一、JK-Net [2018]
《Representation Learning on Graphs with Jumping Knowledge Networks》
图是一种普遍存在的结构,广泛出现在数据分析问题中。现实世界的图(如社交网络、金融网络、生物网络和引文网络)代表了重要的丰富的信息,这些信息无法仅仅从单个实体中看到(如一个人所在的社区、一个分子的功能角色、以及企业资产对外部冲击的敏感性)。因此,图中节点的
representation learning旨在从节点及其邻域中抽取高级特征,并已被证明对许多application非常有用,如节点分类、节点聚类、以及链接预测。最近的工作集中在
node representation的深度学习方法上。其中大多数深度学习方法遵循邻域聚合(也称作消息传递message passing)方案。这些模型迭代式地聚合每个节点的hidden feature及其周围邻域节点的hidden feature,从而作为该节点的新的hidden feature。其中每一次迭代都由一层神经网络来表示。理论上讲,执行hidden feature的聚合过程,利用了以节点Weisfeiler-Lehman图同构测试(graph isomorphism test)的推广,并且能够同时学习图的拓扑结构以及邻域节点特征的分布。但是,这种聚合方式可能会产生出人意料的结果。例如,已经观察到
GCN的深度为2时达到最佳性能;当采用更深网络时,虽然理论上每个节点能够访问更大范围的信息,但是GCN的效果反而更差。在计算机视觉领域中,这种现象称作学习退化 (degradation),该问题可以通过残差连接来解决,这极大地帮助了深度模型的训练。但是在GCN中,在很多数据集(如,引文网络)上即使采用了残差连接,多层GCN的效果仍然比不过2层GCN。基于上述观察,论文
《Representation Learning on Graphs with Jumping Knowledge Networks》解决了两个问题:首先,论文研究了邻域聚合方案的特点及其局限性。
其次,基于这种分析,论文提出了
jumping knowledge network: JK-Net框架。该框架和现有的模型不同,JK-Net为每个节点灵活地利用不同的邻域范围,从而实现自适应的结构感知表示 (structure-aware representation)。
通过大量实验,论文证明了
JK-Net达到了SOTA性能。另外,将JK-Net框架和GCN/GraphSage/GAT等模型结合,可以持续改善这些模型的性能。模型分析:为评估不同邻域聚合方案的行为,论文分析了节点
representation依赖的邻域范围。论文通过节点的影响力分布 (the influence distribution)(即不同邻域节点对于representation的贡献的分布)来刻画这个邻域范围。邻域范围隐式的编码了nearest neighbors的先验假设。具体而言,我们将看到这个邻域范围严重受到图结构的影响。因此引发了一个疑问:是否所有的节点
tree-like子图、expander-like子图)。进一步地,论文形式化地分析将
eigenvalue)的函数。改变的局部性(
changing locality):为了说明图结构的影响和重要性,请回想一下许多现实世界的图具有强烈局部变化的结构(locally strongly varying structure)。在生物网络和引文网络中,大多数节点几乎没有连接,而一些节点 (hub)连接到许多其它节点。社交网络和web网络通常由expander-like部分组成,它们分别代表well-connected实体和小社区 (small community)。除了节点特征之外,这种子图结构对于邻域聚合结果也有非常大的影响。邻域范围扩张的速度(或者叫影响半径的增长)通过随机游走的
mixing time来刻画(即:从节点例如考虑如下
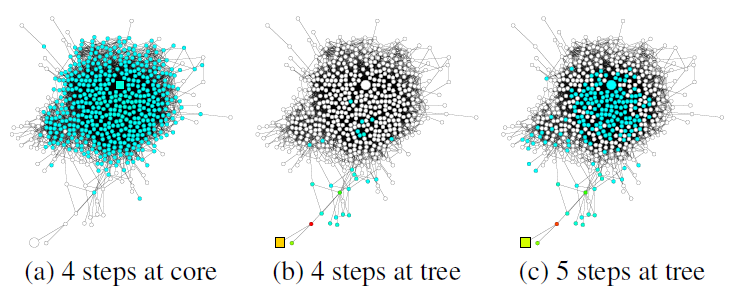
GooglePlus的社交网络,该图说明了从正方形节点开始的随机游走的扩散(随机游走的扩散也代表了影响力分布的扩散)。可以看到:不同结构的子图带来不同的邻域范围。图
a中,来自核心区域内节点的随机游走很快就覆盖了几乎整个图(随机游走覆盖的节点以绿色表示)。图
b中,来自tree形区域节点的随机游走经过相同的step之后,仅覆盖图的一小部分(随机游走覆盖的节点以绿色表示)。图
c中,来自tree形区域节点使用更长的step之后达到了核心区域,并且影响力突然快速扩散。
在
graph representation模型中,这种随机游走的扩散转换为影响力分布。这表明:在同一个图中,相同数量的随机游走step可以导致非常不同的效果。因此我们需要根据具体的图,同时结合较大的邻域范围和较小的邻域范围:太大的邻域范围可能会导致过度平滑,从而丢失局部信息。
太小的邻域范围可能信息不足,从而不足以支撑准确的预测。
JK network:上述观察提出一个问题:能否有可能对不同的图和不同的节点自适应地调整邻域范围。为此论文《Representation Learning on Graphs with Jumping Knowledge Networks》提出了JK-Net框架,该框架在网络最后一层选择性地组合不同邻域范围,从而自适应地学习不同邻域的局部性(locality)。如,将不同邻域范围jump到最后一层,因此这个网络被称作Jumping Knowledge Networks: JK-Nets。相关工作:谱图卷积神经网络 (
spectral graph convolutional neural network)使用图拉普拉斯特征向量作为傅里叶基,从而在图上应用卷积。与诸如邻域聚合之类的空间方法(spatial approach)相比,谱方法(spectral method)的一个主要缺点是:需要提前知道图拉普拉斯矩阵(是transductive的)。因此,谱方法无法推广到unseen的图。
1.1 模型
定义图
定义图
假设基于消息传递的模型有
hidden feature为hidden feature的维度。为讨论方便,我们选择所有层的hidden feature维度都相等。另外,我们记定义节点
则典型的消息传递模型可以描述为:对于第
hidden feature更新方程为:其中:
AGG为聚合函数,不同的模型采用不同的聚合函数。
GCN图卷积神经网络(《Semi-supervised classification with graph convolutional networks》)hidden feature更新方程为:其中
degree。《Inductive representation learning on large graphs》推导出一个在inductive learing中的GCN变体(即,GraphSAGE),其hidden feature更新方程为:其中
degree。Neighborhood Aggregation with Skip Connections:最近的一些模型并没有同时聚合节点及其邻域,而是先聚合邻域,然后将得到的neighborhood representation和节点的上一层representation相结合。其hidden feature更新方程为:其中
在这种范式中,
COMBINE函数是关键,可以将其视为跨层的跳跃连接(skip connection)。 对于COMBINE的选择,GraphSAGE在特征转换之后直接进行拼接,Column Network对二者进行插值,Gated GCN使用GRU单元。但是,该跳跃连接是
input-specific的,而不是output-specific的。考虑某个节点skip。则后续更高层skip。我们无法做出这样的选择:对于第skip、对于第skip。即跳跃连接是由输入决定,而不是由输出决定。因此,跳跃连接无法自适应地独立调整final-layer representation的邻域大小。Neighborhood Aggregation with Directional Biases:最近有些模型没有平等地看到邻域节点,而是对“重要”的邻居给与更大的权重。可以将这类方法视为directional bias的邻域聚合,因为节点受到某些方向的影响要大于其它方向。例如:
GAT和VAIN通过attention机制选择重要的邻居,GraphSAGE的max-pooling隐式地选择重要的邻居。这个研究方向和我们的研究方向正交。因为它调整的是邻域扩张的方向,而我们研究的是调整邻域扩张的范围。我们的方法可以和这些模型相结合,从而增加模型的表达能力。
在下文中,我们证明了
JK-Net框架不仅适用于简单的邻域聚合模型(GCN),还适用于跳跃连接 (GraphSAGE)和directional bias(GAT)。
1.1.1 影响力分布
我们首先利用
《Understanding black-box predictions via influence functions》中的敏感性分析(sensitivity analysis) 以及影响力函数的思想,它们衡量了单个训练样本对于参数的影响。给定节点representation。从这个影响范围,我们可以了解到节点我们通过衡量节点
final representation的影响程度,从而测量节点影响力得分和分布的定义:给定一个图
hidden feature,final representation。定义雅可比矩阵:
定义节点
influence score)为:雅可比矩阵其中:
定义节点
influence distribution)为:所有节点对于节点对于任何节点
representation的影响。考虑在
其物理意义为:随机游走第
类似的定义适用于具有非均匀转移概率的随机游走。
随机游走分布的一个重要属性是:如果图是非二部图(
non-bipartite),则它随着spread,并收敛到极限分布。收敛速度取决于以节点spectral gap(或者conductance) 的限制(bounded) 。
1.1.2 模型分析
不同聚合模型和节点的影响力分布可以深入了解各个
representation所捕获的信息。以下结果表明:常见的聚合方法的影响力分布和随机游走分布密切相关。这些观察暗示了我们接下来要讨论的优缺点。假设
relu在零点的导数也是零(实际上relu函数在零点不可导),则我们得到GCN和随机游走之间的关系:定理:给定一个
GCN变体,假设以相同的成功率证明:令
则有:
这里我们简化了
这里
假设存在
其中
则根据链式法则,我们有:
对于每条路径
现在我们考虑偏导数
其中
relu激活函数在假设
因此有:
另外,我们知道从节点
假设每一层的权重相同:
这里的证明缺少了很多假设条件的说明,因此仅做参考。
很容易修改上述定理的证明,从而得到
GCN版本的近似结果。唯一区别在于,对于随机游走路径其中
degree接近时。类似地,我们也可以证明具有
directional bias的邻域聚合方案类似于有偏的随机游走分布。这可以通过替换掉上述定理中相应的概率得到证明。从经验上看,我们观察到即使假设有所简化,但是我们的理论分析仍然接近于实际情况。
我们可视化了训练好的
GCN的节点(正方形标记)的影响力分布的热力图,并与从同一节点开始的随机游走分布的热力图进行比较。较深的颜色对应于较高的影响力得分(或者较高的随机游走概率)。我们观察到GCN的影响力分布对应于随机游走分布。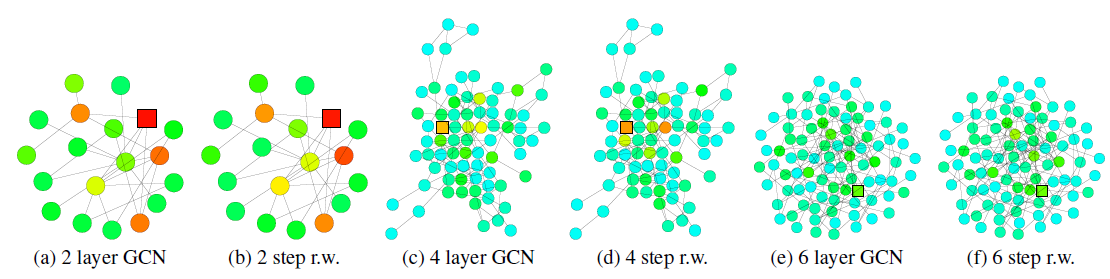
为显示跳跃连接的效果,下图可视化了一个带跳跃连接的
GCN的节点的影响力分布热力图。同样地,我们发现带跳跃连接的GCN的节点影响力分布大致对应于lazy随机游走分布(lazy表示每步随机游走都有较高的概率停留在当前节点,这里lazy因子为0.4)。由于每次迭代过程中,所有节点的局部信息都以相似的概率进行保留,因此这无法适应不同高层节点的各种各样的需求。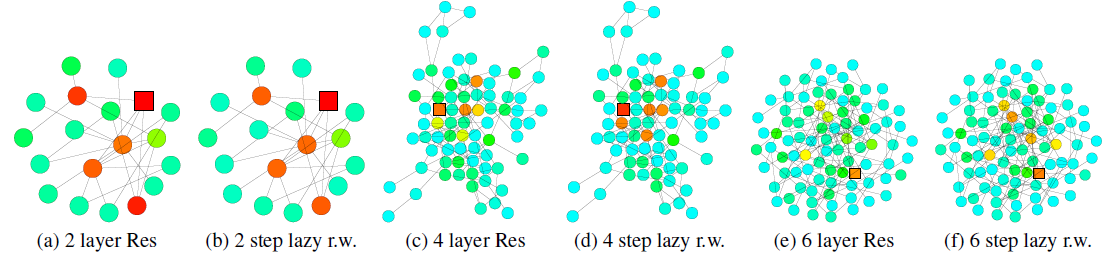
为进一步理解上述定理,以及相应邻域聚合算法的局限性,我们重新审视了下图中社交网络的学习场景。
对于
expander(左图)内部开始的随机游走以step快速收敛到几乎均匀分布。根据前述的定理,在经过representation几乎受到expander中所有任何其它节点的影响。因此,每个节点的representation将代表global graph,以至于过度平滑并带有节点自身的非常少的信息。对于
tree-like(右图)开始的随机游走,其收敛速度较慢。这使得经过消息传递模型的聚合之后,每个节点的representation保留了更多的局部信息。
如果消息传递模型的层数
representation。最后我们描述了热力图的相关细节,并提供了更多的可视化结果。
热力图中的节点颜色对应于影响力分布得分或者随机游走分布的概率。颜色越浅则得分越低、颜色越深则得分越高。我们使用相同的颜色来表示得分(或者概率)超过
0.2的情形,因为很少有节点的影响力得分(或概率)超过0.2。对于得分(或概率)低于0.001的节点,我们没有在热力图中展示。首先我们比较
GCN的影响力分布vs随机游走概率分布,以及带跳跃连接的GCN的影响力分布vs惰性随机游走概率分布。目标节点(被影响的节点或者随机游走的起始节点)标记为方块。
数据集为
Cora citation网络,模型分别为2/4/6层训练好的GCN(或者带跳跃连接的GCN Res)。我们使用《Semi-supervised classification with graph convolutional networks》描述的超参数来训练模型。影响力分布、随机游走分布根据前述的公式进行计算。
lazy随机游走使用lazy factor = 0.4的随机游走,即每个节点在每次转移时有0.4的概率留在当前节点。注意:对于
degree特别大的节点,GCN影响力和随机游走概率的颜色有所不同。这是因为我们这里的GCN是基于公式这使得在
GCN影响力模型中,degree更大的节点,其权重越低。
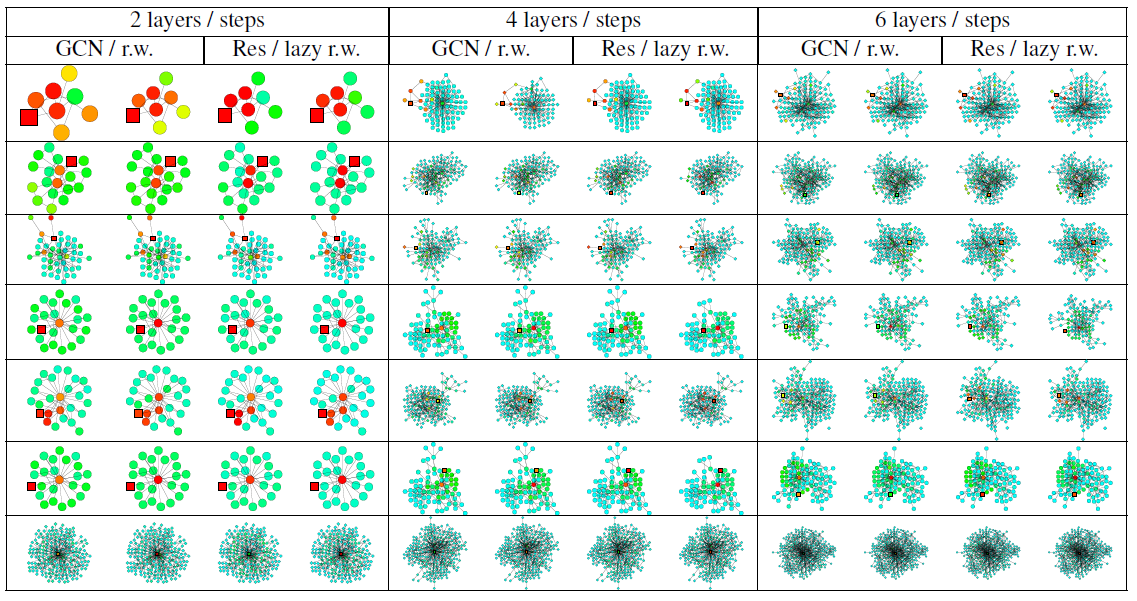
然后我们考察了不同子结构,这些可视化结果进一步支持了前述的定理。
下图中,使用
2层的GCN模型分类错误,但是使用3层或4层GCN模型分类结果正确。当局部子图结构是
tree-like时,如果仅仅使用2层GCN(即查看2-hop邻域),则抽取的信息不足以支撑其预测正确。因此,如果能够从3-hop邻域或4-hop邻域中抽取信息,则可以学到节点的局部邻域的更好表示。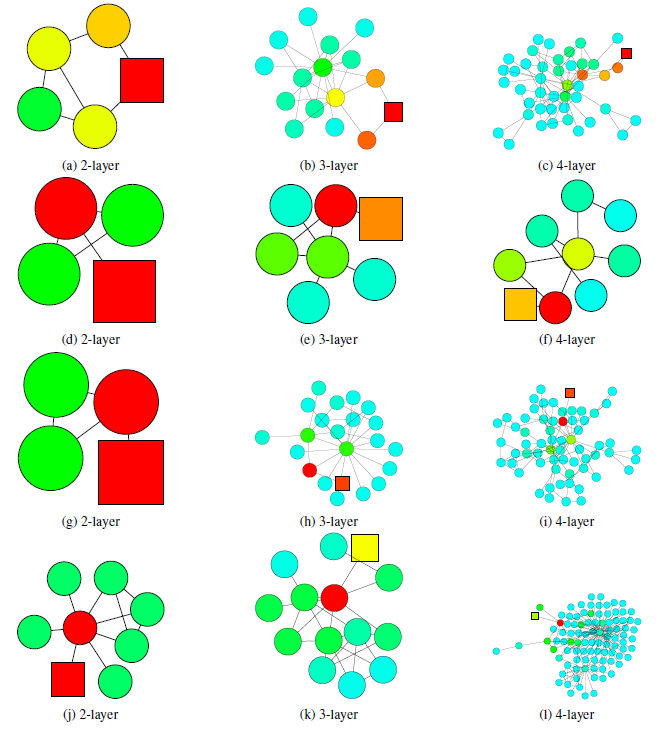
下图中,使用
3或4层的GCN模型分类错误,但是使用2层GCN模型分类结果正确。这意味着从3-hop或4-hop邻域中抽取了太多无关的信息,从而使得节点无法学到正确的、有助于预测的representation。在
expander子结构中,随机游走覆盖的节点爆炸增长,3-hop或者4-hop几乎覆盖了所有的节点。因此这种全局信息的representation对于每个节点的预测不是很理想。在
bridge-like子结构中,抽取更远的节点的信息可能意味着从一个完全不同的community中获取信息,这可能意味着噪音并影响最终预测。
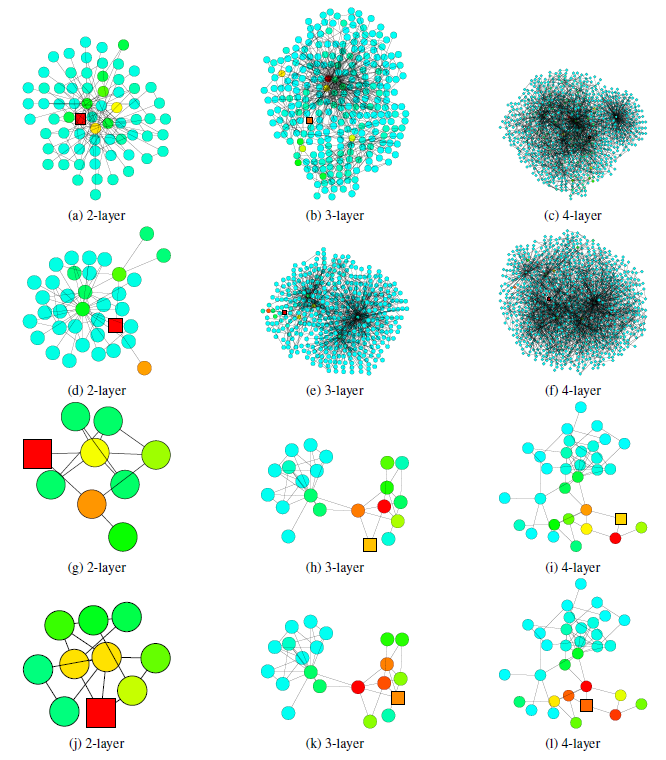
1.1.3 JK-Net
前述观察提出了一个问题,即:在通用聚合方案中使用固定的、但是结构依赖的影响力半径大小是否能够实现所有任务中节点的
best representation。如果选择的影响力半径过大,则可能导致过度平滑(
oversmoothing)。如果选择的影响力半径国小,则可能导致聚合的信息量不足。
为此,我们提出了两个简单有效的体系结构调整:跳跃连接 + 自适应选择的聚合机制。
如下图所示为
JK-Net的主要思想。和常见的邻域聚合网络一样,每一层都是通过聚合来自上一层的邻域来扩大影响力分布的范围。
但是在最后一层,对于每个节点我们都从所有的这些
intermediate representation中仔细挑选(jump到最后一层),从而作为最终的节点representation。
由于这是针对每个节点独立完成的,因此模型可以根据需要为每个节点调整有效邻域范围,从而达到自适应的效果。
可以理解为常规的
GCN模型之上再添加一个聚合层。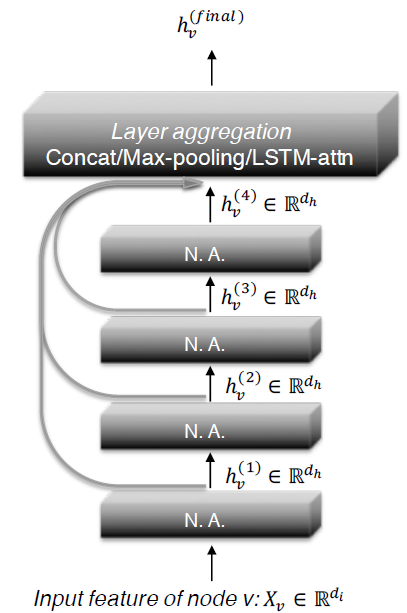
JK-Net也使用通用的层聚合机制,但是最终的节点representation使用自适应选择的聚合机制。这里我们探索三种主要的聚合方法,其它方法也可以在这里使用。令
representation(每个中间层代表了不同的影响力范围),并将它们jump到最后一层。concatenation聚合:直接拼接如果这个线性变换的权重
node-adaptive的。如果这个线性变换的权重
node-adaptive的。
max-pooling聚合:对feature coordinate选择信息最丰富的layer。这种方式是自适应的,并且不会引入任何其它额外的学习参数。LSTM-attention聚合:注意力机制通过对每个节点representation对于节点representation为所有中间层的representation的加权平均:对于
LSTM-attention:先将
LSTM的输入,并对每层LSTM hidden featureLSTM hidden feature然后通过对层
hidden feature然后通过一个
softmax layer应用到attention得分。最后,将
attention得分的加权和,作为节点final representation。
LSTM-attention是node-adaptive的,因为不同节点的attention score是不同的。实验表明,这种方法适用于大型复杂的图。由于其相对较高的复杂度,会导致在小型图上过拟合。另外,也可以将
LSTM和最大池化相结合,即LSTM max-pooling。这种
LSTM聚合的方式太复杂,可以简单地基于
JK-Net的实现比较简单,大量的篇幅都在形容理论。但是,这里的理论仅仅是解释问题,并没有解决问题。这里的layer aggregation方式既没有理论解释,也没有解决问题(针对不同的节点自适应地选择不同的邻域大小):为什么如此聚合?论文未给出原因。
不同的聚合方式代表了什么样的领域大小?这里也没有对应的物理解释。
层聚合(
layer aggregation)函数设计的关键思想是:在查看了所有中间层学到的representation之后,确定不同影响力范围内子图representation的重要性,而不是对所有节点设置固定的、相同的影响力范围。假设
relu在零点的导数也是零(实际上relu函数在零点不可导),则layer-wise max-pooling隐式地自适应地学习了不同节点的局部影响力。layer-wise attention也是类似的。推论:假设计算图中相同长度的路径具有相同的激活概率
layer-wise max-pooling的JK-Net中,对于任意证明:假设经过层聚合之后节点
representation为其中
根据前述的定理,我们有:
其中:
下图给出了采用
max-pooling的6层JK-Net如何学习从而自适应引文网络上不同的子结构。在
tree-like结构中,影响力仍然停留在节点所属的small community中。相反,在
6层GCN模型中,影响力可能会深入到与当前节点不想关的其它community中;而如果使用更浅层的GCN模型,则影响力可能无法覆盖当前节点所在的community。对于
affiliate to hub(即bridge-like)节点,它连接着不同的community,JK-Net学会了对节点自身施加最大的影响,从而防止将其影响力扩散到不想关的community。GCN模型不会捕捉到这种结构中节点自身的重要性,因为在几个随机游走step之后,停留在bridge-like节点自身的概率很低。对于
hub节点(即expander),JK-Net会在一个合理范围内将影响力扩散到相邻节点上。这是可以理解的,因为这些相邻节点和hub节点一样,都具有信息性。

JK-Net的结构有些类似于DenseNet,但是一个疑问是:是否可以像DenseNet一样在所有层之间都使用跳跃连接,而不仅仅是中间层和最后一层之间使用跳跃连接。如果在所有层之间都使用跨层的跳跃连接,并使用layer-wise concatenation聚合,则网络结构非常类似于DenseNet。从
graph theory角度审视DenseNet,图像对应于规则的graph,因此不会面临具有变化的子图结构的挑战。确实,正如我们在实验中看到的,使用concatenation聚合的模型在更规则的图(如图像、结构良好的社区)上表现良好。作为更通用的框架,
JK-Net接受更通用的layer-wise聚合模型,并在具有更复杂结构的图上实现更好的structure-aware representation。
1.2 实验
数据集:
引文网络数据集 (
Citeseer, Cora) :数据集中每个节点代表一篇论文,特征为论文摘要的bag-of-word,边代表论文之间的引用链接。节点类别为论文的主题。Reddit数据集:数据集中每个节点代表一个帖子,特征为帖子所有单词的word vector。如果某个用户同时在两个帖子上发表评论,则这两个帖子之间存在链接。节点类别为帖子所属的community。PPI数据集:数据集包含24个图,每个图对应于一个人体组织的蛋白质结构图。图中每个节点都有positional gene sets, motif gene sets, immunological signatures作为特征,gene ontology sets作为标签。我们使用
20个图进行训练、2个图进行验证、剩余的2个图作为测试。
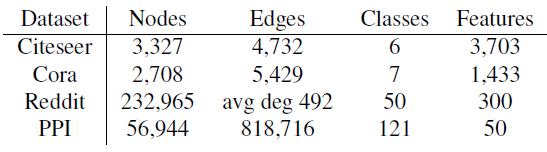
数据集的统计信息如下表所示:
baseline模型:GCN、GraphSage、GAT。实验配置:
在
transductive实验中,我们只允许访问单个图中的节点子集作为训练数据,剩余节点作为验证集/测试集。在
Citeseer, Cora, Reddit数据集上的实验是transductive的。在
inductive实验中,我们使用多个完整的图作为训练数据,并使用训练时未见过的、剩余的图作为验证集/测试集。在
PPI数据集上的实验是inductive的。
对于
Citeseer和Cora数据集,我们选择GCN作为base模型,因为在我们的数据集实验中它超越了GAT。我们分别选择
MaxPooling(JK-MaxPool)、Concatenation(JK-Concat)、LSTM-attention(JK-LSTM)作为最终聚合层来构建JK-Net。在进行最终聚合时,被聚合的representation除了图卷积中间层的representation之外,我们还考虑了第一个线性变换的representation(可以理解为第零层的representation)。最终预测是通过final聚合层的representation之上的全连接层来完成。我们将每个图的节点根据
60%:20%:20%的比例随机拆分为训练集、验证集、测试集。对于每个模型,我们将层数从1到6,针对验证集选择性能最佳的模型(及其对应的卷积层深度)。JK-Net配置:学习率为
0.005的Adam优化器。比例为
0.5的dropout。从
hidden feature维度(Citeseer为16,Cora为32)。在模型参数上添加
0.0005的
每组实验随机执行
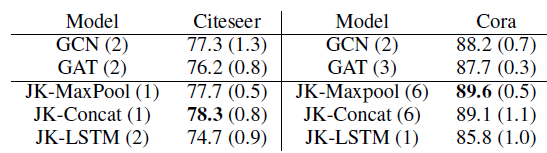
3次并报告准确率accuracy的均值和标准差(标准差在括号中给出),实验结果如下表所示。可以看到:就预测准确率而言,
JK-Net优于GAT和GCN这两个baseline。尽管
JK-Net总体表现良好,但是没有始终如一的赢家,并且各个数据集上的性能略有不同。模型名字后面括号中的数字(
1~6之间)表示表现最佳的层数。仔细研究Cora的结果发现:GCN和GAT都在模型为2层或3层时才能达到最佳准确率。这表明局部信息比全局信息更有助于分类。层数越浅,则表明邻域范围越小,则表明是局部信息。
JK-Net在模型为6层上获得最佳性能,这表明全局信息和局部信息事实上都有助于提高性能。这就是JK-Net这类模型发挥价值的所在。
LSTM-attention可能由于复杂性太高,从而不适用于此类小模型。因此JK-LSTM在这两个数据集中表现最差。
对于
Reddit数据集,由于它太大使得无法由GCN或GAT很好地处理。因此我们使用可扩展性更高的GraphSAGE作为JK-Net的base模型。在
GraphSAGE中存在不同的节点聚合方式,我们分别使用MeanPool和MaxPool来执行节点聚合,然后跟一个线性变换。考虑到JK-Net最后一层的三种聚合模式MaxPooling、Concatenation、LSTM-attention,两两组合得到6种JK-Net变体。我们采用和原始论文完全相同的
GraphSAGE配置,其中模型由两层卷积层组成,hidden layer维度为128维。我们使用学习率维0.01的Adam优化器,无权重衰减。实验结果如下表所示,评估指标维
Micro-F1得分。结论:当采用
MaxPool作为节点聚合器、Concat作为层聚合器时,JK-Net获得了最佳的Micro-F1得分。注意:原始的
GraphSAGE在Reddit数据集上的表现已经足够好(Micro-F1 = 0.950),JK-Net继续将错误率下降了30%。Reddit数据集中的社区是从表现良好的中等规模大小的社区中挑选而来,这是为了避免太大的社区中包含大量噪音、太小的社区是tree-like的。结果,该图比原始Reddit数据集更加规则,因此不会出现子图结构多样性的问题。在这种情况下,
node-specific自适应邻域选择所增加的灵活性可能不是那么重要,而concatenation的稳定特点开始发挥作用。这也是为什么JK-Concat效果较好的原因。
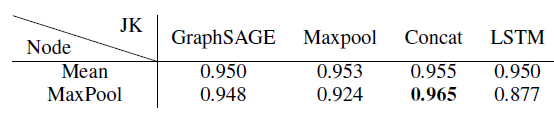
对于
PPI数据集,我们用它来证明自适应JK-Net的强大能力,该数据集的子图结构比Reddit数据集的子图结构更多样和复杂。我们将
GraphSAGE和GAT都作为JK-Net的base model。GraphSAGE和GAT有很大的区别:GraphSAGE基于采样,其中对每个节点的邻域采样固定的邻居数量;GAT基于attention,它考虑每个节点的所有邻居。这种差异在可扩展性和性能方面导致巨大的差距。鉴于GraphSAGE可以扩展到更大的图,因此评估JK-Net在GraphSAGE上的提升显得更有价值。但是我们的实验在二者上都进行。我们的评估指标为Micro-F1得分。对于
GraphSAGE,我们遵循Reddit实验中的配置,只是在可能的情况下使用3层网络,并训练10到30个epoch。带有*的模型采用2层(由于GPU内存限制),其它模型采用3层。作为对比,采用两层的GraphSAGE性能为0.6(未在表中给出)。实验结果见下表。
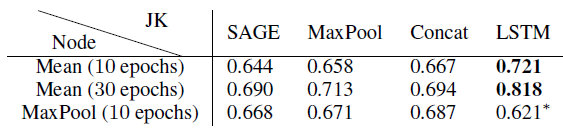
对于
GAT及其JK-Net变体,我们使用两层或三层网络,其中有4个attention head,每个head有256维(共1024维)。最后一个预测层有6个attention head,每个head有121维。我们将这6个head执行均值池化,并灌入到sigmoid激活函数。我们在中间attention层之间引入跳跃链接。所有这些模型都使用学习率为
0.005的Adam优化器,并使用batch size = 2的mini-batch训练。我们的
baseline为GAT和MLP模型,网络层数从2,3之间选择。由于GPU内存限制,JK-Dense-Concat和JK-Dense-LSTM的层数为2。实验结果见下表。
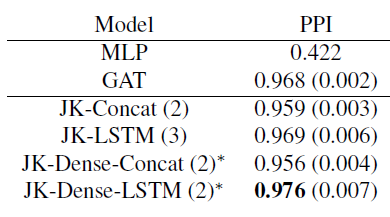
结论:
带有
LSTM-attention聚合器的JK-Net超越了具有concatenation聚合器的非自适应性JK-Net模型,以及GraphSAGE/GAT/MLP等baseline模型。在训练
30个epoch之后,JK-LSTM在Micro-F1得分上比GraphSAGE高出0.128(绝对提升)。结构感知的节点自适应模型在
PPI这类具有不同结构的复杂图上特别有效。