一、AutoDis [2021]
《An Embedding Learning Framework for Numerical Features in CTR Prediction》
如下图所示,大多数现有的深度
CTR模型遵循Embedding & Feature Interaction (FI)的范式。由于特征交互在CTR预测中的重要性,大多数工作集中在设计FI模块的网络架构从而更好地捕获显式特征交互或隐式特征交互。虽然在文献中没有很好的研究,但embedding模块也是深度CTR模型的一个关键因素,原因有二:embedding模块是后续FI模块的基石,直接影响FI模块的效果。深度
CTR模型中的参数数量大量集中在embedding模块,自然地对预测性能有很高的影响。
然而,
embedding模块被研究界所忽视,这促使《An Embedding Learning Framework for Numerical Features in CTR Prediction》进行深入研究。embedding模块通常以look-up table的方式工作,将输入数据的每个categorical field特征映射到具有可学习参数的潜在embedding空间。不幸的是,这种categorization策略不能用于处理数值特征,因为在一个numerical field(如身高)可能有无限多的特征取值。在实践中,现有的数值特征的
representation方法可以归纳为三类(如下图的红色虚线框):No Embedding:直接使用原始特征取值或转换,而不学习embedding。Field Embedding:为每个numerical field学习单个field embedding。Discretization:通过各种启发式离散化策略将数值特征转换为categorical feature,并分配embedding。
然而,前两类可能会由于
representation的低容量而导致性能不佳。最后一类也是次优的,因为这种基于启发式的离散化规则不是以CTR模型的最终目标进行优化的。此外,hard discretization-based的方法受到Similar value But Dis-similar embedding: SBD和Dis-similar value But Same embedding: DBS问题的影响,其细节将在后面讨论。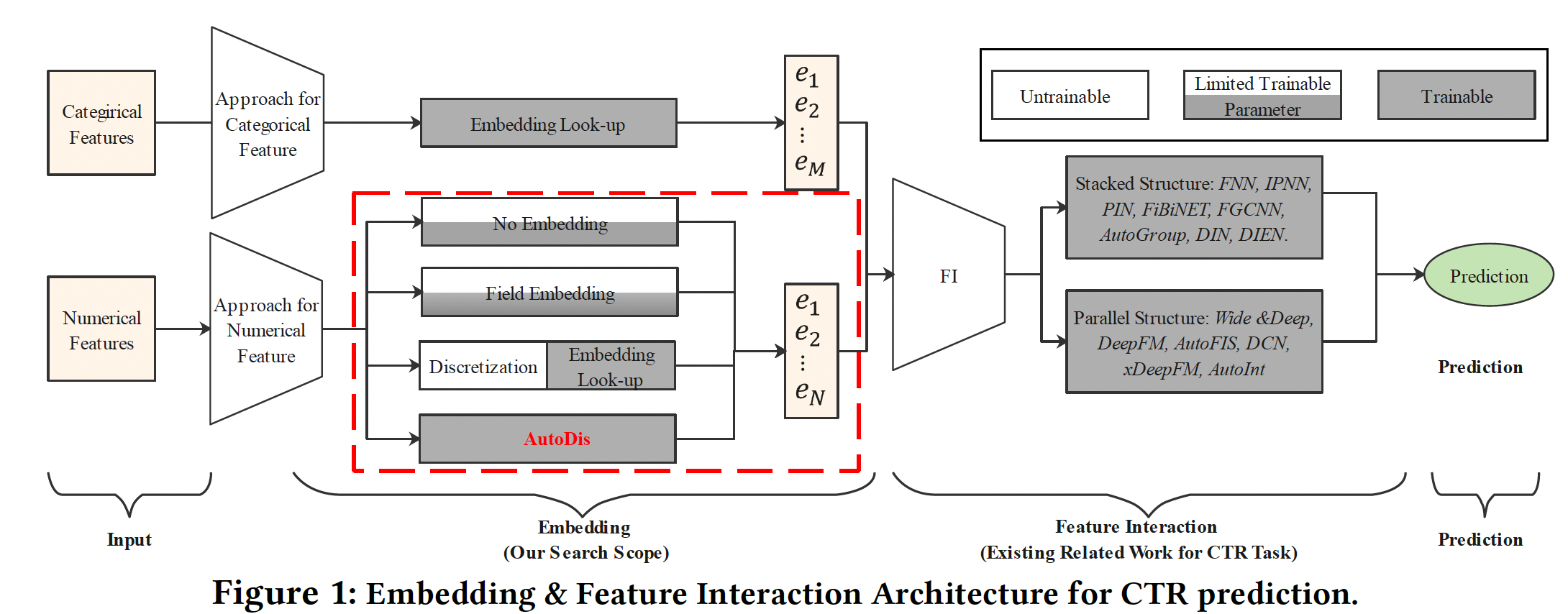
为了解决现有方法的局限性,论文
《An Embedding Learning Framework for Numerical Features in CTR Prediction》提出了一个基于soft discretization的数值特征的automatic end-to-end embedding learning framework,即AutoDis。AutoDis由三个核心模块组成:meta-embedding、automatic discretization和aggregation,从而实现高的模型容量、端到端的训练、以及unique representation等特性。具体而言:首先,论文为每个
numerical field精心设计了一组meta-embedding,这些meta-embedding在该field内的所有特征取值之间是共享的,并从field的角度学习全局知识,其中embedding参数的数量是可控的。然后,利用可微的
automatic discretization模块进行soft discretization,并且捕获每个数值特征和field-specific meta-embedding之间的相关性。最后,利用一个
aggregation函数从而学习unique Continuous-But-Different representation。
据作者所知,
AutoDis是第一个用于numerical feature embedding的端到端soft discretization框架,可以与深度CTR模型的最终目标共同优化。论文主要贡献:
论文提出了
AutoDis,一个可插拔的用于numerical feature的embedding learning框架,它具有很高的模型容量,能够以端到端的方式生成unique representation并且具有可管理的参数数量。在
AutoDis中,论文为每个numerical field设计了meta-embedding从而学习全局的共享知识。此外,一个可微的automatic discretization被用来捕获数值特征和meta-embedding之间的相关性,而一个aggregation过程被用来为每个特征学习一个unique Continuous-But-Different representation。在两个公共数据集和一个工业数据集上进行了综合实验,证明了
AutoDis比现有的数值特征的representation方法更有优势。此外,AutoDis与各种流行的深度CTR模型兼容,大大改善了它们的推荐性能。在一个主流广告平台的online A/B test表明,AutoDis在CTR和eCPM方面比商业baseline提高了2.1%和2.7%。
相关工作:
Embedding:作为深度CTR模型的基石,embedding模块对模型的性能有重大影响,因为它占用了大部分的模型参数。我们在此简单介绍推荐领域中基于embedding look-up的研究。现有的研究主要集中在设计
adaptable的embedding算法,通过为不同的特征分配可变长度的embedding或multi-embeddings,如Mixed-dimension(《Mixed dimension embeddings with application to memory-efficient recommendation systems》),NIS(《Neural Input Search for Large Scale Recommendation Models》)和AutoEmb(《AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations》)。另一条研究方向深入研究了
embedding compression,从而减少web-scale数据集的内存占用。然而,这些方法只能以
look-up table的方式应用于categorical feature、或离散化后的数值特征。很少有研究关注数值特征的embedding learning,这在工业的深度CTR模型中是至关重要的。Feature Interaction:根据显式特征交互和隐式特征交互的不同组合,现有的CTR模型可以分为两类:堆叠结构、并行结构。堆叠结构:首先对
embeddings进行建模显示特征交互,然后堆叠DNN来抽取high-level的隐式特征交互。代表性的模型包括FNN、IPNN、PIN、FiBiNET、FGCNN、AutoGroup、DIN和DIEN。并行结构:利用两个并行网络分别捕捉显式特征交互信号和隐式特征交互信号,并在输出层融合信息。代表性的模型包括
Wide & Deep、DeepFM、AutoFIS、DCN、xDeepFM和AutoInt。在这些模型中,隐式特征交互是通过
DNN模型提取的。而对于显式特征交互,Wide & Deep采用手工制作的交叉特征,DeepFM和AutoFIS采用FM结构,DCN采用cross network,xDeepFM采用Compressed Interaction Network: CIN,AutoInt利用多头自注意力网络。
1.1 模型
1.1.1 基础概念
假设用于训练
CTR模型的数据集由categorical fields和numerical fields的multi-field数据记录:其中:
numerical field的标量值;categorical field的特征取值的one-hot vector。对于第
categorical field,可以通过embedding look-up操作获得feature embedding:其中:
categorical field的embedding matrix,embedding size,categorical field的词表规模。因此,
categorical field的representation为:对于
numerical field,现有的representation方法可以总结为三类:No Embedding、Field Embedding、Discretization。No Embedding:这种方式直接使用原始值或原始值的变换,而不学习embedding。例如,Google Play的Wide & Deep和JD.com的DMT分别使用原始数值特征和归一化的数值特征。此外,YouTube DNN利用了归一化特征取值在
Facebook的DLRM中,他们使用了一个多层感知机来建模所有的数值特征:其中
DNN的结构为512-256-d,直观而言,这些
No Embedding方法由于容量太小,很难捕获到numerical field的informative知识。Field Embedding:学术界常用的方法是Field Embedding,即同一个field内的的所有数值特征共享一个uniform field embedding,然后将这个field embedding与它们的特征取值相乘:其中:
numerical field的uniform embedding vector。然而,由于单个共享的
field-specific embedding、以及field内不同特征之间的线性缩放关系,Field Embedding的representation容量是有限的。例如,收入
Field Embedding的做法:即,收入分别为
1和10000的两个用户,其相似度大于收入分别为1和1的两个用户。这在实际场景中是不恰当的。Discretization:在工业推荐系统中,处理数值特征的一个流行方法是Discretization,即把数值特征转化为categorical feature。对于第numerical field的特征feature embeddingdiscretization)和embedding look-up:其中:
numerical field的embedding matrix;numerical field人工设计的离散化函数,它将该特征内的每个特征取值映射到具体来说,有三种广泛使用的离散化函数:
Equal Distance/Frequency Discretization: EDD/EFD:EDD将特征取值划分到numerical field的特征取值范围为interval width)定义为EDD离散化函数类似地,
EFD将范围Logarithm Discretization: LD:Kaggle比赛中Criteo advertiser prediction的冠军利用对数和floor操作将数值特征转化为categorical形式。离散化后的结果LD离散化函数Tree-based Discretization: TD:除了深度学习模型外,tree-based模型(如GBDT)在推荐中被广泛使用,因为它们能够有效地处理数值特征。因此,许多tree-based方法被用来离散化数值特征。
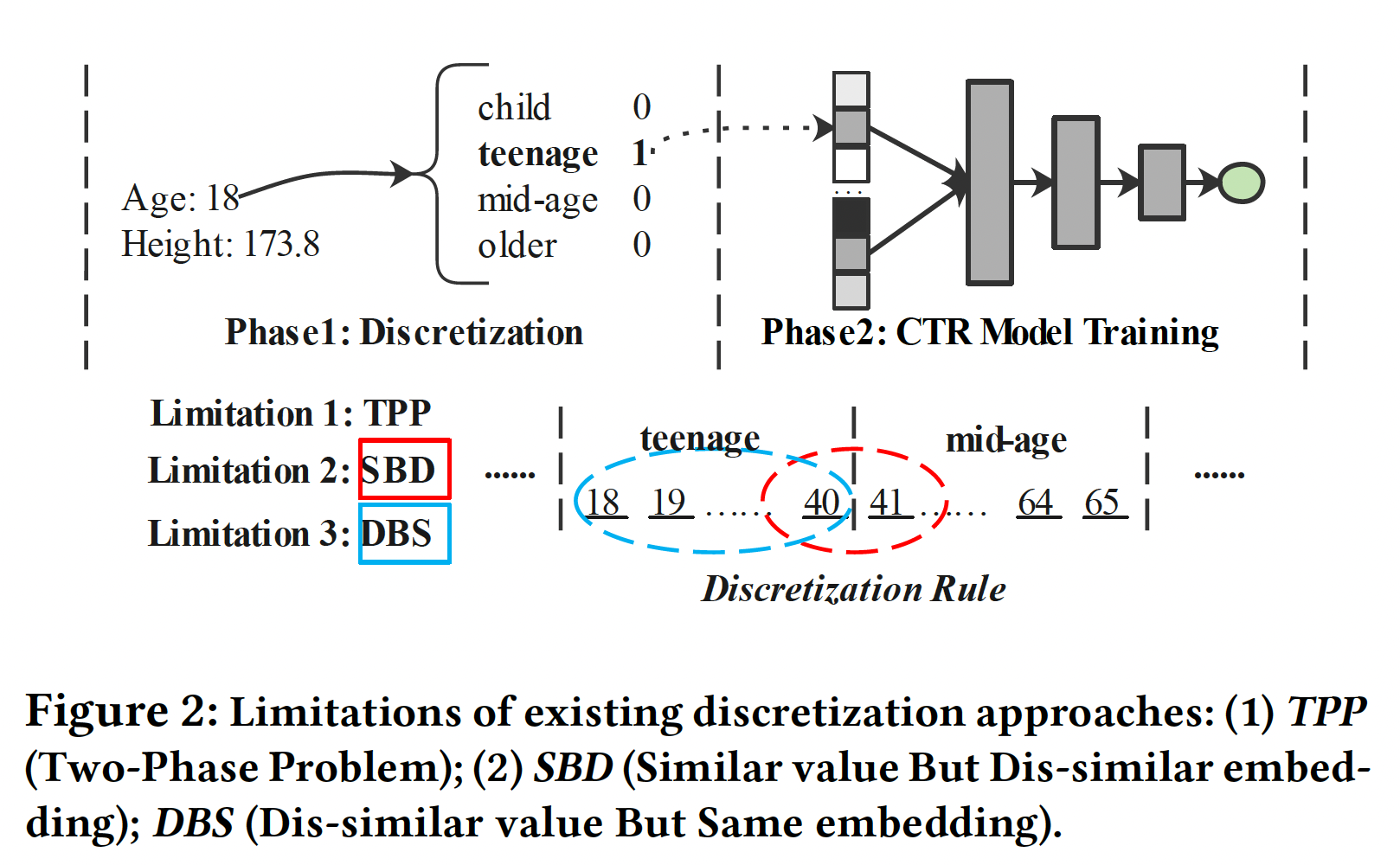
虽然
Discretization在工业界被广泛使用,但它们仍然有三个限制(如下图所示):Two-Phase Problem: TPP:离散化过程是由启发式规则或其他模型决定的,因此它不能与CTR预测任务的最终目标一起优化,导致次优性能。Similar value But Dis-similar embedding: SBD:这些离散化策略可能将类似的特征(边界值)分离到两个不同的桶中,因此它们之后的embedding明显不同。例如,
Age field常用的离散化是将[18,40]确定为青少年、[41,65]确定为中年,这导致数值40和41的embedding明显不同。Dis-similar value But Same embedding: DBS:现有的离散化策略可能将明显不同的元素分组同一个桶中,导致无法区分的embedding。使用同一个例子(Age field),18和40之间的数值在同一个桶里,因此被分配了相同的embedding。然而,18岁和40岁的人可能具有非常不同的特征。基于离散化的策略不能有效地描述数值特征变化的连续性。
综上所述,下表中列出了
AutoDis与现有representation方法的三方面比较。我们可以观察到,这些方法要么因为容量小而难以捕获informative知识、要么需要专业的特征工程,这些可能会降低整体性能。因此,我们提出了AutoDis框架。据我们所知,它是第一个具有高模型容量、端到端训练、以及保留unique representation特性的numerical features embedding learning框架。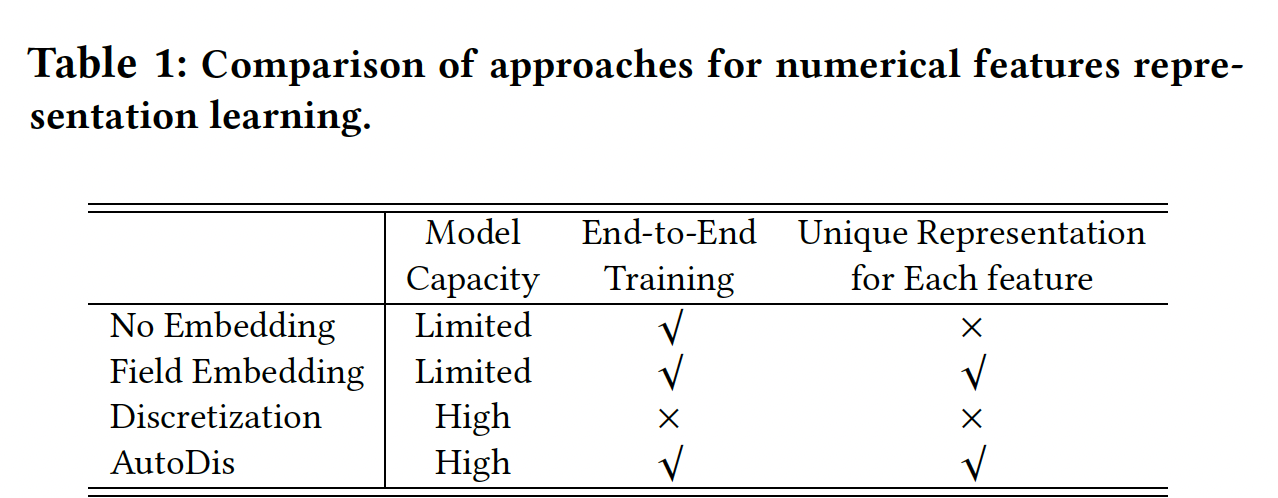
1.1.2 AutoDis
AutoDis框架如Figure 3所示,它可以作为针对数值特征的可插拔的embedding framework,与现有的深度CTR模型兼容。AutoDis包含三个核心模块:meta-embedding、automatic discretization、aggregation。代码实现比较简单直观: 数值特征
DNN网络(隐层维度为relu激活函数) -> 带skip-connection的单层DNN网络(隐层维度为softmax激活函数) -> 单层DNN网络(隐层维度为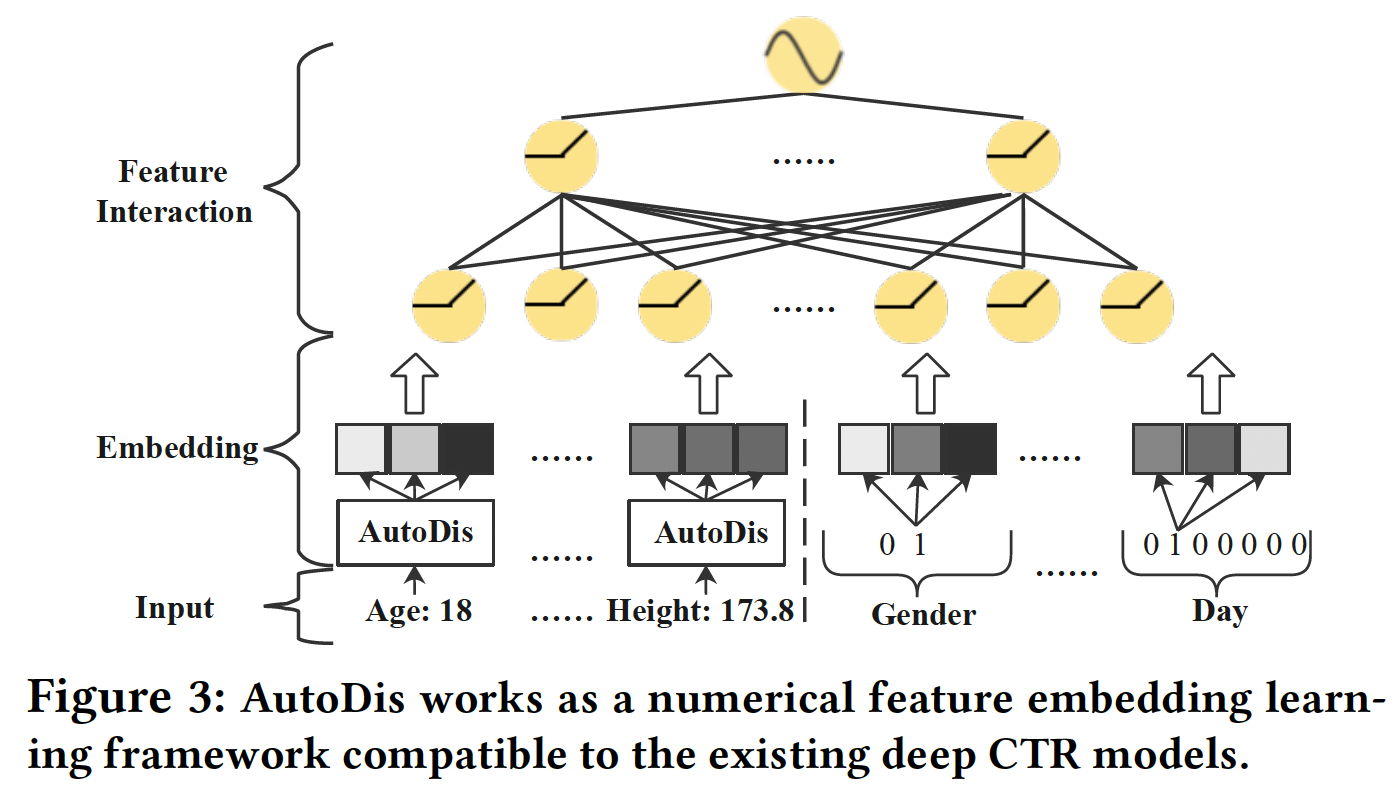
对于第
numerical field,AutoDis可以通过如下方式为每个数值特征unique representation(如Figure 4所示):其中:
numerical field的meta-embedding matrix。numerical field的automatic discretization函数。所有
numerical field都使用相同的聚合函数。
最后,
categorical特征和数值特征的embedding被拼接起来,并馈入一个深度CTR模型进行预测: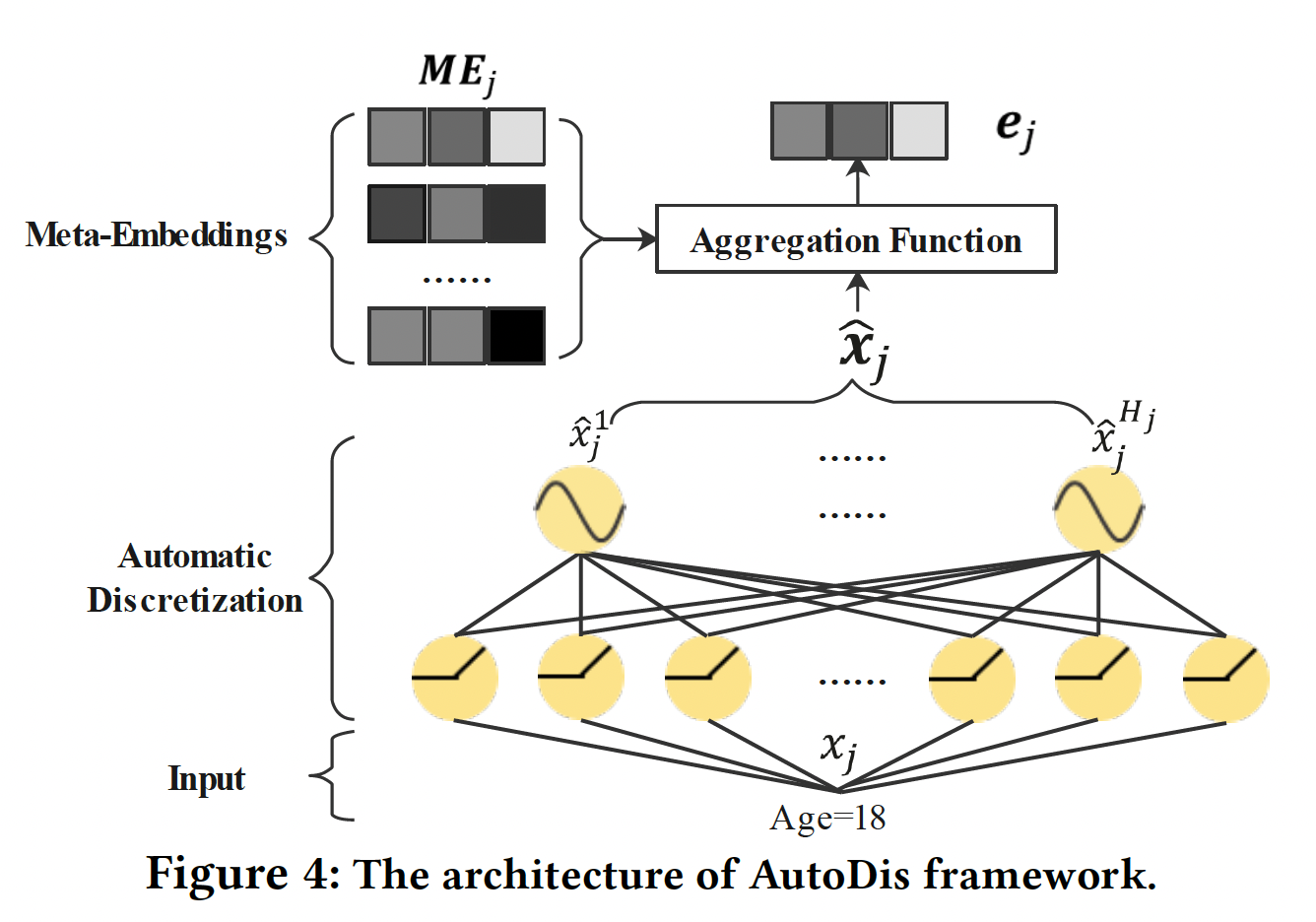
Meta-Embeddings:为了平衡模型的容量和复杂性,对于第numerical field,我们设计了一组meta-embeddingsfield内的特征所共享,meta-embedding的数量。 每个meta-embedding可以被看作是潜在空间中的一个子空间,用于提高表达能力和容量。通过结合这些meta-embedding,学习到的embedding比Field Embedding方法更informative,因此可以很好地保留高的模型容量。此外,所需参数的数量由scalable。对于不同的
fieldfield,field,Automatic Discretization:为了捕获数值特征的值和所设计的meta-embeddings之间的复杂关联,我们提出了一个可微的automatic discretization模块numerical field的每个数值特征被离散化到bucket embedding对应于上面提到的meta-embedding。具体而言,利用一个带有
skip-connection的两层神经网络,将numerical field特征取值其中:
automatic discretization network在第numerical feature field上的可学习参数。Leaky-ReLU为激活函数,skip-connection的控制因子(control factor)。
投影结果为:
numerical field特征取值Softmax函数将numerical field特征取值meta-embedding其中:
discretization分布。因此,通过automatic discretization函数numerical field特征取值numerical field特征取值meta-embedding(即bucket embedding)之间的相关性。这种离散化方法可以理解为soft discretization。与前面提到的hard discretization相比,soft discretization没有将特征取值离散化到一个确定的桶中,这样就可以很好地解决SBD和DBS问题。此外,可微的soft discretization使我们的AutoDis能够实现端到端的训练,并以最终目标进行优化。值得注意的是:当温度系数
discretization分布趋于均匀分布;当discretization分布趋于one-hot分布。因此,温度系数automatic discretization distribution中起着重要作用。此外,不同field的特征分布是不同的,因此对不同的features学习不同的temperature coefficient adaptive network)(双层网络),它同时考虑了global field statistics feature和local input feature,公式如下:其中:
numerical field特征的全局统计特征向量,包括:采样的累积分布函数Cumulative Distribution Function: CDF、均值。local input feature。
为了指导模型训练,
rescale为这个温度系数自适应网络的设计不太简洁,工程实现也更复杂。根据实验部分的结论,这里完全可以微调
global温度来实现。Aggregation Function:在得到feature value和meta-embeddings之间的相关性后,可以通过对meta-embeddings进行聚合操作embedding。我们考虑了以下聚合函数Max-Pooling:选择最相关的meta-embedding(具有最高概率其中:
meta-embedding的索引,meta-embedding。然而,这种
hard selection策略使AutoDis退化为一种hard discretization方法,从而导致上述的SBD问题和DBS问题。Top-K-Sum:将具有最高相关性top-K个meta-embedding相加:其中
meta-embedding的索引,meta-embedding。然而,
Top-K-Sum方法有两个局限性:尽管与
Max-Pooling相比,可能生成的embedding数量从DBS问题。学习到的
embedding
Weighted- Average:充分地利用整个meta-embeddings集合、以及meta-embedding与特征取值的相关性:通过这种加权聚合策略,相关的元嵌入对提供一个信息丰富的嵌入有更大的贡献,而不相关的元嵌入则在很大程度上被忽略了。此外,这种策略保证了每个特征都能学到
unique representation,同时,学到的embedding是Continuous-But-Different,即,特征取值越接近则embedding就越相似。
训练:
AutoDis是以端到端的方式与具体的深度CTR模型的最终目标共同训练的。损失函数是广泛使用的带有正则化项的LogLoss:其中:
ground truth label和预测结果;L2正则化系数;categorical field的feature embedding参数、meta-embedding和automatic discretization参数、以及深度CTR模型的参数。为了稳定训练过程,我们在数据预处理阶段采用了特征归一化技术,将数值特征取值缩放到
[0, 1]。第numerical field的取值
1.2 实验
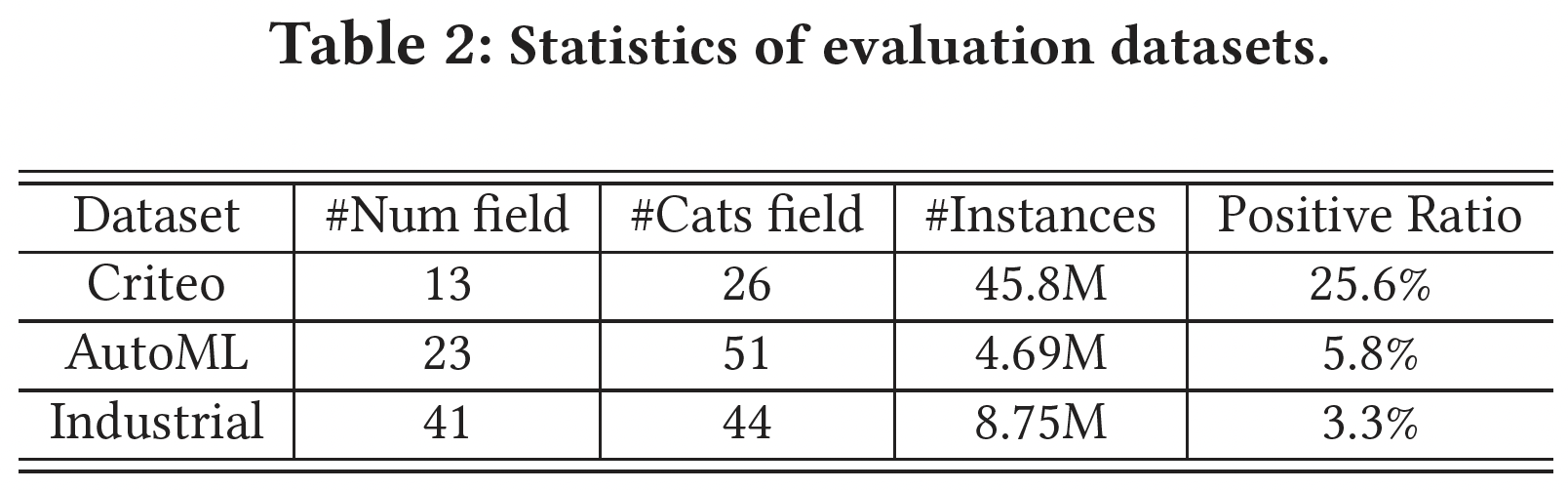
数据集:
Criteo:Criteo Display Advertising Challenge 2013发布的,包含13个numerical feature field。AutoML:AutoML for Lifelong Machine Learning Challenge in NeurIPS 2018发布的,包含23个numerical feature field。工业数据集:从一个主流的在线广告平台上采样收集的,有
41个numerical feature field。
数据集的统计数据如下表所示。
评估指标:
AUC, LogLoss。所有的实验都通过改变随机数种子重复
5次。采用two-tailed unpaired t-test来检测AutoDis和最佳baseline之间的显著差异。baseline方法:为了证明所提出的AutoDis的有效性,我们将AutoDis与数值特征的三类representation learning方法进行了比较:No Embedding(YouTube, DLRM)、Field Embedding: FE(DeepFM)、Discretization(EDD,如IPNN;LD以及TD,如DeepGBM)。此外,为了验证
AutoDis框架与embedding-based的深度CTR模型的兼容性,我们将AutoDis应用于六个代表性模型:FNN、Wide & Deep、DeepFM、DCN、IPNN、xDeepFM。实现:
我们用
mini-batch Adam优化所有的模型,其中学习率的搜索空间为{10e-6, 5e-5, ... , 10e-2}。此外,在
Criteo和AutoML数据集中,embedding size分别被设置为80和70。深度
CTR模型中的隐层默认固定为1024-512-256-128,DCN和xDeepFM中的显式特征交互(即CrossNet和CIN)被设置为3层。L2正则化系数的搜索空间为{10e-6, 5e-5, ... , 10e-3}。对于
AutoDis,每个numerical field的meta-embedding数量为:Criteo数据集为20个,AutoML数据集为40个。skip-connection控制因子的搜索空间为{0, 0.1, ... , 1},temperature coefficient adaptive network的神经元数量设置为64
和其它
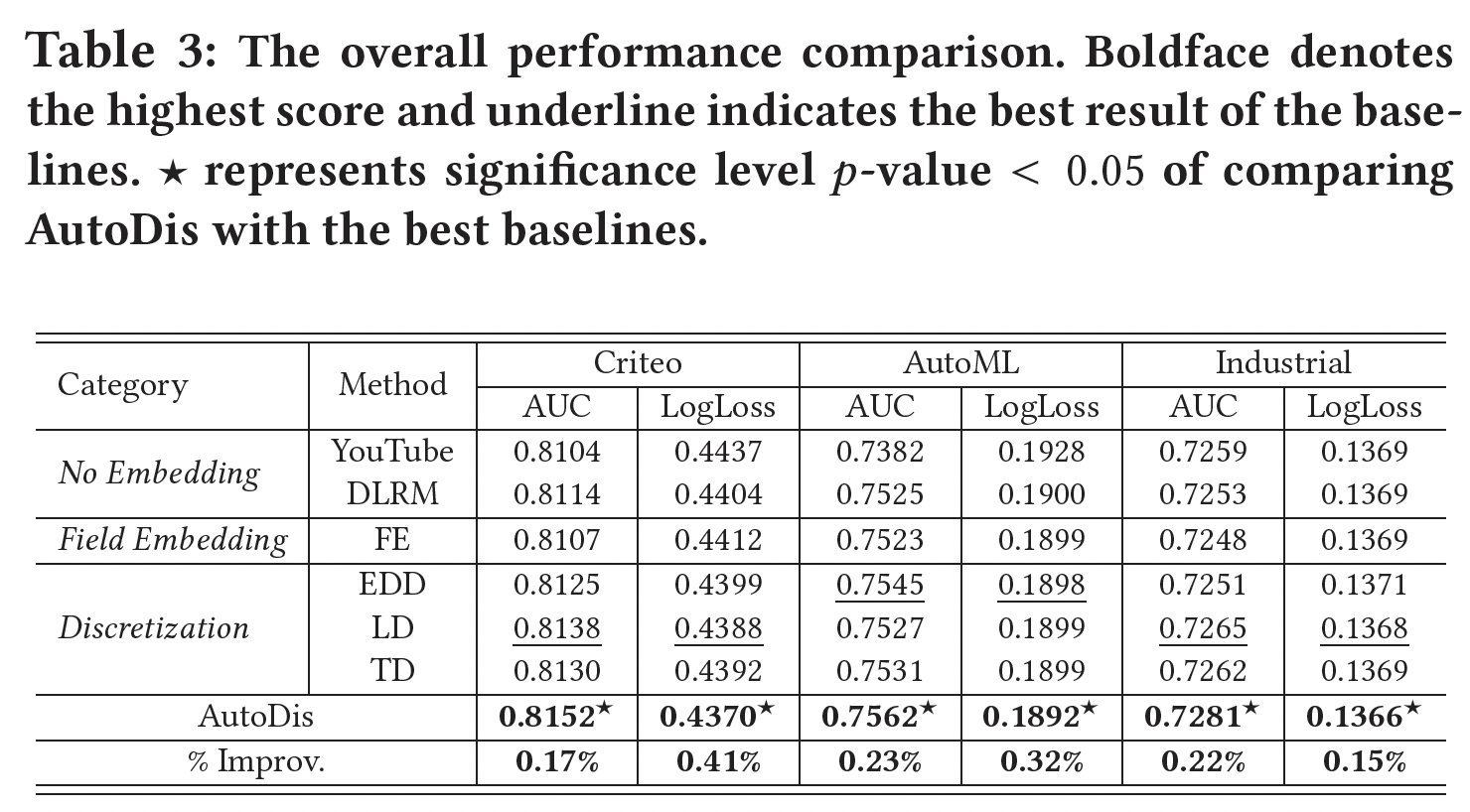
Representation Learning方法的比较:我们在三个数据集上执行不同的numerical feature representation learning方法,并选择DeepFM作为深度CTR模型。结果如下表所示。可以看到:AutoDis在所有数据集上的表现都远远超过了所有的baseline,显示了其对不同数值特征的优越性和鲁棒性。No Embedding和Field Embedding方法的表现比Discretization和AutoDis更差。No Embedding和Field Embedding这两类方法存在容量低和表达能力有限的问题。No Embedding, Field Embedding二者之间的差距不大,基本上在0.1%以内。与现有的三种将数值特征转化为
categorical形式的Discretization方法相比,AutoDis的AUC比最佳baseline分别提高了0.17%、0.23%、以及0.22%。
不用
CTR模型的比较:AutoDis是一个通用框架,可以被视为改善各种深度CTR模型性能的插件。为了证明其兼容性,这里我们通过在一系列流行的模型上应用AutoDis进行了广泛的实验,结果如下表所示。可以看到:与Field Embedding representation方法相比,AutoDis框架显著提高了这些模型的预测性能。numerical feature discretization和embedding learning过程的优化是以这些CTR模型为最终目标的,因此可以得到informative representation,性能也可以得到提高。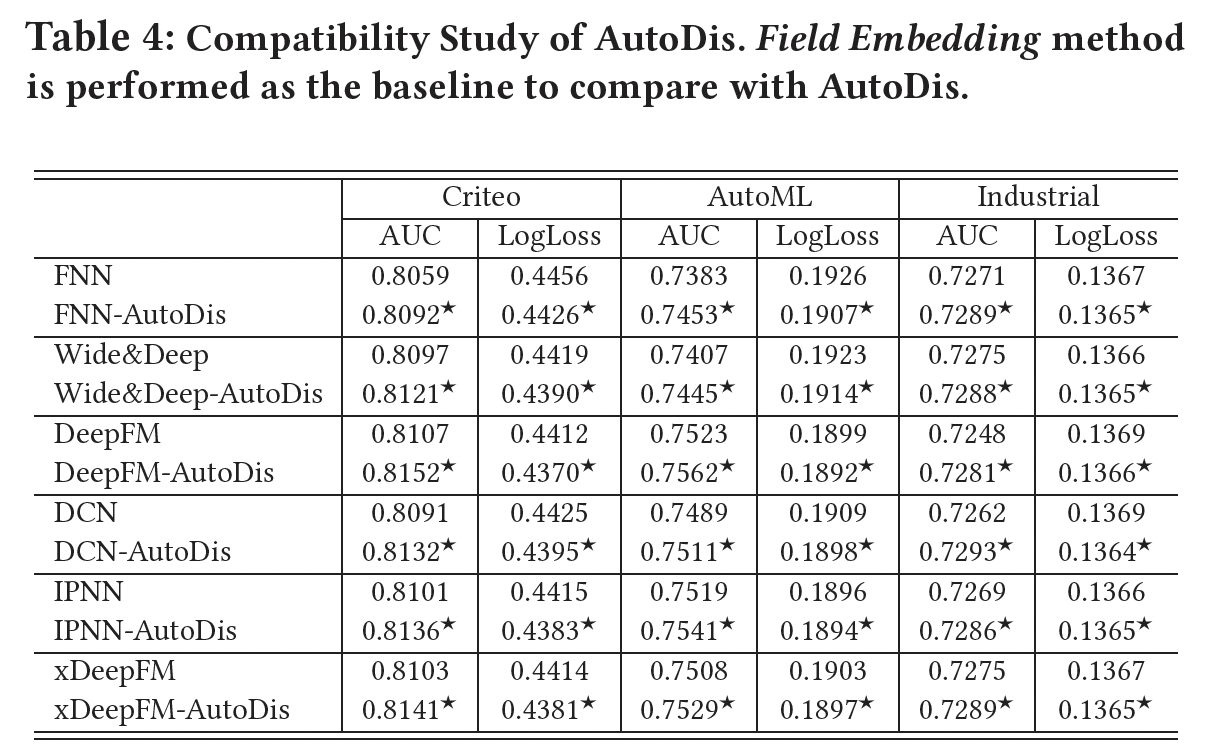
Online A/B Testing:我们在一个主流广告平台上进行在线实验从而验证AutoDis的优越性能,该平台每天有数百万活跃用户与广告互动,并产生数千万的用户日志事件。对于控制组,数值特征通过hybrid manually-designed rules(如EDD、TD等)进行离散化。实验组则选择AutoDis对所有数值特征进行离散化和自动学习embedding。将AutoDis部署到现有的CTR模型中很方便,几乎不需要online serving系统的工程工作。AutoDis实现了0.2%的离线AUC的提升。此外,相对于对照组,实验组在线CTR和eCPM分别提升了2.1%和2.7%(统计学意义),这带来了巨大的商业利润。此外,随着
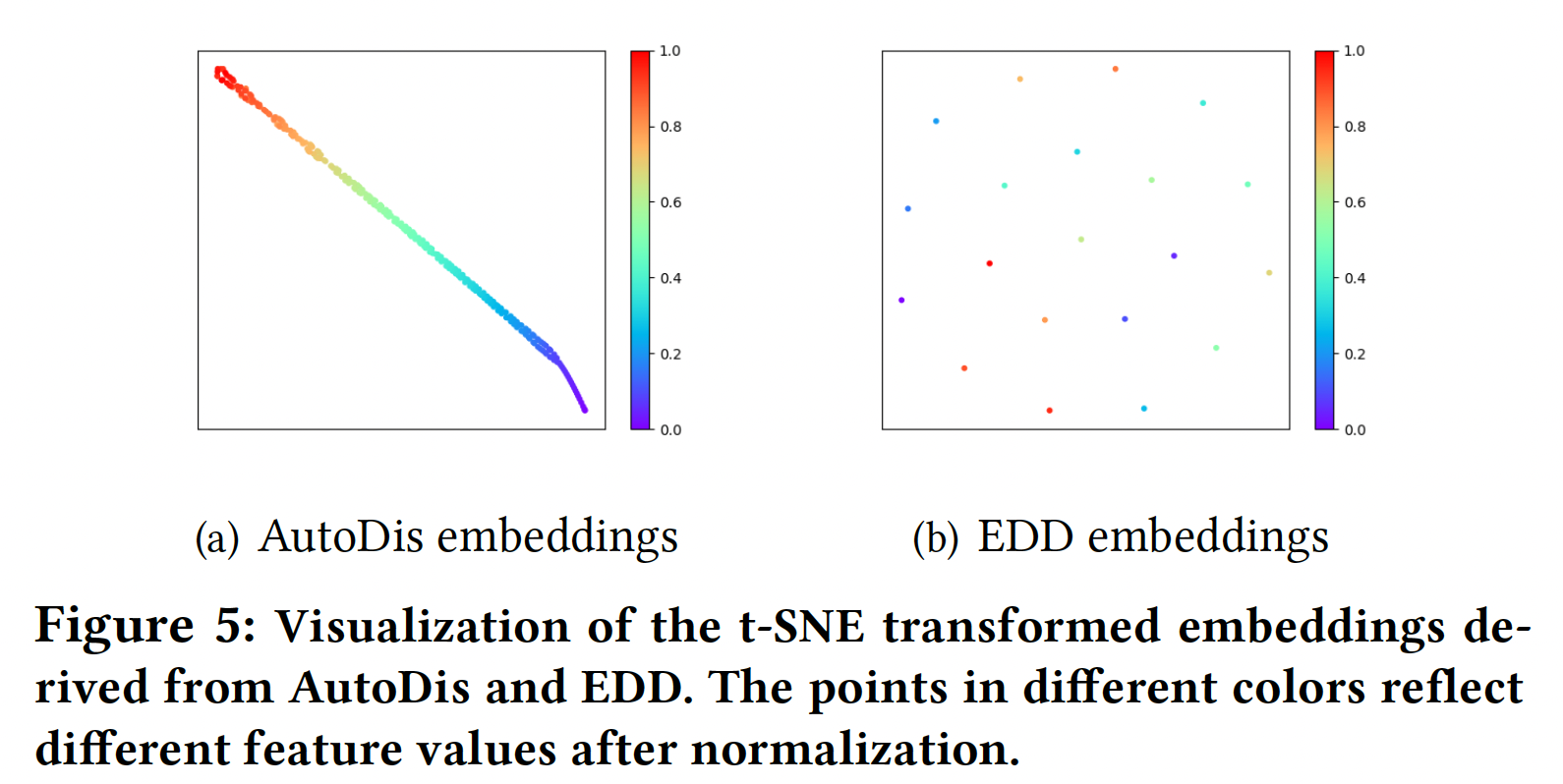
AutoDis的融合,现有的数值特征不再需要任何离散化规则。此外,在未来引入更多的数值特征将更加有效,而不需要探索任何人工制作的规则。Embedding Analysis:为了更深入地理解通过AutoDis学到的Continuous-But-Different embedding,我们分别在embeddings的宏观分析、以及soft discretization的微观分析中做了进一步的调研。Embeddings的宏观分析:下图提供了DeepFM-AutoDis和DeepFM-EDD在Criteo数据集的第3个numerical field中得出的embedding的可视化。我们随机选择250个embedding,并使用t-SNE将它们投影到一个二维空间。具有相似颜色的节点具有相似的值。可以看到:AutoDis为每个特征学习了一个unique embedding。此外,相似的数值特征(具有相似的颜色)由密切相关的embeddings(在二维空间中具有相似的位置)来表示,这阐述了embedding的Continuous-But-Different的特性。然而,
EDD为一个桶中的所有特征学习相同的embedding、而在不同的桶中学习完全不同的embedding,这导致了to step-wise "unsmooth" embedding,从而导致了较差的任务表现。
Soft Discretization的微观分析:我们通过调查DeepFM-AutoDis的soft discretization过程中的Softmax分布进行一些微观分析。我们从Criteo数据集的第8个numerical field中选择一个相邻的feature-pair(特征取值为1和2)、以及一个相距较远的feature-pair(特征取值为1和10),然后在下图中可视化它们的discretization distribution。可以看到:相邻的feature-pair具有相似的Softmax分布,而相距较远的feature-pair具有不同的分布。这一特点有利于保证相似的特征取值能够通过
AutoDis学习相似的embedding,从而保持embedding的连续性。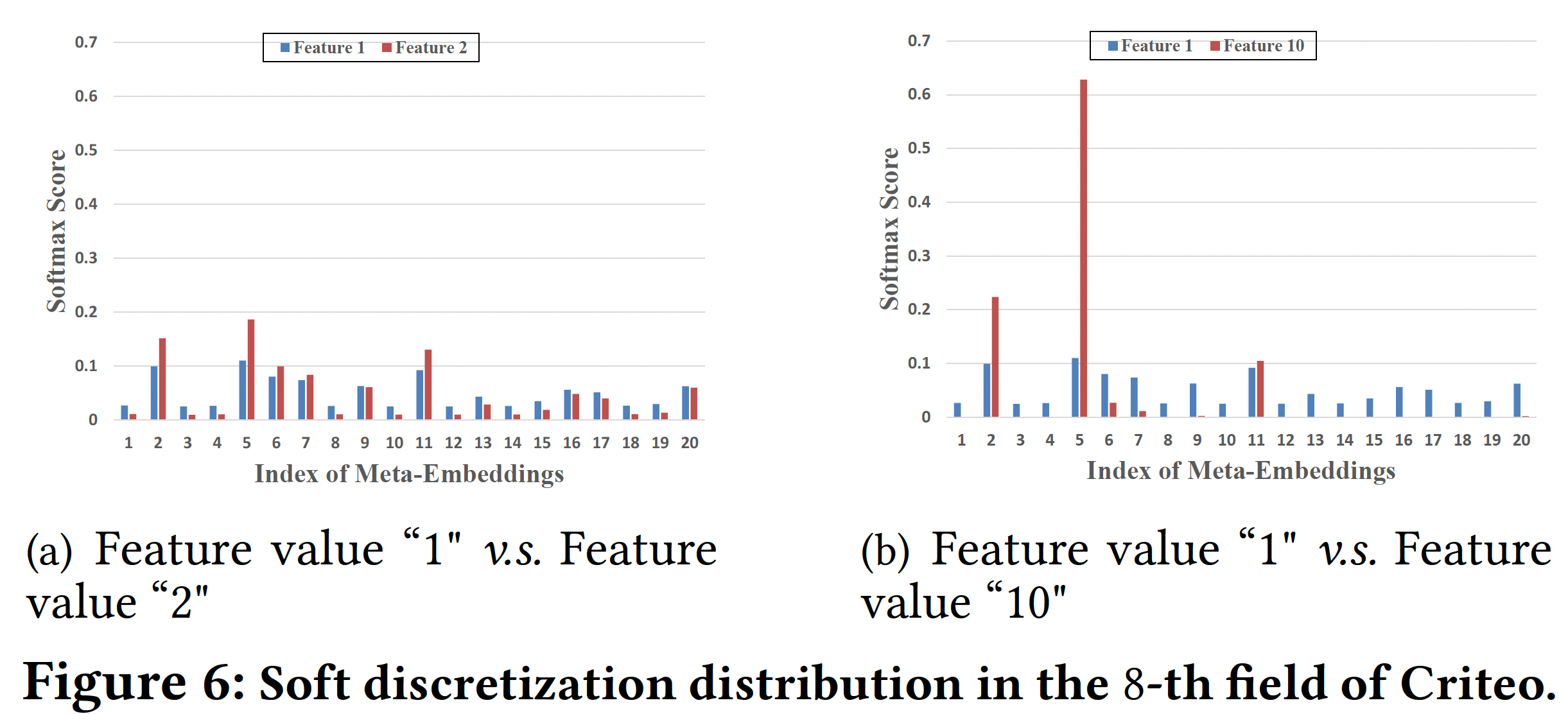
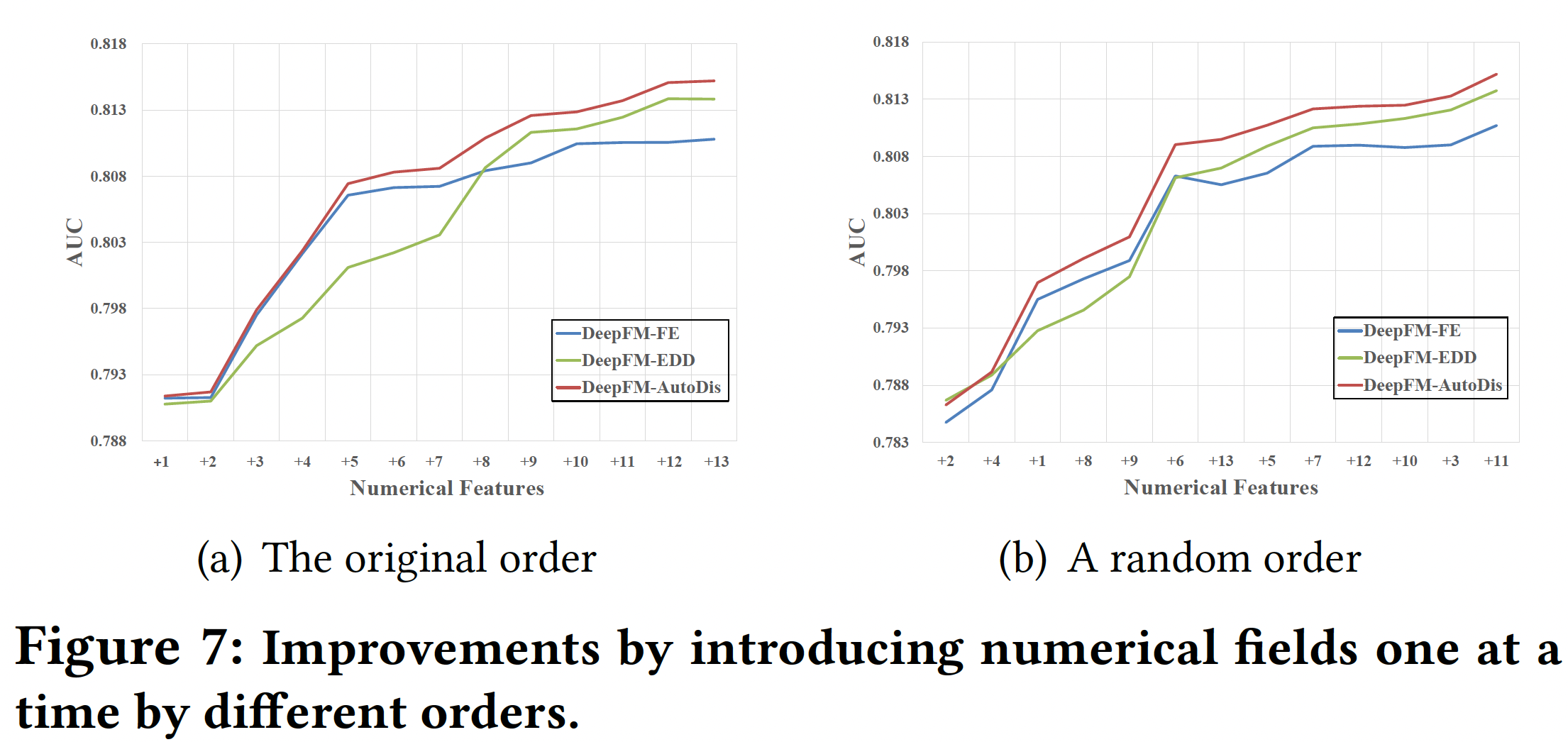
Numerical Fields Analysis:为了评估DeepFM-AutoDis对每个numerical field的影响,在Criteo数据集中,我们选择了所有26个categorical fields作为基础特征,并每次累积添加13个numerical fields中的一个。下图展示了根据数据集的原始顺序和随机顺序添加numerical fields的预测性能。可以看到:即使只有一个
numerical field,AutoDis也能提高性能。AutoDis对多个numerical fields具有cumulative improvement。与现有方法相比,
AutoDis取得的性能改善更加显著和稳定。
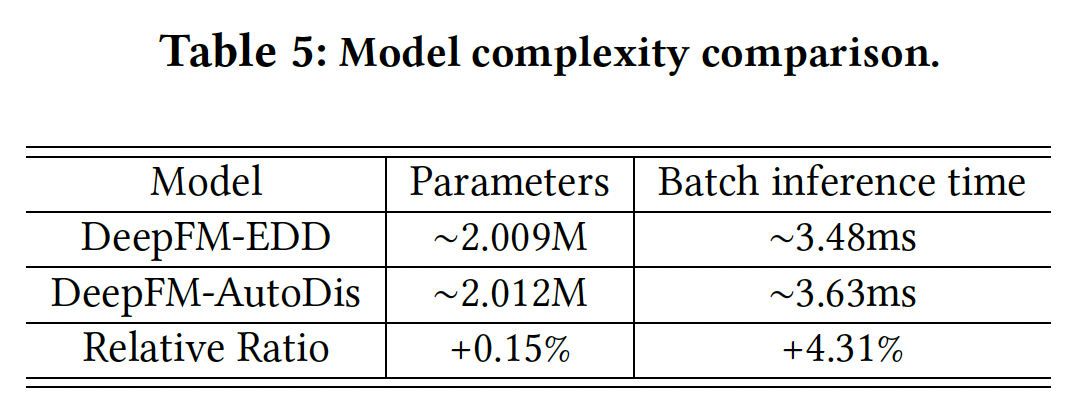
Model Complexity:为了定量分析我们提出的AutoDis的空间复杂度和时间复杂度,我们比较了DeepFM上的EDD离散化方法的模型参数、以及batch inference time,结果如下表所示。可以看到:与
EDD相比,AutoDis增加的模型参数量可以忽略不计。此外,
AutoDis的计算效率也是可比的。
消融研究和超参数敏感性:
聚合策略:下图总结了
DeepFM-AutoDis采用Max-Pooling、Top-K-Sum、Weighted-Average等聚合策略的预测性能。可以看到:Weighted-Average策略实现了最好的性能。原因是:与其他策略相比,Weighted-Average策略充分利用了meta-embeddings及其相应的关联性,完全克服了DBS和SBD问题。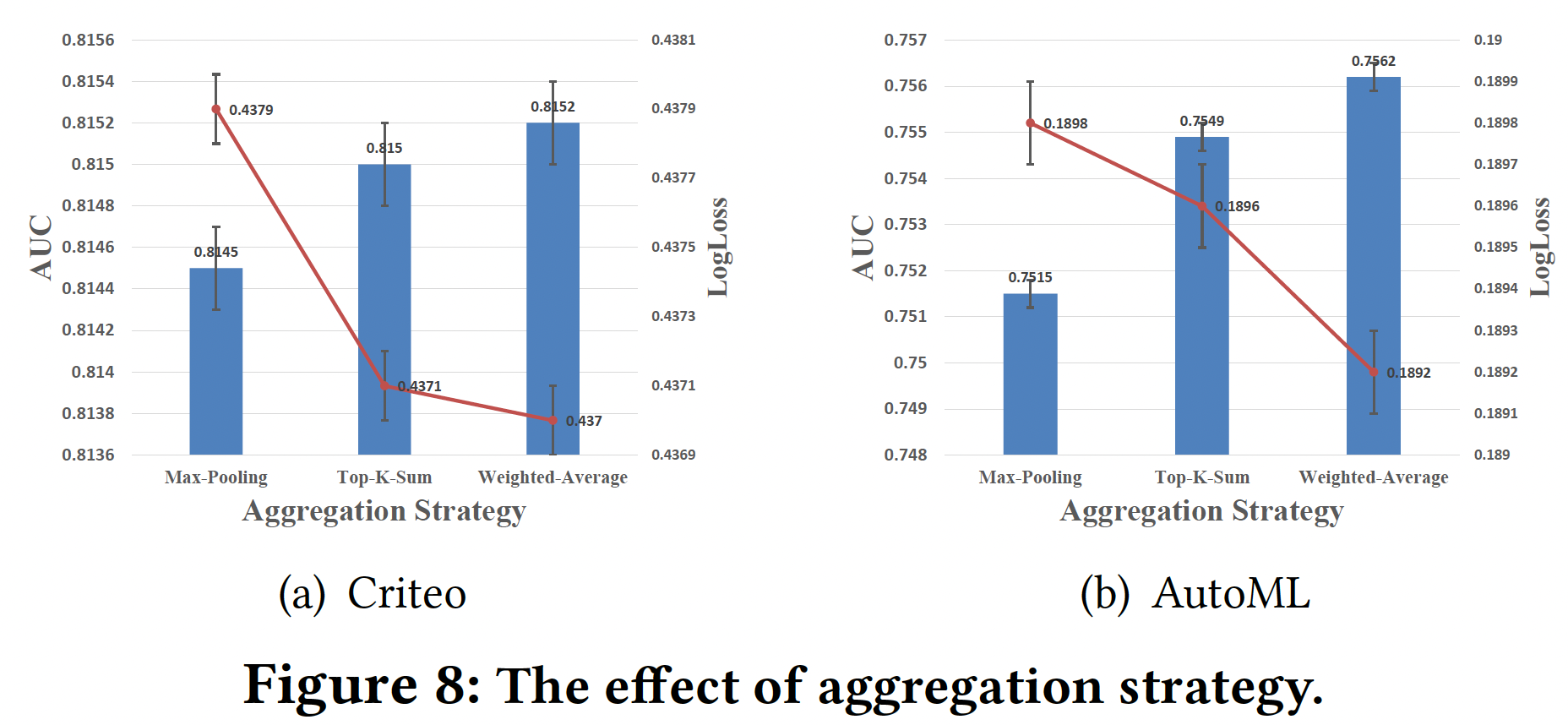
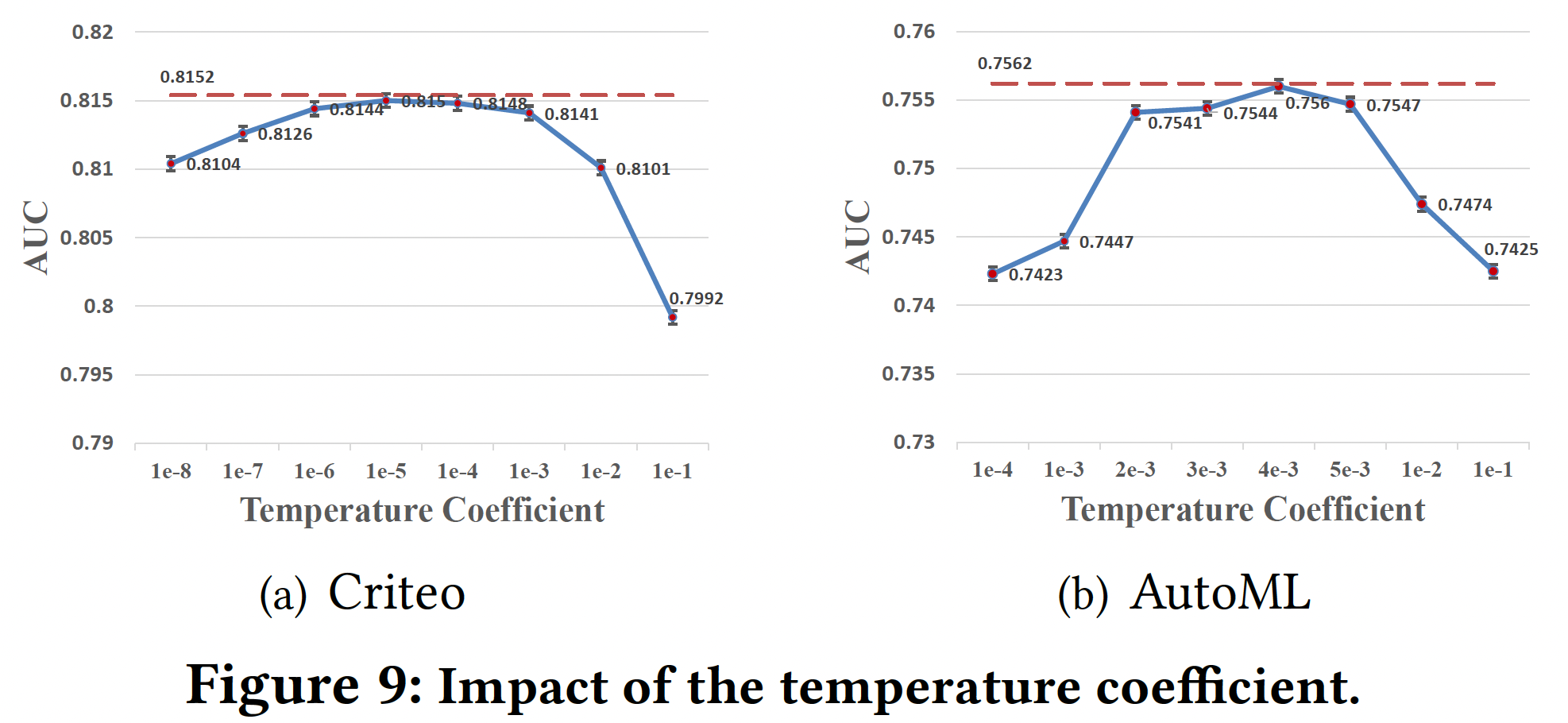
温度系数:为了证明
temperature coefficient adaptive network在生成feature-specific在
Criteo和AutoML数据集上,最佳全局温度分别为1e-5和4e-3左右。然而,我们的
temperature coefficient adaptive network取得了最好的结果(红色虚线),因为它可以根据global field statistics feature和local input feature,针对不同的特征自适应地调整温度系数,获得更合适的discretization distribution。
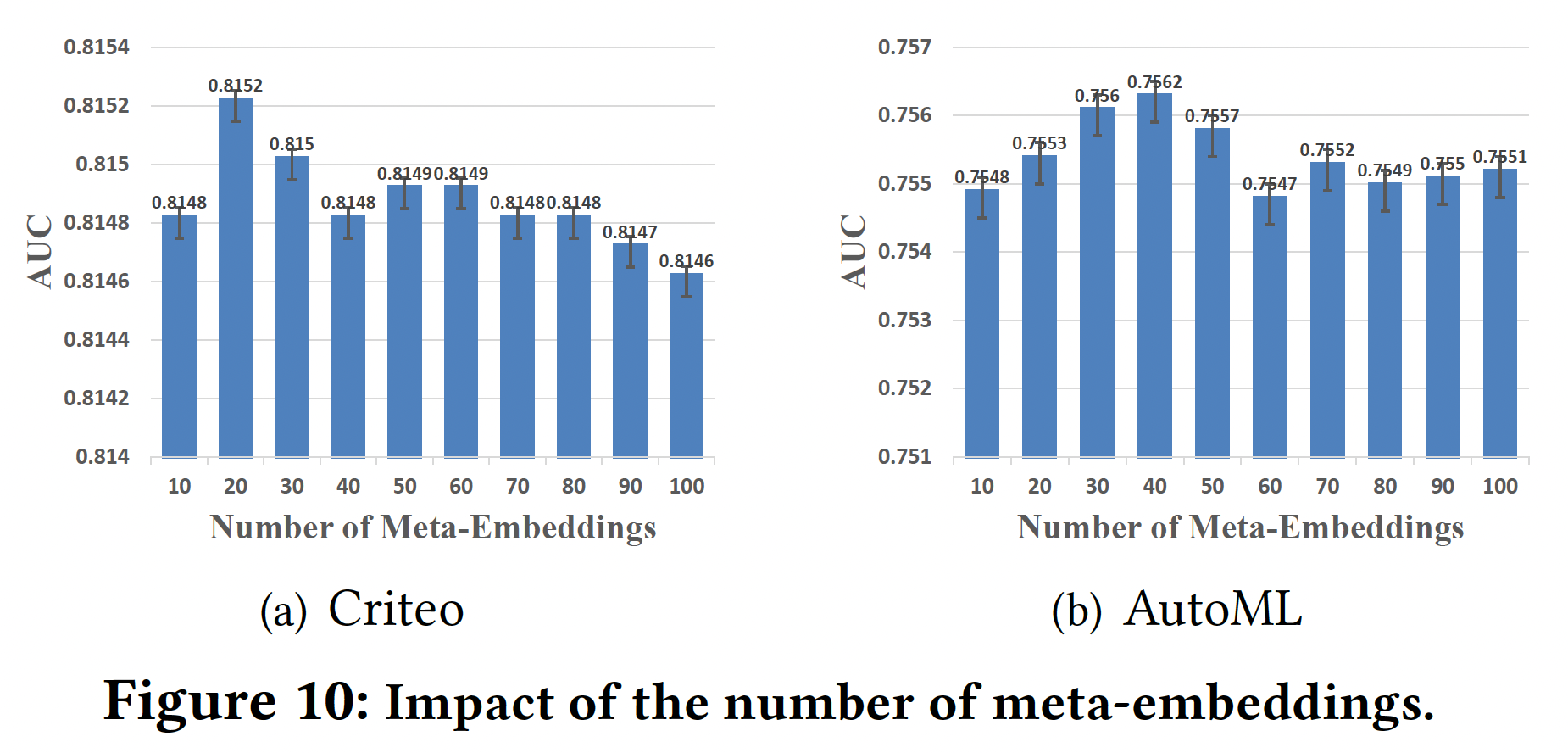
Meta-Embeddings的数量:实验结果如下图所示。可以看到:Meta-Embeddings数量的增加有助于在开始时大幅提高性能,因为meta-embeddings中涉及更丰富的信息。然而,使用过多的
meta-embeddings不仅会增加计算负担,而且会使性能受挫。
考虑到预测效果和训练效率,我们将
Criteo和AutoML数据集的数量分别设定为20和40。