一、ESMM [2018]
《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》
转化率(
conversion rate: CVR)预估是工业application(如在线广告、推荐等等)中ranking系统的一项重要任务。例如,在optimized cost-per-click: OCPC广告中使用预估的CVR来调整每次点击的出价,从而实现平台和广告主的双赢。在推荐系统中,预估的CVR也是平衡用户点击偏好和购买偏好的一个重要因子。论文
《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》聚焦于点击后(post-click)的CVR预估任务。为简化讨论,论文以电商网站推荐系统中的CVR建模为例。给定推荐的item,用户可能会点击感兴趣的item并进一步购买其中的某些点击item。换句话讲,用户操作遵循 “曝光 --> 点击 --> 转化” 的序列模式(sequential pattern)。这样,CVR建模指的是估计post-click CVR任务,即pCVR = p(conversion | click, impression)。通常,传统的
CVR建模方法采用类似于点击率(click-through rate: CTR)预估任务中开发的技术,例如最近流行的深度网络。然而,存在几个task-specific的问题,使得CVR建模具有挑战性。其中,论文报告了实践中遇到的两个关键问题:样本选择偏差(
sample selection bias: SSB)问题:如下图所示,传统的CVR模型在由点击样本组成的数据集上训练,同时在整个曝光空间上执行预测。训练空间由点击样本构成,它只是所有曝光组成的推断空间的一部分。SSB问题会损害模型的泛化性能。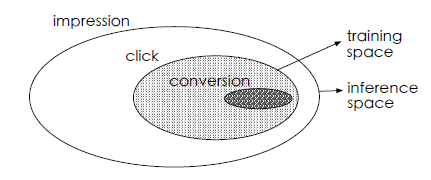
数据稀疏(
data sparsity: DS)问题:在实践中,训练CVR模型的数据通常远远少于训练CTR模型的数据。训练数据的稀疏性使得CVR模型很容易陷入过拟合。
有几项研究试图应对这些挑战:
《Estimating conversion rate in display advertising from past erformance data》建立了不同特征的层级估计器(hierarchical estimators),并结合逻辑回归模型融合这些估计器来解决数据稀疏问题。然而,它依赖于先验知识来构建层级结构(hierarchical structures),这很难应用于具有数千万用户和item的推荐系统。过采样(
oversampling)方法拷贝了罕见类(rare class)的样本,这有助于缓解数据的稀疏性,但是对采样率很敏感。All Missing As Negative: AMAN应用随机采样策略来选择未点击的曝光作为负样本。它可以通过引入未观测到(unobserved)的样本在一定程度上消除SSB问题,但是会导致始终被低估的预测。因为在未点击的曝光样本中,假如所有曝光都被用户点击,则可能存在一定比例的转化行为(正样本),而
AMAN方法假设所有未点击的曝光都是负样本。无偏的方法(
unbiased method)通过rejection采样从观测中拟合真实的潜在分布,从而解决了CVR建模中的SSB问题。但是,通过rejection概率对样本进行加权时(需要除以拒绝率rejection probability),可能会遇到数值不稳定的情况。
总之,在
CVR建模场景中,SSB和DS问题都没有得到很好的解决,而且上述方法都没有利用序列动作(sequential actions)的信息。在论文
《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》中,通过充分利用用户动作的序列模式,作者提出了一种叫做Entire Space Multitask Model: ESMM的模型,它能够同时消除SSB和DS问题。在
ESMM中,作者引入两个辅助任务:曝光后(post-view)点击率预估任务、曝光后(post-view)点击转化率clickthrough& conversion rate: CTCVR预估任务。ESMM不是直接使用点击样本训练CVR模型,而是将pCVR视为中间变量,乘以pCTR等于pCTCVR。pCTCVR和pCTR都是用所有曝光样本在整个曝光空间上估计的,因此派生的pCVR也适用于整个曝光空间。这表明SSB问题已经消除。此外,
CVR网络的feature representation参数与CTR网络共享,而CTR用更丰富的样本进行训练。这种parameter transfer learning有助于显著地缓解DS问题。
在这项工作中,作者从淘宝的推荐系统中收集流量日志构建数据集。整个数据集由
89亿个样本组成,其中包含带点击label、转化label的序列labels。作者进行了仔细的实验,结果表明ESMM始终优于竞争模型,这证明了ESMM的有效性。作者还公布了数据集(采样之后),以便于该领域的未来研究。据作者所知,这是第一个包含用于CVR建模的、带点击label和转化label样本的公共数据集。
1.1 模型
假设观测到的数据集为
label空间,multi-fields(例如用户字段、item字段等等)的高维稀疏向量。label和转化label的序列依赖性(sequential dependence),即转化事件发生之前总是发生了点击事件。
post-click的CVR建模是估计pCVR相关:post-view的点击率(click-through rate: CTR)预估:post-view的点击转化率(click&conversion rate: CTCVR)预估:
这些概率满足公式:
最近,人们提出了基于深度学习的方法用于
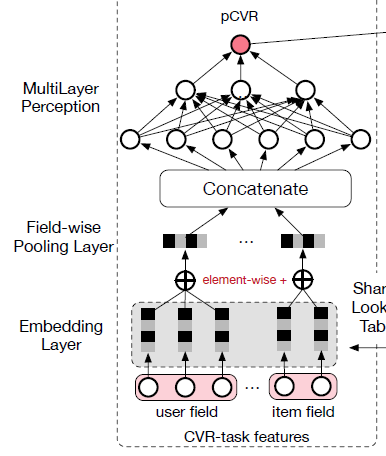
CVR建模,从而实现了SOTA性能。这些方法中大多数都遵循类似的Embedding & MLP网络架构。下图说明了这种架构,为简单起见,我们将其称作BASE模型。简而言之,传统的
CVR建模方法直接估计post-click的转化率注意,在
在实践中,
CVR建模会遇到几个task-specific的问题,这使得任务具有挑战性。样本选择偏差(
sample selection bias: SSM):事实上,传统的CVR建模通过引入辅助特征空间limited space)。pair对label。通过这种方式,在推断阶段,
pair对一方面,
另一方面,如果在实践中没有足够的观察,则空间
CVR建模的泛化性能。
数据稀疏性(
data sparsity: DS):传统方法使用点击样本CVR模型,而点击事件很少发生导致CVR建模的训练数据极其稀疏。直观上,CVR任务训练样本量通常比相关的CTR任务(在所有曝光样本1 ~ 3个量级。下表显示了我们实验数据集的统计数据,其中CVR任务的样本数量仅为CTR任务的4%。
值得一提的是,
CVR建模还存在其它挑战,例如延迟反馈(delayed feedback)。这项工作暂且不关注它,原因之一是我们系统中的转化延迟程度是可以接受的,另一个原因是我们的方法可以结合之前的工作(《Modeling delayed feedback in display advertising》)来处理。我们提出的
ESMM如下图所示,它很好地利用了用户动作的序列模式。借鉴多任务学习的思想,ESMM引入了CTR预估和CTCVR预估这两个辅助任务,同时消除了上述CVR建模的问题。总体而言,
ESMM同时输出关于给定曝光的pCTR、pCVR、pCTCVR。ESMM主要由两个子网络组成:下图中左侧的CVR网络和右侧的CTR网络。CVR网络和CTR网络都采用与BASE模型相同的结构。CVR网络和CTR网络输出的乘积作为CTCVR。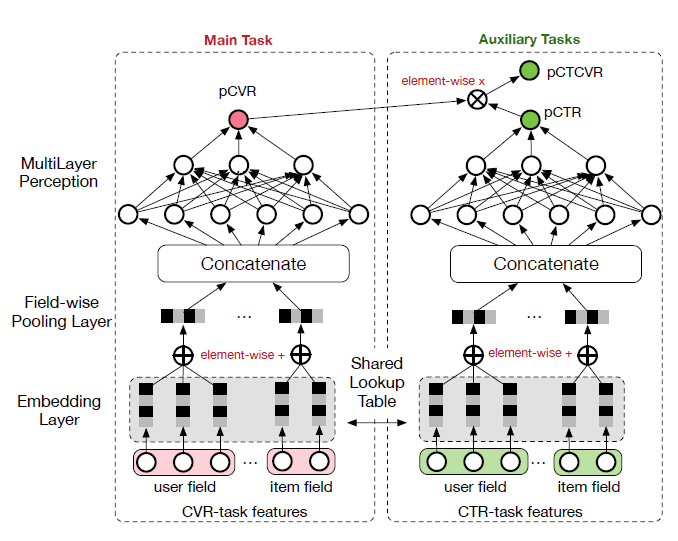
ESMM有一些亮点对CVR建模有显著影响,从而将ESMM与传统方法区分开:在整个空间上建模:根据前面的推导,我们有:
这里
pCTCVR和pCTR,可以在整个输入空间pCVR,这直接解决了样本选择偏差问题。通过分别使用单独训练的模型估计
pCTR和pCTCVR,并通过上述等式获得pCVR,这似乎很容易。为简单起见,我们将其称作DIVISION。然而,pCTR实际上是一个很小的数字,除以它会引起数值不稳定。ESMM使用乘法形式避免了这种情况。在ESMM中,PCVR只是一个中间变量,pCTR和pCTCVR是ESMM在整个空间中实际估计的主要因子。乘法形式使得三个相关联(
associated)的、共同训练(co-trained)的估计器(estimators)能够利用数据的序列模式并在训练期间相互交流信息。此外,乘法形式还确保了估计的
pCVR取值在[0.0, 1.0]的范围内,而在DIVISION方法中可能会超过1.0。
ESMM的损失函数定义为:其中
CTR网络和CVR网络的参数,这个损失函数由来自
CTR任务损失和CTCVR任务损失这两项组成,并且在所有曝光样本上计算,而没有使用CVR任务的损失。在数学上,上式将label和转化label的序列依赖性。特征表示迁移 (
feature representation transfer):如前所述,embedding layer将大规模稀疏输入映射到低维representation向量。embedding layer贡献了深度网络的大部分参数,其学习需要大量的训练样本。在
ESMM中,CVR网络的embedding dictionary和CTR网络共享,这遵循feature representation transfer learning的范式。CTR任务的所有曝光样本相比较于CVR任务的点击样本要丰富的多。这种参数共享机制使得ESMM中的CVR网络能够从未点击的曝光中学习,为缓解数据稀疏问题提供了很大帮助。
注意,
ESMM中的子网络可以替换为一些最近开发的模型,这可能会获得更好的性能。由于篇幅所限我们将其略去,我们聚焦于解决CVR建模在实际实践中遇到的挑战。
1.2 实验
数据集:在我们的调查中,在
CVR建模领域没有发现具有点击label、转化label的序列labels的公共数据集。为了评估ESMM方法,我们从淘宝的推荐系统收集流量日志,并发布整个数据集的1%随机抽样版本,其大小仍然达到38GB(未压缩)。在本文的剩余部分,我们将发布的数据集称作公共数据集(Public Dataset),将整个数据集(未采样的)称作产品数据集(Product Dataset)。下表总结了两个数据集的统计数据。竞争方法:
BASE:即前面介绍的简单DNN模型,不采取任何额外的策略。AMAN:应用负采样策略的BASE模型,负采样比例从{10%,20%,50%,100%}中搜索并报告最佳结果。OVERSAMPLING:执行正样本过采样策略的BASE模型,采样率从{2,3,5,10}中搜索并报告最佳结果。UNBIAS:执行rejection采样策略的BASE模型,通过拒绝采样使得训练分布(即点击数据集的数据分布)和真实分布(即曝光数据集的数据分布)保持一致,pCTR被视作拒绝概率。DIVISION:使用单独训练的CTR网络和CTCVR网络分别估计pCTR和pCTCVR,然后计算pCVR = pCTCVR/pCTR。其中CTR网络和CTCVR网络均采用BASE模型。ESMM-NS:ESMM模型的一个精简版,它不共享embedding参数。
前四种方法是直接基于
SOTA深度网络对CVR直接建模的不同变体。DIVISION、ESMM-NS、ESMM共享相同的思想,即在整个空间上对CVR进行建模,其中涉及CVR网络、CTR网络、CTCVR网络等三个网络。ESMM-NS和ESMM共同训练这三个网络,并从CVR网络中获取输出。为公平比较,包括
ESMM在内的所有竞争方法都采用BASE模型相同的网络结构和超参数,其中包括:使用ReLU激活函数、embedding向量维度为18、MLP网络的每一层维度为360 × 200 × 80 × 2、使用adam优化器(超参数为评估指标:我们在两个不同的任务上进行比较:
传统的
CVR预估任务:在具有点击样本的数据集上估计pCVR。CTCVR预估任务:在具有曝光样本的数据集上估计pCTCVR。在
CTCVR任务中,所有模型都通过pCTR x pCVR来计算pCTCVR,其中:pCVR分别由每个模型估计,pCTR是使用相同的、独立训练的CTR网络估计的(与BASE模型相同的网络结构和超参数)。
第二个任务旨在在整个输入空间上比较不同的
CVR建模方法,这反映了对应于SSB问题的模型性能。这两个任务都将时间序列中的前
1/2数据作为训练集、后1/2数据作为测试集。评估指标为
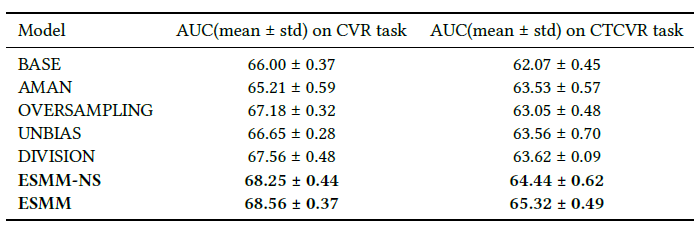
AUC,所有实验重复10次并报告平均结果。Public Dataset结果:下表显式了不同模型在Public Dataset上的结果。在
BASE模型的所有三个变体中,只有AMAN在CVR任务上表现稍差,这可能是由于随机采样的敏感性。OVERSAMPLING和UNBIAS在CVR和CTCVR任务上都比BASE模型有所改进。DIVISION和ESMM-NS都估计了整个空间的pCVR,并且在BASE模型上取得了显著的提升。由于避免了数值不稳定,ESMM-NS的性能优于DIVISION。ESMM进一步改进了ESMM-NS。通过利用用户动作的序列模式,并从未点击的数据以迁移机制来学习,ESMM为CVR建模提供了一个优雅的解决方案,从而同时消除SSB问题和DS问题并击败所有竞争对手。和
BASE模型相比,ESMM在CVR任务上实现了2.56%的绝对AUC增益,这表明它即使对有bias的样本也具有良好的泛化性能。和
BASE模型相比,ESMM在全样本的CTCVR任务上实现了3.25%的 绝对AUC增益。
这些结果验证了我们建模方法的有效性。
Product Dataset结果:我们在我们的Product Dataset上进一步评估了ESMM,其中包含89亿个样本,比公开的Public Dataset大两个数据量级。为了验证训练集规模的影响,我们针对不同的采样率对这个大规模数据集进行了仔细的比较,结果如下图所示。
所有方法都随着训练样本量的增加而有所改善。这表明了数据稀疏性的影响。
除了
AMAN在1%采样的CVR任务以外,所有其它模型在所有任务的所有训练集规模上都超越了BASE模型。ESMM-NS和ESMM在不同采样率方面始终优于所有竞争对手。特别是,ESMM在CVR和CTCVR任务上比所有竞争对手都保持了很大的AUC提升幅度。BASE模型是为我们真实系统中的主要流量提供服务的最新版本。使用整个数据集进行训练,ESMM在CVR任务上相对于BASE模型实现了2.18%的绝对AUC增益,在CTCVR任务上相对于BASE模型实现了2.32%的绝对AUC增益。对于工业application而言,这是一项重大改进,其中0.1%的AUC提升就非常显著。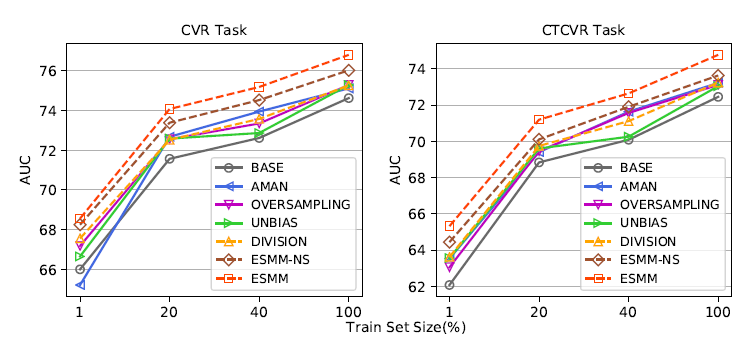
未来工作:我们打算在具有 “请求 --> 曝光 --> 点击 --> 转化” 等
multi-stage动作的application中设计全局优化模型(global optimization model)。