一、HNE [2015]
《Heterogeneous Network Embedding via Deep Architectures》
向量化的
data representation经常出现在许多数据挖掘application中。向量化的data representation更容易处理,因为每个数据都可以被视为驻留在欧式空间中的一个point。因此,可以通过一个合适的指标来直接衡量不同data point之间的相似性,从而解决分类、聚类、检索等传统任务。如《Data Classification: Algorithms and Applications》所示,学习良好的representation是数据挖掘和web搜索中的基本问题之一。与设计更复杂的模型相比,学习良好的representation对任务效果的影响通常更大。不幸的是,许多
network数据源(如Facebook, YouTube, Flickr, Twitter)无法自然地表示为向量化的输入。这些社交网络和社交媒体数据通常以图数据 (graph data) 和关系数据 (relational data) 二者组合的形式来表示。当前的研究集中在预定义(pre-defined)的特征向量、或者复杂的graph-based的算法来解决底层任务。人们在各种主题上完成了大量的研究,例如协同分类(collective classification)、社区检测(community detection) 、链接预测(link prediction)、社交推荐(social recommendation) 、定向广告(targeted advertising)等等。对于内容和链接而言,网络数据(network data) 以embedding形式开发的unified representation非常重要。unified representation的基本假设是:一旦获得向量化的representation,网络挖掘任务就可以很容易地通过现有的机器学习算法来解决。然而,网络数据的
feature learning并不是一项简单的任务,因为网络数据具有许多特有的特性,例如网络的规模、动态性、噪声、以及异质性(heterogeneity)。首先,社交网站上的多媒体数据量呈指数级增长。到2011年年中,Facebook上的照片估计数量已达1000亿张,并且每天上传的新照片数量高达3.5亿张。其次,鉴于用户的不同背景(background) ,社交媒体往往噪音很大。而且研究人员注意到,垃圾邮件发送者产生的数据比合法用户更多,这使得网络挖掘更加困难。最后,社交媒体数据包含多样(diverse) 的、异质的信息。例如,当事件发生时,不同类型的媒体数据都会进行报道。如下图所示,当在谷歌中搜索 “马航MH17” 时,相关结果中不仅包含文本文档,还包含图像和视频。
此外,社交媒体数据不是孤立存在的,而是由各种类型的数据组合而成的。这些交互可以通过它们之间的链接显式或隐式地形成。例如,在同一网页中同时出现的图像和文本提供了它们之间的显式链接,而文本到文本的链接是通过不同
web document之间的超链接显式形成的。另一方面,用户的交互活动可以被视为隐式反馈,它链接了不同的社交媒体部分(social media component) 。如果用户以相似的标签(tag)描述多张图像,那么一个合理的假设是:这些图像之间存在语义关系。很明显,如此庞大的数据量导致了复杂的异质网络,这给学习uniform representation带来了巨大的挑战。为了应对上述挑战,论文
《Heterogeneous Network Embedding via Deep Architectures》提出了一种关于network representation learning的新思想,称作Heterogeneous Network Embedding: HNE。HNE同时考虑了内容信息(content information)和关系信息(relational information) 。HNE将不同的异质对象映射到一个统一的潜在空间中,以便可以直接比较来自不同空间的对象。与传统的线性
embedding模型不同,HNE将feature learning过程分解为深层的多个非线性层。HNE通过迭代求解关于feature learning和objective minimization的问题,从而协调并相互加强这两个部分。HNE同时建模了底层网络的全局链接结构(global linkage structure)和局部链接结构(local linkage structure),这使得它在捕获网络链接方面比浅层embedding方案更强大,特别是当链接信息在揭示不同对象之间的语义相关性方面起关键作用时。沿着这个研究方向,论文利用网络链接来设计一个损失函数,从而迫使网络中存在链接的不同对象在embedding空间是相似的。network-preserved embedding的思想如下图所示。事实上根据
HNE的模型公式,HNE仅建模了局部链接结构(即,保留一阶邻域),并未建模全局链接结构。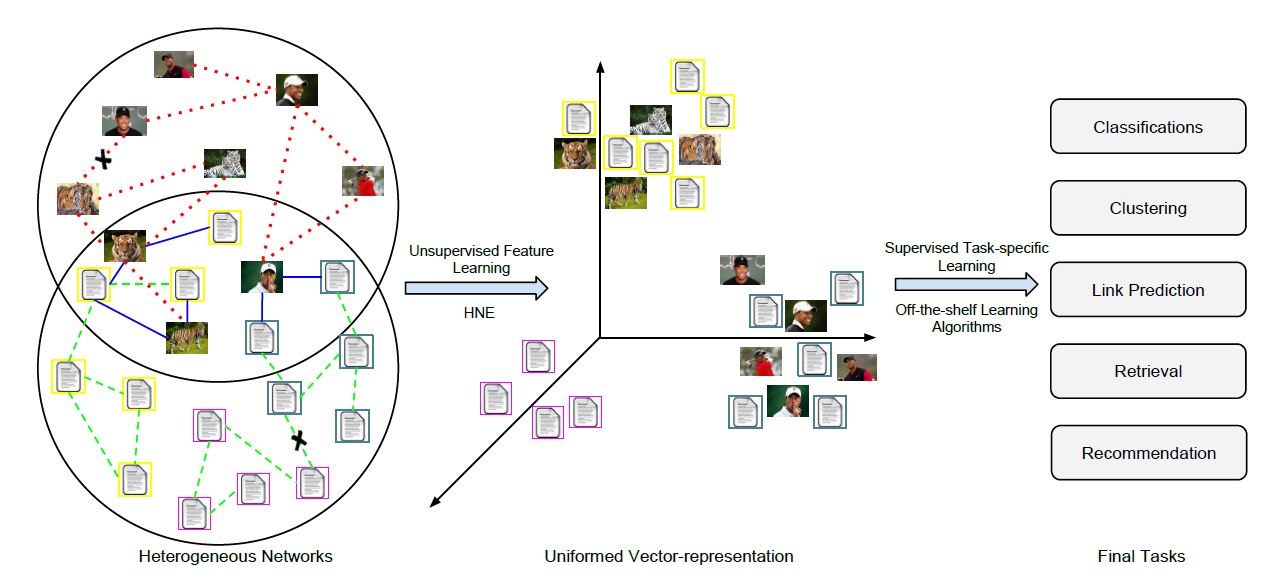
HNE框架的主要优点如下:鲁棒性:
HNE探索不同异质对象之间的全局一致性(global consistency),从而学习由网络结构指导的unified feature representation。无监督:
HNE是无监督并且独立于任务的,这使其适用于许多面向网络的数据挖掘application。out-of-sample:HNE能够处理out-of-sample问题(即unseen顶点)。这解决了动态网络相关的挑战,其中随着时间的推移可能会在网络中添加新顶点。
相关工作:
Network Embedding:feature embedding的一个分支是由网络中的协同过滤和链接预测等application所推动的。这些application根据潜在属性对实体之间的关系进行建模。这些模型通常将问题迁移 (transfer) 为学习实体的embedding,这在数学上对应于对观察到的关系矩阵的矩阵分解问题。《Combining content and link for classification using matrix factorization》提出了一种在链接邻接矩阵(linkage adjacency matrix)和document-term frequency矩阵上联合分解的方法,从而用于网页分类。此外,
《Structure preserving embedding》提出了一种structure preserving的embedding框架,该框架将图嵌入到低维欧式空间中,并保持了全局拓扑属性。此外,
DeepWalk从截断的随机游走中学习网络中顶点的潜在representation。
然而,这些模型仅关注单一关系(
single relation),这无法应用于异质网络。而且这些模型中的大多数很难泛化到unseen sample(即训练期间未见过的顶点)。这些方法对异质网络的自然扩展是将多个关系矩阵堆叠在一起,然后应用传统的张量分解。这种
multi-relational embedding的缺点是不同term之间共享参数,这无法扩展到大型网络。《Latent feature learning in social media network》提出的非线性embedding模型使用Restricted Boltzmann Machine: RBM进行跨模型链接分析(crossmodel link analysis)。但是,它没有利用原始数据中的所有社交信息,这导致了次优的解决方案。此外,计算机视觉和语音方面的工作表明,与DNN和CNN相比,layer-wise的RBM训练对于大规模数据而言效率低下。深度学习:近年来,机器学习研究已经从基于人工制作的特征显著转向为基于原始数据学到的特征,这主要归功于深度学习的成功。深度学习模型在语音识别、图像识别/检测、以及最近的自然语言处理中变得越来越重要。深度学习技术是通用函数的逼近器(
approximator)。然而,从历史上来看,训练具有两层以上隐层的深度神经网络很难成功。困难在于高维的参数空间、以及高度非凸的目标函数,这使得基于梯度的方法受到局部极小值的困扰。深度学习的最新进展得益于多种因素的推动,例如大规模数据集的使用、算力的增长、以及无监督和监督训练算法的进步。
无监督深度学习(通常被称为预训练
pre-training),借助大量可用的未标记数据来提供鲁棒的初始化和正则化。例如,《Reducing the dimensionality of data with neural networks》首次使用RBM对深度神经网络进行layer-wise初始化。《Greedy layer-wise training of deep network》也提出了类似的方法,采用自编码器来进行权重初始化。最近,多层神经网络的监督学习已经成为可能。
dropout的方法已经展示出特别的前景。《Imagenet classification with deep convolutional neural networks》提出的七层卷积神经网络在ImageNet大规模视觉识别挑战赛上取得了SOTA的性能。该挑战赛是计算机视觉中最具挑战性的任务之一。来自这个七层卷积神经网络的中间层的特征,后来被证明是其它计算机视觉任务(如对象检测object detection)的良好的feature representation。
在深度学习架构的背景下,人们对利用来自多模态(
multiple modalities)的数据越来越感兴趣。自编码器和RBM等无监督深度学习方法被部署并联合重建(部分共享的网络partially shared network)音频和视频来执行feature learning,从而成功应用于多模态任务(multimodal task) 。另一种方案,也有人努力学习具有多个任务的联合representation。对于图像和文本,一种特别有用的场景是通过将语义上有意义的embedding空间与图像label相结合,从而实现对unseen的label进行图像分类的zero-shot learning。据我们所知,之前很少有人尝试利用网络中的链接结构进行
representation learning。在《A deep learning approach to link prediction in dynamic network》中,它使用条件的动态的RBM对网络链接的动态性进行建模,主要任务是使用历史数据预测未来的链接。与我们最相似的工作是《Latent feature learning in social media network》,其中它在多媒体链接数据上训练一个content RBM。我们在几个方面与他们的工作不同:我们在无监督环境中使用监督学习的方案,我们的方法可以扩展到大规模数据集,我们执行多任务学习从而融合来自不同模态的形式。
1.1 模型
异质网络(
heterogeneous network)指的是具有不同类型对象、和/或具有不同类型链接的网络。从数学上讲,我们定义一个无向图此外,图
网络的异质性分别由集合
heterogeneous) 的。否则网络是异质 (heterogeneous) 的。下图说明了一个异质网络的示例,其中包含两种对象类型和三种链接类型。为了进一步便于理解,我们将假设对象类型为image: I、text: T。链接关系image-to-image(红色点虚线)、text-to-text(绿色短虚线)、image-to-text(蓝色实线),分别用RII, RTT, RIT表示。因此,在这种情况下,我们有因此,任何顶点
unique的内容信息。具体而言:对于每个图像顶点
对于每个文本顶点
例如,图像的内容是
RGB颜色空间中的原始像素格式,文本的内容是文档的Term Frequency - Inverse Document Frequency: TF-IDF得分。我们将链接关系表示为一个对称的邻接矩阵注意,这里的邻接矩阵元素取值为
{+1, -1},这和经典的{+1, 0}不同。这是为了后面的损失函数服务,给 “负边”(即,未链接的顶点对)一个非零值可以在损失函数中引入 “负边” 的信息。虽然这种邻接矩阵是完全稠密的矩阵,但是我们可以仅存储“正边”,从而仍然存储一个稀疏版本的邻接矩阵。接下来,我们首先引入一种新的损失函数来衡量跨网络的相关性,并以数学方式展示我们的
HNE框架。本质上,embedding过程为每个对象同时将异质内容和异质链接编码到一个representation中。然后我们提出了一种
linkage-guided的深度学习框架,从而同时对潜在空间embedding和feature learning进行联合建模。这可以通过使用反向传播技术有效地求解。最后,我们讨论了将
HNE算法直接扩展到多于两种对象类型的一般情况。
1.1.1 线性 HNE
异质
embedding任务的主要目标是学习映射函数,从而将不同模态的数据映射到公共空间,以便直接衡量对象之间的相似性。假设与图像顶点相关联的原始内容representationfeature machine。值得一提的是,我们使用两个线性变换矩阵
represetnation分别为尽管图像和文本可能在不同维度的空间中表示,但是变换矩阵
data point之间的相似性可以表示为投影空间中的内积,即:注意,由于嵌入到公共空间,不同类型对象(如文本和图像)之间也可以进行相似度计算,即:
这里
潜在
embedding与文献《Learning locally-adaptive decision functions for person verification》中已被广泛研究的相似性学习(similarity learning)和度量学习(metric learning)密切相关。即,两个顶点之间的相关性(correlation)可以通过投影矩阵application-specific的方式来建模异质关系的灵活性。对象之间的交互被表示为网络中的异质链接。我们假设:如果两个对象是连接的,则它们之间的相似性应该比孤立对象之间的相似性更大,从而反映这一事实(即,对象是连接的)。
注意,这里仅考虑一阶邻近性,即直接连接关系。
考虑两个图像
pairwise决策函数注意,要推断
in-sample。这意味着该方法具有泛化能力从而嵌入unseen顶点。这句话的意思是,
unseen的顶点,我们也可以计算对于所有顶点
bias值。则损失函数可以定义为:这可以视为由网络链接引导的二元逻辑回归。
text-text损失函数和image-text损失函数也是类似的,只需要将bias值。该损失函数仅捕获一阶邻近性(即局部网络结构),没有捕获高阶邻近性(既全局网络结构)。
该损失函数迫使相连的顶点之间的
embedding是相似的、不相连的顶点之间的embedding是不相似的。这就是为什么最终我们的目标函数如下:
其中:
image-image链接的数量,即text-text链接的数量,即image-text链接的数量,即F范数。bias值既可以从数据中学习得到,也可以设为固定值。为简单考虑,我们都设置为固定值。
该最优化问题可以通过坐标下降法(
coordinate descent)得到有效解决,每次固定一个变量从而求解另一个变量:首先固定参数
1.1.2 深度 HNE
目前为止,我们已经证明了我们的损失函数融合了网络结构,从而将不同异质成分(
heterogeneous component)映射到统一的潜在空间。然而,这种embedding函数仍然是线性的,可能缺乏建模复杂网络链接的能力。接下来我们引入深度学习框架。前面部分我们的解决方案可以分为两个步骤:
手动构造顶点的
feature representation:对于文本顶点使用其TF-IDF向量,对于图像顶点使用其原始RGB像素点拼接而成的向量。将不同的
feature representation嵌入到公共的低维空间中。
这里我们通过深度学习将
feature representation的learning和embedding合并在一起。feature representation learning:定义图像特征抽取的非线性函数为
CNN来抽取图像特征。下图为一个图像特征抽取模型,它由五个卷积层、两个全连接层组成。所有层都采用ReLU非线性激活函数。该模块称作deep image模块。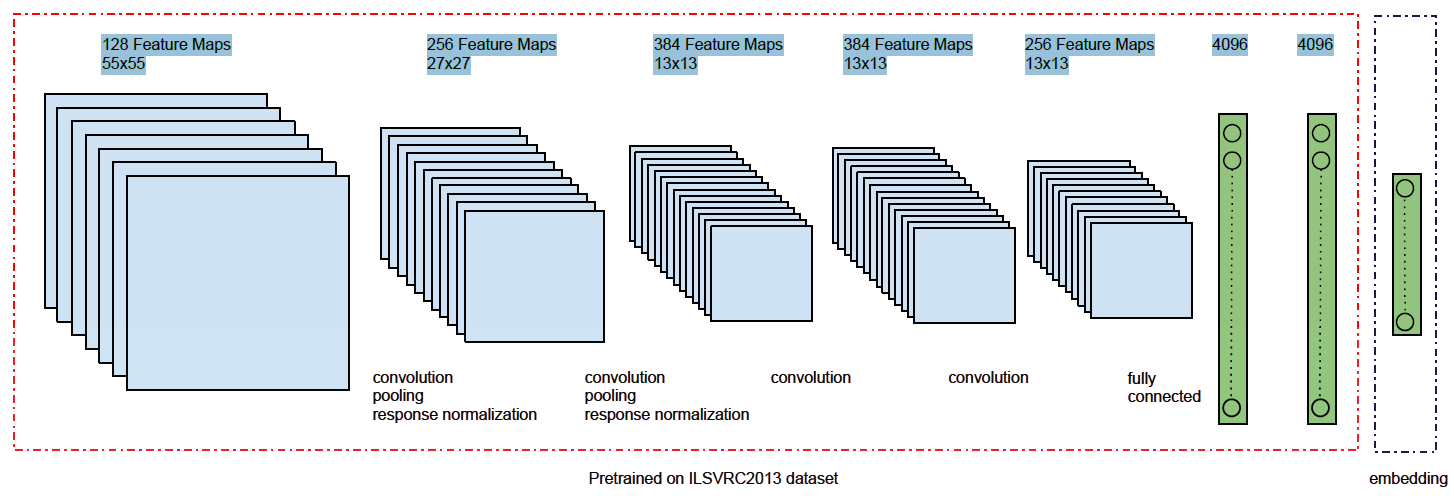
定义文本特征抽取的非线性函数为
FC对文本的TF-IDF输入来抽取特征。该模块称作deep text模块。
则我们的损失函数变为:
feature representation embedding:我们可以通过一个额外的线性embedding layer来级联deep image模块和deep text模块。定义
其中:
我们使用
dropout代替了我们使用新的损失函数:
与前面的
bias项。
该目标函数可以通过随机梯度下降(
SGD) 来求解。为进行端到端的
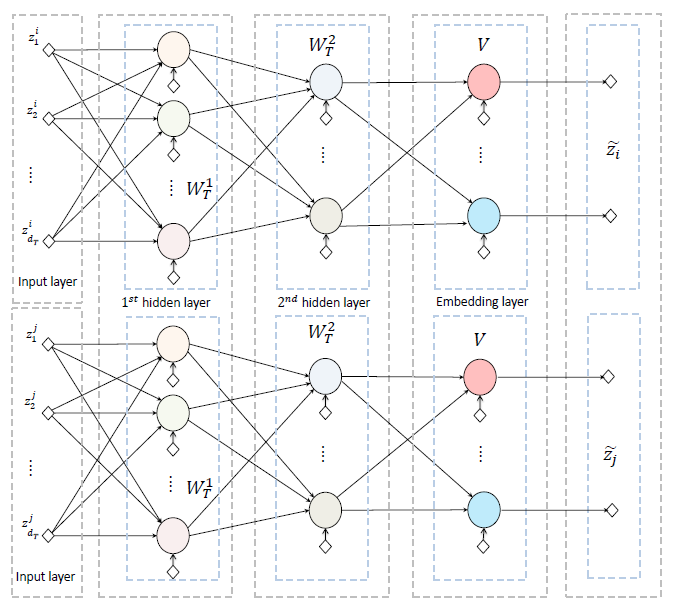
HNE学习,我们将deep image模块和deep image模块连接起来。我们以text-text链接为例,另外两种类型的链接也是类似的。下图包含两个deep text模块,它们构成了pairwise的text-text模块。deep text模块包含两个FC全连接层,然后是一个线性embedding层。这里有些违反直觉。主流的
DNN模型都是先通过一个embedding层,然后再通过FC层。线性
embedding层的输出是公共潜在空间中的低维向量,该低维向量进一步送到预测层prediction layer来计算损失函数。text-text模块是对称的,下图中相同颜色的神经元共享相同的权重和偏差,箭头表示前向传播的方向。
HNE的整体架构如下图所示,图中展示了三个模块,从左到右依次为image-image模块、image-text模块、text-text模块。这些模块分别连接到prediction layer来计算损失函数。下图中,相同的颜色代表共享权重。箭头表示前向传播和反向传播的方向。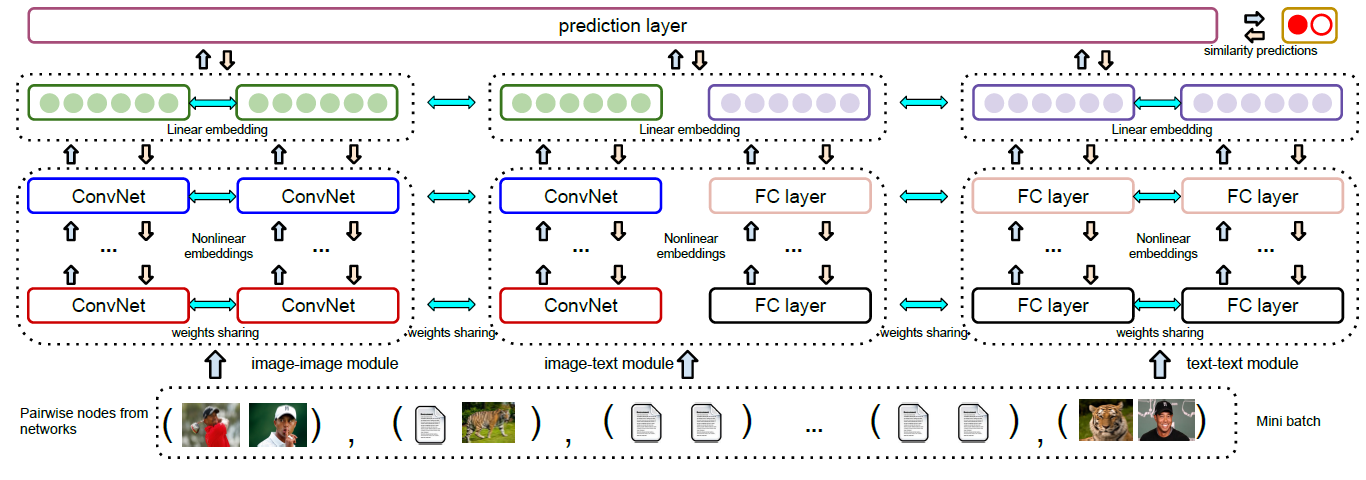
讨论:
目前为止我们仅展示了两种类型顶点的异质网络
embedding方法。事实上,我们的框架也支持多种类型顶点的异质网络embedding。由于深度学习是高度非线性和非凸的,因为无法保证全局最优解。参数的初始化对模型性能至关重要。文献表明,即使最终任务与
pre-training任务不同,精心设计的pre-training也可以显著提高最终任务的表现。值得一提的是,我们提出的方法是无监督学习方法,因此可以作为下游
fine-tuning微调阶段的预训练(pretraining)步骤来使用。换句话讲,如果我们想对网络顶点进行分类,那么我们可以从embedding layer获得最终特征并应用相应的机器学习算法。或者我们也可以将prediction layer替换为softmax层,然后进行微调为task-specific的端到端监督学习深度神经网络。
1.2 实验
数据集:我们使用来自现实世界社交网络的两个公开数据集。所有实验结果均在五次不同的运行中取均值。
BlogCatalog:一个社交博客网络,博主可以在预定义的类别下对其博客进行分类。这样的分类用于定义类标签,而following(即,关注)行为用于构建博主之间的链接。我们使用每个博主的所有博客内容的TF-IDF向量作为博主的内容特征。最终我们得到一个无向、同质图,每个顶点代表一个博主,顶点的特征为TF-IDF向量。最终该图包含5196个顶点、171743条边、类别数量6、内容向量维度8189,并且该数据集各类别是平衡的。NUS-WIDE:Flickr上的图像和文本数据,包含269648张关联有tag的图像,其中tag集合大小为5018。每一组image-tag标记有一个label,一共81个类别。由于原始数据中包含很多不属于任何类别的噪音样本,因此这些样本被删除。另外,我们将频次最高的
1000个tag作为文本并抽取其TF-IDF向量作为特征。我们进一步删除了不包含任何这1000个tag中单词的样本。最终我们分别随机抽样了53844和36352个样本进行训练和测试。我们将图像和文本分别视为独立的顶点来构建异质网络,训练网络包含
107688个顶点、测试网络包含72704个顶点。如果两个顶点共享至少一个概念(concept),则构建它们之间的语义链接。我们对每个顶点最多随机采样30个链接,从而构建稀疏的邻接矩阵值得一提的是,我们以
out-of-sample方式来评估不同的算法。即,训练样本绝对不会出现在测试数据集中。
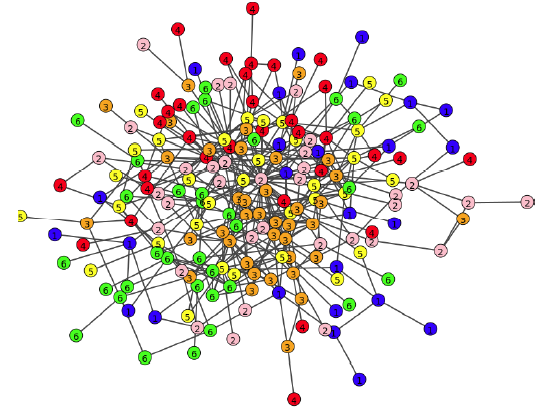
网络重建(
Network Reconstruction):在分类、聚类或检索任务之前,我们首先对网络链接重建的质量进行基本的、直观的评估,从而验证我们的假设。我们从BlogCatalog数据集中随机选择500个顶点,然后可视化其链接,其中每个顶点的颜色代表其类别。可以看到:相对而言,社交“关注” 关系倾向于将具有相似属性的用户聚合在一起。
绝对而言,这种聚合之中存在大量噪音,其中
59.89%的链接连接到了不同类别的顶点。这是可以理解的,因为即使
HNE百分之百地重建了网络,但是原始网络本身就存在大量的、不同类别的顶点链接在一起的情况。
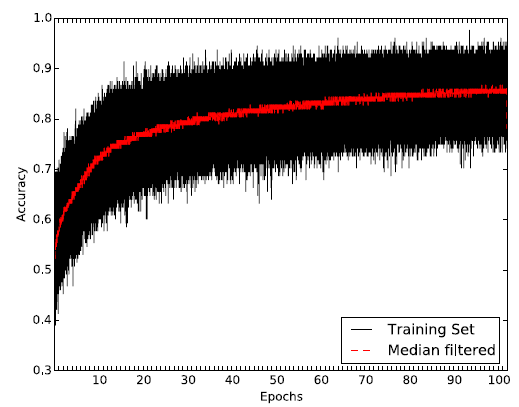
我们评估了算法学习
embedding过程中,训练集每个mini-batch的链接重建准确率 :预估正确的pair对的数量, 除以所有的pair对的数量。其中mini-batch = 128。结果如下图所示,其中横轴表示epoch,每个epoch包含500个step。红线表示每个epoch重建准确率的均值。可以看到:随着学习的推进,算法能够正确地重建80%以上的链接,而一开始的准确率只有55%。注意,这里是训练集的重建准确率,而不是测试集的。
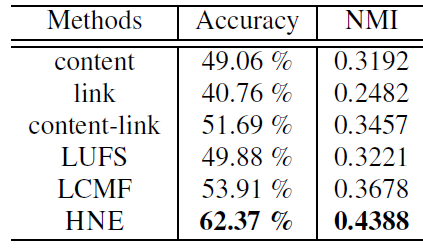
1.2.1 BlogCatalog 数据集
分类任务:在
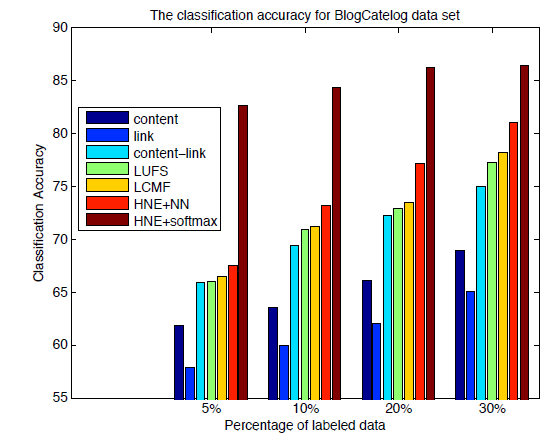
BlogCatalog数据集上,我们将我们的feature learning方法和以下feature learning方法进行比较:Content:基于原始空间的内容特征,即用户所有博主的TF-IDF特征向量。Links:基于原始空间的链接特征,即用户的邻接关系作为特征。Link-Content:将内容和邻接关系都视为特征。LUFS:针对内容和链接的无监督特征抽取框架。LCMF:基于链接和内容的矩阵分解方法。HNE:我们提出的异质网络特征抽取方法。
对于这些抽取出来的特征,我们使用标准的
kNN分类器来评估特征的分类效果。为确保公平比较,所有方法的embedding维度固定为100。对于Content/Links/Link-Content方法抽取的特征,我们使用PCA算法投影到100维的空间。这些模型的分类准确率如下所示。可以看到:
在不同规模的训练集中,
HNE始终优于其它的baseline方法。这是因为网络链接可以编码很多有用的信息。如果将
embedding视为预训练步骤,并通过将多类softmax替换掉predict layer来微调整个模型,则我们的效果会进一步提升。这表明了无监督的embedding学习对于有监督分类任务提供了很好的初始化,并能进一步提升性能。
聚类任务:我们还比较了
BlogCatalog数据集上不同方法得到的embedding的聚类表现。与分类任务相比,聚类任务是完全无监督的,并很大程度上依赖于相似性度量函数。这里我们采用最常见的余弦相似度。我们根据聚类后的结果以及label信息,同时给出了准确率和归一化互信息 (normalized mutual information :NMI)作为评估指标。结果表明:
类似分类任务,仅使用链接会带来最差的结果。这可能是因为:在没有全局内容信息指导的条件下,相似性往往是局部的,并且对噪音非常敏感。
仅内容相似性不足以捕获关系信息。
通过链接和内容的简单组合,这可以提供与其它
baseline相当的性能。我们的
HNE模型优于所有其它baseline模型并达到SOTA的水平。
1.2.2 NUS-WIDE 数据集
与
BlogCatalog相比,NUS-WIDE数据集构成了一个包含图像、文本的异质网络。我们将在分类任务、跨模态检索(cross-modal retrieval) 任务中评估HNE的性能。注意,跨模态检索任务在前一个数据集的同质场景中是不可行的。分类任务:鉴于
BlogCatalog的异质场景,我们将我们的方法和以下无监督的、能够处理多模态输入的baseline进行比较:Canonical Correlation Analysis: CCA:根据输入的多个数据源的关系将它们嵌入到共同的潜在空间。DT:一种迁移学习方法,通过潜在embedding来减少图像和文本之间的语义距离。LHNE:HNE的线性版本。
我们为所有其它
baseline方法抽取了4096维的特征,但是由于我们的HNE方法是端到端的,因此不需要为图像手动抽取特征。由于NUS-WIDE数据集是类别不平衡的,因此我们用平均精度(average precsision:AP)来评估每种可能的标签结果的分类性能。AP就是P-R曲线下的面积,mAP就是所有类别的AP的均值。事实上,AP就是把recall的取值根据11个水平(也可以划分更小的单位),然后取对应的Precision的平均值。在P-R曲线上这等价于曲线的线下面积。为了方便比较,所有方法的公共嵌入空间的维度为
400维,并且使用线性支持向量机SVM来作为所有方法产出的embedding的通用分类器。之所以用SVM是因为计算AP需要预估一个概率值,而这不方便从深度神经网络分类器中取得。我们比较了三种配置:
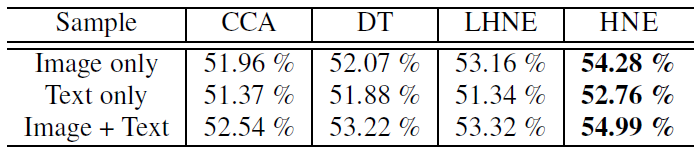
image only:仅在图像顶点上学习embedding,然后训练SVM、执行分类测试。text only:仅在文本顶点上学习embedding,然后训练SVM、执行分类测试。image + text:同时使用图像顶点和文本顶点学习embedding,然后后训练SVM、执行分类测试。
可以看到:
对于所有方法,仅使用文本数据进行分类效果最差。这可能是由于:和图像输入相比,文本输入非常稀疏。
仅使用线性的
HNE,我们就可以获得与DT相当的结果,并且优于CCA。非线性
HNE在所有三种配置中进一步提高性能,这表明使用非线性函数同时优化feature learning和潜在embedding的优势。
跨模态检索:为进一步验证
HNE的能力,我们在跨模态检索任务中将我们的方法和baseline进行比较。我们的目标是希望通过文本query来召回对应的图片。在所有81个label中,有75个出现在TF-IDF文本向量中。因此我们基于这75个label word来构建query向量:其中
query向量长度为1000, 除了第label对应的位置为1,其它所有位置为零。query向量一共有75个。根据学到的
embedding函数,我们将这些query向量都映射到公共潜在空间中,并通过欧式距离来检索测试集中的所有图像。我们报告了average precision at rank k: p@k(top k结果中的平均precision值) 的结果。 可以看到:HNE明显优于其它baseline。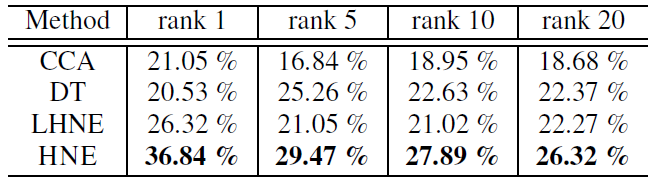
然后我们给出一些检索的案例。可以看到:
Mountain的第三个检索结果不正确,这可能是由于其它Mountain图像和带有牛的Mountain图像之间存在极大的视觉相似性。Cow的检索结果中包含三只鹿,这是因为这些图像具有多个tag,并通过“动物” 概念进行链接。由于我们的方法以及
ranking函数完全是无监督的,因此cow和deer等对象之间的联系会混淆我们的embedding学习。我们预期使用监督ranking可以提升性能。

1.2.3 其它
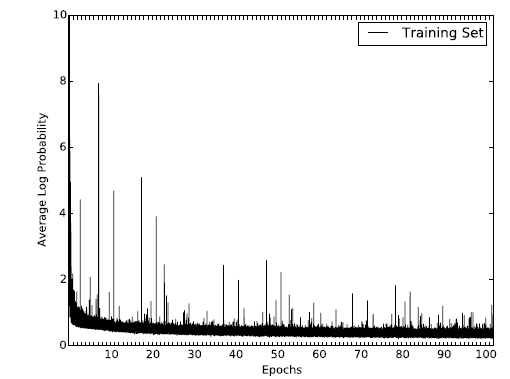
训练收敛性:我们展示了
HNE在BlogCatalog数据集上目标函数的变化,从而验证模型的收敛性。其中x轴代表epoch。可以看到:目标函数经过60个epoch的持续性降低之后趋向于平稳,这表明算法可以收敛到稳定结果。