一、UBR4CTR [2020]
《User Behavior Retrieval for Click-Through Rate Prediction》
CTR prediction在现代的online personalization services中起着关键作用。在实践中,需要通过对用户行为序列进行建模来捕获用户的兴趣变化,以构建准确的CTR prediction模型。然而,随着用户在平台上积累越来越多的行为数据,对sequential models而言,利用每个用户的whole behavior history变得并非易事。首先,直接馈入长的行为序列将使在线推理时间和系统负载变得不可行。
其次,如此长的历史行为序列中存在大量噪音,导致
sequential model learning的失败。
当前的业界的解决方案主要截断序列并仅将近期行为馈入
prediction model,这导致一个问题,即:周期性或长期依赖性等sequential patterns未被纳入近期的若干个behaviors中,而是包含在很久以前的历史中。为了解决这些问题,在本文中,我们从数据的角度考虑它,而不仅仅是设计更复杂的模型,并提出了User Behavior Retrieval for CTR prediction: UBR4CTR框架。在UBR4CTR中:首先使用可学习的搜索方法从整个用户历史序列中检索最相关、最合适的
user behavior。然后将这些被检索到的行为(而不是简单地使用近期行为)馈入到
deep model中以进行最终预测。
以低成本将
UBR4CTR部署到industrial model pipeline中是非常可行的。在三个真实世界大型数据集上的实验证明了我们提出的框架和模型的优越性和有效性。CTR prediction在当今的在线个性化平台(例如电商、在线广告、推荐系统)中起着关键作用,其目标是预测用户在特定情境下点击特定item的概率。在线个性化平台经过十多年的发展,平台上记录的user behaviors数量迅速增长。23%的用户在六个月内在淘宝上有超过1000次behaviors(《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》)。由于user behavior中存在丰富的时间模式(temporal patterns),因此建立一个有效且高效的模型,利用user behavior序列来获得准确的CTR prediction成为业界和学术界的一个重要问题。在深度学习时代,有许多
DNN-based的CTR prediction模型,例如Wide&Deep、FNN、DeepCross、DeepFM、PNN和xDeepFM,其中大多数已部署在商业的个性化平台上。这些模型强调挖掘特征交互(feature interactions),并被用于更好地利用数据的multi-categorical features。然而,这些模型忽略了user behavior的序列模型或时间模式(sequential or temporal patterns)。如
《Spatio-temporal models for estimating click-through rate》、《Vista: a visually, socially, and temporally-aware model for artistic recommendation》、《Recurrent neural networks with top-k gains for session-based recommendations》、《Collaborative filtering with temporal dynamics》所示,user behavior的temporal dynamics在预测用户未来兴趣方面起着关键作用。这些序列模式(sequential patterns)包括概念漂移(concept drifting)、长期behavior依赖性(long-term behavior dependency)、周期性模式(periodic patterns)等。因此,在CTR prediction和序列推荐任务中,人们提出了一些模型来捕获用户的序列模式。对于
CTR prediction,有attention-based的模型,如DIN和DIEN;有memory network-based的模型,如HPMN。对于序列推荐,人们提出了更多的
user behavior modeling方法,这是一项与CTR prediction非常相似的任务。有RNN-based的模型、CNN-based的模型、Transformer-based的模型、以及memory network-based的模型。
然而,上述大多数序列模型在实际应用中都有一个共同的问题。当平台记录了大量的
user behavior时,常见的工业解决方案是截断整个行为序列,只使用最近的behavior作为prediction model的输入,如Figure 1上半部分所示。online serving time的严格要求,加上系统负载和计算能力的瓶颈,限制了可使用的用户序列的长度。因此,在大多数情况下,使用的近期行为不超过50个(《Deep interest evolution network for click-through rate prediction》)。 使用最近behavior的传统框架可能会带来负面问题。很明显,有效的序列模式可能不仅仅包含在最近的行为序列中。它可以追溯到更远的历史,如周期性和长期依赖性。然而,如果我们尝试使用更长的序列,可能会引入大量不相关的behavior和噪音。更不用说更长的历史带来的时间复杂性和空间复杂性了。 在本文中,为了解决上述实际问题,我们尝试从数据的角度解决问题,而不是设计更复杂更精密的模型。具体来说,我们的目标是设计一个框架来检索对每个CTR prediction target最有用的有限数量的历史行为。如Figure 1所示,prediction target由三部分组成,即:target user、target item和相应的上下文。prediction target的特征包括用户的位置、性别、职业,以及item的category、品牌、商家,以及时间和场景等上下文特征。然后我们使用模型选择这些特征的一个子集,该子集构建一个query来检索相关的历史行为。用户的所有behavior都作为information items来存储在搜索引擎中,我们使用所生成的query从历史记录中进行搜索。被检索到的behavior用于CTR prediction。 对于同一用户的每个不同target item,我们将检索不同的behaviors来用于prediction,因为所生成的queries不同。对同一用户的不同items上的预测而言,与使用完全相同的最近behavior的传统框架相比,这是一个重大变化。最终的解决方案框架称为
User Behavior Retrieval for CTR: UBR4CTR。在UBR4CTR中,任务分为两个模块:第一个是可学习的检索模块,它由两个组件:
一个
self-attentive network,用于选择特征并形成query。以及一个搜索引擎,其中以倒排索引的方式存储
user behavior。
另一个模块是
prediction模块,其中构建了一个attention-based deep neural network,从而根据检索到的user behavior、以及prediction target的特征进行最终预测。
本文的贡献可以概括为三点:
我们揭示了一个重要事实,即在
user response prediction中,检索更相关的user behavior比仅仅使用最近的behavior更重要。我们没有设计更复杂的模型,而是将更多注意力放在检索用户的behavior数据上。我们提出了一个名为
UBR4CTR的新框架,该框架可以检索不同的behaviors从而用于同一用户在不同上下文中对不同items的CTR prediction。所有先前的序列模型仅使用用户最近的behavior。我们提出了一种search engine based的方法和一种有效的训练算法来学习检索适当的behavior数据。我们在三个现实世界的大型电商数据集上进行了大量的实验,并将我们的框架与传统框架中几个强大的
baselines进行了比较。结果验证了UBR4CTR框架的有效性。
UBR4CTR是SIM(hard)的扩展。在SIM(hard)中,我们使用catgory of target item作为query从而执行检索。而在UBR4CTR中,我们根据不同的input来自动选择合适的query来执行检索。但是,更复杂的query引入了更复杂的检索系统(一个搜索引擎客户端),增加了工程量。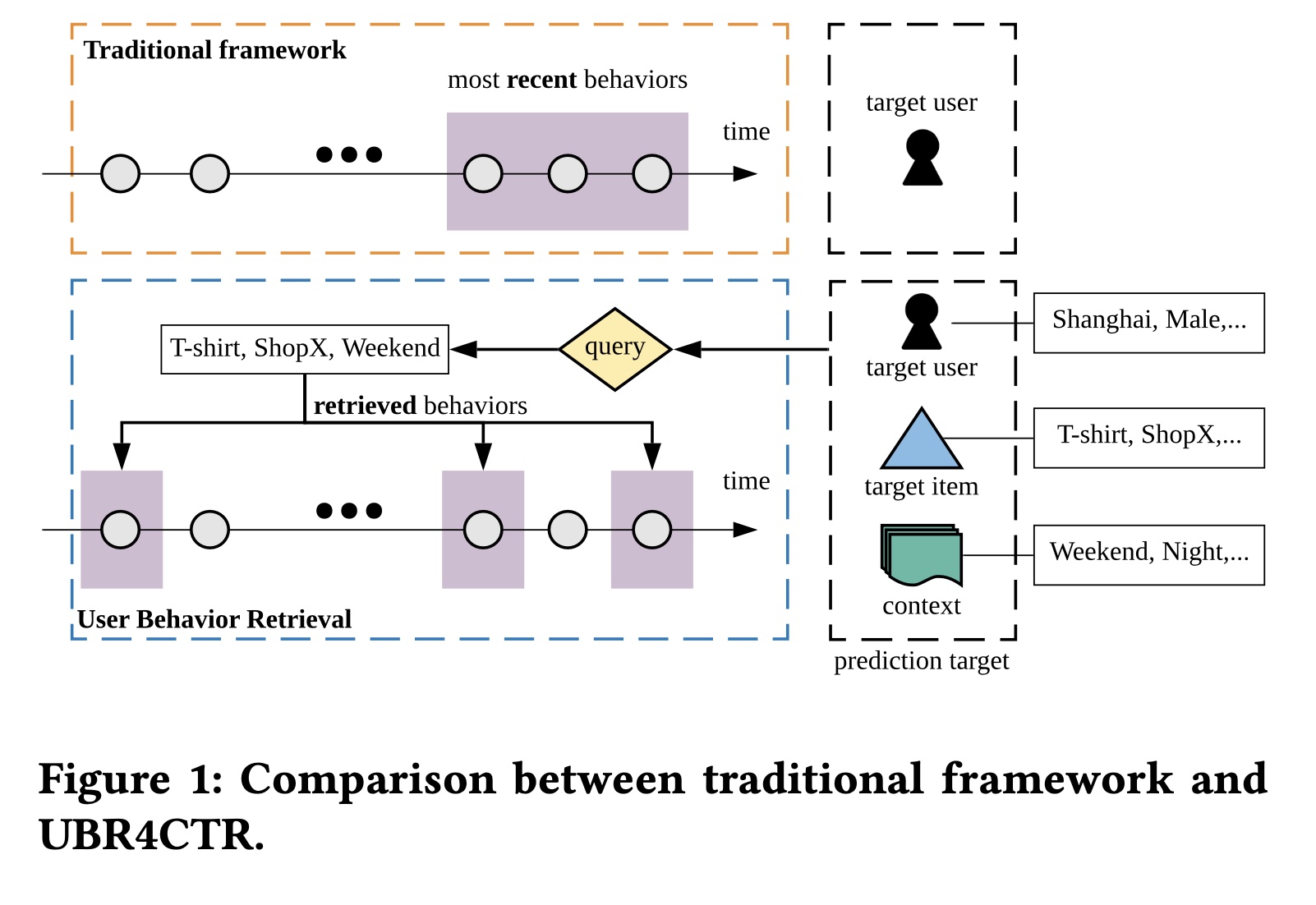
1.1 基础知识
在本节中,我们将问题公式化并引入符号。在
CTR prediction任务中,有itemsuser-item interactions记作此外,每个
user-item interaction都有一个时间戳和一个上下文,时间戳和上下文是interaction发生时刻的。因此数据被公式化为四元组,即item为了建模用户不断变化的兴趣,我们将用户历史行为组织为
behavior记录,按时间戳升序排序。点击率本质上是用户、item、以及上下文之间的匹配概率,因此每条behavioritem,在特征层面,每个用户
multiple categorical特征。如果有numerical特征,则将其离散化为categorical特征。类似地,
item、以及上下文的特征数量。这里的特征数量就是
field数量。例如,userfield。CTR prediction的目标是:根据target usertarget item其中:
我们在
Table 1中总结了符号和相应的描述。
1.2 方法论
本节将详细描述我们提出的
UBR4CTR(User Behavior Retrieval for CTR prediction)框架。我们首先给出整体框架的总体概述,然后详细描述user behavior retrieval模块和prediction模块。此外,以下各节将给出训练方法和一些时间复杂度分析。
1.2.1 整体框架
UBR4CTR的整体框架如Figure 2所示。该框架可分为两个主要模块:user behavior retrieval模块和prediction模块。user behavior retrieval模块由一个feature selection model、一个search engine client和一个user history archive组成。所有用户历史行为都存储在archive中,并以feature-based的倒排索引方式组织,这将在后续章节中详细说明。如
Figure 2所示,当我们需要在特定上下文中预测target user和target item之间的点击率时,所有这三部分信息结合在一起形成prediction target。prediction target本质上是由target user、target item和上下文的一系列特征组成。因此,prediction target随后被馈入到feature selection model中,该模型将选择适当的特征来形成一个query。feature selection model的详细设计见后续章节。然后,我们使用该query通过搜索search engine client在user history archive中进行搜索。search engine client检索出一定数量的user behaviors,然后这些被检索到的behaviors被prediction模块使用。在prediction模块中,我们使用attention-based的深度模型来区分每个behavior对点击概率的影响,并做出最终预测,这将在后续章节中讨论。
feature selection model和prediction model轮流进行训练。feature selection model的目标是选择最有用的特征子集。该子集的特征将组合起来生成一个query,该query用于检索与final prediction最相关的user behavior。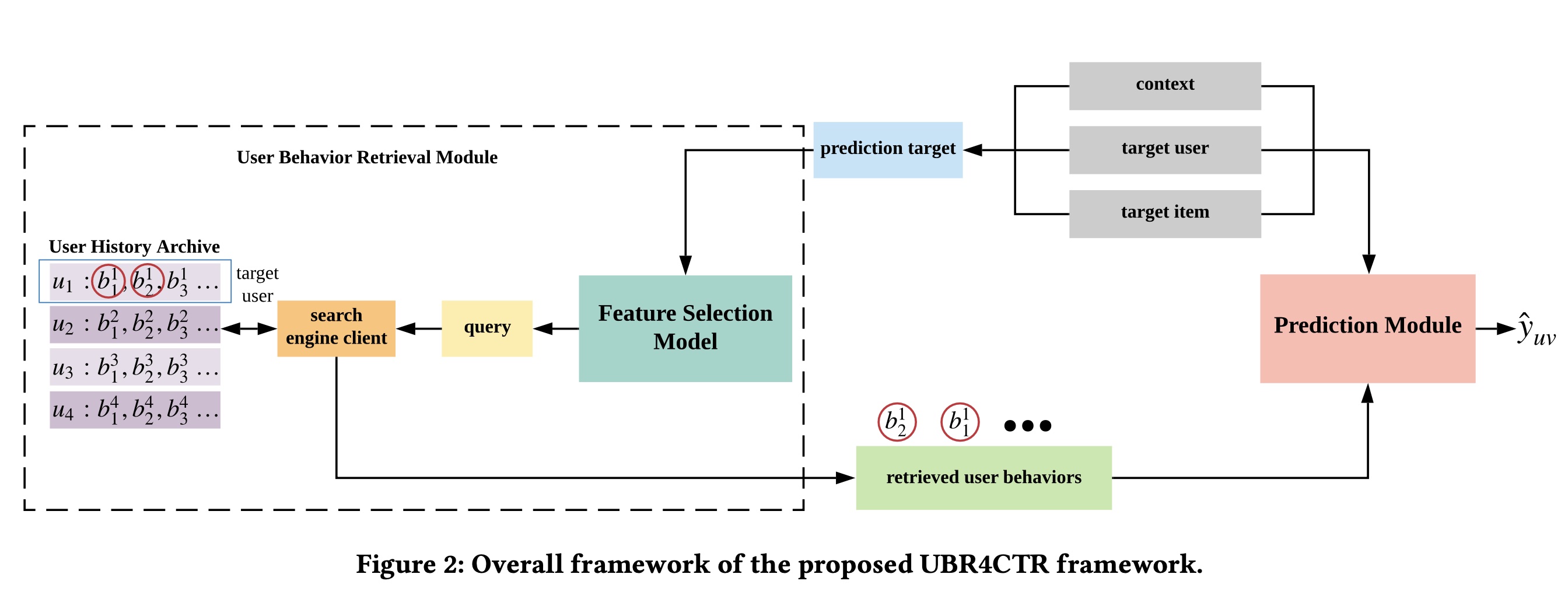
1.2.2 User Behavior Retrieval Module
在本节中,我们介绍用
user behavior retrieval module,该模块由feature selection model和behavior searching过程组成。Feature Selection Model:如Figure 3所示,我们将target usertarget itemfeature selection model的输入。不失一般性,我们将user id特征。user id是一个特殊的特征,我们必须选择它,因为我们想要检索用户behavior。所有其他特征都拼接成一个整体。为简单起见,我们将所有特征注意:这里的
field。每个field的取值都是离散值。为了更好地建模特征之间的关系和交互模式,我们使用
self-attention机制。具体来说,我们定义:其中:
dense embedding representation;embedding size。这里的
feature embedding是否与Prediction Module共享?根据Prediction Module章节的描述,读者认为是共享的。self-attention定义为:multi-head self-attention定义为:其中:
head数量;然后,
multi-head self-attention的输出multi-layer perceptron:相应特征被选择的概率通过取
sigmoid函数获得:其中:
然后我们根据这些概率对特征进行采样,从而得到选择好的特征子集。请注意,
user id特征始终在子集中,因为我们必须从target user自己的behavior中检索。实际上被采样到的是
field;但是在下一步检索时,将这个field在这个样本上的取值作为条件。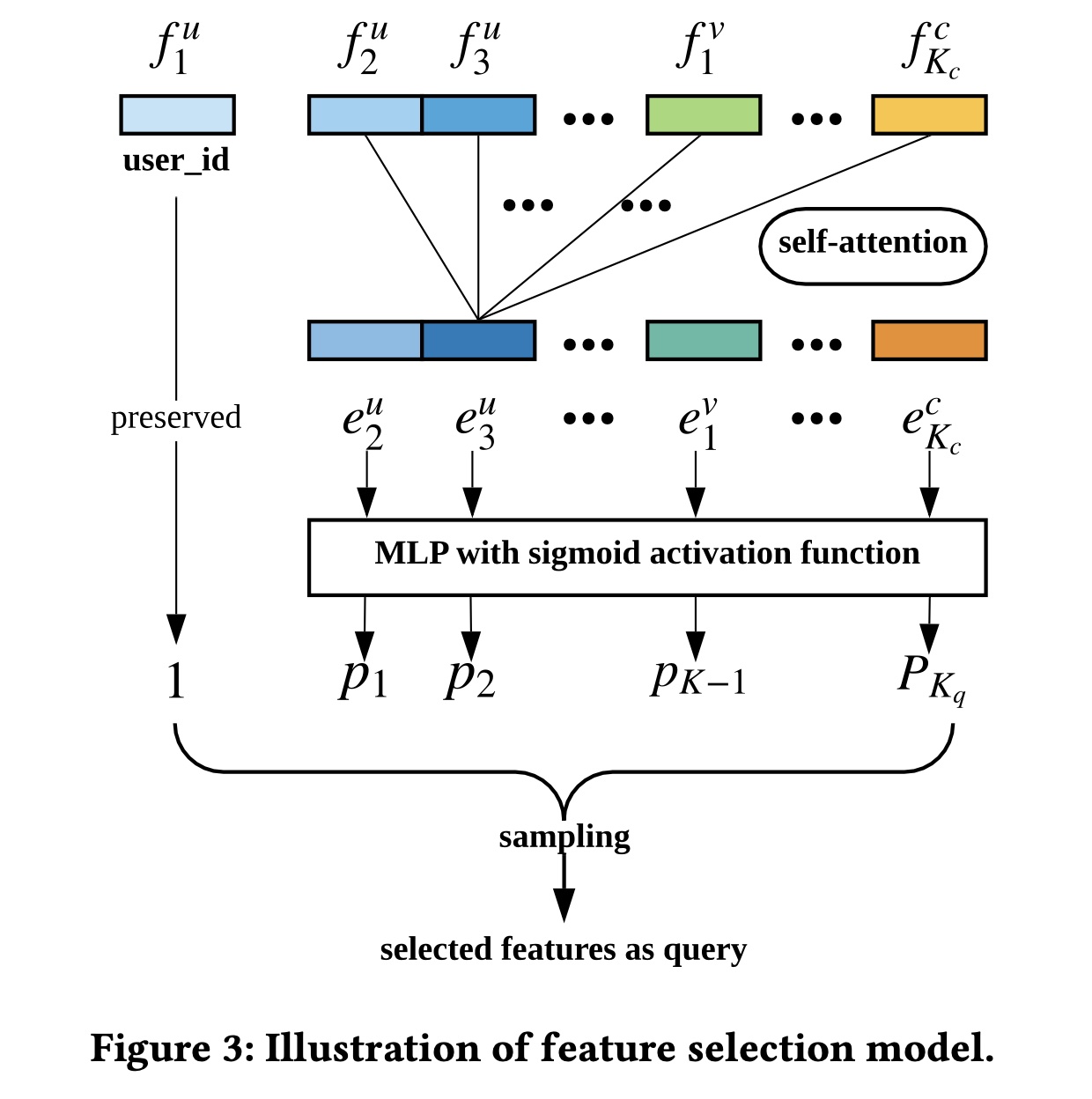
Behavior Searching:我们使用典型的搜索引擎方法来存储和检索user behavior。我们将每个user behavior视为一个文档,将每个特征视为一个term。倒排索引用于跟踪所有behavior,如Figure 4所示。每个feature value都与一个posting list相关联,该列表由具有此特定feature value的所有behavior组成。例如:"user_id_1"包含user id = 1的用户的所有behavior的posting list。"Nike"具有由brand id = "Nike"的所有behavior组成的posting list。
query的逻辑本质上表述为:其中:
user_id;所选中的query feature set为我们将
posting list与posting lists的并集进行相交,交集的结果就是candidate behavior set。然后我们使用BM25对候选集中的每个behavior document进行评分,并检索出top S个behavior document。querybehavior document其中:
1或0。behavior document的长度behavior中的特征数量,因此所有behavior document的长度相同。因此平均长度是每个文档的长度,并且可以进一步化简为:
考虑到
0或1,因此:因此
IDF定义为:其中:
behavior documents的总数,behavior documents总数。IDF项赋予常见特征比罕见特征更少的重要性。与常见特征相比,罕见特征对用户偏好的暗示更强,这是有道理的。 通过使用BM25对candidate behaviors进行排序,我们获得了top S的behavior documents作为所检索到的behavior,记作实际应用时会采用双层索引,最外层为
user_id,最内层为各个特征的取值,从而降低存储需求。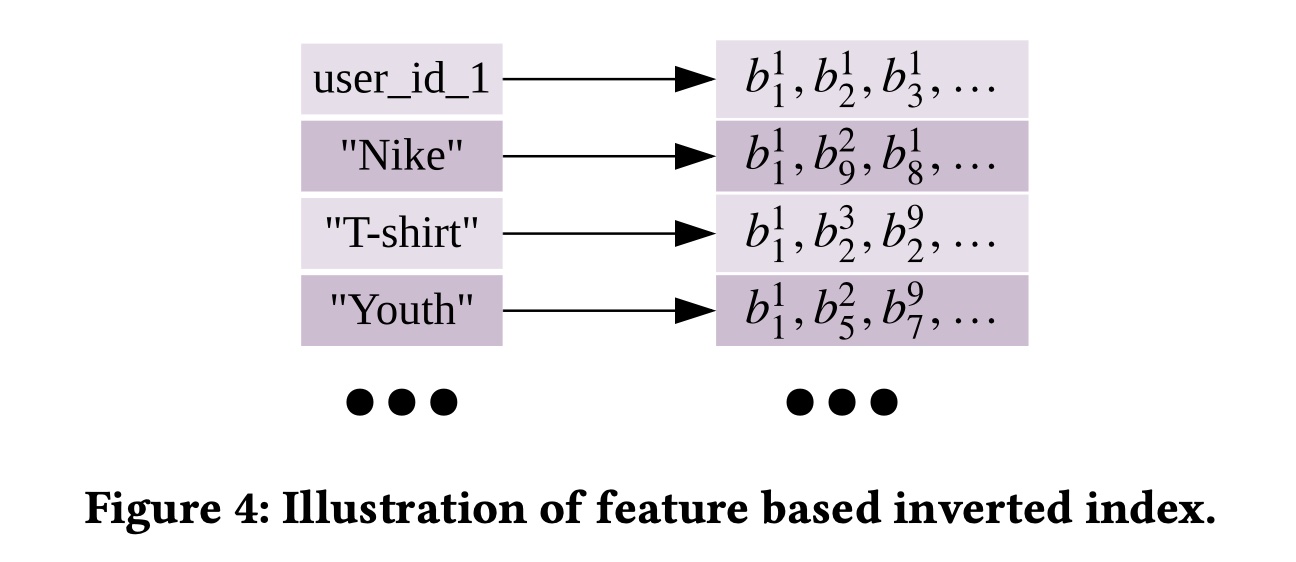
1.2.3 Prediction Module
对于
prediction module,我们使用attention-based的深度神经网络来建模不同user behavior对final prediction的重要性。如
Figure 5所示,我们通过加权池化得到user representation其中:
user behaviorembedding向量,behavior document的数量。user behaviorprediction target向量。Att()是一个具有ReLU激活函数的多层深度网络。这个
prediction target向量user ID特征
final prediction计算如下:其中:
sigmoid函数,其他层采用ReLU作为激活函数。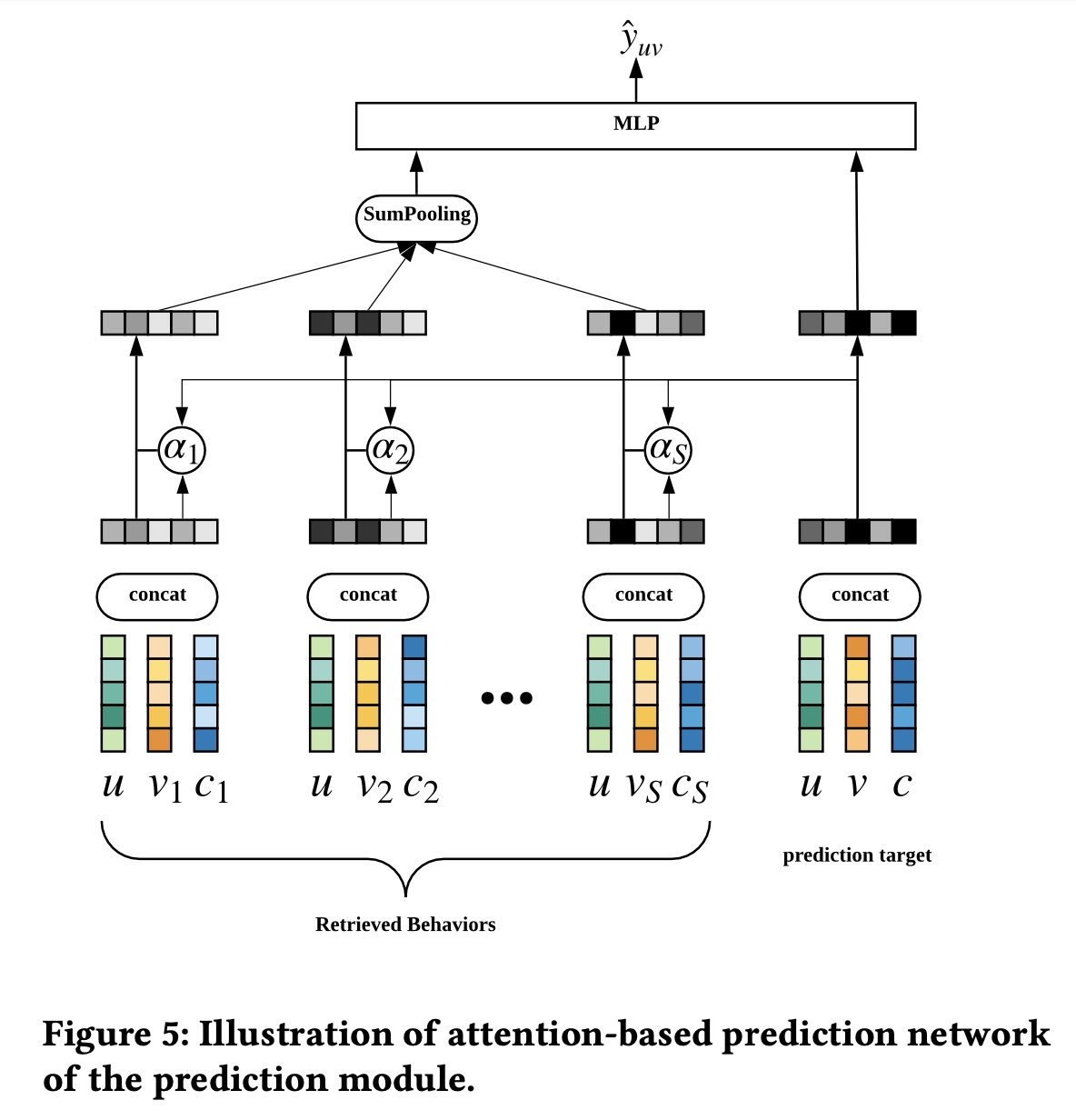
1.2.4 Model Training
由于目标是准确估计点击率,我们使用对数似然作为目标函数,其定义为:
其中:
LL(.)是在给定所检索到的user behaviortarget user-item pairquery。我们使用抽样来选择特征,然后被选中的特征形成query string。query string形成后,搜索结果(即,检索到的behavior)是确定性的。因此,我们可以认为这些behavior是从概率分布
优化
Prediction Module:为了优化attention-based预测网络其中:
注意,这里是负的对数似然,所以是
min。当我们优化
prediction network时,检索模块保持不变,因此如果函数优化检索模块:对于检索模块,只需要优化
feature selection model。随着采样过程的发展,我们不能直接使用SGD来优化它。相反,我们使用REINFORCE算法来处理离散优化(discrete optimization)。 具体而言,在保持prediction networkfeature selection model:我们将
query我们将检索模块
likelihood ratio来估计其梯度:这是对
query数量。由于整个检索模块的不确定性实际上来自
feature selection model,我们可以得出:其中:
其中:其中
query的第为了使用
reward训练一个更好的模型,我们在这里用相对信息增益 (Relative Information Gain: RIG)替换LL(·)作为奖励函数。RIG定义为RIG = 1 − NE,其中NE是归一化熵:其中
CTR。可以参考
UBR模型,它是UBR4CTR的升级版。训练过程的伪代码:在本小节中,我们给出了训练过程的详细伪代码。
首先,我们使用
feature selection model对预测网络进行预热。feature selection model如何初始化?如果是随即初始化是否会带来不利影响?作者没有提及。读者猜测是不影响的,因为后续的迭代训练会对feature selection model进行优化。为什么要预热?因为
prediction model是feature selection model的奖励函数,它必须要有一定的准确性才能指导feature selection model的学习。预训练后,我们轮流优化两个模型,每个模型被训练一个
epoch之后,再训练另一个模型一个epoch,轮流往复。
Algorithm 1显示了训练过程。
1.2.5 模型分析
本节分析了该方法的时间复杂度和可行性。我们使用
user behavior的总数,使用unique features(相当于term)的总数。然后,user history archive中posting lists的平均长度为回想一下之前内容所描述的搜索操作,我们首先检索
postings,这需要然后交互操作需要
selected features数量的上限。接下来的
scoring操作不会增加复杂度,因为它与feature selection model中的self-attention的复杂度为attention-based prediction network需要attention操作都可以并行执行。
两个常数可以忽略,因此
UBR4CTR的总时间复杂度为
1.3 实验
在本节中,我们详细介绍了我们的实验设置和相应的结果。我们将我们的模型与几个强大的
baselines进行了比较,并实现了SOTA的性能。此外,我们已经发布了代码用于复现(https://github.com/qinjr/UBR4CTR)。 我们从三个研究问题(research question: RQ)开始,并用它们来引导以下讨论。RQ1:与其他baselines相比,UBR4CTR是否实现了最佳性能?RQ2:Algorithm 1的收敛性能如何?训练过程是否有效且稳定?RQ3:UBR4CTR中的检索模块有什么影响,retrieval size如何影响性能?
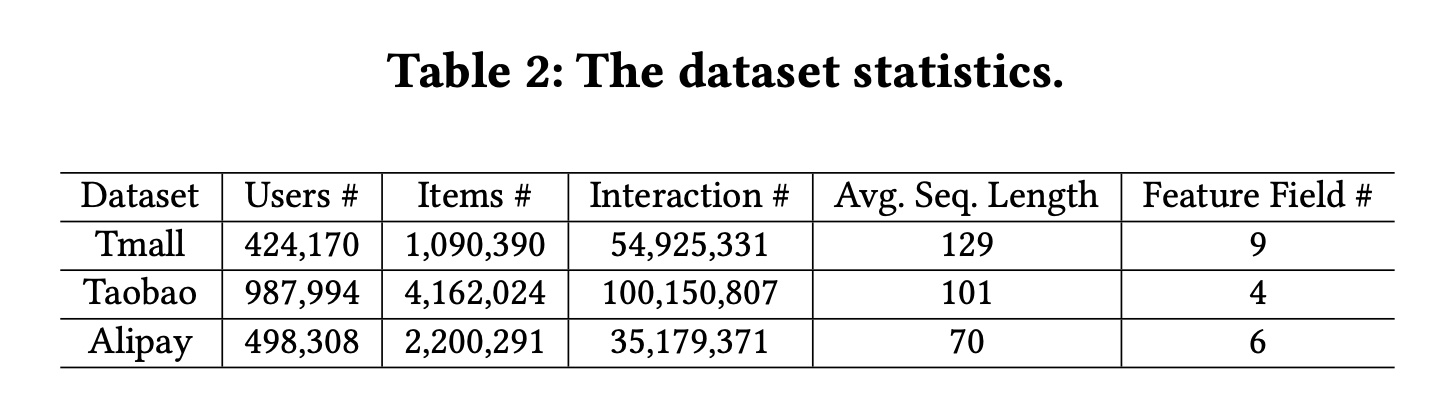
数据集:我们使用三个真实的、大型的
users online behaviors数据集,它们来自阿里巴巴集团三个不同平台。数据集的统计数据可以在Table 2中找到。Tmall数据集:由阿里巴巴集团提供,其中包含2015年5月至2015年11月天猫电商平台上的user behavior历史记录。Taobao数据集:包含来自中国最大的电商平台之一淘宝中检索到的user behavior数据。它包含2017年11月25日至12月3日的user behavior,包括点击、购买、添加到购物车、以及喜欢商品等几种behavior类型。Alipay数据集:由在线支付应用程序支付宝收集。用户的在线购物behavior是从2015年7月1日到2015年11月30日。
数据集预处理:
对于
UBR4CTR,数据集被处理成逗号分隔特征的格式。包含user, item and context features的一行被视为一个behavior document。对于
baselines,user behavior仅按时间戳排序。由于数据集不包含特定的上下文特征,我们使用behavior timestamp手动设计一些特征,以便能够捕获周期性。我们设计了一些特征,例如season id(春季、夏季等)、是否是周末、以及是哪个半月(上半月还是下半月)。
搜索引擎:数据集预处理后,使用逗号分隔的
tokenizer将它们插入搜索引擎。我们使用基于Apache Lucene的Elastic Search作为搜索引擎客户端。Train & Test Splitting:我们使用time step来拆分数据集。训练集包含第
user behavior,其中第behavior用于预测第behavior。类似地,验证集使用第
behavior来预测第behavior;测试集使用第behavior来预测第behavior。
超参数:
UBR4CTR的feature selection model的学习率从attention based prediction network的学习率从baseline模型的学习率和正则化项的搜索空间与UBR4CTR的prediction network相同。所有模型的
batch size均从
每个模型的超参数都经过调优并报告最佳性能。
评估指标:
CTR、Logloss。Baselines:我们将我们的框架和模型与来自sequential CTR prediction和推荐场景的七个不同的强基线进行比较。GRU4Rec基于GRU,它是第一个工作使用recurrent cells建模user behavior序列从而用于session-based推荐。Caser是一个CNNs-based的模型,它将用户序列视为图像,因此使用horizontal and vertical convolutional layers来捕获user behavior的时间模式。SASRec使用Transformer。它将user behavior视为tokens的一个序列,并使用自注意机制和position embedding来捕获behavior之间的依赖关系。HPMN是一个hierarchical periodic memory network,旨在处理非常长的用户历史序列。此外,user memory state可以增量更新。MIMN基于Neural Turing Machine,它建模了用户兴趣漂移的multiple channels。该模型作为user interest center的一部分实现,可以对非常长的user behavior序列进行建模。DIN是第一个在在线广告CTR prediction中使用注意力机制的模型。DIEN使用具有注意力机制的双层RNN来捕获不断变化的用户兴趣。它使用所计算出的attention values来控制第二个recurrent layer,称为AUGRU。UBR4CTR是我们提出的框架和模型。
1.3.1 性能比较:RQ1
我们对
UBR4CTR和基线模型进行了两组比较。在第一组实验中,所有模型都使用相同数量的
user behavior,对三个数据集分别为20、20、12。唯一的区别是:baselines使用的是最近的behavior(约占总长度的20%),而UBR4CTR从整个序列中检索了20%的behavior。实验结果如Table 3所示。从表中,我们可以发现以下事实:
(i):与baseline相比,UBR4CTR的性能显著提高。在三个数据集上AUC分别提高了4.1%、10.9%和22.3%,Logloss分别改善了9.0%、12.0%和32.3%。(ii):巨大的改进表明最近的behaviors没有包含足够的时间模式(temporal patterns),因此baselines无法有效地捕获它们。尽管有些baselines模型相当复杂和fancy,但如果它们试图捕获的模式不包含在最近的行为序列中,它们就无法很好地发挥作用。
根据
MIMN论文的报告,MIMN的效果是优于DIEN的。这里MIMN效果反而更差,因为这里对MIMN近使用最近的20个behaviors,而没有用所有的behaviors。这是不公平的比较。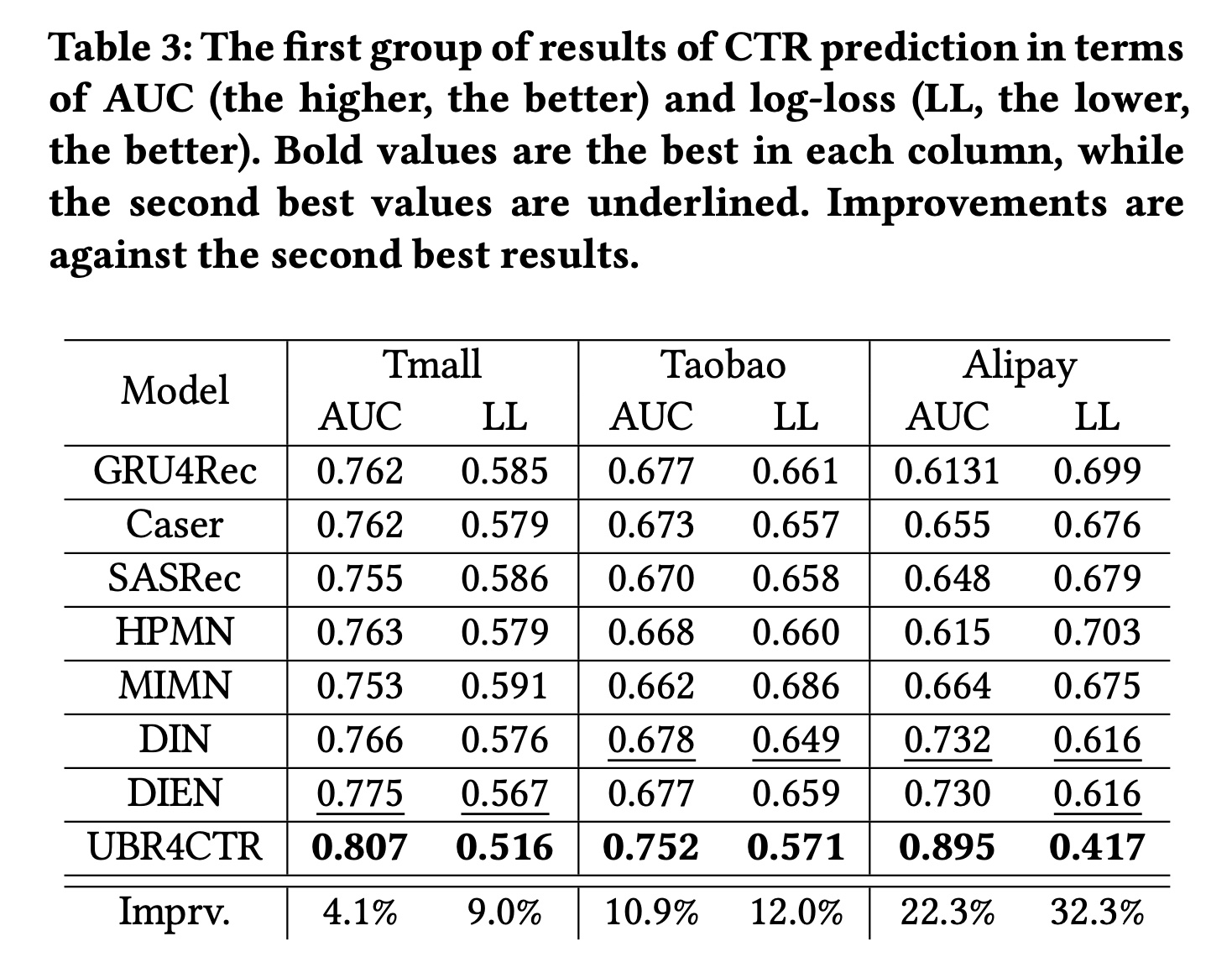
在第二组实验中,我们对
baselines模型使用不同的设置,对UBR4CTR的设置与第一组实验完全相同。我们将整个序列馈入到所有的baseline模型,其中这三个数据集的序列长度分别为100、100、60。它们是这些数据集中user behavior的最大长度。对于UBR4CTR,检索到的behavior大小保持不变,分别为20、20和12。结果如
Table 4所示。在Table 4中,UBR4CTR的性能与Table 3中相同,因为我们没有更改任何设置。从表中,我们可以发现以下事实:(i):UBR4CTR使用的behavior比其他baselines少80%,但仍然具有最佳性能。这表明较长的序列可能包含更多噪音和不相关信息,因此有必要从整个序列中仅获取最有用的数据。(ii):与Table 3相比,大多数baselines都取得了比其自身更好的性能,尤其是DIN和DIEN。这表明来自更远历史的behavior确实包含更丰富的信息和模式。并且这些模式更容易通过attention机制被捕获。(iii):虽然由于性能更好的baselines导致AUC的改进要小得多,但Logloss仍然有显著改善。原因是retrieval module的优化目标为RIG(相当于对数损失)。retrieval module的优化目标会影响最终模型的指标。
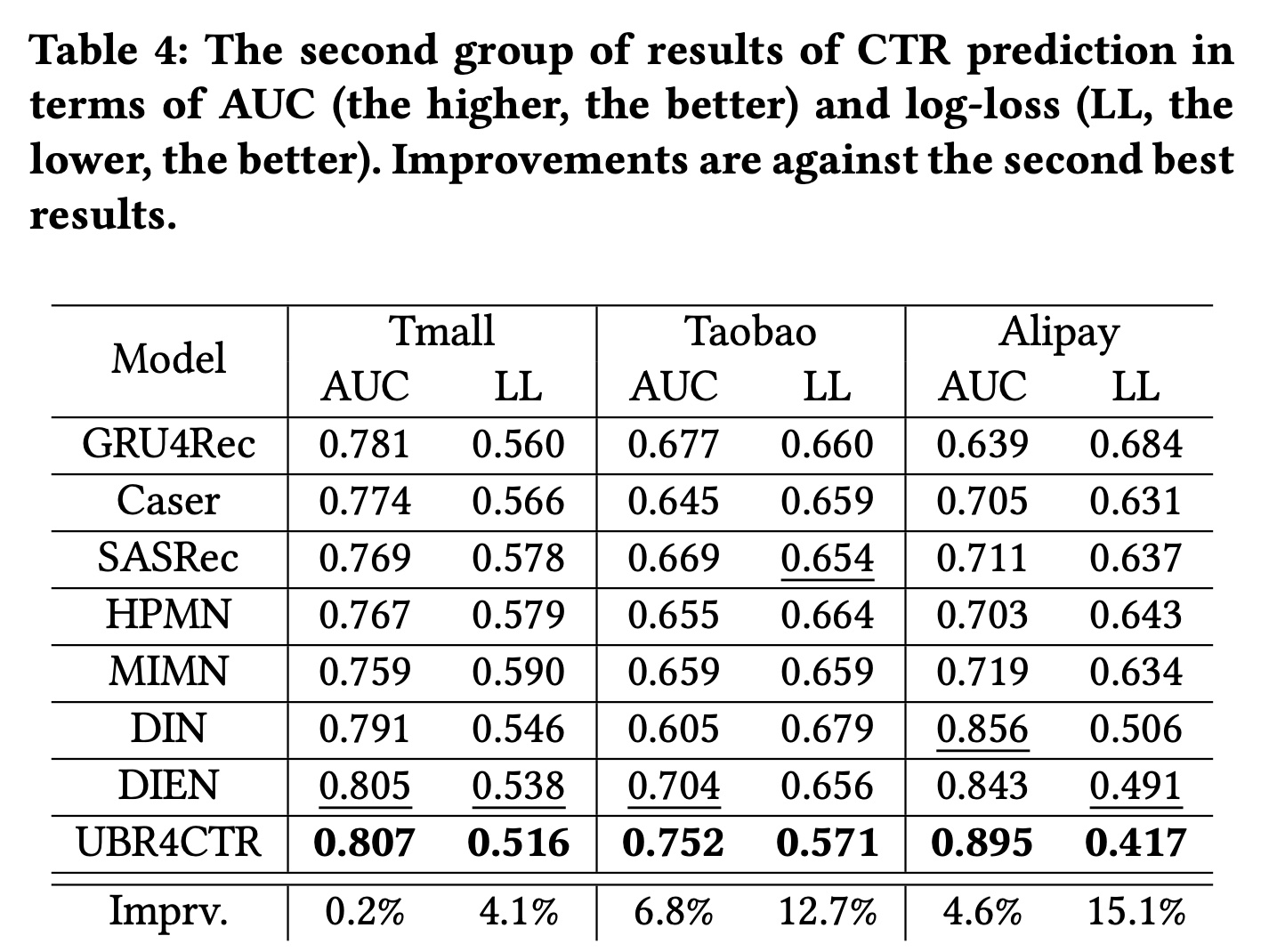
1.3.2 学习过程:RQ2
为了说明我们框架的收敛性,我们绘制了
UBR4CTR的learning curves。在Figure 6中,上面的三个子图分别是在三个数据集上训练时
attentive prediction network的AUC曲线。x轴的每个step对应于超过4%的训练集的迭代。下面的三个子图显示了
REINFORCE算法相对于检索模块的feature selection model的 “奖励”。“奖励”本质上是RIG,它是对数似然的一种变体。x轴的每个step表示超过4%的训练集的迭代。在训练过程中,奖励会增加,这意味着feature selection model实际上学习了有用的模式。
从
AUC图中,我们可以发现我们的模型有效地收敛了。对于prediction network,我们可以观察到在训练过程的中间有平坦区域,然后快速增加,尤其是在第二和第三个AUC图中。回想一下我们在Algorithm 1中描述的训练过程,检索模块是在prediction network之后训练的。这意味着当prediction network即将收敛时,检索模块开始训练,之后prediction network的性能将有所突破。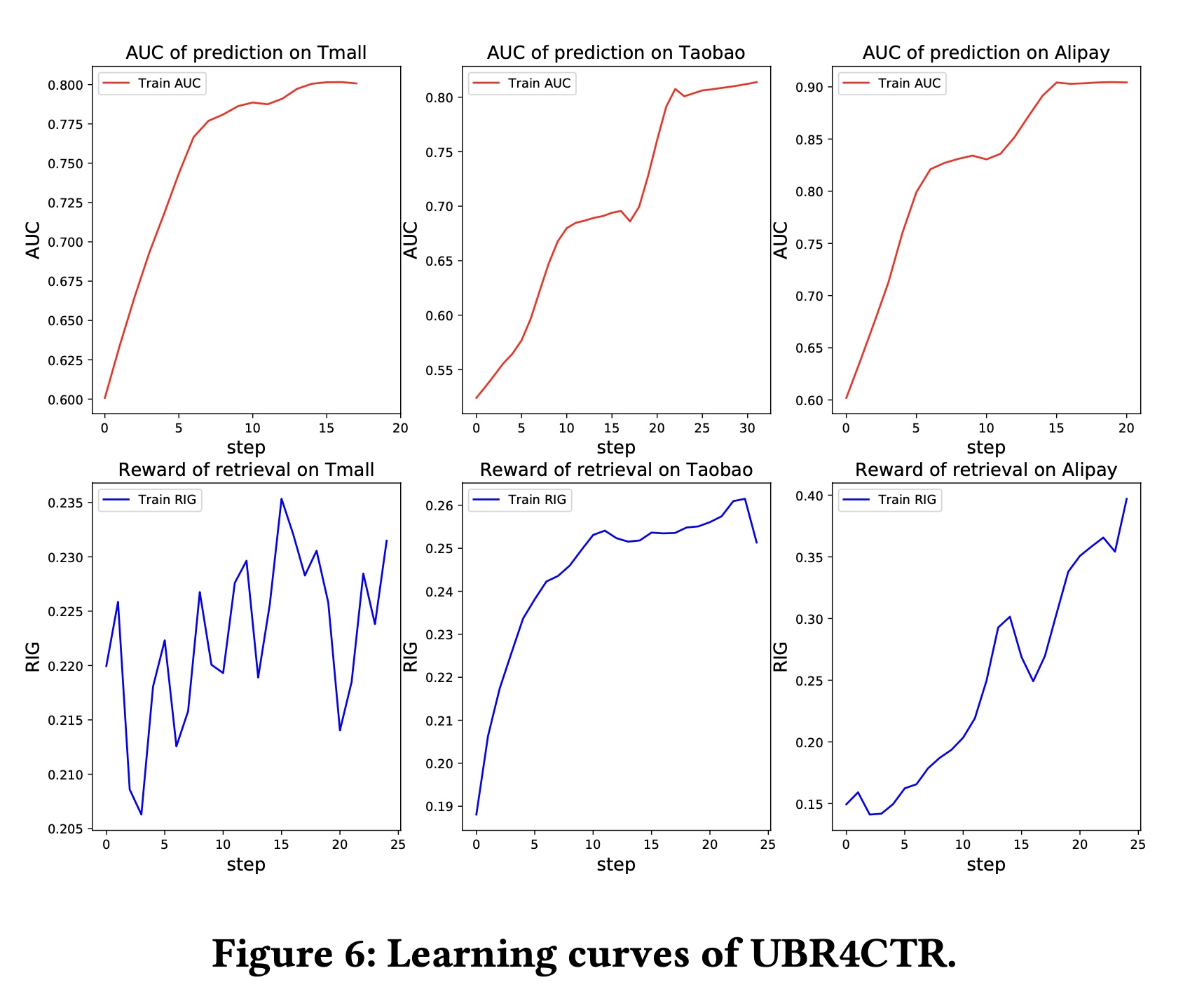
1.3.3 广泛研究:RQ3
在本节中,我们对我们的框架进行了一些广泛的和消融的研究。
采样的特征数量
query数量Figure 7说明了不同retrieval sizes对预测性能的影响。从图中可以看出,AUC和Logloss的波动在绝对值方面并不是很严重。然而,每个数据集都存在一个最佳大小。这表明:太少的
retrieved behaviors可能未包含足够的behavior和信息。而太多的
retrieved behaviors也不总是提高性能,因为它会引入太多噪音。
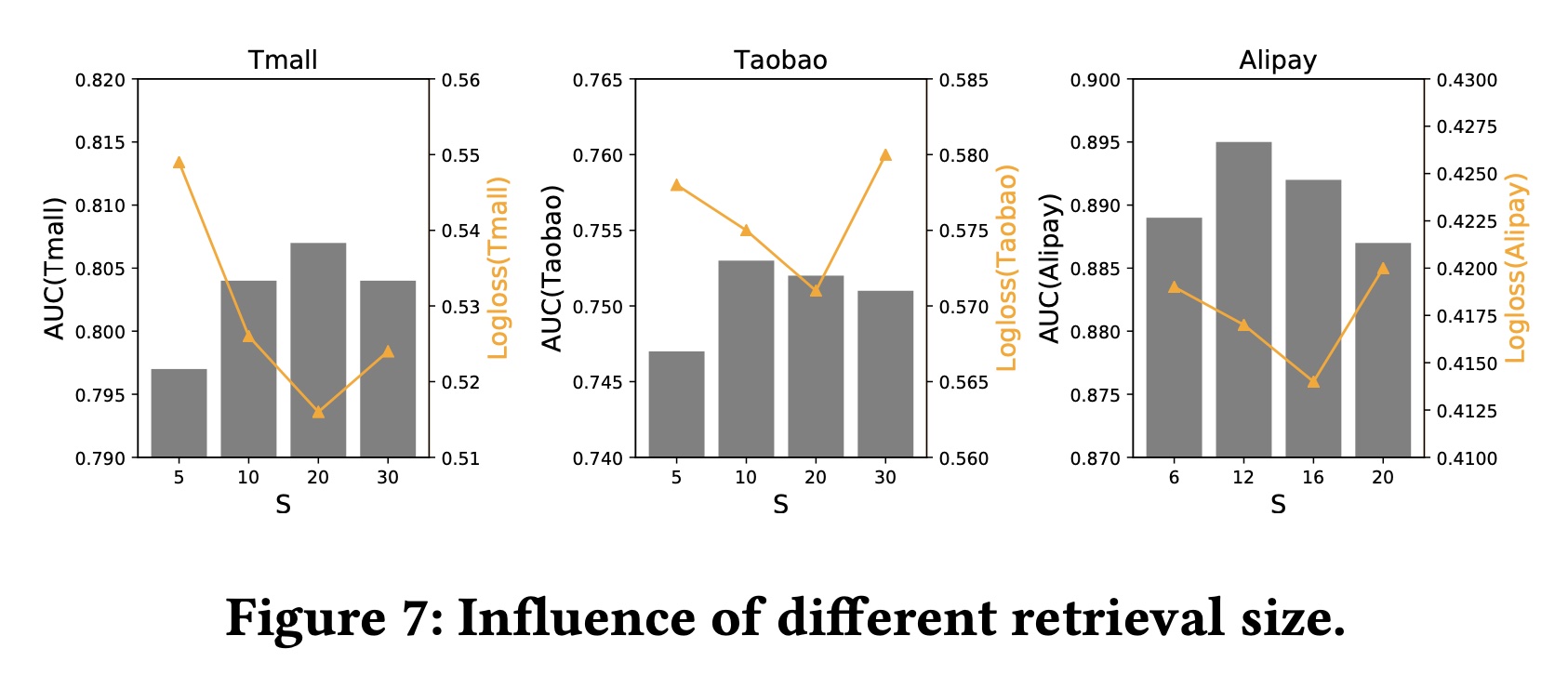
为了说明我们框架的检索模块的重要性,我们绘制了
sum pooling model和attention network,分别在具备和不具备user behaviors retrieval的情况下的性能比较。sum pooling model只是对user behavior做了一个非常简单的sum池化操作。结果如Figure 8所示。从图中我们发现:没有检索的
sum池化模型(SP)表现很差。一旦配备了检索模块,它的性能就会显著提高(UBR_SP)。同样的现象也适用于注意力网络,当配备了
behavior retrieval module时,其性能会大大提高(ATT vs. UBR4CTR)。
1.4 部署
UBR4CTR已在某主流银行旗下的daily item recommendation平台的engineering schedule中部署。本节主要讨论UBR4CTR框架在工业应用中的可行性。首先,将目前的模型流程切换到
UBR4CTR并不困难,因为UBR4CTR带来的主要变化是如何获取历史user behavior。要将model pipeline更新为UBR4CTR,需要构建历史user behavior的一个搜索引擎,而整个CTR prediction model pipeline基本保持不变,但增加了一个额外的检索模块。如Figure 2所示,prediction module与传统解决方案的prediction module并无不同。效率是工业应用中的另一个重要关注点。我们在 ”模型分析“ 章节中分析了
UBR4CTR的时间复杂度,为RNN的sequential CTR models,它们的时间复杂度为GRU rolling)的成本。UBR4CTR的时间复杂度并非完全不可行,因为从系统负载的角度来看,
UBR4CTR更好,因为它不需要在内存中维护所有behavior。为维护所有behavior,这是传统方法的常见做法。此外,我们在实验中比较了我们的
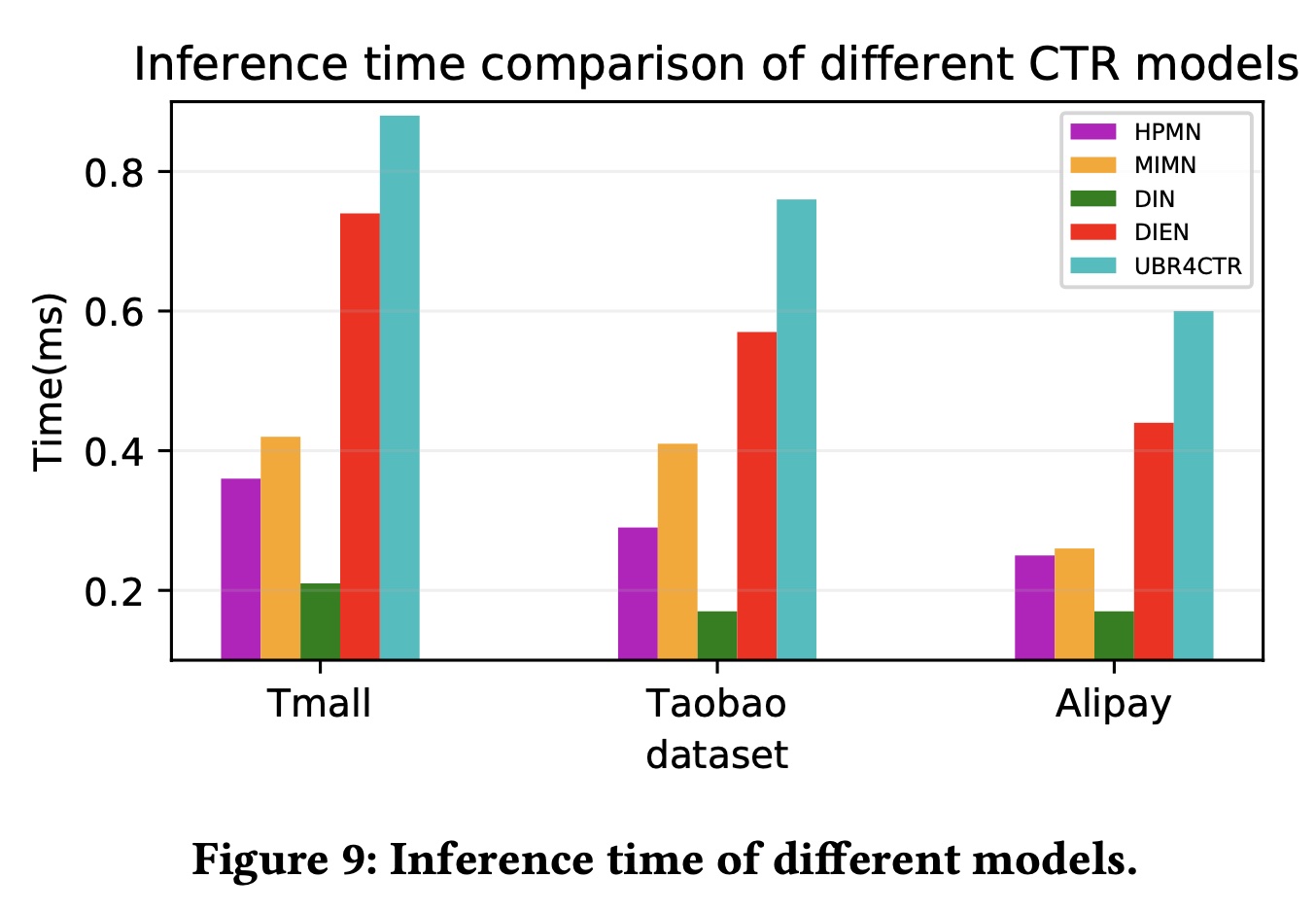
UBR4CTR和其他sequential CTR baselines之间的实际inference time。模型的平均inference time如Figure 9所示。时间是通过将测试数据集上的总时间(仅包含前向计算和behavior搜索的时间)除以prediction targets的数量来计算的。从图中可以看出,
UBR4CTR在三个数据集上的推理时间绝对值小于1ms,这对于online serving来说已经足够高效了。UBR4CTR的inference time是所有sequential CTR models中最长的,但差距并不大。具体而言,与已在阿里巴巴在线广告平台中部署的DIEN相比,UBR4CTR的平均inference time大约增加了15%到30%,可以通过进一步的infrastructure implementation来进行优化。