一、AutoDim [2021]
《AutoDim: Field-aware Embedding Dimension Search in Recommender Systems》
大多数现有的推荐系统为所有的
feature field指定了固定的、统一的embedding维度,这可能会导致内存效率的降低。首先,
embedding维度往往决定了编码信息的能力。因此,为所有的feature field分配相同的维度可能会失去highly predictive特征的信息,而将内存浪费在non-predictive特征上。因此,我们应该给highly informative和highly predictive的特征分配一个大的维度,例如,location-based的推荐系统中的"location"特征。其次,不同的
feature field有不同的cardinality(即unique value的数量)。例如,性别特征只有两个(即male和female),而itemID特征通常涉及数百万个unique value。直观而言,我们应该为具有较大cardinality的feature field分配较大的维度从而编码它们与其他特征的复杂关系,并为具有较小cardinality的feature field分配较小的维度从而避免由于过度参数化而产生的过拟合问题。
根据上述原因,我们非常希望能以一种
memory-efficient的方式为不同的feature field分配不同的embedding维度。在论文
《AutoDim: Field-aware Embedding Dimension Search in Recommender Systems》中,作者的目标是为不同的feature field提供不同的embedding维度从而用于推荐。但是这里面临着几个巨大的挑战:首先,
embedding维度、特征分布、以及神经网络架构之间的关系是非常复杂的,这使得我们很难为每个feature field手动分配embedding维度。其次,现实世界的推荐系统往往涉及成百上千的
feature field。由于难以置信的巨大搜索空间(feature field的候选维数,feature field的数量)带来的昂贵的计算成本,很难为所有feature field人为地选择不同的维度。
作者试图解决这些挑战,从而得到一个端到端的可微的
AutoML-based框架(AutoDim),它可以通过自动化的、数据驱动的方式有效地分配embedding维度给不同的feature field。论文主要贡献:
作者发现了将
various的embedding维度分配给不同的feature field可以提高推荐性能的现象。作者提出了一个
AutoML-based的端到端框架AutoDim,它可以自动选择各种embedding维度到不同的feature field。作者在真实世界的
benchmark数据集上证明了所提框架的有效性。
1.1 模型
AutoDim是一个AutoML-based框架,它可以为不同feature field自动分配不同的embedding维度。框架如下图所示,其中包括维度搜索阶段、参数重训练阶段。AutoDim的思想和AutoEmb类似,也是为每个id分配embedding size,然后用强化学习进行择优。但是,AutoDim相对容易落地,因为AutoDim本质上是寻找每个词表的最佳维度,是一个超参数调优工具,找到最佳维度之后应用到目标模型中。二者不同的地方:AutoEmb使用popularity信息作为特征来获得筛选概率,而AutoDim仅依靠特征本身的embedding来获得筛选概率。AutoDim有一个重训练阶段。实际上也可以在AutoEmb中引入重训练。
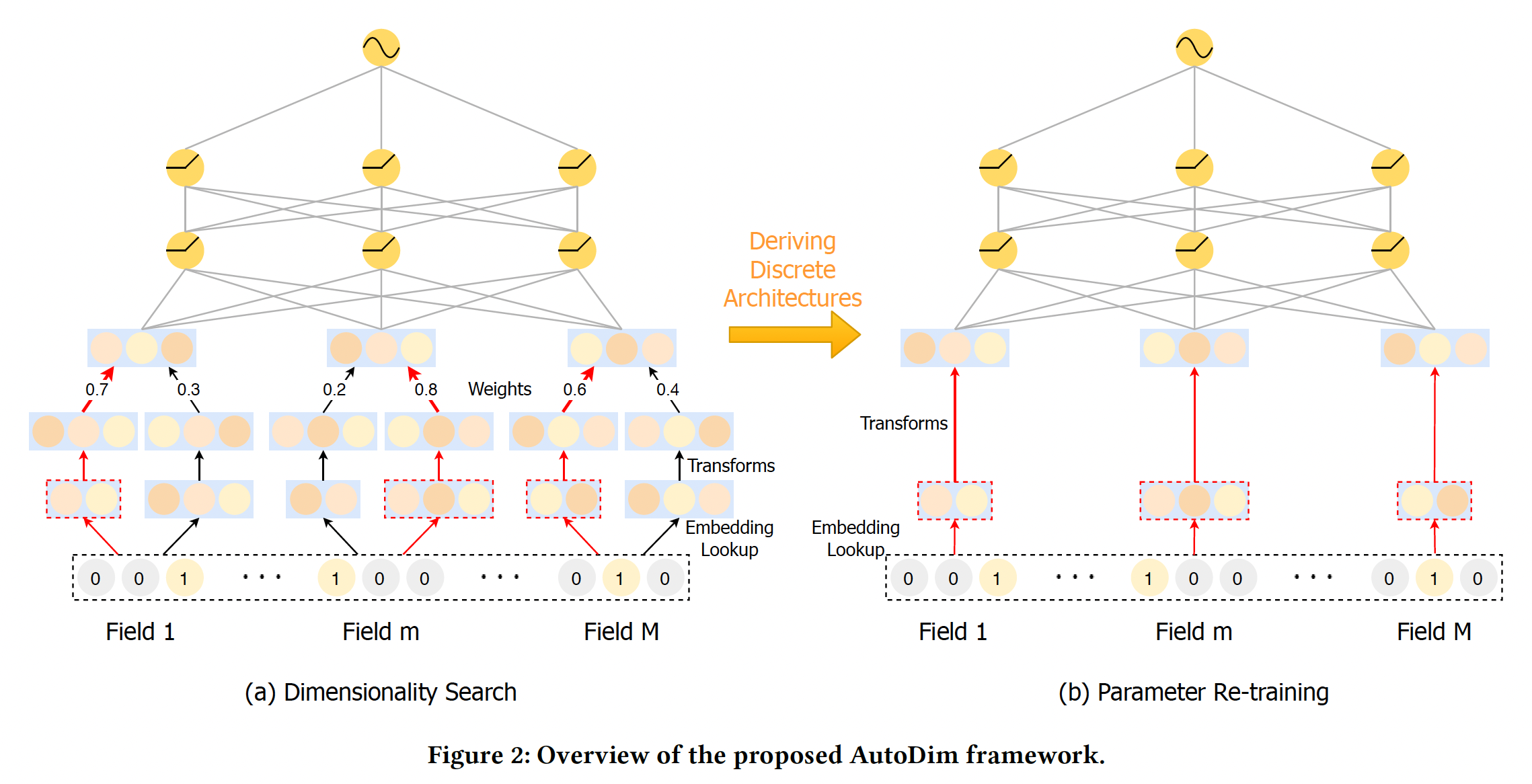
1.1.1 Dimensionality Search
Embedding Lookup:对于每个user-item交互样本,我们有feature field,如性别、年龄等等。对于第feature field,我们分配了emebdding空间embedding空间的维度分别为embedding空间的cardinality是该feature field中unique feature value的数量。相应地,我们定义
embedding空间的候选embedding的集合,如下图所示。因此,分配给特征feature field分配相同的候选维度集合,但引入不同的候选集合是很直接的。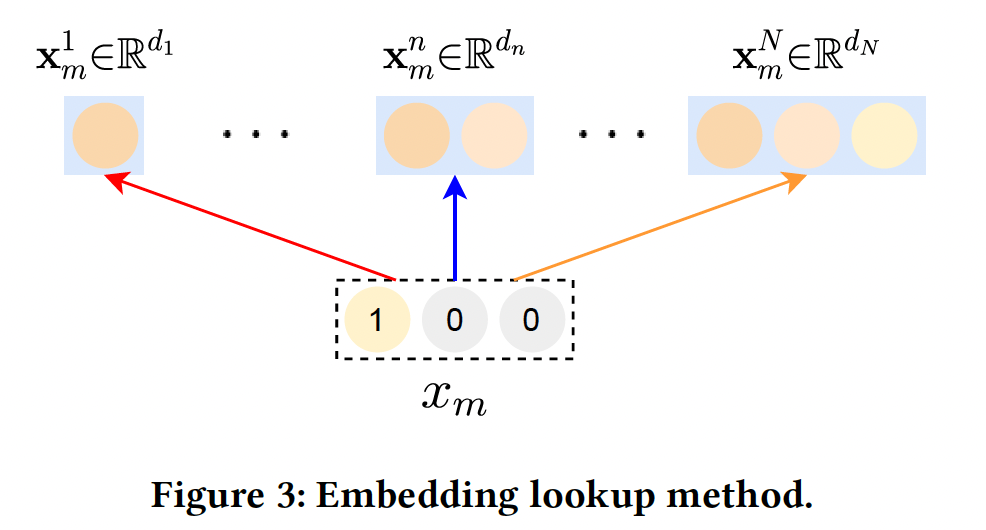
统一各种维度:由于现有的
DLRS中第一层MLP的输入维度通常是固定的,所以它们很难处理各种候选维度。因此,我们需要将embedding向量embedding向量其中:
bias向量。对于不同的feature field,所有具有相同维度的候选embedding都共享相同的权重矩阵和bias向量,这可以减少模型参数的数量。过线性变换,我们将原始
embedding向量embeddingmagnitude)方差很大,这使得它们变得不可比incomparable。为了解决这一难题,我们对转换后的嵌入进行BatchNorm:其中:
mini-batch的均值,mini-batch的方差,Dimension Selection:我们通过引入Gumbel-softmax操作,对不同维度的hard selection进行了近似处理(因为hard selection是不可微的)。具体而言,假设权重Gumbel-max技巧得到一个hard selection其中:
0-1之间的均匀分布,gumbel噪声(用于扰动argmax操作等价于通过然而,由于
argmax操作,这个技巧是不可的。为了解决这个问题,我们使用softmax函数作为argmax操作的连续的、可微的近似,即gumbel-softmax:其中:
gumbel-softmax操作的输出的平滑度。当gumbel-softmax的输出就会变得更接近于ont-hot向量。embedding维度的概率。
为什么要用
gumble-softmax操作?直接用softmax操作如何?作者并未说明原因。embedding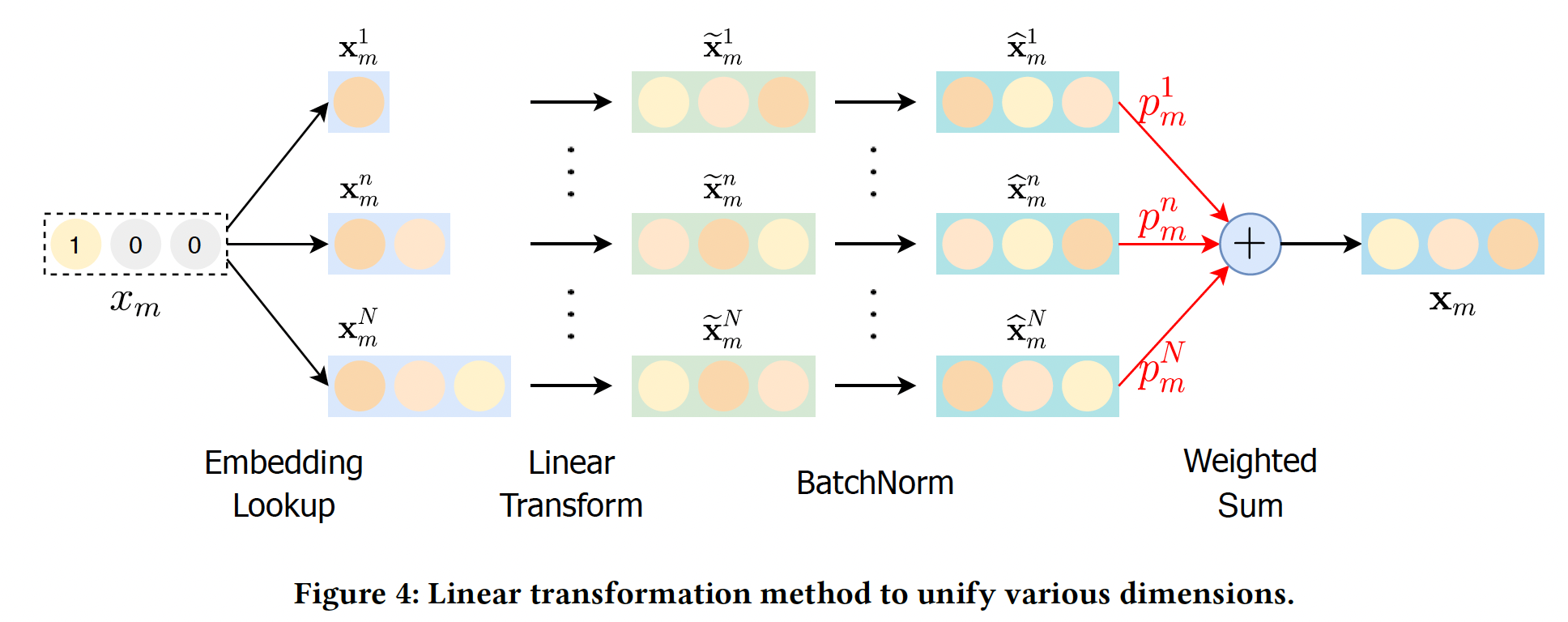
然后我们拼接所有特征的
embedding,即其中:
bias,感知机的输出馈入
output layer,得到最终预测:其中:
output layer的权重和bias,目标函数为负的对数似然:
其中:
ground-truth。
1.1.2 优化
AutoDim中需要优化的参数有两个方面:DLRS的参数,包括embedding部分和MLP部分。embedding维度的权重。
DLRS参数受可微分架构搜索(
differentiable architecture search: DARTS)技术的启发,这种优化形成了一个
bilevel的优化问题,其中权重DLRS参数DARTS的近似方案:其中:
在近似方案中,当更新
优化方法与
AutoEmb完全相同。AutoDim中DARTS based优化算法:输入:特征
ground-truth label输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤为:
从验证数据集中采样一个
mini-batch的数据。通过
收集一个
mini-batch的训练数据。基于当前的
通过
1.1.3 参数重训练
由于
dimensionality search阶段的次优embedding维度也会影响模型的训练,所以希望有一个重训练阶段,只用最优维度训练模型,消除这些次优的影响。Deriving Discrete Dimensions:在重训练过程中,每个feature field的最佳embedding空间(维度)被选择为与最大权重相对应的维度:Figure 2(a)给出了一个示例,红色箭头表示所选中的embedding维度。Model Re-training:给定所选的embedding空间,我们可以为特征unique的embedding向量embedding拼接起来再馈入隐层。最后,DLRS的所有参数,包括embedding和MLP,将通过反向传播使监督损失函数注意:
现有的大多数深度推荐算法都是通过交互操作(如内积)来捕获
feature field之间的交互。这些交互操作要求所有field的embedding向量具有相同的尺寸。因此,被选中的embedding仍然被映射到相同的维度。在重训练阶段,不再使用
Batch-Norm操作,因为每个field的候选embedding之间没有竞争。
DLRS重训练阶段的优化过程:输入:特征
ground-truth label输出:训练好的
DLRS参数算法步骤:
迭代直到收敛,迭代步骤为:
采样一个
mini-batch的训练数据。基于当前的
通过
1.2 实验
数据集:
Criteo。每个样本包含13个数值feature field、26个categorical feature field。我们按照
Criteo竞赛获胜者的建议,将数值特征归一化:然后将数值特征进行分桶从而转换为
categorical feature。我们使用
90%的数据作为训练集/验证集(8:1),其余10%作为测试集。实现细节:
DLRS:embedding组件:在我们的GPU内存限制下,我们将最大的embedding维度设置为32。对于每个feature field,我们从embedding维度{2, 8, 16, 24, 32}中选择。MLP组件:我们有两个隐层,形状分别为Criteo数据集的feature field数量。我们对两个隐层使用batch normalization、dropout(dropout rate = 0.2)和ReLU激活。输出层为Sigmoid激活函数。
feature field的softmax激活来产生的。对于Gumbel-Softmax,我们使用退火温度training step。
更新
DLRS和0.001和0.001,batch size = 2000。我们的模型可以应用于任何具有embedding layer的深度推荐系统。在本文中,我们展示了在著名的FM、W&D、以及DeepFM上应用AutoDim的性能。评估指标:
AUC, Logloss, Params。Params指标是该模型的embedding参数数量。我们省略了MLP参数的数量,因为MLP参数仅占模型总参数的一小部分。baseline方法:Full Dimension Embedding: FDE:所有的feature field分配了最大的候选维度,即32。Mixed Dimension Embedding: MDE:参考论文《Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems》。Differentiable Product Quantization: DPQ:参考《Differentiable product quantization for end-to-end embedding compression》。Neural Input Search: NIS:参考《Neural input search for large scale recommendation models》。Multi-granular quantized embeddings: MGQE:参考《Learning Multi-granular Quantized Embeddingsfor Large-Vocab Categorical Features in Recommender Systems》。Automated Embedding Dimensionality Search: AEmb:参考《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》。Random Search: RaS:随机搜索是神经网络搜索的强大baseline。我们应用相同的候选embedding维度,在每个实验时间随机分配维度到feature field,并报告最佳性能。AD-s:它与AutoDim共享相同的架构,同时我们在同一training batch上以端到端反向传播的方式同时更新DLRS参数和AutoDim。
实验结果如下表所示,可以看到:
FDE实现了最差的推荐性能和最大的Params,其中FDE对所有feature field分配了最大的embedding维度32。这一结果表明,为所有feature field分配相同的维度,不仅内存效率低下,而且会在模型中引入许多噪音。RaS, AD-s, AutoDim比MDE, DPQ, NIS, MGQE, AEmb表现得更好,这两组方法的主要区别在于:第一组方法旨在为不同的
feature field分配不同的embedding维度,而相同feature field中的embedding共享同一维度。第二组方法试图为同一
feature field中的不同特征取值分配不同的embedding维度,分配方式基于特征取值的popularity。
第二组方法具有几个方面的挑战:
每个
feature field都有许多unique值。例如,在Criteo数据集中,每个feature field平均有unique值。这导致每个feature field的搜索空间非常大(即使在分桶之后),这就很难找到最优解。而在AutoDim中,每个feature field的搜索空间为仅根据
popularity(即一个特征取值在训练集中出现的次数)来分配维度可能会失去该特征的其他重要特性。在实时推荐系统中,特征取值的
popularity通常是动态的,预先未知。例如,冷启动的user/item。
AutoDim优于RaS和AD-s。AutoDim在验证集的mini-batch上更新AD-s在同一训练集mini-batch上同时更新DLRS,可能导致过拟合。RaS随机搜索维度,其中搜索空间很大。
AD-s的Params比AutoDim大得多,这说明更大的维度能更有效地减少训练损失。因为
AD-s是监督学习训练的,目标是最小化训练损失,最终筛选到的维度更大。而AutoDim是强化学习训练的,奖励是最小化验证损失,最终筛选到的维度更小。
综上所述,与有代表性的
baseline相比,AutoDim取得了明显更好的推荐性能,并节省了70%∼80%的embedding参数。这些结果证明了AutoDim框架的有效性。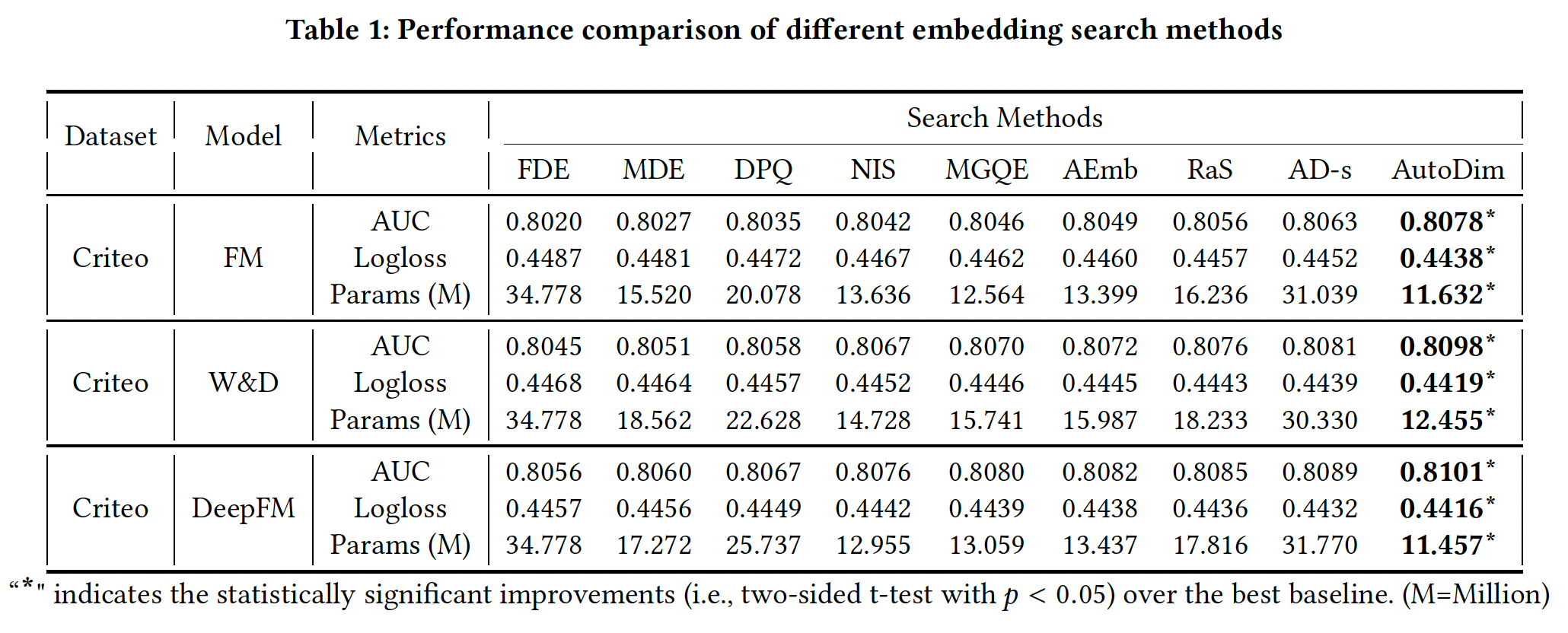
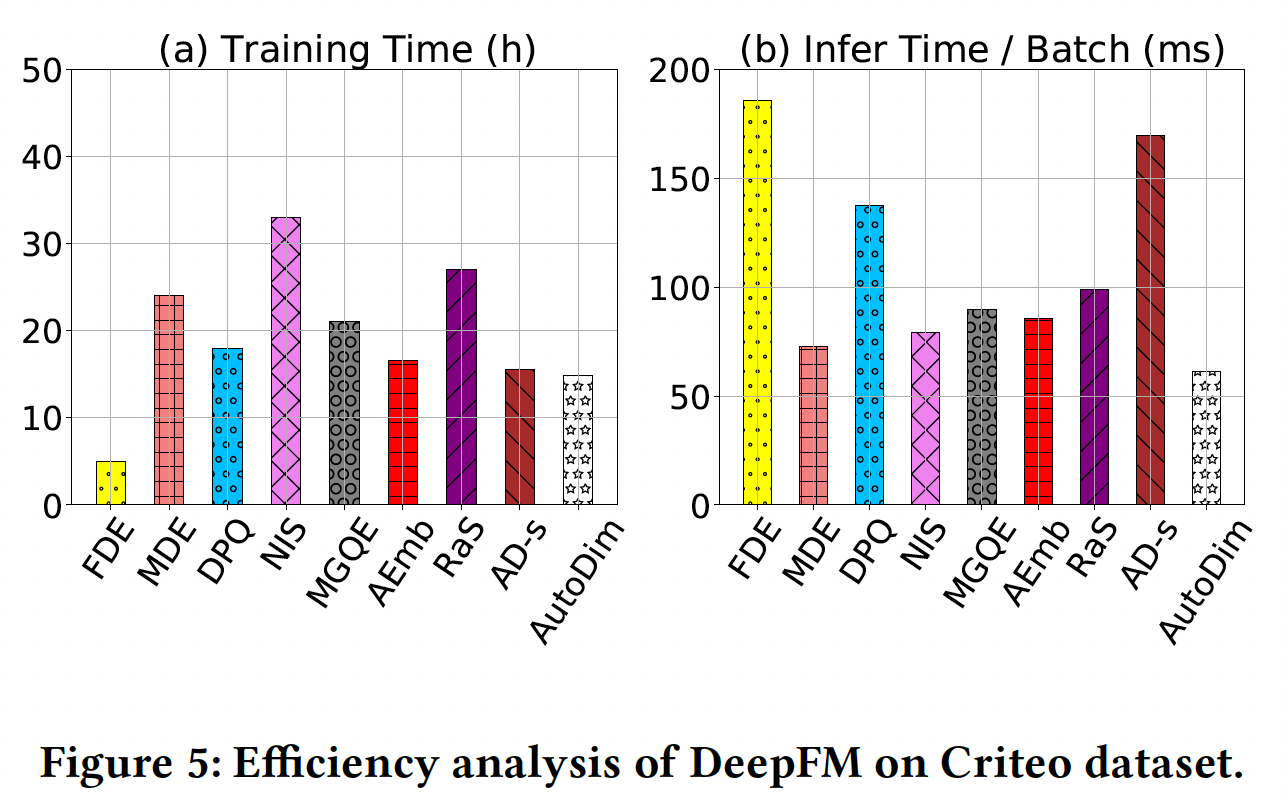
效率分析:本节研究了在
Criteo数据集上对DeepFM应用搜索方法的效率(在一个Tesla K80 GPU上),如下图所示。可以看到:对于训练时间(图
(a)):AutoDim和AD-s具有很快的训练速度,原因是它们的搜索空间比其他baseline小。FDE的训练速度最快,因为我们直接把它的embedding维度设置为32,即没有搜索阶段。然而它的推荐效果是所有方法中最差的。
对于推理时间(图
(b)):AutoDim实现了最少的推理时间,因为AutoDim最终选择的推荐模型的embedding参数最少(即Params指标)。
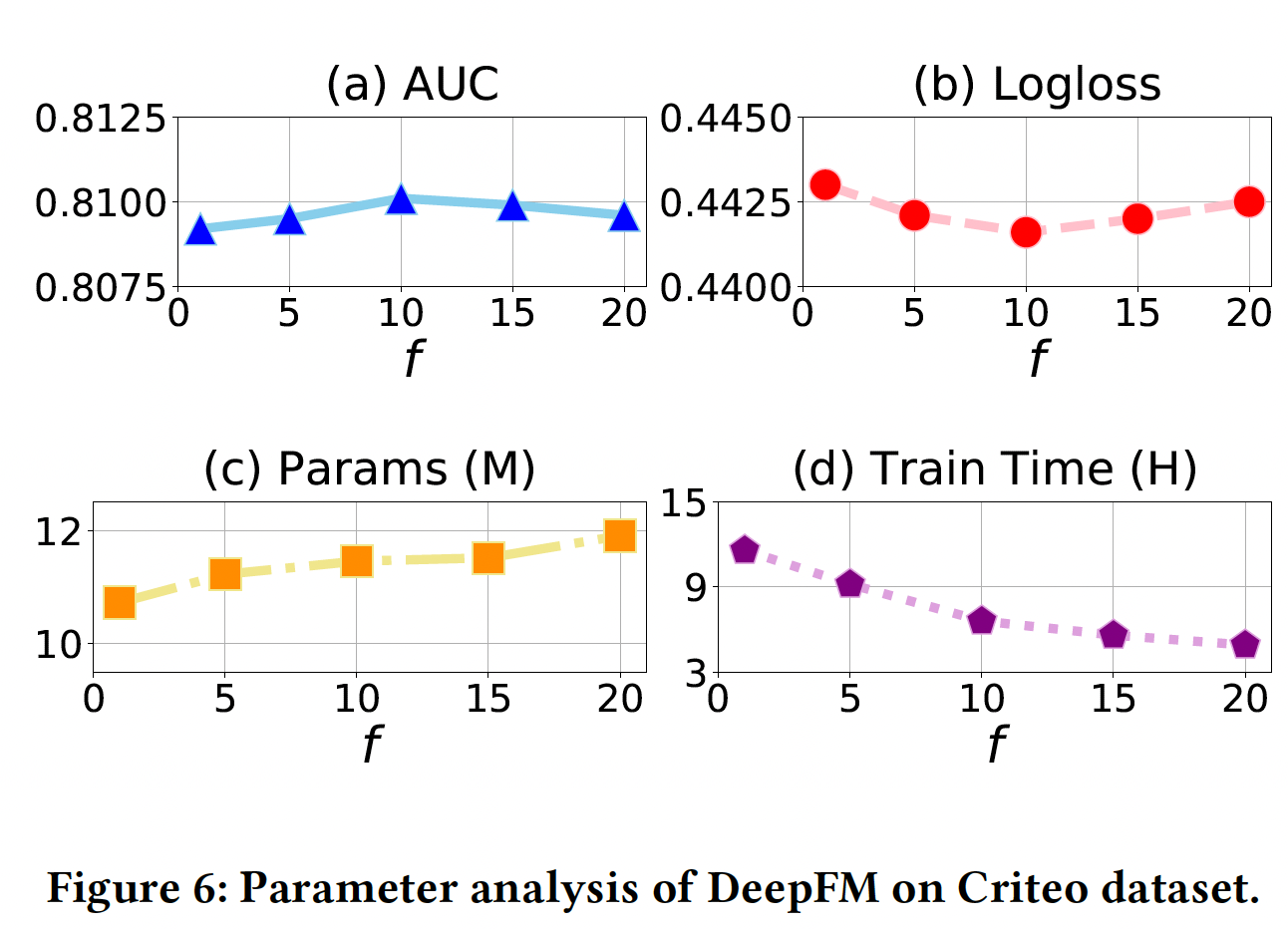
超参数研究:除了深度推荐系统常见的超参数(如隐层的数量,由于篇幅有限,我们省略这种常规超参数的分析),我们的模型有一个特殊的超参数,即更新
AutoDim优化过程中,我们交替地在训练数据上更新DLRS的参数、在验证数据上更新DLRS的参数,这显然减少了大量的计算,也提高了性能。为了研究
AutoDim的DeepFM在Criteo数据集上的表现如何。结果如下表所示,x轴上,DLRS参数。从图
(a), (b)可以看到,当AutoDim达到了最佳AUC/Logloss。换句话说,更新从图
(d)可以看到,与设置50%∼的训练时间。从图
(c)可以看到,较低的Params,反之亦然。原因是AutoDim通过最小化验证损失来更新当频繁更新
AutoDim倾向于选择较小的embedding size,具有更好的泛化能力,同时可能存在欠拟合问题。而当不频繁地更新
AutoDim倾向于选择较大的embedding size,在训练集上表现更好,但可能导致过拟合问题。
案例研究:这里我们研究
AutoDim是否可以为更重要的特征分配更大的embedding维度。由于Criteo的feature field是匿名的,我们在MovieLens-1m数据集上应用具有AutoDim的W&D。MovieLens-1m数据集有categorical feature field:movieId, year, genres, userId, gender, age, occupation, zip。由于MovieLens-1m比Criteo小得多,我们将候选embedding维度设定为{2, 4, 8, 16}。为了衡量一个
feature field对最终预测的贡献,我们只用这个field建立一个W&D模型,训练这个模型并在测试集上评估。较高的AUC和较低的Logloss意味着该feature field更有predictive。然后,我们建立一个包含所有
feature field的、全面的W&D模型,并应用AutoDim来选择维度。结果如下表所示:没有一个
feature field被分配到16维的embedding空间,这意味着候选embedding维度{2, 4, 8, 16}足以覆盖所有可能的选择。对比每个
feature field的W&D的AUC/Logloss,我们可以发现,AutoDim为重要的(高预测性的)feature field分配了较大的embedding维度,如movieId和userId,反之亦然。我们建立了一个
full dimension embedding: FDE版本的W&D,其中所有的feature field都被分配为最大维度16。其表现为AUC=0.8077, Logloss=0.5383,而带有AutoDim的W&D的表现为AUC=0.8113, Logloss=0.5242,并且后者节省了57%的embedding参数。
总之,上述观察结果验证了
AutoDim可以将更大的embedding维度分配给更predictive的feature field。