一、 MTGR [2025]
《MTGR: Industrial-Scale Generative Recommendation Framework in Meituan》
Scaling law已在自然语言处理、计算机视觉等多个领域得到广泛验证。在推荐系统中,近期研究采用generative recommendations以实现scalability,但这些生成式方法需要舍弃传统推荐模型中精心构建的cross features。我们发现这种做法会显著降低模型性能,且通过scaling up模型规模完全无法弥补这一损失。本文提出Meituan Generative Recommendation: MTGR框架以解决该问题。MTGR基于HSTU架构进行建模,能够保留原始deep learning recommendation model: DLRM的所有特征(包括cross features)。此外,MTGR通过user-level compression实现training与inference的加速,确保高效的scaling。我们还提出Group-Layer Normalization: GLN以提升不同语义空间(semantic spaces)内的encoding性能,并设计dynamic masking策略避免信息泄露。我们进一步优化了训练框架,使其能够支持计算复杂度较DLRM高10至100倍的模型,且无显著成本增加。与DLRM模型相比,MTGR的单样本前向推理(single-sample forward inference)计算量(FLOPs)达到65倍,在离线和在线场景中均实现了近两年来的最大性能提升。该突破已成功部署于全球最大的外卖平台Meituan,目前正承载着核心流量。Scaling law已被证实适用于大多数深度学习任务,包括语言模型、计算机视觉、以及信息检索。本文致力于实现工业级推荐系统中ranking模型的高效scaling up。在工业级推荐系统对高Queries Per Second: QPS和低延迟的要求下,模型scaling通常受到training cost和inference time的双重限制。目前,scaling ranking models的研究主要分为两类:Deep Learning Recommendation Model (DLRM)和Generative Recommendation Model (GRM)。DLRM对单个user-item pairs进行建模,学习probability of interest以实现排序,并通过设计更复杂的mappings来实现scales up。GRM则借鉴自然语言处理的思路,将数据组织为token的形式,通过Transformer架构进行next token prediction。
在工业级推荐系统中,
DLRM已应用近十年,其inputs通常包含大量精心设计的人工特征(如cross features)以提升模型性能。然而,DLRM在scaling过程中存在两个显著缺陷:1):随着用user behavior的指数级增长,传统DLRM无法高效处理完整的user behavior sequence,往往需要借助sequence retrieval、或设计低复杂度模块(low-complexity modules)进行学习,这限制了模型的学习能力。2):基于DLRM的scaling导致训练成本和推理成本随candidates数量近似线性增长,使得开销高到难以承受。
对于
GRM,近期研究指出其具有出色的scalability(《OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment》、《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)。我们总结了两个关键因素:1):GRM直接对完整的chain of user behavior进行建模,将同一用户的multiple samples of exposure压缩为一个,显著减少了计算冗余,同时相比DLRM能够对更长序列进行端到端的encoding。2):GRM采用具有高效attention computation的Transformer架构,使模型的training和inference能够满足工业级推荐系统的要求。
然而,
GRM严重依赖next token prediction来建模完整的user behavior sequence,这需要移除candidates与用户之间的cross features。我们发现,排除cross features会严重损害模型性能,且这种性能下降完全无法通过scaling up模型规模来弥补。如何构建一个既能利用
cross features保证有效性,又具备GRM的scalability的ranking模型?为解决这一问题,我们提出Meituan Generative Recommendation: MTGR框架。与传统DLRM和GRM相比,MTGR取其精华、去其糟粕:保留了传统
DLRM的所有inputs feature(包括cross features),同时通过将user and candidate features转换为不同tokens从而来重新组织features,形成a token sequence以实现高效的model scaling。随后,
MTGR将cross feature融入candidate tokens中,并通过一个判别式损失函数(discriminative loss)进行学习。
MTGR采用与《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》中类似的Hierarchical Sequential Transduction Units: HSTU架构进行建模。在HSTU中,我们提出Group-layer Normalization: GLN,对不同类型的token分别进行归一化,从而能够同时更好地建模多种异构信息(multiple heterogeneous information)。此外,我们提出动态掩码策略(dynamic masking strategy),通过full-attention、auto-regressive和visibility only to itself三种掩码模式,确保模型性能并避免信息泄露。与行业中常用的
TensorFlow不同,MTGR的训练框架基于TorchRec构建,并针对计算效率进行了优化。具体而言:为处理
sparse embedding entries的实时insert/delete,我们采用dynamic hash tables替代static tables。为提升效率,我们通过
dynamic sequence balancing来解决GPU间的计算负载不均衡(computation load imbalances)问题,并采用embedding ID de-duplication与automatic table merging来技术加速embedding lookup。我们还融入了
mixed precision training和operator fusion等implementation optimization。
与
TorchRec相比,我们优化后的框架将训练吞吐量提升了1.6倍至2.4倍,同时在超过100 GPUs上运行时仍能保持良好的scalability。我们首先在小规模数据集上验证了
MTGR的scalability,随后设计了三种不同规模的模型,利用超过六个月的数据进行训练,以验证离线性能和在线性能的scaling law。其中,large version相比经过多年优化的DLRM基线模型,单样本的前向传播(forward)计算量(FLOPs)达到65倍,在我们的业务场景中实现了1.22%的转化量(conversion volumes)提升和1.31%的点击率(Click-Through Rate: CTR)提升;同时,训练成本保持不变,推理成本降低了12%。MTGR-large已部署于Meituan外卖推荐系统,服务数亿用户。综上所述,本文的贡献如下:
MTGR融合了DLRM和GRM的优势,保留了DLRM的所有特征(包括cross feature),同时具备GRM出色的scalability。提出
Group-Layer Normalization: GLN和dynamic masking strategies,以实现更优的模型性能。在基于
TorchRec的MTGR training framework上进行了系统性优化,提升了training性能。通过离线实验和在线实验验证了
MTGR性能与计算复杂度之间的幂律关系(power-law relationship),以及其相比DLRM的优越性。
MTGR的模型结构非常类似于OneTrans,但是技术含量不如OneTrans。建议阅读OneTrans即可。
1.1 相关工作
Deep Learning Recommendation Model:经典的DLRM结构通常包含多种inputs,如上下文信息(如时间time、位置location)、用户画像(如性别gender、年龄age)、user behavior sequences、以及target item with many cross features。ranking模型中两个尤为重要的模块是behavior sequence processing和feature interactions learning。behavior sequence module(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》、《Twin v2: Scaling ultra-long user behavior sequence modeling for enhanced ctr prediction at kuaishou》、《Deep interest network for click-through rate prediction》)通常采用target attention机制来捕获user historical behavior与待预测item之间的相似性。feature interactions module(《xdeepfm: Combining explicit and implicit feature interactions for recommender systems》、《Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations》、《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》、《HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou》)则用于捕获不同特征(包括user features和item features)之间的交互,以生成final prediction。
Scaling up Recommendation Model:在DLRM中,基于不同的scaling modules,存在两种截然不同的方法。一种是
scaling cross module,即scaling up特征交互模块(feature interactions module),其中feature interactions module融合user and item information。《Wukong: Towards a scaling law for large-scale recommendation》提出了可堆叠的Wukong layer用于scaling up。《On the embedding collapse when scaling up recommendation models》采用a multi-embedding strategy来解决embedding collapse问题,从而提升模型的scalability。
另一种是
scaling user module,仅scaled up用户部分,这种方法更适合inference。《Enhancing CTR Prediction through Sequential Recommendation Pretraining: Introducing the SRP4CTR Framework》、《Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta》通过仅scaling up user representations并将其caching or broadcasting到所有待预测items,降低了online inference成本。《Scaling law for recommendation models: Towards general-purpose user representations》、《Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model》设计了user representations的pre-training方法,在下游任务中展现出scalability。
与
DLRM相对应的是GRM。《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》通过HSTU架构验证了scaling law,模型参数规模高达万亿级。《OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment》采用semantic coding替代传统的ID representations,将Direct Preference Optimization: DPO与transformer-based的框架相结合,用a unified generative model替代cascaded learning framework。
1.2 预备知识
1.2.1 Data Arrangement
传统上,对于一个用户和对应的
candidates,用户与第candidate组成的pair对构成了第user’s profile feature(如年龄age、性别gender等等)。每个特征items组成的item sequence。每个元素item(items。item的一个特征(item ID、item tag、average CTR on the item等等。每个item一共有注意,根据论文的描述,
interaction,即不包含request前几小时或一天内最近的interaction,代表用户的real-time actions and preference,与candidates之间的cross features。candidates的特征(如item ID、item tag、item brand等),与用户无关,为所有用户共享。
1.2.2 Ranking Model in Recommendation Systems
给定一组
首先对
a dense representation。具体而言,embedding and concating之后,得到:其中:
user representation维度;cross feature representation维度;candidate representation维度。注意:这
user representation重复对于
itemembedding and concating之后得到item representation维度。然后items堆叠起来得到:为提取
historical interacted items与candidates之间的user interest,通常采用target attention机制,以target item为query,sequence feature为key/value。形式化表示为:该公式根据
candidates最终,
MLP),为每个样本输出logit。logit被用于learning in training和ranking when inference。
Figure 1展示了传统ranking model的简化的data arrangement和workflow:首先对所有特征进行嵌入。
然后对
leading embeddings采用不同方法处理。最后将处理后的特征拼接并通过
MLP进行feature interaction,并生成每个candidates的final logit。
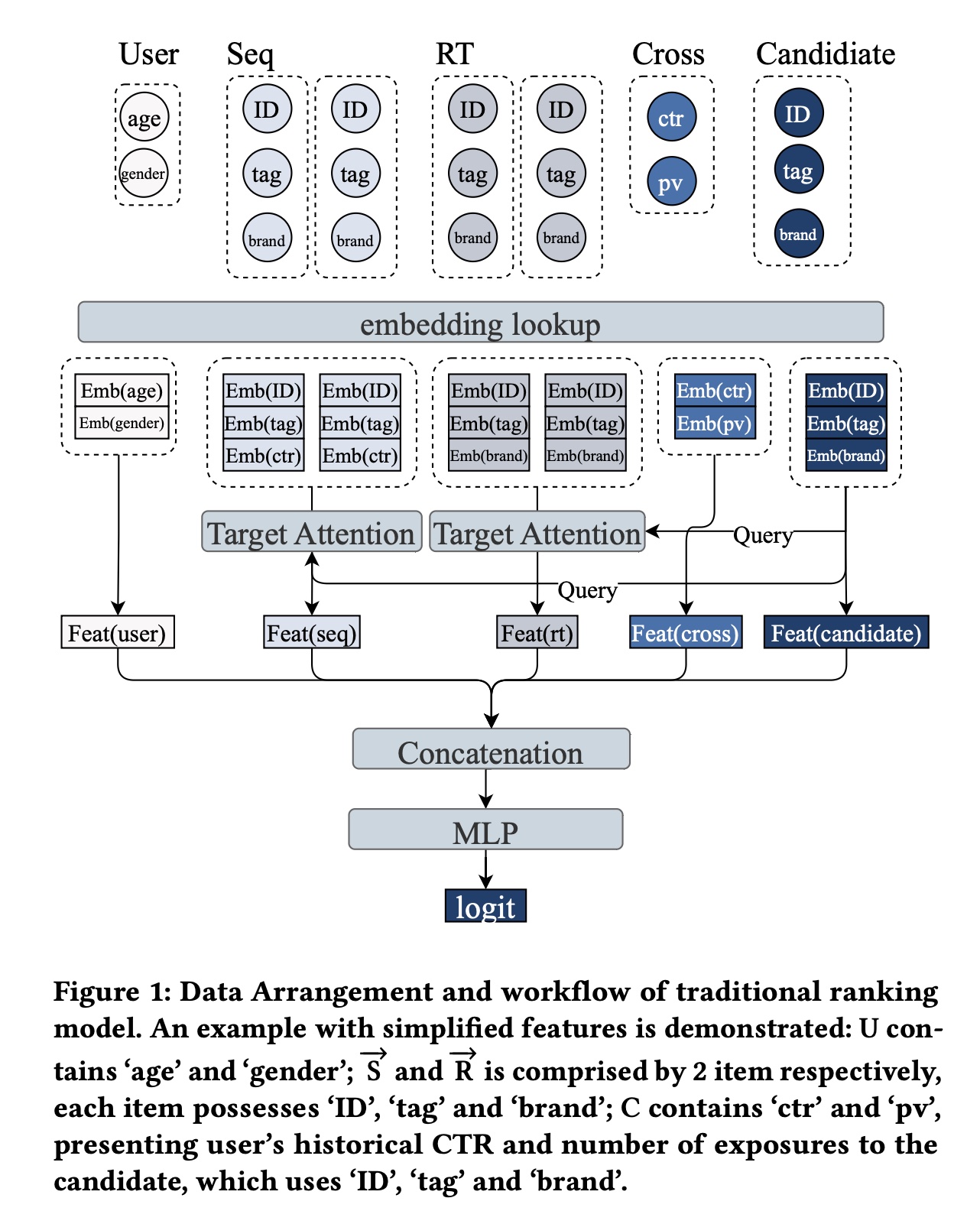
1.2.3 Scaling Dilemma in Recommendation Systems
Model scaling已成为提升ranking性能的常用方法,通常旨在扩大user module和cross module的参数规模。user module处理包括sequence features在内的user feature,生成user-dependent representation。Scaling user module能获得更优的user representation;而且,由于user representation可共享并一次性推理所有candidates,即使user module的推理成本较高,也不会给系统带来过重负载。然而,仅scaling user module无法直接促进user and item之间的feature interaction。相反,另一种趋势是
scaling cross module(即feature concatenation之后的feature interaction MLP)。这类方法通过更关注user and candidates之间的interaction来提升ranking能力。但由于cross module需要为每个candidate单独推理,计算量随candidates数量线性增长,导致不可接受的system latency。传统推荐系统的
scaling困境迫切需要一种新的scaling方法,能够实现user and candidates之间的高效feature interaction,同时使inference成本随着candidates数量呈亚线性增长。MTGR通过data re-arrangement和相应的架构优化,创新了推荐系统的scaling方式。
1.3 Data Rearrangement and Architecture of MTGR
1.3.1 User Sample Aggregation for Training and Inference Efficiency
对于
candidates中的第MTGR将features组织为cross featureitem feature of candidates的一部分。在MTGR中,训练时按用户在一个特定窗口内聚合candidates,推理时按request来聚合candidates。由于aggregation是基于同一用户,聚合后的样本可复用相同的user representationinteraction time顺序来排列的所有real-time interaction items。Figure 2(a)展示了聚合过程:与Figure 1中仅预测一个candidate不同,Figure 2(a)将3 items聚合到一个样本中,复用相同的user representation。形式化而言,给定同一个用户,feature representation为:通过将
candidates聚合到一个样本中,MTGR仅需一次计算即可为所有candidates生成scores,大幅节省了资源。具体而言,user aggregation过程将training samples数量从all candidates * all users大幅减少;推理时,将一个request中的candidates按上述方式分组,MTGR仅需一次inference即可完成所有candidates的ranking,无需按照candidates数量来多次inference。这aggregation方式打破了inference成本对candidates数量的依赖,为model scaling提供了可能性和潜力。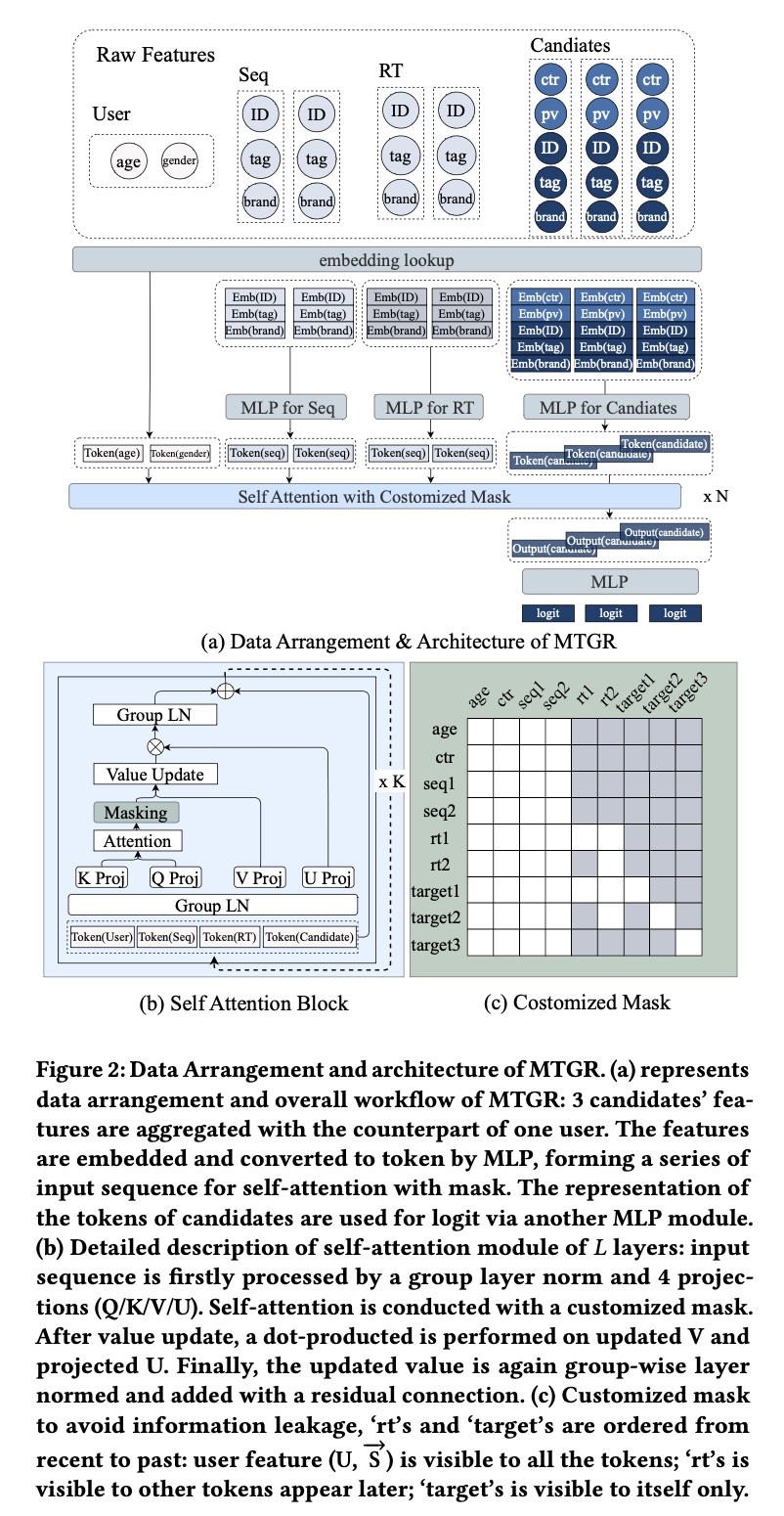
公式
scalar features和sequence features。为统一input格式,MTGR将features and sequence转换为tokens。具体而言:对于
scalar features,每个feature自然转换为单个token。转换后的结果为tokens的统一维度,对于
sequence feature,每个itemtoken:首先对MLP模块来统一维度。然后堆叠所有
items的representations得到:candidates中的每个itemtoken。对candidate的特征进行嵌入并拼接起来,再通过另一个MLPP转换为统一维度。然后堆叠所有
candidates的representations得到:candidates数量。与
Figure 1的区别在与:Figure 1采用独立的Cross Features,因此是:
最后,所有
tokens拼接起来,得到a long sequence of tokens:这里的
candidates。
1.3.2 Unified HSTU Encoder
同一用户的样本被聚合为
a sequence of tokens,天然适合采用self-attention机制处理。受HSTU启发,MTGR采用堆叠的self-attention layer和encoder-only architecture进行建模。与大语言模型(
LLM)类似,input token sequences按层处理。如Figure 2所示,在self-attention block中:input sequencegroup layer norm: GLN进行归一化。同一domain的特征(例如,group。GLN确保在self-attention之前不同domains的tokens具有相似分布,并对齐不同domains的semantic spaces,即Layer Norm的定义:其中:均值
Group LN的定义:将样本的特征分为分组:输入特征
batch size、然后在每个样本的每个分组上计算统计量:
归一化:
重塑:将形状恢复为
归一化后的
inputs投影到4种不同的representation:其中:其中
multi-head attention computation,并采用silu非线性激活。attention分数除以total length of input features作为an average factor。然后attention score施加自定义掩码(value update:将投影后的
group layer norm。最后添加residual connection并叠加另一个MLP:Transformer Layer的做法。
Dynamic Masking:Dynamic Masking(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)采用causal mask进行sequence modeling,但在MTGR中未带来显著性能提升。此外,由于most recent interactions),其时间可能与sample aggregation window重合。MTGR中使用简单的causal mask可能导致信息泄露。例如,晚上的interactions不应暴露给下午的candidates,但这些信息可能被聚合到同一个样本中。这一困境需要灵活高效的masking策略。在
MTGR中:static(接下来我们称它们为'static sequence'),因其信息来自aggregation window之前,不会导致因果错误(causality errors)。因此MGTR对它们应用full attention。interaction(接下来我们称它们为'dynamic sequence')。因此MGTR对它采用自回归动态掩码(auto-regressive with dynamic masking)。candidates仅可见自身,采用对角线掩码(diagonal masking)。
具体而言,
MTGR的masking设置了三条规则:static sequence对所有tokens可见。实际上,
dynamic sequence的可见性遵循因果关系(causality),每个token仅对后续出现的tokens(包括candidate tokens)可见。candidate tokens
Figure 2(c)展示了dynamic masking的示例:'age', 'ctr'代表feature token。'seq1', 'seq2代表'rt1', 'rt2'代表'target1', 'target2', 'target3'代表candidates。
行中的白色块表示该
token可使用其他tokens的信息;列中的白色块表示该token对其他tokens可见:Full attention,因此'age'到'seq2'形成白色方块。假设
'rt1'晚于'rt2'出现,'rt1'到'rt2'的上三角为白色块,意味着'rt1'可使用'rt2'的信息,但'rt2'不可使用'rt1'的信息。假设
'target2'和'target3'早于'rt1'出现,因此'rt1'对它们不可见;假设'rt2'早于'target1'和'target2'、晚于'target3'出现,因此'rt2'对'target3'不可见,'target3'也无法使用'rt1', 'rt2'的信息。
注意:
masking矩阵中,行名表示target,列名表示src。行名(或者列名)的排列中,
rt是按照recent to past的时间顺序排列;target也是按照recent to past的时间顺序排列。但是,rt2有可能晚于target1。
1.4 训练系统
为便于
MTGR模型结构的设计和开发,并方便融合大语言模型领域快速发展的更多特性,我们决定不再沿用之前基于TensorFlow的训练框架,而是在PyTorch生态中重构training framework。具体而言,我们扩展并优化了TorchRec的功能,针对MTGR模型的特点进行了专项增强,最终实现了MTGR模型的高效训练。与TorchRec相比,我们优化后的框架将训练吞吐量(training throughput)提升了1.6倍至2.4倍,同时在超过100块GPU上运行时仍能保持良好的scalability。与DLRM baseline相比,我们实现了单样本的forward computation FLOPs的65倍的提升,而训练成本几乎保持不变。以下是我们的核心工作:Dynamic Hash Table:TorchRec采用固定大小的table来处理sparse embeddings,不适合大规模工业的流式训练(streaming training)的场景:一方面,
static table达到预设容量(preset capacity)后,无法为new users和new items实时分配additional embeddings。另一方面,
static embedding tables通常需要预留超出需求的空间以避免ID溢出,导致低效的内存资源利用。
为解决这些问题,我们开发了基于
hash技术的high-performance embedding table,支持训练过程中对sparse IDs的动态的空间分配(dynamic allocation of space)。我们的设计采用解耦的hash table架构(《MTGRBoost: Boosting Large-scale Generative Recommendation Models in Meituan》),将key storage和value storage分离:key storage提供轻量级的keys to pointers的映射,其中指针(pointers)指向embedding vectors。value storage包含embedding vectors,以及用于淘汰策略(eviction policies)的元数据(如计数器、时间戳)。
这种
two-part系统实现了两个核心目标:(1):仅需复制key storage即可实现容量的动态扩展,无需复制庞大的embeddings。(2):keys按紧凑格式来排列,提升key scanning的效率。
Embedding Lookup:embedding lookup过程采用All-to-all communication进行跨设备的embedding exchange。为减少设备间重复的ID transfers,我们实现了一种two-step处理流程,确保通信前后IDs是unique的。Load balance:在推荐系统中,user behavior sequences通常呈现长尾分布:少数用户拥有长序列,而大多数用户的序列较短。这导致fixed batch size(简写为BS)训练时出现显著的计算负载不均衡(computational load imbalance)。常用解决方案是序列打包(
sequence packing)技术(《Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance》),将多个短序列合并为一个长序列。但这种方法需要仔细调整mask,以避免不同序列在attention calculation中相互干扰,实现成本较高。我们的解决方案简洁高效:引入动态批次大小(
dynamic batch size),根据input data的实际序列长度调整每个GPU的local batch size,确保计算负载相近。同时调整梯度聚合(gradient aggregation)策略,根据每个GPU的batch size对梯度进行加权,保持与fixed batch size一致的计算逻辑。Other Optimizations:为进一步提升训练效率,我们采用pipeline技术,使用三个独立的streams:copy、dispatch和compute。copy stream负责将input data从CPU传输到GPU。dispatch stream执行基于IDs的table lookups。compute stream同时处理前向计算(forward computations)和反向更新(backward updates)。
例如,当
compute stream处理batch T的forward and backward passes时,copy stream同时加载batch T+1,以最小化I/O delay。batch T的backward updates完成后,dispatch stream立即启动batch T+1的table lookups和communication。此外,我们采用bf16 mixed-precision training,并基于cutlass设计了专用的attention kernel,以加速训练进程。
1.5 实验
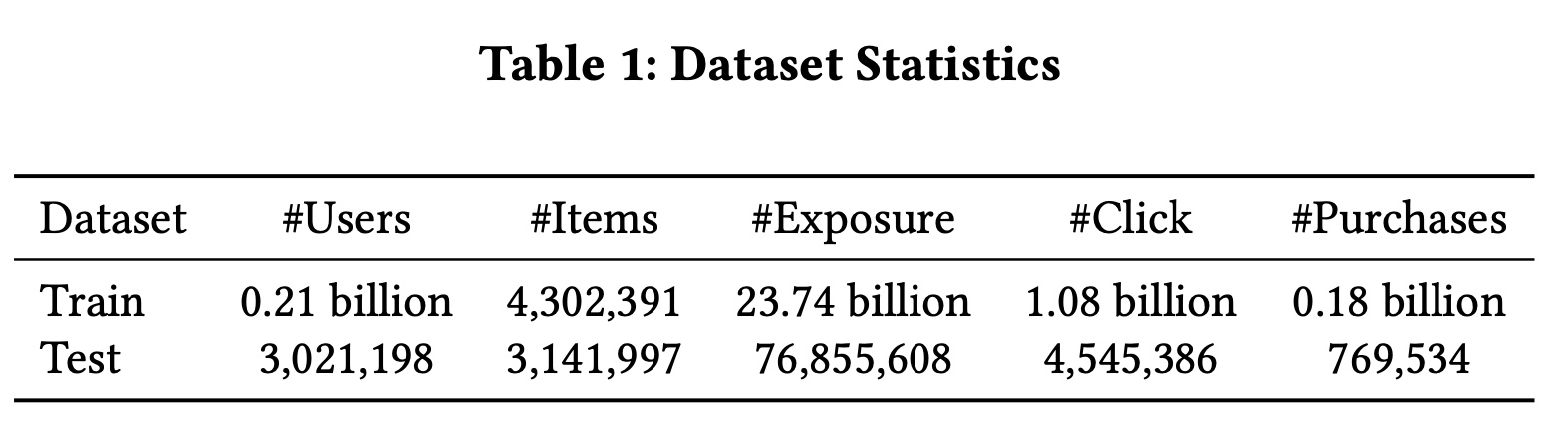
数据集:公开数据集广泛使用独立的
ID features和attribute features,很少包含cross features。但cross features在实际应用中至关重要。在我们的业务场景中,cross features是一类重要的特征,通常由人工精心设计,包括user-item、user and higher-level categories、item and spatio-temporal information等交互关系。为弥补公开数据集缺乏cross feature的不足,我们基于Meituan真实工业级推荐系统的日志构建了训练数据集。与公开数据集不同,我们的真实数据集包含更丰富的cross features set和更长的user behavior sequences。使用工业级数据进行实验能更好地凸显这些cross features对真实推荐系统的显著影响。此外,我们的数据集规模庞大,使complex models在训练过程中能够实现更充分的收敛。离线实验使用
10天的数据集,统计信息如Table 1所示。在线实验为了与训练超过
2年的DLRM baseline进行对比,构建了更长周期的数据集,使用超过6个月的数据。
baseline模型:对于
DLRM,我们比较了两种sequence modeling方法:基于sequence retrieval的SIM、基于original long sequences的端到端建模(E2E)。在
scaling方面,我们对比了DNN、MoE、Wukong、MultiEmbed(《On the embedding collapse when scaling up recommendation models》)和UserTower。具体设置如下:MoE使用4 experts,每个expert包含一个与base DNN复杂度相同的网络。Wukong和MultiEmbed配置为与MoE相同的计算复杂度。UserTower使用一组可学习的queries,在user behavior上插入qFormer layer(《Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models》)和另一个MoE(16 experts)模块,计算复杂度是MoE的3倍。但推理时可为同一用户的多个predicted items共享该计算,从而降低推理成本。UserTower在我们的场景中已取得良好效果。
MTGR采用E2E处理所有sequence information,并设置了三种不同规模以验证scalability,如Table 2所示。
UserTower是啥结构?论文没说。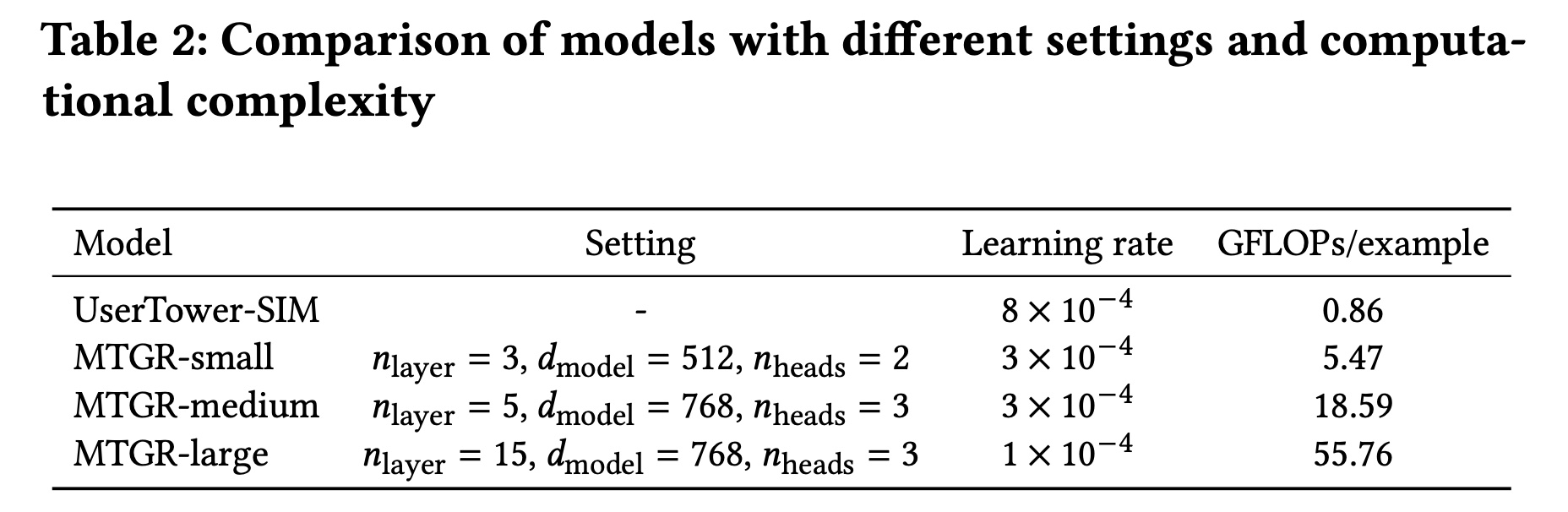
评估指标:
离线评估:关注点击率(
CTR)和点击转化率(Click-Through Conversion Rate: CTCVR)两个任务,使用AUC和Group AUC: GAUC进行评估。GAUC是对每个用户的AUC进行平均,相比AUC更关注模型对同一用户的ranking能力。在线评估:关注两个指标:页面浏览点击率(
CTR per page view: PV_CTR)和用户浏览转化率(CTCVR per user view: UV_CTCVR),其中UV_CTCVR是评估业务增长的最关键指标。
参数配置:
模型使用
Adam optimizer训练。对于
DLRM,每个GPU处理的batch size为2400,使用8块NVIDIA A100 GPUs训练。对于MTGR,batch size = 96,使用16块NVIDIA A100 GPUs训练。如
Table 2所示,模型复杂度越高,学习率越低。此外,随着计算复杂度的增加,我们通过配置不同的
embedding维度按比例扩大size of the sparse parameters。假设一个token包含embedding维度通常设置为接近因为一个
token可能是由多个feature embedding拼接而成。值得注意的是,为避免
sparse parameters过度扩展导致开销过大,我们主要增加cardinality较小的sparse features的维度,而保持cardinality极大的sparse features的维度不变。最后,
1000,100。
1.5.1 整体性能对比
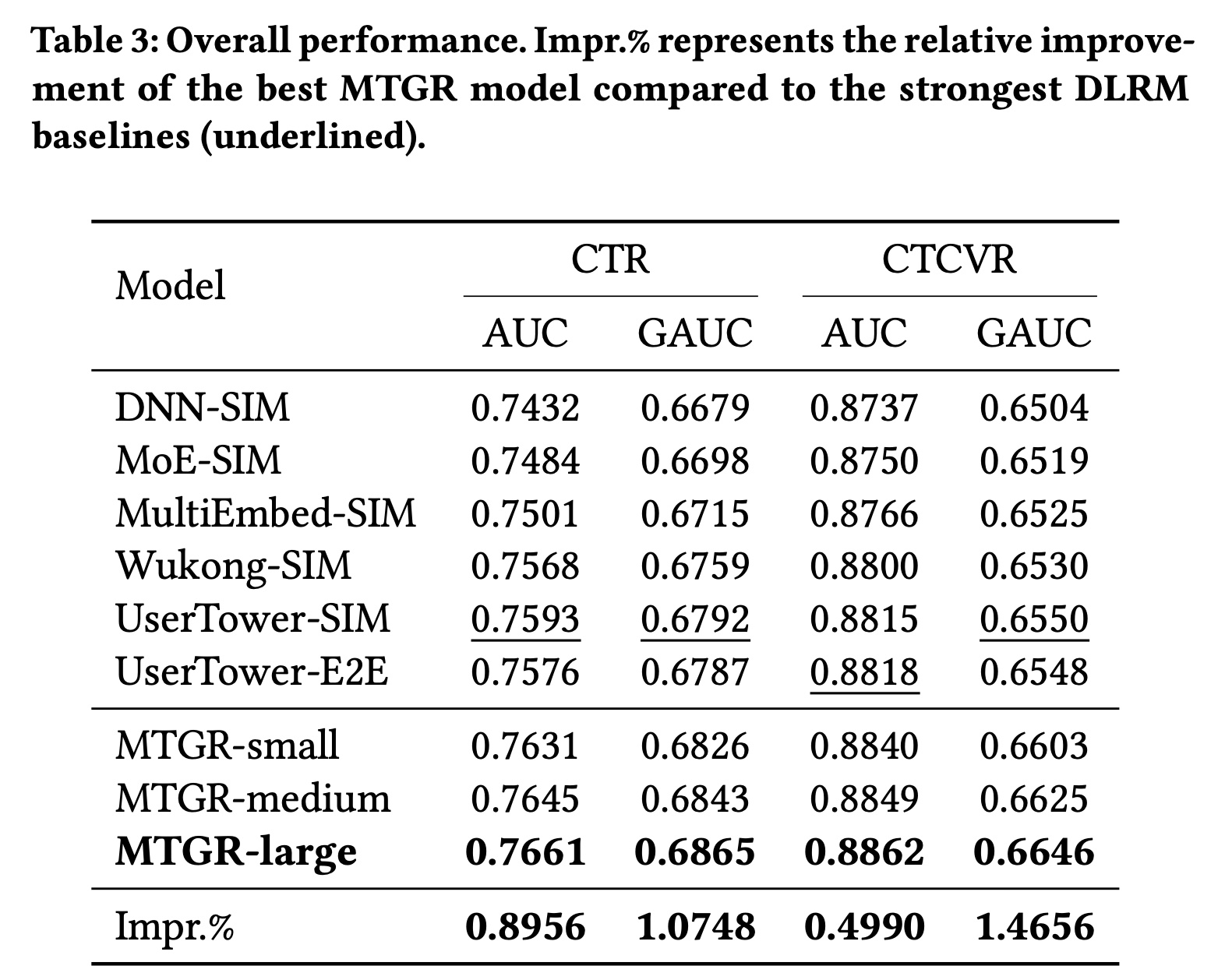
我们使用
10-day dataset评估MTGR和其他基线方法的性能,结果如Table 3所示。不同模型在各离线指标上的差异的趋势一致。根据以往经验,离线指标提升0.001即被认为具有显著意义。在各类
DLRM中:Wukong-SIM和MultiEmbed-SIM的性能优于MoE-SIM。UserTower-SIM表现最佳,而UserTower-E2E相比UserTower-SIM性能略有下降。我们推测在DLRM范式下,模型复杂度不足以建模所有sequence information,导致欠拟合。
我们提出的
MTGR,即使是最小的版本,也超过了性能最强的DLRM模型。且三种不同规模的MTGR模型均展现出scalability,性能随模型复杂度的增加而平稳提升。
1.5.2 消融实验
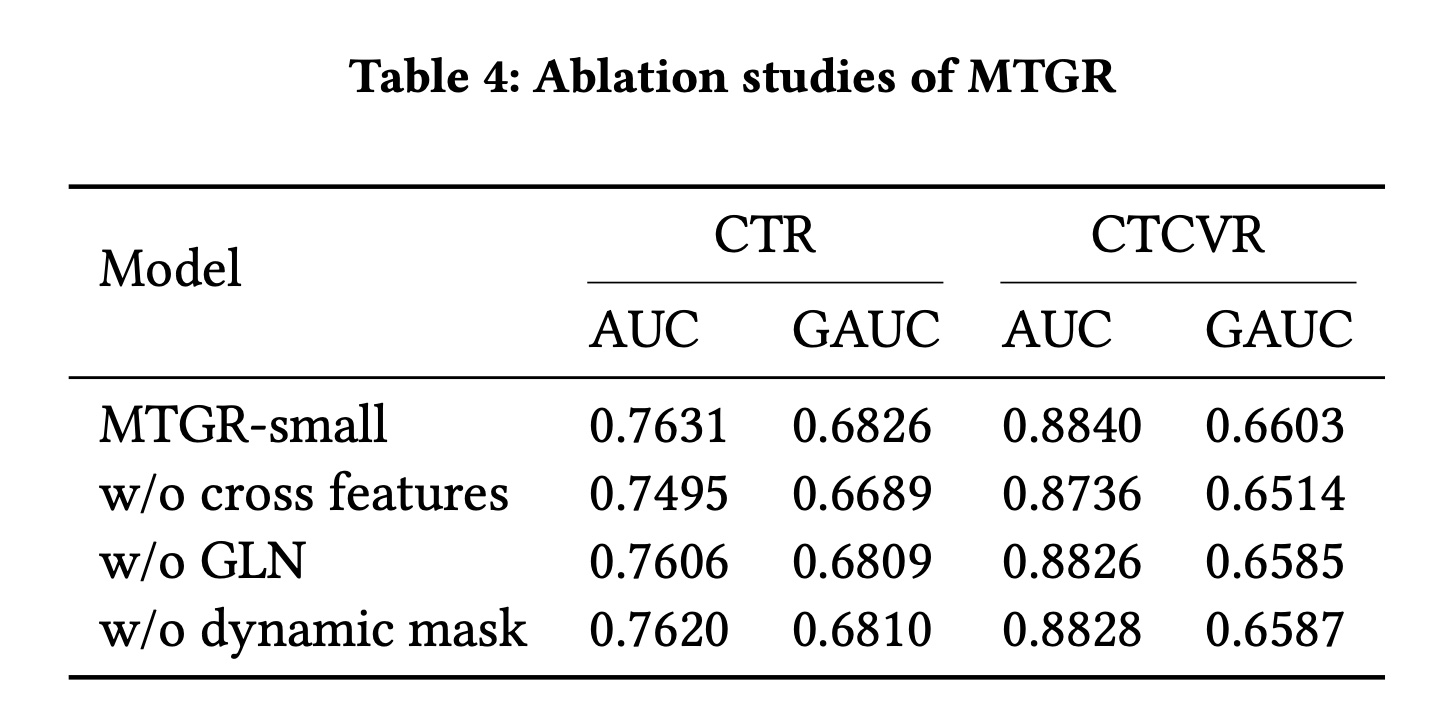
我们基于
MTGR-small对两个核心组件(Dynamic Masking和group layer norm: GLN)进行了消融实验,结果如Table 4所示。移除其中任何一个组件都会导致性能显著下降,下降幅度与
MTGR-small到MTGR-medium的性能提升幅度相当。这表明Dynamic Masking和GLN对MTGR至关重要。GLN提升效果还可以。此外,我们还额外实验了
cross features对MTGR的重要性:移除cross features后,性能指标大幅下降,甚至抵消了MTGR-large相比DLRM的性能优势,凸显了cross features在真实推荐系统中的关键作用。
1.5.3 Scalability
Figure 3展示了MTGR的scalability:我们基于MTGR-small,对三个不同超参数(HSTU blocks数量、模型维度input sequence length)进行了测试。可以看出,MTGR在不同超参数下均展现出良好的scalability。此外,
Figure 3(d)呈现了性能与计算复杂度之间的幂律(power-law)关系:纵轴表示CTCVR GAUC相比性能最佳的DLRM模型(UserTower-SIM)的提升幅度,横轴表示计算复杂度相比UserTower-SIM的对数倍数。这里的
sequence length是100。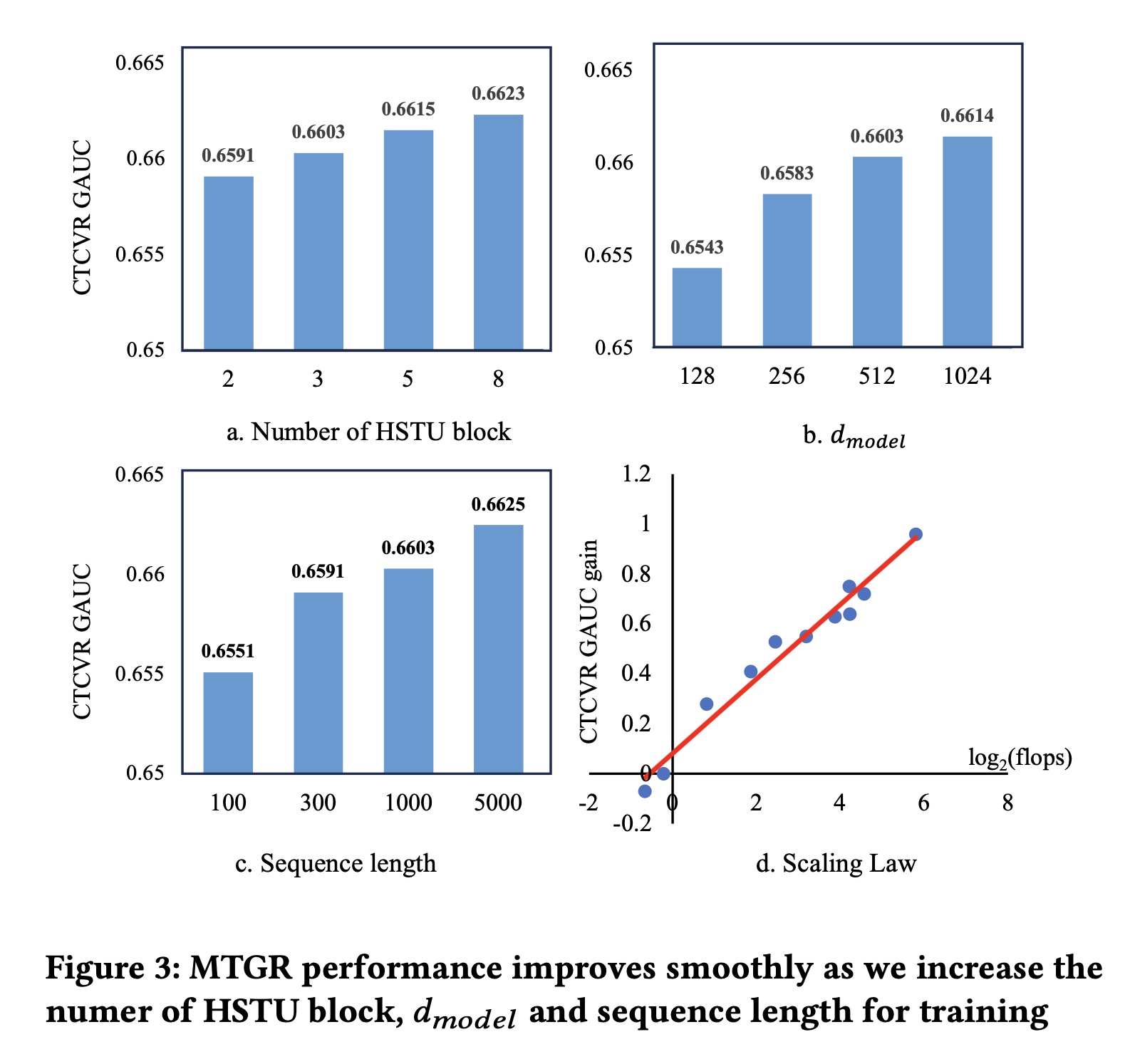
1.5.4 在线实验
为进一步验证
MTGR的有效性,我们将其部署于Meituan外卖平台,进行了2%流量的AB test。实验流量规模达到每天数百万次曝光,确保了实验的可靠性。对比的baseline是当前最先进的在线DLRM模型(UserTower-SIM),该模型已持续学习2年。我们使用过去6个月的数据训练MTGR模型,然后在线部署MTGR进行对比。尽管训练数据量显著少于
DLRM模型,但MTGR的离线指标和在线指标仍大幅超过DLRM基线。如Table 5所示,离线指标和在线指标均展现出scalability。我们还发现,随着training tokens数量的增加,与DLRM相比,MTGR的优势持续放大。最终,就CTCVR GAUC而言,我们的large version甚至超过了过去一年所有优化方案的累计提升幅度。该模型已在我们的场景中全面部署,训练成本与
DLRM相当,推理成本降低了12%。对于DLRM而言,其inference成本与candidates数量近似呈线性关系。然而,MTGR对request中的所有candidates都进行了user aggregation,从而实现了inference成本与candidates数量呈亚线性增长。这有助于我们降低online inference的开销。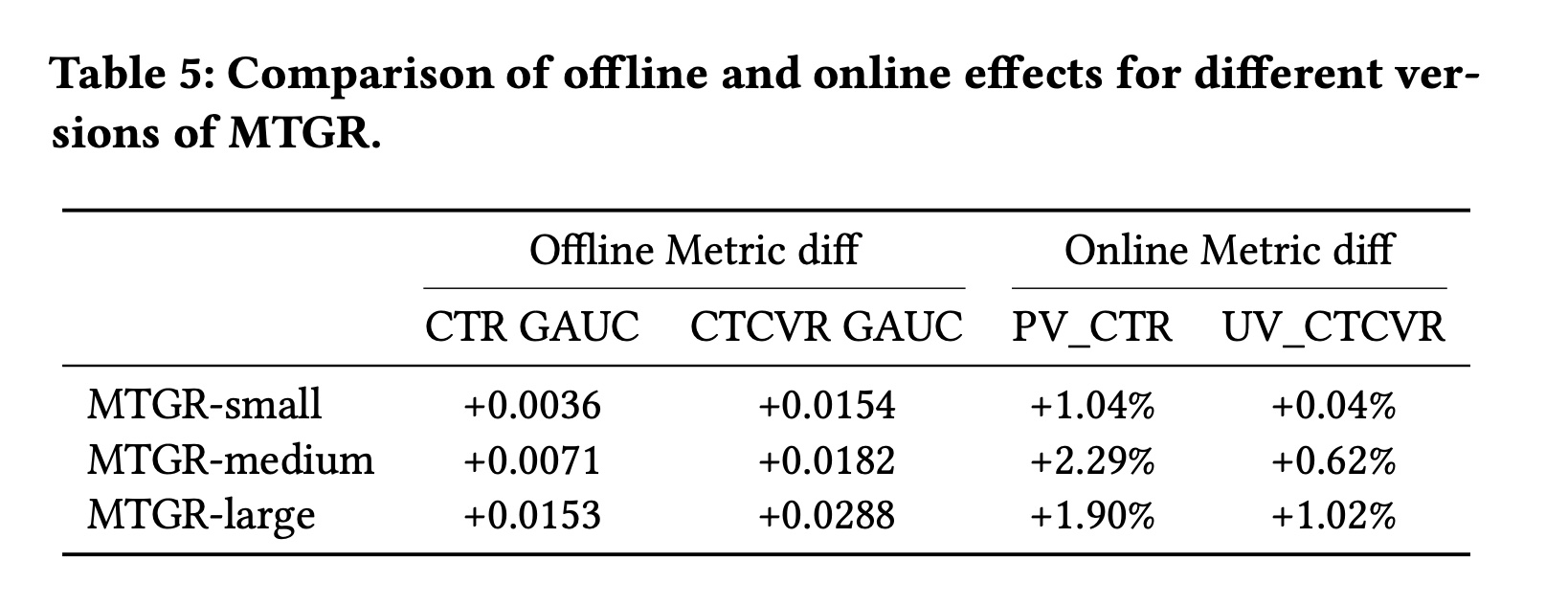
1.6 结论
本文提出了
MTGR,一种基于HSTU的新型ranking framework来探索recommendation systems中scaling law。MTGR融合了DLRM和GRM的优势,能够使用cross-features以保证模型性能,同时具备与GRM相当的scalability。MTGR已在我们的业务场景中全面部署,并取得了显著效益。未来,我们将探索如何将MTGR扩展到多场景建模,借鉴大语言模型的思路,构建具有广泛知识的recommendation foundation model。实际上,这篇论文与
GRM关系不大。