一、FinalMLP [2023]
《FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction》
虽然多层感知机 (
multi-layer perceptron: MLP)是许多deep CTR预测模型的核心组件,但人们普遍认为,单独应用简单的MLP网络在学习乘性特征交互(multiplicative feature interactions)方面效率低下。因此,许多双流交互(two-stream interaction)模型(例如DeepFM和DCN)已通过将MLP网络与另一个专用网络(dedicated network)集成从而来增强CTR预测。由于MLP stream隐式学习特征交互(feature interactions),现有研究主要侧重于提升complementary stream中的显式特征交互(explicit feature interactions)。相比之下,我们的实证研究表明,只需结合两个
MLP即可获得令人惊讶的良好性能,这是现有工作从未报道过的。基于这一观察,我们进一步提出了可以轻松插入的feature gating layers和interaction aggregation layers,从而得到enhanced two-stream MLP model。这样,它不仅可以实现差异化的feature inputs,还可以有效地融合两个streams之间的stream-level interactions。我们在四个开放benchmark datasets上的评估结果,以及我们工业系统中的online A/B test表明,FinalMLP比许多复杂的two-stream CTR模型取得了更好的性能。CTR预测的关键挑战之一是学习特征之间的复杂关系,使得模型能够在罕见的feature interactions情况下仍能很好地泛化。多层感知机作为深度学习中强大而通用的组件,已成为各种
CTR预测模型的核心构建块(building block)。尽管MLP在理论上被认为是一种通用近似器,但人们普遍认识到,在实践中,应用简单的MLP网络学习multiplicative feature interactions(例如,点乘dot)效率低下。为了提升学习
explicit feature interactions(二阶或三阶特征)的能力,人们已经提出了各种feature interaction网络。典型的例子包括factorization machines: FM、cross network、compressed interaction network: CIN、self-attention based interaction、adaptive factorization network: AFN等。这些网络引入了
inductive bias来有效地学习feature interactions,但失去了MLP的expressiveness,如Table 3中的实验所示。因此,双流(two-stream)CTR预测模型得到了广泛应用,例如DeepFM、DCN、xDeepFM和AutoInt+,它们将MLP网络和专用的feature interaction网络集成在一起,以提升CTR预测。具体来说,MLP stream隐式地学习feature interactions,而另一个stream以互补的方式提升explicit feature interactions。由于其有效性,双流模型已成为工业部署的热门选择。尽管许多现有研究已经验证了双流模型相对于单个
MLP模型的有效性,但没有一项研究报告了双流模型与简单地并行组合两个MLP网络的双流MLP模型(记作DualMLP)的性能比较。因此,我们的工作首次尝试描述DualMLP的性能。我们在开放benchmark datasets上进行的经验研究表明,尽管DualMLP很简单,但可以实现令人惊讶的良好性能,与许多精心设计的双流模型相当甚至更好(参见我们的实验)。这一观察促使我们研究这种双流MLP模型的潜力,并进一步扩展它以构建一个简单但强大的CTR预测模型。
双流模型实际上可以看作是两个并行网络的
ensemble。这些双流模型的一个优点是每个流都可以从不同的角度学习feature interactions,从而互补以实现更好的性能。例如:Wide&Deep和DeepFM提出使用一个流来捕获低阶feature interactions,另一个流来学习高阶feature interactions。DCN和AutoInt+提倡分别在两个流中学习explicit feature interactions和implicit feature interactions。xDeepFM从vector-wise和bit-wise的角度进一步提升了feature interaction learning。
这些先前的结果验证了两个
network streams的差异化(或多样性)对双流模型的有效性有很大影响。与现有的通过设计不同的网络结构(例如,
CrossNet、CIN)来实现stream differentiation的双流模型相比,DualMLP的局限性在于两个流都只是MLP网络。我们的初步实验还表明,当针对两个MLP使用不同的网络大小(如,不同的层数、不同的units数量)来调优DualMLP时,可以获得更好的性能。这一结果促使我们进一步探索如何扩大两个流的差异化,以改进DualMLP作为base model。此外,现有的双流模型通常通过
summation或concatenation来组合两个流,这可能会浪费对高阶(即stream-level) 的feature interactions进行建模的机会。如何更好地融合stream outputs成为另一个值得进一步探索的研究问题。为了解决这些问题,本文构建了一个增强型双流
MLP模型,即FinalMLP,它在两个MLP module networks之上集成了feature gating层和interaction aggregation。更具体地说,我们提出了一个
stream-specific的feature gating layer,它允许获得gating-based的feature importance weights从而用于soft feature selection。也就是说,可以通过以learnable parameters、用户特征、或item特征为条件,从不同角度计算feature gating,从而分别产生全局的、user-specific、或item-specific的feature importance weights。通过灵活地选择不同的gating-condition features,我们能够为每个流得出stream-specific features,从而增强feature inputs的差异化,以实现两个流的complementary feature interaction learning。为了将
stream outputs以stream-level feature interaction来融合,我们提出了一个基于二阶双线性融合(second-order bilinear fusion)的interaction aggregation层 。为了降低计算复杂度,我们进一步将计算分解为sub-groups,从而实现高效的multi-head bilinear fusion。
feature gating层和interaction aggregation层都可以轻松插入现有的双流模型中。我们在四个开放benchmark datasets上的实验结果表明,FinalMLP优于现有的双流模型,并达到了新的SOTA。此外,我们通过离线评估和在线A/B testing验证了其在工业环境中的有效性,其中FinalMLP还显示出比所部署的baseline显著的性能提升。我们设想,简单而有效的FinalMLP模型可以作为未来开发双流CTR模型的新的强大baseline。本文的主要贡献总结如下:
据我们所知,这是第一项通过实证证明双流
MLP模型令人惊讶的有效性的研究,这可能与文献中的普遍看法相反。我们提出了
FinalMLP,这是一种增强型双流MLP模型,具有pluggable feature gating and interaction aggregation layers。我们在
benchmark datasets上进行了离线实验,并在生产系统中进行了online A/B test,以验证FinalMLP的有效性。
1.1 模型
双流
MLP模型:尽管双流MLP模型很简单,但据我们所知,之前的研究尚未报道过这种模型。因此,我们首次尝试研究这种用于CTR预测的模型,称为DualMLP,它简单地将两个独立的MLP网络组合成两个流。具体而言,双流MLP模型可以表述如下:其中:
MLP网络。两个MLP的规模(即,层数、隐层大小)可以根据数据进行不同的设置。feature inputs,而output representations。
在大多数以前的工作中,
feature inputsfeature embeddings的拼接(可能包含一些池化操作)stream outputs通常通过简单的操作进行融合,例如summation和concatenation,忽略stream-level interactions。接下来,我们介绍两个可以分别被插入到inputs中和outputs中的模块,以提升双流MLP模型。
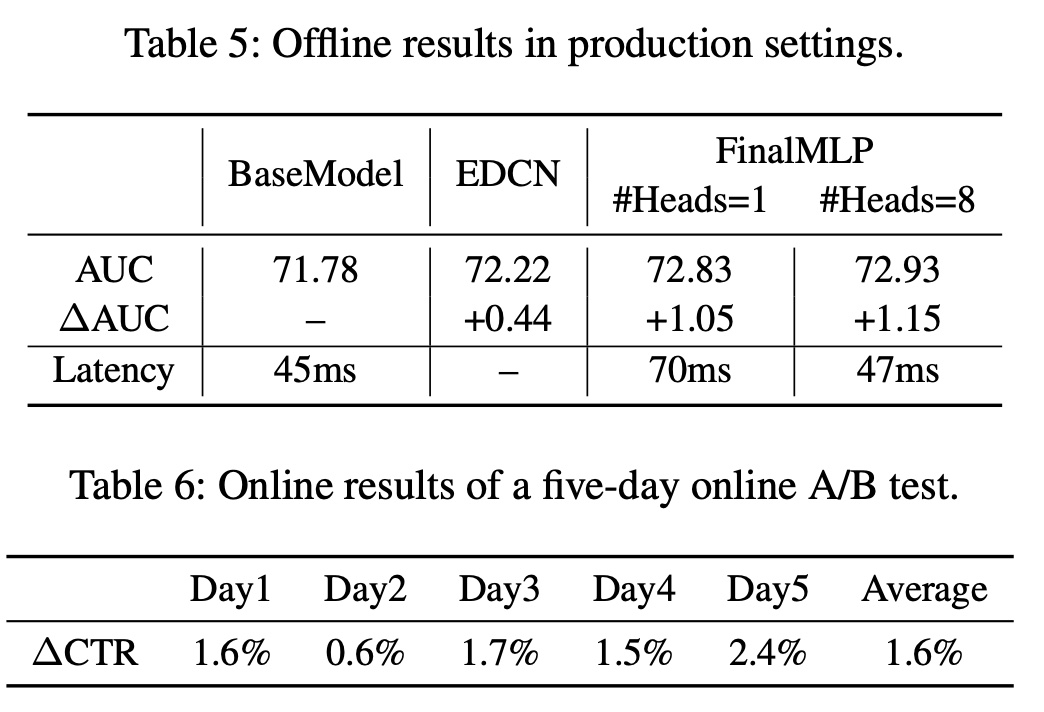
1.1.1 Stream-Specific Feature Selection
许多现有研究强调了结合两种不同的
feature interaction网络(例如,implicit vs. explicit、low-order vs. high-order,、bit-wise vs. vector-wise)以有效地实现准确的CTR预测。我们的工作不是设计专用的网络结构,而是旨在通过stream-specific的feature selection来扩大两个流之间的差异,从而产生差异化的feature inputs。 受MMOE中使用的门控机制的启发,我们提出了一个stream-specific的feature gating模块来soft-select stream-specific features,即为每个流不同地重新加权feature inputs。在MMOE中,gating weights以task-specific features为条件,从而重新加权expert outputs。同样地,我们通过以learnable parameters, user features, or item features为条件,从不同角度执行feature gating,从而分别产生global, user-specific, or item-specific feature importance weights。具体来说,我们通过
context-aware feature gating layer进行stream-specific feature selection,如下所示:其中:
MLP的门控网络,它以stream-specific conditional featureselement-wise gating weightsuser/item的一组特征中选择learnable parameters。feature importance weights是通过使用sigmoid函数2将其转换为[0, 2]的范围从而获得的,使得权重的平均值为1。给定
concatenated feature embeddingsfeature outputs
我们的
feature gating模块允许通过从不同角度设置conditional featuresfeature inputs。例如,Figure 1(a)演示了user-specific和item-specific的feature gating的案例,它分别从用户的角度和item的角度来调制(modulate)每个流。这减少了两个相似的MLP streams之间的“homogeneous”学习,并能够实现feature interactions的更多的complementary learning。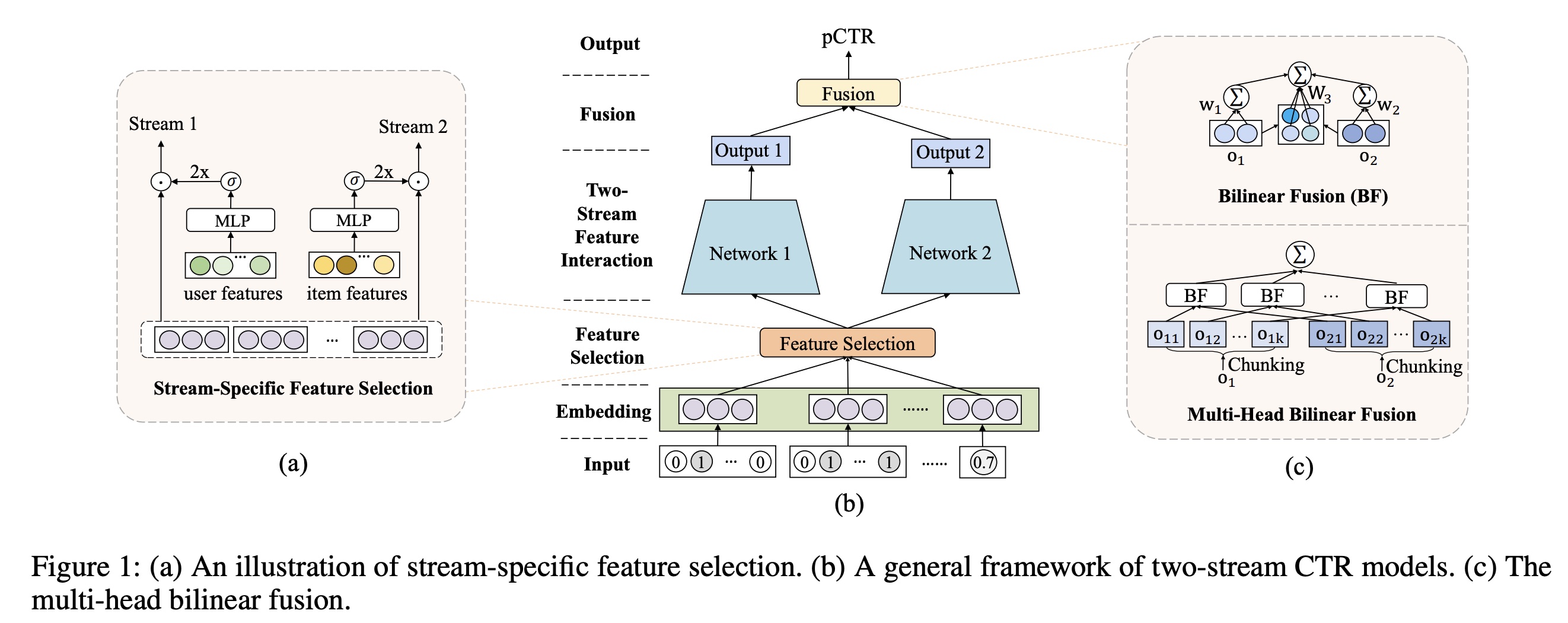
1.1.2 Stream-Level Interaction Aggregation
Bilinear Fusion:如前所述,现有工作大多采用summation或concatenation作为融合层(fusion layer),但这些操作无法捕stream-level feature interactions。受到CV领域中广泛研究的双线性池化(bilinear pooling)的启发,我们提出了一个双线性交互聚合层(bilinear interaction aggregation layer),通过用stream-level feature interaction来融合stream outputs。如Figure 1(c)所示,所预测的点击率公式如下:其中:
双线性项
当
当
concatenation fusion,即
有趣的是,
bilinear fusion也与常用的FM模型有联系。具体来说,FM通过以下公式来建模one-hot/multi-hot feature encoding和concatenation来获得)之间的二阶特征交互,从而进行CTR预测:其中:
embedding矩阵。可以看出,当
FM是bilinear fusion的一种特殊形式。然而,当
1000维输出,1M参数,计算成本高昂。为了降低计算复杂度,我们在下面介绍了扩展的多头双线性融合(multi-head bilinear fusion)。通常
embedding维度相等,都是选择较小的维度,如128。很少选择非常大的维度。Multi-Head Bilinear Fusion:multi-head attention之所以具有吸引力,是因为它能够将来自不同representation subspaces并使用相同attention pooling的知识结合起来。在最近成功的Transformer模型中,它减少了计算量,并一致性地提高了性能。受Transformer成功的启发,我们将bilinear fusion扩展为多头的版本。具体来说,我们不是直接计算其中:
sub-space representation,multi-head attention类似,我们在每个子空间中执行bilinear fusion,将sum pooling聚合subspace computation,以得到最终的预测的点击率:其中:
sigmoid激活函数的bilinear fusion。通过与
multi-head attention类似的subspace computation,理论上我们可以将bilinear fusion的参数数量和计算复杂度减少element-wise product fusion。如果multi-head learning,从而使模型获得更好的性能。实际上,multi-head fusions在GPU中并行计算,从而进一步提高效率。最后,我们的
stream-specific feature gating模块和stream-level interaction aggregation模块可以被插入到模型中,从而生成增强型的双流MLP模型,即FinalMLP。
1.1.3 模型训练
为了训练
FinalMLP,我们应用了广泛使用的二元交叉熵损失:
1.2 实验
数据集:
Criteo, Avazu, MovieLens, and Frappe。
评估指标:
AUC。此外,AUC增加0.1被认为是CTR预测的显著改善。baseline:single-stream的显式的feature interaction网络:一阶:
Logistic Regression (LR)。二阶:
FM、AFM、FFM、FwFM、FmFM。三阶:
HOFM(3rd)、CrossNet(2L)、CrossNetV2(2L)和CIN(2L)。我们特意将最大阶次设置为“3rd”、或将交互层数设置为“2L”,从而获得三阶特征交互。高阶:
CrossNet、CrossNetV2、CIN、AutoInt、FiGNN、AFN和SAM,可自动学习高阶feature interaction。
双流
CTR模型:相关工作中所介绍的。
实现:
重用
baseline模型。基于
FuxiCTR实现我们的模型。我们的评估遵循与
AFN相同的实验设置,将embedding维度设置为10,将batch size设置为4096,将默认MLP大小设置为[400, 400, 400]。对于DualMLP和FinalMLP,我们调优在1∼3层中的两个MLP以增强stream diversity。 我们将学习率设置为1e−3或5e−4。我们通过广泛的网格搜索(平均每个模型约30次运行)调优所有研究模型的所有其他超参数(例如,embedding regularization和dropout rate)。我们注意到,通过优化后的FuxiCTR实现和足够的超参数调优,我们获得的模型性能比AFT原始论文中报告的要好得多。因此,我们报告自己的实验结果,而不是重复使用他们的实验结果来进行公平的比较。为了促进可重复的研究,我们开源了FinalMLP的代码和running logs以及所有使用的baseline。
1.2.1 MLP vs. Explicit Feature Interaction
这里我们将
MLP与精心设计的feature interaction网络进行比较,如下表所示。令人惊讶的是,我们观察到MLP的表现可以与精心设计的显式feature interaction网络不相上下,甚至超越它们。这一观察结果也与DCN-V2论文中报告的结果一致,其中表明经过良好调优的MLP模型(即DNN)可获得与许多现有模型相当的性能。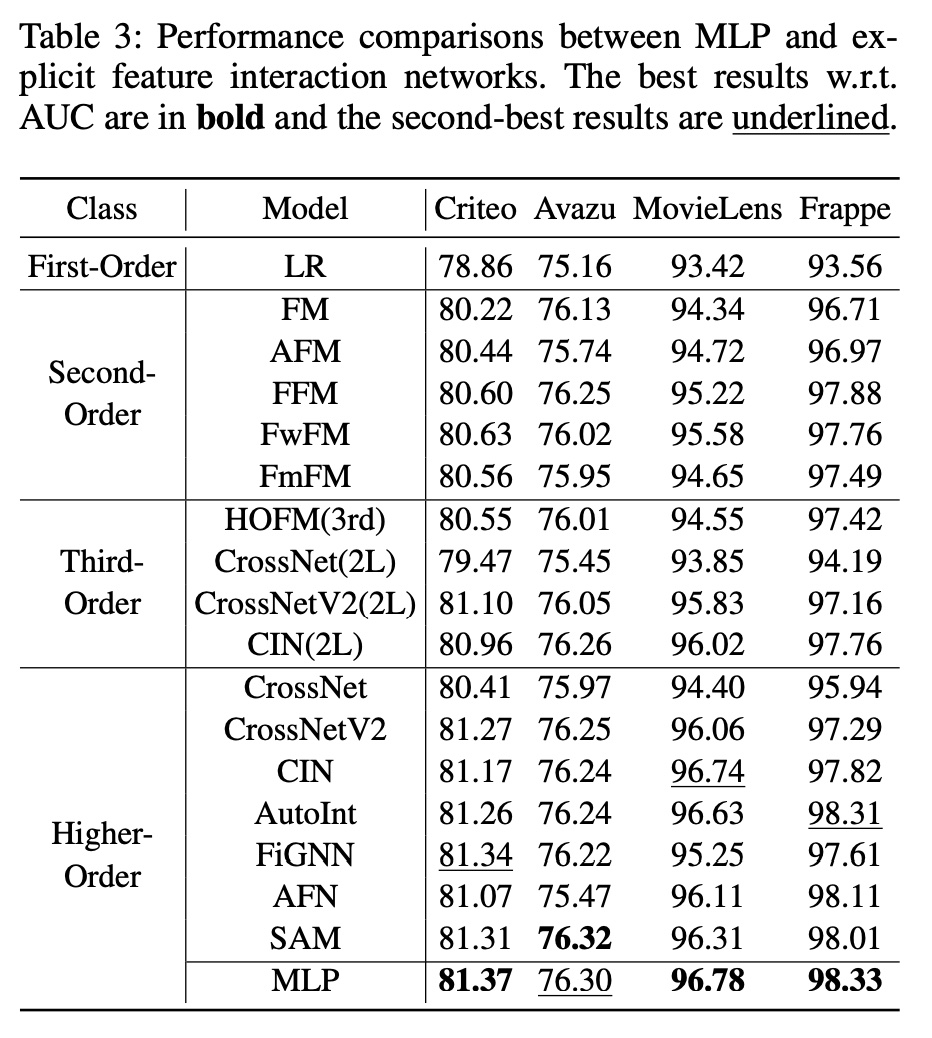
总体而言,
MLP取得的出色表现表明,尽管其结构简单且在学习multiplicative features方面较弱,但MLP在以隐式方式学习feature interactions方面非常具有表达能力。这也部分解释了为什么现有研究双流模型,其中双流模型将显式feature interaction网络与MLP结合起来作为CTR预测。不幸的是,MLP的优势从未在任何现有工作中得到明确揭示。受上述观察的启发,我们更进一步研究一种未经探索的模型结构的潜力,该模型结构简单地将两个MLP作为双流MLP模型。
1.2.2 DualMLP and FinalMLP vs. Two-Stream Baselines
我们对下表中所示的代表性的双流模型进行了全面比较。从结果中,我们得出以下观察结果:
首先,我们可以看到双流模型通常优于
Table 3中报告的单流模型,尤其是单个MLP模型。这符合现有工作,表明双流模型可以学习互补的特征,从而能够更好地建模CTR prediction。其次,简单的双流模型
DualMLP表现得出奇地好。通过仔细调优两个流的MLP layers,DualMLP可以实现与其他复杂的双流baseline相当甚至更好的性能。据我们所知,DualMLP的强大性能从未在文献中报道过。在我们的实验中,我们发现通过在两个流中设置不同的MLP size来增加stream network的多样性可以提高DualMLP的性能。这促使我们进一步开发增强的双流MLP模型,即FinalMLP。/第三,通过我们在
feature gating和fusion方面的可插入式扩展,FinalMLP在四个开放数据集上的表现始终优于DualMLP以及所有其他的双流基线。这证明了我们的FinalMLP的有效性。截至撰写本文时,FinalMLP在Criteo上的PapersWithCode和BARS的CTR prediction排行榜上排名第一。
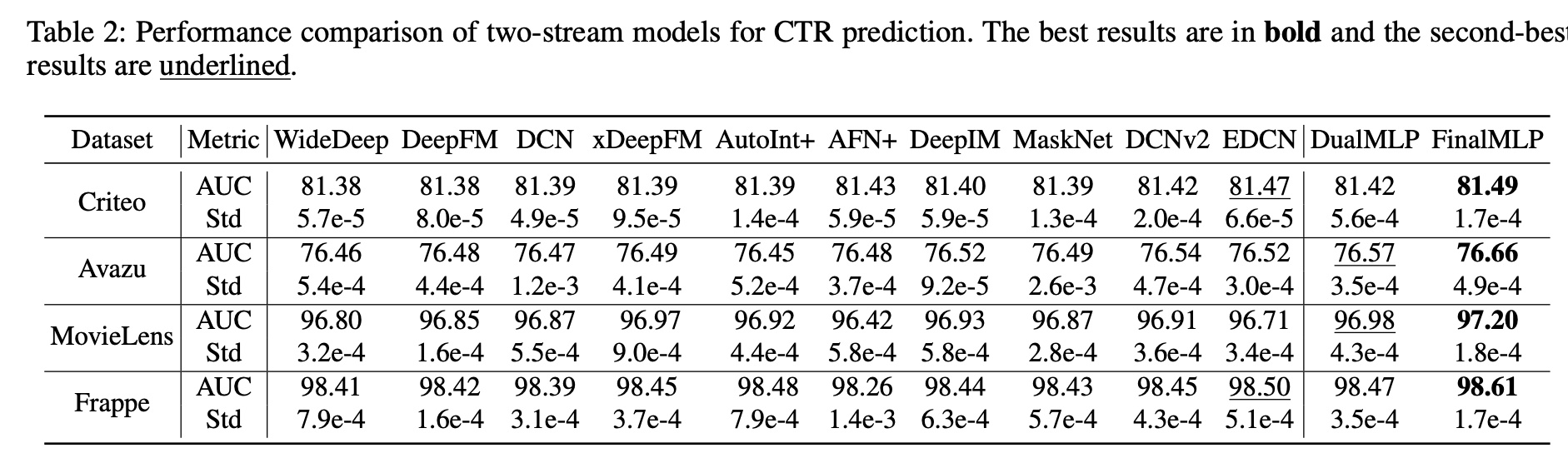
1.2.3 消融研究
Feature Selection and Bilinear Fusion的效果:具体来说,我们将FinalMLP与以下变体进行比较:DualMLP:简单的双流MLP模型,仅将两个MLP作为两个流。w/o FS:缺乏通过context-aware feature gating实现stream-specific的特征选择模块的FinalMLP。Sum:在FinalMLP中使用summation融合。Concat:在FinalMLP中使用concatenation融合。EWP:在FinalMLP中使用Element-Wise Product(即Hadamard乘积)融合。
消融研究结果如
Figure 2所示。我们可以看到:当删除
feature selection模块、或用其他常用融合操作替换bilinear fusion时,性能会下降。这验证了我们的feature selection模块和bilinear fusion模块的有效性。此外,我们观察到
bilinear fusion比feature selection起着更重要的作用,因为替换前者会导致更多的性能下降。
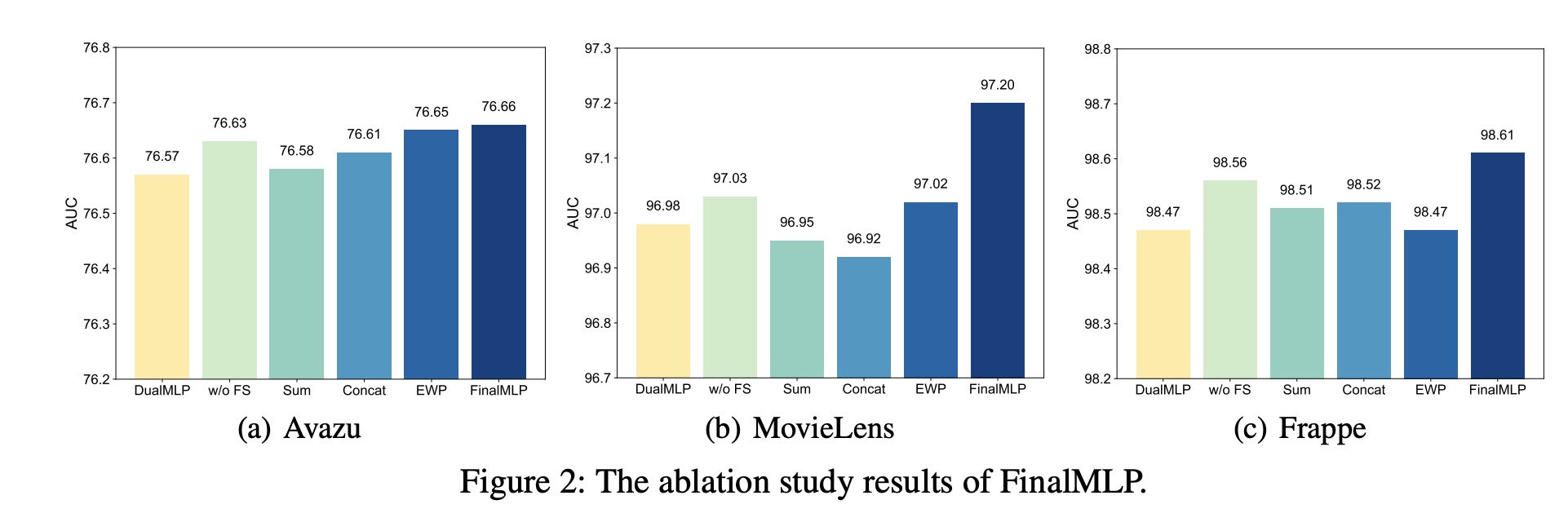
Multi-Head Bilinear Fusion的效果:我们研究了subspace grouping技术对bilinear fusion的影响。下表显示了通过改变子空间数量(即heads数量bilinear fusion时FinalMLP的性能。OOM表示在设置中发生Out-Of-Memory错误。我们发现使用更多参数(即较小的
stream-level特征交互,同时减少冗余的特征交互,类似于multi-head attention。在实践中,可以通过调优effectiveness和efficiency之间的良好平衡。
Industrial Evaluation:我们进一步在新闻推荐生产系统中评估FinalMLP,该系统每天为数百万用户提供服务。我们首先使用来自3天的用户点击日志(包含1.2B个样本)的训练数据进行离线评估。AUC结果如Table 5所示。与在线部署的
deep BaseModel相比,FinalMLP在AUC上获得了超过一个点的改进。我们还将其与
EDCN进行了比较,这是一项最近的工作,它通过双流网络之间的交互增强了DCN。FinalMLP在AUC上比EDCN获得了额外的0.44个点的改进。
此外,我们测试了接收用户请求和返回预测结果之间的端到端的推理延迟(
inference latency)。我们可以看到,通过应用我们的multi-head bilinear fusion,延迟可以从70毫秒(使用1 head)减少到47毫秒(使用8 heads),与在线部署的BaseModel(45毫秒)达到相同的延迟水平。此外,通过选择适当的head num,AUC结果也会略有改善。我们最终报告了
7月18日至22日进行的在线A/B test的结果,结果显示在Table 6中。FinalMLP平均实现了1.6%的CTR改进。这样的改进对我们的生产系统意义重大。