一、BarsCTR [2021]
《BarsCTR: Open Benchmarking for Click-Through Rate Prediction》
与其他数据类型(如图像和文本)相比,
CTR预测问题通常涉及大规模和高度稀疏的数据,并包括许多不同field的categorical feature(例如,在Google Play的app推荐中,有数十亿的样本和数百万的特征)。因此,在CTR预测中大幅提高准确性是一个巨大的挑战。CTR预测的重要性和独特的挑战已经吸引了学术界和工业界的大量研究关注。CTR预测模型已经从简单的logistic regression: LR、factorization machine: FM和决策树,发展到deep neural network: DNN。值得注意的是,许多深度模型已经被提出,并在工业的CTR预测问题上显示出显著的性能提升,如Wide&Deep、DeepFM、DCN、xDeepFM、FiBiNET、DIN,等等。尽管这些研究取得了成功,但仍然缺乏标准化的
benchmark和统一的CTR预测任务的评估协议。因此,即使采用了一些常见的数据集(如Criteo和Avazu),现有的研究往往会进行他们自己的数据集拆分(例如,使用未知的train-test拆分,或使用未知的随机数种子)、以及预处理步骤(关于如何处理数值特征,以及如何过滤低频的categorical feature)。这导致了这些研究中的实验结果不可复现,甚至不一致,因为他们的非标准化的数据预处理使得任何两篇不同的论文的结果都没有可比性。每项工作都声称在他们自己的data partition上取得了显著改进的最佳结果,然而没有人知道:如果采用相同的评估协议进行公平的比较会是什么结果。由于缺乏公开的benchmarking结果作为参考,读者可能会怀疑论文中的baseline模型是否实现正确、是否经过了严格的超参数调优,但是这些研究都没有报告细节、也没有公开他们baseline实现的源代码。在某些case中,一些流行模型的官方或第三方源代码是可用的(如DeepCTR),但我们发现关于超参数设置、数据加载、以及early stopping的训练细节通常是缺失的,这使得我们很难重用代码来复现已有结果。 这种不可复现性和不一致性问题在很大程度上限制了该领域研究的实用价值和潜在影响。此外,由于文献中缺乏可重复使用和可比较的
benchmarking结果,研究人员在发表新的论文时,需要重新实现所有的baseline,并在自己的data partition上重新评估。这是一项繁琐而冗余的工作,严重地增加了研究人员开发新模型的负担。受
ImageNet benchmark在CV领域、以及GLUE benchmark在NLP领域的成功启发,在论文《BarsCTR: Open Benchmarking for Click-Through Rate Prediction》中,作者建议对CTR预测进行open benchmarking。论文不仅规范了CTR预测的open benchmarking pipeline,而且还对不同的模型进行了严格的比较,以便进行可复现的研究。为此,论文用统一的setup在12000多个GPU hours内进行了7000多个实验,在两个广泛使用的数据集(包括Criteo和Avazu)的多个数据集setting上重新评估了24个现有模型。论文的实验显示了有些令人惊讶的结果:经过充分的超参数搜索和模型调优,许多模型的差异比预期的要小,有时甚至与文献中的报道不一致。一项类似的研究(
《Are wereally making much progress? A worrying analysis of recent neural recommendation approaches》)也对推荐系统的多篇代表性论文进行了重新评估,提出了结果的可复现性问题以及对用于比较的baseline缺乏足够优化的担忧。与这项工作相比,作者更进一步,建立了一个CTR预测的open benchmark,记做BarsCTR。目前,BarsCTR已成为BARS benchmark project的主要benchmarking任务之一。BARS benchmark project旨在为推荐系统研究建立一个标准化的open benchmarking pipeline,并通过开放最全面的benchmarking结果以及有据可查的复现步骤,从而推动该领域的可复现研究。作者相信,这样的benchmarking研究对多个不同的读者群体都有好处:研究人员:该
benchmark不仅可以帮助研究人员分析现有模型的优势和瓶颈,还可以让他们方便地衡量新模型的有效性。此外,论文的benchmark还展示了一些良好的实践,为未来的研究提供公平的比较。从业人员:
benchmark代码和结果可以帮助工业的从业者评估新研究模型在他们自己问题中的适用性,并允许他们在自己的数据集上以较少的努力尝试新模型。比赛选手:利用论文的源代码和超参数,比赛选手可以在相关比赛中轻松实现高性能的
baseline和ensemble。初学者:对于这个领域的初学者,特别是学生,论文的
benchmarking code(https://openbenchmark.github.io/ctr-prediction/)和详细的复现步骤可以作为学习CTR预测的模型实现和模型调优技巧的指导手册。将论文的项目用于教育目的也是很有价值的。
总而言之,论文的主要贡献如下:
就作者所知,论文的工作为
CTR预测的open benchmarking迈出了第一步。论文在网站上公开了所有的
benchmarking code、评估协议、超参数设置和实验结果,以促进CTR预测的可复现性研究。论文的工作揭示了现有研究中的不可复现性(
non-reproducibility)和不一致性(inconsistency)问题,并呼吁在未来的CTR预测研究中保持模型评估的开放性和严谨性。
相关工作:
CTR Prediction:在过去的十年中,CTR预测模型被广泛研究,并经历了从线性模型、到FM、再到基于深度学习的模型的几代演变。这些工作被总结为以下几类:Feature interaction learning:虽然简单的线性模型(如LR和FTRL)由于简单和高效而被广泛使用,但它们很难捕捉到非线性特征。《Practical Lessons from Predicting Clicks on Ads at Facebook》提出了GBDT+LR的方法,应用Gradient Boosting Decision Tree: GBDT来抽取有意义的feature conjunction。FM:FM是一个有效的模型,通过特征向量的内积来捕获pairwise feature interaction。由于它的成功,人们从不同方面提出了许多后续模型,如field awareness(FFM, FwFM)、特征交互的重要性(AFM, IFM)、基于外积的交互(HFM)、鲁棒性(RFM)、可解释性(SEFM)。然而,这些模型在实践中无法捕获高阶特征交互。DNN:最近,深度学习已经成为推荐系统中的一种流行技术,产生了大量用于CTR预测的深度模型,包括YoutubeDNN, Wide&Deep, PNN, DeepFM, DistillCTR等等。其中一些模型旨在显式地捕获不同阶次的特征交互(如,DCN, xDeepFM),另一些模型探索使用卷积网络(如CCPM, FGCNN)、递归网络(DSIN, DIEN)、或注意力网络(AutoInt, FiBiNET)来学习隐式的特征交互。Behaviour sequence modeling:用户的历史行为对预测下一个item的点击概率有很大影响。为了更好地捕获这种历史行为(如item购买序列),最近的一些研究提出了通过注意力机制、LSTM、GRU、以及memory network为CTR预测建立用户兴趣模型。典型的例子包括DIN, DIEN, DSIN, HPMN, DSTN。Multi-task learning:在许多推荐系统中,用户可能会有点击以外的各种行为,如浏览、收藏、添加到购物车、以及购买。为了提高CTR预测的性能,最好能利用其他类型的用户反馈来丰富CTR预测的监督信号。为了实现这一目标,一些工作提出了multi-task learning模型(如,ESMM, MMoE, PLE)来学习不同用户行为之间的task relationship。Multi-modal learning:如何利用item丰富的多模态信息(如文本、图像和视频)来增强CTR预测模型是一个重要的研究问题,需要更多的探索。一些先驱性的工作证明了将多模态内容特征纳入CTR预测的有效性。
Benchmarking and Reproducibility:open benchmarking对促进研究进展很有价值。例如,ImageNet和GLUE是两个著名的benchmark,分别对计算机视觉和自然语言处理的进展做出了很大贡献。在推荐系统中,一些数据集(如Criteo和Avazu)被广泛使用。然而,仍然缺乏标准化的评估协议,这导致了现有研究的不一致性和不可复现性问题。值得注意的是,同时进行的一项工作(
《Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison》)也报告了一些经典推荐模型的benchmarking结果。然而,他们的工作未能提供详细的配置和超参数设置,以实现可复现性。在这项工作中,我们通过建立第一个用于CTR预测的open benchmark、以及发布20多个模型的benchmarking结果,向可复现性研究迈出了重要一步。更重要的是,我们提供了所有的中间工件artifact(如复现步骤、运行日志),以确保我们结果的可复现性。
1.1 CTR Prediction
Overview:一般而言,一个CTR预测模型由以下关键部分组成:Feature Embedding:CTR预测的输入样本一般包含三组特征,即user profile, item profile, context information,每组特征都包含一些feature field。每个field的特征可以是categorical的、numeric的、或multi-valued的(例如,一个item的多个tag)。由于大多数特征是非常稀疏的,在
one-hot encoding或multi-hot encoding后会导致高维的特征空间,所以通常会应用feature embedding来将这些特征映射成低维的稠密向量。有三种类型的feature embedding过程:Categorical:对于一个categorical feature fieldone-hot feature vectorembedding matrix,embedding维度。Numeric:对于数值特征字段feature embedding的选择:可以通过对数值特征进行分桶从而转换为离散特征,通过手动设计(例如,将
13~19岁归为青少年)、或通过在数值特征上训练决策树(如,GBDT)。给定一个归一化的标量值
embedding设为fieldshared embedding vector。与其将每个值进行分桶、或为每个数值
field分配一个向量,例如应用AutoDis这种numeric feature embedding方法,动态地将数值特征分桶,并从meta embedding matrix计算embedding。
Multi-valued:对于一个multi-valued fieldembedding为:one-hot encoded vector,embeddingsum池化。一个进一步的潜在改进是应用序列模型(如
DIN中的target attention、以及DIEN中的GRU)来聚合multi-valued行为序列特征。
Feature Interaction:对于CTR预测任务,特征之间的交互(又称feature conjunction)是提高分类性能的核心。在factorization machine: FM中,内积被证明是一种简单而有效的方法来捕获pairwise feature interaction。自
FM成功以来,大量的研究致力于以不同的方式捕捉特征之间的交互。典型的例子包括:PNN中的内积层和外积层、NFM中的Bi-interaction、DCN中的cross network、xDeepFM中的compressed interaction、FGCNN中的卷积、HFM中的循环卷积、FiBiNET中的双线性交互、AutoInt的自注意力、FiGNN的图神经网络、InterHAt的分层注意力。此外,目前的大部分工作都在研究如何同时将显式特征交互和隐式特征交互(通过普通的全连接网络,即
MLP)结合起来。损失函数:二元交叉熵损失目前广泛应用于
CTR预测任务中,它的定义为:其中:
ground-truth,我们定义:
sigmoid函数,model function。
代表性的模型:
浅层模型:
Logistic Regression: LR:LR是CTR预测的一个简单的baseline模型。Factorization Machine: FM:FM将特征嵌入到稠密的向量中,并建模pairwise特征交互为相应embedding vector的内积。值得注意的是,FM是特征数量的线性时间复杂度。Field-aware factorization machine: FFM:FFM是FM的一个扩展,针对特征交互时考虑了field信息。 它是Kaggle关于CTR预测的几个竞赛中的获胜模型。HOFM:由于FM只能捕获到二阶的特征交互,HOFM旨在将FM扩展到高阶factorization machine。然而,它导致指数级的特征组合、消耗巨大的内存、并且需要很长的运行时间。FwFM:FwFM通过考虑特征交互的field-wise权重扩展了FM。与FFM相比,它的性能相当,但使用的模型参数少得多。LorentzFM:LorentzFM将特征嵌入双曲空间,并通过洛伦兹距离(Lorentz distance)的三角形不等式建模特征交互。
深层模型:与浅层模型相比,深层模型在捕获复杂的高阶特征交互方面更加强大,通常会产生更好的性能。然而,效率已经成为深层模型在实践中
scale的主要瓶颈。DNN:DNN是《Deep Neural Networks for YouTube Recommendations》报告的一个直接的深层模型,它在拼接feature embedding后应用一个全连接网络(称为DNN)进行CTR预测。CCPM:CCPM报告了使用卷积方法进行CTR预测的首次尝试,其中feature embedding通过卷积网络进行分层聚合。Wide&Deep:Wide&Deep结合了wide network(或浅层网络)和deep network,从而同时实现了两者的优势。IPNN:IPNN是product-based network,它将feature embedding的内积(或外积)作为DNN的输入。由于pairwise外积需要巨大的内存,我们选择内积版本,即IPNN。DeepCross:受残差网络的启发,《Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Feature》提出了deep crossing来在DNN层间增加残差连接。NFM:与PNN类似,NFM提出了一个Bi-interaction层,将pairwise特征交互池化为一个向量,然后将其馈入DNN进行CTR预测。AFM:AFM通过注意力网络学习特征交互的权重,而不是像FM那样平等对待所有的特征交互。与FwFM不同的是,AFM根据输入的数据样本动态地调整权重。DeepFM:DeepFM是Wide&Deep的一个扩展,它用FM代替LR,显式地建模二阶的特征交互。DCN:DCN提出了一个cross network,以显式的方式执行高阶的特征交互。此外,遵从Wide&Deep,它还集成了一个DNN网络。xDeepFM:DCN所建模的高阶特征交互是bit-wise的,但xDeepFM提出compressed interaction network: CIN以vector-wise的方式捕获高阶特征交互。HFM+:HFM提出了holographic representation,并通过循环卷积计算压缩外积来建模pairwise特征交互。HFM+进一步将DNN网络与HFM相结合。FGCNN:FGCNN应用卷积网络和recombination layer来生成额外的组合特征,以丰富现有的feature representation。AutoInt+:AutoInt利用自注意力网络来学习高阶的特征交互。AutoInt+将AutoInt与一个DNN网络整合在一起。FiGNN:FiGNN利用图神经网络的消息传递机制来学习高阶的特征交互。ONN(也叫NFFM):ONN是一个建立在FFM上的模型。它将FFM的交互输出馈入DNN网络。FiBiNET:FiBiNET利用squeeze-excitation network来捕获重要的特征,并提出bilinear interaction来加强特征交互。AFN+:AFN应用对数转换层(logarithmic transformation layer)来学习自适应阶次的特征交互。AFN+进一步将AFN与DNN网络整合在一起。InterHAt:InterHAt采用分层注意力网络,以有效的方式建模高阶特征交互。
1.2 实验
1.2.1 可复现性要求
我们强调了以下五个关键要求,以确保可复现的研究。然而,目前许多研究未能满足所有这些可复现性要求,如下表所示。请注意,我们用
✓ , - , ×分别表示每个要求是否完全、部分、或未满足。它还表示artifacts是否完全可用、部分可用或不可用从而复现每个step。例如,-表示FiBiNET只有非官方的模型源代码。数据预处理:大多数工作将训练集、验证集和测试集随机拆分,但其他人往往由于缺乏脚本、或使用的随机数种子而无法复现相同的数据拆分。更有甚者,一些预处理的细节(例如,如何处理数值特征、用什么阈值来过滤低频的
categorical feature)可能缺失或不完整。在这种情况下,研究人员不得不进行他们自己的数据拆分和预处理,从而导致无法比较的结果。值得注意的是,AutoIn、AFN和InterHAt的作者在分享数据处理代码或预处理数据方面做了一个很好的起点。模型源代码:本着开源的精神,一些研究在
GitHub上发布了他们的模型源代码。一些流行的模型也有非官方的实现,可以从第三方库中获得(例如DeepCTR)。但在很多情况下,我们发现源代码还不能用于可复现性研究,因为它可能缺少训练代码(如加载数据、early stopping等)、或者错过了给定数据集上的一些关键超参数。模型超参数:大多数研究在论文中指定了他们自己模型的详细超参数。但如果不能获得作者预处理的原始数据集,其他人在新的数据集拆分上使用相同的超参数是不合适的。它可能只能达到次优的性能,需要重新调参。这种做法会导致现有论文中出现不一致的结果。
baseline源代码:许多研究报告了他们自己模型的细节,但没有说明他们如何应用baseline模型。我们注意到,现有的研究很少开放baseline模型的源代码,也没有说明哪种实现被用于比较。模型的性能在很大程度上取决于其代码实现的质量。糟糕的实现可能会引入bias,并使模型的比较变得不公平。然而,这一方面往往被现有的研究所忽视,使得他们的性能改进难以复现。baseline超参数:最好能详尽地调优baseline模型的超参数以公平地比较模型的性能。然而,由于缺乏open benchmarking,这一点还没有得到保证。大多数现有的研究,由于其未知的数据预处理和baseline实现,通常报告同一baseline模型的不一致的结果。
为了实现研究的可复现性和比较的公平性,在这项工作中,我们旨在建立一个标准化的
benchmarking pipeline,并为CTR预测提供最全面的open benchmarking结果。
1.2.2 评估协议
数据集:
Criteo和Avazu。我们之所以选择它们,是因为它们都是从生产中的真实点击日志中收集或采样的,而且都有数千万的样本,使得benchmarking结果对行业从业者有意义。下表总结了数据统计信息。我们还在BarsCTR网站上提供了更多数据集的benchmarking结果。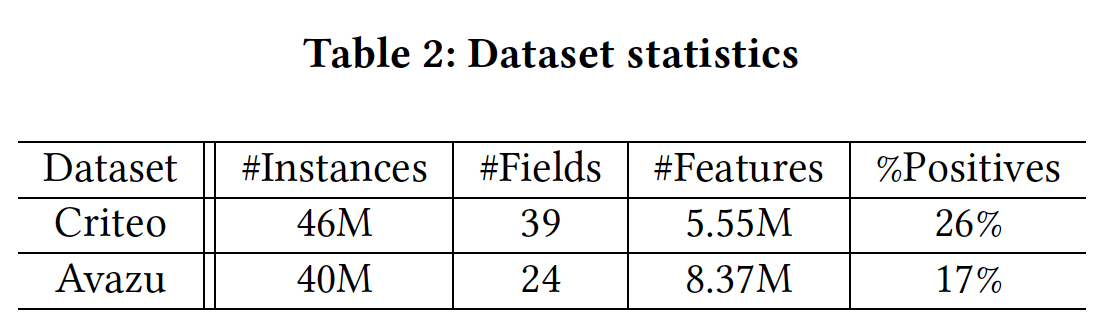
数据集拆分:遵循大多数现有的研究,分别将
Criteo和Avazu随机拆分为8:1:1从而作为训练集、验证集和测试集。为了使其完全可复现,并易于与现有工作进行比较,我们重用AutoInt提供的代码,并控制随机种子(即seed=2018)进行拆分。我们将这两个数据拆分分别记做Criteo_x4和Avazu_x4。数据预处理:我们主要遵循与
AutoInt相同的步骤对特征进行预处理。此外,我们做了一些修改,并修复了AutoInt中的一个缺陷,以改善benchmark结果。Criteo:我们创建了两个不同的评估设置,分别表示为Criteo_x4_001和Criteo_x4_002。Criteo_x4_001:对于数值特征,我们没有像
AutoInt那样对数值进行归一化处理,而是按照Criteo竞赛的获胜方案,将每个数值特征按照如下方式离散化从而获得更好的性能:对于数值特征:我们用默认的
"OOV" token取代低频特征(min_count=10)。
此外,我们还将
feature embedding的维度固定为16。Criteo_x4_002:与Criteo_x4_001不同之处在于,我们为categorical feature设置了min_count=2,而feature embedding维度在调优之后等于40。
Avazu:我们也创建了两个评估设置,即Avazu_x4_001和Avazu_x4_002。Avazu_x4_001:我们删除了在每个数据样本中具有
unique值的id字段,这对于CTR预测来说应该是无用的。但它在AutoInt中被保留了下来,导致了一个缺陷。此外,我们将
timestamp字段转化为三个新字段:hour, weekday, is_weekend。对于所有的
categorical feature,我们用默认的"OOV" token代替低频特征(min_count=2)。我们进一步将
feature embedding的维度固定为16,正如AutoInt。
Avazu_x4_002:与Avazu_x4_001的不同之处在于,我们为categorical feature设置了min_count=1,而feature embedding维度在调优之后等于40。
我们强调,对于
Avazu_x4,我们设置了一个小的min_count阈值,因为它确实导致了比AutoInt中的原始设置(min_count=10)更好的性能。然而,我们注意到,在我们的benchmark中,不同模型之间的相对比较是公平的,因为所有的模型都处于相同的embedding size。我们的benchmark力求在进行模型比较时提高baseline的水平。评估指标:
AUC, logloss。Benchmarking toolkit:虽然有许多开源项目用于CTR预测,但它们大多以临时的方式实现一些模型,缺乏完整的workflow来进行benchmarking。具体而言,DeepCTR提供了一个很好的软件包,对许多CTR预测模型进行统一实现。尽管如此,我们的benchmarking需要一个完整的workflow(而不仅仅是CTR预测模型)。在这项工作中,我们建立了开源的
FuxiCTR toolkit(https://github.com/xue-pai/FuxiCTR) ,用于对CTR预测模型进行benchmarking,提供了关于可配置、可调优和可复现的惊人特性。FuxiCTR的代码由以下部分组成:数据预处理部分从
CSV文件中读取原始数据,转换所有数值特征、categorical feature、以及序列特征,并将转换后的数据输出到HDF5文件。用
Pytorch以统一的方式实现了数十个模型。训练部分的实现是为了读取
batch数据、计算前向传播和后向传播、并在必要时进行学习率衰减和early stopping。seeding和logging工具也是专门为可复现性设计的,为每个benchmarking实验记录详细的运行日志(包括使用的超参数)。超参数调优部分提供了一个可配置的界面,允许对用户指定的超参数进行网格搜索。
我们将所有这些部分整合为一个完整的
benchmarking框架,使研究人员能够轻松地复用我们的代码,建立新的模型,或增加新的数据集。FuxiCTR的目标是为CTR预测的可复现性研究提供一个易于使用的软件包。训练细节和超参数的调优:
在训练过程中,我们默认应用
Reduce-LR-on-Plateau scheduler,当给定指标停止改善时,将学习率降低10倍。为了避免过拟合,当验证集上的指标在连续
2或3个epoch中停止改善时,就会采用early stopping。默认的学习率是batch size最初被设置为10000,如果GPU出现OOM错误,则使用[5000, 2000, 1000]逐渐减少。 我们发现,对于在数百万样本上训练的CTR预测模型,使用大的batch size通常会使模型运行得更快,并达到更好的结果。考虑到大量的特征,
feature embedding通常占据了大部分的模型参数。为了公平起见,我们在两个独立的设置中分别将embedding固定为16或40。我们还发现,正则化权重对模型性能有很大影响。因此,我们在
0 ~ 1的范围内仔细调优它,以10倍的搜索比例。model size(如层数、隐层单元数)与数据高度相关,因此我们详尽地调优了这些超参数。我们还仔细调优了其他一些超参数(例如,是否使用
batch normalization),从而达到每个模型的最佳结果。为了避免指数组合空间,我们通常先调优重要的超参数,然后再逐组调优其他参数。平均而言,我们对每个模型进行了
73次实验以获得最佳结果。所有的实验都是在一个共享的GPU集群上(P100 GPU)进行的,每个GPU有16GB内存。
可复现性:为了实现可重复性,我们保留了每个数据集拆分的
md5sum值。我们为每个实验明确设置随机数种子,并将数据设置和模型超参数记录到配置文件中。此外,我们选择在Pytorch中实现模型,因为它比Tensorflow有更好的能力来避免在GPU设备上运行模型时的非确定性。
1.2.3 结果分析
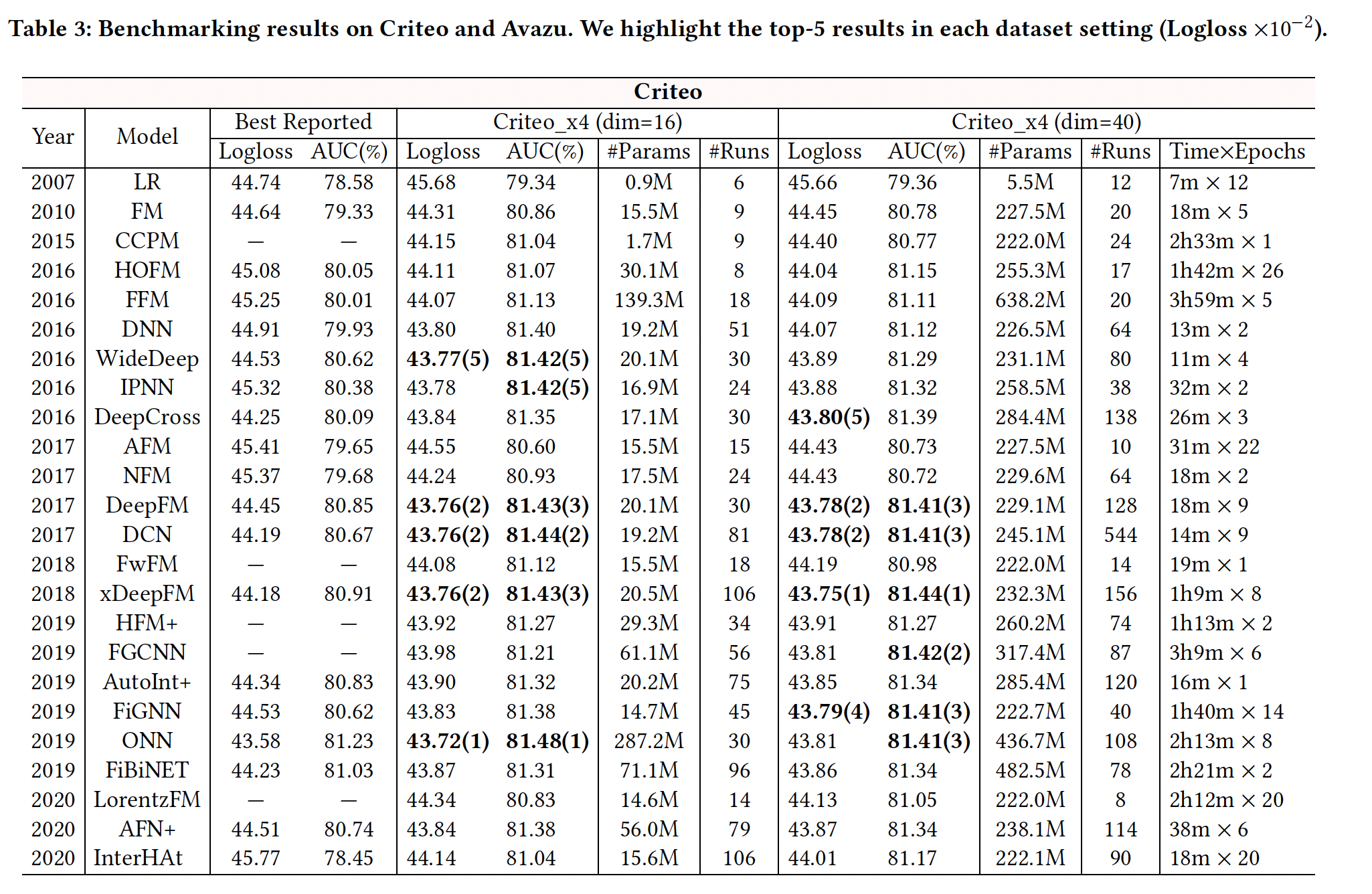
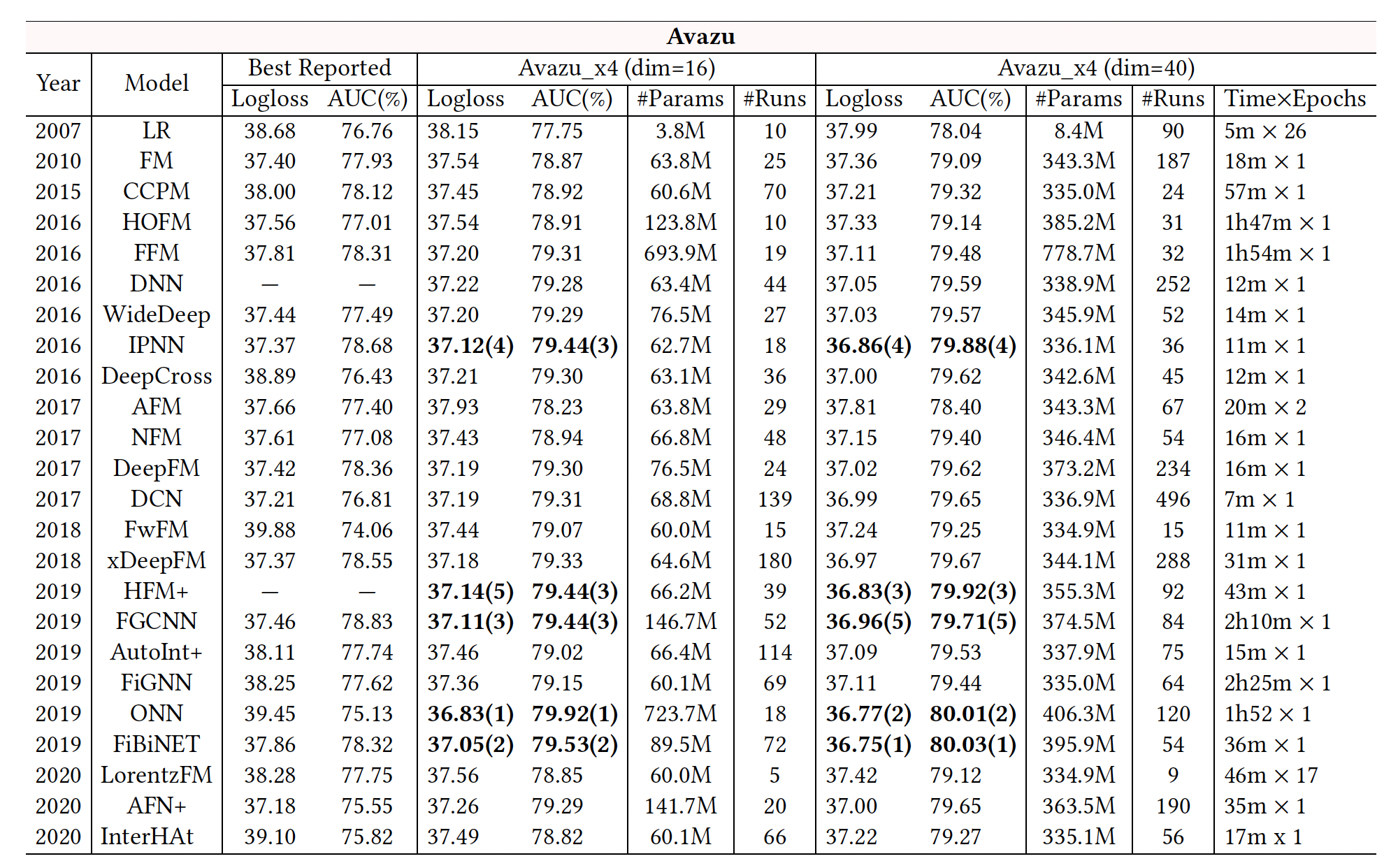
我们报告了
24个模型的benchmarking结果,如下表所示。"Best Reported"列显示了我们从现有研究中选出的关于Criteo和Avazu数据集的最佳结果。我们报告了我们在四个数据集(
Criteo _x4_001, Criteo_x4_002, Avazu_x4_001, Avazu_x4_002)setting上的benchmarking结果(logloss, AUC)。对于模型的效率,我们也报告了
Criteo_x4_002和Avazu_x4_002的训练时间,即每个epoch的时间和epoch的数量。此外,
"#Params"表示每个模型中使用的参数数量,"#Runs"记录了我们用网格搜索进行模型调优的实验次数。请注意,"#Runs"的数值通常取决于模型中要调优的超参数的数量。大量的运行(平均~73次)揭示了在我们的benchmarking中,模型已经得到了很好的调优。此外,我们先在
Criteo_x4_002和Avazu_x4_002上运行实验,所以我们在Criteo_x4_001和Avazu_x4_001上进行了较少数量的实验来调优模型。
结论:
现有研究报告中的最佳结果显示出一定的不一致性。如:
InterHAt在两个数据集上的表现都比LR差;DeepCross在Avazu上的表现也比LR差。这主要是由于即使在相同的数据集上,通常也会采用不同的数据拆分或预处理步骤。这表明标准化的数据拆分和预处理是必要的,以使各模型之间的结果可以直接比较。
在我们的数据集
setting上进行模型调优后,我们大多获得了比最佳报告结果更好的性能。我们的
benchmarking遵循相同的评估协议,使结果具有可比性。然而,经过详尽的重新调优,我们发现
SOTA模型之间的差异变得很小。例如:IPNN, DeepFM, DCN, xDeepFM, ONN在Criteo上都达到了相同水平的准确性(∼0.814 AUC),而DNN, DeepFM, DCN, xDeepFM在Avazu上达到了可比的性能。此外,一些最新的模型(如
InterHAt, AFN+, LorentzFM)获得的结果甚至比先前的一些SOTA模型还要差。我们还在
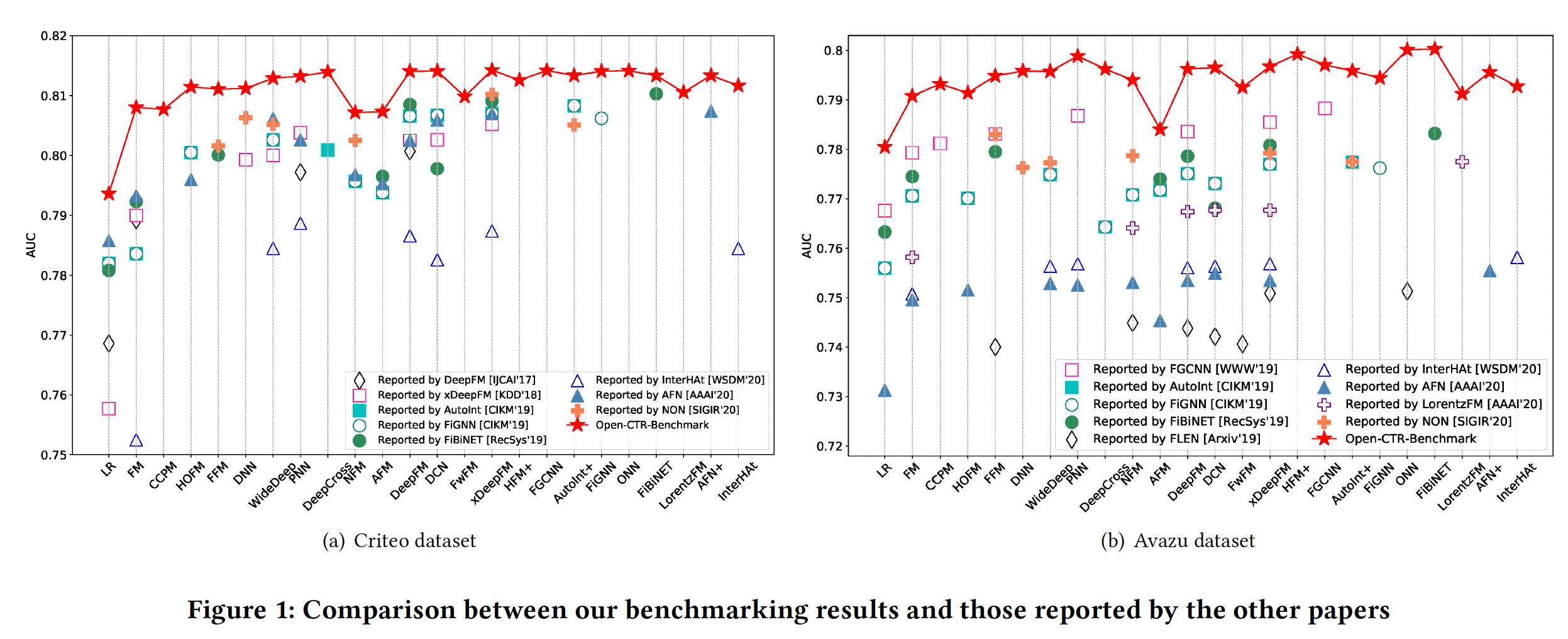
Figure 1中对我们的benchmarking结果和其他论文报告的结果进行了明确的比较。对于每个数据集,我们绘制了8∼9篇现有论文的AUC结果。我们可以看到,由于未知的数据拆分和预处理,不同论文的结果差异很大。一些最新的模型只获得了微弱的改进,有时甚至导致性能下降。值得注意的是,我们的
benchmarking提出了迄今为止所有模型的最佳结果。内存消耗和模型效率是工业
CTR预测任务的另两个重要方面。如下表所示,由于使用了卷积网络(如CCPM, FGCNN, HFM+)、field-wise交互(如FFM, ONN)、图神经网络(如FiGNN)等,一些模型运行非常缓慢(每个epoch数小时)。还有一些模型有更多的参数,如FFM, ONN, FGCNN等。这些缺点可能会阻碍它们在工业中的实际应用。整体而言,
IPNN, DCN的效果好、训练时间短,取得了良好的tradeoff。这两个模型都进行了显式的特征交叉,一个是堆叠式、一个是并行式。
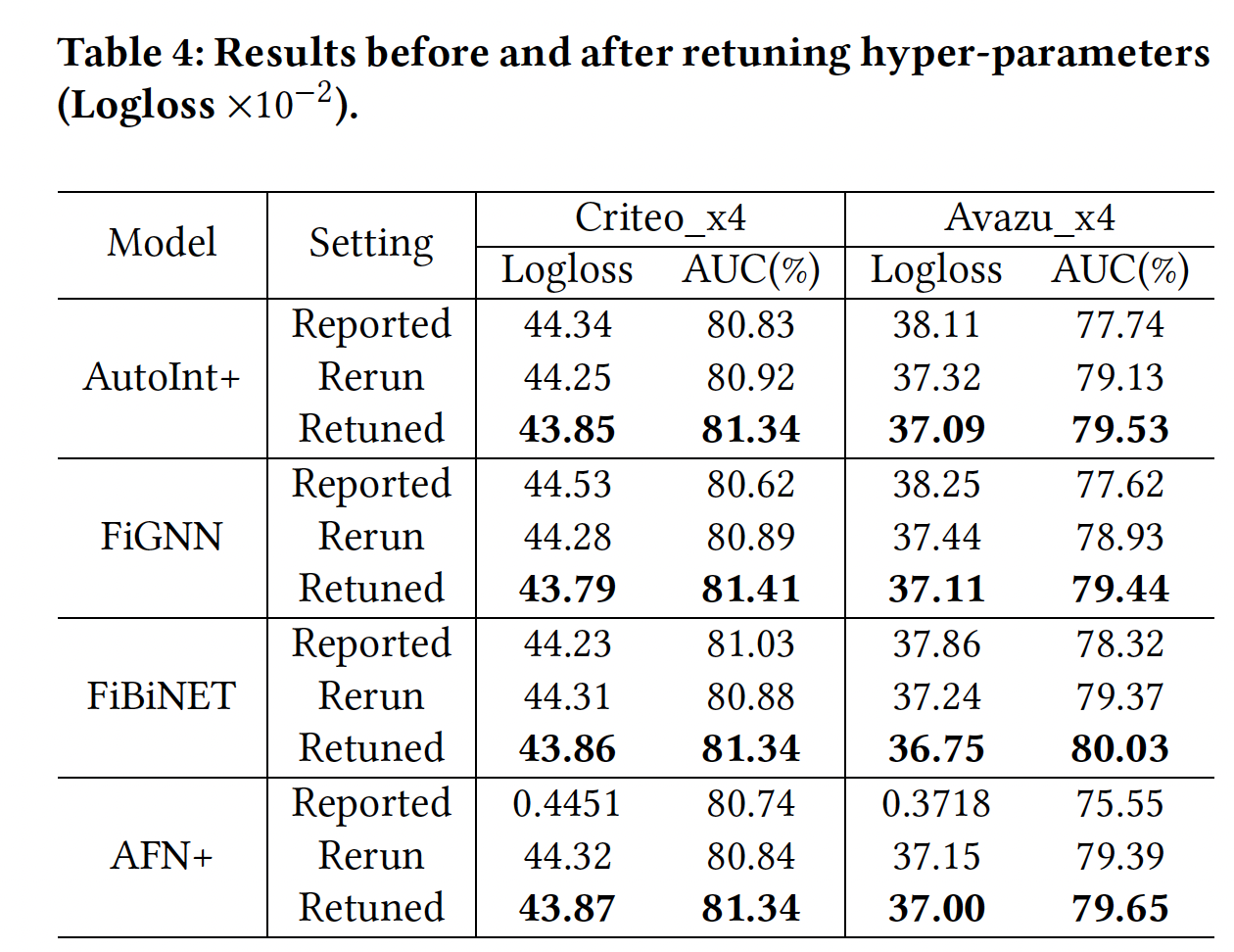
模型重新调优:为了进一步证明重新调优
baseline模型的必要性,在下表中,我们展示了四个代表性模型在三种setting下的结果:Reported setting:表示相应论文所报告的结果。Rerun setting:表示我们根据原始论文中给出的超参数,在我们的数据拆分上重新进行实验的情况。Retuned setting:表示广泛的超参数调优后取得的结果。
可以看到:
即使在相同的数据集上,直接复用原来的超参数来重新进行实验,也会在新的数据
setting中带来很大的性能gap(即我们case中的Criteo_x4_002和Avazu_x4_002)。在模型重新调优后,我们比原来的超参数取得了相当大的改进。这表明,在新的数据拆分上测试一个模型时,有必要重新调优超参数(即使是同一数据集)。
然而,我们不难发现,有些研究为了公平比较,选择遵循论文中使用的
baseline超参数,但他们在不同的数据拆分上进行实验。因此,希望有一个common benchmark来缓解这个问题。
1.2.4 性能调优的关键因素
在我们的
benchmarking工作中,我们也确定了一些对性能调优至关重要的关键因素:数据预处理:数据往往决定了一个模型的上限。然而,现有的工作很少在数据预处理期间对
categorical feature的min_counts阈值进行调优。在我们的工作中,我们为低频特征过滤设置了一个适当的阈值,这产生了更好的性能。batch size:我们观察到,大的batch size通常会带来更快的训练和更好的性能。例如,如果GPU没有引发OOM错误,我们将其设置为10000。embedding size:虽然现有的工作在实验中通常将其设置为10或16,但我们也通过在GPU内存限制范围内使用更大的embedding size(如40)来实验其他setting。正则化权重和
dropout:正则化权重和dropout是减少模型过拟合的两个关键技术。它们对CTR预测模型的性能有很大影响。我们在一定范围内详尽地搜索最佳值。batch normalization:在某些情况下,在DNN模型的隐层之间添加batch normalization可以进一步提升预测性能。
局限性和未来方向:
更多数据集:
Criteo和Avazu这两个数据集都是匿名的,缺乏明确的user field和item field的信息。我们计划从工业规模的应用中扩展更多的数据集,使其成为一个更全面的用于CTR预测的open benchmark。数据拆分:为了与大多数现有的研究保持一致,我们将数据集随机拆分。然而在生产中,如果
train - test分布有很大的不同,就有必要在预测后进行CTR校准。我们计划通过按时间顺序拆分数据来评估模型,并在必要时也进行CTR校准。效率基准:在这个版本中,我们主要通过其训练时间来评估这些模型的效率。在将来考虑测试它们的推理时间。由于实时应用中的
CTR预测有严格的延迟限制。超参数自动调优:如何为一个给定的模型快速找到最佳的超参数仍然是一个开放的研究问题。当数据随时间演变时,模型的超参数也需要重新调优以适应新的数据分布。我们非常期待探索一些先进的
AutoML技术从而以进一步促进未来的超参数调优过程。