一、TWIN [2023]
《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》
终身用户行为建模(
life-long user behavior modeling),即从数月甚至数年的丰富历史行为中提取用户的隐藏兴趣(hidden interests),在现代CTR prediction系统中起着核心作用。传统算法大多遵循两个级联的阶段:简单的通用搜索单元 (
General Search Unit: GSU),用于对数万个长期behaviors进行快速且粗略的搜索。精确搜索单元 (
Exact Search Unit: ESU),用于对来自GSU的少数最终入围者进行有效的Target Attention: TA。
现有算法虽然高效,但大多存在一个关键限制:
GSU和ESU之间的target-behavior的相关性指标(relevance metrics)不一致。因此,这些算法的GSU通常会错过高度相关的behaviors,但会检索出被ESU认为不相关的behaviors。在这种情况下,无论如何分配注意力,ESU中的Target Attention大多会偏离真正的用户兴趣,从而降低整体的CTR prediction的准确率。为了解决这种不一致性,我们提出了两阶段兴趣网络(
TWo-stage Interest Network: TWIN),其中我们的Consistency-Preserved GSU: CP-GSU采用与ESU中的Target Attention相同的target-behavior relevance metric,使两个阶段成为孪生。具体来说,为了突破Target Attention的计算瓶颈并将其从ESU扩展到GSU,即将behavior长度从behavior feature splitting构建了一种新颖的注意力机制。对于behavior的视频固有特征,我们通过高效的pre-computing & caching策略来计算它们的线性投影。对于user-item交叉特征,我们在注意得分计算中将每个特征压缩为一维的bias项从而节省计算成本。两个阶段之间的一致性,加上CP-GSU中有效的Target Attention-based相关性指标,有助于显著提高CTR prediction的性能。在快手
46B规模的真实生产数据集上的离线实验和在线A/B test表明,TWIN的表现优于所有对比的SOTA算法。通过优化在线基础设施,我们降低了99.3%的计算瓶颈,这有助于TWIN在快手上的成功部署,服务于每天数亿活跃用户的主要流量。作为中国最受欢迎的短视频分享应用(
short video sharing apps)之一,快手高度依赖其强大的推荐系统 (recommendation system: RS)。每天,推荐系统帮助数亿活跃用户过滤掉数百万个不感兴趣的视频,找到他们感兴趣的视频,留下数百亿条点击日志。这些海量数据不仅为推荐系统的训练提供了数据,还推动了技术革命,不断提升该平台的用户体验和业务效率。 在现代推荐系统中,一项基本任务是CTR prediction,旨在预测用户点击某个item / video的概率。准确的CTR prediction指导推荐系统为每个用户提供他们最喜欢的内容,并将每个视频传递给其感兴趣的受众。为了实现这一点,CTR模型应该高度个性化,并充分利用稀缺的用户信息。因此,终身用户行为建模(life-long user behavior modeling),即从丰富的长期历史行为中提取用户的隐藏兴趣(hidden interests),通常是CTR模型的关键组成部分。 工业级的life-long behavior modeling算法大多遵循两个级联的阶段(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》):(1):一个通用搜索单元 (General Search Unit: GSU)对数万个长期behaviors进行快速且粗略的搜索,并输出少量的most target-relevant的行为;(2):一个精确搜索单元 (Exact Search Unit: ESU)对来自GSU的少数最终入围者进行有效的Target Attention: TA。
这种两阶段设计背后的原因有两个方面:
一方面,为了精确捕获用户兴趣,
Target Attention是强调target-relevant behaviors和抑制target-irrelevant behaviors的适当选择。另一方面,
Target Attention昂贵的计算成本将其适用的序列长度限制为最多几百。为此,一个简单快速的GSU作为pre-filter至关重要从而用于截断工业规模的用户行为序列,因为这些序列在短短几个月内很容易达到
近年来,出现了许多关于两阶段
life-long behavior modeling的新兴研究,而它们的关键区别在于GSU策略,其中GSU策略粗略地选择target-relevant behaviors。例如:SIM Hard简单地从与target item相同的category中选择behaviors;而SIM Soft通过内积从pre-trained item embeddings中计算target-behavior relevance score,并选择相关性最高的behaviors。ETA使用局部敏感哈希(locality-sensitive hashing: LSH)和汉明距离来近似relevance score的计算。SDIM通过多轮哈希碰撞(multi-round hash collision)等方法对具有与target-behavior相同哈希签名(hash signature)的behaviors进行采样。
尽管已被广泛研究,但现有的两阶段
life-long behavior modeling算法仍然存在一个关键限制:GSU和ESU之间的不一致(如Figure 1所示)。具体来说,GSU中使用的target-behavior relevance metric既粗略又与ESU中使用的Target Attention不一致。因此,GSU可能会错过relevant behaviors,而且可能会检索ESU认为不相关的behaviors从而浪费ESU宝贵的计算资源。在这种情况下,无论如何分配注意力,ESU中的Target Attention会很大地偏离真实的用户兴趣,从而降低整体CTR prediction的准确率。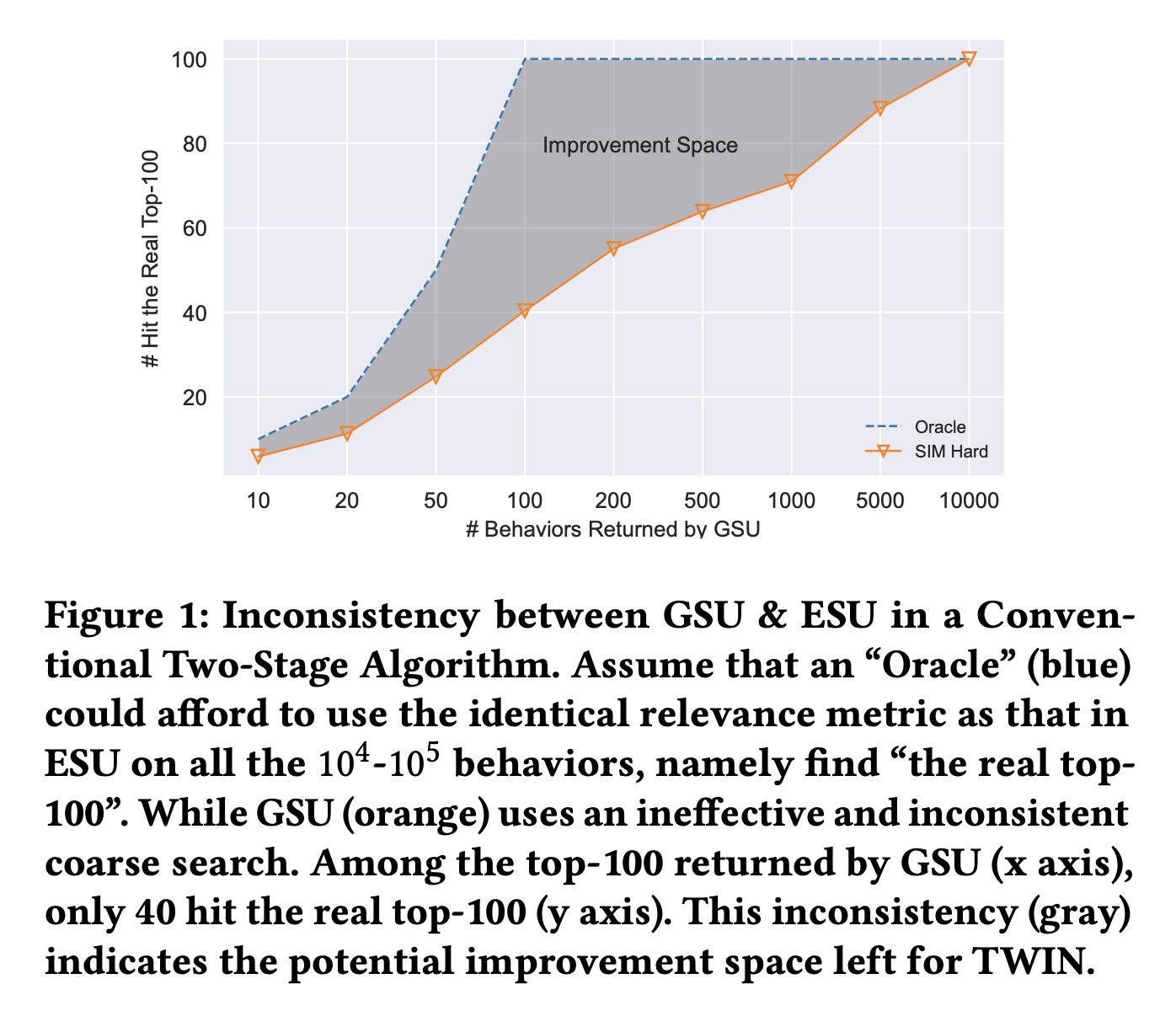
为了解决这种不一致(
inconsistency),我们提出了两阶段兴趣网络(TWo-stage Interest Network: TWIN)从而用于lifelong user behavior modeling,其中Consistency-Preserved GSU: CP-GSU采用与ESU中的Target Attention相同的target-behavior relevance metric,使两个阶段成为孪生(twins)。为了将昂贵的Target Attention扩展到CP-GSU,TWIN通过有效的behavior feature split、简化的Target Attention架构、以及高度优化的在线基础设施,突破了Target Attention的关键计算瓶颈,即所有behaviors的线性投影。1):具体来说,对于跨users / behavior sequences共享的video inherent features of a behavior(例如video id, author, duration, topic),我们通过高效的pre-computing & caching策略加速它们的投影。2):对于behavior的user-video交叉特征(例如用户的click timestamp, play time, rating),当caching不适用时,我们通过将它们的投影压缩为bias项来简化Target Attention架构。
通过优化后的在线基础设施,我们成功地将
Target Attention的适用序列长度从ESU中的CP-GSU中的CP-GSU中的Target Attention-based relevance metric,有助于显著提高CTR prediction的性能。总体而言,我们做出了以下贡献:
在我们提出的
TWIN中,CP-GSU精确且一致地检索不仅target-relevant而且被ESU认为重要的behaviors,从而最大限度地提高了behavior modeling的retrieval效果。据我们所知,我们是第一个成功解决两阶life-long behavior modeling问题中不一致性的人。我们通过对快手
46B规模的工业级数据集进行大量的离线实验,以及在线A/B test,从而验证TWIN的有效性。我们通过消融研究验证了我们的有效性,并表明TWIN带来了显著的online benefits。我们构建了高效的工业级的基础设施,将
TWIN应用于真实的在线推荐系统。我们提出了有效的pre-computing & caching策略,将TWIN的计算瓶颈(即CP-GSU中linear projection of behaviors)减少了99.3%,并满足了online serving system的低延迟要求。目前TWIN已经部署在快手的推荐系统上,服务于每日3.46亿活跃用户的主要流量。
在本文中,我们建议将
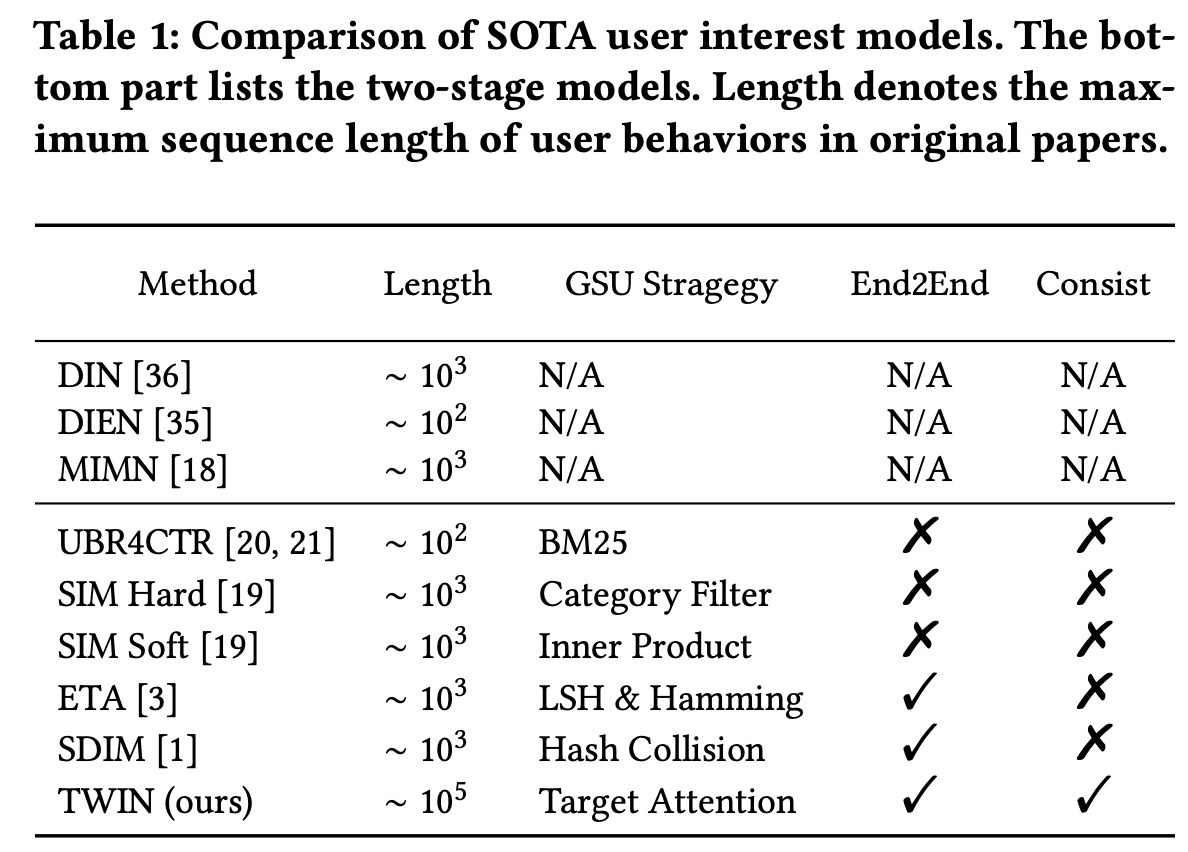
Target Attention结构扩展到GSU,并将embeddings and attention parameters从ESU同步到GSU,从而保持端到端训练。结果,我们同时实现了网络结构和模型参数的一致性,与ETA和SDIM相比,这有助于显著提高性能。我们在Table 1中详细说明了我们的模型与其他模型的不同之处。ESU和GSU的网络结构和网络参数完全相同,所以称之为 “孪生”。请注意,我们的工作不同于旨在加速
Transformer的indexing算法(例如LISA)。它们通过将behaviors映射到codebooks并查找距离来近似relevance score的计算。然而我们的工作以及许多其他两阶段算法都使用精确的距离计算,但使用GSU作为pre-filter从而减少了behaviors的数量。TWIN算法的核心是对attention score计算中最耗时的linear projection进行优化。但是这种优化仅适用于inference阶段,而不适用于training阶段。论文创新点一般,对算法层面优化较少,更多地是工程优化。
1.1 TWIN
首先,我们回顾了
CTR prediction问题的一般基础知识。然后,我们描述了快手CTR prediction系统的模型架构。接着,我们进一步深入探讨了我们提出的consistency-preserved lifelong user behavior modeling module,即TWo-stage Interest Network: TWIN。最后,我们介绍了确保TWIN在快手主流量上成功在线部署的基本accelerating的策略。Table 2总结了所使用的符号。
1.1.1 基础知识
CTR prediction的目的是预测用户在特定上下文中点击一个item的概率。准确的CTR prediction不仅可以通过提供preferred contents来提升用户体验,还可以通过触达interested audiences来提高内容生产者和平台的业务效率。因此,CTR prediction已成为各种工业级推荐系统(尤其是快手等短视频推荐平台)的核心部分。CTR prediction通常被表述为一个二分类问题,其目标是在给定训练数据集predictor函数feature vector(即user, item and contexts features的拼接);ground truth label,表示用户是否点击该item。predicted CTR计算如下:其中:
sigmoid函数,它将prediction(0, 1)之间。模型通过最小化
negative log-likelihood来训练:为简洁起见,我们在以下章节中省略了训练样本索引
1.1.2 CTR Prediction 的架构
现在我们来介绍快手的
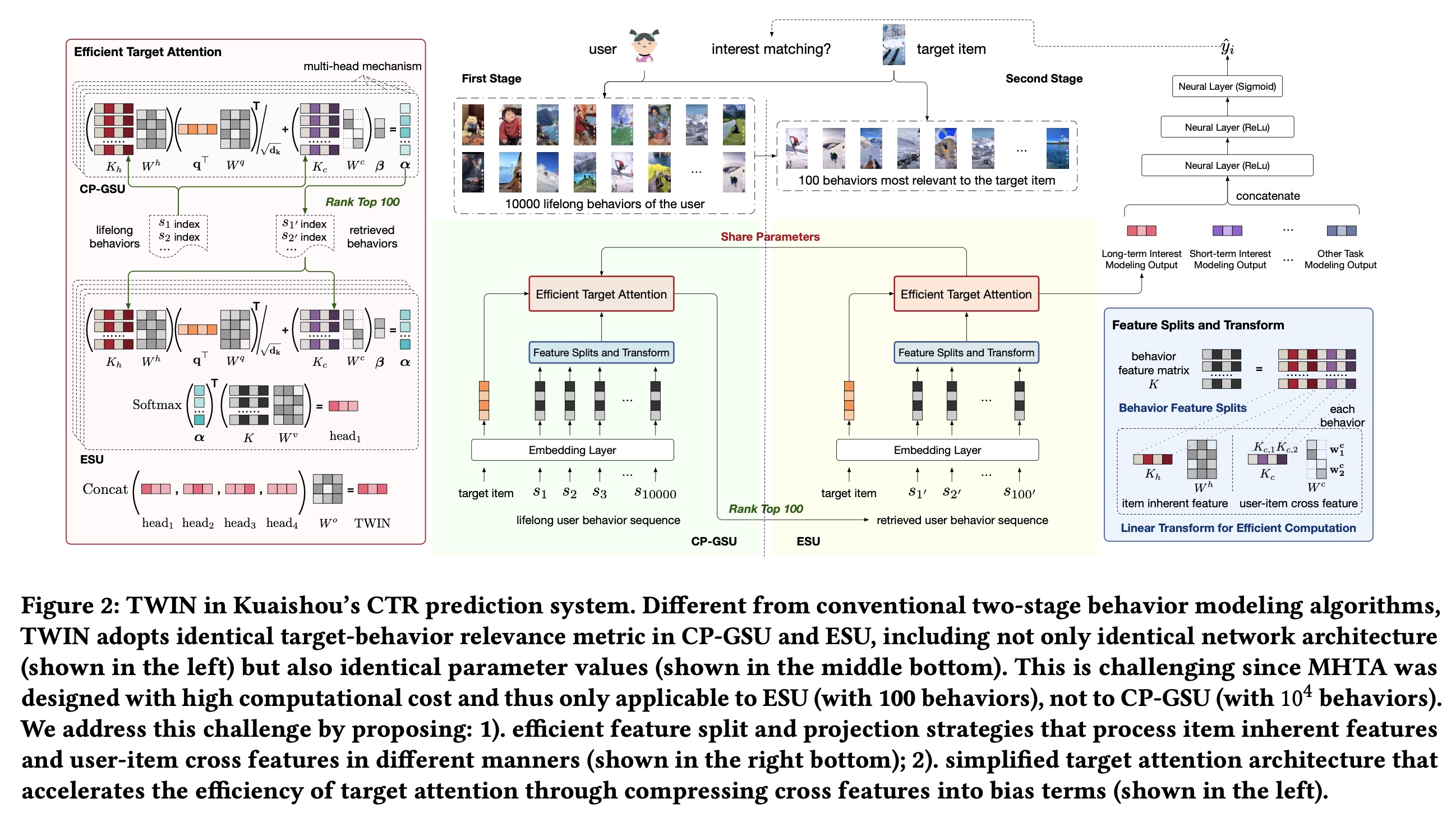
CTR prediction系统的架构。详细信息如Figure 2所示。下图中,
ESU和CP-GSU的网络结构和网络参数一模一样,那为什么弄两个一模一样的东西?是否可以移除掉ESU?根据论文的解释:在
ESU的MHTA: multi-head target attention中,对于CP-GSU,那么embedding,这个投影的代价非常高。那么:
是否可以仅仅使用
CP-GSU,然后仅仅选择top-k来做线性投影从而用于加权聚合?或者,在
ESU中使用不同的网络参数,即,使用原始的线性投影而不做拆分,从而计算attention score?
Embedding Layer: 在最底层,我们的模型从feature embedding layer开始,该层将训练样本的原始特征转换为embedding vectors。在不失一般性的情况下,我们假设所有特征在经过必要的预处理后都处于
categorical的形式。对于vocabulary size为categorical information编码为one-hot / multi-hot code请注意,在大多数工业级系统中,
vocabulary size(尤其是user / author / video ids的vocabulary size)可以轻松扩展到数亿。因此,一种常见的策略是将极高维的hot codes转换为低维embeddings:其中:
embedding dictionary,embedding维度。在我们的系统中,我们将vocabulary大的id特征的embedding维度设置为64,将其他特征(如video topic, video played timestamp)的embedding维度设置为8。 在所有upper layers中,我们将embedding vectors作为输入,因此为了简洁起见省略了下标“emb”。Deep Networks:我们的CTR prediction的总体架构如Figure 2所示。upper module由堆叠的神经网络和ReLU组成,充当mixer,用于学习三个intermediate modules的输出之间的交互:TWIN:所提出的consistency-preserved life-long user behavior modeling模块,通过两个cascading stages的behavior modeling子模块提取用户兴趣:1):Consistency-Preserved General Search Unit: CP-GSU,从数万个长期历史行为中粗略搜索100个最相关的行为。2):Exact Search Unit: ESU,采用注意力机制对CP-GSU的100个最终入围者来捕获精确的用户兴趣。
传统算法通常由“轻量级”的
GSU和“重量级”的ESU组成。与传统算法不同,我们提出的CP-GSU遵循与ESU相同的relevance evaluation metric,使两个cascading stages成为TWINS。因此,CP-GSU始终检索出来ESU认为重要的items,从而最大限度地提高behavior modeling的有效性。Short-term behavior modeling:从最近的50个behaviors中提取用户兴趣。该模块关注用户最近几天的短期兴趣,是TWIN的有力补充。其他任务建模:除了
behavior modeling之外,我们还拼接了各种其他任务建模的输出,这些任务建模可以建模用户的性别、年龄、职业、位置、视频时长、主题、受欢迎程度、质量和上下文特征,上下文特征包括播放日期、时间戳、页面位置等。
1.1.3 TWIN: TWo-stage Interest Network
我们将提出的算法命名为
TWIN,以强调CP-GSU遵循与ESU相同的relevance evaluation metric。请注意,这种一致性并非微不足道,因为:有效的
behavior modeling算法通常基于多头目标注意力 (Multi-Head Target Attention: MHTA) ,它通过强调target relevant behaviors来精确地捕获用户兴趣。不幸的是,由于计算复杂度高,MHTA适用的behavior sequence长度大多仅限于几百。为了详尽地捕获用户的长期兴趣,
CP-GSU应该涵盖过去几个月的user behaviors,这些user behaviors很容易达到数万。考虑到在线系统严格的低延迟要求,这个序列长度远远超出了传统MHTA的容量。
本节旨在回答这个关键问题:如何提高
MHTA的效率,以便我们可以将其从ESU扩展到CP-GSU?或者换句话讲,从数百的序列长度扩展到至少数万的序列长度?Behavior Feature Splits and Linear Projection:按照MHTA的标准符号,我们将长度为behavior sequencebehavior的特征。在实践中,MHTA的注意力得分计算中,MHTA在极长user behavior sequences上应用的关键计算瓶颈。因此,我们提出以下措施来降低其复杂性。我们首先将
behavior features matrix我们将
behavior items的固有特征(例如video id, author, topic, duration),这些特征与特定的user / behavior sequence无关。我们将
user-item交叉特征(例如user click timestamp, user play time, clicked page position, user-video interactions)。
这种分割可以高效计算接下来的线性投影
对于固有特征
id特征为64,field数量),但线性投影实际上并不昂贵。特定item的固有特征在users / behavior sequences之间共享。通过必要的缓存策略,look up and gathering过程有效地“计算”。在线部署的细节将在接下来章节中介绍。但是,训练的时候没有
caching,因此会非常消耗资源。然而,训练的时候没有inference latency的限制,可以堆显卡来解决。对于
user-item交叉特征1):交叉特征描述a user and a video之间的交互细节,因此不会跨users behavior sequences来共享。2):对于一个视频,每个用户最多观看一次。也就是说,在投影cross features时没有重复计算。因此,我们通过简化linear projection weight来降低计算成本。
给定
embedding维度为vocabulary size的id特征)。我们有linear projection简化如下:其中:
使用这个简化的投影,我们将每个
cross feature压缩到一个维度,即diagonal block matrix)。
复杂度分析:在传统的
MHTA中,通常
而在我们对
TWIN的MHTA中:item固有特征pre-computed并有效地gathered,复杂度为在训练阶段是没有
pre-computed的而
user-item交叉特征
由于
MHTA能够在CP-GSU和ESU中一致地实施。这里仅仅优化了线性投影的计算复杂度,但是没有优化
attention的计算复杂度。attention的计算复杂度为:attention的计算复杂度为Target Attention in TWIN:基于linear projection of behaviorsCP-GSU和ESU中统一使用的target-behavior relevance metric。不失一般性,我们假设用户和
target item之间没有交互,并将target item的固有特征记作target item与历史行为之间的relevance score其中:
projected query and key的维度。注意,这里
bias项的计算与这个
relevance score由query(即target的固有特征)与key(即behaviors的固有特征)之间的内积计算得出。此外,由于交叉特征被压缩为1维,因此可用作bias项。我们使用在
CP-GSU中,这个relevance score100个最相关的behaviors。而在ESU中,我们对100个最终入围者执行加权平均池化:其中:
我们通过设置
100个behaviors执行,因此可以在线高效进行。我们不需要像为behaviors计算注意:在
ESU中,仍然使用了Behavior Feature Splits and Linear Projection策略从而计算注意力权重。但是,对于为了共同关注来自不同
representation子空间的信息,我们在MHTA中采用4个头。因此,TWIN的final output定义为:其中
head之间相对重要性。
1.1.4 系统部署
我们在快手的
ranking system上部署了TWIN,服务于3.46亿日活用户的主要流量。在本节中,我们介绍我们在部署中的实际经验。我们的系统架构细节如Figure 3所示。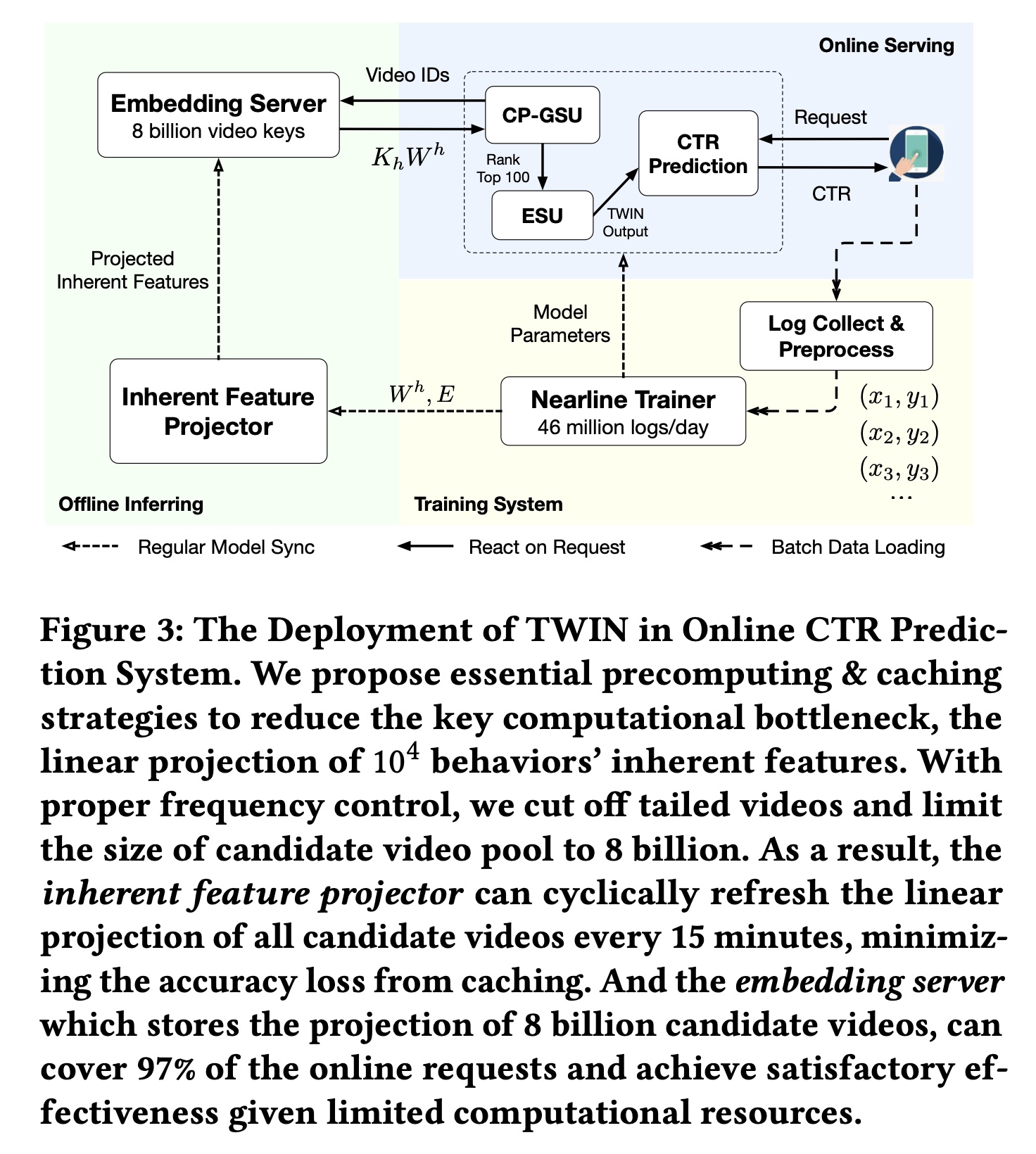
训练系统:我们的
TWIN模块与整个CTR prediction模型在快手的large-scale distributed nearline learning system上进行联合训练。 每天,有数亿用户访问快手,观看短视频以及与短视频互动,每天留下46B条观看和互动日志。在8分钟时间内,每条日志都被实时收集、实时预处理并用于模型训练。该nearline training system使用8分钟内发生的user-video互动中的最新知识增量地更新模型参数。Figure 3里给出的是46 million/day,但是正文部分说的是46 billion/day。此外,我们的
message queue system每5分钟一次将最新的参数值从training system持续同步到离线推理系统和在线服务系统。这种同步确保了online CTR prediction service始终基于最新模型。离线推理:
offline inferring system旨在通过提供lookup service来加速online serving。当接收到lookup keys(即,一个batch的video ids)时,此service将返回lookup values,即相应的projected inherent features的拼接形式(即,所有headsoffline inferring system由两部分组成:1):一个inherent feature projector,使用从training system同步的最新embeddings和TWIN参数linear projection of inherent features。通过适当的频率控制,该projector可以每15分钟刷新一次8B规模的candidate video pool的projected inherent features,从而最大限度地减少caching造成的准确率损失。2):一个embedding server,将inherent feature projector的结果存储到key-value结构中,并提供上述key lookup service。通过截断尾部视频,8B keys可以覆盖97%的online request,平衡了效率和效果。
Online Serving:一旦收到一个request,online serving system就会向offline inferring system查询从而得到projected inherent featuresuser-item relevance score100个behaviors,并将这100个behaviors输入到ESU。这种设计在实践中将TWIN的计算瓶颈(即99.3%。请注意,只有
100 behaviors的ESU足够轻量,可以使用从training system同步的最新参数来实时进行所有计算。因此,ESU计算出的CP-GSU中的略微更新,这进一步提升了我们的Target Attention机制的性能。通过加速设计,
TWIN成功部署在快手的ranking system上,服务于3.46亿活跃用户的主要流量,峰值请求为每秒30M个视频。
1.2 实验
在本节中,我们详细介绍了在真实工业数据上进行的离线和在线实验,以评估我们提出的方法,目的是回答以下五个研究问题(
research question: RQ)。RQ1:与lifelong user behavior modeling中的其他SOTA相比,TWIN在离线评估中的表现如何?RQ2:与其他SOTA相比,TWIN能实现多大的一致性?或者说,为什么TWIN有效?RQ3:随着用户行为序列长度的增长,TWIN的有效性如何变化?RQ4:所提方法中的关键组件、以及不同实现方式的效果如何?RQ5:TWIN在实际在线推荐系统中的表现如何?
数据集:为了在现实情况下评估
TWIN在lifelong user behavior modeling中的作用,我们需要一个大型的CTR prediction数据集,该数据集应具有丰富的用户历史behaviors,理想情况下可以scale up到每个用户数万个behaviors。不幸的是,现有的公共数据集要么相对较小,要么缺乏足够的用户历史behaviors。例如,在广泛使用的Amazon数据集中,每个用户平均只有不到10个历史行为。在Taobao数据集中,用户行为的平均序列长度最多为500。因此,我们从快手(中国顶级短视频分享平台之一)收集了一个工业数据集。 我们从每日用户日志中构建样本,以用户的点击作为标签。如Table 3所示,快手的每日活跃用户规模约为3.46亿。每天发布45M条短视频,这些视频总共播放了46B次。平均而言,每位用户每天观看133.7个短视频。为了利用丰富的behavior信息,我们从数月前的旧日志中收集完整的用户历史行为。平均而言,每位用户在过去六个月内观看了14,500个视频,这为模型提供了一个试验台,这个试验台包含了可供学习的丰富的用户历史行为。我们将最大用户行为序列长度限制为100,000,这大约是重度用户一年的总观看次数。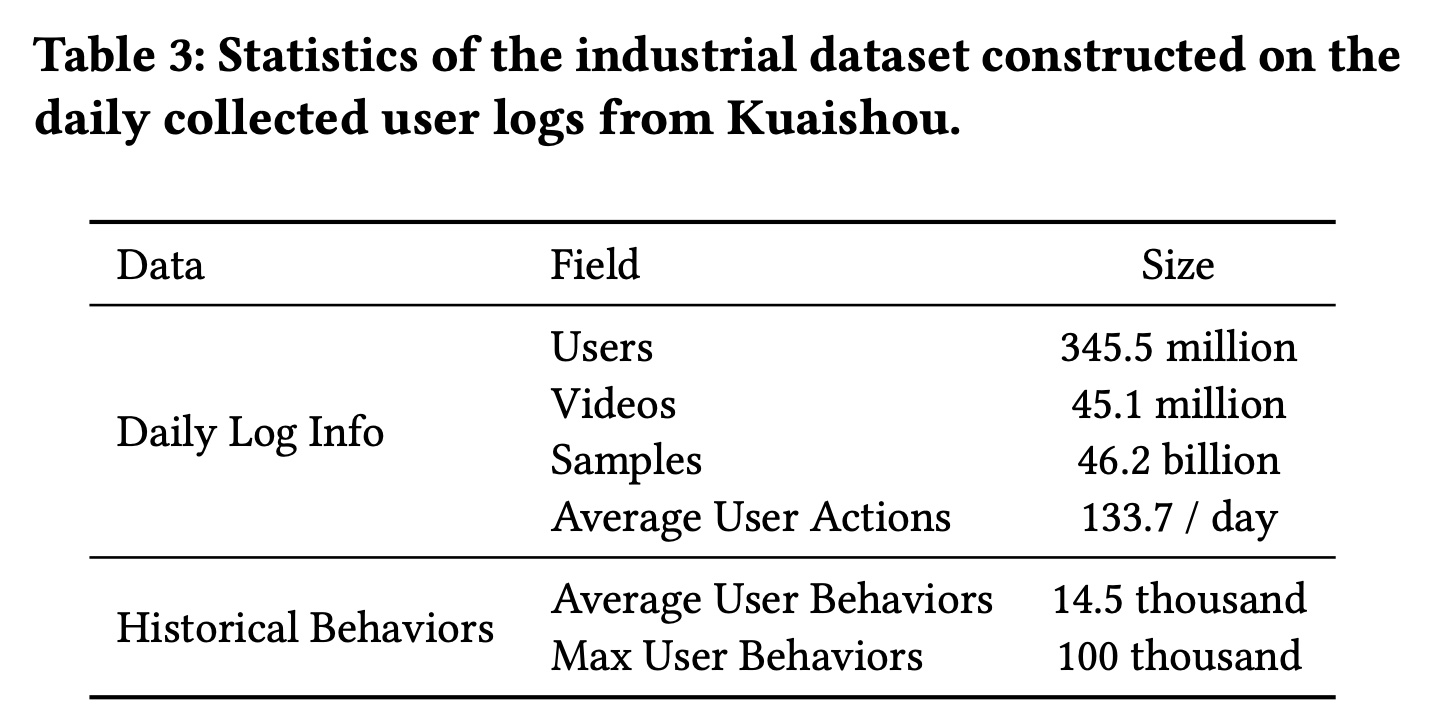
baselines:为了证明有效性,我们将TWIN与以下SOTA的lifelong user behaviors modeling算法进行了比较。Avg-Pooling:user lifelong behaviors的均值池化。DIN:最广泛采用的short-term behavior modeling方法,它使用Target Attention从而用于target-specific interests。SIM Hard:GSU从与target item相同的category中选择behaviors,ESU遵循DIN中的Target Attention。在我们的场景中,video categories总数为37。ETA:局部敏感哈希 (Locality-sensitive hash : LSH) 用于为target video and behaviors生成哈希签名(hash signature)。然后GSU使用汉明距离作为target-behavior relevance metric。SDIM:GSU通过多轮哈希碰撞(multi-round hash collision)选择具有与target video相同哈希签名的behaviors。在原始论文中,ESU线性聚合了multi-round hash collision所采样到的behaviors从而获得用户兴趣。在我们的实验中,为了公平比较,ESU采用了更强大的Target Attention。SIM Cluster:由于“category”需要昂贵的人工标注,并且在短视频场景中通常不可靠,因此我们实现了SIM Cluster作为SIM Hard的改进版本。我们根据pre-trained embeddings将视频分组为1,000 clusters。GSU从与target item相同的clusters中检索behaviors。SIM Cluster+:是SIM Cluster的改进版,其中clusters数量从1,000个扩展到10,000个。SIM Soft:GSU使用视频的pre-trained embeddings的内积得分来检索relevant behaviors。内积是一种比汉明距离和哈希碰撞更精细的检索方法,但计算成本更高。
综上所述:
ETA和SDIM采用端到端训练方法,但使用粗略的检索方法以避免高复杂度的计算。SIM Cluster、SIM Cluster +、以及SIM Soft采用精细的检索方法,但代价是它们必须使用pre-trained embeddings并提前生成离线倒排索引(offline inverted index)。
请注意,
SIM Soft尚未被后续工作ETA和SDIM击败。我们没有与UBR4CTR进行比较,因为它的迭代式训练(iterative training)不适合我们的流式场景(streaming scenario)。此外,UBR4CTR被证实比SIM Hard和ETA的表现更差。实验设置:
我们使用一天中连续
23个小时的样本作为训练数据,并使用接下来一个小时的样本进行测试。我们连续5天评估所有算法并报告5天的平均性能。相当于将算法重复
5次并报告平均性能。对于离线评估,我们使用两个广泛采用的指标:
AUC和GAUC。AUC表示正样本得分高于负样本得分的概率,反映了模型的排序能力。GAUC对所有用户的AUC进行加权平均,权重设置为该用户的样本数。GAUC消除了用户之间的bias,以更精细和公平的粒度评估模型性能。
为了公平比较,在所有算法中,除了
long-term behavior modeling模块外,我们使用相同的网络结构,包括embedding layers、upper deep networks、short-term behavior modeling和other task modelings。对于两阶段模型,我们使用最近的
10,000 behaviors为作为GSU的输入,并在ESU中检索100 behaviors用于Target Attention。对于
DIN,我们使用最近的100 behaviors,因为它在处理长序列方面存在瓶颈。虽然
TWIN的CP-GSU在attention score computation中使用了四个head,但我们通过四个head递归遍历top ranked items,直到收集到100 unique behaviors。为什么要做这种简化?会不会影响性能?
对于所有模型,
embedding layer都使用AdaGrad优化器,学习率为0.05。DNN参数由Adam更新,学习率为batch size设置为8192。
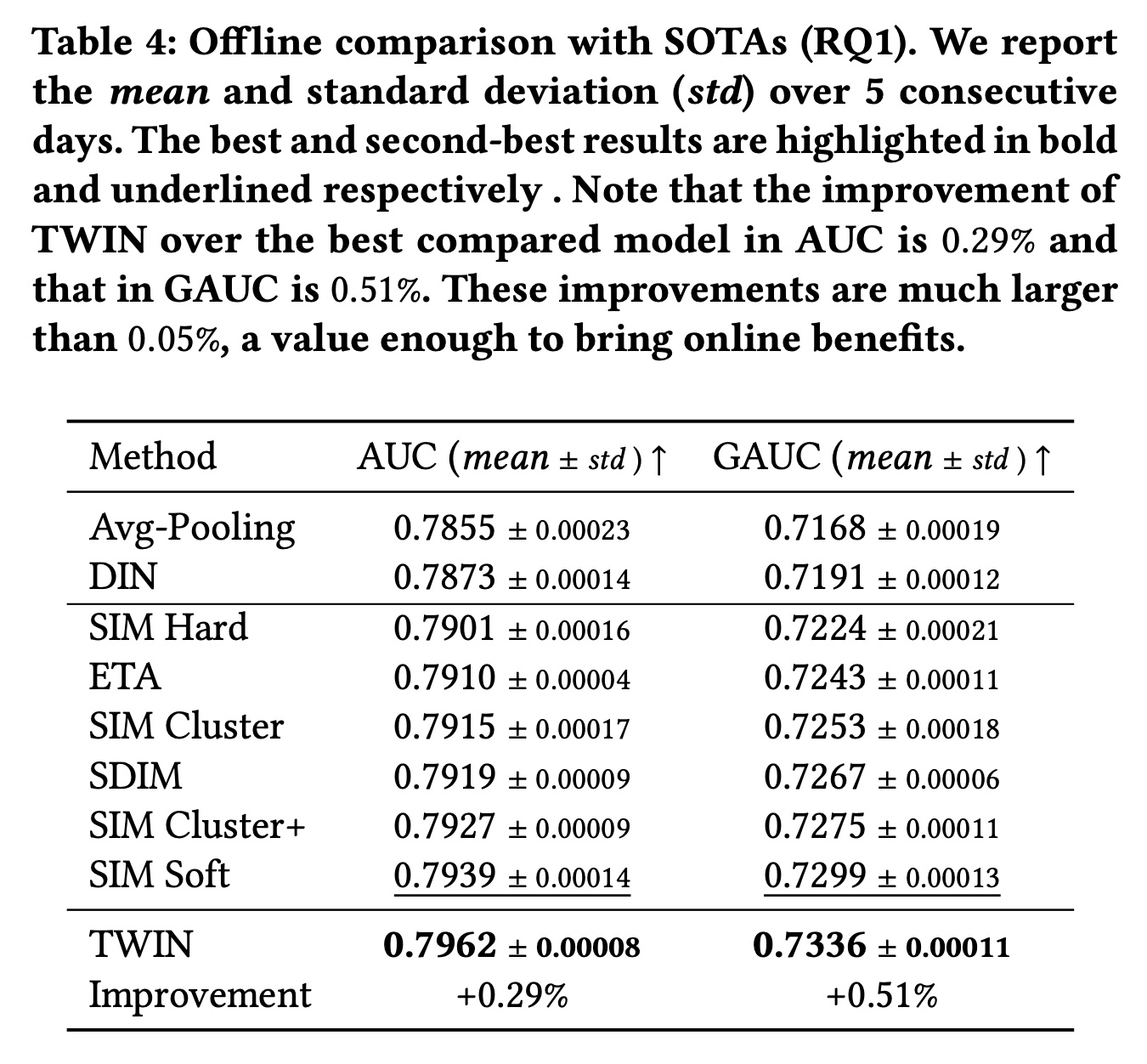
1.2.1 整体性能 RQ1
Table 4显示了所有模型的性能。请注意,由于我们的数据集中有大量的用户和样本,因此离线评估中AUC和GAUC的0.05%的改进足以为业务带来online gains。首先,
TWIN的表现明显优于所有基线,尤其是具有不一致GSU的两阶段SOTA。这验证了TWIN在life-long behavior modeling中的关键优势,即CP-GSU中强大而一致的Target Attention。具体而言,CP-GSU精确地检索出了ESU认为高度相关的behaviors,为最重要的user information节省了ESU宝贵的计算资源。而在其它基线中,无效且不一致的GSU可能会错过重要behaviors并引入noisy behaviors,从而降低Target Attention的性能。此外,从
Avg-pooling到DIN的增益显示了Target Attention在检索有效信息方面的能力。其他两阶段SOTA相对于DIN的增益验证了modeling long behaviors的必要性。这两者共同支持了我们的动机:将Target Attention扩展到长序列。其次,仅有端到端训练是不够的。我们观察到
TWIN明显优于ETA和SDIM,而这两个强大的基线在GSU中的embeddings也以端到端的方式进行训练。具体来说,ETA使用LSH和汉明距离,而SDIM使用多轮哈希碰撞。与Target Attention相比,这两种GSU策略都不太精确,并且与它们在ESU中使用的target-behavior relevance metric不一致。而TWIN中的CP-GSU不仅是端到端训练的,而且与ESU中的Target Attention一致。这表明精确的relevance metric对GSU至关重要,验证了我们优于现有的端到端算法。第三,以更细的粒度来建模
lifelong behaviors是有效的。我们比较了SIM的变体:具有37 categories的SIM Hard、具有1,000 / 10,000 clusters的SIM Cluster(+)、以及针对每个behavior单独计算target-behavior relevance score的SIM Soft。随着
GSU中使用更细粒度的检索方法,我们观察到性能持续改进。这是因为当GSU能够更精细地捕获视频之间的relevance score时,它会更准确地检索behaviors。从这个角度来看,我们进一步将我们优于SIM Soft的原因归功于TWIN采用更准确的relevance metric。
1.2.2 一致性分析 RQ2
正如所声称的,我们卓越的
behavior modeling能力来自CP-GSU和ESU中一致的relevance metrics。但我们真正实现了多大的一致性(Figure 4)? 对于每个well-trained的两阶段模型,我们重用其ESU的参数作为其Oracle,从而从10,000 behaviors中检索“the real top-100”。换句话说,这些real top-100是ESU认为真正重要的ground-truth。然后,对于所有被比较算法,我们遍历GSU output size,从outputs命中real top-100。请注意,每个被比较算法都有自己的Oracle和top-100。但我们只绘制一条Oracle曲线,因为所有Oracles都完美地击中了ground truth。SIM Soft得益于GSU中更精确的retrieval策略,在retrieval consistency方面有所改进。此外,
TWIN在返回100 behaviors时实现了94次命中,这验证了我们在保持两个阶段之间的一致性方面的优势。请注意,这是最值得注意的value,因为考虑到推理时间、以及Target Attention计算复杂度的限制,100是ESU input的上限。由于caching中的刷新延迟(refresh delay),我们在实践中没有达到理论上的100%的一致性,如正文章节所述。
基于以上结果,我们推测
CP-GSU比传统GSU具有更强的match user interests with the target video的能力。这归因于一致性。通过与ESU共享相同的结构和参数,CP-GSU能够准确判断和检索具有相似内容的videos。此外,由于CP-GSU参数是实时更新的,该模型可以捕获用户的动态变化的兴趣。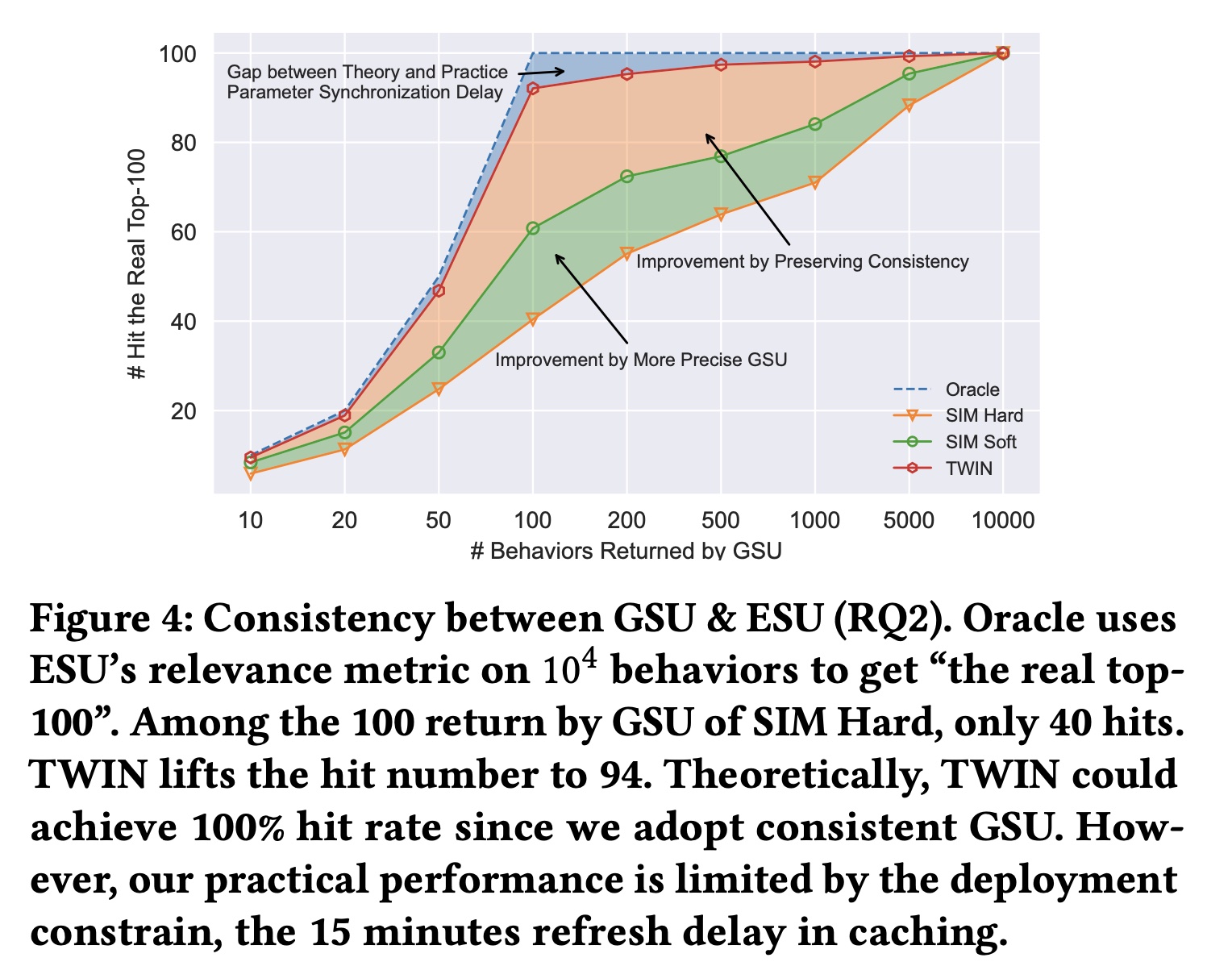
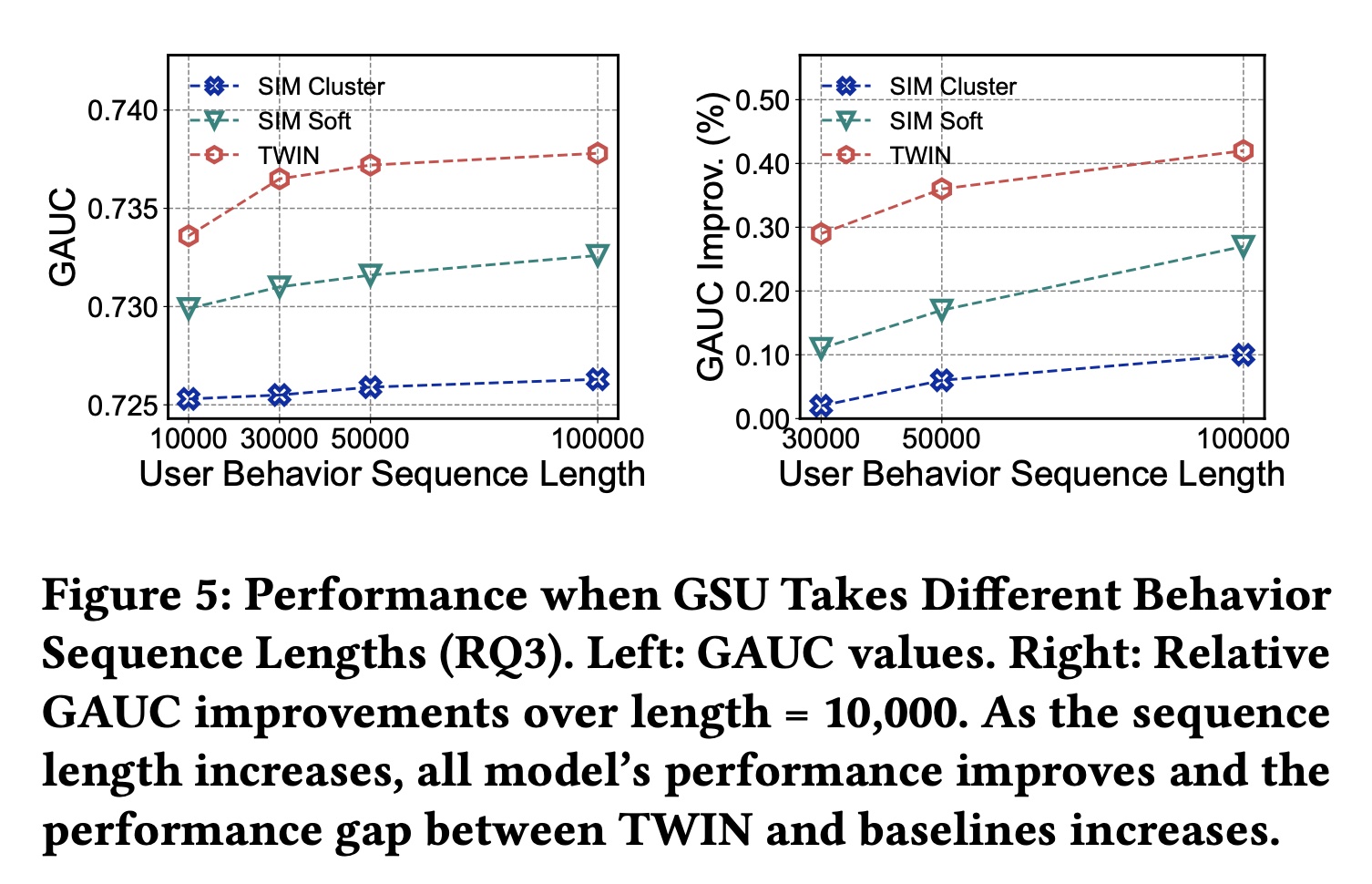
1.2.3 Behavior Length 的影响 RQ3
我们旨在测试
TWIN在不同behavior sequence长度下的有效性,并进一步挖掘TWIN的潜力。请注意,仅更改了GSU的输入序列长度,输出长度保持为100。结果如Figure 5所示。 我们观察到:1):TWIN始终表现最佳,2):随着序列长度的增加,TWIN与其他方法之间的性能差距越来越大。这表明TWIN在建模极长序列方面具有更好的效果。
1.2.4 消融研究 RQ4
我们通过对
TWIN应用不同的操作来进行消融研究,以评估我们的关键模型设计的贡献:1)两个阶段之间的一致性;2)高效的MHTA。TWIN在两个方面保持了两个阶段之间的一致性:网络结构和参数。为了研究每个方面带来的好处,我们实现了一个名为TWIN w/o Para-Con的变体,它不保留参数一致性。具体来说,我们首先训练一个辅助模型TWIN-aux,它使用与TWIN相同的网络结构和训练数据,但单独进行训练。然后,我们将GSU参数从TWIN-aux同步到TWIN w/o Para-Con。这是为了确保TWIN w/o Para-Con仍然实时被更新,并且TWIN和TWIN w/o Para-Con之间的差距都是由参数不一致造成的。 如Figure 6 (left)所示,TWIN w/o Para-Con的表现明显优于SIM Soft(结构和参数都不一致),但略逊于TWIN。这表明网络结构一致性和参数一致性都有好处,但网络结构一致性的贡献更大。这个配置有点奇怪,为什么不训练这样的模型:
CP-GSU和ESU采用相同的网络结构,但是不共享网络参数,然后训练?这个实验不太靠谱。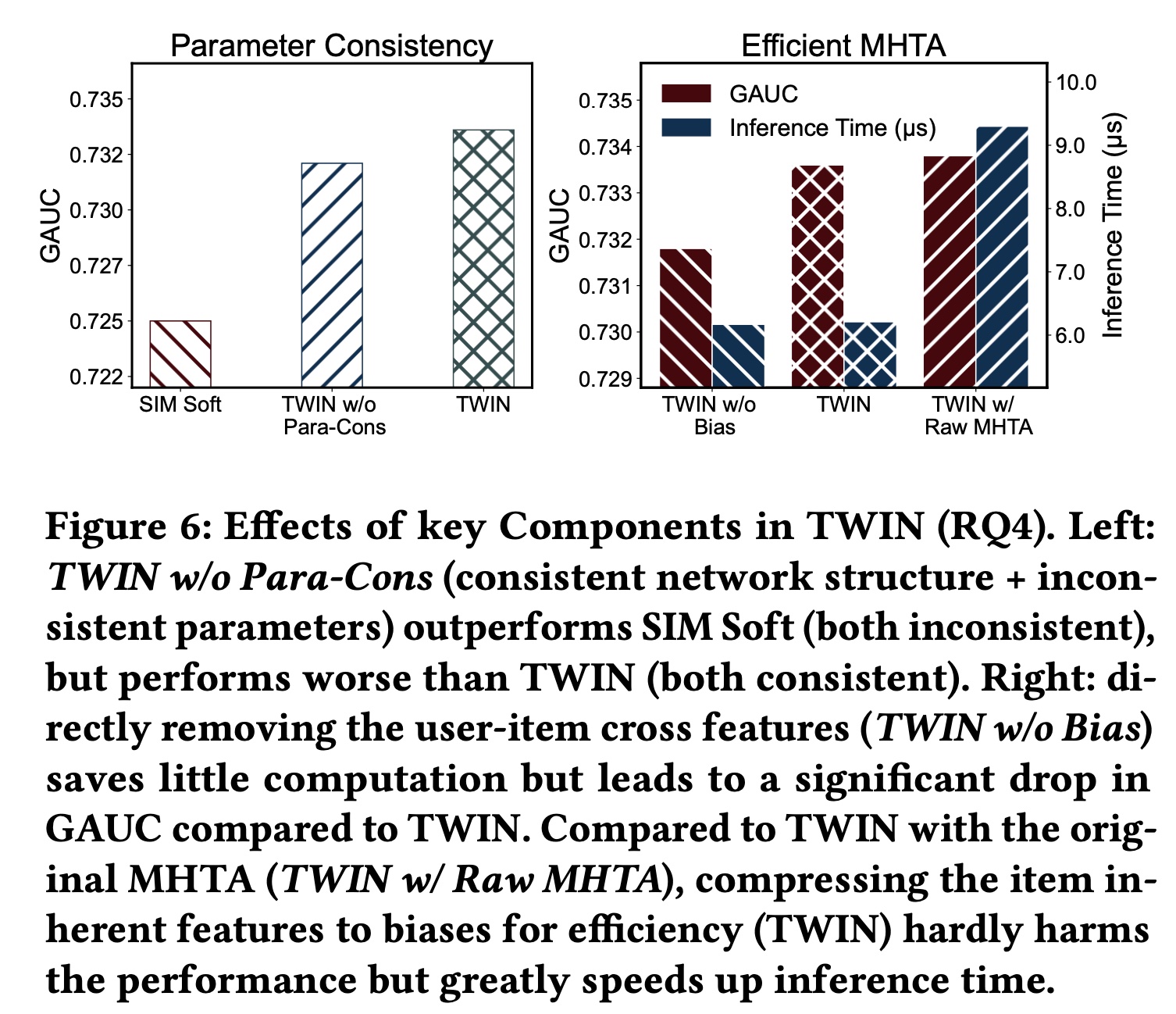
为了高效地计算
MHTA从而用于工业级部署,我们拆分user behavior features,并将每个user-item cross feature压缩为一维bias项。为了研究这种修改的影响以及在注意力计算中保留user-item cross features的好处,我们实现了两个变体并比较了它们的性能和推理时间:具有原始
MHTA的TWIN,其中使用直接的线性投影feature split。缩写为TWIN w/ Raw MHTA。MHTA中不使用user-item cross features的TWIN,缩写为TWIN w/o Bias。
如
Figure 6 (right)所示,TWIN明显优于TWIN w/o Bias,并且性能几乎与TWIN w/Raw MHTA相同,验证了我们对MHTA提出的修改几乎不会影响性能。至于计算成本,由于当user-item cross features用于caching不适用于TWIN w/ Raw MHTA(详见正文章节),因此TWIN w/ Raw MHTA的推理时间显著增加。相反,删除user-item cross features(TWIN w/o Bias)不会节省太多计算量,但会损害性能。
1.2.5 在线结果 RQ5
为了评估
TWIN的在线性能,我们在快手的短视频推荐平台上进行了严格的在线A/B test。Table 5比较了快手三个代表性业务场景(Featured-Video Tab, Discovery Tab, and Slide Tab)下TWIN与SIM Hard和SIM Soft的性能。与电商常用的线上评价指标CTR和GMV不同,短视频推荐场景通常使用观看时长(Watch Time),衡量用户观看视频的总时长。如表所示,
TWIN在所有场景中的表现都明显优于SIM Hard和SIM Soft。在快手上,观看时长增加0.1%被认为是一个有效的改进,TWIN实现了显著的商业收益。