一、PPNP [2018]
《 Predict then propagate: Graph neural networks meet personalized pagerank》
目前有很多流行的图神经网络算法。
graph embedding算法使用随机游走或矩阵分解来直接训练每个节点的embedding,这类算法通常以无监督的方式学习并且不需要节点的特征信息。另外一些方法以有监督方式学习,并且同时利用了图结构和节点特征信息,其中包括谱图卷积神经网络 (
spectral graph convolutional neural network)、消息传递 (message passing)方法(或者也称作邻域聚合neighbor aggregation方法)以及基于RNN的邻域聚合方法。
所有这些方法中,消息传递方法由于其灵活性和良好的性能最近引起了特别的关注。已有一些工作通过使用
attention机制、随机游走、edge feature来改善基础的邻域聚合方式,并使得邻域聚合可以扩展到大图。但是,所有这些方法对于每个节点仅支持非常有限的邻域规模。事实上,如果能够使用更大的邻域,则可以为模型提供更多的有效信息。尤其是对于图的外围节点或者标签稀疏的节点。增加这些算法的邻域大小并不简单,因为这些方法中的邻域聚合本质上是拉普拉斯平滑的一种,如果层数太多将导致过度平滑(
over-smoothing)。在JK-Net的论文中,作者强调了这个挑战,并建立了随机游走和消息传递机制之间的关联。通过这个关联我们发现:随着层数的增加,GCN会收敛到随机游走的极限分布。这个极限分布是整个图的属性,和随机游走的起始节点无关。因此这个分布无法描述随机游走起始节点的邻域(因为过度平滑)。因此GCN的性能必然会随着卷积层数量(具体而言是随着aggregation层的数量)的增加而下降。为解决这个问题,论文
《 Predict then propagate: Graph neural networks meet personalized pagerank》首先分析了这个极限分布和PageRank之间的内在联系,然后提出了personalized propagation of neural predictions: PPNP算法,该算法利用Personalized PageRank衍生而来的消息传递方案。PPNP算法增加了消息回传根节点的机会,从而确保PageRank Score编码了每个根节点的局部邻域。这个回传概率(teleport probability)使得我们能够平衡以下两方面的需求:保留节点的局部性(即,避免过度平衡)vs利用来自大型邻域的信息。作者表明,这种消息传递方案允许使用更多的层(理论上无限多),而不会导致过度平滑。另外,
PPNP的训练时间相比以前的模型相同或者更快,参数数量相比以前的模型相同或者更少,计算复杂度和边的数量呈线性关系。此外,PPNP利用一个大的、可调整的邻域来分类,并且可以轻松地和任何神经网络相结合。实验表明,PPNP超越了最近提出的几种GCN-like的半监督分类模型。在传统的消息传递方法中,
propagation和classification固有地耦合在一起,即classification依赖于propagation。但是在PPNP中,作者将propagation和classification解耦,使得二者相互独立。这使得我们能够在不改变神经网络的情况下实现更大的邻域。而在消息传递方法中,如果想多传递一个step就需要多加一个layer。PPNP的基本思想是:首先预测节点的标签(classification步骤),然后利用标签传播算法重新修正得到最终的标签(propagation步骤)。这种方法有效的前提是:相邻节点具有相似的label。PPNP还允许传播算法、以及根据节点特征执行预测的神经网络独立开发。这意味着我们可以将任何SOTA预测方法和PPNP的传播算法相结合。作者甚至发现:在训练期间没有使用到任何图结构信息的模型,仅在inference阶段使用PPNP的传播算法可以显著提升模型预测的准确性。相关工作:
有些工作试图在每个节点添加跳跃连接,从而改善消息传递算法的训练,以及增加每个节点上可用的邻域大小。如,
JK-Net将跳跃连接和邻域聚合方案相结合。但是这些方法的邻域范围仍然有限,当消息传递的layer数量很少的情况下非常明显。虽然可以在我们的
PPNP中使用的神经网络中添加跳跃连接,但是这不会影响我们的传播方案。因此,我们解决邻域范围的方法和这些模型无关。《Deeper Insights Into Graph Convolutional Networks for Semi-Supervised Learning》通过将消息传递和co-training & self-training相结合来促进训练,通过这种组合实现的改善与其它半监督分类模型报告的结果相似。注意,大多数算法,包括我们的算法,都可以用
co-training & self-training进行改进。但是,这些方法使用的每个additional setp都对应一个完整的训练周期,因此会大大增加训练时间。在最近的工作中,人们通过将跳跃连接和
batch normalization相结合,提出了避免过度平滑问题的Deep GNN(《Mean-field theory of graph neural networks in graph partitioning》、《Supervised Community Detection with Line Graph Neural Networks》)。但是,我们的模型通过解耦预测和传播,从而简化了体系结构并解决该问题。并且我们的方法不依赖于任何临时性(
ad-hoc)技术,这些临时性的技术进一步复杂化模型并引入额外的超参数。此外,我们的
PPNP在不引入额外层的情况下增加了邻域范围,因此和Deep GNN相比,训练速度会更快更容易。
1.1 模型
定义图
假设每个节点
假设每个节点
one-hot向量假设图的邻接矩阵为
self-loops)的邻接矩阵。
1.1.1 GCN 及其限制
卷积神经网络
GCN是一种用于半监督分类的简单且应用广泛的消息传递算法。假设有两层消息传递,则预测结果为:其中:
label分布。
对于两层
GCN,它仅考虑2-hop邻域中的邻居节点。基本上有两个原因使得消息传递算法(如GCN)无法自然地扩展到使用更大的邻域:首先,如果使用太多的层,则基于均值的聚合会导致过度平滑(
over-smoothing)。因此,模型失去了局部邻域的信息。其次,最常用的邻域聚合方案在每一层使用可学习的权重矩阵,因此使用更大的邻域必然会增加神经网络的深度和参数数量。虽然参数数量可以通过权重共享来避免,但这不是通用的做法。
理论上,邻域大小和神经网络的深度是不相关的、完全正交的两个因素。它们应该互不影响才对。实际上在
GCN中它们是相互捆绑的(给定神经网络深度就意味着给定了邻域大小),并导致了严重的性能问题。我们首先关注第一个问题。在
JK-Net中已经证明:对于一个GCN,任意节点如果选择极限
irreducible且非周期性的,则这个随机游走概率分布显然,极限分布取决于整个图,并且独立于随机游走的起始节点
1.1.2 PPNP
我们可以考察极限分布和
PageRank之间的联系来解决这个局部邻域失去焦点(lost focus)问题。极限分布和
PageRank的区别仅在于前者在邻接矩阵中增加了自循环,并对分布进行了归一化。原始的PageRank的分布为:其中
建立这种联系之后,我们现在可以考虑使用结合了根节点的
PageRank变体:Personalized PageRank。我们定义回传向量(
teleport vector)one-hot向量,只有节点1、其它元素为0。对于节点
Personalized PageRank的分布为:其中
teleport probability)(也叫做重启概率)。通过求解该等式,我们得到:
可以看到:通过使用回传向量
因为在该模型中,节点
考虑所有节点的回传向量,则我们得到了完整的
Personalized PageRank矩阵其中
注意到由于对称性
事实上这里需要考虑矩阵
证明:要想证明矩阵
由于
通过
Gershgorin circle theorem可以证明1,因此为了将上述影响力得分用于半监督分类,我们首先根据每个节点的自身特征来生成预测(
prediction),然后通过我们的Personalized PageRank机制来传播prediction从而生成最终的预测结果。这就是personalized propagation of neural predictions: PPNP的基础。PPNP模型为:其中:
注意:由于
PPNP每个节点预测的label分布。
事实上,还可以用任何传播矩阵来代替
可以看到,
PPNP将神经网络预测和图的传播相互分离。这种分离还解决了上述提到的第二个问题:神经网络的深度现在完全独立于传播算法。正如我们将在GCN和PageRank联系时所看到的,Personalized PageRank能够有效地使用无限多个卷积层,这在传统的消息传递框架中显然是不可能的。此外,分离还使得我们可以灵活地运用任何方法来生成预测。这个就是标签传播
label propagation: LP的思想,将MLP和LP相结合。该方法有效的前提是:相邻节点具有相似的label。PPNP传播的是prediction,而传统GCN传播的是representation。虽然在
inference阶段,生成单个节点的预测和传播这个预测是连续进行的(看起来是多阶段的),实际上模型的训练是端到端的。即,在反向传播期间梯度流经传播框架(相当于隐式地考虑了无限多个邻域聚合层)。因此,采用传播框架之后大大提高了模型的准确性。
1.1.3 APPNP
直接计算完整的
Personalized PageRank矩阵为解决这个问题,重新考虑等式:
除了将
Personalized PageRank矩阵prediction矩阵Topic-sensitive PageRank的变体,其中每个类别对应于一个主题。在这个角度下,teleport set。因此,我们可以通过采用Topic-sensitive PageRank来近似计算PPNP,我们称其为approximate personalized propagation of neural predictions: APPNP。APPNP通过Topic-sensitive PageRank的幂次迭代(power iteration)来达到线性复杂度。Topic-sensitive PageRank的幂次迭代和带重启的随机游走相关,它的每个幂次迭代步定义为:其中:
prediction矩阵starting vector和teleport set的作用;注意:这个方法保持了图的稀疏性,并且从未构建一个
但是,
可以证明:当
APPNP收敛到PPNP。证明:
APPNP的迭代公式:在经过
当取极限
这就是
PPNP。PPNP/APPNP的传播框架(propagation scheme)不需要训练任何其它额外的参数。与GCN这样的模型不同,GCN通常需要为每个propagation layer(GCN中的传播层就是聚合层)提供更多的参数。因此,PPNP/APPNP中可以使用很少的参数传播得更远。实验结果表明:这种传播能力确实非常有益。将
PPNP视为不动点(fixed-point)迭代,这和最原始的图神经网络GNN模型存在关联。图神经网络中也是需要通过迭代来求解不动点,但是PPNP和GNN存在以下几点不同:PPNP的不同点迭代实际上通过Personalized PageRank已经求解到,因此直接使用Personalized PageRank矩阵PPNP在传播之前应用学到的特征变换,而GNN中在传播过程中应用学到的特征变换。
PPNP/APPNP中,影响每个节点的邻域大小可以通过回传概率最后,我们给出
PPNP模型的示意图。首先利用神经网络
然后使用
Personalized PageRank来传播预测
注意该模型是端到端训练的,而不是
pipeline训练的。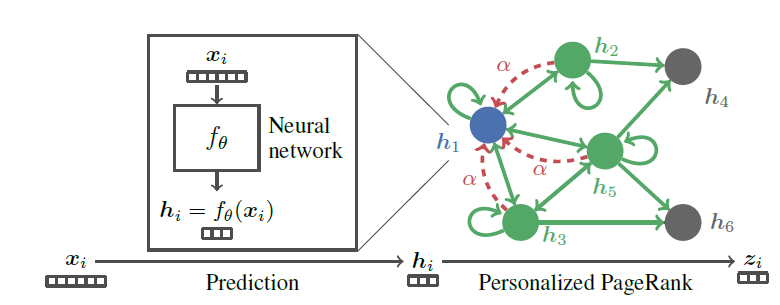
1.2 实验
数据集:我们使用四个文本分类数据集。
CITESEER:引文网络,每个节点代表一篇论文,边代表它们之间的引用。CORA-ML:引文网络,每个节点代表一篇论文,边代表它们之间的引用。PUBMED:引文网络,每个节点代表一篇论文,边代表它们之间的引用。MICROSOFT ACADEMIC数据集:引文网络,每个节点代表一篇论文,边代表co-authorship。
对于每个图,我们使用其最大连通分量。所有数据集都使用论文摘要的
bag-of-word作为特征。下图给出了这些数据集的统计信息,其中SP表示平均最短路径长度。注意:更大的图不一定具有较大的直径(以
SP来衡量)。总体而言,这些图的平均直径为5~10,因此常规的两层GCN网络无法覆盖整个图。
因为使用了不同的训练配置和过拟合,很多实验评估都遭受了肤浅的统计评估(
superficial statistical evaluation)和实验偏差(experimental bias)。实验偏差的原因是:对于训练集/验证集/测试集的单次拆分没有明显区分验证集和测试集,或者对于每个数据集甚至是数据集的每次拆分都微调超参数。正如我们评估结果中显示的,消息传递算法对于数据集的拆分以及权重初始化非常敏感,因此精心设计的评估方法非常重要。
我们的工作旨在建立一个全面彻底的评估方法:
首先,我们对每个实验执行
100次,其中每次都是随机拆分训练集并随机初始化权重。我们采用Glorot权重初始化方法。其次,我们将数据集拆分为可见集和测试集,这种拆分固定不变。其中测试集仅用于报告最终性能,并不会进行训练和超参数择优。
对于引文网络,可见集采样了
1500个节点,剩余节点为测试集。对于
MICROSOFT ACADEMIC网络,可见集采样了5000个节点,剩余节点为测试集。
可见集被随机拆分为训练集、验证集、以及早停集。训练集中每种类别包含
20个节点,早停集包含500个节点,剩余节点作为验证集。我们选择
20个不同的随机数种子并固定下来,接下来选择其中的一部分用于随机拆分可见集--测试集、另一部分用于随机拆分训练集--验证集。 另外,每种数据拆分都进行5次随机初始化,因此实验一共进行100次。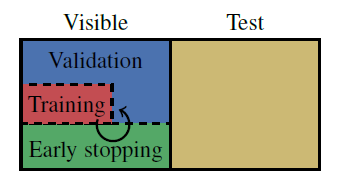
为进一步防止过拟合,考虑到所有实验的数据集都使用
bag-of-word特征,因此我们对所有数据集都采用相同数量的层数、相同的hiddel layer维度、相同的dropout比例、相同的为防止实验偏差,我们使用
CITESEER和CORA-ML上的网格搜索来分别优化所有模型的超参数,并在模型之间使用相同的早停准则:patience = 100的阈值,以及最多epoch(实际上永远无法达到这么多epoch)。只要在早停数据集的准确率提升或者损失函数降低,则重设
patience。我们选择在早停数据集上准确率最高的patience。该准则受到GAT的启发。最后,为了确保我们实验配置的统计鲁棒性,我们通过
bootstrapping计算出置信区间,并报告主要结论的t-test的p-value。
据我们所知,这是迄今为止对
GCN模型的最严格的研究。Baseline方法:GCN:图卷积神经网络。N-GCN:结合了无监督的随机游走和半监督学习两方面优势的N-GCN模型。GAT:图注意力神经网络。bootstrapped feature propagation: FP:将经典的线性的图扩散结合self-training框架,从而得到的FP网络。jumping knowledge networks with concatenation: JK:JK-Net网络。对于
GCN我们还给出了未经过超参数优化的普通版本V.GCN来说明早停和超参数优化的强大影响。
模型配置:
V.GCN:使用原始论文的配置,其中包括两层的卷积层、隐层维度dropout、200个step,以及早停的patience = 10。择优的
GCN:使用两层卷积层、隐层维度dropout rate = 0.5的dropout、N-GCN:每个随机游走长度使用4个head以及隐层维度1 step到4 step。使用attention机制来合并所有head的预测。GAT:使用优化好的原始论文的超参数,除了0.01。和原始论文相反,对于PUBMED数据集我们并未使用不同的超参数。FP:使用10个传播step、10个self-training step,每个step增加我们在预测中添加交叉熵最小的训练节点。每个类别添加的节点数基于预测的类别的比例。注意,该模型在初始化时不包含任何随机性,因此我们在每个
train/early stopping/test集合拆分时仅拆分一次。JK-Net:我们使用concatenation层聚合方案,采用三层卷积神经网络,每层的隐层维度dropout rate = 0.5的dropout。但是正则化和dropout并不作用在邻接矩阵上。PPNP:为确保公平的模型比较,我们为PPNP的预测模型使用了神经网络,该网络在结构上和GCN非常相似,并具有相同的参数数量。我们使用两层网络,每层的隐层维度为我们在第一层的权重矩阵上应用
dropout rate = 0.5的dropout。对于
APPNP,我们在每个幂次迭代步之后,都会对邻接矩阵的dropout重新采样。对于传播过程,我们使用
对于
MICROSOFT ACADEMIC数据集,我们使用
注意:
PPNP使用浅层的神经网络和较大的APPNP不同深度的网络对于验证集的准确率。可以看到:更深的预测网络无法提高准确率,这可能是因为简单的Bag-of-word特征以及训练集太小导致的。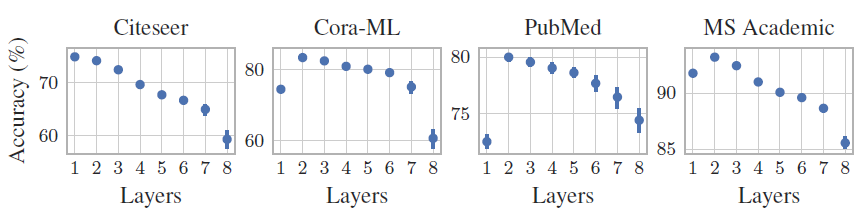
另外,我们使用
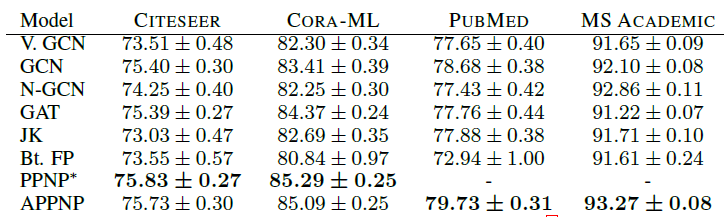
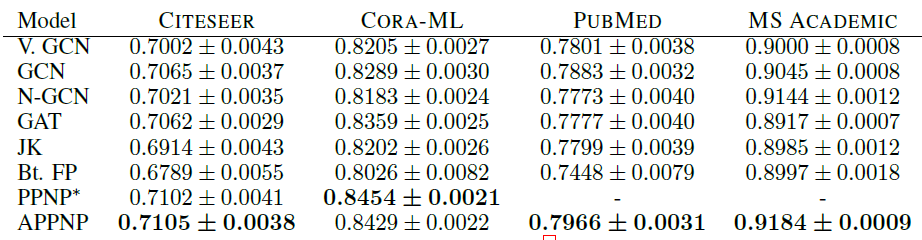
Adam优化器并且所有模型的学习率都为0.01。我们使用交叉熵损失函数,并且将特征矩阵按行进行不同模型在测试集上的指标如下表所示,其中第一张表为
Micro-F1 Score,第二张表为Macro-F1 Score,最后两张表为t检验结果。*表示模型在PUBMED, MS ACADEMIC上Out Of Memory。结论:
我们的
PPNP/APPNP在所有数据集上均明显优于SOA baseline方法。我们的严格的比较方式可能会低估
PPNP/APPNP的优势。通过t检验表明,该比较结果具有统计学意义这种严格的比较方式还表明:当考虑更多的数据集拆分、适当地超参数优化、合理地模型训练时,最近的一些工作(如
N-GCN, GAT, JK-Net, FP等)的优势实际上消失了。在我们的配置中,一个简单的、经过超参数优化的
GCN就超越了最近提出的这几种模型。

我们给出不同模型在不同数据集上,由于不同的随机初始化以及不同的数据集拆分带来的测试准确率的变化。这表明严格的评估方式对于模型比较的结论至关重要。
此外,这还展示了不同方法的鲁棒性。如
PPNP, APPNP, GAT通常具有较低的方差。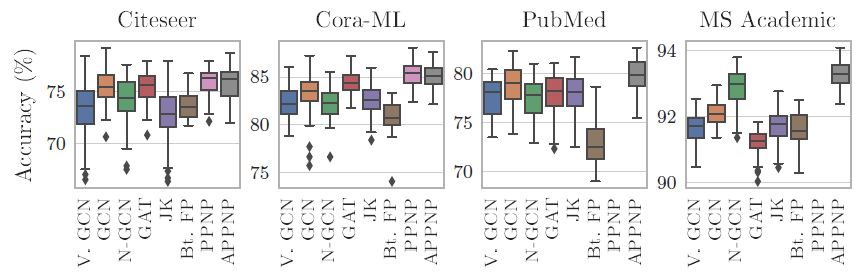
我们考虑不同模型的训练时间。这里考虑每个
epoch的平均训练时间(而不是整个训练过程的时间)。我们并未考虑收敛速度(需要多少个epoch收敛),因为不同模型的超参数都各自调优,并且不同模型使用的early stopping准则不同(调优之后各自的patience不一样)。*表示无法实现,因为无法训练;**表示在PUBMED, MS ACADEMIC上Out Of Memory。结论:
PPNP只能应用于中等规模的图,APPNP可以扩展到大图。平均而言,
APPNP比GCN慢25%,因为APPNP的矩阵乘法的数量更多。但是APPNP的可扩展性和GCN相似。APPNP比GCN慢一些但是效果好一点点,所以这是一个速度和效果的trade-off。此外,如果GCN总的训练时间与APPNP相同(即,GCN多25%的epoch),是否二者效果一致?这样的话,APPNP就没有什么优势了。APPNP比其它更复杂的模型(如GAT)快得多。

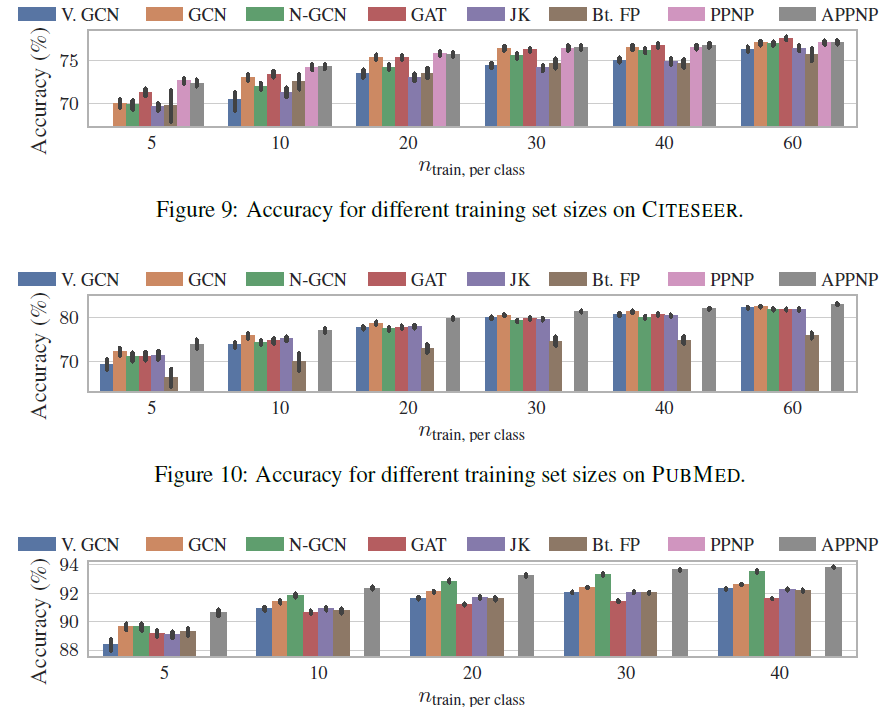
由于现实世界数据集的
label比例通常很小,因此研究小样本模型的性能非常重要。下图依次给出CORA_ML, CITESEER, PUBMED数据集上,每个类别训练节点数量结论:训练的
label节点越稀疏,PPNP/APPNP的优势越大。这可以归因于PPNP/APPNP较高的传播范围,从而将label节点传播到更远的地方。为支持这种归因,我们找到了更多的证据:我们比较了
APPNP和GCN的准确率的提升幅度 ,发现准确率提升幅度依赖于测试节点和训练集的距离(以最短路径衡量)。如下面最后一幅图所示,横坐标为最短路径(单位为hop),纵坐标为提升幅度,APPNP相对于GCN的性能提升,随着测试节点到训练集的距离的增加而增加。这表明距训练集较远的节点从APPNP的传播范围的增加中收益更多。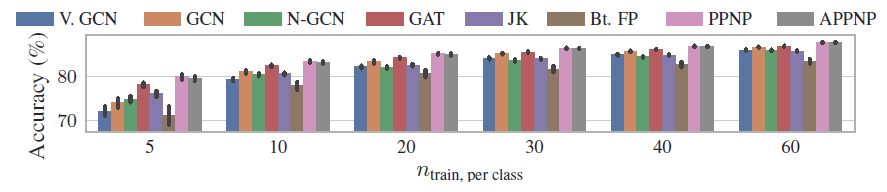
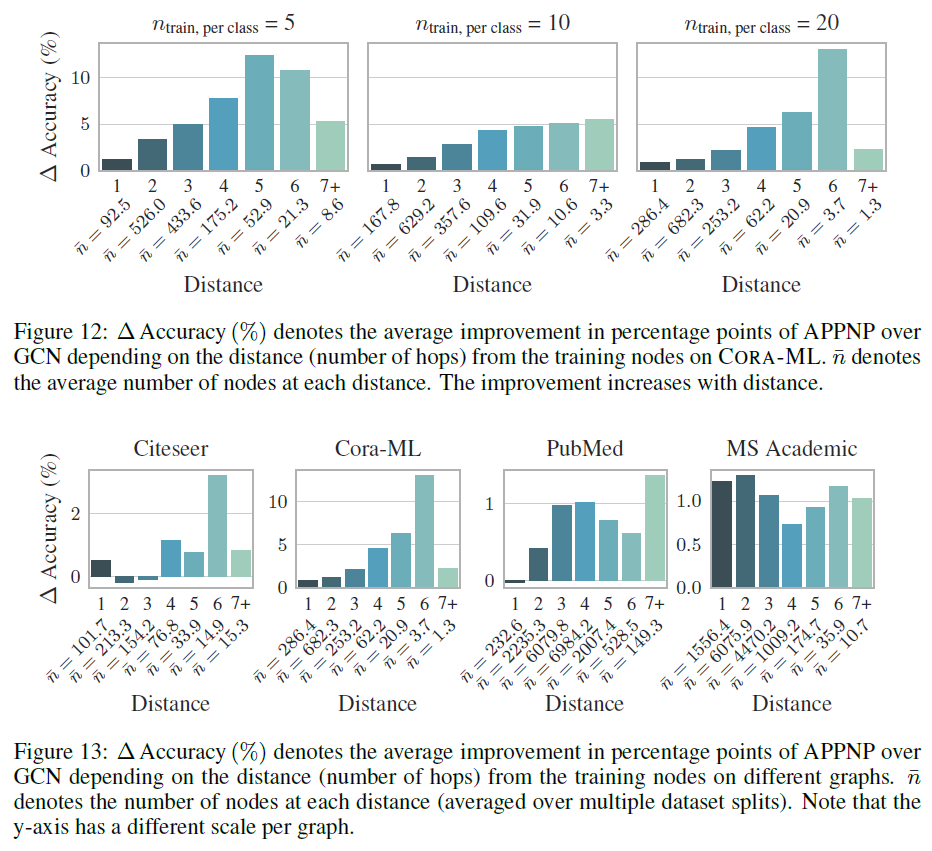
我们评估了幂次迭代(
power iteration)数量K来表示)对于模型准确性的影响。结论:
对于
GCN-like(对应于PageRank方法),其性能随着对于
APPNP(对应于Personalized PageRank),其性能随着当
APPNP收敛到PPNP。但是我们发现,当APPNP已经足以有效地逼近PPNP。有趣的是,我们发现这个数字和数据集的半径相符。
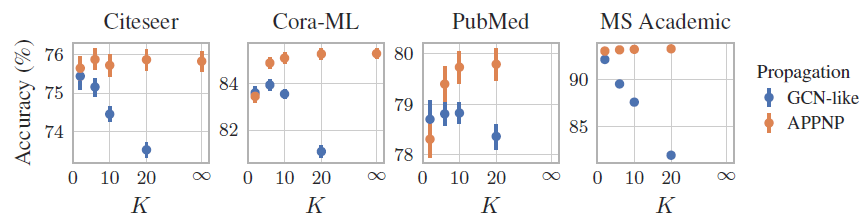
我们评估了超参数
结论:
尽管每个数据集的最优
应该对不同的数据集采用不同的
注意:较高的
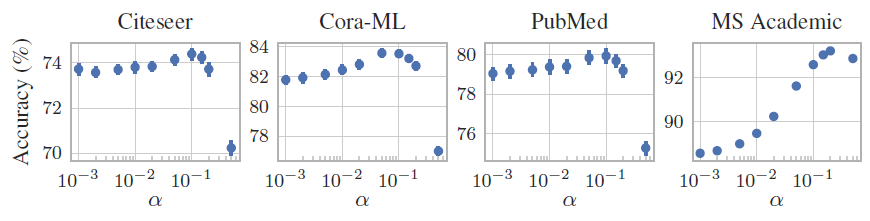
PPNP和APPNP虽然分为预测网络Never:表示从来不使用传播。这表示我们仅使用节点特征来训练和使用一个标准的多层感知机MLPTraining:表示我们使用APPNP来训练模型(采用了传播),但是在inference时仅使用Inference:表示我们仅使用特征来训练多层感知机inference时结合传播来预测。Inf & Training:表示常规的APPNP模型,即在训练和inference时总是使用传播。
结论:
Inf & Training总是可以获得最佳结果,这验证了我们的方法。在大多数数据集上,仅在
inference中使用传播时,准确率下降得很少。训练期间跳过传播可以大大减少大型数据集的训练时间,因为所有节点都可以独立地处理。
这也表明我们的模型可以与不包含任何图结构信息的预训练神经网络相结合,并可以显著提高其准确性。
Training相对于Never也有较大的改善。这表明仅在训练期间进行传播也是有价值的。因此我们的模型也可以应用于online/inductive learning,其中只有特征信息(而不是观察到的邻域信息)可用。
