一、LANE [2017]
《Label Informed Attributed Network Embedding》
属性网络(
attributed network)在各种现实世界的信息系统中无处不在,例如学术网络、医疗保健系统。与仅观测节点之间交互和依赖关系的常规网络不同,属性网络中的每个节点通常关联一组丰富的特征。例如,随着社交网络服务的普及,人们不仅可以结识朋友从而形成在线社区,还可以积极分享意见、发表评论。在社会科学中,人们已经研究了社交影响理论(social influence theory) ,即:个体的属性既可以反映、也可以影响他们的社区结构。此外,许多数据挖掘应用程序(如情感分析、信任预测)都可以受益于几何结构和节点属性之间的相关性。network embedding作为一种高效的图挖掘计算工具,旨在将网络中所有节点的拓扑邻近性(topological proximity) 映射为连续的低维向量representation。学到的embedding representation有助于节点分类、链接预测、网络可视化等众多应用。虽然network embedding已被广泛研究,但是对Attributed Network Embedding: ANE的研究仍处于早期阶段。与从纯网络(pure network)学习的network embedding相比,ANE的目标是利用网络邻近性(proximity) 和节点属性亲和性(affinity)。由于两种信息源的异质性,现有的network embedding算法很难直接应用于ANE。人们在各种现实世界的网络中收集了丰富的
label,如group或者社区类别。例如,在Facebook和Flickr等许多社交网络中,用户被允许加入一些预定义的分组。同组的用户倾向于分享类似主题的帖子或照片,并且组内用户之间也经常互动。引文网络是另一个例子。在同一个研究社区中发表的论文通常具有共同的主题,它们还大量引用来自同一社区的其它论文。这些事实可以用同质性假设(homophily hypothesis)来解释,即,具有相同label的个体通常具有相似的社交关系和相似的节点属性。label受到网络结构和属性信息的强烈影响,并与它们固有地相关。受到这一事实(即,label可能有助于学习更好的联合embedding representation)的启发,而现有方法关注于以无监督的方式学习embedding,论文《Label Informed Attributed Network Embedding》建议研究如何利用label信息并将其整合到ANE中。然而,在属性网络中建模和利用
label是一项困难的任务。有两个主要挑战:首先,属性网络和
label信息可能是稀疏(sparse) 的、不完整(incomplete)的、噪音(noisy)的。例如,在社交网络中,单个用户的好友数量相比总用户量而言总是极少的,特定label的活跃用户的占比也可能很小。其次,鉴于属性网络及其
label的异质性,学习统一的representation具有挑战性。与评论和帖子等属性不同,label将实例划分为不同的分组或社区。很难显式地建模所有这些多模态信息源之间的相关性(correlation) ,并将它们共同嵌入到信息量丰富的embedding representation中。
因此,利用异质的、噪音的信息来相互补充从而获得有效的、鲁棒的
embedding representation是一项具有挑战性的任务。在论文
《Label Informed Attributed Network Embedding》中,作者研究了label informed attributed network embedding的问题,并提出了一个有效的框架LANE。具体而言,论文旨在回答以下问题:如何将
label建模且融合到ANE框架中?label对embedding representation learning的潜在影响是什么?LANE通过利用label对其它学习任务(如节点分类)做出多大贡献?
总之,论文的主要贡献如下:
正式定义
label informed attributed network embedding问题。提出一个新的框架
LANE。LANE可以将label与属性网络关联,并通过建模它们的结构邻近性和相关性,将它们平滑地嵌入到低维representation中。提出一种有效的交替算法来解决
LANE的优化问题。实验评估和验证了
LANE在真实世界属性网络上的有效性。
相关工作:
近年来,
network embedding越来越受欢迎。network embedding的开创性工作可以追溯到graph embedding问题,该问题由《On determining the genus of a graph in O(v^{O(g)}) steps》在1979年作为graph genus determining问题所引入。一系列更通用的
graph embedding方法是在2000年代左右开发的。他们的目标是生成可以对数据的非线性几何进行建模的低维流形(low-dimensional manifold),包括Isomap、Laplacian Eigenmap、谱技术。到目前为止,由于网络数据的普遍性,人们已经实现了各种
network embedding算法。《Probabilistic latent semantic visualization: topic model for visualizing documents》将概率潜在语义分析(probabilistic latent semantic analysis: pLSA)应用于嵌入文档网络。《Community evolution in dynamic multi-mode networks》研究了利用时间信息分析动态多模式网络的优势。《Structure preserving embedding》利用半定程序(semidefinite program)来学习低维representation,从而很好地保留了全局拓扑结构。《Topic modeling with network regularization》设计了一种基于harmonic regularization的embedding框架来解决具有网络结构的主题建模问题。《Distributed large-scale natural graph factorization》提出了一种用于大规模图的异步分布式矩阵分解算法。《Learning social network embeddings for predicting information diffusion》将观察到的时间动态投影到潜在空间中,从而更好地建模网络中的信息扩散。《node2vec: Scalable feature learning for networks》通过增加邻域的灵活性,进一步推进了基于随机游走的embedding算法。为了嵌入异质网络,
《Learning latent representations of nodes for classifying in heterogeneous social networks》将transductive模型和深度学习技术扩展到该问题中。《Revisiting semi-supervised learning with graph embeddings》利用概率模型以半监督方式进行network embedding。
最近,人们提出了几种基于深度学习的
embedding算法,从而进一步提高学习representation的性能。
在众多现实世界网络中,节点往往关联丰富的节点属性信息,因此人们提出了属性网络分析。在这些网络中,人们普遍认为几何结构和节点属性之间存在相关性。因此,同时利用这两者的算法可以提高整体的学习性能。例如,
《What's in a hashtag? content based prediction of the spread of ideas in microblogging communities》通过分析社交图的拓扑和内容,从而推进对思想(ideas)传播的预测。为了解决复杂的数据结构,人们致力于将两个信息源联合嵌入到一个统一的空间中。《Exploring context and content links in social media: A latent space method》探索了一种有效的算法,通过构建语义概念semantic concept的潜在空间,从而联合嵌入社交媒体中的链接和内容。《Probabilistic latent document network embedding》提出一个整体框架来同时处理文档链接和文本信息,并找到一个统一的低维representation。他们通过联合概率模型来实现这一目标。《Unsupervised streaming feature selection in social media》利用流式特征选择框架联合学习高维内容数据和链接信息中的潜在因子的概率。《Heterogeneous network embedding via deep architectures》将内容转换为另一个网络,并利用非线性多层embedding模型来学习构建的内容网络与原始网络之间的复杂交互。
在许多应用中,数据表现出多个方面(
multiple facets),这些数据被称作多视图数据。多视图学习(multi-view learning)旨在从多个信息源中学习统计模型。人们已经提出了许多算法。《A reconstruction error based framework for multi-label and multi-view learning》研究了一种基于重构误差的框架,用于处理multi-label和multi-view学习。该框架可以显式量化多个label或视图的合并的性能。《Pre-trained multi-view word embedding using two-side neural network》应用了一个two-side多模态神经网络来嵌入基于多个数据源的word。
《A survey of multi-view machine learning》对多视图学习给出了更详细的回顾。我们的工作与多视图学习之间的主要区别在于:属性网络可以被视为一个特殊构建的数据源,而且ANE本身就是一个具有挑战性的问题。label也是具有特定形式的特殊数据源。
1.1 模型
1.1.1 基本概念
定义
除了网络结构和节点属性之外,每个节点还关联一组
label。节点的label矩阵为label种类。label向量,label,每个节点可以属于其中某一类label或者某几类label。我们定义
label informed attributed network embedding为:给定属性网络label信息representationlabel信息。我们提出了一种新颖的
informed attributed network embedding: LANE方法。LANE可以建模属性网络空间和label信息空间中的节点邻近性,并将它们联合嵌入到统一的低维representation中。下图说明了LANE的主要思想,图中有一个含有六个节点的属性网络,每个节点都有各自的label。LANE通过两个模块来学习节点的embedding:属性网络嵌入 (Attributed Network Embedding)、标签信息嵌入 (Label Informed Embedding) 。首先,我们将网络结构邻近性和网络节点属性邻近性映射到两个潜在
representation其次,我们利用融合的
label信息,从而统一嵌入到另一个潜在空间最后,我们将所有学到的潜在
representation映射到一个统一的representation
如下图所示,节点
1和节点3的embedding向量分别为[0.54, 0.27]和[0.55, 0.28],这意味着它们在原始空间中具有相似的属性。为了有效地学习节点embedding,我们设计了一种高效的交替优化算法。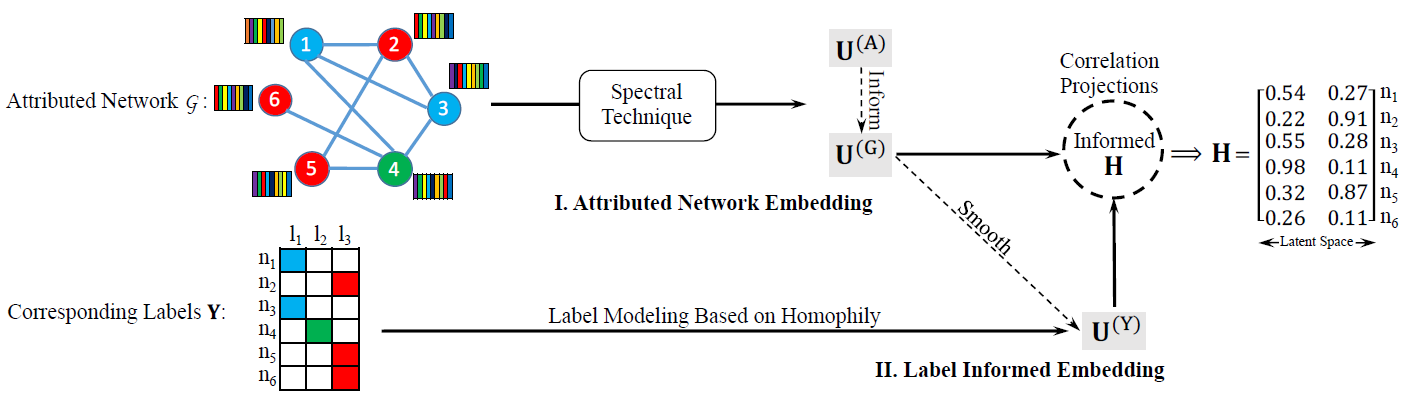
1.1.2 Attributed Network Embedding: ANE
Attributed Network Embedding模块的目标是寻找两个representation。首先考虑对网络结构进行建模。网络结构建模的核心思想是:如果节点
representation向量representation向量的相似性,其中AANE中采用边权重我们通过
当节点
当
该损失函数无法解决结构不相似但是
embedding都相等。因此论文增加了约束条件考虑所有节点,则我们得到总的不一致程度为:
定义图结构的
pair-wise结构相似性矩阵为这里采用这种归一化形式是为了得到拉普拉斯矩阵的矩阵形式。
则我们的目标函数为:
其中
representation矩阵,其第其中:
我们添加约束
与网络结构建模类似,我们对节点属性邻近性建模过程也是类似的。定义节点属性
pair-wise邻近性矩阵为representation矩阵为定义归一化拉普拉斯矩阵
为了将
这里是通过正则化的方式,迫使结构邻近性和节点属性邻近性产生高度的相关。
为了使得网络结构信息和节点属性信息互补,我们在模型中共同最大化
其中
ANE模块内部网络结构和节点属性的贡献。论文
《Accelerated Attributed Network Embedding》提出的AANE中,我们在
ANE模块基于pair-wise相似性来执行属性网络embedding。这种方法和谱聚类相一致,它有几个优点:对于输入没有很强的假设,即普适性较好,可以推广到很多实际问题。
目标函数可以使用很多图论来解释,如
ratio-cut partitioning、随机游走。可以通过
eigen-decomposition特征值分解很容易求解问题。
1.1.3 Label Informed Embedding: LIE
label信息在确定每个节点内部结构方面起着至关重要的作用,它和网络结构、节点属性有着强烈的、固有的相关性。除了这些强相关性之外,label还可能被纳入前面提到的ANE模块中。然而,label通常是噪音(noisy)的、且不完整(incomplete) 的。直接探索label可能会对最终的embedding产生负面影响。我们提出了一种对label进行建模的方法,并且使用两个步骤来强化embedding representation learning:label information modeling、correlation projection。Label Information Modeling:在这一步中,我们将label邻近性映射到潜在representationembedding来平滑label邻近性,使得当节点具有相同的label时,它们的网络结构、节点属性、以及最终的representation都趋近于相似。具体而言,我们根据
label将节点划分到对应的团(clique) 中,对应的表示形式为label向量的内积。假设每个节点仅属于一个label类别:当节点
clique。当节点
clique。
如果节点可以有多个
label类别,则我们根据
label邻近性来建模。令我们可以参考网络结构邻近性和节点属性邻近性建模,通过矩阵的特征值分解来求解
label信息的特殊结构:为解决该问题,我们利用学到的网络结构邻近性
smooth模型。我们定义以下目标函数使得相同label的节点具有相似的representation:这里假设结构相似的节点可能具有相同的
label。这里没有考虑属性邻近性,主要是为了将label融合到网络结构中。这里是否可以考虑引入一个平衡因子
label信息和属性网络embedding信息,即:embedding也是用网络结构邻近性smooth模型。这种方式有几个优点:
首先,矩阵
其次,联合的邻近性融合了更多的信息,这使得
label信息与网络结构、节点属性等信息相一致。另外第二项
label邻近性学习,因为label和节点结构、节点属性是高度相关的。最后,学到的潜在
representationlabel空间中大部分信息可被恢复。
因此,尽管
label信息可能是不完整的、且噪音的,但我们仍然能够捕获label空间中的节点邻近性。Correlation Projection:现在我们已经得到了属性网络embeddinglabel信息embeddingembedding我们将这些
embedding都投影到新的embedding空间则投影的目标函数定义为:
其中
embedding。这里通过相关性最大,从而从三个潜在
embedding中得到统一的embedding
1.1.4 联合学习
现在我们考虑所有的
embedding,以及所有的相关性。我们定义两个参数来平衡不同度量的重要性从而得到LANE的目标函数:其中:
ANE模块内部网络结构和节点属性的贡献,ANE模块和LIE模块的贡献。通过求解
embedding representation learning和correlation projection高度相关。通过这种方式,label邻近性,以及它们之间的相关性。优化算法:目标函数有四个矩阵变量需要优化,因此无法得到闭式解。这里我们采用一种交替优化算法来逼近最优解。基本思想是:每轮迭代时固定其中三个变量而求解另外一个变量的局部最优解。当固定其中三个变量时,目标函数就是剩下变量的凸函数。
考虑
其中
当
则
top类似地,最大化
top由于每个
updating step都是求解凸优化问题,因此可以保证收敛到局部最优解。我们从主要的信息源的
representationLANE训练算法:输入:
异质网络
label信息矩阵embedding维度收敛阈值
输出:节点的
embedding矩阵步骤:
构建结构邻近度矩阵
label邻近度矩阵计算拉普拉斯矩阵
初始化:
迭代,直到
通过求解下式来更新
通过求解下式来更新
通过求解下式来更新
通过求解下式来更新
算法复杂度:
LANE框架在收敛之前只需要进行少量的迭代,在每轮迭代过程中都需要进行四个特征值分解。为计算top d个特征向量,类似于Lanczos方法的特征值分解方法最坏情况需要令
LANE的总的时间复杂度为spectral embedding的计算复杂度相同。由于LANE总的时间复杂度为另外,可以很容易得到
LANE的空间复杂度为这种复杂度对于大型网络而言是不可行的。
在某些网络中节点属性或者节点
label可能不可用。如,当移动通信公司希望分析客户网络以便提供更好的服务时,他们只能收集到通讯网络及其部分label信息,通讯内容、用户偏好之类的属性不可用。LANE也能够处理这类场景,其中节点属性或节点label之一发生缺失,或者二者全部缺失。我们以
label信息缺失为例,此时label信息建模)、label邻近性和其中
LANE的这种变体我们称作LANE_w/o_LABEL,其求解方法也类似于上述交替优化算法。
1.2 实验
数据集:
BlogCatalog数据集:一个博客社区,用户彼此关注从而构成一个网络。用户可以生成关键词来作为其博客的简短描述,我们将这些关键词作为节点(用户)的属性。用户也可以将其博客注册为指定的类别,我们将这些类别作为用户的label。Flickr数据集:一个在线图片共享社区,用户彼此关注从而构成一个网络。用户可以为图片指定tag,我们将这些tag作为节点(用户)的属性。用于可以加入不同的组,我们将这些组作为用户的label。

Baseline模型可以分为四类:首先,为评估
embedding的效果,我们使用原始特征作为baseline。然后,为评估节点属性的贡献,我们考虑三种仅嵌入网络结构的方法,包括
DeepWalk,LINE, LANE_on_Net。接着,为评估
label信息的贡献,我们考虑两种ANE方法,包括LCMF和LANE_w/o_Label。最后,为评估
LANE的效果,我们考虑SpecComb和MultiView方法。
具体描述如下:
Original Features原始特征:将原始网络结构特征、原始节点属性特征直接拼接,从而作为节点特征。DeepWalk:使用SkipGram学习基于图上的、截断的随机游走序列从而得到图的embedding。LINE:建模图的一阶邻近度和二阶邻近度从而得到图的embedding。LCMF:它通过对网络结构信息和节点属性信息进行联合矩阵分解来学习图的embedding。SpecComb:将属性网络labelnormalized spectral embedding)。最后选择top d的特征向量作为embedding。MultiView:将网络结构、节点属性、节点label视为三个视图,并在它们上共同应用正则化的谱聚类(spectral clustering) 。LANE_on_NET和LANE_W/o_LABEL:是LANE的两个变种。LANE_on_NET仅对单纯的网络结构建模,LANE_W/o_LABEL对网络结构和节点属性建模(没有节点label信息)。
实验配置:我们验证不同算法学到的
embedding对节点分类任务的有效性。我们使用五折交叉验证,并随机将数据集划分为训练集和测试集。其中,训练集不包含任何测试集的信息(训练期间测试节点是unseen的),但是测试集包含测试节点到任何其它节点的链接信息。我们首先在训练集上学到节点的
embedding,然后在训练集上训练一个SVM分类器,分类器的输入为节点的embedding、输出为节点的label类别。然后,为了得到测试集的embedding,我们首先构造两个线性映射函数embedding空间这相当于是根据
unseen节点的为简单起见这里我们使用线性映射,也可以使用其它非线性映射函数。我们并没有根据测试集来训练
embedding,因为这会泄露测试集的label信息embedding向量为:其中:
最后我们基于测试集的
embedding和训练集学到的SVM分类器来对测试集进行分类,并报告分类的F1指标。每种配置都随机执行10次并报告指标的均值。对于所有方法,
embedding维度为Baseline方法的其它超参数都使用原始论文中的超参数,LANE方法的超参数通过grid search搜索到合适的值。为证明
embedding的有效性,我们将LANE及其变体与原始特征进行比较。其中BlogCatalog数据集的原始特征为12346维、Flickr数据集的原始特征为18107维。实验中,我们将embedding维度从5增加到100。我们给出了Flickr数据集上不同BlogCatalog数据集,因为结果也类似。结论:
当
18107时,LANE_w/o_Label可以达到和原始特征相近的分类能力。当
18107时,LANE可以达到和原始特征相近的分类能力。LANE_on_Net比原始特征效果更差,这是因为它仅包含网络结构信息。
因此,通过利用
embedding representation learning,LANE实现了比原始特征更好的性能。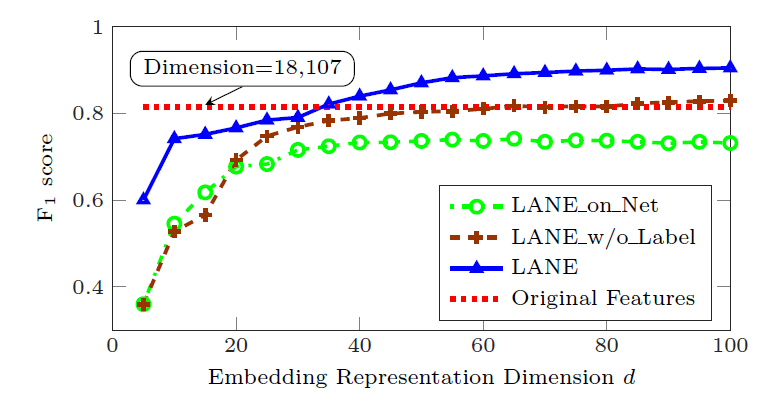
为研究
LANE的有效性,我们对比了所有的Baseline模型。我们固定结论:
所有情况下,
LANE总是优于Baseline模型。当训练数据规模从
100%时,LANE的性能持续改善,但增长的幅度变小。
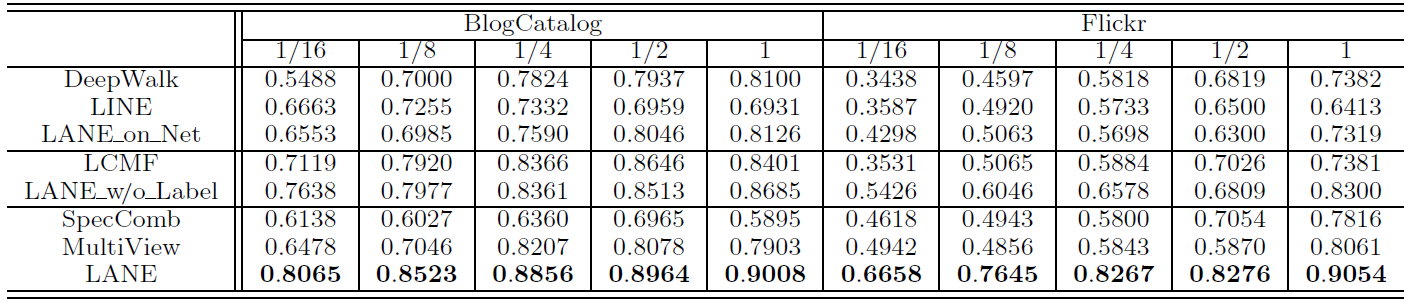
为评估
label信息对于embedding的影响,我们分析上表中的数据。与单纯的网络结构
embedding方法(DeepWalk, LINE, LANE_on_Net)相比,使用了节点属性信息的LANE_w/o_Label的效果更好。但是利用了label信息之后,LANE进一步超越了LANE_w/o_Label。这证明了将label信息融合到embedding中的优势。另外
LANE也超过了属性网络embedding方法LCMF,这进一步证明了label信息的优势。通过
LANE和SpecComb/MultiView的比较发现,SpecComb/MultiView的效果始终不如LANE,甚至比单纯的网络结构embedding方法(如DeepWalk)更差。这是因为:SpecComb没有明确考虑固有的相关性,并且直接拼接异质信息并不是组合异质信息的合适方法。MultiView会平等对待网络结构、节点属性、label信息,这也不是融合这些异质信息的好方法。
所有这些观察结果表明:
属性网络和
label之间确实存在很强的相关性。label信息确实可以帮助我们获得更好的embedding representation。如何融合
label信息需要一种合适的方法。
LINE通过执行label informed embedding成功地实现了这一提升,并始终优于所有baseline方法。我们要强调的是:在节点分类任务中,所有方法都可以访问训练集中的label,并以不同的方式利用label信息。只有LANE, SpecComb, MultiView可以将这些label合并到embedding representation learning中。因此,LANE的优势不是拥有额外的信息源,而是执行label informed embedding的结果。超参数
label信息的贡献。我们同时将它们从0.01增加到100。Flickr数据集上的指标如下,BlogCatalog也有类似结果因此省略。结论:
当属性网络和
label信息都具有足够的贡献时,即LANE会实现相对较高的性能。当
当固定
0.01变化到100时,模型性能提升了42.7%;当固定0.01变化到100时,模型性能提升了16.07%。这表明label信息对于LANE的影响大于属性网络。因为在相同范围内取值时,模型性能随
label信息的影响更大。
总之,通过配置合理的参数,
LANE可以实现相对较高的性能。同时,label信息在embedding过程中非常重要。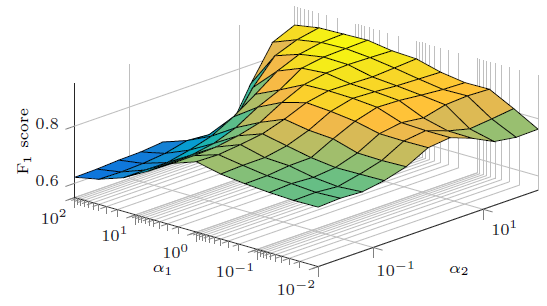
我们将
20变化到180来研究分类性能的影响。。在Flickr数据集上不同方法的效果和d的关系如下图,BlogCatalog也有类似结果因此省略。结论:
当
LANE始终比所有基准方法效果更好。增加
LANE的分类性能首先提高,然后保持稳定。这在实际应用中很有吸引力,因为人们可以在大范围内安全地调整超参数
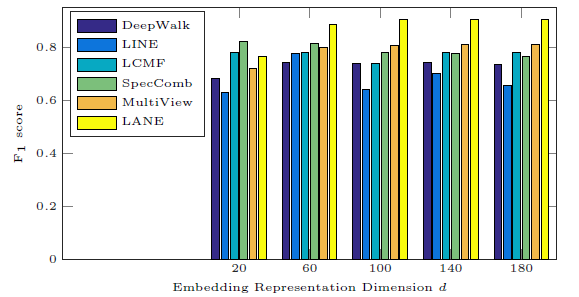
最后我们比较
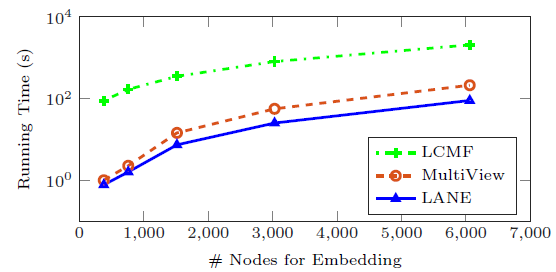
LANE和两种属性网络ANE方法(LCMF和MultiView)的运行时间。我们在Flickr数据集上观察输入节点数量和训练时间(对数表示)的关系,BlogCatalog也有类似结果因此省略。结论:
LANE的运行时间最少。原因是:LCMF基于随机梯度下降来优化,这通常收敛速度很慢。MultiView具有和LANE相同的时间复杂度,但经验表明LANE可以在这两个数据集上仅使用几个迭代就能收敛。因此这证明了LANE的计算效率。