五十五、TWIN[2023]
《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》
终身用户行为建模(
life-long user behavior modeling),即从数月甚至数年的丰富历史行为中提取用户的隐藏兴趣(hidden interests),在现代CTR prediction系统中起着核心作用。传统算法大多遵循两个级联的阶段:简单的通用搜索单元 (
General Search Unit: GSU),用于对数万个长期behaviors进行快速且粗略的搜索。精确搜索单元 (
Exact Search Unit: ESU),用于对来自GSU的少数最终入围者进行有效的Target Attention: TA。
现有算法虽然高效,但大多存在一个关键限制:
GSU和ESU之间的target-behavior的相关性指标(relevance metrics)不一致。因此,这些算法的GSU通常会错过高度相关的behaviors,但会检索出被ESU认为不相关的behaviors。在这种情况下,无论如何分配注意力,ESU中的Target Attention大多会偏离真正的用户兴趣,从而降低整体的CTR prediction的准确率。为了解决这种不一致性,我们提出了两阶段兴趣网络(
TWo-stage Interest Network: TWIN),其中我们的Consistency-Preserved GSU: CP-GSU采用与ESU中的Target Attention相同的target-behavior relevance metric,使两个阶段成为孪生。具体来说,为了突破Target Attention的计算瓶颈并将其从ESU扩展到GSU,即将behavior长度从behavior feature splitting构建了一种新颖的注意力机制。对于behavior的视频固有特征,我们通过高效的pre-computing & caching策略来计算它们的线性投影。对于user-item交叉特征,我们在注意得分计算中将每个特征压缩为一维的bias项从而节省计算成本。两个阶段之间的一致性,加上CP-GSU中有效的Target Attention-based相关性指标,有助于显著提高CTR prediction的性能。在快手
46B规模的真实生产数据集上的离线实验和在线A/B test表明,TWIN的表现优于所有对比的SOTA算法。通过优化在线基础设施,我们降低了99.3%的计算瓶颈,这有助于TWIN在快手上的成功部署,服务于每天数亿活跃用户的主要流量。作为中国最受欢迎的短视频分享应用(
short video sharing apps)之一,快手高度依赖其强大的推荐系统 (recommendation system: RS)。每天,推荐系统帮助数亿活跃用户过滤掉数百万个不感兴趣的视频,找到他们感兴趣的视频,留下数百亿条点击日志。这些海量数据不仅为推荐系统的训练提供了数据,还推动了技术革命,不断提升该平台的用户体验和业务效率。 在现代推荐系统中,一项基本任务是CTR prediction,旨在预测用户点击某个item / video的概率。准确的CTR prediction指导推荐系统为每个用户提供他们最喜欢的内容,并将每个视频传递给其感兴趣的受众。为了实现这一点,CTR模型应该高度个性化,并充分利用稀缺的用户信息。因此,终身用户行为建模(life-long user behavior modeling),即从丰富的长期历史行为中提取用户的隐藏兴趣(hidden interests),通常是CTR模型的关键组成部分。 工业级的life-long behavior modeling算法大多遵循两个级联的阶段(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》):(1):一个通用搜索单元 (General Search Unit: GSU)对数万个长期behaviors进行快速且粗略的搜索,并输出少量的most target-relevant的行为;(2):一个精确搜索单元 (Exact Search Unit: ESU)对来自GSU的少数最终入围者进行有效的Target Attention: TA。
这种两阶段设计背后的原因有两个方面:
一方面,为了精确捕获用户兴趣,
Target Attention是强调target-relevant behaviors和抑制target-irrelevant behaviors的适当选择。另一方面,
Target Attention昂贵的计算成本将其适用的序列长度限制为最多几百。为此,一个简单快速的GSU作为pre-filter至关重要从而用于截断工业规模的用户行为序列,因为这些序列在短短几个月内很容易达到
近年来,出现了许多关于两阶段
life-long behavior modeling的新兴研究,而它们的关键区别在于GSU策略,其中GSU策略粗略地选择target-relevant behaviors。例如:SIM Hard简单地从与target item相同的category中选择behaviors;而SIM Soft通过内积从pre-trained item embeddings中计算target-behavior relevance score,并选择相关性最高的behaviors。ETA使用局部敏感哈希(locality-sensitive hashing: LSH)和汉明距离来近似relevance score的计算。SDIM通过多轮哈希碰撞(multi-round hash collision)等方法对具有与target-behavior相同哈希签名(hash signature)的behaviors进行采样。
尽管已被广泛研究,但现有的两阶段
life-long behavior modeling算法仍然存在一个关键限制:GSU和ESU之间的不一致(如Figure 1所示)。具体来说,GSU中使用的target-behavior relevance metric既粗略又与ESU中使用的Target Attention不一致。因此,GSU可能会错过relevant behaviors,而且可能会检索ESU认为不相关的behaviors从而浪费ESU宝贵的计算资源。在这种情况下,无论如何分配注意力,ESU中的Target Attention会很大地偏离真实的用户兴趣,从而降低整体CTR prediction的准确率。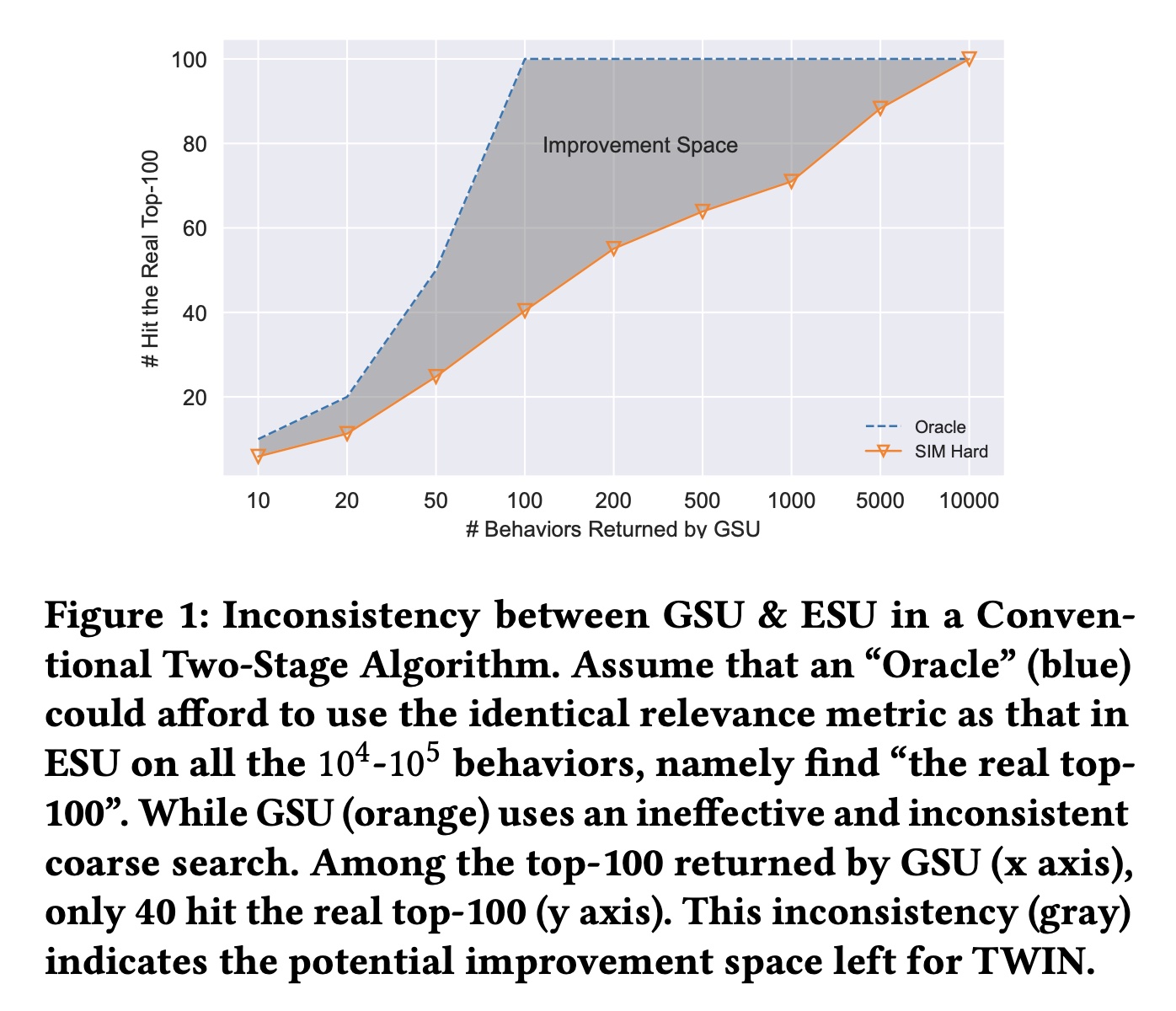
为了解决这种不一致(
inconsistency),我们提出了两阶段兴趣网络(TWo-stage Interest Network: TWIN)从而用于lifelong user behavior modeling,其中Consistency-Preserved GSU: CP-GSU采用与ESU中的Target Attention相同的target-behavior relevance metric,使两个阶段成为孪生(twins)。为了将昂贵的Target Attention扩展到CP-GSU,TWIN通过有效的behavior feature split、简化的Target Attention架构、以及高度优化的在线基础设施,突破了Target Attention的关键计算瓶颈,即所有behaviors的线性投影。1):具体来说,对于跨users / behavior sequences共享的video inherent features of a behavior(例如video id, author, duration, topic),我们通过高效的pre-computing & caching策略加速它们的投影。2):对于behavior的user-video交叉特征(例如用户的click timestamp, play time, rating),当caching不适用时,我们通过将它们的投影压缩为bias项来简化Target Attention架构。
通过优化后的在线基础设施,我们成功地将
Target Attention的适用序列长度从ESU中的CP-GSU中的CP-GSU中的Target Attention-based relevance metric,有助于显著提高CTR prediction的性能。总体而言,我们做出了以下贡献:
在我们提出的
TWIN中,CP-GSU精确且一致地检索不仅target-relevant而且被ESU认为重要的behaviors,从而最大限度地提高了behavior modeling的retrieval效果。据我们所知,我们是第一个成功解决两阶life-long behavior modeling问题中不一致性的人。我们通过对快手
46B规模的工业级数据集进行大量的离线实验,以及在线A/B test,从而验证TWIN的有效性。我们通过消融研究验证了我们的有效性,并表明TWIN带来了显著的online benefits。我们构建了高效的工业级的基础设施,将
TWIN应用于真实的在线推荐系统。我们提出了有效的pre-computing & caching策略,将TWIN的计算瓶颈(即CP-GSU中linear projection of behaviors)减少了99.3%,并满足了online serving system的低延迟要求。目前TWIN已经部署在快手的推荐系统上,服务于每日3.46亿活跃用户的主要流量。
在本文中,我们建议将
Target Attention结构扩展到GSU,并将embeddings and attention parameters从ESU同步到GSU,从而保持端到端训练。结果,我们同时实现了网络结构和模型参数的一致性,与ETA和SDIM相比,这有助于显著提高性能。我们在Table 1中详细说明了我们的模型与其他模型的不同之处。ESU和GSU的网络结构和网络参数完全相同,所以称之为 “孪生”。请注意,我们的工作不同于旨在加速
Transformer的indexing算法(例如LISA)。它们通过将behaviors映射到codebooks并查找距离来近似relevance score的计算。然而我们的工作以及许多其他两阶段算法都使用精确的距离计算,但使用GSU作为pre-filter从而减少了behaviors的数量。TWIN算法的核心是对attention score计算中最耗时的linear projection进行优化。但是这种优化仅适用于inference阶段,而不适用于training阶段。论文创新点一般,对算法层面优化较少,更多地是工程优化。
55.1 TWIN
首先,我们回顾了
CTR prediction问题的一般基础知识。然后,我们描述了快手CTR prediction系统的模型架构。接着,我们进一步深入探讨了我们提出的consistency-preserved lifelong user behavior modeling module,即TWo-stage Interest Network: TWIN。最后,我们介绍了确保TWIN在快手主流量上成功在线部署的基本accelerating的策略。Table 2总结了所使用的符号。
55.1.1 基础知识
CTR prediction的目的是预测用户在特定上下文中点击一个item的概率。准确的CTR prediction不仅可以通过提供preferred contents来提升用户体验,还可以通过触达interested audiences来提高内容生产者和平台的业务效率。因此,CTR prediction已成为各种工业级推荐系统(尤其是快手等短视频推荐平台)的核心部分。CTR prediction通常被表述为一个二分类问题,其目标是在给定训练数据集predictor函数feature vector(即user, item and contexts features的拼接);ground truth label,表示用户是否点击该item。predicted CTR计算如下:其中:
sigmoid函数,它将prediction(0, 1)之间。模型通过最小化
negative log-likelihood来训练:为简洁起见,我们在以下章节中省略了训练样本索引
55.1.2 CTR Prediction 的架构
现在我们来介绍快手的
CTR prediction系统的架构。详细信息如Figure 2所示。下图中,
ESU和CP-GSU的网络结构和网络参数一模一样,那为什么弄两个一模一样的东西?是否可以移除掉ESU?根据论文的解释:在
ESU的MHTA: multi-head target attention中,对于CP-GSU,那么embedding,这个投影的代价非常高。那么:
是否可以仅仅使用
CP-GSU,然后仅仅选择top-k来做线性投影从而用于加权聚合?或者,在
ESU中使用不同的网络参数,即,使用原始的线性投影而不做拆分,从而计算attention score?
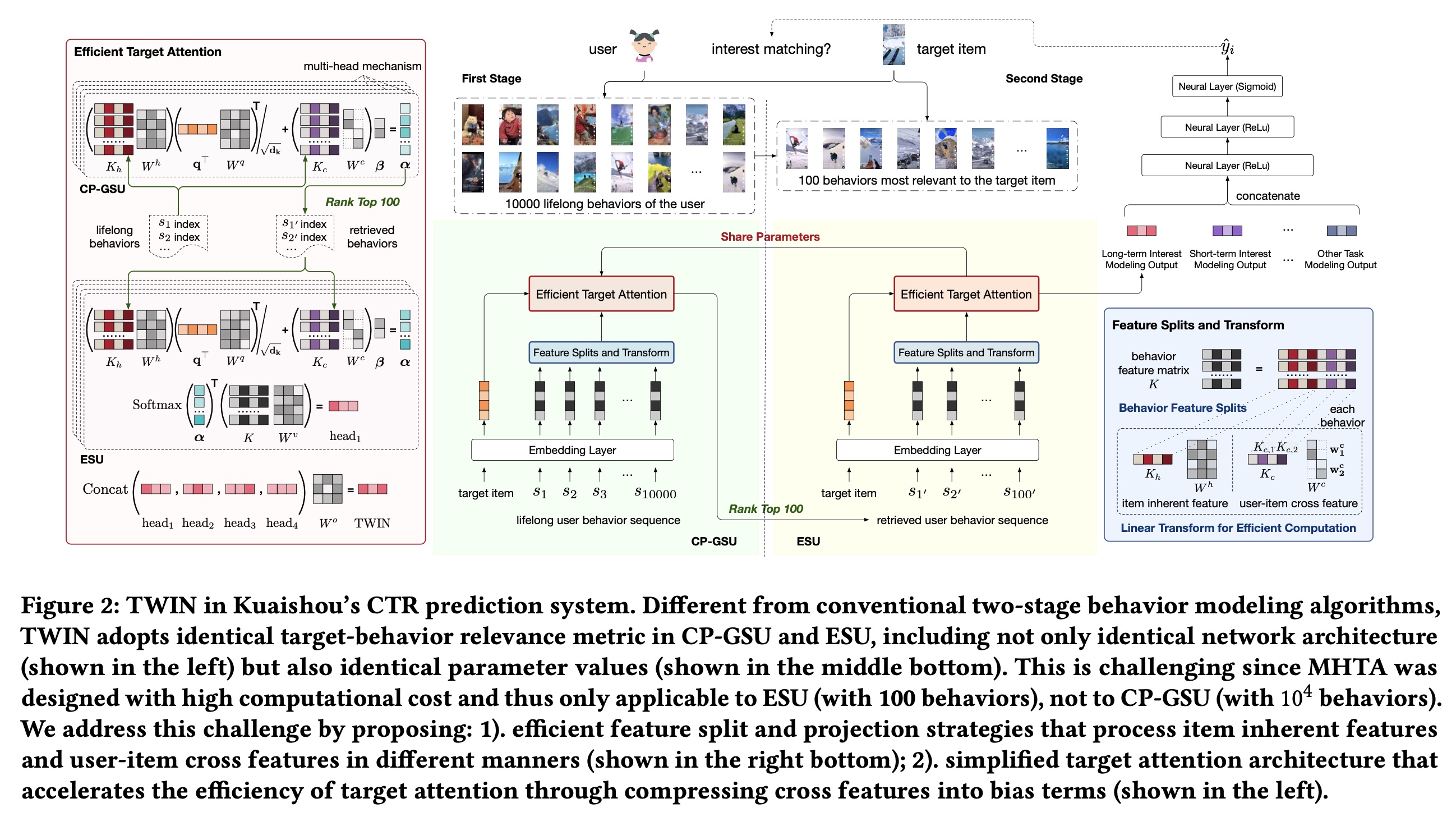
Embedding Layer: 在最底层,我们的模型从feature embedding layer开始,该层将训练样本的原始特征转换为embedding vectors。在不失一般性的情况下,我们假设所有特征在经过必要的预处理后都处于
categorical的形式。对于vocabulary size为categorical information编码为one-hot / multi-hot code请注意,在大多数工业级系统中,
vocabulary size(尤其是user / author / video ids的vocabulary size)可以轻松扩展到数亿。因此,一种常见的策略是将极高维的hot codes转换为低维embeddings:其中:
embedding dictionary,embedding维度。在我们的系统中,我们将vocabulary大的id特征的embedding维度设置为64,将其他特征(如video topic, video played timestamp)的embedding维度设置为8。 在所有upper layers中,我们将embedding vectors作为输入,因此为了简洁起见省略了下标“emb”。Deep Networks:我们的CTR prediction的总体架构如Figure 2所示。upper module由堆叠的神经网络和ReLU组成,充当mixer,用于学习三个intermediate modules的输出之间的交互:TWIN:所提出的consistency-preserved life-long user behavior modeling模块,通过两个cascading stages的behavior modeling子模块提取用户兴趣:1):Consistency-Preserved General Search Unit: CP-GSU,从数万个长期历史行为中粗略搜索100个最相关的行为。2):Exact Search Unit: ESU,采用注意力机制对CP-GSU的100个最终入围者来捕获精确的用户兴趣。
传统算法通常由“轻量级”的
GSU和“重量级”的ESU组成。与传统算法不同,我们提出的CP-GSU遵循与ESU相同的relevance evaluation metric,使两个cascading stages成为TWINS。因此,CP-GSU始终检索出来ESU认为重要的items,从而最大限度地提高behavior modeling的有效性。Short-term behavior modeling:从最近的50个behaviors中提取用户兴趣。该模块关注用户最近几天的短期兴趣,是TWIN的有力补充。其他任务建模:除了
behavior modeling之外,我们还拼接了各种其他任务建模的输出,这些任务建模可以建模用户的性别、年龄、职业、位置、视频时长、主题、受欢迎程度、质量和上下文特征,上下文特征包括播放日期、时间戳、页面位置等。
55.1.3 TWIN: TWo-stage Interest Network
我们将提出的算法命名为
TWIN,以强调CP-GSU遵循与ESU相同的relevance evaluation metric。请注意,这种一致性并非微不足道,因为:有效的
behavior modeling算法通常基于多头目标注意力 (Multi-Head Target Attention: MHTA) ,它通过强调target relevant behaviors来精确地捕获用户兴趣。不幸的是,由于计算复杂度高,MHTA适用的behavior sequence长度大多仅限于几百。为了详尽地捕获用户的长期兴趣,
CP-GSU应该涵盖过去几个月的user behaviors,这些user behaviors很容易达到数万。考虑到在线系统严格的低延迟要求,这个序列长度远远超出了传统MHTA的容量。
本节旨在回答这个关键问题:如何提高
MHTA的效率,以便我们可以将其从ESU扩展到CP-GSU?或者换句话讲,从数百的序列长度扩展到至少数万的序列长度?Behavior Feature Splits and Linear Projection:按照MHTA的标准符号,我们将长度为behavior sequencebehavior的特征。在实践中,MHTA的注意力得分计算中,MHTA在极长user behavior sequences上应用的关键计算瓶颈。因此,我们提出以下措施来降低其复杂性。我们首先将
behavior features matrix我们将
behavior items的固有特征(例如video id, author, topic, duration),这些特征与特定的user / behavior sequence无关。我们将
user-item交叉特征(例如user click timestamp, user play time, clicked page position, user-video interactions)。
这种分割可以高效计算接下来的线性投影
对于固有特征
id特征为64,field数量),但线性投影实际上并不昂贵。特定item的固有特征在users / behavior sequences之间共享。通过必要的缓存策略,look up and gathering过程有效地“计算”。在线部署的细节将在接下来章节中介绍。但是,训练的时候没有
caching,因此会非常消耗资源。然而,训练的时候没有inference latency的限制,可以堆显卡来解决。对于
user-item交叉特征1):交叉特征描述a user and a video之间的交互细节,因此不会跨users behavior sequences来共享。2):对于一个视频,每个用户最多观看一次。也就是说,在投影cross features时没有重复计算。因此,我们通过简化linear projection weight来降低计算成本。
给定
embedding维度为vocabulary size的id特征)。我们有linear projection简化如下:其中:
使用这个简化的投影,我们将每个
cross feature压缩到一个维度,即diagonal block matrix)。
复杂度分析:在传统的
MHTA中,通常
而在我们对
TWIN的MHTA中:item固有特征pre-computed并有效地gathered,复杂度为在训练阶段是没有
pre-computed的而
user-item交叉特征
由于
MHTA能够在CP-GSU和ESU中一致地实施。这里仅仅优化了线性投影的计算复杂度,但是没有优化
attention的计算复杂度。attention的计算复杂度为:attention的计算复杂度为Target Attention in TWIN:基于linear projection of behaviorsCP-GSU和ESU中统一使用的target-behavior relevance metric。不失一般性,我们假设用户和
target item之间没有交互,并将target item的固有特征记作target item与历史行为之间的relevance score其中:
projected query and key的维度。注意,这里
bias项的计算与这个
relevance score由query(即target的固有特征)与key(即behaviors的固有特征)之间的内积计算得出。此外,由于交叉特征被压缩为1维,因此可用作bias项。我们使用在
CP-GSU中,这个relevance score100个最相关的behaviors。而在ESU中,我们对100个最终入围者执行加权平均池化:其中:
我们通过设置
100个behaviors执行,因此可以在线高效进行。我们不需要像为behaviors计算注意:在
ESU中,仍然使用了Behavior Feature Splits and Linear Projection策略从而计算注意力权重。但是,对于为了共同关注来自不同
representation子空间的信息,我们在MHTA中采用4个头。因此,TWIN的final output定义为:其中
head之间相对重要性。
55.1.4 系统部署
我们在快手的
ranking system上部署了TWIN,服务于3.46亿日活用户的主要流量。在本节中,我们介绍我们在部署中的实际经验。我们的系统架构细节如Figure 3所示。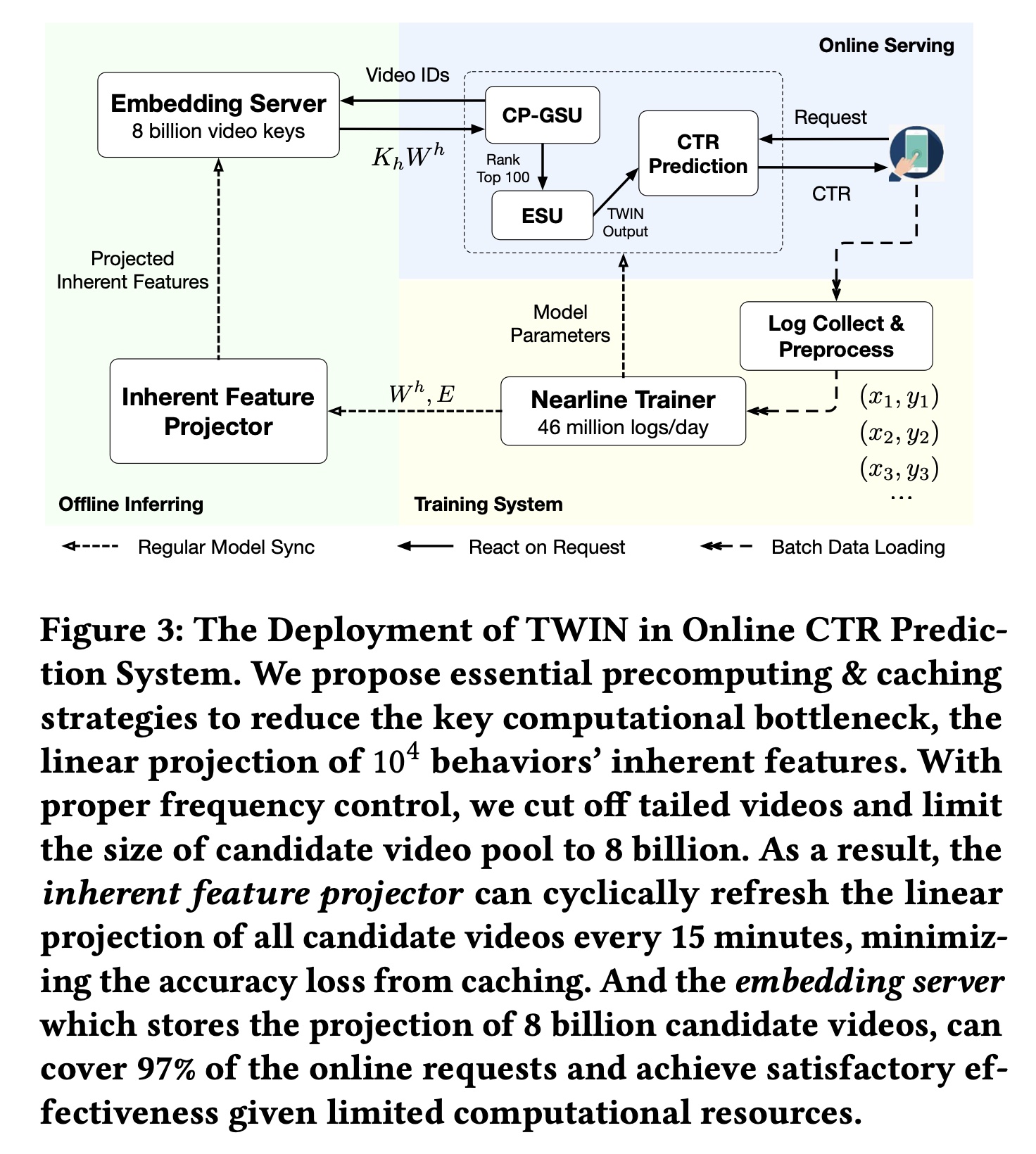
训练系统:我们的
TWIN模块与整个CTR prediction模型在快手的large-scale distributed nearline learning system上进行联合训练。 每天,有数亿用户访问快手,观看短视频以及与短视频互动,每天留下46B条观看和互动日志。在8分钟时间内,每条日志都被实时收集、实时预处理并用于模型训练。该nearline training system使用8分钟内发生的user-video互动中的最新知识增量地更新模型参数。Figure 3里给出的是46 million/day,但是正文部分说的是46 billion/day。此外,我们的
message queue system每5分钟一次将最新的参数值从training system持续同步到离线推理系统和在线服务系统。这种同步确保了online CTR prediction service始终基于最新模型。离线推理:
offline inferring system旨在通过提供lookup service来加速online serving。当接收到lookup keys(即,一个batch的video ids)时,此service将返回lookup values,即相应的projected inherent features的拼接形式(即,所有headsoffline inferring system由两部分组成:1):一个inherent feature projector,使用从training system同步的最新embeddings和TWIN参数linear projection of inherent features。通过适当的频率控制,该projector可以每15分钟刷新一次8B规模的candidate video pool的projected inherent features,从而最大限度地减少caching造成的准确率损失。2):一个embedding server,将inherent feature projector的结果存储到key-value结构中,并提供上述key lookup service。通过截断尾部视频,8B keys可以覆盖97%的online request,平衡了效率和效果。
Online Serving:一旦收到一个request,online serving system就会向offline inferring system查询从而得到projected inherent featuresuser-item relevance score100个behaviors,并将这100个behaviors输入到ESU。这种设计在实践中将TWIN的计算瓶颈(即99.3%。请注意,只有
100 behaviors的ESU足够轻量,可以使用从training system同步的最新参数来实时进行所有计算。因此,ESU计算出的CP-GSU中的略微更新,这进一步提升了我们的Target Attention机制的性能。通过加速设计,
TWIN成功部署在快手的ranking system上,服务于3.46亿活跃用户的主要流量,峰值请求为每秒30M个视频。
55.2 实验
在本节中,我们详细介绍了在真实工业数据上进行的离线和在线实验,以评估我们提出的方法,目的是回答以下五个研究问题(
research question: RQ)。RQ1:与lifelong user behavior modeling中的其他SOTA相比,TWIN在离线评估中的表现如何?RQ2:与其他SOTA相比,TWIN能实现多大的一致性?或者说,为什么TWIN有效?RQ3:随着用户行为序列长度的增长,TWIN的有效性如何变化?RQ4:所提方法中的关键组件、以及不同实现方式的效果如何?RQ5:TWIN在实际在线推荐系统中的表现如何?
数据集:为了在现实情况下评估
TWIN在lifelong user behavior modeling中的作用,我们需要一个大型的CTR prediction数据集,该数据集应具有丰富的用户历史behaviors,理想情况下可以scale up到每个用户数万个behaviors。不幸的是,现有的公共数据集要么相对较小,要么缺乏足够的用户历史behaviors。例如,在广泛使用的Amazon数据集中,每个用户平均只有不到10个历史行为。在Taobao数据集中,用户行为的平均序列长度最多为500。因此,我们从快手(中国顶级短视频分享平台之一)收集了一个工业数据集。 我们从每日用户日志中构建样本,以用户的点击作为标签。如Table 3所示,快手的每日活跃用户规模约为3.46亿。每天发布45M条短视频,这些视频总共播放了46B次。平均而言,每位用户每天观看133.7个短视频。为了利用丰富的behavior信息,我们从数月前的旧日志中收集完整的用户历史行为。平均而言,每位用户在过去六个月内观看了14,500个视频,这为模型提供了一个试验台,这个试验台包含了可供学习的丰富的用户历史行为。我们将最大用户行为序列长度限制为100,000,这大约是重度用户一年的总观看次数。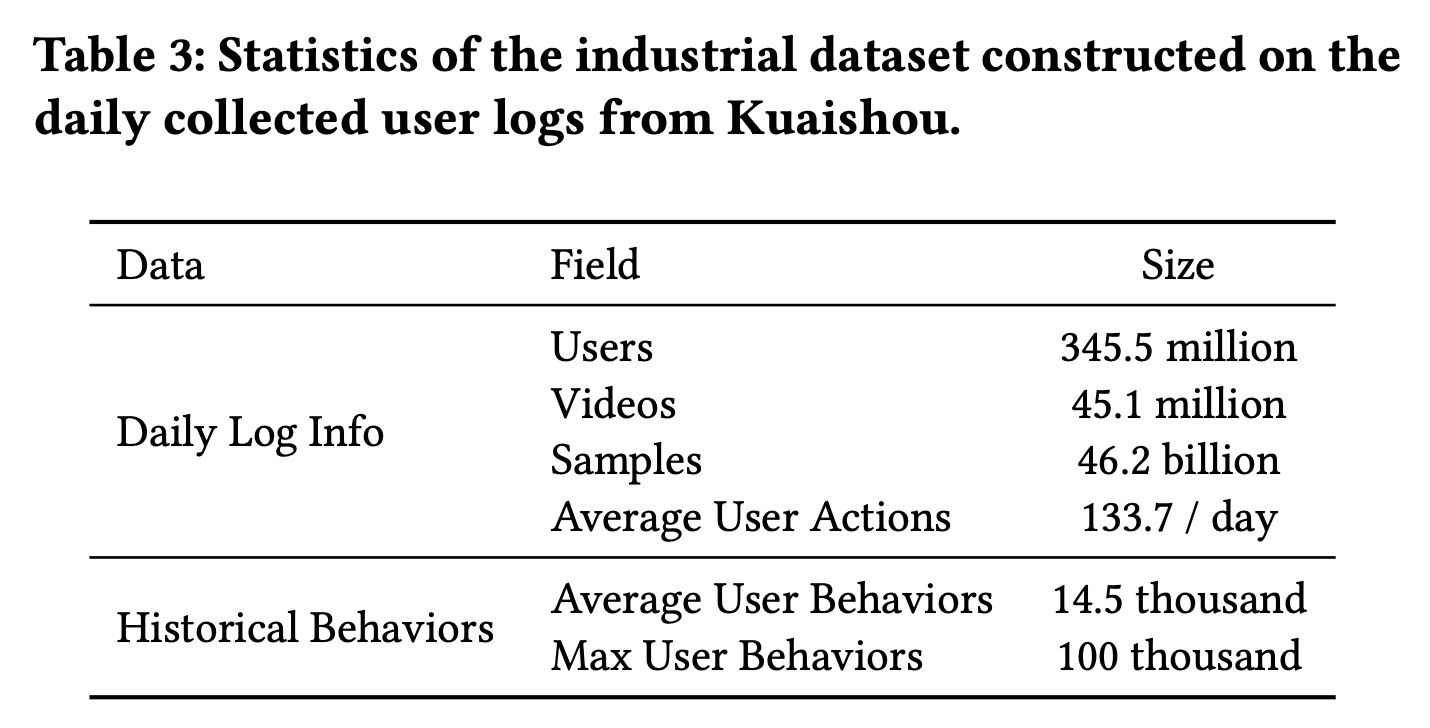
baselines:为了证明有效性,我们将TWIN与以下SOTA的lifelong user behaviors modeling算法进行了比较。Avg-Pooling:user lifelong behaviors的均值池化。DIN:最广泛采用的short-term behavior modeling方法,它使用Target Attention从而用于target-specific interests。SIM Hard:GSU从与target item相同的category中选择behaviors,ESU遵循DIN中的Target Attention。在我们的场景中,video categories总数为37。ETA:局部敏感哈希 (Locality-sensitive hash : LSH) 用于为target video and behaviors生成哈希签名(hash signature)。然后GSU使用汉明距离作为target-behavior relevance metric。SDIM:GSU通过多轮哈希碰撞(multi-round hash collision)选择具有与target video相同哈希签名的behaviors。在原始论文中,ESU线性聚合了multi-round hash collision所采样到的behaviors从而获得用户兴趣。在我们的实验中,为了公平比较,ESU采用了更强大的Target Attention。SIM Cluster:由于“category”需要昂贵的人工标注,并且在短视频场景中通常不可靠,因此我们实现了SIM Cluster作为SIM Hard的改进版本。我们根据pre-trained embeddings将视频分组为1,000 clusters。GSU从与target item相同的clusters中检索behaviors。SIM Cluster+:是SIM Cluster的改进版,其中clusters数量从1,000个扩展到10,000个。SIM Soft:GSU使用视频的pre-trained embeddings的内积得分来检索relevant behaviors。内积是一种比汉明距离和哈希碰撞更精细的检索方法,但计算成本更高。
综上所述:
ETA和SDIM采用端到端训练方法,但使用粗略的检索方法以避免高复杂度的计算。SIM Cluster、SIM Cluster +、以及SIM Soft采用精细的检索方法,但代价是它们必须使用pre-trained embeddings并提前生成离线倒排索引(offline inverted index)。
请注意,
SIM Soft尚未被后续工作ETA和SDIM击败。我们没有与UBR4CTR进行比较,因为它的迭代式训练(iterative training)不适合我们的流式场景(streaming scenario)。此外,UBR4CTR被证实比SIM Hard和ETA的表现更差。实验设置:
我们使用一天中连续
23个小时的样本作为训练数据,并使用接下来一个小时的样本进行测试。我们连续5天评估所有算法并报告5天的平均性能。相当于将算法重复
5次并报告平均性能。对于离线评估,我们使用两个广泛采用的指标:
AUC和GAUC。AUC表示正样本得分高于负样本得分的概率,反映了模型的排序能力。GAUC对所有用户的AUC进行加权平均,权重设置为该用户的样本数。GAUC消除了用户之间的bias,以更精细和公平的粒度评估模型性能。
为了公平比较,在所有算法中,除了
long-term behavior modeling模块外,我们使用相同的网络结构,包括embedding layers、upper deep networks、short-term behavior modeling和other task modelings。对于两阶段模型,我们使用最近的
10,000 behaviors为作为GSU的输入,并在ESU中检索100 behaviors用于Target Attention。对于
DIN,我们使用最近的100 behaviors,因为它在处理长序列方面存在瓶颈。虽然
TWIN的CP-GSU在attention score computation中使用了四个head,但我们通过四个head递归遍历top ranked items,直到收集到100 unique behaviors。为什么要做这种简化?会不会影响性能?
对于所有模型,
embedding layer都使用AdaGrad优化器,学习率为0.05。DNN参数由Adam更新,学习率为batch size设置为8192。
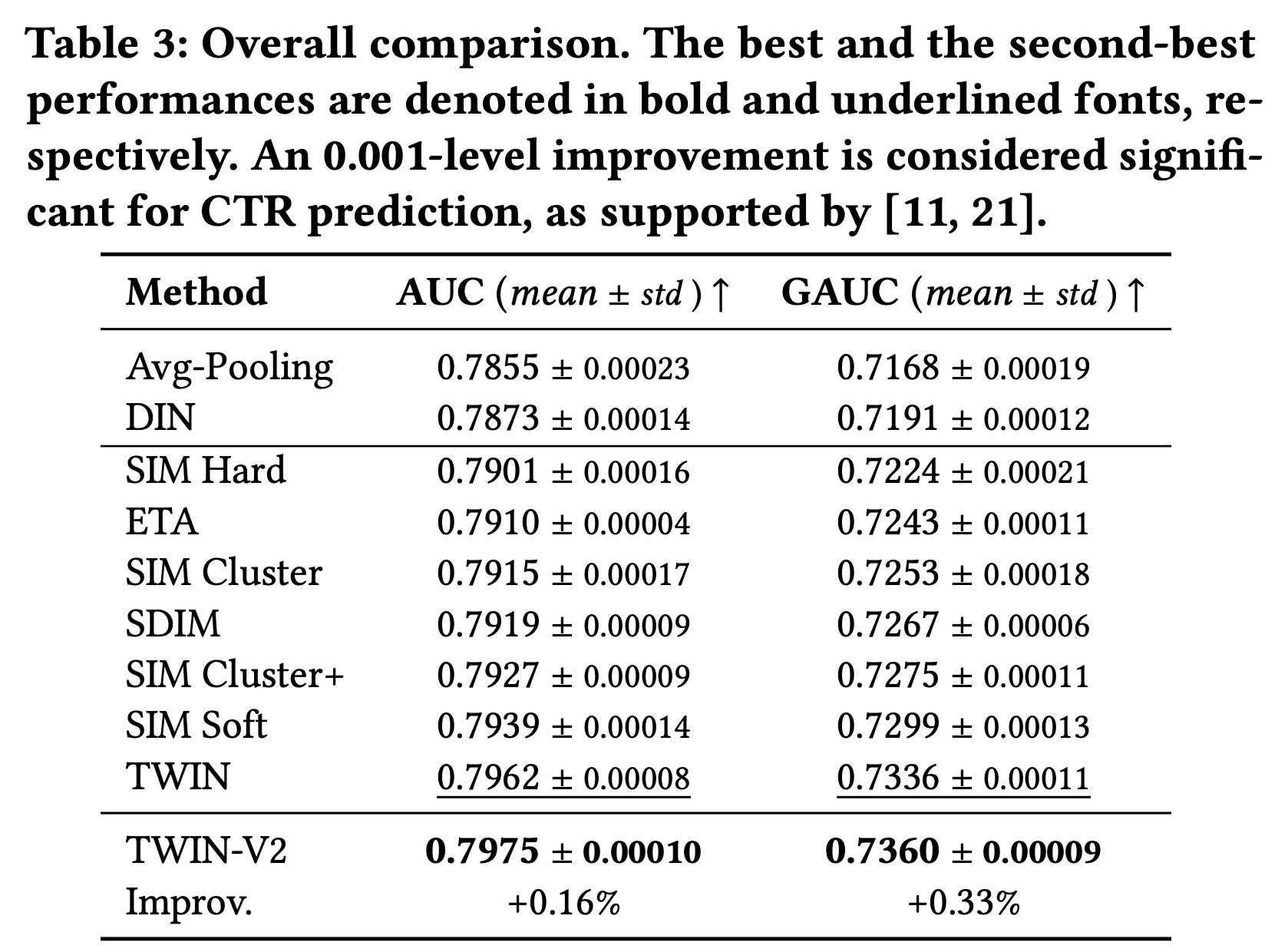
55.2.1 整体性能 RQ1
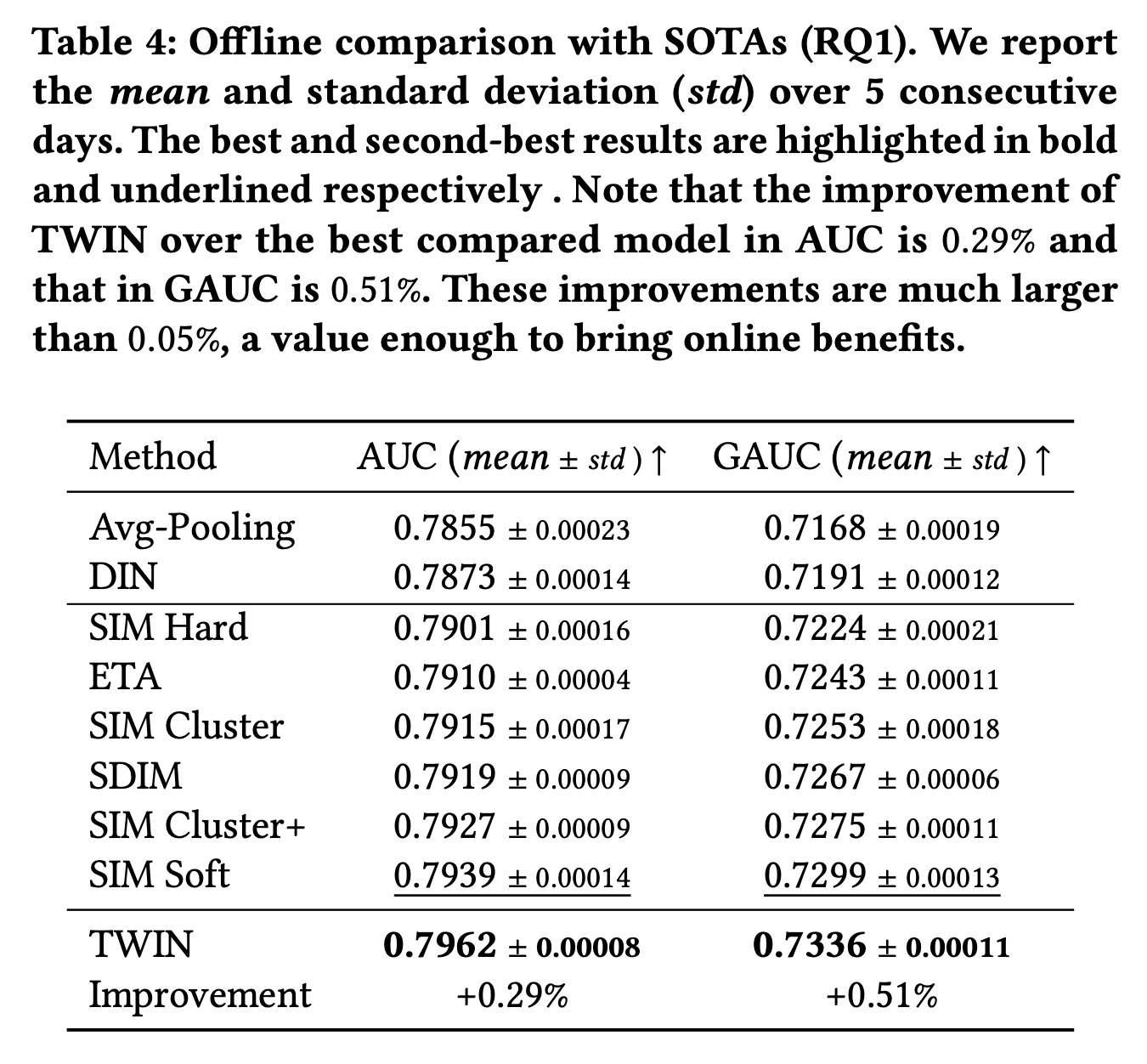
Table 4显示了所有模型的性能。请注意,由于我们的数据集中有大量的用户和样本,因此离线评估中AUC和GAUC的0.05%的改进足以为业务带来online gains。首先,
TWIN的表现明显优于所有基线,尤其是具有不一致GSU的两阶段SOTA。这验证了TWIN在life-long behavior modeling中的关键优势,即CP-GSU中强大而一致的Target Attention。具体而言,CP-GSU精确地检索出了ESU认为高度相关的behaviors,为最重要的user information节省了ESU宝贵的计算资源。而在其它基线中,无效且不一致的GSU可能会错过重要behaviors并引入noisy behaviors,从而降低Target Attention的性能。此外,从
Avg-pooling到DIN的增益显示了Target Attention在检索有效信息方面的能力。其他两阶段SOTA相对于DIN的增益验证了modeling long behaviors的必要性。这两者共同支持了我们的动机:将Target Attention扩展到长序列。其次,仅有端到端训练是不够的。我们观察到
TWIN明显优于ETA和SDIM,而这两个强大的基线在GSU中的embeddings也以端到端的方式进行训练。具体来说,ETA使用LSH和汉明距离,而SDIM使用多轮哈希碰撞。与Target Attention相比,这两种GSU策略都不太精确,并且与它们在ESU中使用的target-behavior relevance metric不一致。而TWIN中的CP-GSU不仅是端到端训练的,而且与ESU中的Target Attention一致。这表明精确的relevance metric对GSU至关重要,验证了我们优于现有的端到端算法。第三,以更细的粒度来建模
lifelong behaviors是有效的。我们比较了SIM的变体:具有37 categories的SIM Hard、具有1,000 / 10,000 clusters的SIM Cluster(+)、以及针对每个behavior单独计算target-behavior relevance score的SIM Soft。随着
GSU中使用更细粒度的检索方法,我们观察到性能持续改进。这是因为当GSU能够更精细地捕获视频之间的relevance score时,它会更准确地检索behaviors。从这个角度来看,我们进一步将我们优于SIM Soft的原因归功于TWIN采用更准确的relevance metric。
55.2.2 一致性分析 RQ2
正如所声称的,我们卓越的
behavior modeling能力来自CP-GSU和ESU中一致的relevance metrics。但我们真正实现了多大的一致性(Figure 4)? 对于每个well-trained的两阶段模型,我们重用其ESU的参数作为其Oracle,从而从10,000 behaviors中检索“the real top-100”。换句话说,这些real top-100是ESU认为真正重要的ground-truth。然后,对于所有被比较算法,我们遍历GSU output size,从outputs命中real top-100。请注意,每个被比较算法都有自己的Oracle和top-100。但我们只绘制一条Oracle曲线,因为所有Oracles都完美地击中了ground truth。SIM Soft得益于GSU中更精确的retrieval策略,在retrieval consistency方面有所改进。此外,
TWIN在返回100 behaviors时实现了94次命中,这验证了我们在保持两个阶段之间的一致性方面的优势。请注意,这是最值得注意的value,因为考虑到推理时间、以及Target Attention计算复杂度的限制,100是ESU input的上限。由于caching中的刷新延迟(refresh delay),我们在实践中没有达到理论上的100%的一致性,如正文章节所述。
基于以上结果,我们推测
CP-GSU比传统GSU具有更强的match user interests with the target video的能力。这归因于一致性。通过与ESU共享相同的结构和参数,CP-GSU能够准确判断和检索具有相似内容的videos。此外,由于CP-GSU参数是实时更新的,该模型可以捕获用户的动态变化的兴趣。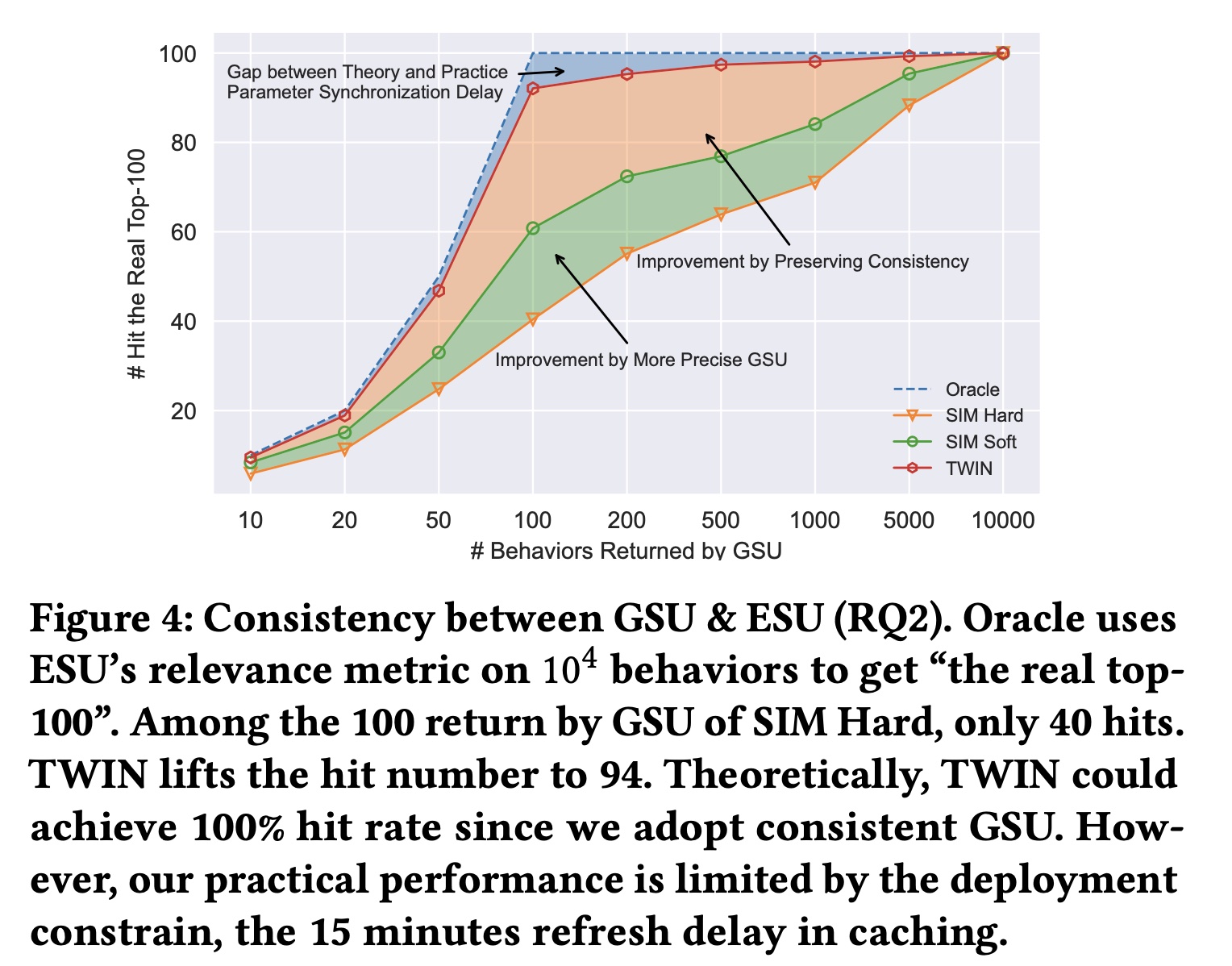
55.2.3 Behavior Length 的影响 RQ3
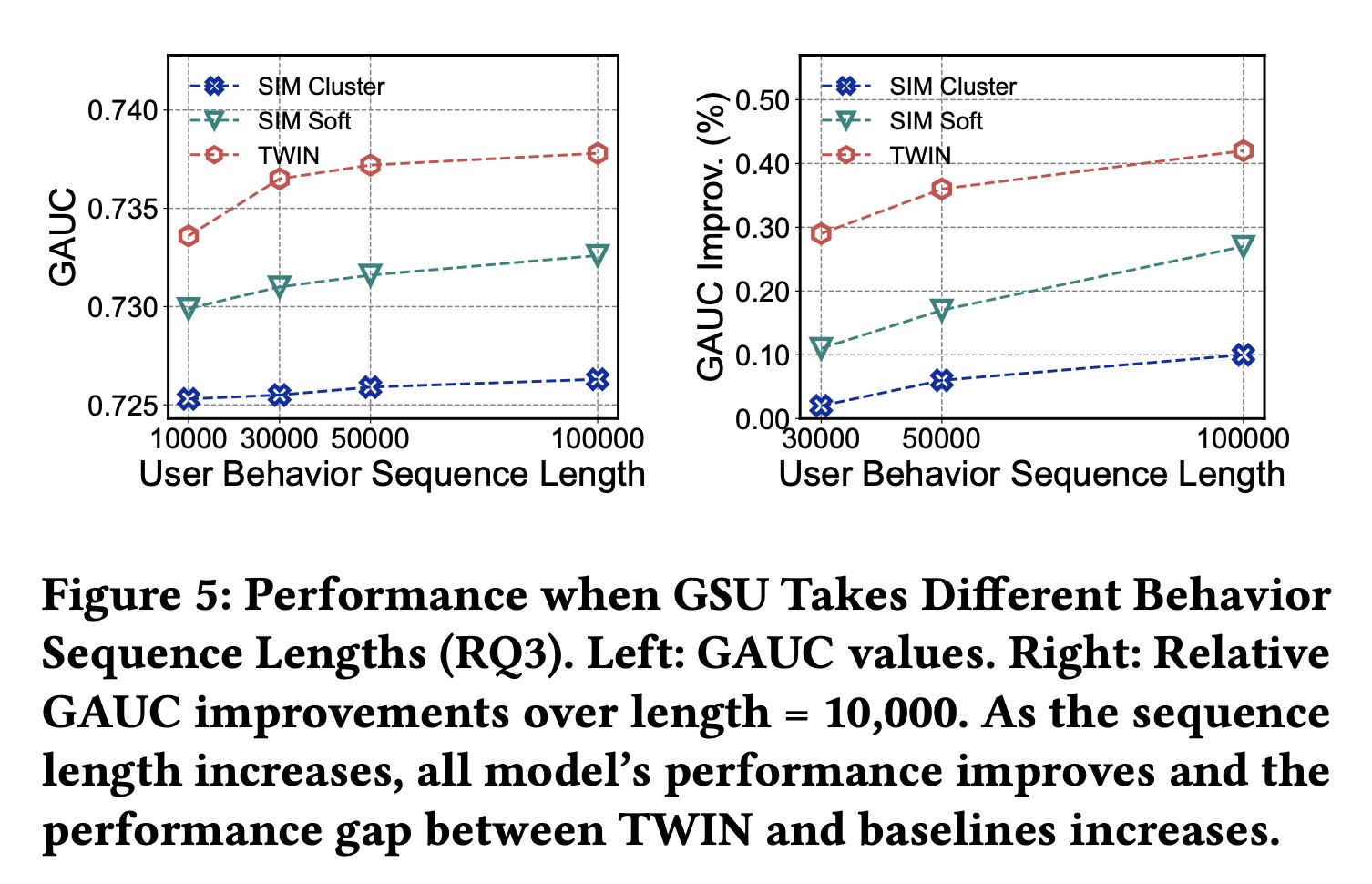
我们旨在测试
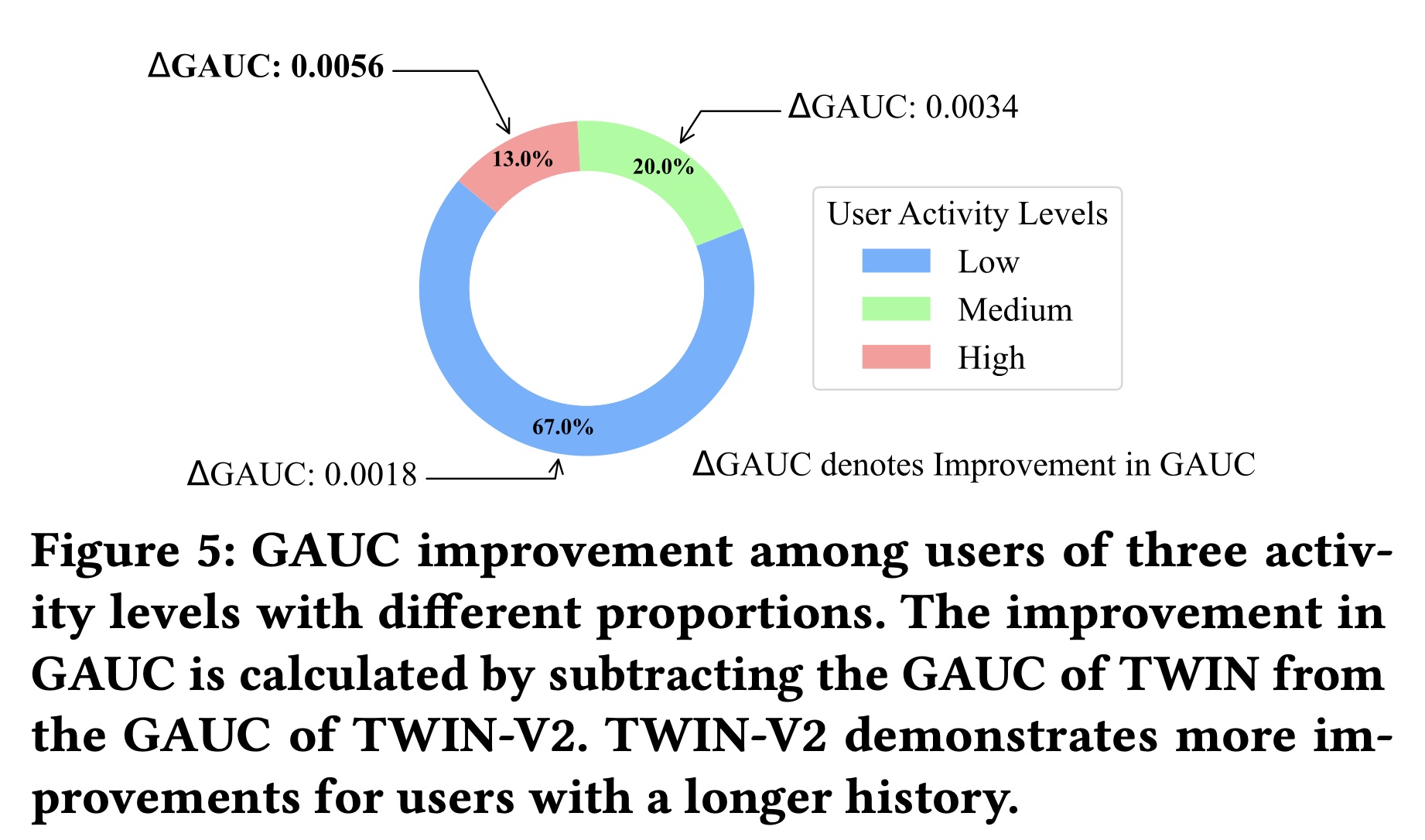
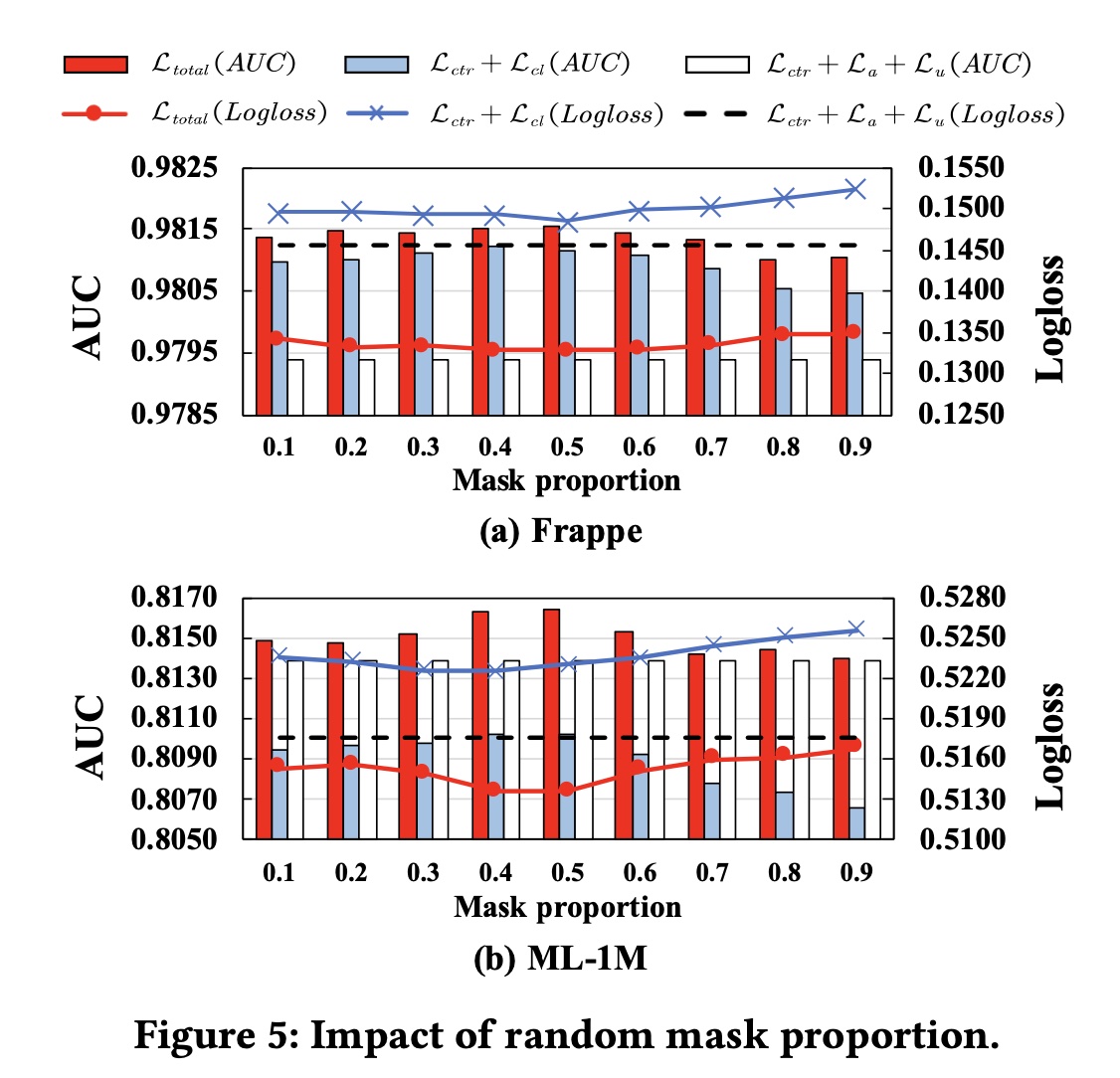
TWIN在不同behavior sequence长度下的有效性,并进一步挖掘TWIN的潜力。请注意,仅更改了GSU的输入序列长度,输出长度保持为100。结果如Figure 5所示。 我们观察到:1):TWIN始终表现最佳,2):随着序列长度的增加,TWIN与其他方法之间的性能差距越来越大。这表明TWIN在建模极长序列方面具有更好的效果。
54.2.4 消融研究 RQ4
我们通过对
TWIN应用不同的操作来进行消融研究,以评估我们的关键模型设计的贡献:1)两个阶段之间的一致性;2)高效的MHTA。TWIN在两个方面保持了两个阶段之间的一致性:网络结构和参数。为了研究每个方面带来的好处,我们实现了一个名为TWIN w/o Para-Con的变体,它不保留参数一致性。具体来说,我们首先训练一个辅助模型TWIN-aux,它使用与TWIN相同的网络结构和训练数据,但单独进行训练。然后,我们将GSU参数从TWIN-aux同步到TWIN w/o Para-Con。这是为了确保TWIN w/o Para-Con仍然实时被更新,并且TWIN和TWIN w/o Para-Con之间的差距都是由参数不一致造成的。 如Figure 6 (left)所示,TWIN w/o Para-Con的表现明显优于SIM Soft(结构和参数都不一致),但略逊于TWIN。这表明网络结构一致性和参数一致性都有好处,但网络结构一致性的贡献更大。这个配置有点奇怪,为什么不训练这样的模型:
CP-GSU和ESU采用相同的网络结构,但是不共享网络参数,然后训练?这个实验不太靠谱。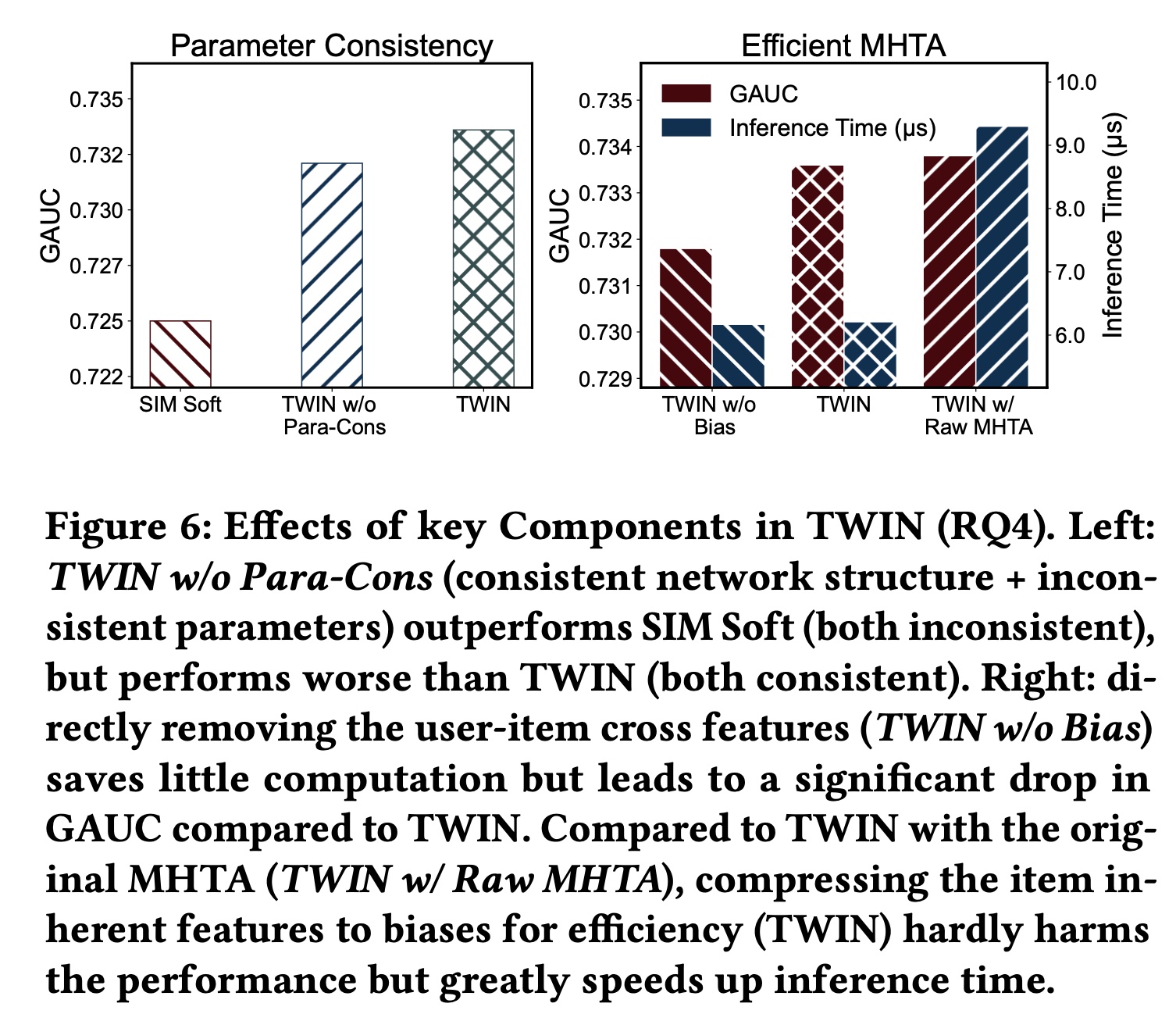
为了高效地计算
MHTA从而用于工业级部署,我们拆分user behavior features,并将每个user-item cross feature压缩为一维bias项。为了研究这种修改的影响以及在注意力计算中保留user-item cross features的好处,我们实现了两个变体并比较了它们的性能和推理时间:具有原始
MHTA的TWIN,其中使用直接的线性投影feature split。缩写为TWIN w/ Raw MHTA。MHTA中不使用user-item cross features的TWIN,缩写为TWIN w/o Bias。
如
Figure 6 (right)所示,TWIN明显优于TWIN w/o Bias,并且性能几乎与TWIN w/Raw MHTA相同,验证了我们对MHTA提出的修改几乎不会影响性能。至于计算成本,由于当user-item cross features用于caching不适用于TWIN w/ Raw MHTA(详见正文章节),因此TWIN w/ Raw MHTA的推理时间显著增加。相反,删除user-item cross features(TWIN w/o Bias)不会节省太多计算量,但会损害性能。
54.2.5 在线结果 RQ5
为了评估
TWIN的在线性能,我们在快手的短视频推荐平台上进行了严格的在线A/B test。Table 5比较了快手三个代表性业务场景(Featured-Video Tab, Discovery Tab, and Slide Tab)下TWIN与SIM Hard和SIM Soft的性能。与电商常用的线上评价指标CTR和GMV不同,短视频推荐场景通常使用观看时长(Watch Time),衡量用户观看视频的总时长。如表所示,
TWIN在所有场景中的表现都明显优于SIM Hard和SIM Soft。在快手上,观看时长增加0.1%被认为是一个有效的改进,TWIN实现了显著的商业收益。
五十六、TWIN V2 [2024]
《TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou》
在大型推荐系统中,建模长期用户兴趣对于
CTR prediction任务的重要性正逐渐引起研究人员和从业者的关注。现有的研究工作,如SIM和TWIN,出于效率考虑,通常采用两阶段方法来建模长期用户行为序列:第一阶段使用
search-based的机制,即General Search Unit: GSU,从长序列中快速检索与target item相关的a subset of sequences。而第二阶段使用
Exact Search Unit: ESU对检索到的结果计算interest scores。
鉴于用户行为序列跨越整个生命周期,可能达到
TWIN-V2,这是TWIN的增强版,其中采用分而治之的方法来压缩life-cycle behaviors并发现更准确更多样化的用户兴趣。具体来说,离线阶段,我们通过
hierarchical clustering方法将life-cycle behaviors中具有相似特性的items归为一个cluster。通过clusters的规模,我们可以将远远超过GSU retrieval的online inference。Cluster-aware target attention可以提取用户的全面的、多方面的长期兴趣,从而使最终的推荐结果更加精准和多样化。在数十亿规模的工业级数据集上的大量离线实验、以及线上
A/B test,证明了TWIN-V2的有效性。在高效的部署框架下,TWIN-V2已成功部署到快手主流量中,从而服务于数亿日活用户。CTR prediction对于互联网应用至关重要。例如,快手(中国最大的短视频分享平台之一)已将CTR prediction作为其ranking system的核心组件。最近,人们投入了大量精力来对CTR prediction中的用户长期历史行为进行建模。由于生命周期中的behaviors的长度很长,modeling life-cycle user behaviors是一项具有挑战性的任务。尽管现有研究不断努力延长historical behavior modeling的长度,但尚未开发出可以对用户整个生命周期进行建模的方法,从而覆盖application中高达1 million behaviors。 现代工业系统采用了两阶段方法,以便在可控的推理时间内尽可能多地利用用户历史记录。具体来说:在第一阶段,通用搜索单元 (
General Search Unit: GSU) 模块用于过滤长期历史行为,选择与target item相关的items。在第二阶段,精确搜索单元 (
Exact Search Unit: ESU) 模块对filtered items进行进一步处理,通过target attention提取用户的长期兴趣。
GSU的粗粒度的pre-filtering使系统能够在online inference过程中以更快的速度建模更长的历史行为。许多方法尝试了不同的GSU结构来提高pre-filtering的准确率,例如ETA、SDIM和TWIN。 尽管现有的第一阶段的GSU很有效,但它们通常存在长度限制,无法对整个生命周期的user behaviors进行建模。例如:SIM、ETA和SDIM可以过滤最大长度为TWIN将最大长度扩展到
在部署过程中,
TWIN使用最近的10,000 behaviors作为GSU的输入。不幸的是,这10,000 behaviors仅涵盖了用户在快手App中最近三到四个月的历史记录,无法涵盖user behavior的整个生命周期。如Figure 1所示,我们分析了快手App中过去三年的user behavior。medium and high user groups在三年内可以观看App使用时长的大部分(60% + 35% = 95%)。因此,modeling the full life-cycle behaviors可能会增强用户体验并提高平台的商业收益。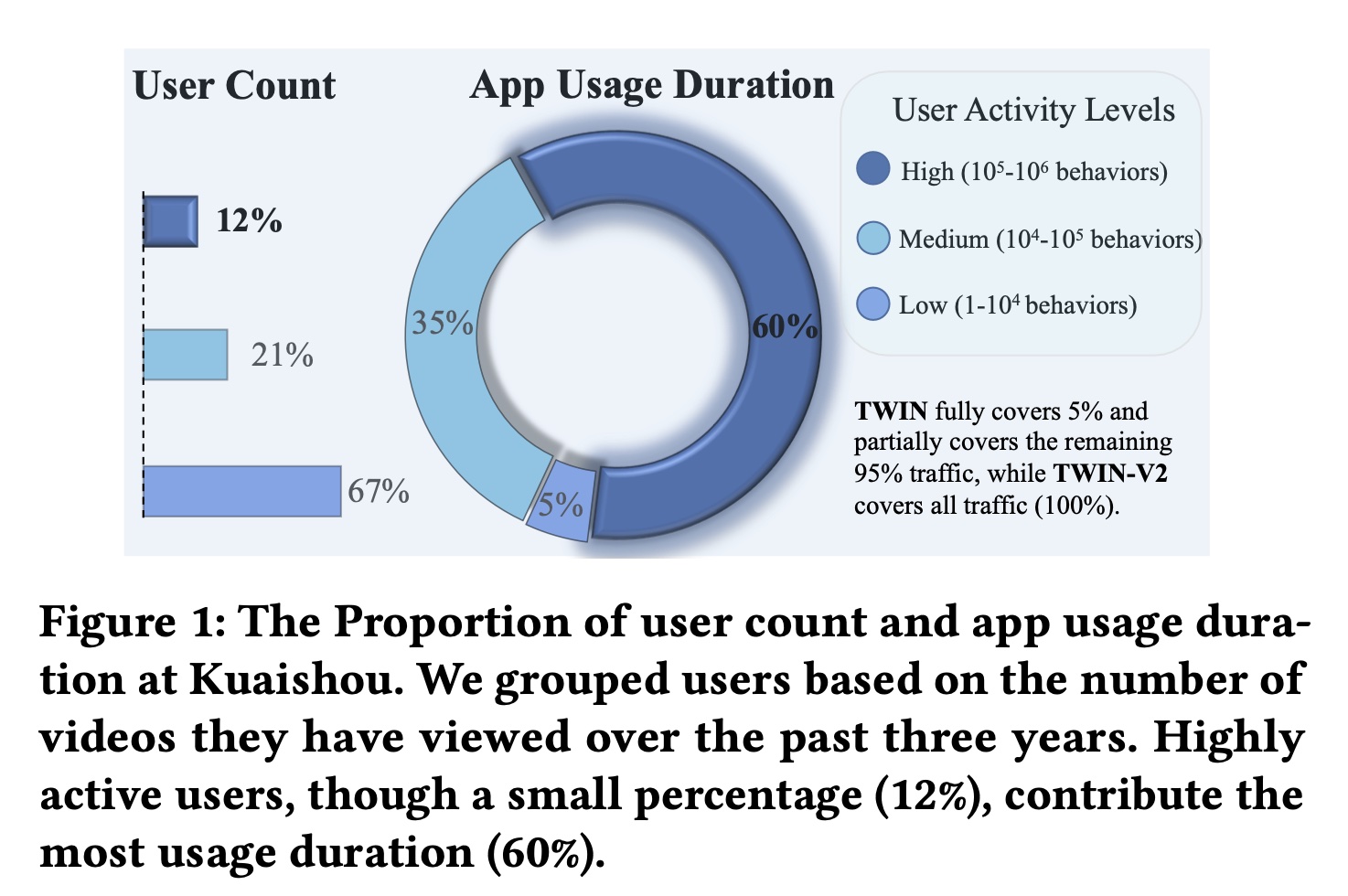
为了解决这个问题,我们提出了
TWIN-V2,这是TWIN的增强版,使其能够对user behavior的全生命周期进行建模。TWIN-V2采用分而治之的方法,将完整的生命周期历史(full life-cycle history)分解为不同的clusters,并使用这些clusters来建模用户的长期兴趣。具体来说,我们将模型分为两个部分:离线和在线。在离线部分,我们使用层次聚类(
hierarchical clustering)将life-cycle behaviors中的相似items聚合到clusters中,并从每个cluster中提取特征以形成一个虚拟的item。在在线部分,我们利用
cluster-aware target attention从而基于clustered behaviors来提取长期兴趣。在这里,attention scores根据相应的cluster size被重新加权。
大量实验表明,
TWIN-V2在各种类型用户上提升了性能,从而带来更准确和多样化的推荐结果。 本文主要贡献总结如下:我们提出
TWIN-V2从极长的user behavior中捕获用户兴趣,成功地延长了user modeling across the life cycle的最大长度。hierarchical clustering和cluster-aware target attention提升了long sequence modeling的效率,建模了更准确、更多样化的用户兴趣。大量离线实验和在线实验验证了
TWIN-V2在超长用户行为序列的扩展方面的有效性。我们分享了
TWIN-V2的部署实践,包括离线处理和在线服务。TWIN-V2已经服务于快手每日约4亿活跃用户的主要流量。
TWIN V2 vs TWIN V1的在线指标提升,要比TWIN V1 vs SIM低得多。这意味着TWIN V2上线之后,系统的商业增益没有那么大。本文旨在将
long-term history modeling扩展到生命周期级别,同时保持效率。Table 1总结了TWIN-V2与之前工作的比较。TWIN V2比TWIN多了一步:先对用户行为序列进行聚类,并对每个cluster构造一个virtual item来代表这个cluster。然后将这些virtual items馈入TWIN中。但是,
TWIN V2的效果依赖于一个训练好的recommendation model。我们需要从这个recommendation model中获取item embedding从而进行聚类、以及virtual item的构造。然而,论文没有提到这个recommendation model是如何创建和训练的,在实验部分也没有说这个recommendation model的性能对于TWIN V2效果的影响。从 “TWIN-V2 的部署” 这一章节来看,我们只需要提供一个初始的
recommendation model,然后在训练过程中可以用上一轮的TWIN-V2模型作为这个recommendation model从而优化下一轮的TWIN-V2。从这个角度来看,recommendation model似乎不是特别重要?此外,读者猜测初始的
recommendation model来自于训练好的TWIN-V1模型。
56.1 方法
本节详细阐述了所提出的模型,详细介绍了从整体工作流到
deployment framework的整个过程。符号总结如下。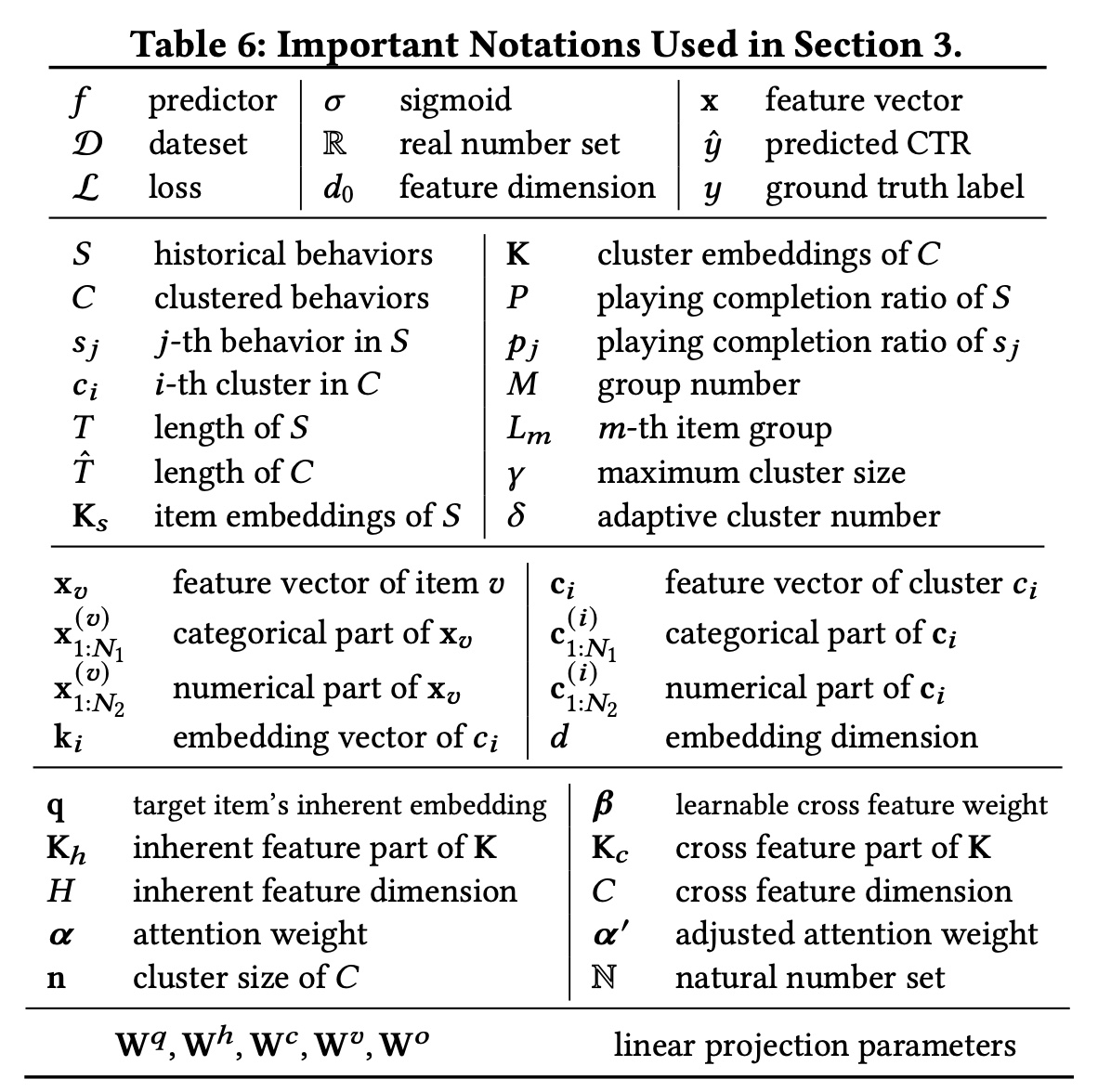
56.1.1 基础知识
CTR prediction的核心任务是预测用户点击某一个item的概率。令feature representation,令label。CTR prediction的过程可以写成:其中:
sigmoid函数。CTR模型predicted probability。
模型
其中:
56.1.2 整体工作流
Figure 2展示了TWIN-V2的整体框架,包括离线和在线部分。本文重点介绍life-cycle behavior modeling。因此我们强调这一部分并省略其他部分。 由于整个生命周期的behavior对于online inferring来说太长,我们首先在离线阶段对behaviors进行压缩。User behavior通常包括许多相似的视频,因为用户经常浏览他们喜欢的主题。因此,我们使用hierarchical clustering将用户历史中具有相似兴趣的items聚合到clusters中。Online inferring使用这些clusters及其representation vectors来捕获用户的长期兴趣。 在online inferring过程中,我们采用两阶段方法进行life-cycle modeling:首先,我们使用
GSU从clustered behaviors中检索与target item相关的top 100 clusters。然后,我们使用
ESU从这些clusters中提取长期兴趣。
在
GSU和ESU中,我们实现了cluster-aware target attention,并调整不同clusters的权重。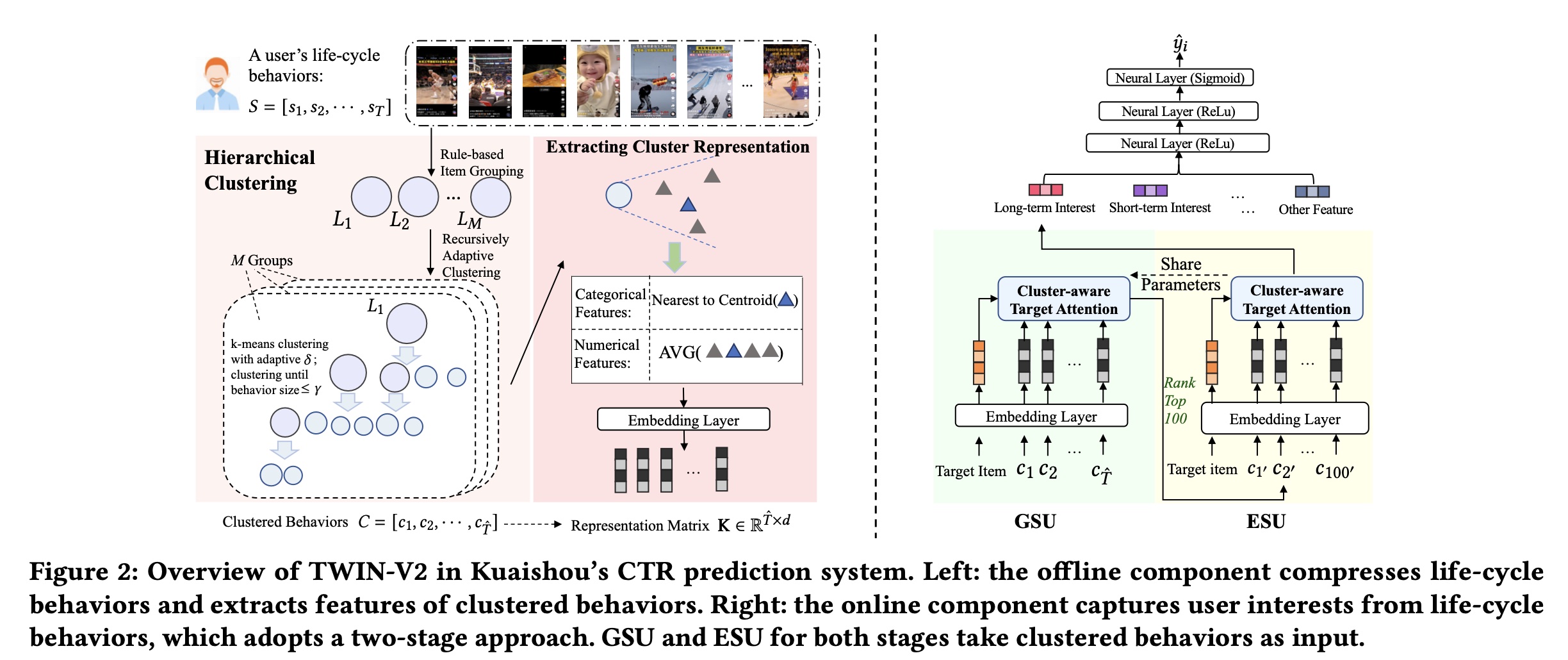
56.1.3 Life-Cycle User Modeling
考虑到用户在生命周期中的历史行为具有超长序列,我们首先采用分而治之的方法压缩这些
behaviors,然后从compressed behaviors中提取用户的长期兴趣。
a. Hierarchical Clustering Over Life Cycle
对于用户
items的一个序列life-cycle behaviors的数量,item。用户可能在similar items。例如,一个喜欢NBA比赛的用户在其历史中可能拥有数百个与篮球相关的视频。因此,一个自然的想法是将similar items聚合成clusters,用一个cluster来表示许多similar items,从而减小正式地,我们旨在使用压缩函数
behavior sequence其中:
clustered behaviorsclustered items的第具体而言,我们采用分层聚类(
hierarchical clustering)方法来实现Algorithm 1所示。在第一步中,我们简单地将
historical behaviors分成几组。我们首先根据用户playing time ratio将historical items分为historical item,这个playing time ratio记作在第二步中,我们递归地对每组的
life-cycle historical behaviors进行聚类,直到每个cluster中的items数量不超过k-means方法对behaviorsembeddingsrecommendation model中获得。maximum cluster size的超参数。这意味着我们需要一个
pre-trained模型从而获得pre-trained模型的质量会影响TWIN-V2的效果。

接下来,我们将详细说明
Algorithm 1背后的原理:Item Grouping:在短视频场景中,视频的完播率(playing completion ratio)可以看作是用户对视频感兴趣程度的指标。我们首先按完播率对behaviors进行分组,以确保final clustering results具有相对一致的playing time ratio。如果不这样做,将导致每个cluster内的分布不平衡,因为k-means仅考虑item embeddings。函数playing time ratio的范围分成五个相等的部分。5。在电商场景下,我们可以按照
action type对behaviors进行分组,如click, add_cart, purchase。Recursively Adaptive Clustering:我们选择hierarchical clustering而不是single-step clustering,因为用户历史是个性化的,因此设置通用的clustering iterations数量是不切实际的。我们还动态设置
number of clusters(items数量的0.3次方),允许clustering适应不同规模的behaviors。当
item size低于clustering过程停止,其中20。
单次迭代逻辑:
首先从
groupItem Grouping所初始化,刚开始包含group。如果
groupitem数量低于groupcluster。当前迭代结束,进入下一轮迭代。如果
groupitem数量大于等于groupKmeans聚类,cluster数量为groupitem数量的0.3次方。聚类后的每个cluster都追加到
这种做法使得每个
cluster的item size都小于在我们的实践中,平均
cluster size约为cluster的数量),大大缩短了life-cycle behaviors的长度。用于聚类的item embeddingsrecommendation model中获得的,这意味着clustering是由协同过滤信号所指导的。因此,我们通过将
similar items聚合到clusters中,将原本很长的用户行为序列
b. Extracting Cluster Representation
获得
clustersitems of each cluster中抽取特征。为了最大限度地减少计算和存储开销,我们使用一个virtual item来表示features of each cluster。 我们将item features分为两类(numerical and categorical),并使用不同的方法抽取它们。Numerical features通常使用标量来表示,例如视频时长和用户播放视频的时间。Categorical features通常使用one-hot (or multi-hot)向量来表示,例如video ID和author ID。
正式地,给定一个任意
item为简单起见,我们使用
categorical features,numerical features。对于cluster我们计算其包含的所有
items的所有numerical features的平均值作为numerical feature representation:对于
categorical features,由于它们的平均值没有意义,我们采用距离clusteritem来表示cluster其中:
itemembeddings。这些embeddings可以从注意:这是将距离质心最近的
item的categorical feature作为这个cluster的categorical feature。
因此,整个
clusteraggregated, virtual item featureembedding layers之后,每个cluster的特征都被嵌入到一个向量中,例如,对于embedding向量为GSU和ESU模块根据这些embedded vectors估计每个cluster与target item之间的相关性。item(即,virtual item),作为这个cluster的代表。
c. Cluster-aware Target Attention
遵从
TWIN,我们同时在ESU和GSU中采用了相同的有效的注意力机制,将clustersrepresentations作为输入。给定
clustered behaviorsembedding layer得到由representation vectors组成的矩阵cluster的特征embedding向量。对于
numerical featurebucktize,然后再做embedding。然后我们使用
target attention机制来衡量target item与historical behaviors的相关性。我们首先应用TWIN中的“Behavior Feature Splits and Linear Projection”技术来提升target attention的效率,详细信息见论文附录A.2。该方法将item embeddings拆分为固有的部分和交叉的部分。target item的固有特征的向量。clustered behaviors的固有embedding和交叉embedding,其中target item与clustered behaviors之间的relevance scores其中:
由于
clusters中的item counts千差万别,clusters与target item之间的关系。假设两个clusters具有相同的相关性(与target item的相关性),则具有更多items的cluster应该更重要,因为items越多意味着用户偏好越强。因此,我们根据cluster size调整relevance scores:其中:
clusters的大小,每个元素clustercluster size。在
GSU阶段,我们使用clustered behaviors(总长度为relevance scores最高的top 100 clusters。然后,将这100 clusters被输入到ESU,在那里根据relevance scores对它们进行聚合,从而得到用户长期兴趣的representation:其中
为了简单起见,这个等式中的符号被稍微滥用:在
ESU阶段设置其中每个
cluster的relevance scorecluster size我们使用具有
4个头的多头注意力来获得最终的长期兴趣:其中
备注:利用从
GSU中的hierarchical clustering中得出的behaviors,使模型能够容纳更长的历史行为,从而在我们的系统中实现life-cycle level modeling。与TWIN相比,GSU的life-cycle behaviors的input涵盖了更广泛的历史兴趣,从而提供了更全面、更准确的用户兴趣建模。此外,虽然现有的方法使用
top 100 retrieved behaviors作为ESU的输入,但TWIN-V2使用100 clusters。这些clusters涵盖了超过100 behaviors,使ESU能够对更广泛的behaviors进行建模。所有这些优势带来了更加准确和多样化的推荐结果,这在实验章节中得到了验证。
56.1.4 TWIN-V2 的部署
我们将部署
TWIN-V2的实践分为两个部分:在线和离线,如Figure 3所示。在
Figure 3中,我们以单个用户为例进行说明。当系统收到用户的request时:它首先从离线处理好的
user life-cycle behaviors中提取behavioral features。然后,使用
GSU和ESU,将behavioral features建模长期兴趣的input从而用于CTR模型以进行预测。
我们使用一个
nearline trainer来进行real-time model training,该trainer使用实时用户交互数据(数据在8分钟的时间窗口内)增量地更新模型参数。对于
life-cycle behaviors,我们应用hierarchical clustering和feature extraction来处理它们。这是通过周期性的offline processing和updates进行的。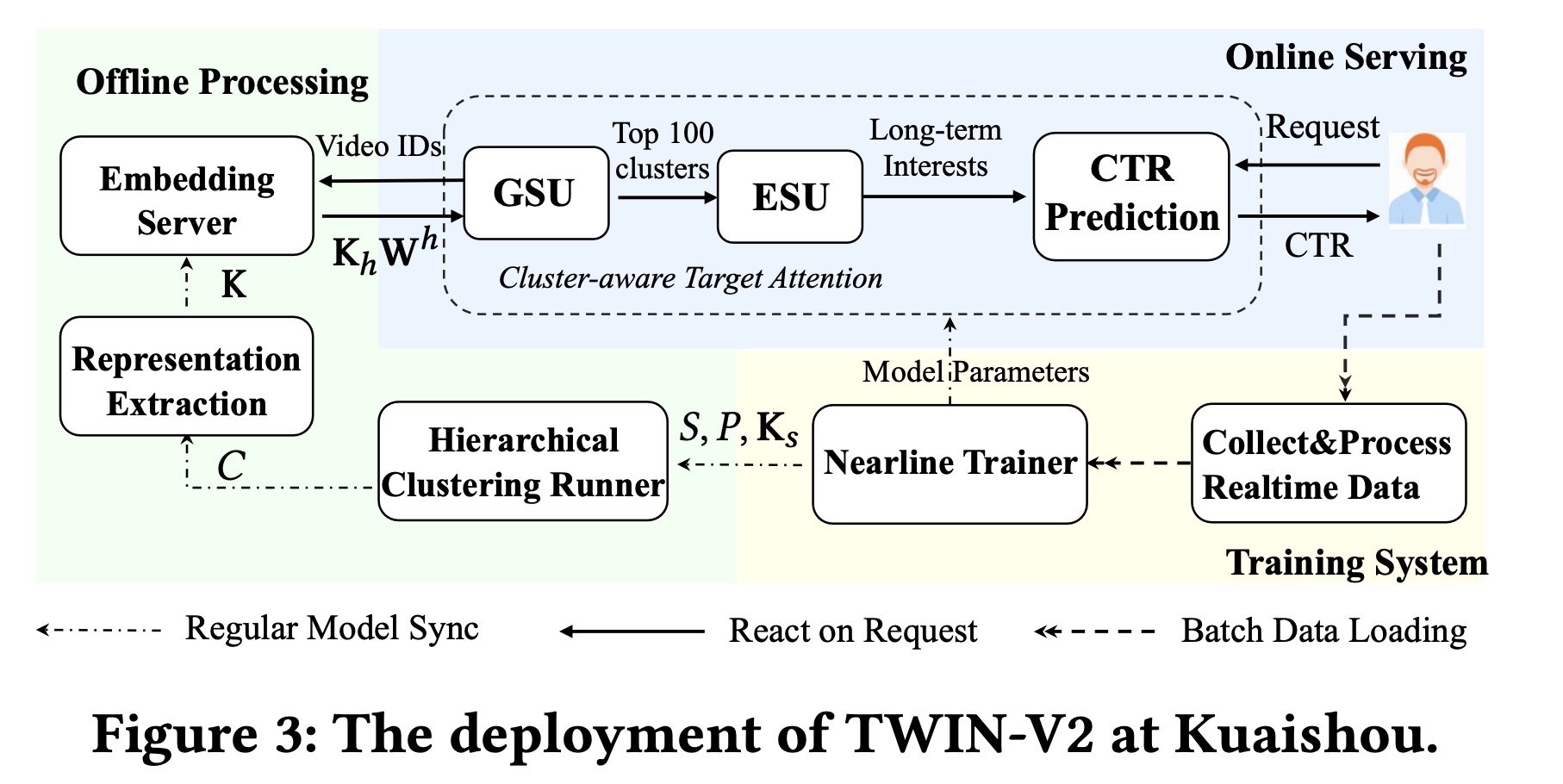
Offline Processing:离线处理旨在压缩用户的整个life-cycle behaviors。考虑到快手的用户数量是十亿级的,我们会定期压缩他们的life-cycle behaviors。hierarchical clustering runner每2周执行一次全面更新。我们将
hierarchical clustering中的maximum cluster size20,导致平均cluster size约为10。通过cluster representation extraction,每个cluster被聚合为一个虚拟item。在我们的实践中,historical behavior被压缩为原始长度的10%,从而将存储成本降低了90%。我们为
embedding server采用了TWIN中提出的inherent feature projector,每15分钟从最新的CTR模型刷新一次projector的参数。Online Serving:用户向系统发送request后,离线系统将数据特征发送到GSU,GSU计算behavior-target relevance scoresESU选择并聚合top 100 clustered behaviors作为长期兴趣从而用于CTR模型的预测。为了确保online inference的效率,我们保留了TWIN的precomputing and caching策略(即,预计算并缓存TWIN-V2是TWIN的增量部署:TWIN对最近几个月的behaviors进行建模,而TWIN-V2对整个生命周期的behaviors进行建模,使得它们相互补充。
56.2 实验
在本节中,我们通过进行大量的离线实验和在线实验来验证
TWIN-V2的有效性。数据集:由于
TWIN-V2是为极长的user behaviors而设计的,因此需要使用具有丰富用户历史的数据集。据我们所知,目前还没有平均历史长度超过App中提取了连续五天的用户交互数据作为训练集和测试集。样本由点击日志构成,并以click为标签。为了捕获用户的life-cycle历史,我们进一步追溯了每个用户的过去所有行为,每个用户的最大历史长度为100,000。Table 2展示了该工业数据集的基本统计数据。每天的前23个小时用作训练集,而最后一个小时用作测试集。这种测试集会不会有偏?因为最后一个小时的交互数据的分布可能与前
23个小时不同。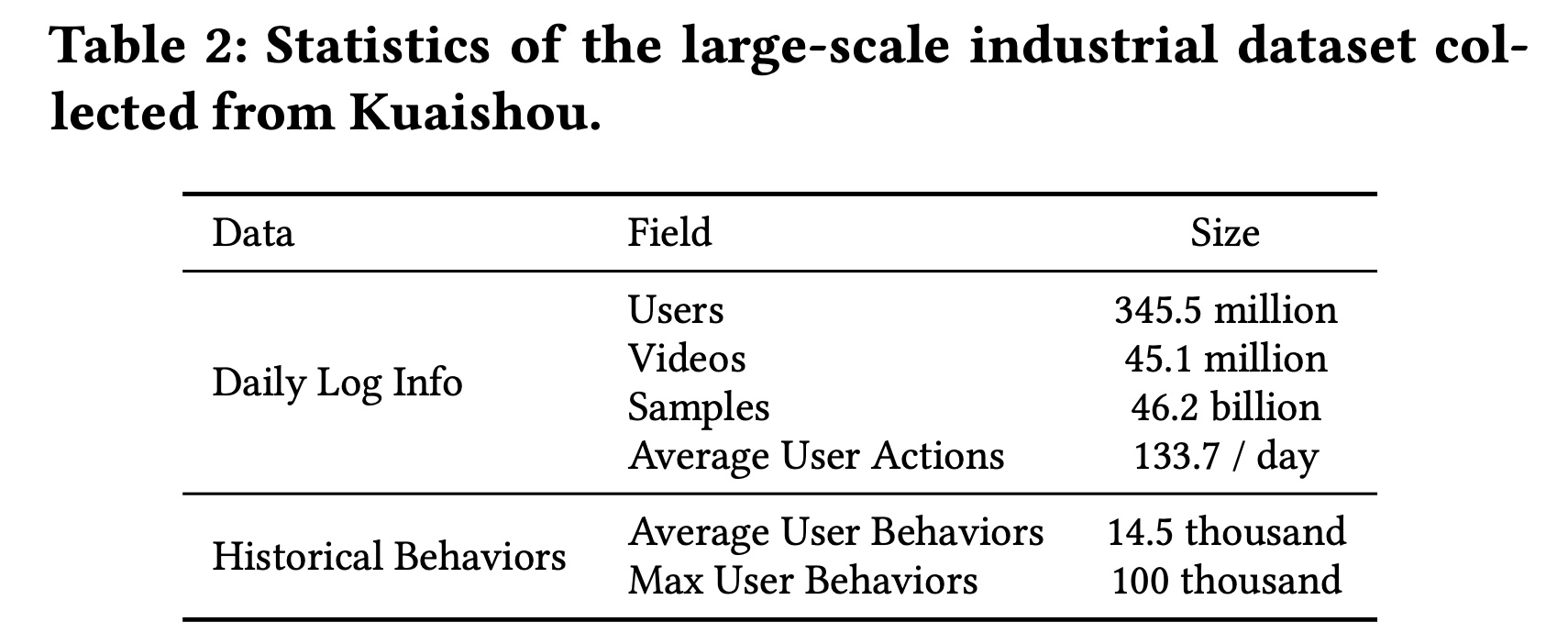
baseline:遵循常见做法(《Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction》、《TWIN: TWo-Stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》),鉴于我们的重点是建模极长的用户历史记录,我们将TWIN-V2与以下SOTA baselines进行比较:(1) Avg-Pooling:一种利用均值池化的简单方法。(2) DIN:它为推荐算法引入了target attention。(3) SIM Hard:Hard-search是指GSU根据category过滤长期历史。(4) SIM Soft:Soft search涉及通过计算target item和历史记录中的items之间的向量点积来选择top-k items。(5) ETA:它采用局部敏感哈希(Locality Sensitive Hashing: LSH)来促进端到端的训练。(6) SDIM:GSU通过收集与target item共享相同哈希签名(hashing signature)的behaviors来聚合长期历史。(7) SIM Cluster:由于SIM Hard依赖于annotated categories,我们通过video embeddings的聚类对其进行了改进。GSU检索与target item位于相同cluster中的历史行为。在这里,我们将所有items聚类为1,000 groups。(8) SIM Cluster+:这是SIM Cluster的高级变体,其cluster数量增加到10,000个。(9) TWIN:它为GSU和ESU阶段提出了一种有效的target attention。
为了确保公平比较,除了
long-term interest modeling外,我们在模型的所有方面都保持一致。评估指标和评估设置:
我们使用一天中连续
23个小时的样本作为训练数据,并使用接下来一个小时的样本进行测试。我们连续5天评估所有算法并报告5天的平均性能。相当于将算法重复
5次并报告平均性能。至于评估指标,我们采用了广泛使用的
AUC和Group AUC: GAUC。我们计算了连续5天这两个指标的均值和标准差。GAUC对所有用户的AUC进行加权平均,权重设置为该用户的样本数。GAUC消除了用户之间的bias,以更精细和公平的粒度评估模型性能。
实现细节:
对于所有模型,我们都使用
industrial context中相同的item and user features,包括video ID, author ID and user ID等大量属性。TWIN-V2将单个用户历史长度限制为最多100,000 items,从而对life-cycle user behavior进行聚类。如前文所述,TWIN-V2经验性地将历史行为压缩为原始大小的约10%,从而导致GSU中的maximum input length约为10,000。对于其他两阶段模型,输入
GSU的历史行为最大长度限制为10,000 behaviors。对于
DIN和Avg-Pooling,recent history的最大长度为100,因为它们不是为long-term behaviors而设计的。Avg-Pooling事实上可以支持任意长度的用户行为序列。为什么这里截断为100?所有两阶段模型都利用
GSU来检索top 100 historical items并将它们输入ESU从而用于interest modeling。batch size设置为8192。Adam的学习率为5e-6。
56.2.1 整体性能
从
Table 3的结果中,我们得出以下观察结果:TWIN-V2的表现远超其他基线。现有文献(《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》、《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems》)表明,AUC提高0.001对CTR prediction具有重要意义,足以产生online benefits。TWIN-V2比表现第二好的TWIN模型有所改进,AUC提高了0.0013,GAUC提高了0.0024。这些改进验证了TWIN-V2的有效性。TWIN-V2在GAUC上的相对改进高于AUC上的相对改进。GAUC提供了更细粒度的模型指标。GAUC的较大改进表明TWIN-V2在各种类型的用户中都实现了提升,而不仅仅是在整体样本上表现更好,而且它在特定子集上也表现出色。由于TWIN-V2包含更长的行为序列,我们相信它在高度活跃的用户群体中取得了更大的进步,这一假设在附录A.3中得到了验证(如Figure 5所示)。
56.2.2 消融研究
我们进行了一项消融研究,以调查核心模块在
TWIN-V2中的作用以及我们设计背后的原理。不同
Hierarchical Clustering方法的比较:我们的hierarchical clustering方法有两个主要特点:1):它利用动态clustering numbersizes of behaviors。2):k-means clustering是非均匀的,最终导致不同大小的clusters。
我们首先验证自适应的
cluster number“Binary”。此外,为了测试均匀cluster sizes的效果,我们创建了一个在balanced k-means clustering结果的变体,记作“Balanced&Binary”。在这个变体中,每次k-means iteration之后,对于larger cluster中的一部分item,如果它们比另一部分item更靠近另一个cluster的质心,则这些items会被移动到另一个cluster中,以确保最终两个cluster的大小相等。Table 4报告了对TWIN-V2和这两个变体的统计分析。在这三种方法中,我们的方法实现了最高的
cluster accuracy。这表明我们的方法创建的clusters中,items具有更紧密匹配的representation vectors,从而导致每个cluster内的items具有更高的相似度。cluster accuracy:每个item和它所属的cluster的质心进行cos相似度计算,然后取平均。我们的方法还实现了最短的运行时间,证实了自适应
此外,我们还报告了这些方法在测试集上的性能,如
Figure 4 (left)。
这些结果验证了自适应方法(
adaptive method)可以在每个cluster内分配更相似的items,并与其他方法相比加快了hierarchical clustering的过程。
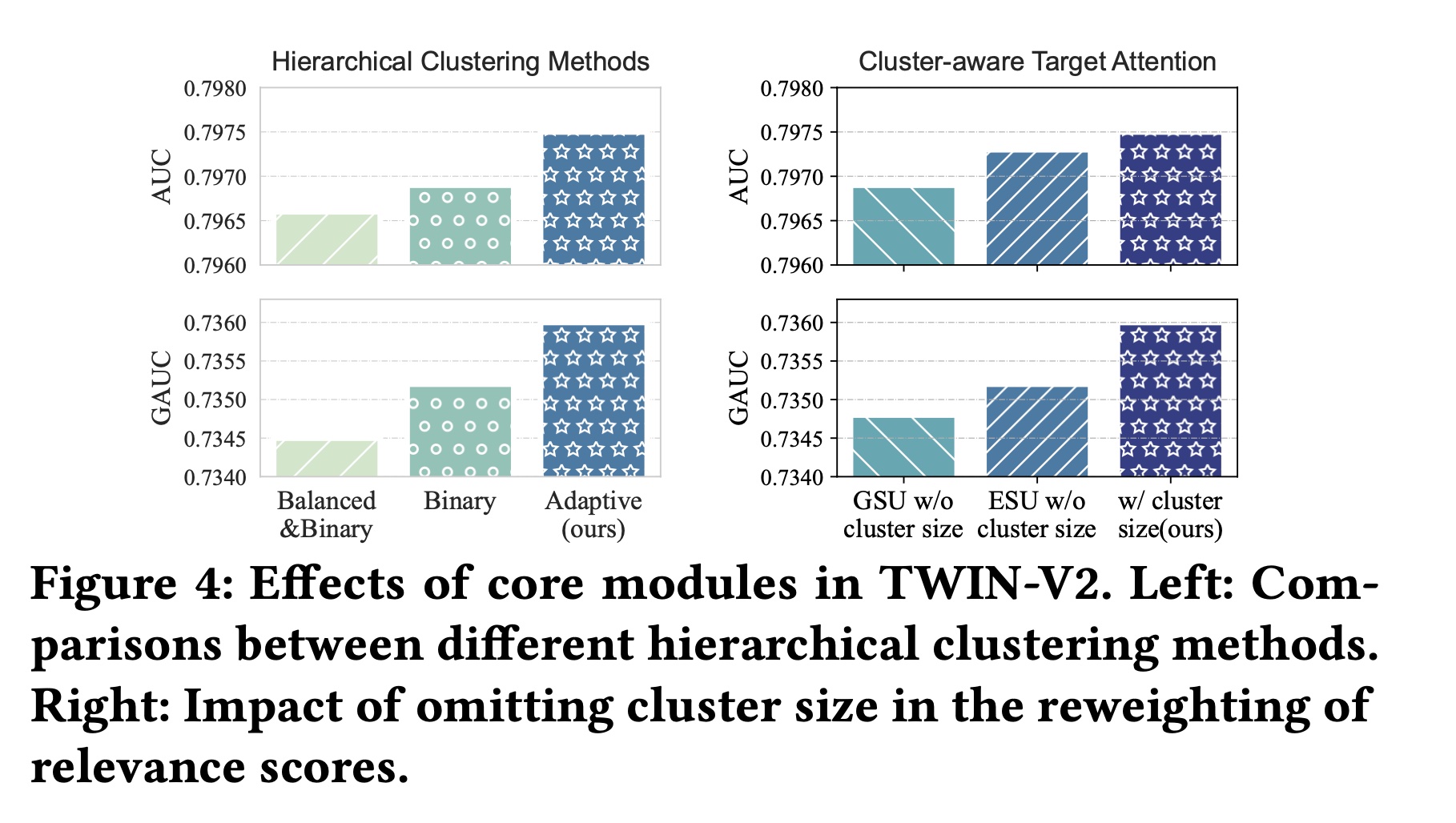
Cluster-aware Target Attention的有效性:在提出的cluster-aware target attention中,与TWIN相比,主要区别在于使用clustered behavior作为输入,并根据cluster size重新加权attention scores。我们分别从GSU和ESU中删除了cluster size reweighting部分,以评估其对性能的影响。具体来说,我们分别将GSU和ESU的Figure 4 (right)显示了实验结果。省略reweighting会导致性能下降,这验证了通过cluster size来调整attention scores的有效性。
56.2.3 在线实验
我们进行了在线
A/B test,以验证TWIN-V2在我们工业级系统中的性能。Table 5显示了TWIN-V2在快手三个代表性场景(Featured-Video Tab, Discovery Tab, and Slide Tab)中在观看时长(Watch Time)和推荐结果多样性方面的相对改进。观看时长衡量用户花费的总时间。
多样性是指模型推荐结果的多样性,比如视频类型的丰富性。
多样性指标公式是什么?这里没给出来。
从结果来看,
TWIN-V2可以更好地建模用户兴趣,从而提升观看时长。此外,通过建模更长的历史行为,TWIN-V2可以发现更多样化的用户兴趣,从而带来更加多样化的推荐结果。
五十七、CL4CTR[2022]
《CL4CTR: A Contrastive Learning Framework for CTR Prediction》
许多
CTR prediction工作侧重于设计高级架构来建模复杂的feature interactions,但忽略了feature representation learning的重要性,例如,对每个特征采用一个简单的embedding layer,这会导致次优的feature representations,从而导致CTR prediction的性能较差。例如,低频特征(在许多CTR任务中占大多数特征)在标准的supervised learning settings中较少得到考虑,导致次优的feature representations。在本文中,我们引入自监督学习(self-supervised learning)来直接生成高质量的feature representations,并提出了一个与模型无关的Contrastive Learning for CTR: CL4CTR框架,该框架由三个self-supervised learning signals组成,以规范化feature representation learning:contrastive loss、feature alignment和field uniformity。contrastive module首先通过data augmentation构建positive feature pairs,然后通过contrastive loss最小化每对positive feature pair的representations之间的距离。feature alignment constraint使得来自同一field的特征的representations是接近的。而
field uniformity constraint使得来自不同fields的特征的representations是远离的。
大量实验验证了
CL4CTR在四个数据集上取得了最佳性能,并且具有良好的有效性,以及具有与各种代表性baselines模型的兼容性。CTR prediction旨在预测给定item被点击的概率,已被广泛应用于推荐系统和计算广告等许多应用领域。最近,许多方法通过建模复杂的特征交互(feature interactions: FI) 取得了巨大成功。根据最近的研究,我们将CTR prediction方法分为两类:(1)传统方法,如逻辑回归 (
logistic regression: LR)和基于FM的模型,它们只能建模低阶特征交互。(2)基于深度学习的方法,如
xDeepFM和DCN-V2,可以通过捕获高阶特征交互从而进一步提高CTR prediction的准确性。此外,许多新颖的架构(例如,self-attention、CIN、PIN)已被提出并广泛部署从而捕获复杂的任意阶的特征交互。
尽管在性能上取得了成功,但许多现有的
CTR prediction方法都存在一个固有问题:高频特征比低频特征有更高的机会被训练,导致低频特征的representations不是最优的。在Figure 1中,我们展示了Frappe数据集和ML-tag数据集的特征累积分布(feature cumulative distributions)。我们可以观察到特征频率的明显“长尾”分布,例如,在ML-tag数据集中尾部80%的特征仅出现38次或更少。由于大多数CTR prediction模型通过反向传播来学习feature representations,低频特征由于出现次数较少而无法得到充分训练,导致feature representations不是最优的,从而导致CTR prediction性能也不理想。 先前的一些研究(《A Dual Input-aware Factorization Machine for CTR Prediction》、《An Input-aware Factorization Machine for Sparse Prediction》)也意识到了feature representation learning的重要性,并建议在embedding layer之后部署weight learning模块(即FEN、Dual-FEN),为每个特征分配权重以提升其representations。 然而,额外的weighting模块会增加模型参数和推理时间。 此外,与基于特征交互的方法类似,这些方法仅使用supervised learning signals来优化来自plain embedding layer的feature representations,这不足以产生足够准确的feature representations。 因此,在本文中,我们专注于直接从embedding layer学习准确的feature representations,而不引入额外的加权机制,这是模型无关的并且尚未得到广泛研究。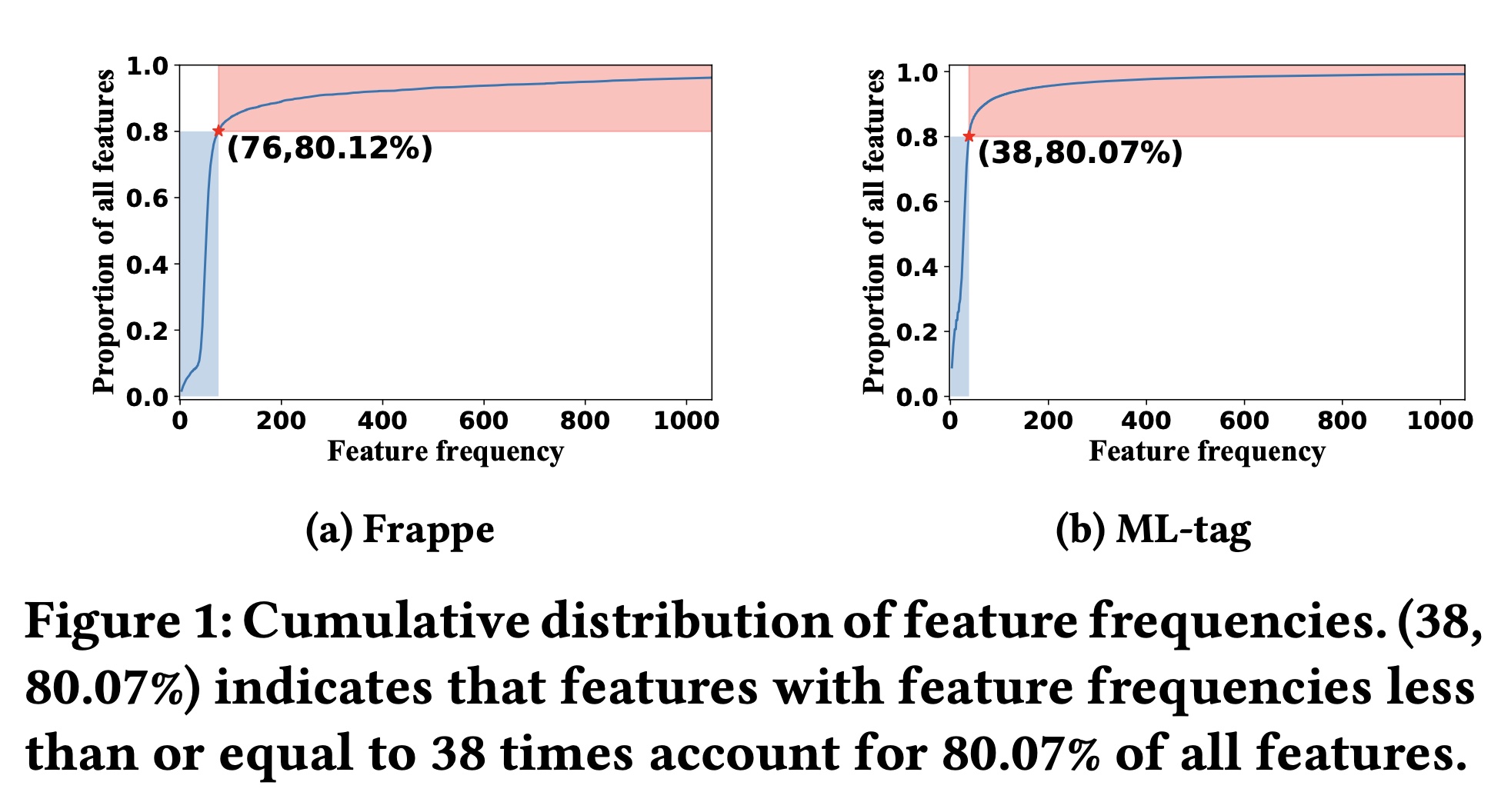
在本文中,我们试图利用自监督学习(
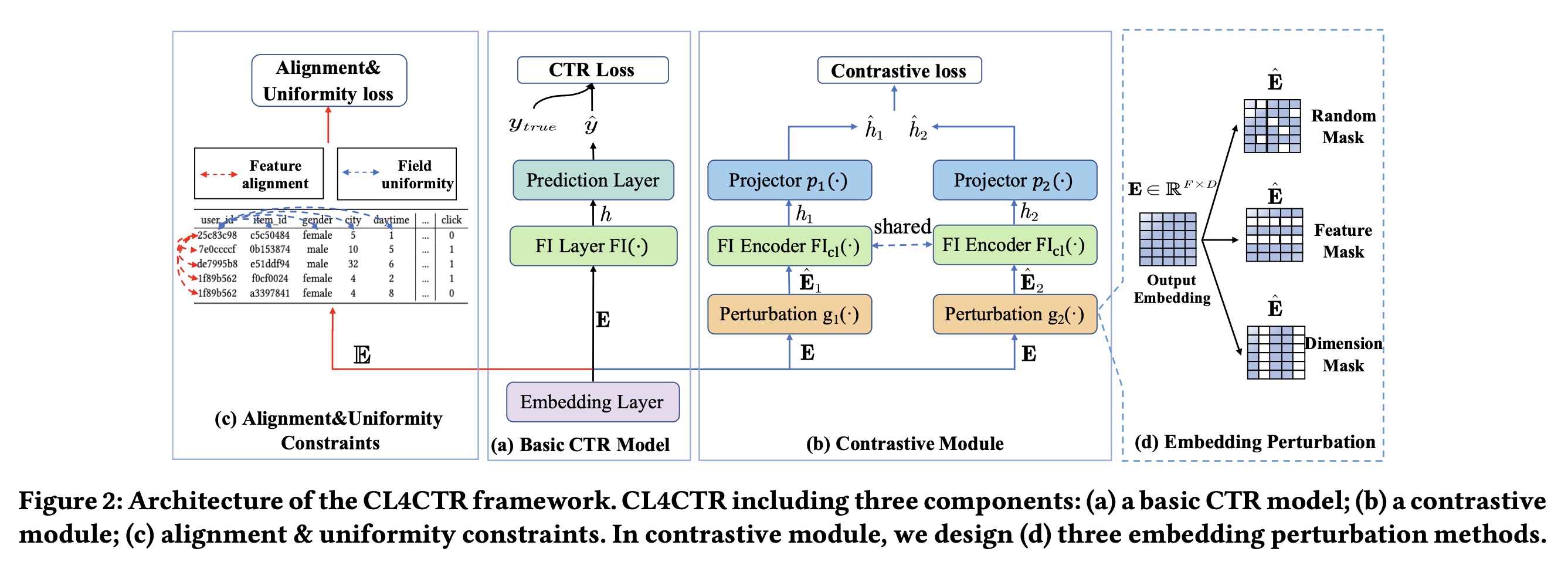
self-supervised learning: SSL)来解决上述问题,其中我们设计self-supervised learning signals作为约束,从而在训练过程中规范化所学到的feature representations。如Figure 2所示,我们提出了一种称为Contrastive Learning for Click Through Rate Prediction: CL4CTR的新框架,该框架由三个关键模块组成:CTR prediction model、contrastive module、以及alignment&uniformity constraints。具体来说:CTR prediction model旨在预测用户点击item的可能性,在CL4CTR框架中可以用大多数现有的CTR模型来代替它。在
contrastive module中,我们设计了三个关键组件:(1)数据增强单元(data augmentation unit),旨在为output embedding生成两个不同的视图作为positive training pairs,其包括三种不同的permutation方法:random mask、feature mask和dimension mask。(2)特征交互编码器(feature interaction encoder),旨在基于来自数据增强单元的perturbed embeddings从而学习紧凑的feature interaction representations。(3)面向任务的对比损失(contrastive loss),旨在最小化positive training pairs之间的距离。
此外,我们引入了两个约束:
feature alignment和field uniformity,以促进contrastive learning。feature alignment迫使来自同一field的特征的representations尽可能接近,而field uniformity迫使来自不同field的特征的representations尽可能远离。
我们的主要贡献总结如下:
我们提出了一个与模型无关的对比学习框架
CL4CTR,它可以以端到端的方式直接提高feature representations的质量。考虑到
CTR prediction任务的独有特点,我们设计了三个自监督学习信号(self-supervised learning signals):contrastive loss、feature alignment constraint以及field uniformity constraint,以提高对比学习的性能。在四个数据集上进行的大量实验表明,只需将
CL4CTR应用于FM即可超越SOTA的方法。更重要的是,CL4CTR与现有方法具有很高的兼容性,即它通常可以提高许多代表性的baselines的性能。
57.1 CL4CTR 框架
57.1.1 CTR Prediction
CTR prediction是一个二分类任务。假设用于训练CTR prediction模型的数据集包含multi-field表格型的数据记录,包含fields和Table 1所示。
最近,如
Figure 2(a)所示,许多CTR prediction模型遵循常见的设计范式:embedding layer、FI layer和prediction layer。Embedding layer:通常,每个输入one-hot vector表示的稀疏高维向量。而embedding layer将稀疏的高维特征向量embedding matrix:其中
embedding size,;表示向量拼接。注意:这里是将
embedding vector,然后拼接成矩阵(而不是一维向量)。另外,我们使用
feature representations,其中field的representation,fieldFeature interaction layer:FI layer通常包含各种类型的交互操作从而捕获任意阶次的特征交互,例如MLP、Cross Network、Cross Network2和transformer layer等。我们将这些结构称为feature interaction encoders,用embedding matrixfeature interaction representationPrediction layer:最后,prediction layer(通常是一个线性回归或MLP模块)根据来自FI layer的紧凑representationssigmoid函数。
最后,利用
predicted labeltrue labelCTR模型常用的损失函数如下:对比学习(
Contrastive learning):如Figure 2所示,除了上述组件之外,我们在embedding layer之上提出了三个contrastive learning signals:contrastive loss、feature alignment constraint和field uniformity constraint,以规范化representation learning。由于这些信号在模型推理过程中不是必需的,我们的方法不会增加推理时间和底层CTR prediction模型的参数。
57.1.2 Contrastive Module
受到自监督学习的成功的启发,我们寻求在
CTR prediction任务中部署contrastive learning,从而生成高质量的feature representations。如Figure 2(b)所示,contrastive module由三个主要组件组成:data augmentation unit、FI encoder和contrastive loss function。在
data augmentation unit中,我们提出了三种不同的面向任务的后验embedding augmentation技术来生成positive training pairs,即每个feature embedding的两个不同视图。然后,我们将两个
perturbed embeddings馈入到同一个FI encoder以生成两个compressed feature representations。最后,应用
contrastive loss来最小化两个compressed feature representations之间的距离。
通过
Output Perturbation实现的Data Augmentation:在自监督学习中,数据增强(Data Augmentation)在提高feature representations的性能方面显示出巨大的潜力。人们提出了不同的、设计良好的augmentation方法,并将它们用于构建同一输入实例的不同视图。例如,在序列推荐(sequential recommendation)场景中,三种广泛使用的augmentation方法是item masking、reordering和cropping(《Self-Supervised Learning for Recommender Systems: A Survey》)。然而,这些方法旨在augment行为序列,并不适合部署在FI-based CTR prediction模型中。因此,我们首先提出了三种面向任务的augmentation方法,旨在为FI-based模型来扰动feature embeddings。如Figure 2(d)所示,我们使用函数data augmentation过程。随机掩码(
Random Mask)。首先,我们介绍random mask方法,它类似于Dropout。该方法以一定的概率embeddingrandom mask生成如下:其中:
1的概率都是特征掩码(
Feature Mask):受先前研究(《Feature generation by convolutional neural network for click-through rate prediction》、《Autoint: Automatic feature interaction learning via self-attentive neural networks》)的启发,我们建议在初始embedding中掩码特征信息,其中feature mask可以按如下方式生成:其中:
如果一个特征被掩码,那么这个特征的
representation将被[mask]替换,它是一个零向量。
维度掩码(
Dimension Mask):feature representations的维度影响deep learning模型的有效性。受FED(《Dimension Relation Modeling for Click-Through Rate Prediction》)的启发,它试图通过捕获维度关系来提高预测性能,我们建议通过替换feature representations中特定比例的维度信息来扰乱初始embedding,这可以描述如下:其中:
1的概率都是
在训练过程中,我们选择上述掩码方法之一来生成两个
perturbed embeddingFigure 2(b)中,采用什么类型的掩码,这是在训练之前就确定好的,而不是在训练过程中动态三选一来选择的。
Feature Interaction Encoder:我们利用一个共享的FI encoder从两个perturbed embeddingfeature interaction信息,如下所示:其中:
FI encoder函数;perturbed embeddings生成的两个compressed representations。值得注意的是,任何
FI encoder都可以部署在我们的CL4CTR中,例如cross-network(《DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systems》)、self-attention(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)和bi-interaction(《Neural factorization machines for sparse predictive analytics》)。具体来说,我们选择Transformer layer作为我们的主要FI encoder。Transformer layer被广泛用于提取特征之间的vector-level关系。 此外,我们发现一些FI encoders(例如cross network、PIN)生成的compressed representations(fieldFI encoder的representations的维度降低到其中,投影函数
MLP。如果采用了
Transformer Layer,是不是就不需要Projector了?Contrastive Loss Function:最后,应用对比损失函数(contrastive loss function)来最小化上述两个perturbed representations之间的期望距离,如下所示:其中:
batch size,
57.1.3 Feature Alignment and Field Uniformity
为了确保低频特征和高频特征得到同等的训练,一种简单的方法是在训练期间增加低频特征的频率、或降低高频特征的频率。受到其他领域(
CV,NLP)中先前研究(《Understanding the behaviour of contrastive loss》、《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》)的启发,它们可以通过引入两个关键属性(即alignment and uniformity constraints)来实现类似的目标,但它们需要构造positive and negative sample pairs来优化这两个约束。在
CTR prediction任务中,我们发现同一field的特征类似于positive sample pairs,不同field的特征类似于negative sample pairs。因此,我们为CTR prediction中的对比学习提出了两个新属性,即feature alignment和field uniformity,它们可以在训练过程中规范化feature representations。具体而言:feature alignment将来自同一field的特征的representations拉得尽可能接近。相反,
field uniformity将来自不同field的特征的representations推得尽可能远。
Feature Alignment:首先,我们引入feature alignment约束,旨在最小化来自同一field的特征之间的距离。直观地讲,通过添加feature alignment约束,同一field中的特征的representations应该在低维空间中分布得更紧密。正式地,feature alignment的损失函数如下:其中:
feature的embedding,它们来自同一field;fieldembeddings。field Uniformity:现有的CTR prediction方法尚未广泛研究不同field之间的关系。例如,FFM学习每个特征的field-aware representation,而NON提取intra-field信息,但它们的技术不能直接应用于对比学习。不同的是,我们引入field uniformity来直接优化feature representation,从而最小化属于不同fields的特征之间的相似性。field uniformity的损失函数正式定义如下:其中:
《Self-Supervised Learning for Recommender Systems: A Survey》、《SelfCF: A Simple Framework for Self-supervised Collaborative Filtering》)类似,我们使用余弦相似度来正则化negative sample pairs:这里也可以使用其他相似度函数。
field
在
feature alignment约束和field uniformity约束中,我们都发现低频特征和高频特征被考虑的机会是均等的。因此,在训练期间引入这两个约束可以大大缓解低频特征的suboptimal representation问题。对于某些
field,例如item id,它的特征取值范围非常大,那么feature alignment约束和field uniformity约束如何处理?读者猜测是:采样一部分特征而不是使用该field的全部特征。
57.1.4 Multi-task Training
为了将
CL4CTR框架融入CTR prediction场景,我们采用multi-task training策略,以端到端的方式联合优化这三个辅助的自监督学习losses和原始CTR prediction loss。因此,最终的目标函数可以表示如下:其中:
contrastive loss和feature alignment and field uniformity loss。
57.2 实验
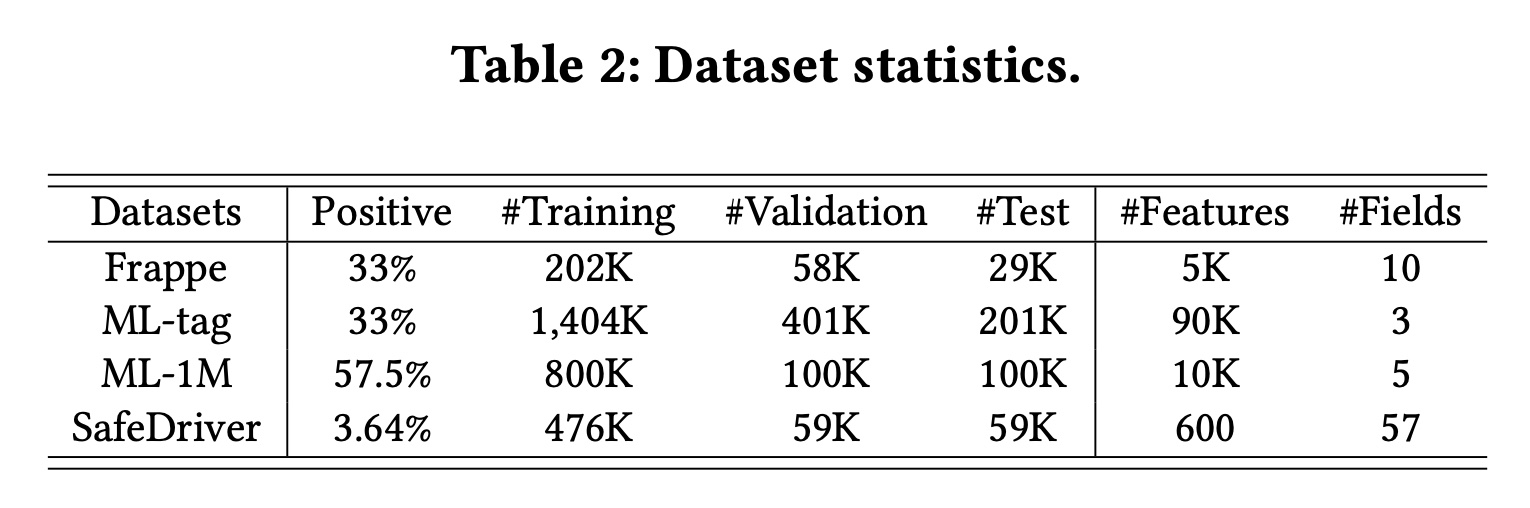
数据集:
Frappe、ML-tag、SafeDriver和ML-1M。四个数据集的统计数据如Table 2所示。NFM和AFM严格按照7:2:1将Frappe和ML-tag分为训练集、验证集和测试集,我们直接遵循它们的设置。对于
SafeDriver和ML-1M,我们按照《GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction》和《DCAP: Deep Cross Attentional Product Network for User Response Prediction》随机将实例分为8:1:1。这些数据集的详细描述可以在链接或参考资料中找到。这些数据集都是
toy数据集,没有工业数据集,因此说服力不是很强。
baselines:为了评估提出的CL4CTR框架,我们将其性能与四类代表性CTR prediction方法行了比较:1)一阶方法,即原始特征的加权和,包括LR。2)基于FM的方法,考虑二阶的特征交互,包括FM、FwFM、IFM和FmFM。3)建模高阶的特征交互的方法,包括CrossNet、IPNN、OPNN、FINT和DCAP。4)ensemble方法或多塔结构,包括WDL、DCN、DeepFM、xDeepFM、FiBi-NET、AutoInt+、AFN+、TFNET、FED和DCN-V2。
所提出的
CL4CTR框架与模型无关。为简单起见,base模型CL4CTR之后记作FM作为base模型来验证CL4CTR的有效性,它仅仅建模二阶的特征交互,除了feature representations之外没有其他参数。因此,feature representations的质量。CL4CTR仅帮助base CTR model的训练,不会向推理过程添加任何操作或参数。有可能在更优秀的
base模型上,CL4CTR的增益会很小甚至消失。因为更优秀的base模型可能学到更好的representation。评估指标:
AUC, Logloss。实现细节:
为了公平比较,我们使用
Pytorch实现所有模型,并使用Adam优化所有模型。Frappe和ML-tag的embedding size设置为64,ML-1M和SafeDriver的embedding size设置为20。同时,batch size固定为1024。SafeDriver的学习率为0.01,其他数据集的学习率为0.001。对于包含
DNN的模型,我们采用相同的结构{400,400,400,1}。所有激活函数均为ReLU,dropout rate为0.5。我们根据验证集上的
AUC执行早停,从而避免过拟合。我们还实现了Reduce-LR-On-Plateau scheduler,当给定指标在四个连续epochs内停止改进时,将学习率降低10倍。每个实验重复
5次,并报告平均结果。在
CL4CTR中,Transformer layers。我们在最终损失函数中使用超参数:
57.2.1 整体比较
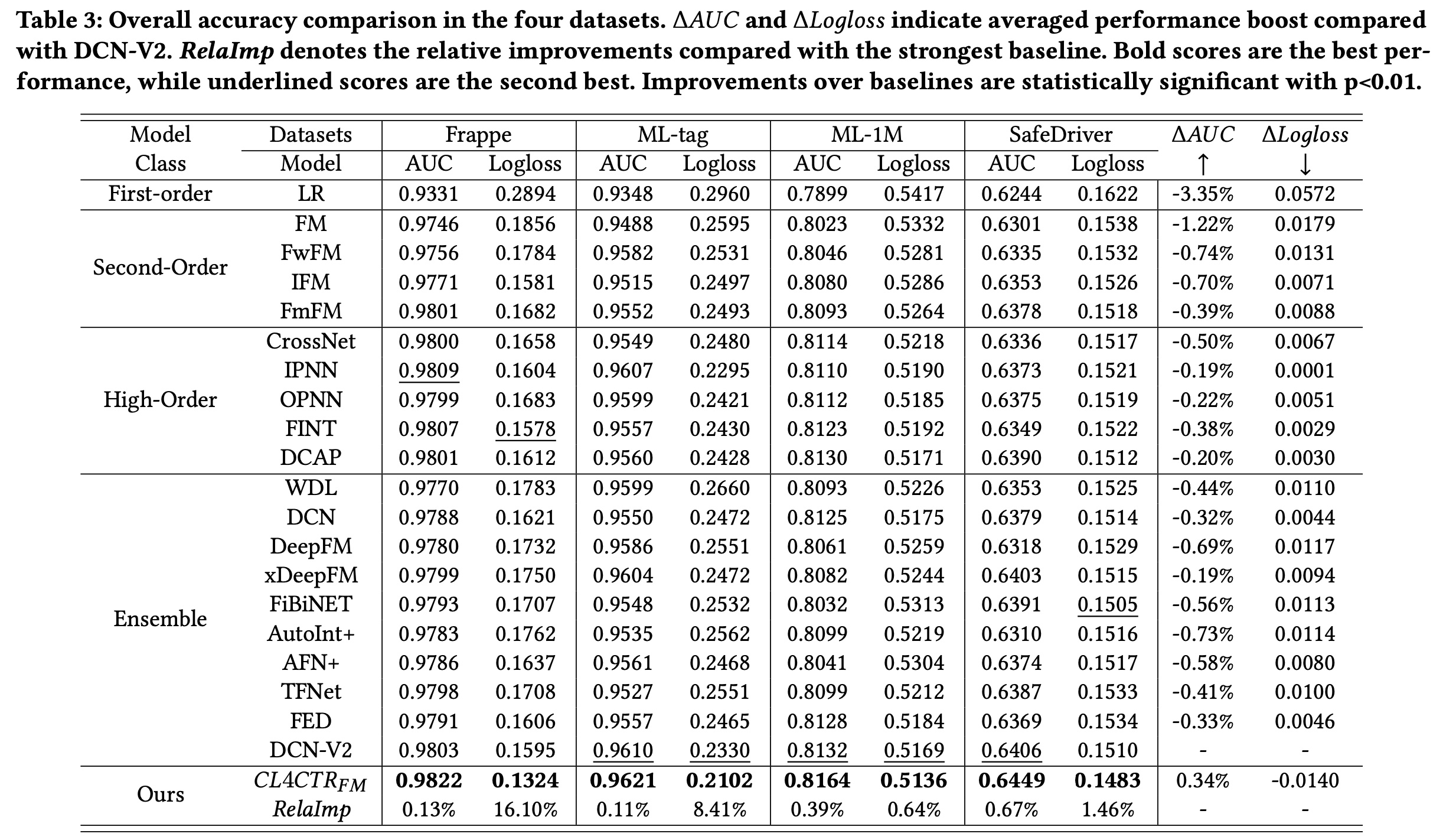
在本节中,我们将
SOTA的CTR prediction模型进行了比较。Table 3显示了所有被比较的模型在四个数据集上的实验结果。 可以观察到:与其他
baselines相比,LR和FM的性能最差,这表明浅层模型不足以进行CTR prediction。其他
FM-based的模型通过引入field importance机制(例如,FwFM和IFM)、或部署新颖的field-pair matrix方法(例如,FmFM)来改进FM。通常,基于
deep-learning的模型(例如,DeepFM、DCN、DCN-V2)将高阶特征交互与精心设计的特征交互结构相结合,比FM具有更好的性能。baselines。在Frappe、ML-tag、ML-1M和SafeDriver上,AUC显著优于最强的基线DCN-V2分别为0.13%、0.11%、0.39%和0.67%(Logloss值分别为16.10%、8.41%、0.64%和1.46%)。此外,我们发现
Logloss的改进比AUC的改进更显著,这表明CL4CTR使我们能够有效地预测真实的点击率。同时,
Table 3显示了平均性能提升(ΔAUC和ΔLogloss)。值得注意的是,大多数SOTA的CTR prediction模型都设计了复杂的网络来产生高级的feature representations和有用的feature interactions来提高性能。然而,我们的CL4CTR仅仅帮助FM通过对比学习从embedding layer学习准确的feature representations,而不是引入额外的模块。我们CL4CTR的改进验证了在CTR prediction任务中学习准确的feature representations的必要性。
57.2.2 Ablation Study
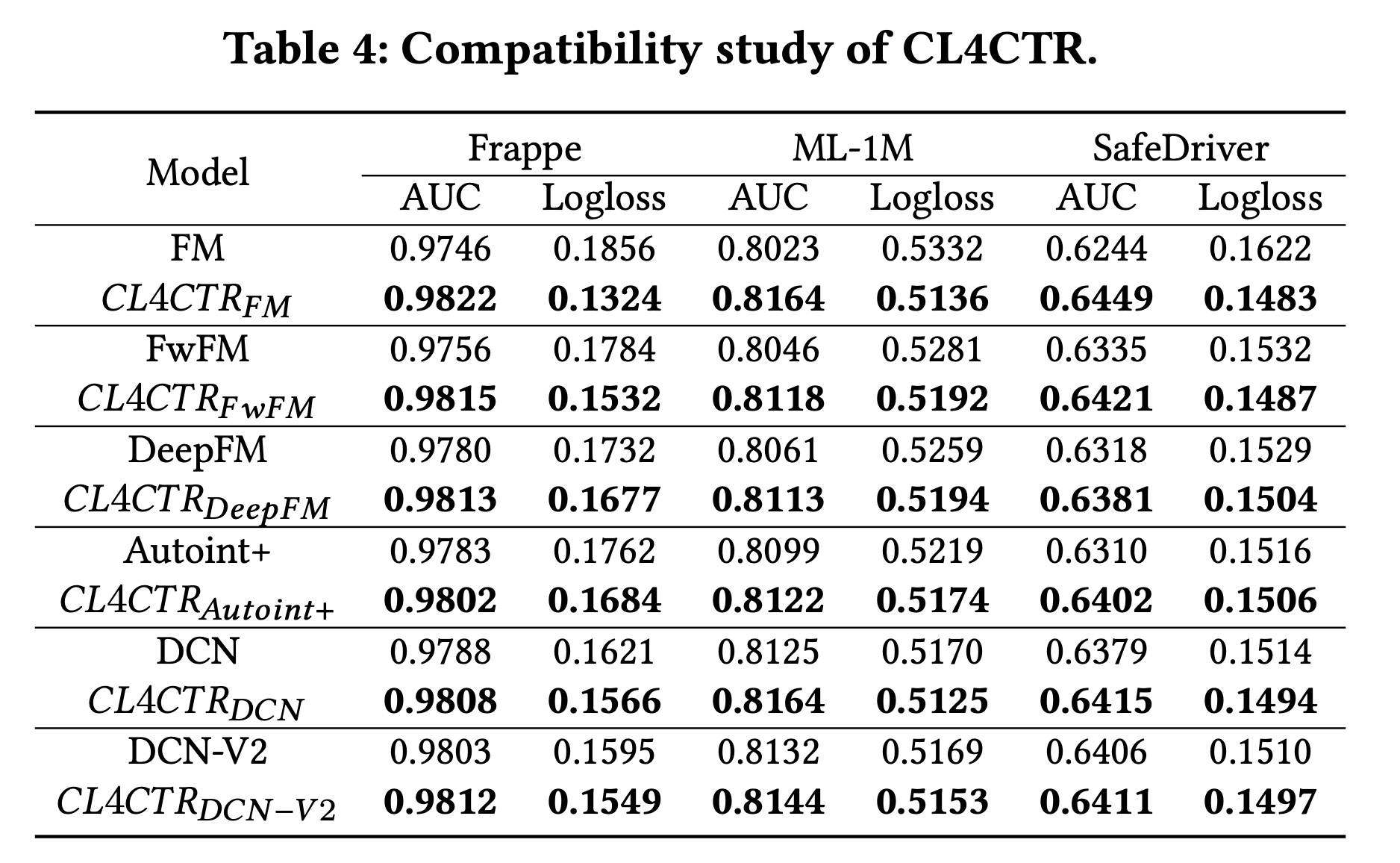
兼容性分析:为了验证
CL4CTR的兼容性,我们将其部署到其他SOTA模型中,例如DeepFM、AutoInt+和DCN-V2。结果如Table 4所示。首先,使用
CL4CTR来learning feature representation可以显著提高CTR prediction的性能。应用CL4CTR后,base模型的性能得到显著提升,这证实了我们通过提高feature representations的质量来提高CTR prediction模型性能的假设,并证明了CL4CTR的有效性。此外,实验结果表明,学习高质量的
feature representations至少与设计高级的特征交互技术一样重要。当这些模型利用监督信号进行训练时,建模复杂的特征交互可以提高CTR模型的性能,这解释了为什么FI-based的模型优于FM。然而,在将自监督信号引入
CTR模型以学习高质量的feature representations后,在配备了CL4CTR的所有模型之间,FM可以取得最佳性能。可能的原因是:在FM中feature representations中的参数,而不会受到其他参数的干扰。因为
FM模型除了embedding layer之外没有其它参数。
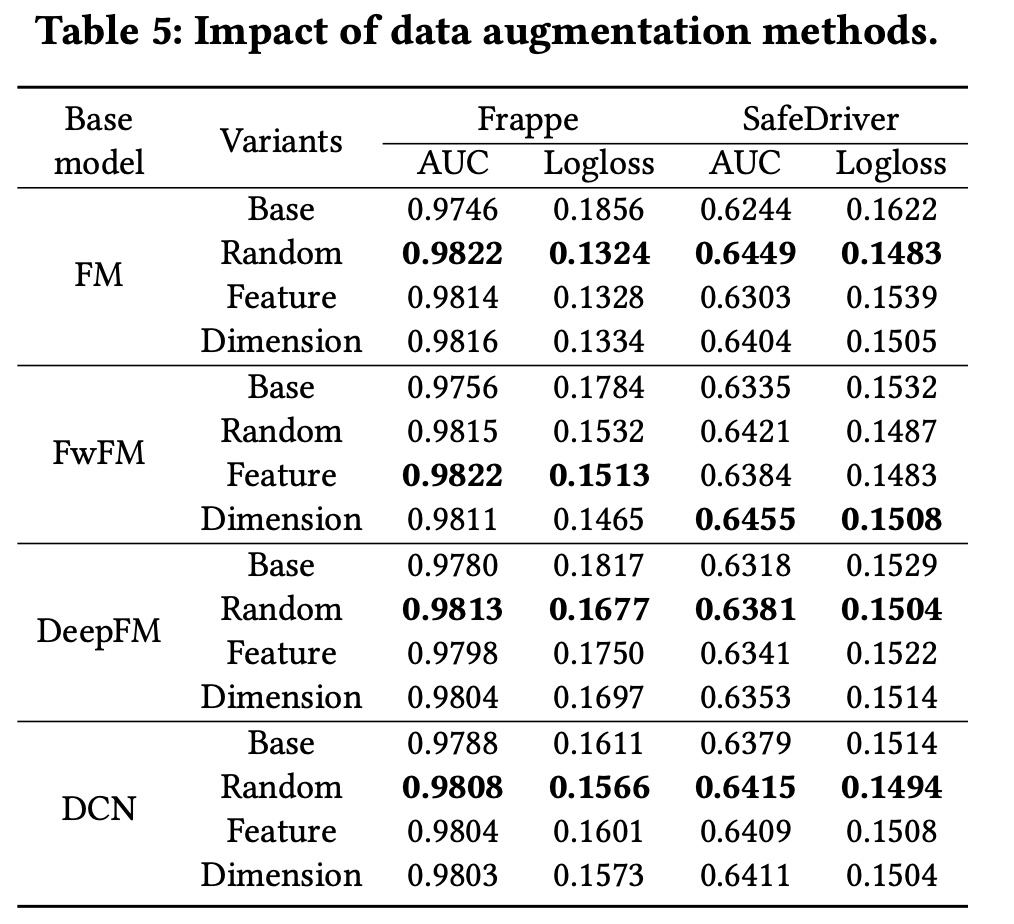
Data Augmentation方法:为了验证我们提出的data augmentation方法的有效性,我们更改了contrastive module中的augmentation方法,并固定了其他settings以进行公平比较。此外,我们选择了不同的baseline模型并将CL4CTR部署到其中,以比较它们在此setting下的性能。Table 5展示了实验结果。在大多数情况下,
random mask方法取得了最佳性能。我们认为random mask比feature mask和dimension mask更具缓和性,因为它省略了element信息。此外,在
Frappe上,FwFM模型使用feature mask方法取得了最佳性能;相反,在SafeDriver上FwFM模型使用dimension mask方法取得了最佳性能,这表明我们提出的augmentation方法是有效的,并且可以用于不同的baseline模型和数据集。
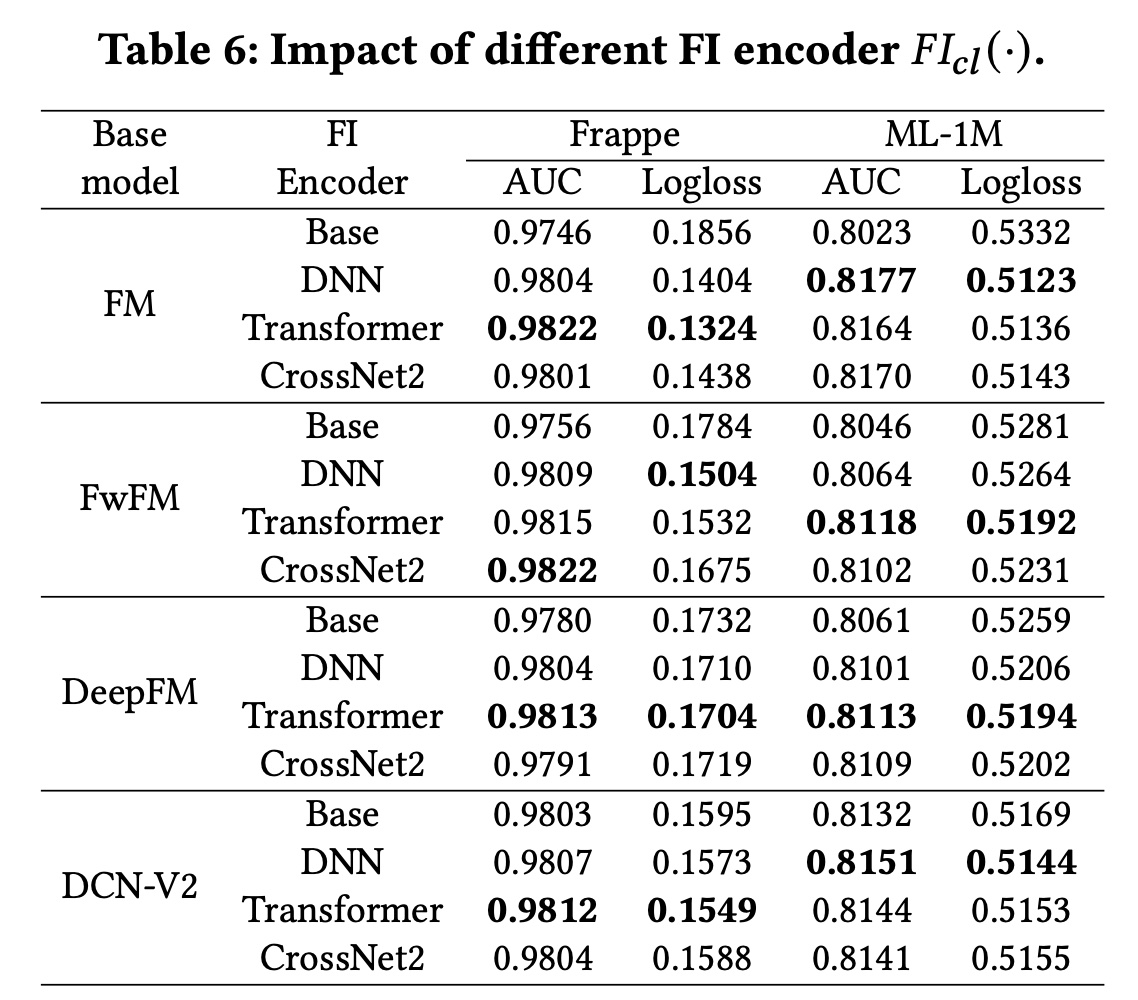
FI Encoder:在contrastive module中,FI encoder也会影响CL4CTR的性能,因为不同结构的FI encoder抽取了不同的信息。例如:Transformer layer可以显式地建模feature-level的高阶特征交互。而
CrossNet2则专注于显式地建模element-level的有界阶次的特征交互。DNN是大多数CTR模型中一种常见且广泛使用的结构,用于隐式地建模bit-level的特征关系。
我们选择上述三种代表性的结构作为
FI encoders并验证其性能。值得注意的是,我们采用了他们论文中报告的三层架构。Table 6展示了实验结果。 可以观察到:使用不同的
FI encoders,CL4CTR可以一致地提高这些baseline模型的性能。此外,由于不同的
FI encoders根据特定的base模型和数据集提取不同的信息,这些模型的性能也不同。然而,带有Transformer layers的CL4CTR在大多数情况下都能达到最佳性能,因为Transformer layer比其他的layers更有效。
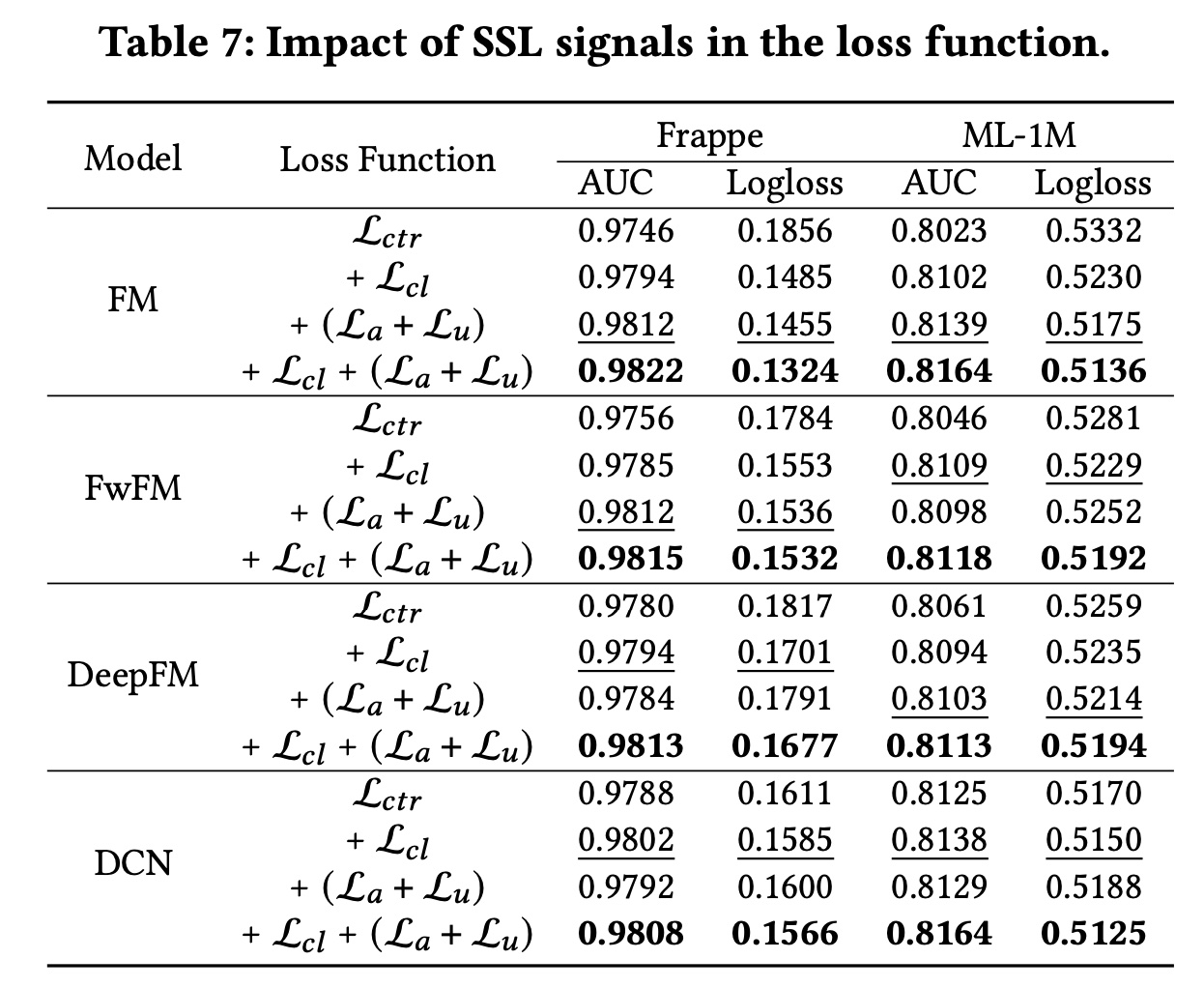
损失函数:在本节中,我们通过分别从
CL4CTR中剔除自监督学习信号(即Table 7所示。首先,我们可以发现,在
baseline模型中部署每一种自监督学习信号都可以提高其性能。此外,通过分别比较
contrastive loss和alignment&uniformity constraints,我们得出结论,它们在不同的数据集和baseline模型中发挥着不同的作用。具体而言:具有
FM的表现优于具有FM。相反,具有
DCN的表现不如具有DCN,这验证了我们的假设。
此外,当
此外,在
Logloss评估的两个数据集上,采用FM的表现始终优于采用FM,这表明将feature alignment and field uniformity引入CTR prediction模型使我们的预测概率更接近true label。
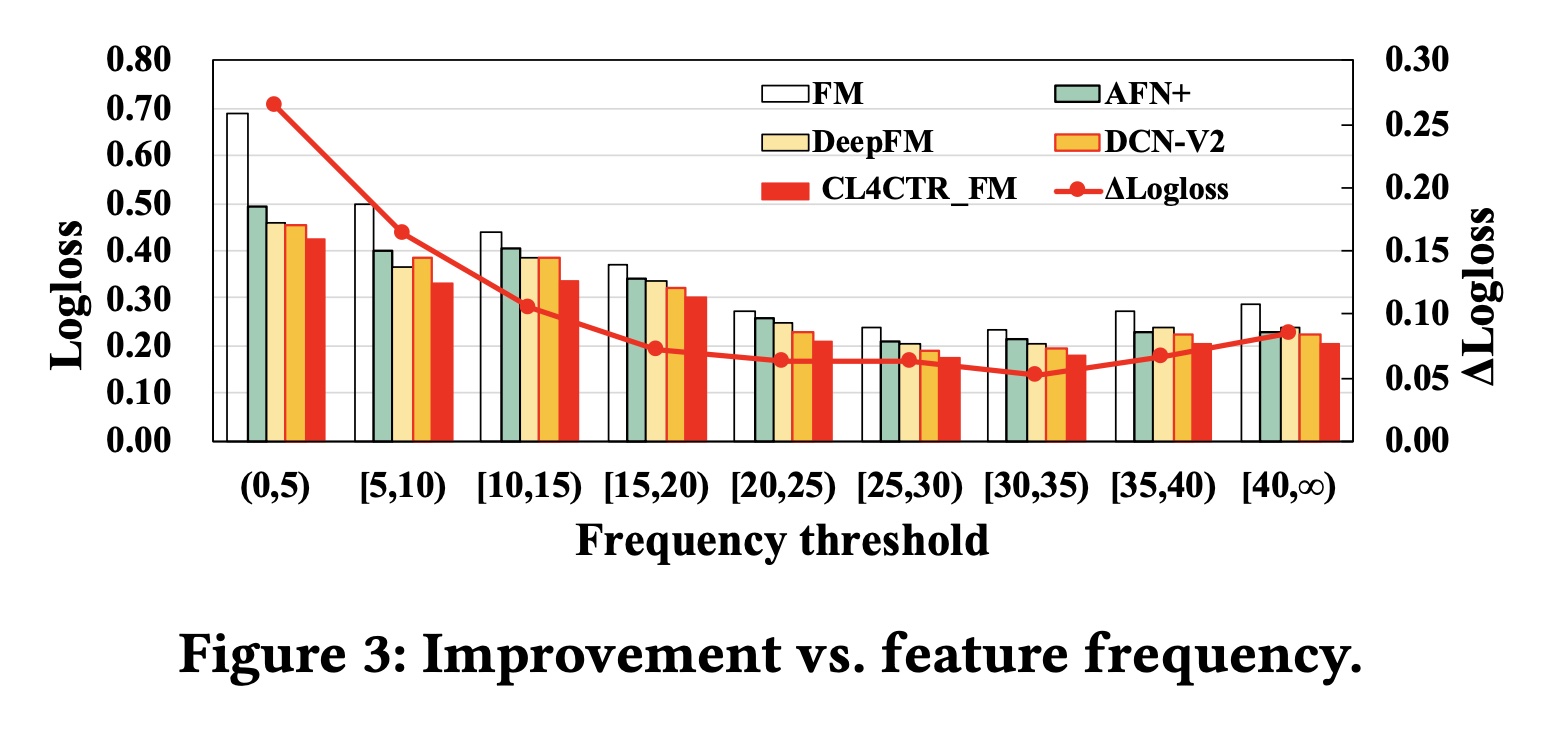
57.2.3 Feature Frequency Analysis
为了验证特征频率对不同模型的影响,我们将
ML-tag测试集按照特征频率进行划分,并计算相应的Logloss,其中ΔLogloss表示应用CL4CTR后相对于base FM模型的提升。Figure 3展示了实验结果。首先,低频特征对
base模型的准确率有负面影响。具体而言,我们展示了FM、三个SOTA模型(AFN+,DeepFM,DCN-V2)、以及当输入子集包含低频特征时,所有模型的表现最差。
随着特征频率的增加,所有模型的性能都在持续提升。
当特征频率超过
20时,所有模型的性能都趋于稳定。
Figure 3证实了我们的假设,即仅使用具有单个监督信号的反向传播来学习低频特征的representations无法实现最佳性能。其次,
CL4CTR可以有效缓解低频特征带来的负面影响,并在不同特征频率范围内保持最佳性能。通过应用alignment&uniformity constraints,我们确保低频特征可以在每个反向传播过程中得到优化,并且与高频特征有同等的机会。此外,contrastive module还可以提高所有特征(包括低频和高频特征)的representations的质量。这里的分组指的是被点击的
label tag的频次。
57.2.4 超参数分析
损失函数中权重的影响:我们进一步研究了不同权重(
{1, 1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 0}中调优settings不变,以便进行公平比较。Figure 4显示了实验结果。此外,在这两个数据集上Logloss的趋势与AUC的趋势一致。 总体而言,对于Frappe和ML-1M数据集,当CL4CTR的性能最佳。具体来说:当
CL4CTR的性能会下降。此外,当
1或1e-1)时,CL4CTR的性能会显著降低。同时,当
CL4CTR的表现更差。

掩码比例:我们在
0.1的步长更改掩码比例Figure 5显示了结果。 对于具有Frappe和ML-1M上的性能显示出相似的趋势。当掩码比例在0.4或0.5左右时,当选择较小的掩码比例(即
0.1到0.3)时,模型性能会略有下降。当掩码比例超过
0.5时,模型性能持续下降,这是因为FI encoders仅使用一小部分信息来生成有效的interaction representations,以计算具有较高掩码比例的contrastive loss。
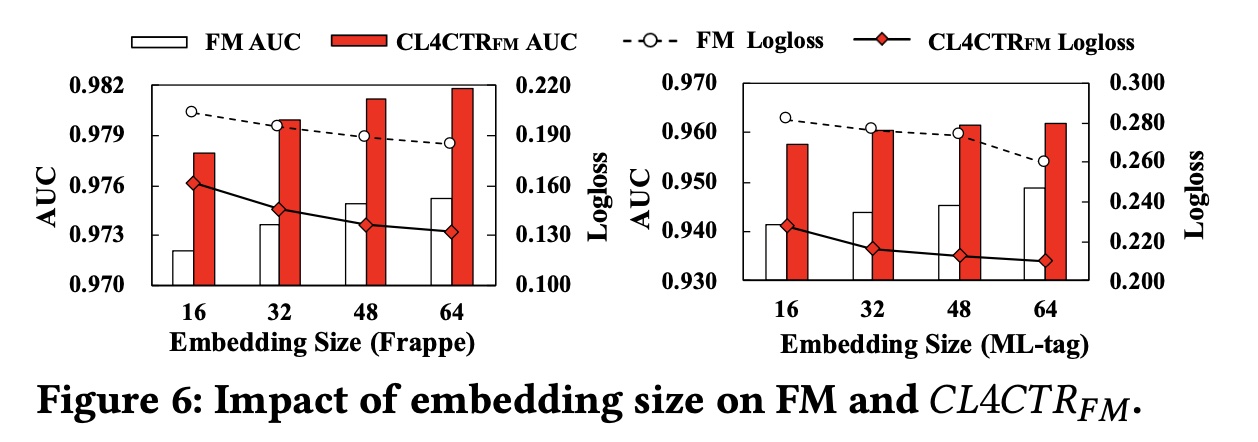
embedding size:我们在embedding layer中将embedding size更改为从16到64,步长为16,并在Figure 6中展示实验结果。可以观察到:
随着
embedding size的增加,同时,
CL4CTR可以提高所有embedding size的FM的性能。此外,与具有
embedding size = 64的FM相比,embedding size = 16的小尺寸下实现了更好的性能。这意味着我们可以通过在FM上应用CL4CTR来减少参数,同时获得更好的结果。