一、MaskNet [2021]
《MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask》
点击率(
Click-Through Rate: CTR)预估已成为许多实际应用中最基础的任务之一。对于ranking模型而言,有效捕获复杂的高阶特征至关重要。浅层前馈网络(shallow feed-forward network)广泛应用于FNN、DeepFM和xDeepFM等许多SOTA的DNN模型中,用于隐式地捕获高阶特征交互。然而,有研究证明,加性(addictive)特征交互(尤其是前馈神经网络)在捕获常见特征交互时效率低下。为解决这一问题,我们通过提出实例引导的掩码(instance-guided mask)将特定的乘性操作(multiplicative operation)引入DNN ranking system。instance-guided mask在input instance的引导下,对feature embedding layer和feed-forward layer执行逐元素乘法。input instance就是embedding vector(来自embedding layer的output)本文还提出
MaskBlock,将DNN模型中的feed-forward layer转变为addictive and multiplicative feature interactions的混合体。MaskBlock结合了layer normalization、instance-guided mask和feed-forward layer,是用于在各种配置下设计新ranking model的basic building block。由MaskBlock组成的模型在本文中称为MaskNet。我们提出了两种新的MaskNet模型,以展示MaskBlock作为basic building block的有效性从而用于构建高性能ranking systems。在三个真实数据集上的实验结果表明,我们提出的MaskNet模型显著优于DeepFM和xDeepFM等SOTA模型,这表明MaskBlock是构建新型高性能ranking systems的有效basic building unit。instance-guided mask更像是一种input-driven的element-wise的selection-gate。CTR prediction是指预测用户点击recommended items的概率,它在个性化广告和推荐系统中起着重要作用。许多模型已被提出用于解决这一问题,例如Logistic Regression: LR、Polynomial-2 (Poly2)、tree-based models、tensor-based models、Bayesian models、以及Field-aware Factorization Machines (FFMs)。近年来,采用DNN进行CTR estimation也成为该领域的研究趋势。一些基于深度学习的模型被引入,如Factorization-Machine Supported Neural Networks(FNN)、Attentional Factorization Machine (AFM)、Wide & Deep (W&D)、DeepFM、xDeepFM等。特征交互(
feature interaction)对于CTR任务至关重要,ranking模型有效捕获这些复杂特征至关重要。大多数DNN ranking models模型(如FNN、W&D、DeepFM和xDeepFM)使用浅层MLP layers以隐式方式建模高阶交互,这是当前SOTA的ranking systems的重要组件。然而,
《Latent cross: Making use of context in recurrent recommender systems》已证明:addictive feature interaction(尤其是前馈神经网络)在捕获常见特征交叉时效率低下。他们提出了一种简单但有效的方法,称为"latent cross",这是RNN模型中context embedding与neural network hidden states之间的一种乘性交互(multiplicative interactions)。最近,《Neural Collaborative Filtering vs. Matrix Factorization Revisited》还表明,精心配置的dot product baseline在协同过滤中显著优于MLP layer。尽管MLP在理论上可以近似任何函数,但他们表明,用MLP学习dot product并非易事。对于较大的embedding维度,要高准确性地学习dot product需要较大的模型容量和大量训练数据。他们的工作也证明了MLP layer建模复杂特征交互能力的低效性。受
"latent cross"(《Latent cross: Making use of context in recurrent recommender systems》)和《Neural Collaborative Filtering vs. Matrix Factorization Revisited》的启发,我们关注以下问题:能否通过向DNN ranking systems引入特定的multiplicative operation,使其有效捕获复杂的特征交互,从而改进DNN ranking systems?为了克服
feed-forward layer捕获复杂feature cross效率低下的问题,本文向DNN ranking system引入了一种特殊的multiplicative operation。首先,我们提出一种instance-guided mask,它对feature embedding layer和feed-forward layer执行逐元素乘法。instance-guided mask利用从input instance中收集的全局信息,以统一的方式动态地highlight在feature embedding layer和hidden layer中的informative elements。采用instance-guided mask有两个主要优点:首先,
mask与hidden layer or feature embedding layer之间的逐元素乘法以统一的方式将multiplicative operation引入DNN ranking system,从而更有效地捕获复杂的特征交互。其次,这是一种由
input instance引导的细粒度的bit-wise attention,既可以减弱feature embedding layer和MLP layers中噪声的影响,又可以highlight在DNN ranking systems中的informative signals。
通过结合
instance-guided mask、以及后续的feed-forward layer和layer normalization,我们提出了MaskBlock。MaskBlock将常用的feed-forward layer转变为addictive and multiplicative feature interactions的混合体。instance-guided mask引入乘性交互(multiplicative interactions),后续的feed-forward hidden layer对masked information进行聚合,以更好地捕获重要的特征交互。而layer normalization可以使得网络的optimization更加容易。MaskBlock可被视为在某种配置下设计新ranking models的basic building block。由MaskBlock组成的模型在本文中称为MaskNet。我们提出了两种新的MaskNet模型,以展示MaskBlock作为构建高性能ranking systems的basic building block的有效性。我们的工作贡献总结如下:
(1):在这项工作中,我们提出了一种instance-guided mask,对DNN模型中的feature embedding layer和feed-forward layers执行逐元素乘法。instance-guided mask中包含的全局上下文信息被动态融入feature embedding layer和feed-forward layer,以highlight重要元素。(2):我们提出了一个名为MaskBlock的basic building block,它由三个关键组件组成:instance-guided mask、后续的feed-forward hidden layer和layer normalization module。通过这种方式,我们将标准DNN模型中广泛使用的feed-forward layer转变为a mixture of addictive and multiplicative feature interactions。(3):我们还提出了一个名为MaskNet的新的ranking框架,以MaskBlock为basic building unit来构建新的ranking system。具体而言,本文基于MaskBlock设计了串行MaskNet模型和并行MaskNet模型。串行rank model一块又一块地堆叠MaskBlock;而并行rank model在共享的feature embedding layer上并行地放置多个MaskBlock。(4):在三个真实数据集上进行了广泛的实验。实验结果表明,我们提出的两种MaskNet模型显著优于SOTA模型。结果表明,MaskBlock通过instance-guided mask向DNN模型引入multiplicative operation,确实增强了DNN模型捕获复杂特征交互的能力。
1.1 相关工作
SOTA的CTR模型:近年来,许多基于深度学习的CTR模型被提出,这些基于神经网络的模型大多以有效建模特征交互为关键因素。Factorization-Machine Supported Neural Networks: FNN是一种使用FM对embedding layer进行预训练的feed-forward neural network。Wide & Deep Learning联合训练wide linear models和deep neural networks,从而结合推荐系统的记忆能力和泛化能力。然而,Wide & Deep模型的Wide部分输入仍需要专业的特征工程。为了减轻特征工程的手动工作,
DeepFM用FM替换了Wide & Deep模型的Wide部分,并在FM组件和Deep组件之间共享feature embedding。
大多数
DNN ranking models通过MLP layers以隐式方式处理高阶特征交互,但一些工作通过子网络显式引入高阶特征交互。Deep & Cross Network: DCN以显式方式有效地捕获有限阶的特征交互。类似地,
eXtreme Deep Factorization Machine: xDeepFM通过提出新颖的Compressed Interaction Network: CIN部分,以显式方式建模低阶和高阶特征交互。AutoInt使用多头自注意力神经网络在低维空间中显式建模特征交互。FiBiNET可以通过Squeeze-Excitation network: SENET机制动态学习特征重要性,并通过双线性函数学习特征交互。
Feature-Wise Mask Or Gating:feature-wise mask or gating已在视觉、自然语言处理、以及推荐系统中得到广泛探索。例如:Highway Networks(《Highway networks》)利用feature gating来使得very deep networks的gradient-based training更加容易。Squeeze-and-Excitation Networks(《Squeeze-and-excitation networks》)通过将每个通道与学到的sigmoidal mask values显式相乘来重新校准feature responses。《Language modeling with gated convolutional networks》提出gated linear unit: GLU,用于控制在语言建模任务中预测next word时应传播的信息。
gating or mask机制也被应用于推荐系统:《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》提出了一种新颖的多任务学习方法,Multi-gate Mixture-of-Experts: MMoE,该方法显式地从数据中学习建模任务关系。《Hierarchical gating networks for sequential recommendation》提出了一种hierarchical gating network: HGN,以捕获用户的长期和短期兴趣。HGN中的feature gating模块和instance gating模块分别从feature levels和instance levels选择可以传递到下游layers的item features。
Normalization:归一化技术已被公认为深度学习中非常有效的组件。许多归一化方法被提出,其中最流行的两种是BatchNorm和LayerNorm。Batch Normalization (Batch Norm or BN)通过mini-batch内计算的mean and variance对特征进行归一化。layer normalization (Layer Norm or LN)的提出是为了使得RNN的优化更加容易,layer normalization的统计量不是在mini-batch中的layer-wise的方式独立估计的。
归一化方法已被证明在加速深度网络的训练方面取得了成功。
1.2 我们提出的模型
在本节中,我们首先描述
feature embedding layer。然后介绍我们提出的instance-guided mask、MaskBlock和MaskNet结构的细节。最后介绍作为损失函数的log loss。
1.2.1 Embedding Layer
CTR任务的输入数据通常由sparse features和dense features组成,sparse features大多为categorical类型。此类特征被编码为one-hot vectors,对于大型词表来说,这通常会导致特征空间维度过高。解决这个问题的常用方法是引入embedding layer。一般来说,sparse input可以表示为:其中:
fields数量。categorical field的one-hot vector。
我们可以通过以下方式获得
one-hot vectorfeature embedding其中,
embedding矩阵,field embedding的维度。数值特征
其中:
field embedding,维度通过上述方法,在原始
feature input上应用embedding layer,将其压缩为低维稠密的实值向量。embedding layer的输出是一个wide concatenated vector:其中:
fields数量;field的embedding。尽管
input instances的特征长度可能不同,但它们的embedding的长度均为field embedding的维度。实际上
input instances的特征长度是相同的,就是等于特征数量。我们使用
instance-guided mask将multiplicative operation引入DNN ranking system。在本文的后续部分中,所谓的"instance"指的是当前输入实例的feature embedding layer。
1.2.2 Instance-Guided Mask
我们利用
instance-guided mask从input instance中收集的全局信息,动态地highlight了feature embedding layer和feed-forward layer中的informative元素。对于
feature embedding,mask强调具有更多信息的关键元素,以有效表示该特征。对于
hidden layer中的神经元,mask通过考虑input instance中的上下文信息,帮助那些重要的特征交互凸显出来。
除此之外,
instance-guided mask还将multiplicative operation引入DNN ranking system,以更有效地捕获复杂的特征交叉。input instance就是feature embedding:它是第一层feature embedding layer的输出。如
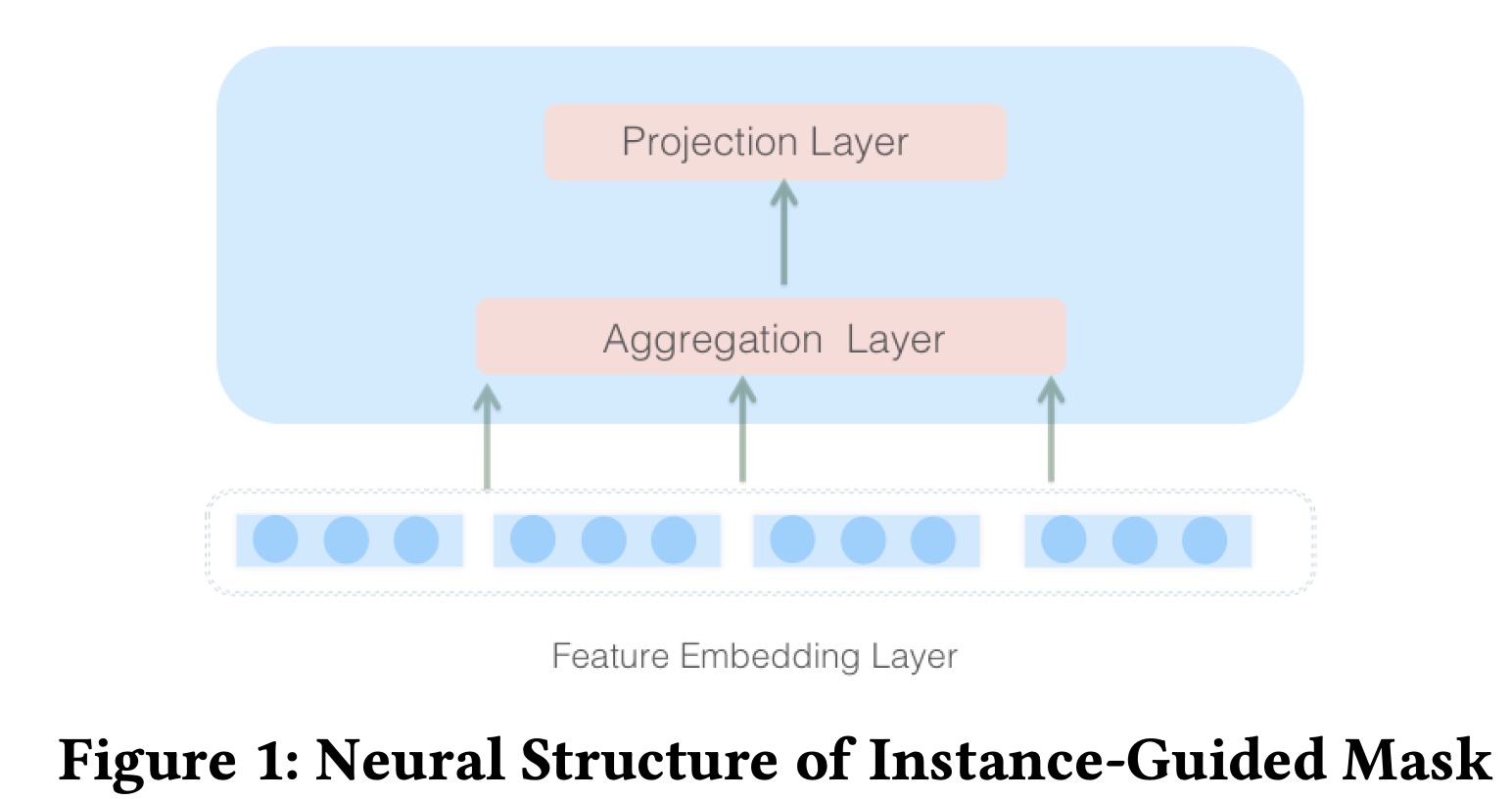
Figure 1所示,instance-guided mask中使用了两个带有恒等函数的全连接(fully connected: FC)层。需要注意的是,instance-guided mask的输入始终来自input instance,即feature embedding layer。第一个
FC layer称为"aggregation layer"。与第二个FC layer相比,它是一个相对更宽的层,以便更好地收集input instance中的全局上下文信息。aggregation layer具有参数mask。对于feature embedding layer和不同的MLP layers,我们采用不同的instance-guided mask;每个mask拥有自己的参数,以从input instance中学习捕获各层的不同信息。第二个
FC layer称为"projection layer",使用参数feature embedding layerhidden layer其中:
input instance的embedding layer。instance-guided mask的参数;aggregation layer和projection layer的神经元数量,fields数量,field embedding的维度。FC layer的learned bias。
注意:
如果作用在
Feature Embedding Layer之上,那么:如果作用在
MaskBlock之上,那么:hidden size。
需要注意的是,
aggregation layer通常比projection layer更宽,因为projection layer的大小需要与feature embedding layer或MLP layer的大小相等。因此,我们将注意:这里的
1的。把它叫做 “膨胀比” 可能更合适。
在这项工作中,逐元素乘法用于将
instance-guided mask聚合的全局上下文信息融入feature embedding layer或hidden layer,如下所示:其中,
embedding layer,feed-forward layer,instance-guided mask可以被视为一种特殊的bit-wise attention or gating机制。它使用input instance中包含的全局上下文信息来指导训练期间的parameter optimization。feature embedding layer或hidden layer中的一个重要元素。这个值被用于增强向量相反,
uninformative elements甚至噪声。
采用
instance-guided mask的两个主要优点是:首先,
mask与hidden layer或feature embedding layer之间的逐元素乘法以统一的方式将multiplicative operation引入DNN ranking system,以更有效地捕获复杂的特征交互。其次,这种由
input instance引导的细粒度bit-wise attention既可以减弱feature embedding layer和MLP layers中噪声的影响,又可以highlightDNN ranking systems中的informative信号。
instance-guided mask更像是一种input-driven的element-wise的selection-gate。
1.2.3 MaskBlock
为了克服
DNN模型中feed-forward layer捕获复杂特征交互效率低下的问题,我们在这项工作中为DNN ranking systems提出了一个名为MaskBlock的basic building block,如Figure 2和Figure 3所示。提出的MaskBlock由三个关键组件组成:layer normalization模块、instance-guided mask、以及feed-forward hidden layer。layer normalization可以使得网络的optimization更加容易。instance-guided mask为标准DNN模型的feed-forward layer引入multiplicative interactions。feed-forward hidden layer对masked information进行聚合,以更好地捕获重要的特征交互。
通过这种方式,我们将标准
DNN模型中广泛使用的feed-forward layer转变为addictive and multiplicative feature interactions的混合体。

Layer Normalization:首先,我们简要回顾LayerNorm的公式。一般来说,
normalization旨在确保信号在通过网络传播时具有零均值和单位方差,以减少"covariate shift"(《Batch normalization: Accelerating deep network training by reducing internal covariate shift》)。例如,layer normalization(LayerNorm或LN)(《Layer normalization》)的提出是为了使得RNN的优化更加容易。具体来说,设normalization layers的大小为input(vector representation)。LayerNorm将输入re-centers和re-scales为:其中:
LayerNorm layer的输出;input的均值和标准差;bias、gain,它们是具有相同维度作为
MaskBlock中的关键组件之一,layer normalization可以同时用于feature embedding layer和feed-forward layer。对于
feature embedding layer,我们将每个特征的embedding视为一层,以计算LN的均值、标准差、bias和gain,如下所示:这种在每个
embedding上进行LN的方法值得借鉴。对于
DNN模型中的feed-forward layer,LN的统计量是在相应hidden layer包含的神经元中估计的,如下所示:其中:
feed-forward layer的输入;feed-forward layer的参数;input的大小、feed-forward layer的神经元数量。需要注意的是,我们在
MLP中有两个位置可以放置normalization operation:一个位置是在非线性操作之前,另一个位置是在非线性操作之后。我们发现,非线性操作之前的normalization性能始终优于非线性操作之后的normalization性能。因此,在本文中,MLP部分使用的所有normalization都放置在非线性操作之前。这个发现也值得我们借鉴。
Feature Embedding上的MaskBlock:我们通过结合三个关键元素(layer normalization、instance-guided mask和后续的feed-forward layer)来提出MaskBlock。MaskBlock可以堆叠形成更深的网络。根据每个MaskBlock的不同输入,我们有两种类型的MaskBlock:MaskBlock on feature embedding、MaskBlock on Maskblock。在本小节中,我们将首先介绍如Figure 2所示的MaskBlock on feature embedding。feature embeddingMaskBlock on feature embedding的唯一输入。在对embeddinglayer normalization操作后,MaskBlock利用instance-guided mask通过逐元素乘法来highlightinformative elements。形式上:其中:
masked feature embedding。需要注意的是,
instance-guided maskinput也是feature embedding我们在
MaskBlock中引入feed-forward hidden layer和后续的layer normalization操作,以通过归一化的非线性变换(normalized non-linear transformation)更好地聚合masked information。MaskBlock的输出可以计算如下:其中:
MaskBlock中feed-forward layer的参数,feed-forward layer的神经元数量。注意:最外层的
ReLU并未在Figure 2中展示出来。instance-guided mask作为细粒度注意力将逐元素乘法引入feature embedding,而normalization both on feature embedding and hidden layer使得网络的optimization更加容易。MaskBlock中的这些关键组件帮助feed-forward layer更有效地捕获复杂的特征交叉。MaskBlock on MaskBlock:在本小节中,我们将介绍如Figure 3中所示的MaskBlock on MaskBlock。这种MaskBlock有两个不同的输入:feature embeddingMaskBlock的输出MaskBlock的input of instance-guided mask始终是feature embeddingMaskBlock利用instance-guided mask通过逐元素乘法来highlight前一个MaskBlock的输出其中:
masked hidden layer。为了更好地捕获重要的特征交互,
MaskBlock中引入了另一个feed-forward hidden layer和后续的layer normalization。通过这种方式,我们将标准DNN模型中广泛使用的feed-forward layer转变为a mixture of addictive and multiplicative feature interactions,以避免那些addictive feature cross models的低效性。MaskBlock的输出可以计算如下:其中:
MaskBlock中feed-forward layer的参数,feed-forward layer的神经元数量。
1.2.4 MaskNet
基于
MaskBlock,可以根据不同的配置设计各种新的ranking models。由MaskBlock组成的rank model在这项工作中称为MaskNet。我们还通过将MaskBlock用作basic building block,提出了两种MaskNet模型:串行MaskNet(Serial MaskNet)、并行MaskNet(Parallel MaskNet)。对于
Parallel MaskNet,所有的Block都是Feature Embedding上的MaskBlock, 它没有MaskBlock on MaskBlock。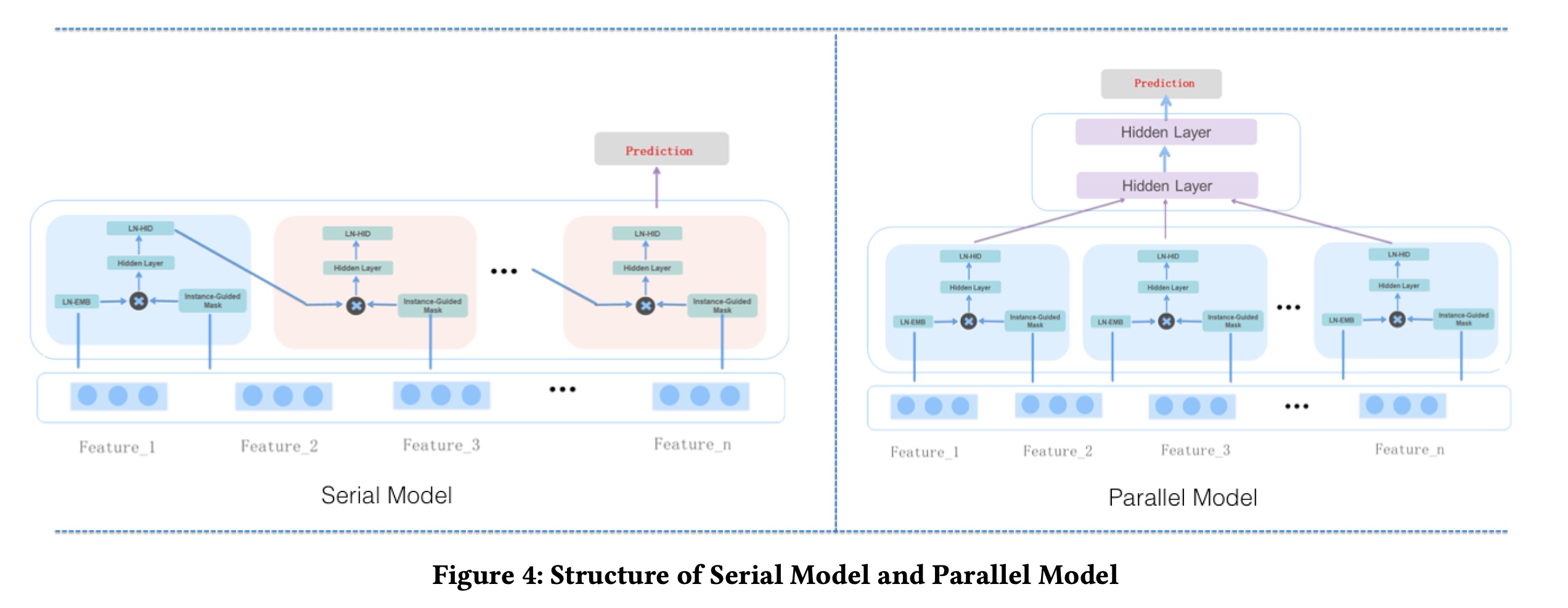
Serial MaskNet:我们可以将MaskBlock逐个堆叠以构建ranking system,如Figure 4左侧的模型所示:第一个
block是MaskBlock on feature embedding。所有其他
blocks都是MaskBlock on Maskblock,以形成更深的网络。prediction layer放置在final MaskBlock的output vector上。
在本文中,这种串行配置下的
MaskNet称为SerMaskNet。每个MaskBlock中instance-guided mask的输入均来自feature embedding layerMaskNet模型看起来像一个在每个时间步共享输入的RNN模型。Parallel MaskNet:我们通过在共享的feature embedding layer上并行地放置多个MaskBlocks on feature embedding,从而提出了另一种MaskNet,如Figure 4右侧的模型所示。在这种配置下,每个block的输入仅为shared feature embedding我们可以将这种
ranking model视为a mixture of multiple experts,就像MMoE(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》) 所做的那样。每个MaskBlock关注特定类型的重要特征或特征交互。我们通过拼接每个MaskBlock的输出来收集每个专家的信息,如下所示:其中:
MaskBlock的输出;MaskBlock中feed-forward layer的神经元数量;MaskBlock的数量。为了进一步合并每个专家所捕获到的特征交互,在
concatenation informationfeed-forward layers。设concatenation layer的输出,然后feed forward process为:其中:
ReLU是激活函数;bias;output。prediction layer放置在这组feed-forward networks的最后一层上。在本文的后续部分,我们将这种版本的MaskNet称为“ParaMaskNet”。
1.2.5 Prediction Layer
综上所述,我们给出
proposed model的输出的整体公式:其中:
CTR的预测值;sigmoid函数。如果是
SerMaskNet,那么last MaskBlock的output size;如果ParaMaskNet,那么last feed-forward layer的output size。feed-forward layer的bit value;bit value的learned weight。
对于二分类问题,损失函数为
log loss:其中:
ground truth;predicted CTR。optimization process是最小化以下目标函数:其中:
feature embedding matrix、instance-guided mask matrix、feed-forward layer in MaskBlock、以及prediction部分。
1.3 实验
在本节中,我们在三个真实数据集上评估所提出的方法,并进行详细的消融研究,以回答以下研究问题:
RQ1:基于MaskBlock的MaskNet模型是否比现有的SOTA深度学习CTR模型表现更好?RQ2:MaskBlock架构中各个组件的影响是什么?每个组件对于构建有效的ranking system是否必要?RQ3:网络的超参数如何影响我们提出的两种MaskNet模型的性能?RQ4:instance-guided mask是否根据input instance来highlight了feature embedding layer和feed-forward layers中的重要元素?
下面,我们将首先描述实验设置,然后回答上述研究问题。
数据集:
Criteo数据集:作为一个非常著名的公开真实世界的display ad dataset,包含每条广告的display information和相应的用户点击反馈,Criteo数据集被广泛用于许多CTR模型的评估。Criteo数据集中有26个匿名categorical fields、以及13个continuous feature。Malware数据集:Malware是Kaggle竞赛中发布的微软恶意软件预测(Microsoft Malware prediction)数据集。该竞赛的目标是预测Windows机器被感染的概率。恶意软件预测任务可以像典型的CTR prediction任务一样被公式化为二分类问题。Avazu数据集:Avazu数据集包含按时间顺序排列的若干天的广告点击数据。对于每条点击数据,有23个字段表示单个ad impression的元素。
我们将样本按
8:1:1的比例随机划分为训练集、验证集和测试集。Table 1列出了评估数据集的统计信息。
评估指标:
Area Under ROC: AUC。RelaImp:遵从《Deep Feedback Network for Recommendation》,RelaImp也被用作另一个评估指标。RelaImp用于衡量:模型相对于baseline model的AUC相对改进。由于随机策略的AUC为0.5,我们可以去除AUC分数的常数部分,并将RelaImp形式化为:
对比的模型:
FM、DNN、DeepFM、Deep&Cross Network: DCN、xDeepFM、AutoInt模型。这些模型均在 “相关工作” 中讨论过。FM被视为评估中的base模型。实现细节:
我们在实验中使用
TensorFlow来实现所有模型。对于优化方法,我们使用
Adam,mini-batch size = 1024,学习率设置为0.0001。对于本文中的神经网络结构,我们将所有模型的
field embedding维度固定为10。对于包含DNN部分的模型,hidden layers的深度设置为3,每层神经元数量为400,所有激活函数为ReLU。在
MaskBlock的默认设置中,instance-guided mask的压缩比(reduction ratio)设置为2。我们使用
2块Tesla K40 GPU进行实验。
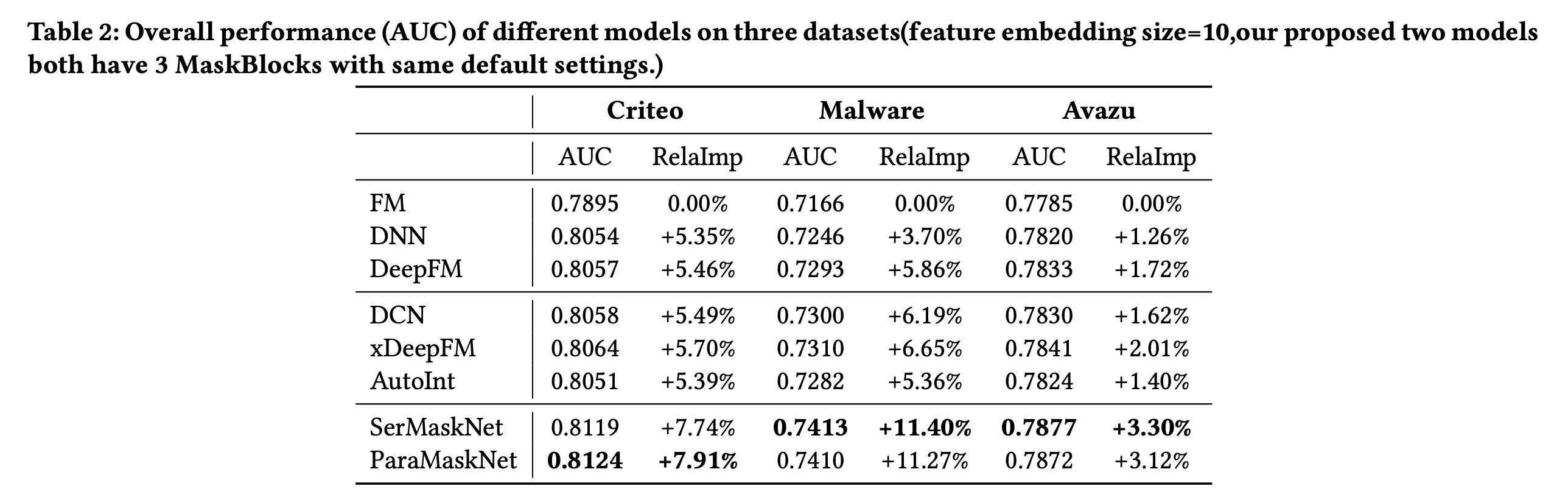
1.3.1 性能对比 (RQ1)
不同模型在三个评估数据集上的整体性能如
Table 2所示。从实验结果中,我们可以看到:串行模型和并行模型在所有三个数据集上均取得了更好的性能,并且相对于
SOTA方法有显著改进。与基线
FM相比,其准确率提升了3.12%到11.40%。与基线
DeepFM相比,其准确率提升了1.55%到5.23%。与基线
xDeepFM相比,其准确率提升了1.27%到4.46%。
我们还进行了显著性检验,验证了我们提出的模型在显著性水平(
尽管
MaskNet模型缺乏类似xDeepFM中CIN这样的显式地捕获高阶特征交互的模块,但由于MaskBlock的存在,它仍然取得了更好的性能。实验结果表明,MaskBlock通过instance-guided mask在normalized feature embedding and feed-forward layer上引入乘法操作,确实增强了DNN模型捕获复杂特征交互的能力。关于串行模型和并行模型之间的比较,实验结果显示它们在三个评估数据集上的性能相当。这明确证明 了
MaskBlock是构建各种高性能ranking systems的有效basic building unit。
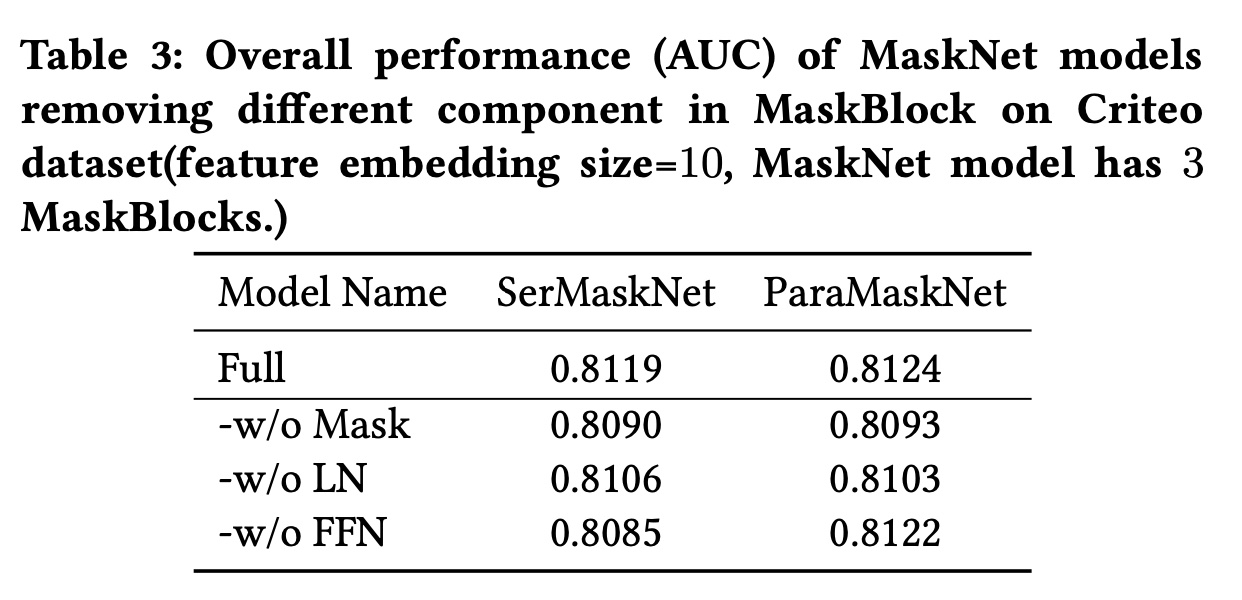
1.3.2 MaskBlock的消融研究 (RQ2)
为了更好地理解
MaskBlock中每个组件的影响,我们对MaskBlock的关键组件进行了消融实验:每次仅移除其中一个组件,观察性能变化,包括mask模块、layer normalization(LN)、feed-forward network(FFN)。Table 3显示了我们的两种完整版本MaskNet模型及其仅移除一个组件的变体的结果。从
Table 3的结果中,我们可以看到:移除
instance-guided mask或layer normalization都会降低模型性能,这表明instance-guided mask和layer normalization都是MaskBlock有效性的必要组件。至于
MaskBlock中的feed-forward layer,其对串行模型或并行模型的影响存在差异:移除feed-forward layer时,串行模型的性能显著下降,而对并行模型似乎没有影响。feed-forward layer即我们认为这表明:
MaskBlock中的feed-forward layer对于instance-guided mask之后聚合feature interaction information很重要。对于并行模型,并行MaskBlock上方的multiple feed-forward layers具有与MaskBlock中feed-forward layer类似的功能,这可能导致在移除feed-forward layer组件时两种模型的性能差异。
1.3.3 超参数研究 (RQ3)
在本文的后续部分,我们研究了超参数对两种
MaskNet模型的影响,包括:feature embedding size、MaskBlock的数量、instance-guided mask的压缩比。实验在Criteo数据集上进行,每次改变一个超参数,同时保持其他设置不变。超参数实验在其他两个数据集上显示出类似的趋势。Feature Embedding Size:Table 4的结果显示了feature embedding size对模型性能的影响。可以观察到:两种模型的性能在
embedding size开始增加时均有所提高。但当在
embedding size设置为大于50(SerMaskNet模型)和30(ParaMaskNet模型)时,模型性能下降。
实验结果表明,模型受益于更大的
feature embedding size。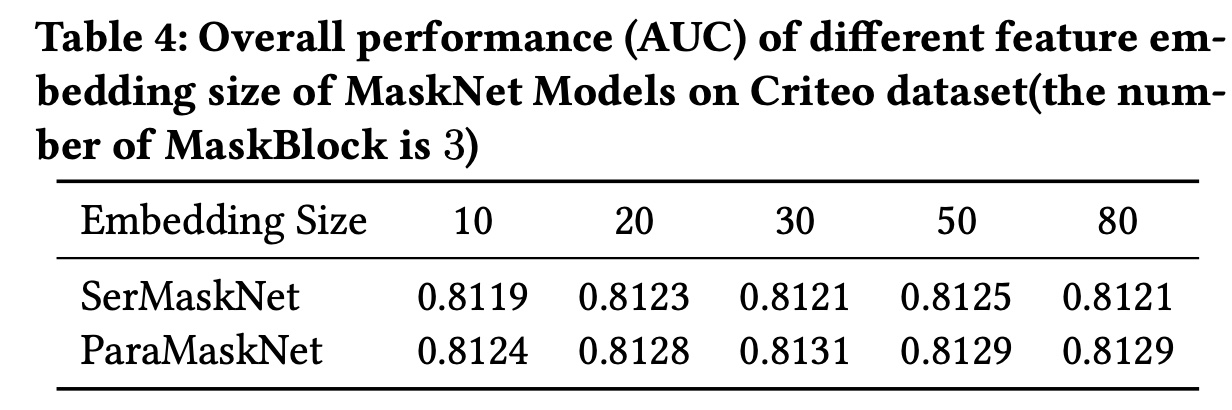
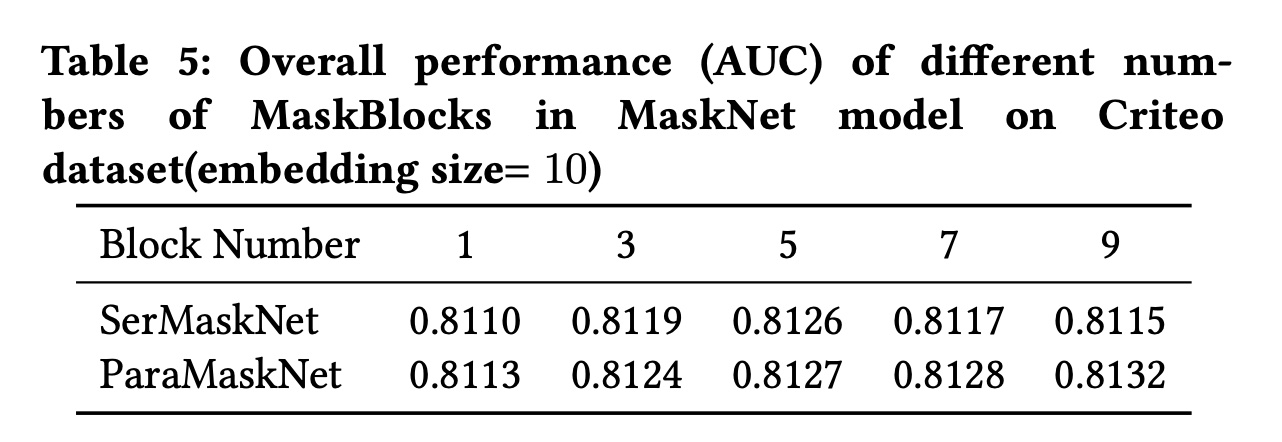
MaskBlock的数量:为了了解MaskBlock数量对模型性能的影响,我们对两种MaskNet模型进行了从1 ~ 9个blocks的堆叠实验。实验结果列于Table 5。对于
SerMaskNet模型,性能在开始时随着blocks数的增加而提高,直到blocks数量设置为大于5。而对于
ParaMaskNet模型,当我们继续向其中添加更多MaskBlock时,性能缓慢提高。这可能表明,更多的专家提升了ParaMaskNet模型的性能,尽管这会更耗时。
Instance-Guided Mask中的压缩比:为了探索instance-guided mask中压缩比的影响,我们进行了一些实验,通过改变size of aggregation layer从而将压缩比从1调整到5。实验结果如
Table 6所示,我们可以观察到:不同的压缩比对模型性能的影响很小。这表明,在实际应用中,我们可以在aggregation layer中采用较小的压缩比以节省计算资源。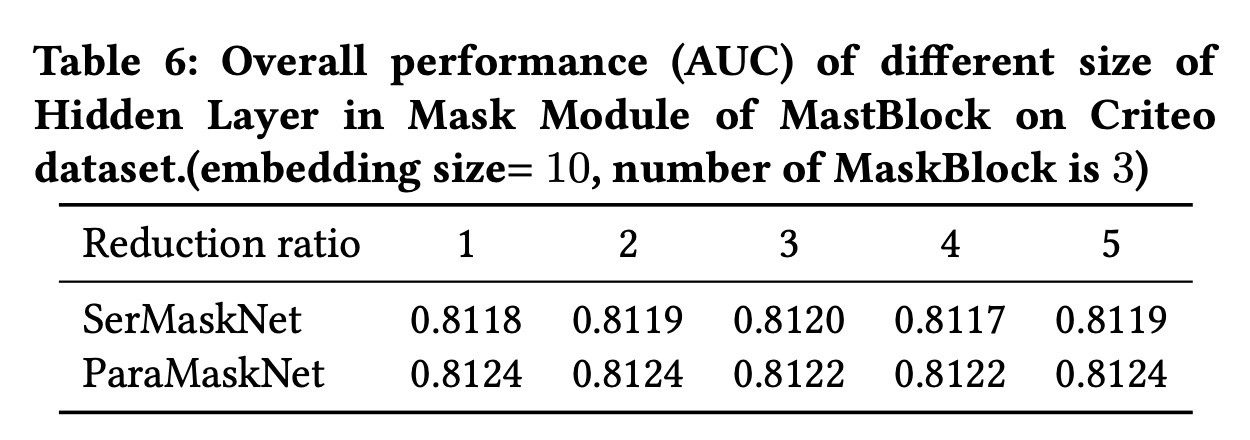
1.3.4 Instance-Guided Mask 研究 (RQ4)
如
"Instance-Guided Mask"章节所述,instance-guided mask可以被视为一种特殊的bit-wise attention机制,用于基于当前input instance来highlight重要信息。我们可以利用instance-guided mask来增强informative elements,并抑制feature embedding layer和feed-forward layer中的uninformative elements甚至噪声。为了验证这一点,我们设计了以下实验:在训练
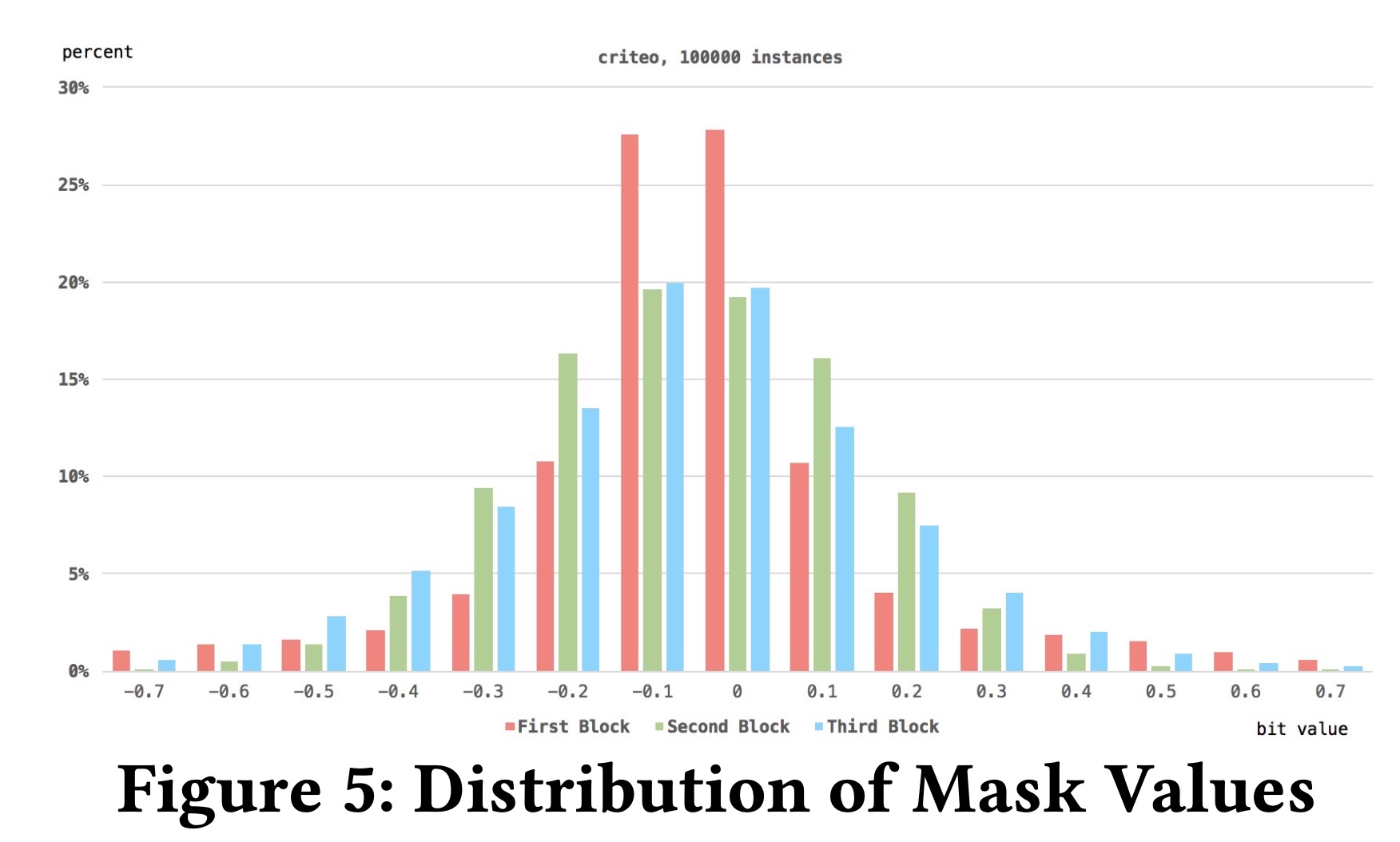
SerMaskNet with 3 blocks后,我们将不同的实例输入模型,并观察相应instance-guided masks的输出。首先,我们从
Criteo数据集中随机采样100,000个不同的实例,并观察来自不同blocks的instance-guided mask产生的值的分布。Figure 5显示了结果。我们可以看到:mask values的分布遵循正态分布。超过50%的mask values是接近零的小数,只有一小部分mask values是相对较大的数。这表明:
feature embedding layer和feed-forward layer中的大部分信号是uninformative的甚至是noise,这些信号被small mask values所抑制。然而,一些
informative information通过instance-guided mask被较大的mask values所增强。
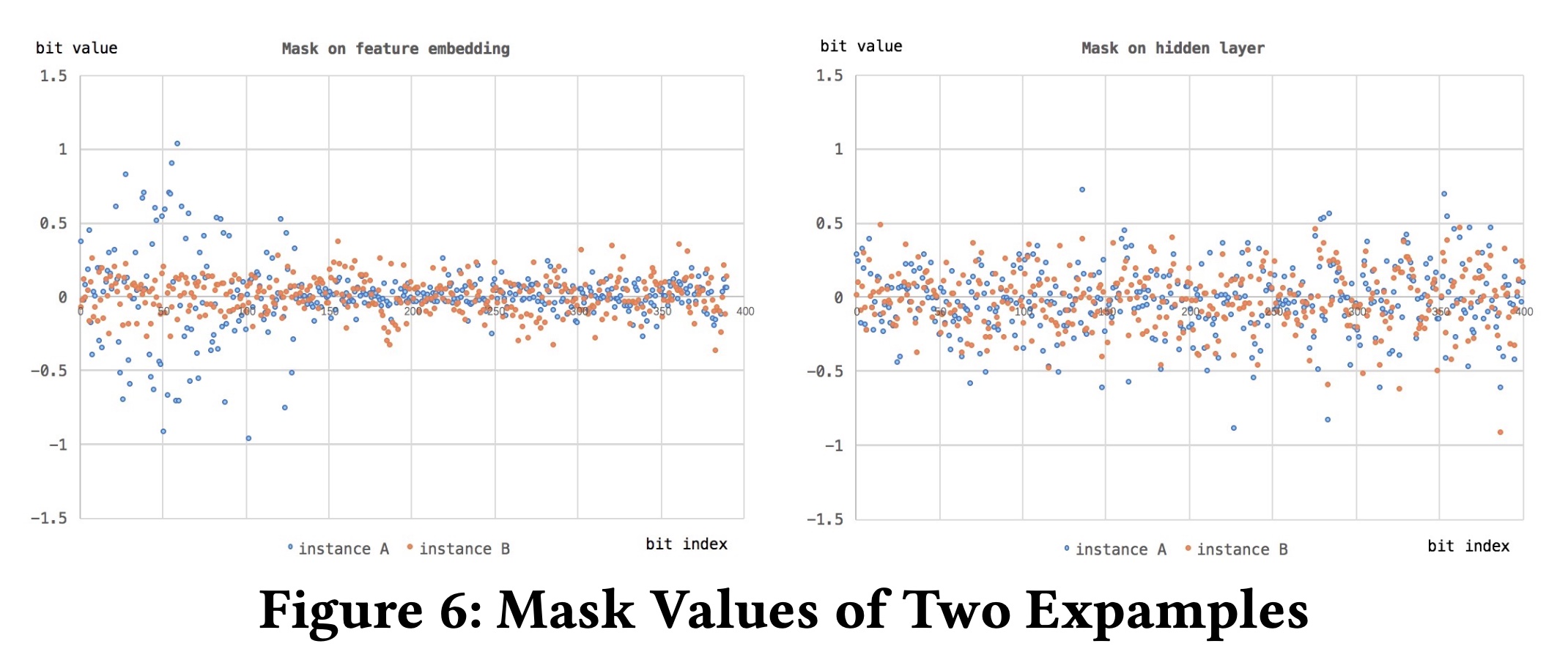
其次,我们随机采样两个实例,并比较
instance-guided mask所产生的值的差异。结果如Figure 6所示。我们可以看到:对于
feature embedding layer的mask values,不同的input instances导致mask关注不同的区域:instance A的mask outputs更多地关注前几个特征,而instance B的mask values则关注其他特征的某些bits。在
feed-forward layer的mask values中,我们观察到类似的趋势。
这表明,
input instance确实引导mask关注feature embedding layer和feed-forward layer的不同部分。