一、 InterHAt [2020]
《Interpretable Click-Through Rate Prediction through Hierarchical Attention》
点击率(
click-through rate: CTR)预测是在线广告和营销领域的关键任务。针对这一问题,现有的浅层或深层架构方法存在三大主要缺陷。首先,这些方法通常缺乏有说服力的理由来解释模型的输出结果。无法解释的预测和推荐可能难以验证,因此不可靠且不值得信任。在许多应用场景中,不恰当的建议甚至可能带来严重后果。
其次,现有方法在分析高阶特征交互(
high-order feature interactions)方面效率低下。第三,不同语义子空间(
semantic subspaces)中feature interactions的多义性(polysemy)在很大程度上被忽视。
在本文中,我们提出了
InterHAt模型,该模型采用a Transformer with multi-head self-attention进行feature learning。在此基础上,利用hierarchical attention layers进行点击率预测,同时为预测结果提供可解释性的洞察。InterHAt通过一种计算复杂度低的且高效的attentional aggregation策略来捕获high-order feature interactions。在四个公开的真实数据集和一个合成数据集上进行的大量实验证明了InterHAt的有效性和效率。点击率(
click-through rate: CTR)定义为用户点击网页上特定recommended item或广告的概率。它在推荐系统(如在线广告)中起着重要作用,因为它直接影响广告代理商的收入。因此,CTR prediction旨在根据描述user-item场景的信息准确估计点击率,对于实现精准推荐和增加企业良好收入至关重要。深度学习的发展提供了一种新的机器学习范式,它利用更深的神经网络结构从
training data中捕获更复杂的信息。因此,现有的CTR prediction models的架构和计算复杂度不断增加,以便学习多个特征的联合效应(即高阶特征,又称交叉特征),并获得更好的prediction accuracy。具体来说,一个latent variable。由于神经网络具有大量的层和单元,深度神经网络具备捕获丰富的高阶信息的强大能力。例如,DeepFM和xDeepFM分别通过多层前馈神经网络(feed-forward neural networks: FNN)和多块(multi-block)压缩交互网络(compressed interaction networks: CIN)来学习高阶特征。然而,不断增长的模型复杂度存在两个缺点:可解释性受损和效率低下。
在可解释性方面,由于神经网络层的
weights和activations通常被认为是无法解释的,因此prediction-making过程难以得到合理说明。例如,Wide & Deep的wide组件对feature embeddings应用叉积变换(cross-product transformations),但无法量化和证明其对CTR的预测性能的有效性。模型预测缺乏有说服力的理由,使其可靠性和安全性受到质疑。在许多
applications中,例如药物推荐和金融服务,不可信和不可靠的广告可能误导用户点击那些统计上热门但实际上无用的甚至有害的链接,从而导致经济损失或健康损失等严重后果。现有方法的第二个缺陷是效率低下,因为深度神经网络生成高阶
interaction feature涉及极其繁重的矩阵计算。例如:xDeepFM中的compressed interaction network: CIN通过一个外积层(outer product layer)和一个全连接层计算feature matrix,这导致其计算复杂度与embedding size呈三次方关系。Wide & Deep中的deep组件包含多个全连接层,每个全连接层都涉及平方数量级的乘法运算。
在实际应用中,效率问题普遍存在且至关重要。广告代理商更倾向于快速提供
click recommendation,而不是缓慢或成本高昂的click recommendation,尤其是在面临大量real-time recommendation queries的压力下。例如,互联网广告公司Criteo在24天内处理超过4 billion次点击。尽管数据量庞大,但新的特征(如新的users和新的items)迅速涌现,推荐系统必须快速适应这些新特征以提供更好的用户体验。因此,使用现有方法学习大量现有特征或新兴特征的representations,这在计算上可能难以实现。
除了可解释性和效率问题外,我们还指出了另一个障碍,这个障碍可能降低
detecting important cross-feature interactions的性能:不同的cross-features可能对CTR产生相互冲突的影响,必须对其进行综合分析。例如,一条电影推荐记录"movie.genre = horror, user.age = young, time = 8am"存在相互冲突的因素:前两个特征的组合会促进点击,而后两个特征的组合会抑制点击,因为看电影通常发生在晚上。这种冲突问题是由不同语义子空间(semantic subspaces)中feature interactions的多义性(polysemy)引起的。在这个例子中,当用"user.age=young"时,与"movie.genre"和"time"这两个不同属性的组合时,"user.age"的多义性交互(polysemic interactions)对CTR产生了相反的影响。然而,现有方法在很大程度上忽视了这个问题。为了解决上述问题,在本文中,我们提出了一种基于
Hierarchical Attention的可解释的CTR预测模型(Interpretable CTR prediction model with Hierarchical Attention: InterHAt),该模型以端到端的方式高效地学习不同阶次的显著特征(salient features of different orders)作为解释性的洞察(interpretative insights),同时准确地预测CTR。具体来说,InterHAt通过一种新颖的hierarchical attention机制显式地量化任意阶次feature interactions的影响,为了提高效率而聚合重要的feature interactions,并根据学到的特征显著性(feature salience)来解释推荐决策(recommendation decision)。与《Hierarchical attention networks for document classification》研究语言层级(词和句子)的hierarchical attention network不同,InterHAt在特征阶次(feature orders)上使用hierarchical attention,并且高阶特征基于低阶特征来生成。为了适应不同语义子空间中
feature interactions的多义性,InterHAt利用a Transformer with multi-head self-attention来全面研究可能存在的各种feature-wise interactions。Transformer已被广泛应用于自然语言处理任务,如情感分析、自然语言推理、和机器翻译。多个attention heads能够从不同的潜在子空间(latent subspaces)中捕获词语之间的多种相互作用,而这种相互作用共同构成了文本的语义。我们利用Transformer的这一优良特性来检测feature interactions的复杂多义性,并学习一个多义性增强的特征列表(polysemy-augmented feature list),将其作为hierarchical attention layers的输入。值得注意的是,不但Transformer在feature learning方面具有强大的能力,根据《Attention is all you need》的研究,该模型也保持了较高的效率。我们将本文的贡献总结如下:
我们提出了用于
CTR prediction的InterHAt模型。具体来说,InterHAt采用hierarchical attention来精准识别对click-through有重大贡献的significant single features or different orders of interactive features。然后,InterHAt可以基于各种阶次的feature interactions为CTR prediction来生成相应的attention-based的解释。InterHAt利用a Transformer with multi-head self-attention来全面分析不同潜在语义子空间中特征之间可能存在的交互关系。据我们所知,InterHAt是第一个采用Transformer with multi-head self-attention来学习潜在特征的多义性(polysemy of latent features)以进行CTR prediction的方法。InterHAt在预测CTR时不使用计算成本高昂的深度多层感知器网络(deep multilayer perceptron networks)。相反,它对特征进行聚合,从而节省了枚举指数级规模feature interactions的开销。因此,与现有算法相比,它在处理高阶特征时更高效。我们在三个主要的
CTR benchmark datasets(Criteo, Avazu, and Frappe)、一个流行的推荐系统数据集(MovieLens-1M)和一个合成数据集上进行了大量实验,以评估InterHAt的可解释性、效率和有效性。结果表明,InterHAt能够解释decision-making过程,在训练时间上有巨大改进,并且仍然取得了与SOTA模型相当的性能。
InterHAt没有不合理的deep MLP模块,仅在feature levels上工作,因此它可解释性更好,训练速度和inference速度更快。
1.1 相关工作
在本节中,我们讨论现有的
CTR prediction模型和attention机制。
1.1.1 CTR Prediction Models
由于
CTR prediction对在线广告具有重大影响,它引起了学术界和工业界的广泛关注。CTR prediction算法的发展本质上呈现出向更深的模型架构(deeper model architectures)发展的趋势,因为更深的模型在feature interaction learning方面更具优势(《AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks》)。浅层模型:
因子分解机(
Factorization Machine: FM)(《Factorization machines》)为每个distinct feature分配一个continuous-valued representation),学习representations of distinct features,并通过first- and second-order features的线性聚合进行预测。尽管
FM可以推广到高阶情况,但它面临指数级复杂度的计算成本(《Higher-order factorization machines》)、以及浅层架构的低模型容量(model capability)的问题。Field-aware Factorization Machine: FFM(《Field-aware factorization machines for CTR prediction》)假设特征在不同fields下可能具有不同的语义,并通过使feature representation具有field-specific来扩展FM的思想。尽管
FFM比FM取得了更好的CTR prediction结果,但参数规模和复杂度也有所增加,并且更容易发生过拟合。Attentional Factorization Machine: AFM(《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》)通过添加"attention net来扩展FM,不仅提高了性能,还增强了可解释性。作者认为,attention network所提供的特征显著性(feature salience)极大地提高了FM的透明度(transparency)。然而,由于FM固有的架构限制,AFM最多只能学习second-order attention-based salience。
深层模型:
Wide & Deep(《Wide & deep learning for recommender systems》)由一个wide组件和一个deep组件组成,它们本质上分别是一个广义线性模型和一个多层感知器(MLP)。CTR prediction通过对两个组件的输出结果进行加权组合来实现。值得注意的是,deep组件(即MLP)破坏了对预测进行解释的可能性,因为layer-wise transformations是在unit level而不是feature level进行的,并且单个unit level的值无法承载features的concrete and complete semantic information。Deep & Cross Network: DCN(《Deep & Cross Network for Ad Click Predictions》)与Wide & Deep略有不同,DCN用a cross-product transformation替代了线性模型,以将高阶信息(来自于DCN模块)与非线性deep features相结合。DeepFM(《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》)通过用FM组件替代多项式乘积(polynomial production)来改进Wide & Deep和DCN。deep MLP组件捕获高阶feature interaction,而FM分析二阶feature interaction。xDeepFM(《xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems》)声称MLP参数实际上是在建模"implicit" feature interactions。因此,作者引入了compressed interaction network: CIN来建模"explicit" feature interactions,从而与隐式feature interactions(即MLP模块)一起工作。来自工业实践的最新工作包括
DIN(《Deep Interest Network for Click-Through Rate Prediction》)和DIEN(《Deep Interest Evolution Network for Click-Through Rate Prediction》),它们分别对用户的静态和动态购物兴趣进行建模。这两项工作都严重依赖于通常无法解释的deep feed-forward networks。
上述所有
CTR prediction模型都严重依赖深度神经网络,并取得了不断提升的性能。然而,正如一把双刃剑,深度学习算法在可靠性和安全性方面存在潜在风险。hidden layers的weights和activations几乎无法解释,inputs and outputs之间的因果关系(causal relationships)被隐藏且不确定。它们都未能提供任何feature-level的线索来解释为什么此类deep feature learning策略会提高或降低CTR performance。因此,由此产生的缺乏明确解释的预测被认为是不可信的。相比之下,
InterHAt通过在feature-level上使用attention-based的解释来解决CTR prediction问题。也就是说,InterHAt没有不合理的deep MLP模块,仅在feature levels上工作,这也提高了InterHAt的效率。
1.1.2 Attention Mechanism
attention机制学习一个函数,该函数对中间特征(intermediate features)进行加权,并对机器学习算法的其他模块可见的信息进行操作。它最初是为神经机器翻译(neural machine translation: NMT)(《Neural Machine Translation by Jointly Learning to Align and Translate》)提出的。在NMT中,它为源语言(source language)和目标语言(destination language)之间密切相关的单词分配更大的权重,以便在翻译过程中关注重要的单词。由于
attention机制能够精准识别并放大对predictions有重大影响的显著特征(《Explaining explanations: An overview of interpretability of machine learning》),因此它被认为是解释许多任务(如推荐系统、医疗保健系统、计算机视觉、视觉问答等)中决策过程的合理且可靠的方法。例如:RETAIN(《Retain: An interpretable predictive model for healthcare using reverse time attention mechanism》)使用a two-layer attention network研究患者的电子健康记录(Electric Health Records: EHR),该网络识别并解释与就诊相关的有影响力的就诊记录和重要的临床诊断。视觉问答(
visual question answering: VQA)中的协同注意力机制(《Multimodal explanations: Justifying decisions and pointing to the evidence》)在单词级别、短语级别和问题级别上提出了question-guided visual attention和visual-guided question attention。结合三个级别的信息来预测答案,在保持结果可解释性的同时提高了性能。
在自然语言领域,基于语言层次结构(
linguistic hierarchy)的language-specific and across-language attention networks被提出用于文档分类任务。自然语言处理中另一种形式的注意力是self-attention。谷歌的研究人员基于multi-head self-attention设计了Transformer(《Attention is all you need》),其中句子中的tokens关注同一句子中的其他tokens,以学习复合的句子语义(compound sentence semantics)。利用Transformer强大的学习能力,BERT通过堆叠多个双向Transformer层,在11个主要的自然语言处理任务上取得了SOTA的性能。BERT的成功展示了Transformer出色的feature interaction能力。总之,各种现有工作都证明了利用
attention机制可以同时提高模型的准确性和透明度(transparency)。尽管attention模块并非为生成人类可读的预测理由(prediction rationales)而训练,但当feature representations流经模型架构时,它们仍然可以揭示信息的显著性的分布(salience distribution),这可以作为一种解释形式。因此,我们在InterHAt中采用attention机制作为解释CTR prediction的解决方案。
1.2 InterHAt 模型
在本节中,我们详细阐述
Figure 1所示的InterHAt流程、以及根据attentional weights进行CTR prediction interpretation的方法。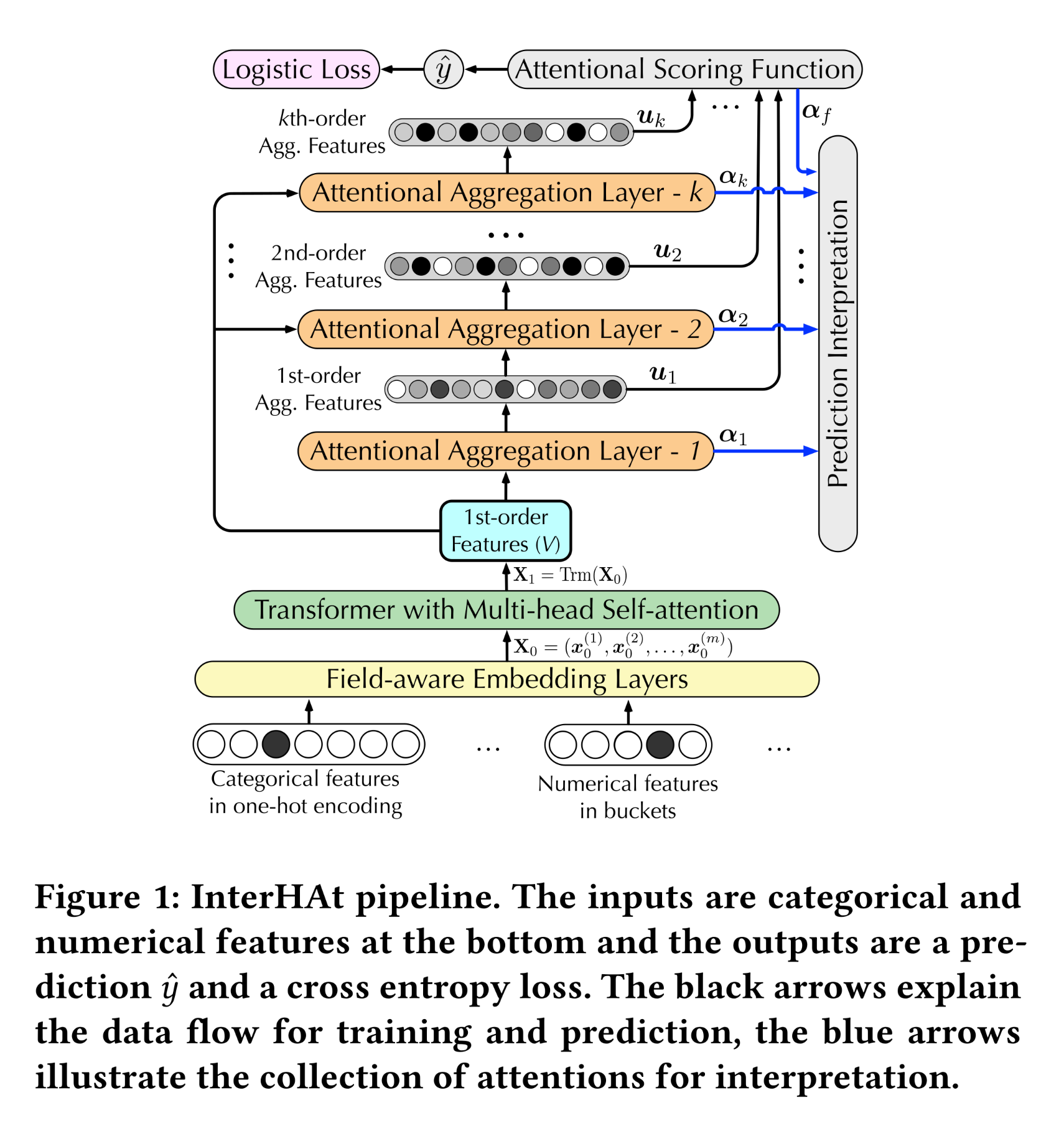
1.2.1 Embedding Layer
embedding layer是CTR prediction的先决条件,因为click-through records包含离散的categorical terms,这些categorical terms不能直接应用于数值计算。一条
click-through record包含一组fieldsground truth,表示是否实际发生了点击)。每个fieldcategorical的,要么是numerical的。distinct values被定义为different features。对于
categorical fields,我们将multi-field one-hot encoding应用于field-aware embedding layers,以获得low-dimensional real-valued feature representations。具体来说,为一个字段的每个distinct feature valuerepresentation。如果某个特定feature出现在click-through record中,则该feature对应的embedding被视为field representation。对于
numerical fields,我们为每个field分配一个向量作为其embedding。给定numerical fieldnormalized value),field相关联的trainable representation,则该特征的representation或者对
numerical fieldembedding layer从而获取embedding。
initial input representation矩阵其中:
1.2.2 Multi-head Transformer
由于
Transformer具有出色的能力,能够学习句子内或句子间word pairs的文本语义(text semantics)的共同影响,而不受单词顺序和距离的限制,因此它在自然语言处理中得到了广泛应用。在CTR prediction的背景下,我们将特征的co-effects(即,feature interactions)对不同极性(polarity)的影响定义为“多义性”("polysemy")。因此,我们为InterHAt配备了multi-head self-attention based Transformer,以捕获丰富的pair-wise feature interactions,并学习不同语义子空间中feature interactions的多样化多义性(即在不同click-through contexts下对CTR的多样化影响)。每个
head代表一个语义子空间。给定
input matrixa training CTR record的特征的learnable embeddings,Transformer headlatent representationscaled dot-product attention来获得:其中:
矩阵
headweight parameters。
hidden featurescombination形成了augmented representation matrixintrinsic information)和多义性信息(polysemic information)。在计算上,我们使用concatenation操作,随后是前馈层(feed-forward layer)和ReLU激活函数来组合这些特征,从而学习combined information的非线性:其中:
attention heads数量;polysemy-augmented features)的矩阵,准备发送到hierarchical attention layer进行可解释的CTR prediction。注意:这里没有
position embedding。因为input fields的顺序是给定的,例如第一个位置是age、第二个位置是launguage,...。这种固定的input fields在训练和inference的时候都是确定的。
1.2.3 Hierarchical Attention
augmented feature matrixhierarchical attention layers的输入。hierarchical attention layers同时学习feature interaction并生成解释。然而,通过枚举所有可能的组合来计算高阶multi-feature interactions的成本很高,因为会产生组合爆炸。这种潜在的高成本促使我们在进行更高阶计算之前先对当前阶数进行聚合。也就是说,为了生成
cross-featureshidden features聚合为summarization。interaction是通过attentional aggregationfeature matrixattentional aggregation representation其中:
attentional aggregation layer中第field的注意力权重。其中:
layerattention space size。layercontext vector。
注意,在实验部分中,
attention space size。值得注意的是,这里也可以采用其他
attention机制,例如gated attention机制(《Attention-based Deep Multiple Instance Learning》)。field的重要性。利用
cross-product变换导出其中:
Hadamard product(即,逐元素乘积)。注意这里有一个残差连接,即
通过堆叠一系列
attentional aggregation layer,我们得到了从一阶到cross-feature阶次)的hierarchy),从低阶到高阶来抽取特征;并且低阶特征通过所提出的attentional aggregation和cross-product变换从而为构建高一阶的特征做出贡献。作为最后一步,我们组合
attentional aggregationsCTR。combinatorial feature semantics。通过修改InterHAt能够捕获任意阶次的feature interactions,同时避免了高阶feature combinations的指数级的cardinality。
1.2.4 Objective Function and Optimization
最终的
CTR prediction functionCTR的一个概率。首先计算
attentional aggregation,以获得其聚合值attention其中:
feature orders)的重要性分布。即,哪些阶次的
feature interactions重要、哪些阶次的不重要。
最后,
prediction其中:
Multi-layer Perceptron: MLP),将output dimension从
InterHAt的objective function是二分类的交叉熵损失:其中:
feature embedding、Transformer layers的参数、以及hierarchical layers的参数。对我们通过
Adam梯度下降优化器来优化
1.2.5 Interpretation
本节详细阐述如何将
hierarchy中的attentions理解为触发prediction of CTR的重要因素。值得注意的是,attention机制仅突出特征的显著性(salience),因此不期望生成完全人类可读的解释。这一假设与其他attention-based interpretable models(《Explaining explanations: An overview of interpretability of machine learning》)一致。以下是使用显著性分布(
salience distribution)ultimate CTR prediction有影响的feature orders。dominant weights)精准识别了包含显著的recommended ads影响最大的阶数(即interacting features的数量)。相应
attention weights识别了candidate individual features,这些特征贡献了第fieldattention weights(即fieldaggregation features积极地交互。
最后,按照上述步骤,我们可以识别不同阶次的所有特征。然后,通过逐层地、逐阶地识别显著特征(
salient features)来解释实际的点击行为。
1.3 实验
在本节中,我们展示
InterHAt在效率、有效性、以及可解释性方面的实验结果。InterHAt的原型由Python 3.7 + TensorFlow 1.12.0实现,并在16GB Nvidia Tesla V100 GPU上运行。
1.3.1 效率和有效性
数据集:我们在三个公开可用的数据集(即
Criteo、Avazu和Frappe)上评估InterHAt。Criteo和Avazu包含来自两家在线广告公司(Criteo和Avazu)的按时间顺序排列的click-through records。我们使用它们的top 30% records进行评估。Frappe数据集包含context-aware app usage log。
Table 1显示了数据集的统计信息。训练集、测试集和验证集的大小比例为8:1:1。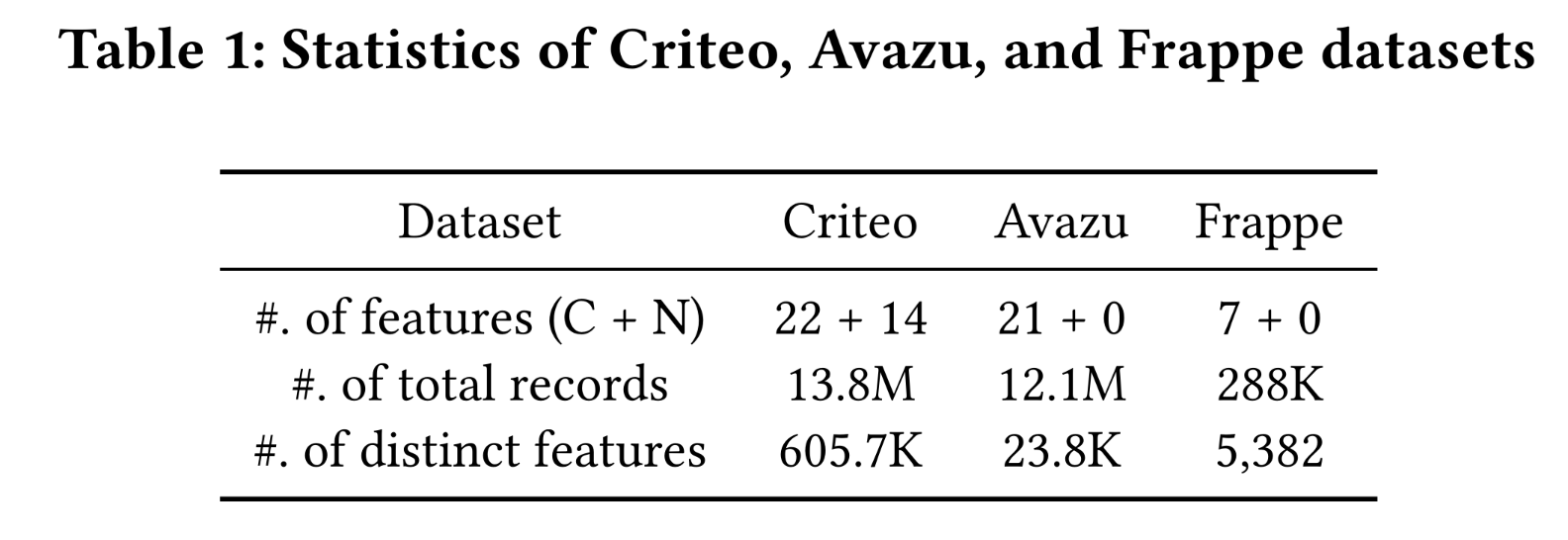
baseline方法:将InterHAt的性能与以下专门为CTR任务设计的SOTA方法进行比较:FM:因子分解机,使用一阶特征和二阶特征的线性组合(feature vectors的点积)来计算CTR。Wide&Deep:一种集成方法(ensemble method),结合了广义线性模型和无法解释的deep MLP。DCN:一种集成方法,结合了用于cross-product变换(用于高阶特征)和deep MLP。PNN:一种基于乘积的特征工程算法,使用由简单内积、外积、以及非线性激活函数组成的架构进行CTR prediction。DeepFM:结合了deep MLP和factorization machine: FM来计算CTR。xDeepFM:结合了deep MLP和新颖的compress information network: CIN模块以进行CTR prediction。
我们认为所考虑的
baseline模型足够强大,可以呈现CTR prediction的SOTA,特别是在Criteo和Avazu数据集上。评估指标:
Logloss, AUC。配置:为了可重复性,
Table 2列出了每个数据集的默认设置。由于数据集大小不同,三个数据集的设置也有所不同。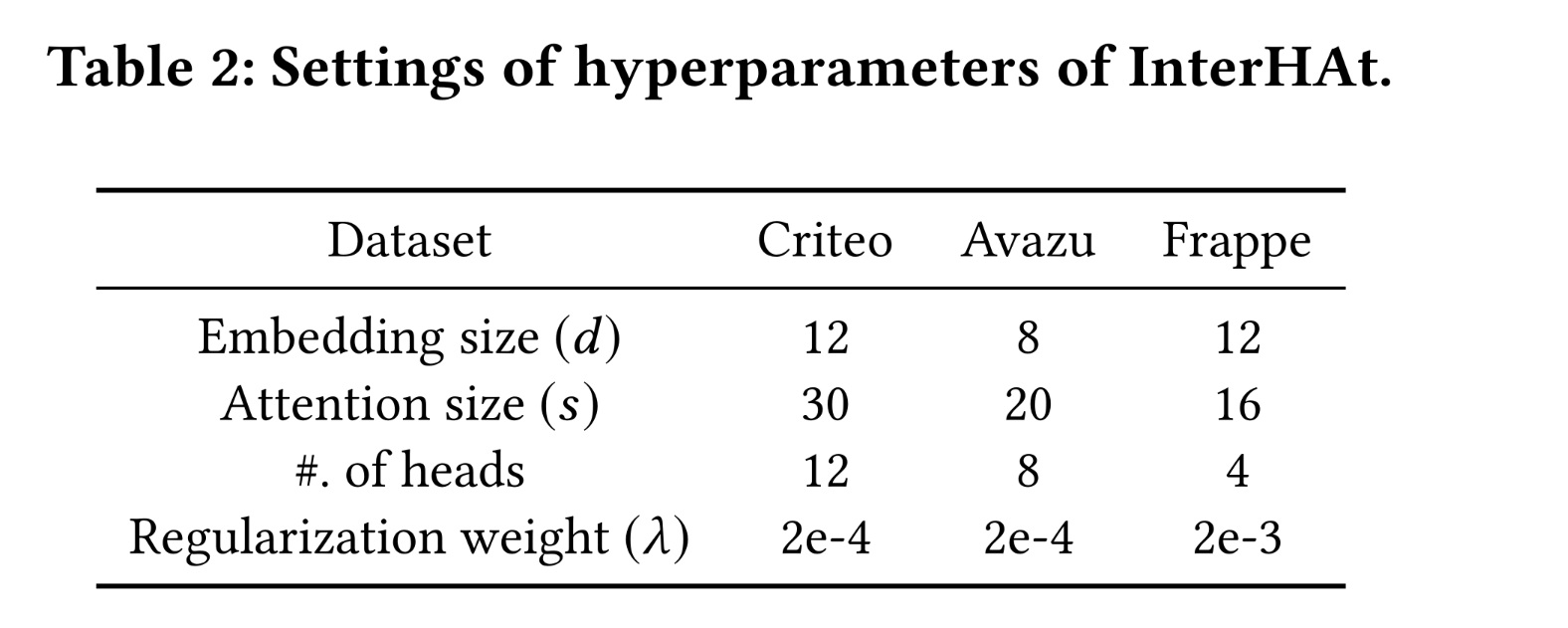
a. 效率和有效性
我们通过将
InterHAt与baseline模型和变体进行比较,展示其效率和有效性。效率:
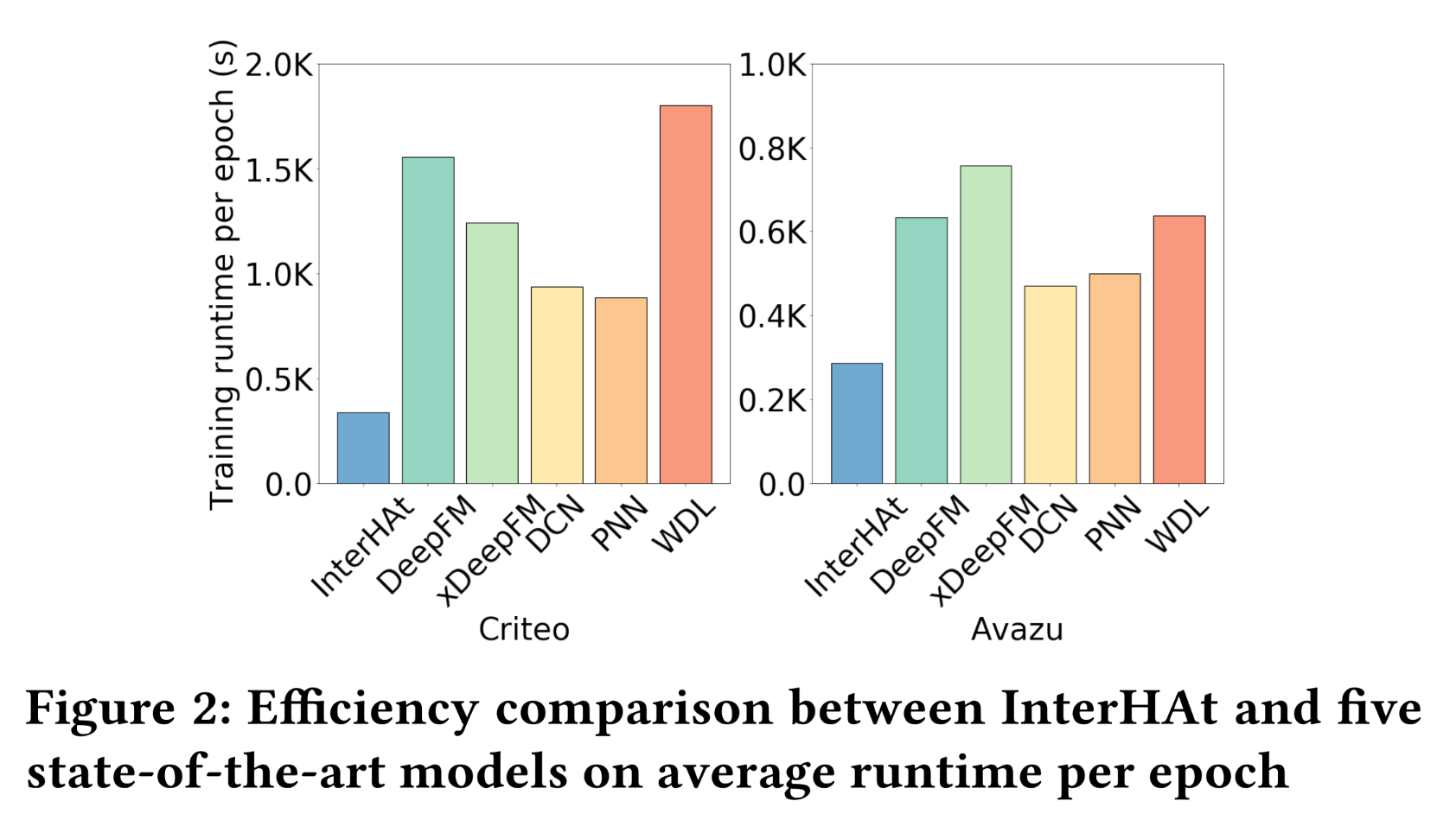
Figure 2展示了InterHAt与五个SOTA模型在Criteo和Avazu数据集上的GPU实现的运行时间比较。由于Frappe数据集的规模相对较小,计算开销占运行时间的大部分,因此未将其用于效率测试。FM也未被使用,因为只有基于CPU的实现可用。y轴表示五个training epochs后的平均每个epoch的运行时间,其中在5个training epochs之后所有模型开始明显收敛。硬件设置与实验设置部分中提到的相同。从图中可以看出,
InterHAt表现出卓越的效率,在六个模型中每个epoch花费的时间最少。InterHAt的两个特性实现了巨大加速:(1):跨特征的attentional aggregation操作将问题规模从指数级降至线性级,通过避免枚举feature combinations。(2):与baseline模型中使用的deep MLP相比,InterHAt仅涉及浅层MLP layers。由于深度神经网络的参数规模庞大,它们会大幅减慢计算速度。
有效性:在
CTR prediction任务中,AUC或Logloss上Table 3中可以看出:InterHAt在Frappe和Avazu数据集的两个指标上都优于所有模型,并且在Criteo数据集上取得了相当的性能。因此,尽管InterHAt在结构上比其他模型更简单,但其有效性得到了证实。InterHAt-S是InterHAt的变体,作为消融研究,它移除了multi-head self-attention模块。InterHAt-S性能的下降证明了multi-heads based Transformer的贡献。
InterHAt在Criteo数据集上与其他模型几乎持平的原因是:与Avazu和Frappe数据集相比,Criteo数据集的特征在语义(semantics)上更复杂。baseline模型使用无法解释的deep全连接(fully-connected: FC)层来捕获复杂的隐式信息并提高性能。然而,InterHAt没有使用损害模型可解释性的deep FC layers。此外,当前的field-aware embedding策略(其中numerical fields只有一个embeddingInterHAt对numerical-numerical feature interactions和categorical-numerical feature interactions进行参数化的能力。我们将探索适当的feature representation和parameterization方案作为未来的工作。我怎么感觉主要是
multi-head self-attention模块带来的性能增益呢?如果没有multi-head self-attention模块,那么InterHAt模型性能感觉会差不少。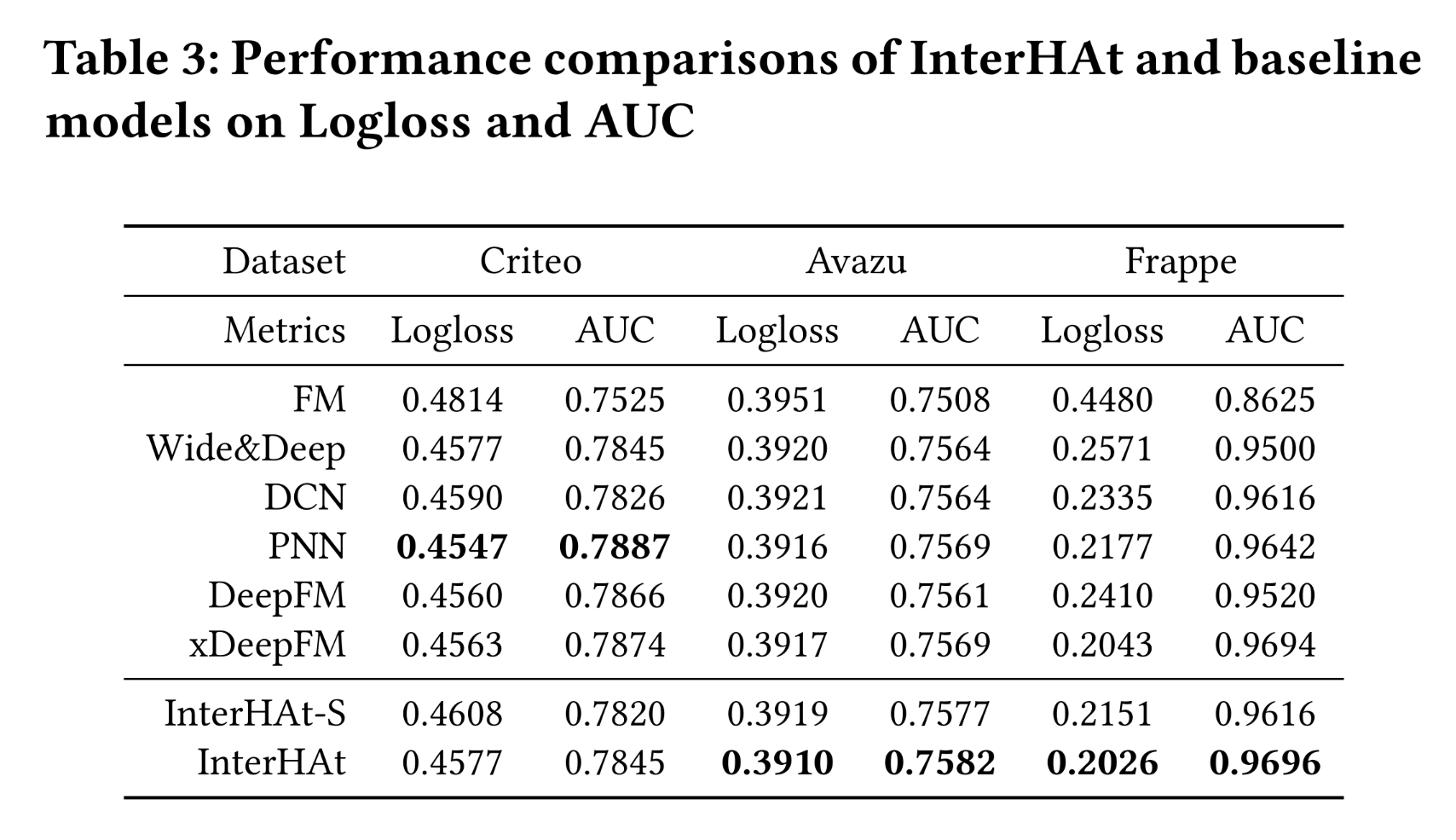
b. Transformer heads 的敏感性分析
本节作为消融研究,阐述了
Transformer head numbers这个超参数的敏感性。Figure 3给出了不同heads数量下InterHAt的Logloss和AUC。我们将heads数量修改为1 ~ 12,保持其他设置不变,并训练模型直到收敛。对于
Criteo和Avazu数据集,heads数量的最佳选择分别为8和4。对于
Frappe数据集,最佳heads数量为1,这与我们的观察一致:即,Frappe fields的语义彼此独立,没有任何潜在的交互。
结果证明了复杂数据集的
click-through records中存在语义的多个方面(即特征多义性feature polysemy),并证明了使用multi-head Transformer的合理性。随着heads数量的增加,由于过参数化(over-parameterization),性能会下降。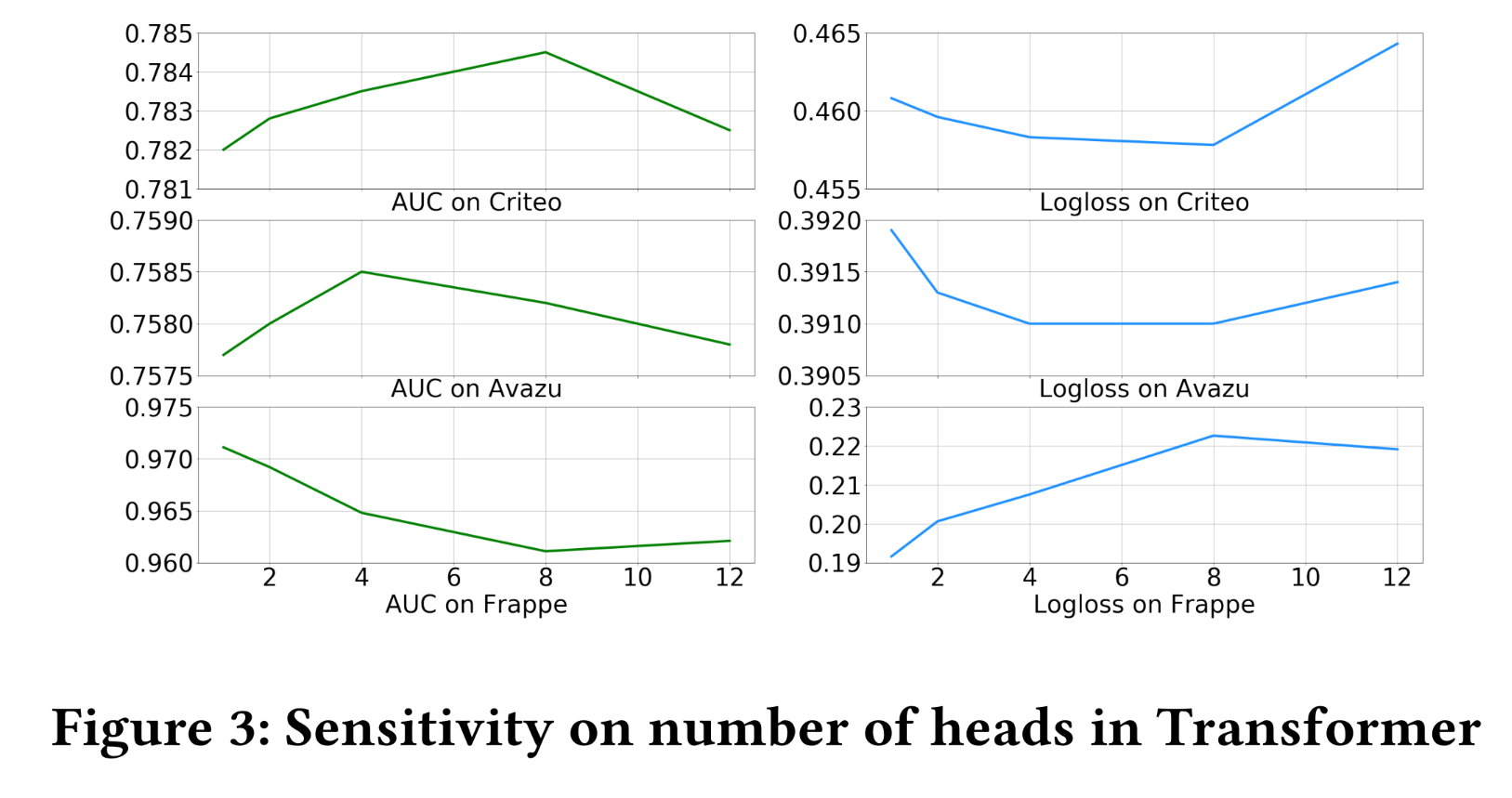
c. 最佳 feature order
我们在三个数据集上评估了不同最高
feature order(即不同的InterHAt。1到4。在这些实验中,我们使用从一阶到cross-features。结果如Figure 4所示。在大型数据集(
Criteo和Avazu)上,当阶数增加时,AUC和Logloss有微小波动。然而,在
Frappe数据集上,当阶数大于3时会出现过拟合现象。
总体而言,
InterHAt在high-order learning方面表现出稳定的性能。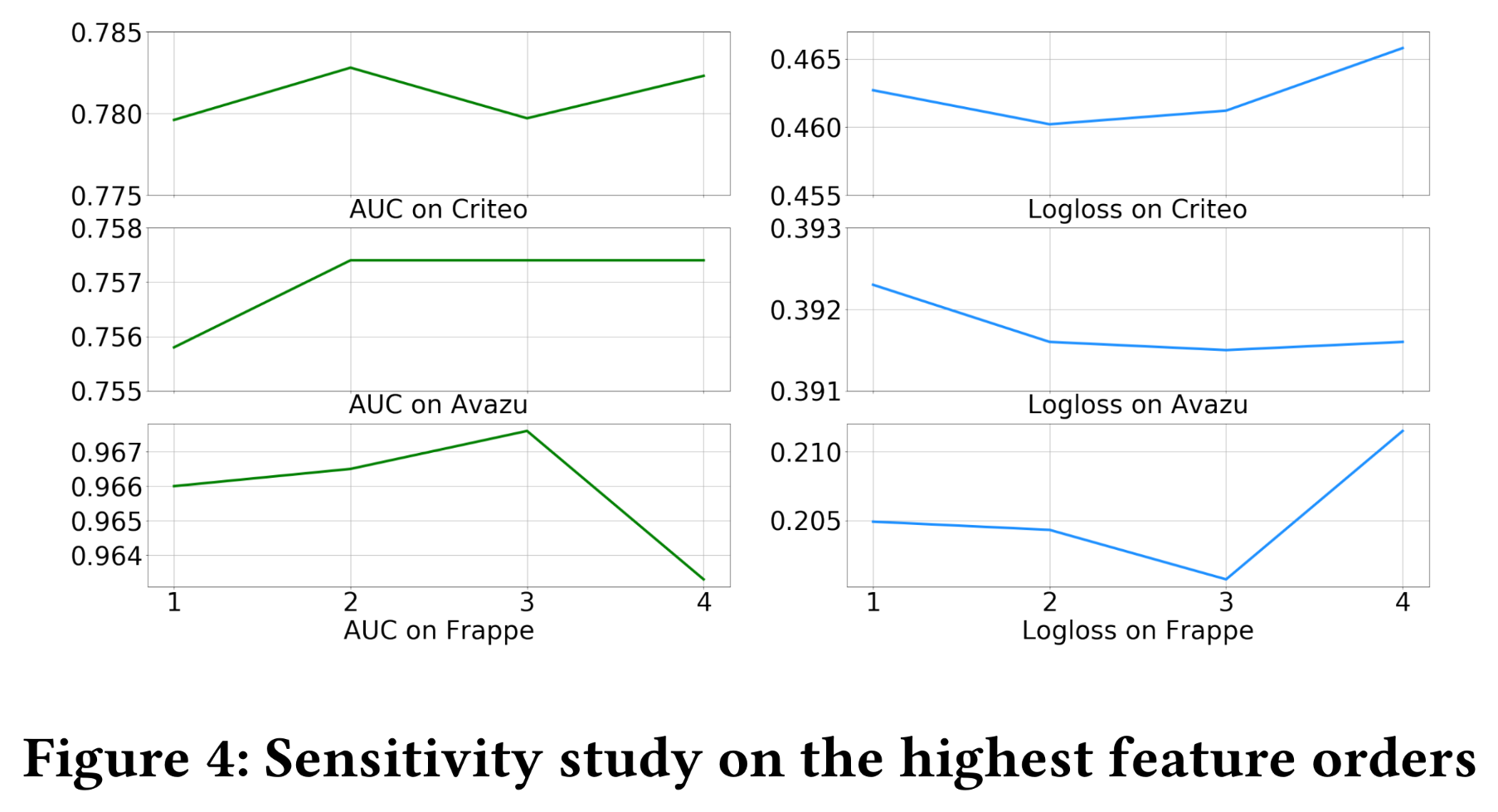
1.3.2 可解释性
解释(
Interpretation)与预测(predictions)同时生成,这是InterHAt的主要贡献之一。在本节中,我们通过可视化所学到的显著低阶或高阶特征(salient low- or high-order features)来展示interpretations。然而,两个公开的真实世界基准数据集(Criteo和Avazu)中click-through records的实际内容为了隐私保护而被加密,这使得无法验证InterHAt构建的interpretation。因此,为了全面测试InterHAt的解释生成能力,我们使用一个真实世界数据集和一个合成数据集来模拟真实的click-through records。在以下小节中,我们讨论基于这两个数据集的data collection和结果。
a. 在真实数据集上的评估
数据集:
Criteo和Avazu数据集中特征的真实语义被加密。其他同样属于推荐系统领域的数据集是合适的替代品。因此,我们选择MovieLens-1M数据集用于此任务。MovieLens-1M具有明文属性,并且也被广泛用于评估推荐系统。它由6040名MovieLens用户给出的大约1M条匿名电影评分组成。每条记录包含user profile、电影类型(movie genres)、以及1-5分的评分。user profile包括年龄(Age)、性别(Gender)和职业(Profession)。电影属性包括发行年份(
Release year)和18种类型。
我们将
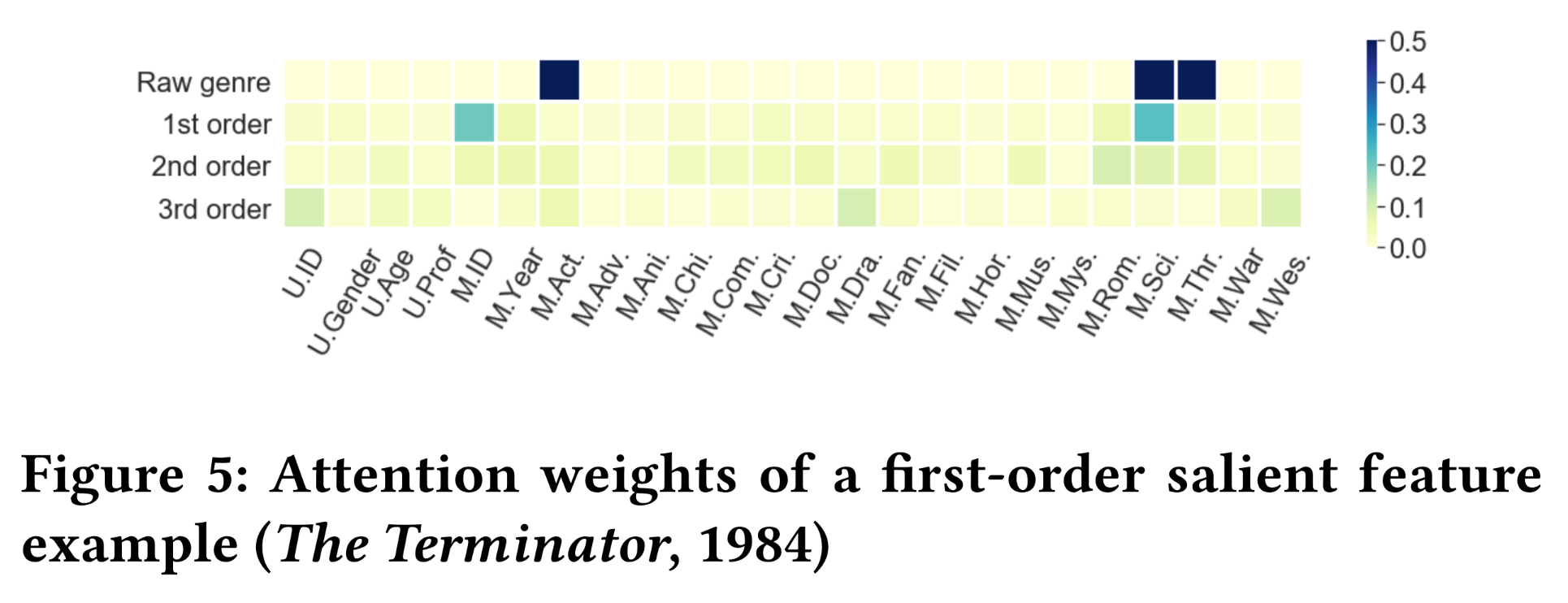
MovieLens-1M中的“评分”行为视为CTR prediction中的点击,即label = 1的正样本。我们通过随机抽样(user, movie) pair来创建负样本,并将其标签设为0。其中,负样本数量与正样本数量相同。正样本和负样本数据集彼此不相交。结果:我们绘制了从一阶到三阶的
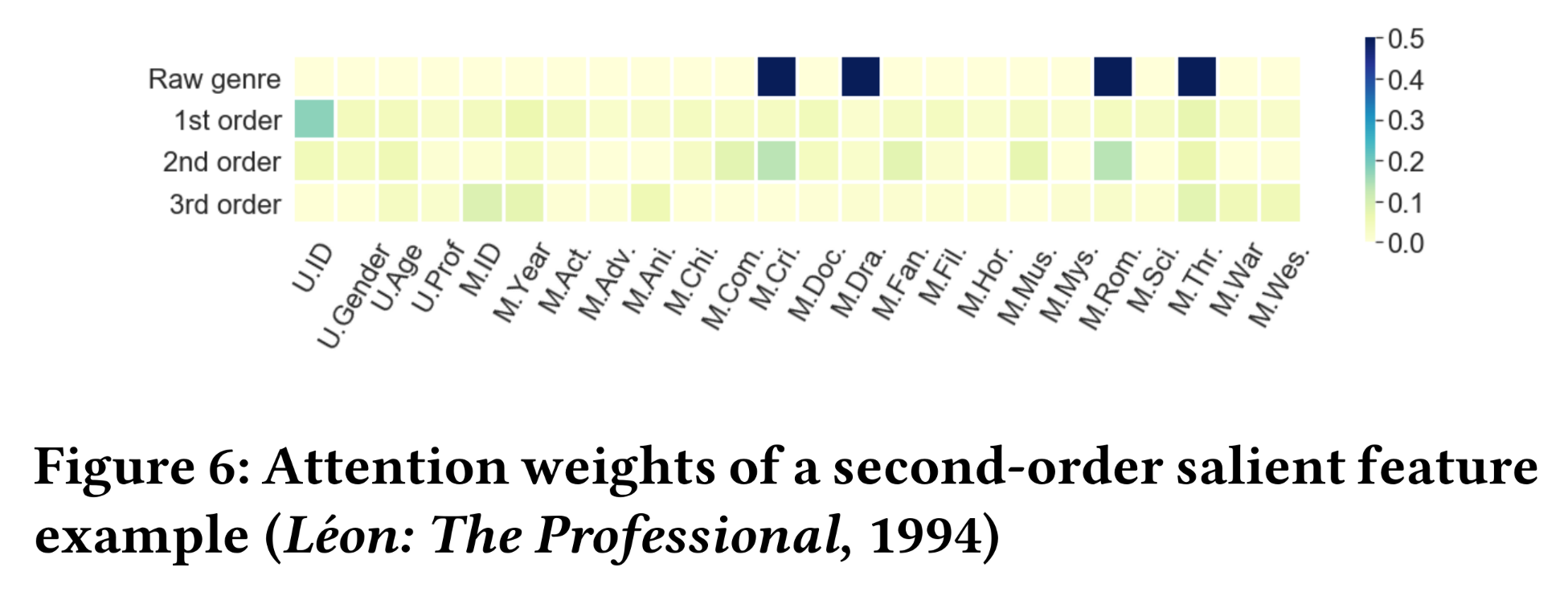
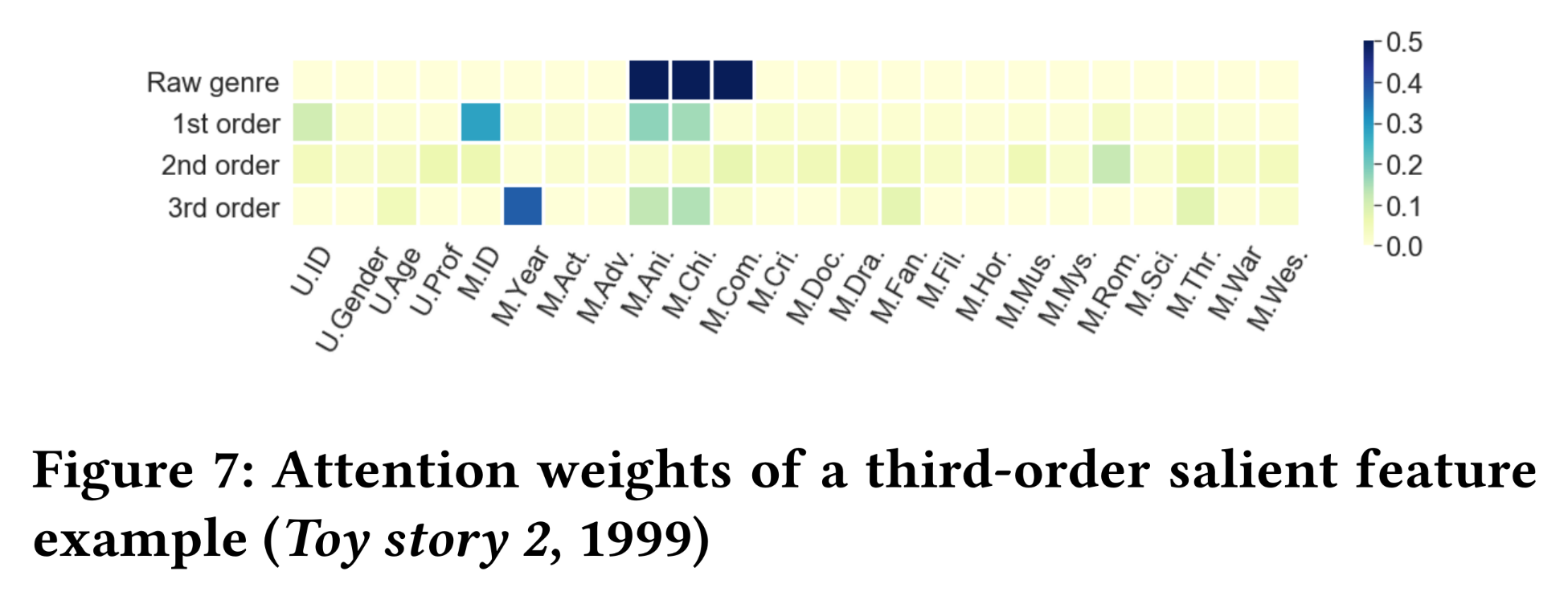
attention weights的热力图,即Figure 5、Figure 6和Figure 7中颜色越深的单元格表示InterHAt从rating records中学到的特征重要性越大。图中的电影类型已缩写为三个字母。在原始类型(Raw genre)行中,黑色单元格表示电影在原始数据(即训练数据)中具有相应的类型属性。Figure 5显示了对电影《终结者The Terminator》(1984年)的评分,该评分在一阶特征上具有最大的aggregation attention weight。在这条记录中,我们观察到电影ID(M.ID)和科幻类型(M.Sci.)在1st-order row中明显优于其他单元格,这归因于电影本身的高声誉及其作为科幻电影(Science Fiction: Sci-Fi)的突出特点。InterHAt还检测到另外两个类型标签(动作Action和惊悚Thriller)对prediction而言不够准确,因此没有被突出显示。没有观察到强烈的更高阶的交互,因为人们可能已经通过《终结者》作为科幻电影的良好声誉做出了观看决定。Figure 6展示了一个以二阶交互为主的案例,即对《这个杀手不太冷Léon: The Professional》(1994年)的评分。我们观察到一个一阶特征和两个二阶特征具有更高的“热力”。对于两个二阶特征,由于电影讲述的感人爱情和犯罪故事,捕获到了犯罪(
Crime)和浪漫(Romance)类型的交互。这两个特征的组合影响增加了这部电影被观看和评分的概率。一阶特征
user ID(U.ID)被突出显示,因为InterHAt从训练数据中发现该特定用户经常对电影进行评分。因此,InterHAt认为当他或她存在时,很可能会发生评分行为。这与1.1.2节中attention-based model interpretation的逻辑一致,即:它只能突出模型中信息流动的导向,而无法创建直观的关于predictions的人类可读的故事。
Figure 7给出了一个以三阶交互为主的示例,其中描绘了对《玩具总动员2Toy story 2》(1999年)评分的特征重要性。我们观察到一个三特征交互"Release year, Animation, and Children"。我们好奇Release year如何与其他两个密切相关的特征进行交互。事实证明,1999年对于动画电影来说是重要的一年,根据电影市场调查,这一年在1995年至2000年间的总票房达到了最大值。
b. 在合成数据集上的评估
数据集:考虑到
MovieLens-1M实际上是评分数据而非点击数据,我们使用合成数据进行了一系列实验以展示可解释性。合成数据包含100k条合成的click-through records,其中有10 fieldsclick-through records。每个field被独立地创建,取值范围为feature groups决定,使用Table 4中的规则:对单独地或联合地影响CTR prediction的feature groups的模拟。标签的确定方式如下:给定a feature group例如,启用
Table 4中的Rule 2意味着:当满足
1,0。否则,标签将以
1,以0。
我们将
0.9,0.2,以表示高和低的点击概率。为了不失一般性,我们评估从一阶到三阶的特征。
结果:我们通过每层注意力的热力图呈现
salient features。以下热力图中records的aggregation attentionrule,即Figure 8描绘了通过执行Rule 1得到的一阶热力图。我们观察到
attention,这与Rule 1一致。另一个观察结果是
attention的方差很小,这意味着仅使用一阶进行学习和预测的稳定性较低。
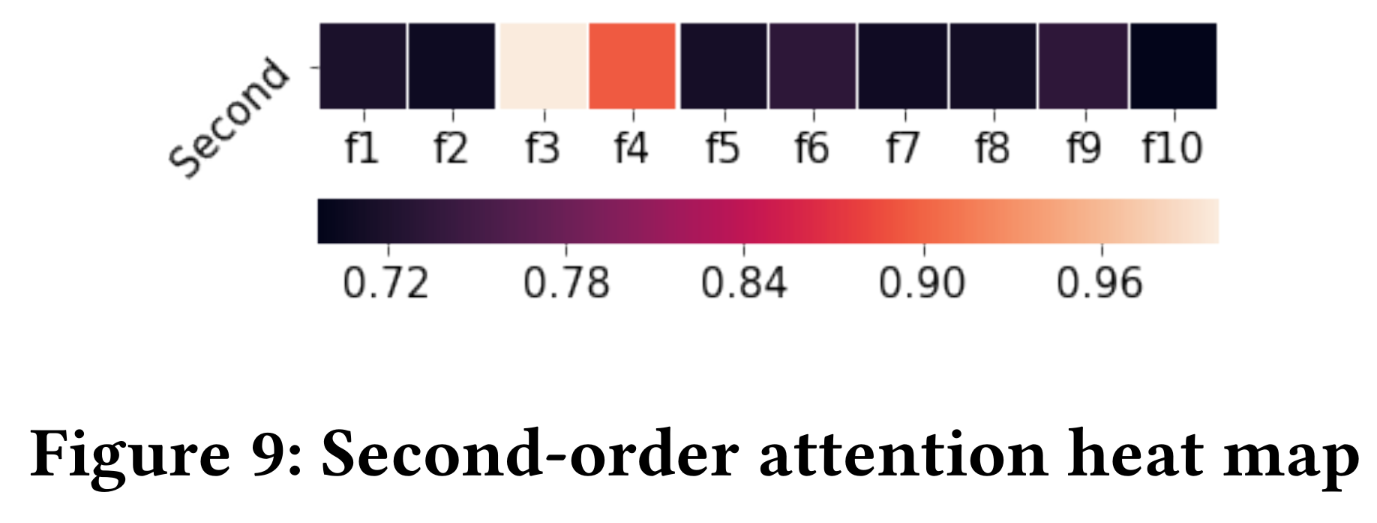
我们在
Figure 9中绘制了二阶热力图,以通过Rule 2可视化二阶特征交互。attention值明显大于其他单元格,因为与黑色单元格相比,它们的颜色更浅。尽管
因此,
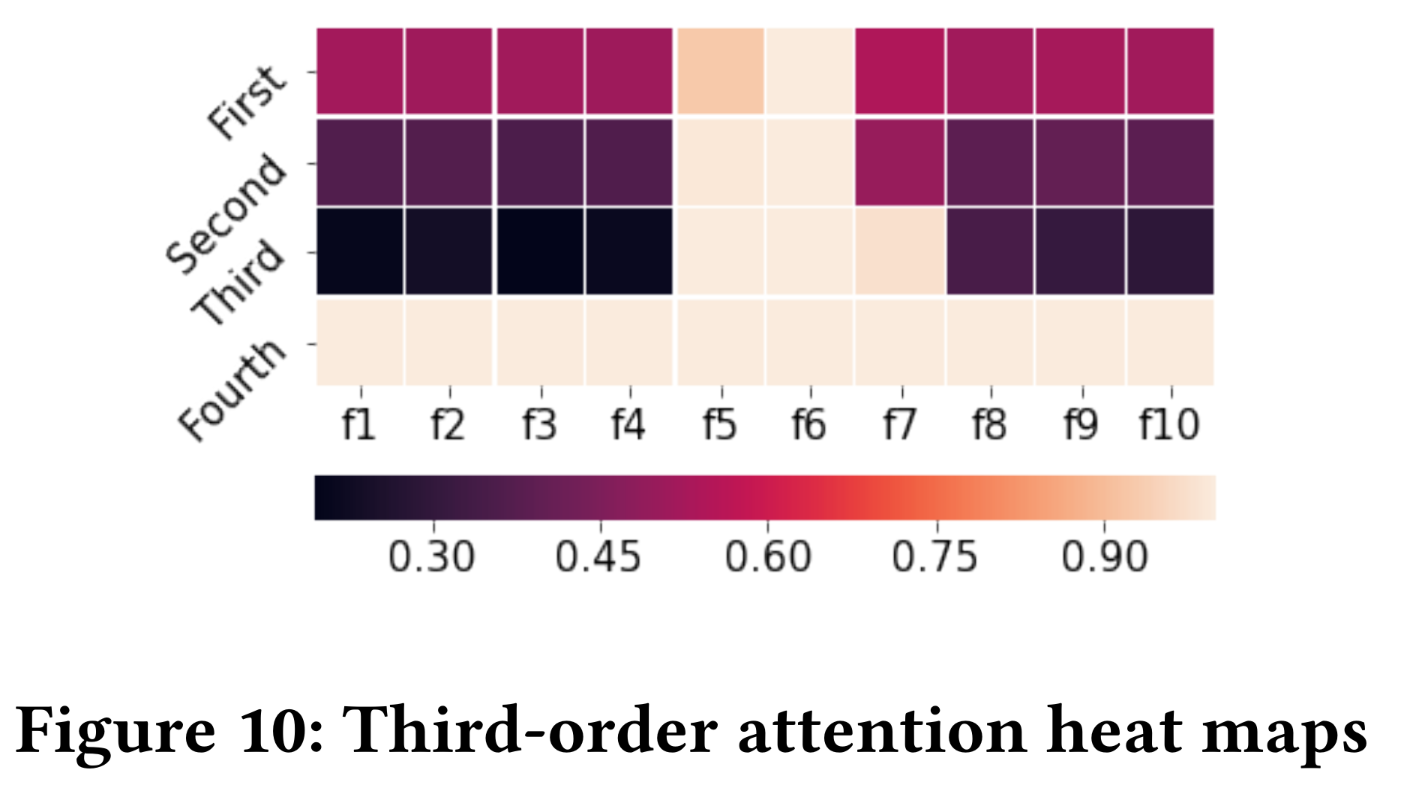
Figure 9中的结果也展示了InterHAt提取salient features和解释click-through predictions的能力。Rule 3展示了高阶场景下的可解释性。我们在Figure 10中包含了从一阶到四阶的热力图。从前三行中,我们发现InterHAt从数据集中获取feature interaction知识的过程。在一阶中,学习到了
接下来,在二阶行中,除了
然后,三阶完成了所有交互信息的获取。
最后,四阶特征显示出均匀的
attention值,变化很小,这表明high-order feature learning在三阶终止,数据集中不存在更高阶的特征。
总之,我们使用真实世界数据集和合成数据集全面评估了
InterHAt在预测CTR的同时具备生成理由的能力。两个数据集的热力图可视化都可以根据人类感知进行合理解释,这证明了InterHAt的可解释性。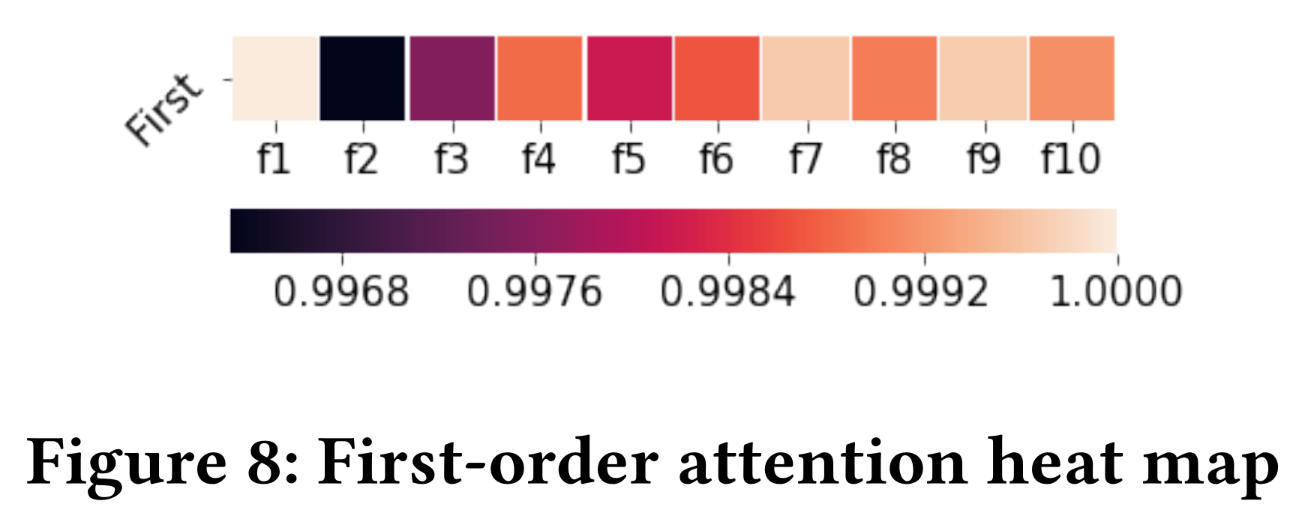
1.4 结论
在本文中,我们提出了
InterHAt,一种可解释、高效且有效的CTR predictor。InterHAt利用a multi-head Transformer来学习feature interactions的多义性,并利用hierarchical attention结构来学习不同orders of features的重要性。explanation是根据学到的importance distribution来推断出来的。此外,与其他模型相比,InterHAt实现了相对较低的计算成本。大量实验表明,InterHAt可以学习feature interactions的interpretable importance,运行速度比SOTA的模型更快(意味着CTR prediction的高效率),并取得了相当甚至更好的性能。未来的工作方向包括:
(1):需要更好的numerical features的embedding learning范式来提高性能。(2):需要可解释的深度神经网络(如MLP和outer products-based网络)来实现高准确性和可解释性。