一、GDCN [2023]
《Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction》
有效地建模
feature interactions对于提高CTR模型的预测性能至关重要。然而,现有的方法面临三个重大挑战:首先,虽然大多数方法可以自动捕获高阶
feature interactions,但随着feature interactions的阶次增加,它们的性能往往会下降。其次,现有方法缺乏能力对预测结果提供令人信服的解释,特别是对于高阶
feature interactions,这限制了其预测的可信度。第三,许多方法都存在冗余参数,特别是在
embedding layer中。
本文提出了一种称为
Gated Deep Cross Network (GDCN)的新方法,以及一种Field-level Dimension Optimization (FDO)方法来应对这些挑战。作为GDCN的核心结构,Gated Cross Network (GCN)捕获显式的高阶feature interactions,并在每个阶次中使用information gate来动态地过滤important interactions。此外,我们使用FDO方法,根据每个field的重要性来学习condensed dimensions。在五个数据集上进行的综合实验证明了GDCN的有效性、优越性和可解释性。此外,我们验证了FDO在learning various dimensions和reducing model parameters方面的有效性。大多数
CTR建模方法通常由三种layer组成:feature embedding, feature interaction, and prediction。为了提高CTR预测的准确性,人们已经提出了许多专注于设计有效feature interaction架构的方法。然而,以前的工作,如Logistic Regression (LR)和FM-based的方法,只能建模低阶feature interactions或固定阶次的feature interactions。随着互联网规模的推荐系统变得越来越复杂,对捕获高阶feature interactions的方法的需求日益增长。因此,一些最新的方法能够对显式的和隐式的高阶feature interactions进行联合建模,并实现显著的性能改进。虽然这些方法取得了很大进展,但它们仍然有三个主要局限性:首先,随着
feature interactions阶次的增加,这些方法的有效性趋于下降。一般来说,所能够捕获的交互的最大阶次由feature interactions的depth决定。随着interaction layers的加深,interactions的数量呈指数增长,这使得模型能够生成更多的高阶交互。然而,并不是所有的交互都是有帮助的,这也带来了许多不必要的交互,导致性能下降和计算复杂度增加。许多现有的SOTA工作已经通过hyper-parameter analysis证实,当交互阶次超过一定深度(通常是三阶)时,它们的性能会下降。因此,至关重要的是进行改进从而确保高阶交互具有positive影响,而不是引入更多噪音并导致次优性能。其次,现有方法缺乏可解释性,限制了其
predictions and recommendations的可信度。大多数方法由于隐式的feature interactions(通过DNN)、或为所有feature interactions分配相等的权重,从而导致可解释性较低。尽管一些方法(《DCAP: Deep Cross Attentional Product Network for User Response Prediction》、《Interpretable click-through rate prediction through hierarchical attention》、《Autoint: Automatic feature interaction learning via selfattentive neural networks》)试图通过self-attention机制学到的attention scores来提供解释,但这种方法倾向于融合(fuse)所有features information,因此很难区分哪些交互是必不可少的,尤其是对于高阶的crosses。因此,开发方法能够从模型的和实例的角度来提供有说服力的解释,至关重要,从而实现更可靠的、更可信的结果。第三,大多数现有模型包含大量冗余参数,尤其是在
embedding layer中。许多方法依赖于feature-wise的交互结构,这些结构假设所有fields的embedding dimensions是相等的。然而,考虑到fields的信息容量,有些fields只需要相对较短的维度。因此,这些模型在embedding layer产生大量冗余参数。但直接降低embedding维度会导致模型性能下降。同时,大多数方法仅侧重于减少non-embedding参数,与减少embedding参数相比,对整体参数减少的影响并不显著。尽管DCN和DCN-V2使用经验公式为每个field分配不同的维度,该公式仅基于feature numbers来计算维度,但它们忽略了每个field的重要性,并且经常无法减少模型参数。因此,我们的目标是为每个field分配field-specific and condensed dimensions,考虑其固有的重要性,并有效减少embedding参数。
本文提出了一种称为
Gated Deep Cross Network (GDCN)的模型、以及一种称为Field-level Dimension Optimization (FDO)的方法来解决上述限制。在DCN-V2优雅而高效的设计的基础上,GDCN进一步提高了低阶交互和高阶交互的性能,并且在模型的和实例的视角下都表现出了很好的可解释性。GDCN通过提出的Gated Cross Network (GCN)对explicit feature interactions进行建模,然后与DNN集成以学习implicit feature interactions。GCN由两个核心组件组成:feature crossing和information gate。feature crossing组件在bounded degree内捕获显式的交互,而information gate则在每个cross order上选择性地放大重要性高的important cross features并减轻不重要特征的影响。此外,考虑到field各自的重要性,FDO方法可以为每个field分配压缩的和独立的维度。贡献:
我们引入了一种新方法
GDCN,通过GCN和DNN学习显式的和隐式的feature interactions。GCN设计了一个information gate来动态地过滤next-order cross features并有效地控制信息流。与现有方法相比,GDCN在捕获更深层次的高阶交互方面表现出更高的性能和稳定性。我们开发了
FDO方法,为每个field分配压缩的维度,考虑到每个field固有的重要性。通过使用FDO,GCN仅以原始模型参数的23%实现了可比性能,并且以更小的模型大小、以及更快的训练速度超越了现有的SOTA模型。综合实验表明
GDCN在五个数据集上具有很高的有效性和泛化能力。此外,我们的方法在model level和instance level提供了出色的可解释性,增强了我们对模型预测的理解。
论文其实创新点不多也不大,更多的是工程上的工作。而且创新点之间(
GCN和FDO)没啥关系,强行拼凑一起得到一篇论文。
1.1 GDCN
受
DCN-V2的启发,我们开发了GDCN,它由embedding layer、gated cross network (GCN)和deep network (DNN)组成。embedding layer将高维稀疏的输入转换为低维稠密的representations。GCN旨在捕获显式的feature interactions,并使用information gate来识别重要的交叉特征。然后,
DNN被集成进来从而建模隐式的feature crosses。
本质上,
GDCN是DCN-V2的泛化,继承了DCN-V2出色的表达能力,并具有简单而优雅的公式,易于部署。然而,GDCN通过采用information gates从而引入了一个关键的区别,它在每个阶次中自适应地过滤交叉特征,而不是统一聚合所有特征。这使GDCN能够真正利用deeper的高阶cross-information,而不会出现性能下降,并为GDCN赋予了针对每个实例的动态可解释性。GDCN的架构如Figure 1所示,展示了结合GCN和DNN网络的两种结构:(a) GDCN-S and (b) GDCN-P。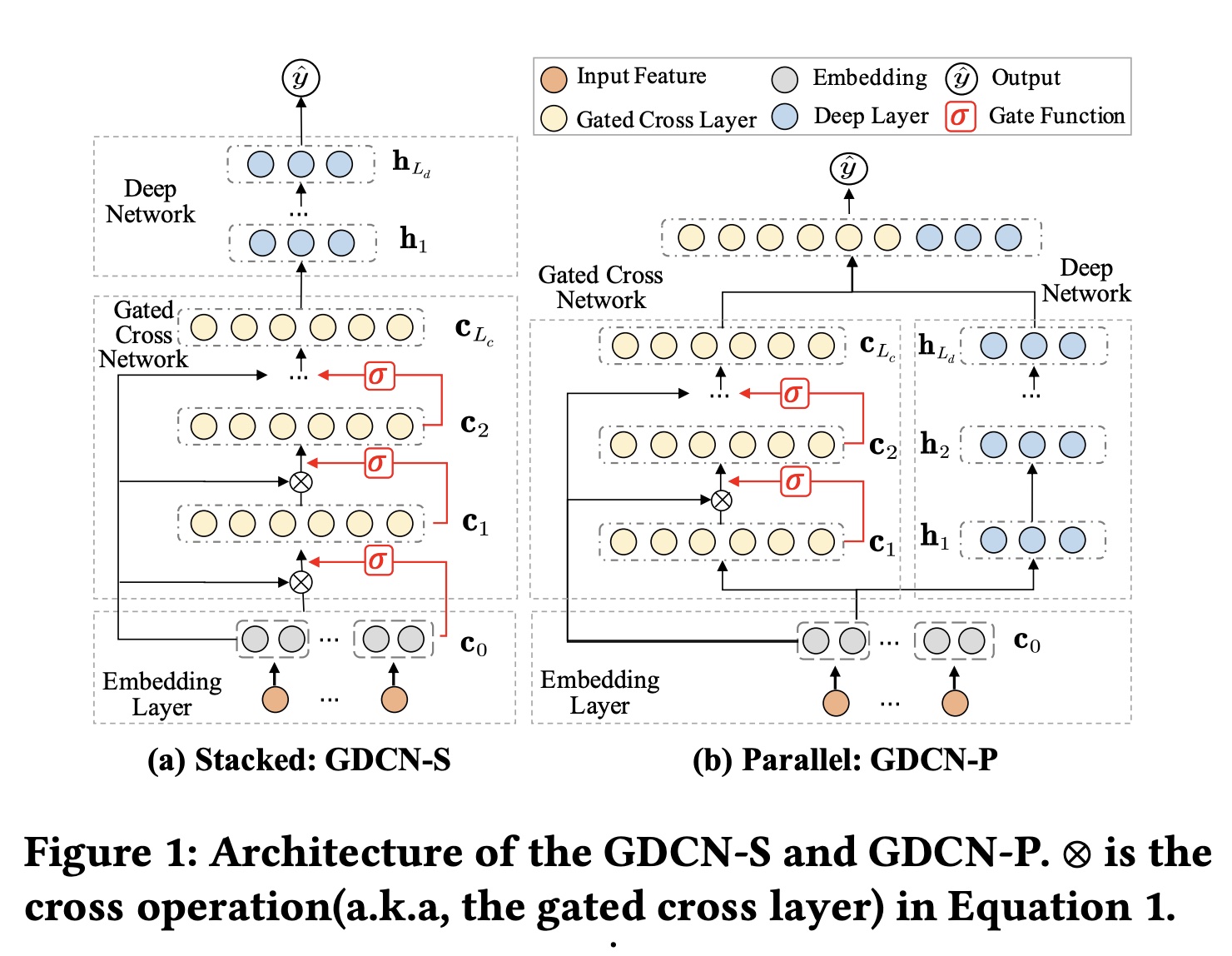
Embedding Layer:输入实例通常是multi-field tabular data records,其中包含fields和field-aware one-hot vector来表示。embedding layer将稀疏的高维特征转换为稠密的低维embedding matrixCTR模型要求embedding维度相同,从而匹配特定的interaction操作。然而,GDCN允许任意embedding维度,并且embedding layer的输出以向量拼接来表示:Gated Cross Network (GCN):作为GDCN的核心结构,GCN旨在通过information gate来建模显式的有界的feature crosses。GCN的第gated cross layer表示为:其中:
embedding layer的base input,其中包含一阶特征。gated cross layer(即,第gated cross layer)的输出特征,用作当前第gated cross layer的输入。gated cross layer的输出。sigmoid函数,
Figure 2可视化了gated cross layer的过程。下图中的
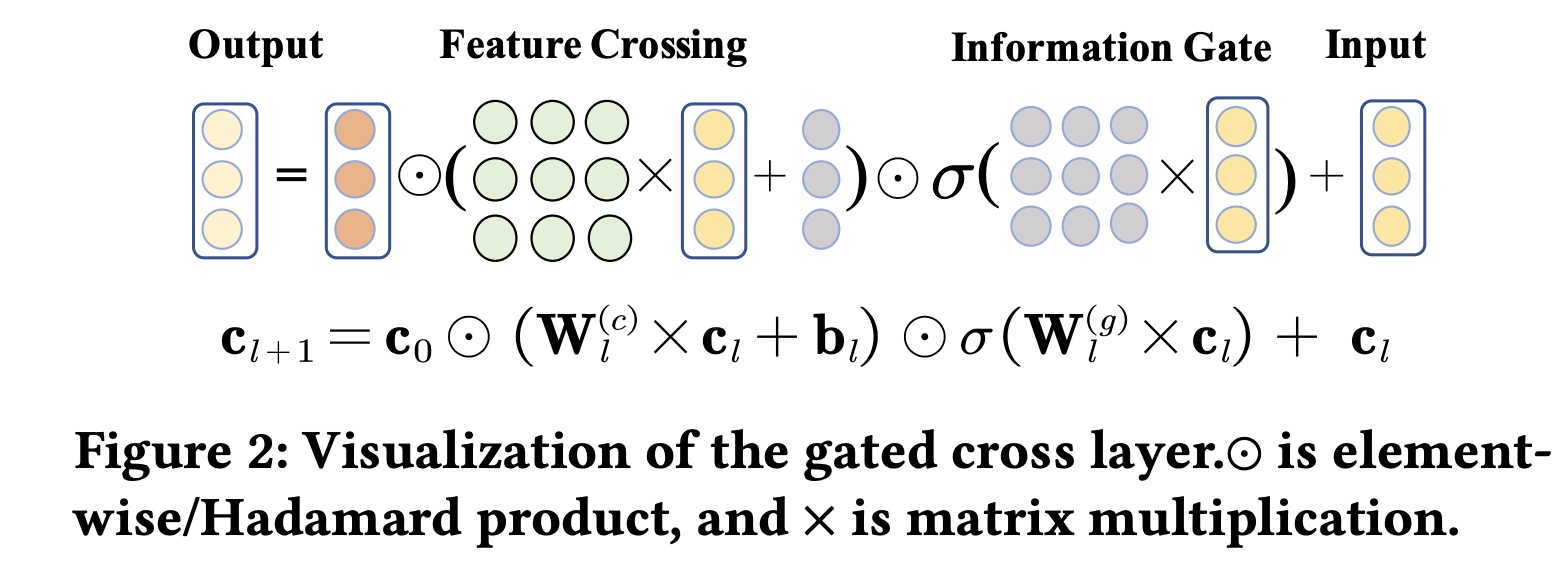
在每个
gated cross layer中,都有两个核心组件:feature crossing和information gate,如公式和Figure 2所示。feature crossing组件以bit-level计算一阶特征cross matrix),表示第field之间的固有重要性。但是,并非所有的
positive影响。随着cross depth的增加,交叉特征呈现指数级增长,这会引入交叉噪声并可能导致性能不佳。为了解决这个问题,我们引入了
information gate组件。作为soft gate,它自适应地学习第sigmoid函数gate values。然后将它们逐元素乘以feature crossing的结果。此过程放大了重要特征,并减轻了不重要特征的影响。随着cross layers数量的增加,每个cross layer的information gate都会过滤下一阶次的交叉特征并有效控制信息流。
最后,通过将输入
feature crossing and information gate的结果相加,生成最终的output cross vector0阶到第事实上,
GCN是DCN的变体,区别在与GCN多了一个Information Gate而已。那么,是否有更好的Information Gate?比如,直接用information gate的输入?Deep Neural Network (DNN):DNN的目标是建模隐式feature interactions。DNN的每个deep layer表示为:其中:
deep layer中可学习的权重矩阵和偏置向量。deep layer的input和output,ReLU。
整合
GCN和DNN:现有的研究主要采用两种结构来整合显式的和隐式的交互信息:堆叠和并行。因此,我们也以两种方式将GCN和DNN结合起来,得到了两个版本的GDCN。Figure 1(a)展示了堆叠结构:GDCN-S。embedding向量GCN并输出然后
DNN从而生成最终的交叉向量
gated cross layer and deep network的深度。Figure 1(b)展示了并行结构:GDCN-P。embedding向量GCN和DNN中。GCN和DNN的输出(即
训练和预测:最后,我们通过标准的逻辑回归函数计算预测点击率:
其中:
sigmoid函数。
损失函数是广泛使用的二元交叉熵损失(又名
LogLoss):其中:
与
DCN-V2的关系:GDCN是DCN-V2的推广。当省略information gate或所有gate values都设置为1时,GDCN会退回到DCN-V2。在DCN-V2中,cross layer(即CN-V2)平等对待所有交叉特征并直接将它们聚合到下一个阶次,而未考虑不同交叉特征的不同重要性。然而,GDCN引入了GCN,在每个gated cross layer中都包含一个information gate。这个information gate自适应地学习所有交叉特征的bit-wise gate values,从而实现对每个交叉特征的重要性的细粒度控制。值得注意的是,GDCN和DCN-V2都能够建模bit-wise and vector-wise特征交叉,如DCN-V2中所示。虽然
GDCN和DCN-V2都使用了门控机制,但它们的目的和设计原理不同。DCN-V2引入了MMoE的思想,将cross matrix分解为多个较小的子空间或“专家”。然后,门控函数将这些专家组合在一起。这种方法主要减少了cross matrices中的non-embedding参数,同时保持了性能。不同的是,
GDCN利用门控机制自适应地选择重要的交叉特征,真正利用deeper的交叉特征,而不会降低性能。它提供了动态的instance-based的可解释性,可以更好地理解和分析模型的决策过程。
为了进一步提高
GDCN的cost-efficiency,接下来提出了一种field-level维度优化方法,以直接减少embedding参数。
1.2 FDO
embedding维度通常决定了编码信息的能力。然而,为所有field分配相同的维度会忽略不同field的信息容量。例如,“性别” 和“item id” 等field中的特征的数量范围从DCN-V2和DCN采用经验公式根据每个field的特征的数量,为每个field分配独立的维度,即field的真正重要性。 受FmFM的启发,我们使用后验的Field-level Dimension Optimization (FDO)方法,该方法根据每个field在特定数据集中的固有重要性来学习其独立的维度。首先,我们训练一个完整模型,采用固定的
field维度为16,正如先前的研究所建议的那样。此过程使我们能够为每个field生成一个informative embedding table。接下来,我们使用
PCA为每个field的embedding table计算一组奇异值,按奇异值的幅值(magnitude)降序排列。通过评估信息利用率(即information ratio),我们可以通过识别对整体information summation贡献最大的field选择合适的压缩维度。最后,我们使用上一步中学到的
field维度训练一个新模型。
实际上,我们只需要基于
full model学习一次一组field dimensions,然后在后续模型refresh时重复使用它。Table 1列出了具有80%和95%的information ratio时,每个field的优化后的维度。当保留
95%比率时,field维度范围为2到15。降低
information ratio会导致每个field的维度减少。具有大量特征的
field有时需要更高的维度,如在fields {#23, #24}中观察到的那样。然而,情况并非总是如此;例如,fields {#16, #25}表现出更小的维度。在实验部分中,我们提供了实验证据,表明field的维度与其在预测过程中的重要性密切相关,而不是其特征数量此外,通过保留超过
80%的information ratio,我们可以获得更轻的GCN模型,其性能略优于具有完整embedding维度的GCN模型,并超过其他SOTA模型。
我们还对
FDO进行了更全面的分析,以了解field维度与其固有重要性之间的联系。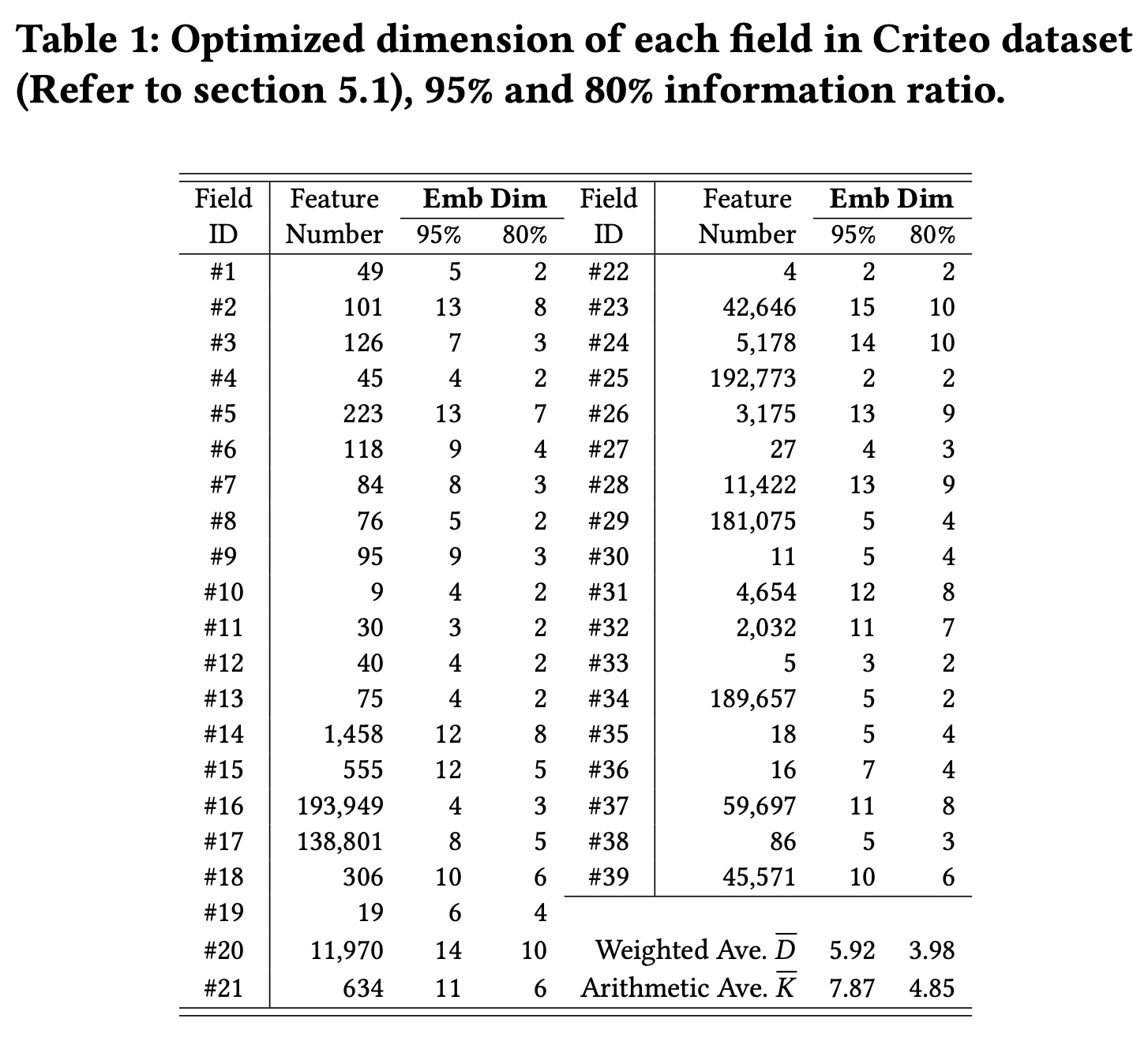
参数分析:定义:
embedding;feature representations子集,对应于第field,第
field中的特征的数量记作类似地,令
field的embedding维度,其中field的embedding维度。
对于一个输入的实例,算数平均的维度为
embedding layer的输出维度为embedding参数的总量为Criteo数据集中,原始特征数量超过30M,稀疏度超过99.99%,embedding参数占据了模型参数的绝大部分。因此,embedding参数的数量,而non-embedding参数的数量,例如DCN-V2和GCN中的cross matrix时间复杂度主要与
通过采用
FDO方法,我们可以通过缩小某些field的不必要维度来refine特征维度,以减少冗余的embedding参数。当使用固定维度
16时,embedding参数为然而,在
95% information ratio的FDO之后,embedding参数减少到embedding参数的37%。如果我们根据公式(即
field维度,加权平均维度18.66,导致emebdding参数为field分配了更大的维度,忽略了每个field的特定重要性。相比之下,FDO是一种后验方法,它基于从训练好的embedding table中提取的特定信息来学习field-level维度。
随着
field维度的降低,算术平均维度16降至7.87)。这样,GCN网络中的non-embedding参数,即cross matrixgate matrix
1.3 实验
数据集:
Criteo、Avazu、Malware、Frappe、ML-tag。这些数据集的统计数据如Table 2所示,详细描述可在给定的参考文献中找到。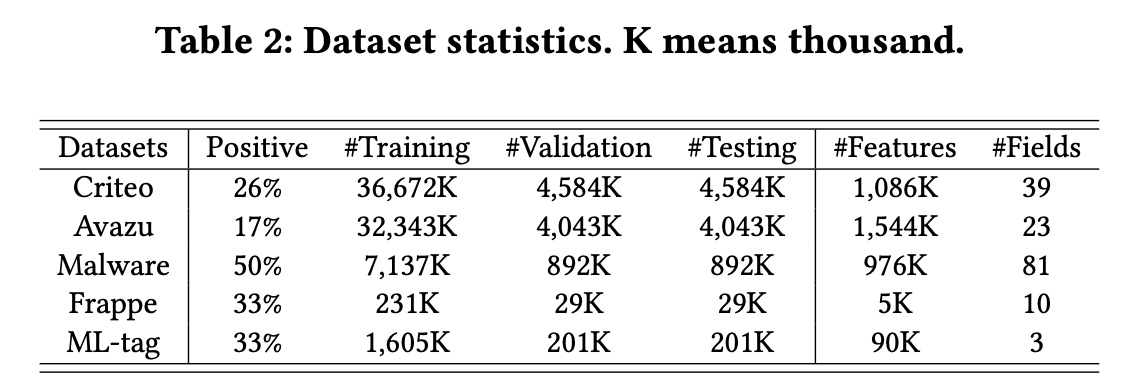
数据预处理:
首先,我们将每个数据集随机分成训练集(
80%)、验证集(10%)和测试集(10%)。其次,在
Criteo和Avazu中,我们删除某个field中出现次数少于阈值的低频特征,并将其视为dummy feature "<unkonwn>"。Criteo和Avazu的阈值分别设置为{10, 5}。最后,在
Criteo数据集中,我们通过将实数值1。这是Criteo竞赛的获胜者所采用的。
评估指标:
AUC、Logloss。baseline方法:我们与四类代表性的方法进行了比较。一阶方法,例如
LR。建模二阶交叉特征的基于
FM的方法,包括FM、FwFM、DIFM和FmFM。捕获高阶交叉特征的方法,包括
CrossNet(CN)、CIN、AutoInt、AFN、CN-V2、IPNN、OPNN、FINT、FiBiNET和SerMaskNet。代表性的集成/并行方法,包括
WDL、DeepFM、DCN、xDeepFM、AutoInt+、AFN+、DCN-V2、NON、FED和ParaMaskNet。
我们没有展示某些方法的结果,例如
CCPM、GBDT、FFM、HoFM、AFM、NFM,因为许多模型已经超越了它们。实现细节:
我们使用
Pytorch实现所有模型,并参考现有工作。我们使用
Adam优化器优化所有模型,默认学习率为0.001。我们在训练过程中使用Reduce-LR-On-Plateau scheduler,当性能在连续3 epochs停止改善时,将学习率降低10倍。我们在验证集上应用
patience = 5的早停(early stopping),以避免过拟合。batch size设置为4096。所有数据集的embedding维度均为16。根据先前的研究,我们对涉及
DNN的模型采用相同的结构(即3层,400-400-400),以便进行公平比较。除非另有说明,所有激活函数均为ReLU,dropout rate = 0.5。对于我们提出的
GCN、GDCN-S和GDCN-P,除非另有说明,默认的gated cross layer数量为3。对于其他
baseline,我们参考了两个benchmark工作(即BARS和FuxiCTR)及其原始文献来微调它们的超参数。
显著性检验:为了确保公平比较,我们在单个
GPU(NVIDIA TITAN V)上使用随机种子运行每种方法10次,并报告平均的测试性能。我们执行双尾t-test来检测我们的方法与最佳baseline方法之间的统计显着性。在所有实验中,与最佳baseline相比的改进具有统计学意义(Table 3和Table 4中用 ★ 表示。
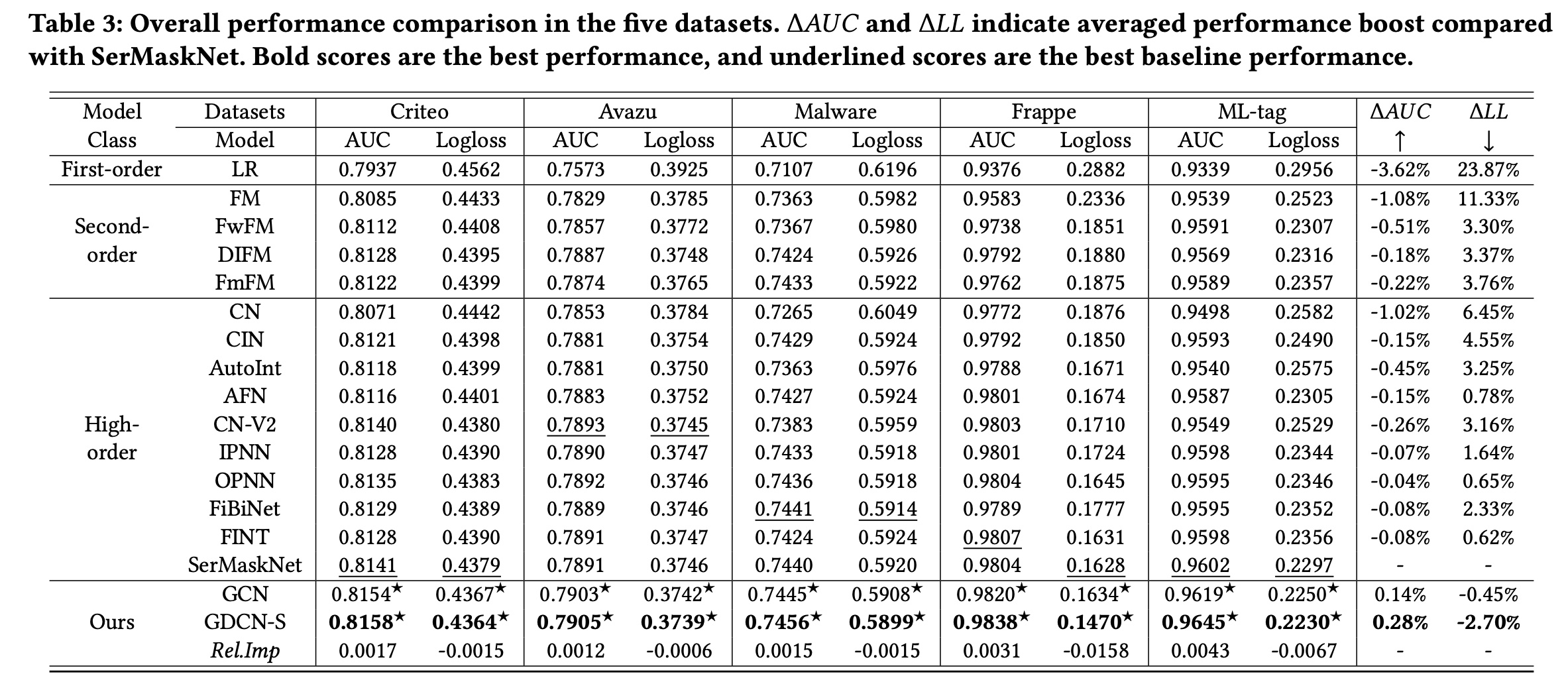
1.3.1 整体性能
注意,这里的结果是在没有应用
FDO的情况下得出的。
与堆叠式模型的比较:我们将
GCN和GDCN-S与stacked baseline模型进行比较,包括一阶、二阶和高阶模型。整体性能总结在Table 3中。我们有以下观察结果:首先,在大多数情况下,高阶模型优于一阶模型和二阶模型,证明了学习复杂的高阶
feature interactions的有效性。值得注意的是,OPNN、FiBiNet、FINT和SerMaskNet等模型表现更佳,它们使用一个stacked DNN同时捕获显式的和隐式的特征交叉。这证实了对显式的和隐式的高阶feature interactions进行建模背后的原理。其次,
GCN通过仅考虑显式的多项式feature interactions,始终优于所有堆叠的baseline模型。GCN是CN-V2的泛化,增加了一个information gate来识别有意义的交叉特征。GCN的性能验证了并非所有交叉特征都对最终预测有益,大量不相关的交互会引入不必要的噪音。通过自适应地re-weighting每个阶次中的交叉特征,GCN比CN-V2实现了显著的性能提升。此外,它优于SerMaskNet,平均0.14%,平均0.45%。第三,
GDCN-S超越了所有堆叠的baseline并实现最佳性能。在GDCN-S中,stacked DNN进一步学习GCN结构之上的隐式交互信息。因此,与其他堆叠式模型(例如OPNN、FINT和SerMaskNet)相比,GDCN-S优于GCN并实现更高的预测准确率。具体来说,与SerMaskNet相比,GDCN-S实现了平均0.28%(2.70%(
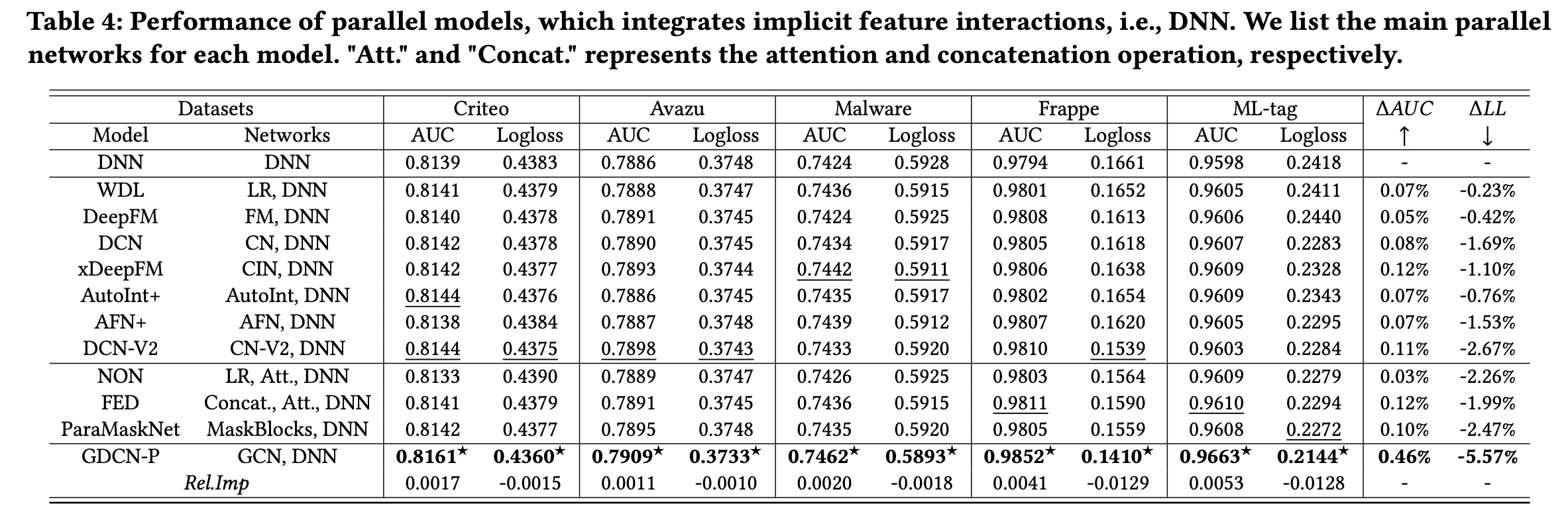
与并行式模型的比较:
Table 4展示了SOTA的ensemble/parallel模型的性能。每种方法都包含并行网络,例如DeepFM中的FM和DNN,以及DCN-V2中的CN-V2和DNN。此外,我们将这些模型与常规的DNN模型进行比较,并在此基础上计算首先,整合隐式的和显式的
feature interactions可以增强预测能力。DNN仅建模隐式的feature interactions,而将DNN与捕获显式feature interactions的其他网络相结合得到的并行模型优于单个网络。值得注意的是,GCN显示出最显著的平均性能改进,从0.46%和5.57%可以看出。这凸显了GCN与其他basic operation网络相比的卓越能力。其次,
GDCN-P的表现优于所有并行式模型和堆叠式模型。与Table 4中的并行式模型相比,GDCN-P实现了卓越的性能,超越了所有最佳baseline。此外,当考虑堆叠式模型并使用Table 3中的SerMaskNet作为benchmark时,GDCN-P实现了0.38%(4.26%(
1.3.2 Deeper 高阶特征交叉
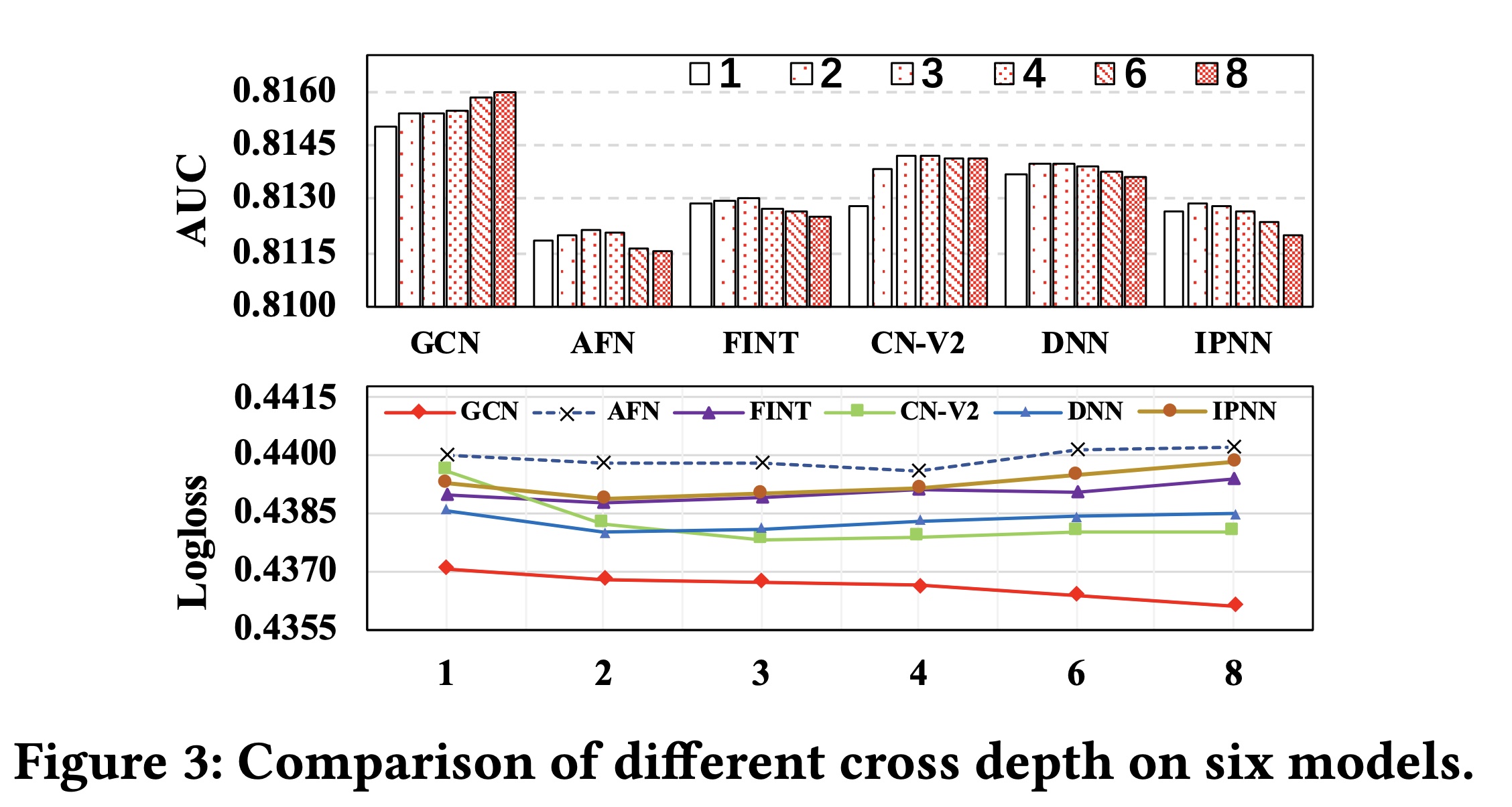
通过改变
cross depth将GCN与其他模型进行比较:我们将GCN与五个可以捕获高阶交互的代表性模型进行比较,即AFN、FINT、CN-V2、DNN和IPNN。Figure 3说明了在Criteo数据集上随着cross depth的增加而出现的测试AUC和Logloss。随着交叉层的增加,五个被比较的模型的性能得到改善。然而,当
cross depth变得更深(例如,超过2、3或4个交叉层)时,它们的性能会显著下降。这些模型可以在功能上捕获更深的高阶显式和隐式的feature interactions,但高阶的交叉特征也会引入不必要的噪声,这可能会导致过拟合并导致结果下降。在许多SOTA工作中进行的cross depth超参数分析中也观察到了这个问题。相反,随着交叉层数从
1增加到8,GCN的性能不断提高。具体来说,与CN-V2模型相比,GCN包含了一个information gate。该information gate使GCN能够对每个阶次识别有用的交叉特征,并仅积累最终预测所需的信息。因此,即使cross depth变得更深,GCN的表现始终优于CN-V2和其他模型,验证了information gate设计的合理性。
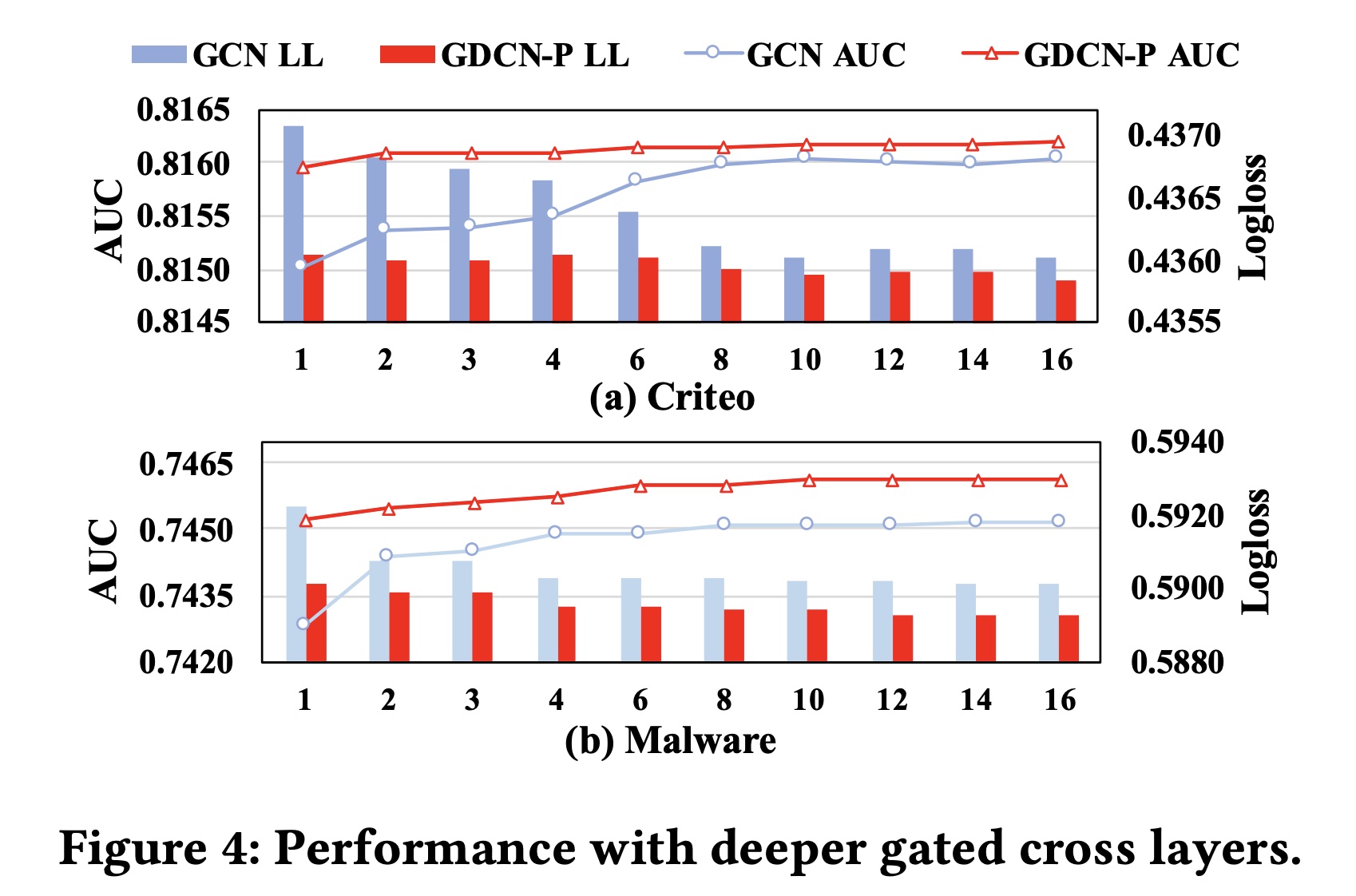
具有更深
gated cross layers的GCN和GDCN-P的性能:在Criteo和Malware数据集上,我们进一步将GCN和GDCN-P的cross depth从1增加到16。值得注意的是,我们将GDCN-P中的DNN深度固定在3,以防止DNN导致的过拟合。Figure 4展示了实验结果。随着
cross depth的增加,GCN和GDCN-P的性能都得到了改善,在GDCN-P中观察到的趋势与GCN的趋势一致。在加入
DNN组件后,GDCN-P的表现始终优于GCN,这凸显了使用DNN捕获隐式feature interactions的重要性。此外,
DNN使GDCN-P能够更早地获得最佳结果。具体来说,当深度超过8或10时,GCN的性能会达到稳定状态,而GDCN-P的阈值为4或6。尽管
GCN和GDCN-P可以选择有价值的交叉特征,但随着cross depth的增加,高阶交叉特征的有用性会急剧下降。这种现象符合人们的普遍直觉,即个人在做出决策(例如点击或购买item)时通常不会同时受到太多特征的影响。值得注意的是,在
cross depth超过稳定阈值后,我们的模型的性能保持稳定,而不是下降。
1.3.3 GCN 的可解释性
可解释性对于理解
specific predictions背后的原因、以及增强对预测结果的信心至关重要。GCN从模型的和实例的角度提供静态的和动态的解释,有助于全面理解模型的决策过程。静态的
model interpretability:在GCN中,交叉矩阵fields之间交互的相对重要性的指标。如果每个实例由F个fields组成,每个field具有相同的field sizebit-wise和block-wise的方式来表示:其中,每个分块矩阵
field和第field之间一阶交叉的重要性。当应用FDO学习各个field维度时,分块矩阵field和第field的不同维度。field与第field之间的一阶交叉的重要性。此外,随着交叉层的增加,相应的交叉矩阵可以进一步表明多个
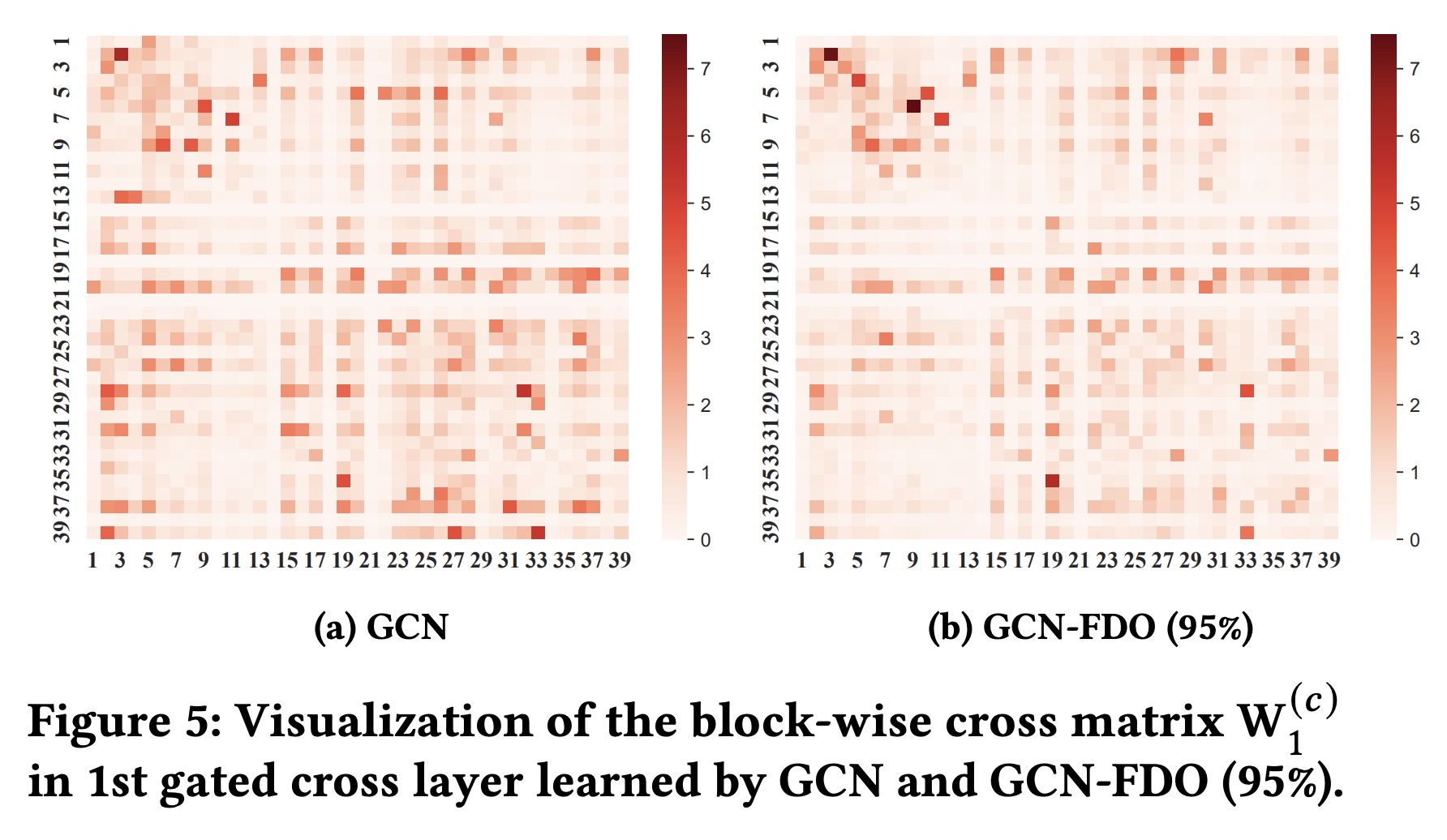
field之间的固有的relation importance。Figure 5(a)展示了GCN在Criteo数据集上学到的第一阶交叉层的分块交叉矩阵DCN-V2类似,每个color box代表相应分块矩阵Frobenius范数,表示field cross的重要性。红色越深,表示学到的交叉越强,例如<#3, #2>和<#9, #6>。将
FDO方法应用于GCN时,GCN-FDO仍然能够捕获相似的交叉重要性,如Figure 5(b)所示。两个矩阵之间的余弦相似度为0.89,表明在应用FDO之前和之后,在捕获固有field cross重要性方面具有很强的一致性。
动态的
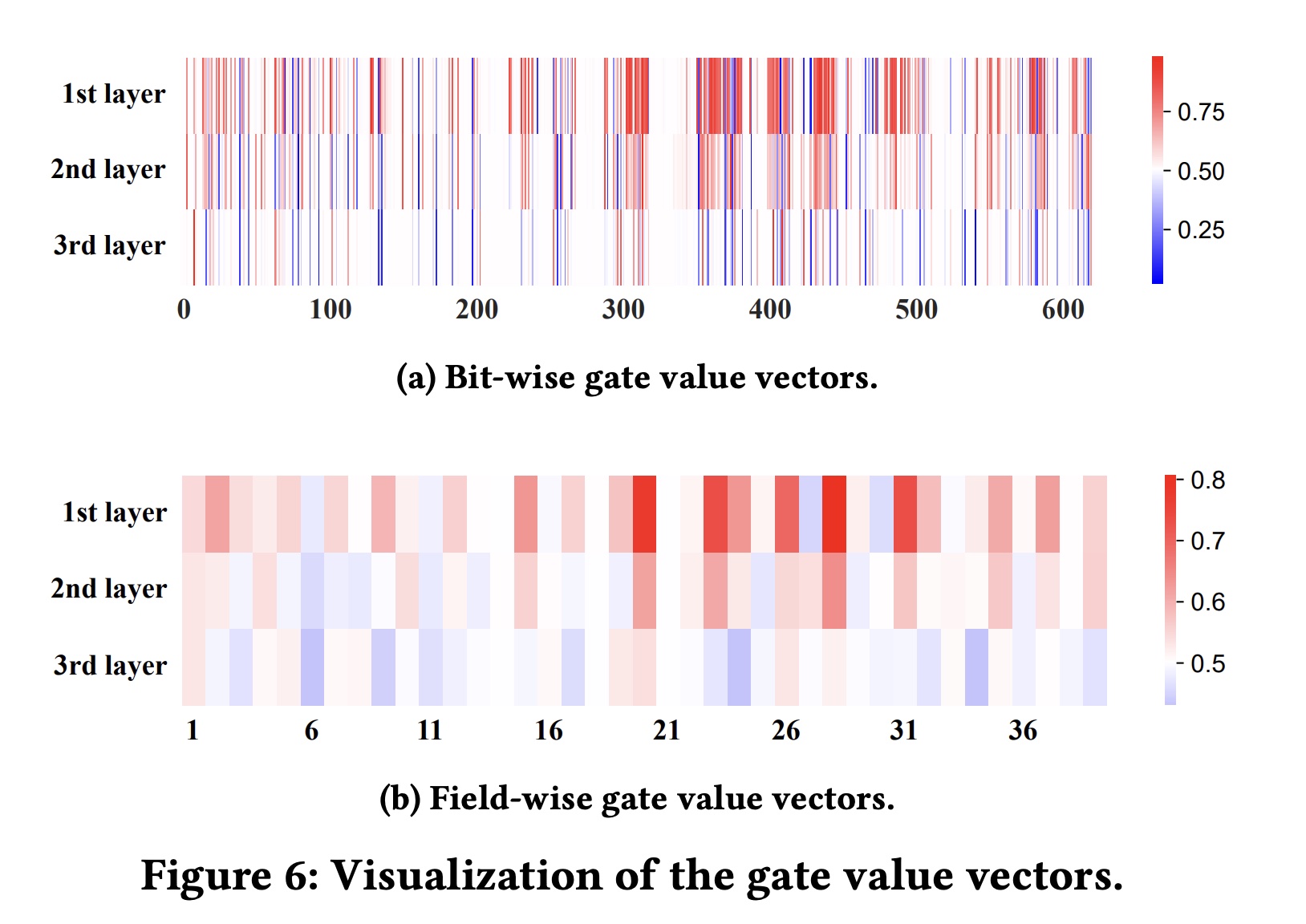
instance interpretability:基于模型的可解释性可以捕获不同field之间的静态关系,但由于模型训练完成后交叉矩阵保持不变,因此存在局限性。然而,GCN还通过information gate学到的gate weights提供动态可解释性,为每个input instance提供bit-wise的和field-wise的解释。我们从
Criteo数据集中随机选择两个实例来可视化学到的gate weights,并检查从第一个到第三个gated cross layer的gate values。Figure 6(a)展示了bit-wise gate weight vectors,每层的维度为bit-wise cross的重要性。使用bit-wise gate vector,我们通过对每个field对应的16-bit values取平均值来导出field-wise gate vectors。Figure 6(b)显示了field-wise gate weight vectors(specific feature的重要性。由于gated cross layer中的gate weights是使用sigmoid函数计算的,因此red blocks(大于0.5)表示重要特征,而blue blocks(小于0.5)表示不重要特征。
Figure 6(a)和Figure 6(b)揭示了bit-level和field-level的交叉特征的重要性,以及它们在每个实例的不同cross layers中是如何变化的。通常,低阶特征交叉包含更重要的特征,而高阶特征交叉包含不太重要的特征。在第一层中,许多特征交叉被标识为重要的(红色块),而在第二和第三交叉层中,大多数交叉是中性的(白色块)或不重要的(蓝色块),尤其是在第三层。这符合我们的直觉:随着交叉层的增加,重要的交叉特征的数量显著减少,因此我们设计了
information gate来自适应地选择重要特征。相反,大多数模型在建模高阶交叉时无法选择有用的特征交叉,导致性能下降,如《Deeper 高阶特征交叉》章节所证实的。此外,从
Figure 6(b)中,我们可以识别出重要的或不重要的特定特征,例如特征{#20, #23, #28}很重要,而特征{#6, #11, #30}不重要。我们还可以从input instance中引用这些specific important features的名称。一旦我们知道哪些特征有影响,我们就可以解释甚至干预有助于用户点击率的相关特征。
最后,在
Figure 7中,我们记录并平均了M个实例的field-level gate vectors,表明每个field的平均重要性,特别是在第一层。例如,field {#20, #23, #24}非常重要,而field {#11, #27, #30}相对较不重要。此外,Figure 7从统计角度进一步验证了随着交叉层的增加,重要交叉特征的数量显著减少。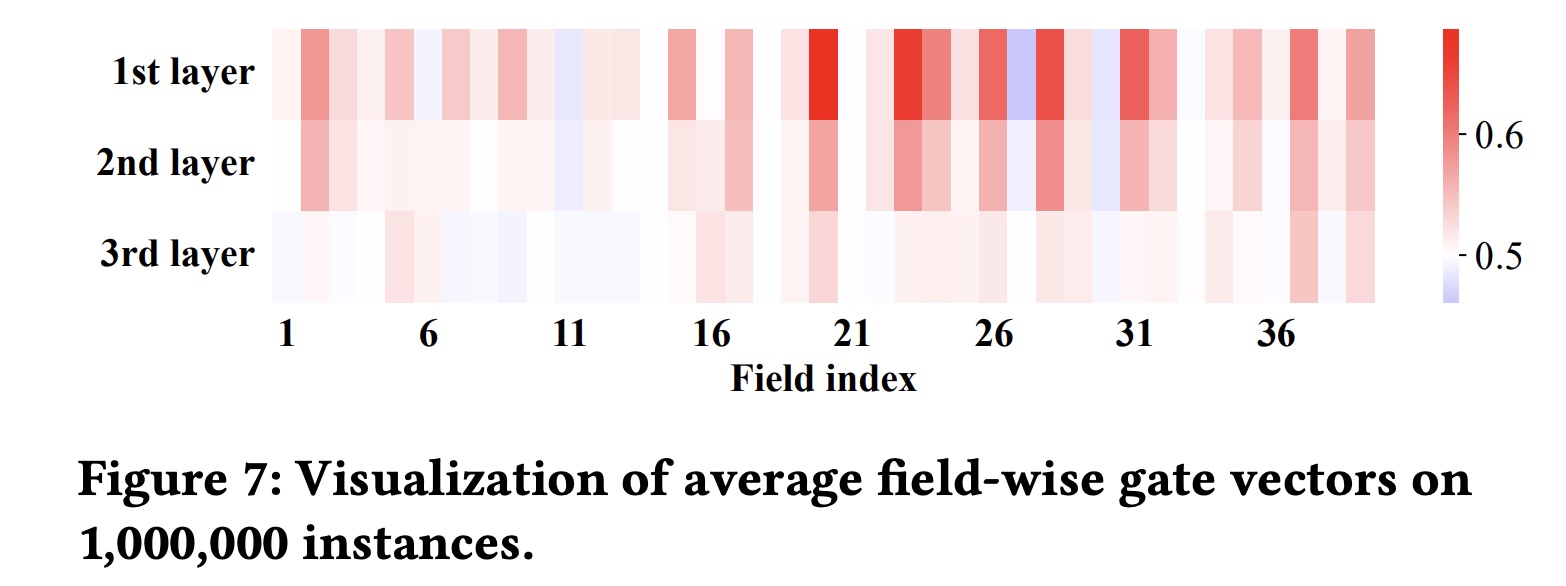
413.4 FDO 的综合分析
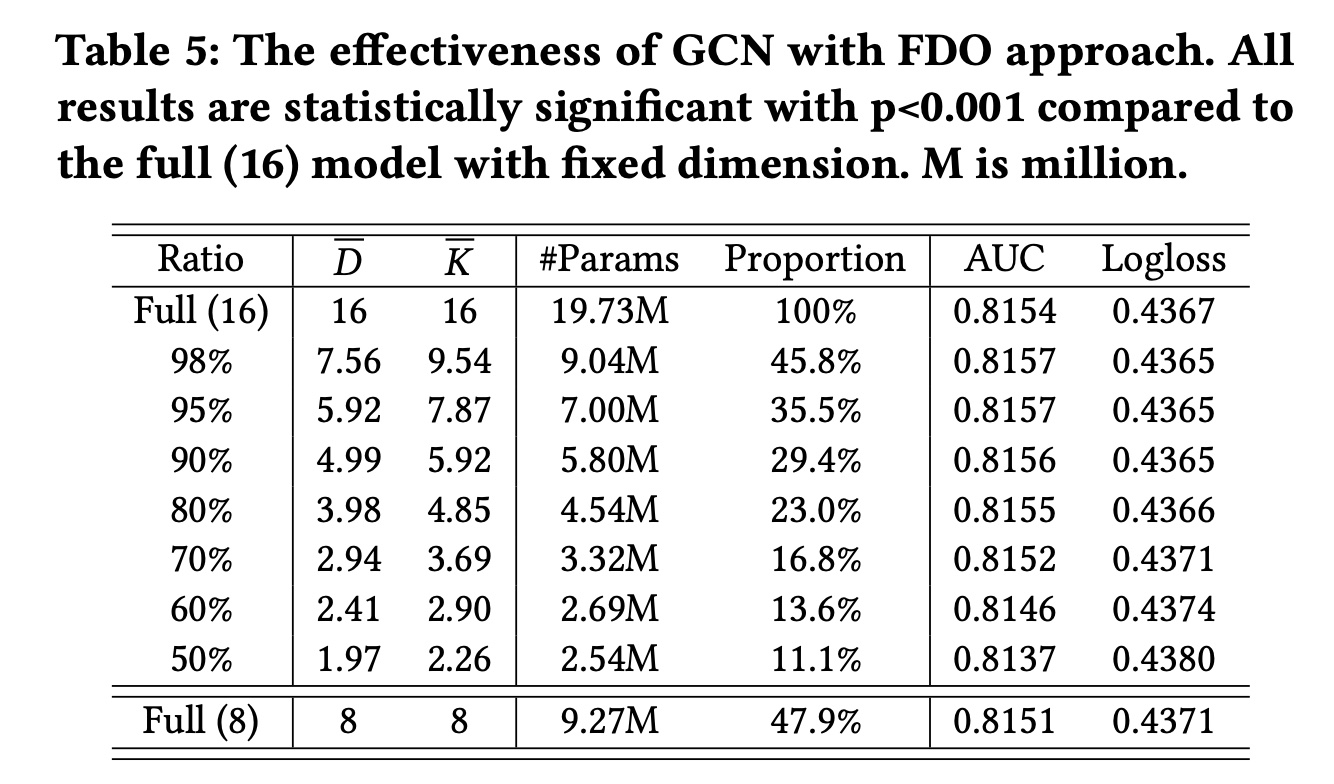
效果分析:我们将
FDO方法应用于GCN,并通过保持information ratio从50%到98%来评估其性能。Table 5显示了结果,包括权重平均维度#Params)。当保持
80%的information ratio时,我们只需要23%的参数,而模型的性能与完整模型相当。此外,当
information ratio在80%到98%之间时,模型性能甚至比完整模型更好。这是因为FDOrefine了每个field的特征维度,消除了非必要的维度信息并减少了交叉过程中的冗余。然而,当
information ratio较低(即低于80%)时,较短的维度无法充分表示相应field的特征,导致预测性能显著下降。最后,我们将整个模型的维度从
16减少到8,大约相当于95%比率下的加权平均维度(7.56)。虽然它直接减少了模型的参数,但也导致了性能的下降。其他研究同样证实了减少embedding大小的负面影响。相比之下,FDO方法可以更直接地减少参数数量,同时实现相媲美的性能。
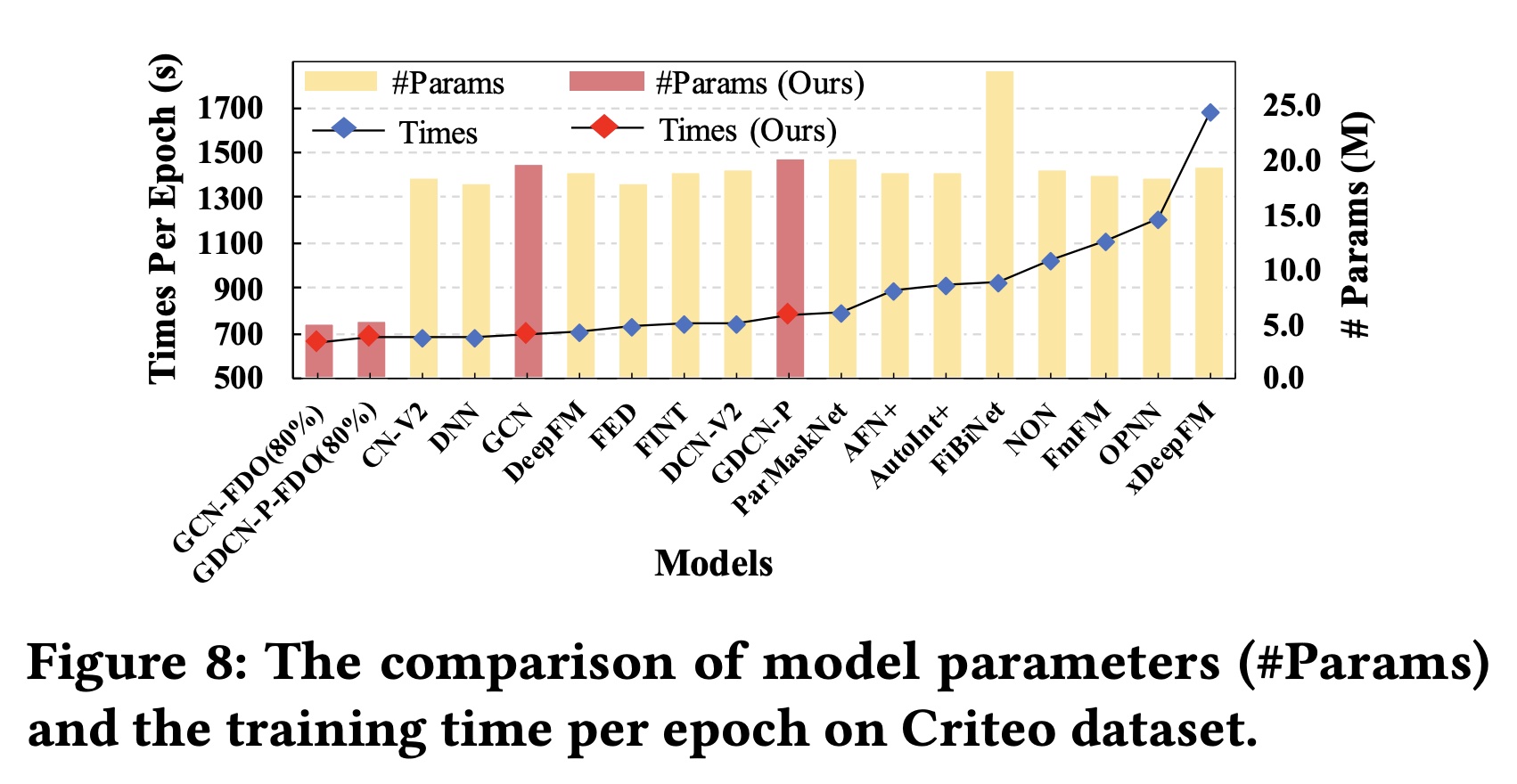
内存和效率比较:在
Criteo数据集上,我们在删除低频特征后总共有1.086M个特征。当使用固定维度(embedding参数约为17.4M。如Figure 8所示:大多数现有模型的参数范围从
18M到20M,主要是由于embedding参数。通过应用
FDO,我们可以直接减少embedding参数。同时,GCN-FDO和GDCN-PFDO仅使用约5M模型参数就实现了相媲美的准确率
我们进一步比较了现有
SOTA模型的训练时间:未经维度优化的
GCN和GDCN的训练时间与DNN和DCN-V2相当。应用
FDO后,GCN-FDO和GDCN-P-FDO以更少的参数和更快的训练速度超越了所有的SOTA模型。
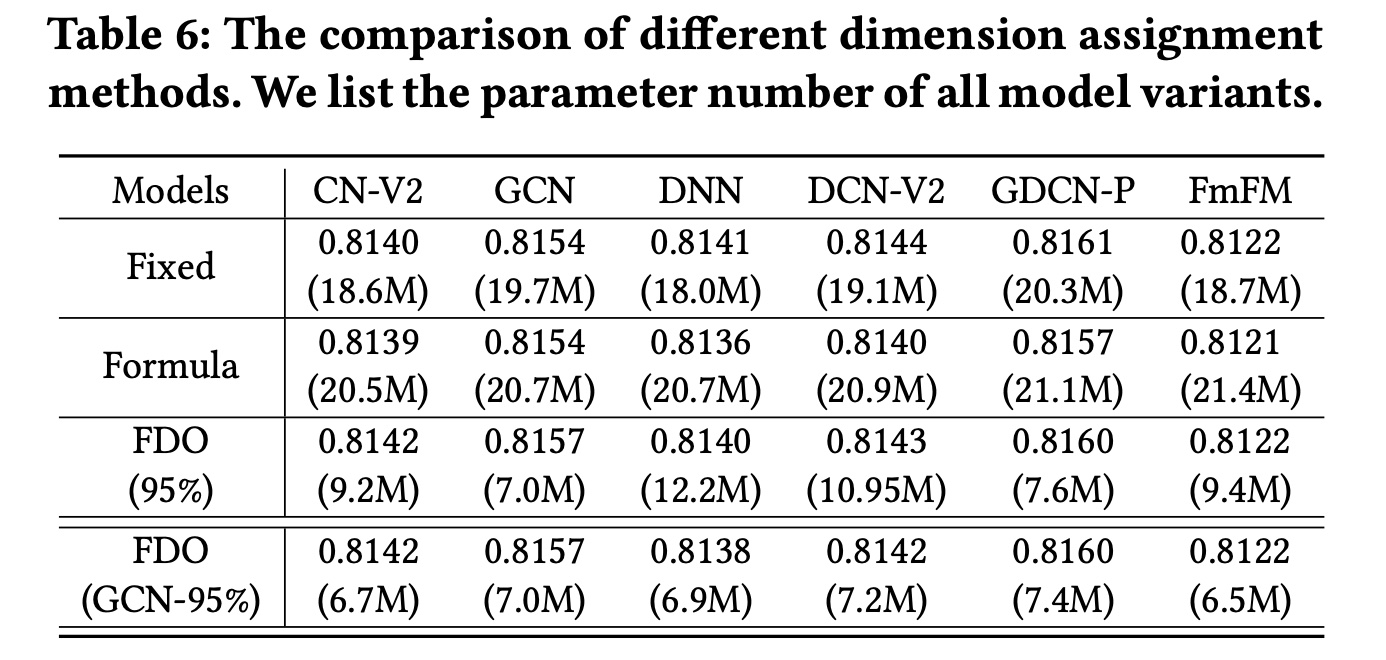
兼容性分析:我们进一步将
FDO应用于DNN、CNV2、DCN-V2和FmFM,它们不需要相同的field维度。此外,我们将FDO与分配固定维度、以及FDO章节中提到的分配不同维度的Formula method进行了比较。Table 6显示了结果。首先,
Formula method增加了模型参数并降低了其性能,因为它只考虑每个field中的特征数量,而忽略了field在训练过程中的重要性。相反,FDO是一种后验方法,它通过在trained embedding table中合并重要信息来学习field维度。其次,将
FDO应用于CN-V2和GCN比base模型获得了更好的性能。由于CN-V2和GCN主要关注显式的bit-level特征交叉,FDO通过删除不必要的embedding信息来refinefield维度。然而,将FDO应用于包含DNN网络的DNN、DCN-V2和GDCN-P会导致性能略有下降。最后,这些结果表明,我们可以使用
FDO基于SOTA模型获取group field dimensions,并将其复用为其他模型的默认维度。在Table 6的最后一行,我们基于GCN学习了具有95% information ratio的group field dimensions,并将其应用于其他五个模型。与使用模型本身学到维度相比,这种方法实现了相媲美的性能,并且进一步减少了参数数量。可以只需要训练一次,就可以将
group field dimension应用到多个模型,这降低了获取group field dimension的成本。
对
condensed field dimensions的理解:通过FDO学到的field维度表明了相应field的重要性。如
Figure 7所示,我们可以确定每个field的平均重要性,例如field {#20, #23, #24}很重要,而field {#11, #27, #30}则不重要。参考
Table 1,在应用95% information ratio的FDO后,field {#20, #23, #24}确实具有更长的维度。相反,field {#11, #27, #30}的维度较短。
为了进一步验证这一观察结果,我们计算了第一层中
averaged field importance与95% ratio的optimization field dimensions之间的皮尔逊相关系数。相关系数为0.82,p-value小于field维度与其各自重要性之间存在显著相关性。因此,我们可以直接从FDO学到的field维度粗略地识别哪些field是重要的。请注意,
field维度并不总是与field中的特征数量相关。例如,field {#16, #25}具有最大的特征数量,但它们的field维度很短,其重要性也不大。如果使用Formula method分配field维度,则field {#16, #25}将具有最长的维度。这种比较进一步凸显了所引入的FDO方法的合理性和优越性。