一、NIS [2020]
《Neural Input Search for Large Scale Recommendation Models》
大多数现代神经网络模型可以被认为是由两个组件组成的:
一个是将原始(可能是
categorical的)输入数据转换为浮点值的输入组件。另一个是将输入组件的输出结合起来并计算出模型的最终输出的
representation learning组件。
自
《Neural Architecture Search with Reinforcement Learning》发表以来,以自动化的、数据驱动的方式设计神经网络架构(AutoML)最近吸引了很多研究兴趣。然而,该领域以前的研究主要集中在representation learning组件的自动化设计上,而对输入组件的关注很少。这是因为大多数研究都是在图像理解问题上进行的,其中representation learning组件对模型性能非常重要,而输入组件是微不足道的,因为图像像素已经是浮点形式。对于工业界经常遇到的大规模推荐问题,情况则完全不同。虽然
representation learning组件很重要,但输入组件在模型中起着更关键的作用。这是因为许多推荐问题涉及到具有大cardinality的categorical特征,而输入组件为这些离散特征的每一项分配embedding向量。这就导致了输入组件中有大量的embedding参数,这些参数在模型大小和模型归纳偏置(inductive bias)上都占主导地位。例如,
YouTube视频推荐模型使用了一个规模为1M的video ID vocabulary,每个video ID有256维的embedding向量。这意味着仅video ID特征就使用了256M个参数,而且随着更多离散特征的加入,这个数字还会迅速增长。 相比之下,representation learning组件只包括三个全连接层。因此,模型参数的数量主要集中在输入组件,这自然对模型性能有很高的影响。在实践中,尽管categorical特征的vocabulary size和embedding size很重要,但它们往往是通过尝试一些具有不同手工制作的配置的模型从而以启发式的方式选择的。由于这些模型通常体积大,训练成本高,这种方法计算量大,可能会导致次优的结果。在论文
《Neural Input Search for Large Scale Recommendation Models》中,作者提出了Neural Input Search: NIS,这是一种新颖的方法,为模型输入组件的每个离散特征自动寻找embedding size和vocabulary size。NIS创建了一个由Embedding Blocks集合组成的搜索空间,其中blocks的每个组合代表不同的vocabulary and embedding配置。最佳配置是通过像ENAS这样的强化学习算法在单个training run中搜索而来。此外,作者提出一种新的
embedding类型,称之为Multi-size Embedding: ME。ME允许将较大尺寸(即,维度)的embedding向量分配给更常见的、或更predictive的feature item,而将较小尺寸的embedding向量分配给不常见的、或没有predictive的feature item。这与通常采用的方法相反,即在词表的所有item中使用同样维度的embedding,这称之为Single-size Embedding: SE。作者认为,SE是对模型容量和训练数据的低效利用。这是因为:对于频繁出现的、或高
predictive的item,我们需要一个大的embedding维度来编码它们与其他item的细微关系(nuanced relation)。但对于长尾
item,由于它们在训练集中的稀有性(rarity),训练相同维度的good embedding可能需要太多的epoch。并且当训练数据有限时,对于rare item采用大维度的embedding可能会过拟合。
有了
ME,在相同的模型容量下,我们可以覆盖词表中更多的item,同时减少所需的训练数据规模和计算成本从而为长尾item训练良好的embedding。下图概览了基于
Embedding Blocks的搜索空间、以及强化学习控制器如何对候选SE和ME进行采样。图
(a):Single-size Embedding,其中仅保留top 2M个item,embedding维度192。图
(b):Multi-size Embedding,其中top 2M个item的embedding维度为192、剩余7M个item的embedding维度为64。注意:这要求词表中的
id是根据频次来降序排列。这对于频次分布的波动较大的field而言,需要经常重新编码id和重新训练。embedding table包含两个超参数:emebdding size、以及词表大小(即,保留高频的多少个item)。这篇论文保留了所有的item,并针对性地优化embedding size。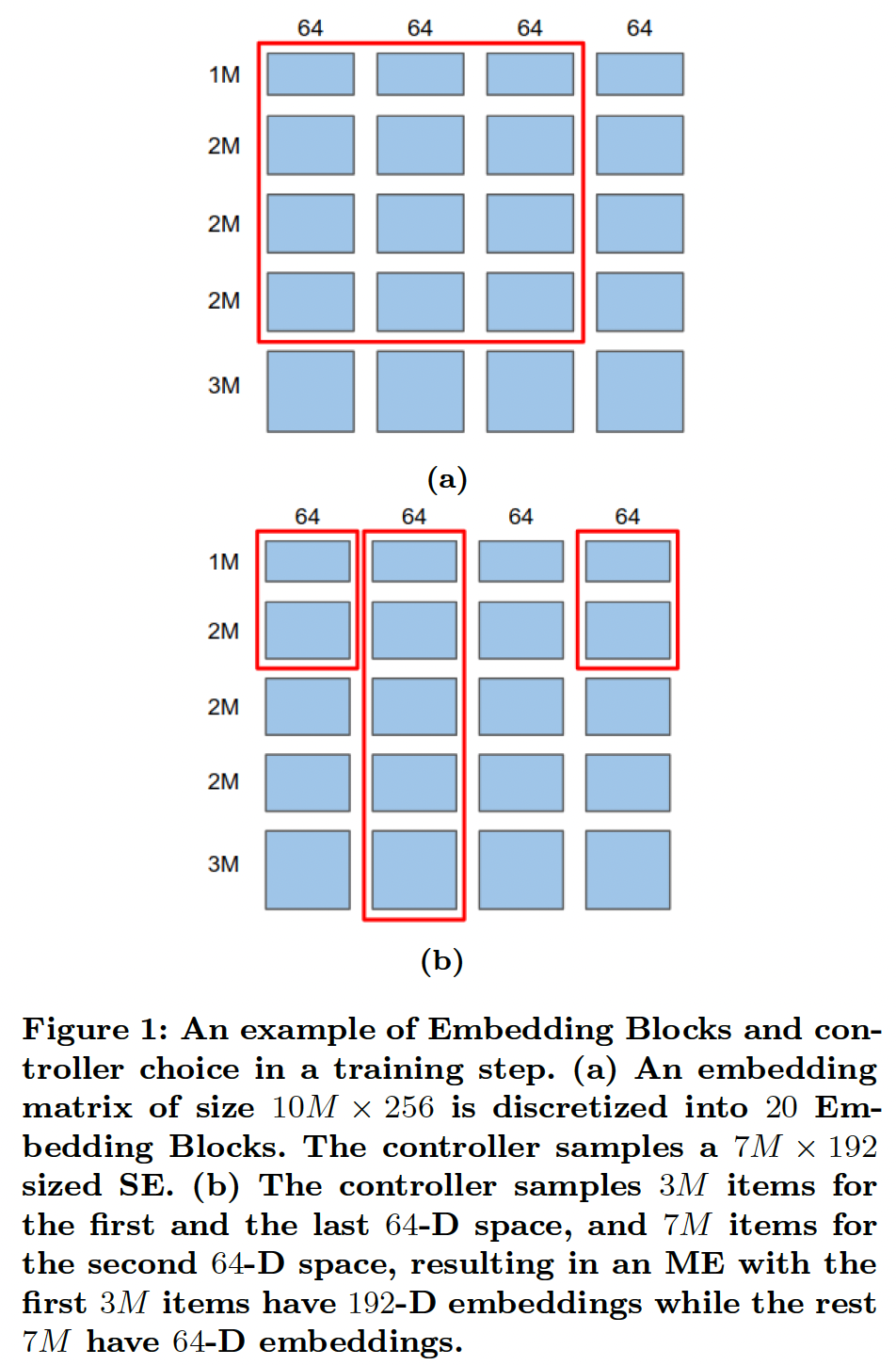
作者通过在两个广泛研究的推荐问题的公共数据集上的实验,证明了
NIS在为SE和ME寻找良好的vocabulary size和embedding size配置方面的有效性。给定baseline推荐模型,NIS能够显著提高它们的性能,同时在所有实验中显著减少embedding参数的数量(从而减少模型的规模)。此外,作者将NIS应用于Google App store中的一个真实世界的大规模App ranking模型,并进行了离线实验和在线A/B test,结果是+1.02%的App Install,而模型大小减少了30%。这个新的NIS App ranking模型已经部署在生产中。相关工作:几乎所有以前的
NAS研究工作都集中在为图像/视频理解问题寻找最佳的representation learning组件。对于大规模的推荐问题,通过利用先进的representation learning组件(如CNN, RNN等)也取得了很大的成果。然而,尽管输入组件由于embedding从而包含了很大一部分模型参数,但它在整个工业界中经常被启发式地设计,如YouTube, Google Play, Netflix等。据我们所知,我们的工作首次将自动化的神经网络设计引入输入组件从而用于大规模推荐问题。
1.1 模型
假设模型的输入由一组
categorical特征vocabulary)。一个
embedding变量vocabulary size,embedding维度。对于任何item的embedding向量。令
"memory budget",它指的是模型的embedding矩阵使用的浮点数的总数。对于一个embedding矩阵,它的浮点数总数为
1.1.1 Neural Input Search Problems
Single-size Embedding: SE:single-size embedding是一个形状为embedding矩阵,其中词表中的每一个item(共计item)都表示为一个embedding向量。以前的工作大多使用SE来表示离散的特征,每个特征的下面我们提出一个
Neural Input Search问题从而自动寻找每个特征的最佳SE,即NIS-SE。解决这个问题的方法将在后面介绍。Problem NIS-SE:为每个vocabulary sizeembedding dimension该问题涉及两个
trade-off:特征之间的
memory budget:更有用的特征应该得到更多的预算。每个特征内部的
vocabulary size和embedding dimension之间的memory budget。大的
vocabulary size给了我们更高的覆盖率,让我们包括尾部item作为输入信号。大的
embedding dimension可以提高我们对头部item的预测,因为头部item有更多的训练数据。此外,大的embedding dimension可以编码更细微的信息。
在
memory budget内,SE使得我们很难同时获得高覆盖率和高质量embedding。为了克服这一困难,我们引入了一种新的embedding类型,即Multi-size Embedding。Multi-size Embedding: ME:Multi-size Embedding允许词表中的不同item有不同维度的embedding。它让我们对头部item使用大维度的embedding、对尾部item使用小维度的embedding。对尾部item使用较少的参数是有意义的,因为它们的训练数据较少。现在,一个
embedding变量(对应于一个特征)的vocabulary size和embedding size是由Multisize Embedding Spec: MES给出的。MES是pair的列表:pair的vocabulary size,满足categorical feature的总的vocabulary size。这相当于将单个词表划分为
pair的embedding size,满足
这可以解释为:最开始的
item有embedding维度item有embedding维度ME就等价于SE。我们对于每个
embedding矩阵SE中那样只有一个embedding矩阵embedding投影到reduction操作在同一个embedding矩阵的累计vocabulary size,则词表中第item的ME定义为:其中:
item在第block内的相对编号。通过对每个特征的适当的
MES,ME能够同时实现对尾部item的高覆盖率、以及头部item的高质量representation。然而,为所有特征手动寻找最佳MSE是非常困难的,因此需要一个自动方法来搜索合适的MES。下面我们介绍Multi-size Embedding的Neural Input Search问题,即NIS-ME。解决这个问题的方法将在后面介绍。NIS-ME:为每个MES在任何使用
embedding的模型中,ME都可以用来直接替代SE。通常,给定一组vocabulary IDSE,然后对这些SE进行一个或多个reduce操作。例如,一个常用的reduce操作是bag-of-words: BOW,即对embedding进行求和或求平均。为了了解在这种情况下ME是如何直接替代SE的,即BOW的ME版本(我们称之为MBOW),由以下公式给出:其中
ME是相加的。这在下图中得到了说明。请注意,对于那些embedding进行求和是更高效的。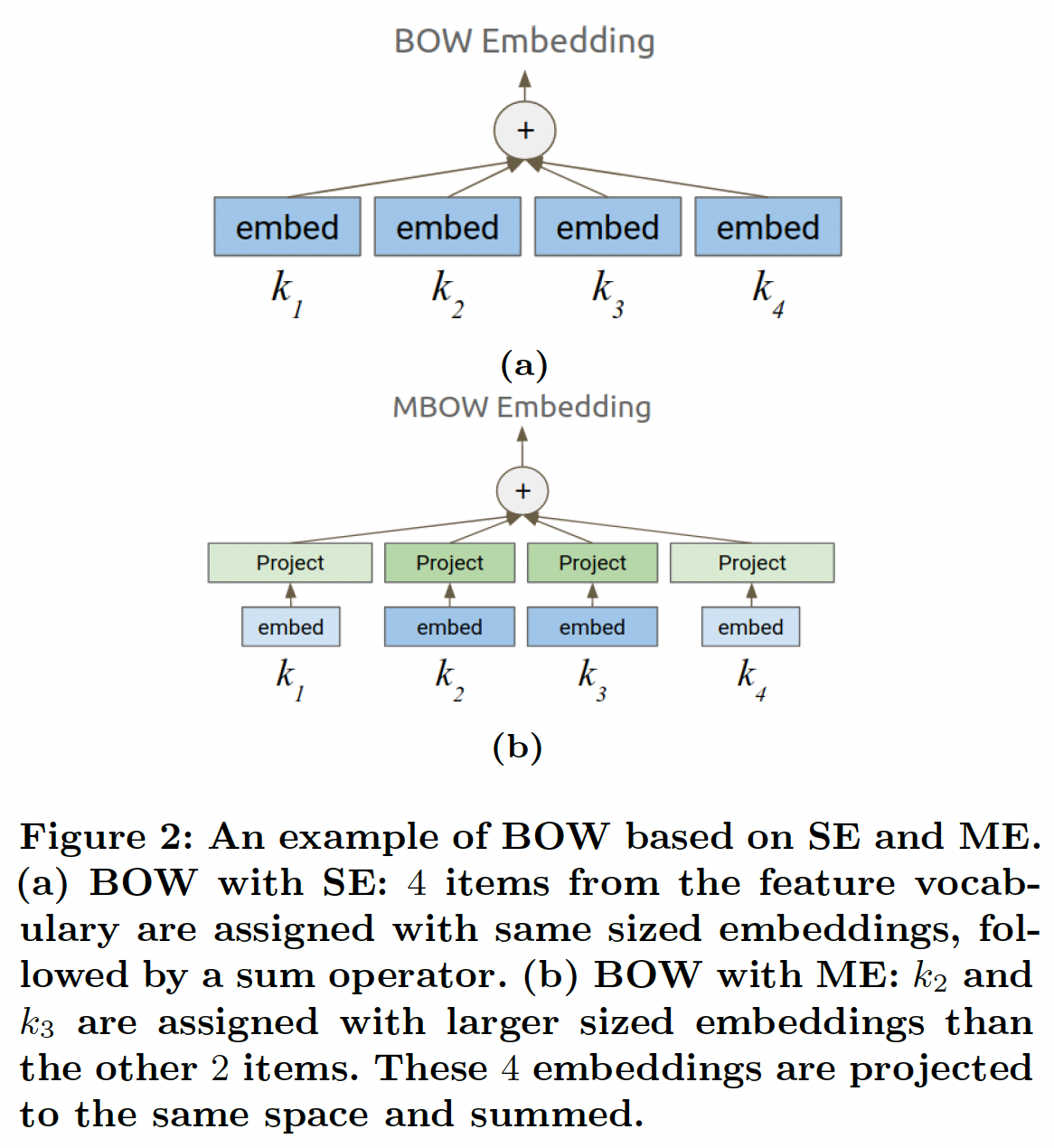
1.1.2 Neural Input Search Approach
我们在模型的输入组件开发了一个新的搜索空间,它包含了我们想要搜索的
SE或ME。我们使用一个独立的controller,从而在每一个step中为每个离散特征挑选一个SE或ME。这些选中的SE或ME与主模型的其他部分(不包括控制器)一起被训练。此外,我们使用主模型的前向传播来计算控制器的选择的奖励(是准确率和内存成本的组合),并使用A3C策略梯度方法将奖励用于训练控制器变量。正如论文在实验部分所述,
NIS方法对具有大vocabulary size的categorical特征的影响更大。至于像性别、学历这种词典规模较小的categorical特征,则NIS方法的价值不大。搜索空间:
Embedding Blocks:对于vocabulary size为vocabulary中的item允许的最大embedding size。 我们称这些矩阵为Embedding Blocks。这可以看作是将一个大小为embedding矩阵离散化为例如,假设
v=10M(M代表一百万),[1M, 2M, 2M, 2M, 3M];可以把列离散成四块:[64, 64, 64, 64]。这样就有20个Embedding Blocks,如Figure 1所示。此外,对于每个
embedding映射到一个共同的reduction操作。 显然,对于所有的embedding中的参数数量相比,投影矩阵中的参数数量是可以忽略的。Embedding Blocks是搜索空间的构建块,允许控制器在每个training step中采样不同的SE或ME。Controller Choices:controller是一个神经网络,从softmax概率中采样不同的SE或ME。它的确切行为取决于我们是对SE还是ME进行优化。下面我们将描述控制器在一个特征SE:为了对SE进行优化,在每个training step中,控制器集合pairEmbedding Blockstraining step。因此,控制器有效地挑选了一个SE,如Figure 1(a)中的红色矩形内的SE,它代表了一个大小为SE。在这一步中,词表中第item中的embedding为:其中:
vocabulary size。
定义
embedding size,显然,embedding表示第item,然后将其投影到一个vocabulary ID为item都被认为是out-of-vocabulary,要特别处理,通常采用的方法是使用零向量作为它们的embedding。因此,这种SE的选择带来的内存成本(参数数量)为:如果在
training step中选择了(0, 0),就相当于从模型中去除该特征。因此,在这个training step中,zero embedding被用于这个特征的所有item,相应的存储成本为0。随着控制器探索不同的SE,它根据每个choice引起的奖励进行训练,并最终收敛到最佳选择。如果它收敛到(0, 0),意味着这个特征应该被删除。显然,对于一个给定的特征,搜索空间的大小是ME:当对ME进行优化时,控制器不是做出单个选择,而是做出一连串的如果
Embedding Blockstraining step。如果
item,整个embedding都将被移除。
因此,控制器选择了一个自定义的
Embedding Blocks子集(而不仅仅是一个网格),它组成了一个MES。如Figure 1(b)所示:第一个
64-D embedding被开头的3M个item所使用。第二个
64-D embedding被所有10M个item所利用。第三个
64-D embedding不被任何item所使用。最后一个
64-D embedding被开头的3M个item所使用。
因此,词表中开头的
3M个item被分配了192维的embedding,而最后7M个item只被分配了64维的embedding。换句话说,在这个training step中实现了MES [(3M, 192), (7M, 64)]。数学上,令
item在当前training step的embedding为:如果
SE的emebdding公式为:SE相比,ME公式中的sum不是从ME的内存成本为:
奖励:由于主模型是通过控制器对
SE或ME的选择来训练的,控制器是通过主模型对验证集样本的前向传播计算出来的奖励来训练的。我们将奖励定义为:其中:
embedding配置,质量奖励:一类常见的推荐问题是检索问题,其目的是给定模型的输入从而在一个可能非常大的
vocabularyitem。这类问题的objective通常是实现high recall,因此我们可以直接让Recall@N(Recall@N变得太昂贵,我们可以通过采样一个小的negative set(即,负采样),使用Sampled Recall@N作为代理。另一类常见的问题是排序(
ranking)问题。ranking模型的质量通常由ROC-AUC来衡量,他可以作为质量奖励。同样,对于回归问题,质量奖励可以设置为
prediction和label之间的L2-loss的负值。内存成本:我们定义内存成本为:
注意:
embedding参数的代价所对应的质量奖励的增量。例如,如果质量奖励是ROC-AUC,embedding参数,如果它能使ROC-AUC增加0.1。这是因为额外的
1.1.3 Training the Neural Input Search Model
Warm up阶段:如前所述,训练NIS模型涉及到主模型和控制器之间consecutive steps的交替训练。如果我们从第0步开始训练控制器,我们会得到一个恶性循环:没有被控制器选中的Embedding Blocks没有得到充分的训练,因此给出了不好的奖励,导致它们在未来被选中的机会更少。为了防止这种情况,前几个
training steps包括一个warm up阶段,我们训练所有的Embedding Blocks,并固定控制器参数。warm up阶段确保所有Embedding Blocks得到一些训练。在warm up阶段之后,我们转向使用A3C交替训练主模型和控制器。在预热阶段,控制器被固定为选择所有的
Embedding Blocks。Baseline Network:作为A3C算法的一部分,我们使用一个baseline网络来预测每个控制器(使用已经做出的选择)的期望奖励。baseline网络的结构与控制器网络相同,但有自己的变量,这些变量与控制器变量一起使用验证集进行训练。然后,我们从每个step的奖励中减去baseline,计算出advantage从而用于训练控制器。baseline网络是主模型的拷贝,但是采用了不同的变量。每次更新主模型之后,就将主模型的参数拷贝给baseline。总体训练流程为:
warm up:通过训练集来更新主模型,此时选择所有的Embedding Blocks。迭代:
在验证集上评估主模型的奖励,并通过奖励最大化来更新控制器参数。
通过新的控制器参数,在训练集上更新主模型。
1.2 实验
1.2.1 公共数据集
数据集:
MovieLens-1M:包含了由6千多个用户创建的1M条电影评分记录。我们通过遵循一个广泛采用的实验设置来制定一个电影推荐问题。用户的评分被视为隐性反馈,也就是说,只要用户给电影打了分,就被认为是对该电影感兴趣。此外,对于每个用户,从电影词表中均匀地采样4部随机电影作为用户的负样本(负采样策略,而不是在训练之前提前准备并固定了负样本)。意外的命中会被删除,即:负样本集合中包含了正样本,则把正样本从负样本集合中剔除。由于每条评分记录都有一个时间戳,我们把每个用户的最近一个评分记录拿出来进行测试。在测试阶段,对于每个正样本,我们随机采样
99部电影作为负样本来计算评价指标。测试期间的采样策略与训练期间相同。KKBox:来自WSDM KKBox音乐推荐挑战赛,任务是预测用户在一个时间窗口内第一次可观察到的听歌事件后是否会重复听歌。数据集同时包含了正样本和负样本:正样本表示用户重复听了这首歌,负样本表示用户没有再听这首歌。因此,与MovieLens-1M数据集不同的是,我们没有通过随机采样来手动构造负样本,而是使用数据集提供的负样本。由于该数据集没有与每条记录相关的时间戳,我们随机采样
80%的记录用于训练、20%的记录用于测试。
对于这两个数据集,我们进一步从训练集中随机采样
10%的样本用于训练控制器的验证集。下表给出了我们应用
NIS的特征的vocabulary size(即,feature的unique item数量)。注意,原始的KKBox数据集有更多的特征,这些特征要么是浮点特征(如 "歌曲长度")、要么是小vocabulary size的categorical特征(如 "流派")。由于NIS对具有大vocabulary size的categorical特征的影响更大,在我们的实验中,为了简单起见,我们只使用下表中列出的特征。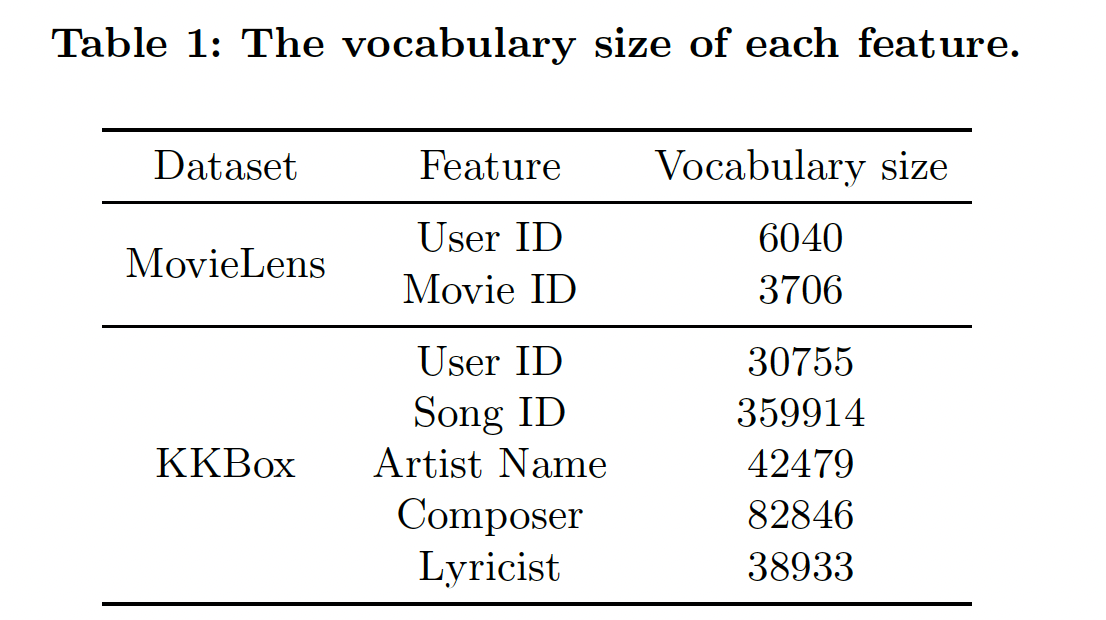
vocabulary构建细节:以MovieLens-1M为例,遍历每个user-movie评分记录,并计算每个用户在整个数据集中出现的记录数量,根据计数结果给每个用户分配vocabulary ID:最高频的用户分配ID 0、最低频的用户分配最大的ID。其它特征、其它数据集也以类似的方式构建vocabulary。在生产环境中,特征的频次分布有变化,如何处理?如何处理新出现的
ID,如新广告的ID?这些论文都没有提到。读者猜测,NIS仅适用于ID分布变化不大的场景。对于新闻、广告等等ID不断生成、消亡的领域,NIS可能需要进行适配。实验配置:
NIS方法实际上是模型结构无关的,可以应用于各种类型的模型。这里我们采用Neural Collaborative Filtering: NCF模型。NCF模型包括两个组件:Matrix Factorization: MF组件、多层感知器MLP组件,如下图所示。MF组件中的user embedding和item embedding是MF embedding。MLP组件中的user embedding和item embedding是MLP layer(ReLU激活函数),其大小分别为top MLP layer的输出被称作MLP embedding。我们没有使用任何规范化技术,如
BatchNorm、LayerNorm等。这意味着
MLP组件和MF组件并没有共享embedding,因此每个id都有两套embedding。
MF embedding和MLP embedding拼接起来,然后被用于计算logit(通过一个所有权重(包括隐层权重和
embedding矩阵)使用高斯分布随机初始化,高斯分布的均值为零、标准差为embedding的维度。任何权重都没有使用正则化或dropout。当一个特征有多个取值时(如,一首歌有多个作曲家),这些特征的取值的embedding是均值池化。当某些训练样本中存在缺失的特征值时,使用全零的embedding。对于
MovieLens-1M数据集,item embedding是简单的movie embedding。于KKBox数据集,由于每个item(即歌曲)有多个特征,即song ID、艺术家姓名、作曲家、作词人,item embedding的计算方法如下:对于
MF组件,四个特征中的每一个都表示为一个embedding,然后将它们拼接起来并通过一个MF组件中的item embedding。对于
MLP组件,四个特征中的每一个都表示为一个embedding,然后将它们拼接起来并通过一个MLP组件中的item embedding。
给出一个预先选择的
embedding参数的模型,我们首先将其作为baseline,不应用NIS。然后,我们将每个特征的embedding size增加一倍,从而产生embedding参数,并应用NIS的内存预算baseline模型相同)。我们预期NIS通过更好地分配baseline更好。我们进一步用NIS的极限,看看它是否还能比baseline模型表现更好。我们为
baseline模型实验了NIS模型将有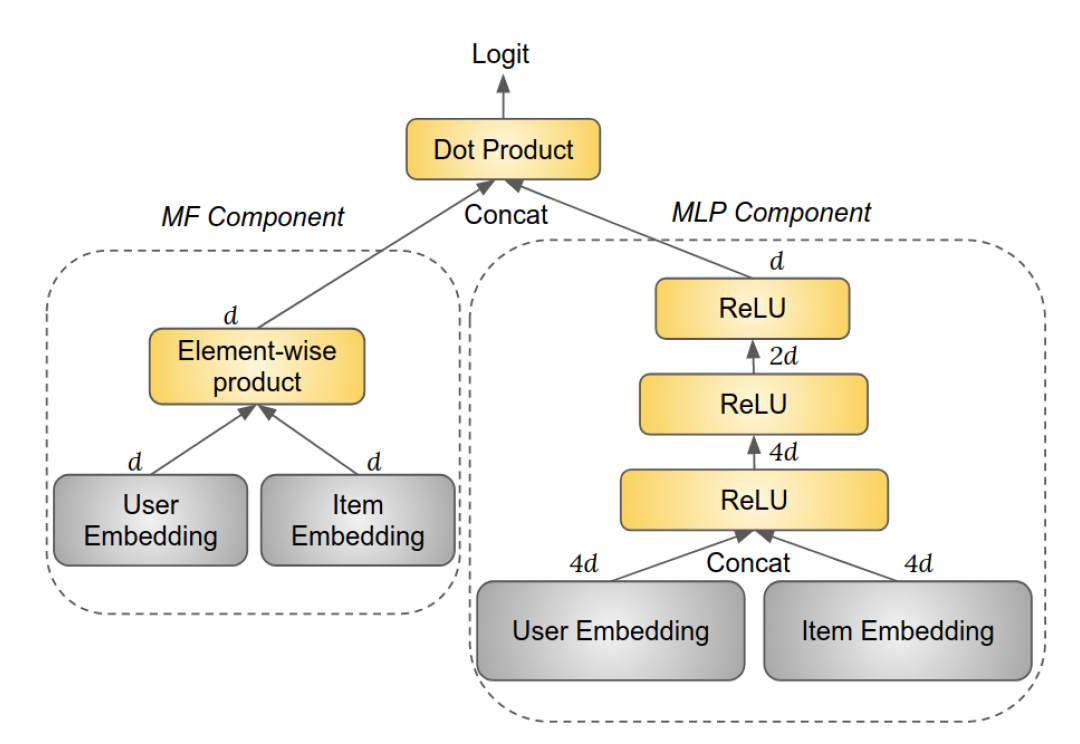
控制器:控制器用于在所有候选的
choice上产生一个概率分布。我们在所有的实验中使用了一个简单的控制器:对于
SE settting,控制器为每个特征分配一个logit。该向量被初始化为零向量。控制器从这个多样式分布中采样不同的
SE。注意:每个特征的搜索空间大小为SE是独立采样的。我们没有使用更复杂的控制器结构,如
RNN,因为不清楚对一个特征做出的决策是否会影响其他特征,以及应该按照何种顺序做出决策。对于
SE setting,控制器为每个特征从对于
ME setting,控制器为每个特征分配对于
ME setting,控制器为每个特征从
每个特征构建了
20个Embedding Blocks,其中:total vocabulary size。在实践中,我们发现这种配置在细粒度和搜索空间大小之间取得了良好的平衡。如前所述,控制器使用验证集进行训练。对于
MovieLens-1M数据集,我们使用Recall@1(也称作HitRate@1)作为质量奖励Recall, MRR, NDCG。对于KKBox数据集,我们使用ROC-AUC作为质量奖励 ,并报告测试集上的ROC-AUC。在所有的实验中,我们设定训练细节:
主模型:
batch size = 256,应用梯度裁剪(梯度范数阈值为1.0),学习率为0.1,使用Adagrad优化器。在开始A3C算法之前,进行了100K步的预热阶段。控制器:使用
Adagrad优化器,学习率为0.1,不使用梯度裁剪(因为一个低概率但高回报的行动应该得到一个非常高的梯度,以显著提高其概率)。每个控制器的决策都由验证集的64个样本所共享,从中计算出一个奖励值。
在预热阶段结束后,控制器和主模型每隔一个
mini-batch step进行交替训练。在所有的实验中,我们在主模型和控制器都收敛后停止训练(而不是仅有一个收敛)。我们使用了分布式训练,其中
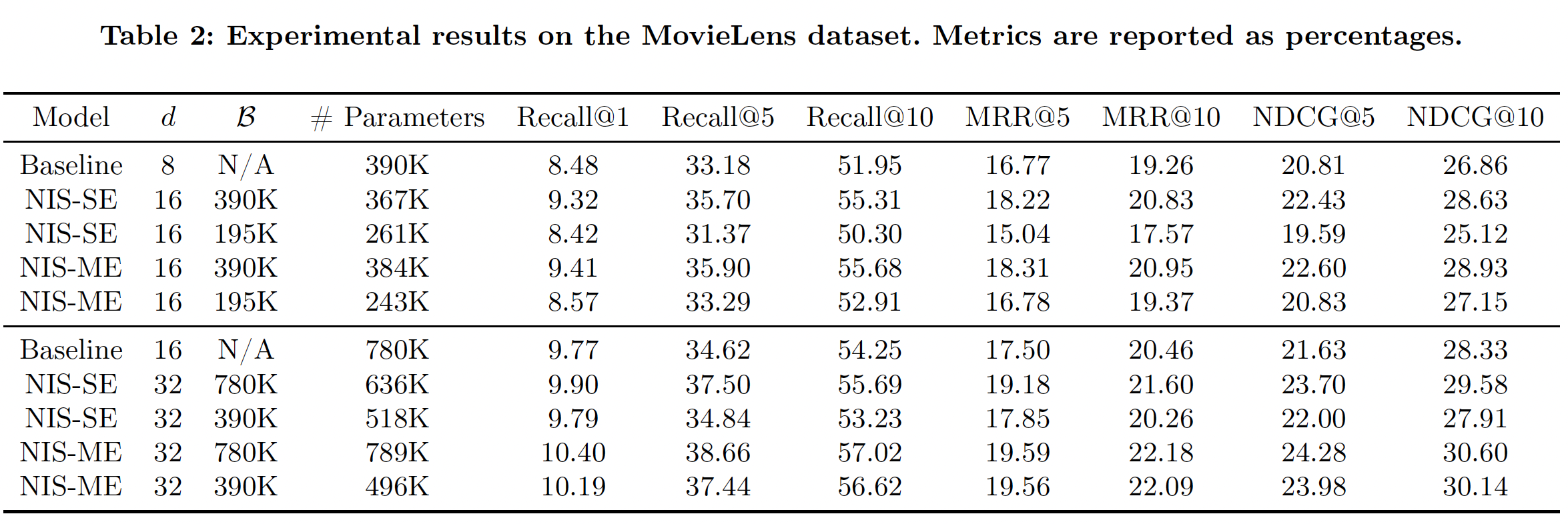
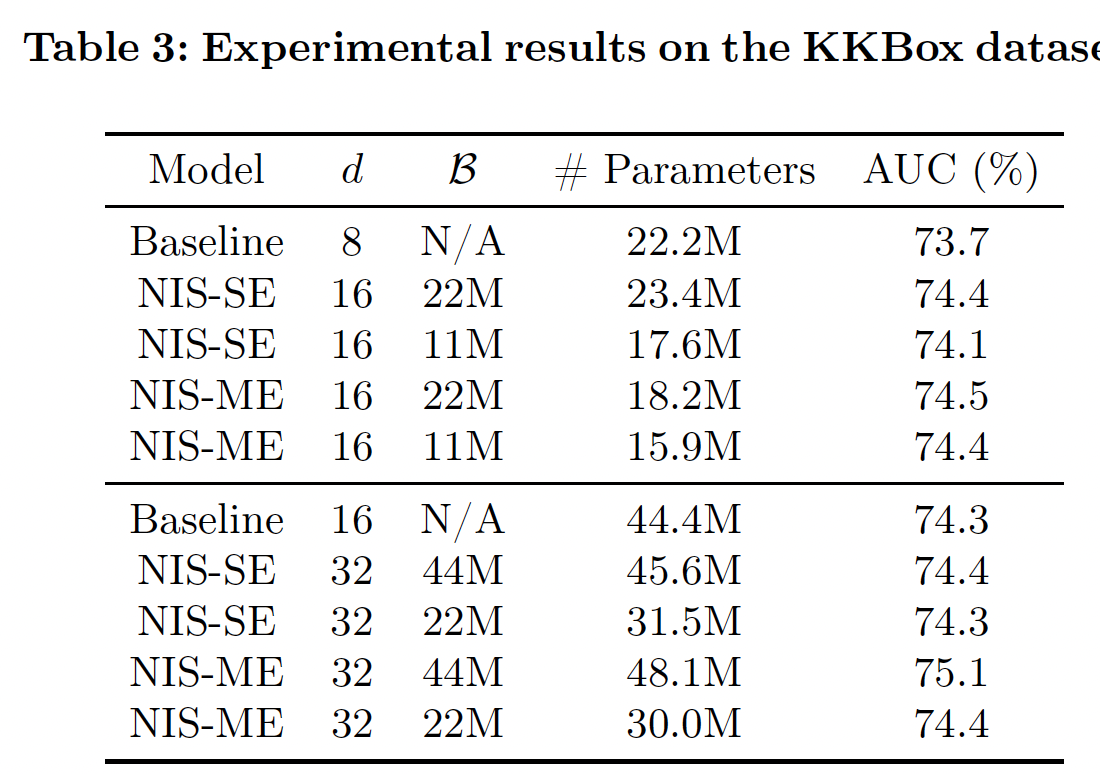
5个worker独立地进行并行训练。Table 2和Table 3分别报告了MovieLens-1M数据集和KKBox数据集的实验结果。注意,NIS模型的内存预算。可以看到:NIS能够持续取得比baseline模型更好的性能,很多时候参数明显减少,证明了我们方法的有效性。在相同的条件下,
NIS-ME模型总是优于NIS-SE,而且通常参数比NIS-SE更少。即使
baseline模型大小的一半,NIS模型也几乎总是优于baseline。这不仅证明了我们方法的有效性,而且还表明在重度约束条件下有可能实现卓越的性能。一些
NIS模型通过超出内存预算获得了卓越的性能。这种模型质量和模型规模之间的tradeoff反映在奖励函数的设计中。当内存预算只是一个指导方针而不严格时,这一点特别有用。
1.2.2 真实世界大型数据集
这里我们描述如何将
NIS应用到Google Play App store的ranking model。该模型的目标是:根据App被安装的可能性对一组App进行排序。数据集由(Context, App, Label)组成,其中Label=0表示App未被安装、Label=1表示App被安装。总共有20个离散特征被用来表示Context和App,如App ID、Developer ID、App Title等。离散特征的vocabulary size从数百到数百万不等。每个特征的embedding维度和vocabulary size经过几年的手工优化。实验配置:对于
Embedding Blocks,我们设置vocabulary size。需要注意的是,对于每个特征,我们没有平均分割vocabulary,而是给top-10%的item分配了一个Embedding Block,因为数据集中的高频特征都是最重要的,也就是说,top-10%的item通常出现在大多数训练样本中。这进一步证明了Multi-size Embedding在实践中的必要性。此外,我们设置
production model的embedding size(在不同特征上取值为8 ~ 32)。在将embedding size增加到三倍从而允许更高的模型容量的同时,我们设置内存预算production model的embedding参数的总数。显然,这里的目标是提高模型的预测能力,同时减少模型的大小。我们使用
ROC-AUC作为质量奖励,并设置0.001的ROC-AUC增长从而允许离线实验:离线
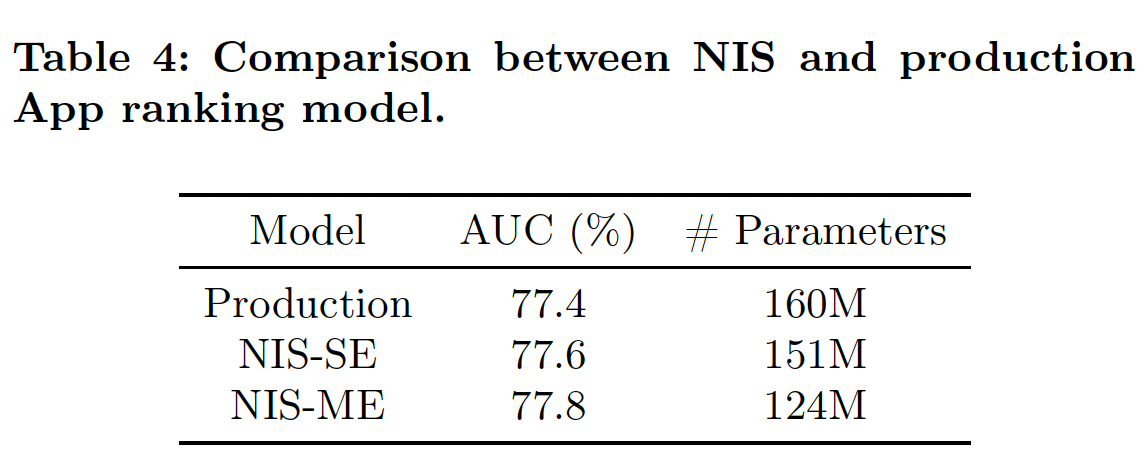
ROC-AUC指标如下表所示。可以看到:在
SE setting和ME setting中,NIS能够以较少的参数数量改善production model的ROC-AUC性能。NIS-ME模型在参数数量更少的情况下也能取得比NIS-SE更好的性能,因为Multi-size Embedding可以通过给head items更多的参数、给tail items更少的参数来更好地利用内存预算。与production model相比,NIS-ME在ROC-AUC上得到了0.4%的改进,而模型大小减少了30%。
在线
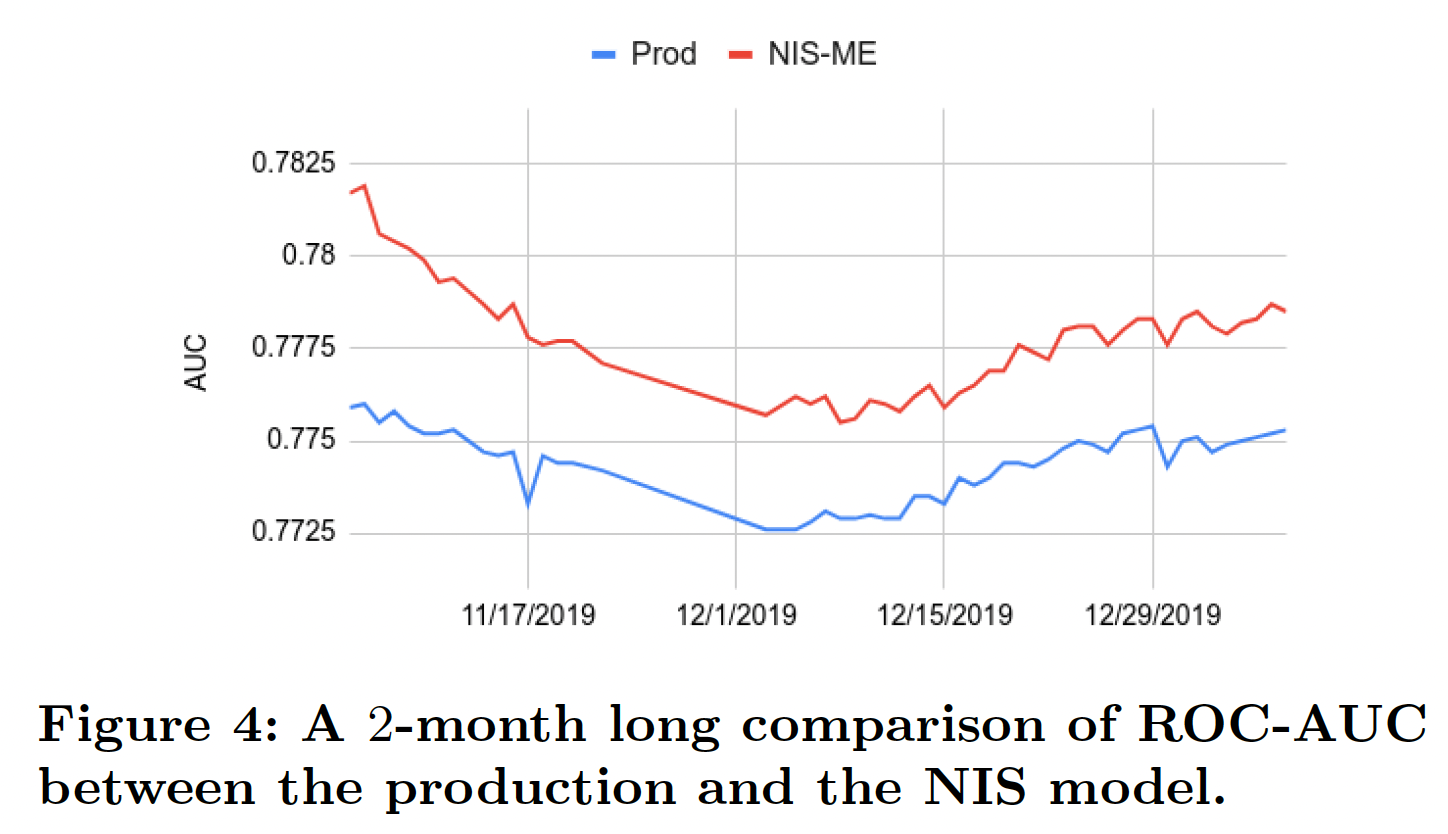
A/B test:我们进一步用实时流量进行了A/B test的在线实验。由于NIS-ME模型优于NIS-SE模型,A/B test只在NIS-ME模型上进行。我们监测了App Install指标,并得出结论:NIS-ME模型能够将App Install增加1.02%。NIS-ME模型目前部署在100%的流量上,取代了本实验中使用的production baseline model。稳定性:当部署在生产中时,
NIS-ME模型需要每天进行重新训练和刷新。了解模型的性能可以维持多久是很重要的。这是因为每个特征的数据分布可能会随着时间的推移而发生重大变化,所以MES可能不再是最优的,在这种情况下,我们需要重新运行NIS,找到更适合新数据分布的MES。因为
NIS的词表构建依赖于ID频次分布,而在生产环境中,ID频次分布可能随时间发生变化。我们进行了为期
2个月的研究,监测原始production model和NIS-ME模型的ROC-AUC,如下图所示。显然,NIS-ME模型相对于production model的优势在2个月的时间里非常稳定,说明没有必要经常重新运行NIS。在实践中,我们只在模型结构发生变化或要增加新特征时才运行NIS。