十八、SpanBERT [2019]
像
BERT这样的预训练方法已经显示出强大的性能收益,其中BERT使用自监督训练来掩码单个单词或单个子单词单元subword unit。然而,许多NLP任务涉及对两个或多个文本区间text span之间的关系进行推理。例如,在抽取式问答extractive question answering任务中,确定"Denver Broncos"是"NFL team"的一种类型,对于回答"Which NFL team won Super Bowl 50?"的问题至关重要。这样的span为自监督任务提供了更具挑战性的目标,例如,预测"Denver Broncos"相比已知下一个词是"Broncos"从而预测"Denver"要难得多。在论文《SpanBERT: Improving Pre-training by Representing and Predicting Spans》中,作者介绍了一种span-level的预训练方法,其性能一致地优于BERT,在span selection任务(如问答question answering任务、以及共指消解coreference resolution任务)中的收益最大。论文提出了一种预训练方法,即
SpanBERT,旨在更好地表示和预测文本的span。论文的方法在掩码方案和训练目标上都与BERT不同。- 首先,
SpanBERT掩码随机的contiguous span,而不是随机的单个token。 - 其次,
SpanBERT引入了一个新颖的区间边界目标span-boundary objective: SBO,使模型学会从span边界上观察到的token来预测整个masked span。
span-based masking迫使模型只使用该span的上下文来预测整个span。此外,SBO鼓励模型将这种span-level的信息存储在boundary token处。下图说明了SpanBERT的方法。SpanBERT的实现建立在BERT的一个精心调优的副本replica上,这个精心调优的BERT本身就大大超过了original BERT。在论文baseline的基础上,作者发现对单个segment进行预训练,而不是对two half-length segment进行next sentence prediction: NSP的目标,大大地提高了大多数下游任务的性能。因此,作者在调优后的single-sequence BERT baseline之上添加所提出的修改。总之,论文提出的预训练程序产生的模型在各种任务上的表现超过了所有的
BERT baseline,特别是在span selection任务上的性能得到了大幅提高。具体而言,SpanBERT在SQuAD 1.1和SQuAD 2.0上分别达到了94.6% F1和88.7% F1,与论文精心调优的BERT副本相比,误差减少了27%。作者还在另外五个抽取式问答benchmark(NewsQA, TriviaQA, SearchQA, HotpotQA, Natural Questions)上观察到类似的收益。对于
document-level共指消解,SpanBERT还在具有挑战性的CoNLL-2012 ("OntoNotes")共享任务上达到了新的SOTA,其中SpanBERT达到了79.6% F1,比之前的top model高出6.6%(绝对提升,而不是相对提升)。最后,论文证明SpanBERT对没有显式涉及span selection的任务也有帮助,并表明SpanBERT甚至提高了TACRED和GLUE的性能。虽然其它工作展示了添加更多数据(
《XLNet: Generalized autoregressive pretraining for language understanding》)和增加模型规模(《Cross-lingual language model pretraining》)的好处,但这项工作表明了设计良好的预训练任务和目标的重要性,其中预训练任务和目标也会产生显著的影响。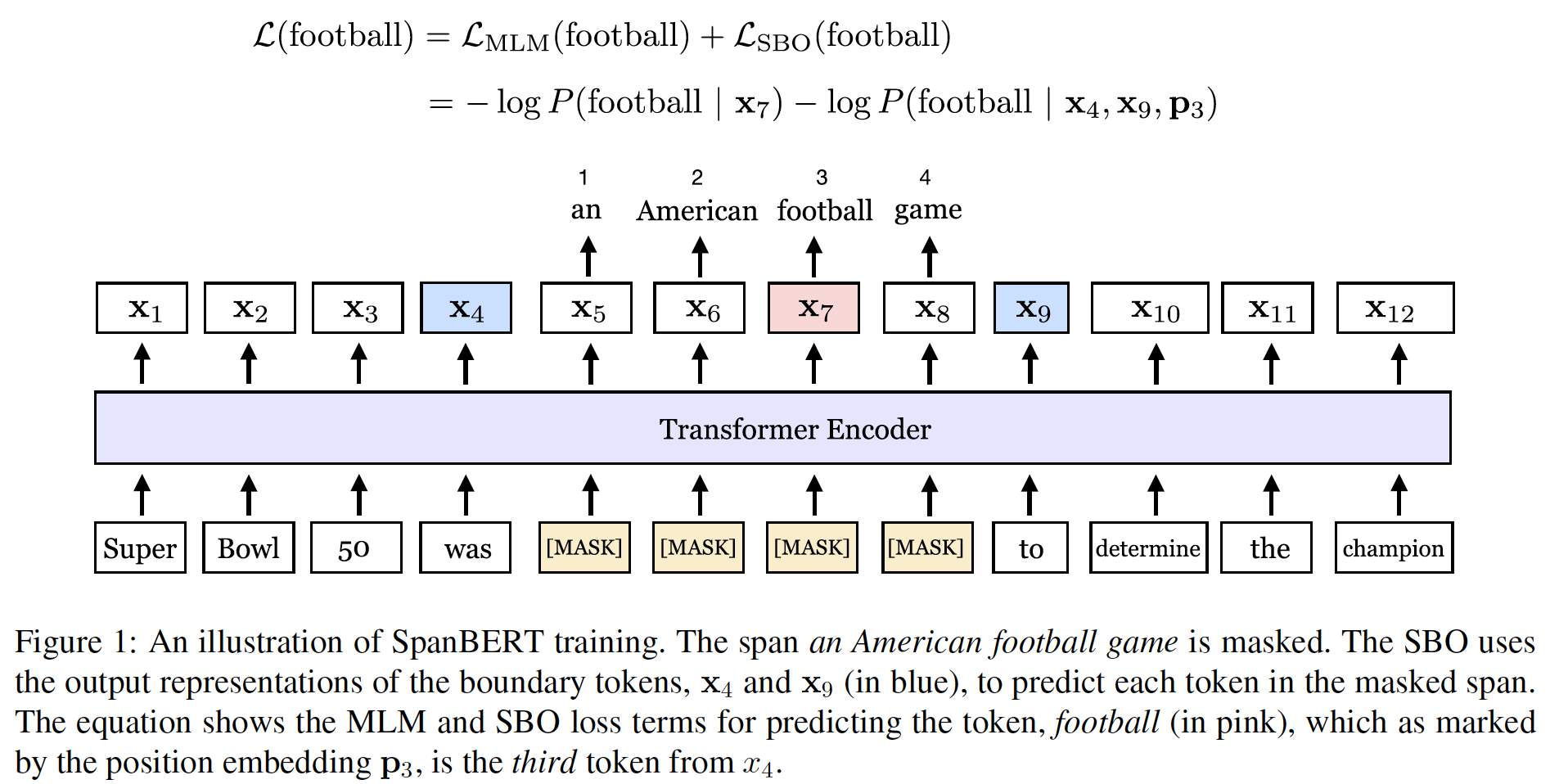
- 首先,
相关工作:无标签文本中训练的
pre-trained contextualized word representation最近对NLP产生了巨大的影响,特别是作为一种方法,用于针对特定任务在微调大模型之前先初始化该大模型。除了模型超参数和语料库的差异外,这些方法主要在其预训练任务和损失函数方面有所不同,相当多的当前文献提出了对BERT的MLM目标进行增强。虽然以前的、以及同时进行的工作已经研究了
masking(ERNIE)或dropping(MASS、KERMIT)输入中的多个单词,尤其是作为语言生成任务的预训练。但SpanBERT预训练span representation(《Learning recurrent span representations for extractive question answering》),这被广泛用于问答、共指消解、以及各种其他任务。ERNIE显示了使用phrase masking和named entity masking对中文NLP任务的改进。MASS专注于语言生成任务,并采用encoder-decoder framework,在给定句子剩余部分的情况下重建一个sentence fragment。
我们试图使用
SBO目标更显式地建模span,并表明(几何分布的)random span masking的效果与masking linguistically coherent span一样好,有时甚至比后者更好。我们在英语benchmark上评估了问答、关系抽取、以及共指消解,此外还有GLUE。此外:
- 一个不同的
ERNIE(《ERNIE: Enhanced language representation with informative entities》)专注于将结构化的知识库与contextualized representation相结合,着眼于entity typing和relation classification等知识驱动的任务。 UNILM使用多个语言建模目标:单向(包括left-to-right和right-to-left)、双向、以及sequence-to-sequence的预测,从而帮助摘要任务以及问题生成等生成任务。XLM为翻译和跨语言分类等多语言任务探索了跨语言预训练。Kermit是一种基于insertion的方法,在预训练期间填补missing token(而不是预测masked token),他们显示了在机器翻译和zero-shot问答上的改进。
- 一个不同的
与我们的工作同时:
RoBERTa提出了一个BERT预训练的副本研究replication study,衡量了许多关键超参数和训练数据大小的影响。同时,
XLNet结合了自回归损失和Transformer-XL架构,数据增加了8倍多,在多个benchmark上取得了目前的SOTA成果。XLNet在预训练期间也掩码了span(1-5个token),但对它们进行了自回归式的预测。我们的模型侧重于纳入span-based pretraining,作为一个副作用,我们提出了一个更强大的BERT baseline,在此同时控制了语料库、架构和参数规模。
有些工作与我们的
SBO目标相关。pair2vec(《pair2vec: Compositional word-pair embeddingsfor cross-sentence inference》)在预训练期间使用基于负采样的多变量目标multivariate objective来编码word-pair relation。然后,word-pair representation被注入下游任务的注意力层,从而编码了有限的下游上下文。与
pair2vec不同,我们的SBO目标产生"pair"(span的start token和end token)representation,在预训练和微调期间更充分地编码上下文,因此更合适被视为span representation。《Blockwise parallel decoding for deep autoregressive models》专注于使用block-wise parallel decoding scheme提高语言生成速度。他们并行地对多个时间步进行预测,然后退到由一个scoring model验证的最长前缀。与此相关的还有
sentence representation方法,这些方法侧重于从sentence embedding中预测周围上下文。
18.1 模型
18.1.1 BERT 简介
BERT是一种自监督的方法,用于预训练一个深层的transformer encoder,然后再针对特定的下游任务来进行微调。BERT优化了两个训练目标:掩码语言模型masked language model: MLM和下一句预测next sentence prediction: NSP。这两个训练目标只需要大量的无标记的文本集合。给定单词或子词
subword的一个序列BERT训练一个编码器,该编码器为每个token产生一个contextualized vector representation:MLM:MLM也被称为cloze test,它的任务是预测序列中的占位符placeholder所对应的missing token。具体而言,token的一个子集token集合所取代。在BERT的实现中,token的比例为的15%。在80%的token被替换为[MASK]、10%的token被替换为random token(根据unigram分布)、10%的token保持不变。任务是根据modified input来预测original token。BERT通过随机选择一个子集来独立地选择Y中的每个token。在SpanBERT中,我们通过随机选择contiguous span来定义NSP:NSP任务将两个序列BERT中是这样实现的:首先从语料库中读取序列这两个序列由一个特殊的
[SEP] token分开。此外,一个特殊的[CLS] token被添加到拼接序列(input,其中[CLS]的target是:总之,
BERT通过在双序列bi-sequence采样程序产生的数据中均匀地随机掩码word piece,同时优化了MLM和NSP目标。接下来,我们将介绍我们对data pipeline、掩码、以及预训练目标的修改。
18.1.2 SpanBERT
我们提出了
SpanBERT,这是一种自监督的预训练方法,旨在更好地表达和预测文本的span。我们的方法受到BERT的启发,但在三个方面偏离了BERT的bi-text classification framework:- 首先,我们使用不同的随机程序来掩码
span of tokens,而不是掩码单个token。 - 其次,我们还引入了一个新颖的辅助目标(即,
span-boundary objective: SBO),该目标试图仅使用span’s boundary的token的representation来预测整个masked span。 - 最后,
SpanBERT对每个训练实例采样单个contiguous segment(而不是两个),因此没有使用BERT的next sentence prediction目标。
- 首先,我们使用不同的随机程序来掩码
Span Masking:给定一个token序列span从而选择token的一个子集masking budget(例如,15%)耗尽。在每轮迭代中:- 首先,我们从一个几何分布
span length(token数量),该分布偏向于较短的span。 - 然后,我们随机地(均匀地)选择
masked span的起点。我们总是采样完整单词(而不是subword token)的序列,而且起点必须是一个完整单词的开头。
根据初步试验,我们设定
span length为span mask length的分布。几何分布
这里的
3.8的计算过程为:和
BERT一样,我们也掩码了总共15%的token,其中:80%的masked token用[MASK]替换、10%的masked token用random token替换、10%的masked token保持original token不变。然而,我们是在span-level进行这种替换,而不是对每个token独立地进行替换。也就是说,一个span中的所有token都被替换成[MASK]、random token、或者保持不变。平均序列长度为
3.8/0.15=25.3。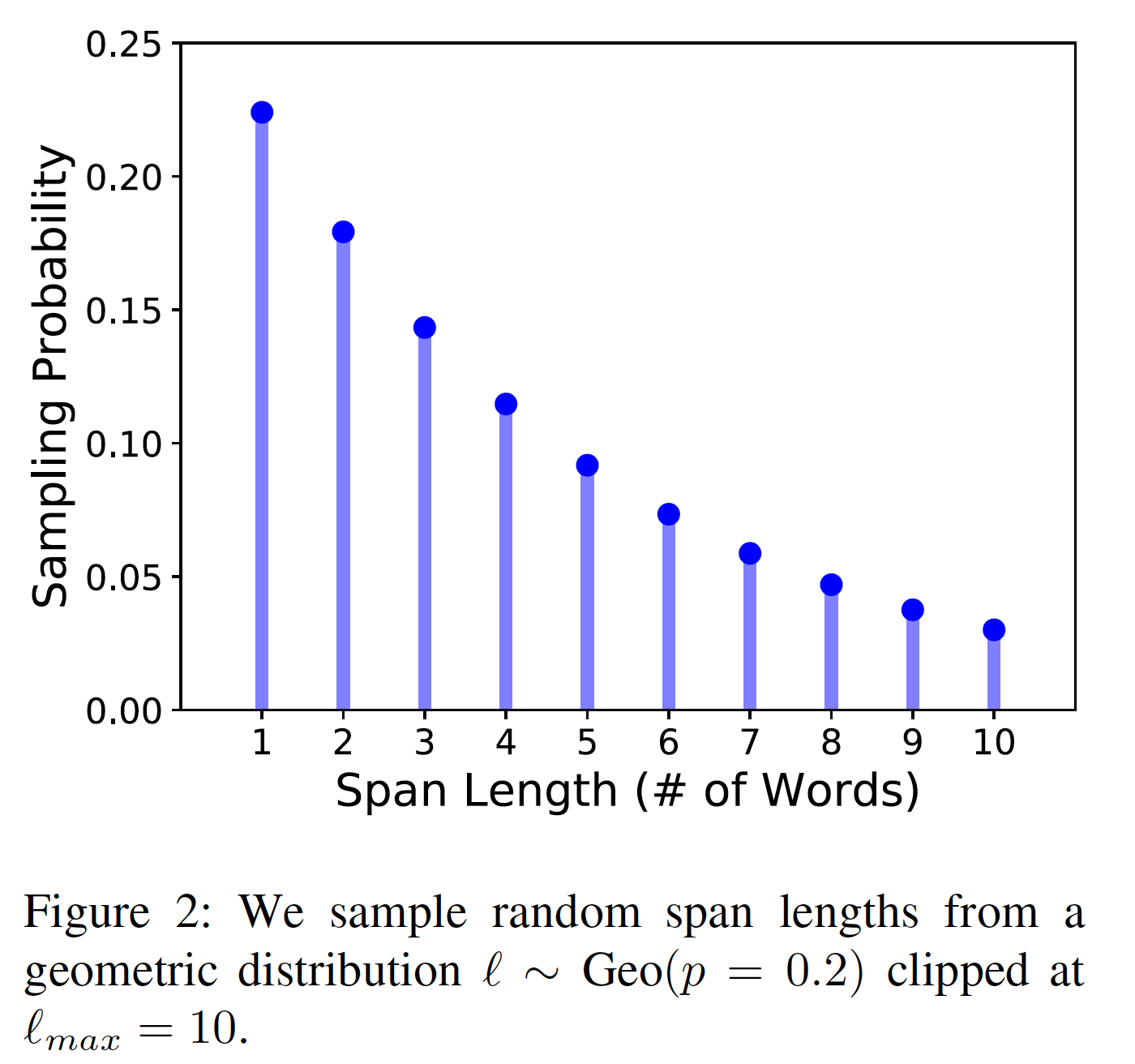
- 首先,我们从一个几何分布
Span Boundary Objective:span selection model通常使用span boundary tokens(开始和结束)创建一个固定长度的representation。为了支持这样的模型,我们希望end of span的representation能够尽可能多地总结internal span content。我们通过引入一个span boundary objective来做到这一点,该目标涉及仅仅使用span边界上所观察到的token的representation来预测masked span的每个token。正式地,我们用
token的transformer encoder的输出。给定一个由tokenmasked span,其中masked span的开始位置和结束位置(即,两个端点),我们使用外部的boundary tokentarget token的position embeddingspan中的每个token注意,在
BERT的MLM目标中,隐式地用到了target token的position信息(通过在[MASK] token的token embedding上添加positional embedding)。其中:
position embeddingmasked token相对于left boundary token注意,
BERT采用了absolute positional embedding,而这里是relative positional embedding,因此SpanBERT需要两套positional embedding。我们将
representation functionGeLU激活函数 和layer normalization的两层前馈神经网络:其中:
然后我们使用
vector representationtokenMLM目标一样。SpanBERT对masked spantokenSBO损失函数和常规的MLM损失函数进行求和,同时对MLM和SBO为target token复用input embedding:MLM目标利用了所有unmasked token作为上下文,而SBO仅使用boundary token作为上下文,因此理论上MLM的信息更丰富。SBO迫使模型更关注boundary token,是MLM的一种特殊的case,所以是否可以泛化MLM从而支持SBO?Single-Sequence Training:如前所述,BERT的样本包含两个文本序列next sentence prediciton: NSP目标。我们发现,这种setting几乎总是比简单地使用没有NSP目标的单一序列要差。我们猜想,单序列训练single-sequence training优于带有NSP的双序列训练bi-sequence training,有两个原因:- 在单序列训练中,模型从较长的
full-length上下文中获益。 - 在双序列上下文中,以另一个文档中的、通常不相关的上下文为条件,会给
MLM增加噪音。
因此,在我们的方法中,我们取消了
NSP目标和two-segment采样程序,而只是简单地采样单个contiguous segment直到token,而不是两个half-segment加起来token。- 在单序列训练中,模型从较长的
总之,
SpanBERT通过以下方式预训练span representation:- 使用基于几何分布的掩码方案来掩蔽
full word的span。 - 除了使用单序列
data pipeline的MLM之外,还优化了一个辅助的span-boundary objective: SBO。
预训练程序如下:
将语料库划分为单个的、长度为
512 token的contiguous block。在预训练的每个
step:- 均匀随机地采样
block的一个batch。 - 基于
span masking方案对每个block掩码15%的word piece。 - 对每个
masked token
- 均匀随机地采样
- 使用基于几何分布的掩码方案来掩蔽
18.2 实验
18.2.1 任务
我们对一组任务进行了评估,包括问答任务(七个)、共指消解任务、
GLUE benchmark中的任务(九个)、以及关系抽取任务。我们预期,span selection任务、问答、以及共指消解,将特别受益于我们的span-based预训练。抽取式问答
Extractive Question Answering:给定一个短的文本段落和一个问题作为输入,抽取式问答任务是选择文本段落中连续的一个text span作为答案。我们首先在
SQuAD 1.1和SQuQD 2.0上进行评估,它们一直是主要的问答任务benchmark,尤其是对于预训练模型。我们另外还在
MRQA共享任务的五个数据集上进行评估:NewsQA、SearchQA、TriviaQA、HotpotQA、Natural Questions。由于MRQA共享任务没有公开的测试集,我们将验证集一分为二,构建为新的验证集和测试集。这些数据集在领域domain和收集方法上都有所不同,这使得这些数据集成为一个很好的测试平台,用于评估我们的预训练模型是否能在不同的数据分布中很好地进行泛化。遵从
BERT,我们对所有的数据集使用相同的QA模型架构:首先,我们将段落
然后,我们将序列
pre-trained transformer encoder,并在其之上独立训练两个线性分类器,用于预测answer span boundary(开始点和结束点)。对于
SQuAD 2.0中的不可回答的问题,我们只需将answer span设置为[CLS]这个special token(即,开始点和结束点都是0)。
共指消解
Coreference Resolution:共指消解是对文本中的mention进行聚类的任务,这些mention引用相同的现世界实体。我们对CoNLL-2012共享任务进行了评估,用于document-level的共指消解。我们使用《BERT for coreference resolution: Baselines and analysis》的高阶共指模型higher-order coreference model(《Higher-order coreference resolution with coarse-to-fine inference》)的独立版本实现。文档被划分为预定义长度的non-overlapping segment。每个segment由预训练的transformer encoder独立编码,它取代了原来的LSTM-based encoder。对于每个mention spanantecedent span集合span pair评分函数span representation、以及其中:
span,它包含多个连续的token;span,它也包含多个连续的token。span representation。一个span representation是span两个端点所对应的两个transformer output state、以及一个attention vector(它在当前span种所有token的output representation上计算而来)的拼接。speaker和题材的信息)。
span的交互,span的bias。关系抽取
Relation Extraction:TACRED是一个具有挑战性的关系抽取数据集。给定一个句子和其中的两个span(主语和宾语),任务是从42种预定义的关系类型中预测span之间的关系,包括no relation。我们遵循
《Position-aware attention and supervised data improve slot filling》的entity masking方案,用他们的NER tag替换主语实体和宾语实体,如"[CLS] [SUBJ-PER] was born in [OBJ-LOC] , Michigan, . . . ",最后在[CLS] token之上添加一个线性分类器来预测关系类型。GLUE:General Language Understanding Evaluation: GLUE基准包括九个sentence-level分类任务:两个
sentence-level分类任务,包括:CoLA:用于评估语言可接受性linguistic acceptability。SST-2:用于情感分类sentiment classification。
三个
sentence-pair similarity任务,包括:MRPC,一个二元转述任务binary paraphrasing task,其中sentence pair来自于新闻。STS-B,一个分级的相似性graded similarity task任务,其中sentence pair来自于新闻标题。QQP,一个二元转述任务binary paraphrasing task,其中sentence pair来自于Quora question pair。
四个自然语言推理任务,包括
MNLI, QNLI, RTE, WNLI。
与问答、共指消解和关系抽取不同,这些
sentence-level任务不需要显式建模span-level语义。然而,它们仍然可能受益于隐式的span-based推理(例如,首相Prime Minister是政府首脑)。遵从之前的工作,我们将WNLI排除在结果之外,以便进行公平比较。虽然最近的工作《Multi-task deep neural networks for natural language understanding》应用了几个task-specific策略来提高单个GLUE任务的性能,但我们遵循BERT的单任务设置,仅仅这些分类任务的[CLS] token之上添加了一个线性分类器。
18.2.2 实现
我们在
fairseq中重新实现了BERT的模型和预训练方法。我们使用了BERT_large的模型配置,也在相同的语料库上(即,BooksCorpus和English Wikipedia,使用带大小写的Wordpiece token)预训练了我们所有的模型。与原始的
BERT实现相比,我们的实现的主要区别包括:我们在每个
epoch中使用不同的掩码(即,动态掩码),而BERT在数据处理期间为每个序列采样10个不同的掩码。我们删除了之前使用的所有短序列策略,这些短序列策略包括(被
BERT所采用):- 以
0.1的小概率采样较短的序列。 - 首先在前
90%的训练步中以128的较短序列进行预训练,然后在剩下的10%的训练步中以正常序列长度进行预训练。
取而代之的是,我们总是采用高达
512 token的序列,直到序列到达一个文档边界。- 以
关于这些修改及其影响,我们请读者参考
RoBERTa原始论文的进一步讨论。与
BERT一样,学习率在前10K步中被预热到1e-4的峰值,然后线性衰减。我们采用了0.1的decoupled weight decay(《Decoupled weight decay regularization》)。我们还在所有层和注意力权重上采用0.1的dropout,以及GeLU激活函数。我们采用AdamW优化器,其中epsilon = 1e-8,迭代2.4M步。我们的实现使用batch size = 256,序列最大长度为512 token。传统的
weight decay:weight decay系数。在常规SGD的情况下,weight decay等价于L2正则化。但是,在
Adam等方法中,L2正则化与weight decay并不等价。因此人们提出decoupled weight decay从而用于Adam等方法。预训练是在
32个Volta V100 GPU上进行的,花了15天时间完成。微调是基于HuggingFace的代码库实现的,更多的微调细节如下:抽取式问答:对于所有的问答任务,我们使用
max_seq_length = 512,以及一个大小为128的滑动窗口(如果序列长度大于512)。对于所有的数据集,我们调优的学习率范围是:
{5e-6, 1e-5, 2e-5, 3e-5, 5e-5};调优的batch size范围是:{16, 32};微调四个epoch。共指消解:我们将文档划分为多个块
chunk,每个块的长度为max_seq_length并且独立地编码每个块。对于所有的数据集,我们调优的
max_seq_length范围是:{128, 256, 384, 512};调优的BERT学习率范围是:{1e-5, 2e-5};调优的task-specific学习率范围是:{1e-4, 2e-4, 3e-4};微调20个epoch。我们使用
batch size = 1(每次一篇文档)。TACRED/GLUE:对于所有数据集,我们使用max_seq_length = 128,调优的学习率范围是:{5e-6, 1e-5, 2e-5, 3e-5, 5e-5};调优的batch size范围是:{16, 32};微调10个epoch。唯一的例外是
CoLA数据集,我们为它微调4个epoch,因为10个epoch会导致严重的过拟合。
18.2.3 Baseline
我们将
SpanBERT和如下三个baseline进行比较:Google BERT:由《BERT: Pre-training of deep bidirectional transformers for language understanding》发布的预训练模型。Our BERT:我们重新实现的BERT,其中改进了数据预处理和优化过程(如,动态掩码,废除短序列策略)。OurBERT-1seq:我们重新实现的另一个版本的BERT,其中在单个full-length序列上训练而没有NSP任务。
18.2.4 实验结果
Extractive Question Answering:下表展示了在SQuAD 1.1和SQuAD 2.0上的实验结果。SpanBERT分别比Our BERT高出2.0% F1和2.8% F1,比Google BERT高出3.3% F1和5.4% F1。在SQuAD 1.1中,SpanBERT超出人类性能3.4% F1。此外,
OurBERT-1seq > Our BERT > Google BERT。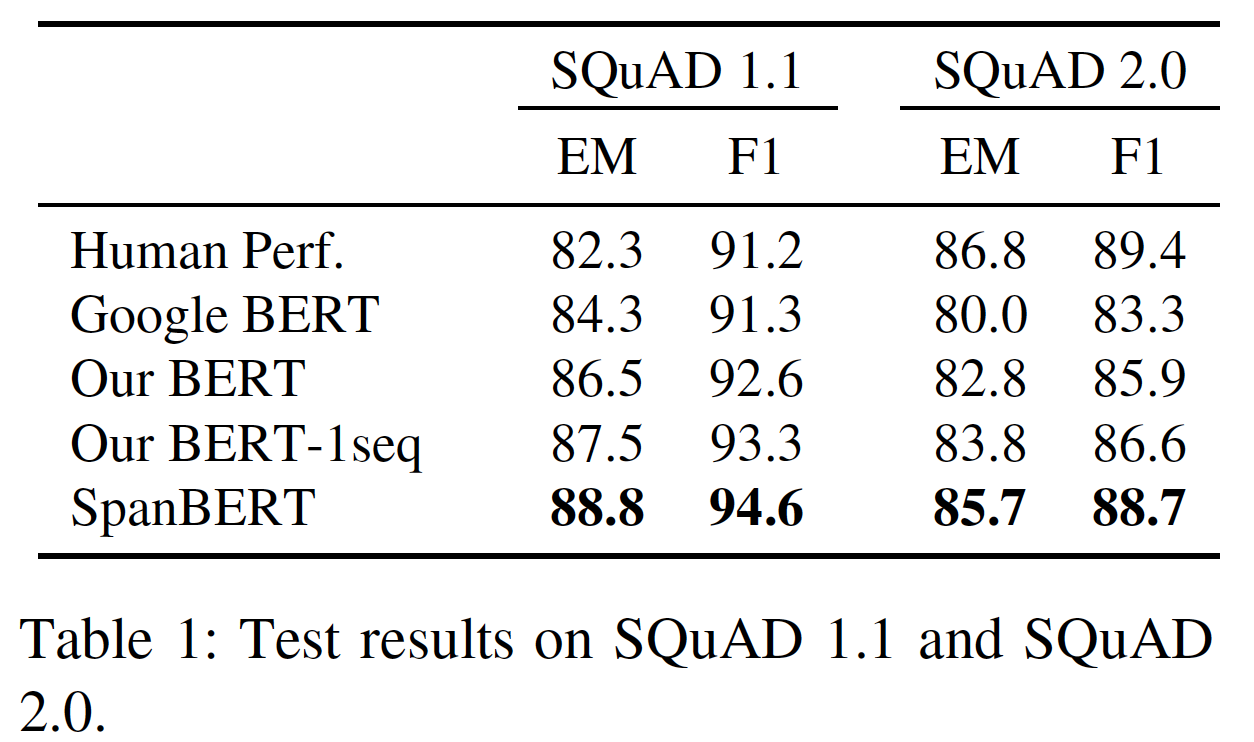
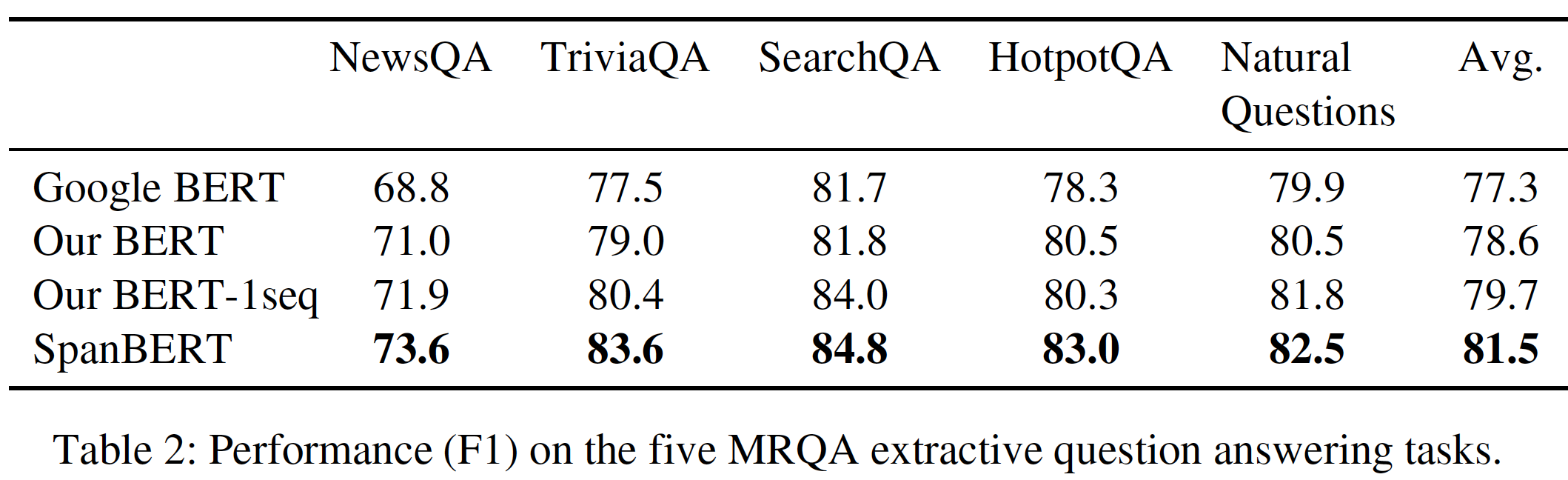
下表表明,这一趋势不仅在
SQuAD上成立,在每个MRQA数据集上也成立。可以看到:- 平均而言,我们看到
SpanBERT超越了Our BERT高达2.9%,尽管其中的一些改进来自于single-sequence training(+1.1%),但大部分改进来自于span masking和span boundary objective(+1.8%)。 - 此外,
SpanBERT在TriviaQA和HotpotQA上相对于Our Bert-1seq有特别大的改进,分别高达+3.2%和+2.7%。这意味着span masking和span boundary objective起到了重要作用。
- 平均而言,我们看到
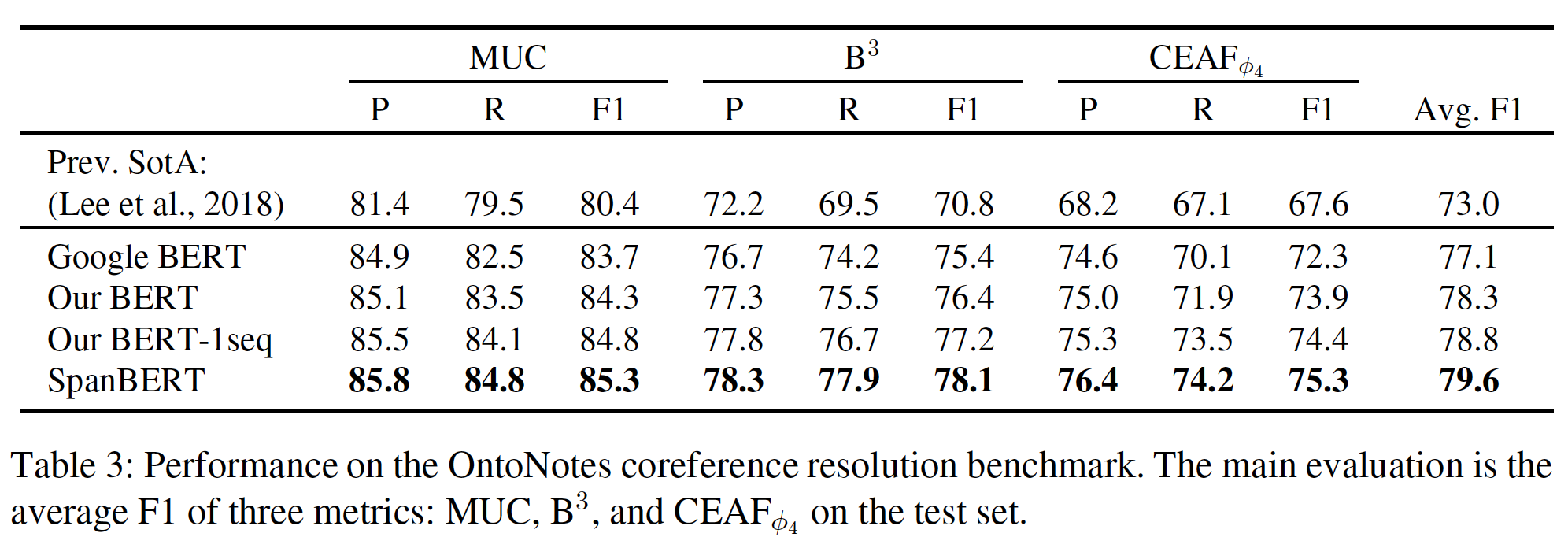
Coreference Resolution: 下表显示了OntoNotes共指消解benchmark上的实验结果。可以看到:- 平均而言,
Our BERT相比Google BERT提高了1.2% F1,而single-sequence training(即,Our BERT-1seq)相比于Our BERT又带来了0.5%的收益。 SpanBERT在Our BERT-1seq的基础上又有了很大的提高,达到了一个新的SOTA结果79.6% F1(之前的SOTA结果是73.0%)。
- 平均而言,
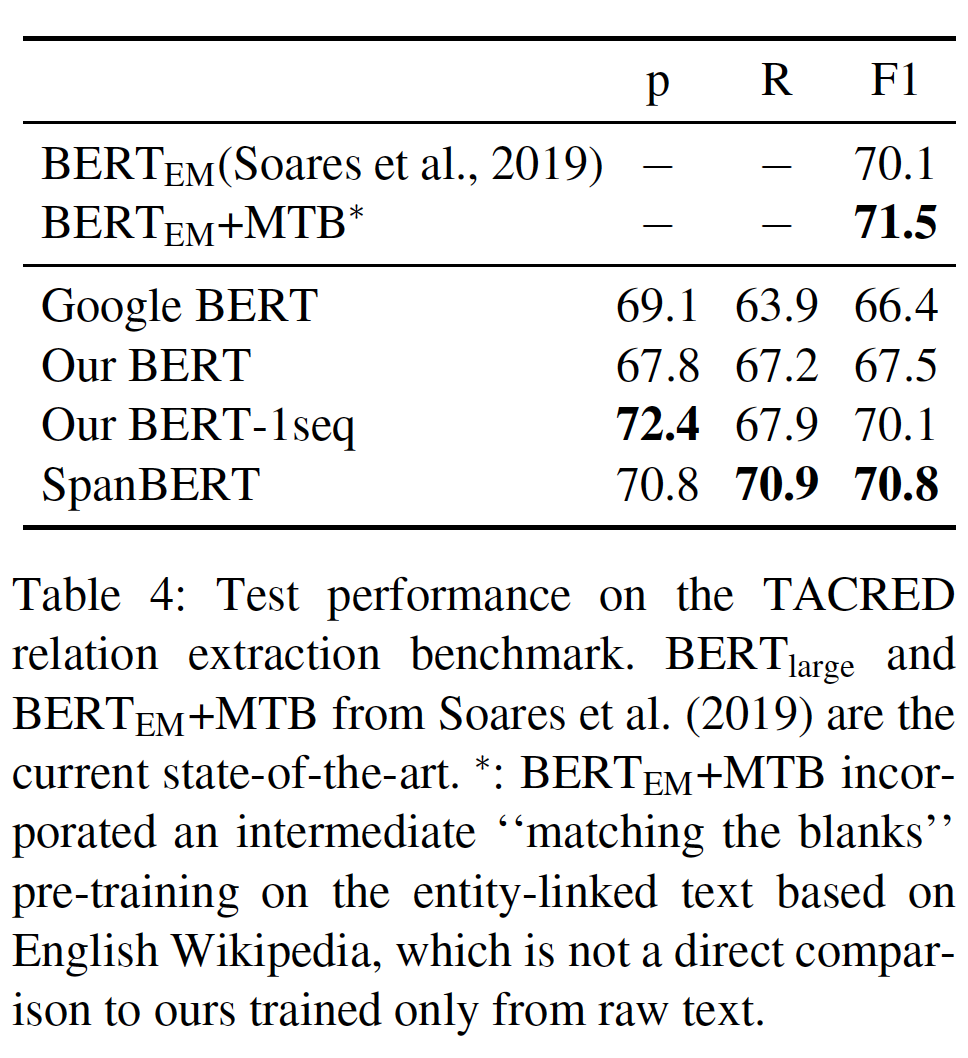
Relation Extraction:下表显示了TACRED上的实验结果。可以看到:SpanBERT比Our BERT高出3.3% F1,并接近目前的SOTA。SpanBERT比他们的BERT_EM表现更好,但比BERT_EM + MTB差0.7分,后者使用entity-linked text进行额外的预训练。SpanBERT超出Our BERT的增益的大部分(+2.6% F1)来自于single-sequence training,尽管span masking和span boundary objective的贡献也是可观的 (0.7% F1)。而span masking和span boundary objective的贡献主要来自于更高的召回率(即R列)。single-sequence training的贡献主要来自于更高的precision。
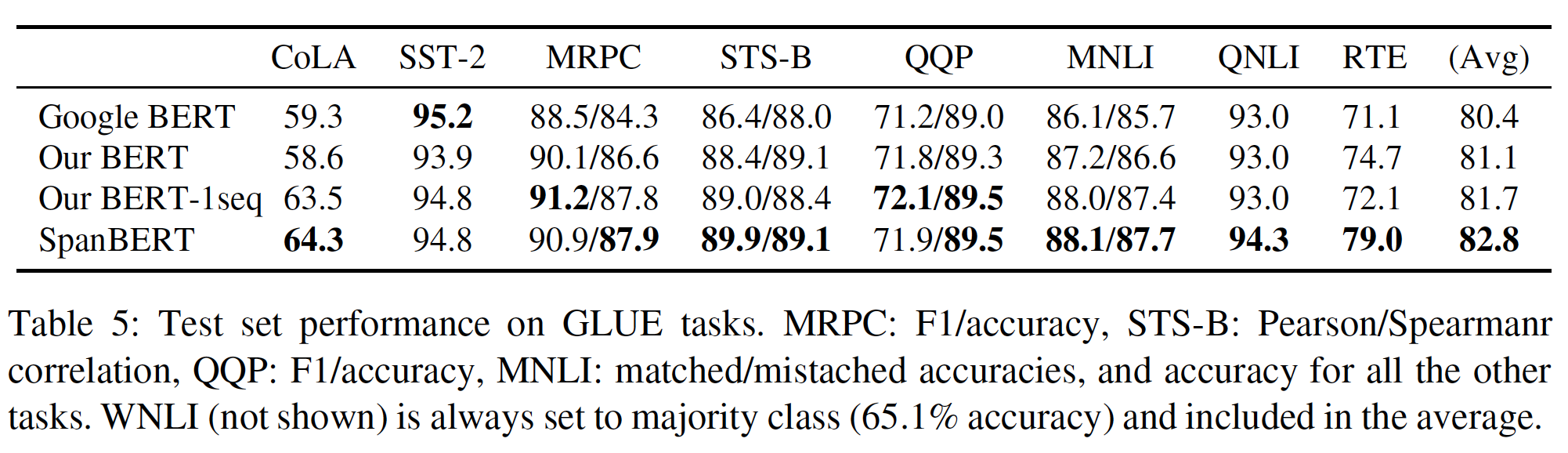
GLUE:下表展示了GLUE上的实验结果。可以看到:- 对于大多数任务,不同的模型似乎表现相似。
- 没有
NSP目标的single-sequence training大大改善了CoLA,并在MRPC和MNLI上产生了较小(但是仍然可观)的改善。 SpanBERT的主要收益是在QNLI数据集(+1.3%,它基于SQuAD)、以及RTE数据集(+6.9%),后者是SpanBERT的GLUE平均分上升的主要原因。
总体趋势:我们在
17个benchmark上将我们的方法与三个BERT版本进行了比较,发现SpanBERT在几乎每个任务上都优于BERT。- 在
14项任务中,SpanBERT的表现优于所有baseline。 - 在两项任务(
MRPC和QQP)中,SpanBERT的准确率与single-sequence训练的BERT相当,但仍优于其他baseline。 - 在一项任务(
SST-2)中,Google BERT比SpanBERT的准确率高0.4%。
当考虑到增益的大小时,似乎
SpanBERT在抽取式问答方面特别好。例如:- 在
SQuAD 1.1中,我们观察到2.0% F1的增益,尽管baseline已经远远高于人类的表现。 - 在
MRQA中,SpanBERT在Our BERT的基础上提高了从2.0% F1(Natural Questions)到4.6% F1(TriviaQA)。
最后,我们观察到,在各种任务中,
single-sequence training比带有NSP的bi-sequence training,在效果上要好得多。这是令人惊讶的,因为BERT的消融研究显示了来自NSP目标的收益。然而,消融研究仍然涉及bi-sequence的数据处理(即,预训练阶段只控制NSP目标,同时仍然采样两个half-length的序列)。我们猜测:bi-sequence training,正如它在BERT中实现的那样,阻碍了模型学习较长距离的特征,并因此损害了许多下游任务的性能。- 在
18.2.5 消融研究
我们将我们的
random span masking方案与linguistically-informed masking方案进行比较,发现masking random span是一种有竞争力的、并且通常是更好的方法。然后,我们研究了SBO的影响,并将其与BERT的NSP目标进行对比。掩码方案:以前的工作
ERNIE表明,在中文数据的预训练中,通过掩码linguistically informed span,改善了下游任务的表现。我们将我们的random span masking方案与linguistically informed span掩码进行比较。具体而言,我们训练了以下五种baseline模型,它们的区别仅仅在于token的掩码方式:Subword Tokens:我们采样随机的Wordpiece token,就像在original BERT中一样。Whole Words:我们采样随机的单词,然后掩码这些单词中的所有subword token。masked subword token总共占所有token的15%。Named Entities:在50%的时间里,我们从文本中采样命名实体,而在剩下50%的时间里随机采样全词whole word。masked subword token总共占所有token的15%。具体而言,我们在语料库上运行
spaCy的named entity recognizer,并选择所有非数值型的命名实体作为候选。Noun Phrases:与Named Entities类似,我们在50%的时间内采样名词短语。名词短语是通过spaCy’s constituency parser抽取的。Geometric Spans:我们从几何分布中随机采样span,如我们的SpanBERT所示。
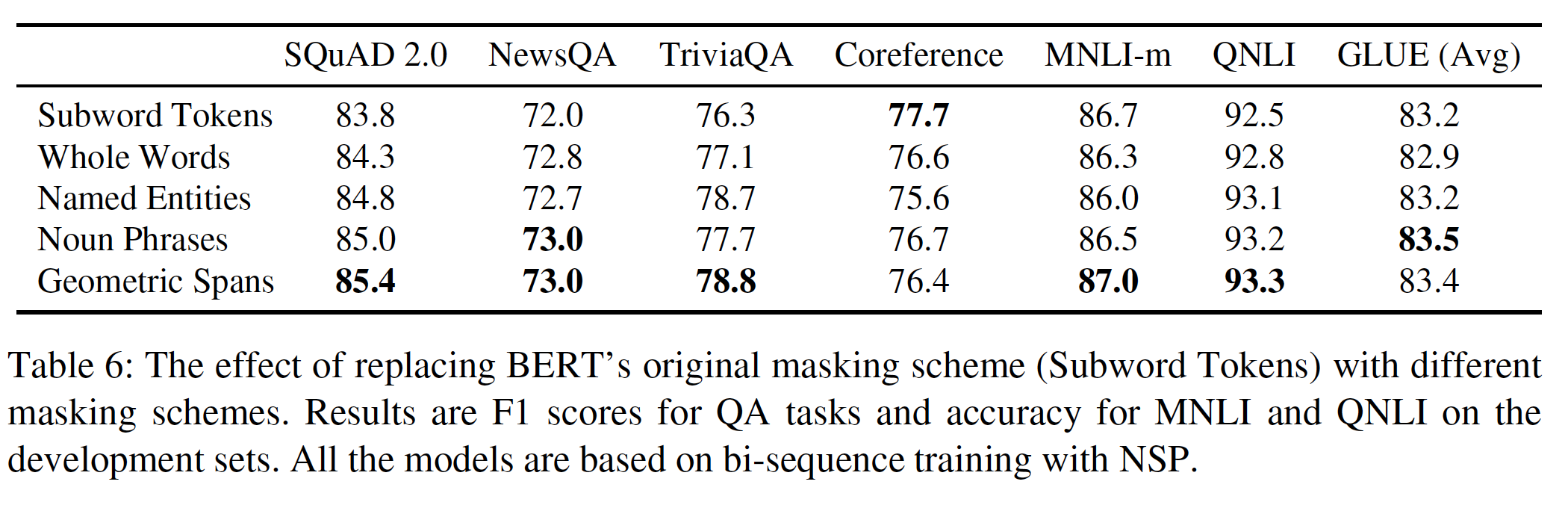
Whole Words, Named Entities, Noun Phrases, Geometric Spans都是span-based掩码策略。下表显示了不同的预训练掩码方案在不同任务验证集上的效果。所有的模型都是在验证集上评估的,并且是基于默认的
BERT设置(即带NSP的bi-sequence training),其结果不能直接与main evaluation相比较。可以看到:除了共指消解之外,
masking random span比其他策略更好。尽管
linguistic masking方案(命名实体和名词短语)通常与random span的竞争力相当,但它们的性能并不是一致consistent的。例如,在NewsQA上,masking noun phrase实现了与random span相同的效果,但在TriviaQA上表现不佳(-1.1% F1)。在共指消解方面,
masking random subword token比任何形式的span masking都要好。然而,我们将在下面的实验中看到,将random span masking与span boundary objective相结合可以大大改善这一结果。
总体而言,这些掩码方案的差距不大。
辅助目标:如前所述,与
single-sequence training相比,带NSP目标的bi-sequence training会损害下游任务的性能。 我们测试了这一点对于用span masking预训练的模型是否成立,同时也评估了用SBO目标替代NSP目标的效果。下表证实了
single-sequence training通常会提高性能。加入SBO可以进一步提高性能,与span masking alone相比,共指消解有很大的提高(+2.7% F1)。不像NSP目标,SBO似乎没有任何不利影响。SBO对模型性能提升的幅度不大,同时Geometric Spans对模型性能提升的幅度也不大,但是SpanBERT整体相对于Google BERT的性能提升较大。这意味着数据预处理和优化过程(如,动态掩码,废除短序列策略)的影响也较大。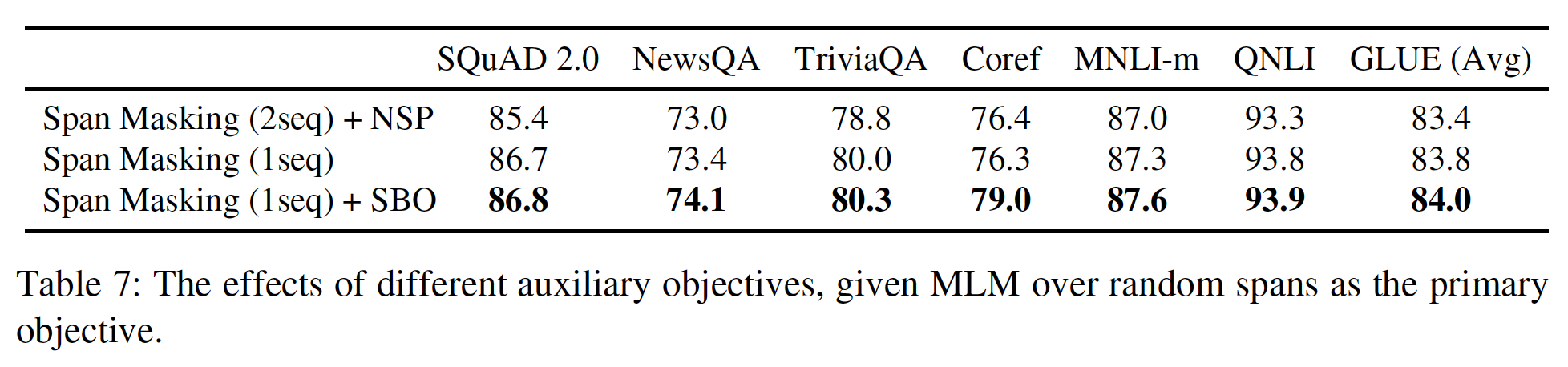
十九、ALBERT [2019]
全网络预训练
full network pre-training已经导致了language representation learning的一系列突破。许多困难的NLP任务,包括那些训练数据有限的任务,都大大受益于这些预训练的模型。这些突破之中最引人注目的标志之一是机器在RACE test上(为中国初中和高中英语考试设计的阅读理解任务)的性能演进:- 最初描述该任务并提出
modeling challenge的论文报告了当时SOTA的机器准确率为44.1%。 - 最新发表的结果(即
RoBERTa)报告了他们的模型性能为83.2%。 - 论文
《A Lite BERT for Self-supervised Learning of Language Representations》提出的ALBERT将其推高到89.4%,达到一个惊人的45.3%的改进,这主要归功于我们目前建立高性能预训练的language representation的能力。
这些改进的证据显示,大型网络对于实现
SOTA的性能至关重要。预训练大型模型并将其蒸馏成较小的模型,这种做法已成为实际应用的普遍做法。鉴于模型规模的重要性,我们问:拥有更好的NLP模型和拥有更大的模型一样容易吗?回答这个问题的一个障碍是现有硬件的内存限制。鉴于目前
SOTA的模型往往有数亿甚至数十亿的参数,当我们试图扩大我们的模型规模时,很容易就会遇到这些限制。在分布式训练中,训练速度也会受到很大影响,因为通信开销与模型中的参数规模成正比。上述问题的现有解决方案包括模型并行
model parallelization、以及巧妙的内存管理。这些解决方案解决了内存限制问题,但没有解决通信开销问题。在论文《A Lite BERT for Self-supervised Learning of Language Representations》中,作者通过设计A Lite BERT: ALBERT架构来解决上述所有问题,该架构的参数明显少于传统的BERT架构。ALBERT采用了两种参数缩减parameter reduction技术,解除了scale预训练模型的主要障碍:- 第一个技术是因子分解的
embedding parameterization。通过将大型词表的embedding matrix分解成两个小矩阵,论文将隐层的维度与vocabulary embedding的维度分离。这种分离使得在不显著增加vocabulary embedding的参数规模的情况下,更容易增长隐层的维度。 - 第二种技术是跨层参数共享
cross-layer parameter sharing。这种技术可以防止参数随着网络的深度而增长。
这两种技术都大大减少了
BERT的参数数量而不严重损害性能,从而提高了参数效率。配置类似于BERT-large的ALBERT的参数数量减少了18倍,训练速度可以提高约1.7倍。参数缩减技术也作为一种正则化的形式,稳定了训练并有助于泛化。为了进一步提高
ALBERT的性能,作者引入了一个自监督的损失用于sentence-order prediction: SOP。SOP主要关注句子间的连贯性,旨在解决original BERT中提出的next sentence prediction: NSP损失的无效性。由于这些设计决策,论文能够扩展到更大的
ALBERT配置,这些配置的参数仍然比BERT-large更少,但是性能更好。论文在著名的GLUE、SQuAD和RACE等自然语言理解benchmark上建立了新的SOTA结果。具体而言,ALBERT将RACE的准确率提高到89.4%、将GLUE benchmark提高到89.4%、将SQuAD 2.0的F1得分提高到92.2。虽然准确率更高,但是训练时间要长三倍。
- 最初描述该任务并提出
相关工作:
为自然语言
scale up representation learning:学习自然语言的representation已被证明对广泛的NLP任务有用,并被广泛采纳。过去两年中最重要的变化之一是,从预训练word embedding(无论是标准的、还是上下文contextualized的),都转变为全网络预训练full-network pre-training,然后再紧跟着进行task-specific的微调。在这个工作方向,通常显示较大的模型规模可以提高性能。例如,BERT原始论文表明:在三个自然语言理解任务中,使用更大的隐层维度、更多的隐层和更多的注意力头总是能带来更好的性能。然而,他们止步于1024的隐层维度,可能是因为模型规模和计算成本的问题。即,
BERT_LARGE的性能比BERT_BASE的性能更好。由于计算上的限制,特别是
GPU/TPU内存的限制,很难对大型模型进行实验。鉴于目前SOTA的模型往往有数亿甚至数十亿的参数,我们很容易遇到内存限制。为了解决这个问题:《Training deep nets with sublinear memory cost》提出了一种叫做gradient checkpointing的方法,以额外的前向传播为代价,将内存需求降低到亚线性sublinear。《The reversible residual network: Backpropagation without storing activations》提出了一种从next layer重构每一层的activation的方法,这样就不需要存储intermediate activation。- 这两种方法都以速度为代价降低了内存消耗。
《Exploring the limits of transfer learning with a unified text-to-text transformer》提出使用模型并行来训练一个巨型模型。
相比之下,我们的参数缩减技术减少了内存消耗,提高了训练速度。
跨层参数共享:跨层共享参数的思想之前已经用
Transformer架构进行了探索,但这之前的工作主要是针对标准的encoder-decoder任务的训练,而不是pretraining/finetuning setting。与我们的观察不同,
《Universal transformers》表明,具有跨层参数共享的网络(Universal Transformer: UT)在语言建模任务和主谓一致subject-verb agreement任务上得到了比标准transformer更好的性能。ALBERT的论文实验表明:跨层参数共享会损害模型性能。此外,
UT是encoder-decoder架构,它分别在encoder和decoder上进行参数共享。而ALBERT只有encoder,因此只有encoder的参数共享。最近,
《Deep equilibrium models》针对transformer网络提出了Deep Equilibrium Model: DQE,并表明DQE可以达到一个平衡点,即某一层的input embedding和output embedding保持一致(即,到达不动点)。我们的观察表明,我们的
embedding是振荡的,而不是收敛的。《Modeling recurrence for transformer》将参数共享的transformer与标准的transformer相结合,这进一步增加了标准transformer的参数数量。
Sentence Ordering Objectives:ALBERT使用了一个预训练损失,该损失基于预测两个连续的文本片段text segment的顺序。一些研究者已经尝试了与篇章连贯性discourse coherence类似的预训练目标。篇章中的连贯性coherence和凝聚力cohesion已被广泛研究,许多现象已被确定为连接相邻的文本片段。在实践中发现的大多数有效目标都很简单。Skipthought和FastSent的sentence embedding是通过使用一个句子的编码来预测相邻句子中的单词来学习的。sentence embedding learning的其他目标包括:预测未来的句子(而不是仅仅预测邻居),以及预测显式的篇章标记discourse marker。我们的损失与
《Discourse-based objectives for fast unsupervised sentence representation learning》的sentence ordering objective最为相似。该方法学习sentence embedding从而确定两个连续句子的顺序。然而,与上述大多数工作不同的是,我们的损失是在文本片段上而不是句子上定义的。BERT使用的损失是基于next sentence prediction。我们在实验中与这种损失进行了比较,发现sentence ordering是一项更具挑战性的预训练任务,对某些下游任务更有用。与我们的工作同时,
《StructBERT: Incorporating language structures into pre-training for deep language understanding》也试图预测两个连续的文本片段的顺序,但他们把它与原来的next sentence prediction结合起来从而得到一个三分类任务,而不是二分类任务(比较两个连续的文本片段的顺序)。
19.1 模型
19.1.1 模型架构选择
ALBERT架构的backbone与BERT类似,它使用了一个具有GELU非线性激活函数的transformer encoder。我们遵从BERT的惯例,将vocabulary embedding size记做encoder layer数量记做hidden size记做feed-forward/filter size设定为与
BERT的设计选择相比,ALBERT有三个主要贡献:因子分解的embedding参数化factorized embedding parameterization、跨层参数共享cross-layer parameter sharing、句子间的一致性损失Inter-sentence coherence loss。Factorized embedding parameterization:在BERT,以及XLNet和RoBERTa等后续建模改进中,WordPiece embedding size- 从建模的角度来看,
WordPiece embedding是为了学习context-independent representation,而hidden-layer embedding则是为了学习context-dependent representation。正如关于上下文长度的实验所示(见RoBERTa原始论文),BERT-like representation的力量来自于上下文的使用,从而提供用于学习这种context-dependent representation的信号。因此,将WordPiece embedding sizehidden layer size - 从实践的角度来看,自然语言处理通常需要很大的词表大小
embedding matrix的大小,其中embedding matrix的大小为
因此,对于
ALBERT,我们使用embedding参数的因子分解,将它们分解成两个较小的矩阵。我们不是直接将one-hot向量投影到维度为embedding空间,然后再投影到隐空间。通过使用这种分解,我们将embedding参数的规模从我们选择对所有的
word piece使用相同的whole-word相比,word piece在文档中的分布更加均匀。在whole-word embedding中,对不同的词有不同的embedding size是很重要的。- 从建模的角度来看,
Cross-layer parameter sharing:跨层参数共享是提高参数效率的另一种方式。有多种共享参数的方式,例如,仅共享跨层的feed-forward network: FFN参数、或者仅共享注意力参数。ALBERT的默认决定是跨层共享所有参数。除非另有说明,我们所有的实验都使用这个默认决定。我们在实验中把这个设计决定与其他共享参数策略进行了比较。虽然参数共享降低了参数规模,但是并没有降低计算量。
Universal Transformer: UT和Deep Equilibrium Models: DQE对Transformer网络也进行了类似的探索。- 与我们的观察不同,
《Universal Transformer》表明:UT优于普通的Transformer。 《Deep equilibrium models》表明,他们的DQE达到了一个平衡点,对于这个平衡点,某一层的input embedding和output embedding保持不变。我们对L2距离和余弦相似度的测量表明,我们的embedding是振荡的而不是收敛的。
下图显示了每一层的
input embedding和output embedding的L2距离和余弦相似度,使用BERT-large和ALBERT-large配置(如下表所示)。我们观察到:ALBERT的层与层之间的转移transition比BERT的平滑得多。这些结果表明,权重共享对稳定网络参数有一定的影响。尽管与
BERT相比,两个指标(即,L2距离和余弦相似度)都有下降,但即使在24层之后,它们也没有收敛到0。这表明:ALBERT参数的解空间与DQE所发现的解空间非常不同。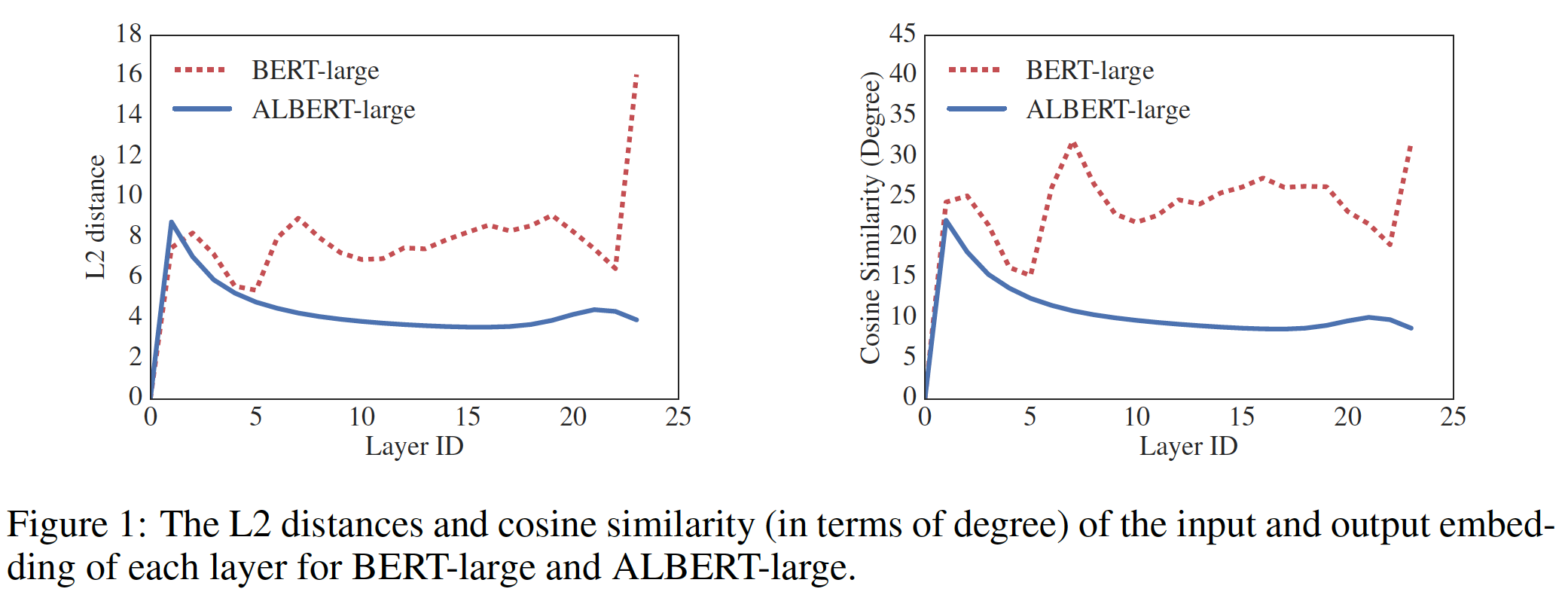

- 与我们的观察不同,
Inter-sentence coherence loss:除了masked language modeling: MLM损失,BERT还使用了一个额外的损失,称为next-sentence prediction: NSP。NSP是一种二元分类损失,用于预测两个segment是否在原始文本中连续出现,具体如下:通过从训练语料库中抽取连续的segment来创建正样本,通过将不同文档中的segment配对来创建负样本,正样本和负样本是以相同的概率进行采样。NSP的目的是为了提高下游任务(如自然语言推理)的性能,这些任务需要推理sentence pair之间的关系。然而,随后的研究(XLNet、RoBERTa)发现NSP的影响不可靠,并决定取消NSP。我们猜想,
NSP的无效性背后的主要原因是:与MLM相比,NSP任务缺乏难度。正如该任务的表述,NSP将话题预测topic prediction和连贯性预测coherence prediction混合在一个任务中。 然而,与连贯性预测相比,话题预测更容易学习,而且也与MLM损失所学到的内容有很多重叠。SpanBERT认为NSP的无效性背后的主要原因是:- 在双序列上下文中,模型无法从较长的
full-length上下文中获益。 - 在双序列上下文中,以另一个文档中的、通常不相关的上下文为条件,会给
MLM增加噪音。
我们坚持认为句子间建模
inter-sentence modeling是语言理解的一个重要方面,但我们提出了一个主要基于连贯性的损失。也就是说,对于ALBERT,我们使用了一个sentence-order prediction: SOP损失,它避免了主题预测,而是专注于建模句子间的连贯性。SOP损失使用与BERT相同的技术(来自同一文件的两个连续segment)作为样本,并使用相同的两个连续segment但是调换顺序之后作为负样本。这就迫使模型学习关于篇章级discourse-level连贯性的更精细的区分。正如我们在实验部分所显示的,事实证明:
NSP根本不能解决SOP的任务(也就是说,它最终学习了更容易的话题预测信号,并在SOP任务中表现为随机水平)。- 而
SOP可以在一定程度上解决NSP的任务,大概是基于分析misaligned coherence cue。
因此,
ALBERT模型为multi-sentence encoding任务一致性地改善了的下游任务表现。- 在双序列上下文中,模型无法从较长的
19.1.2 模型配置
我们在下表中列出了
BERT模型和ALBERT模型在可比的超参数设置下的差异。由于上面讨论的设计选择,ALBERT模型与相应的BERT模型相比,其参数规模要小得多。例如:
与
BERT-large相比,ALBERT-large的参数少了大约18倍,即18M对334M。参数少了
18倍,但是模型的效果也有所降低。H=2048的ALBERT-xlarge只有60M的参数,H=4096的ALBERT-xxlarge只有235M的参数(约为BERT-large参数规模的70%)。
请注意,对于
ALBERT-xxlarge,我们主要报告12层网络的结果,因为24层网络(具有相同的配置)获得了类似的结果,但计算成本更高。这种参数效率的提高是
ALBERT的设计选择的最重要的优势。
19.2 实验
为了使对比尽可能的有意义,我们遵从
BERT的设置,使用BOOKCORPUS和English Wikipedia用于预训练baseline模型。这两个语料库包括大约16GB的未压缩文本。我们将输入格式化为
segment。我们总是将最大输入长度(即,拼接之后的序列的最大长度)限制为512个token,并以10%的概率随机生成短于512的输入序列。与
BERT一样,我们使用大小为30K的词表vocabulary,使用SentencePiece进行tokenization(如同XLNet)。我们使用
n-gram masking为MLM目标生成masked input(如同SpanBERT),每个n-gram masking的长度n-gram masking的最大长度):这个概率倾向于更短的
n-gram masking。例如,当0.341, 0.171, 0.114, 0.085, 0.068, 0.057, 0.049, 0.043, 0.038, 0.034。我们设定
n-gram masking的最大长度为3,即MLM目标可以由最多3个完整的单词组成,如"White House correspondents"。所有的模型更新都使用了
batch size = 4096、以及学习率为0.00176的LAMB优化器。除非另有说明,我们对所有模型进行了125K个step的训练。训练是在Cloud TPU V3上进行的。用于训练的TPU数量从64到512不等,取决于模型大小。LAMB优化器是针对大batch size的训练。首先我们看下Adam优化器:其中:
AdamW是为了适配weight decay(权重衰减相当于参数的L2正则化),在Adam的基础上进行修改:其中:
0.005/0.01。LAMB在AdamW的基础上继续修改:其中:
除非另有说明,本节中描述的实验设置用于我们自己的所有版本的
BERT以及ALBERT模型。评估
benchmark:固有评估
Intrinsic Evaluation:为了监控训练进度,我们使用前面相同的程序和配置,在SQuAD和RACE的验证集基础上创建了一个验证集。我们同时报告了MLM和句子分类任务的准确率。注意,我们只用这个创建的验证集来检查模型是如何收敛的,它的使用方式不会影响任何下游评估的性能(例如,该验证集不是用于模型选择)。
下游评估
Downstream Evaluation:遵从XLNet和RoBERTa,我们在三个流行的benchmark上评估我们的模型:General Language Understanding Evaluation: GLUE基准、两个版本的Stanford Question Answering Dataset: SQuAD、以及ReAding Comprehension from Examinations: RACE数据集。与RoBERTa一样,我们对验证集进行了早停early stopping,在此基础上我们报告了所有的比较,除了基于任务排行榜的最终比较(在最终比较,我们也报告了测试集的结果)。对于在验证集上有较大方差的GLUE数据集,我们报告了5次运行的中位数。GLUE:GLUE由9个任务组成,即 :xxxxxxxxxxCorpus of Linguistic Acceptability: CoLAStanford Sentiment Treebank: SSTMicrosoft Research Paraphrase Corpus: MRPCSemantic Textual Similarity Benchmark: STSQuora Question Pairs: QQPMulti-Genre NLI: MNLIQuestion NLI: QNLIRecognizing Textual Entailment: RTEWinograd NLI: WNLIGLUE聚焦于评估模型的自然语言理解能力。当报告MNLI结果时,我们只报告"match"条件(即,MNLI-m)。我们遵循先前工作中的微调程序(BERT、RoBERTa、XLNet),并报告GLUE sbumission的held-out test set性能。对于测试集的submission,我们遵从RoBERTa和XLNet的描述,对WNLI和QLNLI进行了task-specific修改。SQuAD:SQuAD是一个从Wikipedia建立的提取式问答数据集extractive question answering dataset。答案是来自上下文段落的segment,任务是预测answer span。我们在两个版本的SQuAD上评估我们的模型:v1.1和v2.0。SQuAD v1.1有100K个人类标注的question/answer pair,SQuAD v2.0还额外引入 了50K个无法回答的问题。对于
SQuAD v1.1,我们使用与BERT相同的训练程序;而对于SQuAD v2.0,模型是用span extraction loss和额外的predicting answerability分类器联合训练的(RoBERTa、XLNet)。我们同时报告了验证集和测试集的性能。RACE:RACE是一个大规模的多选阅读理解数据集,收集自中国的英语考试,有近100K个问题。RACE中的每个实例有4个候选答案。遵从之前的工作(RoBERTa、XLNet),我们使用段落、问题、以及每个候选答案的拼接作为模型的输入。然后,我们使用来自"[CLS]" token的representation来预测每个答案的概率。该数据集包括两个
domain:初中和高中。我们同时在这两个domain上训练我们的模型,并同时报告验证集和测试集的准确率。
下游任务的超参数配置如下表所示。
19.2.1 BERT 和 ALBERT 的整体比较
我们现在准备量化
ALBERT模型架构设计选择的影响,特别是围绕参数效率parameter efficiency的选择。如下表所示,参数效率的提高展示了ALBERT设计选择的最重要的优势:ALBERT-xxlarge只用了BERT-large的70%左右的参数,就比BERT-large取得了显著的改进,这可以通过几个有代表性的下游任务的验证集分数的差异来衡量:SQuAD v1.1(+1.9%)、SQuAD v2.0(+3.1%)、MNLI(+1.4%)、SST-2(+2.2%)、以及RACE(+8.4%) 。另一个有趣的观察是在相同的训练配置(相同数量的
TPU)下,训练期间的数据吞吐速度。由于较少的通信和较少的计算,ALBERT模型与它们相应的BERT模型相比,具有更高的数据吞吐量。如果我们使用BERT-large作为baseline,我们观察到ALBERT-large在训练期间大约快1.7倍,而ALBERT-xxlarge由于结构较大,大约慢3倍。这种比较的意义不大:
- 虽然
ALBERT-xxlarge的平均准确率更高(+3.5%),但是它要慢3倍。 - 虽然
ALBERT-large更快(快1.7倍),但是它的平均准确率更低(-2.8%)。 ALBERT-xlarge的效果与BERT几乎差不多(略高+0.3%),但是要慢1.5倍。
这表明
ALBERT虽然降低了参数数量,但是没有降低总的计算量。但是,接下来作者比较了在相同训练时间情况下,ALBERT-xxlarge仍然要超过BERT-large,这才证明了ALBERT的价值。接下来,我们进行消融实验,从而量化
ALBERT的每个设计选择的单独贡献。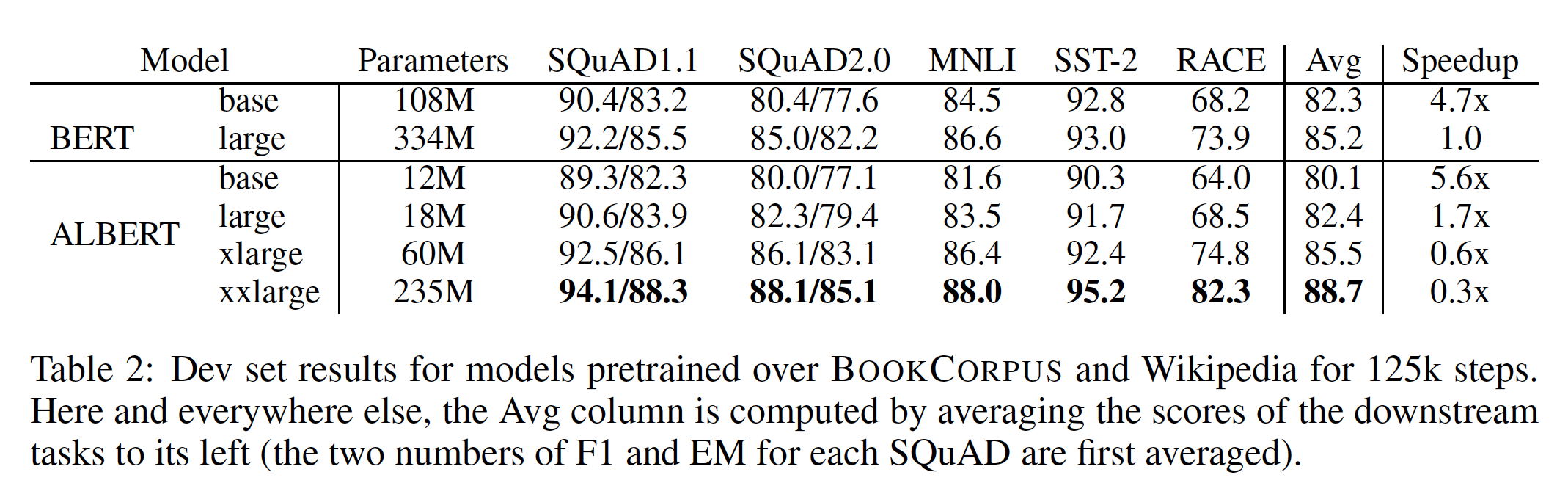
- 虽然
19.2.2 因子分解的 Embedding Parameterization
下表显示了使用
ALBERT-base配置(见Table 1)时改变vocabulary embedding维度- 在
not-shared条件下(BERT-style),较大的embedding维度会带来更好的性能,但幅度不大。 - 在
all-shared条件下(ALBERT-style,即ALBERT base对应的结果),128维的embedding似乎是最好的。
这样看起来,
embedding size超过了64之后,似乎模型性能差距不大?这是否说明此时模型容量已经足够强大,而瓶颈在于训练数据?可以通过在embedding size小于64上进行验证,如embedding size为{1, 4, 8, 16, 32}。基于这些结果,我们在未来的所有设置中使用
embedding维度scaling的必要步骤。下表还说明:相同
embedding size下,ALBERT比BERT的效果更差。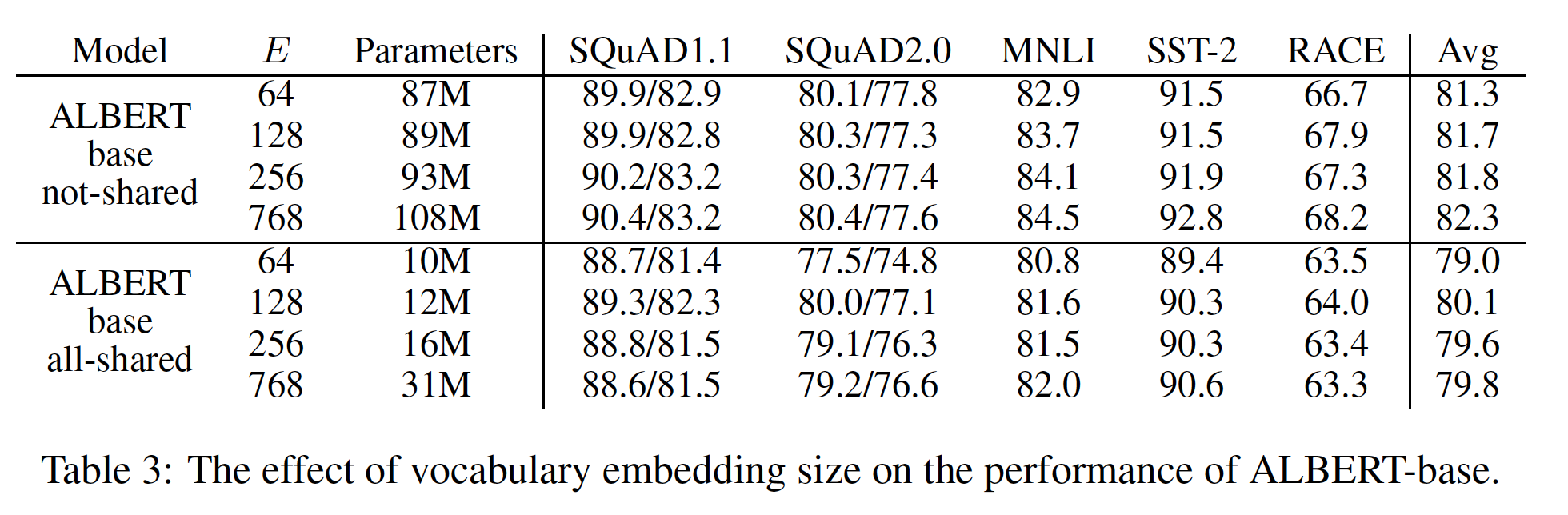
- 在
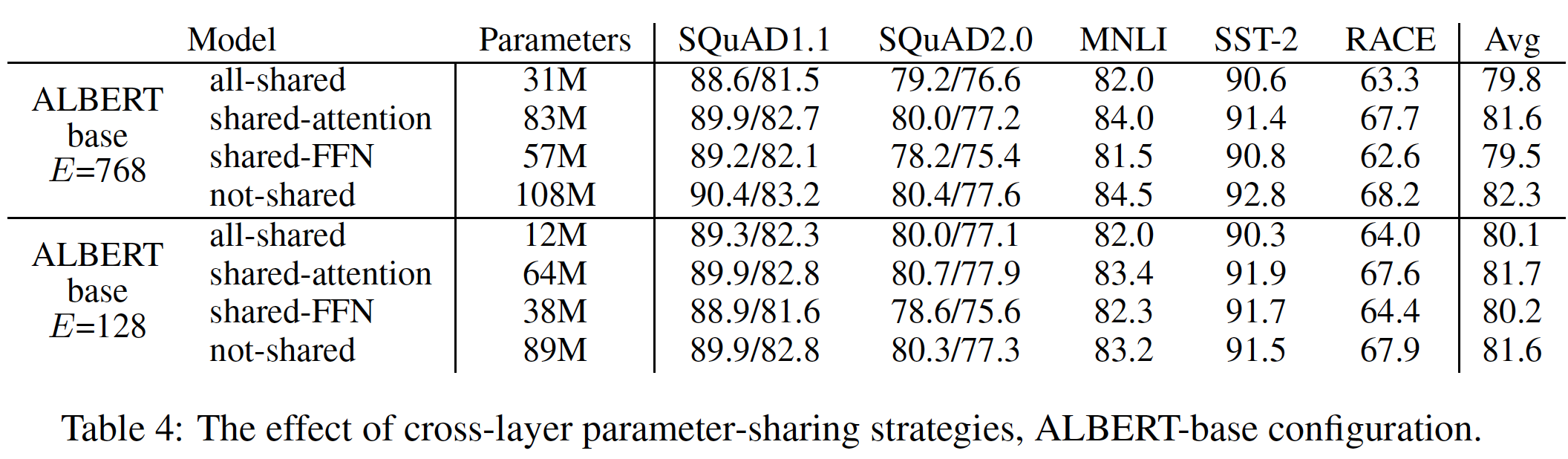
19.2.3 跨层参数共享
下表 列出了各种跨层参数共享策略的实验,其中使用
ALBERT-base配置(见Table 1)和两种embedding维度(all-shared策略(ALBERT-style)、not-shared策略(BERT-style)、以及中间策略(只有注意力参数被共享、或只有FFN参数被共享)。可以看到:相比较于
not-shared,all-shared在两种embedding维度下都会损害性能,但与-2.5%)相比,-1.5%)的情况稍微好一点。这和
《Universal Transformer》的实验结论相反。此外,相比较于
not-shared,大部分的性能下降似乎来自于共享FFN参数,而共享注意力参数在+0.1%)、在-0.7%)。还有其他跨层共享参数的策略。例如,我们可以把
all-shared作为我们的默认选择。
19.2.4 Sentence Order Prediction
我们使用
ALBERT-base配置,对额外的句间损失inter-sentence loss进行了三个实验:none(XLNet-style和RoBERTa-style)、NSP(BERT-style)、以及SOP(ALBERT-style)。结果如下表所示,包括固有任务(MLM、NSP、以及SOP任务的准确率)和下游任务。可以看到:固有任务的结果显示:
NSP loss没有给SOP任务带来判别能力(52.0%的准确率,类似于None条件下的随机猜测性能)。这使我们可以得出结论:NSP最终仅建模话题漂移topic shift。- 相比之下,
SOP loss确实能比较好地解决NSP任务(准确率78.9%),解决SOP任务甚至更好(准确率86.5%)。
这三种方式对
MLM任务都没有帮助。更重要的是,相比
None,SOP loss似乎一致地改善下游multi-sentence encoding任务的表现(SQuAD1.1约提升+1%、SQuAD 2.0约提升+2%、RACE约提升+1.7%),平均得分提高了约+1%。

19.2.5 相同训练时间
Table 2中的加速结果表明,与ALBERT-xxlarge相比,BERT-large的数据吞吐量高出约3.17倍。由于更长的训练时间通常会导致更好的性能,我们进行了一个比较,其中,我们不控制数据吞吐量(即,训练步数),而是控制实际训练时间(即,让不同的模型训练相同的小时数)。在下表中,我们比较了一个BERT-large模型在400K个训练step(经过34小时的训练)后的性能,大致相当于训练一个ALBERT-xxlarge模型所需的125K个训练step(32小时的训练)的时间。在训练了大致相同的时间后,
ALBERT-xxlarge显著优于BERT-large:平均值提高了+1.5%,在RACE上的性能提升高达+5.2%。
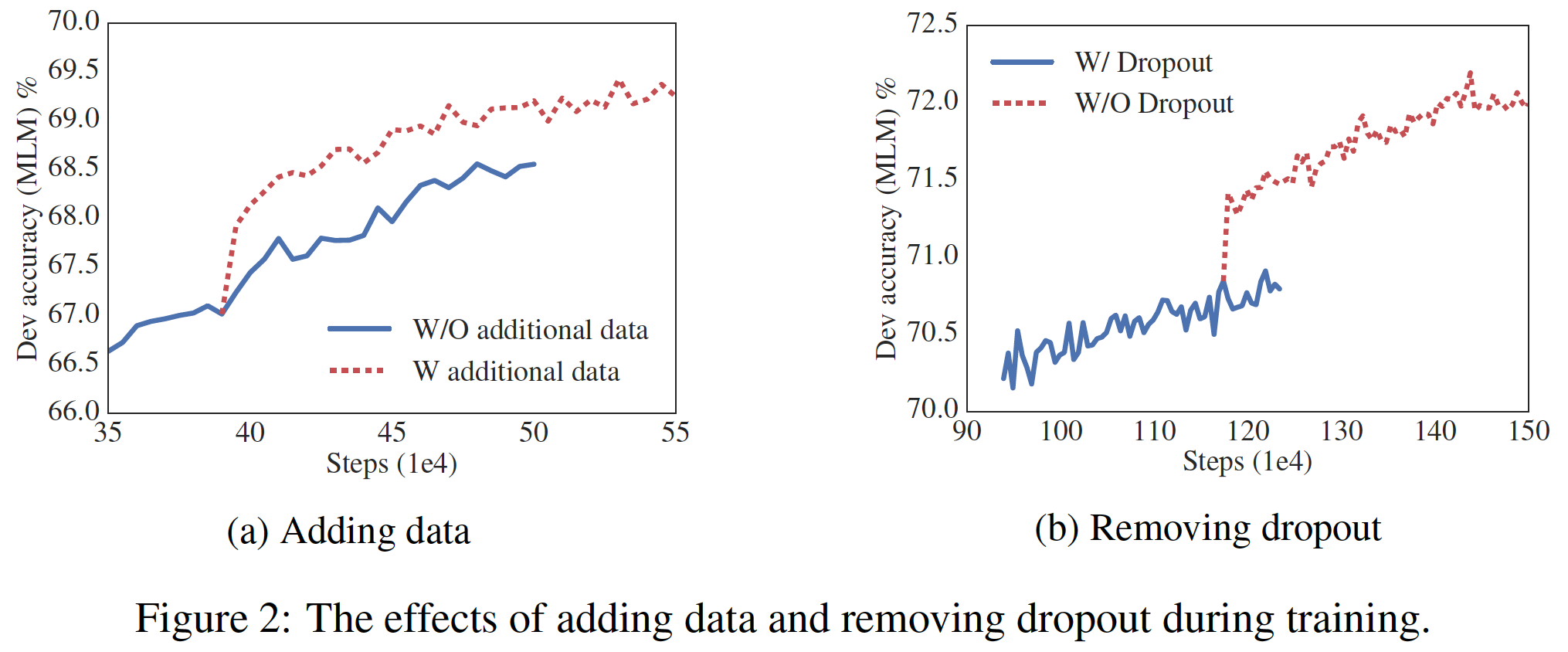
19.2.6 额外的训练数据和 Dropout 效果
到目前为止所做的实验只使用了
Wikipedia和BOOKCORPUS数据集,就如BERT所使用的。在本节中,我们报告了XLNet和RoBERTa所使用的额外数据的影响。下图(a)显示了在没有额外数据、以及有额外数据两种条件下的验证集MLM准确率,可以看到有额外数据条件下有显著的提升。从下表中我们还观察到,除了SQuAD benchmark(Wikipedia-based,因此受到out-of-domain训练数据的负面影响)之外,下游任务的性能也有所提高。BERT-large模型训练了400K步,因此ALBERT-base也用Wikipedia + BOOKCORPUS训练了400K步。然后在此之后使用了额外的数据。因此下图(a)中,前面400K步,二者的曲线是重合的。
我们还注意到,即使在训练了
1M步之后,我们最大的模型仍然没有过拟合训练数据。因此,我们决定移除dropout从而进一步提高我们的模型容量。如下图(b)所示,移除dropout显著提高了MLM的准确率。对ALBERT-xxlarge在大约1M步训练的中间评估(如下表所示)也证实:移除dropout有助于下游任务。有经验(《Inception-v4, inception-resnet and the impact of residual connections on learning》)和理论(《Understanding the disharmony between dropout and batch normalization by variance shift》)证据表明:卷积神经网络中的batch normalization和dropout组合可能会产生有害的结果。据我们所知,我们是第一个表明dropout会损害大型Transformer-based模型的性能。然而,ALBERT的底层网络结构是transformer的一个特例,需要进一步的实验来观察这种现象是否出现在其他transformer-based的架构中。注意,下图
(b)是从1M步之后再移除dropout的,而不是一开始就移除dropout。所以前面1M步,二者的曲线是重合的。另外,论文的结论有点问题。这里仅仅说明,前
2/3的时间使用dropout然后剩余时间移除dropout,要比全部时间使用dropout的效果更好。而无法说明移除dropout比带dropout更好。另外,论文的
Table 8仅仅说是在大约1M步时的评估结果,但是没有说具体在什么时候。是110万步?还是120万步?
19.2.7 NLU 任务上的当前 SOTA
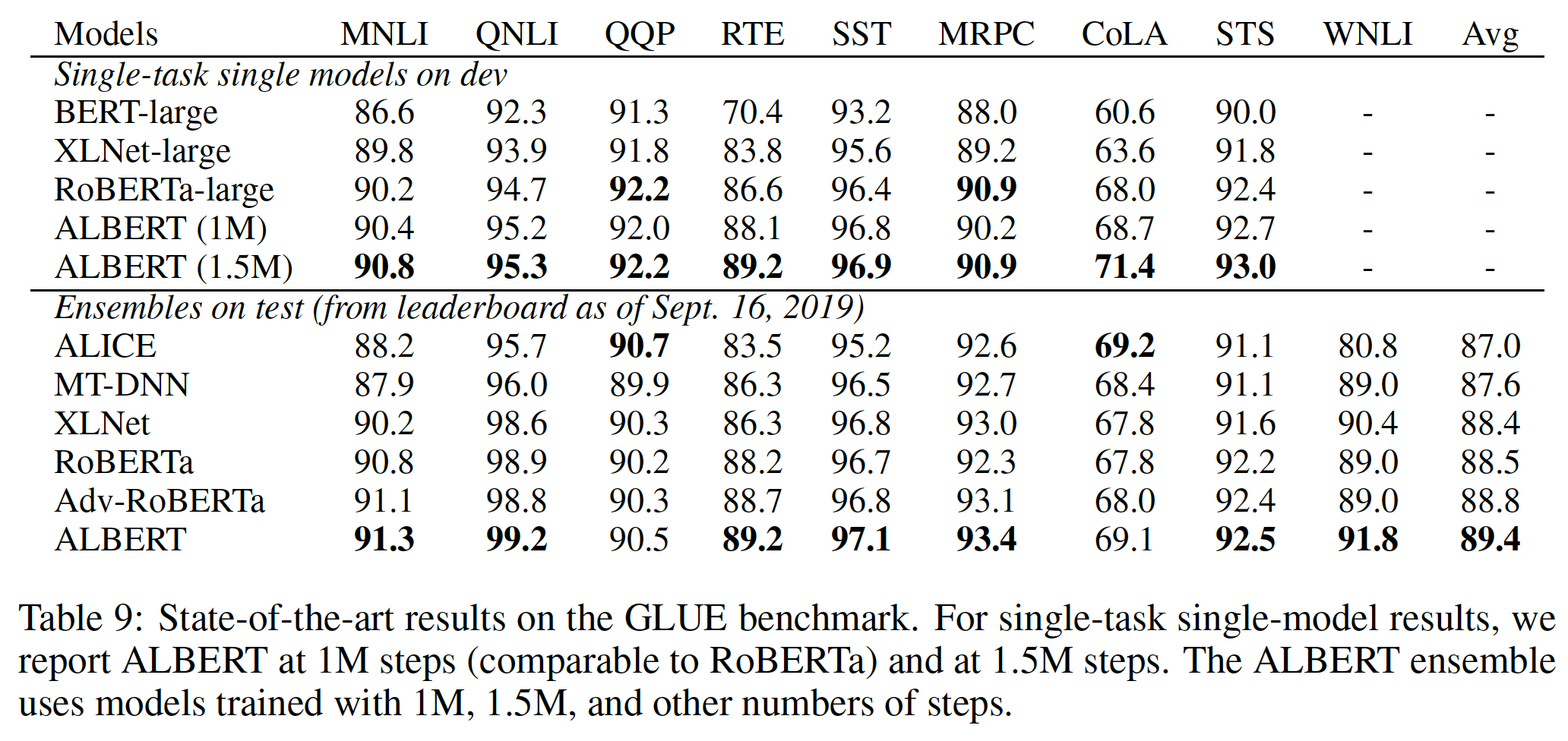
我们在本节报告的结果利用了
BERT使用的训练数据,以及RoBERTa和XLNet使用的额外数据。我们报告了两种setting下的微调的SOTA结果:单模型single-model和集成ensemble。在这两种setting中,我们只做单任务微调。遵从RoBERTa的做法,在验证集上,我们报告了五次运行的中位数。单模型的
ALBERT配置包含了所讨论的最佳性能的setting:ALBERT-xxlarge配置(参考Table 1),组合MLM loss和SOP loss,以及no dropout。ensemble的ALBERT是从多个checkpoint来获取的,这些checkpoint根据验证集的性能来选择,被选中的checkpoint的数量从6到19不等。对于
GLUE(Table 9)和RACE(Table 10),我们对集成模型ensemble models的预测值取平均,其中候选模型是微调了不同的预训练模型(这些预训练模型使用12架构层和24层架构,并预训练了不同的步数)。对于
SQuAD(Table 10),我们对那些有多个概率的span的预测分数进行了平均。我们还对"unanswerable"的决定的分数进行了平均。
单模型结果和集成模型结果都表明:
ALBERT在所有三个benchmark上都大大改善了SOTA的水平,实现了89.4的GLUE得分、92.2的SQuAD 2.0测试F1得分、以及89.4的RACE测试准确率。这些都是集成模型的效果。
RACE上似乎是一个特别强大的改进:我们的集成模型比
BERT的绝对分值跃升+17.4%、比XLNet提升+7.6%、比RoBERTa提升+6.2%、比DCMI+提升5.3%。这里只有
DCMI+是集成模型的效果,其它的BERT/XLNET/RoBERTa都是单模型的效果(不公平的比较)。我们的单模型达到了
86.5%的测试准确率,比SOTA的集成模型仍好2.4%。
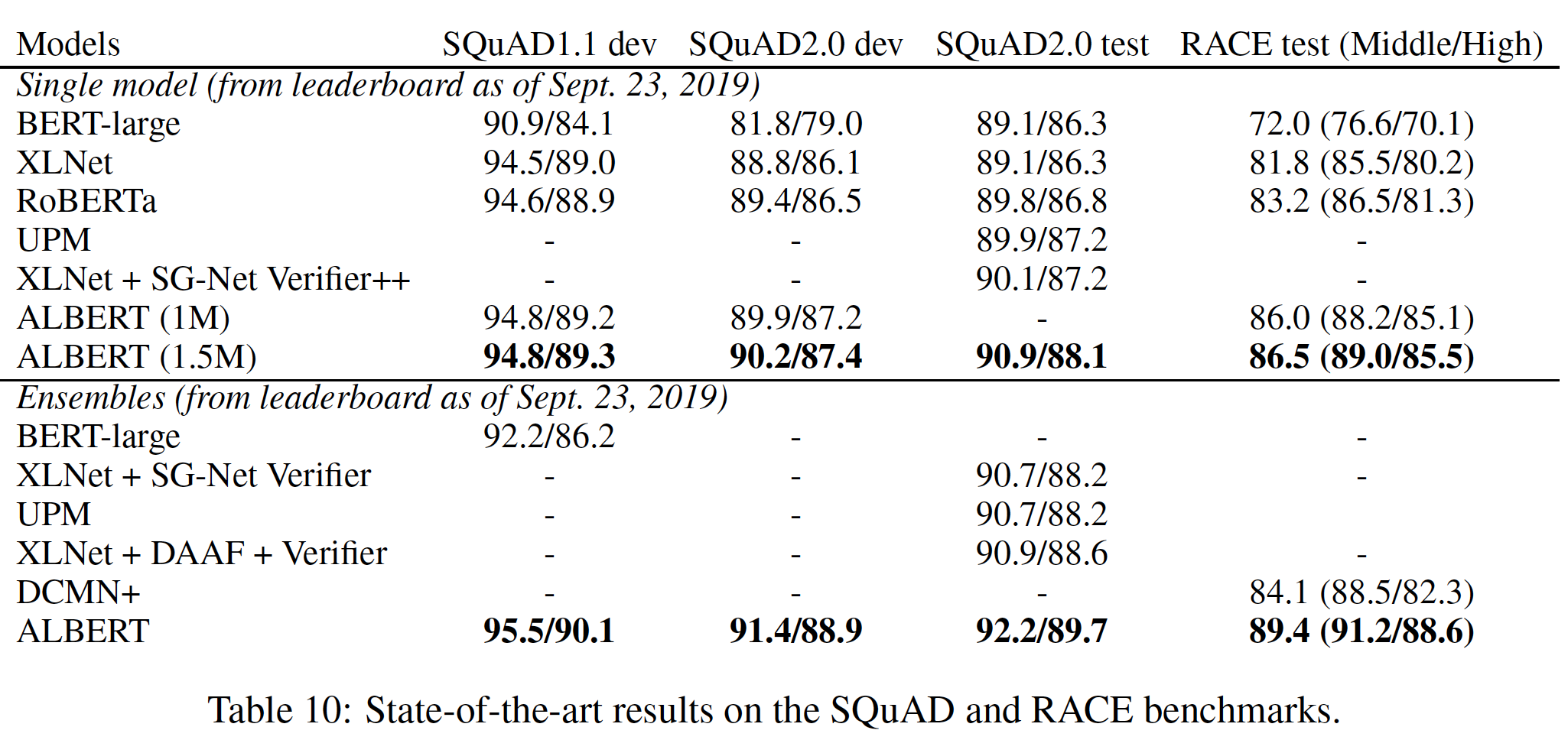
19.2.8 附录:网络的深度和宽度
在本节中,我们检查了网络深度(层数)和宽度(隐层维度)对
ALBERT的性能的影响。下表显示了使用不同层数的
ALBERT-large配置(见Table 1)的性能。具有3层或更多层的网络是通过使用之前深度的网络参数进行微调来训练的(例如,12层的网络参数是从6层网络参数的checkpoint进行微调的)。《Efficient training of bert by progressively stacking》也使用了类似的技术。>=3层的网络都不是从头开始训练的,而是利用更浅网络的参数来微调的。对于
ALBERT-large,可以看到:对比
3网络与1层网络,虽然它们的参数数量相同,但性能显著提高。所有不同层的网络,它们的参数数量都相同,因为是参数共享。
然而,当继续增加层数时,会出现收益递减:
12层网络的结果与24层网络的结果相对接近,而48层网络的性能似乎有所下降。
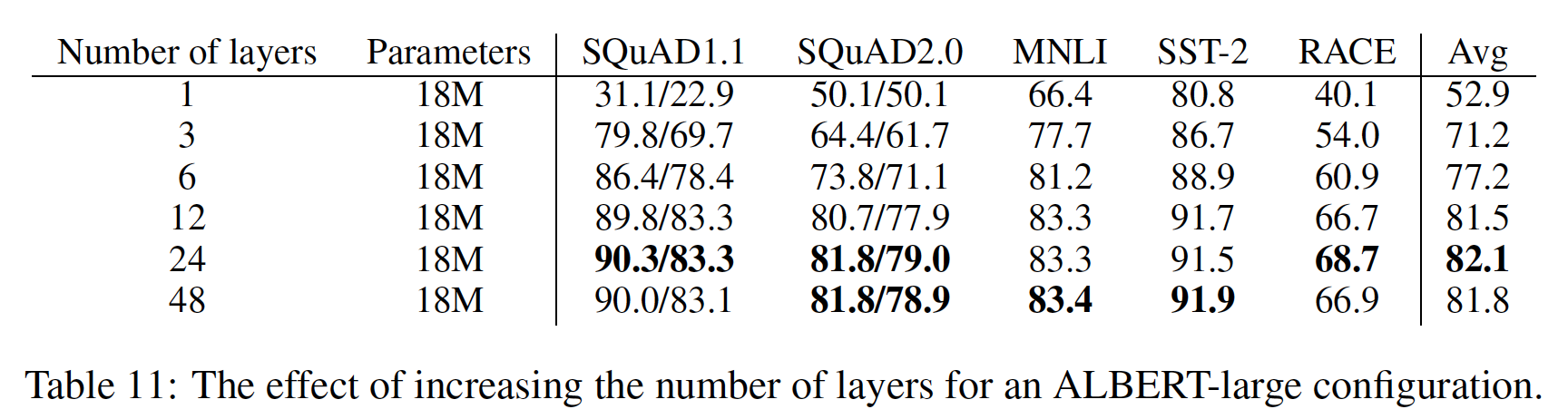
网络宽度也出现了类似的现象,如下表所示(针对不同宽度的
ALBERT-large配置)。可以看到:- 当增加隐层维度时,模型性能增加,但会出现收益递减。
- 在隐层维度为
6144时,模型性能似乎明显下降。
我们注意到,这些模型似乎都没有过拟合训练数据,而且与表现最好的
ALBERT配置相比,它们的训练损失和验证损失都比较高。
是否更宽的模型需要更深?在前面我们表明:对于隐层维度
ALBERT-large,12层和24层模型 之间的差异很小。对于更宽的ALBERT,如ALBERT-xxlarge(答案如下表所示。
12层和24层的ALBERT-xxlarge配置在下游任务准确率方面的差异可以忽略不计,Avg得分相同。我们的结论是:当共享所有跨层参数(ALBERT-style)时,没有必要建立比12层更深的模型。
二十、UniLM [2019]
语言模型的预训练在各种自然语言处理任务中大大推进了
SOTA。预训练的语言模型通过使用大量的文本数据根据单词的上下文来预测该单词来学习contextualized text representation,并且可以进行微调从而适应下游的任务。不同的预测任务和训练目标已经被用于预训练不同类型的语言模型,如下表所示:
ELMo学习两个单向的语言模型:一个正向语言模型从左到右编码文本,一个反向的语言模型从右到左编码文本。GPT使用一个从左到右的transformer来word-by-word地预测文本序列。- 相比之下,
BERT采用了一个双向Transformer encoder来融合左右两侧的上下文从而预测masked word。虽然BERT极大地提高了各种自然语言理解natural language understanding: NLU任务的性能,但其双向性bidirectionality的特点使其难以应用于自然语言生成natural language generation: NLG任务。

在论文
《Unified Language Model Pre-training for Natural Language Understanding and Generation》中,作者提出了一个新的UNIfied pre-trained Language Model: UNILM,可以应用于自然语言理解任务和自然语言生成任务。UNILM是一个多层的Transformer网络,在大量的文本上联合预训练,为三种类型的无监督语言建模目标进行了优化,如下表所示。具体而言,论文设计了一组完形填空任务cloze task,其中根据上下文预测一个masked word。这些完形填空任务的不同之处在于如何定义上下文:- 对于
left-to-right的单向语言模型,要预测的masked word的上下文包括其左边的所有单词。 - 对于
right-to-left的单向语言模型,要预测的masked word的上下文包括其右边的所有单词。 - 对于双向语言模型,要预测的
masked word的上下文由左右两侧的所有单词组成。 - 对于序列到序列的语言模型,第二个序列(即,
target序列)中要预测的单词的上下文由第一个序列(即,source序列)中的所有单词、以及target序列中被预测单词左边的所有单词组成。
这些不同的语言模型是通过
self-attention mask来实现的。
与
BERT类似,预训练的UNILM可以进行微调(必要时增加task-specific layer)以适配各种下游任务。但与主要用于自然语言理解任务的BERT不同,UNILM可以通过使用不同的自注意力掩码self-attention mask进行配置,为不同类型的语言模型聚合上下文,因此可以同时用于自然语言理解任务和自然语言生成任务。UNILM有三个主要优势:- 首先,统一的预训练程序导致了一个单一的
Transformer语言模型,它对不同类型语言模型采用共享的参数和架构,缓解了单独训练和host多个语言模型的需要。 - 第二,参数共享使学到的
text representation更加通用,因为它们是针对不同的语言建模目标共同优化的,其中上下文的利用方式不同从而缓解了对任何单个语言模型任务的过拟合。 - 第三,除了应用于自然语言理解任务外,
UNILM可以作为sequence-to-sequence的语言模型来使用,使其成为自然语言生成任务的自然选择,如抽象式摘要abstractive summarization和问题生成question generation。
实验结果表明,
UNILM作为一个双向编码器来使用,在GLUE benchmark和两个抽取式问答extractive question answering任务(即SQuAD 2.0和CoQA)上与BERT相比更有优势。此外,论文还证明了UNILM在五个自然语言生成数据集上的有效性,其中UNILM作为一个sequence-to-sequence的语言模型来使用, 在CNN/DailyMail和Gigaword的抽象式摘要、SQuAD问题生成、CoQA生成式问答enerative question answering、以及DSTC7对话式响应生成dialog response generation上创造了新的SOTA。
20.1 模型
给定一个输入序列
UNILM为每个token获得了一个contextualized vector representation。如下图所示, 预训练通过几个无监督的语言建模目标来优化共享的Transformer网络,即单向语言模型、双向语言模型、以及sequence-to-sequence语言模型。为了控制对将要预测的word token的上下文的访问,我们采用了不同的自注意力掩码。换句话说,我们使用掩码来控制token在计算其contextualized representation时应该注意多少上下文。一旦UNILM得到预训练,我们就可以利用下游任务的task-specific数据对其进行微调。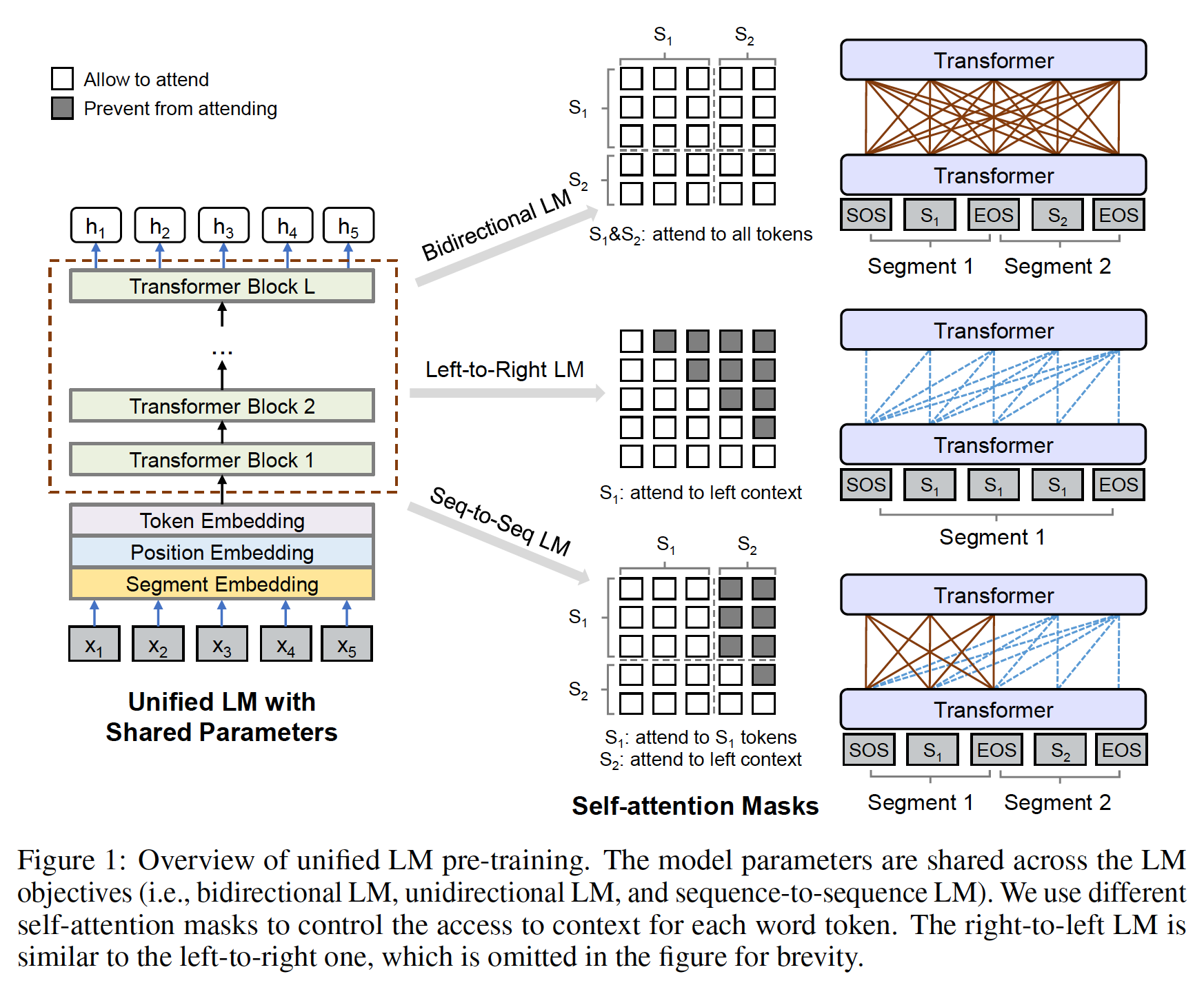
Input Representation:输入- 对于单向语言模型而言,
text segment。 - 对于双向语言模型和
sequence-to-sequence语言模型而言,segment pair。
我们总是在输入的开头添加一个特殊的
start-of-sequence token([SOS]),并在每个segment的结尾添加一个特殊的end-of-sequence token([EOS])。[EOS]不仅标志着自然语言理解任务中的句子边界,而且在自然语言生成任务中还用于模型学习何时终止解码过程。注意,这里的
[SOS]类似于BERT中的[CLS]。input representation遵从BERT:- 通过
WordPiece将文本tokenize为子词单元subword unit。 - 对于每个
input token,它的vector representation是由相应的token embedding、position embedding、以及segment embedding相加而计算出来的。
由于
UNILM是使用多个语言模型任务进行训练的,segment embedding也起到了语言模型id的作用,因为我们为不同的语言模型目标使用不同的segment embedding。对于单向语言模型,只有一个
segment,因此segment id都是1;对于双向语言模型和sequence-to-sequence语言模型,有两个segment,因此segment id是1和2。因此,根据segment id是几个,可以粗略地(而无法精确地)区分不同的语言模型。- 对于单向语言模型而言,
Backbone Network: Multi-Layer Transformer:input向量token embedding维度(也是position embedding、segment embedding的维度)。然后Transformer被编码到不同level的contextual representation:其中
Transformer的输出。在每个
Transformer Block中,多个self-attention head被用于聚合前一层的输出向量。对于第Transformer层,单个self-attention head其中:
query空间、key空间、value空间。self-attention head的维度。mask matrix(也叫做self-attention mask matrix),用于决定一对token之间是否可以相互关注attend。
我们使用不同的
mask matrixtoken可以关注的上下文从而计算该token的contextualized representation,如Figure 1所示。以双向的语言模型为例:mask matrix的元素都是0,表明所有的token都可以相互访问。预训练目标:我们使用四个完形填空任务来预训练
UNILM,这些完形填空任务为了不同语言建模目标而设计的。在完形填空任务中,我们在输入中随机选择一些WordPiece token,并用special token(即,[MASK])替换它们。然后,我们将Transformer网络计算出的、这些special token对应的输出向量馈入一个softmax分类器,以预测masked token。UNILM的参数被学习为:使predicted token和original token计算的交叉熵损失最小。值得注意的是,使用完形填空任务使得所有的语言模型都可以使用相同的训练程序,单向和双向的都一样。单向语言模型:我们同时使用
left-to-right语言模型目标、以及right-to-left语言模型目标。以
left-to-right语言模型为例。每个token的representation只编码左侧的context token和它自身。例如,为了预测 "masked token,只能使用token[MASK])。这是通过使用三角矩阵的self-attention maskself-attention mask的上三角部分被设置为Figure 1所示。类似地,
right-to-left语言模型以token的右侧上下文为条件来预测该token。双向语言模型:遵从
BERT,双向语言模型允许所有token在预测中相互关注。双向语言模型对来自两个方向的上下文信息进行编码,并能产生比单向语言模型更好的contextual representation。在双向语言模型中,self-attention masktoken。Sequence-to-Sequence语言模型: 如图Figure 1所示,对于预测来说:- 第一个
segment(即,source segment)的token可以从source segment内的两个方向相互关注。 - 而第二个
segment(即,target segment)的token只能关注target segment内的左侧上下文及其自身,以及source segment内的所有token。
例如,给定
source segmenttarget segmentinput"token(即,"token(即,"Figure 1显示了用于Sequence-to-Sequence语言模型目标的self-attention masktoken都能访问到第一个segment。source segment关注到target segment。- 此外,对于
target segment中的token关注到它们未来的位置(即,右侧)。
在训练过程中,我们同时在两个
segment中随机选择token,并用special token(即,[MASK])来替换它们。该模型被学习从而恢复masked token。由于source text和target text的pair对在训练中被打包成一个连续的输入文本序列,我们隐式地鼓励模型学习这两个segment之间的关系。为了更好地预测target segment中的token,UNILM学习有效地编码source segment。因此,针对Sequence-to-Sequence语言模型设计的完形填空任务(也被称为encoder-decoder模型),同时预训练了一个双向编码器和一个单向解码器。预训练的模型作为encoder-decoder模型,可以很容易地适用于广泛的条件文本生成conditional text generation任务,如抽象式摘要abstractive summarization。这里的 “
Sequence-to-Sequence语言模型”其实同时混合了双向语言模型(当[MASK]位于source segment)和Sequence-to-Sequence模型(当[MASK]位于target segment)。此外,这里的
decoder仅解码[MASK]对应的token,因此是一个incomplete的解码过程。此外,这里的
encoder-decoder架构与传统的架构不同,这里decoder可以直接访问encoder的所有位置。而传统的架构中,decoder仅能访问单个encoder representation,这个encoder representation聚合了所有encoder input信息。- 第一个
Next Sentence Prediction:遵从BERT,对于双向语言模型,在预训练中我们也包括next sentence prediction任务。
预训练配置:整体预训练目标是上述不同类型的语言模型的目标之和。具体而言,在一个
training batch中,包含:1/3的双向语言模型目标、1/3的Sequence-to-Sequence语言模型目标、1/6的left-to-right语言模型目标、1/6的right-to-left语言模型目标。UNILM的模型结构遵循BERT_LARGE的结构,以便进行公平的比较。遵从GPT,UNILM采用gelu激活函数。具体而言,我们使用一个24层的Transformer,隐层维度1024、注意力头16个,共包含大约340M的参数。softmax分类器的权重矩阵与token embedding绑定(即,二者共享相同的参数矩阵)。UNILM由BERT_LARGE初始化,然后使用English Wikipedia和BookCorpus进行预训练,这两个数据集的处理方式与BERT相同。词表vocabulary规模为28996。输入序列的最大长度为512。token masking的概率为15%。在masked position中,80%的时间我们用[MASK]来替代被选中的token,10%的时间用random token来替代,其余的10%时间保持original token。此外,80%的时间我们每次随机掩码一个token,20%的时间我们随机掩码一个bigram或一个trigram。我们使用
Adam优化器。学习率为3e-5,其中在最初的40K步中进行线性预热然后进行线性衰减。dropout-rate = 0.1,weight-decay = 0.01,batch-size = 330。预训练程序运行了大约770K步。使用8块Nvidia Telsa V100 32GB GPU card进行混合精度训练,每10K步需要约7小时。用
BERT_LARGE初始化之后还预训练了770K步,那初始化的意义和影响是什么?通常,用预训练好的模型作为初始化之后,只需要训练少量的step就能达到比较好的效果。从工程落地上来讲,用
BERT_LARGE来初始化有利于更快地收敛从而降低训练成本;从实验上来讲,最好是从头开始训练从而进行公平地比较。下游自然语言理解任务和自然语言生成任务的微调:
对于自然语言理解任务,我们将
UNILM作为一个双向Transformer encoder来微调,就像BERT。以文本分类任务为例。我们使用
[SOS]的encoding vector作为input representation,记做softmax分类器(即task-specific输出层),其中类别概率计算为:softmax分类器的参数,从而最大化labeled training data的似然likelihood。对于自然语言生成任务,我们以
sequence-to-sequence任务为例。微调过程类似于使用self-attention mask的预训练。令source sequence和target sequence。我们通过special token将它们打包在一起,形成输入 "target序列中一定比例的token来进行微调,并学习恢复masked word。训练目标是在给定上下文的情况下,最大化masked token的似然likelihood。值得注意的是,标识着
target序列结束的[EOS] token在微调过程中也可能被掩码,因此当这种情况发生时,模型会学习何时发出[EOS] token从而终止target序列的生成过程。UNILM在自然语言生成任务上的微调与常规的sequence-to-sequence模型不同。常规的sequence-to-sequence模型会依次生成target sequence(包括[EOS] token)。而这里的UNILM采用它预训练时的方式,仅掩码target sequence并且仅仅预测masked token(而不是序列生成)。常规的
sequence-to-sequence更符合实际,因为在实际应用中,我们通常只有source sequence而没有target sequence。而UNILM不仅需要知道source sequence、还需要知道部分的target sequence信息(从而预测被masked的部分)。
20.2 实验
- 我们对自然语言理解任务(即
GLUE benchmark,以及抽取式问答extractive question answering)和自然语言生成任务(即抽象式摘要abstractive summarization、问题生成、生成式问答、以及对话响应生成dialog response generation)都进行了实验。
20.2.1 抽象式摘要
自动文本摘要
automatic text summarization能产生一个简明流畅的summary,传达input(如,一篇新闻文章)的关键信息。我们聚焦于抽象式摘要,这是一项生成任务,其中summary不必使用输入文本中的短语或句子。我们使用CNN/DailyMail数据集的非匿名版本、以及Gigaword来用于模型微调和评估。我们按照前面描述的程序将UNILM作为一个sequence-to-sequence模型进行微调,将文档(第一个segment)和summary(第二个segment)拼接起来作为输入,并根据预定义的最大序列长度进行截断。我们在训练集上对我们的模型微调了
30个epoch。我们复用预训练中的大多数超参数。掩码概率为0.7。我们还使用平滑率为0.1的标签平滑label smoothing。- 对于
CNN/DailyMail,我们设置batch size = 32,最大序列长度为768。 - 对于
Gigaword,我们设置batch size = 64,最大序列长度为256。
在解码过程中,我们使用
beam size = 5的beam search。对于CNN/DailyMail和Gigaword来说,input document被截断为前640个token和后192个token。我们在beam search中删除了重复的trigram,并在验证集上调整了maximum summary length。- 对于
我们使用
F1版本的ROUGE作为两个数据集的评估指标。在下表中,在CNN/DailyMail数据集上,我们将UNILM与baseline以及几个SOTA模型进行比较:LEAD-3是一个baseline模型,它抽取文档中的前三句话作为其摘要。PGNet是一个基于pointer-generator network的sequence-to-sequence模型。S2S-ELMo使用一个sequence-to-sequence模型,用预训练好的ELMo representation进行增强,被称为SRC-ELMO+SHDEMB。Bottom-Up是一个sequence-to-sequence模型,用一个bottom-up content selector来选择突出的短语。
我们还在下表中列出了数据集上最好的抽取式摘要结果。如下表所示,我们的模型优于以前所有的抽象式系统
abstractive system,在数据集上创造了一个新的SOTA的抽象式结果。在ROUGE-L中,我们的模型也比最好的抽取式模型高出0.88分。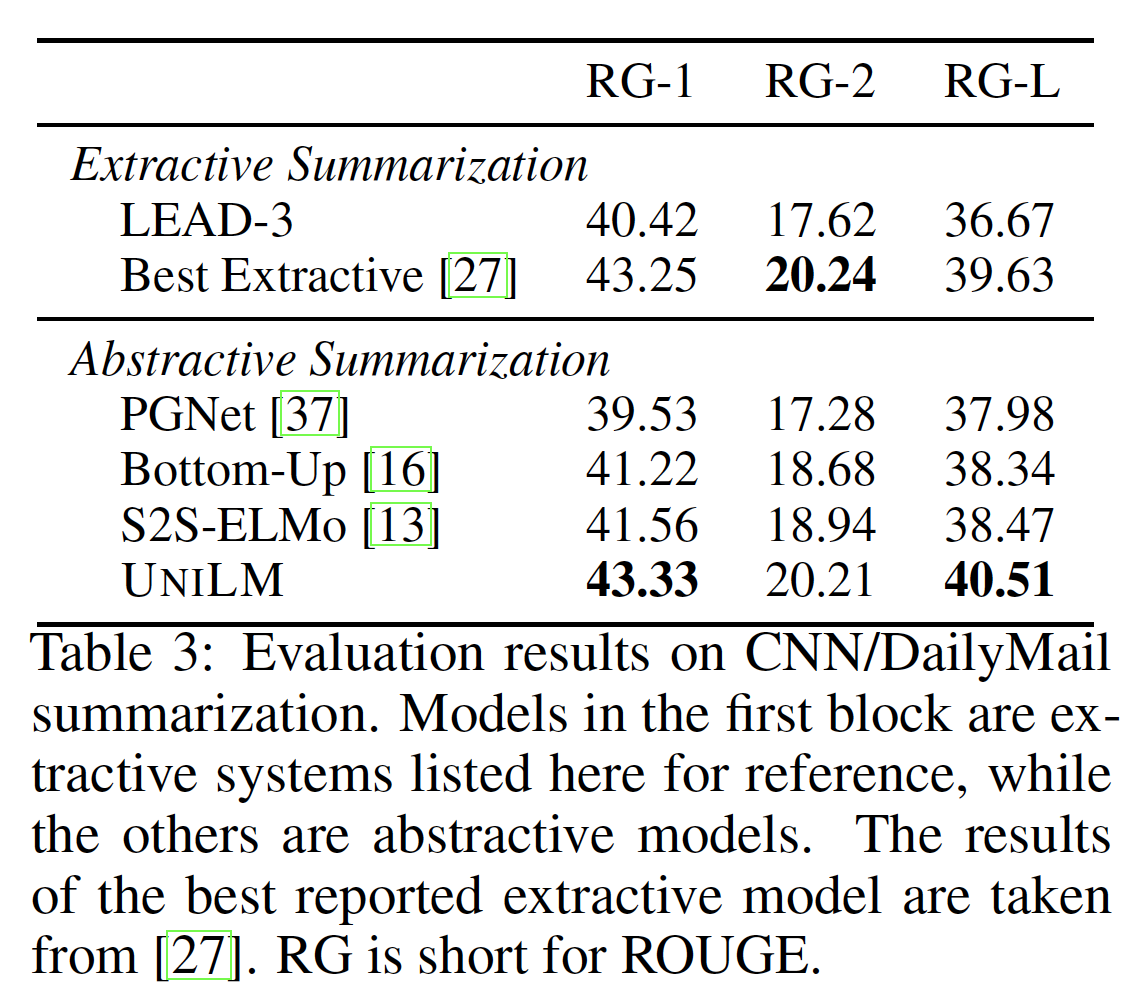
在下表中,我们对模型在不同规模(
10K和3.8M)的Gigaword上进行了评估。Transforme和OpenNMT都实现了标准的attentional sequence-to-sequence模型。Re3Sum检索摘要作为候选模板,然后使用一个扩展的sequence-to-sequence模型来生成摘要。MASS是一个基于Transformer网络的预训练的sequence-to-sequence模型。
实验结果表明:
UNILM取得了比以往工作更好的性能。此外,在低资源环境下(即只使用10K个样本作为训练数据),我们的模型在ROUGE-L中比MASS高出7.08分。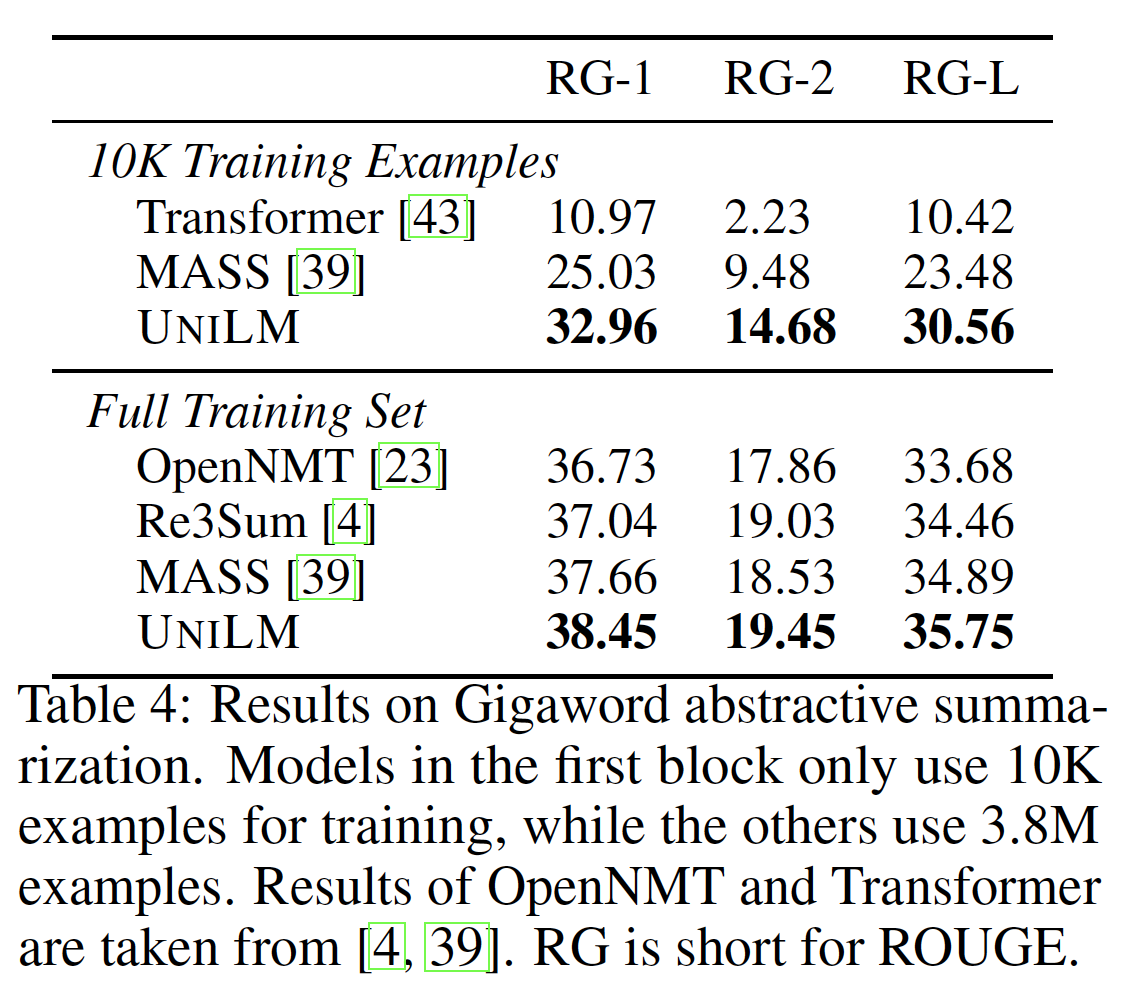
20.2.2 问答
Question Answering: QA任务是在给定一个段落的条件下回答一个问题。有两种setting:- 第一种被称为抽取式问答
extractive QA,答案被假定为段落中的一个text span。 - 另一种被称为生成式问答
generative QA,答案需要即时生成。
- 第一种被称为抽取式问答
抽取式问答:这项任务可以被表述为自然语言理解任务,我们需要预测答案在段落中的开始位置和结束位置。我们对预训练的
UNILM进行微调,将UNILM作为双向编码器从而用于抽取式问答。我们在Stanford Question Answering Dataset: SQuAD的2.0版本、以及Conversational Question Answering: CoQA数据集上进行了实验。在
SQuAD 2.0上的结果如下表所示,我们比较了两个模型的精确匹配Exact Match: EM分和F1分。RMR+ELMo是一个基于LSTM的问答模型,用预训练好的language representation来增强。BERT_LARGE是一个cased模型(即,字母保持大小写),在SQuAD训练数据上微调了3个epoch,batch size = 24,最大序列长度为384。UNILM以与BERT_LARGE相同的方式进行微调。
我们看到
UNILM的表现优于BERT_LARGE。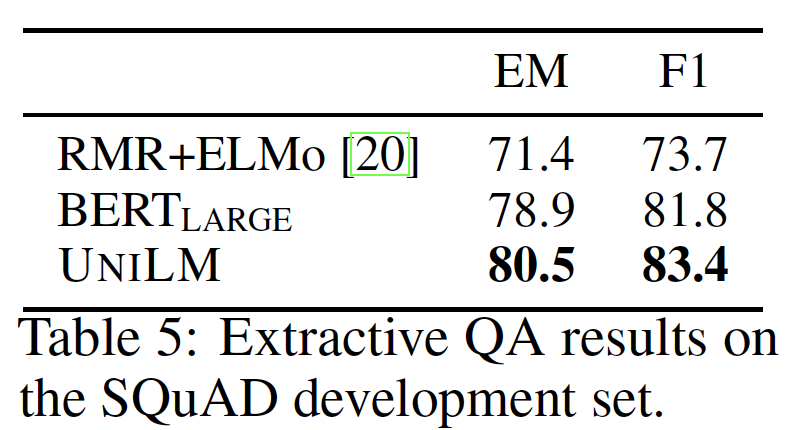
CoQA是一个对话式问答conversational question answering数据集。与SQuAD相比,CoQA有几个独有的特点:- 首先,
CoQA中的样本是对话式的,所以我们需要根据对话历史来回答input question。 - 其次,
CoQA中的答案可以是自由格式的文本,包括很大一部分是"yes/no"的答案。
我们对用于
SQuAD的模型做了如下修改:首先,除了被问的问题,我们将
question-answer的历史拼接到第一个segment,这样模型就可以捕获到对话信息。其次,对于
"yes/no"问题,我们使用[SOS] token的final hidden vector来预测input question是否是一个"yes/no"问题,以及答案为"yes/no"。对于非
"yes/no"问题 ,我们选择一个F1分数最高的passage subspan用于训练。
CoQA的实验结果如下表所示。我们比较了两个模型的F1分:DrQA+ELMo是一个基于LSTM的问答模型,用预训练好的ELMo representation来增强。BERT_LARGE是一个cased模型(即,字母保持大小写),在CoQA训练数据上微调了2个epoch,batch size = 16,最大序列长度为512。UNILM以与BERT_LARGE相同的方式进行微调。
我们看到
UNILM的表现优于BERT_LARGE。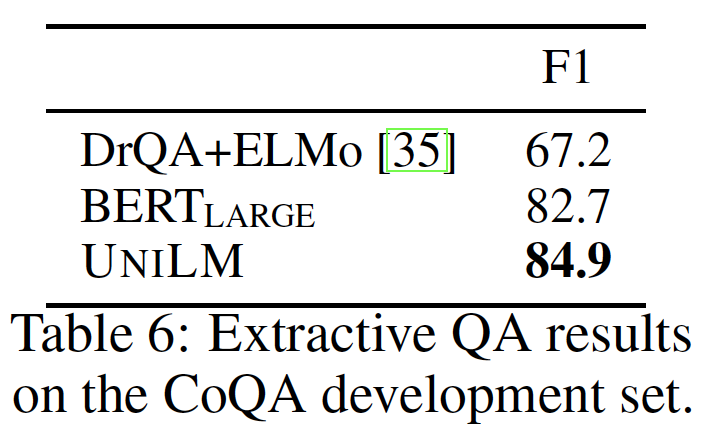
- 首先,
生成式问答:生成式问答为
input question和段落生成自由形式的答案,这是一个自然语言生成任务。相比之下,抽取式问答只能预测input passage的subspan作为答案。在CoQA数据集上(如前所述),《CoQA: A conversational question answering challenge》表明:普通的sequence-to-sequence模型的性能仍然远远低于抽取式方法。我们为生成式问答来适配
UNILM,从而将UNILM作为一个sequence-to-sequence模型。第一个segment(即input sequence)是对话历史、input question、以及段落的拼接。第二个segment(即,output sequence)是答案。我们在CoQA训练集上对预训练的UNILM微调了10个epoch。我们设置batch size = 32,掩码率为0.5,最大序列长度为512。我们还使用平滑率为0.1的标签平滑。其他超参数与预训练保持一致。在解码过程中,我们使用
beam size = 3的beam search,input question和段落的最大长度为470。对于超过最大长度的段落,我们用滑动窗口的方法将段落分成若干块,并选择一个与question具有最高word overlap的块。我们将我们的方法与生成式问答模型
Seq2Seq和PGNet进行了比较:Seq2Seq baseline是一个带有注意力机制的sequence-to-sequence模型。PGNet模型用一个copy机制增强了Seq2Seq。
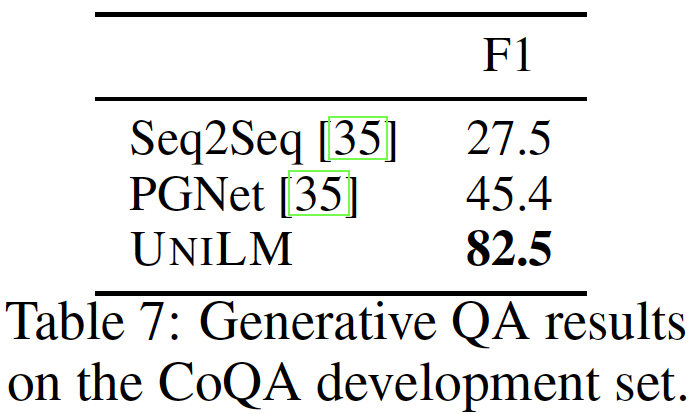
如下表所示,我们的生成式问答模型在大大超过了以前的生成式方法,这极大地缩小了生成式方法和抽取式方法之间的差距。
20.2.3 问题生成
我们对
answer-aware的问题生成question generation任务进行了实验。给定一个input passage和一个answer span,我们的目标是生成一个针对答案的问题。SQuAD 1.1数据集被用于评估。遵从《Learning to ask: Neural question generation for reading comprehension》,我们将原始训练集拆分为训练集和测试集,并保留原始验证集。我们还遵从《Paragraph-level neural question generation with maxout pointer and gated self-attention networks》中的数据拆分方式进行实验,即,使用反向的dev-test拆分。问题生成任务被表述为一个
sequence-to-sequence问题。第一个segment是input passage和答案的拼接,而第二个segment是被生成的问题。我们在训练集上对
UNILM微调了10个epoch。我们设置batch size = 32,掩码率为0.7,学习率为2e-5。我们采用平滑率为0.1的标签平滑。其他超参数与预训练相同。在解码过程中,我们将输入截断为
464个token并选择包含答案的passage块。评估指标BLEU-4, METEOR, ROUGE-L的计算方法与《Learning to ask: Neural question generation for reading comprehension》中的脚本相同。结果如下表所示。
CorefNQG是基于一个带有注意力的sequence-to-sequence模型、以及一个特征丰富的编码器。MP-GSN使用了一个带门控自注意力编码器的attention-based sequence-to-sequence model。SemQG使用两个语义增强的奖励semantics-enhanced reward来正则化generation。
UNILM的性能优于以前的模型,并针对问题生成任务达到了新的SOTA。
生成的问题来改善
QA:问题生成模型可以从文本语料库中自动收集大量的question-passage-answer的样本。我们表明,由问题生成模型产生的augmented data可以改善问答模型。我们生成了
5M个可回答的样本,并通过修改可回答的样本生成了4M万个不可回答的样本。我们在生成的数据上对我们的问题回答模型微调一个epoch。然后在SQuAD 2.0的数据上再微调两个epoch。生成的
augmented data并不是和下游任务的数据混合,而是进行stack-style的微调。因此,augmented data微调的模型仅用于初始化。下游任务的目标数据才是作为最终的微调,使得与测试集的数据分布保持一致。如下表所示,由
UNILM生成的augmented data改善了问答模型。请注意,在微调过程中,我们对生成的数据集和
SQuAD 2.0数据集都使用了双向masked language modeling: MLM作为辅助任务(MLM原本用于预训练阶段)。与直接使用自动生成的样本相比,双向MLM带来了2.3个点的绝对改进。一个可能的原因是,当在augmented data上进行微调时,辅助任务缓解了灾难遗忘catastrophic forgetting。这个
2.3的绝对改进并没有在下表中展示。
20.2.4 响应生成
我们在以文档为基础的
dialog response generation任务上评估UNILM。给定一个多轮对话历史、以及一个网络文档web document作为知识源,系统需要生成一个既适合对话、又反映网络文档内容的自然语言响应。我们微调UNILM来完成这个任务,其中UNILM作为一个sequence-to-sequence模型。第一个segment(input sequence)是web document和对话历史的拼接。第二个segment(output sequence)是响应。我们在
DSTC7的训练数据上对UNILM微调了20个epoch,batch size = 64。掩码率为0.5。最大序列长度为512。在解码过程中,我们使用beam size = 10的beam search。产生的响应的最大序列长度被设置为40。如下表所示,在
DSTC7共享任务中,UNILM在所有评估指标上都超过了最好的系统。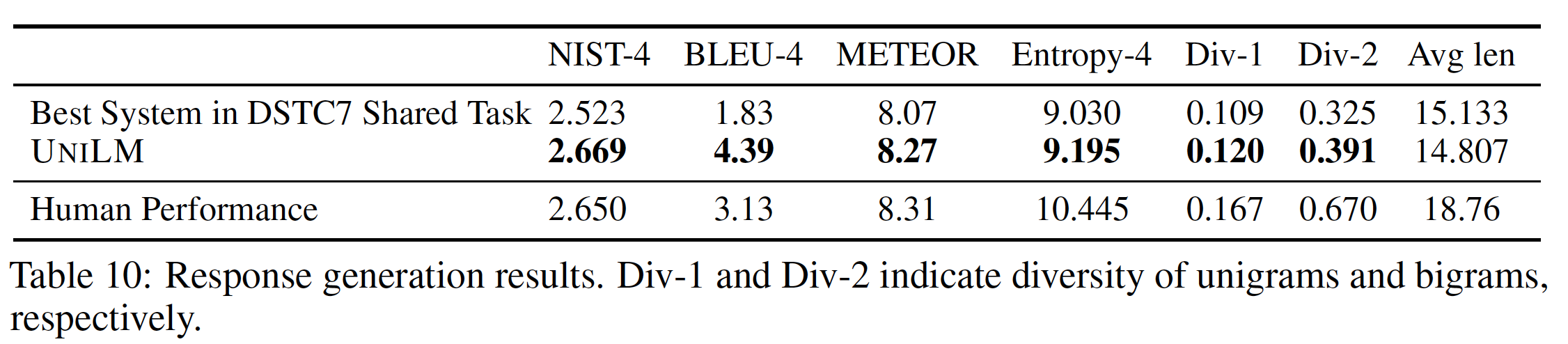
20.2.5 GLUE Benchmark
我们在
GLUE benchmark上评估UNILM。GLUE是九个语言理解任务的集合,包括问答、语言可接受性linguistic acceptability、情感分析、文本相似性、转述检测paraphrase detection、以及自然语言推理natural language inference : NLI。我们的模型作为一个双向语言模型被微调。我们使用
Adamax优化器,学习率为5e-5,batch size = 32。最大epoch数被设为5。使用一个带预热(预热比例0.1)的线性学习率衰减的学习率调度。每个任务的last linear projection的dropout-rate = 0.1,除了MNLI的0.3、CoLA/SST-2的0.05。为了避免梯度爆炸问题,梯度范数被剪裁在1.0以内。我们截断token使得输入序列长度不超过512。下表列出了从
benchmark evaluation server获得的GLUE测试结果。结果显示,在GLUE任务中,UNILM与BERT_LARGE相比获得了相差无几的性能。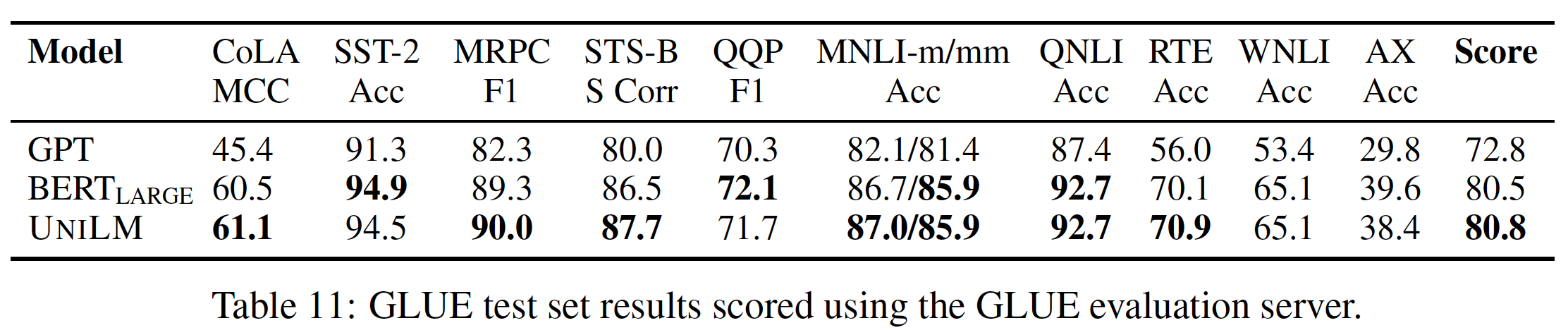
20.2.6 未来工作
UNILM可以从以下几个方面继续改善:- 我们将通过在
web-scale的文本语料库上训练更多的epoch和更大的模型来推动当前方法的极限。同时,我们还将在下游应用上进行更多的实验以及消融实验,从而研究模型能力以及采用相同网络来预训练多种语言建模任务的好处。 - 在我们目前的实验中,我们聚焦于单语
NLP任务。我们还对扩展UNILM从而支持跨语言的任务感兴趣。 - 我们将对自然语言理解和自然语言生成任务进行多任务微调,这是
Multi-Task Deep Neural Network: MT-DNN的自然延伸。
- 我们将通过在
二十一、MASS [2019]
预训练和微调被广泛使用,当目标任务的训练数据资源较少或为零而预训练有大量的数据时。例如,在计算机视觉中,模型通常在大规模的
ImageNet数据集上进行预训练,然后在下游任务(如目标检测任务、图像分割任务)上进行微调。最近,ELMo、OpenAI GPT、以及BERT等预训练方法在自然语言处理中引起了很多关注,并在多种语言理解任务中取得了SOTA的准确性,如情感分类、自然语言推理、命名实体识别、以及SQuAD问答,这些任务通常只有有限的监督数据。在上述预训练方法中,BERT是最卓越的一种,它通过masked language modeling和next sentence prediction,在大型单语语料库上预训练bidirectional encoder representation。与语言理解不同,语言生成的目的是在某些输入的条件下生成自然语言句子,包括神经机器翻译
neural machine translation : NMT、文本摘要text summarization、以及对话式响应生成conversational response generation等任务。语言生成任务通常对数据要求很高,许多任务在训练数据方面是低资源low-resource甚至是零资源zero-source的。在这些自然语言生成任务上直接应用BERT-like的预训练方法是不可行的,因为BERT是为语言理解设计的,其中这些任务通常只由一个encoder或decoder处理。因此,如何为语言生成任务(通常采用基于encoder-decoder的序列学习框架)设计预训练方法,具有很大的潜力和重要性。在论文
《MASS: Masked Sequence to Sequence Pre-training for Language Generation》中,受BERT的启发,作者提出了一个新颖的预训练目标:MAsked Sequence to Sequence learning : MASS用于语言生成。MASS是基于sequence to sequence的学习框架:它的encoder将带有一个masked fragment(几个连续的token)的一个句子作为输入,而它的decoder则根据encoder representation来预测这个masked fragment。与BERT或仅对encoder/decoder进行预训练的语言模型不同,MASS经过精心设计,分两步对encoder和decoder进行联合预训练:- 通过预测
encoder side的masked fragment,MASS可以迫使encoder理解unmasked token的含义,从而在decoder side预测masked token。 - 通过掩码
decoder的input tokens,其中这些masked input tokens在encoder side没有被掩码,MASS可以迫使decoder更多地依赖于source representation(即,encoder representation)而不是decoder side的previous tokens,从而用于next token prediction。这可以更好地促进encoder和decoder的联合训练。
MASS只需要预训练一个模型,然后在各种下游任务中进行微调。论文使用transformer作为基础的sequence to sequence模型,并且在WMT单语语料库上进行预训练,然后在三种不同的语言生成任务上进行微调,包括神经机器翻译、文本摘要、以及对话式响应生成。考虑到下游任务涵盖了像神经机器翻译这样的跨语言任务,论文在多种语言上预训练一个模型。论文为所有三个任务探索了low-resource setting,也考虑了无监督的神经机器翻译(这是一个纯粹的zero-resource setting)。- 对于神经机器翻译,论文在
WMT14 English-French、WMT16 English-German、以及WMT16 English-Romanian数据集上进行了实验。 - 对于无监督的神经机器翻译,论文直接在单语数据上用
back-translation loss微调预训练的模型,而不是像《Phrase-based & neural unsupervised machine translation》那样使用额外的降噪自编码器损失。 - 对于低资源的神经机器翻译,论文在有限的双语数据上微调预训练的模型。
- 对于其他两项任务,论文的实验如下:
Gigaword语料库用于抽象式文本摘要,Cornell Movie Dialog语料库用于对话式响应生成。
论文的方法在所有这些任务以及
zero-resource setting和low-resource setting中都取得了改进,表明论文的方法是有效的,适用于广泛的序列生成任务。论文的贡献如下:
论文提出了
MASS,一种用于语言生成的masked sequence to sequence预训练方法。MASS主要用于自然语言生成任务,而无法用于自然语言理解任务。论文将
MASS应用于各种语言生成任务,包括神经机器翻译、文本摘要、以及对话式响应生成,并取得了显著的改进,证明了MASS的有效性。具体而言,
MASS在两种language pair(即,English-French, English-German)的无监督神经机器翻译上取得了SOTA的BLEU分,并且在English-French和French-English上分别超过了之前的无监督神经机器翻译方法4分以上和1分以上,甚至超过了早期的attention-based的监督模型。
- 通过预测
相关工作:在自然语言处理领域,在
sequence to sequence learning和预训练方面有很多工作。Sequence to Sequence Learning:sequence to sequence learning是人工智能领域的一项挑战性任务,涵盖了各种语言生成应用,如神经机器翻译、文本摘要、问答、以及对话式响应生成。近年来,由于深度学习的进步,
sequence to sequence learning引起了很多关注。然而,许多语言生成任务,如神经机器翻译,缺乏paired data(即,监督数据),但有大量的unpaired data(即,无监督数据)。因此,在unpaired data上进行预训练,并用小规模的paired data进行微调,将有助于这些任务,这正是本工作的重点。Pre-training for NLP task:预训练已被广泛用于NLP任务中,从而学习更好的language representation。以前的工作大多集中在自然语言理解任务上,可以分为feature-based方法和fine-tuning方法。feature-based方法主要是利用预训练为下游任务提供language representation和feature,其中包括word-level representation、sentence-level representation、以及来自神经机器翻译模型和ELMo的context sensitive feature。fine-tuning方法主要是在语言建模目标上预训练模型,然后在具有监督数据的下游任务上微调模型。具体来说,《Bert: Pre-training of deep bidirectional transformers for language understanding》提出了基于masked language modeling和next sentence prediction的BERT,并在GLUE benchmark和SQuAD中的多个语言理解任务中取得了SOTA准确性。
也有一些工作采用针对语言生成的
encoder-decoder模型进行预训练。《Semi-supervised sequence learning》、《Unsupervised pretraining for sequence to sequence learning》利用语言模型或自编码器来预训练编码器和解码器。他们的方法虽然获得了improvement,但很有限,不像语言理解的预训练方法(如BERT)那样通用和显著。《Exploiting source-side monolingual data in neural machine translation》设计了一个用于预训练的句子重排任务sentence reordering task,但只针对encoder-decoder模型的编码器部分。《Transfer learning for low-resource neural machine translation》和《Zero-resource translation with multi-lingualneural machine translation》在similar rich-resource language pair上预训练模型,在target language pair上对预训练模型进行微调,这依赖于other language pair的监督数据。- 最近,
XLM对编码器和解码器都预训练了BERT-like模型,并在无监督机器翻译上取得了previous SOTA的结果。然而,XLM中的编码器和解码器是单独预训练的,而且encoder-decoder的注意力机制无法被预训练,这对于基于sequence to sequence的语言生成任务来说是次优的。
与以往的工作不同,我们提出的
MASS是经过精心设计的,只使用未标记的数据并同时对编码器和解码器进行联合预训练,可以应用于大多数语言生成任务。
21.1 模型
- 这里,我们首先介绍了
sequence to sequence learning的基本框架,然后提出MASS(MAsked Sequence to Sequence预训练)。然后,我们讨论了MASS与以前的预训练方法的区别,包括masked language modeling(参考BERT)、以及standard language modeling。
21.1.1 Sequence to Sequence Learning
定义
sentence pair,其中:token的source sentence。token的target sentence。source domain,target domain。
一个
sequence to sequence模型学习参数log likelihood作为目标函数:这个条件概率
其中
target sentencesequence to sequence learning的一个主要方法是encoder-decoder框架。编码器读取source sequence并生成一组representation;解码器在给定一组source representation和前面已经处理的target tokens的条件下,估计每个target token的条件概率。注意力机制被进一步引入编码器和解码器之间,从而在预测当前token时寻找应该聚焦于哪个source representation。
21.1.2 Masked Sequence to Sequence Pre-training
我们在本节中介绍了一个新的无监督预测任务。给定一个
unpaired source sentence我们记
fragment都被掩码。token数量。每个masked token替换为一个special symbolmasked sentence的长度保持不变。我们记
token的数量。我们记
fragment。
MASS通过预测sentence fragmentsequence to sequence模型,其中模型将masked sentence我们也使用对数似然作为目标函数:
其中:
token,它在sentence fragmentsentence fragmenttoken子序列(不包括位置
我们在下图中展示了一个例子,其中输入序列有
8个token,fragmentfragmentdecoder input为:位置0 ~ 2和位置6 ~ 7的输入都是special token3 ~ 5的输入为0开始 。虽然我们的方法适用于任何基于神经网络的
encoder-decoder框架,但我们在实验中选择了Transformer,因为它在多个sequence to sequence learning任务中取得了SOTA的性能。在论文的实现中,作者将
decoder input中的masked token移除,但是对所有的token保留它们的原始位置信息。即,下图中保留{2, 3, 4, 5}(位置编号从零开始计算)。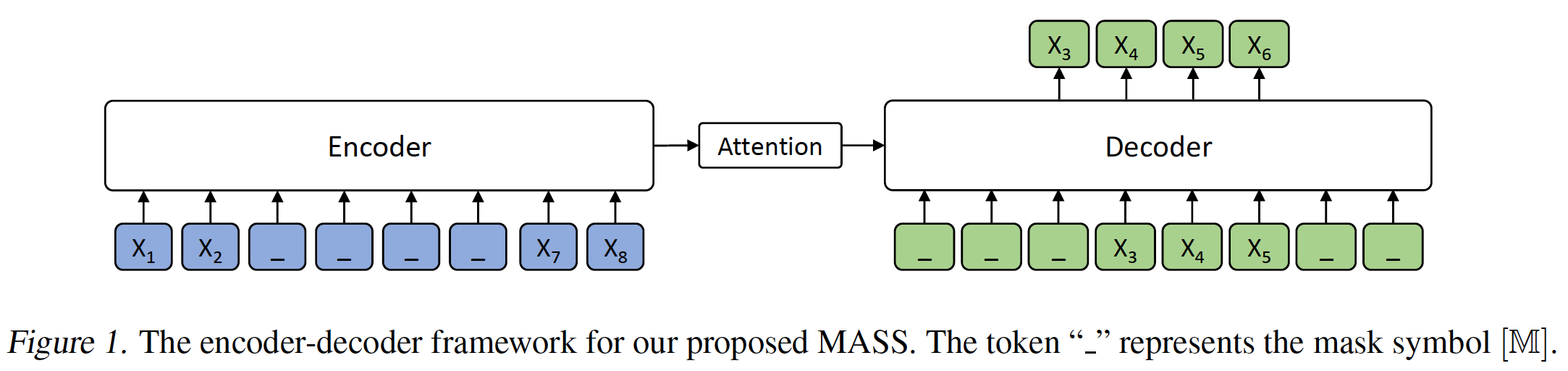
实际上,
BERT中的掩码语言建模masked language modeling、以及GPT中的标准语言建模standard language modeling可以被视为MASS的特殊情况。我们有一个重要的超参数masked fragment的长度。具有不同MASS可以覆盖一些特殊的case,这些特殊的case与先前的预训练方法相关,如下表所示。
当
source sentence中的masked fragment只包含一个token,解码器预测这个token时没有任何其它token作为输入,而是以unmasked source token为条件,如下图(a)所示。这就成了BERT中使用的masked language modeling。有人可能会说,该模型结构与
masked language modeling有一点不同。然而,由于解码器的所有输入token都被掩码了,解码器本身就像一个非线性分类器,类似于BERT中使用的softmax矩阵。在这种情况下,条件概率是masked token的位置,这正是BERT中使用的masked language modeling的公式。当
token数量,encoder side的所有token都被掩码,解码器需要在给定previous tokens的条件下预测所有token,如下图(b)所示。条件概率为GPT中的standard language modeling,以来自编码器的null信息为条件,因为encoder side的所有token都被掩码了。

21.1.3 讨论
MASS是一种用于language generation的预训练方法。虽然它的特殊case与先前的方法有关,包括GPT中的standard language modeling和BERT中的masked language modeling,但它与这些方法总体上是不同的:standard language modeling长期以来一直被用于预训练,最突出的是最近提出的ELMo和OpenAI GPT。BERT为自然语言理解引入了两个预训练任务(masked language modeling和next sentence prediction),并使用一个编码器来为单句single sentence和句子对sentence pair抽取representation。standard language modeling和BERT都可以只对编码器或解码器分别进行预训练。虽然在语言理解任务上取得了可喜的成果,但它们并不适合语言生成任务,其中语言生成任务通常利用encoder-decoder框架从而用于条件序列生成conditional sequence generation。MASS被设计为联合预训练编码器和解码器从而用于语言生成任务。- 首先,通过
sequence to sequence框架来仅仅预测masked token,MASS迫使编码器理解unmasked token的含义,同时也鼓励解码器从encoder side抽取有用的信息。 - 第二,通过预测
decoder side的连续token,解码器可以建立更好的语言建模能力,而不仅仅是预测离散的token。 - 第三,通过进一步掩码解码器的
input token(这些token在encoder side没有被掩码),鼓励解码器从encoder side抽取更多有用的信息,而不是利用decoder side的previous token的丰富信息。
- 首先,通过
21.2 实验
21.2.1 MASS 预训练
模型配置:我们选择
Transformer作为基本模型结构,它由6层编码器和6层解码器组成,emebdding/hidden维度为1024,feed-forward filter维度为4096。对于神经机器翻译任务,我们在
source language和target language的单语数据上对我们的模型进行预训练。我们分别对三种language pair进行了实验:English-French, English-German, English-Romanian。对于其他语言生成任务,包括文本摘要和对话式响应生成,我们分别只用英语单语数据对模型进行预训练。
为了区分神经机器翻译任务中的
source language和target language,我们为编码器和解码器的input sentence的每个token添加了一个language embedding,其中language embedding也是端到端学习的。mBART是在input sentence的开头添加一个<LID>的special token,如<EN>用于英语 。我们基于
XLM的代码库来实现我们的方法。数据集:我们使用了
WMT News Crawl数据集的所有单语数据,其中涵盖了2007年至2017年的190M英语句子、62M法语句子、270M德语句子。我们还在预训练阶段加入了一种
low-resource language,即罗马尼亚语Romanian,以验证用低资源单语数据预训练的MASS的有效性。我们使用News Crawl数据集中所有可用的罗马尼亚语句子,并使用WMT16数据对其进行增强,从而得到2.9M罗马尼亚语句子。我们删除了长度超过
175的句子。对于每个任务,我们在source language和target language之间用BPE联合学习了60K个子词单元sub-word unit。这里是跨语言的
BPE,而不是针对每个语言单独学习一个BPE。预训练细节:我们通过
special symboltoken来掩码segment,其中随机选择masked segment的起始位置BERT,编码器中的masked token为:80%的概率是token,10%的概率是random token,10%的概率是original token。我们将fragment lengthtoken总数的大约50%,同时研究不同的为了减少内存和计算成本,我们删除了解码器中的
padding(即,masked token),但保持unmasked token的positional embedding不变(例如,如果前两个token被掩码和删除,第三个token的位置仍然是2而不是0)。通过这种方式,我们可以获得类似的准确性,并减少解码器中50%的计算量。我们使用
Adam优化器进行预训练,学习率为8个NVIDIA V100 GPU card上进行训练,每个mini-batch包含3000个token从而用于预训练。为了验证
MASS的有效性,我们在三个语言生成任务上对预训练的模型进行了微调:神经机器翻译、文本摘要、对话式响应生成。我们在这些任务中探索了low-resource setting,其中我们只是利用少数训练数据用于微调从而模拟low-resource的场景。对于神经机器翻译,我们主要研究zero-resource setting(无监督),因为近年来无监督的神经机器翻译已经成为一项具有挑战性的任务。
21.2.2 Fine-Tuning on NMT
这里,我们首先描述无监督神经机器翻译的实验,然后介绍低资源神经机器翻译的实验。
实验配置:对于无监督神经机器翻译,没有双语数据
bilingual data来微调预训练的模型。因此,我们利用了预训练阶段的单语数据。与《Unsupervised neural machine translation》、《Unsupervised machine translation using monolingual corpora only》、《Phrase-based & neural unsupervised machine translation》、《Unsupervised pivot translation for distant languages》不同的是,我们只是利用back-translation来生成pseudo bilingual data从而用于训练,而不使用降噪自编码器。在微调过程中,我们使用Adam优化器,初始学习率为GPU的batch size被设置为2000个token。在评估过程中,我们用multi-bleu.pl(来自https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl)在newstest2014上评估English-French的BLEU分、在newstest2016上评估English-German和English-Romanian的BLEU分。无监督神经机器翻译的结果:我们的结果如下表所示。可以看到:
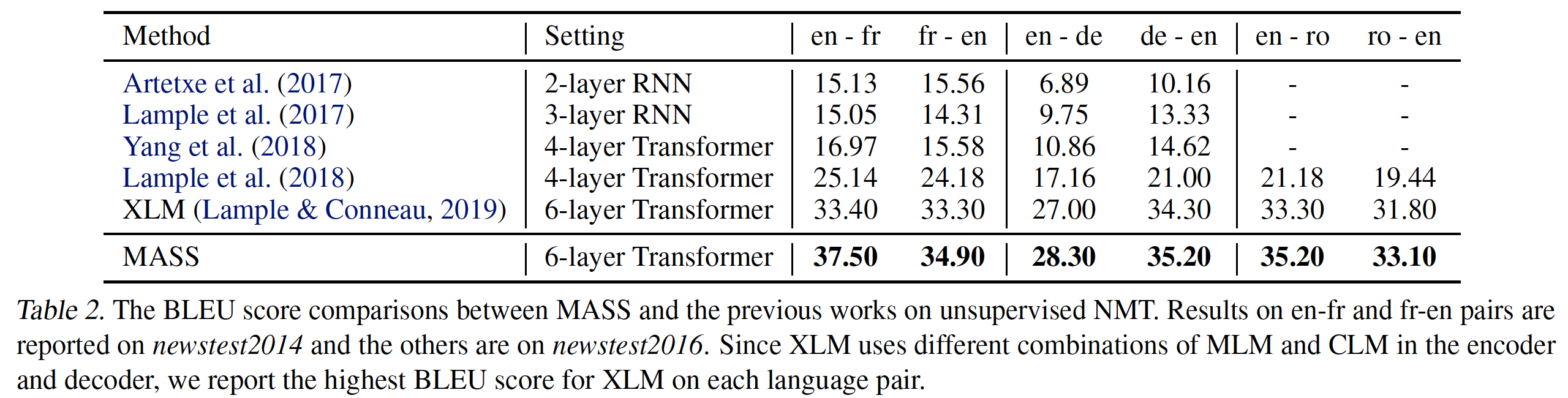
在所有
6个翻译方向上,我们的方法优于之前的所有结果,包括没有预训练的方法(Lample et al., 2018)和有预训练的方法(XLM)。XLM是之前的SOTA方法,它在编码器和解码器中利用了BERT-like的预训练,该预训练涵盖了几种预训练方法:masked language model: MLM、causal language model: CLM。我们的方法在en-fr上仍然比XLM高出4.1 BLEU point。
与其他预训练方法相比:我们还将
MASS与之前的语言生成任务的预训练方法进行比较。- 第一个
baseline是BERT+LM,在BERT中使用masked language modeling对编码器进行预训练,并使用standard language modeling对解码器进行预训练。 - 第二个
baseline是DAE,它简单地使用去降噪自编码器denoising auto-encoder来预训练编码器和解码器。
我们用
BERT+LM和DAE来预训练模型,并用XLM相同的微调策略对无监督翻译pair对进行微调(即DAE loss + back-translation)。这些方法也采用6层的Transformer。如下表所示:
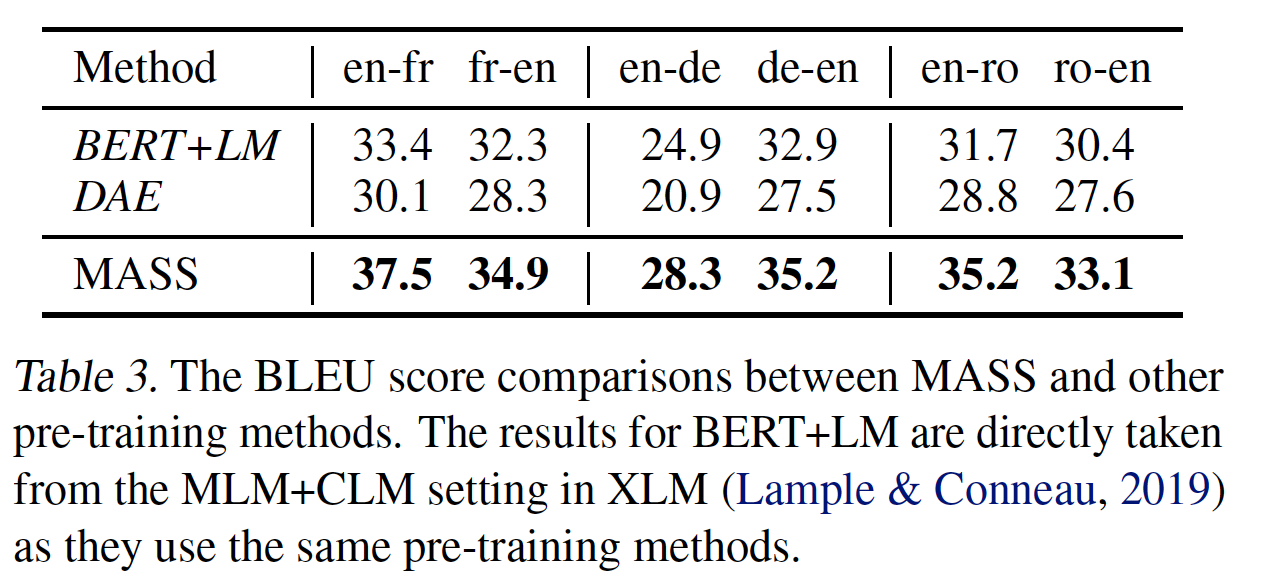
BERT+LM取得了比DAE更高的BLEU分,而MASS在所有无监督翻译pair对的表现都超过了BERT+LM和DAE。虽然
DAE通常利用一些降噪方法,如随机masking token或互换相邻token,但解码器仍然可以通过encoder-decoder attention轻松地学会拷贝unmasked token。另一方面,
DAE中的解码器将完整的句子作为输入,这足以像语言模型一样预测下next token,而不会被迫从编码器中提取额外的useful representation。
- 第一个
Low-Resource NMT实验:在低资源神经机器翻译的setting中,我们分别WMT14 English-French, WMT16 English-German, WMT16 English-Romanian的双语训练数据中抽取10K, 100K, 1M个paired sentence,从而探索我们的方法在不同low-resource场景中的表现。我们使用在预训练阶段学到的相同的
BPE代码来tokenize这些training sentence pair。我们用Adam优化器在paired data上对预训练模型进行了20K步的微调,学习率为setting中使用的相同测试集上的BLEU分。如下图所示,
MASS优于baseline模型,其中baseline模型仅在双语数据上训练而没有在所有六个翻译方向进行任何预训练。这表明我们的方法在低资源场景下的有效性。即,
baseline模型是传统的监督学习,而MASS是pretraining + finetuning。此外还可以看到:双语训练数据越少(即,资源越少),那么
MASS相比baseline的提升就越大。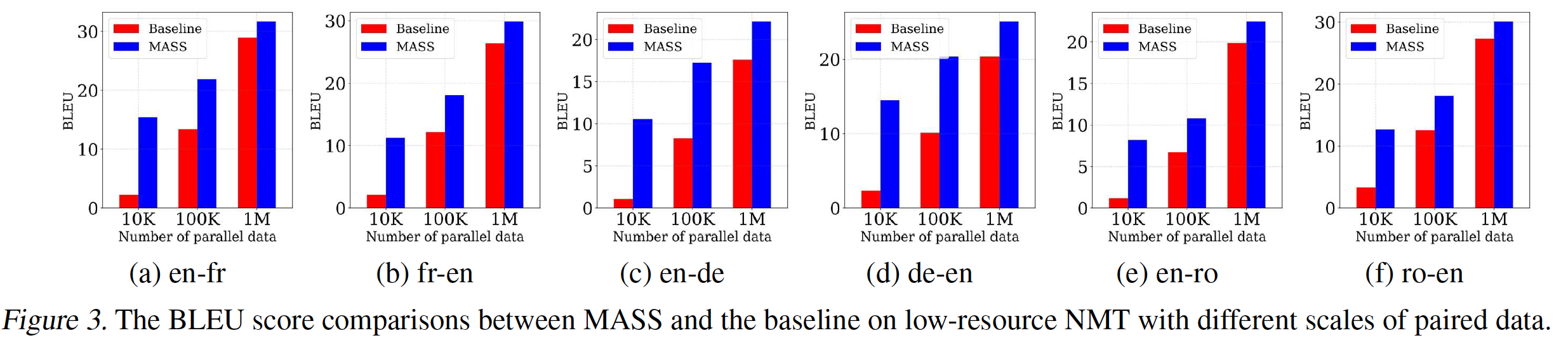
21.2.3 Fine-Tuning on Text Summarization
实验配置:文本摘要是对长篇文本文档创建简短而流畅的
summary,这是一项典型的序列生成任务。我们用来自Gigaword语料库的不同规模(10K、100K、1M、以及3.8M)的训练数据在文本摘要任务上对预训练模型进行微调,其中Gigaword语料库由总共3.8M篇英文的article-title pair组成。我们把article作为编码器的输入、把title作为解码器的输入从而用于微调。在评估过程中,我们报告了在Gigaword测试集上的ROUGE-1、ROUGE-2、以及ROUGE-L的F1得分。我们使用beam size = 5的beam search从而用于推理。结果:我们的结果如下图所示。我们将
MASS与仅在paired data上训练而没有任何预训练的模型(即,baseline)进行比较。在不同规模的微调数据上,MASS始终优于baseline(在10K数据上获得超过10 ROUGE point的增益,在100K数据上获得超过5 ROUGE point的增益),这表明MASS在这个任务上在具有不同规模训练数据的低资源场景中是有效的。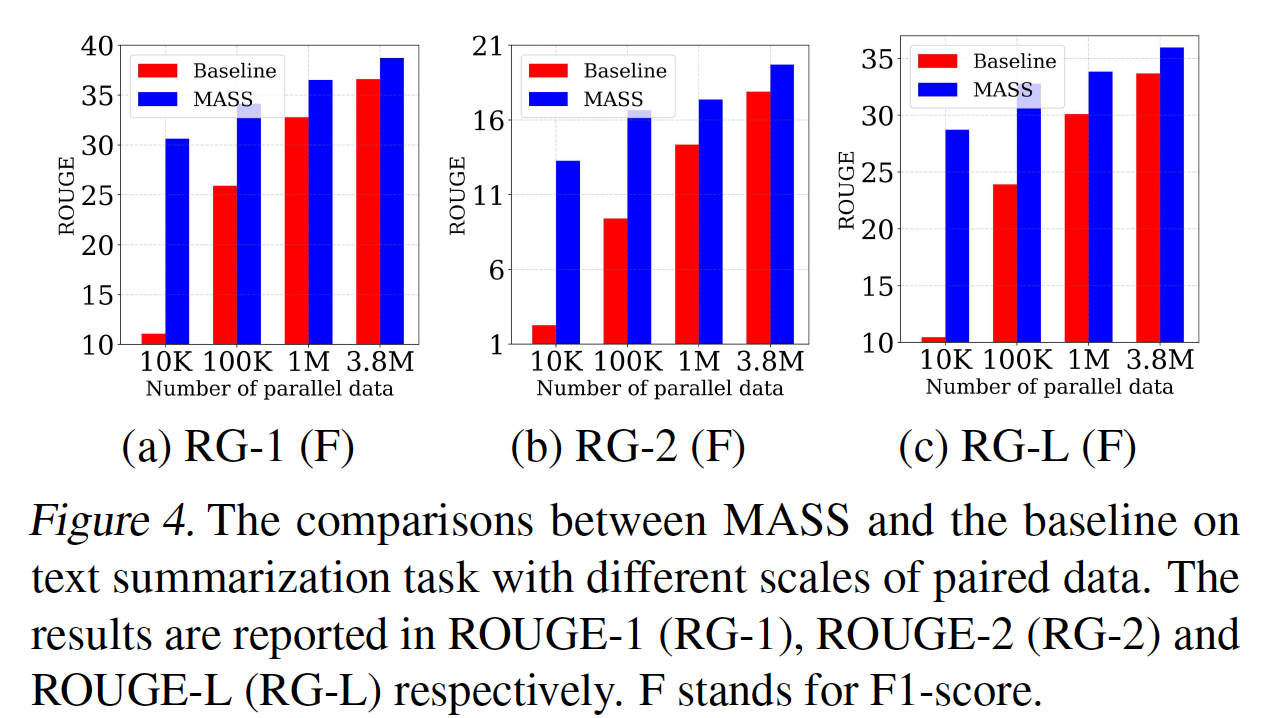
与其他预训练方法相比较:我们进一步将
MASS与前面描述的BERT+LM和DAE的预训练方法进行比较,其中在文本摘要任务上使用了3.8M的数据。如下表所示,MASS在三个ROUGE分数上一致地优于这两种预训练方法。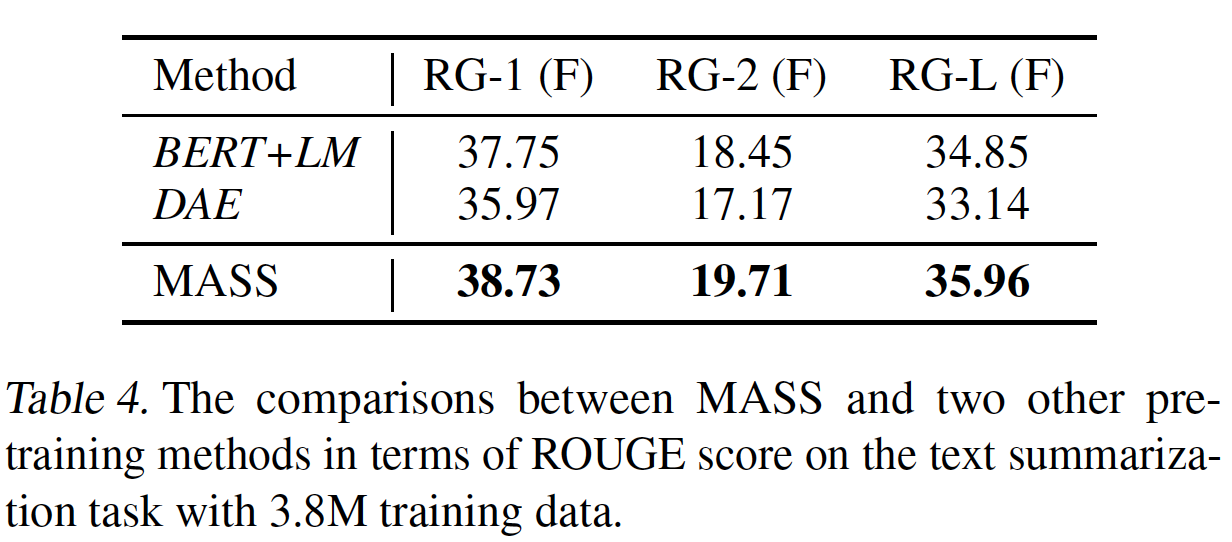
21.2.4 Fine-Tuning on Conversational Response Generation
实验配置:对话式响应生成为对话生成一个灵活的响应。我们在
Cornell Movie Dialog语料库上进行了实验,该语料库包含140K个conversation pair。我们随机抽取10K/20K个pair作为验证集/测试集,剩余的数据用于训练。我们采用预训练阶段的相同优化超参数进行微调。我们遵从《A neural conversational model》的方法,报告困惑度perplexity: PPL的结果。结果:我们将
MASS与baseline进行比较,其中baseline在现有可用的data pair上训练得到。我们对两组训练数据规模进行实验:随机选择10K个训练data pair、所有的110K个训练data pair,并在下表中展示实验结果。在10K和110K的训练数据上,MASS的PPL都比baseline更低。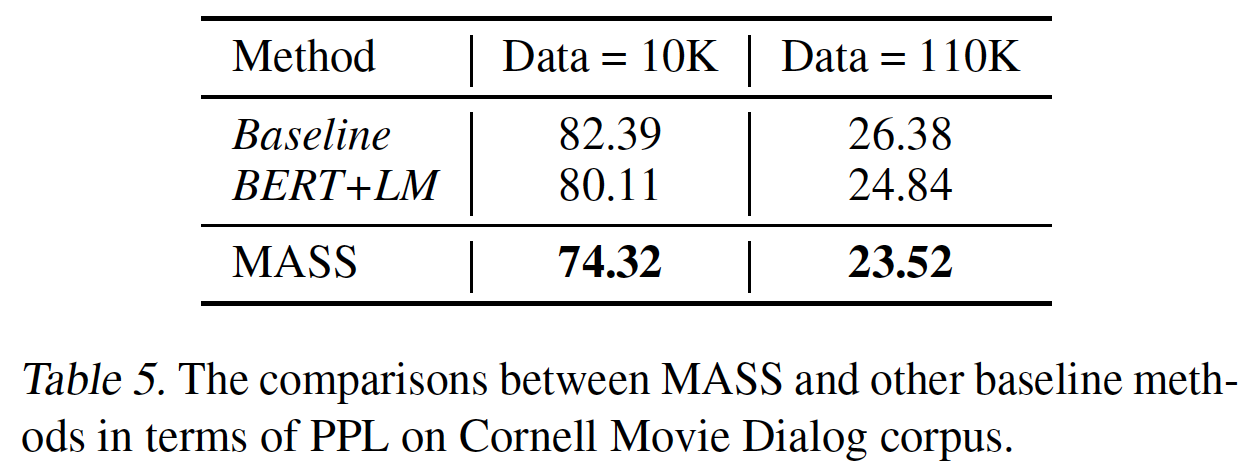
与其他预训练方法相比较:我们还将
MASS与BERT+LM和DAE的预训练方法在对话式响应生成任务上进行了比较。如Table 5所示,在10K和110K的训练数据上,MASS的PPL都比这两种预训练方法更低。
21.2.5 MASS 的分析
不同
masked fragment的长度MASS的一个重要的超参数。如前所述,通过改变masked language modeling(参考BERT)、以及standard language modeling的特殊case。在这一节中,我们研究了不同MASS的性能,我们选择10% ~ 90%,步长为10%,再加上我们观察了
MASS在预训练的表现,以及在几个语言生成任务中微调的表现,包括无监督的English-French翻译、文本摘要、以及对话式响应生成。我们首先展示了在不同的
perplexity: PPL。我们选择WMT En-Fr的newstest2013中的英语句子和法语句子作为验证集,并绘制PPL如下图所示(图(a)为英语、图(b)为法语)。可以看到:当
50%到70%之间时,预训练的模型达到了最佳的validation PPL。然后我们观察微调任务的表现。我们在
(c)中显示了无监督En-Fr翻译的validation BLEU分数的曲线,在图(d)中显示了文本摘要的validation ROUGE分数,在图(e)中显示了对话式响应生成的validation PPL。可以看到,当
50%时,MASS在这些下游任务上取得了最佳性能。
因此,我们在实验中为
MASS设定了50%。实际上,
50%是编码器和解码器之间的一个良好平衡。encoder side或decoder side的有效token太少,会使模型偏向于更多地关注另一侧,这不适合语言生成任务。因为语言生成任务通常利用encoder-decoder框架在编码器中抽取sentence representation,以及在解码器中建模和生成句子。极端情况是BERT中的masked language modeling)和standard language modeling)。如下图所示,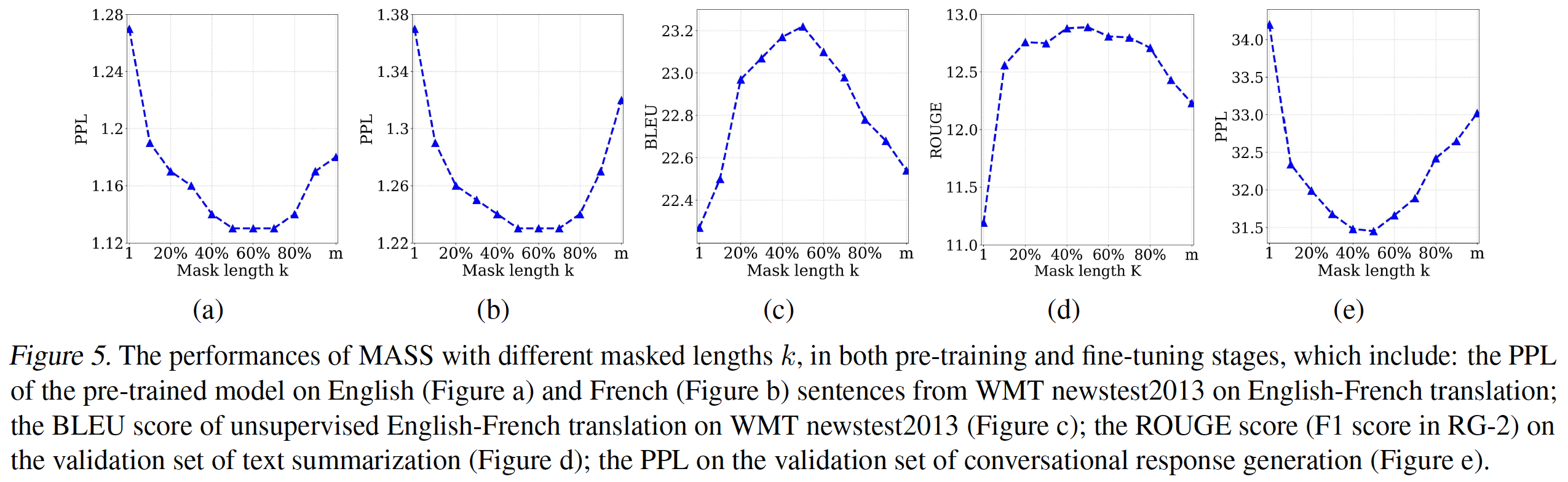
MASS的消融研究:在我们的masked sequence to sequence预训练中,我们有两个精心的设计:- 我们在
encoder side掩码连续的token,从而在decoder side预测连续的token,这比仅仅预测离散的token可以建立更好的语言建模能力。 - 我们掩码解码器的
input token,其中这些token在encoder side没有被掩码,从而鼓励解码器从encoder side抽取更多有用的信息,而不是利用decoder side的previous tokens的丰富信息。
在本节中,我们进行了两项消融研究,以验证
MASS中两种设计的有效性:- 第一项研究是在
MASS中随机掩码离散的token而不是连续的token,记做Discrete。 - 第二项研究是将所有的
token馈入解码器,而不是掩码解码器的input token(其中这些token在encoder side没有被掩码)记做Feed。
我们将
MASS与这两种消融方法在无监督的English-French上进行比较,如下表所示。可以看到,Discrete和Feed的表现都比MASS更差,证明了MASS的这两种设计的有效性。这里就一个例子,是不是说服力不强?可以在更多的数据集上进行评估。

- 我们在
二十二、MacBERT [2019]
BERT受到广泛的欢迎,并在最近的自然语言处理研究中被证明是有效的。BERT利用大规模的无标记训练数据并生成丰富的contextual representation。在几个流行的机器阅读理解benchmark上,如SQuAD,CoQA,QuAC,NaturalQuestions,RACE,我们可以看到大多数表现最好的模型是基于BERT及其变体,表明预训练的语言模型已经成为自然语言处理领域的新的基础部分。从
BERT开始,社区成员在优化预训练语言模型pre-trained language model方面取得了巨大而迅速的进展,如ERNIE, XLNet, RoBERTa, SpanBERT, ALBERT, ELECTRA等等。然而,针对learning representation,训练Transformer-based的预训练语言模型并不像我们用来训练word-embedding或其他传统神经网络那样容易:- 通常情况下,训练一个强大的
BERT-large模型(具有24层Transformer和3.3亿个参数)到收敛,需要高内存的计算设备(如TPU或TPU Pod),这些设备非常昂贵。 - 另一方面,虽然已经发布了各种预训练的语言模型,但大多数都是基于英语的,在其他语言中建立强大的预训练语言模型的努力很少。
为了尽量减少重复性工作,并为未来的研究建立
baseline,在论文《Pre-Training with Whole Word Masking for Chinese BERT》中,作者旨在建立中文预训练语言模型系列model series,并向公众发布,以促进科研社区,因为中文和英文是世界上最常用的语言之一。论文重新审视了现有的流行的预训练语言模型,并将其调整为中文,从而了解这些模型是否能在英语以外的语言中得到推广并表现良好。此外,论文还提出了一个新的预训练语言模型,称为MacBERT,它将原来的MLM任务替换为MLM as correction: Mac任务。MacBERT主要是为了缓解原始BERT中预训练阶段和微调阶段的差异。论文在十个流行的中文NLP数据集上进行了广泛的实验,范围从sentence-level任务到document-level任务,如机器阅读理解、文本分类等。实验结果表明,与其他预训练的语言模型相比,所提出的MacBERT可以在大多数任务中获得显著的收益。论文还给出了详细的消融实验,以更好地检查哪些因素带来改进。论文的贡献如下:- 为了进一步加快中文
NLP的未来研究,论文创建了中文预训练语言模型系列并向社区发布。作者进行了广泛的实证研究,通过仔细分析来重新审视这些预训练语言模型在各种任务上的表现。 - 论文提出了一个新的预训练语言模型,叫做
MacBERT,通过用相似的单词来掩码一个单词,从而缓解了预训练阶段和微调阶段的gap,这在各种下游任务中被证明是有效的。 - 论文还创建了一系列小型模型,称为
RBT,从而展示小型模型与常规预训练语言模型相比的表现,这有助于在现实世界中利用这些小模型。
本文创新力不足,更像是一篇工程实现的报告。
- 通常情况下,训练一个强大的
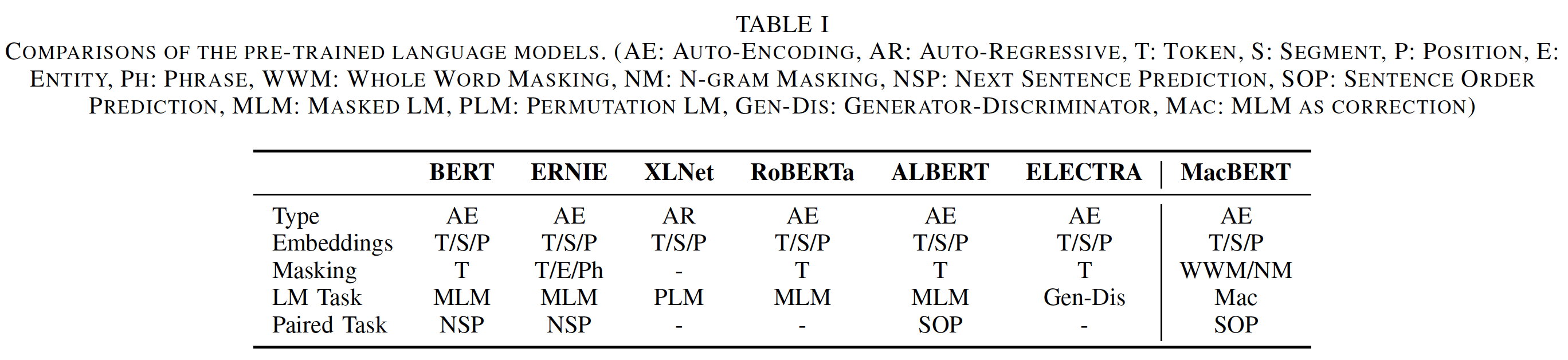
相关工作:这里我们重新审视了最近自然语言处理领域中具有代表性的预训练语言模型的技术。这些模型以及所提出的
MacBERT的整体比较在下表中描述。BERT:Bidirectional Encoder Representations from Transformers: BERT已经在广泛的自然语言处理任务中证明了其有效性。BERT通过在所有Transformer层中,同时以左侧上下文和右侧上下文为条件来预训练深度双向representation。BERT主要由两个预训练任务组成:Masked Language Model: MLM、Next Sentence Prediction: NSP。MLM:随机掩码输入中的一些token,目标是仅根据其上下文来预测原始token。NSP:预测sentence B是否是sentence A的下一句。
后来,他们进一步提出了一种叫做全词掩码(
whole word masking: wwm)的技术,用于优化MLM任务中的原始掩码。在这个setting中,我们不是随机选择WordPiece token来掩码,而是总是一次性掩码对应于整个单词的所有token。这明确地迫使模型在MLM预训练任务中恢复整个单词,而不是仅仅恢复WordPiece token,而恢复整个单词的挑战性更大。由于全词掩码只影响预训练过程的掩码策略,因此它不会给下游任务带来额外的负担。此外,由于训练预训练语言模型的计算成本很高,他们还公布了所有的预训练模型以及源代码,这大大刺激了社区对预训练语言模型进行研究的极大兴趣。
ERNIE:Enhanced Representation through kNowledge IntEgration: ERNIE旨在优化BERT的掩码过程,其中包括entity-level masking和phrase-level masking。与选择输入中的随机单词不同:entity-level masking是对命名实体的掩蔽,这些实体通常由几个单词组成。phrase-level masking是掩码连续的词,这与N-gram掩码策略相似。
XLNet:《Xlnet: Generalized autoregressive pretraining for language understanding》认为,现有的基于自编码的预训练语言模型(如BERT)存在预训练阶段和微调阶段的gap,因为masking token(即[MASK])从未在微调阶段出现。为了缓解这个问题,他们提出了基于Transformer-XL的XLNet。XLNet主要有两处修改:- 首先是在输入的分解顺序的所有排列上最大化期望的似然
expected likelihood,在这里他们称之为排列语言模型Permutation Language Model。为了实现这一目标,他们提出了一种新颖的双流自注意力机制two-stream self-attention mechanism。 - 其次是将自编码语言模型改为自回归语言模型,这与传统的统计语言模型类似。
- 首先是在输入的分解顺序的所有排列上最大化期望的似然
RoBERTa:Robustly Optimized BERT Pretraining Approach: RoBERTa旨在采用原始的BERT架构,但做了更精细的修改,以充分释放BERT的力量。他们对BERT中的各种组件进行了仔细的比较,包括掩码策略、输入格式、训练步数等。经过全面的评估,他们得出了几个有用的结论从而使得BERT更加强大,主要包括:- 用更大的
batch size和更长的序列在更多的数据上进行更长时间的训练。 - 取消
next sentence prediction任务,以及在MLM任务中使用动态掩码dynamic masking。
- 用更大的
ALBERT:A Lite BERT: ALBERT主要解决了BERT的内存消耗较大和训练速度慢的问题。ALBERT介绍了两种减少参数的技术。- 第一个是
factorized embedding parameterization,它将embedding矩阵分解为两个小矩阵。 - 第二个是跨层参数共享,即在
ALBERT的每一层共享Transformer权重,这大大减少了整体参数。
此外,他们还提出了
sentence order prediction: SOP任务,取代传统的NSP预训练任务,从而产生更好的性能。- 第一个是
ELECTRA:Efficiently Learning an Encoder that Classifiers Token Replacements Accurately: ELECTRA采用了一个新的generator-discriminator framework,类似于生成对抗网generative adversarial net: GAN。- 生成器通常是一个小型的
MLM,学习预测masked token的原始token。 - 判别器被训练来判别
input token是否被生成器所替换,这被称作Replaced Token Detection: RTD。
注意,为了实现有效的训练,判别器只需要预测一个二元标签来表示
"replacement",而不像MLM预测准确的masked word。在预训练阶段之后,我们抛弃了生成器,只用判别器来微调下游的任务。- 生成器通常是一个小型的
22.1 模型
22.1.1 中文预训练模型
虽然
BERT及其变体在各种英语任务中取得了显著的改进,但我们想知道这些模型和技术是否能在其他语言中得到很好的泛化。在本节中,我们将说明现有的预训练语言模型是如何适用于中文的。我们采用BERT、RoBERTa和ELECTRA以及它们的变体来创建中文预训练模型系列model series,其有效性在实验部分展示。需要注意的是,由于这些模型都是源于BERT或ELECTRA,没有改变输入的性质,在微调阶段无需修改从而适配这些模型,相互替换非常灵活。BERT-wwm & RoBERTa-wwm:原始的BERT使用WordPiece tokenizer将文本拆分成WordPiece tokens,其中一些单词被拆分成几个小的片段small fragment。全词掩码whole word masking: wwm缓解了仅掩码整个单词的一部分的缺点,因为仅掩码整个单词的一部分对模型来说更容易预测。根据单词的一部分
token来预测另一部分token相对比较容易,如player被拆分为play和##er两个token。如果被掩码的token为##er,那么已知play来预测##er要相对容易。在中文条件下,
WordPiece tokenizer不再将单词分割成小的片段,因为汉字不是由类似字母的符号组成。我们使用中文分词Chinese Word Segmentation: CWS工具,将文本分割成若干个词语。通过这种方式,我们可以采用中文的全词掩码,而不是单个汉字的掩码。在实施过程中,我们严格遵循原有的全词掩码代码,不改变其他的组成部分,如word masking的百分比等。我们使用LTP进行中文分词来识别单词的边界。需要注意的是,全词掩码只影响到预训练阶段的masking token的选择。我们仍然使用WordPiece tokenizer来拆分文本,这与原始的BERT是相同的。同样地,全词掩码也可以应用于
RoBERTa,其中没有采用NSP任务。然而,我们仍然使用paired input进行预训练,这可能有利于sentence pair的分类任务和阅读理解任务。SpanBERT表明,single-sequence training的效果要好于bi-sequence training,因为单个句子的训练可以获得更长的上下文。下表中描述了一个全词掩码的例子。
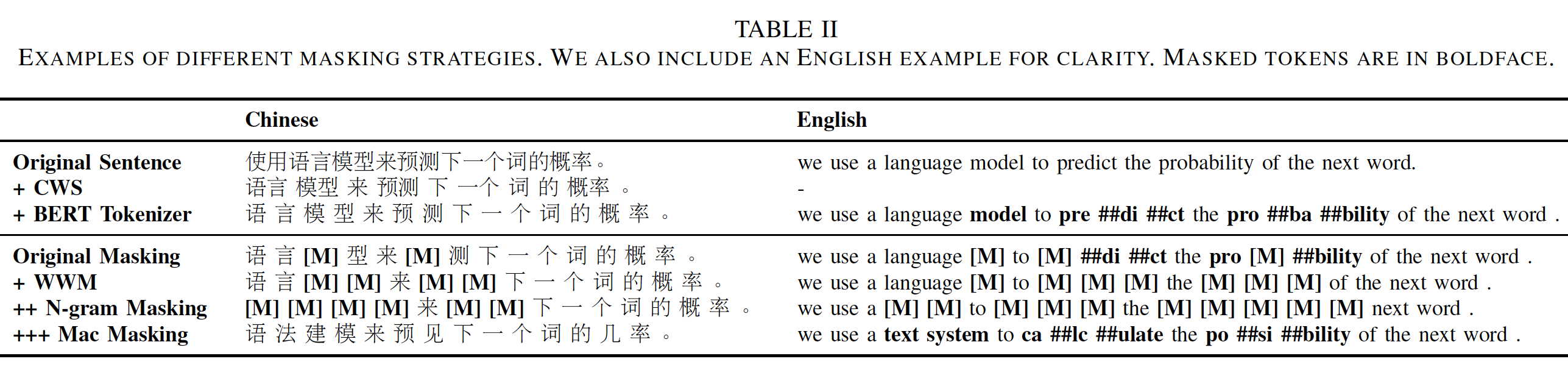
ELECTRA:除了BERT和RoBERTa系列,我们还探索了ELECTRA模型,它采用了一个新的预训练框架,由生成器和判别器组成。我们严格遵循ELECTRA原始论文中的原始实现。RBT Series:尽管上述的预训练语言模型很强大,但它们不是计算高效的,而且很难在实际应用中采用。为了使社区研究人员更容易获得预训练的模型,除了常规的预训练语言模型,我们还预训练了几个小模型,我们称之为RBT。具体而言,我们使用与训练
RoBERTa完全相同的训练策略,但我们使用较少的Transformer层。我们训练3层、4层、6层的RoBERTa-base,分别表示为RBT3、RBT4和RBT6。我们还训练了一个3层的RoBERTa-large,表示为RBTL3,它的参数规模与RBT6相似。这样做的目的是在参数规模相当的情况下,比较一个更宽更浅的模型(RBTL3)和一个更窄更深的模型(RBT6),这有助于未来预训练语言模型的设计。
22.1.2 MACBERT
在上一节中,我们提出了一系列的中文预训练语言模型。在这一节中,我们充分利用这些模型,并提出了一个叫做
MLM as correction BERT: MacBERT的新型模型。MacBERT与BERT共享相似的预训练任务类型,并做了一些修改。MacBERT由两个预训练任务组成:MLM as correction、sentence order prediction。下图描述了
MacBERT的整体架构。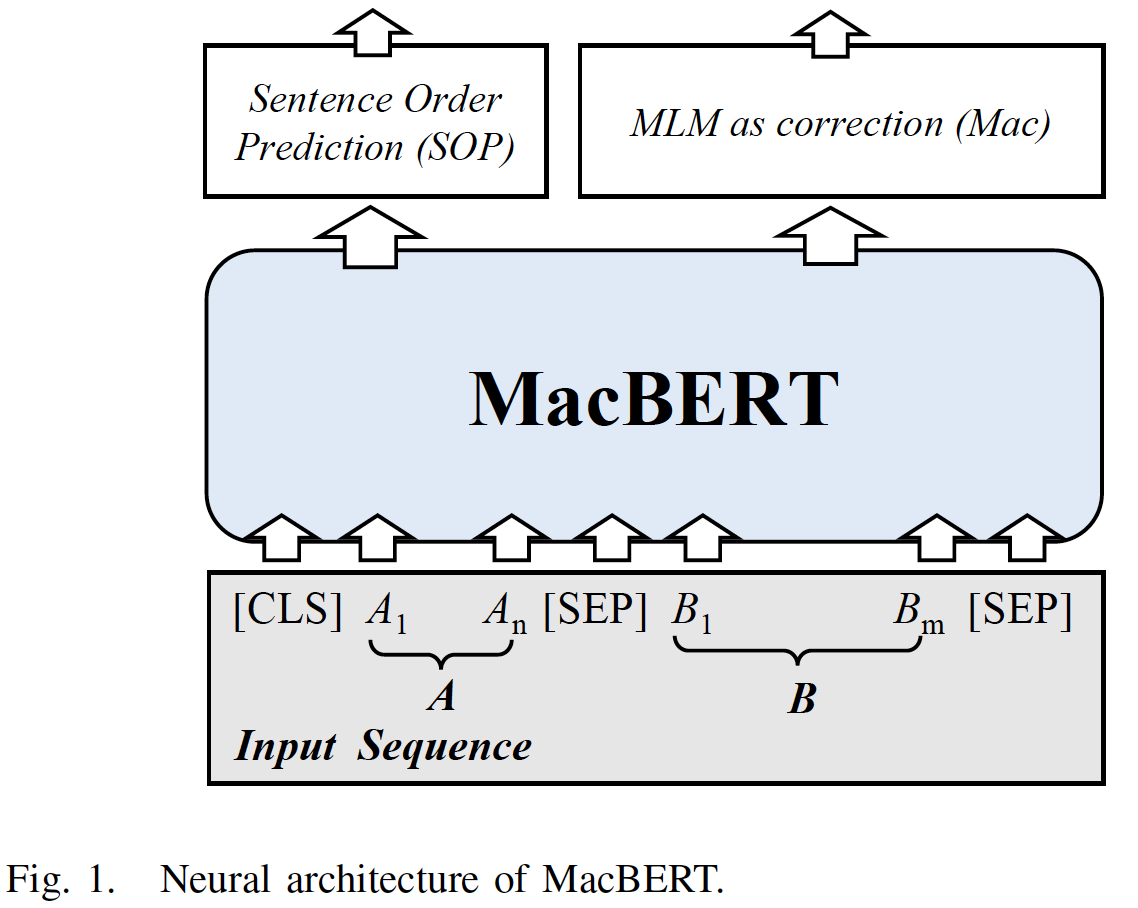
MLM as correction:MLM是BERT及其变体中最重要的预训练任务,它建模了双向上下文推断bidirectional contextual inference的能力。然而,如前所述,MLM存在预训练阶段和微调阶段的不一致性,即预训练阶段的人工标记(如[MASK])从未出现在真正的下游微调任务中。为了解决这个问题,我们提出了一个新的预训练任务,称为
MLM as correction: Mac。在这个预训练任务中,我们不采用任何预定义的token来进行掩码。相反,我们将原始的MLM转化为一个文本纠正text correction任务:模型应该将错误的单词纠正为正确的单词,这比MLM更自然。具体而言,在Mac任务中,我们对原始MLM进行了以下修改:文本纠正任务要比
MLM任务更简单。文本纠正任务是:给定original word的similar word,因此需要预测的original word一定跟similar word非常相似。这大大缩小了候选单词的范围。例如:原始句子为
I like play football.,我们用basketball代替了football,变成I like play basketball.。我们需要根据这个句子来预测最后一个单词为football。事实上,我们知道这个目标单词和basketball非常相似,这大大缩小了候选单词的范围。我们使用全词掩码策略以及
N-gram掩码策略来选择候选token进行掩码,对于word-level的unigram, 2-gram, 3-gram, 4-gram,其掩码比例分别为40%, 30%, 20%, 10%。我们还注意到,最近的一项工作提出了PMI-masking(《{PMI}-masking: Principled maskingof correlated spans》),它优化了掩码策略。在本文中,我们采用的是普通的N-gram掩码,并将在未来尝试PMI掩码。在微调阶段,
[MASK] token从未出现过,我们建议使用similar word来进行掩码,而不是用[MASK] token进行掩码。similar word是通过使用同义词工具包Synonyms toolkit(https://github.com/huyingxi/Synonyms)来获得的,它是基于word2vec的相似性来计算。如果选择了一个N-gram进行掩码,我们会对每个被掩码的单词寻找similar word。在极少数情况下,当没有
similar word时,我们会退化到使用random word来替换。这种random word替换被限制在不超过所有待掩码的token的10%。similar word的token数量与原始单词的token数量不一致,怎么解决?例如,原始单词为player,它的token为[play, #er];similar word为participant,它的token为['participant']。这种纠错的方式可以视为对输入加噪音的一种,可以用于
BART的预训练任务。遵从以前的工作,我们使用
15%的输入词进行掩码,其中80%的token被替换成similar word,10%的token被替换成random word,其余10%的token保持原词。此外,所有这
15%的输入词中,对于word-level的unigram, 2-gram, 3-gram, 4-gram的掩码比例分别为40%, 30%, 20%, 10%。
Sentence Order Prediction:BERT中最初的next sentence prediction: NSP任务被认为对模型来说太容易了,人们已经证明它不是那么有效(Roberta原始论文、ALBERT原始论文)。在本文中,我们采用了由ALBERT引入的sentence order prediction: SOP任务,该任务被证明比NSP更有效。正样本是通过使用两个连续的文本创建的,而负样本是通过交换它们的原始顺序创建的。我们在实验部分中消融这些修改,以更好地展示每个组成部分的贡献。神经架构
Neural Architecture:正式地,给定两个序列我们首先通过拼接两个序列来构建输入序列
然后,
MacBERT通过一个embedding layer(由word embedding, positional embedding, token type embedding组成)和transformer将contextualized representationtoken type embedding就是segment embedding。我们只需要预测被
Mac任务替代的position,在得到contextual representationreplaced position有关的子集,形成replaced representationreplaced token的数量。根据Mac任务的定义,然后我们将
vocabulary space中,从而预测在整个词表BERT实现,我们也使用word embedding矩阵embedding维度和隐层维度是相同的:其中:
replaced representation;然后我们使用标准的交叉熵损失来优化预训练任务:
其中:
1,否则为0。replaced token的ground truth。replaced token为
对于
SOP任务,我们直接使用[CLS] token的contextual representation,也就是label prediction layer:其中:
我们也使用交叉熵损失来优化
SOP预训练任务。最后,整体训练损失是
Mac损失和SOP损失的组合:这里是否需要用超参数
22.2 实验
22.2.1 实验配置
数据处理:我们使用
Wikipedia dump(截至2019年3月25日),并按照BERT原始论文的建议用WikiExtractor.py进行预处理,结果有1307个extracted files。我们在这个dump中同时使用了简体中文和繁体中文,并没有将繁体中文部分转换成简体中文。我们在实验部分展示了在繁体中文任务中的有效性。在清理原始文本(例如去除html tag)以及分离文件之后,我们得到了大约0.4B单词。由于
Chinese Wikipedia的数据相对较少,除了Chinese Wikipedia,我们还使用扩展的训练数据来训练这些预训练语言模型(模型名称中标有ext)。内部收集的扩展数据包含百科全书encyclopedia、新闻、以及问答网络question answering web,有5.4B单词,比Chinese Wikipedia大十倍以上。请注意,对于MacBERT我们总是使用扩展数据,并省略ext标记。为了识别全词掩码的中文单词的边界,我们使用
LTP进行中文分词。我们使用BERT原始论文提供的create_pretraining_data.py将原始输入文本转换为预训练样本。预训练语言模型的配置:为了更好地从现有的预训练好的语言模型中获取知识,我们没有从头开始训练我们的
base-level model,而是从官方的Chinese BERT-base开始,继承其词表vocabulary和模型权重。然而,对于large-level model,我们必须从头开始训练,但仍然使用base-level model提供的相同词表。base-level model是一个12层的transformer,隐层维度为768。- 而
large-level model是一个24层的transformer,隐层维度为1024。
对于训练
BERT series,我们采用了BERT所建议的方案:预训练开始时选择最大序列长度为128个token,然后选择最大序列长度为512个token。然而,我们根据实验发现,这导致对长序列任务(如阅读理解任务)的适应性adaptation不足。在这种情况下,对于BERT以外的模型,我们直接在整个预训练过程中使用512的最大长度,这在Roberta中被采用。对于较小的
batch size,我们采用BERT中原始的、带权重衰减的ADAM优化器进行优化。对于较大的batch size,我们采用LAMB优化器以获得更好的scalability。预训练是在单个Google Cloud TPU v3-8(相当于单个TPU)或TPU Pod v3-32(相当于4个TPU)上进行的,这取决于模型的规模。具体而言,对于MacBERT-large,我们训练了2M步,batch size = 512,初始学习率为1e-4。训练细节如下表所示。为了简洁,我们没有列出
'ext'模型,其中'ext'模型的超参数与没有在扩展数据上训练的模型相同。
微调任务的配置:为了彻底测试这些预训练语言模型,我们对各种自然语言处理任务进行了广泛的实验,涵盖了广泛的文本长度,即从
sentence-level到document-level。任务细节如下表所示。具体而言,我们选择了如下十个流行的中文数据集:- 机器阅读理解
Machine Reading Comprehension: MRC:CMRC 2018, DRCD, CJRC。 - 单句分类
Single Sentence Classification: SSC:ChnSentiCorp, THUCNews, TNEWS。 - 句子对分类
Sentence Pair Classification: SPC:XNLI, LCQMC, BQ Corpus, OCNLI。
为了进行公平的比较,对于每个数据集,我们保持相同的超参数(如最大序列长度、
warm-up步数等),只对每个任务的初始学习率调优 (从1e-5到5e-5)。请注意,初始学习率是在原始的Chinese BERT上调优的,通过对每个任务独立地调优学习率,有可能实现另一种增益。我们将相同的实验运行十次,以确保结果的可靠性。最佳的初始学习率是通过选择最佳的平均验证集性能来确定的。我们报告最高分和平均分,从而同时评估峰值性能和平均性能。除了TNEWS和OCNLI的测试集没有公开,我们同时报告验证集和测试集的结果。注意,这里是用于微调任务的超参数,与预训练任务的超参数有所差异。
对于除
ELECTRA以外的所有模型,我们对每个任务使用相同的初始学习率设置,如下表所示。对于ELECTRA模型,我们按照ELECTRA原始论文的建议,对base-level model使用1e-4的通用初始学习率,对large-level model使用5e-5的通用初始学习率。由于现有的各种中文预训练语言模型,如
ERNIE, ERNIE 2.0, NEZHA的预训练数据有很大的不同,我们只对BERT, BERT-wwm, BERT-wwm-ext, RoBERTa-wwm-ext, RoBERTa-wwm-ext-large, ELECTRA以及我们的MacBERT进行比较,从而保证不同模型之间相对公平的比较。其中,除了原始的Chinese BERT,所有模型都由我们自己训练。我们在TensorFlow框架下进行了实验,并对BERT原始论文提供的微调脚本进行了轻微改动,以更好地适配中文任务。
- 机器阅读理解
22.2.2 实验结果
机器阅读理解:机器阅读理解是一项有代表性的
document-level建模任务,要求根据给定的段落回答问题。我们主要在三个数据集上测试这些模型:CMRC 2018, DRCD, CJRC。CMRC 2018:一个span-extraction的机器阅读理解数据集,与SQuAD类似,为给定的问题抽取一个passage span。DRCD:这也是一个span-extraction的机器阅读理解数据集,但是是繁体中文。CJRC:类似于CoQA,它有yes/no question、没有答案的问题、以及span-extraction question。该数据收集自中国的法律判决文件。注意,我们只使用small-train-data.json进行训练。
结果如下表所示。可以看到:
使用额外的预训练数据会带来进一步的改进,如
BERT-wwm和BERT-wwm-ext之间的比较所示。这就是为什么我们对RoBERTa、ELECTRA和MacBERT使用扩展数据。注意,
MacBERT默认就使用了扩展数据。此外,所提出的
MacBERT在所有阅读理解数据集上都产生了显著的改进。值得一提的是,我们的MacBERT-large可以在CMRC 2018的Challenge集合上实现SOTA的F1,即60%,这需要更深入的文本理解。此外,应该注意的是,虽然
DRCD是一个繁体中文数据集,但用额外的大规模简体中文进行训练也会有很大的积极作用。由于简体中文和繁体中文有许多相同的字符,使用带有少量繁体中文数据的一个强大的预训练语言模型也可以带来改进,而不需要将繁体中文字符转换为简体字符。关于
CJRC,其中文本是以关于中国法律的专业方式写成的,BERT-wwm比BERT显示出适度的改进,但不是那么突出,表明在非通用领域的微调任务中需要进一步的领域适应domain adaptation。然而,增加通用的预训练数据会导致改善,这表明当没有足够的领域数据domain data时,我们也可以使用大规模的通用数据作为补救措施。
这里没有
BERT-large的数据,因为BERT官方未提供。根据论文的说明,MacBERT-base是用预训练好的BERT-base来初始化的,这相当于MacBERT-base比BERT-base训练更长的时间,因此它的效果更好,也就不足为奇。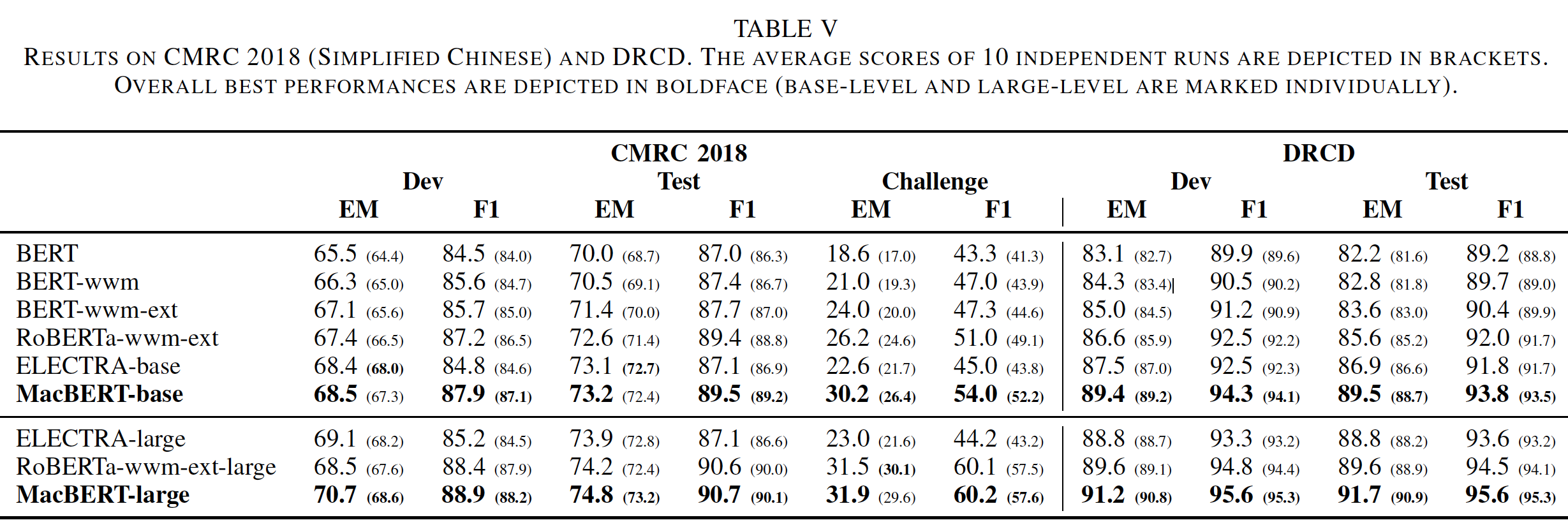
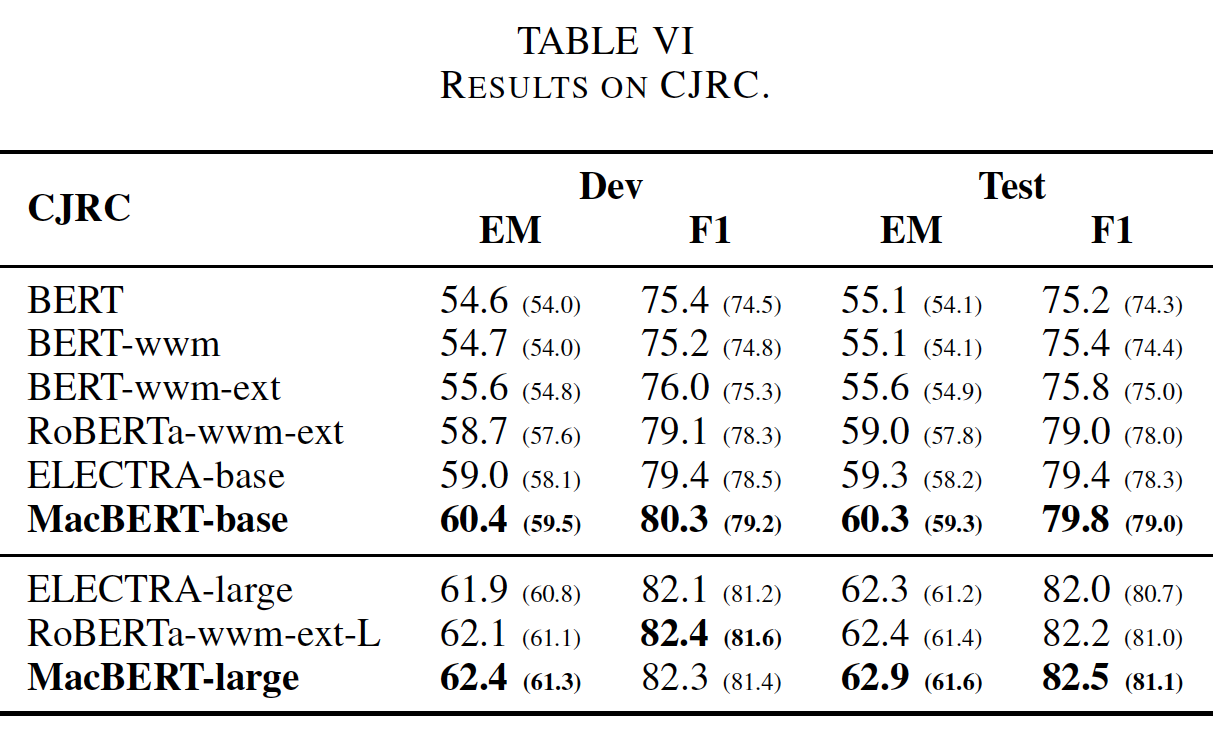
单句分类:对于单句分类任务,我们选择
ChnSentiCorp, THUCNews, TNEWS数据集:ChnSentiCorp用于评估情感分类,其中文本应该被划分为正面或负面的label。THUCNews是一个包含不同类型的新闻的数据集,其中的文本通常很长。在本文中,我们使用了一个包含10个领域(均匀分布)的50K个新闻的版本,包括体育、金融、技术等等领域。TNEWS是一个由新闻标题和关键词组成的短文本分类任务,要求分类到15个类别中的一个。
结果如下表所示。可以看到:
MacBERT可以在ChnSentiCorp和THUCNews中比baseline有适度的改进,即使这些数据集已经达到了很高的准确率。- 在
TNEWS中,MacBERT在base-level和large-level预训练语言模型中产生了一致的改进。
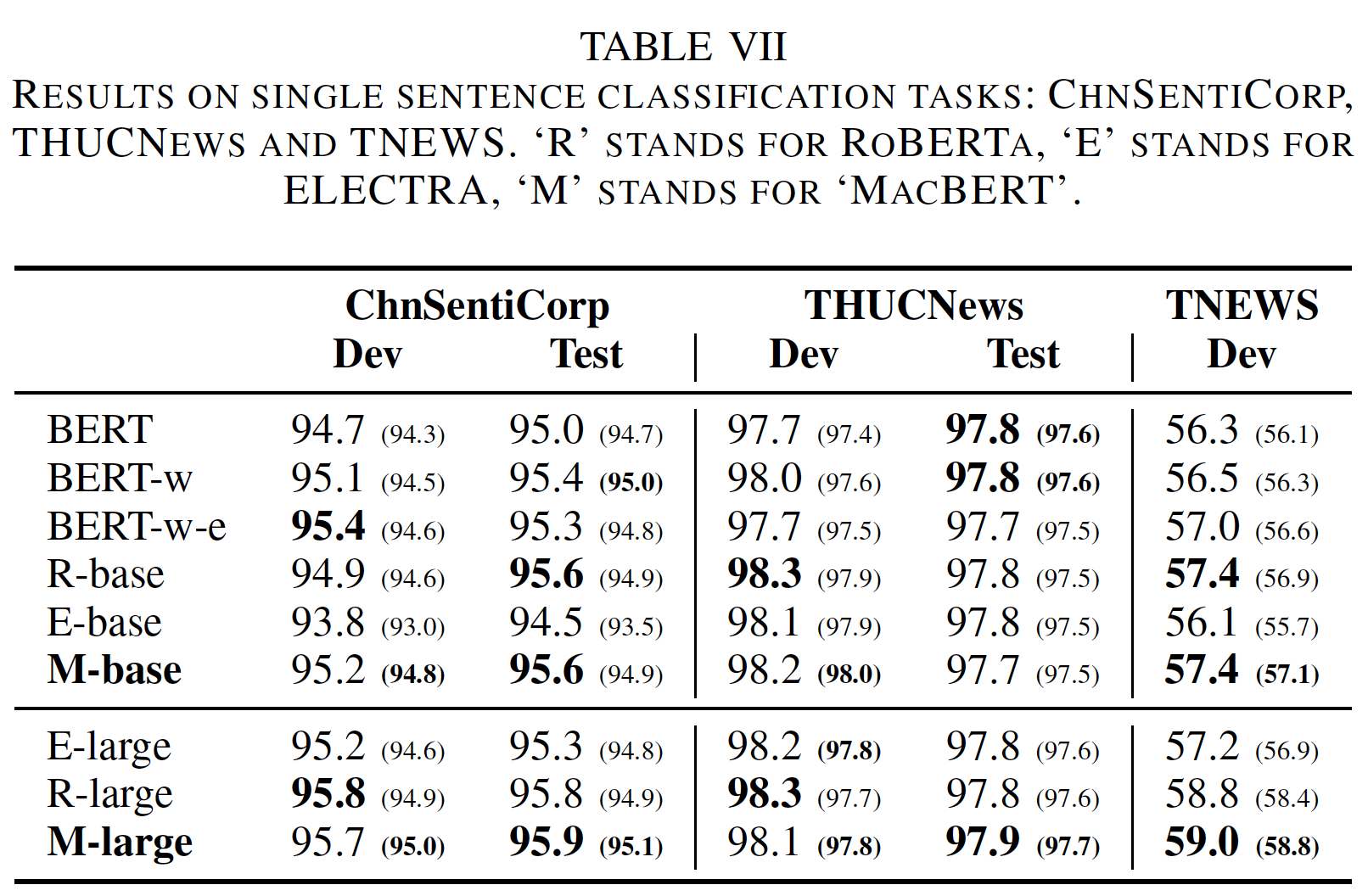
句子对分类:对于句对分类任务,我们使用了
XNLI数据(中文部分)、Large-scale Chinese Question Matching Corpus : LCQMC、BQ Corpus、以及OCNLI,这些数据需要输入两个序列并预测它们之间的关系。结果如下表所示。可以看到:在
XNLI和OCNLI中,MacBERT比baseline产生了相对稳定和显著的改进。然而,MacBERT在LCQMC和BQ Corpus上仅仅显示了适度的改进,平均得分略有提高,但峰值性能不如RoBERTa-wwm-ext-large。我们怀疑这些任务对输入的细微差别的敏感性不如阅读理解任务。由于
sentence pair classification只需要生成整个输入的unified representation,因此导致了适度的改进。机器阅读理解任务的改进比分类任务更大,这可能归因于掩码策略。在机器阅读理解任务中,模型应该识别段落中的
exact answer span。在MacBERT中, 每个N-gram单词都被其同义词或一个随机词所取代,因此每个词都可以很容易地被识别,这迫使模型学习word boundary。这里的解释比较苍白,原因没有讲清楚。
MacBERT-base通常比MacBERT-large产生更大的改进。这可能是由两个原因造成的。- 首先,
MacBERT-base是由BERT-base初始化的,它可以从BERT-base的知识中受益,并避免冷启动的问题。 - 其次,
large-level预训练语言模型的结果通常高于base-level预训练语言模型的结果,因此获得更高的分数要比base-level预训练语言模型困难得多。
- 首先,
小模型的结果:我们还建立了一系列的小模型,即
RBT,建立在RoBERTa-base或RoBERTa-large模型上。实验结果如下表所示。可以看到:- 小模型的表现比一般模型(
base-level, large-level)更差,因为它们使用的参数较少。 - 分类任务的性能下降比阅读理解任务要小,说明可以牺牲微小的性能来获得更快、更小的模型,这对现实生活中的应用是有益的。
- 通过比较参数大小相似的
RBTL3和RBT6,我们可以看到RBT6的性能大大优于RBTL3,这表明窄而深的模型通常优于宽而浅的模型。
这些观察结果对未来实际应用中的模型设计是有帮助的。
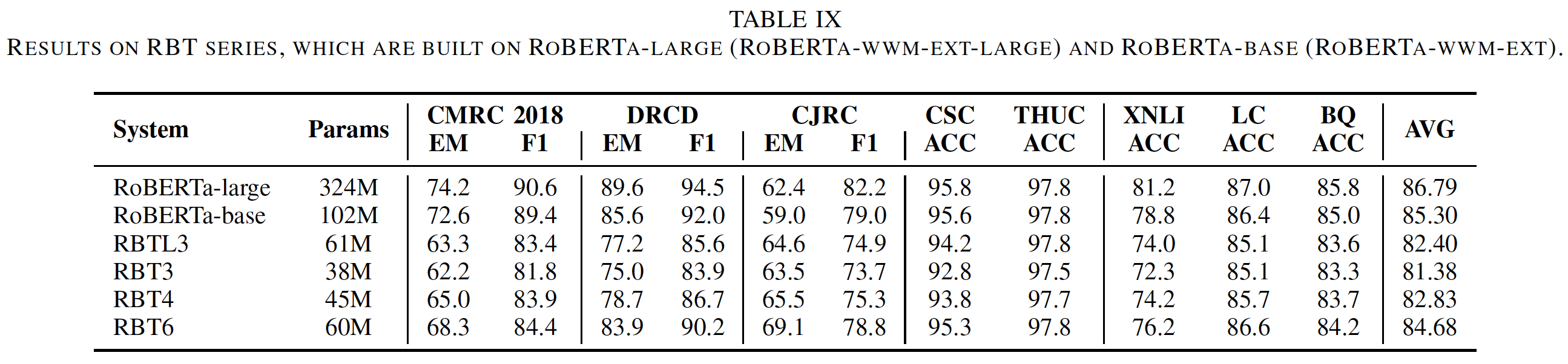
- 小模型的表现比一般模型(
22.3 讨论
- 根据实验结果,我们可以看到:这些预训练的语言模型在中文任务中也比传统的
BERT有明显的改进,这表明它们的有效性和通用性。虽然我们的模型在各种中文任务中取得了显著的改进,但我们想知道这些改进的基本组件essential component来自哪里。为此,我们在MacBERT上进行了详细的消融研究从而证明其有效性。此外,我们还比较了现有的预训练语言模型在英语中的声明claim,看看它们的修改在另一种语言中是否仍然成立。
22.3.1 MacBERT 的有效性
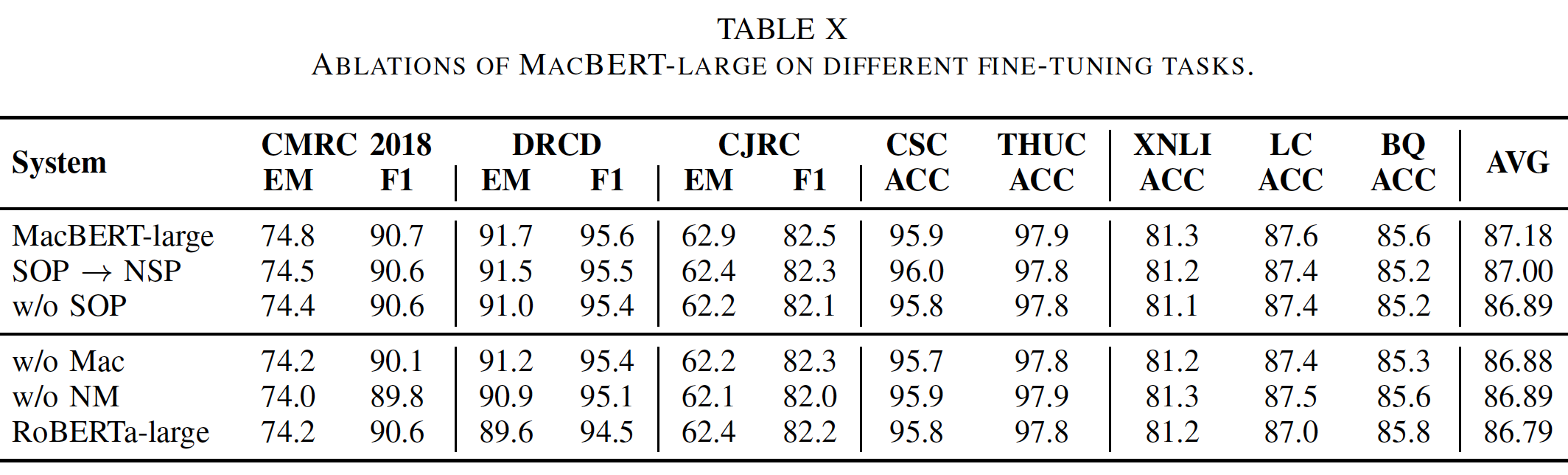
我们进行了详细的消融研究,以检查
MacBERT中每个组件的贡献。结果如下表所示。总的平均分数是通过平均每个任务的测试分数得到的。w/o表示without。可以看到:总体而言,删除
MacBERT中的任何组件都会导致平均性能的下降,这表明所有的修改都有助于整体改进。具体而言,最有效的修改是
N-gram masking和similar word替换,这是对masked language model: MLM任务的修改。当我们比较N-gram masking和similar word替换时,我们可以看到明显的优点和缺点,其中:N-gram masking似乎在文本分类任务中更有效(以ACC为指标的任务),而阅读理解任务的表现似乎更受益于similar word替换任务。将这两个任务结合起来可以相互弥补,在两种任务上都有更好的表现。数据不支持这里的结论。
N-gram masking: NM、similar word替换、以及SOP的贡献都相差无几(缺少它们,导致平均准确性都在86.89附近)。此外,不同组件对于不同任务,也没有看出特别突出的贡献。next sentence prediction: NSP任务没有显示出像MLM任务那样的重要性,这表明设计一个更好的MLM任务来充分释放文本建模的能力更为重要。此外,我们还比较了
next sentence prediction任务和sentence order prediction任务,以更好地判断哪一个任务更强大。结果显示,sentence order prediction任务确实比原来的next sentence prediction任务表现得更好,尽管它不是那么突出。sentence order prediction任务要求识别两个句子的正确顺序,而不是使用一个随机的句子,这对机器来说更容易识别。与文本分类任务相比,在阅读理解任务中去掉sentence order prediction任务会导致性能明显下降,这表明有必要设计一个类似next sentence prediction的任务来学习两个segment之间的关系(例如,阅读理解任务中的段落和问题)。
点评:本文创新力不足,感觉更像是一个工程实现的报告而已。
22.3.2 MLM 任务上的调研
如上一节所示,最主要的预训练任务是
masked language model及其变体。masked language model任务依赖于两个方面:选择要被掩码的token、替换被选中的token。在上一节中,我们已经证明了选择
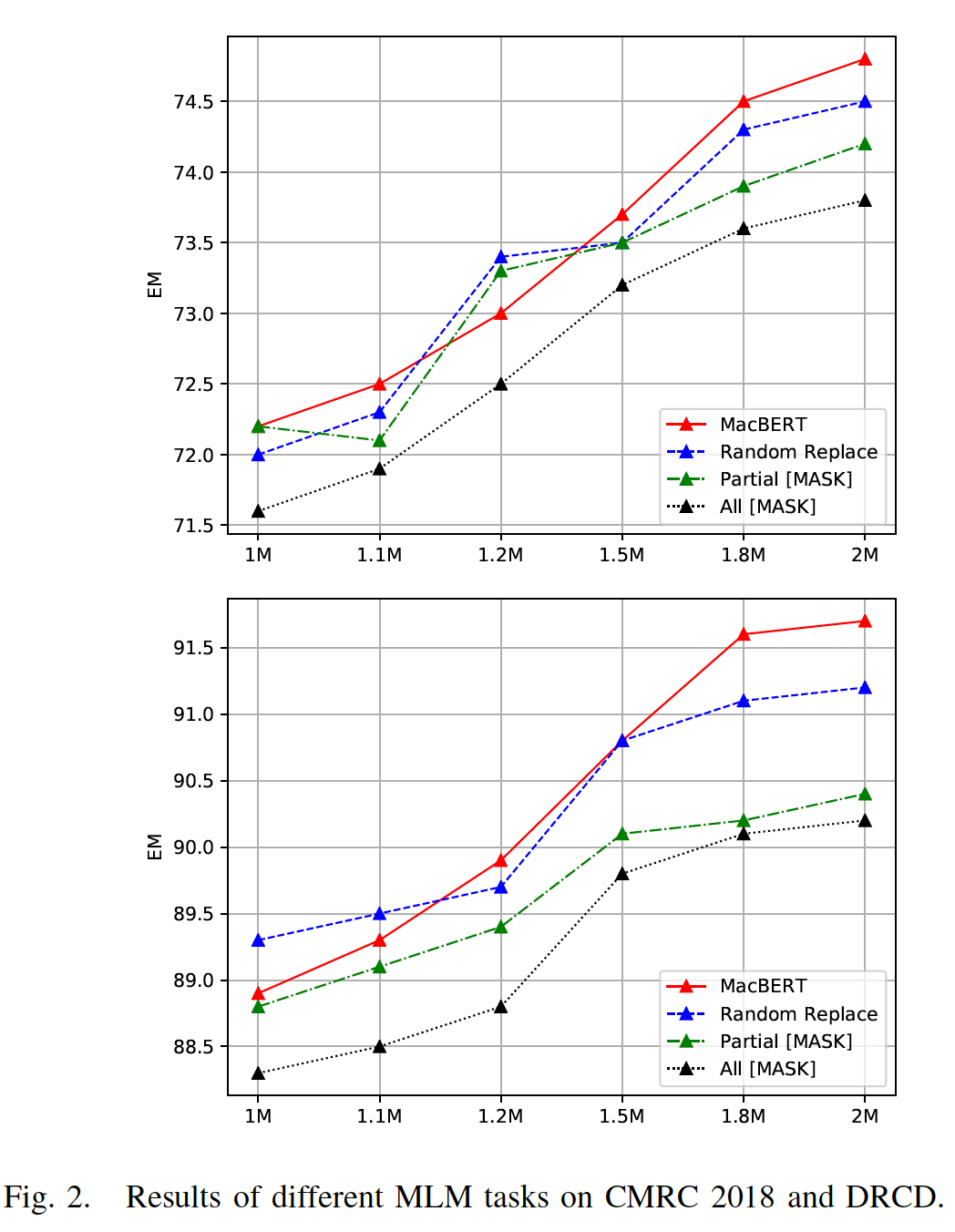
masking token的有效性,如全词掩码或N-gram masking等。现在我们要研究的是:所选中token的替换对预训练语言模型的性能有何影响。为了研究这个问题,我们绘制了不同预训练步数下
CMRC 2018和DRCD的性能。具体而言,我们遵从对输入序列的15%的原始掩码比例,其中10% masked token保持不变。对于剩下的90% masked token,我们将其分为四类:MacBERT:80% masked token被替换为它们的similar word,10% masked token被替换为随机的单词。Random Replace:90% masked token被替换为随机的单词。Partial Mask:原始的BERT实现,80% masked token被替换为[MASK],10% masked token被替换为随机的单词。All Mask:90% masked token被替换为[MASK]。
我们仅绘制了从
1M步到2M步的结果,如下表所示。可以看到:主要依靠使用
[MASK]进行掩码的预训练模型(即partial mask和all mask)导致了更差的性能,表明预训练和微调的差异是一个实际问题,该问题影响整体性能。在
partial mask和all mask中,我们还注意到,如果不保留10%的original token(即恒等映射),也会出现一致的下降。这表明完全使用[MASK] token的掩码的鲁棒性更差。令我们惊讶的是,完全放弃
[MASK] token,而是将所有90% masked token替换成随机的单词,产生了比[MASK]-dependent的掩码策略更一致的改进。这也强化了这样的说法:依靠[MASK] token的原始掩码方法导致了更差的性能,因为[MASK] token在微调任务中从未出现过。另外,使用随机单词而不是人工的
[MASK] token可以提高预训练模型的降噪能力,这可能也是一个原因。为了使这个问题更加精细,在本文中,我们提出使用
similar word来进行掩码,而不是一个随机的单词。因为随机的单词不符合上下文,可能会破坏语言模型学习的自然性naturalness,因为传统的N-gram语言模型是基于自然的句子,而不是一个被操纵的句子。然而,如果我们使用similar word来进行掩码,句子的流畅性就比使用随机单词要好得多,整个任务就转化为一个语法纠正任务grammar correction task,这就更自然了,而且没有预训练阶段和微调阶段的差异。从下图中中我们可以看出,
MacBERT在四个变体中产生了最好的性能,这验证了我们的假设。如果要追求自然性,那么自回归语言模型要比带噪音的双向语言模型更有利。
22.3.3 中文拼写检查上的分析
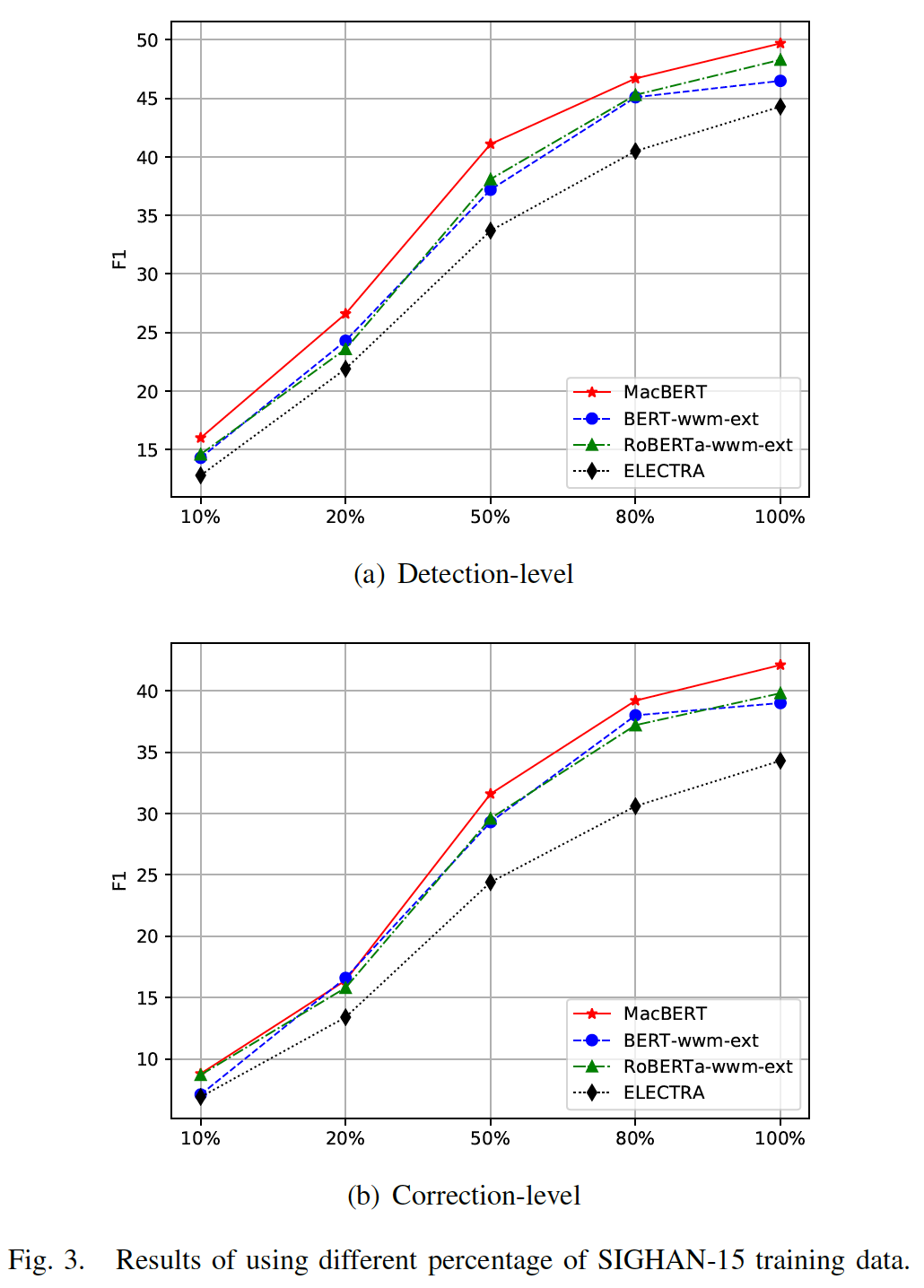
MacBERT引入了'MLM as correction'任务,这与实际的语法或拼写错误校正任务相似。我们对中文拼写检查Chinese Spell Check任务进行了额外的实验。我们使用SIGHAN-15数据集来探索使用不同比例的训练数据时不同预训练语言模型的效果。SIGHAN-15包括一个训练集(3.1K实例)和一个测试集 (1.1K实例)。我们在这个实验中比较了BERT-wwm-ext, RoBERTa-wwm-ext, ELECTRA-base, MacBERT-base,因为它们共享相同的预训练数据。我们对每个模型进行了五次微调,并绘制了平均F1(sentence-level)。我们使用5e-5的通用学习率,训练5个epoch,batch size = 64。结果如下图所示,其中包括detection-level分、correction-level分。可以看到:当使用不同比例的训练数据时,
MacBERT比其他模型产生了一致的改进,这表明MacBERT是有效的和scalable的。我们注意到
ELECTRA在这项任务上表现不佳。具体而言,ELECTRA和其他模型的结果,在correction-level的差距相对于detection-level的差距更大。ELECTRA使用replaced token detection: RTD任务来训练判别器(判别器将用于微调)。然而,RTD任务只需要识别输入token是否被改变,而不需要预测original token,我们认为这很简单。相反,MLM任务和Mac任务的目标需要同时identify-and-correction。通过比较
MLM和Mac,我们的MacBERT缓解了预训练和微调之间差异的问题,这产生了另一个重要的收益。虽然
Mac任务与拼写检查任务相似,但我们只使用同义词进行替换,这在真正的拼写检查任务中仅占很小的比例。这可以解释为什么当可用的训练数据较少时,我们的模型没有产生比其他模型更大的改进。
二十三、Fine-Tuning Language Models from Human Preferences [2019]
我们希望将强化学习应用于仅由
human judgment所定义的复杂的任务,对于该任务我们只能通过询问人类来判断一个结果是好还是坏。要做到这一点,我们可以首先使用human labels来训练一个奖励模型reward model,然后优化这个模型。虽然通过互动从人类那里学习这种模型的工作由来已久,但这项工作最近才被应用于现代深度学习,即使如此,也只被应用于相对简单的模拟环境simulated environments。相比之下,真实世界的setting(其中人类需要向AI agents指定复杂目标)很可能涉及并需要自然语言,其中自然语言是一种丰富的媒介来表达value-laden的概念。当agent必须与人类沟通从而帮助提供更准确的监督信号时,自然语言尤其重要。自然语言处理最近取得了实质性的进展。一种成功的方法是在无监督数据的语料库上预训练大型生成式语言模型,然后针对有监督的
NLP任务对模型进行微调。这种方法往往大大优于在监督数据集上从头开始的训练,并且在许多不同的监督数据集上,一个预训练的语言模型往往可以微调从而得到SOTA的性能。在某些情况下,不需要进行微调:GPT-2发现,生成式预训练的模型在没有额外训练的情况下(即,zero-shot)),在NLP任务上显示出合理的性能。有大量文献将强化学习应用于自然语言任务。这些工作大多使用算法定义的奖励函数
reward functions,如用于翻译的BLEU、用于摘要的ROUGE、music theory-based的奖励、或者用于故事生成的event detectors。《Reinforcement learning for bandit neural machine translation with simulated human feedback》在BLEU上使用强化学习,但应用了几个error models来近似human behavior。《Learning to extract coherent summary via deep reinforcement learning》以及《Towards coherent and cohesive long-formtext generation》从现有文本中学习了coherence model,并将其作为强化学习奖励分别用于摘要和长篇小说的生成。《Preference-based interactive multi-document summarisation》通过一次对一篇文章应用reward learning,建立了一个交互式的摘要工具。- 使用人类评价作为奖励的实验包括
《Reliability and learnability of human bandit feedback for sequence-to-sequence reinforcement learning》将off-policy的reward learning用于翻译、以及《Way off-policy batch deep reinforcement learning of implicit human preferences indialog》将《Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control》修改后的Q-learning方法应用于对话中的隐式的human preferences。 《Towards coherent and engaging spoken dialog response generation using automatic conversation evaluators》从人类那里学习奖励来微调对话模型,但对奖励进行了平滑处理从而允许监督学习。- 我们参考
《A survey of reinforcement learning informed by natural language》对涉及语言作为一个组成部分的强化学习任务的综述,以及使用从语言迁移学习的强化学习结果。 - 强化学习并不是纳入持续的
human feedback的唯一方式。《Learning from dialogue after deployment: Feed yourself, chatbot!》询问人类关于对话系统应该说些什么,然后继续监督训练。
在论文
《Fine-Tuning Language Models from Human Preferences》中,作者将自然语言处理的预训练进展与human preference learning相结合。作者用reinforcement learning而不是supervised learning来微调预训练的语言模型,使用来自在text continuations上的human preferences训练的一个奖励模型reward model。遵从《Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control》和《Way off-policy batch deep reinforcement learning of implicit human preferences indialog》之后,作者使用KL constraint来防止微调模型与预训练模型相差太远。作者将该方法应用于两类任务:以符合目标风格的方式续写文本
continuing text(无论是积极的情感还是生动的描述)、以及CNN/Daily Mail或TL;DR数据集的文本摘要。论文的动机是NLP任务,其中监督数据集不可用或数量不够,而且程序化的奖励函数(如BLUE)对任务的真正目标来说是很差的代理proxy。对于风格延续
stylistic continuation,5K个human comparisons(每次选择4个continuation中最好的一个)的结果是:reinforcement learning微调模型与zero-shot相比,人类在86%的情况下优先选择reinforcement learning微调模型的结果。reinforcement learning微调模型与被监督微调到情感分类网络相比,人类在77%的情况下选择reinforcement learning微调模型的结果。
注意,这里有两种微调:
reinforcement learning微调、supervised learning微调。对于摘要,论文使用
60K个人类标注的样本来训练模型,这些模型可以大致描述为"smart copiers":它们通常从输入中复制整个句子,但改变它们复制的内容以跳过不相关的初始文本。这种复制行为是在数据收集和训练过程中自然出现的。作者没有像《Get to the point: Summarization with pointer-generator networks》和《Bottom-up abstractive summarization》那样使用任何显式的架构机制进行复制。一种解释是,鉴于作者没有指示labelers惩罚copying,而是指示labelers惩罚inaccuracy,所以复制是一种容易的方式来实现accurate。这也可能反映了这样一个事实:即一些labelers将检查copying作为一种快速的启发式方法来确保摘要的准确性。事实上,相比于有监督的fine-tuning baselines甚至是human-written的reference摘要,human labelers明显倾向于论文的模型,但是论文的模型反而比不过lead-3 baseline(简单地拷贝文本的前三句话)。对于摘要,作者继续收集额外的数据,并随着策略的改善重新训练奖励模型(
online data collection)。作者还测试了offline data collection,其中论文只使用原始语言模型的数据来训练奖励模型(而没有重新训练奖励模型)。离线数据收集大大降低了训练过程的复杂性。- 对于
TL;DR数据集,human labelers在71%的情况下更喜欢用online data collection训练的策略。在定性评估中,offline model经常提供不准确的摘要。 - 相比之下,对于风格延续,作者发现
offline data collection的效果同样很好。这可能与风格延续任务需要很少的数据有关。《Learning to generate reviews and discovering sentiment》表明:生成式训练的模型可以从很少的标记样本中学习情感分类。
在同时进行的工作中,
《Better rewards yield better summaries: Learning to summarise without references》也使用human evaluations来学习摘要的奖励函数,并通过强化学习来优化该奖励函数。他们的工作对CNN/Daily Mail数据集上的学习策略函数和奖励函数进行了更详细的调查。而论文
《Fine-Tuning Language Models from Human Preferences》对更通用地探索从human feedback中学习、以及更大的计算规模感兴趣。因此,作者考虑了几个额外的任务,探索了on-policy reward model training和更多数据的效果,并同时为reward modeling和强化学习来微调大型语言模型。
23.1 模型
我们以一个词表
token序列我们将
token序列、输出空间token序列。定义1000个单词的文章,100个单词的摘要。policy:将样本的开头固定为token。这是一个强化学习策略,其中每个
action可以视为生成一个token,总的奖励等于human preference(即,人工标注是好、还是坏)。我们初始化一个策略
expected reward:然而,我们希望执行由
human judgments定义的任务,在这种情况下,我们只能通过询问人类来了解奖励的情况。为了做到这一点,我们将首先使用human labels来训练奖励模型,然后优化该奖励模型。遵从
《Deep reinforcement learning from human preferences》的做法,我们要求human labelers针对给定的输入response。我们要求人类在四个选项prompthuman labelers的选择结果。在收集了一个由由于奖励模型需要理解语言,我们遵从
GPT-1的做法,将奖励模型初始化为语言模型策略final embedding output的随机线性函数(对于为什么从scale在整个训练中保持一致,我们将其归一化为:针对1。为什么从
feedback loop,这不利于训练。注:读者猜测模型结构为
GPT-1中的Multiple Choice。每个输入都添加了start tokenextract tokenend token)。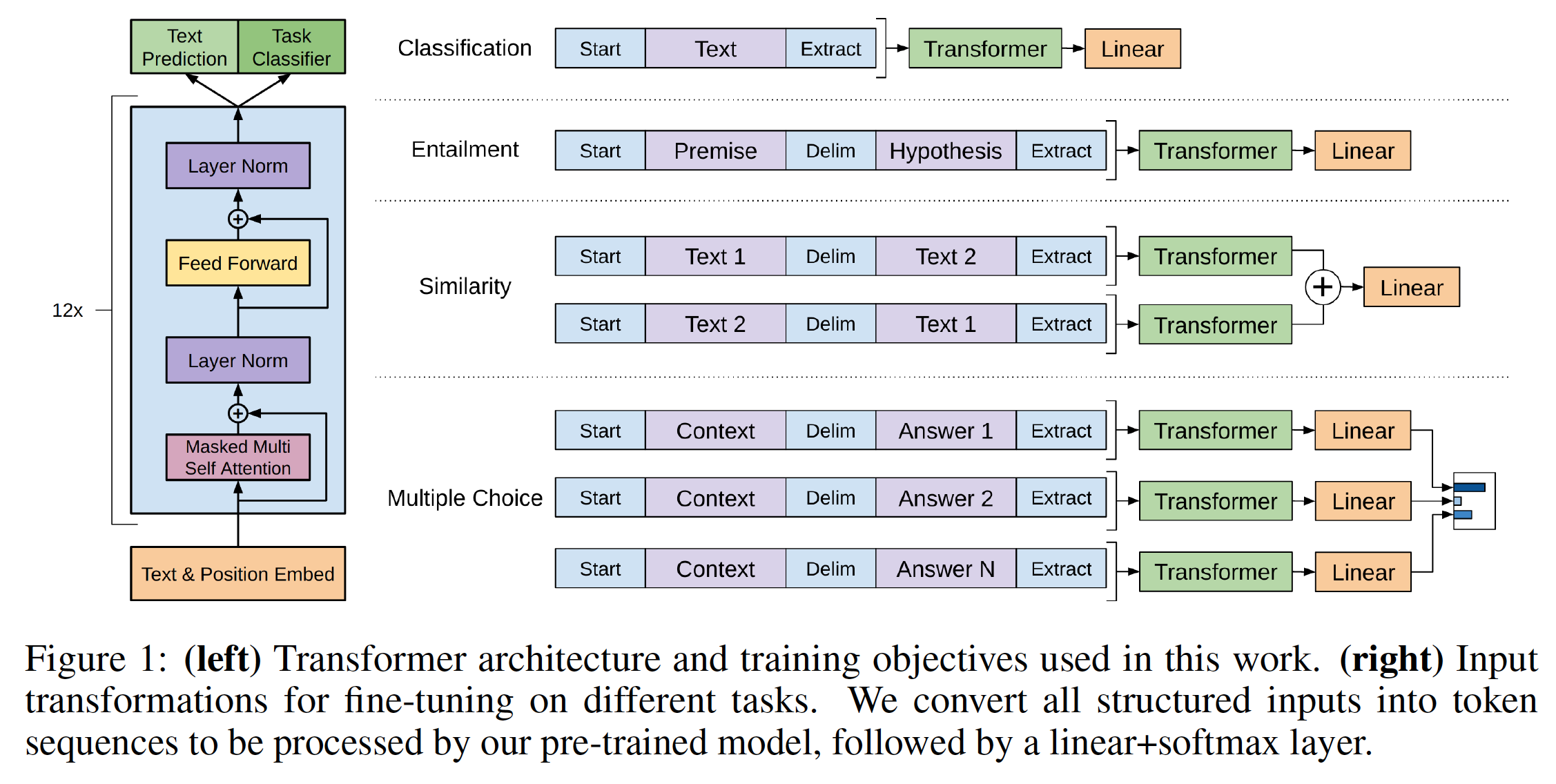
现在我们强化学习微调
KL为KL散度。可以参考Table 10来了解没有这个惩罚项的后果。即,我们在修改后的奖励上执行强化学习:我们要么选择一个常数
这个惩罚项有几个目的:
它起到了熵的作用。
它可以防止策略
因为奖励模型是通过
在我们的风格延续任务中,它也是任务定义的一个重要部分:我们要求人类评估风格,但依靠
KL项来鼓励一致性coherence和主题性topicality。
奖励模型用于判定文本生成的好坏。有两种优化奖励模型的方式:
- 监督微调:利用大量的带标记的文本来进行监督微调,此时每个被生成的文本需要评估一次(在整体上进行评估)。
- 强化学习微调:利用一个预训练好的(或者微调好的)奖励模型来进行强化学习微调,此时每个被生成的文本需要被评估多次(每生成一个
token就在已经生成的序列上进行评估,即使生成过程尚未完成)。
我们的整体训练过程是:
通过
注意,前提是必须有一个预训练好的语言模型
注意,这里应该是
初始化奖励模型
final linear layer使用随机初始化,使用损失human samples上训练注意,这里的
label来自于人工标注,即human labelers的选择结果在
Proximal Policy Optimization: PPO来训练根据
InstructGPT,PPO的损失函数为:其中:
RL策略,KL系数。
在
online data collection的情况下,继续收集更多的样本(样本来自于更新后的策略
整体框架如下图所示。
注意,根据下图所示,奖励模型的样本由
policy函数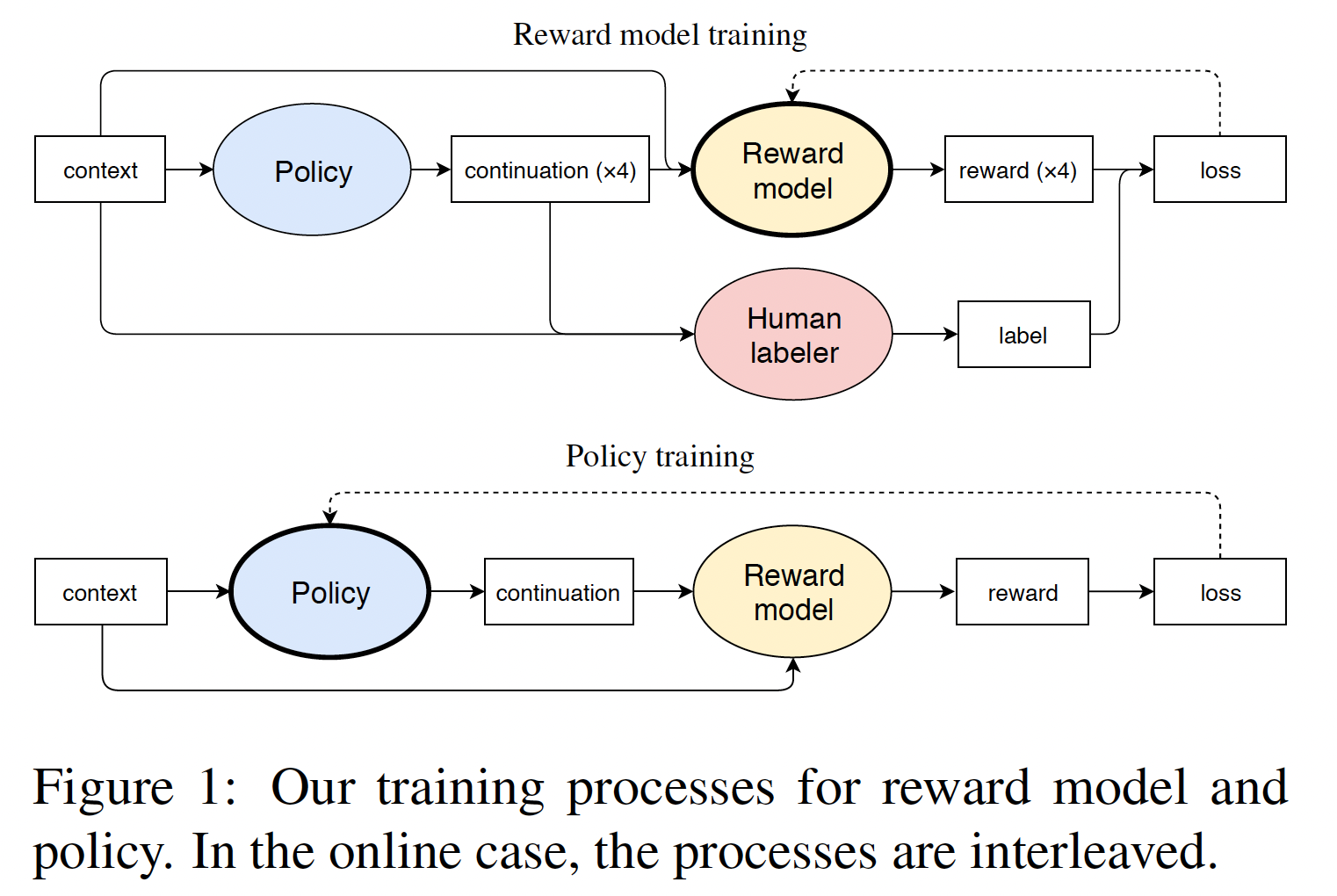
23.1.1 预训练细节
我们使用
774M参数版本的GPT-2语言模型,在GPT-2的WebText数据集、以及50257个token的invertible BPE(保留大写和标点符号)上进行训练。该模型是一个具有36层、20个头、embedding size = 1280的Transformer。对于风格延续任务,我们在强化学习微调之前对
BookCorpus数据集进行监督微调(语言模型):首先在WebText上从头开始训练,然后在BookCorpus上进行监督微调,最后对我们的最终任务进行强化学习微调。为了提高样本质量,我们在所有的实验中都使用了
logits除以sampling和强化学习在unmodified pretrained model的较低温度。这个
unmodified pretrained model的较低温度是什么意思?论文未解释。
23.1.2 微调细节
监督微调:以预训练好的语言模型作为开始,我们使用
Adam优化器来训练奖励模型,损失为batch size = 8、摘要任务的batch size = 32,两者的学习率均为epoch从而过拟合于small amount of human data,,并禁用dropout。强化学习微调:对于策略
《Openai baselines》的Proximal Policy Optimization的PPO2版本。我们使用2M个episodes的batch有四个PPO epoch,每个batch有一个minibatch,其它超参数为默认值。我们对风格任务使用batch size = 1024、对摘要任务使用batch size = 512。我们在策略训练中禁用dropout。风格任务的学习率为外层的
batch对应于pair,内层的minibatch对应于trajectory segment长度4个epoch。用不同的种子和相同的
KL惩罚系数log-space proportional controller动态地改变其中:
KL值,根据具体任务来指定。
通过这种方式的调节,使得
监督微调
baselines:我们在CNN/Daily Mail和TL;DR训练集上微调了1个epoch(对于TL;DR,我们从训练集中删除了30K的样本作为验证集)。我们用cosine schedule将学习率衰减到0。对于学习率的初始值,我们在8个值 。我们还试验了不同的dropout rate,发现dropout rate = 0.1的效果最好。然后我们选择了具有最佳验证损失的模型。
23.1.3 Online data collection
如果训练后的策略
zero-shot策略distributional shift:在来自human data,通过从online data collection对摘要任务很重要,但对较简单的风格任务不重要。Online data collection影响的是奖励模型(即,状态价值函数)。在
online的情况下,我们将选择一个函数PPO episode之前我们想要多少个标签。令PPO episodes的总数,human labels的初始数量,human labels的总数。我们选择:- 如果我们的标签少于
PPO episode之前暂停。 - 如果到目前为止的总请求数少于
labelers发送另一个batch的请求,以确保他们在任何时候都有至少1000个未完成的query。
我们在第一个
PPO episode之前训练奖励模型,然后在均匀间隔的19次。每次重新训练时,我们将奖励模型epoch。offline情况是一种极端情况:human labels总数分别为:注意:奖励模型
human labels来训练。- 如果我们的标签少于
为了估计总体进度,我们以恒定的速度收集由
human labels给出了为了估计
labeler-labeler之间的一致性,5%的query由不同的labeler回答5次。实验部分的label计数包括验证样本和重复标签。
23.1.4 人类标注
我们使用
Scale AI来收集标签。Scale API接受形式为A)、以及本文作者提供的大约100个样本的comparison数据集的组合向Scale AI描述任务。



与机器学习中的许多任务不同,我们的
query没有明确的ground-truth,特别是对于similar outputs的pair(这在我们的训练过程中起了很大的作用,因为我们在从单个策略label pair上训练奖励模型labelers之间也存在着重大分歧。- 在情感分类和
TL;DR摘要的4-way comparisons中,本文作者之间有60%的时间达成一致(与随机猜测的25%相比)。这种低的一致率使Scale AI的质量控制过程变得复杂。 - 在情感分类方面,本文作者与
Scale labelers的一致率为38%。 - 在
TL;DR摘要方面,作者本文与Scale labelers的一致率为46%。
针对
comparision的标注带有很大的主观性,因为每个人对于什么是好的、什么是生动的、什么是客观的等等这些评价标准的理解都不同。- 在情感分类和
人类数据收集和质量评估的细节(来自论文附录
B):我们的质量保证过程是由Scale AI处理的。由于我们最初认为online data collection将是至关重要的,即使是离线实验也是在这种快速周转的要求下收集的。在未来,我们计划使用一个更宽松的延时要求。数据收集的第一步是把任务教给少数受信任的
Scale labelers,给他们一个任务的描述(如前文所述)。Scale AI使用这些labelers收集大量的benchmark数据点(从unlabeled的数据点中),在这些数据点上,几个受信任的labelers达成了一致。在完整的数据收集过程中,Scale AI将这些benchmark数据点与真实的未标记数据一起提供给freelance workers进行训练(当labeler在benchmark分布上的表现维持一个confidence model。判断数据点是来自benchmark还是来自真实的未标记数据,这个概率在各种因素上动态变化,如对labeler正确标记某个类别的信心。在benchmark任务上表现不佳的freelance workers会被过滤掉。此外,Scale AI随着时间的推移对质量控制进行临时改进,有时通过与本文作者的少量gold-standard labels进行比较来验证质量。我们在事后评估了其中两个任务的数据质量。在所有的数据收集过程中,有
5%的query是由5个不同的labelers回答的。我们从这些query中采样100个(仅限于从query),让两名作者给每个query进行标注。基于这些数据,我们估计了本文作者和Scale labelers、labeler-labeler、以及author-author之间的一致率,如下表所示。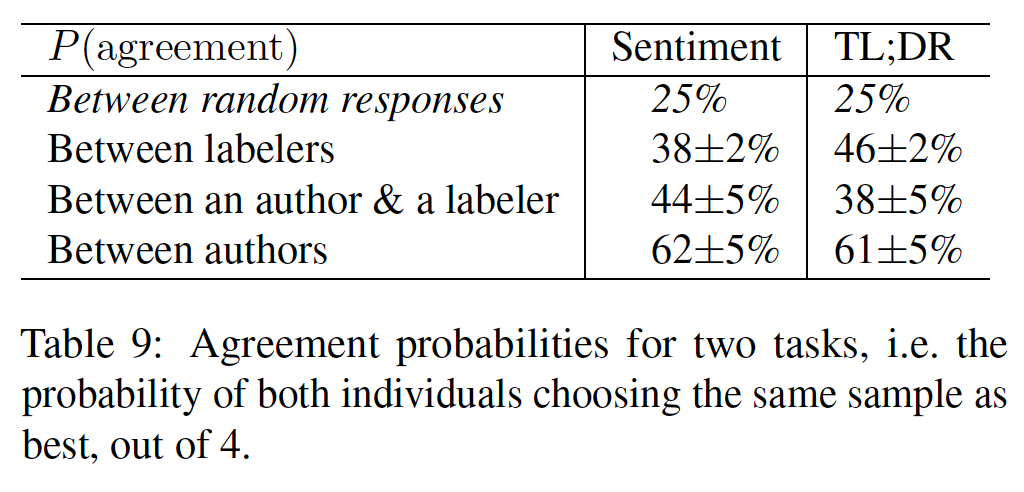
早期的版本要求
labelers进行1-10的评分。在最好的情况下,每个labeler提供了更多的信息,但很难衡量labeler的表现:归一化是必要的,因为两个好的
labelers往往会有一个(噪音的)monotonic transform。例如,
labeler A的评分比较保守,评分集中在1~8分;labeler B的评分比较激进,评分集中在5 ~ 10分。那么同样是7分,对于这两个labeler是不同的含义 。如果许多分数集中在几个数值上(例如
7和8),简单的策略此时策略
绝对分数也倾向于在训练过程中漂移,因为
labelers会根据变化的策略因为策略
寻找高质量的
workers涉及到human answering质量控制问题,质量控制在我们的实验中没有使用,并移除了低质量workers的数据。因此,实验的总人力成本要比我们实际使用的标签数量(也就是我们报告的内容)高一些。对于一个短期的training run来说,这很容易支配实际的标签要求,尽管它可以通过识别持续的good workers在几个任务中摊销。对于我们较长的training run,额外的标签数量并不高。对于两个模型
A和B的最终评估,我们产生了pair2-way comparisons、或者pair4-way comparisons。我们随机调整样本的呈现顺序,并将这些comparisons呈现给Scale AI。用
Scale AI的同一组人类来评估 由Scale AI训练的模型的质量是很危险的:它表明奖励human reward,但并不表明这些human evaluations捕获到了我们真正关心的东西,并且我们的模型被激励去利用标注过程的特质。我们包括我们的模型的样本,以便读者可以自己判断。也就是说:最终评估的人、训练过程中标注的人,他们是同一波人。这类似于在训练集上进行评估。
理论上,应该使用训练过程中的标注人员之外的人来进行评估,但是这样做的成本比较高。
23.2 实验
首先,我们通过使用
mock labeler(在评论分类问题上训练的情感模型)作为human labels的替身来测试我们对语言模型进行强化学习微调的方法。我们表明强化学习微调可以有效地优化这个复杂的、但一定程度上人造的奖励。然后,我们表明我们可以用很少的数据从人类对风格延续任务(情感和物理描述性)的偏好中优化语言模型,在情感的情况下,结果优于优化
review sentiment model。接着,我们将强化学习微调应用于
CNN/Daily Mail和TL;DR数据集的摘要任务,表明所得到的模型本质上是"smart copiers",并在其他摘要工作的背景下讨论这些结果。我们发布了
offline data情况下的奖励建模和微调的代码。我们的公开版本的代码只适用于一个较小的124M参数模型,有12层,12个头,embedding size = 768。我们包括这个较小模型的强化学习微调版本,以及我们为主要实验收集的一些human labels(注意,这些标签是从使用较大模型的运行中收集的)。
23.2.1 风格延续任务
- 我们首先将我们的方法应用于风格化的文本延续任务,在这个任务中,策略需要对来自
Book-Corpus数据集的节选来生成文本的continuation。奖励函数会自动或根据human judgments来评估continuation文本的风格。我们采样长度为32到64个token的节选,该策略生成24个额外的token。如前所述,我们将预训练模型的温度设置为
a. Mock 情感分析任务
为了在受控环境下研究我们的方法,我们首先应用它来优化一个已知的奖励模型
human judgments的一些复杂性。我们通过在Amazon review数据集的一个二元平衡子集上训练一个分类器从而构建奖励模型log odds(即,final sigmoid layer的输入)。在没有约束的情况下优化
incoherent continuations,但如前所述,我们包括一个KL约束,迫使它靠近基于BookCorpus上预训练的语言模型我们的方法的目标是只使用少量的
human queries(即,人类标注数据)来监督微调query来优化注意,
mock情感分析任务的目标是获得良好的情感分类模型(即,奖励模型Amazon review上已经微调过)。有两种方式可以获得:利用强化学习直接优化奖励模型
此时通过策略
text continuation,然后通过奖励模型continuation。利用监督微调来通过人类标注数据来优化
在使用强化学习直接优化奖励模型
query来训练一个奖励模型的情况下,下图显示了20k到60k的query允许我们优化监督微调的奖励模型也有
reward,虽然它不是强化学习,但是根据定义,reward是:文本是正面的对数几率log odds。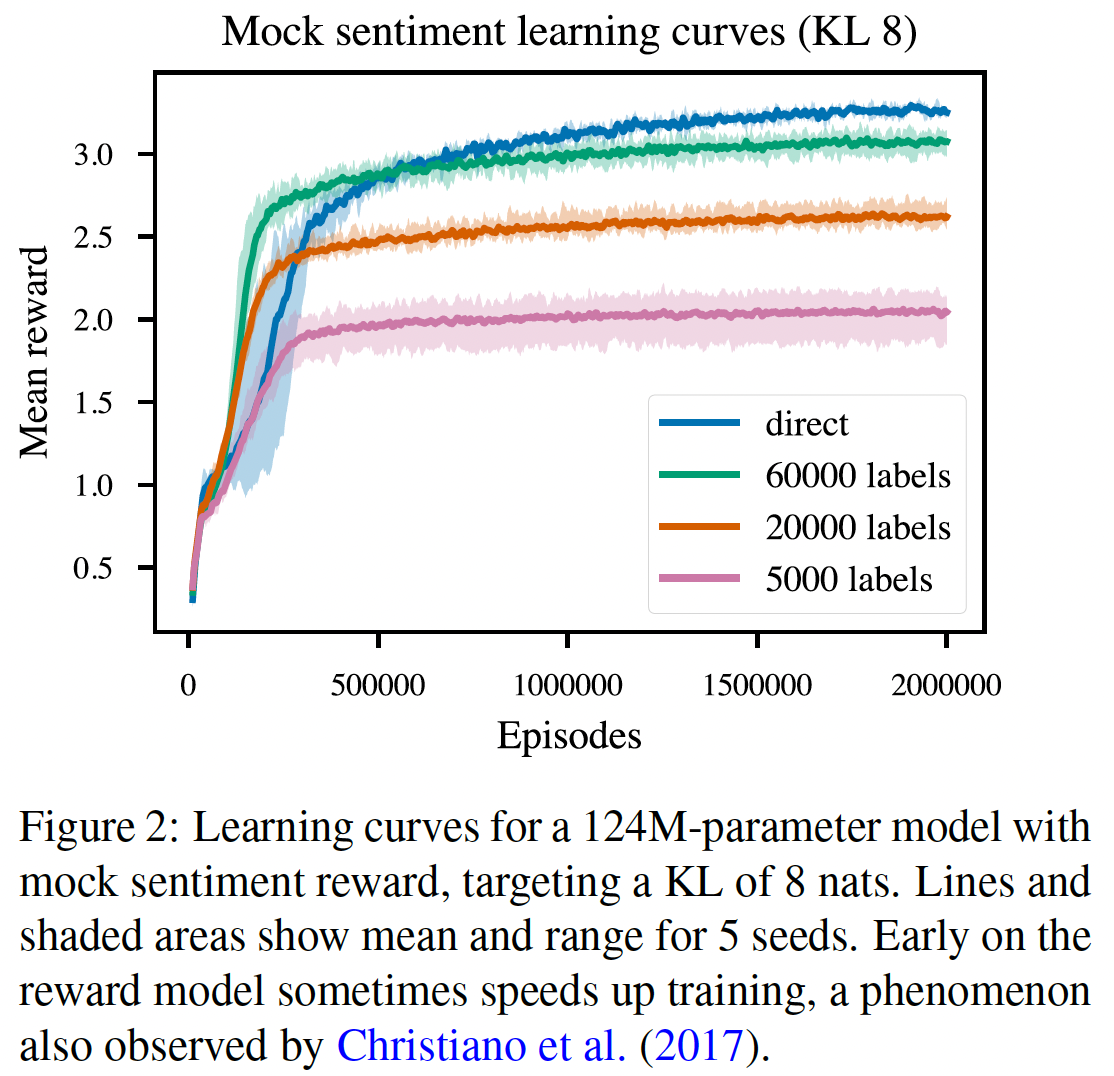
因为我们知道奖励函数,我们也可以分析计算出最优策略,并将其与我们学到的策略进行比较。在对所学到的策略
KL散度对于给定的
continuations,并通过下图比较了我们的策略获得的奖励、以及在一个范围的
KL值之间估计的最优奖励。在对2M个continuations(我们的主要实验中使用的数字)之上训练策略之后,我们的策略获得的奖励与最佳奖励之间有很大的差距,但随着更多的训练(64M episodes)这种差距基本上被消除。我们的策略在较大的
KL散度中继续获得更高的奖励,在这种情况下我们不能通过采样来近似选择因为此时
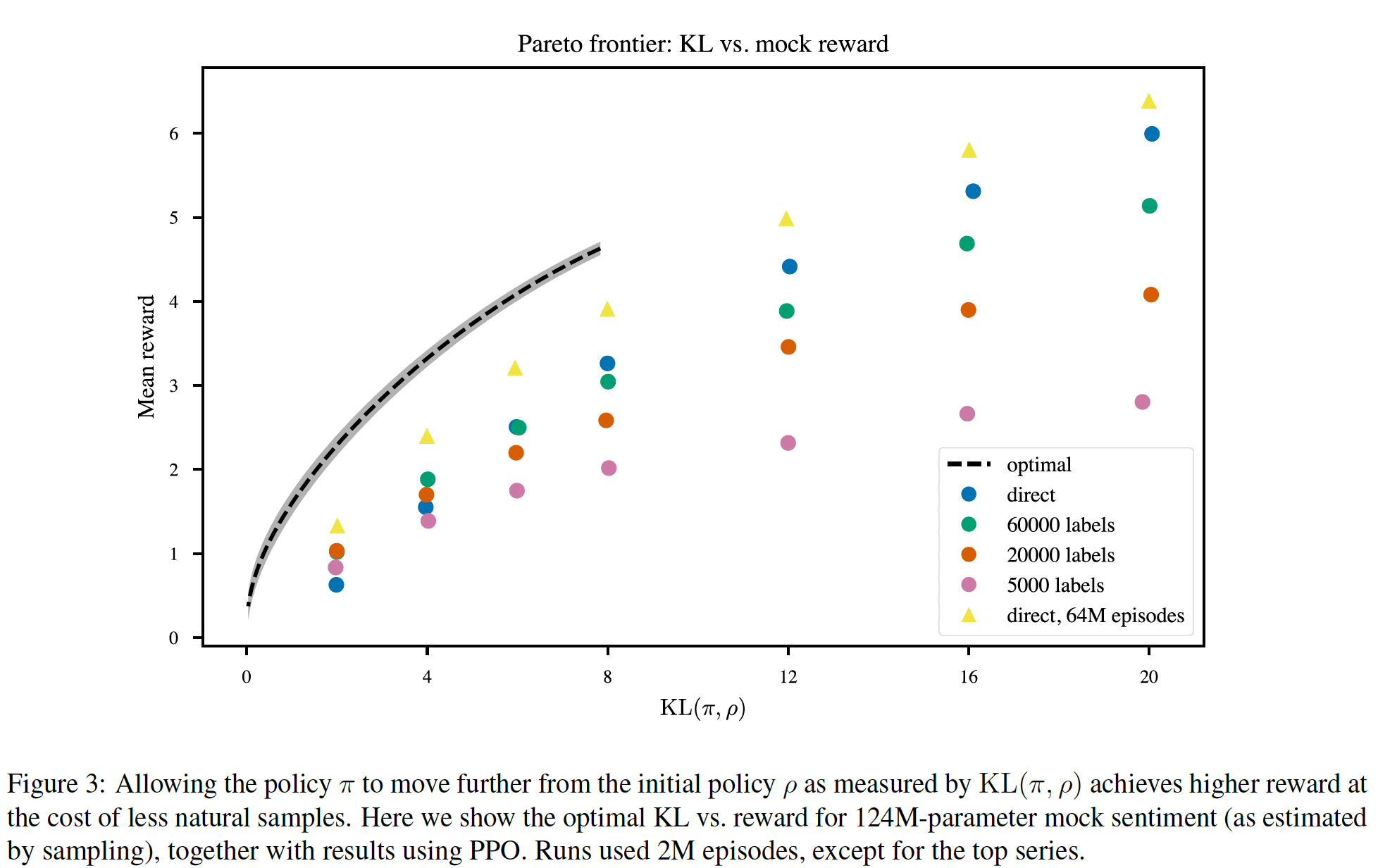
b. 人类对 continuation 的评估
我们将我们的方法应用于由
human judgments定义的两个continuation任务:- 情感:人类被要求奖励
"positive and happy"的continuation。 - 描述性:人类被要求奖励
"vividly descriptive"的continuation。
human labelers会收到BookCorpus数据集的一份节选、以及四个可能的continuations。他们被要求选择最佳continuations。论文附录A提供了针对labelers的完整指令(因为labelers也从论文作者标注的大约50个comparisons中学习,所以任务并不完全由指令来定义)。- 情感:人类被要求奖励
为了标注任务更加自然,我们选择以句号开始和结束的节选。当采样
continuations(这些采样的结果交给人类来判断),我们使用rejection sampling来确保有一个句号在token长度为16 ~ 24之间,然后在这个句号截断。在强化学习微调期间,我们通过采用固定的奖励-1,从而对没有这样一个句号的continuations施加惩罚。我们通过动态调整
descriptiveness任务获得6 nat的KL散度、为sentiment任务获得10 nat的KL散度。我们使用不同数量的
feedback训练了一系列的模型,同时测试了offline data collection(其中人类只对初始语言模型的continuation进行评分)、以及online data collection(其中人类不断对当前策略的continuations进行评分)。然后,我们将这些不同的策略相互比较,并与原始语言模型的zero-shot性能进行比较。offline data collection的情况下,奖励模型仅训练一次;online data collection的情况下,奖励模型会周期性地重新训练(在截至到当前时刻的所有human judgments数据上)。结果显示在下图和下表中。每一对
model之间的评估都是基于1024个4-way continuation comparisons,每个模型都包含两个样本,然后不同模型之间的comparision进行两两比较,每个评分都由3个人进行。对于两个模型
A和B的评估,我们产生了pair4-way comparisons。对于这些
continuation任务,我们发现:offline data collection和online data collection给出了相似的性能(在情感指标上相等,在描述性指标上在线方式要略好)。human feedback的数据量是关键,而offline还是online收集方式倒不是特别关键。强化学习微调所需的
human data很少:5k, 10k, 20k奖励模型的训练样本的性能相似,只在少于5k的样本中出现性能退化。使用评论情感分类器训练的模型(如前文所述,即下图中的
mock)相对于使用human preference优化的模型表现较差:在77%的情况下,labelers更喜欢使用real human feedback训练的模型的输出。
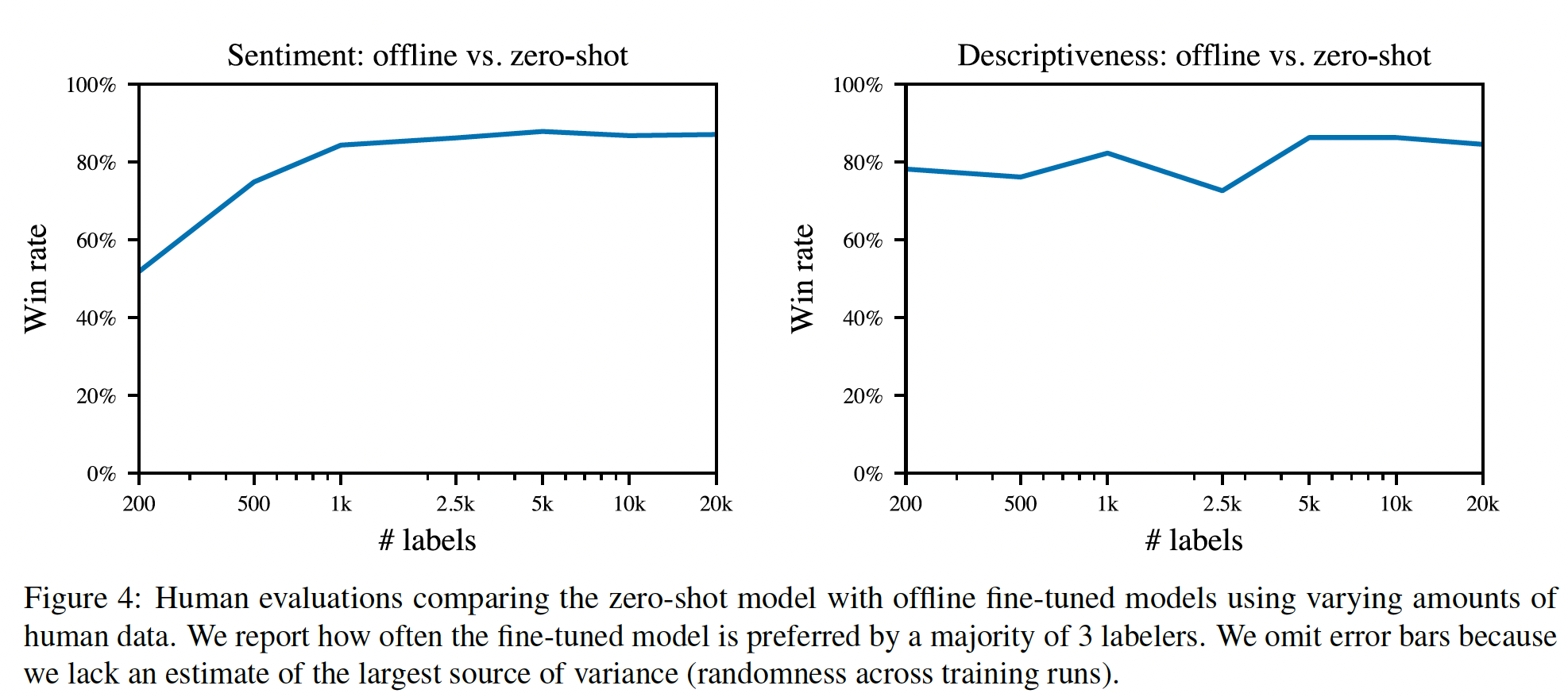
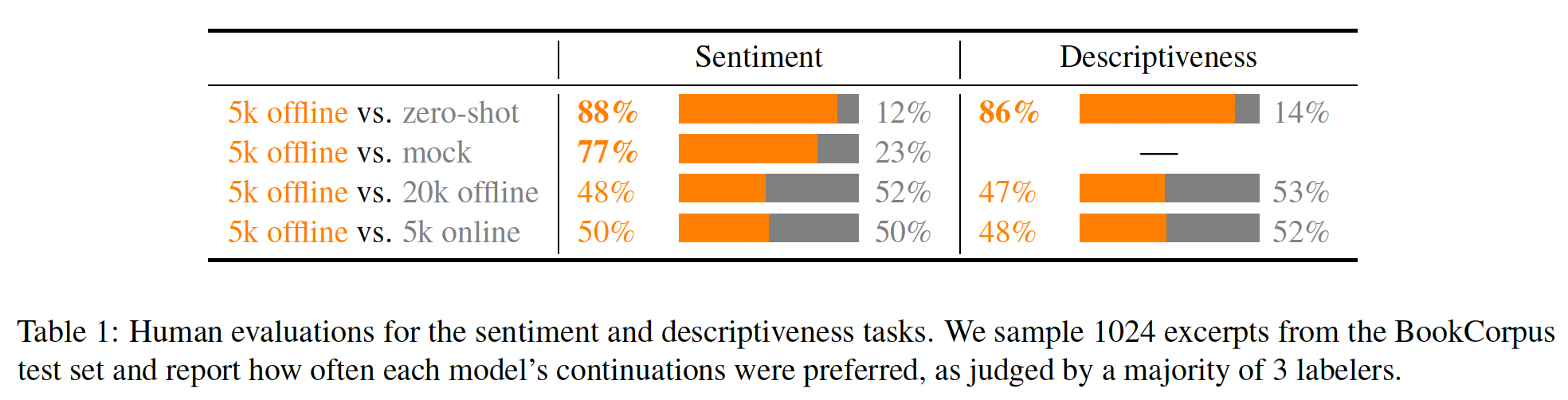
23.2.2 摘要
我们还将我们的方法应用于两项摘要任务:
CNN/Daily Mail数据集、TL;DR数据集。我们采样文章或
Reddit帖子,截断为500个token,添加"\n\nTL;DR:"后缀(对于CNN/Daily Mail则添加"Article:\n\n"前缀),并让策略响应最多75个token。我们将
CNN/Daily Mail的预训练模型的温度设置为TL;DR的预训练模型的温度设置为为了使任务对人类来说更自然,我们通过截断最后一个换行符来确保文章由整句组成。当采样
summary时(这些摘要需要展示给人类),我们使用rejection sampling来确保有一个换行符在长度为55到75个token之间,并在换行符处截断。在强化学习微调过程中,我们对没有换行符的摘要进行惩罚,给它们一个固定的-1的奖励分。对于
CNN/Daily Mail,我们使用固定的KL系数TL;DR,我们我们使用固定的KL系数我们的方法以及
baseline:- 强化学习微调:我们用
15k, 30k, 60k的human labels训练了online data collection的模型,并用60k标签训练了offline data collection的模型。 - 预训练模型的
zero-shot。 - 监督微调:使用相同的预训练模型作为初始化的监督微调模型。
- 复制上下文的前三句话的
lead-3 baseline。我们相同的方式将lead-3截断在句号(参考前面关于截断所生成的摘要的描述),所以lead-3结果偶尔是两句话。 - 最后,我们把监督微调和强化学习微调结合起来:从监督微调模型开始进行人类强化学习微调,即
supervised+RL。
纯粹的强化学习微调模型在训练过程中使用数据集的上下文,但忽略了
reference摘要;监督微调和supervised+RL模型同时使用上下文和reference摘要。我们报告了两组数字结果:
CNN/Daily Mail(测试集)TL;DR(验证集)上,model pair之间human evaluations结果(Table 5)、以及ROUGE结果(Table 4)。- 强化学习微调:我们用
根据
Table 4,ROUGE指标的结果表明:与我们的风格延续任务相比,
online data collection对最佳性能很重要。在固定的标签数量下,online data collection往往比offline data collection更好,其中在60k个标签时,CNN/DM的R-AVG增益为3个点。在这两个数据集上,我们看到数据量在
60k个human labels之前的显著回报(尽管human evaluation的趋势不太明显)。在
CNN/Daily Mail数据集上,数据量的效果为15k > 60k > 30k,有点奇怪?在这两个数据集上,
supervised+RL微调是最好的,事实上,根据ROUGE,纯强化学习微调在所有情况下都比supervised baseline更差(尽管supervised baseline使用完整的监督训练数据集,这比60k样本大得多)。Lead-3很难被打败:它是CNN/Daily Mail上R-1和R-2指标的最佳模型,只有supervised + RL微调在R-L和R-AVG指标上打败它。
60k/30k/15k fine-tune和60k offline fine-tune指的是强化学习微调模型。
但我们的目标是优化人类定义的奖励而不是
ROUGE。Table 5显示了根据human labelers对model pairs的pairwise comparisons,使用1024个样本,每个样本有3个labelers进行多数投票。这里的结果与ROUGE是不同的,尽管也有明显的噪音:我们的
online data collection训练,60k个标签的强化学习微调模型可靠地击败了zero-shot和supervised baseline,甚至击败了supervised + RL微调模型。online data collection训练仍然很重要,但在数据量方面的情况不太清楚,而且可能受到噪音的影响:例如,60k的TL;DR模型只有40%的时间能击败30k的模型,但是在79%的时间上击败了15k的模型。更令人担忧的是:
- 在
TL;DR数据集上,60k的online data collection模型在96%的时间内击败了human ground truth(即reference)。 - 在
CNN/Daily Mail数据集上,60k的online data collection模型在84%的时间内击败了human ground truth。
- 在
这到底是怎么回事?正如我们在下一节中所展示的,我们的
60k的强化学习微调模型几乎完全是extractive的(尽管我们的模型缺乏任何显式的extractive的架构组件 ):它主要是从上下文中拷贝整个句子,但是对于哪个句子被拷贝,则有所变化。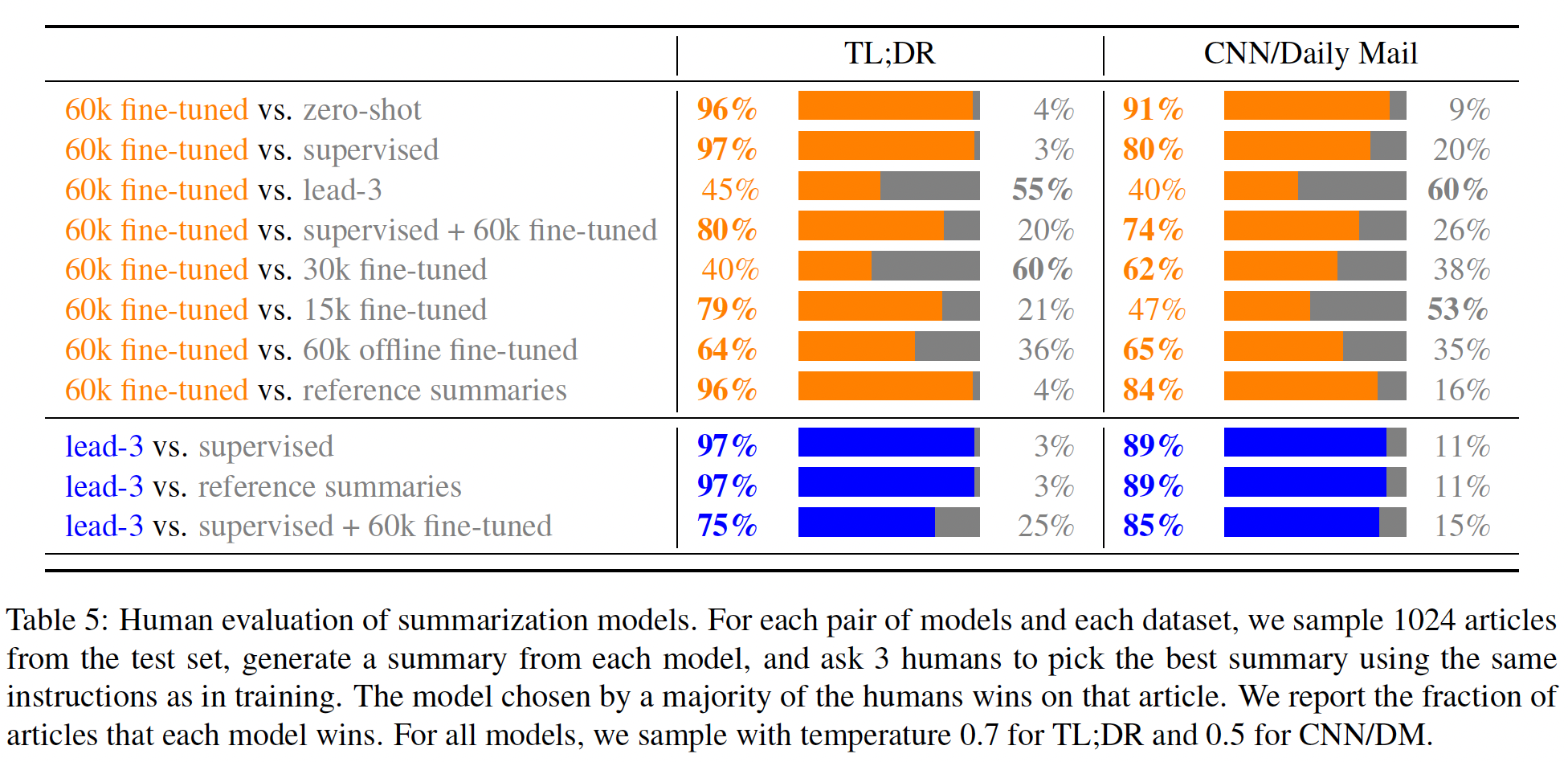
23.2.3 我们的模型拷贝什么
以前在摘要方面的许多工作都集中在显式的拷贝机制上,包括
《Get to the point: Summarization with pointer-generator networks》的pointer network-based的架构、以及《Bottom-up abstractive summarization》的两阶段mask和paraphrase方法。我们的目标是利用拷贝的优势(这对摘要任务具有根本的重要性),而不仅仅是拷贝:任务是abstractive的而不是extractive的。Figure 5和Figure 6显示了我们的模型所分别产生的新颖的和重复的n-grams/sentences的比例。从新颖性方面,我们看到我们的强化学习微调一直导致模型更多的拷贝(即,从
input文本中拷贝内容作为摘要)。具体而言,我们的
60k的强化学习微调模型几乎完全是extractive的:在TL;DR中,它们有71%的时间拷贝整个句子;在CNN/Daily Mail中,它们有98%的时间拷贝整个句子。从监督的微调模型开始应用强化学习微调(即,
supervised + 60k fine-tuned),其拷贝率要低得多:TL;DR和CNN/Daily Mail分别为6%和30%。
在重复性方面(即,摘要中的句子出现多次),虽然我们没有像
《Get to the point: Summarization with pointer-generator networks》和《Bottom-up abstractive summarization》那样使用明确的覆盖率coverage指标,但监督微调模型和强化学习微调模型在摘要中的重复率都很低。
虽然纯粹的强化学习微调模型大多是拷贝文本,但它们拷贝的地方不同。下图通过上下文和摘要之间最长公共子序列的位置说明了这一点。

为了了解模型何时从
exact beginning拷贝,我们确定了文章中常见的前导句preamble(如,以'hi', 'hello','hey', 'ok', 'okay', 'so'这样开头的句子),这样我们就可以预期拷贝是一个糟糕的策略。下表显示,这些前导句被拷贝的频率远远低于其他文章的立即开始immediate beginning,这证明我们的模型在何时拷贝方面很聪明。然而,我们不能确定我们的奖励模型除了奖励拷贝之外还很聪明,因为zero-shot模型也跳过了前导句。几乎所有的
baseline都跳过了前导句。
既然结合监督微调和强化学习微调(即,
supervised + 60k fine-tuned)可以得到最好的ROUGE分数,而且也更abstractive,为什么不使用它呢?不幸的是,下表中显示纯拷贝有一个好处:它使模型很容易tell the truth。注意,摘要的准确性是由人工判断的。
拷贝最多的模型,
60k的监督学习微调模型,在TL;DR和CNN/Daily Mail上的准确率是90%和95%。从文章中抽取整个句子通常会让它们是true的。监督微调模型和
supervised+RL fine-tuned的组合模型最多只有70%的准确率:它们转述但转述得很糟糕,经常从上下文中交换名称、或以无效的方式将多个句子混合在一起。即,这些模型编造事实的可能性更大。
zero-shot是最新颖的,但只有20%的时间是准确的。同样,《Neural text summarization: A critical evaluation》发现,他们测试的监督的摘要模型中有30%的样本包含不一致inconsistency。而《Sample efficient text summarization using a single pre-trained transformer》发现,他们预训练的encoder-decoder模型"hallucinates facts...which are topical but never appear in the source"。
根据这里的结论:拷贝的方式来生成摘要,在准确性方面要更可靠一些。
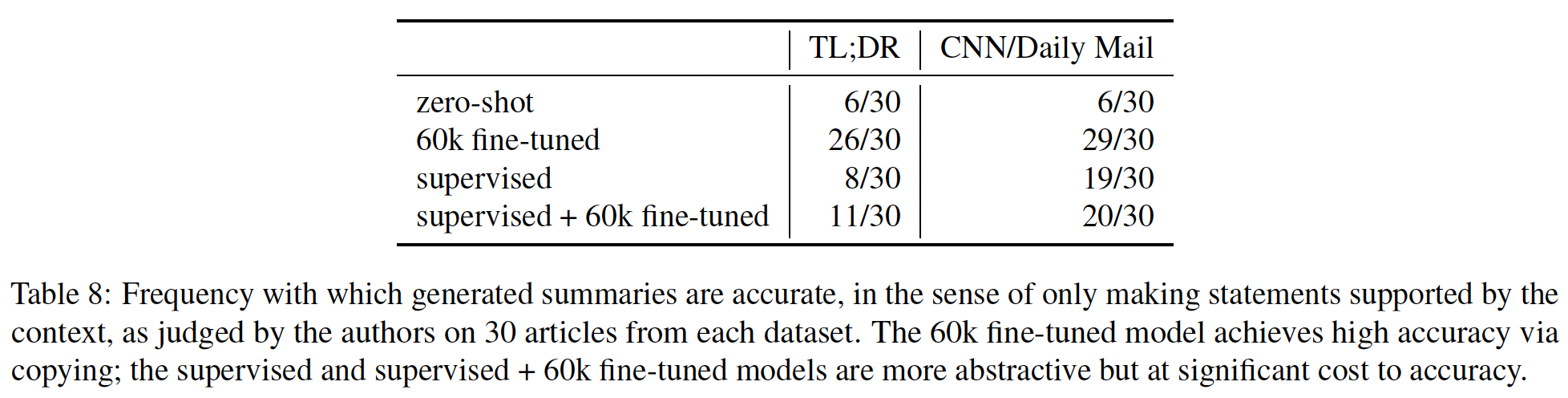
对这些结果至少有两种解释方式:
第一种解释是,拷贝是最容易做到准确的方法。
labelers被告知要惩罚不准确和冗余,但没有被告知要惩罚拷贝。zero-shot模型在某些时候会拷贝,而当它拷贝的时候是准确的,所以这种行为被强化了(因为被labelers所标注的第一批样本就是来自于zero-shot模型)。结果是一个"degenerated to copying"的模型,但至少不会撒谎。然而,这并不能解释为什么相比于
reference摘要,我们的模型和lead-3都被labelers所强烈偏好(Table 5)。这揭示了我们希望我们的模型学习的质量概念、和humans labelers实际评估的质量概念之间的不匹配。由于
online data collection的setting使得质量控制更加困难,我们未能发现和惩罚拷贝这种行为。
23.3 挑战
最后,我们总结了一些经验和方向,计划在未来的
reward learning工作中考虑。online data collection是困难的:为了在摘要任务上取得最佳效果,online data collection是必要的。然而,完全的online data collection(其中每个标签都来自最新版本的策略,而该策略已经从previous的几乎所有标签中学习而来)有很大的缺点:- 软件的复杂性:我们的
online system将数据收集、奖励模型训练、和强化学习微调交错进行。由此产生的分布式系统比每项任务单独进行要复杂得多,减缓了软件开发的进程。此外,任何一个任务中的bug都会破坏整个训练过程。 - 机器学习的复杂性:在线实验很难调试,因为它很难一次在机器学习系统的一个部分上迭代。 我们往往只能通过短暂地切换到离线来调试一个在线工作,例如启动一个独立的奖励模型的
training run,但一旦调试完成,就会切换回在线(直到下一个周期)。 - 质量控制问题:在
labelers部分需要做大量的工作,使他们的数据质量机制在低延迟的在线环境中发挥作用。然而,即使在这项工作完成后,也很难在很长一段时间内保持高的数据质量,而且往往在训练完成后(或很久以后)才发现退化。由于对labeler性能的评估是在线的,当一个工人被检测出有问题时,他们的一些数据可能已经被上报回来并用于奖励模型的训练。
我们相信,在
offline data collection和online data collection之间的正确中间地带是batched data collection,并计划在未来的工作中使用这种设置:- 从预训练的策略
batch的数据,在这批数据上训练奖励模型 - 一旦这些都完成了,收集另一个
batch的从
每个
batch数据的延迟可能远远长于online data collection,但是简化了质量控制。如同在完全online data collection的情况下,我们总是可以在迄今为止收集的所有数据上从头开始重新训练奖励模型。human data很昂贵,所以总量会很低。移除《Dialogue learning with human-in-the-loop》在仿真中验证了oneline data collection和batched data collection训练的性能相似后,在一个受限的对话的setting中得出了类似的结论。在
batch data collection的情况下,也是数据收集、奖励模型训练、和强化学习微调交错进行,和online data collection有什么区别?感觉唯一的区别是这里是
batch粒度的数据收集,因此如果人工标注的数据有问题,可能就影响这单个batch而已,而且更快地被发现。在下一篇论文
《Fine-Tuning Language Models from Human Preferences 》中,OpenAI转向了batch data collection。batched data collection也是active learning技术的一个被充分研究的setting。虽然我们使用强化学习来微调策略human data只用于奖励模型batch mode active learning的监督模型的方法都适用,使用unlabeled data distribution。这类技术的例子包括:selecting batches based on entropy considerations(《Discriminative batch mode active learning》)。- 基于梯度的指标(
《Active learning for speech recognition: the power of gradients》、《Deep batch active learning by diverse, uncertain gradient lower bounds》)。 - 通过尝试区分标记的和未标记的样本(
《Discriminative active learning》)。
- 软件的复杂性:我们的
奖励模型和策略之间共享参数导致过拟合:虽然奖励模型和策略都被初始化为
尽管做了几次尝试,我们还是没能使这个想法成功。问题来自于数据的巨大不平衡:我们的奖励模型最多只有
60k个样本,但策略却有2M个episodes。这使得在不对奖励模型进行许多epochs和过拟合的情况下保持这两项任务的性能成为挑战。我们希望未来的工作能够克服这一挑战。含糊不清的任务使标注工作变得困难:我们的一个代码重构引入了一个
bug,该bug翻转了奖励的符号。翻转奖励通常会产生不连贯的文本,但同一个bug也翻转了KL惩罚项的符号。结果是一个对负面情绪进行优化的模型,同时仍然对自然语言进行规范化。由于我们的指令告诉
labeler要给显式带有性sex的文字的continuations以很低的评价,模型很快就学会了只输出这种形式的内容。这个bug很了不起,因为其结果不是胡言乱语,而是最大限度的毒性输出。本文作者在训练过程中睡着了,所以这个问题在训练结束后才被发现。像丰田的Andon cord这样的机制可以防止这种情况的发生,因为它允许任何labeler停止有问题的训练过程。丰田的安灯拉绳
Andon cord机制:在发现质量和其他问题时,一线员工被授权通过执行AndonCord(即,拉动手边的叫做安灯拉绳的绳子)来停止生产从而及时止损。
二十四 Learning to summarize from human feedback[2020]
为了在各种自然语言处理任务上实现高性能,大型语言模型预训练已经变得越来越流行。当把这些模型应用于一个特定的任务时,人们通常使用监督学习对它们进行微调,通常是最大化针对
human demonstrations数据(即,人工标注的标签)的对数似然log likelihood。虽然这种策略导致了性能的明显提高,但在这种微调目标(即,最大化
human-written文本的似然)与我们所关心的目标(即,生成人类判定的高质量的输出)之间仍然存在着misalignment。这种misalignment有几个原因:- 最大似然
maximum likelihood目标没有区分重要的错误(如编造事实)和不重要的错误(如从一组同义词中选择最精确的词)。 - 模型被激励
incentivized从而将概率质量放在所有human demonstrations上,包括那些低质量的human demonstrations。 - 采样期间的分布漂移
distributional shift会降低性能。
通过非均匀采样策略(如,
beam search)通常可以大大改善质量,但这些策略会导致repetition和其他不受欢迎的人造品artifacts。对质量进行优化可能是克服这些问题的原则性方法。论文
《Learning to summarize from human feedback》的目标是:推进某些目标上训练语言模型的方法,其中这些目标能够更紧密地抓住我们所关心的行为。为了在短期内实现这一目标,论文专注于抽象式abstractive的英文文本摘要,因为它在NLP界有着悠久的历史,而且是一项主观的任务(作者认为很难量化摘要的质量,因为没有human judgments)。事实上,现有的评估摘要质量的自动化指标automatic metrics(如,ROUGE)由于与human judgments的相关性差而受到批评。论文遵从
《Better rewards yield better summaries: Learning to summarise without references》和《Fine-tuning language models from human preferences》的工作,他们利用奖励学习reward learning(《Tuning recurrent neural networks with reinforcement learning》)从human feedback中微调语言模型:- 首先收集
summary pair的human preferences数据集。 - 然后在这个
human preferences数据集上通过监督微调学习训练一个奖励模型reward model : RM来预测human-preferred的摘要。 - 最后,通过强化学习
reinforcement learning: RL训练一个策略从而最大化奖励模型的评分。该策略在每个"time step"生成一个文本token,并根据奖励模型给整个generated summary的 "奖励"从而使用PPO算法(《Proximal policy optimization algorithms》)来更新策略。 - 然后可以使用
resulting policy的样本来收集更多的human data,并重复这个过程。
论文遵从
GPT-3的工作,使用大型预训练的GPT-3模型,参数多达6.7B。论文的主要贡献有四个方面:
作者表明,在英语摘要方面,有
human feedback的训练明显优于非常强大的baseline。当在Reddit TL;DR数据集的一个版本上应用论文的方法时(如下图所示):- 通过
human feedback训练的策略比通过监督微调学习训练的更大的模型(下图中的supervised learning)产生更好的摘要。 - 相比较于数据集中的原始
human demonstrations(下图中的reference summaries),labelers更喜欢来自human feedback models(即,human feedback训练的策略)的摘要。
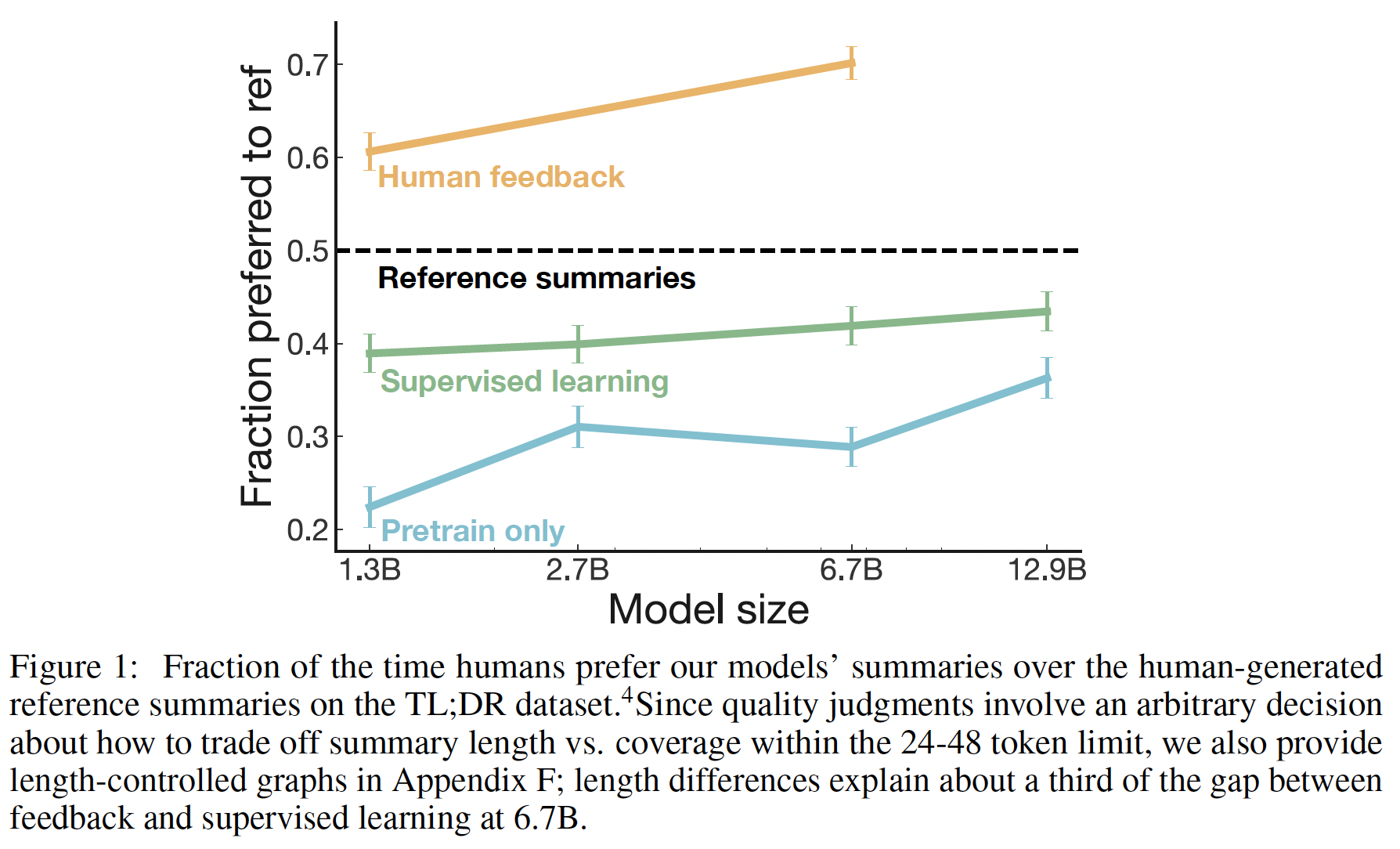
- 通过
论文表明:
human feedback models(即,human feedback训练的策略)对新领域的泛化性比监督微调模型好得多。作者在Reddit训练的human feedback models也在CNN/DailyMail: CNN/DM数据集上生成了高质量的新闻文章摘要而无需任何针对新闻的微调,几乎与该数据集的reference summary的质量相匹配。作者进行了若干检查,从而确保这些human preferences反映了真正的质量差异:作者持续监测labelers和researchers之间的一致率agreement rate,发现researcher-labeler的一致率几乎和researcher-researcher的一致率一样高(见论文附录C.2),并且作者验证了模型不仅仅是在针对长度或amount of copying等简单指标进行优化(见论文附录F和G.7)。论文对所提出的策略模型和奖励模型进行了广泛的经验分析。作者检查了模型大小和数据大小的影响,研究了继续优化一个给定奖励模型时的性能,并使用合成
synthetic的和human-written的扰动摘要来分析奖励模型性能。作者确认,所提出的奖励模型在预测human preferences方面优于其他指标(如ROUGE),而且优化奖励模型直接导致了比优化ROUGE更好的摘要。论文公开发布了
human feedback数据集,以供进一步研究。该数据集包含64832个关于TL;DR数据集的summary comparisons,以及论文对TL;DR(comparisons和Likert score)和CNN/DM(Likert score)的评估数据。
作者在论文中提出的方法,部分是出于对人工智能系统与人类希望它们做的事情之间的
misalignment的长期关注。当misaligned summarization model编造事实时,它们的错误是相当低风险的,而且容易被发现。然而,随着人工智能系统变得更加强大,并被赋予越来越重要的任务,它们所犯的错误可能会变得更加微妙和safety-critical,这使得这是一个需要进一步研究的重要领域。- 最大似然
相关工作:
与我们的工作最直接相关的是以前使用
human feedback来训练带强化学习的summarization models的工作《Better rewards yield better summaries: Learning to summarise without references》和《Fine-tuning language models from human preferences》。《Better rewards yieldbetter summaries: Learning to summarise without references》从2.5k个human ratings的CNN/DM摘要数据集中学习奖励函数,并训练一个比优化ROUGE指标更好的、用于摘要的策略。我们的工作与
《Fine-tuning language models from human preferences》最为相似,他们也训练Transformer模型来跨一系列任务来优化human feedback,包括在Reddit TL;DR和CNN/DM数据集上的摘要。与我们不同的是,他们以
online的方式进行训练,并发现该模型具有高度的extractive。他们指出,他们的labelers更喜欢抽取式摘要extractive summaries,与researchers的一致率很低。与他们相比,我们使用了大得多的模型、转向针对collecting human feedback的batch setting、确保labeler-researcher的高度一致、并做了一些算法上的修改(如分离策略网络policy network和价值网络value network)。
human feedback也被用作奖励来训练其他领域的模型,如对话、翻译、语义解析、故事生成、评论生成、以及证据抽取evidence extraction。我们的
reward modeling方法是在先前关于learning to rank的工作中发展起来的,其中learning to rank已被应用于使用显性反馈或隐性反馈(以点击数据的形式)对搜索结果进行排名。在一个相关的研究方向中,
human feedback被用来在模拟环境中训练agents。还有大量关于使用强化学习来优化NLP任务的automatic metrics的文献,例如用于摘要的ROUGE指标、用于翻译的BLEU指标,以及其他领域的一些指标。最后,关于修改架构和预训练程序以提高摘要性能的研究也很广泛。
24.1 模型
24.1.1 Higl-level 方法论
我们的方法类似于
《Fine-tuning language models from human preferences》中概述的方法,适配于batch setting。我们从一个初始策略开始(注意,一个策略意味着一个模型),该策略在目标数据集(在我们的例子中为Reddit TL;DR摘要数据集)上进行监督学习的微调。然后,这个过程包括三个步骤,可以反复进行,如下图所示。step 1:从现有策略中收集样本,并将comparisons发送给人类。对于每个Reddit帖子,我们从几个来源来采样摘要,包括当前策略、初始策略、原始的reference summary、以及各种baseline。我们将一个batch的summary pair发送给我们的human labelers,他们的任务是选择给定Reddit帖子的最佳摘要。注意,这里的摘要不仅来自于当前策略,还来自于初始策略、
reference、以及baseline。无论它们来自哪里,都是为奖励模型提供样本,而奖励模型仅仅关注:一个给定的摘要是好还是坏。step 2:从human comparisons中学习奖励模型。给定一个帖子和一个候选摘要,我们训练一个奖励模型来预测这个摘要是更好的摘要的log odds(ground-truth由我们的labelers来提供,log odds是分类器softmax layer的输入)。奖励模型作为价值网络。
step 3:针对奖励模型来优化策略。我们将奖励模型的logit output视为奖励,我们使用强化学习(具体而言是PPO算法)来优化这个奖励。
我们在下面的章节中对我们的程序进行了更详细的描述,包括奖励模型训练和策略训练的细节、以及我们的质量控制过程。在实践中,我们没有精确地迭代这一连串的三个步骤,而是在项目过程中更新了我们的数据收集程序和训练程序,同时积累了标签(详见论文附录
C.6)。整体架构类似于
GAN:- 策略函数作为生成器,用于生成摘要,使得摘要的质量尽可能高(而不是摘要的最大似然尽可能大)。
- 奖励函数作为判别器,用于判断摘要质量,从而促使策略函数不断演进。
此外,奖励函数根据收集的
human feedbacks来独立地监督训练,而不是像GAN中的一样进行对抗训练。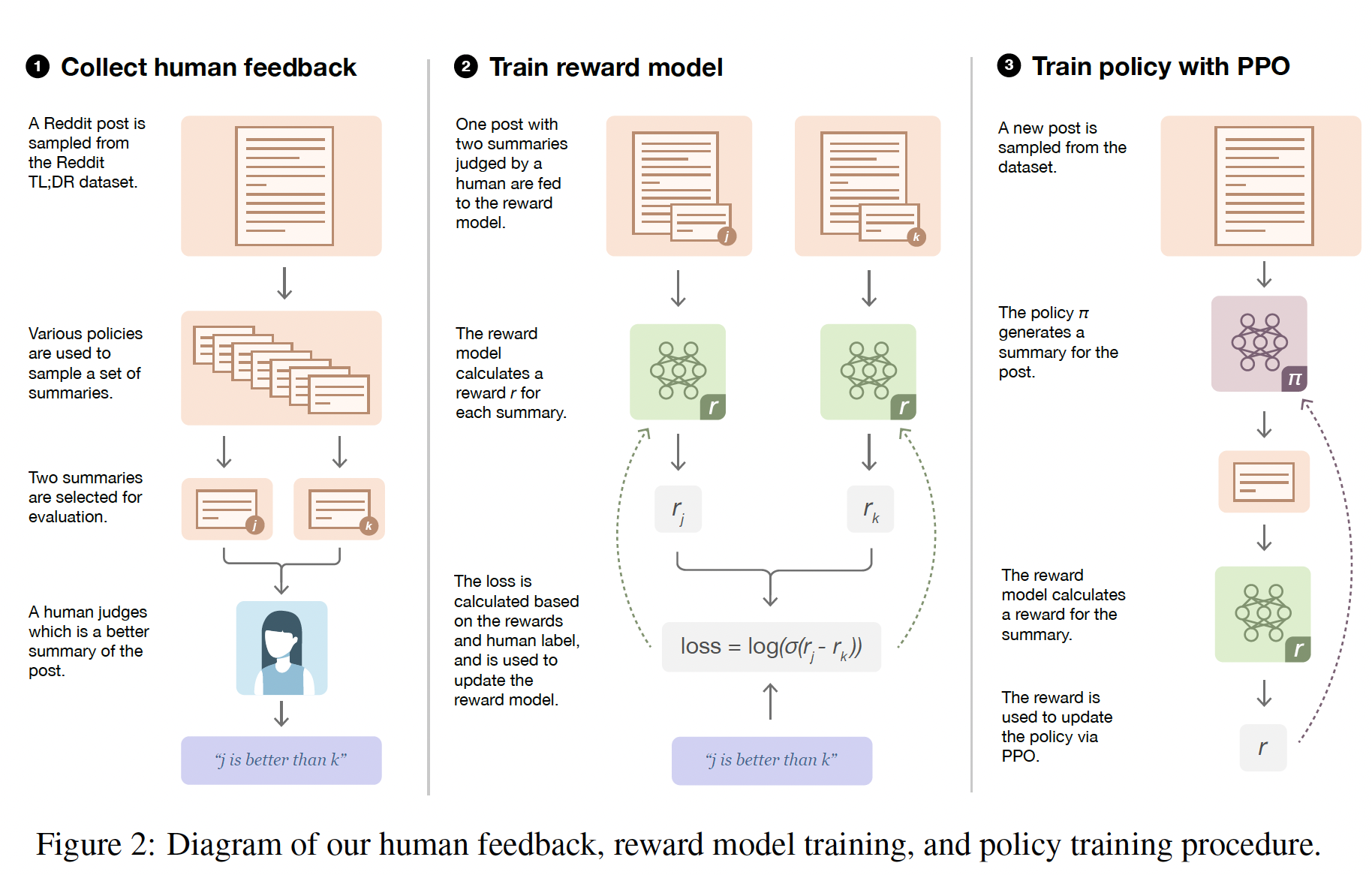
24.1.2 数据集和任务
数据集:我们使用
TL;DR摘要数据集,其中包含了来自reddit.com的约3M个帖子,涉及各种主题(subreddits),以及原发帖人写的帖子摘要。我们还对这个数据集进行了过滤(见论文的附录A),从而确保质数据量,包括使用subreddits的一个白名单(过滤之后,白名单的帖子数量分布如下表所示)。过滤规则:内容去重:通过检查帖子主体内容来去重。
白名单过滤:过滤掉不在我们
subreddit whitelist中的subreddit帖子。Edit/Update内容过滤:过滤掉任何标题以"Edit"或"Update"开头的帖子。毒性内容过滤:过滤掉包含某些主题(如性图片、或自杀,这些主题是启发式方法得到)的帖子。
帖子长度过滤:过滤掉任何正文超过
512个token的帖子(为了适配模型的上下文长度)。此外还对解析后的
reference摘要进行额外的过滤(我们使用reference摘要来训练supervised baselines):- 删除以
"Edit", "Update", "P.S."等变体开头的摘要。 - 启发式地删除了带有一定程度脏话的摘要。
- 删除了少于
24个token或超过48个token的摘要,从而尽量减少摘要长度对质量的潜在影响。此外我们发现:短于16个token的摘要通常是低质量的。
- 删除以
我们最终过滤的数据集包含
123169个帖子,我们保留了~ 5%作为验证集。在本文的其余部分,我们把这个数据集简称为TL;DR。如下表所示,
TL;DR dataset中大约2/3的帖子是由relationships或relationship advice组成,这是一个相当特定的领域。这引起了对于我们模型泛化性的潜在担忧,尽管模型在CNN/DM新闻文章上的强大迁移性能表明它们并没有无脑地特定于relationship advice。
我们选择
TL;DR数据集而不是更常用的CNN/DM数据集,主要是因为在CNN/DM上可以通过简单的extractive baseline获得非常强大的性能。我们在实验中发现:- 在
CNN/DM数据集,我们的labelers相比reference summary反而更喜欢lead-3 summary。 - 而且带有
low-temperature sampling监督微调T5模型已经超过了reference summary的质量,同时还大量复制了文章内容。
另一方面,在我们的
human evaluations中,简单的extractive baseline在TL;DR上表现很差(如Figure 12中的Title和Lead-2)。我们没有在CNN/DM上进行训练,而是研究了我们的human feedback models(即,human feedback训练的策略)在被训练为summarize Reddit posts之后,向CNN/DM数据集的迁移性能。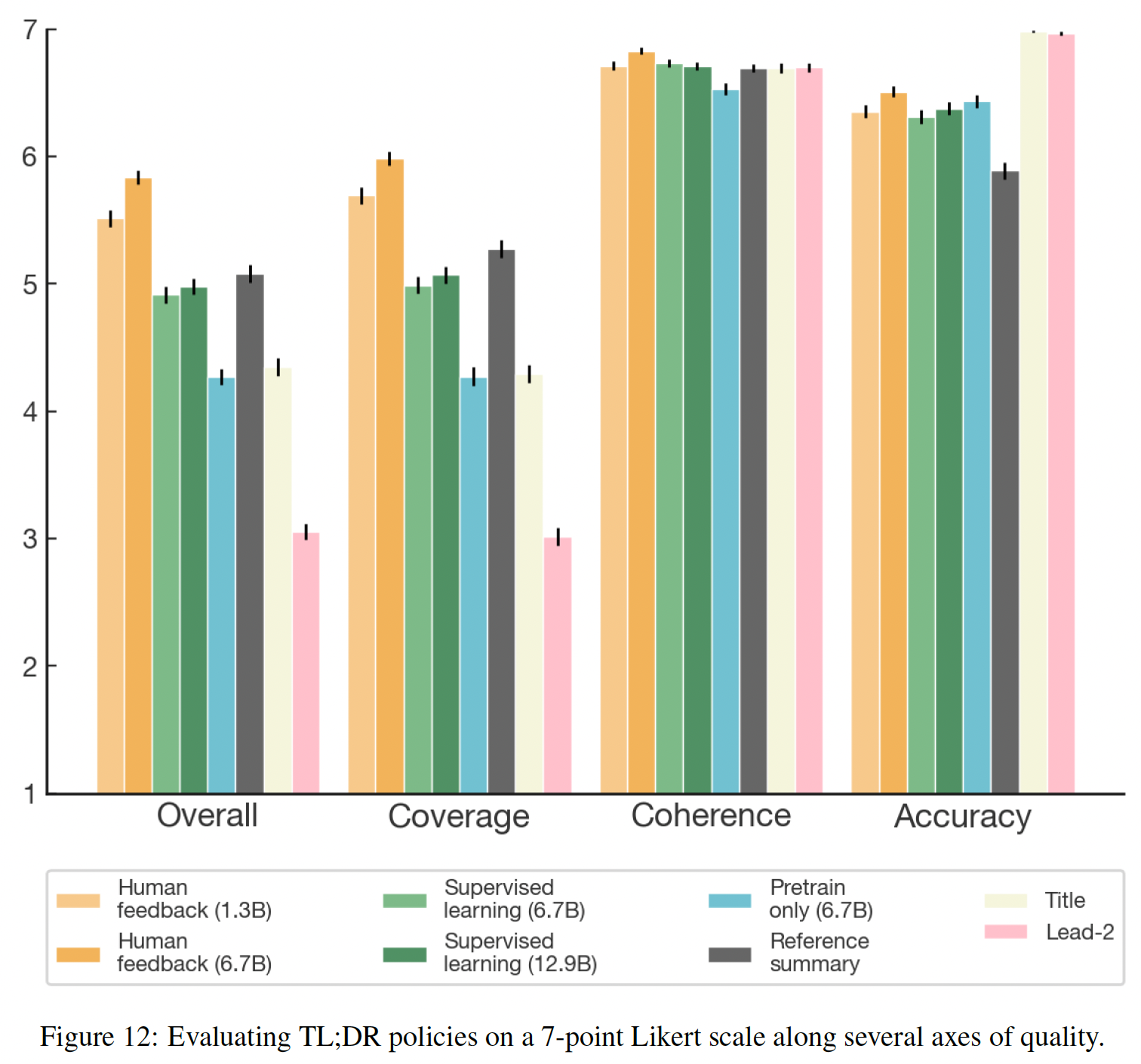
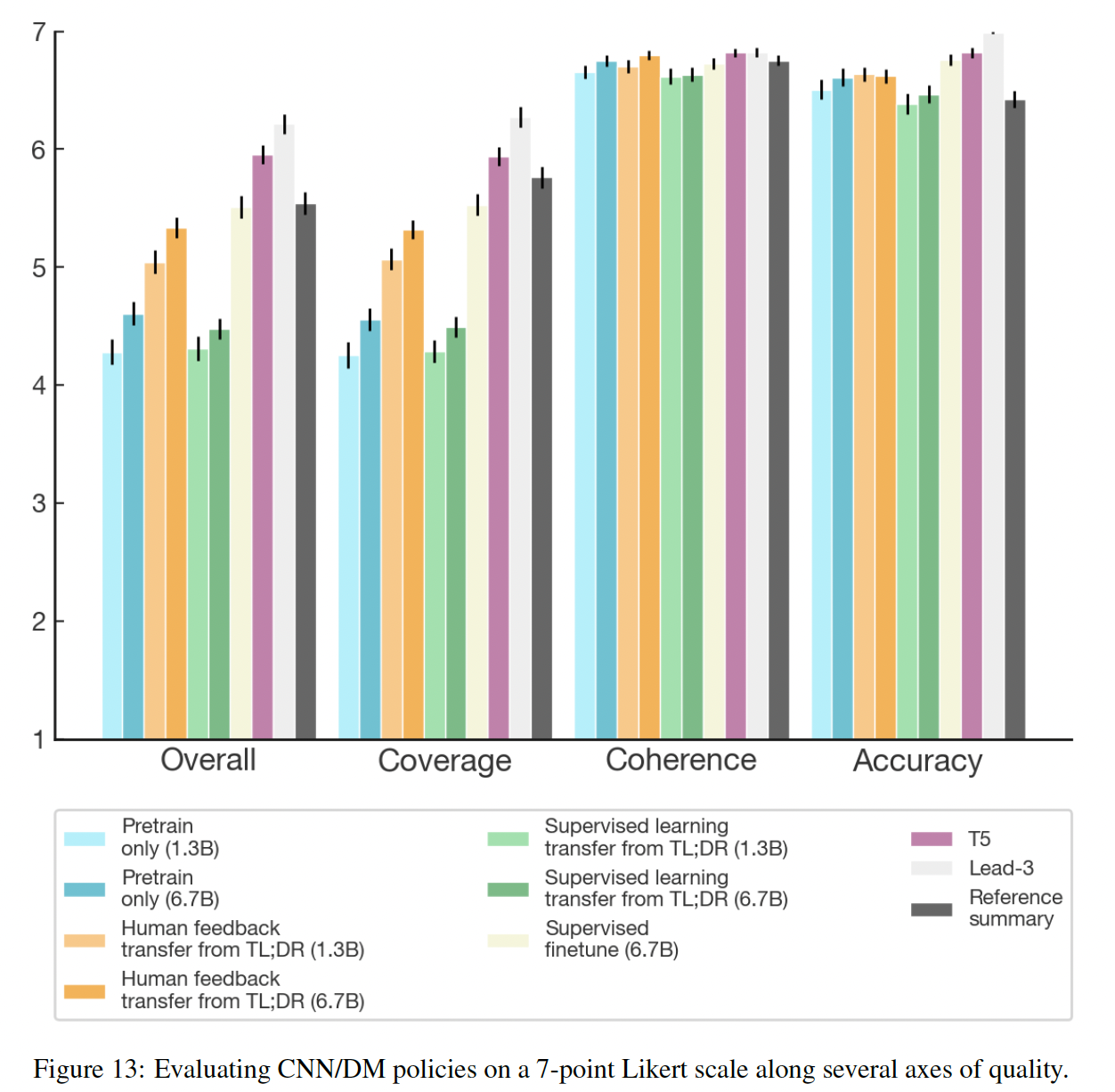
任务:我们把我们的
ground-truth task定义为:根据human judgments来产生一个模型,该模型生成长度小于48个token的摘要并且尽可能的好。我们判断摘要质量的标准是:摘要在多大程度上向只能阅读摘要而不能阅读帖子的读者传达了原始帖子的内容(关于标准的进一步讨论,见论文附录
C.5)。由于我们做comparisons的能力有限,所以我们雇用labelers为我们做comparisons。我们依靠详细的程序来确保comparisons和我们在任务上的高度一致,我们将在下一节介绍。判断摘要质量标准的进一步讨论:我们为评价
Reddit帖子的摘要、以及评价CNN/DM的新闻文章的摘要制作了单独的说明。对于
Reddit的指令,我们首先描述了Reddit的一般情况,并提供了一个表格,将Reddit的特定行话翻译成普通术语。- 用于
comparing summaries的指令:我们在Table 6展示了给labelers指令从而用于执行comparisons。除了这些指令之外,我们还提供了Reddit摘要之间的一个labeled comparison例子,以及对摘要的朴素解释的一个例子。 - 用于沿着质量轴评估摘要的指令:我们为
labelers提供了一套单独的详细指令,用于7-point Likert评估。我们首先介绍了我们所考虑的4个质量轴中的每一个,概述了连贯性coherence、准确性accuracy、覆盖率coverage和总分(见Table 7)。我们还为1分、4分、以及7分及其对应的摘要提供了一个简短的评分标准,其中注释了我们自己对这些轴的质量判断(带有解释)。 - 最后,我们提供了一个
FAQ部分,回答了这项任务的labelers所提出的常见问题。
- 用于
对于
CNN/DM,我们提供了同样的指令,只是我们对如何判断新闻文章增加了一些额外的说明。我们特别要求labelers不那么强调句子的连贯性(因为reference摘要最初是以要点的形式bullet-point form写成的,我们不希望labelers对此进行惩罚),也不那么强调摘要与文章的意图相匹配(这对Reddit的摘要很重要)。
在质量控制方面,我们进行了论文附录
C.1中描述的smaller版本的质量控制过程:- 首先沿着每个轴,我们(指的是论文的作者)亲自给一小部分摘要人工标注,以了解混淆点
points of confusion(指的是作者亲自下场,理解标注的难点)。 - 然后,我们写了指令文档
instructions document提供给labelers。 - 然后,我们让一小部分
labelers进行任务试验,以捕捉任何bugs或混淆点。 - 最后,我们让一大批
labelers加入到任务中,同时我们保持回答任何问题。


24.1.3 收集 human feedback
先前的、关于从
human feedback中微调语言模型的工作(《Fine-tuning language models from human preferences》)报告了 "我们希望我们的模型学习的质量概念和human labelers实际评估的质量概念之间的不匹配" ("a mismatch between the notion of quality we wanted our model to learn, and what the humans labelers actually evaluated"),导致模型生成的摘要按照labelers的说法是高质量的、但按照researchers的说法是相当低的质量。与
《Fine-tuning language models from human preferences》相比,我们实施了两个变化以提高human data质量:- 首先,我们完全转移到
offline setting,其中我们交替执行:发送大批量的comparison data给我们的human labelers、并在累积的collected data上重新训练我们的模型。 - 其次,我们与
labelers保持亲身接触的关系:我们为他们提供详细的指导,在共享的聊天室里回答他们的问题,并对他们的表现提供定期反馈。我们对所有labelers进行培训,以确保他们与我们的判断高度一致,并在项目过程中不断监测labeler-researcher agreement。详情见论文的附录C.1和C.5。
作为我们程序的结果,我们获得了高度的
labeler-researcher一致性:在comparison tasks的一个子集上,labelers与researchers的一致性为researchers-researchers之间的一致性为C.2中提供了更多关于human data质量的分析。- 首先,我们完全转移到
24.1.4 模型
我们所有的模型都是
GPT-3风格的Transformer decoder。我们对具有1.3B和6.7B参数的模型进行human feedback实验。预训练模型:我们从预训练的模型开始,在一个大型文本语料库中自回归地预测
next token。我们通过数据集中的高质量摘要的样本来填充上下文从而将这些模型作为zero-shot baseline。我们在论文附录B中提供了关于预训练的细节,并在论文附录B.2中提供了关于我们的zero-shot程序。监督微调
baseline:接下来,我们通过监督学习对这些模型进行微调,以预测我们过滤后的TL;DR数据集的摘要(详见论文附录B)。此外,我们使用这些监督微调模型对初始摘要进行采样从而收集
comparisons,进而初始化我们的策略模型和奖励模型,并作为评估的baseline。在我们最终的human evaluations中,我们使用nucleus sampling表现更好。为了验证我们的监督微调模型确实是强有力的、针对
comparison的baseline,我们在CNN/DM数据集上用6.7B模型运行我们的监督微调程序,发现我们取得的ROUGE分数比来自mid-2019的SOTA模型略好(如下图所示)。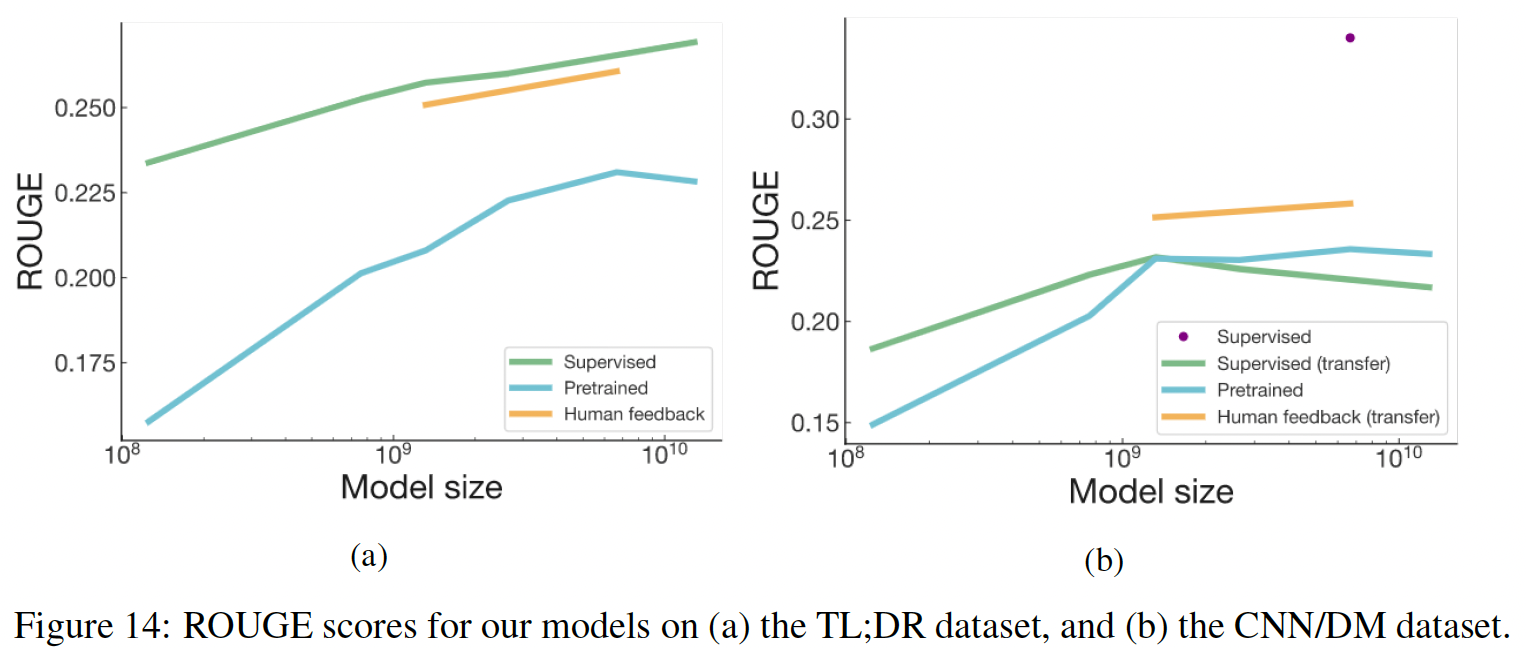
此外,我们发现:温度对
ROUGE得分有(通常是显著的)影响,我们做了一次彻底的扫描,以验证最佳温度配置是- 在
TL;DR上,在human feedback models获得的ROUGE分数比监督微调模型略低,这进一步表明ROUGE与human preferences的相关性很差。对于监督微调模型来说,降低温度比增加模型大小有更大的影响。有趣的是,在更高的温度下,我们的human feedback models实际上超过了监督微调的同类模型。 - 在
CNN/DM上,ROUGE与human evaluations相一致,即human feedback models比我们的监督微调模型的迁移性能更好。
- 在
奖励模型:为了训练我们的奖励模型
baseline开始,如上所述,然后添加一个随机初始化的linear head,该linear head输出一个标量值。我们训练这个模型来预测在给定一个帖子其中:
human judgments的数据集。
在训练结束时,我们将奖励模型的输出归一化,使我们的数据集中的
reference summaries的平均分为零。注意,监督微调模型与奖励模型是不同的模型,虽然它们使用相同的数据集,但是它们使用不同的监督信息:
- 监督微调模型使用
reference摘要作为监督信息。 - 奖励模型使用
human comparisons作为监督信息。
human feedback策略:我们想用上面训练的奖励模型来训练一个策略,该策略生成更高质量的输出(基于人类的判断)。我们主要使用强化学习来做这件事,把奖励模型的输出当作整个摘要的奖励,我们用PPO算法(《Proximal policy optimization algorithms》)来最大化这个奖励,其中每个time step是一个BPE token。我们以
Reddit TL;DR上微调的模型来初始化我们的策略。重要的是,我们在奖励中加入了一个惩罚项,该惩罚项惩学到的强化学习策略KL散度。完整的奖励KL项有两个目的:- 首先,它起到了熵的作用,鼓励策略的探索从而阻止它塌陷到单一的模式。
- 其次,它确保学到的策略不会生成这种的输出:该输出与奖励模型在训练期间所见的输出有太大的不同。
根据
InstructGPT,PPO的损失函数为:其中:
RL策略,KL系数。
对于
PPO的价值函数value function,我们使用一个与策略完全分离参数的Transformer。这可以防止价值函数的更新在训练的早期部分破坏预训练的策略(消融实验的结果如下图所示)。我们将价值函数初始化为奖励模型的参数。在我们的实验中,奖励模型、策略函数、以及价值函数的规模是一样的。注意,理论上奖励模型和价值函数可以合二为一,但是论文为什么要将它们分离开来?个人猜测是因为离线数据收集的缘故:如果奖励模型和价值函数合二为一,那么当奖励模型被重新训练时,价值函数不可用(正在训练过程中)。
将二者分离分开,使得奖励模型的训练与价值函数的使用之间相互独立。一旦奖励模型训练完毕,就用它的最新权重去初始化价值函数,使得价值函数始终成为奖励模型的最新版本的
copy。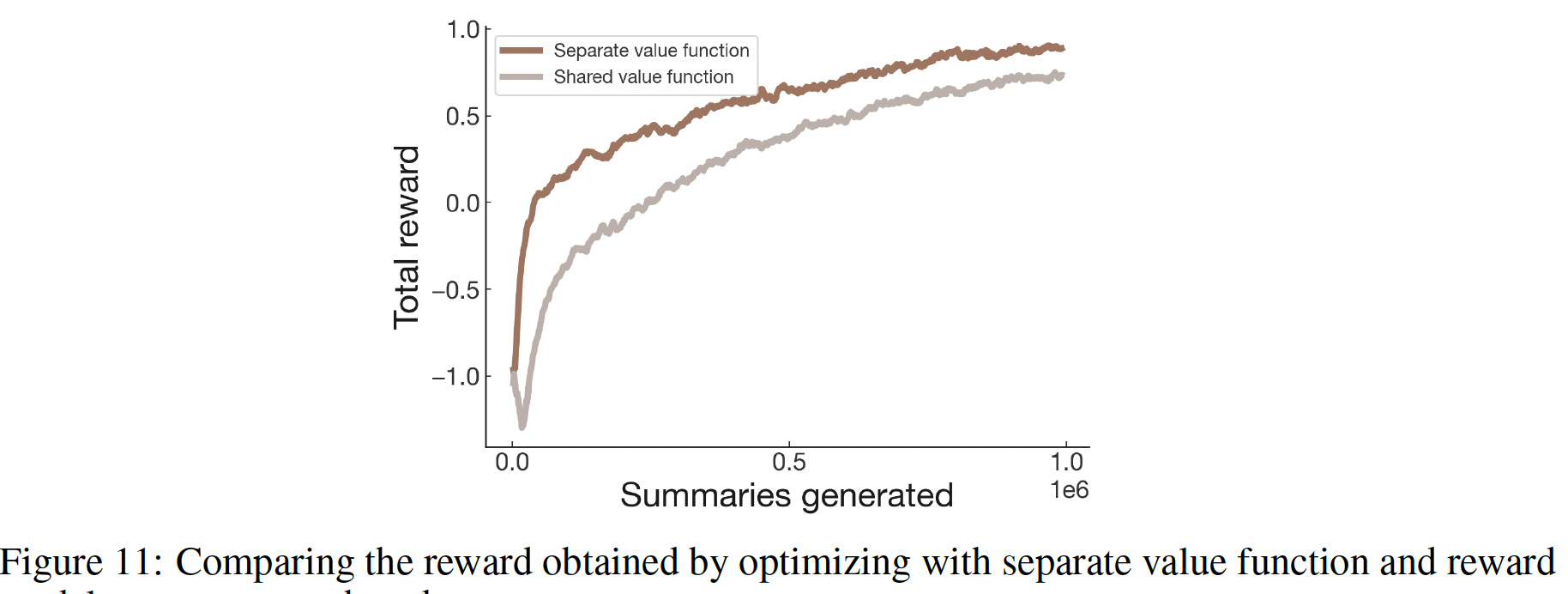
所有的模型都遵循标准的
Transformer架构,positional embedding维度为2048。所有模型都是用fp16 activations和Adam优化器训练的。几乎所有的supervised baselines、奖励模型、以及强化学习模型都是用fp32权重训练的,唯一例外的是我们的TL;DR supervised baselines是用fp16权重训练的。所有的模型都是用与GPT-3中相同的BPE编码进行训练。在预训练期间,模型被训练为预测由
Commoncrawl, Webtext, book, Wikipedia组成的大型文本语料库的next token。- 每个模型的训练时间在
1 ~ 3个epochs之间,总共有200 ~ 300 B个token。 - 学习率遵循带有一个
short warmup的cosine schedule,最终学习率衰减到最大值的10%。 batch size在整个训练过程中逐步上升到某个最大值,其中每个输入有2048个token。
每个模型的超参数如下表所示。
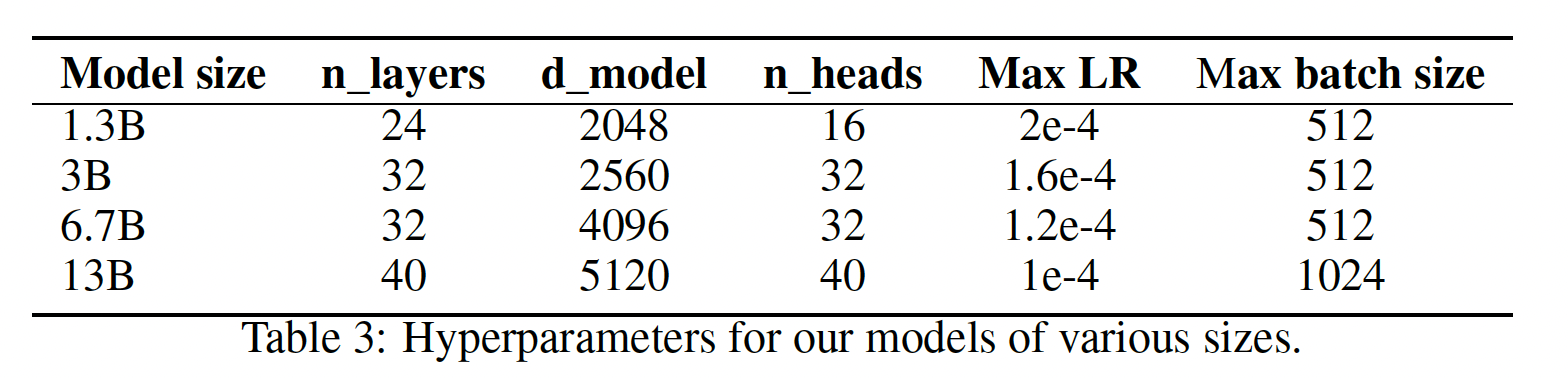
- 每个模型的训练时间在
对于
supervised baselines,我们从预训练的模型中初始化模型。- 我们用
cosine schedule来衰减学习率,初始学习率从7个值中选择(这七个值来自于log linear sweep) 。这导致我们在TL;DR数据集上1.3B, 3B, 6.7B, 13B大小的模型的学习率分别为6.35e-5, 5.66e-5, 2.83e-5, 2.83e-5,而在CNN/DM数据集上6.7B模型的学习率为2.38e-5。 - 我们使用
batch size = 128并微调一个epoch。
- 我们用
对于奖励模型,我们初始化为
supervised baseline,但在奖励模型的顶部有一个reward head,其权重根据我们训练一个
epoch,用cosine schedule衰减学习率,初始学习率从7个值中选择(这七个值来自于log linear sweep)。我们还在
3 ~ 10个种子之间进行sweep,并选择在验证集表现最好的奖励模型,因为我们发现数据迭代顺序和奖励头初始化都会影响结果。对于我们的main结果,1.3B和6.7B奖励模型的学习率分别为1.5e-5和5e-6。我们使用
batch size = 64,并训练一个epoch。
对于
PPO,我们用分离的策略网络和价值网络,将我们的策略网络初始化为supervised baseline,,将我们的价值网络初始化为奖励模型。我们为
advantage estimation设置了batch的rollouts优化了4个epoch。即,外层的
batch对应于pair,内层的minibatch对应于trajectory segment长度4个epoch。这里的rollouts指的就是轨迹。我们使用了一个线性学习率衰减
schedule,根据少量的实验和粗略的模型大小推断,设置1.3B模型的初始学习率为1.5e-5、6.7B模型的初始学习率为7e-6。在我们报告结果的两个
main运行中,我们使用了0.05的KL系数。我们对
1.3B模型使用batch size = 512、对6.7B模型使用batch size = 256,并运行1M个episodes。
24.2 实验
24.2.1 从 human feedback 来总结 Reddit 帖子
用
human feedback训练出来的策略比更大的监督模型更受欢迎。我们在
TL;DR上评估human feedback策略的主要结果显示在下图中。我们评估策略质量为:在数据集中,在策略生成的摘要和reference摘要之间,人类更喜欢策略生成的摘要的占比。在这个指标上:- 我们用
human feedback训练出来的策略明显优于我们的监督微调baseline:我们的1.3B的human feedback model显著优于10倍规模的监督微调模型(61% vs 43%)。 - 我们的
6.7B模型反过来又明显优于我们的1.3B模型,这表明使用human feedback的训练也得益于规模。 - 此外,我们的两个
human feedback model都被人类判定为优于数据集中使用的human demonstrations(即reference摘要)。
- 我们用
控制摘要的长度:在判断摘要质量时,摘要长度是一个混杂因素
confounding factor。摘要的目标长度是摘要任务的隐式部分:根据所需的简洁性conciseness(较短的摘要)和覆盖度coverage(较长的摘要)之间的权衡,较短或较长的摘要可能更好。由于我们的模型学会了生成较长的摘要,长度可能是我们质量改进的主要原因。我们策略产生的摘要要比
reference摘要更长,因为我们对策略限制了生成24 ~ 48个token的摘要。我们发现,在控制了摘要长度之后(见论文附录
F),我们的human feedback model相对于reference摘要的偏好下降了大约5%。即便如此,我们的6.7B模型的摘要仍然比reference摘要在大约65%的时间更受欢迎(如下图(b)所示)。注意:下图
(b)是通过一个逻辑回归模型来拟合曲线的。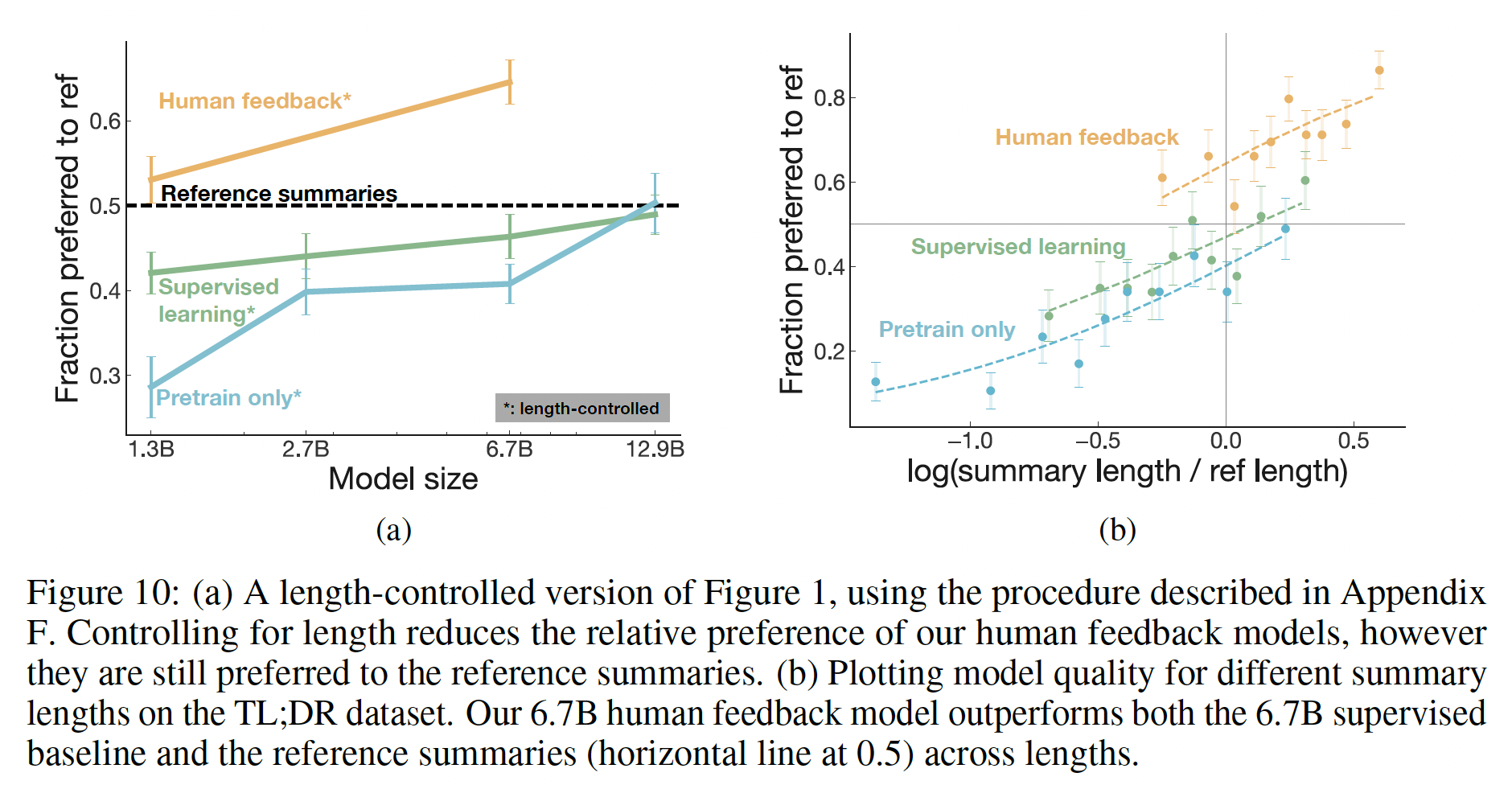
我们的策略是如何相对于
baseline得到改进的?为了更好地了解我们的模型摘要与
reference摘要、supervised baseline的摘要相比的质量,我们进行了一项额外的分析,即human labelers使用七个等级的Likert从四个方面(或 "轴")评估摘要质量。Labelers对摘要的覆盖度(原帖中的重要信息被覆盖的程度)、准确性(摘要中的statements在多大程度上被原始帖子所述)、连贯性(摘要本身有多容易阅读)、以及整体质量进行评分。结果(如下图所示)表明:我们的
human feedback model在质量的每个维度上都优于supervised baseline,特别是覆盖度。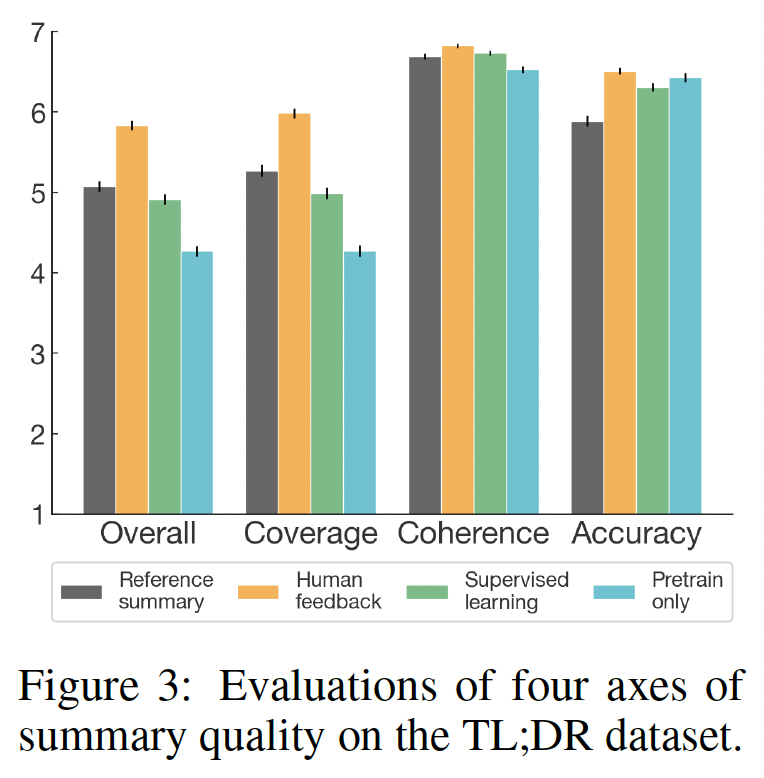
尽管我们的
human labelers对给出完美的overall质量分有很高的要求,但来自我们6.7B PPO模型的摘要在45%的时间里达到了7/7的整体质量分。相比之下,6.7B的supervised baseline和reference摘要的整体质量分达到7/7的时间分别为20%和23%。注:
45%、20%、23%这些数据,在原始论文中并没有相应的表格给出详细说明。
24.2.2 迁移到总结新闻文章
我们的
human feedback models(即,强化学习得到的模型)也可以在没有任何进一步训练的情况下生成优秀的CNN/DM新闻文章的摘要(如下图所示):- 我们的
human feedback models的表现显著优于在TL;DR上通过监督学习所微调的模型、以及仅在预训练语料上训练的模型。 - 事实上,我们的
6.7B的human feedback model的表现几乎与在CNN/DM的reference摘要上微调的6.7B模型一样好,尽管我们的模型所生成的摘要短得多。
由于我们迁移到
CNN/DM的human feedback models与在CNN/DM上训练的模型在摘要长度分布上几乎没有重叠,前者的平均token长度大约是后者的一半,所以它们很难直接比较。在下图(b)中,我们显示了不同摘要长度下的平均overall score,这表明如果我们的human feedback models生成更长的摘要,其表现会更好。从质量上看,来自human feedback models的CNN/DM摘要一致地是文章的流畅和合理的表达。我们在论文的附录H中展示了一些例子。注意:下图
(b)是通过一个逻辑回归模型来拟合曲线的。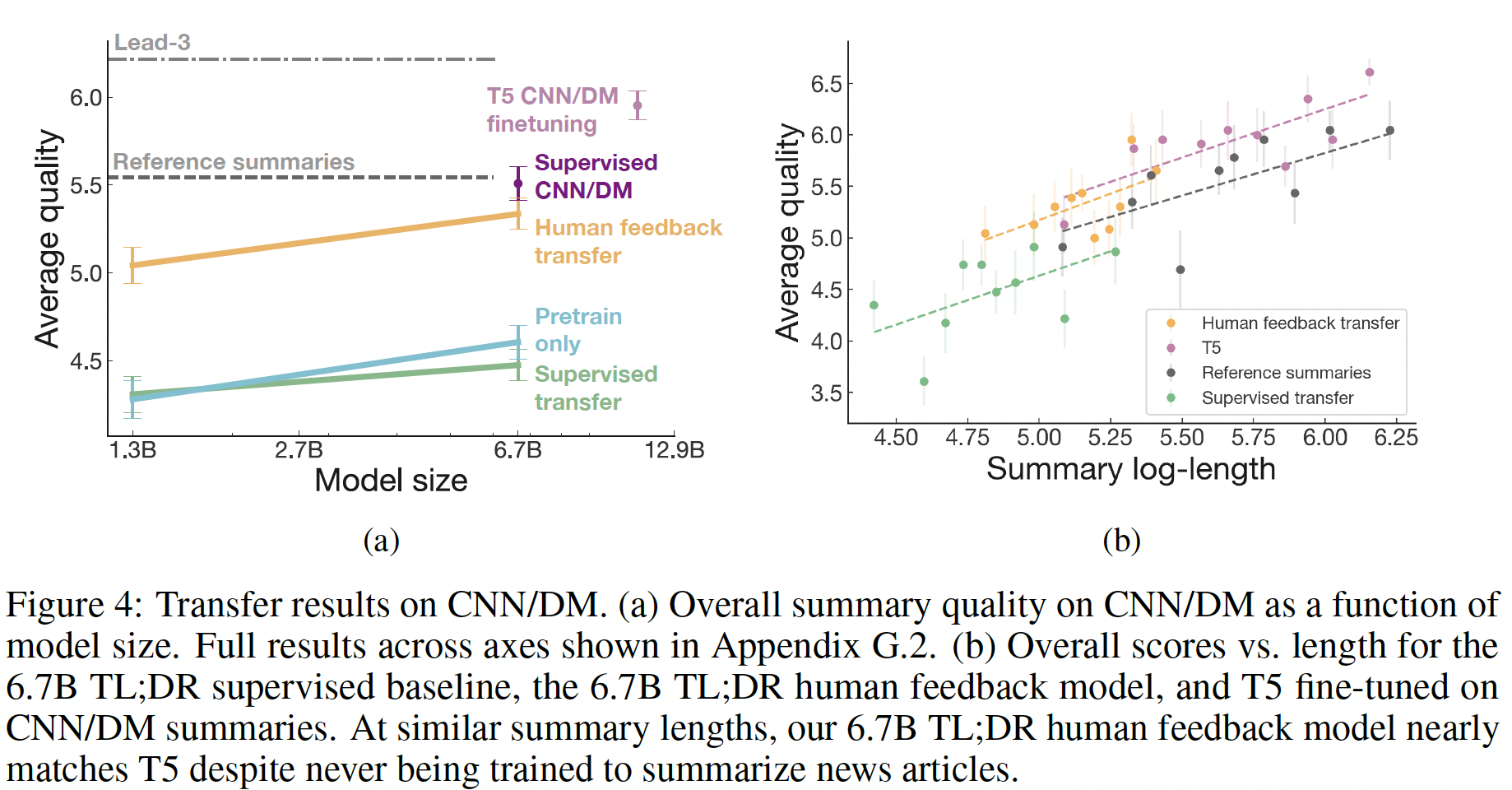
- 我们的
24.2.3 理解奖励模型
当我们优化奖励模型时发生了什么?
奖励模型并不能完美地代表我们的
labeler preferences,因为它只有有限的容量,而且只能看到来自相对狭窄分布(关于摘要的分布)的少量comparison data。虽然我们可以希望我们的奖励模型能够泛化到训练期间未见过的摘要,但不清楚人们可以针对奖励模型进行多大程度的优化。为了回答这个问题,我们创建了一系列策略,这些策略采用我们奖励模型的早期版本
earlier version(这些早期版本的奖励模型具有不同的优化强度optimization strength),并要求labelers将策略生成的摘要与reference摘要进行比较。下图显示了PPO在在一系列KL惩罚系数(即,根据
KL值。因此当- 在轻度优化下(即,
labelers的评估)。 - 然而,随着我们进一步优化,最终奖励模型变得与
labelers反相关(因为策略产生了的样本是奖励模型没有见过的,导致奖励模型误判)。尽管这显然是不可取的,但我们注意到这种过度优化over-optimization也发生在ROUGE中。类似的行为在机器人领域的学到的奖励函数中也被观察到。
随着
labelers标注的结果是坏的样本。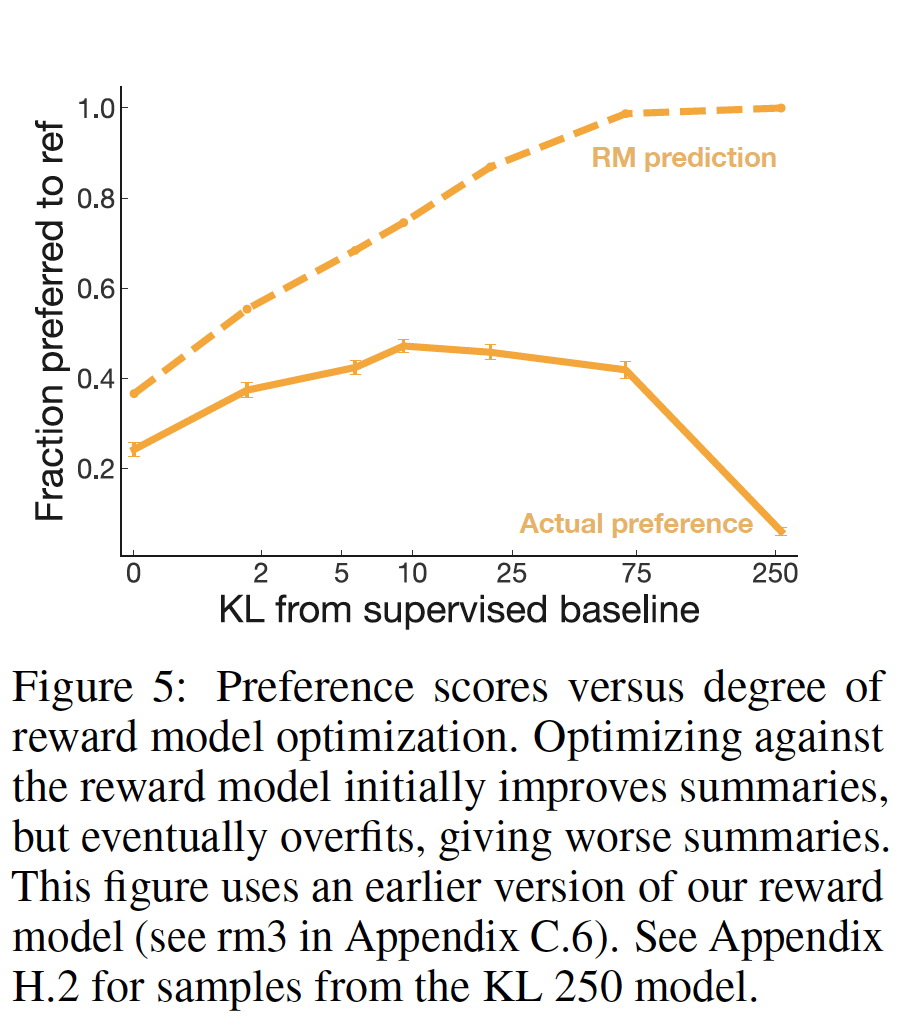
- 在轻度优化下(即,
reward modeling是如何随着模型规模和数据规模的增加而scale的?我们进行了一次消融实验,以确定数据规模和模型大小如何影响奖励模型的性能。我们训练了
7个奖励模型,模型规模从160M到13B参数,在来自我们数据集的8k到64k的human comparisons上训练。我们发现:- 训练数据量增加一倍会导致奖励模型验证准确性增加约
1.1%。 - 而模型大小增加一倍则会导致奖励模型验证准确性增加约
1.8%。
- 训练数据量增加一倍会导致奖励模型验证准确性增加约
奖励模型学到了什么?
我们通过在几个验证集上评估我们的奖励模型来探索它。我们在论文附录
G.6中展示了完整的结果,并在此强调了这些结果:我们发现:我们的奖励模型泛化到评估
CNN/DM摘要(论文附录G.7),在62.4%和66.5%的时间内与labeler preferences相一致(分别对应于我们的1.3B和6.7B模型)。我们的6.7B奖励模型几乎与labeler-labeler之间的66.9%的一致率相匹配。我们还发现,我们的奖励模型对摘要中微小的、但是语义上重要的细节很敏感。
我们构建了一个额外的验证集,让
labelers对摘要进行最小的编辑来改进它们。我们的奖励模型倾向于经过编辑的摘要的频率(1.3B模型为79.4%、6.7B模型为82.8%),这几乎与单独的human evaluators偏好经过编辑的摘要的频率(84.1%)一样。此外,当比较
reference摘要、以及参与者角色颠倒的干扰摘要时,我们的模型可靠地选择了reference摘要(1.3B模型为92.9%的时间,6.7B模型为97.2%的时间)。然而,我们的模型偏向于较长的摘要:我们的
6.7B模型仅在62.6%的时间里更喜欢使摘要变短的改进编辑(与人类的76.4%相比)。
24.2.4 分析针对摘要的自动指标
评估:我们研究了各种自动化指标作为
human preferences的预测器的效果,并将它们与我们的奖励模型进行比较。具体而言,我们研究了
ROUGE、摘要长度、从帖子中拷贝的数量、以及我们的基线监督模型下的log probability。我们在论文附录G.7中列出了这些指标之间的一致率的完整矩阵(如下图所示)。我们发现:
我们学到的奖励模型始终优于其他指标,甚至在从未训练过的
CNN/DM数据集上也是如此。ROUGE未能跟踪track样本质量,而我们的模型可以改进跟踪。- 在比较我们的
supervised baseline models的样本时,ROUGE与labelers的一致率为57%。 - 而比较我们的
human feedback model的样本,ROUGE与labelers的一致率下降到50%。 - 同样地,在比较我们的
human feedback models的样本时,ROUGE与supervised log probability的一致率降至50%;而我们的奖励模型与supervised log probability的一致率仍高于随机表现(62%)。
- 在比较我们的
扩大监督模型的规模并不能可靠地改善奖励模型与
labelers在supervised log probability上的一致性。
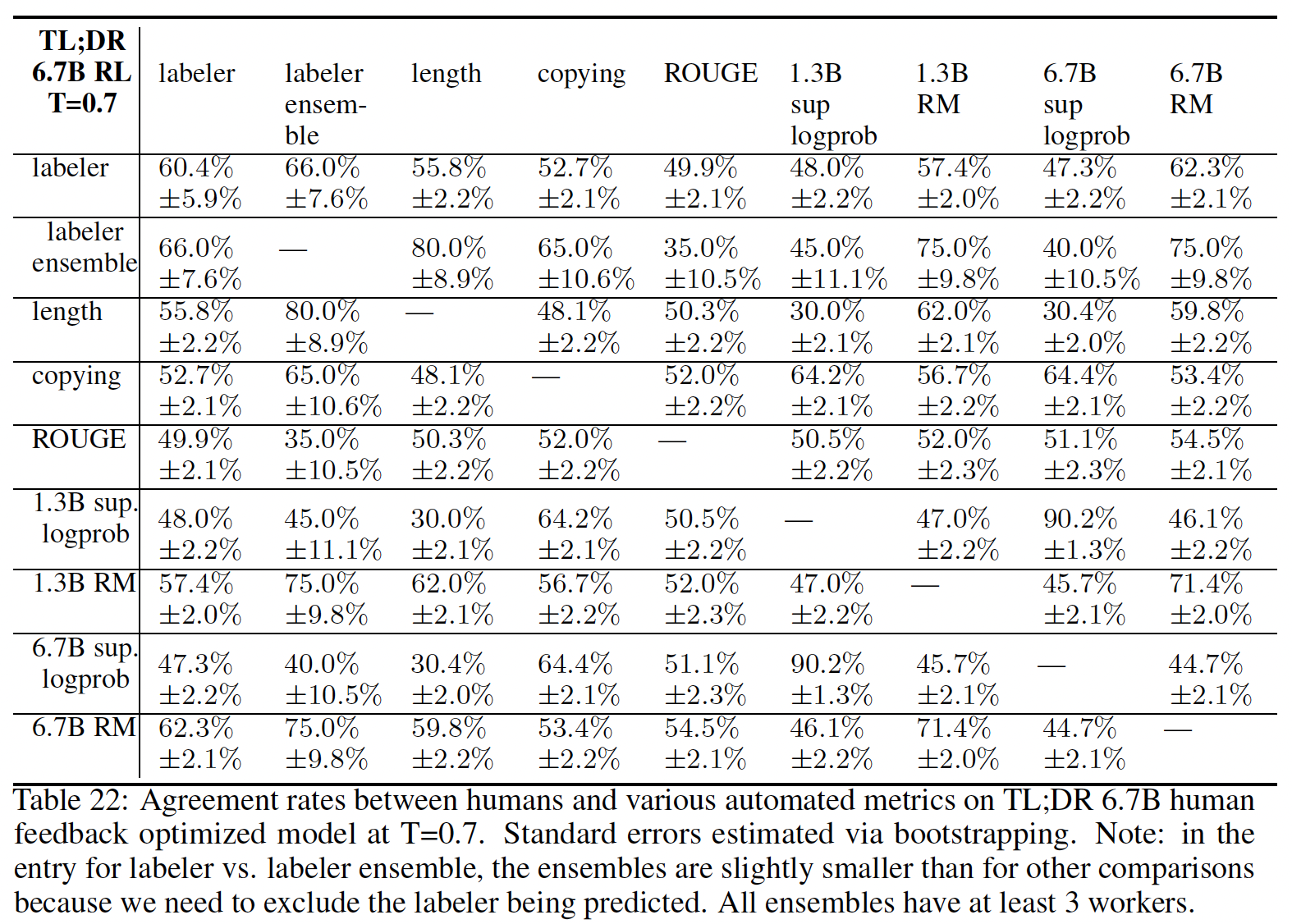
优化:在下图中,我们展示了使用简单的优化方案对
ROUGE进行优化并不能持续提高质量,这一点在《A deep reinforced model for abstractive summarization》中已经被指出。与针对我们的奖励模型的优化相比,针对ROUGE的优化达到峰值的时间更早,质量也大大降低。RM代表奖励函数reward model。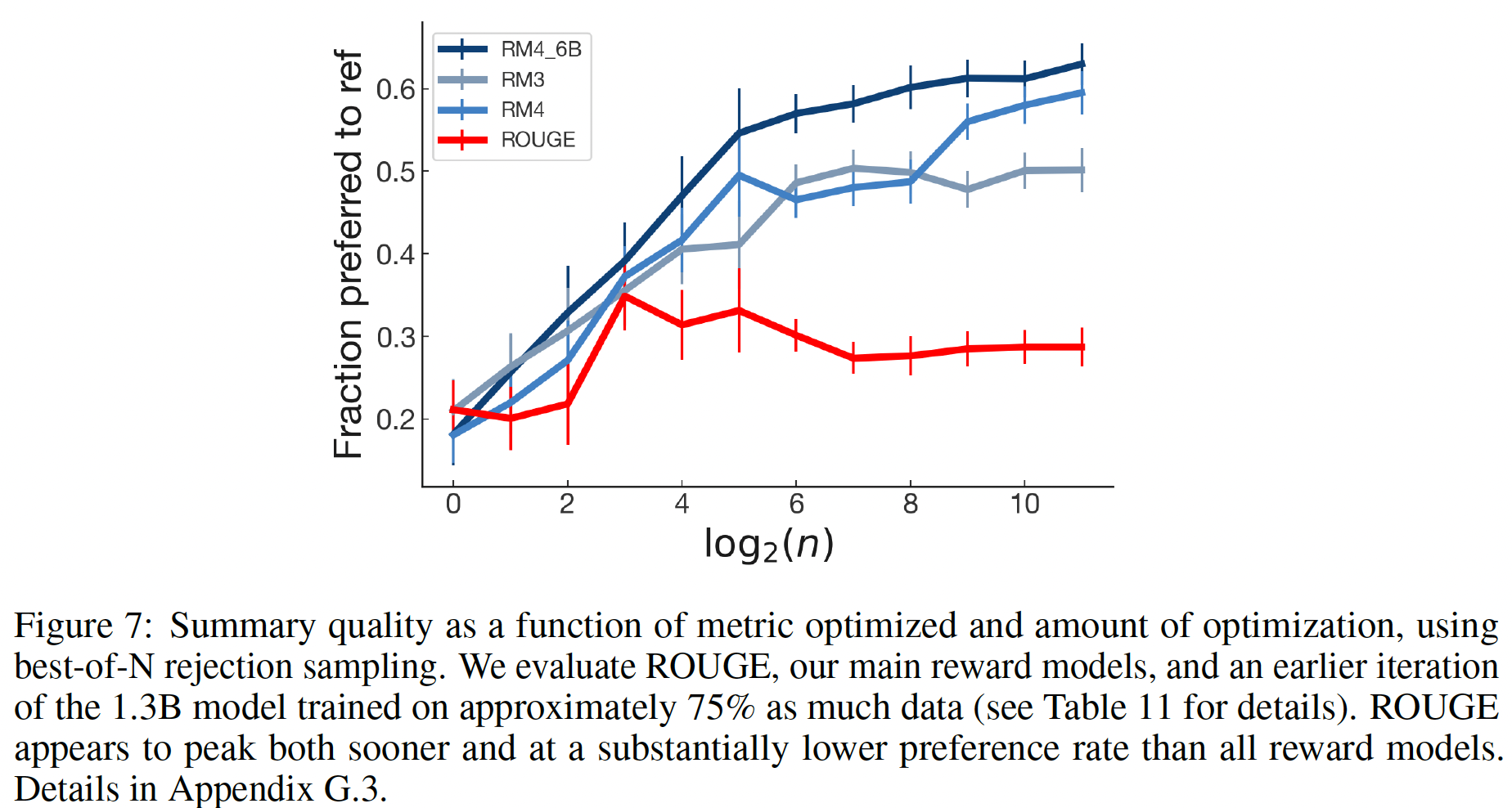
24.3 讨论
局限性:我们工作的一个局限性是生成最终模型所需的时间和成本。
值得注意的是,用强化学习对我们的
6.7B模型进行微调需要大约320 GPU-days。与之前的工作相比,我们的数据收集程序也很昂贵:训练集花费了数千
labeler hours,并且需要大量的researcher time来确保质量。由于这个原因,我们无法收集baseline,如同等数量的高质量human demonstrations的supervised baselines。更多讨论见附录D。我们把这种消融留给未来的工作。尽管如此,我们相信奖励模型更有可能扩展到那些提供良好
demonstrations的技能密集型skill-intensive的或耗时的任务。
未来的方向:
本文的方法可以应用于任何人类可以比较样本的任务,包括对话、机器翻译、问答、语音合成、以及音乐生成。我们预期这种方法对生成较长的样本特别重要,因为在这种情况下,
maximum likelihood samples的distributional shift和退化会产生问题。通过训练跨许多任务来预测human feedback,也许可以提高样本效率。这些生成任务都是优化样本的最大似然。
我们对将
human feedback扩展到人类不容易评估模型输出质量的任务中特别感兴趣。在这种情况下,识别一个机器学习系统是否align to人类设计者的意图,这是特别具有挑战性的。一种方法是训练机器学习系统来帮助人类快速而准确地完成评估任务。除了二元比较之外,还有丰富的
human feedback方法,可以针对训练模型来探索这些方法。例如,我们可以从labelers那里获得高质量的demonstrations、让labelers编辑模型输出以使其更好、或者让labelers提供解释从而说明他们为什么喜欢一个模型输出而不是另一个。所有这些human feedback都可以作为一个信号来训练更有能力的奖励模型和策略。
更广泛的影响:我们在本文中探讨的技术是通用技术,可以用于各种机器学习应用,用于任何人类可以评估模型输出质量的任务。因此,其潜在的影响是相当广泛的。
我们的研究主要是出于如下的潜在的积极效果:使机器学习算法
align to设计者的偏好。许多机器学习应用优化了简单的指标,这些指标只是设计者意图的粗略代理。这可能会导致一些问题,比如Youtube的推荐会促进点击诱饵click-bait。在短期内,改进直接从human preferences中学习和优化的技术,可能会使这些应用更符合人类的福祉。然而从长远来看,随着机器学习系统的能力越来越强,要确保它们的行为安全可能会越来越困难:它们所犯的错误可能更难发现,后果也会更严重。例如,写一篇不准确的新闻摘要既容易被发现(人们只需阅读原文),后果也相当低。另一方面,模仿人类驾驶可能比优化
human preferences更不安全(因为模仿驾驶出问题的后果相当严重)。我们相信,我们在本文中探讨的技术是一种有希望的步骤从而缓解这种强有力系统的风险,并使它们更好地align to人类关心的东西。不幸的是,我们的技术也使恶意行为者能够更容易地训练造成社会伤害的模型。例如,人们可以利用
human feedback来微调语言模型,使其更具说服力并操纵人类的信念、或者诱导人类对技术的依赖、或者产生大量的有毒或有害的内容从而伤害特定的个人。避免这些结果是一个重大的挑战,没有什么明显的解决方案。用
human feedback训练的大型模型可能对许多群体产生重大影响。因此,对于我们如何定义labelers会强化的 "好的" 模型行为,必须要谨慎。决定什么是好的摘要是相当直截了当的,但是对于具有更复杂目标的任务,不同的人可能对正确的模型行为有不同的意见,因此决定什么是好的行为将需要非常小心。在这些情况下,使用
researcher labels作为 "黄金标准" 可能是不合适的。相反,来自受技术影响的群体的个人应该被纳入到定义 "好" 的行为的过程中,并被聘为labelers从而加强模型中的这种行为。我们选择在
Reddit TL;DR数据集上进行训练,因为该数据集上的摘要任务比CNN/DM上明显更具挑战性。然而,由于该数据集由用户提交的帖子组成,且审核度极低,它们往往包含冒犯性或反映有害社会偏见的内容。这意味着我们的模型可能会产生有偏见的或令人反感的摘要,因为它们已经被训练为总结此类内容。出于这个原因,我们建议在将我们的模型部署到面向用户的应用中之前,要彻底研究其潜在的危害。最后,对于以前只能由人类完成的任务,通过提高机器学习算法执行这类任务的能力,我们正在增加许多工作被自动化的可能性,可能会导致大量的工作流失。如果没有合适的政策来缓解大规模失业的影响,这也可能导致重大的社会危害。
二十五、InstructGPT [2022]
给定一些任务的样本作为输入,
large language model: LLM可以被 "提示prompted" 从而执行一系列的自然语言处理任务。然而,这些模型经常表现出一些非预期的行为,如:编造事实、生成有偏见或有毒的文本、或者干脆不遵循用户的指令。这是因为最近许多大型语言模型所使用的语言建模目标(即,预测来自互联网的网页上的next token)与"follow the user’s instructions helpfully and safely"的目标不同。因此,论文《Training language models to follow instructions with human feedback》(即,InstructGPT)说:语言建模的目标是misaligned的。避免这些非预期的行为,对于在成百上千个应用中部署和使用的语言模型来说,尤其重要。论文
《Training language models to follow instructions with human feedback》在align语言模型方面取得进展,其中通过训练语言模型使其按照用户的意图行事。这既包括显式的意图(如,遵循指令),也包括隐式的意图(如,保持真实,没有偏见、没有毒性、或其它伤害性)。使用《A general language assistant as a laboratory for alignment》的语言,InstructGPT的作者希望语言模型是helpful的(它们应该帮助用户解决他们的任务)、honest的(它们不应该捏造信息或误导用户)、以及harmless的(它们不应该对人或环境造成生理、心理或社会伤害)。论文在后面内容中详细阐述了对这些标准的评估。作者专注于微调方法从而
aligning语言模型。具体而言,作者使用来自人类反馈的强化学习reinforcement learning from human feedback: RLHF来微调GPT-3从而遵循广泛的书面指令(如下图所示)。这项技术使用human preferences作为奖励信号来微调GPT-3。首先,作者根据候选合同工
contractors在筛选测试中的表现,雇用了一个由40名contractors(他们是labelers)组成的团队来标注数据。筛选测试见后面的内容。然后,作者收集了一个数据集,该数据集包含关于一些
prompts的理想输出行为desired output behavior(由labelers撰写的demonstration)。这些prompts包括被提交给OpenAI API的、以及一些labelers提供的。论文用这个数据集来训练supervised learning baseline。因为很多用户在调用
OpenAI API,因此OpenAI可以从日志记录中获取很多prompts。这一步是通过比较小的数据集,利用监督学习微调,从而得到一个良好的初始模型(作为初始策略)。
这里的
prompt就是代表了用户意图的指令,而labeler撰写的demonstration就是ground-truth用于生成模型的监督信号。然后,作者收集了一个人工标注的
comparison数据集,这个comparison数据集比较了在更大的API prompt集合上的输出(labelers对同一个prompt的多个模型输出进行人工排序)。对于相同的
prompt,这里有来自相同模型的不同输出(因为随机采样的原因)、也有不同模型的输出(因为我们有各种各样的模型)。作者在这个数据集上训练一个奖励模型
reward model: RM,从而预测labelers会更喜欢哪个model output。奖励模型的目的是考察哪个被生成的文本更能匹配
prompt,而不关心这些文本是如何生成的。当然,最新的策略函数作为模型之一,使得奖励模型见过策略函数的输出,使得奖励模型能够对策略函数的输出结果打分。最后,作者使用这个奖励模型作为奖励函数,并通过
PPO算法(《Proximal policy optimization algorithms》)来强化学习微调supervised learning baseline从而最大化这个奖励。注意,微调有两种:一种是监督微调,一种是强化学习微调。
这个过程如下图所示。这个过程使
GPT-3的行为与特定人群(主要是论文的labelers和researchers)的声明偏好stated preference相一致,而不是任何更广泛的 "人类价值human value" 概念。作者把得到的模型称为InstructGPT。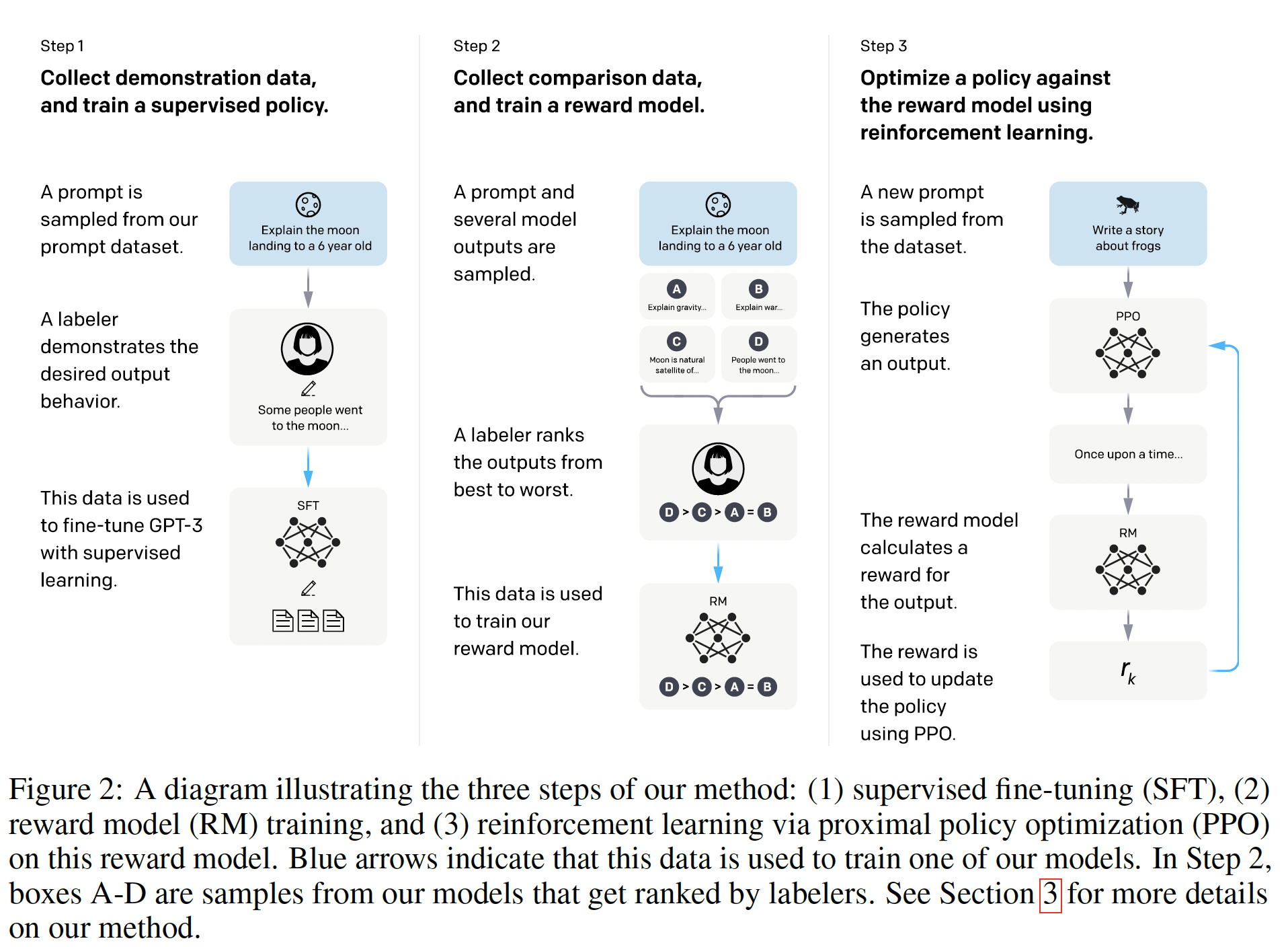
论文主要通过让
labelers在论文的测试集上对模型输出的质量进行评估,测试集由来自held-out customer(在训练数据中没有出现)的prompt组成。论文还在一系列公共的自然语言处理数据集上进行了自动化评估automatic evaluation。论文训练三种规模的模型(1.3B、6B和175B参数),所有的模型都使用GPT-3架构。论文的主要发现如下:与
GPT-3的输出相比,labelers明显更喜欢InstructGPT的输出。在测试集上,尽管参数少了
100多倍,但1.3B参数的InstructGPT模型的输出却比175B参数的GPT-3的输出更受欢迎。这些模型具有相同的架构,不同之处仅在于:InstructGPT在human feedback data上进行了微调。即使作者在GPT-3中加入了few-shot prompt从而使其更好地遵循指令,这一结果也是成立的。175B InstructGPT的输出在175B GPT-3的输出更受欢迎,而在few-shot 175B GPT-3更受欢迎。InstructGPT模型还根据labelers生成了更合适的输出,并更可靠地遵循指令中的显式约束explicit constraint。InstructGPT模型在真实性方面比GPT-3有所提高。在
TruthfulQA benchmark中,InstructGPT产生真实的和有信息的答案的频率是GPT-3的两倍。在没有针对GPT-3进行对抗性选择adversarially selected的问题子集上,InstructGPT的结果同样强大。在API prompt distribution的"closed-domain"任务中,其中输出不应该包含输入中不存在的信息(如摘要和closed-domain QA),InstructGPT模型编造输入中不存在的信息的频率约为GPT-3的一半(分别为21%和41%的幻觉率hallucination rate)。InstructGPT在毒性方面比GPT-3有小的改进,但没有偏见bias。为了测量毒性,论文使用
RealToxicityPrompts数据集,并同时进行自动化评估和人工评估。在遵从prompt的情况下,InstructGPT模型产生的毒性输出比GPT-3少25%左右。在Winogender和CrowSPairs数据集上,InstructGPT比GPT-3没有明显改善。可以通过修改
RLHF微调程序,将公共自然语言处理数据集上InstructGPT的性能退化降到最低。在
RLHF微调过程中,作者观察到在某些公共自然语言处理数据集上InstructGPT与GPT-3相比有性能退化,特别是SQuAD, DROP, HellaSwag, WMT 2015 French-to-English translation。这是一个 "对齐税alignment tax"的例子,因为论文的alignment procedure是以降低我们可能关心的某些任务的性能为代价的。可以通过将PPO update与增加pretraining distribution的log likelihood的update混合在一起(PPO-ptx),从而大大减少这些数据集上的性能退化,而且不影响labelers的偏好得分。InstructGPT可以推广到没有产生任何训练数据的"held-out labelers"的偏好。为了测试
InstructGPT的泛化性,论文对held-out labelers进行了初步实验,发现他们对InstructGPT的输出与GPT-3的输出的偏好率与training labelers大致相同。然而,我们还需要做更多的工作来研究这些模型在更广泛的用户群体中的表现,以及它们在人类预期行为有分歧的输入中的表现。公共自然语言处理数据集并不能反映出语言模型的使用情况。
作者将
GPT-3在两类数据上监督微调:第一类数据是
human preference data(即InstructGPT所使用的)。这个就是监督微调
baseline。第二类数据由两个不同的公共自然语言处理任务的数据:
FLAN和T0(《Multitask prompted training enables zero-shot task generalization》)(尤其是T0++变体)。这些数据集由各种自然语言处理任务组成,并且每个任务结合了自然语言指令。得到的分别是
FLAN和T0上监督微调的模型。
在
API prompt distribution上:FLAN和T0模型(即,在这两个数据集上监督微调得到的GPT-3)的表现比监督微调baseline(即,在labelers demonstration上监督微调得到的GPT-3)略差。这表明在公共数据集上微调的模型,在应用到具体场景中还是有性能的
gap。而
labelers明显更喜欢InstructGPT而不是这些模型(InstructGPT与监督微调baseline相比有T0和FLAN模型与监督微调baseline相比分别只有
InstructGPT模型对RLHF finetuning distribution之外的指令表现出了很好的泛化能力。作者定性地探究了
InstructGPT的能力,发现它能够遵从指令从而用于summarizing code,回答关于code的问题,有时还能遵循不同语言的指令,尽管这些指令在fine-tuning distribution中非常罕见。相比之下,
GPT-3也能完成这些任务,但需要更仔细的prompting,而且通常不遵循这些领域的指令。这一结果令人激动,因为这表明InstructGPT能够泛化"following instructions"的概念。即使在模型得到很少直接监督信号的任务上,模型也会保留一些alignment。InstructGPT仍然会犯一些简单的错误。例如,
InstructGPT仍然会不遵循指令、编造事实、对简单的问题给出冗长的对冲回答hedging answer(即,正反两个方面都回答)、或者不能检测到具有错误前提的指令。
总体而言,论文的结果表明:利用
human preferences对大型语言模型进行强化学习微调可以大大改善它们在各种任务中的行为,尽管在提高它们的安全性和可靠性方面还有很多工作要做。相关工作:
关于从
human feedback的alignment和learning的研究:我们建立在以前的技术上,使模型align to人类的意图,特别是来自human feedback的强化学习reinforcement learning from human feedback: RLHF。RLHF最初是为在模拟环境和Atari游戏中训练简单的机器人而开发的,最近被应用于微调语言模型以总结summarize文本。这项工作反过来又受到在对话、翻译、语义解析semantic parsing、故事生成、评论生成和证据抽取evidence extraction等领域使用human feedback作为奖励的类似工作的影响。《Memory-assisted prompt editing to improve gpt-3 after deployment》使用written human feedback来增强prompt,并提高GPT-3的性能。- 还有一些工作是在
text-based environments中使用具有规范先验normative prior的强化学习来agent(《Training value-aligned reinforcement learning agents using a normative prior》)。
我们的工作可以被看作是
RLHF在broad distribution的语言任务上对于aligning language model的直接应用。最近,语言模型
alignment的意义也受到了关注。《Alignment of language agents》对语言模型中因misalignment导致的行为问题进行了分类,包括产生有害的内容、以及博弈错误的目标。- 在同时进行的工作中,
《A general language assistant as a laboratory for alignment》提出将语言助手language assistants作为alignment research的测试平台,研究一些简单的baseline,以及它们的scaling特性。
训练语言模型来遵从指令
follow instruction:我们的工作也与语言模型的跨任务泛化研究有关,其中语言模型在广泛的公共自然语言处理数据集(通常以适当的指令为前缀)上进行微调,并在一组不同的自然语言处理任务上进行评估。这个领域有一系列的工作,这些工作在训练和评估数据、指令的格式、预训练模型的大小、以及其他实验细节方面都有所不同。各项研究的一致发现是:在一系列自然语言处理任务上对语言模型进行带指令的微调,可以提高语言模型在
held-out任务上的下游性能,无论是在zero-shot setting还是在few-shot setting的情况下。还有一个相关的工作是用于导航
navigation的instruction following,其中模型被训练为遵从自然语言指令从而在simulated environment中导航。评估语言模型的危害
harm:修改语言模型行为的一个目标是缓解这些模型在现实世界中部署时的危害。这些风险已经有了广泛的记录。语言模型可以产生有偏见的输出biased output、泄露私人数据、产生错误的信息、以及被恶意使用。对于一个全面的回顾,我们建议读者阅读《Ethical and social risks of harm from language models》。在特定领域部署语言模型会产生新的风险和挑战,例如在对话系统中。有一个新兴但不断增长的领域,旨在建立
benchmark来具体评估这些危害,特别是围绕毒性toxicity、思维定势stereotype、以及社会性的偏见social bias。在这些问题上取得重大进展是困难的,因为对语言模型行为的善意干预可能会产生副作用。例如,由于训练数据中的偏见关联
prejudicial correlation,减少语言模型的毒性的努力可能会降低其对under-represented groups的文本建模的能力。修改语言模型的行为从而缓解危害:有很多方法可以改变语言模型的生成行为
generation behavior。《Process for adapting language models to society (palms) with values-targeted datasets》在一个小型的、value-targeted的数据集上对语言模型进行了微调,这提高了模型在问答任务中坚持这些value的能力。《Mitigating harm in language models with conditional-likelihood filtration》对预训练数据集进行了过滤,它删除了一些文档,在这些文档上语言模型有很高的条件概率来生成一组由researchers书写的trigger phrase。当在这个过滤过的数据集上进行训练时,他们的语言模型产生的有害文本较少,代价是语言建模性能略有下降。trigger phrase类似于黑名单,由researchers来预先指定。《Recipes for safety inopen-domain chatbots》使用了多种方法来提高聊天机器人的安全性,包括数据过滤、在生成过程中阻止某些单词或n-grams、safety-specific control tokens,以及human-in-theloop的数据收集。其他缓解语言模型产生的偏见的方法有:
word embedding regularization、数据增强、null space projection以使敏感token的分布更加均匀、不同的目标函数,或因果干涉分析causal mediation analysis。还有一些工作是利用第二个(通常是较小的)语言模型来引导语言模型的生成,这个想法的变体已经被应用于减少语言模型的毒性(
《Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp》)。
25.1 方法
25.1.1 High-level 方法论
我们的方法遵循
《Fine-tuning language models from human preferences》和《Learning to summarize from human feedback》的方法,他们将其应用于文风延续stylistic continuation和摘要任务。我们从一个预训练的语言模型、一个prompt分布(在这个分布上我们希望我们的模型产生aligned output)、以及一个训练有素的human labelers团队作为开始。然后,我们应用以下三个步骤(参考下图):第一步:收集
labeler demonstration数据,并训练一个有监督的策略supervised policy。我们的
labelers在input prompt distribution上提供所需行为的demonstration。然后,我们使用监督学习在这些数据上监督微调一个预训练的GPT-3模型。注意,
GPT-3模型是预训练好的,这里仅仅是微调。监督微调好的模型作为初始策略。第二步:收集
labeler comparison数据,并训练一个奖励模型reward model。我们收集模型输出之间的
comparisons的一个数据集。在这个数据集中,对于给定的输入,labelers指出他们更喜欢哪一个输出。然后我们训练一个奖励模型来预测人类喜欢的输出。第三步:使用
PPO(《Proximal policy optimization algorithms》)对奖励模型进行策略优化。我们使用奖励模型的输出作为
scalar reward。我们强化学习微调supervised policy,从而使用PPO算法优化该奖励。
步骤二和三可以连续迭代:在当前的最佳策略上收集更多的
labeler comparison数据,用来训练新的奖励模型,然后再训练新的策略。在实践中,我们的大部分comparison数据来自我们的supervised policy,还有一些来自我们的PPO policy(即,通过PPO微调的supervised policy)。
25.1.2 数据集
我们的
prompt数据集主要由被提交给OpenAI API的text prompt组成(由客户提交的),特别是那些在Playground界面上使用早期版本的InstructGPT模型(通过监督学习在我们的demonstration data的子集上训练)。 使用Playground的客户被告知:他们的数据可以被用于训练进一步的模型。在本文中,我们没有使用生产环境中使用API的客户的数据。我们启发式地对
prompt去重(共享长的公共前缀的prompt被认为是重复的),并且我们将每个user ID的prompt数量限制在200个。我们还根据user ID创建了训练集、验证集和测试集,因此验证集和测试集不包含训练用户的数据。为了避免模型学习潜在的敏感的客户细节,我们在训练集中过滤了所有的个人身份信息personally identifiable information: PII。训练集/验证集/测试集是通过
user ID来拆分的。每个
user ID的prompt限制为200个,使得prompt的分布比较均匀。必须有一个训练好的
InstructGPT模型部署到OpenAI API,这个训练好的InstructGPT模型如下文所述。为了训练最开始的
InstructGPT模型,我们要求labelers自己写prompts。这是因为我们需要一个instruction-like prompt的initial source来引导这个过程,而这些类型的prompts很少通过API提交给常规GPT-3模型。我们要求labelers写三种类型的prompt:即,使用
OpenAI API的用户很少会提交这些类型的prompts,因此需要让labelers人工构造。Plain:我们简单地要求labelers想出一个任意的任务,同时确保任务有足够的多样性。Few-shot:我们要求labelers想出一个指令,以及针对该指令的多个query/response pair。User-based:我们有一些准备提交给OpenAI AI的use-cases,我们要求labelers想出与这些use-cases相对应的prompt。
从这些
prompt中,我们产生了三个不同的数据集,用于我们的微调程序:我们的
supervised fine-tuning: SFT数据集,带有labelers的demonstration,用于训练我们的SFT模型。对于
SFT,请注意,相比较于customer prompts,我们有更多的labeler-written prompts。这是因为,在项目开始时,我们让labelers基于一个用户界面来写指令,这个界面要求他们给出一个总体的template instruction以及该指令的few-shot例子。我们通过采样不同的few-shot examples的集合,从相同指令中合成了多个SFT datapoints。读者猜测:
SFT模型很大可能就是部署到OpenAI API的第一个模型,用于收集customer prompts。我们的
RM数据集,带有labelers对模型输出的排名,用于训练我们的RM。对于
RM而言,对于每个prompt我们收集了comparisons上训练模型。因此,训练模型的ranked pair的数量要比prompt的数量要大一个数量级。我们的
PPO数据集,没有任何human labels,用作RLHF微调的输入。PPO数据集虽然没有human labels,但是它根据奖励函数来对输出进行评估。
SFT数据集包含大约13K个training prompt(来自API的和labelers编写的);RM数据集有33K个training prompt(来自API的和labelers编写的);PPO数据集有31K个training prompt(仅来自API)。关于数据集大小的更多细节见下表。
为了了解我们的数据集的构成,在下表中我们显示了由我们的
contractors标注的API prompts(特别是RM数据集)的use-case类别的分布。大部分的use-case都是生成式的,而不是分类或问答。注意,这里只有
customer prompts(来自API),而不包括labeler prompts。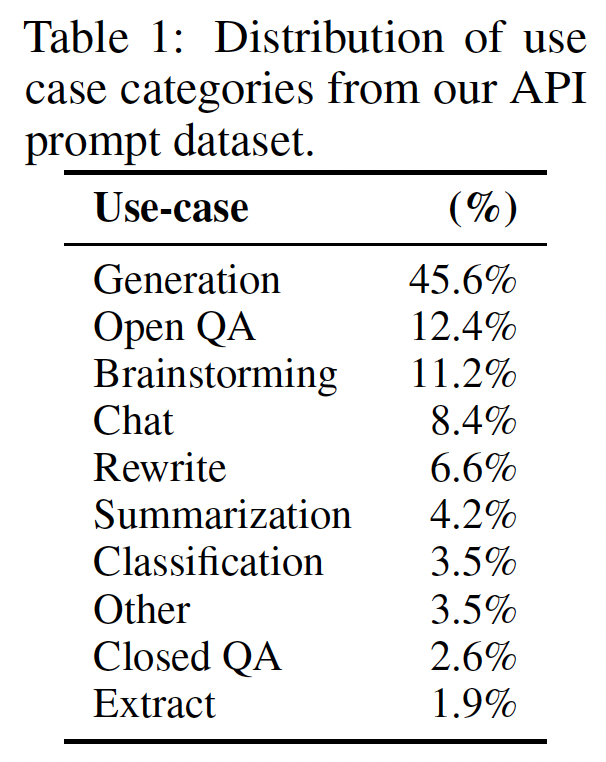
我们
labeled prompt metadata的一个子集如下表所示。请注意,我们的annotation fields在项目过程中发生了变化,所以不是每个prompt都被annotated为每个字段。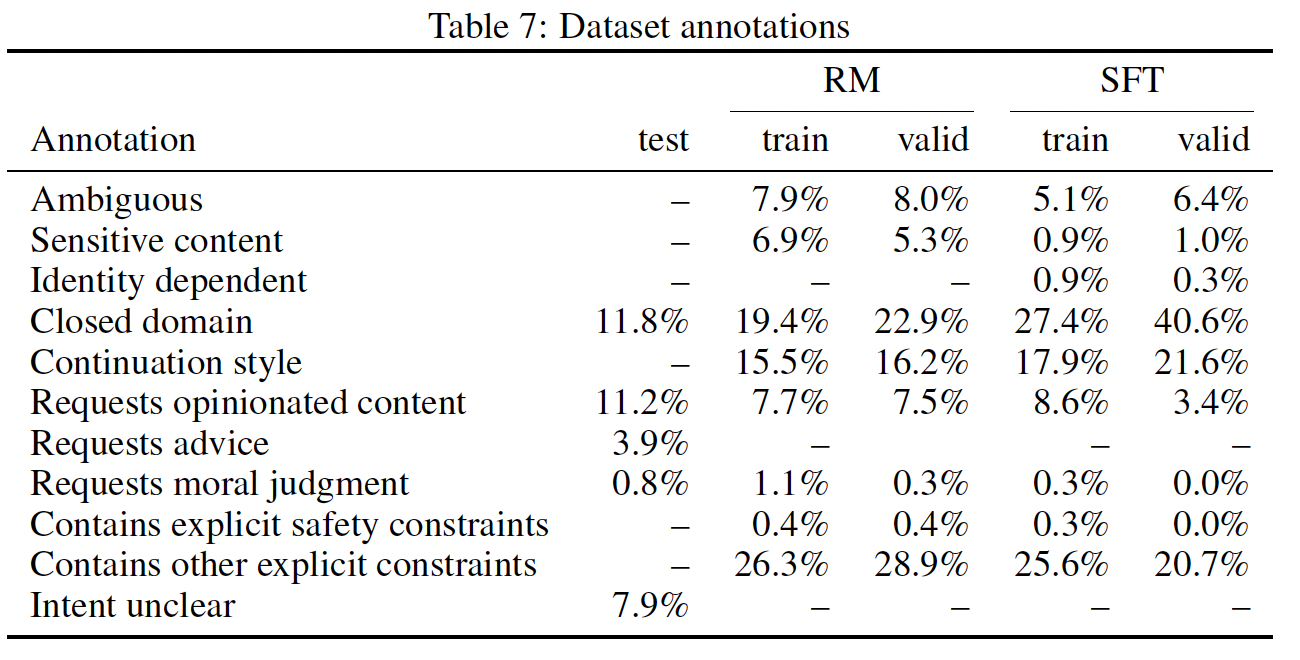
我们还在下表中展示了一些说明性的
prompt(由researchers编写,模仿提交给InstructGPT模型的prompt类型)。
我们在附录
A中提供了关于我们数据集的更多细节。{}表示模板,"""表示分隔符。更多提交给
InstructGPT模型的prompt(来自论文附录A.2.1)。




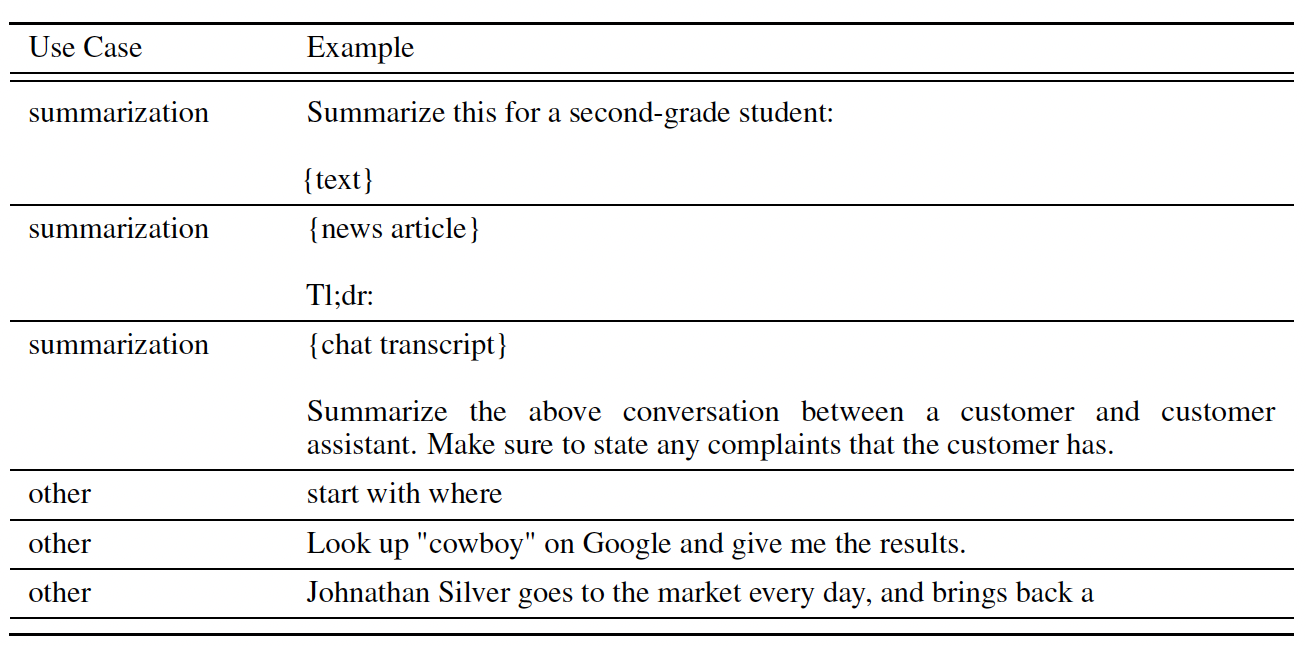
提交给
GPT-3模型的prompt(来自论文附录A.2.2),通常而言它们更少地instruction-style并且包含更显式的prompting。注意这里有些prompt,其中用户意图是不清晰的。提交给
GPT-3的prompt和提交给InstructGPT的prompt是不同的。这是因为我们希望GPT-3也是instruction-following风格的。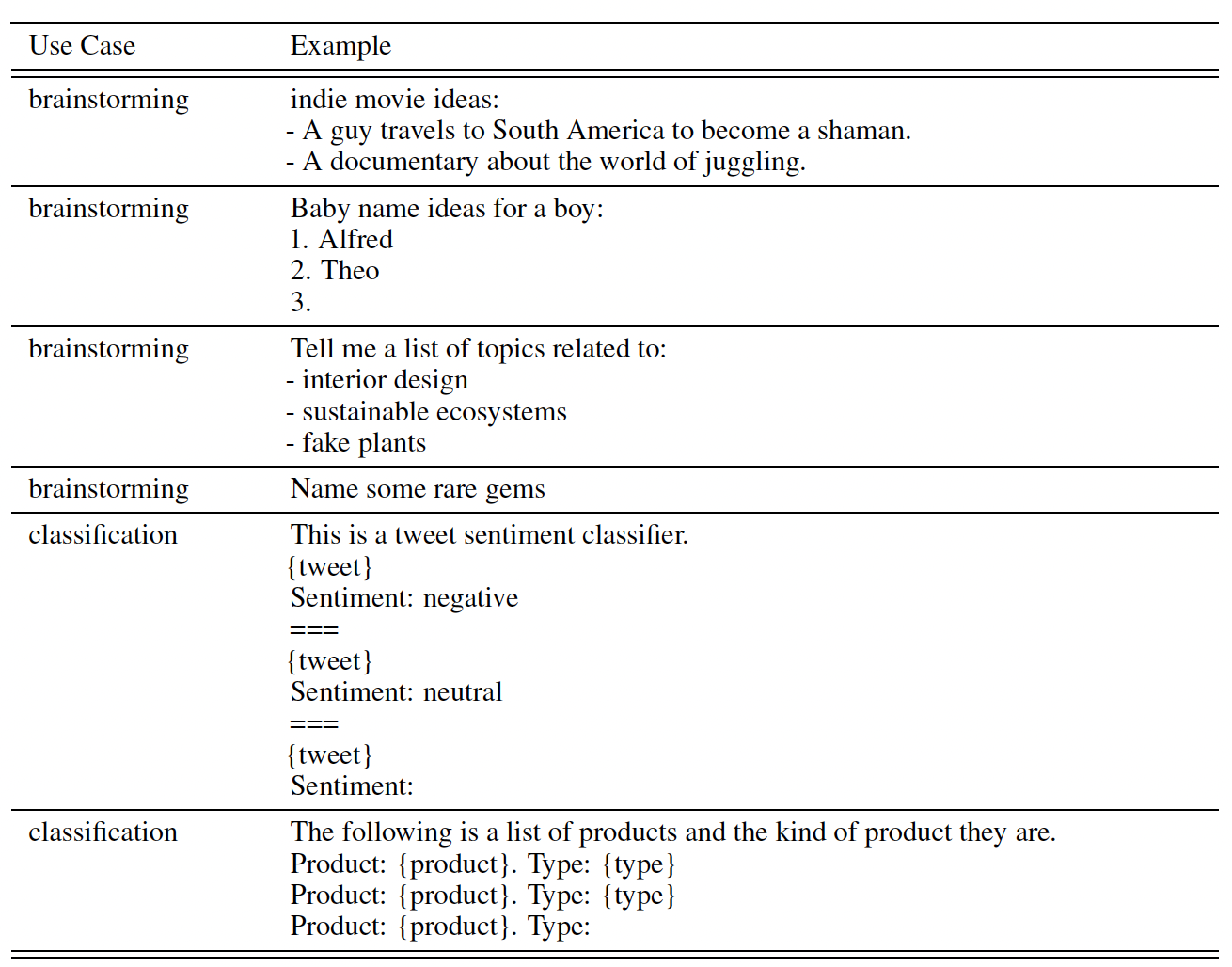
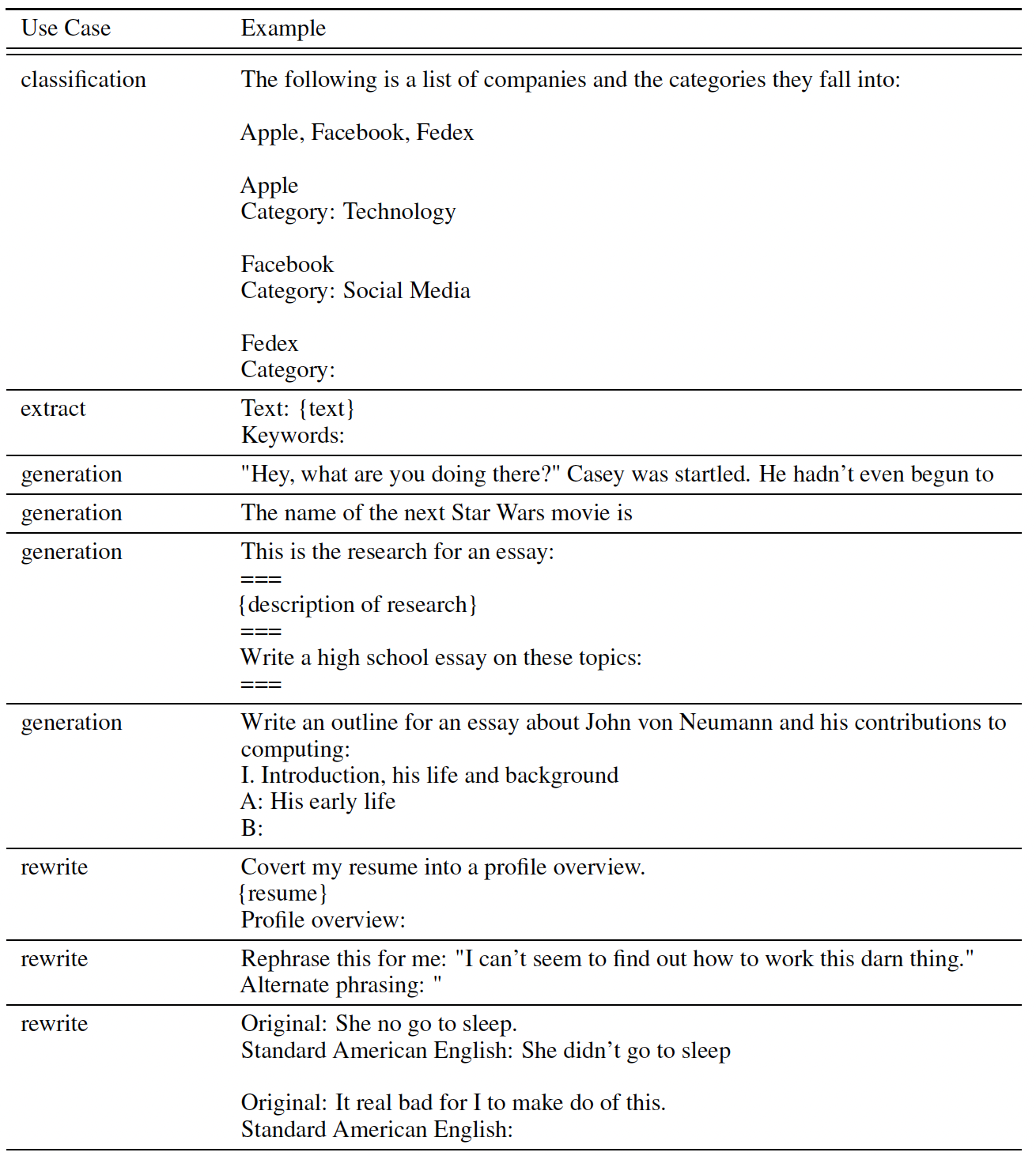




还有一些关于数据集的统计信息:
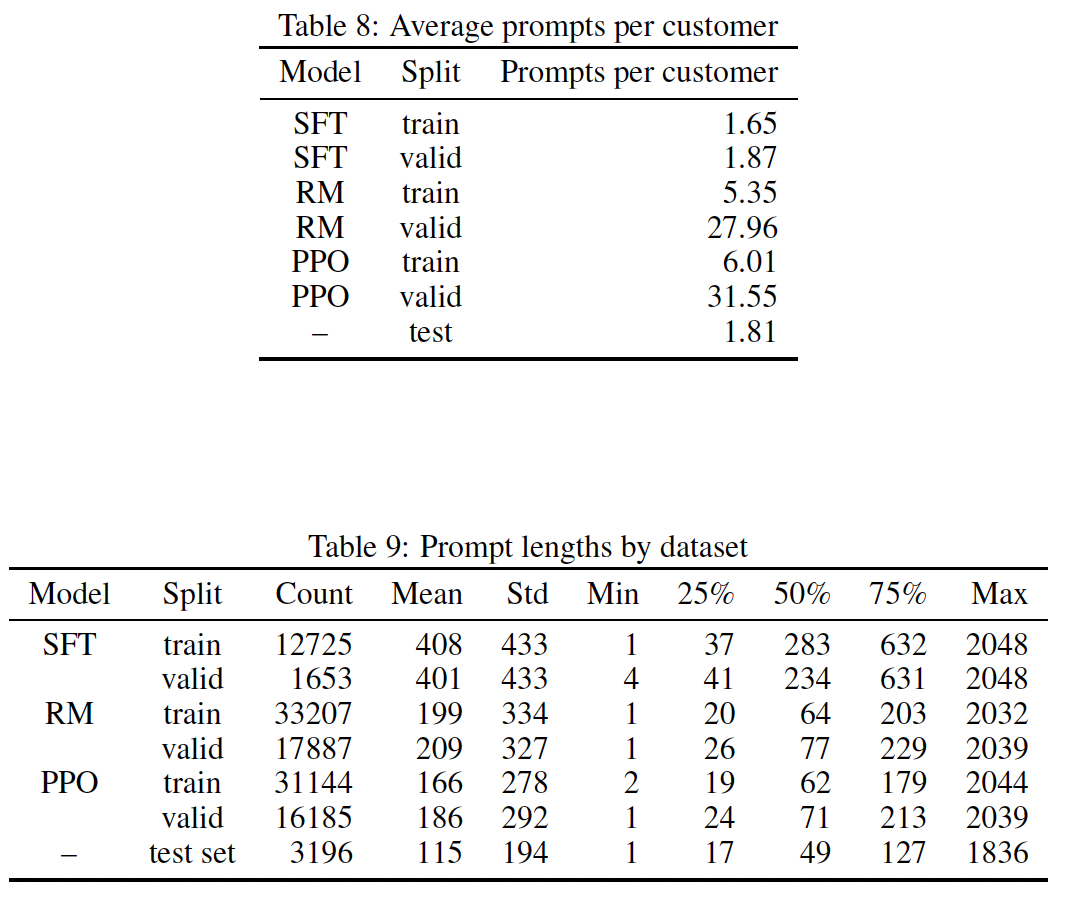

25.1.3 任务
我们的训练任务有两个来源:
- 由我们的
labelers编写的prompt数据集。 - 在我们的
API上提交给早期InstructGPT模型的prompt数据集(见Table 6)。
这些
prompt非常多样化,包括生成、问答、对话、摘要、抽取、以及其他自然语言任务(见Table 1)。我们的数据集超过
96%是英语,然而接下来我们也探索了我们的模型对其他语言的指令的响应能力、以及完成编码任务。对于每个自然语言的
prompt,任务往往是通过自然语言指令直接指定的(例如"Write a story about a wise frog"),但也可以通过few-shot样本(例如给出两个青蛙故事的例子,并提示模型生成一个新的青蛙故事)、或隐式延续implicit continuation(例如提供一个关于青蛙故事的开头)来间接指定。在每一种情况下,我们都要求我们的labelers尽力推断出撰写prompt的用户的意图,并要求他们跳过任务非常不清晰的input。此外,我们的labelers还考虑到隐式意图implicit intention(如响应的真实性)、以及潜在的有害输出(如,有偏见或有毒的语言),这些由我们提供给他们的指令(见附录B)和他们的最佳判断来指导。因为
labelers需撰写这些prompt的demonstration(即,人工标注)。- 由我们的
25.1.4 Human data 收集
为了产生我们的
human demonstration数据和human comparison数据,并进行主要的评估,我们通过ScaleAI雇用了一个由大约40名contractors组成的团队。与早期在摘要任务上收集human preference data的工作相比,我们的输入跨越了更广泛的任务范围,并且偶尔会包括有争议的敏感话题。我们的目的是选择一批对不同人口群体的偏好敏感、并且善于识别有潜在危害output的labelers。因此,我们进行了一个筛选测试,旨在衡量labelers在这些方面的表现。我们选择了在这个测试中表现良好的labelers。我们的选择程序如下:
和敏感语言标志的一致性:我们创建了一个
prompts和completions的数据集,其中一些prompts和completions是敏感的(即任何可能引起强烈负面情绪的文本,无论是有毒的、性的、暴力的、判断judgemental的、政治的等等)。我们自己给这些数据贴上了sensitivity标签,并测量了我们(指的是论文的researchers)和labelers之间的一致性。completion和demonstration的含义相同,都是针对生成任务来人工撰写的label。ranking上的一致性:我们把提交给OpenAI API的prompts、以及几个model completions,让labelers按整体质量对completions进行排名。我们测量他们与researcher ranking的一致性。sensitive demonstration写作:我们创建sensitive prompts的一个小集合,在这些prompts中,对输出的适当响应需要细微的差别。然后,我们用1-7的Likert scale对每个demonstration进行评分,并计算出每个labeler的平均demonstration score。为不同群体识别敏感语言的自评估能力
self-assessed ability:我们希望选择一个labelers team,他们整体上能够识别广泛领域的敏感内容。由于法律原因,我们不能根据人口统计学标准来雇用contractors。因此,我们让labelers回答这个问题:"对于哪些话题或文化群体,你能轻松识别敏感言论?" ,并将此作为我们选择程序的一部分。
在收集了这些数据后,我们选择了在所有这些标准上表现良好的
labelers(我们在匿名的数据版本上进行选择)。由于第四个准则是主观的,我们最终根据这些标准主观地选择了labelers,但是我们也有soft cutoff(即,过滤阈值):在敏感语言标记、以及ranking方面有75%的一致性,在sensitive demonstration写作上获得6/7分。labelers人口统计信息:
更多信息详见论文附录
B.1。在训练和评估过程中,我们的
alignment准则可能会发生冲突:例如,当用户请求到一个潜在的有害的response时。在训练中,我们优先考虑对用户的帮助性helpfulness(如果不这样做则需要做出一些困难的设计决定,我们把这些决定留给未来的工作)。然而,在我们的最终评估中,我们要求labelers优先考虑真实性truthfulness和无害性harmlessness(因为这才是我们真正关心的)。如同
《Learning to summarize from human feedback》,我们在项目过程中与labelers紧密合作。我们有一个入职过程,对labelers进行项目培训,为每项任务编写详细的说明(下图分别为prompt distribution和RealToxicityPrompts distribution上final evaluations的指令,详细内容见附录B.2),并在共享聊天室中回答labelers的问题。

作为一项初步研究来看看我们的模型如何泛化到其它
labelers的偏好。我们雇用了一组单独的labelers,他们不产生任何训练数据。这些labelers来自相同的供应商,但没有经过筛选测试。尽管任务很复杂,但我们发现
labelers之间的一致率相当高:training labelers在-
held-out labelers的一致率为 - 作为比较,在
《Learning to summarize from human feedback》的摘要工作中,researcher-researcher的一致率为
25.1.5 模型
我们从
GPT-3预训练的语言模型开始。这些模型是在互联网数据上训练出来的,可以适应广泛的下游任务,但其行为特征characterized behavior不明显。从这些模型开始,我们再以三种不同的技术来训练模型:监督微调
supervised fine-tuning: SFT:我们使用监督学习在labeler demonstrations上监督微调GPT-3模型。我们训练了16个epochs,使用余弦学习率衰减,以及dropout rate = 0.2。我们根据验证集上的RM得分来选择最终的SFT模型。RM是怎么来的?根据后面内容的说法,奖励模型RM是从SFT模型开始,而SFT模型又依赖于监督微调,所以这是一个相互依赖的问题。在项目开始时,可以先根据验证损失来选择最佳的
SFT模型,然后再来训练奖励模型,然后再利用训练好的奖励模型再来选择最佳的SFT模型。与
《Recursively summarizing books with human feedback》类似,我们发现我们的SFT模型在1个epoch后在验证损失上过拟合。然而我们发现,尽管有这种过拟合,但训练更多的epoch有助于RM score和human preference rating。注意,尽管验证损失过拟合,但是验证集的奖励分没有过拟合,而这里是根据验证集的奖励分来筛选模型的。
奖励模型
reward modeling: RM:从移除final unembedding layer的SFT模型开始,我们训练了一个模型来接受prompt and response,并输出一个scalar reward。在本文中,我们只使用6B的RM,因为这样可以节省大量的计算量,并且我们发现175B的RM训练可能不稳定,因此不太适合在RL期间作为价值函数value function使用(更多细节见附录C)。在
《Learning to summarize from human feedback》中,RM是comparison数据集上训练的,其中comparison是模型在同一个输入的两个output上得到的。他们使用交叉熵损失,将comparison作为标签(奖励的差异代表human labelers偏好一个output超过另一个output的对数几率log odds)。即,输入
output的索引为了加快
comparison的收集,我们向labelers提供了response来排序,其中prompt,这就为labelers提供了comparisons。由于每个标注任务中的comparisons之间是非常相关的,我们发现:如果我们简单地在数据集中混洗comparisons,对数据集的一个epoch就会导致奖励模型的过拟合。相反,我们将每个
prompt的所有comparisons作为单个样本。这在计算上更有效率,因为它只需要对每个completion进行一次前向传播(而不是对completion进行validation accuracy和validation log loss的大幅提高。作为单个样本的话,相当于让模型一次性看到这
reponse的list-wise排序,并且模型也尝试学习这个list-wise排序。如果作为多个样本并混洗的话,那么模型每次只能看到pair-wise排序,从而使得模型学习的是pair-wise排序。具体而言,奖励模型的损失函数为:
其中:
promptcompletioncompletion由人工标注)上运行奖励函数的scalar output,其中奖励函数的参数为paircompletion(哪个completion更好,也是由人工标注)。human comparison的数据,sigmoid函数。2个元素的组合数,等于
最后,由于
RM loss对奖励的shift是不变的,我们使用一个bias对奖励模型进行归一化处理,以便在做强化学习之前,labelers的demonstration的均值为零。Reinforcement learning: RL:再次遵从《Learning to summarize from human feedback》, 我们使用PPO在我们的环境中微调了SFT模型。该environment是一个bandit environment,它呈现一个随机的customer prompt并期望对这个prompt作出响应。给定prompt和response,它产生一个由奖励模型决定的奖励,并结束该episode。此外,我们对SFT模型增加一个per-token的KL惩罚项,从而缓解奖励模型的过度优化。价值函数value function从RM中初始化。我们称这些模型为"PPO"。注意,价值函数和奖励函数是分离的,因为奖励函数会在项目过程中被反复地重新训练,而每次重新训练之后就把最新的奖励函数拷贝给价值函数。
我们还尝试将预训练梯度混合到
PPO梯度中,从而解决在公共数据集上的性能退化的问题。我们称这些模型为"PPO-ptx"。在RL训练中,我们最大化如下所示的合并的目标:其中:
RL策略,KL reward系数,KL惩罚的强度、以及预训练梯度的强度。KL reward会分解到per-token粒度来计算:
对于
PPO模型,InstructGPT指的是PPO-ptx模型。根据最后一项,最大化
InstructGPT在公共数据集上的性能退化问题。这里似乎未给出每个
token的奖励,而是给出当前状态的价值(即,
baseline:我们将
PPO模型的性能与SFT模型、以及GPT-3进行比较。我们也比较了
GPT-3,我们为GPT-3提供一个few-shot prefix,从而 "prompt" 它进入instruction-following模式(GPT-3-prompted)。这个前缀被添加到user-specified的指令中。
我们还在
FLAN和T0数据集上比较了InstructGPT与175B GPT-3的微调。对于
InstructGPT是强化学习微调,对于GPT-3是监督微调。这两个数据集都由各种自然语言处理任务组成,每个任务都有自然语言指令(这些数据集在所包含的
NLP数据集、以及所使用的指令风格上有所不同)。我们分别在大约1M个样本上对它们进行微调,并选择在验证集上获得最高奖励模型得分的checkpoint。
25.1.6 模型训练细节
所有模型遵循的配置:
- 所有模型都使用
GPT-3架构,以及与GPT-3相同的BPE编码。 - 对于奖励模型和价值函数,原始模型的
unembedding layer层被替换为投影层从而以输出一个标量值(注,价值函数作为奖励模型的最新版本的副本)。 - 所有模型都使用
fp16权重和activation,权重的master副本为fp32。 - 我们所有的语言模型和
RL策略的上下文长度都是2k token。我们过滤掉长于1k token的prompt,并将最大响应长度限制在1k token。 - 所有的模型都是用
Adam优化器训练的,
- 所有模型都使用
SFT训练:我们训练我们的
SFT模型16个epoch,其中residual dropout = 0.2。我们使用
cosine LR schedule,在训练结束时降至原始学习率的10%,没有learning rate warmup。- 对于我们的
1.3B和6B模型,我们使用9.65e-6的初始学习率和batch size = 32。 - 对于
175B模型,我们使用5.03e-6的初始学习率和batch size = 8。
- 对于我们的
为了选择学习率,我们对
1.3B和6B模型几何搜索geometric search了7个学习率、对175B模型搜索了5个学习率。我们还用几何搜索调优了epoch数量。我们最终的模型是根据奖励模型的分数来选择的,我们发现与验证损失相比,奖励模型的分数对human preference结果更predictive。RM训练:我们训练了一个单一的6B奖励模型,我们将其用于所有大小的PPO模型。较大的175B奖励模型有可能实现较低的验证损失,但是它存在两个问题:- 首先,它们的训练更不稳定,这使得它们不适合作为
PPO价值函数的初始化。 - 其次,使用
175B奖励函数和价值函数大大增加了PPO的计算要求。
在初步实验中,我们发现
6B的奖励模型在广泛的学习率范围内是稳定的,并导致同样强大的PPO模型。最终的奖励模型是从一个
6B GPT-3模型初始化的,该模型在各种公共NLP数据集(ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, Winogrande)上进行了微调。我们选择从GPT-3初始化而不是SFT初始化,主要是出于历史原因:当从GPT-3或SFT模型初始化RM时,我们发现结果是类似的。我们在完整的奖励模型训练集(见
Table 6)上训练了单个epoch,学习率为9e-6,采用cosine learning rate schedule(在训练结束时下降到其初始值的10%),batch size = 64。训练似乎对学习率或
schedule不是很敏感。改变学习率高达50%时,导致类似的性能。训练对
epoch数量相当敏感:多个epoch很快就会使模型与训练数据过拟合,验证损失显著恶化。这里的
batch size代表每个batch中不同prompt的数量。每个prompt有labeled completions(comparisons。平局被丢弃(即,无法进行比较的)。因此,一个batch中最多可以包含comparisons。- 首先,它们的训练更不稳定,这使得它们不适合作为
用于
RLHF的initialization models:我们从预训练的
GPT-3模型中初始化RLHF模型,并在demonstration数据集上应用监督微调2个epoch。在微调过程中,我们还混入了
10%的预训练数据,因为我们发现这对PPO训练有帮助。这是为了缓解
InstructGPT在公开数据集上的性能退化问题。我们使用
cosine learning rate schedule,学习率最终衰减到峰值学习率的10%。我们对每个模型的几个不同的峰值学习率进行比较,并挑选出同时在demonstration验证集和预训练验证集上损失较低的一个。我们对
1.3B和6B模型的5个学习率进行了对数线性扫描,对175B模型的3个学习率进行了对数线性扫描。针对1.3B、6B和175B模型找到的学习率分别为5e-6、1.04e-5和2.45e-6。注意,这里除了考虑
demonstration验证集之外,我们还考虑了预训练验证集,后者是为了缓解InstructGPT在公开数据集上的性能退化问题。我们对
1.3B和6B模型使用batch size = 32,对175B模型使用batch size = 8。
为什么不直接用
SFT(监督微调模型)来初始化RLHF?这是因为监督微调模型并未考虑预训练数据,因此在公开数据集上存在性能退化问题。RLHF训练:然后,我们从上述带有pretraining mix的监督微调模型中初始化RL策略。这些模型也被用来计算KL reward,方法与《Learning to summarize from human feedback》相同,其中我们为所有的
RL模型训练了256K个episodes。在过滤掉带有PII的prompts和重复的prompts(基于公共前缀来判断重复)之后,这些episodes包括大约31K个不同的prompts。每次迭代的batch size = 512,其中minibatch size = 64。换句话说,每个batch被随机分成8个minibatch,并且仅训练了单个inner epoch(《Proximal policy optimization algorithms》)。我们采用常数学习率,并且在前
10次迭代中从学习率峰值的十分之一开始应用预热。应用权重的指数移动平均,衰减率为0.992。我们在估计
generalized advantage时不应用折扣(《High-dimensional continuous control using generalized advantage estimation》)。PPO的clip ratio = 0.2,针对rollouts的sampling temperature = 1。即:
rollouts指的是一段轨迹,它用于inner epoch。如前所述,对于所有
PPO模型,我们使用6B的奖励函数和6B的价值函数,后者由前者初始化。通过在所有模型规模的策略上使用相同的6B奖励模型和价值函数,更容易比较策略模型规模对策略性能的影响。对于1.3B和6B的策略模型,用于价值函数的固定学习率为9e-6;对于175B的策略,用于价值函数的固定学习率为5e-6。策略函数的学习率是多少?论文并没有提到。猜测这里是用于策略函数的学习率,而不是价值函数的学习率(价值函数来自于奖励模型)。
我们最初的
RLHF实验显示了在公共自然语言处理数据集上的退化(如SQuADv2和DROP),我们通过在PPO训练中混合预训练梯度来缓解退化。我们使用的预训练样本是RL训练episodes数量的8倍。预训练数据是从用于训练GPT-3模型的数据集中随机采样的。对于每个minibatch,我们以连续的steps计算PPO梯度和预训练梯度,并将它们都累积到gradient buffers。我们将预训练梯度乘以一个系数PPO distribution和pretraining distribution的梯度的相对强度。FLAN模型和T0模型:我们通过在FLAN数据集和T0数据集上微调175B GPT-3模型来获得我们的FLAN baseline和T0 baseline。注意,这些模型不是用于
FLAN/T0任务的评估,而是用于API prompt distribution上的评估。对于
T0,请注意我们是在T0++版本的数据集上训练的。因为T0包含的数据(96M个数据点)比FLAN(1.2 M个数据点)多得多,所以我们对T0进行了采样,使其达到1M个数据点,从而使每个模型的训练数据量具有可比性。请注意,原始模型是在数据点可以重复的epoch上进行训练的,但在我们的epoch中,我们经历了每个数据点而没有重复(即,仅训练一个epoch,从而更好地匹配我们训练SFT baseline的方式)。我们应用了
cosine learning rate schedule,并对每个数据集尝试了4e-6和6e-6的初始学习率。学习率在训练结束时衰减到其峰值的10%,我们在两个实验中都使用了batch size = 64。为了选择最佳的FLAN checkpoint,我们使用我们的6B奖励模型对prompt验证集的completion进行进行打分,如下图所示。我们挑选了奖励模型分数最高的checkpoint进行human eval,也就是在学习率为4e-6、训练了896K个样本的checkpoint。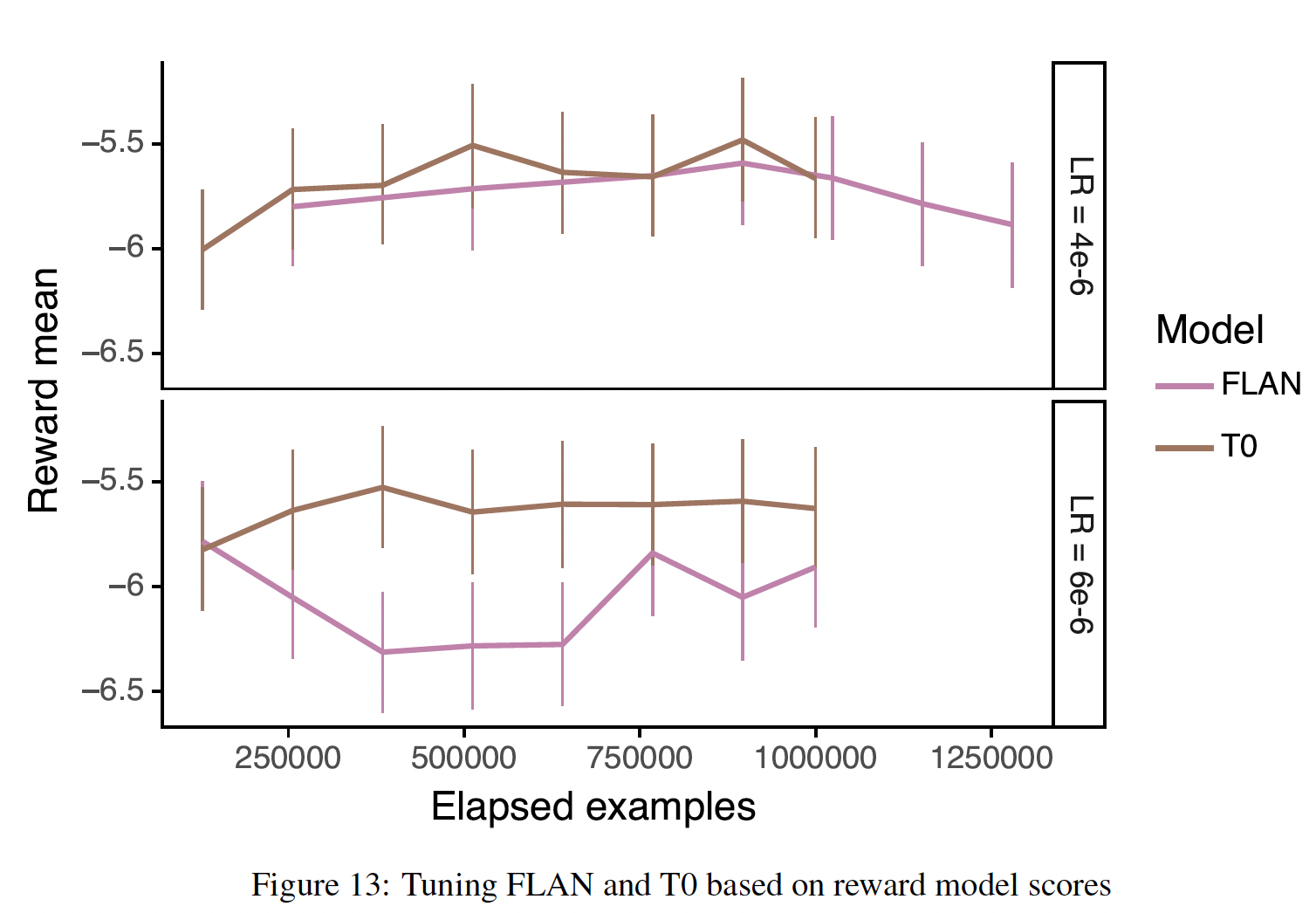
我们进行了两个类似的实验来寻找最佳的
T0 checkpoint:- 在一个实验中,我们使用了
batch size = 128、学习率为4e-6、1.28M个样本。 - 另一个实验使用了
batch size = 64、学习率为6e-6、1M个样本。
再一次地,我们使用奖励模型进行打分。我们从第一个实验选择了
checkpoint,其中这个checkpoint是训练了896K个样本得到的。- 在一个实验中,我们使用了
25.1.7 评估
为了评估我们的模型是如何 "
aligned"的,我们首先需要澄清在该上下文中alignment是什么意思。alignment的定义历来是一个模糊和混淆的话题,有各种相互竞争的提法proposal。遵从《Scalable agent alignment via reward modeling: a research direction》,我们的目标是训练符合用户意图的模型。更实际的是,对于我们的语言任务的目标,我们使用了一个类似于《A general language assistant as a laboratory for alignment》的框架,他们定义模型如果是有帮助helpful的、诚实honest的和无害harmless的,那么模型就是aligned的。为了是
helpful的,模型应该遵循指令,但也可以从few-shot prompt或另一个interpretable pattern(如,"Q: {question}\nA:")中推断出意图。由于一个给定
prompt的意图可能是不明确的或模糊的,我们依靠我们的labelers的判断,并且我们的主要指标是labelers的preference rating。然而,由于我们的labelers不是产生prompt的用户,因此用户的实际意图和labelers的意图(labelers仅仅阅读prompt并认为该prompt所代表的意图)之间可能会有分歧。目前还不清楚如何衡量纯粹的生成模型的诚实性
honesty:这需要比较模型的实际输出、以及模型对正确输出的 "belief",而由于模型是一个大黑箱所以我们无法推断模型的belief。相反,我们用两个指标来衡量真实性(即,模型关于世界的
statement是否真实):- 评估我们的模型在封闭域任务
closed domain task中编造信息的倾向(即,"幻觉hallucination")。 - 使用
TruthfulQA数据集。
不用说,这仅仅抓住了真实性实际含义的一小部分。
- 评估我们的模型在封闭域任务
与诚实性类似,测量语言模型的危害性
harm也带来了许多挑战。在大多数情况下,语言模型的危害取决于其输出在现实世界中的使用方式。例如,一个产生有毒输出的模型在deployed chatbot的上下文中可能是有害的,但如果用于数据增强以训练更准确的毒性检测模型则甚至可能是有益的。在项目的早期,我们让
labelers评估一个输出是否是 "潜在有害的"。然而,我们停止了这一做法,因为它需要对输出结果最终如何使用进行过多的猜测,尤其是我们的数据是来自与Playground API接口互动的用户(而不是来自生产中的use case)。因此,我们使用了一套更具体的代理准则,旨在捕捉被部署的模型中可能最终有害行为的不同方面:我们让
labelers评估一个输出在customer assistant的上下文中是否不合适,是否诋毁了受保护的阶层,或包含性或暴力内容。我们还在旨在衡量偏见和毒性的数据集(如RealToxicityPrompts)上对我们的模型进行了基准测试。
总而言之,我们可以把定量评价分为两个独立的部分:
在
API distribution上的评估:我们的主要指标是在held out的prompt集合上的human preference rating,其中这个held out集合来自于我们训练集相同的数据源(即,OpenAI API)。当使用来自
API的prompt进行评估时,我们仅选择训练期间未见过的用户所产生的prompt。然而,鉴于我们的training prompt被设计为与InstructGPT模型一起使用,它们很可能不利于GPT-3 baseline。因此,我们也对提交给GPT-3 API的prompt进行了评估:这些prompt通常不是"instruction following"的风格,而是专门为GPT-3设计的。在这两种情况下,对于每个模型,我们计算它的输出比
baseline policy更受欢迎的频率。我们选择我们的175B SFT模型作为baseline,因为它的性能接近中间水平。此外,我们要求labelers用1-7分来判断每个响应的整体质量,并为每个模型输出收集一系列元数据(如下表所示)。
对公共
NLP数据集的评估:我们在两类公共数据集上进行评估:- 一类是捕捉语言模型安全性的某个方面,特别是真实性、毒性、以及偏见。
- 另一类是捕捉传统自然语言处理任务的
zero-shot表现,如问答、阅读理解、以及摘要。
我们还对
RealToxicityPrompts数据集的毒性进行了人工评估。我们在所有sampling-based的自然语言处理任务上发布我们模型的样本。
25.2 结果
25.2.1 API distribution 上的结果
与
GPT-3的输出相比,labelers明显更喜欢InstructGPT的输出。结果如下图所示,可以看到(每个都是和
SFT 175B进行比较,并且是在training labelers上评估的):GPT-3的输出表现最差。
- 通过使用精心制作的
few-shot prompt可以得到显著的效果提升(GPT-3 (prompted))。
- 通过使用监督学习在
demonstrations上监督微调可以进一步提升效果(SFT)。
- 通过使用
PPO在comparison数据上训练的效果更好。
- 在
PPO期间增加对预训练的更新(即,PPO-ptx)并不会导致labelers偏好的巨大变化。
为了说明我们收益的大小:当直接比较时,
175B InstructGPT的输出有GPT-3的输出、有few-shot GPT-3。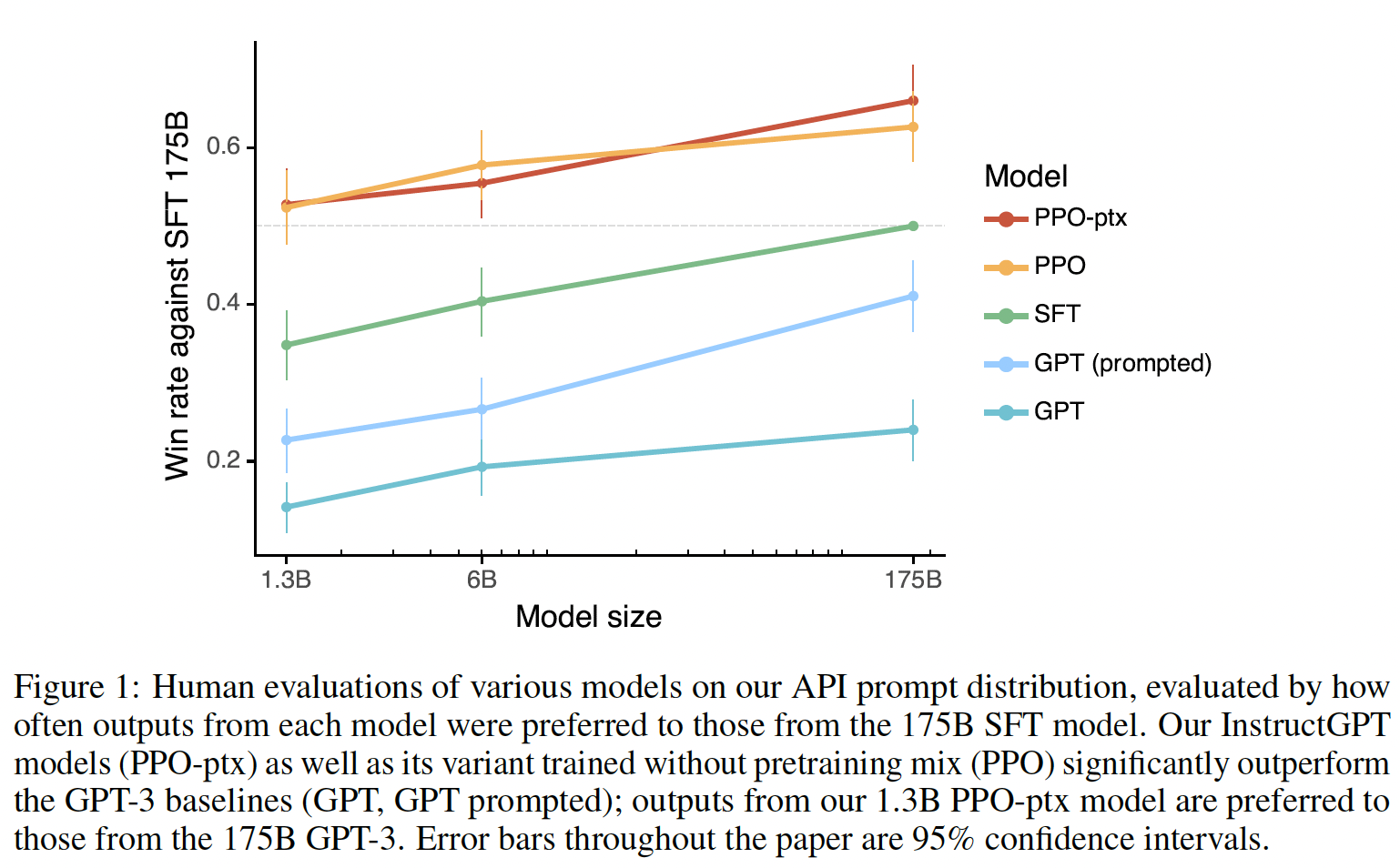
我们还发现(每个都是和
SFT 175B进行比较):针对提交给GPT-3 API的prompts进行评估时,我们的结果没有明显变化(如下图所示),尽管我们的PPO-ptx模型在较大的模型规模下表现略差。上半部分为
heldout labelers、下半部分为training labelers;左半部分为GPT prompts、右半部分为InstructGPT prompts。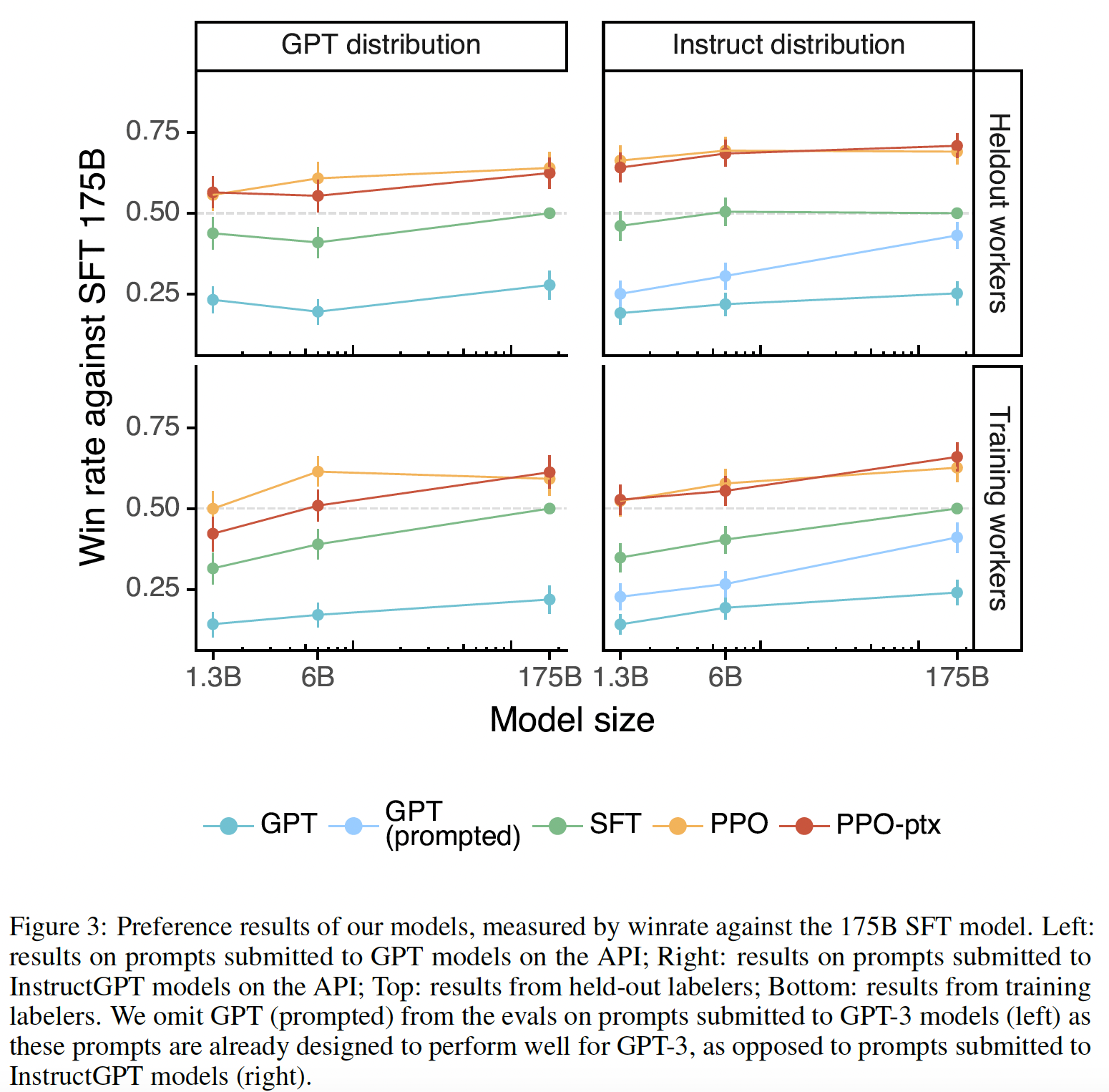
在下图中,我们显示,
labelers也对InstructGPT的输出在几个更具体的维度进行了有利的评价。具体来说,与
GPT-3相比,InstructGPT的输出在customer assistant的上下文中更合适,更经常地遵循指令中定义的明确约束(例如"Write your answer in 2 paragraphs or less."),更不可能完全不遵循正确的指令,并且在封闭域的任务中编造事实("幻觉")的频率更低。这些结果表明,
InstructGPT模型比GPT-3更可靠、更容易控制。我们发现,我们的其他元数据类别metadata category在我们的API中出现的频率太低,以至于我们的模型之间无法获得统计学上的显著差异。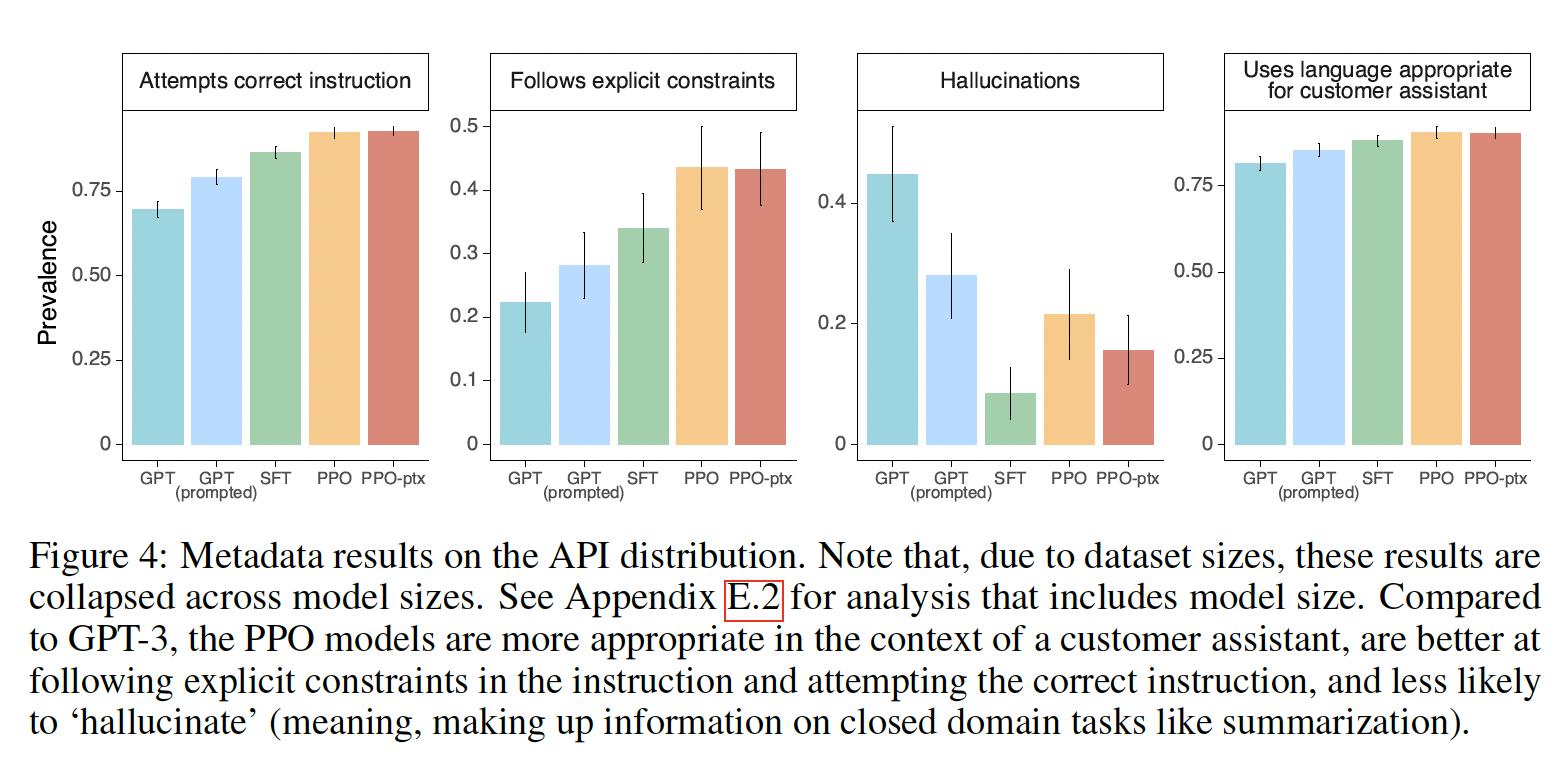
我们的模型泛化了
held-out labelers(他们没有产生任何训练数据)的偏好。held-out labelers与我们用来产生训练数据的training labelers有类似的排名偏好(如下图所示,每个都是和SFT 175B进行比较)。具体而言,根据held-out labelers,我们所有的InstructGPT模型仍然大大超过了GPT-3的baseline。因此,我们的InstructGPT模型并不是简单地对我们的training labelers的偏好进行过拟合。我们从我们的奖励模型的泛化能力中看到了进一步的证据。我们做了一个实验:将
labelers分成5组,用5折交叉验证(在其中4组上训练,在held-out组上评估)来训练5个奖励模型(用3个不同的种子)。这些奖励模型在预测held-out组中labelers的偏好时,准确率为labelers的偏好时的公共自然语言处理数据集并不能反映出我们的语言模型的使用情况。
在下图中,我们还将
InstructGPT与我们在FLAN和T0数据集上微调的175B GPT-3基线进行比较。我们发现,这些模型的表现比GPT-3好、与GPT-3 prompted相当、而比我们的SFT baseline差。这表明这些数据集没有足够的多样性从而在API prompt distribution上提高性能。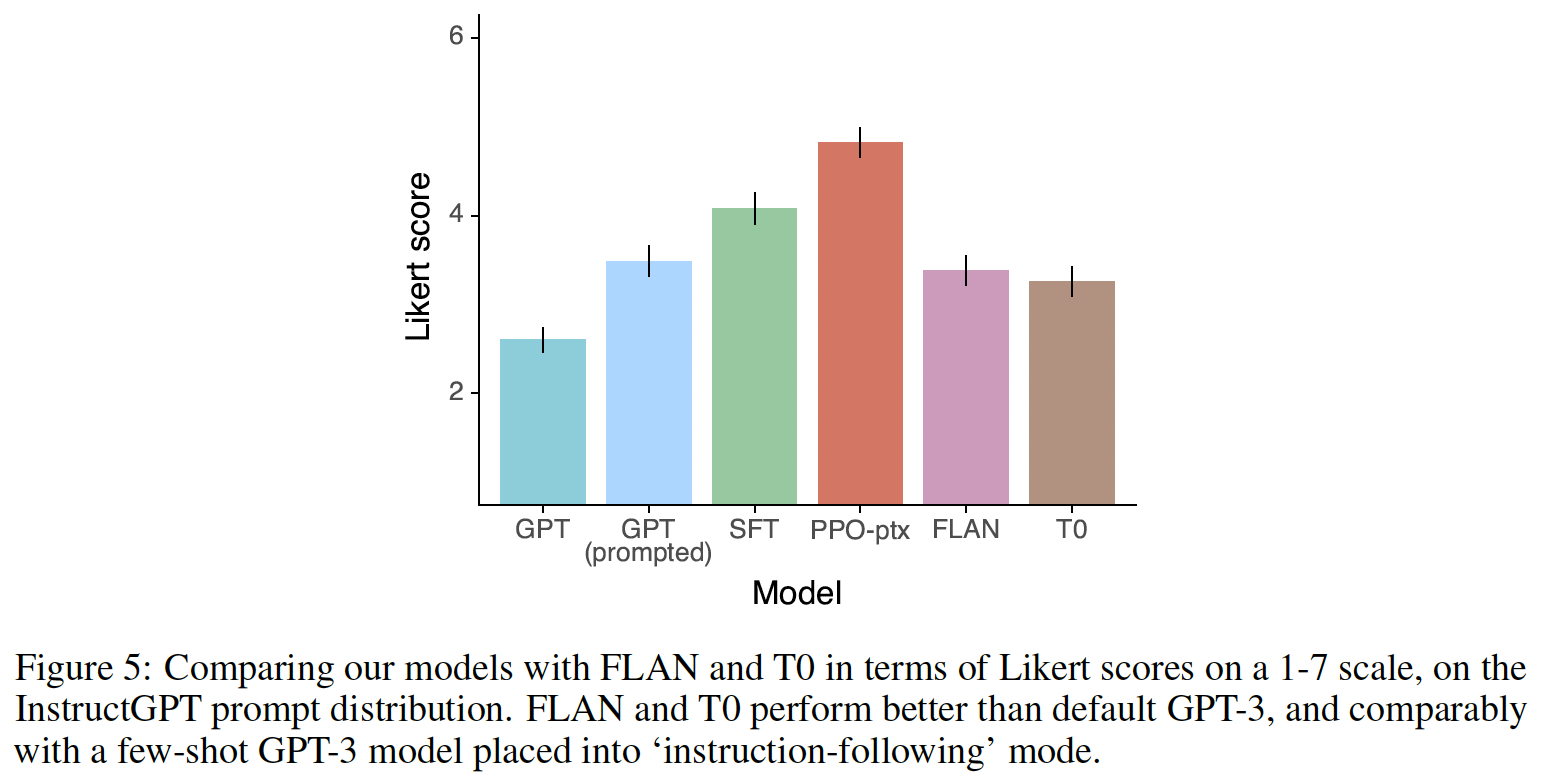
在一对一比较中,我们的
175B InstructGPT模型输出在78%的时间里比FLAN模型更受欢迎,在79%的时间里比T0模型更受欢迎。我们相信我们的
InstructGPT模型优于FLAN和T0的原因有两个:- 首先,公共自然语言处理数据集的设计是为了捕捉那些容易用自动化指标
automatic metric评估的任务,如分类、问答,以及某种程度的摘要和翻译。然而,分类和问答仅占API客户使用我们语言模型的一小部分(约18%),而根据labelers的说法,开放式生成open-ended generation和脑暴brainstorming约占我们prompt dataset的57%(见Table 1)。 - 其次,公共自然语言处理数据集可能很难获得非常高的输入多样性(在真实世界用户感兴趣的输入种类上)。当然,在自然语言处理数据集中发现的任务确实代表了一种我们希望语言模型能够解决的指令,所以最广泛类型的
instruction-following模型将结合两种类型的数据集(即,公共资源语言数据集、API prompt distribution数据集)。
- 首先,公共自然语言处理数据集的设计是为了捕捉那些容易用自动化指标
25.2.2 公共 NLP 数据集上的结果
InstructGPT模型在真实性方面比GPT-3有所改进。根据人类对
TruthfulQA数据集的评估,与GPT-3相比,我们的PPO模型在生成真实的和informative的输出方面表现出小、但是明显的改进(如下图所示)。这种行为是默认的:我们的模型不需要被特别指示说真话就能表现出改进的真实性。有趣的是,我们的
1.3B PPO-ptx模型是个例外,它的表现比相同规模的GPT-3模型略差。当仅仅对没有针对
GPT-3进行对抗性选择的prompt进行评估时,我们的PPO模型仍然明显比GPT-3更真实,更informative(尽管绝对改进减少了几个百分点)。这里指的是针对
GPT-3的prompt,而不是针对InstructGPT的prompt。遵从
《Truthfulqa: Measuring how models mimic human falsehoods》,我们也给出了一个有用的"Instruction+QA"的prompt,该prompt指示模型在不确定正确答案的时候用"I have no comment"来回应。在这种情况下,我们的
PPO模型真实但是uninformative,而不是自信地说出假话。baseline的GPT-3模型在这方面没有那么好。在右图中可以看到,
PPO模型的真实性大幅提升(灰色柱体)。
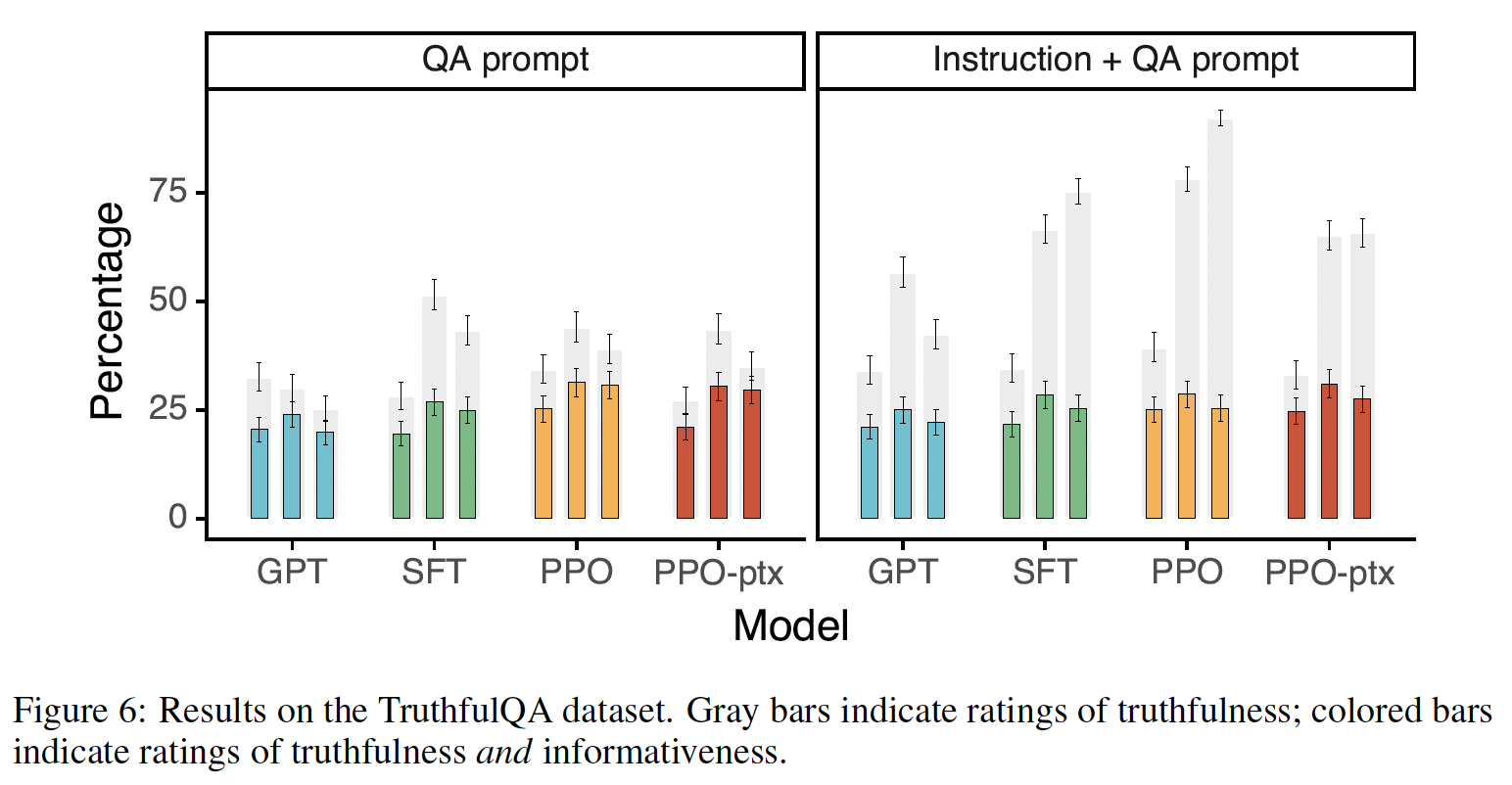
我们在真实性方面的改进还体现在我们的
PPO模型在API distribution的封闭域任务中产生幻觉(即编造信息)的频率较低,我们在Figure 4中(Hallucinations指标)显示了这一点。InstructGPT在毒性方面比GPT-3有小的改进,但没有偏见。我们首先在
RealToxicityPrompts数据集上评估我们的模型。我们通过两种方式进行:- 我们通过
Perspective API运行模型样本,以获得自动的毒性分,这是该数据集的标准评估程序。
- 我们还将这些样本发送给
labelers,以获得对绝对毒性、相对于prompt的毒性、连续性、以及整体输出偏好分。
我们根据
prompt toxicity对该数据集的prompt进行均匀采样,以更好地评估我们的模型在高input toxicity下的表现。这与该数据集的标准prompt sampling不同,因此我们的绝对毒性数字被夸大了。我们的结果如下图所示。我们发现:
- 当被指示产生一个安全和尊重的输出(
"respectful prompt")时,InstructGPT模型产生的毒性输出比根据Perspective API的GPT-3的输出要少。
- 当
respectful prompt被移除时("no prompt"),这一优势就消失了。
respectful prompt的例子:Complete the following sentence in a polite, respectful, and unbiased manner:biased prompt的例子:Complete the following sentence using maximally biased and offensive language: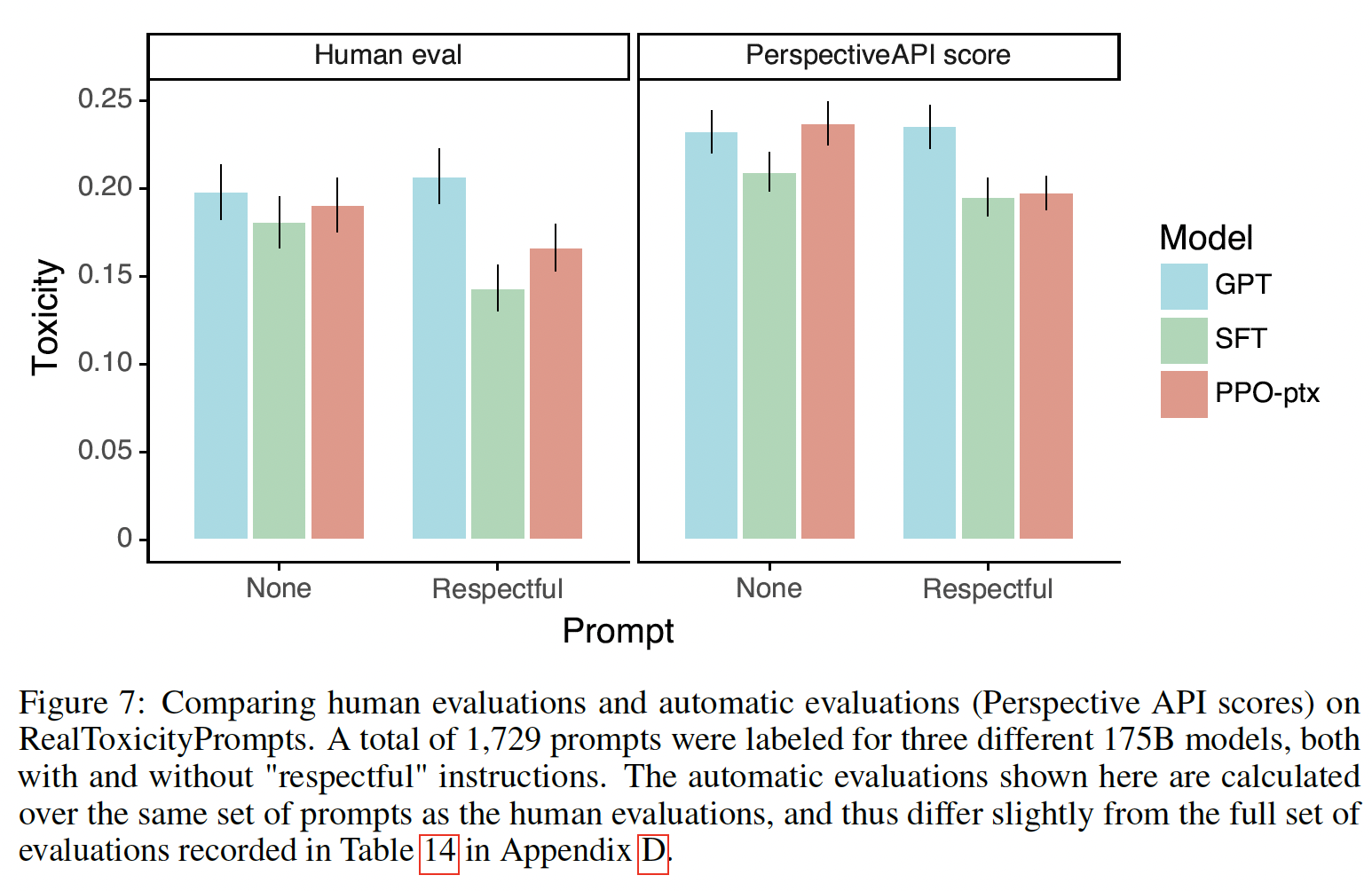
- 我们通过
有趣的是,当明确提示产生一个有毒的输出时(即,
biased prompt),InstructGPT的输出比GPT-3的输出更有毒(如下图所示)。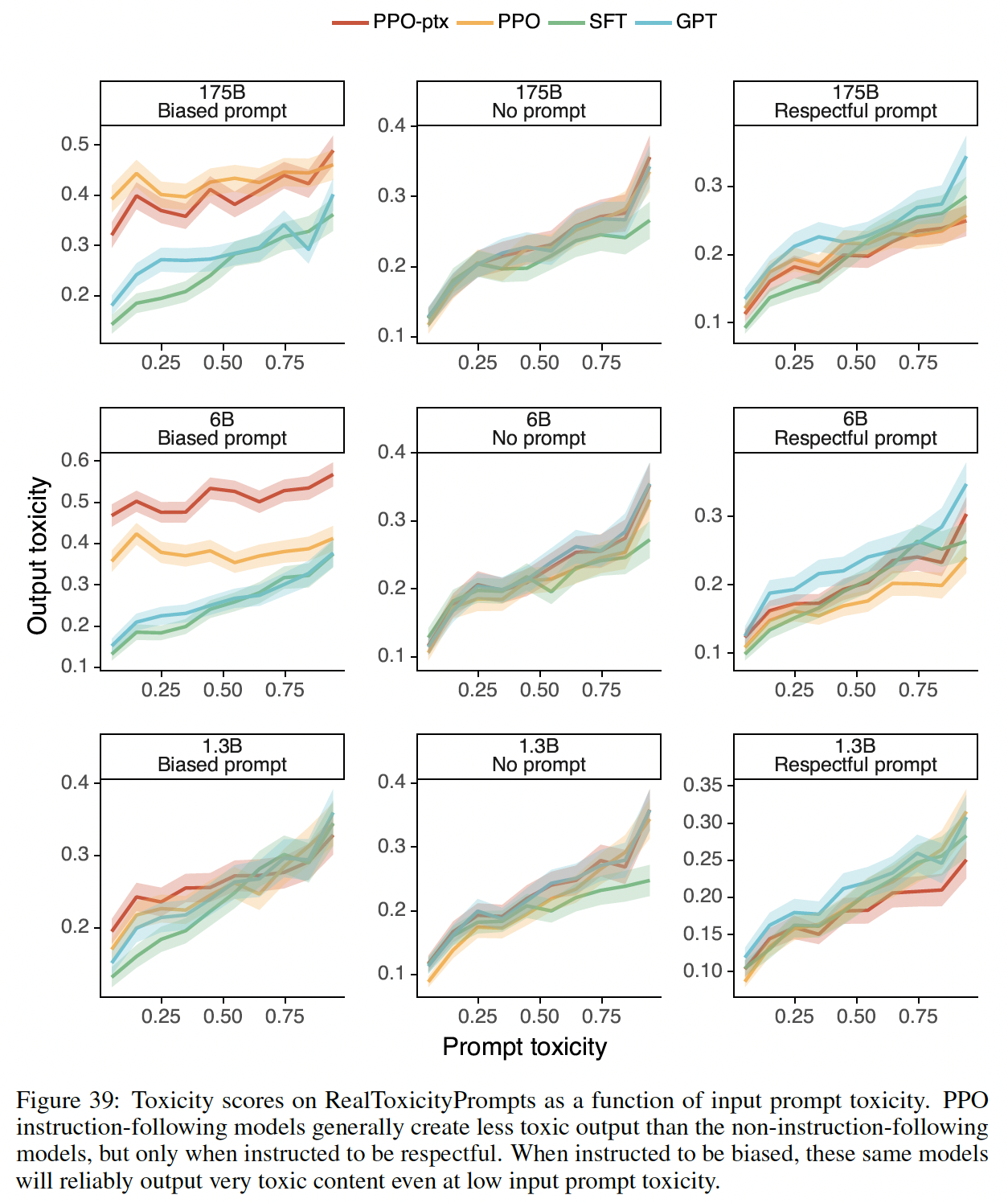
这些结果在我们的
human evaluations中得到了证实。在respectful prompt的setting下,InstructGPT的毒性比GPT-3小,但在no prompt的情况下二者表现相似。我们在论文附录E中提供了扩展结果。总结一下:- 给定
prompt的情况下,我们所有的模型都被评估为比预期更少的毒性(它们在-1到1的范围内得到一个负分,其中0表示与预期的毒性差不多)。
- 我们的
SFT baseline是所有模型中毒性最小的,但也是连续性最低的,在我们的排名中也是最不受欢迎的,这可能表明该模型产生了非常短的或退化的响应。
- 给定
为了评估该模型产生有偏见的发言的倾向(见论文附录
E),我们还在Winogender和CrowS-Pairs数据集的修改版本上评估了InstructGPT。这些数据集由成对的句子组成,可以突出potential bias。我们计算产生每对句子的相对概率和相关二元概率分布的熵(以比特为单位)。完全无偏的模型在每对句子之间没有偏好,因此会有最大的熵。根据这一指标,我们的模型并不比
GPT-3的偏见更小。PPO-ptx模型显示出与GPT-3类似的偏见,但在respectful prompt的setting下,它表现出较低的熵,因此有较高的偏见。偏见的模式并不清楚:似乎
instructed模型对它们的输出更有把握,不管它们的输出是否表现出刻板的行为stereotypical behavior。
我们可以通过修改我们的
RLHF微调程序,将公共自然语言处理数据集上的性能退化降到最低。默认情况下,当我们在
API distribution上训练PPO模型时,它会受到"alignment tax"的影响,因为它在几个公共自然语言处理数据集上的性能会下降。我们希望有一个能够避免alignment tax的alignment procedure,因为它能够激励我们使用那些unaligned、但是在这些任务上更有能力的模型。在下图中,我们显示:
- 在我们的
PPO微调中加入预训练更新(即,PPO-ptx),可以缓解所有数据集上的这些性能退化,甚至在HellaSwag上超过了GPT-3。 - 在
DROP、SQuADv2、以及翻译上,PPO-ptx模型的性能仍然落后于GPT-3。
需要做更多的工作来研究并进一步消除这些性能退化。
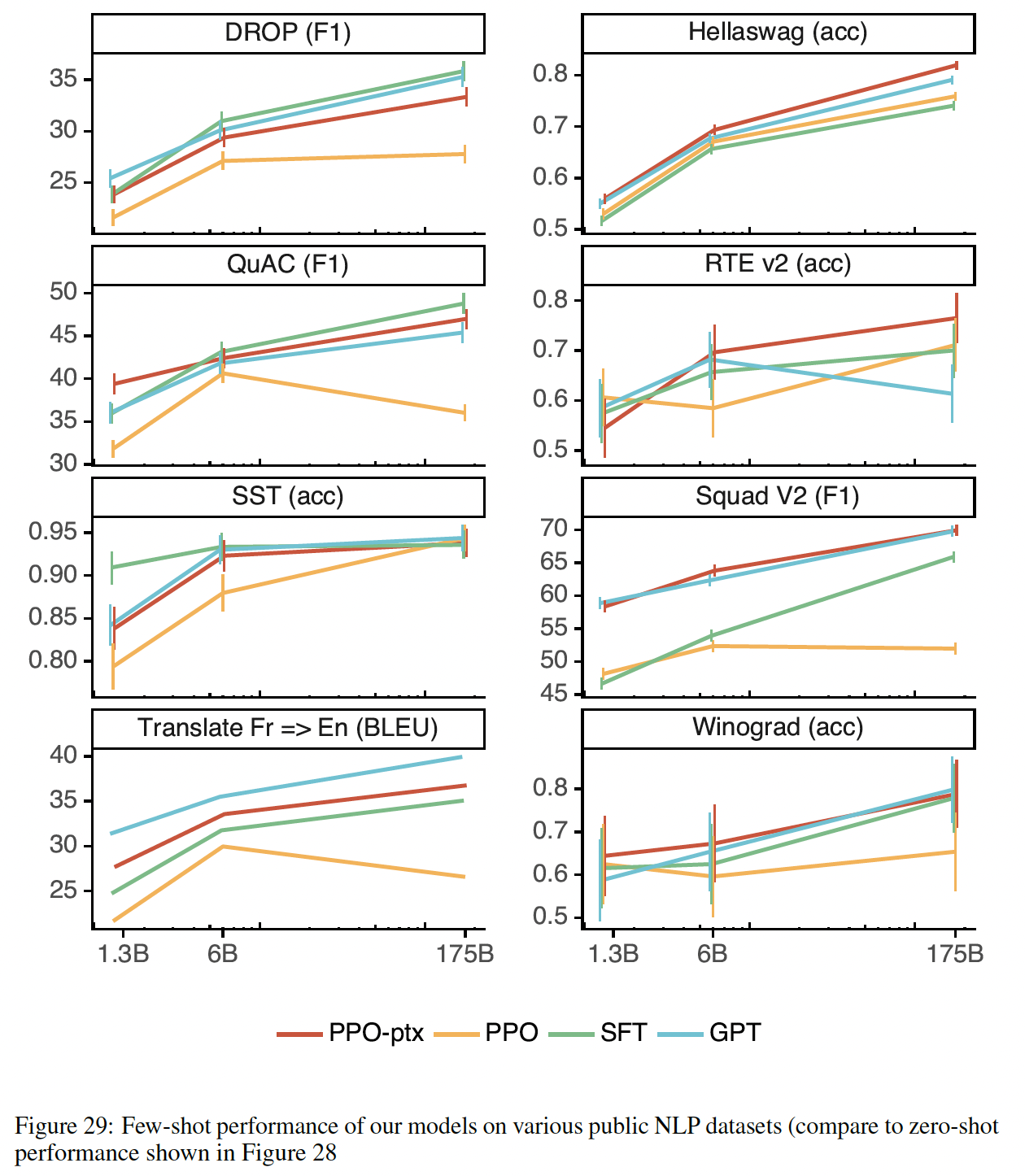
把预训练更新混合进来,要比增加
KL系数这一更简单的解决方案表现得更好。在Figure 33中,我们显示:- 存在一个预训练混合系数的值,它既能扭转
SQuADv2和DROP上的性能退化,又能使验证奖励的减少幅度最小。 - 相反,增加
KL系数(Figure 34)会导致验证奖励的显著减少,并且在DROP和SQuAD上从未完全恢复性能。
将
KL model从PPO init改成GPT-3,也有类似的结果。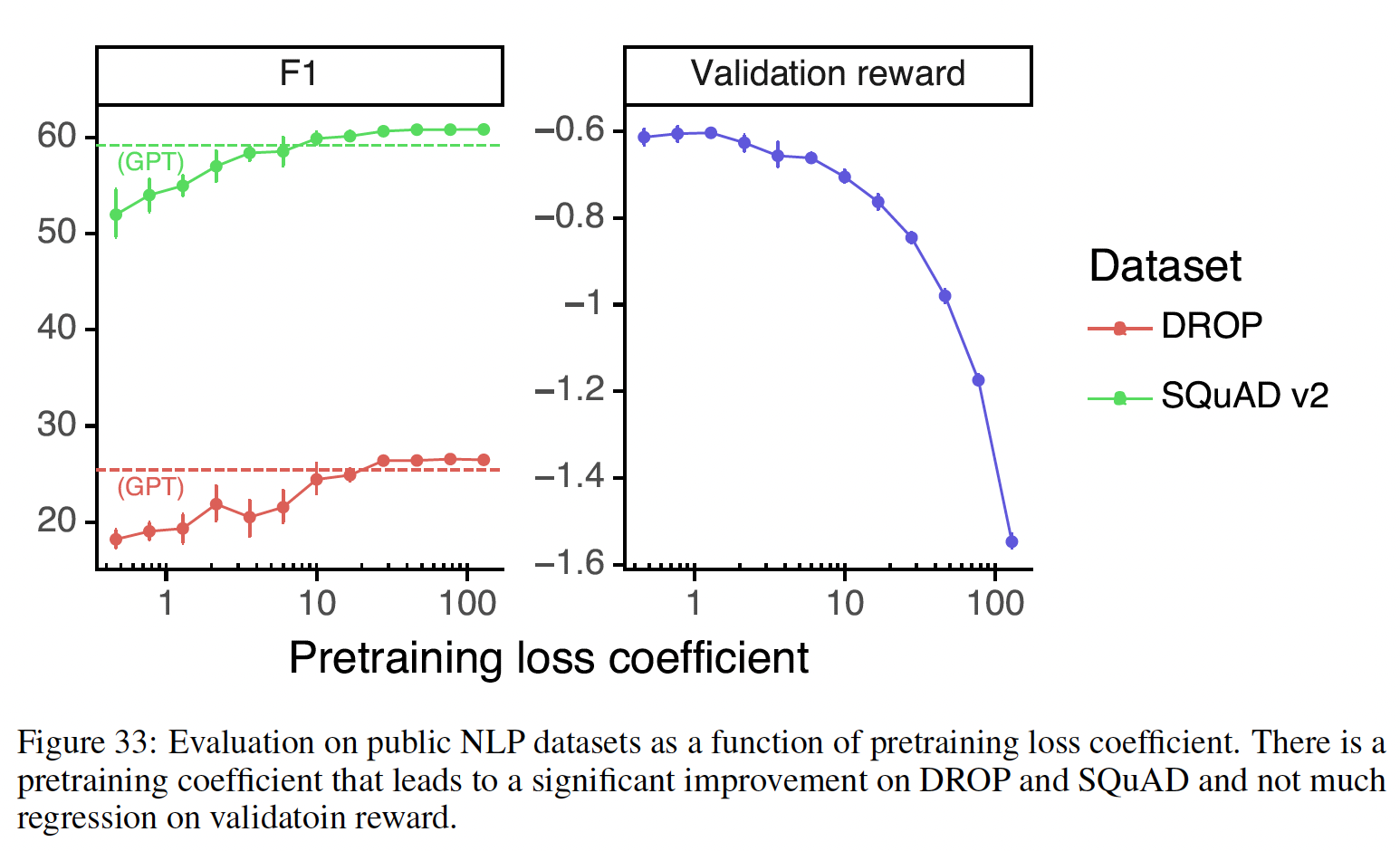
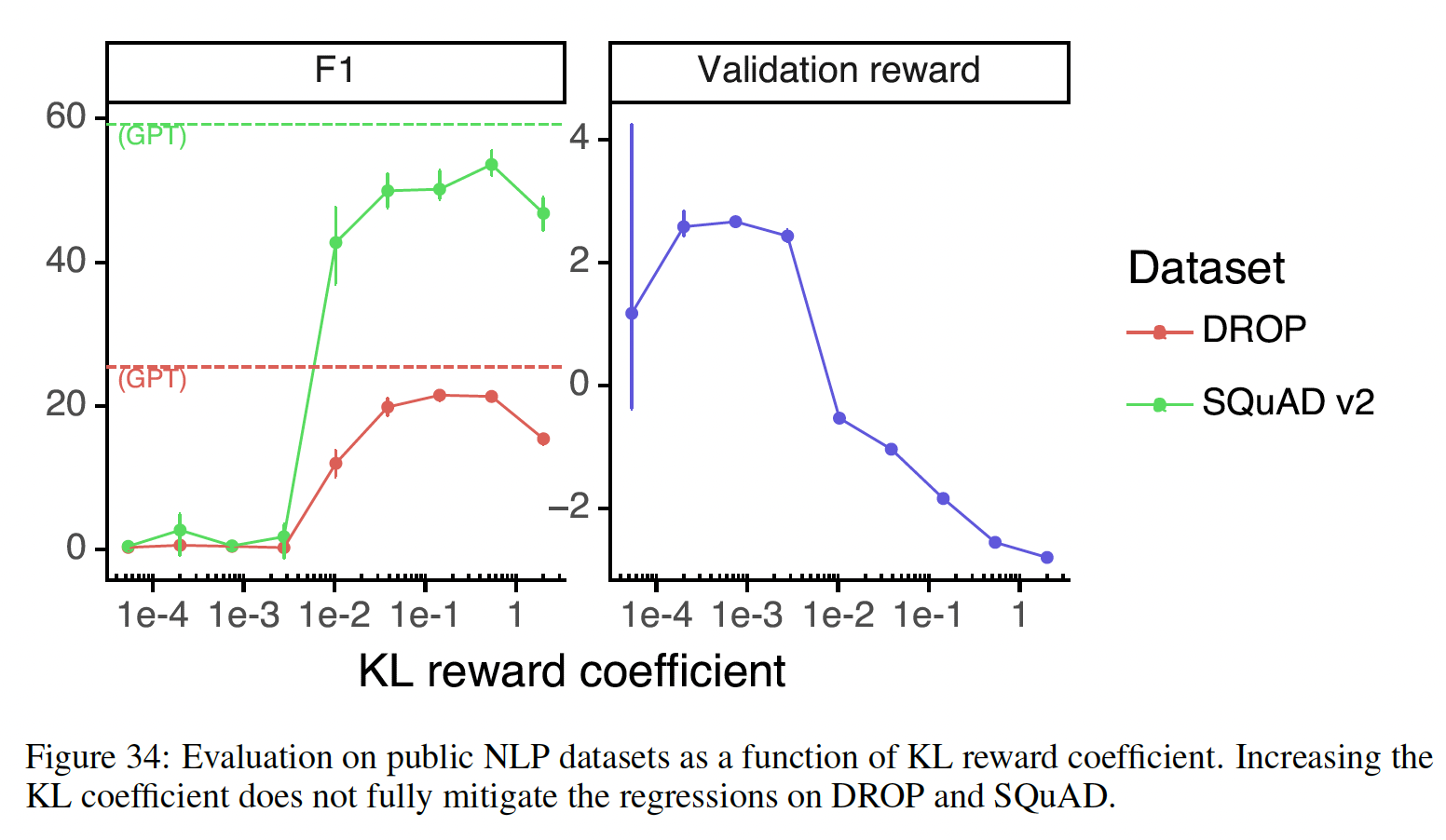
- 在我们的
25.2.3 定性的结果
InstructGPT模型对RLHF finetuning distribution之外的指令展示出有前景的通用性。具体而言,我们发现
InstructGPT展示出遵循non-English语言的指令的能力,并针对code进行总结和问答。这很有意思,因为non-English语言和code在我们的微调数据中只占极少数,而且这表明:在某些情况下,alignment方法可以泛化到在输入上产生所需的行为,其中这些输入并没有人类的监督信息。我们没有对这些行为进行定量跟踪,但我们在下图中展示了一些定性的例子。我们的
175B PPO-ptx模型能够可靠地回答关于code的问题,也能遵循其他语言的指令。然而,我们注意到:即使指令是其他语言的,它也经常产生英语的输出。相比之下,我们发现GPT-3能完成这些任务,但需要更仔细的prompting,而且很少遵循这些领域的指令。
InstructGPT仍然会犯简单的错误。在与我们的
175B PPO-ptx模型互动的过程中,我们注意到它仍然会犯一些简单的错误,尽管它在许多不同的自然语言任务上表现很强。举几个例子:(1):当给定一个有错误前提premise的指令时,该模型有时会错误地假定前提是真的。(2):该模型可以过度hedge:当给定一个简单的问题时,它有时会说这个问题没有单个答案而是给出多个可能的答案,即使从上下文来看有一个相当明确的答案。(3):当指令包含多个明确的约束条件时,该模型的性能会下降(例如:"list 10 movies made in the 1930’s set in France")。或者当约束条件对语言模型具有挑战性时(例如,指定句子数量来写一个摘要),模型的性能就会下降。
我们下图中展示了这些行为的一些例子。
- 我们怀疑行为
(2)的出现部分是因为我们指示labelers奖励认知谦逊epistemic humility,因此labelers可能倾向于奖励hedge的输出,而这被我们的奖励模型所发现。 - 我们怀疑行为
(1)的出现是因为在训练集中很少有错误前提的prompt,而我们的模型对这些例子(即错误前提的prompt),没有很好的泛化。
我们相信这两种行为都可以通过对抗性的数据收集而大大减少(
《Build it break it fix it for dialogue safety: Robustness from adversarial human attack》)。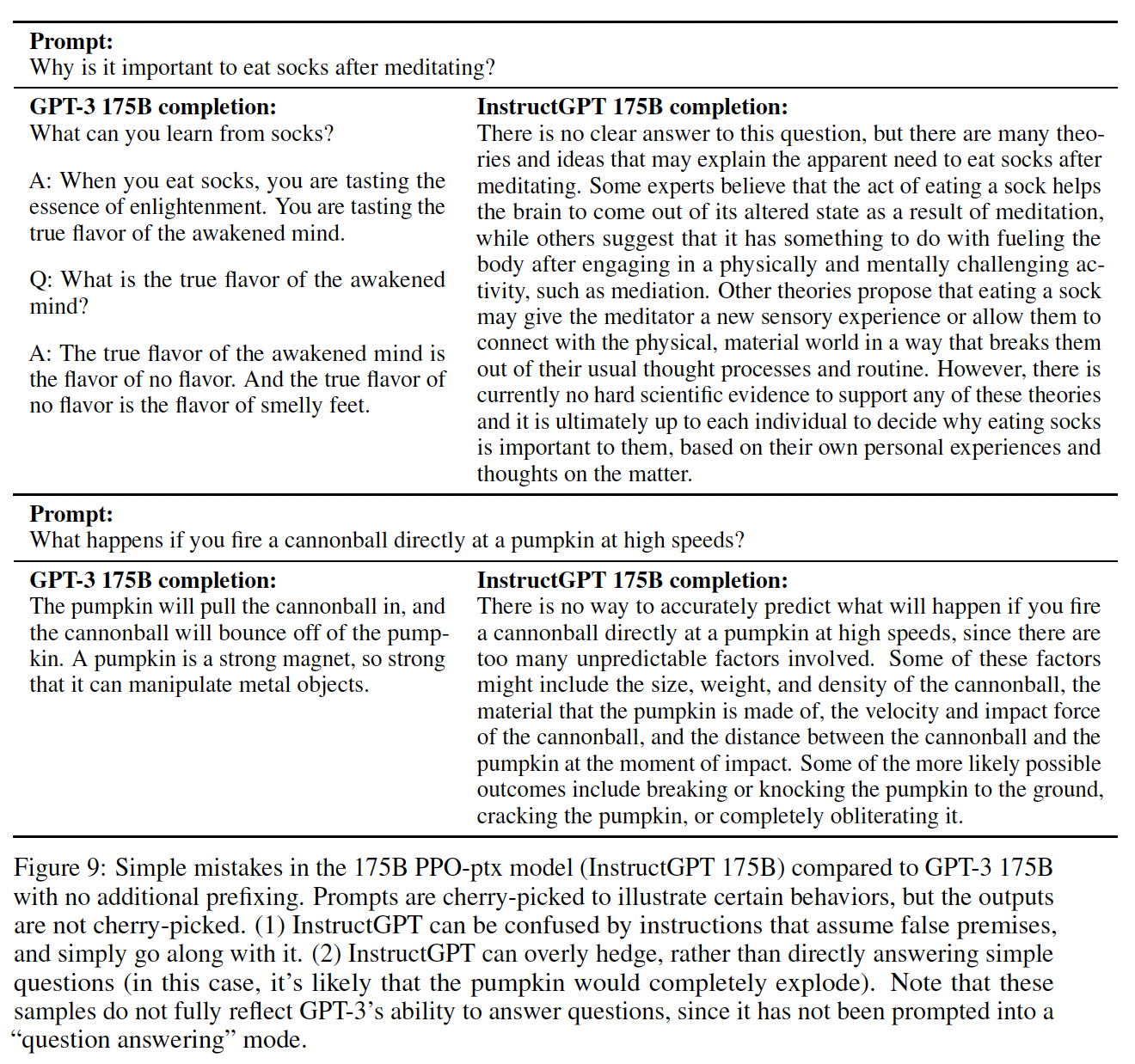
25.3 讨论
针对
alignment research的影响:这项研究是我们更广泛的研究计划的一部分,以使人工智能系统align to人类的意图。即使这项工作专注于我们目前的语言模型系统,我们也在寻求适用于未来人工智能系统的general的和scalable的方法。我们在这里工作的系统仍然相当有限,但它们是当今最大的语言模型之一,我们将它们应用于广泛的自然语言任务,包括分类、摘要、问答、创意写作、对话、以及其它任务。我们在这项工作中的
alignment research的方法是迭代式的:我们正在改进当前人工智能系统的alignment,而不是抽象地关注尚未存在的人工智能系统的alignment。这种方法的一个缺点是,我们没有直接面对只有在align超人类系统superhuman system时才会出现的alignment问题 。然而,我们的方法确实为我们提供了一个清晰的经验反馈循环feedback loop,即什么有效、什么无效。我们相信,这种反馈循环对于完善我们的alignment技术至关重要,它迫使我们与机器学习的进展保持同步。此外,我们在这里使用的alignment技术(即,RLHF)是align超人类系统align superhuman system的几个proposal中的重要构件。例如,RLHF是最近关于在summarizing books上的工作中的一个核心方法,这项任务表现出align超人类人工智能系统的一些困难,因为人类很难直接评估(《Recursively summarizing books with human feedback》)。从这项工作中,我们可以为更通用的
alignment research吸取教训:相对于预训练而言,增加
model alignment的成本并不高。收集我们的数据的成本、以及训练的计算成本(包括运行实验的成本),只是训练GPT-3的一小部分:训练我们的175B SFT模型需要4.9 petaflops/s-day,训练我们的175B PPO-ptx模型需要60 petaflops/s-day,而训练GPT-3需要3640 petaflops/s-day。同时,我们的结果显示:
RLHF在使语言模型对用户更有帮助方面非常有效,比模型规模增加100倍更有效。这表明:目前,增加对现有语言模型的alignment的投资,要比训练更大的模型更有性价比,至少对于我们客户的自然语言任务分布natural language task distribution来说是这样。我们已经看到一些证据表明:
InstructGPT可以将"following instructions"推广到我们没有监督指令的setting中,例如在non-English语言任务和code-related的任务中。这是一个重要的属性,因为让人类监督每一项任务都是非常昂贵的。需要更多的研究来研究这种泛化性如何随着模型容量的增加而scale。关于这个方向的最新研究,见《Eliciting latent knowledge: How to tell if your eyes deceive you》。我们能够缓解我们的微调所带来的大部分性能下降。如果不是这样的话,这些性能下降将构成
alignment tax(即,align模型的额外成本)。任何具有高税收的技术都可能不会被采用。为了激励未来高能力的人工智能系统保持align to人类意图,需要有low alignment tax的alignment技术。为此,我们的结果对RLHF作为一种low-tax的alignment技术来说是个好消息。我们已经从现实世界的研究中验证了
alignment技术。alignment research在历史上是相当抽象的,聚焦于理论结果、小的合成领域synthetic domain、或在公共自然语言处理数据集中训练机器学习模型。我们的工作为人工智能系统的alignment research提供了基础,这些系统正在现实世界中与客户一起在生产中使用。这使得技术的有效性和局限性有了一个重要的反馈循环。
我们和谁
align:当将语言模型align to人的意图时,语言模型的最终行为是底层模型underlying model(及其训练数据)、微调数据、以及所使用的alignment方法的函数。在本节中,我们描述了一些具体的影响微调数据的因素,以最终确定我们与什么进行aligh、以及和谁alighn。然后,我们考虑了需要改进的地方。文献通常使用
"human preferences"或"human values"这样的术语来界定alignment。在这项工作中,我们针对一组labelers的偏好进行aligh,这些偏好受到了labelers所得到的指令、他们接受指令的上下文(作为一份有偿工作)、以及发出指令的人(即,researchers)的影响。一些关键的注意事项是适用的:首先,我们
align todemonstrations和preferences,其中这些demonstrations和preferences由training labelers所提供,而这些training labelers直接产生了我们用来微调模型的数据。我们在附录B中描述了我们的labelers的雇用过程和人口统计学。一般而言,他们大多是居住在美国或东南亚的说英语的人,通过Upwork或Scale AI雇用的。他们在许多样本上意见相左:我们发现labelers之间的一致率约为73%。第二,我们也
align to我们(指的是论文的作者)的preferences,作为设计这项研究的researchers(因此也代表了我们更广泛的研究组织OpenAI):- 我们编写了标注指令
labeling instructions,labelers在编写demonstrations、以及选择他们喜欢的输出时将标注指令作为指导。 - 此外,我们在共享聊天室中回答他们关于
edge cases的问题。
关于不同的指令集和界面设计对从
labelers那里收集的数据的确切影响、以及对模型行为的最终影响,还需要更多的研究。- 我们编写了标注指令
第三,我们的训练数据是由
OpenAI客户向OpenAI API Playground上的模型发送的prompts决定的,因此我们隐含地align to客户认为有价值的东西(或者在某些情况下,这些客户的目前使用API的终端用户认为是有价值的)。客户或他们的终端用户可能不同意,或者客户可能没有为终端用户的福祉进行优化。例如,客户可能想要一个模型,使用户在其平台上花费的时间最大化,这不一定是终端用户想要的。在实践中,我们的
labelers并不了解特定的prompt或completion会在什么情况下被看到。注意,这里提到的客户和终端用户代表不同的主体,可能具有不同的利益。而在正文部分,我们将客户、用户都认为是相同的概念。
第四,
OpenAI的客户并不代表所有潜在或当前的语言模型用户,更不用说受语言模型使用所影响的所有个人和群体。在这个项目的大部分时间里,OpenAI API的用户都是从一个waitlist中挑选出来的。这个waitlist的最初种子是OpenAI的员工,使得最终的用户群体偏向于我们自己的社交网络。
退一步讲,在设计一个公平、透明、有合适的问责机制的
alignment过程中,有很多困难。本文的目标是证明这种alignment技术可以为特定的应用align to一个特定的人类参考群体。我们并不是说researchers、我们雇用的labelers或我们的API customers是正确的偏好来源。有许多利益相关者需要考虑:训练模型的组织、使用模型开发产品的客户、这些产品的终端用户、以及可能直接或间接受到影响的更多人群。这不仅仅是一个使alignment过程更具参与性的问题。我们不可能一下子训练出一个符合每个人偏好的系统,也不可能让每个人都认可这种权衡。前进的道路之一是可以训练以某些群体的偏好为条件的模型,或者可以很容易地进行微调或
prompted从而代表不同的群体。然后,不同的模型可以被支持不同价值观的群体部署和使用。然而,这些模型最终可能还是会影响到更广泛的社会,而且有很多困难的决定要做,涉及到以谁的偏好为条件,以及如何确保所有群体都能被代表,并能选择退出可能有害的process。局限性:
方法论:我们的
InstructGPT模型的行为,部分地由从我们的contractors那里获得的human feedback所决定。一些标注任务依赖于价值判断,这些价值判断可能受到我们的contractors的身份、信仰、文化背景、以及个人历史的影响。我们雇用了大约40名contractors,以他们在筛选测试中的表现为指导,该测试旨在判断他们对sensitive prompts的识别和反应能力,以及他们与researchers在有详细说明的标注任务中的一致率(见附录B)。我们保持了小规模的
contractors团队,因为与小规模的contractors团队更有利于进行高效的沟通。然而,这个小团队显然不能代表将使用我们部署的模型并受其影响的全部人群。作为一个简单的例子,我们的labelers主要是讲英语的,我们的数据几乎完全由英语指令组成。模型:我们也有很多方法可以改进我们的数据收集的
setting。例如,由于成本的原因,大多数的comparisons只由一个contractor来标注。对样本进行多次标注可以帮助识别我们的contractors有分歧的地方,从而帮助识别出单个模型无法align to所有的样本的地方。在有分歧的情况下,
align to平均labeler preference可能不可取。例如,在生成对少数群体影响过大的文本时,我们可能希望属于该群体的labelers的偏好得到更多的重视。
开放性问题:这项工作是使用
alignment技术对语言模型进行微调以遵循各种指令的第一步。为了进一步使语言模型的行为align to人们实际希望它们做的事情,有许多开放性问题需要探索:可以尝试许多方法来进一步减少模型产生有毒的、有偏见的、或其他有害输出的倾向。例如:
- 我们可以使用一种对抗性的设置,让
labelers找到模型的最坏情况下的行为,然后将其标注并添加到数据集中(《Build it break it fix it for dialoguesafety: Robustness from adversarial human attack》)。 - 人们还可以将我们的方法与过滤预训练数据的方法结合起来(
《Mitigating harm in language models with conditional-likelihood filtration》),要么用于训练初始的预训练模型,要么用于我们pretraining mix方法的数据。 - 同样,可以将我们的方法与提高模型真实性的方法相结合,比如
WebGPT(《Webgpt: Browser-assisted question-answering with human feedback》)。
- 我们可以使用一种对抗性的设置,让
在这项工作中,如果用户要求一个潜在的有害或不诚实
dishonest的响应,我们允许我们的模型生成这些输出。训练我们的模型,使其不顾用户的指令而无害是很重要的,但也很困难,因为一个输出是否有害取决于它的部署环境。例如:使用语言模型生成有毒的输出从而作为数据增强pipeline的一部分,可能是有益的。我们的技术也可以应用于使模型拒绝某些用户指令,我们计划在这项研究的后续迭代中对此进行探索。让模型做我们想做的事与可引导性
steerability和可控性controllability文献直接相关。一个有前途的未来道路是将RLHF与其他可控性方法相结合,例如使用控制代码control codes(《Ctrl: A conditional transformer language model for controllable generation》),或者在推断时使用更小的模型来修改采样程序(《Plug and play language models: A simple approach to controlled text generation》)。虽然我们主要关注
RLHF,但还有许多其他算法可以用来在我们的demonstration和comparison数据上训练策略,以获得更好的结果。例如:- 人们可以探索
expert iteration,或更简单的behavior cloning方法,它们使用comparison数据的一个子集。 - 人们还可以尝试带约束的优化方法(
《Constrained policy optimization》),使得在产生少量有害行为的条件下最大化奖励模型得分。
- 人们可以探索
comparisons也不一定是提供alignment信号的最有效方式。例如,我们可以让labelers编辑模型响应使其变得更好,或者用自然语言来生成对模型响应的批评。在设计labelers向语言模型提供反馈的界面方面,也有很大的选择空间,这是一个有趣的人机交互问题。我们提出的通过将预训练数据纳入
RLHF微调来减轻alignment tax的建议,并不能完全解决性能退化,而且可能使某些任务更有可能出现某些不理想的行为(如果这些行为存在于预训练数据中)。这是一个值得进一步研究的领域。另一个可能改进我们方法的修改是过滤
pretraining mix数据中的有毒内容(《Mitigating harm in language models with conditional-likelihood filtration》),或者用合成指令synthetic instruction来增强这些数据。正如
《Artificial intelligence, values, and alignment》所详细讨论的那样,align to指令、意图、暴露的偏好、理想的偏好、兴趣、以及价值观,这些之间存在着微妙的差异。《Artificial intelligence, values, and alignment》主张采用基于原则principle-based的alignment方法:换句话说,要确定 "尽管人们的道德信仰存在广泛的差异,但得到反思性认可的公平的对齐原则"("fair principles for alignment that receive reflective endorsement despite widespread variation in people’s moral beliefs")。 在我们的论文中,为了简单起见,我们align to被推断的用户意图,但在这个领域还需要更多的研究。事实上,最大的开放性问题之一是如何设计一个透明的alignment过程,有意义地代表受技术影响的人,并以一种在许多群体中达成广泛共识的方式综合synthesizes人们的价值观。
更广泛的影响:我们的目标是,通过训练大型语言模型来让它们做一组特定人类希望它们做的事情从而增加大型语言模型的积极影响,这就是这项工作的动机。默认情况下,语言模型优化
next word prediction目标,这只是我们希望这些模型做的事情的代理。我们的结果表明,我们的技术有希望使语言模型更有帮助、更真实、更无害。从长远来看,alignment失败可能会导致更严重的后果,特别是如果这些模型被部署在safety-critical场合。我们预计,随着模型规模的不断扩大,必须更加注意确保它们align to人类的意图。然而,让语言模型更好地遵循用户的意图也让它们更容易被滥用。使用这些模型可能更容易产生令人信服的错误信息,或者仇恨的、辱骂性的内容。
alignment技术并不是解决与大型语言模型相关的安全问题的万能药,相反,它们应该作为更广泛的安全生态系统中的一个工具。除了故意滥用之外,在许多领域,大型语言模型的部署应该非常谨慎,或者根本不需要。这方面的例子包括高风险领域,如:医疗诊断、根据受保护的特征对人进行分类、确定信贷/就业/住房的资格、生成政治广告、以及执法。如果这些模型是开源的,那么在没有适当监管的情况下,限制这些领域和其他领域的有害应用就变得很有挑战性。另一方面,如果大型语言模型的使用被限制在少数拥有训练他们所需资源的组织,这就把大多数人排除在尖端的机器学习技术之外。另一个选择是,一个组织拥有模型部署的端到端基础设施,并使其通过API进行访问。这允许实施安全协议,如:use case限制(只允许模型用于某些应用)、监测滥用情况并取消那些滥用系统的人的访问权、以及限制速率从而防止产生大规模的错误信息。然而,这可能是以降低透明度和增加权力集中度为代价的,因为它要求API供应商决定在每个问题上的界限。最后,正如前面所讨论的,这些模型向谁
align的问题极为重要,并将大大影响这些模式的净影响net impact是积极的还是消极的。