一、UBR [2023] (UBR4CTR V2)
《Learning to Retrieve User Behaviors for Click-through Rate Estimation》
CTR estimation在现代在线个性化服务中起着至关重要的作用。通过建模用户行为序列来捕获用户兴趣的变化,对构建准确的CTR estimation模型至关重要。然而,随着用户在在线平台上积累了大量的behavior数据,当前的CTR模型必须截断用户行为序列并利用最近的behavior,这导致一个问题,即诸如周期性(periodicity)或长期依赖性(long-term dependency)之类的序列模式(sequential patterns)不被包含在最近的behavior中,而是包含在遥远的历史中。然而,直接使用整个用户序列并对其进行建模并非易事,原因有二:首先,非常长的输入序列会使在线
inference time和系统负载变得不可行。其次,非常长的序列包含很多噪音,因此
CTR模型很难有效地捕获有用的模式。
为了解决这个问题,我们从
input data的角度来考虑它,而不是设计更精巧但更复杂的模型。由于整个用户行为序列包含很多噪音,因此没有必要输入整个序列。相反,我们可以只检索其中的一小部分作为CTR模型的输入。在本文中,我们提出了用户行为检索(User Behavior Retrieval: UBR)框架,旨在根据每个CTR estimation request来学习从而检索最informative的user behavior。只检索一小部分behavior可以缓解utilizing very long sequences的两个问题(即推理效率和噪声输入)。UBR的显著特性在于它支持任意且可学习的检索函数,而不是使用固定的且预定义的函数,这与当前retrieval-based的方法不同。在三个大型真实数据集上的离线评估证明了
UBR框架的优越性和有效性。我们进一步在Huawei App Store部署了UBR,在线A/B test中实现了6.6%的eCPM增益,现在服务于Huawei App Store广告场景的主要流量。CTR estimation在当今的在线个性化平台(例如电商、在线广告、推荐系统)中起着关键作用,其目标是预测用户在特定上下文中点击特定item的概率。近年来,基于用户行为序列的CTR estimation模型引起了工业界和学术界越来越多的关注。这些基于user behavior的CTR模型旨在捕获包含在user behavior中的丰富的时间模式(temporal patterns),并学习用户兴趣的变化,从而获得准确的CTR estimations。这些序列模式包括概念漂移(concept drifting)、长期行为依赖性(long-term behavior dependency)、周期性模式(periodic patterns)等等。Deep Interest Network: DIN和Deep Interest Evolution Network: DIEN是在CTR prediction中,通过建模用户行为序列从而捕获用户兴趣的代表性模型。DIN结合了注意力机制来学习不同user behaviors的重要性,而DIEN利用GRU来捕获user behavior的dynamics。其他user behavior-based的CTR estimation模型(《Behavior sequence transformer for e-commerce recommendation in alibaba》、《Deep session interest network for click-through rate prediction》)具有相似的动机和结构。至于
CTR estimation的类似文献,在序列推荐(sequential recommendation)领域,有很多关于如何对用户行为序列进行建模的研究工作。有RNN-based的模型,如GRU4Rec、GRU4Rec+;有CNN-based的模型,如CaseR;有Transformer-based的模型,如SASRec、TiSASRec;还有memory network-based的模型。随着在线个性化平台十多年的发展,平台上记录的
user behavior数量迅速增长。在淘宝上,仅在六个月内,就有23%的用户积累了超过1,000次behavior(《Lifelong sequential modeling with personalized memorization for user response prediction》)。尽管上述基于user behavior的CTR模型取得了巨大成功,但它们无法处理非常长的用户序列。如Figure 1上半部分所示,仅使用最近的行为进行CTR estimation(通常为50或100)。但是,如果仅使用最近的行为,序列中可能不包含长期依赖性或周期性等序列模式(sequential patterns)。一种直接的解决方案是将整个用户序列馈入到CTR模型中,但这不可行。它会给系统开销带来沉重的负担并牺牲推理效率。更糟糕的是,在非常长的行为序列中,这种做法会带来很多噪音。为了解决上述问题,一种解决方案是设计具有更多参数和更大容量的复杂模型,以支持更长的用户行为序列作为输入,如
Figure 1上半部分所示。HPMN和MIMN是两种用于处理长序列建模的memory network架构。然而,这些模型非常复杂,需要大量的工程工作才能在现实世界的在线系统中实现和部署。尽管HPMN或MIMN可以处理包含大约1,000个behavior的序列,但全量的用户序列通常要长得多。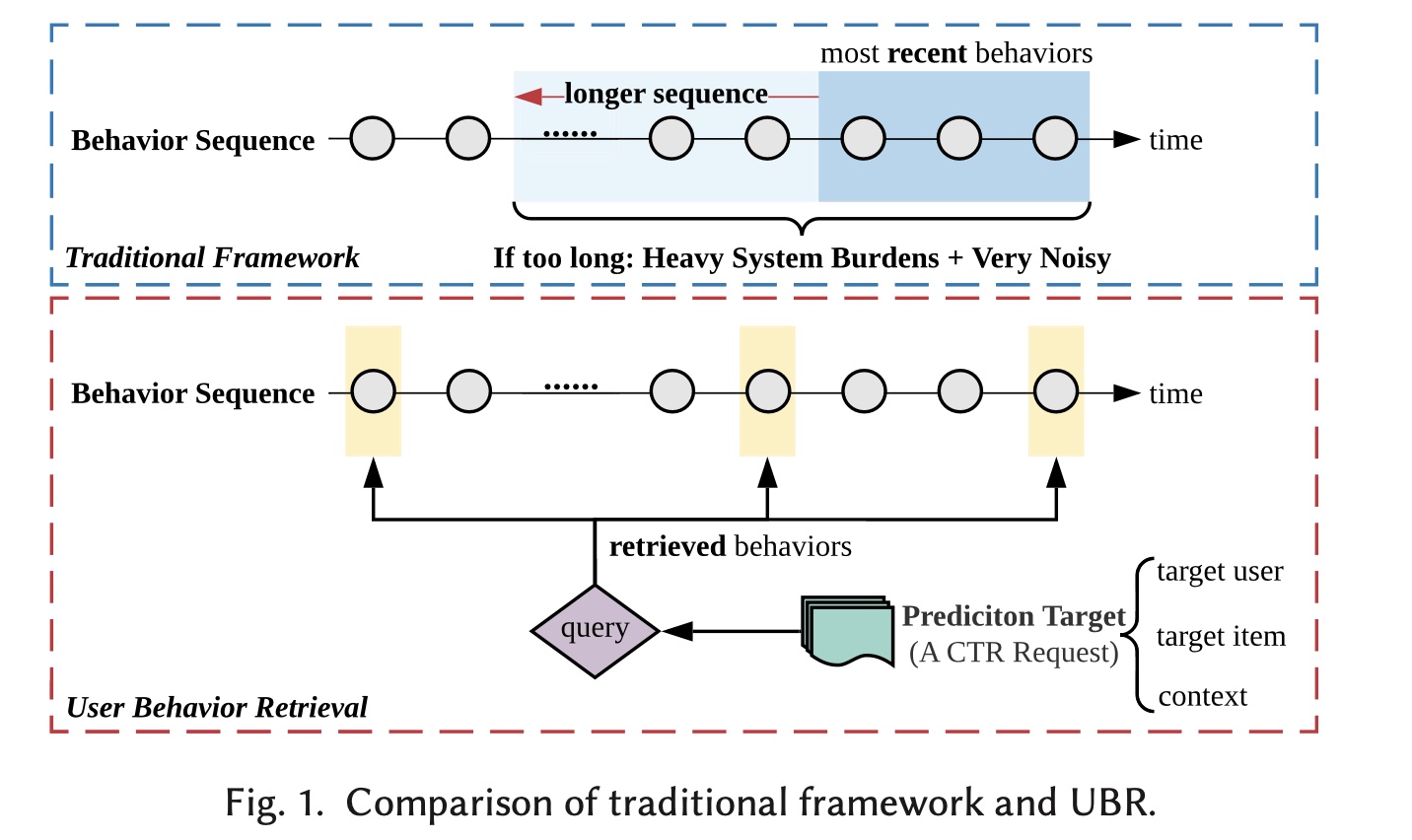
与上述解决方案不同,我们尝试从数据角度解决问题,而不是设计更精巧但更复杂的模型。由于非常长的序列包含很多噪音,因此没有必要输入整个序列。相反,只有一小部分
behavior与prediction相关。因此,我们只需要检索相关的behavior。检索到的behavior取决于每个CTR estimation request。我们将每个request称为prediction target。如Figure 1所示,prediction target由三部分组成,即target user features(职业、地理位置等)、target item features(category、品牌等)、以及相应的上下文特征(场景等)。然后,这些特征将被视为query,并被用于从整个用户序列中检索behaviors。检索系统的目标是学习检索最相关的behavior data,从而辅助特定的request的prediction(即prediction target)。这样的检索过程利用索引结构,以整个用户历史行为作为检索池(retrieval pool),效率很高。为此,通过检索user behavior,长的用户序列可以有效地纳入CTR模型,而不会引入太多噪音。在本文中,我们提出了用于
CTR estimation的User Behavior Retrieval: UBR框架,从而对非常长的用户行为序列进行建模。由于现实世界在线个性化平台中的检索池通常很大,我们将检索过程分为两个子过程:matching和ranking,类似于信息检索系统。对于
matching过程,通过访问存储behaviors的索引可以快速检索一组候选behavior。此过程本质上是获取具有与prediction target所匹配特征的behaviors。获得
candidate behaviors后,ranking函数根据candidate behaviors与prediction target的相关性对其进行排序,并返回top-k个behavior。
然后,被检索到的
behaviors可以被任意CTR模型使用。本文的重点是整合可学习的参数化的检索函数,并提出相应的训练方法。在现有的
retrieval-based behavior models中,检索函数总是采用某种预定义形式,例如特征匹配(《Retrieval and interaction machine for tabular data prediction》)、内积 (《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)、余弦相似度(《Learn over past, evolve for future: Search-based time-aware recommendation with sequential behavior data》)或汉明距离(《End-to-end user behavior retrieval in click-through Rate Prediction model》)。检索函数是固定的,因此它们不够灵活;并且由于其pre-defined form所引入的inductive bias,可能导致次优性能。相反,在UBR框架中,我们使用prediction的性能作为信号来训练检索函数。behavior retrieval过程本质上是获取相对于prediction target(即CTR request)的top-ranked behaviors。使用参数化的结构(例如DNN)作为ranking metric可以大大提高检索函数的容量和表达能力。为实现该目标,我们提出了三种UBR变体:UBR-M利用REINFORCE来优化retrieval function的matching过程。UBR-R使用learning-to-rank: LTR技术来优化retrieval function中的ranking过程。UBR-MR是上述变体的混合版本,其中matching和ranking过程都得到了优化。
通过比较这些变体,我们得到了一些有趣的观察结果和有意义的见解,指导我们在实践中选择最佳变体。详细信息可参见实验章节。
本文的贡献可以总结如下:
对于长行为序列的建模,我们从数据角度提供了一种新的解决方案,即从整个用户序列中检索
user behavior。这是一个实用的解决方案,它使当前的CTR系统在受到严格的效率约束的情况下能够使用整个用户序列。我们系统地数学化了
learning to retrieve user behaviors的问题,并提出了一个有效的模型和相应的训练算法。UBR是第一个支持可学习的任意检索函数(而不是预定义的检索函数)的工作。我们提出了更强大的变体:
UBR-R和UBR-MR。它们采用了由LTR技术优化的可学习的ranking函数。我们进一步证明LTR optimization函数可以引导optimization方向,从而获得更准确的CTR estimation模型。它为我们的优化算法提供了理论保证。UBR有效且易于部署。离线实验表明,它达到了SOTA的性能。此外,UBR已成功部署在Huawei App Store的广告场景中。在线A/B test期间,它实现了6.6%的平均effective cost per mille: eCPM(有效的每千次展示费用)的提升率。它现在服务于Huawei App Store的主要广告流量。
本文是其会议版本
《User behavior retrieval for click-through rate prediction》(即,UBR4CTR)的实质性扩展。期刊版本(本文)和会议文章(即UBR4CTR)之间的主要区别在于:在本文中,我们提出
UBR-R和UBR-MR作为UBR框架的更好实现,而不是会议文章中提出的框架(表示为UBR-M)。新版本加入了可学习的ranking函数,使检索模块更加强大。我们提出了一个
LTR optimization objective来训练参数化的ranking函数,而不是会议文章中使用的REINFORCE算法。我们进一步对LTR objective function进行了广泛的理论分析。我们提供了与一些
retrieval-based序列建模算法的比较实验的结果,这些算法比我们的会议文章更晚被提出。UBR已在实际应用中部署,而我们在会议版本中仅对公共数据集进行了实验。在工业数据集上进行的新实验验证了UBR可以与各种CTR模型结合使用。我们进一步提供了在线实验细节。这些事实表明,UBR在实际应用中部署是高度可行的。
未来工作:对于未来的工作,我们的目标是将
UBR扩展为一个更通用的框架,不仅可以从单个用户那里检索,还可以从其他相似的用户那里检索。当前的UBR框架仅从target user自身的behaviors中检索。来自其他相似用户或items的协同过滤信息可能会进一步提高UBR的性能。在这种情况下优化其效率是另一个重要方向。
1.1 基础知识
在本节中,我们将问题公式化并引入符号。对于
CTR estimation任务,有item构成的item集user-item interactions表示为此外,每个
user-item interaction都与相应的上下文一起发生。我们分别使用timestamp和其他的上下文特征。因此,每个数据点被公式化为itemmulti-field features组成,其中item、以及上下文的第item、以及上下文的feature fields的数量。
为了建模用户不断变化的兴趣,我们将整个
user behavior历史组织为behavior,按timestamp升序排序。用户behavioritem注意,在
UBR4CTR中,CTR estimation的目标是根据target usertarget item其中:
behavior作为prediction函数noisy的。它表示为:其中:
retrieval函数,返回behavior。无论
retrieval函数set of user behaviors。相比之下,对于我们的UBR框架,CTR estimation任务的公式为其中:
retrieval函数,可以在给定target iteminformative的user behavior(注意,target userUBR能够根据不同的target items或上下文从而动态选择最合适的user behavior,而不是像以前的工作那样使用静态和固定的selection策略。我们在
Table 1中总结了符号和相应的描述。
1.2 Behavior Retrieval 系统的架构
在本节中,我们介绍了
UBR框架的基本架构。本节介绍的检索过程是UBR的basic实现,是不可学习的。但它构成了系统的骨干。一些模块可以用参数化的组件替换,从而自动优化UBR。可学习的组件的详细信息将在下一个章节中描述。
1.2.1 UBR 的总体框架
如
Figure 2所示,UBR由retrieval模块和prediction模块组成。顾名思义,
retrieval模块负责根据prediction target从user history archive中检索behaviors。prediction target由CTR prediction request中的user, item, and context features组成。prediction target被用作query从而从user history archive中执行搜索。retrieval engine检索出一部分behaviors,这些被检索到的behaviors被馈入到prediction模块。prediction模块由两部分组成。第一部分是
aggregation网络,它将学习retrieved behaviors的一个unified representation。该aggregated representation可以与其他特征组合起来并输入到任意CTR模型中,第二部分是这个
CTR模型。由于CTR模型可以是任意结构,因此UBR具有很高的灵活性,可以与现有的CTR estimation系统一起部署。
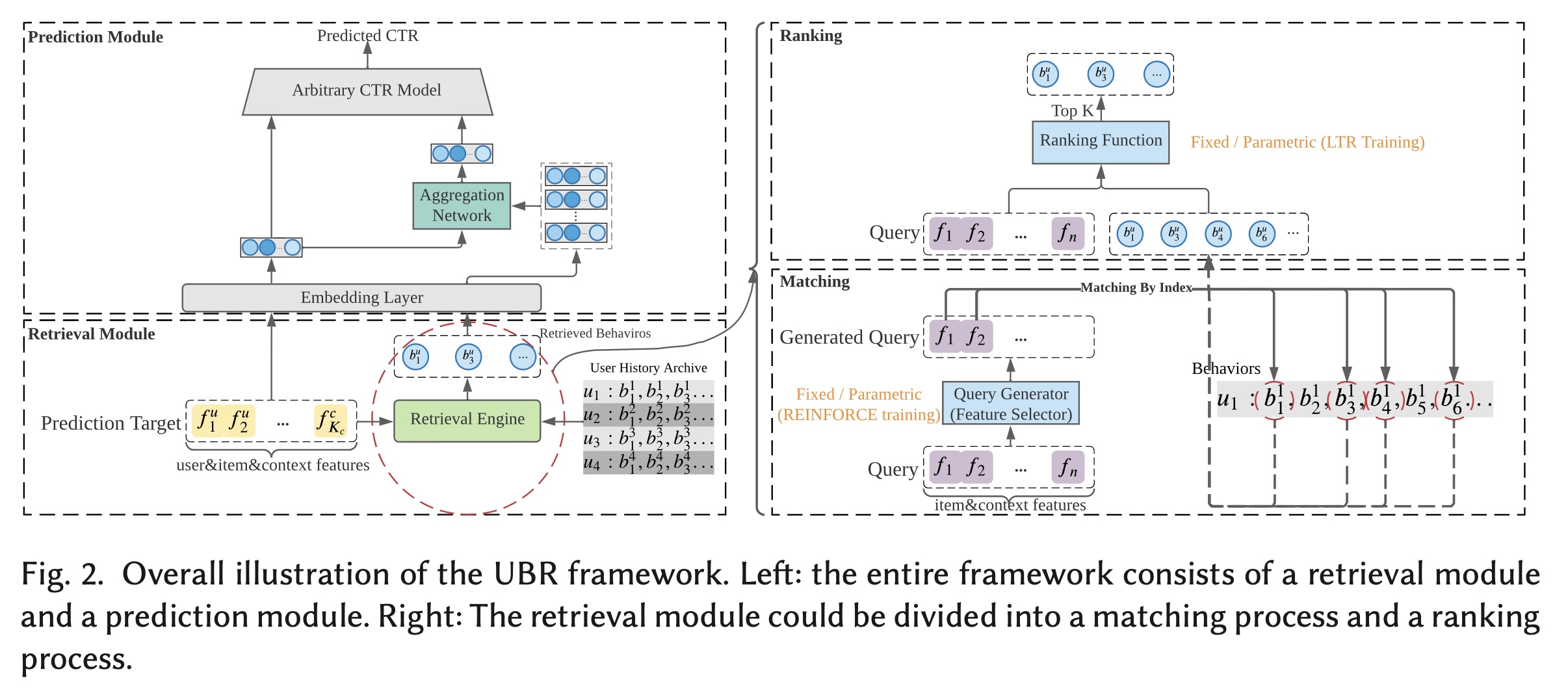
由于检索
user behaviors类似于检索recommender system literature的items,我们使用matching and ranking来划分整个检索过程。matching子模块通过访问索引结构从而快速获取candidate behavior的一个集合。然后,接下来的
ranking子模块将计算每个behavior的分数,从而返回top-k behaviors。
1.2.2 Matching 子模块
matching子模块的目的是:通过快速获取candidates的一个小集合,从而来降低计算复杂度。为了实现此目的,我们选择将其实现为index accessing过程。倒排索引(
Inverted Index):作为典型的搜索引擎系统,我们将每个user behavior视为一个文档,将每个特征视为一个term。user behavior以倒排索引的方式存储。如Figure 3所示,我们以一条behavior记录user id, category id, brand id, purchase day, and item price。在特征工程过程中,原始特征全部重新映射到unique id。numerical特征被离散化,然后重新映射。user id(“ID-1”)用作第一个索引,因为我们需要获取用户behaviors,而其他remapped features则以倒排索引的方式作为第二个索引。behaviorposting lists中。我们对每条behavior record遵循相同的协议并构建倒排索引。即,两层索引结构:最外层是
user-id,这一层索引将保存每个用户的所有行为。第二层是不同的field,给定用户的不同behavior将根据特征取值的不同放入不同的索引。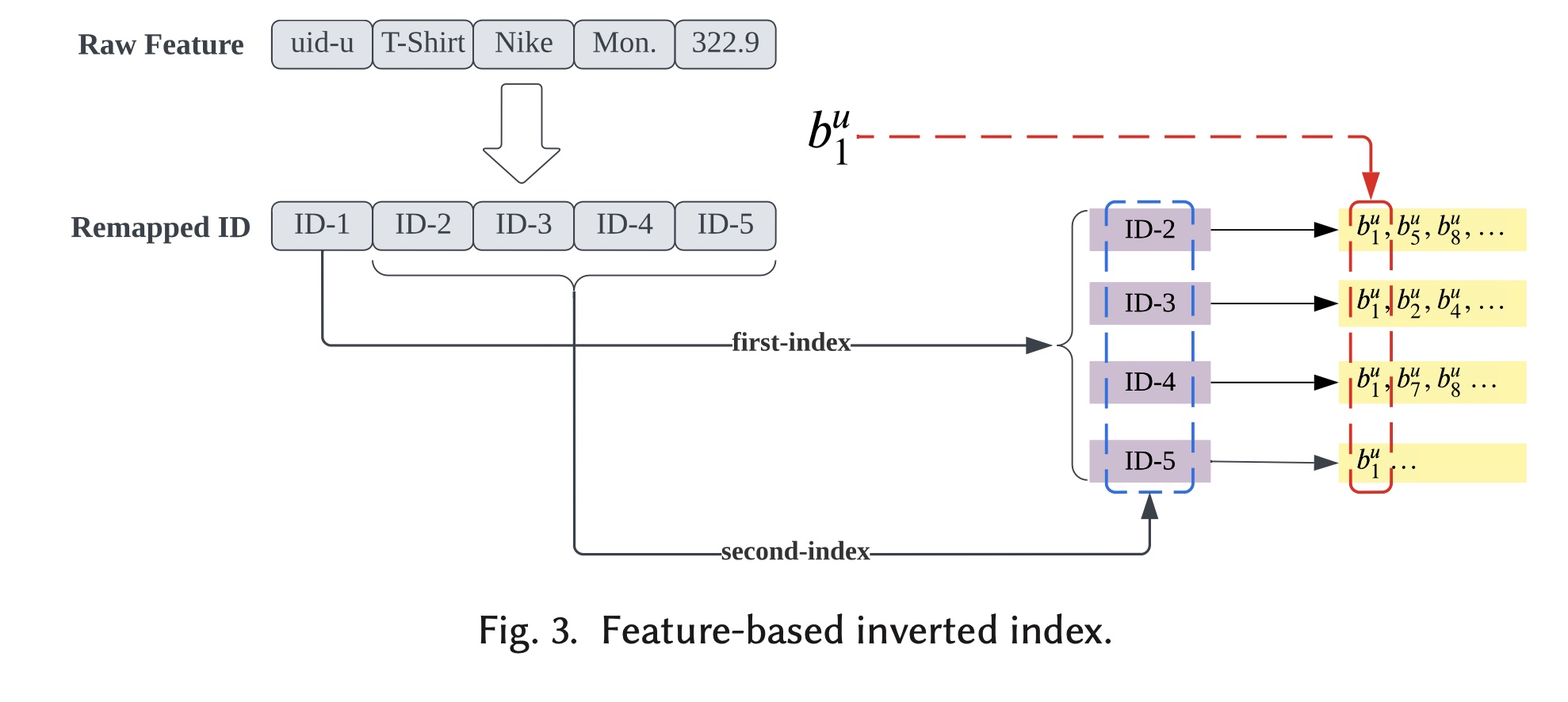
query:prediction targetquery。retrieval的query其中:
注意,这里不包含用户特征
UBR4CTR中包含了用户特征user-id特征matching子模块本质上是一个特征匹配的布尔搜索过程。用户behaviors都将被检索出来。
1.2.3 Ranking 子模块
从
matching子模块获取candidate behaviors后,我们执行ranking程序,从而返回top-k结果作为final retrieved behaviors。我们使用BM25来计算每个behavior的得分,因为它是搜索引擎系统中广泛使用的ranking函数。每个
behaviorqueryranking score定义为:其中:
term frequency)。根据match,其取值为1或0。behaviorbehavior中的特征数量,因此所有behavior都具有相同的长度avgdl代表平均的文档长度。可以进一步化简为:
考虑到
0或1,因此:因此
IDF定义为:其中:
behaviors的总数,IDF项赋予常见特征比罕见特征更少的重要性。与常见特征相比,罕见特征意味着对用户偏好的更强信号,这是有道理的。
top-k behaviors构成retrieval set,即retrieval set被下游prediction模块使用,如Figure 2所示。
1.2.4 Prediction 模块
在本节中,我们介绍
UBR的prediction模块。在prediction模块中,所检索到的user behaviors被聚合起来,相应的representation与其他特征一起馈入到CTR模型中,如Figure 2所示。UBR框架具有高度灵活性,因为它可以与任意CTR prediction模型一起使用,因此可以方便地部署到实际应用中。Retrieved Behaviors的聚合:为了聚合retrieved behaviors并获得全面的representation,我们使用注意力机制来聚合behavior representations:其中:
aggregated behavior representation。retrieved behavior的embedding,embedding size,注意:在
UBR4CTR中,attention权重:其中:
attention layer的权重矩阵。querydense embedding,它是feature embeddings的拼接。注意:在
UBR4CTR中,
aggregated retrieved behaviors的comprehensive representationprediction target的其他特征一起输入到CTR模型中。CTR Estimation Model:UBR可以配备任意的CTR estimation模型。在这里我们使用一个简单的DNN结构作为CTR模型,在实验章节,我们还基于其他工业级的CTR模型测试了性能。final prediction的计算方式为:其中:
user embedding、item embedding、context embedding。behavioral representation,MLP的参数。
由于我们的目标是准确地估计
CTR,因此prediction loss的自然选择是广泛使用的交叉熵损失。带L2范数的prediction loss定义为:其中:
prediction模块的所有参数,包括CTR estimation模型中的参数、以及aggregation函数中的参数。retrieved behaviors。在优化prediction模块时,retrieval模块是固定的。
prediction模块通过使用SGD来最小化
1.3 可学习的 Retrieval System
在本节中,我们介绍如何使
retrieval system成为参数化的和可学习的。我们提出了三种可学习的UBR变体:UBR-M、UBR-R和UBR-MR。UBR-M和UBR-R,顾名思义,是将matching/ranking过程分别转换为一个parametric and learnable function。UBR-MR,是同时优化matching和ranking子模块的混合版本。
可学习的
UBR变体与prediction模块一起训练。在训练retrieval模块时,prediction模块是固定的,反之亦然。我们将首先为可学习的
retrieval system公式化optimization问题,然后给出UBR变体及其相应optimization的实现细节。
1.3.1 Retrieval 模块的优化目标
首先,我们为
retrieved behavior set定义一个效用(utility)。它表示一个behavior set有多 “有用”。Utility的定义:behavior setnon-positive scalar),可以反映prediction模块使用CTR estimation的准确性。在实现上,我们使用negative log-likelihood的倒数作为效用函数,即:其中:
效用越高,
CTR模型使用集合retrieval模块的general objective公式化为:其中:
retrieved behaviors的底层概率分布。令
optimization旨在找到最好的retrieval函数,从而能够最大化CTR模型的期望准确率。在以下小节中,我们将介绍UBR的不同变体及其相应的optimizations。
1.3.2 Matching 子模块的优化:UBR-M
可学习的
UBR的第一个变体是UBR-M,它提出了一个可学习的matching函数。UBR-M的结构:为了将matching过程变成一个可学习的子模块,我们选择将query generation参数化为一个可学习的feature selection过程。它将从querymatch the behaviors,而不是Figure 4所示,我们使用self-attention network来建模特征之间的交互和关系。具体来说,我们定义:其中:
embedding。自注意力机制定义为:
而
multi-head self-attention定义为:其中:
head数量;然后,
multi-head self-attention的输出multi-layer perceptron:相应特征被选择的概率通过取
sigmoid函数获得:其中:
然后我们根据这些概率对特征进行采样,从而得到所选的特征子集。
原来有
总而言之,
UBR-M使用self-attentive feature selection function来参数化matching子模块。至于ranking,UBR-M仍然使用BM25 ranking function。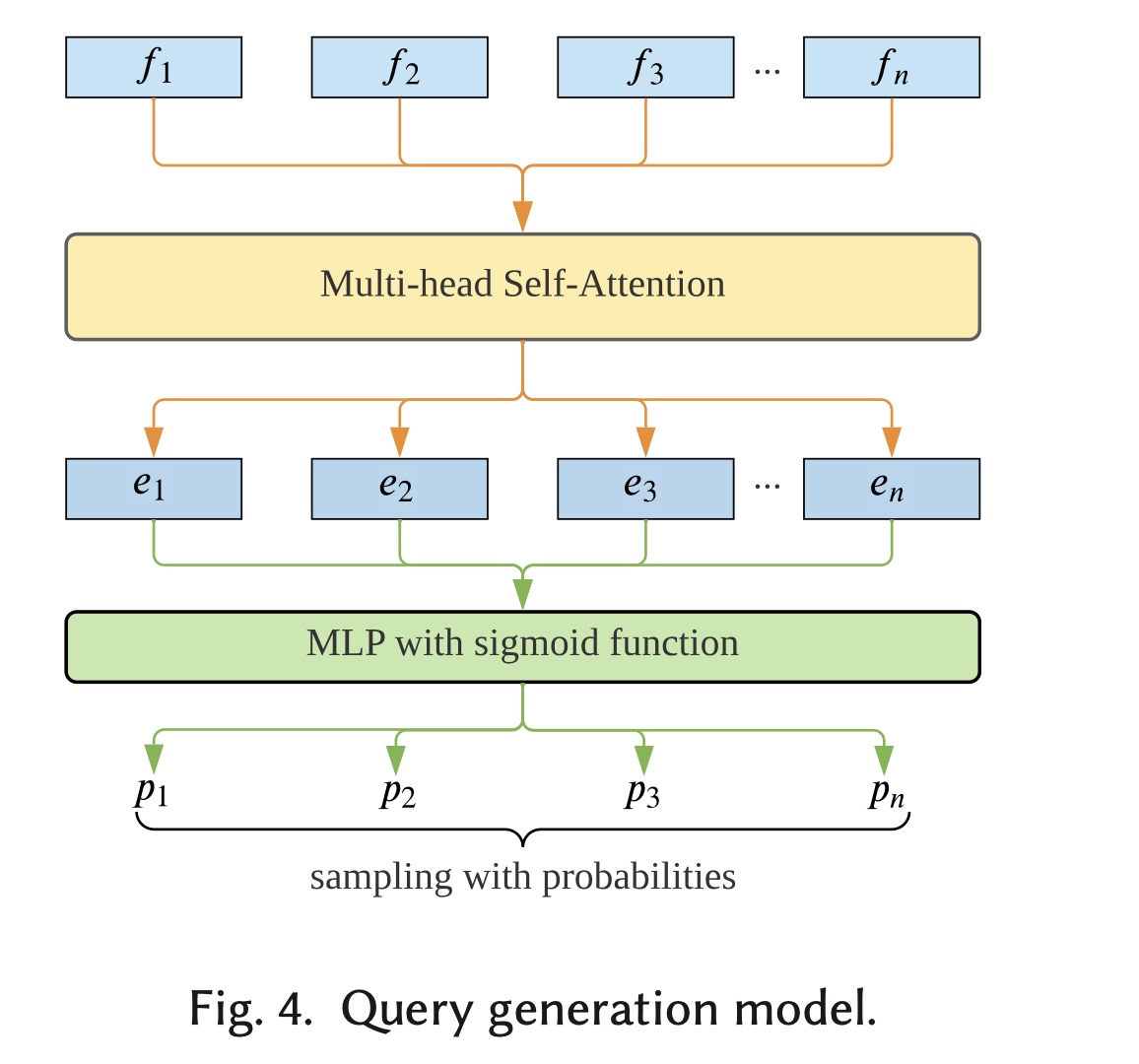
UBR-M Optimization:由于上述feature selection函数通过使用概率来采样,从而涉及不确定性并且不可微,我们可以直接通过REINFORCE(《Simple statistical gradient-following algorithms for connectionist reinforcement learning》)算法优化我们给出了
retrieved behaviors的概率likelihood ratio)来估计,如下所示:其中:
retrieved sets。UBR-M的不确定性实际上来自feature selection model,我们可以得出:其中:
当
因此,我们得到:
其中:
通过使用
REINFORCE算法,可以在prediction模块固定的情况下优化UBR-M。UBR-M是我们在之前的文章《User behavior retrieval for click-through rate prediction》中提出的。虽然UBR-M提供了参数化的retrieval函数的实现,但它仍然是粗粒度的,因为特征对应的posting list(例如Figure 3中的“T-shirt” list)的所有behaviors可能会被完全删除,并且不会被prediction模块使用。此外,UBR-M的ranking模型是固定的BM25函数,这可能不是最佳选择。我们希望模型能够自动学习合适的ranking函数。matching子模块本质上是为ranking子模块缩小候选空间。实验结果表明,优化ranking要比优化matching取得更好的效果。而优化matching的效果一般般。mathcing子模块也可以认为是一种ranking:将未被匹配的behaviors设置ranking score = 0。
1.3.3 Ranking 子模块的优化:UBR-R
UBR的第二种变体是UBR-R,它提出了一个可学习的ranking函数。UBR-R的结构:固定的ranking函数不灵活,无法捕获每个behavior与query之间的复杂关系。因此,我们需要一个可学习的ranking函数。对于UBR-R,我们将ranking函数从确定性的BM25更改为参数化的函数,同时保留前面章节中描述的固定的matching过程。参数化的ranking函数定义为:其中:
behaviorranking score。MLP。,
UBR-R Optimization:由于getting the top-k behaviors的操作不可微,所以我们无法直接优化ranking函数的参数optimization转换为LTR问题,并将其用作UBR-R的优化函数。因为LTR是训练ranking函数最广泛的范式。作为
LTR问题,我们要排名的"items"本质上是一个包含behaviors的集合。总共有matching子模块的behaviors总数,这意味着我们有behavior集合。如果我们将每个
behavior setfinal retrieved behaviors并将其输入到prediction模块,我们将得到效用Figure 5所示,CTR模型给出的效用可以看作是"relevance labels"。ranking函数behavior sets时的性能从而对behavior sets进行排名。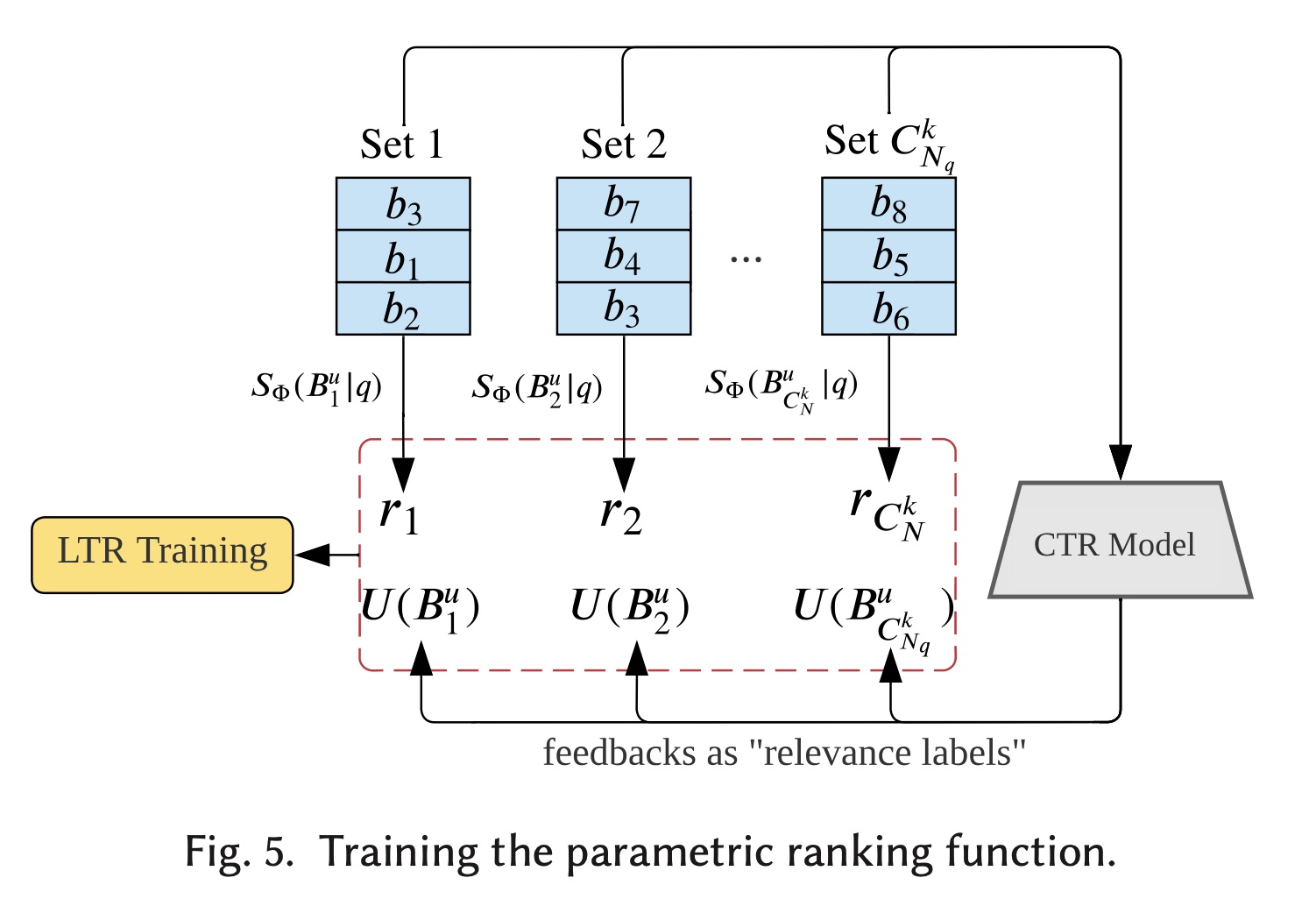
在接下来的内容中,我们将分析
LTR目标函数之间的理论关系。我们证明对LTR loss进行优化可以优化方程将原始问题转换为
LTR任务:我们将probabilistic choice model定义为:选择ranking score成正比:其中:
LTR objective function的定义:给定queryranking list其中:
sigmoid函数sigmoid函数的输入为desired and latent ranking。
我们记
LTR任务的general optimization goal。定理:
LTR objective function其中:
并且:
定理的证明参考论文的附录。
由于定理的成立,原始的目标函数可以转换为最大化
LTR objectiveLTR技术来优化它。我们进一步给出LTR loss的实现细节。实现细节:为了有效地
inference,我们将ranking函数表述为:其中:
scoring函数。为了进行推理,我们可以只使用
top-k ranking behaviors(使用retrieved setscores。我们使用
lambda loss(《The lambdaloss framework for ranking metric optimization》)作为LTR loss来优化UBR-R:其中:
由于我们关心的是
top-1 behavior set,并且为了快速训练,我们将损失函数简化为:其中:
top-k behaviors组成(使用behavior set且它的ranking score低于虽然简化了,但是
实现方式:
对于每个样本,计算它的
query然后计算每个
behaviorscore然后选择
top-k scores的behaviors,得到inference。然后采样
behaviors,得到inference。最后,计算
1.3.4 同时优化两个子模块:UBR-MR
在以上章节中,我们分别讨论了如何优化
matching子模块和ranking子模块。将它们放在一起并尝试同时优化两个子模块是合理的。两个子模块的目标是统一的:prediction模块更好的预测准确率。因此,可以如Algorithm 1所示,同时优化matching和ranking函数。我们首先使用前面章节中描述的
fixed behavior retrieval system对prediction模块进行预训练。由于prediction模块在matching和ranking子模块的训练过程中提供监督信号,因此首先对其进行热身并使其具有基本的判别能力非常重要。之后,轮流训练
retrieval模块(第4-8行)和prediction模块(第9行),直至收敛。是每个子模块训练一个
epoch再轮流、还是每个子模块训练一个batch再轮流?作者未讲明这一点。UBR4CTR是每个子模块训练一个epoch,然后再训练另一个子模块一个epoch。
如
Algorithm 1所示,matching和ranking函数朝着同一目标一起优化。
1.4 模型分析
本节分析了时间复杂度,并将我们的框架与现有的
retrieval-based的CTR模型进行了比较。
1.4.1 时间复杂度分析
我们关注
retrieval过程的时间复杂度,因为它是UBR中最耗时的部分。对于
UBR,由于matching过程只是简单地访问索引,因此其时间是一个常数feature fields的数量,inverted index entry的时间。对于查找
top-k behaviors的ranking过程,时间复杂度为matching子模块中获取的candidate behavior set的大小。因为评分过程的时间复杂度与列表长度成线性关系。
因此,
UBR的总复杂度为UBR带来的主要耗时是GPU或CPU在内存中计算。然而,大多数基于behavior modeling的CTR模型可能具有user behaviors。此外,可以使用快速存储、更快的数据访问系统(如Redis等)对这只是
inference的时间复杂度。而训练的时间复杂度相当高。
1.4.2 不同的 Retrieval-based 的方法的比较
作为用于
CTR estimation的behavior modeling的新研究方向,关于retrieval-based的CTR模型的研究很少。最相似的模型是
SIM。SIM有两个变体,SIM-Hard和SIM-Soft。SIM-Hard是一个固定的搜索函数,它使用category id等单一特征从用户行为序列中进行搜索,这不够灵活,并且可能导致retrieved behaviors不是最优的。SIM-Soft使用局部敏感哈希 (local-sensitive hashing : LSH)进行MIPS从而找到相对于target item embedding最邻近的item embedding。item embedding使用辅助损失进行训练。SIM-Soft的第一个缺点是它依赖于辅助任务,如果user behaviors太多,则需要随机采样。第二个缺点是
LSH使用的索引应该经常更新(但是实际上没有更新),因为item embedding在训练时会发生变化。最后,
ranking函数仅限于内积形式,缺乏建模能力。
ETA使用SimHash生成item embeddings的二进制指纹,并计算target item指纹与behaviors指纹之间的汉明距离STARec利用item embeddings之间的余弦相似度作为ranking函数。
因此,所有现有的
retrieval-based的模型都遵循预定义的函数来检索behaviors,因此缺乏灵活性和学习能力。基于本文中描述的
matching和ranking,我们在Table 2中总结了现有模型。SIM-Hard本质上使用预定义的特征来匹配user behaviors,而SIM-Soft直接使用MIPS对behaviors进行排序,而无需matching过程。ETA和STARec也在Table 2中进行了总结。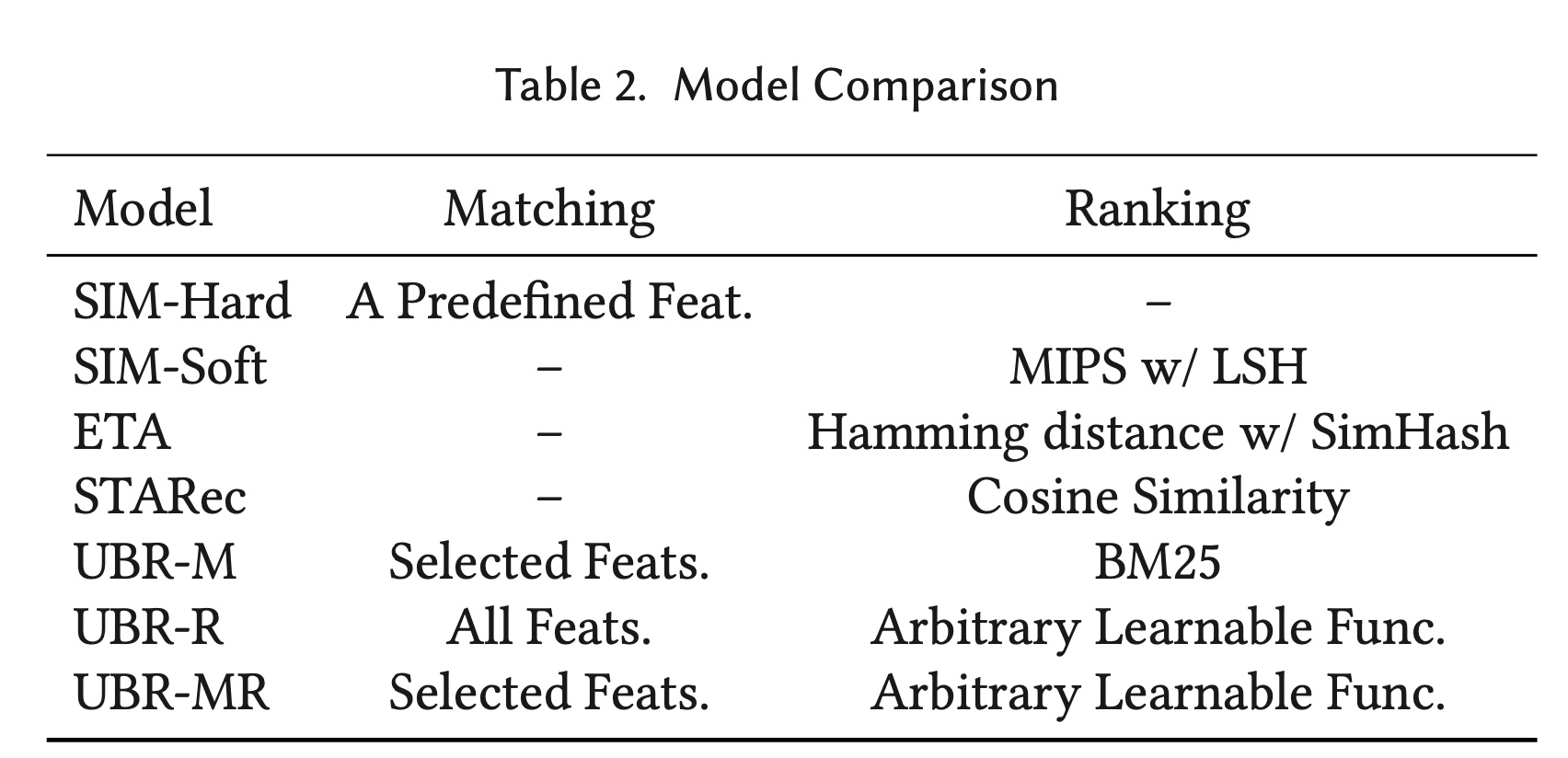
总体而言,
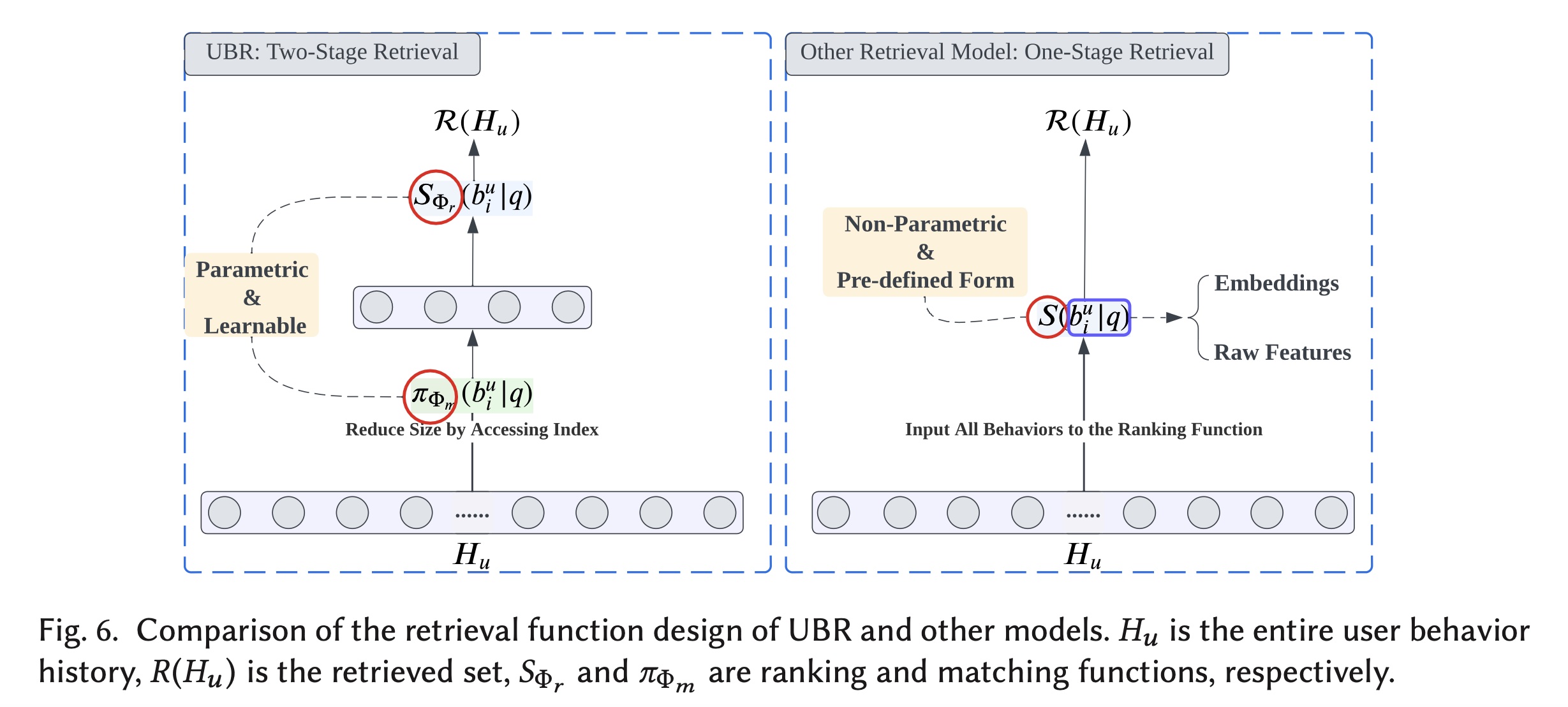
UBR的检索机制与其他模型的比较如Figure 6所示。对于
UBR,matching子模块在很大程度上减少了user behavior set的大小。由于这个reducing过程本质上是访问selected features的倒排索引,因此可以非常快速地进行,效率很高。设计这样的matching过程最重要的原因是避免对整个用户历史序列相反,其他
one-stage retrieval models选择对整个序列进行计算。为了快速地进行计算,它们实现尽可能简单的检索函数,例如汉明距离(ETA) 或余弦相似度 (STARec)。因此,这些模型的检索函数都是非参数化的,并且基于某种预定义形式。尽管非参数化的检索函数的输入可以是learnable embeddings,但函数的预定义形式限制了建模能力。因此,具有任意参数的可学习的检索函数是我们文章的主要关注点。此外,我们将检索函数实现为一个两阶段过程,以平衡有效性和效率。更多实验证据可在实验章节中找到。
至于
UBR的不同变体:UBR-M是由我们的会议文章(《User behavior retrieval for click-through rate prediction》)提出的,它使用selected features来匹配相应的user behaviors。feature selection由REINFORCE算法优化。但它仍然使用固定的ranking函数。UBR-R是一种新模型,它使用所有特征来匹配behaviors,从而产生比UBR-M更大的candidate behavior set。我们提出了一个参数化的ranking函数,它可以是任意结构,我们使用LTR对其进行优化。由于LTR过程有效地训练了ranking函数,UBR-R可以使用所有特征来匹配candidate set并准确获得top-k behaviors。UBR-MR是上述变体的混合版本,同时优化了matching子模块和ranking子模块。虽然UBR-MR同时优化了两个子模块并可以获得更好的性能,但它并不总是最好的选择。第一个原因是它的复杂性。在训练中,两个子模块都进行了优化,并且消耗的时间比
UBR-M或UBR-R大得多。第二个原因是,如果数据集只有非常有限的特征(例如,
item features只有item id以及category id),那么在matching中选择特征并不总是一个好主意。在这种情况下,使用所有特征来匹配behaviors是更好的选择。
实验章节中介绍了更多相应的结果,以及选择更好变体的见解。
1.5 实验
本节将介绍大量实验的细节。我们将我们的模型与几个强大的
baselines进行了比较,我们的模型在离线和在线评估中都取得了SOTA的性能。实现代码已发布(https://github.com/qinjr/UBR4CTR)。数据集:我们使用三个真实的、大型的
users online behaviors数据集。数据集的统计数据可以在Table 3中找到。Tmall数据集:由阿里巴巴集团提供,其中包含2015年5月至2015年11月天猫电商平台上的user behavior历史记录。Taobao数据集:包含来自淘宝中检索到的user behavior数据。它包含2017年11月25日至12月3日的user behaviors,包括点击、购买、添加到购物车、以及喜欢商品等几种behavior类型。Alipay数据集:由支付宝收集。用户的在线购物behaviors是从2015年7月1日到2015年11月30日。
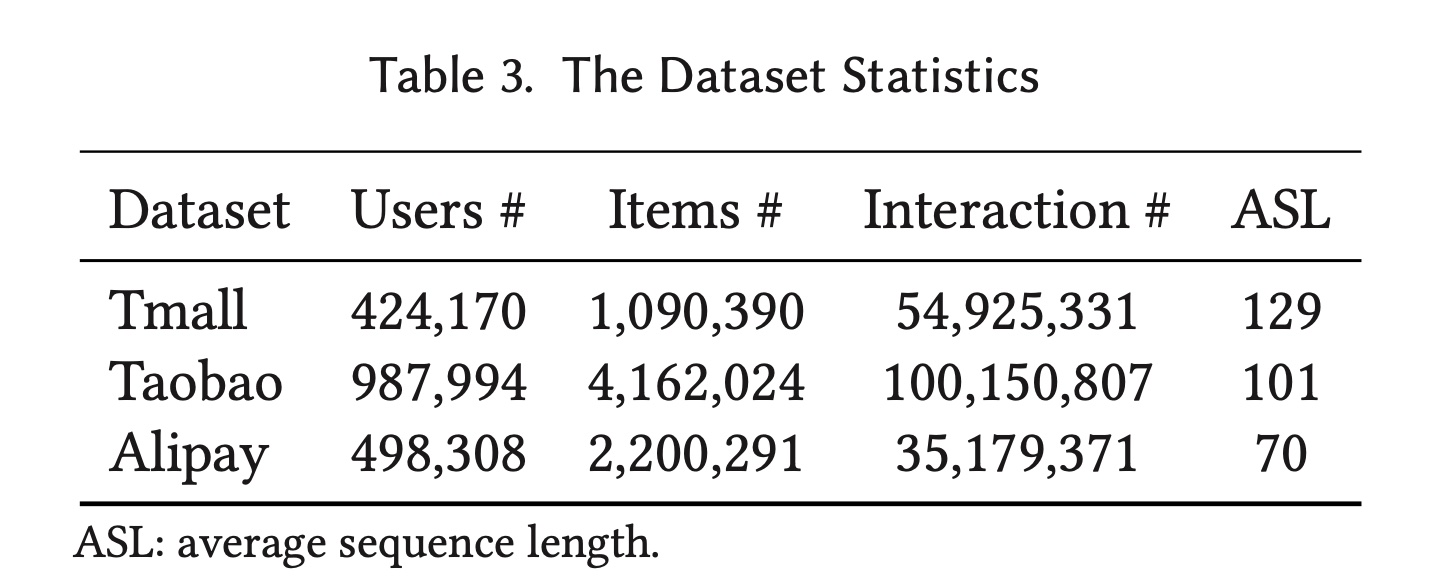
数据集预处理:对于
UBR,数据集被处理成逗号分隔特征的格式。包含user, item and context features的一行被视为一个behavior。对于baselines,user behaviors仅按时间戳排序。由于这三个数据集仅包含点击样本(即正样本),我们按照《Deep interest evolution network for click-through rate prediction》、《Deep interest network for click-through rate prediction》中的处理协议进行1:1负采样。Basic Retrieval Engine:我们使用逗号分隔的tokenizer将数据集插入一个retrieval engine。我们使用ElasticSearch作为backbone retrieval engine client,从而对公共数据集进行离线实验。Tmall、Taobao、以及Alipay数据集的posting list平均长度分别为6.9、7.3和8.9。训练集和测试集的拆分:我们使用
leave-one-out策略(按时间顺序排序)来拆分数据集。训练集包含第
user behaviors,其中第behaviors用于预测第behavior。类似地,验证集使用第
behaviors来预测第behavior。测试集使用第
behaviors来预测第behavior。
评估指标:
AUC、Logloss(简写为LL)。baselines:我们将UBR与一些强基线进行比较,这些baseline来自user behavior-based的CTR模型、以及序列推荐模型。DeepFM是一种混合模型,以双塔方式结合了FM和深度神经网络。PNN是一种单塔模型,在深度网络中结合了基于内积的特征交互。DCN使用多层交叉网络来建模特征交互。GRU4Rec基于GRU,这是第一篇使用recurrent cells来建模sequential user behaviors从而用于session-based recommendation的工作。Caser是一种CNNs-based的模型,它将用户序列视为图像,因此使用水平的和垂直的卷积层来捕获user behaviors的时间模式。SASRec使用Transformer。它将user behaviors视为tokens的一个序列,并使用自注意力机制和position embedding来捕获behaviors之间的依赖关系和关联。HPMN是一种分层周期性记忆网络(hierarchical periodic memory network),旨在处理非常长的用户历史序列。此外,user memory state可以增量地更新。MIMN基于神经图灵机(Neural Turing Machine),可对建模用户兴趣漂移的multiple channels。该模型是作为ser interest center的一部分来实现的,可以建模非常长的用户行为序列。DIN是第一个在在线广告的CTR prediction中使用注意力机制的模型。DIEN使用带有注意力机制的两层RNN来捕捉不断演变的用户兴趣。它使用计算出的attention values来控制第二个recurrent layer,称为AUGRU。R-Att使用Reformer是针对Transformer结构提出的,可以有效地处理长序列。它使用LSH来降低自注意力的计算复杂度。SIM是retrieve-based的模型,其动机与UBR相似。SIM有两种变体:SIM-Hard和SIM-Soft,分别利用确定性的hard search、以及embedding-based MIPS。ETA利用SimHash算法生成target item的二进制指纹、以及historical items的二进制指纹。它使用汉明距离来获取top-k nearest behaviors从而作为retrieved behaviors。STARec直接根据target item的embedding和behaviors embeddings来计算余弦相似度。然后它检索与target item最相似的behaviors。
1.5.1 实验结果
在本节中,我们对
UBR进行了详细的实验,包括整体性能比较、消融研究和超参数研究。此外,还介绍了UBR的训练过程的比较、以及推理时间比较。
a. 整体性能
我们对基线进行了两组实验。
第一组:由于传统的
user behavior modeling利用最近的连续行为,我们将最近的behaviors馈入基线。20%。第二组:整个用户序列被馈入到基线模型中。
为了公平比较,
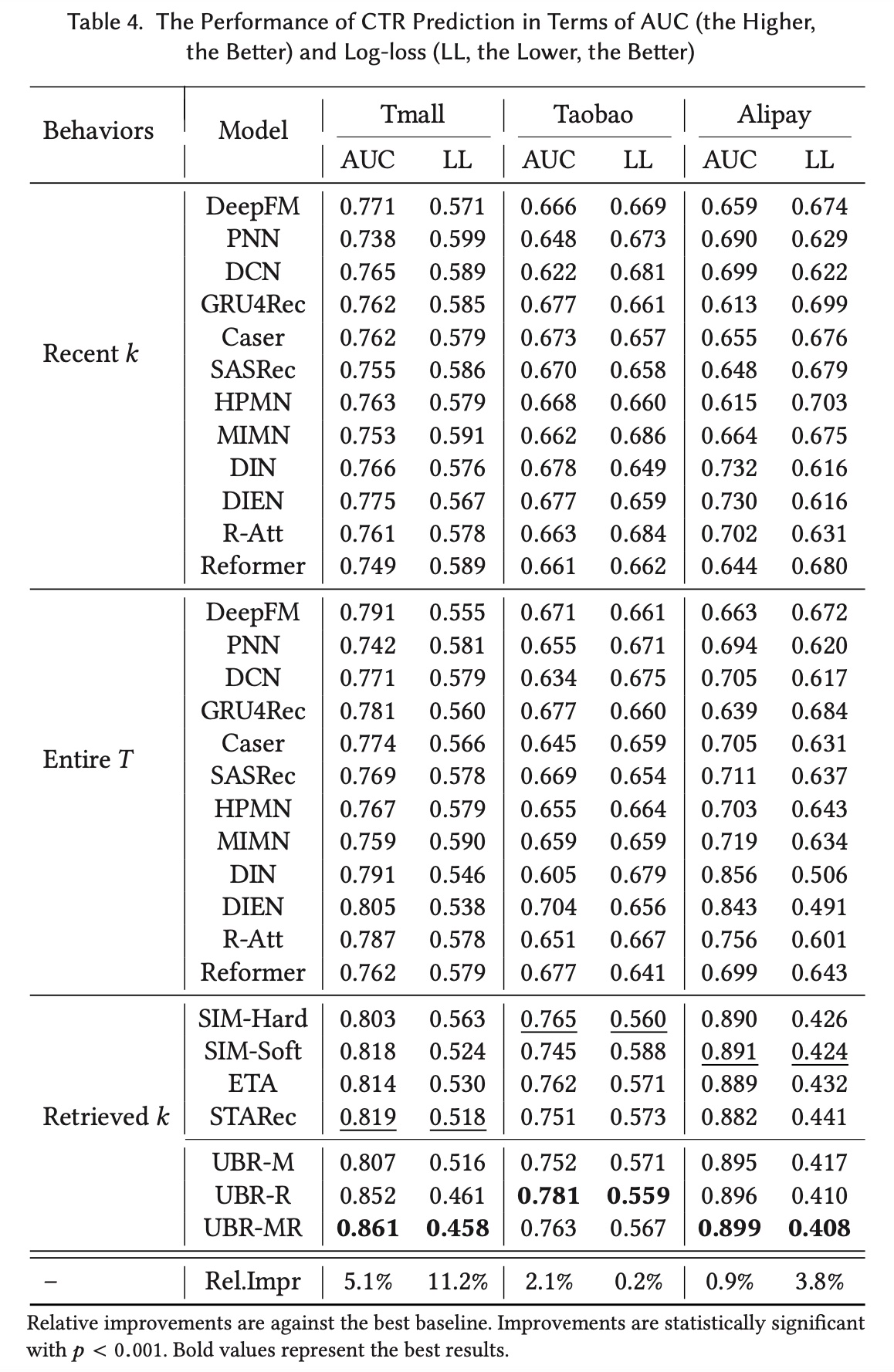
UBR将从整个用户序列中检索behaviors。基线使用不同的网络结构来学习user behaviors的unified representation,而UBR聚合retrieved behaviors。不同模型计算出的representation of user behaviors和其它特征一起被馈入到DNN。我们对不同的模型使用相同的DNN结构,唯一的区别是模型如何利用用户行为数据。 结果如Table 4所示。从表中我们发现以下事实:(i):UBR(UBR-R/UBR-MR)取得了最佳性能。在三个数据集上,它的AUC比最佳基线模型分别高出5.1%、2.1%和0.9%。在三个数据集上,Logloss分别改善了11.2%、0.2%和3.8%。结果证明了UBR的有效性。(ii):通过比较retrieved-based的模型和传统模型(recent k behaviors),观察到显著的改进,这表明直接检索user behaviors的重要性。使用
recent k behaviors的传统模型表现不佳。这表明最近的连续行为序列可能没有包含足够的时间模式。因此,模型无法有效地捕获patterns。虽然基线模型使用了复杂的网络结构,但由于输入数据的原因,它们无法获得良好的性能。(iii):对于使用全长序列的传统基线,我们可以发现大多数基线模型的性能都有所提高,表明较长的序列携带着更丰富的信息和模式。然而,
UBR仍然优于传统基线。这表明较长的序列可能包含更多的噪音和不相关信息,因此有必要从整个序列中只获取最相关的信息。(iv):UBR-R和UBR-MR优于现有的retrieval-based的模型和UBR-M。这验证了我们新提出的参数化的ranking函数和相应的LTR training的优越性。
为了增加测试难度并进一步验证
UBR的有效性,我们通过按用户而不是时间来拆分Tmall数据集,并进行了额外的实验。我们从non-retrieval models中选择了DIN和DIEN,因为它们在Tmall数据集上表现良好,并列出了所有retrieval-based的基线。我们根据用户来拆分,训练集、验证集、测试集分别包含80%的用户及其对应的用户行为序列。结果如Table 5所示。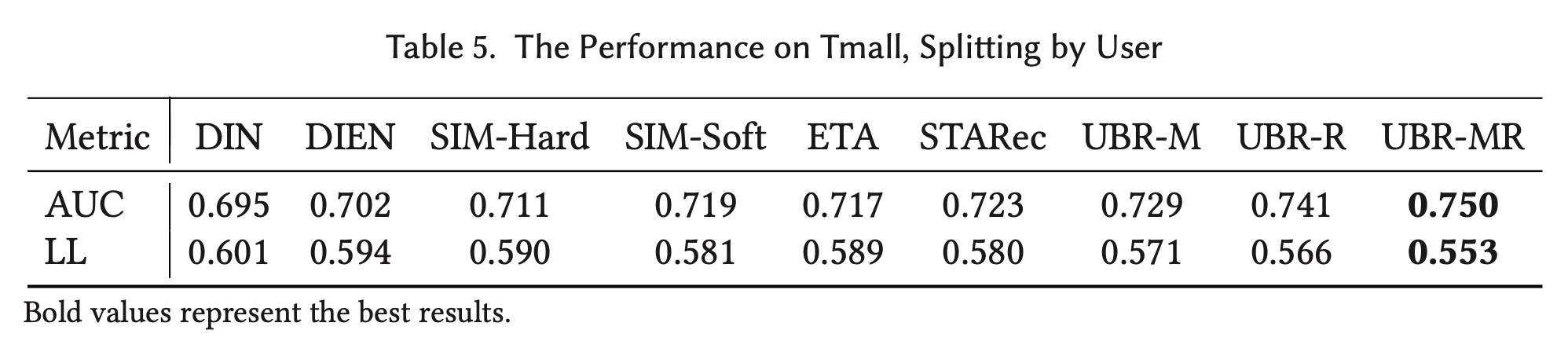
b. 消融研究
Retrieval模块的重要性:为了验证retrieval模块的必要性,我们使用最近k behaviors而不是retrieval模块,然后使用不同的聚合函数。结果如Table 6所示。我们测试了两种不同的behavior聚合函数:sum pooling: SP和attention: ATT。 从表中我们发现:配备
UBR模块后,两种聚合函数的预测性能都得到了很大程度的提高。结果证明了retrieval模块的重要性。此外,我们可以发现,即使采用像
sum pooling一样简单的聚合函数,SP w\ UBR-R也可以实现与ATT相比具有竞争力的性能。这一事实证明了retrieved behavior data的有效性。此外,
UBR-R可以带来比UBR-M更多的性能提升,这验证了我们提出的ranking函数和LTR training的有效性。

不同
UBR变体之间的比较:为了弄清retrieval模块的不同子过程的影响,我们在UBR-Fix(固定的retrieval system)、UBR-M、UBR-R(使用两种不同的ranking losses:BPR loss(《BPR: Bayesian Personalized Ranking from Implicit Feedback》)、lambdaloss)以及UBR-MR之间进行了另一次消融实验。 结果如Table 7所示。我们有以下观察和分析:(i):UBR-Fix在大多数情况下表现不如UBR的三个可学习的变体,这表明有必要使retrieval system可学习。(ii):在这三个数据集中,UBR-R (Lambda)优于UBR-R (BPR)。这表明在ranker的性能。(iii):UBR-MR在Tmall和Alipay数据集上优于UBR-R和UBR-M,但在Taobao数据集上表现较差。此外,在Taobao数据集上,UBR-Fix优于UBR-M。UBR-M和UBR-MR的共同点在于它们都使用selected features作为query来进行matching过程。但是,Taobao数据集只有两个item features(item id, category id)。如果selector为某些样本删除一个特征(例如category id),则许多有用的behaviors将被删除,并且没有机会进行排名。相反,Tmall和Alipay数据集有四个item features(item id, category id, merchant id, and brand id),这为feature selector提供了更大的操作空间。因此,matching过程可以得到更充分的训练,并产生更好的性能。至于
UBR-Fix/UBR-R,它们从更大candidate set(从所有可能得特征中获取)中对behaviors进行排名,因此它们在Taobao数据集上取得了更好的性能。
(iv):我们进一步介绍了每个UBR变体的训练时间。UBR-Fix无疑是最快的,因为它使用了不可训练的retrieval模块。UBR-MR的训练时间大约是UBR-R的2-3倍,因为两个子模块都经过了优化。因此,UBR-MR的收敛速度要慢得多。
在大多数情况下,考虑到
UBR-R在训练效率和测试性能之间的良好平衡,它已经足够好了。特别是当数据集的特征很少时,learning to match不是一个好主意(例如Taobao数据集)。总而言之,UBR-R是一个足够好的做法;而UBR-MR是一个更难的版本,可以实现更好的性能,但它需要更多的成本训练并增加整个系统的复杂性。
c. 超参数研究
本节我们研究了
retrieval size k的影响。Figure 7展示了UBR-M、UBR-R和UBR-MR在不同retrieval size k下的性能。从图中可以看出,AUC和logloss的波动在绝对值上并不是很剧烈。然而,每个数据集都存在一个最优规模。这表明较小的behaviors和信息;而太多的retrieved behaviors并不总是对性能有益,因为它们会包含更多的噪音。
d. 训练过程
本节我们展示了
UBR框架的训练过程。我们以UBR-R为例。prediction模块的性能曲线如Figure 8所示。在曲线中,我们绘制了不同test points的test AUC值。图中,“P”对应于prediction模块的训练过程(蓝色阴影区域),而“R”代表retrieval模块的训练(粉色阴影区域)。我们在训练数据集每间隔迭代
20%后测试一次CTR estimation的性能。因此,对于prediction module training的一个epoch,我们可以有五个test points。当训练好
retrieval模块时,我们每个training epoch测试一次prediction模块。
从图中可以看出:
在第一个粉色区域(
retrieval模块正在训练)中,prediction模块的测试性能显著提高。在粉色区域中,prediction模块是固定的,因为两个模块是轮流训练的。在第一个粉色区域之后,
prediction模块接近收敛。接下来的训练逐渐提高性能,直到最终收敛。
test AUC曲线验证了UBR的训练策略,retrieval模块实际上学习了有意义的模式,因为它可以在训练期间检索更多有用的behaviors(test AUC正在提高表明了这一点)。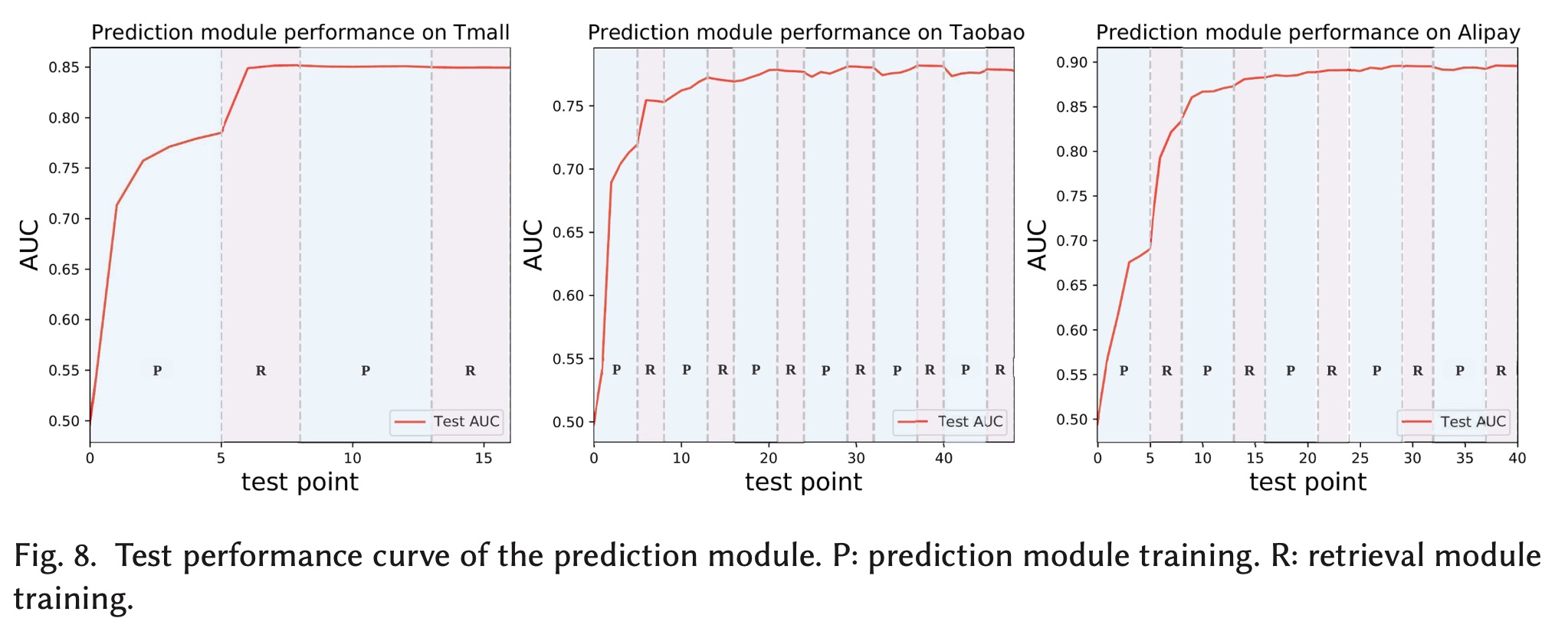
e. 推理时间和内存开销
为了解决效率问题,我们比较了
UBR和其他user behavior-based的CTR模型的推理时间。Figure 9显示了模型的平均推理时间。该时间是通过将测试数据集上的总时间除以batches数量来计算的。仅包括包含前向计算和behavior retrieval的时间。我们在具有Intel(R) Core(TM) i7-6900K CPU处理器、一块NVIDIA GeForce GTX 1080Ti GPU处理器和128 GB内存的机器上实现了两个版本的index storage。一种索引基于Elastic Search,并持久保存在磁盘上;而另一个版本则将索引结构加载并存储在内存中。UBR-M、UBR-R和UBR-MR具有相似的推理时间,因此我们使用UBR作为统一的名称。因为主要开销来自retrieval过程。 如图所示,UBR (in disk)的推理时间最长。但是,在这三个数据集上,每个样本的推理时间不超过1ms,这表明合并retrieval模块不会严重损害效率。由于公共数据集的索引结构可以存储在内存中,我们实现了内存存储版本的
UBR并测试了它的推理时间。我们发现更快的存储将显著提高retrieval模块的效率,并验证了UBR的主要开销来自访问磁盘。 倒排索引所消耗的内存存储如Table 8所示。
总体而言,
UBR会带来一些效率问题和内存开销,但并非无法忍受。我们接下来的在线实验进一步验证了这一点。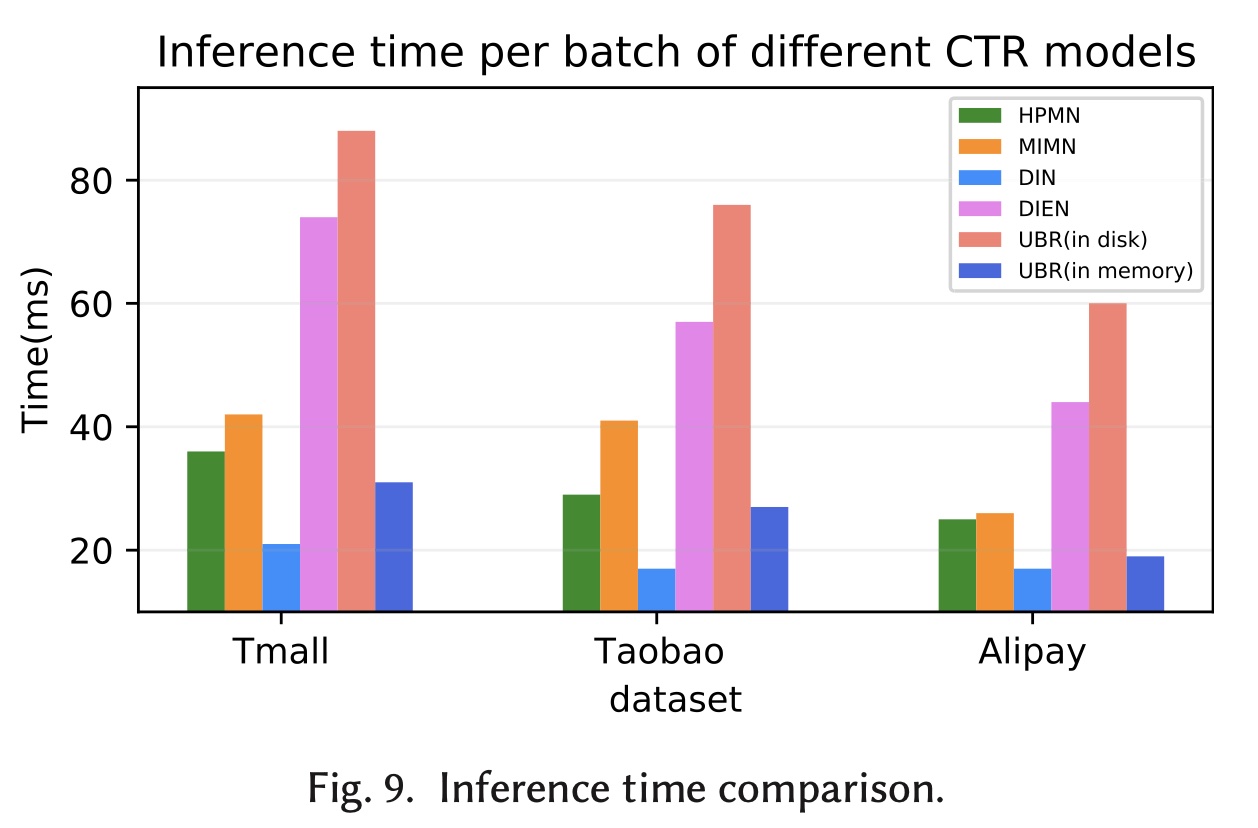

f. UBR 与其他 Retrieval-based 的模型的详细比较
在本节中,我们从有效性和复杂度方面比较了
UBR-MR和one-stage retrieval models。我们在Table 9中列出了test AUC、训练时间、以及推理时间。T-Inf是模型完成一个batch测试样本的计算的wall time。 从表中我们可以看出:UBR的性能最好,但其训练时间明显超过基线,这表明没有免费的午餐。UBR的推理复杂度为matching过程给出的candidate behaviors的数量);而其他模型的复杂度为UBR的matching操作需要额外的开销
综上所述,结果表明,与其他
one-stage retrieval models相比,UBR具有更好的效果,以及具有竞争性的推理效率。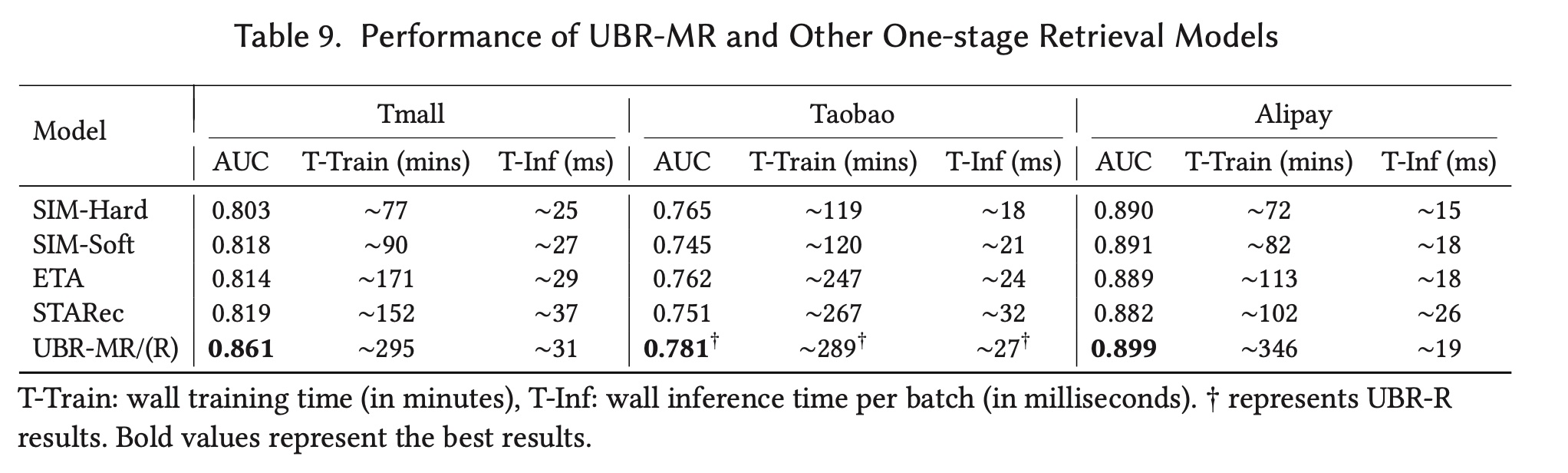
g. 非常长的用户行为序列
我们在
Tmall数据集中选取了behaviors超过1,000个的用户,从而对非常长的序列进行了广泛的实验。选定的用户数量为2,900。我们为每个用户使用一个positive item和九个随机采样的negative items,形成一个名为Tmall-Long的数据集。这个数据集用于推理过程。本次实验在具有12 GB GPU内存的NVIDIA 1080 Ti卡上进行。我们在这个数据集上测试了UBR与其他attention-based models的性能和开销。 结果如Table 10所示。从表中可以看出:UBR-MR明显优于attention-based的模型。这表明,对于非常长的序列,UBR表现出比注意力机制更好的建模能力。因为在1,000 behaviors中,可能会有很多噪音,而retrieval模块可以直接关注最相关的行为。就开销而言,
DIN是最快的模型,但UBR-MR在速度上仍然优于DIEN。这种推理效率是可以接受的。至于
GPU内存消耗,UBR-MR是最好的,因为只有matching子模块给出的candidate behaviors才会放入GPU内存中,我们将candidate behaviors size设置为100。这意味着不会有超过100 behaviors被馈入到ranking子模块。SASRec占用了太多内存,超过了GPU的内存大小。
这个实验展示了从很长的序列中
retrieving behaviors(而不是直接将整个用户序列馈入到attention model)的优势。如果序列长度增长到10,000的级别(如《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》所示),由于计算和GPU内存的负担很重,attention无法直接使用。但是retrieval模块可以处理它,因为我们总是可以获取一小部分behaviors,并仅将这一小部分behaviors提供给prediction模型。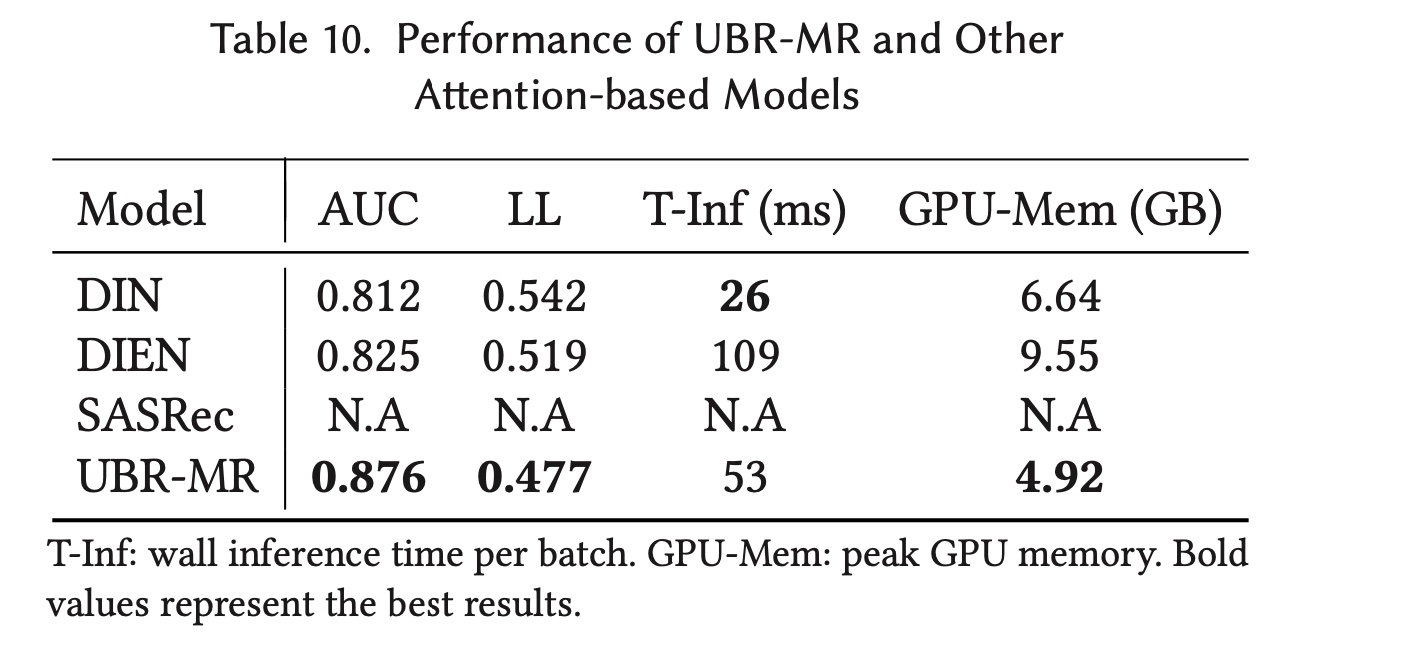
1.5.2 真实世界的部署
UBR已在真实世界部署中进行了测试,并取得了可喜的成果。在本节中,我们展示了在Huawei App Store付费广告场景中获得的离线和在线评估结果。app store每天有数亿活跃用户,每天会产生数百亿个用户日志事件,这些事件包括浏览、点击和下载apps等隐式反馈。
a. 工业数据上的离线评估
设置:离线评估是在工业数据集上进行的。工业数据集由
Huawei App Store上主页广告场景的八天日志组成。前七天的日志用于训练,第八天的日志用于测试。对于工业数据集,positive ratio约为0.3%。UBR从用户过去一年的behaviors中检索数据,这意味着每个用户的retrieval pool都包含该用户去年的所有behaviors。我们通过将
retrieved behaviors(聚合后)作为新特征添加到base model来测试UBR性能。此UBR特征与其他常规特征拼接在一起,并馈入到CTR模型。base模型是DCN、DeepFM和PNN,因为它们是广泛使用的工业级CTR estimation模型。结果:结果如
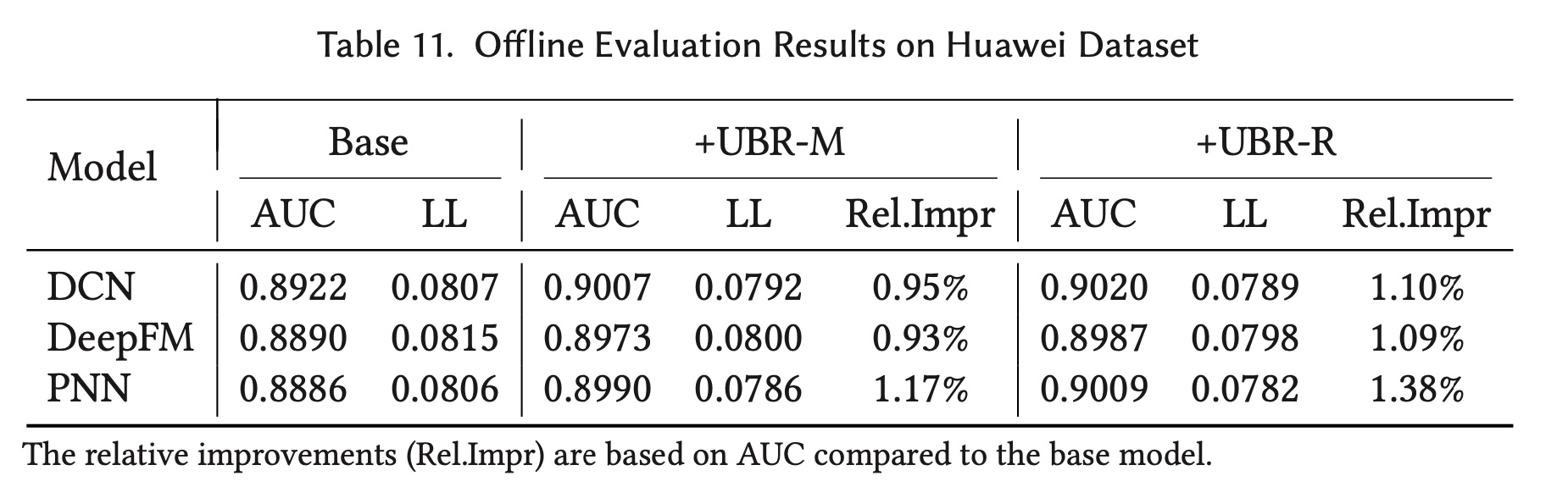
Table 11所示。对于三个不同的
base models,UBR-M带来了0.95%、0.93%和1.17%的AUC改进。与
base model相比,UBR-R将AUC指标提高了1.10%、1.09%和1.38%。结果验证了UBR可以与其他模型一起使用,并实现显著的性能提升。从表中,我们还观察到
UBR-R可以比UBR-M带来更多的性能提升,这表明ranking function是UBR系统的重要组成部分。至于
UBR的开销,每个batch的推理时间增加了31%,但仍少于100毫秒。由于倒排索引结构在内存中被存储,内存消耗增加了56%。这个成本对于工业级应用来说是可以接受的。
b. 在线 A/B Test
设置:我们在
Huawei App Store的付费广告场景中进行A/B test。部署的场景位于Huawei App Store的主页上,它是App Store的主要广告服务。商业的baseline表示为UBR-enhanced model表示为UBR(具体而言是UBR-R)从过去一年检索到的user behaviors。在A/B Test实验持续24天,分为两个阶段:第一阶段随机选取总用户数的
20%,其中一半作为实验组,另一半作为对照组。第二阶段随机选取
50%的用户进行A/B Test。
两个阶段都持续
12天。每个阶段,我们进行5天的A/A test,然后进行7天的A/B test。在A/A test期间,所有用户都由base modelA/B test期间,对照组用户使用base modelapps,而实验组用户使用apps。我们使用Redis存储user behaviors的倒排索引结构。 我们使用一台配备48 core Intel Xeon CPU E5-2670 (2.30 GHz)、400 GB RAM、以及2张NVIDIA TESLA V100 GPU卡的机器来部署UBR。在压力测试中,30%。指标:我们检查了
online evaluation中广泛采用的两个指标:有效的每千次展示费用(
effective Cost per Mille: eCPM):点击率(
Click-Through Rate: CTR):
其中:
num of downloads和num of impressions分别是下载次数和展示次数。结果:
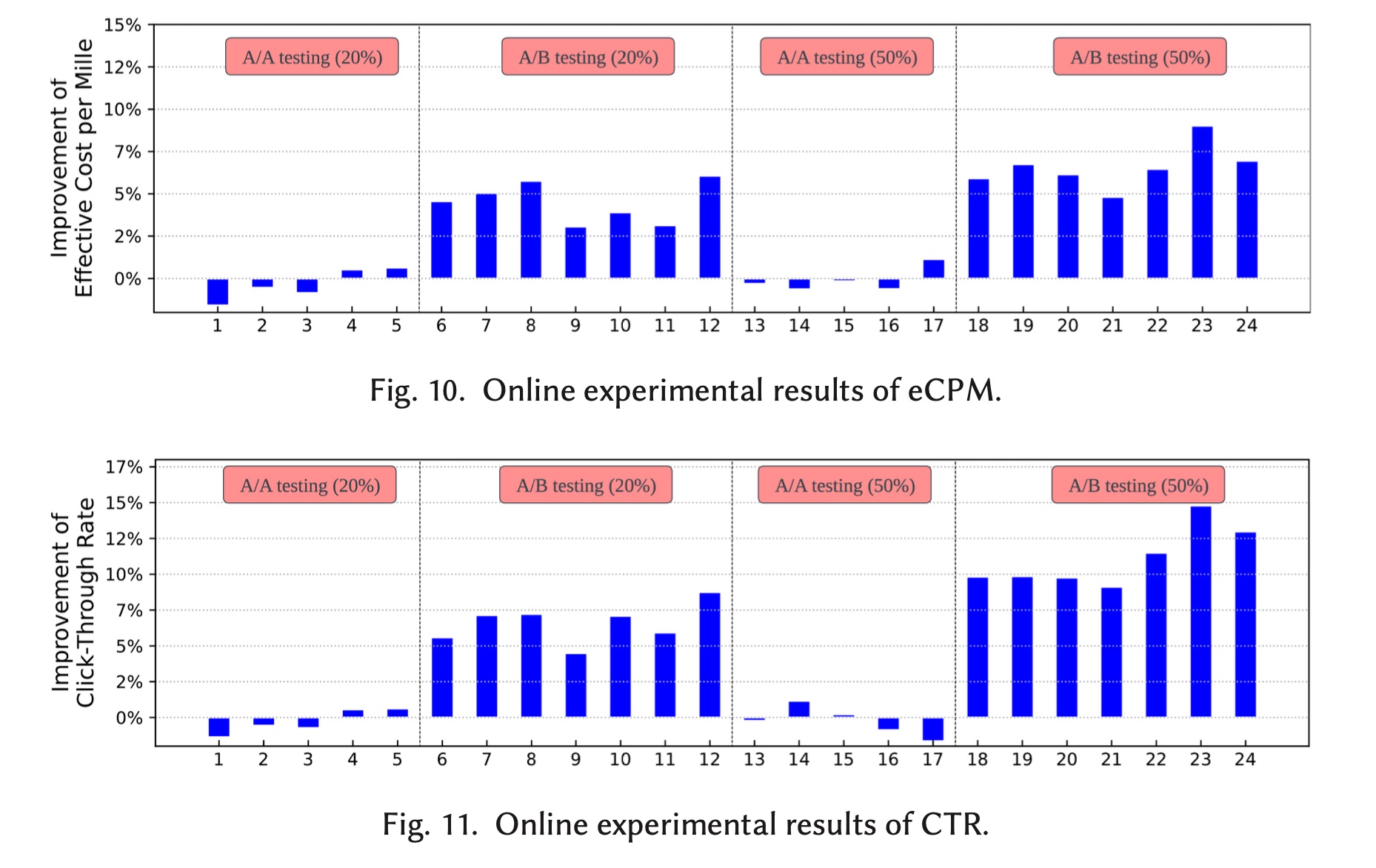
eCPM和CTR的改进分别如Figure 10和Figure 11所示。可以看到,系统非常稳定:在
A/A test期间,eCPM和CTR在1.5%以内波动。在第
6天到第12天和第18天到第24天,A/B test期间,当在
20%流量A/B test中,eCPM和CTR的平均提升分别为4.5%和6.6%。对于
50%流量的A/B test,eCPM和CTR平均分别提高了6.6%和11.1%。
这些结果清楚地证明了
UBR的优越性,目前它已全面部署在Huawei App Store的付费广告场景中,并服务于所有流量。