一、Longer [2025]
《LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders》
在工业级推荐系统中,对超长的用户行为序列(
user behavior sequences)进行建模对于捕获长期偏好(long-term preferences)和短期偏好(short-term preferences)至关重要。现有的解决方案通常依赖于两阶段检索(two-stage re-trieval)或间接建模范式(indirect modeling paradigms),导致了上下游不一致和计算效率低下的问题。在本文中,我们提出LONGER,即:Long-sequence Optimized traNsformer for GPU-Efficient Recommenders。LONGER融合了:(i):一个global token机制,用于稳定long contexts的attention。global token就是non-sequence features所构建的tokens,这些features包括用户画像、target item画像、上下文等等。(ii):一个token merge模块,它具有轻量级InnerTransformers和hybrid attention策略,从而降低平方复杂度。以及
(iii):一系列工程优化,包括training with mixed-precision and activation recomputation、KV cache serving,以及fully synchronous model training and serving framework用于GPU-based dense and sparse parameter updates。
LONGER在ByteDance的广告和电子商务服务中的离线指标和online A/B testing中均持续优于strong baselines,验证了其一致的有效性和工业级别的scaling laws。目前,LONGER已在ByteDance数十个有影响力的现实场景中得到验证并全面部署,服务于数十亿用户。在推荐系统中,超长的用户历史行为序列(
user historical behavior sequences)全面封装了用户的长期偏好和短期偏好。虽然早期的sequential modeling架构已被广泛研究并在学术界和工业界广泛采用,但它们的应用仍然主要局限于短序列场景(序列长度为 (fully modeling长序列(长度Two-stage retrieval:从原始超长序列中选择与当前candidate item最相关的top-k items(通常short sequence modeling)。最具代表性的工作包括SIM和TWIN。Pre-trained User Embeddings:在工业界,通常的做法是在source model中预训练整个超长序列并导出一个condensed user embedding: UE,然后可以将这个user embedding传输到下游recommendation模型。利用高性能先进的GPU,该方法支持对长达multiple-layered transformers进行预训练。Memory-augmented Models:multi-channeluserinterest memory network: MIMN提供了一种基于神经图灵机(neural Turing machine)和记忆归纳单元(memory induction unit)的结构用于user sequence memorizing。而
large memory network: LMN(《Large Memory Network for Recommendation》)提出了一种基于product quantization-based decomposition的轻量级结构。memory augmented recommenda- tion model: MARM(《MARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity》)提出了一种memory-for-computation trade-off的范式,它缓存了计算密集型模块的中间结果。
虽然这些策略显著提高了计算效率,但由于上下游不一致、或者对原始超长序列的间接感知等问题,它们不可避免地牺牲了原始完整序列信息,因此这些方法本质上是向
end-to-end long-sequence modeling的演进提供了一个中间阶段。最近,以
GPT为代表的大语言模型的快速发展确立了scaling laws——这些经验法则预测了随着模型大小、数据量和计算量的增加而带来的性能提升。这些scaling laws最近指导了推荐系统的创新。例如:HSTU由相同的self-attention layers堆叠而成,通过residual connections来连接,用于建模长序列,其性能优于普通Transformer架构。Wukong开发了一种基于堆叠的factorization machine block and linear compression block的架构用于interaction,并验证了recommendation中的scaling laws。
与此同时,随着
computing基础设施(例如,GPU FLOPs/Memory、工程化大规模计算平台和框架)的快速进步,令人兴奋的是,它使我们能够在工业级推荐系统中开创一种端到端的超长序列建模(ultra-long sequence modeling)范式。因此,推进超长序列的端到端建模,同时持续扩展序列长度并改进长序列建模的架构,代表了下一代序列建模框架的关键要务。为此,我们提出了
Long-sequence Optimized traNsformer for GPU-Efficient Recommenders: LONGER。在该框架中,我们将sequence input组织为global tokens(来自于non-sequence features) 和raw sequences(来自于sequence features),基于此,开发了一种基于inner-transformer的token merge方法,以有效减少计算预算。此外,由于用户的超长序列中通常存在大量噪声,我们利用高效的hybrid attention策略来提高计算效率,同时保持模型性能。此外,为了在拥有十亿用户规模的industrial level全面部署LONGER,我们提出了一系列工程优化,包括a fully synchronous training and serving framework with mixed-precision and activation recomputation,以及a KV cache serving strategy。总的来说,贡献主要总结如下:我们提出了
long-sequence optimized transformer structure for GPU-efficient recommenders: LONGER。它通过优化Transformer结构,提供了一个工业级GPU-efficient的视角,并在工业界以端到端方式将用户序列建模长度扩展到10,000。LONGER通过token merge和hybrid attention策略充分提高了计算效率,这减少了约50%的FLOPs,并经验证在性能上几乎无损。此外,设计了一个fully-optimized industrial training and serving framework,以进一步提高GPU计算效率和在线部署。进行了全面的实验来验证其有效性。在十亿规模的工业数据集上进行了离线实验,并在抖音的两个有影响力的业务场景上进行了
online A/B tests以验证其性能。目前,LONGER已在ByteDance数十个场景中得到广泛应用,影响着数十亿用户。
1.1 相关工作
传统的
Short-Sequence Modeling:迄今为止,工业界的推荐系统主要遵循sequence modeling和feature interaction相结合的modeling范式。在该框架内,sequence modeling长期以来在描绘用户偏好方面扮演着关键角色。在广泛的研究中,一个关键的里程碑是
DIN。随后的方法包括DIEN、CAN等。此外,multi-domain、multi-interest和sequence denoising被广泛用于从不同方面建模用户偏好。值得注意的是,大多数此类精心设计的结构是为short sequence modeling开发的,而long sequence modeling方法后来吸引了越来越多的研究关注。Long-Sequence Modeling:正如引言章节中讨论的,long sequence modeling方法通常可以分为two-stage retrieval、pre-trained user embedding和memory-augmented models。总体而言,retrieval-based方法和pre-trained方法属于两阶段策略,而memory-enhanced models通常需要较长的训练周期来积累memory slots中的命中率。最近,一些努力致力于直接建模长序列(
《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》、《Scaling law of large sequential recommendation models》、《Scaling Sequential Recommendation Models with Transformers》)。然而,在大规模工业推荐系统中,GPU-efficient long sequence modeling仍然探索不足。
1.2 方法论
Problem Statement:令user集合和item集合。给定一个用户basic特征为target itemrecommendation任务旨在预测点击率或转化率:其中
模型通过
historical interaction数据其中
1.2.1 整体框架
我们提出的框架旨在解决推荐系统中建模
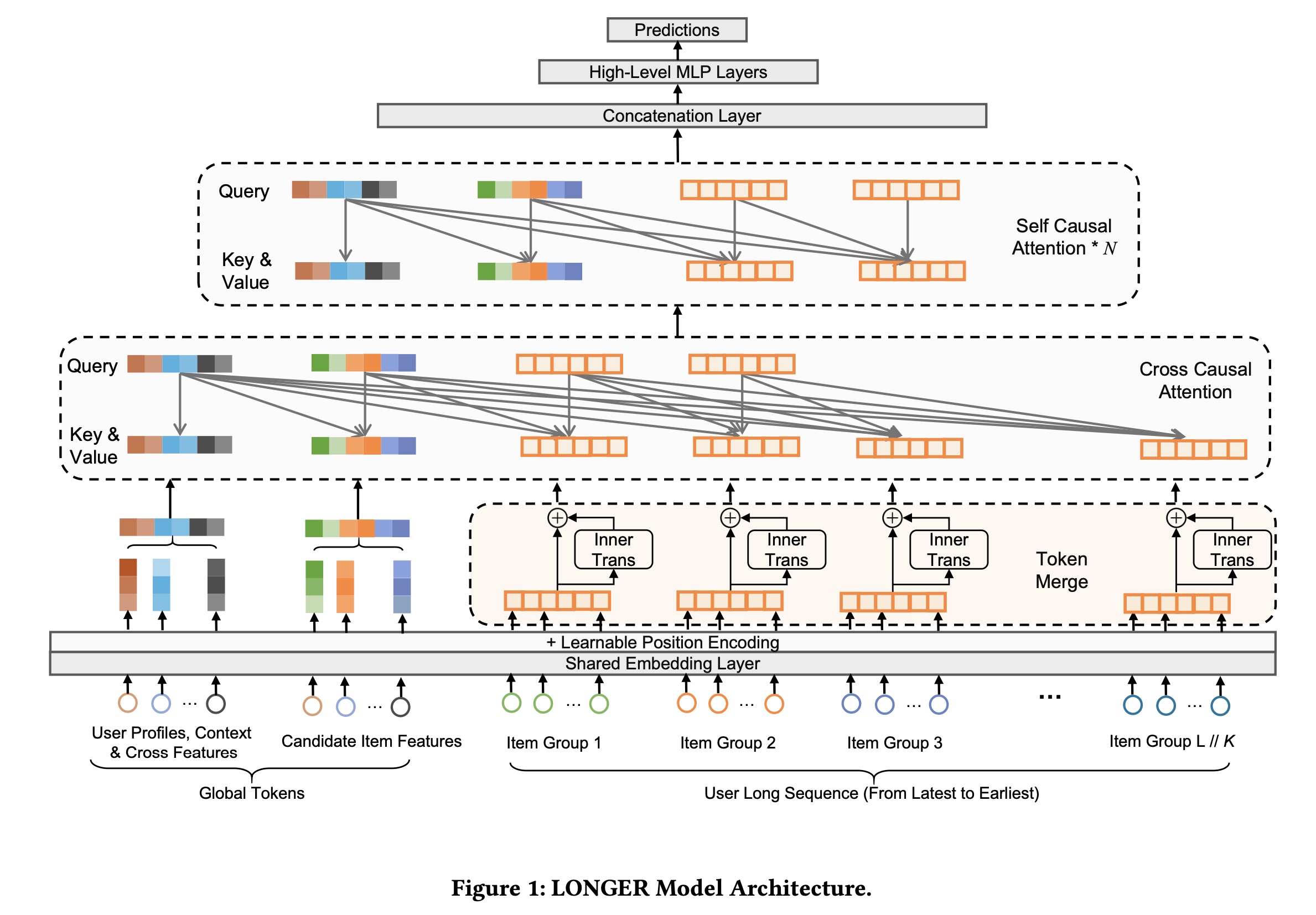
long and complex user behavior sequences的挑战,同时保持工业规模的训练和推理效率。Figure 1展示了我们提出的模型LONGER的整体架构。该框架集成了input generation、token merge、hybrid attention机制以及training-serving optimizations,以实现高效且可扩展的long-sequence modeling。首先,我们通过引入
Global Tokens来enhance模型的input structure,这些Global Tokens充当aggregated anchor representations(例如,target item representation、user ID (UID) embedding)以促进global information fusion并稳定attention distributions。接下来,我们应用
Token Merge来压缩long behavior sequences,降低计算复杂度,同时保留必要的local patterns。为了进一步保留组内依赖关系(
intra-group dependencies),我们引入了InnerTrans,一个轻量级的inner transformer应用于merged token segments上。
核心模型架构(在
LONGER Model Structure章节中描述)采用了一种hybrid attention设计,结合了cross causal-attention layers(以强调序列的显著部分salient parts)和stacked self causal-attention(以捕获序列上的高阶依赖关系)。注意:
这里的
user sequence按照 “逆时序存储”。即,前面的engagement是最近的、后面的engagement是最远的。在获得
a list of tokens之后,需要经过一个MLP投影,从而投影到公共子空间。在
Cross Causal Attention,Query通过如下方式构建:所有的non-sequence tokens、最近的sequence tokens。有两层机制来降低计算复杂度:一个是
Token merge来降低序列长度,从Cross Causal Attention,仅考虑最近的engagements、以及no-sequence tokens作为query。
为了确保
scalability和部署可行性,我们整合了几个工程系统级别的优化。该框架在超大规模
GPU集群上提供fully synchronous training and serving with unified dense and sparse parameter storage。我们通过
Mixed Precision Training and Recompute进一步提高了内存和计算效率,实现了activation memory减少和customized numerical precision。最后,在
inference过程中,我们部署了KV Cache Serving strategy,该策略缓存user sequence rep-resentations并在candidate scoring中重复使用它们,显著减少了冗余计算。
所有这些组件共同形成了一个连贯的系统,支持具有高表达能力和高效率的
long-sequence modeling,并且可以轻松部署在大规模现实世界推荐场景中。
1.2.2 Global Tokens
我们引入
Global Tokens作为auxiliary representations,拼接到input sequence,从而促进global information extraction and anchoring。这些tokens可以包括target item representation tokens、learnable CLS tokens、UID embeddings、以及high-order compressed user–item interaction features。通过设计,global tokens拥有full attention receptive field,允许它们聚合来自整个序列的contextual signals,同时也影响所有其他sequence tokens。这种
architectural augmentation有两个主要目的:首先,
global tokens作为centralized information anchors,能够增强user history、contextual attributes和candidate items之间的feature interactions。其次,它们稳定了长序列中的
attention dynamics,特别是在sparse attention configurations下。如StreamLLM(《Efficient Streaming Language Models with Attention Sinks》)所示,引入少量global tokens可以缓解"注意力汇聚"效应("attention sink" effect),即deeper attention layers不成比例地关注early tokens。这些tokens充当anchor points,保持attention diversity并保留long-range dependency modeling。
其实
global tokens就是除了user sequence以外的其它特征。包括:user ID、target item ID、learnable CSL tokens、user-item历史统计的交叉特征等等。
1.2.3 Token Merge
令
embedding维度。使用普通Transformer处理long behavior sequences(通常sequence truncation)会导致long-range dependencies的丢失。为了解决这个问题,我们提出了一种
Token Merge策略,该策略将相邻的tokens分组并将它们压缩成更短的序列,从而在模型效率和representational fidelity之间实现权衡。该策略将序列长度减少了grouped token representations可以通过简单的concatenation形成,或者通过intra-group interactions(利用轻量级InnerTrans blocks)来进一步增强。这种设计在效率和表达能力之间提供了灵活的权衡,保留了local semantics,同时支持在shorter sequence上进行global modeling。Token Merge就是把一个长的user sequence,按照时间顺序划分为items,组与组之间不重叠;然后计算每一组的representation;然后用group representation来进行后续的Transformer layer。如何计算
group representation?基础方式:直接拼接。将组内的
items的embeddings进行简单拼接,形成一个group representation。高级方式:采用
InnerTrans。将组内的items的embeddings馈入一个InnerTrans,然后将transformer的output进行聚合(如,均值池化、最大池化)从而得到group representation。
给定一个标准结构的
Transformer encoder layer,FLOPs和参数量可以表示为(《Efficient large-scale language model training on gpu clusters using megatron-lm》):Computational Complexity:token merge前后的注意力复杂度之比为:对于典型的
Vanilla Transformer:Merging(42.8%)。
Parameter Expansion:token merging通过缩短序列长度来降低计算复杂度,同时增加了参数数量InnerTrans:为了将多个adjacent tokens合并为一个,组内tokens的简单拼接可能导致tokens之间的interaction不足,可能丢失细粒度细节。为了解决这个问题,我们引入了InnerTrans,它在每个token group内应用一个Transformer以实现local interactions。这种方法确保每个组内的interactions被有效捕获,而不会出现direct concatenation通常发生的information loss。由于维度非常小且序列长度短,InnerTrans的计算预算在实践中非常有限。InnerTrans是什么结构?读者猜测是一个Self-Attention结构。其中:
representation,item embedding。TransformerBlock是将这些embeddings馈入一个Transformer layer,然后对output进行聚合(均值池化、或者最大池化)。根据论文的
Figure 1,InnerTrans包含了residual connection。但是,这里的公式并未包含residual connection。读者猜测,论文应该是采用了InnerTrans和 “简单拼接”这两种方式:其中:
Proj是一个线性投影,将维度或者:直接是一个标准的
Transformer Layer:self-attention -> residual and LN -> FFN -> residual and LN。
1.2.4 LONGER Model Structure
在我们的模型架构中,我们使用一种
hybrid attention机制,该机制结合了cross-attention layers和self-attention layers,以高效处理input sequences。Input Generation:模型的输入包括两个主要部分:global tokens和sequence tokens。global tokens,代表contextual information(如前面章节讨论的target item features和user ID),与sequence tokens拼接起来以形成input。为了更好地捕获
user behavior sequences中的时间动态(temporal dynamics),我们用额外的positional side information来增强sequence tokens。具体来说,我们结合了两种形式的positional encoding:(1):一个absolute time-difference feature,用于量化每个user interaction与target item的时间距离,作为side information并拼接到每个item embedding。注意:针对这个特征,没有
feature embedding,而是这个feature直接使用。另外,这个特征是否需要归一化?作者并未说明。读者认为:需要归一化。
(2):一个可学习的absolute positional embedding,用于编码每个token在序列中的位置,该embedding被add到item embedding中。
在
position encoding之后,生成的tokens通过一个多层感知机(multi-layer perceptron: MLP)来生成它们的input representationsglobal token representations和sequence token representations。然后,query matrixglobal tokenssampled sequence tokenssampled sequence tokens是根据预定义的采样策略从full sequence tokensquery compression也在其他研究领域中被探索过,例如Perceiver(《Perceiver: General perception with iterative attention》)和Q-Former(《Blip-2:Bootstrapping language-image pre-training with frozen image encoders and large language models》),它们采用一个learnable token strategy进行压缩。在实验中,我们全面比较了不同的策略,包括取most recent k tokens或uniformly sampled tokens,或initialize k learnable tokens,并发现most recent k tokens提供了最好的结果。这种hybrid attention设计也受到以下观察的推动:模型性能在sequence tokens数量方面表现出强烈的边际效应:仅采样完整序列的40%就能保留超过95%的性能提升,同时减少约50%的FLOPs(见实验章节)。然后,composite query构造如下:这种
hybrid设计将attention集中在关键的local behaviors和global contextual signals上,使模型能够有效地捕获specific sequence dependencies和broader contextual information。由于
user sequence按照 “逆时序存储”,因此most recent k tokens就是最开头的tokens。Cross-Causal Attention (First Layer):在第一个attention layer中,我们使用上一步生成的query matrixinput tokenscross-causal attention。cross-causal attention机制计算如下:其中:
query, key, value投影矩阵。一种改进方法是采用类似于
FAT或者Hiformer中的思想:对No-sequence features中的fields采用field-specific projection(这也是OneTrans论文中所用到的主要思想)。其中
注意:由于
user sequence按照 “逆时序存储”,因此
causal mask设计,一方面,保持了sequence items之间的时间相关性。另一方面,它确保了从sequence到candidate item的不可见性,从而实现了KV Cache Serving机制。计算attention后,结果通过一个feed-forward network: FFN进行进一步处理。Cross-Causal Attention (First Layer)是为了降低计算复杂度。理论上Self-Causal Attention (Subsequent Layers):在cross-causal attention layer之后,后续层由几个self-causal attention blocks组成。这些层专注于学习sampled tokens sequence内的内部关系(internal relationships),允许模型捕获行为behavior sequence的tokens之间的依赖关系和模式。每个self-causal attention layer后面都有一个FFN,这有助于进一步处理attention机制学到的信息。self-causal attention机制使用类似的公式计算:这里,
querykeyvalueoutput而得到的。为什么要用两种类型的
Attention?Cross-Causal Attention解决 “跨源定向关联” 问题 —— 当存在明确的Query(即,target item)与Key/Value(信息源)时,用于筛选与target相关的信息,同时排除未来泄露和噪音,核心是 “精准匹配”。类似于DIN,只是这里的query是一组向量而不是target item embedding。此外,它也将
tokens长度从Self-Causal Attention:解决 “单一序列内部时序连贯” 问题 —— 当需捕捉序列内的长程依赖(如用户历史的行为)时,用于建立内部因果链,核心是 “时序一致”。
Stacking and Compression:self-causal attention layers被堆叠refine了input sequence的representations。在通过这些层之后,模型产生一个compressed output,它代表了attention机制的final output。然后这个output被用于下游prediction任务。通过在第一层使用
cross-attention和在后续层使用self-attention的组合,我们的模型能够高效处理长序列,同时利用global context和internal dependencies。后续还有
High-Level MLP Layers、以及Predictions Layer。
1.2.5 Training and Deployment Optimization
Training Framework:我们的训练框架是一个为large-scale sparse models设计的全同步系统(fully synchronous system),旨在利用现代高性能GPU的能力。基于硬件--软件协同设计(hardware–software co-design)的理念,它旨在最大化distributed training中的计算吞吐量和内存效率。training pipeline始于batch form或streaming form的数据摄入,然后通过Fountain模块进行预处理。处理后的training data随后被分发到多个GPU runners,在那里dense parameters和sparse parameters都被同步地更新。这种unified design促进了跨devices和nodes的有效scaling,为在生产环境中训练large-parameter models提供了坚实的基础。该框架的一个定义性特性(
defining characteristic)是unified parameter storage and training architecture。dense parameters和sparse parameters都被同步地存储和同步地更新在GPU机器上,消除了对外部Parameter Server组件的需求。为了更好地适应推荐系统中的feature distribution patterns,该框架采用了hierarchical memory system用于sparse embedding,从而有效支持large embedding tables。在这种设计中,高频特征存储在高带宽的GPU内存(HBM)中,中频特征驻留在CPU主内存(MEM)中,低频特征被卸载到本地固态硬盘(SSD)上。这种分层存储布局(stratified storage layout)经过优化以匹配recommendation数据的访问特性(access characteristics),在latency、吞吐量、容量之间提供了practical trade-off。核心创新在于将computation和parameter storage完全共置于GPU机器上,从而减少了通信开销和memory transfer latency。这带来了training throughput的提高、陈旧度(staleness)的降低、以及收敛稳定性(convergence stability)的增强。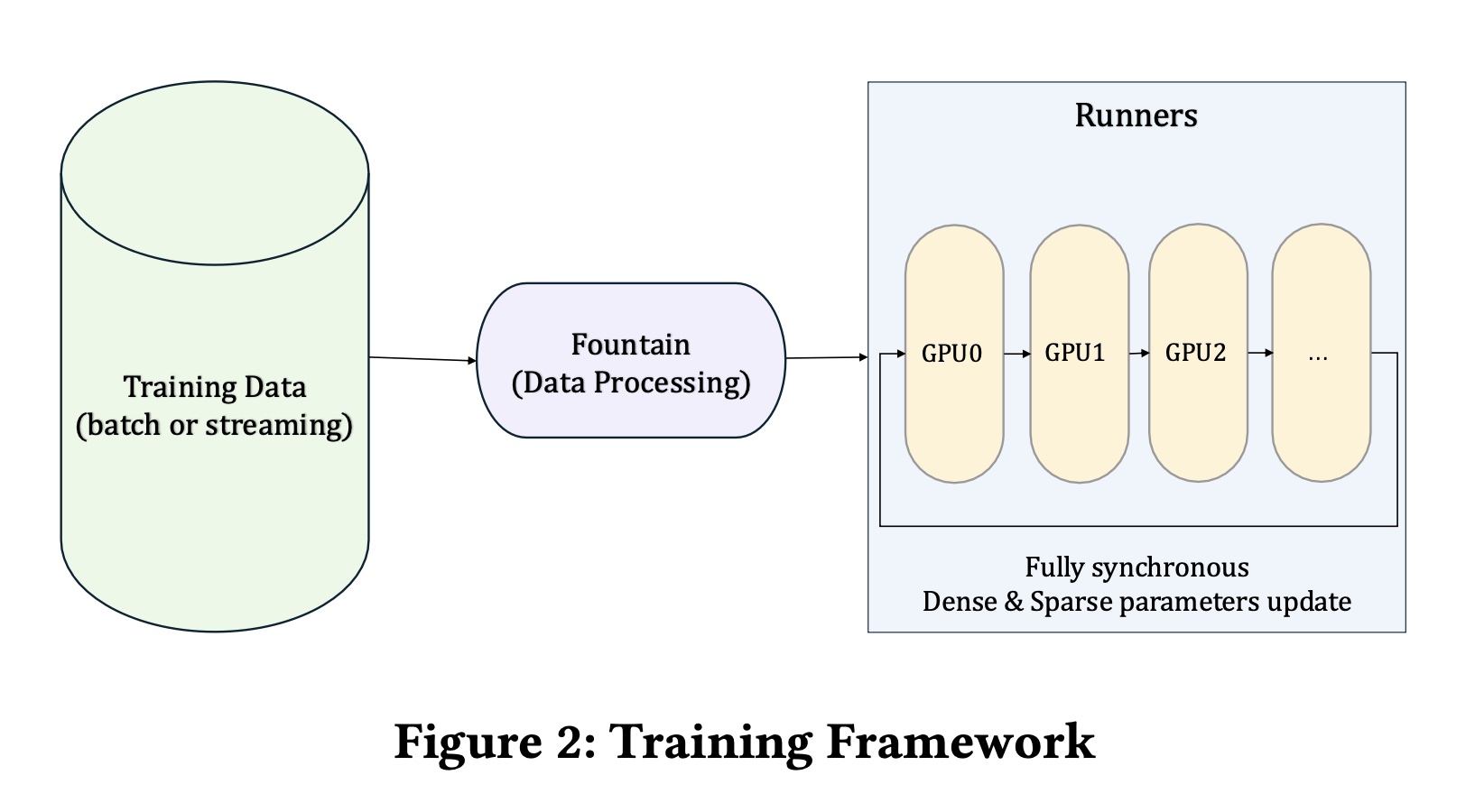
Mixed Precision Training and Recompute:为了缓解训练期间的GPU内存压力,我们采用了重计算(recompute)策略以及混合精度训练(mixed precision training)。对于
gradient computation,我们使用反向模式自动微分(reverse-mode automatic differentiation),这比前向模式(forward-mode)更高效,但需要存储前向传递(forward pass)中的所有intermediate activations。这些activations可能成为主要的memory bottleneck。为了解决这个问题,我们支持在model definition level进行重计算声明(recomputing declarations),允许在forward pass期间丢弃selected activations,并在backward pass期间重新计算它们。这用computation换取了内存节省。由于原生TensorFlow不提供对recomputation的官方支持,我们使用custom_gradient机制实现它,通过code-level annotations实现细粒度控制。此外,为了减少由
dense model scaling引起的计算开销,我们采用基于BF16/FP16的混合精度训练。用户可以在model level来配置精度,对关键组件应用更高精度,对其他部分应用较低精度。这种方法在production工作负载中显示出显著的好处,包括平均+18%吞吐量、-16%训练时间和-18%内存使用,在dense layers中内存减少高达-28%。
KV Cache Serving:为了提高在scoring multiple candidates时的inference效率,受M-FALCON启发,我们引入了一种KV caching机制,该机制解耦了user behavior tokens和candidate-specific global token之间的注意力计算。由于user sequence在candidates之间保持不变,其internal representation可以计算一次并重复使用。具体来说,我们将
attention input分为两部分:user sequence tokens、与candidate item的global token。用户序列的key and value projections被预计算并缓存。对于每个candidate,仅计算其global token与cached user sequence之间的注意力。这导致了一个两阶段的推理过程:预计算并缓存
key-value tensors of the user sequence。计算每个
candidate的global token与cached user sequence之间的注意力。
如
Figure 3所示,这种优化避免了冗余计算并显著降低了serving latency。在实践中,它提高了online serving效率,将吞吐量下降从高达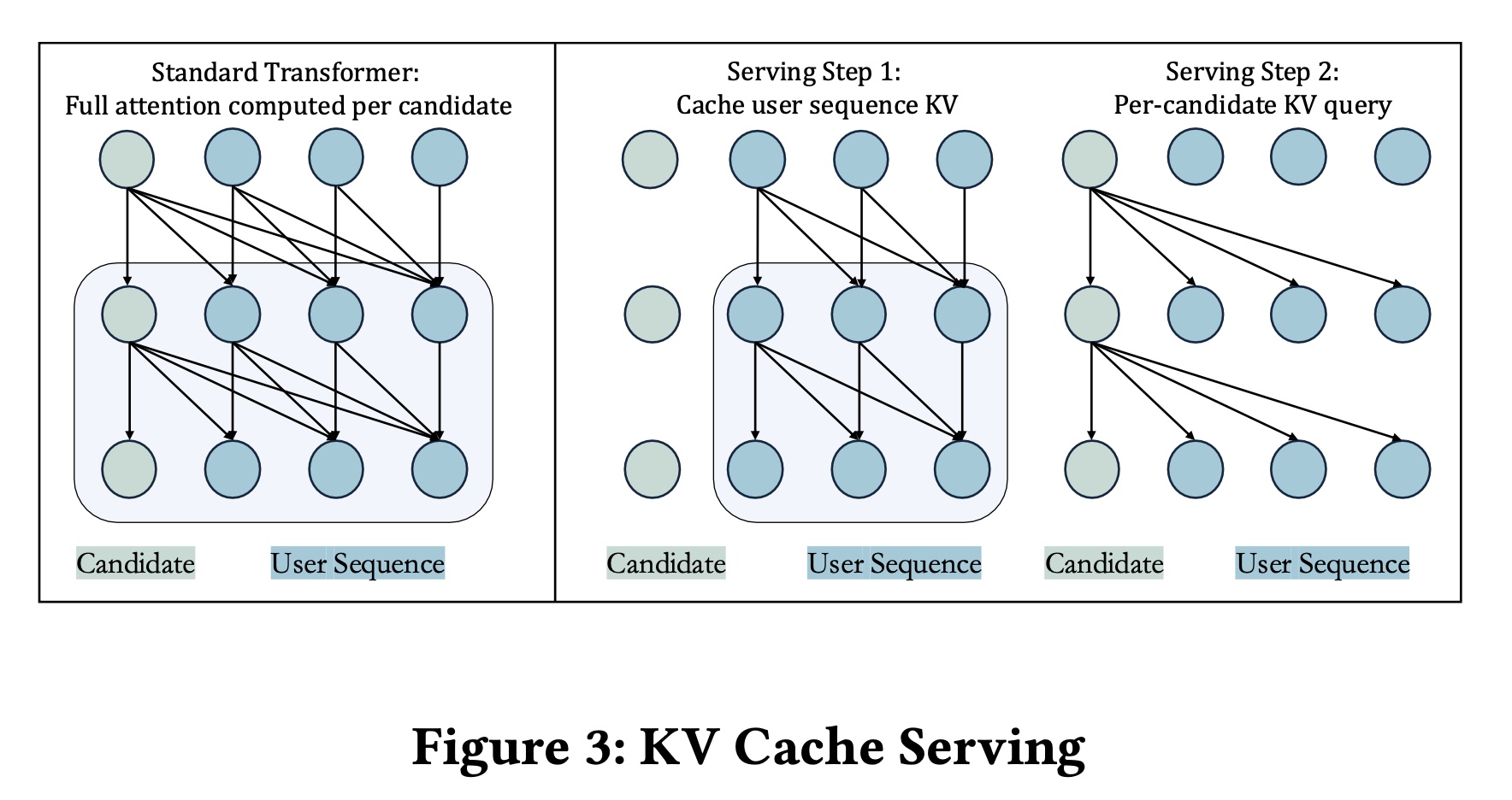
1.3 实验
数据集:我们在抖音广告系统中的转化率(
Conversion Rate: CVR)prediction任务上评估我们的模型,这是一个真实世界、大规模工业广告推荐场景。该数据集构建自2024-10-16至2025-02-23期间收集的在线用户交互日志子集,包含130个连续天的5.2B样本。每个样本包括用户人口统计特征,如user ID: UID、性别、超长用户行为序列、以及一个candidate ad item。用户行为序列包含各种交互类型,包括page views、clicks和conversions;而item-side features涵盖广告内容、display context、和相关的元数据。我们采用时间一致的
data split策略:前123天用于训练,剩余7天保留用于离线评估。这种设置与现实世界部署实践一致,并有效防止模型在开发期间泄漏未来数据。baselines:为了进行比较,我们根据其建模短期用户行为序列或长期用户行为序列的能力,将我们的模型与几个强基线进行比较。短期用户行为序列方法,包括
TWIN和DIN(Recent50),它们依赖于50次交互。长期用户行为序列方法,包括
SumPooling、DIN、HSTU和Transformer,处理扩展的行为历史,这些方法在工业环境中常常面临scalability和效率问题。
所有模型都使用相同的预处理
pipeline和hyperparameter tuning进行训练,实验在48 x A100s GPU集群上进行。
1.3.1 实验结果
现有方法比较:我们使用推荐系统中二分类的两个标准指标:
AUC (Area Under the ROC Curve)和LogLoss,在offline evaluation set上报告模型性能。Table 1总结了多个基线和我们提出的模型的结果。根据该表,我们的模型优于所有基线,实现了
0.85290的AUC和0.47103的LogLoss;与base model相比,AUC相对提高了1.57%,并且与最具竞争力的模型(即Transformer)相比,AUC提高了0.21%。值得注意的是,在工业案例中,0.1%的改进被认为是一个可以影响online A/B test性能的显著改进。此外,与普通
Transformer相比,所提出的模型还表现出显著更高的效率(见后续章节)。这一改进证明了我们的方法在捕获long-range behavior dependencies并且同时保持计算效率方面的有效性。base模型是什么?作者并未说明。这个base模型甚至要比SumPooling更差。读者猜测是:不包含用户行为序列的一个DNN模型。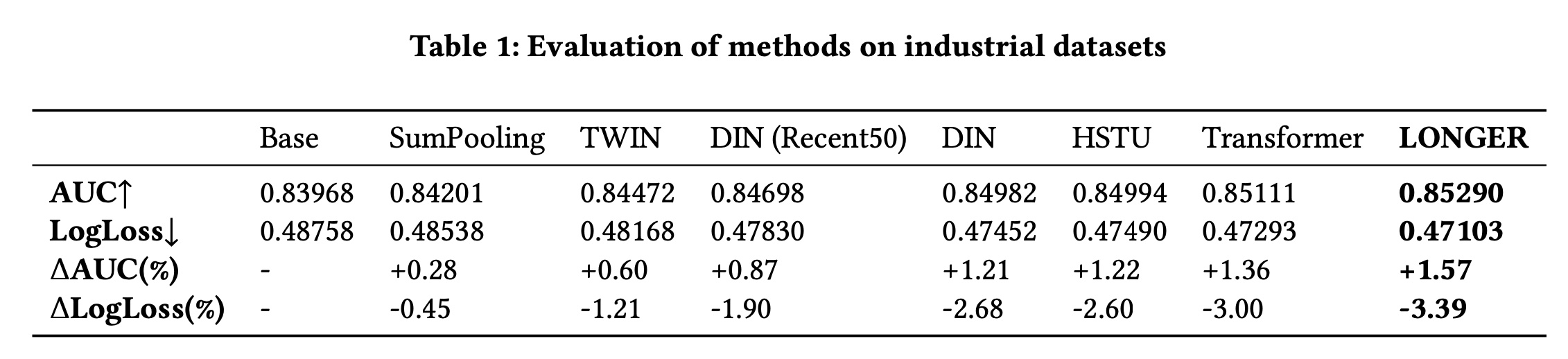
消融研究:
Table 2展示了关于LONGER中关键组件和query-related configurations的消融研究。我们首先检查了
TokenMerge模块和InnerTrans组件的影响。与
base model without merging相比,集成TokenMerge (Concat, 250)将FLOPs从AUC提高了0.22%,并将LogLoss降低了0.48%。进一步结合
InnerTrans带来了额外的增益,实现了0.47052的最佳overall LogLoss和1.63%的AUC改进。
接下来,我们改变用于
summarize recent user behaviors的queries数量 (增加
值得注意的是,使用
100 queries实现了强有力的权衡,AUC为0.85290,LogLoss为0.47103——非常接近使用all queries(54%的FLOPs。此设置在Table 2中以粗体突出显示,显示了其在computational budgets至关重要的现实世界部署中的实用性。
最后,我们比较了不同的
query selection策略。这些策略可以看作是query set的不同初始化方法。其中,使用
learnable queries(随机初始化)表现最差(AUC = 0.84946)。相比之下,直接选择
most recent 100 user behaviors(Recent 100)实现了最佳的整体性能。其他策略,如均匀采样(
uniform sampling)或combining recent and uniformly sampled items,产生略低的AUC和较高的LogLoss。
这些发现表明,使用
informative behaviors——特别是最近的行为——初始化queries对于在long-sequence modeling中有效捕获user intent至关重要。
总体而言,消融研究证实了
architectural enhancements(例如,TokenMerge、InnerTrans)和query-related策略(例如,query number和selection method)在平衡准确性和效率方面都起着关键作用。研究结果验证了LONGER通过精心设计其关键组件和behavior modeling pipeline,可以在降低计算成本的同时实现强大的性能。这种配置使我们的方法非常适合于large-scale industrial deployment,其中low-latency inference和系统吞吐量至关重要。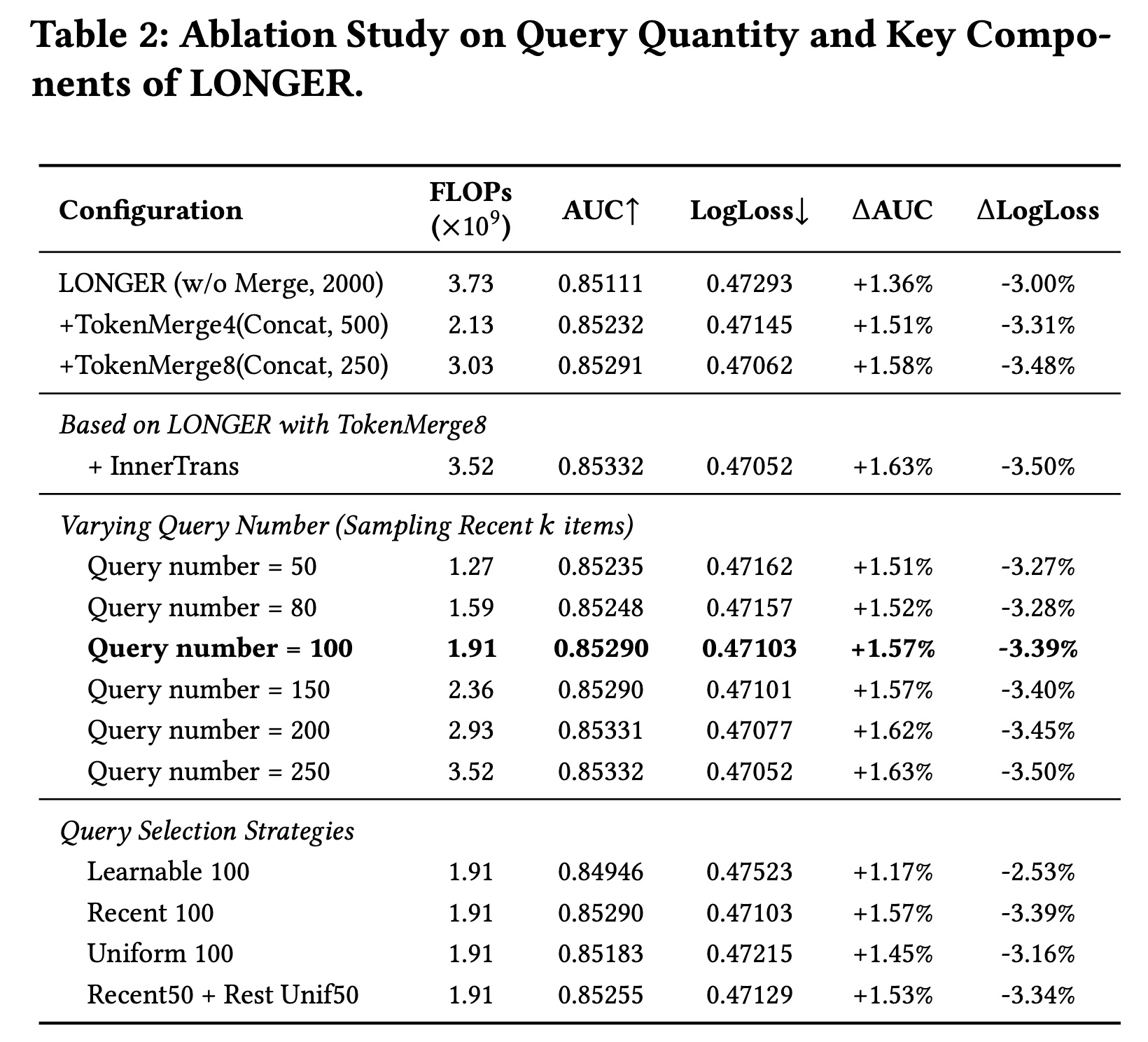
1.3.2 Scaling 分析
在本节中,我们展示了模型性能相对于
sequence length、FLOPs和parameters数量的scaling分析。这些因素的扩展行为遵循一般形式:其中:
其中
AUC和LogLoss)。scaling factor(sequence length、FLOPs、或parameters)。constant offset。
Sequence Length:我们分析了在不同model depths下,性能如何随input sequence length来scale。如Figure 4所示:增加
tokens数量持续提高AUC并降低LogLoss,遵循幂律趋势(power-law trend)。Deeper models从longer sequences中受益更多,但AUC的改善随depth增加而减慢,表明收益递减。optimal depth应平衡model capacity和computational constraints。
总体而言,
longer sequences增强了性能,特别是与适当选择的depth进行配对时。超过一定depth后,进一步的增益是微乎其微的。序列长度翻倍大致能带来
0.1%的AUC提升。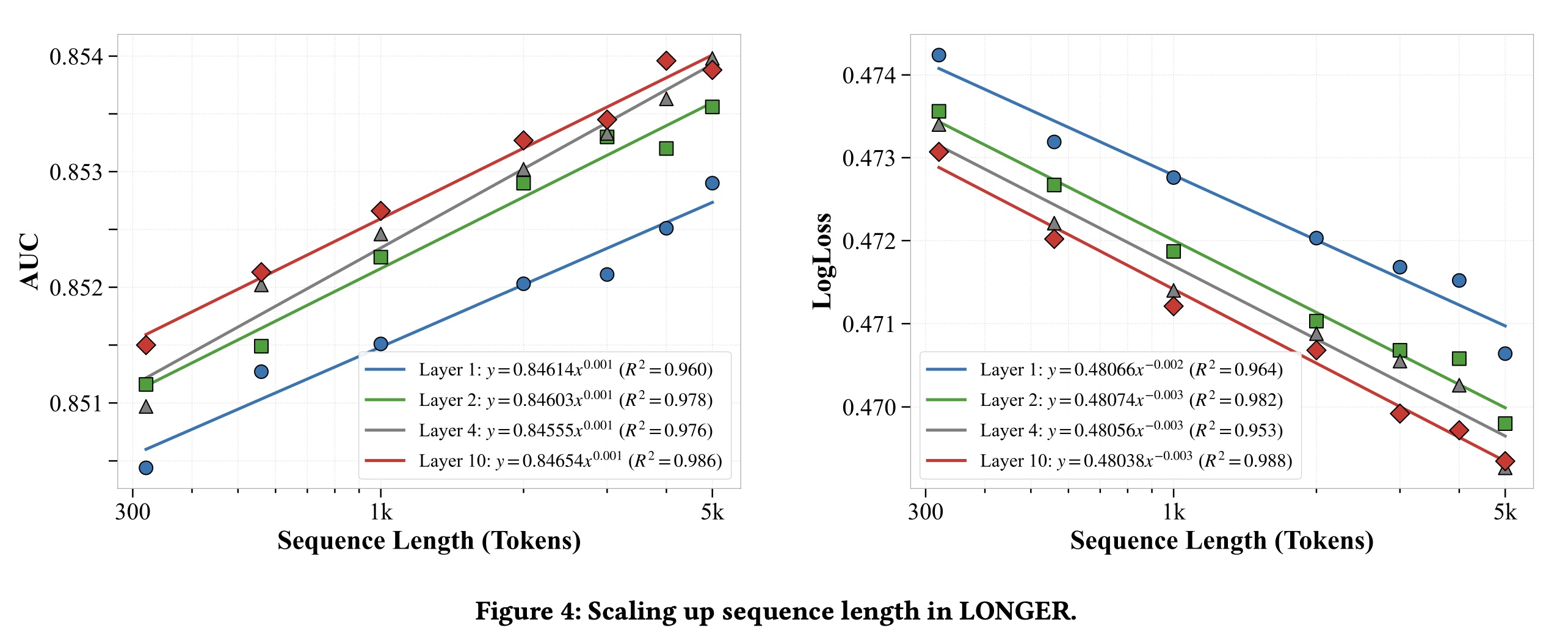
Parameters:我们通过scalinghid- den dimension size来评估模型容量(model capacity),同时将层数固定为2,输入序列长度固定为2000。如Figure 5(a)所示,AUC随着parameter数量的增加而稳步增长,遵循强power-law趋势 (width有效地增强了性能,并且在当前参数范围内没有饱和迹象。参数量翻
10倍大致能带来0.3%的AUC提升。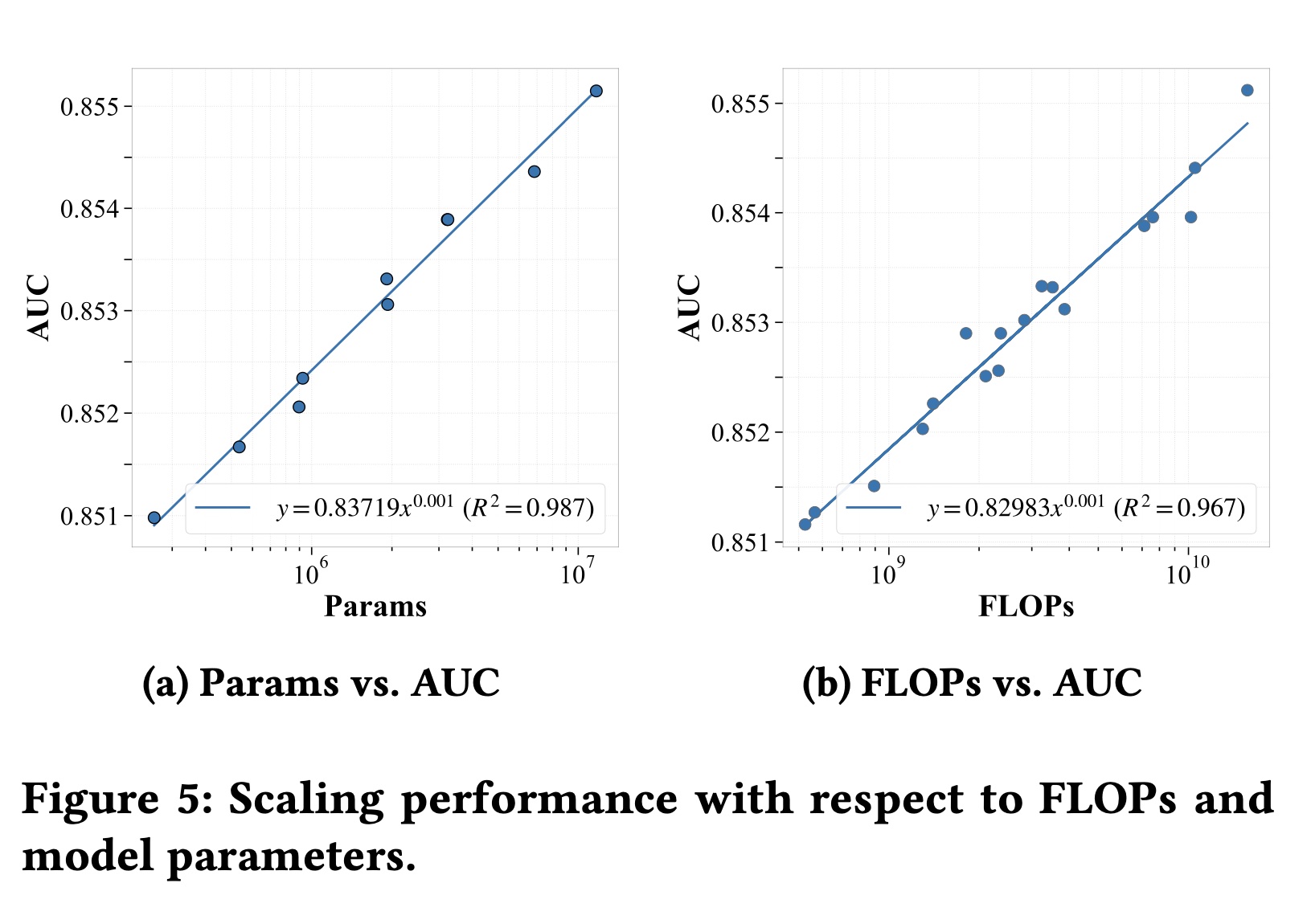
FLOPs:我们通过改变number of layers和sequence length来分析模型性能,同时将模型维度固定为32。如Figure 5(b)所示,AUC随着FLOPs的增加而稳步增长,遵循强power-law趋势 (user behavior sequences,捕获更高阶的依赖关系并提高预测准确性,即使在固定模型width下也是如此。这些结果表明:增加计算资源是提高性能的有效方法,但
efficiency gain应与现实世界系统中通常遇到的computational constraints和memory constraints相平衡。
1.3.3 Online A/B Tests
在本节中,我们展示了
online A/B tests的结果,这些测试旨在评估所提出模型在Douyin Ads和Douyin E-Commerce Platforms这两个非常有影响力的商业平台内的真实场景中的有效性,这两个平台都吸引了数十亿用户。这些场景中的baseline模型已经相当强大,使得观察到的改进更加显著。双领域测试(dual-domain testing)使我们能够评估模型在广告和电商环境中的泛化能力,这两个环境是平台生态系统的关键组成部分。Douyin Ads Platform:本节展示了Douyin Ads上A/B test的结果,我们使用两个关键指标评估我们模型的性能:ADSS (Advertiser Score)和ADVV (Advertiser Value),这两个指标是工业广告系统中最重要的指标。测试在三种广告格式上进行:直播(Live Streaming)、短视频(Short Video)和商城(Mall)。ADSS可能是点击率或者转化率之类的指标,ADVV可能是CPC或者CPM之类的指标。对于直播,模型在
ADSS上实现了1.063%的改进,在ADVV上实现了1.168%的改进。对于短视频,
ADSS增加了2.097%,而ADVV显示出2.151%的改进。对于商城,
ADSS提高了1.816%,ADVV增加了1.407%。
这些结果证实了该模型在所有广告格式上都能有效提升性能,并带来一致的改进。
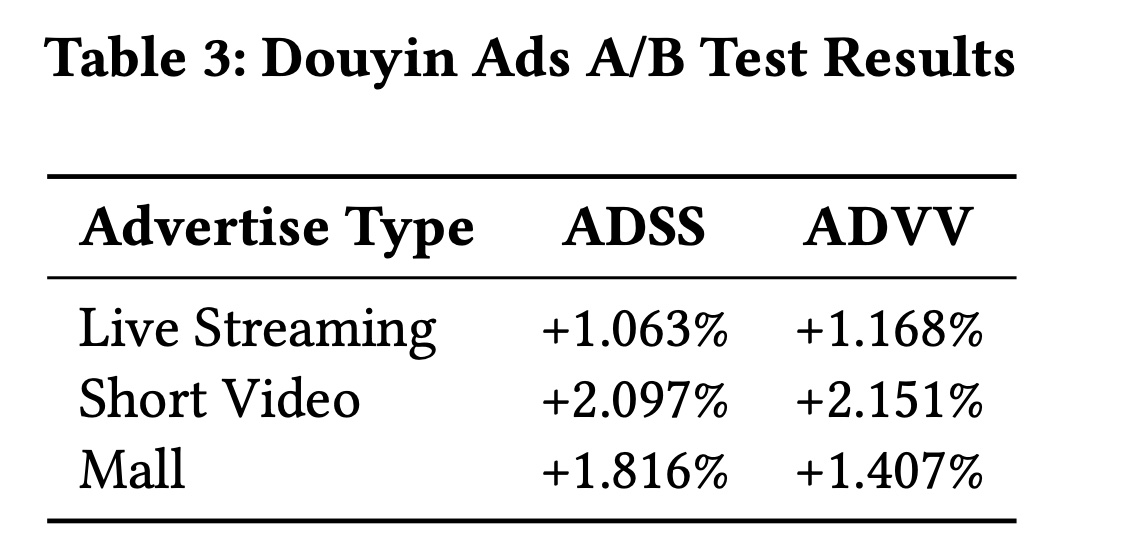
Douyin E-Commerce Service:对于Douyin E-Commerce上的A/B test,我们使用两个关键指标评估不同内容格式的有效性:Order/U(每用户的订单数)和GMV/U(每用户的GMV)。这些指标帮助我们理解模型不仅对总销售额的影响,还对user-level engagement和user-level value generation的影响。结果显示两个指标均有显著改善。对于直播,
Order/U增加了7.9222%,GMV/U提升了6.5404%,表明直播内容对orders per user和value generated per user都有强烈的积极影响。对于短视频,
Order/U改善了4.6125%,GMV/U增加了5.2771%,证明了短视频内容在提升overall sales per user方面的有效性。
这些结果突出了两种广告格式的显著影响,其中直播在
Order/U和GMV/U方面显示出明显更大的改进。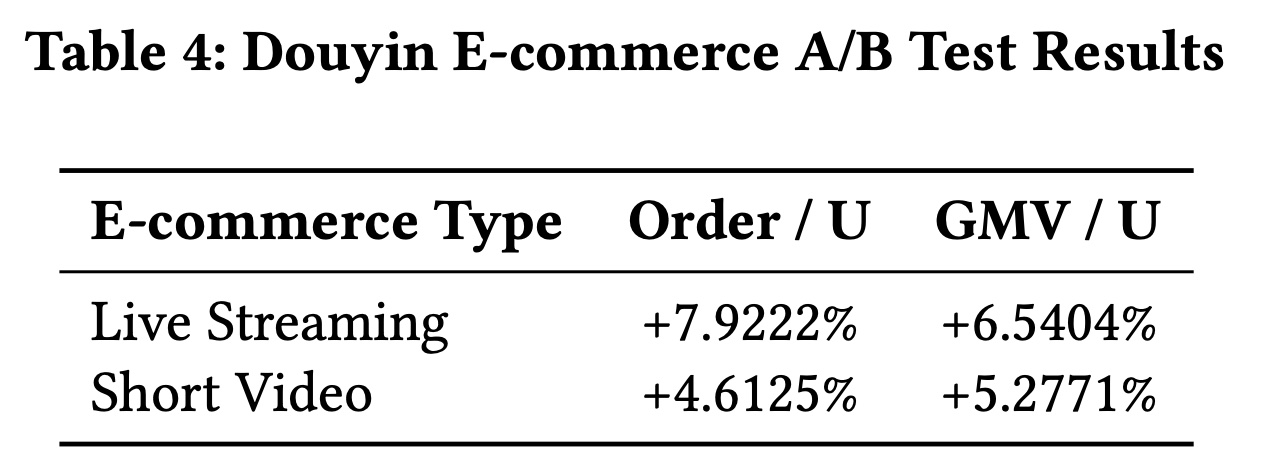
1.4 结论
在本文中,我们提出了
LONGER,一个基于Transformer的框架,旨在工业推荐系统中实现高效且scalable的超长user behavior sequences的建模。通过:引入一系列架构设计,包括
global tokens、token merge with InnerTrans、hybrid causal attention;引入系统级优化,包括
GPU-synchronous framework、mixed-precision and recomputation training、以及KV cache serving。
LONGER能够在现实世界工业级约束下实现端到端的超长序列建模。在工业十亿规模数据集上的广泛实验以及跨广告和电商领域的online A/B tests验证了其在十亿用户工业规模下的鲁棒性和泛化能力。值得注意的是,LONGER在显著降低计算开销的同时实现了有竞争力的准确性,使其非常适合在latency-sensitive production environments中部署。未来的工作包括研究更高效的序列建模技术以及改进工业中的cross-domain behavior modeling。