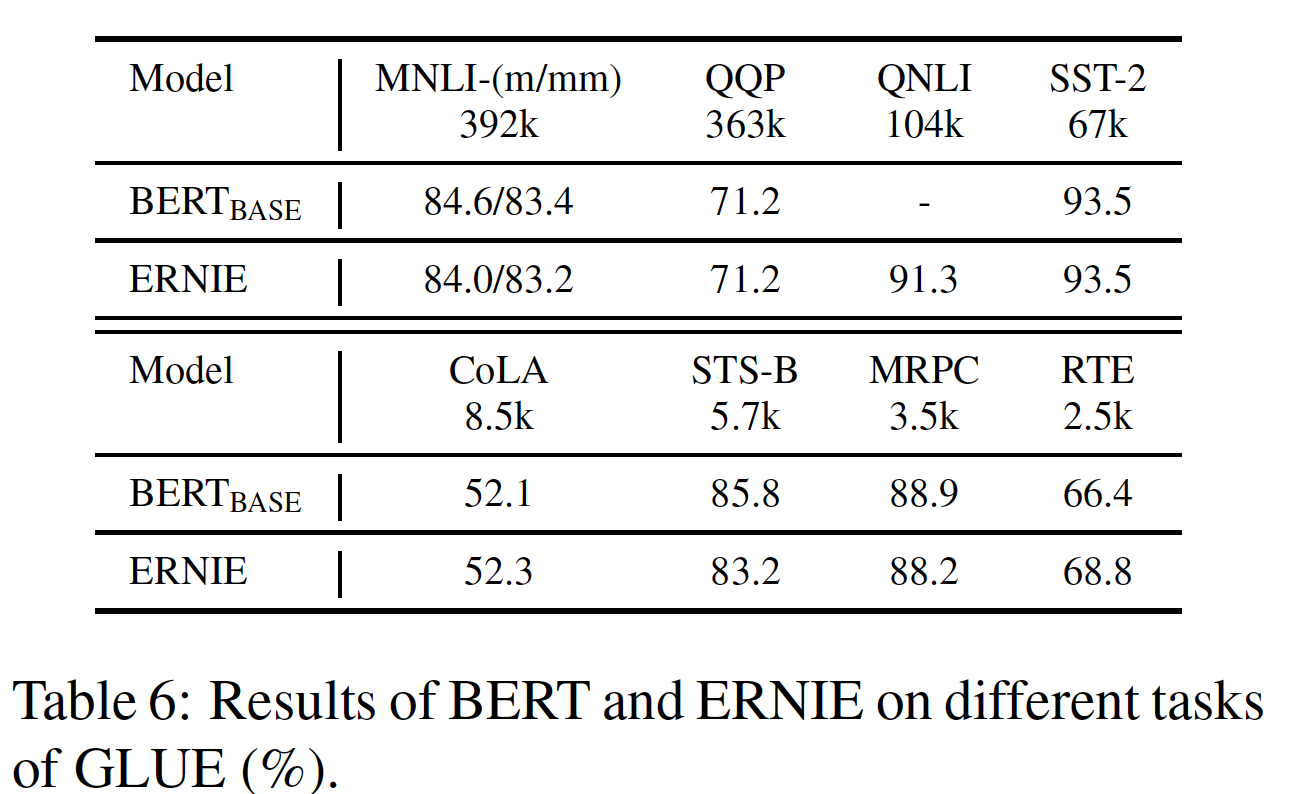
- 在
消融研究:我们利用
FewRel数据集探讨了informative entity和knowledgeable pretraining task(dEA)对ERNIE的影响。w/o entities和w/o dEA分别指在没有实体序列输入和预训练任务dEA的情况下对ERNIE进行微调。如下表所示:在没有实体序列输入的情况下,
dEA在预训练期间仍然将知识信息注入到language representation中,这使F1分相对于BERT增加了0.9%。没有实体序列输入,是怎么执行
dEA的?作者没有讲。在没有
dEA的情况下,informative entity带来了很多知识信息,从直观上有利于关系分类,这使F1分相对于BERT增加了0.7%。
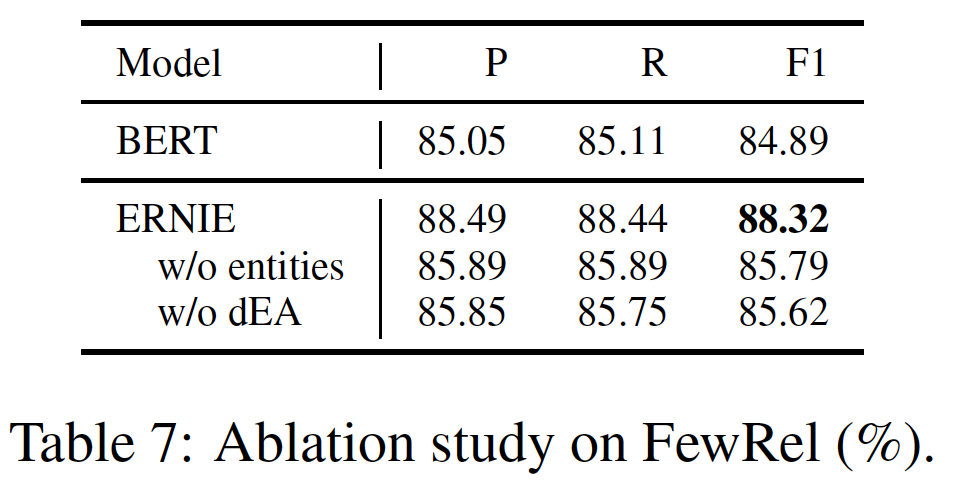
十五、MT-DNN [2019]
学习文本(如单词和句子)的
vector-space representation是许多自然语言理解natural language understanding: NLU任务的基础。两个流行的方法是多任务学习multi-task learning: MTL和语言模型预训练language model pre-training。在论文《Multi-Task Deep Neural Networks for Natural Language Understanding》中,作者通过提出一个新的Multi-Task Deep Neural Network: MT-DNN来结合这两种方法的优势。多任务学习的灵感来自于人类的学习活动,人们经常应用从以前的任务中学到的知识来帮助学习新的任务。例如,一个知道如何滑雪的人比不知道的人更容易学习滑冰。同样地,多个(相关的)任务联合起来学习是很有用的,这样在一个任务中学到的知识可以使其他任务受益。
最近,人们对将多任务学习应用于深度神经网络的
representation learning越来越感兴趣,有两个原因:- 首先,
DNN的监督学习需要大量的task-specific的标记数据,而这些数据并不总是可用的。多任务学习提供了一种有效的方式来利用来自许多相关任务的监督数据。 - 其次,多任务学习通过缓解对特定任务的过拟合从而从正则化效应中获益,从而使学到的
representation在不同的任务中通用。
- 首先,
与多任务学习不同的是,通过利用大量未标记的数据,语言模型预训练显示出针对学习通用
language representation的有效性。一些最突出的例子是ELMo、GPT、以及BERT。这些都是使用无监督目标在文本数据上训练的神经网络语言模型。例如,BERT基于多层双向Transformer,在纯文本上进行训练从而用于masked word prediction任务和next sentence prediction任务。为了将预训练的模型应用于特定的自然语言理解任务,我们通常需要针对每项任务,利用task-specific的训练数据来微调具有task-specific layer的模型。例如,BERT原始论文表明:BERT可以通过这种方式进行微调从而为一系列自然语言理解任务(如,问答、自然语言推理)创建SOTA的模型。
作者认为,多任务学习和语言模型预训练是互补的技术,可以结合起来改善
text representation的学习,以提升各种自然语言理解任务的性能。为此,作者扩展了最初在《Representation learning using multi-task deep neural networks for semantic classification and information retrieval》中提出的MT-DNN模型,将BERT作为其shared text encoding layer。如下图所示:- 较低的层(即文本编码层)在所有任务中都是共享的。
- 而顶层是
task-specific,结合了不同类型的自然语言理解任务,如单句分类、成对文本pairwise text分类、文本相似性、以及相关性排名。
这里的多任务指的是 微调期间的多任务,而不是预训练期间的多任务。
BERT在预训练期间就是多任务的。与
BERT模型类似,MT-DNN可以通过微调来适配特定的任务。与BERT不同,MT-DNN除了语言模型预训练外,还使用多任务学习来学习text representation。
MT-DNN在通用语言理解评估General Language Understanding Evaluation: GLUE基准中使用的9个自然语言理解任务中的8个获得了SOTA的结果,将GLUE benchmark得分推到82.7%,相比于BERT有2.2%的绝对改进。论文进一步将
MT-DNN的优势扩展到SNLI和SciTail任务。由MT-DNN学到的representation允许以比预训练的BERT representation少得多的域内标签in-domain label进行域适应domain adaption。例如:因为训练数据的
domain和目标任务的domain不同,因此需要执行domain adaption。MT-DNN在SNLI上实现了91.6%的准确率、在SciTail上实现了95.0%的准确率,分别比SOTA高出1.5%和6.7%。- 即使只有
0.1%或1.0%的原始训练数据,MT-DNN在SNLI和SciTail数据集上的表现也优于许多现有模型。
所有这些都清楚地表明,
MT-DNN通过多任务学习具有卓越的泛化能力。
15.1 模型
15.1 任务
MT-DNN模型结合了四种类型的自然语言理解任务:单句分类single-sentence classification、成对文本分类pairwise text classification、文本相似度评分text similarity scoring、以及相关性排名relevance ranking。单句分类:给定一个句子,模型使用预定义的类标签之一对其进行标注。例如:
CoLA的任务是预测一个英语句子在语法上是否合理。SST-2的任务是判断从电影评论中提取的句子的情感是正面positive的还是负面negative的。
文本相似度评分:这是一项回归任务。给定一对句子,模型预测一个实值分数来表示这两个句子的语义相似度
semantic similarity。STS-B是GLUE中该任务的唯一例子。成对文本分类:给定一对句子,模型根据一组预先定义的标签来确定这两个句子之间的关系。例如:
RTE和MNLI都是语言推理任务,其目标是预测一个句子相对于另一个句子是蕴含关系entailment、矛盾关系contradiction还是中性关系neutral。QQP和MRPC是由句子对组成的同义转述paraphrase数据集,其任务是预测这对句子是否在语义上等价。
相关性排名:给出一个
query和一个候选答案列表,该模型按照与query的相关性顺序对所有候选答案进行排名。QNLI是Stanford Question Answering Dataset数据集的一个版本。该任务涉及评估一个句子是否包含给定query的正确答案。虽然QNLI在GLUE中被定义为二分类任务,但在本研究中,我们将其表述为pairwise ranking task,其中预期模型将包含正确答案的候选candidate排在比不包含正确答案的候选更高的位置。我们将表明,这种形式化导致了比二分类更高的准确性。
15.2 MT-DNN Model
MT-DNN模型的架构如下图所示。低层是所有任务共享的,而顶层代表task-specific的输出。- 输入
sentence pair),首先在embedding vector的一个序列,每个单词都有一个embedding。 - 然后,
transformer encoder通过自注意力捕获每个单词的上下文信息,并在contextual embedding的一个序列。这就是我们的多任务目标所训练的shared semantic representation。
在下面的内容中,我们将详细阐述该模型。
- 输入
Lexicon Encoder(token序列。遵从BERT的做法,第一个token[CLS] token。如果token,即[SEP],来分隔这两个句子。lexicon encoder将input embedding vectors的一个序列,每个token对应一个embedding向量(由相应的word embedding、segment embedding和positional embedding相加而成)。Transformer Encoder(Transformer encoder将input representation vectorcontextual embedding vector的一个序列shared representation。与通过预训练学习
representation的BERT模型不同,MT-DNN除了预训练之外还使用多任务目标学习representation。下面,我们将以
GLUE中的自然语言理解任务为例来描述具体的task specific layer,尽管在实践中我们可以加入任意的自然语言任务(如文本生成,其中output layer被实现为神经解码器)。单句分类输出
Single-Sentence Classification Output:假设token [CLS]的contextual embedding(semantic representation。 以SST-2任务为例,softmax的逻辑回归来预测的:其中:
task-specific参数矩阵。文本相似性输出
Text Similarity Output:以STS-B任务为例。假设[CLS]的contextual embedding(semantic representation。我们引入一个task-specific的参数向量其中
成对文本分类输出
Pairwise Text Classification Output:以自然语言推理natural language inference: NLI为例。这里定义的NLI任务涉及一个由premisehypothesisNLI任务旨在找到stochastic answer network: SAN(一个SOTA的neural NLI模型)的答案模块answer module。SAN的答案模块使用多步骤推理multi-step reasoning。它不是直接预测给定输入的蕴含entailment,而是保持一个state并迭代地refine它的预测。直接用句子对
semantic representation馈入softmax layer进行分类,简单又直接,不是挺好的吗?SAN的答案模块工作如下:首先,我们通过拼接
premisecontextual embedding(这是transformer encoder的输出)来构建premise的working memory,记做hypothesisworking memory,记做然后,我们对
memory进行K-step reasoning从而输出关系标签,其中开始时,初始状态
summary:其中:
hypothesis中的单词contextual embedding;在
time stepstate定义为:其中,
memory其中:
premise中的单词contextual embedding;
最终,一个单层分类器被用来在每个
steprelation:其中:
最后,我们通过均值池化来利用所有的
其中
在训练期间,我们在上述均值池化之前应用
stochastic prediction dropout。相关性排名输出
Relevance Ranking Output:以QNLI为例。假设[CLS]的contextual embedding(question及其候选答案semantic representation。我们计算相关性分数为:其中:
sigmoid)。对于一个给定的
question,我们根据计算的相关性分数对其所有的候选答案进行排序。
15.3 训练过程
MT-DNN的训练程序包括两个阶段:预训练阶段、多任务学习阶段。预训练阶段:遵循
BERT模型的预训练。lexicon encoder和Transformer encoder的参数是通过两个无监督的预测任务来学习的:masked language modeling和next sentence prediction。根据
RoBERTa的实验结论,应该去掉next sentence prediction任务。多任务学习阶段:在多任务学习阶段,我们使用
mini batch-based的随机梯度下降SGD来学习模型的参数(即所有shared layer和task-specific layer的参数)。在每个epoch中,选择一个mini-batch9个GLUE任务中),并根据任务sum。即,一个
mini-batch仅包含特定任务mini-batch。另外,这里并没有先训练完一个任务、然后再训练其他任务,而是不同任务之间交错地训练。
分类任务:即单句分类或成对文本分类,我们使用交叉熵损失作为目标。
其中:
ground-truth标签为1,否则返回0。
文本相似性任务:如
STS-B,其中每个sentence pair都被标注以一个实值分数其中
相关性排名任务:其目标遵循
pairwise learning-to-rank范式。以QNLI为例。给定一个queryquery的正样本的负对数似然:其中:
queryanswerheld-out data上调优。在我们的实验中,我们设置
MT-DNN模型的训练算法:输入:
- 模型参数
- 预训练的数据集和任务。
- 最大的训练
epoch数量 - 学习率
- 模型参数
输出:训练好参数
算法步骤:
随机初始化模型的参数
根据预训练的数据集和任务,预训练
shared layer(即,lexicon encoder和transformer encoder)。构建
dataset-level的mini-batch:迭代:
epoch从1到合并所有的数据集:
随机混洗
遍历
mini-batchmini-batch)计算损失函数
- 如果
- 如果
- 如果
- 如果
计算梯度
更新参数:
15.4 实验
数据集:我们使用了
GLUE、SNLI、以及SciTail数据集,如下表所述。General Language Understanding Evaluation: GLUE:GLUE benchmark是一个由9个自然语言理解任务组成的集合,如下表所示,包括问答、情感分析、文本相似性、以及文本相关性。它被认为是为评估自然语言理解模型的泛化性和鲁棒性而精心设计的。Stanford Natural Language Inference: SNLI:SNLI数据集包含57万个人工标注的句子对,其中的前提premises来自Flickr30语料库的标题,假设hypotheses则是人工标注的。这是最广泛使用的蕴含数据集entailment dataset从而用于自然语言推断NLI。在本研究中,该数据集仅用于domain adaptation。SciTail:SciTail是一个源自科学问答science question answering: SciQ数据集的文本蕴含数据集textual entailment dataset。该任务涉及评估一个给定的前提premise是否蕴含一个给定的假设hypothesis。与前面提到的其他蕴含数据集不同,
SciTail中的假设是从科学问题创建的,而相应的答案候选和前提来自于从大型语料库中检索的相关的web sentence。因此,这些句子在语言上具有挑战性,而且前提和假设的词汇相似度lexical similarity往往很高,从而使SciTail特别困难。在本研究中,该数据集仅用于domain adaptation。
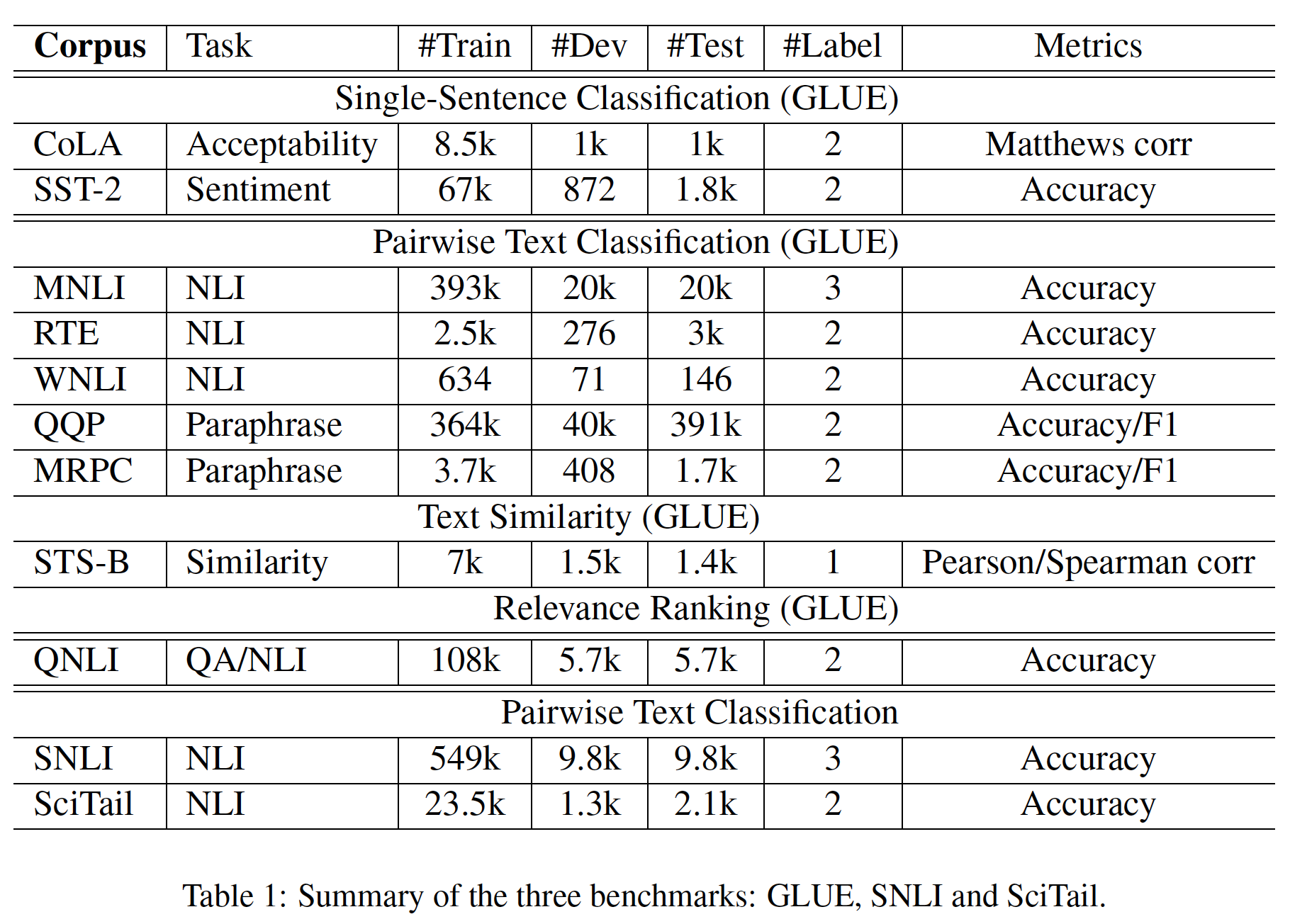
实现细节:我们对
MT-DNN的实现是基于BERT的PyTorch实现。- 遵循
BERT,我们使用Adamax优化器,学习率为5e-5,batch size为32。除非另有说明,我们使用了一个线性学习率衰减的调度,并且在10%的训练步上执行预热。 - 我们还将所有
task-specific层的dropout rate设置为0.1,除了MNLI设置为0.3和CoLa设置为0.05。 - 最大的训练
epoch数量被设置为5。 - 为了避免梯度爆炸的问题,我们将梯度规范剪裁在
1以内。 - 所有的文本都使用
wordpiece进行tokenize,并拆分为不超过512个token。
这里是预训练细节还是多任务学习的细节?从作者这里的描述来看,作者应该是用到了预训练好的
BERT,然后再继续多任务学习,从而省略了预训练阶段。因此,将
MT-DNN与BERT直接进行比较是不公平的,因为MT-DNN使用了更多的数据、训练了更多的轮次。因此作者引入了ST-DNN从而与MT-DNN进行更公平的对比。- 遵循
GLUE结果:我们将MT-DNN及其变体,与GLUE排行榜的SOTA模型的列表进行比较。结果如下表所示。BERT_LARGE:这是large BERT模型,我们将其作为baseline。我们为每个GLUE任务在task-specific数据上微调了模型。为了公平地比较,
BERT_LARGE也应该在多任务数据集上进行预训练相同的epoch数。事实上,
ST-DNN才是和MT-DNN公平的比较,二者都采用预训练好的BERT_LARGE,也都在多任务数据集上进行预训练。MT-DNN:这是我们提出的模型。我们使用预训练好的BERT_LARGE来初始化它的shared layer,通过多任务学习在所有的GLUE任务上refine模型,并使用task-specific数据为每个GLUE任务微调模型。Table 2中的测试结果显示,MT-DNN在所有任务上都优于现有的系统,除了WNLI,在八个GLUE任务上创造了新的SOTA结果,并将benchmark推高到82.7%,这比BERT_LARGE有2.2%的绝对改进。由于MT-DNN使用BERT_LARGE来初始化它的shared layer,因此收益主要归功于使用多任务学习来refine shared layer。收益不仅仅归功于多任务学习来
refine shared layer,还归功于多任务学习来refine task-specific layer。多任务学习对于域内
in-domain训练数据少的任务特别有用。正如我们在表中所观察到的,在同一类型的任务上,对于域内训练数据较少的任务,相比那些有较多域内数据的任务,对BERT的改进要大得多,即使它们属于同一任务类型,例如,两个NLI任务(RTE vs. MNLI),以及两个转述任务(MRPC vs. QQP)。MT-DNN_no-fine-tune:由于MT-DNN的多任务学习使用了所有的GLUE任务,因此可以直接将MT-DNN应用于每个GLUE任务,而不需要进行微调。MT-DNN经过三个阶段的训练:预训练、多任务训练、task-specific任务的微调。其中,前两个阶段是所有任务都共享的,得到一个所有任务都通用的模型。最后一个阶段是每个任务独自微调的,得到task-specific的模型(有多少个任务就得到多少个模型)。MT-DNN_no-fine-tune是两个阶段的训练:预训练、多任务训练。最后得到一个所有任务都通用的模型。ST-DNN也是两个阶段的训练:预训练、task-specific任务的微调。最后得到task-specific的模型(有多少个任务就得到多少个模型)。Table 2中的结果显示,除了CoLA,MT-DNN_no-fine-tune在所有任务中仍然一致地优于BERT_LARGE。我们的分析表明,CoLA是一个挑战性的任务,它的域内数据比其他任务小得多,而且它的任务定义和数据集在所有GLUE任务中是独一无二的,这使得它很难从其他任务中获得知识。因此,多任务学习倾向于不适合CoLA数据集。在这种情况下,有必要进行微调以提高性能。如下表所示,经过微调后,准确率从
58.9%提高到62.5%,尽管只有非常少量的域内数据可用于adaptation。这个事实,再加上微调后的MT-DNN在CoLA上的表现显著优于微调后的BERT_LARGE(62.5% vs. 60.5%),显示出学到的MT-DNN representation比预训练的BERT representation得到更有效的domain adaptation。我们将在接下来通过更多的实验重新审视这个话题。ST-DNN:MT-DNN的收益也归功于其灵活的建模框架,它允许我们纳入task-specific的模型结构和训练方法。这些模型结构和训练方法都是在单任务setting中开发的,有效地利用了现有的研究成果。两个这样的例子是:将SAN answer module用于pairwise text classification output module、以及将pairwise ranking loss用于QNLI任务(该任务在GLUE中的设计是一个二分类问题)。为了研究这些建模设计选择的相对贡献,我们实现了MT-DNN的一个变体,即Single-Task DNN: ST-DNN。ST-DNN使用与MT-DNN相同的模型结构。但它的shared layer是预训练好的BERT模型,没有通过多任务学习进行refine。然后,我们使用task-specific数据为每个GLUE任务微调ST-DNN。因此,对于pairwise text classification任务,其ST-DNN和BERT模型之间的唯一区别是task-specific output module的设计。Table 3中的结果显示:在所有四个任务(MNLI、QQP、RTE和MRPC)中,ST-DNN都优于BERT,证明了SAN answer module的有效性。这四个任务上,
ST-DNN相对于BERT的提升都很小。这是因为多任务数据集的数据规模相比BERT预训练数据集的数据规模小得多。我们还比较了
ST-DNN和BERT在QNLI上的结果。ST-DNN使用pairwise ranking loss进行微调,而BERT将QNLI视为二分类,并使用交叉熵损失进行微调。ST-DNN明显优于BERT,清楚地表明了问题形式problem formulation的重要性。ST-DNN优于BERT,除了task-specific模块、问题形式的优势之外,还有更多的预训练数据(来自于多任务数据集)、更多的训练步数(来自于多任务 数据集上的预训练)。
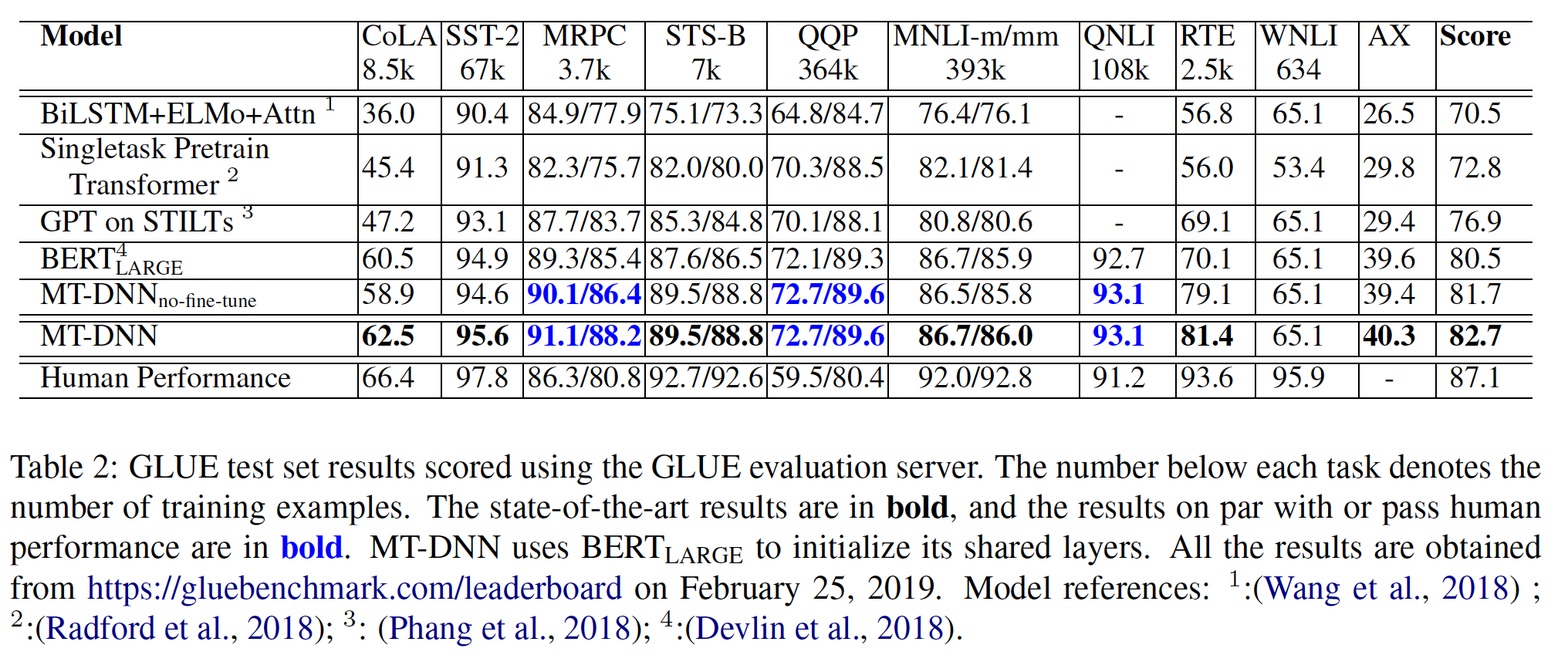
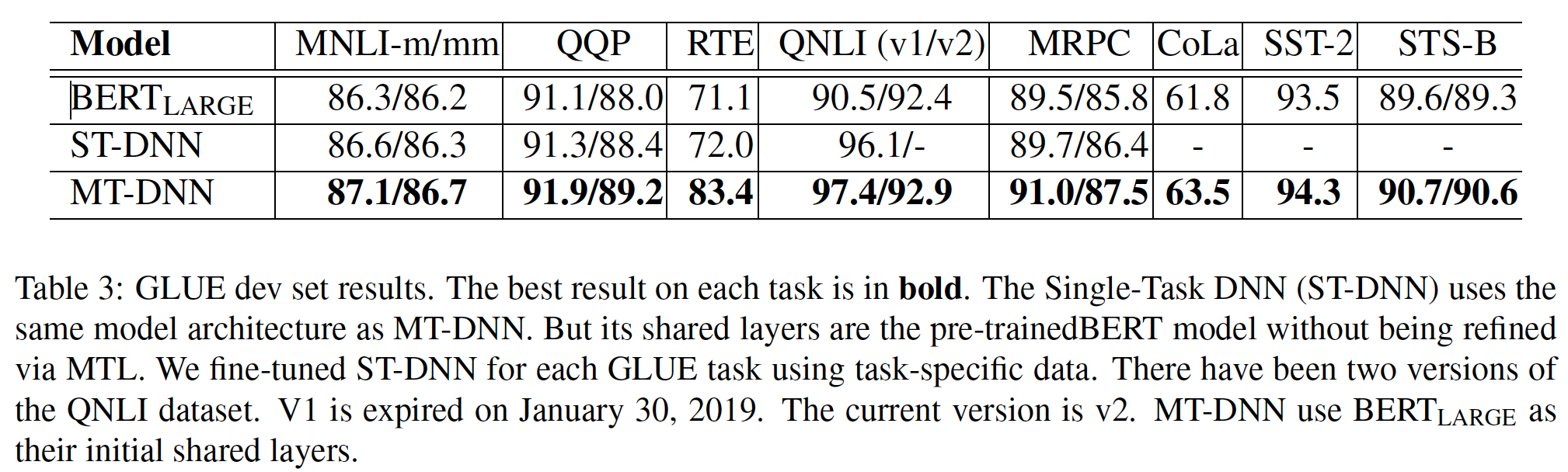
SNLI和SciTail的domain adaption结果:构建实际系统practical system的最重要标准之一是快速适应新的任务和领域。这是因为为新的领域或任务收集带标签的训练数据是非常昂贵的。很多时候,我们只有非常小的训练数据,甚至没有训练数据。为了使用上述标准评估模型,我们在两个自然语言推断任务(即
SNLI和SciTail)上进行了domain adaptation实验,使用如下过程:- 使用
MT-DNN模型或BERT作为初始模型,包括BASE和LARGE的model setting。 - 为每个新任务(
SNLI或SciTail)创建一个task-specific的模型,通过使用task-specific的训练数据来适配训练好的MT-DNN。 - 使用
task-specific的测试数据评估模型。
我们以这些任务的默认
train/dev/test set开始。但我们随机抽取训练数据的0.1%、1%、10%和100%。因此,我们为SciTail获取了四组训练数据,分别包含23、235、2.3k、23.5k的训练样本。同样地,我们为SNLI获取了四组训练数据,分别包含549、5.5k、54.9k、549.3k的训练样本。我们进行了五次随机采样,并报告了所有运行中的平均值。 来自
SNLI和SciTail的不同训练数据量的结果在下图中报告。可以看到:MT-DNN的性能一直优于BERT baseline,更多细节见Table 4。使用的训练样本越少,
MT-DNN比BERT的改进就越大。例如在SNLI数据集上:- 仅用
0.1%(23个样本)的训练数据,MT-DNN就达到了82.1%的准确率,而BERT的准确率是52.5%。 - 用
1%的训练数据,MT-DNN的准确率是85.2%,BERT是78.1%。
我们在
SciTail上观察到类似的结果。- 仅用
结果表明,由
MT-DNN学到的representation在domain adaptation方面比BERT更有效。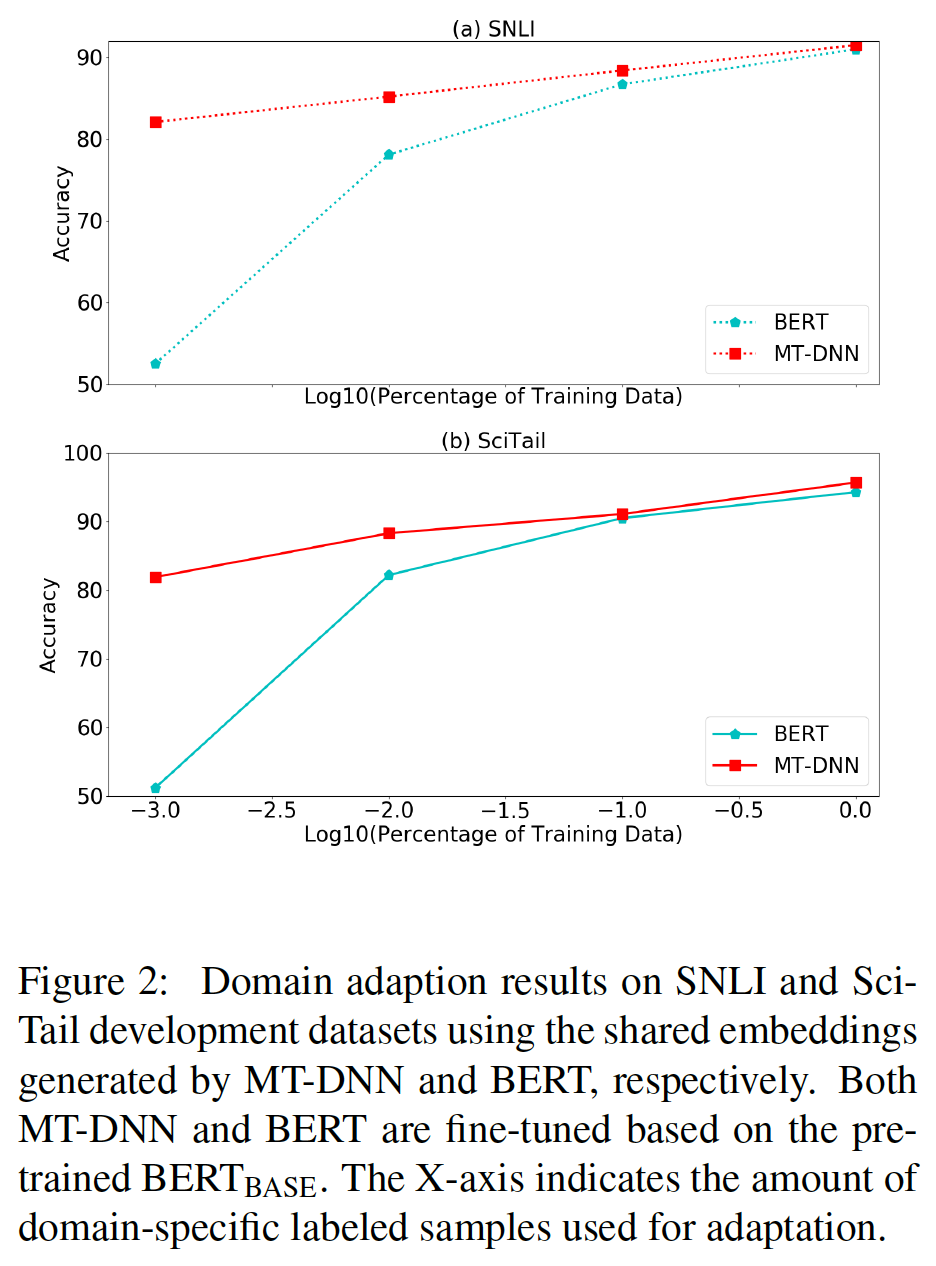
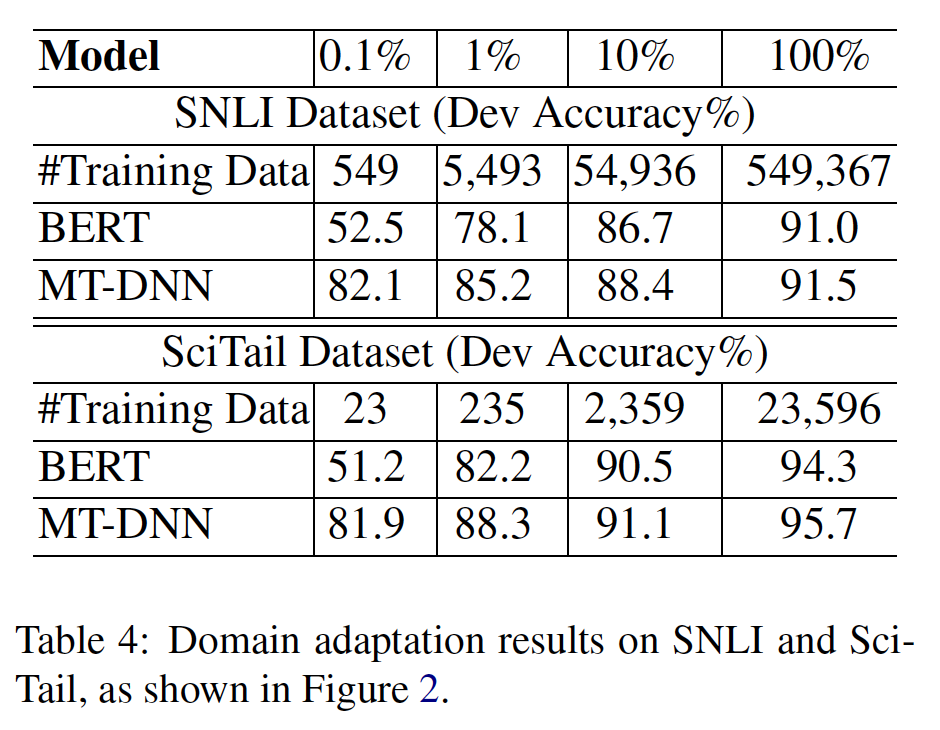
在下表中,我们使用所有的
in-domain训练样本,将我们的adapted model与几个强大的baseline(包括排行榜中报告的最佳结果)进行比较。可以看到:MT-DNN_LARGE在两个数据集上都产生了新的SOTA结果,在SNLI上将baseline推高到91.6%(绝对改进1.5%)、在SciTail上将baseline推高到95.0%(绝对改进6.7%)。这同时为SNLI和SciTail带来了新的SOTA。所有这些都证明了MT-DNN在domain adaptation上的卓越表现。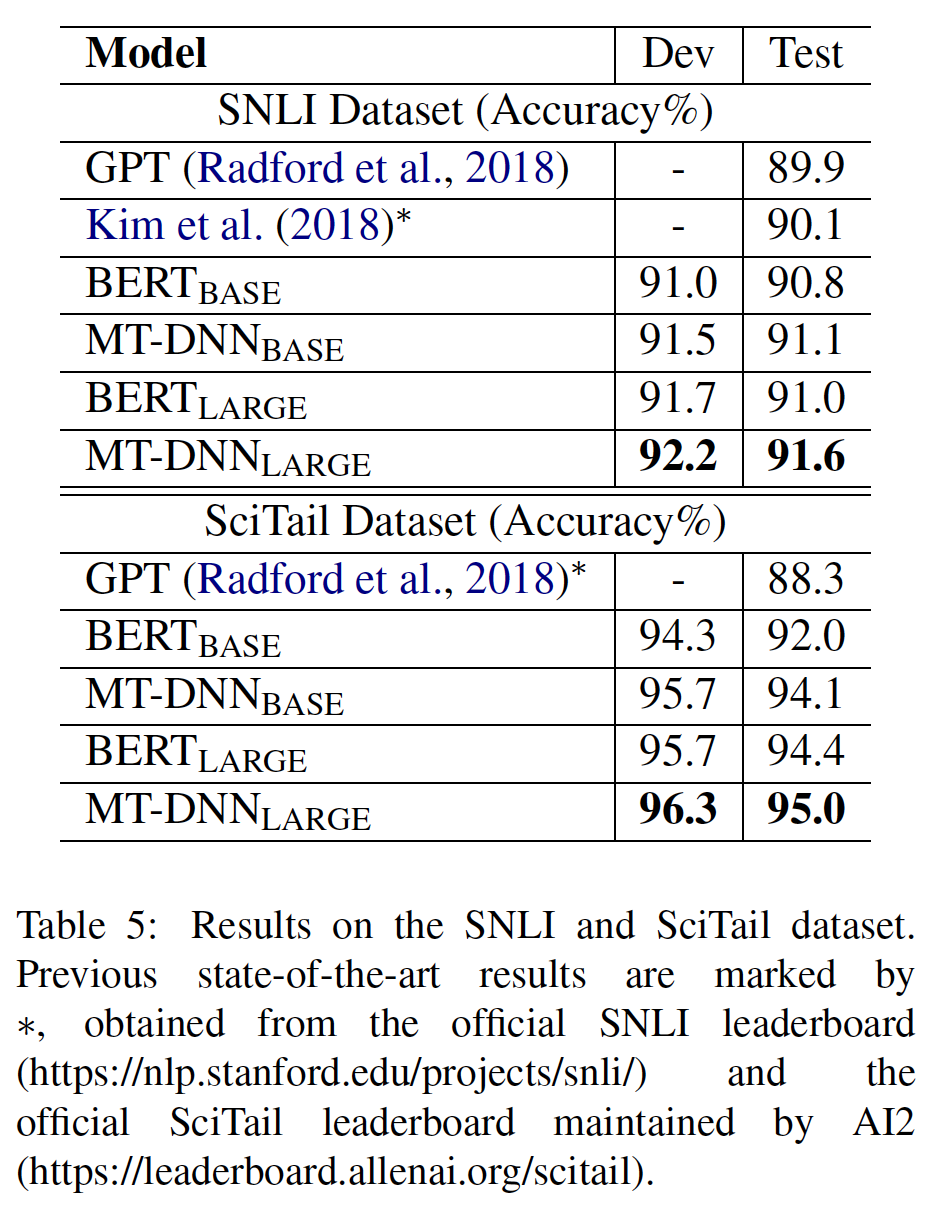
- 使用
十六、BART [2019]
自监督方法在广泛的
NLP任务中取得了显著的成功。最成功的方法是masked language model的变体,它是降噪自编码器denoising autoencoder,被训练从而重建文本,其中掩码了一组随机的单词。最近的工作显示,通过改善masked token的分布(SpanBERT)、masked token的预测顺序(XLNet)、以及替换masked token的可用上下文(UNILM)而获得收益。然而,这些方法通常专注于特定类型的下游任务(如span prediction任务、生成任务等),限制了其适用性。在论文
《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》中,作者提出了Bidirectional and Auto-Regressive Transformer: BART,它预训练了一个结合了双向的和自回归的Transformer的模型。BART是一个用sequence-to-sequence模型构建的降噪自编码器,适用于非常广泛的下游任务。预训练有两个阶段:- 以任意的噪音函数破坏文本。
- 学习一个
sequence-to-sequence的模型来重建原始文本。
BART使用一个标准的基于Tranformer的神经机器翻译架构,尽管它很简单,但可以看作是对BERT(具有双向编码器)、GPT(具有有从左到右的解码器)、以及许多其他最近的预训练方案的推广(如下图所示)。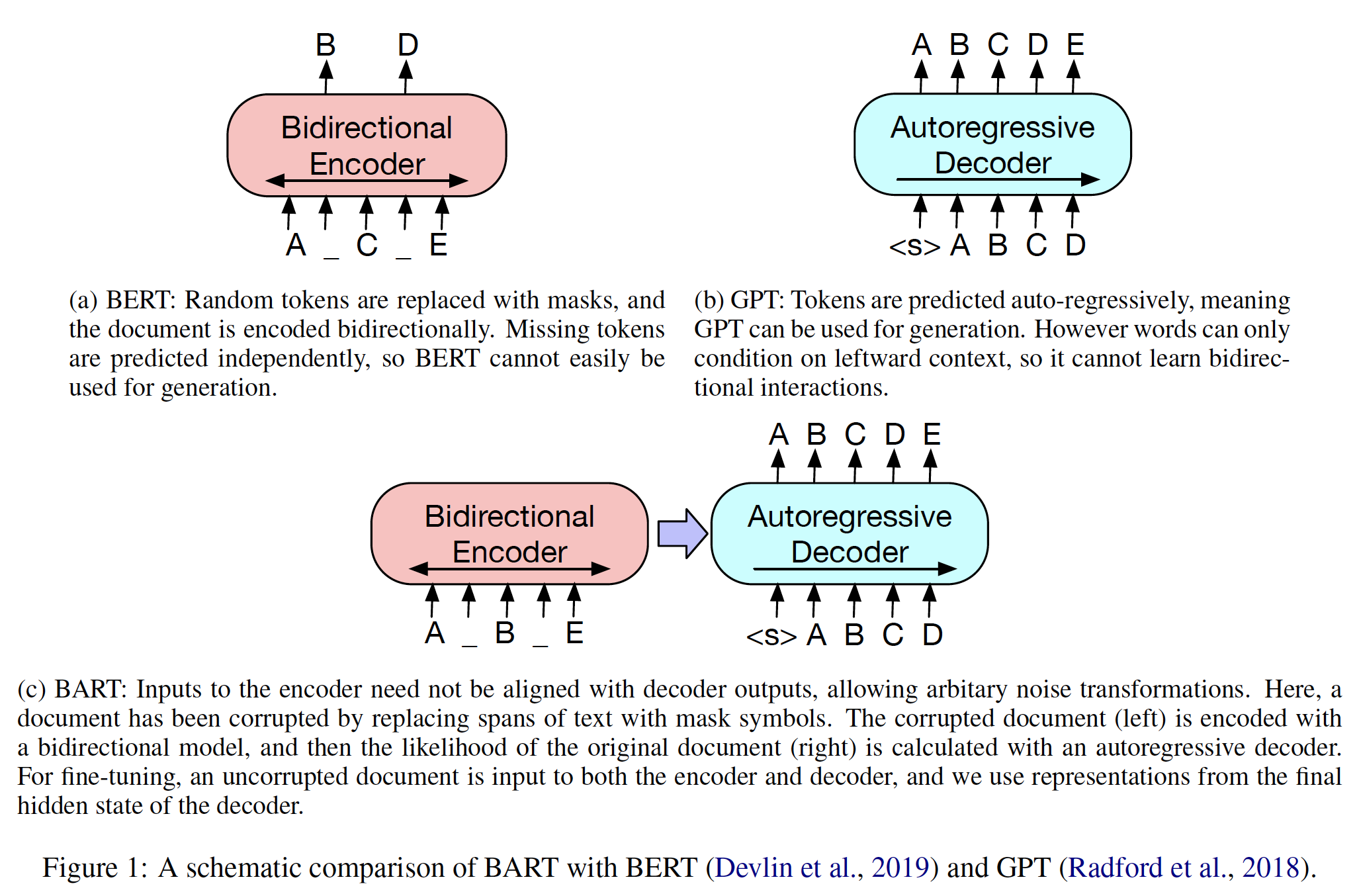
这种设置的一个关键优势是噪音的灵活性:可以对原始文本进行任意的变换,包括改变其长度。论文评估了一些噪音方法,发现性能最佳的方法是:同时进行随机混洗原始句子的顺序、以及使用一种新颖的
in-filling方案(任意长度的文本区间text span,包括零长度,被替换为单个mask token)。这种方法通过迫使模型对整体句子的长度进行更多的推理,以及对输入进行更长范围的变换,从而推广了BERT中的原始word masking和next sentence prediction的目标。当对文本生成任务进行微调时,
BART特别有效,但对文本理解任务也很有效。BART在GLUE和SQuAD上以comparable的训练资源获得与RoBERTa相匹配的性能,并在一系列抽象式对话abstractive dialogue、问答、和摘要summarization任务上取得了新的SOTA的结果。例如,BAER比以前关于XSum的工作提高了6 ROUGE的性能。abstractive dialogue是非抽取式的。抽取式对话是从给定的段落中抽取答案,而抽象式对话需要生成答案。BART还开辟了微调的新思维方式。论文提出了一个新的机器翻译方案,其中BART模型被堆叠在几个额外的transformer layer之上。这些额外的transformer layer被训练成将外语翻译成有噪音的英语,通过BART的传播,从而将BART作为预训练的target-side language model。在WMT Romanian-English benchmark中,这种方法比强大的机器翻译baseline的性能提高了1.1 BLEU。为了更好地理解这些效果,论文还报告了复现最近提出的其他训练目标的消融研究。这项研究使我们能够仔细控制一些因素,包括数据和优化超参数,这些因素已被证明和训练目标的选择一样对整体性能同样地重要。论文发现,在所考虑的所有任务中,
BART表现出一致的最强大性能。相关工作:
早期的预训练方法是基于语言模型的。
GPT只建模左侧的上下文,这对某些任务来说是有问题的。ELMo拼接了纯左侧和纯右侧的representation,但没有预训练这些特征之间的交互。GPT-2证明,非常大的语言模型可以作为无监督的多任务模型。
BERT引入了masked language modelling,允许预训练学习左右两侧上下文单词之间的交互。最近的工作表明,通过更长的训练时间(Roberta)、通过跨层绑定参数(Albert)、以及通过masking span而不是单词(Spanbert),可以实现非常强大的性能。然而,预测不是自回归地进行的,这降低了BERT对生成任务的有效性。UniLM用an ensemble of masks对BERT进行了微调,其中某些mask只允许左侧的上下文。与BART一样,这使得UniLM可以同时用于生成式的和判别式的任务。一个区别是:UniLM的预测是条件独立的,而BART的预测是自回归的。BART减少了预训练和生成任务之间的不匹配,因为解码器总是在未被破坏的上下文中被训练。MASS可能是与BART最相似的模型。掩码了一个连续区间token的input sequence被映射到由这些缺失的token组成的序列上。MASS对判别式任务不太有效,因为不相交的token集合被馈入编码器和解码器。XL-Net通过以permuted order来自回归地预测被masked token从而扩展了BERT。这一目标允许预测同时以左侧上下文和右侧上下文为条件。相比之下,BART decoder在预训练期间从左到右地工作,在generation期间与setting相匹配。
有几篇论文探讨了使用预训练的
representation来改进机器翻译。最大的改进来自于同时对源语言和目标语言的预训练,但这需要对所有感兴趣的语言进行预训练。其他工作表明,使用预训练的representation可以改善编码器(《Pre-trained language model representations for language generation》),但解码器的收益更为有限。我们展示了如何使用BART来改善机器翻译解码器。
16.1 模型
BART是一个降噪自编码器denoising autoencoder: DAE,它将被破坏的文档映射到其原始文档。BART被实现为一个sequence-to-sequence的模型,包含一个双向编码器(作用于被破坏的文本上)、以及一个从左到右的自回归解码器。对于预训练,我们优化原始文档的负对数似然。这意味着仅在自回归解码器上计算生成原始文本的损失函数,而编码器用于编码各种被破坏的文本,因此统一了各种预训练任务(如
masked languate modeling、next stentence prediction)。架构:
BART使用《Attention is all you need》中的sequence-to-sequence的Transformer架构,除了以下不同:遵从GPT,我们将ReLU激活函数修改为GeLU,并从对于我们的
base model,我们在编码器和解码器中各使用6层;对于我们的large model模型,我们在编码器和解码器中各使用12层。BART架构与BERT架构密切相关,但有以下区别:- 解码器的每一层都额外地对编码器的
final hidden laye进行交叉注意cross-attention(就像在sequence-to-sequence的transformer模型中那样)。 BERT在word-prediction之前使用了一个额外的前馈网络,而BART没有这样做。
总体而言,
BART比同等规模的BERT模型多了大约10%的参数。- 解码器的每一层都额外地对编码器的
预训练
BART:BART是通过破坏文档,然后优化重建损失(解码器的输出和原始文档之间的交叉熵)来训练的。与现有的降噪自编码器不同,BART允许我们应用任何类型的文档损坏document corruption。在极端的情况下,关于原始文档的所有信息都丢失了,BART就相当于一个语言模型。我们用几个先前提出的、新颖的变换
transformation来进行实验,但我们相信其它的一些新的替代方案有很大的潜力。我们使用的变换总结如下,一些例子如下图所示。Token掩码Token Masking:遵从BERT,随机采样的token被替代为[MASK]。Token删除Token Deletion:随机采样的token被直接删除。与Token Masking相反,模型必须决定哪些位置是缺失的(Token Masking通过[MASK]知道哪些位置是缺失的)。下图中的
Token Deletion有误,应该是AC.E.,因为原始的文本只有两个.。文本填充
Text Infilling:随机采样一些text span,其中span长度服从泊松分布span都被替换为一个[MASK]。如果span长度为0,那么对应于插入[MASK]。Text Infilling受到SpanBERT的启发,但是SpanBERT从一个不同的分布(截断的几何分布clamped geometric)中采样span长度,并且用一个长度完全相同的[MASK]序列来替换每个span。Text Infilling使模型能够预测一个span中缺失多少个token。泊松分布的
span长度的期望为3。假设平均的输入序列长度为句子排列
Sentence Permutation:一个文档根据句号被分成几个句子,这些句子以随机的顺序被混洗。文档旋转
Document Rotation:均匀随机地选择一个token,然后旋转文档,使其以该token开始。这项任务训练模型来识别文档的开始。
这些
transformation的价值在不同的下游任务中差异很大。
微调
BART:BART产生的representation可以通过多种方式用于下游应用。序列分类任务
Sequence Classification Tasks:对于序列分类任务,相同的输入被馈入编码器和解码器,final decoder token的final hidden state被馈入新的线性分类器。编码器输入:被整体分类的文本序列;解码器输入:被整体分类的文本序列。
这种方法与
BERT中的[CLS] token有关。但是,我们将additional token添加到最后,这样解码器中的additional token的representation就可以从完整的输入中attend解码器状态(如下图(a)所示)。BART中没有[CLS] token,而是把解码器整个序列的representation视为additional token(下图中没有画出来)的representation。因为解码器是从左右到的,因此
[CLS] token不能位于左侧第一个位置,因为这个位置无法看到任何上下文。Token分类任务Token Classification Tasks:对于token分类任务,如SQuAD的answer endpoint分类 ,我们将完整的文档馈入编码器和解码器,并使用解码器的top hidden state作为每个单词的representation。这个representation被用来对token进行分类。编码器输入:被
token分类的文本序列;解码器输入:被token分类的文本序列。序列生成任务
Sequence Generation Tasks: 因为BART有一个自回归解码器,它可以直接为序列生成任务进行微调,如抽象式问答abstractive question answering任务、摘要任务。在这两项任务中,信息都是从输入中复制出来的,这与降噪预训练的目标密切相关。在这里,编码器的输入是输入序列,而解码器则自动生成输出。编码器输入:上下文序列;解码器输入:目标序列。
机器翻译
Machine Translation: 我们还探索使用BART从而为英语翻译来改进机器翻译解码器。之前的工作《Pre-trained language model representations for language generation》表明,通过融合预训练的编码器可以改善模型,但在解码器中使用预训练的语言模型的收益有限。我们表明:可以将整个BART模型(包括编码器和解码器)作为机器翻译的单个预训练解码器,方法是增加一组新的编码器参数,这些参数是从bi-text中学到的(如下图(b)所示)。bi-text指的是同时包含源语言文本和对应的翻译语言文本的text pair。更准确而言,我们用一个新的随机初始化的编码器取代
BART的encoder embedding layer。该模型是端到端来训练的,它训练新的编码器将外语单词映射成BART可以降噪成英语单词的input。新的编码器可以使用与原始BART模型不同的词表。我们分两步训练新的编码器,在这两种情况下,都是从
BART模型的输出中反向传播交叉熵损失:在第一步中,我们冻结了大部分
BART参数,只更新随机初始化的新编码器、BART positional embedding、以及BART编码器第一层的self-attention input projection matrix。给定
query矩阵key矩阵value矩阵self-attention的输入,self-attention为:其中:
self-attention的输入投影矩阵。 通过针对不同的任务来适配这三个输入投影矩阵,模型就可以很好地迁移到不同的任务。因为冻结后面的层,只需要调整第一层,就可以使得第一层的输出能够适配后面层的需求。在第二步中,我们以少量的迭代来训练所有模型参数。
16.2 预训练目标的比较
与以前的工作相比,
BART在预训练期间支持更广泛的噪声方案。我们使用base-size的模型(6个编码器层和6个解码器层,隐层维度为768)对一系列方案进行了比较,在一个有代表性的任务子集上进行了评估。预训练目标之间的比较:虽然人们已经提出了许多预训练目标,但这些目标之间的公平比较一直难以进行,至少部分原因是训练数据、训练资源、模型之间的结构差异、以及微调程序的不同。我们重新实现了最近提出的强大的预训练方法。我们的目标是尽可能地控制与预训练目标无关的差异。然而,我们确实对学习率和
layer normalisation的使用做了微小的改变,以提高性能(为每个预训练目标分别调优这些)。作为参考,我们将我们的实现与BERT公布的数字进行了比较。BERT也是在Books和Wikipedia数据的组合上训练了100万步。我们比较了以下预训练目标:Language Model:与GPT类似,我们训练一个left-to-right的Transformer语言模型。这个模型等同于BART解码器,没有与编码器的cross-attention。Permuted Language Model:基于XLNet,我们采样了1/6的token,并以随机顺序自回归地生成它们。为了与其他模型保持一致,我们没有实现XLNet的relative positional embedding或跨segment的注意力。Masked Language Model:遵从BERT,我们随机选择15%的token并用[MASK]符号来替代,并训练模型独立地预测被掩码的原始token。Multitask Masked Language Model:与UniLM一样,我们用额外的自注意力掩码来训练Masked Language Model。自注意力掩码是按以下比例随机选择的:1/6从左到右、1/6从右到左、1/3无掩码、1/3采用前50%的token无掩码而剩下的50%是从左到右的掩码。Masked Seq-to-Seq:受MASS的启发,我们掩码了一个span,其中这个span包含了50%的token,并训练一个sequence-to-sequence模型来预测被掩码的token。
对于
Permuted LM、Masked LM、以及Multitask Masked LM,我们使用双流注意力two-stream attention(参考Xlnet的原始论文)来有效地计算序列的输出部分的似然likelihood。我们进行了两种实验:
将任务视为标准的
sequence-to-sequence问题,其中source sequence馈入编码器,而target sequence是解码器的输出。在解码器中把
source sequence作为前缀加入target sequence作为一个整体序列,仅在这个整体序列的target sequence部分上计算损失。即,把
source sequence视为上下文,而target sequence视为预测目标。
我们发现前者对
BART模型的效果更好,而后者对其他模型的效果更好。论文没有数据来支撑这个结论,所以感觉很突兀。
为了最直接地比较我们的模型对微调目标的建模能力,对于生成任务,我们在
Table 1中报告了困惑度(而不是ROUGE指标)。任务:
SQuAD:是一项关于百科全书段落的抽取式问答任务extractive question answering task。答案是从一个给定的文档上下文中抽取的text span。与BERT类似,我们使用拼接的问题和上下文作为BART编码器的输入;此外,我们也把拼接的问题和上下文传递给解码器,并在解码器上为每个token预测:该token作为答案开始的概率、作为答案结束的概率。MNLI:一个bi-text的分类任务,预测一个句子是否包含另一个句子。微调后的模型将两个句子与附加的EOS token拼接起来,并将它们同时传递给BART编码器和解码器。与BERT不同的是,解码器上EOS token的representation被用来对句子关系进行分类。ELI5:一个格式很长的抽象式问答数据集abstractive question answering dataset。模型拼接问题和支持性文档supporting document,然后以拼接后的字符串为条件来生成答案。XSum:一个新闻摘要数据集。ConvAI2:一个对话响应生成任务dialogue response generation task,以上下文和人物为条件。CNN/DM:一个新闻摘要数据集。这里的摘要通常与源句子source sentence密切相关。
结果如下表所示,有几个趋势是明显的:
同一个预训练方法的性能在不同的任务中差异很大:预训练方法的有效性高度依赖于任务。例如,简单的语言模型在
ELI5中取得了最好的性能,但是在SQUAD中取得了最差的性能。根据下表的第二个
block(即Masked Language Model到Multitask Masked Language Model)。Token Masking是至关重要的:基于Document Rotation或Sentence Shuffling的预训练目标在单独的情况下表现很差。成功的方法要么使用Token Deletion或Token Masking,要么使用Text Infilling。在生成任务上,Token Deletion似乎比Token Masking更有优势。最后四个任务为生成式任务(指标为
PPL)。从左到右的预训练改善了生成任务:
Masked Language Model和Permuted Language Model在生成方面的表现不如其他模型。双向编码器对
SQuAD至关重要 :正如以前的工作(BERT论文)所指出的,仅仅从左到右的解码器在SQuAD上表现不佳(参考Language Model这一行),因为未来的上下文对分类决策至关重要。然而,BART只用一半数量的bidirectional layer就能达到类似的性能。预训练目标不是唯一的重要因素:我们的
Permuted Language Model的表现不如XLNet。这种差异的一部分可能是由于没有包括XLNet的其他改进,如relative-position embedding或segment-level recurrence。纯语言模型在
ELI5上表现最好:ELI5数据集是一个例外,其困惑度比其他任务高得多,是唯一的、其他模型优于BART的生成任务。纯语言模型表现最好,这表明当输出只受到输入的松散约束时,BART的效果较差。BART取得了最一致的强劲表现:除了ELI5之外,使用Text Infilling的BART模型在所有任务中都表现良好。
16.3 大型预训练实验
最近的工作表明,当预训练扩展到大
batch size和大型语料库时,下游任务的性能可以大幅提高。为了测试BART在这种范围下的表现,并为下游任务创建一个有用的模型,我们使用与RoBERTa模型相同的规模来训练BART。实验配置:我们预训练了一个大型模型,编码器和解码器各有
12层,隐层维度为1024。遵从RoBERTa的做法,我们batch size = 8K,并对模型训练500K步。文档采用与GPT-2相同的BPE进行tokenize。根据前面的实验结果,我们使用
text infilling和sentence permutation的组合。对于每篇文档我们掩码了30%的token,并对所有的句子进行permute。虽然sentence permutation在CNN/DM摘要数据集上显示出明显的加性增益additive gain,但我们假设更大的预训练模型可能会更好地从这个任务中学习。为了帮助模型更好地适应数据,我们在最后
10%的训练step中禁用dropout。我们使用与Roberta相同的预训练数据,由新闻、书籍、故事和网络文本组成的160Gb数据。判别式任务:下表将
BART的性能与最近几种方法在SQuAD和GLUE任务上进行了比较。最直接的可比baseline是RoBERTa,它是用相同的资源进行预训练的,但采用不同的预训练目标。总的而言,
BART和这些模型的表现相似。在大多数任务上,模型之间只有很小的差异。这表明BART在生成任务上的改进并没有牺牲分类任务上的性能。在
CoLA任务上,BART与CoLA的差距有点大。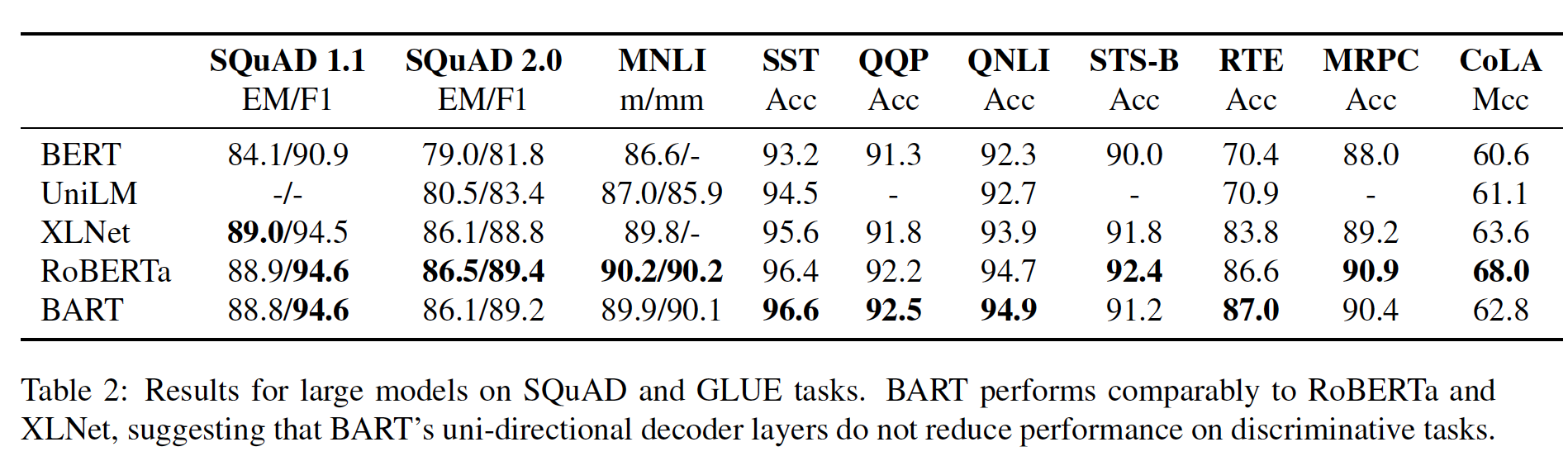
生成任务:我们还对几个文本生成任务进行了实验。
BART作为标准的sequence-to-sequence模型来被微调。在微调过程中,我们使用label smoothed的交叉熵损失,平滑参数设置为0.1。在生成过程中,我们将beam size设置为5,在beam search中删除重复的trigram,并在验证集上调优min-len, max-len, length penalty。摘要:为了提供与
SOTA的文本摘要方法的比较,我们在两个摘要数据集CNN/DailyMail和XSum上展示了结果,这两个数据集有不同的属性。CNN/DailyMail中的摘要倾向于类似于源句子。抽取式模型extractive model在这里表现良好,甚至前三个源句子的baseline也具有很强的竞争力。然而,BART的表现超过了所有现有的工作。相比之下,
XSum是高度抽象abstractive的,抽取式模型表现很差。BART在所有的ROUGE指标上比以前最好的工作高出大约6.0分(这表明这个问题上性能的重大进步)。从质量上看,样本质量很高(参考本文后续的定性分析)。ROUGE-N为:ground-truth的N-gram召回率;ROUGE-L为:prediction与ground-truth的最长公共子序列(以token来计算)的F1得分。
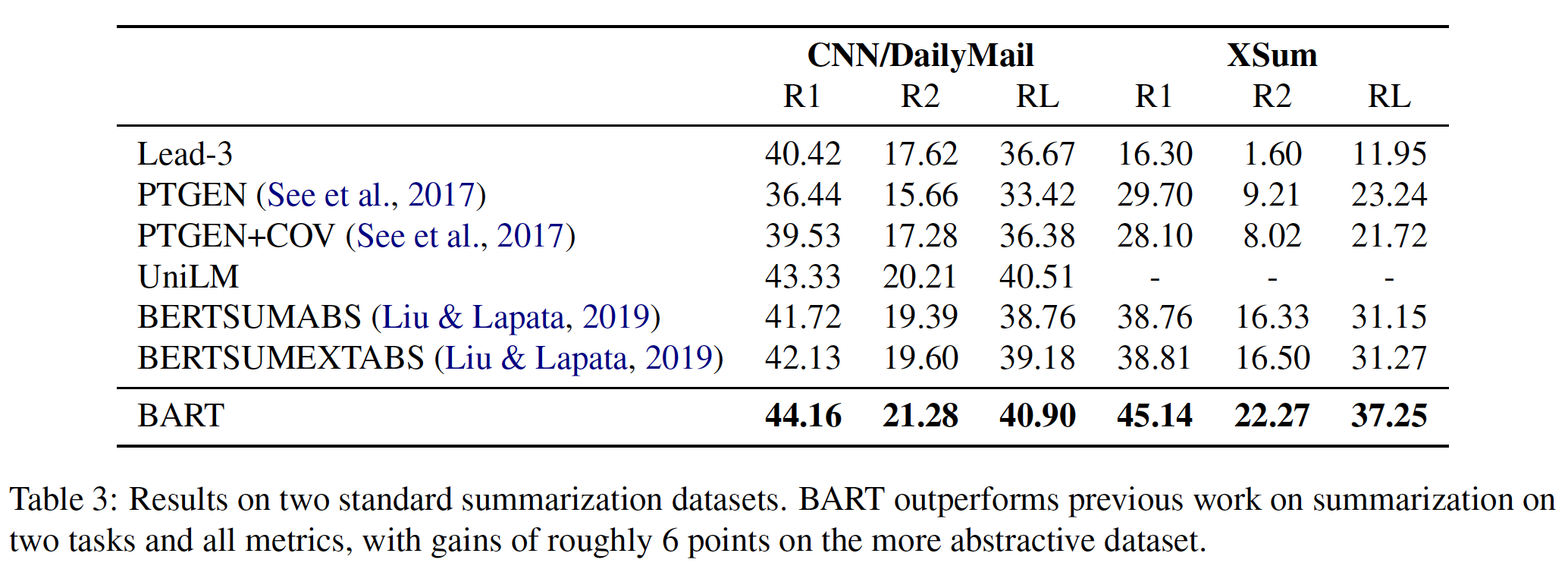
对话:我们评估了
CONVAI2的对话响应生成dialogue response generation,其中agent必须同时根据先前的上下文和文本指定的角色来生成响应。BART在两个automated metrics上优于之前的工作。
抽象式问答:我们使用最近提出的
ELI5数据集来测试该模型生成长的自由格式答案的能力。我们发现BART比以前最好的工作高出1.2 ROUGE-L。但该数据集仍然具有挑战性,因为答案只是由问题弱弱地指定了。
翻译: 我们还评估了
WMT16 Romanian-English的性能,并以《Edinburgh neural machine translation systems for WMT 16》的back-translation数据作为数据增强。我们使用一个6层的transformer source encoder将罗马尼亚语Romanian映射成一个representation,然后BART能够利用这个representation来降噪成英语English。即,
Romanian句子首先馈入一个6层的transformer source encoder,这个encoder的输出再馈入BART。假设我们需要将
A语言翻译成B语言,back-translation的做法分为三步:- 首先,利用
B -> A的bi-text语料来训练一个从B语言翻译成A语言的模型(与目标方向相反)。 - 然后,利用
B语言的单语语料、以及B -> A的模型,翻译得到A语言的单语语料。 - 将生成的
A语言的单语语料与B语言的单语语料人工合成A -> B的bi-text语料。
实验结果如下表所示。
baseline为Transformer-Large。我们同时评估了Fixed BART和Tuned BART。我们beam width = 5、以及length penalty = 1。初步结果表明:我们的方法在没有back-translation数据的情况下效果较差,而且容易出现过拟合。未来的工作应该探索更多的正则化技术。这个结论没有数据支撑?
Fixed BART和Tuned BART表示什么?作者都没有讲。BLEU为prediction的n-gram的precision的加权和,n=1,2,...,N,权重分为两部分:第一部分是n-gram取平均;第二部分是句子简短惩罚Brevity Penalty,用于惩罚太短的prediction。
- 首先,利用
定性分析:
BART在文本摘要指标上有很大的改进,比之前的SOTA提升高达6个点。为了理解BART在automated metrics之外的表现,我们对它的生成内容进行了定性分析。下表展示了由
BART生成的摘要实例。样本来自WikiNews文章,该文章是在我们创建预训练语料库之后才发表的,以消除被描述的事件存在于模型训练数据中的可能性。遵从《Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization》的做法,在总结文章之前,我们删除了文章的第一句话,所以不存在容易抽取的文章摘要。不出所料,模型输出是流利的、符合语法的英语。然而,模型的输出也是高度抽象的,很少有从输入中复制的短语。输出通常也是事实上准确的,并将整个输入文件的支持性证据
supporting evidence与背景知识结合起来(例如,正确补全名字,或推断PG&E在California运营)。在第一个例子中,推断出 “鱼在保护珊瑚礁免受全球变暖的影响” 需要从文本中进行困难的推理。然而,关于 “这项工作发表在《科学》上” 的说法并没有得到source document的支持。这些样本表明,
BART预训练已经学会了自然语言理解和自然语言生成的强大组合。
十七、mBART[2020]
尽管已被广泛用于其他
NLP任务,但自监督的预训练在机器翻译machine translation: MT中还不是常见的做法。现有的方法要么是对模型进行部分预训练partially pre-train、要么是仅关注英语语料。在论文《Multilingual Denoising Pre-training for Neural Machine Translation》中,作者表明:通过预训练一个完整的自回归模型可以获得显著的性能提升,其中这个自回归模型的目标是跨多种语言的完整文本进行加噪音和重建。在这项工作中,论文提出了
mBART,一个多语言sequence-to-sequence: Seq2Seq降噪自编码器。mBART是通过将BART应用于跨多种语言的大型单语语料库monolingual corpora而训练的。通过masking phrase和permuting sentence来对输入文本添加噪音,并学习一个Transformer模型来恢复文本。与其他机器翻译的预训练方法不同,mBART预训练了一个完整的自回归Seq2Seq模型。mBART仅对所有语言进行一次训练,提供一组参数。这组参数可以在supervised setting和unsupervised setting下对任何language pair进行微调,无需任何task-specific或language-specific修改或初始化方案initialization scheme。大量的实验表明,这种简单的方法效果非常好。
对于
supervised sentence-level机器翻译,mBART initialization在low-resource/medium-resource pair(小于10M个bi-text pair)中带来了显著的增益(高达12个BLEU point),而在high-resource setting中没有牺牲性能。这些结果通过back-translation: BT进一步改善,在WMT16 English-Romanian和FloRes测试集上创造了新的SOTA。Romanian:罗马尼亚语;Nepali:尼泊尔语;Korean:韩语;Italian:意大利语。对于
document-level机器翻译,mBART的document-level预训练将结果提高了5.5个BLEU point。在无监督的情况下,mBART得到了一致的增益,并对相关性较低的语言对产生了首个非退化non-degenerate的结果(例如,Nepali-English上的9.5 BLEU增益)。以前的预训练方案只考虑了这些application的子集,但论文尽可能地比较了性能,并证明mBART始终表现最佳。论文还表明,
mBART能够实现新类型的跨language pair的迁移。例如,对一个language pair(如Korean-English)中的bi-text进行微调,可以创建一个模型,该模型可以翻译在单语预训练集中的所有其他语言(如Italian-English),而无需进一步训练。论文还表明,不在预训练语料库中的语言也能从
mBART中受益,这强烈表明initialization至少部分地是语言通用language universal的。
最后,论文详细分析了哪些因素对有效的预训练贡献最大,包括语言的数量和它们的整体相似度
overall similarity。相关工作:
用于文本生成的自监督学习:这项工作继承了最近预训练为
NLP application带来的成功,尤其是文本生成。预训练的模型通常被用作initialization从而用于微调下游任务(如,可控语言建模controllable language modeling、摘要、和对话生成)。具体到机器翻译,无监督的预训练方法也被探索出来,以提高性能。
《When and why are pretrained word embeddings useful for neural machine translation?》研究了预训练的word embedding在机器翻译中的应用。《Unsupervised pretraining for sequence to sequence learning》提出将encoder-decoder模块作为两个独立的语言模型进行预训练。《Towards making the most of bertin neural machine translation》和《Incorporating BERT into neural machine translation》探索了融合方法从而集成预训练的BERT权重来改善神经机器翻译的训练。
与大多数先前的工作相比,我们专注于预训练一个降噪自编码器,并为各种机器翻译
application来适配整个模型的权重。NLP中的多语言性Multilinguality:这项工作也与多语言学习的持续趋势continual trend有关,包括将multilingual word embedding对齐到通用空间,以及学习跨语言模型crosslingual model从而利用跨语言的shared representation。对于机器翻译来说,最相关的领域是多语言翻译
multilingual translation。多语言翻译的最终目标是联合训练一个翻译模型,该模型同时翻译多种语言,并共享representation从而提高low-resource language的翻译性能(《Universal neural machine translation for extremely low resource languages》)。low-resource language:bi-text语料很少的language pair。在本文中,我们聚焦于预训练阶段的多语言,并在标准的双语场景
bi-lingual scenario下对所学模型进行微调。与多语言翻译相比,我们不需要跨多种语言的平行数据parallel data,只需要目标方向targeted direction(即,翻译方向),这提高了对low-resource language和specific domain的可扩展性。假设有
100种语言,多语言翻译需要language pair的平行数据 。而这里我们只需要100种语言的单语语料,以及翻译方向。文档翻译
Document Translation:作为关键应用之一,我们的工作也与之前将document-level上下文纳入神经机器翻译的工作有关。《Pretrained language models for document-level neural machine translation》是最相关的工作,也利用预训练的编码器(BERT)来处理更长的上下文。然而,他们的重点是设计新的task-specific技术,并在更wider的input context下做sentence-level翻译 。据我们所知,我们的多语言预训练模型是首个显示出在
document-level翻译上相比标准Seq2Seq模型有改进的结果。无监督翻译:这项工作也总结了之前的一些工作,其中在语言之间没有直接的平行语料库的情况下来学习翻译。
- 当没有任何类型的平行数据时,
《Unsupervised neural machine translation》和《Unsupervised machine translation using monolingual corpora only》提出从两个direction联合学习降噪自编码器和back-translation,然而,这需要良好的initialization,并且只在相似的language pair上效果良好。 《Machine translation with weakly paired bilingual documents》通过从维基百科中挖掘句子并将其作为弱监督的translation pair来解决这个问题。
类似于
《Cross-lingual language model pretraining》和《MASS: Masked sequence to sequence pre-training for language generation》,我们遵循第一种方法,并将我们预训练的模型作为initialization。我们还研究了使用
language transfer的无监督翻译,这与《Translating translationese: A two-step approach to unsupervised machine translation》类似,其中他们生成源语言的翻译语translationese,并在high-resource language上训练一个系统来纠正这些中间结果。我们的工作也与
《XNLI: Evaluating cross-lingual sentence representations》和《On the cross-lingual transferability of monolingual representations》的跨语言representation learning密切相关,我们也表明通过mBART学到的representation可以在没有监督数据的情况下轻松地在语言之间迁移。- 当没有任何类型的平行数据时,
17.1 预训练
- 我们使用
Common Crawl: CC语料库来预训练BART模型。我们的实验涉及微调一组模型(这些模型在不同子集上预训练)。
17.1.1 Data: CC25 语料库
数据集:我们对从
CC语料库中提取的25种语言(CC25)进行预训练。CC25包括来自不同语言的、不同数量的文本(如下图所示)。遵从《Cross-lingual language model pretraining》,我们通过对每种语言up/down-sampling,从而重新平衡语料库:
其中:CC-25 中的百分比;
是以 byte-level还是character-level还是word-level还是document-level?作者并未说明。根据下图,猜测是byte-level。
时, ,即语言 的文本越少则采样比例越大; 是, ,即均匀采样。 语言缩写:
En英语,Ru俄语;Vi越南语;Ja日语;De德语;Ro罗马尼亚语;Fr法语;Fi芬兰语;Ko韩语;Es西班牙语;Zh中文;It意大利语;NI尼加拉瓜语;Ar阿拉伯语;Tr土耳其语;Hi印度语;Cs捷克语;Lt立陶宛语;Lv拉脱维亚语;Kk哈萨克语;Et爱沙尼亚语;Ne尼泊尔语;Si斯里兰卡语;Gu古吉拉特语;My马来西亚语。
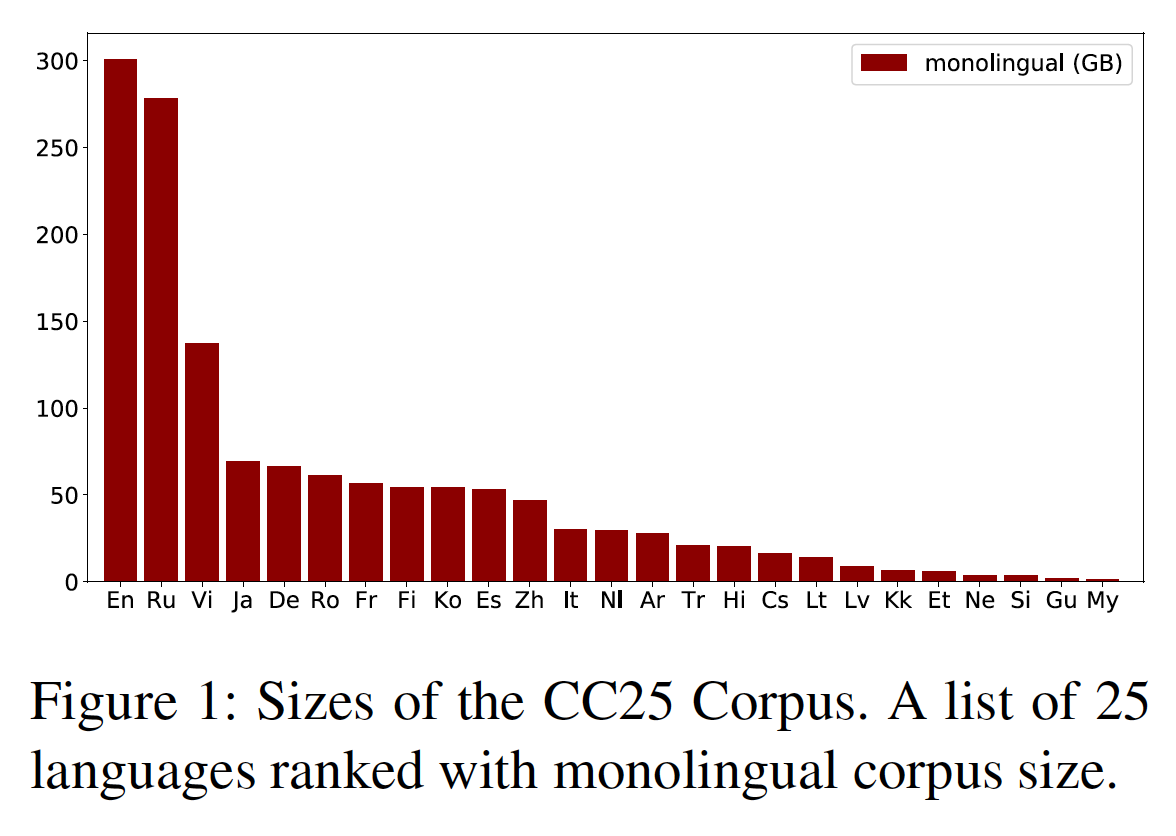
预处理:我们用一个在完整的
CC数据上学习的sentence-piece model(包括250K个subword token)来tokenize。虽然不是所有这些语言都被用于预训练,但这种tokenization支持对额外的语言进行微调。我们不应用额外的预处理,如true-casing(即决定单词的合适的大小写)、或者对标点符号以及字符进行规范化。因为有
25种语言,因此相当于每种语言包含10K规模的词表。
17.1.2 Model: mBART
我们的模型遵循
BART的Seq2Seq预训练方案。然而BART只对英语进行了预训练,我们系统地研究了在不同语言的集合上预训练的影响。架构:我们使用标准的
Seq2Seq Transformer架构,模型配置为:12层编码器和12层解码器,隐层维度为1024,16个注意力头,一共大约680M参数。我们在编码器和解码器的基础上加入了一个额外的layer-normalization层,我们发现它在FP16精度下稳定了训练。学习:我们的训练数据覆盖了
其中:
Seq2Seq模型定义的条件概率分布。噪声函数
Noise Function:遵从BART,我们在首先,我们删除一个区间
span的文本并代之以一个mask token。我们根据泊松分布(span length,从而掩码每个文本实例中35%的单词。这意味着平均每个文本序列的长度为
10个单词。我们还对每个文本实例中的句子顺序进行了排列。
解码器的输入是带有一个位置偏移的原始文本。一个
language id符号<LID>被用来作为initial token从而用于预测句子。假设原始文本为
ABCDEFG,而被掩码的文本为[mask]EFG。那么:- 编码器的输入为
[mask]EFG<LID>。 - 解码器的输入为
<LID>ABCDEF,解码器的label为ABCDEFG<LID>。
也可以使用其他噪音类型,如
《Phrase-based & neural unsupervised machine translation》中的噪音,但我们将最佳噪音策略的探索留给未来工作。实例格式
Instance Format:对每个batch的每个文本实例,我们对一个language id符号<LID>进行采样,并尽可能多地打包从<LID>的相应语料库中采样的连续句子,直到它命中文档边界或达到512的max token length。实例中的句子由end of sentence token(</S>)分隔。然后,我们将选定的<LID> token附加到该实例的末尾。在"multi sentence"层面的预训练使我们能够同时在句子翻译和文档翻译上工作。每个
batch包含多种语言的文本,即:xxxxxxxxxxabcdefg...</S>ABCDEFG...</S>abAB<En>一二三四五...</S>甲乙丙丁...<Zh>注意:这里的
<LID>是位于输入序列的末尾,但是在馈入到BART时:- 如果是编码器的输入,则
<LID>仍然位于原始序列的末尾。 - 如果是解码器的输入,则
<LID>放置到原始序列的开头。如果是解码器的输出,那么<LID>仍然位于原始序列的末尾。一旦 解码器发现解码的token为<LID>,那么解码结束。
- 如果是编码器的输入,则
优化:我们的完整模型(包括
25种语言)是在256个Nvidia V100 GPU(32GB)上训练了500K步 。每个GPU的总batch size约为128K个token,与BART的配置相匹配。因为采用了梯度累加策略,因此
GPU的batch size会增加。我们使用
Adam优化器 (2.5周。我们以dropout rate = 0.1开始训练,在250K步时减少到0.05,在400K步时减少到0。所有的实验都是用
Fairseq完成的。可复现性:所提出方法的一个潜在问题是可复现性问题,因为需要大量的单语语料和计算资源,以及在预训练期间对超参数进行细粒度选择。如果我们再次对系统进行重新训练,可能会得到略有不同的微调性能。为了解决这个问题,我们将发布预训练的
checkpoint,以及完整说明的代码从而用于预训练一个新模型。相关工作
XLM(-R)和MASS:有几种密切相关的机器翻译多语言预训练的方法。XLM和XLM-R以多语言方式预训练BERT,结果得到的参数可用于初始化翻译模型的编码器。与XLM(-R)不同的是,由于Seq2Seq的配置,mBART同时预训练编码器和解码器,这对于适配机器翻译应用来说更为自然。- 与
mBART类似,MASS也是一种基于Seq2Seq的、具有word-masking的预训练技术。然而,MASS的解码器只预测在编码器中被masked的token,而mBART重建了完整的target序列,不仅可以应用于"masking"(是噪音函数中的一种) ,还可以应用任何可能的噪音函数。
此外,
XLM和MASS都没有显示出预训练模型改善两种语言上的翻译性能的证据。
17.1.3 预训练的模型
为了更好地衡量预训练期间不同
level的多语言性的影响,我们构建了一系列模型,具体如下:mBART25:如前所述,我们在所有25种语言上预训练一个模型。mBART06:为了探索对相关的语言进行预训练的效果,我们对所有语言的一个子集(包含6种欧洲语言)进行预训练:Ro, It, Cs, Fr, Es, En(即 ,罗马尼亚语、意大利语、捷克语、法语、西班牙语、英语)。为了进行公平的比较,我们使用了mBART25 batch size的大约1/4,这使得我们的模型在预训练期间对每种语言有相同的更新数量。mBART02:我们预训练双语模型,采用英语和另外一种语言,最终包括各种language pair:En-De, En-Ro, En-It。我们使用了mBART25 batch size的大约1/12。注意,这里是每种
language pair训练一个模型,而不是在这三个pair上总共训练一个模型。BART-En/Ro:为了帮助建立对多语言预训练的更好理解,我们还分别在仅包含En语料库、以及仅包含Ro语料库上训练单语言BART模型。注意,这里是每种语言训练一个模型,而不是在包含英语和罗马尼亚语的语料库上总共训练一个模型。
Random:作为额外的baseline,我们还将包括与随机初始化的模型的比较,不对每个翻译任务进行预训练。由于不同下游数据集的大小不同,我们总是对超参数(架构、dropout rate等)进行网格搜索,从而找到最佳的non-pretrained configuration。
所有模型都使用相同的词表
vocabulary(CC25语料库上学到的,包括250K个subword token)。并非所有的token都会频繁地出现在所有的预训练语料库中,但后来的实验表明:这种大型词表可以在多语言环境中提高泛化能力,即使是对未见过的语言。
17.1.4 扩大规模的问题
- 扩大训练数据和模型参数的规模一直是预训练的关键因素。与传统的半监督方法(如
back-translation)和其他机器翻译的预训练相比,我们以相对更深的架构在更多的单语数据上预训练mBART。这种数据规模和模型参数规模,结合新的多语言训练,是我们结果的核心,尽管未来的工作可以更仔细地研究每一种因素的相对贡献。
17.2 Sentence-level Machine Translation
- 本节显示,
mBART预训练在low resource到medium resource的sentence-level Machine Translation setting中提供了一致的性能提升,包括仅有bi-text和有back translation的情况,并且优于其他现有的预训练方案。我们还进行了详细的分析,以更好地了解哪些因素对这些提升贡献最大,并显示预训练甚至可以提高那些不在预训练数据中的语言的性能。
17.2.1 实验配置
数据集:我们收集了
24对公开可用的平行语料parallel corpora,这些语料涵盖了CC25的所有语言。大多数pair来自以前的WMT(Gu, Kk, Tr, Ro, Et, Lt, Fi, Lv, Cs, Es, Zh, De, Ru, Fr <-> En)和IWSLT(Vi, Ja, Ko, Nl, Ar, It <-> En)比赛。我们还使用FLoRes pair(《The FLORES evaluation datasets for low-resource machine translation: Nepali–English and Sinhala–English》),IITB的En-Hi(《The IIT Bombay English-Hindi parallel corpus》),以及WAT19的En-My。我们将数据集分为三类:low resource(小于1M的sentence pair),medium resource(大于1M且小于10M的sentence pair),以及high resource(大于10M的sentence pair)。微调和解码:我们在
bi-text数据的单个pair上微调mBART,将source language馈入编码器并且解码target language。如下图所示,我们加载预训练的权重,在bi-text上训练机器翻译模型。对于所有的翻译方向,我们用dropout rate = 0.3、label smoothing = 0.2、warm-up steps = 2500、最大学习率为3e-5来进行训练。我们对所有low resource, medium resource的pair使用最多40K的训练更新,对high resource pair使用最多100K的训练更新。最后的模型是根据验证集的似然likelihood来选择的。这里没有说明微调的序列长度是多少。由于这里是
sentence-level的翻译,因此序列长度可能不大。相比较而言,document-level的翻译中,序列长度为512个token。我们解码期间使用
beam-search,beam size = 5。我们的初步实验表明,微调过程在不同的随机数种子下通常是稳定的。因此,为了减少总的计算量,我们所有的结果都是以单次执行来报告的。我们用mosesdecoder的脚本来验证统计意义。注意:
- 编码器输入的末尾为
<LID>,例如<En>;解码器输入的开头为<LID>、解码器输出的末尾为<LID>,如<Ja>。 - 编码器输入、解码器输入、解码器输出中,句子之间的分隔符均为
</s>。
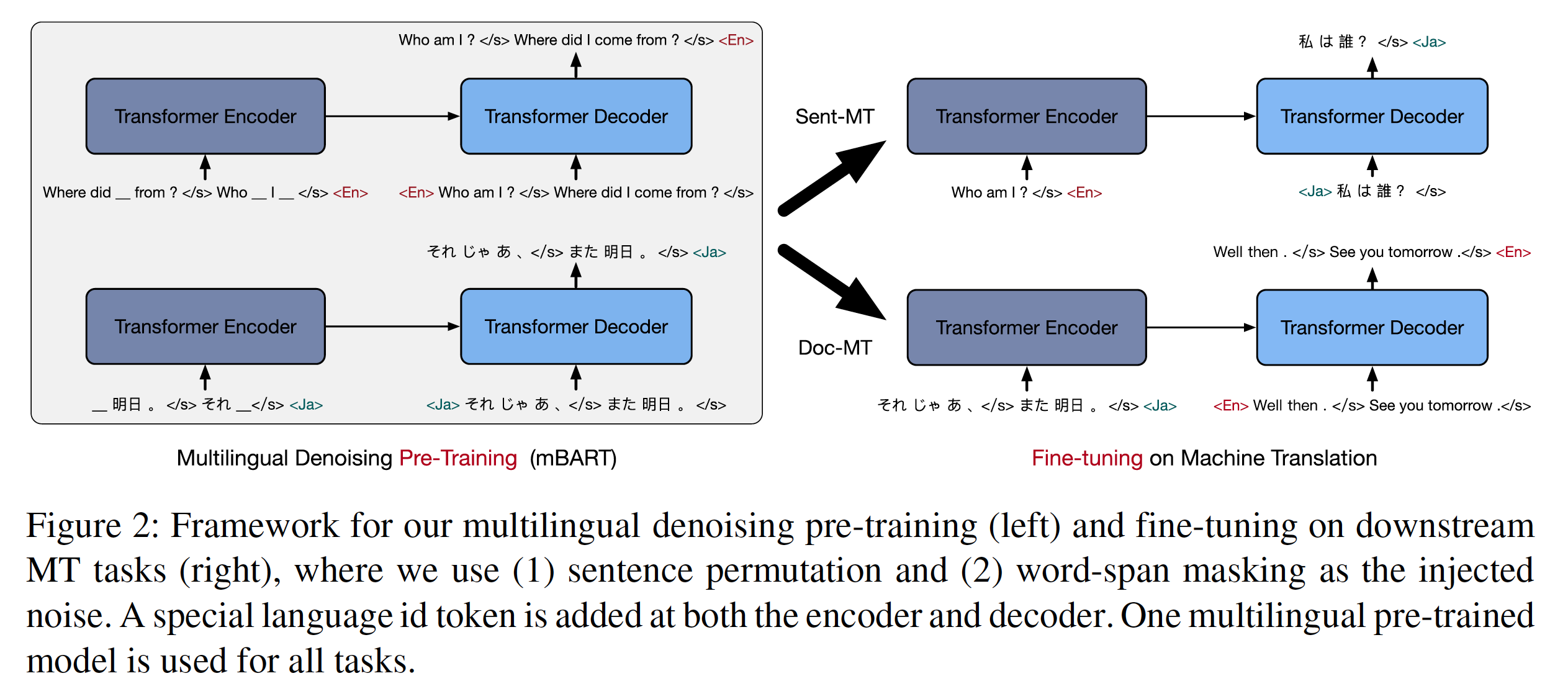
- 编码器输入的末尾为
17.2.2 实验结果
主要结果:
如
Table 1所示,与随机初始化的baseline相比,用预训练的mBART25权重初始化在所有low resource pair、medium resource pair上都有提高。我们观察到:- 在
low resource pair(如En-Vi、En-Tr)和noisily aligned pair(如En-Hi)上有12个点或更多的BLEU收益。 - 微调在
extremely low-resource的情况下仍然失败,如En-Gu,它仅有大约10K个样本。在这些情况下,无监督翻译更合适,见后面的实验。
注意,我们的
baseline系统使用随机初始化权重的常规Transformers的一些运行报告,这与原始竞赛中报告的SOTA系统有相当明显的差距。这种差异主要是因为:我们只在官方提供的bi-text中训练和搜索baseline的超参数,而没有使用任何单语语料库或多语适配。例如:- 在
WMT19中,En -> Gu的SOTA得分是28.2,而Table 1中是0。这基本上是因为原始bi-text data的质量很低,而SOTA系统通常使用额外的语言(如Hi)来提高性能。 - 类似的差距也可以在
Kk-En和Lt-En等pair中观察到,其中Ru作为额外的语言也很关键。
这一部分的主要目的是讨论多语言预训练在受限的
bi-text setting中的效果,以便进行更好的比较。我们将在未来的工作中加入更多关于多语言翻译与预训练相结合的讨论。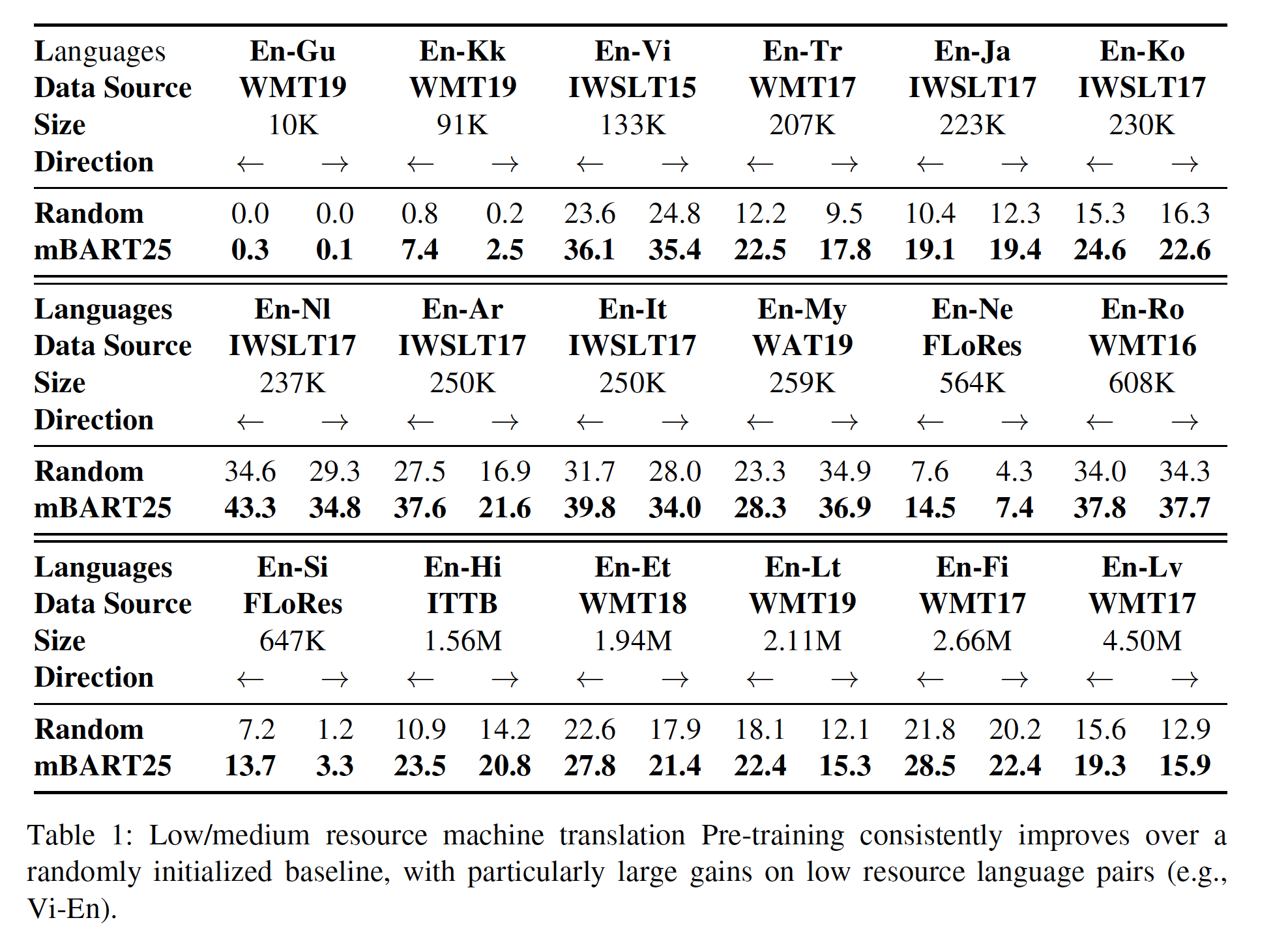
- 在
对于
high resource的情况(Table 2),我们没有观察到一致的收益,当有超过25M的平行句子parallel sentence时,预训练略微损害了性能。当给出大量的bi-text data时,我们怀疑监督训练会刷掉预训练的权重。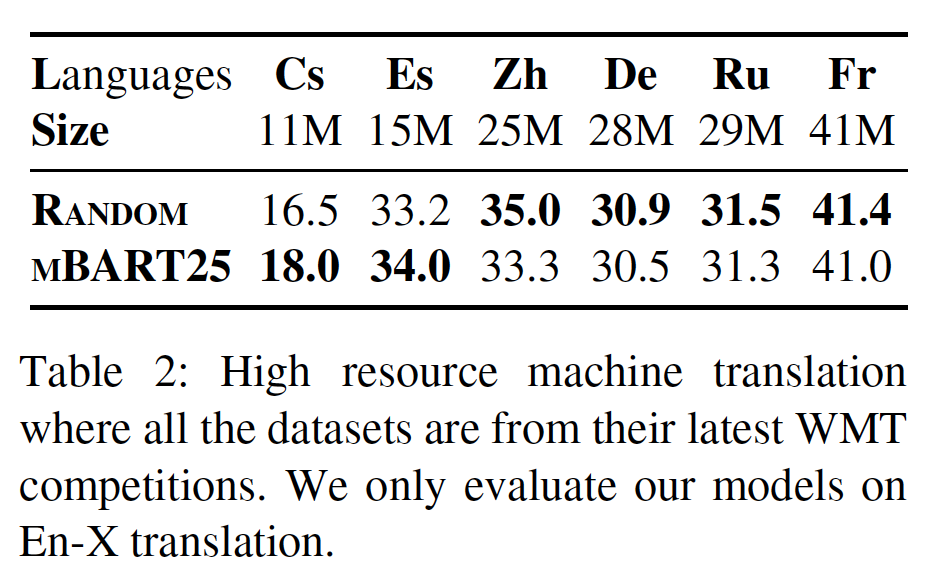
Plus Back-Translation:back-translation(《Improving neural machine translation models with monolingual data》)是一种标准的方法,用target-side的单语数据增强bi-text。我们将我们的预训练与back-translation相结合,并使用FLoRes数据集在low resource language pair(En-Si和En-Ne)上进行测试。我们使用与《The FLORES evaluation datasets for low-resource machine translation: Nepali–English and Sinhala–English》相同的单语数据来生成back-translation数据。结果如下图所示。可以看到:用我们的
mBART25预训练的参数初始化模型,在back-translation的每个迭代中提高了BLEU分数,从而在所有四个翻译方向上产生了新的SOTA的结果。这表明,预训练的mBART权重可以直接插入到使用back-translation的现有pipeline中。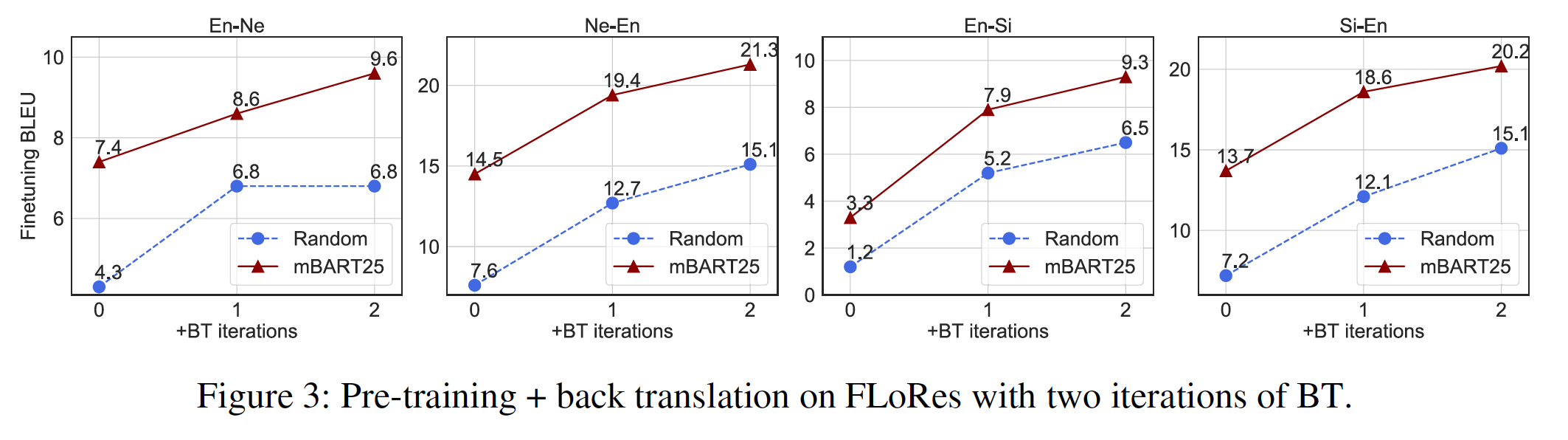
对比其它的预训练方法:我们还将我们的预训练模型与最近的自监督预训练方法进行了比较,如下表所示。我们考虑了
En-Ro翻译,这是唯一一对有既定结果的翻译。可以看到:- 我们的
mBART模型优于所有其他预训练模型,无论是否有back-translation增强。 - 我们还展示了与仅在相同的
En和Ro数据上训练的传统BART模型的比较。尽管比mBART的结果要差,但两者都比baseline有改进,这表明在多语言环境下的预训练是非常重要的。 - 此外,结合
back-translation可以带来额外的收益,从而使Ro-En翻译达到新的SOTA。
此外,
mBART25的效果比mBART02的效果更差,是否意味着更多的无关预训练数据反而影响下游任务的效果?因为mBART25的CC25预训练数据集包含了mBART02的预训练数据集。接下来的实验表明:如果目标语言的单语料数据很少,那么对更多语言进行预训练对下游翻译任务有帮助;否则,对更多语言进行预训练会略微损害下游翻译任务的性能。
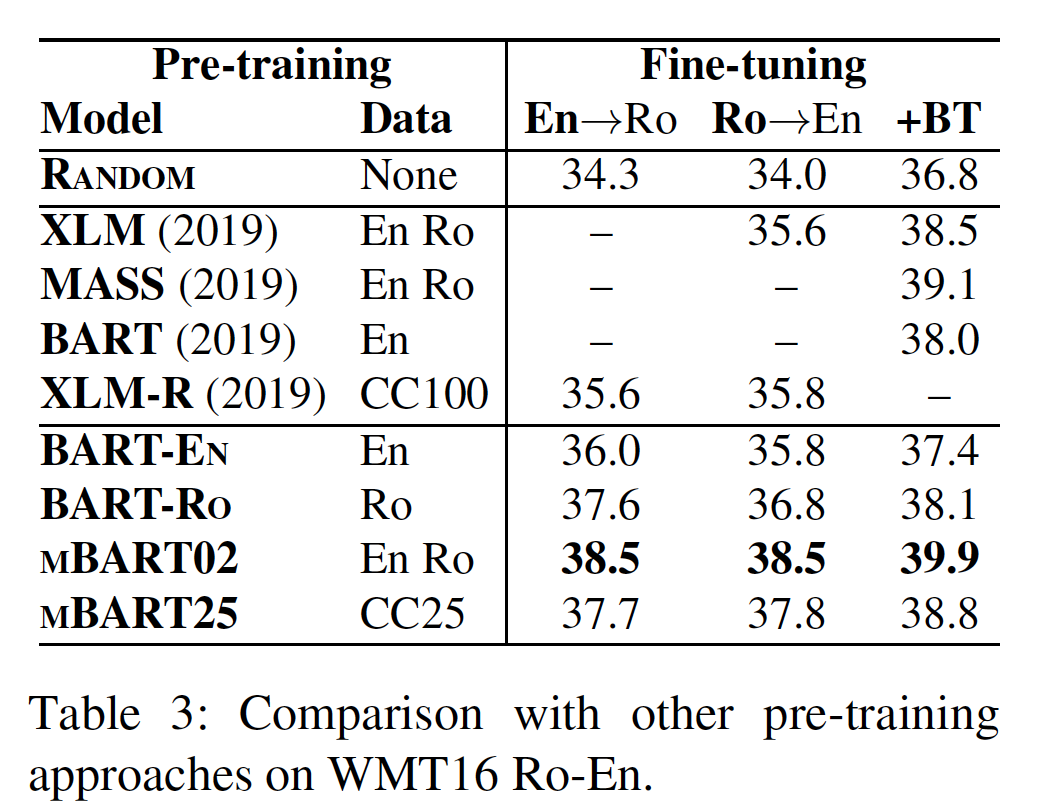
- 我们的
17.2.3 分析
需要对多少种语言进行预训练:我们研究了在什么情况下,将目标
language pair以外的语言纳入预训练是有帮助的。下表显示了四组X-En pair的表现。可以看到:- 当
target language的单语数据有限时(如En-My,My的单语言数据大小约为En的0.5%),对更多语言进行预训练最有帮助。 - 相反,当
target language的单语数据丰富时(如De,Ro),对多语言的预训练对最终结果略有损害(小于1 BLEU)。在这些情况下,额外的语言可能会减少每种测试语言的可用容量。此外,mBART06在Ro-En上的表现与mBART02相似,这表明用类似语言(都是欧洲语言)进行预训练特别有帮助。
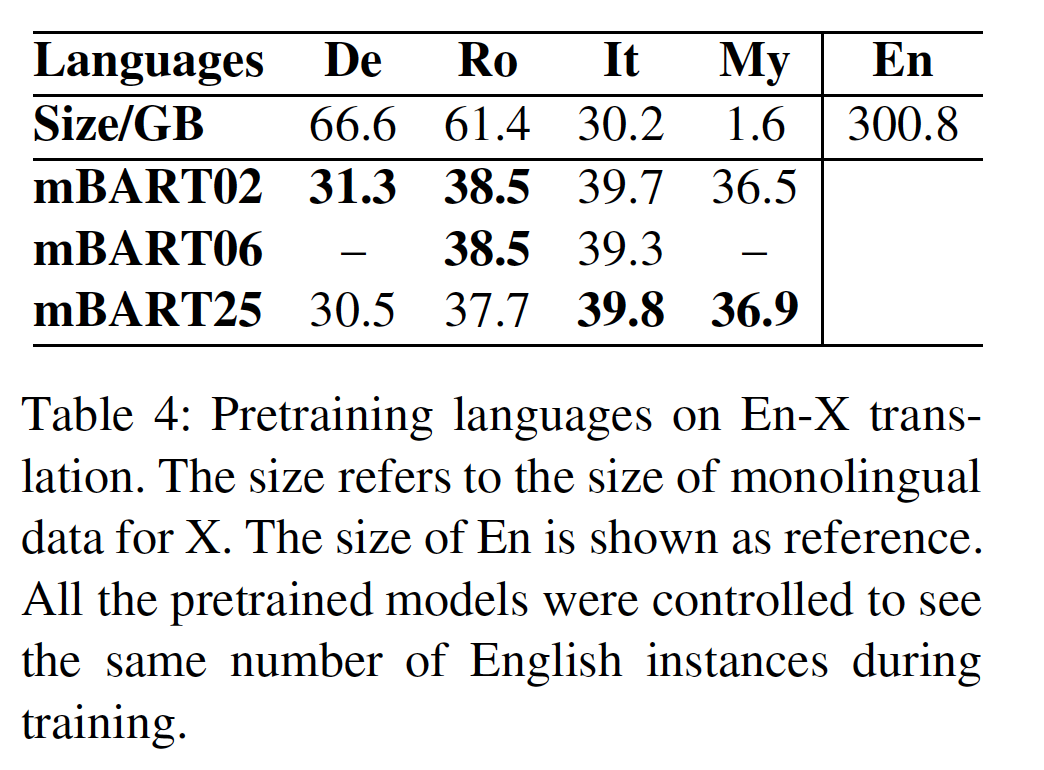
- 当
需要预训练多少个
step:我们在下图中绘制了Ro-En的BLEU得分与预训练step数的对比,在图中我们采用了保存的checkpoint(每25K步)并应用了前面描述的相同的微调过程。可以看到:- 在没有任何预训练的情况下,我们的模型过拟合,表现比
baseline差很多。 - 然而,在仅仅
25K步(5%的训练)的预训练之后,两个模型的表现都超过了最佳baseline。 - 在剩下的预训练中,这两个模型一直在超越了
baseline高达3 BLEU以上,在500K步之后还没有完全收敛。 - 此外,
mBART25始终比mBART02略差,这证实了Table 4的观察。
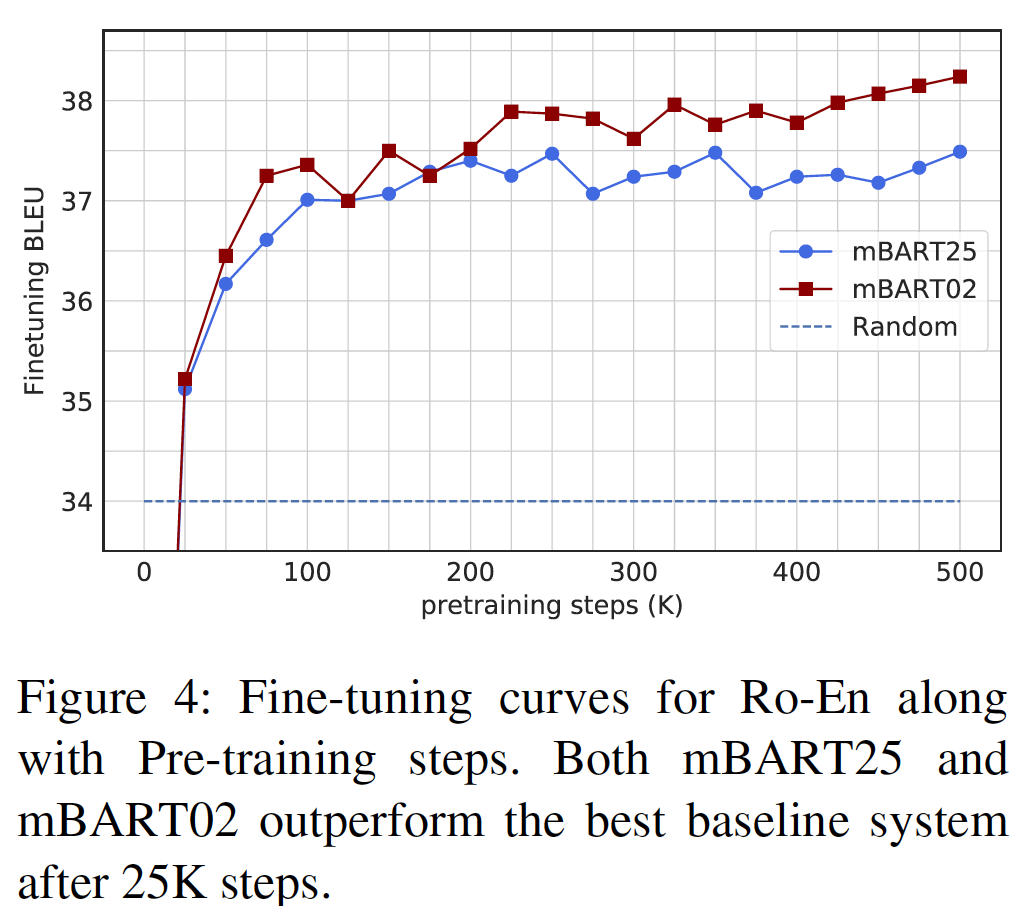
- 在没有任何预训练的情况下,我们的模型过拟合,表现比
需要多少
bi-text:Table 1和Table 2显示,预训练对low resource、medium resource的language pair有持续改善。为了验证这一趋势,我们绘制了不同大小的En-De数据集子集的性能。更确切地说,我们采用了完整的En-De语料库(2800万pair),并随机抽取了10K、50K、100K、500K、1M、5M、10M的子集。我们将没有预训练的性能与mBART02的结果进行比较,如下图所示。可以看到:- 预训练的模型能够在只有
10K个训练样本的情况下达到高于20 BLEU的效果,而baseline系统的得分是0。不难看出,增加bi-text语料库的规模可以改善这两个模型。 - 我们的预训练模型一直优于
baseline模型,但随着bi-text数量的增加,差距也在缩小,特别是在10M个sentence pair之后。这一结果证实了我们在前面的观察,即我们的预训练对high-resource pair的翻译没有帮助。
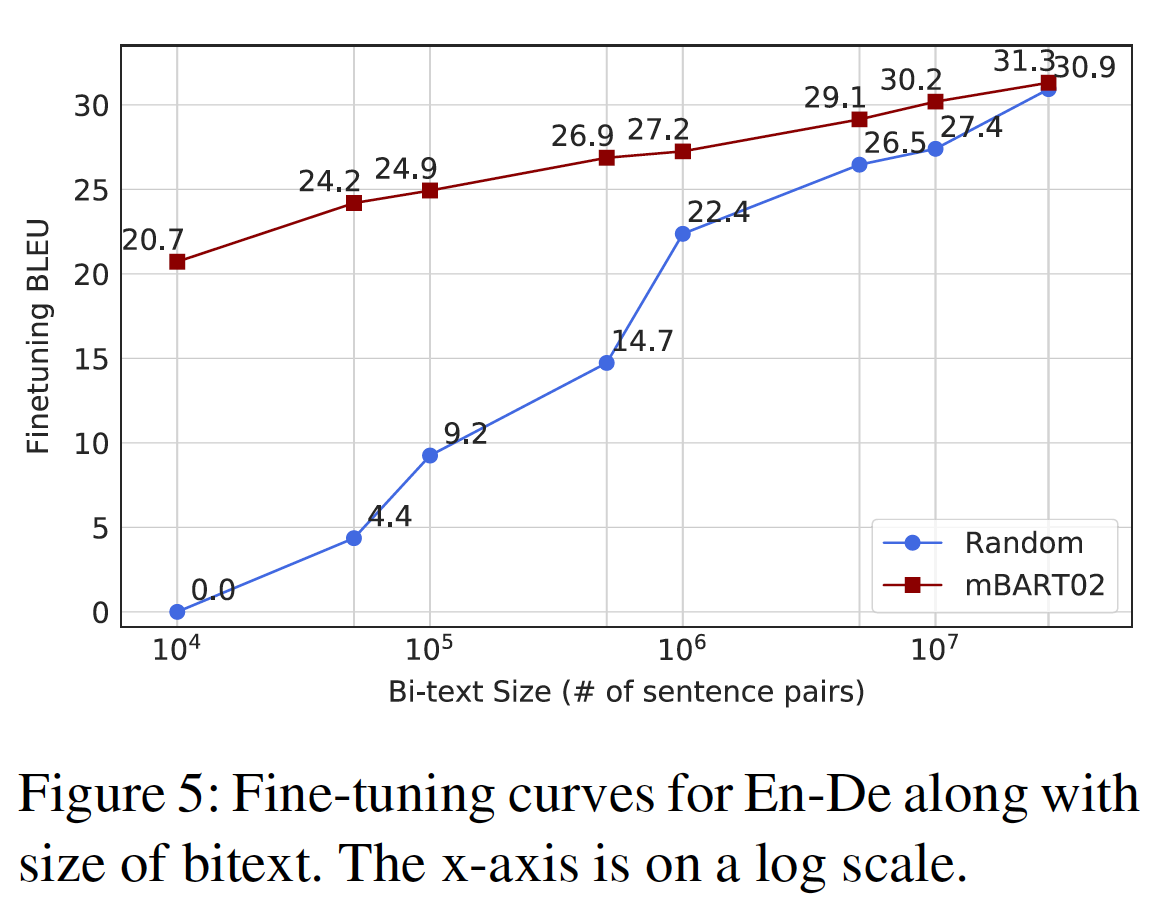
- 预训练的模型能够在只有
17.2.4 泛化到不在预训练中的语言
在这一节中,我们表明:即使对于没有出现在预训练语料库中的语言,
mBART也能提高性能,这表明预训练具有语言通用性。类似的现象在其他NLP应用中的其他多语言预训练方法中也有报道。实验设置:我们报告了使用预训练的
mBART25、mBART06和mBART02(En-Ro)模型对Nl-En、Ar-En和De-Nl三种pair进行微调的结果。mBART06和mBART02模型没有对Ar、De或Nl文本进行预训练,但所有语言都在mBART25中。De和Nl都是欧洲语言,与En、Ro以及mBART06预训练数据中的其他语言有关。实验结果:如下表所示:
我们发现
English-Romanian预训练相比baseline获得了很大的增益,即使在翻译一种不相关且未见过的语言(阿拉伯语Arabic)、以及两种未见过的语言(德语German和荷兰语Dutch)时也是如此。NI尼加拉瓜语是荷兰语的一种。当预训练中包括双方的语言时(即,
mBART25),取得了最好的结果,尽管在其他情况下的预训练也具有令人惊讶的竞争力。
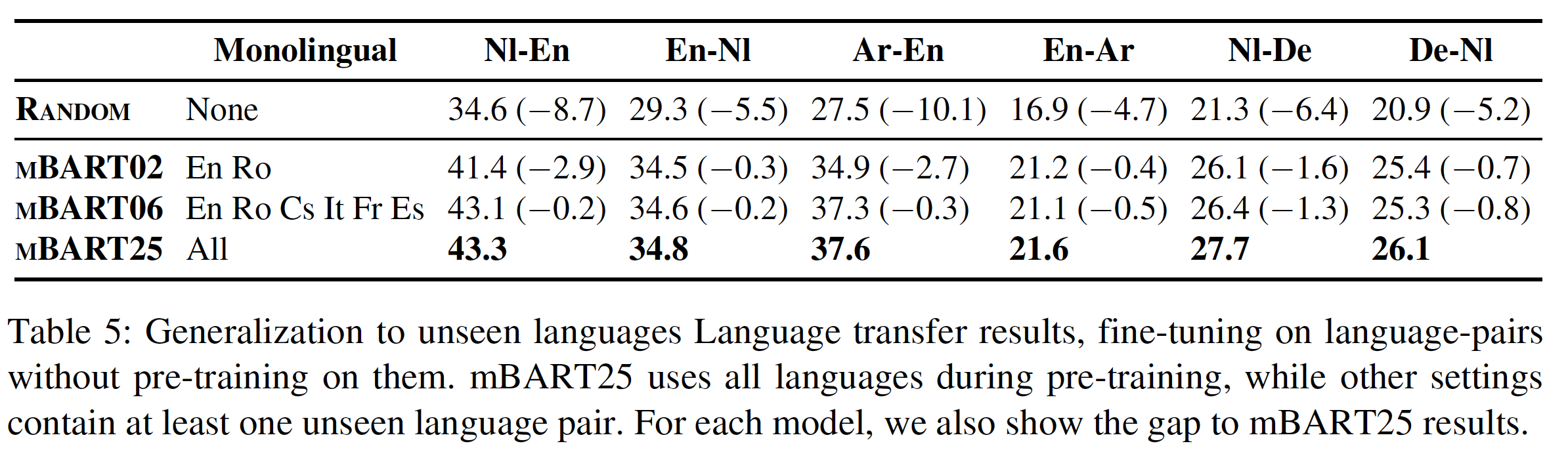
未见过的词汇:
Arabic与mBART02和mBART06中的语言关系较远,并且有一个不相交的字符集character set。这意味着它的word embedding在很大程度上没有在预训练中被估计。然而,从Table 5中可以看到:mBART02/mBART06在Ar-En pair上获得的改进与在Nl-En pair上获得的改进相似。这一结果表明:预训练的
Transformer layer学习了语言的普遍属性,即使在词汇重叠度lexical overlap极低的情况下也能很好地进行泛化。未见过的
source language和未见过的target language:从Table 5中可以看到:- 如果两边都是未见过的语言,其性能(从与
mBART25的差异来看)比在预训练期间至少见到一种语言(source language或者target language)的情况要差。 - 此外,
mBART06在X-En pair上的表现优于mBART02,尽管它们在En-X pair上表现相似。在source-side对未见过的语言进行微调是比较困难的(这里source-side就是NI和Ar),值得今后广泛研究。
- 如果两边都是未见过的语言,其性能(从与
17.3 Document-level Machine Translation
- 我们在
document-level机器翻译任务中评估了mBART,其目标是翻译包含一个以上句子的文本片段(直到整个文档)。在预训练期间,我们使用多达512个token的文档片段,允许模型学习句子之间的依赖关系。我们表明,这种预训练大大改善了document-level的翻译。
17.3.1 实验配置
数据集:我们在两个常见的
document-level机器翻译数据集上评估性能:WMT19 En-De和TED15 Zh-En。- 对于
En-De,我们使用WMT19的文档数据来训练我们的模型,没有任何额外的sentence-level数据。 Zh-En数据集来自IWSLT 2014和IWSLT 2015。遵从《Document-level neural machine translation with hierarchical attention networks》,我们使用2010-2013 TED作为测试集。
- 对于
预处理:我们用预训练中使用的方法进行预处理。对于每个
block,句子被符号</S>所分隔,整个实例以specific language id(<LID>)结束。平均而言,一个文档被分割成2到4个实例。微调和解码:
- 我们使用与
sentence-level翻译相同的微调方案,不使用以前的工作所开发的任何task-specific的技术,如约束的上下文constrained context、或受限注意力restricted attention。 - 对于解码,我们只是将
source sentence打包成block,并对每个实例block进行自回归地翻译。该模型不知道要提前生成多少个句子,当预测到<LID>时,解码就会停止。我们默认使用beam size = 5。
- 我们使用与
baseline和评估:我们训练了4个模型:一个document-level(Doc-MT)机器翻译模型,以及baseline为一个对应的sentence-level(Sent-MT)机器翻译模型,包括预训练和不预训练。我们使用mBART25作为En-De和Zh-En的通用预训练模型。- 对于
En-De,即使我们的mBART25 Doc-MT模型将多个句子解码在一起,但翻译的句子仍然可以与source sentence对齐,这使得我们可以同时在sentence-level(s-BLEU)和document-level(d-BLEU)评估BLEU分数。 - 然而,对于
Zh-En,由于测试数据中的对齐错误,我们无法产生与reference相同数量的翻译句子。我们只提供d-BLEU分数。
我们还将我们的模型与
Hierarchical Attention Networks(《Document-level neural machine translation with hierarchical attention networks》)在Zh-En上进行了比较,这是document-level翻译的SOTA的non-pretraining方法。它们结合了两层注意力:首先是在句子内部,然后是跨句子。- 对于
17.3.2 实验结果
下表显示了
En-De和Zh-En在sentence-level和document-level的主要结果:随机初始化
vs.预训练初始化:- 对于
sentence-level训练和document-level训练,用预训练权重初始化的机器翻译模型比随机初始化的机器翻译模型要好得多。 - 我们的
mBART25模型(Sent-MT和Doc-MT)也优于HAN,尽管Sent-MT和Doc-MT不是为document-level机器翻译而定制化的。
- 对于
Sent-MT vs. Doc-MT:对于En-De和En-Zh:mBART25 Doc-MT模型的表现超过了mBART25 Sent-MT。超出的绝对数值在
1.0分左右,不是特别多。相反,没有预训练的模型的趋势相反,即
Random Doc-MT模型的表现远远差于Random Sent-MT。对于这两个数据集,随机初始化的
Doc-MT未能发挥作用,导致其结果比sentence-level模型差得多。如此大的性能gap表明,预训练对document level的性能至关重要。一般而言,很难大量收集高质量的document level数据,这表明预训练可能是未来工作的一个强有力的策略。我们还在Figure 6中包括一个采样到的例子。

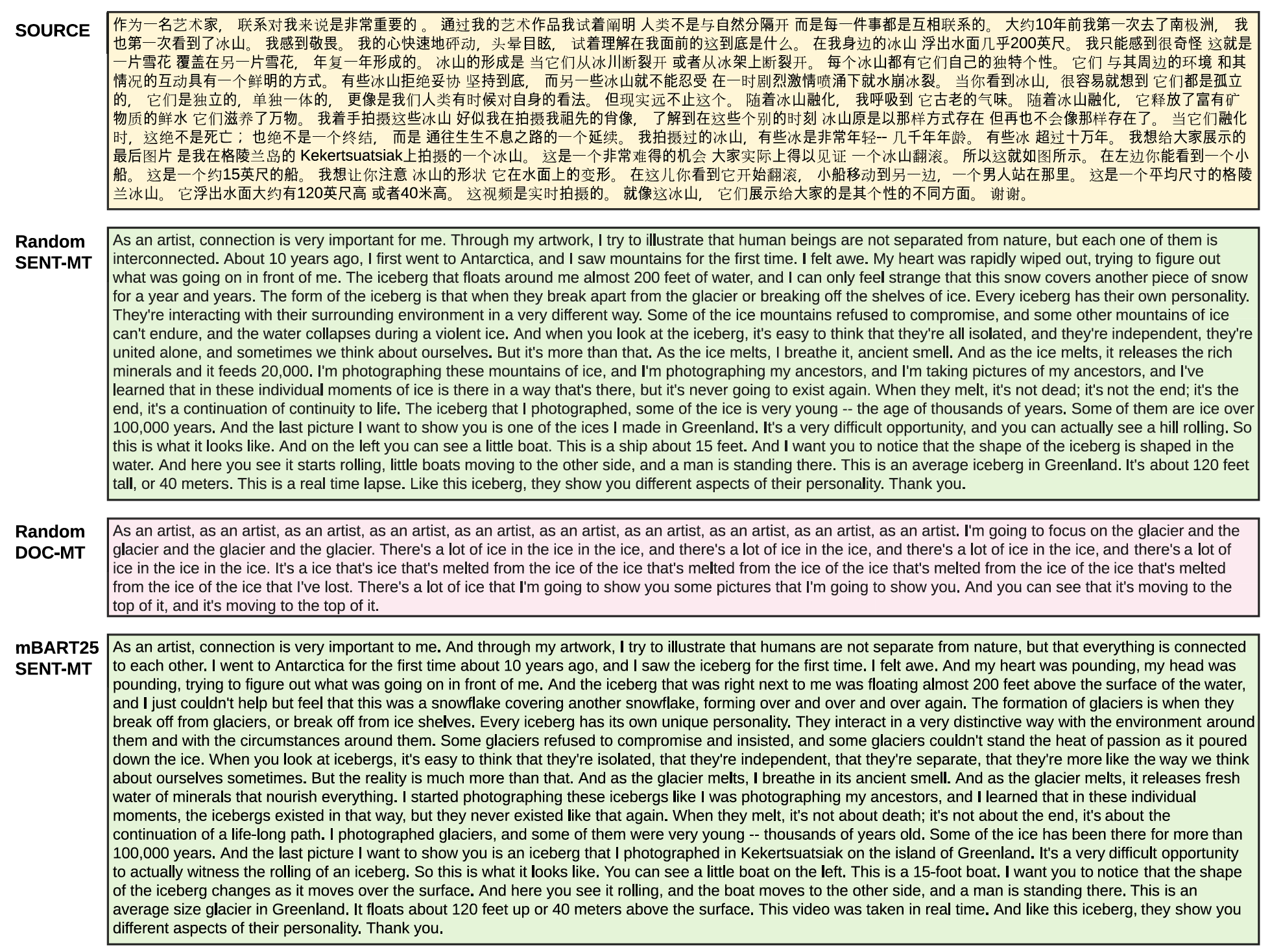
17.4 Unsupervised Machine Translation
除了有监督的机器翻译,我们还在对于
target language pair没有bi-text的任务上评估我们的模型。我们定义了三种类型的无监督翻译:没有任何类型的
bi-text:一个常见的解决方案是从back-translation中学习。我们表明,mBART为这些方法提供了一个简单而有效的初始化方案。即,这里只有单语语料。
对于
target language pair没有bi-text,但两种语言都出现在与其他pair的bi-text语料中:这种配置在多语言机器翻译系统中很常见。在本文中,我们将重点限制在为单个language pair建立模型,并将多语言机器翻译的讨论留给未来的工作。即,没有
A -> B的bi-text,但是有A -> C和D -> B的bi-text。注意,
A,B,C,D都在预训练语料中。没有
target pair的bi-text,但有从其他语言翻译成target language的bi-text:即使source language没有任何形式的bi-text,mBART也支持有效的迁移。即,没有
A -> B的bi-text,但是只有D -> B的bi-text,没有A的任何bi-text。注意,
A,B,D都在预训练语料中。
17.4.1 通过 Back-Translation 的无监督机器翻译
数据集:我们在
En-De、En-Ne和En-Si上评估我们的预训练模型。En和De都是共享许多子词subword的欧洲语言,而Ne和Si则与En完全不同。我们使用与监督学习相同的测试集,并使用相同的预训练数据(CC25)进行back-translation以避免引入新信息。只有
CC25如何进行back-translation?因为back-translation需要预先训练好一个翻译模型。而CC25没有bi-text来微调从而得到一个翻译模型。猜测是:不需要微调,用CC25预训练好的模型本身就可以充当一个翻译模型。学习:遵从
《Cross-lingual language model pretraining》(XLM)的做法,我们用mBART的权重初始化翻译模型,然后以source sentence(通过on-the-fly back-translation来生成)为条件来生成单语句子monolingual sentence(即,翻译为单语文本)。此外,对于on-the-fly back-translation的前面1000步,我们将mBART限制为仅生成target language的token,从而避免mBART复制source text。这里是没有任何类型的
bi-text的情形。结果:下表显示了与
non-pretrained模型、以及采用现有预训练方法的模型相比的无监督翻译结果。可以看到:- 我们的模型在所有方向上都比
non-pretrained模型取得了很大的进步。 - 对于不相似的
pair(En-Ne, En-Si), 我们的模型显著超越了XLM。在这些pair上,现有的方法完全失败。 - 对于
En-De,我们的模型与XLM和MASS相比也是相差无几的。
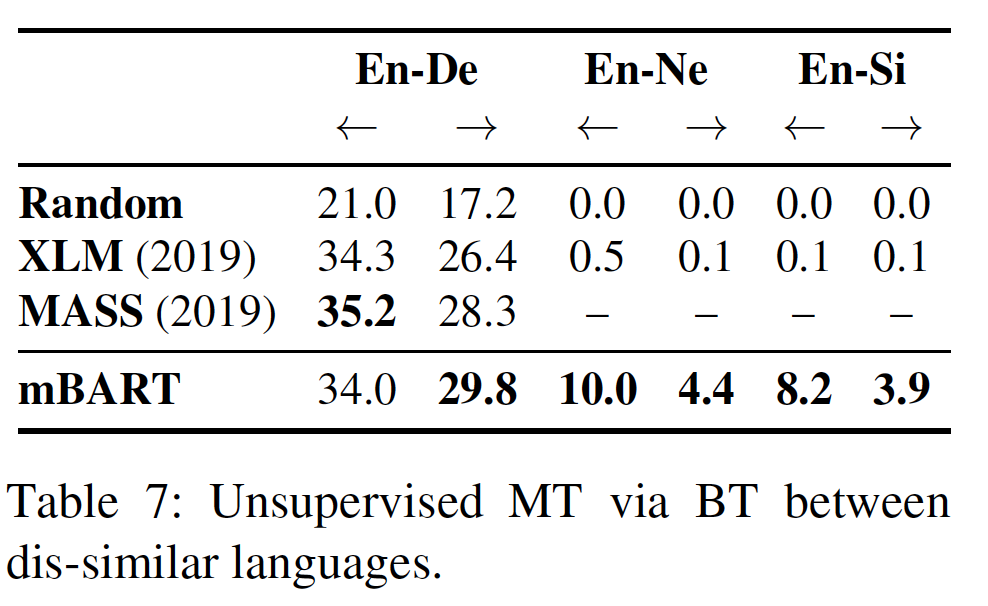
- 我们的模型在所有方向上都比
17.4.2 通过 Language Transfer 的无监督机器翻译
我们还报告了
target language与其他source language出现在bi-text中时的结果。即,没有
A -> B的bi-text,但是只有D -> B的bi-text,没有A的任何bi-text。数据集:我们只考虑
X -> En的翻译,并从监督学习的配置中选择了12种language pair的bi-text,包括Indic language(Ne, Hi, Si, Gu)、European language(Ro, It, Cs, Nl)、East Asian language(Zh, Ja, Ko)以及Arabic(Ar)。结果:如下表所示,预训练的
mBART25模型在每个language pair上进行了微调,然后在剩余language pair上进行了评估。我们还在对角线上展示了直接的微调性能,以供参考。可以看到:- 除了
Gu-En之外(最后一列),所有微调模型都能实现迁移,因为在Gu-En中,监督模型完全失败(0.3 BLEU)。 - 在某些情况下,我们可以取得与监督结果相似(
Cs-En,第四行)甚至更好的结果(Ne-En, Gu-En,倒数第三行和最后一行)。
我们还在下图中展示了一个语言迁移的例子。
作为对比,我们也在没有预训练的随机初始化模型上应用同样的程序,其结果总是约为
0 BLEU。这表明多语言预训练是非常重要的,它能产生跨语言的universal representation,因此一旦模型学会了将一种语言翻译成英语,它就能学会用类似的representation来翻译所有语言到英语。下图中,同一个浅色阴影块表示相同语系。
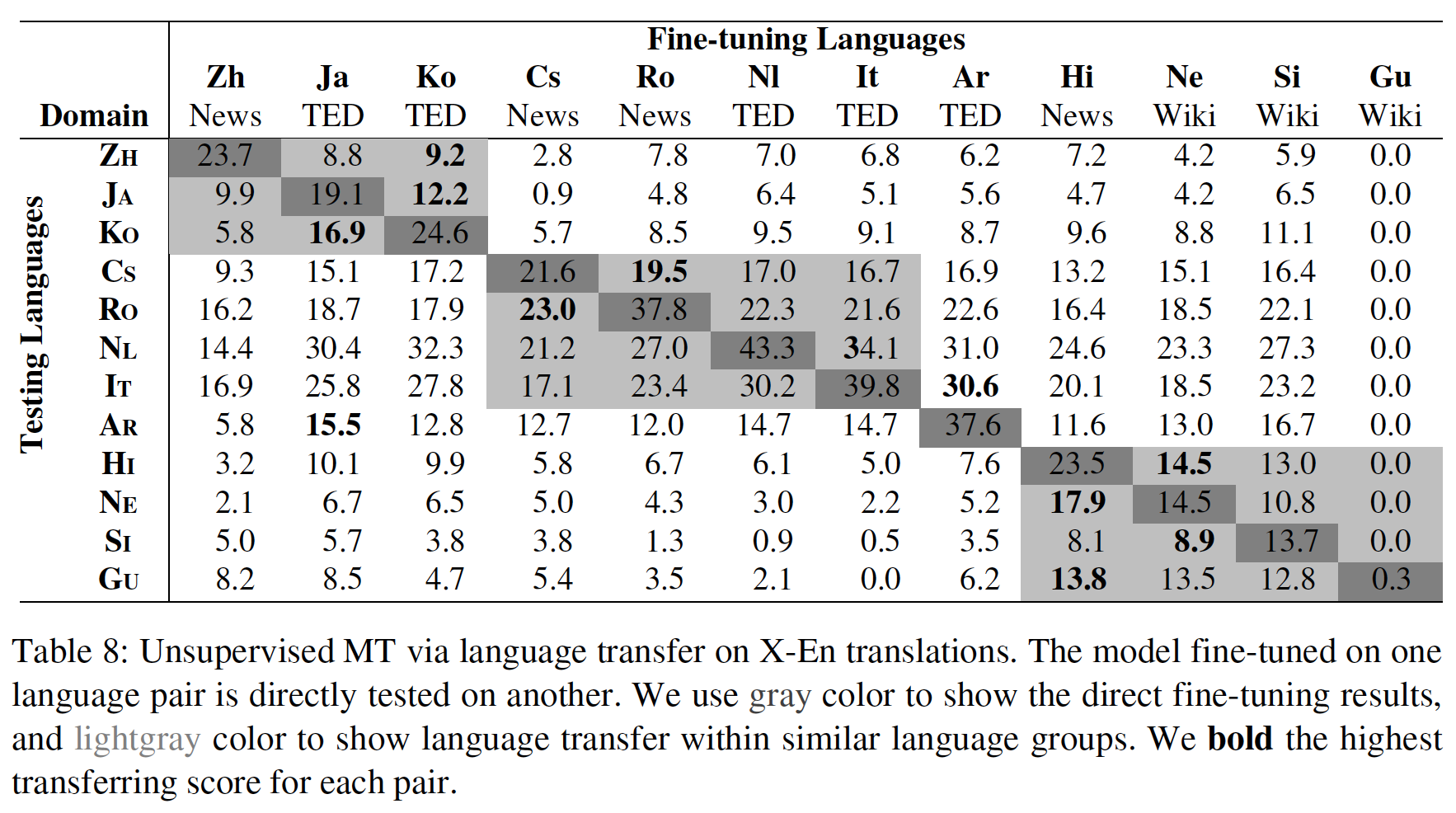

- 除了
什么时候
language transfer是有用的:Table 8还显示,迁移效应的大小随着不同语言的相似度而变化。- 首先,对于大多数语言对来说,当微调也是在同一语系
language family中进行时(浅色阴影块所示),语言迁移效果更好,特别是在Indic language(Hi, Ne, Gu)之间。 - 然而,显著的词表共享
vocabulary sharing并不是有效迁移的必要条件。例如,Zh-En(第一行)和It-En(第七行)分别从Ko-En和Ar-En上取得了最好的迁移学习效果。尽管(Zh,Ko)和(It,Ar)之间的词表重合度很低(甚至是字符重合度也很低)。
- 首先,对于大多数语言对来说,当微调也是在同一语系
使用
back-translation:我们在下表中比较了使用back-translation的无监督机器翻译vs.语言迁移的无监督机器。当有相近的语言翻译可以迁移时,语言迁移效果更好。此外,我们显示了结合这两种技术的有前景的结果。我们从最好的被迁移模型
transferred model开始,在预训练中使用的同一单语语料库上应用(迭代式的)back-translation。下表显示了back-translation的1轮迭代的结果。我们看到所有的language pair都有改进。对这两种方法的完整分析将作为未来的工作。