一、DHEN [2022]
《DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction》
学习特征交互(
feature interactions)对在线广告服务的模型性能至关重要。因此,研究者们致力于设计有效的架构来学习feature interactions。然而我们发现,即使声称捕获的interactions阶数相同,这些设计的实际性能也会因数据集而异。这表明不同的设计可能具有不同的优势,并且它们捕获的interactions存在非重叠的信息。基于这一观察,我们提出了DHEN,一种深度的分层的集成(ensemble)架构,该架构可以利用异构的interaction模块的优势,并学习不同阶数下的a hierarchy of the interactions。为了克服DHEN的deeper和multi-layer structure在训练中带来的挑战,我们提出了一种新的co-designed training system,该系统可以进一步提高DHEN的训练效率。在CTR prediction任务的大规模数据集上进行的DHEN实验表明,prediction的归一化熵(Normalized Entropy: NE)提高了0.27%,训练吞吐量比SOTA的基线高1.2倍,这些证明了其在实际应用中的有效性。在线广告已迅速发展成为一项价值数十亿美元的业务:仅在美国,其
2021财年的收入就达到284.3B美元,相比2020财年增长了25%(《Brad Adgate. Agencies agree; 2021 was a record year for ad spending, with more growth expected in 2022, Dec 2021》)。预测用户点击特定广告的概率(即CTR prediction)在在线广告中起着重要作用。这是因为CTR prediction的性能会影响business providers的用户满意度(user satisfaction)。由于
CTR prediction的重要性,学术界和工业界都投入了大量精力来提高prediction model的性能。早期,逻辑回归(logistic regression: LR)被用于建模特征与标签之间的关系。不幸的是,其线性假设使其无法捕获非线性的input-output关系,限制了它在复杂场景中的能力和适用性。这一限制在《Practical lessons from predicting clicks on ads at facebook》中通过使用决策树(decision tree: DT)得到了部分解决,其中input features首先通过DT进行非线性变换。然而,LR和DT的成功都需要大量的特征工程工作;而在现实中,由于存在大量的原始特征以及特征交叉(interactions),这一过程需要大量资源。为了应对这一挑战,《Factorization machines》提出了因子分解机(factorization machine: FM),它可以通过latent embeddings的内积来捕获二阶的feature interaction。同时,FM预定义的浅层结构(pre-defined shallow structure)限制了其表达能力。FM关于更具表达性的扩展,如HOFM、FFM和AFM,则面临over-fitting以及计算成本过高的问题。上述所有限制都可以通过基于深度学习的模型得到妥善处理:deep hidden layers和非线性激活函数的使用,使得能够以端到端的方式捕获非线性的高阶feature interactions,缓解了ranking engineers繁琐的手动特征工程负担、以及浅层模型表达能力不足的问题。自
2016年以来,各种深度模型已被business providers用于其ads ranking services,包括Wide&Deep(Google Play)、DeepFM(Huawei AppGallery)、DIN(Taobao)和FiBiNET(Weibo)。这些深度模型大多由两个主要部分组成:feature embedding learning、feature interaction modeling。feature embeddings是通过将categorical features映射到embedding vectors来学习的。feature interactions则是通过利用函数对embeddings之间的关系进行建模来学习的。多项研究表明,interaction部分的更好设计可以显著提高实际应用中的prediction accuracy。这激发了从捕获低阶interactions向高阶interactions发展的各种研究。
尽管先前的一些研究声称其
feature interaction模块的设计可以捕获高阶interactions,但我们注意到,即使它们声称捕获相同阶数的interaction,其实际性能排名也会因数据集而异。这表明,旨在捕获相同阶数interaction的不同interaction模块在不同数据集上具有不同的优势,而且其根本原因可能是它们捕获的信息并不重叠。同时,如这些研究的实验部分所示,通过学习高阶interaction(通常通过堆叠更多interaction layers来实现)有时会产生负面影响(例如DCN中的Figure 3、xDeepFM中的Figure 7(a)、InterHAt中的Figure 4、xDeepInt中的Table 2以及GIN中的Figure 3(a)等)。这与理论相悖,因为根据理论,捕获高阶interaction应该导致更好、或至少中性的性能。我们假设这个问题源于使用同质的interaction模块,这限制了可以捕获的interactions类型。这一观察表明模型中存在异构interaction modules的重要性。基于此,我们提出了DHEN:一种具有分层结构的深度分层集成网络(Deep and Hierarchical Ensemble Network)。在
DHEN layer中,存在一组异构的interaction modules和ensemble components。异构
interaction modules的集合可以补充不同interaction modules能够捕获的非重叠信息。ensemble component捕获异构模块之间的相关性。
因此,通过递归堆叠
DHEN layers,模型可以学习不同阶数interactions的hierarchy,并捕获异构模块的相关性,我们通过实验发现这对获得更好的性能起着重要作用。本文的主要贡献可总结如下:我们基于不同
interaction modules在不同数据集上具有不同优势的观察,设计了一种名为Deep and Hierarchical Ensemble Network: DHEN的新型架构。通过递归地堆叠interaction layers和ensemble layers,DHEN可以学习不同阶数interactions的hierarchy。其中,不同阶数interactions由heterogeneous modules所学习而来。ensemble layer其实就是concat/sum/weighted_sum等等。与以往的
CTR prediction模型相比,DHEN更深的、multi-layer的结构增加了训练的复杂性,给实际训练带来了挑战。我们提出了一系列机制来提高DHEN training的性能,包括一种名为Hybrid Sharded Data Parallel的新分布式训练范式。该范式的吞吐量比SOTA的fully sharded data parallel高1.2倍,支持对大型DHEN模型进行高效训练。在
CTR prediction任务的大规模数据集上对DHEN进行了全面评估。评估结果表明,与SOTA的AdvancedDLRM baseline相比,归一化熵(Normalized Entropy: NE)提高了0.27%。
1.1 架构
大多数跨
multiple prediction tasks的SOTA的高性能模型架构都采用深度堆叠(deep stacking)结构(例如ResNet、Transformers、Metaformer)。在这里,深度堆叠结构通常由包含相同interaction module的重复blocks组成。例如,Transformer使用self-attention blocks进行堆叠,而ResNet使用convolution blocks。每个block将前一个block的输出或原始embedding tokens作为输入。在结构上,DHEN遵循这种整体堆叠策略,同时构建了一个新颖的hierarchical ensemble framework来捕获多个interaction modules的相关性。Figure 1展示了一个通用的DHEN building block,其中包含多个Interaction modules的ensemble。请注意,原始numerical(dense)特征可以作为任何modules的输入,以便在每一层中进行ensembling。基本思想类似于
MMOE,每个interaction module就是一个expert。作者对比了DHEN和MMOE,发现DHEN效果更好。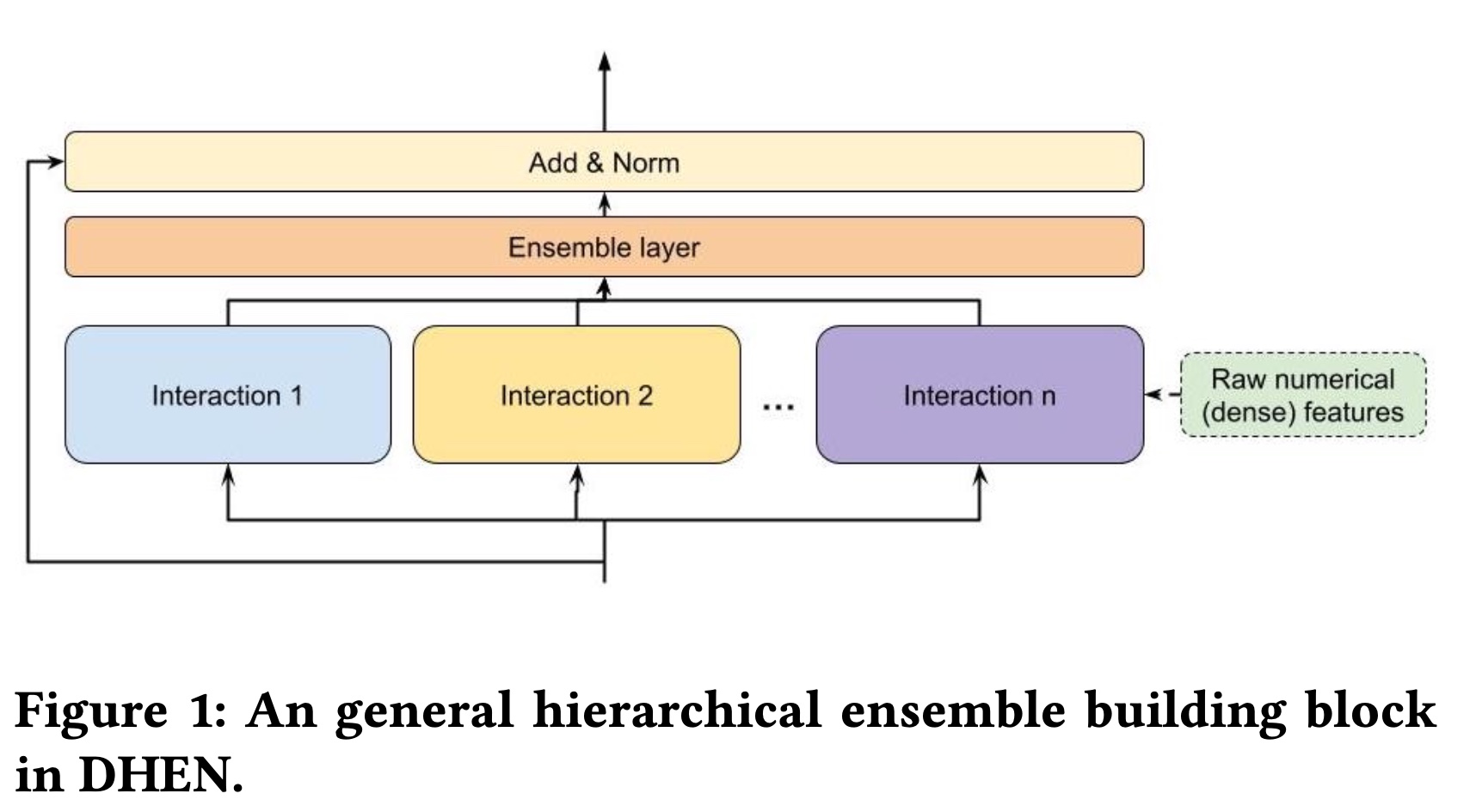
1.1.1 Feature Processing Layer
在
CTR prediction任务中,特征输入通常包含离散的categorical terms(sparse features)和numerical values(dense features)。在这项工作中,我们使用与DLRM(《Deep learning recommendation model for personalization and recommendation systems》)相同的feature processing layer,如Figure 3所示。sparse lookup tables将categorical terms映射到a list of numerical embeddings。具体来说,每个categorical term被分配一个可训练的feature representation。另一方面,
numerical values通过dense layers进行处理。dense layers由几个多层感知器(Multi-layer Perception: MLP)组成,从中计算出一个output。
在
sparse lookup table output和dense layer output拼接后,feature processing layer的final outputoutput embeddings的数量,embedding维度。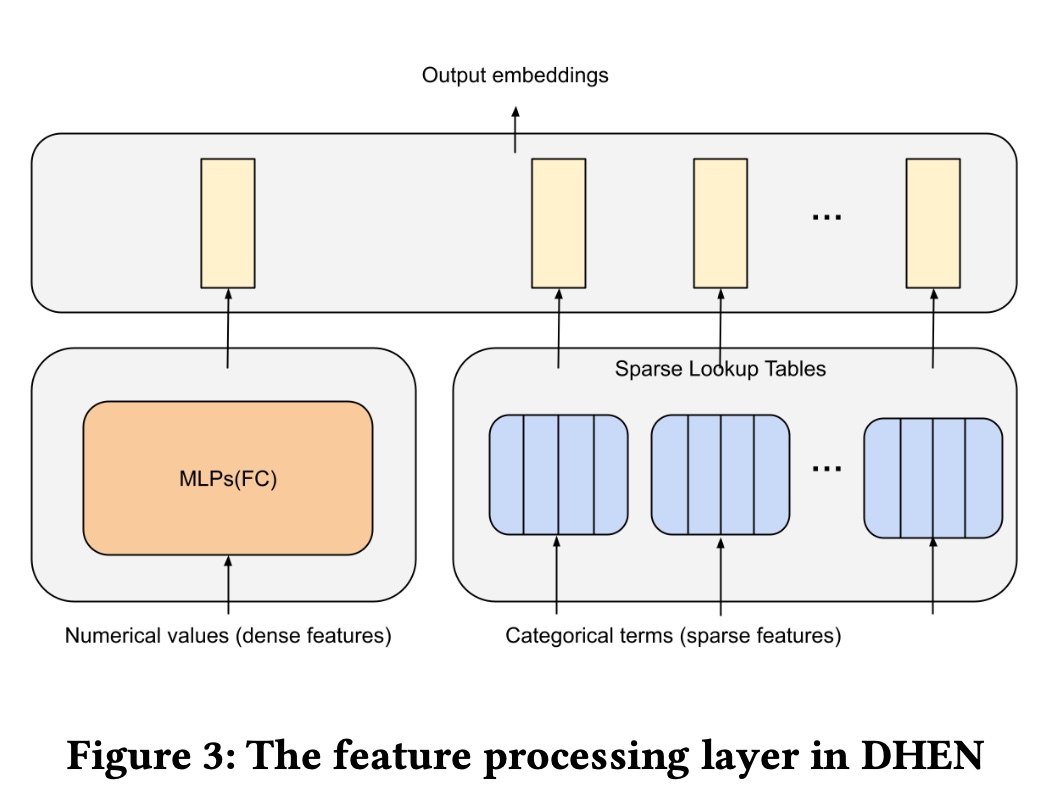
1.1.2 Hierarchical Ensemble
我们提出了一种新颖的
hierarchical ensemble framework,该框架包含多种类型的interaction modules、以及它们的相关性。从概念上讲,deep hierarchical ensemble network可以描述为一个深度的、全连接的interaction module network,类似于具有全连接神经元的deep neural network。hierarchical ensemble mechanism为多层堆叠的多个interaction modules的ensemble提供了一个框架。每层的input表示为a list of embeddings,记为stacked layers。请注意,第一层的input是来自feature processing layer的list of embeddings其中:
normalization方法,如Layer Normalization。concatenation、sum或weighed sum等等。什么
ensemble的效果最好?论文未说明。ensemble output的维度与last layer input最后,
ensemble result和shortcut通过element-wise sum进行组合,output
hierarchical ensemble的主要目标是捕获interaction modules的相关性。Figure 2 (left)展示了一个两层、两模块的hierarchical ensemble component。与传统的仅捕获一种类型高阶interaction的stacking model structures不同,hierarchical ensembles可以捕获a mixture of high-order interactions。如Figure 2 (right)所示,DHEN的设计通过让每个模块消耗outputs of various interaction modules,例如interactions的优势。因此,这种mixture of interaction modules可以利用多种feature interaction类型来实现更好的model prediction accuracy。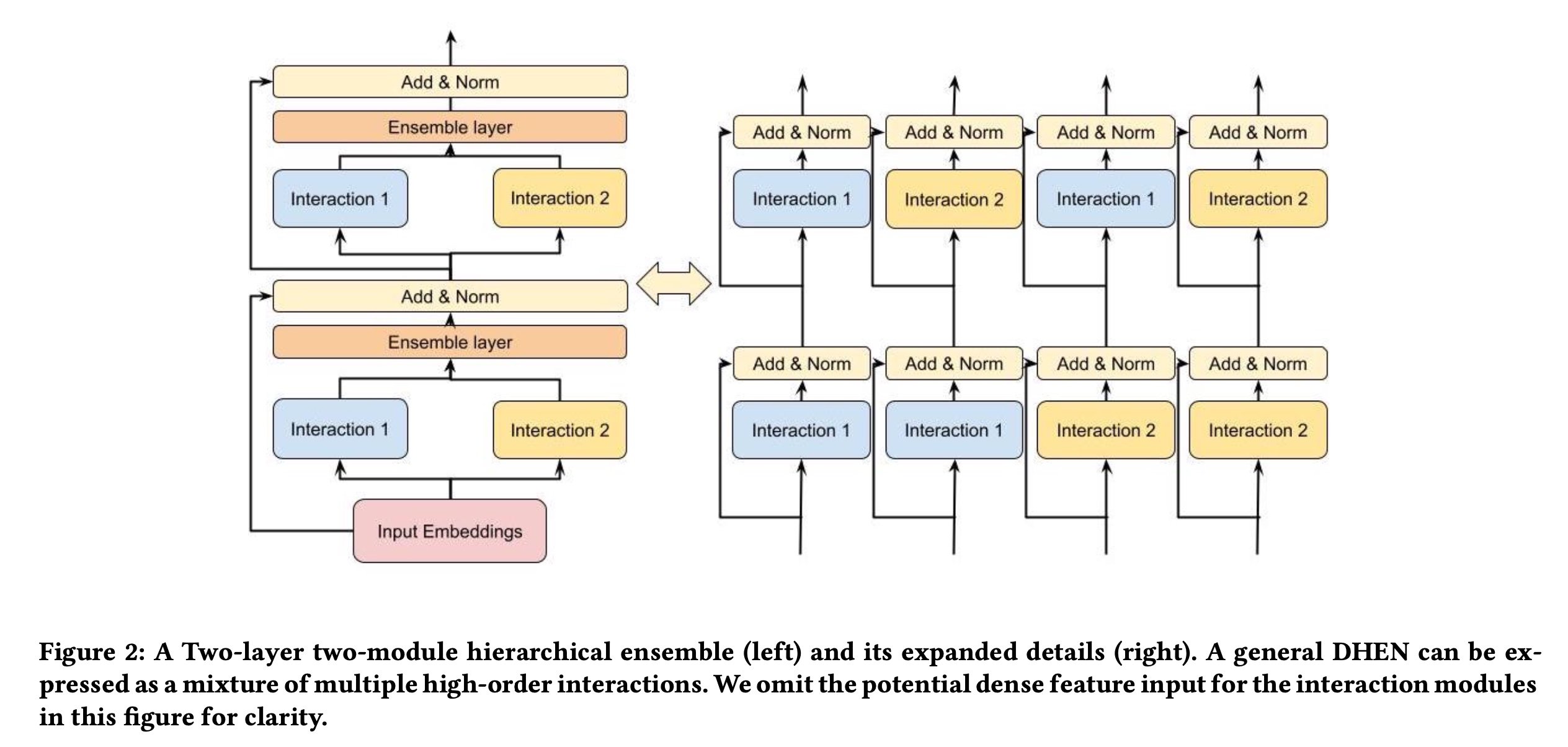
1.1.3 Interaction Modules
我们在模型中应用了五种类型的
interaction模块:AdvancedDLRM、self-attention、Linear、Deep Cross Net、以及Convolution。实际上,DHEN中可以包含的interaction模块不限于上述五种。此外,请注意,如果一个interaction模块输出单个张量MLP的张量输出),我们将应用embeddings的列表,其中embedding维度、interaction模块output embeddings的数量。下面我们简要介绍DHEN中使用的这些interaction模块。AdvancedDLRM:我们使用DLRM风格的interaction模块来捕获feature interactions,在后续实验中称其为AdvancedDLRM。给定embeddings的输入AdvancedDLRM输出embeddings的一个新的列表其中:
reshape将embeddings组成的列表,embedding维度为
Self-attention:我们考虑自注意力作为本文的一种interaction模块。self-attention被广泛应用于Transformer网络。它之前也被用于CTR prediction任务(《Interpretable click-through rate prediction through hierarchical attention》)。典型的Transformer包含多个堆叠的encoder/decoder layers,其核心是self-attention机制。在本文中,给定embeddings的输入Transformer encoder layer:其中:
interaction模块的输出维度。Convolution:卷积层广泛应用于计算机视觉任务,也被应用于自然语言处理(NLP)和CTR任务。在本文中,我们将卷积作为interaction模块之一。给定embeddings的输入embeddings的列表其中:
interaction模块的输出维度。Linear:线性层是捕获原始feature embeddings中信息的最直接模块之一。在本文中,我们使用线性层作为interaction模块之一来压缩每层的信息。给定embeddings的输入embeddings的列表其中:
interaction模块的输出维度。Deep Cross Net: DCN:DCN是CTR prediction任务中广泛使用的feature interaction模块。它引入了一个cross network,能够高效地学习特定有界阶数的feature interactions。在本文中,我们将DCN模块作为每层的interaction模块之一。给定embeddings的输入embeddings的列表其中:
由于我们已经使用
skip connection在堆叠层之间传递信息,因此上述公式中省略了原始论文中的skip connection过程。原始论文中:
1.2 训练系统
直观来看,
stacked hierarchical ensemble layers的深度有助于提升DHEN的表达能力,但这也给DHEN的实际训练带来了挑战。本节将重点介绍我们如何在集群中实现DHEN的高效的、可扩展的训练。看起来训练难度很大。
1.2.1 训练策略
每个
DHEN训练样本包含categorical features和numerical features,所有特征在被DHEN layers处理之前必须转换为dense representations。这一过程的直接挑战在于,DHEN的规模和复杂性完全超出了单个标准datacenter server的处理能力:这类服务器通常配备8 GPUs,总高带宽内存(high bandwidth memory: HBM)仅几百GB,计算能力最高达数十PetaFLOPs。因此,与训练单个DHEN样本所需的参数数量(可达trillions)和计算量(可达giga flops)相比,单台服务器的能力严重不足。为了实现
DHEN的高效训练,我们利用了《Software-hardware co-design for fast and scalable training of deep learning recommendation models》中详细介绍的ZionEX全同步训练系统。概括来说,ZionEX系统将16台主机组成一个“超级节点”(称为pod),其中包含128块A100 GPU(每台主机8块),总HBM容量达5TB,BF16计算能力为40PF/s。在主机内部,每块GPU通过NVLink连接;pod中的每台主机则通过高达200GB/s的高带宽网络连接,8块GPU共享该网络。借助
ZionEX,我们通过以下分布式训练策略解决计算和内存容量问题:我们首先将
embedding tables分布式存储在一个pod中。为了更好地实现负载均衡并处理超大规模embedding tables,我们不将完整的embedding tables放置在不同GPU上,而是主动将超大规模embedding tables按列等分为多个shards,并根据经验成本函数(empirical cost function)分配这些列到这些shards。该成本函数同时考虑了这种分配方式的计算开销和通信开销。我们使用LPT(《Longest-processing-time-first scheduling》)近似集合划分(approximate set partition)算法,根据成本函数以负载均衡的方式分布table shards。这个成本函数如何定义?论文并未详细说明。
另一方面:对于包括
DHEN layers在内的dense模块,我们在每块GPU上复制它们,并以数据并行(data parallel: DP)方式进行训练。这一选择基于以下观察:dense DHEN layers的activation规模可能远大于weights本身,因此同步weights的成本低于通过网络传输activations的成本。这种训练策略形成了一种混合训练范式:每个batch从DP开始,进入模型并行(model parallelism: MP)以进行分布式embedding lookup,最后通过DP处理dense layers。
使用
DP训练dense模块会将stacked DHEN layers的参数大小限制在单GPU的HBM容量内,这阻碍了我们对DHEN可扩展性极限的探索。为解决这一问题,我们采用以下技术:fully sharded data parallel: FSDP:通过将权重进一步分片到不同GPUs,消除传统数据并行中的内存冗余。activation checkpointing: 通过用更多计算换取更少的峰值内存使用(peak memory usage)。cpu offloading:通过积极将参数和梯度存储到CPU,并在需要前将其加载回GPU,从而进一步减少GPU内存使用。
由于所有这些技术都会影响训练效率,我们根据
DHEN的层数精心调整系统,仅启用满足训练需求的最小技术集合。DHEN的训练策略总结如Figure 4所示。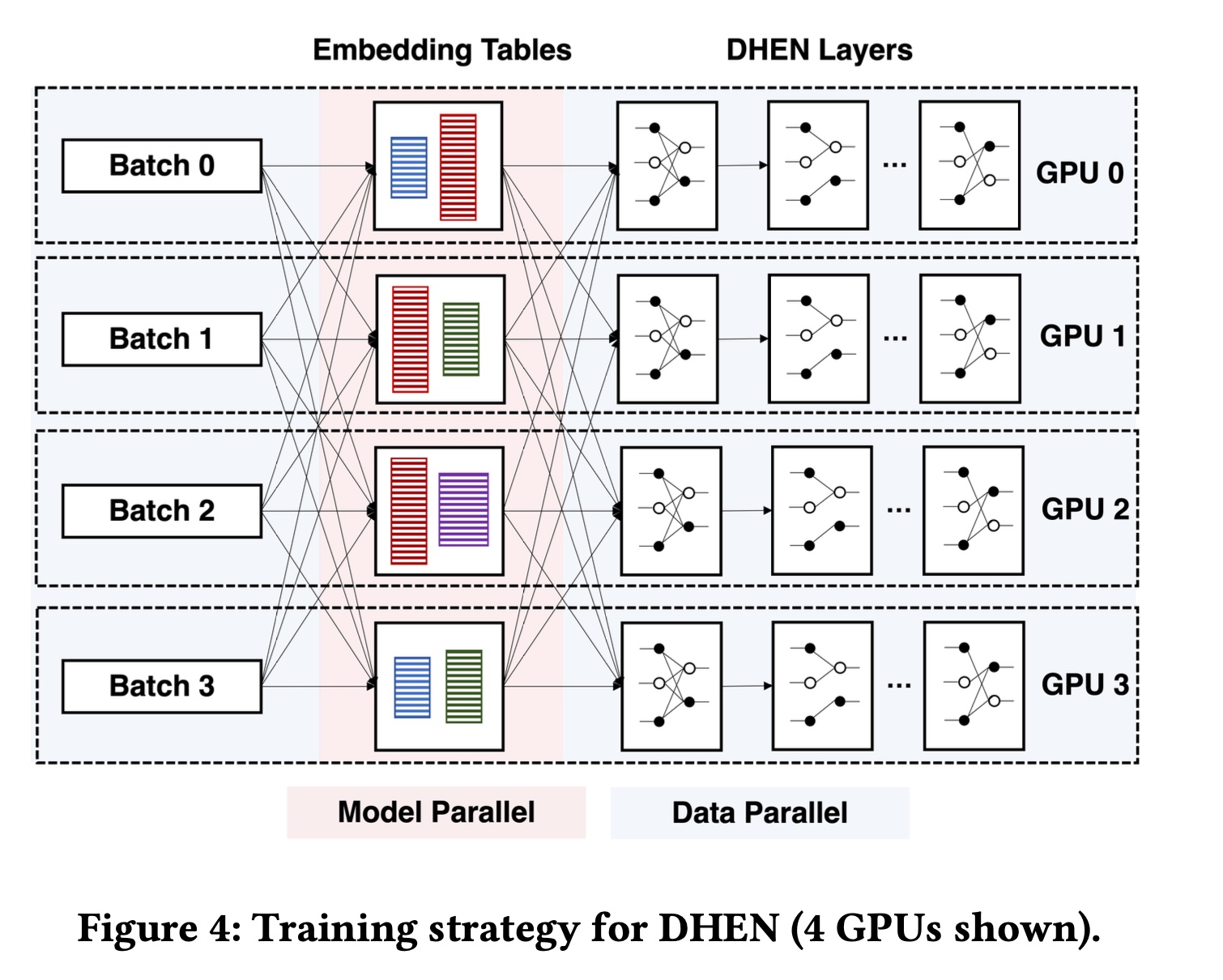
1.2.2 训练优化
我们提供了额外的优化措施以进一步加速训练。
通用
Optimizations:我们启用了一组广泛使用的优化措施,包括:large batch training从而减少synchronization频次。带随机
rounding的FP16 embedding、BF16 optimizer、quantized all to all and allreduce collectives从而降低内存占用,并提升数值稳定性。使用
Tensor Core等专用加速硬件来减少通信开销。
Hybrid Sharded Data Parallel:为了在训练成本预算内找到最佳的DHEN配置,我们必须同时探索configuration of token mixers和层数。在实践中,我们需要频繁实验内存占用略超过单GPU的HBM容量的候选DHEN模型(我们称这些模型为 “尴尬尺寸” 模型),这使得数据并行不可行,必须使用FSDP。然而,在这些情况下,我们发现直接应用FSDP无法实现最佳效率,尤其是在生产规模(数百块GPU)下训练时。这是因为在前向传播和反向传播的关键路径上,从每块GPU收集weights不同分片的全收集(allgather)操作需要较长时间完成,原因包括:(1):需要与集群中的所有GPU通信。(2):每个分片太小了,无法有效利用网络带宽。
尽管预取(
prefetching)等技术有助于缓解这一问题,但它们会给系统带来内存压力,从而违背使用FSDP的初衷。为此,我们针对这些 “尴尬尺寸” 网络提出了一种新的训练范式——
hybrid sharded data parallel: HSDP,该范式与DHEN模型协同设计,适用于我们的训练集群。HSDP利用了GPU互连(NVLink,600GB/s)和主机互连(RoCEv2,25GB/s)之间24倍的带宽差异,其工作原理如下:(1):HSDP在单个主机内对整个模型进行分片,使得FSDP中反向传播的reduce-scatter操作、以及前向和反向传播的allgather操作完全在主机内进行。(2):当反向传播中的reduce-scatter操作完成后,我们通过hook来触发并发的allreduce操作,每个操作涉及具有相同local host ID内的所有GPU,从而以异步方式计算其local shard的平均梯度,避免阻塞反向传播的计算。(3):最后,我们注册一个backward hook来等待pending的allreduce操作的handles,从而确保HSDP在训练语义上与FSDP和DDP保持一致。
我们在
Figure 5中对比了FSDP和HSDP。定性来看,与
FSDP相比,HSDP具有以下优势:(1):前向传播和反向传播关键路径上的allgather操作的延迟显著减少,因为它可以利用高速NVLink互连,无需通过较慢的RoCE链路进行跨主机通信。(2):通信操作的规模随主机数量而非GPU数量扩展,提高了效率。
然而,
HSDP的tradeoff在于:它支持的模型最大规模是纯数据并行支持规模的
8倍(每台主机的GPU数量)。由于添加了
allreduce操作,在数据传输量上会产生1.125倍的通信开销。
对于这些 “尴尬尺寸” 模型,这些
tradeoff是可接受的,因为allreduce开销可以通过下一层的计算来隐藏,且allreduce是高度优化的操作。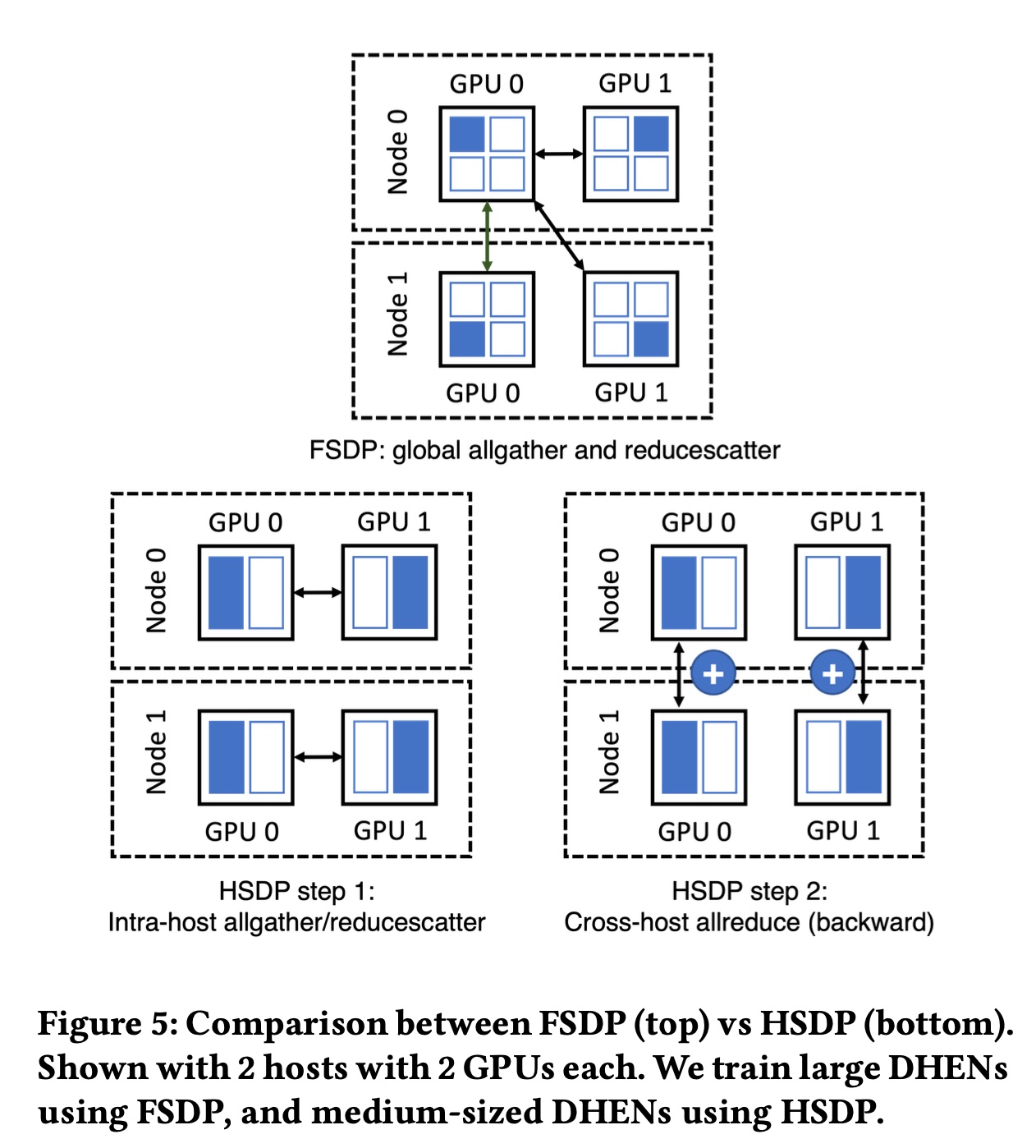
1.3 实验
在本节中,我们进行实验以评估
Deep Hierarchical Ensemble Network在CTR prediction任务中的有效性。我们的实验旨在:(1):评估hierarchical ensemble的有效性,并确定一组适合集成的interaction模块。(2):将DHEN与SOTA的DLRM model进行端到端的准确性对比,验证其增益,并展示我们system-level optimizations对DHEN的training throughput的提升效果。
我们使用工业数据集进行所有实验。如前所述,内部的
AdvancedDLRM模型被视为interaction模块之一。为简洁起见,我们省略了AdvancedDLRM和数据集设置的详细描述。所有实验的训练超参数(包括学习率和优化器配置)均保持一致。所有模型均使用数百个sparse (categorical) features和数千个dense (numerical) features进行训练。全同步训练方案(full-sync training scheme)确保模型性能和训练吞吐量具有可复现性。我们使用归一化熵损失(Normalized Entropy loss)评估CTR prediction准确性。如何
ensemble?作者并未说明。也没有消融实验。
1.3.1 不同 Interaction 模块的模型变体
本节旨在了解在常用模块下
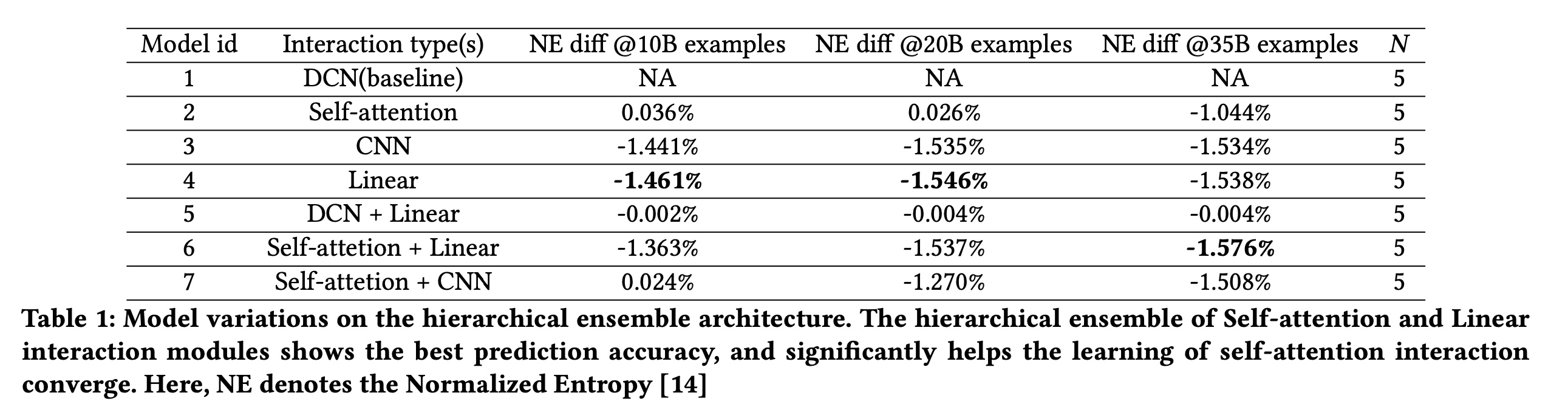
DHEN的表现。具体而言,我们使用四种interaction模块(DCN、Self-attention、CNN和Linear)来测试hierarchical ensemble的性能(下一节将深入与AdvancedDLRM进行对比)。在每个实验中,每层包含不同类型的interaction模块。Table 1显示了不同模型设置的性能,其中DCN为基线,使用不同training steps(training examples)下的relative Normalized Entropy loss的差异来评估模型性能。从
Table 1可以看出:model (4) with linear interaction module在models with single interaction module per layer中表现最佳,而model (2) with self-attention interaction module需要大量训练数据才能收敛。我们进一步观察到,
self-attention interaction module和linear interaction module的hierarchical ensemble模型(6)在所有变体中表现最佳。这一结果表明,hierarchical ensemble architecture捕获了self-attention interaction module和linear interaction module的相关性,并显著帮助self-attention interaction module收敛。此外,我们注意到每层集成更多
interaction模块并非总是有益,例如:DCN和线性层的hierarchical ensemble模型(5)的性能优于单独堆叠DCN layer,但不如单独使用线性层。类似地,
self-attention interaction module和CNN interaction module的集成模型(7)也存在这种情况。
这些观察证实了我们的初始假设,即不同 interaction 模块捕获非重叠的 interaction 信息,因此 hierarchical ensemble 机制是 DHEN 性能的关键。
1.3.2 工业级 AdvancedDLRM 实验
Model Prediction性能:在验证了具有各种interaction模块的DHEN的有效性后,我们进一步评估其在工业级模块AdvancedDLRM上的效果。具体而言,我们利用SOTA的AdvancedDLRM模块(《Deep learning recommendation model for personalization and recommendation systems》)和线性模块作为hierarchical ensemble的两个interaction模块。Table 2显示了DHEN与AdvancedDLRM模型的性能对比。我们训练了
4个DHEN模型,每层均集成AdvancedDLRM interaction module和Linear interaction module。每个模型都有Table 2可以看出:所有
DHEN模型均优于工业级AdvancedDLRM模型,且更深的DHEN模型实现了更大的Normalized Entropy改善。在所有情况下,我们都观察到随着处理的训练样本的增加,
gain持续扩大。
这表明高阶
interactions、以及各种interactions的相关性在CTR prediction任务中均起着重要作用;且更大数据集下Normalized Entropy改善的扩大表明DHEN的性能具有一致性和泛化性。这个对比有问题:
baseline只有1层,而其他模型都不止一层。因此很难说明效果是由于模型架构更先进?还是由于模型更深?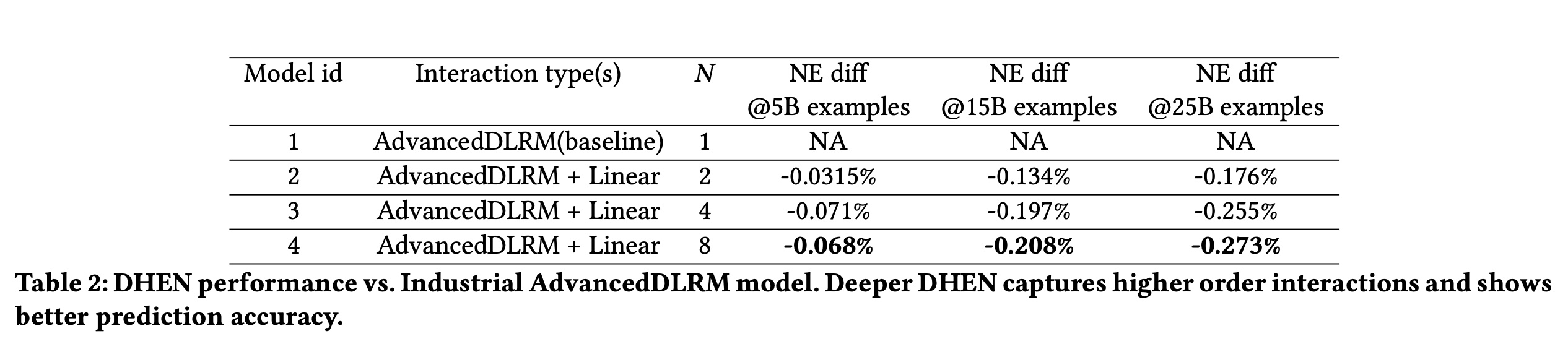
Scaling效率:为评估DHEN模型的scaling效率,我们在Table 3中总结了使用MoE和stacking DHEN layers两种scaling方法的对比结果。两种scaling方法均基于相同的工业级AdvancedDLRM实现。我们使用MoE架构扩展AdvancedDLRM中的MLPlayers,同时使用AdvancedDLRM模块和Linear模块的ensemble来堆叠DHEN layers。结果表明,在训练复杂度(以
FLOPs衡量)相近的情况下,DHEN在准确性上始终优于AdvancedDLRM MoE,因此stacking DHEN layers是一种具有更高投资回报的有效scaling机制。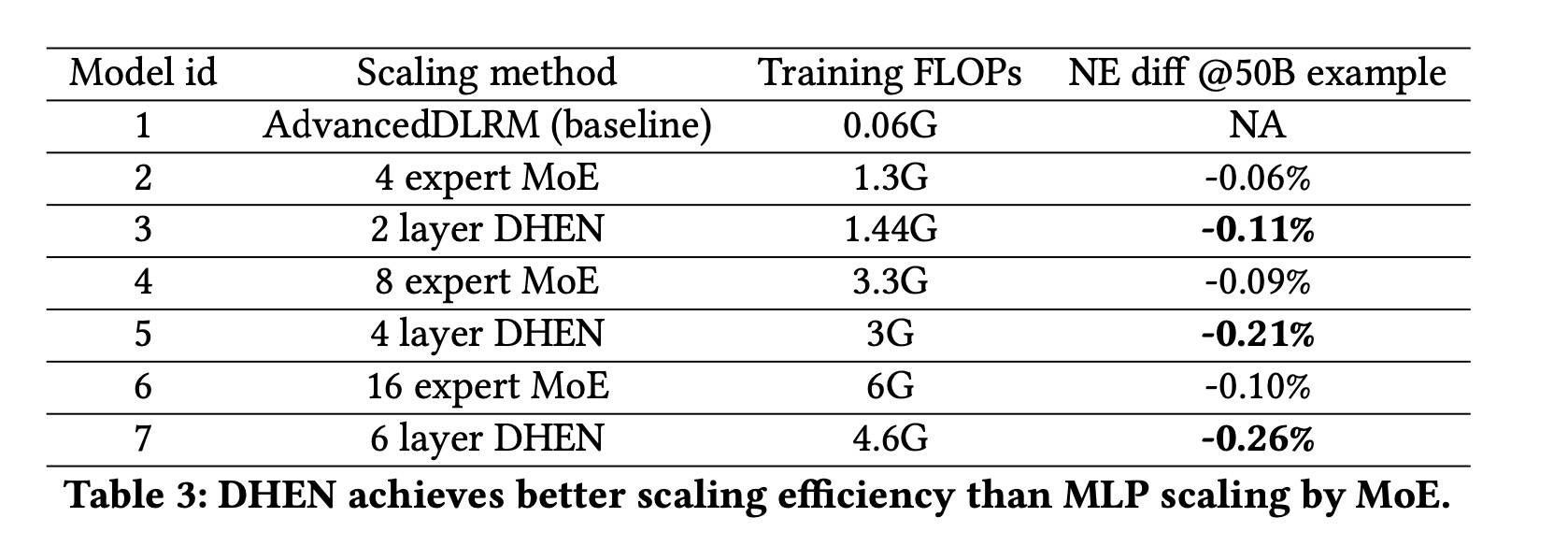
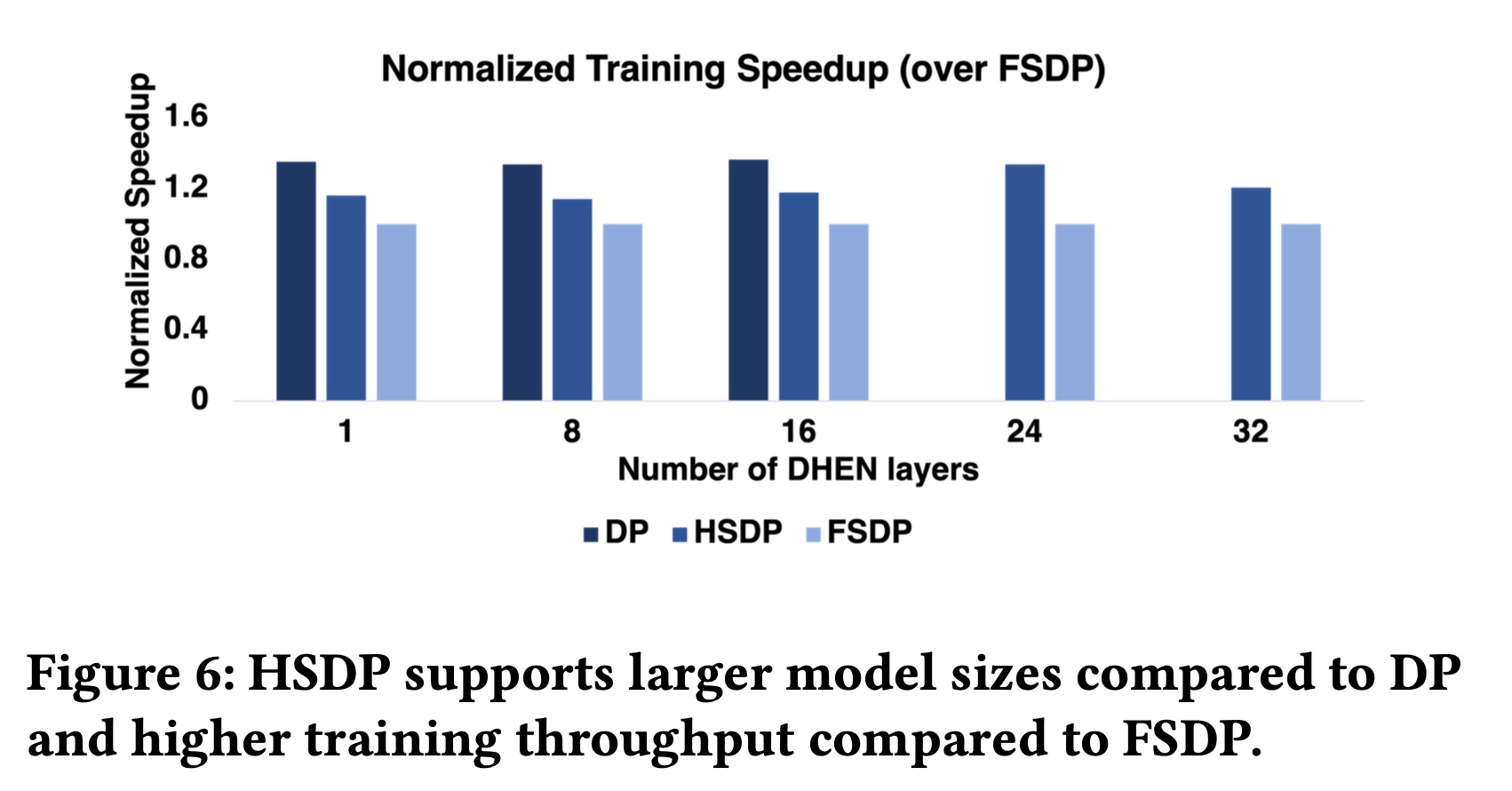
Training吞吐量:基于ZionEX设计,本节评估在256-GPU集群上训练DHEN模型的吞吐量。我们首先展示使用DP训练8层DHEN模型时system level optimizations的有效性。总体而言,应用FP16 embedding、自动混合精度(AMP)、quantized BF16 allreduce and all to all collectives后,端到端速度提升了1.08倍。这一改进源于quantized collectives操作减少了通信延迟,剩余瓶颈在于optimizer cost和all to all collectives调用(该调用无法与密集层的计算完全重叠)。尽管
DHEN随层数的增加而scale良好,但训练更深的DHEN模型需要范式转变,因为DP在我们的集群中最多只能支持22层DHEN。我们现在量化所提出的与DHEN协同设计的训练范式HSDP如何弥补FSDP与DP在吞吐量上的差距,以及DP在内存上的限制。我们对不同层数的DHEN模型进行训练吞吐量实验,使用三种范式训练每个模型并对比结果。如Figure 6所示:DP在16层内表现良好,层数进一步增加会导致错误。另一方面,
FSDP和HSDP均支持更多层数,且HSDP始终比FSDP快1.2倍。
我们的
trace analysis表明,HSDP的吞吐量提升确实源于training的关键路径上allgather latency的大幅减少,这得益于单主机内快速的NVLink连接。