一、FiBiNET [2019]
《FiBiNET: Combining Feature Importance and Bilinear Feature Interaction for Click-Through Rate Prediction》
近年来,许多基于深度学习的
CTR模型被提出并取得了成功,如Factorization-Machine Supported Neural Network: FNN、Wide&Deep model: WDL、Attentional Factorization Machine: AFM、DeepFM、XDeepFM等等。论文
《FiBiNET: Combining Feature Importance and Bilinear Feature Interaction for Click-Through Rate Prediction》提出了一个叫做FiBiNET的新模型,它是Feature Importance and Bilinear feature Interaction NETwork的缩写,用于动态地学习特征重要性和细粒度的特征交互。众所周知,不同的特征对目标任务有不同的重要性。例如,当我们预测一个人的收入时,职业这个特征比爱好这个特征更重要。考虑到这一点,论文引入了
Squeeze-and-Excitation network: SENET来动态地学习特征的权重。此外,特征交互是
CTR预测领域的一个关键挑战,许多相关工作以简单的方式计算特征交互,如Hadamard积和内积。论文提出了一种新的细粒度的方法采用双线性函数来计算特征交互。
论文主要贡献:
受
SENET在计算机视觉领域的成功启发,论文使用SENET机制来动态地学习特征的权重。论文引入了三种类型的双线性交互层(
Bilinear-Interaction layer),以一种精细的方式学习特征交互。而之前的工作用Hadamard积或内积来计算特征交互。结合
SENET机制和双线性特征交互,论文的浅层模型在Criteo和Avazu数据集上的浅层模型之间(如FFM)实现了SOTA。为了进一步提高性能,论文将经典的深度神经网络组件与浅层模型相结合,构成一个深度模型。深度
FiBiNET在Criteo和Avazu数据集上的表现一直优于其他SOTA的深度模型。
相关工作:
FM及其变体:factorization machine: FM和field-aware factorization machine: FFM是两个最成功的CTR模型。FM使用因子化的参数建模所有的特征交互。它的时间复杂度和空间复杂度都很低,在大型稀疏数据上表现很好。FFM引入了field-aware的潜在向量,并赢得了由Criteo和Avazu主办的两个比赛。然而,FFM的空间复杂度太高,不容易在互联网公司中使用。
Deep Learning based CTR Models:近年来,许多基于深度学习的CTR模型被提出。大多数基于神经网络的CTR模型的关键因素是:如何有效地建模特征交互。Factorization-Machine Supported Neural Network: FNN是一个前馈神经网络,使用FM来预训练embedding layer。然而,FNN只能捕获高阶的特征交互。Wide & Deep model: WDL联合训练wide linear model和deep neural network,从而为推荐系统来结合memorization和generalization的好处。然而,对于WDL的wide部分的输入,仍然需要专业的特征工程,这意味着cross-product transformation也需要手工设计。为了减轻特征工程中的人工努力,
DeepFM用FM取代了WDL的wide部分,并在FM和deep组件之间共享feature embedding。DeepFM被认为是CTR预估领域中的SOTA模型之一。Deep & Cross Network: DCN以一种显式的方式有效地捕捉了有界阶次的特征交互。eXtreme Deep Factorization Machine: xDeepFM也通过提出一个新颖的Compressed Interaction Network : CIN组件来显式地建模低阶特征交互和高阶特征交互。正如
《Attentional factorization machines: Learning the weight of feature interactions via attention networks》所提到的,FM的一个不足是它对所有特征交互采用相同的权重,然而并不是所有的特征交互都同样有用和具有预测性。因此,他们提出了Attentional Factorization Machine: AFM模型,该模型使用注意力网络来学习特征交互的权重。Deep Interest Network: DIN用兴趣分布(interest distribution)表示用户的多样化兴趣,并设计了一个类似注意力的网络结构从而根据候选广告局部地激活相关的兴趣。
SENET Module:《Squeeze-and-excitation networks》提出了Squeeze-and-Excitation Network: SENET,通过显式地建模卷积特征通道之间的相互依赖关系,从而提高网络的表达能力。SENET被证明在图像分类任务中是成功的,并在ILSVRC 2017分类任务中赢得了第一名。除了图像分类,
SENET还有其他的应用。《Recalibrating Fully Convolutional Networks with Spatial and Channel’Squeeze & Excitation’Blocks》介绍了三种用于语义分割任务的SE模块的变体。对常见的胸部疾病进行分类,以及对胸部
X光片上的可疑病变区域进行定位(《Weakly Supervised Deep Learning for Thoracic Disease Classifcation and Localization on Chest X-rays》)是另一个应用领域。《Global-andlocal attention networks for visual recognition》用global-and-local attention: GALA模块扩展了SENET模块,在ILSVRC上获得SOTA的准确性。
1.1 模型
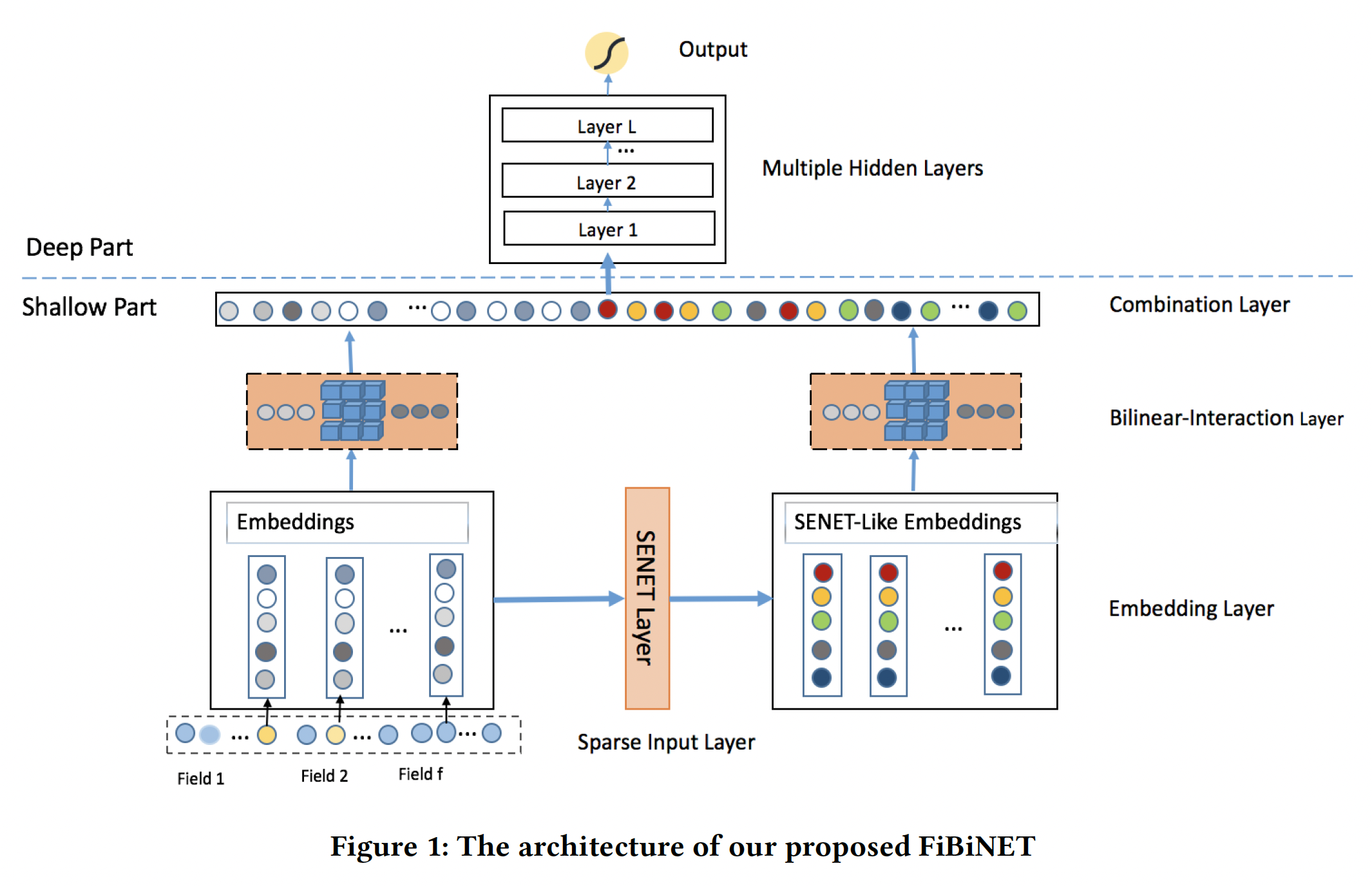
我们的目标是以一种细粒度的方式动态地学习特征的重要性和特征交互。为此,我们提出了用于
CTR预估任务的Feature Importance and Bilinear feature Interaction NETwork: FiBiNET。我们的模型结构如下图所示。为了清晰起见,我们省略了
logistic regression的部分,这部分可以很容易地纳入。我们的模型由以下部分组成:sparse input layer, embedding layer, SENET layer, Bilinear-Interaction layer, combination layer, multiple hidden layers, output layer。sparse input layer和embedding layer与DeepFM相同,它对输入特征采用稀疏表示并将原始特征嵌入到稠密向量中。SENET layer可以将embedding layer转换为SENET-Like embedding feature,这有助于提高特征的discriminability。由于原始
Embeddings和SENET-Like Embeddings都作为后续模块的输入,因此SENET-Like Embeddings仅仅是作为原始Embeddings的补充(类似于残差机制),而不是作为原始Embeddings重要性的解释。如果仅仅将
SENET-Like Embeddings作为后续模块的输入,这时候才具有可解释性。接下来的
Bilinear-Interaction layer分别对原始embedding和SENET-Like embedding的二阶特征交互进行建模。combination layer拼接了Bilinear-Interaction layer的输出。最后,我们将
combination layer的输出馈入一个深度神经网络从而得到预测分数。
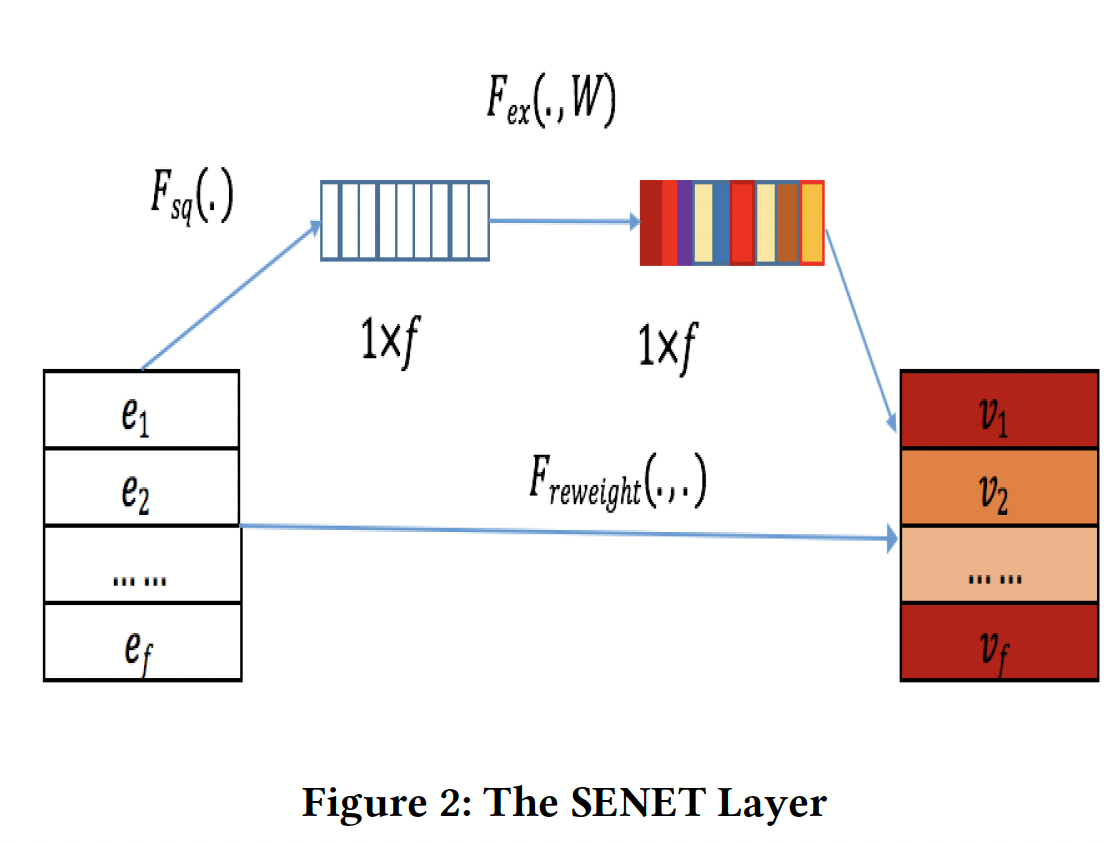
Sparse Input and Embedding layer:sparse input layer对原始输入特征采用了sparse representation,embedding layer将sparse feature嵌入到一个低维稠密的实值向量中。embedding layer的输出是由field embedding向量所拼接而来:field数量,field embedding维度。SENET Layer:我们都知道,不同的特征对目标任务有不同的重要性。例如,当我们预测一个人的收入时,职业这个特征比爱好这个特征更重要。受到SENET在计算机视觉领域的成功启发,我们引入了SENET机制,让模型更加关注特征的重要性。对于特定的CTR预估任务,我们可以通过SENET机制动态地增加重要特征的权重、减少不重要特征的权重。以
feature embedding作为输入,SENET针对field embedding产生权重向量embeddingembedding(即,SENET-Like embedding):其中:
field的权重;field的SENET-Like embedding。如下图所示,
SENET由三个步骤组成:squeeze step、excitation step、re-weight step。squeeze:这一步是用来计算每个field embedding的summary statistics的。具体而言,我们使用一些池化方法(如max/mean)从而将原始的embeddingsum池化、或者最大池化。原始
SENET论文中的squeeze函数是最大池化。然而,我们的实验结果表明,均值池化的性能比最大值池化的性能更好。excitation:这一步可以用来基于统计向量field embedding的权重。我们使用两个全连接层来学习权重:第一个全连接层是一个降维层,参数为
第一个全连接层是一个升维层,参数为
正式地,
field embedding的权重的计算公式为:其中:
这一步是降维,从而最多保留最重要的
re-weight:SENET的最后一步是reweight,在原始论文中被称为re-scale。SENET-Like embedding
Bilinear-Interaction Layer:Interaction layer用于计算二阶的特征交互。特征交互的经典方法是内积和Hadamard积,其形式分别为:Hadamard积过于简单,不能有效地建模稀疏数据集中的特征交互。因此,我们提出了一种更加细粒度的方法来结合内积和Hadamard积,如下图(c)所示。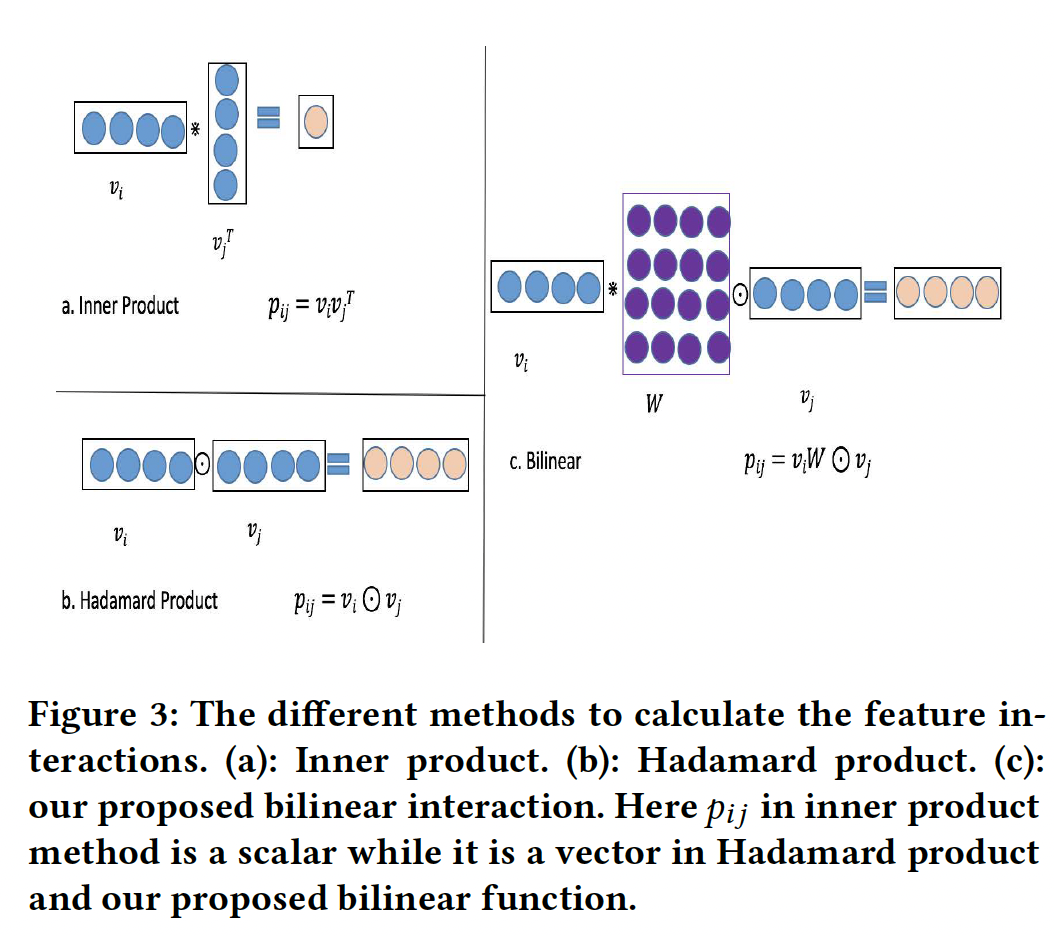
具体来说,我们在
Interaction layer提出了三种类型的双线性函数,并称这一层为Bilinear-Interaction layer。以第field embeddingfield embeddingField-All Type:其中:
field interaction pair之间共享。Field-Each Type:其中:
field都有一个。Field-Interactoin Type:其中:
field interaction pair都有一个。
如
Figure 1所示,我们有两种embedding:原始embedding、SENET-like embedding。对于每一种embedding,我们可以选择采用bilinear函数或Hadamard积。最终,
Bilinear-Interaction layer可以从原始embeddigninteraction vectorSENET-like embeddinginteraction vectorCombination Layer:combination layer将interaction vector如果我们将向量
sigmoid函数来输出预测值,我们就有了一个浅层的CTR模型。为了进一步提高性能,我们将浅层组件和
DNN组件组合成一个统一的模型,形成深度网络结构。这个统一的模型在本文中称为深度模型。而更好的办法是:拼接
Deep Network:深度网络由多个全连接层组成,隐式地捕获了高阶的特征交互。Deep Network的输入是什么?论文没有说明。但是根据Figure 1,应该是Output Layer:我们模型的输出为:其中:
sigmoid函数,deep part的输出,wide part的输出。目标函数为交叉熵损失:
其中:
ground-truth。与
FM, FNN的联系:假设我们去掉
SENET layer和Bilinear-Interaction layer,不难发现我们的模型将退化为FNN。当我们进一步去掉
DNN部分,同时使用常数的sum,那么浅层FiBiNET就退化为传统的FM模型。
1.2 实验
数据集:
Criteo:包含有4500万个样本的点击日志。在Criteo数据集中有26个匿名的categorical feature field和13个continuous feature field。我们将数据集随机分成两部分:90%用于训练,其余用于测试。Avazu:包含有4000万个样本的点击日志。对于每个点击数据,有24个feature field。我们将其随机分成两部分:80%用于训练,而其余部分用于测试。
评估指标:
AUC, LogLoss。baseline方法:浅层
baseline模型:LR、FM、FFM、AFM。深层
baseline模型:FNN、DCN、DeepFM、XDeepFM。
实现细节:
所有模型用
TensorFlow来实现。embedding layer的维度:Criteo数据集设为10、Avazu数据集设为50。使用
Adam优化器,Criteo数据集的batch size = 1000,Avazu数据集的batch size = 500,学习率设为0.0001。对于所有的深度模型,层深度都是
3、激活函数都是RELU、dropout rate都是0.5。Criteo数据集的隐层维度为400、Avazu数据集的隐层维度为2000。对于
SENET部分,两个全连接层中的激活函数是RELU函数,缩减率设置为硬件配置:
2个Tesla K40 GPU。
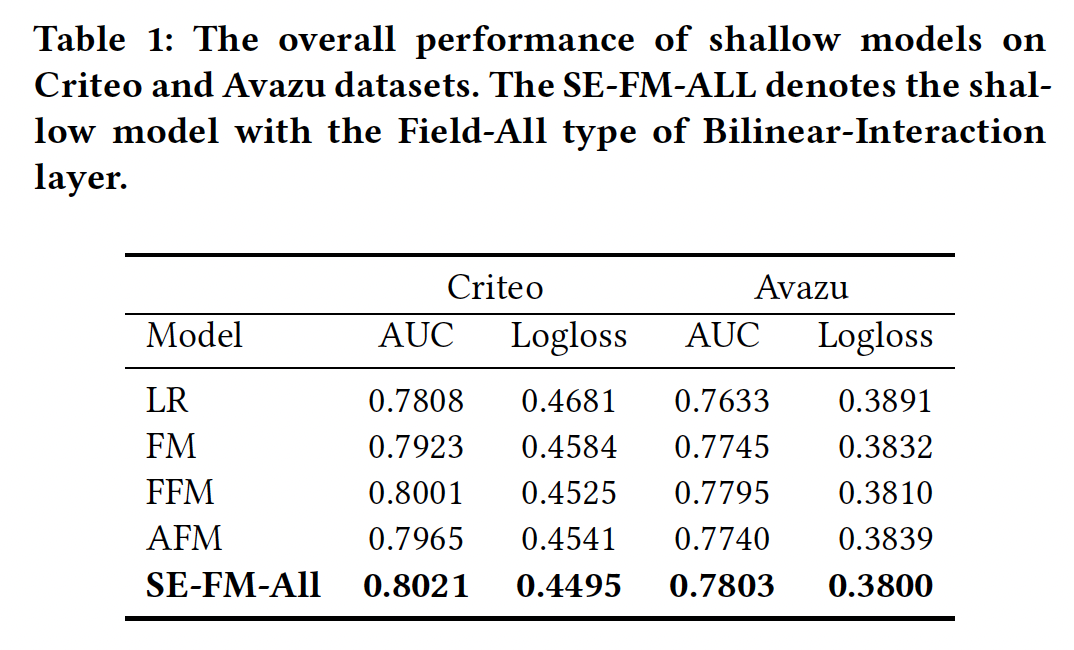
Table 1和Table 2中分别总结了浅层模型和深层模型在Criteo测试集和Avazu测试集上的总体表现。这里
Interaction layer使用Field-All双线性函数,如表格的标题所示。浅层模型:我们的浅层
SE-FM-All模型一直优于其他模型,如FM、FFM、AFM等。一方面,结果表明,将
SENET机制与稀疏特征上的bilinear interaction结合起来,对于许多现实世界的数据集来说是一种有效的方法。另一方面,对于经典的浅层模型来说,
SOTA的模型是FFM,但是它受到大内存的限制,不能轻易用于互联网公司。我们的浅层模型的参数较少,但仍然比FFM表现更好。因此,它可以被视为FFM的一个替代方案。
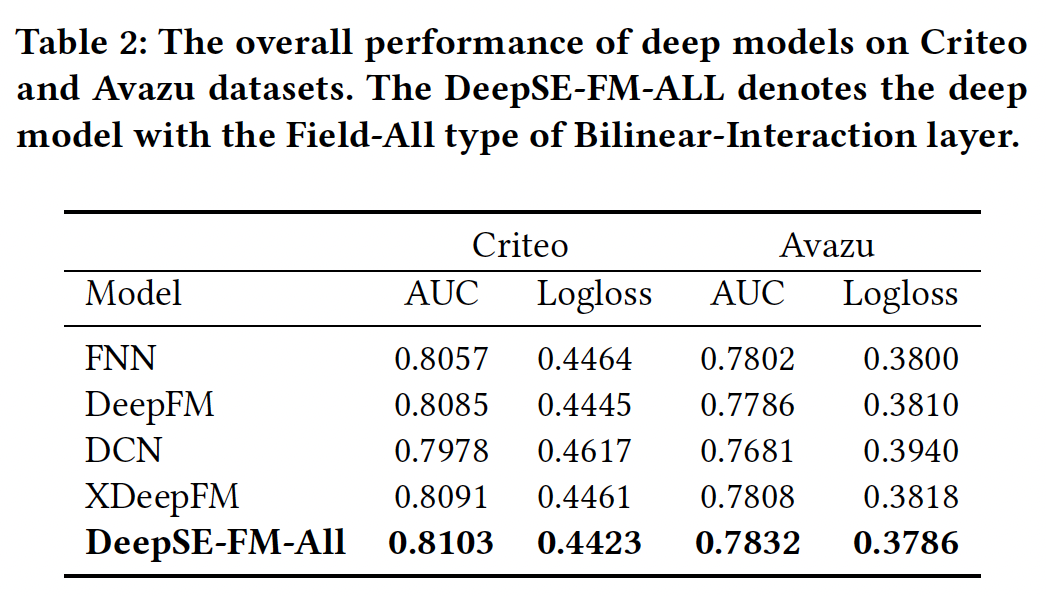
深层模型:
将浅层部分和
DNN结合成一个统一的模型,浅层模型可以获得进一步的性能提升。我们可以从实验结果中推断,隐式的高阶特征交互有助于浅层模型获得更多的表达能力。在所有的比较方法中,我们提出的深度
FiBiNET取得了最好的性能。在Criteo数据集上和Avazu数据集上,我们的深度模型以0.222%和0.59%的AUC(0.494%和0.6%的logloss)优于DeepFM。结果表明,将
SENET机制与DNN中的Bilinear-Interaction相结合进行预测是有效的。一方面,
SENET固有地引入了以输入为条件的动态性,有助于提高特征的discriminability;另一方面,与内积或Hadamard积等其他方法相比,双线性函数是一种有效的方法来建模特征交互。
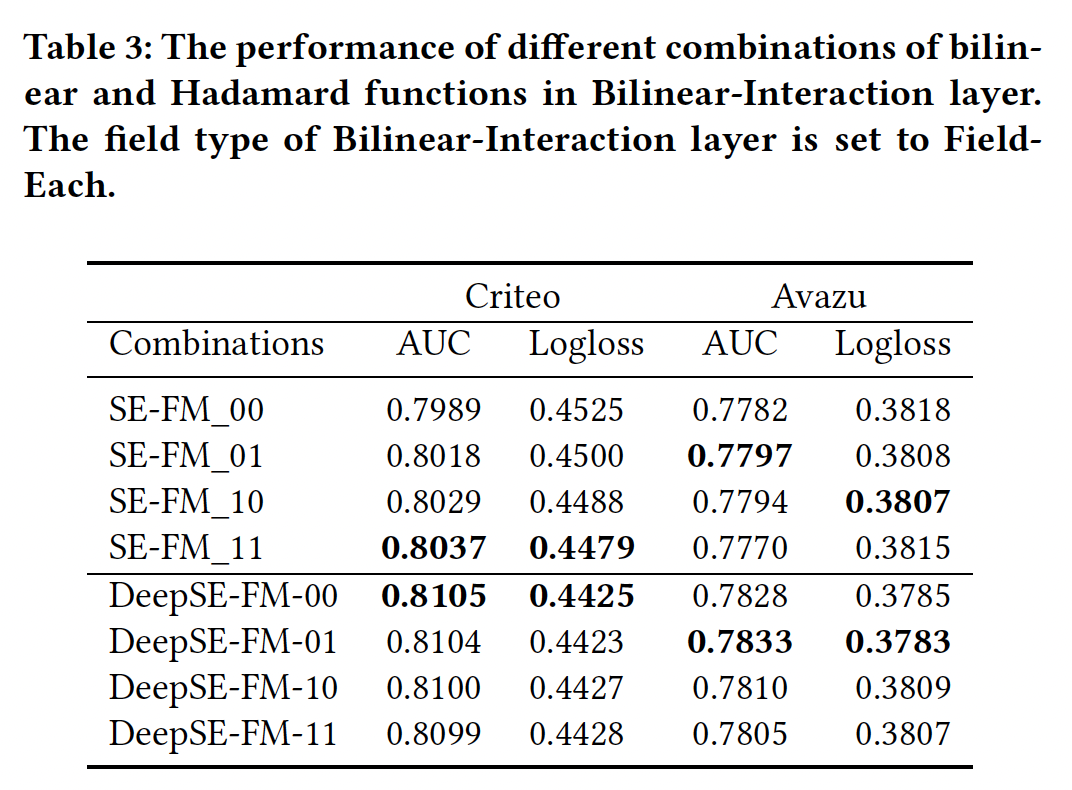
不同的特征交互方式:我们将讨论在
Bilinear-Interaction layer中,双线性函数和Hadamard积不同类型的组合的影响。为方便起见,我们用0和1来表示在Bilinear-Interaction layer使用哪种函数:1表示使用双线性函数,而0表示使用Hadamard积。Interaction layer使用Field-Each双线性函数。很奇怪Table3和Table1/2使用了不同的双线性函数。我们有两个
embedding,所以使用两个数字。第一个数字表示用于原始embedding的特征交互方法,第二个数字表示用于SENET-like embedding的特征交互方法。例如:10表示双线性函数被用作原始embedding的特征交互方法、Hadamard函数被用作SENET-like embedding的特征交互方法。实验结果如下表所示。可以看到,在
Criteo数据集上:11的组合在浅层模型中表现最好,但是在深度模型中表现最差。深层模型中的首选组合应该是
01。这种组合意味着双线性函数只适用于SENET-Like embedding layer。
不同数据集的结论不同,因此这个双线性函数的组合方式需要根据不同的数据进行调优。
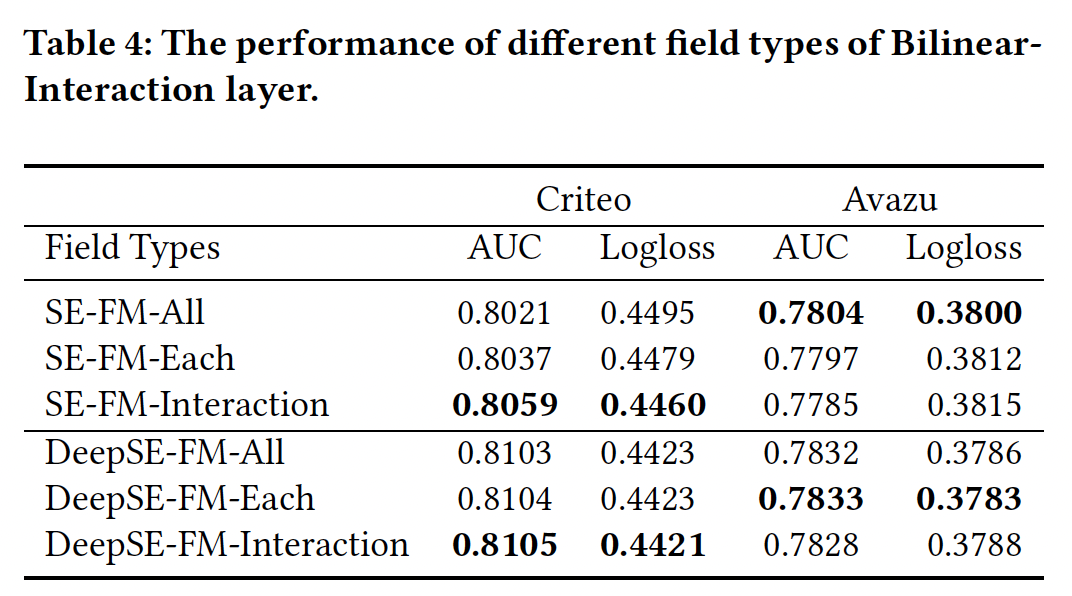
Bilinear-Interaction的Field Types:这里我们研究了Bilinear-Interaction layer的不同field类型(Field-All, Field-Each, Field-Interaction)的影响。对于深层模型,Bilinear-Interaction layer的组合被设置为01;对于浅层模型,Bilinear-Interaction layer的组合被设置为11。对于浅层模型,与
Field-All类型相比(见Table 1),Field-Interaction类型可以在Criteo数据集上获得0.382%(相对提升0.476%)的AUC改进。对于深层模型,与
Field-All类型相比(见Table 2),Criteo数据集的Field-Interaction类型、以及Avazu数据集的Field-Each类型可以分别获得一些改进。不同类型的
Bilinear-Interaction layer的性能取决于数据集。
超参数:
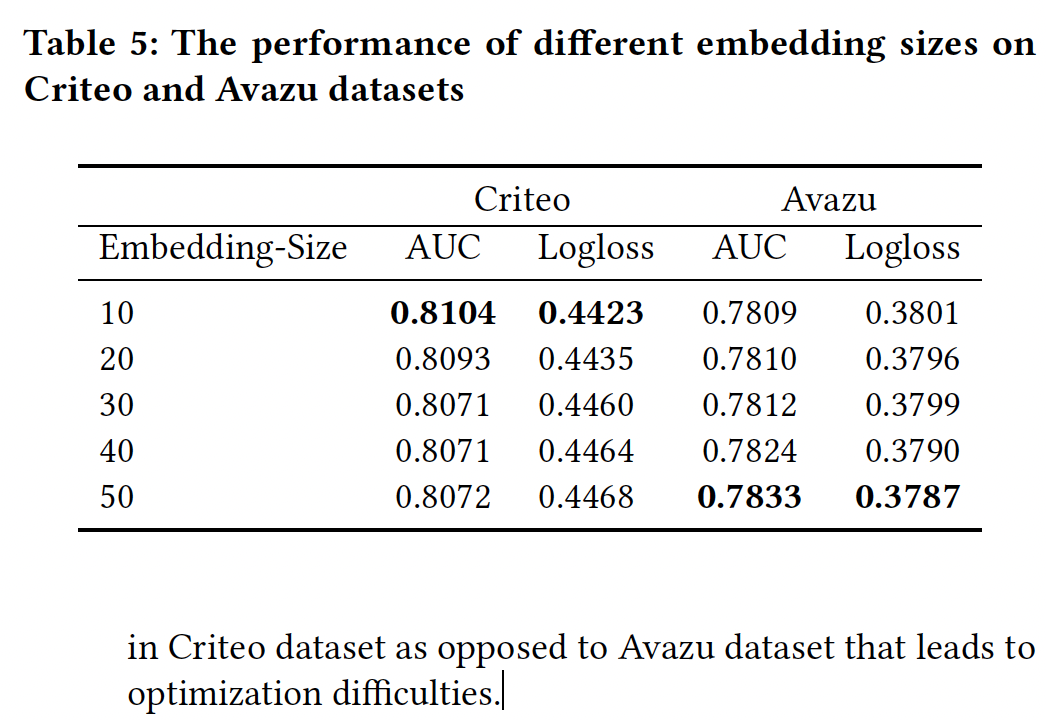
Embedding部分:我们将embedding size从10改变到50。可以看到:随着维度从
10扩大到50,在Avazu数据集上我们的模型可以获得大幅改善。当我们增加
Criteo数据集的embedding size时,性能就会下降。扩大
embedding size意味着增加embedding layer和DNN部分的参数数量。我们猜测可能是Criteo数据集的特征比Avazu数据集多得多,导致了优化的困难。有两个原因:过拟合、以及优化困难。因为这两个数据集的样本量都在
4000万以上,因此二者的过拟合程度应该相差无几。
SENET部分:squeeze函数:下表总结了不同squeeze函数的性能,我们发现GlobalMeanPooling在Criteo数据集和Avazu数据集上优于GlobalMaxPooling或GlobalSumPooling。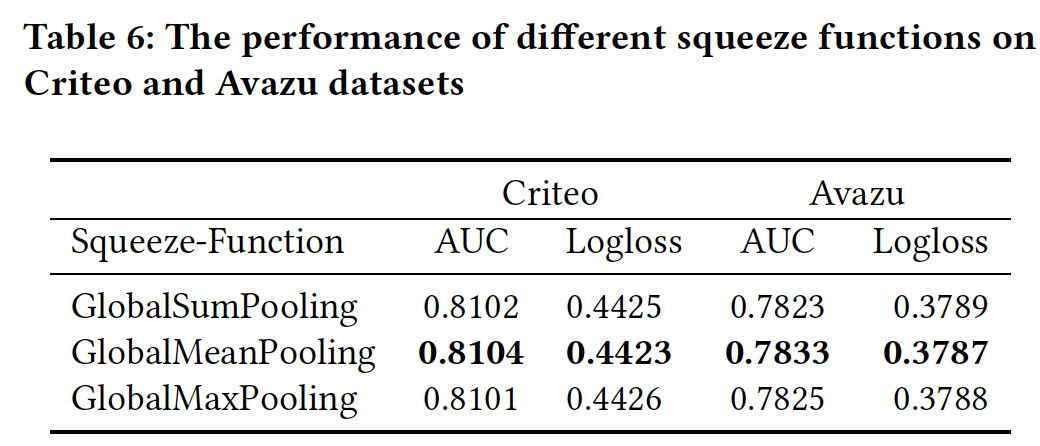
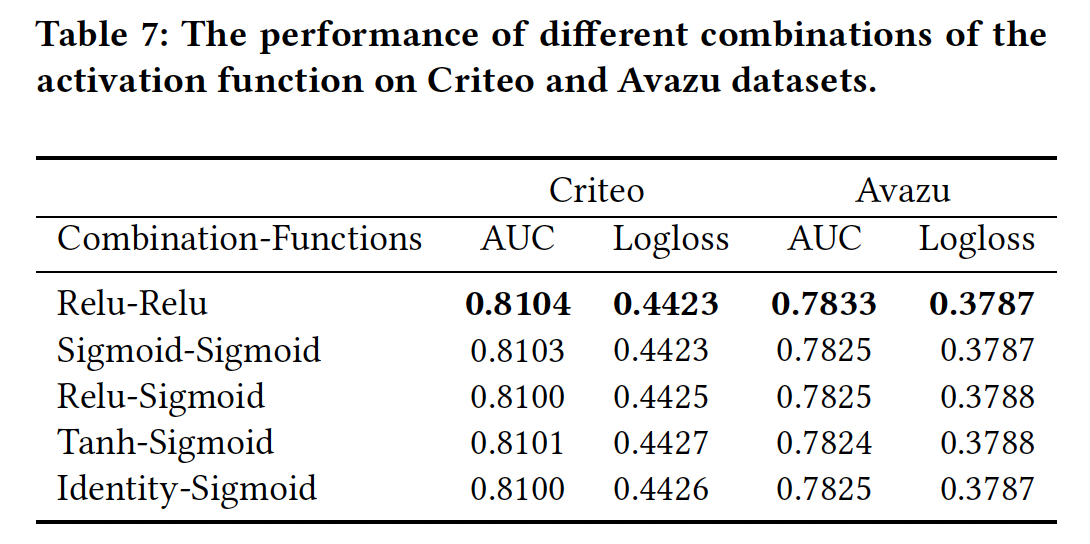
激活函数:我们改变了激活函数的组合,如下表所示。
在这些激活函数的组合中,
Relu-Relu略胜于其他组合。与原始
SENET的设置不同,FiBiNET的SENET组件中的第二个激活函数是Relu函数,其性能比sigmoid函数更好。
此外,我们还改变了压缩率(
DNN部分:网络层数:增加层数可以增加模型的复杂性。我们可以从下图中观察到,增加层数在开始时可以提高模型性能。然而,如果层数不断增加,性能就会下降。这是因为过于复杂的模型很容易过拟合。对于
Avazu数据集和Criteo数据集,将隐藏层的数量设置为3是一个不错的选择。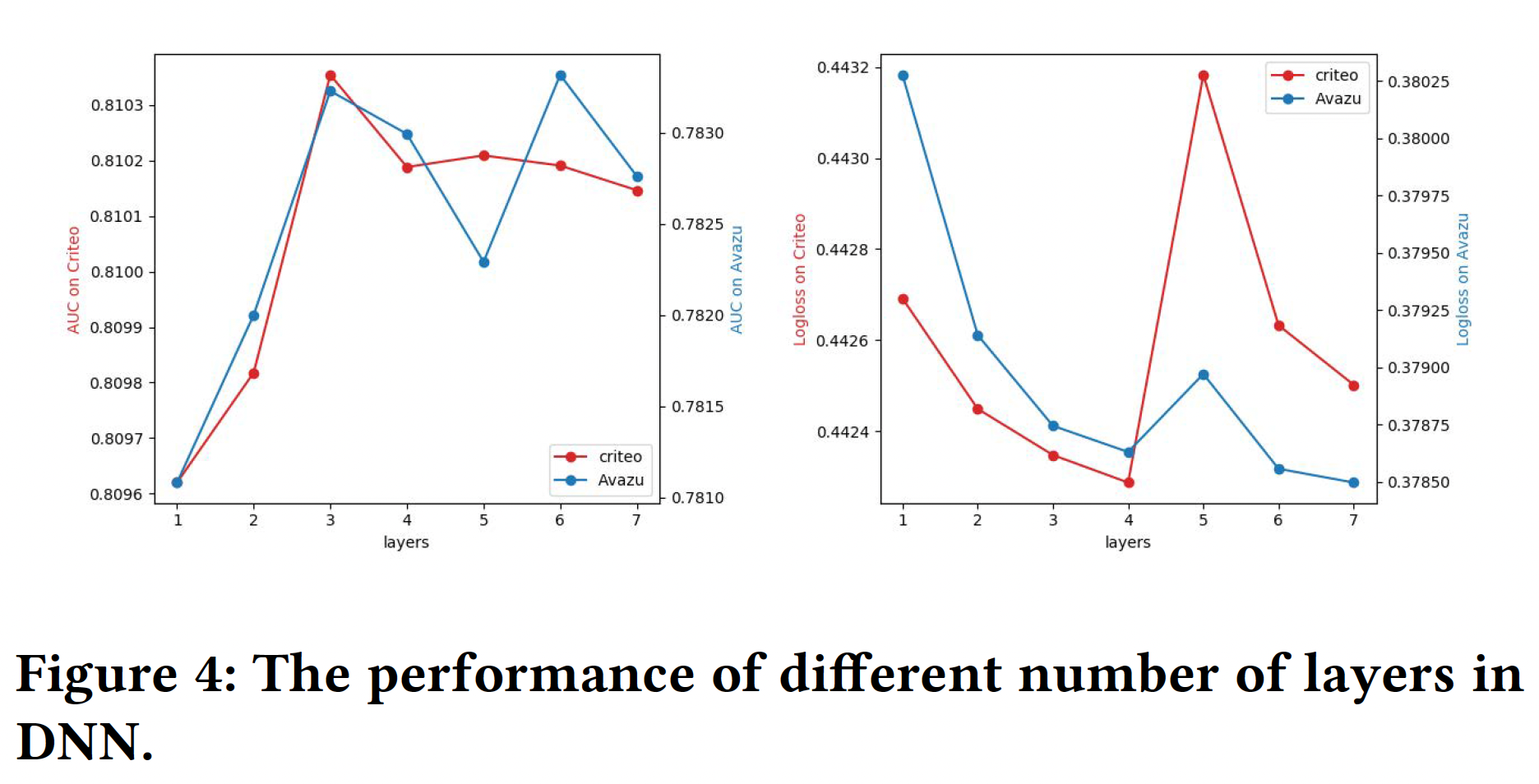
隐层神经元数量:同样,增加每层的神经元数量也会引入复杂性。在下图中,我们发现对于
Criteo数据集,每层设置400个神经元比较好;对于Avazu数据集,每层设置2000个神经元比较好。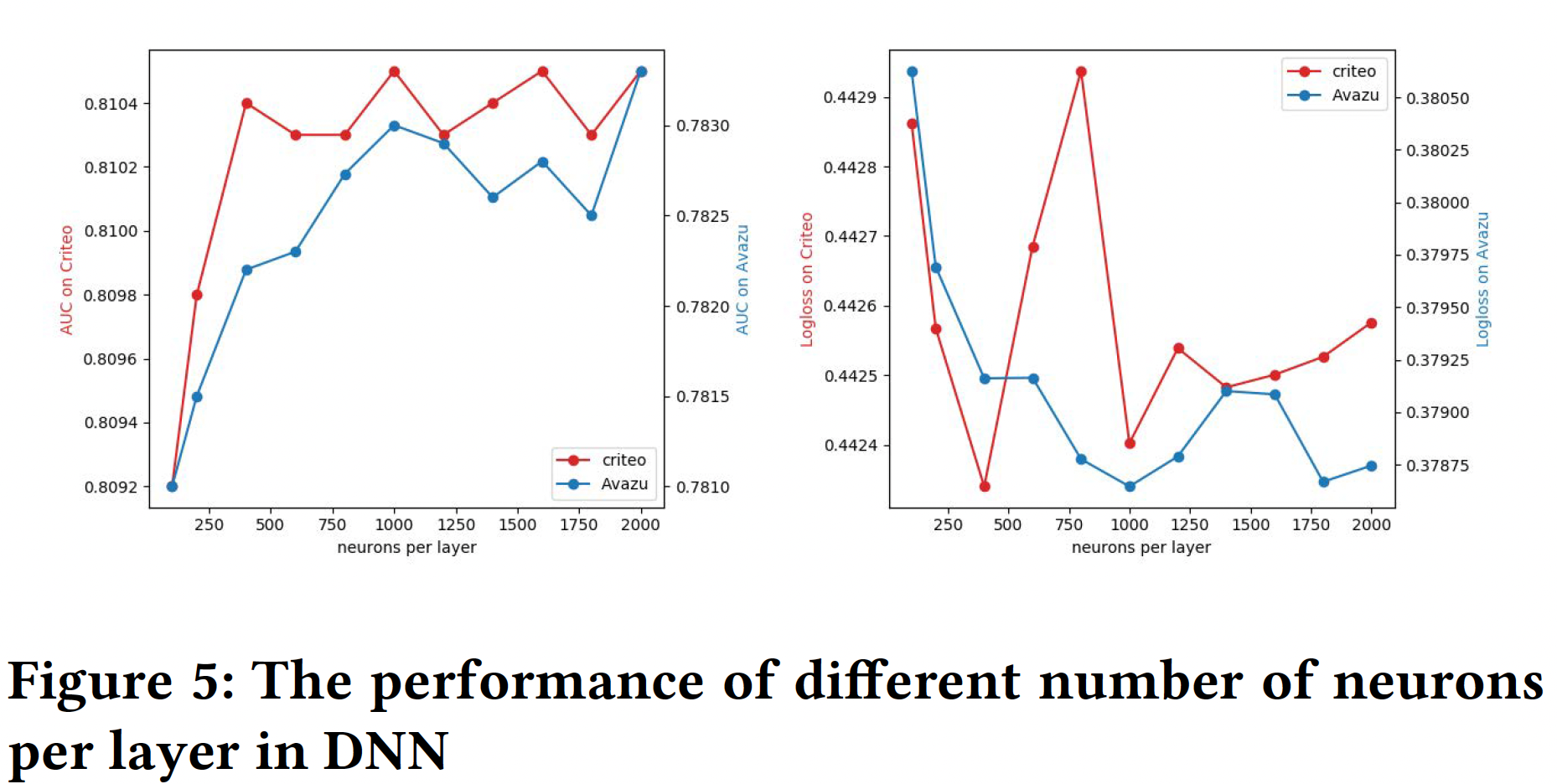
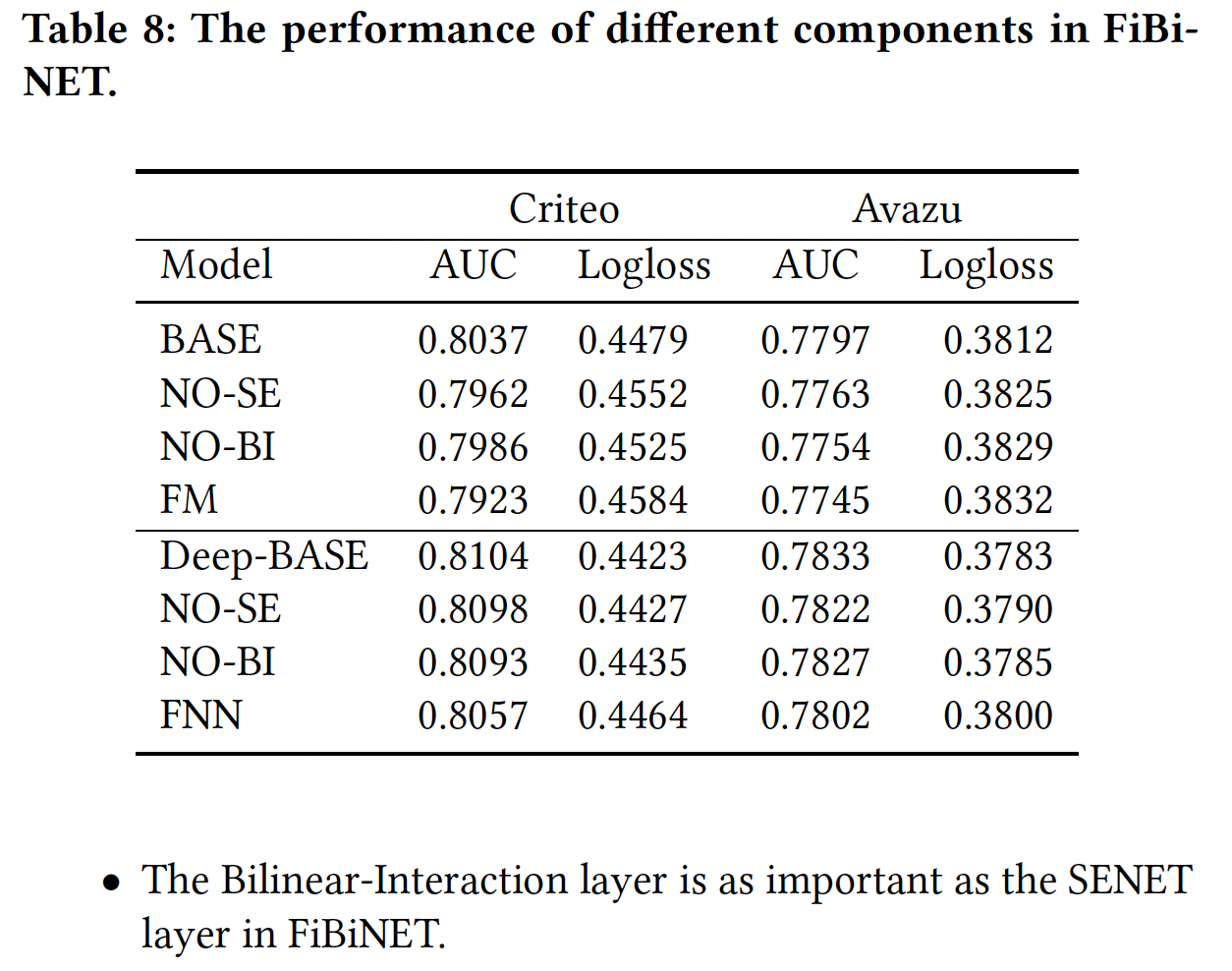
消融研究:目前为止,我们还没有分离出
FiBiNET的每个组件的具体贡献。在本节中,我们对FiBiNET进行了消融实验,以便更好地了解它们的相对重要性。我们将DeepSE-FM-Interaction设定为基础模型,并以下列方式进行:No BI:从FiBiNET中删除Bilinear-Interaction layer。No SE:从FiBiNET中删除SENET layer。
如果同时我们删除
SENET layer和Bilinear-Interaction layer,我们的浅层FiBiNET和深层FiBiNET将降级为FM和FNN。实验结果如下表所示。Bilinear-Interaction layer和SENET layer对于FiBiNET的性能都是必要的。我们可以看到,当我们删除任何组件时,性能将明显下降。在
FiBiNET中,Bilinear-Interaction layer与SENET layer一样重要。