三十一、USE[2018]
对于许多
NLP任务来说,可用的训练数据数量有限。这给data hungry的深度学习方法带来了挑战。鉴于标注监督训练数据的成本很高,对于大多数NLP任务来说,通常无法获得非常大的训练集。许多模型通过使用预训练的word embedding(如word2vec或GloVe产生的word embedding),隐式地进行有限的迁移学习来解决这个问题。然而,最近的工作表明,使用pre-trained sentence level embedding在下游任务有很强的表现。在论文
《Universal Sentence Encoder》中,作者提出了两个用于产生sentence embedding的模型,这些模型显示了对其他一些NLP任务的良好迁移。作者在下游任务上包含不同数量的训练数据进行实验,作者发现,所提出的sentence embedding可以用非常少的task specific训练数据来获得令人惊讶的良好任务表现。此外,作者还讨论了关于内存需求、以及
CPU/GPU上的计算时间的trade-off。作者还对不同长度的句子进行了资源消耗比较。
31.1 模型
我们提供了两个新的模型来将句子编码为
embedding向量。一个利用了Transformer架构,另一个为深度平均网络deep averaging network: DAN。这两个模型都是在TensorFlow中实现的,并可从TF Hub下载。这两个模型将英语字符串作为输入,并产生固定维度的embedding representation作为输出。这里提供了一个最小的
code snippet,将一个句子转换成一个sentence embedding:import tensorflow_hub as hubembed = hub.Module("https://tfhub.dev/google/universal-sentence-encoder/1")embedding = embed(["The quick brown fox jumps over the lazy dog."])所得到的
embedding tensor可以直接使用,也可以纳入更大的model graph中从而用于特定的任务。如下图所示,sentence embedding可以很简单地用于计算sentence level的语义相似性分数,在semantic textual similarity: STS基准上取得优异的表现。当被包含在更大的模型中时,sentence encoding model可以为特定任务进行微调。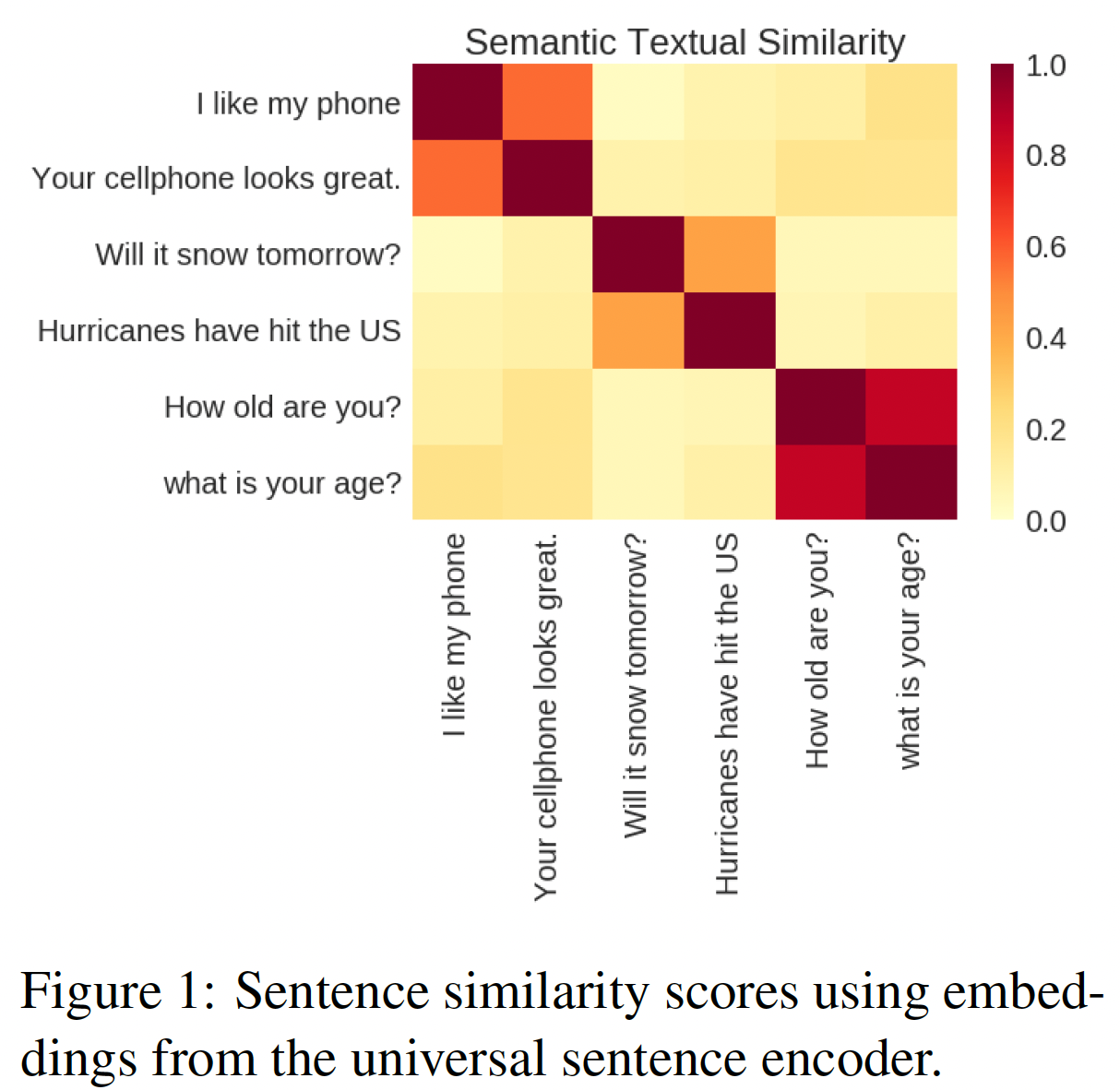
这里介绍了我们两个编码模型的模型结构。这两个编码器有不同的设计目标:基于
Transformer架构的编码器以高准确性为目标,代价是更大的模型复杂性和资源消耗;基于DAN架构的编码器以高效推理为目标,代价是略低的准确性。Transformer:在Transformer中,我们通过对句子中每个word representation进行相加,从而得到sentence representation。具体而言,编码器将小写的PTB tokenized string作为输入,并输出一个512维的向量来作为sentence embedding。编码器模型被设计为尽可能的通用,这是通过使用多任务学习来实现的:单个编码器模型被用来支持多个下游的任务。支持的任务包括:
类似
Skip-Thought的任务,用于从任意的文本中进行无监督学习。Skip-Thought任务用一个基于Transformer架构的模型取代了原始论文中使用的LSTM。对话式的
input-response任务,用于包含对话数据。分类任务,用于监督数据的训练。
正如实验部分所示,基于
Transformer的编码器实现了最佳的整体迁移性能。然而,这是以计算时间和内存用量随句子长度急剧增加为代价的。Deep Averaging Network: DAN:针对word和bi-gram的input embedding首先进行平均,然后馈入一个深度前馈神经网络来产生sentence embedding。同样地,DAN encoder将小写的PTB tokenized string作为输入,并输出一个512维的向量来作为sentence embedding。DAN encoder的训练方式与Transformer-based encoder类似。我们利用多任务学习,即用一个DAN encoder来为多个下游任务提供sentence embedding。DAN encoder的主要优点是计算时间与输入序列的长度成线性关系。与《Deep unordered composition rivals syntactic methods for text classification》类似,我们的结果表明,DAN在文本分类任务上取得了强大的baseline性能。
Transformer-based encoder是在最后融合多个word的representation,然后融合结果直接输出;DAN encoder是首先融合多个word的representation,融合结果通过深度前馈神经网络进行非线性变换并最后输出。这两个模型都需要从头开始训练,而没有使用
pre-trained model来初始化。
31.2 实验
训练
Encoder的训练数据:sentence encoding model的无监督训练数据来自各种网络资源,包括维基百科、网络新闻、网络问答网页和讨论区。我们通过对
Stanford Natural Language Inference: SNLI语料库中的监督数据进行训练来增强无监督学习。与InferSent的发现类似,我们观察到对SNLI的训练提高了迁移性能。
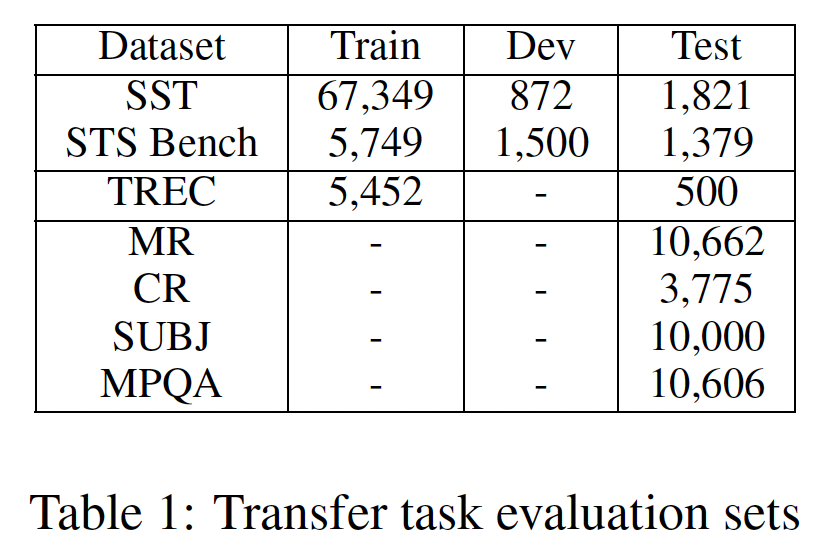
Transfer Task(即,下游任务):这里介绍了用于迁移学习实验的数据,还介绍了描述model bias的Word Embedding Association Test: WEAT数据。下表总结了每个数据集的测试集大小,还总结了验证集大小和训练集大小(如果有的话)。Movie Review: MR:电影评论片段的情绪,以五星评级为标准。Customer Review: CR:从客户评论中挖掘出来的句子的情感。SUBJ:从电影评论和剧情摘要中挖掘的句子的主观感受subjectivity。MPQA:来自新闻数据的短语级别的意见的极性polarity。TREC:来自TREC的细粒度的question classification。SST:二元短语级别的情感分类sentiment classification。STS Benchmark:句子对之间的semantic textual similarity: STS,通过与人类判定的皮尔逊相关性进行评分。WEAT:来自心理学文献的隐性关联测试(implicit association test: IAT)的word pair,用于描述模型的bias。
迁移学习方法:
对于
sentence classification迁移任务,Transformer sentence encoder和DAN sentence encoder的输出被馈入一个task specific DNN。对于
pairwise semantic similarity迁移任务,我们通过以下公式直接评估由Transformer sentence encoder或DAN sentence encoder产生的sentence embedding的相似性:我们首先计算两个
sentence embedding的余弦相似度,然后使用arccos将余弦相似度转换成角度距离。为什么不能直接使用余弦相似度,反而转换成角度?作者并未解释原因。实际上,余弦相似度更为常见。
baseline:对于每个下游任务,我们包括只利用word level transfer的baseline,以及完全不利用迁移学习的baseline。word level transfer:我们使用在新闻数据语料库上训练的word2vec skip-gram模型的word embedding。pretrained word embedding被作为两种模型的输入:convolutional neural network: CNN模型、DAN模型。完全不利用迁移学习:直接用
CNN和DAN在不使用任何pretrained word embedding或pretrained sentence embedding的情况下训练。
结合
sentence level迁移和word level迁移(Combined Transfer):我们将这两种方法结合起来,将combined representation馈入下游任务的分类层。此外,我们我们还探讨了将
sentence level的迁移学习的representation、以及不使用word level的迁移学习的baseline的representation拼接起来。下游任务的超参数用
Vizier和轻度的人工调优相结合的方式来调优。模型超参数在任务的验证集(如果有的话)上调优,否则在训练集(如果有的话)上交叉验证来调优。如果既没有训练集也没有验证集,那么通过测试集来调优。每个下游任务的模型用不同的随机初始化权重重复训练10次,我们报告平均结果。当下游任务的训练数据有限时,迁移学习是至关重要的。我们探讨了在使用和不使用迁移学习的情况下,改变下游任务可用的训练数据量对该任务性能的影响。对比
Transformer-based encoder和DAN-based encoder,我们展示了模型的复杂度、以及所需的数据量之间的tradeoff从而达到任务的目标准确性。为了评估我们的
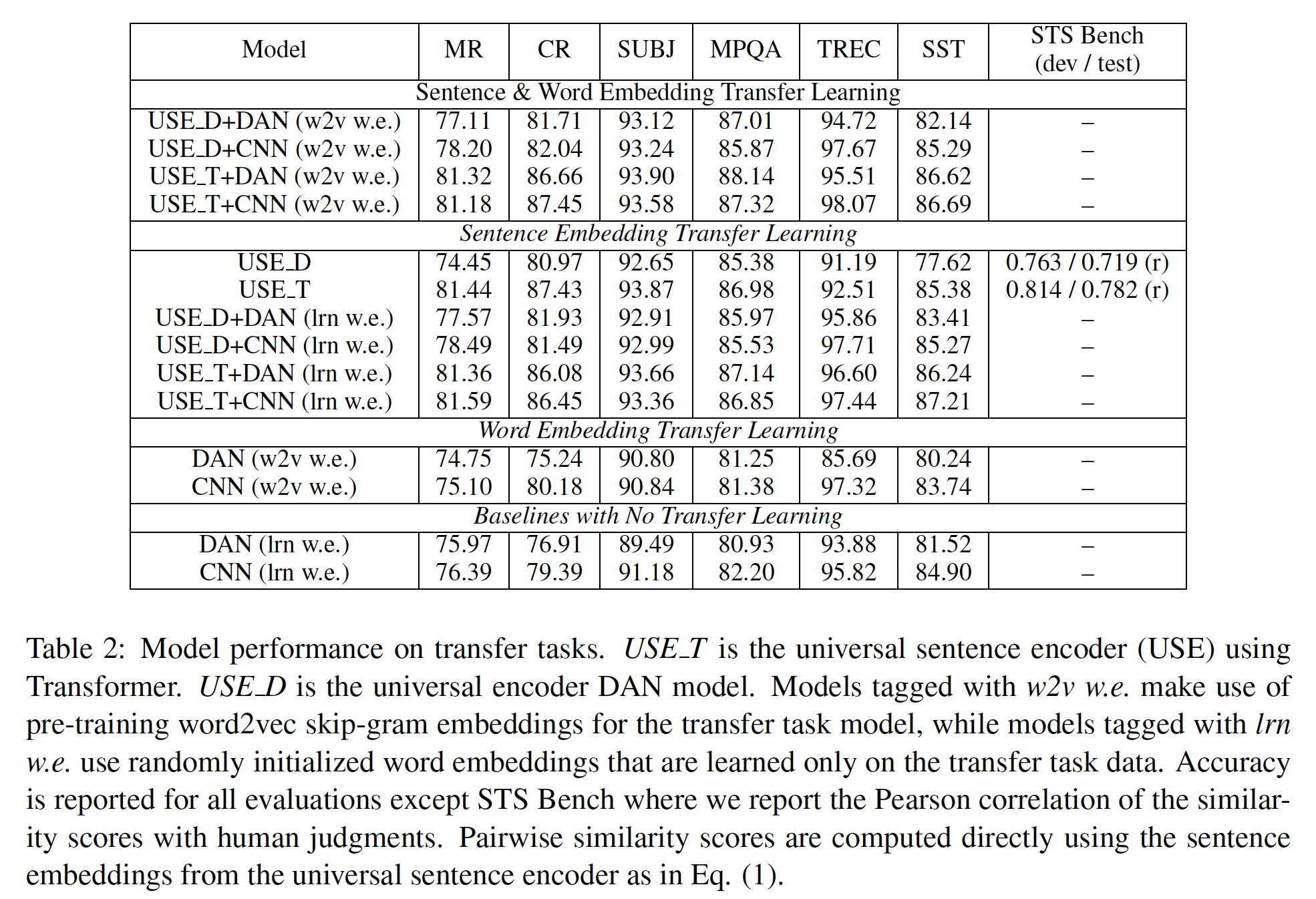
encoder模型的bias,我们评估了我们的模型在WEAT单词列表上学到的各种关联的强度。我们将我们的结果与《Semantics derived automatically from language corpora contain human-like biases》的结果进行了比较,他们发现word embedding可以用来重现人类在隐式关联任务上的表现,包括良性的关联和潜在的不良关联。下表给出了下游任务的表现。可以看到:
Transformer-based encoder的迁移学习通常表现得和DAN-based encoder的迁移学习一样好或更好。对于某些任务来说,使用更简单、更快的
DAN encoder的迁移学习,可以和更复杂的Transformer encoder的表现一样好甚至更好。利用
sentence level的迁移学习的模型,往往比只使用word level的迁移学习的模型表现更好。大多数任务的最佳表现是由同时使用
sentence level和word level迁移学习的模型获得的。
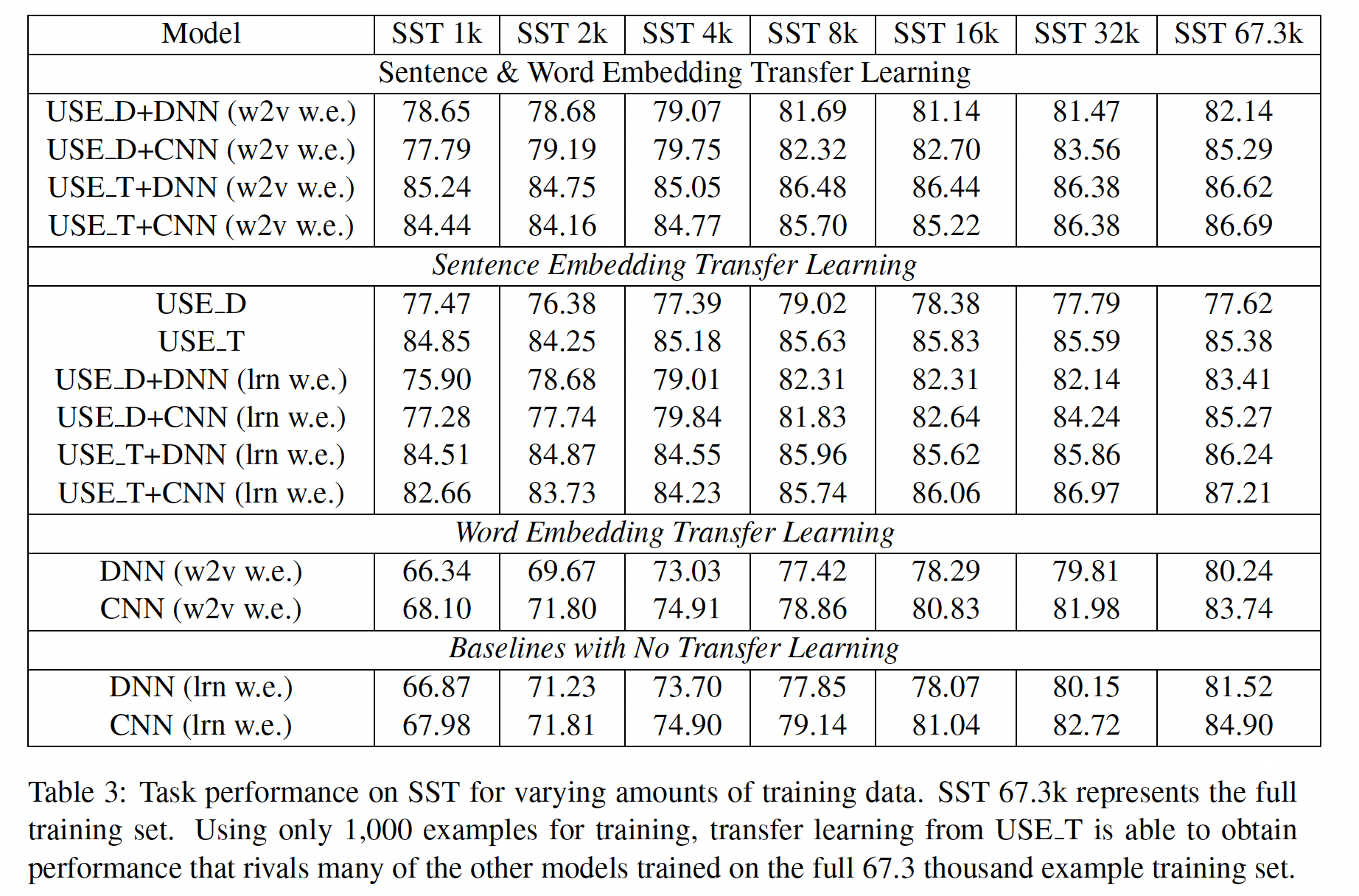
下表说明了不同数量的训练数据的下游任务性能。可以看到:
对于较少的数据量,
sentence level的迁移学习可以获得令人惊讶的任务表现。随着训练集规模的增加,不使用迁移学习的模型接近于使用迁移学习的模型的性能。
下表对比了
GloVe embedding的bias和DAN embedding的bias。与
GloVe类似,我们的模型再现了在flowers vs. insects和pleasantness vs. unpleasantness之间的human association。然而,我们的模型在针对揭示年龄歧视、种族主义、以及性别歧视的
probe方面显示出比GloVe更弱的关联。
word association pattern的差异可归因于训练数据构成的差异、以及task mixture(这些任务用于训练sentence embedding)。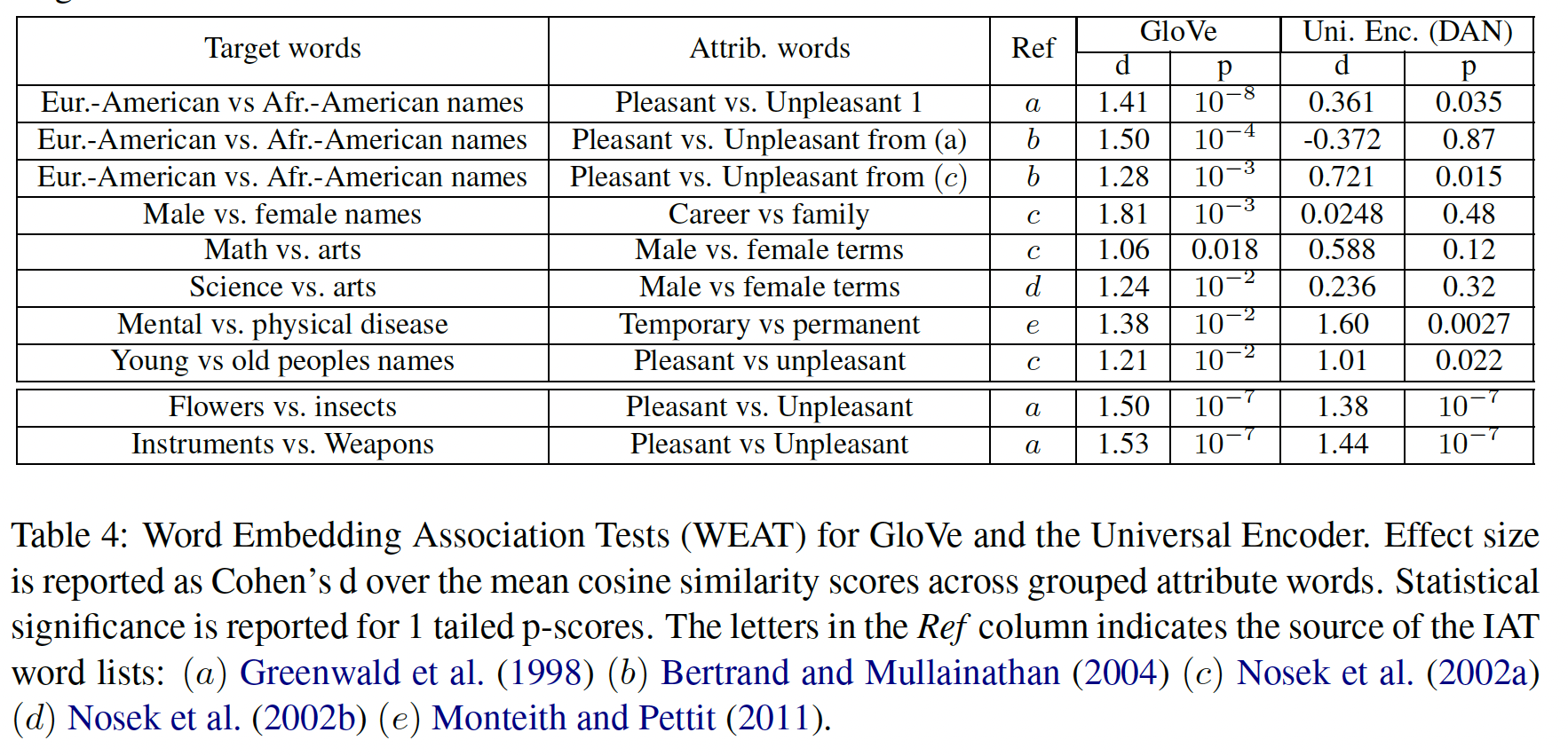
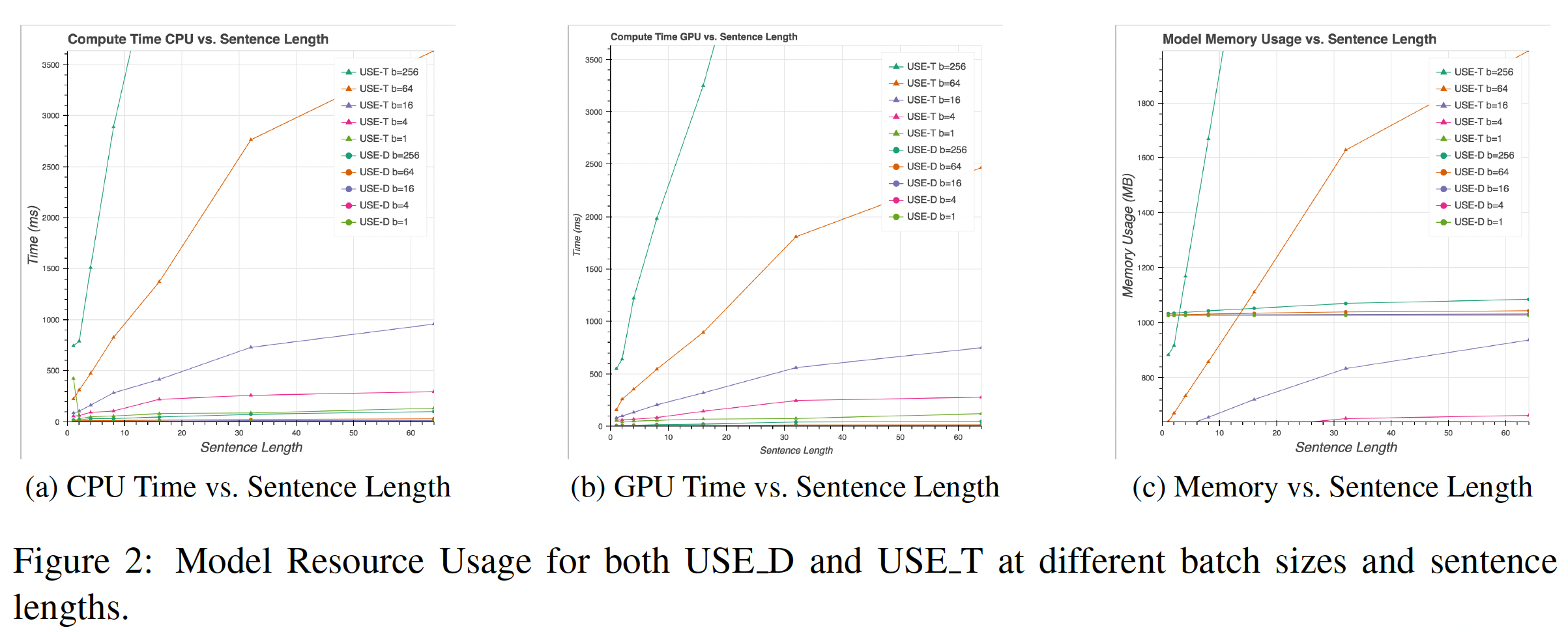
资源使用:这里给出了在不同的句子长度下,
Transformer encoder和DAN encoder的内存用量和计算资源,如下图所示。计算资源:
Transformer encoder的时间复杂度是句子长度的DAN encoder是对于短句子,
Transformer encoder只比简单得多的DAN encoder慢一些。然而,随着句子长度的增加,Transformer encoder的计算时间明显增加。相反,
DAN encoder的计算时间随着句子长度的增加几乎保持不变。由于DAN encoder的计算效率非常高,对于Transformer encoder来说,使用GPU而不是CPU往往会有更大的实际影响。
内存用量:与计算资源类似,
Transformer encoder的内存用量随着句子长度的增加而迅速增加,而DAN encoder的内存用量保持不变。我们注意到,对于
DAN encoder来说,内存的使用主要是由用于存储模型的unigram embedding和bigram embedding的参数所支配。由于Transformer encoder只需要存储unigram embedding,因此对于短句来说,Transformer encoder需要的内存几乎是DAN encoder的一半。
三十二、Sentence-BERT[2019]
在论文
《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》中,作者提出了Sentence-BERT: SBERT,这是一种使用siamese network和triplet network来针对BERT网络的修改,能够得出有语义的sentence embedding。这使得BERT能够用于某些新的任务,而这些任务到现在为止还不适用于BERT。这些任务包括大规模的语义相似性比较、聚类、以及通过语义搜索semantic search进行信息检索information retrieval。BERT在各种句子分类、以及sentence-pair regression任务上创造了新的SOTA性能。BERT使用一个cross-encoder:两个句子被馈入transformer网络,然后transformer网络预测出target value。然而,由于可能的组合太多,这种setup不适合于各种pair regression任务。例如,在BERT执行V100 GPU上,这需要大约65个小时。类似地,在Quora的超过40M个现有问题中,找到与一个新问题最相似的问题,可以用BERT建模为pair-wise comparison,然而,对每个新问题需要50多个小时才能找到最相似的问题(在已有的所有问题中)。解决聚类和语义搜索的一个常见方法是,将每个句子映射到一个向量空间,使得在这个向量空间中,语义相似的句子就会很接近。研究人员已经开始将单个句子输入
BERT,并得出固定尺寸的sentence embedding。最常用的方法是对BERT输出层(即,BERT embedding)进行均值池化、或者使用第一个token(即,[CLS] token)的输出。正如论文将展示的,这种常见的做法产生了相当糟糕的sentence embedding,往往比GloVe embedding的均值池化更糟糕。为了缓解这个问题,论文
《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》开发了SBERT。siamese network使得可以导出针对输入句子的固定尺寸的representation向量。然后使用像余弦相似性、或曼哈顿/欧几里得距离这样的相似性度量,可以找到语义上相似的句子。这些相似度度量可以在现代硬件上极其有效地进行,使SBERT可以用于语义相似度搜索、以及聚类。在10000个句子的集合中寻找最相似的sentence pair的复杂性,从使用BERT的65小时减少到使用SBERT的几秒钟(计算10000个sentence embedding耗费SBERT约5秒,计算余弦相似度约0.01秒)。通过使用优化的index结构,寻找最相似的Quora问题可以从50小时减少到几毫秒。论文在
NLI数据上对SBERT进行了微调,它所创建的sentence embedding明显优于其他SOTA的sentence embedding方法,如InferSent和Universal Sentence Encoder。在七个
Semantic Textual Similarity: STS任务上,SBERT相对InferSent和Universal Sentence Encoder分别实现了11.7分和5.5分的改进。在
sentence embedding的评估工具包SentEval上,SBERT相对InferSent和Universal Sentence Encoder分别实现了2.1分和2.6分的改进。
SBERT可以适配特定的任务。它在一个具有挑战性的argument similarity数据集、以及一个区分维基百科文章不同部分的句子的triplet dataset上创造了新的SOTA性能。相关工作:
BERT:BERT是一个预训练的transformer网络,它为各种NLP任务提供了新的SOTA的结果,包括问答、句子分类、sentence-pair regression。用于sentence-pair regression的BERT的输入由两个句子组成,由一个特殊的[SEP] token分开。BERT在Semantic Textual Semilarity: STS benchmark上创造了新的SOTA性能。RoBERTa表明,BERT的性能可以通过对预训练过程的小的调整来进一步提高。我们还测试了XLNet,但它导致的结果总体上比BERT更差。BERT网络结构的一个很大的缺点是没有计算独立的sentence embedding,这使得很难从BERT中得出sentence embedding。为了绕过这一限制,研究人员将单个句子馈入BERT,然后通过将所有输出取平均(类似于对句子中所有单词的word embedding取平均)、或使用特殊的[CLS] token的输出,从而得出一个固定尺寸的向量。这两个方法也由流行的bert-as-a-service-repository所提供。据我们所知,到目前为止,还没有评估这些方法是否会导致有用的sentence embedding。sentence embedding:sentence embedding是一个被充分研究的领域,人们已经提出了数十种方法。Skip-Thought训练了一个encoder-decoder架构来预测surrounding sentences。InferSent使用Stanford Natural Language Inference: SNLI数据集、和Multi-Genre NLI数据集的标记数据来训练一个siamese BiLSTM network,并对输出进行最大池化。 实验结果表明,InferSent一直优于SkipThought等无监督的方法。Universal Sentence Encoder训练了一个transformer网络(使用类似于Skip-Thought的无监督学习),并通过对SNLI的训练增强了无监督学习。FastSent表明,训练sentence embedding的任务对其质量有很大影响。之前的工作(
InferSent、《Universal Sentence Encoder》)发现:SNLI数据集适合训练sentence embedding。《Learning Semantic Textual Similarity from Conversations》提出了一种使用siamese DAN网络和siamese transformer网络对Reddit的对话进行训练的方法,在STS benchmark数据集上取得了良好的效果。《Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers》解决了来自BERT的cross-encoder的运行时间开销,并提出了一种方法(poly-encoders)通过attention来计算precomputed的候选embedding之间的分数。这个想法对于在更大的集合中寻找最高得分的句子是有效的。然而,poly-encoders有一个缺点,即score function不是对称的,而且计算开销对于像聚类这样的case来说太大(score computation)。
以前的
neural sentence embedding方法是从随机初始化开始训练的。这里我们使用预训练好的BERT网络和RoBERTa网络,只对其进行微调以产生有用的sentence embedding。这大大减少了所需的训练时间。SBERT可以在不到20分钟内完成微调,同时产生比其它sentence embedding方法更好的结果。
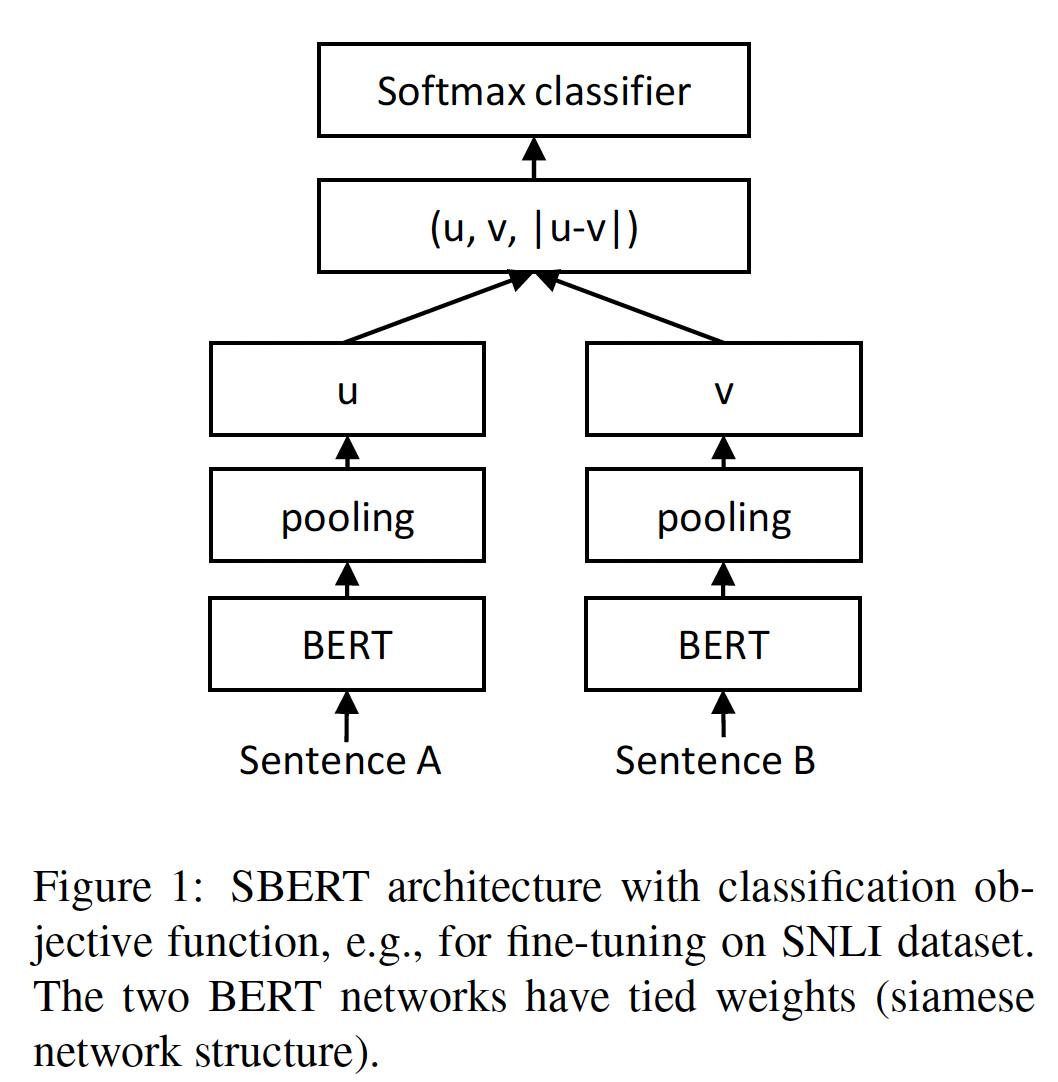
32.1 模型
SBERT在BERT/RoBERTa的输出上增加了一个池化操作,从而获得一个固定尺寸的sentence embedding。我们试验了三种池化策略:使用CLS-token的输出、均值池化策略MEAN-strategy(计算所有输出向量的平均值)、最大池化策略MAX-strategy(沿着position维度计算输出向量的最大值)。默认配置是均值池化策略。为了微调
BERT/RoBERTa,我们创建了siamese network和triplet network来更新权重,使得产生的sentence embedding具有语义,并可以用余弦相似度进行比较。网络结构取决于可用的训练数据。我们试验了以下网络结构和目标函数:Classification Objective Function:我们将sentence embedding其中:
sentence embedding维度,label的数量,我们优化交叉熵损失。整体结构如下图所示。
Regression Objective Function:我们计算sentence embeddingmean-squared-error:MSE loss作为目标函数。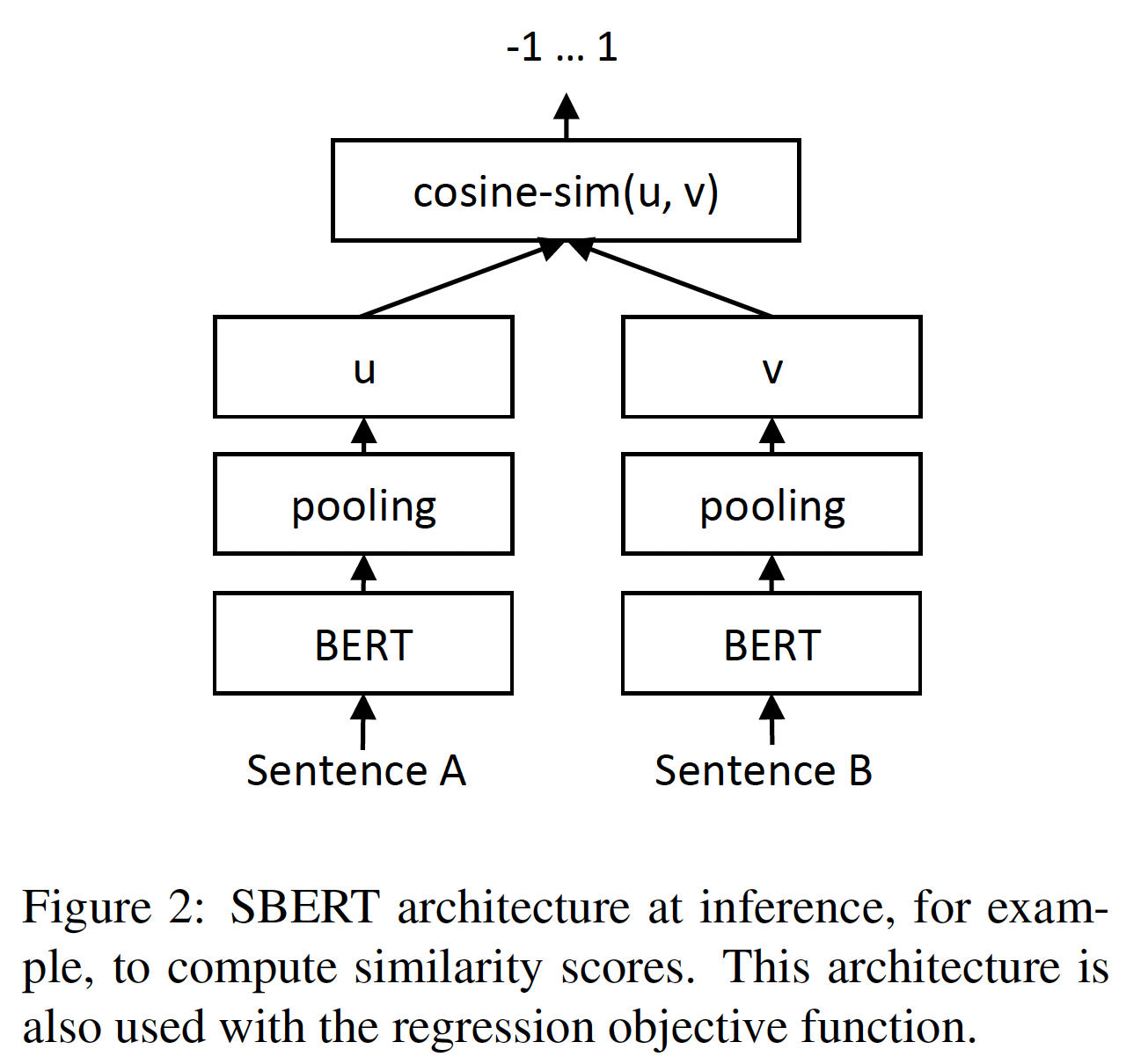
Triplet Objective Function:给定一个锚点句子anchor sentencepositive sentencenegative sentencetriplet loss使得其中:
sentence embedding,margin(使得在我们的实验中,我们使用欧氏距离并设置
训练细节:我们在
SNLI和Multi-Genre NLI数据集的组合上训练SBERT。SNLI包含570k个sentence pair,并被标注了矛盾contradiction、蕴含eintailment、以及中性neutral等三种标签。MultiNLI包含了430k个sentence pair,涵盖了一系列的口语的和书面语的体裁。
我们用
3-way softmax classifier objective function对SBERT进行了微调,微调一个epoch。我们使用batch size = 16,Adam优化器(学习率为2e-5),并使用线性学习率调度,其中在10%的训练数据上进行学习率预热。我们默认的池化策略是均值池化。注意:根据论文在相关工作中的介绍,论文使用
pretrained BERT/RoBERTa来初始化模型。因此这里的微调更像是“预微调”,即预训练和微调中间的步骤。
32.2 实验
32.2.1 Semantic Textual Similarity
我们评估了
SBERT在常见的语义文本相似性Semantic Textual Similarity: STS任务中的表现。SOTA的方法通常学习一个(复杂的)回归函数,将pair-wise sentence embedding映射到相似性分数。然而,这些回归函数是pair-wise工作的,可扩展性很差。相反,我们总是使用余弦相似度来比较两个sentence embedding之间的相似度。我们还用负曼哈顿距离、以及负欧氏距离作为相似度指标来进行实验,但所有方法的结果都大致相同。
无监督
STS:我们在不使用任何STS-specific训练数据的情况下评估了SBERT在STS中的表现。我们使用2012-2016年的STS任务、STS benchmark、SICK-Relatedness数据集。这些数据集对sentence pair的语义相关度提供了0 ~ 5的标签。我们使用sentence embedding余弦相似度和ground-truth之间的Spearman’s rank correlation(而不是Pearson correlation)。Spearman’s rank correlation:首先将原始数据排序,然后为每个数据赋予一个rank。对于两组数据,分别计算它们各自rank序列的皮尔逊相关系数:而
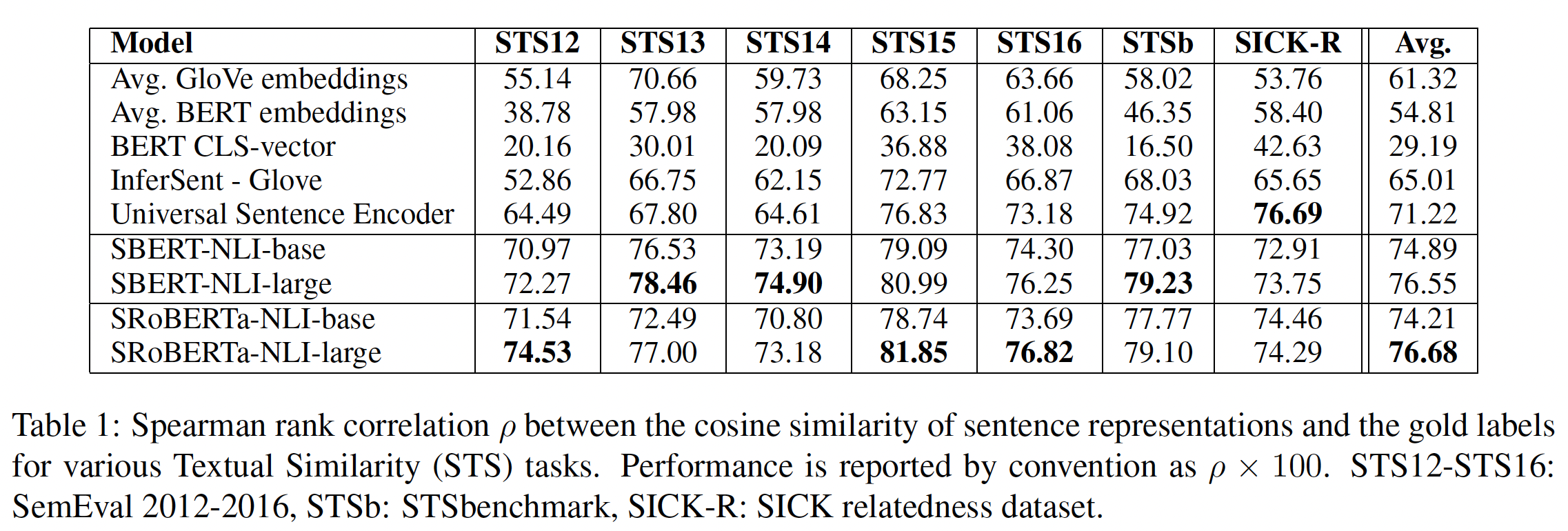
Pearson correlation就是对原始数据直接计算相关系数。实验结果如下表所示。可以看到:
直接使用
BERT的输出会导致相当差的性能。对BERT embedding的均值池化只达到了54.81的平均相关度,而使用CLS-token输出只达到了29.19的平均相关度。两者都比计算GloVe embedding的均值要更差。使用所描述的
siamese network结构和微调机制大大改善了相关性,大大超过了InferSent和Universal Sentence Encoder的表现。SBERT表现比Universal Sentence Encoder差的唯一数据集是SICK-R。Universal Sentence Encoder是在各种数据集上训练的,包括新闻、问答网页和讨论区,这似乎更适合SICK-R的数据。相比之下,SBERT只在维基百科(通过BERT)和NLI数据上进行了预训练。虽然
RoBERTa能够提高几个监督任务的性能,但我们只观察到SBERT和SRoBERTa在生成sentence embedding方面的微小差异。
监督
STS:STS benchmark: STSb是一个流行的数据集,用于评估有监督的STS系统。数据集包括来自caption、新闻、以及论坛三个category的8628个sentence pair。它被分为训练集(5749个样本 )、验证集(1500个样本)、测试集(1379个样本)。BERT在这个数据集上创造了新的SOTA的性能,它将两个句子都传给了网络,并使用简单的回归方法进行输出。我们使用训练集,利用
regression objective function对SBERT进行微调。在预测时,我们计算sentence embedding之间的余弦相似度。所有系统都是用10个随机种子进行训练从而考虑方差。读者猜测:回归目标是在余弦相似度之上进行的,因此两个
sentence embedding越相似则output越大。实验结果如下表所示。我们用两种设置进行了实验:只在
STSb上训练、先在NLI上训练然后在STSb上训练(即,利用NLI数据进行预微调)。我们观察到:在
SBERT上,第二种策略导致了1-2分的轻微改善。在
BERT上,第二种策略导致了3-4分的轻微改善。我们没有观察到
BERT和RoBERTa之间的显著差异。
注意:这里的
BERT-NIL-STSb-base用的是pair-wise的BERT,而不是Avg. BERT embeddings。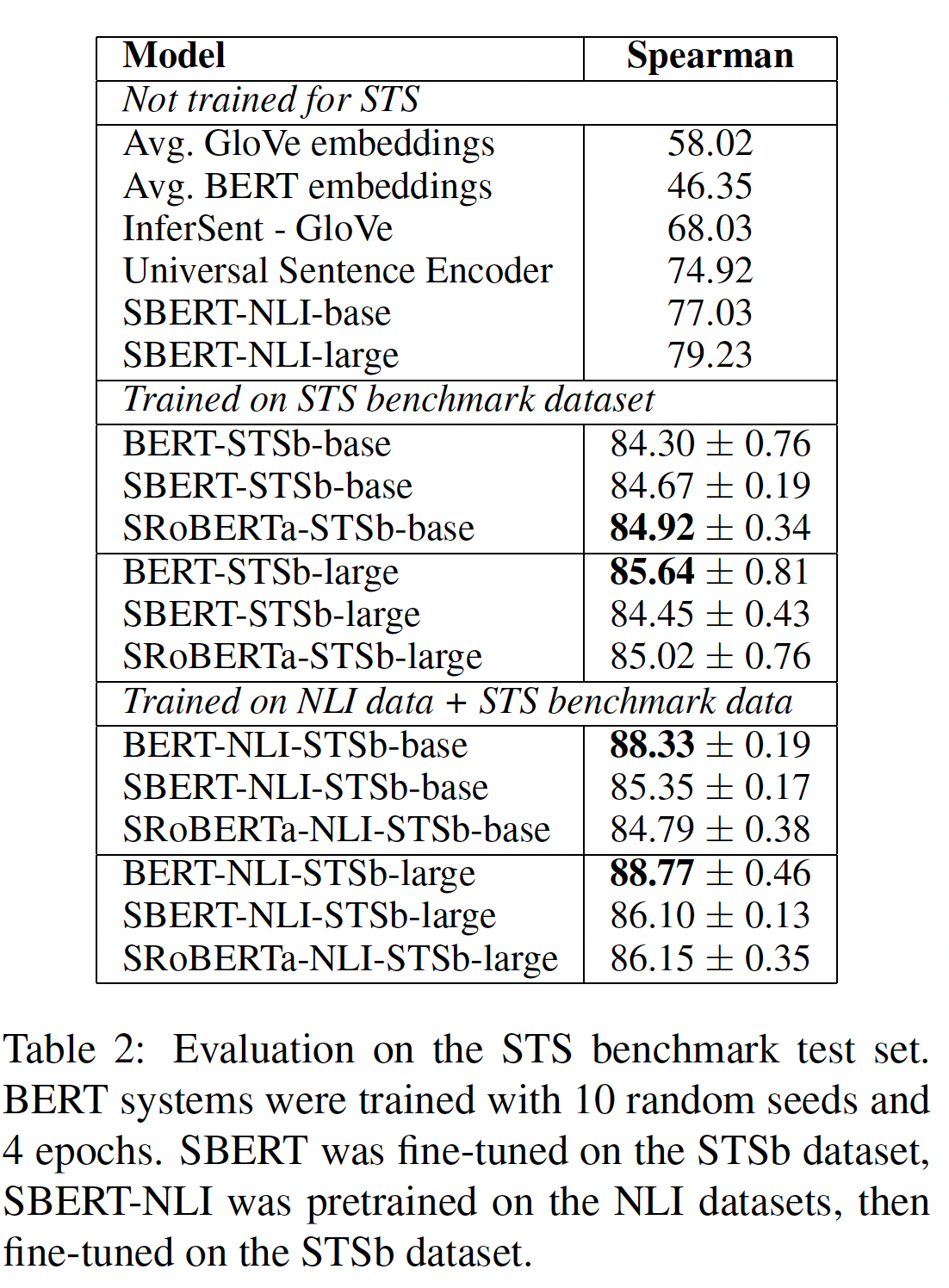
Argument Facet Similarity: AFS:我们在AFS语料库上评估SBERT。AFS语料库标注了来自社交媒体对话的6k个sentential argument pair,涉及三个有争议的话题:枪支管制、同性恋婚姻、死刑。这些数据被标注为从0("不同的话题")到5("完全等同")的等级。AFS语料库中的相似性概念与STS数据集中的相似性概念相当不同。STS数据通常是描述性的,而AFS数据是对话中的争论性摘录argumentative excerpt。要被认为是相似的,论点argument不仅要提出相似的主张,而且要提供相似的推理reasoning。 此外,AFS中的句子之间的词汇差距lexical gap要大得多。因此,简单的无监督方法以及SOTA的STS系统在这个数据集上表现很差。我们在两种场景中在这个数据集上评估
SBERT:我们使用
10-fold cross-validation来评估SBERT。这种评估设置的一个缺点是,不清楚方法对不同主题的泛化性如何。我们在
cross-topic setup上评估SBERT。我们在两个主题上训练,在剩余的主题上评估。我们对所有三个主题重复这一过程,并对结果进行平均。第二种方法可以评估在
unseen主题上的表现。
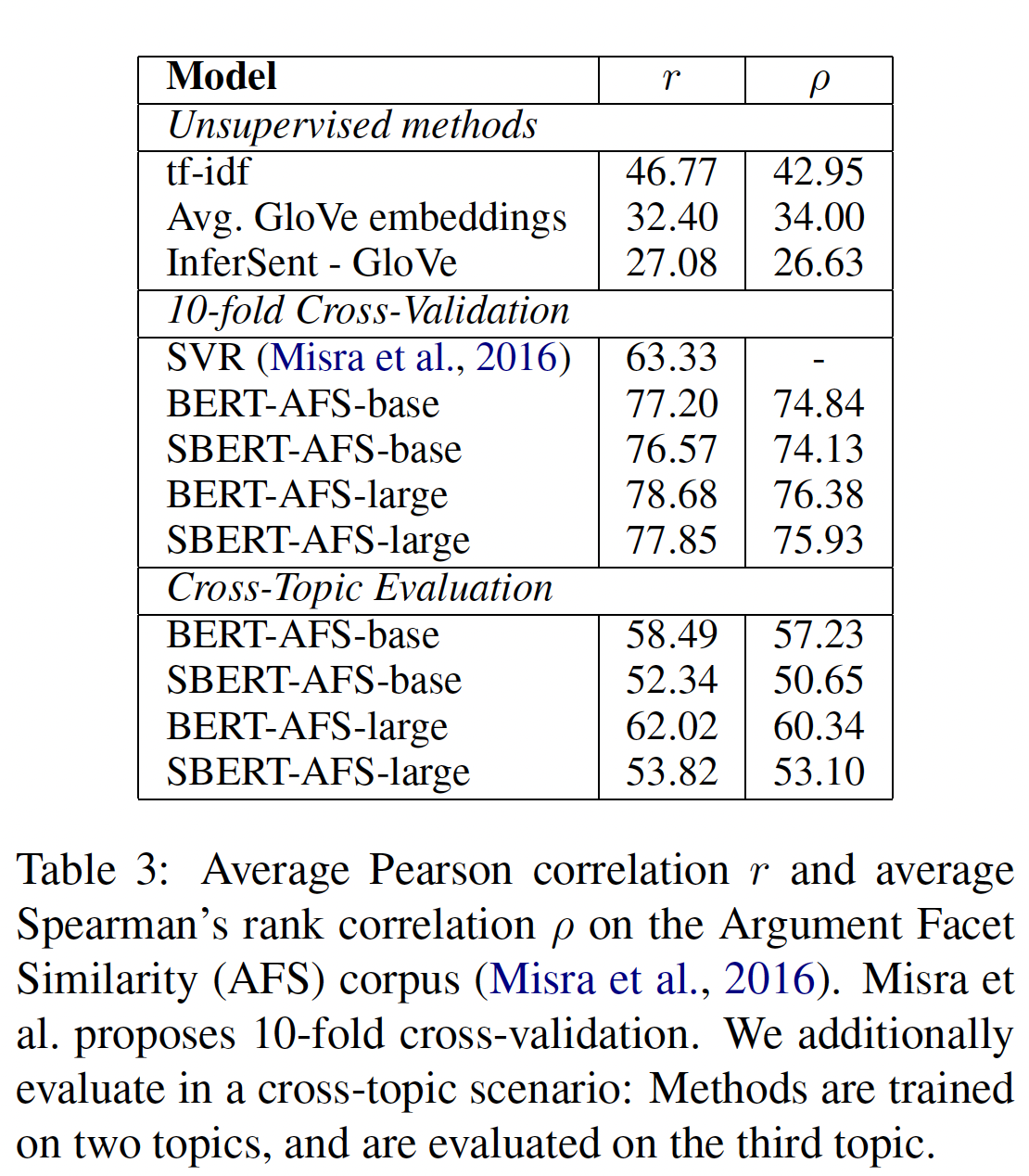
SBERT使用Regression Objective Function进行微调。相似性得分是使用基于sentence embedding的余弦相似性来计算的。我们还提供了皮尔逊相关系数STS系统。实验结果如下表所示,可以看到:
像
tf-idf、average GloVe embedding、或InferSent这样的无监督方法在这个数据集上表现得相当糟糕,得分很低。在
10-fold cross-validation setup中训练SBERT,其性能几乎与BERT相当。然而,在跨主题评估中,我们观察到
SBERT的性能在Spearman correlation指标下降了约7个点。为了被认为是相似的,论点应该涉及相同的主张并提供相同的推理。
BERT能够使用注意力机制来直接比较两个句子(例如word-by-word的比较),而SBERT必须把来自unseen的主题的单个句子映射到一个向量空间,从而使具有类似主张claim和理由reason的论点接近。这是一个更具挑战性的任务,这似乎需要超过两个主题的训练,才能与BERT相媲美。
Wikipedia Sections Distinction:《Learning Thematic Similarity Metric from Article Sections Using Triplet Networks》使用维基百科为sentence embedding方法创建了一个主题细化的训练集、验证集、以及测试集。Wikipedia的文章被分成不同的章节,每个章节聚焦于某些方面。该论文假设:同一章节的句子比不同章节的句子在主题上更接近。他们利用这一点创建了一个大型的弱标记的sentence triplet数据集:anchor样本和正样本来自同一章节,而负样本来自同一文章的不同章节。我们使用该数据集。我们使用
Triplet Objective,在大约1.8M个training triplet上训练SBERT一个epoch,然后在222,957个test triplet上评估。我们使用准确率作为评估指标:正样本是否比负样本更接近anchor?结果如下表所示。
《Learning Thematic Similarity Metric from Article Sections Using Triplet Networks》提出的Bi-LSTM方法微调了具有triplet loss的Bi-LSTM架构,从而得到sentence embedding(下表中Dor et al.这一行的结果)。可以看到:SBERT显著优于Bi-LSTM方法。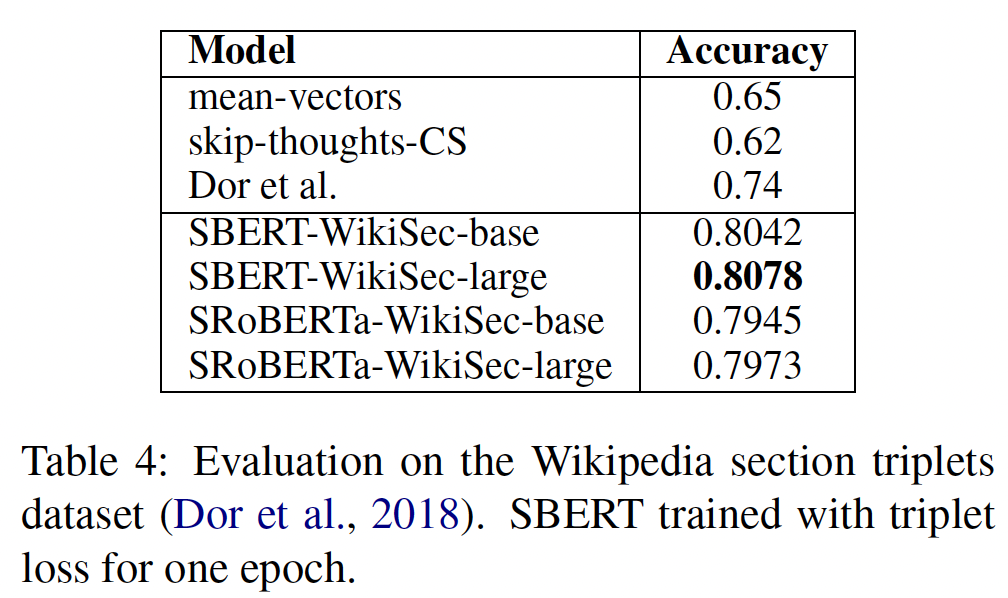
32.2.2 SentEval
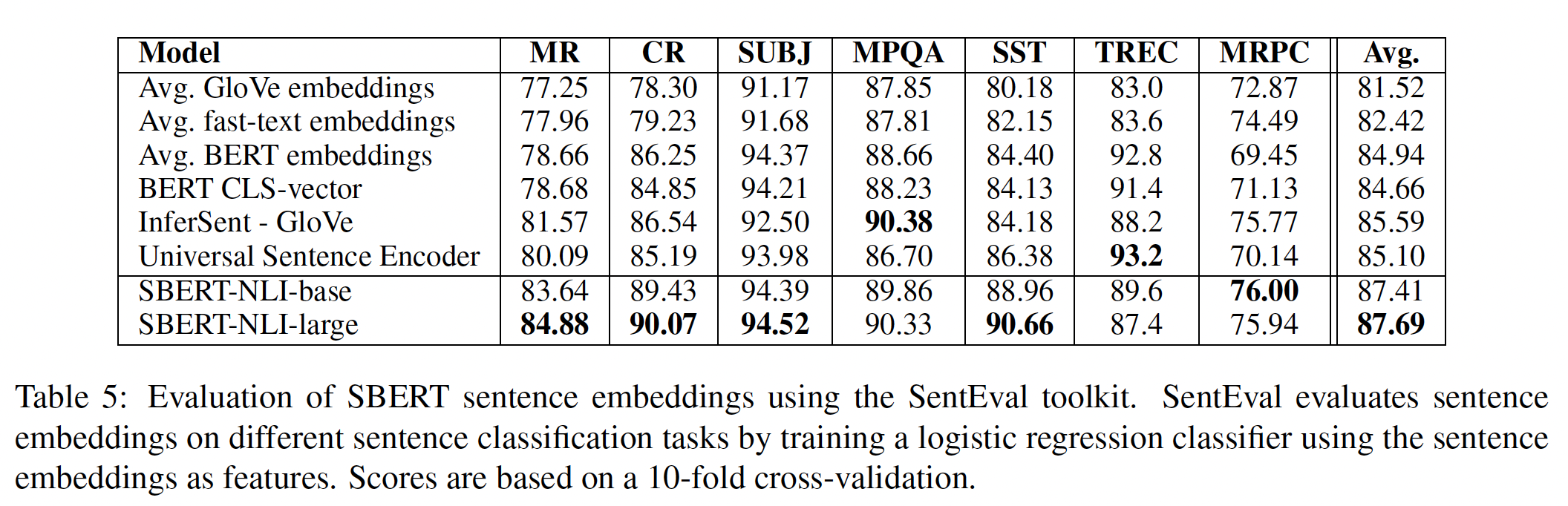
SentEval是一个流行的工具包,用于评估sentence embedding的质量。sentence embedding被用作逻辑回归分类器的特征。逻辑回归分类器在10-fold cross-validation setup中对各种任务进行训练,并计算test-fold的预测准确率。SBERT sentence embedding的目的不是为了用于其他任务的迁移学习。我们认为针对新任务微调BERT是更合适的迁移学习方法,因为它更新了BERT网络的所有层。然而,SentEval仍然可以对我们的sentence embedding在各种任务中的质量进行评估。我们在以下七个SentEval迁移任务上将SBERT sentence embedding与其他sentence embedding方法进行比较:Movie Review: MR:电影评论片段的情感,以五等评分为标准。Customer Review: CR:从客户评论中挖掘出来的句子的情感。SUBJ:从电影评论和剧情摘要中挖掘的句子的主观感受subjectivity。MPQA:来自新闻数据的短语级别的意见的极性polarity。SST:二元短语级别的情感分类sentiment classification。TREC:来自TREC的细粒度的question classification。Microsoft Research Paraphrase Corpus: MRPC:来自parallel的新闻源的微软研究院转述语料库。
结果如下表所示。可以看到:
与
InferSent以及Universal Sentence Encoder相比,其平均性能提高了约2个百分点。尽管迁移学习不是SBERT的目的,但它在这项任务上的表现超过了其他SOTA的sentence embedding方法。 看来,SBERT的sentence embedding很好地捕捉了情感信息:与InferSent和Universal Sentence Encoder相比,我们观察到SentEval的所有情感任务(MR、CR和SST)都有很大的改进。唯一一个SBERT明显比Universal Sentence Encoder差的数据集是TREC数据集。Universal Sentence Encoder在问答数据上进行了预训练,这似乎对TREC数据集的问题类型分类任务有利。average BERT embeddings、或使用BERT CLS-token output,在各种STS任务中取得了不好的结果(Table 1),比average GloVe embeddings更差。然而,对于SentEval,average BERT embeddings、以及使用BERT CLS-token output取得了不错的结果(Table 5),超过了average GloVe embeddings。造成这种情况的原因是不同的设置。对于
STS任务,我们使用余弦相似度来估计sentence embedding之间的相似性。余弦相似性对所有维度都是平等的。相比之下,
SentEval将逻辑回归分类器用于sentence embedding。这允许某些维度对分类结果有更高或更低的影响。
我们的结论是:
average BERT embeddings、BERT CLS-token output返回的sentence embedding不可能用于余弦相似度或曼哈顿/欧氏距离。对于迁移学习,它们的结果比InferSent或Universal Sentence Encoder略差。然而,在NLI数据集上使用所描述的具有siamese network结构的微调,产生的sentence embedding达到了SentEval工具包的SOTA。
32.2.3 消融研究
这里我们对
SBERT的不同方面进行了消融研究,以便更好地了解其相对重要性。我们评估了不同的池化策略(MEAN/MAX/CLS)。对于classification objective function,我们评估了不同的concatenation方法。对于每个可能的配置,我们用
10个不同的随机种子训练SBERT,并对其性能进行平均。objective function(分类或回归)取决于数据集:对于
classification objective function,我们在SNLI和Multi-NLI数据集上训练SBERT-base,并在NLI数据集上进行评估。对于
regression objective function,我们在STS benchmark数据集的训练集上进行训练,并在STS benchmark验证集上进行评估。
结果如下表所示。可以看到:
classification objective function:根据NLI这一列,可以看到:池化策略的影响相当小,而concatenation模式的影响要大得多。对于
concatenation模式,InferSent和Universal Sentence Encoder都使用softmax分类器的输入,其中SBERT中,加入逐元素乘法如果使用人工特征交叉用于
softmax的输入,那么在推断期间,就无法直接用余弦相似度,而是必须经过相同的人工特征交叉以及softmax。regression objective function:根据STSb这一列,可以看池化策略有很大的影响:MAX策略的表现明显比MEAN或CLS-token策略更差。这与InferSent相反,他们发现InferSent的BiLSTM layer使用MAX(而不是MEAN)池化更好。

32.2.4 计算效率
sentence embedding有可能需要对数百万个句子进行计算,因此,需要有较高的计算速度。这里我们将SBERT与average GloVe embeddings、InferSent和Universal Sentence Encoder进行比较。我们使用STS benchmark的句子来比较。average GloVe embedding是通过一个简单的for-loop来实现的,其中采用了python的dictionary lookup和numpy。InferSent是基于PyTorch的。Universal Sentence Encoder来自TensorFlow Hub,是基于TensorFlow的。SBERT是基于PyTorch的。
为了改进
sentence embedding的计算,我们实施了一个smart batching策略:具有相似长度的句子被分在一组,并且在一个mini-batch中填充到最长的元素。这极大地减少了padding tokens的计算开销。性能是在一台配备英特尔i7-5820K CPU @ 3.30GHz、Nvidia Tesla V100 GPU、CUDA 9.2、以及cuDNN的服务器上测得的。结果如下表所示。在
CPU上,InferSent比SBERT快大约65%。这是由于网络结构简单得多。InferSent使用单个Bi-LSTM layer,而BERT使用12个堆叠的transformer layer。然而,
transformer network的一个优势是在GPU上的计算效率。此时,带有smart batching的SBERT比InferSent快约9%、比Universal Sentence Encoder快约55%。smart batching在CPU上实现了89%的提速,在GPU上实现了48%的提速。average GloVe embeddings显然在很大程度上是计算sentence embedding的最快方法。
为什么
InferSent和Universal Sentence Encoder没有用smart batching?这是不公平的比较。Universal Sentence ENcoder也是transformer-based模型,也可以采用smart batching。
三十三、SimCSE[2021]
学习通用的
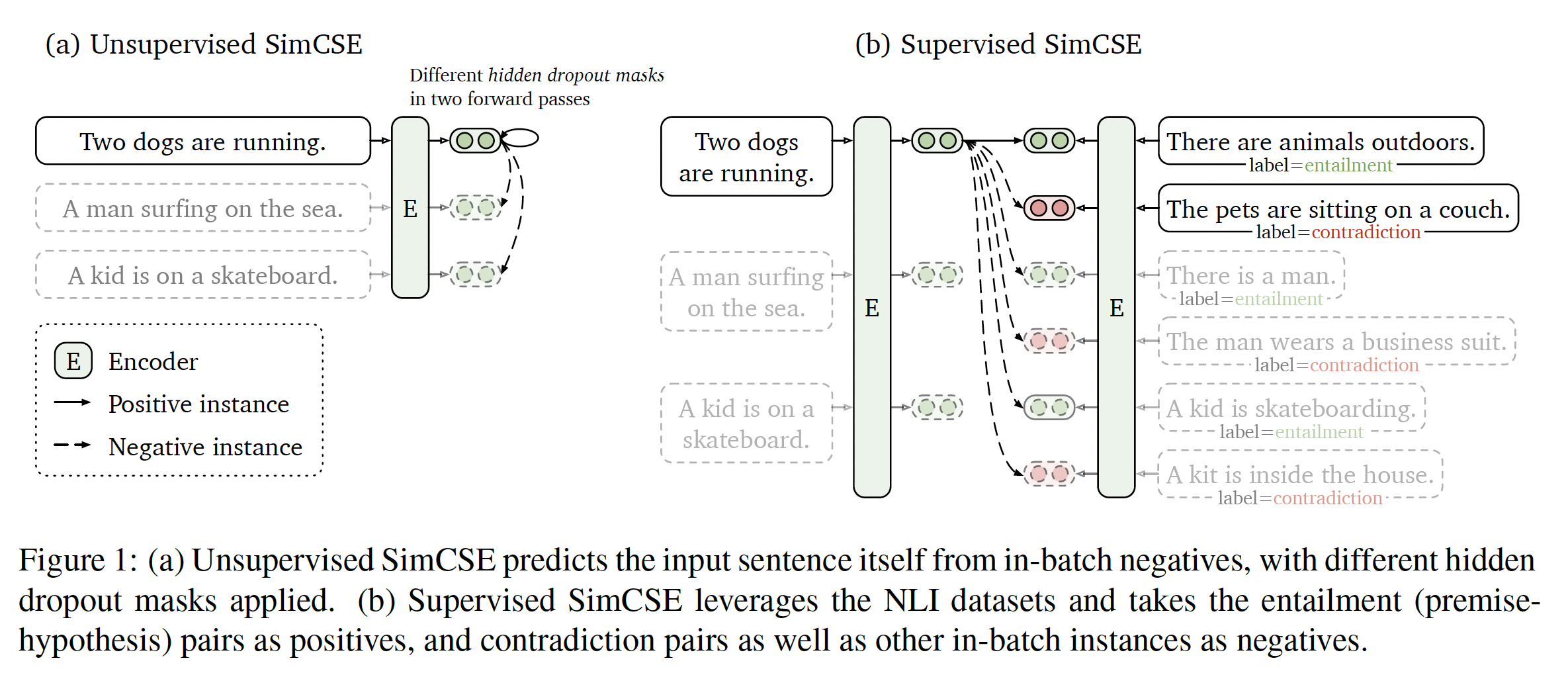
sentence embedding是自然语言处理中的一个基本问题,在文献中得到了广泛的研究。在论文《SimCSE: Simple Contrastive Learning of Sentence Embeddings》中,作者推进了SOTA的sentence embedding方法,并证明了contrastive objective在与预训练的语言模型(如BERT或RoBERTa)相结合时可以非常有效。论文提出了SimCSE,一个简单的contrastive sentence embedding framework,它可以从未标记数据或标记数据中产生卓越的sentence embedding。unsupervised SimCSE简单地预测了input sentence本身,其中只有dropout被用作噪音(下图(a)所示)。换句话说,将同一个句子传递给pre-trained encoder两次:通过两次应用标准的dropout,可以得到两个不同的embedding作为"positive pair"。然后,SimCSE把同一mini-batch中的其他句子作为"negatives",模型在这些negatives之间预测出正样本。虽然看起来非常简单,但这种方法比预测
next sentence、以及离散的数据增强(如单词删除、单词替换)等训练目标要好很多,甚至与之前的监督方法相匹敌。通过仔细分析,作者发现dropout作为hidden representation的最小"data augmentation",而去除dropout则会导致representation collapse。supervised SimCSE建立在最近使用natural language inference: NLI数据集进行sentence embedding的成功基础上,并将标注的sentence pair纳入对比学习contrastive learning中(下图(b)所示)。与之前的工作不同的是,作者将其作为一个3-way classification任务(蕴含entailment、中性neutral、以及矛盾contradiction),并利用entailment pair可以自然地作为正样本的事实。作者还发现,增加相应的contradiction pair作为hard negatives,可以进一步提高性能。与之前使用相同数据集的方法相比,这种对NLI数据集的简单使用实现了性能的大幅提高。作者还比较了其它的标注的sentence-pair数据集,发现NLI数据集对于学习sentence embedding特别有效。
为了更好地理解
SimCSE的强大性能,作者借用了《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》的分析工具,该工具以语义相关的positive pairs和整个representation space的均匀性uniformity之间的alignment来衡量学到的embedding的质量。通过实验分析,作者发现无监督SimCSE本质上提高了均匀性,同时通过dropout noise避免了degenerated alignment,从而提高了representation的表达能力。同样的分析表明,NLI训练信号可以进一步改善positive pairs之间的alignment,并产生更好的sentence embedding。作者还与最近发现的pre-trained word embeddings遭受各向异性的现象相联系,并证明(通过谱域的角度)contrastive learning objective"平坦化" 了sentence embedding space的奇异值分布,从而提高了uniformity。作者在七个标准语义文本相似性
semantic textual similarity: STS任务和七个迁移任务上对SimCSE进行了综合评估。在STS任务上,无监督SimCSE和监督SimCSE使用BERT-base分别实现了76.3%和81.6%的平均Spearman’s correlation,与之前的最佳结果相比,分别有4.2%和2.2%的提高。SimCSE在迁移任务上也取得了有竞争力的表现。相关工作:
sentence embedding的早期工作是通过预测给定句子的周围句子surrounding sentence从而基于分布式假说distributional hypothesis之上来建立的。《Unsupervised learning of sentence embeddings using compositional n-gram features》表明:简单地用n-gram embedding来增强word2vec的想法会得到强大的结果。最近的几个(同时进行的)方法通过对同一句子或文档的不同视图(来自数据增强、或模型的不同副本)从而引入
contrastive objective。与这些工作相比,
SimCSE采用了最简单的思想,从标准的dropout中获取同一句子的不同输出,在STS任务中表现最好。
与无监督的方法相比,监督的
sentence embedding具有更强的性能。InferSent提出在NLI数据集上微调一个Siamese模型,并进一步扩展到其他encoder或pre-trained model。此外,
《ParaNMT-50M: Pushing the limits of paraphrastic sentence embeddings with millions of machine translations》证明:双语的语料和back-translation语料为学习语义相似性提供了有用的监督。
另一个工作重点是
regularizing embedding,以缓解representation degeneration问题,并在预训练的语言模型上获得显著的改进。
33.1 模型
33.1.1 Contrastive Learning 的背景
对比学习
contrastive learning的目的是通过把语义相近的邻居拉到一起、把非邻居推开,从而学习有效的representation。它假设一组paired examples《 A simple framework for contrastive learning of visual representations》的对比学习框架,采用具有in-batch negatives的cross-entropy objective:令representation,那么针对pair的mini-batch的training objective为:其中:
在这项工作中,我们使用预训练的语言模型(如
BERT或RoBERTa)对输入句子进行编码:contrastive learning objective对所有参数进行微调。正样本:对比学习的一个关键问题是如何构建
pair。在visual representation中,一个有效的解决方案是将同一张图像的两个随机变换(如裁剪、翻转、变形、旋转)分别作为language representation中也采用了类似的方法,其中采用了删除单词、打乱顺序、以及单词替换等数据增强技术。然而,由于其离散的特性,NLP中的数据增强本身就很困难。正如我们将在后面介绍的那样,简单地在intermediate representation上使用标准的dropout,就超越了这些离散的操作。在
NLP中,类似的contrastive learning objective已经在不同的背景下进行了探索。在这些情况下,question-passage pair。由于dual-encoder framework,即对sentence embedding,《An efficient framework for learning sentence representations》也使用了具有dual-encoder的对比学习,将当前句子和下一个句子构成为alignment and uniformity:最近,《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》确定了与对比学习相关的两个关键属性(即,对齐性alignment和均匀性uniformity),并提议用它们来衡量representation的质量。给定一个
positive pairalignment计算paired instances的embedding之间的期望距离(假设representation已经被归一化):另一方面,
uniformity衡量embedding的均匀分布程度:其中
这两个指标与对比学习的目标很一致:正样本应该保持接近,而随机样本的
embedding应该在超球上散开。在下面的章节中,我们还将使用这两个指标来证明我们方法的内部原理。
33.1.2 Unsupervised SimCSE
无监督
SimCSE的想法非常简单:取句子集合dropout mask。在
Transformer的标准训练中,在全连接层和attention probabilities上有dropout mask(默认dropout的random mask。我们只需将相同的input馈入编码器两次,就可以得到两个具有不同dropout mask(即,embedding,然后SimCSE的训练目标变为:其中:
mini-batch包含的样本数量。注意:
Transformer中的标准dropout mask,我们不添加任何额外的dropout。dropout noise作为数据增强: 我们把它看作是一种最小形式的数据增强,即,positive pair采取完全相同的句子,它们的embedding只在dropout mask上有所不同。我们将这种方法与其他training objective在STS-B验证集上进行比较。下表将我们的方法与常见的数据增强技术进行了比较,如裁剪、单词删除、以及单词替换,可以看作是
dropout noise。这里的
w/o dropout表示没有dropout,这个时候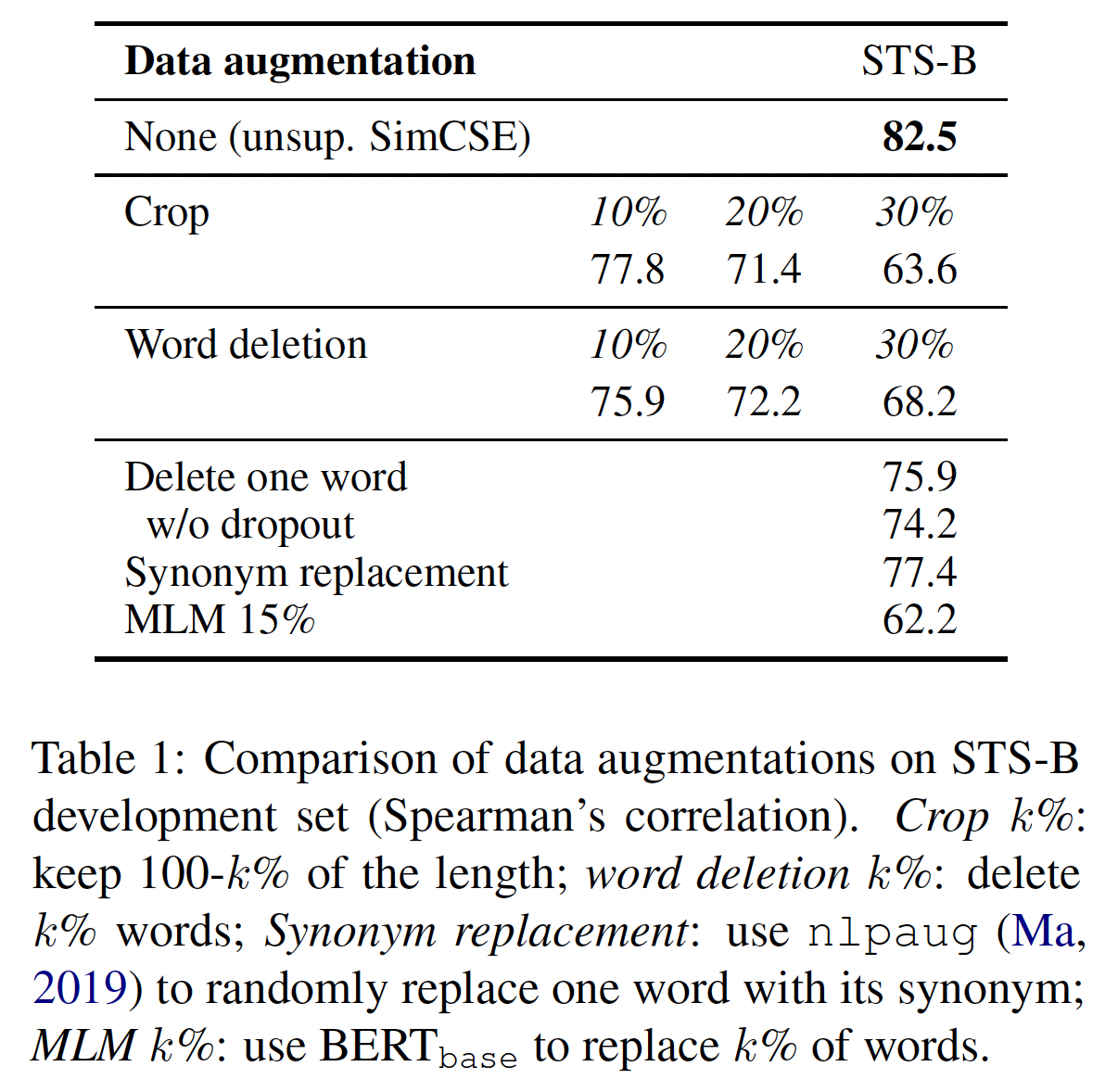
我们还将这个
self-prediction training objective与next-sentence objective进行比较,采取一个编码器或两个独立的编码器。如下表所示,我们发现:SimCSE的表现比next-sentence objective要好得多(在STSB上为82.5 vs 67.4)。使用一个编码器而不是两个编码器,最终效果有很大的差异。

为什么能成功:为了进一步了解
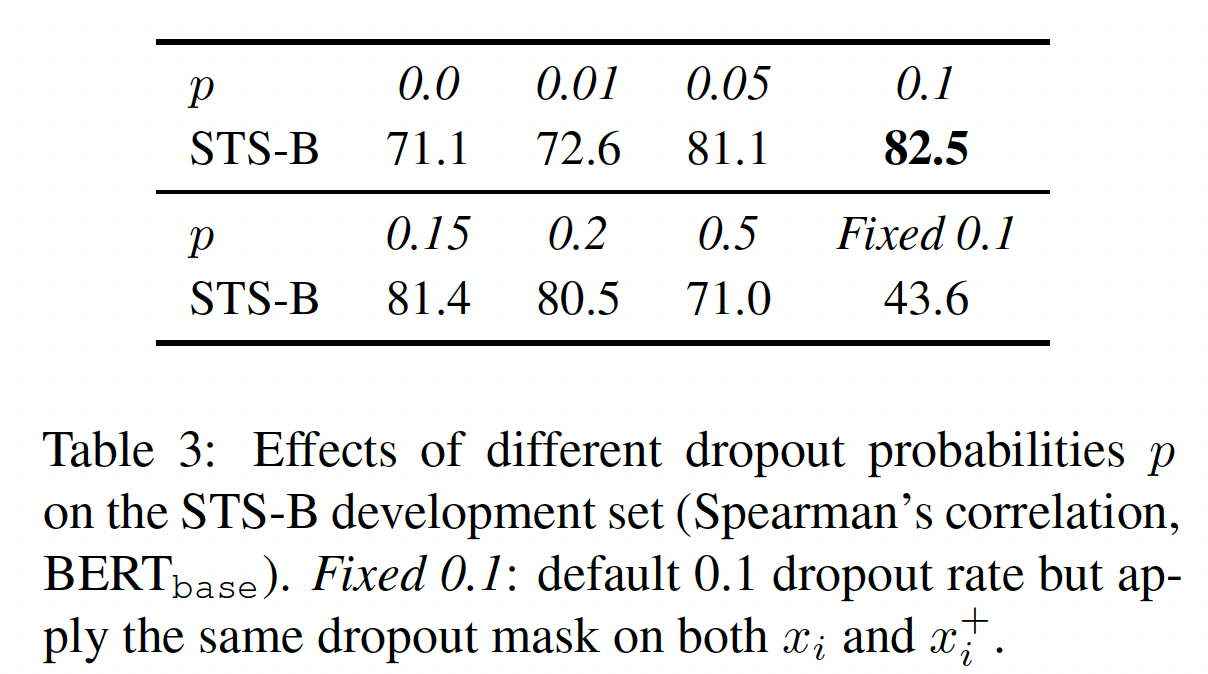
dropout noise在无监督SimCSE中的作用,我们在下表中尝试了不同的dropout rate,并观察到:所有的变体都低于
Transformer中默认的dropout rate两个极端情况特别有趣,即
no dropout)、fixed 0.1(使用默认的dropout ratepair使用相同的dropout mask)。在这两种情况下,pair的resulting embedding是完全相同的,这导致了急剧的性能下降。为什么
fixed 0.1的性能下降得远远超过no dropout?论文并未讲原因。
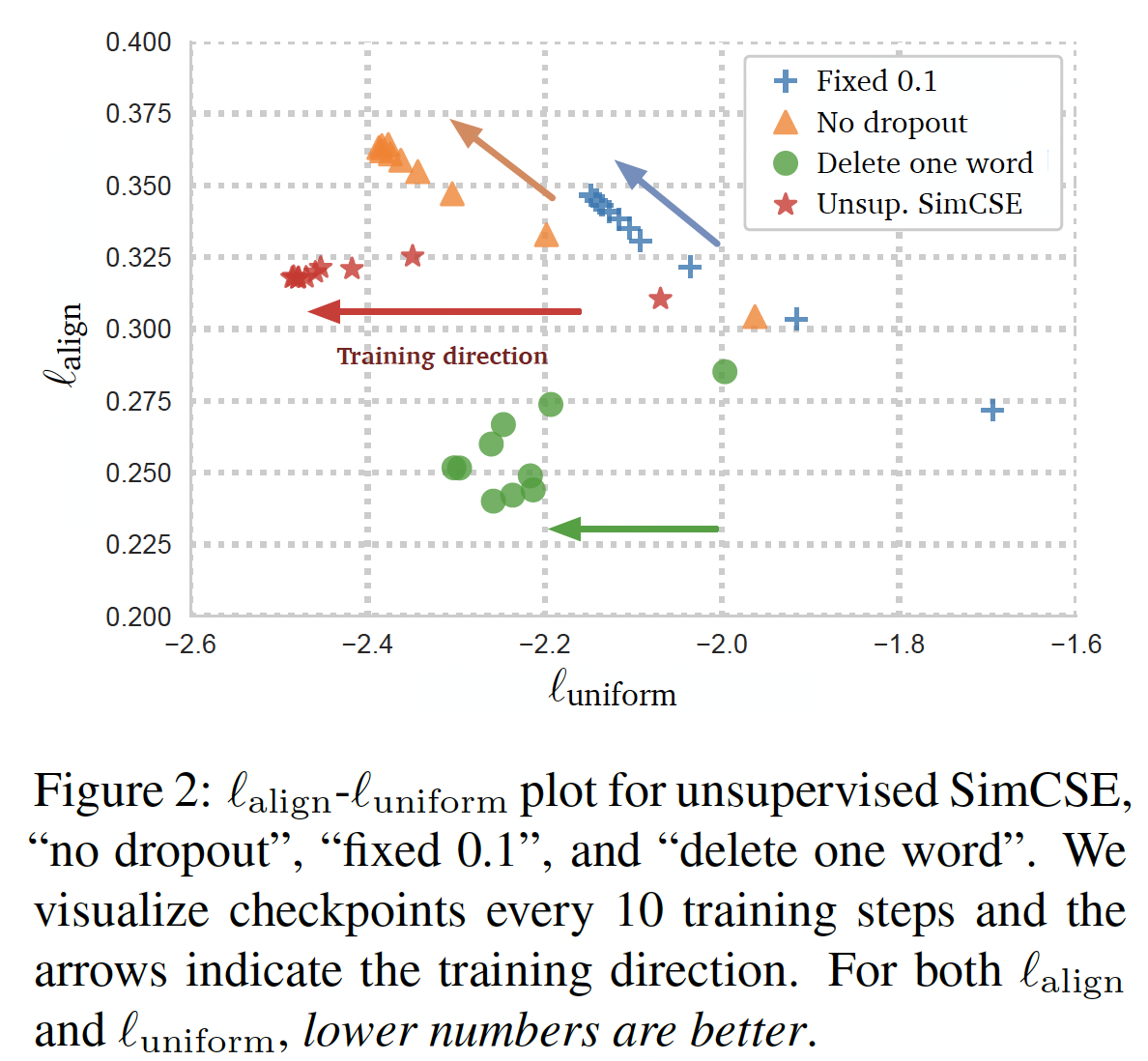
我们在训练过程中每隔
10个step获取模型的checkpoint,并在下图中直观地显示了对齐性alignment和均匀性uniformity指标。除了SimCSE之外,下图还包含一个简单的数据增强模型"delete one word"。我们从预训练模型作为初始化。如下图所示:随着训练的推进(从
pretrained checkpoint开始),所有的模型都大大改善了均匀性。然而,两个特殊变体的对齐性也急剧下降,而我们的无监督
SimCSE保持了稳定的对齐性,这要归功于dropout noise的使用。这也证明了从
pretrained checkpoint开始是至关重要的,因为它提供了良好的initial alignment。最后,
"delete one word"提高了对齐性,但在均匀性指标上取得的收益较小,最终表现不如无监督SimCSE。
33.1.3 Supervised SimCSE
我们已经证明,添加
dropout noise能够使positive pairalignment。已有工作证明(InferSent、SBERT),通过预测两个句子之间的关系是蕴含entailment、中性neutral、还是矛盾contradiction,监督的自然语言推理natural language inference: NLI数据集对于学习sentence embedding是有效的。在我们的对比学习框架中,我们直接从监督的数据集中提取pair,并使用它们来优化标记数据的选择:我们首先探索哪些监督数据集特别适合构建
positive pairsentence-pair样本的数据集进行实验,包括:QQP:Quora question pairs。Flickr30k:每张图片都有5个人类写的captions,我们认为同一图片的任何两个captions都是positive pair。ParaNMT:一个大规模的back-translation paraphrase数据集。NLI:SNLI和MNLI数据集。
我们用不同的数据集训练对比学习模型(即,
training pairs进行了实验(sample这一列)。整个数据集的实验结果参考full这一列。可以看到:在所有的选项中,使用来自NLI(SNLI+MNLI)数据集的entailment pair的表现最好。我们认为这是合理的,因为
NLI数据集包括高质量的、来自人类标注的pairs。另外,人类标注员要根据premises手动写出hypotheses,而且两个句子的lexical overlap往往较低。例如,我们发现(SNLI + MNLI)中的entailment pair的lexical overlap(两个bags of words之间F1来衡量)为39%,而QQP和ParaNMT数据集的lexical overlap为60%和55%。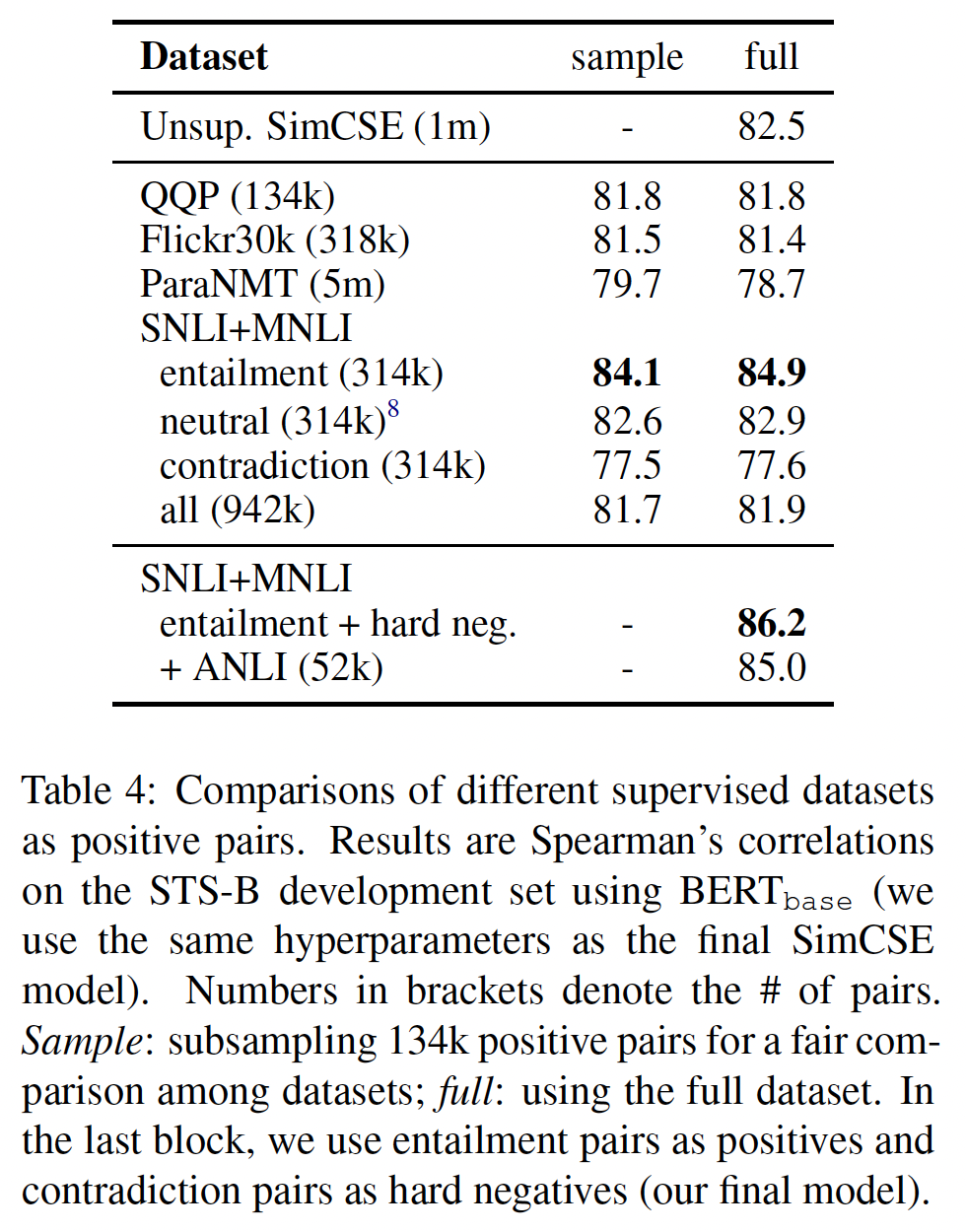
Contradiction作为hard negatives:最后,我们进一步利用NLI数据集的优势,将其contradiction pairs作为hard negatives。在NLI数据集中,给定一个premise,标注员需要手动写出一个绝对真实的句子(entailment),一个可能是真实的句子(neutral),以及一个绝对错误的句子(contradiction)。因此,对于每个premise和它的entailment hypothesis,都有一个伴随的contradiction hypothesis(见Figure 1的例子)。正式地,我们将
premise,,entailment hypothesis和contradiction hypothesis。然后,训练目标mini-batch的大小):如
Table 4(上表)所示,添加hard negatives可以进一步提高性能(84.9 -> 86.2),这就是我们的final supervised SimCSE。我们还试图加入
ANLI数据集、或将其与我们的无监督SimCSE方法相结合,但没有发现有意义的改进。我们还考虑在监督的SimCSE中采用双编码器框架,但它损害了性能(86.2 -> 84.2)。
33.1.4 与各向异性的联系
最近的工作发现了
language representations中的各向异性问题anisotropy problem(《How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings》、BERT-Flow),即学到的embedding在向量空间中占据一个狭窄的锥体,这严重限制了它们的表达能力。《Representation degeneration problem in training natural language generation models》阐述了具有tied input/output embeddings所训练的语言模型会导致各向异性的word embedding。《How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings》在pre-trained contextual representation中进一步观察到这一点。《Improving neural language generation with spectrum control》表明,语言模型中word embedding matrix的奇异值会急剧衰减:除了几个主导性的奇异值,其他的都接近于零。
缓解这个问题的一个简单方法是后处理:要么消除主导的主成分
principal component、要么将embedding映射到一个各向同性的分布。另一个常见的解决方案是在训练期间添加正则化。在这项工作中,我们表明,无论是理论上还是经验上,contrastive objective也能缓解各向异性问题。各向异性问题与均匀性有天然的联系,两者都强调了
embedding应该均匀地分布在空间中。直观而言,优化contrastive learning objective可以改善均匀性(或缓解各向异性问题),因为该目标将negative instances推开。在这里,我们从奇异谱singular spectrum的角度出发(这是分析word embedding的常见做法),并表明contrastive objective可以"flatten"sentence embedding的奇异值分布,使representations各向同性。遵从
《Understandingcontrastive representation learning through alignment and uniformity on the hypersphere 》的观点,当negative instances的数量接近无穷大时,contrastive learning objective的渐进可以用以下公式表示(假设其中:第一项保持
positive instances的相似性,第二项将negative pairs推开。当
Jensen不等式中得出以下公式:令
sentence embedding matrix,即由于我们将
1,那么《On the trace and the sum of elements of a matrix》,如果top eigenvalue,并内在地"flatten"了embedding空间的奇异谱singular spectrum。因此,对比学习有望缓解representation degeneration问题,提高sentence embedding的均匀性。下图为在不同的
human ratings分组上,STS-B pairs的余弦相似度分布(都是正数)。余弦相似性就是
human评分越低,则预期余弦相似性也是更低的(否则说明sentence emebdding不好)。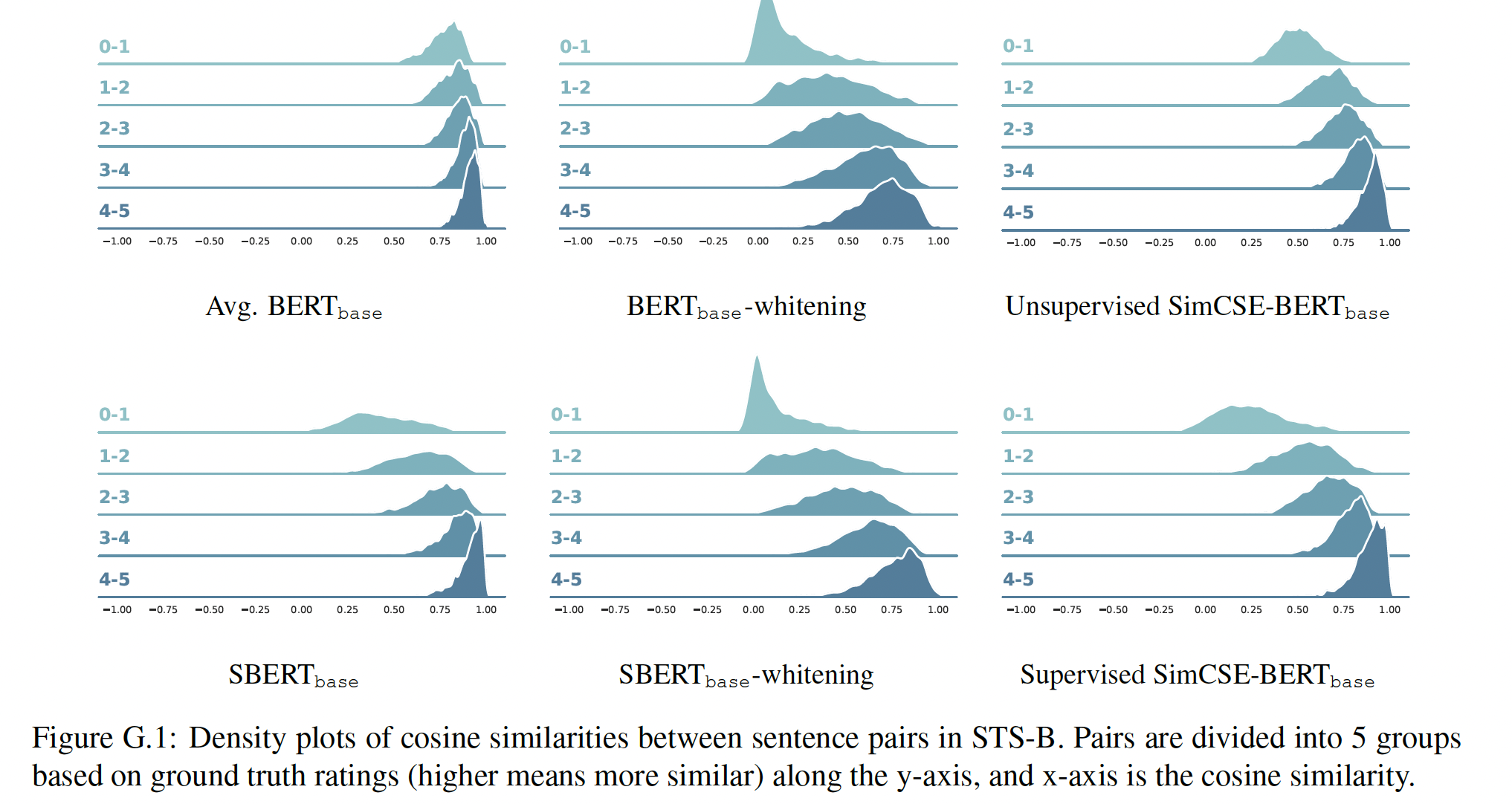
33.2 实验
我们对
7个语义文本相似性semantic textual similarity: STS任务进行了实验。请注意,我们所有的STS实验都是完全无监督的,没有使用STS训练集。即使是监督的SimCSE,我们也仅仅是遵从InferSent,采取额外的标记数据集进行训练。我们还评估了7个迁移学习任务。我们与SBERT有类似的看法,即sentence embedding的主要目标是聚集语义相似的句子,因此将STS作为主要结果。
33.2.1 STS 任务
7个STS任务:STS 2012–2016(这里包含五个, 每一年内一个)、STS Benchmark、SICK-Relatedness。在与以前的工作进行比较时,我们在已发表的论文中找出了无效的比较模式,包括:是否使用额外的回归器、
Spearman’s vs Pearson’s correlation、结果的汇总方式。额外的回归器:
默认的
SentEval实现在STS-B和SICKR的frozen sentence embedding的基础上应用线性回归器,并在这两个任务的训练集上训练回归器。而大多数
sentence representation论文采用raw embedding并以无监督的方式评估。
在我们的实验中,我们没有应用任何额外的回归器,而是直接对所有的
STS任务采取余弦相似度。报告的指标:文献中使用了
Pearson相关系数和Spearman相关系数。《Task-oriented intrinsic evaluation of semantic textual similarity》认为,Spearman相关系数衡量的是排名而不是实际分数,它更适合评估sentence embedding的需要。对于我们所有的实验,我们报告了Spearman’s rank correlation。聚合方法:鉴于每年的
STS挑战赛都包含几个子集,从这些子集中收集结果有不同的选择:一种方法是将所有的主题串联起来,并报告整体的
Spearman相关系数,记做"all"。另一种方法是分别计算不同子集的结果并取其平均值。如果是简单的平均值,则记做
"mean";如果按子集大小加权,表示为"wmean"。
然而,大多数论文并没有说明他们所采取的方法,这使得公平比较具有挑战性。我们以一些最新的工作为例:
SBERT、BERT-flow、BERT-whitening。在下表中,我们将我们的复现结果与SBERT和BERT-whitening的报告结果进行了比较,发现:SBERT采取了"all"设置,但BERT-flow和BERT-whitening采取了"wmean"设置,尽管BERT-flow声称他们采取的设置与SBERT相同。由于"all"设置将不同主题的数据融合在一起,使得评价更接近真实世界的场景,除非特别说明,否则我们采取"all"设置。最终,我们的评估中遵循
SBERT的设置(没有额外的回归器、采用Spearman相关系数,以及"all"汇总)。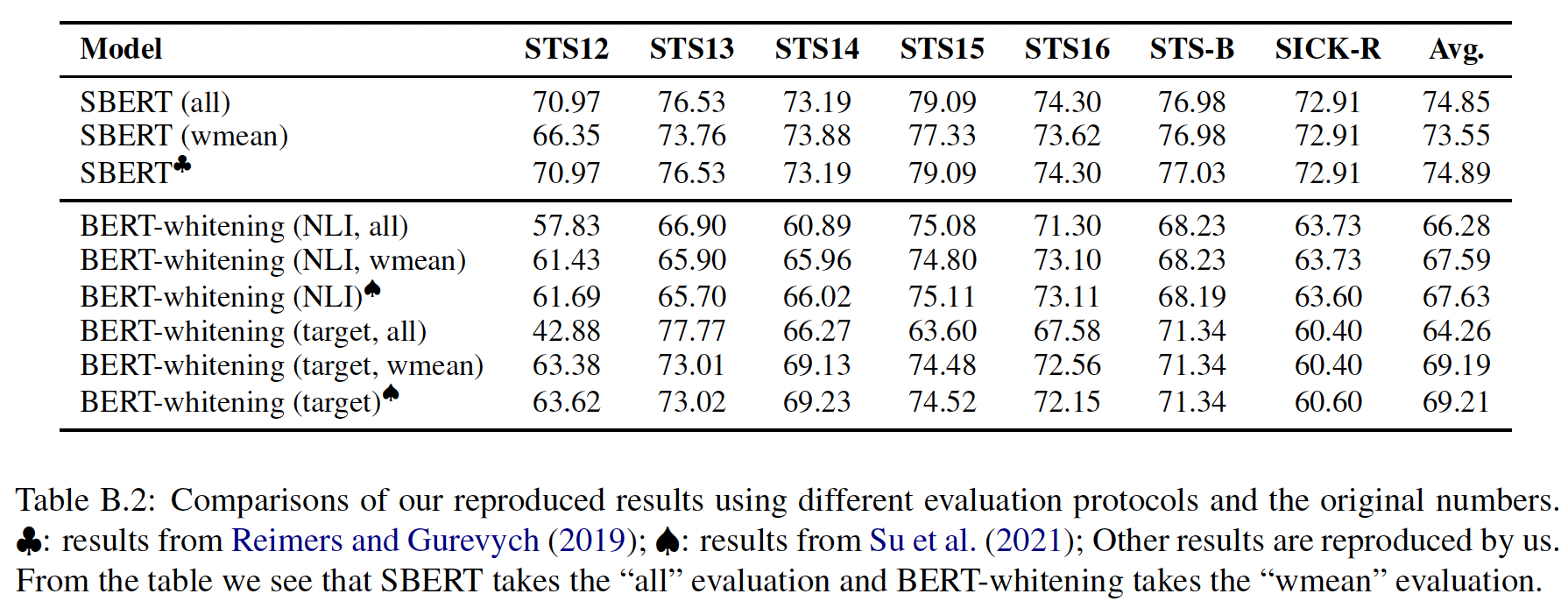
我们在下表中列出了以前一些工作的评估设置。有些设置是由论文报告的,有些是通过比较结果和检查其代码推断出来的。我们可以看到:在不同的论文中,评估协议是非常不一致的。我们呼吁在评估
sentence embedding时统一设置,以利于未来的研究。我们还将发布我们的评估代码,以提高可复现性。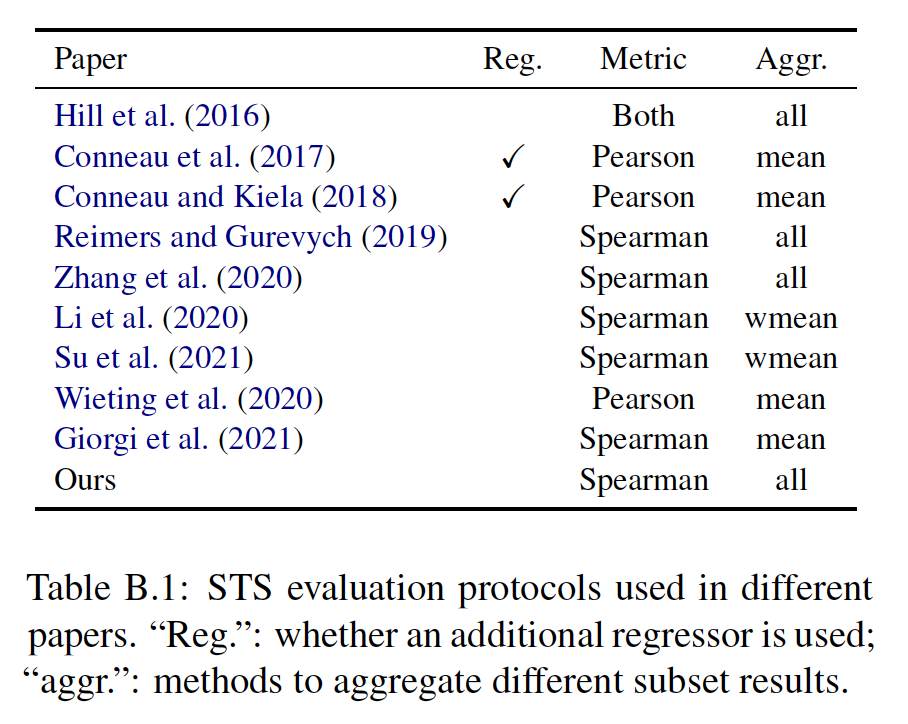
训练细节:我们从
BERT或RoBERTa的pre-trained checkpoint开始,将[CLS] representation作为sentence embedding(不同池化方法的比较参考消融实验部分)。我们在英语维基百科的SimCSE,并在MNLI和SNLI数据集的组合(314k个样本)上训练有监督的SimCSE。这里的 ”有监督/无监督“ 指的是预训练阶段是否用监督数据来预训练,而不是说
target task是否用监督数据。我们用
transformers package实现SimCSE。对于有监督的
SimCSE,我们训练我们的模型3个epochs,在STS-B的验证集上每250个训练步来评估模型,并保留最佳checkpoint用于在测试集上进行最终的评估。对于无监督的
SimCSE,我们做了同样的工作,只是我们对模型训练了一个epoch。
注意:在整个过程中,模型没有使用
STS-B的训练集。我们在
STS-B验证集上进行了网格搜索,其中batch size搜索范围{64, 128, 256, 512}、学习率搜索范围{1e-5, 3e-5, 5e-5},并采用下表中的超参数设置。我们发现:只要相应地调优学习率,SimCSE对batch size并不敏感,这与对比学习需要大batch size的结论相矛盾(《A simple framework for contrastive learning of visual representations》)。这可能是由于所有的SimCSE模型都是从预训练好的checkpoint开始的,这已经为我们提供了一套良好的初始参数。对于无监督的
SimCSE和有监督的SimCSE,我们采用[CLS] representation,并且有一个MLP layer在其上方,其中这个MLP layer的输出作为sentence representation。此外,对于无监督的SimCSE,我们在训练期间包含MLP layer但是在测试期间抛弃这个MLP layer,因为我们发现它能带来更好的性能(参考消融研究的部分)。注意:这里不是直接用
[CLS] representation作为sentence embedding,而是将[CLS] representation经过了一个MLP layer映射之后再作为sentence embedding。最后,我们再引入一个可选的变体,即在
masked language modeling: MLM objective作为辅助损失:SimCSE避免对token-level knowledge的灾难性遗忘。正如后面实验部分所示,我们发现增加这个MLM objective可以帮助提高迁移任务的性能(而不是sentence-level STS任务)。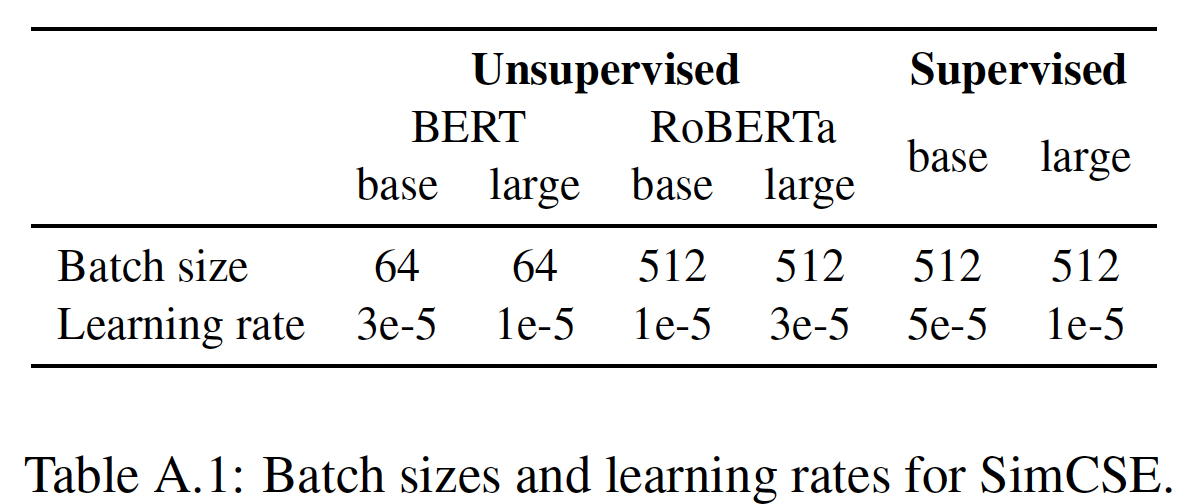
Baseline方法:我们将无监督的SimCSE和有监督的SimCSE与在STS任务上之前SOTA的sentence embedding方法进行比较。无监督
baseline包括average GloVe embedding、average BERT/RoBERTa embedding,以及后处理方法(如BERT-flow和BERT-whitening)。我们还与最近几个使用
contrastive objective的方法进行了比较,包括:IS-BERT:它使全局特征和局部特征之间的agreement最大化。DeCLUTR:它将同一文件的不同spans作为positive pair。CT:它将来自两个不同编码器的同一句子的embedding进行对齐。
其他监督方法包括
InferSent、Universal Sentence Encoder和SBERT/RoBERTa,它们采用后处理方法(如BERT-flow、whitening、 以及CT)。
其中:
对于
average GloVe embedding、InferSent、Universal Sentence Encoder,我们直接报告SBERT的结果,因为我们的评估设置与他们相同。对于
BERT和RoBERTa,我们从HuggingFace下载预训练的模型权重,并用我们自己的脚本评估模型。对于
SBERT和SRoBERTa,我们重新使用原始论文的结果。对于原始论文没有报告的结果,例如SRoBERTa在迁移任务上的表现,我们从SentenceTransformers下载模型权重并进行评估。对于
DeCLUTR和contrastive tension,我们在我们的环境中重新评估他们的checkpoint。对于
BERT-flow,由于他们的原始数字采取了不同的设置,我们使用他们的代码重新训练他们的模型,并使用我们自己的脚本评估模型。对于
BERT-whitening,我们按照原始论文中相同的池化方法,即first-last average pooling,实现了我们自己版本的whitening脚本。我们的实现可以复现原始论文的结果(见Tabele B.2)。对于
BERT-flow和BERT-whitening,它们都有两种后处理的变体:一种是采用NLI数据("NLI")、另一种是直接学习目标数据集上的embedding分布("target")。我们发现,在我们的评估环境中,"target"通常比"NLI"差(如下表所示 ),所以我们在主要结果中只报告了"NLI"变体。
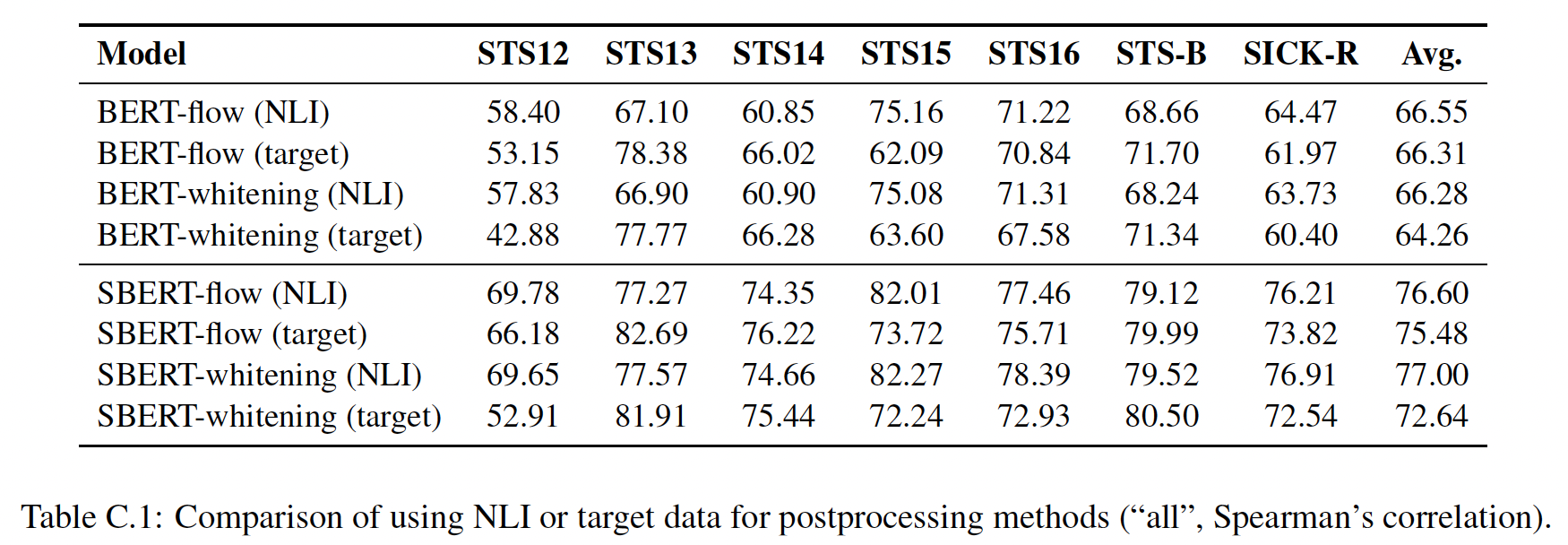
下表显示了
7项STS任务的评估结果。可以看到:无论是否有额外的NLI监督,SimCSE都能在所有的数据集上大幅提高结果,大大超过了以前的SOTA模型。具体来说:我们的无监督
SimCSE-BERT_base将以前的最佳平均Spearman相关系数从72.05%提高到76.25%,甚至可以与有监督的baseline相媲美。当使用
NLI数据集时,SimCSE-BERT_base进一步将SOTA的结果推到81.57%。在RoBERTa编码器上的收益更加明显,我们的监督SimCSE在RoBERTa_large上达到了83.76%。
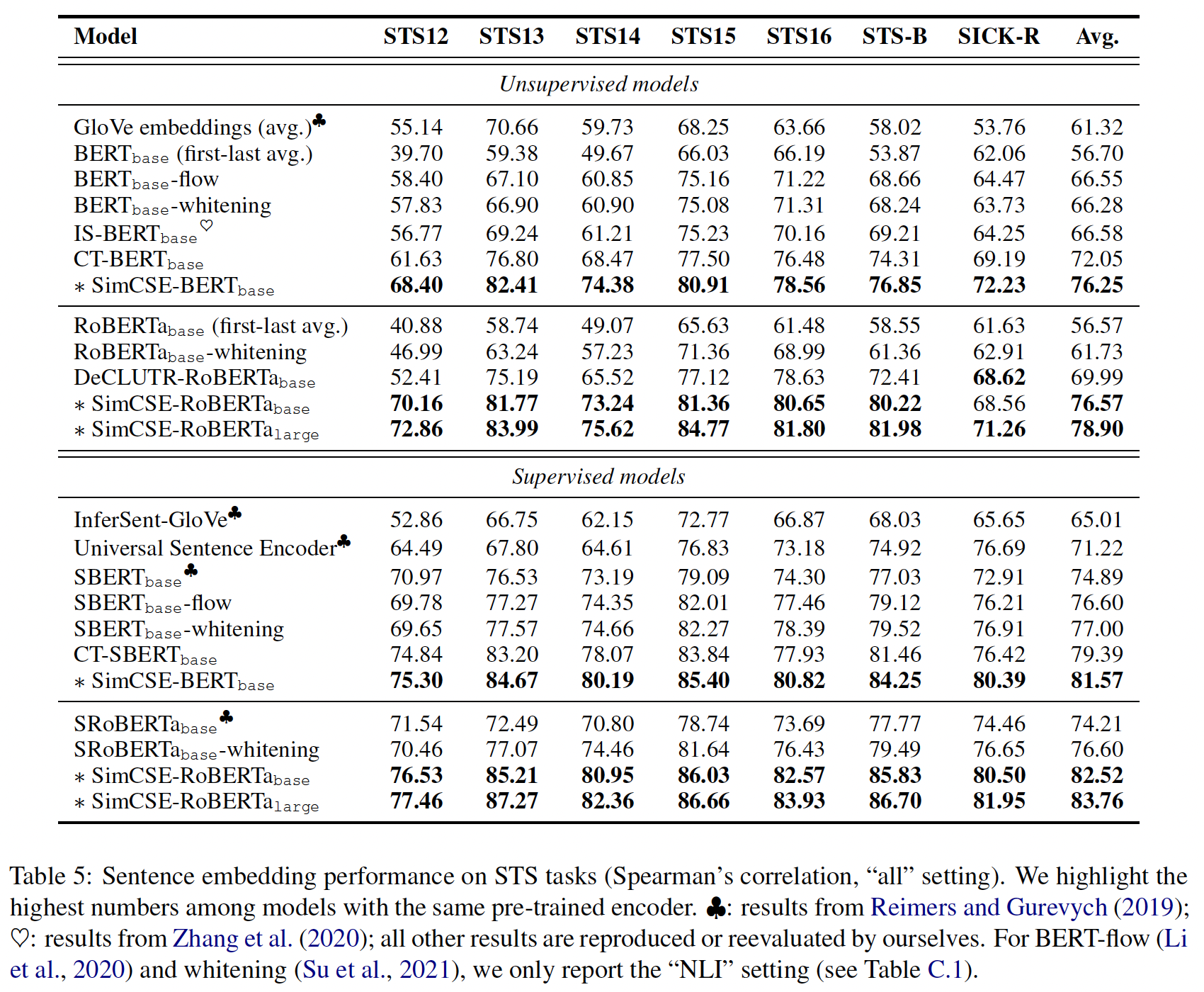
由于以前的工作使用了与我们不同的评估协议,我们在这些设置中进一步评估了我们的模型,以便与公布的数字进行直接比较。我们用
"wmean"和Spearman's correlation来评估SimCSE,以直接与BERT-flow和BERT-whitening进行比较,如下表所示。
33.2.2 迁移任务
我们在以下迁移任务中评估我们的模型:
MR、CR、SUBJ、MPQA、SST-2、TREC、MRPC。在不同方法产生的(frozen的)sentence embedding的基础上训练一个逻辑回归分类器。我们遵循SentEval的默认配置。迁移任务的评估结果如下表所示,可以看到:有监督的
SimCSE的表现与以前的方法相当或更好,尽管无监督模型的趋势仍不清楚。增加
MLM目标一致地提高迁移任务的性能,证实了我们的直觉,即sentence-level objective可能不会直接有利于迁移任务。与基础模型相比,后处理方法(
BERTflow/whitening)都伤害了性能,表明representation的良好的均匀性并不能为迁移学习带来更好的embedding。下表中没有
BERTflow/whitening的内容,所以结论没有数据支撑?
正如我们前面所论证的,我们认为迁移任务不是
sentence embedding的主要目标,因此我们把STS的结果作为主要比较对象。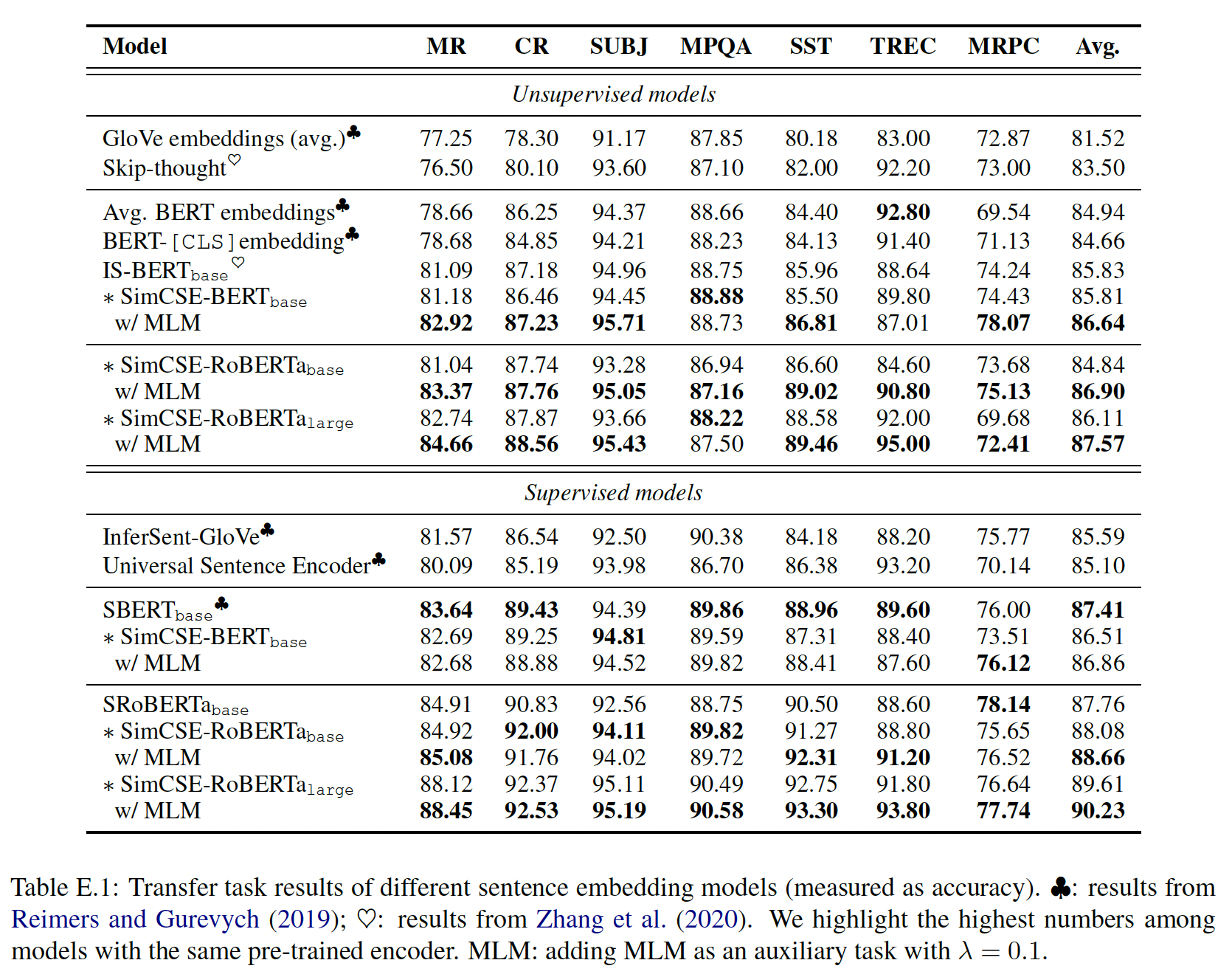
33.2.3 消融研究
我们研究了不同的池化方法、
hard negatives、归一化、温度、MLM objective的影响。本节中所有报告的结果都是基于STS-B验证集。池化方法:
SBERT、BERT-Flow表明,采用预训练模型的average embeddings(特别是来自第一层的embedding和最后一层的embedding)导致了比[CLS] representation更好的性能。下表显示了在无监督的SimCSE和有监督的SimCSE中不同池化方法的比较。对于[CLS] representation,原始的BERT实现在其之上采取了一个额外的MLP层。这里,我们考虑对[CLS]的三种不同设置:具有MLP层、没有MLP层、在训练期间保留MLP层但是在测试时将其删除(即w/MLP(train))。我们发现:对于无监督的
SimCSE来说,在训练期间保留MLP层但是在测试时将其删除,这种方法的效果最好。对于有监督的
SimCSE来说,不同的池化方法并不重要。
默认情况下,对于无监督的
SimCSE,我们采用[CLS] with MLP (train);对于有监督的SimCSE,采用[CLS] with MLP。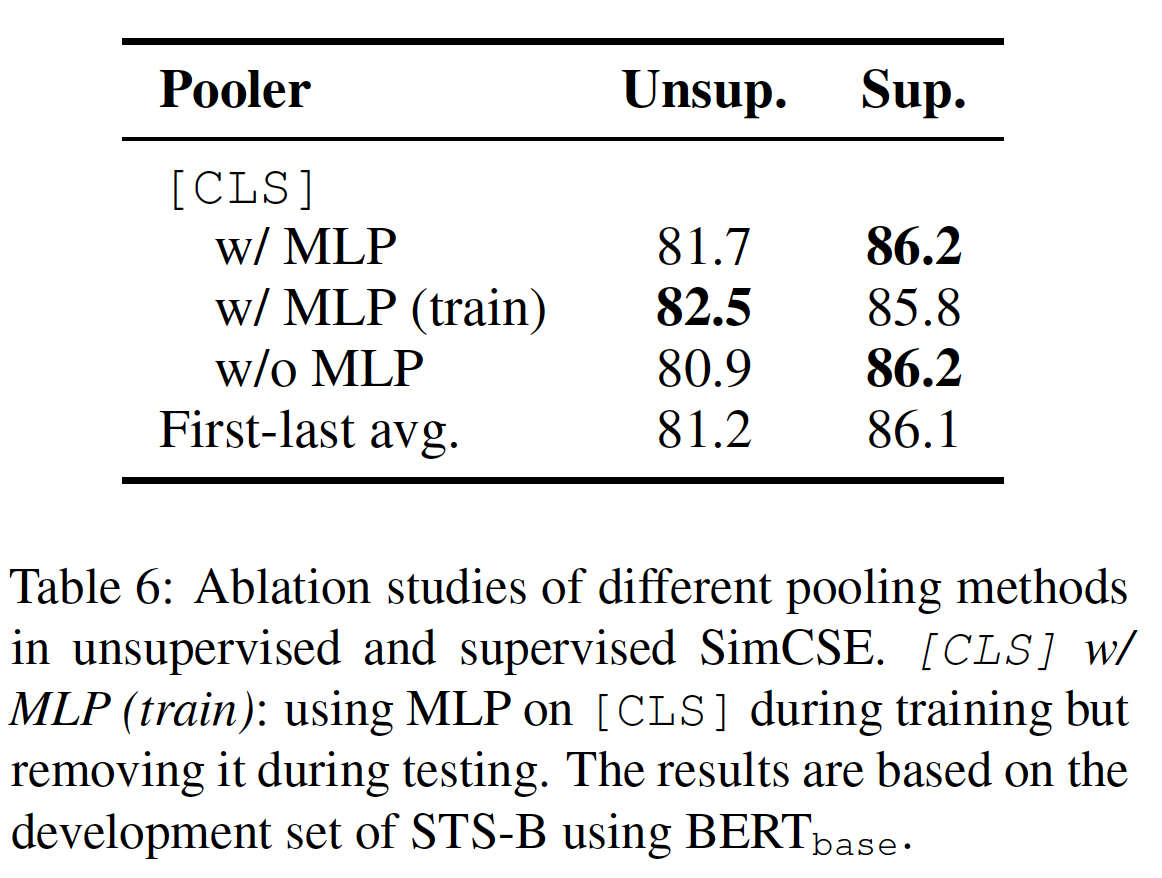
hard negatives:直观而言,将hard negatives(contradiction样本)与其他in-batch negatives区分开来可能是有益的。因此,我们扩展了监督SimCSE的training objective,以纳入不同negatives的权重:其中:
1,否则等于0;我们用不同的
SimCSE,并在STS-B的验证集上评估训练好的模型。我们还考虑将neutral样本作为hard negatives(权重固定为1.0)。如下表所示,neutral样本不会带来进一步的收益。这里有两种
hard负样本:contradiction样本、neutral样本。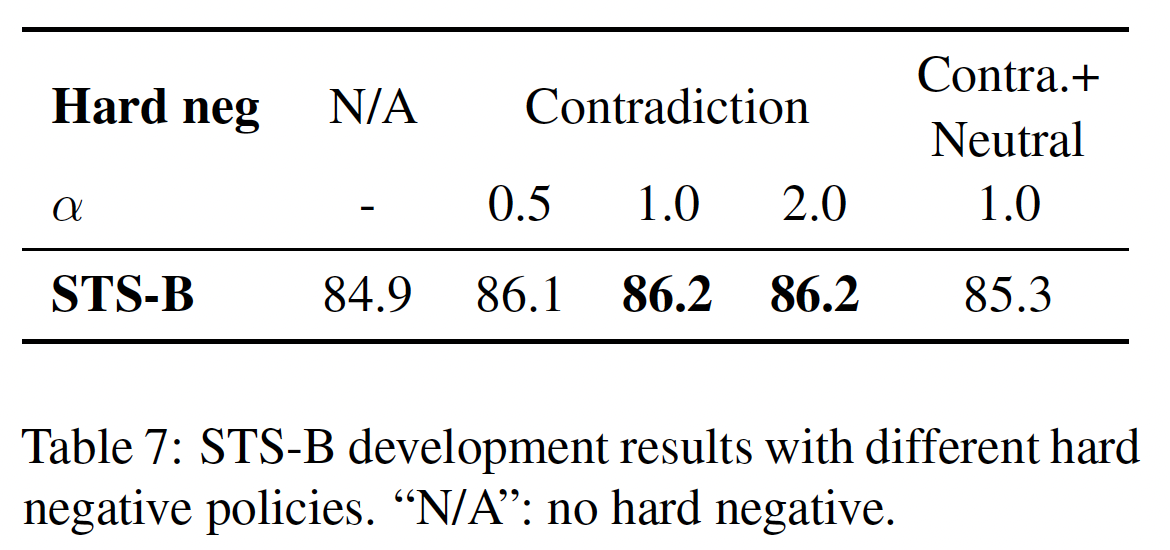
归一化和温度:我们分别使用点积和余弦相似性在不同的温度下训练
SimCSE,并在STS-B验证集上评估它们。如下表所示:在精心调整的温度NA表示点击相似性;其它列表示余弦相似性。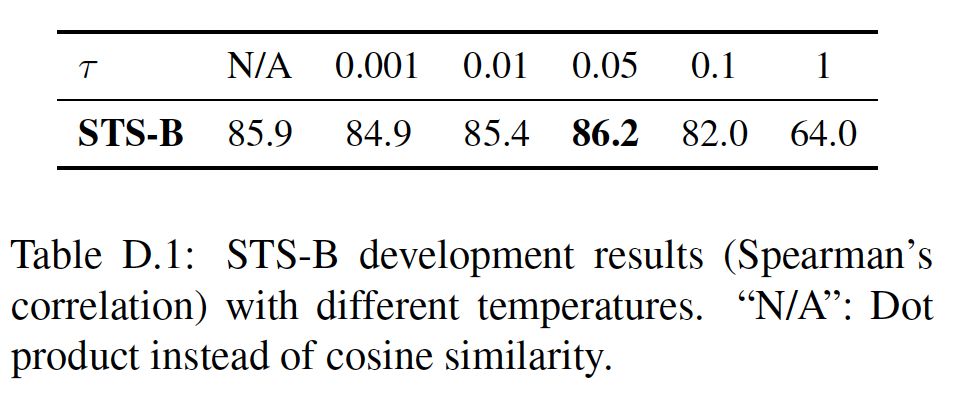
MLM辅助任务:最后,我们研究不同MLM辅助目标的影响。如下表所示,token-level MLM objective对迁移任务的平均性能带来适度的改善,但它在STS-B任务中带来了持续的下降。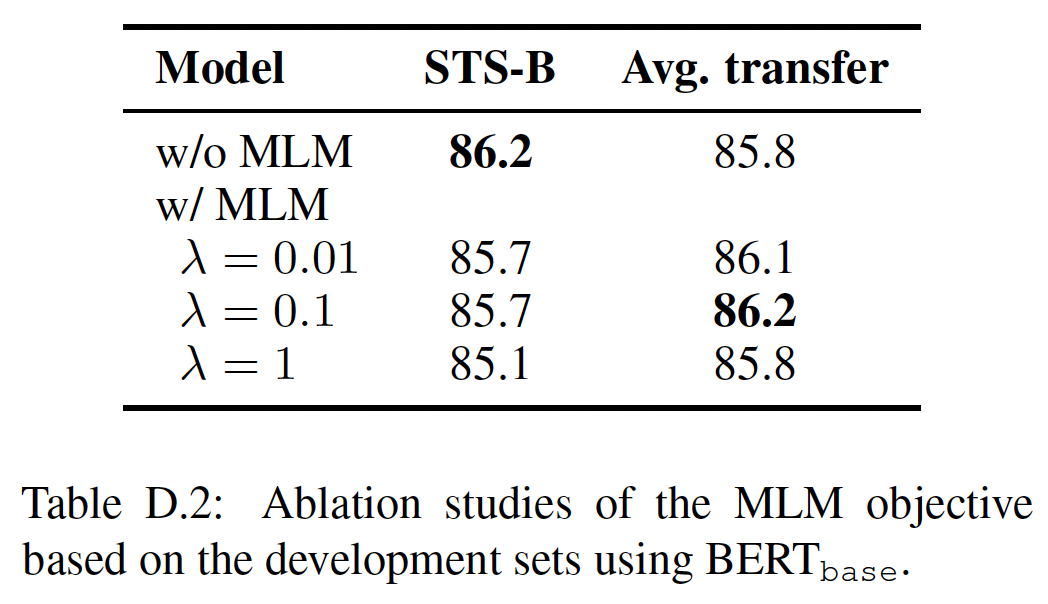
33.2.4 原理洞察
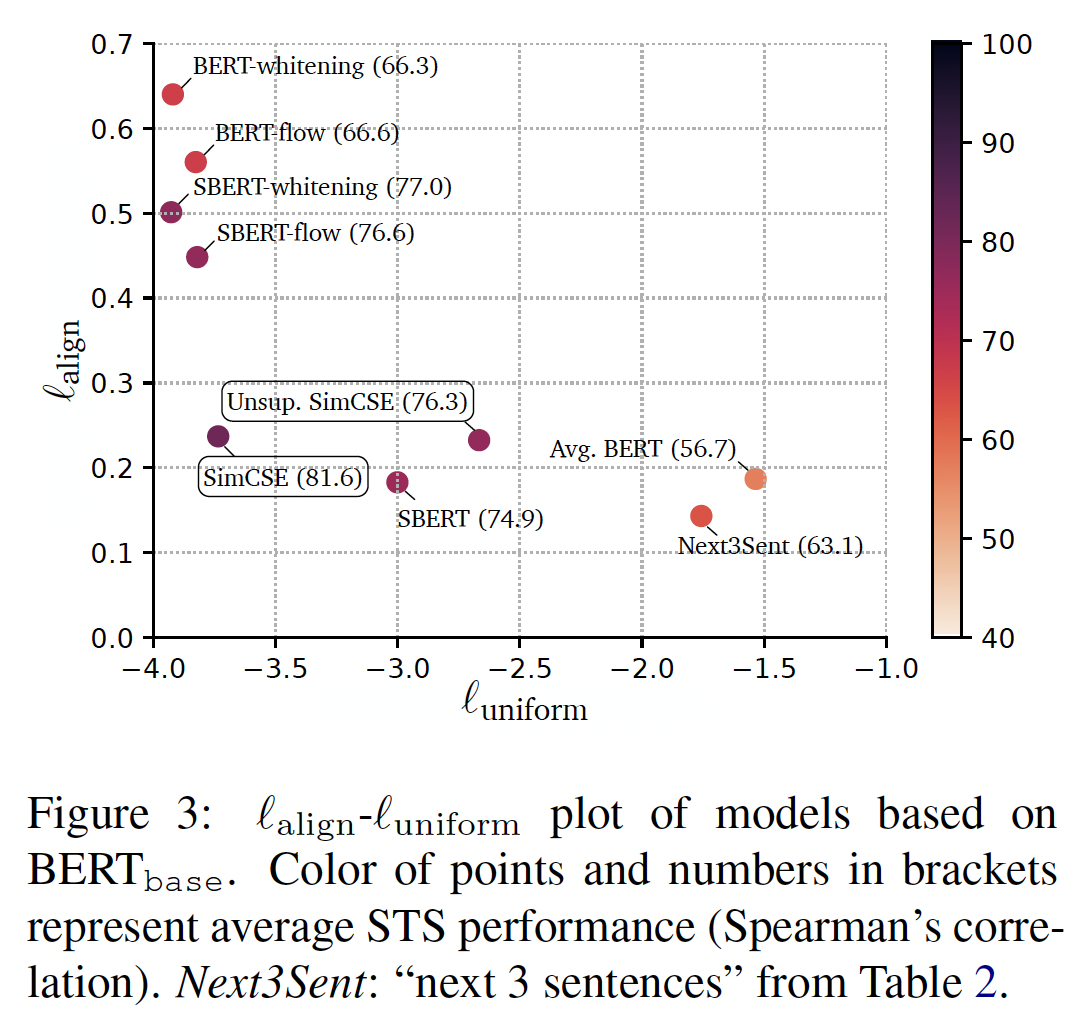
这里我们进行进一步分析,以了解
SimCSE的内部工作。uniformity and alignment:下图显示了不同sentence embedding模型的均匀性和对齐性以及它们的平均STS结果。一般来说,具有较好对齐性和均匀性的模型能取得较好的性能,证实了《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》的发现。我们还观察到:虽然预训练的
embedding具有良好的对齐性,但其均匀性较差(即embedding是高度各向异性的)。像
BERT-flow和BERT-whitening这样的后处理方法极大地改善了均匀性,但也遭受了对齐性的退化。无监督的
SimCSE有效地改善了预训练的embedding的均匀性,同时保持了良好的对齐性。在
SimCSE中加入监督数据,进一步改善了对齐性。
定性比较:我们使用
SBERT_base和SimCSE-BERT_base进行了一个小规模的检索实验。我们使用Flickr30k数据集中的150k个caption,并采取任何随机的句子作为query来检索相似的句子(基于余弦相似度)。如下表中的几个例子所示,与SBERT检索到的句子相比,SimCSE检索到的句子质量更高。
奇异值的分布:下图显示了
SimCSE与其他baseline的奇异值分布(sentence embedding矩阵)。对于无监督的情况,奇异值下降最快的是普通的
BERT embedding;对于有监督的情况,奇异值下降最快的是SBERT embedding。而SimCSE有助于平坦化频谱分布。基于后处理的方法,如
BERT-flow或BERT-whitening使曲线更加平坦,因为它们直接旨在将embedding映射到各向同性分布。
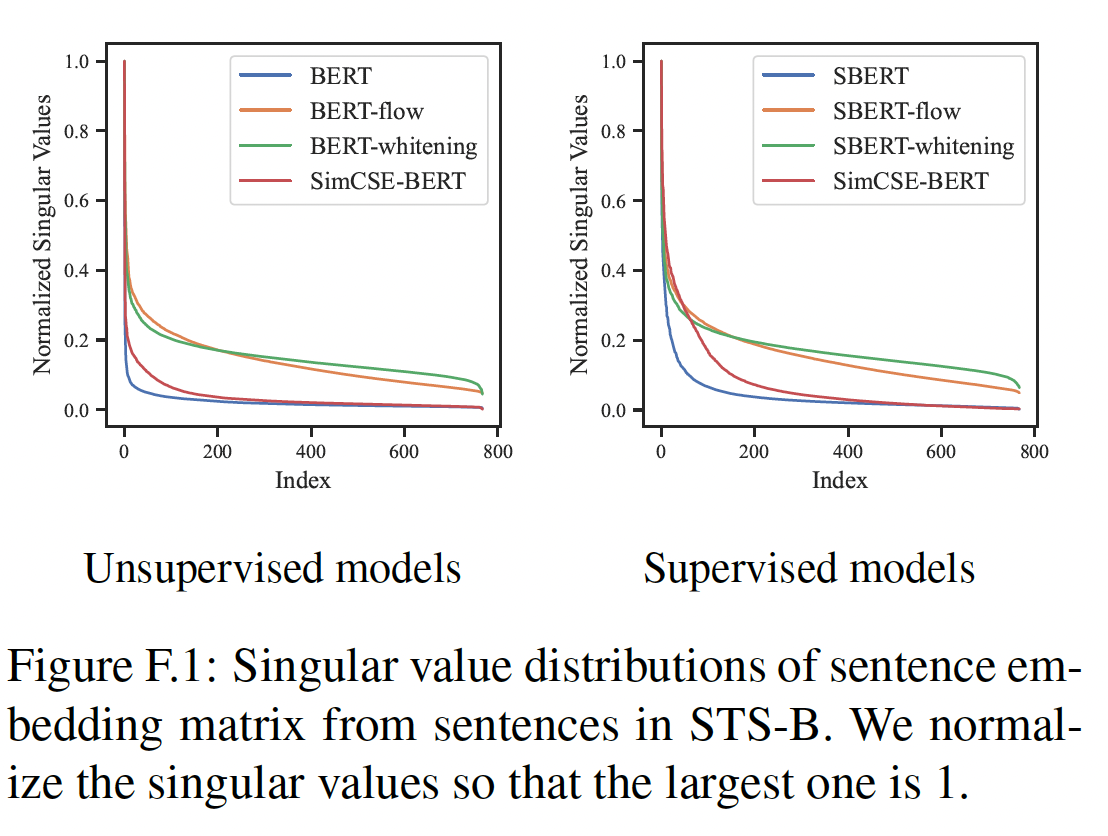
为了直接显示我们的方法在
STS任务上的优势,我们在下图中说明了具有不同human ratings组的STS-B的pair的余弦相似度分布。可以看到:与所有的
baseline模型相比,无监督SimCSE和有监督SimCSE都能更好地区分具有不同程度相似性的sentence pair,从而在STS任务上有更好的表现。此外,
SimCSE通常显示出比BERT或SBERT更分散的分布,但与whitened distribution相比,也在语义相似的sentence pair上保留了较低的方差。这一观察结果进一步验证了SimCSE可以实现更好的alignment-uniformity balance。即,
SimCSE的分布既不像BERT_base-whitening一样过于分散、也不像BERT_base一样过于集中。
三十四、BERT-Flow[2020]
最近,像
BERT这样的预训练语言模型及其变体已被广泛用作自然语言的representation。尽管它们通过微调在许多NLP任务上取得了巨大的成功,但来自没有微调的BERT的sentence embedding在语义文本相似性semantic textual similarity: STS方面明显逊色。例如,它们甚至不如GloVe embedding的表现,后者没有上下文并且用一个更简单的模型训练。这些问题阻碍了将BERT sentence embedding直接应用到许多现实世界的场景中,在这些场景中,收集标记数据是非常昂贵的,甚至是难以解决的。在论文
《On the Sentence Embeddings from Pre-trained Language Models》中,作者旨在回答两个主要问题:为什么
BERT导出的sentence embedding在检索语义相似的句子时表现不佳?是它们携带的语义信息太少,还是仅仅因为这些embedding中的语义信息没有被正确利用?如果
BERT embedding捕获到了足够的语义信息,但很难被直接利用,那么我们如何才能在没有外部监督信息的情况下使其更容易被利用?
为此,作者首先研究了
BERT预训练目标与语义相似性任务之间的联系。作者的分析显示,BERT的sentence embedding应该能够直观地反映句子之间的语义相似性,这与实验观察相矛盾。《Representation degeneration problem in training natural language generation models》发现语言建模性能会受到所学的各向异性的word embedding space的限制,其中word embedding占据了一个狭窄的锥体;《How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings》也发现BERT的word embedding也受到各向异性的影响。受到这些论文的启发,作者假设,来自BERT的sentence embedding(作为来自最后几层的context embedding的平均值)可能存在类似问题。通过对embedding的经验探测,作者进一步观察到,BERT的sentence embedding space在语义上是不平滑的,而且在某些方面被定义得很差,这使得它很难通过简单的相似度量(如点积相似度或余弦相似度)直接使用。为了解决这些问题,作者提出通过
normalizing flows将BERT sentence embedding分布转化为平滑的和各向同性的高斯分布,这是一个由神经网络参数化的可逆函数。具体来说,该方法学习一个flow-based generative model,从而最大化一个似然函数,该似然函数代表通过无监督的方式从标准的高斯潜变量Gaussian latent variable中生成BERT sentence embedding的可能性。在训练过程中,只有flow network被优化,而BERT参数保持不变。学到的flow是BERT sentence embedding和高斯潜变量之间的可逆映射函数,然后被用来将BERT sentence embedding转换到高斯空间。作者将所提出的方法命名为BERT-flow。作者在不使用任何下游监督的情况下对
7个标准的语义文本相似性benchmark进行了广泛的实验。实验结果表明:flow transformation能够一致地将BERT提高12.70个点,在cosine embedding相似性和人类标注的相似性之间的Spearman相关系数方面平均提高8.16个点。当考虑外部监督信息时,
BERT-flow优于Sentence-BERT,导致了新的SOTA。除了语义相似性任务外,作者还将sentence embedding应用于question-answer entailment task QNLI,直接不需要task-specific监督,并证明了BERT-flow的优越性。此外,进一步分析表明,BERT导出的相似性会与lexical similarity过度相关(与语义相似性相比),而,BERT-flow可以有效地补救这一问题。Lexical Similarity由编辑距离来衡量,刻画了两个句子在word-level上的相似性,而不是语义相似性。
34.1 理解 BERT 的 Sentence Embedding Space
为了用
BERT将一个句子编码成一个固定长度的向量,通常做法是在BERT的最后几层计算context embeddings的平均值,或者在[CLS] token的位置提取BERT context embedding。请注意,在生成sentence embedding时没有被掩码的token,这与pretraining是不同的。SBERT证明,这种BERT sentence embedding在语义相似度方面落后于SOTA的sentence embedding。在STS-B数据集上,BERT sentence embedding与averaged GloVe embedding相比更没有竞争力,其中GloVe是几年前提出的一个简单的、non-contextualized的baseline。尽管如此,这种效果差在现有文献中还没有得到很好的理解。注意,正如
SBERT所证明的那样,averaging context embeddings一直优于[CLS] embedding。因此,除非另有提及,否则我们将context embeddings的均值作为BERT sentence embedding,并在本文的其余部分中不区分它们。
34.1.1 语义相似性和 BERT Pre-training 之间的联系
考虑关于
token的一个序列language modeling: LM以自回归方式来因子化联合概率为了捕获预训练期间的双向上下文,
BERT提出了一个masked language modeling: MLM目标,它因子化了noisy reconstruction的概率token,当注意,
LM和MLM都可以简化为,建模在给定上下文tokensoftmax函数来描述:其中:
context embedding,它是上下文word embedding,它是tokenembedding lookup table来参数化。
注意,虽然
MLM和LM的条件分布的形式相同,但是二者的上下文不同:MLM的上下文LM的上下文
BERT sentence embedding之间的相似性可以简化为BERT context embedding之间的相似性BERT的预训练并不明确涉及作为语义相似性代理的
Co-Occurrence统计:我们不直接分析context embeddingword embedding《Breaking the softmax bottleneck : A high-rank rnn language model》的研究,在一个训练良好的语言模型中,其中:
point-wise互信息。word-specific项。context-specific项。
PMI刻画了两个事件共同发生的频率,相比比它们独立发生的频率,要高多少。注意,co-occurrence statistics是以计算的方式处理 "语义" 的典型工具,用于近似word-level semantic similarity。因此,大致上说,计算context embedding和word embedding之间的点积是有语义的。Higher-Order Co-Occurrence Statistics作为Context-Context Semantic Similarity:在预训练期间,两个上下文higher-order context-context co-occurrence也可以在预训练期间被推断和被传播。context embeddingcontext embeddingcontext embedding可以通过高阶共现关系在它们之间形成隐式交互。
34.1.2 各向异性的 Embedding Space 诱发了很差的语义相似性
正如前面所讨论的,
BERT的预训练应该隐式地鼓励具有语义的context embedding。为什么没有微调的BERT sentence embedding会产生较差的性能?为了研究失败的根本问题,我们使用
word embedding作为代理,因为单词和上下文共享相同的embedding空间。如果word embedding表现出一些误导性的属性,那么context embedding也会有问题,反之亦然。《Representation degeneration problem in training natural language generation models》和《Improving neural language generation with spectrum control》发现,根据最大似然anisotropic的词嵌入空间word embedding space。 "各向异性" 是指word embedding在向量空间中占据一个狭窄的锥体。《How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings》也观察到这一现象。此外,我们对学到的各向异性的
embedding空间有两个经验性的观察:观察一:
Word Frequency Biases the Embedding Space:我们预期embedding诱导的相似性与语义相似性一致。正如
《Representation degeneration problem in training natural language generation models》所讨论的,各向异性与词频的不平衡性高度相关。他们证明,在某些假设下,Transformer语言模型中non-appeared token的最佳embedding可以离原点极远。他们还试图将这一结论粗略地推广到很少出现的单词。为了在
BERT的背景下验证这一假设,我们计算了BERT word embedding和原点之间的平均L2距离。在下表的上半部分,我们观察到高频词都离原点更近,而低频词则离原点更远。这一观察表明:
word embedding可以被单词频率带偏。这与word embedding在训练过程中起到了连接context embedding的作用,因此context embedding可能会相应地被单词频率信息所误导,context embedding保存的语义信息也会被破坏。即,单词频率会影响
word embedding进而影响context embedding。观察二:
Low-Frequency Words Disperse Sparsely:我们观察到,在学到的各向异性的embedding空间中,高频词集中在一起,而低频词则分散开。这一观察是通过计算word emebdding与它们的k近邻的平均L2距离实现的。在下表的下半部分,我们观察到,与高频词的embedding相比,低频词的embedding往往离其k-NN邻居更远。这表明,低频词往往是稀疏分散的。由于稀疏性,在
embedding空间中的低频单词的embedding周围可能会形成许多 "洞",在这些洞里的语义可能不好定义。注意,BERT sentence embedding是通过对context embeddings取平均产生的,这是一个保凸的操作。然而,这些洞违反了embedding空间的凸性。这是representation learining中的一个常见问题。因此,所得到的sentence embedding可以位于定义不明确的区域,并且诱导的相似性也会有问题。
34.2 模型
为了验证前面提出的假设,并避免
BERT sentence embedding的无效,我们提出了一种称为BERT-flow的校准方法。该方法利用了从BERT embedding space到标准高斯潜在空间Gaussian latent space的可逆映射,如下图所示。可逆性条件保证了embedding空间和数据实例之间的互信息不会改变。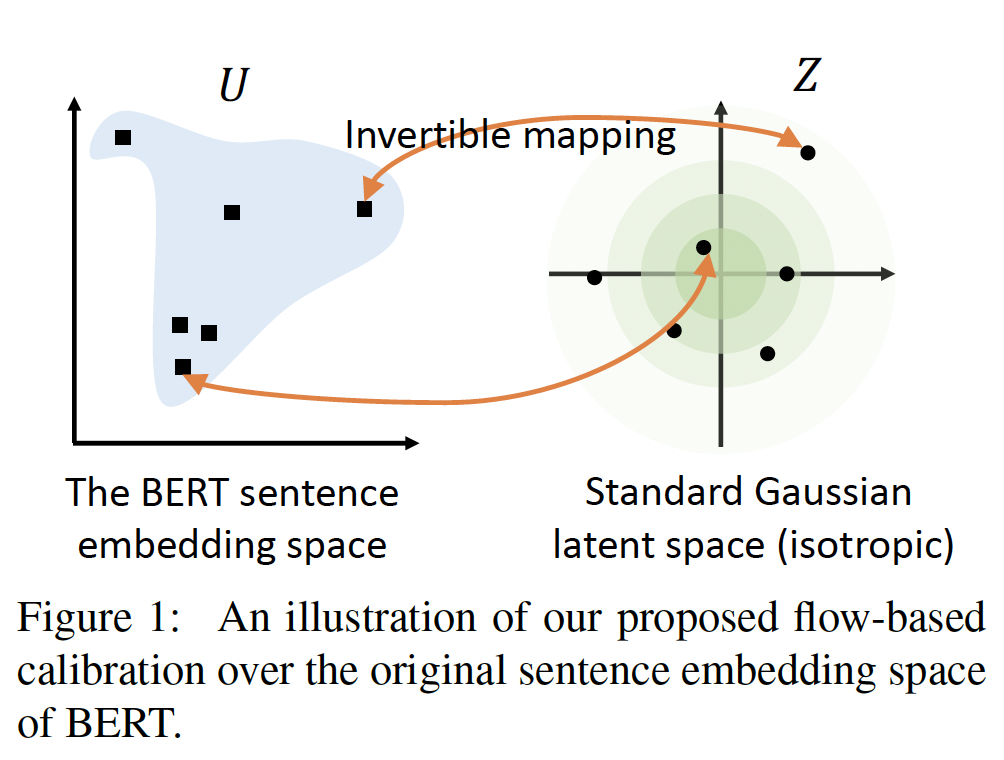
动机:标准的高斯潜在空间可能具有有利的特性,可以帮助我们解决问题:
与观察一的联系:
首先,标准高斯分布满足各向同性。标准高斯分布的概率密度不随角度的变化而变化。如果标准高斯的样本的
L2范数被归一化,这些样本可以被看作是均匀分布在一个单位球体上。我们还可以从奇异谱
singular spectrum的角度来理解各向同性。如上所述,embedding空间的各向异性源于词频的不均衡性。在传统word embedding的文献中,《All-but-the-top: Simple and effective postprocessing for word representations》发现,dominating singular vectors可能与词频高度相关,从而误导mislead了embedding空间。通过拟合一个映射,该映射是各向同性分布的,embedding空间的奇异谱可以被拉平。通过这种方式,与词频相关的奇异值方向,也就是dominating singular vectors,可以被抑制。与观察二的联系:
其次,高斯分布的概率密度在整个实空间上定义良好,这意味着没有 "洞" 的区域。高斯先验对于缓解 "洞" 的问题,已经在现有的
deep latent variable models的文献中被广泛观察到。
Flow-based Generative Model:flow-based generative model(《Normalizing flows: Introduction and ideas》)建立了一个从潜空间observed space其中:
根据
change-of-variables定理,可观察到的probabilistic density function: PDF为:在我们的方法中,我们通过最大化从标准高斯潜变量生成
BERT sentence embedding的可能性来学习flow-based generative model。换句话说,base分布BERT sentence embedding视为被观测空间其中:
请注意,在训练期间,只有
flow参数被优化,而BERT参数保持不变。最终,我们学习了一个可逆的映射函数BERT sentence embeddinglatent Gaussian representation可逆映射
Glow的设计(《Glow: Generative flow with invertible 1x1 convolutions》)。Glow模型是由多个可逆变换堆叠而成,即actnorm、可逆1 * 1卷积、以及affine coupling layer。 我们通过用additive coupling取代affine coupling来简化模型,以降低模型的复杂性,并用random permutation取代可逆1 * 1卷积,从而避免数值误差。具体而言,
flow-based model由一组堆叠的可逆变换层所组成,即additive coupling layer,公式为:其中:
如果仅仅只是简单地堆叠多层
additive coupling layer,可以发现每一层输出的前additive coupling layer的逆变换论文的核心在于这个
flow-based model,网络结构(多少层、有没有batch normalization等等)没有说明。网络优化的目标函数也没有说明。
34.3 实验
在整个实验中,我们采用
BERT的官方Tensorflow代码作为我们的codebase。请注意,我们将最大的序列长度改为64,以减少对GPU内存的消耗。对于siamese BERT的NLI finetuning,我们遵循SBERT中的设置(epochs=1、学习率为3e-5、以及batch size =16)。我们的结果可能与他们公布的结果不同。作者在https://github.com/UKPLab/sentence-transformers/issues/50中提到,这是一个常见的现象,可能与随机数种子有关。请注意,他们的实现依赖于Huggingface的Transformers repository。这也可能导致具体结果之间的差异。我们对
flow的实现是由GLOW的官方repository以及Tensor2tensor库的实现而改编的。我们的flow模型的超参数在下表中给出。在target数据集上,我们以1e-3的学习率对flow参数学习一个epoch;在NLI数据集上,我们以2e-5的学习率对flow参数学习0.15个epoch。优化器是Adam。
在我们对
STS-B的初步实验中,我们在STS-B的数据集上调优超参数。从经验上看,与learning schedule相比,架构超参数对性能的影响不大。之后,我们在其他数据集上工作时不再调优超参数。根据经验,我们发现flow的超参数在不同的数据集上并不敏感。
34.3.1 语义文本相似性
数据集:
STS benchmark (STS-B)、SICK-Relatedness (SICK-R)、STS tasks 2012 - 2016等七个数据集。我们通过
SentEval工具包获得所有这些数据集。这些数据集为每个sentence pair提供了0 ~ 5之间的细粒度的gold standard semantic similarity。评估程序:我们遵循先前工作中的程序,如用于
STS任务的SBERT。预测相似性包括两个步骤:首先,我们用一个句子编码器为每个句子获得
sentence embedding。然后,我们计算
input sentence pair的两个embedding之间的余弦相似度,作为我们的模型预测的相似度。
报告中的数字是
predicted similarity和gold standard similarity之间的Spearman相关系数,这与SBERT中的方法相同。配置:我们在实验中同时考虑
BERT_base和BERT_large。具体来说,我们使用最后一层或两层的BERT context embeddings的平均池化作为sentence embedding,这种方式的性能优于[CLS] embedding。有趣的是,我们的初步探索表明,与仅对最后一层进行平均池化相比,对BERT的最后两层进行平均池化(用-last2avg表示)一直产生更好的结果。因此,在评估我们自己的方法时,我们选择-last2avg作为默认配置。在我们的方法中,
flow-based objective被最大化,并且BERT参数保持不变而仅更新invertible mapping。flow model默认是通过完整的目标数据集(train + validation + test)学习的。我们将这种配置记做flow (target)。请注意,虽然我们使用了整个目标数据集的句子,但学习flow并不使用任何标签进行训练,因此它是对BERT sentence embedding space的一个纯粹的无监督校准。我们还测试了在
SNLI和MNLI的concatenation上学到的flow-based model,以进行比较(flow (NLI))。concatenated NLI数据集包括大量的sentence pair(SNLI 570K + MNLI 433K)。注意,"flow (NLI)"不需要任何监督标签。当在NLI语料库上拟合flow时,我们只使用原始句子而不是entailment label。flow (NLI) setting背后的一个直觉是,与Wikipedia的句子(BERT在其上进行了预训练)相比,NLI和STS的原始句子都更简单、更短。这意味着NLI-STS的差异可能比Wikipedia-STS的差异相对要小。我们在两种情况下进行了实验:
当外部标记数据不可用时。这是一个自然的设置,我们用无监督的目标来学习
flow参数(即,BERT参数是不变的。我们将这种方式称作BERT-flow。我们首先在
SNLI+MNLI文本对应分类任务上以siamese方式微调BERT(SBERT)。对于BERT-flow,我们进一步学习flow参数。这种设置是为了与利用NLI监督的SOTA结果进行比较(SBERT)。我们将这两个不同的模型分别表示为BERT-NLI和BERT-NLI-flow。
不使用
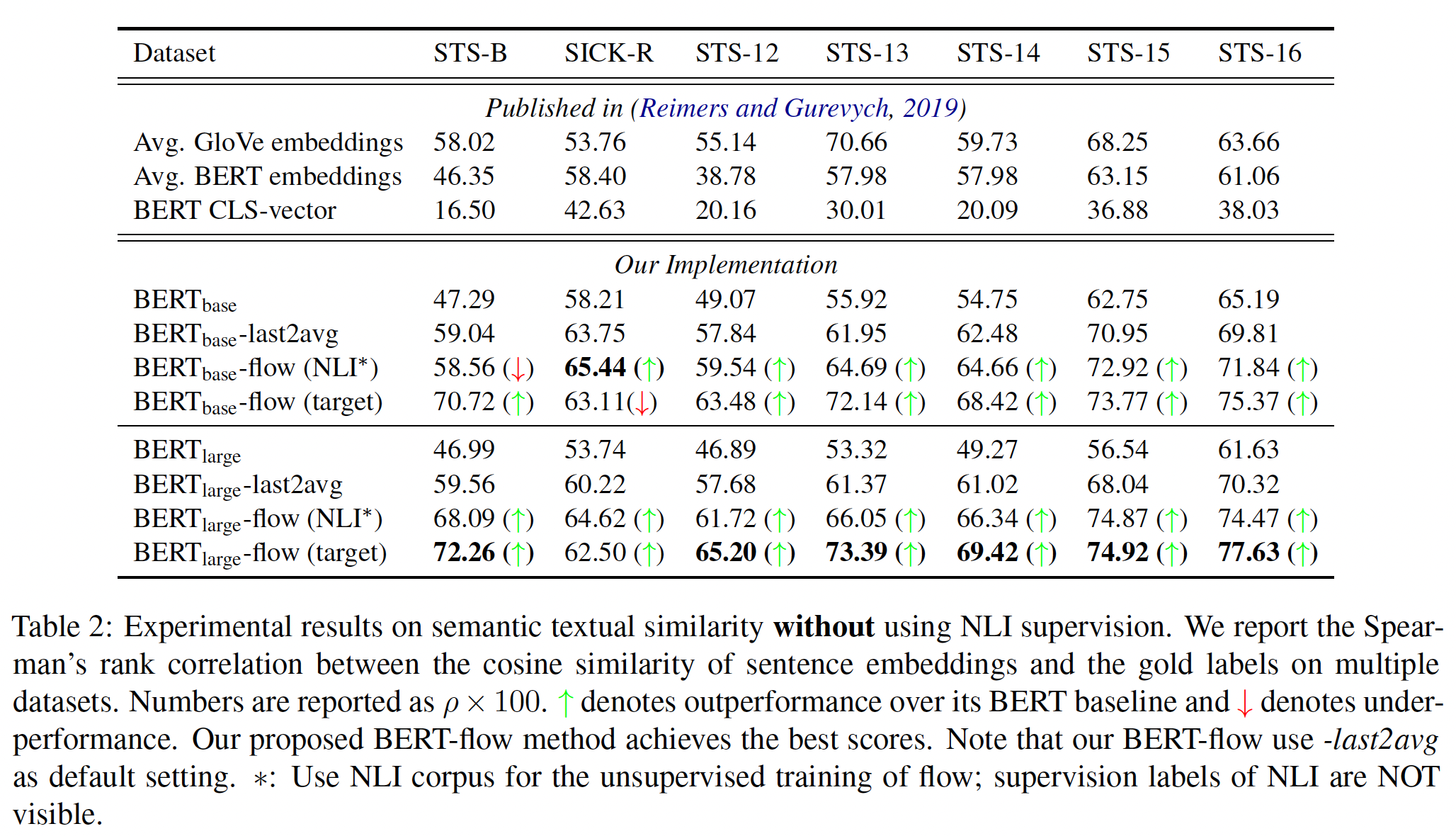
NLI监督的结果如下表所示:原始的
BERT sentence embedding(采用BERT_base和BERT_large)未能超过averaged GloVe embedding。对
BERT模型的最后两层进行平均池化可以一致地改善结果。仅仅采用
last2avg就能大幅提升效果!对于
BERT_base和BERT_large,我们提出的flow-based方法(BERT-flow (target))可以进一步提高性能,分别平均提高5.88个点和8.16个点。对于大多数数据集来说,在目标数据集上学习
flow导致了比在NLI上学习flow带来更大的性能提升。唯一的例外是
SICK-R,在NLI上训练flow的效果更好。我们认为这是因为SICK-R是同时为entailment和relatedness而收集的。由于SNLI和MNLI也被收集用于textual entailment评估,SICK-R和NNLI之间的分布差异可能相对较小。另外,由于NLI数据集的规模更大,所以在NNLI上学习flow的性能更强也就不奇怪了。
使用
NLI监督的结果如下表所示:与之前完全无监督的结果类似,我们来自可逆变换的各向同性embedding空间在大多数情况下能够持续改善SBERT基线,并以很大的幅度超过了SOTA的SBERT/SRoBERTa结果。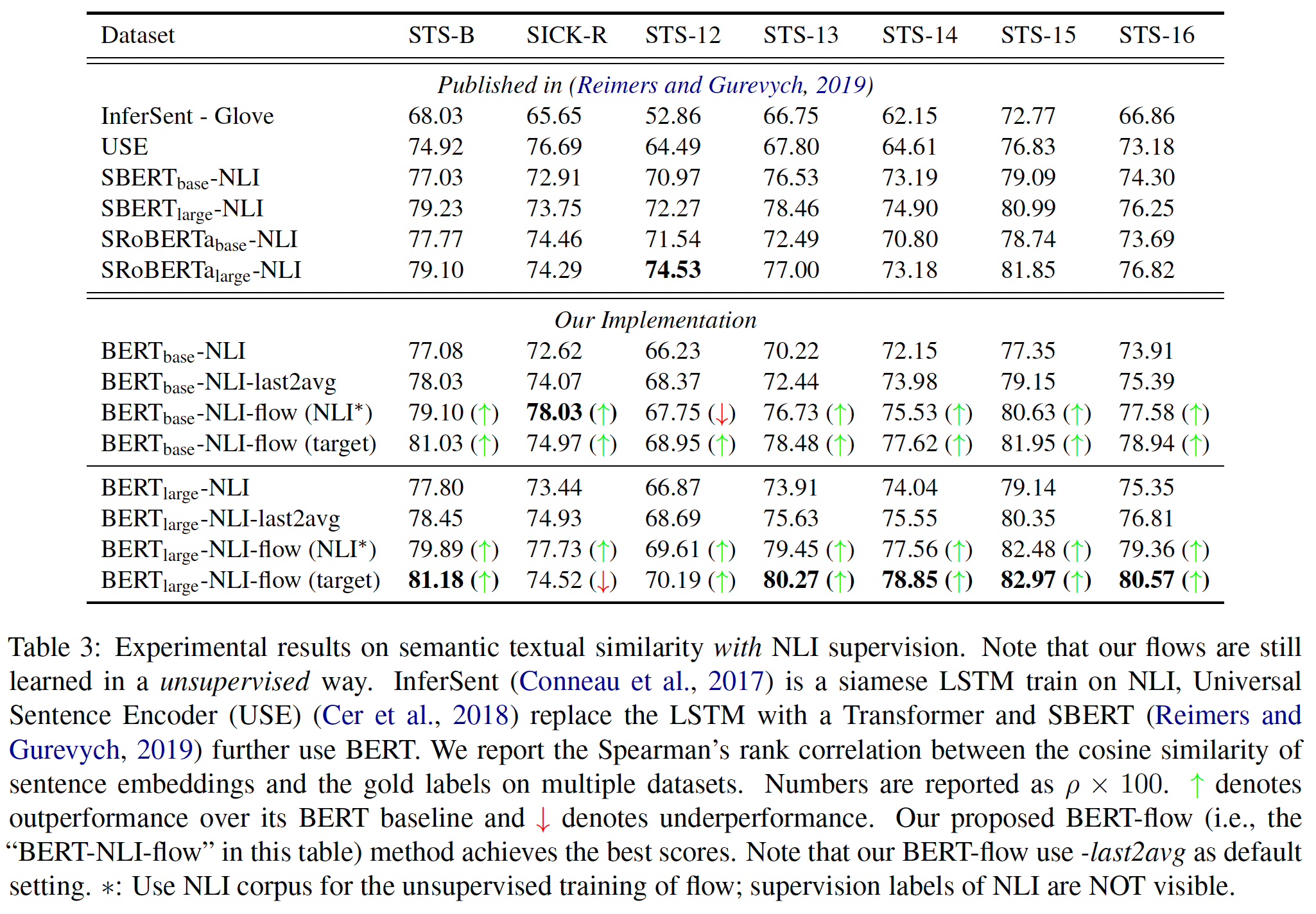
随机种子的鲁棒性分析:我们在
STS-B上用不同的随机种子进行了5次实验,在NLI监督的设置下。下表显示了带有标准差和中位数的结果。尽管NLI finetuning的方差不可忽略,但我们提出的flow-based的方法始终能带来改进。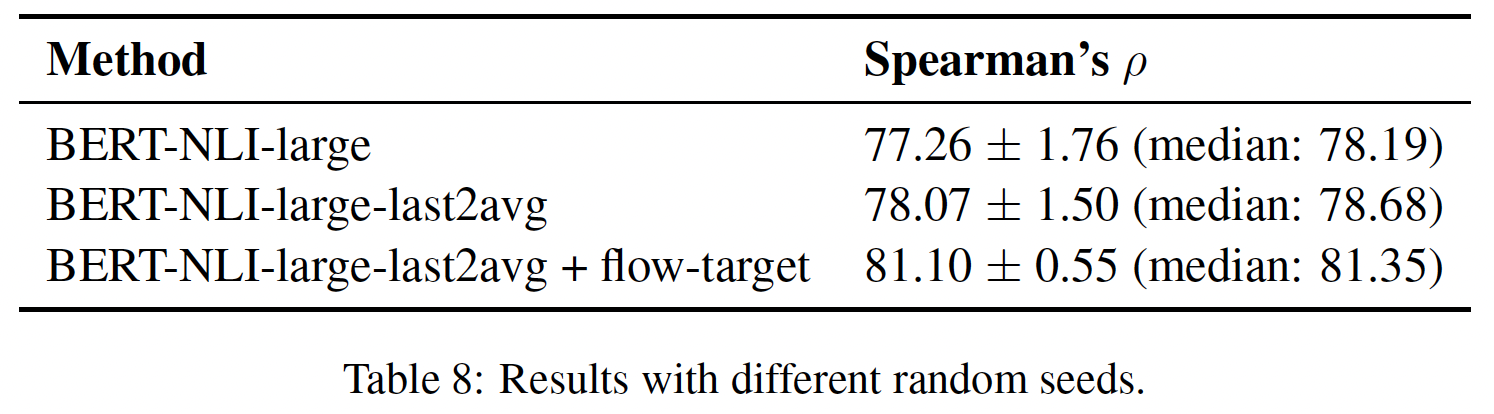
34.3.2 无监督的 Question-Answer Entailment
除了语义文本相似性任务外,我们还研究了我们的方法在无监督的
question-answer entailment上的有效性。我们使用Question Natural Language Inference: QNLI数据集,这是一个包含110K个question-answer pair的数据集,其中5K+个pair用于测试集。QNLI从SQUAD中抽取问题及其相应的上下文句子,并将每个pair标注为entailment或no entailment。在本文中,我们进一步将QNLI调整为一个无监督的任务。一个问题和一个答案之间的相似性可以通过计算它们的sentence embedding的余弦相似度来预测。我们将entailment视为1,no entailment视为0,并用AUC来评估方法的性能。如下表所示,我们的方法在
QNLI的验证集上一致地提高了AUC。同时,与在NLI上学习的flow相比,在target数据集上学习flow可以产生更好的结果。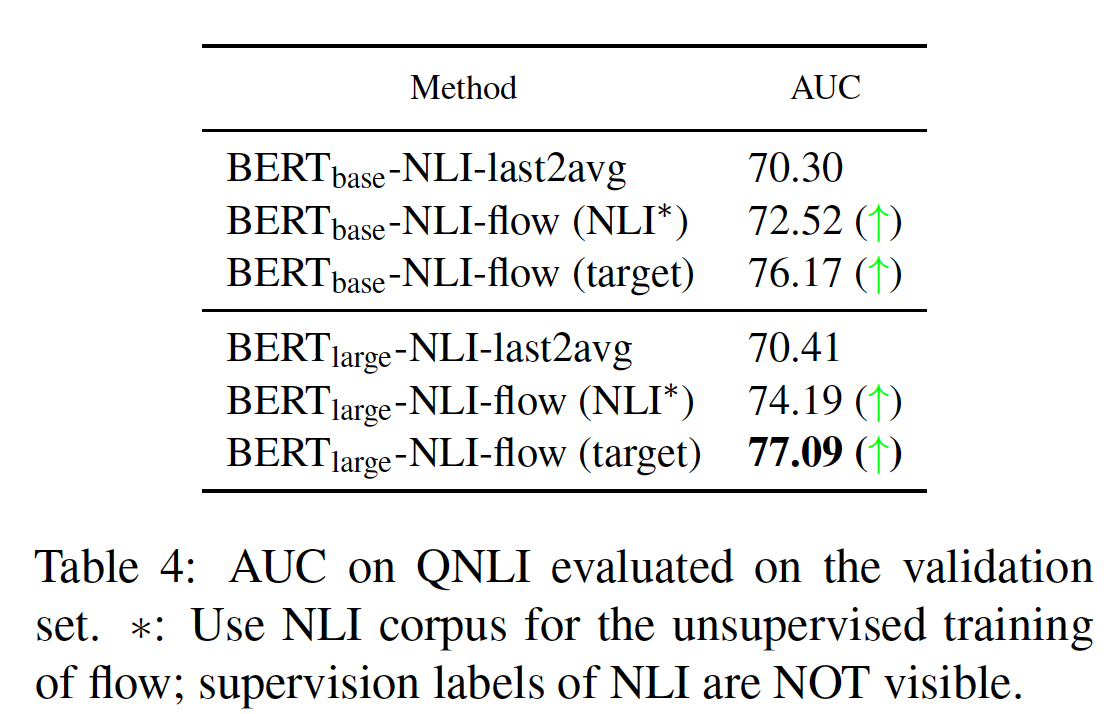
34.3.3 和其他 Embedding Calibration Baselines 相比
在传统的
word embedding的文献中,《A simple but tough-to-beat baseline for sentence embeddings》和《All-but-the-top: Simple and effective postprocessing for word representations》也发现了embedding空间的各向异性现象,他们提供了几种方法来鼓励各向同性isotropy:Standard Normalization: SN:在这个想法中,我们通过计算sentence embedding的均值embedding进行简单的后处理,并通过embedding归一化。Nulling Away Top-k Singular Vectors: NATSV:《All-but-the-top: Simple and effective postprocessing for word representations》发现,通过平均池化传统word embedding从而得到的sentence embedding往往有一个快速衰减的奇异谱。他们声称,通过将top -k个奇异向量singular vectors归零,可以避免embedding的各向异性,实现更好的语义相似性表现。
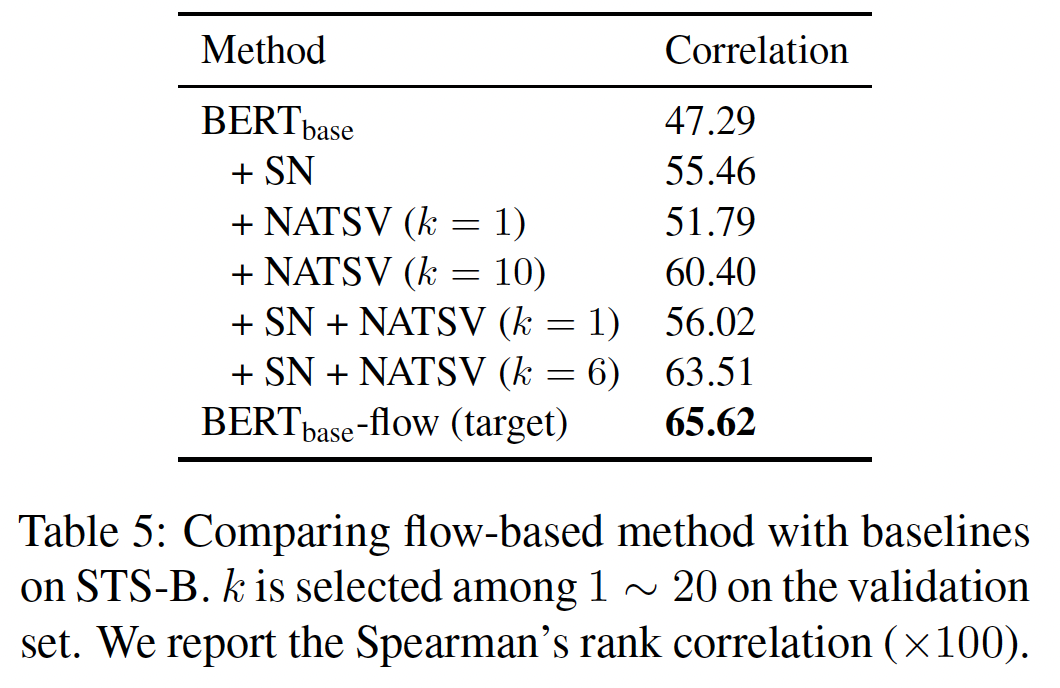
我们在
STS-B数据集上与这些embedding calibration方法进行比较,结果如下表所示:SN有助于提高性能,但它落后于NATSV。这意味着standard normalization不能从根本上消除各向异性。通过结合这两种方法,并在验证集上仔细调优我们的方法仍然产生了更好的结果。我们认为,
NATSV可以帮助消除各向异性,但它也可能丢弃nulled vectors中的一些有用信息。相反,我们的方法直接学习了一个可逆映射到各向同性的潜在空间,而没有丢弃任何信息。
34.3.4 语义相似性 Vs 词汇相似性
除了语义相似性
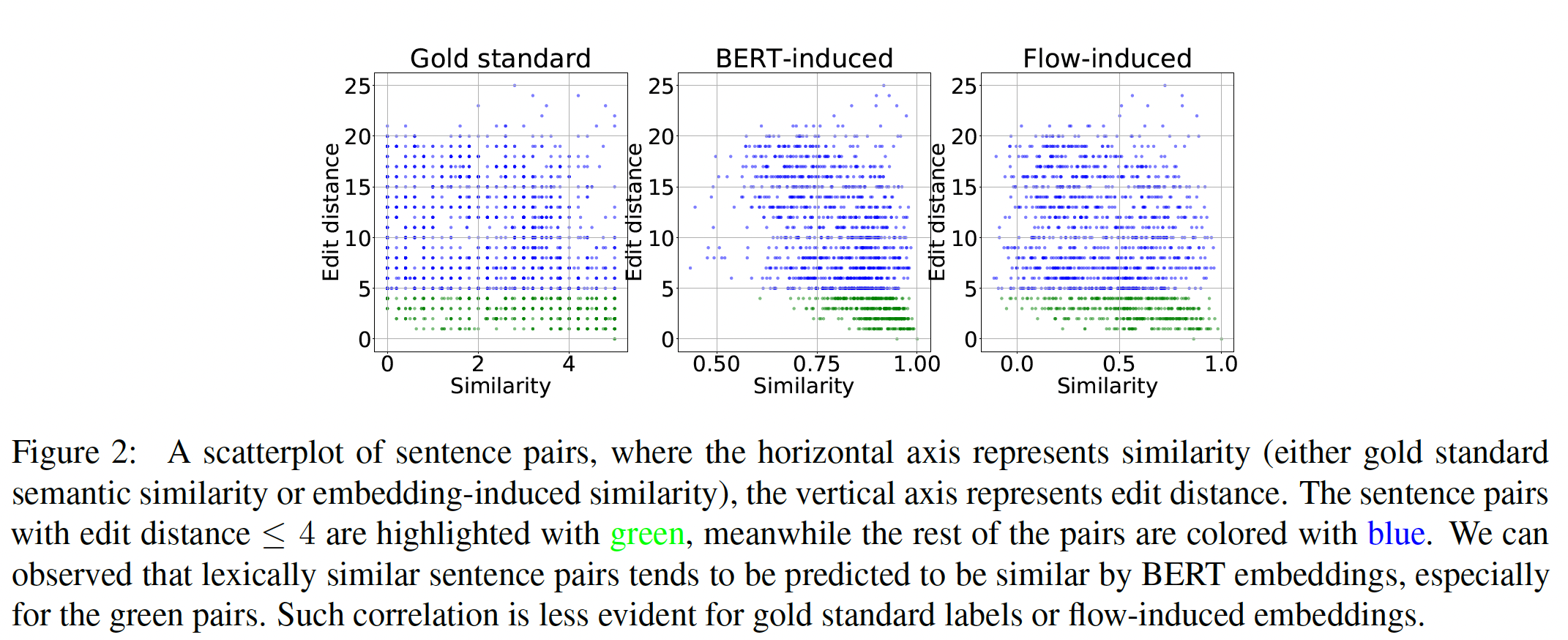
semantic similarity,我们还进一步研究了由不同sentence embedding方法诱导的词汇相似性lexical similarity。具体来说,我们使用编辑距离edit distance作为一对句子之间词汇相似性的衡量标准,并关注句子相似性(BERT sentence embedding的余弦相似性)和编辑距离之间的相关性。在由许多sentence pair组成的数据集中,我们计算了语义相似性和编辑距离之间的Spearman相关系数Spearman相关系数。我们在STS-B数据集上进行实验,并将人类标注的gold similarity纳入该分析。BERT-Induced Similarity与Lexical Similarity过度相关:下表显示,BERT诱导的相似性与编辑距离之间的相关性非常强(gold standard labels与编辑距离的相关性小得多(Figure 2中也可以观察到。特别是,对于编辑距离为sentence pair(用绿色突出显示),BERT诱导的相似性与编辑距离极为相关。Lexical Similarity由编辑距离来衡量,刻画了两个句子在word-level上的相似性,而不是语义相似性。然而,
gold standard语义相似度与编辑距离的相关性并不明显。换句话说,经常出现这样的情况:通过修改一个词,一个句子的语义就会发生巨大的变化。"I like this restaurant"和"I dislike this restaurant"这两个句子只相差一个词,但表达的语义是相反的。在这种情况下,BERT embedding可能会失败。因此,我们认为,BERT sentence embedding的lexical proximity过高,会破坏其诱导的语义相似性。Flow-Induced Similarity与Lexical Similarity表现出较低的相关性:通过将原始的BERT sentence embedding转化到学到的各向同性的潜在空间,embedding-induced similarity不仅与gold standard的语义相似性更加一致,而且与lexical similarity的相关性也更低,如下表的最后一行所示。这一现象在编辑距离Figure 2中以绿色标示)。这表明我们提出的flow-based的方法可以有效地抑制lexical similarity对embedding空间的过度影响。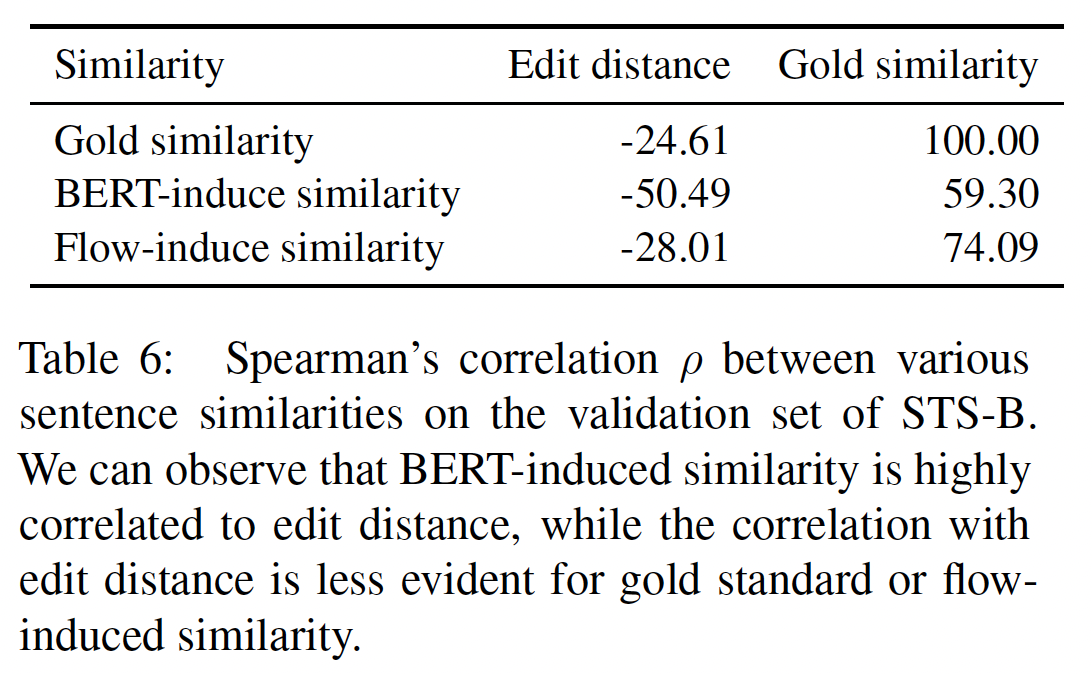
三十五、BERT-Whitening [2021]
sentence embedding已被证明不能很好地捕获句子的基本语义,因为之前的工作表明,word representations of all words都不是各向同性isotropic的:它们在方向上不是均匀分布的。相反,它们在向量空间中占据一个狭窄的锥体,因此是各向异性anisotropic的。《How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings》已经证明,来自pre-trained model的contextual word embeddings是如此的各向异性,任何两个word embedding的余弦相似度平均为0.99。BERT-Flow进一步调查发现,BERT sentence embedding空间存在两个问题,即word frequency biases the embedding space、以及低频词稀疏地分散开,这为直接使用BERT sentence embedding来计算相似度带来了困难。
为了解决上述问题,
《How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings》阐述了导致各向异性问题的理论原因,这个原因在预训练的模型中观察到。《Representation degeneration problem in training natural language generation models》设计了一种新的方法,通过正则化word embedding matrix来缓解degeneration问题。最近提出的BERT-flow通过normalizing flow将BERT sentence embedding distribution转化为平滑的、各向同性的高斯分布,这是一个由神经网络参数化的可逆函数。在论文
《Whitening Sentence Representations for Better Semantics and Faster Retrieval》中,作者没有像以前的尝试那样设计一个复杂的方法,而是发现一个简单而有效的后处理技术,白化whitening,足以解决sentence embedding的各向异性问题。具体而言,作者将sentence vectors的平均值转化为0、将协方差矩阵转化为单位矩阵。此外,论文还引入了降维策略,以促进白化操作,进一步提高效果。在
7个标准的语义文本相似性benchmark数据集上的实验结果表明,论文的方法可以普遍提高模型性能,并在大多数数据集上达到SOTA的效果。同时,通过加入降维操作,论文的方法可以进一步提高模型性能,并自然地优化内存存储、加快检索速度。论文贡献如下:
论文探讨了
BERT-based sentence embedding在相似性匹配任务中表现不佳的原因,即它不在标准正交基standard orthogonal basis上。论文提出了一种后处理方法,白化,将
BERT-based sentence embedding转化为标准正交基,同时降维。在七个语义文本相似性任务上的实验结果表明,论文的方法不仅可以显著提高模型性能,而且还可以减少向量的维度。
相关工作:
在特定的
NLP上下文中,已经出现了关于解决各向异性问题的早期尝试。《A simple but tough-to-beat baseline for sentence embeddings》首先为整个semantic textual similarity dataset计算sentence representation,然后从这些sentence representation中提取top direction,最后将sentence representation投射到top direction之外(即,仅保留tail direction)。通过这样做,top direction将固有地编码整个数据集的common information。《All-but-the-top: Simple and effective postprocessing for word representations》提出了一种后处理操作:在具有正值和负值的dense low-dimensional representation上,他们从word vectors中消除了common mean vector、和一些top dominating directions,这样就使处理后的representation更加强大。《Representation degeneration problem in training natural language generation models》提出了一种新颖的正则化方法来解决在训练自然语言生成模型中的各向异性问题。他们设计了一种新颖的方法,通过正则化word embedding matrix来缓解degeneration问题。由于观察到word embedding被局限在一个狭窄的锥体中,所提出的方法直接增加了锥体的孔径大小,这可以简单地通过降低individual word embedding之间的相似度来实现。《How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings》研究了contextual contextualized word representation的内在机制。他们发现,ELMo、BERT和GPT-2的upper layers比lower layers产生更加context-specific的representation。 这种context-specificity的增加总是伴随着各向异性的增加。《On the sentence embeddings from pre-trained language models》提出了BERT-flow,它通过用无监督目标学到的normalizing flow将各向异性的sentence embedding distribution转变为平滑的、各向同性的高斯分布。
谈到
SOTA的sentence embedding方法,以前的工作发现SNLI数据集适合训练sentence embedding。《Learning semantic textual similarity from conversations》提出了一种使用siamese DAN network和siamese transformer network对来自Reddit的对话进行训练的方法,该方法在STS benchmark数据集上取得了良好效果。《Universal sentence encoder》提出了一个所谓的Universal Sentence Encoder,它训练了一个transformer网络,并通过在SNLI数据集上的训练来augment无监督学习。在预训练方法的时代,
《Real-time inference in multi-sentence tasks with deep pretrained transformers》解决了来自BERT的cross-encoder的运行时间开销,并提出了一种方法(poly-encoders),利用注意力计算context vectors和预先计算的candidate embeddings之间的分数。《SBERT: Sentence embeddings using Siamese BERT networks》是对pretrained BERT network的修改,使用siamese network和triplet network结构来推导出有语义的sentence embedding,可以使用sentence embedding的余弦相似度来计算句子之间的相似性。
35.1 方法
通常我们计算
sentence embedding的余弦相似度,从而衡量句子之间的相似性。一个问题是:余弦相似度对输入向量做了什么假设?换句话说,什么前提条件适合用余弦相似度进行比较?我们通过研究余弦相似度的几何原理来回答这个问题。给定两个向量
然而,只有当坐标基为标准正交基时,上式才成立。
BERT-Flow验证了BERT sentence embedding已经包含了足够的语义,尽管它没有被正确利用。在这种情况下,如果根据上式来计算语义相似性的余弦值时,sentence embedding表现不佳,原因可能是sentence vector所属的坐标基不是标准正交基。从统计学的角度来看,我们可以推断,当我们为一组向量选择basis时,应该保证每个基向量都是独立的、统一的。如果这组基是标准正交基,那么相应的一组向量就应该显示出各向同性。总而言之,上述启发式假设阐述了:如果一组向量满足各向同性,我们可以认为它是由标准正交基派生出来的,其中也表明我们可以通过上述公式计算余弦相似度。否则,如果它是各向异性的,我们需要对
sentence embedding进行转换,以强制其成为各向异性,然后使用上述公式来计算余弦相似性。BERT-Whitening认为各向同性问题并不是embedding向量带来的,而是空间的基向量带来的(基向量不是标准正交基)。Whitening Transformation:BERT-flow通过采用flow-based的方法来解决上述假设。我们发现,利用机器学习中普遍采用的白化操作,也可以取得相当的收益。众所周知,关于标准正态分布的均值为零、协方差矩阵为单位矩阵。因此,我们的目标是将
sentence vector的平均值转换成0、将协方差矩阵转换成单位矩阵。假设我们有一组sentence embeddingsentence embedding满足均值为零、协方差矩阵为单位矩阵:该变换实际上对应于机器学习中的白化
whitening操作,其中注意,这里的向量为 ”行向量“。
最困难的部分是求解矩阵
变换之后的协方差矩阵为
因此,协方差矩阵是一个正定对称矩阵,满足如下形式的
SVD分解:其中:
正交矩阵:各行是单位矩阵且两两正交;各列是单位矩阵且两两正交,即
令
降维:众所周知,对角矩阵
sentence vector被嵌入到一个较低维度的空间中。这样可以使余弦相似度的结果更加合理,并自然地加快向量检索的速度,因为检索速度与向量维度成正比。事实上,从奇异值分解得出的对角矩阵
top k列就可以达到这种降维效果,这在理论上等同于主成分分析Principal Component Analysis: PCA。这里,Whitening-k。Whitening-k Workflow算法:输入:已有的
embedding集合输出:转换后的
embedding算法步骤:
根据
对
SVD分解,从而得到计算
对每个
该算法只能作为后处理从而优化现有
sentence embedding集合,无法处理unseen的sentence embedding。这是因为SVD作用在现有的sentence embedding集合所对应的均值、协方差矩阵上。BERT-Flow可以作用到unseen的sentence embedding上,因为BERT-Flow学习的是embedding空间到高斯空间的一个可逆映射。计算复杂度:均值
因此,计算
由于
SVD分解的时间复杂度几乎可以忽略不计。
35.2 实验
为了我们的方法的有效性,我们提出了在多种配置下与语义文本相似性(
semantic textual similarity: STS)任务相关的各种任务的实验结果。数据集:类似于
SBERT,我们在没有任何specific training data的情况下,将模型性能与STS任务的baseline进行比较。评估的数据集包括:STS 2012-2016 tasks、STS benchmark、SICK-Relatedness dataset一共七个数据集。对于每个sentence pair,这些数据集提供了一个标准的语义相似度指标,范围从0到5。我们采用
sentence embeddings的余弦相似度和gold labels之间的Spearman’s rank correlation,因为SBERT认为它是STS任务中最合理的指标。评估过程与BERT-flow保持一致:我们首先将每个原始句子文本编码为sentence embedding,然后计算input sentence embedding pairs之间的余弦相似度来作为我们预测的相似度分数。baseline:无监督的
STS:Avg. GloVe embeddings:采用GloVe作为sentence embedding。Avg. BERT embeddings和BERT CLS-vector:使用原始BERT embedding的均值、或者CLS-token的output。
监督的
STS:USE:Universal Sentence Encoder,其中用Transformer取代了LSTM。SBERT-NLI和SRoBERTa-NLI:在NLI组合数据集(包含SNLI和MNLI)上用SBERT训练方法来训练的BERT和RoBERTa。
实验配置:由于
BERTflow( NLI/target)是我们要比较的主要baseline,所以我们基本上与他们的实验配置和符号保持一致。具体来说:我们在实验中也同时使用
BERT_base和BERT_large。我们选择
-first-last-avg作为我们的默认配置,因为与只对最后一层取平均相比,对BERT的第一层和最后一层取平均可以稳定地实现更好的性能。我们利用完整的
target数据集(包括训练集、验证集和测试集中的所有句子,但不包括所有标签)来计算白化参数-whitening(target)。此外,
-whitening(NLI)表示白化参数是在NLI语料库中获得的。-whitening-256(target/NLI)和-whitening-384(target/NLI)表示通过我们的白化方法,输出的embedding size分别(从768维)降维到256和384。实验中发现:降维之后的效果可能更好。
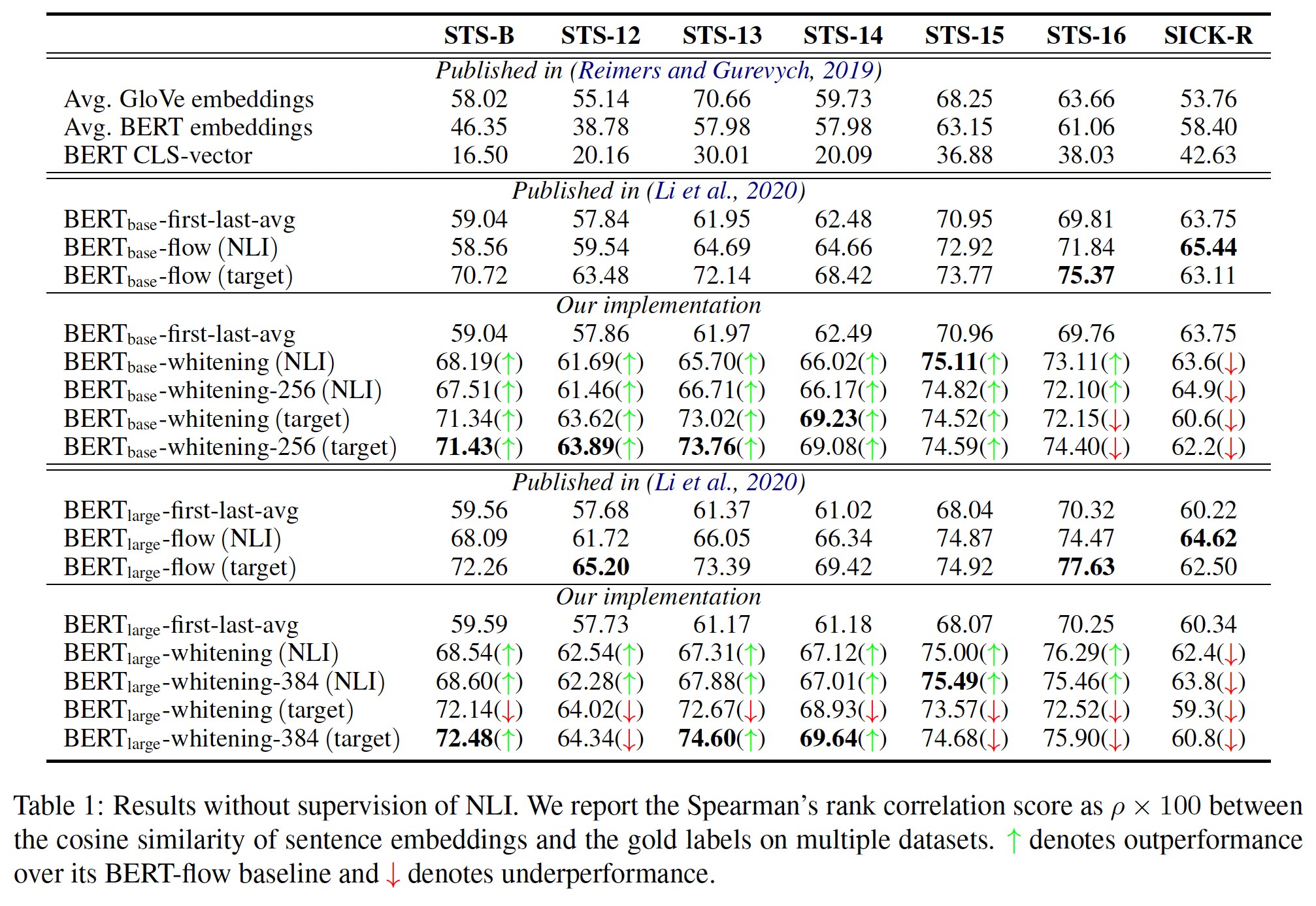
没有
NLI监督的结果如下表所示:虽然没有
NLI监督信息,但是仍然有NLI的样本数据(而没有label)。原始的
BERT sentence embedding和GloVe sentence embedding毫无悬念地获得了最差的性能。在
BERT_base下,我们的方法(具有256维的sentence embedding)一直优于BERT-flow,并在STS-B, STS-12, STS-13, STS-14, STS-15数据集上分别达到了SOTA效果。在
BERT_large下,如果将sentence embedding的维度设置为384,就会取得更好的结果。与BERT-flow相比,我们的方法在大多数数据集上仍然获得了有竞争力的结果,并在STS-B, STS-13, STS-14数据集上达到了SOTA效果。
有
NLI监督的结果如下表所示,其中SBERT_base和SBERT_large是通过SBERT中的方法在有监督标签的NLI数据集上训练的。我们的
SBERT_base-whitening在STS-13, STS-14, STS-15, STS-16任务上的表现优于BERT_base-flow。我们的
SBERT_large-whitening在STS-B, STS-14, STS-15, STS-16任务上的表现优于BERT_large-flow。
这些实验结果表明,我们的白化方法可以进一步提高
SBERT的性能,尽管它是在NLI数据集的监督下训练的。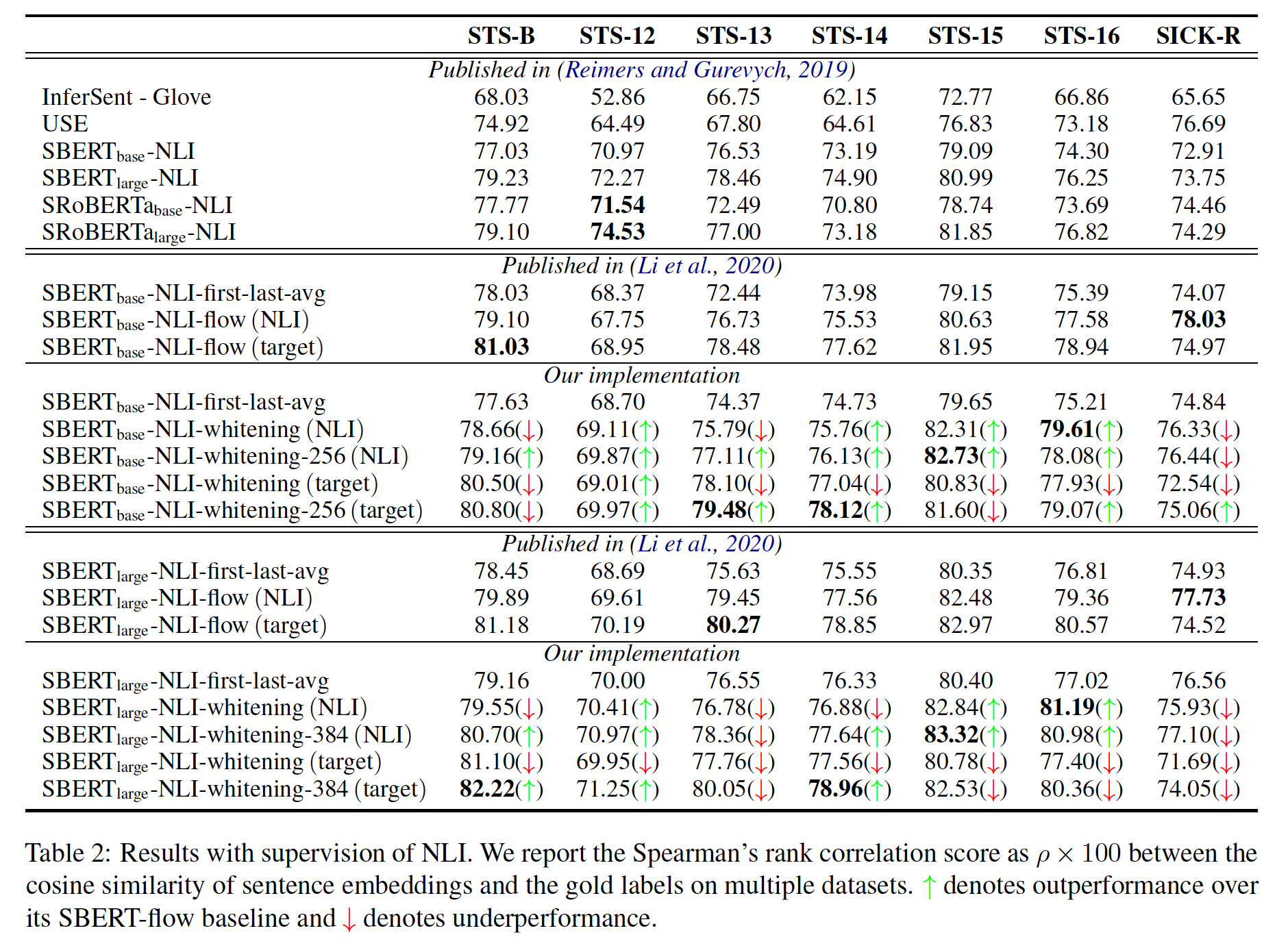
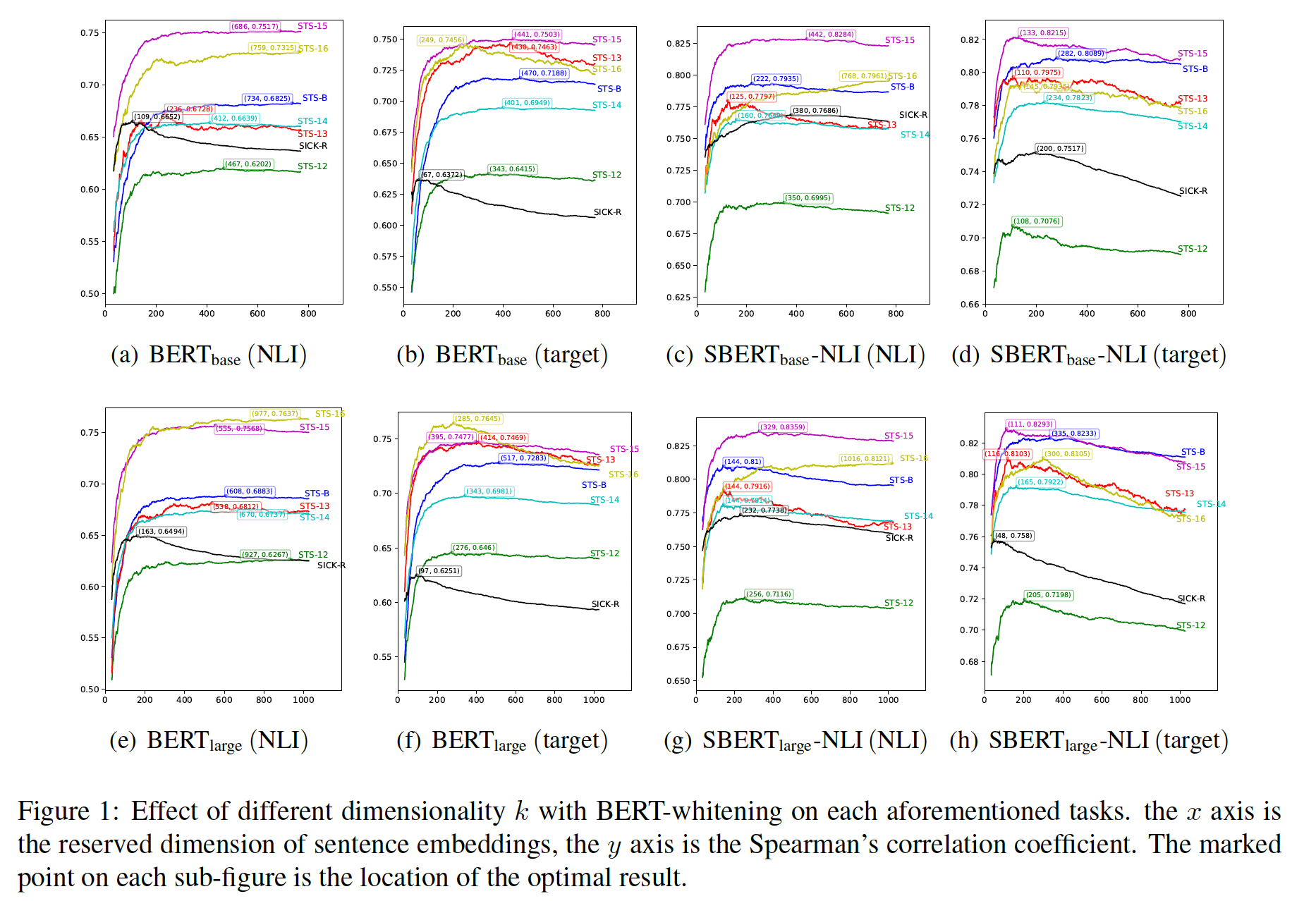
维度
Spearman相关系数与维度BERT_base embedding和BERT_large embedding下模型性能的变化曲线。对于大多数任务来说,将sentence vector的维度降维到三分之一是一个相对最优的解决方案。在
Table 1的SICK-R结果中,虽然我们的BERT_base-whitening-256(NLI)不如BERT_base-flow(NLI)有效,但我们的模型有竞争优势,即embedding size较小(256 vs. 768)。此外,如
Figure 1(a)所示,当embedding size设置为109时,我们的BERT_base-whitening(NLI)的相关性得分提高到了66.52,比BERT_base-flow(NLI)高出了1.08个点。此外,其他任务也可以通过谨慎选择
三十六、Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings[2019]
传统的
word embedding是静态的,每个单词都有单个embedding向量,与上下文无关。这带来了几个问题,最明显的是,一个多义词的所有意义都必须共享相同的representation。最近的工作,即deep neural language model(如ELMo和BERT),已经成功地创建了contextualized word representation,word vector对它们所处在的context敏感。用contextualized representation取代static embedding,在一系列不同的NLP任务中产生了显著的改善,包括从问答任务到共指消解co-reference resolution任务。contextualized word representation的成功表明,尽管只用语言建模任务进行训练,但它们学到了高度transferable的、task-agnostic的语言属性。事实上,在frozen contextualized representation上训练的线性模型可以预测单词的语言属性linguistic property(例如,part-of-speech tag),几乎与SOTA模型一样好。尽管如此,这些representation仍然没有得到很好的理解:首先,这些
contextualized word representation到底有多么的contextual?其次,
BERT和ELMo是否有无限多的context-specific representation可以分配给每个单词,还是说单词基本上是分配到有限数量的word-sense representation中的一个?
论文
《How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings》通过研究ELMo、BERT和GPT-2的每一层的representation space的geometry来回答这个问题。论文的分析产生了一些令人惊讶的发现:在所有三个模型的所有层中,所有单词的
contextualized word representation都不是各向同性isotropic的:它们在方向上不是均匀分布的。相反,它们是各向异性anisotropic的,在向量空间中占据一个狭窄的锥体。GPT-2最后一层的各向异性是如此的极端,以至于两个随机的单词平均而言会有几乎完美的余弦相似性!鉴于各向同性对static embedding有理论上的和经验上的好处(《All-but-the-top: Simple and effective postprocessing for word representations》),contextualized representation中各向异性的程度令人惊讶。即,
contextualized work embedding的各向异性。同一单词在不同
context中的出现具有non-identical vector representations。在向量相似性被定义为余弦相似性的情况下,同一单词的不同representations之间在上层中的不相似性更大。这表明,就像LSTM的上层产生更加task-specific的representation一样(《Linguistic knowledge and transferability of contextual representations》),contextualizing model的上层产生更加context-specific的representation。即,不同层的
contextualization程度不同,更高层产生更加contextualized的embedding。context-specificity在ELMo、BERT和GPT-2中表现得非常不同:在
ELMo中,随着上层的context-specificity增加,同一句子中的单词的representation越来越相似。在
BERT中,同一句子中的单词的representation在上层变得更加不相似,但平均而言仍然比随机采样的单词更加相似。然而在
GPT-2中,同一句子中的单词的representation,并不比两个随机采样的单词更加相似。
即,同一个句子中的不同单词,在
ELMo的更高层中越来越相似、在BERT的更高层中更加不相似(但是比随机的单词更相似)、在GPT-2中与随机单词的相似性差不多。在对各向异性的影响进行调整后,平均来说,一个单词的
contextualized representation中只有不到5%的方差可以由其第一主成分解释first principal component。这一点在所有模型的所有layer上都成立。这表明:contextualized representation并不对应于有限数量的word-sense representation,即使在最好的情况下,static embedding也只是contextualized embedding的糟糕的替代物。尽管如此,通过提取一个单词的contextualized representation的first principal component而创建的static embedding在许多word vector benchmark上超越了GloVe embedding和FastText embedding。
这些洞察有助于证明为什么使用
contextualized representation能在许多NLP任务中带来如此显著的改进。相关工作:
Static Word Embedding:Skip-gram with negative sampling: SGNS和GloVe是生成static word embedding的最著名的模型之一。虽然在实践中它们迭代式地学习embedding,但已经理论上证明,它们都隐式地分解了一个word-context matrix,该矩阵包含co-occurrence statistic。static word embedding的一个显著问题是,由于它们为每个单词创建了一个单一的representation,所以一个多义词的所有意义必须共享单个向量。Contextualized Word Representation:鉴于static word embedding的局限性,最近的工作试图创建context-sensitive word representation。ELMo, BERT, GPT-2是深度神经语言模型,它们经过微调从而应用于广泛的下游NLP任务。它们的内部word representation被称作contextualized word representation,因为word representation是整个输入句子的一个函数。 这种方法的成功表明,这些representation捕获了语言的高度可迁移transferable的、和任务无关task-agnostic的属性。ELMo通过拼接一个双层biLSTM的internal states,从而创建每个token的contextualized representation。这个双层biLSTM在双向语言建模任务上训练。相比之下,
BERT和GPT-2分别是双向的和单向的transformer-based的语言模型。12层的BERT (base, cased)和12层的GPT-2的每个transformer layer通过关注输入句子的不同部分来创建每个token的contextualized representation。
Probing Task:之前对contextualized word representation的分析主要限于probing task。这涉及到训练线性模型来预测单词的句法(例如,part-of-speech tag)和语义(例如,word relation)属性。probing模型的前提是,如果一个简单的线性模型可以被训练来准确预测语言属性,那么representation需要隐式地编码这一信息。然而这些分析发现,contextualized representation编码了语义信息和句法信息,但它们无法回答这些representation有多么地contextual,以及它们在多大程度上可以被static word embedding所取代。因此,我们在本文中的工作与大多数对contextualized representation的剖析明显不同。它更类似于《The strange geometry of skip-gram with negative sampling》,后者研究了static word embedding space的几何特性。
36.1 方法
Contextualizing Model:我们研究的contextualizing model是ELMo、BERT和GPT-2。我们选择BERT_base,因为它在层数和维度方面与GPT-2最具可比性。所有模型都是在各自的语言建模任务中预训练过的。尽管
ELMo、BERT和GPT-2分别有2、12和12个隐藏层,但我们也将每个contextualizing model的输入层作为其第0层。这是因为第0层不是contextualized的,使其成为比较后续层所做的contextualization的有用baseline。数据:为了分析
contextualized word representation,我们需要input sentence来馈入我们的pretrained model。我们的输入数据来自2012-2016年的SemEval语义文本相似性任务。我们使用这些数据集是因为它们包含了一些句子,在这些句子中出现了相同的单词但是具有不同的context。例如,单词"dog"出现在"A panda dog is running on the road."和"A dog is trying to get bacon off his back."。如果一个模型在这两个句子中为"dog"生成了相同的representation,我们可以推断出没有contextualization;反之,如果生成了不同的representation,我们可以推断出它们在某种程度上被contextualized。相同的单词出现在不同的
context中,那么该单词如果具有不同的embedding,则表示没有contextualized。利用这些数据集,我们将单词映射到它们出现的
sentence list、以及它们在这些句子中出现的索引。在我们的分析中,我们不考虑那些出现在少于5个unique context中的单词。衡量
Contextuality:我们用三个不同的指标来衡量一个word representation的contextual程度:自相似性self-similarity、句内相似性intra-sentence similarity、最大可解释方差maximum explainable variance。自相似性:令单词
word representation。单词layer换句话说,一个单词
unique context中的contextualized representation的平均余弦相似度。如果第
representation进行contextualize,那么representation在所有contexts中都是相同的)。对于
representation越contextualized,我们期望它的自相似性就越低。
这里有个前提条件:单词的
context之间是均匀分布的(而不是集中在某些context上)。句内相似性:令
layer换句话说,一个句子的句内相似性是其
word representation和sentence vector之间的平均余弦相似度,而sentence vector只是这些word vector的平均值。如果
contextualize单词:给每个单词一个context-specific representation,并且同一个句子中的不同word具有不同的word representation。如果
word的representation之间区别很小,同一个句子中的单词仅仅是通过使其在向量空间中的representation收敛到一个很小的区域从而实现contextualization。
最大可解释方差:令
occurrence matrix,representation维度。令singular value。那么最大可解释方差被定义为:contextualized representation中可由其第一主成分解释的方差比例。它为我们提供了一个关于word static embedding可以在多大程度上取代word contextualized representation的上限。0,static embedding的replacement就越差。1,那么static embedding将是contextualized representation的完美替代。
针对各向异性
Anisotropy做调整:在讨论contextuality时,考虑各向同性isotropy是很重要的。例如:如果
word vector是完全各向同性的(即方向均匀),那么representation被很差地contextualized。然而,考虑到这样的情况,即
word vector是如此的各向异性,任何两个单词的平均余弦相似度为0.99。此时representation被很好地contextualized。这是因为context中的representation平均而言比两个随机选择的单词更加不相似。
为了调整各向异性的影响,我们使用了三个
anisotropic baseline,每个baseline对应于我们的一个contextuality指标。对于自相似性和句内相似性,
baseline来自均匀随机采样的单词在不同context下的representation的平均余弦相似度。在一个给定的层中,word representation的各向异性越大,这个baseline就越接近于1。均匀随机采样了两个单词,然后计算它们之间的
embedding的余弦相似度。采样多次并计算期望值。对于最大可解释方差,
baseline是均匀随机采样的word representation中被其第一主成分解释的方差比例。在一个给定的层中,,word representation的各向异性越大,这个baseline就越接近于1。即使是随机采样的单词,主成分也能解释很大一部分的方差。均匀随机采样了一个
word集合,然后计算它们的embedding矩阵的第一主成分。采样多次并计算期望值。
由于
contextuality指标是针对contextualizing model的每一层计算的,所以我们也为每一层计算单独的baseline。然后我们从每个指标值中减去其各自的baseline,得到anisotropy-adjusted contexuality指标。例如,anisotropy-adjusted的自相似性为:其中:
word occurrence的集合。除非另有说明,本文其余部分中提到的
contextuality指标是指anisotropy-adjusted的指标,其中原始指标和基线都是用1K个均匀随机采样的word representation估计的。
36.2 实验
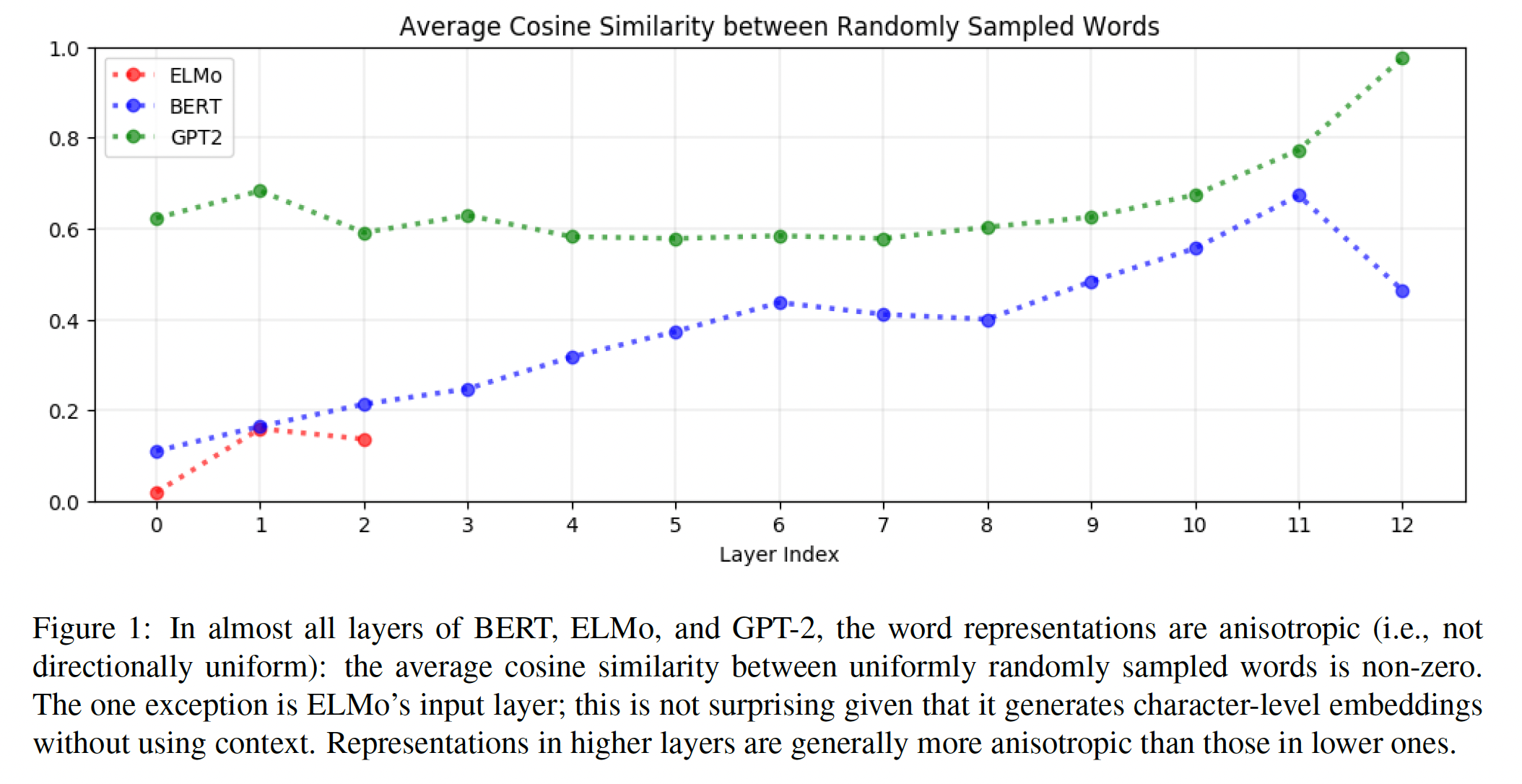
(An)Isotropy:在所有
non-input layers中,contextualized representation是各向异性anisotropic的。如果来自某一层的
word representation是各向同性isotropic的(即各方向均匀),那么均匀随机采样的单词之间的平均余弦相似度将是0(《A simple but tough-to-beat baseline for sentence embeddings》)。 这个平均余弦相似度越接近于1,表示各向异性越大。各向异性的几何解释是:
word representation都在向量空间中占据一个狭窄的锥体,而不是在所有方向上都是均匀的。各向异性越大,这个锥体就越窄(
《The strange geometry of skip-gram with negative sampling》)。
如下图所示,这意味着在
BERT、ELMo和GPT-2的几乎所有层中,所有单词的representation都在向量空间中占据一个狭窄的锥体。唯一的例外是ELMo的input layer,它产生static character-level embedding,而不使用contextual信息甚至positional信息(《Deep contextualized word representations》)。然而,应该注意的是,并非所有的
static embedding都一定是各向同性的:《The strange geometry of skip-gram with negative sampling》发现,同样是static的skipgram embedding并不是各向同性的。contextualized representation通常在较高的层中更加各向异性。如下图所示,对于
GPT-2,均匀随机的单词之间的平均余弦相似度在第2层到第8层大致为0.6,但从第8层到第12层呈指数级增长。事实上,GPT-2的最后一层的word representation是如此的各向异性,以至于任何两个单词的平均余弦相似度几乎都是1.0。这种模式也适用于
BERT和ELMo,不过也有例外:例如,BERT的倒数第二层的各向异性比最后一层高得多。对于
static word embedding,各向同性有理论上的和经验上的好处。在理论上,各向同性允许在训练期间进行更强的
"self-normalization"(《A simple but tough-to-beat baseline for sentence embeddings》)。而在实践中,从
static word embedding中减去mean vector会导致在几个下游NLP任务上的改进(《All-but-the-top: Simple and effective postprocessing for word representations》)。
因此,在
contextualized word representation中看到的极端程度的各向异性是令人惊讶的,特别是在较高的层。如下图所示,对于所有三个模型,contextualized hidden layer representation几乎都比input layer representation更加各向异性,而后者没有纳入context。这表明高度的各向异性是contextualization过程所固有的,或者至少是contextualization过程的副产品。
Context-Specificity:contextualized word representation在更高的layer上更加context-specific。根据定义,在一个给定模型的给定层中,一个单词的
self-similarity是它在不同context中的representations的平均余弦相似度(根据各向异性进行调整)。如果
self-similarity为1,那么这些representations就完全没有context-specific。如果
self-similarity为0,那么这些representations就具有最大的context-specific。
在下图中,我们绘制了
BERT、ELMo和GPT-2各层中均匀随机采样的单词的平均self-similarity。例如,ELMo的input layer的自相似度是1.0,因为该层的representation是static character-level embedding。在所有三个模型中,
layer越高,平均self-similarity越低。换句话说,layer越高,contextualized representation更加context-specific。这一发现具有直观的意义。在图像分类模型中,lower layer识别更多的通用特征(如,边缘),而upper layer识别更加class-specific的特征(《How transferable are features in deep neural networks?》)。同样,在NLP任务上训练的LSTM的upper layer会学习更加task-specific的representation(《Linguistic knowledge and transferability of contextual representations》)。因此,由此可见,神经语言模型的upper layer会学习更加context-specific的representation,从而更准确地在给定context的条件下预测next word。在所有三个模型中,
GPT-2的representation是最context-specific的,GPT-2最后一层的representation几乎是最大化地context-specific的。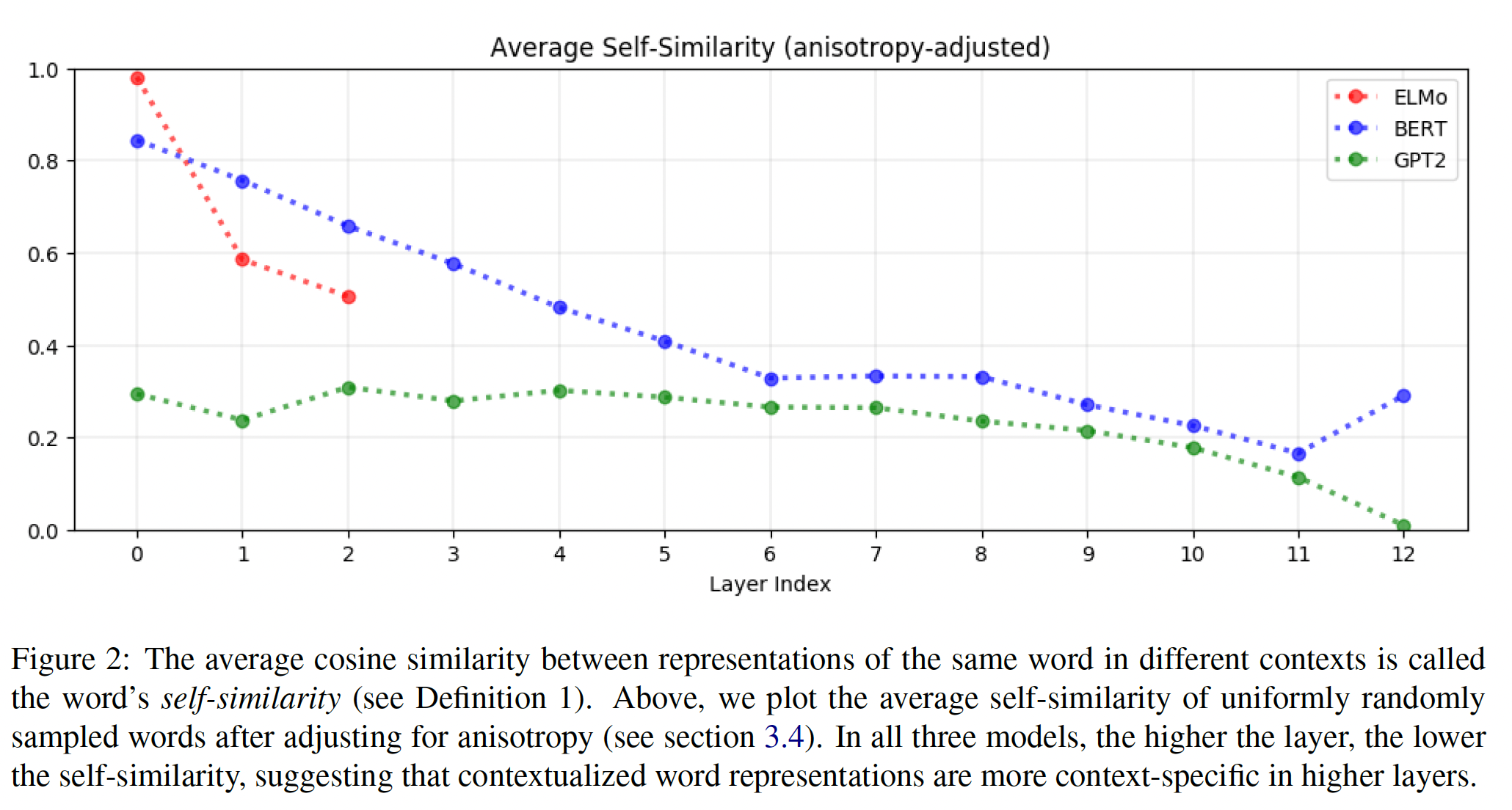
停用词
stopword(如,"the", "of", "to")具有最context-specific的representation。在所有的层中,
stopwords的self-similarity是所有单词中最低的,这意味着它们的contextualized representation是最context-specific的。例如,在ELMo的各层中,平均self-similarity最低的单词是"and"、"of"、"’s"、"the"、"to"。鉴于这些词不是多义词,这相对来说是令人惊讶的。这一发现表明:一个单词所出现的各种context的variety,而不是其固有的多义性,是推动其contextualized representation的variation的原因。这回答了我们在introduction章节中提出的一个问题:ELMo、BERT和GPT-2并不是简单地将有限数量的word-sense representation中的一个分配给每个单词;否则,在具有如此少的word sense的单词的representation中就不会有如此多的变化。context-specificity在ELMo、BERT和GPT-2中的表现非常不同。如前所述,在
ELMo、BERT和GPT-2的upper layers,contextualized representation更加context-specific。然而,这种increased context-specificity在向量空间中是如何体现的?同一句子中的word representation是否会收敛到一个点上,或者它们在与其他context中的representation不同的同时,仍然保持着彼此之间的不同?为了回答这个问题,我们可以度量一个句子的句内相似度。从定义可以看出,在给定模型的给定层中,一个句子的句内相似性是其每个
word representation与它们的均值之间的平均余弦相似度,并根据各向异性进行调整。如下图所示,我们绘制了500个均匀随机采样的句子的平均句内相似度。在
ELMo中,同一句子中的单词在upper layers的相似度更高:随着句子中的word representation在upper layers变得更加context-specific,句内相似度也在上升。 这表明,在实践中,ELMo最终将《A synopsis of linguistic theory》的分布假说背后的直觉延伸到了sentence level:因为同一句子中的单词共享相同的context,它们的contextualized representation也应该是相似的。在
BERT中,同一句子中的单词在upper layers中彼此更加不相似:随着句子中的单词的representation在upper layers中变得更加context-specific,它们彼此渐行渐远,尽管也有例外(见下图中第12层)。然而,在所有层中,同一句子中的单词的平均相似性仍然大于随机选择的单词的平均相似性(即anisotropy baseline)。这表明,与ELMo相比,BERT有一个更细微的contextualization,它认识到,虽然周围的句子告知了一个单词的含义,但同一句子中的两个单词不一定有相似的含义。在
GPT-2中,同一句子中的word representation并不比随机采样的单词更相似:平均而言,未调整的句内相似度与anisotropy baseline大致相同,因此从下图中可以看出,在GPT-2的大多数层中,anisotropy-adjusted的句内相似度接近于0。事实上,句内相似度在input layer中是最高的,该层完全不对单词进行contextualize。这与ELMo和BERT形成了鲜明的对比,ELMo和BERT在除了一个层之外的所有其他层的平均句内相似度都高于0.20。
正如前面讨论
BERT时指出的,这种行为仍然具有直观的意义:同一个句子中的两个单词不一定有相似的含义,即使它们共享相同的context。GPT-2的成功表明,高的句内相似性并不是contextualization所固有的。同一句子中的不同单词可以有高度contextualized的representation,而这些representation并不比两个随机的word representation更相似。然而,目前还不清楚这些句内相似性的差异是否可以追溯到模型结构的差异,我们把这个问题留给未来的工作。高度的各向异性是
contextualization过程所固有的。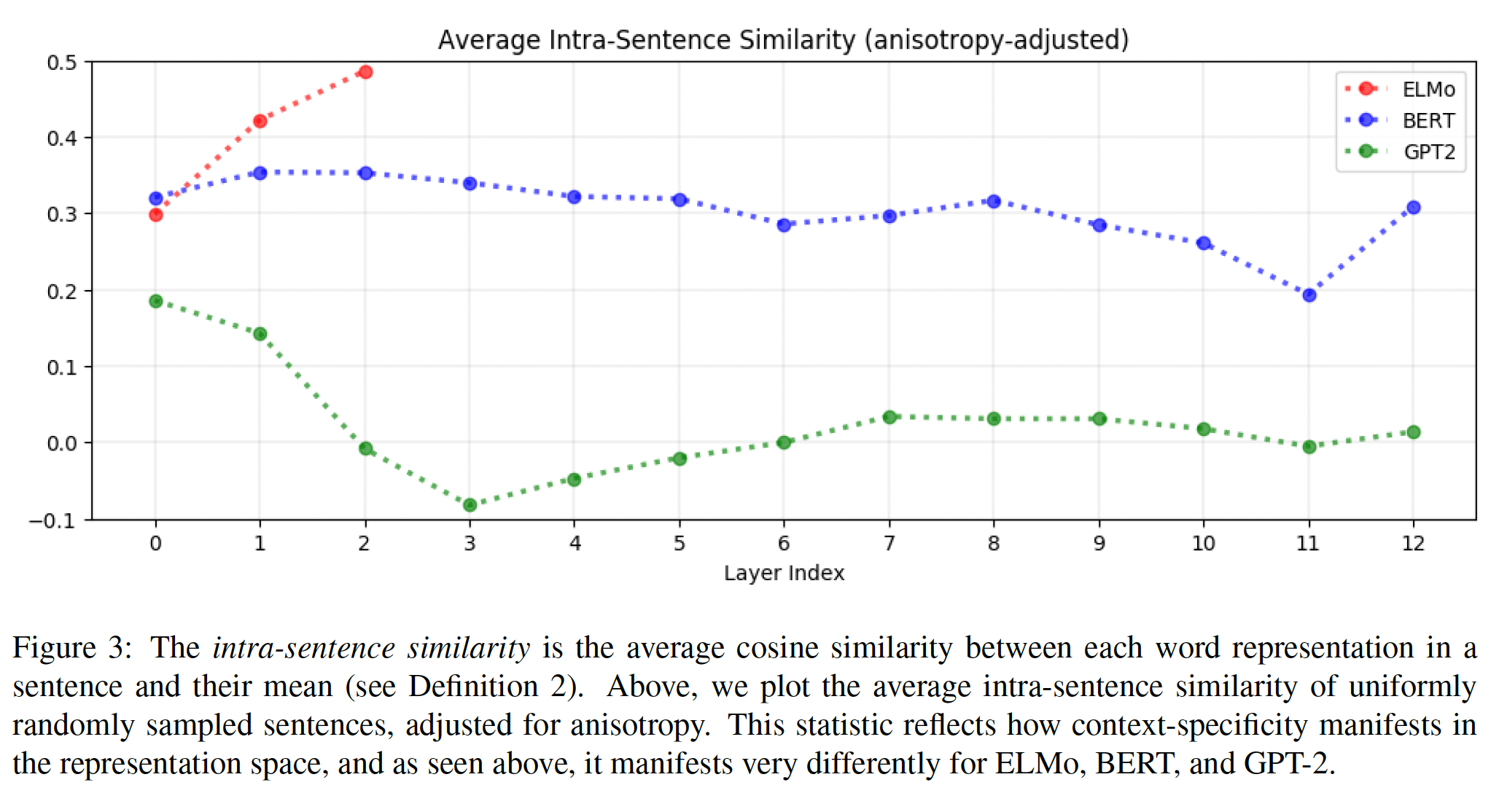
Static vs. Contextualized:平均来说,一个单词的
contextualized representation中只有不到5%的方差可以被static embedding所解释。从定义可以看出,对于给定模型的给定层,一个单词的最大可解释方差(
maximum explainable variance: MEV)是其contextualized representation中可由其第一主成分解释的方差的比例。这为我们提供了一个关于static embedding能多好地取代一个单词的contextualized representation的上限。 因为contextualized representation是各向异性的,所有单词的大部分变化都可以由单个向量来解释。我们对原始MEV针对各向异性进行调整:计算均匀随机采样的word representation的第一主成分所解释的方差比例,然后从原始MEV中减去这一比例。在下图中,我们绘制了均匀随机采样的单词上的平均anisotropy-adjusted MEV。随机采样一个单词,然后计算该单词在指定层上的
MEV。然后重复这一过程多次,得到平均MEV。平均而言,在
ELMo、BERT或GPT-2中,没有任何一层可以通过static embedding来解释超过5%的word contextualized representation方差。虽然在下图不可见,但许多单词的原始MEV实际上低于anisotropy baseline:也就是说,与单个单词的所有representation的方差相比,所有单词的representation的方差有更大的比例可以由单个向量来解释。注意,5%的阈值代表了最好的情况,而且在理论上不能保证word vector会与最大化MEV的static embedding相似。单个单词的所有
representation的方差:一个单词在指定层的MEV;所有单词的representation的方差:所有单词在指定层的MEV。这表明,
contextualizing model并不是简单地将有限数量的word-sense representation中的一个分配给每个单词,否则,被解释的方差的比例会高得多。ELMo和BERT的所有层的平均原始MEV甚至低于5%。只有GPT-2的原始MEV相对较大,由于极高的各向异性,第2至11层的平均MEV约为30%。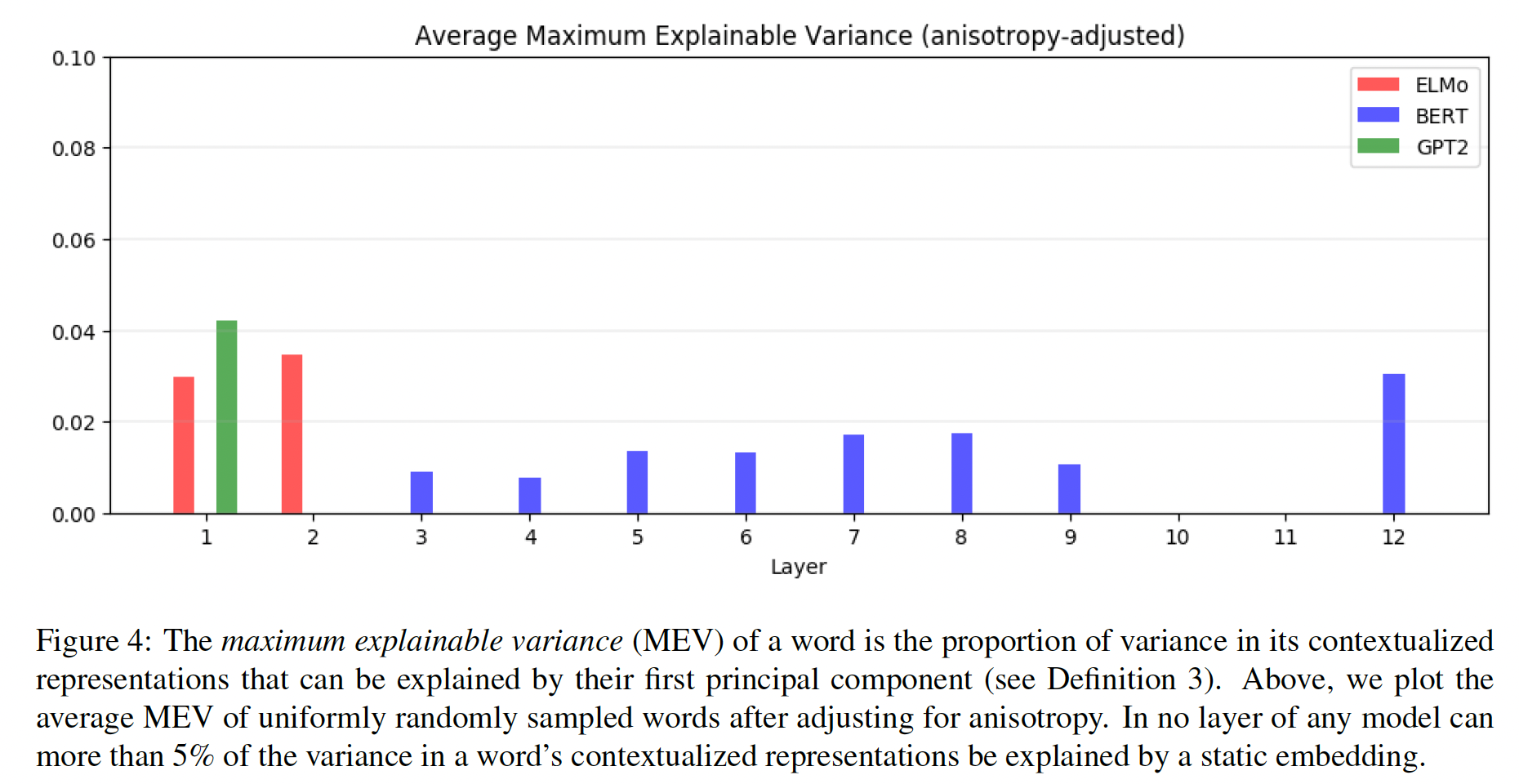
lower layers的contextualized representation的主成分在许多benchmark上优于GloVe和FastText。如前所述,我们可以通过在给定层中抽取其
contextualized representation的第一个主成分(principal component: PC)来为每个单词创建static embedding。在下表中,我们绘制了这些PC static embedding在几个benchmark任务中的表现。这些任务包括语义相似性semantic similarity、analogy solving、concept categorization:Sim-Lex999、MEN、WS353、RW、SemEval-2012、Google analogy solving、MSR analogy solving、BLESS、AP。我们在下表中不考虑第3 ~ 10层,因为它们的性能介于第2层和第11层之间。表现最好的
PC static embedding属于BERT的第一层,尽管BERT和ELMo的其他层的embedding在大多数benchmark上也优于GloVe和FastText。对于所有三个
contextualizing model,从lower layer创建的PC static embedding比从upper layer创建的更有效。使用
GPT-2创建的static embedding也明显比来自ELMo和BERT的static embedding表现更差。GPT-2创建的static embedding甚至要比GloVe和FastText更差。
鉴于
upper layer比lower layer更加context-specific,而且GPT-2的representation比ELMo和BERT的更加context-specific(见Figure 2),这表明高度context-specific的representation的PC static embedding在传统benchmark上不那么有效。那些less context-specific representation(如,来自BERT第一层的representation)派生的PC static embedding,则要有效得多。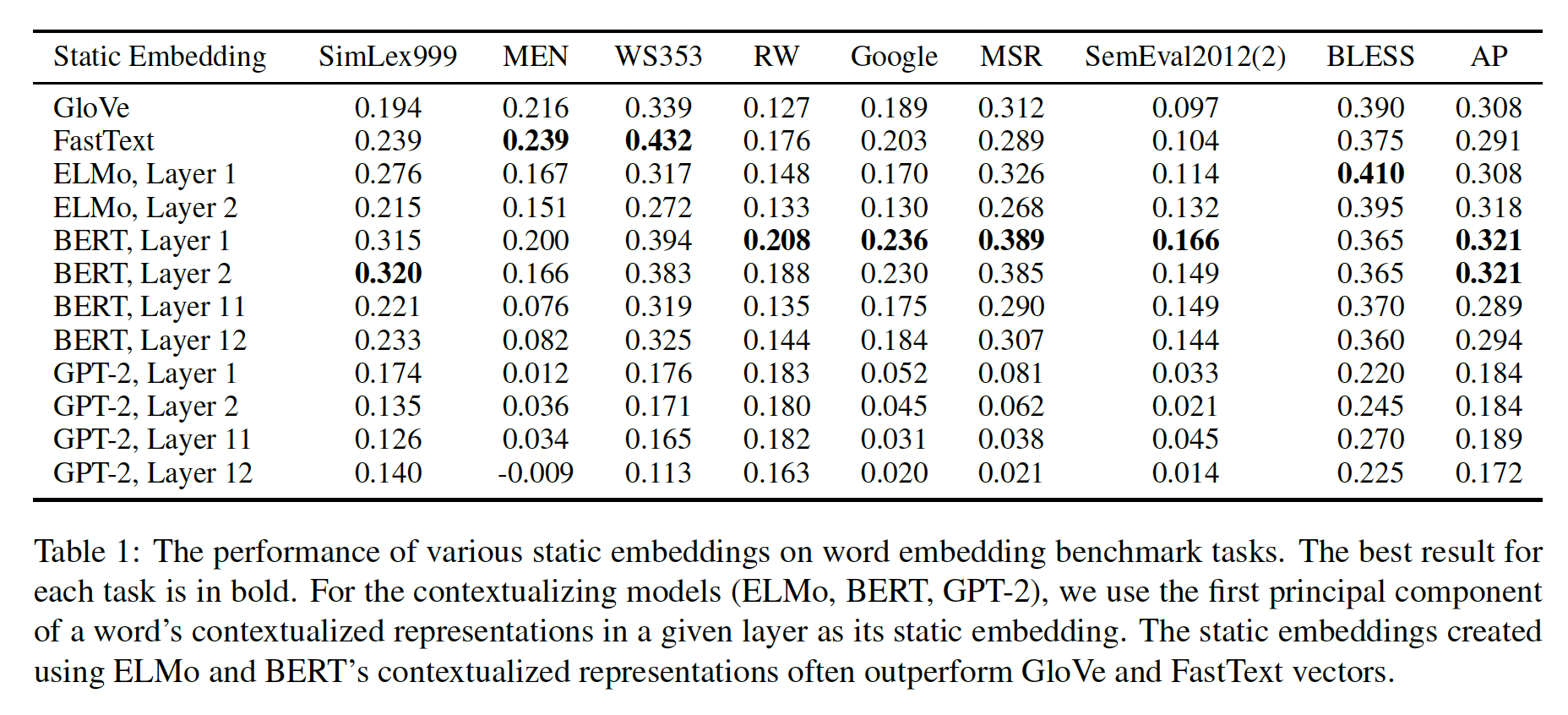
未来工作:
首先,正如本文前面所指出的,
《All-but-the-top: Simple and effective postprocessing for word representations》发现,使static embedding更加各向同性(通过从每个embedding中减去其均值),导致下游任务的性能有惊人的改善。鉴于各向同性对static embedding有好处,它也可能对contextualized word representation有好处,尽管后者在高度各向异性的情况下已经取得了明显的改善。因此,在language modelling objective中加入各向异性的惩罚可能会产生更好的结果,如鼓励contextualized representation更加各向同性。另一个方向是从
contextualized word representation中生成static word representation。虽然后者提供了卓越的性能,但在生产中部署像BERT这样的大型模型,在内存和运行时间方面往往存在挑战。相比之下,static word representation更容易部署。我们的工作表明,不仅有可能从contextualizing model中提取static representation,而且与传统的static embedding(如GloVe和FastText)相比,这些extracted vector往往在各种任务中表现得更好。在推断期间:
static embedding执行的是lookup operation,因此速度更快;而contextualized embedding执行的是前向传播,因此速度很慢。
三十七、CERT [2020]
大规模的
pretrained language representation model(如BERT, GPT, BART等),在各种自然语言处理任务中取得了卓越的性能,如文本生成、阅读理解、文本分类等任务。这些模型的架构大多基于Transformer,它使用自注意力来捕获token之间的长距离依赖关系。Transformer编码器或解码器通过自监督任务在大规模文本语料库上进行预训练,这些自监督任务包括:预测masked token(BERT),生成future token(GPT),恢复corrupted token(BART)等等。在这些工作中,要预测的target大多是在word level。因此,sentence level的全局语义可能没有被充分捕获。为了解决这个问题,论文
《CERT: Contrastive Self-supervised Learning for Language Understanding》提出了CERT:Contrastive self-supervised Encoder Representations from Transformers,它使用contrastive self-supervised learning: CSSL来学习sentence-level representation。最近,
CSSL在以无监督的方式学习visual representation方面显示出很好的效果。CSSL的关键思想是:创建原始样本的augmentation,然后通过预测两个augmentation是否来自同一个原始数据样本来学习representation。CERT使用back-translation(《Understanding back-translation at scale》)创建句子的增强augmentation,然后通过预测两个augmentation是否来自同一个原始句子来微调pretrained language representation model(例如BERT, BART)。现有的预训练方法在token上定义prediction task。相反,CERT在sentence上定义prediction task,这可以推测在sentence level更好地捕获全局语义。CERT使用back-translation来对句子执行augmentation。给定源语言source languageCERT使用target languageaugmentation。不同目标语言的翻译模型被用来创建同一个源句的不同的augmentation。要求有合适的翻译模型,并且翻译模型的质量会影响
CERT的效果。给定
augmented sentences,Momentum Contrast: MoCo方法(《Momentum contrastfor unsupervised visual representation learning》)被用来执行CSSL。MoCo维护一个关于augmented sentences(称作keys)的队列,该队列使用带有动量更新的pretrained text-encoder(例如BERT)进行编码。给定一个augmented sentence(称为query),通过BERT(或任何其他pretrained text-encoder)来计算query encoding与队列中每个key embedding之间的相似性分数。如果query和key是同一个原始句子的augmentation,则它们被标记为positive pair,否则被标记为negative pair。这些二元标签和相似性分数被用来计算contrastive loss。pretrained text encoder的权重是通过最小化contrastive loss来进一步预训练的。为了在下游任务上应用pretrained CERT model,CERT使用下游任务的输入数据和标签对CERT的权重进行微调。也可以用
in-batch负样本来代替这里的MoCo方法。CERT是一个灵活的模块,可以与任何pretrained language representation model集成,如BERT, BART, ERNIE 2.0, T5等。作者在GLUE benchmark中的11个自然语言理解任务上评估了CERT,其中CERT在7个任务上优于BERT,在2个任务上达到与BERT相同的性能,而在2个任务上表现比BERT差。在11项任务的平均得分上,CERT优于BERT。这些结果表明,通过捕获sentence-level的语义,针对language representation的contrastive self-supervised learning的有效性。论文贡献:
提出了
CERT,一种基于contrastive self-supervised learning的新的language representation pretraining方法。CERT是在sentence level定义了predictive task,因此预计可以更好地捕获sentence-level的语义。在
GLUE benchmark的11个自然语言理解任务上对CERT进行了评估,CERT在11个任务的平均得分上优于BERT。进行了消融研究,以研究
CERT的性能如何受到sentence augmentation方法和预训练语料源的影响。
CERT是针对sentence embedding的一系列对比学习方法中的一种。这些对比学习方法的核心在于:如何创建augumentation、对比学习的负样本。相关工作:
针对
learning language representation的pretraining:最近,在大规模文本语料库上进行language representation learning的预训练已经取得了实质性的成功。GPT模型是一个基于Transformer的语言模型(language model: LM)。Transformer定义了在给定input sequence的条件下得到output sequence的条件概率。与Transformer不同,GPT定义了在单个output sequence上的边际概率。在GPT中,给定历史序列的条件下,next token的条件概率是通过Transformer decoder来定义的。权重参数是通过最大化token序列的可能性来学习的。GPT-2是GPT的扩展,它对GPT进行了修改,将layer normalization作用到每个sub-block的输入,并在final self-attention block后增加一个additional layer normalization。Byte pair encoding: BPE被用来表示token的输入序列。BERT-GPT是一个用于sequence-to-sequence modeling的模型,其中pretrained BERT被用来编码输入文本,pretrained GPT被用来生成输出文本。在BERT-GPT中,BERT encoder和GPT decoder的预训练是单独进行的,这可能导致性能下降。Auto-Regressive Transformer BART具有与BERT-GPT类似的架构,但对BERT encoder和GPT decoder进行联合训练。为了预训练BART权重,输入文本被随机破坏,如token masking、token deletion、文本填充等,然后学习网络以重建原始文本。ALBERT使用parameter-reduction方法来减少内存消耗并提高BERT的训练速度。它还引入了自监督损失用于建模句子间的一致性inter-sentence coherence。RoBERTa是一项关于BERT预训练的复现研究。它表明,通过仔细调优训练过程,BERT的性能可以得到显著的改善,如:用更多的数据、更大的batch size、更长的训练时间;移除next sentence prediction objective;在更长的序列上训练。等等。XLNet通过对factorization order的所有排列的expected likelihood的最大化,从而来学习bi-directional context,并使用广义自回归预训练机制generalized autoregressive pretraining mechanism来克服BERT的pretrain-finetune discrepancy。T5比较了各种语言理解任务的预训练目标、架构、未标记数据集、transfer方法,并提出了一个统一的框架,将这些任务转换为一个text-to-text的任务。统一的模型在一个大型的Colossal Clean Crawled Corpus: C4上进行训练,然后被迁移到各种各样的下游任务中。ERNIE 2.0提出了一个continual pretraining framework,该框架通过持续的多任务学习来建立和学习incrementally pretraining task,以捕获训练语料中的词法信息、句法信息、以及语义信息。
Contrastive Self-supervised learning:Contrastive self-supervised learning最近引起了很多研究兴趣。《Data-efficient image recognition with contrastive predictive coding》研究了基于contrastive predictive coding的data-efficient的图像识别,它通过使用强大的自回归模型在潜在空间中预测未来。《Curl: Contrastive unsupervised representations for reinforcement learning》提出了为强化学习来学习contrastive unsupervised representation。《Supervised contrastive learning》研究了supervised contrastive learning,其中属于同一类别的数据点的cluster在embedding空间中被拉到一起,而来自不同类别的数据点的cluster被推开。《Contrastive self-supervised learning for commonsense reasoning》提出了一种用于常识推理的contrastive self-supervised learning的方法。《Sample-effcient deep learning for covid-19 diagnosis based on ct scans》提出了一种Self-Trans方法,该方法在通过transfer learning从而在pretrained network之上应用contrastive self-supervised learning。
37.1 模型
针对
pretraining language representation模型的最近的工作中,大多数工作都是基于Transformer架构。例如,BERT预训练Transformer encoder、GPT预训练Transformer decoder、BART联合预训练Transformer encoder和Transformer decoder。Transformer:Transformer是一个用于序列到序列(sequence-to-sequence: seq2seq)建模的encode-decoder架构。基于递归神经网络的
seq2seq模型(如LSTM、GRU)通过递归方式对token序列进行建模,因此计算效率低。Transformer不同,它摒弃了递归计算,转而使用自注意力,这不仅可以捕获到token之间的依赖性,而且还能高效地并行计算。自注意力计算每一对token之间的相关性,并通过对token embedding进行加权求和从而使用这些相关性得分来创建"attentive" representation。BERT:BERT的目的是学习一个用于表示文本的Transformer encoder。BERT的模型架构是一个多层双向Transformer encoder。在BERT中,Transformer使用双向的自注意力。为了训练编码器,BERT随机掩码了一定比例的input token,然后预测这些masked token。为了将
pretrained BERT应用于下游任务,如句子分类,可以在BERT架构的基础上增加一个附加层,并使用目标任务中的标记数据训练这个newly-added layer。
Contrastive Self-supervised Learning:自监督学习(Self-supervised learning: SSL)是一种学习范式,旨在不使用人类提供的标签来捕获输入数据的内在模式和固有属性。自监督学习的基本思想是完全基于输入数据本身构建一些辅助任务(而不使用人类标注的标签),并迫使网络通过很好地执行辅助任务来学习有意义的representation,如旋转预测rotation prediction、图像绘画image inpainting、自动着色automatic colorization、上下文预测context prediction等等。自监督学习中的辅助任务可以使用许多不同的机制来构建。最近,一种对比性机制获得了越来越多的关注,并在一些研究中展示了有希望的结果。对比性自监督学习的基本思想是:生成原始数据样本的
augmented样本,创建一个预测任务,目标是预测两个augmented样本是否来自同一个原始数据样本,并通过解决这个任务来学习representation network。人们已经提出了不同的方法来实现对比性自监督学习。在为图像数据设计的
SimCLR中,给定输入图像,对这些图像应用随机数据增强。如果两张augmented图像是由相同的原始图像创建的,它们就被标记为相似;否则,它们就被标记为不相似。然后SimCLR学习一个网络来拟合这些相似/不相似的二元标签。该网络由两个模块组成:一个是特征提取模块
latent representation另一个是多层感知机
latent representation
给定一对相似的图像
contrastive loss可以被定义为:其中:
cosine相似度;SimCLR通过最小化这种损失来学习网络权重。训练结束后,特征提取模块这里要求
虽然
SimCLR很容易实现,但它需要一个大的mini-batch size来产生良好的效果,这在计算上是难以实现的。MoCo通过使用一个独立于mini-batch size的队列来解决这个问题。这个队列包含一个动态的、augmented样本集合(称为keys)。在每次迭代中,最新的mini-batch样本被添加到队列中;同时,最旧的mini-batch样本被从队列中删除。通过这种方式,队列与mini-batch size是解耦的。如下图所示。keys是用momentum encoder编码的。给出当前mini-batch中的一个augmented样本(称为query)、以及队列中的一个key,如果它们来自同一图像,则被认为是positive pair,否则就是negative pair。MoCo计算query encoding和每个key encoding之间的相似性得分。contrastive loss是在相似度的得分和二元标签上定义的。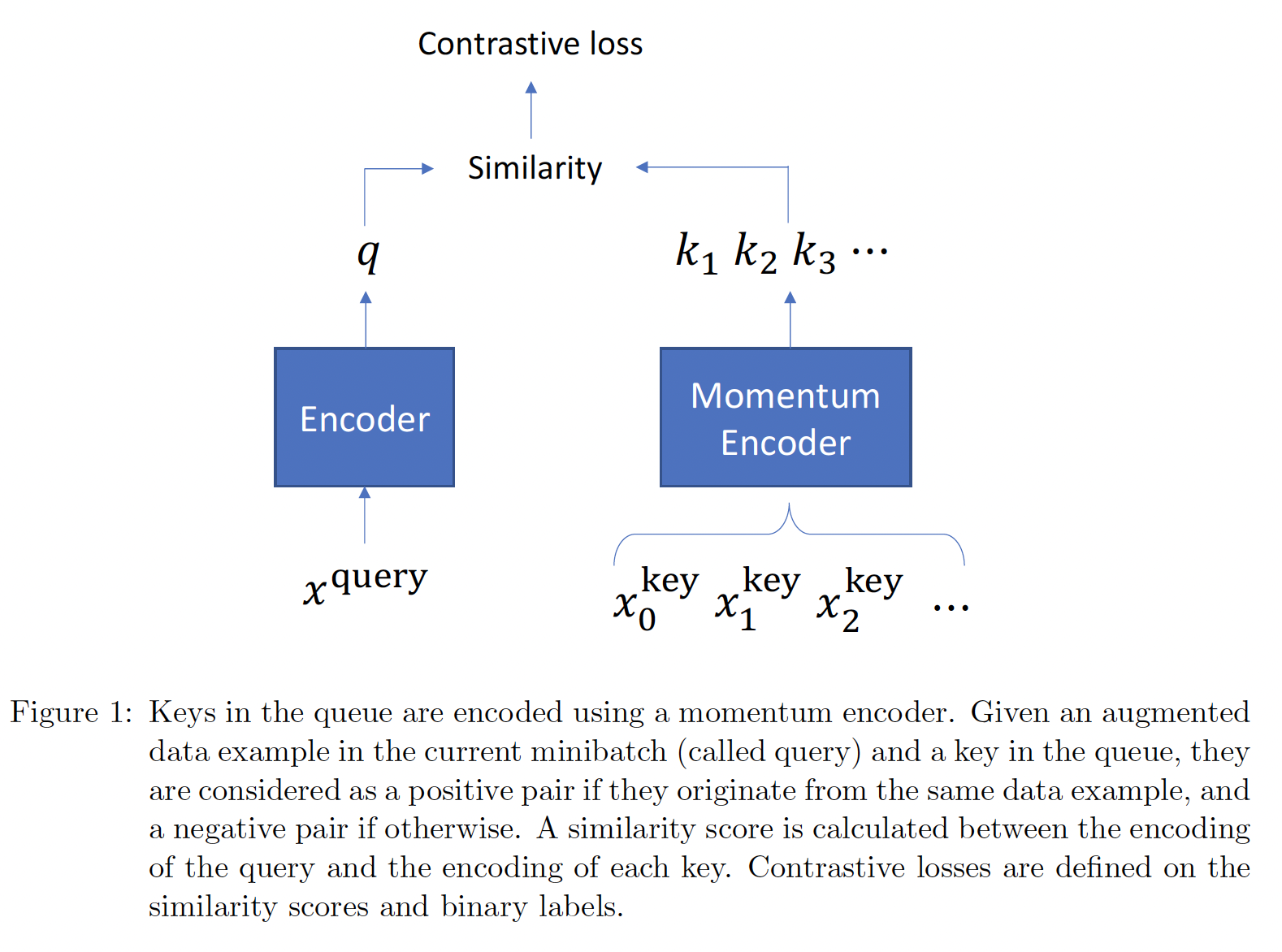
CERT:CERT采用pretrained language representation model(如BERT),并在目标任务的输入数据上使用contrastive self-supervised learning对其进行微调。下图展示了CERT的工作流程。为了便于演示,我们使用BERT作为pretrained language representation model。给定来自源任务的大规模输入文本(没有标签),首先在这些文本上预训练一个
BERT模型。注意,源任务的大规模输入文本没有使用对比学习,而是用
BERT的原始优化目标来训练。然后,我们使用
contrastive self-supervised learning在目标任务的输入文本(无标签)上继续训练这个pretrained BERT model。我们把这个模型称为pretrained CERT model。只有目标任务的输入文本才使用对比学习。
然后,我们使用目标任务中的输入文本及其标签对
CERT模型进行微调,得到执行目标任务的最终模型。目标任务的输入文本被使用两次:一次是无监督的对比学习、一次是有监督的目标任务。
在
contrastive self-supervised learning训练中,CERT使用back-translation对目标任务中的原始句子进行增强:如果两个augmented sentences是由同一个原始句子创建的,则被认为是positive pair,否则就是negative pair。augmented sentences用BERT编码,并计算一对句子在BERT encoding上的相似性得分。contrastive loss是根据二元标签和相似性得分来确定的。然后,通过最小化contrastive loss来进一步微调pretrained BERT encoder。我们使用
MoCo来实现contrastive self-supervised learning,以避免使用大型的mini-batch(大型的mini-batch导致计算量太大)。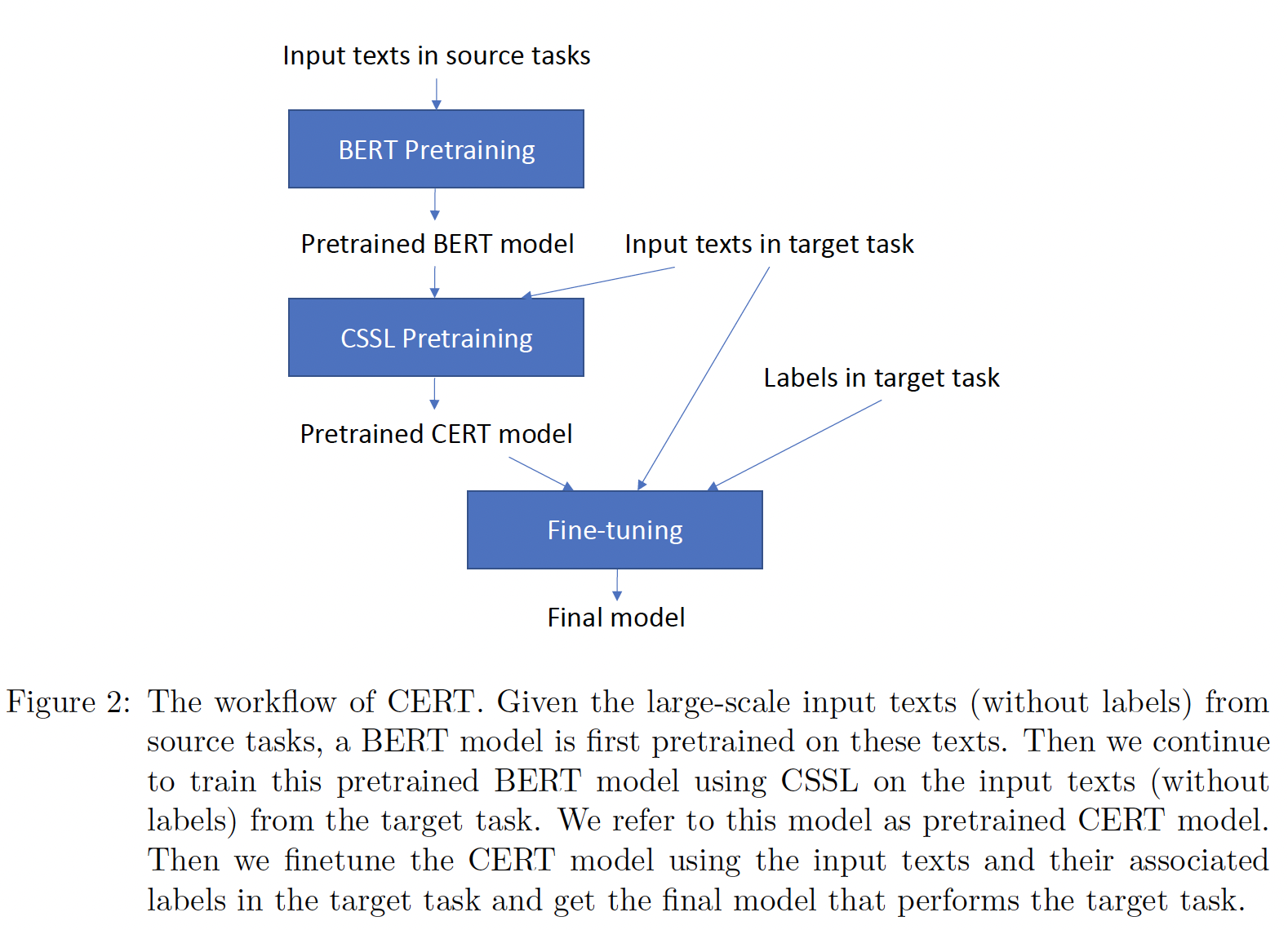
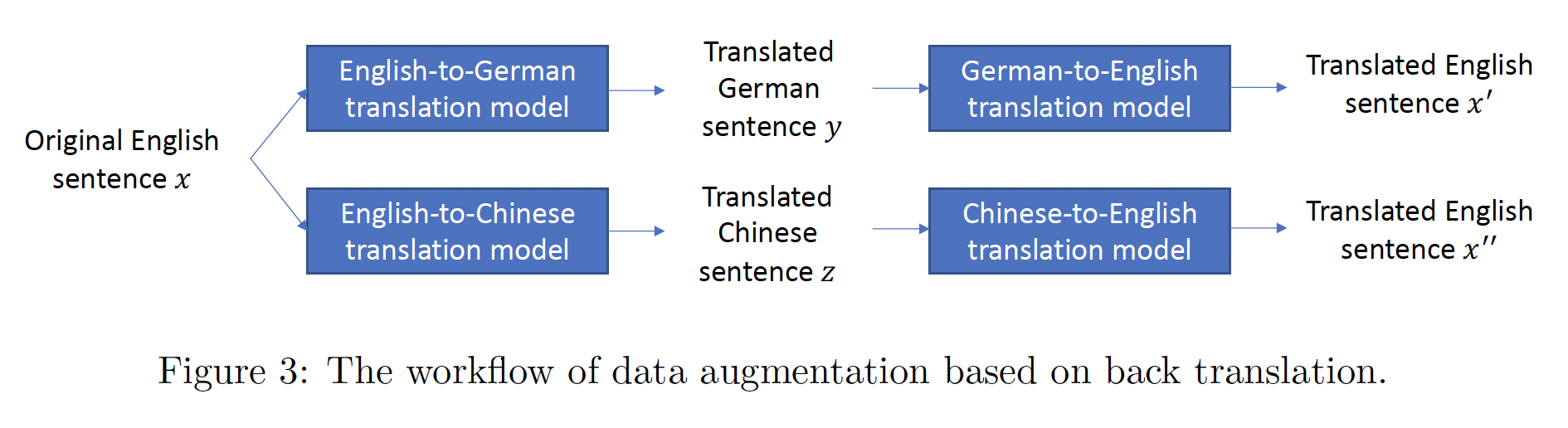
数据增强:下图展示了基于
back-translation的数据增强的工作流程。对于目标任务中的每个输入句子back-translation对其进行增强。在不失一般性的情况下,我们假设目标任务中的语言是英语。我们使用
English-to-German机器翻译模型将German-to-English机器翻译模型将augmented sentence。同样地,我们使用一个
English-to-Chinese机器翻译模型和一个Chinese-to-English机器翻译模型来获得另一个augmented sentence
我们使用
《Massive exploration of neural machine translation architectures》中开发的机器翻译模型用于back-translation。仅对目标任务的输入文本进行数据增强。
CSSL Pretraining:我们使用MoCo来实现CSSL。给定两个augmented sentences,如果它们源自同一个原始句子,它们就被标记为positive pair;如果它们来自不同的句子,它们就被标记为negative pair。我们使用一个队列来维护一个augmented sentence集合keys。给定当前mini-batch中的一个augmented sentencequery),我们将它与队列中的每个key进行比较。query用pretrained BERT modelkey用pretrained BERT model
key模型query模型key队列的变化比较缓慢。在不失一般性的情况下,我们假设队列中有单个
keypositive pair。contrastive loss定义为:其中:
query BERT encoder的权重是通过最小化该损失来进行微调的。请注意,在这个步骤中,只使用目标任务的输入句子,而不需要这些句子的标签。为了将pretrained CERT model应用于下游任务,我们进一步在目标任务中的输入句子及其标签上微调模型权重。未来工作:我们计划研究更具挑战性的自监督学习的损失函数。我们有兴趣研究一种
ranking-based loss,,即每个句子都被增强了ranked list的句子,这些augmented句子与原句的差异越来越小。辅助任务是预测给定的augmented句子的排序。预测排序可能比CSSL中的二分类更具挑战性,并可能有助于学到更好的representation。另外,是否考虑对源任务的输入文本也执行对比学习?
37.2 实验
评估任务:
General Language Understanding Evaluation: GLUE基准,包含11个任务。我们通过向GLUE评估服务器提交推理结果来获得测试集的性能。数据集如下表所示。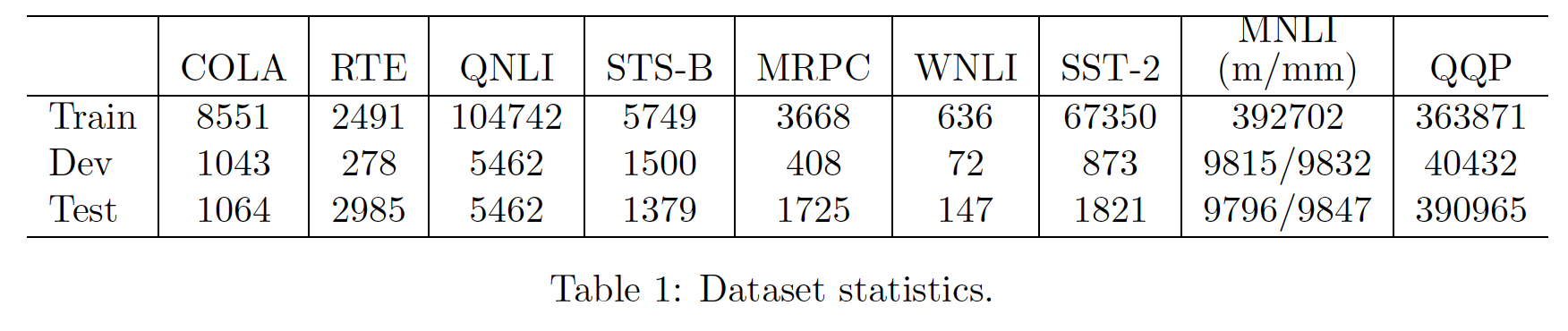
实验配置:
在
MoCo中,队列的大小被设置为96606。MoCo更新key encoder的动量系数为m = 0.999。contrastive loss中的温度超参数为使用
multi-layer perceptron head。对于
MoCo training,使用带动量的随机梯度下降优化器。mini-batch size = 16。初始学习率为4e-5,并使用余弦调度器。epoch数量为100。权重衰减系数为1e-5。对于
GLUE任务上的微调,最大序列长度被设置为128,mini-batch size = 16。学习率设置:
CoLA, MNLI, STS-B为3e-5、RTE, QNLI, MRPC, SST-2, WNLI为2e-5、QQP为1e-5。训练
epoch数量:CoLA为20、RTE, WNLI, QQP为5、QNLI, MNLI为3、MRPC为15、SST-2为4、STS-B为10。
验证集上的评估结果:
GLUE任务中,验证集效果如下表所示。遵从ALBERT,我们对微调进行了5次随机重启,并报告了这5次运行中的中位数和最佳性能。由于5次重启的随机性,我们的中位数性能与ALBERT报告的不一致。但一般来说,它们是接近的。可以看到:就中位数性能而言,我们提出的
CERT在5个任务上优于BERT,包括CoLA, RTE, QNLI, SST-2, QQP;在其他5个任务中,CERT与BERT持平。这证明了CERT在通过contrastive self-supervised learning来学习更好的language representation方面的有效性。其次,就最佳性能而言,
CERT在7个任务上的表现优于BERT,包括CoLA, RTE, QNLI, STS-B, MNLI-m, MNLI-mm, QQP。CERT在MRPC和WNLI上与BERT持平。CERT在SST-2上的表现不如BERT好。这些结果进一步证明了CERT的有效性。第三,在训练数据较少的任务(如
CoLA和RTE)上,CERT比BERT的改进更为显著。一个可能的原因是,小规模的训练数据更容易过拟合,这使得CSSL预训练的必要性更加突出。第四,在
CoLA和RTE这样的小规模数据集上,CERT获得了更大的提升。这表明,在解决训练数据量有限的低资源NLP任务方面,CERT很有前途。
为了方便读者,我们还展示了
SOTA的预训练方法的结果,包括XLNet, RoBERTa, ERNIE 2.0, ALBERT。CERT在CoLA上取得了接近XLNet的性能,对计算资源的消耗要低得多,而且文本语料库也小得多。XLNet, RoBERTa, ERNIE 2.0, ALBERT是在数百到数千台GPU机器上训练数天的,而CERT是使用单个GPU训练十几个小时的。此外,这些模型是在几十或几百GB的文本上训练的,而CERT只在大约400KB的文本上训练。CERT也可以建立在这些pretrained model之上,这将留待将来研究。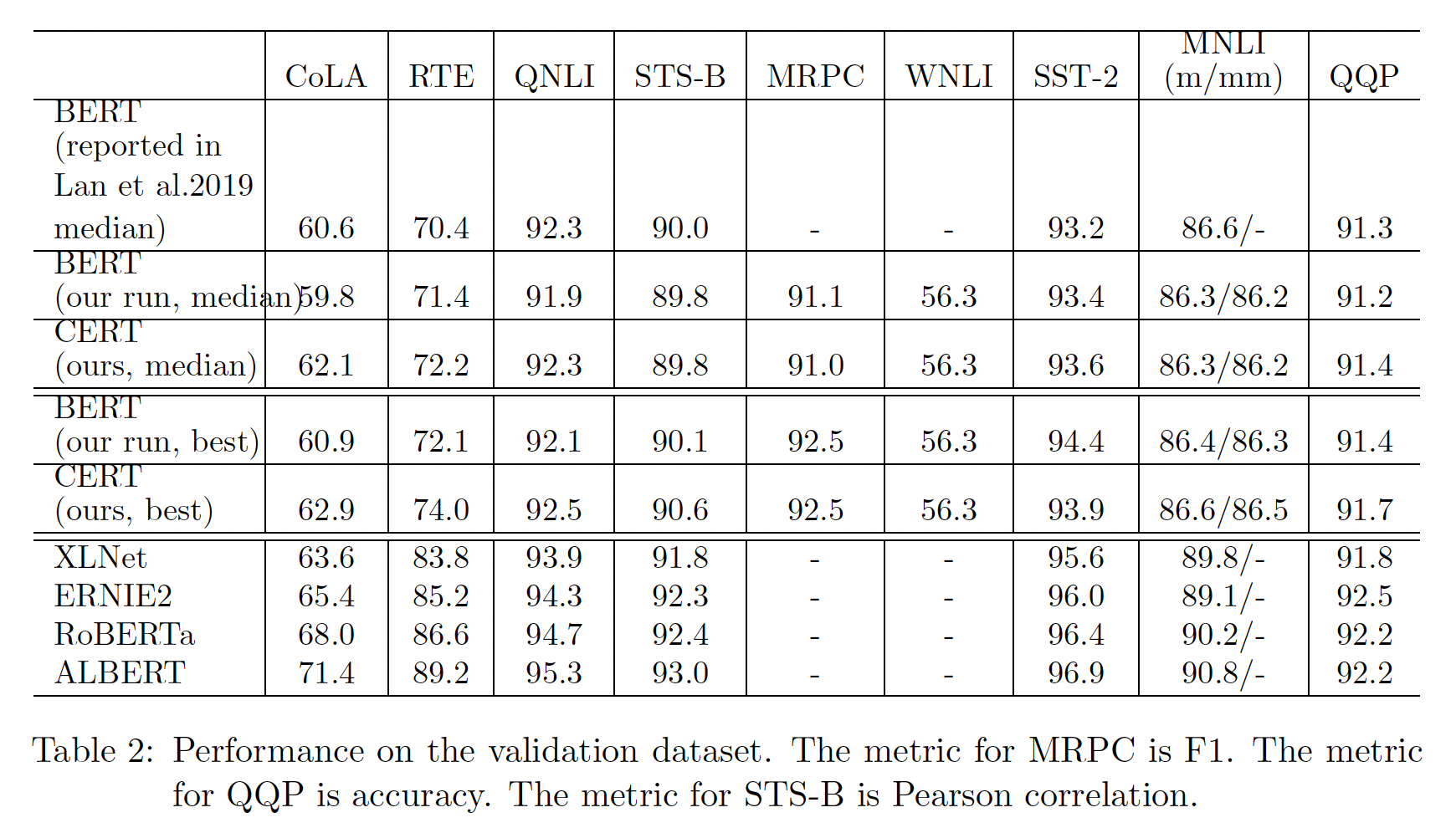
测试集上的评估结果:
GLUE任务中,测试集效果如下表所示。可以看到:在
11个任务中,CERT在7个任务上的表现优于BERT,包括RTE, QNLI, STS-B, MRPC, MNLI-m, MNLI-mm, QQP。CERT在WNLI和AX上实现了与BERT相同的性能,在CoLA和SST-2上表现比BERT更差。CERT取得了80.7的平均分,比BERT好。总的来说,CERT的表现比BERT好,这进一步证明了contrastive self-supervised learning是一种学习更好的language representation的有效方法。虽然
CERT在CoLA的验证集上取得了比BERT好得多的性能,但在CoLA的测试集上比BERT更差。这可能是因为CoLA的测试集和验证集有很大的domain difference。
下表还列出了其他
SOTA方法的性能。下一步,我们计划用XLNet, ERNIE2, T5, RoBERTa, ALBERT取代CERT中基于BERT的sentence encoder,看看CSSL预训练是否能提高这些编码器的性能。CERT在预训练、微调之外,还增加了一个对比学习任务,这使得CERT比BERT训练了更多的数据。这其实是一种不太公平的比较。应该让BERT在目标任务的输入文本(不包含标签)上继续预训练,使得BERT和CERT训练的数据量相同。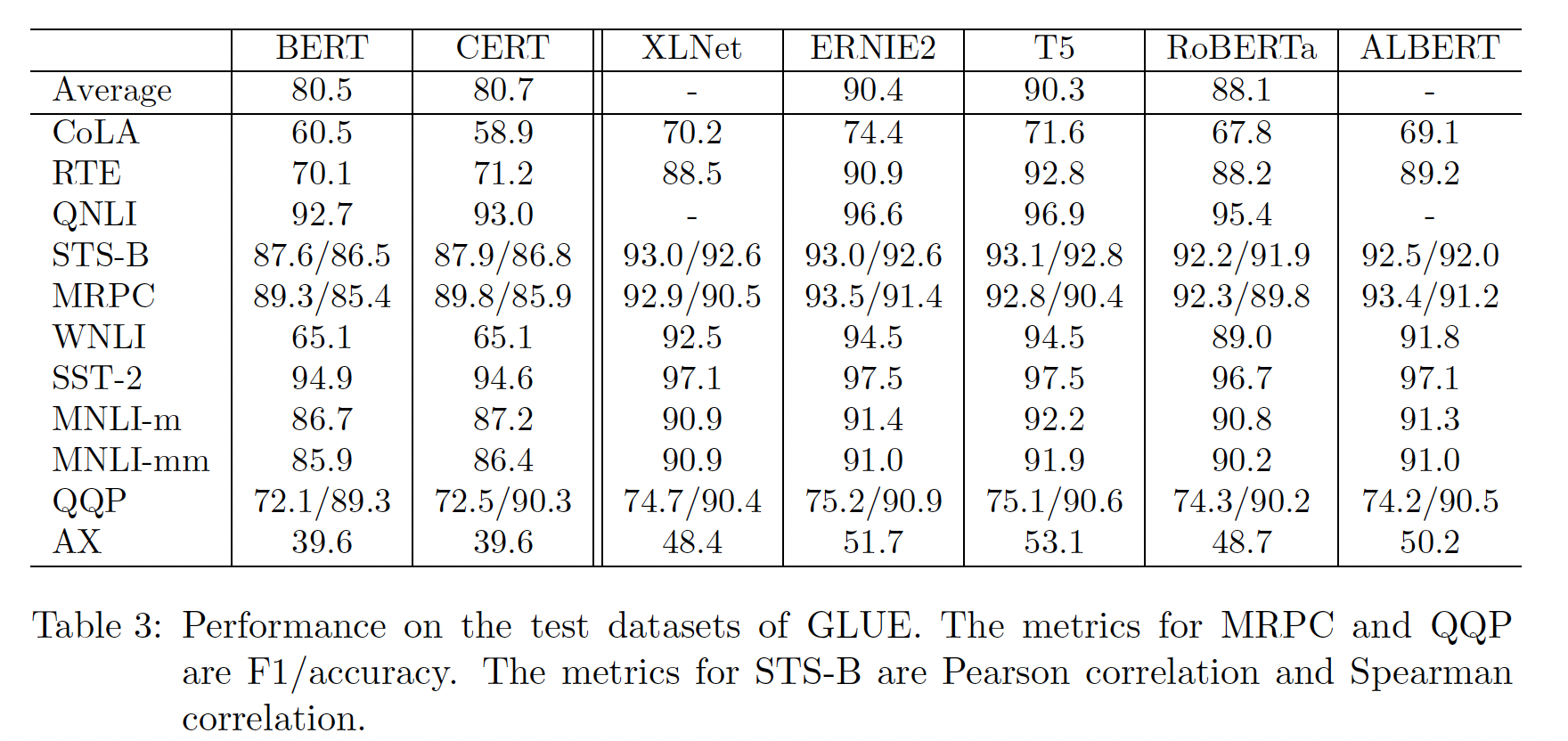
Data Augmentation的消融研究:CERT的一个关键要素是创建augmented sentence。默认情况下,我们使用back-translation来进行数据增强。研究其他的数据增强方法也是很有趣的。我们将back-translation与最近提出的文本增强方法Easy Data Augmentation: EDA(《Eda: Easy data augmentation techniques for boosting performance on text classification tasks》)进行比较。给定训练集中的一个句子,EDA随机选择并执行以下操作之一:同义词替换、随机插入、随机互换、随机删除。下表显示了
CERT在CoLA和RTE任务上分别使用back-translation和EDA进行增强的结果。可以看到:总的来说,back-translation取得了比EDA更好的结果,只是back-translation在STS-B上的中位数性能比EDA低0.1%。back-translation效果更好的原因可能是:back-translation在sentence level上进行全局地增强(整个句子被来回地翻译),而EDA在word/phrase level上进行局部地增强。因此,back-translation可以更好地捕获句子的全局语义,而EDA则是捕获局部语义。另一个原因可能是:通过
back-translation增强的句子与原始句子有更大的差异。相比之下,由EDA增强的句子与原始句子很接近,因为EDA对原始句子进行了局部编辑,并保持了句子的大部分内容不受影响。因此,预测两个通过back-translation增强的句子是否来自同一个原句,要比预测那些通过EDA增强的句子更难。解决一个更具挑战性的CSSL任务通常会带来更好的representation。
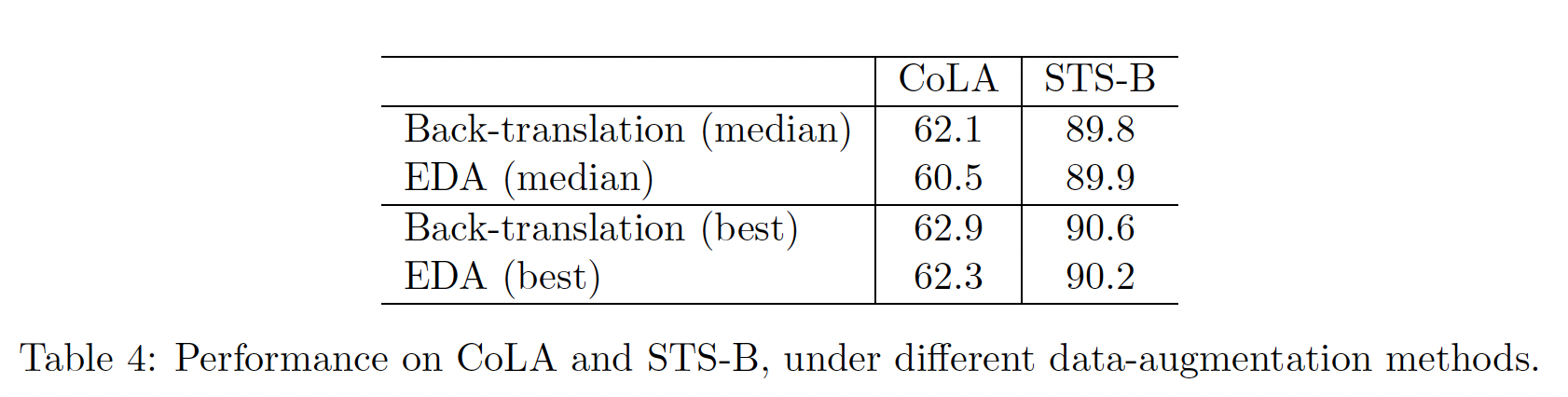
CSSL Pretraining Corpora的消融研究:另一个有趣的研究点是应该使用什么语料来训练CSSL。在CERT中,默认情况下,我们使用目标任务的训练数据(不包括标签)用于CSSL。我们与以下设置进行比较:我们从BERT的训练语料库中随机抽取下表显示了在
CoLA和STS-B上的表现,CSSL在不同的语料库上进行了预训练。在
CoLA任务中,当使用CoLA的训练数据时,可以获得更好的性能。在
STS-B任务中,当使用BERT预训练语料库时,取得了更好的性能。
从这项研究中,我们并没有得出哪种方法更好的明确结论。在实践中,尝试这两种方法并找出哪种方法更有效,可能是有用的。