一、 MultiEmbed [2023]
《On the Embedding Collapse When Scaling Up Recommendation Models》
foundation models的最新进展催生了一个极具前景的趋势,即开发大型推荐模型以充分利用海量的可用数据。然而,主流推荐模型的规模仍然小得令人尴尬,且单纯扩大模型规模并不能带来足够的性能提升,这表明现有模型在scalability方面存在不足。在本文中,我们指出嵌入坍缩(embedding collapse)现象是阻碍model scalability的关键因素:embedding matrix往往会占据一个低维子空间。通过实证分析和理论分析,我们揭示了recommendation models特有的two-sided effect of feature interaction:一方面,
interacting with collapsed embeddings会限制embedding learning,进而加剧collapse问题。另一方面,
interaction作为保障scalability的关键机制,在缓解过拟合方面发挥着至关重要的作用。
即,
interaction具有两面性:好的一面是缓解过拟合,坏的一面是加剧collapse问题。基于上述分析,我们提出了一种简单而有效的
multi-embedding design,该设计融合了embedding-set-specific interaction modules,能够学习具有高度多样性的embedding sets,从而减少embedding collapse。大量实验表明,所提出的设计能够为各类推荐模型提供稳定的scalability,并有效缓解embedding collapse问题。相关代码已开源至以下仓库:https://github.com/thuml/Multi-Embedding。推荐系统是重要的
machine learning应用场景,其基于海量的multi-field categorical data来预测用户对items的行为。在日常生活中,推荐系统扮演着不可或缺的角色,帮助人们发现符合自身兴趣的信息,并已被广泛应用于电子商务、社交媒体、新闻推送和音乐流媒体等各类online applications中。研究人员已开发出基于deep-learning的推荐模型,能够灵活挖掘feature representations。这些模型已成功部署于众多application场景,充分证明了其广泛的适用性和有效性。受
large foundation models通过增加参数数量实现性能提升这一进展的启发,scale up推荐模型规模以充分利用海量数据,这本应是一个极具前景的研究方向。然而,与直觉相悖的是,作为对性能起关键作用的核心组件,推荐模型的embedding size通常设置得极小(例如《Bars: Towards open benchmarking for recommender systems》中设置为10维),因此无法充分捕获数据中的丰富信息。更糟糕的是,如Figure 1a所示,增加embedding size不仅不能充分提升模型性能,甚至可能对模型造成负面影响。这表明:现有架构设计在model scalability方面存在缺陷,限制了推荐系统的性能上限。对于
DCNv2,模型性能虽然并未随着embedding size的增加而下降,但是它提升幅度非常低,几乎可以忽略不计。为探究这一现象背后的原因,我们通过奇异值分解(
singular value decomposition)对学到的embedding matrices进行谱分析(spectral analysis),并在Figure 1b中展示了归一化后的奇异值(normalized singular values)。令人惊讶的是,大多数奇异值(singular values)都非常小,即学到的embedding matrices阵近乎低秩(low-rank),我们将这一现象称为embedding collapse。随着模型规模的扩大,模型并未学习到更高维度的信息,这意味着参数利用效率(parameter utilization)低下,进而限制了模型的scalability。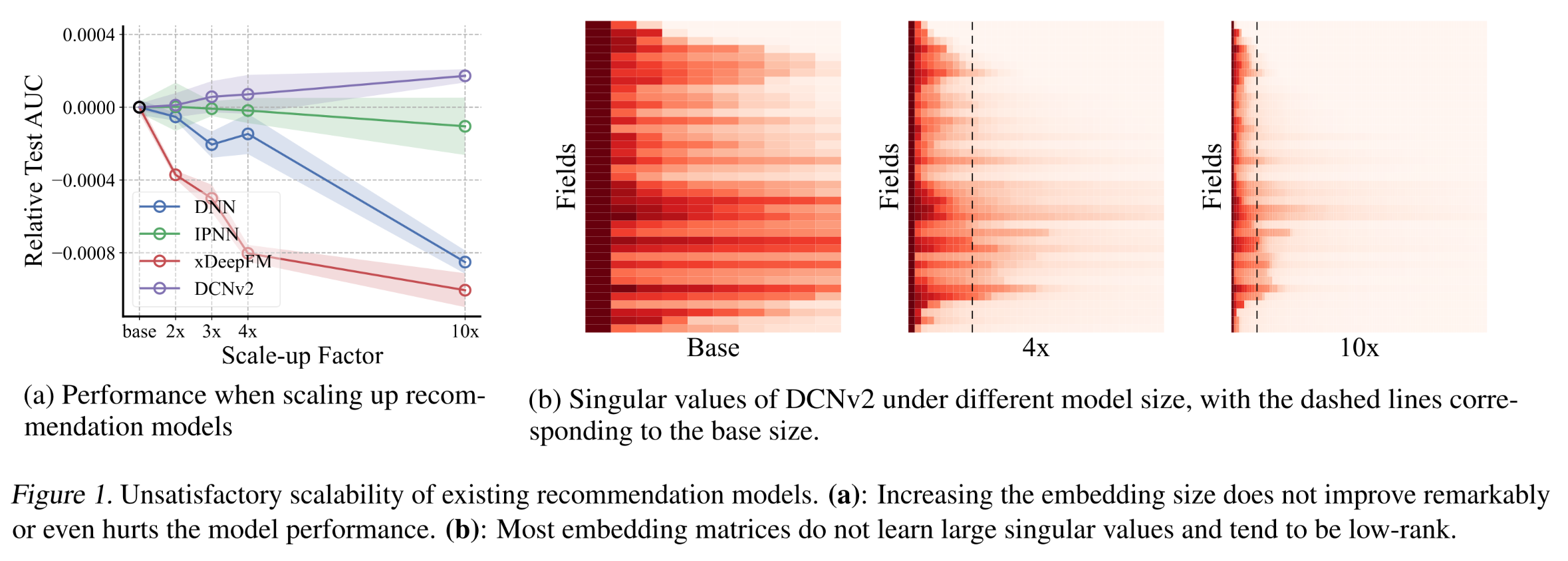
在本文中,我们通过实证分析和理论分析深入研究了
embedding collapse的形成机制,并揭示了作为推荐模型核心组件(用于建模higher-order correlations)的feature interaction module对model scalability的two-sided effect:一方面,
interaction with collapsed embeddings会限制embedding learning,进而加剧embedding collapse问题。另一方面,
feature interaction在scaling up模型规模时对减少overfitting至关重要,因此不能简单地限制或移除feature interaction模块。
基于上述分析,我们得出了在不抑制
feature interaction的前提下缓解embedding collapse的核心原则,从而为构建scalable models提供了理论依据。我们提出了multi-embedding,作为一种简单而高效的model scaling机制。multi-embedding通过增加独立的embedding sets的数量,并融合embedding-set-specific interaction modules,从而共同捕获不同的模式。实验结果表明,multi-embedding能够为各类主流推荐模型提供scalability,并显著缓解multi-embedding问题,为突破推荐系统的size limit提供了一种有效方法。本文的主要贡献如下:
据我们所知,我们首次指出了推荐系统中的
model scalability问题,并发现了embedding collapse现象。embedding collapse是提升推荐模型scalability亟需解决的关键问题。通过实证分析和理论分析,我们基于
embedding collapse现象揭示了feature interaction过程对model scalability的two-sided effect:feature interaction会导致embedding collapse,但同时提供了必要的对抗过拟合的能力。基于 “在不抑制
feature interaction的前提下缓解embedding collapse” 这一核心原则,我们提出了一种统一的multi-embedding设计。该设计能够持续提升各类SOTA推荐模型的scalability,并有效缓解embedding collapse问题。
1.1 相关工作
推荐系统中的模块:已有大量工作研究推荐系统的模块设计。一类研究专注于
feature interaction过程,其中feature interaction是推荐系统特有的。这些工作旨在融合推荐系统的domain-specific knowledge。我们的工作不是提出新的模块,而是从机器学习的角度出发,分析现有模型的scalability。Collapse现象:neural collapse或representation collapse描述了representation vectors的退化。这一现象在监督学习、无监督对比学习、迁移学习、以及generative models中得到了广泛研究。《On the representation collapse of sparse mixture of experts》讨论了sparse MoEs中的representation collapse。受这些工作的启发,我们将embedding vectors视为representations,从而认识到推荐模型中的embedding collapse现象。然而,我们面临的是field-level interaction的场景,这在之前的研究中尚未得到充分探讨。固有维度和压缩理论:为描述数据的复杂性,现有工作包括基于固有维度(
intrinsic-dimension)的量化、以及基于剪枝的分析。我们提出的SVD-based的信息丰度(information abundance)概念与这些工作相关。
1.2 预备知识
推荐模型旨在基于多个
fields的特征来预测user action。在本文中,我们考虑推荐系统的基本场景,涉及categorial features和binary outputs。形式化地,假设存在fields,,第field表示为field的cardinality。令:则推荐模型的目标是:学习从
除了考虑来自各种各样的
fields的单个特征外,推荐系统领域已有大量研究通过feature interaction模块来建模combined features。在本文中,我们研究了主流推荐模型广泛采用的以下架构:一个推荐模型通常包含:(1):每个field的embedding layerembedding size,(2):一个interaction模块embeddings整合为a combined feature scalar or vector。(3):一个后续的postprocessing模块MLP和MoE)。
该模型的前向传播(
forward pass)过程可形式化为:其中:
one-hot encoding。即,embedding table
1.3 Embedding Collapse
奇异值分解(
singular value decomposition)已被广泛用于衡量collapse现象(《Understanding dimensional collapse in contrastive self-supervised learning》)。在Figure 1b中,我们展示了推荐模型学到的embedding matrices接近low-rank,且存在一些极小的奇异值(singular values)。为了量化这类具有低秩(low-rank)倾向的矩阵的collapse程度,我们提出了信息丰度(information abundance)作为一种广义的度量指标。信息丰度的定义:考虑矩阵
即,所有奇异值的和除以最大奇异值。
其中:
因此有,
left singular vector)。right singular vector)。
直观地,信息丰度高的矩阵在向量空间中具有均衡的分布(因为其
singular values较为接近)。相反,信息丰度低的矩阵表明,对应于较小奇异值的分量可以被压缩,而不会对结果产生显著影响。与矩阵秩(matrix rank)相比,信息丰度可以看作是一种简单扩展(注意non-strictly low-rank matrices),尤其是对于fields数量rank K)。我们计算了扩大规模后的
DCNv2(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems》)的embedding matrices的信息丰度,并与随机初始化的矩阵进行了比较,结果如Figure 2所示。可以观察到,学到的embedding matrices的信息丰度极低,这表明存在embedding collapse现象。这是按照随机初始化方法中信息丰度从大到小来排序
Fields。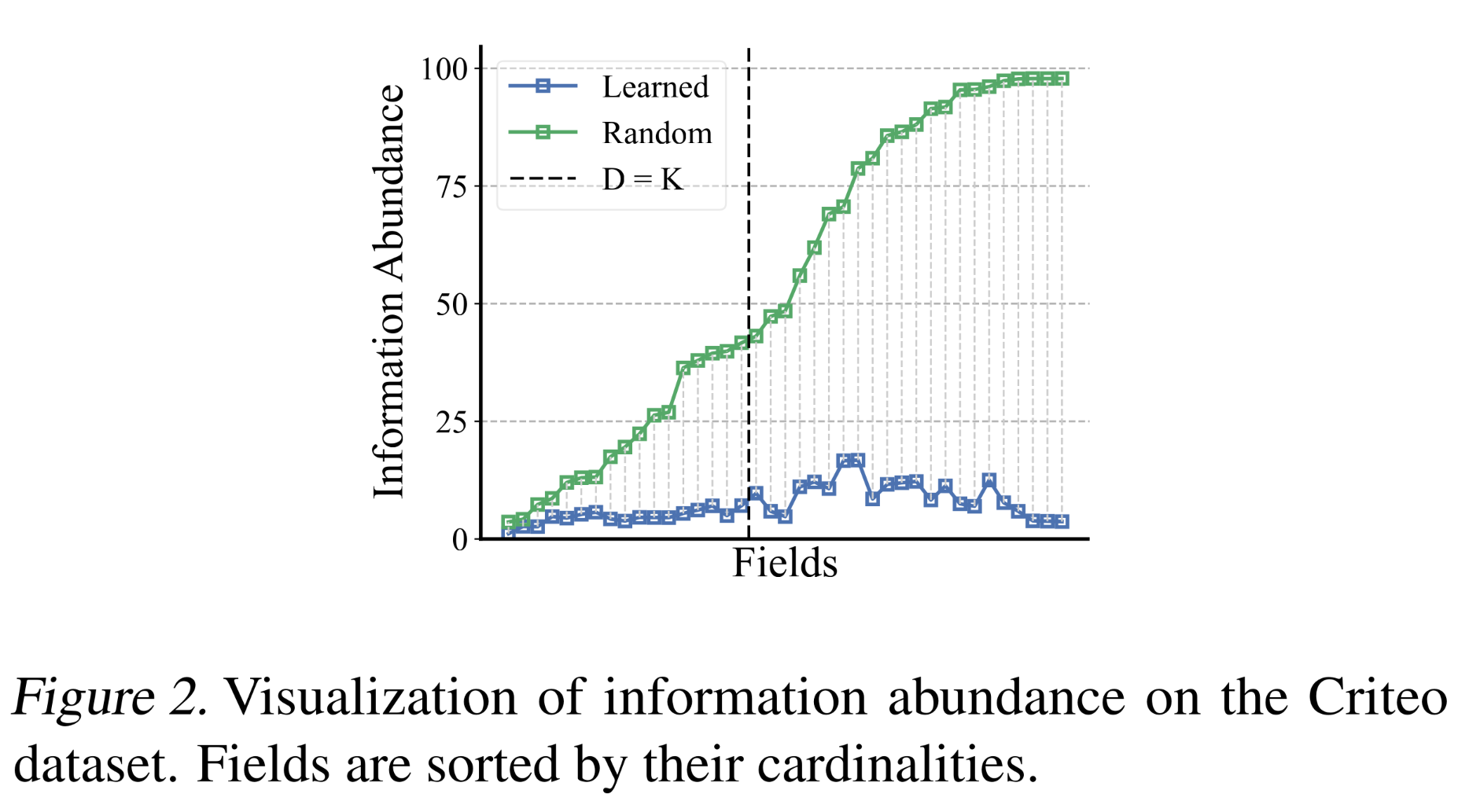
1.4 Feature Interaction Revisited
在本节中,我们深入探讨推荐模型中的
embedding collapse现象。我们重新审视了作为推荐模型核心的feature interaction模块,并围绕以下两个问题展开研究:(1):embedding collapse是如何产生的?(2):如何有效缓解embedding collapse并提升model scalability?
通过实证研究和理论研究,我们揭示了
feature interaction模块对model scalability的two-sided effect。
1.4.1 Interaction-Collapse Theory
为了确定
feature interaction如何导致embedding collapse,直接分析原始embedding matrices是不够的:因为学到的embedding matrix是interactions with all other fields的结果,因此难以分离impact of field-pair-level interaction对embedding learning的影响。为解决这一难题,我们通过对models with sub-embeddings进行实证分析,并对一般模型进行理论分析,得出feature interaction会导致embedding collapse的结论,我们将其称为interaction-collapse theory。为什么直接分析原始
embedding matrices是不够的?因为只看最终的
embedding矩阵的话,难以判断embedding collapse到底是由于field本身引起的,还是由于与其它field的交互所引起的。而为什么分析
models with sub-embeddings是可行的?因为每个
sub-embedding专门用于field pair之间的交互。从而有助于判断embedding collapse到底是由于field本身引起的,还是由于与其它field的交互所引起的。
Evidence I: Empirical analysis on models with sub-embeddings:DCNv2通过在每个field pair之上引入一个crossing network(由transformation矩阵fieldembedding vector进行投影,然后fieldfieldall projected embedding vectors,DCNv2可以被视为从embedding matrixfield-aware sub-embeddingsfields进行交互。这些field-aware sub-embeddings的形式为:DCNv2由多个堆叠的cross layers组成,为简化分析,我们仅讨论第一层。为了确定sub-embedding matrices的collapse程度,我们计算了所有pairs的Figure 3a所示。为方便起见,我们根据信息丰度的升序对field indices进行预排序,即根据可以观察到,
注意,横轴的
field是根据有趣的是,我们还观察到另一种相关性(
correlation):sub-embeddings的信息丰度受到其交互的fields的共同影响,表现为沿Figure 3b和Figure 3c所示。上升趋势和相关系数证实了
我们还对同样包含
sub-embeddings的FFM模型的信息丰度进行了分析,得到了类似的观察结果(见附录H)。这一段的核心结论是:
sub-embeddings的信息丰度受到其交互的fields的共同影响。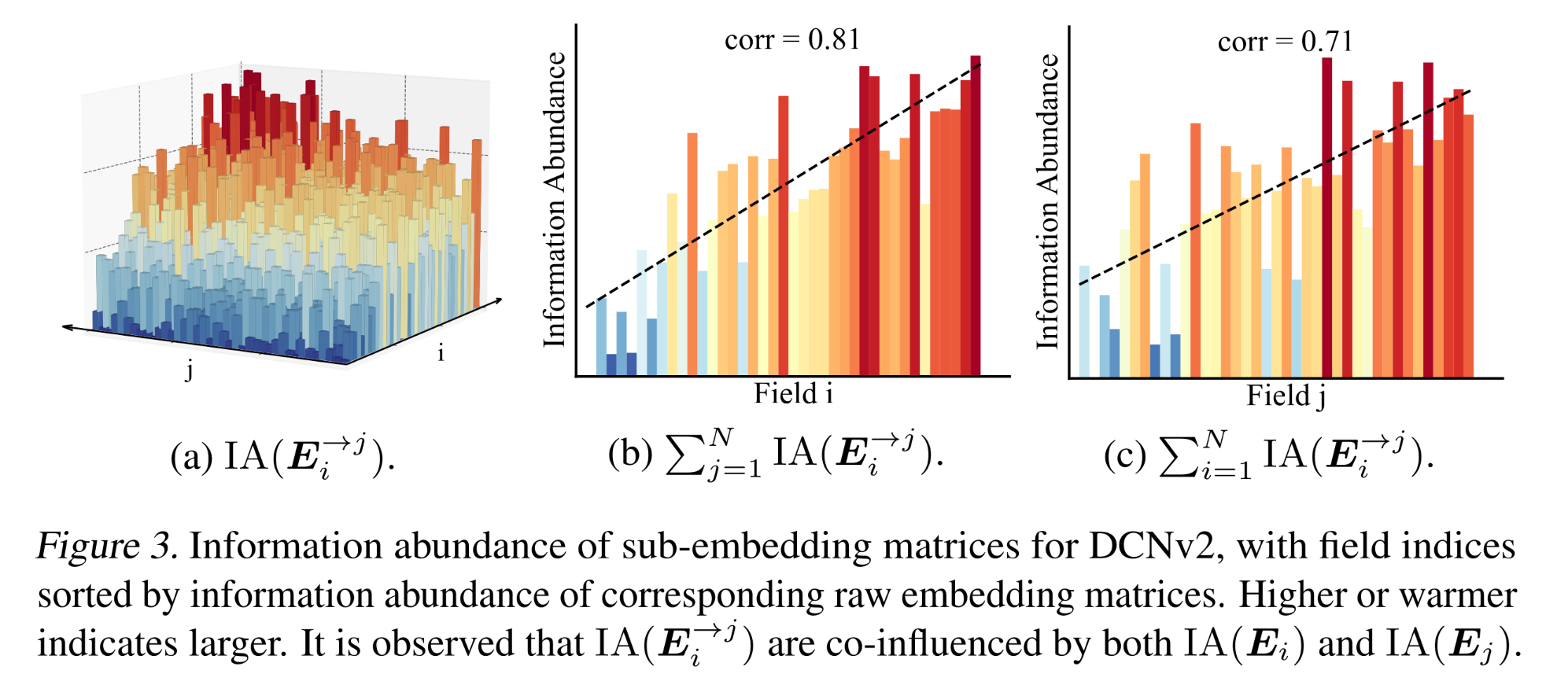
Evidence II: Theoretical analysis on general recommendation models:现在,我们从理论上证明,即使没有sub-embedding,一般模型中的feature interaction也会导致embedding collapse。为简化分析,我们考虑FM风格的feature interaction。形式化地,feature interaction过程定义为:其中:
combined feature)。不失一般性,我们讨论
embedding matrices的fixed的。考虑一个batch size = B的mini-batch。令该方程表明,梯度可以分解为
field-specific的项。我们考虑某个fieldembedding matrixtraining data和objective function决定。因此,variety显著影响梯度分量类似地,因此
a collapsed matrix。当
对应于大奇异值
对应于小奇异值的项贡献微乎其微。
因此,梯度分量
梯度
刚开始
为进一步说明,我们在合成数据上进行了一个简单实验。假设存在
fields,我们将field cardinality的diverse range相符。我们在保持G。Figure 4展示了两种情况下low-information-abundance matrix进行交互会导致a collapsed embedding。当
在固定
embedding矩阵会通过特征交互的梯度传播机制,限制其他字段embedding的学习空间,导致其也趋向坍塌。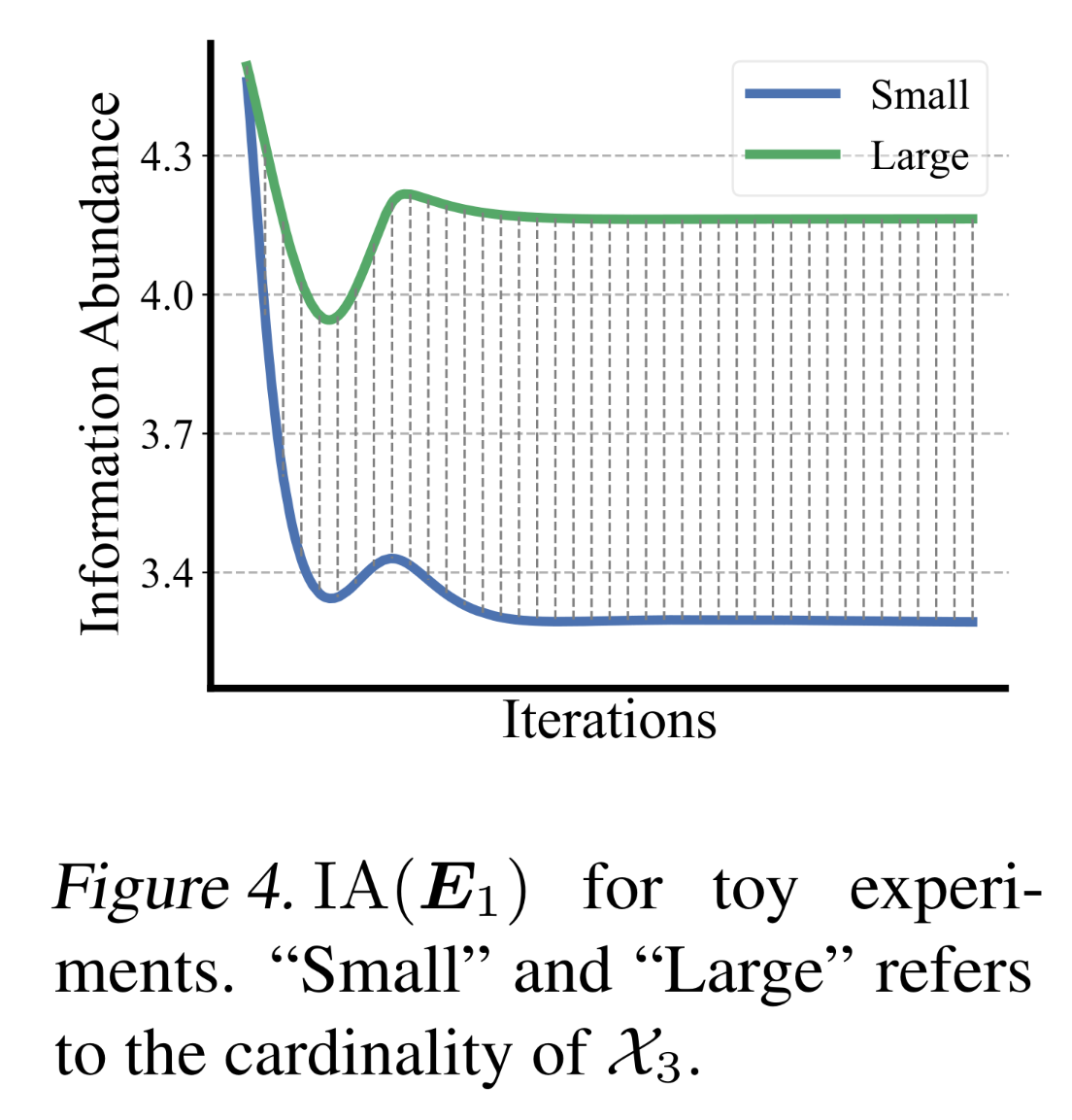
Summary: How is collapse caused in recommendation models?:Evidence I表明,与low-information-abundance field进行交互会导致a more collapsed sub-embedding。考虑到sub-embeddings源于原始embeddings,反映了fields interact的影响,我们认识到feature interaction导致embedding collapse的内在机制——这一机制得到了我们理论分析的进一步证实。我们得出interaction-collapse theory:Finding 1 (Interaction-Collapse Theory):在推荐模型的feature interaction中,fields with low-information-abundance embeddings会限制其他fields的信息丰度,导致collapsed embedding matrices。
interaction-collapse theory表明,feature interaction是导致embedding collapse的主要诱因,从而限制了模型的理想的scalability。
1.4.2 避免 Collapse 是否足以实现 Scalability ?
根据上述讨论,我们已经表明推荐模型的
feature interaction过程会导致embedding collapse,进而限制模型的scalability。现在我们讨论其逆命题:即抑制feature interaction以缓解embedding collapse是否会带来模型scalability的提升?为回答这一问题,我们设计了以下两个实验,对比标准模型、以及feature interaction被抑制的模型。Evidence III: Limiting the modules in interaction that leads to collapse:Evidence I表明,投影矩阵sub-embeddings的信息丰度,从而导致embedding collapse。现在,我们通过引入以下带有可学习参数model scalability:其中:
该正则化项将投影矩阵
normalized singular values),并在投影后保持信息丰度。我们在不同embedding sizes下进行了实验,对比了标准模型和正则化后的模型的性能变化、信息丰度、以及optimization dynamics。结果如Figure 5所示。正如预期的那样,DCNv2中的正则化有助于学习具有更高信息丰度的embeddings。然而,模型出现了出乎意料的结果:即使embedding collapse得到缓解,scalability也没有提升,甚至有所恶化。研究发现,正则化后的模型在学习过程中会发生过拟合,表现为training loss持续下降而validation AUC下降。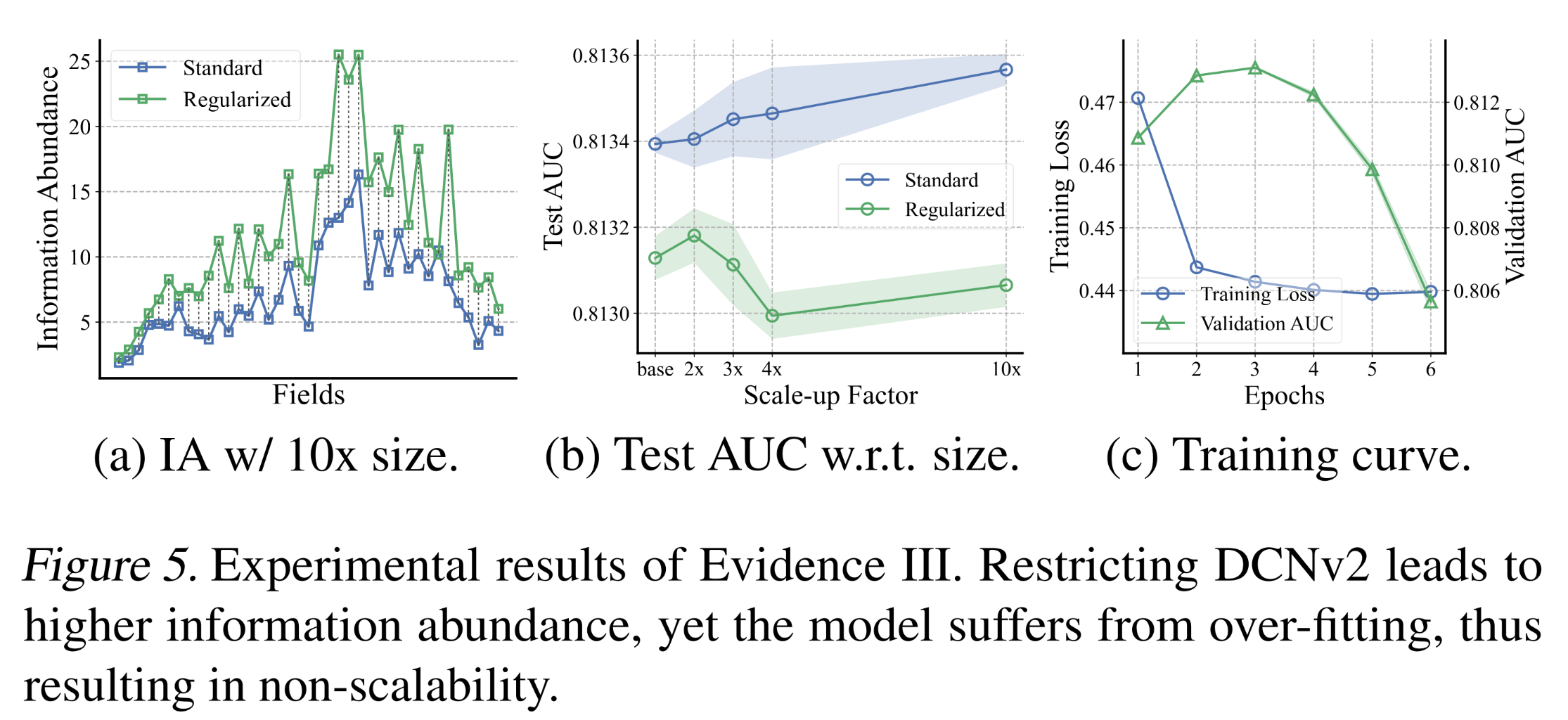
Evidence IV: Directly avoiding explicit interaction:现在,我们研究直接抑制feature interaction对scalability的影响。我们以DNN为例——它包含一个简单的interaction模块,将来自不同fields的所有feature vectors拼接起来,并用MLP进行处理。由于DNN不进行显式的二阶feature interaction,根据我们之前的interaction-collapse theory,它受到的embedding collapse影响应该较小。我们对比了DCNv2和DNN学到的embeddings、以及它们的性能随embedding size增长的变化。考虑到不同架构或目标函数在建模方面可能存在差异,我们主要讨论性能趋势以进行公平比较。结果如Figure 6所示。DNN学到的embedding matrices的collapse程度较低,表现为信息丰度高于DCNv2。然而,事与愿违的是,当增加
embedding size时,DNN的AUC反而下降。
这一观察结果表明,尽管
DNN受到的embedding collapse影响较小,但它仍然存在过拟合问题,且缺乏scalability。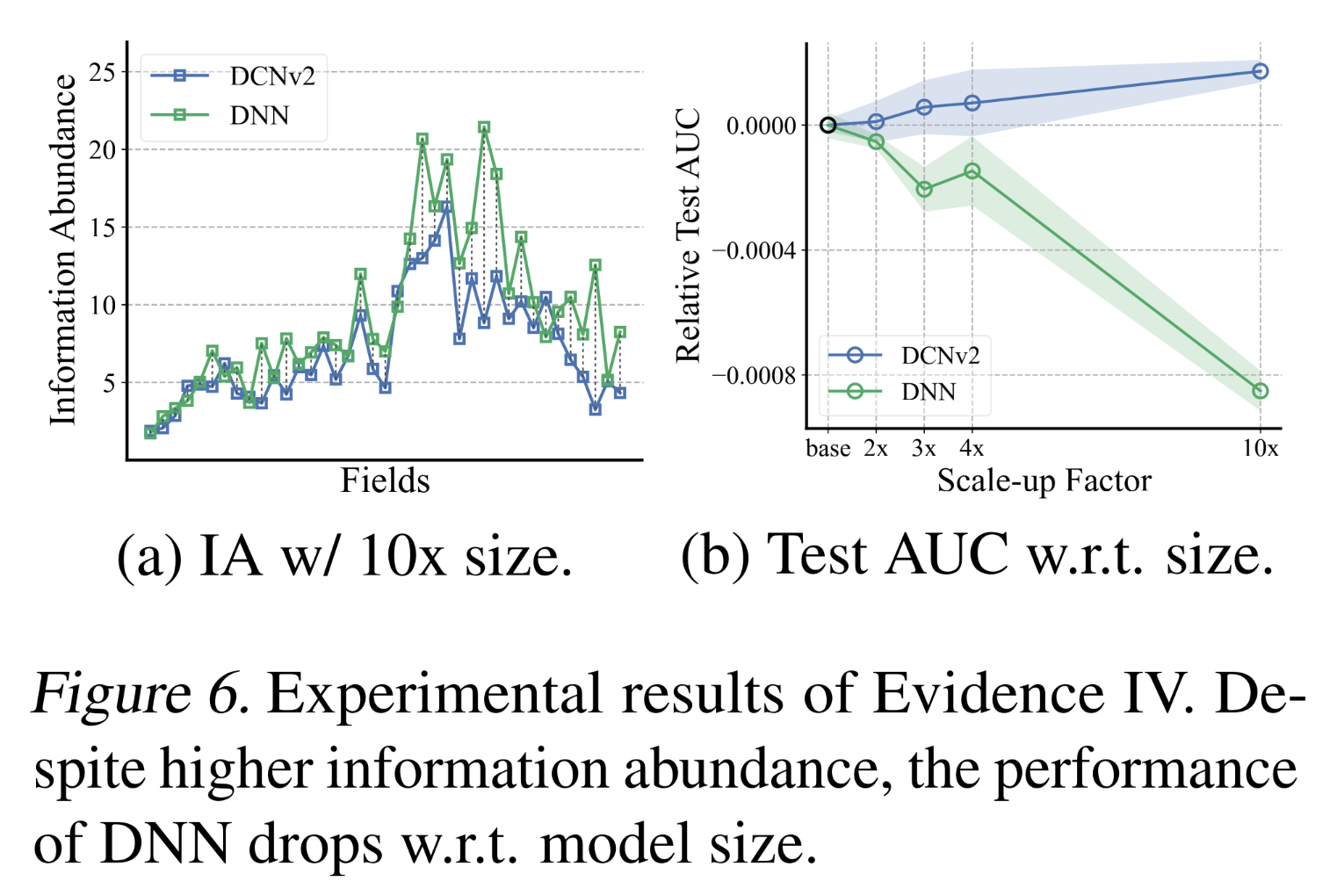
Summary: Does suppressing collapse definitely improve scalability?:Regularized DCNv2和DNN都是feature interaction被抑制的模型——正如预期的那样,它们学到的embedding matrices的collapse程度低于DCNv2。然而,evidence III&IV中的观察结果表明,Regularized DCNv2和DNN都无法随着模型规模的增长而在AUC上实现提升,并且都存在严重的过拟合问题。我们得出以下发现:Finding 2:由于过拟合问题,通过不恰当地抑制feature interaction而获得的a less-collapsed model不足以实现scalability。
这一
finding是合理的,因为feature interaction融入了推荐系统中higher-order correlations的domain knowledge,有助于形成具有泛化能力的representations。当feature interaction被抑制时,随着embedding size的增加,模型往往会拟合噪声,导致泛化能力下降。
1.5 Multi-Embedding Design
在本节中,我们提出了一种简单的
multi-embedding design——它是一种适用于多种推荐模型架构的有效的scaling机制。我们将介绍其整体架构、展示实验结果,并分析multi-embedding的工作原理。我们还将讨论data的作用,从而为multi-embedding提供全面的分析。
1.5.1 Multi-Embedding
feature interaction对scalability的two-sided effect为model design提供了一个核心原则:即a scalable model应能够在现有feature interaction框架内学习less-collapsed embeddings,而不是移除interaction。基于这一原则,我们提出了multi-embedding: ME作为一种简单而高效的设计,以提升模型scalability。具体来说,我们通过增加
independent and complete embedding sets的数量(而非embedding size),并融合embedding-set-specific feature interaction模块。与group convolution(《Imagenet classification with deep convolutional neural networks》)、multi-head attention(《Attention is all you need》)、以及推荐系统中其他decoupling-based的工作类似,这种设计允许模型联合学习不同的interaction patterns,从而得到具有large diversity的embedding sets。而a single-embedding model在pattern extraction方面受到限制,容易遭受严重的embedding collapse。通过multi-embedding,模型在保留原始interaction模块的同时,受到interaction-collapse theory的影响较小,从而缓解了embedding collapse。形式化地,具有embedding sets的推荐模型定义为:其中:
embedding set的index。这里,多个
feature interactiongate-based或者attention-based方法来融合,从而考虑不同interaction的重要性。注意:
interaction的融合发生在postprocessing模块multi-embedding的一个关键要求是,interaction模块ReLU)。否则,模型将等价于single-embedding,无法捕获不同的模式。作为解决方案,我们在具有线性interaction模块的模型的interaction之后添加一个非线性投影,并减少postprocessing模块MLP层,以实现公平比较。single-embedding models和mult-embedding models的整体架构对比如Figure 7所示。对于
multi-head attention网络,multi-head本身就起到了multi-embedding的作用。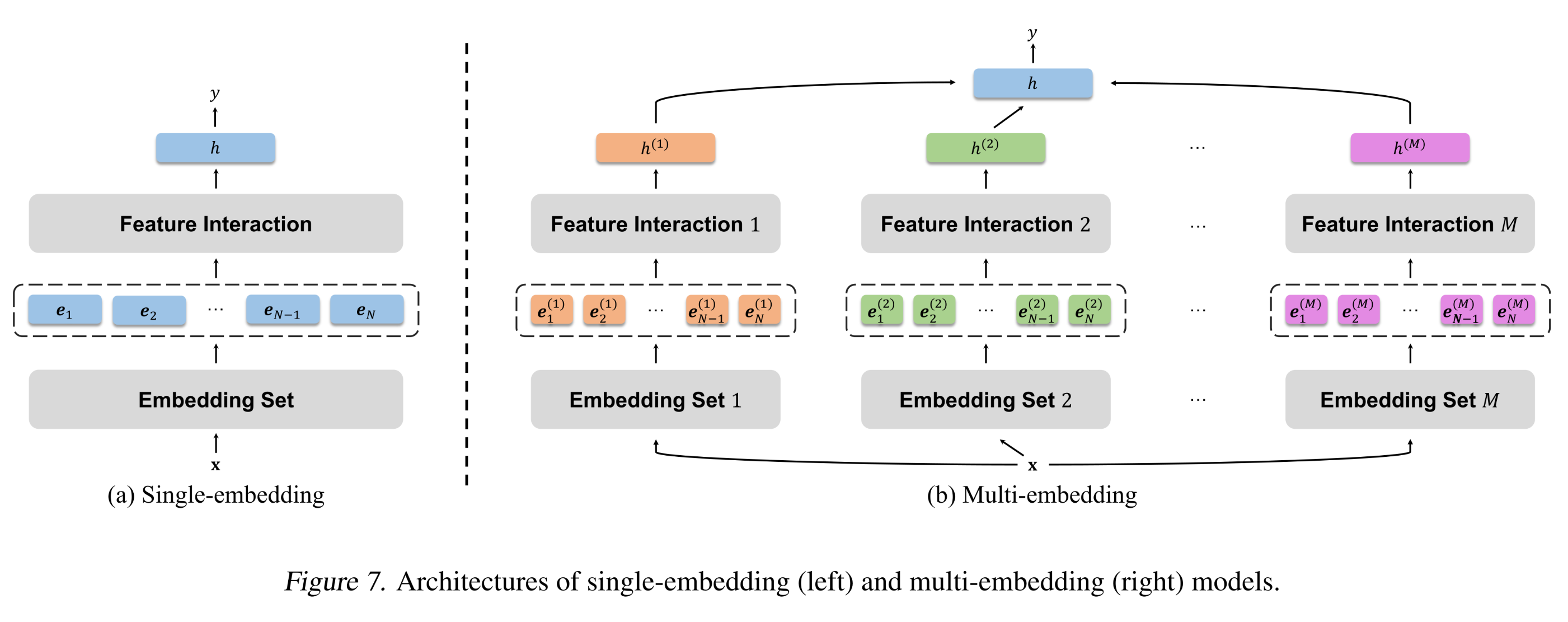
1.5.2 实验
数据集:我们在两个推荐系统基准数据集上进行了实验:
Criteo和Avazu。这两个数据集规模庞大、具有挑战性,被广泛用于推荐系统研究。baseline 方法:包括DNN、IPNN、NFwFM、xDeepFM、DCNv2、FinalMLP、以及它们对应的multi-embedding变体(模型规模为2倍、3倍、4倍和10倍)。其中,NFwFM是NFM的一个变体,它用FwFM替换了FM。所有实验均采用
8/1/1的training/validation/test splits,并基于validation AUC进行early stopping。更多细节见附录C.2。实验结果:我们每个实验重复
3次,并报告不同scaling factors下的平均test AUC。结果如Table 1所示。对于
single-embedding模型,我们观察到所有模型都表现出较差的scalability:只有
DCNv2和NFwFM随着embedding size的增加表现出轻微的性能提升(Criteo/Avazu上分别提升0.00036/0.00093)。而对于高度依赖
non-explicit interaction的DNN、xDeepFM和FinalMLP,当规模扩大到10倍时,性能甚至下降(Criteo上下降0.00136,Avazu上下降0.00118)。这与1.4.2章节中的讨论一致。
相比之下,我们的
multi-embedding随着embedding size的增长表现出持续且显著的性能提升,并且在最大的10倍规模下始终取得最佳性能。对于
DCNv2和NFwFM,multi-embedding在Criteo上通过扩大到10倍实现了0.00099的性能提升、在Avazu上实现了0.00223的性能提升。这是single-embedding无法实现的。在所有模型和数据集上,与
baselines相比,最大规模的multi-embedding模型平均在test AUC上实现了0.00110的提升。
multi-embedding为突破现有模型的non-scalability限制提供了一种有效方法。Figure 8a可视化了multi-embedding在Criteo数据集上的scalability。标准差和详细的scalability对比见附录C.3。根据实验结果来看,直接扩大
embedding参数似乎带来的提升都很微弱,即使是采用MultiEmbed。但是,采用MultiEmbed的效果要比SingleEmbed更好,这有利于embed size的超参数调优。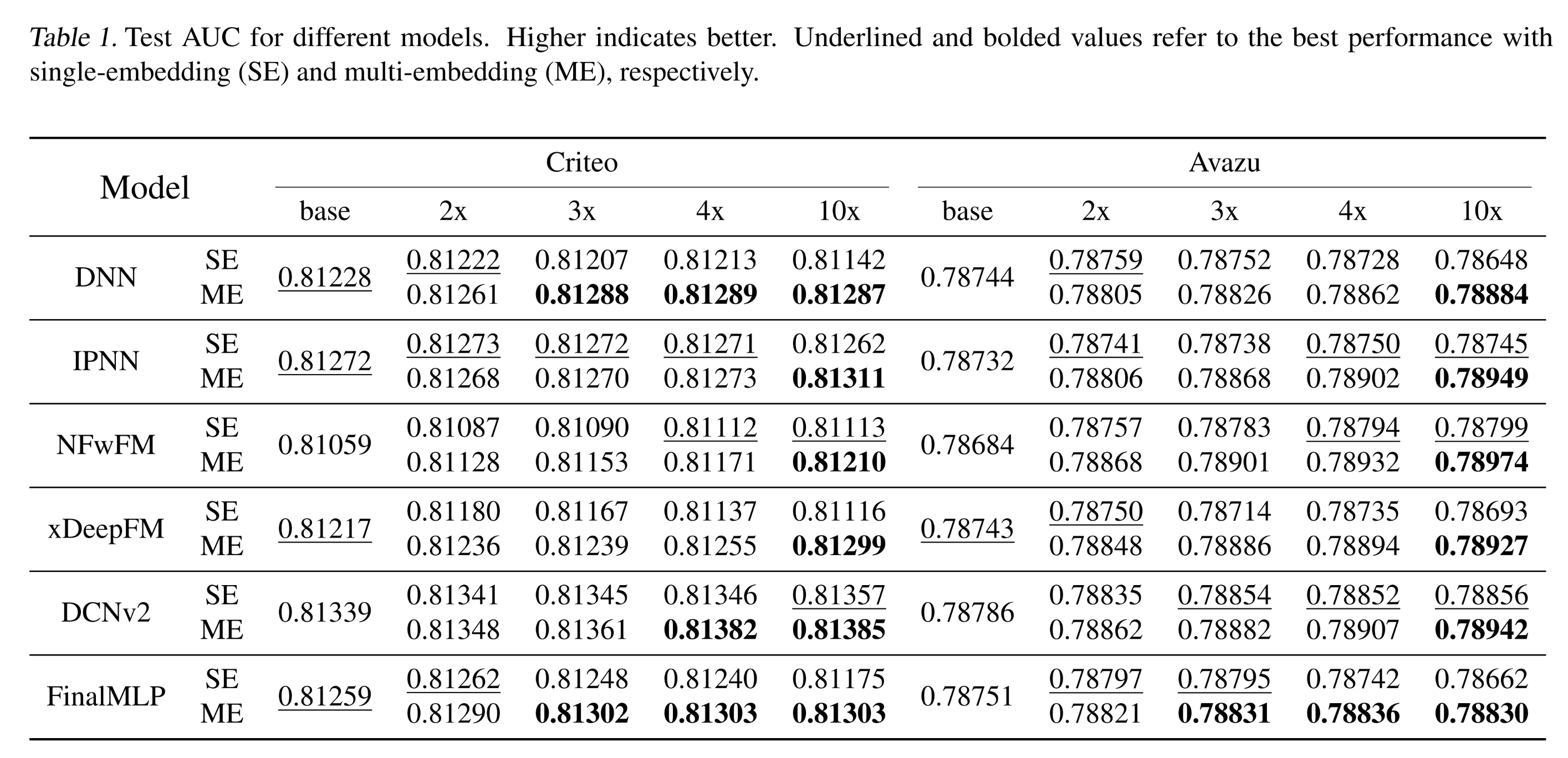
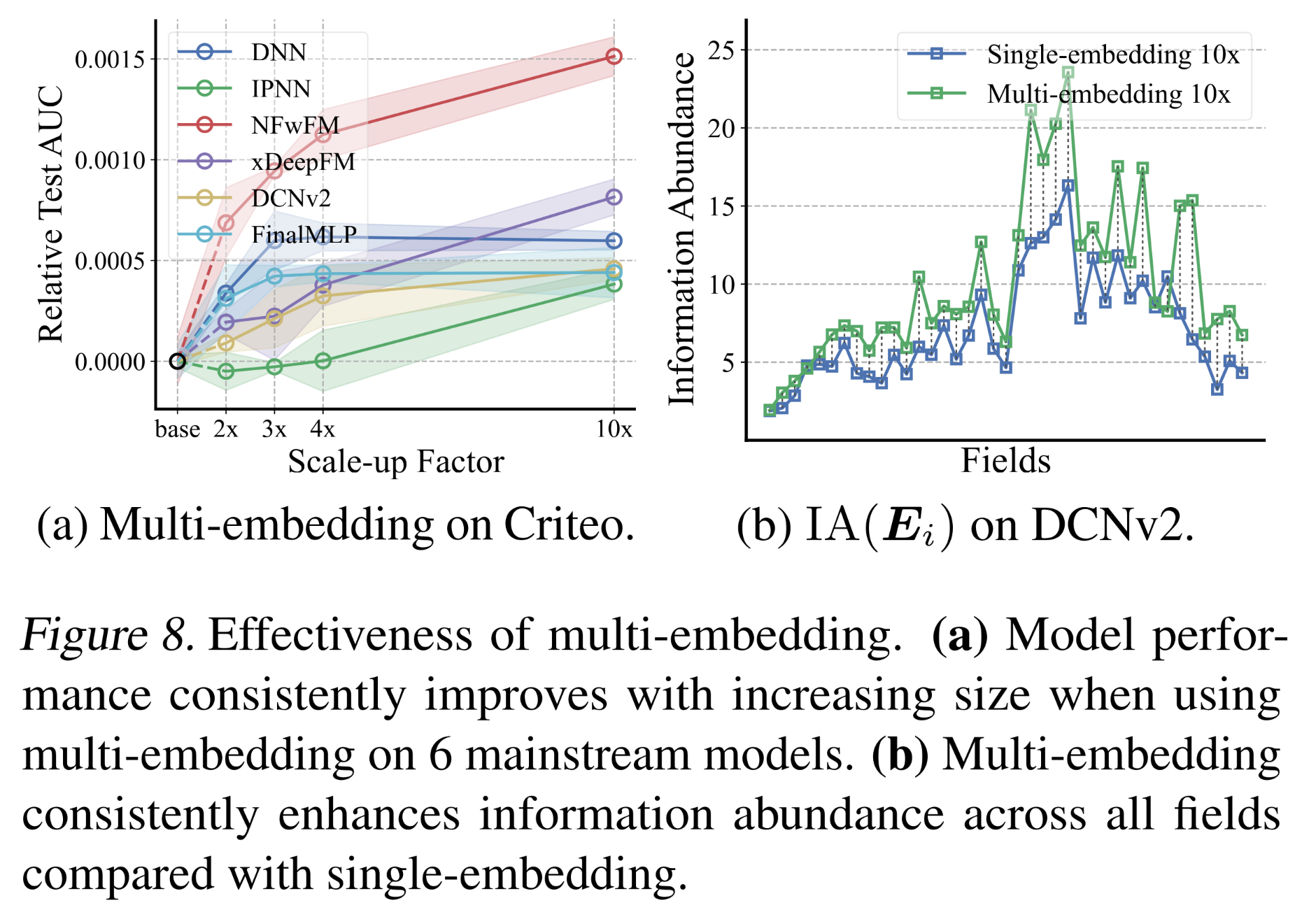
embedding collapse的缓解:为了衡量mitigation of collapse,我们对比了single-embedding DCNv2和multi-embedding DCNv2(最大10x embedding size)的信息丰度。为了计算multi-embedding DCNv2的信息丰度,我们将multi-embedding DCNv2中a single field的所有embeddings拼接在一起,作为这个field的overall embedding。结果如Figure 8b所示。可以观察到,与single-embedding DCNv2相比,multi-embedding DCNv2一致地提高了所有fields的信息丰度,尤其是对于fields with larger cardinality。这些结果表明,
multi-embedding是一种简单而有效的方法,能够在不引入大量计算资源或超参数的情况下,缓解embedding collapse并获得scalability gain。Deployment in the online system:经过2023年1月的online A/B testing,multi-embedding范式已成功部署于腾讯在线广告平台(全球最大的广告推荐系统之一)。将微信朋友圈(WeChat Moments)的click prediction model从single-embedding升级为我们提出的multi-embedding范式后,商品交易总额(Gross Merchandise Value: GMV)提升了3.9%——这意味着每年带来数亿美元的收入增长。
1.5.3 Multi-Embedding 工作原理
受
interaction-collapse theory的影响较小:根据我们之前的interaction-collapse theory和相应分析,embedding collapse是由不同fields之间的feature interaction引起的,具体表现为对sub-embeddings信息丰度的共同影响。我们证明了multi-embedding受这种影响较小。回顾1.4节,我们通过计算the field to interact with的影响。在这里,我们相应地可视化了multi-embedding DCNv2和single-embedding DCNv2的结果,如Figure 9所示。可以观察到,multi-embedding中的相关系数显著小于single-embedding(0.52对比0.68)。因此,信息丰度受the field to interact with的影响较小,从而减轻了interaction-collapse theory的影响。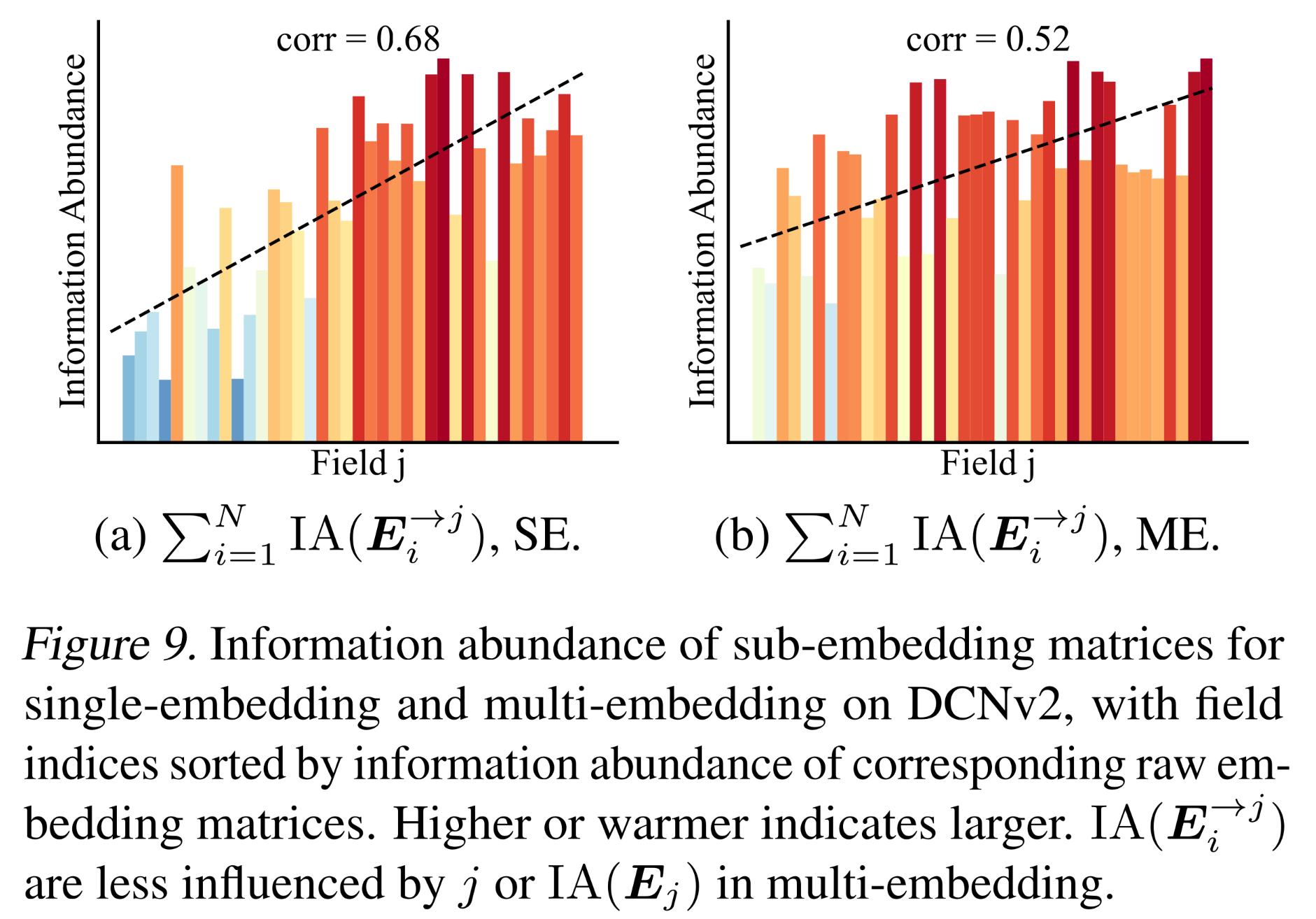
通过
embedding diversity缓解embedding collapse:我们进一步证明,multi-embedding通过允许diversity of embedding sets来缓解embedding collapse。为说明这一点,我们引入主角度(principal angle)的余弦fielda pair of embedding setsspace similarity):通过以下进一步的奇异值分解计算:低秩的
overall embedding来描述
diversity of embedding sets。多样性越大,表明overall embedding的信息丰度越高,或embedding collapse的缓解效果越好。为进行对比,我们分别将
embedding of a single-embedding DCNv2和ideal random-initialized matrix分割为embedding sets,并与multi-embedding DCNv2进行比较。Figure 10a展示了所有embedding set pairs和所有fields的平均多样性。结果表明,与single-embedding相比,multi-embedding能够显著降低embedding set similarity,从而缓解embedding collapse。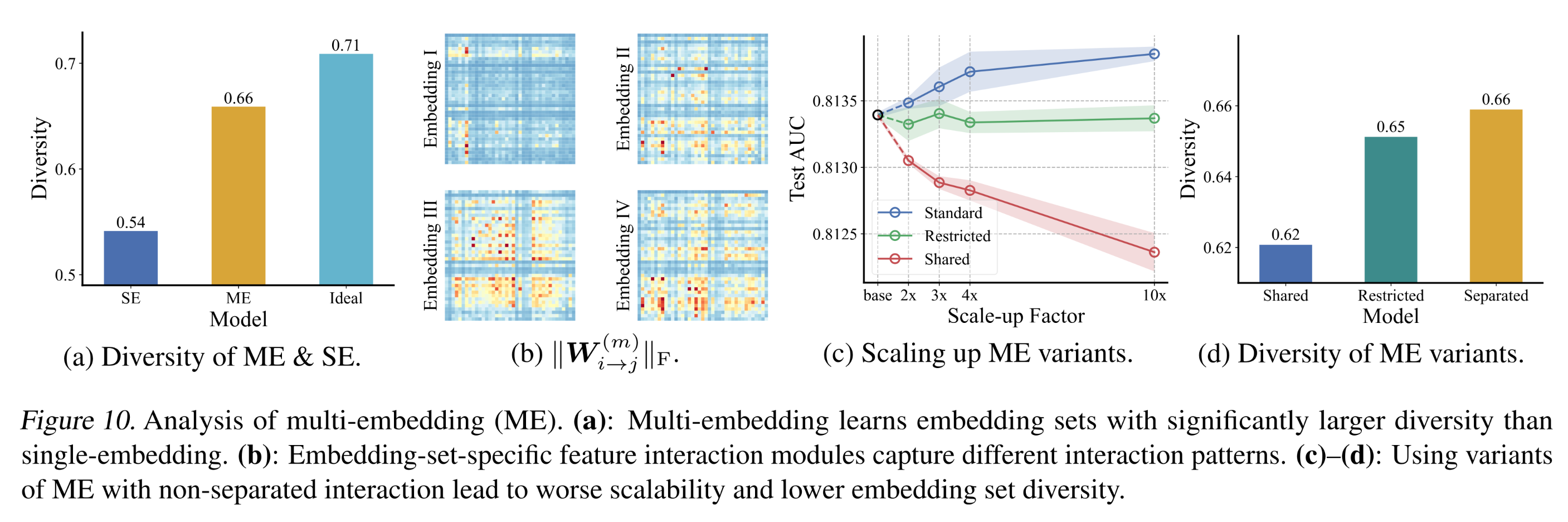
从
separated interaction中获得diversity:我们进一步证明,multi-embedding模型的embedding diversity源于embedding-set-specific feature interaction模块——这允许embedding sets捕获diverse interaction patterns。一方面,我们在
Figure 10b中可视化了multi-embedding DCNv2模型的interaction pattern(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems》)。结果表明,interaction模块学习到了多样化的模式。另一方面,我们将
multi-embedding与两种具有non-separated interaction的变体进行了比较:(a):所有feature interaction模块在所有embedding sets之间共享。(b):通过正则化来限制所有embedding sets之间
结果如
Figure 10c和Figure 10d所示。与multi-embedding中的separated design相比,这两种feature interaction design变体表现出更差的scalability和embedding diversity,表明multi-embedding的有效性源于separation of interaction modules。
1.5.4 Data 在 Embedding Collapse 中的作用
在本文中,我们主要关注
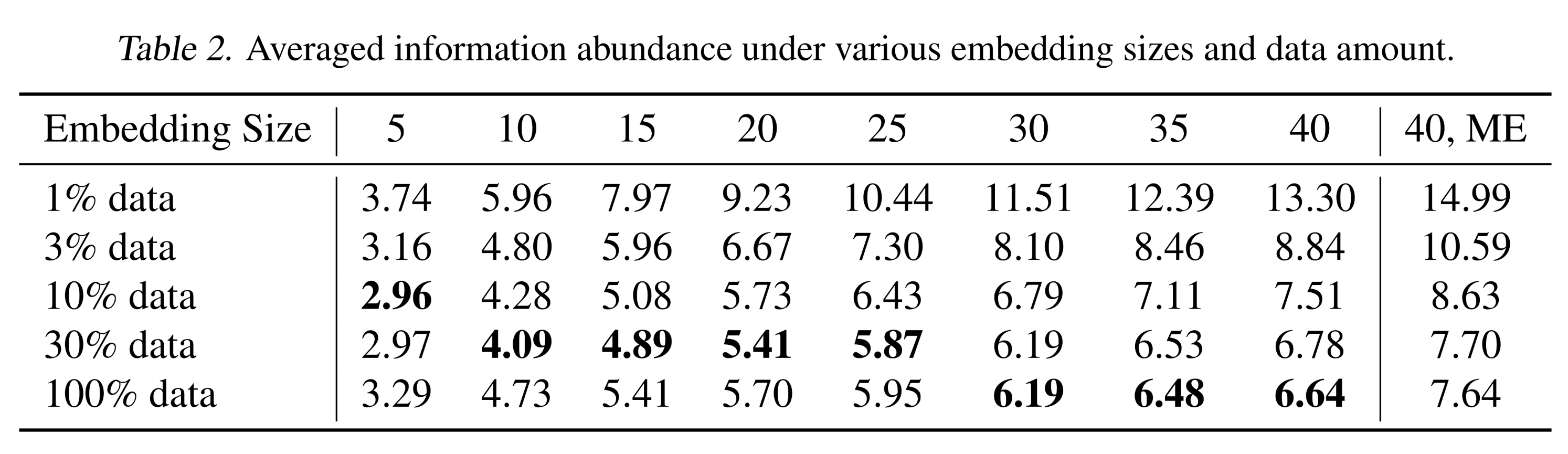
model scalability,并指出了推荐模型的固有问题——embedding collapse。我们实验中benchmark datasets的海量数据量,为embedding collapse现象提供了与数据量无关的可信度。在本节中,我们进一步讨论embedding collapse现象在不同数据量下的表现。为说明这一点,我们使用Criteo数据集的不同规模子集进行了额外实验。我们测量了不同model scales下embedding矩阵的平均信息丰度,结果总结于Table 2。从结果可以观察到,数据规模确实会影响
embedding矩阵的信息丰度,但信息丰度并不会随着数据规模的增加而严格增加,甚至可能下降(尤其是对于较大的模型)。这一发现背后的原因是,embedding collapse由两个方面决定:(1):数据规模,会增加信息丰度。(2):interaction-collapse law,会降低信息丰度。
在给定
embed size的情况下,数据量越多,信息丰度越低。这代表了embedding matrix拟合数据的结果。这通常是由于feature interaction的影响,因为更多的数据包含了更多的interaction。在所有结果中:
只有当数据规模为
10%∼100%且embedding size = 5、或数据规模为30%∼100%且embedding size in (10, 15, 20, 25)时,我们观察到embedding collapse是由limited data导致的。而在大多数其他情况下,异常的下降趋势表明
embedding collapse是由interaction-collapse law而非limited data导致的。此外,
multi-embedding在不同数据量下都一致地优于single-embedding,表明我们提出的multi-embedding design具有普适性。
1.6 结论
在本文中,我们指出了现有推荐模型的
non-scalability问题,并确定了阻碍scalability的embedding collapse现象。通过围绕embedding collapse的实证分析和理论分析,我们得出了feature interaction对scalability的two-sided effect:即feature interaction会导致embedding collapse,但同时减少过拟合。我们提出了一种统一的multi-embedding design,在不抑制feature interaction的前提下缓解embedding collapse。benchmark datasets上的实验表明,multi-embedding能够一致地提升模型scalability,并有效缓解embedding collapse。
二、附录
2.1 Embedding 的重要性 (Appendix A)
对于推荐模型,
embedding模块占据了参数量的最大部分(对于Criteo数据集,在我们的DCNv2 baseline中超过92%;在工业模型中的比例更高),因此是模型中重要且关键的bottleneck部分。为进一步说明,我们讨论了推荐模型其他模块的scaling up——即feature interaction模块postprocessing prediction模块DCNv2 baseline中的#cross layers和#MLP layers,并在Table 3中展示了结果。可以观察到,增加
#cross layers或#MLP layers并不会带来性能提升,因此扩大embedding size是合理且必要的。
2.2 讨论:语言模型中的 Embeddings (Appendix B)
为了将分析扩展到其他模型,我们考察了
pretrained T5模型,并评估了其(归一化的)奇异值以进行比较。结果如Figure 11所示。观察发现,T5与DCNv2相比:(1):保持了更高的归一化奇异值(normalized singular values)。(2):尽管其embedding size更大,但其极小奇异值的比例更低。
这些观察结果表明,
T5对embedding collapse现象的敏感性较低,这可能是因为text-based models受field interactions的interaction-collapse law的影响较小;而field interactions是导致embedding collapse的原因。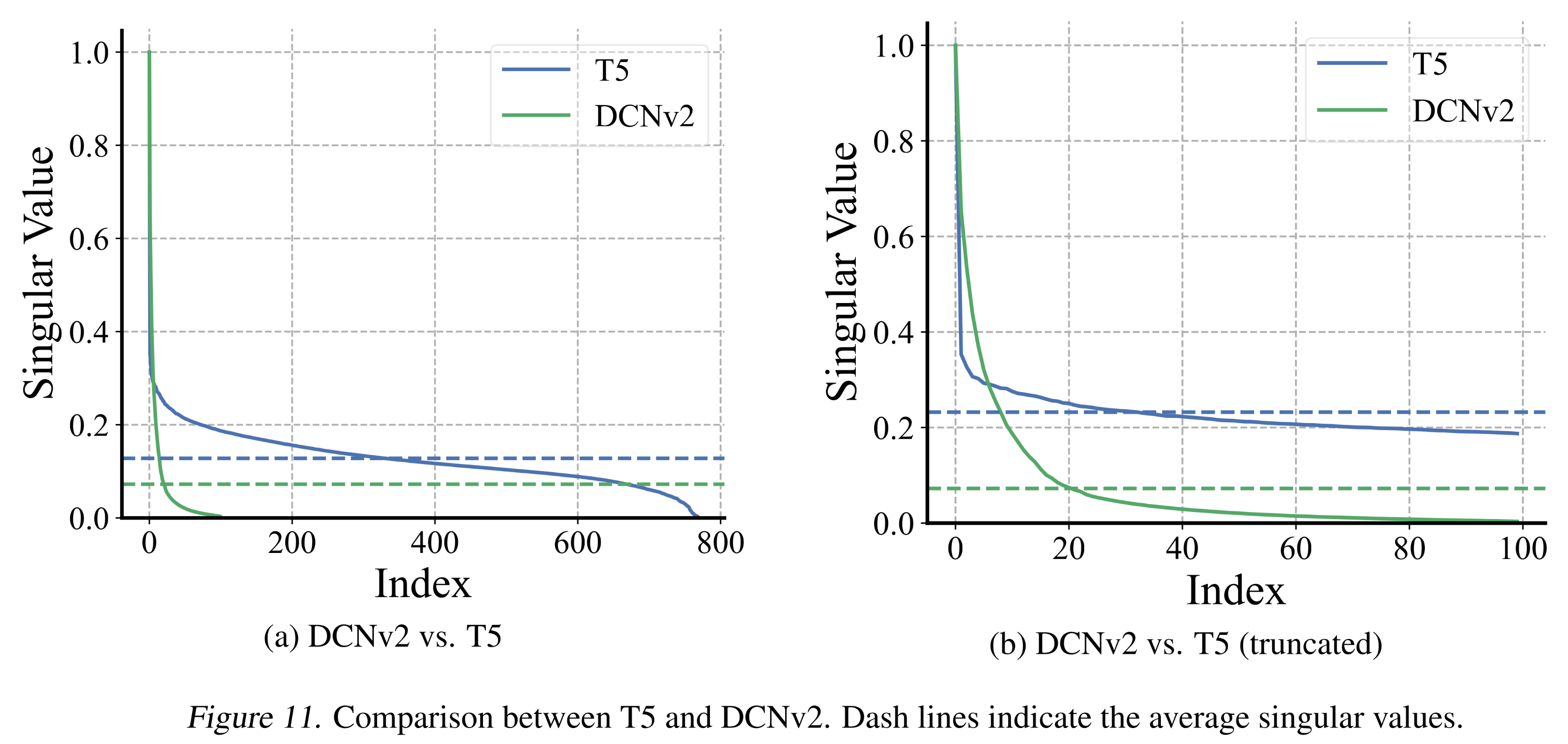
2.3 实验细节 (Appendix C)
数据集(
Appendix C.1):Criteo和Avazu的统计信息如Table 4所示。可以看出,数据量充足,且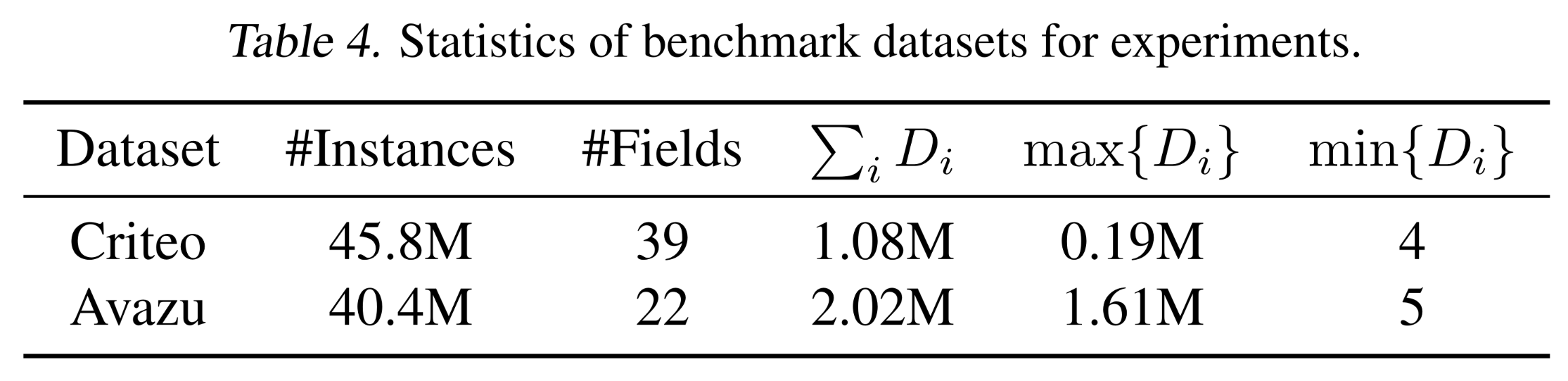
实验配置(
Appendix C.2):Specific multi-embedding design:对于
DCNv2、DNN、IPNN和NFwFM,我们分别在the stacked cross layers、the concatenation layer、the inner product layer和the field-weighted dot product layer之后添加一个非线性投影。对于
xDeepFM,我们直接对compressed interaction network的输出进行平均,并以与pure DNN model相同的方式处理the ensembled DNN。对于
FinalMLP,我们分别对two-stream outputs进行平均。
超参数:
所有实验均使用
random seed 0将数据集按8:1:1分割为training/validation/test。我们使用
Adam optimizer,batch size = 2048,学习率为0.001,weight decay = 1e-6。对于
base size,考虑到池化操作因此NFwFM的embedding size = 50,其他所有实验的embedding size设置为10。我们发现
MLP的hidden size和depth对结果影响不大;为简化起见,所有模型的hidden size均设置为400,depth设置为3(2 hidden layers和1 output layer)。DCNv2使用4 cross layers,xDeepFM的hidden size设为16。所有实验均基于
validation AUC进行early stopping(patience = 3)。每个实验使用不同的
random initialization重复3次。所有实验均可在单个
NVIDIA GeForce RTX 3090上完成。
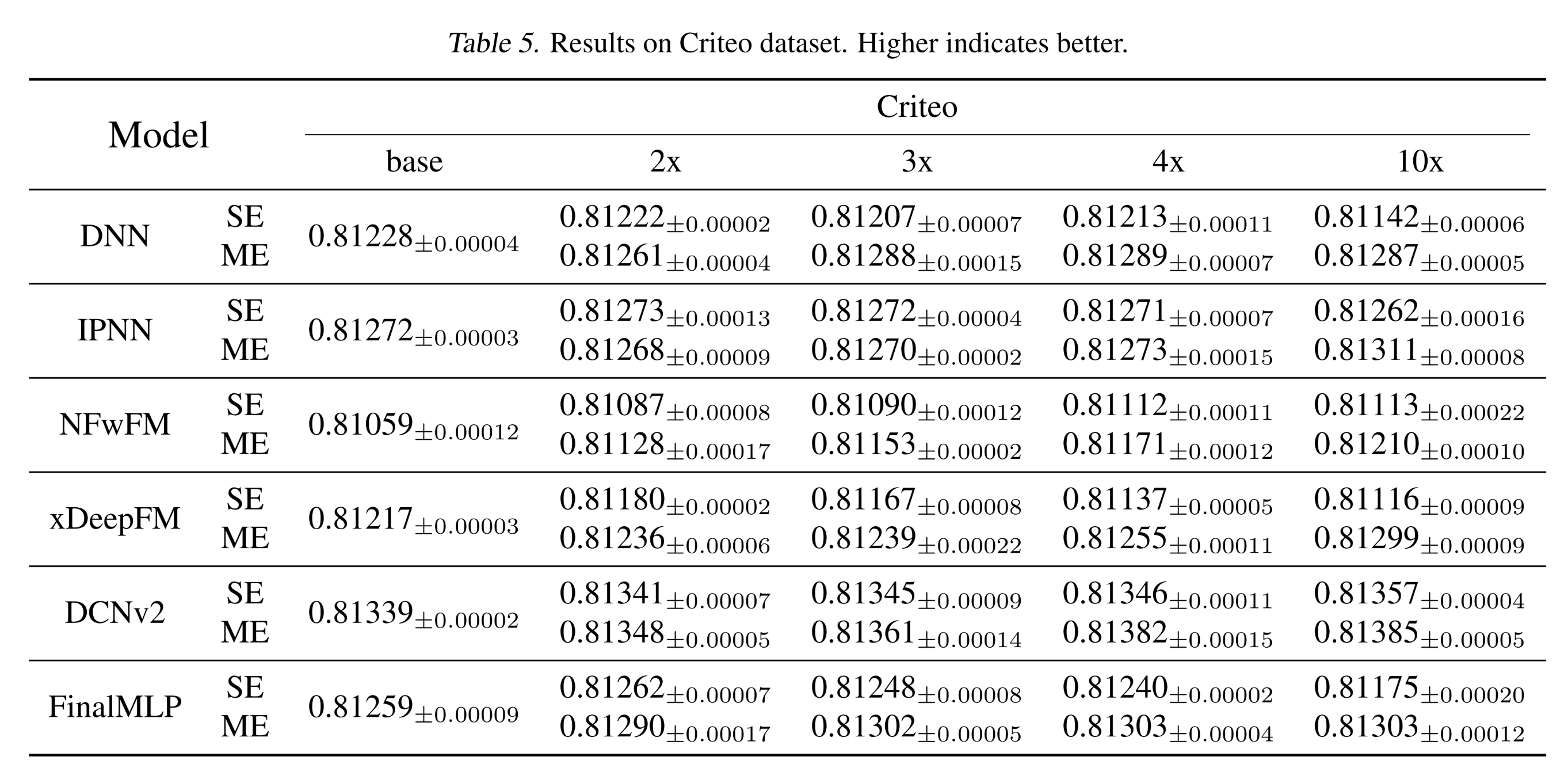
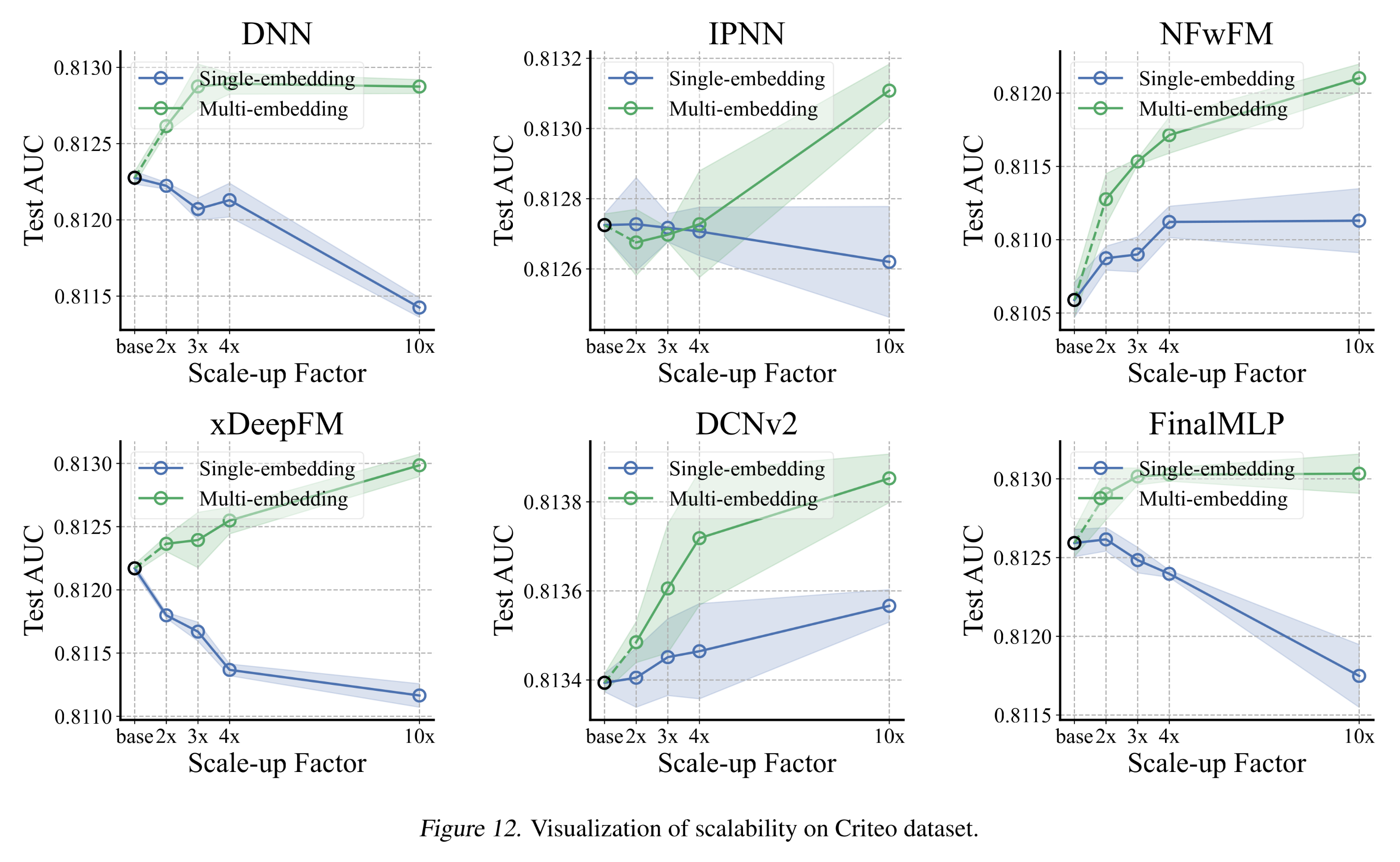
实验结果(
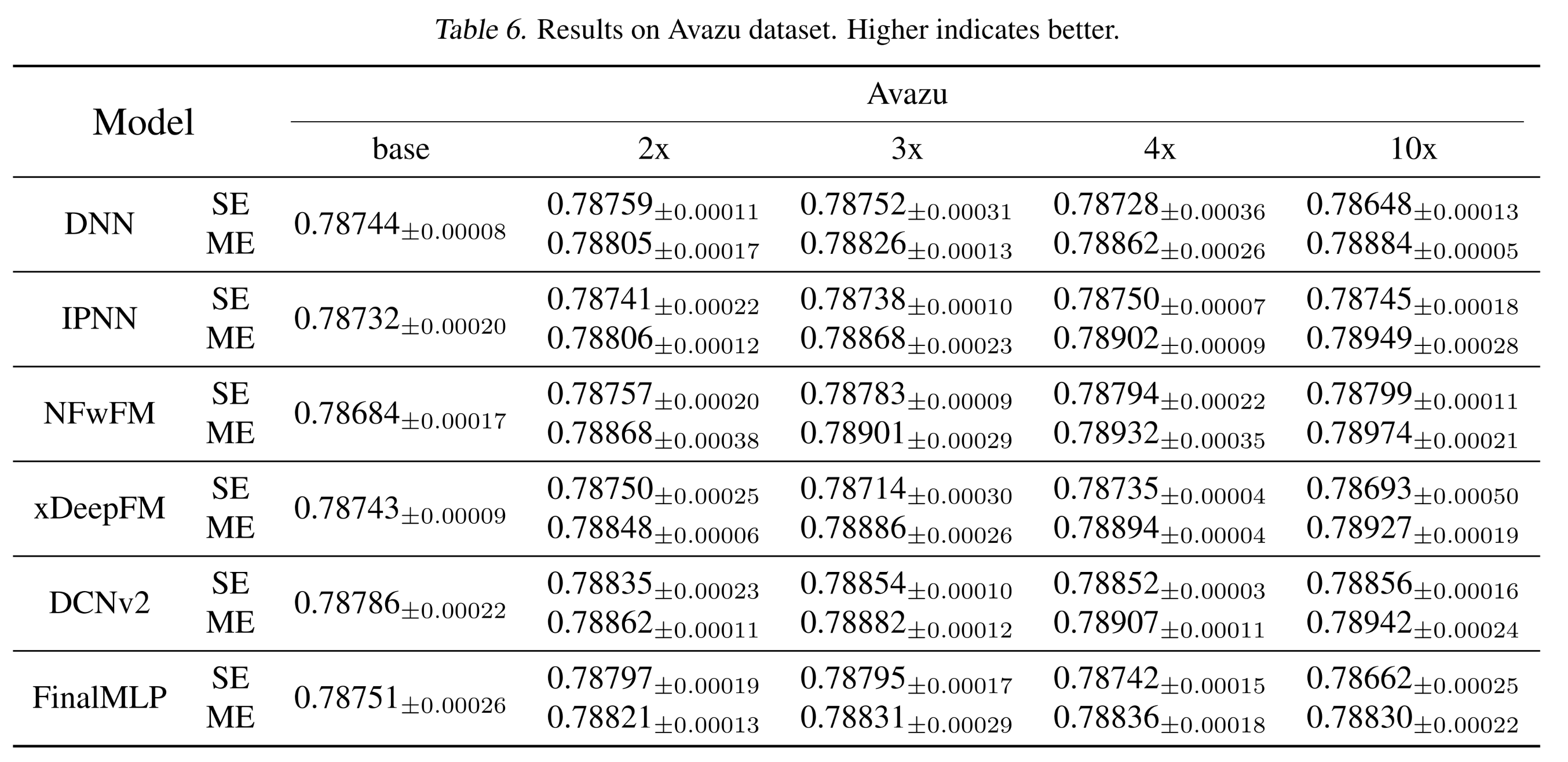
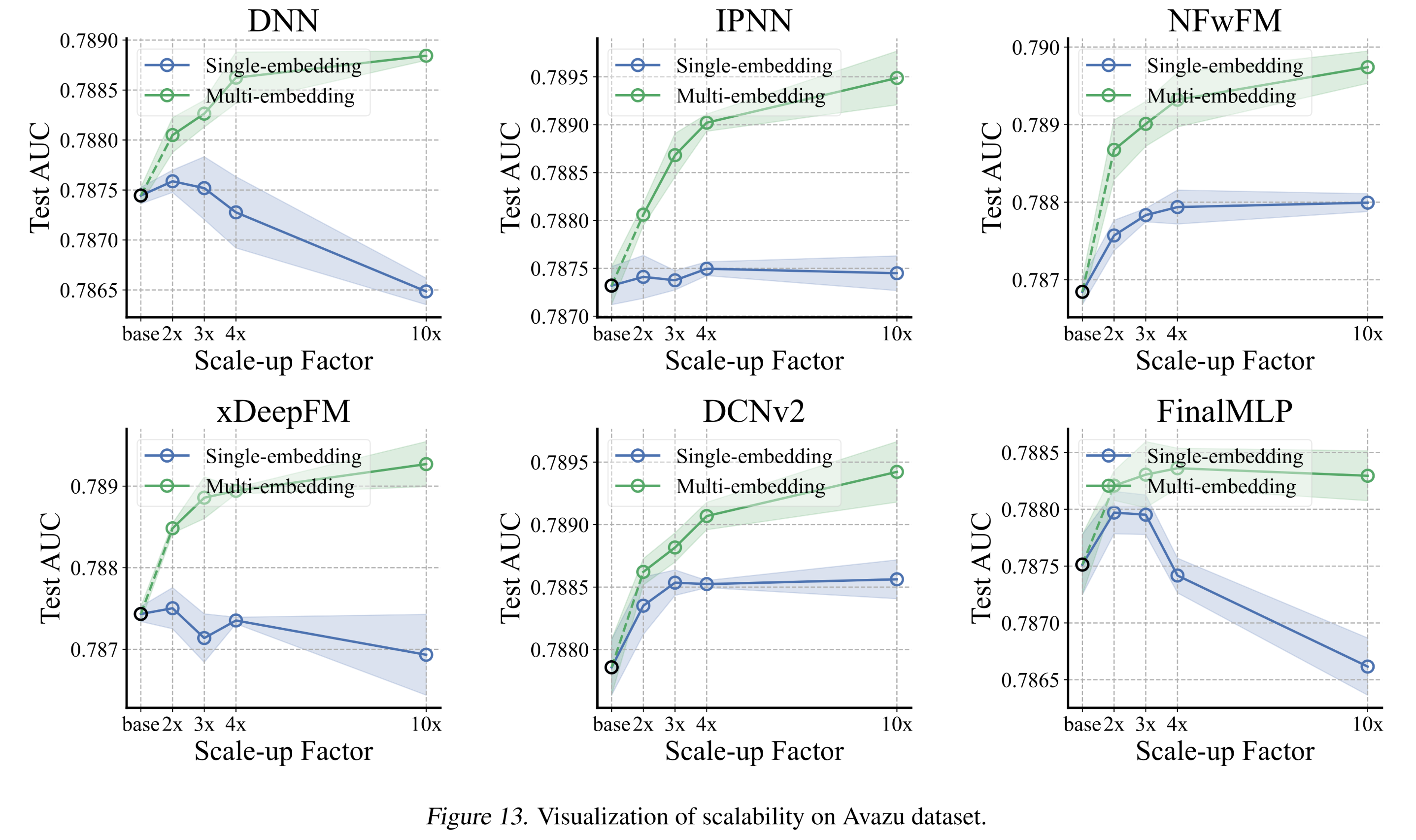
Appendix C.3):此处提供详细的实验结果及estimated的标准差。具体来说:Tbale 5和Figure 12展示了Criteo数据集上的结果。Table 6和Figure 13展示了Avazu数据集上的结果。
2.4 更多 Baseline 方法 (Appendix D)
我们还在
AutoInt上进行了实验,对比了single-embedding和multi-embedding的性能。由于计算资源有限,我们仅在Criteo数据集上将模型扩大到4倍。结果如Table 7所示。可以观察到,single-embedding存在non-scalability的问题,而我们的multi-embedding随着模型规模的增长持续提升性能:通过简单地scaling up从而实现了6e-4的AUC提升。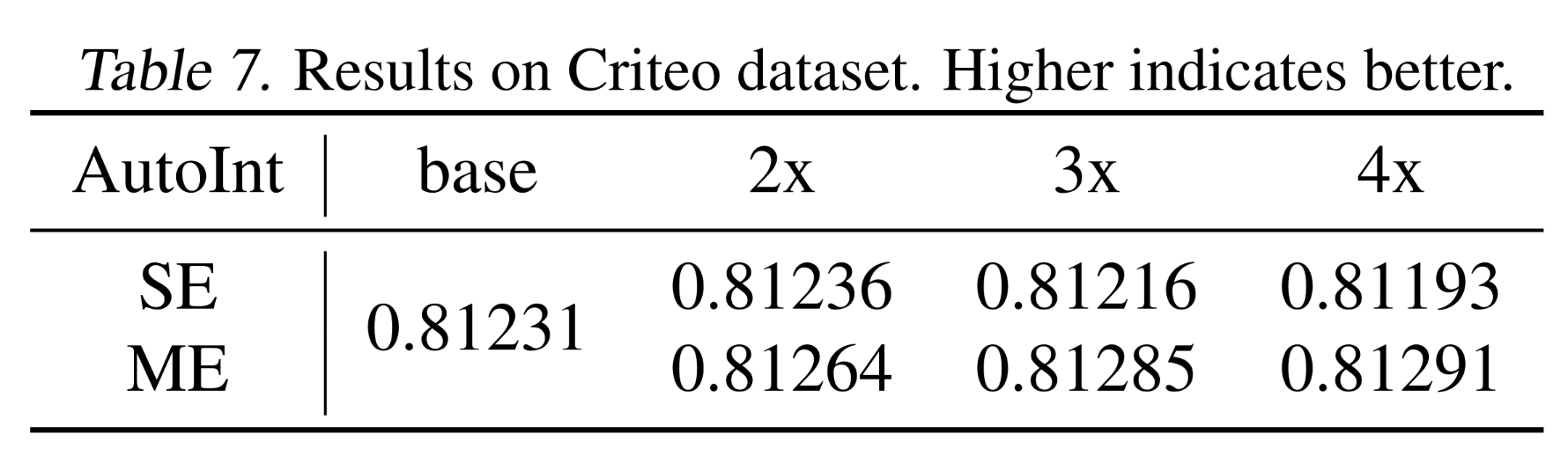
2.5 Multi-Embedding 的 Non-Linearity 要求 (Appendix E)
我们之前提到,
multi-embedding的embedding-set-specific feature interaction应包含非线性(non-linearity);否则,模型将退化为single-embedding模型。为简化起见,我们考虑一种更强版本的
multi-embedding:来自不同embedding sets的combined features被拼接起来,而不是均值池化。为进一步说明,考虑linear feature interaction模块linear feature interaction模块这表明:
a multi-embedding model等价于a model by concatenating all embedding sets。我们将进一步证明,所推导出的具有embedding size = MK的single-embedding模型是同构的:即,对于linear feature interaction模块,multi-embedding与single-embedding相似。令single-embedding的feature interaction模块为homogeneity)。DNN:忽略后续的MLP,DNN通过将所有fields拼接起来从而包含一个non-parametric interaction module。形式化地,我们有:换句话说,
multi-embedding和single-embedding是等价的。Projected DNN:如果我们在DNN之后添加一个线性投影(linear projection),则可以将投影针对fields和embedding sets进行拆分,并推导得到:换句话说,
combined features进行平均(而非拼接)以恢复我们所提出的multi-embedding版本,则multi-embedding乘以标量single-embedding之间是等价的。DCNv2:DCNv2通过以下方式融合feature interaction:因此,通过拆分
通过简单地令
permutation)从而将multi-embedding模型转换为single-embedding模型。因此,对于DCNv2,multi-embedding是single-embedding的一个特例。
总结:总之,
linear feature interaction module会导致single-embedding和multi-embedding的同构性。因此,在feature interaction模块中使用或引入非线性是必要的。
2.6 Embedding Diversity 的详细解释 (Appendix F)
在
1.5.3节中,我们提出使用主角度(principal angle)来衡量embedding set diversity。此处我们介绍其动机和一个示例。注意:其中倒数第二行由
因此,我们将其推广为
1 − similarity作为多样性。考虑以下的
example of diversity:一个embedding size = 2的embedding被学习为:其中:
如果将其扩大到
embedding size = 4,由于interaction-collapse theory,它可能被学习为:其中:
embedding size并没有增加信息丰度。当使用
multi-embedding时,embedding sets可能被学习为具有高度多样性,overall embedding被学习为:其中:
multi-embedding是有效的。
2.7 Toy Expermient 的细节 (Appendix G)
在本节中,我们介绍
toy experiment的详细设置。我们考虑fields的场景,embedding矩阵,固定full-batch SGD,学习率为1。模型总共训练5000 iterations。
2.8 Evidence I 中 FFM 的实证分析 (Appendix H)
Field-aware factorization machines: FFM将fieldembedding矩阵拆分为多个sub-embeddings:其中:
sub-embeddingfieldfield我们进行了与
Evidence I相同的实验,类似地发现Figure 14所示。这一结果令人惊讶:即使使用独立的embeddings来表示相同的field features,这些embeddings在学习后也会具有不同的信息丰度。这些
embeddings在学习之后:即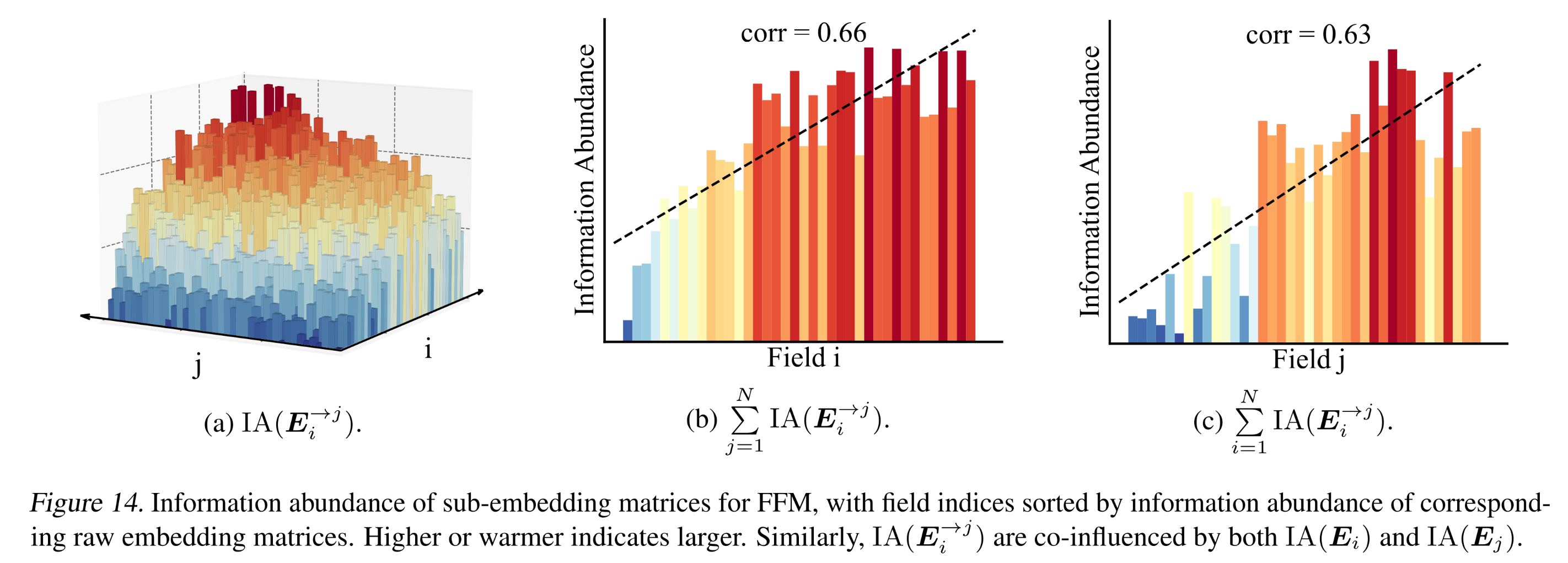
2.9 Information Abundance 的扩展 (Appendix I)
当两个
embedding矩阵具有相同的embedding size时,我们提出的信息丰度是一个公平的度量指标。为了将该定义应用于不同embedding size之间的比较,一些可能的扩展包括embedding size,我们在
Figure 15中对比了第一种扩展(即,embedding size下的表现。结果表明,collapse程度随着embedding size的增加而加剧:这与Figure 1b中的观察结果一致。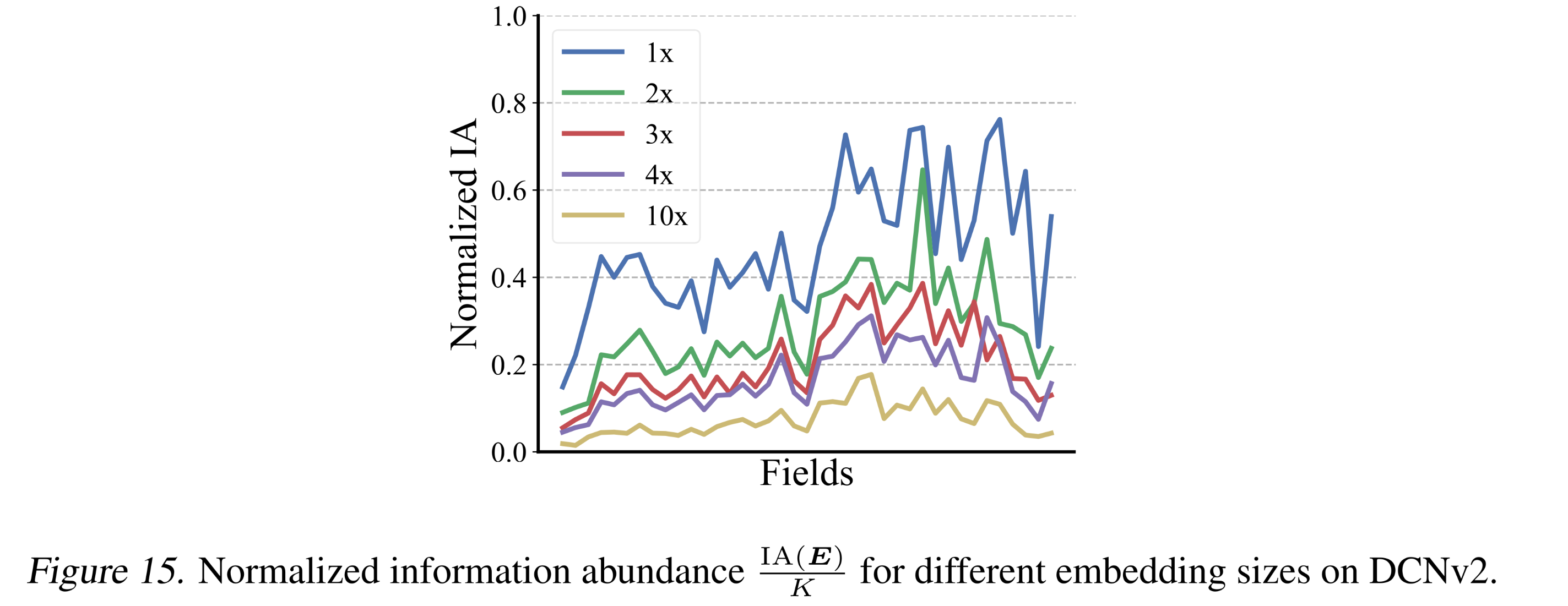
2.10 Regularized DCNv2 的详细解释 (Appendix J)
关于
Evidence II,我们提出了对权重矩阵sub-embeddings中投影collapse。通过将sub-embedding的所有奇异值都得到保留。因此,regularized DCNv2中sub-embeddings的信息丰度大于standard DCNv2。我们在Figure 16中绘制了embeddings和sub-embeddings的信息丰度的热力图。这清楚地表明,regularized DCNv2具有更高的信息丰度。基于我们的Finding 1,regularized DCNv2通过增加了sub-embeddings(这个sub-embedding是当前sub-embedding直接interact with的)的信息丰度,缓解了embedding collapse问题。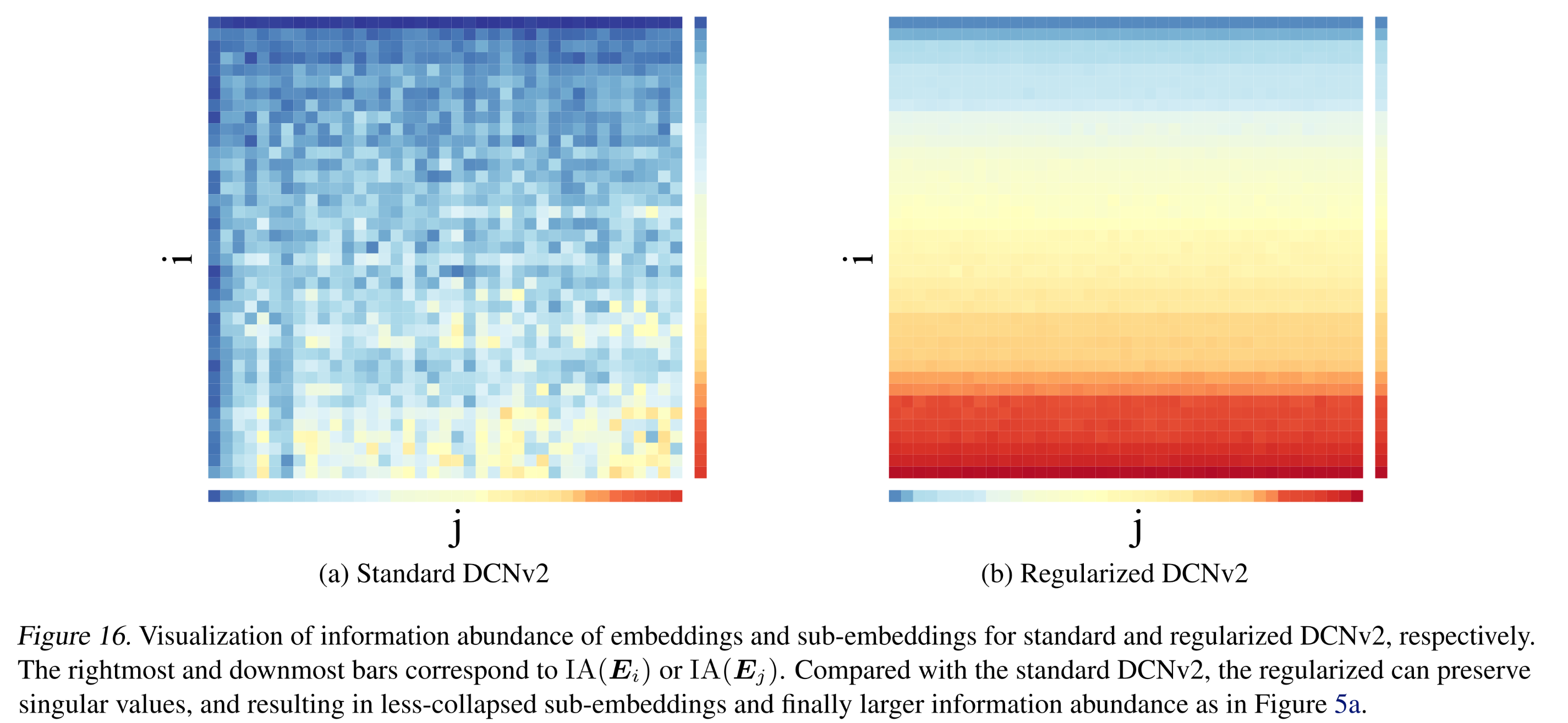
2.11 当 Feature Interaction 被抑制时,Multi-Embeddings 的表现如何?(Appendix K)
在本节中,我们分析了
feature interaction被抑制的模型中的Multi-Embeddings——如1.4.2节所讨论的,Single-Embeddings在这些模型中会遭受过拟合。Evidence III for Multi-Embeddings:我们为Multi-Embedding DCNv2添加了正则化:并在不同
embedding size下进行了实验。结果如Figure 17a所示。尽管其性能低于without regularization的情况,但与Single-Embeddings相比,Multi-Embeddings仍然随着模型规模的增长持续提升性能。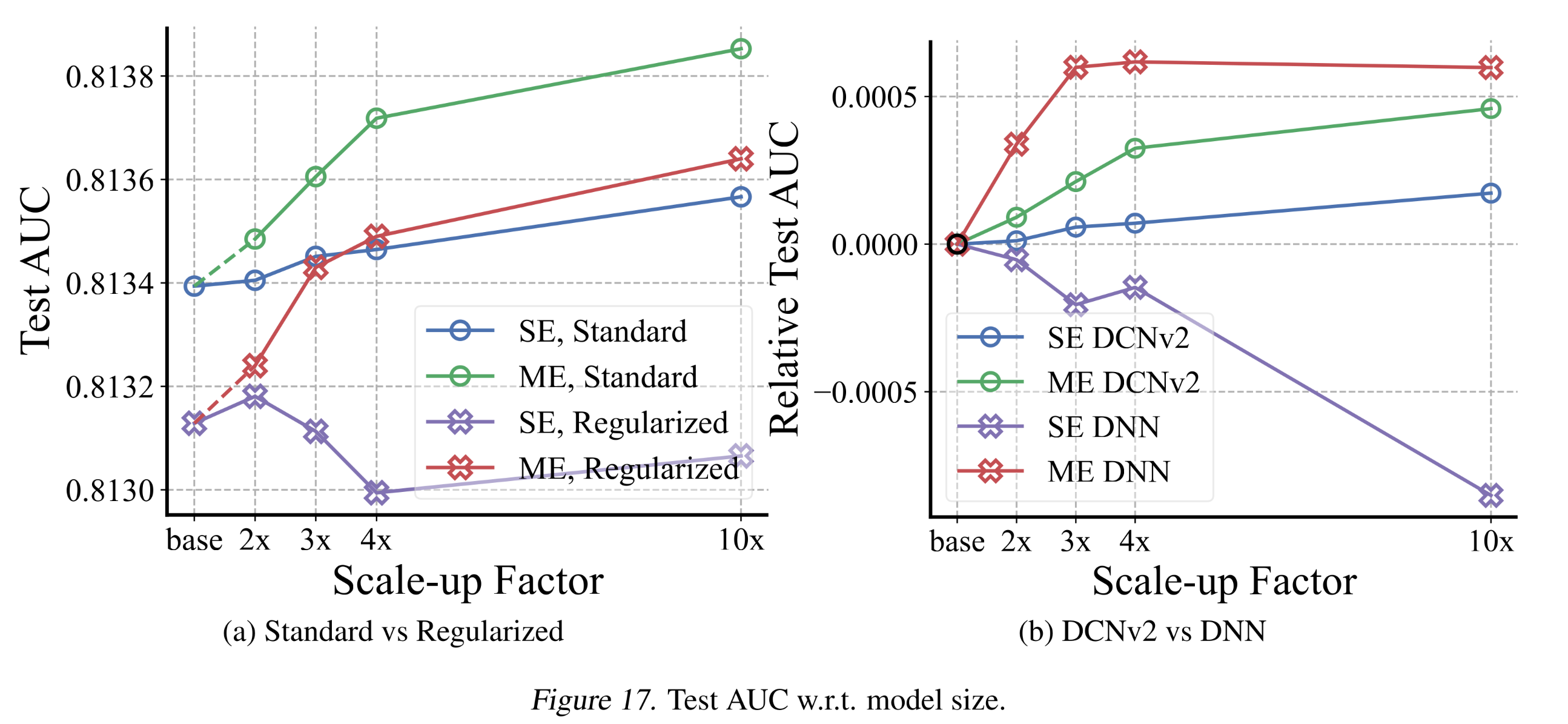
Evidence IV for Multi-Embeddings:我们对比了Single-Embeddings/Multi-Embeddings在DNN/DCNv2上的性能,结果如Figure 17b所示。与Single-Embeddings DNN相比,Multi-Embeddings DNN随着模型规模的增长提升了性能。总结:即使
feature interaction被抑制,Multi-Embeddings仍能提供scalability。对于feature interaction被抑制的模型(如regularized DCNv2和DNN),Single-Embeddings的性能可能会随着模型规模的扩大而下降——因为feature interaction提供了domain knowledge,而大型模型可能会遭受过拟合。实验表明,这些模型与Multi-Embeddings结合后能够实现适当的scale up。这一结果是合理的,因为Multi-Embeddings通过捕获diverse patterns来提升scalability,而不是依赖单个interaction pattern进行学习。