一、GAT [2017]
《Graph attention networks》
卷积神经网络(
Convolutional Neural Network: CNN)已经成功应用于图像分类、语义分割以及机器翻译之类的问题,其底层数据结构为网格状结构(grid-like structure)。这些架构通过将它们应用于所有的input position从而有效地reuse具有可学习参数的局部滤波器(local filter)。然而,许多人们感兴趣的任务涉及的数据无法以网格状结构来表达,而是位于不规则域(
irregular domain)。例如,3D mesh、社交网络、电信网络、生物网络、脑连接组(brain connectome)等等。这些数据通常可以通过graph的形式来表达。有一些文献尝试扩展神经网络从而处理任意结构的图。
早期的工作使用递归神经网络(
recursive neural network: RNN)来处理graph domain中表示为有向无环图的数据。《A new model for learning in graph domains》和《The graph neural network model》提出了图神经网络(Graph Neural Network: GNN)作为RNN的泛化,从而可以直接处理更通用的graph类型,如:循环图、有向图、无向图。GNN包含一个迭代过程,该迭代过程传播节点状态直到达到平衡。然后是一个神经网络,它根据每个节点的状态为每个节点生成一个输出。这个思想被
《Gated graph sequence neural networks》所采纳和改进,该方法提出在传播过程中使用门控循环单元(gated recurrent unit: GRU)。
然而,人们将卷积推广到
graph domain的兴趣越来越大。这个方向的进展通常分为谱方法(spectral approach)和非谱方法 (non-spectral approach)。一方面,谱方法与图的谱表示(
spectral representation)一起工作,并已成功应用于节点分类的context中。在
《Spectral networks and locallyconnected networks on graphs》中,卷积运算是通过计算图拉普拉斯矩阵(graph Laplacian)的特征分解(eigen decomposition)从而在傅里叶域 (Fourier domain)中定义的,这导致潜在的稠密计算以及非空间局部化的滤波器(non-spatially localized filter)。 这些问题在随后的工作中得到解决。《Deep convolutional networks on graph-structured data》引入了具有平滑系数的谱滤波器(spectral filter)的参数化(parameterization),使得滤波器在空间上局部化。后来,
《Convolutional neural networks on graphs with fast localized spectral filtering》提出通过图拉普拉斯矩阵的切比雪夫展开来近似滤波器,从而无需计算图拉普拉斯矩阵的特征向量从而生成空间局部化的滤波器。最后,
《Semi-supervised classification with graph convolutional networks》通过限制滤波器仅操作每个节点周围的1-step邻域内来简化之前的方法。
然而,在所有上述谱方法中,学到的滤波器依赖于拉普拉斯矩阵的特征基(
Laplacian eigenbasis),而这个特征基依赖于图结构。因此,在特定图结构上训练的模型无法直接应用于具有不同结构的其它的图。另一方面,我们有非谱方法,该方法直接在图上定义卷积从而操作空间近邻的节点集合。这些方法的挑战之一是:定义一个与不同规模的邻域一起工作,并能保持
CNN的权重共享属性的算子。在某些情况下,这需要为每个节点
degree学习一个特定的权重矩阵(《Convolutional networks on graphs for learning molecular fingerprints》),或者需要使用转移矩阵(transition matrix)的幂来定义邻域并同时针对每个输入通道和邻域degree来学习权重(《Diffusion-convolutional neural networks》),或者需要抽取和归一化邻域从而包含固定数量节点(《Learning convolutional neural networksfor graphs》)。《Geometric deep learning on graphs and manifolds using mixture model cnns》提出了mixture model CNN(MoNet),这是一种空间方法,可以将CNN架构统一泛化到图。最近,
《representation learning on largegraphs》提出了GraphSAGE,这是一种以归纳式的方式计算node representation的方法。该技术通过对每个节点采样固定尺寸邻域,然后该邻域执行特定的聚合器(如,均值池化聚合器,或LSTM聚合器)。GraphSAGE在多个大规模归纳式benchmark中取得了令人印象深刻的性能。GAT无需对邻域进行采样,能够处理可变邻域。
在许多
sequence-based任务中,注意力机制几乎已经成为事实上的标准。注意力机制的好处之一是:注意力机制允许处理可变尺寸的输入,并聚焦于输入中最相关的部分从而作出决策。当使用注意力机制来计算单个序列的representation时,它通常被称作self-attention或intra-attention。与RNN或卷积一起,self-attention已被证明对机器阅读、sentence representation学习等任务很有用。而且,《Attention is all you need》表明:self-attention不仅可以改进基于RNN或卷积的方法,而且足以构建一个强大的模型并且在机器翻译任务上获得SOTA的性能。受最近这项工作的启发,论文
《Graph attention networks》引入了一种attention-based架构来执行图结构数据的节点分类。基本思想是:遵从self-attention策略,可以通过attend节点的邻居来计算图中每个节点的hidden representation。注意力架构有几个有趣的特性:操作是高效的,因为它可以跨
node-neighbor pair进行并行化。self-attention通过给邻居赋予可学习的、任意的权重,从而可以应用于具有不同degree的图节点。该模型直接适用于归纳式的学习问题,包括模型必须泛化到完全
unseen的图的任务。
作者在四个具有挑战性的
benchmark上验证了所提出的方法,实现或接近SOTA的结果。实验结果凸显了attention-based模型在处理任意结构的图时的潜力。注:
inductive learning和transductive learning的区别:inductive learning是从具体样本中总结普适性规律,然后泛化到训练中unseen的样本。transductive learning是从具体样本中总结具体性规律,它用于预测训练集中已经出现过的unlabelled样本,常用于半监督学习。
相关工作:
正如
《Semi-supervised classification with graph convolutional networks》和《Diffusion-convolutional neural networks》一样,我们的工作也可以重新表述为MoNet的一个特定实例。此外,我们跨
edge共享神经网络计算(neural network computation)的方法让人联想起关系网络(relational network)(《A simple neural network module for relational reasoning》)和VAIN(《Vain: Attentional multi-agent predictive modeling》)的公式,其中object或agent之间的relation是通过采用一种共享机制来pair-wise聚合的。同样地,我们提出的注意力模型可以与
《One-shot imitation learning》和《Programmable agents》等工作联系起来,它们使用邻域注意力操作(neighborhood attention operation)来计算环境中不同对象之间的注意力系数。其它相关方法包括局部线性嵌入(
locally linear embedding: LLE)、记忆网络 (memory network) 。LLE在每个data point周围选择固定数量的邻居,并为每个邻居学习一个权重系数,从而将每个point重构为其邻居的加权和。然后第二步优化是抽取point的feature embedding。memory network也与我们的工作有一些联系。具体而言,如果我们将节点的邻域解释为memory,那么该memory被用于通过attendmemory的values来计算node feature(READ过程),然后通过将新的特征存储在node对应的位置从而进行更新(WRITE过程)。
1.1 模型
这里我们介绍用于构建任意
graph attention network: GAT的building block layer(通过堆叠该层),即graph attentional layer: GAL。然后我们概述与神经图处理(neural graph processing)领域的先前工作相比,这种layer的理论和实践上的优势和局限性。
1.1.1 Graph Attentional Layer
我们将从描述单个
graph attentional layer: GAL开始,其中GAL作为我们实验中使用的GAT架构中使用的唯一一种layer。我们使用的特定的attentional setup与《Neural machine translation by jointly learning to align and translate》的工作密切相关,但是GAT框架与注意力机制的特定选择无关。GAL的输入为一组节点特征:representation维度。GAL输出这些节点的新的representation:representation维度(可能与为了获得足够的表达能力(
expressive power)从而将input feature转化为higher-level feature,至少需要一个可学习的线性变换。为此,作为初始的step,我们首先对所有节点应用一个共享权重的线性变换,权重为self-attentionattentional mechanism) :attention系数:其中
理论上讲,我们允许每个节点关注图中所有其它的节点,因此这可以完全忽略所有的图结构信息。实际上,我们采用
masked attention机制将图的结构信息注入到attention机制:对于节点attention系数注意:这里
为使得系数可以在不同节点之间比较,我们使用
softmax函数对所有的在我们的实验中,注意力机制
LeakyReLU激活函数,其中负轴斜率其中:
注意:这里的节点
query,邻域key。query节点representation和每个key的representation进行拼接。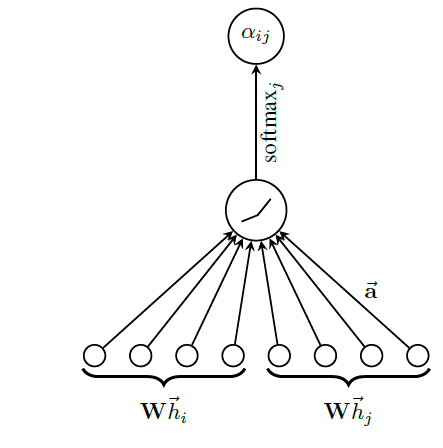
一旦得到归一化的注意力得分,我们就可以用它对相应的邻居节点的特征进行加权线性组合,从而得到每个节点的
final output feature:其中
理论上也可以使用不同的
我们使用
multi-head attention来稳定self-attention的学习过程。我们采用head,然后将它们的输出拼接在一起:其中:
head的归一化的注意力得分。head的权重矩阵。
最终的输出
但是,如果
GAL是网络最后一层(即输出层),我们对multi-head的输出不再进行拼接,而是直接取平均,因为拼接没有意义。同时我们延迟使用最后的非线性层,对分类问题通常是softmax或者sigmoid:理论上,最后的
GAL也可以拼接再额外接一个输出层。例如,实验部分作者就在最后一层使用attention head。如下图所示为
multi head = 3,当且节点head。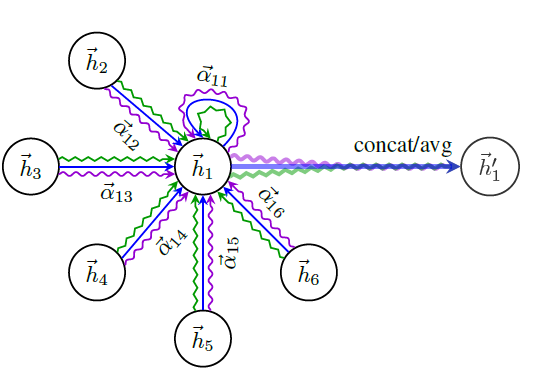
1.1.2 和相关工作的比较
GAL解决了现有的、基于神经网络对图结构数据建模的方法的问题。GAL计算高效:self-attentional layer的操作可以跨所有edge并行化,输出特征的计算可以跨所有节点并行化。即,单个
self-attention内部的、计算self-attention也可以并行化。不需要特征分解(
eigen decomposition)或类似的昂贵矩阵计算。单个
attention head计算baseline方法(如GCN)差不多。首先计算所有节点的
再计算所有的
再计算所有的
degree,则
最终计算复杂度为
应用
multi-head attention将存储需求和参数需求乘以head的计算是完全独立的并且可以并行化。
GCN:和GCN相比,GAT模型允许为同一个邻域内的节点分配不同的重要性,从而实现模型容量(model capacity)的飞跃。另外,和机器翻译领域一样,对学到的注意力权重进行分析可能会带来可解释性的好处。注意力机制以共享的方式应用于图的所有边,因此它不需要预先得到整个图结构或者所有节点(这是许多现有技术的局限性)。这有几个理想的含义:
图可以是有向图,也可以是无向图。如果边
GAT可以直接应用到归纳式学习(inductinve learning):模型可以预测那些在训练期间中unseen的图。
GraphSAGE:最近发表的归纳式方法GraphSAGE对每个节点采样固定大小的邻域,从而保持计算足迹(computational footprint)的一致性。这使得模型无法在测试期间访问整个邻域。注意:由于训练期间训练多个
epoch,则GraphSAGE可能访问到节点的整个邻域。此外,当使用
LSTM-based邻域集合器时,GraphSAGE取得了一些最强的结果。LSTM假设在邻域之间存在一致的节点排序,并且作者通过向LSTM持续地提供随机排序的序列来使用LSTM。GAT没有这两个问题:GAT作用在完整的邻域上,并且不假设邻域内有任何节点的排序。注意:虽然
GAT作用在完整的领域上,但是在大型图的训练过程中可能还需要对邻域进行采样。因为对于大型图,对于每个mini-batchGAT有如果使用完整的邻域,那么每个
mini-batch所需要的节点可能就是整个大图。这对于大型图而言是无法接受的(空间复杂度太高)。MoNet:如前所述,GAT可以重写表述为MoNet的特定实例。更具体而言:设定伪坐标函数(
pseudo-coordinate function)为MLP变换而来),设定权重函数为
softmax。
此时,这种
MoNet的补丁算子 (patch operator)将类似于我们的方法。然而,应该注意的是:与这个
MoNet实例相比,我们的模型使用节点特征来计算相似性,而不是节点的结构属性(假设预先知道图结构)。
我们可以使用一种利用稀疏矩阵操作的
GAL层,它可以将空间复杂度下降到节点和边的线性复杂度,从而使得模型能够在更大的图数据集上运行。但是我们的tensor计算框架仅支持二阶tensor的稀疏矩阵乘法,这限制了当前版本的batch处理能力,特别是在具有很多图的数据集上。解决该问题是未来一个重要的方向。另外,根据现有图结构的规律,在稀疏矩阵的情况下,GPU的运算速度并不会比CPU快多少因此无法提供主要的性能优势。还应该注意的是,我们模型的感受野 (
receptive field)的大小是网络深度的上限(类似于GCN或类似的模型)。然而,诸如skip connection之类的技术可以解决该问题,从而允许GAT使用更深的网络。最后,跨图中所有
edge的并行化,尤其是以分布式方式,可能会涉及大量冗余计算,因为图中邻域通常高度重叠。
1.1.3 未来工作
一些有待改进的点:
如何处理更大的
batch size。如何利用注意力机制对模型的可解释性进行彻底的分析。
如何执行
graph-level的分类,而不仅仅是node-level的分类。如何利用边的特征,而不仅仅是节点的特征。因为边可能蕴含了节点之间的关系,边的特征可能有助于解决各种各样的问题。
1.2 实验
1.2.1 Transductinve Learning
数据集:三个标准的引文网络数据集
Cora, Citeseer,Pubmed。每个节点表示一篇文章、边(无向)表示文章引用关系。每个节点的特征为文章的
BOW representation。每个节点有一个类别标签。Cora数据集:包含2708个节点、5429条边、7个类别,每个节点1433维特征。Citeseer数据集:包含3327个节点、4732条边、6个类别,每个节点3703维特征。Pubmed数据集:包含19717个节点、44338条边、3个类别,每个节点500维特征。
对每个数据集的每个类别,我们使用
20个带标签的节点来训练,然后在1000个测试节点上评估模型效果。我们使用额外的500个带标签节点作为验证集(与GCN论文中使用的相同)。注意:训练算法可以利用所有节点的结构信息和特征信息,但是只能利用每个类别
20个节点的标签信息。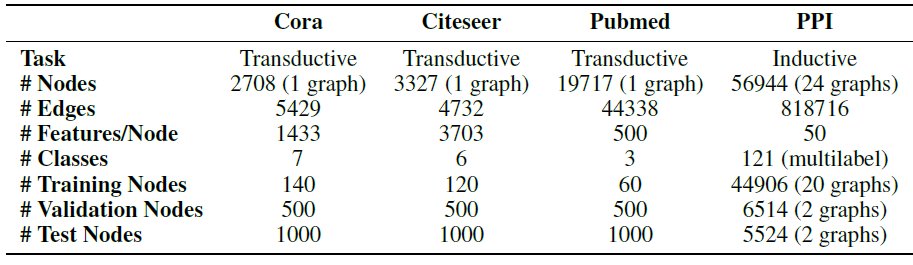
Baseline模型:我们对比了论文
《Semi-supervised classification with graph convolutional networks》中指定的相同的baseline。包括:标签传播模型(label propagation: LP)、半监督嵌入模型(semi-supervised embedding: SemiEmb)、流型正则化模型 (manifold regularization: ManiReg)、基于SkipGram的graph embeding模型(如DeepWalk)、迭代式分类算法模型(iterative classification algorithm: ICA),Planetoid模型。我们也直接对比了
GCN模型、利用高阶切比雪夫的图卷积模型Chebyshev filter-based(《Convolutional neural networks on graphs with fast localized spectral filtering》)、以及MoNet模型。我们还提供了每个节点共享
MLP分类器的性能,该模型完全没有利用图的结构信息。
参数配置:
我们使用一个双层的
GAT模型,它的架构超参数已经在Cora数据集上进行了优化,然后被Citeseer复用。第一层包含
attention head,每个head得到64个特征。第一层后面接一个exponential linear unit: ELU非线性激活层。第二层用作分类,采用一个
attention head计算softmax激活函数。
当处理小数据集时,我们在模型上施加正则化:
我们采用
两个层的输入,以及
normalized attention coefficient都使用了dropout。即每轮迭代时,每个节点需要随机采样邻居(因为有些邻居被dropout了)。
对于
60个样本的Pubmd数据集,我们需要对GAT架构进行微调:输出为
attention head,而不是一个。
除此之外都和
Cora/Citeseer的一样。所有模型都采用
Glorot初始化方式来初始化参数,优化目标为交叉熵,使用Adam SGD优化器来优化。初始化学习率为:Pubmed数据集为0.01,其它数据集为0.005。我们在所有任务上执行早停策略,在验证集上的交叉熵和
accuracy如果连续100个epoch没有改善,则停止训练。
我们报告了
GAT随机执行100次实验的分类准确率的均值以及标准差,也使用了GCN和Monet报告的结果。对基于切比雪夫过滤器的方法,我们提供了
我们进一步评估了
GCN模型,其隐层为64维,同时尝试使用ReLU和ELU激活函数,并记录执行100次后效果最好的那个(实验表明ReLU在所有三个数据集上都最佳),记作GCN-64*。结论:
GAT在Cora和Citeseer上超过GCN分别为1.5%, 1.6%,这表明为邻域内节点分配不同的权重是有利的。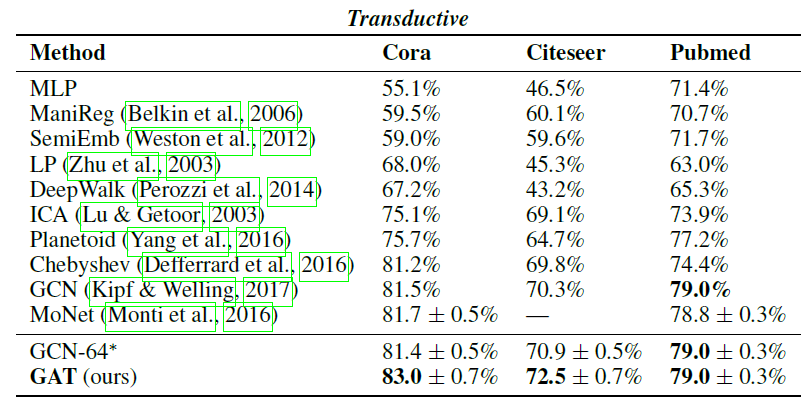
1.2.2 Inductinve learning
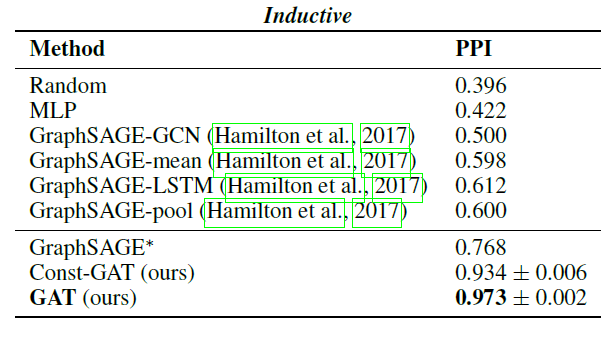
数据集:
protein-protein interaction: PPI数据集,该数据集包含了人体不同组织的蛋白质的24个图。其中20个图为训练集、2个图为验证集、2个图为测试集。至关重要的是,这里测试的图在训练期间完全未被观测到。我们使用
GraphSAGE提供的预处理数据来构建图,每个图的平均节点数量为2372个,每个节点50维特征,这些特征由positional gene sets, motif gene sets, immunological signatures组成。从
Molecular Signatuers Database收集到的gene ontology有121种标签,这里每个节点可能同时属于多个标签。Baseline模型:我们对比了四个不同版本的监督GraphSAGE模型,它们提供了多种方法来聚合采样邻域内的节点特征:GraphSAGE-GCN:将图卷积方式的操作扩展到归纳式setting。GraphSAGE-mean:取特征向量的逐元素均值来聚合。GraphSAGE-LSTM:通过将邻域特征馈入LSTM来聚合。GraphSAGE-pool:采用共享非线性多层感知机转换后的特征向量的逐元素最大池化来聚合。
剩下的
transductinve方法要么完全不适用于inductive的情形,要么无法应用于在训练期间完全看不到测试图的情形,如PPI数据集。我们还提供了每个节点共享
MLP分类器的性能,该模型完全没有利用图的结构信息。参数配置:
我们使用一个三层
GAT模型:第一层包含
attention head,每个head得到1024个特征。第一层后面接一个exponential linear unit:ELU非线性激活层。第二层和第一层配置相同。
第三层为输出层,包含
attention head,每个head得到121个特征。我们对所有
head取平均,并后接一个sigmoid激活函数。
由于该任务的训练集足够大,因此我们无需执行
dropout。我们在
attention layer之间应用skip connection。训练的
batch size = 2,即每批2个graph。为评估
attention机制的效果,我们提供了一个注意力得分为常数的模型进行对比(所有模型都采用
Glorot初始化方式来初始化参数,优化目标为交叉熵,使用Adam SGD优化器来优化。初始化学习率为:Pubmed数据集为0.01,其它数据集为0.005。我们在所有任务上执行早停策略,在验证集上的交叉熵和
micro-F1如果连续100个epoch没有改善,则停止训练。
我们报告了模型在测试集(两个从未见过的
Graph)上的micro-F1得分。我们随机执行10轮 “训练--测试”,并报告这十轮的均值。对于其它基准模型,我们使用GraphSAGE报告的结果。具体而言,由于我们的setting是有监督的,我们将与有监督的GraphSAGE方法进行比较。为了评估聚合整个邻域的好处,我们进一步提供了
GraphSAGE架构的最佳结果,记作GraphSAGE*。这是通过一个三层GraphSAGE-LSTM得到的,三层维度分别为[512,512,726],最终聚合的特征为128维。最后,我们报告常数的注意力系数为
Const-GAT的结果。结论:
GAT在PPI数据集上相对于GraphSAGE的最佳效果还要提升20.5%,这表明我们的模型在inductive任务中通过观察整个邻域可以获得更大的预测能力。相比于
Const-GAT,我们的模型提升了3.9%,这再次证明了为不同邻居分配不同权重的重要性。
注意:这里作者并未给出超参数研究的实验分析,包括:
GAT层数、multi-head数量、是否使用skip connection等等。
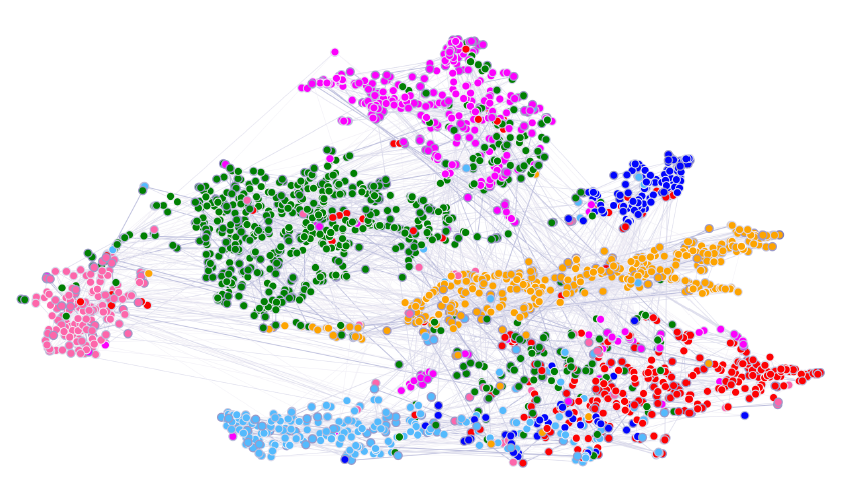
1.2.3 可视化
学到的
feature representation也可以进行定性研究。为此,我们采用t-SNE对学到的特征进行可视化。我们对Cora数据集训练的GAT模型的第一层的输出进行可视化,该representation在投影到的二维空间中表现出明显的聚类。这些簇对应于数据集的七种类别,从而验证了模型的分类能力。此外我们还可视化了归一化注意力系数的相对强度(在所有
8个attention head上的均值)。如何正确的解读这些系数需要有关该数据集的进一步的领域知识。下图中:颜色表示节点类别,线条粗细代表归一化的注意力系数均值: