一、Wukong [2024]
《Wukong: Towards a Scaling Law for Large-Scale Recommendation》
scaling laws在模型质量的持续提升中起着关键作用。遗憾的是,由于现有推荐模型的upscaling机制的效率低下,其尚未展现出类似大语言模型领域中观察到的scaling laws。这一局限使其在适应日益复杂的真实世界数据集时面临显著挑战。本文提出一种完全基于堆叠因子分解机(stacked factorization machines)的高效网络架构,以及协同扩展策略(synergistic upscaling strategy),统称为Wukong,旨在为推荐领域建立scaling law。Wukong的独特设计使其能够通过增加网络层数和宽度,捕获任意阶数的interactions。我们在六个公开数据集上进行了广泛评估,结果表明Wukong在模型质量上始终优于SOTA的模型。此外,我们在内部大规模数据集上评估了Wukong的可扩展性,结果显示其不仅在质量上优于现有SOTA模型,还能在模型复杂度跨越两个数量级(超过100 GFLOP/example)时保持scaling law,而这是现有方法无法实现的。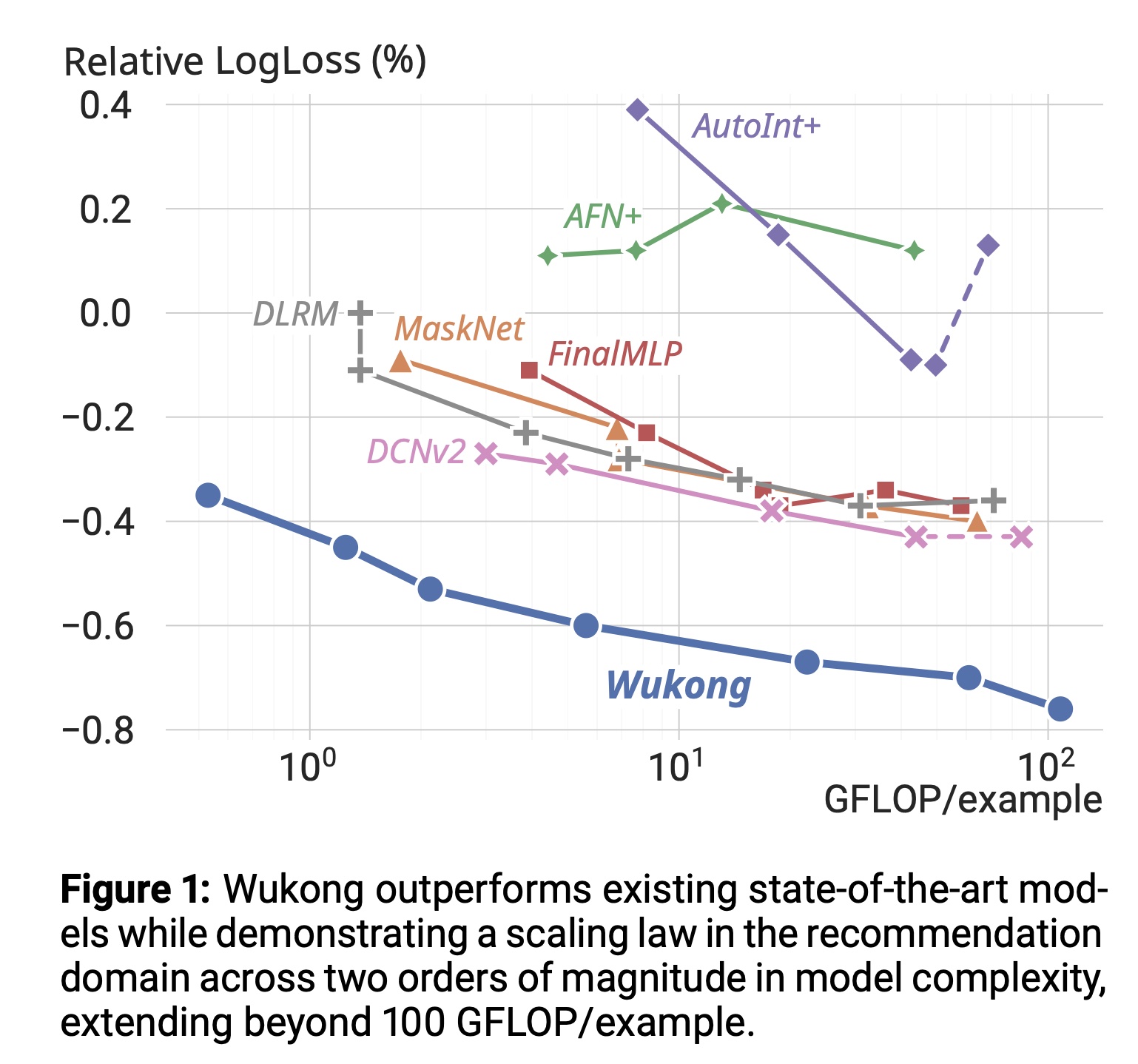
基于深度学习的推荐系统(
Deep learning-based recommendation systems: DLRS)如今为广泛的在线服务提供支持。现代DLRS旨在处理混合的continuous dense features(如日期)和categorical sparse features(如用户点击历史)。每个sparse feature通过可训练的embedding lookup table转换为dense embedding representation,这些dense embeddings随后被馈入到interaction component中,以捕获特征之间的复杂交互。尽管现有模型在较小数据集上表现出良好的准确性,但其适应更大规模和更复杂数据集的能力,以及在模型
scale up时持续提升质量的能力仍不明确。随着现代数据集呈指数级增长,这种可扩展性变得愈发重要。例如,当前的生产数据集可能包含数百亿个训练样本。此外,foundational models(《On the opportunities and risks of foundation models》)需要scale,以同时处理更复杂的多源输入(multiple complex input sources)。因此,构建能够有效扩展或收缩、适应不同数据集规模和计算约束的DLRS至关重要,这一特性即所谓的"scaling law"。目前,
DLRS up-scaling的主要趋势是通过sparse scaling,即扩大embedding tables的规模(更多行数和/或更高维度)以减少冲突(collision)并提升表达能力。这使得DLRS的参数规模达到数万亿(《Learning to embed categorical features without embedding tables for recommendation》、《High-performance, distributed training of large-scale deep learning recommendation models》、《Persia: An open, hybrid system scaling deep learning-based recommenders up to 100 trillion parameters》),其中embedding tables占主导地位。然而,这种传统up-scaling存在实际缺陷:单纯扩大模型的sparse component并不能增强其捕获日益复杂的interactions的能力;此外,这一趋势与硬件发展方向明显背离,因为下一代accelerators的性能提升主要体现在计算能力上,而embedding table lookups无法利用这些能力。因此,单纯扩展embedding table会导致基础设施成本过高且accelerator利用率低下,尤其在分布式环境中。我们的工作旨在为推荐模型寻找一种替代的
scaling机制,以建立类似大语言模型领域的scaling law,即设计一个统一的架构,通过综合策略(synergistic strategy)使其质量随数据集规模、计算量和参数预算(parameter budgets)的增加而持续提升。我们聚焦于扩展
interaction components(称为dense scaling),以缓解sparse scaling在质量和效率上的缺陷。然而,现有模型因各种原因无法从这一范式中受益。例如,DLRM缺乏捕获高阶交互的能力;DCNv2和AutoInt+缺乏有效的upscaling策略,导致scaling up时收益迅速递减;此外,即使采用residual connection、layernorm、gradient clip等现代技巧,扩展现有模型仍容易出现训练稳定性问题(《Improving training stability for multitask ranking models in recommender systems》)。为建立推荐模型的
scaling law,我们提出Wukong,这是一种简单的交互架构,具有高效的dense scaling特性。受二进制指数(binary exponentiation)思想启发,我们的关键创新是使用一系列堆叠的因子分解机(Factorization Machines: FMs)来高效且可扩展地捕获任意阶数的特征交互。在设计中,每个FM负责捕获输入的二阶交互;FM的输出通过MLP转换为新的embeddings,这种方式将对interactions的结果进行编码并作为下一层的输入。我们使用六个公开数据集和一个大规模内部数据集对
Wukong进行了评估。结果表明,Wukong在所有公开数据集上的AUC均优于SOTA模型,证明了其架构的有效性和跨广泛recommendation tasks and datasets的泛化能力。在内部数据集上,Wukong不仅在相当复杂度水平下质量显著优于现有模型,还能在模型复杂度跨越两个数量级(超过100 GFLOP/example)时持续提升质量,而现有方法在此范围内已无法有效scale up。
1.1 相关工作
Deep Learning Recommendation Systems (DLRS):现有的DLRS具有相似的结构。典型的模型由sparse component和dense component组成。sparse component本质上是embedding lookup tables,将sparse categorical features转换为dense embeddings。而
dense component则负责捕获这些embeddings之间的交互以生成prediction。
Dense Interaction Architectures:捕获特征之间的交互是DLRS有效性的关键,我们在此梳理一些先前的研究成果:AFN+:将特征转换到对数空间(logarithmic space)以捕获任意阶数的交互(《Adaptive factorization network: Learning adaptive-order feature interactions》)。AutoInt+:使用多头自注意力机制(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)。DLRM和DeepFM:利用因子分解机(Factorization Machines: FM)显式捕获二阶交互(《Deep learning recommendation model for personalization and recommendation systems》、《Deepfm: a factorization-machine based neural network for ctr prediction》)。HOFM:优化FM以高效捕获高阶交互(《Higher-order factorization machines》)。DCNv2:使用CrossNet,通过stacked feature crossing来捕获交互,可视为一种elementwise input attention(《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)。FinalMLP:采用双线性融合(bilinear fusion)来聚合两个MLP streams的结果,每个stream以stream-specific gated features为输入(《Finalmlp: An enhanced two-stream mlp model for ctr prediction》)。MaskNet:采用一系列MaskBlock进行interaction capture,对input和DNN的intermediate activations应用"input attention"(《Masknet: Introducing feature-wise multiplication to ctr ranking models by instance-guided mask》)。xDeepFM:将DNN与Compressed Interaction Network结合,通过外积捕获交互并通过element-wise summation来压缩结果(《xdeepfm: Combining explicit and implicit feature interactions for recommender systems》)。
Scaling up DLRS:《Learning to embed categorical features without embedding tables for recommendation》、《High-performance, distributed training of large-scale deep learning recommendation models》、《Persia: An open, hybrid system scaling deep learning-based recommenders up to 100 trillion parameters》提出了sparse scaling机制。《Scaling law for recommendation models: Towards general-purpose user representations》专注于scaling up user representation models,其报告的最大模型总计算量小于0.1 PF-days。《Scaling law of large sequential recommendation models》旨在改进用户侧的sequence modeling,最大模型参数少于0.8B。此外,
《Understanding scaling laws for recommendation models》研究了DLRM的scaling law,该模型在我们的工作中作为基线,并在实验中进一步scaled up。与之正交的是,
《Breaking the curse of quality saturation with user-centric ranking》提出以用户为中心的ranking公式以提高可扩展性。《On the embedding collapse when scaling up recommendation models》对sparse scaling的局限性进行了分析,与我们的工作形成互补。此外,
VIP5(《Vip5: Towards multimodal foundation models for recommendation》)利用LLM中的现有scaling laws将多模态LLM应用于推荐,然而《How can recommender systems benefit from large language models: A survey》指出需要进一步研究验证基于LLM的推荐是否“模型越大性能越好”,而《Foundation models for recommender systems: A survey and new perspectives》建议需在更多样化的数据集上进行评估以得出结论。
1.2 Wukong 的设计
在设计
Wukong的架构时,我们牢记两个目标:(1):有效捕获复杂的高阶feature interactions。(2):确保Wukong的质量随数据集规模、GFLOP/example、以及parameter budgets的增加而优雅地扩展。
a. 概述
在
Wukong中,categorical features和dense features首先经过Embedding Layer,将这些inputs转换为Dense Embeddings。 如Figure 2所示,Wukong随后采用Interaction Stack,这是一组unified neural network layers,用于捕获embeddings之间的交互。Interaction Stack的设计灵感来自二进制指数(binary exponentiation)的概念,允许每一层捕获指数级高阶的特征交互。Interaction Stack中的每一层包含一个Factorization Machine Block: FMB和一个Linear Compression Block: LCB。FMB和LCB独立地接收input(来自于上一层),它们的outputs被集成(ensembled)从而作为当前层的output。interaction stack之后是一个final的Multilayer Perceptron: MLP层,将interaction结果映射为prediction。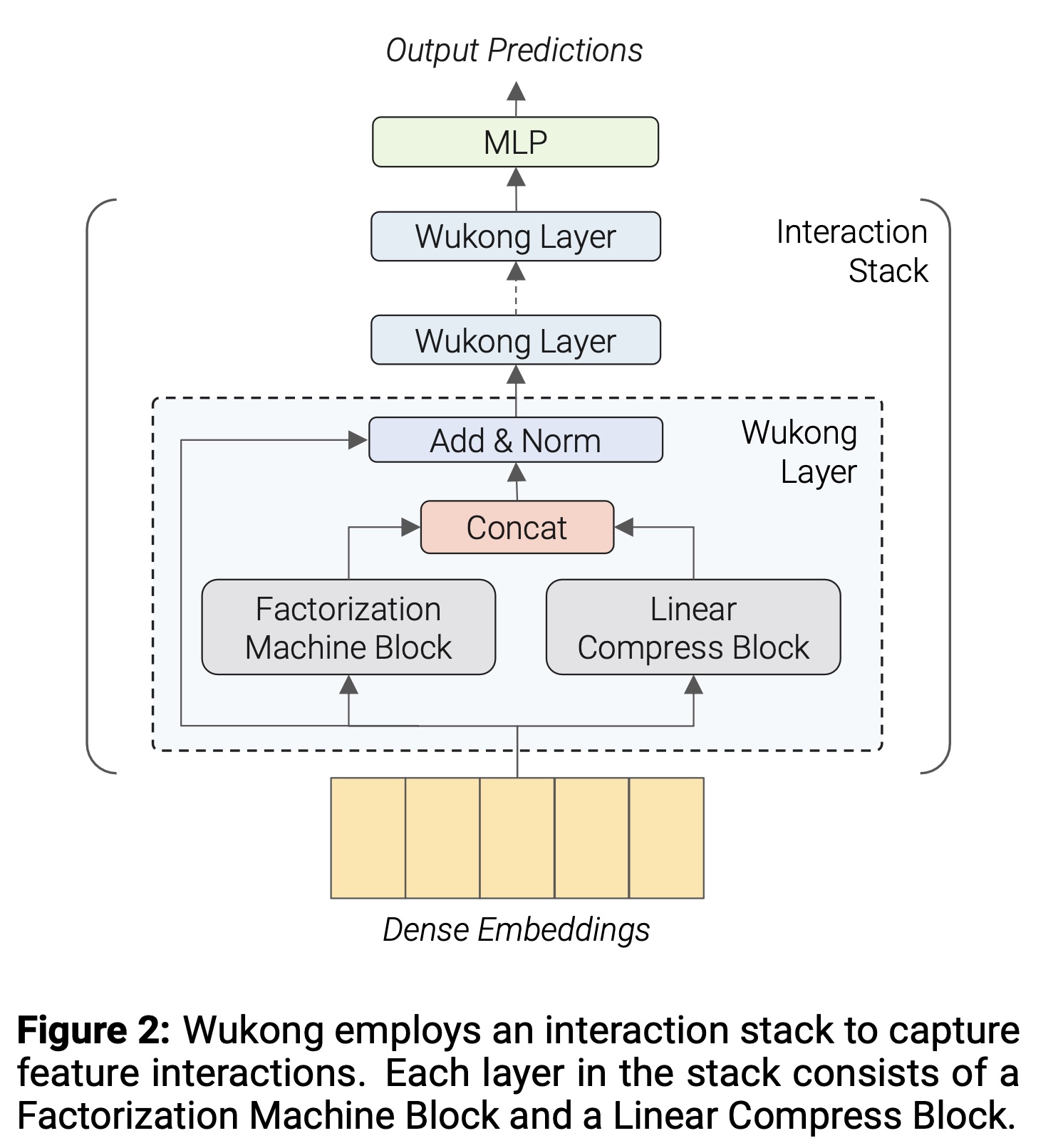
b. Embedding Layer
给定一个
multi-hot categorical input,embedding table将其映射到dense embedding。该过程涉及一系列lookups操作,每个操作对应input中的一个“hot” dimensions,lookup结果通过池化操作(通常为summation)聚合。在我们的设计中,所有由
Embedding Layer生成的embedding dimension被标准化为global embedding dimensionembeddings。less important特征分配更小的underlying embedding dimensions。这些smaller embeddings被分组、拼接后通过MLP转换为embeddings。如何做?论文并未详细说明。这种
multi embeddings可以提升模型的表达能力。为进行公平比较,所有其他baseline模型也应该这样做。dense inputs通过MLP转换为相同维度latent embeddings,并与categorical input的embedding outputs拼接,得到大小为output tensor,其中dense part和sparse part的embeddings的总数。Interaction Stack进一步处理。如何做?论文也并未详细说明。读者猜测:是将所有
dense inputs拼接在一起,构成一个向量。然后通过MLP进行映射。但是这里有个疑问:是否需要对
dense inputs进行归一化、或者batch normalize?值得注意的是,与
DCN(《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)等传统方法不同,我们将每个embedding向量视为一个整体单元(细节见后文),因此我们将
c. Interaction Stack
interaction modules堆叠interaction layers),每层通过因子分解机(Factorization Machines: FMs)逐层捕获高阶的特征交互。每个交互层包含并行的两个模块:
Factorization Machine Block: FMB、Linear Compression Block: LCB。FMB计算层内input embeddings的特征交互,LCB则简单地对input embeddings进行线性压缩并forwards。FMB和LCB的outputs随后被拼接起来。对于
stack中的第FMB在给定LCB的输出保证,上界由FM对input中两个interactions的交互而生成。为稳定训练,我们在层间采用
residual connections和layer normalization: LN。整体公式为:根据
FMB和LCB的具体配置,embeddings数量可能不同(常见于第一层)。此时,残差连接会通过线性压缩调整形状以匹配。
d. Factorization Machine Block (FMB)
FMB包含一个FM和一个MLP。FM用于捕获input embeddings的显式特征交互,输出为一个二维interaction matrix,其中每个元素表示a pair of embeddings之间的交互。该
interaction matrix被展平,然后通过MLP被转换为一个尺寸为reshape为embeddings以供后续使用。
具体操作如下:
注意,这里有个
LN layer,位于flatten之后。Wukong的FM模块完全可定制:例如,在最基础版本中,我们采用《Deep learning recommendation model for personalization and recommendation systems》的FM设计,即对embedding vectors之间的所有pairs取内积,即:更优化的
FM设计见后续章节。
e. Linear Compress Block (LCB)
LCB仅对embeddings进行线性重组而不增加交互阶数,这对确保各层交互阶数的不变性(invariance)至关重要。具体而言,它保证第LCB的操作可描述为:其中:
embeddings数量),input embeddings数量。
f. Optimized FM
传统
FM通过pair-wise内积计算交互矩阵,其计算和存储复杂度随embeddings数量呈二次方增长,这在具有数千特征的真实数据集上难以承受。 为在降低计算成本的同时有效捕获特征交互,我们采用类似《Feature fusion for the uninitiated》、《Dot product matrix compression for machine learning》的方案,利用pair-wise内积矩阵的低秩性质(这在许多真实数据集上已被观察到,《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)。当
embedding维度的大规模数据集上常见)。因此,我们可通过将读者猜测具体的做法是:先将
MLP从而得到MLP的权重矩阵。然后计算此外,为提升模型质量,可通过对
compressed input进行MLP处理从而得到投影矩阵input具有注意力机制。除非特别说明,我们在后续实验中默认使用optimized FM。怎么做?作者也未详细说明。
g. 复杂度分析
假设
Interaction Stack的每层使用相同超参数,且MLP中最大的全连接层大小为对于第一层:
FMB的时间复杂度为FM和MLP的总和:FM部分为MLP部分为LCB的时间复杂度为
对于后续层,时间复杂度为
因此,
Wukong的总时间复杂度为
h. Scaling Wukong
以下总结与
scale up的主要超参数:Interaction Stack的层数。FMB所生成的embeddings的数量。LCB所生成的embeddings的数量。optimized FM中的compressed embeddings的数量。MLP:FMB中MLP的层数和全连接层大小。
在
scaling up过程中,我们首先增加
i. Wukong 的 Enhanced Effectiveness 的直觉
与现有以
FM为主要交互架构的工作相比,Wukong通过堆叠FM的创新方法显著增强了传统FM的能力,使其能够捕获任意阶交互,这对需要高阶推理的大规模复杂数据集尤为有效。尽管已有高阶FM的研究,Wukong捕获高阶交互的指数级效率避免了HOFM的线性复杂度和xDeepInt中外积操作的高成本。MLP在隐式地捕获交互方面存在局限性(《Latent cross: Making use of context in recurrent recommender systems》)。Wukong不同于依赖MLP进行interaction capture的方法,而是主要利用MLP将交互结果转换为embedding representations,供后续interactions使用。这种对MLP的独特用法增强了模型处理和解释复杂异构特征的能力。 此外,Wukong将每个embedding视为一个独立单元,专注于embedding-wise交互,这与捕获element-wise的架构相比,显著降低了计算需求。
1.3 实现
本节讨论在大规模数据集上有效训练高复杂度
Wukong模型的实践方法。总体而言,分布式训练是使
Wukong training可行的必要条件。对于
embedding layer,我们使用Neo(《High-performance, distributed training of large-scale deep learning recommendation models》)和NeuroShard(《Pretrain and search: Efficient embedding table sharding with pre-trained neural cost models》)提供的column-wise sharded embedding bag implementation。在
dense部分,我们通过采用FSDP(《Pytorch fsdp: experiences on scaling fully sharded data parallel》)并调整sharding factor,平衡性能与内存容量,确保模型适合内存且不产生过多冗余。
为提高训练效率,我们通过
automatic operator fusion以提升训练性能。此外,我们积极应用quantization技术以同时降低计算、内存和通信开销。具体而言:Wukong的embedding tables以FP16训练。embedding lookup结果在前向传播中以FP16通信,在反向传播中以BF16通信。反向传播中
dense参数的梯度传输采用BF16 quantization。
1.4 评估概述
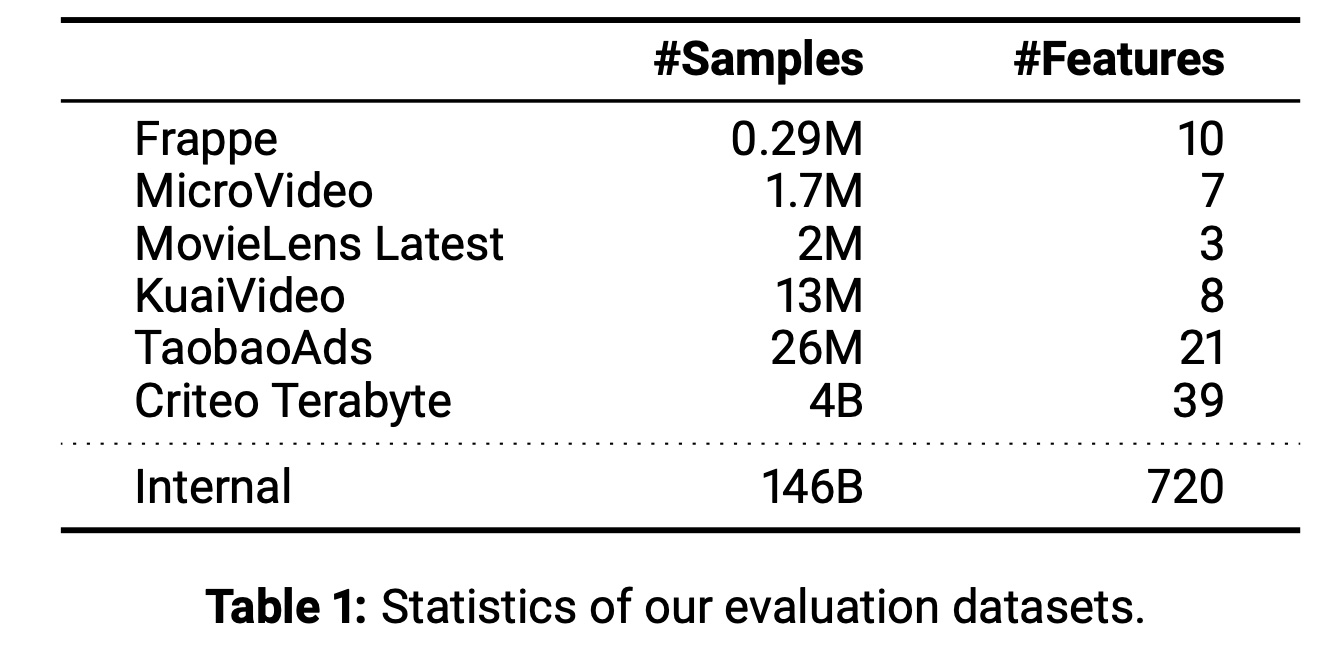
我们使用六个公开数据集和一个内部数据集对
Wukong进行评估,详情汇总于Table 1。评估结果分为两个部分呈现。首先,我们在六个公开数据集上评估
Wukong,重点展示其在低复杂度场景下的有效性。结果表明,Wukong在所有六个数据集上均超越先前的SOTA方法,证明了其有效性。然后,我们在大规模内部数据集上评估
Wukong的可扩展性。该数据集的样本量是最大公开数据集Criteo的30倍,特征数是其20倍。结果显示:(1):Wukong在模型质量和运行速度上始终优于所有基线模型,并在所有复杂度范围内保持这一优势。(2):与基线模型相比,Wukong展现出更好的scaling趋势。
我们还进行了消融实验,以了解
Wukong各组件的独立贡献和有效性。
1.5 公开数据集上的评估
本节旨在展示
Wukong在多种公开数据集上的有效性。除非另有说明,为与先前工作保持一致,我们使用BARS benchmark提供的预处理数据。数据集:
Frappe:是一个app usage log。该数据集预测用户在给定上下文下是否使用app。MicroVideo:由THACIL提供的基于内容理解的数据集,包含用户与微视频的交互,日志包含多模态embeddings和传统特征。MovieLens Latest:著名的用户对电影评分的数据集。KuaiVideo:快手发布的竞赛数据集,用于预测用户对新微视频的点击概率,包含基于内容理解的embeddings、及其他categorical and float features。TaobaoAds:包含淘宝广告CTR prediction的8天数据。Criteo Terabyte:包含24天广告点击反馈数据,我们使用最后一天数据进行测试。
基线模型:我们将
Wukong与学术界和工业界广泛认可的七种SOTA模型进行基准测试,包括AFN+、AutoInt+、DLRM、DCNv2、FinalMLP、MaskNet和xDeepFM。评估指标:
Area Under the Curve (AUC):衡量模型在所有阈值下正确分类正负样本的能力,值越高越好。遵循推荐领域惯例,我们使用AUC作为超参数调优和报告的主要指标。LogLoss:衡量prediction与actual label的距离,值越低越好。
模型配置:
对于除
Criteo外的五个较小数据集,我们采用公开的BARS评估框架。在可能的情况下,直接使用BARS上搜索到的最佳模型配置,其余使用默认超参数。除框架提供的默认embedding维度外,我们进一步测试128维embedding,并报告两种配置中表现更好的结果。对于Wukong,我们调优dropout rate、optimizer settings和compression of LCB以适应特征数量。我们利用较大的
Criteo数据集评估模型在真实在线推荐系统中的性能,进行one-pass training。鉴于新的training setup,我们使用"Implementation"章节所述的系统对所有基线模型和Wukong进行了广泛的网格搜索,以促进公平比较,该过程涉及近3000次独立运行。模型特定的搜索空间见附录A。搜索得到的最佳模型超参数随后作为下一节的base config。
结果汇总于
Table 2。总体而言,Wukong在所有公开数据集中在AUC指标上达到SOTA水平。这一结果证明了Wukong架构的有效性及其理解多样化数据集、跨广泛推荐任务泛化的能力。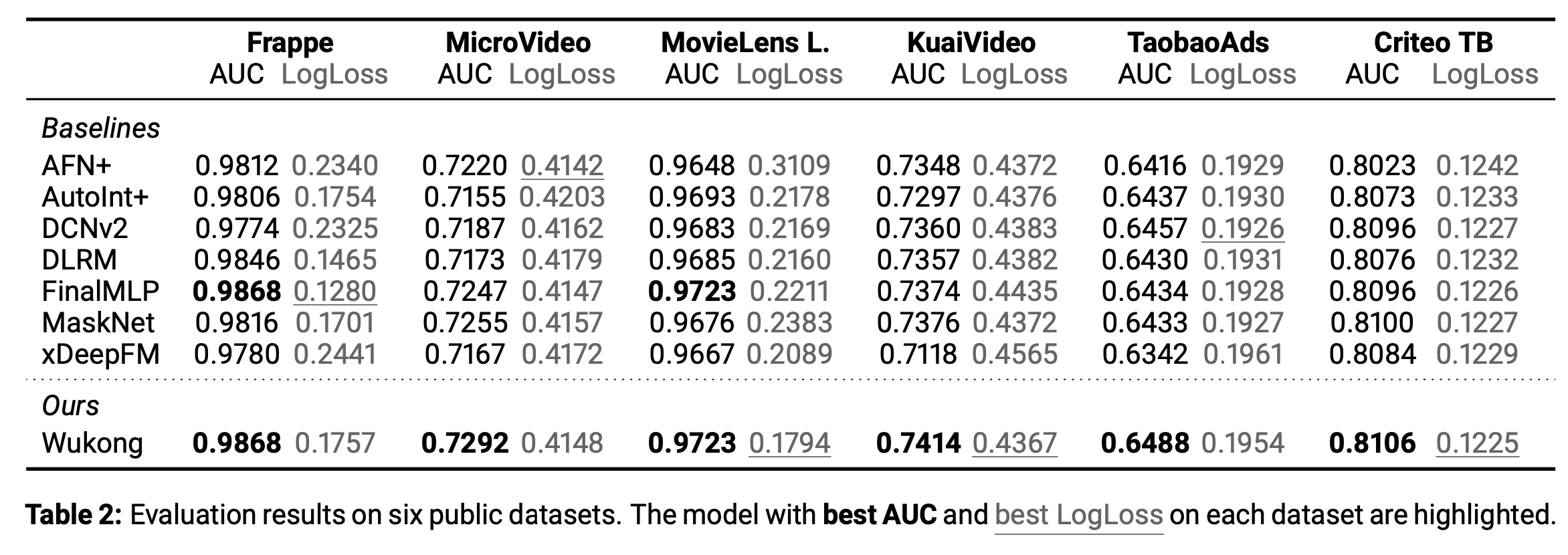
1.6 内部数据集上的评估
本节通过一个大规模数据集展示
Wukong的可扩展性,并深入理解其各组件的有效性。该数据集能够揭示小规模公开数据集未体现的模型特性。数据集:该数据集共包含
146B条记录和720个不同特征,每个特征描述用户或item的属性。数据集关联两项任务:Task 1:预测用户是否对item表现出兴趣(如点击)。Task 2:预测是否发生转化(如点赞、关注)。
评估指标:
GFLOP/example:Giga Floating Point Operations per example,量化模型训练的计算复杂度。PF-days:总训练计算量,相当于单台机器运行1 PetaFLOP/s for 1 day的计算量。#Params:模型参数数量(以参数个数衡量),sparse embedding table size固定为627B参数。Relative LogLoss:相对于固定基线的LogLoss改善率。我们选择basic config的DLRM作为基线,在该数据集上0.02%的Relative LogLoss改善被视为显著。我们报告online training最后1B-window的Relative LogLoss。
基线模型:我们沿用公开数据集上的基线设置,但
xDeepFM因昂贵的外积操作与大规模数据集不兼容,即使在minimal setups下也持续导致内存不足问题,故未包含在结果中。训练:所有实验均使用
pilot study中找到的最佳优化器配置:dense部分使用Adam优化器(lr=0.04,beta1=0.9,beta2=1),sparse embedding tables使用Rowwise Adagrad优化器(lr=0.04)。模型以online training方式进行训练和评估,所有runs的embedding维度固定为160。我们以前一节
Criteo Terabyte评估中找到的最佳配置作为起点,逐步增加各模型的参数数量。所有实验的global batch size为262,144,根据模型大小在128或256块H100 GPU上运行。
a. 实验结果
两项任务的结果是差不多的,正文仅报告
Task 1的结果,Task 2的详细结果见附录C。Quality vs. Compute Complexity:如Figure 1所示,我们描绘了质量与计算复杂度的关系。经验公式:结果显示,
Wukong在各种复杂度水平下始终优于所有基线模型,LogLoss改善超过0.2%。值得注意的是:Wukong在模型复杂度跨越两个数量级(约每四倍复杂度带来0.1%改善)时保持scaling law。而基线模型中,
AFN+、DLRM和FinalMLP在特定复杂度后趋于平台期;AutoInt+、DCNv2和MaskNet无法进一步提升质量。即使是表现最佳的基线模型DCNv2,也需要40倍复杂度提升才能达到Wukong的质量。
Quality vs. Model Size:如Figure 3所示,我们展示了模型质量与模型规模的相关性。与计算复杂度扩展趋势一致,Wukong在所有规模下均以约0.2%的优势持续优于所有基线模型,并在超过637B参数时保持稳定提升趋势。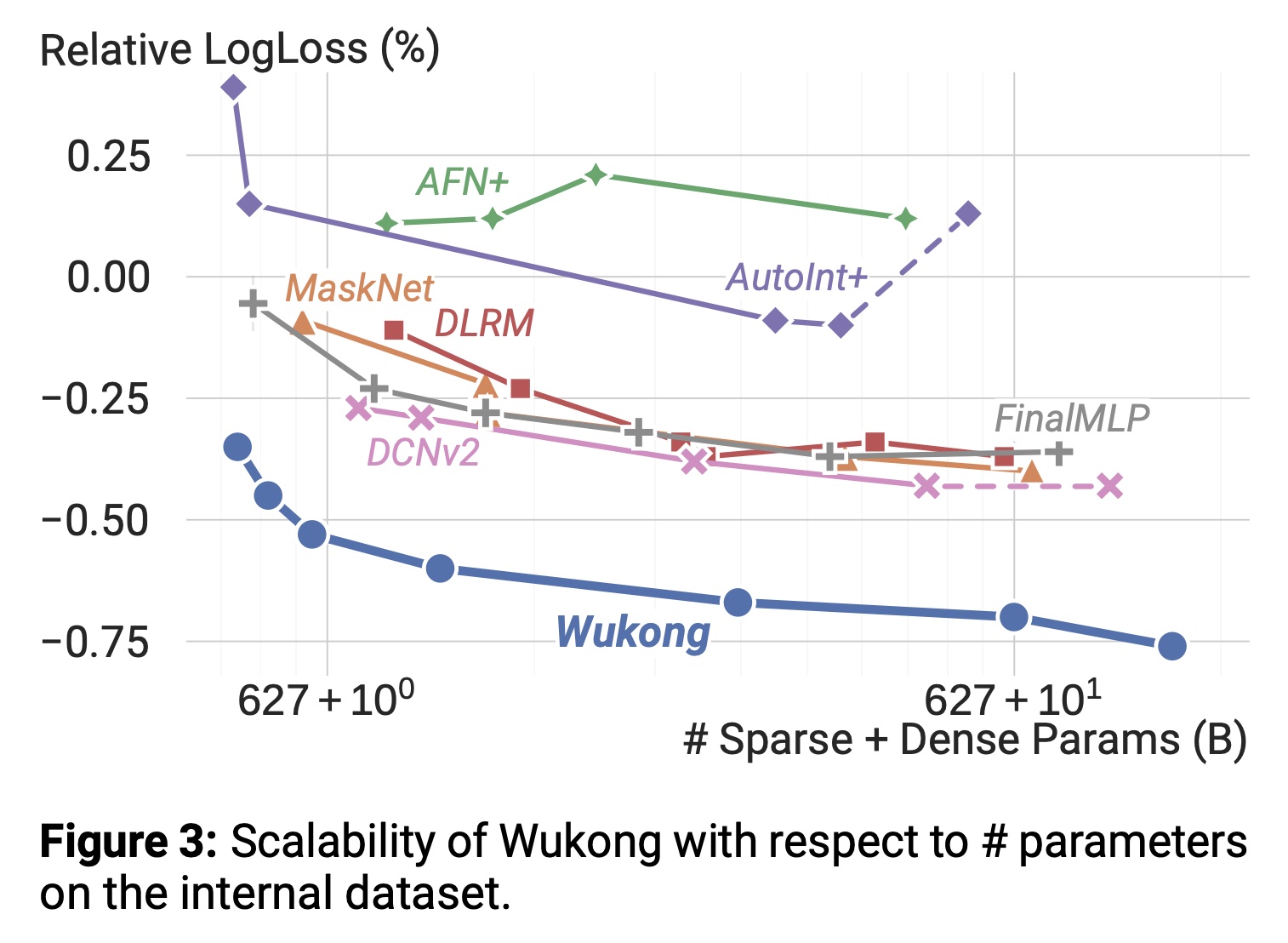
Quality vs. Data Size:见附录E。Model-Specifc Scaling:在扩展过程中,我们为每个模型采用不同策略,每次运行的详细超参数设置见附录C。各模型扩展过程总结如下:Wukong:通过调优"Scaling Wukong"章节所述超参数进行scale up。AFN+:扩展AFN的hidden layers、ensemble DNN、以及对数神经元的数量。结果显示scaling up AFN未提升模型质量。AutoInt+:扩展multi-head attention和ensemble DNN。模型质量最初低于其他模型,但scaling up后显著改善。DLRM:扩展topMLP,结果显示质量在超过31 GFLOP/example后饱和。DCNv2:同时扩展Cross Network和Deep Network。扩展Cross Network未带来质量提升。训练稳定性低于其他模型,需严格梯度裁剪。FinalMLP:扩展two MLP streams和Feature Selection模块。质量在低复杂度区域提升,但超过36 GFLOP/example后饱和。MaskNet:测试Parallel MaskNet和Serial MaskNet,发现并行变体更优。降低初始压缩率(reduction ratio)以确保模型可运行,逐步扩展MaskBlock数量、DNN和压缩率。
b. 消融实验
组件重要性:我们通过实验验证
Wukong的Interaction Stack中FMB、LCB和残差连接的重要性:将各组件结果置零(zero-padding),观察质量变化。 如Figure 4所示:图中的描述错误:下图的
FCB应该是FMB。置零
FMB导致质量大幅下降。单独置零
LCB或残差连接仅引起质量小幅下降。而同时置零两者则导致显著退化。
这表明,通过对
FMB输出零填充并结合残差连接,LCB可被简化。本质上是因为:
LCB、残差连接都提供了一阶信息,因此二者的功能重复。因此,可以去掉LCB,然后将FMB的输出、全零(代表一个fake LCB)拼接起来,从而简化模型。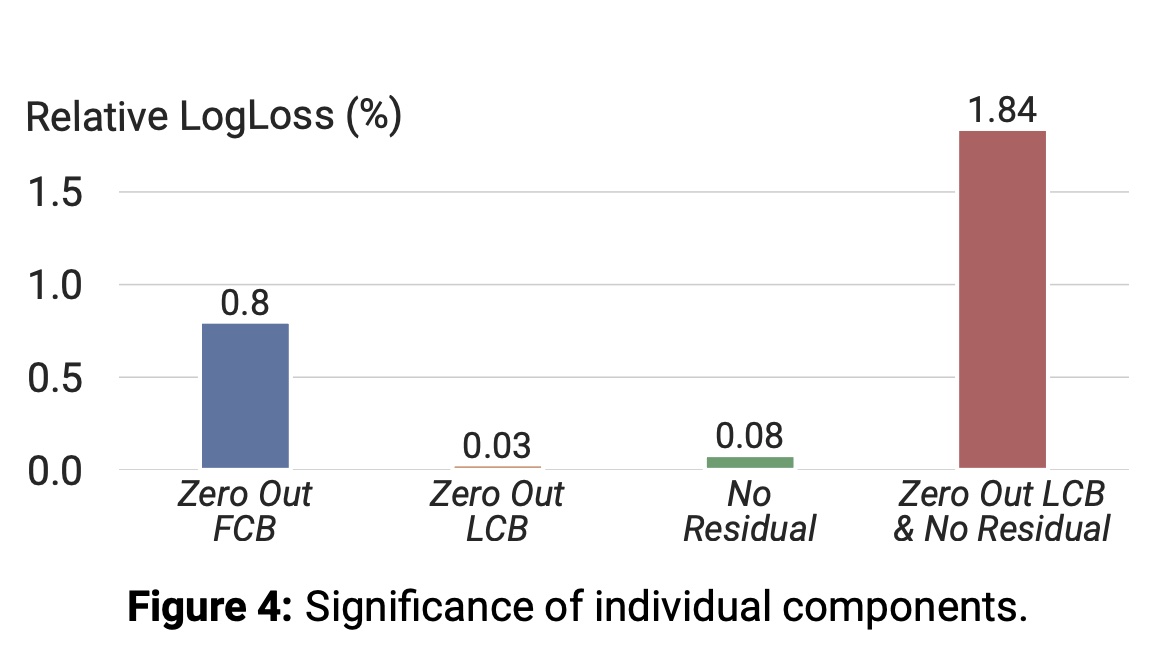
单个组件扩展的影响:我们剖析扩展
Wukong各超参数对模型质量的贡献:从基础配置开始,逐步将每个超参数加倍。结果如Figure 5所示:增加
Wukong层数扩大
MLP规模也带来显著性能提升。提升
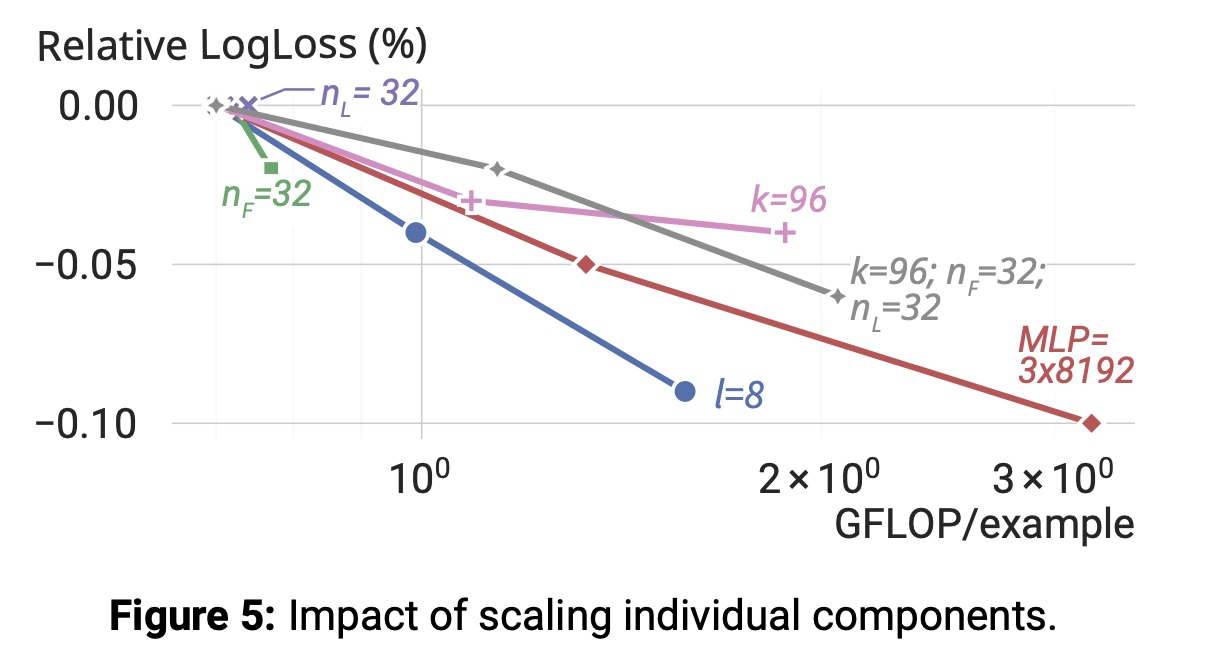
1.7 讨论
大型模型的实际
Serving:扩展到高复杂度模型对real-time serving提出显著挑战。潜在解决方案包括训练多任务foundation model以分摊成本,或将大模型的知识蒸馏到小型高效模型用于serving。局限性与未来工作:我们也注意到工作的局限性和待探索方向,可作为未来研究目标:
理解
Wukong可扩展性的具体极限是重要研究方向。由于计算需求巨大,我们尚未达到可观察极限的复杂度水平。尽管
Wukong在各项评估中表现出优越质量,但其底层原理的全面理论分析(尤其是与具有stacked dot product结构的Transformer等架构的对比)仍需进一步探索。Wukong在推荐领域之外的泛化能力(尤其是涉及类似推荐中heterogeneous input data sources的领域)有待进一步研究和理解。
1.8 结论
我们提出了一种高效的网络架构 “
Wukong”,并证明其在推荐领域建立了此前未被观察到的scaling law:Wukong能够在计算复杂度跨越两个数量级的范围内高效扩展与收缩,同时保持对其他SOTA模型的竞争优势,使其成为跨广泛任务和数据集、从小型垂直模型到的大型foundational models的backbone的可扩展架构。
1.9 附录
a. Criteo 数据集上的模型特定网格搜索空间
我们对
dense arch optimization使用Adam优化器,对sparse arch optimization使用Rowwise AdaGrad优化器,并在最初10%的training steps中采用linear warmup period。我们使用global batch size为ReLU作为激活函数。在pilot experiments中,我们发现embedding维度设为128时所有模型表现更佳,因此采用该值。所有runs均使用FP32精度。由于数据集规模和模型大小的限制,我们使用《High-performance, distributed training of large-scale deep learning recommendation models》作为sparse distributed training framework,dense synchronization采用数据并行。为促进公平比较,我们在
Criteo数据集上对通用超参数和模型特定配置进行了广泛的网格搜索(超过3000 runs)。对于所有模型,
sparse learning rate和dense learning rate分别在对于所有模型中的
MLP,hidden layers数量在{1,2,3,4}范围内,layer sizes在{512,1024,2048}范围内。为减少过大的搜索空间,我们在
optimizer的超参数上执行pilot experiments,并确定dense部分学习率设为sparse部分学习率设为runs固定此学习率。
以下为各模型的特定搜索空间:
AFN+:AFN hidden units和DNN hidden units在所有runs中保持一致,遵循通用MLP搜索空间;对数神经元的数量在{128,256,512,1024}范围内。AutoInt+:基于论文《Autoint: Automatic feature interaction learning via self-attentive neural networks》报告的最佳配置创建搜索空间,每个超参数额外考虑更大值。注意力层数在{3,4}范围内,注意力维度在{256,512}范围内,注意力头数在{4,8}范围内;DNN hidden units遵循通用MLP搜索空间。DCNv2:cross layers数量在1 ~ 4之间;rank搜索范围为full-rank或512。DLRM:bottom MLP layer为两层,维度为[512,256]。FinalMLP:遵循公开基准设置(《BARS: towards open benchmarking for recommender systems》),将一个流的FeatureSelection: FS设为所有浮点特征,另一流的FS搜索8 selected sparse features之一。FS MLP设为[800]。head数量固定为256。MaskNet:测试Parallel MaskNet和Serial MaskNet。并行变体的blocks数量在{1,8,16}范围内,block维度在{64,128}范围内。串行变体的层数在{1,4,8}范围内,layer size在{64,256,1024}范围内。两种变体的压缩率均固定为1。xDeepInt:考虑Compressed Interaction Network (CIN),层数在{3,4}范围内,层维度在{16,32,64}范围内。Wukong:bottom MLP layers为两层,维度设为[512,256]。1 ~ 4。{8,16}内。24。
b. 公开数据集上的模型复杂度 / 规模
具体细节见
Table 3。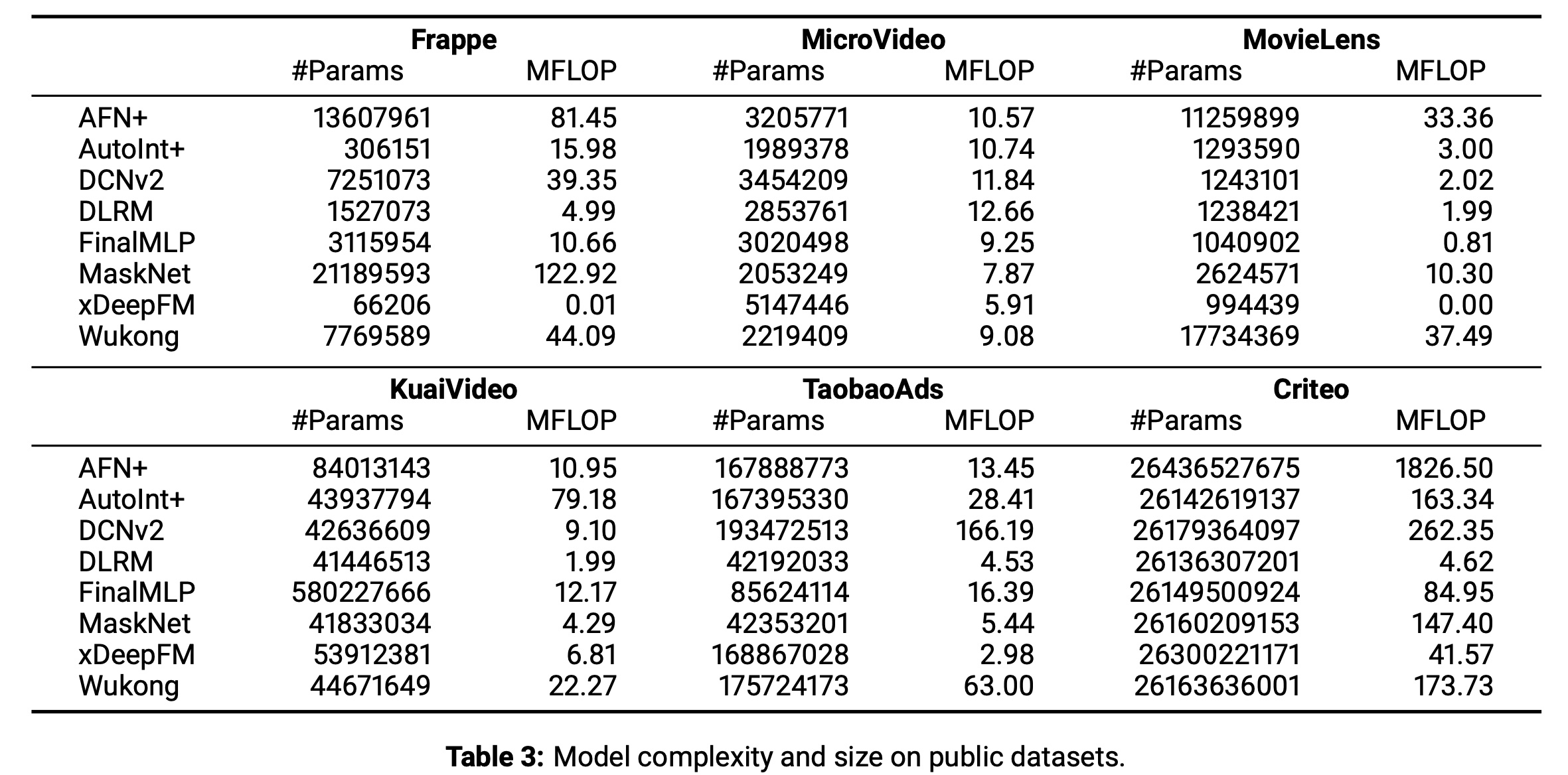
c. Model-Specific Scaling-up Configurations
具体细节见
Table 5。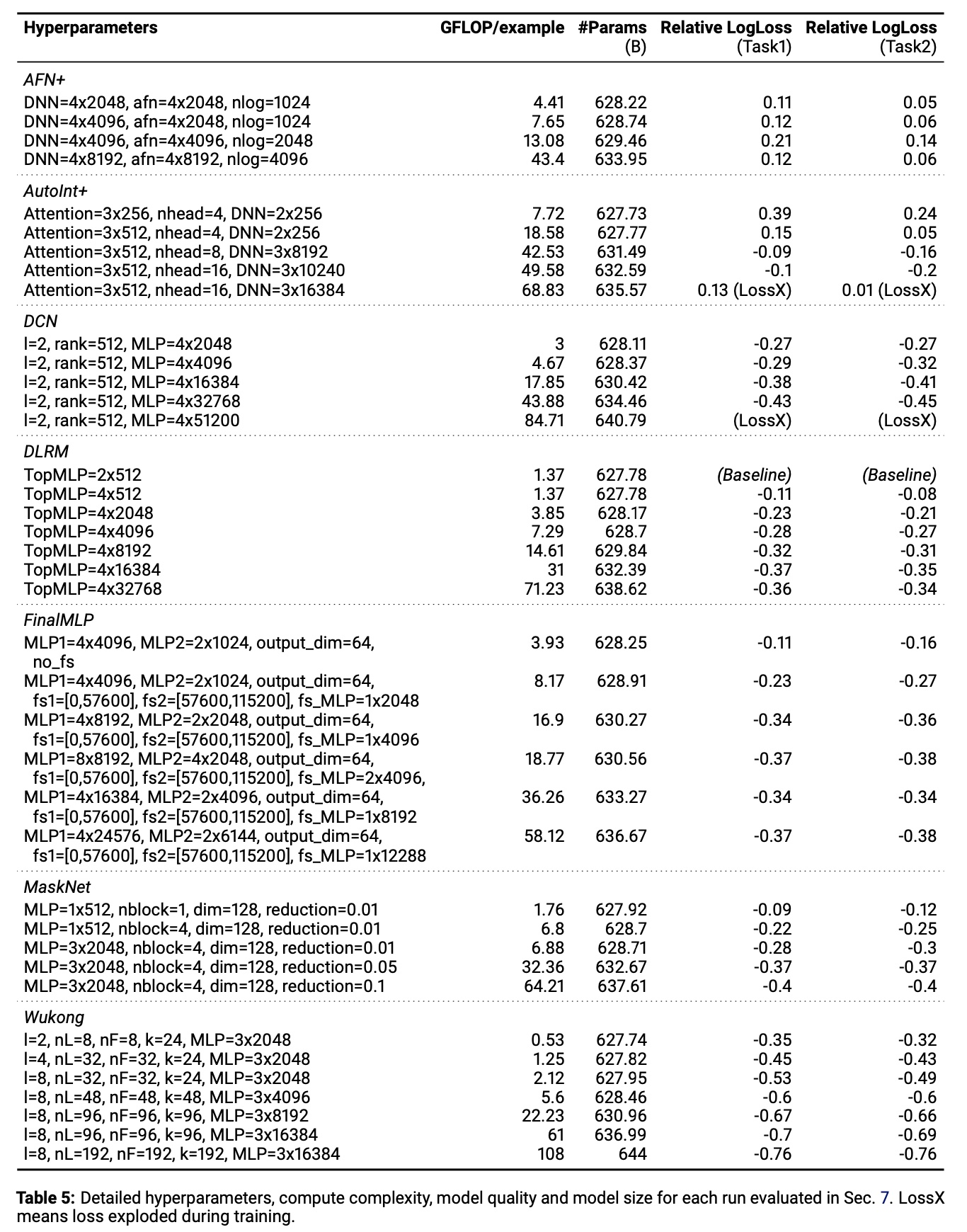
d. Wukong 中的高阶交互分析
传统
factorization machine方法通过最小化如下公式(《Deep learning recommendation model for personalization and recommendation systems》)来解决二阶交互问题:其中:
userand item representations (embeddings),上标1表示embedding包含一阶信息。
这些
embedding向量的内积为二阶交互的后续评分提供了有意义的prediction。在Wukong中,这些有意义的交互随后通过MLP转换为二阶交互representationsFMB中,通过残差和LCB connection,Wukong通过最小化以下公式来求解问题:因此,与传统因子分解方法相比,
Wukong能够通过更丰富的交互阶数解决recommendation问题。
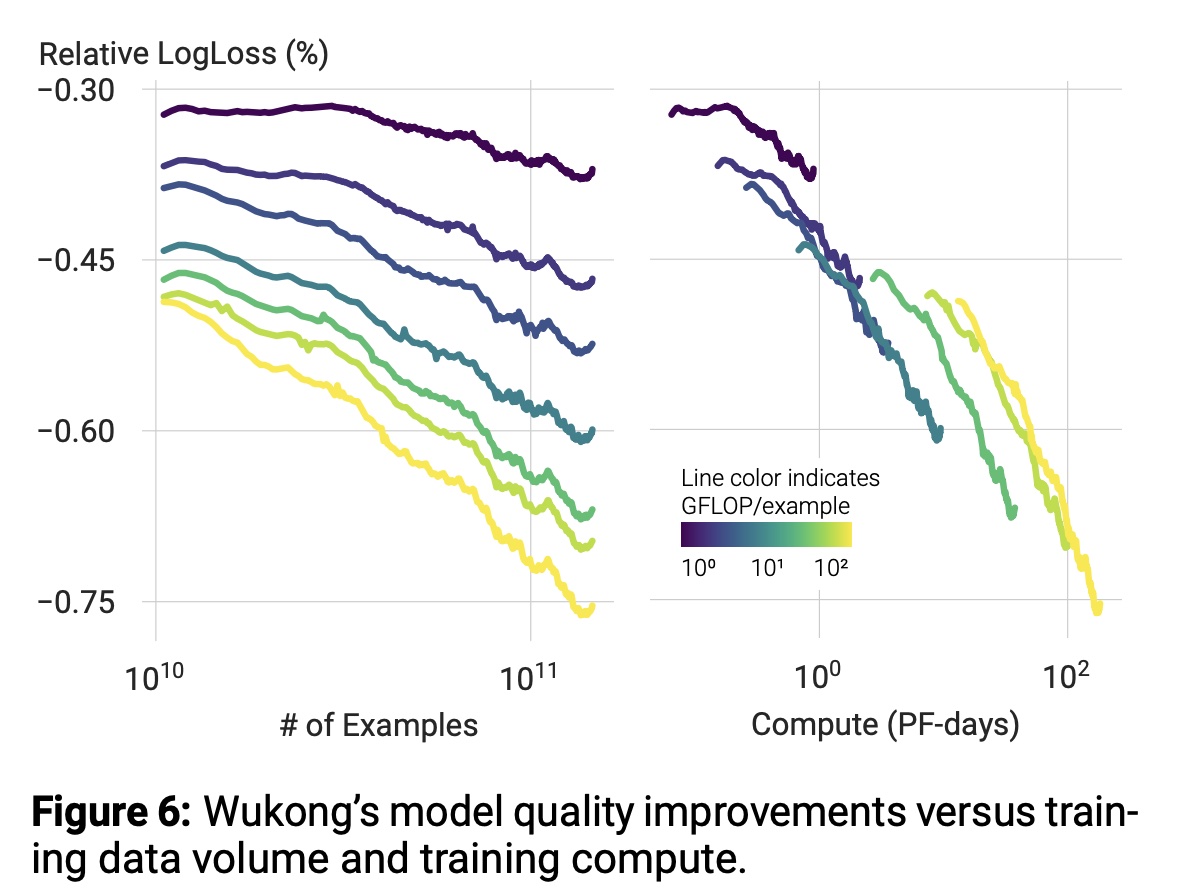
e. Training Data 上的 Scaling Law
Figure 6总结了Wukong在不同训练数据集规模(one pass训练)上的性能。与大语言模型中观察到的现象类似,我们发现大型模型具有更高的数据效率,即实现相同质量提升所需的样本更少。
此外,我们发现所有
Wukong模型在高达146B数据时均持续提升质量,且更大模型在质量提升趋势上更为陡峭。我们也注意到,本研究的数据集规模对于大型模型收敛而言仍不足,这将是未来研究的方向之一。
f. 与 Transformer-based 方法的比较
我们强调
Wukong与AutoInt+等Transformer-based方法在scaling上的差异及背后的直觉:尽管Wukong的结构与Transformer类似,但存在以下架构差异:首先,
Wukong在FMB和每一层中使用MLP(bit-wise操作)进行投影,而非Transformer中的FFN(embedding/position-wise操作)。其次,
Wukong采用金字塔形(pyramid shape)配置,而Transformer采用统一形状(uniform shape)。
我们假设投影方式的差异对质量起关键作用。这些
MLPs在flattened input embeddings上操作,本质上为每个特征提供不同的投影矩阵。这帮助模型从heterogeneous input features中学习,这与LLM中single embedding space的设计形成对比。在效率方面,金字塔形配置使
Wukong能够通过压缩每层使用的embeddings数量排除不必要的计算。虽然
Wukong的每一层的input embeddings数量与output embeddings数量相同,但是:output embeddings中仅有一半是来自于FMB,而另一半来自于input embeddings自身(如果用残差连接来简化LCB)。为验证这些假设,我们通过将
Wukong的独特组件应用于AutoInt +进行实验,结论如下:(1):使用bit-wise MLP而非FFN进行V-projection可使LogLoss改善0.34%。(2):在自注意力后添加bit-wise MLPs可使LogLoss改善0.65%。(3):结合两者并采用金字塔层形状(通过在第一层输出使用LCB)可实现0.57%的质量提升。与scaled up Autoint+相比,Wukong在节省90% FLOPs的同时实现0.08%的质量提升。
结果汇总于
Table 4。