一、SNE [2018]
《Attributed Social Network Embedding》
社交网络是一类重要的网络,涵盖各种媒体,包括
Facebook和Twitter等社交网站、学术论文的引文网络、移动通信的caller–callee网络等等。许多application需要从社交网络中挖掘有用的信息。例如,内容供应商(content provider)需要将用户分组从而用于定向广告投放 (targeted advertising),推荐系统需要估计用户对item的偏好从而进行个性化推荐。为了将通用机器学习技术应用于网络结构化数据,学习有信息量(informative)的node representation是有必要的。最近,人们对
representation learning的研究兴趣已经从自然语言扩展到网络数据。人们已经提出了许多network embedding方法,并在各种application中展示出有前景的性能。然而,现有的方法主要集中在通用网络上,并且仅利用结构信息。对于社交网络,论文《Attributed Social Network Embeddin》指出:除了链接结构之外,几乎总是存在关于社交参与者(social actor) 的丰富信息。例如,社交网站上的用户可能拥有年龄、性别、文本评论等画像信息。我们将所有此类辅助信息称为属性(attribute),这些辅助信息不仅包含人口统计学数据,还包括其它信息如附属文本、可能存在的标签等等。社交参与者的这些丰富的属性信息揭示了同质效应 (homophily effect),该效应对社交网络的形成产生了巨大的影响。本质上,属性对社交网络的组织产生巨大的影响。许多研究证明了属性的重要性,从客观的人口统计学数据,到主观的政治取向和个人兴趣等偏好数据。为了说明这一点,我们从三个视图绘制了
Facebook数据集的user-user友谊矩阵。每一行或每一列代表一个用户,一个彩色点表示对应的用户是好友关系。每个视图是用户按照“年级” (class year) 、“专业” (major)、“宿舍” (dormitory)等特定属性重新排序的结果。例如,图(a)首先按照 “年级” 属性对用户进行分组,然后按照时间顺序对 “年级” 进行排序。可以看到,每个视图中都存在清晰的块状结构(block structure),其中块内的用户的连接更紧密。每个块结构实际上都指向相同属性的用户,例如,图(a)的右下角对应于2009年毕业的用户。这个现实世界的例子支持了属性同质性 (attribute homophily)的重要性。通过共同考虑属性同质性和网络结构,我们相信可以学到更有信息量的node representation。此外,通过利用辅助的属性信息,可以很大程度上缓解链接稀疏 (link sparsity)和冷启动 (cold-start)问题。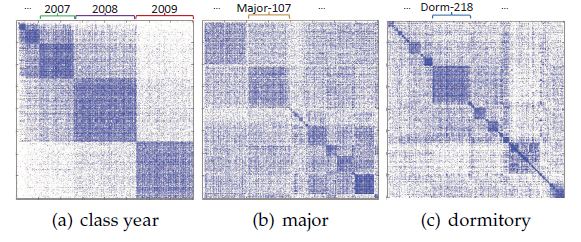
在论文
《Attributed Social Network Embedding》中,作者提出了一个叫做SNE的神经网络框架,用于从社交网络数据中学习node representation。SNE是使用实值特征向量的通用machine learner,其中每个特征表示节点的ID(用于学习网络结构)或一个属性。通过这种方式,我们可以轻松地集成任何类型和数量的属性。在论文的SNE框架下,每个特征都关联一个embedding,节点的final embedding是从节点的ID embedding(保持结构邻近性structural proximity)和属性embedding(保持属性邻近性attribute proximity)聚合而成。为了捕获特征之间的复杂交互,论文采用多层神经网络来利用深度学习的强大的representation和generalization能力。总之,论文贡献如下:
论文证明了集成网络结构和属性对于学习更有信息量的社交网络
node representation的重要性。论文提出了一个通用框架
SNE,该框架通过保持社交网络的结构邻近性和属性邻近性来执行社交网络embedding。论文对四个数据集进行了广泛的实验,其中包括链接预测、节点分类这两个任务。实验结果和案例研究证明了
SNE的效果和合理性。
相关工作:这里我们简要总结了关于属性同质性 (
attribute homophily)的研究,然后我们讨论与我们的工作密切相关的network embedding方法。社交网络中的属性同质性:社交网络属于一类特殊的网络,其中社交关系的形成不仅涉及自组织的网络过程(
self-organizing network process) ,还涉及基于属性的过程 (attribute-based process) 。在embedding过程中考虑属性邻近性的动机源自属性同质性的巨大影响,其中属性邻近性在基于属性的过程中起着重要作用。因此,我们在这里对同质性研究进行简要概述。一般而言,“同质性原则” (
homophily principle)(即,“物以类聚,人以群分”)是社交生活中最引人注目和最强大的经验规律之一。相似的人倾向于成为好友的假设至少可以追溯到上世纪
70年代。在社会科学中,人们普遍预期:个体与大约同龄的其他人建立好友关系(《“Friendships and friendly relations》)。在
《Homophily in voluntary organizations: Status distance and the composition of face-to-face groups》中,作者研究了群体的同质构成 (homogeneous composition) 和同质性涌现 (the emergence of homophily)的相互联系。在
《Homophily in online dating: when do you like someone like yourself?》中,作者试图找出同质性在用户做出的在线约会选择中的作用。他们发现,在线约会系统的在线用户寻找像他们一样的人的频率要比系统预测的要高得多,就像在离线世界中一样。近年来,
《Origins of homophily in an evolving social network》调查了大型大学社区中同质性的起源,该论文记录了随着时间推移的交互(interaction) 、属性(attribute)、以及附属关系 (affiliation)。
毫不奇怪,人们已经得出结论,除了结构邻近性之外,属性相似性的偏好也为社交网络的形成过程提供了一个重要因素。因此,为了获得更多关于社交网络的、有信息量的
representation,我们应该考虑属性信息。network embedding:一些早期的工作,例如局部线性嵌入(Local Linear Embedding: LLE)、IsoMap、Laplacian Eigenmap首先将数据转换为基于节点的特征向量的亲和图 (affinity graph)(例如节点的k近邻),然后通过求解亲和矩阵(affinity matrix)的top-n的eigenvector来嵌入graph。最近的工作更侧重于将现有网络嵌入到低维向量空间中,从而帮助进一步的网络分析并实现比早期工作更好的性能。
在
《Deepwalk: Online learning of social representations》中,作者在网络上部署了截断的随机游走来生成节点序列。生成的节点序列在语言模型中被视为句子,并馈送到SkipGram模型来学习node mebdding。在
《node2vec: Scalable feature learning for networks》中,作者通过平衡广度优先采样和深度优先采样,从而改变了生成节点序列的方式,最终实现了性能的提升。《Line: Large-scale information network embedding》没有在网络上随机游走,而是提出了显式的目标函数来保持节点的一阶邻近性和二阶邻近性。《Structural deep network embedding》也没有在网络上随机游走,并且引入了具有多层非线性函数的深度模型来捕获高度非线性的网络结构。
然而,所有这些方法都只利用了网络结构。在社交网络中,存在大量的属性信息。单纯基于结构的方法无法捕获这些有价值的信息,因此可能会导致信息量少的
embedding。此外,当发生链接稀疏问题时,这些方法很容易受到影响。最近的一些工作探索了集成内容从而学习更好的representation的可能性。例如,
TADW提出了关联文本的DeepWalk,从而将文本特征融合到矩阵分解框架中。但是,TADW仅能处理文本属性。面对同样的问题,
TriDNR提出从基于结构的DeepWalk和label-fused的Doc2Vec模型中分别学习embedding,学到的embedding以iterative的方式线性组合在一起。在这样的方案下,两个独立模型之间的知识交互(knowledge interaction)只经过一系列的加权和运算,并且缺乏进一步的收敛约束(convergence constrain) 。相比之下,我们的方法以端到端的方式同时建模结构邻近性和属性邻近性,并且没有这些限制。此外,通过早期融合结构模型和属性模型,这两部分将相互补充从而产生足够好的知识交互。
也有工作致力于探索用于
network embedding的半监督学习。《Deep learning via semi-supervised embedding》将基于embedding的正则化器与监督学习器结合起来,从而集成了标签信息。《Revisiting semi-supervised learning with graph embeddings》没有强迫正则化,而是使用embedding来预测graph中的context,并利用标签信息来构建transductive公式和inductive公式。在我们的框架中,标签信息可用的时候可以通过类似的方式融合。我们将这种扩展作为未来的工作,因为我们的工作聚焦于network embedding的属性建模。
1.1 模型
1.1.1 基本概念
定义社交网络
每条边
社交网络
embedding的目的是将节点映射到低维向量空间中。由于网络结构和节点属性提供了不同的信息源,因此关键是要同时捕获这两者。如下图所示,数字代表节点编号,相同的颜色代表相同的属性。基于网络结构
embedding的方法通常假设连接紧密的节点在embedding空间中彼此靠近。如,computer science。尽管要学到用户的更有信息量的
representation,必须捕获属性信息。在这项工作中,我们努力开发embedding方法从而同时保持社交网络的结构邻近性和属性邻近性。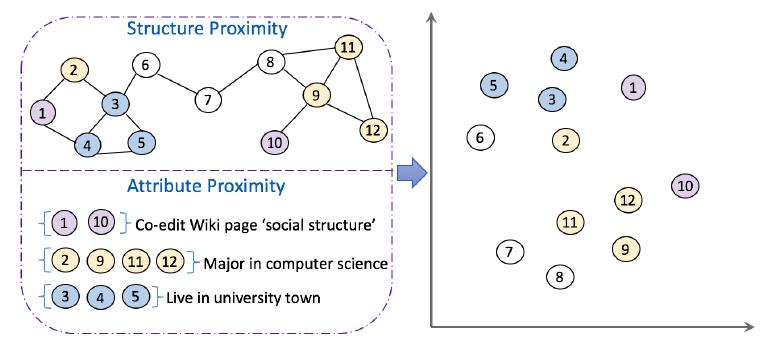
我们首先定义结构邻近性和属性邻近性:
结构邻近性(
Structural Proximity):以网络链接关系表示的节点邻近性。对于节点node2vec的随机游走策略。属性邻近性 (
Attribute Proximity):以属性表示的节点邻近性。对于节点embedding空间中彼此靠近。这里假设用户属性特征都是离散型的(如果有连续型属性则可以离散化)。
1.1.2 SNE 模型
结构建模(
Structure Modeling) :根据结构邻近性的定义,网络结构建模的关键在于定义节点的pairwise邻近性。令
令节点
通过最大化所有节点上的这种条件概率,我们可以实现保持网络结构邻近性的目标。具体而言,我们建模全局网络结构的目标函数为:
建立了学习的目标函数之后,现在我们需要设计一个
embedding模型来估计pairwise邻近性函数embedding向量的内积。但是,众所周知,简单地将embedding向量内积会限制模型的表达能力,并导致较大的ranking loss。为了捕获现实世界网络的复杂非线性,我们建议采用一种深度架构来对节点的pairwise邻近性建模:其中:
embedding向量。context embedding向量。
注意:在我们的方案中,每个节点
embedding表示形式:节点embeddingcontext embeddingembedding,从而作为节点embedding。根据经验,这种方式效果更好。浅层
embedding模型到深层embedding模型是一种很自然的想法。属性编码(
Encoding Attributes) :很多现实世界的社交网络包含丰富的属性信息,这些属性信息可能是异质并且多样化的。为了避免人工特征工程,我们将所有属性转化为通用的feature vector的形式,从而有助于设计一种从属性数据中学习的通用方法。无论属性的语义如何,我们都可以将属性分为两类:离散属性:我们通过
one-hot encoding将离散属性转换为一组binary feature。如:性别属性的取值集合为{male, female},那么对于一位女性用户,我们用female。连续属性:社交网络上自然地存在连续属性,如图像原始特征和音频原始特征。或者也可以通过离散变量人为地转换生成连续属性,如通过
TF-IDF将文档的bag-of-words representation转换为实值向量。另一个例子是历史特征,如用户购买item历史行为特征、用户checkin地点的历史行为特征,它们总是被归一化为实值向量从而减少可变长度的影响。
假设属性特征向量
embedding向量所示。然后我们聚合用户所有的属性特征
embedding:这里没有进行连续特征离散化,而是将连续特征直接嵌入并乘以特征取值。此外,这里直接均值聚合,可以结合
attention机制进行聚合。类似于网络结构建模,节点属性建模的目标是采用深度模型来近似属性之间的复杂的相互作用,从而对属性邻近性建模:
其中
context embedding向量。pair-wise属性邻近性建模从直觉上需要馈入两个节点的内容,但是这里只有一个节点内容和另一个节点的context embedding?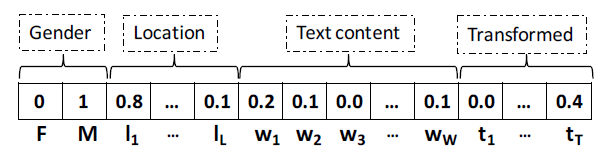
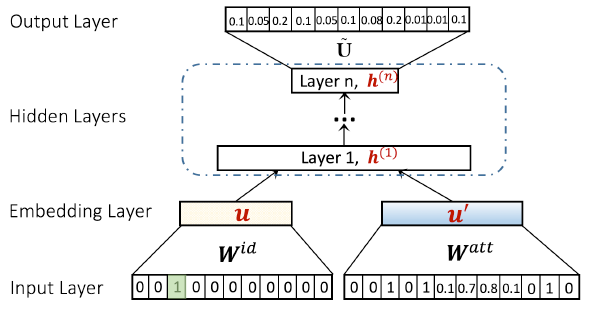
SNE模型:为了结合网络结构建模和节点属性建模,一种直观的方法是:将各自模型学到的embedding拼接起来,即后期融合(late fusion)方案。这种方法的主要缺点是:各个模型在彼此不知道对方的情况下单独训练,训练之后简单地组合各模型的embedding从而得到结果。相反,早期融合(early fusion)方案允许同时优化所有参数,因此属性建模和结构建模相互补充,使得两个部分密切交互。从本质上讲,早期融合方案在端到端深度学习方法中更为可取,因此,我们提出了如下所示的通用社交网络嵌入框架SNE,它通过在输入层之后进行早期融合来集成网络结构建模和节点属性建模。输入层:
网络结构建模的输入层为节点的
one-hot。节点属性建模的输入层为节点的属性特征向量
embedding层:网络结构建模的
embedding层将one-hot映射到捕获了网络结构信息的稠密向量节点属性建模的
embedding层对属性特征向量进行编码,并生成聚合了属性信息的稠密向量
隐层:我们选择了
embedding向量。注意:一种常见的网络架构设计是使用塔式结构,即每层的神经元数量从底部到顶部依次减少。我们也遵循该设计原则,如下图所示。
输出层:定义邻居
context embedding为context embedding中缺乏节点的属性信息。因此节点
输出层将最后一层隐层
优化(
Optimization) :为求解模型参数,我们需要选择一个目标函数来进行优化。我们的目标函数是:使得所有节点上的条件链接概率最大化。即:其中:
这个目标函数有两个效果:强化
两个用户之间没有链接,并不意味着他们是不相似的。如,社交网络中很多用户之间没有链接,不是因为他们不相似,而是因为他们没有彼此认识的机会。因此,迫使
目标函数中,为了计算单个概率
为避免这些问题,我们使用负采样,从整个社交网络中采样一小部分负样本。主要思想是在梯度计算过程中进行近似,即:
其中:
注意,给定用户
为优化上述框架,我们使用了
Adam优化算法。此外,我们还使用了batch normalization。在embedding layer和每个隐层中,我们还使用了dropout。最终我们使用final embedding。
1.1.3 与其它模型关联
这里我们讨论
SNE框架与其它相关模型的联系。我们展示了SNE包含了SOTA的network embedding方法node2vec,也包含了线性潜在因子模型SVD++。具体而言,这两个模型可以视为浅层SNE的一个特例。为便于进一步讨论,我们首先给出单层SNE的预测模型为:当选择:
此时
SNE退化为node2vec。当选择:
此时
SNE退化为SVD++。
通过
SNE与一系列浅层模型的联系,我们可以看到我们设计SNE背后的合理性。具体而言,SNE加深了浅层模型,从而捕获网络结构和属性之间的底层交互。在建模可能具有复杂的、非线性固有结构的真实世界数据时,我们的SNE更有表达能力,并且可以更好地拟合真实世界数据。
1.2 实验
这里我们对四个可公开访问的社交网络数据集进行实验,旨在回答以下研究问题。
与
SOTA的network embedding相比,SNE能否学到更好的node representation?导致
SNE学到更好representation的关键原因是什么?更深的隐层是否有助于学到更好的社交网络
embedding?
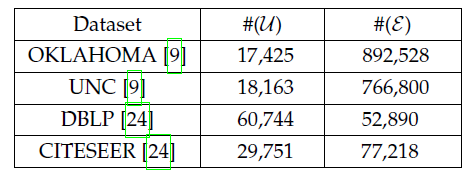
数据集:
社交网络:我们使用
Facebook的两个网络,分别包含来自两所美国大学的学生:University of Oklahoma(OKLAHOMA)、University of North Carolina at Chapel Hill(UNC) 。除了用户ID之外,还有七个用户属性:状态、性别、专业、第二专业、宿舍、高中、入学年份。注意,并非所有学生都有这七个属性,如在UNC数据集中的18163个学生中只有4018个学生包含所有属性。引文网络:我们使用
DBLP和CITESEER数据集,每个节点代表一篇论文。属性为去除停用词以及词干化之后每篇论文的标题和内容。DBLP数据集由计算机科学四个研究方向的会议论文组成。CITESEER数据集由来自十个不同研究领域的科学出版物组成。这些研究方向或研究领域在节点分类任务中被视为标签。
评估方式:我们采用了链接预测和节点分类任务。链接预测任务评估
node representation在重建网络结构中的能力,节点分类评估node representation是否包含足够的信息用于下游应用。链接预测任务:我们随机将
10%的链接作验证集来调整超参数,随机将10%的链接作为测试集,剩下80%的链接作为训练集来训练SNE。由于测试集/验证集仅包含正样本,因此我们随机选择数量相等、不存在的边作为负样本。我们使用AUROC作为评估指标(ROC曲线的面积),该指标越大越好。节点分类任务:我们首先在训练集上训练模型(包含所有节点、所有边、所有属性,但是没有节点
label),从而获得node embedding。其中模型的超参数通过链接预测任务来选取。然后我们将node embedding输入到LIBLINEAR分类器进行节点分类。我们随机选择根据链接预测任务获取节点分类任务的超参数,这种做法可能不是最佳的,应该根据节点分类任务来得到模型超参数。但是这里是两阶段的,因此如何根据第二阶段的标签信息来得到第一阶段的模型超参数,这是一个问题。
我们重复该过程十次并报告平均的
Macro-F1和Micro-F1得分。注意:由于只有DBLP和CITESEER数据集包含节点的类别标签,因此仅针对这两个数据集执行节点分类任务。
baseline方法:这里我们将SNE和若干个SOTA的network embedding方法进行比较。node2vec:基于有偏的随机游走产生节点序列,然后对节点序列应用SkipGram模型来学习node embedding。有两个关键的超参数1.0时,node2vec降级为DeepWalk。LINE:分别通过保持网络的一阶邻近性和二阶邻近性来为每个节点学习一阶邻近性embedding和 二阶邻近性embedding。节点的final embedding为二者的拼接。TriDNR:通过耦合多个神经网络来联合建模网络结构、node-content相关性、label-content相关性,从而学习node embedding。我们搜索文本权重超参数
所有的
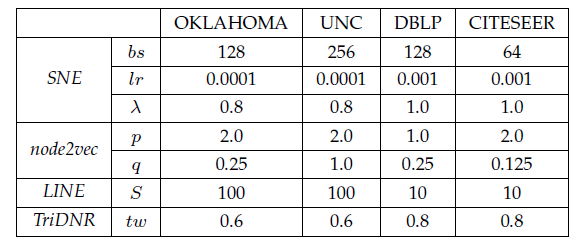
baseline都采用原始作者发布的实现。注意,node2vec/LINE都是仅考虑结构信息,为了和利用属性信息的SNE进行公平的比较,我们将它们学到的node embedding和属性向量拼接起来,从而扩展为包括属性的形式。我们称这类变体为node2vec+attr和LINE+attr。此外,我们了解到最近的network embedding工作《Label informed attributed network embedding》也考虑了属性信息,但是由于他们的代码不可用,因此我们没有进一步比较它。SNE参数配置:和
node2vec/LINE方法一致,我们选择embedding维度p/q和node2vec相同。我们的实现基于
tensorflow,选择mini-batch的Adam优化器,搜索的batch size范围从[8,16,32,64,128,256],搜索的学习率从[0.1,0.01,0.001,0.0001]。我们搜索超参数
SNE退化为仅考虑网络结构。我们使用
softsign函数作为隐层激活函数。我们尝试了多种激活函数,最终发现softsign的效果最好。我们使用均值
0.0、标准差0.01的高斯分布来随机初始化模型参数。如无特殊说明,我们选择两个隐层,即
下表给出了通过验证集择优的每种方法的最佳超参数。
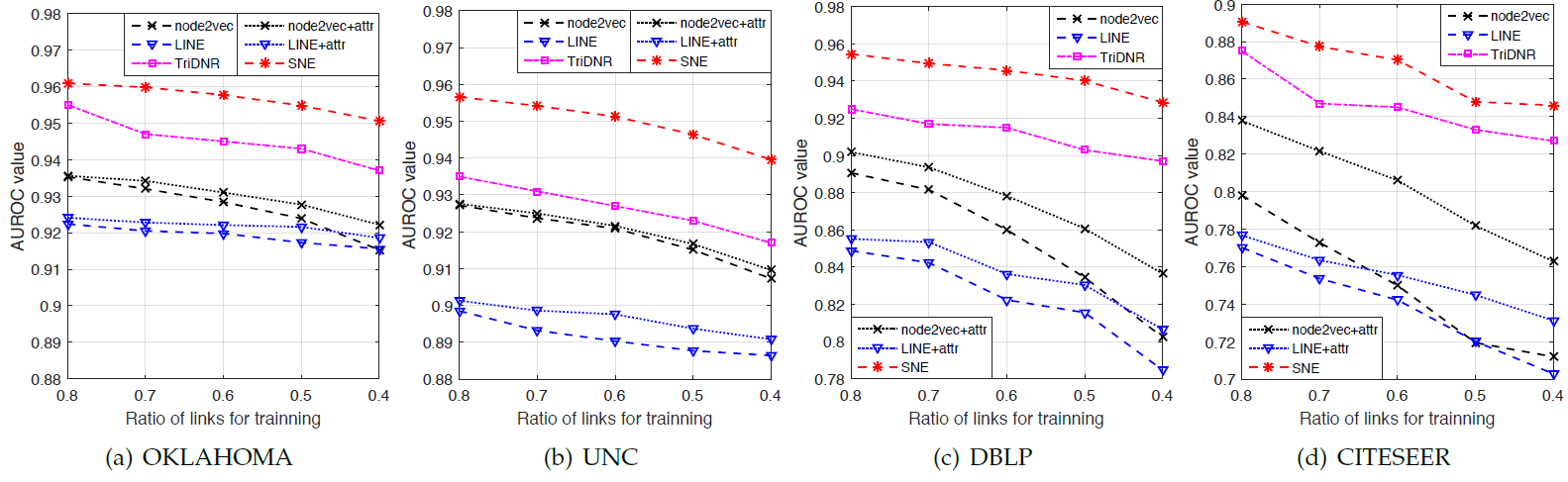
不同方法在四个数据集上链接预测任务的效果如下图所示。为探索不同网络稀疏性条件下各方法的鲁棒性,我们改变了训练链接的比例并研究了性能的变化。
结论:
SNE在所有方法中效果最佳。值得注意的是:和单纯的基于网络结构的node2vec/LINE相比,SNE在使用一半链接的条件下,性能更好。这证明了节点属性在链接预测方面的有效性,以及SNE通过节点属性学到更好的node embedding的合理性。此外,我们观察到
node2vec/LINE在DBLP和CITESEER上的性能随着训练比例越低,性能下降的更为明显。原因是DBLP/CITESEER数据集本身的链接就很少,因此当训练链接的比例降低时,链接的稀疏问题变得更加严重。相反,当我们使用更少的链接进行训练时,我们的SNE表现出更高的稳定性。这证明了对属性建模是有效的。聚焦于带属性的方法,我们发现集成属性的方式对于性能起着关键作用。
带属性的
node2vec+attr/LINE+attr相比node2vec/LINE略有改进,但是改进的幅度不大。这表明简单地将节点属性和embedding向量进行拼接的方式,无法充分利用属性中丰富的信号。这说明了将节点属性融合到网络embedding过程中的必要性。SNE始终优于TriDNR。尽管TriDNR也是联合训练节点属性,但是我们的方法是在模型早期(输入层之后)就无缝地融合了属性信息,使得随后的非线性隐层可以捕获复杂的 ”网络结构-节点属性“ 交互信息,并学习更有效的node embedding。
在基于结构的
embedding方法中,我们观察到node2vec在四个数据集中都优于LINE。一个合理的原因是:通过在社交网络上执行随机游走,node2vec可以捕获更高阶的邻近信息。相比之下,LINE仅对一阶邻近性和二阶邻近性建模,无法为链接预测捕获足够的信息。为验证这一点,我们进一步探索了一个额外的baseline:在随机游走时,选择和当前节点共享最多邻居的节点,从而直接利用二阶邻近性(即选择二阶邻近性最大的节点来游走)。不出所料,该baseline在所有数据集上的表现都很差(低于每个子图的底线)。这再次表明需要建模网络的高阶邻近性。由于
SNE使用和node2vec相同的随机游走过程,因此它可以从高阶邻近性中学习,并通过属性信息得到进一步补充。
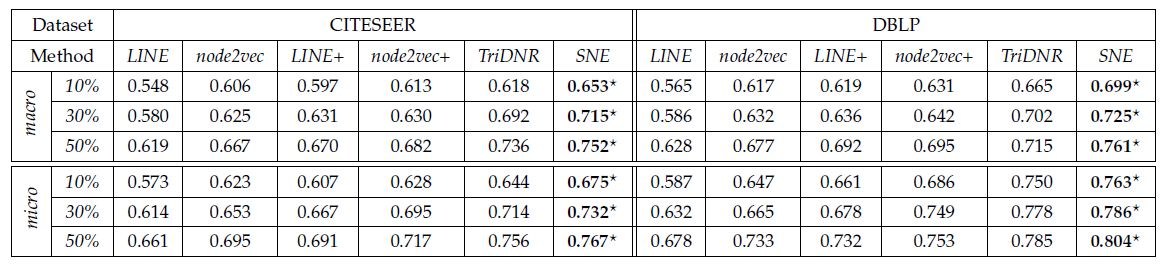
不同方法在两个数据集上的节点分类任务效果如下表所示。性能趋势和链接预测任务中的趋势一致。
在所有情况下,
SNE方法均超越了所有baseline。仅使用网络结构的
node2vec和LINE表现最差,这进一步证明了社交网络上建模节点属性的有效性,并且正确建模属性信息可以导致更好的representation learning并有利于下游application。
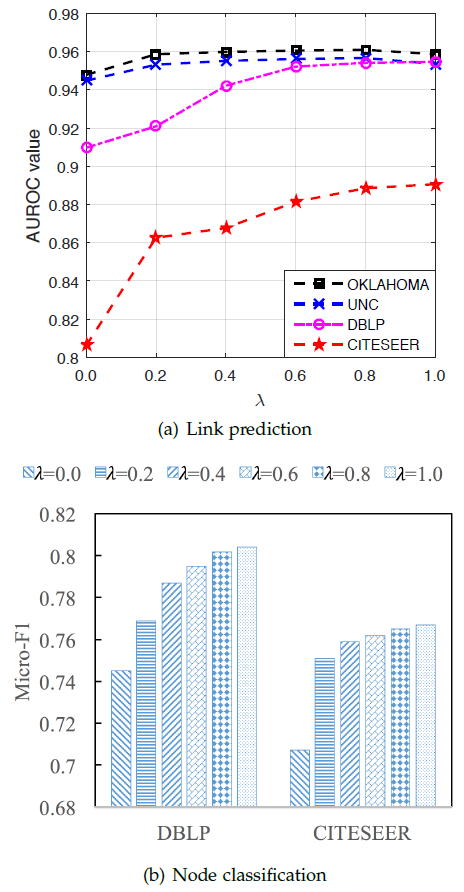
超参数
SNE模型的效果。我们以相同的方式来评估链接预测任务、节点分类任务,其中链接预测任务采用80%的链接作为训练集,节点分类任务采用50%的标记节点作为训练集。注意:当
最佳结果通常在
0.2。通常属性信息在
SNE中起着重要作用,这一点可以通过SNE性能得到提升得以证明。当0.0增加到0.2时,我们观察到CITESEER的性能显著提高。由于该数据集的链接较少,因此性能的提升表明属性有助于缓解链接稀疏问题。当
SNE的效果优于node2vec。由于我们使用和node2vec相同的游走过程以及超参数
为了解
SNE为什么要比其它方法效果好,这里我们对DBLP数据集进行研究。我们首先用每种方法学习每个节点的embedding,然后给定query paper我们利用node embedding检索最相似的三篇论文。其中,相似性是通过embedding的余弦相似度来衡量。为了和基于结构的方法进行公平比较,我们选择了
KDD 2006的一篇热门论文Group formation in large social networks: membership, growth, and evolution,该论文引用量达到1510。根据这篇论文的内容,我们预期相关结果应该是关于社交网络中群体或社区的结构演变。不同embedding方法检索到的最相关论文如下表。结论:
SNE返回了非常相关的结果:三篇论文都是关于动态社交网络分析和社区结构的。仅利用结构信息,
node2vec返回的结果似乎与query不太相似。node2vec似乎倾向于找到相关性较低、但是引用率较高的论文。这是因为随机游走过程可能容易偏向于具有更多链接的热门节点。尽管SNE也依赖于随机游走,但是SNE可以通过利用属性信息在一定程度上纠正这种偏差。LINE也返回了和query不太相似的结果。这可能是由于仅建模一阶邻近性和二阶邻近性,忽略了丰富的属性信息。
通过以上定性分析我们得出结论:使用网络结构和节点属性都有利于检索相似节点。和单纯的基于结构的
embedding方法相比,SNE返回的结果与query更为相关。值得注意的是,对于本次研究,我们特意选择了一个热门的节点来缓解稀疏性问题,这实际上有利于基于结构的方法。即便如此,基于结构的方法也无法识别相关的结果。这揭示了仅依赖网络结构进行社交网络embedding的局限性,也证明了对节点属性进行建模的重要性。
最后我们探索隐层对于
SNE的影响。众所周知,增加神经网络的深度可以提高模型的泛化能力,但是由于优化困难这也可能降低模型性能。因此我们迫切想知道:使用更深层的网络是否可以提升SNE的性能。我们在DBLP上验证了SNE模型不同数量的隐层对应的链接预测、节点分类任务的性能。在其它数据集上的结论也是类似的,因此我们仅以DBLP为例。由于最后一层隐层的大小决定了SNE模型的表达能力,因此我们将所有模型的最后一层隐层都设为128维从而公平地比较。对每个比较的模型,我们都重新调优超参数从而充分发挥模型的能力。结论:
可以看到一个趋势:隐层越多模型性能越好。这表明在
SNE中使用更深的网络效果更好。但是,其代价是更多的训练时间。在普通的商用服务器上(2.4GHz的Intel Xeon CPU),单层SNE耗时25.6秒/epoch、三层SNE耗时81.9秒/epoch。我们停止探索更深层的模型,因为当前的
SNE使用全连接层,而深层的全连接层很难优化。并且很容易随着层的加深出现过拟合over-fitting和退化degrading。表中效果提升的衰减也暗示了这一点。为了解决该问题,我们建议采用现代的神经网络设计方法,如残差单元
residual unit或highway network。我们将该工作留给未来的工作。值得注意的是:当没有隐层时
SNE的性能会很差,与TriDNR处于同一水平。当增加了一层隐层时,模型效果大幅提升。这证明了以非线性方式学习 “网络结构 -- 节点属性” 交互的有效性。为证明这一点,我们进一步尝试在隐层使用恒等函数identity替代softsign激活函数,最终效果要比非线性softsign激活函数差得多。
