一、Cluster-GCN [2019]
《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》
图卷积网络(
graph convolutional network: GCN)在解决许多graph-based的应用程序中变得越来越流行,包括半监督节点分类、链接预测、推荐系统。给定一个图,GCN使用图卷积操作逐层获得node embedding:在每一层,节点的embedding是通过收集其邻居的embedding来获得的,然后是一层或几层的线性变换和非线性激活。然后将最后一层的embedding用于一些终端任务。由于
GCN中的图卷积运算需要利用图中节点之间的交互来传播embedding,因此GCN的训练非常困难。和其它神经网络不同,GCN的损失函数中每个节点对应的损失不是相互独立的,而是依赖于大量其它节点,尤其是当GCN的深度很深时。相比之下,其它神经网络的损失函数中,每个样本的损失是相互独立的。由于节点的依赖性,GCN的训练非常缓慢并且需要大量的内存,因为反向传播阶段需要将图中所有的embeding存储到GPU内存中。为了说明研究可扩展的
GCN训练算法的必要性,我们从以下三个因素来讨论现有算法的优缺点:内存需求、epoch训练速度(每个epoch的训练时间)、epoch收敛速度(每个epoch损失函数下降的值)。这三个因素对于评估训练算法至关重要。注意:内存需求直接限制了算法的可扩展性,epoch训练速度和epoch收敛速度一起决定了整个训练时间。令
embedding维度、GCN的深度。full-batch梯度下降:GCN原始论文使用full-batch梯度下降来训练。为计算整个训练集损失的梯度,它需要存储所有中间embedding(intermediate embedding),从而导致另外,尽管每个
epoch训练时间高效(单个epoch训练时间很短),但是单个epoch的收敛速度很慢,因为每个epoch仅更新一次参数。整体而言,
full-batch梯度下降内存需求差、epoch训练速度快、epoch收敛速度慢。mini-batch随机梯度下降:GraphSAGE使用了基于mini-batch的随机梯度下降来训练。由于每次迭代仅基于mini-batch梯度,因此它可以减少内存需求,并在每个epoch进行多次更新从而加快epoch收敛速度。但是,由于邻域扩展问题,
mini-batch随机梯度下降会引入大量的计算开销:为计算第embedding,而这又需要邻域节点的邻域节点在第embedding,并向底层不断递归。这导致计算的时间复杂度和GCN的深度GraphSAGE提出使用固定数量的邻域样本,而FastGCN提出了重要性采样。但是这些方法的开销仍然很大,并且当GCN层数更深时情况更糟。整体而言,
mini-batch随机梯度下降内存需求好、epoch训练速度慢、epoch收敛速度快。VR-GCN:VR-GCN提出方差缩减(variance reduction)技术来减少邻域采样规模。尽管这种方法成功地降低了邻域采样的数量(在Cluster-GCN的实验中,VR-GCN对每个节点仅采样2个邻居的效果很好),但是它仍然需要将所有节点的中间embedding存储在内存中,从而导致VR-GCN的内存需求可能太高导致无法放入到GPU中。整体而言,
VR-GCN内存需求差、epoch训练速度快、epoch收敛速度快。
论文
《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》提出了一种新的GCN训练算法,该算法利用图聚类结构 (graph clustering structure)来加速GCN的训练。作者发现:
mini-batch算法的效率可以通过embedding利用率(embedding utilization) 的概念来刻画。embedding利用率和单个batch内的边的数量成正比。这一发现促使作者利用图聚类算法来设计batch,目标是构造分区(partition)使得同一个分区内的边的数量比跨区之间的边的数量更多。基于图聚类(
graph clustering)的思想,作者提出了Cluster-GCN:一种基于图聚类算法(如METIS)来设计batch的算法。进一步地,作者提出一个随机多聚类框架 (stochastic multi-clustering framework)来改善Cluster-GCN的收敛性。核心思想是:尽可能地将内存和计算控制在
batch内。这要求仔细安排batch内节点。但是,这么做破坏了
mini-batch的随机性要求,因为mini-batch要求随机选取batch-size),而Cluster-GCN中的采样方法不再随机。这使得mini-batch梯度不再是full-batch梯度的无偏估计。作者的解决办法是:随机将多个簇合并为一个大簇,然后将这个大簇作为
mini-batch,使得batch内的节点分布尽可能和full-batch一致。Cluster-GCN带来了巨大的内存优势和计算优势:在内存需求方面,
Cluster-GCN仅需要将当前batch中的节点embedding存储在内存中,内存复杂度为batch-size。这比VR-GCN、full-batch梯度下降、以及其它mini-batch随机梯度下降等方法要小得多。在计算复杂度方面,
Cluster-GCN在每个epoch都具有相同的时间代价,并且比邻域搜索方法快得多。在收敛速度方面,
Cluster-GCN相比其它SGD-based方法具有可比的竞争力。最后,
Cluster-GCN算法易于实现,因为它只需要计算矩阵乘法,而无需任何邻域采样策略。
整体而言,
Cluster-GCN内存需求好、epoch训练速度快、epoch收敛速度快。通过对几个大型图数据集进行全面实验,证明了
Cluster-GCN的效果:Cluster-GCN在大型图数据集(尤其是深层GCN)上实现了最佳的内存使用效率。例如在Amazon2M数据集上的3层GCN模型中,Cluster-GCN使用的内存比VR-GCN少5倍。对于浅层网络(例如
2层),Cluster-GCN达到了和VR-GCN相似的训练速度;但是当网络更深(如4层)时,Cluster-GCN可以比VR-GCN更快。这是因为Cluster-GCN的复杂度和层数VR-GCN的复杂度是Cluster-GCN能够训练具有很大embedding size并且非常深的网络。尽管之前的一些工作表明:深层
GCN无法提供更好的性能,但是作者发现通过适当的优化,深层GCN可以帮助提高模型准确性。例如使用5层GCN,Cluster-GCN在PPI数据集上的accuracy为99.36,而之前的最佳效果为98.71。
1.1 模型
给定图
节点
节点
labellabel的节点集合为
定义一个包含
GCN,其中第其中:
representation矩阵,representation向量的维度。representation向量。为简化讨论,我们假设
其中
self-loop的邻接矩阵。ReLU。
GCN模型的损失函数为:其中:
final representation。
我们首先讨论之前方法的一些不足,从而启发我们提出
Cluster-GCN。原始
GCN:原始GCN中,作者通过full-batch梯度下降来训练GCN,其计算代价和内存需求都很高。在内存需求方面,通过反向传播来计算损失函数的梯度需要
embedding矩阵在收敛速度方面,由于模型每个
epoch仅更新一次参数,因此模型需要训练很多个epoch才能收敛。
GraphSAGE:GraphSAGE通过mini-batch SGD来改善GCN的训练速度和内存需求。SGD不需要计算完整的梯度,而是仅在每轮更新中基于一个mini-batch来计算梯度。记
mini-batch节点集合为SGD迭代中,梯度的估计量为:尽管
mini-batch SGD在收敛速度方面更快,但是它在GCN训练过程中引入了另一种计算开销,这使得它与full batch梯度下降相比,每个epoch的训练速度慢得多。原因如下:考虑计算单个节点embeddingrepresentation,而这又依赖于这些邻域节点的邻域节点在第representation,... 。假设
GCN具有degree为hop-k(representation向量需要如果一个
batch中有很多节点,则时间复杂度就不是那么直接,因为不同节点具有重叠的top-k邻域,那么依赖的节点数量可以小于最差的
为反应
mini-batch SGD的计算效率,我们定义embedding利用率(embedding utilization) 的概念,从而刻画计算效率。在算法过程中,如果节点
embedding计算之后,被第embedding计算过程使用了embedding利用率为对于具有随机采样的
mini-batch SGD,由于图通常比较大且稀疏,因此hop-k邻域之间几乎没有重叠),则mini-batch SGD在每个batch需要计算embedding,这导致每个mini-batch的训练时间为epoch的训练时间为相反,对于
full-batch梯度下降,每个embedding将在更上一层中重复利用degree),因此具有最大的embedding利用率。结果full-batch SGD在每个epoch需要计算embedding,训练时间为embedding就可以得到一个节点的梯度,相比之下mini-batch SGD需要计算embedding。
如下图所示给出了传统的
GCN中指数级邻域扩展(左图)。红色节点是扩展的起始节点,不同颜色代表不同的hop。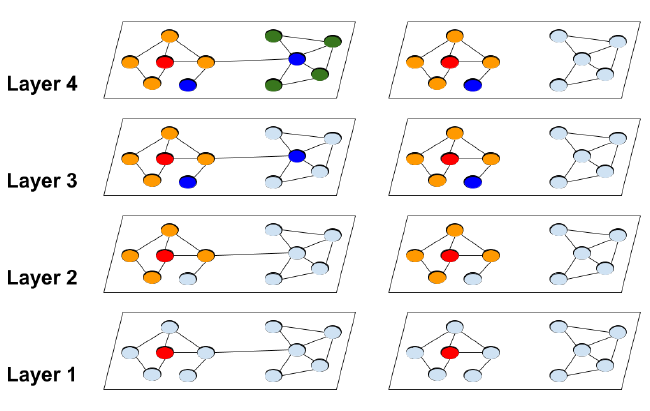
为了使得
mini-batch SGD顺利工作,已有的一些算法试图限制邻域扩展的大小,但是这无法提升embedding利用率。GraphSAGE均匀采样一个固定大小的邻域,而不是完整的邻域集合。我们将这个固定大小记作embedding,并且也使得梯度估计的准确性降低。FastGCN提出了一种重要性采样策略来改善梯度估计。VR-GCN提出了一种策略,通过存储所有embedding的历史均值,从而应用于未采样邻居节点的embedding计算。尽管存储所有
embedding的内存需求很高,但我们发现该策略非常有效,并且在实践中即使对于非常小的
1.1.1 Cluster-GCN
Cluster-GCN技术受到以下问题的启发:在mini-batch SGD更新过程中,能否设计mini-batch以及对应的计算子图,使得最大程度地提高embedding利用率?解决该问题的关键在于将embedding利用率和聚类相结合。考虑我们计算
batch1层到第embedding。定义embedding利用率是这个batch内链接的数量因此,为了最大化
embedding利用率,我们应该设计一个batchbatch内链接的数量,这使得我们可以将SGD更新的效率和图聚类算法联系起来。现在我们正式地介绍
Cluster-GCN。对于图subgraph):其中
经过节点的重新排列之后,图
其中:
每个对角块
同样地,我们可以根据
label为label组成。现在我们用块对角矩阵
cluster(每个cluster对应一个batch)。令
embedding矩阵变为:其中
因此损失函数可以分解为:
在每一步我们随机采样一个簇
SGD更新。在这个更新过程中,仅依赖于当前batch的子图label可以看到,
Cluster-GCN仅需要进行矩阵乘法和前向/反向传播,而之前的SGD-based方法中需要对邻域进行搜索,因此我们的方法更容易实现。Cluster-GCN使用图聚类算法对图进行分组。图聚类算法(如Metis和Graclus)旨在对图的节点进行划分,使得簇内的链接比簇间的链接更多,从而更好地捕获图的聚类和社区结构。这正是我们需要的结果,因为:如前所述,
embedding利用率等于每个batch的batch内链接数量。由于我们用块对角矩阵
下图给出了在完整图
hop。可以看到:
Cluster-GCN可以避免繁重的邻域搜索,从而将精力集中在每个簇内的邻居上。我们比较了两种不同的节点划分策略:随机划分(
random partition)、聚类划分(clustering partition)。我们分别通过随即划分、
METIS聚类划分将图划分为10个分组,然后每个分组作为一个batch来执行SGD更新。数据集为三个GCN公共数据集,评估指标为测试集F-1 score。可以看到:在相同epoch下,使用聚类划分可以获得更高的准确性。这表明使用图聚类很重要,并且不应该使用随机划分。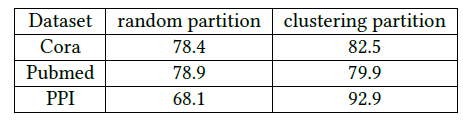
算法复杂度:由于仅考虑
batch的复杂度仅有矩阵乘法batch的时间复杂度为epoch的时间复杂度为平均而言,每个
batch只需要计算embedding,它是线性的而不是batch的空间复杂度为另外,我们的算法仅需要将子图加载到
GPU内存中,无需加载整个图(虽然整个图的存储通常不是瓶颈)。我们在下表中总结了时间复杂度和空间复杂度。显然,所有
SGD-based算法在层数方面都是指数复杂度。对于VR-GCN,即使GPU的内存容量。接下来我们介绍我们的
Cluster-GCN算法,它兼顾了full-batch梯度下降下每个epoch的时间复杂度、以及在普通SGD梯度下降下的空间复杂度。其中:
embedding维度(为方便起见,所有层的embedding以及输入特征的维度都是node degree,mibi-batch size,注意:
由于采用了方差缩减技术,
VR-GCN的GraphSAGE和FastGCN。对于空间复杂度,
embedding。为简单起见,我们忽略了存储
Graph以及子图的需求,因为它们通常都是固定的,且通常不是主要瓶颈。Cluster-GCN具有最好的计算复杂度和最好的空间复杂度。从实验部分得知,
Cluster-GCN的最大优势是内存需求更小从而可以扩展到更大的图。训练速度和训练准确率方面,Cluster-GCN和VR-GCN各有优势(在不同的层数方面)。
1.1.2 随机多重聚类 SMC
尽管前述的
Cluster-GCN实现了良好的计算复杂度和空间复杂度,但是仍然有两个潜在的问题:对图进行划分之后,某些链接被删除了(即
图聚类算法倾向于将相似的节点聚合在一起,因此每个
batch的节点分布和原始数据集不一致,从而导致在SGD更新时,batch的梯度是完整梯度的一个有偏的估计。
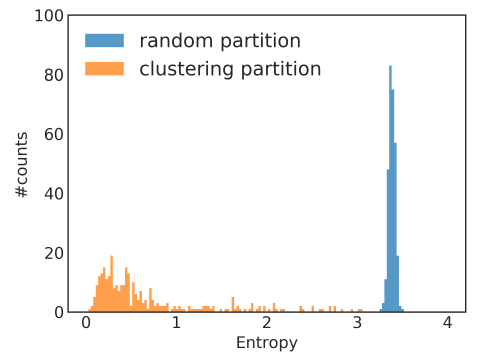
我们以
Reddit数据集为例,考察随机划分来选择mini-batch、通过Metis聚类算法选择mini-batch的数据分布的差异,划分数量为300个分区。数据分布以batch内节点标签分布的熵来衡量。我们给出不同batch的标签熵(label entropy)的分布直方图如下所示,可以看到:大多数聚类
batch具有较低的标签熵,这表明聚类的batch倾向于某些特定的label,从而与整体的数据分布不一致。这可能会影响SGD算法的收敛性。随机
batch具有较高的标签熵,这表明随机batch的数据分布和整体数据分布更为一致。
为解决这些问题,我们提出了一个随机多重聚类框架(
stochastic multiple clustering: SMC),该框架通过随机合并多个簇,从而减少batch之间的数据分布差异。我们首先将节点划分到
batchbatch通过这种方式,所有簇间链接将被重新合并到模型中,并且簇的随机组合可以使得
batch之间的数据分布的差异更小。这种随机多重聚类框架如下图所示,每个
batch包含2个簇,相同的batch的簇具有相同的颜色。不同的epoch中选择不同的簇组合。这种方法只能缓解问题,但是无法解决问题。因为即使是随机组合多个簇,新的
batch内节点分布与整体分布仍然是有差异的。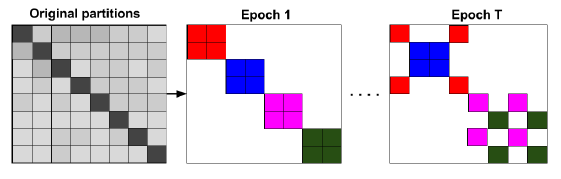
我们在
Reddit数据集上进行实验,对比了SMC和普通Cluster-GCN的效果。在Cluster-GCN中我们选择划分为300个分区,在SMC中我们选择划分为1500个分区并随机选择5个簇来构成一个batch。实验结果如下图所示,其中
x轴为epoch,y轴为F1-score。可以看到随机多重聚类可以显著改善Cluster-GCN的收敛性。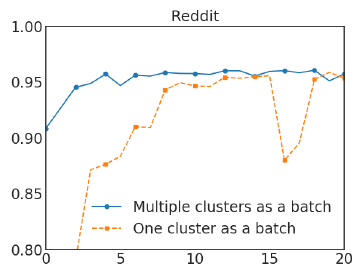
Cluster-GCN算法:输入:
图
输入特征矩阵
节点标签矩阵
one-hot或者multi-hot向量)最大迭代步
max-iter划分簇的数量
每个
batch的簇的数量
输出:模型的参数
embedding矩阵算法步骤:
通过
METIS聚类算法划分迭代:
随机无放回选择
以节点集合
根据子图的损失函数来计算梯度
基于
Adam优化算法使用梯度
输出模型的参数
embedding矩阵
METIS是Karypis Lab开发的一个功能强大的图切分软件包,支持多种切分方式。优势:METIS具有高质量的划分结果,据称比常规的谱聚类要准确10% ~ 50%。METIS执行效率非常高,比常见的划分算法块1~2个数量级。百万规模节点的图通常几秒钟之内就可以切分为256个簇。METIS具有很低的空间复杂度和时间复杂度,从而降低了存储负载和计算量。
1.1.3 深层 GCN
GCN原始论文表明:对GCN使用更深的层没有任何效果。但是,实验中的这些数据集太小,可能没有说服力。例如,实验中只有数百个节点的图,太深的GCN可能会导致严重过拟合。另外,我们观察到更深的
GCN模型的优化变得更困难,因为更深的模型可能会阻碍前几层的消息传递。在原始GCN中,他们采用类似于残差连接的技术,使得模型能够将信息从前一层传递到后一层。具体而言,第这里我们提出另一种简单的技术来改善深层
GCN的训练。在原始GCN中,每个节点都聚合了来自前一层邻域的representation。但是在深层GCN的背景下,该策略可能不太合适,因为它没有考虑深度。凭直觉,附近的邻居应该比远处的节点贡献更大。因此我们提出了一种更好的解决该问题的技术:放大邻接矩阵
GCN层的聚合把更大的权重放到前一层的representation上。即:这种方式看起来似乎合理,但是这对所有节点都使用相同的权重,无论其邻居数量是多少,这现得有些不合适。此外,当使用更深的层时,某些数值可能出现指数型增长,可能会导致数值不稳定。因此我们提出修改版,从而更好地维护邻域信息和数值范围。
我们首先将一个单位矩阵添加到原始的
然后对消息进行传播:
其中
实验表明这种对角线增强(
diagonal enhancement)技术可以帮助构建更深的GCN并达到SOTA性能。这就是人工构造的
attention:对self施加相对更大的重要性(这意味着对邻居施加更小的重要性)。可以通过GAT来自适应地学习self和邻居的重要性。根据论文的实验,当层数很深时,模型效果退化并且训练时间大幅上涨,因此没有任何意义。所以这一小节的内容没有价值。
1.2 实验
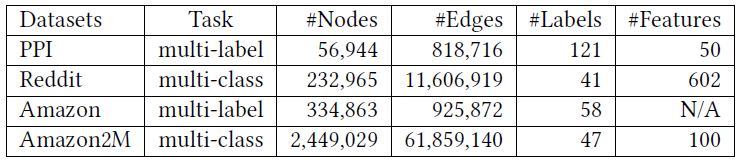
我们在两种任务上评估了
Cluster-GCN的效果:在四个公共数据集上的multi-label分类任务和multi-class分类任务。这些数据集的统计信息如下表所示。注意:
Reddit数据集是迄今为止我们所看到的最大的GCN公共数据集。而
Amazon2M数据集是我们自己收集的,比Reddit数据集更大。
这些数据集的
training/validation/test拆分如下表所示: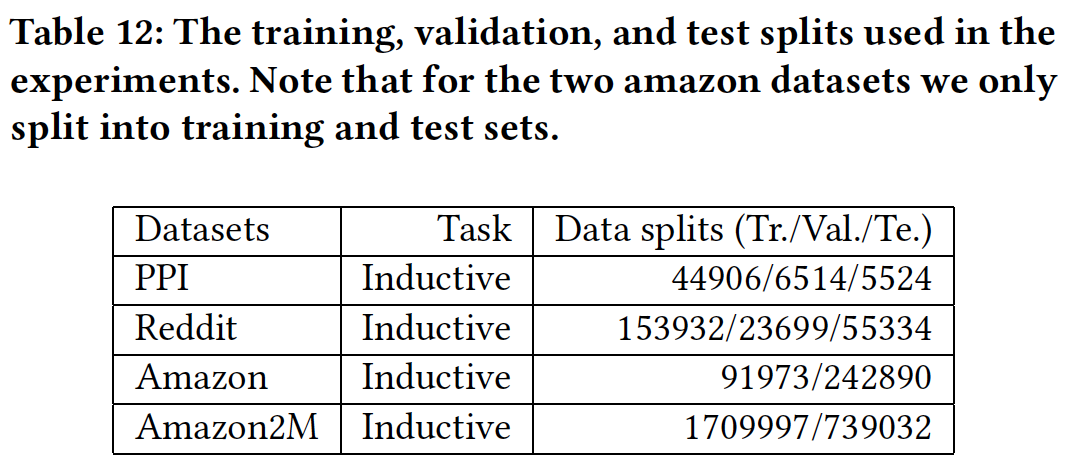
baseline方法:我们比较了以下SOTA的GCN训练算法以及Cluster-GCN方法:VRGCN:保留图中所有节点的历史embedding均值,并仅采样少数几个邻居来加快训练速度。我们采用原始论文中的建议,将采用邻居数量设为2。GraphSAGE:对每个节点采样固定数量的邻居。我们使用原始论文中默认的邻居数量 :双层GCN第一层、第二层采样数量分别为
由于原始
GCN很难扩展到大图,因此我们不比较原始GCN。根据VRGCN论文所述,VRGCN比FastGCN更快,因此我们也不比较FastGCN。实验配置:我们使用
PyTorch实现了Cluster-GCN。对于其它baseline,我们使用原始论文提供的代码。所有方法都采用
Adam优化器,学习率为0.01,dropout比例为20%,权重衰减weight decay为零。所有方法都采用均值聚合,并且隐层维度都相同。
所有方法都使用相同的
GCN结构。在比较过程种我们暂时不考虑
diagonal enhancement之类的技术。对于
VRGCN和GraphSAGE,我们遵循原始论文种提供的配置,并将batch-size设为512。对于
Cluster-GCN,下表给出了每个数据集的分区数量,以及每个batch的簇的数量。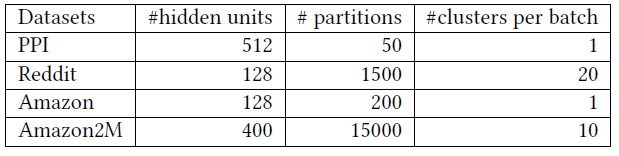
所有实验均在
20核的Intel Xeon CPU(2.20 GHz)+192 GB内存 +NVIDIA Tesla V100 GPU(16GB RAM)上执行。
注意:在
Cluster-GCN种,聚类算法被视为预处理步骤,并且未被计入训练时间。聚类只需要执行一次,并且聚类时间很短。此外,我们遵从
FastGCN和VR-GCN的工作,对GCN的第一层执行pre-compute),这使得我们节省了第一层昂贵的邻域搜索过程。为了用于
inductive setting,其中测试节点在训练期间不可见,我们构建了两个邻接矩阵:一个邻接矩阵仅包含训练节点,另一个邻接矩阵包含所有节点。图划分仅作用在第一个邻接矩阵上。为了计算内存用量,对于
TensorFlow我们使用tf.contrib.memory_stats.BytesInUse(),对于PyTorch我们使用torch.cuda.memory_allocated()。
1.2.1 中等规模数据集
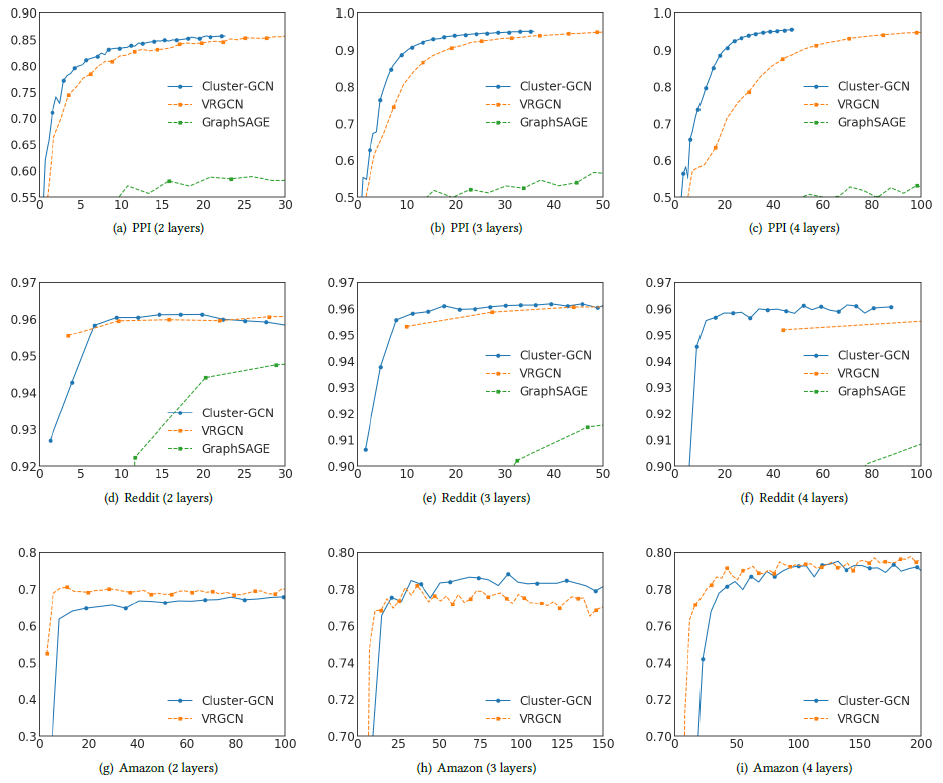
我们首先在训练速度和训练准确性方面评估
Cluster-GCN。我们给出两层GCN、三层GCN、四层GCN在三个中等规模数据集PPI、Reddit、Amazon上的训练时间和预测准确性,如下图所示。其中x轴为训练时间(单位秒),y轴为验证集准确性(单位F1-Score)。由于
GraphSAGE比VRGCN、Cluster-GCN更慢,因此GraphSAGE的曲线仅出现在PPI、Reddit数据集上。对于
Amazon数据集,由于没有节点特征,因此我们用一个单位矩阵334863 x 128。因此,计算主要由稀疏矩阵运算决定(如结论:
在
PPI和Reddit数据集中,Cluster-GCN的训练速度最快,同时预测准确性也最好。在
Amazon数据集中,Cluster-GCN训练速度比VRGCN更慢,预测准确性除了三层GCN最高以外都差于VRGCN。
Cluster-GCN比VRGCN更慢的原因可能是:不同框架的稀疏矩阵的运算速度不同。VRGCN在Tensorflow中实现,而Cluster-GCN在PyTorch中实现。PyTorch中的稀疏张量支持目前处于早期阶段。下表中我们显示了
Tensorflow和PyTorch对于Amazon数据集执行前向、反向操作的时间,并使用一个简单的、两层线性网络对这两个框架进行基准测试,括号中的数字表示隐层的维度。我们可以清楚地看到Tensorflow比PyTorch更快。当隐层维度更高时,差异会更大。这解释了为什么Cluster-GCN在Amazon数据集中训练时间比VRGCN更长。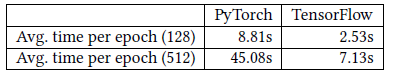
对于
GCN而言,除了训练速度以外,内存需求通常更重要,因为这将直接限制了算法的可扩展性。内存需求包括训练多个
epoch所需的内存。为加快训练速度,VRGCN需要在训练过程中保持历史embedding,因此和Cluster-GCN相比VRGCN需要更多的内存。由于指数级邻域扩展的问题,
GraphSAGE也比Cluster-GCN需要更多的内存。
下表中,我们给出了不同方法在不同数据集上训练两层
GCN、三层GCN、四层GCN所需要的内存。括号中的数字表示隐层的维度。可以看到:当网络更深时,
Cluster-GCN的内存使用并不会增加很多。因为每当新增一层,引入的额外变量是权重矩阵尽管
VRGCN只需要保持每一层的历史embedding均值,但是这些embedding通常都是稠密向量。因此随着层的加深,它们很快统治了内存需求。Cluster-GCN比VRGCN有更高的内存利用率。如在Reddit数据集上训练隐层维度为512的四层GCN时,VRGCN需要2064MB内存,而Cluster-GCN仅需要308MB内存。

1.2.2 大规模数据集
迄今为止评估
GCN的最大的公共数据集是Reddit数据集,其统计数据如前所述。Reddit数据集大约包含200K个节点,可以在几百秒之内训练GCN。为测试
GCN训练算法的可扩展性,我们基于Amazon co-purchasing网络构建了一个更大的图,图中包含200万节点、6100万边。原始的co-purchase数据来自于Amazon-3M。图中每个节点都是一个商品,图中的连接表示是否同时购买了两个商品。每个节点特征都是从商品描述文本中抽取的
bag-of-word,然后通过PCA降维到100维。此外,我们使用top-level的类别作为节点的label。下表给出了数据集中频次最高的类别: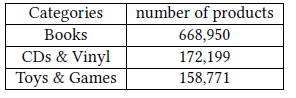
我们在这个大型数据集上比较了
Cluster-GCN和VRGCN的训练时间、内存使用、测试准确性(F1-Score来衡量)。可以看到:
训练速度:对于两层
GCN,VRGCN训练速度更快;但是对于更深的GCN,Cluster-GCN训练速度更快。内存使用:
VRGCN比Cluster-GCN需要多得多的内存,对于三层GCN时VRGCN所需内存是Cluster-GCN的五倍。当训练四层GCN时VRGCN因为内存耗尽而无法训练。测试准确性:
Cluster-GCN在四层GCN时可以达到该数据集上的最佳准确性。

1.2.3 深层 GCN
这里我们考虑更深层的
GCN。我们首先给出Cluster-GCN和VRGCN在PPI数据集上不同深度的训练时间的比较,其中每种方法都训练200个epoch。可以看到:
VRGCN的训练时间因为其代价较高的邻域发现而呈现指数型增长,而Cluster-GCN的训练时间仅线性增长。
然后我们研究更深的
GCN是否可以得到更好的准确性(衡量指标为验证集的F1-score)。我们在PPI数据集上进行实验并训练200个epoch,并选择dropout rate = 0.1。其中:Cluster-GCN with (1)表示:原始的Cluster-GCN。Cluser-GCN with (10)表示:考虑如下的Cluster-GCN:Cluster-GCN with (10) + (9)表示:考虑如下的Cluster-GCN:Cluster-GCN with (10) + (11)表示:考虑如下的Cluster-GCN:其中
可以看到:
对于
2层到5层,所有方法的准确性都随着层深度的增加而提升,这表明更深的GCN可能是有效的。当使用
7层或8层时,前三种方法无法在200个epoch内收敛,并会大大降低准确性。可能的原因是针对更深GCN的优化变得更加困难。其中红色的数字表示收敛性很差。即使是第四种方法,它在层数很深时虽然收敛,但是模型效果下降、训练时间暴涨(根据前面的实验),因此没有任何意义。
此外,原始
Cluster-GCN在五层时达到最好的效果,所以对角增强技术失去了价值。

为考察更深层
GCN的详细收敛性,我们给出了采用对角增强技术(即GCN在不同epoch上的验证准确性(F1-Score)。可以看到:我们提出的对角增强技术可以显著改善模型的收敛性,并得到较好的准确性。
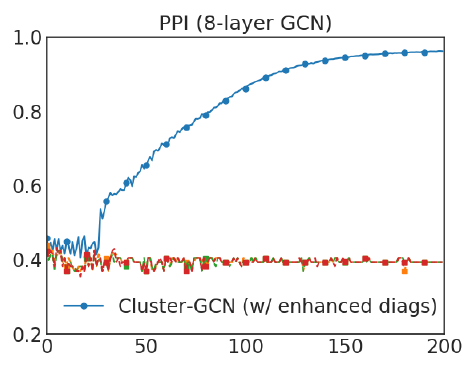
采用了对角增强技术的
Cluster-GCN能够训练更深的GCN从而达到更好的准确性(F1-Score)。我们在下表中给出不同模型在不同数据集上的测试F1-Score。可以看到:
在
PPI数据集上,Cluter-GCN通过训练一个具有2048维的隐层的5层GCN来取得SOTA效果。在
Reddit数据集上,Cluster-GCN通过训练一个具有128维隐层的4层GCN取得SOTA效果。
这个优势并不是对角增强技术带来的,而是因为
Cluster-GCN的内存需求更少从而允许训练更深的模型,而更深的模型通常效果更好。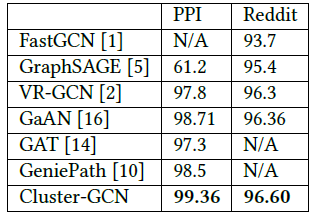
前面的实验都未考虑
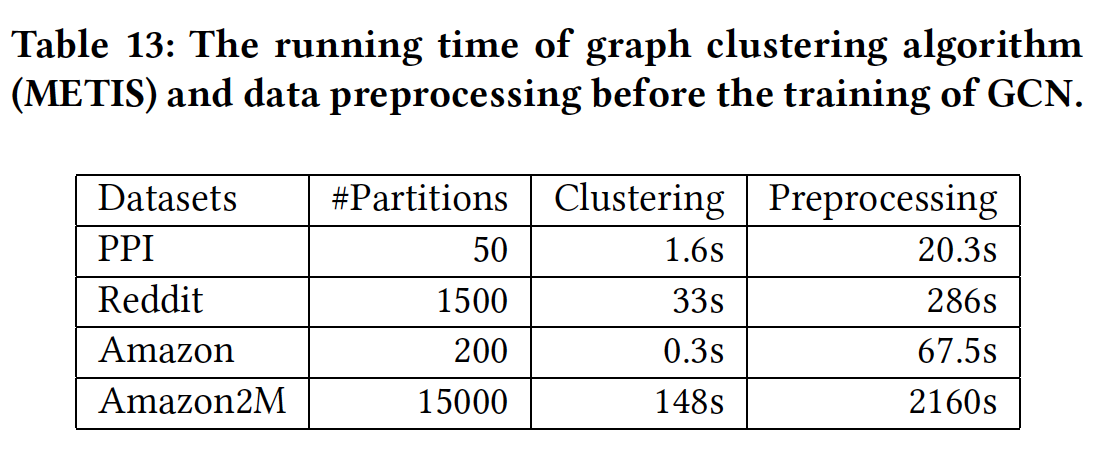
ClusterGCN的预处理时间(如,数据集加载,graph clustering等等)。这里我们给出Cluster-GCN在四个数据集上的预处理时间的细节。对于graph clustering,我们使用Metis。结果如下表所示。可以看到:graph clustering算法仅占用预处理时间的很小比例。graph clustering可以扩展到大型的数据集。
此外,
graph clustering仅需要执行一次,并且之后被后续的训练过程重复使用。