一、HGT [2020]
《Heterogeneous Graph Transformer》
异质图通常用于对复杂系统进行抽象和建模,图中包含不同类型的对象、不同类型的链接。如,
Open Academic Graph:OAG数据中包含五种类型的节点:论文(Paper)、作者(Author)、机构(Institution)、会议(Venue)、领域(Field),以及它们之间各种不同类型的关系,如下图所示。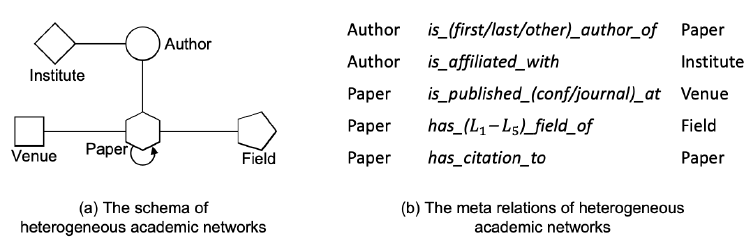
关于异质图挖掘已有大量的研究。一种经典的范式(
paradigm)是定义和使用元路径(metapath)来建模异质图,例如PathSim和metapath2vec。最近,鉴于图神经网络(GNN)的成功,有几种方法尝试采用GNN来学习异质图。然而,这类工作面临以下几个问题:首先,大多数针对异质图的
metapath设计需要特定的领域知识。其次,它们要么简单地假设不同类型的节点/边共享相同的特征和
representation space,要么假设不同类型的节点/边都有各自的特征和representation space。这两种极端使得它们都不足以捕获异质图的属性。再次,大多数现有方法忽略了异质图的动态特性。
最后,它们固有的设计和实现使其无法建模
web-scale异质图。
以
OAG为例:首先,
OAG中的节点和边可能有不同的特征分布,例如paper节点有文本特征,而institution节点可能有附属学者的特征,作者之间的co-authorship关系明显不同于论文之间的citation关系。其次,
OAG一直在不断演变,例如,出版物的数量每隔12年翻一番,KDD会议在1990年更多地与数据库相关而近年来更多地与机器学习相关。最后,
OAG包含数亿个节点和数十亿个关系,这使得现有的异质GNN无法扩展以处理它。
为了解决上述问题,论文
《Heterogeneous Graph Transformer》提出了建模web-scale异质图的Heterogeneous Graph Transformer:HGT架构,目标是:维护node-type dependent representation和edge-type dependent representation、捕获网络动态、避免自定义metapath、以及能够扩展到web-scale的图。为了处理图的异质性,
HGT引入了节点类型依赖的attention机制node-type dependent attention、边类型依赖的attention机制(edge-type dependent attention)。HGT并未参数化每种类型的边,而是通过每条边HGT的异质互注意力(heterogeneous mutual attention)。这个关系三元组为<node type of s, edge type of e between s&t , node type of t >。HGT使用这些元关系来对权重矩阵进行参数化,从而计算每条边上的注意力。这样允许不同类型的节点、边保持其特有的representation space,同时不同类型的、相连的节点仍然可以交互、传递、聚合消息,不受它们类型不同的影响。由于
HGT架构的性质,HGT可以通过跨层信息传递来聚合来自不同类型高阶邻居的信息,这些信息可以被视为soft metapath。换句话讲,HGT仅使用其one-hop边作为输入,无需手动设计metapath,最终提出的注意力机制也可以自动隐式地学习和提取针对不同下游任务很重要的metapath。为解决动态图的问题,
HGT提出了相对时间编码(relative temporal encoding:RTE)策略来增强HGT。HGT建议不要把输入图划分为不同的时间戳,而是建议将在不同时间发生的所有边作为一个整体来维护,并设计RTE策略来建模任意时间区间(甚至是未知的和未来的)的时间依赖性(temporal dependency)。通过端到端的训练,RTE使HGT能够自动学习异质图的时间依赖和演变。为处理
web-scale规模的图数据,HGT设计了用于mini-batch图训练的首个异质子图采样算法(HGSampling)。其主要思想是对异质子图进行采样,在采样到的子图中不同类型的节点具有相似的比例。因为如果直接使用现有的同质图采样算法,如GraphSage/FastGCN/LADIES,会导致采样子图的节点类型、边类型高度不平衡。此外,HGSampling还被设计为使得采样子图保持稠密,从而最大程度地减少信息丢失。通过
HGSampling,所有的GNN模型包括论文提出的HGT,都可以在任意大小的异质图上进行训练和推断。
论文在
web-scale的OAG数据集上实验了HGT的有效性和效率,该数据集由1.79亿个节点、20亿条边组成,时间跨度1900 ~ 2019年,是迄今为止规模最大、时间跨度最长的异质图数据集。实验结果表明:和
SOTA的GNN以及异质图模型相比,HGT可以显著改善各种下游任务,效果提高9% ~ 21%。进一步研究表明,HGT确实能够自动捕获隐式metapath针对不同任务的重要性。
1.1 基础知识和相关工作
1.1.1 异质图挖掘
异质图定义:定义异质图
元关系(
meta relation)定义:对于每条边meta relation)为三元组inverse relation)。经典的metapath范式被定义为这种元关系的序列。注意:为更好地建模真实世界的异质网络,我们假设不同类型的节点之间可能存在多种类型的关系。如
OAG中,通过考虑作者顺序(如“第一作者”、“第二作者”等),作者类型节点和论文类型节点之间存在不同类型的关系。动态异质图:为建模真实世界异质图的动态特性,我们为每条边
我们假设边的时间戳是不变的,表示边的创建时间。例如当一篇论文在时刻
我们假设节点可以有多个时间戳。例如,会议节点
WWW可以分配任何时间戳。WWW@1994意味着我们正在考虑第一版WWW,它更多地关注互联网协议和web基础设施;而WWW@2020意味着即将到来的WWW,其研究主题将扩展到社交分析、普适计算(ubiquitous computing)、搜索和信息检索、隐私等等。
在挖掘异质图方面已经有了重要的研究方向,例如节点分类、节点聚类、节点排序、以及
node representation learning,然而异质图的动态视角尚未得到广泛的探索和研究。
1.1.2 GNN
GNN可以视为基于输入图结构的消息传递,它通过聚合局部邻域信息来获得节点的representation。假设节点
GNN第representation为GNN的node representation更新方程为:其中:
GNN有两个基本的算子:Extract(.)算子:邻域信息抽取器(extractor)。它使用target节点representationquery,并从source节点representationAgg(.)算子:邻域信息聚合器(aggregator)。它用于聚合target节点mean, sum, max等函数作为聚合函数,也可以设计更复杂的聚合函数。
此外,还有很多将注意力机制集成到
GNN的方法。通常,基于注意力的模型通过估计每个source节点的重要性来实现Extract(.)算子,并在此基础上应用加权聚合。在上述
GNN通用框架之后,人们已经提出了各种GNN架构(同质的):《Semi-Supervised Classification with Graph Convolutional Networks》提出了图卷积网络(graph convolutional network: GCN),它对图中每个节点的一阶邻域进行均值池化,然后进行线性投影和非线性激活操作。《Inductive Representation Learning on Large Graphs》提出了GraphSAGE,将GCN的聚合操作从均值池化推广到sum池化、最大池化、以及RNN。《Graph Attention Networks》通过将注意力机制引入GNN从而提出了graph attention network: GAT。这种注意力机制允许GAT为同一个邻域内的不同节点分配不同的重要性。
1.1.3 异质 GNN
最近,一些工作试图扩展
GNN从而建模异质图。《Modeling Relational Data with Graph Convolutional Networks》提出了relational graph convolutional network: RGCN来建模知识图谱。RGCN为每种类型的边保留不同的线性投影权重。《Heterogeneous Graph Neural Network》提出了heterogeneous graph neural network: HetGNN,它针对不同的节点类型采用不同的RNN来融合多模态特征。《Heterogeneous Graph Attention Network》基于注意力机制为不同的metapath-based边保留不同的权重,同时对不同的metapath也保留不同的权重。
尽管实验上看这些方法都比普通的
GCN或GAT要好,但是它们对不同类型的节点或不同类型的边采用不同的权重矩阵,从而没有充分利用异质图的特性。因为不同类型的节点/边的数量可能差异很大,对于出现次数不多的边,很难准确地学到合适的relation-specific权重。为解决这个问题,我们提出了参数共享从而实现更好的泛化,这类似于推荐系统中的
FM思想。具体而言,给定一条边meta relation)为例如,在 “第一作者”关系 和 “第二作者”关系中,它们的源节点类型都是作者、目标节点类型都是论文。换句话讲,从一种关系中学到的有关作者和论文的知识可以迅速地迁移并适应于另一种关系。因此,我们将该思想和功能强大的、类似于
Transformer注意力体系结构相结合,这就是Heterogeneous Graph Transformer: HGT。综上所述,
HGT和现有异质图建模方法的主要区别在于:我们并没有试图对单独的节点类型或单独的边类型建模,而是使用元关系
HGT使用相同的甚至更少的参数来同时捕获不同模型之间的通用模式(common pattern)以及特定模式(specific pattern)。与大多数现有的
metapath-based方法不同,我们依赖于神经网络体系结构本身来融合高阶异质邻域信息,从而自动学习隐式的metapath的重要性。以前的大多数工作都未考虑图(异质的)的动态特性,而我们提出了相对时间编码
RTE技术,从而在有限的计算资源内融合了时间信息。现有的异质
GNN都不是为了web-scale图数据而设计的,也没有在web-scale图上进行实验。我们提出了为web-scale的图训练设计的mini-batch异质子图采样算法,可以在十亿规模的Open Academic Graph上进行实验。
1.2 模型
HGT的核心思想是:使用元关系来参数化权重矩阵,从而实现异质互注意力 (heterogeneous mutual attention)、消息传递(message passing)、传播(propagation)。另外,为进一步融合网络的动态性,我们在模型中引入相对时间编码机制。下图给出了
HGT的总体架构。给定一个采样的异质子图(sampled heterogeneous sub-graph),HGT提取所有相连的节点pair对,其中目标节点HGT的目标是聚合来自于源节点的信息,从而获得目标节点contextualized representation)。这样的过程可以分解为三个部分:元关系感知的异质互注意力(meta relation-aware heterogeneous mutual attention)、从源节点发出的异质消息传递(heterogeneous message passing from source nodes)、特定于目标的异质消息聚合(target-specific heterogeneous message aggregation)。我们将第
HGT层的输出记作HGT层的输入。通过堆叠representation为下图中,
HGT使用边HGT遵循GAT的attention机制,但是HGT在计算query, key, value时考虑了节点和边的异质性。此外,在计算节点的representation时考虑了相对时间编码(类似于相对位置编码)。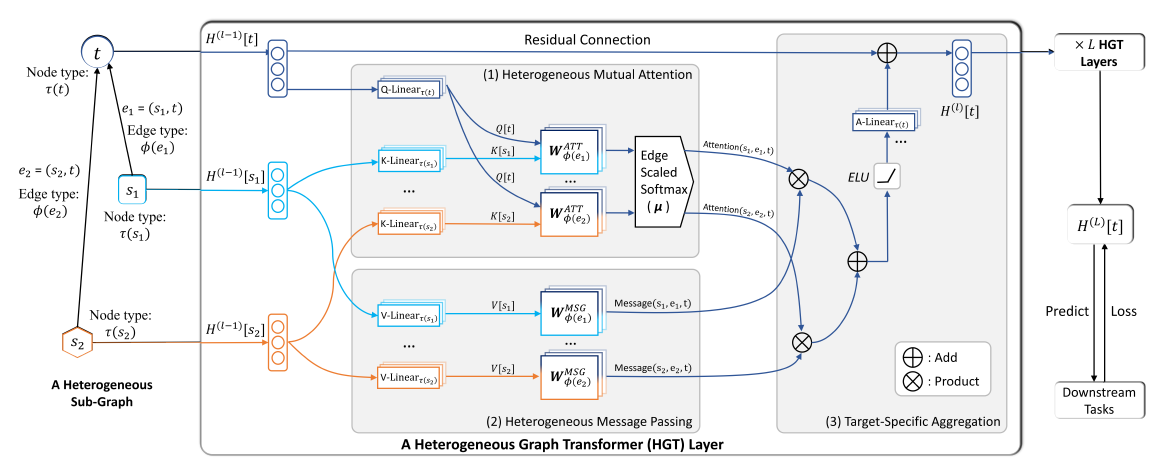
1.2.1 Heterogeneous Mutual Attention
HGT的第一步是计算源节点GNN为:其中有三个基础算子:
Attention算子:评估每个源节点Message算子:抽取源节点Agg算子:利用注意力权重来聚合邻域的消息。
例如,
GAT采用一种加性机制(additive mechanism)来作为Attention算子,采用共享的权重矩阵来计算每个节点的消息,采用简单的均值然后接一个非线性激活函数来作为Agg算子。即:其中:
attention vector)。
尽管
GAT可以有效地给更重要的节点以更高的注意力,但是它假设节点有鉴于此,我们设计了异质互注意力机制。给定一个目标节点
受到
Transformer体系结构设计的启发,我们将目标节点Query向量,将源节点Key向量,然后计算它们内积作为attention。但是和Transformer的区别在于:常规的Transformer对所有单词都使用同一组映射矩阵,但是在HGT中每种元关系都有它们自己的一组映射矩阵。为最大程度地共享参数,同时保持不同关系的各自特性,我们将元关系的权重矩阵参数化为源节点投影矩阵、边投影矩阵、目标节点投影矩阵。具体而言,对于
attention为:其中:
attention head中的query向量,它是类型为attention head中的key向量,它是类型为attention head中,query向量key向量异质图的一个特点是:在一对节点之间可能存在多种不同类型的边。因此,和常规的
Transformer将query向量和key向量直接内积不同,HGT考虑对每种边类型edge-based矩阵此外,由于并非所有关系均对目标节点做出相同的共享,因此我们采用了一个先验张量(
prior tensor)最后,我们将
attention head拼接起来,从而获得每对节点pair对的attention向量。然后对于每个目标节点softmax,使其满足:即:对于目标节点
head邻域内的注意力之后为1:
1.2.2 Heterogeneous Message Passing
和注意力计算过程类似,我们希望将边的元关系融合到消息传递过程中,从而缓解不同类型节点和不同类型边的分布差异。
对于边
multi-head消息为:其中:
message head,它先将类型为这里的
然后,我们拼接所有的
message head从而为每条边得到
计算
multi-head注意力过程和计算multi-head消息过程,二者之间可以并行进行。
1.2.3 Target-Specific Aggregation
在计算出异质
multi-head注意力、异质multi-head消息之后,我们需要将它们从源节点聚合到目标节点。我们可以简单地使用每个
head的注意力向量作为权重,从而加权平均对应head每个源节点的消息。因此聚合过程为:这将信息从不同类型的所有邻居(源节点)的信息聚合到目标节点
最后一步是将目标节点
representation向量映射回其特定类型。为此,我们采用一个线性投影这样我们就获得了目标节点
因为前面将邻域节点信息 映射到公共空间,那么现在需要将公共空间映射回目标节点的特定类型空间。
由于真实世界的图具有
small-world属性,因此堆叠HGT层(HGT为每个节点生成高度上下文相关的表示在
HGT的整个体系结构中,我们高度依赖使用元关系和常规的
Transformer相比,我们的模型区分了不同的节点类型和不同的关系类型,因此能够处理异质图中的分布差异。和为每种元关系保留独立的权重矩阵的现有方法相比,
HGT的三元组参数化可以更好地利用异质图的schema来实现参数共享。一方面,几乎从未出现过的关系仍然可以从这种参数共享中受益,从而可以实现快速适应和泛化。
另一方面,不同类型的节点和关系仍然可以使用更少的参数集合来维持其独有的特点。
1.2.4 Relative Temporal Encoding
这里我们介绍用于
HGT的相对时间编码RTE技术来处理动态图。传统的融合时间信息的方法是为每个时间片(
time slot)构建一个独立的图,但是这种方式可能丢失跨不同时间片的结构相关性。同时,节点在时刻representation可能依赖于其它时刻发生的连接。因此,对动态图进行建模的一种正确方式是:维持在不同时刻发生的所有边,并允许具有不同时间戳的节点和边彼此交互。有鉴于此,
HGT提出了相对时间编码RTE机制来建模异质图中的动态依赖性(dynamic dependency)。RTE的灵感来自于Tansformer中的位置编码方法,该方法已成功地捕获了长文本中单词的顺序依赖性 (sequential dependency)。具体而言,给定源节点
注意:训练数据集可能没有覆盖所有可能的时间间隔,因此
RTE应该能够泛化到未看到的时间和时间间隔。因此我们使用一组固定的正弦函数作为basis,并使用一个可训练的线性映射RTE:最终,针对目标节点
representation中:该过程发生在每个
step的信息聚合之前。通过这种方式,融合时间的
representationRTE的详细过程如下图所示: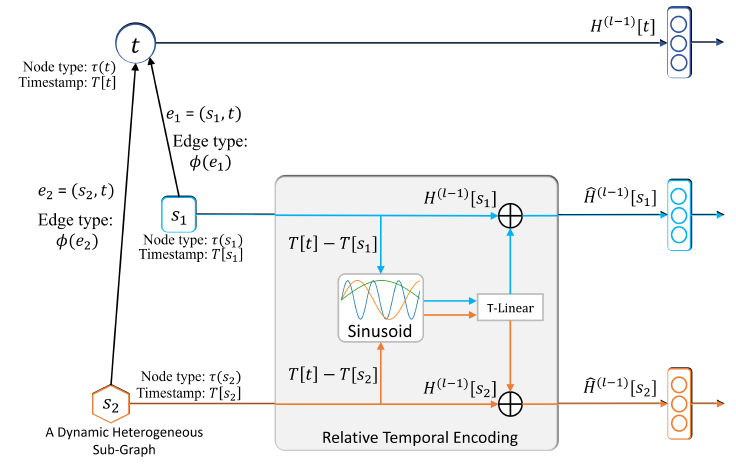
目前为止我们为每个节点
plain节点。如:论文数据集中,WWW会议在1974年和2019年都举行,但是这两年的研究主题截然不同。因此我们需要决定将哪个时间戳添加到WWW节点。与
plain节点相反,异质图中存在一些event节点,它存在唯一的、固定的时间戳。如:论文数据集中,论文节点和该论文发表时间明确相关。为此,我们提出了一种
inductive时间戳分配算法,它对plain节点基于该plain节点相连的event节点来分配时间戳。基本思想是:plain节点从event节点中继承时间戳。我们检查节点是否为event节点:如果节点是
event节点,如特定年份发表的论文节点,则我们保留该event节点的时间戳从而捕获时间依赖性temporal dependency。如果节点不是
event节点,则可以像作者节点一样关联多个时间戳,我们将相连节点的时间戳分配给这个plain节点。如果有多个时间戳,那么怎么计算
这样我们可以在子图采样过程中自适应地分配时间戳。
1.2.5 HGSampling
full-batch的GNN训练要求计算每层所有节点的representation,这使得它无法扩展到web-scale图。为解决这些问题,已有各种基于采样的方法在一个节点子集上训练GNN。但是这些方法无法直接应用到异质图,因为在异质图中每种类型节点的degree分布和节点总数可能差异非常大,所以这些采样方法直接应用到异质图中可能得到节点类型极为不平衡的子图。为解决该问题,我们提出了一种有效的异质图
mini-batch采样算法HGSampling,使得HGT和传统GNN都能够处理web-scale异质图。其核心是为每种节点类型importance sampling strategy)来降低方差。HGSampling优势:为每种类型保留相似数量的节点和边。
采样到的子图保持稠密,从而最大程度地减少信息损失并降低采样方差。
HGSampling算法:输入:
包含所有元关系的邻接矩阵
每种类型的节点的采样数量
采样深度
mini-batch节点集合
输出:最终输出节点集合
算法步骤:
初始化采样节点集合
初始化一个空的预算
degree。对
degree。迭代
对
对
其中分子为节点
degree的平方,分母为degree的平方和。从
对于每个采样到的节点
添加节点
添加节点
从
基于输出节点集合
返回
Add-In-Budget算法:输入:
集合
degree被添加的节点
包含所有元关系的邻接矩阵
采样节点集合
输出:更新后的集合
算法步骤:
对于每种可能的源节点类型
根据
degree:其中
这里计算的是目标节点
degree,而不是degree。对于每个源节点
如果
s.time = t.time。将节点
degree:
返回更新后的
算法解释:假设节点
Add-In-Budget算法将其所有一阶邻居添加到对应的degree添加到这些邻居上,然后将其应用于计算采样概率。这样的归一化等效于累积每个采样节点到其邻域的随机游走概率,从而避免采样被高阶节点统治。直观地看,该值越高,则候选节点和当前节点之间的相关性越大,因此应该赋予其更高的采样概率。HGSampling算法的前几行计算采样概率,通过计算degree的平方来计算重要性采样的概率。通过这种采样概率,我们可以降低采样方差。然后,我们使用计算到的概率对类型为
重复这样的过程
通过使用上述算法,被采样的子图对每个类型包含相似的节点数量,并且足够稠密,且通过归一化的
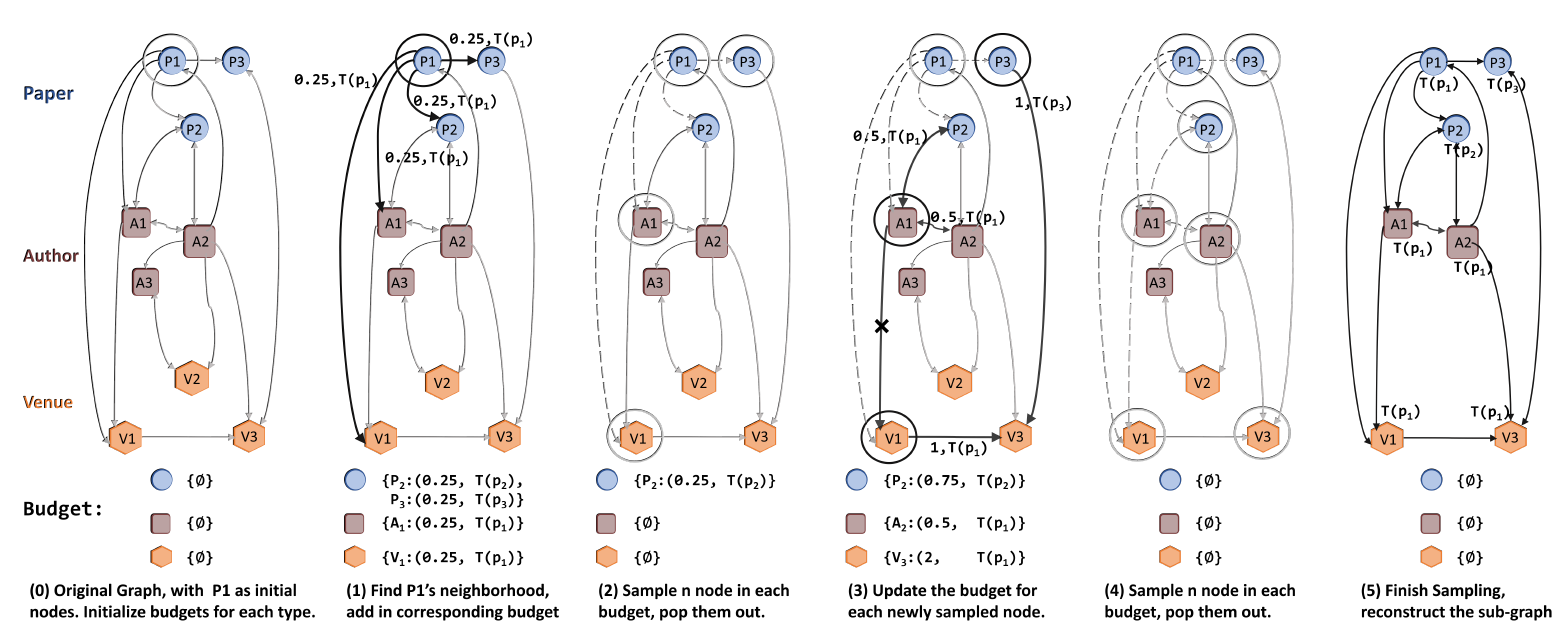
degree和重要性采样来降低方差。因此这种方式适用于web-scale图上训练GNN。整个采样过程如下图所示:不同颜色表示不同的节点类型。
(0):选择初始节点(1):选择degree和时间戳(根据inductive时间戳分配)。(2):对每种类型采样(3):对于新采样的节点degree值进行累加。(4):对每种类型采样(5):采样结束。
1.3 实验
我们在三个异质学术图数据集上评估
HGT,并分别执行Paper-Field预测、Paper-Venue预测、Author Disambiguation任务。数据集:我们使用
Open Academic Graph:OAG数据集,它包含超过1.78亿节点和22.36亿条边,这是最大的公开可用的异质学术数据集。此外,OAG中所有论文关联一个发表日期,该日期从1900到2019年。数据集包含五种类型的节点
Paper、Author、Field、Venue、Institute,其中OAG的领域Field字段一共包含L0到L5共六个层级,这些层级通过层级树(hierarchical tree)来组织。因此,我们根据领域层级来区分Paper-Field边。此外,我们还区分了不同的作者顺序(第一作者、最末作者、其它作者)和会议类型(期刊jornal、会议conference、预印本preprint)。最后,self类型对应于自环连接,这是GNN架构中广泛添加的。除了self关系是对称的之外,其余所有关系都是不对称的,每种关系reverse relation)为测试
HGT的泛化能力,我们还从OAG构造了两个特定领域的子图:计算机科学CS学术图、医学Med学术图。CS和Med图都包含数千万个节点和数亿条边。所使用的三个数据集比以前
GNN研究中广泛使用的小型引文网络(Cora,Citeseer,Pubmed)大得多,后者仅包含数千个节点。下表给出了数据集的统计信息,其中
P-A表示“论文 -- 作者”、P-F表示 “论文 -- 研究领域”、P-V表示 “论文 -- 会议”、A-I表示 “作者 -- 研究机构”、P-P表示论文引用。
我们通过四个不同的下游任务来评估
HGT:Paper -- Field(L1)预测、Paper -- Field(L2)预测、Paper -- Venue预测、Author Disambiguation。前三个任务是节点分类任务,目标是分别预测每篇论文的一级领域、二级领域、发表会议。
我们使用不同的
GNN获取论文的上下文节点representation,并使用softmax输出层来获取其分类标签。对于
Author Disambiguation任务,我们选择所有同名的作者及其相关的论文,任务目标是在这些论文和候选作者之间进行链接预测。从
GNN获得论文节点和作者节点的representation之后,我们使用Neural Tensor Network来获得每个author -- paper节点对之间存在链接的概率。
对于所有任务,我们使用
2015年之前发布的论文作为训练集,使用2015 ~ 2016年之间的论文作为验证集,使用2016 ~ 2019年之间的论文作为测试集。我们使用
NDCG和MRR这两个广泛应用的ranking指标作为评估指标。我们对所有模型进行5次训练,并报告测试集性能的均值和标准差。baseline方法:我们比较了两类SOTA图神经网络,所有baseline以及我们的HGT都通过PyTorch Geometric(PyG) package来实现。同质图
GNN baseline:GCN:简单地对邻域embedding取平均,然后跟一个线性映射。我们使用PyG提供的实现。GAT:对邻域节点采用multi-head additive attention。我们使用PyG提供的实现。
异质图
GNN baseline:RGCN:对每种元关系(三元组)保持不同的权重。我们使用PyG提供的实现。HetGNN:对不同的节点类型采用不同的Bi-LSTM来聚合邻域信息。我们根据作者提供的官方代码使用PyG重新实现。HAN:通过不同的metapath使用分层注意力来聚合邻域信息。我们根据作者提供的官方代码使用PyG重新实现。
此外,为了系统地分析
HGT的两个主要部分的有效性,即异质权重参数化(Heterogeneous Weight Parameterization: Heter)、相对时间编码(Relative Temporal Encoding: RTE),我们进行了消融研究。我们比较了移除这些部分的HGT模型性能。具体而言,我们用-Heter表示对所有元关系使用相同的权重集合,使用-RTE表示没有相对时间编码。考虑所有的排列,我们得到以下模型:我们使用
HGSampling采样算法应用到所有baseline GNN,从而处理大规模的OAG数据集。为了避免数据泄露,我们从子图中删除我们目标预测的链接。输入特征:我们对不同的节点类型采用不同的特征:
论文节点:使用预训练的
XLNet来获取标题中每个单词的representation。然后,我们根据每个单词的注意力对它们进行加权平均,从而得到每篇论文的标题representation。作者节点:使用该作者发表的所有论文的标题的
representation取平均。领域节点、会议节点、机构节点:使用
metapath2vec来训练其node embedding,从而反映异质网络结构。
另外,同质
GNN假设所有节点都是相同类型的特征。因此,为了进行公平的比较,我们在输入特征和同质GNN之间添加一个适配层,该层用于对不同类型的节点进行不同的线性映射。可以认为该过程能够将异质特征映射到相同的特征空间。实现方式:
对于所有的
baseline,我们在整个神经网络网络中使用隐层维度为256。对于所有基于
multi-head attention方法,我们将head数量设为8。所有
GNN均为三层(不包括适配层),使得每个网络的感受野完全相同。所有
baseline方法均通过Cosine Annealing Learning Rate Scheduler的AdamW优化器优化。每个模型我们训练
200个epoch,然后选择验证损失最小的那个作为评估模型。我们选择使用
GNN文献中默认使用的超参数,并未进行超参数调优。
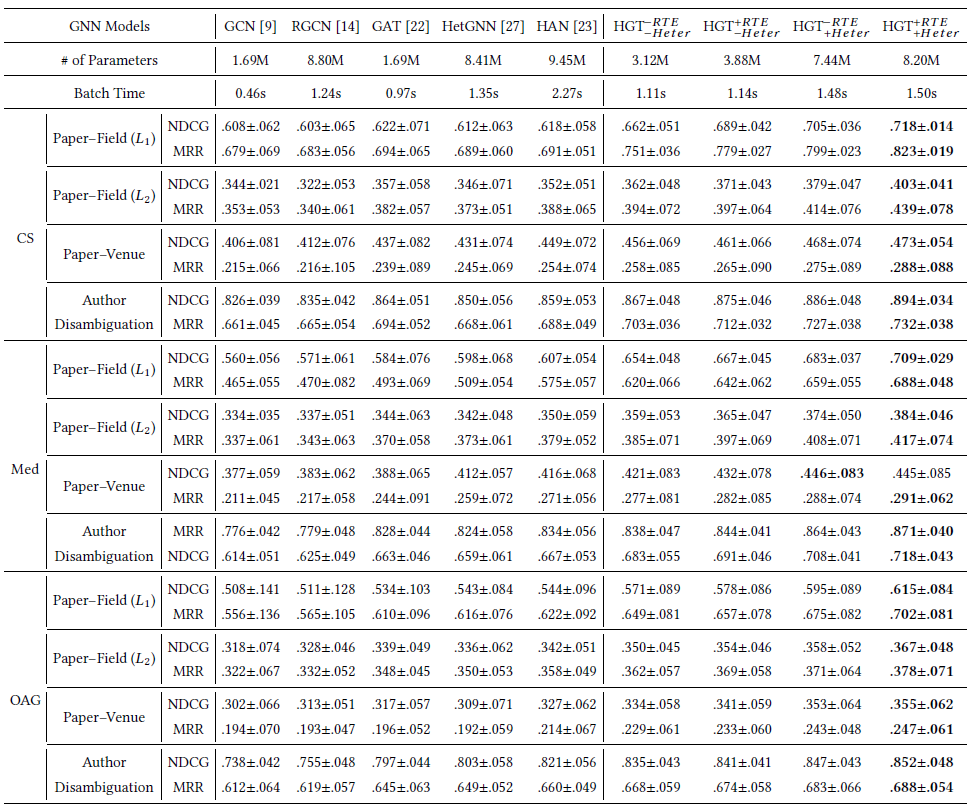
所有模型在所有数据集上的表现如下表所示,其中评估指标为
NGCD, MRR。结论:HGT在所有数据集的所有任务上均显著优于所有baseline。总体而言,在所有三个大规模数据集上的四个任务中,HGT平均优于GCN, GAT, RGCN, HetGNN, HAN大约20%。此外,
HGT具有更少的参数、差不多的batch时间。这表明HGT根据元关系schema建模异质边,从而以更少的资源实现更好的泛化和完整模型
删除异质权重参数化的模型,即
4%的性能。删除相对时间编码的模型,即
2%的性能。
这表明了权重参数化、相对时间编码的重要性。
最后我们还尝试了一个
baseline,它为每个关系类型保留不同的参数矩阵。但是,这样的baseline包含太多参数,因此我们的实验设置没有足够的GPU内层对其进行优化。这也表明:使用元关系对权重矩阵进行分解可以在较少的资源条件下获得有竞争力的优势。
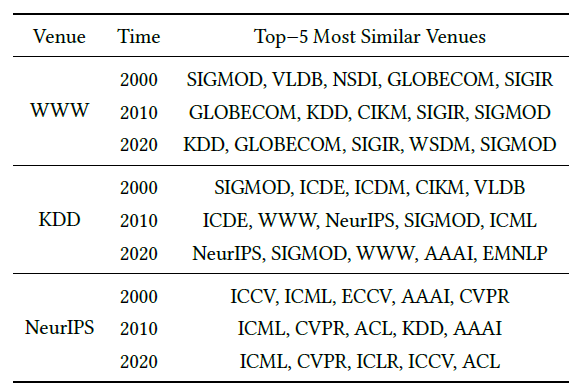
为进一步评估相对时间编码
RTE如何帮助HGT捕获图的动态性,我们进行一个案例研究来展示会议主题的演变。我们选择被引用次数最多的100个计算机科学会议,为它们分配了三个不同的时间戳2000、2010、2020,并构造了由它们初始化的子图。我们使用训练好的HGT来获取这些会议的representation,然后计算这些会议之间的欧式距离。我们以
WWW、KDD、NeuraIPS为例,对于每个会议我们选择其top 5最相似的会议,从而显示会议主题随时间的变化。结果如下表所示。结论:2000年的WWW和某些数据库会议(SIGMOD和VLDB) 以及一些网络会议(NSDI和GLOBECOM) 更相关。但是,除了SIGMOD, GLOBECOM之外,2020年的WWW和某些数据挖掘和信息检索会议(KDD, SIGIR, WSDM) 更相关。2000年的KDD和传统的数据库和数据挖掘会议更相关,而2020年的KDD倾向于和多种主题相关,如机器学习(NeurIPS)、数据库 (SIGMOD)、Web(WWW)、AI(AAAI)、NLP(EMNLP)。除此之外,
HGT还能捕获新会议带来的差异。例如2020年的NeurIPS和ICLR(这是一个新的深度学习会议) 相关。
该案例研究表明:相对时间编码可以帮助捕获异质学术图的时间演变。
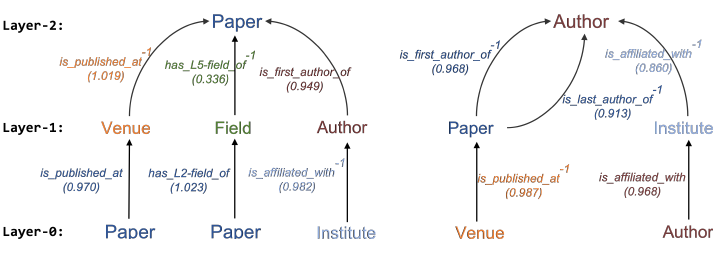
为说明融合的元关系模型如何使得异质消息传递过程受益,我们选择在前两层
HGT层中具有最高注意力的模式,并在图中绘制元关系注意力层次树。例如,为计算论文的
representation,最重要的三个元关系序列为:这可以分别视为
metapath: PVP, PFP, IAP。注意:无需手动设计既可以自动从数据中学到这些
metapath及其重要性。右图给出了计算作者
representation的另一个case。这些可视化结果表明,HGT能够隐式地学到为特定下游任务构造的重要的metapath,无需手动构建。