一、TADW [2015]
《Network Representation Learning with Rich Text Information》
网络在我们的日常生活中无处不在,例如
Facebook用户之间的友谊或学术论文之间的引用。近年来,研究人员广泛研究了网络中许多重要的机器学习应用,例如顶点分类(vertex classification)、标签推荐(tag recommendation)、异常检测 (anomaly detection)、链接预测(link prediction)。数据稀疏(data sparsity)是这些任务面临的常见问题。为了解决数据稀疏性问题,network representation learning: NRL在统一的低维空间中编码和表达每个顶点。NRL有助于我们更好地理解顶点之间的语义相关性(semantic relatedness),并进一步缓解稀疏性带来的不便。NRL中的大多数工作从网络结构中学习representation。例如,social dimensions是计算网络的拉普拉斯(Laplacian)矩阵或modularity矩阵的特征向量(eigenvectors)。最近,NLP中的word representation模型SkipGram被引入,用于从社交网络中的随机游走序列中学习顶点的representation,称作DeepWalk。social dimensions和DeepWalk方法都将网络结构作为输入来学习network representation,但是没有考虑任何其它信息。在现实世界中,网络中的顶点通常具有丰富的信息,例如文本内容和其它元数据(
meta data)。例如,维基百科文章相互连接并形成网络,每篇文章作为一个顶点都包含大量的文本信息,这些文本信息可能对NRL也很重要。因此,论文《Network Representation Learning with Rich Text Information》提出了同时从网络结构和文本信息中学习network representation的想法,即text-associated DeepWalk: TADW。一种直接的方法是:分别独立地从文本特征和网络特征中学习
representation,然后将两个独立的representation拼接起来。然而,该方法没有考虑网络结构和文本信息之间复杂的交互interaction,因此通常会导致效果不佳。在现有的
NRL框架中加入文本信息也不容易。例如,DeepWalk在网络中的随机游走过程中,无法轻松地处理附加信息。
幸运的是,给定网络
DeepWalk实际上是分解矩阵steps随机游走到顶点(a)展示了MF风格的DeepWalk:将矩阵DeepWalk将矩阵representation。我们将在后面进一步详细介绍。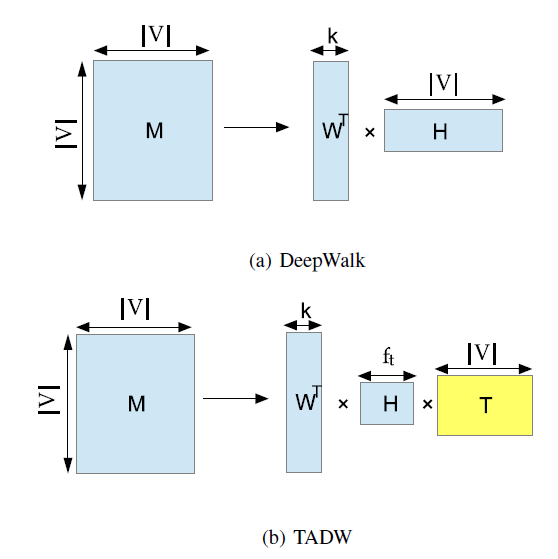
DeepWalk的矩阵分解视角启发了作者将文本信息引入到NRL的MF中。如上图(b)展示了论文方法的主要思想:将矩阵representation。论文在三个数据集上针对多个
baseline测试了TADW算法。当训练集比率training ratio在10% ~ 50%的范围内时,TADW的representation的分类准确率比其它baseline高达2% ~ 10%。当训练集比率小于10%时,论文还使用半监督分类器Transductive SVM: TSVM测试这些方法。TADW在1%的训练集比率下,相比其它baseline方法提升了5% ~ 20%,尤其是在网络信息包含噪音的情况下。论文主要贡献:
论文证明了
DeepWalk算法实际上分解了一个矩阵closed form。论文将文本特征引入
NRL,并相比其它baseline获得了5% ~ 20%的优势,尤其是在训练集比率较小的情况下。
相关工作:
representation learning广泛应用于计算机视觉、自然语言处理、knowledge representation learning。一些研究集中在NRL,但它们都无法泛化来处理顶点的其它特征。据作者所知,很少有工作致力于考虑NRL中的文本信息。有一些主题模型
topic model,如NetPLSA,在主题建模时同时考虑了网络和文本信息,然后可以用主题分布(topic distribution)来表示每个顶点。在本文中,作者以NetPLSA作为baseline方法。
1.1 模型
1.1.1 DeepWalk 作为矩阵分解
公式化
NRL:给定网络representation向量real-valued representation,network representation的稀疏性。我们可以将SVM。注意,representation不是特定于任务(task-specific)的,可以在不同任务之间共享。我们首先介绍
DeepWalk,然后给出DeepWalk和矩阵分解之间的等价证明。
a. DeepWalk
DeepWalk首次将应用广泛的分布式word representation方法SkipGram引入到社交网络的研究中,从而根据网络结构来学习vertex representation。DeepWalk首先生成短的随机游走(short random walk)(短的随机游走也被用作相似性度量)。给定一条由随机游走生成的顶点序列window size) 。遵循SkipGram的思想,DeepWalk旨在最大化随机游走顶点序列vertex-context pair的平均对数概率(average log probability):其中
softmax函数的方式来定义:其中 :
center vertex时的represetation向量。context vertex时的representation向量。
即,每个顶点
representation向量:当center vertex时的context vertex时的之后,
DeepWalk使用SkipGram和Hierarchical Softmax从随机游走生成的序列中学习顶点的representation。注意,Hierarchical Softmax是用于加速的softmax的变体。
b. 等价性证明
假设一个
vertex-context集合vertex-context pairvertex集合为context集合为DeepWalk将一个vertexcontextvertex embedding组成的矩阵,其中第vertex representation。令context embedding组成的矩阵,其中第context representation。我们的目标是找出矩阵closed form,其中现在我们考虑一个
vertex-context pairvertexcontext《Neural word embedding as implicit matrix factorization》已经证明:当维度SkipGram(SkipGram with Negative Sampling: SGNS) 相当于隐式地分解word-context矩阵其中
word-context pair的负样本数量。word-context pairPointwise Mutual Information: PMI的类似地,我们可以证明带
softmax的SkipGram相当于分解矩阵我们现在讨论
DeepWalk中的vertex-context pair的采样方法会影响矩阵connected)和无向 (undirected)的,窗口大小为DeepWalk算法的理想的采样方法来讨论首先我们生成一条足够长的随机游走序列
然后我们将
vertex-context pair
PageRank值。将
PageRank中的转移矩阵表示为degree,则有:我们使用
1之外其它项均为零。假设我们从顶点上述证明也适用于有向图。因此,我们可以看到
通过证明
DeepWalk等价于矩阵分解,我们提出融合丰富的文本信息到基于DeepWalk派生的矩阵分解中。
1.1.2 TADW
这里我们首先简要介绍低秩矩阵分解,然后我们提出从网络和文本信息中学习
representation的方法。
a. 低秩矩阵分解
矩阵是表示关系型数据(
relational data) 的常用方法。矩阵分析的一个有趣主题是通过矩阵的一部分项来找出矩阵的内在结构。一个假设是矩阵complete)矩阵rank constraint optimization)始终是NP难的。因此,研究人员求助于寻找矩阵trace norm constraint)(这个约束可以通过在损失函数中添加一个惩罚项从而进一步地移除)。在本文中,我们使用平方损失函数。低秩分解:形式上,令矩阵
其中
Frobenius范数,归纳矩阵补全:低秩矩阵分解仅基于
item具有附加特征(additional feature),那么我们可以应用归纳矩阵补全(inductive matrix completion)来利用它们。归纳矩阵补全通过融合两个特征矩阵(feature matrix) 到目标函数中从而利用更多行单元(row unit)和列单元(column unit)的信息。假设我们有特征矩阵
注意,归纳矩阵补全最初是为了补全具有基因特征和疾病特征的 “基因-疾病”矩阵,其目标与我们的工作有很大不同。受归纳矩阵补全思想的启发,我们将文本信息引入
NRL。
b. TADW
给定一个网络
DeepWalk(text-associated DeepWalk: TADW)从网络结构representaion。回想一下,
DeepWalk分解矩阵DeepWalk使用基于随机游走的采样方法来避免显式地、精确地计算矩阵DeepWalk采样更多的随机游走序列时,性能会更好,但是计算效率会更低。在
TADW中,我们找到了速度和准确性之间的tradeoff:分解矩阵即使是
我们的任务是求解矩阵
为了优化
TADW可能收敛到局部最小值而不是全局最小值,但我们的方法在实践中效果很好,如我们的实验所示。也可以直接应用随机梯度下降法来优化。
不同于低秩矩阵分解(
low-rank matrix factorization)和归纳矩阵补全(inductive matrix completion)(它们聚焦于补全矩阵TADW的目标是结合文本特征从而获得更好的network representation。此外,归纳矩阵补全直接从原始数据中获得矩阵MF风格的DeepWalk的推导中人为地构建矩阵由于从
TADW获得的representation,因此我们可以通过拼接它们为network representation构建一个统一的、representation显著优于将network representation和文本特征(即矩阵复杂度分析:在
TADW中,计算《Large-scale multi-label learning with missing labels》引入的快速过程来求解TADW的优化问题。最小化
nnz(.)为矩阵非零元素的个数。作为比较,传统矩阵分解的复杂度(即低秩矩阵分解的优化问题) 为10次迭代中收敛。未来工作:针对大规模网络数据场景的
TADW在线学习和分布式学习。另外,还可以研究矩阵分解的其它技术,例如matrix co-factorization,从而包含来自其它来源的丰富信息。
1.2 实验
我们使用顶点分类问题来评估
NRL的质量。正式地,我们得到顶点的低维representation作为顶点特征,然后我们的任务是基于顶点特征用标记顶点集合label。机器学习中的许多分类器可以处理这个任务。我们分别选择
SVM和transductive SVM从而进行监督的、半监督的学习和测试。注意,由于representation learning过程忽略了训练集中的顶点label,因此representation learning是无监督的。我们使用三个公开可用的数据集,并使用
representation learning的五种baseline方法来评估TADW。我们从文档之间的链接或引用,以及这些文档的term frequency-inverse document frequency: TF-IDF矩阵(即矩阵representation。数据集:
Cora数据集:包含来自七个类别的2708篇机器学习论文。论文之间的链接代表引用关系,共有5429个链接。每篇文档映射为一个1433维的binary向量,每一位为0/1表示对应的单词是否存在。Citeseer数据集:包含来自六个类别的3312篇公开发表出版物。文档之间的链接代表引用关系,共4732个链接。每篇文档映射为一个3703维的binary向量,每一位为0/1表示对应的单词是否存在。Wiki数据集:包含来自十九个类别的2405篇维基百科文章。文章之间的链接代表超链接,共17981个链接。我们移除了没有任何超链接的文档。每篇文章都用内容单词的TFIDF向量来表示,向量维度为4973维。
Cora和Citeseer数据集从标题、摘要中生成短文本作为文档,并经过停用词处理、低频词处理(过滤文档词频低于10个的单词),并将每个单词转化为one-hot向量。Cora、Citeseer数据集平均每篇文档包含18~32个单词,数据集被认为是有向图。Wiki数据集是长文本,平均每篇文档包含640个单词,数据集被认为是无向图。baseline方法及其配置:TADW:通过SVD分解TFIDF矩阵到200维的文本特征矩阵content-only的baseline。对于
Cora,Citeseer数据集Wiki数据集注意:最终每个顶点的
representation向量的维度为DeepWalk:DeepWalk是一种network-only representation learning方法。我们选择参数为:窗口尺寸Cora,Citeseer数据集维度Wiki数据集维度50 ~200之间选择的性能最佳的维度。我们还通过求解“低秩分解”方程并将
representation从而评估MF-style DeepWalk的性能。结果与DeepWalk相比差不多,因此我们仅报告了原始DeepWalk的性能。pLSA:我们使用PLSA通过将每个顶点视为一个文档来从TF-IDF矩阵训练主题模型。因此,PLSA是content-only baseline方法。PLSA通过EM算法估计文档的主题分布和主题的word分布。我们使用文档的主题分布作为顶点representation。Text Features:使用文本特征矩阵200维representation,这也是一种content-only baseline方法。Naive Combination:直接拼接DeepWalk的embedding向量和文本特征向量。对于Cora,Citeseer数据集这将得到一个300维向量;对于Wiki数据集这将得到一个400维向量。NetPLSA:NetPLSA将文档之间的链接视为网络正则化来学习文档的主题分布,存在链接的文档应该共享相似的主题分布。我们使用网络增强的文档主题分布作为network representation。NetPLSA可以视为一种兼顾网络和文本信息的NRL方法。我们将Cora,Citeseer数据集主题数量设置为160,将Wiki数据集主题数量设置为200。
评估方式:对于监督分类器,我们使用由
Liblinear实现的linear SVM。对于半监督分类器,我们使用SVM-Light实现的transductive SVM。我们对TVSM使用线性核。我们为每个类别训练一个one-vs-rest分类器,并选择linear SVM和transductive SVM中得分最高的类别。我们将顶点的
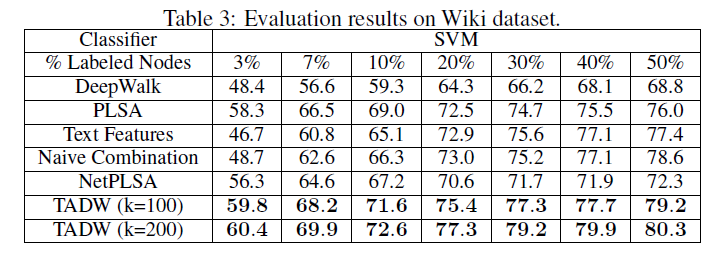
representation作为特征来训练分类器,并以不同的训练比率training ratio来评估分类准确性。训练比率从linear SVM的10% ~ 50%,以及从TSVM的1% ~ 10%不等。对于每个训练比率,我们随机选择文档作为训练集,剩余文档作为测试集。我们重复试验10次并报告平均准确率。实验结果:下表给出了
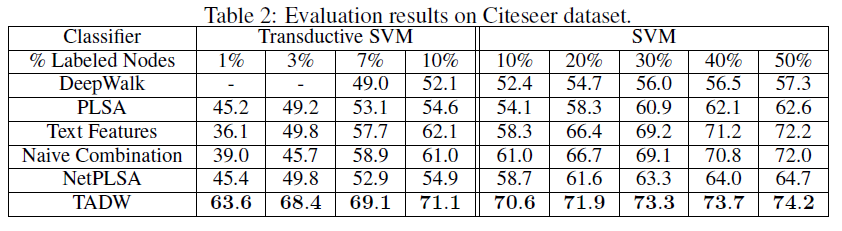
Cora数据集、Citeseer数据集、Wiki数据集的分类准确率。这里-表示TSVM不能在12小时内收敛,因为representation的质量较低(对于TADW,TADM总是可以在5分钟内收敛)。我们没有在Wiki数据集上展示半监督学习的结果,因为监督SVM已经在这个数据集上以较小的训练比率获得了有竞争力的、甚至更好的性能。因此,我们仅报告Wiki数据集的有监督SVM的结果。Wiki数据集的类别要比其它两个数据集多得多,这需要更多的数据来进行足够的训练,因此我们将最小训练比率设为3%。从这些表中我们可以看到:
TADW在所有三个数据集上始终优于所有其它baseline。此外,TADW可以在Cora数据集和Citeseer数据集上减少50%的训练数据从而击败其它baseline。这些实验证明TADW是有效且鲁棒的。TADW对于半监督学习有更显著的提升。TADW的表现优于最佳的baseline(即naive combination),在Cora数据集上提升4%、在Citeseer数据集上提升10% ~ 20%。这是因为在Citeseer上的network representation质量很差,而TADW从噪音的数据中学习比naive combination更鲁棒。TADW在训练比率较小时有更好的表现。大多数baseline的准确率随着训练比率的降低而迅速下降,因为它们的vertex representation对于training和testing而言非常noisy和inconsistent。相反,由于TADW从网络和文本信息中联合学习representation,因此representation具有更少的噪音并且更加一致。
这些观察结果证明了
TADW生成的高质量representation。此外,TADW不是task-specific的,representation可以方便地用于不同的任务,例如链接预测、相似性计算、顶点分类等等。TADW的分类准确性也与最近的几种collective分类算法相媲美,尽管我们在学习representation时没有对任务执行特别的优化。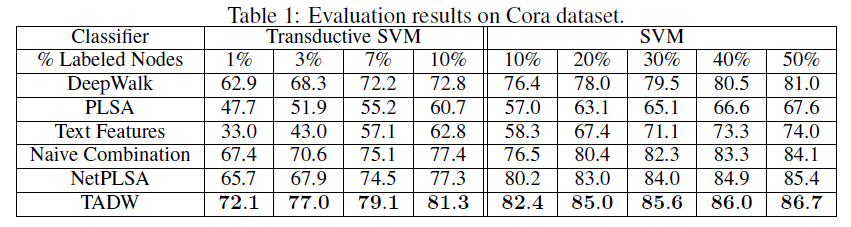
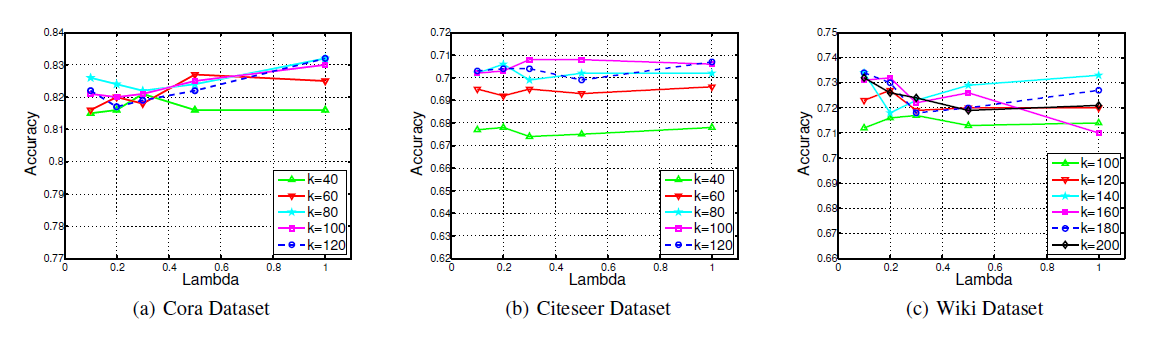
参数敏感性:
TADW有两个超参数:维度10%,并使用不同的Cora数据集和Citeseer数据集,我们让40 ~ 120之间变化,而0.1 ~ 1之间变化。对于Wiki数据集,我们让100 ~ 200之间变化,而0.1 ~ 1之间变化。下图显示了不同可以看到:
对于
Cora, Citeseer, Wiki上的固定1.5%, 1%, 2%的波动范围内。当
Cora和Citeseer上的Wiki上的competitive。因此,当TADW可以保持稳定。
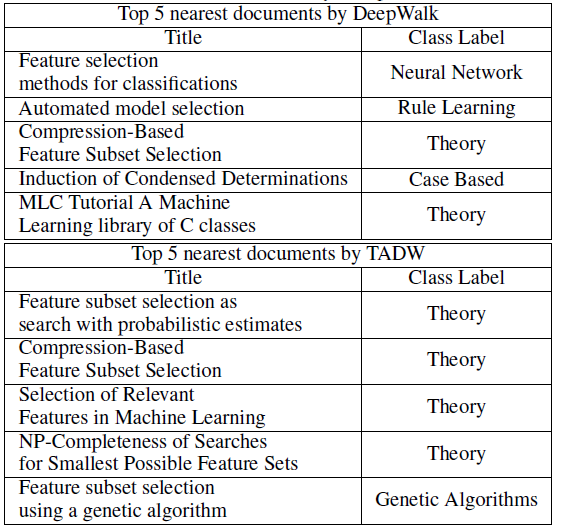
案例研究:为了更好地理解
NRL文本信息的有效性,我们在Cora数据集中提供了一个案例。document标题为Irrelevant Features and the Subset Selection Problem(不相关特征和子集选择问题)。我们将这篇论文简称为IFSSP。IFSSP的类别标签为Theory。如下表所示,使用DeepWalk和TADW生成的representation,我们找到了5篇最相似的论文,并基于余弦相似度来排序。我们发现,所有这些论文都被
IFSSP引用。然而,DeepWalk发现的5篇论文中有3篇具有不同的类别标签,而TADW发现的前4篇论文具有相同的类别标签Theory。这表明:与单纯的基于网络的DeepWalk相比,TADW可以借助文本信息学到更好的network representation。DeepWalk发现的第5篇论文也展示了仅考虑网络信息的另一个限制。《MLC Tutorial A Machine Learning library of C classes》(简称MLC)是一个描述通用toolbox的论文,可以被不同主题的许多论文引用。一旦其中一些论文也引用了IFSSP,DeepWalk将倾向于给IFSSP一个与MLC类似的representation,即使它们具有完全不同的主题。