一、Hiformer [2023]
《Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems》
learning feature interaction是构建推荐系统的核心支柱。在大型互联网applications中,由于input feature space的稀疏性和高维性,learning feature interaction面临巨大挑战;同时,由于feature interactions的解空间(solution space)呈指数级增长,手动设计有效的feature interactions的方法已不现实。本文提出利用带有attention layers的Transformer-based架构来自动捕获feature interactions。Transformer架构已在自然语言处理、计算机视觉等多个领域取得显著成功,但在工业界的feature interaction modeling中尚未得到广泛应用,本文旨在填补这一空白。我们发现,将原始Transformer架构应用于web-scale recommender systems时存在两个关键挑战:(1):Transformer的self-attention layer无法捕获异构的feature interactions。(2):Transformer架构的serving latency可能过高,难以部署在web-scale recommender systems中。
为此,我们首先提出一种异构的
self-attention layer,通过对Transformer中的self-attention layer进行简单而有效的改进,以兼顾feature interactions的异构性。随后,我们引入Heterogeneous Interaction Transformer: Hiformer模型,进一步提升模型的表达能力。通过低秩近似(low-rank approximation)和模型剪枝(model pruning)技术,Hiformer实现了快速推理,适用于在线部署(online deployment)。大量离线实验结果验证了Hiformer模型的有效性和高效性。我们已成功将Hiformer模型部署到Google Play的large scale App ranking model中,key engagement指标实现了显著提升(最高达2.66%)。互联网上信息海量,用户难以高效浏览并定位相关内容。推荐系统通过过滤信息,为用户呈现最相关的内容。通常,推荐系统被构建为有监督的机器学习问题,目标是提高用户对推荐内容的
positive engagements,例如点击(clicks)、观看(watches)或购买(purchases)等行为。因此,部署具有high prediction accuracy的推荐系统至关重要,这直接影响企业的销售、收入等财务业绩。feature interactions指多个features对prediction产生复杂的协同影响(collaborative effects),是推荐系统的关键组成部分之一。例如,观察发现用户常在用餐时段下载外卖(food delivery)application,这表明app ids(如外卖apps)和时间上下文(如用餐时段)的feature interactions,能为predicting user behavior和making personalized recommendations提供重要信号。然而,在web-scale recommender systems中建模feature interactions面临三大显著挑战:首先,有效的
feature interactions往往是domain-specific,手动设计feature interactions既耗时又需要domain knowledge。其次,在
web-scale applications中,由于原始features数量庞大,search of possible feature interactions的解空间(solution space)呈指数级增长,手动抽取所有interactions已不现实。最后,
extracted feature interactions在其他任务中的泛化能力可能较差。
鉴于其重要性,
feature interaction一直受到学术界和工业界的广泛关注。近年来,
deep neural networks: DNNs凭借出色的模型性能和representation learning能力,在多个研究领域备受关注。DNNs已被广泛应用于推荐系统,用于sparse input features representation learning和feature interaction learning。DNNs已经成为将large and sparse input映射到低维语义空间的强大工具。在feature interaction learning方面,一些近期研究基于显式特征交互函数(explicit feature interaction functions),例如Factorization Machine: FM、内积(inner product: IP)、kernel Factorization Machine: kFM和Cross Network: CN等。此外,DNNs还通过带有非线性激活函数的multiple layers,用于学习隐式的feature interactions。另一类研究基于
attention机制,特别是采用Transformer架构进行feature interaction learning。Transformer架构已成为计算机视觉(CV)、自然语言处理(NLP)等多个任务的SOTA模型。AutoInt和InterHAt(《Interpretable click-through rate prediction through hierarchical attention》)提出利用multi-head self-attention layer进行feature interaction learning。然而,与NLP领域不同,推荐系统中的feature semantics在不同上下文下具有动态性(dynamic)。假设我们向用户推荐外卖
apps,涉及的特征包括app_id、hour_of_day、以及user_country。在这种情况下,app_id在app_id & hour_of_day交互时的语义,可能与它在app_id & user_country交互时的语义不同。要实现不同features间的有效的interaction,需要语义感知(semantic awareness)和语义空间对齐(semantic space alignment)的能力,而Transformer模型并未考虑这一点。在原始attention layer中,所有features通过相同的投影矩阵(即features间共享。这种设计适用于feature semantics与上下文无关的场景(如text token);但在推荐系统中,feature semantic往往依赖于上下文,这种同质化设计(homogeneous design)会限制模型的表达能力。除了无法捕获
heterogeneous feature interactions这一局限外,Transformer模型的另一问题是latency。在web-scale applications中,用户数量和requests数量庞大;模型必须能够处理极高的queries per second: QPS,以提供最佳用户体验。然而,Transformer架构的推理成本(inference cost)随input length呈二次方增长,这使得其在web-scale recommender systems中难以实现real-time inference。尽管存在这些局限,我们仍认为针对
feature interaction来研究和改进Transformer-based架构,具有重要意义。首先,由于
Transformer架构在多个领域的成功,已有大量针对该架构的改进和优化工作,提升其性能和能力。将Transformer-based feature interaction models应用于推荐系统,可为Transformer架构的最新进展向推荐领域的迁移搭建桥梁。其次,随着
Transformer的广泛应用,硬件设计(如芯片设计)可能更倾向于Transformer-like架构,因此基于Transformer架构的推荐系统有望受益于硬件层面的优化。最后,基于
Transformer的模型基于attention机制,具有良好的模型可解释性,在web-scale applications中构建recommender models with attention mechanism,可能会开辟新的研究方向。
本文针对原始
Transformer模型的局限性,提出一种新模型,Heterogeneous Feature Interaction Transformer: Transformer,用于推荐系统中的feature interaction learning。Hiformer具有feature semantic aware的能力;且更重要的是,其适用于online deployment的高效性。为了在
feature interaction learning中实现feature semantic awareness,我们设计了一种新颖的heterogeneous attention layer。为了满足
web-scale applications严格的latency要求,我们利用低秩近似(low-rank approximation)和模型剪枝(model pruning)技术来提升效率。
我们以
Google Play的large-scale App ranking model为案例进行研究,通过离线实验和在线实验验证Hiformer在feature interaction modeling中的有效性(effectiveness)和efficiency in serving。据我们所知,本文首次证明Transformer-based架构(即Hiformer)在feature interaction learning中能够优于现有的SOTA推荐模型。目前,我们已成功将Hiformer部署为production模型。总结而言,本文的贡献如下:
提出
Hiformer模型,其包含新颖的heterogeneous attention layer,能够捕获feature interaction learning中features的复杂协同效应(complex collaborative effects)。与现有的基于原始Transformer的方法相比,该模型具有更强的表达能力。利用低秩近似和模型剪枝技术,在不损害模型性能的前提下,降低
Hiformer的推理延迟(serving latency)。通过一个大型数据集进行广泛的离线对比实验,验证了捕获
heterogeneous feature interactions的重要性,并证明了Transformer-based架构的Hiformer能够优于SOTA的推荐模型。进行
online A/B testing,衡量不同模型对key engagement指标的影响,结果表明Hiformer在latency增加有限的情况下,相比baseline模型实现了显著的online性能提升。
1.1 相关工作
在深度学习时代之前,人们通常手动构建
cross features并将其添加到logistic regression: LR模型中以提升性能,也有研究利用decision tree based模型(《Practical lessons from predicting clicks on ads at facebook》)来学习feature crosses。随后,embedding技术的发展催生了Factorization Machines: FMs(《Factorization machines》),该模型通过两个latent vectors的内积来建模二阶feature interactions。近年来,
DNNs已成为工业界许多模型的核心。为了提高feature cross learning的效率,许多研究通过设计函数feature interactions,同时利用DNNs学习隐式的feature crosses。Wide & Deep模型(《Wide & deep learning for recommender systems》)将DNN模型与一个wide组件相结合,其中这个wide组件包含原始特征的crosses。此后,许多研究通过引入
FM-like操作(即,内积inner products)或Hadamard products,从而自动化Wide & Deep中的manual feature cross工作:DeepFM(《Deepfm: a factorization-machine based neural network for ctr prediction》)和DLRM(《Deep learning recommendation model for personalization and recommendation systems》)在模型中采用FM。Neural FM(《Neural collaborative filtering》)通过融入Hadamard product对FM进行泛化;PNN(《Product-based neural networks for user response prediction》)也使用内积(inner products)和外积(outer products)来捕获pairwise feature interactions。
然而,这些方法最多只能建模二阶
feature crosses。此外,还有一些研究能够建模高阶
feature interactions:Deep Cross Network: DCN(《Deep & cross network for ad click predictions》)设计了cross network,用于显式地学习高阶feature interactions,其interaction阶数随网络深度增加。DCN-V2(《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)增强了DCN的表达能力,使其更适用于large-scale industrial settings。xDeepFM(《xdeepfm: Combining explicit and implicit feature interactions for recommender systems》)同样改进了DCN中cross network的表达能力,并依赖Hadamard product来捕获高阶的feature crosses。
另一类研究利用
Transformer模型中的attention机制来捕获feature interactions。AutoInt(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)提出通过multi-head self-attention layer来捕获feature interaction。然而,由于Transformer最初设计用于建模context independent的关系(如text tokens),直接将multi-head self-attention layer应用于feature interaction导致模型的表达能力非常有限。类似地,
InterHAt(《Interpretable click-through rate prediction through hierarchical attention》)基于attention机制,通过cross-product transformation来捕获hierarchical attention,但缺乏feature awareness和semantic alignment的能力。
Heterogeneous Graph Transformer(《Heterogeneous graph transformer》)与本文相关,该研究在heterogeneous mutual attention layer中考虑了node types。尽管动机有相似之处,但本文的工作存在显著差异:Hiformer模型旨在捕获web-scale recommender system中的feature interactions,the design of the Hiformer attention layer具有更强的表达能力。field-aware factorization machine: FFM(《Field-aware factorization machines for ctr prediction》)也与本文相关:FFM通过独立的embedding lookup tables实现feature interaction learning的feature awareness,而本文提出的方法通过heterogeneous attention layer中的information transformation来实现。PNN(《Product-based neural networks for user response prediction over multi-field categorical data》)利用kernel Factorization Machine考虑feature interaction learning中的feature dynamics,这与heterogeneous attention layer有相似之处。但
heterogeneous attention layer基于attention机制,而PNN源于factorization machine。此外,本文通过
Query and Key projection来学习heterogeneous feature interactions,而PNN基于kernel matrices。
此外,我们在
Hiformer中进一步提升了模型表达能力,并降低了计算成本。
1.2 问题定义
推荐系统的目标是提高用户的
positive engagement,例如clicks、conversion等行为。与以往工作类似,我们将其构建为用于engagement predictions的有监督机器学习任务。Recommender System的定义:设(user, item) pair的features,包含categorical featuresdense featurescategorical features采用one-hot encoding来表示,dense features可视为embedding size = 1的special embedding features。categorical features数量和dense features数量分别为input featuresuser是否会与item产生交互。如前所述,
feature interaction learning使模型能够捕获features间更复杂的关系,从而为更准确的recommendations提供有效信息。接下来,我们正式定义heterogeneous feature interaction learning。Heterogeneous z-order Feature Interaction:给定包含feature interaction是学习一个独特的non-additive的映射函数feature listrepresentation或标量,以捕获该feature listfeatures之间的复杂关系。当feature interactions。例如:
feature interaction,因为additive的。而
feature interaction,且heterogeneous feature interaction具有对称性。
在深入模型细节之前,我们定义符号:小写字母(例如,
1.3 模型
本节首先介绍整体框架,然后提出
heterogeneous attention layer,并基于该层进一步介绍Hiformer模型。这是一个
multi-task model,基于transformer架构来实现的。是否可以考虑利用MMOE?Transformer-based` 多任务学习:
优点:
参数效率高:只需要少量额外参数(即,
task token embedding)。模型尺寸小:与单任务模型几乎相同,内存占用小。
隐式知识迁移:共享底层
representation促进跨任务知识迁移。对于相关性强的任务,可以提升学习效率。架构简单:没有复杂的路由机制。训练和推理流程统一。
缺点:
任务干扰:所有任务采用同一组参数,可能导致任务冲突,也难以平衡不同任务的学习进度。
容量限制:单个模型可能不足以捕获所有任务的复杂模式。而且任务数量增加时可能遇到瓶颈。
优化困难:可能遇到严重的梯度冲突问题。
MMoE多任务学习:优点:
任务解耦:每个专家用于特定任务,减少任务间负面干扰。
灵活组合:门控机制可以动态选择专家组合。
容量可扩展:增加专家数量即可扩展模型容量,可以处理更多或更复杂的任务。
缺点:
参数效率低:参数数量随专家数量线性增长,内存和计算成本高。
专家稀疏化问题:某些专家可能训练不足,需要精心设计门控和训练策略。
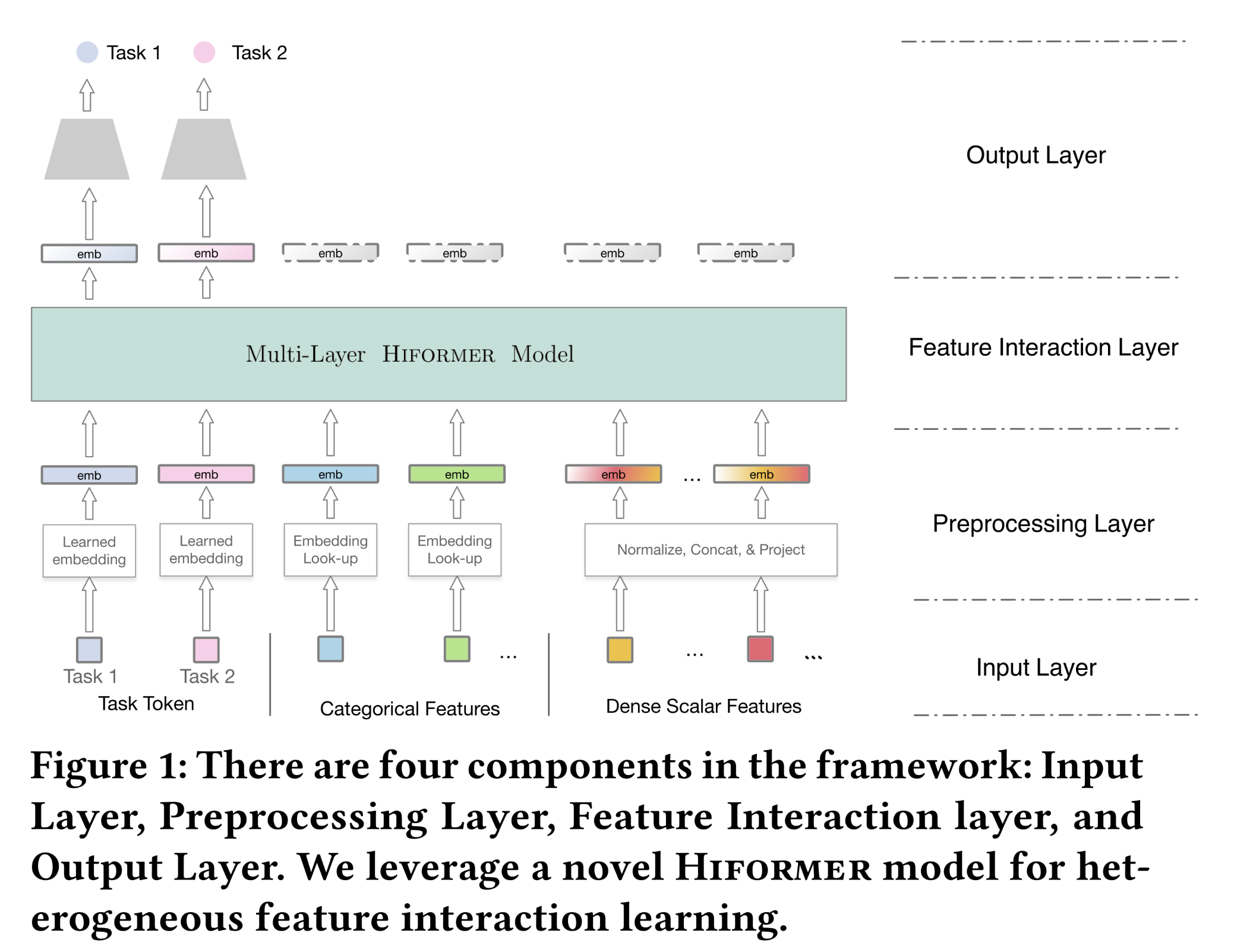
1.3.1 整体框架
Input Layer:input layer包含categorical features、dense features。此外,我们还有task embedding。task embedding可视为CLS token(《Bert: Pre-training of deep bidirectional transformers for language understanding》)。该框架可轻松扩展至多任务场景,通过多个task embeddings来实现,每个task embedding代表对应training objective的信息。input layers中的task embeddings是模型参数,通过端到端的model training进行学习。我们将task embeddings的数量记作Preprocessing Layer:preprocessing layer将input layer转换为a list of feature embeddings(包含task embeddings),从而作为feature interaction layers的input。针对不同类型的特征,我们设计了对应的preprocessing layer。Categorical Features:input categorical features通常是稀疏的且高维的,直接使用one-hot encoding进行模型训练容易导致过拟合。因此,常用的策略是将categorical features投影到低维稠密空间。具体而言,我们为每个categorical feature学习一个投影矩阵其中:
one-hot encoding向量;one-hot encoding维度,embedding向量。embedding look-up tables。随后,我们将
dense embedded vectorcategorical featurerepresentation。Dense Scalar Features:dense scalar features是数值型特征。由于不同dense scalar features的分布可能差异较大,需要将其转换为相似分布(即均匀分布)以保证数值稳定性(《Feature transformation for neural ranking models》)。此外,在
web-scale applications中,dense scalar features的数量较多,但远少于categorical features。因此,我们将所有dense scalar features聚合后,投影为embeddings(《Deep learning recommendation model for personalization and recommendation systems》);其中features总数。投影函数multilayer perceptron: MLP):其中:
concat()是向量拼接函数,normalize()为feature transformation函数;input tensor分割为多个dimension = SplitSize的sub tensors并输出第sub tensor
在
transformer-based的架构中,推理成本随input embedding list的长度呈二次方增长。通过将dense scalar features聚合为embeddings,减少了length of feature embeddings,从而降低了推理成本,同时仅需额外引入注意:需要先对数值特征进行归一化;然后把所有数值特征聚合起来;最后通过一个
综上所述,
preprocessing layers将categorical features、dense scalar features和task embeddings,转换为a list of embeddings,embeding size为模型维度preprocessing layers的output embeddings数量为task embeddings也被视为embedding list中的special features。因此,feature interactions不仅指features之间的交互,还包括features and tasks之间的交互。Feature Interaction Layer:feature interaction layer用于学习features之间的复杂的协同效应(collaborative effects),这对于捕获不同context下的用户的偏好至关重要。feature interaction layer的输入是preprocessing layers输出的embedding list。Output Layer and Training Objectives:我们仅使用feature interaction layer输出的encoded task embeddings进行任务预测。通过训练一个MLP tower,将encoded task embedding投影到final predictions。training tasks可根据recommendation application场景灵活配置,例如:若
labels为click, installation, or purchase等等,则training task为分类任务。若
labels为watch time等等,则training task为回归任务。
不失一般性,本文考虑分类任务,其中
0表示negative engagement,1表示positive engagement。因此,training objective可构建为二元分类问题,采用Binary Cross Entropy(即Log Loss)作为损失函数:其中:
ground truth label和prediction,
1.3.2 Heterogeneous Feature Interactions
Transformer架构已成为NLP、CV等多个任务的事实标准,multi-head self-attention layer在建模序列中的复杂关系方面取得了显著性能。然而,Transformer架构尚未在web-scale recommender systems中得到广泛应用。研究发现,Transformer-based的架构(如AutoInt)在应用于web-scale recommender systems时,可能无法达到最优性能。回顾原始
Transformer的attention score computation过程,在multi-head self-attention layer中,feature interactions learning的参数在所有feature groups之间共享。这种parameter sharing design在NLP任务中是自然的,因为NLP任务中Transformer的输入通常是由a list of text embeddings所表示的句子。text embeddings主要编码与上下文无关的信息。我们将这种setup称为homogeneous feature interactions。Transformer架构的详细示意图如Figure 4(a)所示。相比之下,推荐系统中存在多样化的上下文信息,学到的
embedding representations更具动态性,且包含多方面的信息。以外卖app推荐为例,涉及三个特征:app_id(如Zomato)、hour_of_day(如12pm)和user_country(如India)。app Zomato所学到的embedding representations编码了多种隐式信息,包括app类型、所流行的国家、常用时段、用户语言等。但在特定的feature interaction learning中,并非所有encoded information都有用。例如,在学习app_id与user_country的feature interaction时,与app所流行国家相关的信息可能比其他信息重要得多。因此,heterogeneous feature interaction learning的核心是提供contextual awareness能力,用于information selection and transformation,以实现更准确的feature interaction learning。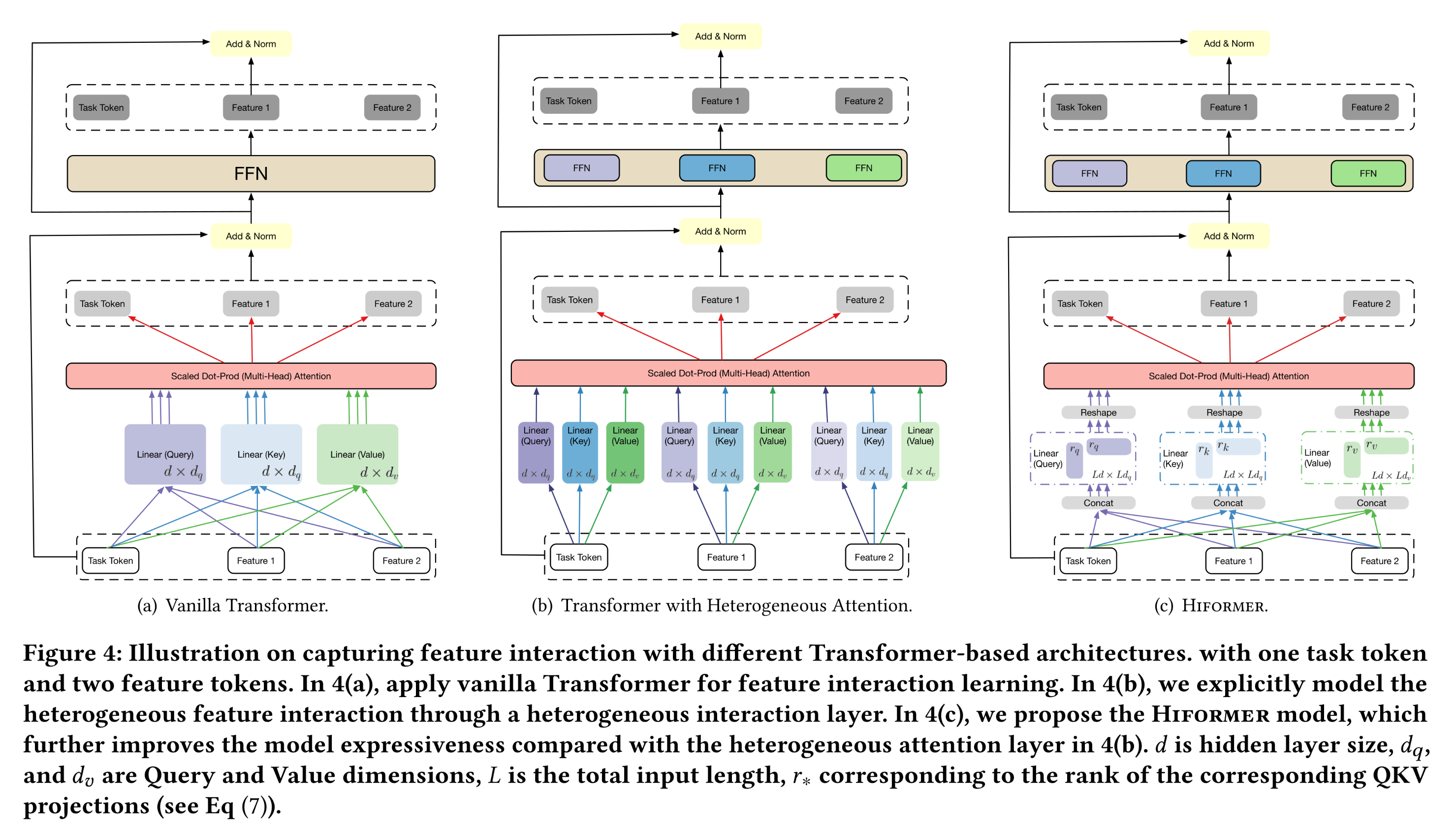
1.3.3 Heterogeneous Attention Layer
首先,我们对
Transformer模型中的multi-head self-attention layer进行简单而有效的改进,提出heterogeneous multi-head self-attention layer(简称heterogeneous attention layer),用于捕获异构的二阶的feature interactions。相应地,采用该层的模型称为heterogeneous attention model。具体而言,我们重新设计了featuremulti-head self-attention score computation:其中:
attention head中的第embedding list的长度,attention headembeddingssemantic correlation)。可以将它与
GatedAttention结合起来。注意,这里没有
position embedding。因为两个features之间的语义相关性与位置无关。我们将原始的
self-attention layer称为同构注意力层(homogeneous attention layer)。对于每个
feature pairunique的semantic correlation。换句话说,feature pairnon-additive的函数、带有非线性变换的神经网络等。为简洁起见,我们选择点积(dot-product)函数,即:其中:
featurequery投影矩阵、以及feautrekey投影矩阵;magnitude),通常设置利用计算得到的
attention weights,heterogeneous attention layer的输出可计算如下:其中:
featurevalue投影矩阵、featureoutput投影矩阵,对于
heterogeneous attention layer,featurequery/key/value/output投影矩阵都是feature-specific的:相比之下,原始的
self attention layer中,query/key/value/output投影矩阵是feature-shared的:与
heterogeneous attention layer类似,我们还为每个特征设计了异构的全连接前馈网络(heterogeneous FFN)。FFN通过两个带有高斯误差线性单元(GELU)激活的线性变换函数来实现:其中:
feature-specific的待学习的参数。intermediate layer)的维度;参考现有的研究(《Attention is all you need》),设置GELU为CDF)。
另一种做法(这种做法的效果会更差,因为模型容量不足):
首先将
featue-specific投影,从而投影到公共子空间:然后采用标准的
self-atention layer和标准的FFN。
可以看出,与
self-attention layer相比,heterogeneous attention layer的关键改进在于:为每个feature学习独立的query/key/value/output投影矩阵。因此,与原始Transformer模型相比,heterogeneous attention layer的参数数量有所增加,且参数数量与input embedding list的长度呈线性关系。但值得注意的是,heterogeneous attention layer与homogeneous attention layer(Transformer中的标准multi-head self-attention layer)的浮点运算量(FLOPs)总量相同,因为两者的运算操作完全一致,仅参数化方式不同。我们在
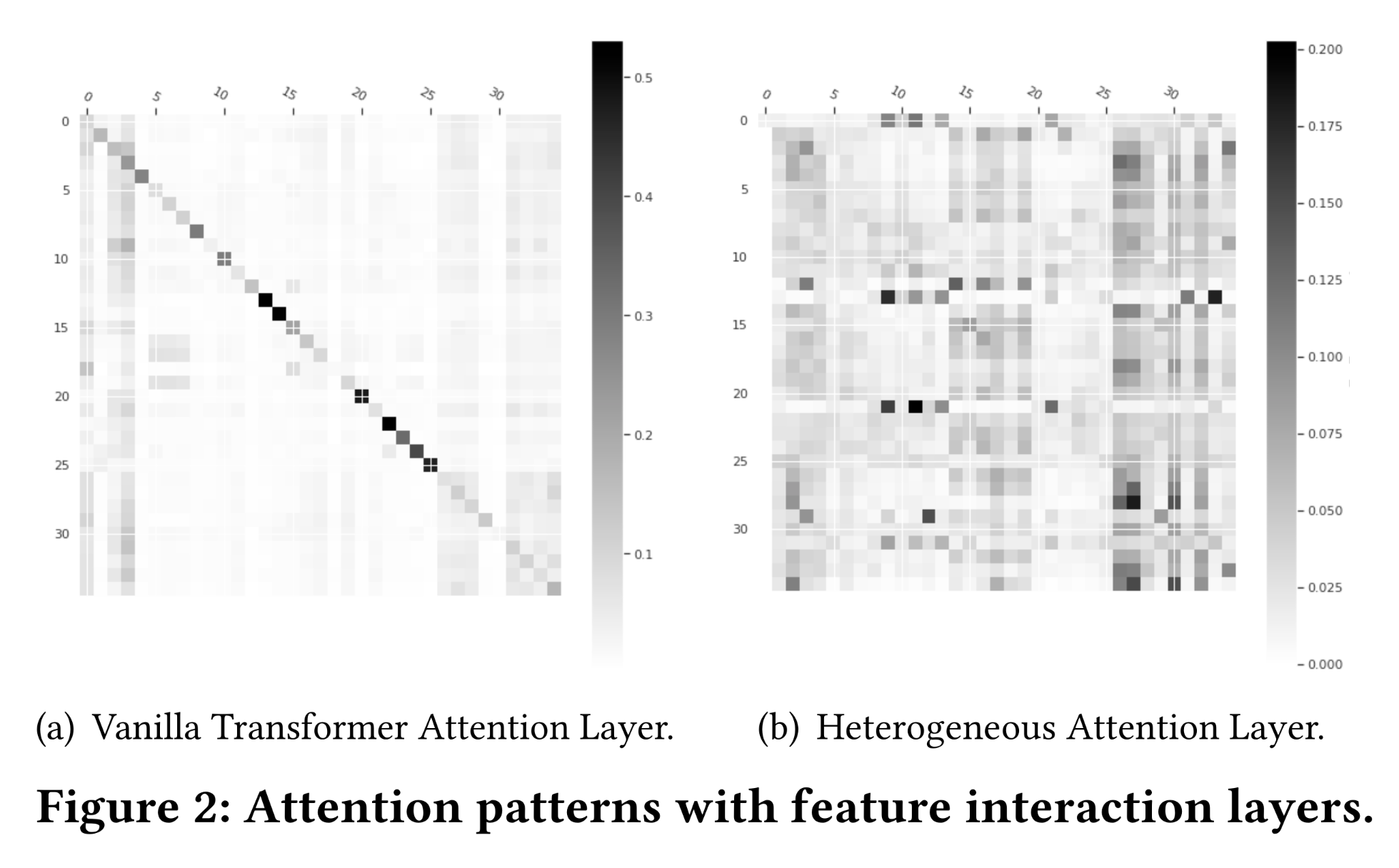
Figure 2中可视化了学到的attention patternFigure 2(a)中原始Transformer模型的attention pattern相对稀疏,且呈现明显的对角线模式,表明该层可能无法有效地捕获不同特征间的协同效应(collaborative effects)。Figure 2(b)中heterogeneous attention layer的attention pattern更稠密。直观来看,这一现象可解释为:由于heterogeneous attention layer通过变换矩阵(transformation matrix)(即,query/key/value/output投影矩阵)实现了特征语义对齐(feature semantic alignment),因此更擅长捕获特征间的协同效应。
1.3.4 Hiformer 模型
接下来,我们介绍
Hiformer模型。通过在query/key/value投影中引入复合特征学习(composite feature learning),进一步提升模型的表达能力。以key projection为例,我们不再为每个特征学习key projection矩阵,而是重新定义key projection如下:其中:
与
1.3.3节中的key projection矩阵key projection通过增加参数数量提升了模型表达能力,我们将这种新的投影composite projection)。从数学角度来看,该方法并非通过feature pairs来显式地学习feature interactions,而是首先将feature embedding list转换为composite features(作为keys和values),然后学习复合特征(composite features)与task embeddings之间的heterogeneous feature interaction。类似地,我们对
query projections和value projections也采用cross projection。然后,
Hiformer计算querykeyattention scores为:利用
attention score,Hiformer模型中attention layer的输出可计算为:为什么要提出
composite features?这是为了后续的低秩近似(Low-rank approximation)。用单个矩阵来替代Hiformer的模型结构如下图所示。
1.3.5 Hiformer 的高效性优化
与
Transformer模型和heterogeneous attention layer相比,Hiformer模型具有更强的表达能力,但同时也增加了推理过程中的计算成本。由于引入了Composite attention layer,现有的高效Transformer架构无法直接应用于Hiformer。feature embedding list的长度为Hiformer的推理成本分解如下:query/key/value projection:attention score computation:output projection:FFN network:
因此,总计算复杂度为
Hiformer部署于real-time inference的场景,我们通过低秩近似(low-rank approximation)和剪枝(pruning)技术降低其推理成本。Low-rank approximation:可以看出,Hiformer推理成本的主要部分是query/key/value projection,其计算复杂度为对于
composite key projectionlow-rank approximation)进行逼近:其中:
rank。低秩近似将
composite key projection的计算成本降低至composite query projection和composite value projection,对应的rank分别为low-rank structure):以Figure 3展示了其奇异值(singular values)分布,可见应用低秩近似后,
Hiformer的模型复杂度计算如下:query and key projection:value projection:attention layer:output projection:FFN layer:
当
input embedding list长度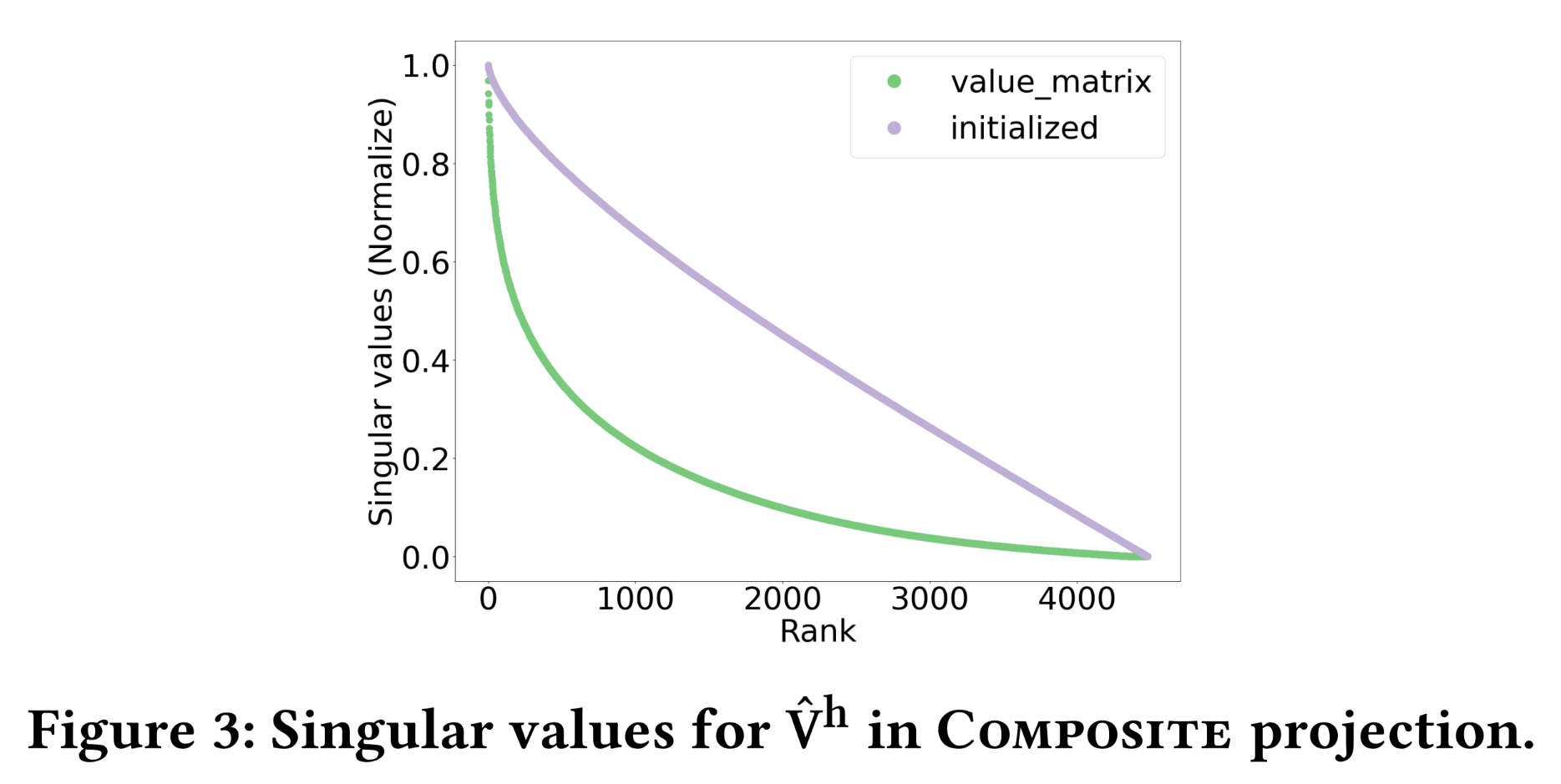
Model Pruning:回顾Output Layer(见Figure 1),我们仅使用encoded task embeddings进行final objective training and predictions。因此,通过剪枝encoding feature embeddings的计算过程,可以节省Hiformer模型最后一层的计算量。具体而言,剪枝(
pruning)操作是在Hiformer attention layer中,仅将task embeddings作为query,将task embedding and feature embeddings均作为key和value。因此,Hiformer最后一层的计算复杂度为:query projection:key projection:value projection:attention layer computation:output projection:FFN layer:
假设任务数量
Hiformer最后一层的计算复杂度变为剪枝技术将
Hiformer最后一层的计算复杂度从与Transformer-based的架构。近期一些研究(如Perceiver,《Perceiver: General perception with iterative attention》)也引入了类似思想,将Transformer模型的推理成本从二次方增长降低为线性增长。本质上是因为:在最后一层
transformer layer,我们仅仅关心task representations;其它位置的representation我们不关心,因此也无需计算。
1.4 实验
我们在
Google Play的web-scale App ranking model上,对所提出的模型架构进行了全面的实证验证。通过离线实验和在线实验,旨在回答以下研究问题:Q1:与原始Transformer模型相比,heterogeneous attention layer是否能够捕获heterogeneous feature interactions,从而提供更优的推荐效果?Q2:由于Hiformer模型具有更强的表达能力,其是否能进一步提升模型性能?即,与
SOTA模型相比的预测能力如何。Q3:与SOTA模型相比,Hiformer的推理效率如何?Q4:hyper-parameter settings如何影响模型性能和serving latency?如何在性能和效率之间进行权衡?
1.4.1 Offline Evaluation Setup
数据集:对于
offline evaluation,我们使用ranking model的logged data,user engagements作为training labels(0表示no engagement,1表示has engagement),training loss采用LogLoss。我们使用35天的滚动窗口数据(rolling-window data)进行模型训练,在第36天的数据上进行评估。模型每天使用最新数据进行重新训练。数据集包含31个categorical features和30个dense scalar features,用于描述apps,(如app id、app title、user language等)。categorical features的vocabulary size从数百到数百万不等。评估指标:
AUC。AUC可解释为:随机选择一个正例和一个负例,模型将正例排在负例之前的概率。在web-scale application dataset中,由于evaluation dataset规模庞大,AUC提升0.001即可达到统计显著性。此外,我们以
Transformer one layer模型为baseline,报告normalized LogLoss。模型在
TPU上进行训练,通过training的每秒查询量(QPS)衡量training速度。inference latency通过离线模拟来估算:在20 batches(batch size = 1024)的样本上进行inference,然后将所有模型的latency相对于baseline(a one-layer Transformer model with pruning)进行归一化。由于online serving requests数量巨大,serving latency比training QPS更为关键。
模型架构:注意,本文的研究重点是基于
Transformer的feature interaction learning,与基于Transformer的user history sequence modeling有显著区别。因此,我们将所提出的模型与以下SOTA的feature interaction models进行对比:AutoInt:通过multi-head self-attention layer学习feature interaction,然后通过多层感知机(MLP)进行最终预测。DLRM:通过factorization machine: FM学习explicit feature interactions,再通过MLP layer学习implicit feature interactions,最终完成预测。DCN(即DCN-v2):web-scale application中feature interaction learning的SOTA模型之一,其cross network显式生成有界的feature crosses,feature interaction阶数随网络深度增加。Transformer:采用multi-head self-attention layer进行feature interaction learning。Transformer与AutoInt的主要区别在于:1):Transformer使用encoded task embeddings进行预测,而AutoInt使用all encoded feature and task embeddings。2):Transformer架构包含FFN layer,而AutoInt layer没有。
Transformer + PE:在Transformer架构中添加Position Encoding,为每个特征额外学习一个embedding作为feature encoding。HeteroAtt:本文提出的Heterogeneous Attention layer,用于捕获heterogeneous feature interactions。HeteroAtt没有composite feature learning。Hiformer:本文提出的模型,结合了低秩近似和模型剪枝技术。
实现细节:
模型
training和serving基于TensorFlow 2和Model Garden来构建。为保证公平对比,除
feature interaction layers外,所有模型组件保持一致。在
embedding layer中,所有模型的embedding size均设置为128。注意,对于
Transformer架构、HeteroAtt和Hiformer,我们仅使用encoded CLS token(即learned task token)进行final task predictions。对于
Transformer模型,设置模型维度attention head数量FFN的中间层维度对于其他
Transformer-based的模型中,我们设置在线实验中,基于某一天(如
2月1日)的数据进行超参数调优,并在后续日期(即2月2日之后)固定该设置。
1.4.2 同构特征交互 vs. 异构特征交互 (Q1)
如
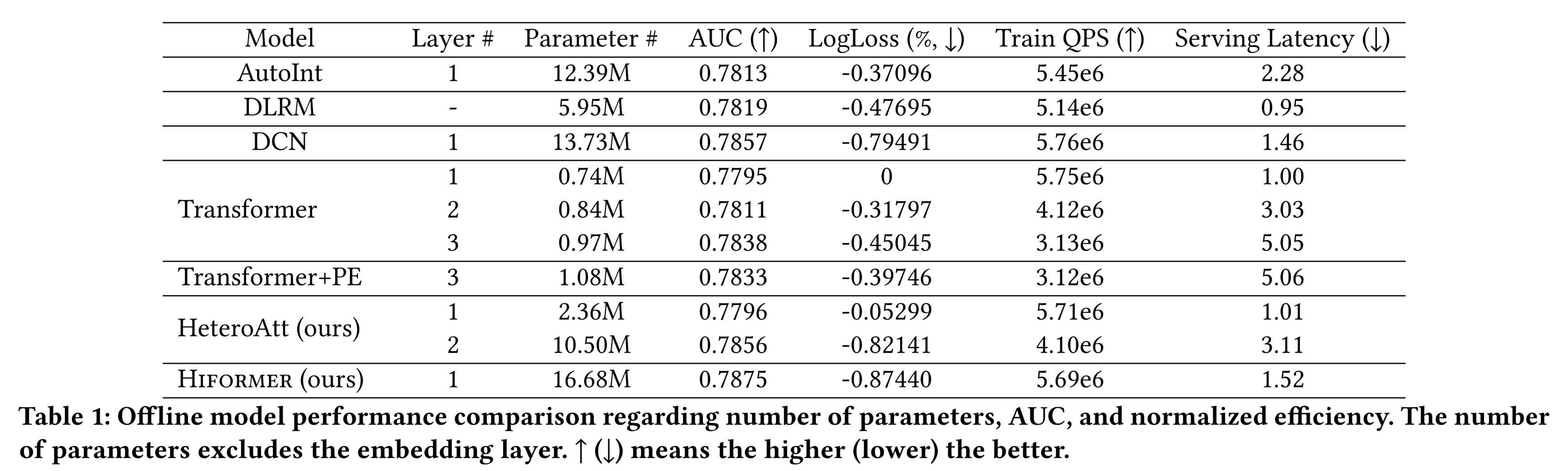
Table 1所示:首先,观察到
Transformer+PE模型的性能与原始Transformer模型相近,这与我们的假设一致:尽管Transformer+PE增加了参数,但feature encoding仅为每个特征学习一个bias embedding项,不足以实现heterogeneous feature interaction learning所需的feature transformation。其次,带有
heterogeneous attention layer的Transformer模型(HeteroAtt)的性能显著优于原始Transformer模型。这一结果验证了我们的论点:HeteroAtt通过transformation matrices(即,query/key/value/output投影矩阵),能够有效捕获复杂的feature interactions。此外,两层
HeteroAtt模型的参数数量远多于两层Transformer模型,因为HeteroAtt具有更强的模型表达能力。因此,我们可以对Q1给出肯定答案:具有更好特征上下文感知能力的heterogeneous feature interaction,对于提供个性化推荐至关重要。
1.4.3 模型性能对比 (Q2)
baseline模型与所提出模型的离线对比结果如Table 1所示,报告了每个模型在对应层数下的最佳性能。深入分析
AutoInt、DLRM和原始Transformer模型:这些模型的feature interaction learning缺乏feature awareness和semantic alignment能力,因此性能相对较弱。在
DCN模型中,Cross Net隐式地生成所有的pairwise crosses,然后投影到低维空间;all pairwise crosses的参数化方式是不同的,类似于提供了feature awareness能力,因此DCN模型的性能与HeteroAtt模型相当。与
heterogeneous attention layer(即,HeteroAtt)相比,Hiformer模型在query/key/value projection中具有更强的表达能力,仅需一层即可实现最佳模型性能,优于HeteroAtt模型和其他SOTA模型。
1.4.4 Serving Efficiency (Q3)
我们对比了所有模型的
serving效率。首先,对比两层的
Transformer模型和一层的Transformer模型(如Table 1所示):两层模型的延迟(latency)是一层模型的两倍多,这是因为我们仅对两层模型的第二层应用了剪枝,而一层模型已完全应用剪枝。类似地,
HeteroAtt模型也得出相同结论,因为这两种模型的运算操作相同,因此延迟一致。然而,AutoInt模型无法应用此类剪枝技术,因此一层AutoInt模型的推理成本远高于一层原始Transformer模型和一层HeteroAtt模型。其次,对比一层的
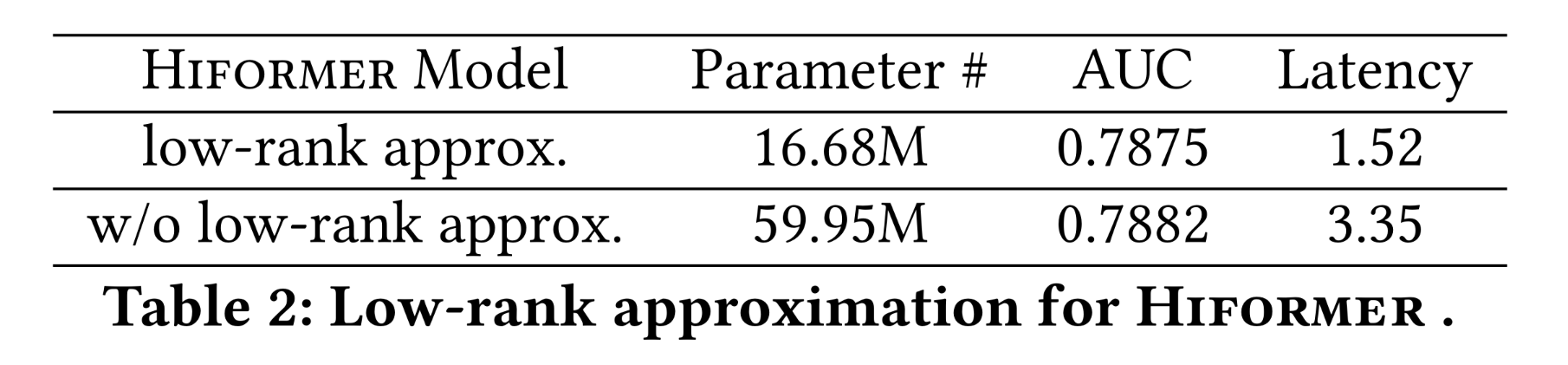
Hiformer模型和一层的HeteroAtt模型:两者均受益于剪枝带来的inference optimization,但由于Hiformer的query/key/value projection具有更强的表达能力,其推理成本比HeteroAtt高50.05%。值得注意的是,若不采用低秩近似,
Hiformer的推理成本会显著更高。在实验中,设置query and key的rank为value的rank为Table 2对比了with and without low-rank approximation的Hiformer模型:低秩近似使inference延迟降低了62.7%,且模型性能无显著损失——这与我们预期的一致,因为观察到的Hiformer的query/key/value projection矩阵是低秩结构(例如Figure 3中的
1.4.5 参数敏感性分析 (Q4)
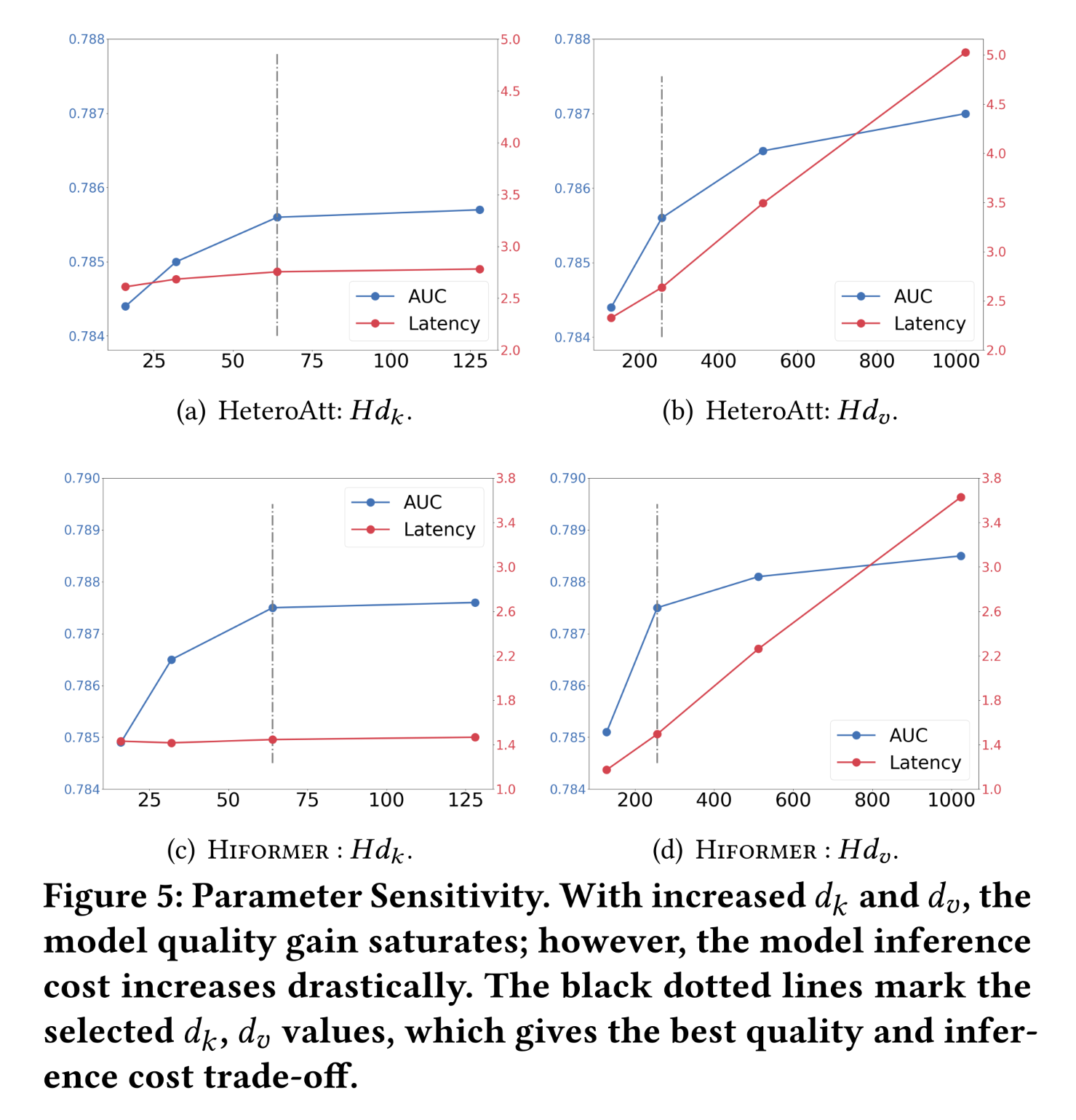
由于降低
serving latency是核心挑战之一,我们同样关注Q4中的参数敏感性(parameter sensitivity)问题。如前所述,本文并未直接设置HeteroAtt和Hiformer模型,serving latency之间进行权衡。首先,对于
Figure 5(a)中HeteroAtt的64时,模型性能无损失,但serving latency获得了3%的“无成本”的改善;若进一步降低相比之下,增加
HeteroAtt模型的serving latency显著增加(见Figure 5(b))。综合性能和延迟权衡,设置类似地,在
Figure 5(c)中观察到,对于Hiformer模型,将64时性能无损失;但与HeteroAtt模型不同,几乎没有serving latency。这是因为query/key/value projection中的低秩近似(特别是设置的query/key rankvalue rank较小,其中value rankquery projection成为计算成本的主要部分。如
Figure 5(d)所示,增加latency显著增加。HeteroAtt和Hiformer模型在latency权衡方面的这一观察结果具有独特性,可作为以latency为代价调整模型容量的工具。例如,当QPS相对较小时,可以通过增加SOTA模型(如DCN)中可能并不具备。
1.4.6 Online A/B Testing
除了广泛的离线实验外,我们还基于所提出的模型框架进行了
online A/B testing实验。control group和treatment groups各包含1%的随机选择用户,这些用户将接收基于不同ranking algorithms所输出的item recommendations。为了验证heterogeneous feature interaction learning带来的提升,baseline model采用one-layer Transformer model捕获feature interactions。我们收集了10天的user engagement指标,结果如Table 3所示:one layer HeteroAtt模型显著优于one layer Transformer模型,这与离线分析结果一致。此外,
two layer HeteroAtt模型相比one layer HeteroAtt进一步提升了性能。Hiformer模型在所有模型(包括DCN模型)中表现最佳。
这一观察结果表明,
Transformer-based的架构能够优于SOTA的feature interaction模型。目前,我们已成功将Hiformer模型部署到生产环境中。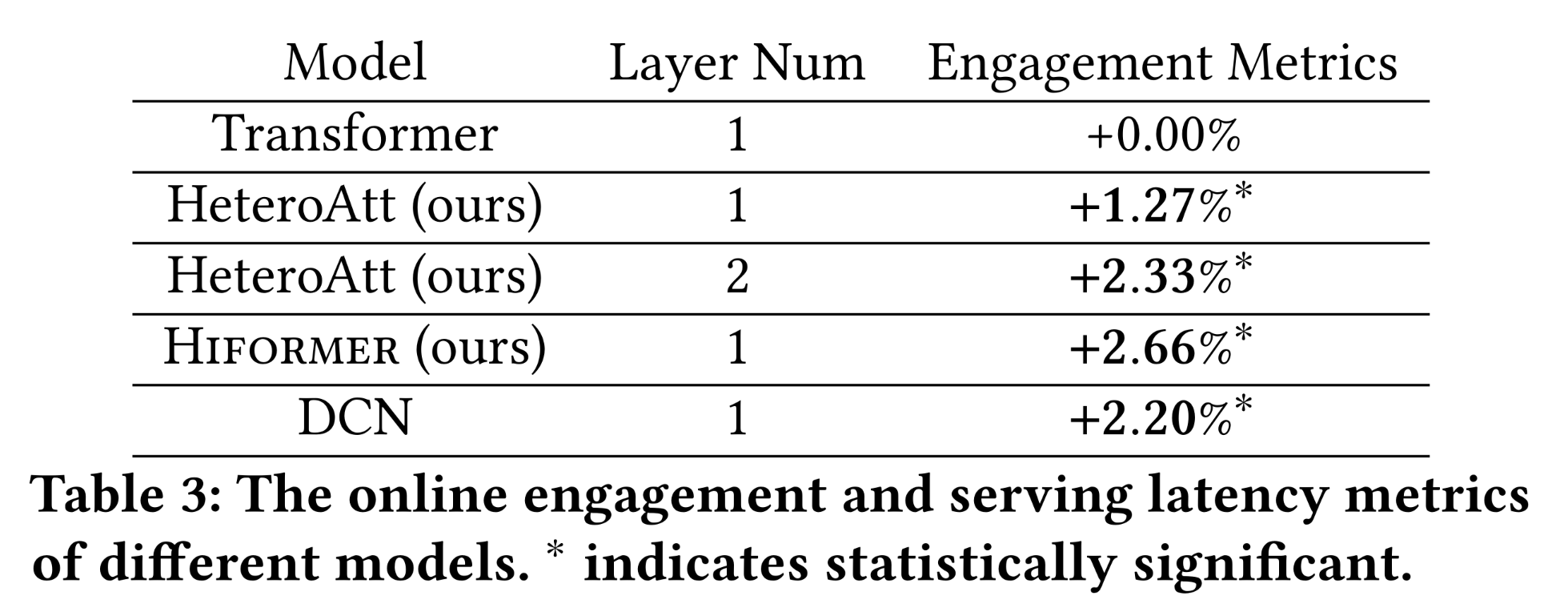
1.5 结论与未来工作
本文提出了一种
heterogeneous attention layer,通过对self-attention layer进行简单而有效的改进,为feature interaction learning提供feature awareness能力。随后,我们进一步提升模型表达能力,提出
Hiformer模型以改进feature interaction learning。同时,我们优化了Hiformer的serving效率,使其能够满足web-scale applications的serving latency要求。本文方法的核心创新在于:在
attention机制中识别不同特征之间的异质关系,从而在学到的feature embeddings中捕获动态信息的语义相关性(semantic relevance)。在全球领先的数字分发服务平台上进行的离线实验和在线实验,验证了本文方法的有效性和高效性。实验结果表明,基于Transformer的feature interaction learning模型在web-scale applications中能够优于SOTA的方法。本文的工作为将
Transformer-based的架构应用于web-scale recommender system搭建了桥梁。未来,我们计划探索其他领域(如NLP和CV)中Transformer架构的最新进展如何迁移到推荐系统中。此外,本文引入的新feature interaction组件,也可用于神经架构搜索(neural architecture search),以进一步改进推荐系统。