词的表达
给定包含
每篇文档
词的表达任务要解决的问题是:如何表示每个词汇
最简单的表示方式是
one-hot编码:对于词汇表中第1,剩余位取值为0。这种表示方式有两个主要缺点:
无法表达单词之间的关系:对于任意一对单词
向量维度过高:对于中文词汇表,其大小可能达到数十万,因此
one-hot向量的维度也在数十万维。这对于存储、计算都消耗过大。
BOW:Bag of Words:词在文档中不考虑先后顺序,这称作词袋模型。
一、向量空间模型 VSM
向量空间模型主要用于文档的表达。
向量空间模型假设单词和单词之间是相互独立的,每个单词代表一个独立的语义单元。实际上该假设很难满足:
文档中的单词和单词之间存在一定关联性,单词和其前面几个单词、后面几个单词可能存在语义上的相关性,而向量空间模型忽略了这种上下文的作用。
文档中存在很多的一词多义和多词同义的现象,每个单词并不代表一个独立的语义单元。
1.1 文档-单词 矩阵
给定语料库
文档-单词矩阵为:令矩阵为
于是文档
事实上,文档的上述表达并未考虑单词的顺序,也未考虑单词出现的次数。一种改进策略是考虑单词出现的次数,从而赋予
文档-单词矩阵以不同的权重:其中
如果单词
如果单词
权重
单词权重等于单词出现的频率
TF:函数
其缺点是:一些高频词(如:
我们,是,大家)以较大的权重出现在每个文档中,这意味着对每篇文档这些高频词是比较重要的。事实上对于绝大多数NLP任务,将这些词过滤掉不会有任何影响。
单词权重等于单词的
TF-IDF:函数
TF-IDF对于高频词进行降权。如果单词
TF-IDF不仅考虑了单词的局部特征,也考虑了单词的全局特征。词频
逆文档频率
1.2 相似度
给定
文档-单词矩阵,则很容易得到文档的向量表达:给定文档
其中
也可以使用其它方式的相似度,如
二、LSA
潜在语义分析
latent semantic analysis:LSA的基本假设是:如果两个词多次出现在同一篇文档中,则这两个词具有语义上的相似性。
2.1 原理
给定
文档-单词矩阵其中
0/1值、单词TF-IDF值。定义
单词-文档向量,描述了该单词和所有文档的关系。向量内积
矩阵乘积
定义
文档-单词向量,描述了该文档和所有单词的关系。向量内积
矩阵乘积
对矩阵
SVD分解。假设矩阵其中
SVD分解的物理意义为:将文档按照主题分解。所有的文档一共有第
文档-主题向量)为:第
主题-单词向量)为:第
单词-主题向量)为:根据
则该分解的物理意义为:
文档-单词矩阵 =文档-主题矩阵 x主题强度x主题-单词矩阵。
2.2 应用
得到了文档的主题分布、单词的主题分布之后,可以获取文档的相似度和单词的相似度。
文档
单词
虽然获得了文档的单词分布,但是并不能获得主题的相似度。因为
则有:
因此,任意两个主题之间的相似度为 0 。
文档-主题向量由文档-主题向量为文档-单词向量为因此对于一篇新的文档
文档-单词向量为文档-主题向量为:LSA可以应用在以下几个方面:通过对文档的
文档-主题向量进行比较,从而进行基于主题的文档聚类或者分类。通过对单词的
单词-主题向量进行比较,从而用于同义词、多义词进行检测。通过将
query映射到主题空间,进而进行信息检索。
2.3 性质
LSA的本质是将矩阵SVD进行降维,降维主要是由于以下原因:原始的
文档-单词矩阵原始的
文档-单词矩阵原始的
文档-单词矩阵
LSA的降维可以解决一部分同义词的问题,也可以解决一部分二义性的问题。经过降维,意义相同的同义词的维度会因降维被合并。
经过降维,拥有多个意义的词,其不同的含义会叠加到对应的同义词所在的维度上。
LSA的缺点:产生的主题维度可能存在某些主题可解释性差。即:它们并不代表一个人类理解上的主题。
由于
Bag of words:BOW模型的局限性,它无法捕捉单词的前后顺序关系。一个解决方案是:采用二元词组或者多元词组。
LSA假设单词和文档形成联合高斯分布。实际观察发现,它们是一个联合泊松分布。这种情况下,用pLSA模型效果会更好。
三、Word2Vec
3.1 CBOW 模型
CBOW模型(continuous bag-of-word):根据上下文来预测下一个单词。
3.1.1 一个单词上下文
在一个单词上下文的
CBOW模型中:输入是前一个单词,输出是后一个单词,输入为输出的上下文。由于只有一个单词作为输入,因此称作一个单词的上下文。
一个单词上下文的
CBOW模型如下: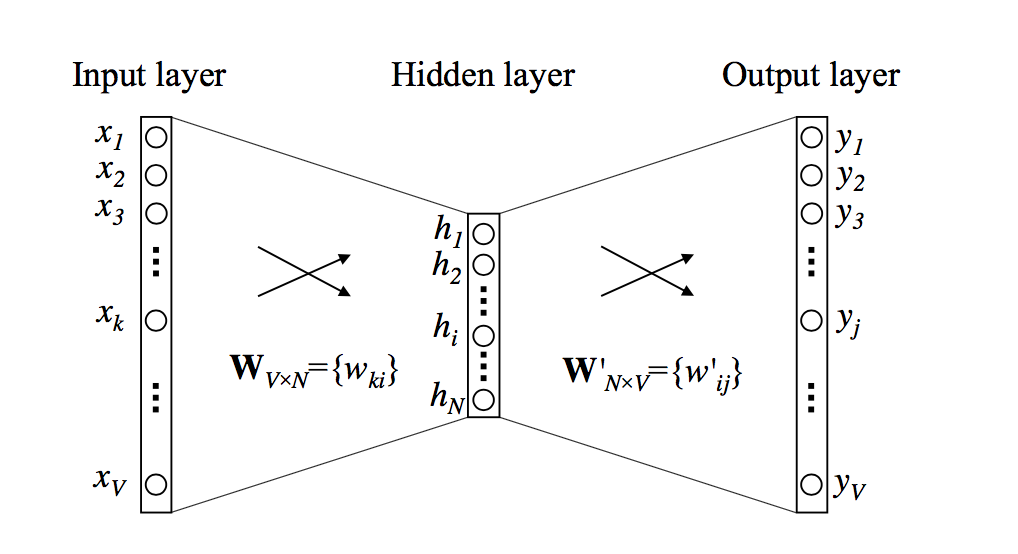
其中:
网络输入
one-hote编码,其中只有一位为 1,其他位都为 0 。网络输出
相邻层之间为全连接:
输入层和隐层之间的权重矩阵为
隐层和输出层之间的权重矩阵为
假设没有激活函数,没有偏置项。给定输入
令:
由于
one-hot编码,假设它为词表则有:
即:
给定隐向量
则有:
softmax层,则有:即
假设输入单词为
考虑语料库
则网络的优化目标为:
设张量
则该参数的单次更新
因此本节的参数更新推导是关于单个样本的更新:
3.1.2 参数更新
定义
它刻画了每个输出单元的预测误差:
当
当
根据:
则
其物理意义为:
当估计过量 (
当估计不足 (
当
定义:
根据:
考虑到
写成矩阵的形式为:
由于
one-hote编码,所以它只有一个分量非零,因此其中
考虑更新
当
当
当给定许多训练样本(每个样本由两个单词组成),上述更新不断进行,更新的效果在不断积累。
根据单词的共现结果,输出向量与输入向量相互作用并达到平衡。
输出向量
这里隐向量
输入向量
这里
平衡的速度与效果取决于单词的共现分布,以及学习率。
3.1.3 多个单词上下文
考虑输入为目标单词前后的多个单词(这些单词作为输出的上下文),输入为
隐向量为所有输入单词映射结果的均值:
其中:
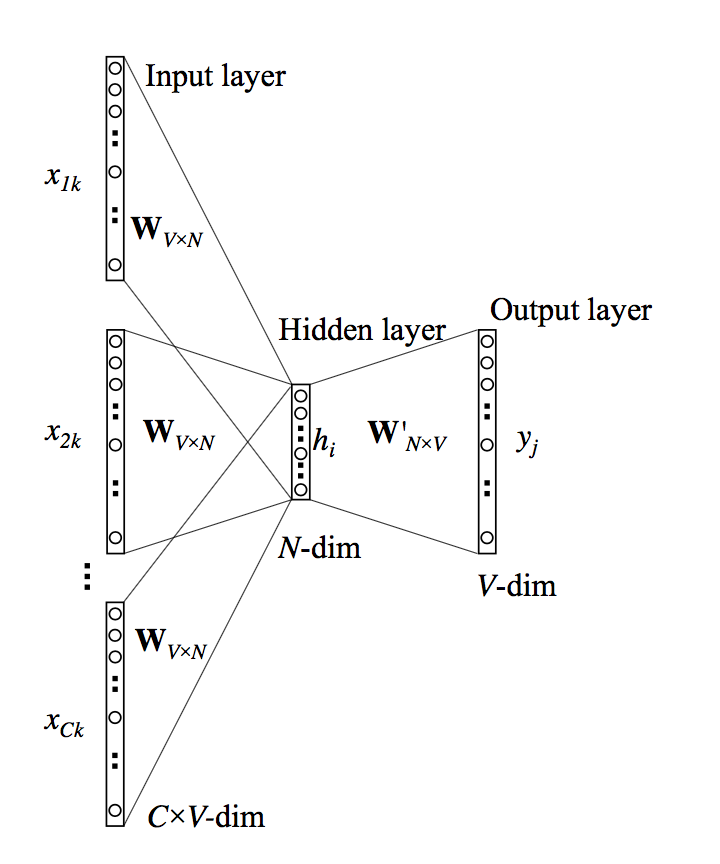
假设给定一个单词序列
定义损失函数为交叉熵:
它的形式与
一个单词上下文中推导的完全相同,除了这里的考虑语料库
则网络的优化目标为:
.
与
一个单词上下文中推导的结果相同,这里给出参数更新规则:更新
其中
更新
其中 :
在更新
你也可以直接减去
3.2 Skip-Gram
Skip-Gram模型是根据一个单词来预测其前后附近的几个单词(即:上下文)。
3.2.1 网络结构
Skip-Gram网络模型如下。其中:网络输入
one-hot编码,其中只有一位为 1,其他位都为 0 。网络输出
对于网络的每个输出
这里的权重共享隐含着:每个单词的输出向量是固定的、唯一的,与其他单词的输出无关。
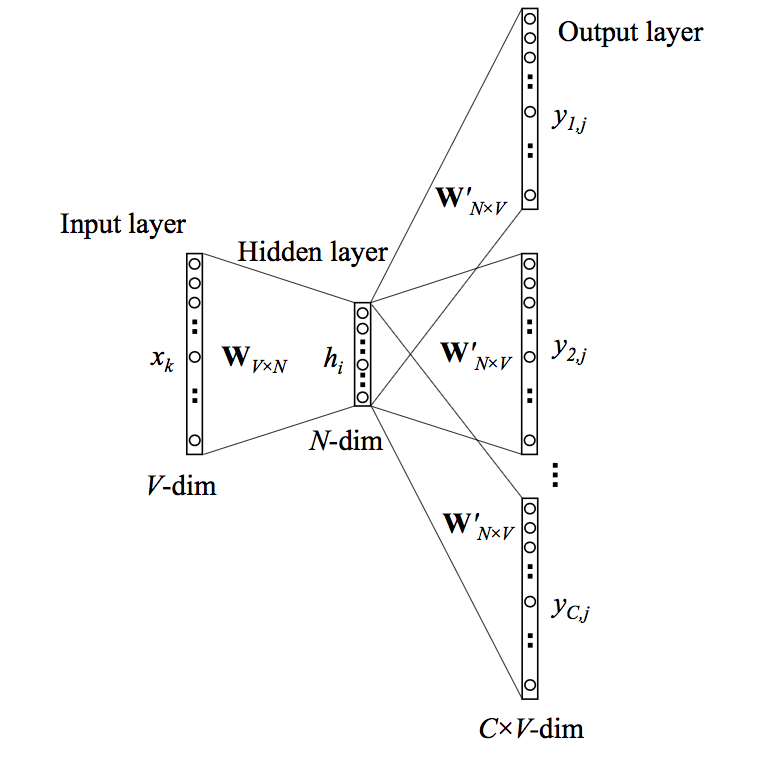
Skip-Gram网络模型中,设网络第因为
并不是网络每个输出中,得分最高的单词为预测单词。因为每个输出中,概率分布都相同,即:
Skip-Gram网络的目标是:网络的多个输出之间的联合概率最大。假设输入为单词
其中
由于网络每个输出的得分的分布都相同,令
.
3.2.2 参数更新
定义
定义:
它刻画了网络第
当
当
根据:
定义
则有更新方程:
定义:
根据:
则有:
考虑到
写成矩阵的形式为:
由于
one-hote编码,所以它只有一个分量非零,因此其中
3.3 优化
原始的
CBOW模型和Skip-Gram模型的计算量太大,非常难以计算。模型在计算网络输出的时候,需要计算误差 。对于
CBOW模型,需要计算Skip-Gram模型,需要计算另外,每个误差的计算需要用到
softmax函数,该softmax函数涉及到每次梯度更新都需要计算网络输出。
如果词汇表有
100万单词,模型迭代100次,则计算量超过 1 亿次。虽然输入向量的维度也很高,但是由于输入向量只有一位为 1,其它位均为 0,因此输入的总体计算复杂度较小。
word2vec优化的主要思想是:限制输出单元的数量。事实上在上百万的输出单元中,仅有少量的输出单元对于参数更新比较重要,大部分的输出单元对于参数更新没有贡献。
有两种优化策略:
通过分层
softmax来高效计算softmax函数。通过负采样来缩减输出单元的数量。
3.3.1 分层 softmax
分层
softmax是一种高效计算softmax函数的算法。经过分层
softmax之后,计算softmax函数的算法复杂度从
a) 网络结构
在分层
softmax中,字典叶子结点值为某个具体单词的概率(如下图中的白色结点)
中间节点值也代表一个概率(如下图中的灰色结点)。它的值等于直系子节点的值之和,也等于后继的叶子结点值之和,也等于从根节点到当前节点的路径的权重的乘积。
之所以有这些性质,是由于结点值、权重都是概率,满足和为1的性质
根据定义,根节点的值等于所有叶子结点的值之和,即为 1.0
二叉树的每条边代表分裂:
向左的边:表示选择左子节点,边的权重为选择左子节点的概率
向右的边:表示选择右子节点,边的权重为选择右子节点的概率
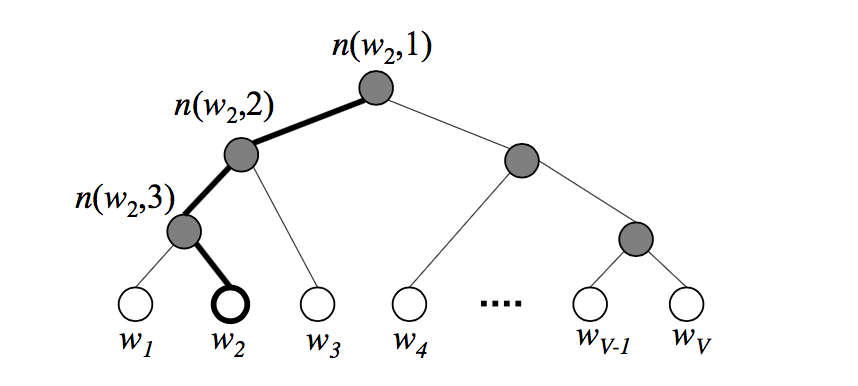
对于任意一个中间节点
选择左子节点的概率为:
选择右子节点的概率为 :
如果求得所有中间节点的向量表达,则根据每个中间节点的分裂概率,可以很容易的求得每个叶节点的值。
在分层
softmax中,算法并不直接求解输出向量当需要计算某个单词的概率时,只需要记录从根节点到该单词叶子结点的路径。给定单词
定义
定义
定义
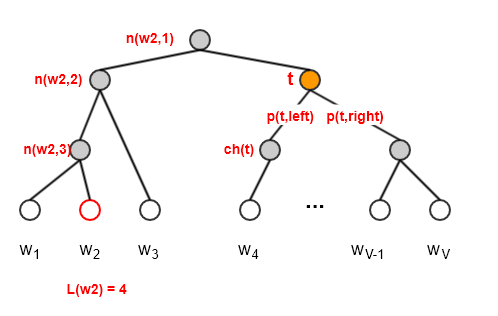
输出为单词
其中:
当第
当第
对于从根节点到单词
因此
对于所有的叶子节点,有
利用数学归纳法,可以证明:
左子节点的值+右子节点的值=父节点的值。上式最终证明等于根节点的值,也就是 1.0 。
b) 参数更新
为了便于讨论,这里使用
CBOW的一个单词上下文模型。记
则有:
其中:
定义:
如果下一个节点选择第
如果下一个节点选择第
考虑内部节点
得到向量表达为
对于每个单词
当模型的预测概率较准确,即
当模型的预测概率较不准,则
对于内部结点的向量表达
CBOW模型和Skip-Gram模型。但是在Skip-Gram模型中,需要对CBOW输入参数更新:对于CBOW模型,定义:考虑到
写成矩阵的形式为:
将
其中
Skip-Gram输入参数更新:对于Skip-Gram模型,定义:其中:
注意:由于引入分层
softmax,导致更新路径因为输出单词的不同而不同。因此与
Skip-Gram中推导相同,其中
3.3.2 负采样
a) 原理
在网络的输出层,真实的输出单词对应的输出单元作为正向单元,其它所有单词对应的输出单元为负向单元。
正向单元的数量为 1,毋庸置疑,正向单元必须输出。
负向单元的数量为
可以从所有负向单元中随机采样一批负向单元,仅仅利用这批负向单元来更新。这称作负采样。
负采样的核心思想是:利用负采样后的输出分布来模拟真实的输出分布。
对于真实的输出分布,有:
对于负采样后的输出分布,假设真实输出单词
在参数的每一轮更新中,负采样实际上只需要用到一部分单词的输出概率。
对于未被采样到的负向单元
随着训练的推进,概率分布
而概率分布
负采样时,每个负向单元是保留还是丢弃是随机的。负向单元采样的概率分布称作
noise分布,记做其中:
b) 参数更新
假设输出的单词分类两类:
正类:只有一个,即真实的输出单词
负类:从
论文
word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method的作者指出:下面的训练目标能够得到更好的结果:其中:
该目标函数是一个经验公式,而不是采用理论上的交叉熵
它是从另一个角度考虑:输出为正向单元的概率 * 输出为负向单元的概率。
其负的对数似然为:
仅仅考虑负采样,则可得到:
根据
其中
令
当
当
根据:
则有输出向量的更新方程:
给定一个样本,在更新输出向量时,只有
相比较而言:
原始算法中,给定一个样本在更新输出向量时,所有输出向量(一共
分层
softmax算法中,给定一个样本在更新输出向量时,
输出向量的更新方程可以用于
CBOW模型和Skip-Gram模型。若用于
Skip-Gram模型,则对每个输出依次执行输出向量的更新。CBOW输入向量参数更新:对于CBOW模型,定义:与
分层softmax: CBOW 输入向量参数更新中的推导相同,其中
Skip-Gram输入向量参数更新:对于Skip-Gram模型,定义:其中:
注意:由于引入负采样,导致网络每个输出中,对应的输出单词有所不同,负采样单词也有所不同。因此
与
Skip-Gram中推导相同,其中
3.3.3 降采样
对于一些常见单词,比如
the,我们可以在语料库中随机删除它。这有两个原因(假设使用CBOW):当
the出现在上下文时,该单词并不会为目标词提供多少语义上的信息。当
the作为目标词时,该单词从语义上本身并没有多大意义,因此没必要频繁更新。
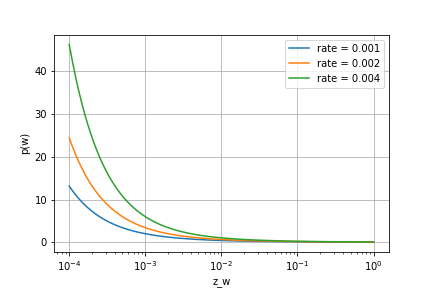
降采样过程中,单词
其中
0.001)。可以看到:随着单词在语料库中出现的词频越来越大,该单词保留的概率越来越低。
3.4 subword embedding
论文
《Enriching Word Vectors with Subword Information》中,作者提出通过增加字符级信息来训练词向量。下图给出了该方法在维基百科上训练的词向量在相似度计算任务上的表现(由人工评估模型召回的结果)。
sisg-和sisg模型均采用了subword embedding,区别是:对于未登录词,sisg-采用零向量来填充,而sisg采用character n-gram embedding来填充。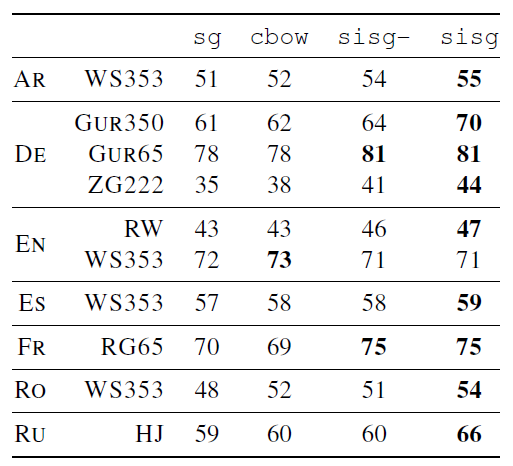
单词拆分:每个单词表示为一组
character n-gram字符(不考虑顺序),以单词where、n=3为例:首先增加特殊的边界字符
<(单词的左边界)和>(单词的右边界)。然后拆分出一组
character n-gram字符:<wh, whe,her,ere,re>。最后增加单词本身:
<where>。
为了尽可能得到多样性的
character n-gram字符,作者抽取了所有3<= n <= 6的character n-gram。以单词mistake为例:<mi,mis,ist,sta,tak,ake,ke>, // n = 3<mis,mist,ista,stak,take,ake>, // n = 4<mist,mista,istak,stake,take>, // n = 5<mista,mistak,istake,stake>, // n = 6<mistake> // 单词本身注意:这里的
take和<take>不同。前者是某个character n-gram,后者是一个单词。一旦拆分出单词,则:
词典
N-gram字符。网络输入包含单词本身以及该单词的所有
character n-gram,网络输出仍然保持为单词本身。
模型采用
word2vec,训练得到每个character n-gram embedding。最终单词的词向量是其所有character n-gram embedding包括其本身embedding的和(或者均值)。如:单词
where的词向量来自于下面embedding之和:单词
<where>本身的词向量。一组
character n-gram字符<wh, whe,her,ere,re>的词向量。
利用字符级信息训练词向量有两个优势:
有利于低频词的训练。
低频词因为词频较低,所以训练不充分。但是低频词包含的
character n-gram可能包含某些特殊含义并且得到了充分的训练,因此有助于提升低频词的词向量的表达能力。有利于获取
OOV单词(未登录词:不在词汇表中的单词)的词向量。对于不在词汇表中的单词,可以利用其
character n-gram的embedding来获取词向量。
3.5 应用
模型、语料库、超参数这三个方面都会影响词向量的训练,其中语料库对训练结果的好坏影响最大。
根据论文
How to Generate a Good Word Embedding?,作者给出以下建议:模型选择:所有的词向量都是基于分布式分布假说:拥有相似上下文的单词,其词义相似。根据目标词和上下文的关系,模型可以分为两类:
通过上下文来预测目标词。这类模型更能够捕获单词之间的可替代关系。
通过目标词来预测上下文。
通过实验发现:简单的模型(
Skip-Gram) 在小语料库下表现较好。复杂的模型在大语料库下略有优势。语料库:实际上语料库并不是越大越好,语料库的领域更重要。
选择了合适的领域,可能只需要
1/10甚至1/100的语料就能够得到一个大的、泛领域语料库的效果。如果选择不合适的领域,甚至会导致负面效果,比随机词向量效果还差。
超参数:
词向量的维度:
做词向量语义分析任务时,一般维度越大,效果越好。
做具体
NLP任务时(用作输入特征、或者网络初始化),50维之后效果提升就比较少了。
迭代次数:由于训练词向量的目标是尽可能精确地预测目标词,这个优化目标和实际任务并不一致。因此最好的做法是:直接用实际任务的验证集来挑选迭代次数。
如果实际任务非常耗时,则可以随机挑选某个简单任务(如:情感分类)及其验证集来挑选迭代次数。
word2vec还有一些重要的超参数:窗口大小:该超参数通常和语料库中句子长度有关,可以统计句子长度分布来设置。
min-count:最小词频训练阈值,词频低于该阈值的词被过滤。降采样率
subsampling_rate:降采样率越低,高频词保留的越少低频词保留的越多。
word2vec结果评估:通过
kmeans聚类,查看聚类的簇分布。通过词向量计算单词之间的相似度,查看相似词。
通过类比来查看类比词:
a之于b,等价于c之于d。使用
tsne降维可视化查看词的分布。
在
word2vec中实际上存在两种类型的embedding向量:大多数论文中都采用输入向量
Using the Output Embedding to Improve Language Models综合了输入向量和输出向量。在该论文中,作者得出结论:在
skip-gram模型中,在常见的衡量词向量的指标上,输出向量略微弱于输入向量。在基于
RNN的语言模型中,输出向量反而强于输入向量。通过强制要求
perplexity。
word2vec可以用于计算句子相似度。博客Comparing Sentence Similarity Methods总结了 6 种计算句子相似度的方法:无监督方法:
对句子中所有的词的词向量求平均,获得
sentence embedding。对句子中所有的词的词向量加权平均,每个词的权重为
tf-idf,获得sentence embedding。对句子中所有的词的词向量加权平均,每个词的权重为
smooth inverse frequency:SIF;然后考虑所有的句子,并执行主成分分析;最后对每个句子的词向量加权平均减去first principal componet,获得sentence embedding。SIF定义为:通过
Word Mover's Distance:WMD,直接度量句子之间的相似度。WMD使用两个句子中单词的词向量来衡量一个句子中的单词需要在语义空间中移动到另一个句子中的单词的最小距离。
有监督方法:
通过分类任务来训练一个文本分类器,取最后一个
hidden layer的输出作为sentence embedding。其实这就是使用文本分类器的前几层作为
encoder。直接训练一对句子的相似性,其优点是可以直接得到
sentence embeding。
最终结论是:简单加权的词向量平均已经可以作为一个较好的
baseline。
3.6 SGNS vs 矩阵分解
论文
《NeuralWord Embedding as Implicit Matrix Factorization》证明了带负采样的SkipGram模型skip-gram with negative-sampling:SGNS等价于隐式的矩阵分解。给定语料库
定义
word-context组合。定义
context单词的词汇表,通常有定义
word-context组合在其中:
定义单词
current word时embedding向量为context时embedding向量为定义单词的
representation矩阵为embeddign向量。定义上下文的
representation矩阵为embeddign向量。
给定一对
word-contextcurrent word的embedding为context的embedding为postive)的概率为:其中
SGNS最大化观察到的word-context组合、最小化未观察到的word-context组合。由于word-context组合都是观察到的,属于postive样本,因此SGNS需要通过随机采样一些word-context作为负样本。这就是负采样名称的由来。理论而言只有随机采样的、未观察到的
word-context才能作为负样本。这里直接使用随机采样的结果作为负样本有两个原因:便于理论上推导。但是二者并不影响
SGNS等价于矩阵分解的性质。由于
word-context集合仅仅占据很小的部分,因此采样得到的word-context组合是未观察到的概率几乎为1。
理论而言未观察到的
word-context组合不一定是负样本,某些word-context组合是合理的,只是它们从未在语料库中出现过。
对于每一对观察到的
word-context组合SGNS的损失函数为:其中
current word非均匀分布:
这和前面介绍的一致。
均匀分布:
虽然非均匀分布在某些任务上能够产生更好的结果,但是这里采用均匀分布从而得到更好的理论推导。另外,二者并不影响
SGNS等价于矩阵分解的性质。
最终得到
SGNS总的损失函数为:SGNS的优化目标使得:观察到的
word-contextembedding,即未观察到的
word-contextembedding,即
当
因此有:
因此样本空间
word-context组合由于样本空间
解得:
给定随机变量
Pointwise Mutual Information :PMI定义为记单词
word-context组合定义矩阵
则有:
这里的推导只有当维度
设矩阵
当负采样个数
SGNS等价于分解PMI矩阵。
直接计算
PMI矩阵非常具有挑战性:矩阵的维度
绝大多数组合
这可以通过引入一些先验概率使得未见过的
PMI为一个有效的数来解决。PMI矩阵是dense矩阵。
一个解决方案是:当
PMI矩阵成为一个巨大的稀疏矩阵,称作事实上当
word-contextword-context
考虑到未观察到的
word-contextword-context的PMI都设置为零,仅考虑正的PMI(即PPMI):这和人类的直觉相符:人们很容易联想到正的关联,如
“加拿大”和“滑雪”,但是很难关注一些无关的组合,如“加拿大”和“沙漠”。因此将无效的信息丢弃(PMI置为零)而仅保留有效信息更符合经验和直觉。如果继续在
PPMI中考虑偏移,则得到Shifted PPMI:SPPMI:可以直接将
PMI矩阵、PPMI矩阵 或者SPPMI矩阵中,单词representation,此时单词的representatioin是一个高维向量。对于PPMI,SPPMI,该向量还是稀疏的。此时有:也可以通过降维获得单词的低维
representatiion,如:可以通过SVD分解来求解首先将
SVD分解:
其中
选择最大的
可以选择 SGNS 效果较差。注意到这种分解方法中,SGNS 中,求解的这两个矩阵都不是正交矩阵,因此可以进行如下分解:
虽然理论上无法证明这种方式的效果更好,但是实践中发现它确实表现更佳。
基于随机梯度下降的
SGNS和基于矩阵分解的方式各有优点:基于矩阵分解的优点:
无需精心调优学习率等超参数。
可以按照
word-context聚合之后的频次数据来训练,这种方式可以训练比SGNS大得多得语料库。与之相反,
SGNS中每个word-context出现一次就需要训练一次。
基于
SGNS的优点:SGNS可以区分观测值和未观测值,而SVD无法判断一个word-context为零是因为未观测还是因为PMI较低。这在word-context矩阵中非常常见。SGNS的目标函数对不同的在
SVD分解中,无法区分SGNS仅仅关注于观测值,因此它不要求底层的矩阵是稀疏的,可以直接优化dense矩阵。因为
SVD的求解困难,所以SVD通常要求底层矩阵是稀疏的,因此它通常采用PPMI/SPPMI。
noise-contrastive estimation:NCE采用类似的推导过程可以分解为:实验:
数据集:英文维基百科。经过清理非文本字符、句子拆分、词干化之后,数据集包含 7750万句子、15亿
token。每个
token分别取左右两侧2个token作为上下文从而生成word-context集合过滤掉
word-context组合。
最终得到
模型:
SPPMI、SGNS以及SVD。其中:所有模型评估当
对于
SPPMI,将该矩阵的各行作为对应单词的representation对于
SVD采用分解
我们根据训练目标函数和理论目标函数来评估各算法的优化算法效果。
考虑目标函数:
对于
SGNS我们直接通过随机梯度下降结束时的目标函数值作为对于
SVD我们根据对于
SPPMI,我们将它的各行作为对应单词的representatioin,上下文采用one-hot向量的形式,因此有:然后根据
然后我们评估优化目标函数值和理论目标函数值的相对误差:
结果见下表。其中
PMI-log k表示理论误差,SPPMI表示采用SPPMI理论值对应的误差。尽管
SPPMI仅考虑非负元素而丢弃大量信息,它与最优解的理论值非常接近。SVD方法中,维度对于
SVD优化效果比SGNS更好;但是当维度更高时SGNS的优化误差比SVD的降低得多得多。SVD对于SVD的分解结果更接近零矩阵。因为SVD的目标函数是无权重的,它无法 “更关注” 那些观测结果。

在四个数据集上评估
word similarity单词相似任务和单词类比任务。在数据集
WordSim353和MEN上评估单词相似任务。这些数据集包含人工标注的pair-wise单词相似度得分。在数据集
Syntactic和Mixed上评估单词类比任务。
在单词相似任务上
SVD超越了SPPMI(采用随机梯度下降),而SPPMI超越了SGNS。在单词相似任务上对于
SGNS任务SPPMI,SVD随着这是因为
SPPMI,SVD中仅保留正的值,随着在单词类比任务上
SGNS超越了SVD。这是因为单词类比任务中更依赖于那些上下文中频繁出现的单词,如the,each,many以及辅助动词will,had。SGNS训练过程会更关注于这些频繁出现的word-context组合,而SVD对所有的word-context是无权重的。

四、GloVe
学习词向量的所有无监督方法最终都是基于语料库的单词共现统计,因此这些模型之间存在共性。
词向量学习算法有两个主要的模型族:
基于全局矩阵分解的方法,如:
latent semantic analysis:LSA。优点:能够有效的利用全局的统计信息。
缺点:在单词类比任务(如:
国王 vs 王后类比于男人 vs 女人)中表现相对较差。
基于局部上下文窗口的方法,如:
word2vec。优点:在单词类比任务中表现较好。
缺点:因为
word2vec在独立的局部上下文窗口上训练,因此难以利用单词的全局统计信息。
Global Vectors for Word Representation:GloVe结合了LSA算法和Word2Vec算法的优点,既考虑了全局统计信息,又利用了局部上下文。
4.1 原理
设
单词-单词共现矩阵为
从经验中可以发现以下规律:
单词 单词 单词 单词 因此
假设单词
GloVe认为:这三个单词的词向量经过某个函数的映射之后等于假设这个映射函数为
现在的问题是
由于
由于
上式左边为差的形式,右边为商的形式。因此联想到函数
要想使得上式成立,只需要令
向量的内积具有对称性,即
为了解决这个问题,模型引入两个偏置项:
上面的公式仅仅是理想状态,实际上只能要求左右两边尽可能相等。于是设计代价函数为:
其中
根据经验,如果两个词共现的次数越多,则这两个词在代价函数中的影响就应该越大。因此可以设计一个权重来对代价函数中的每一项进行加权,权重为共现次数的函数:
其中权重函数应该符合三个条件:
这是为了确保
的与其它词的组合) ,但是它们的重要性并不是很大。
GloVe论文给出的权重函数其中:
GloVe论文给出参数GloVe论文指出:
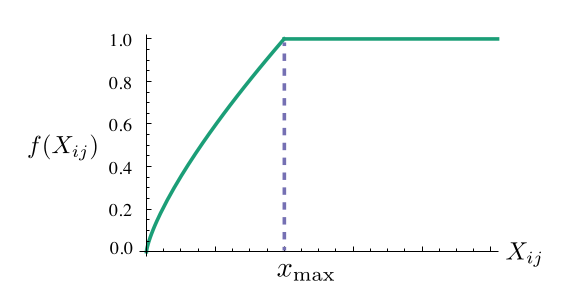
考虑对所有词向量增加一个常量
令
Glove的解,则Glove的解。因此假设
4.2 应用
GloVe模型的算法复杂度取决于共现矩阵实际上单词共现的次数满足齐普夫定律(
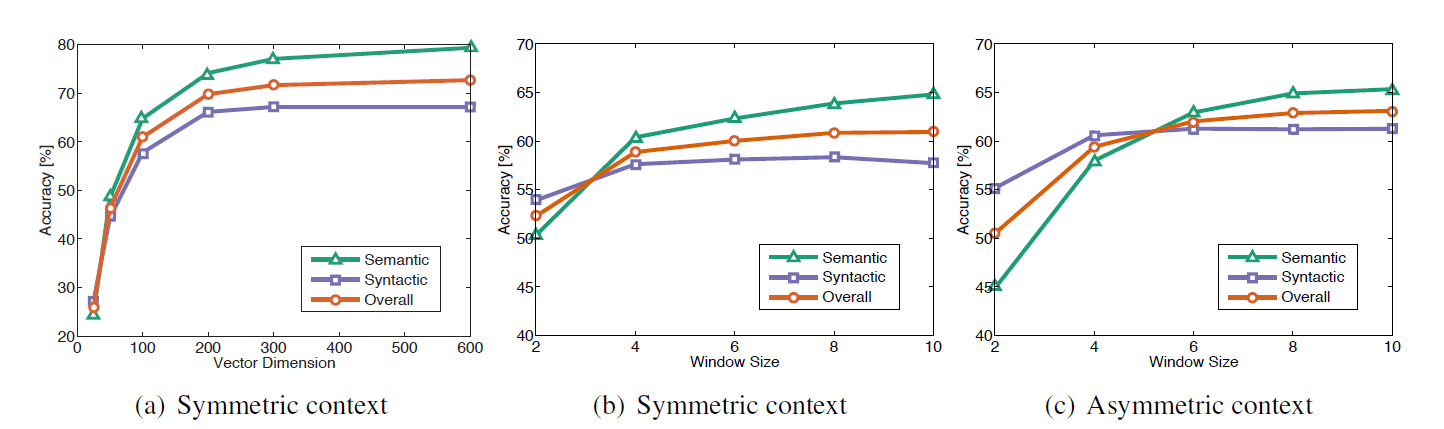
Zipf's Law),因此算法复杂度较低,约为Zipf's Law:如果有一个包含GloVe模型评估任务:semantic任务: 语义任务。如:'雅典'之于'希腊' = '柏林'之于'_'?syntactic任务:语法任务。如:'dance'之于'dancing' = 'fly'之于'_'?
GloVe模型性能与语料库大小的关系:在语法任务中,模型性能随着语料库大小的增长而单调增长。
这是因为语料库越大,则语法的统计结果越可靠。
在语义任务中,模型性能与语料库绝对大小无关,而与语料库的有效大小有关。
有效大小指的是语料库中,与目标语义相关的内容的大小。
GloVe模型超参数选择:词向量大小:词向量大小越大,则模型性能越好。但是词向量超过
200维时,维度增加的收益是递减的。窗口对称性:计算一个单词的上下文时,上下文窗口可以是对称的,也可以是非对称的。
对称窗口:既考虑单词左侧的上下文,又考虑单词右侧的上下文。
非对称窗口:只考虑单词左侧的上下文。
因为语言的阅读习惯是从左到右,所以只考虑左侧的上下文,不考虑右侧的上下文。
窗口大小:
在语法任务中,选择小的、非对称的窗口时,模型性能更好。
因为语法是局部的,所以小窗口即可;因为语法是依赖于单词顺序的,所以需要非对称窗口。
对于语义任务,则需要选择更大的窗口。
因为语义是非局部的。
五、FastText
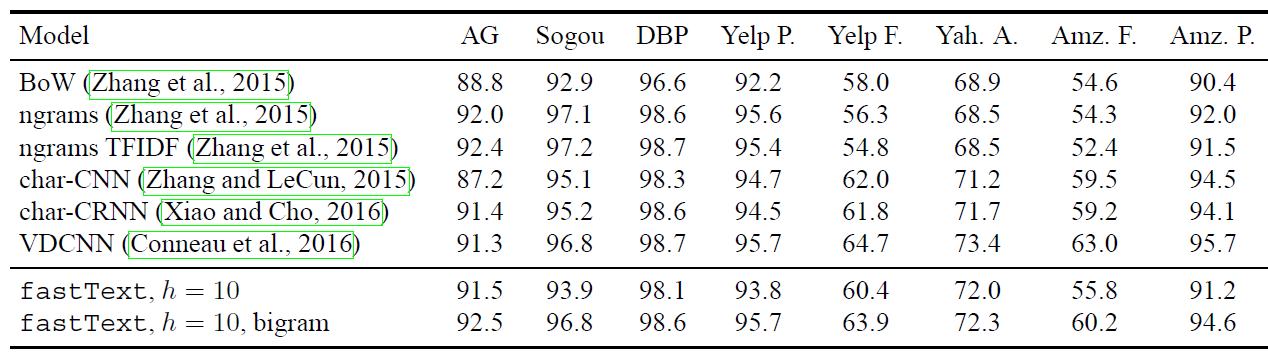
fastText是Facebook AI Research在2016年开源的文本分类器,其提出是在论文《Bag of Tricks for Efficient Text Classification》中。目前fastText作为文本分类的基准模型。fastText的优点是:在保持分类效果的同时,大大缩短了训练时间。在 8个 数据集上,不同模型的测试误差:
单个
epoch的训练时间(char-CNN、VDCNN和fastText):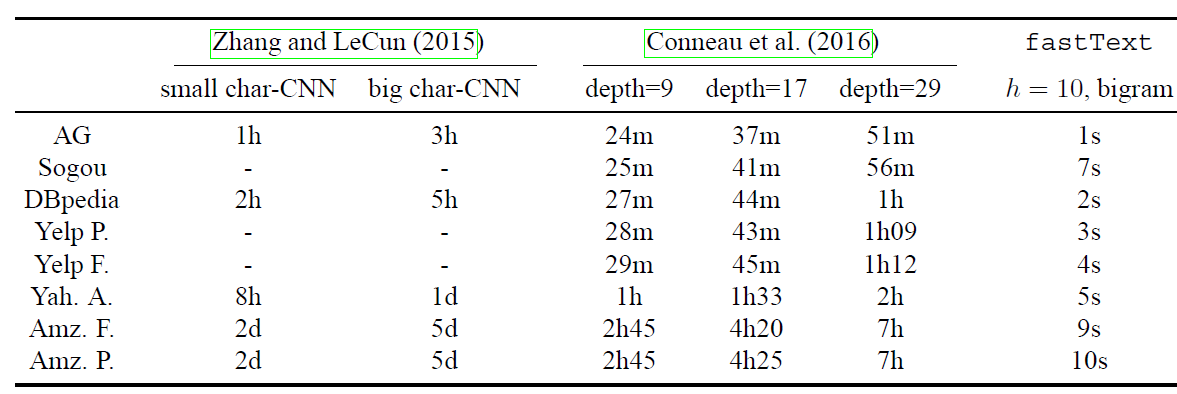
fastText的网络结构与word2vec的CBOW非常相似。区别在两个地方:输入:单篇文档的所有单词都作为网络的输入。因此这里的参数
C是动态的,它等于当前文档的单词数量。输出:这里网络的输出是各类别的概率。通常文本分类的类别
softmax和负采样。

隐向量为所有输入单词映射结果的均值:
其中:
单个样本的损失函数为(
定义每个输出单元的预测误差
CBOW多个单词上下文的推导相同:更新
其中
更新
其中 :
如果考虑词序则分类的效果还可以进一步提升,因此在
fastText中可以引入N-gram特征。如:2-gram合并文档中连续的2个单词作为特征。fastText生成的词向量嵌入的是分类的信息,而word2vec生成的词向量更多的嵌入了通用语义信息。fastText词向量得到的相似度是基于分类类别的相似。如:商品评论情感分类任务中,好吃和好玩是相似的,因为它们都是正向情感词。word2vec词向量得到的相似度是基于语义的相似。此时好吃和美味是相似的,因为这二者经常出现在类似的上下文中。
六、ELMo
ELMo:Embeddings from Language Models引入了一种新的单词表示方式,该 表示方式的建模目标是:对单词的复杂特征建模(如:语法特征、语义特征),以及能适应不同的上下文(如:多义词)。ELMo词向量是由双向神经网络语言模型的内部多层向量的线性加权组成。LSTM高层状态向量捕获了上下文相关的语义信息,可以用于语义消岐等任务。如下图中的左图为语义消岐任务的结果,第一层、第二层分别表示单独使用
biLM的representation的效果。结果表明:越高层的状态向量,越能够捕获语义信息。LSTM底层状态向量捕获了语法信息,可以用于词性标注等任务。如下图中的右图为词性标注任务的结果,第一层、第二层分别表示单独使用
biLM的representation的效果。结果表明:越低层的状态向量,越能够捕获语法信息。

ELMo词向量与传统的词向量(如:word2vec)不同。在ELMo中每个单词的词向量不再是固定的,而是单词所在的句子的函数,由单词所在的上下文决定。因此ELMo词向量可以解决多义词问题。下图中,
GloVe无法区分play这个单词的多种含义。而ELMo由于引入了上下文,因此可以区分其不同含义。
实验表明,
ELMo在多个任务上取得了广泛的提升。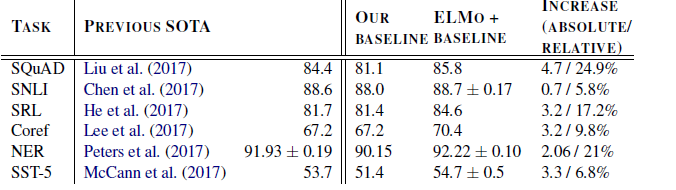
给定一个句子 :
可以用一个
LSTM模型来实现该概率。其中:embedding向量,LSTM层的第第
LSTM的输出经过softmax输出层输出对应的条件概率。softmax输出层由一个全连接函数和一个softmax函数组成。由于
RNN的性质,所有softmax输出层的参数都共享。
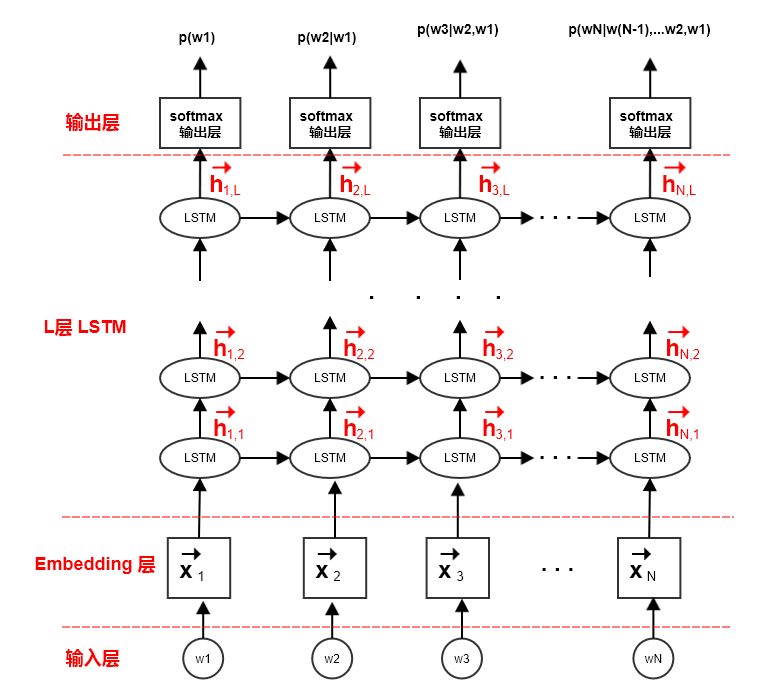
ELMo模型采用双向神经网络语言模型,它由一个前向LSTM网络和一个逆向LSTM网络组成。ELMo最大化句子的对数前向生成概率和对数逆向生成概率。其中:
前向
LSTM网络和逆向LSTM网络共享embedding层的参数softmax输出层的参数LSTM网络的参数,LSTM网络的参数,二者不同。
ELMo认为单词最简单的情况下,
ELMo取出第:表示向量的拼接。也可以直接采用这
可以给每层的向量一个权重,而这些权重(一共
此时
ELMo通用的词表达为:这其中
softmax归一化结果,
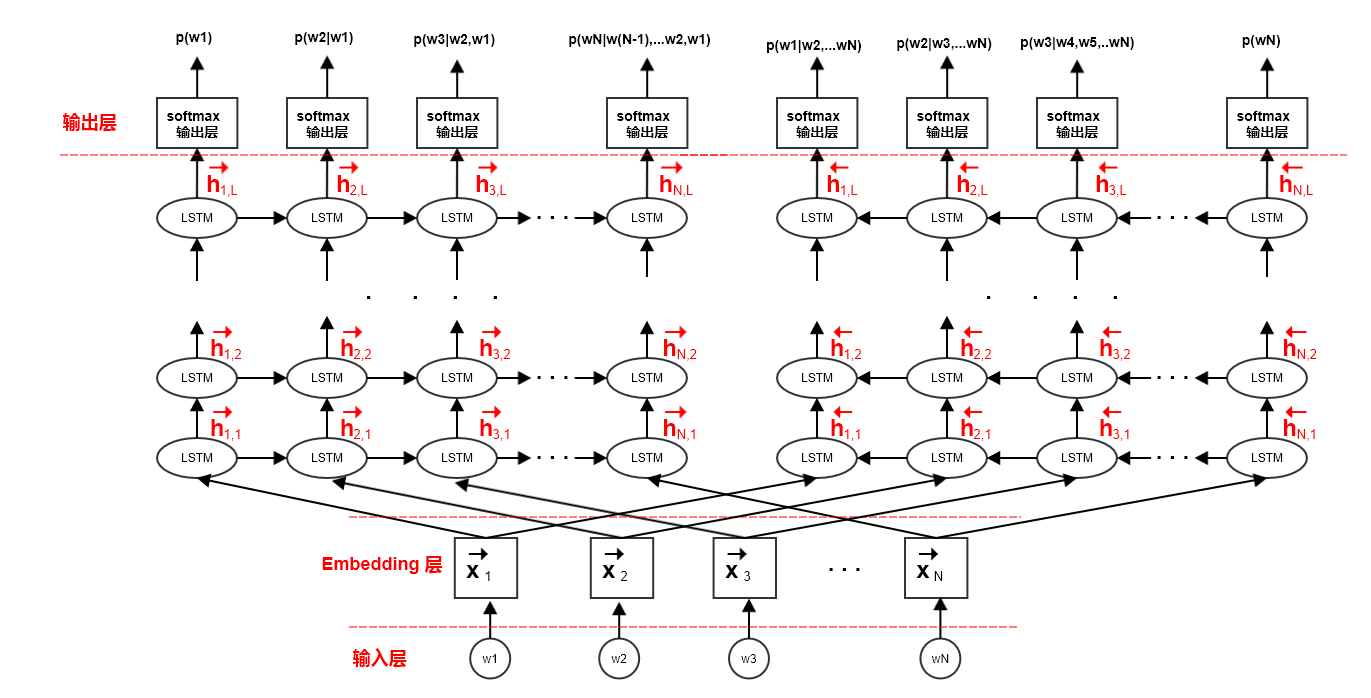
应用
ELMo时,首先训练无监督的ELMo模型,获取每个单词的冻结
ELMo的模型参数并计算得到拼接
embedding。对于
RNN网络,还可以将
实验表明:在
ELMo中添加dropout是有增益的。另外在损失函数中添加ELMo权重倾向于接近所有ELMo权重的均值。