一、R-GCN [2017]
《Modeling Relational Data with Graph Convolutional Networks》
知识库(
knowledge base)组织和存储事实知识(factual knowledge),支持包括问答(question answering)和信息检索在内的多种应用。尽管在维护上投入了巨大的努力,即使是最大的知识库(如DBPedia, Wikidata, Yago)仍然是不完整(incomplete)的, 并且覆盖度(coverage)的缺失会损害下游应用(application)。预测知识库中的缺失信息是统计关系学习(statistical relational learning: SRL)的主要关注点。遵从之前关于
SRL的工作,我们假设知识库存储形式为三元组(subject, predicate, object)的集合。例如,考虑三元组(Mikhail Baryshnikov, educated at, Vaganova Academy),我们将Baryshnikov和Vaganova Academy称作实体(entity),将educated at称作关系(relation)。此外,我们假设实体标有类型(如,Vaganova Academy被标记为大学)。将知识库表示为有向的、带标签的multigraph很方便,其中实体对应于节点,而三元组被labled edge所编码。如下图所示,红色的标签以及边代表缺失信息,是需要我们推断的。。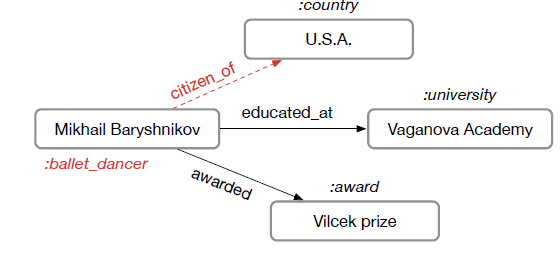
考虑两个基本的
SRL任务:链接预测(missing triple的recovery)、实体分类(为实体分配类型或离散属性)。在这两种情况下,许多缺失的信息都可以预期存在于通过邻域结构(neighborhood structure)编码的图中。例如,知道Mikhail Baryshnikov在Vaganova Academy接受教育,这同时意味着Mikhail Baryshnikov应该有标签person、以及三元组(Mikhail Baryshnikov, lived in, Russia)必须属于知识图谱(knowledge graph)。遵循这个直觉,论文《Modeling Relational Data with Graph Convolutional Networks》为关系图(relational graph)中的实体开发了一个编码器模型,并将其应用于这两个任务。论文的实体分类模型与
GCN类似,并在图中的每个节点处使用softmax分类器。分类器采用relational graph convolutional network: R-GCN提供的node representation来预测label。模型是通过优化交叉熵损失来学习的。论文的链接预测模型可以被视为一个自编码器(
autoencoder),它由一个encoder和一个decoder组成,其中:encoder:一个R-GCN,它用于产生实体的latent feature representation。decoder:一个张量分解模型,它利用这些实体的representation来预测edge label。尽管原则上任何类型的因子分解模型(或者任何评分函数)都可以作为解码器,但是这里作者使用最简单、最有效的因子分解方法:DistMult。
作者观察到,论文的方法在标准
benchmark上取得了有竞争力的结果,优于直接的因子分解模型(如普通的DistMult)。当我们考虑更具挑战性的FB15k-237数据集时,这种改进尤其大。这些结果表明:在R-GCN中对邻域进行显式建模有利于恢复知识库中的missing fact。论文的贡献如下:
首先,据作者所知,这是第一个证明
GCN框架可以应用于建模关系数据(relational data)(尤其是链接预测和实体分类任务)的人。其次,作者介绍了参数共享和强制稀疏约束(
enforce sparsity constraint)的技术,并使用它们来将R-GCN应用于具有大量关系的multigraph。最后,作者展示了分解模型(以
DistMult为例)的性能可以通过使用编码器模型来显著提高,其中该编码器在关系图(relational graph)中执行多个信息传播step。
相关工作:
关系建模:我们用于链接预测的
encoder-decoder方法依赖于解码器中的DistMult,这是RESCAL分解的一种特殊且更简单的情况,在multi-relational knowledge base的背景下比原始的RESCAL更高效。人们在
SRL的背景下已经提出和研究了许多替代的分解模型,包括线性分解模型和非线性分解模型,其中许多方法可以被视为经典的张量分解方法(如CP或Tucker)的修改或特殊情况。对于张量分解模型的全面综述,推荐阅读论文《Tensor decompositions and applications》。合并实体之间的
path到知识库中最近受到了相当大的关注。我们可以将先前的工作分为三个方向:创建辅助三元组(
auxiliary triple)的方法,然后该方法将辅助三元组添加到分解模型的目标函数中。在预测
edge时使用path(或walk)作为特征的方法。同时采用这两个方法。
第一个方向在很大程度上与我们的方向正交,因为我们也预期通过向我们的损失函数中添加类似的项来改善(即,扩展我们的解码器)。
第二个方向更具有可比性,
R-GCN为这些基于path的模型提供了一种计算成本更低的替代方案。直接比较有些复杂,因为path-based方法使用不同的数据集(如,来自知识库的walk的sub-sampled子集)。graph上的神经网络:我们的R-GCN编码器模型与graph上神经网络领域的许多工作密切相关。R-GCN编码器的主要动机是:对先前的GCN工作的适配,使其适用于大规模和高度multi-relational的数据(这是真实世界知识库的特点)。该领域的早期工作包括
《The graph neural network model》的GNN。人们后续对原始GNN提出了许多扩展,最值得注意的是《Gated graph sequence neural networks》和《Column networks for collective classification》,它们都利用了门控机制来促进优化过程。R-GCN可以进一步被视为消息传递神经网络(《Neural message passing for quantum chemistry》)的一个子集,基于可微的消息传递解释。其中,消息传递神经网络包含许多先前的、用于图的神经网络,包括GCN。
1.1 模型
定义一个有向(
directed)、带标签 (labeled) 的multi-graph为relation),其中
1.1.1 R-GCN
我们的模型主要受到
GCN所启发,并将基于局部图邻域(local graph neighborhood)的GCN扩展到大规模的关系数据。GCN相关的方法(如图神经网络)可以理解为简单的、可微的消息传递框架:其中:
incoming message)的集合,它通常等于传入边(incoming edge)的集合(即每条边代表一条消息)。输入的消息按照
message-specific的、类似于神经网络的函数或者仅仅是线性变换
事实证明,这类变换非常有效地从局部的、结构化邻域中累积和编码特征,并在诸如图形分类、图半监督学习领域带来显著改进。
受此类架构的影响,我们在
relational multi-graph中定义了以下简单的消息传播模型:其中:
这里采用单个
representationproblem-specific正则化常数。它可以从数据中学习,也可以预先选择,如attention机制来学习。为了确保可以直接通过节点
skip-connection。这里
one-hot编码(不需要引入embedding layer,因为这种情况下图神经网络的第一层就是embedding layer)。
直观来看,上式累加了相邻节点的特征向量并进行归一化。与常规的
GCN不同,这里我们引入特定于具体关系edge的类型和方向。也可以选择更灵活的函数来替代这里简单的线性变换,如多层神经网络(但是计算代价会更高)。我们把它留待未来的工作。
上式在每个节点的每一层(
layer)执行,实践中通常采用稀疏矩阵乘法来有效实现,从而避免对邻域进行显式求和。可以堆叠多个层,从而允许跨多个关系链的依赖性。
我们将这个图编码器模型称作关系图卷积网络
R-GCN,R-GCN模型中单个节点的更新计算图如下所示。红色节点为待更新的节点,蓝色节点为邻域节点。我们首先收集来自不同类型的相邻节点以及自身的消息,对每种类型的消息在变换之后归一化求和得到绿色的
representation。最后将不同类型的representation相加并通过激活函数,从而得到节点更新后的representation。可以在整个图上共享参数,从而并行地计算每个节点的更新。
整个
R-GCN模型就是堆叠大量的这种层,其中上一层的输出作为下一层的输入。如果实体没有特征,则可以将每个节点的one-hot作为第一层的输入。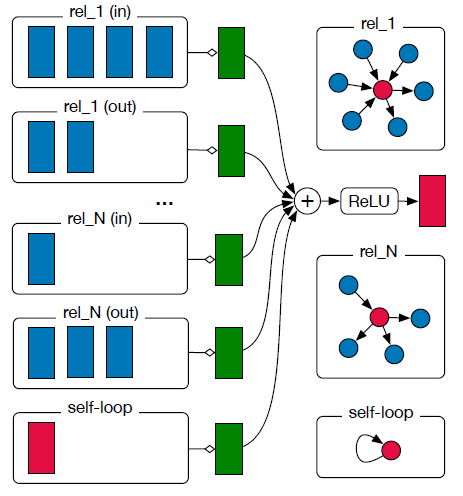
1.1.2 正则化
如果关系类型数量非常庞大,则
R-GCN模型的参数数量爆炸性增长。实际上,这很容易导致模型对稀疏关系的过拟合,并且模型非常庞大。为解决该问题,我们引入两种不同的方法来正则化
R-GCN:basis-decomposition基分解,以及block-diagonal-decomposition块对角分解。basis-decomposition:每个权重其中
这里
block-diagonal-decomposition:令其中
基分解可以视为不同关系类型之间共享权重的一种方式;块对角分解可以视为每种关系类型权重矩阵的稀疏性约束。块分解结构认为:可以将潜在特征分组,使得组内的特征相比组外的特征更为紧密地耦合。
这两种分解都减少了高度
multi-relational的数据(如知识库)所需要的参数数量。同时,我们期望基分解能够缓解稀疏关系的过拟合,因为稀疏关系和非稀疏关系共享基变换矩阵。然后,整个
R-GCN模型堆叠one-hot编码作为模型的输入。虽然我们在这项工作中仅考虑了这种无特征(
featureless)的方法,但是我们注意到GCN的工作表明:这类模型可以使用预定义的特征向量(如,节点的描述文本的bag-of-words)。
1.1.3 实体分类
在节点分类任务中,我们将
R-GCN最后一层(假设有softmax层。我们最小化所有标记节点的交叉熵(忽略所有未标记节点):其中:
定义好目标函数之后,我们使用随机梯度下降来训练模型。
虽然我们在目标函数中仅使用了标记节点,但是这并不意味着算法未使用非标记节点。因为在计算
此外,我们还可以在目标函数中显式添加
LINE算法之类的非监督损失,从而迫使相邻的节点具有相似的embedding。
1.1.4 链接预测
在链接预测任务中,我们的目标是给定可能的链接
普通的链接预测任务需要只需要预测二元组
为解决该问题,我们引入一个图自编码器模型,该模型由一个节点编码器和一个评分函数(解码器)组成。
编码器将每个实体
解码器根据节点的
representation来重建图的边。换句话说,它通过一个评分函数(subject, relation, object)打分:
可以在此框架下解释大多数现有的链接预测方法,但是我们工作的关键区别在于编码器。之前大多数方法直接在训练中优化每个节点
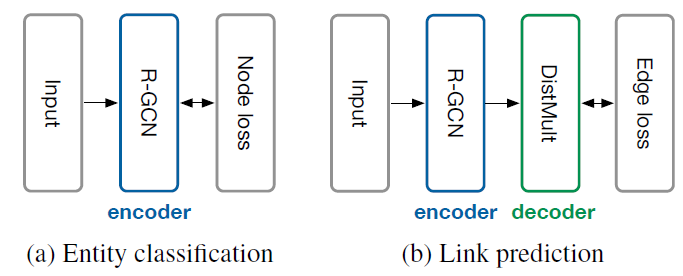
representation向量R-GCN编码器来学到整体架构如下图所示。其中:
图
(a)表示节点分类的R-GCN模型,每个节点具有一个损失函数。图
b表示链接预测模型,包含R-GCN编码器,以及DistMult作为解码器,每条边具有一个损失函数。
在链接预测任务中,我们使用
DistMult因子分解作为解码器(评分函数),该方法独立地应用于标准链接预测baseline时表现良好。在
DistMult方法中,每个关系和之前的矩阵分解工作一样,我们使用负样本来训练模型。对于每个观察到的“正边”,我们随机采样
(subject, predicate, object),我们通过随机选择不同的subject或者不同的object来采样。我们选择交叉熵作为损失函数,目标是最大化“正边”概率、最小化“负边”概率:
其中:
1.2 实验
1.2.1 实体分类
数据集:我们评估了四个数据集,它们以
Resource Description Framework: RDF格式来描述。数据集中的关系不一定要编码为有向的subject-object关系,也可以编码为给定实体之间存在或者不存在某个指定的属性。在每个数据集中,要分类的目标是一组实体的属性。我们删除了用于创建
label的信息,如:AIFB的雇员和从属关系、MUTAG的is Mutagenic关系、BGS的hasLithogenesis关系、AM的objectCategory和material关系。数据集的统计信息见下表,其中
Labeled表示那些带标签的、用于分类的节点,它是所有节点的子集。我们采用
《A collection of benchmark datasets for systematic evaluations of machine learning on the semantic web》的benchmark训练集、测试集拆分的方式,并在训练集的基础上继续拆分20%样本作为验证集从而进行超参数调优。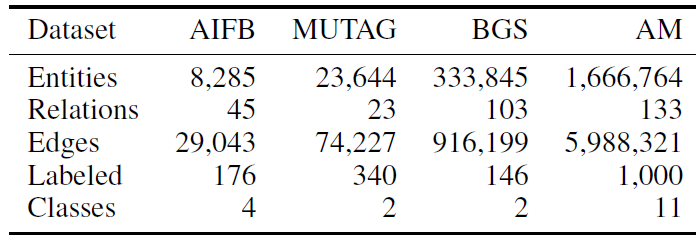
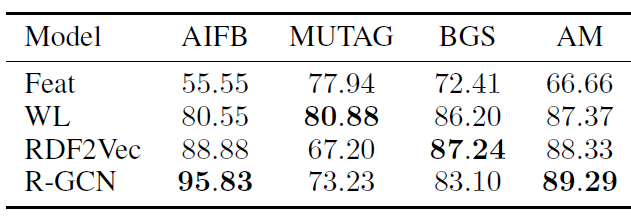
Baseline方法:我们对比了最近的SOTA方法:RDF2VEC embedding、Weisfeiler-Lehman kernel: WL、人工设计的特征提取器Feat。Feat根据每个节点的入度(in-degree)、出度(out-degree)来拼接每个节点的特征向量,即feature-based方法。RDF2VEC在图上执行随机游走,然后基于SkipGram模型来从随机游走序列中学习节点embedding,然后该embedding用于下游的分类任务。
配置:
我们的
R-GCN模型采用两层隐层,隐层维度为16维(AM数据集的隐层维度为10),并采用基分解的正则化方式。我们使用
Adam优化器训练50个epoch,学习率为0.01。最后,我们选择归一化常数为
所有实体分类实验均在具有
64GB内存的CPU节点上运行。
评估指标:测试集的
accuracy。实验效果如下表所示,结论:我们的模型在
AIFB和AM上取得最好的效果,在MUTAG和BGS数据集上效果较差。为了探究
R-GCN模型为什么在MUTAG和BGS数据集上效果较差,我们深入洞察了这些数据集的性质。MUTAG是分子图的数据集,后来被转换为RDF格式,图中的关系要么表示原子键、要么表示某个属性是否存在。BGS是具有分层特征描述(hierarchical feature description)的岩石(rock)的类型,这些描述类似地转换为RDF格式,图中的关系编码了特定属性是否存在、或者属性的层级关系。
MUTAG和BGS中的标记节点仅仅通过编码了某种特征的high-degree的中心节点所连接。我们推测:采用固定的归一化常数对于degree很高的节点可能会成为问题,这导致了我们的模型在MUTAG/BGS数据集上效果不佳。克服该问题的一种潜在解决方案是:引入一种注意力机制
1.2.2 链接预测
数据集:链接预测任务通常在
FB15k(关系数据库Freebase的子集)和WN18(WordNet的子集)上评估。但是在《Observed versus latent features for knowledge base and text inference》中,这两个数据集都观察到严重的缺陷:训练集中的三元组LinkFeak,其效果都很大程度上优于现有的方法。LinkFeak仅仅是将观察到的关系作为特征向量(该特征向量非常稀疏)作为输入,然后采用线性分类器进行分类。为解决该问题,
《Observed versus latent features for knowledge base and text inference》提出了一个简化的数据集FB15k-237,它删除了所有这些逆三元组。因此我们选择FB15k-237作为我们的主要评估数据集。由于FB15k和WN18仍被广泛使用,因此我们也包含这些数据集的结果。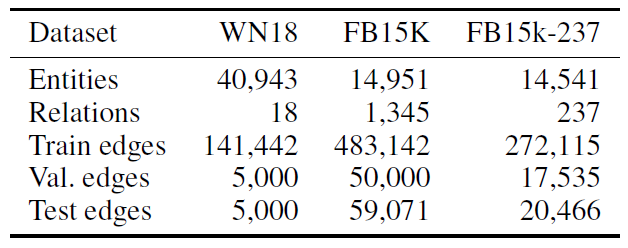
baseline方法:DistMult:对每个节点直接优化embedding,而不是R-GCN编码器。LinkFeat:《Observed versus latent features for knowledge base and text inference》提出的简单的基于邻域的方法。ComplEx:将DistMult泛化为复数域来提升对非对称关系的建模。HoIE:利用circular correlation代替了vector-matrix的乘积。
最后,我们还包含了两种经典算法的比较:
CP(《The expression of a tensor or a polyadic as a sum of products》)和TransE(《Translating embeddings for modeling multi-relational data》)。我们使用两种常用的评估指标:
mean reciprocal rank: MRR、Hits at n: H@n。我们报告了raw MRR, filtered MRR,以及n=1,3,10时的filtered Hits。filtered MRR指的是:对于排名差于n,其排名倒数置为零。配置:
我们通过验证集来选择
R-GCN的超参数。我们发现归一化常数设定为
对于
FB15k和WN18,我们使用具有两个基矩阵的基分解正则化,以及使用200维的单层编码器。对于
FB15k-237,我们发现块对角分解正则化的效果最好,block的大小为5 x 5,同时我们使用500维的两层编码器。我们对编码器执行
dropout正则化,dropout位置在normalization之前,dropout比例为:对于self-loop为0.2,对于其它边为0.4。使用dropout正则化使得我们的训练目标类似于降噪自编码器。我们对解码器执行
0.01。我们使用
Adam优化器,学习率为0.01。
对于
baseline模型,我们从《Complex embeddings for simple link prediction》中的参数(除了FB15k-237数据集上的维度)。为了使得不同方法具有可比性,我们对不同方法采用相同的负样本采样比例(如
对所有的模型,我们使用
full-batch优化。
我们给出了
FB15k数据集上,R-GCN和DistMult在不同degree上的表现。这里的degree表示三元组中subject, object节点的degree均值。在FB15k上,与R0GCN模型的设计形成对比的是,逆关系(inverse relation)形式的局部上下文 (local context) 将主导(dominate)分解的性能。可以发现:
R-GCN在上下文丰富的节点上(即degree较高)表现良好,而DistMult在上下文稀疏的节点上表现较好。我们观察到这两种模型是互补的,因此可以将这两种模型的优势结合在一起,成为一个新的模型,我们称之为R-GCN+:其中
FB15k的验证集来选择的。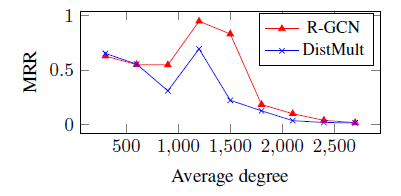
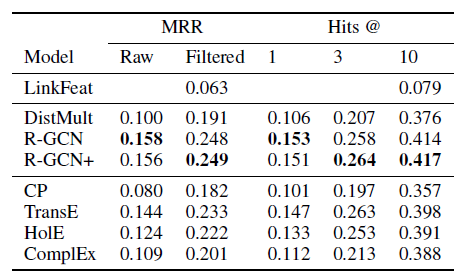
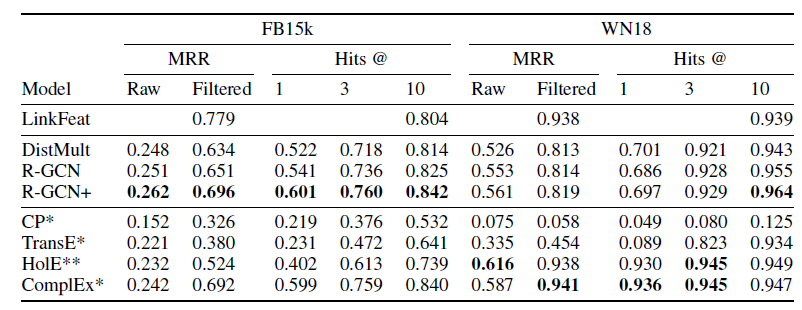
我们给出不同模型在
FB15k和WN18上的表现,其中标记*的结果来自于《Complex embeddings for simple link prediction》, 标记**的结果来自于《Holographic embeddings of knowledge graphs》。R-GCN和R-GCN+均超越了DistMult。但是,和LinkFeat相比,R-GCN和R-GCN+方法均表现不佳。这突出了逆关系的贡献。有意思的是:在
FB15k上R-GCN+超越了CompIEx,尽管R-GCN并未显式建模非对称关系而CompIEx显式建模了非对称关系。这表明:将
R-GCN编码器与CompIEx的解码器相结合,可能是未来工作的一个有前景的方向。解码器的选择和编码器的选择是相互独立的,原则上可以使用任何模型作为解码器,因此可以考虑使用ComIEx作为解码器从而在R-GCN+中显式建模非对称关系。
在
FB15k-237数据集上逆关系被删除,此时LinkFeat效果非常差。而我们的R-GCN比DistMult提升29.8%,这显示了编码器模型的重要性。另外R-GCN/R-GCN+优于所有其它方法。