一、GraRep[2015]
《GraRep: Learning Graph Representations with Global Structural Information》
在许多实际问题中,信息通常是使用图来组织的。例如,在社交网络研究中,基于社交图 (
social graph)将用户分类为有意义的社交群组(social group)在很多实际application中有用,例如用户搜索(user search)、定向广告(targeted advertising)、以及推荐(recommendation)。因此,从图中准确地学习有用的信息至关重要。一种策略是学习图的graph representation:图中的每个顶点都用一个低维向量来表达,这个低维向量可以准确地捕获图所传达的语义信息(semantic information)、关系信息(relational information)、以及结构信息(structural information)。最近,人们对从数据中学习
graph representation的兴趣激增。例如,最近的一个模型DeepWalk使用均匀采样(也称作截断的随机游走truncated random walk)将图结构转换为由顶点组成的线性序列的样本集合。SkipGram模型最初设计用于从线性序列中学习word representation,也可用于从此类样本(即顶点组成的线性序列的样本)中学习顶点的representation。尽管这种方法在经验上是有效的,但是人们并不清楚在学习过程中所涉及的、图上定义的、确切的损失函数是什么。在论文
《GraRep: Learning Graph Representations with Global Structural Information》中,作者首先提出了在图上定义的SkipGram模型的显式损失函数。论文表明:本质上,我们可以使用SkipGram模型以不同的k-step邻居之间的k-step关系(SkipGram模型的一个缺陷是:它将所有这些k-step关系信息投影到一个公共子空间中。论文认为,这种简单的处理可能会导致潜在的问题。通过在不同的子空间中保存不同的k-step关系信息,论文提出的模型GraRep克服了上述限制。最近人们提出的另一个工作是
LINE,它有一个损失函数来同时捕获1-step局部关系信息(local relational information)和2-step局部关系信息。为了捕获此类局部信息中的某些复杂关系,他们还从此类数据中学习非线性变换(LINE用到了sigmoid函数,但是本质上LINE是广义线性函数)。虽然他们的模型不能很容易地扩展到捕获k-step(graph representation,但是他们提出了一个重要策略来提高模型的效果:对于degree较小的顶点,考虑高阶邻域。这一策略在某种程度上隐式地将某些k-step信息捕获到他们的模型中。GraRep的作者相信:对于不同的k值,不同顶点之间的k-step关系型信息揭示了与图相关的、有用的全局结构信息,并且在学习良好的graph representation时显式地充分利用这一点至关重要。在论文
《GraRep: Learning Graph Representations with Global Structural Information》中,作者提出了GraRep,这是一种为知识管理 (knowledge management) 学习graph representation的新模型。该模型通过操作在图中定义的、不同的全局转移矩阵(global transition matrix),直接从图中的顶点中捕获具有不同k-step关系信息,而不涉及慢的、复杂的采样过程。与现有工作不同,GraRep模型定义了不同的损失函数来捕获不同的k-step局部关系信息(即不同的matrix factorization)技术优化每个模型,并通过组合从不同模型中学到的不同representation来构建每个顶点的全局representation。这种学到的全局represetnation可以用作下游任务的特征。论文对
GraRep模型进行了正式的处理(formal treatment),并展示了GraRep模型与之前几个模型之间的联系。论文还通过实验证明了学到的representation在解决几个现实世界问题中的有效性。具体而言,论文对语言网络聚类任务、社交网络多标签分类任务、以及引文网络可视化任务进行了实验。在所有这些任务中,GraRep优于其它graph representation方法,从而证明了GraRep学到的全局representation可以有效地用作聚类、分类、可视化等任务的特征。并且,GraRep可以简单地并行化。论文贡献如下:
论文引入了一种新模型来学习图上顶点的潜在
representation,该模型可以捕获与图相关的全局结构信息。论文从概率的角度提供了对
DeepWalk中用于学习graph representation的均匀采样方法的理解,该均匀采样方法将图结构转换为线性序列。此外,论文在图上显式定义了
DeepWalk的损失函数,并将其扩展为支持加权图。论文正式分析了带有负采样
SkipGram模型(skip-gram model with negative sampling: SGNS)相关的缺陷。论文的模型定义了一个更准确的损失函数,该损失函数允许集成不同局部关系信息的非线性组合。
相关工作:
线性的序列
representation方法(Linear Sequence Representation Method):由单词的stream组成的自然语言语料库可以视为一种特殊的图结构,即线性链(linear chain)。目前,学习word representation有两种主流方法:神经嵌入(neural embedding)的方法、基于矩阵分解(matrix factorization based)的方法。神经嵌入方法采用固定长度的滑动窗口捕获当前单词的
context words。人们提出了像SkipGram这样的模型,这些模型提供了一种学习word representation的有效方法。虽然这些方法可能会在某些任务上产生良好的性能,但是它们不能很好地捕获有用的信息,因为它们使用独立的、局部的上下文窗口,而不是全局共现计数(global co-occurrence count)。另一方面,矩阵分解方法可以利用全局统计。先前的工作包括潜在语义分析(
Latent Semantic Analysis: LSA),该方法分解term-document矩阵从而产生潜在语义representation。《Producing high-dimensional semantic spaces from lexical co-occurrence》提出了Hyperspace Analogue to Language: HAL,它分解一个word-word共现计数矩阵来生成word representation。《Extracting semantic representations from word co-occurrence statistics: A computational study》提出了用于学习word representation的、shifted positive Pointwise Mutual Information: PMI矩阵的矩阵分解,并表明带负采样的SkipGram模型(Skip-Gram model with Negative Sampling: SGNS)可以视为隐式的这样的一个矩阵。
图表示(
Graph Representation)方法:存在几种学习低维graph representation的经典方法,如多维缩放(multidimensional scaling: MDS)、IsoMap、LLE、Laplacian Eigenmaps。最近,
《Relational learning via latent social dimensions》提出了学习图的潜在representation向量的方法,然后可以用于社交网络分类。《Distributed large-scale natural graph factorization》提出了一种图分解方法,该方法使用随机梯度下降来优化大型图中的矩阵。《Deepwalk: Online learning of social Representations》提出了DeepWalk方法,该方法通过使用截断的随机游走算法将图结构转换为多个线性的顶点序列,并使用SkipGram模型生成顶点的representation。《Line: Large-scale information network embedding》提出了一种大规模信息网络的embedding,它优化了一个损失函数从而可以在学习过程中同时捕获1-step关系信息和2-step关系信息。
1.1 模型
1.1.1 图及其 Representation
给定一个图
path)定义为连接一个顶点序列的边序列。邻接矩阵:定义邻接矩阵为
对于无权图,如果顶点
对于带权图,
尽管边的权重可以为负值,但是这里我们仅考虑正的权重。
度矩阵(
degree matrix):定义度矩阵为转移概率矩阵(
probability transition matrix):假设我们想要捕获从一个顶点到另一个顶点的转移,并假设顶点
带全局结构信息的
graph representation:给定一个图graph representation的任务旨在学习图的全局represetation矩阵representation向量可以捕获图的全局结构信息(global structural information) 。在本文中,全局结构信息有两个功能:捕获两个不同顶点之间的长距离关系、根据不同的转移
steps考虑不同的链接。我们将在后面进一步地说明。正如我们之前讨论过的,我们认为在构建这样的全局
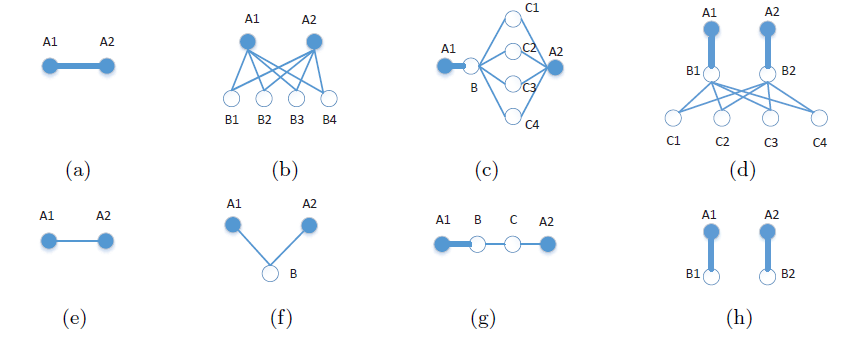
graph representation时需要从图中捕获k-step(具有不同的A1和A2之间捕获的、k-step(其中在
(a)和(e)中显示了捕获彼此直接连接的、顶点之间简单的1-step信息的重要性,其中(a)具有较强的关系,(e)具有较弱的关系。在
(b)和(f)中显示了2-step信息,其中(b)中两个顶点A1和A2共享许多共同的邻居,而(f)中两个顶点A1和A2仅共享一个邻居。显然,
2-step信息对于捕获两个顶点之间的连接强度很重要:顶点之间共享的共同邻居越多,则它们之间的关系就越强。在
(c)和(g)中显示了3-step信息。具体而言:在
(g)中,尽管A1和B之间的关系很强,但是由于连接B和C、以及C和A2的两条较弱的边,A1和A2之间的关系可能会减弱。相比之下,在
(c)中,A1和A2之间的关系仍然很强,因为B和A2之间有大量的共同邻居,这加强了它们的关系。
显然,在学习具有全局结构信息的良好
graph representation时,必须捕获此类3-step信息。类似地,如
(d)和(h)所示,4-step信息对于揭示图的全局结构特性也至关重要。在(d)中,A1和A2之间的关系明显很强。而在(h)中,A1和A2明显不相关,因为从一个顶点到另一个顶点之间不存在路径。在缺乏4-step关系信息的情况下,无法捕获这种重要的区别。
我们还认为:在学习
graph representation时,必须区别对待不同的k-step信息。我们在下图的(a)中展示了一个简单的例子。让我们专注于学习图中顶点A的representation。可以看到,A在学习其representation时接收到两种类型的信息:来自顶点B的1-step信息、以及来自顶点C的2-step信息。我们注意到,如果我们不区分这两种不同类型的信息,我们可以构建如图
(b)所示的替代品,其中顶点A接受与(a)完全相同的信息。但是,图(b)具有完全不同的结构。这意味着如何使用
k-step信息很重要,它们位于不同的子空间,应该区别对待。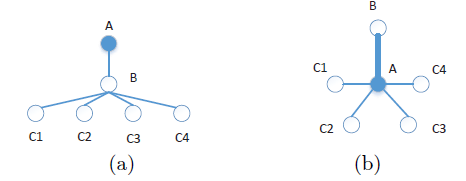
在本文中,我们提出了一种用于学习准确
graph representation的新的框架,它集成了各种k-step信息,这些信息共同捕获了与图相关的全局结构信息。
1.1.2 图上的损失函数
我们将在这里讨论用于学习具有全局结构信息的
graph representation的损失函数。对于图representation来捕获它们之间的关系,我们需要了解这两个顶点之间的连接强度。让我们从几个问题开始。是否存在从顶点
为了回答这些问题,我们首先令
1-step转移概率(即矩阵k-step转移概率,我们引入k-step转移概率矩阵:可以看到
现在考虑一个给定的
k-step的所有路径的集合。这里我们称current vertex、context vertex。我们的目标旨在最大化:这些pair来自图中的概率、以及其它pair不来自图中的概率。受到
SkipGram模型的启发,我们采用了《Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics》提出的噪声对比估计(noise contrastive estimation: NCE)来定义我们的目标函数。遵循《Neural word embedding as implicit matrix factorization》中提出的类似讨论,我们首先介绍我们在图上定义的k-step损失函数为:其中:
k-step关系,即从顶点k-step转移概率。sigmoid函数,定义为current vertex时的representation,context vertex时的representation。二者采用了不同的representation矩阵。k-step负采样分布,
上式物理意义:
第一项为 “正样本” 的加权对数似然,权重为
k-step转移概率,“正样本”为从顶点k-step能够到达的顶点集合。第二项为 “负样本”的对数似然。这里负样本没有加权。
和
DeepWalk相比,GraRep的重要区别在于它对正样本进行了加权。期望部分可以重写为:
因此对于特定的顶点
pair对local loss)为:其物理意义为:
对于从
k-step到达的顶点k-step转移概率),加上作为负样本的加权对数似然(权重为k-step采样概率)。对于从
k-step到达的顶点k-step采样概率)。
k-step负采样分布其物理意义为:以概率
k-step转移到顶点则
k-step损失函数为:为最小化
得到最优解:
其中
可以得到结论:我们本质上需要将矩阵
representation组成。其中矩阵现在我们已经定义了我们的损失函数,并表明优化该损失函数本质上涉及到矩阵分解问题。
在这项工作中,我们为每条路径设置最大长度。换句话讲,我们假设
1.1.3 矩阵分解的最优化
遵从
《Neural word embedding as implicit matrix factorization》的工作,为了降低噪音,我们将0。因为若存在负数,则图中存在的pair对的概率k-step概率矩阵虽然存在各种矩阵分解技术,但是在这项工作中,由于其简单性,我们将重点放在流行的奇异值分解 (
singular value decomposition: SVD)方法上。SVD已经在多个矩阵分解任务中取得成功,被认为是可用于降维的重要方法之一。对于矩阵
SVD分解为:其中:
我们可以用
其中:
d个特征值对应的特征向量。通过这种方式,我们可以分解我们的矩阵
其中
representation向量,representation向量。最终我们返回矩阵representation,它在图中捕获了k-step全局结构信息。在我们的算法中,我们考虑所有
graph representation时整合了所有这些k-step信息,这将在接下来讨论。注意,这里我们实际上是在寻找从
SVD以外的替代方法,包括incremental SVD、独立成分分析(independent component analysis: ICA)、神经网络DNN。 我们这项工作的重点是学习graph representation的新模型,因此矩阵分解技术不是我们的重点。事实上,如果在这一步使用诸如稀疏自编码器之类的替代方法,则相对难以证明我们
representation的实验效果是由于我们的新模型、还是由于降维步骤引入的任何非线性。为了保持与《Neural word embedding as implicit matrix factorization》工作的一致性,这里我们只使用了SVD。
1.1.4 GraRep 算法
这里我们详细介绍我们的学习算法。通常,
graph representation被提取为其它任务的特征,例如分类、聚类。在实践中,编码k-step representation的一种有效方法是将k-step representation拼接起来作为每个顶点的全局特征,因为每个不同的step representation反映了不同的局部信息。GraRep算法:算法输入:
图的邻接矩阵
最大转移阶数
对数偏移系数
维度
算法输出:顶点的
representation矩阵算法步骤:
计算
首先计算
对于带权图,
0-1矩阵。算法都能够处理。对
k-step representation,计算流程:获取正的对数概率矩阵
首先计算
计算
representation矩阵
拼接所有的
未来工作:
研究矩阵操作有关的近似计算和在线计算。
研究通过深度架构代替
SVD矩阵分解来学习低维representation。
1.1.5 SkipGram 作为 GraRep 特例
GraRep旨在学习grap representation,并且我们基于矩阵分解来优化损失函数。另一方面,SGNS已被证明在处理线性结构(如自然语言的句子)方面是成功的。GraRep和SGNS之间有内在的联系吗?这里我们将SGNS视为GraRep模型的一个特例。
a. 图 SkipGram 模型的损失函数
SGNS旨在以线性序列的方式来表达单词,因此我们需要将图结构转换为线性结构。DeepWalk揭示了一种均匀采样(截断的随机游走)的有效方法。该方法首先从图中随机均匀采样一个顶点,然后随机游走到它的一个邻居并重复这个随机游走过程。如果顶点序列长度达到某个预定值,则停止随机游走并开始生成新的序列。该过程可用于从图中生成大量序列。本质上,对于无权图,这种均匀采样的策略是有效的。但是对于加权图,需要一种基于边权重的概率性采样方法,而
DeepWalk中没有采用这种方法。在本文中,我们提出了一种适用于加权图的增强型SGNS方法Enhanced SGNS: E-SGNS。我们还注意到,DeepWalk优化了一个不同于负采样的、替代的损失函数(alternative loss function)即hierarchical softmax)。首先,我们考虑图上的、所有
K-step的损失其中
我们关注特定于
pair定义
则损失函数重写为:
同样的推导过程可以解得最优解:
其中其中
定义矩阵
则
E-SGNS的被分解矩阵factorized matrix。E-SGNS和GraRep模型的区别在于E-SGNS可以认为是K-step loss的线性组合,每个loss的权重相等。E-SGNS和SGNS的主要区别在于对正样本的加权:E-SGNS的正样本权重为我们的
GraRep模型没有做出如此强的假设,但允许在实践中从数据中学习它们的关系(比如,潜在的非线性关系)。直觉上,不同的
k-step转移概率应该有不同的权重。对于异质网络数据(heterogeneous network data),这些损失的线性组合可能无法达到理想的效果。
b. 采样与转移概率之间的内在联系
在我们的方法中,我们使用转移概率来衡量顶点之间的关系。这合理吗?在这里,我们阐明了采样了转移概率之间的内在联系。
在随机游走生成的序列中,我们假设顶点
其中
我们将顶点
1-step距离)的次数的期望为:这对于无权图的均匀采样、或者对于加权图的非均匀采样都成立。
进一步地,顶点
2-step距离)的次数的期望为:其中
类似地,我们可以推导出
然后,我们将它们相加并除以
其中
根据
现在,我们可以计算将顶点
最后,我们将所有这些期望计数代入
定义数据集中所有观察到的
pair的集合为矩阵
《Neural word embedding as implicit matrix factorization》中描述的SGNS完全相同。这表明
SGNS本质上是我们GraRep模型的一个特殊版本,它可以处理从图中采样的线性序列。我们的方法相比缓慢的、昂贵的采样过程有若干优点,并且采样过程通常涉及几个要调整的超参数,例如线性序列的最大长度、每个顶点开始的序列数量等等。
1.2 实验
这里我们通过实验评估
GraRep模型的有效性。我们针对几个不同的任务在几个真实世界数据集上进行了实验,并与baseline算法进行了比较。数据集和任务:为了证明
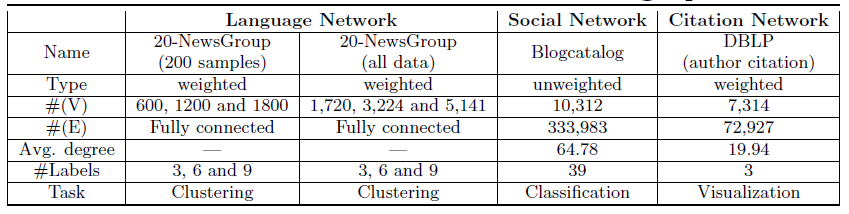
GraRep的性能,我们在三种不同类型的图上进行了实验,社交网络(social network)、语言网络(language network) 、引文网络 (citation network) ,其中包括加权图和无权图。我们对三种不同类型的任务进行了实验,包括聚类(clustering)、分类(classification)、以及可视化(visualization)。正如我们前面提到的,我们工作的重点是提出一个新的框架,用于学习具有全局结构信息的、图的良好representation,旨在验证我们提出的模型的有效性。因此,除了SVD之外,我们不采用其它更有效的矩阵分解方法,并重点关注以下三个真实世界的数据集:语言网络数据集
20-Newsgroup:包含2万篇新闻组文档,并分类为20个不同的组。每篇文档由文档内单词的tf-idf组成的向量来表示,并根据余弦相似度计算得到文档的相似度。根据文档的这些相似度构建语言网络,该网络是一个全连接的带权图,用于聚类效果的评估。为验证模型的鲁棒性,论文分别从
3/6/9个不同的新闻组构建了三个更小规模的语言网络(NG代表Newsgroups):3-NG:由comp.graphics, comp.graphics and talk.politics.guns这三个新闻组的文档构成。6-NG:由alt.atheism, comp.sys.mac.hardware, rec.motorcycles, rec.sport.hockey, soc.religion.christian and talk.religion.misc这六个新闻组的文档构成。9-NG:由talk.politics.mideast, talk.politics.misc, comp.os.ms- windows.misc, sci.crypt, sci.med, sci.space, sci.electronics, misc.forsale, and comp.sys.ibm.pc.hardware这九个新闻组的文档构成。
这些小网络分别使用所有文档(
all data),以及每个主题随机抽取200篇文档两种配置。每个文档上的topic label被认为是ground truth。这些
toplic label被认为是聚类的真正cluster id。社交网络数据集
Blogcatalog:它是一个社交网络,每个顶点表示一个博客作者,每条边对应作者之间的关系。每个作者都带有多个标签信息,标签来自39种主题类别。该网络是一个无权图,用于多标签分类效果的评估。我们的模型以及
baseline算法生成的graph representation被视为特征。引文网络数据集
DBLP Network:它是一个引文网络,每个顶点代表一个作者,边代表一个作者对另一位作者的引用次数。我们选择六个热门会议并分为三组:数据挖掘(
data mining) 领域的WWW,KDD会议、机器学习(machine learning)领域 的NIPS,IML 会议、计算机视觉(computer vision)领域的CVPR,ICCV会议。我们使用可视化工具
t-SNE来可视化所有算法学到的representation,从而提供学到的representation的定性结果和定量结果。
总而言之,我们对加权图和无权图、稀疏图和稠密图进行了实验,其中执行了三种不同类型的学习任务。这些数据集的更多细节如下表所示。
baseline方法:我们使用以下graph representation方法作为baseline。LINE:LINE是最近提出的一种在大规模信息网络上学习graph representation的方法。LINE根据顶点之间的1-step和2-step关系信息定义了一个损失函数。一种提升small degree顶点的性能的策略是:扩展它们的邻域使得图更稠密。如果将1-step关系信息的representation和2-step关系信息的representation拼接起来,并调节邻域最大顶点的阈值,则LINE将获得最佳性能。DeepWalk:DeepWalk是一种学习社交网络representation的方法。原始模型仅适用于无权图。对于每个顶点,截断的随机游走用于将图结构转换为线性序列。带hierarchical softmax的SkipGram模型用作损失函数。E-SGNS:SkipGram是一种有效的模型,可以学习大型语料库中每个单词的representation。对于这个增强版本,我们首先对无权图使用均匀采样、对加权图使用与边权重成正比的概率性采样(即随机游走),从而生成顶点序列。然后引入SGNS进行优化。这种方法可以视为我们模型的一个特例,其中每个
k-step信息的不同representation向量进行均值池化。Spectral Clustering:谱聚类是一种合理的baseline算法,旨在最小化归一化割 (Normalized Cut: NCut)。与我们的方法一样,谱聚类也对矩阵进行分解,但是它侧重于图的不同矩阵:拉普拉斯矩阵(Laplacian Matrix)。本质上,谱聚类和E-SGNS的区别在于它们的损失函数不同。
参数配置:
对于
LINE模型:batch-size=1,学习率为0.025,负采样系数为5,迭代step总数为百亿级。我们还还将
1-step关系信息representation和2-step关系信息representation拼接起来 ,并针对degree较小的顶点执行重构策略来达到最佳性能。对于
DeepWalk和E-SGNS模型:窗口大小为10,序列最长长度为40,每个顶点开始的游走序列数量为80。正则化:
LINE, GraRep模型进行DeepWalk, E-SGNS模型没有正则化也能达到最佳效果。embedding维度Blogcatalog和DBLP数据集的20-NewsGroup数据集的GraRep模型:Blogcatalog和DBLP数据集的20-NewsGroup数据集的
1.2.1 语言网络
我们通过在
k-means算法中使用学到的representation,通过聚类任务在语言网络上进行实验。为了评估结果的质量,我们报告了每个算法在10次不同运行中的平均归一化互信息Normalized Mutual Information (NMI)得分。为了理解不同维度
DeepWalk、E-SGNS、Spectral Clustering在LINE模型这里采用了重构策略,邻居数量阈值分别设定为k-max = 0,200,500,1000取最佳阈值(最佳阈值为200)。最终结果如下表所示,每列的最佳结果用粗体突出显示。结论:
GraRep模型在所有实验中都优于其它baseline方法。对于
DeepWalk, E-SGNS和Spectral Clustering,增加维度representation提供额外的补充信息。对于
LINE模型采用重建策略确实有效,因为它可以捕获图的额外结构信息,例如超出1-step、2-step的局部信息。值得一提的是,
GraRep和LINE模型在很小的Graph上就可以得到良好的性能。我们认为:即使在图很小的条件下,这两个模型也可以捕获丰富的局部关系信息。此外,对于标签较多的任务,例如
9GN,GraRep和LINE可以提供比其它方法更好的性能。一个有趣的发现是:当
Spectral Clustering达到最佳性能,但是对其它算法
由于篇幅所限,我们没有报告所有
baseline方法在LINE的k-max=500, 1000以及没有重建策略的结果。因为这些结果并不比下表的效果更好。后面的实验会进一步探究参数敏感性问题。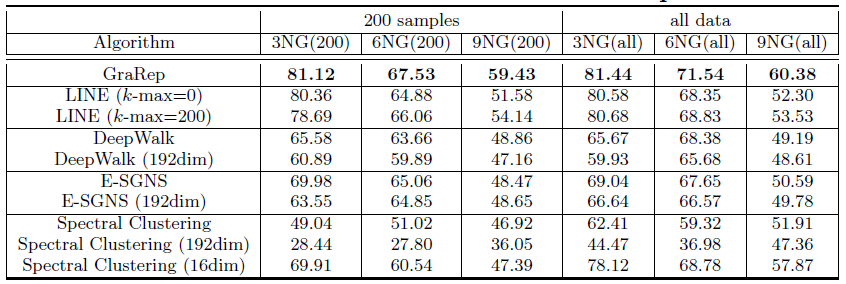
1.2.2 社交网络
在这个实验中,我们专注于社交网络上的监督任务。我们将学到的
representation视为特征,通过多标签分类任务评估不同算法得到的graph representation的有效性。我们使用
LibLinear package来训练one-vs-rest逻辑回归分类器。我们将这个过程运行10轮并报告平均Micro-F1和Macro-F1指标。对于每一轮,我们随机采样10%~90%的顶点来训练,剩下的顶点作为测试集 。 这里LINE模型采用了重构策略,邻居数量阈值分别设定为k-max = 0,200,500,1000取最佳阈值(最佳阈值为500)。最终结果如下表所示,每列的最佳结果用粗体突出显示。结论:总体上
GraPep性能远超过其它方法,尤其是仅使用10%样本训练。这表明
GraRep学到的不同类型的、丰富的局部结构信息可以相互补充从而捕获到全局结构信息。在与现有的baseline相比具有明显的优势,尤其是在数据稀疏时。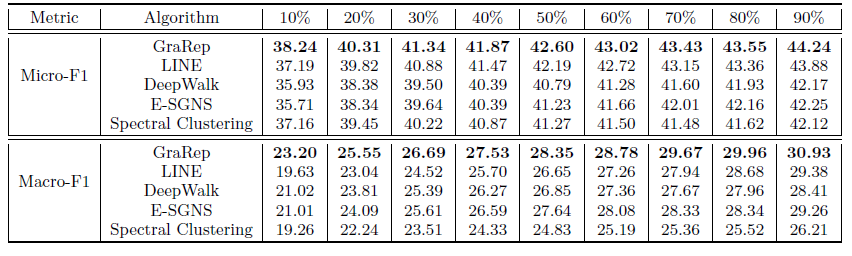
1.2.3 引文网络
在这个实验中,我们专注于通过检查一个真实的引文网络
DBLP来可视化学到的representation。我们将学到的graph representation输入到t-SNE工具中来lay out图,其中来自同一个研究领域的作者使用相同的颜色,绿色表示数据挖掘、紫色表示计算机视觉、蓝色表示机器学习。结论:
使用谱聚类的效果一般,因为不同颜色的顶点相互混合。
DeepWalk和E-SGNS结果看起来好得多,因为大多数相同颜色的顶点似乎构成了分组,但是分组的边界似乎不是很明显。LINE和GraRep结果中,每个分组的边界更加清晰,不同颜色的顶点出现在明显可区分的区域中。与
LINE相比GraRep的结果似乎更好,每个区域的边界更清晰。

引文网络可视化的
KL散度如下表所示。其中KL散度捕获了 ”成对顶点的相似度” 和 “二维投影距离” 之间的误差。更低的KL散度代表更好的表达能力。可以看到:GraRep模型的顶点representation效果最好。
1.2.4 参数敏感性
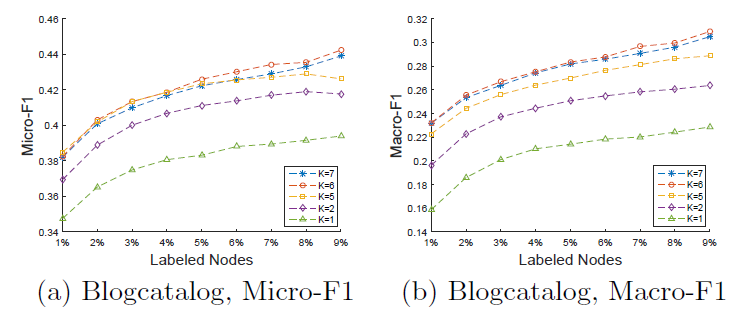
这里我们讨论参数敏感性,具体而言我们评估了最大步长
Blogcatelog数据集上不同Micro-F1和macro-F1得分。为阅读方便,这里仅给出可以看到:
这表明:不同的
这是因为当
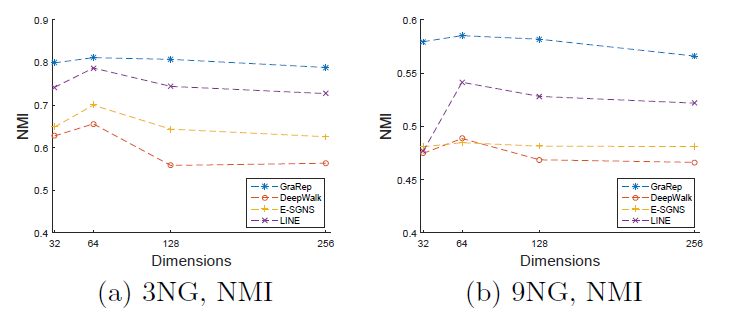
3NG和9NG在不同NMI得分。可以看到:GraRep模型结果始终优于其它模型。几乎所有算法都在
64继续增加到更大值时所有算法效果都开始下降。
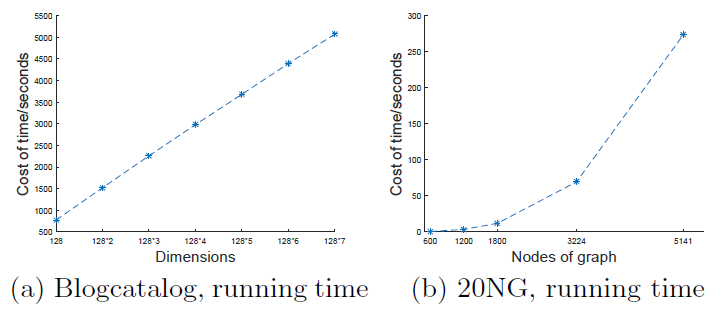
运行时间:下图给出不同总维度和不同图大小时模型的运行时间。总维度等于
GraRep拼接得到的representation向量。图
a给出了Blogcatalog数据集上的模型训练时间。可以看到:模型训练时间随着总维度的增加而几乎线性增加。
图
b给出了在20-NewsGroup数据集不同规模的网络上训练的时间。可以看到:随着
Graph规模的增长,模型训练时间显著增加。原因是随着Graph增长,矩阵幂运算SVD分解涉及到时间复杂度较高的运算。后续可以考虑采用深度学习来替代
SVD技术来做矩阵分解。