一、AANE [2017]
《Accelerated Attributed Network Embedding》
网络分析已经成为许多实际应用中的有效工具,例如精准营销 (
targeted marketing) 和基因分析。识别有效特征对于这些任务至关重要,但是这涉及大量的人力和大规模的工程实验。作为替代方案,network embedding将每个节点的拓扑结构(topological structure)映射为低维的向量represetnation,从而可以很好地保留原始网络邻近性(proximity) 。已有工作表明,network embedding可以使各种任务收益,例如节点分类、链接预测、网络聚类。虽然现有的
network embedding算法专注于纯网络 (pure network),但是现实世界网络中的节点通常关联一组丰富的特征或属性,这称作属性网络(attributed network) 。像同质性(homophily) 和社交影响 (social influence) 等社会科学理论表明:节点属性与网络结构高度相关,即一方的形成取决于并影响了另一方。例如,微博中用户帖子和“关注” 关系之间的强关联,论文主题和引用关系的高度相关性。在各种应用中,已有工作表明联合利用这两个信息源(即节点拓扑结构和节点属性)可以提高学习性能。受到这些的启发,论文《Accelerated Attributed Network Embedding》提出研究节点特征是否可能有助于学到更好的embedding representation。此外,现实世界的网络通常是大规模的,具有大量节点和高维特征。例如,截至
2016年,美国每月有超过6500万活跃的Twitter用户,每个用户可以发布数千条推文。这对embedding算法的可扩展性提出了更高的要求。属性网络embedding在以下三个方面具有挑战性:高的时间复杂度可能是限制算法在实践中应用的瓶颈。一些工作致力于利用网络结构和属性信息来寻找低秩(
low-rank)的潜在representation。它们要么在每次迭代中需要具有eigen-decomposition)(其中由于异质信息(
heterogeneous information)的各种组合,在网络和属性的联合空间中评估节点邻近性(node proximity)具有挑战性。另外,随着网络规模的扩大,节点属性邻近性(node attribute proximity) 矩阵往往太大,无法存储在单机上,更不用说对它的操作了。因此,如果embedding算法也是可扩展的,那么将很有吸引力。两个信息源都可能不完整(
incomplete) 的且充满噪音 (noisy)的,这进一步加剧了embedding representation learning问题。
因此,鉴于数据的独有特性,现有方法不能直接应用于可扩展的、属性网络的
embedding。为了应对上述挑战,论文研究了在属性网络上有效地学习embedding representation的问题。论文旨在回答以下问题:如何在网络结构和节点属性组成的联合空间中有效地建模节点邻近性?
如何使
vector representations learning过程具有可扩展性(scalable)和高效 (efficient) ?
通过调研这些问题,论文提出了一个称作
Accelerated Attributed Network Embedding: AANE的新框架。总之,本文贡献如下:正式定义属性网络
embeding问题。提出一个可扩展的、高效的框架
AANE。AANE通过将节点属性邻近性纳入network embedding,从而学到有效的、统一的embedding representation。提出一种分布式优化算法。该算法将复杂的建模和优化问题分解为许多低复杂度的子问题,使得
AANE能够高效地处理每个节点。在三个真实数据集上验证了
AANE的效率和效果。
相关工作:
network embedding已经成为处理大规模网络的有效工具。人们已经从各个方面进行了努力。《Scalable learning of collective behavior based on sparse social dimensions》提出了一种edge-centric的聚类方案,从而提高学习效率并减轻内存需求。《Distributed large-scale natural graph factorization》提出了一种基于随机梯度下降的分布式矩阵分解算法来分解大规模图。《LINE: Large scale Information Network Embedding》通过将weighted edge展开(unfolding)为多个binary edge来提高随机梯度下降的效率。《Asymmetric transitivity preserving graph embedding》设计了一种Jacobi-Davidson类型的算法来近似和加速high-order proximity embedding中的奇异值分解。《Structural deep network embedding》涉及深度架构从而有效地嵌入节点的一阶邻近性和二阶邻近性。
人们已经研究并分析了各个领域中的属性网络,并表明:通过联合利用几何结构和节点属性来提高学习性能变得越来越有希望。
《What's in a hashtag? content based prediction of the spread of ideas in microblogging communities》通过利用内容和拓扑特征改善了对思想(ideas)传播的预测。《Exploring context and content links in social media: A latent space method》基于pairwise相似性对内容信息进行建模,并通过学习语义概念semantic concept之间的结构相关性(structural correlation),从而将内容信息与上下文链接一起映射到语义潜在空间中。《Probabilistic latent document network embedding》通过为网络链接和文本内容找到一个联合的低维representation,从而为文档网络提出了一个基于概率的框架。《Heterogeneous network embedding via deep architectures》设计了一种深度学习方法,将丰富的链接信息和内容信息映射到潜在空间,同时捕获跨模态数据之间的相关性。
属性网络分析不同于多视图学习。属性网络的网络结构不止一个视图,其底层属性很复杂,包括连通性(
connectivity)、传递性(transitivity) 、一阶和更高阶的邻近性等等。
1.1 模型
1.1.1 基本概念
设
每条边
定义节点
定义
attributed network embedding为:给定网络embedding向量embedding向量能够同时保留节点的结构邻近关系、节点的属性邻近关系。所有节点的embedding向量构成embedding矩阵
1.1.2 AANE
现实世界属性网络的理想
embedding方法需要满足以下三个要求:首先,它需要能够处理任意类型的边(如,无向/有向边、无权/带权边)。
其次,它需要同时在网络空间和属性空间中都很好地保持节点邻近性。
最后,可扩展性很重要,因为节点的数量
为此,我们开发了一个满足所有要求的、有效的、高效的框架
AANE。这里我们将描述AANE如何以有效的方式联合建模网络结构邻近性和属性邻近性。网络结构建模:为了保持
AANE提出两个假设:首先,假设基于图的映射(
graph-based mapping) 在边上是平滑的,特别是对于节点密集的区域。这符合 “聚类假设”(cluster hypothesis)。其次,具有更相似拓扑结构或由更高权重连接的一对节点更有可能具有相似的
embedding。
为了实现这些目标,我们提出以下损失函数来最小化相连节点之间的
embedding差异:其中
embedding representation,属性邻近性建模:节点的属性信息与网络拓扑结构紧密相关。网络空间中的节点邻近性应该与节点属性空间中的节点邻近性一致。为此,我们研究如何使得
embedding representation受对称矩阵分解(
symmetric matrix factorization)的启发,我们提出使用attribute affinity matrix)embedding representation其中亲和矩阵可以通过节点属性相似性来计算,具体而言这里我们采用余弦相似度。假设节点
计算亲和矩阵的时间复杂度为
top k个节点,从而将时间复杂度和空间复杂度降低到Joint Embedding Representation Learning:现在我们有两个损失函数其中
当
embedding,。因此每个节点都可以是一个孤立的cluster。当
embedding相同(即embedding空间中形成单个cluster。
因此我们可以通过调节
embedding空间中cluster的数量。AANE可以视为带正则化项的矩阵分解,其中将embedding空间中彼此靠近。AANE仅考虑网络结构的一阶邻近性,无法捕获网络结构的高阶邻近性。AANE仅捕获线性关系,未能捕获非线性关系。AANE分别独立地建模网络结构邻近性和节点属性邻近性,并未建模二者之间的交互。
1.1.3 加速算法
AANE的目标函数不仅联合建模网络结构邻近性和节点属性亲和性,而且它还具有特殊的设计, 从而能够更有效地和分布式地优化:separable)的,因此可以重新表述为双凸优化问题 (bi-convex optimization) 。如果我们添加一个副本
则目标函数重写为:
这表明
但是, 对于这
Alternating Direction Method of Multipliers: ADMM)的做法来加速优化过程:将学习过程转换为updating step和一个矩阵updating step。也可以用随机梯度下降法来求解。这里介绍的优化算法需要
现在我们介绍优化过程的细节。我们首先引入增强的拉格朗日函数:
其中
我们可以交替优化
step的更新为:根据偏导数为零,我们解得
这里我们使用
《Efficient and robust feature selection via joint-norms minimization》证明了这种更新规则的单调递减特性。由于每个子问题都是凸的,因此当由于原始问题是一个
bi-convex问题, 因此可以证明我们方法的收敛性,确保算法收敛到一个局部极小值点。这里有几点需要注意:在计算
计算
如果机器内存有限,则也可以不必存储亲和矩阵
其中
为了进行适当的初始化,我们在第一次迭代中将
AANE将优化过程分为updating step分配给worker。当原始残差整体而言,
AANE优化算法有几个不错的特性:首先,它使得
updating step彼此独立。因此,在每次迭代中,global coordination可以将任务并行分配给worker并从这些worker中收集结果,而无需考虑任务顺序。其次,所有
updating step都具有低复杂度。最后,该方法快速收敛到一个合适的解。
AANE优化算法:输入:
图
节点属性矩阵
embedding维度收敛阈值
输出:所有节点的
embedding矩阵步骤:
从属性矩阵
初始化:
计算属性亲和矩阵
迭代,直到残差
计算
分配
worker, 然后更新:对于计算
分配
worker, 然后更新:对于计算
更新
返回
下图说明了
AANE的基本思想:给定一个为了加速优化算法,我们提出了一种分布式优化算法,将原始问题分解为
worker。在最终输出中,节点1和节点3分别分配了相似的向量[0.54, 0.27]和[0.55, 0.28],这表明这两个节点在原始网络和属性的联合空间(joint space)中彼此相似。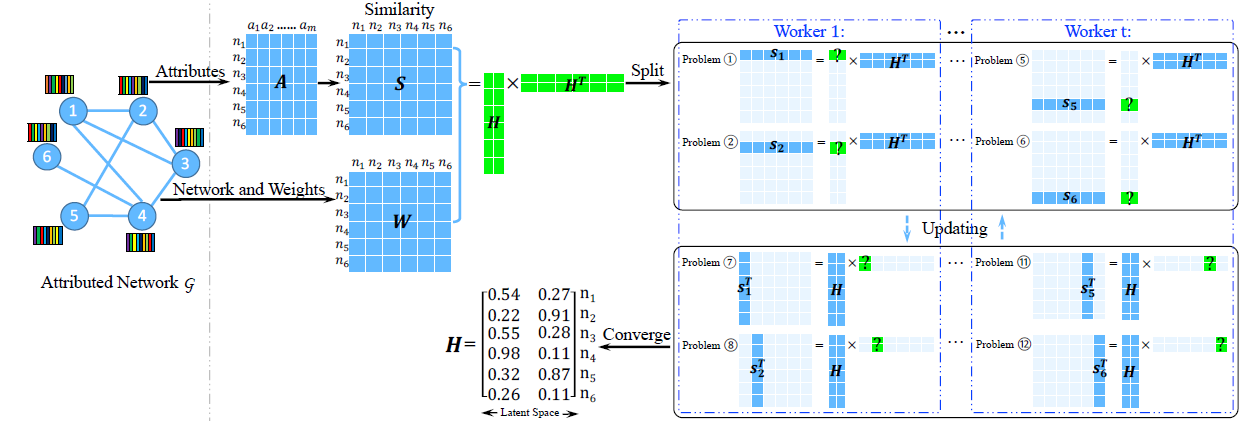
算法复杂度:由于
AANE的优化算法是一个典型的ADMM算法,因此训练算法在迭代很少的几个step之后就能收敛到很高的精度。在初始化步骤,由于需要计算奇异值向量,因此计算复杂度为
在每个子任务过程中,更新
另外,可以验证每个子任务的空间复杂度为
因此
AANE总的时间复杂度为worker数量。AANE的算法复杂度总体而言在
1.2 实验
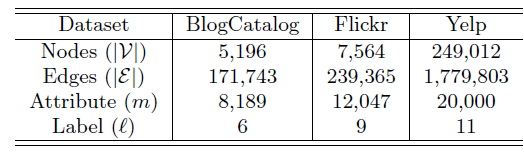
数据集:
BlogCatalog数据集:一个博客社区,用户彼此关注从而构成一个网络。用户可以生成关键词来作为其博客的简短描述,我们将这些关键词作为节点(用户)的属性。用户也可以将其博客注册为指定的类别,我们将这些类别作为用户的label。没有关注或者没有指定类别的用户从网络中剔除。Flickr数据集:一个在线图片共享社区,用户彼此关注从而构成一个网络。用户可以为图片指定tag,我们将这些tag作为节点(用户)的属性。用于可以加入不同的组,我们将这些组作为用户的label。Yelp数据集:一个类似大众点评的本地生活评论网站。我们基于用户的社交关系来构成一个网络。我们从用户的评论中利用bag-of-word抽取文本信息来作为用户的属性信息。所有本地商家分为11个主要类别,如Active Life, Fast Food, Services...,我们将用户所点评的商家的类别作为用户的label。
这些数据集的统计信息如下所示。
baseline模型:为评估节点属性的贡献,我们对比了DeepWalk,LINE,PCA等模型,这些baseline模型仅能处理网络结构或者节点属性,无法处理二者的融合;为了对比AANE的效率和效果,我们对比了其它的两种ANE模型LCMF, MultiSpec。DeepWalk:使用SkipGram学习基于图上的、截断的随机游走序列从而得到图的embedding。LINE:建模图的一阶邻近度和二阶邻近度从而得到图的embedding。PCA:经典的降维技术,它将属性矩阵top d个主成分作为图的embedding。LCMF:它通过对网络结构信息和顶点属性信息进行联合矩阵分解来学习图的embedding。MultiSpec:它将网络结构和顶点属性视为两个视图 (view) ,然后在两个视图之间执行co-regularizing spectral clustering来学习图的embedding。
实验配置:在所有实验中,我们首先在图上学习顶点的
embedding,然后根据学到的embedding向量作为特征,来训练一个SVM分类模型。分类模型在训练集上训练,然后在测试集上评估Macro-F1和Micro-F1指标。在训练
SVM时,我们使用五折交叉验证。所有的顶点被随机拆分为训练集、测试集,其中训练集和测试集之间的所有边都被移除。考虑到每个顶点可能属于多个类别,因此对每个类别我们训练一个二类SVM分类器。所有模型的
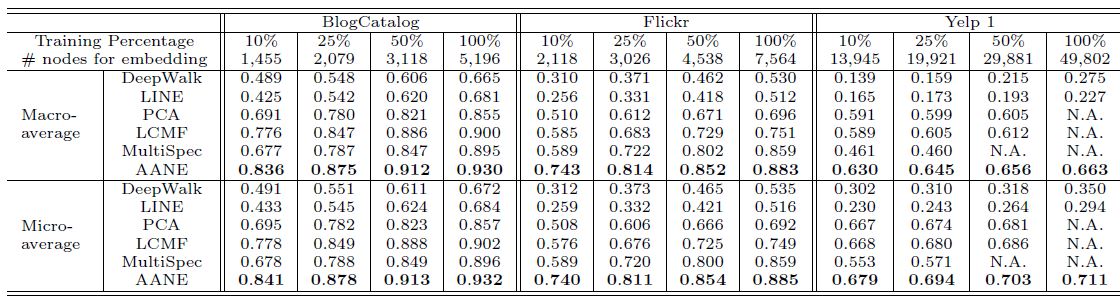
embedding维度设置为10并报告评估指标的均值。属性信息的影响:我们分别将分类训练集的规模设置为
10%,25%,50%,100%。其中,由于Yelp数据集的规模太大,大多数ANE方法的复杂度太高而无法训练,因此我们随机抽取其20%的数据并设置为新的数据集,即Yelp1。所有模型的分类效果如下所示:
所有模型在完整的
Yelp数据集上的分类效果如下所示,其中PCA,LCMF,MultiSpec因为无法扩展到如此大的数据集,因此不参与比较: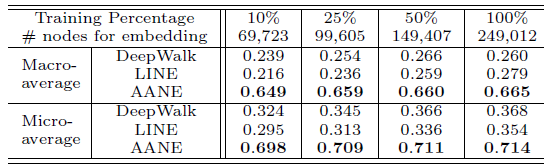
结论:
由于利用了顶点的属性信息,因此
LCMF,MultiSpec,AANE等属性网络embedding方法比DeepWalk,LINE等网络结构embedding方法效果更好。例如,在BlogCatalog数据集上,结合属性信息的AANE在Micro-average得分上比DeepWalk相对提升38.7%、比LINE提升36.3%。我们提出的
AANE始终优于LCMF, MultiSpec方法。例如,在Flickr数据集上,AANE比LCMF相对提升18.2%。这可以解释为通过分解网络矩阵(network matrix)和属性矩阵(attribute matrix)学到的潜在特征是异质的,并且很难将它们直接结合起来。LCMF,MultiSpec方法无法应用于大型数据集。
效率评估:然后我们评估这些方法的训练效率。我们将
AANE和LCMF,MultiSpec这些属性网络embedding方法进行比较。下图给出了这些模型在不同数据集上、不同顶点规模的训练时间。结论:
AANE的训练时间始终比LCMF和MultiSpec更少。随着顶点规模的增加,训练效率之间的
gap也越来越大。AANE可以在多线程环境下进一步提升训练效率。
这种比较意义不大,本质上
AANE是AANE的时间曲线是平行的,也就是相差常数时间。在算法中,相差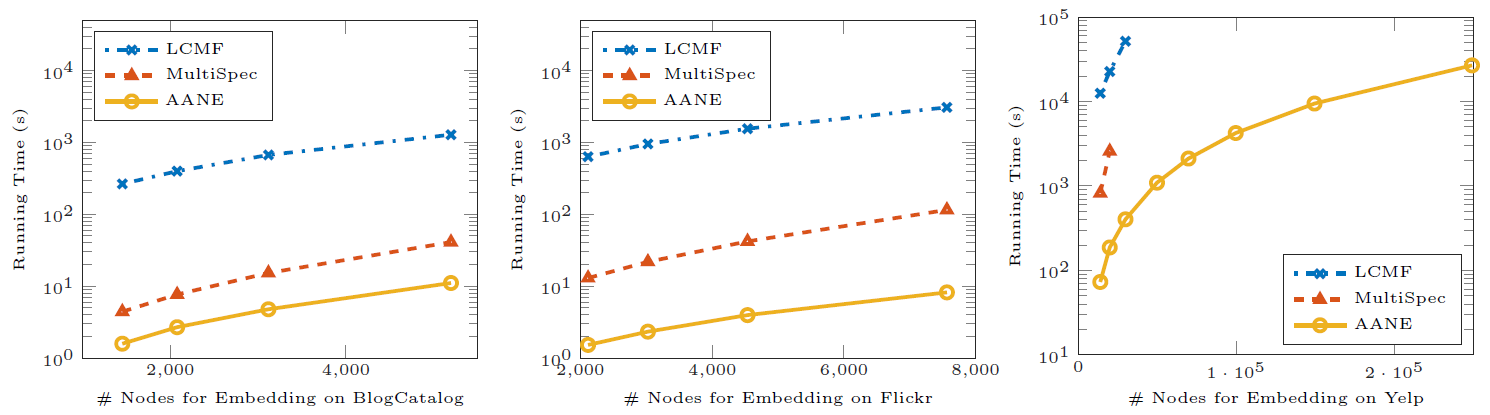
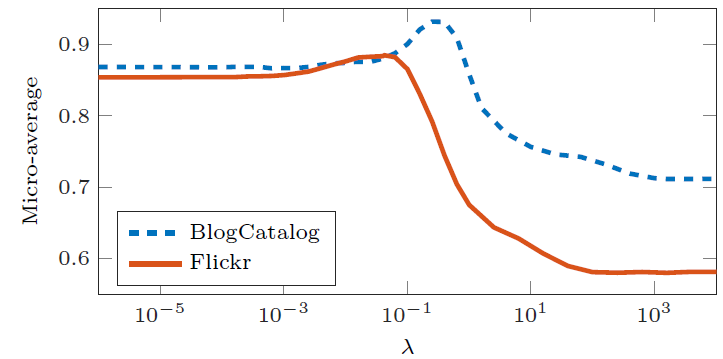
参数敏感性:这里我们研究参数
参数
Micro-F1效果如下所示。当
0时,模型未考虑网络结构信息,就好像所有节点都是孤立的。随着AANE开始根据拓扑结构对节点进行聚类,因此性能不断提升。当
0.1时,模型在BlogCatalog和Flickr上的效果达到最佳。随着embedding。
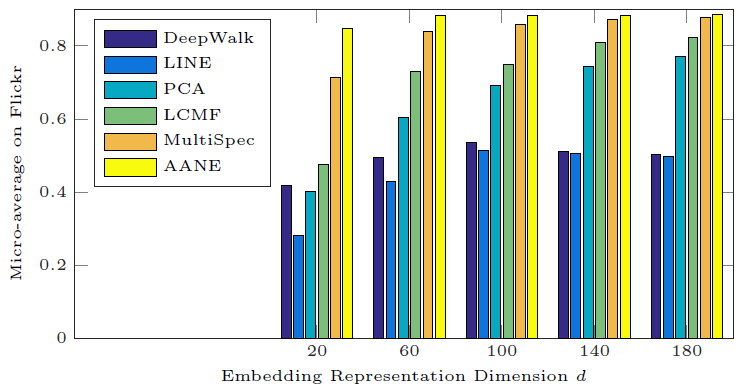
为研究
embedding维度20变化到180,对应的分类Micro-F1效果如下所示。我们仅给出Flickr数据集的结果,BlogCatalog和Yelp的结果也是类似的。可以看到:
无论
DeepWalk和LINE都不如属性网络embedding方法(AANE,LCMF,MultiSpec)无论
AANE的效果始终最佳。当
embedding已经能够捕获大多数有意义的信息。