一、LR For CTR [2007]
《Predicting Clicks: Estimating the Click-Through Rate for New Ads》
在
cost-per-click:CPC广告中广告主按点击付费。为了最大化平台收入和用户体验,广告平台必须预测广告的CTR,称作predict CTR: pCTR。对每个用户的每次搜索query,有多个满足条件的广告同时参与竞争。只有pCTR x bid price最大的广告才能竞争获胜,从而最大化eCPM:基于最大似然准则可以通过广告的历史表现得统计来计算
pCTR。假设广告曝光了100次,其中发生点击5次,则pCTR = 5%。其背后的假设是:忽略表现出周期性行为或者不一致行为的广告,随着广告的不断曝光每个广告都会收敛到一个潜在的真实点击率这种计算
pCTR的方式对于新广告或者刚刚投放的广告问题较大:新广告没有历史投放信息,其曝光和点击的次数均为
0。刚刚投放的广告,曝光次数和点击次数都很低,因此这种方式计算的
pCTR波动非常大。如:一个真实
CTR为5%的广告必须曝光1000次才有85%的信心认为pCTR与真实CTR的绝对误差在1%以内。真实点击率越低,则要求的曝光次数越多。
为解决这个问题,论文
《Predicting Clicks: Estimating the Click-Through Rate for New Ads》提出利用LR模型来预测新广告的CTR。从经验上来看:广告在页面上的位置越靠后,用户浏览它的概率越低。因此广告被点击的概率取决于两个因素:广告被浏览的概率、广告浏览后被点击的概率。
因此有:
假设:
在广告被浏览(即:曝光)到的情况下,广告被点击的概率与其位置无关,仅与广告内容有关。
广告被浏览的概率与广告内容无关,仅与广告位置有关。
广告可能被拉取(推送到用户的页面),但是可能未被曝光(未被用户浏览到)。
则有:
第一项
CTR。第二项与广告无关,是广告位置(即:广告位)的固有属性。
可以通过经验来估计这一项:统计该广告位的总拉取次数
这也称作广告位的曝光拉取比。
1.1 数据集构造
通常广告主会为一个订单(
order)给出多个竞价词 (term),如:Title: Buy shoes now,Text: Shop at our discount shoe warehouse!Url: shoes.comTerms: {buy shoes, shoes, cheap shoes}.此时广告系统会为每个竞价词生成一个广告,每个广告对应相同的
Title/Text/Url、但是不同的竞价词。数据集包含
1万个广告主,超过1百万个广告、超过50万竞价词(去重之后超过10万个竞价词)。注意,不同的竞价词可能会展示相同的广告。样本的特征从广告基本属性中抽取(抽取方式参考后续小节)。广告的基本属性包括:
落地页(
landing page):点击广告之后将要跳转的页面的url。bid term:广告的竞价词。title:广告标题。body:广告的内容正文。display url:位于广告底部的、给用户展示的url。clicks:广告历史被点击的次数。views:广告历史被浏览的次数。
将每个广告的真实点击率
CTR来作为label。考虑到真实点击率
CTR无法计算,因此根据每个广告的累计曝光次数、累计点击次数从而得到其经验点击率CTR。
为了防止信息泄露,训练集、验证集、测试集按照广告主维度来拆分。最终训练集包含
70%广告主、验证集包含10%广告主、测试集包含20%广告主。每个广告主随机选择它的1000个广告,从而确保足够的多样性。因为同一个广告主的广告之间的内容、素材、风格相似度比较高,点击率也比较接近。
对于有专业投放管理的那些优质广告主,在数据集中剔除它们。因为:
优质广告主的广告通常表现出不同于普通广告主的行为:
两种广告主的广告具有不同的平均点击率
优质广告主的广告的点击率方差较低(表现比较稳定)、普通广告主的广告的点击率方差较高(表现波动大)
广告平台更关注于普通广告主,因为这些普通广告主的数量远远超过优质广告主的数量,而且这些普通广告主更需要平台的帮助。
对于曝光量少于
100的广告,在数据集中剔除它们。因为我们使用经验点击率CTR来作为label,对于曝光次数较少的广告二者可能相差很远,这将导致整个训练和测试过程中产生大量噪音。曝光阈值的选取不能太大,也不能太小:
阈值太小,则导致
label中的噪音太多。阈值太大,则离线训练样本(大曝光的广告)和在线应用环境(大量新广告和小曝光广告)存在
gap,导致在线预测效果较差。
1.2 LR模型
论文将
CTR预估问题视作一个回归问题,采用逻辑回归LR模型来建模,因为LR模型的输出是在0到1之间。其中
pCTR正相关:权重越大则pCTR越大。模型通过
limited-memory Broyden-Fletcher-Goldfarb-Shanno:L-BFGS算法来训练。模型的损失函数为交叉熵:
权重通过均值为零、方差为
[0.01,0.03,0.1,0.3,1,3,10,30,100],并通过验证集来选取最佳的值。通过实验发现,
论文采取了一些通用的特征预处理方法:
模型添加了一个
bias feature,该特征的取值恒定为1。即:将偏置项对于每个特征
1是防止0。对所有特征执行标准化,标准化为均值为
0、方差为1。注意:对于验证集、测试集的标准化过程中,每个特征的均值、方差使用训练集上的结果。
对所有特征执行异常值截断:对于每个特征,任何超过均值
5个标准差的量都被截断为5个标准差。如:特征
20,方差为2。则该特征上任何大于30的值被截断为30、任何小于10的值被截断为10。注意:对于验证集、测试集的异常值截断过程中,每个特征的均值、方差使用训练集上的结果。
评价标准:
baseline:采用训练集所有广告的平均CTR作为测试集所有广告的pCTR。即:测试集里无论哪个广告,都预测其
CTR为一个固定值,该值就是训练集所有广告的平均CTR。评估指标:测试集上每个广告的
pCTR和真实点击率的平均KL散度。KL散度衡量了KL散度为0,表示预估点击率和真实点击率完全匹配。为了更好的进行指标比较,论文实验中也给出了测试集的
MSE(均方误差)指标。
模型不仅可以用于预测新广告的
pCTR,还可以为客户提供优化广告的建议。可以根据模型特征及其重要性来给广告主提供创建广告的建议,如:广告标题太短建议增加长度。
1.3 特征工程
1.3.1 Term CTR Feature Set
不同竞价词的平均点击率存在明显的差异,因此在预测某个广告的点击率时,相同竞价词的其它类似广告可能有所帮助。
因此论文对此提出两个特征,称作相同竞价词特征集(
Term CTR Feature Set)。对于广告
ad的term(记作针对该
term竞价的其它广告主所有广告的数量:由于同一个广告主的不同广告之间相关性比较强,因此这里用其它广告主的广告作为特征来源。否则容易出现信息泄露。
针对该
term竞价的其它广告主的广告点击率(经过归一化):其中:
term竞价的其它广告主所有广告的数量term竞价的其它广告主所有广告的平均点击率term出现导致term竞价的广告数量的先验强度,默认取值为1。实验发现,结果对
模型新增这两个特征的实验结果如下图所示,可见
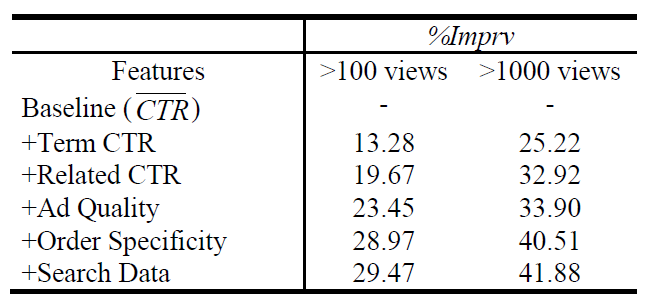
term ctr feature set使得评估指标 “平均KL散度” 提升了13.28%。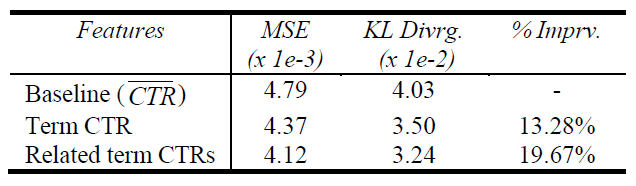
1.3.2 Related Term CTR Feature Set
预测某个广告的点击率时,相关竞价词的其它类似广告可能也有所帮助。
如:广告
a的竞价词是 “电脑”,广告b的竞价词是 “买电脑”,则广告b的点击率对于预测广告a的点击率是有帮助的。考虑竞价词的子集/超集。
给定一个竞价词
t,定义其相关广告集合为term可能包含多个单词word,这里不考虑word之间的词序):如:
t是red shoes如果广告的竞价词是
buy red shoes,则该广告属于t的如果广告的竞价词是
shoes,则该广告属于t的如果广告的竞价词是
red shoes,则该广告属于t的如果广告的竞价词是
blue shoes,则该广告属于t的
由
广告集合
term和t完全匹配。广告集合
term比t少了广告集合
term比t多了
假设
*为任意数值,则定义:t的任何超集(不考虑词序)作为竞价term的广告的集合。t的任何子集(不考虑词序)作为竞价term的广告的集合。
定义相关竞价词的一组特征,它们称为相关竞价词特征集(
Related Term CTR Feature Set):在
term相关的竞价词上竞价的其它广告主所有广告的数量:在
term相关的竞价词上竞价的其它广告主所有广告的平均点击率:其中
x的真实点击率。和
Term CTR Feature Set一样,这里也采用平滑:其中
论文中采取了
5x5=25种组合,得到25 x 2 =50个related term ctr特征。测试集的 “平均KL散度” 表明:采用这一组特征之后,取得了接近20%的提升。
1.3.3 Ad Quality Feature Set
即使是同一个竞价
term,不同广告的点击率也存在显著差异。从经验来看,至少有五种粗略的要素影响用户是否点击:外观(
Appearance):外观是否美观。吸引力(
Attention Capture):广告是否吸引眼球。声誉 (
Reputation):广告主是否知名品牌。落地页质量 (
Landing page quality):点击广告之后的落地页是否高质量。虽然用户只有点击之后才能看到落地页,但是我们假设这些落地页是用户熟悉的广告主(如
ebay, amazon),因此用户在点击之前就已经熟知落地页的信息。相关性 (
Relevance):广告与用户query词是否相关。
针对每个要素,论文给出一些特征:
外观:
广告标题包含多少个单词。
广告标题是在广告体内还是在广告体外。
标题是否正确的大小写首字母。
广告标题是否包含了太多的感叹号、美元符号或其它标点符号。
广告标题用的是短词还是长词。
吸引力:
标题是否包含暗示着转化的单词,如
购买 buy、加入join、订阅subscribe等等。这些转化词是否出现在广告体内还是广告体外 。
标题是否包含数字(如折扣率,价格等)。
声誉:
底部展示的
URL是否以.com/.net/.org/.edu结尾。底部展示的的
url多长。底部展示的
url分为几个部分。如
books.com只有两部分,它比books.something.com更好。底部展示的
url是否包含破折号或者数字。
因为好的、短的
.com域名比较贵,因此url体现了广告主的实力。落地页质量:
落地页是否包含
flash。落地页页面哪部分采用大图。
落地页是否符合
W3C。落地页是否使用样式表。
落地页是否弹出广告。
相关性:
竞价词是否出现在标题。
竞价词的一部分是否出现在标题。
竞价词或者竞价词的一部分是否出现在广告体内。
如果出现,则竞价词或者竞价词的一部分占据广告体的几分之一。
最终在这
5个要素种抽取了81个特征。某些特征可以出现在多个要素里,如:广告内容中美元符号数量。该特征可能会增加吸引力,但是会降低外观。
除了以上
5个内容要素,还有一个重要的内容要素:广告文本的单词。我们统计广告标题和正文中出现的
top 10000个单词,将这1万个单词出现与否作为unigram特征。因为某些单词更容易吸引用户点击,因此unigram特征能够弥补注意力要素遗漏的特征。注意:构造特征时,标题和正文的
unigram分别进行构造。即:单词是否出现在标题中、单词是否出现在正文中。如下所示:单词
shipping更倾向于在高CTR广告中出现,这意味着shipping更容易吸引用户点击。图中的三条曲线从上到下依次代表:每个单词在高
CTR广告中出现的平均频次。每个单词在所有广告中出现的平均频次。
每个单词在低
CTR广告中出现的平均频次。
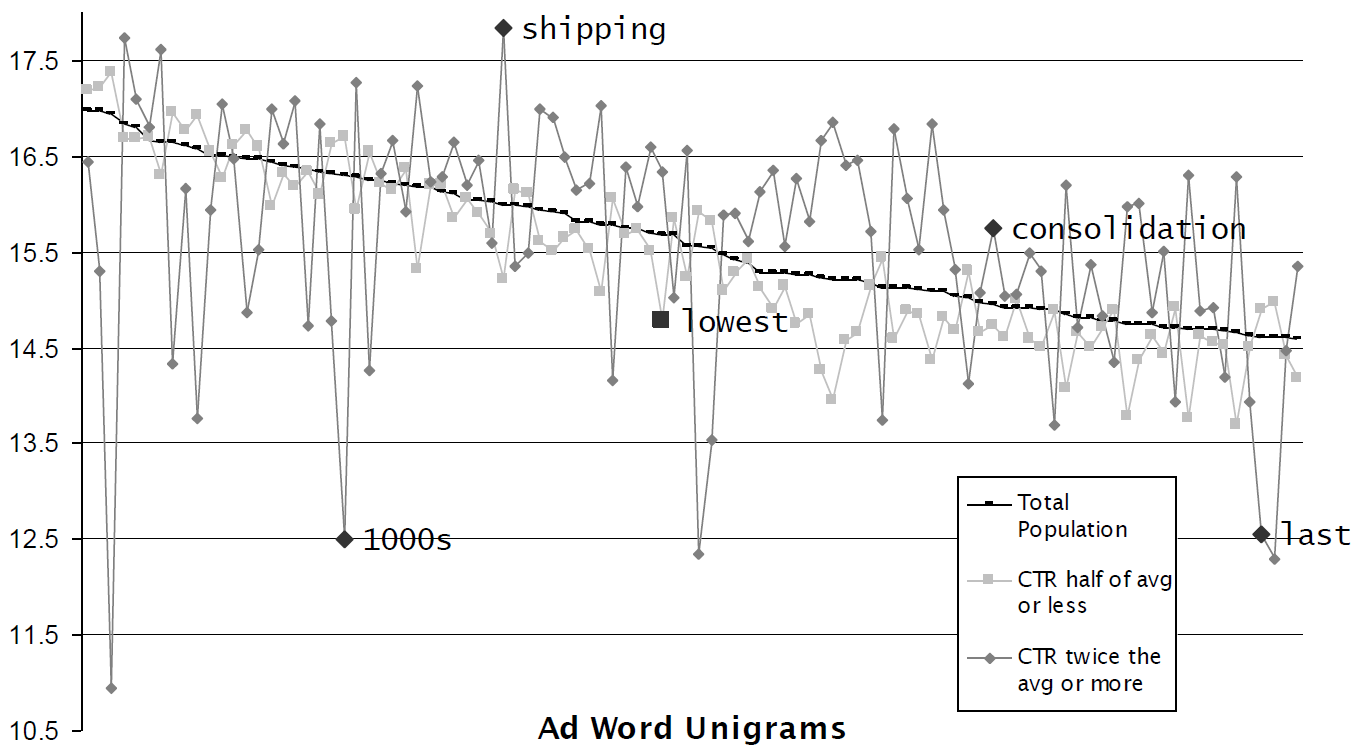
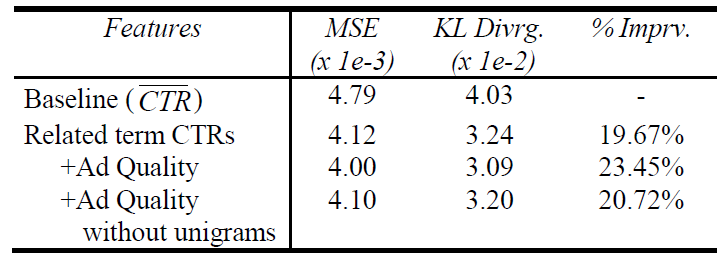
以上5个内容要素,以及
unigram特征一起构成了广告质量特征集 (Ad Quality Feature Set)。结果表明:该组特征能够显著提升性能,将测试集的 “平均
KL散度” 提升约3.8 %。考虑去掉
unigram特征,结果表明:仅仅
5个因素的81个特征能够提升约1.1 %。unigram特征能够提升约2.7 %。
1.3.4 Order Specificity Feature Set
有的订单定向比较窄。如:
xxxxxxxxxxTitle: Buy shoes now,Text: Shop at our discount shoe warehouse!Url: shoes.comTerms: {buy shoes, shoes, cheap shoes}.该订单的竞价词都和
shoes相关,定向比较狭窄。而有的订单定向比较宽,如:
xxxxxxxxxxTitle: Buy [term] now,Text: Shop at our discount warehouse!Url: store.comTerms: {shoes, TVs, grass, paint}该订单的竞价词不仅包含
shoes,还包括TV、grass等等。我们预期:定向越宽的订单,其平均
CTR越低;定向越窄的订单,其平均CTR越高。为了考虑捕捉同一个订单内不同广告的联系,论文提出了订单维度特征集 (
Order Specificity Feature Set)。同一个订单中,去重之后不同竞价词
term的数量:同一个订单中,竞价词
term的类别分布。分布越集中,定向越窄;分布越分散,定向越宽。利用搜索引擎搜索每个竞价词
term,并通过文本分类算法对搜索结果进行分类,将每个竞价词term划分到74个类别中。计算每个订单的竞价词
term的类别熵,并将类别熵作为特征。
采用该特征集之后,测试集的 “平均
KL散度” 提升约5.5 %。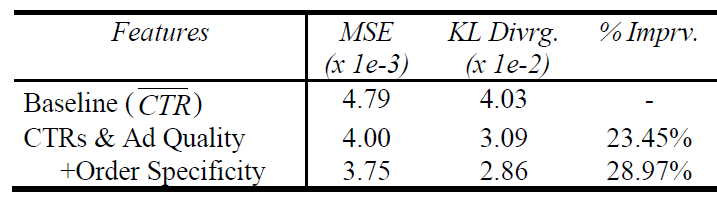
1.3.5 Search Data Feature Set
事实上可以通过使用外部数据来构造特征。
如:给定一个竞价词,可以通维基百科来判断它是否是一个众所周知的词,也可以通过同义词词库来查找其同义词等等。
因此构建外部搜索数据特征集(
Search Data Feature Set),其中包括:每个
term,网络上该term出现的频率。这可以利用搜索引擎的搜索结果中包含该
term的网页数量来初略估计。每个
term,搜索引擎的query中出现该term的频率。这可以用近三个月搜索引擎的搜索日志中,
query里出现该term的数量来粗略估计。
这两个特征离散化为
20个桶,仔细划分桶边界使得每个桶具有相同数量的广告。单独采用该特征集之后,测试集的 “平均
KL散度” 提升约3.1 %。但是融合了前面提到的特征之后没有任何改进,这意味着该特征集相比前面的几个特征集是冗余的。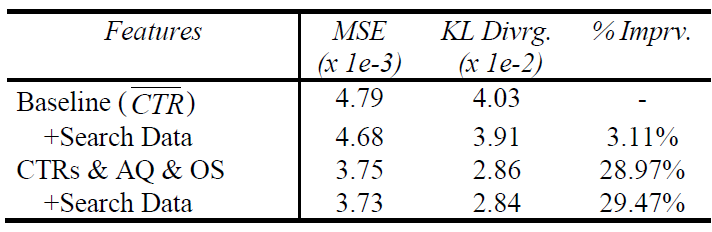
1.3.6 更多特征
当独立的考虑每个
feature set时,测试集的 “平均KL散度” 提升效果如下:related term ctr feature set:19.67%。ad quality feature set:12.0%。unigram features along:10.2%。order specificity feature set:8.9%。search data feature set:3.1%。
有几个特征探索方向:
可以将广告的
term进行聚类,从而提供广告之间的关系。这是从语义上分析term的相似性。这组特征称作Related Term Feature Set。可以基于用户的
query来构造特征。在完全匹配条件下竞价词和用户搜索词完全相同,但是在更宽松的匹配下竞价词和搜索词可能存在某种更广义的关联。此时了解搜索词的内容有助于预测广告的点击率。
因此可以基于用户的搜索词
query term来构建特征,如:query term和bid term相似度、query term的单词数、query term出现在广告标题/广告正文/落地页的频次。可以将落地页的静态排名和动态排名信息加入特征。如:用户访问落地页或者域名的频率、用户在落地页停留的时间、用户在落地页是否点击回退等等。
一个推荐的做法是:在模型中包含尽可能多的特征。这带来两个好处:
更多的特征带来更多的信息,从而帮助模型对于广告点击率预测的更准。
更多的特征带来一定的冗余度,可以防止对抗攻击。
广告主有动力来攻击特征来欺骗模型,从而提升广告的
pCTR,使得他的广告每次排名都靠前。假设模型只有一个特征,该特征是 ”竞价词是否出现在标题“ 。广告主可以刻意将竞价词放置到广告标题,从而骗取较高的
pCTR。一旦模型有多个特征,那么广告主必须同时攻击这些特征才能够欺骗模型。这种难度要大得多。
1.4 特征重要性
由于模型采用逻辑回归,因此可以直观的通过模型权重看到哪些特征具有最高权重、哪些特征具有最低权重。
模型的
top 10和bottom 10权重对应的特征如下: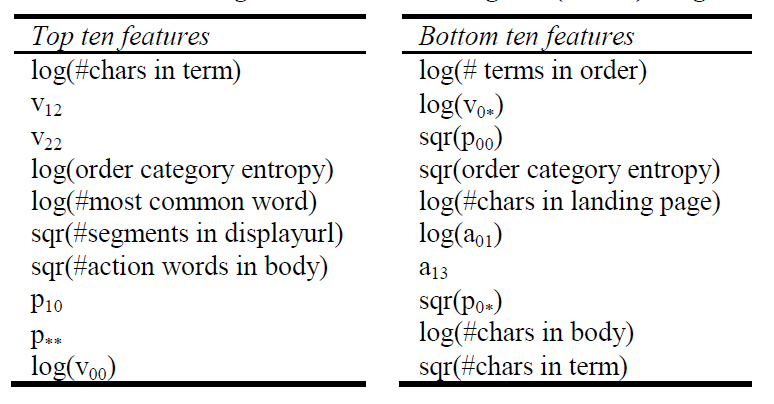
特征的权重不一定直接表示其重要性,因为特征之间不是独立的。
假设有一个重要的特征是文本中每个单词的平均长度(即:平均多少个字符)
因为
在
unigram features中,top 10和bottom 10权重对应的特征如下。可以看到:
排在前面的是更为成熟(
established)的实体词,如official,direct,latest,version。排在后面的是更为吸引眼球的实体词,如
quotes, trial, deals, gift, compare。
从经验上看:用户似乎更愿意点击声誉更好的、更成熟的广告,而不愿意点击免费试用、优惠类的广告。

1.5 曝光量
假设模型能准确预估广告的点击率,一个问题是:广告经过多少次曝光之后,观察到的点击率和预估的点击率接近。
定义观察到的点击率为:
定义预测的点击率为:
其中:
CTR,pCTR,而pCTR和广告已经产生的曝光、点击之后,预测的点击率。模型预测的
pCTR没有考虑广告当前的曝光、点击,因此需要修正。
定义期望绝对损失(
expected absolute error:EAE):其中:
click次的概率。它通过统计其它广告得到。EAE刻画了在不同曝光量的条件下,模型给出的CTR的绝对误差。这和模型优化目标平均KL散度不同。baseline和LR模型的EAE结果如下所示。可以看到:在广告的曝光量超过
100时,baseline和LR模型的EAE几乎相同。在广告的曝光量小于
50时,LR模型的EAE更低。
因此模型对于曝光量
100以内的广告具有明显优势。这也是前面预处理将100次曝光作为阈值截断的原因。对于百万级别广告的广告系统,如果在广告曝光的前
100次期间对广告的CTR预估不准,则导致这些广告以错误的顺序展示,从而导致收入减少和用户体验下降。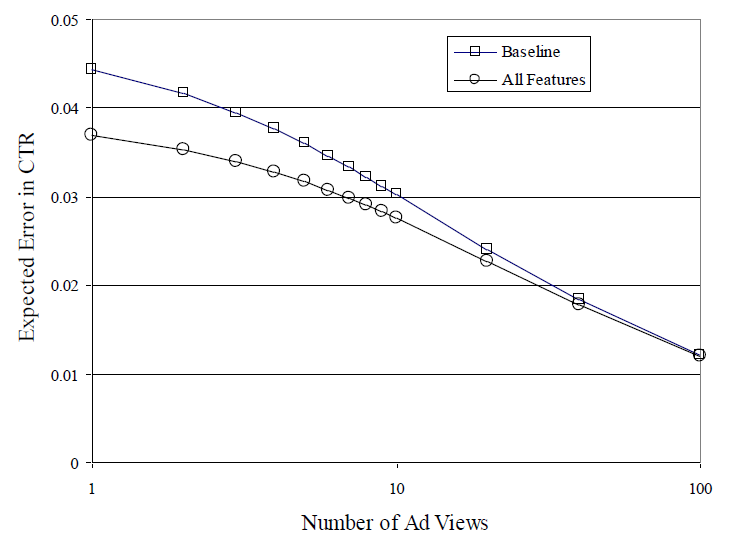
预处理选择
100次曝光作为截断阈值,是希望样本的观察CTR具有合理的置信水平。事实上有一些广告系统更关注于曝光量更大的广告,希望对这些广告能够预测更准确。更大曝光量意味着
label中更少的噪音,模型会学习得效果更好。但是这也意味着广告样本不包含那些被系统判定为低价值的广告,因为系统没有给这些低价值广告足够多的曝光机会。
当曝光阈值提升到
1000次时,模型效果如下。可以看到:曝光量超过1000的广告比曝光量100的广告,模型预测效果(以测试集的平均KL散度为指标)提升了40%左右((41.88-29.47)/29.47)。