一、DIN [2017]
《Deep Interest Network for Click-Through Rate Prediction》
在
cost-per-click: CPC广告系统中,广告按照effective cost per mille: eCPM进行排序。eCPM是竞价(bid price)和点击率(click-through rate: CTR)的乘积,而CTR需要由系统预测,因此CTR预估模型的性能直接影响系统最终收入从而在广告系统中起着关键作用。CTR预估模型受到了学术界和工业界的广泛关注。最近,受到深度学习在计算机视觉和自然语言处理中取得成功的启发,人们已经提出了基于深度学习的方法用于CTR预估任务。这些方法遵循类似的Embedding & MLP范式:首先将大规模稀疏输入特征映射到低维embedding向量,然后以group-wise方式转换为固定长度的向量,最后拼接在一起并馈入多层感知机(multilayer perceptron: MLP)从而学习特征之间的非线性关系。与常用的逻辑回归模型相比,这些深度学习方法可以减少大量的特征工程工作,大大提升了模型容量(model capability)。为简单起见,在本文中我们将这些方法命名为Embedding & MLP,它们现在已经在CTR预估任务中流行开来。然而,
Embedding & MLP方法中维度有限的用户representation向量将成为表达用户多样化兴趣(diverse interests)的瓶颈。以电商网站的展示广告(display advertising)为例。用户在访问电商网站时可能同时对不同种类的商品感兴趣,也就是说,用户的兴趣是多样化(diverse)的。当涉及到CTR预估任务时,用户兴趣通常是从用户行为数据中捕获的。Embedding & MLP方法通过将用户行为的embedding向量转换为固定长度的向量来学习某个用户所有兴趣的representation。这个向量位于所有用户的representation向量所在的欧几里得空间中。换句话讲,用户的多样化兴趣被压缩成一个固定长度的向量,这限制了Embedding & MLP方法的表达能力。为了使
representation足以表达用户的多样化兴趣,固定长度向量的维度需要极大地扩展。不幸的是,这会极大地增加模型参数的规模,并加剧有限数据下模型过拟合的风险。此外,这也会增加计算和存储的负担,这种负担对于工业级在线系统而言是不能容忍的。另一方面,在预测目标广告时没有必要将某个用户的所有多样化兴趣压缩到单个向量中,因为只有部分用户兴趣才会影响到该用户的行为(点击或不点击)。例如,一位女性游泳爱好者会点击推荐的泳镜,主要是因为她上周购物清单中的泳衣,而不是清单中的鞋子。受此启发,论文
《Deep Interest Network for Click-Through Rate Prediction》提出了一个新模型:深度兴趣网络(Deep Interest Network: DIN)。DIN通过考虑历史行为与目标广告的相关性来自适应地计算用户兴趣的representation向量。通过引入局部激活单元(local activation unit),DIN通过软搜索(soft-searching)历史行为与目标广告的相关部分来关注相关的用户兴趣,并采用加权sum池化来获得对目标广告的用户兴趣representation。与目标广告相关性更高的行为将会获得更高的激活权重(activated weight),并将主导用户兴趣representation。论文在实验部分将这种现象可视化。这样,用户兴趣的representation向量随着不同的目标广告而变化,提高了模型在有限维度下的表达能力,使得DIN能够更好地捕获用户的多样化兴趣。训练具有大规模稀疏特征的工业级深度网络是一项巨大挑战。例如,基于
SGD的优化方法只更新出现在每个mibi-batch中的稀疏特征的参数。然而,如果加上传统的L2正则化,则计算变得不可接受,因为这需要为每个mibi-batch计算全部参数的L2范数。在论文的应用场景中,参数规模高达数十亿。在论文中,作者开发了一种新颖的mini-batch aware正则化,其中只有出现在每个mibi-batch中的非零特征的参数参与L2范数的计算,使得计算可以接受。此外,作者设计了一个数据自适应激活函数,它根据输入分布自适应调整校正点(rectified point)来推广常用的PReLU激活函数,并被证明有助于训练具有稀疏特征的工业级深度网络。论文主要贡献:
指出了使用固定长度向量来表达用户多样化兴趣的局限性,并设计了一种新颖的深度兴趣网络(
deep interest network: DIN)。DIN引入了局部激活单元(local activation unit),从而自适应地根据目标广告从用户历史行为中学习用户兴趣的representation。DIN可以大大提高模型的表达能力,更好地捕获用户兴趣的多样性特点(diversity characteristic)。开发了两种新技术来帮助训练工业级深度网络:
mini-batch aware正则化:它可以在具有大量参数的深度网络上节省大量正则化计算,并有助于避免过拟合。数据自适应激活函数:它通过考虑输入的分布来推广
PReLU并显示出良好的性能。
对公共数据集和阿里巴巴数据集进行了广泛的实验,实验结果证明了所提出的
DIN和训练技术的有效性。模型的代码已经公开。所提出的方法已经部署在阿里巴巴的商业展示广告系统(commercial display advertising system)中,服务于主流量,为业务带来了显著提升。
论文聚焦于电商行业展示广告(
display advertising)场景下的CTR预估建模。这里讨论的方法也可以应用于具有丰富用户行为的类似场景,如电商网站的个性化推荐、社交网络的feeds排序。相关工作:
CTR预估模型的结构由浅入深,同时CTR预估模型中使用的样本数量和特征维度也越来越大。为了更好地提取特征关系从而提高性能,一些工作都关注了模型结构的设计。作为先驱者,
NNLM为每个单词学习分布式representation,旨在避免语言模型中的维度诅咒。这种通常被称作embedding的方法启发了许多需要处理大规模稀疏输入的NLP模型和CTR预估模型。LS-PLM和FM模型可以看作是一类具有单个隐层的网络,它们首先在稀疏输入上使用embedding layer,然后对目标拟合(target fitting)施加专门设计的变换函数(transformation function),旨在捕获特征之间的组合关系(combination relation)。Deep Crossing、Wide & Deep、YouTube Recommendation CTR model通过用复杂的MLP网络替代了变换函数来扩展LS-PLM和FM,极大地增强了模型容量。PNN试图通过在embedding layer之后引入product layer来捕获高阶特征交互。DeepFM在Wide & Deep中使用一个factorization machine: FM作为wide部分,从而无需特征工程。
总体而言,这些方法遵循相似的模型结构,即结合了
embedding层(用于学习稀疏特征的稠密representation)和MLP(用于自动学习特征的组合关系)。这种点击率预估模型大大减少了人工特征工程的工作。我们的
base model遵循这种模型结构。然而,在具有丰富用户行为的application中,某些特征通常包含可变长度的id列表,例如,YouTube推荐系统中的历史搜索term列表、或者历史观看视频列表。已有的模型通常通过sum池化或者均值池化将对应的embedding向量列表转换为固定长度的向量,这会导致信息丢失。我们提出的DIN通过考虑目标广告来自适应地学习representation向量,从而解决这个问题,提高了模型的表达能力。注意力机制起源于神经机器翻译(
Neural Machine Translation: NMT)领域。NMT对所有annotations进行加权求和从而获得预期的annotation,并且只关注与下一个目标单词相关的信息。最近的一项工作Deep-Intent在搜索广告的上下文中应用了注意力。与NMT类似,他们使用RNN对文本进行建模,然后学习一个全局隐向量来帮助关注每个query中的所有关键词。结果表明,注意力的使用有助于捕获query或广告的主要意图。DIN设计了一个局部激活单元(local activation unit)来软搜索(soft-search)相关的用户行为,并采用加权sum池化来获得用户关于目标广告兴趣的自适应representation。不同广告的用户representation向量不同,这与广告和用户之间没有交互的DeepIntent不同。我们公开了代码,并进一步展示了如何在世界上最大的广告系统之一中成功部署
DIN,并使用新颖的开发技术来训练具有数亿个参数的大规模深度网络。背景:在阿里巴巴等电商网站中,广告是天然的商品。在本文的其余部分,如果没有特别声明,我们将广告视为商品。下图简要说明了阿里巴巴展示广告系统的运行过程,它主要包括两个阶段:
mathcing阶段:通过协同过滤等方法生成与访问用户相关的候选广告列表。ranking阶段:预测每个目标广告的点击率,然后选择排名靠前的广告。
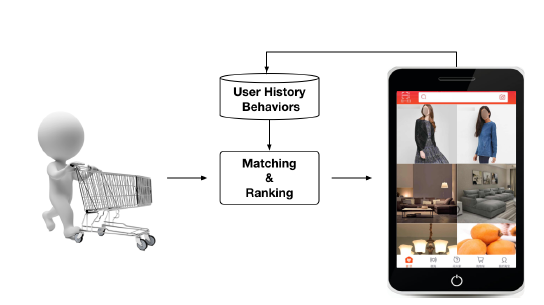
每天,数以亿计的用户访问电商网站,给我们留下了大量的用户行为数据,这些数据对构建
mathcing模型和ranking模型至关重要。值得一提的是,具有丰富历史行为的用户包含多样化的兴趣。例如,一位年轻的妈妈最近浏览了羊毛大衣、T shirt、耳环、手提包、包包、儿童外套等商品。这些行为数据为我们提供了有关她购物兴趣的提示。当她访问电商网站时,系统会向她展示一个合适的广告,例如一个新的手提包。显然,展示的广告只匹配或激活了这位母亲的部分兴趣。总之,对于丰富行为的用户,其兴趣是多样化(
diverse)的,并且可以在给定某些广告的情况下局部激活(locally activated)。我们将在本文后面展示利用这些特点在构建CTR预估模型中起着重要作用。
1.1 模型
与赞助搜索(
sponsored search)不同,在展示广告系统中用户没有显式地表达意图。在构建点击率预估模型时,需要有效的方法从丰富的历史行为中抽取用户兴趣。描述用户和广告的特征是广告系统点击率建模的基本要素(basic elements)。合理利用这些特征并从中挖掘信息至关重要。
1.1.1 Feature Representation
工业
CTR预估任务中的数据大多数采用多组(multi-group)离散(categorial)的形式,例如{ weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book }等。数据会通过one-hot编码转换为高维稀疏特征。对于第
unique值,则我们将这一组特征编码为one-hot向量对于某组特征取值为多个离散值的情况,类似地我们进行
multi-hot编码。其中one-hot编码、multi-hot编码。
假设一共有
这样,上述具有四组特征的样本可以表示为:
我们系统中使用的所有特征如下表所示。我们将其划分为四类:
用户画像特征(
User Profile Features):包括用户基础画像如年龄、性别等。用户行为特征(
User Behavior Features):包括用户历史访问的商品信息(如商品id、店铺id、商品类目id等)。该特征通常是multi-hot encoding向量,包含丰富的用户兴趣信息。广告特征(
Ad Features):包括广告的商品id、店铺id、商品类目id等。上下文特征(
Context Features):包括访问时间等。
这里不包含任何组合特征(
combination features),特征交互由神经网络来捕获。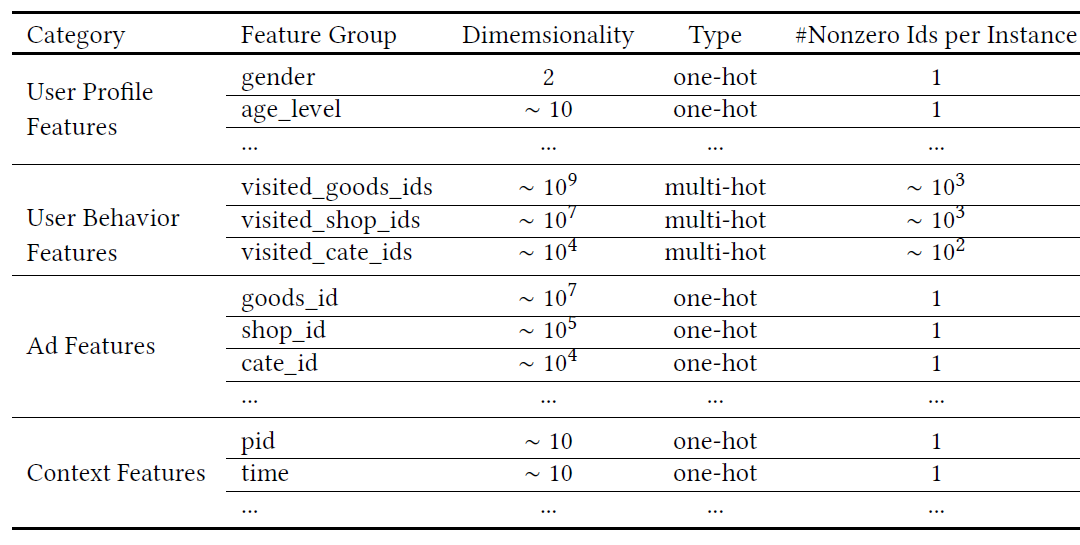
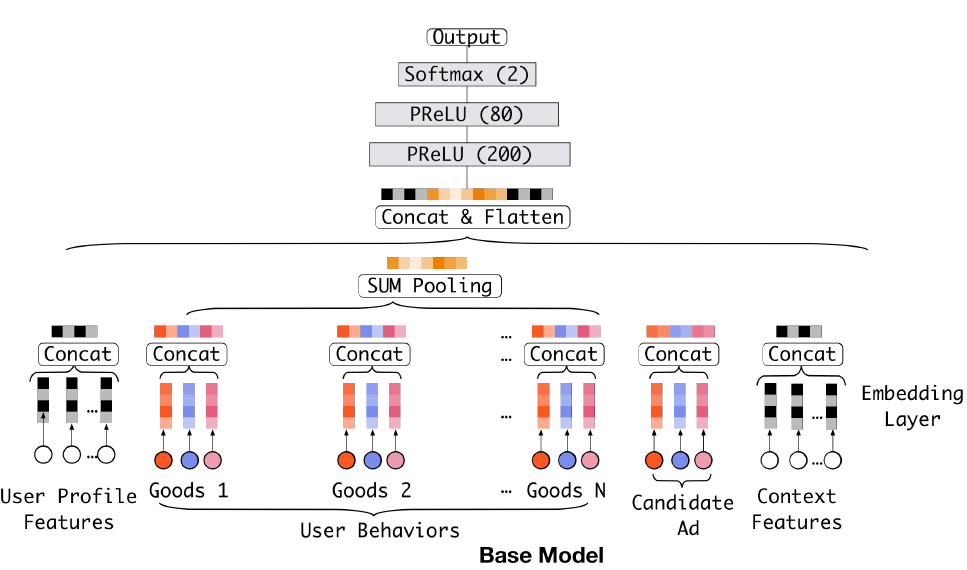
1.1.2 Base Model
大多数流行的模型结构采用类似的
Embedding & MLP范式,我们将其称作base model,如下图所示。base model由几个部分组成:Embedding Layer:由于模型输入是高维稀疏的binary向量,因此embedding层用于将它们转换为低维稠密的representation。对于第
feature groupembedding dictionary,其中第feature group取值为embedding向量,embedding维度。embedding操作遵循table lookup机制。如果
one-hot特征向量,且第feature group被映射为单个embedding向量如果
multi-hot特征向量,且位置1,则该feature group被映射为多个embedding向量multi-hot非零元素的数量。
Pooling layer and Concat layer:注意,不同的用户有不同数量的行为。因此multi-hot行为特征向量embedding向量列表的长度是可变的。由于全连接网络只能处理固定长度的输入,因此通常的做法是通过池化层将embedding向量列表转换为固定长度的向量:两个最常用的池化层是
sum池化和均值池化,它们对embedding向量列表执行element-wise的求和、求均值。embedding层和池化层都以group-wise的方式执行,从而将原始稀疏特征映射到多个固定长度的representation向量中。然后将所有group-wise representation向量拼接在一起从而获得样本的整体representation向量。MLP:给定拼接好的、稠密的整体representation向量,全连接层用于自动学习特征组合。最近开发的方法Wide & Deep、PNN、DeepFM等聚焦于设计MLP的结构以便更好地提取信息。
损失函数:
base model中使用的目标函数是负的对数似然:其中:
sigmoid输出层的输出概率,表示样本被点击的概率。
1.1.3 DIN
在所有这些特征中,用户行为特征至关重要,并且在电商应用场景中对用户兴趣建模起到关键作用。
base model通过聚合用户行为feature group上的所有embedding向量来获得用户兴趣的固定长度representation向量。对于给定的用户,无论目标广告是什么,该representation向量都保持不变。这样,维度有限的用户representation向量将成为表达用户多样化兴趣的瓶颈。为了让模型足够强大,一个简单的方法是扩大
embedding向量的维度。不幸的是,这会大大增加模型参数的规模,从而导致在有限训练数据下模型过拟合,同时增加计算和存储的负担,这对于工业在线系统而言是无法容忍的。是否有一种优雅的方案在有限维度下通过单个向量来表达用户的多样化兴趣?用户兴趣的局部激活特点(
local activation characteristic)给了我们灵感,从而使得我们设计了一个新颖的、叫做深度兴趣网络(deep interest network: DIN)模型。想象一下前面提到的年轻妈妈访问电商网站时,她发现展示的新款手提包很可爱并点击它。我们来剖析一下点击动作的驱动力。目标广告通过软搜索(
soft-searching)她的历史行为,发现她最近浏览了tote bag和leather handbag等类似商品。换句话讲,与目标广告相关的行为对点击行为有很大贡献。DIN通过关注目标广告相关的局部激活兴趣representation来模拟该过程。DIN不是用单个向量来表达用户的所有多样化兴趣,而是通过考虑历史行为与目标广告的相关性来自适应地计算用户兴趣的representation。因此,同一个用户的兴趣representation向量因不同的目标广告而异。下图说明了
DIN的架构。和base model相比,DIN引入了一种新颖设计的局部激活单元(local activation unit),其它结构保持相同。具体而言,局部激活单元作用于用户行为特征(作为加权
sum池化),从而自适应地计算目标广告representation其中:
embedding向量的列表。embedding向量。在
embedding作为输入之外,我们还将它们的外积(out product)作为输入,这是有助于显式建模相关性。representation向量,它随着不同的广告而变化。
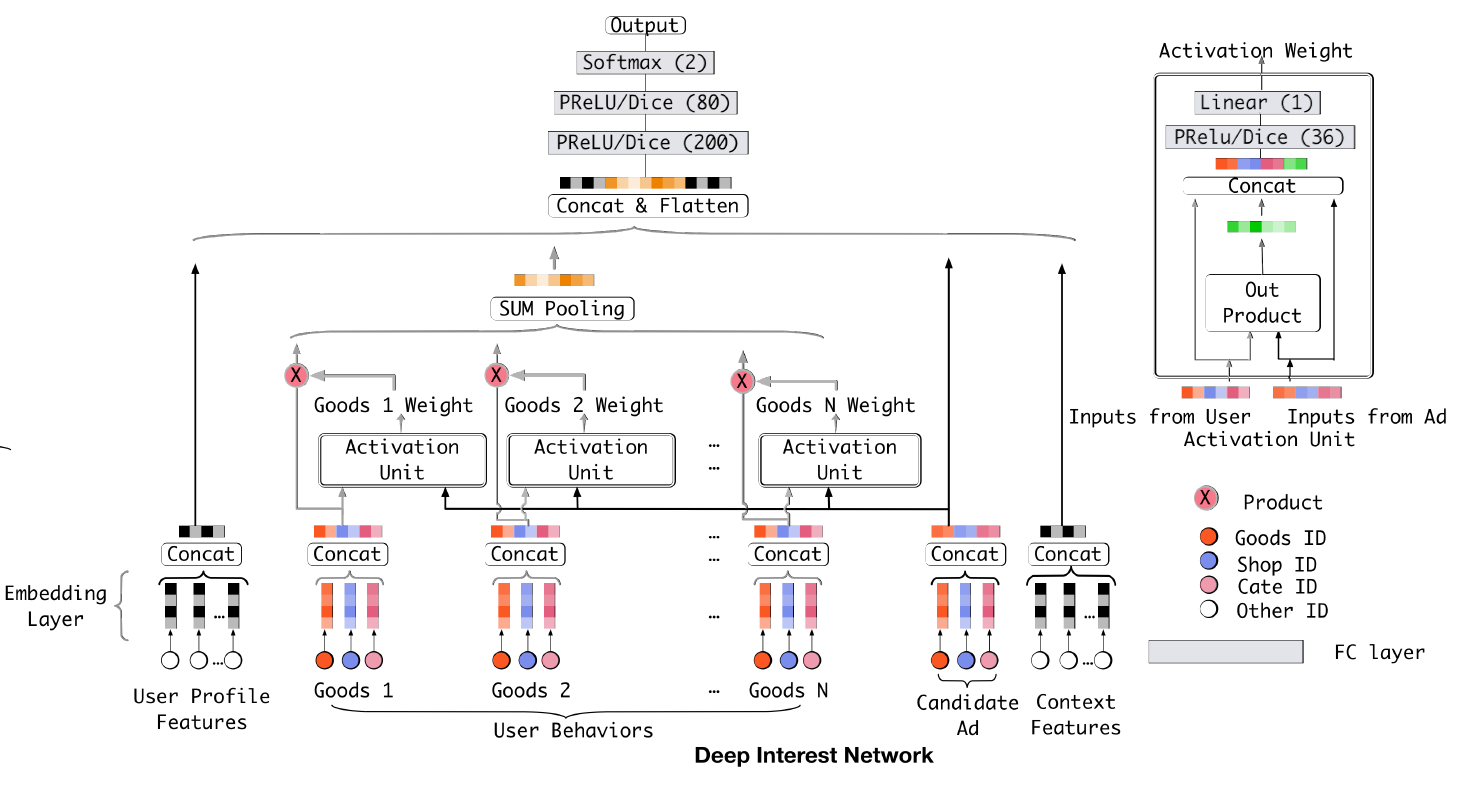
局部激活单元与
NMT任务中开发的注意力方法具有相似的思想。然而,与传统的注意力方法不同,我们放松了softmax归一化。相反,approximation)。例如,假设一个用户的历史行为包含
90%的衣服和10%的电子产品。给定关于T shirt和手机的两个目标广告,T shirt激活了大部分属于衣服的历史行为,并且可能比手机获得更大的numerical scale)上的区分度。我们尝试过
LSTM以序列方式对用户历史行为数据进行建模,但是没有显示出任何改善。与NLP任务中受语法约束的文本不同,用户历史行为序列可能包含多个并发(concurrent)的兴趣。对这些兴趣的快速跃迁和突然结束导致用户行为序列数据看起来充满噪音。一个可能的方向是设计特殊的结构从而以序列方式对此类数据进行建模。我们将其留待未来研究。
1.1.4 训练技巧
在阿里巴巴的广告系统中,商品和用户的数量达到了数亿。实际上,训练具有大规模稀疏输入特征的工业级深度网络具有很大挑战。这里我们将介绍两种在实践中被证明有用的重要技术。
a. Mini-batch Aware 正则化
过拟合是训练工业级深度网络的关键挑战。当添加细粒度特征时,例如维度为
6亿的goods_id特征(包括用户visited_goods_ids特征、广告goods_id特征),如果没有正则化,则在训练的第一个epoch之后,模型性能迅速下降,如下图所示的深绿色线所示。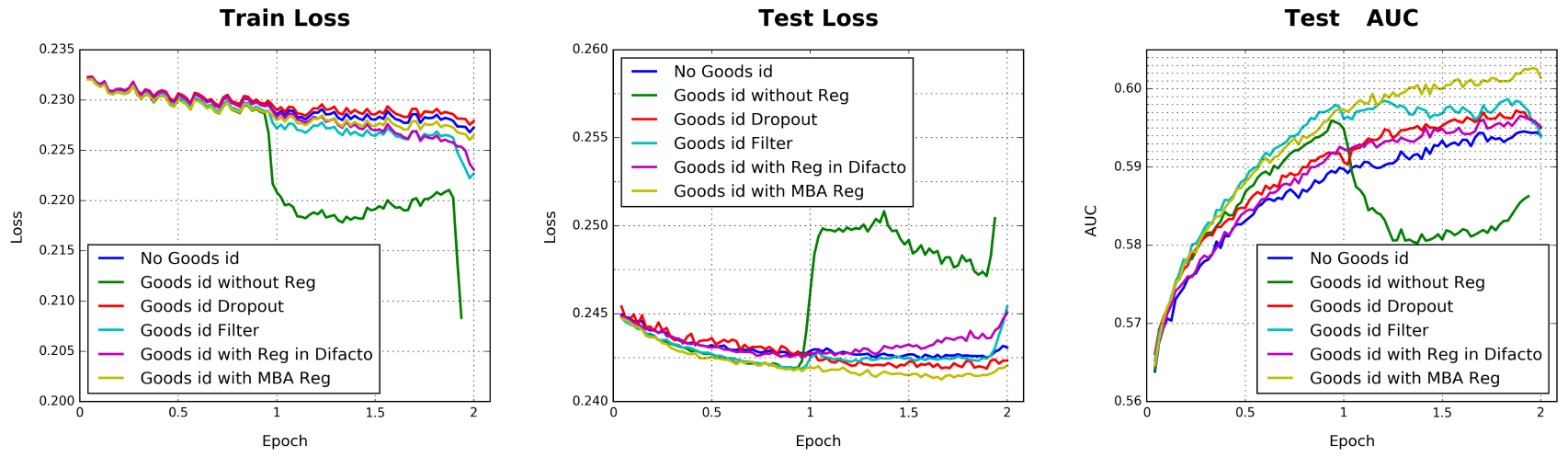
将传统的正则化方法,如
L2正则化和L1正则化,直接应用于具有稀疏输入和数亿参数的网络是不切实际的。以L2正则化为例,在没有正则化的、基于SGD优化方法的场景中,只需要更新每个mini-batch中出现的非零稀疏特征的参数。然而,当添加L2正则化时,它需要在每个mini-batch对所有参数计算L2范数,这导致计算量非常大,并且在参数扩展到数亿时是不可接受的。在本文中,我们引入了一种高效的
mini-batch aware的正则化器(regularizer),它只计算每个mini-batch中出现的稀疏特征的参数的L2范数,使得正则化计算可行。事实上,
embedding dictionary为CTR模型贡献了大部分参数,并产生了繁重(heavy)的计算。令
embedding dictionary的参数,embedding向量的维度、L2正则化:其中:
embedding向量。1,否则取值为零。
这里之所以使用
embedding向量的正则化。事实上,如果某个特征0(表示该特征从未出现过,即embedding向量上式可以转换为
mini-batch aware的方式:其中:
mini-batch,mini-batch数量。令
1次,则上式可以近似为:注意:
0或1。理论上应该将mini-batch通常很小,绝大多数特征最多仅出现一次。这样我们得到了
L2正则化的mini-batch aware版本,其中embedding向量的更新方程为:其中:
mini-batch。1次,
现在
mini-batch中仅对该mini-batch出现过的特征对应的embedding向量进行正则化。
b. 数据自适应激活函数
PReLU激活函数是一种广泛应用的激活函数,其定义为:其中:
channel之间切换。这里我们将
control function)。
PReLU采用值为0的hard rectified point,当每层的输入遵循不同的分布时,这可能不合适。有鉴于此,我们设计了一个名为Dice的新的数据自适应激活函数:在训练阶段,
mini-batch中输入的均值和方差。在测试阶段,
新的控制函数如下图右侧所示(左侧为
PReLU的控制函数)。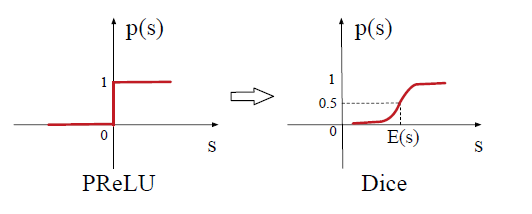
不同配置下的
Dice激活函数如下图所示。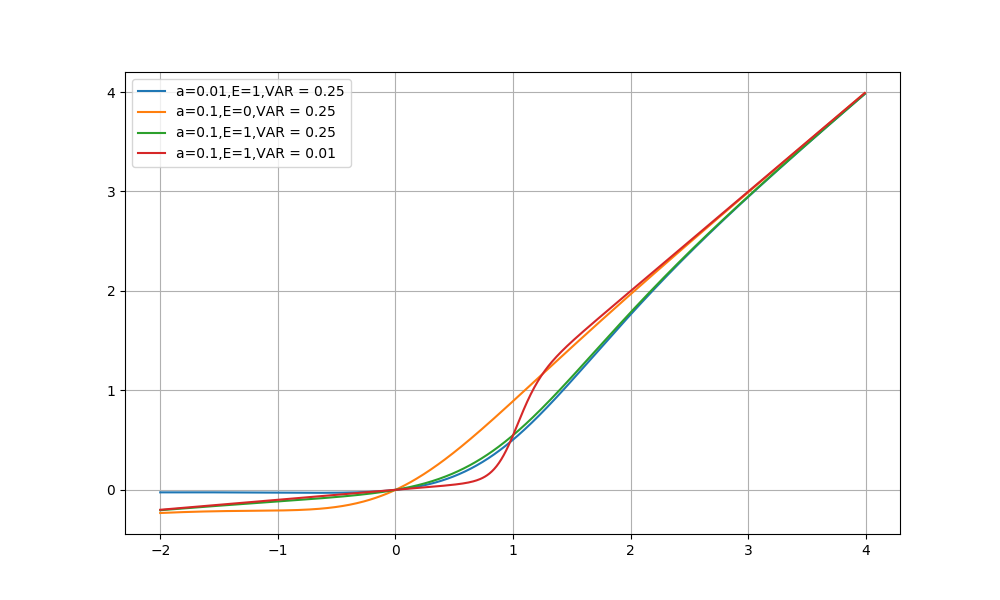
Dice可以看做是PReLU的泛化,其重要思想是根据输入数据的分布自适应调整rectified point(为输入的均值)。另外,
Dice平滑地控制在两个channel之间切换。最后,当
Dice退化为PReLU。
1.1.5 在线部署
值得一提的是,每天都有成千上万的用户来访问我们的系统,对工业深度网络进行在线
serving并非易事。更糟糕的是,在流量高峰期间,我们的系统每秒为超过100万用户提供serving。这要求以高吞吐量、低延迟进行实时CTR预估。例如,在我们的真实系统中,我们需要在不到10ms的时间内为每个用户预估数百个广告的ctr。在我们的工程实践中,我们部署了几种重要技术来加速
CPU-GPU架构下的工业深度网络的在线serving:request batching:合并来自CPU的相邻请求从而利用GPU的性能。GPU内存优化:改进GPU内存访问方式,从而减少GPU内存中的无效的事务(transaction)。并发的
kernel计算:允许使用多个CUDA kernel同时处理矩阵计算。
总之,这些技术的优化实际上使得单台机器的
Query Per Second: QPS翻了一倍。
1.2 实验
这里我们详细介绍了我们的实验,包括数据集、评估指标、实验设置、模型比较、以及相应的分析。在包含用户行为的两个公共数据集以及从阿里巴巴展示广告系统收集的数据集上进行的实验证明了所提出方法的有效性,该方法在
CTR预测任务上优于SOTA的方法。数据集:
Amazon数据集:包含来自亚马逊的商品评论和商品元数据。该数据集通常用作benchmark数据集。我们在Electronics(电子产品)的数据子集上进行实验,该子集包含192403个用户、63001个商品、801个类目,总计1689188个样本。数据集中用户行为丰富,每个用户有给出超过
5条评论,每个商品也收到至少5条评论。特征包括goods_id,cate_id,以及用户查看的goods_id_list, cate_id_list。任务的目标是根据用户的前
对于所有模型,我们使用指数衰减的
SGD优化器,初始学习率为1.0、decay rate = 0.1。mini-batch size = 32。MovieLens数据集:包含138493个用户、27278部电影、21个类目,总计20000263个样本。原始的电影评分是0~5的连续值,为了使其适合CTR预估任务,我们将其转换为二类分类数据:电影评分为4或5分的标记为正样本、其它评分的标记为负样本。我们根据用户
ID来拆分训练集和测试集。我们随机选择100000个用户作为训练集(约14470000万个样本),剩余的38493个用户作为测试集(约553万个样本)。任务的目标是根据用户历史行为来预测用户是否将给定的电影评分高于
3分(正标记)。特征包括:
movie id, movie_cate_id,以及用户评级过的moive_id_list, movie_cate_id_list。我们使用和
Amazon数据集相同的优化器、学习率、以及mini batch size。Alibaba数据集:从阿里巴巴在线展示广告系统(online display advertising system)收集的流量日志,其中连续两周的样本用于训练、接下来一天的样本用于测试。训练集规模为20亿、测试集规模为1.4亿。对所有的深度模型,每一组特征的
embedding向量维度为16。MLP的层数为192 x 200 x 80 x2。由于数据量巨大,我们将mini-batch size=5000,并使用Adam优化器。我们使用指数衰减,其中学习率从0.001开始、衰减率为0.9。
所有数据集的统计信息如下表所示。上标的
a表示:对于MovieLens数据集goods代表电影。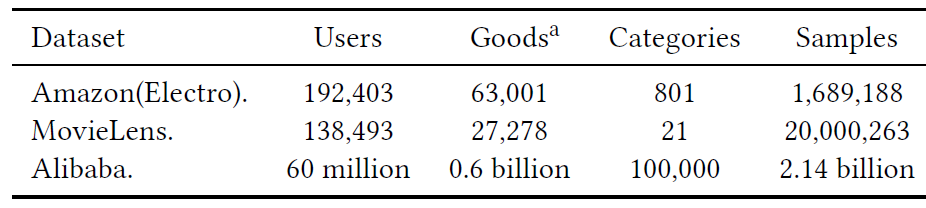
baseline方法:LR:逻辑回归模型。它是一种广泛用于CTR预估任务的浅层模型,我们将其作为weak baseline方法。Base Model:如前所述的遵循Embedding & MLP架构的模型。它是后续大多数建模CTR的深度网络的基础。它充当我们模型比较的strong baseline。Wide & Deep:Wide & Deep模型。它由wide部分和deep部分组成,其中 :wide部分处理手动设计的交叉特征;deep部分自动抽取特征之间的非线性关系,等同于Base Model。由于
wide部分需要专业的特征工程来作为输入,这里我们将用户行为和候选item的叉积 (cross-product)作为wide input。例如,在MovieLens数据集中,我们用的是用户历史评分电影和候选电影之间的叉积 。PNN:它在embedding层之后引入product layer从而捕获高阶特征交互。可以将PNN视为BaseModel的改进版。DeepFM:通过将Wide&Deep中的wide部分替换为FM,它可以视为Wide&Deep的改进版。
评估指标:
在
CTR预估领域,AUC是一个广泛使用的指标。它利用预估的CTR对所有样本进行排序来衡量排序的优劣。GAUC是AUC的推广,它是用户加权AUC的变体,通过对用户的AUC求加权均值来衡量用户侧排序的优劣。一些工作表明,GAUC与展示广告系统中的在线性能更相关。GAUC的计算如下:其中:
i的所有样本对应的auc;i的所有样本数;为了简单起见,后面我们仍然将
GAUC称作AUC。事实证明:
GAUC在展示广告中更具有指导意义。AUC考虑所有样本的排名,而事实上在线上预测时,对于给定用户我们只需要考虑针对该用户的一组候选广告的排名。GAUC对每个用户单独进行处理,先考虑每个用户的预测结果,再对所有用户进行加权。这可以消除用户bias的影响。如:模型倾向于对女性用户打高分(预测为正的概率较高),对男性用户打低分(预测为正的概率较低)。如果采用
AUC则指标效果一般,因为男性正样本打分可能低于女性负样本。如果采用
GAUC则指标效果较好,因为男性用户、女性用户各自的AUC都较高,加权之后的GAUC也较高。这和线上投放的方式一致。
RelaImpr指标衡量模型的相对提升。对于完全随机的模型,AUC的值为0.5。因此RelaImpr的定义为:
注意:所有指标都是在测试集上进行。
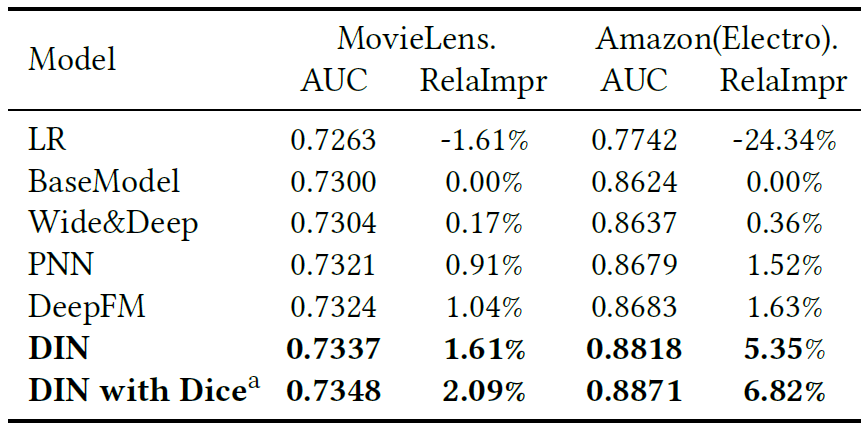
下表给出了
Amazon数据集和MovieLens数据集的实验结果。所有实验重复5次并报告平均结果。其中RelaImpr表示相对BaseModel的提升。可以看到:
所有深度模型都大幅超越了
LR模型,这证明了深度学习的力量。具有特殊设计结构的
PNN和DeepFM超越了Wide & Deep。DIN在所有方法中表现最好。这归因于DIN中的局部激活单元结构的设计。通过这种设计,DIN获得了用户兴趣的自适应的、不同的representation,这极大地提高了模型的表达能力。带
Dice的DIN对DIN进一步地提升,从而证明了数据自适应激活函数Dice的有效性 (其它模型使用PReLU激活函数)。
由于
Amazon数据集和MovieLens数据集的特征维度不太高(约10万维),因此所有的深度模型(包括我们提出的DIN)都未遇到严重的过拟合问题。但是,在Alibaba数据集中涉及到非常高维度的特征,过拟合将成为一个严重的挑战。例如,当训练细粒度特征(如goods_ids特征具有6亿维)的深度学习模型时,如果没有正则化,那么训练的第一个epoch就会发生严重的过拟合,这会导致模型性能迅速下降,如下图的深绿色曲线所示。因此我们进行详细的实验来检查几种常用正则化的性能:
dropout:在每个样本中,随机丢弃50%的feature id。人工频率过滤:在每个样本中,人工去掉历史行为中的低频商品
ID,保留高频商品ID。在我们的实验中,我们保留top2000万的商品id。DiFacto正则化:正则化系数其中低频特征的正则化幅度更小。
MBA:我们提出的mini-batch aware正则化,正则化系数其中低频特征的正则化幅度更大。
Base Model在Alibaba数据集上不同正则化的效果如下表所示。其中RelaImpr是相对于没有正则化(第一行)的提升。训练loss曲线、测试loss曲线、测试auc曲线参考下图所示。可以看到:和没有
good_ids特征的模型相比,带有goods_ids特征的模型在测试AUC上都有所提升。这是因为用户历史行为包含丰富的信息。对于带
good_ids特征的模型,如果没有正则化则过拟合会迅速发生(深绿色曲线)。dropout可以防止过拟合,但是会导致收敛速度变慢。人工频率过滤某种程度上可以缓解过拟合。但是它直接丢弃了大多数低频
good id,使得模型失去机会来更好地利用细粒度特征(即历史行为中的低频商品)。DiFacto会对高频的good_id设置更高的惩罚,其效果要比人工频率过滤更差。我们提出的
mini-batch aware正则化效果最好,它可以有效防止过拟合。

下表给出了
Alibaba数据集的实验结果。RelaImpr表示相对于BaseModel的提升。a表示使用PReLU作为激活函数,b表示使用dropout正则化。可以看到:LR比所有深度模型要弱得多。使用相同的激活函数和正则化的条件下,
DIN比其它所有深度模型都要好。和
BaseModel相比,DIN实现了0.0059的绝对AUC增益和6.08%的RelaImpr。这再次验证了局部激活单元结构的有用设计。基于
DIN的消融研究证明了mini-batch aware: MBA正则化和Dice激活函数的有效性。使用
mini-batch aware正则化器的DIN比dropout带来额外的0.0031的绝对AUC增益。DIN with Dice比PReLU带来了额外的0.0015的绝对AUC增益。
总而言之,相比较于
BaseModel,带有MBA正则化和Dice的DIN实现了总的11.65%的RelaImpr和0.0113的绝对AUC增益。即使与表现最佳的baselineDeepFM相比,DIN仍然实现了0.009的绝对AUC增益。值得注意的是,在具有亿级流量的商业广告系统中,0.001的绝对AUC提升就非常重要,值得模型的部署。DIN显示出极大的优势来更好地理解和利用用户行为数据的特征。此外,我们提出的
MBA正则化和Dice激活函数进一步提高了模型的性能,为训练大规模工业深度网络提供了有力的帮助。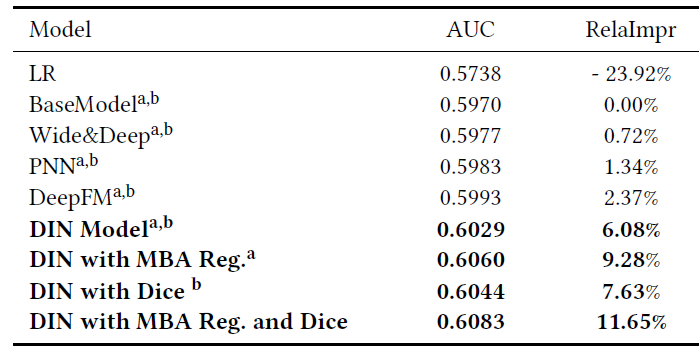
我们在阿里巴巴的展示广告系统 从
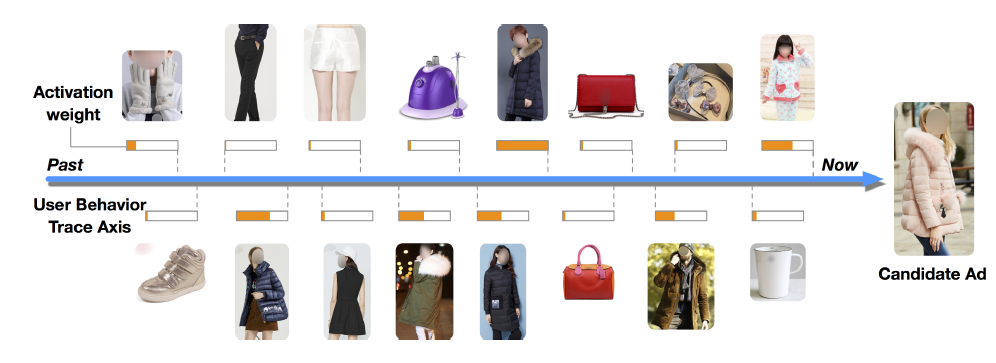
2017年5月到2017年6月进行了在线A/B test实验。在近一个月的测试中,和我们最新版的BaseModel模型(online-serving模型)相比,我们带MBA正则化和Dice激活函数的DIN提升了10.0%的CTR和3.8%的RPM(千次收入Revenue Per Mille: RPM) 。这是一项重大的提升,并证明了我们提出的方法的有效性。目前DIN已经部署并服务于主要流量。可视化:我们在
Alibaba数据集上进行案例研究来揭示DIN的内部结构。首先,我们研究了局部激活单元的有效性。下图给出了用户行为关于候选广告的激活强度。正如预期的那样,和候选广告相关的行为的权重较高。
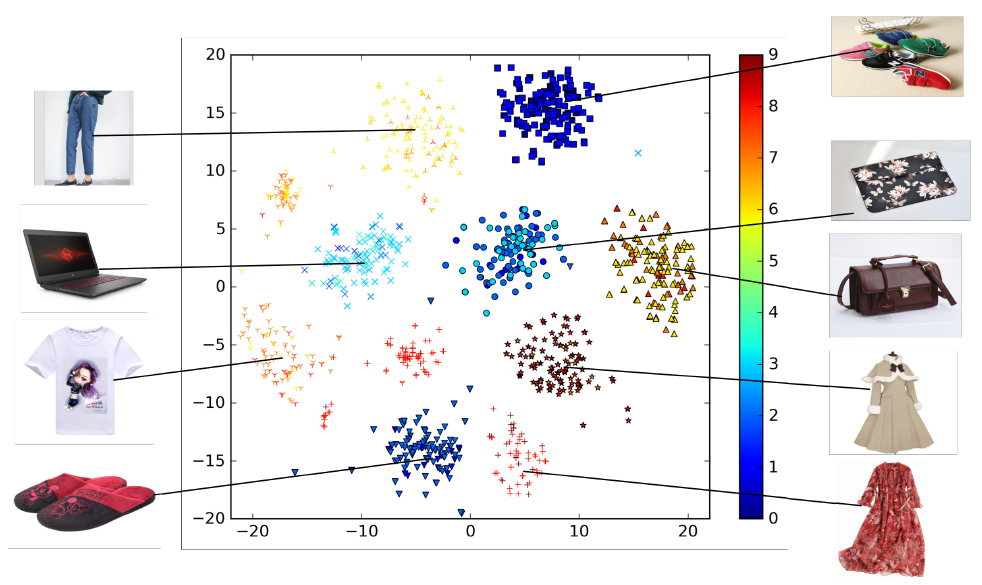
然后,我们将学到的
embedding向量可视化。我们选择一位年轻的母亲,然后随机选择9个类目(服装、运动鞋、箱包等)、每个类目100种商品作为她的候选广告。下图给出了DIN学到的商品embedding进行t-SNE可视化的结果,其中相同形状的点对应同一个类别。可以看到:具有相同类目的商品几乎都在同一个簇(
cluster),这清楚地展示了DIN的聚类属性(clustering property)。此外,我们根据模型预估的
ctr来对候选广告的点进行染色。因此下图也是用户在embedding空间中对潜在候选广告的兴趣密度分布。这表明:DIN可以在候选广告的embedding空间中形成多峰兴趣分布,从而捕获用户的多样化兴趣。