一、Climber [2025]
《Climber: Toward Efficient Scaling Laws for Large Recommendation Models》
基于
Transformer的生成式模型已在多个领域取得显著成功,并呈现出various的scaling law特性。然而,我们的大量实验表明,将Transformer应用于推荐系统时仍面临持续挑战:(1):由于Transformer结构与推荐场景特有的特征(如multi-source data heterogeneity)不兼容,随着计算资源增加,其scaling效果并不理想;(2):online inference latency存在严格约束(数十毫秒级),且随着user behavior sequences变长和计算需求增长,该约束进一步加剧。
为此,我们提出
Climber——一种高效的recommendation框架,包含两个协同组件:支持高效scaling的模型架构、以及协同设计的acceleration技术。所提模型采用两项核心创新:(1):多尺度序列提取(multi-scale sequence extraction),通过一个常数因子(constant factor)降低时间复杂度,实现sequence length的高效scaling。其实就是把用户行为序列拆分为
"click sequence"、"share sequence"等等不同类型的子序列。完全没有技术含量。(2):动态温度调制(dynamic temperature modulation),使注意力分布(attention distributions)适应多场景和多行为模式(multi-behavior patterns)。简单而言,就是
position embedding和温度系数对不同场景、不同子序列采用不同的配置。也是没有技术含量。
在
acceleration技术的辅助下,Climber通过采用"single user, multiple item" batched processing、以及内存高效的Key-Value caching,实现了5.15倍的吞吐量提升,且未出现性能下降。在多个数据集上进行的全面离线实验验证,
Climber展现出更理想的scaling curve。据我们所知,这是首个公开报道的框架——通过可控的model scaling,在不产生过高资源成本(resource costs)的前提下,实现了online metric的持续增长(整体提升12.19%)。Climber已成功部署于中国最大的音乐流媒体平台之一网易云音乐(Netease Cloud Music),每日服务数千万用户。Scaling laws最初在语言模型中被探索(《Training compute-optimal large language models》、《Scaling laws for neural language models》),它确立了模型性能与model size、training data volume等关键因素之间的可预测关系。例如,《Scaling laws for neural language models》证明,随着model parameters和token counts的增加,Transformer-based的语言模型(《Attention is all you need》)在perplexity上遵循power-law improvements。在视觉模型(《Reproducible scaling laws for contrastive language-image learning》、《Scaling vision transformers》)和多模态模型(《Qwen-vl: A frontier large vision-language model with versatile abilities》、《Llama: Open and efficient foundation language models》)中也观察到类似趋势——dimensions of scaling model和diversity of data与下游任务性能直接相关。生成式推荐(
Generative recommendation)已成为在推荐系统中实现scaling laws的最具前景的新技术范式。我们认为,其实际落地(practical implementation)需分阶段推进;当前阶段的核心目标是使Transformer架构适配推荐系统,以建立有效的scaling laws。近期研究(
《Understanding scaling laws for recommendation models》、《Scaling New Frontiers: Insights into Large Recommendation Models》)已验证了scaling laws在推荐系统中的有效性,为模型设计和资源分配提供了宝贵见解。HSTU模型(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)采用hierarchical self-attention对长期用户行为序列(long-term user behavior sequences)进行建模,取得了优于传统Transformer的性能。类似地,
MARM模型(《MARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity》)引入内存增强(memory augmentation)以降低计算复杂度,实现了低推理成本的multi-layer sequence modeling。
然而,这些方法未能充分解决
Transformer架构与recommendation-specific features之间的固有不兼容性。尽管通过资源扩展进行模型scaling仍然可行,但这种策略对于实际工业部署(real-world industrial deployment)而言效率低下。此外,传统推荐系统中,sequence length、model depth和heterogeneous user behaviors等关键scaling factors之间的相互作用尚未得到充分探索,导致资源分配不合理,scaling的收益下降。受
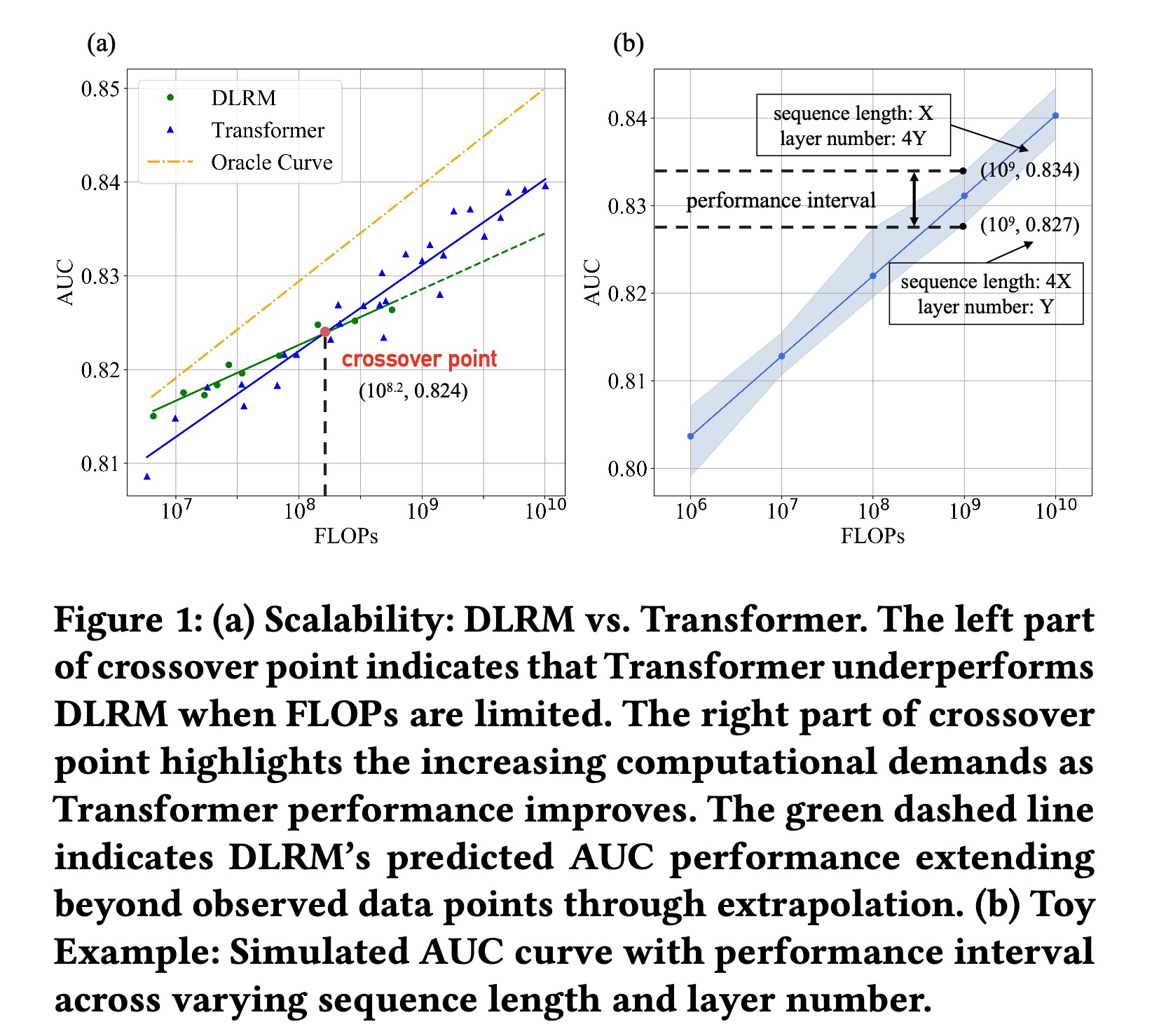
DeepSeek系列(《Deepseek llm: Scaling open-source language models with longtermism》、《Deepseek- v2: A strong, economical, and efficient mixture-of-experts language model》、《Deepseek-v3 technical report》)的启发——该系列显著提升了大型语言模型(LLM)的开发效率并降低了计算资源成本,我们旨在解决以下问题:如何以更低的成本来高效地scale up推荐模型?为获取相关见解,我们对两种主流模型,Deep Learning Recommendation Model: DLRM(《Software-hardware co-design for fast and scalable training of deep learning recommendation models》)和Transformer模型,进行了industrial-scale analysis。Figure 1(a)展示了DLRM*和Transformer的scaling curves,并引入理想曲线(oracle curve)从而代表更优的scaling up的效果——其起点更高、斜率更大。Figure 1(b)展示了不同sequence lengths和层数组合下的AUC曲线;并提出“性能区间”("performance interval")的概念,即模型在等效浮点运算次数(FLOPs)下的AUC变化范围。然而,我们的研究发现,将Transformer应用于推荐系统时仍存在以下问题:FLOPs约束下Transformer的性能退化:如Figure 1(a)所示,交叉点对应的FLOPs为FLOPs值为边界,DLRM和Transformer的性能对比呈现不同趋势:当
FLOPs超过Transformer模型优于DLRM等传统架构。但当
FLOPs低于Transformer模型的性能反而不如DLRM。
这凸显了对更高效模型的需求——
Figure 1(a)中的理想曲线(oracle curve)即为更高效的scaling curve,其截距(intercept)和斜率(slope)均大于其他曲线,使得模型在FLOPs受限的情况下仍能取得更优性能。Transformer与recommendation-specific features的不兼容性:与自然语言处理(NLP)中连续的句法序列(continuous syntactic sequences)不同,推荐系统处理的是跨多个场景的碎片化用户行为(fragmented user behaviors)。由于Transformer难以在稀疏的multi-source patterns中prioritize relevant behaviors,导致注意力分布(attention distributions)是无序的。此外,多场景推荐(
multi-scenario recommendations)面临分布差异(distributional discrepancies)的问题:用户在不同场景下表现出不同行为,但现有方法将场景视为辅助特征(auxiliary features)而非显式的分布控制器(distribution controllers)。这种不兼容性使得Transformer在计算资源受限的情况下,效率低于DLRM等专用架构。等效
FLOPs下factor combinations对模型性能的影响:在推荐系统中,序列长度(sequence length)、层数(layer number)等factors对FLOPs影响显著,不同factor combinations会导致模型性能产生差异。例如,如Figure 1(b)所示,在FLOPs下,不同combinations的性能区间接近1%。当前研究缺乏对factor combinations如何影响推荐模型性能的全面分析,这阻碍了模型的高效scaling。
这些挑战表明,
Transformer在推荐系统中存在效率问题,且当scaling features and model capacity以处理更长序列时,该问题会进一步加剧,导致平方级的计算需求和更严格的延迟约束(《TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou》、《Twin v2: Scaling ultra-long user behavior sequence modeling for enhanced ctr prediction at kuaishou》)。基于上述见解,我们提出
Climber——一种重新思考推荐系统scaling范式的新型框架。其核心是整合两项互补的创新:专为推荐场景设计的Transformer-based的模型架构,以及协同设计的acceleration技术。所提模型通过引入
multi-scale sequence extraction,重新定义了推荐系统处理user behaviors的方式——将user behavior sequences分解为更小的细粒度的子序列(sub-sequence)。该方法不仅降低了计算复杂度,还能更精准地建模不同场景下的用户兴趣(user interests)。此外,模型还融入了动态温度调制(dynamic temperature modulation),通过自适应地调整attention scores,以适应不同behaviors和scenarios的重要性的差异。在工程层面,我们引入了统一的
acceleration技术,将传统的"single user, single item"样本组织形式转换为与实际在线请求一致的"single user, multiple items"形式。
基于这些技术,在
training and inference期间, 结合encoder-level KV cache,前向传播(forward propagation)实现了显著的效率提升。最后,我们研究了Climber的scalability,以及等效FLOPs下factor combinations对AUC的影响,为合理的资源分配和模型快速scaling的关键factors提供了新见解。本文的主要贡献如下:
开展了推荐系统
scaling laws的工业级研究,明确量化了等效FLOPs下factor combinations的影响。分析表明,balanced scaling(交替扩展序列长度和模型深度)可同时提升离线和在线指标。提出了一种新型
Transformer变体Climber,通过multi-scale extraction和adaptive temperature modulation解决了推荐系统中的scaling困境。据我们所知,该方法开创了可持续scaling的先河——实现了12.19%的在线指标增长,这是我们生产系统中年度最大提升。统一加速(
Unified acceleration)技术通过"single user, multiple items" batched processing和block-parallel KV cache,提升了训练和推理效率。在网易云音乐(Netease Cloud Music)部署后,这些技术实现了5.15倍的训练加速,且在线推理速度比DLRM快14.38倍,使得模型能够在不增加计算资源的情况下实现100倍的model scaling。
论文整体写的很差:
首先,论文提到的几点就是工程上的一些小的应用。这也是唯一可以在实际推荐算法中借鉴的地方。
其次,论文很多技术细节都没讲,写的太粗糙。
再次,实验部分不太严谨,没啥说服力。
最后,论文结论部分说是生成式推荐,而本文正文是判别式推荐。
1.1 相关工作
Wukong(《Wukong: Towards a Scaling Law for Large-Scale Recommendation》)探索了retrieval models中的parameter scaling,但依赖于feature engineering的强烈假设(strong assumptions)。错误,
Wukong模型是探索ranking model的scaling。HSTU(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)将recommendations任务重构为sequential transduction任务,通过hierarchical attention and stochastic sequence sampling实现了linear computational scaling的万亿参数模型。然而,HSTU侧重于生成式建模(generative modeling),在衔接传统的feature-based DLRMs方面存在不足。同时,
MARM(《MARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity》)提出缓存中间注意力结果(intermediate attention results),将inference复杂度从cache size作为new scaling dimension的有效性。但MARM的缓存策略假设user patterns是静态的,忽略了real-time behavior的变化。降低计算成本的技术已被广泛采用。
在
NLP领域,KV caching避免了自回归推理(autoregressive inference)过程中的冗余的attention计算。MARM将这一思想适配到推荐系统中,通过存储historical attention outputs,以极小的FLOPs开销实现了multi-layer target-attention。类似地,
HSTU引入随机长度(Stochastic Length)通过算法稀疏化long sequences,在不降低质量的情况下将训练成本降低80%。在广告检索领域,
《Scaling Laws for Online Advertisement Retrieval》设计了eCPM-aware的离线指标,以低成本估算online revenue scaling laws。
这些研究共同强调了针对推荐场景特有约束(如
high-cardinality特征、以及毫秒级latency要求)定制高效的策略的重要性。
1.2 方法
为实现高效的
scaling,我们提出一种专为推荐系统设计的Transformer变体。该变体支持从三个关键维度进行scaling:multi-scale sequence processing、multi-scenario adaptation、multi-interest modeling。此外,我们还详细介绍了所提模型的部署细节。
1.2.1 模型架构
Overall:为解决推荐系统中的计算复杂度和scaling挑战,我们从推荐场景视角出发来设计模型。该模型将recommendation特性融入Transformer架构,具备resource-aware scalability。该模型从三个方面进行scale up:multi-scale sequence、multi-scenario、和multi-interest。模型包含三个模块:多尺度序列提取(Multi-scale Sequence Extraction: MSE)、自适应Transformer层(Adaptive Transformer Layer: ATL)、以及按位门控融合(Bit-wise Gating Fusion: BGF)。具体而言:MSE从user lifecycle sequence中生成multi-scale sequences,这些序列代表不同类型的子序列。每个子序列由对应的
stacked ATLs block处理以抽取interest。同时我们扩展
important subsequences的时间跨度(time span)以覆盖用户全生命周期(entire lifecycle)。ATL采用自适应温度系数(adaptive temperature coefficient)调整多场景(multi-scenario)下的注意力分布(attention distribution)。最后,
BGF通过按位门控(bit-wise gating)机制聚合来自adaptive Transformer blocks的representations,生成a unified output,实现multi-scale sequences间的multi-interest fusion。Figure 2展示了详细工作流程。
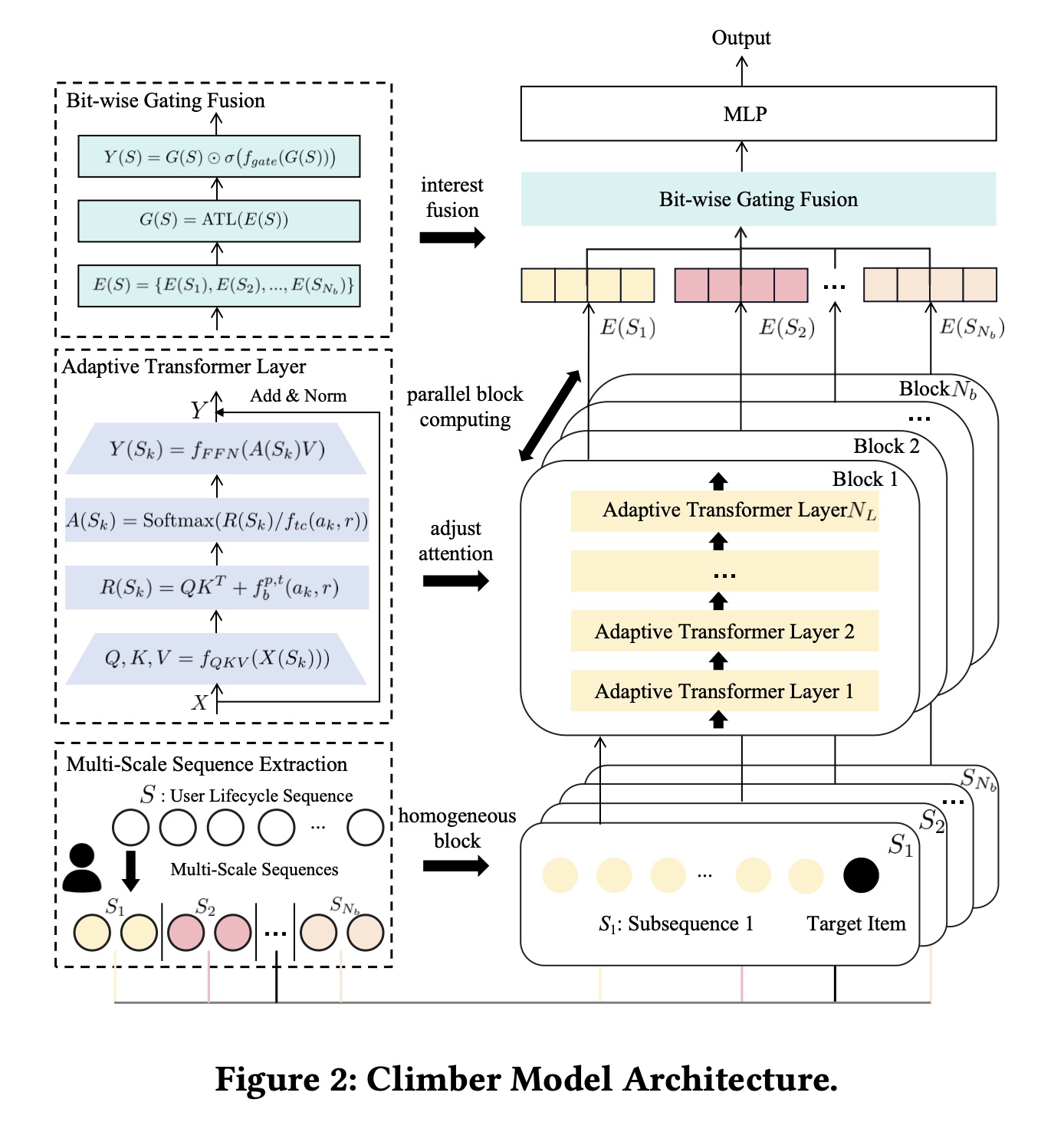
Multi-Scale Sequence Scale-Up:我们提出multi-scale sequence extraction: MSE方法用于multi-scale sequence scale-up。该方法基于不同策略重组user sequences,可表示为以下公式:其中:
user lifecycle sequence,item的item ID,item set。extraction strategy),user lifecycle sequenceitem。
假设共有
extraction strategies,且extraction strategy通常仅保留用户的positive behaviors。因此,单个Transformer的计算复杂度可从我们进一步优化训练过程:为每个子序列
Transformer block,从而实现extraction strategy都会提取等长的子序列,即在完全串行操作的情况下,时间复杂度为
training acceleration)。在计算资源充足的完全并行情况下,复杂度降低至
progressive multi-scale sequence scale-up)。
我们的
extraction strategies包括business-driven sequences(如click/like/share)、model-filtered sequences等。总之,MSE降低了计算复杂度,并将user lifecycle sequence转换为multi-scale sequences,提升了推荐系统的效率和scalability。简单而言,就是把原始的用户行为序列拆分为:点击序列、购买序列、点赞序列、... 等等。
Multi-Scenario Scale-Up:Softmax激活函数用于归一化attention scores,在Transformer架构中起着关键作用。具体而言,attention机制通过attention matrix的分布与《Distilling the Knowledge in a Neural Network》)。然而,我们基于不同extraction strategies从user lifecycle sequence中生成multi-scale sequences,并为每个子序列应用对应的Transformer block,而不同场景下每个子序列的分布也存在显著差异。单一的缩放因子multi-scale sequences对应的所有Transformer blocks的多样化需求(《Deter-mining the optimal temperature parameter for Softmax function in reinforcement learning》)。为进一步优化每个
Transformer block内的attention distribution,我们为每个block的每一层引入自适应温度系数(adaptive temperature coefficient),将这一改进称为Adaptive Transformer Layer: ATL,其数学表达式如下:其中:
layer input,sequence length,feature dimension。inputquery矩阵、key矩阵、以及value矩阵。raw attention matrix,head number。relative attention bias(《Exploring the limits of transfer learning with a unified text-to-text transformer》、《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)。extraction strategy。normalized attention matrix。这个
lookup函数,类似于embedding lookup。layer output。FFN)。
与传统
Transformer layer相比,我们引入了自适应温度系数,并从推荐场景视角调整relative attention bias。需要注意的是,extraction strategyrecommendation scenariorelative attention bias和温度系数。该方法受推荐系统
multi-scenario和multi-behavior的特点的启发。与HSTU的固定温度系数(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)不同,我们的自适应温度系数允许更灵活的attention weighting,解决了固定缩放因子inherence of diverse behaviors and scenarios方面的局限性。简单而言,就是
position embedding和温度系数对不同场景、不同子序列采用不同的配置。Multi-Interest Scale-Up:然而,当user lifecycle sequence被分割为multi-scale sequences后,它们之间缺乏交互。因此,我们提出一个bit-wise gating fusion模块,整合对应blocks的multi-interest scale-up。具体而言:每个
block通过adaptive Transformer block生成output vector将这
output vector拼接为然后,拼接后的向量通过一个新的
ATL处理,再经过sigmoid激活函数实现bit-level gating。最后,
vectors通过后续网络生成final output score。
bit-wise gating fusion模块可表示为:其中:
sigmoid激活函数。sqaueeze-and-excitation模块(《 Squeeze-and-excitation networks》),确保input维度和output维度一致,以动态调整bit-wise attention matrix。fusion module的输出。
Multi-Scenario Scale-Up中的Adaptive Transformer Layer: ATL用于计算不同blocks之间的相似度,以实现子序列间不同interest的交互。相反,fusion function中的ATL不包含relative attention bias,温度系数仅由recommendation scenarioATL对blocks的attention操作可视为field-wise interactions,促进feature level的信息交换。我们的方法通过添加bit-wise interactions增强了multi-interest fusion,使模型能够捕捉序列间的precise relationships,从而显著提升模型理解multi-scale sequences的能力。值得注意的是,尽管该attention机制的复杂度为fusion阶段,extraction strategy数量feature vector的维度bit-wise gating fusion模块的计算复杂度相对较低。loss function是什么?作者都没讲。
1.2.2 部署
我们的
acceleration部署分为两个阶段:offline training和online serving。在
offline training阶段,user interaction日志被记录为"single user, single item"模式,这些原始日志被压缩并归档为"single user, multiple items"模式。其中:"single user, single item"表示记录a user and an item之间一次原子交互(如click/purchase)的日志条目。"single user, multiple items"将用户的historical interactions聚合为一条包含multiple items的记录,支持user-item feature computation的batch processing。"single user, multiple items"模式在每个candidate item与entire history之间使用full-visible masks,并在candidate items之间使用对角掩码(diagonal masks)以实现物品间隔离(inter-item isolation)。这种压缩机制显著减少了样本量,同时为模型训练提供了5.15倍的加速。
在
online serving阶段,受M-FALCON的启发,系统首先从user features生成multi-layered key-value (KV) cache vectors,然后从feature server获取候candidate item features,最后计算item features与cached KV representations之间的attention-based interactions。
值得注意的是,模型在
offline training和online serving阶段均采用"single user, multiple items"数据模式,因此利用KV cache加速user feature computation。此外,我们实现了算子融合(operator fusion)——将连续操作(如embedding lookup、attention layers)合并为unified computational kernels,以减少频繁的global memory accesses,并整合FlashAttention的矩阵分块操作以优化内存利用率(《Flashat-tention: Fast and memory-efficient exact attention with io-awareness》)。这些设计通过cache utilization提升了计算效率,同时保持了prediction准确性,从而提供了能提升用户满意度的个性化推荐服务。
1.3 实验
在本节中,我们详细介绍了在真实工业数据上进行的离线和在线实验,以评估所提方法,并解答以下四个研究问题:
RQ1:与SOTA模型相比,Climber的离线评估性能如何?RQ2:与DLRM和Transformer相比,Climber如何体现更优的scalability?RQ3:考虑等效FLOPs下不同factor combinations对AUC的影响,如何分配资源以scale up模型?RQ4:Climber在工业系统中的性能如何?
数据集:为验证所提方法在推荐系统中的有效性,我们以
real user behavior sequence为主要特征构建数据集,用于基于historical interactions来预测用户对candidate items的不同行为。重要的user behaviors包括完整播放(full-play)、点赞(like)、分享(share)和评论(comment)。此外,我们还在三个推荐数据集(Spotify、30Music和Amazon-Book)上评估了模型。Table 1展示了四个处理后数据集的用户数、items数和interactions数。为保护数据隐私,我们仅展示推荐场景的统计数据,并对工业数据集进行了特殊处理,因此表中显示的数据量低于实际数量。但显然,我们的工业数据集规模仍显著超过其他数据集,这一庞大的数据量为scaling experiments提供了坚实基础。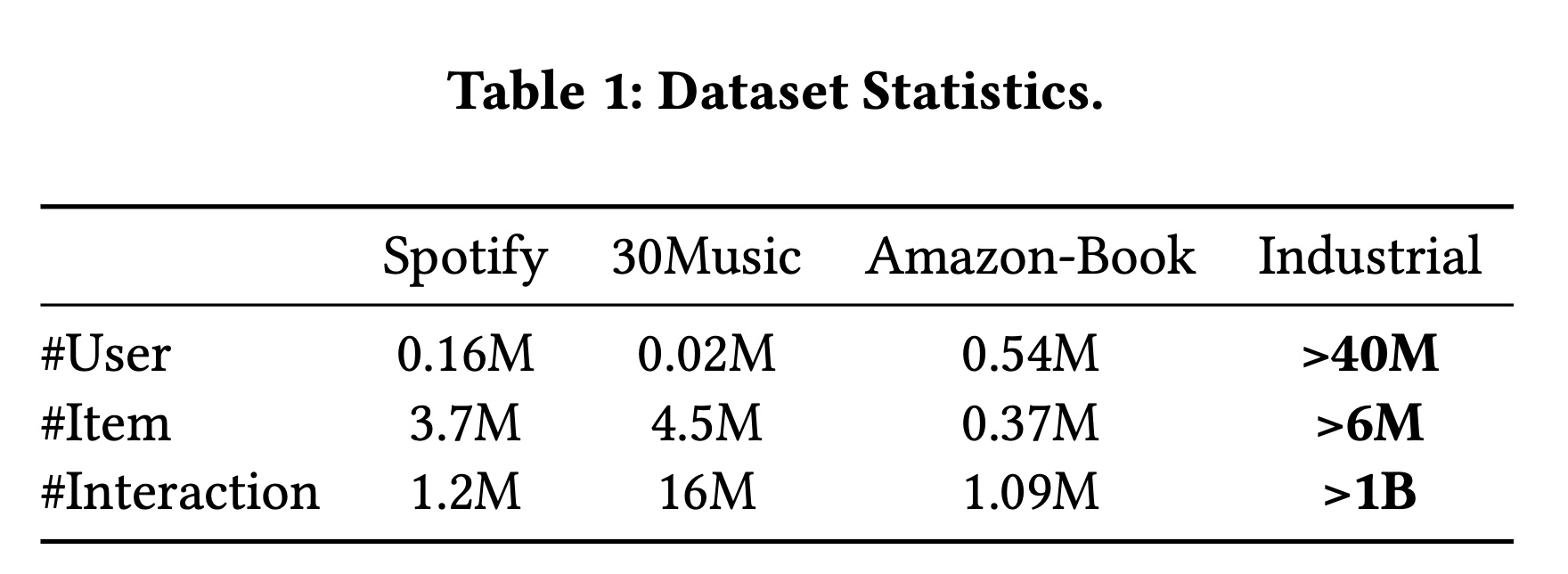
baseline方法:DLRM:该模型利用lifelong user behavior sequences和复杂的feature interactions,已部署于我们的在线系统。实验中,序列长度固定为2000。DIN:通过target attention机制建模user historical behaviors与target item之间的interactions,以捕获user interests。实验中,序列长度设置为1000。TWIN:该模型对齐General Search Unit: GSU和Exact Search Unit: ESU,以增强long-term user behavior建模的一致性。实验中,GSU和ESU的序列长度分别设置为2000和1000。Transformer:Transformer-based的序列建模模型。实验中,a one-stage Transformer encoder处理长度固定为2000的behavior sequences。HSTU:通过按时间顺序重组item-action pairs,将feature-level sequence转换为时间序列,并通过HSTU模型处理,以预测target item-specific user actions。实验中,序列长度固定为2000。Climber系列:先前的方法将序列长度限制在固定时间窗口(窗口大小为2000),且不进行behavior filtering;新方法通过multi-scale sequence extraction,基于业务逻辑驱动的策略将behavior sequences扩展至整个user lifecycle,同时将序列长度缩减至200。模型保持2层结构,与基线配置一致。在工业场景中,Climber-large变体扩展至12层和序列长度800。
1.3.1 整体性能 (RQ1)
性能对比:如
Table 2所示,Climber在四个推荐数据集上均取得最佳性能。值得注意的是,Spotify和30Music的应用场景与我们的工业数据集(音乐推荐系统)属于同一领域,而Amazon-Book与我们的场景差异显著。但我们的模型在该数据集上仍取得了良好结果,表明其具有适应diverse applications的潜力。接下来,我们重点对比
Climber相对于其他方法在Industrial数据集上的AUC提升:1):作为我们的主要在线模型,DLRM优于DIN和TWIN,因为DLRM除了lifelong sequence和attention机制外,还包含多种feature interaction structures。2):Transformer通过在a single stage中计算所有historical items与target item之间的相似度,比TWIN的AUC提升了0.134%。3):HSTU对Transformer进行了多项enhancements,与Transformer相比,AUC提升了0.036%,但这些enhancements也导致计算复杂度增加。4):Climber通过sequence extraction降低了计算复杂度,并通过adaptive temperature coefficients调整多场景和多行为下的注意力分布,与DLRM相比AUC提升了0.170%;此外,Climber-large通过模型scaling up实现了2.21%的AUC提升,是过去一年中最大的离线增益。
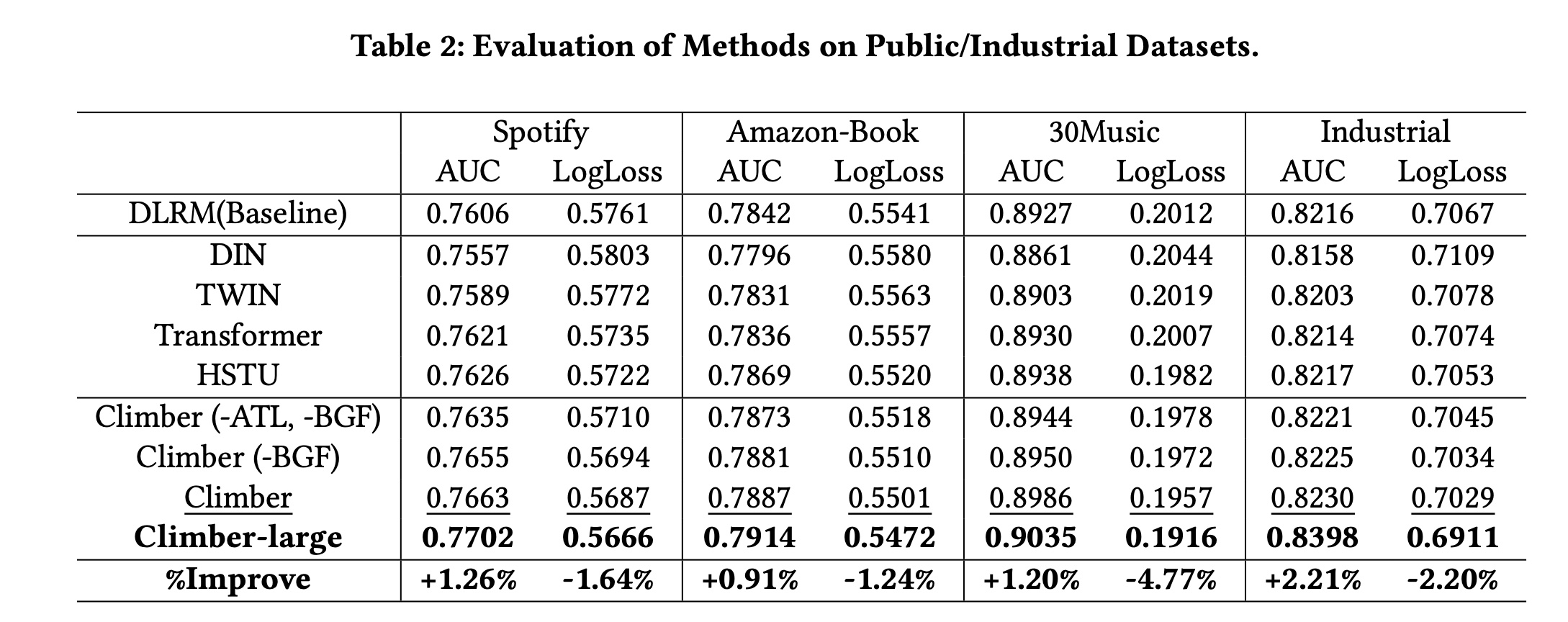
消融实验:为评估
Climber模型各组件的贡献,我们在多个数据集上进行了全面实验。为便于说明,我们重点展示Industrial数据集上的消融实验,并选择Transformer与Climber系列进行对比。Climber (-ATL, -BGF):通过引入MSE,将user lifecycle sequence转换为multi-scale subsequence blocks,与Transformer模型相比,AUC提升了0.085%。Climber (-BGF):进一步引入adaptive temperature coefficient,动态调整注意力分布,AUC提升了0.134%。最后,引入
BGF后,AUC提升了0.195%——该模块整合了不同子序列所代表的user interests,凸显了interest fusion在推荐系统中的重要性。
总之,基于多个数据集的离线评估,我们的模型展现出强大的性能和适应性。
1.3.2 可扩展性 (RQ2)
在讨论
model scalability之前,我们正式定义FLOPs为attention机制的平方计算复杂度在模型整体FLOPs中所占比例仍然很小。因此,在计算分析中,我们仅关注FLOPs可通过TensorFlow的特定工具来计算和验证。"
attention机制的平方计算复杂度在模型整体FLOPs中所占比例仍然很小",这句话明显有问题。实际上平方复杂度所占比例相当大。DLRM、Transformer和Climber的scaling curves如Figure 3(a)所示。尽管当
FLOPs超过Transformer的性能优于DLRM,但FLOPs在DLRM。与
Transformer相比,Climber由于起点更高、斜率更大,展现出更理想的scaling curve。当FLOPs低于Climber的性能仍弱于DLRM,但交叉点左移,使得Climber模型比Transformer更高效地实现性能跃迁。
在本实验中,影响
FLOPs的两个主要因素是层数Climber,Figure 3(b)和Figure 3(c)分别展示了模型性能与层数当序列长度
当层数
因此,我们提出的
Climber模型在FLOPs、序列长度scaling curves,且与Transformer相比具有更高效的scaling curve。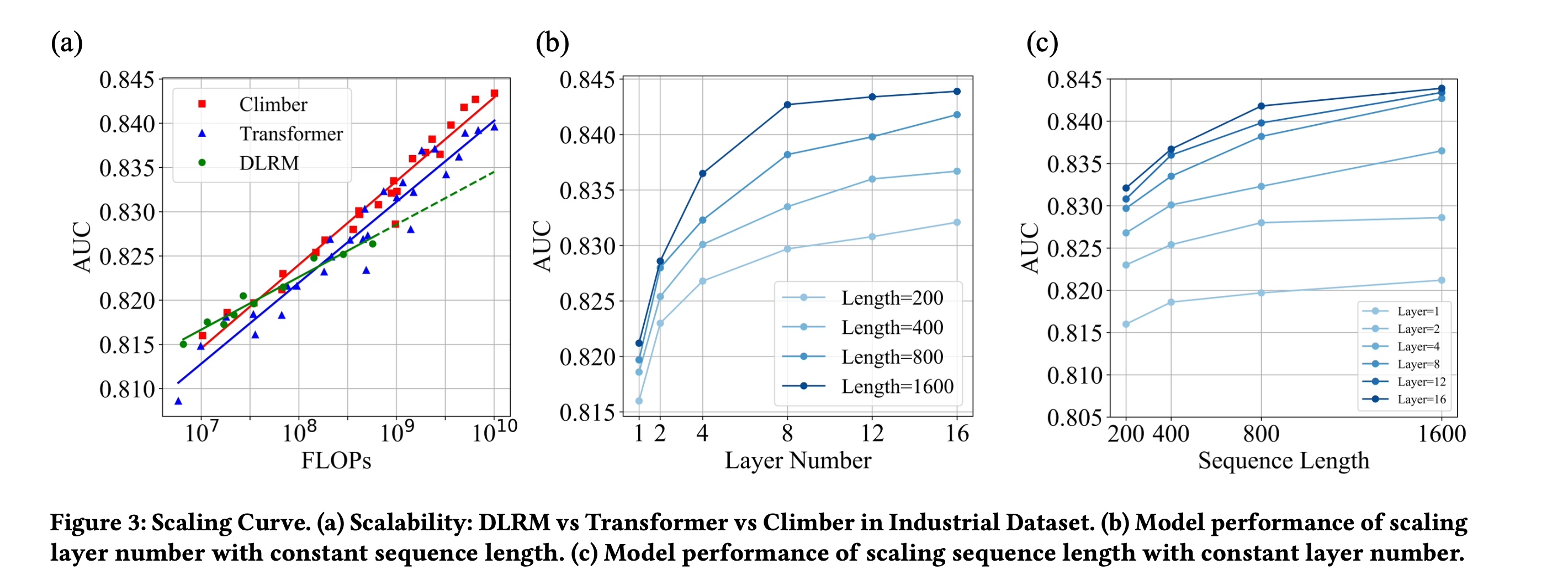
1.3.3 Efficient Allocation (RQ3)
从
Figure 3(b, c)可以看出,增加序列长度AUC,但这两个因素的优先级尚未得到探讨。Table 3展示了等效FLOPs下不同层数AUC。显然,在等效FLOPs下,层数testing AUC发生显著变化。根据FLOPs下层数和序列长度的乘积保持不变。当
FLOPs为AUC=0.8301)。当
FLOPs为AUC=0.8335)。
我们观察到,仅扩展单一
factor可能会限制模型性能提升;因此在scaling up模型时,最好同时考虑层数FLOPs提升4倍,可以选择Table 3可以发现,最佳选择是factors,模型的AUC从0.8301提升至0.8382。这一结论也为在线资源分配提供了指导:在实际推荐系统中,每次迭代通常仅选择一个factor进行调整,因此在scaling up online时,我们会交替增加序列长度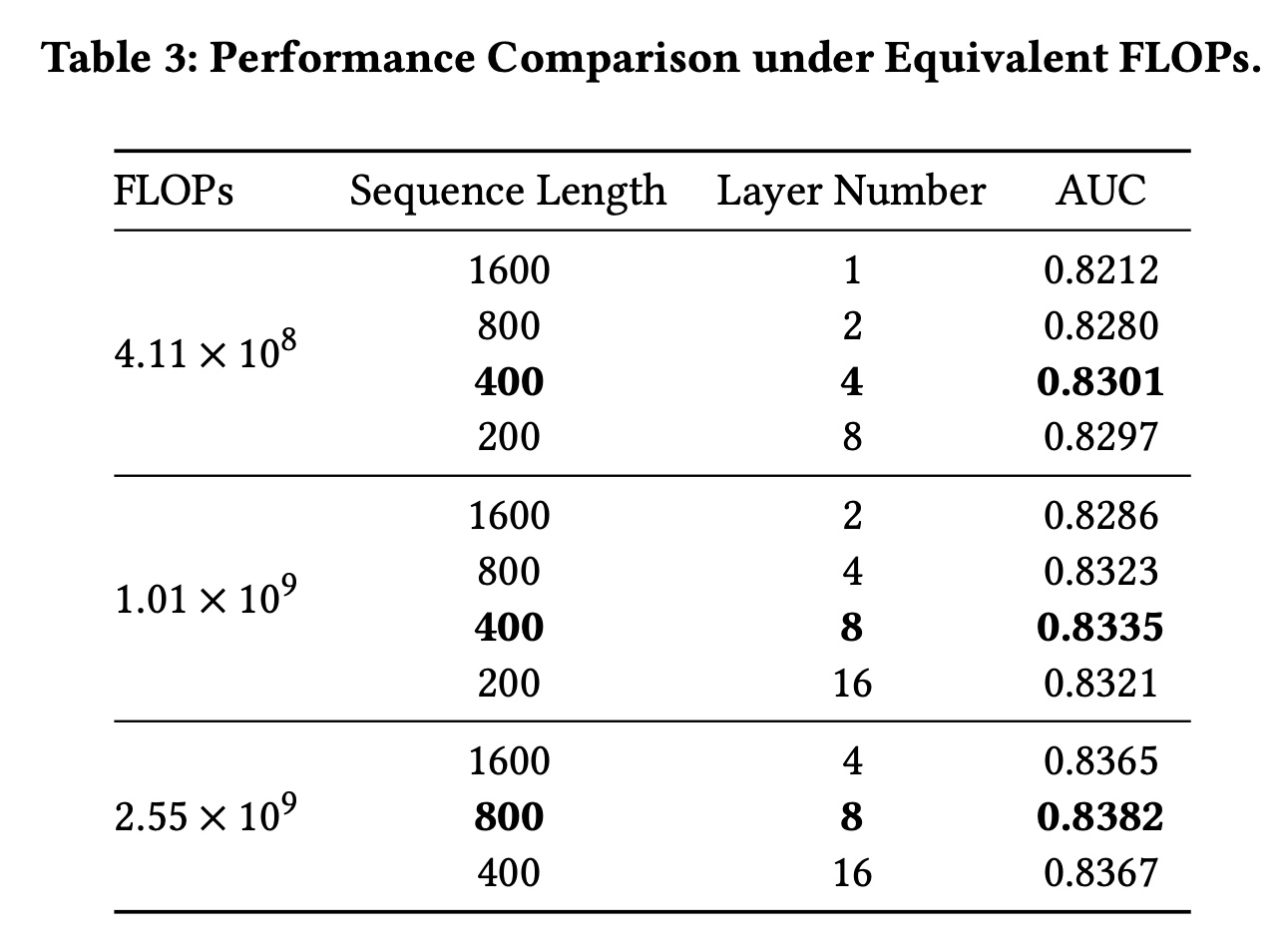
1.3.4 Online A/B Test (RQ4)
Table 4总结了所提Climber框架的online A/B test结果。与 “序列长度和层数同等重要”的结论一致,我们的模型仅通过调整序列长度metric和FLOPs的online scaling curves。首先,
FLOPs为Climber模型表现出负向。当Climber (6x)模型的FLOPs与DLRM (6x)匹配时,仅出现轻微负向,表明在FLOPs较少的情况下,Climber模型的效率低于DLRM。此外,当
Climber (479x)模型的FLOPs为7.78%。最后,当
Climber (620x)模型的FLOPs为12.19%。
根据在线实验的结论,
Climber的成功似乎是FLOPs更大所带来的,而不是因为架构更好所带来的。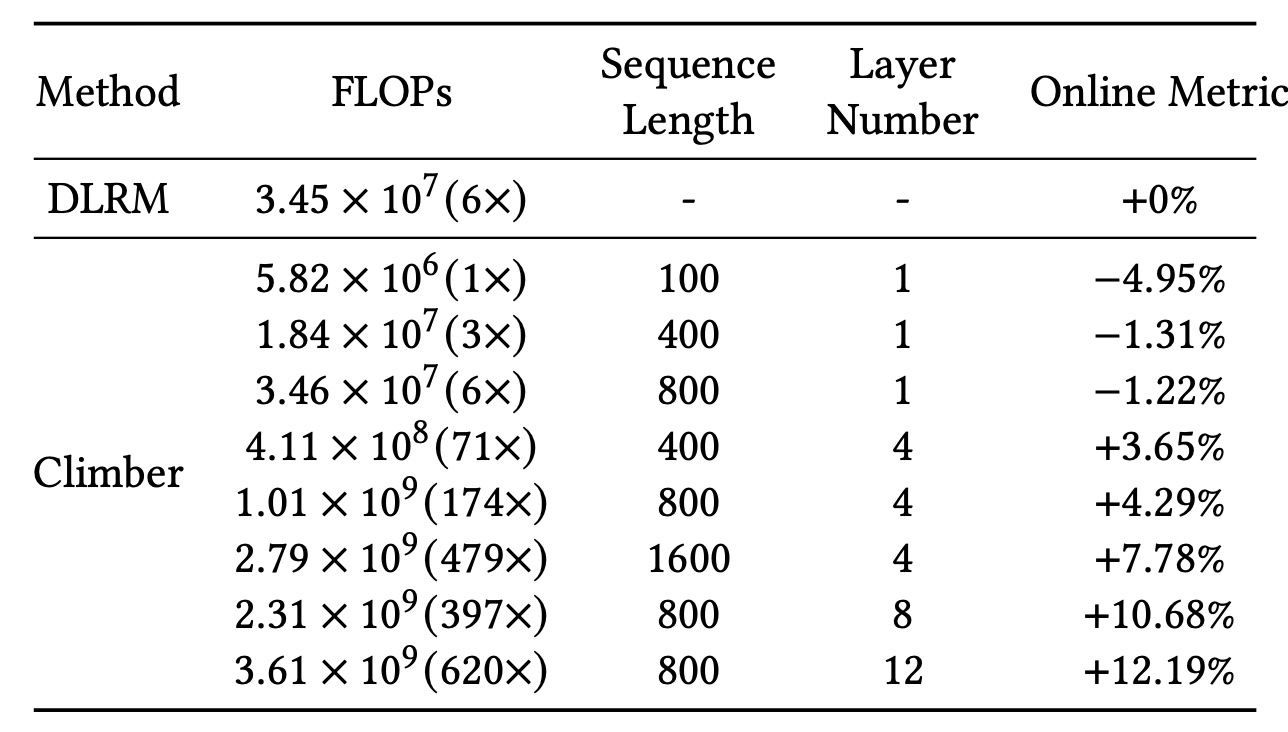
在
online inference阶段,对于不同序列长度和层数,Climber的延迟显著降低——每个request的速度比DLRM快2.92倍至14.38倍。这一acceleration是通过我们的acceleration技术实现的,且使用了与DLRM相当的inference budget,因此我们能够部署复杂度提升100倍的模型。据我们所知,Climber是首个在保持资源平衡的同时,既展现出offline scaling curves又展现出online scaling curves的recommendation模型,且实现了12.19%的指标提升,这是过去一年中最大的提升幅度。
1.4 结论
我们提出了
Climber——一种高效的scaling框架,包含专为推荐场景设计的Transformer变体和协同设计的acceleration技术。该模型通过解决multi-scale sequences、multi-scenario和multi-interest问题,有效降低了计算复杂度,打破了推荐系统中的scaling困境。这种整合使得模型在离线评估中展现出优于DLRM和Transformer的scalability。此外,我们引入的acceleration技术采用"single user, multiple items"样本格式和encoder-level KV cache,能够在不增加过高计算资源的情况下部署复杂度提升100倍的模型。Climber展现出了在线scaling curve,并实现了12.19%的在线指标提升。总之,本研究在资源受限的情况下,使Transformer架构适配了推荐系统,为generative recommendation范式的下一阶段奠定了基础。未来,我们将探索更多生成式技术在推荐系统中的应用,以持续释放scaling的潜力。这篇论文压根不是生成式推荐,而是判别式推荐。