一、MPNN [2017]
《Neural Message Passing for Quantum Chemistry》
机器学习预测分子和材料的性质仍处于起步阶段。迄今为止,将机器学习应用于化学任务的大多数研究都围绕着特征工程展开,神经网络在化学领域并未广泛采用。这使人联想到卷积神经网络被广泛采用之前的图像模型(
image model)的状态,部分原因是缺乏经验证据表明:具有适当归纳偏置(inductive bias)的神经网络体系结构可以在该领域获得成功。最近,大规模的量子化学计算(
quantum chemistry calculation)和分子动力学模拟(molecular dynamics simulation),加上高通量(high throughput)实验的进展,开始以前所未有的速度产生数据。大多数经典的技术不能有效地利用现在的大量数据。假设我们能找到具有适当归纳偏置的模型,将更强大和更灵活的机器学习方法应用于这些问题的时机已经成熟。原子系统的对称性表明,在图结构数据上操作并对图同构(graph isomorphism)不变的神经网络可能也适合于分子。足够成功的模型有朝一日可以帮助实现药物发现或材料科学中具有挑战性的化学搜索问题的自动化。在论文
《Neural Message Passing for Quantum Chemistry》中,作者的目标是为化学预测问题展示有效的机器学习模型,这些模型能够直接从分子图(molecular graph)中学习特征,并且对图同构不变(invariant)。为此,论文描述了一个在图上进行监督学习的一般框架,称为信息传递神经网络(Message Passing Neural Network: MPNN)。MPNN简单地抽象了现有的几个最有前景的图神经模型之间的共性,以便更容易理解它们之间的关系,并提出新的变体。鉴于许多研究人员已经发表了适合MPNN框架的模型,作者认为社区应该在重要的图问题上尽可能地推动这种通用方法,并且只提出由application所启发的新变体,例如论文中考虑的应用:预测小有机分子的量子力学特性(如下图所示)。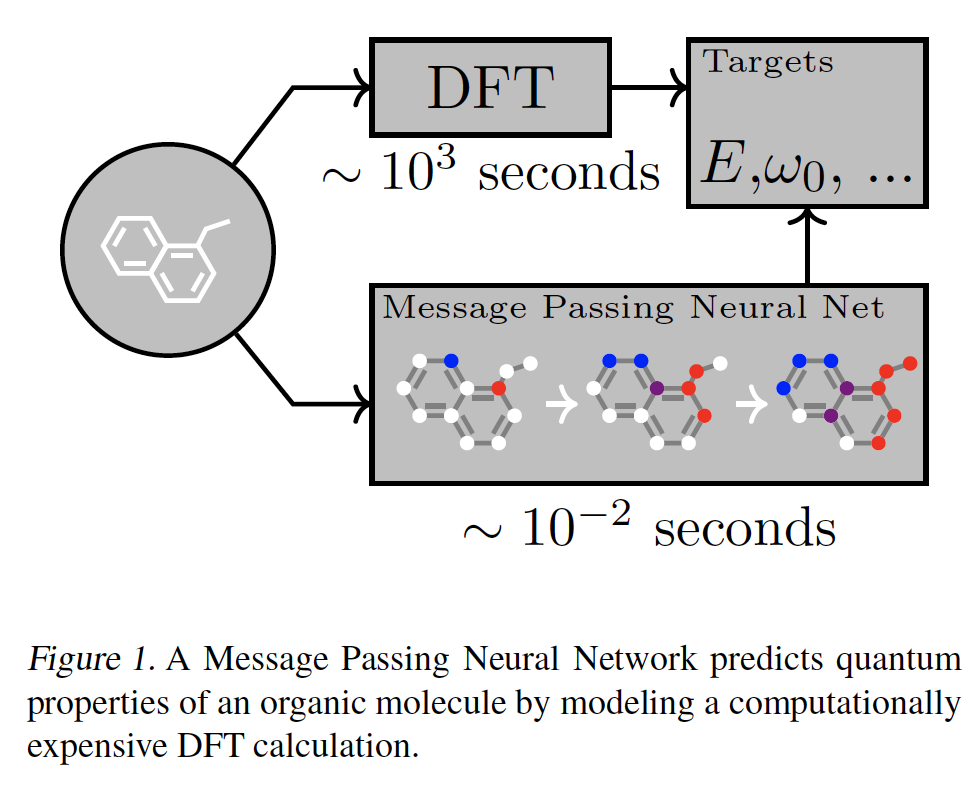
最后,
MPNN在分子属性预测benchmark上取得了SOTA的结果。论文贡献:
论文开发了一个
MPNN框架 ,它在所有13个目标(target)上都取得了SOTA的结果,并在13个目标中的11个目标上预测到DFT的化学准确性。论文开发了几种不同的
MPNN,在13个目标中的5个目标上预测到DFT的化学准确性,同时仅对分子的拓扑结构进行操作(没有空间信息作为输入)。论文开发了一种通用的方法来训练具有更大
node representation的MPNN,而不需要相应地增加计算时间或内存,与以前的MPNN相比,在高维node representation方面产生了巨大的节省。
作者相信论文的工作是朝着使设计良好的
MPNN成为中等大小分子上的监督学习的默认方法迈出的重要一步。为了实现这一点,研究人员需要进行仔细的实证研究,以找到使用这些类型的模型的正确方法,并对其进行必要的改进。相关工作:尽管原则上量子力学可以让我们计算分子的特性,但物理定律导致的方程太难精确解决。因此,科学家们开发了一系列的量子力学近似方法,对速度和准确率进行了不同的权衡,如带有各种函数的密度功能理论(
Density Functional Theory: DFT)以及量子蒙特卡洛(Quantum Monte-Carlo)。尽管被广泛使用,DFT仍然太慢,无法应用于大型系统(时间复杂度为DFT表现出系统误差和随机误差。《Combined first-principles calculation and neural-network correction approach for heat of formation 》使用神经网络来近似DFT中一个特别麻烦的项,即交换相关势能(exchange correlation potential),以提高DFT的准确性。然而,他们的方法未能提高DFT的效率,而是依赖于一大套临时的原子描述符(atomic descriptor)。另一个方向试图直接对量子力学的解进行近似,而不求助于DFT。这两个方向都使用了有固有局限性的手工设计的特征。
1.1 MPNN
为简单起见我们考虑无向图。给定无向图
每个节点
每条边
将无向图推广到有向的多图(
multigraph)(即多条边)也很容易。GNN的前向传播具有两个阶段:消息传递阶段、readout阶段:消息传递阶段执行
step,它通过消息函数(message function)update function)在消息传递阶段,节点
其中
readout阶段根据所有节点在embedding向量其中
readout函数(readout function)。permutation invariant)从而使得MPNN对图的同构不变性(graph isomorphism invariant)。
注意:你也可以在
MPNN中通过引入边的状态向量消息函数
readout函数《Convolutional Networks for Learning Molecular Fingerprints》:消息函数
节点更新函数
degree,并且不同的degree使用不同的映射矩阵。sigmoid函数。
Readout函数skip connection连接所有节点的所有历史状态其中
这种消息传递方案可能是有问题的,因为得到的消息向量
Gated Graph Neural Networks:GG-NN:消息函数
edge labellabel是离散的。节点更新函数
GRU为Gated Recurrent Unit。该工作使用了权重绑定(
weight tying),因此在每个时间步都使用相同的更新函数。即,它将每个节点的
Readout函数sigmoid函数。
Interaction Networks:该工作既考虑了node-level目标,也考虑了graph-level目标。也考虑了在节点上施加的外部效应。消息函数
节点更新函数
当进行
graph-level输出时,Readout函数1。
Molecular Graph Convolutions:该工作和MPNN稍有不同,因为它在消息传递阶段更新了边的表示消息函数
节点更新函数
relu为ReLU非线性激活函数,边更新函数:
其中
Deep Tensor Neural Networks:消息函数
bias向量。节点更新函数
Readout函数
Laplacian Based Methods,例如GCN:消息函数
其中
deg(v)为节点degree。节点更新函数
将这些方法抽象为通用的
MPNN的好处是:我们可以确定关键的实现细节,并可能达到这些模型的极限,从而指导我们进行未来的模型改进。所有这些方法的缺点之一是计算时间。最近的工作通过在每个
time step仅在图的子集上传递消息,已经将GG-NN架构应用到更大的图。这里我们也提出了一种可以改善计算成本的MPNN修改。
1.2 MPNN 变体
我们基于
GG-NN模型探索MPNN,我们认为GG-NN是一个很强的baseline。我们聚焦于探索不同的消息函数、输出函数,从而找到适当的输入representation以及正确调优的超参数。消息函数探索:
矩阵乘法作为消息函数:首先考察
GG-NN中使用的消息函数,它定义为其中
edge labellabel是离散的。Edge Network:为了支持向量值的edge特征,我们使用以下消息函数:其中
edge特征Pair Message:前面两种消息函数仅依赖于隐状态其中
当我们将上述消息函数应用于有向图时,将使用两个独立的函数
虚拟节点 & 虚拟边:我们探索了两种方式来在图中添加虚拟元素,从而修改了消息传递的方式(使得消息传播得更广):
虚拟边:在未连接节点
pair对之间添加虚拟边,这个边的类型是特殊类型。这可以实现为数据预处理步骤,并允许消息在传播阶段传播很长一段距离。虚拟节点:虚拟一个
master节点,该节点以特殊的边类型来连接到图中的每个输入节点。此时
master节点充当全局暂存空间,每个节点都在消息传递的每个step中从master读取信息、向master写入信息。这允许信息在传播阶段传播很长的距离。我们允许
master节点具有单独的节点维度master节点在内部状态更新函数中使用单独的权重矩阵。由于加入了
master节点,理论上模型复杂度有所增加,并提升了模型型容量。
Readout函数:我们尝试了两种Readout函数。一种是在
GG-NN中使用的Readout函数:另一种是
Set2Set模型,该模型专门为Set输入而设计的,并且比简单地累加final node state具有更强的表达能力。该模型首先将线性投影应用于每个元组
set的元组投影作为输入。然后,在经过step之后,Set2Set模型将产生graph-level embeddingembedding对于set的顺序具有不变性。我们将这个embedding
Multiple Towers:MPNN的一个问题是可扩展性,特别是对于稠密图。消息传递阶段的每个step需要我们将
embeddingembeddingembedding。然后我们在每个隐空间
embedding最后这
embedding结果通过以下方式混合:其中:
这种混合方式保留了节点的排列不变性 (
permutation invariant),同时允许图的不同embedding在传播阶段相互交流。这种方法是有利的,因为对于相同数量的参数数量,它能产生更大的假设空间,表达能力更强。并且时间复杂度更低。当消息函数是矩阵乘法时,某种
embedding的传播step花费embedding,因此总的时间复杂度为Multiple Towers就是multi-head的思想。
1.3 实验
数据集:
QM-9分子数据集,包含130462个分子。我们随机选择10000个样本作为验证集、10000个样本用于测试集、其它作为训练集。特征(如下表所示)和label的含义参考原始论文。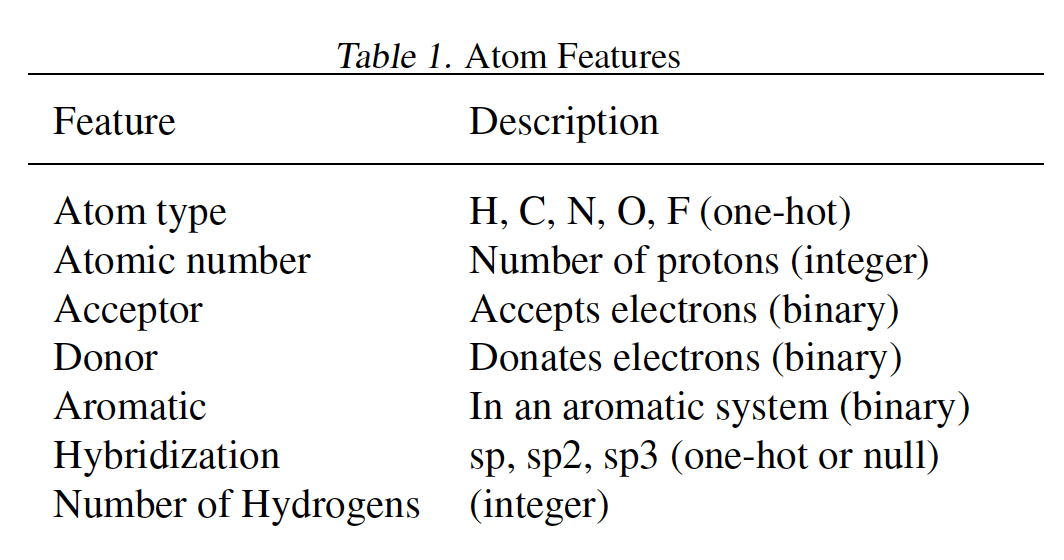
我们使用验证集进行早停和模型选择,并在测试集上报告
mean absolute error:MAE。结论:
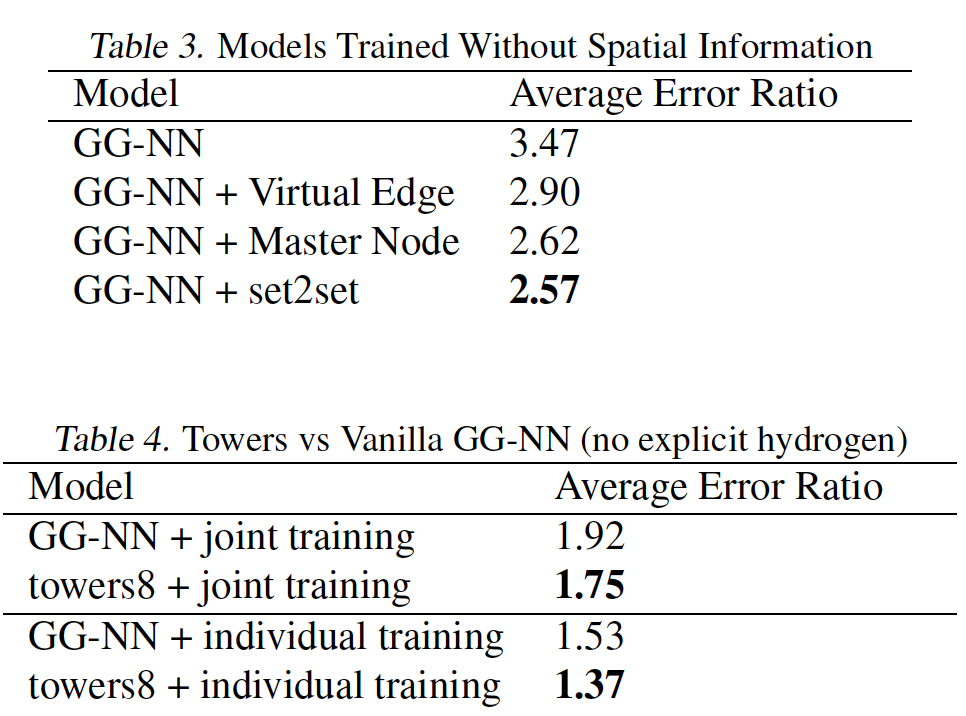
针对每个目标训练一个模型始终优于对所有
13个目标进行联合训练。最优的
MPNN变体使用edge network消息函数。添加虚拟边、添加
master节点、将graph-level输出修改为Set2Set输出对于13个目标都有帮助。Multiple Towers不仅可以缩短训练时间,还可以提高泛化性能。
具体实验细节参考原始论文。
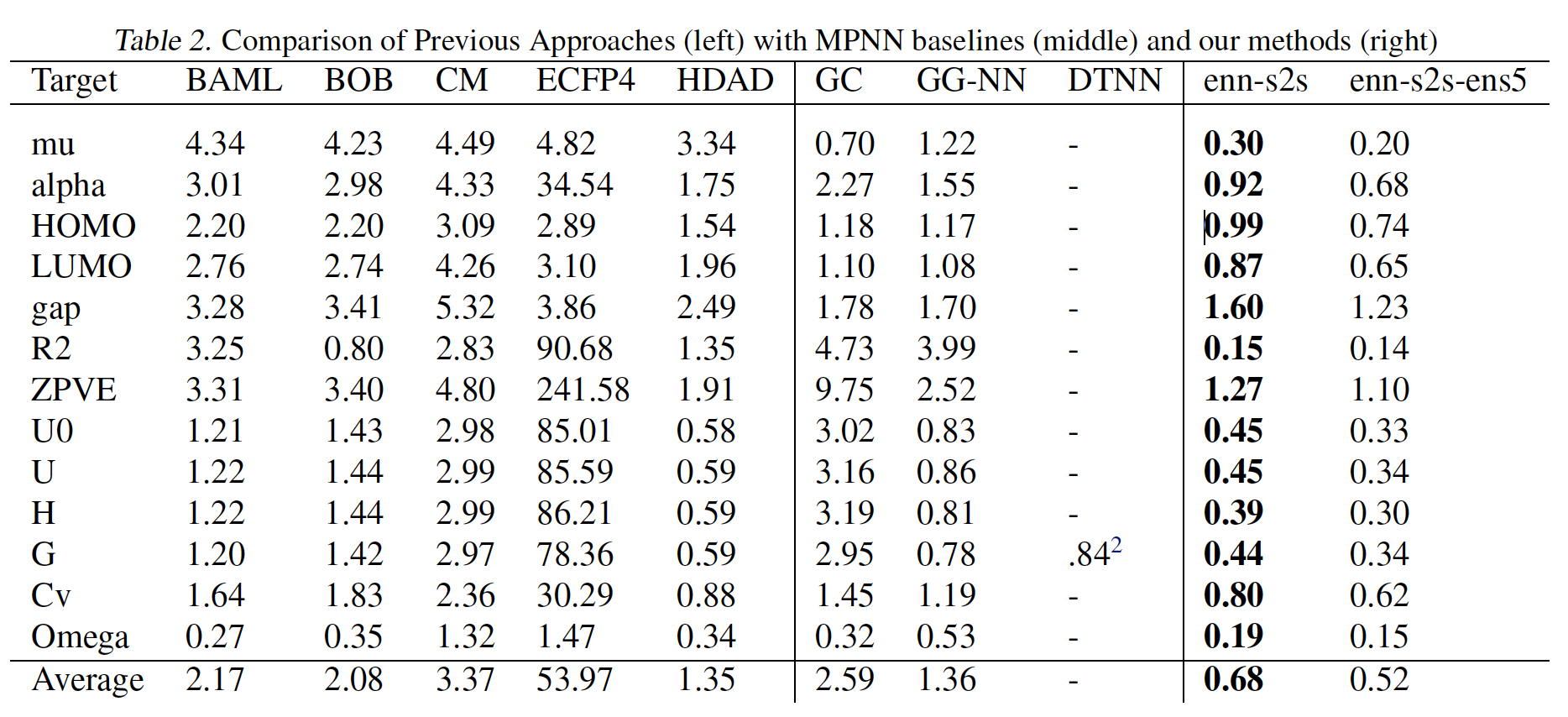
下图中,
enn-s2s表示最好的MPNN变体(使用edge network消息函数、set2set输出、以及在具有显式氢原子的图上操作),enn-s2s-ens5表示对应的ensemble。