一、InterFormer
《InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction》
点击率预测(
Click-through rate: CTR prediction)是推荐系统中的一项基础任务,旨在预测用户点击广告的概率。异质信息(heterogeneous information),如用户画像(user profile)和用户行为序列(user behavior sequences),的出现从不同方面描绘了用户兴趣。对这些异质信息进行互利整合(mutually beneficial integration)是CTR prediction成功的关键。然而,现有大多数方法存在两个基本局限:(1):由于模态间信息流的单向性,导致模态间交互(inter-mode interaction)不足。(2):由于早期总结(early summarization)导致的激进信息聚合(information aggregation),造成过度的信息丢失。
为解决这些局限,我们提出了一种名为
InterFormer的新型模块,以交错方式学习heterogeneous information interaction。为实现更好的interaction learning,InterFormer支持双向信息流,实现不同模态间的互利学习(mutually beneficial learning)。为避免激进的信息聚合,我们在每种数据模态中保留完整信息,并使用独立的Cross Arch进行有效的information selection和information summarization。InterFormer已在Meta Ads的多个平台部署,与SOTA模型相比,实现了0.15%的性能提升和24%的QPS提升,带来了可观的线上影响。CTR prediction是各种applications(如在线广告和推荐系统)的基础任务,旨在预测用户点击某个item的概率。CTR prediction的质量显著影响公司收入和用户体验,引起了学术界和工业界的广泛关注。例如,在广告竞价中,CTR prediction帮助广告主优化出价并定向(target)最易接受的受众。在内容推荐中,它使平台能够向用户推荐相关内容。为了实现更好的
CTR prediction,捕获用户在动态环境中的兴趣至关重要。丰富的异质信息既带来机遇也带来挑战。一方面,异质信息从不同方面描绘用户兴趣,提供多样的上下文(
diverse context)。例如,non-sequence features(如user profile features和context features)提供了关于general user interests的静态视图(static view),而behavior sequences则为建模动态用户兴趣提供了大量信息。另一方面,数据的异质性需要不同的建模方法以及跨不同信息模态的仔细整合。例如,虽然对
non-sequential information之间的交互进行建模对个性化推荐至关重要,但捕获序列依赖关系(sequential dependencies)是用户行为建模(user behavior modeling)的主要关注点。
现有的大多数
CTR prediction模型分为两类,包括non-sequential models和sequential models。non-sequential models侧重于通过内积、MLP和deep structured semantic model进行feature interaction来学习informative embeddings,但忽略了用user behaviors中的序列信息。相比之下,
sequential models采用额外的模块,如CNN modules、RNN modules和Attention modules,来捕获user behaviors中的序列依赖关系。
尽管前景很好,但现有的
sequential methods大多采用单向信息流,其中non-sequential information用于指导sequence learning,而从sequence to non-sequence的逆向信息流则基本被忽略,导致模态间交互(inter-mode interaction)不足。例如,non-sequential information捕获长期兴趣,而sequential information揭示瞬时兴趣(如突然对某类产品产生关注),这可以通过即时偏好(immediate preference)来增强non-sequential context。此外,由于在大量non-sequence features和长序列之间进行interaction learning面临计算挑战,通常在早期阶段进行激进的feature aggregation,例如sequence summation, pooling, and concatenation,这不可避免地导致过度的信息丢失。鉴于上述局限,我们提出了一种新颖的异质交互学习(
heterogeneous interaction learning)模块,名为InterFormer,其思路有两方面。为避免
inter-mode interaction不足,我们启用了不同模态之间的双向信息流,使得non-sequence learning和sequence learning以交错方式进行。具体来说:为了学习
context-aware sequence embeddings,non-sequence summarization通过个性化前馈网络(Personalized FeedForward Network: PFFN)和多头注意力(Multihead Attention: MHA)指导sequence learning。为了学习
behavior-aware non-sequence embeddings,sequence summarization通过interaction模块指导non-sequence learning。
为缓解激进的
information aggregation,我们采用MHA进行有效的information selection,从而保留input and output tokens之间的一一映射。
请注意,我们的框架与各种
interaction learning模型(如DCNv2、DHEN等)兼容。我们总结主要贡献如下:
(1)挑战:我们识别出heterogeneous interaction learning的两个关键瓶颈,即inter-mode interaction不足和激进的information aggregation。(2)模型设计:提出了一个名为InterFormer的新型heterogeneous interaction learning框架,用于有效的feature interaction和选择性的information aggregation。据我们所知,我们是第一个解决heterogeneous interaction learning中互利问题(mutual benefits)的。(3)实验与分析:大量实验表明,InterFormer在基准数据集上实现了高达0.14%的AUC提升,在工业数据集上实现了0.15%的归一化熵(Normalized Entropy: NE)提升。此外,在Meta的内部部署表明,InterFormer展现出有前景的scaling结果,与SOTA的CTR模型相比实现了0.15%的性能提升和24%的QPS提升,并带来了可观的线上影响。
1.1 相关工作
Non-Sequential Methods:绝大多数
non-sequential models建立在因子分解机(Factorization Machine: FM)(《xdeepfm: Combining explicit and implicit feature interactions for recommender systems》、《Factorization machines》、《FM2: Field-matrixed factorization machines for recommender systems》)的思想之上,通过线性组合其低维embeddings来建模user-item interaction(《Deep learning based recommender system: A survey and new perspectives》)。《Factorization machines》是第一个捕获pair-wise interactions的FM模型。为了建模高阶
interactions,不同方法将FM与深度神经网络(deep neural networks: DNN)相结合,其中FM通过pairwise operation来学习低阶interactions,DNN通过深度架构学习高阶interactions。例如,MLP通过特征间的dense connections捕获高阶interactions,注意力机制通过线性组合学习更复杂的embeddings。这些基于深度学习的方法支持端到端训练,无需手工设计特征,并且能够处理文本、图像和视频等异质信息。此外,近期工作解决了推荐中的
scaling law,其中DHEN(《DHEN: A deep and hierarchical ensemble network for large-scale click-through rate prediction》)集成了多个interaction模块,Wukong(《Wukong: Towards a Scaling Law for Large-Scale Recommendation》)堆叠FM以学习a hierarchy of interactions。
尽管有前景,但
non-sequential models无法捕获user behaviors中的序列依赖关系,导致次优解。Sequential Methods:随着推荐系统中序列信息(例如user interaction history)的近期出现,人们投入了大量努力来捕获不断演化的用户兴趣。序列方法背后的一个关键挑战是如何以互利的方式将sequential information与non-sequential information结合起来。马尔可夫模型(
Markov models)(《Fusing similarity models with markov chains for sparse sequential recommendation》、《An MDP-based recommender system》、《A hybrid recommender system for sequential recommendation: combining similarity models with markov chains》)将sequential data视为离散随机变量上的随机过程,但过度简化的马尔可夫性质限制了模型捕获long-term sequential dependencies的能力(《Sequence-aware recommender systems》)。为了建模长期依赖关系,
RNN和Attention机制被用作许多序列方法的骨干模块。例如,人们设计了各种基于注意力的网络(《Deep match to rank model for personalized click-through rate prediction》、《Sequence-aware recommender systems》),并且Transformer(《Bert: Pre-training of deep bidirectional transformers for language understanding》、《Cats: Mitigating correlation shift for multivariate time series classification》、《Attention is all you need》)被用于序列建模(《Behavior sequence transformer for e-commerce recommendation in alibaba》、《BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer》)。此外,为了建模多方面的用户兴趣,
《Efficient Noise-Decoupling for Multi-Behavior Sequential Recommendation》、《Deep multi-interest network for click-through rate prediction》提出从multi-behavior sequences中捕获multiple user interests。最近,
TransAct(《Transact: Transformer-based realtime user action model for recommendation at pinterest》)采用hybrid ranking model,结合real-time user actions以获取即时偏好、以及batch user representations以获取长期兴趣。LiRank(《LiRank: Industrial Large Scale Ranking Models at LinkedIn》)通过集成多个interaction模块并用quantization和vocabulary compression来加速,改进了LinkedIn的CTR prediction。CARL(《Cache-Aware Reinforcement Learning in Large-Scale Recommender Systems》)通过利用cached results并在基于强化学习的框架监控下,在Kuaishou实现了大规模推荐中的fast inference。
虽然大多数现有的
sequential methods利用non-sequential information进行个性化序列建模,但序列信息很少被用于non-sequence learning。我们认为这种单向设计限制了learned embeddings的表达能力,而不同模态之间的双向信息流是实现更好heterogeneous interaction learning的关键。
1.2 方法
预备知识:我们用粗体大写字母表示矩阵(例如
item和时间戳(例如non-sequence feature,用sequence feature。我们考虑包含dense features、sparse features、以及sequence features的场景。我们用CTR模型的embedding维度。即,这里有
click序列、purchase序列、add cart序列),每个序列的长度为CTR prediction在给定static context和behavior sequences等异质信息的情况下,估计用户点击某个item的概率。形式上,给定用户集合item集合interaction sequence定义为time stepitem。我们的目标是根据historical interaction sequencenew itempossible sequences的集合,使得:其中:
接下来,我们介绍所提出的
InterFormer。我们首先介绍预处理模块,然后介绍三个主要模块,包括Interaction Arch、Sequence Arch和Cross Arch。为了学习
behavior-aware non-sequence embeddings,Interaction Arch对feature interactions进行建模。为了学习
context-aware sequence embeddings,我们提出Sequence Arch从而optimize sequence。Cross Arch连接Interaction Arch和Sequence Arch,实现不同模态之间的有效的formation summarization和formation exchange。
InterFormer的概览如Figure 1所示。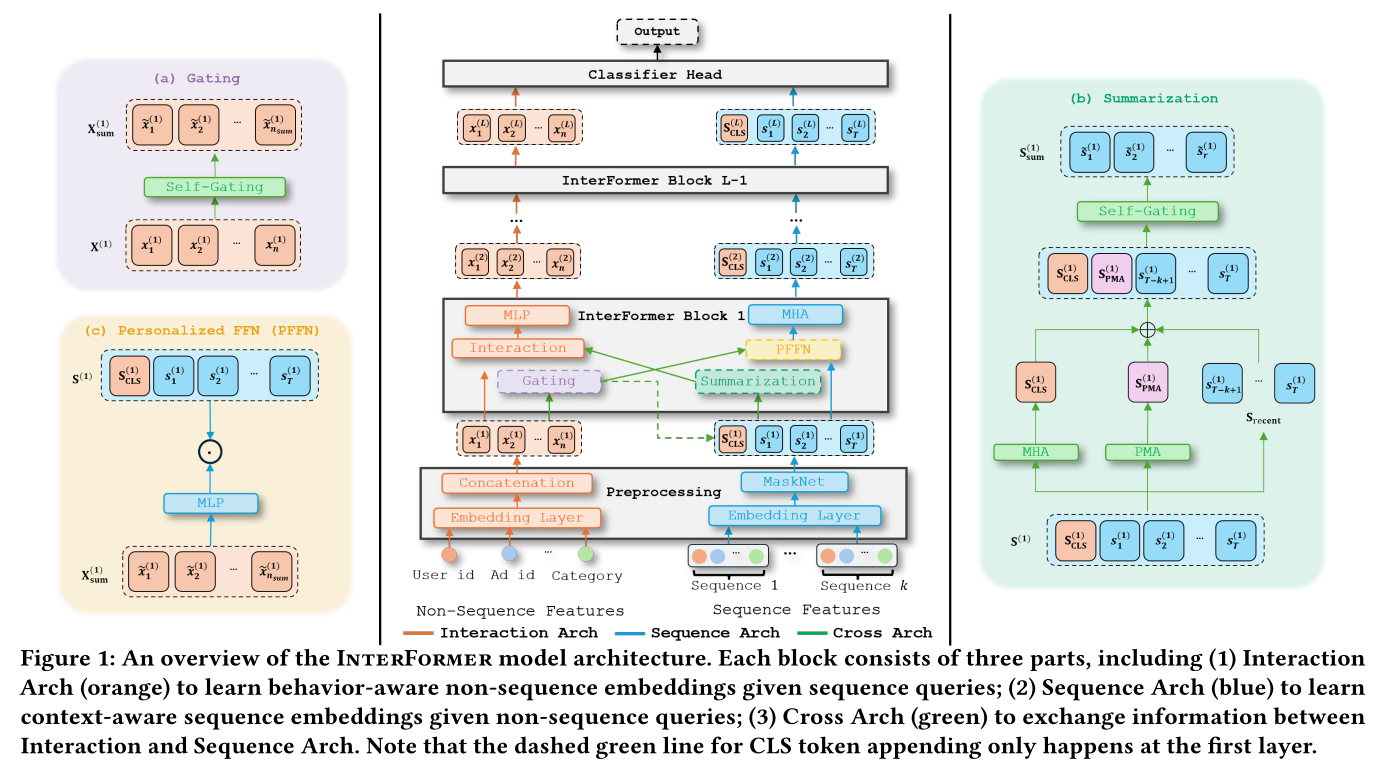
1.2.1 特征预处理
Non-Sequence Feature Preproessing:考虑两种类型的non-sequence features,包括dense features(如用户年龄和item价格)和sparse features(如user id和item category)。为了统一non-sequence features中的异质性,不同特征被转换为相同维度的embeddings。具体来说:原始
dense featuresembedding vector,即类似地,每个原始
sparse feature首先被编码为一个one-hot向量sparse feature的vocabulary size,然后通过embedding vector。
通过拼接
dense embedding vectors和sparse embedding vectors,可以得到input non-sequence embedding matrix如下:Sequence Feature Preprocessing:与non-sequence feature preprocessing类似,我们使用一个embedding layer使得序列中每个interacted item被映射到一个behavior sequences表示为item embeddings的拼接,即现实场景中经常遇到来自不同
user actions(例如click和conversion)或不同平台的多个序列。此外,由于user behaviors的不确定性,这些序列通常包含noisy的和irrelevant的user-item interactions。为了解决这个问题,我们采用MaskNet来统一多个序列并通过self-masking来过滤内部噪声。具体来说,给定
embedding维度拼接,即MaskNet操作处理如下:其中:
self-masking以从input sequences中选择相关信息。sequences线性组合为一个,使non-sequence features和sequence features的维度相匹配。
这里的做法明显有问题:多个
action sequence不能直接拼接起来,它们发生的时间戳都不一样。读者的建议:按照时间戳的先后顺序将
Transformer的时间复杂度为这
1.2.2 Interaction Arch: Towards Behavior-Aware Interaction Learning
Non-sequence features,如user profile和ad content,为理解用户对特定item的偏好提供了大量信息。对non-sequence features之间的interaction进行建模是CTR prediction成功的关键。虽然non-sequence features反映了静态的用户兴趣,但behavior sequence提供了从动态视角描绘用户兴趣的补充信息(《Deep interest evolution network for click-through rate prediction》)。例如,虽然user profile表现出对电子产品的general interest,但最近关于智能手机的浏览历史提供了关于当前需求的更具体的和更及时的信息。因此,学习behavior-aware non-sequence interactions以适应不断演变的环境至关重要。为了学习
behavior-aware non-sequence interaction,我们通过一个interaction模块对non-sequence features之间的交互、non-sequence features和sequence summarization的交互、以及sequence summarization之间的交互进行建模。形式化地,给定第non-sequence inputsequence summarizationInteraction Arch的输出定义为:其中:
interaction模块。请注意,我们不拘泥于特定的interaction模块,而是可以采用各种骨干模型,如内积、DCNv2和DHEN。此外,使用MLP将outputinputselective information aggregation并便于layer stacking。论文中使用的是
DHEN作为interaction模块。通过在
concatenation上(interaction learning,non-sequence features和sequence features。non-sequence features之间的交互通过计算user profile与target item content之间的相关性来捕获显式的用户兴趣。而
non-sequence features与sequence features之间的交互通过计算target item与sequence features中用户当前需求之间的相关性来捕获隐式的用户兴趣。此外,通过计算
sequence features之间的交互,具有高interaction scores的最具代表性的信息被提升,而得分低的inactive items被过滤掉。
通过堆叠多个层,
Interaction Arch捕获不同阶次的rich behavior-aware interactions。
1.2.3 Sequence Arch: Towards Context-Aware Sequence Modeling
除了
non-sequence features中的显式的静态用户偏好外,behavior sequences背后的隐式的动态用户兴趣提供了补充信息。然而,由于behavior sequences具有高度随机性和噪声,仅依靠序列信息是无效的。将non-sequential context融入sequence modeling非常重要。例如,用户可能在购物平台上随机浏览items,但考虑到该用户是电子产品爱好者的静态信息,browsing history中的电子产品(如智能手机和笔记本电脑)提供了需要额外关注的关键信息。为了学习
context-aware sequence embeddings,我们基于两个关键思想设计了Sequence Arch:Personalized FFN: PFFN、Multi-Head Attention: MHA。为了实现
non-sequential information和sequential information之间的交互,我们使用PFFN在给定non-sequence summarization作为query的情况下transform sequence embeddings。给定第non-sequence summarizationsequence embeddingPFFN操作定义为:其中:
MLP,旨在基于non-sequence summarization来学习sequence上的线性投影。注意:
得到的投影矩阵在
此外,为了建模序列中事件之间的关系,我们应用
MHA使模型能够关注序列的不同部分,并捕获长距离依赖关系和上下文信息。为了融入non-sequential context,在馈入第一个InterFormer layer之前,我们将non-sequence summarizationCLS tokens从而添加到sequence开头(有CLS token上的MHA可以使用non-sequential information作为query来聚合sequential information。这类似于TransAct中描述的early fusion思想,但我们主要考虑"append"而非"concat"作为融合方法。non-sequence summarization的数量。此外,我们在
tokens上应用rotary position embeddings(《Roformer: Enhanced transformer with rotary position embedding》),以便有效利用序列中的positional information。总的来说,Sequence Arch可以写为:由于
outputinputaggregation,并且可以轻松堆叠layers。注意,仅仅在第一层有
CLS Token。
通过
layer stacking,一方面,sequence embeddings通过PFFN感知不同阶次的non-sequence interactions;另一方面,不同层的MHA关注序列的不同部分,捕获multi-scale sequential information。因此,该模型能够学到序列数据中丰富的context-aware encoding,同时捕获序列中的local patterns与global patterns。
1.2.4 Cross Arch: Towards Effective Information Selection and Summarization
尽管在
Interaction Arch和Sequence Arch中都实现了selective information aggregation,但由于input features和output features的维度一直保留到最后一层,直接交换这些信息是不可行的,原因在于:(1):由于noisy information导致效率低下。(2):由于高维度导致效率低下。
为了解决这个困境,我们提出了一个
Cross Arch,在交换信息之前select and summarize information。首先,鉴于
non-sequence embeddings的large scale,选择性地summarize它们以指导sequence learning非常重要。为此,我们通过以下personalized gated selection机制来突出最有用的信息:其中:
第一个
sigmoid、tanh、甚至恒等映射。
Self-gating(《Highway transformer: Self-gating enhanced self-attentive networks》)在embeddings上提供sparse masking,使得相关信息被保留,而irrelevant noises被过滤掉,从而为sequence learning提供高质量的上下文。对于
sequential information,我们精心设计了三种类型的summarization,包括CLS tokens、PMA tokens和recent interacted tokens。MHA所学到的CLS tokenscontext-aware sequence summarization。然而,
CLS tokens的质量在很大程度上依赖于learned non-sequential context。为了补偿这种强依赖性并提供更多灵活性,我们采用了基于learnable queries的equence summarization,即PMA tokens《Set transformer: A framework for attention-based permutation-invariant neural networks》)。PMA tokens是通过learnable queries来进行聚合:其中:
queries;此外,最近的
interacted tokens
上述信息的组合进一步通过
self-gating layer进行门控,作为non-sequence interaction的behavior summarization:实验部分表明:
PMA tokens的影响相当大;而recent interacted tokens的影响非常小。
总的来说,
Cross Arch的好处有两方面:一方面,通过将
information summarization与Interaction Arch和Sequence Arch分离,信息可以在两个Arch中保留,避免激进的information aggregation。另一方面,由于高维的
non-sequence/sequence features被selected和summarized为低维embeddings,我们可以实现有效的信息交换。
因此,
Cross Arch在使模型能够捕获non-sequence information与sequential patterns之间的复杂交互方面发挥着关键作用,从而对input data进行更全面的representations。
1.3 实验
在本节中,我们进行大量实验来评估提出的
InterFormer。我们首先介绍实验设置。然后,我们在公共基准数据集上对InterFormer进行评估。最后,我们所提出的InterFormer已在Meta部署,然后我们提供了内部工业规模数据集上的发布后结果。数据集:我们在三个公共基准数据集上进行评估,包括
AmazonElectronics、TaobaoAd、以及KuaiVideo,如table 1所示。此外,我们使用了一个包含超过70 billion条记录的大规模内部数据集,其中有数百个non-sequential user and item features,以及10个长度范围从200 ~ 1000的sequential features。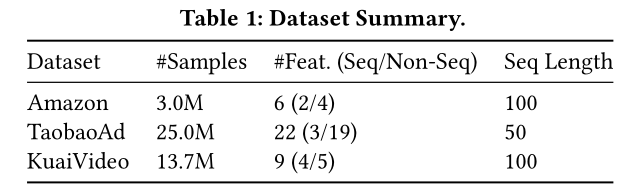
Baseline模型:我们将所提出的InterFormer与11个SOTA模型进行比较,包括(1)非序列方法:FM(《Factorization machines》)。xDeepFM(《xdeepfm: Combining explicit and implicit feature interactions for recommender systems》)。AutoInt+(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)。DCNv2(《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)。FmFM(《FM2: Field-matrixed factorization machines for recommender systems》)。DOT product。DHEN(《DHEN: A deep and hierarchical ensemble network for large-scale click-through rate prediction》)。Wukong(《Wukong: Towards a Scaling Law for Large-Scale Recommendation》)。
(2)序列方法:DIN(《Deep interest network for click-through rate prediction》)。DIEN(《Deep interest evolution network for click-through rate prediction》)。BST(《Behavior sequence transformer for e-commerce recommendation in alibaba 》)。DMIN(《Deep multi-interest network for click-through rate prediction》)。DMR(《Deep match to rank model for personalized click-through rate prediction》)。TransAct(《Transact: Transformer-based realtime user action model for recommendation at pinterest》)。
在实验中,我们采用
DHEN作为Interaction Arch。指标:我们采用四个广泛使用的指标从不同方面评估模型,包括:
AUC:评估了模型在所有阈值下正确分类正负样本能力。越高越好。gAUC:提供了个性化的AUC评估,其中用户按其点击次数加权。越高越好。LogLoss(交叉熵损失cross-entropy loss):衡量预测值labelnormalized entropy:NE(归一化熵):是LogLoss被训练集平均empirical CTR归一化后的结果。NE提供了对模型性能的data-insensitive evaluation,因为归一化减轻了background CTR对model evaluation的影响。越低越好。
可复现性:
我们采用
BARS evaluation framework(《Bars: Towards open benchmarking for recommender systems》)进行基准实验。我们采用带有学习率调度器的
Adam optimizer进行优化,初始学习率在{1e-1, 1e-2, 1e-3}中调优。我们使用
batch size = 2048,训练最多100 epochs并提前停止。基准实验使用
NVIDIA A100,内部实验使用NVIDIA H100。
1.3.1 Benchmark Datasets 上的评估结果
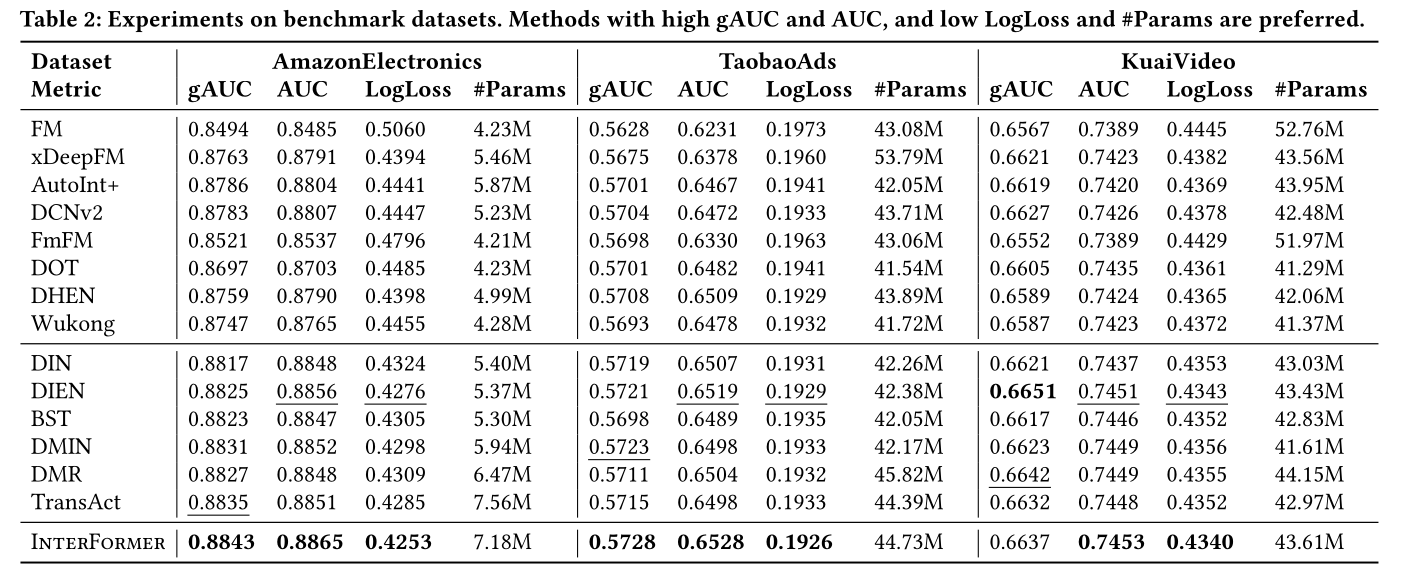
结果:实验结果如
Table 2所示。我们首先观察到,在所有数据集上,序列方法始终优于非序列方法。
对于非序列方法,
sequence information在早期阶段被朴素地聚合,然后与non-sequence information一起处理。而在序列方法中,采用了精心设计的
sequence processing模块,例如RNN和attention机制,使得sequential information可以在感知non-sequence context的情况下进行处理。
序列方法的普遍优越性验证了不同数据模态应该以不同方式处理。此外,结果表明,在早期阶段不考虑
non-sequence context的情况下进行激进的sequence summarization会损害模型性能。比较
InterFormer与其他序列方法,InterFormer达到了SOTA的性能。具体来说,InterFormer在gAUC上优于最佳竞争者最多0.9%,在AUC上最多0.14%,在LogLoss上最多0.54%。这些结果证明了InterFormer在不同数据集上的有效性以及在不同推荐任务上的泛化能力。
模型分析:
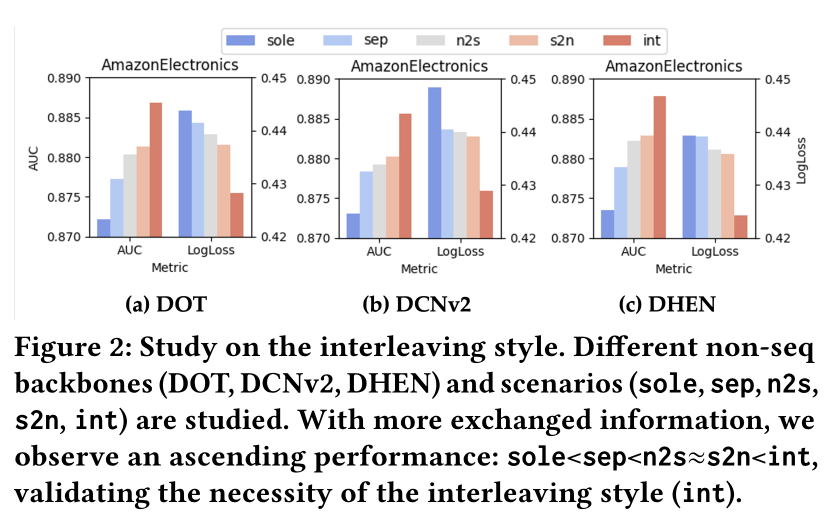
Interleaving Learning Style:我们分析交错学习风格(interleaving learning style)如何有利于heterogeneous interaction learning。为了验证InterFormer的普适性,我们考虑三种骨干Interaction Arch,包括点积(DOT)、DCNv2和DHEN,以及五种不同场景,包括:sole:仅采用Interaction Arch,而序列信息在早期阶段被朴素地聚合。sep:禁用模态间交互,Sequence和Interaction Arch分开学习。s2n:仅启用sequence-to-non-sequence的信息流,而反方向被禁用。n2s:仅启用non-sequence-to-sequence的信息流,而反方向被禁用。int:启用双向信息流。
如
Figure 2所示:无论骨干
Interaction Arch如何,int始终优于其他场景,在AUC上最多提升1.46%,验证了我们提出的interleaving learning style带来的普遍益处。我们还观察到,当不同数据模态之间交换更多信息时,模型性能呈现上升顺序,即
sole < sep < n2s < s2n < int。这验证了我们的主张,即模态间交互(inter-mode interaction)的不足是heterogeneous interaction learning的关键瓶颈,而双向信息流使不同数据模态能够以互利的方式学习。具体来说,当配备额外的
Sequence Arch(sep)时,模型性能始终优于没有序列建模的sole。这不仅显示了为不同数据模态采用不同架构的必要性,也意味着当heterogeneous data被朴素整合时可能出现性能下降。此外,鉴于双向信息流 (int)始终优于单向设置(n2s and s2n),我们将InterFormer相对于其他SOTA序列方法的优越表现归因于双向信息流。
Selective Information Aggregation:我们通过与三种激进的aggregation变体进行比较来评估selective information aggregation的效果,其中sequence information首先通过(1) average pooling、(2) MLP和(3) MHA进行压缩,并通过interaction模块DHEN进一步与non-sequence features相结合。实验结果如Figure 3(b)所示。结果表明,与其他激进的变体相比,
selective aggregation(InterFormer)始终达到最佳性能。一般来说,我们可以将MLP视为均值池化的一种更具selective的版本,因为MLP会渐进地(gradually)压缩序列信息;同样,MHA处理序列的激进程度也不如MLP。因此,我们可以得出结论,通过更具选择性的aggregation,CTR prediction质量得到了提高。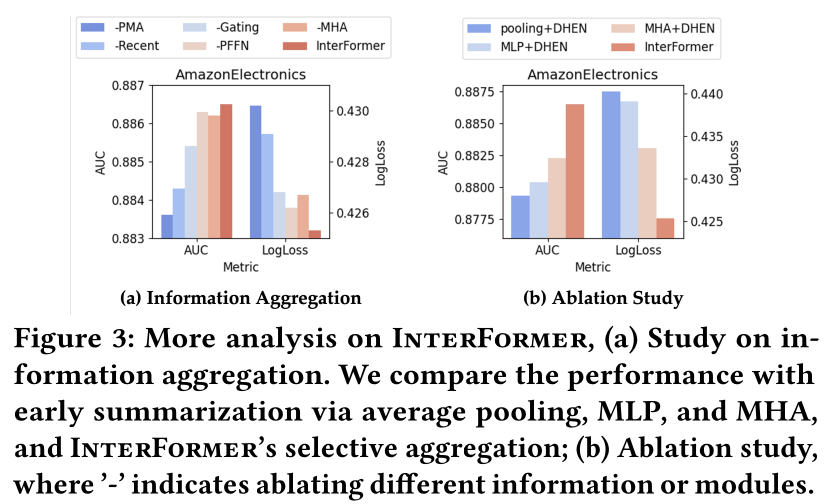
消融研究:为了更好地理解不同模型设计如何对最终性能做出贡献,我们消融了不同的
ex-changed information(包括PMA tokens和recent interacted tokens),以及不同的模块(如门控模块、PFFN和MHA)。结果如
Figure 3(a)所示,所有exchanged information和模块都对模型性能有贡献。具体来说:PMA tokens在给定non-sequence context的情况下提供有效的sequence summarization,并且非常重要,消融它会使AUC降低多达0.004。门控模块有助于从不同数据模态中选择性地
summarize信息,贡献了多达0.003的AUC提升。sequence modeling模块(PFFN和MHA)也在一定程度上提升了性能。
1.3.2 Industrial Datasets 上的评估结果
为了评估工业规模的性能,我们采用了来自
Meta的大规模内部数据集,包含70B样本,数百个non-sequence features和10个长度从200 ~ 1000的sequence features。结果:总的来说,一个
3层的InterFormer与内部SOTA模型相比,在相似FLOPs下实现了0.15%的NE增益和24%的QPS增益。结合feature scaling,NE的增益可以进一步扩大,并且在512 GPUs上达到10%的Model FLOPs Utilization: MFU。InterFormer在广泛的模型上显示出良好的泛化能力,具有可观的投入产出比。Sequence Feature Scaling:我们评估了当内部数据集中sequence feature scale增加时InterFormer的性能如何变化。除了6个长度为100的序列外,我们还增加了2个长度为1000的长序列,观察到NE提升了0.14%。如
Figure 4a所示,与利用cross-attention捕获sequence and non-sequence information的强内部基线(Internal)相比,InterFormer表现出更好的scalability,因为InterFormer的NE曲线在涉及更多训练样本时持续下降,在NE上优于Internal0.06%。此外,我们还尝试合并六个序列生成长度为
600的单个序列,观察到QPS(+20%)和MFU(+17%)的显著效率提升,NE损失为0.02%。从建模角度来看,结果验证了InterFormer能够扩大sequence feature scaling带来的NE增益。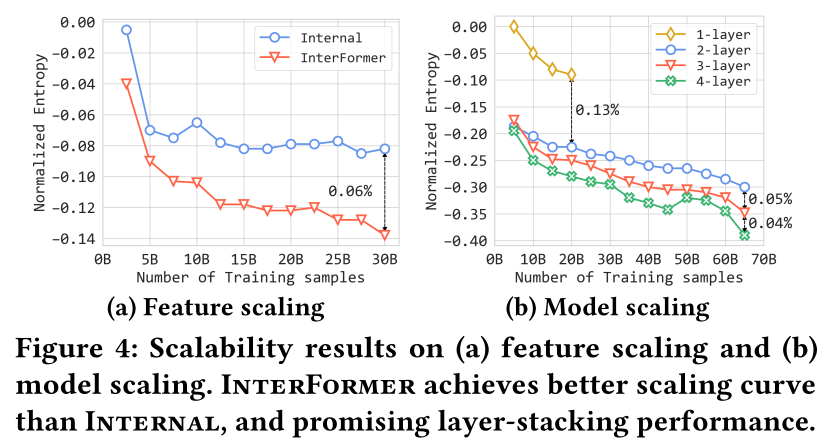
Model Scaling:我们评估了当model scale增加时InterFormer的表现如何。如Figure 4b所示,将InterFormer从1层扩展到4层取得了持续的NE增益,表现出良好的scaling特性。具体来说,与单层InterFormer相比,双层InterFormer取得了显著的0.13%的NE增益,堆叠3层和4层分别获得额外的0.05%和0.04%的NE增益。Model-System Co-Design:模型架构设计对训练效率及其对GPU FLOPs利用率和GPU间通信的影响起着至关重要的作用。我们基于InterFormer架构突出两项优化,总共将训练效率提高了30%以上,包括通信开销减少和计算效率提升。对于通信开销减少,参数庞大但计算相对较轻的
Interaction Arch DHEN在分布式训练中往往受限于FsDP通信,而Sequence Arch Transformer具有更高的计算量(FLOPs)与参数比(parameter ratio),通常是计算受限的。为了缓解这种低效,我们的Interaction Arch和Sequence Arch并行设计使得DHEN模块的暴露通信(exposed communication)能够与序列计算(sequence computation)有效重叠,与串行执行相比实现了20%的QPS提升。对于计算效率,我们执行了一系列优化,包括
1):将FLOPs从小型的、低回报的模块重新分配到更大的、高ROI的模块。2):合并较小的kernels以更好地利用GPU资源。
这些优化将
interaction模块的MFU从11%提高到16%,DHEN的MFU从38%提高到45%,整体InterFormer layer的MFU提高了19%。
线上影响:
InterFormer已部署在关键的Ads模型中,包括通过《M3C: a Multi-Domain Multi-Objective, Mixed-Modality Framework for Cost-Effective, Industry Scale Recommendation》的最大模型,在scaling方面显示出优于其他SOTA架构的ROI。2024年的试点发布使关键指标(topline metrics)提升了0.6%。我们预计在后续部署中将产生巨大影响。
1.4 结论
在本文中,我们为
CTR prediction中的heterogeneous interaction learning提出了一个名为InterFormer的新型building block。其关键思想是在不同数据模态之间采用交错学习风格(interleaving learning style),以实现有效的模态间交互以及selective information aggregation。总的来说,采用Interaction Arch和Sequence Arch分别实现behavior-aware interaction learning和context-aware sequence modeling。我们进一步提出了Cross Arch,用于有效的information selection and summarization。InterFormer在基准数据集上取得了一致的优越性能,并在内部大规模数据集上将CTR prediction的NE提高了0.15%。在关键Ads模型中的试点发布使topline metrics提升了0.6%,我们预计后续将产生巨大影响。