一、DLRM [2019]
《Deep Learning Recommendation Model for Personalization and Recommendation Systems》
个性化(
personalization)和推荐系统(recomme/ndation systems)目前已经被部署在大型互联网公司的各种任务中,包括广告点击率预估(CTR prediction)和排序(ranking)。尽管这些方法已经有很长的历史,但是直到最近这些方法才包含神经网络。有两个基本观点(primary perspectives)有助于个性化和推荐的深度学习模型的架构设计(architectural design)。第一种观点来自推荐系统。这些系统最初采用内容过滤(
content filtering),其中一群专家将产品划分为不同的类目(categories),用户选择他们喜欢的类目,而系统根据用户的偏好进行匹配。该领域随后发展为使用协同过滤(
collaborative filtering),其中推荐是基于用户历史的行为,例如对item的历史评分。邻域(
neighborhood)方法通过将用户和item一起进行分组(grouping)从而提供推荐。潜在因子(
latent factor)方法通过矩阵分解技术从而使用某些潜在因子来刻画用户和item。这些方法后来都取得了成功。
第二种观点来自预测分析(
predictive analytics),它依靠统计模型根据给定的数据对事件的概率进行分类(classify)或预测(predict)。预测模型从简单模型(例如线性模型和逻辑回归)转变为包含深度网络的模型。为了处理离散数据(
categorical data),这些模型采用了(embedding)技术从而将one-hot向量和multi-hot向量转换为抽象空间(abstract space)中的稠密表示(dense representation)。这个抽象空间可以解释为推荐系统发现的潜在因子空间(space of the latent factors)。
在论文
《Deep Learning Recommendation Model for Personalization and Recommendation Systems》中,论文介绍了一个由上述两种观点结合而成的个性化模型。该模型使用embedding来处理代表离散数据的稀疏特征(sparse features)、使用多层感知机(multilayer perceptron: MLP)来处理稠密特征(dense features),然后使用《Factorization machines》中提出的统计技术显式的交互(interacts)这些特征。最后,模型通过另一个MLP对交互作用进行后处理(post-processing)从而找到事件的概率。作者将这个模型称作深度学习推荐模型(
deep learning recommendation model: DLRM),如下图所示。该模型的PyTorch和Caffe2的实现已经发布。此外,作者还设计了一种特殊的并行化方案,该方案利用
embedding tables上的模型并行性(model parallelism)来缓解内存限制(memory constraints),同时利用数据并行性(data parallelism)从全连接层扩展(scale-out)计算。作者将DLRM与现有的推荐模型进行了比较,并在Big Basin AI平台上实验了DLRM的性能,证明了它作为未来算法实验(algorithmic experimentation)、以及系统协同设计(system co-design)的benchmark的有效性。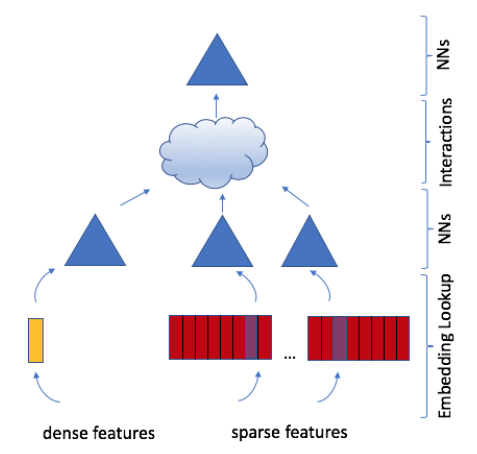
1.1 模型设计和架构
这里我们将描述
DLRM的设计。我们将从网络的高级组件(high level components)开始,并说明如何以及为什么将它们以特定方式组装(assembled)在一起,以及对未来的模型设计产生的影响。然后我们描述组成模型的低级算子(
low level operators)和原语(primitives),以及对未来的硬件和系统设计产生的影响。
1.1.1 DLRM 组件
通过回顾早期模型,我们可以更容易理解
DLRM的高级组件。我们避免全面的科学文献综述,而将重点几种在早期模型中使用的四种技术上,这些技术可以被解释为DLRM的重要高级组件。Embedding:为了处理离散数据,embedding将每个类目(category)映射到抽象空间(abstract space)中的稠密表示(dense representation)。具体而言,每个
embedding lookup可以被解释为使用一个one-hot向量1、其它位为0,索引embedding tablerow vector):其中
在更复杂的场景中,
embedding也可以表示多个item的加权组合,其中包含一个multi-hot向量的权重:其中 :
item;item的权重。包含
embedding lookup的mini-batch可以写作:其中
DLRM利用embedding tables将离散特征映射到稠密表示。然而,即使设计了这些有意义的embedding之后,如何利用它们来生成准确的预测?为了回答这个问题,我们回到潜在因子方法(latent factor methods)。矩阵分解(
Matrix Factorization):回忆一下,在推荐问题的典型公式中,我们得到了对某些item进行评分的某些用户的集合item上已经评分。我们用向量represent)第item、用向量ratings)。矩阵分解方法通过最小化以下公式来求解这个问题:
其中
item上的评分。令
其中
item数量,注意:
embedding tables,其中每一行代表潜在因子空间(latent factor space)中的user/item。这些embedding向量的内积可以得出对评级有意义的后续预测,这是因子分解机(factorization machines)和DLRM设计的关键观察。因子分解机(
Factorization Machine):在分类问题中,我们要定义一个从输入数据点target labelclick-through rate: CTR),其中+1表示点击label、-1表示未点击label。因子分解机(
Factorization machines: FM)通过以下定义形式的模型,将二阶交互(second-order interactions)融合到带有离散数据的线性模型中:其中:
upper(.)函数严格选择矩阵的上三角部分。
FM和多项式核(polynomial kernel)的支持向量机SVM显著不同,因为FM像矩阵分解一样将二阶交互矩阵分解为潜在因子(latent factor)(或embedding向量),从而更有效地处理稀疏数据。通过仅捕获不同
embedding向量pair对之间的交互,FM显著降低了二阶交互的复杂度,从而产生线性计算复杂度。根据原始公式,
FM的算法复杂度为多层感知机(
Multilayer Perceptrons):最近机器学习的成功很大程度上归功于深度学习的兴起。其中,最基本的模型是多层感知机(multilayer perceptron: MLP),它是一个由全连接层(fully connected layers: FC)和激活函数prediction function):其中权重矩阵
bias向量这些方法被用来捕获更复杂的交互(
interactions)。例如,已经表明:给定足够的参数、具有足够深度(depth)和宽度(width)的MLP能够以任何精度(precistion)拟合数据。这些方法的变体已经广泛应用于各种
application,包括计算机视觉和NLP。一个具体的例子是神经协同过滤(Neural Collaborative Filtering: NCF)被用作MLPerf benchmark的一部分,它使用MLP而不是内积来计算矩阵分解中embedding之间的交互。
1.1.2 DLRM 架构
目前为止,我们已经描述了推荐系统和预测分析中使用的不同模型。现在,让我们结合它们的直觉(
intuitions)来构建SOTA的个性化模型。令用户和
item使用很多连续(continuous)的、离散(categorical)的特征来描述。为了处理离散特征,每个离散特征将由相同维度的
embedding向量来表示,从而推广了矩阵分解中潜在因子的概念。为了处理连续特征,所有的连续特征整体上将被一个
MLP转换(这个MLP我们称之为bottom MLP或者dense MLP),这将产生和embedding向量相同维度的dense representation。
注意:每个离散特征会得到一个
embedding,而所有连续特征整体才能得到一个embedding。我们将根据
FM处理稀疏数据的直觉,通过MLP来显式计算不同特征的二阶交互。这是通过获取所有representation向量(包括每个离散特征的embedding向量、连续特征整体的representation向量)之间的pair对的内积来实现的。这些内积和连续特征
representation(即经过原始连续特征经过bottom MLP之后得到的)拼接起来,馈入另一个MLP(我们称之为top MLP或者output MLP)。最终这个MLP的输出馈入到一个sigmoid函数从而得到概率。我们将这个模型称作
DLRM。top MLP的特征有:显式二阶交互特征、连续representation特征。这里并没有馈入一阶embedding特征。和早期模型的比较:许多基于深度学习的推荐模型使用类似的基本思想来生成高阶项
term从而处理稀疏特征。例如:Wide and Deep、Deep and Cross、DeepFM、xDeepFM网络等等,它们设计了专用网络(specialized networks)来系统地构建高阶交互(higher-order interactions)。然后,这些网络将它们专用网络和MLP的结果相加,并通过线性层和sigmoid激活函数产生最终的概率。DLRM特别地模仿因子分解机,以结构化方式与embedding交互,从而在最终MLP中仅考虑embedding pair对之间的内积所产生的的交叉term,从而显著降低了模型的维度。我们认为,在其他网络中发现的、超过二阶的更高阶交互可能不一定值得额外的计算代价和内存代价。DLRM和其它网络之间的主要区别在于:网络如何处理embedding特征向量及其交叉项 (cross-term)。具体而言:DLRM(以及xDeepFM)将每个embedding向量解释为表示单个类目(category)的单元(unit),交叉项仅在类目之间产生。像
Deep and Cross这样的网络将embedding向量中的每个元素视为单元,交叉项在元素之间产生。因此,
Deep and Cross不仅会像DLRM那样通过内积在不同embedding向量的元素之间产生交叉项,而且会在同一个embedding向量内的元素之间产生交叉项,从而导致更高的维度。
1.2 并行性
现代的个性化和推荐系统需要大型复杂的模型来利用大量的数据。
DLRM尤其包含大量参数,比其它常见的深度学习模型(例如CNN、RNN、GAN)多几个数量级。这导致训练时间长达数周或者更长。因此,更重要的是有效地并行化这些模型,以便在实际数据规模上解决这些问题。如前所述,
DLRM以耦合的方式(coupled manner)处理离散特征(通过embedding)和连续特征(通过bottom MLP)。embedding贡献了大部分参数,每个lookup table都需要超过几个GB的内存,使得DLRM的内存容量和带宽(bandwidth)代价昂贵。由于
embedding太大,因此无法使用数据并行(data parallelism),因为数据并行需要在每个设备上拷贝超大的embedding。在很多情况下,这种内存限制需要将模型分布在多个设备上,从而满足内存容量要求。另一方面,
MLP参数在内存中较小,但是却有相当可观的计算量。因此,对于MLP而言,数据并行是首选的,因为这样可以在不同的设备上同时处理样本,并且仅在累计更新(accumulating updates)时才需要通信。
我们的并行化
DLRM联合使用模型并行(model parallelism)和数据并行 (data parallelism):针对embedding使用模型并行、针对MLP使用数据并行,从而缓解embedding产生的内存瓶颈(memory bottleneck),同时并行化MLP上的前向传播和反向传播计算。由于
DLRM的体系结构和较大的模型尺寸,因此将模型并行和数据并行相结合是DLRM的独特要求。Caffe2或PyTorch(以及其它流行的深度学习框架)均不支持这种组合并行性,因此我们设计了一个自定义的实现。我们计划在未来的工作中提供其详细的性能研究。在我们的设置
setup中,top MLP和交互算子(interaction operator)要求从bottom MLP和所有embedding中访问部分mini-batch。由于模型并行已用于在设备之间分布embedding,因此这需要个性化的all-to-all通信。在
embedding lookup的最后,每个设备都针对mibi-batch中的所有样本,将对应的embedding table中的embedding向量驻留在这些设备上。需要驻留的embedding向量需要沿着mibi-batch维度分割,并传送到适当的设备,如下图所示(如黄色embedding向量都传送到Device 3)。PyTorch和Caffe2都不提供对模型并行的原生支持,因此我们通过将embedding算子显式映射到不同的设备来实现它。然后使用butterfly shuffle算子实现个性化的all-to-all通信,该算子将生成的embedding向量适当的分片(slice),并将其传输到目标设备(target device)。在当前版本中,这些传输是显式拷贝,但是我们打算使用可用的通信原语(如all-gather和send-recv)进一步优化这一点。下图为用于
all-to-all通信的butterfly shuffle。注意,目前
pytorch.distributed package已经支持模型并行、数据并行,也支持个性化的all-to-all通信。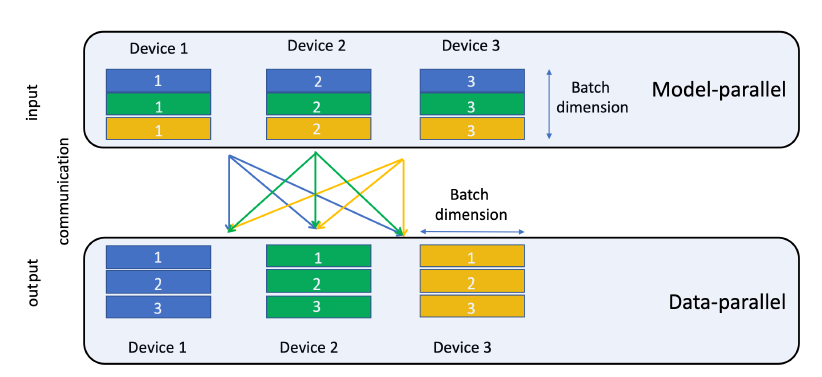
我们注意到,对于数据并行
MLP,反向传播中的参数更新以allreduce进行积累(accumulated),并以同步(synchronous)的方式应用于每个设备上的拷贝参数(replicated parameters),从而确保每个设备上的更新参数(updated parameters)在每次迭代之前都是一致(consistent)的。在
PyTorch中,通过nn.DistributedDataParallel和nn.DataParallel模块启用数据并行,这些模块在每个设备上拷贝模型并插入allreduce以及必要的依赖。在
Caffe2中,我们在梯度更新之前人工插入allreduce。
1.3 实验
为了衡量模型的准确性(
accuracy)、测试模型的整体性能、并描述各个算子(operator)的特征,我们需要为DLRM创建或获取一个数据集。我们提供了三种类型的数据集:随机数据集(
random dataset)、人工合成数据集(synthetic dataset)、公共数据集(public dataset)。从系统的角度来看,前两个数据集可用于试验模型。具体而言,它允许我们通过动态生成的数据来试验不同的硬件属性和瓶颈,同时消除对数据存储系统的依赖。后者允许我们对真实数据集进行实验,并度量模型的的准确性(accuracy)。随机数据集:回忆一下,
DLRM接受连续 特征和离散特征作为输入。对于连续特征,可以通过使用
numpy.random package的rand或者randn调用具有默认参数的均匀分布或正态分布(高斯分布)生成随机向量来建模。 然后可以通过生成一个矩阵来获得一个mini-batch的输入,其中矩阵的每一行代表mini-batch中的一个样本。对于离散特征,我们需要确定给定的的
multi-hot向量中有多少个非零元素。benchmark允许非零元素数量是固定的、或者是1~k范围内的一个随机数。然后,我们生成相应数量的整数索引,数量范围在
1~m范围内,其中m为embedding矩阵最后,为了创建一个
mini-batch的lookup,我们拼接上述索引,并用lengths(Caffe中的SparseLengthsSum)、或者offsets(PyTorch中的nn.EmbeddingBag)来描述每个单独的lookup。
人工合成数据集:有很多理由支持对应于离散特征的索引的自定义生成。例如,如果我们的
application使用一个特定的数据集,但出于隐私的目的我们不愿意共享它,那么我们可以选择通过索引分布来表达离散特征。这可能会替代联邦学习(federated learning)等应用于application中的隐私保护技术。此外,如果我们想要测试系统组件(system components),例如研究内存行为(memory behavior),我们可能希望在合成的trace中捕获原始trace访问的基本局部性(fundamental locality)。让我们说明如何使用合成数据集。假设我们有索引的
trace,这些索引对应于某个离散特征的所有embedding lookup轨迹。我们可以在这个trace中记录去重访问(unique accesses) 和重复访问(repeated accesses)之间的距离频次,然后生成合成trace。具体生成算法参考原始论文。公共数据集:
Criteo AI Labs Ad Kaggle和Criteo AI Labs Ad Terabyte数据集是公开的数据集,由用于广告点击率预测的点击日志组成。每个数据集包含
13个连续特征和26个离散特征。通常,连续特征使用简单的对数变换log(1+x)进行预处理。离散特征映射到相应的embedding index,而未标记的离散特征映射到0或者NULL。Criteo Ad Kaggle数据集包含7天内的4500万个样本,每天的样本量大致相等。在实验中,通常将第7天拆分为验证集和测试集,而前面6天用作训练集。Criteo Ad Terabyte数据集包含24天的样本,其中第24天分为验证集和测试集,前面23天用作训练集。每天的样本量大致相等。
模型配置:
DLRM模型在PyTorch和Caffe2框架中实现,可以在Github上获得。模型分别使用fp32浮点数作为模型参数,以及int32(Caffe2)/int64(PyTorch)作为模型索引。实验是在BigBasin平台进行的,该平台具有双路Intel Xeon 6138 CPU @ 2.00GHz以及8个Nvidia Tesla V100 16GB GPUs。我们在
Criteo Ad Kaggle数据集上评估了模型的准确率,并将DLRM和Deep and Cross network: DCN的性能进行了比较,后者没有进行额外的调优。我们和DCN进行比较,因为它是在相同数据集上具有综合结果(comprehensive results)的少数模型之一。DLRM既包含用于处理连续特征的bottom MLP(该bottom MLP分别由具有512/256/64个节点的三个隐层组成),又包括top MLP(该top MLP分别由具有512/256个节点的两个隐层组成)。DCN由六个cross layer和一个具有512/256个节点的深度网络组成。embedding的维度为16。
这样产生的
DLRM和DCN两者都具有大约540M的参数。我们使用
SGD和Adagrad优化器绘制了两个模型在完整的单个epoch内的训练准确率(实线)、验证准确率(虚线)。我们没有使用正则化。可以看到:
DLRM获得了稍高的训练准确率和验证准确率,如下图所示。我们强调,这没有对模型的超参数进行大量的调优。DLRM和DCN都没有经过超参数调优,因此实验结果的对比没有任何意义。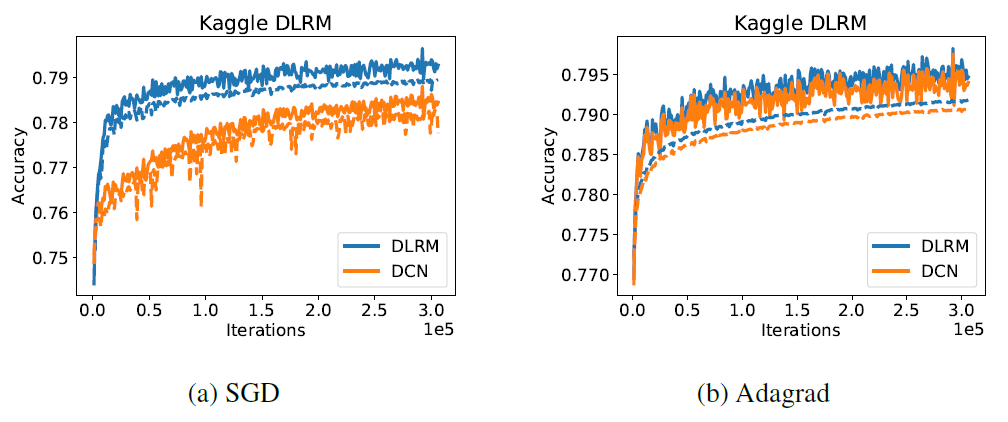
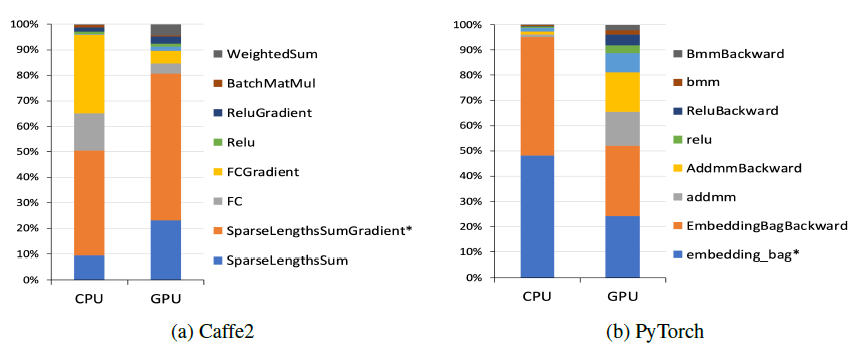
为了分析我们模型在单设备上的性能,我们考虑了一个具有
8个离散特征、512个连续特征的模型。每个离散特征都通过一个包含1M个向量的embedding table(即类目总数有1M)进行处理,向量维度为64。而连续特征被组装(assembled)为一个512维的向量。bottom MLP有两层,而top MLP有四层。我们让具有2048K个随机生成样本的数据集上分析了该模型,其中mini-batch的batch size = 1K。Caffe2中的这个模型实现在CPU上运行大约256秒,在GPU上运行大约62秒,每个算子的分析如下图所示。正如预期所示:大部分时间都花在了执行embedding lookup和全连接层上。在CPU上,全连接层占了很大一部分计算,而GPU上全连接层的计算几乎可以忽略不计。