一、 FAT [2025]
《From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction》
尽管在
scale up方面投入巨大,但用于点击率(click-through rate: CTR)预测的deep models往往表现出快速的收益递减效应——这与大型语言模型(LLM)中观察到的平稳的、可预测的性能提升形成鲜明对比。我们发现其根本原因在于结构错位(structural misalignment):Transformers假设序列组合性(sequential compositionality),而CTR data需要对高基数(high-cardinality)的semantic fields进行组合推理(combinatorial reasoning)。无结构化的注意力(unstructured attention)会无差别地分配模型容量(capacity),在极端稀疏性(extreme sparsity)下放大噪声,并破坏可扩展学习(scalable learning)。为了恢复这种对齐关系(
alignment),我们提出了Field-Aware Transformer: FAT,该模型通过decomposed content alignment和cross-field modulation,将field-based interaction priors嵌入到attention中。这种设计确保模型复杂度随fields数量total vocabulary sizeAUC值呈现出power-law scaling特性。我们基于拉德马赫复杂度(Rademacher complexity),提出了首个针对CTR模型的正式scaling law,用于解释和预测这一现象。在
large-scale benchmarks中,FAT相较于现有最优方法,AUC值最高提升了0.51%。在线上部署后,它实现了2.33%的点击率提升和0.66%的每千次展示收入(RPM)提升。我们的研究表明,推荐系统中的effective scaling并非源于模型大小,而是源于结构化表达(structured expressivity)——即架构与data semantics的一致性(coherence)。大型语言模型(
LLMs)的成功揭示了一个重要事实:当模型架构与data对齐时,scaling会变得可预测。随着模型大小、数据量和计算量的增加,性能会平稳提升——这一过程由经验性的scaling laws主导,从而实现系统性的进步。这一原则启发了人们将Transformer架构移植到工业推荐系统中的广泛尝试,尤其是在点击率(CTR)预测领域。然而,尽管取得了一定的收益,大多数现有方法仍停留在架构模仿(
architectural mimicry)层面:它们通过将CTR特征进行令牌化(tokenization)并应用标准的Transformer,从而直接移植LLM designs;要么采用传统的pointwise prediction框架,要么采用生成式重构(generative reformulations)方法。虽然这些方法受益于model capacity的增加,但实证研究发现,随着模型规模的scale up,性能提升会逐渐递减(《Scaling new frontiers: Insights into large recommendation models》),这表明架构扩展与effective learning之间存在脱节。我们认为,这种差异(
divergence)并非源于资源不足,而是源于标准的Transformer中包含的假设(assumptions)与CTR data特性之间的根本性结构错位(fundamental structural misalignment)。乍看之下,这两种模态都涉及sequences of discrete tokens,但它们的semantic structures存在深刻差异:在语言中,语义(
meaning)通过组合语法(compositional syntax)来产生:单词在语法规则(grammatical rules)下层次地组合,形成短语和句子,单词的语义(semantics)依赖于顺序(order)和上下文(context)。tokens是同构(homogeneous)的(来自一个共享的vocabulary),并基于语法角色(syntactic role)和语义相似性(semantic similarity)进行注意力分配。在
CTR prediction中,预测能力源于组合交互(combinatorial interactions):用户的click behavior由cross-field conjunctions来驱动,例如'young user x luxury brand'或'mobile device x evening session'。Inputs是异质(heterogeneous)的高基数的(high-cardinality)categorical features set,每个特征都属于一个semantic field(例如,user_age、ad_category、device_type)。顺序(order)是任意的;关键在于哪些fields发生交互,以及交互的非对称性如何。
标准的
self-attention机制专为dense, ordered sequences的组合语义(compositional semantics)来设计的,无法区分这一差异。它通过全局共享的projection矩阵来统一处理所有embeddings,将表征容量(representational capacity)无差别地分配到不同feature types上。在极端稀疏性(extreme sparsity)下——大多数field-value combinations很少被观察到——这种无结构化的注意力(unstructured attention)会放大噪声、扭曲梯度,并最终破坏scalable learning。更令人担忧的是,推荐系统中缺乏
scaling的理论基础。虽然LLM受益于完善的泛化边界(generalization bounds)和基于统计学习理论的scaling laws,但CTR模型尚无此类框架。没有它,scaling就变成了试错过程,与架构设计原则(architectural design principles)脱节。这引出了一个关键问题:我们能否重新设计用于推荐系统的
Transformer,使其表达能力与数据的潜在的交互复杂度(interaction complexity)协调增长——不仅是raw parameter count的增长,更是结构化表达能力(structured expressivity)的提升?为了回答这个问题,我们回归到一个经典的洞察:
field-aware interaction modeling。诸如Field-aware Factorization Mchines: FFM之类的模型为每个ordered field pairlatent vectors,支持非对称的(asymmetric)且上下文敏感的(context-sensitive)的modeling of interactions(例如,user_gender如何影响针对ad_category的response)。然而,FFM是浅层的且静态的,无法进行深度组合(deep composition)或上下文优化(contextual refinement)。受这一原则启发,一个自然的架构扩展方向是使
attention机制中的query/key/value projections针对每个field pair进行专门化(specialized),允许每个attention head捕获source field和target field之间不同的交互模式(interaction patterns)。虽然这一概念具有吸引力,但这种朴素的实现会导致参数激增:对于semantic fields,interaction-specific parameters的数量会以embedding size。在实际系统中,当base model,参数数量也可能从100 million膨胀到10 trillion以上——这使得训练和部署变得不可行。为了解决表达能力(
expressivity)与可扩展性(scalability)之间的这一矛盾,我们提出了Field-Aware Transformer: FAT,这是一种基于两种协同机制(synergistic mechanisms)构建的新型架构。首先,
Field-Decomposed Attention将完整的field-pair-specialized transformation分解为两个组件:(i):field-aware content alignment,其中query和key通过各自field-sepecific的矩阵进行投影(scaling为(ii):field-pair interaction modulation,通过轻量级的标量(lightweight scalars)控制field pairs之间的信息流(scaling为
这种分解(
decomposition)确保模型复杂度随fields数量注意,参数规模与总词汇量
embedding size其次,为了进一步将模型容量(
model capacity)与fields数量解耦并消除存储开销(storage overhead),FAT采用了基于超网络的生成机制(Hypernetwork-Based Generation mechanism):field-specific parameters通过轻量级神经模块从一组紧凑的基矩阵(basis matrices)中动态地合成。
至关重要的是,我们通过拉德马赫复杂度分析(
Rademacher complexity analysis),为CTR模型推导了首个具有理论依据的scaling law。我们表明,FAT的泛化误差(generalization error)取决于field interactions的组合结构(combinatorial structure)——特别是fields的数量——而非vocabulary size。这种结构对齐(structural alignment)解释了为什么FAT随着模型宽度增加,AUC值呈现出平稳的power-law scaling,而这一现象在baseline Transformer中是不存在的。模型宽度即
我们的贡献如下:
架构(
Architecture):提出FAT,一种将field-aware priors整合到attention机制中的Transformer变体,支持对组合语义进行结构化的、可解释且可扩展的建模。可扩展性机制 (
Scalability Mechanism):通过Field-Decomposed Attention和Hypernetwork-Based Generation,设计了参数高效(parameter-efficient)的实现方案。理论(
Theory):针对CTR模型提出首个generalization-aware scaling law,证明effective scaling需要架构与data structure的一致性——而不仅仅是更大的模型。实证验证(
Empirical Validation):在large-scale benchmarks中,FAT相较于SOTA方法,AUC值最高提升了0.51%。在线上部署后,实现了2.33%的点击率提升和0.66%的每千次展示收入(RPM)提升,展现出显著的业务价值。
本研究表明,
CTR prediction中的scalable性能并非仅源于模型大小,而是源于结构化表达(structured expressivity)——即,架构设计(architectural design)与特征交互组合语义(combinatorial semantics of feature interactions)的刻意对齐。FAT超越了对LLM的单纯的架构模仿,为构建更大的、更强的且更可预测的推荐系统提供了一条具有理论依据的路径。
1.1 相关工作
我们围绕现代
CTR modeling中的两个核心挑战展开讨论:(1):捕获结构化的feature interactions。(2):实现可预测的scaling。
我们的工作填补了这两个目标之间的关键空白。
Modeling Structured Feature Interactions:有效的CTR模型必须捕获semantic fields之间的高阶的、非对称的interactions。Factorization Machines: FM引入了低秩的(low-rank)pairwise的建模,随后被FFM改进;FFM为field-pair分配特定的latent vectors以建模上下文敏感效应(context-sensitive effects)。这些模型具有可解释性(interpretable)和参数高效性(parameter-efficient),但仅限于浅层交互(shallow interactions)。DeepFM、AutoInt和DCNv2等神经扩展(neural extensions)使用多层感知机(MLPs)或attention机制来学习复杂的模式。这些方法的一个普遍局限性是,结构化交互建模(structured interaction modeling)仍然局限于浅层架构——通常只有少数几层——这阻碍了深度组合(deep compositionality),并使principled scaling变得不可行。
Towards Predictable Scaling in Recommendation:受Transformer在语言建模中的成功启发,近期研究尝试将其架构应用于CTR prediction。然而,标准self-attention的假设——序列顺序(sequential order)、稠密令牌(dense tokens)、组合语法(compositional syntax)——在推荐系统中并不成立,因为推荐系统的inputs是具有组合语义(combinatorial semantics)的无序(unordered)的且稀疏(sparse)的集合。应用无结构化注意力(unstructured attention)可能导致低效的representation learning、以及稀疏性下的泛化性能不佳。更根本的是,与遵循
well-characterized scaling laws的LLM不同,CTR模型在scaling时往往表现出性能饱和或下降(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)。这表明架构容量(architectural capacity)与数据结构(data structure)之间存在错位,且没有任何研究将model design与scalable behavior以一个principled way来联系起来。这些空白揭示了一个关键挑战:如何构建模型从而同时支持表达性(
expressive)的、可解释性(interpretable)的interaction modeling,和可预测的、稳定的scaling。现有研究至少在一个维度上存在不足。我们的工作表明,弥合这一鸿沟需要将domain-aware inductive biases直接嵌入到架构的核心计算中。
1.2 方法
如
Figure 1所示,Field-Aware Transformer: FAT通过沿semantic fields分解attention来实现structured expressivity:query/key/value projections通过field-aware content alignment和field-pair interaction modulation,针对每个field pairparameter dependency从structural prior确保effective model complexity随fields数量vocabulary sizeextreme sparsity)下实现更严格的泛化边界(tighter generalization bounds)。为了将模型容量(
model capacity)与fields数量解耦,FAT采用超网络(hypernetwork)来生成field-specific parameters,在不增加推理成本的情况下消除存储开销。接下来,我们详细介绍架构和parameterization。核心的
idea就是修改attention公式:对每个
field采用不同的投影矩阵,而不是全局共享的投影矩阵。对
attention结果进行pair-wise的调制(利用可训练的参数
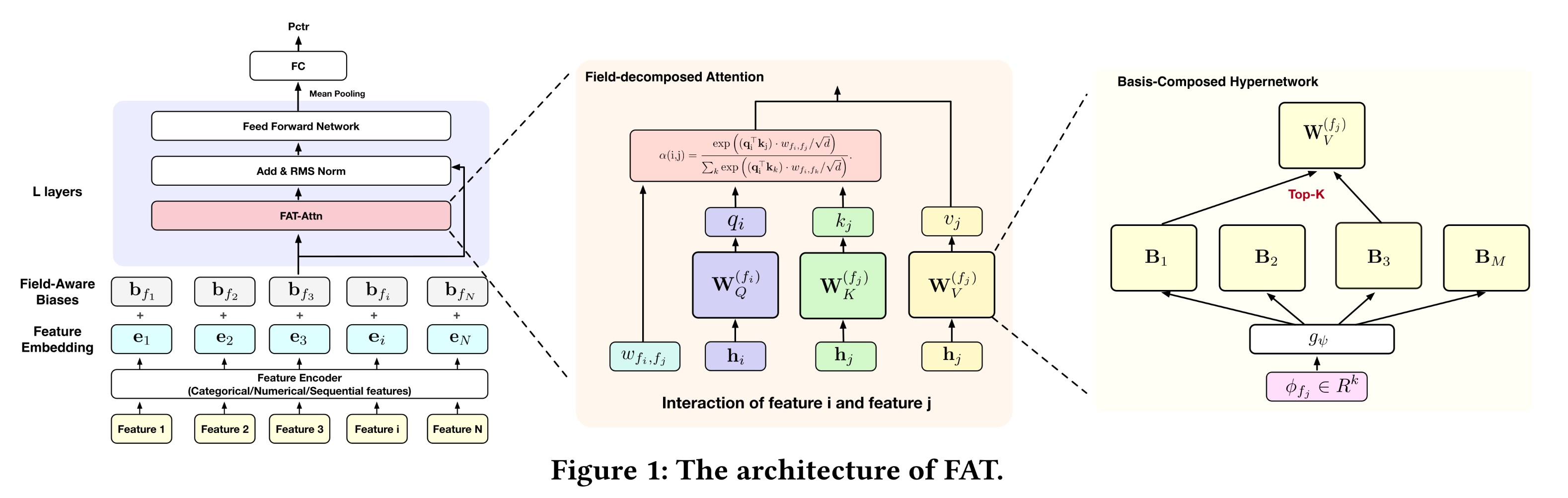
1.2.1 Structured Tokenization via Field-Aware Representation Learning
在
CTR prediction中,inputs是来自distinct semantic fields(例如,user、item、context)的heterogeneous features的集合——包括categorical特征、numerical特征和sequential特征。与language中语义由序列组合性(sequential compositionality)驱动不同,CTR data的语义源于fields之间的组合交互(combinatorial interactions)。为了支持结构化交互建模(structured interaction modeling),我们将每个特征representation spacetype-specific transformations来生成一个embedded tokencategorical特征使用embedding lookup tables。numerical特征通过单调网络(monotonic networks)或quantile discretization with embedding lookup tables进行处理。sequential特征通过专用的编码器(例如,DIN)汇总为field-level representations。
所有
embeddings都被投影到相同的维度input order是任意的,我们用反映语义角色(semantic roles)而非语法位置(syntactic positions)的field-aware biases替换index-based positional encodings。对于属于fieldtokenfinal input representation为:其中:
fieldlearnable bias vector。这注入了与field semantics对齐的structural priors,确保在排列组合(permutation)下的一致的泛化(consistent generalization)。b_cs),谁是生物专业(b_bio),从而采用不同的互动方式。没有这顶帽子,老师就需要通过长时间的对话(从数据中学习)才能分辨出他们的专业。在
CTR模型中,输入字段的顺序通常是固定的,也就是field name和field position是一一对应的。此时position embedding等价于field-aware biases。也可以对每个field采用free variable来训练。但是,在
Hiformer论文中,作者发现添加了position embedding的Transformer的效果不如Transformer without position embedding。由此产生的序列
field-identified的token stream,为FAT中可解释的(interpretable)和可扩展(scalable)的interaction modeling奠定了基础。其中fields的数量。
1.2.2 From Standard Transformer to Field-Pair-Specialized Attention
在标准
Transformer中,attention其中:使用全局共享的
query投影矩阵key投影矩阵这统一处理所有
tokens,忽略它们的field来源——这在interactions是非对称(asymmetric)且上下文敏感(context-sensitive)的时候是一个关键的局限。受
FFM的启发(FFM通过专用的latent vectors建模pairwise field interactions),我们考虑一种自然的泛化:使query/key/value projections针对每个有序的field pairspecialized)。也就是说,对于每个attention head然后计算:
这种设计支持细粒度的控制:
user_gender中的query对ad_category的注意力分配,可能与对device_type的注意力分配存在根本性差异。它捕获了非对称性(asymmetry)、上下文敏感性(context sensitivity)和域角色感知(field-role awareness)——直接反映了CTR data的组合语义(combinatorial semantics)。然而,朴素的实现需要每层
attention head的数量)。当base model,参数数量也可能超过数百亿。因此,虽然概念上理想,但完全的field-pair specialization对于工业部署而言不切实际。我们现在推导一种更具scalable的实现方案,同时保留其语义本质。
1.2.3 Filed-decomposed Attention: Field-Aware Content Alignment with Field-Pair Interaction Modulation
为了在确保
scalability的同时保留field-pair modeling的表达能力,我们将attention机制分解为两个互补的组件:域感知内容对齐(
Field-aware content alignment):给定两个tokens各自的语义角色(semantic roles),该组建刻画它们的交互程度。这个思想已经在
Hiformer(《Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems》)中被提出了。此外,
Hiformer不仅在attention layer进行域感知内容对齐,也在FFN layer进行了域感知内容对齐。域对交互调制(
Field-pair interaction modulation):信息从一个field流向另一个field的强度。
这种分解允许我们以极低的成本保留细粒度的
interaction modeling。具体而言,我们将attention score定义为:现在,
similarity measure)——它是field-aware content alignment,因为query和key都通过依赖于source fields的矩阵进行投影:tokentransformation),基于tokenfielduser-side vs. item-side encoding)。fieldkey。
因此,即使不考虑跨域强度(
cross-field strength),模型也能区分:an age value在与a user context计算注意力,以及与a contextual ad signal计算注意力时,是否应进行不同编码。这代表了一种粗粒度但至关重要的field awareness:每个field学习自己的"encoding style",支持tokens之间基于语义的比较。标量参数
field-pair modulation factor,基于source fields和target fields来调整attention weight。这支持对semantic fields之间信息流的细粒度控制。例如,较大的behavior-category的敏感性,而较小的irrelevant couplings)。总之,这种分解分离了不同关注点:
field-specific interpretation)下,捕获tokens represent。representations是否交互以及交互强度。
value vector遵循相同原则:从而确保
output transformations也与field semantics对齐。multi-head attention聚合output如下:这种公式具有以下几个优点:
多层次的
field感知(Hierarchical Field Awareness) :content alignment在per-field level(粗粒度)运作,编码了语义角色(semantic roles);interaction modulating在field-pair level(细粒度)运作,控制路由强度(routing strength)。可解释性(
Interpretability):interaction模式的洞察。非对称性(
Asymmetry):directional effects)。效率和可扩展性(
Efficiency and Scalability):朴素的field-pair projections对于每个head需要FAT仅使用16B减少到50M)将参数数量减少99%以上。这使得训练大型模型而不牺牲语义保真度(semantic fidelity)成为可能。
通过将
field-aware representation与field-pair-governed routing分离,FAT实现了结构化表达(structured expressivity):它不是通过增加无结构化容量(unstructured capacity)来扩展,而是通过以可控的、可解释的方式深化语义分辨率(semantic resolution)。
1.2.4 Basis-Composed Hypernetwork for Scalable Parameter Generation
尽管具有表达能力,但存储
large-scale systems中会产生巨大的内存成本和维护成本,尤其是当fields数量embedding sizesemantic fidelity)的同时将参数增长(parameter growth)与fields数量a basis-composed hypernetwork,动态生成field-specific projections。设
basis matrices),canonical linear transformations)(例如,缩放scaling、旋转rotation)。这些矩阵通过端到端来学习,并在所有fields之间共享。在这里
注意:由于模型可能包含多层
FAT Layer,因此在实验章节,作者在每一层之间共享对于每个
fielda meta-embeddingMLPmeta-embedding然后,我们应用
Top-K sparse selection(其中,
并将
query projection综合如下:类似的方法使用单独的
basis set生成Top-K parse selection如何训练?读者猜测:利用直通估计器(Straight-Through Estimator: STE)。这是处理离散操作最常用、最直接的方法。前向传播:执行硬性的
Top-K selection,得到选中的索引集合反向传播:将梯度直接传递给被选中的
selection操作本身是可微的一样。效果:虽然梯度在数学上不精确,但在实践中非常有效,能让模型学习到哪些基矩阵应该被选中。
hypernetwork支持scalable的架构设计,具有两个关键优点:与
field growth解耦的复杂度:field-specific projections通过动态合成来生成,无需显式存储,打破了shared bases(meta-embeddings(scaling——这对于不断引入新特征的工业applications至关重要。零推理开销:所有生成的参数——包括
serving时不执行hypernetwork evaluation,确保与low-latency的production pipelines完全兼容。
1.2.5 CTR Prediction
FAT堆叠field-decomposed attention,每层之后跟随一个前馈网络(FFN)、residual connection、以及layer normalization:根据论文的
Figure 1,它每层的结构应该为:即:先添加残差、再进行
RMS Norm、最后馈入FFN。其中RMS Norm仅用均方根进行缩放,不进行中心化:然后应用池化操作并生成
final prediction:其中:
sigmoid函数。learnable的权重向量。fieldfinal-layer representation。
1.3 理论意义:A Principled Scaling Law
推荐系统中最受追捧的目标之一是随着模型大小增加,实现可预测的、平稳的性能提升——这一现象在
LLM中通过empirical scaling laws得到了充分证明。然而,在CTR prediction中,naive scaling往往导致性能饱和或下降,因为unstructured capacity growth放大了noise而不是放大了signal。我们表明,
FAT通过使architectural design与combinatorial semantics of feature interactions进行对齐,实现了principled scaling。具体而言,我们证明FAT的有效模型复杂度(effective model complexity)取决于semantic fields数量interaction structure rank,而非total vocabulary sizefieldvocabulary。这种structural alignment产生了更严格的泛化边界(generalization bounds),并为表现良好的scaling law铺平了道路。我们的主要理论结果建立了单个
FAT attention layer泛化误差的上界。基于拉德马赫复杂度分析(Rademacher complexity analysis)的完整证明见附录A。定理
4.1(Generalization Bound for FAT):设input sequencesFrobenius norm有界于interaction scalars(FAT layer的泛化误差(generalization error)其中:
norm bounds)和embedding size的常数。这个上界揭示了
FAT相较于standard Transformer的根本优势。标准
self-attention的假设空间复杂度(hypothesis space complexity)隐含地随token-level interactions,这使得它在极端数据稀疏性(extreme data sparsity)下极易过拟合。注意,这里讨论的是 “假设空间复杂度”。因为在标准
self-attention中,每个token都可以和任意一个token进行交互,因此自由度为而在
FAT中,交互是发生在field-level,因此与相比之下,
FAT将表达能力限制在语义有效的路径(semantically valid pathways)上——仅学习field-specific transformations和cross-field modulations。这种结构约束(structural constraint)将有效假设空间(effective hypothesis space)从field内的大量数据中共享,显著提高了统计效率(statistical efficiency)并减轻了过拟合。
至关重要的是,这种严格的泛化边界支持可预测的
scaling。对于固定的数据分布和field schemaembedding sizefield-aware content alignment(field-pair interaction modulation(representational fidelity)。这允许模型学习fields之间更高秩的(higher-rank)、更细致的交互函数,从而系统地降低训练误差data’s combinatorial structure对齐,这些额外参数细化了有意义的模式,而非拟合噪声。注意,这里的总参数数量仅包含
FAT layer的参数,不包括embedding layer的参数。实际上embedding layer的参数规模vocabulary决定,它不是一个可以调整的超参数。结合这两种效应——增强表达能力带来的偏差(
bias)减少、以及严格泛化带来的方差(variance)减少——我们得到了principled scaling law。在固定数据量field schemapower-law趋势提升:其中
baseline的性能增益。这为CTR模型中观察到的经验性的power-law scaling趋势提供了理论依据,将architectural design与predictable scalability联系起来。这一定律的实证验证见实验章节。
1.4 实验
我们进行了全面的实验,以严格评估我们提出的
Field-Aware Transformer: FAT的有效性、可解释性、可扩展性和可部署性。我们旨在回答五个关键研究问题:RQ1:FAT在预测准确性方面是否优于SOTA的CTR模型?RQ2:各个组件对性能的贡献如何?decomposition是否有效?RQ3:FAT能否提供对field-level interactions的可解释洞察?RQ4:FAT是否表现出理论预测的良好scaling law?RQ5:当部署在实际在线系统中时,FAT在A/B testing中是否改善了业务指标?
数据集:我们在来自
Taobao's sponsored search的a large-scale CTR dataset上进行评估,该数据集包含两周内收集的超过14 billion的user impressions。输入包括数百个异质特征(heterogeneous features)——features—categorical特征(例如,user/item IDs)、numerical特征(例如,CTR、停留时间dwell time)、以及sequential特征(例如,行为轨迹behavior trails)——涵盖数十亿users and items。这种setting捕获了工业推荐的核心挑战:极端规模、高稀疏性和复杂的跨域交互(cross-field interactions)。baselines:我们与具有代表性的SOTA方法进行比较,按建模范式分类:传统交互模型(
Traditional Interaction Models):FFM、DeepFM、AutoInt和DCNv2,这些模型强调structured or learned的pairwise feature crosses。此外,我们将
Embedding+MLP用于feature crossing从而作为strong baseline,记为DeepCTR。面向
scaling的架构(Scaling-Oriented Architectures):HiFormer、Wukong、HSTU和RankMixer,代表了scalable and adaptive model design的最新进展。
这一选择涵盖了
CTR建模的进化谱系——从field-aware factorization到large-scale representation learning——使我们能够以principle的方式评估structured field awareness是否能够超越经典交互机制(classical interaction mechanisms)和现代缩放范式(modern scaling paradigms)。实现细节:
所有实验都在配备
128个NVIDIA GPU的分布式训练系统上进行,使用同步数据并行SGD(synchronous data-parallel SGD)。模型使用
TensorFlow实现,并通过Adam optimizer(global batch size = 262,144(每个GPU为2048);对每个模型和每个scale configuration,初始学习率在{1e-4, 3e-4, 5e-4, 1e-3}中进行调优。为了进行公平且有洞察力的比较,我们采用了与
architectural design principles对齐的双规模评估协议(dual-scale evaluation protocol):Traditional Interaction Models(DeepCTR, FFM, DeepFM, AutoInt, DCNv2):在约50M参数的典型容量下进行评估。所有超参数——包括embedding size、hidden size、dropout(0.1-0.5)、L2正则化(1e-6 to 1e-3)和网络深度——通过在验证集上的贝叶斯搜索(Bayesian search)进行优化,以确保最佳性能。Scaling-Oriented Architectures(HiFormer, Wukong, HSTU,RankMixer):通过调整width或depth,在保持核心架构约束(例如,RankMixer中的experts数量、HSTU中的hierarchy levels)的同时,统一扩展到约0.5B参数。在这一固定容量范围内重新调优超参数。
我们根据上述协议定义了
FAT的三个实例:FAT-Small:约50M参数,与Traditional Interaction Models进行比较;FAT-Large:约0.5B参数,与Scaling-Oriented Architectures进行比较;FAT-XL:约1.5B参数,专门用于分析scaling趋势。
所有模型共享相同的:
(1):特征预处理:categorical特征使用hashed vocabularies;numerical特征离散化为不同的bins;sequential特征(例如,user behavior history)通过共享的DIN风格的兴趣提取器(interest extractor)来处理。(2):embedding size:所有模型的不同特征固定为
FAT-specific配置:multi-head attention使用heads。field meta-embeddings超网络(
hypernetwork)采用basis matrices),采用Top-𝐾 = 3 sparse activation。field-pair interaction scalars
1.4.1 Main Results (RQ1): Superior Predictive Performance
本节评估
FAT是否比SOTA的CTR模型实现了更优的性能——更关键的是,为什么。我们没有报告孤立的收益,而是设计了一个严格的比较框架,以区分架构优势与参数膨胀(parameter inflation)。核心问题是:FAT性能更好是因为其结构设计,还是仅仅因为更大的容量?为了回答这个问题,我们采用了双规模评估框架(
dual-scale evaluation framework),支持三个关键调查:(1):FAT是否优于现有模型?(2):FAT的改进是否归因于更好的架构,而非更多的参数?(3):FAT的相对优势在scaling下是否持续——甚至增长?
如
Table 1所示,我们报告了相对于baseline(DeepCTR)的ΔAUC。在小规模场景(约
50M参数)下,FAT-Small优于traditional interaction models,包括DeepCTR, FFM, DeepFM, AutoInt, and DCNv2。这一点尤为重要,因为这些方法在这一容量下已达到性能上限,进一步scaling只会带来递减收益。例如,我们也将traditional interaction models扩展到0.48B参数(例如,DeepCTR-Large),但未观察到进一步的改进——表明性能很早就饱和了。FAT在相同参数约束下的收益表明,其field-aware attention decomposition能够更有效地利用有限的模型容量。在大规模场景(约
0.5B参数)下,FAT-Large超越了scalable architectures(包括Hiformer, Wukong, HSTU, and RankMixer),尽管参数大小完全匹配。所有baselines在保持架构完整性的同时,通过width/depth进行了统一扩展,并且为了公平起见重新调优了超参数。FAT的持续领先表明,其性能优势并非源于规模,而是源于更优的归纳偏置(inductive bias):field-aware content alignment和interaction-aware routing的分离允许更基于语义且更稳定的信息流。值得注意的是,当进一步扩展到
1.5B参数(FAT-XL)时,性能继续提升,没有出现饱和迹象——这初步表明了良好的scaling行为(将在接下来的实验中深入分析)。
总之,在公平的容量控制下,
FAT始终优于经典的和现代的CTR模型。其收益并非参数数量的产物,而是结构化表达(structured expressivity)的结果。这确立了FAT作为一种根本上更强大的架构——其优势源于设计,而非仅仅是规模。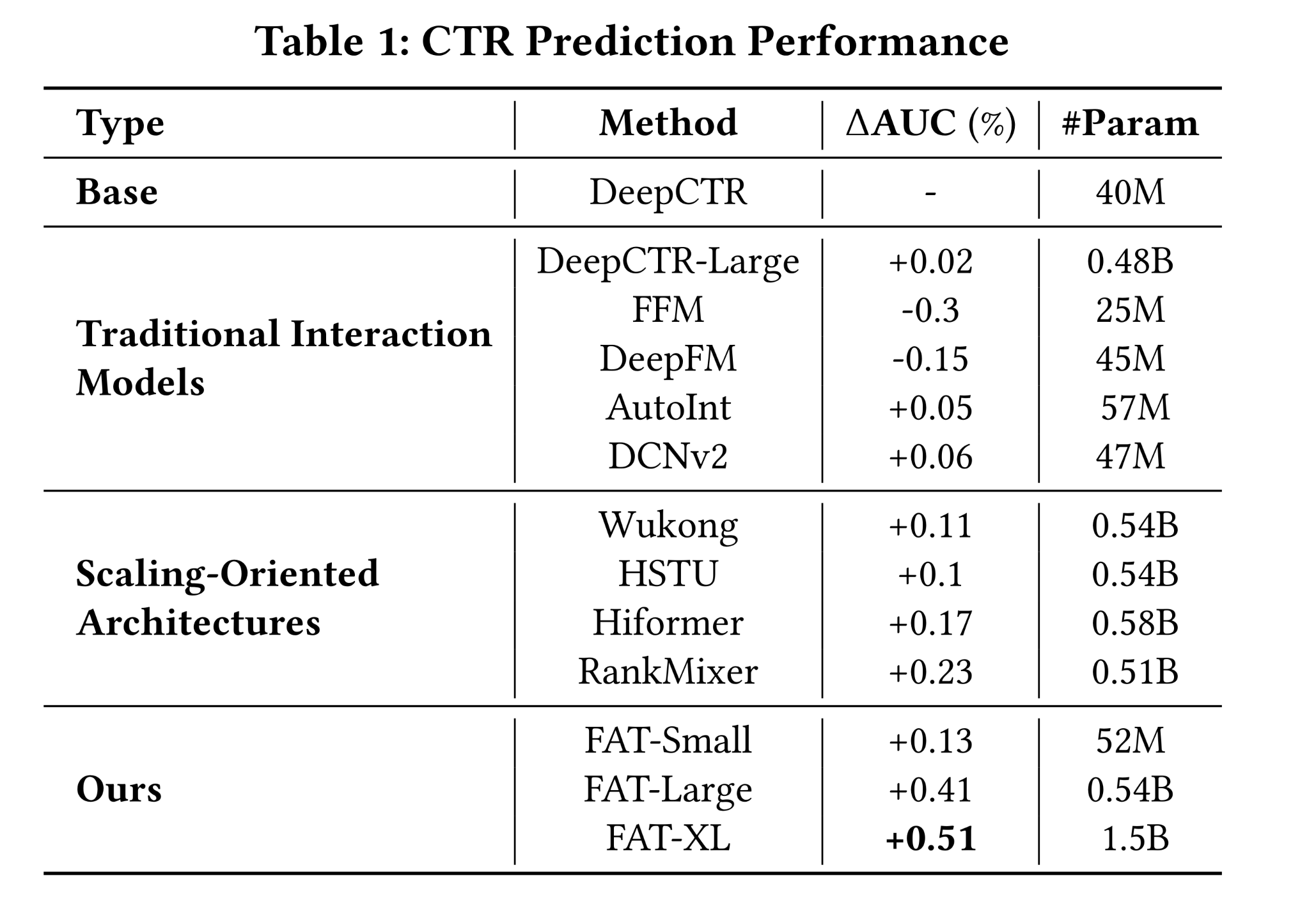
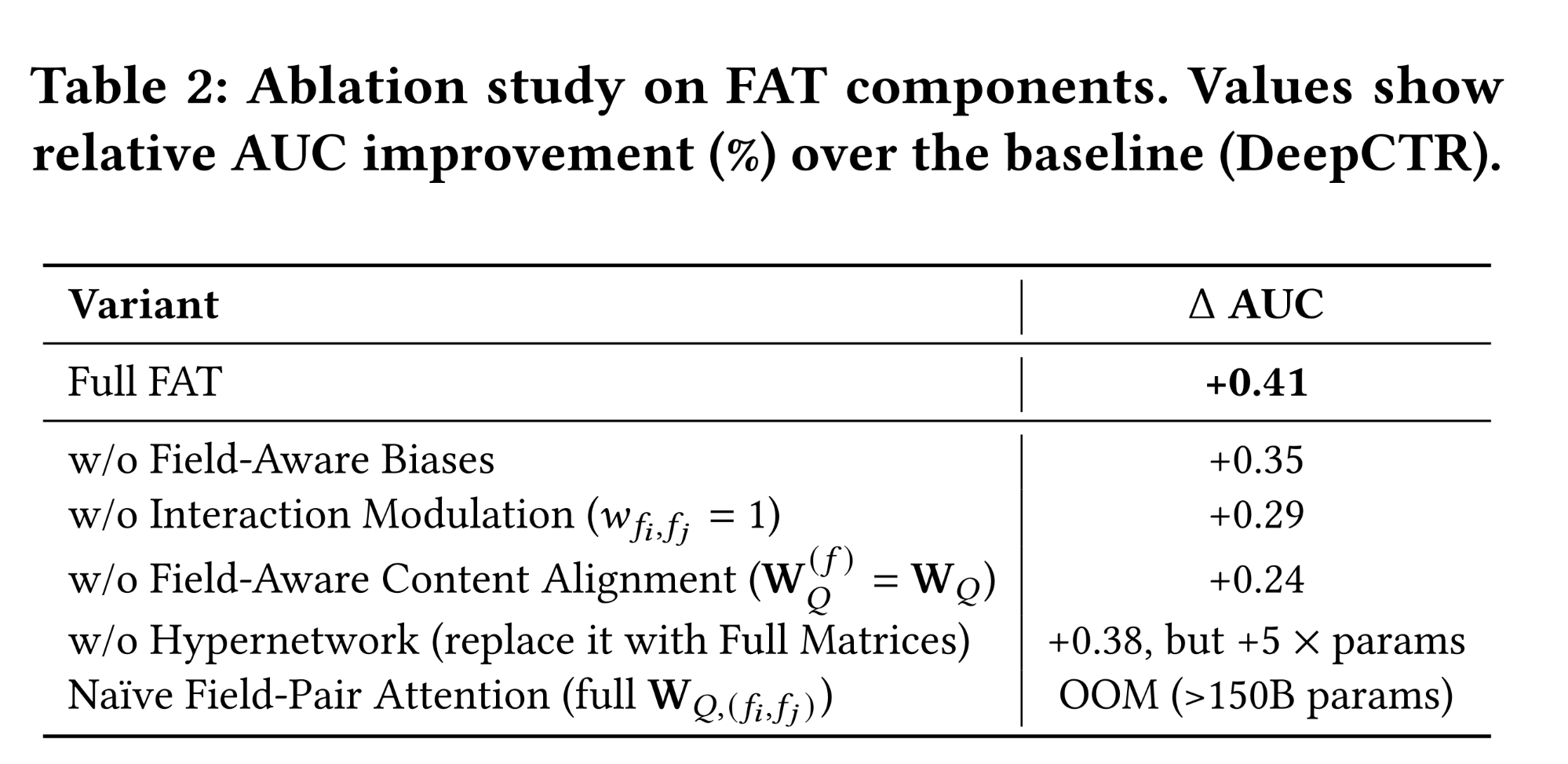
1.4.2 Ablation Study (RQ2): Component-wise Analysis
为了理解
FAT收益的来源,我们进行了消融实验,测量相对于baseline(DeepCTR)的相对AUC改进(Table 2)。所有变体保持相似的training setups,支持对design choices的受控比较。完整的
FAT(FAT-Large)实现了最高的收益(+0.41),验证了我们整体设计的有效性。移
field-aware biases(w/o field-aware biases)导致轻微下降至+0.35,表明虽然结构先验(structural priors)有帮助,但并非性能的主要驱动因素。至关重要的是,
attention机制的分解(decomposing)揭示了明确的贡献层次:Field-Aware Content Alignment——建模field-specific query projections(+0.24,损失0.17个百分点,大于任何其他单一消融。这表明,按字段角色(field role)(例如,user, item, context)进行早期专门化(early specialization),构成了有意义交互建模(meaningful interaction modeling)的基础。Interaction Modulating——使用field-pair-specific scalars+0.29(损失0.12个百分点)。虽然它的粒度更细,但它的影响是次要的,这表明非对称交互强度(asymmetric interaction strength)很重要,但仅在content representations被正确地对齐之后。
对于
scalability,用完整的参数矩阵替换hypernetwork会产生相似的性能(+0.38),但参数成本增加5倍,这表明dynamic generation以最小的存储实现了接近最优的表达能力。最重要的是,没有参数分解(
parameter decomposition)的naïve field-pair-specialized attention由于内存溢出(>150B参数)而完全失败,这凸显了无结构化容量增长(unstructured capacity growth)在实际系统中是不可行的。
1.4.3 Interpretability Analysis (RQ3): Uncovering Semantic Interaction Patterns
为了理解
FAT如何捕获语义交互(semantic interactions),我们分析了学到的modulation weightsfieldfieldfield pair的tokens之间共享,反映了全局交互模式(global interaction patterns)。我们在Figure 2中可视化了所有attention heads的平均structured coherence)和非对称影响(asymmetric influence)。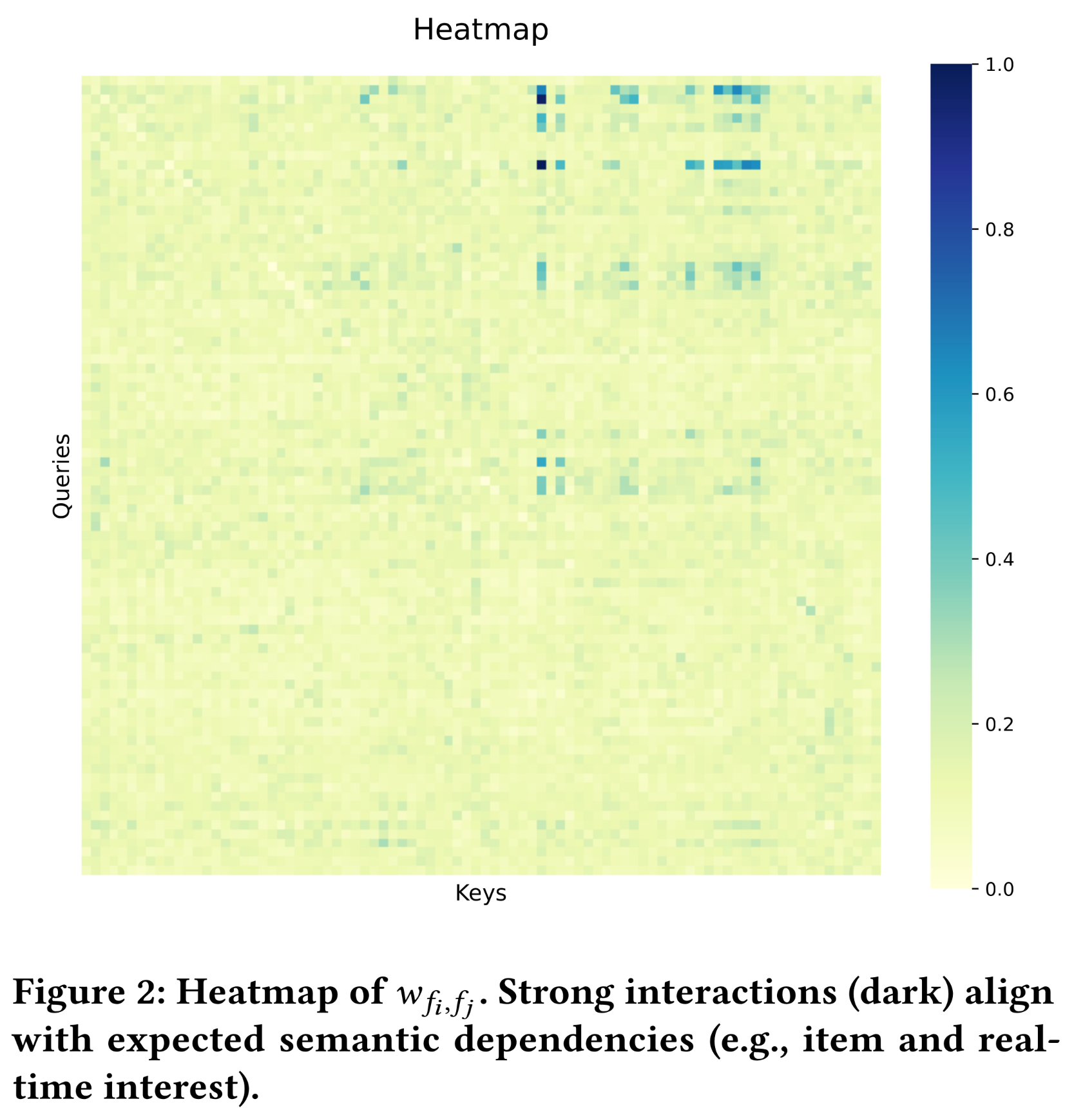
Structured Coherence:权重矩阵是稀疏的,表现出明确的块结构(block-wise structure)。high values集中在语义有意义的pairs上:Candidate item features(例如,item_cate, shop_level)与real-time user signals(例如,recent_clicks)显示出强烈的关联。User profile fields(例如,age, gender)与长期偏好指标(例如,fav_brands, longterm_clicks)的交互最强。
相比之下,不相关模态之间的
cross-field interactions(例如,device_type -> income)接近于零。这种模式与业务先验(business prior)一致:短期意图(short-term intent)驱动物品相关性(item relevance),而静态画像(static profiles)塑造稳定偏好(stable preferences)。FAT在没有显式监督的情况下自然地学习到这种separation,表明其结构化表达(structured expressivity)将容量集中在有意义的路径上。由于数据隐私的要求,作者没有给出热力图中每个字段的名字。所以也不知道具体是什么情况。
Asymmetric Influence:交互强度(interaction strength)具有高度的方向性。如Table 3所示:当
item feature作为query时,它为recent user behaviors(及rec_clicks)分配高权重(0.97),表明对当前意图的强烈依赖。相比之下,当
recent behavior feature(例如,rec_clicks)作为query时,分配的权重明显更弱且更分散(例如,
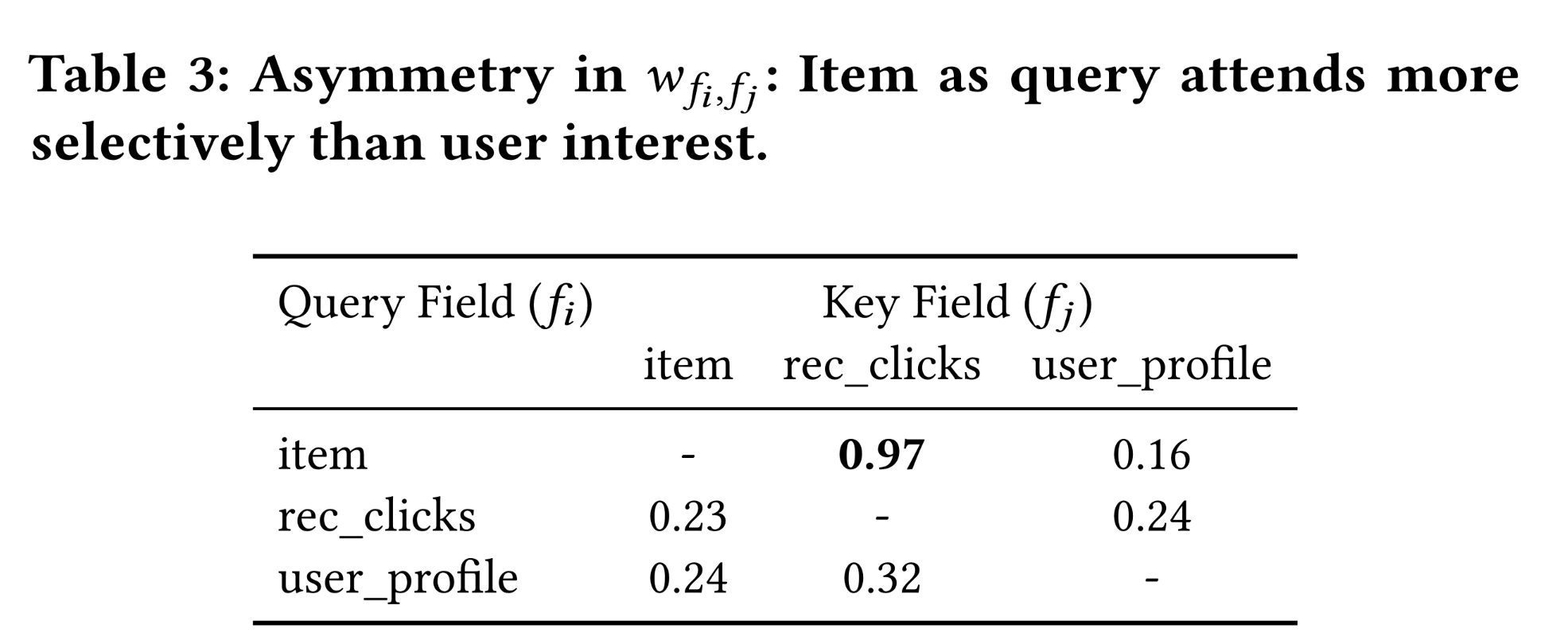
这些结果证实,
FAT学到了可解释的且语义合理的交互模式。与广泛分配attention的standard Transformer不同,FAT的field-aware design确保interaction strengths既结构化又具有方向性。
1.4.4 Scaling Behavior (RQ4): Validating the Theoretical Law
我们检验了
FAT是否表现出理论的泛化边界(定理4.1)所暗示的可预测的且持续的scaling行为。具体而言,我们研究在固定的feature semantics下,性能是否随着模型容量的增加而系统地提升——这是structured and controllable scalability的标志。“固定的
feature semantics“,意味着固定的fields数量为此,我们评估了一系列从
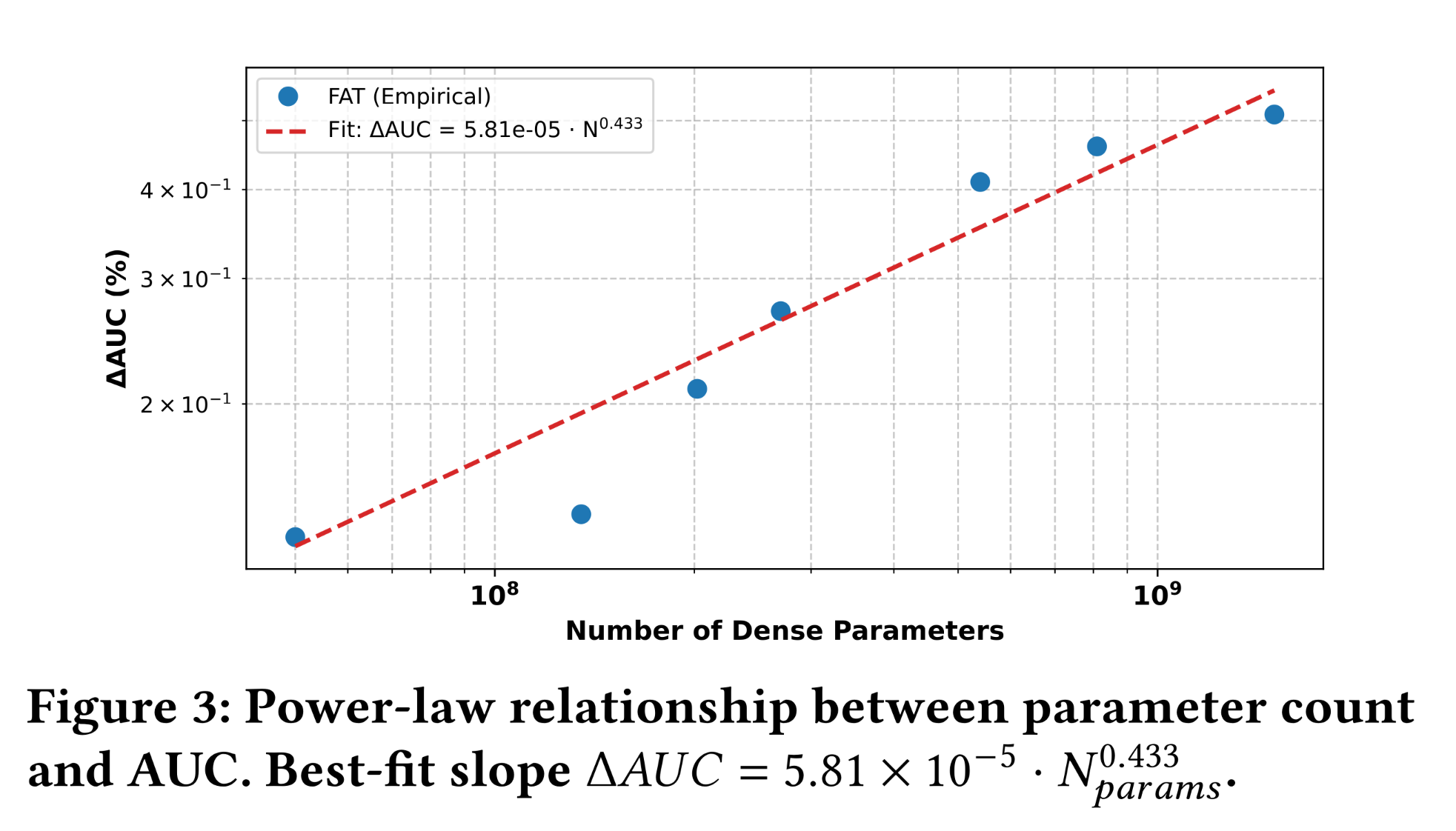
50M到1.5B参数的FAT变体,在相同数据集上使用一致的超参数和基础设施进行训练。如Figure 3所示,ΔAUC在三个数量级上随参数数量单调增加,遵循power-law趋势。观察到的relationship可以通过经验函数很好地描述:在测试范围内未观察到饱和,表明
FAT继续从increased capacity中受益——这在CTR模型中是不常见的,因为unstructured architectures在scaling下通常会达到平台期或性能下降。这种平稳的
scaling行为与定理4.1一致,该定理确立了FAT的有效复杂度随token vocabulary sizeexpressive capacity限制在field-aware interaction pathways上,FAT确保额外参数细化了语义有意义的模式(semantically meaningful patterns),而非过拟合稀疏组合(parse combinations)。因此,通过增加embedding size和depth所实现的容量增加转化为一致的收益。这里参数增长来自于
需要澄清的是,
interaction topology),而非直接的scaling维度。增加input schema并引入新的组合挑战(combinatorial challenges),这超出了standard scaling laws的范畴。相比之下,Figure 3中的趋势反映了架构内可扩展性(intra-schema scalability):在固定结构基础上,随着表征保真度(representational fidelity)的深化,性能可预测地提升。进一步的消融实验表明,移除
field-decomposed projections会破坏这种scaling趋势,证实观察到的行为源于架构设计,而非单纯的参数膨胀(parameter inflation)。总之,
FAT展示了CTR prediction中首个经验验证的scaling law:性能遵循由structured expressivity所主导的可重现的power-law轨迹。这实现了理论与实践之间的闭环,为scalable recommendation modeling提供了一条principled的路径。
1.4.5 Online A/B Test Results (RQ5): Business Impact in Production
为了评估
FAT的实际影响,我们在Taobao’s sponsored search system(全球最大的电子商务推荐系统之一)上进行了大规模online A/B test。流量平均分配给对照组和实验组:对照组:服务于现有的
production模型,一种高度优化的带有手动feature crosses的传统CTR模型。实验组:仅用
FAT-Large(约0.5B参数)替换prediction module。所有其他组件——包括feature extraction、embedding lookup、以及serving基础设施——保持不变,以确保公平比较。
我们报告了两个关键业务指标的相对改进:
(1) CTR:点击率,衡量user engagement。(2) RPM:每千次展示收入,反映货币化的效率。
如
Table 4所示,FAT实现了统计显著的收益:CTR提升2.33%,RPM提升0.66%。结果证实,FAT的structured expressivity在实际条件下转化为可衡量的业务价值。更重要的是,它们表明,由field-aware inductive biases指导的principled architectural scaling,不仅改善了离线性能,还推动了一致的在线收益,验证了其工业适用性和影响。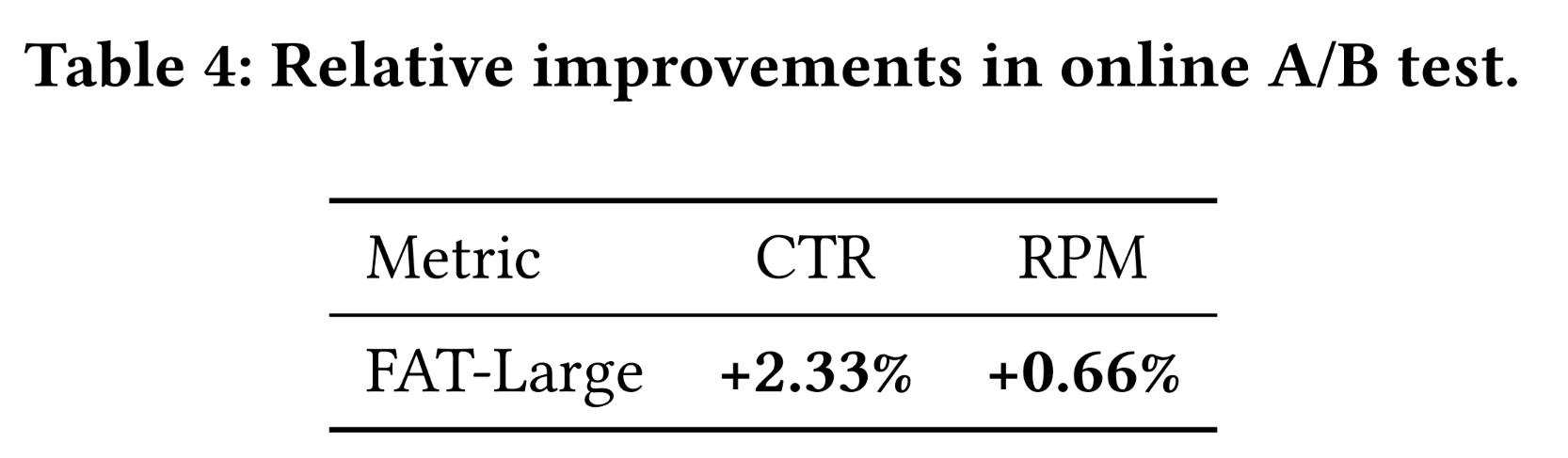
1.5 结论
我们发现
standard Transformer与combinatorial semantics of CTR data之间存在根本性不匹配:虽然语言模型受益于序列组合性(sequential compositionality),但推荐系统需要对无序的、高基数的semantic fields进行结构化推理。盲目扩展unstructured attention会导致泛化性能不佳和性能提升无效。为了解决这一问题,我们提出了
Field-Aware Transformer: FAT,通过field-decomposed attention使architectural inductive biases与data structure对齐。通过支持非对称的、可解释的cross-field interactions,FAT实现了结构化表达(tructured expressivity)——模型容量与interaction complexity和谐地增长。理论上,我们表明FAT的泛化误差取决于fields的数量vocabulary sizeCTR模型提供了首个principled scaling law。实验表明,FAT始终优于SOTA方法,AUC最高提升0.51%,并且在模型规模和数据量上呈现出平稳的power-law scaling。它已部署在production推荐系统中,产生了显著的在线收益。我们的研究表明,推荐系统中的scalable performance并非仅源于规模,而是源于架构与domain semantics之间的结构对齐(structural alignment)。